







Le lingue
Pagine
Legale


Recapiti
q Massimiliano Adamodel Consiglio Nazionale delle Ricerchepresso l'Istituto per le Applicazioni del Calcolo M. Picone di Roma.e-mail: [email protected] page: http://www.iac.cnr.it/~adamoTel.IAC: 06/88470235

Obiettivi del CorsoObiettivi del Corso
Il corso ha come obiettivo di fornire allo studente una conoscenza generale del calcolatore ed il suo utilizzo

Obiettivi del Corso
Questi obiettivi vengono raggiunti proponendo due tipi di nozioni:
q quelle più generali che riguardano l'informatica di base tese a sviluppare nello studente il senso critico per le problematiche informatiche,
q quelle più tecniche che abbiano una ricaduta pratica: in particolare l‟uso di internet
Il corso si articola in lezioni teoriche ed in lezioni pratiche, l'accertamento della preparazione consisterà in un esame scritto ed orale.

Programma del Corso
q Architettura dei Calcolatori
q Sistemi Operativi
q Linguaggi di Programmazione
q Rappresentazione dei Dati ed Algoritimi
q Gestione Distribuita dei Calcolatori
q Il funzionamento di una rete locale e di Internet
q Trattamento Ipertestuale dell'Informazione

Applicativi
q Applicativi 1: Il web
q Applicativi 2: il foglio elettronico
q Applicativi 3: il wordprocessor
q Applicativi 4: i database

C os’è un C om puter ?
q Un calcolatore digitale è una macchina che può risolvere problemi eseguendo le istruzioni fornitegli.
q Una sequenza di istruzioni che descrive come eseguire un certo compito è chiamata programma.
q I circuiti di un calcolatore elettronico possono riconoscere ed eseguire un numero limitato di istruzioni semplici in cui tutti i programmi devono essere convertiti prima di poter essere eseguiti.

Informatica, Linguaggi e Programmi
L'etimologia italiana di informatica proviene dai termini informazione e automatica, e sicuramente Philippe Dreyfus, che per primo utilizza nel 1962 il termine informatique(informatica) voleva significare la gestione automatica dell'informazione mediante calcolatore. Sebbene successivamente ne siano state date diverse definizioni, forse si avvicina di più alla realtà quella secondo cui l'informatica è la scienza che si occupa della conservazione, dell'elaborazione e della rappresentazione dell'informazione.

Informatica, Linguaggi e Programmi
l„elaborazione viene effettuata attraverso dei PROGRAMMI scritti in un qualche LINGUAGGIO DI PROGRAMMAZIONE
un linguaggio di programmazione è un linguaggio formale dotato di una sintassi e di una semantica ben definite
per dare un programma occorre un algoritmo, cioè una sequenza di istruzioni deterministichecomprensibili dall'esecutore
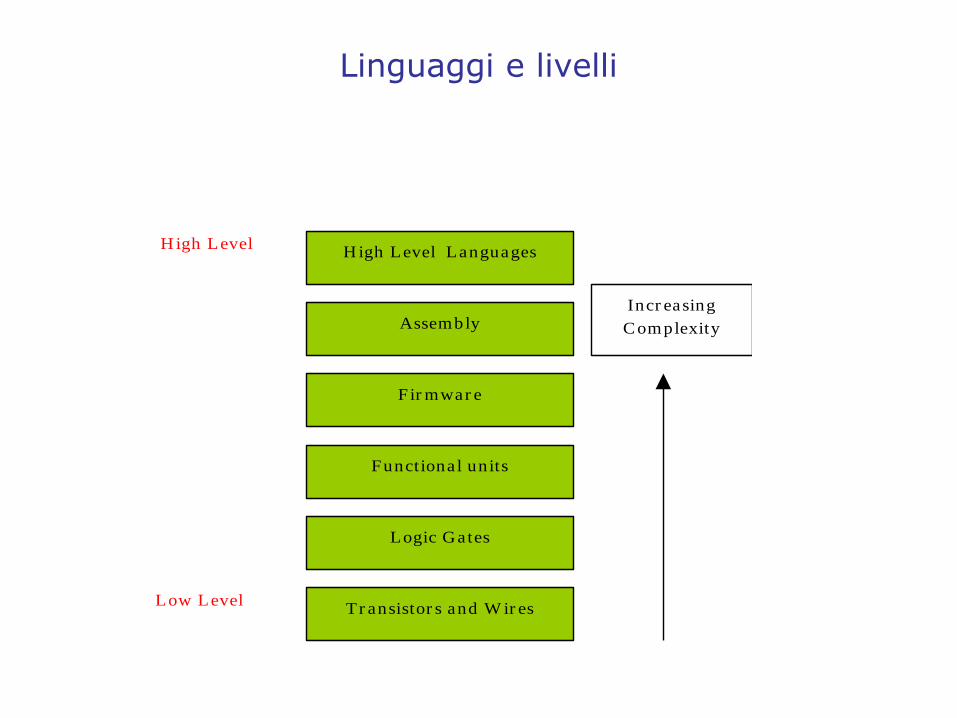
Linguaggi e livelli
Functional units
Assembly
Firmware
Logic Gates
High Level Languages
Transistors and Wires
Increasing Complexity
Low Level
High Level

Componenti di un elaboratore
In un elaboratore possiamo distinguere quattro componenti elementari:
q la La CPU (acronimo di CentralProcessing Unit, detta comunemente processore)
q la memoria principale (o centrale)
q la memoria secondaria
q i dispositivi di input/output
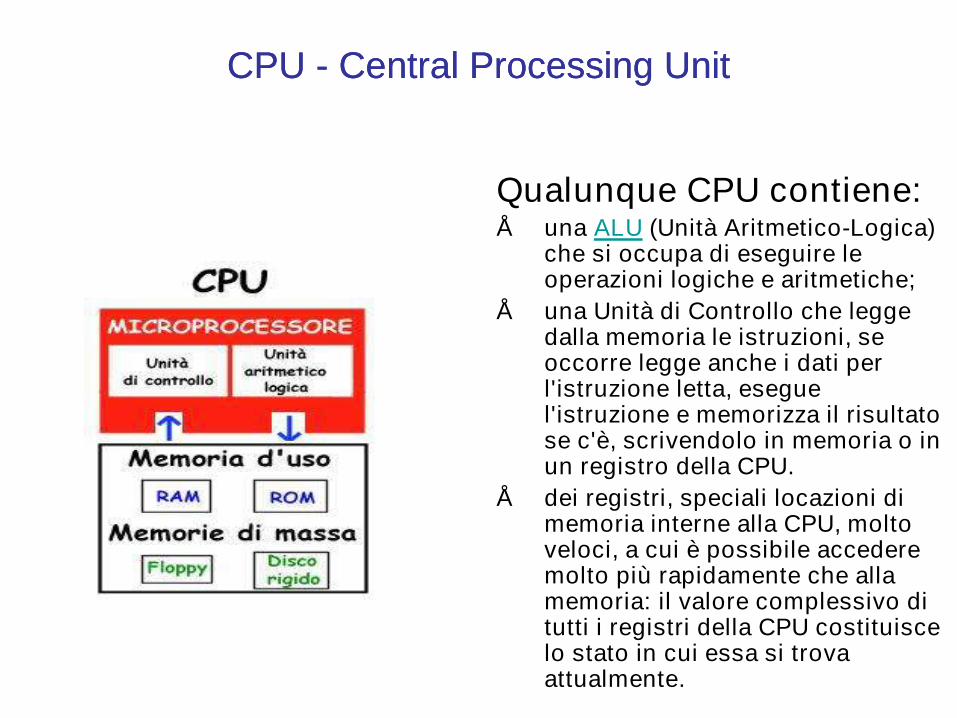
CPU CPU -- Central Processing UnitCentral Processing Unit
Qualunque CPU contiene:• una ALU (Unità Aritmetico-Logica)
che si occupa di eseguire le operazioni logiche e aritmetiche;
• una Unità di Controllo che legge dalla memoria le istruzioni, se occorre legge anche i dati per l'istruzione letta, esegue l'istruzione e memorizza il risultato se c'è, scrivendolo in memoria o in un registro della CPU.
• dei registri, speciali locazioni di memoria interne alla CPU, molto veloci, a cui è possibile accedere molto più rapidamente che alla memoria: il valore complessivo di tutti i registri della CPU costituisce lo stato in cui essa si trova attualmente.
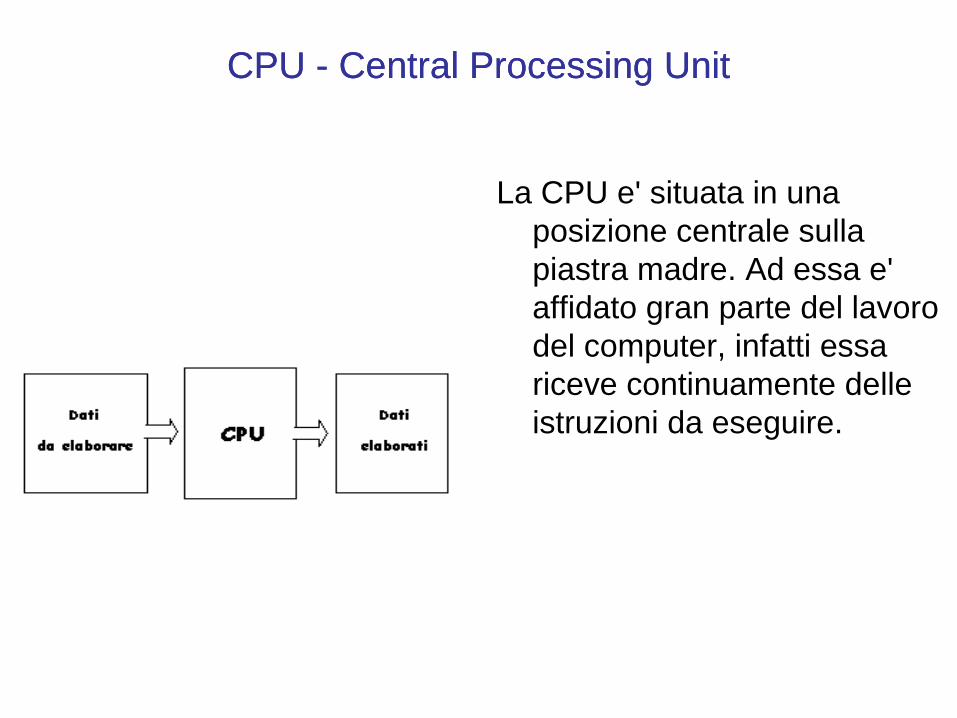
CPU CPU -- Central Processing UnitCentral Processing Unit
La CPU e' situata in una posizione centrale sulla piastra madre. Ad essa e' affidato gran parte del lavoro del computer, infatti essa riceve continuamente delle istruzioni da eseguire.

Hertz
• L'hertz (simbolo Hz) è l'unità di misura del Sistema Internazionale della frequenza.
• Un hertz significa semplicemente uno al secondo
• L'unità può essere applicata a qualsiasi evento periodico
• Per esempio, si può dire di un orologio che ticchetta a 1 Hz.

Hertz
• 1 chilohertz (simbolo kHz) = 103 Hz = 1.000 Hz• 1 megahertz (simbolo MHz) = 106 Hz = 1.000.000 Hz• 1 gigahertz (simbolo GHz) = 109 Hz = 1.000.000.000
Hz• 1 terahertz (simbolo THz) = 1012 Hz =
1.000.000.000.000 Hz• 1 petahertz (simbolo PHz) = 1015 Hz =
1.000.000.000.000.000 Hz

CPU CPU -- Central Processing UnitCentral Processing Unit
• Una misura della velocità e data dal numero di cicli al secondo (hertz) che e in grado di compiere
• Una performance oggi ragionevole e intorno ai 3.0 Gigahertz
• Gli ultimi pentium 4 lavorano oggi a circa 3,8 GHz
• Nei primi pc IBM si aggira tra i 4,77 e i 10 MHz

CPU - Central Processing Unit
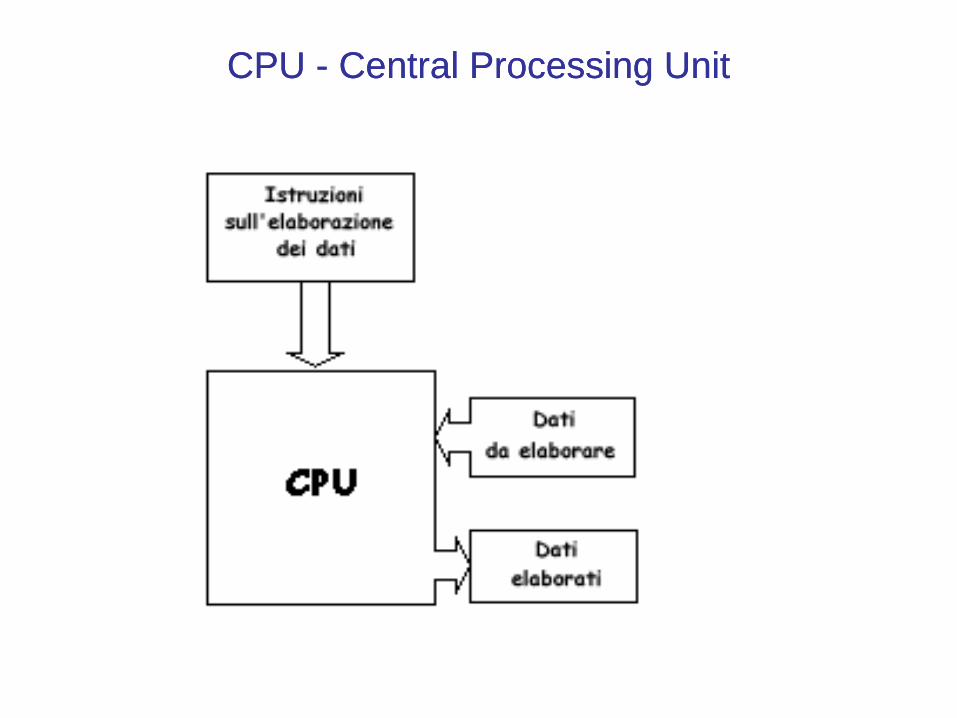
• Ogni istruzione rappresenta un ordine di elaborazione dei dati; il lavoro svolto e' composto soprattutto da calcoli e trasporto dei dati, che seguono un percorso verso la CPU. Questo percorso si chiama bus di sistema.
• Alla CPU viene fornito un lungo flusso di dati attraverso il bus di sistema; questi dati possono essere di due tipi: nIstruzioni(per manipolare dati)nDati (da gestire secondo le istruzioni)
CPU CPU -- Central Processing UnitCentral Processing Unit

CPU - Central Processing Unit
• Il compito piu' importante per la CPU consiste nel decodificarele istruzioni e nel localizzare i dati.
• La decodifica consiste nell'interpretare le istruzioni che il programma-utente invia alla CPU.
• T utte le C P U com patibili “Intel” dei P C sono anche "com patibili 8086“: l'Intel 8086 è un microprocessore a 16 bit progettato dalla Intel nel 1978, che diede origine appunto all'architettura x86

CPU - Central Processing Unit
• Dal 1978 l'8086 e le successive CPU hanno sempre ricevuto dei set di istruzioni compatibili che hanno permesso di affrontare senza traumi il passaggio da una generazione all'altra di microprocessori.
• Le prime CPU avevano il cosiddetto CISC (Complex Instruction Set Computer, Set d'istruzioni complesse).
• Il set d'istruzioni X 86 (la X sta per 2, 3 e 4, 5 ecc… ), e' stato sviluppato in origine per l'8086, con i suoi miseri 29000 transistor!

CPU - Central Processing Unit
• Il RISC (Reduced Instruction Set Computer, computer con un set d'istruzioni ridotto), contiene un numero molto inferiore d'istruzioni rispetto al CISC.
• Questi processori hanno una unità di controllo molto semplice e riservano invece molto spazio per i registri interni: – una CPU RISC ha di solito da un minimo di un centinaio ad alcune
migliaia di registri interni generici, organizzati in un file di registri. – Il tipico set di istruzioni RISC è molto piccolo, circa 60/70 istruzioni molto
elementari (logiche, aritmetiche e istruzioni di trasferimento memoria-registro e registro-registro);
– Le istruzioni hanno tutte lo “stesso form ato” e la stessa lunghezza, e tutte o quasi vengono eseguite in un solo ciclo di clock.

Scheda MadreScheda Madre

Le MemorieLe Memorie
• La memoria e' quella parte del computer dove sono contenute tutte le informazioni da elaborare ed i risultati derivanti da queste o le istruzioni utili affinche' vengano elaborate.

Le Memorie (Principali)Le Memorie (Principali)
• RAM (Random Access Memory) • EPROM, acronimo di ErasableProgrammable Read Only MemorySono memorie centrali direttamente collegate, senza intermediazioni, al cuore pulsante del computer, la CPU.Il termine ROM viene ancor oggi utilizzato per indicare (impropriamente) quelle memorie non volatili che mantengono i dati in memoria anche in mancanza di alimentazione.

Le Memorie
• Abbiamo anche una memoria detta secondaria che si contrappone alla primaria: qualunque mezzo usiamo per una memorizzazione non volatile (hard disk, floppy disk, cd-rom. dvd) nella quale vengono depositate informazioni gia' elaborate dalla CPU o che non lo saranno nell'immediato.
• Tutta la memoria esterna indirizzabile da quella centrale, alla quale si può giungere per mezzo di canali di I/O (Input/Output): viene anche chiamata memoria esterna (external storage), secondary storage (memoria secondaria), auxiliary storage(memoria ausiliare).
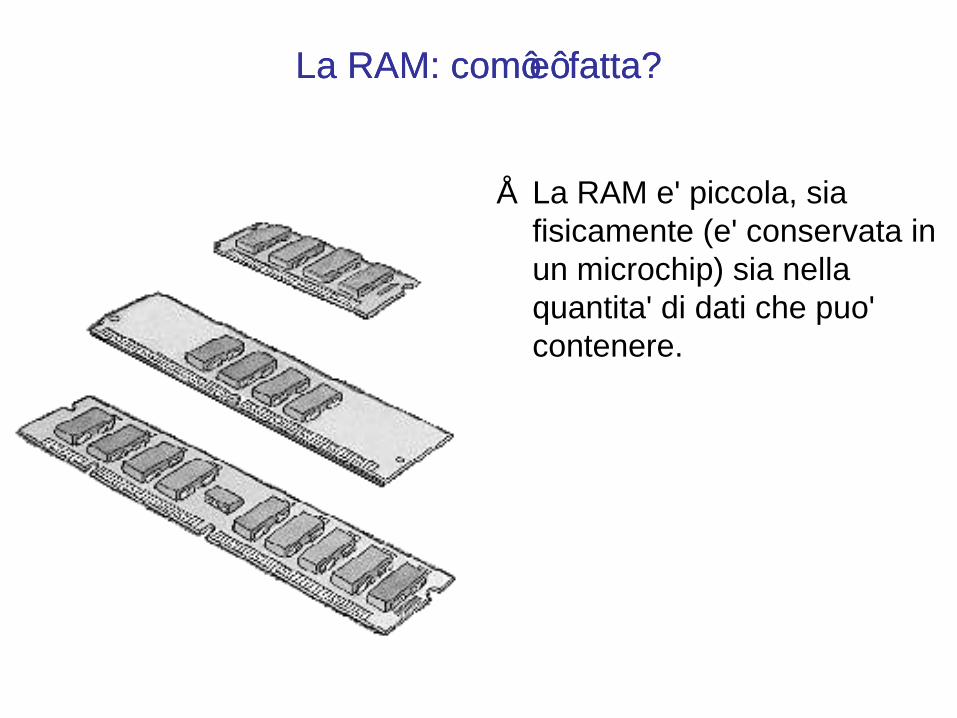
La R A M : com ‟e‟ fatta?La R A M : com ‟e‟ fatta?
• La RAM e' piccola, sia fisicamente (e' conservata in un microchip) sia nella quantita' di dati che puo' contenere.

La R A M : com ‟e‟ fatta?La R A M : com ‟e‟ fatta?
• E' molto piu' piccola dell'hard disk sia fisicamente sia come capacita' di contenimento dati: un computer, oggi, e' dotato di 256/512 MB di RAM mentre gli Hard disk hanno una capacità di 80/120 GB
Tre "cose" da ricordare:n La velocità della RAM e' misurata in MHz: una velocità oggi accettabile è di 300/400 MHzn SDRAM (synchronous DRAM) nome generico per dynamic randomaccess memory (DRAM) che sono sincronizzate ed ottimizzate con il clock del Microprocessore. Queste caratteristiche permettono di massimizzare il numero di istruzioni elaborate in una unità di tempo. n DIMM (dual in-line memorymodule )

Rappresentazione dei dati in memoria
• La memoria puo essere vista come una lunga sequenza di componenti elementari (celle) ognuna delle quali e in grado di conservare un bit.

Rappresentazione dei dati in memoria
• Es. per rappresentare il numero 27 con 8 bit posso scrivere
27=2*13+1=2(6*2+1)+1=22(2*3)+2+1=23(2+1)+2+1=24+23+21+20
27 26 25 24 23 22 21 20
0 0 0 1 1 0 1 1
27 in base 2 si rappresenta quindi con 00011011

Rappresentazione dei dati in memoria
• Ogni cella di memoria e caratterizzata da un indirizzo espresso mediante un numero intero.
• Tale indirizzo è a sua volta rappresentato internamente mediante la sua codifica binaria:– il numero di bit utilizzati per scrivere tale codifica
prende il nome di spazio di indirizzamento.

Unità di misura della memoria
• Bit (unita' di codifica elementare: 0/1, v/f)
• Byte (2^3 bits)
• KB (KiloByte: 2^10 bytes, pari a circa 1000 byte)
• MB (MegaByte 2^20 bytes ovvero circa un milione di byte)
• GB (GigaByte 2^30 bytes, circa un miliardo di byte)
• TB (TeraByte 2^40 bytes, circa mille miliardi di byte) di byte)
• PB (PetaByte 2^50 bytes)

Capacità di alcuni dispositivi di memoria
• Hard DISK : decine di GB fino a qualche TB
• Floppy: 1.4 MB
• CD-ROM: > 650 MB, < 800 MB
• DVD: >4.7 GB; < 9 GB (Dual Layer)
• Penne USB: fino a 2 GB
• Memory Stick e simili: fino a 2 GB

Caratteristiche delle schede di memoria
• parole di memoria (word): permettono di trasferire sequenze di bit di una determinata lunghezza (ad es. 32 bits),
• tempo di accesso: e una misura della rapidita con cui l'informazione viene recuperata dalla memoria, si misura in nano-secondi,
• costo: e un parametro importante perche se ci sipuò permettere una grande quantità di memoria molto veloce le performances del sistema migliorano)
• volatilità: la memoria principale ha bisogno di un continuo refresh dunque tutte le informazioni contenute in essa sono perse al momento dello spegnimento del sistema.

Architetture a 32 ed a 64 bitArchitetture a 32 ed a 64 bit
• I termini 32 e 64 bit sono utilizzati in informatica per indicare che, in una determinata architettura, gli interi sono indicati con al massimo 64 bit di larghezza o per descrivere l'architettura di una determinata CPU, che usa i registri interni, il bus degli indirizzi o bus dei dati di quella dimensione.

Architetture a 32 ed a 64 bitArchitetture a 32 ed a 64 bit
• Ad oggi (2006) le CPU a 64 bit sono comuni nei server, e si stanno diffondendo sempre più anche nell'ambito dei personal computer(precedentemente a 32 bit), con le architetture AMD64, EM64T e PowerPC 970
• Il processore diventa in grado di gestire interi a 64 bit in modo nativo. I processori a 32 bit possono gestire in modo nativo solo numeri interi fino a circa 4 miliardi, dopodiché devono combinare più numeri in modo piuttosto complicato. Un processore a 64 bit sposta questo limite a 16 miliardi di miliardi.
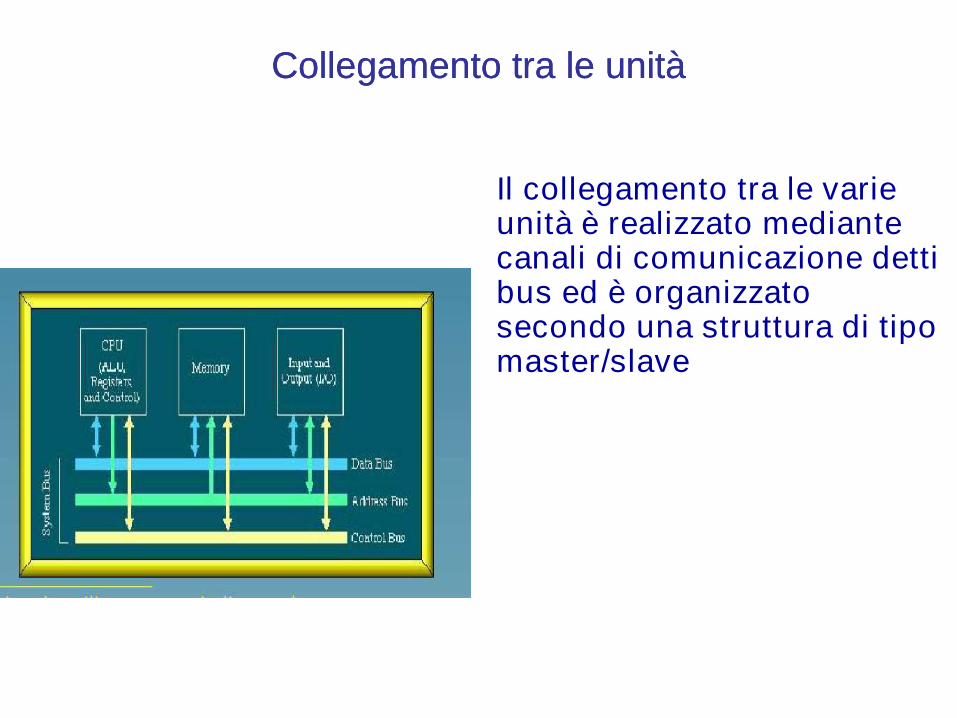
Collegamento tra le unitàCollegamento tra le unità
Il collegamento tra le varie unità è realizzato mediante canali di comunicazione detti bus ed è organizzato secondo una struttura di tipo master/slave

Collegamento tra le unita
Pregi e difetti di un collegamento a bus sono:
Semplicità Lentezza
Estendibilità Limitata capacità
Standardizzabilità Sovraccarico della CPU
Da un punto di vista funzionale il bus puoessere suddiviso in 3 componenti: il bus dati, il bus degli indirizzi, il bus di controllo..

La memoria principale
1. La memoria centrale fornisce all'elaboratore lacapacità di ricordare le informazioni.
2. In particolare la memoria dovrà contenere siail programma, cioè la lista di istruzioni chel'unità di controllo deve leggere ed eseguire,che i relativi dati.
• N.B. la memoria rappresenta queste diverseinformazioni allo stesso modo mediante cifrebinarie (detti bit dall'inglese binary digit).

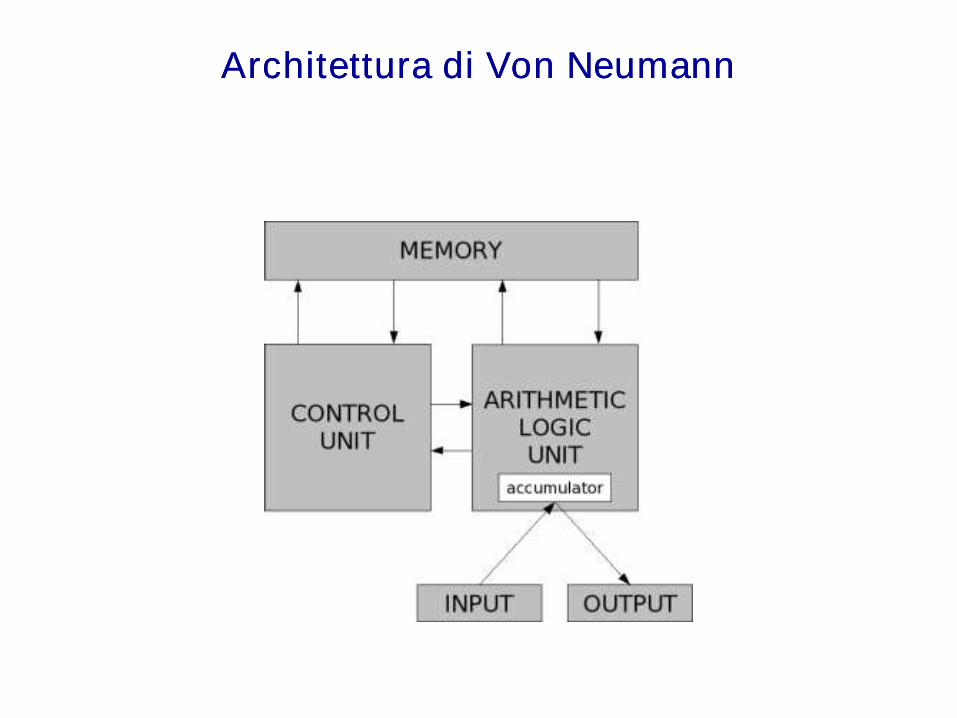
Architettura di Von Neumann
• Con l'espressione architettura di von Neumann o macchina di vonNeumann ci si riferisce a uno schema di progettazione di calcolatori elettronici che prende nome dal matematico John von Neumann.
• Lo schema si basa su quattro componenti fondamentali:
• CPU o unità di lavoro che si divide a sua volta in
– Unità di calcolo o ALU
– Unità di controllo
• Unità di memoria, intesa come memoria di lavoro o memoria principale (RAM, Random Access Memory)
• Unità di input, tramite la quale i dati vengono inseriti nel calcolatore per essere elaborati
• Unità di output, necessaria affinché i dati elaborati possano essere restituiti all'operatore
• Uno speciale registro dentro la ALU detto accumulatore, che faceva da buffer tra input e output grazie a una speciale istruzione che caricava una parola dalla memoria all'accumulatore e viceversa.

Architettura di Von Neumann
• Bisogna comunque precisare che questa è unaschematizzazione molto sintetica, sebbene moltopotente: basti pensare che il computer con il qualestate leggendo questo articolo è progettato secondol'architettura von Neumann (purché non si tratti diqualche mainframe aziendale). Inoltre, quando siparla di unità di memoria si intende la memoriaprincipale, mentre le memorie di massa sonoconsiderate dispositivi di I/O. Il motivo di ciò èinnanzitutto storico, in quanto negli anni Quaranta,epoca a cui risale questa architettura, la tecnologianon lasciava neanche presupporre dispositivi comehard disk, CD-ROM o anche solo nastri magnetici,ma anche tecnico, se si considera che in effetti i datida elaborare devono comunque essere caricati inRAM, siano essi provenienti da tastiera o da hard-disk.
Architettura di Von NeumannArchitettura di Von Neumann

Rappresentazioni dei dati in memoria :gli interi
• Un unico byte è una quantità troppo piccola per rappresentare un numero intero.
• La rappresentazione dei numeri interi, sia positivi che negativi, avviene nell'elaboratore considerando più byte consecutivi; usualmente si utilizzano 2 o 4 byte e, in certe situazioni, anche più. Un unico bit (di regola il primo a sinistra) rappresenta il segno: il bit 0 indica il "+" e il bit 1 il "-".
• Per certe applicazioni, due byte sono sufficienti e in due byte si possono memorizzare tutti i numeri interi relativi da -32768 a +32767, esattamente un numero negativo in più rispetto ai positivi, poiché 0 è considerato un numero positivo.

Rappresentazioni dei dati in memoria:con virgola
• Si consideri ad esempio il numero 12,345. Il numero viene prima di tutto "normalizzato", cioè scritto in una forma standard, del tipo 0,... seguito da una parte decimale la cui prima cifra sia diversa da zero. Per esempio il numero 12,345 diviene: 0,12345*10^2.
• Nella terminologia tecnica, 0,12345 si dice la "mantissa" del numero 12,345, mentre l'esponente del 10 (in questo caso il 2) si dice l'"esponente" del numero considerato.

Rappresentazioni dei dati in memoria:con virgola
• Mantissa ed esponente individuano univocamente il numero e quindi possono servire a rappresentarlo nella memoria dell'elaboratore.
• Un numero con la virgola del tipo descritto si dice un "numero reale" nel gergo dell'informatica, e viene memorizzato in un certo numero di byte consecutivi, da 4 fino a 64 e anche più, a seconda dell'elaboratore e della particolare applicazione.
• C ioe‟: SEGNO X MANTISSA X BASE ^ ESPONENTE

Rappresentazioni dei dati in memoria:le lettere
• Un testo letterale è una sequenza di "caratteri" presi da un "alfabeto" finito e ben caratterizzato. La codifica dei caratteri è stata a suo tempo standardizzata e fu detta "codifica ASCII", dove la sigla sta per "American Standard Code for Information Interchange". Tale codifica è oggi accettata quasi universalmente e comprende:
• le lettere maiuscole e minuscole dell'alfabeto inglese (codici da 65 a 90 e da 97 a 122)
• le cifre decimali (codici da 48 a 57)

Rappresentazioni dei dati in memoria:le lettere
• i caratteri di interpunzione, cioè lo spazio, la virgola, il punto fermo, i due punti, il punto esclamativo, ecc.; i segni aritmetici, come il più, il meno, l'asterisco, le parentesi tonde, quadre e graffe; alcuni simboli speciali, come il dollaro, la barra verticale, la chiocciola (codici da 32 a 47, da 58 a 64, da 91 a 96 e da 123 a 127)

Rappresentazioni dei dati in memoria:le lettere
• La codifica estesa (codici da 128 a 255) ha permesso di introdurre una serie di caratteri speciali, molto utili in varie applicazioni:
• i caratteri nazionali, cioè accentati o con altri segni particolari • alcuni caratteri particolari, come !, ? e le virgolette • i caratteri semigrafici che permettono di disegnare, sullo
schermo o sulla stampante, semplici disegni, schemi o diagrammi
• i caratteri matematici, come alcune lettere greche, alcuni simboli e alcuni caratteri speciali

Programmi
• L'elaborazione delle informazioni da parte del processore avviene secondo sequenze di istruzioni che ne regolano il comportamento, dette programmi.
• Secondo il modello di Von Neumann la memoria principale deve ospitare contemporaneamente almeno due tipi di informazioni:1. la sequenza delle istruzioni2. l'insieme dei dati su cui operare

I compiti del processore
• Ad ogni ciclo il processore:
1. legge dalla memoria principale la prossima istruzione da eseguire,
2. esegue l'istruzione.

I registri
• Sono piccole unità di memoria interne al processore ed estremamente veloci.
• Servono per mantenere le informazioni di necessità immediata per il processore.
• Possono essere speciali (per scopi particolari ad es. registro Program Counter, registro istruzioni, registro di stato, registri di comunicazione)
• o generali detti anche aritmetici per contenere risultati parziali.
(Il numero e le dimensioni di questi registri variano da processore a processore).

Il registro Program Counter
• Contiene l'indirizzo della cella di memoria in cui si trova la prossima istruzione da eseguire.
• Dimensioni del registro:
PC = dimensioni degli indirizzi

I compiti del processore (2)
Dettagliando il comportamento del processore, abbiamo che ad ogni ciclo il processore:
1. legge dalla memoria principale l'istruzione che si trova all'indirizzo indicato dal registro PC,
2. modifica il valore del PC aumentandolo di 13. esegue l'istruzione letta dalla memoria.

Il registro delle istruzioni
• Ad ogni ciclo l'istruzione letta dalla memoria principale viene scritta nel Registro Istruzioni (RI).
• L'istruzione verrà a poi decodificata dalla unita di controllo

I compiti del processore
Dettagliando ulteriormente il comportamento del processore, abbiamo che ad ogni ciclo:
1. Legge dalla memoria principale l' istruzione che si trova all'indirizzo indicato dal registro PC
2. Scrive l'istruzione all'interno del registro RI3. Modifica il valore del PC aumentandolo di 14. La UC decodifica l'istruzione e individua la sequenza
di azioni che devono essere svolte5. Esegue le azioni specificate dall'istruzione

Registro di stato
Contiene delle informazioni sullo stato di esecuzione del processore e segnala eventuali errori.

L'unita Logica-Aritmetico (ALU)
E costituita da un insieme di circuiti in grado di effettuare operazioni di tipo aritmetico e logico.
La ALU legge i dati contenuti nei registri generali, esegue le operazioni e memorizza il risultato in uno dei registri generali.
In alcuni casi oltre alla ALU può essere presente un coprocessore matematico.

Le principali porte logiche
Differenti livelli di tensione vengono utilizzati perrappresentare i singoli bit. I semi-conduttori permettono di realizzare i vari tipi di
porte necessarie per il funzionamento dei calcolatori.Inoltre le tecniche VLSI (very large system integration)
permettono di integrare una gran quantità di questi circuiti in uno spazio molto ridotto.

Le principali porte logiche
Una lista (non esaustiva) dei principali tipi di porte:NOT: negate the inputAND: high only both inputs are highOR: high if one or both inputs are highNAND: negate ANDNOR: negate ORXOR: high only if the two inputs are different
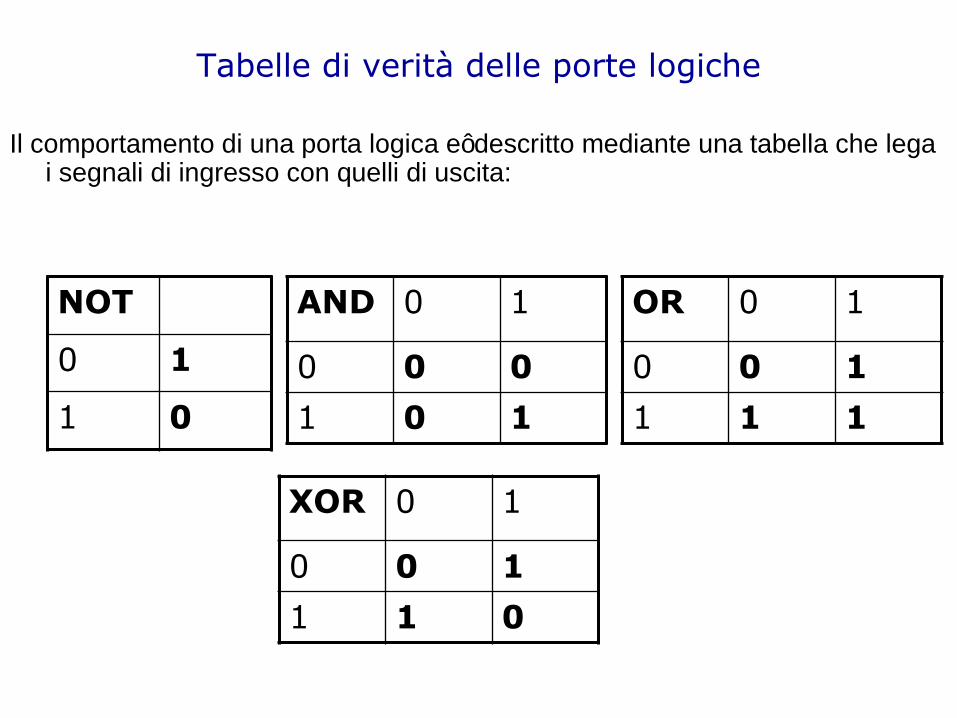
Tabelle di verità delle porte logiche
Il com portam ento di una porta logica e‟ descritto m ediante una tabella che lega i segnali di ingresso con quelli di uscita:
NOT
0 1
1 0
AND 0 1
0 0 0
1 0 1
OR 0 1
0 0 1
1 1 1
XOR 0 1
0 0 1
1 1 0

La logica dell'elaboratore
• La capacità decisionale è alla base dell'operatività degli elaboratori. I principi logici di questa capacità sono gli stessi della "logica delle proposizioni", scienza inventata da George Boole.
• L'idea originaria di Boole fu quella di affrontare il problema della formalizzazione della logica arrivando ad un formalismo di tipo matematico che permetta un "calcolo" della logica stessa.

La logica dell'elaboratore
• Si dice "proposizione" ogni frase che sia vera o falsa. Convenzionalmente, "vero" e "falso" si dicono "valori di verità", e si indicano simbolicamente rispettivamente con 1 e 0.
• Boole osservò che ci sono tre modi fondamentali di connettere due (o più) proposizioni, in modo tale che ogni altra possibile connessione sia esprimibile per mezzo delle tre di base:

La logica dell'elaboratore
• la congiunzione, espressa con il connettivo "e"; essa indica la verità simultanea delle due proposizioni che compongono la frase. Boole chiamò questa operazione "prodotto logico" o AND
• la disgiunzione, espressa dal connettivo "oppure"; essa indica la verità disgiunta di due proposizioni. Boole chiamò questa operazione "somma logica" o OR
• la negazione, espressa dall'avverbio "non"; essa indica il valore complementare della proposizione originaria (NOT)

La logica dell'elaboratore
• Seguendo le indicazioni date nella definizione, è possibile associare un preciso valore di verità alle proposizioni composte, quando si conosce il valore di verità di due proposizioni p e q.
• Questa associazione ha la forma di una tabella di operazione, e si dice "tabella di verità" del connettivo. Essa mostra come i connettivi costituiscano delle vere e proprie operazioni sulle proposizioni.
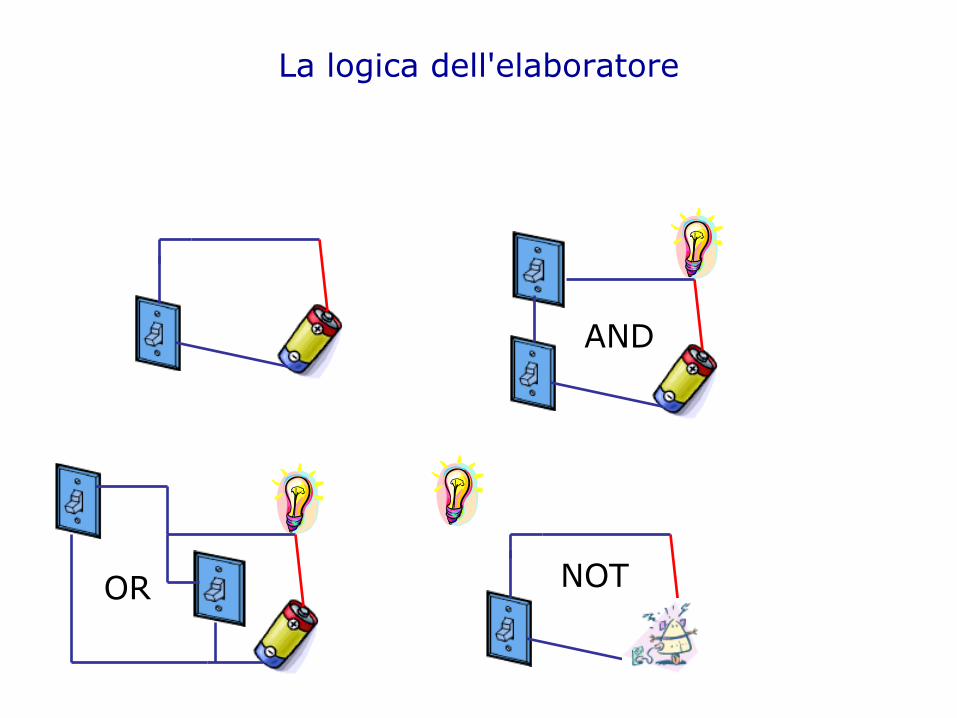
La logica dell'elaboratore
AND
OR NOT

Esecuzione delle istruzioni in linguaggio macchina
* Ogni istruzione e caratterizzata da un nome e da un certo numero di argomenti.
* Gli argomenti possono contenere nomi (numeri) di registri o indirizzi di memoria principale (metodi di indirizzamento).
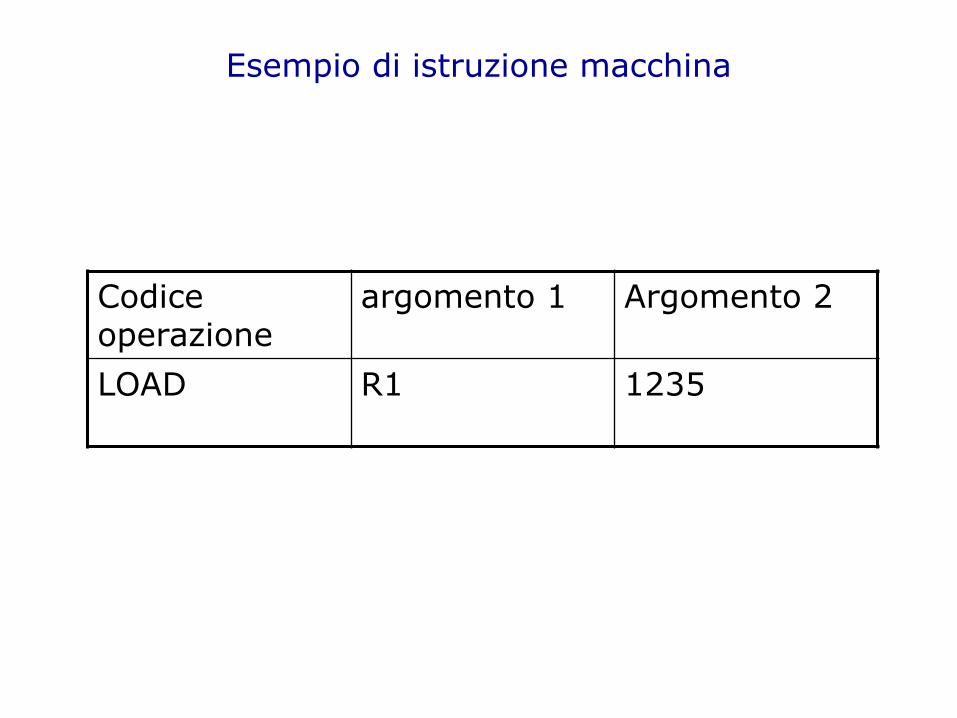
Esempio di istruzione macchina
Codice operazione
argomento 1 Argomento 2
LOAD R1 1235

Esempi di istruzioni
Tipici esempi di istruzioni sono:• Istruzioni di lettura dalla memoria (due argomenti)• Istruzioni di scrittura in memoria (due argomenti)• Istruzioni aritmetiche (due o tre argomenti)• Istruzioni logiche• Istruzioni di spostamento (due argomenti)• Istruzioni di salto (istruzioni goto)

Lettura e scrittura in memoria
• Le operazioni di lettura e scrittura in memoria sono fondamentali per il funzionamento di un processore.
• Per effettuarle e necessario specificare l'indirizzodella cella su cui si vuole operare.
• Inoltre è necessario che il processore e la memoria principale possano comunicare.
• Tale comunicazione avviene attraverso i cosiddetti registri di comunicazione del processore.

Registri di Comunicazione
• Il Registro Indirizzi Memoria (DOVE) RIM• Il Registro Dati Memoria (COSA) RDM• Il Registro di Controllo (OPERAZIONI ed ERRORI)
RC

Istruzioni di salto
• Finora abbiamo detto che le istruzioni di un programma devono essere eseguite in sequenza.
• Ma la semplice sequenzializzazione delle istruzioni non permette di scrivere programmi che risolvano qualunque tipo di problema.
• Esistono quindi istruzioni particolari (istruzioni di salto) che permettono di specificare la successiva istruzione da eseguire. L'argomento di tali istruzioni e l'indirizzo della prossima istruzione da eseguire.
• E possibile così modifica re il flusso di esecuzione di un programma.

Esempio di esecuzione di un semplice programma
1. LOAD 3568 R12. ADD R1 R23. STORE R1 35684. JUMP 65. … … … … … ..6. … … … … … ..7. ..… .. … … … ..

Il software e il computer
• Dopo aver esplorato la struttura interna del calcolatore ci chiediamo:
• cosa vediam o noi del “cuore" di un com puter quando lo usiamo?
• Chi fa da mediatore tra noi e le varie parti dell'architettura che abbiamo studiato?
• RISPOSTA: il software!

MACCHINE VIRTUALI
• Perché tra l'utente e la CPU la comunicazione diretta fallisce?
perchè è un compito difficile scrivere sequenze di istruzioni in linguaggio macchina, per questo ci vuole una catena di intermediari !

Schema della macchina virtuale
• Il software di base che ci fa dialogare con l'hardware sottostante è la macchina virtuale.
• l'hardware comprende solo il linguaggio macchina• la m acchina virtuale com prende com andi “più naturali“
e sà tradurli verso l'hardware

Gerarchie di macchine virtuali
• UTENTE• macchina virtuale esterna• macchina virtuale intermedia 1• macchina virtuale intermedia 2• … … … … … … … … … … … … ..• macchina virtuale intermedia n• hardware

Esempio
• MEDICO:decide terapie e lo dice all'infermiera• INFERMIERA:ascolta medico e pratica terapia a
paziente• PAZIENTE:riceve cure dall'infermiera

Schema generale del sistema operativo
• HW • kernel • gestione interna• gestione periferiche• Interazione UTENTEE sam inerem o via via gli strati della “cipolla", dall'interno
verso l'esterno

Classicazione dei sistemi operativi
Mono-utente Multi-utente
Mono-programmato Multi-programmato o Multi-tasking
Non distribuito Distribuito

I livelli della “cipolla" che esplorerem o
• bootstrap• gestore dei processi• gestore della memoria principale• gestore della memoria secondaria• gestore delle periferiche• gestore della interazione con l'utente (shell e GUI)

Bootstrap
• Il bootstrap e il prim o “program m a" che viene eseguito dal kernel
• Esso e responsabile dell'attivazione di tutti le altre componenti del kernel, che a loro volta faranno partire i programmi della gestione interna e l'interprete con l'esterno.
• (T utta questa “catena" si avvia all'accensione autom aticam ente, attenzione: questa e la parte piu‟ sensibile ai virus !!!)

I processi
• O gni “program m a” che viene eseguito e un processo(detto anche JOB).
• Anche un sistema non multi-tasking deve eseguire piu‟ program m i “contem poraneam ente”.
• Tipicamente la gestione interna del computer e adatta ad una gran numero di programmi che l'utente non vede e non conosce ma che sono tutti indispensabili al funzionamento del computer.

Un processo
Un processo è un programma in esecuzione, esso può essere identicato con la struttura di dati utilizzata dal sistema per gestirlo.
Per descrivere questa struttura occorrono:• la sequenza di istruzioni che costituiscono il
programma stesso• l'indirizzo della prossima istruzione che deve essere
eseguita• lo stato di tutte le informazioni gestite dal programma
(i dati)Queste tre componenti formano l'immagine del
processo.

Un processo
Stati di un processo in esecuzione:• pronto, • in attesa, • in fase di creazione, • in terminazione• in scambio di esecuzione• richiesta di I/O o di risorsa• I/O terminato o risorsa disponibile
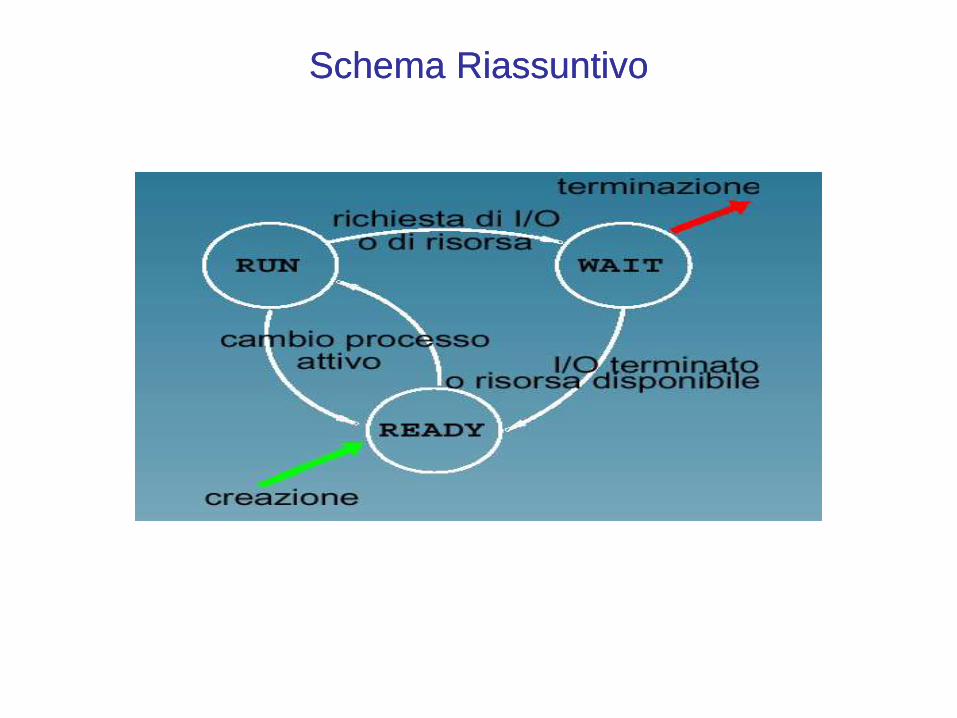
Schema RiassuntivoSchema Riassuntivo

E il processore?
• Può essere:ATTIVO o IDLE
• Può alternarsi tra piu‟ processi, “cam biando contesto" cioe‟ salvando o leggendo l'im m agine del processo dalla memoria.
• Deve restare IDLE il meno possibile: il tempo è una risorsa, non va sciupata !

Il gestore dei processi
Compito (ideale) di un gestore di processi:• Operare in maniera che ogni processo proceda come
se ci fosse una CPU completamente dedicata a lui.Tale CPU sarà meno veloce di quella reale ma così il
processo non deve occuparsi degli altri processi che vengono eseguiti in quel momento.

Principio di funzionamento del gestore
U n principio essenziale e‟ che (anche per un sistem a di modeste dimensioni) il processo da eseguire non deve avere bisogno di conoscere lo stato di tutti gli altri processi per poter eseguire il suo programma.
N asce quindi la necessità di un processo “super partes“ di coordinamento (lo scheduling ).

Dove stanno i processi pronti non attivi?
Obiettivi di una politica di scheduling (per processi eventualmente conflittuali tra loro):
• Minimo tempo di esecuzione di ciascun processo,• Massimo utilizzo processore,• Massimo numero di processi elaborati nell'unita di
tempo (throughput),• Minimo tempo di attesa per processo.

Tipo di esecuzione richiesta dai vari processi
• Processi batch: vengono lanciati dall'utente e debbono dare una risposta dopo qualche tempo.
Per giungere alla risposta non richiedono ulteriore intervento dell'utente.
• Processi time-sharing: richiedono una interazione con l'utente e nei tempi di attesa lasciano libero il processore di fare altre cose.
• Processi real-time: non possono tollerare alcun ritardo nell'elaborazione. Il processore deve dedicarsi completamente a tali processi. Richiedono sistemi dedicati.

Politiche a lungo termine e politiche abreve termine
• Q uanti processi si possono “tenere" in elaborazione su un processore nel caso di un sistema multi-tasking ? ... ovviamente un numero non eccessivo.
• Il sistema operativo utilizza allora diverse strategie di gestione per decidere quale processo deve avere la priorità.
• C om e distribuire tra i vari processi “in esecuzione" il tempo del processore?

Politiche di gestione dei processi
politiche a breve termine: short term scheduling politiche a lungo termine: long term scheduling

Politiche a breve termine
Tra le politiche a breve termine si distinguono:• politiche non pre-emptive: il processo in esecuzione
può essere sostituito solo se l'utente lo arresta volontariamente o se il programma stesso termina (e adatta ai programmi batch).
• politiche pre-emptive: il sistema ha la facoltà di fermare e sostituire i processi in qualsiasi momento, nei modi che esso stesso valuta essere i più appropriati alla situazione (adatta al time sharing e al real time).

Esempio
Una politica non pre-emptive derivata dalla gestione delle code:
• First Come - First Served detta anche First In - First Out: i processi vengono eseguiti nell'ordine in cui si presentano, viene completata l'esecuzione del primo arrivato mentre gli altri processi stanno ad aspettare il proprio turno.
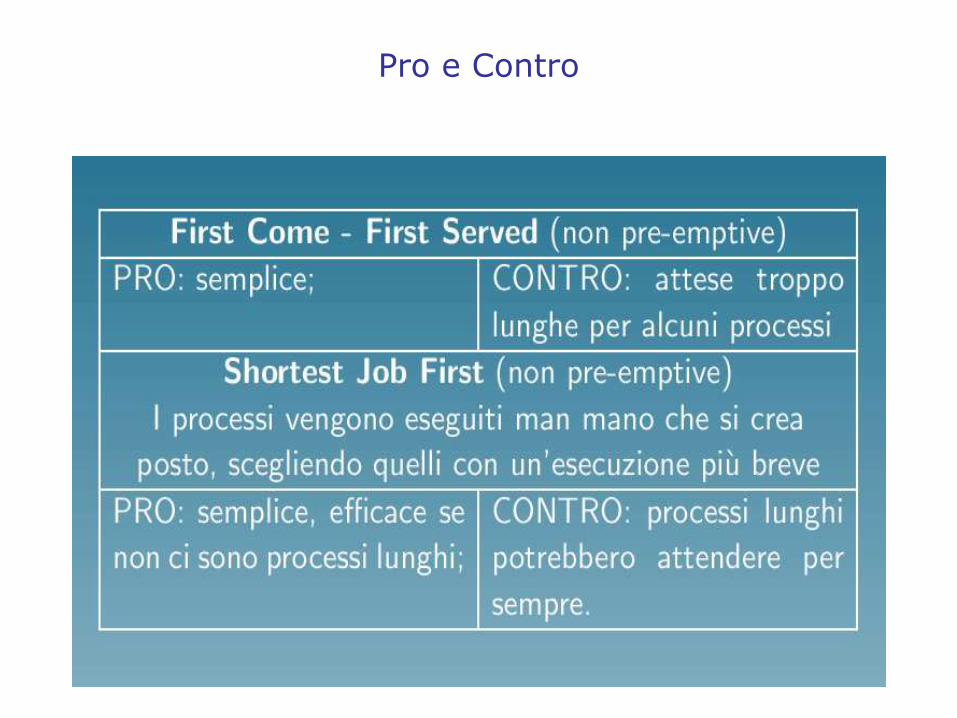
Pro e Contro

Altre politiche per le code
• Shortest Remaining-Time First (politica preemptive). Controlla quale sia il minore tra il tempo residuo di ogni processo in esecuzione e il tempo dei processi in attesa.
• Selezione di priorità: Ogni processo ha una priorità. Vengono eseguiti i processi a priorità maggiore. Esistono varianti pre-emptive e non pre-emptive.
• Round Robin (politica pre-emptive). Il tempo e diviso in “quanti". A turno ogni processo viene eseguito per un quanto di tempo.

Gestione della memoria principale
• Ogni processo usa memoria. Inoltre quando si “m ette un processo in attesa" occorre salvare da qualche parte la sua immagine.
Come viene regolato l'uso della memoria? • Di questo si occupa un'altra porzione del sistema
operativo (gestore della memoria) che assegna ad ogni processo porzioni della memoria disponibile.

Gestione della memoria principale
• ...ancora una volta il compito ideale un gestore della m em oria è di “sim ulare" per ogni processo una memoria dedicata completamente a lui.

Sistema monoprogrammato
• Due sono i task in esecuzione: il programma del sistema operativo e il processo avviato dall'utente. Sistema Operativo Processo Utente
La gestione e semplicissima: basta porre una barriera invalicabile tra la zona di memoria dedicata al sistema operativo e quella dedicata al processo utente.
• Operazione non consentita: superare lo steccato(causa la terminazione forzata del processo utente).

Nel sistema che ha piu’processi
• Cosa fare con l'immagine?• PRIMA OPZIONE: tutta l'immagine di un processo è
rappresentata in una area contigua della memoria.• SECONDA OPZIONE: l'im m agine viene “segm entata"
e scritta in pezzi non contigui della memoria.

Cosa fare con la memoria?
• PRIMA OPZIONE: dividerla in porzioni di dimensioni fisse.
• SECONDA OPZIONE: dividerla in porzioni di dimesione adattabile.

Obiettivi
Ridurre per quanto possibile:• Frammentazione interna (mancato utilizzo di una parte
dell'area assegnata ad un processo da parte di quel processo)
• Frammentazione esterna (mancato utilizzo di porzioni della memoria che non vengono assegnata a nessun processo)

RAM
I problemi sono alleviati • se se c'e tanta RAM! (non ci basta mai! E costa
molto!)• se parte della m em oria e organizzata in “pagine fisse“
che non risiedono tutte sulla memoria principale ma che vengono copiate e lette da e sulla memoria secondaria (hard disk).
Q uesta attività di copiare sul disco le “pagine" dimemoria non utilizzate al momento (perche' i processi
relativi sono in attesa o pronti ma non in esecuzione) si chiam a “paginazione" o “swapping di pagine".

MEMORIA VIRTUALE
• L'espediente di ricorrere all'hard disk con la paginazione crea quella che si chiama MEMORIA VIRTUALE
• Essa e più lenta ma più economica di quella principale.

L'inform azione che più spesso utilizzata dov’è?
Viene posta in una memoria ultra-rapida detta memoria cache:
• In questa memoria per esempio vivono i dati importanti relativi alla gestione del sistema operativo.
• 128 – 256 - 512 Kbyte e la misura standard della cache nei PC più diffusi.

Gestione della memoria secondaria

Gestione della memoria secondaria
tracce e settori formano sulla superficie del disco un “sistema di riferimento” in m odo che il sistem a operativo abbia la possibilità di indirizzare singoli blocchi (o records) di memoria.

I compiti fondamentali del file system
• Mantenere un INDICE (o un sistema di indici) che leghi la struttura fisica con la struttura logica.
• Consentire di creare, distruggere, alterare un file.• Mantenere informazioni sulla data di creazione, sul
creatore, sulla grandezza, sui livelli di protezione di ogni file.

Sulle tecniche di indicizzazione
• Un file è spezzato in tanti record.• I record possono essere contigui o non contigui
all'interno della memoria secondaria.• L'indicizzazione può essere “indexata" oppure
“linkata".

L'organizzazione logica e gerarchica
• Una serie di scatole annidate l'una dentro l'altra.• Le scatole che contengono altre scatole si chiamano
DIRECTORY• Le scatole che contengono solo le informazioni nali
sono i veri e propri FILE• Una directory fisicamente non e altro che un file che
mantiene l'indice di un gruppo di file. Intuitivamente (e graficamente) essa ci appare come un contenitore.

Gestione delle periferiche
• Ogni periferica deve scambiare messaggi con la CPU: tali messaggi vengono chiamati INTERRUPT
• Essi sospendono le azioni della CPU per fornire servizio e attenzione alle periferiche stesse.
• I dati sono condivisi da periferica o CPU: o accedendo ad una m em oria “dedicata" a ciascuna periferica(esempio le schede video, il buffer della tastiera) o condividendo direttamente parte della RAM (alcune stampanti, i dischi di memoria secondaria).

I programmi di controllo di ciascuna periferica
• Sono detti driver: essi sono specifici di ogni periferica;• Sono specifici di ogni CPU.• Debbono essere sempre forniti dal produttore della
periferica! Altrimenti questa e inutilizzabile

Interprete comandi
La buccia esterna della cipolla!Si distinguono due modalità (che possono anche
convivere sul medesimo sistema):• A “shell",ossia mediante scambio di comandi
alfanumerici digitati da tastiera.• Ad oggetti grafici (Windows, Icone, Mouse, Puntatore),
detta Graphic User Interface (GUI).

Linguaggi di Programmazione
Linguaggi di programmazione ad alto livelloNascono e si sviluppano principalmente per due ragioni :1) E' difficile scrivere i programmi direttamente inlinguaggio macchina per:• Istruzioni a basso livello• Dati codicati mediante sequenze di bit2) I programmi in linguaggio macchina non sono portabili
da un elaboratore all'altro.

Obiettivi
• Quindi l'obiettivo di base dei linguaggi di programmazione ad alto livello e quello di consentire al programmatore di astrarre dalle caratteristiche fisiche della macchina e scrivere il programma utilizzando un insieme di istruzioni fornite dal linguaggio stesso.
• Il linguaggio di programmazione fornisce anche i costrutti necessari a combinare le varie istruzioni.

Programmi ad alto livello
• I programmi scritti nei linguaggi ad alto livello non sono eseguibili direttamente.
• Si deve avere un meccanismo intermedio che traducale istruzioni di tali programmi in istruzioni macchina.
• In questa traduzione deve essere preservato il signicato di ogni istruzione.
• Perciò è necessario che i linguaggi ad alto livello siano denfiiti in modo preciso e non ambiguo.

Come si denisce un linguaggio
Definire un linguaggio vuol dire definire le frasi del linguaggio e il loro signicato.
Per definire un linguaggio e quindi necessario introdurre:• Un alfabeto (denisce l'insieme dei simboli)• Un lessico (denisce l'insieme delle parole)• Una sintassi (denisce l'insieme delle frasi ben formate)• Una semantica (definisce il signicato delle frasi ben
formate) • Le frasi ben formate di un linguaggio di
programmazione costituiscono i programmi.

La Sintassi
La sintassi di un linguaggio si specifica mediante una grammatica cioè un insieme di regole che stabiliscono:
• come combinare le diverse parole del lessico per costruire le frasi corrette (frasi ben formate) del linguaggi.
Le grammatiche possono essere definite in modidifferenti: nell'informatica si usano delle definizioni di tipo
generativo.

La semantica
• Il compito di associare un significato alle frasi e legato all'analisi semantica.
• P unto di partenza della analisi sem antica è l‟ipotesi che sia noto il signicato di ogni parola.

La semantica
Consideriamo le due frasi seguenti entrambe esatte dal punto di vista sintattico:
1. La ragazza mangia un pollo2. Un pollo mangia la ragazzaChiaramente soltanto la prima e esatta dal punto di vista
semantico.Notare che la interpretazione semantica viene data
rispetto ad un determinato contesto

La definizione di un linguaggio di programmazione
Per la definizione di un linguaggio di programmazione bisogna fare in modo che:
•La sintassi sia semplice e non ambigua•La semantica sia chiara

Il parser
• Data la grammatica di un linguaggio di programmazione è possibile costruire un parser (cioè un analizzatore sintattico) in grado di riconoscere le frasi ben formate del linguaggio (i programmi).
• Il parser inoltre quando esamina frasi non corrette,segnala il punto in cui è stato riscontrato un errore e suggerisce eventuali correzioni.

Problema
• Definito un linguaggio di programmazione ad alto livello e scritto un programma in tale linguaggio, come è possibile eseguire il programma su una macchina in grado di eseguire soltanto istruzioni in linguaggio macchina ?
• Abbiamo bisogno di un “traduttore" che traduca le istruzioni del linguaggio ad alto livello in istruzioni equivalenti del linguaggio macchina.

Modalità di traduzione
Esistono due diverse tecniche per farlo: • la compilazione• l' interpretazione• Osservazione: i linguaggi ad alto livello sono portabili
su macchine differenti.

Compilazione
La compilazione può essere descritta nel modo seguente:
per eseguire su una macchina M un programma P scritto in un linguaggio ad alto livello L, bisogna:
1. Tradurre P in un programma P' scritto in linguaggio macchina.
2. Eseguire il programma P' sulla macchina M.

Compilazione
In questo caso la traduzione viene eseguita da unprogramma che prende il nome di compilatore per il
linguaggio L sulla macchina M. • In realtà il compilatore prima di effettuare la traduzione
esegue l'analisi sintattica segnalando gli eventuali errori sintattici.
• Il programma P prende il nome di programma sorgente mentre il programma P' prende il nome di programma oggetto.

Riassumendo
• Dal programma P tramite compilatore per il linguaggio L si ottiene il programma P' nel linguaggio macchina di M e quindi si può passare all'esecuzione di P' su M.
• Il programma oggetto (P') potrà poi essere eseguito tutte le volte che si desidera senza dover rifare ogni volta la traduzione.

Attenzione !
E ‟ necessario un compilatore diverso per ogni diversa macchina.
• Lo stesso programma sorgente viene tradotto in programmi oggetto differenti per le diverse architetture hardware.
• Linguaggi compilati sono il Pascal, il C, il Fortran

Interpretazione
L'idea alla base dell'interpretazione e quella di tradurre il programma durante la sua esecuzione:
• quando il programma P in un linguaggio L viene mandato in esecuzione, le istruzioni di P vengono in sequenza tradotte e poi eseguite
• il programma che esegue la traduzione viene chiamato interprete per il linguaggio L sulla macchina M.
• contemporaneamente alla traduzione viene vericata la correttezza sintattica di ogni istruzione e vengono segnalati eventuali errori. Esempi di linguaggi interpretati sono il Basic, il Prolog, il Lisp, Perl, PHP, Javascript, ASP!

Interpreti contro compilatori
• La compilazione è più efficiente della interpretazione.• L'interpretazione è più flessibile della compilazione.• L'interpretazione è più utile durante la fase di sviluppo
del programma.ma.• La compilazione è più comoda una volta che il
programma è già stato messo a punto.

Interpreti contro compilatori
Esistono linguaggi che mettono a disposizione entrambe la modalità di esecuzione (Lisp, Prolog e Basic).
Esistono linguaggi che usano uno schema misto.

Java
Ad esempio, un programma scritto nel linguaggio Java,al momento della compilazione viene compilato in un programma in un codice intermedio (Java byte-code) che può essere eseguito da un interprete (JVM -java virtual machine).
Il codice intermedio prodotto dalla compilazione ha il vantaggio di essere indipendente dall'architettura, mentre ad una data architettura corrisponderà un dato interprete in grado di eseguire un qualsiasi java-byte-code.

Ingegneria del software
• Un programma ben scritto dovrebbe essere semplice, efficiente, facilmente leggibile , facilmente modificabile e di facile manutenzione.
• La semplicità e l'efficienza di un programma sono legate all'algoritmo utilizzato per risolvere il problema.

L‟Ingegneria del Softw are
• L'ingegneria del software formalizza i diversi passi dello sviluppo di un programma.
• In particolare, nello sviluppo di un programma si possono distinguere le seguenti fasi:
1. Analisi,2. Progettazione, 3. Codifica,4. Verifica, 5. Correzione, 6. Documentazione,7. Manutenzione, 8. Aggiornamento, 9. Dismissione.

1. Analisi del problema
• Questa prima fase deve produrre una specifica chiara del problema che si vuole risolvere.
• In questa fase si devono individuare:• Il tipo di macchina da utilizzare• La disponibilità di linguaggio di programmazione su
tale macchina• I requisiti di tempo di sviluppo• I requisiti di efficienza

2. Progettazione dello schema di base2. Progettazione dello schema di base
• Individuazione delle strutture dati fondamentali • Stesura dell'algoritmo per la soluzione del problema.
In questa fase spesso si usa un approccio di tipo modulare (ad esempio per gli algoritmi un approccio di tipo top-down, si denfiiscono le funzionalità più esterne fino ad arrivare ai dettagli più interni).

3. Codica dell'algoritmo
• Si passa dallo schema a blocchi al vero e proprio codice scritto nel linguaggio scelto.

4. Verica di correttezza
• In alcuni casi la verifica puo' essere fatta formalmente, in altri ci si deve limitare ad eseguire dei test.

5. Correzione (debugging)
• Gli errori di natura sintattica possono essere individuati ed eliminati facilmente (in fase di compilazione).
• Più difficile affrontare gli errori di natura semantica: di solito succede che il programma funzioni correttamente nella maggior parte dei casi e si comporti male in alcuni casi particolari.
• Programmi di debugging. Vi sono programmi che aiutano a seguire esattamente tutte le fasi dell'esecuzione del programma per individuarne i malfunzionamenti (bugs, o bachi).

6. Documentazione
• Stesura della documentazione e manuali per l'uso del programma.

7. Manutenzione e revisione del programma
• Il programma può essere revisionato per correggere alcuni malfunzionamenti e fare delle modifiche minori.

8. Aggiornamento
• In seguito all'utilizzo del programma possono emergere nuove esigenze per le quali servirà una nuova fase di sviluppo.
• Si noti che durante lo sviluppo di un programma possono essere coinvolte diverse figure professionali: il progettista, l'analista, il programmatore.

L‟inform azione sulla “rete”L‟inform azione sulla “rete”
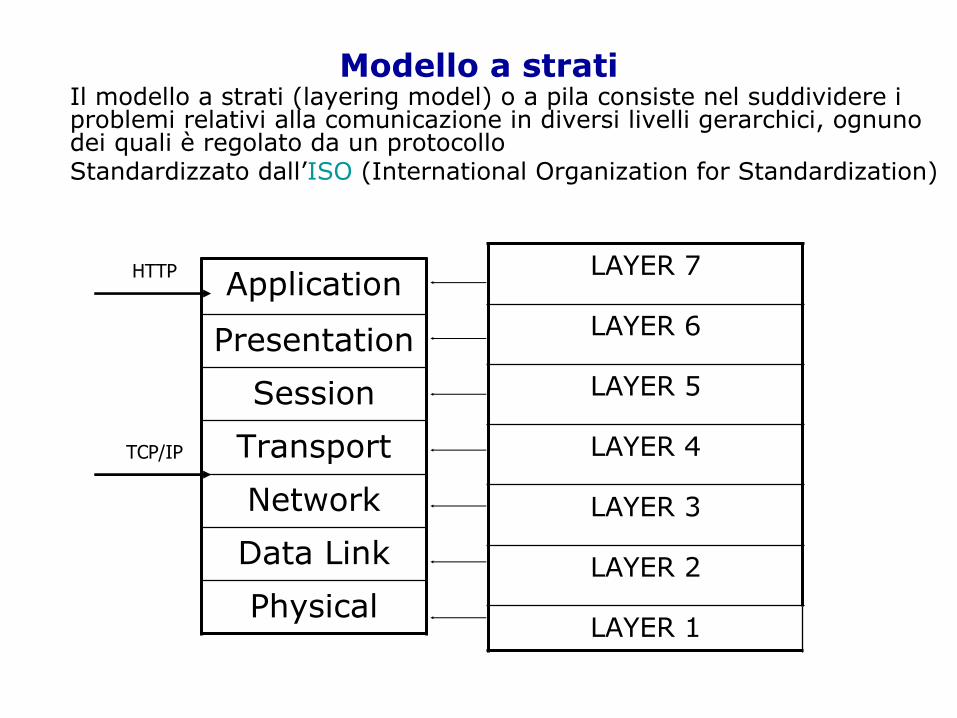
Modello a strati
Application
Presentation
Session
Transport
Network
Data Link
Physical
LAYER 7
LAYER 6
LAYER 5
LAYER 4
LAYER 3
LAYER 2
LAYER 1
TCP/IP
HTTP
Il modello a strati (layering model) o a pila consiste nel suddividere i problemi relativi alla comunicazione in diversi livelli gerarchici, ognuno dei quali è regolato da un protocolloS tandardizzato dall’ISO (International Organization for Standardization)

I sette livelli ISOliv.1: fisico Stabilisce i dettagli e gli standard dei dispositivi
fisiciliv.2: data link Stabilisce come organizzare i dati in frame e
come trasmetterli lungo la rete (es. formato, stuffing, controllo degli errori)
liv.3: rete S i occupa dell’indirizzamento e inoltro dei pacchetti
liv.4: trasporto Stabilisce le direttive per assicurare il trasporto affidabile dei dati
liv.5: sessione Specifica come stabilire una sessione di comunicazione a distanza con un altro sistema
liv.6: presentazione
Converte le diverse rappresentazioni di dati (diverse marche di calcolatori utilizzano differenti formati per la rappresentazione interna degli interi e dei caratteri
liv.7: applicazioni I protocolli di questo livello specificano come una certa applicazione utilizza
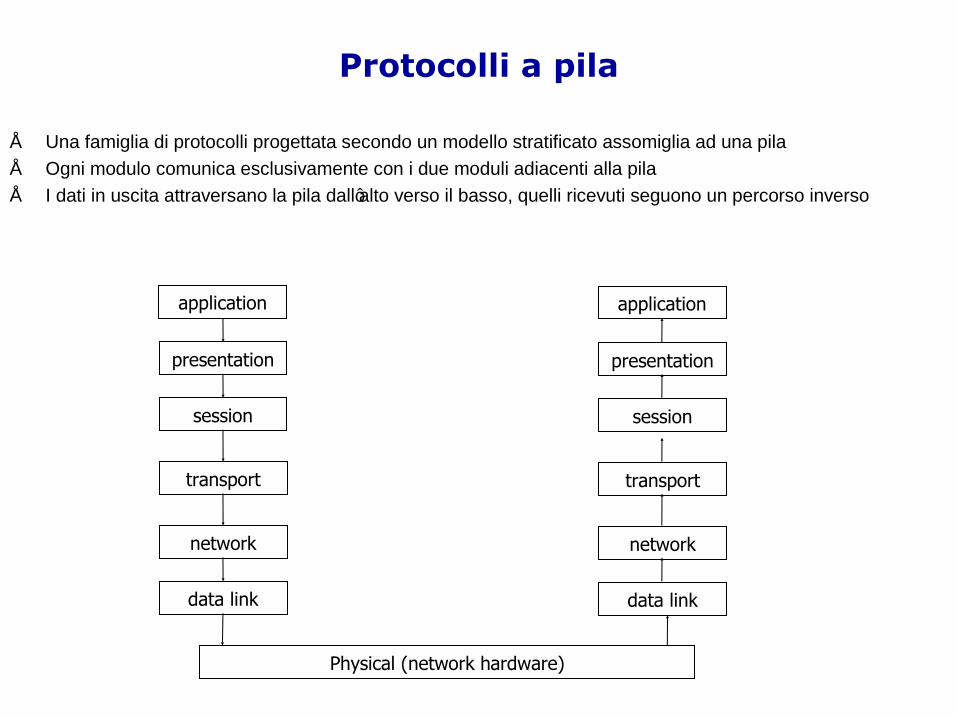
Protocolli a pila
• Una famiglia di protocolli progettata secondo un modello stratificato assomiglia ad una pila• Ogni modulo comunica esclusivamente con i due moduli adiacenti alla pila• I dati in uscita attraversano la pila dall‟alto verso il basso, quelli ricevuti seguono un percorso inverso
application
presentation
session
transport
network
data link
Physical (network hardware)
application
presentation
session
transport
network
data link
ReteRete LocaleLocale
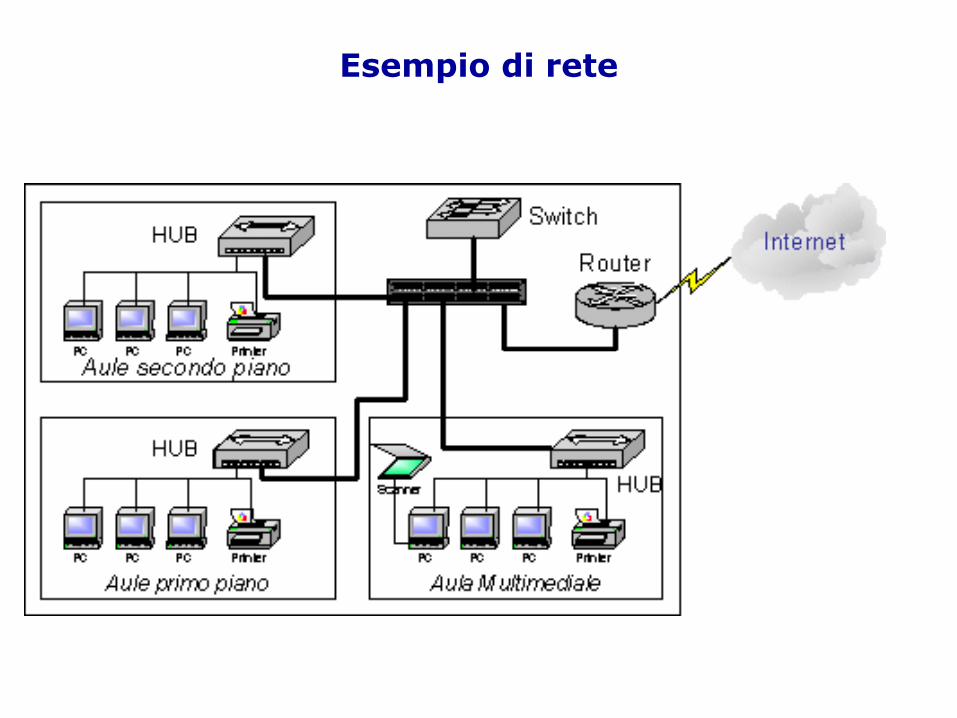
Esempio di rete
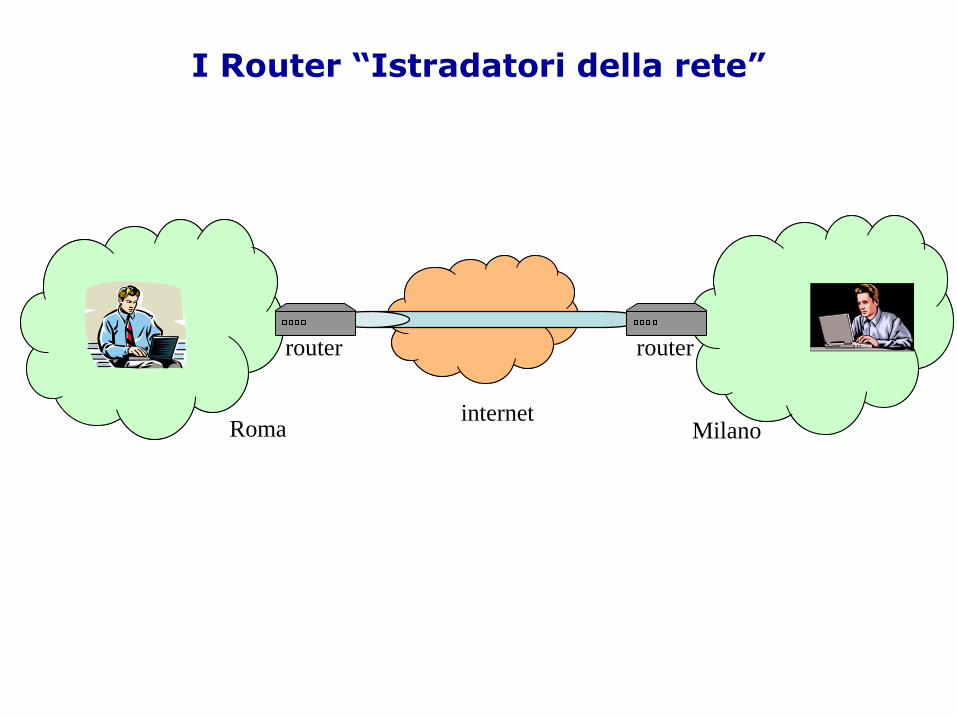
I Router “Istradatori della rete”
router
internet
router
Roma Milano
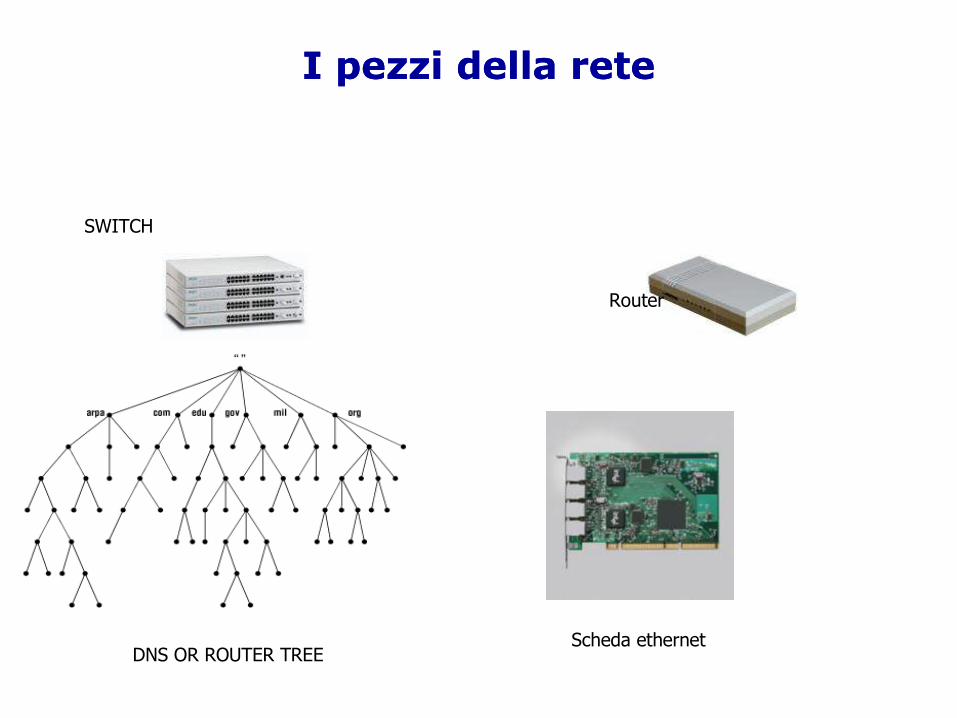
I pezzi della reteI pezzi della rete
SWITCH
Router
DNS OR ROUTER TREEScheda ethernet
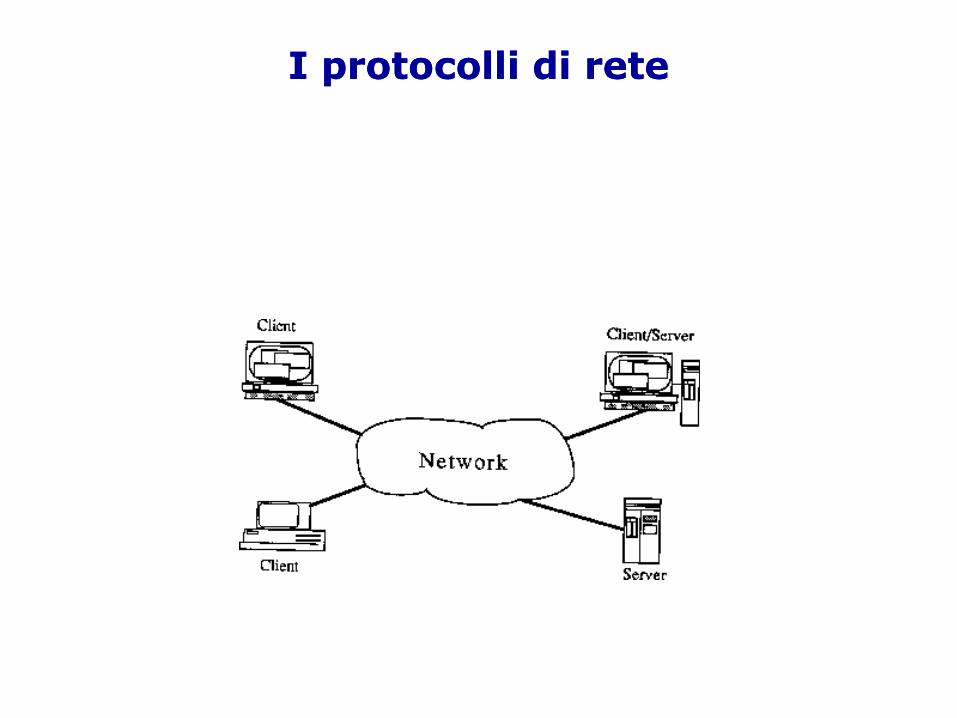
I protocolli di reteI protocolli di rete

L‟A R CH ITETTU R A TCP/IP
• N egli anni „70 la Defense Advanced Research Project Agency (DARPA) finanziò la ricerca di una rete per l‟interconnessione di calcolatori eterogenei
• Nasce Internet Protocol Suite di cui fanno parte i due protocolli più noti: Internet Protocol (IP) e il Transmission Control Protocol (TCP)
• E ‟ il protocollo adottato da centinaia di m ilioni di sistemi nel mondo e su cui si basa Internet.

Il protocollo TCP/IP
È il protocollo fondamentale per il funzionamento di Internet (Transmission Control Protocol / Internet Protocol)
Si basa la comunicazione fra i nodi della rete Internet attraverso una “pacchettizzazione” dell‟inform azione
Ad ogni nodo della Rete è assegnato un indirizzo IPcomposto da quattro numeri compresi tra 0 e 255 (es.: 150.146.2.25, servono pertanto 4 byte per la rappresentazione binaria!!!)

INDIRIZZAMENTO IP
• Gli indirizzi IP devono essere UNICI su tutta la rete.• Formati da 32 bit, in 4 byte separati da un punto: Es:
193.205.203.38• Agli indirizzi IP sono associati, per comodità, uno o più
nomi, detti hosts, assegnati e garantiti a livello mondiale. I nomi sono risolti da sistemi detti Domain Name Server (DNS)
• Non sono i NODI a possedere indirizzo IP, ma le interfacce (vi possono essere schede di rete multiple su un unico sistema)

Il Pacchetto IP
• IP si occupa di instradare, frammentare, riassemblare i messaggi sulla rete e di rilevare (senza correggere) gli errori.
Parole da 32 bit
Indirizzo IP destinazione
Indirizzo IP sorgente
Opzioni Padding
Controllo testataProtocolloTempo di vita
Identificazione Flags Fragment Offset
Lunghezza TotaleTipo di servizioHLENVersione
Bit 0 4 8 16 19 24 31
1
6
Testata del pacchetto IPTestata del pacchetto IP

Pacchetto IP
In particolare:
• TEMPO DI VITA: contatore temporale. Quando arriva a zero il pacchetto viene scartato. Evita i loop di pacchetti difettosi
• PROTOCOLLO: specifica il protocollo del pacchetto di livello superiore
• INDIRIZZO DI SORGENTE/DESTINAZIONE: indirizzi IP di mittente e destinatario

Il protocollo TCP/IP
Mediante opportuni meccanismi (DNS= Domain Name Server ) è possibile convertire gli IP address numerici in indirizzi mnemonici e viceversa.
(es.: 150.146.2.201 = www.iac.rm.cnr.it).

Indirizzi Pubblici
Per comunicare su Internet, è necessario quindi utilizzare indirizzi IP, tali indirizzi vengono assegnati da una autorità internazionale: IANA (Internet Assigned Numbers Authority). In genere, per le società di piccole dimensioni o gli uffici privati, gli indirizzi pubblici vengono assegnati dal provider di servizi Internet, che a loro volta hanno ricevuto un intervallo di indirizzi pubblici dall'autorità IANA.Pertanto, per consentire a più computer di un piccolo ufficio o di un'abitazione di comunicare su Internet, è necessario che questi dispongano di un indirizzo. Questo requisito implicherebbe, nel caso di soli indirizzi pubblici, un utilizzo intensivo degli stessi. E’ per questo che sem pre lo IA N A ha stabilito una serie di range di indirizzi denom inati “privati”

Indirizzi Privati Internet
G li indirizzi privati sono definiti nell‟am bito dei seguenti intervalli:
• 10.*.*.*• 172.16.*.*• 192.168.*.*
Questi indirizzi possono essere utilizzati per realizzare reti locali (LAN), ma non possono essere utilizzati per navigare su Internet.
Nel caso in cui si voglia permettere ad un computer con indirizzo privato di navigare su internet e‟ necessaria una operazione di trasform azione dell‟indirizzo detta NAT (Network Address Traslation)

Il protocollo HTTP
• HTTP = HyperText Transfer Protocol
• HTTP è il protocollo internet attraverso cui avvengono le trasmissioni di dati per i Browser.

Il protocollo HTTP
• S i “appoggia” sul protocollo IP (Internet P rotocol)• Consente l'accesso a documenti ipertestuali in cui
vengono realizzati dei link tra file di vario genere (non solo testuali) fisicamente residenti anche su host differenti.

Il protocollo HTTP
• È gestito da un software (server HTTPD) residente sugli host che intendono essere fornitori di informazioni. Chi vuole accedere alle informazioni fornite dal server HTTP deve utilizzare un software client (browser) in grado di interpretare le informazioni inviate dal server.
• HTTP è un protocollo "stateless": ad ogni richiesta si effettua una connessione al server che viene chiusa al termine del trasferimento dell'oggetto richiesto (pagina HTML, immagine, ecc.).

Il protocollo HTTP
• HTTP identifica le risorse in rete mediante URL(Uniform Resource Locator):

Il server HTTP
• È un programma che "gira" su un computer di rete in attesa di una richiesta di connessione su una delle sue tante “porte di accesso” (la porta assegnatagli è la 80)
• Il server HTTP svolge un ruolo di interfaccia tra il client remoto che effettua delle richieste sulla “porta”

Il server HTTP
• Svolge tre compiti fondamentali:
– invia al client le risorse disponibili localmente, richieste mediante l'indicazione di una URL;
– richiama eventuali procedure esterne con cui comunica mediante l'interfaccia CGI (Common Gateway Interface) per lo scambio di parametri e per ottenere in risposta informazioni in formato HTML;
– effettua, ove esplicitamente richiesto dalla sua configurazione, l'autenticazione degli utenti mediante username e password.

Il server HTTP: struttura
• In ogni sito Web deve esistere una home directory. • La home directory rappresenta il punto di partenza per
i visitatori che esplorano il sito ed è la directory di livello superiore nella struttura di directory di pubblicazione.
• Essa contiene un file indice o una home pageintroduttiva in cui viene dato il benvenuto ai visitatori e sono inclusi i collegamenti ad altre pagine del proprio sito Web. La home directory è mappata nel nome di dominio del proprio sito.

Il server HTTP: struttura
• Tutti i file contenuti nella home directory e nelle relative sottodirectory sono automaticamente disponibili ai visitatori che si connettono al sito
• Per pubblicare un documento contenuto in una directory qualsiasi non compresa nella home directory, è necessario creare una directory virtuale. Per directory virtuale si intende una directory che non è realmente contenuta nella home directory, ma che compare come tale ai browser dei client.

Il server HTTP: struttura
• Le directory virtuali sono contraddistinte da un alias, ovvero un nome che i browser dei client utilizzano per accedervi. Per gli utenti gli alias sono più comodi da digitare poiché solitamente sono più brevi rispetto al nome di percorso della directory.
• Grazie agli alias, lo spostamento delle directory all'interno del sito diventa più facile. Anziché modificare l'URL per la pagina, è sufficiente modificare la mappatura tra l'alias e la posizione reale della pagina.

Il browser
• Il browser è l'applicazione client di questo sistema ad architettura "client/server".
• Gira sulla macchina dell'utente remoto, legge ed interpreta l'output in formato HTML
• Visualizza o gestisce le informazioni codificate in formati a lui noti (es.: immagini GIF o JPEG, filmati QuickTime, scene VRML) e rimanda ad altri programmi esterni presenti sulla macchina client per la gestione di formati non conosciuti (es.: documenti Word, documenti Postscript, ecc.).

Il browser
• Le procedure CGI non vengono eseguite sulla macchina client• I programmi in linguaggio Java vengono invece scaricati sul
client, compilati in tempo reale ed eseguiti su di esso• Il browser consente di impaginare l'output indipendentemente
dalla piattaforma che lo ospita (X11, Macintosh, Windows, ecc.)

Il linguaggio HTML
HTML = HyperText Markup Language èil linguaggio dei browsers http Il concetto di ipertesto e` quello di un documento che contenga, oltre al
testo, anche parti di diversa natura, come immagini, suoni, applicazioni, aree interattive, rimandi ad altri documenti (hyperlinks). È un semplice "linguaggio" di marcatura del testo (come il LateX), ereditato da SGML (Standard Generalized Markup Language).
Consiste in un insieme di tag che consentono di caratterizzare porzioni di testo; è compito del client (browser) l'interpretazione dei tag.

Markup = Marcatura
Il concetto di markup e` da intendersi come un linguaggio impostato con dei "marcatori" (tags) di inizio e fine. Per esempio, il grassetto (bold) si ottiene cosi`:
<b>Questa parte e` in grassetto</b>Questa parte e` in grassetto
Vale a dire che il tag <b> identifica la marcatura di inizio del testo in grassetto, mentre il tag </b> ne identifica la fine.

Struttura della pagina HTML
La pagina html e` strutturata in due parti principali:
• l'intestazione (head) ed il
• corpo del documento (body).
• Per convenzione, l'intero documento va racchiuso tra i tag <HTML> e </HTML>.

Tag HEAD
L'intestazione e` identificata dal tag <HEAD>. Alcuni dei parametri che accetta sono:
TITLETITLE: Indica il titolo del documento. Il contenuto appare nella barra superiore della finestra del browser. Parametro opzionale.
<TITLE>Titolo del Documento</TITLE>

Tag BODY
• Piu` importante e ricco e` il tag di corpo del documento, cioe` il BODYBODY.Alcuni dei parametri che accetta sono:
BGCOLORBGCOLOR: Imposta il colore dello sfondo. Il colore viene passato o come stringa (tipo blue, black, aqua, ecc.) o come componenti RGB secondo la notazione #RRGGBB, dove RR, GG e BB sono le componenti rossa, verde e blu in esadecimale (00 - FF). Per impostare uno sfondo color giallo, ad esempio, l'impostazione sara`:
•• BGCOLORBGCOLOR=“# 00FFFF”

Tag BODY
TEXTTEXT: Stessa funzione del BGCOLOR, solamente riferita al colore di default del testo.
LINKLINK, VLINKVLINK, ALINKALINK: Stessa sintassi di BGCOLOR e TEXT per il testo associato ad hyperlink ancora da visitare (LINK), gia` visitati (VLINK) o selezionati in quel momento (ALINK).
BACKGROUNDBACKGROUND: Uno dei parametri piu` "succulenti" del BODY. Permette di impostare come sfondo un file grafico, in formato JPEG o GIF, che verra` visualizzato in piu`copie affiancate sul documento.

Un semplice esempio
<HTML><HEAD><TITLE="Prova della Lezione"></HEAD><BODY BACKGROUND=”prova.gif"
TEXT=”Arial"><!-- Il testo comparira` con il file prova.gif
come sfondo -->Questo e` il mio primo documento HTML!!!</BODY></HTML>

Intestazioni <Hn> … < /Hn>, n=1, 2, … .., 6
• Esistono due modi fondamentali per variare le dimensioni del carattere nelle pagine html: l'uso delle intestazioni e degli stili. Le intestazioni sono semplicemente sei stili predefiniti
• Intestazione di livello 1 Intestazione di livello 2
Intestazione di livello 3 Intestazione di livello 4
Intestazione di livello 5Intestazione di livello 6

<FONT>
Il tag <FONT>...</<FONT>...</FONTFONT>> è uno tra i piu` usati. Permette di variare colore e dimensione del testo. I parametri che accetta sono:
SIZE:SIZE:Dimensione del font, da 1 a 7. Puo` essere data in modo assoluto (appunto da 1 a 7) o relativo rispetto alla dimensione attuale (+2, -1, ecc.)
COLOR:COLOR: Imposta il colore del carattere, utilizza le stesse modalita` di BGCOLORBGCOLOR

Es. TAG Font
<FONT SIZE=2 COLOR="fuchsia" FACE="TimesRoman">Questo e` un Font di dimensione 2, color fuchsia
(magenta) con stile Times New Roman</FONT><FONT SIZE=+1 COLOR=#FF8000 FACE="Arial">Questo e` un Font un punto piu` grande dello standard
(=3) , color arancio(255 rosso, 128 verde, 0 blu) con stile Arial</FONT>Risultato!:Questo e` un Font di dimensione 2, color fuchsia
(magenta) con stile Times New RomanQuesto e` un Font un punto piu` grande dello standard
(=3) , color arancio (255 rosso, 128 verde, 0 blu) con stile Arial

Separatori
<BR> <P> e <HR><BR> <P> e <HR>
• Il tag <BR><BR> introduce l'equivalente di un return, introducendo un a capo SENZA spazi di interlinea
•• <P><P>, invece, oltre al return si introduce anche un salto di linea, in modo da separare due paragrafi
•• <HR><HR> introduce una linea di separazione

Formattatori di blocco
•• <CENTER>...</<CENTER>...</CENTERCENTER>>:: Uno dei piu`usati. Centra il testo, oltre alle immagini, contenuto nel blocco, rispetto alla larghezza di pagina

Liste
• HTML propone dei metodi semplici per costruire liste. I tags che svolgono questa funzione sono cinque:
<UL>:<UL>: Lista non ordinata<OL>:<OL>: Lista ordinata<MENU>:<MENU>: Simile a <OL><DL>:<DL>: Lista di definizioni<DIR>:<DIR>: Rientri consecutivi

Anchors (<A>)
I vari modi di utilizzo del Tag <A>•• Riferimento IpertestualeRiferimento Ipertestuale: <a
href="http://www.prova.com"> Sito prova </a>
•• Immissione di una Immissione di una labellabel per un blocco di per un blocco di testotesto:<A NAME="prova">
•• Richiamo di una Richiamo di una labellabel: <A HREF=”this.htm # prova"> V ai alla prova< /A >

FRAMESET:
• Ordina al browser di impostare il frame. I parametri accettati sono:
ROW, COLROW, COL: Righe o colonne interne al frame. Il parametro e` passato come lista, vale a dire che, per esempio, se vogliamo tre colonne larghe 100 pixel, 300 pixel ed il resto per la terza, scriveremo COL="100,300,*". I valori in percentuale sono ammessi.

FRAME:
• Indica il contenuto del frame generato. I parametri ammessi sono:
SRC: indica il documento da visualizzare nel frame.
NAME: Indica il nome della frame. Esistono anche alcuni nomi predefiniti, quali:
_BLANK: Apre una nuova finestra vuota, _SELF: Carica il link correlato sopra il frame stesso, _PARENT: Carica il linkcorrelato sopra il frame "padre" (se e` il primo frame, equivale a _SELF).
MARGINWIDTH, MARGINHEIGHT: Controllano le dimensioni dei bordi delle frames, come valori destro/sinistro (MARGINWIDTH) o alto/basso (MARGINHEIGHT). Valori in pixel.
NORESIZE: E` un flag che, quando inserito, vieta il ridimensionamento del frame.

Esempio

<FORM>
• Per impostare il documento HTML in modo da poter inviare dati al server viene usato il tagFORM. Questo tag accetta tre parametri, che sono:
ACTIONACTION: Indica l'URL da attivare per inviare i dati. Generalmente, il file indirizzato e` uno script o un eseguibile.
METHODMETHOD: Specifica POST o GET.
ENCTYPEENCTYPE: Indica la natura dei dati inviati, in formato MIME. Quando l'URL utilizza il protocollo HTTP (nella maggior parte dei casi), ENCTYPE e` impostato di default a "application/x-www-form-urlencoded".
"multipart/form-data" | "application/x-www-form-urlencoded" |"text/plain"

<Input>
• Questo tag genera tutti gli altri tipi di interfaccia di dialogo quali pulsanti, check box, text box, ecc.
NAMENAME: anche qui come per TEXTAREA. SIZESIZE: dimensione del campo da visualizzare,
dipendentemente dal tipo di campo. SRCSRC: un URL per associare un'immagine ad un
pulsante, se desiderato. MAXLENGHTMAXLENGHT: numero massimo di caratteri
introducibili in un campo testo. Se maggiore di SIZE, il testo scorrera` in accordo all'introduzione dei dati.
CHECKEDCHECKED: In caso di un oggetto pulsante, lo crea gia` selezionato.
VALUEVALUE: Il valore iniziale del campo da visualizzare.

<Input>
• TYPE: Specifica il tipo di interfaccia di dialogo da creare. I tipi sono:
CHECKBOXCHECKBOX: Genera una casella selezionabile.
HIDDENHIDDEN: Non genera interfaccia di dialogo. Viene usato per inviare dati al server che dipendono dal client, tipo nome o indirizzo IP.
IMAGEIMAGE: Un campo immagine, cliccando sul quale i dati vengono inviati al server. Al campo verranno inoltre associate le coordinate sulle quali era puntato il mouse al momento del click.
PASSWORDPASSWORD: Un campo testo, digitando nel quale, invece dei caratteri, vengono visualizzati dei '*'.

<Input>
• TYPE (segue) RADIORADIO: Genera un radio button, cioe` un pulsante
che, selezionato, deseleziona automaticamente gli altri del suo gruppo. E` obbligatorio il parametro VALUE.
RESETRESET: Genera un pulsante che azzera tutti i valori del FORM.
SUBMITSUBMIT: Genera un pulsante che invia i dati al server. Il parametro VALUE imposta l'etichetta del pulsante. Se manca, viene visualizzato "SUBMIT".
TEXTTEXT: Una singola linea di testo.

<Textarea>
• Crea un'area di testo scrivibile su piu` linee. I parametri che accetta sono:
ROW,COLROW,COL: Dimensioni, in caratteri, della finestra.
WRAPWRAP: Indica la modalita` di wrapping del testo. I valori ammessi sono:
OFFOFF: Default. Il testo non va a capo automaticamente.
VIRTUALVIRTUAL: Il testo va a capo automaticamente, ma viene inviato come linea unica.
PHISICALPHISICAL: Il testo va a capo automaticamente e viene inviato come visualizzato.
NAMENAME: Imposta il nome del campo, che verra` poi usato dall'applicativo per rintracciare il contenuto del campo stesso

<Select>
• Crea una lista di scelte possibili. Accetta tre parametri, che sono:
NAME: Equivalente al NAME di TEXTAREA
SIZE: Indica l'altezza massima, in righe, della lista. Se la lunghezza supera questo valore, verra`visualizzata una barra di scorrimento verticale.
MULTIPLE: Se presente, consente di fare scelte multiple nella lista

<Select>
•• OPTIONOPTION: si accompagna alla SELECTSELECT ed indica il contenuto della lista di scelte. I parametri ammessi sono: SELECTEDSELECTED: Indica il valore inizialmente selezionato
nella lista. VALUEVALUE: Indica il valore da inviare come dato al
server. Quando non e` presente, viene preso il contenuto della OPTION

Strumenti per la programmazione
• Ogni linguaggio di programmazione fornisce all'utente strumenti per facilitare l'esecuzione delle varie fasi della programmazione.
Tra questi strumenti ricordiamo:1. Gli editor per la scrittura dei programmi.2. I compilatori e gli interpreti.3. I debugger.4. I sistemi di mantenimento di versioni diverse
di programmi.

Linguaggi di scripting
• I linguaggi di questo tipo nacquero com e linguaggi “batch”: vale a dire liste di comandi di programmi interattivi che invece di venire digitati uno ad uno su una linea di comando, potevano essere salvati in un file, che diventava così una specie di comando composto che si poteva eseguire per automatizzare compiti lunghi e ripetitivi.
• I primi linguaggi di scripting sono stati quelli delle shellUnix; successivamente, vista l'utilità del concetto molti altri programmi interattivi iniziarono a permettere il salvataggio e l'esecuzione di file contenenti liste di comandi, oppure il salvataggio di registrazioni di comandi visuali (le cosiddette Macro dei programmi di videoscrittura, per esempio).
• Il passo successivo fu quello di far accettare a questi programmi anche dei comandi di salto condizionato (If) e delle istruzioni di ciclo (for, while), regolati da simboli associati ad un certo valore: in pratica implementare cioè l'uso di variabili.

Linguaggi di Scripting
Si dividono in:• linguaggi di scripting lato server come
ASP, PHP, JavaScript Server• linguaggi di scripting lato client come
JavaScript, Vbscript• linguaggi di scripting CGI comePerl

JavaScript
• JavaScript è un linguaggio di scripting orientato agli oggetti comunemente usato nei siti web.
• Fu originariamente sviluppato da Brendan Eich della Netscape Communications con il nome di Mocha e successivamente di LiveScript, ma in seguito è stato rinominato "JavaScript" ed è stato formalizzato con una sintassi più vicina a quella del linguaggio Java di SunMicrosystems.
• JavaScript è stato standardizzato per la prima volta tra il 1997 e il 1999 dalla ECMA con il nome ECMAScript. L'ultimo standard, del dicembre 1999, è ECMA-262 Edition

JavaScript: potenzialita‟
• JS può individuare tutti gli eventi generati dalBrowser come i clic del mouse sui pulsanti o la navigazione tra le varie pagine e provocareazioni conseguenti
Per es. JS può accorgersi di quando un utenteesce da una pagina e dare inizio ad unarisposta appropriata
o anche può individuare la selezione di un elemento da un elenco

JavaScript: potenzialita‟
• C on JS è possibile generare “al volo” codice HTML
• JS e’ basilare per il Controllo di validità di quanto immesso nei campi di un form HTML prima di inviare al server

JavaScript: potenzialita‟
• Creare documenti sofisticati per la navigazione utilizzando frame e finestre
• Individuare le applet Java e i plug-in Netscapee interfacciarsi con essi

JavaScript e Java: differenze
Javascript:• Interpretato dal client mentre viene letta la
pagina HTML. Non puo' essere eseguito fuori dal browser web
• Codice scritto all' interno delle pagine HTML
• I tipi di variabile non devono essere dichiarati

JavaScript e Java: differenze
Java:• Bytecode compilato, scaricato dal server ed
eseguito dal client. Comunque e' un linguaggio multipiattaforma e puo' essere eseguito all' interno di qualsiasi sistema operativo. Occorre solo una macchina virtuale Java (percio' non e' indispensabile un browser web)
• Applet distinta dalla pagina web • I tipi di variabili usati devono essere dichiarati

Integrazione di JS con l‟H TM L
Impariamo ora a:• Utilizzare il container <SCRIPT> per inserire
programmi JS in una pagina Web• Occultare le linee di codice JS per i browser che
non lo supportano• Gestire i messaggi di errore e le caselle di
avvertimento

<HTML><HEAD>< S C R IPT Language= “Javascript”>function Foo(obj) {... }...</SCRIPT>
...<FORM>< IN PU T TYPE= “button” V A LU E= “G O !!” onClick= “Foo(this.form)”></FORM>
...</HTML>
Richiamare una funzione in un punto del Body
Solitamente il tag <SCRIPT> va inserito in questo punto
Come Come inserireinserire codicecodice JavascriptJavascript in in unauna paginapagina HTMLHTML

La Sintassi di < SCR IPT> … < /SCR IPT>
<SCRIPT [language=“JavaScript”]>
[JavaScript-statem ents… … .]
</SCRIPT>

Caricamento di JS locali
<html><head><script language="JavaScript"><!--window.alert(“C iao da M assi!”);
//--></script></head></html>
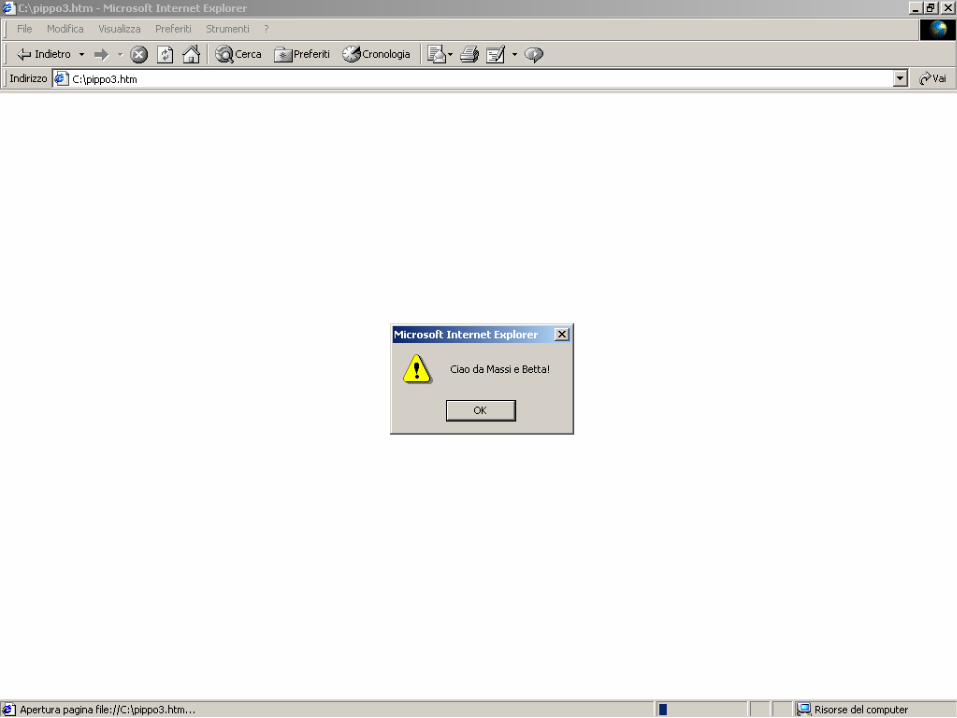

<HTML><BODY>Today:< SCR IPT LA N G U A G E = “JavaScript”><!--
var today = new Date();document.write (today.getMonth() + “/” + today.getDate() +
“/” + today.getYear() );// --></SCRIPT></BODY></HTML>
NascondereNascondere ilil codicecodice JavascriptJavascript aiai BrowserBrowsernon non abilitatiabilitati
Questo è un commento HTML
Questo è un commento JS
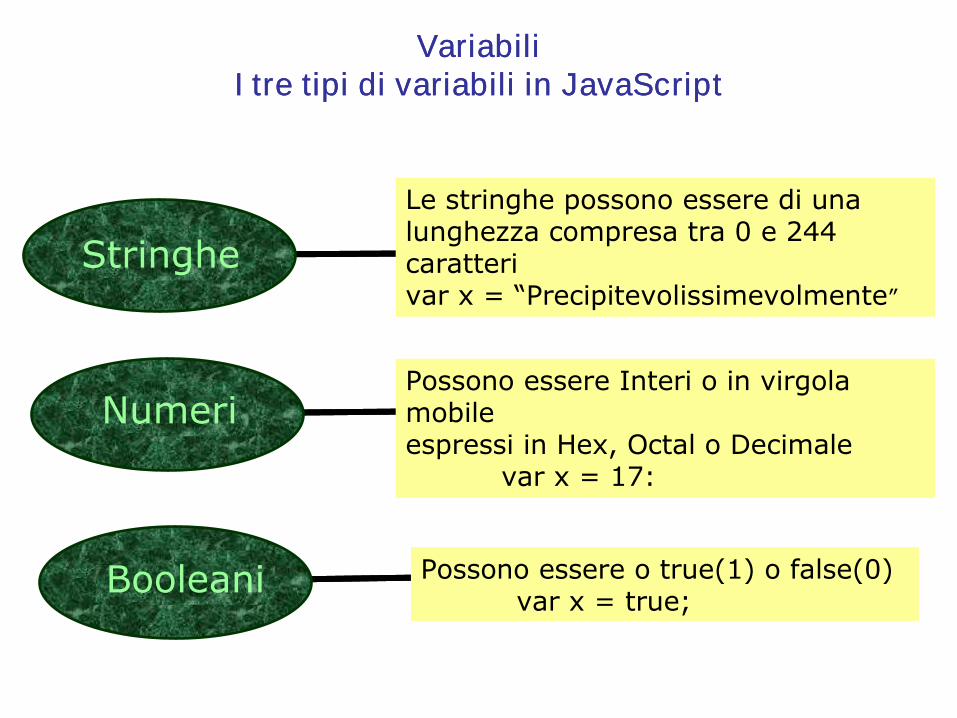
VariabiliVariabiliI I tretre tipi tipi didi variabilivariabili in JavaScriptin JavaScript
Possono essere Interi o in virgolamobile espressi in Hex, Octal o Decimale
var x = 17:
Le stringhe possono essere di unalunghezza compresa tra 0 e 244 caratterivar x = “Precipitevolissimevolmente”
Possono essere o true(1) o false(0)var x = true;
Numeri
Stringhe
Booleani

Variabili Weak Data typingVariabili Weak Data typing
Javascript è un weakly typed language (linguaggio debolmente tipizzato), ossia le variabili possono contenere ogni tipo di datoammesso e cambiare tipo di dato durantel’esecuzione!
Il seguente esempio è completament “legale”:VAR i; // Dichiarazione della var i
i = “precipitevolissimevolmente”; // Assegna ad i un valore“stringa”i = (1 > 0 ); //Assegna ad i un valore booleano (vero)i = 6.023e23; // Assegna ad i un valore a virgola mobile

VariabiliVariabiliWeak data typingWeak data typing
Domanda: qual è il valore di K ?
var i = “abc”;var j = “def”;var k = i + j;
var i = “123”;var j = 456;var k = i + j;
var i = 123;var j = 456;var k = i+j;
k = 579 k = 123456k = abcdef

Gli ArrayGli ArrayIn generale un array o vettore è una struttura dati complessa usata in molti linguaggi di programmazione e chiaramente ispirata alla nozione matematica di vettore. Si può immaginare un array come una sorta di casellario, le cui caselle sono dette celle dell'array stesso. Ciascuna delle celle si comporta come una variabile tradizionale; tutte le celle sono variabili di uno stesso tipo preesistente, detto tipo basedell'array. Si parlerà perciò di tipi come "array di interi", "array di stringhe", "arraydi caratteri" e così via. In alcuni linguaggi, la dimensione dell'array (ovvero il numero celle di cui esso è composto) viene considerato parte della definizione del tipo array; in tal caso, si parlerà più precisamente di tipi come "array di 100 caratteri" o "array di 10 interi".Ciascuna delle celle dell'array è identificata da un valore di indice. L'indice è generalmente numerico e i valori che gli indici possono assumere sono numeri interi contigui che partono da 0 o da 1. Si potrà quindi parlare della cella di indice 0, di indice 1, e, in generale, di indice N, dove N è un intero compreso fra 0 (o 1) e il valore massimo per gli indici dell'array.

Gli Array JSGli Array JS
La dichiarazione è molto semplice
var x = new Array();
Non c’è bisogno di definire la “size” dell’array: è allocatodinamicamente in memoria. Gli array possono contenere “m ix” divariabili:
x[0] = 3.14159;x[1] = “Javascript Rules!”;x[59] = true;
Inoltre, si può utilizzare l’oggetto length per conoscere la “size” di un’array
i = x.length;

LoopLoop
Nella programmazione dei computer, l'iterazione, chiamata anche ciclo o con il termine inglese loop, è una struttura di controllo che ordina all'elaboratore di eseguire una sequenzadi istruzioni ripetutamente, solitamente fino al verificarsi di particolari condizioni.
Loop For in JS:
for (espressione iniziale; condizione; espressione diincremento)
{comandi
}
Loop While in JS:
while ( espressione logica ){
comandi}

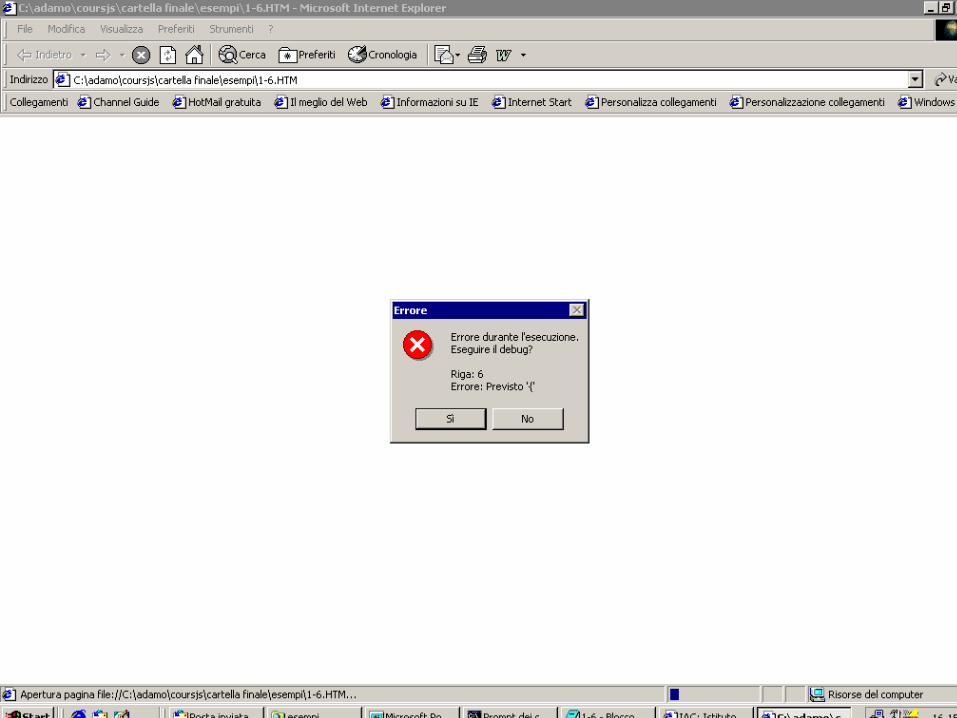
Messaggi di errore es.
<script language="JavaScript">function AnError()
// There is a { missing above ...
alert("This function will generate an error");}</script>

Oggetti, proprietà, metodi e gestori di eventi
• Un oggetto JS è un'entità che racchiude dentro di se dati e codice per manipolare i dati; una volta costruiti gli oggetti, tutto ciò che serve per costruire un programma è correlare con “messaggi” i singoli oggetti che com porranno l'applicazione
• I valori associati a ciascun oggetto sono le proprietà• Una funzione appartenente ad un oggetto viene detta metodo, • I gestori di eventi sono particolari funzioni generalmente attivate
dall‟interazione dell‟utente con alcuni oggetti del brow ser

Oggetti, proprietà, metodi e gestori di eventi
Per fare riferimento alla proprietà di un oggetto è necessario specificare l‟oggetto stesso seguito da un punto e dal nome della proprietà.
E s. supponiam o che esista un oggetto “immagine” con due proprietà “larghezza” ed “altezza” allora per istanziare le due proprietà scriverò:
immagine.larghezzaimmagine.altezza

Oggetti, proprietà, metodi e gestori di eventi
Le proprietà degli oggetti sono analoghe alle variabili JS e possono contenere qualsiasi tipo di dato cioè
• array• metodi• altri oggettiper es. document.miomodulo.pulsante si riferisce alla proprietà pulsante di un
oggetto miomodulo che a sua volta e‟ una proprietà dell‟oggetto document
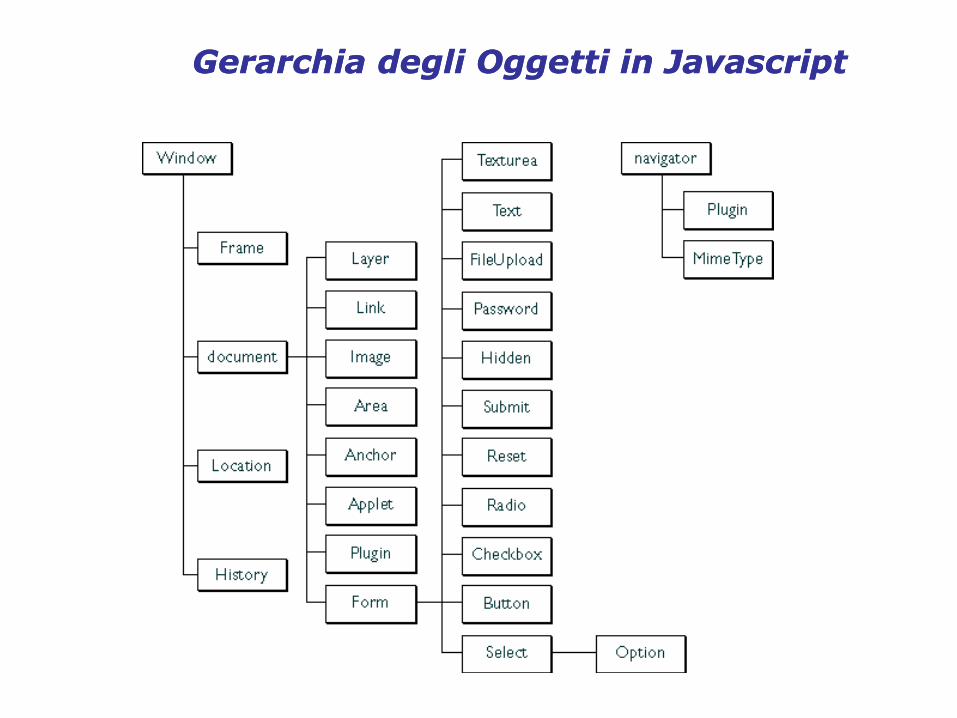
GerarchiaGerarchia degli Oggetti in degli Oggetti in JavascriptJavascript

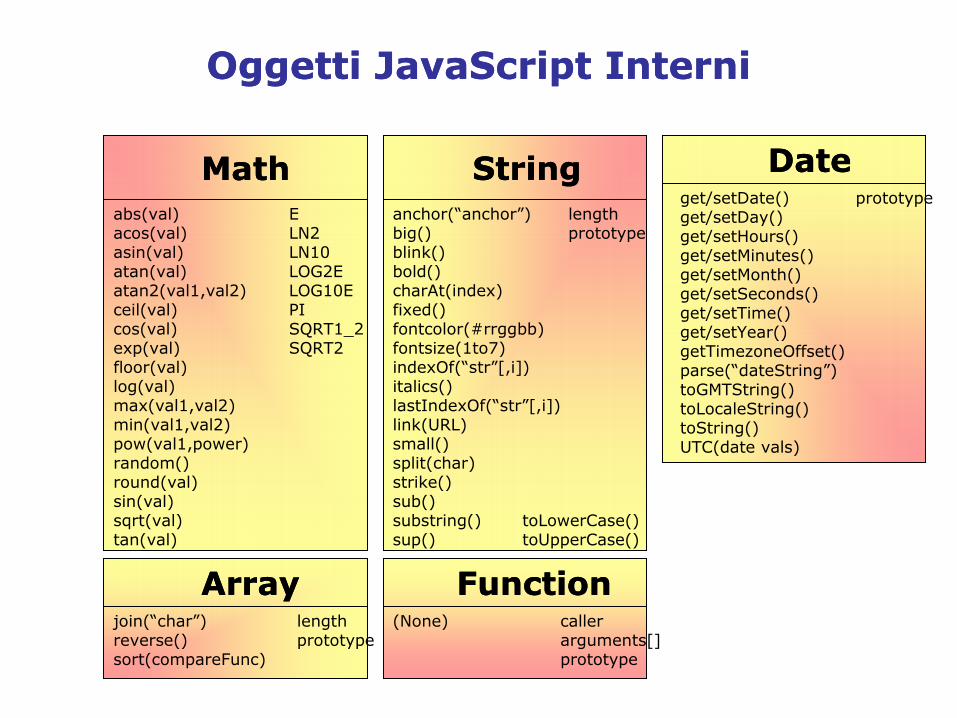
Oggetti JS
Si dividono in tre famiglie:
• Oggetti interni o integrati • Oggetti in Navigator• O ggetti “riflessi” dall‟H tm l
MathMathabs(val)acos(val)asin(val)atan(val)atan2(val1,val2)ceil(val)cos(val)exp(val)floor(val)log(val)max(val1,val2)min(val1,val2)pow(val1,power)random()round(val)sin(val)sqrt(val)tan(val)
ELN2LN10LOG2ELOG10EPISQRT1_2SQRT2
StringStringanchor(“anchor”) big()blink()bold()charAt(index)fixed()fontcolor(#rrggbb)fontsize(1to7)indexOf(“str”[,i])italics()lastIndexOf(“str”[,i])link(URL)small()split(char)strike()sub()substring() toLowerCase()sup() toUpperCase()
lengthprototype
get/setDate()get/setDay()get/setHours()get/setMinutes()get/setMonth()get/setSeconds()get/setTime()get/setYear()getTimezoneOffset()parse(“dateString”)toGMTString()toLocaleString()toString()UTC(date vals)
prototype
DateDate
join(“char”)reverse()sort(compareFunc)
lengthprototype
ArrayArraycallerarguments[]prototype
(None)
FunctionFunction
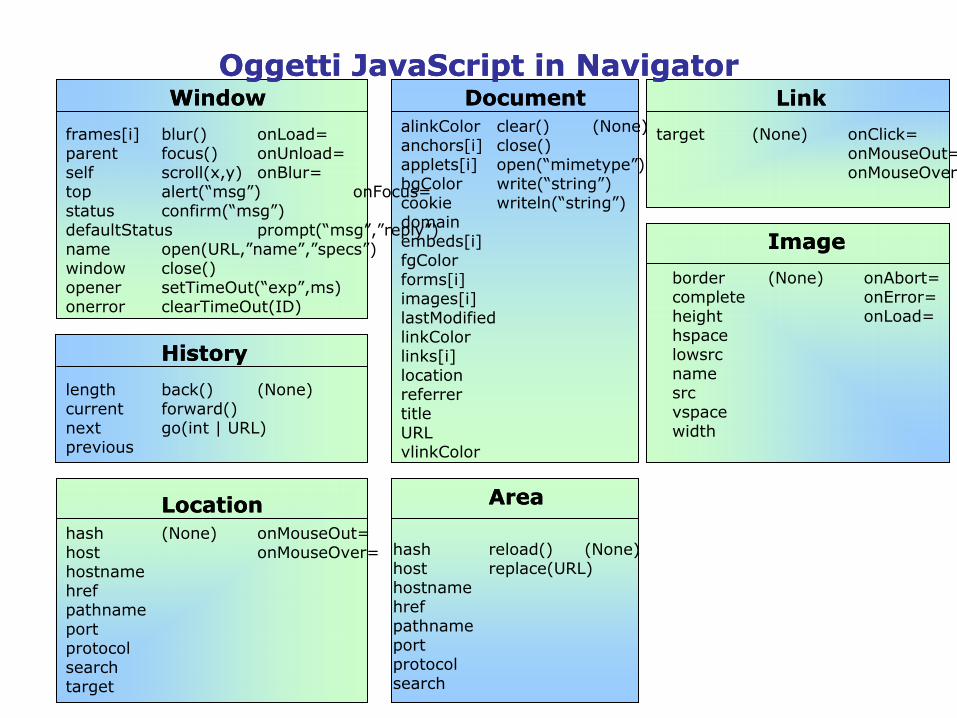
OggettiOggetti JavaScript JavaScript InterniInterni
frames[i] blur() onLoad=parent focus() onUnload=self scroll(x,y) onBlur=top alert(“msg”) onFocus=status confirm (“msg”)defaultStatus prom pt(“m sg”,”reply”)name open(U R L,”nam e”,”specs”)window close()opener setTimeOut(“exp”,m s)onerror clearTimeOut(ID)
alinkColor clear() (None)anchors[i] close()applets[i] open(“mimetype”)bgColor w rite(“string”)cookie writeln(“string”)domainembeds[i]fgColorforms[i]images[i]lastModifiedlinkColorlinks[i]locationreferrertitleURLvlinkColor
length back() (None)current forward()next go(int | URL)previous
hash reload() (None)host replace(URL)hostnamehrefpathnameportprotocolsearch
hash (None) onMouseOut=host onMouseOver=hostnamehrefpathnameportprotocolsearchtarget
target (None) onClick=onMouseOut=onMouseOver=
border (None) onAbort=complete onError=height onLoad=hspacelowsrcnamesrcvspacewidth
WindowWindow
HistoryHistory
LocationLocation
DocumentDocument
AreaArea
ImageImage
LinkLinkOggettiOggetti JavaScript in NavigatorJavaScript in Navigator

name blur() onBlur=value focus() onFocus=
select() onSelect=
action reset() onReset=elements[i] submit() onSubmit=encodingmethodnametarget
defaultValue focus() onBlur=name blur() onChange=type select() onFocus=value onSelect=
checked click() onClick=defaultCheckedlengthnametypevalue
name click() onClick=typevalue
checked click() onClick=defaultCheckednametypevalue
length blur() onBlur=name focus() onChange=options[i] onFocus=selectedIndexoptions[i].defaultSelectedoptions[i].indexoptions[i].selectedoptions[i].textoptions[i].valuetype
FormForm
Text,textarea,passwordText,textarea,password
RadioRadio
Button,reset,submitButton,reset,submit
CheckboxCheckbox
SelectSelect
FileUploadFileUpload
AltriAltri OggettiOggetti JavaScript “JavaScript “legatilegati” ” all‟H TM Lall‟H TM L

Comandi JS
• I comandi possono essere rappresentati da blocchi di codice o da singole istruzioni. I blocchi di codice sono gruppi di com andi racchiusi all‟interno di parentesi graffe { … . }
• Ogni comando che occupa una singola linea può avere un ;

Commenti ed Annotazioni
Sintassi
// Comment Text/* Comment Text */// Questo è un normale commento
/*Q uesto e‟ un com m ento su piu‟ righe*/

Comandi di cicli e interazioni
• Il ciclo Forfor(espressione iniziale;condizione;incremento){
statement 1;statement2;… .;
}

Comandi di cicli e interazionies. di for
<html><head><script language="JavaScript"><!--function testLoop() {var String1 = '<hr align="center" width=';document.open();for (var size = 5; size <= 100; size+=5)
document.writeln(String1 + size + '%">');document.close();
}//--></script></head>

Comandi di cicli e interazionies. di for (segue..)
<body><form><input type="button"
value="Test the loop"onClick="testLoop()">
</form></body></html>
Ecco l‟outputEcco l‟output
Ecco l‟output dopo aver Ecco l‟output dopo aver cliccatocliccatoil bottone !il bottone !

Comandi di cicli e interazioni
While
SintassiWhile(condizione){
com andi… .}

L‟oggetto M ath
Oggetto: MathL'oggetto Math serve in JavaScript per effettuare conti matematici.Proprietà:• E - numero di eulero, base dei logaritmi naturali (circa 2.718).• LN10 - logaritmo naturale di 10 (circa 2.302).• LN2 - logaritmo naturale di 2 (circa 0.693).• LOG10E - logaritmo in base 10 di e (circa 0.434).• LOG2E - logaritmo in base 2 di e (circa 1.442).• PI - pi-greco (circa 3.1415).• SQRT1-2 - radice quadrata di un mezzo (circa 0.707).• SQRT2 - radice quadrata di 2 (circa 1.414).

L‟oggetto M ath
M etodi (per ogni m etodo si provi il risultato tram ite l‟U R L javascript)
Metodi:
abs(numero) - ritorna il valore assoluto di numero.acos(numero) - ritorna l'arcocoseno in radianti di numero.asin(numero) - ritorna l'arcoseno in radianti di numero.atan(numero) - ritorna l'arcotangente in radianti di numero.atan2(numero1, numero2) - ritorna l'angolo delle coordinate polari corrispondenti alle
coordinate cartesiane (numero1,numero2).ceil(numero) - ritorna il primo intero maggiore o pari a numero.cos(numero) - ritorna il coseno di numero, angolo espresso in radianti.exp(numero) - ritorna il valore di e elevato alla numero.floor(numero) - ritorna il primo intero inferiore o pari a numero.log(numero) - ritorna il logaritmo naturale di numero.max(numero1,numero2) - ritorna il maggiore tra numero1 e numero2.min(numero1,numero2) - ritorna il minore tra numero1 e numero2.pow(numero1,numero2) - ritorna numero1 elevato alla numero2.random() - ritorna un numero casuale tra 0 e 1.round(numero) - ritorna l'intero più vicino a numero.sin(numero) - ritorna il seno di numero, angolo espresso in radianti.sqrt(numero) - ritorna la radice quadrata di numero.tan(numero) - ritorna la tangente di numero, angolo espresso in radianti

L‟oggetto Date
Metodi:• getDate() - Restituisce un intero (tra 1 e 31) rappresentate il giorno del mese
dell'oggetto Date.• getDay() - Restituisce il giorno della settimana dell'oggetto Date come intero da 1 a
6.• getHours() - Restituisce l'ora dell'oggetto Date come intero da 0 a 23.• getMinutes() - Restituisce i minuti dell'oggetto Date come intero da 0 a 59.• getMonth() - Restituisce il mese dell'oggetto Date come intero da 0 a 11.• getSeconds() - Restituisce i secondi dell'oggetto Date come intero da 0 a 59.• getTime() - Restituisce l'ora dell'oggetto Date come un intero pari al numero di
millisecondi trascorsi a partire dalle ore 00:00:00 del 1 Gennaio 1970.• getTimezoneOffset() - Restituisce un intero pari alla differenza tra l'ora locale e GMT
in minuti.• getYear() - Restituisce l'anno dell'oggetto date come intero da 0 a 99.• parse(stringaData) - Restituisce il numero di millisecondi trascorsi tra il 1 Gennaio
1970 alle 00:00:00 e la data specificata in stringaData.

L‟oggetto Date
• setDate(giorno) - Assegna il giorno del mese (da 1 a 31) all'oggetto Date.• setHours(ore) - Assegna le ore (da 0 a 24) all'oggetto Date.• setMinutes(minuti) - Assegna i minuti (da 0 a 59) all'oggetto Date.• setMonth(mese) - Assegna il mese (da 0 a 11) all'oggetto date.• setSeconds(secondi) - Assegna i secondi (da 0 a 59) all'oggetto Date.• setTime(ora) - Assegna un valore all'oggetto Date. ora è un intero pari al
numero di millisecondi trascorsi dal 1 Gennaio 1970 alle 00:00:00 e la data che si vuole assegnare.
• setYear(anno) - Assegna l'anno (maggiore di 1900) all'oggetto Date.• toGMTString() - Restituisce una stringa contenente il valore dell'oggetto
Date secondo il fuso GMT.• toLocaleString() - Restituisce una stringa contenente il valore dell'oggetto
Date secondo l'orario locale.• UTC(anno, mese, giorno, ore, minuti, secondi) - Restituisce il numero di
millisecondi trascorsi dal 1 Gennaio 1970 alle 00:00:00 alla data

Esempi: DATE
<html><head><script language="JavaScript"><!--theTime = new Date();theHour = theTime.getHours();if (theHour < 18) // < 6pm local time
document.writeln("<body background='day.gif' text='White'>");else
document.writeln("<body background='night.gif' text='White'>");//--></script></head><body>This is the text of the body...</body></html>

Esempi: DATE (output)

Oggetto Stringa
Oggetto: String
L'oggetto String permette di lavorare con variabili di tipo stringa.
Proprietà:length - un intero recante il numero di caratteri che compone la stringa.

Oggetto Stringa
Metodi:anchor(nome) - ritorna la stringa stessa racchiusa in una marcatura A con NAME uguale a nome.big() - ritorna la stringa stessa racchiusa in una marcatura BIG.blink() - ritorna la tringa stessa racchiusa in una marcatura BLINK. Non supportato da Explorer.bold() - ritorna la stringa stessa racchiusa in una marcatura BcharAt(indice) - ritorna il carattere della stringa alla posizione indice.charCodeAt(indice) - ritorna il numero di codice ISO-Latin-1 del carattere in posizione indice.concat(stringa2) - restituisce una nuova stringa ottenuta concatenando la stringa data e stringa2.fixed() - ritorna la stringa stessa racchiusa in una marcatura FIXED.fontColor(colore) - Ritorna la stringa stessa racchiusa in una marcatura FONT con COLOR uguale a colore. Non supportato da Explorer.fontSize(dim) - ritorna la stringa stessa racchiusa in una marcatura FONTSIZE con dimensione dim. Non supportato da Explorer.fromCharCode(n1, n2, ...) - genera una stringa costituita dai caratteri ISO-Latin-1 successivamente indicati in n1, n2 e così via.indexOf(trova, inizio) - Ritorna la posizione della prima occorrenza di trova, a partire dalla posizione inizio (opzionale).italics() - ritorna la stringa stessa racchiusa in una marcatura I.lastIndexOf(trova, fine) - Ritorna la posizione dell'ultima occorrenza di trova, prima di raggiungere la posizione fine (opzionale).

Oggetto Stringa
Metodi:link(href) - ritorna la stringa stessa racchiusa in una marcatura A con
attributo HREF uguale ad href.match(reg_exp) - cerca all'interno di una stringa un'espressione regolare.replace(reg_exp, nuova) - trova l'espressione regolare e la sostituisce con la stringa nuova.search(reg_exp) - cerca all'interno della stringa l'espressione regolare.slice(inizio, fine) - estrae una parte di una stringa, dal carettere inizio al carattere fine, e la restituisce come nuova stringa.split(separatore) - ritorna un Array di stringe formato a partire dalla stringa stessa. In pratica la stringa viene "spezzata" ad ogni occorrenza di separatore.strike() - ritorna la stringa stessa racchiusa in una marcatura STRIKE.sub() - ritorna la stringa stessa racchiusa in una marcatura SUB.substr(inizio, lung) - restituisce una nuova stringa estratta dalla prima a partire dalla posizione inizio per un numero di caratteri pari a lung.substring(inizio, fine) - restituisce una nuova stringa estratta dalla prima a partire dalla posizione inizio fino alla posizione fine.sup() - ritorna la stringa stessa racchiusa in una marcatura SUP.toLowerCase() - ritorna una nuova stringa contenente il valore della stringa con tutti i caratteri convertiti in minuscolo.toUpperCase() - ritorna una nuova stringa contenente il valore della stringa con tutti i caratteri convertiti in maiuscolo.

Operatori aritmetici
+ Somma gli operandi a destra e a sinistra. - Sottrae all'operando di sinistra quello di destra. * Moltiplica tra di loro gli operandi a destra ed a sinistra. / Divide l'operando di sinistra per quello di destra. % Calcola il resto della divisione dell'operando di sinistra per
quello di destra. ++Unario. Posto a destra o a sinistra incrementa di una unità
l'operando. Se l'operando è posto a sinistra viene prima valutato e poi incrementato, altrimenti accade il contrario.
-- Unario. Posto a destra o a sinistra decrementa di una unità l'operando. Se l'operando è posto a sinistra viene prima valutato e poi decrementato, altrimenti accade il contrario.

Operatori logici
• && Ritorna true quando lo sono entrambi gli operatori.
• || Ritorna true quando lo è almeno uno degli operatori.
• ! Unario, precede l'operando. Ritorna true se l'operando è falso, false se l'operando è vero.

Operatori di confronto
== Ritorna true se gli operandi sono uguali. != Ritorna true se gli operandi sono diversi. > Ritorna true se l'operando di sinistra è maggiore di
quello di destra. < Ritorna true se l'operando di sinistra è minore di quello
di destra. >= Ritorna true se l'operando di sinistra è maggiore o
uguale a quello di destra. <= Ritorna true se l'operando di sinistra è minore o
uguale a quello di destra.

Operatori su stringhe
+ Concatena tra di loro le due stringhe. += Concatena alla stringa di sinistra quella di destra e
quindi assegna questo valore alla stringa di sinistra.

L‟O ggetto W indow
L'oggetto window è l'oggetto di livello più alto, e per questo è antenato in particolare degli oggetti documento e degli oggetti frame.

Window Metodi:
alert(messaggio) - visualizza la stringa passata in una finestra di dialogo.
back() - torna al documento precedente nella cronologia.close() - chiude la finestra.confirm(messaggio) - viaualizza la stringa passata in
una finestra di dialogo che interroga l'utente. Ritorna un valore booleano a seconda della risposta, affermativa o negativa, data dall'utente.

Window Metodi:
open(url, nome, features) - apre url in una finestra chiamata nome. Se nome non esiste questa viene craeta. features è una stringa che comprende diverse opzioni per gestire la finestra. Può essere costituita da una o più delle seguenti voci separate da virgola:

Window Metodi:
prompt(messaggio,risposta) - apre una finestra di dialogo che visualizza il messaggio e permette all'utente di immettere una risposta modificando quella passata. La stringa risultante viene restituita.

Window Eventi:
onBlur - specifica il codice da eseguirsi quando viene tolto il focus alla finestra.
onFocus - specifica il codice da eseguirsi quando la finestra riceve il focus.
onMove - specifica il codice da eseguirsi quando la finestra viene spostata.
onResize - specifica il codice da eseguirsi quando la finestra viene ridimensionata.
onLoad - specifica il codice da eseguirsi quando la finestra conclude il caricamento.

Window Eventi:
onUnload - specifica il codice da eseguirsi quando il documento caricato viene abbandonato.
onError - specifica il codice da eseguirsi quando si verifica un errore JavaScript. Ponendo onError = null, su Netscape, si evitano i fastidiosi messaggi di errore.
onDragDrop - specifica il codice da eseguirsi quando un oggetto viene rilasciato nella finestra.

Window Esempi:
<html><script language="JavaScript"><!--function CreateNewWindow() {helpWin = window.open("", "helpWindow",
"width=300,height=150");helpWin.document.writeln("<h1>Help Window<hr></h1>");
}//--></script><body><form><input type="button"
value="Open a window"onClick="CreateNewWindow()"
</form></body></html>

Window Esempio I (output):

L‟oggetto Form
Sintassi: <Form name= “form nam e”
target= “w indow nam e”action= “serverU rl”method= “get|post”encType= “encodingT ype”[onSubmit= “javascriptcom m ands” ]
</Form>

L‟oggetto Form
Dove name è il nom e della struttura e puo‟ essere utilizzato al posto del metodo forms[]
O gni form di un docum ento puo‟ essere individuato tram ite l‟array F orm s cioe‟
• window.document.forms[n] oppure
• window.document.formName

L‟oggetto Form
L‟attributo target specifica la finestra dove dovrebbero essere visualizzate le risposte riguardanti la struttura, e richiede,chiaramente, che esista una finestra o un fram es con lo stesso nom e specificato nell‟attributo.
Possono essere utilizzati i nomi predefiniti: _blank, _parent, _self, _top

L‟oggetto form
L‟attributo action specifica il server che dovrà ricevere i dati dalla struttura e uno script che dovrà elaborarli.
Si possono anche spedire i risultati della struttura via mail utilizzando la Url mailto:

L‟oggetto form
L‟attributo E nctype specifica il form ato M IM E (Multimedia Internet Mail Exstension) con cui i dati vengono spediti.
Il tipo di default è application/www-form-urlencodedin navigator è possibile inviare file attraverso il MIME
type:multipart/form-data

L‟oggetto form
Per specificare un metodo o una proprietà di form si possono utilizzare indifferentemente:
window.document.formName.propertyName
window.document.formName.methodName(parametri)
window.document.forms[i].propertyName
window.document.forms[i].methodName(parametri)

L‟oggetto form
P er accedere alla struttura dell‟array form s è sufficiente indicare il num ero che rappresenta l‟ordine con cui compare nel documento
document.forms[index]per conoscere il num ero di form in docum ento si puo‟
utilizzaredocument.forms.length

L‟oggetto form
È possibile anche assegnare ad una variabile l‟intera struttura
es. Var MyForm=document.forms[1];se il form contiene un elemento per es.<INPUT Type=“text” name=“miocampo”
value=“E lisabetta”>alloraMyForm.miocampo.valuerestituisce il valore di miocampo che e‟ ?

L‟oggetto form di JavaScript
Contiene 6 proprietà:
action: riflesso dell‟attributo actionelements: array degli elementiencoding: riflesso di enctypelength: numero di elementi in formsmethod: riflesso di methodtarget: riflesso di target

L‟oggetto form
Metodi:submit(): per sottomettere il form piuttosto che utilizzare
il bottone submit
Gestori di eventi:onSubmit:inserito nel tag form esegue un comando JS se si clicca
il bottone submit o se viene utilizzata una submit()

Form: esempio I
<html><head><script language="JavaScript"><!--function showElements(f) {
var formElements = "";for (var n=0; n < f.elements.length; n++) {
// Costruisco una stringa per ogni elemento:formElements += n + ":" + f.elements[n].value + "\n";
}alert("Gli elementi del form" +
f.name + " sono:\n\n" +formElements);
}//-->

</script></head><body><form name="Formesempio"><table border=0><tr><td><input name="cb1" type="checkbox" value="uno" checked>Option 1<br><input name="cb2" type="checkbox" value="due">Option 2</td></tr><tr><td>Name:</td><td><input type="text" size=45 name="fullname" value="tre"></td></tr>
Form: esempio I

<tr><td>Address:</td><td><textarea name="ta">quattro</textarea></td></tr><tr><td><input type="button"
value="Mostra Valori"onClick="showElements(this.form)">
</td></tr></form></table></body></html>
Form: esempio I
Form : output dell‟esem pio I


Archivi e gestori di informazione
• Quindi i database archiviano e gestiscono l‟inform azione
• E ‟ immediato un confronto con la Statistica che sioccupa della raccolta e della elaborazione delleinformazioni mentre “idatabase si occupano della loroarchiviazione e della loro gestione”.

II definizione di DataBase
"Collezione di informazioni registrate in formato leggibile dall'elaboratore elettronico e relativa ad un preciso dominio di conoscenze, organizzata allo scopo di poter essere consultata dai suoi utilizzatori"

Evoluzione della definizione
• La definizione del termine base di dati o database è andata via via evolvendosi nel tempo, legandosi sempre più ad un concetto mutevole nel corso della "storia" che ne ha ridefinito non solo gli aspetti formali e concettuali, ma anche gli scopi, gli obiettivi, i ruoli.

Evoluzione della definizione
Ciò è stato possibile soprattutto grazie a vari fattori fondamentali e decisivi:
• l'infrastruttura di rete• la crescita numerica degli oggetti database• l'evoluzione dei software I.R. e la facilità degli
accessi• lo scenario che evolve dovuto all'impatto
dell'information technology• i ruoli che cambiano all'interno del processo
comunicativo

L'infrastruttura di rete
• Senza l'attuale Rete, così come è ora strutturata contutti i suoi strumenti, i database non sarebbero quelloche sono oggi, senza i telnet per raggiungere banchedati in connessioni remote, senza gli ormai superatigopher per la "classificazione di queste risorse",senza il Web con le sue interfacce GUI (GraphicalUser Interface) per la consultazione di basi di dati diogni tipo e genere, senza Internet quindi le basi di datisarebbero strumenti chiusi e muti, senza possibilità dicolloquio verso l'esterno.

La crescita numerica degli oggetti database
• La crescita esponenziale di questi insiemi organizzati di informazioni negli ultimi decenni e quindi la necessità di loro una riorganizzazione per categorie più parcellizzata e più vicina al contesto attuale, è stato uno dei valori che ha portato ad una nuova idea di ciò che può significare l'oggetto database.

L'evoluzione dei software I.R.
Lo sviluppo di software sempre più sofisticati e potenti che rendono l'interrogazione e il recupero dell'informazione sempre più flessibile e anche intuibile, con interfacce di tipo amichevoli e linguaggi che si avvicinano sempre di più alla simulazione di un linguaggio naturale, porta ad accessi più agevoli e rende quindi il prodotto database non più come solo insieme di dati organizzati, ma come risorsa/strumento legata alla sua interfaccia. Database inteso come archivio di dati organizzati, ma anche come modalità di accesso.

Lo scenario che evolve dovuto all'impatto dell'information technology
• Lo scenario, radicalmente mutato dall'information technology sullo strumento database, che ha visto e che vede per esempio la biblioteca, e il bibliotecario addetto al reperimento delle informazioni da basi di dati, come "ponte di raccordo" tra l'utenza e l'informazione, è stato ed è tuttora il motore trainante che ha permesso una ridefinizione dei ruoli delle varie figure coinvolte: distributori dell'informazione, softwarehouse, intermediari, bibliotecari, documentalisti e gli stessi utenti.

I ruoli che cambiano all'interno del processo comunicativo
• L' "anello comunicativo" che rende possibile il trasporto dell'informazione dalle fonti (archivi, basi di dati, ...) all'utente (cliente, consumatore) è stato a suo volta oggetto di mutazioni notevoli.
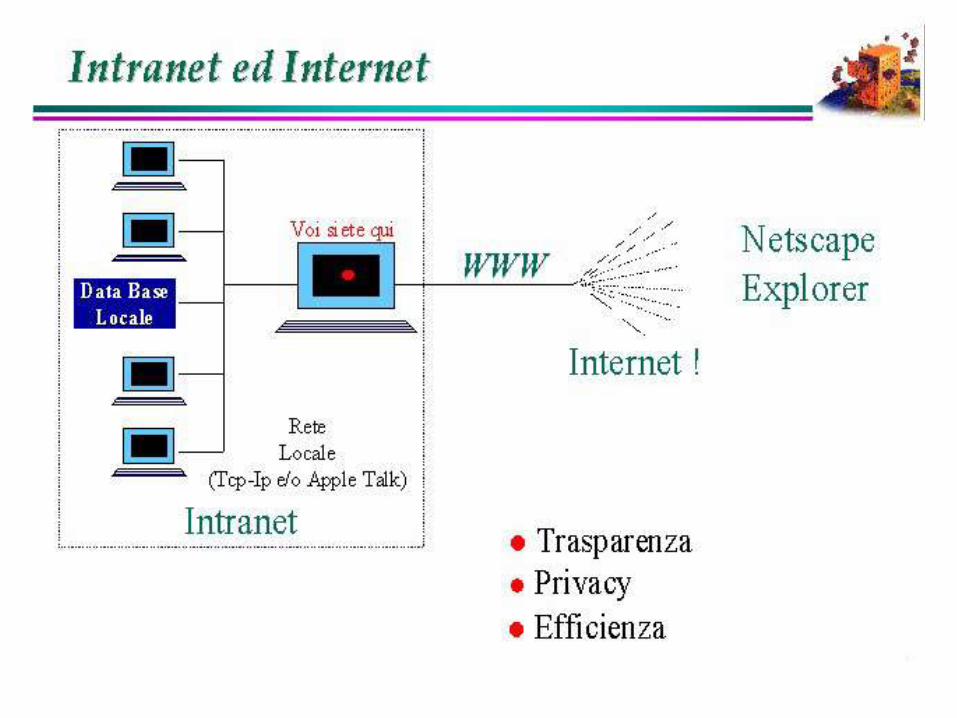
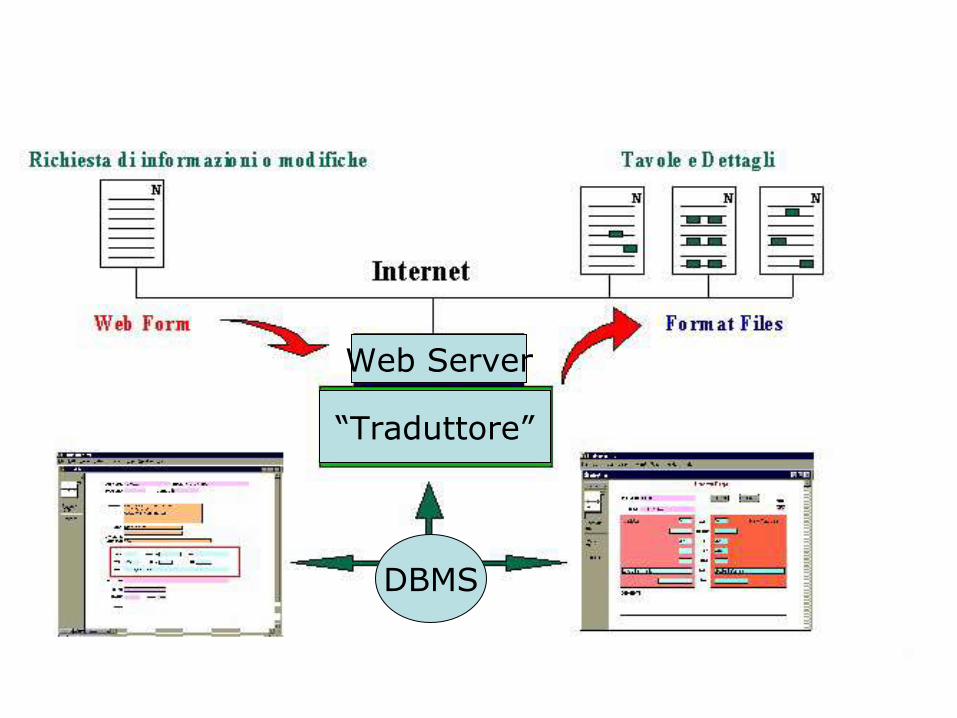
Web Server
“Traduttore”
DBMS

Il database oggi
nelle sue configurazioni on-line (singolo o aggregato) nei sistemi di database networking:
archivio di dati organizzati, unito alla sua interfacciafruibile da una molteplicità di utenze fisicamente distanti, indipendentemente dalla localizzazione fisica di utenti e database

Dati Strutturati
• Ci sono due aggettivi fin qui‟usati “trasversalm ente” nelle varie definizioni per i dati: organizzati e strutturati,

Modello relazionale
• Una base di dati può essere impostata secondo diversi tipi di modelli (logici) di rappresentazione. Quello più comune, che è anche il più semplice dal punto di vista umano, è il modello relazionale. In tal senso, un DBMS relazionale viene anche definito semplicemente come RDBMS.

Il modello relazionale
• Nel modello relazionale, i dati sono raccolti all'interno di relazioni.
• Ogni relazione è una raccolta di nessuna o più nupledi “dati” di tipo om ogeneo.
• La nupla rappresenta una singola informazione completa, in rapporto alla relazione a cui appartiene, e questa informazione è suddivisa in attributi.

Il modello relazionale
• Una relazione, nella sua definizione, non ha una «forma» particolare, tuttavia questo concetto si presta a una rappresentazione “tabellare”: gli attributi sono rappresentati dalle colonne e le nuple dalle righe.

Dati Strutturati
• Più precisamente ad ogni riga della tabella vieneassociato un componente dell‟insiem e di unitàstatistiche che compongono collettivamentel‟inform azione .
• A ll‟interno del database tale componente prende ilnome di record.
• L‟insiem e di unità statistiche nel database prendequindi la forma di una successione di righe, una perogni record.
• Le colonne della tabella vengono riservate allecaratteristiche (caratteri) che ogni unità statisticapossiede.
Dati Strutturati
Indirizzi
Cognome Nome Indirizzo Telefono
Pallino Pinco Via Biglie 1 0222,222222
Tizi Tizio Via Tazi 5 0555,555555
Cai Caio Via Caini 1 0888,888888
Semproni Sempronio Via Sempi 7 0999,999999

I campi
• A ll‟interno del database ogni colonna viene chiam ata campo e viene definita in modo tale da poter contenere il carattere che le è stato assegnato.
• La Tabella è quindi lo strumento principale per l‟archiviazione dei dati in un database (m a non l‟unico!).

Relazioni e Riferimenti
Generalmente, una relazione da sola non è sufficiente a rappresentare tutti i dati riferiti a un problema o a un interesse della vita reale. Quando una relazione contiene tante volte le stesse informazioni, è opportuno scinderla in due o più relazioni più piccole, collegate in qualche modo attraverso dei riferimenti.
Articoli Codice Descrizione Fornitore1 Fornitore2vite30 Vite 3 mm 123 126vite40 Vite 4 mm 126 127dado30 Dado 3 mm 122 123dado40 Dado 4 mm 126 127rond50 Rondella 5 mm 123 126
MovimentiCodice Data Carico Scarico CodFor CodClivite40 01/01/199
91200 124
vite30 01/01/1999
800 825
vite30 02/01/1999
1000 954
vite30 03/01/1999
2000 127
rond50 03/01/1999
500 954
Fornitori CodFor Ditta Indirizzo Telefono
127 Vitoni spa Via Ferri 2 0123,45678 122 Ferroni spa Via Metalli 34 0234,5678 126 Nuova Metal Via Industrie 0345,6789 123 Viti e Bulloni Via di sopra 7 0567,9875
Clienti CodCli Ditta Indirizzo Telefono
925 Tendoni Max Via di sotto 2 0113,44578 825 Arti Plus Via di lato 45 0765,23456

Campi Chiave
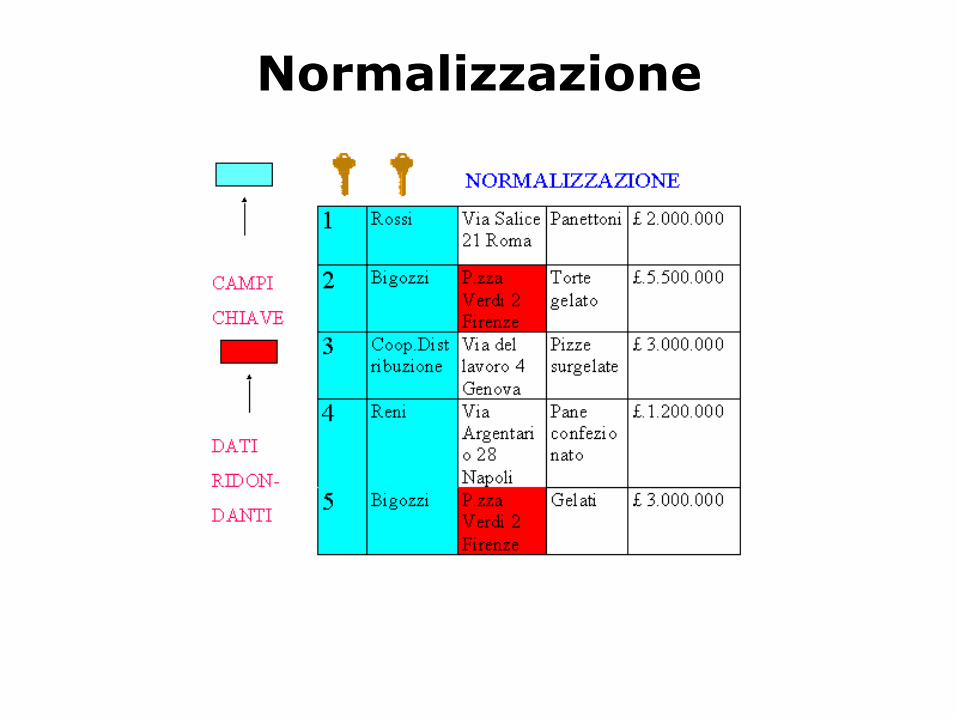
Normalizzazione

Query
metodo per ricercare e visualizzare dati specifici da un database.
• Per esempio, una query può essere utilizzata per estrarre le cifre relative alle vendite della società per un particolare Paese dal database, invece di visualizzare tutti i dati di vendita su scala mondiale.

SQL: Structured Query Language
• Il linguaggio piu‟ utilizzato per effettuare tali interrogazioni e‟ l'S Q L: un linguaggio strutturato di alto livello (come il C o il Basic) che permette la ricerca e lo scambio di informazioni nei database e tra database (distribuiti e non!).

Report
Programma (o sistema) specifico per la generazione distampe (cartacee, “a video”,ecc… )
In un DBMS, un report generalmente visualizza informazioni di due tipi:
• statiche (numero di pagina, intestazione, ingressi ecc..)
• dinamiche (provenienti dalla risposta ad una query o calcolate)
i report possono essere creati attraverso query statiche o dinamiche, ad intervalli programmati (per esempio, al termine del mese).I report possono includere testo, grafica e istogrammi.
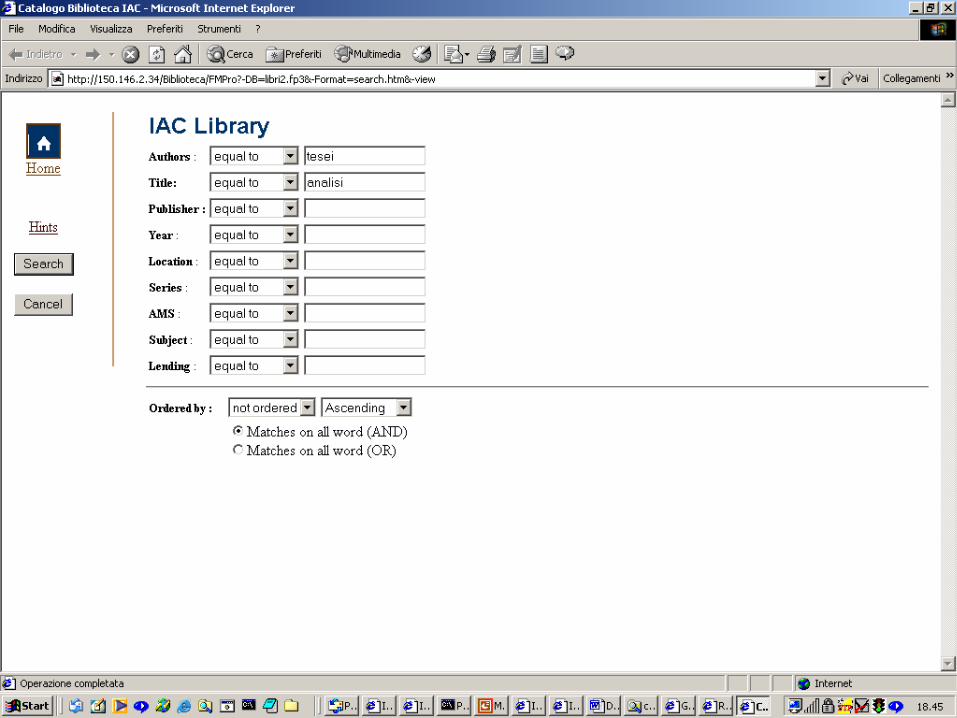
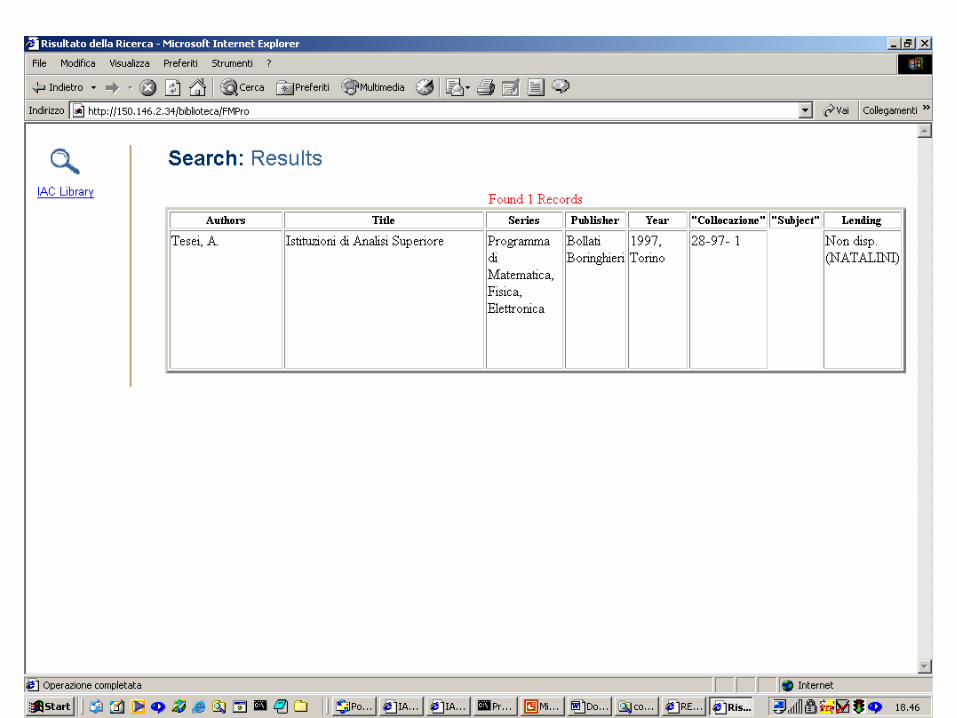
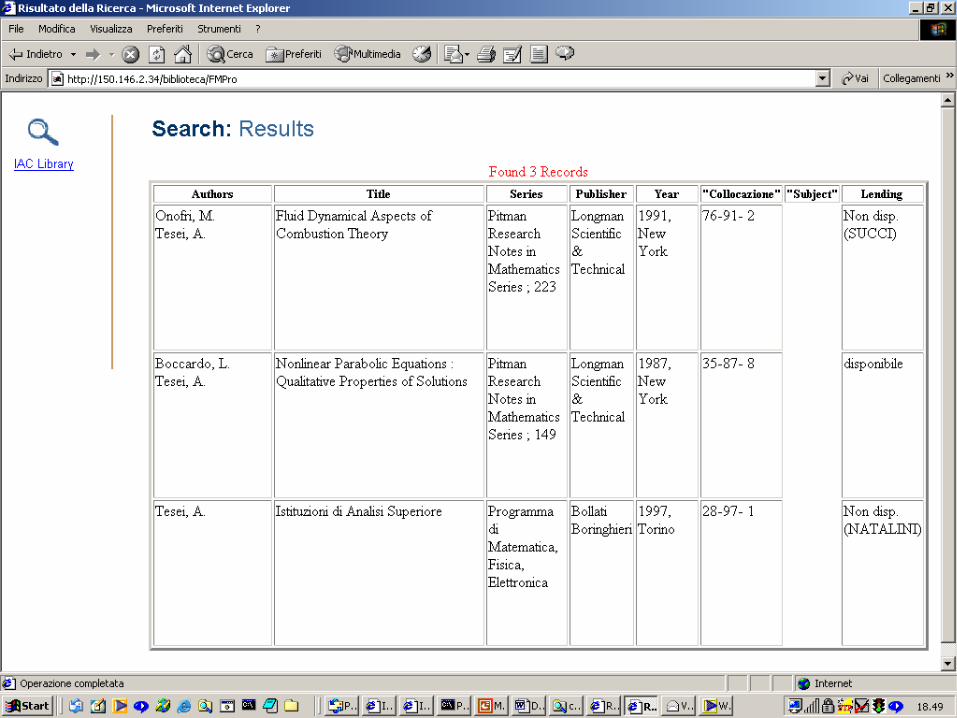
Top Related