
UNIVERSITÀ DEGLI STUDI DI TRENTO - me.unitn.it Alessandra/mazzone... · della ricerca dei quadrati...
30
UNIVERSITÀ DEGLI STUDI DI TRENTO Dipartimento di Matematica Corso di Laurea Triennale in Matematica Number field sieve: Introduzione storica, strategia di base, analisi della complessità asintotica e alcune varianti del metodo Luglio 2018 Relatrice Laureando Prof.ssa Alessandra Bernardi Federico Mazzone
Transcript of UNIVERSITÀ DEGLI STUDI DI TRENTO - me.unitn.it Alessandra/mazzone... · della ricerca dei quadrati...

UNIVERSITÀ DEGLI STUDI DI TRENTO
Dipartimento di Matematica
Corso di Laurea Triennale in Matematica
Number field sieve: Introduzione storica, strategia di base, analisi della complessità
asintotica e alcune varianti del metodo
Luglio 2018
Relatrice Laureando
Prof.ssa Alessandra Bernardi Federico Mazzone


1
Premessa
In questo elaborato viene illustrato il metodo di fattorizzazione per interi denominato crivello dei campi
numerici, o number field sieve (NFS). Verrà fornita una descrizione della strategia alla base del funzionamento
di tale metodo e un’analisi a livello euristico della sua complessità asintotica. In seguito, si procederà alla
risoluzione di alcuni tra i principali problemi legati alle meccaniche del metodo. Infine si concluderà con un
riassunto del crivello e una descrizione di alcune tra le sue più celebri varianti.
L’argomento è interamente affrontato sul piano teorico, non è previsto alcun approccio implementativo:
verrà sempre supposta la possibilità di poter lavorare anche in spazi diversi dagli interi, di poter qui svolgere
le operazioni di somma e prodotto e di poter utilizzare operatori propri di questi spazi, come la norma.
Per la piena comprensione dell’elaborato, vengono assunte conoscenze base di algebra, teoria algebrica dei
numeri [1] e qualche nozione di teoria di Galois. È fondamentale aver noto cosa sia un metodo di
fattorizzazione basato sulla strategia dei due quadrati, come lavorino i crivelli e in particolare come essi siano
impiegati all’interno di questi algoritmi, cosa siano gli interi 𝐵-smooth e quale sia la loro utilità nell’ambito
della ricerca dei quadrati e, infine, come funzioni il crivello quadratico, o quadratic sieve (QS).
Questi ultimi argomenti sono dettagliatamente descritti all’interno della relazione per il percorso di
eccellenza in matematica dell’autore: Il crivello quadratico: Dal metodo di Fermat, al crivello quadratico e
alcune sue varianti [2].

2

3
Sommario
Premessa ........................................................................................................................................................... 1
1. Introduzione .................................................................................................................................................. 4
1.1 Evoluzione storica .................................................................................................................................... 4
1.2 Successi rilevanti ...................................................................................................................................... 5
2. Strategia di base ............................................................................................................................................ 6
2.1 L’anello di numeri ℤ[𝛼] e l’omomorfismo 𝜙 ........................................................................................... 6
2.2 Il polinomio 𝑓 ........................................................................................................................................... 7
3. Ricerca dei quadrati ....................................................................................................................................... 8
3.1 Elementi 𝐵-smooth ................................................................................................................................. 9
3.2 Formare quadrati in ℤ[𝛼] ...................................................................................................................... 10
3.3 Ostruzioni .............................................................................................................................................. 14
4. Radici quadrate ............................................................................................................................................ 17
4.1 Radice quadrata in ℤ ............................................................................................................................. 17
4.2 Radice quadrata in ℤ[𝛼] ........................................................................................................................ 18
5. Complessità asintotica ................................................................................................................................. 19
6. Riassunto dell’algoritmo .............................................................................................................................. 21
7. Potenziamenti e varianti.............................................................................................................................. 23
7.1 Relazioni gratuite ................................................................................................................................... 23
7.2 Relazioni parziali .................................................................................................................................... 24
7.3 Polinomi non monici .............................................................................................................................. 24
7.4 Coppie di polinomi ................................................................................................................................. 25
7.5 Special number field sieve (SNFS) ......................................................................................................... 26
7.6 Variante di Coppersmith: famiglie di polinomi ...................................................................................... 27
Bibliografia ....................................................................................................................................................... 28

4
1. Introduzione
Il number field sieve (NFS) è un algoritmo di fattorizzazione sub-esponenziale per interi 𝑛 composti dispari,
che non siano potenze. Al momento, rappresenta il metodo asintoticamente più efficiente per trovare
divisori non banali di tali interi. La sua complessità computazionale, come mostreremo in seguito mediante
un’analisi euristica, può essere espressa come
𝑂 (𝑒(𝑐+𝑜(1))(log 𝑛)1 3⁄ (log log 𝑛)2 3⁄)
ove 𝑐 è una certa costante reale positiva.
Il NFS è qualitativamente molto simile al quadratic sieve (QS): con esso condivide la strategia di ricerca dei
due quadrati, ossia il trovare due interi 𝑢, 𝑣 tali che 𝑢2 ≡ 𝑣2 (mod 𝑛), da cui è possibile ricavare una
fattorizzazione di 𝑛 mediante gcd(𝑢 − 𝑣, 𝑛). In particolare, i due metodi sono accomunati dalla ricerca di un
insieme di relazioni, le quali vengono setacciate tramite un crivello, al fine di trovare valori 𝐵-smooth; le
relazioni residue vengono poi processate da algoritmi di algebra lineare alla ricerca di sottoprodotti di tali
relazioni che presentino quadrati ad ambo i membri.
La differenza fondamentale con il quadratic sieve risiede nel tipo di relazioni utilizzate. Il QS infatti cerca
relazioni della forma: un quadrato in ℤ congruo al suo residuo in ℤ𝑛. Mentre le relazioni ricercate dal NFS
sono diverse sotto due aspetti: il primo è che, come avviene nel rational sieve, non ci si vincola a partire con
un quadrato ad uno dei membri (in seguito, si dovrà ovviamente applicare l’algebra lineare in simultanea ad
entrambi, per ottenere due quadrati); il secondo è che le relazioni non sono più congruenze in ℤ𝑛, ma sono
corrispondenze, mediante omomorfismo, tra un certo anello algebrico di numeri e ℤ𝑛.
1.1 Evoluzione storica [3]
L’idea di utilizzare numeri smooth in un anello numerico diverso da ℤ fu proposta nel 1988 da J.M. Pollard
con il suo manoscritto “Factoring with cubic integers”. Qui descrisse un nuovo metodo di fattorizzazione per
gli interi di una certa forma e lo illustrò tramite la fattorizzazione del settimo numero di Fermat 𝐹7. Utilizzò
l’anello degli interi ℤ[√23
] del campo di numeri ℚ[√23
]; tuttavia non adoperò alcun crivello.
Pollard terminò il suo manoscritto con una lettera in cui si chiedeva se il nono numero di Fermat potesse
essere fattorizzato con un metodo simile.
Successivamente A.K. Lenstra, H.W. Lenstra Jr, M.S. Manasse e J.M. Pollard descrissero in “The number field
sieve” (1990) la prima implementazione su larga scala del metodo ideato da Pollard, con molte migliorie.
Un’analisi euristica abbastanza approssimativa indicava già che il metodo fosse il più veloce tra tutti quelli
conosciuti per la fattorizzazione degli interi a cui poteva essere applicato. In una delle sezioni di tale
manoscritto venne anche discussa l’idea di Buhler e Pomerance di estendere il number field sieve a interi di
forma generica.
In seguito vennero apportate migliorie e suggerimenti da parte di Adleman e Coppersmith, fino ad arrivare,
sempre nel 1990, alla fattorizzazione del nono numero di Fermat 𝐹9. Infine, negli anni seguenti, diedero il
loro contributo allo sviluppo del NFS diversi matematici come J.M. Couveignes e D.J. Bernstein.
5
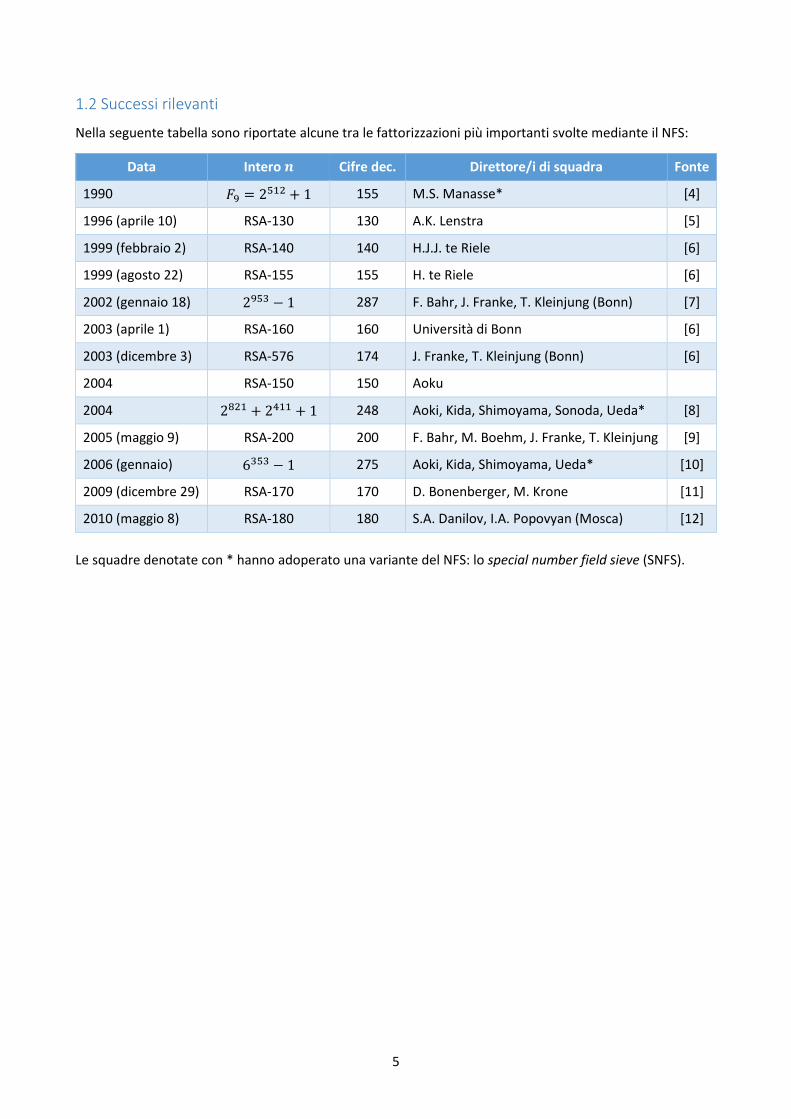
1.2 Successi rilevanti
Nella seguente tabella sono riportate alcune tra le fattorizzazioni più importanti svolte mediante il NFS:
Data Intero 𝒏 Cifre dec. Direttore/i di squadra Fonte
1990 𝐹9 = 2512 + 1 155 M.S. Manasse* [4]
1996 (aprile 10) RSA-130 130 A.K. Lenstra [5]
1999 (febbraio 2) RSA-140 140 H.J.J. te Riele [6]
1999 (agosto 22) RSA-155 155 H. te Riele [6]
2002 (gennaio 18) 2953 − 1 287 F. Bahr, J. Franke, T. Kleinjung (Bonn) [7]
2003 (aprile 1) RSA-160 160 Università di Bonn [6]
2003 (dicembre 3) RSA-576 174 J. Franke, T. Kleinjung (Bonn) [6]
2004 RSA-150 150 Aoku
2004 2821 + 2411 + 1 248 Aoki, Kida, Shimoyama, Sonoda, Ueda* [8]
2005 (maggio 9) RSA-200 200 F. Bahr, M. Boehm, J. Franke, T. Kleinjung [9]
2006 (gennaio) 6353 − 1 275 Aoki, Kida, Shimoyama, Ueda* [10]
2009 (dicembre 29) RSA-170 170 D. Bonenberger, M. Krone [11]
2010 (maggio 8) RSA-180 180 S.A. Danilov, I.A. Popovyan (Mosca) [12]
Le squadre denotate con * hanno adoperato una variante del NFS: lo special number field sieve (SNFS).

6
2. Strategia di base
Sia 𝑛 un intero positivo dispari composto, che non sia una potenza. Il nostro scopo è di trovare una
congruenza di quadrati in ℤ𝑛, ossia due interi 𝑢, 𝑣 tali che 𝑢2 ≡ 𝑣2 (mod 𝑛). In questo capitolo descriveremo
la strategia mediante la quale il number field sieve giunge a tale congruenza.
2.1 L’anello di numeri ℤ[𝛼] e l’omomorfismo 𝜙
Sia ℤ[𝛼] un anello algebrico di numeri, per un certo 𝛼 ∈ ℂ. Consideriamo un generico omomorfismo
𝜙 ∶ ℤ[𝛼] → ℤ 𝑛ℤ⁄
tra tale anello e ℤ𝑛. Siano ora 𝜃1, … , 𝜃𝑘 ∈ ℤ[𝛼] tali che il loro prodotto sia un quadrato in ℤ[𝛼] e tali che
𝜙(𝜃1) ∙∙∙ 𝜙(𝜃𝑘) sia un quadrato in ℤ𝑛. In altre parole, esistono 𝛾 ∈ ℤ[𝛼] e 𝑣 ∈ ℤ tali che
𝜃1 ∙∙∙ 𝜃𝑘 = 𝛾2
𝜙(𝜃1) ∙∙∙ 𝜙(𝜃𝑘) ≡ 𝑣2 (mod 𝑛).
Allora, definito con 𝑢 il residuo 𝜙(𝛾) modulo 𝑛, si ha che
𝑢2 ≡ 𝜙(𝛾)2 = 𝜙(𝛾2) = 𝜙(𝜃1 ∙∙∙ 𝜃𝑘) = 𝜙(𝜃1) ∙∙∙ 𝜙(𝜃𝑘) ≡ 𝑣2 (mod 𝑛)
E abbiamo dunque raggiunto il nostro scopo.
Le questioni principali che dobbiamo affrontare sono quindi le seguenti:
• Cos’è più nello specifico l’anello ℤ[𝛼]? E come si costruisce?
• Come è definito l’omomorfismo 𝜙?
• Come trovare i 𝜃1, … , 𝜃𝑘 ∈ ℤ[𝛼] che soddisfino le condizioni richieste?
Cominceremo subito a rispondere alle prime due domande.
Scegliamo 𝛼 ∈ ℂ come radice di un polinomio 𝑓 monico e irriducibile in ℤ[𝑥], esplicitamente
𝑓(𝑥) ≔ 𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1 + ⋯ + 𝑐1𝑥 + 𝑐0 𝑐𝑖 ∈ ℤ .
Dalla teoria, abbiamo dunque una rappresentazione esplicita per il nostro anello di numeri:
ℤ[𝛼] = {𝑎0 + 𝑎1𝛼 + ⋯ + 𝑎𝑑−1𝛼𝑑−1 ∶ 𝑎𝑖 ∈ ℤ} ≅ ℤ[𝑥] (𝑓)⁄ .
Notiamo che il fatto di prendere 𝑓 monico, ci garantisce che ℤ[𝛼] sia intero su ℤ; vedremo tuttavia in
seguito che questa condizione non è strettamente necessaria.
Per quanto riguarda l’omomorfismo 𝜙, esso è univocamente determinato dal valore che assume su 𝛼.
Inoltre 𝜙(𝛼) è radice di 𝑓 in ℤ𝑛, infatti
𝑓(𝜙(𝛼)) = 𝜙(𝛼)𝑑 + 𝑐𝑑−1𝜙(𝛼)𝑑−1 + ⋯ + 𝑐1𝜙(𝛼) + 𝑐0 = 𝜙(𝛼𝑑 + 𝑐𝑑−1𝛼𝑑−1 + ⋯ + 𝑐1𝛼 + 𝑐0) = 𝜙(𝑓(𝛼))
= 𝜙(0) = 0.
Dunque consideriamo 𝑚 ∈ ℤ𝑛 che sia radice di 𝑓, ossia tale che 𝑓(𝑚) ≡ 0 (mod 𝑛) e poniamo 𝜙(𝛼) ≔ 𝑚.
L’omomorfismo 𝜙 agisce esplicitamente nel seguente modo:
𝜙(𝑎0 + 𝑎1𝛼 + ⋯ + 𝑎𝑑−1𝛼𝑑−1) ≔ [𝑎0 + 𝑎1𝑚 + ⋯ + 𝑎𝑑−1𝑚𝑑−1]𝑛.

7
2.2 Il polinomio 𝑓
Esistono vari metodi per ottenere un polinomio 𝑓(𝑥), che rispetti le nostre condizioni. In questo paragrafo,
ne presentiamo uno che costruisce i coefficienti del polinomio a partire dal grado 𝑑 e dalla radice 𝑚 in ℤ𝑛.
Sia 𝑑 ∈ ℕ il grado del nostro polinomio 𝑓: al momento non specifichiamo il suo valore, lo lasciamo come
parametro libero da ottimizzare durante il calcolo della complessità. Tuttavia, giusto per dare un’idea,
anticipiamo che per numeri di 50, 100 e 200 cifre i valori ottimali di 𝑑 sono rispettivamente 4, 5 e 6.
Calcoliamo ora
𝑚 ≔ ⌊𝑛1 𝑑⁄ ⌋
e scriviamo 𝑛 in base 𝑚:
𝑛 = 𝑐𝑑𝑚𝑑 + 𝑐𝑑−1𝑚𝑑−1 + ⋯ + 𝑐1𝑚 + 𝑐0 𝑐𝑖 ∈ {0, … , 𝑚 − 1}.
Lemma. Sotto l’ipotesi
3
2(
𝑑
ln 2)
𝑑
< 𝑛
si ha che 𝑛 < 2𝑚𝑑.
Dimostrazione. Riconduciamo il risultato ad un problema analitico:
𝑛 < 2𝑚𝑑 ⟺ 𝑛 < 2⌊𝑛1 𝑑⁄ ⌋𝑑
⟺ 21 𝑑⁄ ⌊𝑛1 𝑑⁄ ⌋ > 𝑛1 𝑑⁄ ⟺ 21 𝑑⁄ ⌊𝑛1 𝑑⁄ ⌋ − 𝑛1 𝑑⁄ > 0
⟸ 21 𝑑⁄ (𝑛1 𝑑⁄ − 1) − 𝑛1 𝑑⁄ > 0 ⟺ 𝑛1 𝑑⁄ (21 𝑑⁄ − 1) > 21 𝑑⁄
⟸ (HP) 31 𝑑⁄
21 𝑑⁄
𝑑
ln 2(21 𝑑⁄ − 1) > 21 𝑑⁄ ⟺
31 𝑑⁄
41 𝑑⁄
𝑑
ln 2(21 𝑑⁄ − 1) > 1.
Una volta definita la funzione
ℎ(𝑥) ≔3𝑥
4𝑥
(2𝑥 − 1)
𝑥 ln 2
è sufficiente dimostrare che ℎ(1 𝑑⁄ ) > 1. Ma ciò è effettivamente vero, in quanto si può notare che ℎ è
strettamente crescente in (0, 1] e lim𝑥→0+
ℎ(𝑥) = 1. □
Assumendo l’ipotesi del Lemma, si ricava che la scrittura di 𝑛 in base 𝑚 ha come primo coefficiente 1, ossia
𝑛 = 𝑚𝑑 + 𝑐𝑑−1𝑚𝑑−1 + ⋯ + 𝑐1𝑚 + 𝑐0 𝑐𝑖 ∈ {0, … , 𝑚 − 1}.
Poniamo quindi
𝑓(𝑥) ≔ 𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1 + ⋯ + 𝑐1𝑥 + 𝑐0
e notiamo che, per costruzione, 𝑚 è una sua radice in ℤ𝑛, infatti 𝑓(𝑚) = 𝑛 ≡ 0 (mod 𝑛).

8
L’unica condizione che 𝑓 rischia di non rispettare è l’irriducibilità; in realtà, ciò non è un problema.
Infatti, se 𝑓 fosse riducibile, si avrebbe che 𝑓(𝑥) = 𝑔(𝑥)ℎ(𝑥) con 𝑔, ℎ fattori propri di 𝑓, da cui ricaviamo
una fattorizzazione non banale per 𝑛 = 𝑓(𝑚) = 𝑔(𝑚)ℎ(𝑚).
Il fatto che sia non banale discende dal seguente risultato:
Teorema. Sia 𝑛 un intero positivo, sia 𝑚 ≥ 2 un intero. Scriviamo 𝑛 in base 𝑚 come
𝑛 = 𝑐𝑑𝑚𝑑 + 𝑐𝑑−1𝑚𝑑−1 + ⋯ + 𝑐1𝑚 + 𝑐0 𝑐𝑖 ∈ {0, … , 𝑚 − 1}
e poniamo 𝑓(𝑥) ≔ 𝑐𝑑𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1 + ⋯ + 𝑐1𝑥 + 𝑐0. Se 𝑓 è riducibile in ℤ[𝑥] con 𝑓(𝑥) = 𝑔(𝑥)ℎ(𝑥) ove
𝑔, ℎ non unità, allora 𝑛 = 𝑔(𝑚)ℎ(𝑚) è una fattorizzazione non banale di 𝑛.
Dimostrazione. Diamo solo una traccia di dimostrazione:
1. Notiamo banalmente che 𝑓(𝑚 − 1) > 0.
2. Assumiamo valere la seguente disuguaglianza
|𝑓(𝑧)
𝑧𝑑−1| ≥ 𝑅𝑒(𝑐𝑑𝑧) + 𝑐𝑑−1 + 𝑅𝑒 (
𝑐𝑑−2
𝑧) − ∑
𝑐𝑑−𝑗
|𝑧|𝑗−1
𝑑
𝑗=3
da cui si ricava che 𝑓(𝑧) ≠ 0 per 𝑅𝑒(𝑧) ≥ 𝑚 − 1 2⁄ .
3. Assumiamo che per assurdo la fattorizzazione 𝑛 = 𝑔(𝑚)ℎ(𝑚) sia banale, diciamo con 𝑔(𝑚) = ±1.
Sia 𝐺(𝑥) = 𝑔(𝑚 + 𝑥 − 1 2⁄ ) ∈ ℚ[𝑥], per il punto (2) sappiamo che le radici di 𝐺(𝑥) hanno parte
reale negativa. Da ciò si ricava che tutti i coefficienti di 𝐺(𝑥) hanno lo stesso segno e dunque
|𝐺(− 1 2⁄ )| < |𝐺(1 2⁄ )|, in quanto valutando 𝐺 in − 1 2⁄ si avranno delle cancellazioni.
4. Tuttavia 𝐺(− 1 2⁄ ) = 𝑔(𝑚 − 1) ≠ 0 per il punto (1), dunque |𝐺(− 1 2⁄ )| è un intero positivo.
D’altra parte 𝐺(1 2⁄ ) = 𝑔(𝑚) = ±1, dunque |𝐺(1 2⁄ )| = 1. Dal punto (3) si ha un assurdo. □
3. Ricerca dei quadrati
Una volta scelti 𝑑, 𝑓 ed 𝑚, possiamo iniziare la ricerca dei 𝜃1, … , 𝜃𝑘 ∈ ℤ[𝛼] che soddisfino le condizioni
richieste. Specifichiamo subito che prenderemo come candidati da ℤ[𝛼] solo elementi della forma
𝜃 = 𝑎 − 𝑏𝛼 con gcd(𝑎, 𝑏) = 1.
Giunti a questo punto, riformuliamo al meglio la nostra richiesta: stiamo cercando un insieme 𝑆 di coppie
(𝑎, 𝑏) di interi coprimi tali che
∏ (𝑎 − 𝑏𝑚)
(𝑎,𝑏)∈𝑆
= 𝑣2 𝑣 ∈ ℤ
∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= 𝛾2 𝛾 ∈ ℤ[𝛼].
Come per il QS, ci basterà adoperare un crivello alla ricerca di valori 𝐵-smooth; tuttavia questa volta
bisognerà tenere conto di una informazione doppia. Ciò non causa alcun problema, infatti basterà setacciare
simultaneamente sia i valori 𝑎 − 𝑏𝑚 che i valori 𝑎 − 𝑏𝛼, per poi combinarli in quadrati tramite l’algebra
lineare su ℤ2.
La domanda che può sorgere spontanea è: come saranno fatti i vettori di esponenti per il NFS? Ovviamente
dovranno contenere il “doppio” delle informazioni rispetto al QS. Ma quali saranno esattamente?
Queste sono le domande a cui cominceremo a rispondere in questo capitolo.

9
3.1 Elementi 𝐵-smooth
Per quanto riguarda gli 𝑎 − 𝑏𝑚 la soluzione è immediata: come nel QS ci sarà una factor base 𝐵1 di primi ≤
𝐵 e si setacceranno i vari valori in cerca di 𝐵-smooth. Tuttavia, questa volta il crivello dovrà essere eseguito
su un insieme bidimensionale di indici
𝑈 ≔ {(𝑎, 𝑏) ∈ ℤ × ℤ ∶ |𝑎| ≤ 𝑀, 0 < 𝑏 ≤ 𝑀, gcd(𝑎, 𝑏) = 1}
per un certo parametro 𝑀. Ciò non dà particolari problemi: può essere fatto ciclando su 𝑎 per ogni valore di
𝑏, oppure andando per righe, o combinando vari metodi più complessi.
Per gli 𝑎 − 𝑏𝛼, la questione è più complessa. Anzitutto è necessario un modo per passare da elementi di
ℤ[𝛼] agli interi: la norma.
Ricordiamo che dato un 𝛽 = 𝑠0 + 𝑠1𝛼 + ⋯ + 𝑠𝑑−1𝛼𝑑−1 ∈ ℚ[𝛼] con 𝑠𝑖 ∈ ℚ, si definisce la norma di 𝛽 come
𝑁(𝛽) ≔ det(𝐿𝛽)
ove 𝐿𝛽 è la matrice associata alla mappa ℚ-lineare 𝑙𝛽: ℚ[𝛼] → ℚ[𝛼] di moltiplicazione per 𝛽.
Oppure in maniera equivalente come
𝑁(𝛽) ≔ ∏(𝑠0 + 𝑠1𝛼𝑗 + ⋯ + 𝑠𝑑−1𝛼𝑗𝑑−1)
𝑑
𝑗=1
ove 𝛼 = 𝛼1, … , 𝛼𝑑 ∈ ℂ sono tutte le radici di 𝑓.
Ora che abbiamo il concetto di norma, possiamo dare la seguente:
Definizione. Diciamo che un elemento 𝛽 ∈ ℤ[𝛼] è 𝐵-smooth quando 𝑁(𝛽) è 𝐵-smooth in ℤ.
Osservazione. Notiamo che per fare la norma di un elemento non ci serve calcolare né i coniugati di 𝛼 né la
matrice di moltiplicazione 𝐿𝛽. Infatti
𝑁(𝑎 − 𝑏𝛼) = (𝑎 − 𝑏𝛼1) ∙∙∙ (𝑎 − 𝑏𝛼𝑑) = 𝑏𝑑 (𝑎
𝑏− 𝛼1) ∙∙∙ (
𝑎
𝑏− 𝛼𝑑) = 𝑏𝑑𝑓 (
𝑎
𝑏) .
Consideriamo ora l’omogeneizzato di 𝑓(𝑥)
𝐹(𝑥, 𝑦) ≔ 𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1𝑦 + ⋯ + 𝑐1𝑥𝑦𝑑−1 + 𝑐0𝑦𝑑 = 𝑦𝑑𝑓 (𝑥
𝑦)
da cui si ha che
𝑁(𝑎 − 𝑏𝛼) = 𝐹(𝑎, 𝑏).

10
3.2 Formare quadrati in ℤ[𝛼]
Ricordiamo inoltre che la norma è moltiplicativa e ha valori in ℚ, inoltre se 𝛽 ∈ ℤ[𝛼], allora 𝑁(𝛽) ∈ ℤ.
Dalla moltiplicatività della norma discende una proprietà interessante: sia 𝛽 ∈ ℤ[𝛼] un quadrato, allora esiste
𝛾 ∈ ℤ[𝛼] tale che 𝛽 = 𝛾2; quindi 𝑁(𝛽) = 𝑁(𝛾2) = 𝑁(𝛾)2, ove 𝑁(𝛾) ∈ ℤ. Abbiamo quindi scoperto che se
𝛽 è un quadrato in ℤ[𝛼], allora la sua norma è un quadrato in ℤ.
Purtroppo il viceversa non è vero, come ci illustra il seguente:
Esempio. Consideriamo il polinomio 𝑓(𝑥) = 𝑥2 + 1, che ha come radice 𝛼 = 𝑖. Di conseguenza l’anello di
numeri che otteniamo coincide con gli interi di Gauss ℤ[𝑖]. La norma vale
𝑁(𝑎 + 𝑖𝑏) = 𝑎2 + 𝑏2
e dunque si ha per esempio che 𝑁(2) = 4. Proviamo ora a prendere altri elementi:
𝑁(3 + 4𝑖) = 32 + 42 = 25 = 52 = 𝑁(5𝑖)
e notiamo che 3 + 4𝑖 = (2 + 𝑖)2 è un quadrato, mentre 5𝑖 = (2 + 𝑖)(1 + 2𝑖) non lo è.
Il problema è che divisori primi differenti di un elemento 𝑥 ∈ ℤ[𝛼] possono dare origine allo stesso fattore
primo 𝑝 nella norma 𝑁(𝑥). Di conseguenza, siamo obbligati a tenere traccia dei fattori primi di 𝑥 in ℤ[𝛼].
Definizione. Per ogni primo 𝑝 ∈ ℤ, definiamo l’insieme delle radici di 𝑓 in ℤ𝑝
𝑅(𝑝) ≔ {𝑟 ∈ ℤ𝑝 ∶ 𝑓(𝑟) ≡ 0 (𝑚𝑜𝑑 𝑝)}.
Proposizione. Se gcd(𝑎, 𝑏) = 1, vale che
𝐹(𝑎, 𝑏) ≡ 0 (mod 𝑝) ⟺ ∃𝑟 ∈ 𝑅(𝑝) ∶ 𝑎 ≡ 𝑏𝑟 (mod 𝑝).
Dimostrazione.
(⟸) Supponiamo che 𝑎 ≡ 𝑏𝑟 (mod 𝑝) per un qualche 𝑟 ∈ 𝑅(𝑝), allora
𝐹(𝑎, 𝑏) ≔ 𝑎𝑑 + 𝑐𝑑−1𝑎𝑑−1𝑏 + ⋯ + 𝑐1𝑎𝑏𝑑−1 + 𝑐0𝑏𝑑 ≡ (𝑏𝑟)𝑑 + 𝑐𝑑−1(𝑏𝑟)𝑑−1𝑏 + ⋯ + 𝑐1(𝑏𝑟)𝑏𝑑−1 + 𝑐0𝑏𝑑
= 𝑏𝑑𝑟𝑑 + 𝑐𝑑−1𝑏𝑑𝑟𝑑−1 + ⋯ + 𝑐1𝑏𝑑𝑟 + 𝑐0𝑏𝑑 = 𝑏𝑑(𝑟𝑑 + 𝑐𝑑−1𝑟𝑑−1 + ⋯ + 𝑐1𝑟 + 𝑐0)
= 𝑏𝑑𝑓(𝑟) ≡ 0 (mod 𝑝).
(⟹) Ricordiamo che 𝐹(𝑥, 𝑦) = 𝑦𝑑𝑓(𝑥𝑦−1). Potrebbero esserci problemi con 𝑦−1, quindi dividiamo i casi:
• Se 𝑝 ∣ 𝑏 allora 𝑝 ∤ 𝑎 per ipotesi di coprimalità e dunque 𝐹(𝑎, 𝑏) ≡ 𝑎𝑑 ≢ 0 (mod 𝑝).
• Se 𝑝 ∤ 𝑏 allora esiste l’inverso di 𝑏 in ℤ𝑝. Dunque abbiamo come ipotesi 𝑏𝑑𝑓(𝑎𝑏−1) ≡ 0 (mod 𝑝),
ossia 𝑝 ∣ 𝑏𝑑𝑓(𝑎𝑏−1), da cui 𝑓(𝑎𝑏−1) ≡ 0 (mod 𝑝) e dunque 𝑎𝑏−1 ≡ 𝑟 (mod 𝑝) per 𝑟 ∈ 𝑅(𝑝). □
Mentre setacciamo gli 𝑎 − 𝑏𝛼 alla ricerca di 𝐵-smooth, otteniamo quindi un’informazione aggiuntiva, ossia
un 𝑟 ∈ 𝑅(𝑝) tale che 𝑎 ≡ 𝑏𝑟 (mod 𝑝). Ne terremo traccia nel nostro vettore di esponenti, ove ci sarà una
coordinata per ogni coppia (𝑝, 𝑟𝑝) con 𝑝 primo ≤ 𝐵 e 𝑟𝑝 ∈ 𝑅(𝑝). Più nello specifico, se 𝑎 − 𝑏𝛼 è 𝐵-smooth,
gli associamo il vettore di esponenti �̅�(𝑎 − 𝑏𝛼) con entrate 𝑣𝑝,𝑟(𝑎 − 𝑏𝛼) definite da
𝑣𝑝,𝑟(𝑎 − 𝑏𝛼) ≔ {0, 𝑎 ≢ 𝑏𝑟 (mod 𝑝)
𝑒, 𝑎 ≡ 𝑏𝑟 (mod 𝑝)
ove 𝑒 è l’esponente di 𝑝 nella fattorizzazione di 𝑁(𝑎 − 𝑏𝛼) = 𝐹(𝑎, 𝑏).

11
N.B.: Utilizzeremo più avanti la notazione �̅� per indicare il vettore di esponenti “completo”.
Esempio. Consideriamo il polinomio 𝑓(𝑥) = 𝑥2 + 1 (quindi 𝐹(𝑥, 𝑦) = 𝑥2 + 𝑦2) e prendiamo come limite
𝐵 = 5. I primi della factor base sono dunque 𝑝 ∈ {2, 3, 5}. Calcoliamo quindi gli insiemi 𝑅(𝑝):
𝑅(2) = {1} 𝑅(3) = ∅ 𝑅(5) = {2, 3}.
Dunque il vettore di esponenti per gli elementi di ℤ[𝑖] (con norma) 𝐵-smooth avrà tre coordinate,
corrispondenti alle tre coppie (𝑝, 𝑟) ∈ {(2, 1), (5, 2), (5, 3)}. Consideriamo 𝜃 = 3 − 𝑖, che dunque
corrisponde ad avere 𝑎 = 3 e 𝑏 = 1. La norma di tale elemento è 𝑁(3 − 𝑖) = 𝐹(3, 1) = 10, che è divisibile
per 𝑝 = 2 e 𝑝 = 5. Per il risultato precedente sappiamo che deve esistere un 𝑟 ∈ 𝑅(𝑝) tale che 3 ≡ 1 ∙
𝑟 (mod 𝑝). Per 𝑝 = 2 abbiamo obbligatoriamente 𝑟 = 1 (e infatti 3 ≡ 1 ∙ 1 (mod 2)). Per 𝑝 = 5 notiamo
banalmente che 𝑟 = 3. Dunque il vettore di esponenti corrispondente a 𝜃 = 3 − 𝑖 è dato da (1, 0, 1).
Similmente possiamo procedere con altri elementi della forma 𝜃 = 𝑎 − 𝑏𝑖:
Elemento di ℤ[𝒊] Norma Vettore di esponenti
𝜽𝟏 = 𝟑 − 𝒊 𝐹(3, 1) = 10 �̅�(𝜃1) = (1, 0, 1)
𝜽𝟐 = 𝟐 − 𝒊 𝐹(2, 1) = 5 �̅�(𝜃2) = (0, 1, 0)
𝜽𝟑 = 𝟏 − 𝒊 𝐹(1, 1) = 2 �̅�(𝜃3) = (1, 0, 0)
𝜽𝟒 = 𝟐 + 𝒊 𝐹(2, −1) = 5 �̅�(𝜃4) = (0, 0, 1)
Dalla tabella possiamo provare a fare qualche prodotto:
• 𝑁(𝜃2𝜃4) = 25 che è un quadrato, tuttavia 𝜃2𝜃4 non è un quadrato in ℤ[𝑖].
Notiamo che �̅�(𝜃2) + �̅�(𝜃4) = (0, 1, 1) ≠ (0, 0, 0) (mod 2).
• 𝑁(𝜃1𝜃2𝜃3) = 100 che è un quadrato, tuttavia 𝜃1𝜃2𝜃3 non è un quadrato in ℤ[𝑖].
Notiamo che �̅�(𝜃1) + �̅�(𝜃2) + �̅�(𝜃3) = (0, 1, 1) ≠ (0, 0, 0) (mod 2).
• 𝑁(𝜃1𝜃3𝜃4) = 100 che è un quadrato e 𝜃1𝜃3𝜃4 = 8 − 6𝑖 = (3 − 𝑖)2 è un quadrato in ℤ[𝑖].
Notiamo che �̅�(𝜃1) + �̅�(𝜃3) + �̅�(𝜃4) = (0, 0, 0) (mod 2).
Questo esempio potrebbe suggerire una qualche relazione tra il fatto che un prodotto sia un quadrato e il
fatto che la somma dei vettori di esponenti abbia tutte le componenti pari. Si può mostrare subito che una
direzione di questa congettura non è vera, basti considerare 𝑖 una delle unità di ℤ[𝑖]. Notiamo che,
nonostante 𝑖 non sia un quadrato, si ha che 𝑁(𝑖) = 𝐹(0, −1) = 1 è un quadrato e �̅�(𝑖) = (0, 0, 0).
Se il problema fossero solo le unità, sarebbe facilmente aggirabile; tuttavia non si limita solo a ciò: lo spazio
che abbiamo preso in considerazione per l’esempio, ossia ℤ[𝑖], come vedremo presto, è troppo buono e
dunque non rappresenta il caso medio.
Prima di procedere, ricordiamo un po’ di teoria [13]; le seguenti valgono per ogni anello di numeri 𝑅, non
solo per ℤ[𝛼]:
• Ogni ideale non nullo di 𝑅 ha indice finito.
• 𝑅 è noetheriano e tutti gli ideali primi non nulli sono massimali.
• Un ideale primo 𝑃 di 𝑅 giace su un unico primo 𝑝 di ℤ, ossia 𝑃 ∩ ℤ = 𝑝ℤ.
Tale primo 𝑝 è la caratteristica del campo 𝑅 𝑃⁄ . Il grado di 𝑃 è il grado di |𝑅 𝑃⁄ : 𝔽𝑝|.

12
Definizione. L’anello degli interi algebrici di ℚ[𝛼] è definito come
𝐼 ≔ {𝛽 ∈ ℚ[𝛼] ∶ ∃𝑓 ∈ ℤ[𝑥] monico con 𝑓(𝛽) = 0}.
Osservazione. Valgono i seguenti fatti:
• 𝐼 è un anello.
• Valgono le ovvie inclusioni ℤ[𝛼] ⊆ 𝐼 ⊆ ℚ[𝛼]. La prima delle due può essere talvolta un’uguaglianza,
come nel caso di ℤ[𝑖], talvolta un’inclusione stretta, come nel caso di ℤ[√5] ⊊ 𝐼 = ℤ [1+√5
2].
• 𝐼 è un domino di Dedekind, quindi gli ideali non banali hanno fattorizzazione unica in ideali primi.
Definizione. Sia 𝐽 un ideale di 𝐼, definiamo la norma di 𝐽 come 𝑁(𝐽) ≔ #(𝐼 𝐽⁄ ) se 𝐽 ≠ (0) e 𝑁((0)) ≔ 0.
Osservazione. Valgono i seguenti fatti:
• La norma è moltiplicativa: 𝑁(𝐽1𝐽2) = 𝑁(𝐽1)𝑁(𝐽2).
• C’è una corrispondenza tra la norma di un elemento e la norma dell’ideale da lui generato:
𝑁((𝛽)) = |𝑁(𝛽)|.
Consideriamo una coppia (𝑝, 𝑟) con 𝑝 primo e 𝑟 ∈ 𝑅(𝑝) e sia 𝑎 − 𝑏𝛼 ∈ ℤ[𝛼] tale che gcd(𝑎, 𝑏) = 1 e 𝑎 ≡
𝑏𝑟 (mod 𝑝). Prendiamo ora la 𝑁(𝑎 − 𝑏𝛼) e cerchiamo di capire qual è la massima potenza di 𝑝 che la divide.
Anzitutto notiamo che ci conviene spostarci sugli ideali di 𝐼, ossia andiamo a vedere la norma di (𝑎 − 𝑏𝛼).
Visto che cerchiamo le potenze di 𝑝, dobbiamo andare a vedere gli ideali primi 𝑃 che dividono (𝑎 − 𝑏𝛼) e
che giacciono su 𝑝, o equivalentemente che dividono anche (𝑝). Notiamo che vale il seguente
Lemma. Se gcd(𝑎, 𝑏) = 1, 𝑎 ≡ 𝑏𝑟 (mod 𝑝) e 𝑃 è un ideale primo di 𝐼 che divide (𝑝) e (𝑎 − 𝑏𝛼), allora 𝑃
divide anche (𝑝, 𝛼 − 𝑟).
Dimostrazione. L’ipotesi di coprimalità di 𝑎, 𝑏 e che 𝑎 ≡ 𝑏𝑟 (mod 𝑝) implica che 𝑏 ≢ 0 (mod 𝑝), dunque
esiste 𝑐 ∈ ℤ tale che 𝑐𝑏 ≡ 1 (mod 𝑝). Per ipotesi, 𝑎 − 𝑏𝛼, 𝑝 ∈ 𝑃, quindi
𝑎 − 𝑏𝑟 − 𝑏(𝛼 − 𝑟) = 𝑎 − 𝑏𝛼 ∈ 𝑃 ∧ 𝑝 ∣ 𝑎 − 𝑏𝑟 ⟹ 𝑏(𝛼 − 𝑟) ∈ 𝑃 ⟹ 𝑐𝑏(𝛼 − 𝑟) ∈ 𝑃.
Abbiamo quindi provato che 𝛼 − 𝑟 ∈ 𝑃, dunque (𝑝, 𝛼 − 𝑟) ⊆ 𝑃 e quindi 𝑃 divide (𝑝, 𝛼 − 𝑟). □
Dunque tali ideali 𝑃 devono per forza dividere anche l’ideale (𝑝, 𝛼 − 𝑟). Inoltre abbiamo anche il seguente
Lemma. Vale che
𝑎 − 𝑏𝛼 ∈ (𝑝, 𝛼 − 𝑟) ⟺ 𝑎 ≡ 𝑏𝑟 (mod 𝑝).
Dimostrazione. Basta scrivere 𝑎 − 𝑏𝛼 = 𝑎 − 𝑏𝑟 − 𝑏(𝛼 − 𝑟), dunque
𝑎 − 𝑏𝛼 ∈ (𝑝, 𝛼 − 𝑟) ⟺ 𝑎 − 𝑏𝑟 ∈ (𝑝, 𝛼 − 𝑟) ⟺ 𝑝 ∣ 𝑎 − 𝑏𝑟. □
Abbiamo quindi che (𝑝, 𝛼 − 𝑟) divide (𝑎 − 𝑏𝛼); da ciò consegue che gli ideali primi 𝑃 che dividono
(𝑎 − 𝑏𝛼) sono tutti e soli gli ideali primi che dividono (𝑝, 𝛼 − 𝑟). Notiamo inoltre che vale anche
Lemma. Gli ideali (𝑝, 𝛼 − 𝑟) sono primi tra loro al variare di 𝑟 ∈ 𝑅(𝑝).
Dimostrazione. Siano 𝑟, 𝑟′ ∈ 𝑅(𝑝) radici distinte e sia 𝑃 un ideale che divide sia (𝑝, 𝛼 − 𝑟) sia (𝑝, 𝛼 − 𝑟′).
Essendo 𝑟, 𝑟′ distinte modulo 𝑝, si ha che 𝑝 ∤ 𝑟 − 𝑟′, da cui gcd(𝑟 − 𝑟′, 𝑝) = 1. Notiamo che 𝑝 ∈ 𝑃 e 𝑟 −
𝑟′ = (𝛼 − 𝑟′) − (𝛼 − 𝑟) ∈ 𝑃, dunque 1 ∈ 𝑃, da cui 𝑃 = (1) = 𝐼. □

13
Possiamo riassumere quanto scoperto finora nel modo seguente:
Osservazione. Fissiamo una certa coppia (𝑝, 𝑟) con 𝑝 primo e 𝑟 ∈ 𝑅(𝑝) e consideriamo gli ideali (𝑎 − 𝑏𝛼),
per ogni coppia (𝑎, 𝑏) di interi coprimi tali che 𝑎 ≡ 𝑏𝑟 (mod 𝑝). Allora gli ideali primi 𝑃 che giacciono su 𝑝 e
che dividono gli ideali (𝑎 − 𝑏𝛼) sono tutti e soli gli ideali primi della fattorizzazione di (𝑝, 𝛼 − 𝑟), di
conseguenza sono indipendenti dalla coppia (𝑎, 𝑏). Inoltre, al variare di 𝑟 ∈ 𝑅(𝑝), non si presentano ideali
primi 𝑃 in comune.
Definizione. Sia 𝑃 un ideale primo di 𝐼, denotiamo con 𝑣𝑃(𝑎 − 𝑏𝛼) l’esponente di 𝑃 nella fattorizzazione di
(𝑎 − 𝑏𝛼).
Possiamo finalmente mostrare il seguente
Teorema. Sia 𝑆 un insieme di coppie (𝑎, 𝑏) di interi coprimi tali che 𝑎 − 𝑏𝛼 sia 𝐵-smooth. Se
∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
è un quadrato in 𝐼, allora
∑ �̅�(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
≡ 0̅ (mod 2).
Dimostrazione. Fissiamo una certa coppia (𝑝, 𝑟), il nostro scopo è dimostrare che
∑ 𝑣𝑝,𝑟(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
≡ 0 (mod 2).
Senza perdita di generalità, possiamo supporre che 𝑆 contenga solo coppie (𝑎, 𝑏) tali che 𝑎 ≡ 𝑏𝑟 (mod 𝑝),
in quanto le altre coppie danno contributo nullo alla sommatoria. Consideriamo ora l’ideale (𝑝, 𝛼 − 𝑟) e siano
𝑃1, … , 𝑃𝑘 tutti gli ideali primi che appaiono nella sua fattorizzazione. Per ogni 𝑖 ∈ {1, … , 𝑘}, sia 𝑒𝑖 il grado di
𝑃𝑖, ossia 𝑁(𝑃𝑖) = 𝑝𝑒𝑖 . Per l’Osservazione, il contributo dato da 𝑝 alla norma di (𝑎 − 𝑏𝛼) è proprio quello dato
dagli ideali 𝑃1, … , 𝑃𝑘 per ogni coppia (𝑎, 𝑏), ossia
𝑣𝑝,𝑟(𝑎 − 𝑏𝛼) = ∑ 𝑒𝑗𝑣𝑃𝑗(𝑎 − 𝑏𝛼)
𝑘
𝑗=1
da cui, sommando sulle coppie (𝑎, 𝑏) ∈ 𝑆, si ha che
(∗) ∑ 𝑣𝑝,𝑟(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= ∑ 𝑒𝑖 ∑ 𝑣𝑃𝑖(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
𝑘
𝑖=1
.
Per ipotesi, ∏ (𝑎 − 𝑏𝛼)(𝑎,𝑏)∈𝑆 = 𝛾2 per un certo 𝛾 ∈ 𝐼, ossia
∏ ((𝑎 − 𝑏𝛼))(𝑎,𝑏)∈𝑆
= ( ∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
) = (𝛾2) = (𝛾)2.
Dunque, per ogni ideale primo 𝑃 in 𝐼, abbiamo che ∑ 𝑣𝑃(𝑎 − 𝑏𝛼)(𝑎,𝑏)∈𝑆 è pari. Poiché ogni sommatoria
interna al secondo membro di (∗) è pari, ne consegue che anche l’intero al primo membro deve esserlo. □

14
3.3 Ostruzioni
Dobbiamo ancora trovare una condizione sufficiente (e facilmente verificabile) affinché
𝛽 ≔ ∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
sia un quadrato in ℤ[𝛼]. Proviamo a “invertire” l’ultimo Teorema del capitolo precedente, supponiamo che
∑ �̅�(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= 0̅ (mod 2)
e vediamo quando è possibile dire che 𝛽 è un quadrato in ℤ[𝛼].
Definizione. Un ideale primo di grado 1 in ℤ[𝛼] il nucleo 𝑃 di un qualche omomorfismo di anelli
𝜋 ∶ ℤ[𝛼] → ℤ𝑝
per un qualche primo 𝑝. Tale omomorfismo è univocamente individuato da 𝑝 e da 𝜋(𝛼), che è una radice di
𝑓 in ℤ𝑝, di conseguenza, 𝑃 = ker 𝜋 è identificabile con la coppia (𝑝, 𝜋(𝛼)).
Proposizione. Supponiamo che ℤ[𝛼] = 𝐼 e sia 𝑃 un ideale primo di 𝐼. Se 𝑎 − 𝑏𝛼 ∈ 𝑃 per qualche 𝑎, 𝑏 ∈ ℤ
con gcd(𝑎, 𝑏) = 1, allora 𝑃 è un ideale di ordine 1.
Dimostrazione. Sia 𝜋 ∶ ℤ[𝛼] → ℤ[𝛼] 𝑃⁄ il morfismo di proiezione al quoziente. Notiamo che ℤ[𝛼] 𝑃⁄ è un
campo con cardinalità pari a 𝑁(𝑃). Sia 𝑝 la caratteristica di tale campo, dunque 𝑃 giace su 𝑝, e definiamone
il sottogruppo 𝐹𝑝 dato dalle radici di 𝑥𝑝 − 𝑥. Per il piccolo teorema di Fermat sappiamo che
𝑎𝑝 ≡ 𝑎 (mod 𝑝) ⟹ 𝑎𝑝 − 𝑎 ∈ 𝑃 ⟹ 𝜋(𝑎)𝑝 − 𝜋(𝑎) = 𝜋(𝑎𝑝 − 𝑎) = 0 ⟹ 𝜋(𝑎) ∈ 𝐹𝑝
𝑏𝑝 ≡ 𝑏 (mod 𝑝) ⟹ 𝑏𝑝 − 𝑏 ∈ 𝑃 ⟹ 𝜋(𝑏)𝑝 − 𝜋(𝑏) = 𝜋(𝑏𝑝 − 𝑏) = 0 ⟹ 𝜋(𝑏) ∈ 𝐹𝑝 .
Inoltre, essendo 𝑎 − 𝑏𝛼 ∈ 𝑃, si ha che 𝜋(𝑎) − 𝜋(𝑏)𝜋(𝛼) = 𝜋(𝑎 − 𝑏𝛼) = 0. Se per assurdo 𝜋(𝑏) = 0, si
avrebbe che 𝜋(𝑎) = 0 e, di conseguenza, essendo 𝑎, 𝑏 ∈ ℤ, si avrebbe che 𝑝 ∣ gcd(𝑎, 𝑏), assurdo per la
coprimalità di 𝑎, 𝑏. Dunque 𝜋(𝑏) ≠ 0 e perciò è invertibile in ℤ[𝛼] 𝑃⁄ ; quindi
𝜋(𝛼) = 𝜋(𝑎)𝜋(𝑏)−1 ∈ 𝐹𝑝 ⟹ 𝜋(ℤ[𝛼]) ⊆ 𝐹𝑝 ⟹ ℤ[𝛼] 𝑃⁄ = 𝐹𝑝 ⟹ 𝑁(𝑃) = 𝑝. □
Dunque se ℤ[𝛼] = 𝐼, gli ideali 𝑃1, … , 𝑃𝑘 del capitolo precedente sono tutti di grado 𝑒𝑖 = 1 e ve ne è uno e
uno solo per ogni 𝑝 (quindi 𝑘 = 1), in particolare quello corrispondente alla radice 𝑟 = 𝜋(𝛼) data nella
definizione. DI conseguenza, si ha che
∑ 𝑣𝑝,𝑟(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= ∑ 𝑣𝑃(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
.
Se assumiamo che il membro a sinistra sia pari, otteniamo anche che la sommatoria a destra lo è, e dunque
(𝛽) sarebbe un quadrato in 𝐼.
Per arrivare a questo punto, abbiamo fatto un’ipotesi molto forte, ossia che ℤ[𝛼] = 𝐼. Notiamo inoltre che
non siamo neanche arrivati dove volevamo: abbiamo solo ricavato che (𝛽) è il quadrato di un qualche
ideale di 𝐼.

15
Abbiamo dunque qualche ostruzione da risolvere per procedere. Cerchiamo di elencarle:
1. Se ℤ[𝛼] = 𝐼 allora l’ideale (𝛽) in 𝐼 è il quadrato di qualche ideale 𝐽; ma non è detto che ℤ[𝛼] = 𝐼.
2. Anche se (𝛽) = 𝐽2 per qualche ideale 𝐽 in 𝐼, non è detto che 𝐽 sia principale.
3. Anche se (𝛽) = (𝛾)2 per qualche 𝛾 ∈ 𝐼, non è detto che 𝛽 = 𝛾2.
4. Anche se 𝛽 = 𝛾2 per 𝛾 ∈ 𝐼, non è detto che 𝛾 ∈ ℤ[𝛼].
Iniziamo risolvendo il problema (4).
Lemma. Sia 𝑓(𝑥) un polinomio monico e irriducibile in ℤ[𝑥], con radice 𝛼 ∈ ℂ e sia 𝛾 ∈ 𝐼. Allora
𝑓′(𝛼)𝛾 ∈ ℤ[𝛼].
Dimostrazione. Siano 𝛽0, 𝛽1, … , 𝛽𝑑−1 i coefficienti del polinomio 𝑓(𝑥) (𝑥 − 𝛼)⁄ , allora abbiamo un risultato
di Eulero (Proposizione 3-7-12 a pag. 106 in E. Weiss. Algebraic Number Theory, 1963) che ci dice che
𝛽0
𝑓′(𝛼), … ,
𝛽𝑑−1
𝑓′(𝛼)
è una base per ℚ(𝛼) su ℚ, ogni 𝛽𝑗 ∈ ℤ[𝛼] e 𝑇𝑟(𝛼𝑘𝛽𝑗 𝑓′(𝛼)⁄ ) = 𝛿𝑗𝑘. (Ricordiamo che la traccia è un
operatore ℚ-lineare, è a valori in ℚ ed è a valori in ℤ se l’argomento è in 𝐼). Essendo 𝛾 ∈ 𝐼 per ipotesi, si ha
𝛾 = ∑ 𝑠𝑗
𝛽𝑗
𝑓′(𝛼)
𝑑−1
𝑗=0
𝑠𝑗 ∈ ℚ.
Dunque
𝑇𝑟(𝛾𝛼𝑘) = 𝑇𝑟 (𝛼𝑘 ∑ 𝑠𝑗
𝛽𝑗
𝑓′(𝛼)
𝑑−1
𝑗=0
) = ∑ 𝑠𝑗𝑇𝑟 (𝛼𝑘𝛽𝑗
𝑓′(𝛼))
𝑑−1
𝑗=0
= ∑ 𝑠𝑗𝛿𝑗𝑘
𝑑−1
𝑗=0
= 𝑠𝑘 𝑘 = 0, … , 𝑑 − 1.
Essendo 𝛼𝑘 ∈ ℤ[𝛼] ⊆ 𝐼, si ha che 𝛾𝛼𝑘 ∈ 𝐼 e dunque 𝑠𝑘 ∈ ℤ per ogni 𝑘. Quindi
𝑓′(𝛼)𝛾 = ∑ 𝑠𝑗𝛽𝑗
𝑑−1
𝑗=0
∈ ℤ[𝛼] . □
Come usiamo questo Lemma per risolvere il problema (4)?
Al posto di richiedere che 𝛽 = ∏ (𝑎 − 𝑏𝛼)(𝑎,𝑏)∈𝑆 sia un quadrato in ℤ[𝛼] richiediamo invece che sia un
quadrato in 𝐼, diciamo 𝛾2. Poi, grazie al Lemma, otteniamo che 𝑓′(𝛼)𝛾 ∈ ℤ[𝛼], da cui si ha che 𝑓′(𝛼)2𝛽 è
un quadrato in ℤ[𝛼].
Passiamo ora ai problemi (1), (2) e (3); tutti e tre riguardano lo studio di alcuni gruppi:
• Il problema (1) riguarda il gruppo 𝐼 ℤ[𝛼]⁄ .
• Il problema (2) riguarda il gruppo delle classi di 𝐼.
• Il problema (3) riguarda il gruppo delle unità di 𝐼.

16
Senza scendere nei dettagli è possibile dimostrare i seguenti fatti:
1. Gli ideali primi con esponenti dispari nella fattorizzazione di (𝛽) stanno tutti su primi che dividono
l’indice di ℤ[𝛼] in 𝐼 e il numero di questi ideali primi è limitato da log2|𝐼 ∶ ℤ[𝛼]|.
2. Il problema legato al gruppo delle classi, modulo il sottogruppo dei quadrati, è limitato dal logaritmo
in base 2 dell’ordine del gruppo delle classi, ossia il logaritmo del class number.
3. Il problema legato al gruppo delle unità, modulo il sottogruppo dei quadrati, è limitato da 𝑑.
Tali affermazioni non ci servono in modo diretto per la trattazione, tuttavia aiuteranno a capire come mai è
sensata la strategia che proporremo. Infatti essi ci dicono che i tre problemi corrispettivi sono “piccoli” e
dunque è possibile aggirarli.
Sia 𝑞 un primo dispari e 𝑚 un intero; se (𝑚
𝑞) = −1, allora 𝑚 non è un quadrato. Il risultato opposto è
ovviamente falso, tuttavia L.M. Adleman propone di utilizzarlo in via probabilistica. Ossia dato un certo intero
𝑚, scegliamo 𝑘 primi distinti 𝑞 < |𝑚|. Se per ognuno dei 𝑘 test risulta (𝑚
𝑞) = 1, allora possiamo aspettarci
che 𝑚 sia effettivamente un quadrato; la probabilità che non lo sia è (euristicamente) di 2−𝑘.
Vogliamo applicare quest’idea agli elementi di ℤ[𝛼] e il seguente risultato ci permette di farlo:
Lemma. Sia 𝑓(𝑥) un polinomio monico e irriducibile in ℤ[𝑥] e sia 𝛼 ∈ ℂ una radice di 𝑓. Sia 𝑞 un primo dispari
e 𝑠 un intero tale che 𝑓(𝑠) ≡ 0 (mod 𝑞) e 𝑓′(𝑠) ≢ 0 (mod 𝑞). Sia 𝑆 un insieme di coppie (𝑎, 𝑏) di interi
coprimi tali che 𝑞 non divida 𝑎 − 𝑏𝑠, per ogni (𝑎, 𝑏) ∈ 𝑆 e 𝑓′(𝛼)2 ∏ (𝑎 − 𝑏𝛼)(𝑎,𝑏)∈𝑆 sia un quadrato in ℤ[𝛼].
Allora
∏ (𝑎 − 𝑏𝑠
𝑞)
(𝑎,𝑏)∈𝑆
= 1.
Dimostrazione. Consideriamo l’omomorfismo 𝜙𝑞: ℤ[𝛼] → ℤ𝑞 dato da 𝜙𝑞(𝛼) ≔ [𝑠]𝑞. Per ipotesi abbiamo
𝑓′(𝛼)2 ∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= 𝛾2 𝛾 ∈ ℤ[𝛼]
e, applicandovi 𝜙𝑞, si ottiene che
𝜙𝑞(𝛾2) ≡ 𝑓′(𝑠)2 ∏ (𝑎 − 𝑏𝑠)
(𝑎,𝑏)∈𝑆
≢ 0 (mod 𝑞).
Di conseguenza
(𝜙𝑞(𝛾2)
𝑞) = (
𝜙𝑞(𝛾)2
𝑞) = 1 ∧ (
𝑓′(𝑠)2
𝑞) = 1 ⟹ (
∏ (𝑎 − 𝑏𝑠)(𝑎,𝑏)∈𝑆
𝑞) = 1
da cui la tesi. □
Dunque, per un 𝑘 sufficientemente grande e per 𝑞1, … , 𝑞𝑘 primi dispari che non dividano alcun 𝑁(𝑎 − 𝑏𝛼)
per (𝑎, 𝑏) ∈ 𝑆 e se abbiamo un 𝑠𝑖 ∈ 𝑅(𝑞𝑖) per 𝑖 = 1, … , 𝑘 con 𝑓′(𝑠𝑖) ≢ 0 (mod 𝑞𝑖), allora probabilmente
∑ �̅�(𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
≡ 0̅ (mod 2) ∧ ∏ (𝑎 − 𝑏𝑠𝑖
𝑞𝑖)
(𝑎,𝑏)∈𝑆
= 1 𝑖 = 1, … , 𝑘
⟹ ∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= 𝛾2 𝛾 ∈ 𝐼.

17
Quanto deve essere grande 𝑘? Per i fatti citati prima, la “dimensione” dei problemi (1), (2) e (3) è
relativamente piccola, dunque 𝑘 non ha bisogno di essere molto grande. Se il grado 𝑑 del polinomio soddisfa
𝑑2𝑑2< 𝑛 e i coefficienti 𝑐𝑖 soddisfano |𝑐𝑖| < 𝑛1 𝑑⁄ , allora può essere dimostrato che la “somma delle
dimensioni” dei primi tre problemi è minore di log 𝑛. È stato inoltre congetturato che è sufficiente prendere
𝑘 = ⌊3 log 𝑛⌋, con i 𝑘 primi 𝑞𝑗 scelti i più piccoli possibili, per avere un rapporto probabilità su costo ottimale.
Utilizziamo le coppie (𝑞𝑖 , 𝑠𝑖) per aumentare il nostro vettore di esponenti con 𝑘 entrate aggiuntive. Se
(𝑎−𝑏𝑠𝑖
𝑞𝑖) = 1, l’entrata corrispondente a 𝑞𝑖, 𝑠𝑖 nel vettore di esponenti di 𝑎 − 𝑏𝛼 sarà 0. Se il simbolo di
Legendre è −1, invece l’entrata sarà 1: ciò permette di passare dal gruppo moltiplicativo di ordine due {1, −1} al gruppo additivo di ordine due ℤ2.
Questo vettore di esponenti aumentato risulta essere ora non solo necessario ma anche (nella pratica)
sufficiente per la costruzione dei quadrati.
4. Radici quadrate
Supponiamo ora di avere un insieme 𝑆 di coppie (𝑎, 𝑏) di interi coprimi tali che
𝑓′(𝛼)2 ∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= 𝛾2 𝛾 ∈ ℤ[𝛼]
∏ (𝑎 − 𝑏𝑚)
(𝑎,𝑏)∈𝑆
= 𝑣2 𝑣 ∈ ℤ.
Allora ci siamo quasi, infatti se 𝑢 è un intero tale che 𝜙(𝛾) ≡ 𝑢 (mod 𝑛), allora 𝑢2 ≡ [𝑓′(𝑚)𝑣]2 (mod 𝑛) e
dunque possiamo provare a fattorizzare 𝑛 tramite gcd(𝑢 − 𝑓′(𝑚)𝑣, 𝑛).
Tuttavia rimane un problema: i metodi visti sinora ci permettono di trovare l’insieme 𝑆 e di ottenere un
quadrato in ℤ[𝛼] e uno in ℤ, ma non ci dicono come trovare le loro radici quadrate 𝛾 e 𝑣.
4.1 Radice quadrata in ℤ
Il problema per 𝑣 è semplice e può essere risolto allo stesso modo del QS: dal vettore di esponenti possiamo
dedurre la fattorizzazione in primi di 𝑣2 e da questa possiamo facilmente ottenere 𝑣. In realtà, non ci serve
la fattorizzazione di 𝑣; piuttosto ci serve solo sapere il suo residuo modulo 𝑛. Per ogni potenza di un primo
che divide 𝑣, calcoliamo il suo residuo mod 𝑛 (per esempio con l’algoritmo qui sotto); poi moltiplichiamo
questi residui in ℤ𝑛 ottenendo 𝑣 (mod 𝑛).
Algoritmo (Potenze ricorsive). Dati 𝑥 ∈ ℤ e 𝑚, 𝑛 ∈ ℕ∗; restituisce 𝑥𝑚 (mod 𝑛).
pow(int x, int m, int n) { if (m == 1) return x (mod n); if (m even) return pow(x, m/2, n)^2 (mod n); if (m odd) return x*pow(x, (m-1)/2, n)^2 (mod n); }
Complessità: 𝑂(log3 𝑛).

18
4.2 Radice quadrata in ℤ[𝛼]
Il problema per 𝛾 è invece più complesso. Siano
𝛾 = 𝑎0 + 𝑎1𝛼 + ⋯ + 𝑎𝑑−1𝛼𝑑−1
𝑢 ≔ 𝜙(𝛾) = 𝑎0 + 𝑎1𝑚 + ⋯ + 𝑎𝑑−1𝑚𝑑−1.
Essendo interessati solo al residuo 𝑢 (mod 𝑛), significa che possiamo considerare i coefficienti 𝑎𝑗 (mod 𝑛).
Se siamo nel caso speciale in cui ℤ[𝛼] = 𝐼 e questo è un UFD, allora possiamo utilizzare un metodo simile a
quello utilizzato per 𝑣 (mod 𝑛); tuttavia, nel caso generale, il nostro anello potrebbe essere molto distante
dall’essere un UFD. Un buon modo per risolvere il nostro problema consiste nel trovare un primo 𝑝 tale che
𝑓 sia irriducibile modulo 𝑝; quindi, per trovare la radice 𝛾 (mod 𝑝), possiamo applicare l’algoritmo di Shanks-
Tonelli, modificato in maniera opportuna in modo da poter lavorare nel campo finito ℤ𝑝[𝑥] (𝑓)⁄ .
A questo punto, ripetiamo questa procedura anche per altri primi 𝑝 e poi uniamo i risultati mediante il
Teorema Cinese del Resto. L’unico problema è dato dal fatto che se iteriamo la procedura per 𝑘 primi,
otteniamo 2 soluzioni per ogni primo, dunque 2𝑘 possibilità per combinarle: sostanzialmente il problema è
capire qual è il segno corretto con cui prendere ciascuna della 𝑘 radici.
Ci sono almeno due modi per aggirare il problema della scelta dei segni. Il primo è di non utilizzare il Teorema
Cinese del Resto con primi differenti, ma di usare il Lemma di Hensel per ottenere soluzioni modulo potenze
superiori dello stesso primo 𝑝.
Il secondo prevede l’uso del Teorema Cinese del Resto, ma funziona solo nel caso 𝑑 dispari. Sotto tale ipotesi,
la norma di −1 è −1, dunque possiamo operare la scelta dei segni in modo da preservare il segno della norma
di 𝛾, la quale è nota dal vettore di esponenti. Più nello specifico, calcoliamo 𝑁(𝛾) (mod 𝑝) ove 𝑝 è un primo
per cui 𝑓(𝑥) è irriducibile modulo 𝑝. Quando calcoliamo 𝛾𝑝 tale che 𝛾𝑝2 ≡ 𝛾2 (mod 𝑝), scegliamo 𝛾𝑝 o −𝛾𝑝 a
seconda di quale dei due abbia norma congruente a 𝑁(𝛾) (mod 𝑝). Essendo 𝑁(−1) = −1, ciò permette una
corretta scelta dei segni per ogni primo 𝑝 utilizzato.
In verità esiste un terzo metodo per trovare le radici quadrate 𝛾 e 𝑣. Esso utilizza un approccio euristico che
funziona molto bene nella pratica e rende questo passo dell’algoritmo irrilevante rispetto al costo totale. Tale
metodo combina le due idee appena viste con altre aggiuntive; tuttavia una sua descrizione dettagliata non
rientra negli scopi di questo elaborato.

19
5. Complessità asintotica [8]
Sia nel QS che nel NFS abbiamo un insieme di valori, su cui applichiamo un crivello per trovare i 𝐵-smooth.
Poi utilizziamo le tecniche dell’algebra lineare sui vettori di esponenti e troviamo così un sottoinsieme dei
vettori la cui somma sia 0̅ (mod 2). Quanto tempo ci vuole per completare questa procedura?
Senza entrare troppo nei dettagli, possiamo generalizzare l’analisi euristica effettuata per il QS. Ricordando
la notazione 𝐿(𝑥) ≔ 𝑒√log 𝑥 log log 𝑥, si può dimostrare che se i valori utilizzati sono limitati da un certo 𝑋, il
tempo necessario per l’esecuzione dell’algoritmo è al più
𝐿(𝑋)√2+𝑜(1)
e lo smoothness bound ottimale per ottenerlo è 𝐵 ≈ 𝐿(𝑋)1 √2⁄ . Questo limite può essere rigorosamente
provato tramite il seguente
Teorema (Pomerance). Siano 𝑚1, 𝑚2, … degli interi scelti indipendentemente e con distribuzione uniforme
nell’intervallo [1, 𝑋]. Sia 𝑁 il più piccolo intero tale che un sottoinsieme non vuoto di 𝑚1, … , 𝑚𝑁 abbia come
prodotto un quadrato. Allora il valore atteso per 𝑁 è 𝐿(𝑋)√2+𝑜(1). La stessa media vale anche se imponiamo
che gli 𝑚𝑗 utilizzati nel prodotto siano 𝐵-smooth, con 𝐵 = 𝐿(𝑋)1 √2⁄ .
Osserviamo che per far funzionare questi risultati, siamo obbligati a supporre che i valori da noi utilizzati
siano uniformemente distribuiti. Proprio questa assunzione è ciò che rende l’analisi della complessità per
questi algoritmi euristica e non deterministica.
Giusto per notare che il risultato è in accordo con quanto già visto, ricordiamo che i valori nel QS erano
limitati da 𝑋 = 𝑛1 2⁄ +𝑜(1), da cui si ottiene
𝐿(𝑋)√2+𝑜(1) = 𝐿(𝑛1 2⁄ +𝑜(1))√2+𝑜(1)
= (𝑒√1
2log 𝑛 log log 𝑛
)
√2+𝑜(1)
= 𝐿(𝑛)1+𝑜(1)
che è proprio la complessità ottenuta durante l’analisi del QS.
Cerchiamo ora di calcolare un limite 𝑋 per i numeri che adoperiamo nel NFS; essi sono le valutazioni del
prodotto 𝐹(𝑥, 𝑦)𝐺(𝑥, 𝑦) ove
𝐹(𝑥, 𝑦) = 𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1𝑦 + ⋯ + 𝑐0𝑦𝑑
𝐺(𝑥, 𝑦) = 𝑥 − 𝑚𝑦.
Per costruzione l’intero 𝑚 e i coefficienti 𝑐𝑗 sono limitati da 𝑛1 𝑑⁄ ; inoltre 𝑎, 𝑏 sono limitati da 𝑀, dunque
|𝐹(𝑎, 𝑏)𝐺(𝑎, 𝑏)| ≤ ((𝑑 + 1)𝑛1 𝑑⁄ 𝑀𝑑) (𝑀 − 𝑛1 𝑑⁄ 𝑀) ≤ 2(𝑑 + 1)𝑛2 𝑑⁄ 𝑀𝑑+1
da cui possiamo porre
𝑋 ≔ 2(𝑑 + 1)𝑛2 𝑑⁄ 𝑀𝑑+1.
Per il Teorema ci aspettiamo di dover guardare 𝐿(𝑋)√2+𝑜(1) coppie (𝑎, 𝑏) per vincere; perciò, avendo
all’incirca 𝑀2 coppie, poniamo 𝑀2 = 𝐿(𝑋)√2+𝑜(1). Sostituendo in 𝑋 e prendendo il logaritmo, si ha che
log 𝑋 ∼ log 2(𝑑 + 1) +2
𝑑log 𝑛 + (𝑑 + 1)√
1
2log 𝑋 log log 𝑋 .

20
Notiamo che il primo addendo è di ordine minore al terzo, dunque possiamo scrivere
(∗) log 𝑋 ∼2
𝑑log 𝑛 + 𝑑√
1
2log 𝑋 log log 𝑋 .
Proviamo innanzitutto a proseguire l’analisi fissando il valore 𝑑. In tal caso, essendo 𝑑 costante, il secondo
addendo di (∗) è di ordine inferiore rispetto al termine a primo membro, dunque possiamo scrivere
log 𝑋 ∼2
𝑑log 𝑛 .
Il tempo di esecuzione a 𝑑 fissato è quindi
𝐿(𝑋)√2+𝑜(1) = (𝑒√2
𝑑log 𝑛 log
2𝑑
log 𝑛)
√2+𝑜(1)
∼ 𝐿(𝑛)√4 𝑑⁄ +𝑜(1)
e da ciò si può fare un’osservazione interessante: il NFS è asintoticamente più veloce del QS solo per 𝑑 ≥ 5.
Riprendiamo con l’analisi lasciando libero il parametro 𝑑; più nello specifico, cerchiamo un valore di 𝑑 che
minimizzi il costo totale. Notiamo che, essendo 𝐿(𝑋) monotona crescente, ciò equivale a minimizzare 𝑋.
Derivando (∗) rispetto a 𝑑 e utilizzando la notazione 𝑋′ ≔ 𝜕𝑋 𝜕𝑑⁄ , si ha che
𝑋′
𝑋= −
2
𝑑2log 𝑛 + √
1
2log 𝑋 log log 𝑋 +
𝑑𝑋′(log log 𝑋 + 1)
4𝑋√12 log 𝑋 log log 𝑋
da cui, imponendo 𝑋′ = 0, si ottiene
0 = −2
𝑑2log 𝑛 + √
1
2log 𝑋 log log 𝑋 ⟹ 𝑑 =
(2 log 𝑛)1 2⁄
(12 log 𝑋 log log 𝑋)
1 4⁄ .
Sostituendo tale valore in (∗), si ha che
log 𝑋 = (2 log 𝑛)1 2⁄ (1
2log 𝑋 log log 𝑋)
1 4⁄
+ (2 log 𝑛)1 2⁄ (1
2log 𝑋 log log 𝑋)
1 4⁄
= 2(2 log 𝑛)1 2⁄ (1
2log 𝑋 log log 𝑋)
1 4⁄
⟹ (log 𝑋)3 4⁄ = 2(2 log 𝑛)1 2⁄ (1
2log log 𝑋)
1 4⁄
da cui, applicando il logaritmo e scartando il termine in log log log 𝑋, si ottiene la condizione
3
4log log 𝑋 ∼
1
2log log 𝑛.
Sostituendo tale condizione, si ottiene
(log 𝑋)3 4⁄ = 2(2 log 𝑛)1 2⁄ (1
3log log 𝑛)
1 4⁄
⟹ log 𝑋 =4
31 3⁄(log 𝑛)2 3⁄ (log log 𝑛)1 3⁄ .

21
Dunque il tempo di esecuzione a 𝑑 ottimale è
𝐿(𝑋)√2+𝑜(1) = exp {(√2 + 𝑜(1)) √4
31 3⁄(log 𝑛)2 3⁄ (log log 𝑛)1 3⁄ ∙ log [
4
31 3⁄(log 𝑛)2 3⁄ (log log 𝑛)1 3⁄ ]}
= exp {(√2 + 𝑜(1))2
31 6⁄(log 𝑛)1 3⁄ (log log 𝑛)1 6⁄ ∙ (
2
3log log 𝑛)
1 2⁄
}
= exp {[(64
9)
1 3⁄
+ 𝑜(1)] (log 𝑛)1 3⁄ (log log 𝑛)2 3⁄ }
mentre il valore ottimale per 𝑑 è
𝑑 =(2 log 𝑛)1 2⁄
(12 log 𝑋 log log 𝑋)
1 4⁄=
(2 log 𝑛)1 2⁄
(2
32 3⁄ (log 𝑛)1 3⁄ (log log 𝑛)2 3⁄ )1 2⁄
=31 3⁄ (log 𝑛)1 3⁄
(log log 𝑛)1 3⁄= (
3 log 𝑛
log log 𝑛)
1 3⁄
.
Come considerazione finale notiamo che, se riuscissimo a diminuire i coefficienti di 𝑓(𝑥) e portarli
nell’ordine di 𝑛𝜖 𝑑⁄ , avremmo una complessità, a 𝑑 fissato, pari a
𝐿(𝑛)√2+2𝜖
𝑑+𝑜(1)
.
Mentre, per 𝑑 ottimale, pari a
exp {((32(1 + 𝜖)
9)
1 3⁄
+ 𝑜(1)) (log 𝑛)1 3⁄ (log log 𝑛)2 3⁄ } .
Come vedremo in seguito, il caso 𝜖 = 𝑜(1) si presenterà nella variante SNFS.
6. Riassunto dell’algoritmo
Sia 𝑛 un intero dispari composto che non sia una potenza. Il seguente algoritmo prova a restituire un
fattore non banale di 𝑛.
1. [Inizializzazione]
• 𝑑 ≔ ⌊(3 log 𝑛
log log 𝑛)
1 3⁄
⌋; notiamo che 𝑑2𝑑2< 𝑛.
• 𝐵 ≔ ⌊exp {(8
9)
1 3⁄(log 𝑛)1 3⁄ (log log 𝑛)2 3⁄ }⌋.
• 𝑚 ≔ ⌊𝑛1 𝑑⁄ ⌋.
• Scriviamo 𝑛 in base 𝑚, ossia: 𝑛 = 𝑚𝑑 + 𝑐𝑑−1𝑚𝑑−1 + ⋯ + 𝑐0.
• 𝑓(𝑥) ≔ 𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1 + ⋯ + 𝑐0.
• Fattorizzare 𝑓(𝑥) in polinomi irriducibili in ℤ[𝑥]; gli algoritmi consigliati in [8] sono:
i. A. Lenstra, H. Lenstra Jr, L. Lovasz. Factoring polynomials with rational coefficients.
Math. Ann., 261:515-534, 1982.
ii. H. Cohen. A Course in Computational Algebraic Number Theory, volume 138 of
Graduate Texts in Mathematics. Springer-Verlag, 1993. pag. 139.

22
• Se 𝑓(𝑥) ha fattorizzazione non banale 𝑔(𝑥)ℎ(𝑥), restituisce la fattorizzazione non banale
𝑛 = 𝑔(𝑚)ℎ(𝑚).
• 𝐹(𝑥, 𝑦) ≔ 𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1𝑦 + ⋯ + 𝑐0𝑦𝑑.
• 𝐺(𝑥, 𝑦) ≔ 𝑥 − 𝑚𝑦.
• Per ogni primo 𝑝 ≤ 𝐵 calcola: 𝑅(𝑝) ≔ {𝑟 ∈ ℤ𝑝 ∶ 𝑓(𝑟) ≡ 0 (mod 𝑝)}.
• 𝑘 ≔ ⌊3 log 𝑛⌋.
• Calcolare i primi 𝑘 primi 𝑞1, … , 𝑞𝑘 > 𝐵 tali che 𝑅(𝑞𝑗) contenga elementi 𝑠𝑗
con 𝑓′(𝑠𝑗) ≢ 0 (mod 𝑞𝑗), salvando le 𝑘 coppie (𝑞𝑗, 𝑠𝑗).
• 𝐵′ ≔ ∑ #𝑅(𝑝)𝑝≤𝐵 .
• 𝑉 ≔ 1 + 𝜋(𝐵) + 𝐵′ + 𝑘.
• 𝑀 ≔ 𝐵.
2. [Crivello]
• Utilizzare un crivello per trovare un insieme 𝑆′ di coppie (𝑎, 𝑏) di interi coprimi tali che 0 <
|𝑎|, 𝑏 ≤ 𝑀 e 𝐹(𝑎, 𝑏)𝐺(𝑎, 𝑏) sia 𝐵-smooth, fino a che #𝑆′ > 𝑉.
• Se non se ne trovano abbastanza, aumentare 𝑀 e riprovare; oppure rifare la parte di
Inizializzazione con un 𝐵 maggiore.
3. [Matrice]
• Costruire una matrice booleana #𝑆′ × 𝑉: una riga per ogni coppia (𝑎, 𝑏).
• Dobbiamo calcolare �̅�(𝑎 − 𝑏𝛼), il vettore di esponenti (modulo 2) per 𝑎 − 𝑏𝛼 (𝑉 bits):
i. Porre il primo bit di �̅� a 1 se 𝐺(𝑎, 𝑏) < 0, altrimenti a 0.
ii. I successivi 𝜋(𝐵) bits dipendono dai primi 𝑝 ≤ 𝐵. Sia 𝑝𝛾 la potenza di 𝑝 nella
fattorizzazione in primi di |𝐺(𝑎, 𝑏)|. Porre il bit relativo a 𝑝 come 𝛾 (mod 2).
iii. I successivi 𝐵′ bits dipendono dalle coppie 𝑝, 𝑟 con 𝑝 ≤ 𝐵 primo e 𝑟 ∈ 𝑅(𝑝). Porre
il bit corrispondente a (𝑝, 𝑟) come 𝑣𝑝,𝑟(𝑎 − 𝑏𝛼) (mod 2).
iv. I successivi 𝑘 bits corrispondono alle coppie (𝑞𝑖, 𝑠𝑖). Porre il bit relativo a (𝑞𝑖, 𝑠𝑖) a
1 se (𝑎−𝑏𝑠𝑖
𝑞𝑖) = −1, a 0 altrimenti.
• Inserire il vettore di esponenti �̅�(𝑎 − 𝑏𝛼) come riga della matrice per la coppia (𝑎, 𝑏).
4. [Algebra lineare]
• Tramite qualche algoritmo di algebra lineare trovare un sottoinsieme non vuoto 𝑆 di 𝑆′ tale
che ∑ �̅�(𝑎 − 𝑏𝛼)(𝑎,𝑏)∈𝑆 = 0̅ (mod 2).
5. [Radici quadrate]
• Utilizzare la nota fattorizzazione di ∏ (𝑎 − 𝑏𝑚)(𝑎,𝑏)∈𝑆 per trovare un residuo 𝑣 (mod 𝑛) con
∏ (𝑎 − 𝑏𝑚)(𝑎,𝑏)∈𝑆 ≡ 𝑣2 (mod 𝑛).
• Trovare tramite uno dei metodi descritti prima una radice quadrata 𝛾 ∈ ℤ[𝛼] di
𝑓′(𝛼)2 ∏ (𝑎 − 𝑏𝛼)(𝑎,𝑏)∈𝑆 e poi calcolare 𝑢 = 𝜙(𝛾) (mod 𝑛).
6. [Fattorizzazione]
• Restituire gcd(𝑢 − 𝑓′(𝑚)𝑣, 𝑛).
• Se il divisore di 𝑛 trovato è banale, cercare nuove dipendenze al passo [4].
Se terminano tutte le dipendenze, continuare il crivello al passo [2] in modo da ottenere
più righe per la matrice e, di conseguenza, ulteriori dipendenze lineari.

23
7. Potenziamenti e varianti
7.1 Relazioni gratuite
Sia 𝑝 un primo della factor base 𝐵1, ossia 𝑝 ≤ 𝐵. Il nostro vettore di esponenti ha una coordinata
corrispondente a 𝑝 come un possibile fattore primo di 𝑎 − 𝑏𝑚 e #𝑅(𝑝) coordinate corrispondenti agli interi
𝑟 ∈ 𝑅(𝑝) ≔ {𝑟 ∈ ℤ𝑝 ∶ 𝑓(𝑟) ≡ 0 (mod 𝑝)}. In media si nota che #𝑅(𝑝) = 1, ma può essere anche 0 se 𝑓(𝑥)
non ha radici modulo 𝑝 o può essere anche più alto, fino ad avere cardinalità 𝑑, il grado di 𝑓(𝑥), nel caso in
cui 𝑓 si spezzi in fattori lineari distinti modulo 𝑝. In quest’ultimo caso, abbiamo che il prodotto degli ideali
primi (𝑝, 𝛼 − 𝑟) al variare di 𝑟 ∈ 𝑅(𝑝) nell’anello 𝐼 coincide con (𝑝).
Nel caso in cui 𝑅(𝑝) abbia 𝑑 elementi, inseriamo nella matrice una nuova riga �̅�(𝑝) che ha 1 nelle coordinate
corrispondenti a 𝑝 e a ogni coppia (𝑝, 𝑟) con 𝑟 ∈ 𝑅(𝑝). Nelle ultime 𝑘 coordinate corrispondenti al carattere
quadratico modulo 𝑞𝑖 per 𝑖 = 1, … , 𝑘, porre 0 se (𝑝
𝑞𝑖) = 1 e porre 1 se (
𝑝
𝑞𝑖) = −1. Un tale vettore �̅�(𝑝) è
chiamato relazione gratuita, in quanto è ottenuto senza alcun precalcolo e senza la fase di crivello.
Ora, quando troviamo un sottoinsieme di righe dipendenti, esso corrisponderà all’unione di:
• Un sottoinsieme 𝑆 di coppie (𝑎, 𝑏) di interi coprimi.
• Un insieme 𝐹 di relazioni gratuite.
Sia 𝑤 il prodotto dei primi 𝑝 corrispondenti alle relazioni gratuite in 𝐹. Allora abbiamo che
𝑤𝑓′(𝛼)2 ∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
= 𝛾2 𝛾 ∈ ℤ[𝛼]
𝑤𝑓′(𝑚)2 ∏ (𝑎 − 𝑏𝑚)
(𝑎,𝑏)∈𝑆
= 𝑣2 𝑣 ∈ ℤ
e dunque, se 𝜙(𝛾) = 𝑢, abbiamo che 𝑢2 ≡ 𝑣2 (mod 𝑛).
I vantaggi delle relazioni gratuite sono molteplici:
• Abbiamo un minore bisogno di altre relazioni, dunque meno tempo consumato nella fase di crivello,
che è molto costosa.
• I vettori �̅�(𝑝) sono più sparsi rispetto a quelli �̅�(𝑎, 𝑏), dunque abbiamo una matrice più leggera.
Quante relazioni gratuite possiamo aspettarci? Una relazione gratuita corrisponde ad un primo 𝑝 che si
decompone completamente nel campo algebrico di numeri ℚ(𝛼). Sia 𝑔 l’ordine del campo di spezzamento
di 𝑓(𝑥), ossia la chiusura di Galois di ℚ(𝛼) in ℂ. Mediante il teorema di densità di Chebotarev è possibile
dimostrare che il numero di primi 𝑝 ≤ 𝑋 che si decompongono completamente in ℚ(𝛼) è asintotico a 1
𝑔𝜋(𝑋)
per 𝑋 → +∞. Dunque in media, un primo ogni 𝑔 corrisponde è una relazione gratuita. Supponendo che il
nostro bound 𝐵 sia sufficientemente grande per far scattare l’asintoticità richiesta, ci aspettiamo 1
𝑔𝜋(𝐵)
relazioni gratuite. Ovviamente non sappiamo l’ordine del campo di spezzamento: esso può variare tra 𝑑 e 𝑑!.
Sfortunatamente, nella maggioranza dei casi per polinomi irriducibili 𝑓(𝑥) ∈ ℤ[𝑥] si ha che 𝑔 = 𝑑!. Essendo
i nostri vettori di circa 2𝜋(𝐵) coordinate, abbiamo dunque un incremento di velocità di 1 2𝑔⁄ .
Le relazioni gratuite sono molto utili nel caso in cui il polinomio 𝑓(𝑥) abbia un campo di spezzamento
“piccolo”, per esempio è il caso della fattorizzazione del nono numero di Fermat 𝐹9, per il quale fu utilizzato
il polinomio 𝑓(𝑥) = 𝑥5 + 8. L’ordine del campo di spezzamento è 20, dunque le relazioni gratuite hanno
velocizzato l’algoritmo del 2.5%.

24
Dimostrazione. Sia 𝐾 il campo di spezzamento di 𝑓(𝑥). Le radici di 𝑓(𝑥) sono 𝜁𝑖 ∙ √−85
per 𝑖 = 0, … , 4, ove 𝜁
è una quinta radice primitiva dell’unità. Dunque 𝐾 contiene √−85
e 𝜁 ∙ √−85
, di conseguenza contiene anche
𝜁, dunque 𝐾 ⊇ ℚ(𝜁, √−85
). Ora ogni campo contenente 𝜁 e √−85
, deve contenere il campo di spezzamento
di 𝑓(𝑥), dunque 𝐾 = ℚ(𝜁, √−85
). Si prova facilmente che √−85
ha polinomio minimo 𝑓(𝑥) = 𝑥5 + 8 su ℚ e
che 𝜁 ha polinomio minimo Φ5(𝑥) = 𝑥4 + 𝑥3 + 𝑥2 + 𝑥 + 1, irriducibile su ℚ. Dunque 𝐾 ha ordine al più 20.
Tuttavia per Lagrange l’ordine di un sottogruppo divide l’ordine del gruppo, dunque, essendo 5 e 4 coprimi,
l’ordine di 𝐾 deve essere un multiplo di 20, dunque 𝑔 ≔ |𝐾| = 20.
7.2 Relazioni parziali
Come nel QS, setacciare nel NFS non solo rivela le coppie (𝑎, 𝑏) per cui entrambi i numeri 𝑁(𝑎 − 𝑏𝛼) =
𝐹(𝑎, 𝑏) = 𝑏𝑑𝑓(𝑎 𝑏⁄ ) e 𝑎 − 𝑏𝑚 sono 𝐵-smooth, ma anche le coppie (𝑎, 𝑏) per cui anche uno o entrambi
questi numeri sono un 𝐵-smooth per un primo “grande”. Se permettiamo alle nostre relazioni di tenere in
considerazione anche questi primi, diciamo al più uno per 𝑁(𝑎 − 𝑏𝛼) e uno per 𝑎 − 𝑏𝑚, avremmo
sostanzialmente la stessa struttura della double prime variation del QS.
Si potrebbe anche accettare 𝑁(𝑎 − 𝑏𝛼) con due large primes e 𝑎 − 𝑏𝑚 𝐵-smooth, o viceversa. Qualcuno ha
anche proposto di provare due large primes ciascuno, tuttavia molti, a questo punto, preferiscono piuttosto
incrementare 𝐵.
7.3 Polinomi non monici
In verità non è necessario che 𝑓(𝑥) sia scelto con i coefficienti che abbiamo visto, tantomeno che sia monico:
basta solo che sia irriducibile in ℤ[𝑥]. Ma perché dovremmo utilizzare polinomi non monici?
Come abbiamo visto durante il calcolo della complessità, il segreto per un algoritmo veloce è il ridurre la
grandezza dei numeri su cui operiamo il crivello, in modo da avere maggiore speranza di ottenere numeri
smooth. La grandezza di questi numeri nel NFS dipende direttamente dalla grandezza del numero 𝑚 e dal
fatto che i coefficienti di 𝑓(𝑥) siano limitati da 𝑛1 𝑑⁄ . Se permettiamo polinomi non monici, possiamo scegliere
𝑚 ≔ ⌈𝑛1 (𝑑+1)⁄ ⌉. Scrivendo 𝑛 in base 𝑚 otteniamo
𝑛 = 𝑐𝑑𝑚𝑑 + 𝑐𝑑−1𝑚𝑑−1 + ⋯ + 𝑐0.
Questo ci suggerisce di usare
𝑓(𝑥) ≔ 𝑐𝑑𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1 + ⋯ + 𝑐0 𝑐𝑖 ≤ 𝑛1 (𝑑+1)⁄
cosicché sia 𝑚 che i 𝑐𝑖 sono limitati da 𝑛1 (𝑑2+𝑑)⁄ . Non sembra un miglioramento significativo, infatti si può
calcolare che asintoticamente l’algoritmo viene accelerato di un fattore log1 6⁄ 𝑛.
Supponiamo che 𝑓(𝑥) = 𝑐𝑑𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1 + ⋯ + 𝑐0 sia irriducibile in ℤ[𝑥] e che 𝛼 ∈ ℂ sia una radice. Allora
𝑐𝑑𝛼 è un intero algebrico, in particolare è radice di 𝐹(𝑥) = 𝑥𝑑 + 𝑐𝑑−1𝑥𝑑−1 + 𝑐𝑑𝑐𝑑−2𝑥𝑑−2 + ⋯ + 𝑐𝑑𝑑−1𝑐0,
infatti 𝐹(𝑐𝑑𝑥) = 𝑐𝑑𝑑−1𝑓(𝑥). Concludiamo che se 𝑆 è un insieme di coppie (𝑎, 𝑏) di interi coprimi, se
∏ (𝑎 − 𝑏𝛼)
(𝑎,𝑏)∈𝑆
è un quadrato in ℚ(𝛼) e se 𝑆 ha un numero pari di coppie, allora
𝐹′(𝑐𝑑𝛼)2 ∏ (𝑎𝑐𝑑 − 𝑏𝑐𝑑𝛼)
(𝑎,𝑏)∈𝑆

25
è un quadrato in ℤ[𝑐𝑑𝛼], diciamo 𝛾2. A questo punto, trovare i coefficienti (modulo 𝑛) di 𝛾 rispetto alla base
{1, 𝑐𝑑𝛼, … , (𝑐𝑑𝛼)𝑑−1} ci permette di ottenere due quadrati congruenti modulo 𝑛.
Notiamo che
𝐹(𝑥, 𝑦) ≔ 𝑦𝑑𝑓(𝑥 𝑦⁄ ) ⟹ 𝐹(𝑐𝑑𝑥, 𝑐𝑑) = 𝑐𝑑𝑑𝑓(𝑥) = 𝑐𝑑𝐹(𝑐𝑑𝑥) ⟹ 𝐹𝑥(𝑐𝑑𝛼, 𝑐𝑑) = 𝑐𝑑𝐹′(𝑐𝑑𝛼)
e dunque possiamo utilizzare (𝐹𝑥(𝑐𝑑𝛼, 𝑐𝑑) 𝑐𝑑⁄ )2 al posto di 𝐹′(𝑐𝑑𝛼)2.
Abbiamo quindi scoperto che utilizzare polinomi non monici non genera grosse complicazioni. Giusto un paio
di osservazioni:
• Per assicurarci che la cardinalità dell’insieme 𝑆 sia pari, possiamo inserire una coordinata aggiuntiva
posta sempre a 1 a tutti i vettori di esponenti.
• L’argomento di cui sopra assume che il coefficiente 𝑐𝑑 sia coprimo con 𝑛, non è una grande pretesa:
essendo più piccolo di 𝑛, se gcd(𝑐𝑑 , 𝑛) > 1, allora avremmo trovato un divisore non banale di 𝑛.
7.4 Coppie di polinomi
Nella descrizione del NFS fatta finora, abbiamo dato enfasi solo al polinomio 𝑓(𝑥) per il quale abbiamo una
radice 𝑚 modulo 𝑛; più di preciso, ci siamo interessati alla sua forma omogenea 𝐹(𝑥, 𝑦) = 𝑦𝑑𝑓(𝑥 𝑦⁄ ). In
verità vi è un secondo polinomio che fa funzionare il NFS, ossia 𝑔(𝑥) = 𝑥 − 𝑚, la cui forma omogenea è
𝐺(𝑥, 𝑦) = 𝑦𝑔(𝑥 𝑦⁄ ) = 𝑥 − 𝑚𝑦. I numeri che setacciamo alla ricerca di valori smooth sono le valutazioni del
prodotto delle due forme omogenee, ossia di 𝐹(𝑥, 𝑦)𝐺(𝑥, 𝑦), in un intorno dell’origine.
In questo paragrafo vedremo che è anche possibile prendere un polinomio 𝑔 di grado superiore a 1.
Supponiamo di avere due polinomi distinti irriducibili (non necessariamente monici) 𝑓(𝑥), 𝑔(𝑥) ∈ ℤ[𝑥], e un
intero 𝑚 tale che 𝑓(𝑚) ≡ 𝑔(𝑚) ≡ 0 (mod 𝑛). Siano 𝛼, 𝛽 ∈ ℂ radici di 𝑓(𝑥) e 𝑔(𝑥) rispettivamente.
Assumendo che i termini dominanti 𝑐 di 𝑓(𝑥) e 𝐶 di 𝑔(𝑥) siano coprimi con 𝑛, abbiamo due omomorfismi
𝜙: ℤ[𝑐𝛼] → ℤ𝑛 𝜓: ℤ[𝐶𝛽] → ℤ𝑛
𝜙(𝑐𝛼) ≔ [𝑐𝑚]𝑛 𝜓(𝐶𝛽) ≔ [𝐶𝑚]𝑛
e supponiamo inoltre di avere un insieme 𝑆 di un numero pari di coppie (𝑎, 𝑏) di interi coprimi e che
𝐹𝑥(𝑐𝛼, 𝑐)2 ∏ (𝑎𝑐 − 𝑏𝑐𝛼)
(𝑎,𝑏)∈𝑆
= 𝛾2 𝛾 ∈ ℤ[𝑐𝛼]
𝐺𝑥(𝐶𝛽, 𝐶)2 ∏ (𝑎𝐶 − 𝑏𝐶𝛽)
(𝑎,𝑏)∈𝑆
= 𝛿2 𝛿 ∈ ℤ[𝐶𝛽].
Se 𝑆 ha 2𝑘 elementi e 𝜙(𝛾) ≡ 𝑣 (mod 𝑛) e 𝜓(𝛿) ≡ 𝑤 (mod 𝑛), allora, applicando i rispettivi omomorfismi
alle due identità, si ottiene
𝐹𝑥(𝑐𝑚, 𝑐)2𝑐2𝑘 ∏ (𝑎 − 𝑏𝑚)
(𝑎,𝑏)∈𝑆
≡ 𝑣2 (mod 𝑛)
𝐺𝑥(𝐶𝑚, 𝐶)2𝐶2𝑘 ∏ (𝑎 − 𝑏𝑚)
(𝑎,𝑏)∈𝑆
≡ 𝑤2 (mod 𝑛)
da cui
(𝑐𝑘𝐹𝑥(𝑐𝑚, 𝑐)𝑤)2
≡ (𝐶𝑘𝐺𝑥(𝐶𝑚, 𝐶)𝑣)2
(mod 𝑛)

26
e dunque abbiamo i nostri due quadrati congruenti modulo 𝑛.
Ma è vantaggioso usare due polinomi di grado maggiore di 1? Per capirlo, dobbiamo fare una piccola
digressione sui numeri 𝐵-smooth: cosa fa sì che un certo numero abbia più probabilità di essere 𝐵-smooth di
un altro? Sicuramente avere dimensione più piccola è fondamentale, tuttavia c’è una proprietà secondaria,
che è comunque rilevante. Se un numero vicino a 𝑥 è prodotto di due numeri vicini a √𝑥, allora è più probabile
che sia 𝐵-smooth che se non fosse un numero casuale sempre vicino a 𝑥. Più nello specifico, si può dimostrare
che la probabilità è 2𝑢 volte più alta, con 𝑢 ≔ ln 𝑥 ln 𝐵⁄ .
Se abbiamo due polinomi nel NFS con lo stesso grado e con coefficienti dello stesso ordine di grandezza,
allora le loro rispettive forme omogenee hanno valori che sono a loro volta dello stesso ordine di grandezza.
E noi stiamo setacciando il prodotto delle due forme omogenee, dunque abbiamo questo fattore di 2𝑢. Nel
NFS ordinario, invece, gli ordini di grandezza dei due polinomi sono differenti: si può stimare che 𝐹(𝑎, 𝑏)
rappresenti circa i 3 4⁄ del prodotto, mentre 𝑎 − 𝑏𝑚 il restante 1 4⁄ . È possibile dimostrare che, sotto queste
ipotesi, la probabilità di avere valori 𝐵-smooth è di (4 33 4⁄⁄ )𝑢
più alta rispetto a prendere numeri casuali.
Dunque, utilizzando due polinomi dello stesso grado 𝑑 ≈1
2(
3 log 𝑛
log log 𝑛)
1 3⁄
e con coefficienti limitati da 𝑛1 2𝑑⁄ ,
otteniamo, rispetto alla variante base del NFS, un incremento di probabilità di avere numeri 𝐵-smooth di
2𝑢
(4 33 4⁄⁄ )𝑢= (33 4⁄ 2⁄ )
𝑢.
Ora 𝑢 ≈ 2(3 log 𝑛 log log 𝑛⁄ )1 3⁄ , dunque utilizzando i due polinomi di grado 𝑑 salviamo un fattore di circa
(1.46)(log 𝑛 log log 𝑛⁄ )1 3⁄. Ciò non altera la complessità asintotica, ma è pur sempre un guadagno.
Il problema di usare due polinomi, tuttavia, risiede nel trovarli e al momento non sono ancora stati suggeriti
metodi esaustivi per farlo.
7.5 Special number field sieve (SNFS)
Esistono molti interi 𝑛 per i quali possiamo trovare polinomi decisamente migliori di quello previsto dalla
variante base del NFS e che abbassano di molto la complessità totale. Con special number field sieve (SNFS)
si fa proprio riferimento a quei casi in cui si riesce a trovare un polinomio straordinariamente buono; ciò che
può renderlo tale è, per esempio, avere coefficienti molto piccoli.
Lo SNFS è stato principalmente utilizzato per fattorizzare molti numeri di Cunningham, ossia numeri della
forma 𝑏𝑘 ± 1. Abbiamo già accennato al caso del nono numero di Fermat, 𝐹9 = 2512 + 1, il quale è stato
fattorizzato mediante il polinomio 𝑓(𝑥) = 𝑥5 + 8 e la sua radice 𝑚 = 2103 modulo 𝐹9.
Se abbiamo 𝑛 = 𝑏𝑘 ± 1, possiamo creare un polinomio molto buono di grado 𝑑 con il metodo seguente.
Dividiamo 𝑘 per 𝑑 e otteniamo che 𝑘 = 𝑑𝑞 + 𝑟, per 𝑞, 𝑟 interi con 𝑟 < 𝑑. Quindi
𝑏𝑑−𝑟𝑛 = 𝑏𝑑−𝑟𝑏𝑘 ± 𝑏𝑑−𝑟 = 𝑏𝑑−𝑟+𝑑𝑞+𝑟 ± 𝑏𝑑−𝑟 = 𝑏𝑑(𝑞+1) ± 𝑏𝑑−𝑟.
Possiamo dunque prendere il polinomio 𝑓(𝑥) = 𝑥𝑑 ± 𝑏𝑑−𝑟 e scegliere 𝑚 = 𝑏𝑞+1. Per 𝑘 grande, i coefficienti
di 𝑓(𝑥) sono molto piccoli rispetto a 𝑛.
Un ulteriore piccolo vantaggio, dato dall’avere un polinomio della forma 𝑥𝑑 + 𝑐, è che l’ordine del suo
campo di spezzamento è un divisore di 𝑑𝜙(𝑑), quindi non 𝑑!. Dunque le relazioni gratuite danno un
contributo rilevante in questi casi.

27
7.6 Variante di Coppersmith: famiglie di polinomi
Una volta trovato un polinomio utile per il NFS, ossia un 𝑓(𝑥) ∈ ℤ[𝑥] con coefficienti “piccoli” e con radice
𝑚 in ℤ𝑛, trovarne altri è semplice. Possiamo addirittura trovarne intere famiglie, per esempio
𝑓𝑗(𝑥) ≔ 𝑓(𝑥) + 𝑗𝑥 − 𝑚𝑗
𝑓𝑗,𝑘(𝑥) ≔ 𝑓(𝑥) + 𝑘𝑥2 − (𝑚𝑘 − 𝑗)𝑥 − 𝑚𝑗
ove 𝑗, 𝑘 sono interi “piccoli”. E a cosa ci possono servire più polinomi? Per esempio, potremmo utilizzare tali
famiglie di polinomi per cercarne al loro interno uno particolarmente buono. Oppure, e questa è l’idea che
discuteremo in questo paragrafo, potremmo utilizzarli tutti insieme, dando così origine a più anelli di numeri,
uno per ogni polinomio utilizzato.
C’è un ovvio problema a livelli di costi nel fare ciò: ogni volta che introduciamo un nuovo polinomio, la factor
base deve essere estesa per tener conto dei modi in cui i primi si decompongono per questi polinomi.
Dunque, ogni polinomio dovrebbe avere il suo campo di coordinate nei vettori di esponenti.
Coppersmith ha trovato un modo per aggirare questo problema. Possiamo utilizzare una grande factor base
per la forma lineare 𝑎 − 𝑏𝑚 e una piccola factor base per i vari polinomi utilizzati. Nello specifico, se i primi
fino a 𝐵 sono utilizzati per la forma lineare e vengono impiegati 𝑘 polinomi, allora usiamo i primi solo fino a
𝐵 𝑘⁄ per ognuno di questi polinomi. Prenderemo in considerazione solo le coppie (𝑎, 𝑏) tali per cui 𝑎 − 𝑏𝑚
è 𝐵-smooth e la forma omogenea valutata in (𝑎, 𝑏) di almeno uno dei polinomi è (𝐵 𝑘⁄ )-smooth. Dopo aver
raccolto 𝐵 relazioni, dovremmo averne abbastanza per creare una congruenza di quadrati.
In particolare, Coppersmith suggerisce prima di setacciare i valori 𝑎 − 𝑏𝑚 alla ricerca di 𝐵-smooth e poi, per
le coppie che superano il primo crivello, di controllare la forma omogenea di ciascun polinomio per vedere
se i valori corrispondenti ad (𝑎, 𝑏) siano (𝐵 𝑘⁄ )-smooth. Purtroppo, questa seconda verifica non può essere
svolta efficacemente da un crivello, in quanto le coppie (𝑎, 𝑏) che passano lo smoothness test per 𝑎 − 𝑏𝑚
non è detto che siano spaziate in modo regolare. Una soluzione sarebbe di setacciare lungo la famiglia 𝑓𝑗(𝑥)
dei polinomi, tuttavia essa non dà generalmente luogo ad un array abbastanza lungo da giustificare un
crivello. Coppersmith suggerisce quindi di evitare un crivello e di fattorizzare direttamente ciascun valore per
vedere se è 𝐵-smooth o meno, in particolare suggerisce l’uso del metodo delle curve ellittiche (ECM). Si può
dimostrare che ciò non altera la complessità totale del NFS a meno di un 𝑜(1).
Assumendo di scegliere circa 𝐵2 coppie (𝑎, 𝑏) e scegliendo i parametri in modo che al più 𝐵2 𝑘⁄ coppie
sopravvivano al primo setaccio, allora il tempo speso in totale non è tanto superiore a 𝐵2. Coppersmith,
tramite argomentazioni euristiche, ha provato che la complessità di questa variante del NFS è pari a
𝑂 (𝑒(𝑐+𝑜(1))(log 𝑛)1 3⁄ (log log 𝑛)2 3⁄) con 𝑐 ≔
1
3(92 + 26√13)
1 3⁄≈ 1.9019 .
Ricordiamo che la complessità originale era con 𝑐 = (64 9⁄ )1 3⁄ ≈ 1.9230. Tuttavia l’𝑜(1) è qui appesantito
dall’utilizzo del ECM in sostituzione al crivello, rendendo questa variante efficace solo per 𝑛 molto grandi.
Ciò nondimeno, la variante di Coppersmith del NFS è, al momento, il metodo di fattorizzazione euristico,
asintoticamente più veloce conosciuto.

28
Bibliografia
[1] P. Ellia, «Teoria dei numeri (2013-2014),» 24 Maggio 2014. [Online]. Available:
http://dm.unife.it/philippe.ellia/Docs/TeoriaNumeri2013-14-OnLine.pdf.
[2] F. Mazzone, «Il crivello quadratico: Dal metodo di Fermat, al crivello quadratico e alcune sue varianti,»
[Online]. Available: https://drive.google.com/file/d/1ZgOLY0v8qupLEUHB6s02azVnD2bnd_KA/view.
[3] A. Lenstra e H. Lenstra, «The number field sieve: an annotated bibliography,» in The development of the
number field sieve, Springer-Verlag, 1993.
[4] M. Manasse, «Complete factorization of the ninth Fermat number,» [Online]. Available:
https://groups.google.com/forum/#!topic/sci.math/7usZOcN2_zc.
[5] A. K. Lenstra, «Factorization of RSA-130,» 12 04 1996. [Online]. Available:
http://primes.utm.edu/notes/rsa130.html?id=research&month=primes&day=notes&year=rsa130.
[6] «RSA Laboratories - The RSA Factoring Challenge,» [Online]. Available:
https://web.archive.org/web/20061210142944/http://www.rsasecurity.com/rsalabs/node.asp?id=2092.
[7] F. Bahr, J. Franke e T. Kleinjung, «New Prime Factorisation Record obtained using the General Number
Field Sieve,» [Online]. Available: https://www.ercim.eu/publication/Ercim_News/enw49/franke.html.
[8] R. Crandall e C. Pomerance, Prime Numbers: A Computational Perspective, Springer-Verlag, 2001.
[9] T. Kleinjung, «rsa200,» 9 Maggio 2005. [Online]. Available:
https://web.archive.org/web/20080322125316/http://www.crypto-
world.com/announcements/rsa200.txt.
[10] K. Aoki, «SNFS274,» [Online]. Available: https://members.loria.fr/PZimmermann/records/6353.
[11] D. Bonenberger e M. Krone, «Factorization of RSA-170,» [Online]. Available:
https://web.archive.org/web/20110719004557/http://public.rz.fh-
wolfenbuettel.de/~kronema/pdf/rsa170.pdf.
[12] S. Danilov e I. Popovyan, «Factorization of RSA-180,» [Online]. Available:
https://eprint.iacr.org/2010/270.
[13] P. Stevenhagen, «Number rings,» 13 Ottobre 2017. [Online]. Available:
http://websites.math.leidenuniv.nl/algebra/ant.pdf.
[14] P. Stevenhagen, «The number field sieve,» in Algorithmic Number Theory, MSRI Publications – Volume
44, 2008, pp. 83-100.
















![CNR-INO, Istituto Nazionale di Ottica, Largo E. Fermi 6 ... · arXiv:1410.6957v2 [physics.optics] 3 Jun 2015 Frequencycomb generation in quadratic nonlinear media Iolanda Ricciardi,1](https://static.fdocumenti.com/doc/165x107/5f4618cb922e530621585b06/cnr-ino-istituto-nazionale-di-ottica-largo-e-fermi-6-arxiv14106957v2-.jpg)
