Università degli Studi di Parma - ce.unipr.it · guidato lungo un percorso a prima vista ... 2.2.2...
129
Università degli Studi di Parma Facoltà di Ingegneria Corso di Laurea in Ingegneria Elettronica Analisi del movimento tramite sensori ottici omnidirezionali Relatore: Chiar.mo Prof. Ing. Giovanni Adorni Correlatori: Dott. Ing. Stefano Cagnoni Dott. Ing. Monica Mordonini Tesi di Laurea di: Gabriele Neva Anno Accademico 2000-2001
Transcript of Università degli Studi di Parma - ce.unipr.it · guidato lungo un percorso a prima vista ... 2.2.2...

Università degli Studi di Parma Facoltà di Ingegneria
Corso di Laurea in Ingegneria Elettronica
Analisi del movimento tramite sensori ottici omnidirezionali
Relatore: Chiar.mo Prof. Ing. Giovanni Adorni Correlatori: Dott. Ing. Stefano Cagnoni
Dott. Ing. Monica Mordonini
Tesi di Laurea di: Gabriele Neva
Anno Accademico 2000-2001

Ringraziamenti
Desidero ringraziare il Prof. Giovanni Adorni per avermi dato la possibilità di
svolgere questo lavoro consentendomi di affrontare problematiche appartenenti ad
una materia innovativa ed affascinante: la visione artificiale.
Uno speciale ringraziamento va al Dott. Stefano Cagnoni per l’assoluta disponibilità
dimostratami durante tutto il periodo di svolgimento di questo lavoro e per avermi
guidato lungo un percorso a prima vista difficile.
Ringrazio inoltre la Dott.ssa Monica Mordonini per la presenza costante ed i
preziosi consigli.
Vorrei anche ringraziare gli studenti del Laboratorio di Visione e del Laboratorio di
Robotica i quali mi hanno aiutato a superare i primi ostacoli incontrati nel corso del
progetto.
Un ringraziamento è dovuto anche a chi, nel corso di tutti gli anni universitari, mi è
stato vicino: in primo luogo ai miei compagni Ivan, Mauro, Diego, Marco e Fabio,
ai numerosi amici e parenti i quali mi hanno incoraggiato ed aiutato ad andare
avanti anche nei momenti più difficili.

Indice Ringraziamenti
Introduzione
Capitolo 1 Strumenti per l’elaborazione delle immagini
1.1 La visione artificiale 1
1.2 Elementi hardware di acquisizione ed elaborazione 3
1.2.1 La telecamera ed il sensore CCD 4
1.2.2 Il framegrabber 5
1.3 Analisi del rumore 7
1.4 Gli operatori di filtraggio del rumore 8
1.4.1 Filtro gaussiano 10
1.4.2 Filtro Unsharp Masking 11
1.4.3 Filtro quantizzatore 13
1.5 Segmentazione dell’immagine 14
1.6 Estrazione dei contorni 16
1.6.1 Estrattore di Roberts 17
1.6.2 Estrattore di Sobel 19
1.6.3 Estrattore di Prewitt 20
1.6.4 Estrattore pseudo laplaciano assoluto 21
Capitolo 2 Il flusso ottico
2.1 Definizione di flusso ottico 23
2.1.1 Visione stereoscopica 24
2.1.2 Informazioni derivanti dal flusso ottico 26
2.2 Metodi di stima del flusso ottico 27
2.2.1 Algoritmi di tipo Gradient Based 28
2.2.2 Algoritmo di Horn & Shunk 32
2.2.3 Vantaggi e svantaggi del metodo basato sul gradiente 35

2.2.4 Algoritmi di Matching 36
2.2.5 Algoritmo di Barnard & Thompson 39
2.2.6 Vantaggi e svantaggi degli algoritmi di Matching 50
Capitolo 3 Il sensore omnidirezionale
3.1 “Vedere” a 360° con il sensore catadiottrico 51
3.2 Progettazione del sensore omnidirezionale HOPS 53
3.2.1 Specifiche adottate per la realizzazione del profilo dello specchio 56
3.2.2 Lo specchio 57
3.3 Cenni sulla calibrazione e sulla rimozione prospettica di HOPS 59
3.3.1 Calibrazione geometrica o esplicita 63
3.3.2 Calibrazione empirica o implicita 64
Capitolo 4 L’algoritmo SPY
4.1 Applicazione ad un caso: ambiente ‘RoboCup’ 65
4.2 I vincoli imposti 65
4.2.1 Le scelte strumentali 68
4.3 L’algoritmo 69
4.3.1 Filtraggio del rumore associato ai frame in ingresso 70
4.3.2 Estrazione dei contorni 72
4.3.3 Rimozione prospettica ‘IPM’ 72
4.3.4 Estrazione dei 15 codici significativi 75
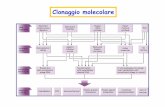
4.3.5 Sottrazione del fondo tramite confronto tra istogrammi 78
4.3.6 Codifica Soft 3×3 82
4.3.7 Estrazione del flusso ottico 84
4.3.8 Filtraggio finale del rumore sui vettori di flusso ottico 88
4.4 Gli operatori di Matching 89

Capitolo 5 Programma, test e risultati
5.1 Il programma SPY 92
5.1.1 Interfaccia grafica di SPY 95
5.1.2 Le caratteristiche dinamiche del programma 96
5.2 Primi test visivi su immagini piane 97
5.3 Test su immagini acquisite dal sensore HOPS 100
5.3.1 Test n°1 102
5.3.2 Test n°2 104
5.3.3 Test n°3 106
5.3.4 Conclusioni riguardo alle prove effettuate sulle immagini del sensore 108
5.4 Stima della velocità e del tempo di esecuzione 113
Conclusioni
Bibliografia

CAPITOLO 1 Strumenti per l’elaborazione delle immagini

Capitolo 1 Strumenti per l’elaborazione delle immagini 1
1.1 La visione artificiale
“La visione artificiale si pone l’obiettivo di automatizzare ed integrare una vasta
gamma di processi e rappresentazioni tipiche della percezione visiva” [Ballard e
Brown, 1982].
Il progetto di calcolatori in grado di interpretare le informazioni di una scena o di
una serie di immagini è stato campo di ricerca dell’intelligenza artificiale degli
ultimi trent’anni.
Come spesso accade in elettronica, la tecnologia è stato un fattore “limitante” per
l’evolversi della ricerca. Infatti, le valide intuizioni teoriche non poterono trovare
riscontro nella pratica [Ballard, 1982] ma con l’evolversi delle architetture e della
potenza di calcolo delle macchine, nell’ultimo decennio sono stati compiuti dei
notevoli passi avanti soprattutto nell’interpretazione di complesse scene 3D.
Per una vasta gamma di problemi ci si deve accontentare di macchine general-
purpose (anche se potenti) perché è in questo senso che le regole di mercato
direzionano la produzione. Per applicazioni specifiche infatti, occorrerebbero
architetture progettate ad hoc ma ovviamente i costi salirebbero notevolmente.
Al fine di progettare sistemi di visione completi che convertano i dati in input in
informazioni preziose che diano informazioni sulla scena circostante, un sistema
tipico usa i seguenti passi:
• Cattura dell’immagine e miglioramento della qualità.
• Segmentazione.
• Estrazione delle feature (contorni, discontinuità, angoli ecc.)
• Processo di confronto ed analisi tra le feature estratte e modelli noti a priori
(riconoscimento di oggetti, studio del flusso ottico, autolocalizzazione ecc.).

Capitolo 1 Strumenti per l’elaborazione delle immagini 2
In questo elenco, il livello di complessità del processo aumenta procedendo verso il
basso, quindi si può notare una natura gerarchica del problema che ha influenzato
gran parte del lavoro svolto nel settore.
Esso è un approccio computazionale alla visione, in cui la percezione visiva è
fondamentalmente un problema di elaborazione di informazione su più livelli
gerarchici [Marr 1980]:
− L’input del sistema è l’immagine (o più immagini) intesa come matrice di valori
di intensità luminosa (o insieme di matrici per le immagini a colori) e assunta
come dato di partenza la cui formazione è un processo indipendente dalle fasi
successive.
− Un primo stadio elaborativo, che produce il cosiddetto raw primal sketch, è
quello di estrazione di informazioni elementari dall’immagine: i contorni, le
discontinuità di intensità.
− Il raw primal sketch contiene un’informazione ancora parziale, frammentaria,
dipendente dal punto di vista della telecamera. Con varie tecniche legate al
gradiente di luminosità (shape from shading, shape from texture, shape from
contour, il metodo delle immagini intrinseche, che cerca di combinare le
precedenti, eccetera) si cerca di completare questa informazione e tramite la
visione stereo ottenerne di aggiuntive sulla profondità spaziale.
− Si giunge quindi alla cosiddetta rappresentazione 2½D, in cui il tipo di
rappresentazione è sempre l’immagine ma tramite la componente di profondità
si aggiunge informazione tridimensionale. Questa informazione è comunque
sempre legata al punto di vista della telecamera: su essa non si è ancora giunti a
introdurre concetti di regione, oggetto, parte.
− L’ultima fase di elaborazione, che porta alla rappresentazione 3D, cerca infine
di astrarsi dal punto di vista della telecamera e di interpretare la scena
individuando oggetti, caratterizzandone la forma in termini di orientazione delle
superfici elementari che li compongono e spostando il sistema di riferimento
negli oggetti individuati stessi, al preciso scopo di renderne la rappresentazione
indipendente dal punto di vista.

Capitolo 1 Strumenti per l’elaborazione delle immagini 3
Quasi tutti i primi studi ed esperimenti riguardanti la percezione robotica si sono
rifatti al paradigma della percezione generalizzata: il sistema visivo veniva
considerato come un modulo a sé stante, indipendente dal resto, anche a causa delle
difficoltà tecniche inizialmente incontrate ed il notevole peso elaborativo richiesto.
Inoltre, per assicurare in ogni situazione l’acquisizione di sufficiente informazione,
ci si poneva l’obiettivo di una ricostruzione tridimensionale completa della scena
osservata. Questi due aspetti finivano per diventare limiti del sistema stesso: si
determinava uno spreco di risorse elaborative e il sistema era troppo rigido per
operare efficientemente in tempo reale.
Dalla rilevazione di questi limiti ebbe origine il secondo paradigma: quello di
percezione modulare. In questo caso il sistema sensoriale non è più una componente
indipendente, ma interagisce e si mette al servizio degli altri moduli del robot. In
pratica, di volta in volta, ricerca e rileva solamente le informazioni necessarie, senza
andare oltre il bisogno di informazioni del robot.
Verranno ora decrittati alcuni dei livelli gerarchici citati in precedenza mantenendo
una successione che rispetti l’ordine di importanza e di complessità.
1.2 Elementi hardware di acquisizione ed elaborazione
Affrontiamo il livello più basso della scala gerarchica della visione artificiale;
quello che nel paragrafo 1.1 è stato chiamato “cattura dell’immagine” .
Diamo ora un accenno ai principali componenti elettronici di una catena di
acquisizione di immagini.
In figura 1.1 viene riportato un semplice schema di questa catena:

Capitolo 1 Strumenti per l’elaborazione delle immagini 4
Fig. 1.1
1.2.1 La telecamera ed il sensore CCD
In ingresso a questo dispositivo entra luce sotto forma di onda elettromagnetica ed
esce un segnale analogico (nella maggior parte dei casi) proporzionale alla
luminosità dell’immagine acquisita .
Essenzialmente, il processo di trasformazione della telecamera si divide in 3 parti:
1 - Attraversamento delle “ottiche”. Si intende tutto ciò che determina il
cammino ottico della luce quindi: sistema di lenti, meccanismo dello zoom, della
messa a fuoco, del diaframma e dell’otturatore.
2 - Il sensore CCD. E’ l’elemento che converte la luce in segnali elettrici; è il
cuore del sistema e l’apparato più critico per ciò che riguarda il rumore ed il suo
filtraggio. E’ costituito da fototransistor che convertono l’intensità luminosa in
elettroni liberi; disponendo di una griglia di questi elementi fotosensibili si ottiene
una matrice ordinata di punti. Il numero di questi elementi determina la risoluzione
dell’immagine.
Focalizzando un’immagine sulla griglia si crea una “copia elettrica” dell’immagine
stessa, nella quale ogni elemento fotosensibile contribuisce con una carica
proporzionale alla luminosità di quel punto. Il tutto viene integrato con un apparato
di trasferimento di carica dal fototransistor al dispositivo di lettura, il quale si
occupa di generare un segnale elettrico continuo che rappresenta l’inviluppo della
distribuzione di carica lungo le righe del CCD.

Capitolo 1 Strumenti per l’elaborazione delle immagini 5
In figura 1.2 viene riportato uno schema del dispositivo nella sua totalità:
Fig. 1.2
3 -I circuiti di controllo. Sono circuiti elettronici che manipolano l’immagine
generata dal sensore e governano il funzionamento della telecamera (messa a fuoco
automatica ecc.)
1.2.2 Il frame grabber
In commercio esistono telecamere la cui uscita è in formato digitale, il quale associa
un numero binario alla luminosità di ogni pixel secondo una certa convenzione, di
modo da rendere l’output direttamente elaborabile dal calcolatore.

Capitolo 1 Strumenti per l’elaborazione delle immagini 6
Più frequentemente (ed è il nostro caso) l’uscita è adattata agli standard televisivi
(PAL, NTSC ecc.); ciò impone l’inserimento, nella catena di figura 1.1, di un
modulo che realizzi una conversione analogico/digitale.
Quindi, in ingresso al frame grabber, vi sarà il segnale analogico di uscita Q(x,y)
della telecamera che verrà trasformato nel frame ovvero in un’immagine (in
codifica numerica) depositata nella memoria del computer.
Il frame grabber compie, quindi, due operazioni: un campionamento per
discretizzare (in pixel) il segnale televisivo continuo, ed una conversione analogico
digitale (per assegnare un valore numerico all’intensità luminosa dei pixel).
Le due operazioni svolte sul segnale introducono dei limiti sistematici alla qualità
dell’immagine. Il segnale elettrico rappresentante il contenuto di elettroni di ogni
pixel, infatti, viene trasformato in un segnale continuo dal dispositivo di lettura del
CCD ma in questo modo il frame grabber è costretto a riprodurre la discretizzazione
tramite un campionamento periodico. Di frequente avviene che il campionamento
non sia sincronizzato con il segnale televisivo e come conseguenza si avrà una
discrepanza geometrica ed in termini di intensità luminosa, tra i pixel prodotti in
output dal frame grabber e quelli reali del sensore CCD.
Questo aspetto è fortunatamente trascurabile quando , come in questa tesi, si lavora
a 8 bpp (bit per pixel) .
Dopo aver elencato gli elementi della più generale delle catene hardware (figura
1.1) per l’acquisizione di immagini, cerchiamo di analizzare uno dei fenomeni
intrinseci al progetto che causa i maggiori problemi: il rumore.
Come in ogni sistema elettronico infatti il risultato è affetto da questo fenomeno
aleatorio il quale si somma algebricamente a tutti i segnali elettrici presenti nella
catena di dispositivi utilizzati falsando i dati in uscita dal sistema.

Capitolo 1 Strumenti per l’elaborazione delle immagini 7
1.3 Analisi del rumore
Soffermiamoci quindi su quel livello gerarchico che nella scala dei processi di
elaborazione delle immagini (paragrafo 1.1) abbiamo chiamato “miglioramento
della qualità”.
Oltre alla distorsione introdotta dall’ottica di tutte le telecamere (se ne parlerà nel
Cap. 3) che in prima approssimazione può essere considerata trascurabile (modello
pin-hole), si aggiunge un fenomeno additivo comune a tutti i circuiti elettronici :
AWGN (letteralmente Additive White Gaussian Noise), il rumore gaussiano bianco.
Gli elementi critici a questo riguardo, in un modulo di acquisizione di immagini e di
successiva elaborazione, possono essere svariati; nel lavoro svolto si è preferito
concentrare l’attenzione sul componente più a rischio della catena di figura 1.1 : il
sensore CCD.
Possiamo infatti attribuire, in buona approssimazione, a questo elemento, la
maggior parte della quantità di rumore che si somma al “segnale immagine”, tra la
cattura da parte della telecamera e la memorizzazione dei dati in forma digitale
nella memoria del computer.
Le sorgenti di rumore del CCD possono essere raggruppate in quattro categorie
principali:
1. Rumore di ingresso : i fototransistor raccolgono luce che, per sua natura,
genera rumore granulare (dovuto alla quantizzazione dell’energia
elettromagnetica).
2. Rumore di trasferimento: La carica raccolta dagli elementi fotosensibili
viene trasferita ai dispositivi di lettura tramite registri CCD; in questa fase si
hanno cariche in movimento su percorsi conduttori non ideali e quindi con
una piccola componente resistiva. Tutto questo produce rumore termico di
tipo Gaussiano bianco e, tra le quattro componenti, questa è probabilmente
quella preponderante.

Capitolo 1 Strumenti per l’elaborazione delle immagini 8
3. Rumore in uscita: l’elemento rivelatore dei pacchetti di carica sito nel
dispositivo di lettura del CCD appare normalmente come un diodo polarizzato
inversamente o come un gate flottante, quindi essenzialmente come una
capacità fonte di rumore capacitivo.
4. Fixed Pattern Noise: quando un sensore viene illuminato uniformemente
dovrebbe fornire un segnale costante, in realtà vi sono fluttuazioni aleatorie,
dovute ai vari tipi di rumore precedentemente esaminati, che tuttavia tendono a
scomparire effettuando delle medie temporali su varie letture di ogni singolo
pixel. Se il numero di dati sul quale si effettua la media tende ad infinito, la
componente aleatoria del rumore scompare, rimane tuttavia una disuniformità
sul livello del singolo pixel che si presenta in modo sistematico e costituisce il
così detto Fixed Pattern Noise.
1.4 Gli operatori di filtraggio del rumore
Nonostante tutte le semplificazioni che si possono adottare, appare chiara l’esigenza
di un modello matematico che consenta, in termini analitici, di stimare ed in
qualche modo diminuire gli effetti del rumore sull’immagine, recuperando
l’originale qualità (image restoration). La letteratura in materia è ricca ma non
esiste un approccio, un algoritmo o un modello di validità generale; occorre infatti
stabilire lo scopo del lavoro da svolgere per poi risalire al tipo di operatore da
utilizzare.
Da un punto di vista della ricerca condotta in questa tesi, risulta di fondamentale
importanza la velocità di esecuzione ed è sulla base di questo vincolo unito al tipo
di architettura del calcolatore utilizzato che sono state operate le scelte progettuali
(si veda Cap. 4).
Gli operatori che verranno illustrati traggono la loro formulazione dalla comune
modellistica delle comunicazioni elettriche, con la sola differenza che, in questo

Capitolo 1 Strumenti per l’elaborazione delle immagini 9
caso, i segnali e tutti gli operatori saranno bidimensionali e non avranno un dominio
temporale ma spaziale.
In figura 1.3 si considera l’intero sistema di ripresa come se fosse un canale che
altera l’immagine aggiungendo rumore.
Il modulo di filtraggio, opera una convoluzione bidimensionale con un’opportuna
risposta impulsiva che descrive il comportamento del filtro.
Fig. 1.3
In riferimento all figura 1.3 il frame filtrato ),( yxf si ottiene attraverso la
convoluzione del frame di ingresso ),( yxi con la funzione di trasferimento ),( yxh
del filtro.
Tale operazione si indica con il seguente formalismo nel dominio spaziale 2ℜ :
∫ ∫∞
∞−
∞
∞−
⋅⋅−−⋅=∗= dYdXYyXxhYXiyxhyxiyxf ),(),(),(),(),( ; (1.1)
Nel campo dell’elaborazione delle immagini si ha necessariamente a che fare con
oggetti discreti e di conseguenza l’integrale di convoluzione diviene una
sommatoria:
∑ ∑−= −=
⋅−−=l
li
J
Jj
jihjmiminmf ),(),(),( . (1.2)

Capitolo 1 Strumenti per l’elaborazione delle immagini 10
Riportiamo un elenco dei principali tipi di filtri presenti in letteratura.
1.4.1 Filtro Gaussiano
Prende questo nome a causa della forma della sua maschera di convoluzione
(equivalente a ciò che nelle telecomunicazioni viene chiamata risposta impulsiva
nel dominio del tempo) di tipo gaussiano.
2
22
2
21),( σ
πσ
yx
eyxg+−
⋅= (1.3)
Riconducendoci ad un sistema discreto applichiamo la (1.2) al pixel di coordinate
(m,n) dell’immagine, applicando una maschera 3×3 (l=3 , J=3) o 5×5 (l=5 , J=5)
centrata sul pixel ed eseguendo la convoluzione discreta 1.2 con i seguenti valori di
),( nmh (Zamperoni 1998):
Il risultato della convoluzione verrà diviso per un fattore di normalizzazione della
gaussiana equivalente a 2.72 per la maschera 3×3 e 10.8 per quella 5×5.
L’uso di maschere di questo tipo, rispetto ad un semplice calcolo di media (che
avrebbe una maschera composta da valori tutti uguali), risiede nel fatto che la
somma pesata con i coefficienti della gaussiana discretizzata preserva molto meglio
i fronti di salita (in corrispondenza delle transizioni tra sfondo ed oggetto).
0.13 0.28 0.37 0.28 0.13
0.28 0.61 0.78 0.61 0.28
0.37 0.78 1.00 0.78 0.37
0.28 0.61 0.78 0.61 0.28
0.13 0.28 0.37 0.28 0.13
0.11 0.32 0.11
0.32 1.00 0.32
0.11 0.32 0.11

Capitolo 1 Strumenti per l’elaborazione delle immagini 11
Il risultato resta comunque quello di un filtro passa basso che filtra con efficienza
massima il rumore alle alte frequenze.
L’efficienza di questo filtro è notevole, il prezzo da pagare è l’uso di coefficienti a
virgola mobile (le variabili di tipo float richiedono risorse elevate al calcolatore) sia
nella convoluzione discreta che nell’operazione di moltiplicazione rallentano il
processo di elaborazione.
1.4.2. Filtro Unsharp Masking
L’effetto delle distorsioni introdotte dal sistema di ripresa sull’immagine è
tipicamente quello di innalzare il livello di grigio del fondo in modo disomogeneo e
di sovrapporre del rumore aleatorio; si hanno quindi le seguenti richieste: sottrarre il
livello di fondo , sottrarre il rumore alle alte frequenze spaziali pur evidenziando le
transizioni fra i diversi oggetti .
Si osserva che solitamente il livello di fondo è variabile ma in modo lento, al
contrario del rumore aleatorio.
Sulla base dell’ipotesi di rumore a media nulla si può pensare di isolare il livello di
fondo tramite un pesante filtraggio passabasso, ovvero tramite l’applicazione di un
filtro Gaussiano di notevoli dimensioni.
Si realizza, così, l’operatore “unsharp masking” (Zamperoni 1996) la cui
formulazione analitica è la seguente:
),(),(),(),( yxgyxiyxiyxf ∗−= ; (1.4)
dove ),( yxg è la risposta impulsiva spaziale di un filtro gaussiano opportunamente
discretizzato per lo scopo.
Per aumentare la velocità di calcolo si può alternativamente sostituire il filtraggio
gaussiano con una più semplice media pesata dei livelli di grigio attorno al pixel su

Capitolo 1 Strumenti per l’elaborazione delle immagini 12
cui viene centrata la solita maschera 3×3 o 5×5; così al nuova formulazione
analitica è la seguente:
{ }),(),(),( yxiEyxiyxf −= ; (1.5)
Riportaimo le maschere di convoluzione per entrambi i casi (1.4) ed (1.5):
Unsharp Masking con gaussiana:
Il risultato in uscita dalla prima maschera verrà diviso per il fattore di
normalizzazione 2.72 mentre quello in uscita dalla seconda, per 10.8.
Unsharp Masking con media:
Il risultato in uscita dalla prima maschera verrà diviso per il fattore di
normalizzazione 9 mentre quello in uscita dalla seconda per 25.
-0.13 -0.28 -0.37 -0.28 -0.13
-0.28 -0.61 -0.78 -0.61 -0.28
-0.37 -0.78 9.80 -0.78 -0.37
-0.28 -0.61 -0.78 -0.61 -0.28
-0.13 -0.28 -0.37 -0.28 -0.13
-0.11 -0.32 -0.11
-0.32 1.72 -0.32
-0.11 -0.32 -0.11
-1.00 -1.00 -1.00 -1.00 -1.00
-1.00 -1.00 -1.00 -1.00 -1.00
-1.00 -1.00 24.00 -1.00 -1.00
-1.00 -1.00 -1.00 -1.00 -1.00
-1.00 -1.00 -1.00 -1.00 -1.00
-1.00 -1.00 -1.00
-1.00 8.00 -1.00
-1.00 -1.00 -1.00

Capitolo 1 Strumenti per l’elaborazione delle immagini 13
Osservando le maschere si nota come il centro abbia un coefficiente decisamente
superiore agli altri punti e ciò rende questo filtro molto sensibile al rumore puntuale
alle alte frequenze rispetto al filtro gaussiano del paragrafo precedente.
Rispetto al precedente, questo filtro, nella versione con media, ha il vantaggio di
non dover operare moltiplicazioni su coefficienti a virgola mobile; la selettività nel
filtraggio risulta però notevolmente diminuita.
1.4.3 Filtro quantizzatore
Da osservazioni di tipo statistico si deduce che il rumore aleatorio provoca
oscillazioni, sul livello originario di grigio di ogni pixel, su una fascia di valori
compresi tra i 3 e gli 8 livelli sui 256 possibili (lavorando a 8 bbp).
Queste oscillazioni rendono “inutilizzabili” i 2 ( o 3) bit meno significativi di ogni
pixel; di conseguenza la loro soppressione non comporta alcuna perdita di
informazione nell’immagine, o meglio, viene distrutta tutta quell’informazione che
è irrimediabilmente corrotta dal rumore.
Tutto ciò si traduce nel dividere il livello di grigio di ogni pixel per 2, 4 o 8 a
seconda della selettività desiderata per il filtro.
Si intuisce immediatamente come la grossolanità di questo operatore lo renda
inadatto per applicazioni (come il riconoscimento di oggetti) in cui la precisione sul
singolo bit riveste un ruolo importante.
Il grande pregio è la semplicità delle operazioni coinvolte nella sottrazione del
rumore; a differenza dei filtri descritti in precedenza infatti, il rumore viene filtrato
operando una semplice traslazione a destra (di 1, 2 o 3 posizioni) dei bit meno
significativi che compongono il byte del livello di grigio e questo lo rende adatto
per applicazioni in real time .

Capitolo 1 Strumenti per l’elaborazione delle immagini 14
1.5 Segmentazione dell’immagine
E’ il secondo gradino nella scala gerarchica citata in precedenza ed anche se viene
posizionata ad un più basso livello, la segmentazione è strettamente correlata con
l’estrazione delle feature.
Con il termine segmentazione si indica quel processo atto a separare, in prima
analisi, gli oggetti dallo sfondo di una scena acquisita. [Marr & Hildredth 1980].
Questa separazione può avvenire in 2 differenti metodi:
• Metodo basato sull’estrazione dei contorni per localizzare le discontinuità.
• Metodo basato sulle similitudini cromatiche dei pixel di certe regioni
dell’immagine.
Il successo della segmentazione è misurato in base all’utilità degli oggetti presenti
nell’immagine che si è riusciti ad evidenziare rispetto allo sfondo [Prager 1987].
In analogia ad altri processi di elaborazione dell’immagine che abbiamo visto e che
saranno descritti nei successivi capitoli, anche le tecniche di segmentazione non
sono giudicabili in assoluto ma vanno introdotti vincoli (solitamente le specifiche
richieste dal problema) che ne influenzano la scelta.
Nell’approccio basato sull’estrazione dei contorni, si evidenziano le discontinuità
dei pixel adiacenti esaltando l’eterogeneità della scena.
La maggior parte degli estrattori dei contorni si basano sulle variazioni
dell’intensità luminosa di ogni singolo pixel mentre i più sofisticati si basano sulle
discrepanze delle texture presenti nella scena ed addirittura sul movimento degli
oggetti tra un immagine ed un’altra.
Questo tipo di approccio è adatto a scene con sfondo cromaticamente uniforme ed
oggetti ben distinguibili (esempio ideale : cubo nero in una stanza bianca) ma si

Capitolo 1 Strumenti per l’elaborazione delle immagini 15
riscontrano difficoltà quando il background dell’immagine diviene via via più
complesso.
Col metodo basato sulle similitudini dei pixel accumulabili in regioni, si tenta
invece di far corrispondere ad un unico oggetto tutti quei pixel che hanno
caratteristiche simili (colore, intensità di illuminazione, riflettanza ecc..). Si assume
quindi, come ipotesi, che un oggetto sia costituito da punti aventi caratteristiche
molto simili tra loro.
Tale ipotesi perde validità quando l’oggetto è caratterizzato da texture complesse.
In un caso ideale, i contorni definiscono una regione chiusa e quindi, teoricamente, i
due metodi dovrebbero portare agli stessi risultati: quando i contorni sono stati
estratti infatti, la regione corrispondente all’oggetto può ottenersi mediante un
algoritmo di riempimento; viceversa, una volta individuata una regione, si
estraggono i contorni semplicemente seguendone il perimetro.

Capitolo 1 Strumenti per l’elaborazione delle immagini 16
1.6 Estrazione dei contorni
Nonostante sia un processo “primordiale” per la visione artificiale e
l’interpretazione delle informazioni, l’estrazione dei contorni riveste (così come il
filtraggio del rumore) tuttora un ruolo chiave; ecco perché il campo di ricerca in
questo settore risulta più che mai attivo.
Nell’affrontare questo lavoro mi sono spesso imbattuto in difficoltà di
interpretazione dei dati dovute principalmente ad una non ideale segmentazione.
Alcuni profili monodimensionali delle
transizioni tra i vari livelli di grigio.
Fig. 1.4
L’estrazione dei contorni si basa sull’osservazione del gradiente :
consideriamo la funzione ),( yxE rappresentante l’intensità luminosa (i livelli di
grigio ipoteticamente continui) sul dominio bidimensionale dell’immagine.

Capitolo 1 Strumenti per l’elaborazione delle immagini 17
Definendo:
dxyxdEyxEx
),(),( = ; e dy
yxdEyxEy),(),( = (1.6)
possiamo rappresentare il gradiente di luminosità che ogni pixel possiede, come un
vettore di intensità pari a:
)),(),(( 22 yxEyxEG yx += ; (1.7)
e di direzione uguale a:
x
y
EE
arctan=θ . (1.8)
La differenza sostanziale, tra gli operatori di estrazione dei contorni presenti in
letteratura, risiede nel diverso modo di approssimare la 1.7 e la 1.8
1.6.1 Estrattore di Roberts
Questo operatore classifica i pixel di un’immagine come i punti di un contorno se il
valore del gradiente dei livelli di grigio calcolato in un’intorno 2×2 del pixel in
questione, supera un certo valore di soglia.
Il calcolo del gradiente non è simmetrico ossia non è centrato attorno al punto che si
sta esaminando.
La definizione dell’estrattore è descritta, assieme alla regola di decisione, nel
seguente modo:
Siano A, B, C e D quattro pixel adiacenti appartenenti all’immagine, allora:

Capitolo 1 Strumenti per l’elaborazione delle immagini 18
G = max { abs (A – D) , abs (B – C) };
Se G > Soglia ⇒ A è un punto di contorno.
Da notare la semplicità con cui viene approssimata la 1.7 grazie alla quale vengono
richieste operazioni semplicissime che rendono questo estrattore adatto per
applicazioni real-time.
Ovviamente il prezzo da pagare è una qualità modesta della forma dei contorni che
esce dall’applicazione dell’operatore.
Questo punto è stato fonte di molti dubbi nello svolgimento del lavoro di tesi, così
da arrivare alle conclusioni che verranno specificate nel Cap. 4.
Fig. 1.4
In figura 1.4, da un’immagine piana vengono estratti i contorni tramite estrattore di
Roberts con soglia pari a 2.
E’ interessante notare come questo operatore (il più veloce) fornisca risultati buoni
all’interno della regione confinata nel contorno (pochi pixel neri) mentre risulta
poco efficace nel delineare nettamente i bordi.
A B
C D

Capitolo 1 Strumenti per l’elaborazione delle immagini 19
1.6.2 Estrattore di Sobel
In questo caso si determina inizialmente il gradiente, utilizzando i pixel dell’intorno
adiacente per poi selezionare i punti di contorno, confrontando il gradiente relativo
con una soglia prefissata:
Siano A, B, C, D, E, F, G, H ed I , nove pixel adiacenti appartenenti all’immagine,
allora:
G = abs [(A+2B+C) – (G+2H+I)] + abs [( A+2D+G) – (C+2F+I)]
Se G > Soglia ⇒ A è un punto di contorno.
Vi è una maggior complessità nel calcolo del gradiente dovuta all’applicazione di
una maschera 3×3 ed alle moltiplicazioni per 2 (anche se quest’ultime si possono
tradurre in un semplice scorrimento a sinistra di una posizione dei bit rappresentanti
il livello di grigio).
Tutto ciò è a vantaggio di precisione e di discreta stima dei contorni.
Fig. 1.5
A B C
D E F
G H I

Capitolo 1 Strumenti per l’elaborazione delle immagini 20
In figura 1.5, da un’immagine piana, a livelli di grigio pressoché uniformi vengono
estratti i contorni tramite estrattore di Sobel con soglia pari a 6. A differenza del
precedente questo operatore marca in maniera netta i bordi degli oggetti; il suo
livello di complessità è superiore a quello che si trova nell’estrattore di Roberts.
1.6.3 Estrattore di Prewitt
E’ analogo al precedente, l’unica differenza risiede nel motodo di approssimazione
della 1.7 .
Siano A, B, C, D, E, F, G, H ed I , nove pixel adiacenti appartenenti all’immagine,
allora:
G = max { abs [(C+F+I) – (A+D+G)] + abs [(G+H+I) –
(A+B+C)] } ;
Se G > Soglia ⇒ A è un punto di contorno.
Fig. 1.6
A B C
D E F
G H I

Capitolo 1 Strumenti per l’elaborazione delle immagini 21
In figura 1.6 sono illustrate le prestazioni dell’estrattore di Prewitt con soglia pari
ad 8. ; il suo livello di complessità è inferiore all’operatore di Sobel. I risultati
ottenuti lo rendono particolarmente adatto per applicazioni su immagini acquisite
tramite sensore omnidirezionale (Cap. 3).
1.6.4 Estrattore pseudo-Laplaciano assoluto
E’ analogo al precedente, l’unica differenza risiede nel metodo di approssimazione
della 1.7 .
Siano A, B, C, D, E, F, G, H ed I , nove pixel adiacenti appartenenti all’immagine,
allora:
G = abs [(D-2E+F) – (B-2E+H)] = abs (B+D+H+F+4E);
Se G > Soglia ⇒ A è un punto di contorno.
Fig. 1.7
A B C
D E F
G H I

Capitolo 1 Strumenti per l’elaborazione delle immagini 22
La figura 1.6 mostra i contorni ottenuti mediante l’utilizzo di un estrattore pseudo-
laplaciano con soglia pari a 7.
Questo operatore è stato testato anche su immagini piane ma i risultati poco
soddisfacenti data la troppa selettività dell’estrazione mi hanno indotto ha scartarlo
in particolar modo nell’utilizzo su immagini (come in figura 1.7) non piane.
Concludendo: i restanti livelli gerarchici della visione artificiale verranno analizzati
ampiamente nei successivi capitoli in quanto facenti parte dell’algoritmo sviluppato

CAPITOLO 2 Il flusso ottico

Capitolo 2 Il flusso ottico 23
2.1 Definizione di flusso ottico
Le prime definizioni di Flusso Ottico risalgono agli anni 50, quando presero il via
ricerche nel campo della visione artificiale.
Impropriamente si potrebbe definire il Flusso Ottico come la “rappresentazione
delle traiettorie seguite da ogni punto degli oggetti inquadrati durante il loro
movimento rispetto alla telecamera
(Gibson 1959)”; ma questa è solo una semplice definizione basata su ciò che
vediamo quando viene visualizzato il flusso ottico ottenuto dal raffronto di due
immagini.
In realtà “optical flow ” (flusso ottico) è l’insieme dei vettori rappresentanti le
velocità (proiettate sul piano immagine) di tutti i punti di un oggetto che si muove
rispetto ad un osservatore (Klaus&Horn 1981) ; i vettori del flusso ottico hanno,
infatti, intensità proporzionale allo spostamento dei punti nell’unità di tempo
(quest’ultima nel campo della visione artificiale è l’intervallo fra l’ acquisizione di
due frame consecutivi) e quindi rappresentano delle vere e proprie velocità.
Consideriamo quindi un oggetto rigido in moto relativo rispetto ad un sensore
posizionato in O, ad esempio una telecamera: indicando con 0P e '0P un punto
dell’oggetto ed il corrispondente punto sul piano immagine ad un certo istante, se
0P possiede una velocità 0V relativa alla telecamera, al suo spostamento 0V δt

Capitolo 2 Il flusso ottico 24
nell’intervallo di tempo δt corrisponderà un analogo spostamento del punto '0P nel
piano immagine di valore 0'V δt dove 0V e 0
'V rappresentano la derivata
temporale dei vettori che congiungono il centro ottico O del sistema con i punti 0P
e '0P , ossia gli spostamenti cui questi due punti sono soggetti nell’intervallo di
tempo δt.
Usando il legame proiettivo tra i due segmenti O 0P e O '0P risulta assegnato un
vettore spostamento ad ogni punto Pi dell’immagine.
L’insieme di questi vettori costituisce il campo di spostamenti che, considerati
nell’unità di tempo δt piccola a piacere (limitata inferiormente dal tempo di
acquisizione di 2 frame consecutivi), permettono di ricavare un campo di velocità.
Il flusso ottico è definito come il campo vettoriale di tali velocità.
2.1.1 Visione Stereoscopica
Come si vede dalla fig. 2.1, a causa degli effetti prospettici la componente del
movimento lungo l’asse focale viene persa.
Ecco quindi che si distinguono due grandezze fondamentali:
1) Campo di velocità: costituito dai vettori associati a tutti i punti
dell’inquadratura (in 3D)
2) Flusso Ottico: costituito dai vettori del campo di velocità ma proiettati in un
mondo 2D.
Appare per la prima volta l’importanza della visione stereo (o binoculare) applicata
al flusso ottico che nasce dall’esigenza di “recuperare” informazioni riguardo al
movimento dell’oggetto nelle 3 dimensioni, partendo da un immagine in 2
dimensioni.

Capitolo 2 Il flusso ottico 25
Occore precisare che per la sua stessa definizione, il flusso ottico è una grandezza
appartenente ad un mondo bi-dimensionale; una volta ricavato va comunque
integrato con altre informazioni pervenenti dalla visione stereo.
Senza trattare questo argomento, in modo approfondito, mi limiterò a riportare i 2
metodi più comunemente adottati per il recupero delle informazioni insite nella
terza dimensione:
Estrazione dei “tokens” (punti particolari o caratteristici) : si individuano
nell’immagine punti caratteristici di un oggetto (quali ad esempio gli angoli) per poi
riuscire, una volta identificati gli stessi punti nell’immagine successiva, a ricavare
ad esempio la giusta orientazione delle facce dell’oggetto tramite una semplice
proiezione ortogonale.
Fig. 2.2
Ad esempio, in figura 2.2 vengono individuati 4 punti non tutti complanari A,B,C
e D; dopo la rototraslazione del cubo, si intercettano tali punti e, conoscendo a
priori la relazione di collegamento tra i 4 , si riesce a stabilire l’orientazione delle
facce del cubo.

Capitolo 2 Il flusso ottico 26
Interpolazione delle traiettorie : anche questo metodo si basa sull’estrazione dei
tokens ma diviene più complesso nel momento in cui dopo aver preso un numero
finito (elevato a piacere) di tokens “campioni” se ne esegue l’interpolazione.
La letteratura, in materia, presente attualmente, indica come le informazioni
derivanti dall’uso di questo tipo di visione siano tutt’ora imprecise a meno
integrarle con tecniche di elaborazione dati assai recenti.
La visione stereo viene attualmente ed in maggior parte ottenuta cercando di
emulare come modello l’occhio umano. Infatti, così come l’occhio invia al cervello
due immagini leggermente differenti che in un ipotetico piano immagine si
sovrappongono creando il senso della profondità e della prospettiva, due sistemi di
visione inviano 2 immagini all’elaboratore il quale, utilizzando alcune semplici
regole di ottica geometrica, risale alle informazioni sulla dimensione mancante.
Questo avviene ovviamente a scapito della velocità di elaborazione dei dati e di un
notevole aumento di complessità nella gestione delle informazioni da parte del
sistema di calcolo.
2.1.2 Informazioni derivanti dal flusso ottico
Come intuibile, la distribuzione spaziale e temporale del flusso ottico dipende in
parte dalla forma dell’oggetto del quale si sta analizzando il movimento.
Assumendo quindi, per ipotesi e per semplicità, che un oggetto rigido
(indeformabile) si muova rispetto ad un sensore visivo fisso, dai valori di optical
flow ottenuti, si potrebbe “stimare” la forma dell’oggetto in questione. Ecco perché,
è un settore di ricerca attuale il riconoscimento di oggetti, auto o pedoni basato
sull’osservazione del flusso ottico della scena.

Capitolo 2 Il flusso ottico 27
Sempre nelle stesse ipotesi è dimostrabile che le parti di contorni come gli angoli o
le occlusioni di un oggetto, presentano un gradiente di velocità considerevole
rispetto ad esempio ai punti di una stessa superficie; ecco come dai valori di
intensità dei vettori di flusso ottico ricavo preziose informazioni su come sia variata
l’orientazione degli oggetti tra un’immagine e quella successiva.
Occorre precisare che l’ipotesi di camera fissa non è assolutamente limitante ne
ideale.
L’analisi e la stima del movimento tramite l’utilizzo di sensori mobili risulta essere
molto più complessa e si preferisce in genere di utilizzare sistemi di visione fissi
rispetto alla scena da osservare di modo da semplificare l’elaborazione delle
informazioni in input e da rendere sempre più affidabili quelle in output.
2.2 Metodi di stima del flusso ottico
Una grande mole di lavoro è stata portata avanti nel corso degli ultimi venti anni e
numerosi sono i metodi proposti, basati per lo più su calcoli pensati per architetture
sequenziali ed alcuni di questi possono essere altresì adattati ad architetture di tipo
parallelo.
Si è giunti ultimamente ad un’uniformità di pensiero riguardo alla stima di optical
flow individuando 2 principali metodi per affrontare il problema:
• Stima di Optical Flow basata sulla variazione della “luminosità” (Gradient
Based)
• Stima di Optical Flow basata sulle corrispondenze discrete (Matching).
Della prima classe fanno parte tutti gli algoritmi che rivelano il flusso ottico dalla
interpretazione delle variazioni di luminosità delle immagini al passare del tempo.

Capitolo 2 Il flusso ottico 28
Esempi di tale approccio sono in Horn e Schunck (1981), Nagel (1983), Haralick e
Lee (1983), Tretiack (1984), Verri et.al. (1990), Nesi (1991), Liu (1994), Andrejii
& Barechi(1998).
E’ importante osservare che il vero flusso ottico viene determinato unicamente da
questa classe di algoritmi; solo in questo caso infatti si ottiene un insieme di vettori
“denso”, nel senso che viene determinato per ogni pixel dell’immagine.
L’implementazione parallela di questi algoritmi è inoltre generalmente semplice
poiché sono richieste unicamente operazioni di tipo locale sostanzialmente
identiche per ogni punto dell’immagine.
Nella seconda classe rientrano tutti gli algoritmi che ricostruiscono il movimento
ricercando nella sequenza di immagini quelle caratteristiche degli oggetti che
possono considerarsi permanenti nel tempo come, per esempio, gli spigoli, i profili,
i pattern particolari, ecc.. Esempi di tale approccio si trovano in (Davies et. Al.
1983) e in (Ducan e Chou 1988), (Zang & Lu 1999), (Davis& Freeman 1995).
Questi algoritmi si prestano ad essere implementati su architetture di tipo
piramidale ( es.Blazer et. al. 1983) ove ad ogni livello della piramide si analizzano i
movimenti a diversi risoluzioni e le traiettorie trovate ad un certo livello guidano la
risoluzione del livello inferiore (risoluzione spaziale più alta). Esistono casi di
Hardware sviluppato ad hoc per la determinazione del F.O. mediante un algoritmo
di tale classe, per esempio (Klaus et. al. 1990).
Analizzeremo qui di seguito le 2 classi di algoritmi citate , riportando per ciascuna,
un esempio presente in letteratura.
2.2.1 Algoritmi di tipo Gradient Based
In questo tipo di algoritmo , l’informazione disponibile risulta essere solamente la
variazione temporale della distribuzione di luminosità presente nel piano

Capitolo 2 Il flusso ottico 29
immagine. Come immediata conseguenza, il flusso ottico può essere estratto dal
calcolo delle velocità, o degli spostamenti, nel piano immagine, delle variazioni di
intensità.
Fig. 2.3
Il punto P (di figura 2.3) appartenente al cubo si sposta rispetto alla sua posizione
iniziale (Old Frame) variando la propria intensità luminosa .
Sia f(x, y, t) la funzione rappresentante l’intensità luminosa nell’immagine nel punto
P di coordinate (x, y) all’istante di tempo t.
Se per ipotesi, assumiamo che tale intensità non dipenda dalle variazioni dovute
all’ambiente circostante (ossia, se nella scena nulla si è mosso, la distribuzione di
luminosità deve rimanere costante tra due frame consecutivi) ma solamente dal
moto 3D che si proietta sul piano immagine, e che quindi sia la medesima al tempo t
+ δt nel punto (x + δx, y + δy), si può scrivere :
f(x + δx, y + δy, t + δt) = f(x, y, t) (2.1)
dove δx = uδt e δy = vδt, essendo u e v le componenti della velocità, cioè del
vettore del flusso ottico applicato in questo punto, nelle direzioni x e y:
u = dx/dt e v = dy/dt (2.2)

Capitolo 2 Il flusso ottico 30
Considerando variazioni temporali e spaziali piccole a “piacere”, si può espandere
il primo membro della (2.1) in serie di Taylor ottenendo la seguente relazione:
f(x, y, t) + fxδx + fyδy +ftδt + ε = f(x, y, t) (2.3)
dove fx, fy e ft indicano le derivate parziali dell’intensità rispetto alle variabili
spaziali e temporale, ed ε contiene i termini di ordine superiore (trascurabili).
Dividendo per dt (tendente a zero) si ricava la cosiddetta “equazione di vincolo del
flusso ottico”:
fxu + fyv + ft = 0 (2.4)
la quale non permette ancora di calcolare le due incognite u e v.
Definendo v = (u,v), si può altresì scrivere dalla (2.4):
v . grad(f) = - ft (2.5)
cioè prodotto scalare tra il vettore gradiente della luminosità e il vettore velocità.
Quest’ultima relazione implica che sono soluzioni della (2.4) tutti i vettori v che la
soddisfano e quindi fornisce l’informazione relativa alla componente del flusso
ottico nella direzione del gradiente :
|v|= ft / (fx2 + fy
2)½)
ma non in quella perpendicolare, cioè lungo le linee a intensità luminosa costante.
Inoltre v non può essere calcolato nei punti in cui il gradiente è nullo.
Per ricavare il flusso ottico è quindi necessario introdurre delle ipotesi aggiuntive
derivate da conoscenze a priori, in questo modo ci si sposta verso un approccio al
problema di tipo “dipendente dal dominio”, oppure tramite l’imposizione di vincoli
aggiuntivi quali possono essere la continuità della funzione luminosità o,
analogamente, del colore all’interno dell’immagine, sempre in funzione del tempo.

Capitolo 2 Il flusso ottico 31
Una possibile soluzione è ottenuta minimizzando contemporaneamente lo
scostamento da zero del primo membro della (2.4) e le variazioni del flusso ottico
misurate dal suo gradiente arrivando alla soluzione minimizzando, rispetto a u e v la
seguente relazione:
∫∫{(fxu + fyv + ft)2 + λ [(ux2 + uy
2) + (vx2 + vy
2)]}dx dy (2.6)
La minimizzazione viene effettuata tramite un processo iterativo dopo aver posto in
forma discreta gli operatori richiesti. Vengono utilizzati degli stimatori discreti delle
derivate spaziali e di quella temporale, limitandoli, tipicamente, alle differenze
finite del primo ordine, e il doppio integrale viene sostituito da una doppia
sommatoria. Per questa possibile soluzione è stata assunta la regolarità del flusso
ottico e la continuità della luminosità dell’immagine. Se il flusso presenta delle
discontinuità, come accade in corrispondenza dei bordi degli oggetti, occorre
evitare che il metodo tenti di estendere con regolarità la soluzione da una regione
all’altra. Una soluzione possibile prevede l’introduzione della segmentazione
nell’algoritmo iterativo di stima, individuando le zone dove il flusso varia
bruscamente ed utilizzando la discontinuità per impedire, all’iterazione successiva,
di collegare con continuità la soluzione.
E’ importante notare che ogni metodo utilizzato propone un problema che necessita
l’introduzione di vincoli per l’ottenimento della soluzione, vincoli che si possono
raggruppare in due categorie : indipendenti dal dominio e dipendenti dal dominio.
Nella prima possiamo evidenziare i due principi di continuità della luminosità e del
colore (non subiscono variazioni brusche passando da un’immagine a quella
successiva), come pure possiamo introdurre gli operatori che ci permettono di
estrarre informazioni caratterizzanti le componenti dell’immagine. Fra questi
possiamo elencare ad esempio la segmentazione come pure la cosiddetta feature
extraction (estrazione delle caratteristiche) nelle loro molteplici versioni: estrazioni
dei contorni, delle regioni, delle textures, dei punti dominanti nelle curve, ecc.

Capitolo 2 Il flusso ottico 32
Nella seconda categoria possiamo raggruppare quei vincoli che dipendono dal
dominio da un punto di vista della “comprensione logica” di quanto può avvenire
nell’ambiente che si sta analizzando. Tra questi possiamo includere: la struttura
degli oggetti presenti, la velocità massima alla quale si possono muovere i punti
soggetti all’analisi, la direzione preferenziale del movimento (moto comune, moto
conosciuto o piccoli cambiamenti nella direzione della velocità), il cosiddetto
consistent match (due punti appartenenti ad una stessa immagine, normalmente, non
si associano con il medesimo punto di un’altra immagine), ecc.
2.2.2 Algoritmo di Horn & Schunk
Questo algoritmo risale al 1981 e rappresenta il punto di partenza per gran parte dei
successivi algoritmi di stima del flusso ottico basati sull’osservazione del gradiente
di luminosità.
Gli oggetti ai quali viene applicato l’algoritmo sono i punti di due immagini
acquisite consecutivamente che chiameremo Old-frame e New-frame.
Sia ),,( tyxΕ la funzione Intensità luminosa associata all’istante t al punto di
coordinate ( x , y ).
Si assume che le variazioni di questa funzione siano dovute solo al moto
dell’oggetto , per cui :
0=dtdE ;
Definiamo dtdxyxu =),( e
dtdyyxv =),( rispettivamente come la componente del
flusso ottico lungo x e lungo y.
Usando delle semplici regole di derivazione parziale si ottiene:
tyx EvuEE −=⋅ ),(),( ; (2.7)

Capitolo 2 Il flusso ottico 33
dove per semplicità si è indicato dxdEEx = ,
dydEEy = ed
dtdEEt = .
Come accennato nel precedente paragrafo, la 2.7 non è risolvibile su tutto il
dominio a meno di introdurre un ulteriore vincolo che Horn & Shunk chiamarono
vincolo di continuità (“Smoothness Constraint”).
Assumendo infatti che i singoli punti di un immagine appartengano ad oggetti di
dimensioni fisiche non infinitesime, si può con certezza affermare che le variazioni
di flusso ottico per punti vicini ( appartenenti ad uno stesso oggetto) siano minime e
ciò equivale a minimizzare il quadrato dell’intensità del gradiente del flusso ottico
ossia il Laplaciano:
2
2
2
22
yu
xuu
∂∂+
∂∂=∇ ; 2
2
2
22
yv
xvv
∂∂+
∂∂=∇ ;
Entrano in gioco, sia sulla funzione ),,( tyxΕ che su ),( vu , delle derivate parziali
di secondo ordine stimabili, senza perdite significative di informazione, nel
seguente modo:
{ }1,,11,1,11,,1,1,,,1,1,1,,,1,41
++++++++++++ −+−+−+−≈ kjikjikjikjikjikjikjikjix EEEEEEEEE ;
Fig. 2.4: ognuna delle 3 derivate parziali
dell’Intensità luminosa al centro del cubo
viene stimata attraverso la media della
differenza di ordine 1 lungo 4 contorni
paralleli del cubo. L’indice di colonna j
corrisponde alla direzione x dell’immagine,
l’indice riga i corrisponde alla direzione y e
k rappresenta la terza coordinata: il tempo.
Quindi l’indice k si riferisce a Old-frame
mentre k+1 a New-frame.

Capitolo 2 Il flusso ottico 34
Analogamente a quanto sopra si stimano yE ed tE .
Horn & Shunk forniscono anche una stima dei Laplaciani di u e v :
)( ,,,,2
kjikjiuuku −≈∇ ;
dove la media locale u è definita come segue:
{ } { }kjikjikjikjikjikjikjikjikji uuuuuuuuu ,1,1,1,1,1,1,1,1,1,,,1,,1,,,1,,121
61
−++++−−−−++− +++⋅++++⋅=
Sono analoghi i calcoli per v .
Ovviamente i 2 vincoli imposti al sistema portano a degli errori di valutazione
diversi da 0 ma fortunatamente quantificabili:
tyxb EvEuE ++=ε ;
rappresenta l’errore dovuto al vincolo sull’ immutabilità temporale della luminosità,
mentre:
2222
2
∂∂+
∂∂+
∂∂+
∂∂=
yv
xv
yu
xu
cε ;
è quello dovuto al vincolo di continuità.
bε è una quantità che dipende fortemente dal rumore presente nell’immagine e
perciò si ha necessità di introdurre un fattore di peso α nel processo di
minimizzazione dei due errori.
Si tratta, ora, di minimizzare il quadrato dell’errore medio totale espresso da:

Capitolo 2 Il flusso ottico 35
∫∫ ⋅+= dxdybcTOT )( 2222 εεαε ;
Rimandando i passaggi matematici alla lettura dell’articolo di Horn & Shunk,
diremo che attraverso un processo iterativo (Horn & Shunk suggeriscono quello di
Gauss-Seidel) si cercano quei valori di u e v che minimizzano 2TOTε .
2.2.3 Vantaggi e svantaggi del metodo basato sul gradiente
La disponibilità del campo vettoriale di velocità o di spostamento in due dimensioni
permette di stimare il movimento e la struttura spaziale degli oggetti in moto.
Quindi consente di dare una rappresentazione dell’ambiente osservato, mediante
un’opportuna formulazione delle relazioni tra i punti delle superfici componenti gli
oggetti nello spazio e quelli nel piano immagine, e tra le associate velocità. Tali
relazioni sono indotte dalla proiezione prospettica e richiedono alcune assunzioni,
tipicamente la variazione “dolce” del flusso ottico e la regolarità della superficie
3D, per poterne troncare ai primi termini lo sviluppo in serie di Taylor. Le
equazioni finali sono, nella forma generale, piuttosto complesse, tuttavia
permettono, dopo aver introdotto ulteriori vincoli, di ottenere un flusso ottico in
modo abbastanza preciso.
Questa precisione viene pagata in termini computazionali, infatti la maggior parte
se non la totalità degli algoritmi che si basano su queste tecniche sono di tipo
iterativo e richiedono la soluzione di equazioni simili alla (2.6) per ogni pixel
appartenente all’immagine o alla regione dell’immagine interessata. Quindi si
richiedono processi di massimizzazione o minimizzazione di funzioni errore che
possono impiegare numerosi cicli iterativi prima di fornire il risultato cercato. Se a
tutto questo aggiungiamo che le funzioni errore richiedono l’utilizzo di operatori
opportuni per il calcolo dei loro termini, che normalmente richiedono dati in virgola
mobile, si comprende come queste tecniche tendano a non essere utilizzate o
comunque poco sfruttate in applicazioni real-time.

Capitolo 2 Il flusso ottico 36
2.2.4 Algoritmi di MATCHING
Il movimento relativo tra gli oggetti della scena ed il sensore produce uno
spostamento di parti delle immagini formatesi nel piano focale del sensore stesso.
Tale spostamento che può essere caratterizzato con il moto di un insieme discreto di
attributi o elementi significativi (“features”). Questo moto può essere ricavato
dall’estrazione delle componenti osservabili in un’immagine della sequenza e dalla
successiva determinazione della corrispondenza nelle immagini successive.
Fig. 2.5
La situazione può essere schematizzata come in figura 2.5, dove le “qualità
specifiche” sono i punti iP individuati sul piano immagine (X, Y) ad un certo
istante come la proiezione dei punti pi dell’oggetto (in coordinate x, y, z): all’istante
successivo i punti si sono spostati rispettivamente in 'iP e '
ip .
Queste variazioni di posizione dei punti corrispondenti in (X, Y) sono i dati
disponibili per tentare di ricavare il movimento di punti pi in (x, y, z) tra i due
istanti, sempre che il problema ammetta soluzione.
Il problema, infatti, oltre ad essere mal condizionato, è anche intrinsecamente
ambiguo: la soluzione, quando esiste, può essere ottenuta solo a meno di una
costante, tipicamente un fattore di scala sulla traslazione.

Capitolo 2 Il flusso ottico 37
Ad esempio, se consideriamo due oggetti, uno di dimensioni doppie rispetto
all’altro, risultano indistinguibili i seguenti 2 moti: l’oggetto più piccolo rototrasla
alla distanza d dal sensore l’altro si muove con velocità di traslazione doppia e di
rotazione identica al precedente ma ad una distanza 2d dal sensore.
Nell’esempio citato in figura si fa riferimento ai punti che compongono l’oggetto,
nell’insieme dei metodi di calcolo affrontabili in questo paragrafo, è possibile
utilizzare come elementi significativi altre caratteristiche rappresentative, quali ad
esempio vertici, linee di separazione tra superfici, regioni ecc. Per questo motivo
risulta difficile descrivere in modo sistematico e sintetico i possibili metodi di
soluzione, che andrebbero classificati secondo una varietà di parametri tra i quali
possiamo citare:
il tipo di osservabili considerato (punti, linee, angoli, …)
eventuali vincoli spaziali tra gli osservabili (la complanarità per
esempio)
il tipo di proiezione impiegata
i parametri del moto ricercati
la linearità o meno del sistema di equazioni
la rigidità o meno del moto
la limitazione o meno a piccoli spostamenti, e analogamente l’uso di
un numero limitato di viste o di una lunga sequenza
L’ipotesi su cui si basano i metodi di stima del movimento da osservabili estratti in
un’immagine e poi “inseguiti” nella sequenza è che siano innanzitutto individuati
elementi caratteristici in una vista, e che sia stata stabilita la corrispondenza tra di
essi nelle successive immagini della sequenza.
Stabilire e mantenere le corrispondenze tra frame successivi può essere tutt’altro
che semplice, sia perché gli elementi da inseguire non permangono necessariamente
in tutte le immagini costituenti la sequenza (possibili occlusioni), sia perché è

Capitolo 2 Il flusso ottico 38
proprio il movimento una delle proprietà che permettono di individuare le
corrispondenze.
In ogni caso, le tecniche più comuni adottate per individuare gli osservabili sono
basate sull’analisi delle caratteristiche locali della distribuzione di luminosità, ad
esempio la tessitura (texture), gli angoli, tratti di contorno rettilineo, intersezioni di
linee. Per trovare la soluzione al problema delle corrispondenze vengono utilizzate
misure di somiglianza opportunamente formulate come ad esempio la correlazione
locale o le misure di somiglianza strutturale.
Anche nell’applicazione di queste metodologie è importante far notare come
vengano impiegati dei vincoli aggiuntivi simili a quelli affrontati nel paragrafo
precedente; si distingue anche in questo caso fra metodi indipendenti o dipendenti
dal dominio.
Occorre ora definire alcune importanti caratteristiche da abbinare alle immagini da
analizzare e da utilizzare solo nel caso di algoritmi basati sul Matching:
• DISPARITA’: E’ il vettore che associa la posizione di un’entità nella prima
immagine (in coordinate relative al frame) con la posizione assunta dalla
corrispondente entità nella seconda immagine. Evidentemente, se l’oggetto
non si muove, la disparità è un vettore di componenti nulle. La
determinazione delle disparità tra due immagini è un argomento importante
nella visione artificiale e viene normalmente indicata con il nome di
MATCH DETECTION oppure con RISOLUZIONE DEL PROBLEMA
DELLE CORRISPONDENZE.
• DISTINGUIBILITA’: Fornisce una valutazione numerica del grado di
separazione cromatica che ha un punto rispetto ai suoi vicini. Per esempio
un’area uniforme è evidentemente costituita da punti indistinguibili tra loro
(almeno sulla base di semplici informazioni cromatiche).
• SIMILITUDINE: E’ un indicatore del grado di somiglianza che hanno due
punti appartenenti ad immagini differenti. In genere si valuta la similitudine
non solo sulla base del loro specifico valore cromatico ma anche sulla

Capitolo 2 Il flusso ottico 39
distribuzione cromatica di un certo loro intorno, in questo modo la
correlazione sfrutta una maggior quantità di informazione e costituisce una
valutazione più attendibile.
• CONSISTENZA : Rappresenta la misura di quanto un particolare match è
in accordo con i match ad esso adiacenti. Nel nostro caso il match identifica
la disparità più corretta (cioè quella che associa le giuste entità) la quale
rappresenta il movimento relativo di un certo punto immagine.
2.2.5 Algoritmo di Barnard & Thompson
Questo algoritmo è, per gli algoritmi di Matching, ciò che quello di Horn & Shunk è
per gli algoritmi di tipo Gradient Based.
Il metodo di stima del flusso ottico viene suddiviso in due fasi principali:
• CORNER DETECTION
• MATCH DETECTION.
La prima fase consiste nel determinare nelle due immagini un insieme di entità con
caratteristiche appropriate al successivo abbinamento. La seconda fase realizza
concretamente l’abbinamento.
CORNER DETECTION :
Consiste nell’applicazione di un determinato operatore matematico alle due
immagini per individuarne le entità da abbinare tra loro. Nella versione originale
dell’algoritmo viene utilizzato l’operatore di Moravec che isola dal contesto quei
punti di una immagine che hanno la massima variabilità cromatica rispetto ai loro
vicini. Questi punti dovrebbero corrispondere agli spigoli degli oggetti mostrati
nell’immagine. Per tale motivo, da ora in avanti, non parleremo più di generiche
entità ma di CORNER.
Si rende necessario l’uso del condizionale in quanto a causa delle imperfezioni
dell’immagine (rumore, distorsioni, ecc.) viene solitamente identificato un grande
numero di falsi corner.

Capitolo 2 Il flusso ottico 40
MATCH DETECTION E’ la fase più complessa dell’algoritmo e conviene per questo suddividerla in un
certo numero di passi.
• IDENTIFICAZIONE DEI CANDIDATI Il primo passo può essere descritto riferendosi alla seguente figura:
Fig. 2.6
nella quale si identificano i punti selezionati dalla corner detection dell’immagine
Old (nella figura sono indicati con le lettere minuscole) e ad ognuno di essi viene
assegnata una lista di elementi.
Ogni elemento di questa lista contiene le coordinate di un corner individuato nella
seconda immagine, dunque il numero di elementi di ogni lista è pari al numero di
corner di New.
La lista associata ad ogni corner di Old rappresenta l’elenco dei candidati per
l’abbinamento di un corner di New con quel corner di Old.
In figura 2.6 vengono rappresentate le due immagini Old e New dopo l’applicazione
della corner detection. Tutta l’informazione pittorica è stata eliminata e sono rimasti
unicamente i punti riconosciuti come corner (che qui vengono indicati
simbolicamente usando le lettere). Le immagini evidentemente rappresentavano
degli oggetti in movimento, si osserva infatti che i punti (a,b,c,d) si sono spostati in
(A,B,C,D) con un movimento verso nord-ovest mentre i punti (e,f,g,h) si sono

Capitolo 2 Il flusso ottico 41
mossi in direzione nord-est finendo in (E,F,G,H). Partendo dai corner di Old si
generano le liste (riportate a lato solo per alcuni punti) dei corner di New che si
trovano entro la distanza massima consentita, dunque entro i riquadri centrati sui
corners di Old. In questo modo la ricerca del corrispondente di a (per esempio)
verrà limitata ai corner (A,B,D) e non all’intero gruppo di otto punti; questo
migliora le prestazioni in termini di velocità di calcolo anche in considerazione del
fatto che nelle immagini reali i corner solitamente soni centinaia. Purtroppo questa
soluzione comporta la necessità di limitare a priori il massimo movimento dei
corner. Nel caso infatti del corner h la sua velocità è stata tale da portare H al di
fuori del range di riconoscimento e così l’accoppiamento (h,H) non potrà aver
luogo. La lista di h evidenzia tra l’altro il caso particolare di assenza di candidati
(lista vuota): in questo come in altri casi bisogna tenere presente che i corner
possono anche uscire dall’immagine e scomparire improvvisamente. Queste
possibilità vengono gestite tramite l’elemento * che definisce la possibilità di
“disparità indefinita”. I casi di comparsa improvvisa (sono in New ma non in Old)
vengono automaticamente risolti non avendo (se non si compiono errori)
corrispondenti in Old.
Chiamiamo d’ora innanzi Li la lista di corrispondenza a per il corner i-esimo di Old;
evidentemente Li(j) rappresenterà il corner i-esimo di New contenuto nella lista del
corner i-esimo di Old (per esempio nella figura l’abbinamento corretto per la prima
lista sarà La(A)).
Generalmente le immagini contengono un elevato numero di corner (reali o fittizi) e
ciò provoca inevitabilmente un allungamento delle liste.
Questo è uno svantaggio in quanto, di tutti i punti inseriti in ogni lista al più un solo
punto sarà poi riconosciuto valido per l’abbinamento; tuttavia essendo inizialmente
incognito, dovrà essere ricercato tra tutti gli elementi della lista influendo
negativamente sia sul tempo di calcolo che sulla quantità di memoria richiesta.
Per ovviare a questo problema si inseriscono nella lista di ogni corner Old le
coordinate dei corner di New che si trovano entro una certa distanza massima (le

Capitolo 2 Il flusso ottico 42
cornici attorno alle lettere in figura). Chiamiamo r (in pixel) il modulo delle
componenti lungo gli assi di tale distanza ; esso rappresenta il limite massimo alla
disparità calcolabile dal nostro sistema (lungo X e lungo Y); in altre parole: è il
limite massimo alle corrispondenti componenti orizzontali e verticali della velocità
rilevabile.
Se un oggetto dovesse essere tanto veloce da coprire una distanza in pixel maggiore
del limite fissato (nel tempo intercorso tra le due immagini) non riusciremmo a
ricostruirne la traiettoria ed esso apparirebbe al sistema di visione come un oggetto
scomparso in Old e apparso dal nulla in New.
Un ulteriore conseguenza di questa scelta è che le liste, ora, non hanno più tutte la
stessa lunghezza e questo complica l’analisi della complessità spaziale e temporale
dell’algoritmo.
Ricapitolando: nelle lista associate ad ogni corner di Old vengono inseriti i soli
corners P(xj,yj) della seconda immagine tali che xi-r ≤ xj ≤ xi +r e yi-r ≤ yj ≤
yi + r.
Ad ogni elemento di Li viene associato anche un numero che rappresenta la
probabilità che quel particolare corner sia quello giusto.
Indichiamo con pi(j) la probabilità che il corner della prima immagine Pi=P(xi,yi)
corrisponda al corner Pj=P(xj,yj) della seconda immagine, ovvero:
pi(j) = p{ Pi∈ Old e Pj ∈ New :rappresentano lo stesso oggetto} .
Si deve tenere conto anche del fatto che gli oggetti entrano ed escono di scena
continuamente e che si possono occultare reciprocamente, questo significa che un
corner di Old potrebbe non avere un corrispondente in New e viceversa. A questo
riguardo viene definito un elemento speciale (una specie di jolly inserito in ogni
lista) che rappresenta una disparità indefinita e che viene indicato con l’asterisco.
Esso subirà in generale le medesime elaborazioni degli altri elementi della lista e, se
al termine del calcolo dovesse risultare il migliore candidato per un certo corner di
Old, trarremmo la conclusione che quel corner è stato “perso di vista”. Indicheremo
la probabilità assegnata all’elemento di disparità indefinita nel seguente modo:

Capitolo 2 Il flusso ottico 43
pi(j*) = p{ Pi ∈ Old : non ha corrispondenti in New} .
Il caso opposto (corner presente in New e assente in Old) non costituisce problema
fuorché per un inutile allungamento delle liste dei corner di Old che lo dovessero
prendere in considerazione.
Necessariamente le probabilità all’interno di ogni lista devono essere normalizzate.
Nel caso della fig. 2.6 per esempio si ha:
pa(A) + pa (B) + pa (D) + (*) =1
pc(C) + pc (E) + pc (*) =1
pe(E) + pe (H) + pe (*) =1
Nel corso della fase di ricerca degli abbinamenti le probabilità all’interno delle liste
subiranno delle modifiche (dovendo alla fine indicare il candidato più probabile)
ma la condizione di normalizzazione dovrà essere sempre rispettata, dunque si
tratterà più che altro di una specie di ridistribuzione dei voti tra i vari candidati di
ogni lista. Il processo sarà evidentemente iterativo e, naturalmente, dovrà
cominciare da una distribuzione iniziale di voti.
Il processo di ridistribuzione avverrà per passi successivi e dunque verrà utilizzato
un formalismo del tipo pi(j)k che indica il valore di probabilità del corner j-esimo
(di New) nella lista relativa al corner j-esimo (di Old) al passo iterativo di k. Di
conseguenza, con pi(j)0 verrà indicata il valore della probabilità iniziale.
• ASSEGNAZIONE DELLE PROBABILITA’ INIZIALI
Una volta generata la lista dei candidati è necessario assegnare dei valori iniziali
alle probabilità pi(j) .
La corretta valutazione di questi valori è importante perché permette di individuare
più rapidamente il candidato vincitore riducendo anche la possibilità di errori e la
formazione di situazioni ambigue.

Capitolo 2 Il flusso ottico 44
Il metodo proposto (dagli autori) utilizza la proprietà di “similitudine”; si definisce
una finestra di dimensioni (Ix , Iv) centrata sul corner j-esimo di New ed una uguale
finestra centrata sul corner j-esimo di Old.
Percorrendo le due finestre si calcola il quadrato della differenza dei pixel di Old e
di New aventi le medesime coordinate all’interno della finestra. Gli (Ix× Iv) valori
ottenuti sono sommati tra loro. Il risultato viene indicato con si(j) (con un
formalismo analogo al caso delle probabilità).
Evidentemente se il corner in Old e il corner in New appartengono al medesimo
oggetto, e se nel tempo trascorso tra le due immagini non si sono verificate
variazioni di illuminazione e modifiche nella forma e nell’orientazione degli
oggetti, ed infine se il rumore introdotto dal sistema di ripresa è stato perfettamente
filtrato, il valore di si(j) non può che essere zero.
In altre parole: nelle condizioni descritte ora, gli insiemi di punti che formano il
corner in Old ed in New sono identici (a parte la differente posizione
nell’immagine) e quindi la sottrazione punto a punto restituisce un risultato pari a
zero.
In questo caso è ovvio che pi(j) deve valere uno (certezza di identificazione).
In generale le ipotesi precedenti non saranno mai verificate perfettamente (e a volte
non lo saranno proprio portando ad errori di valutazione gravi) ma resta
sicuramente valida la relazione di proporzionalità inversa tra s e p.
L’elemento di disparità indefinita ( j* ) non può ovviamente essere gestito allo
stesso modo (rappresentando un oggetto immaginario) ma deve comunque rientrare
nella valutazione delle probabilità. La soluzione al problema viene affrontata
tramite la definizione di una funzione wi(j) che non rappresenta direttamente una
probabilità (non essendo normalizzata) ma che ne segue l’andamento:
wi(j) = 1 / ( 1+c × si(j) ) ∀ j ≠ j* (1)
La costante c viene selezionata sperimentalmente (gli autori indicano il valore 10) e
ovviamente wi(j) ∈ [0,1].

Capitolo 2 Il flusso ottico 45
Con questa funzione possiamo ora determinare la probabilità iniziale associata
all’elemento di disparità indefinita:
pi(j*) = 1 - max( wi(j) ) (2)
In pratica la funzione wi(j) dà una informazione di carattere generale sullo stato
della lista, evidentemente se non vi sono candidati con alta probabilità, è lecito
aspettarsi un’alta probabilità che il corner i-esimo non abbia un corrispondente in
New e, dunque, un valore di pi(j*)0 prossimo ad uno.
Tramite la relazione (2) abbiamo definito il valore di probabilità per un elemento
particolare della lista, resta da definire il valore associato agli altri candidati. A
questo scopo, viene utilizzati il teorema di Bayes relativo alle probabilità
condizionate ottenendo la seguente relazione:
pi(j)0 = pi(j | i) • (1- pi(j*)0 ) (3)
Ove evidentemente valgono le seguenti definizioni:
pi(j | i) = p { Pj ∈ New associato a Pi ∈ Old } vincolata al fatto che Pi abbia
realmente un corrispondente
(1- pi(j*)0 ) = p { Pi ∈ Old abbia un corrispondente in New }
Per calcolare l’espressione (3) è necessario determinare il valore della probabilità
condizionata. Esso viene solo stimato tramite la seguente espressione:
pi(j | i) = wi(j) / c wi(j’) (4)
Ove la sommatoria si intende eseguita ∀ j’ ≠ j* .

Capitolo 2 Il flusso ottico 46
• RAFFINAMENTO RICORSIVO DELLE PROBABILITA’
La distribuzione delle probabilità all’interno di ogni lista ha lo scopo di evidenziare
il corner di New per cui è più probabile l’associazione all’accoppiamento con il
corner di Old a cui la lista si riferisce.
A partire dai valore delle probabilità iniziali calcolate in precedenza, si vuole ora
definire una procedura che ridistribuisca le probabilità sino alla generazione di un
istogramma unimodale ( se possibile) che promuova un solo candidato. La
procedura di calcolo proposta è iterativa e utilizza la proprietà di consistenza.
Sia la pi(j)k il valore di probabilità del corner j-esimo (di New) nella lista relativa al
corner j-esimo (di Old) al passo iterativo k.
La procedura dovrà soddisfare la seguente proprietà, definita informalmente:
pi(j)k+1 > pi(j)k se esistono dei corner di Old attorno al corner j-esimo (sempre di
Old) aventi nelle loro liste dei corner j-esimi (di New) con disparità identica a
quella della coppia (i,j).
In parole povere si aumenta la probabilità della coppia (corner i, corner j) se attorno
al corner j-esimo (di Old) vi sono altri corner che possono confermare la disparità di
(i,j), ovvero il corner j-esimo sembra non essere l’unico a muoversi in questa
direzione. La proprietà di consistenza si esprime nella condizione di identica
disparità e vicinanza ma, a causa delle distorsioni introdotte dalle ottiche della
telecamera, dal digitalizzatore e dal rumore addizionato all’immagine, è molto
difficile rispettare esattamente la proprietà di consistenza. Per questo motivo si
introduce un valore di soglia θ e la proprietà di consistenza si considera soddisfatta
se la disparità dei corner adiacenti non si discosta di più di θ.
Gli autori propongono una condizione di consistenza di questo tipo:
|| d-d’|| = max ( | dx – d’x | , | dy – d’y | ) ≤ 1

Capitolo 2 Il flusso ottico 47
Ove d è la disparità della coppia di corner (i , j), mentre d’ è la disparità della
coppia di corner ( i’, j’) vicini al corner i e le grandezze a secondo membro sono
ovviamente le componenti delle disparità lungo gli assi X e Y.
Viene definita anche una condizione di vicinanza che è in pratica identica a quella
utilizzata nella fase di identificazione dei candidati (e che viene illustrata nella
fig.2.6).
La condizione viene così espressa formalmente:
h ∈ Old è vicino a i ∈ Old se, data una costante intera R, si ha
max ( |xh –xi|, | yh –yi | ) ≤ R
In sostanza la pi(j)k viene aggiornata sulla base di quello che succede nei dintorni
del corner j-esimo osservando le direzioni (cioè le disparità) che hanno la maggiore
probabilità di essere corrette.
A questo punto sorge una difficoltà: le probabilità associate alle disparità vengono
aggiornate sulla base del comportamento degli altri corner, ma anche per essi vale il
medesimo principio e, dunque, siamo di fronte ad una dipendenza circolare: per
stimare un valore occorre un dato che vanga calcolato sulla base del valore che sto
stimando.
Per superare questo ostacolo si ricorre ad una stima provvisoria delle probabilità
ph(j)k del corner h vicini ad i introducendo la seguente funzione:
qi(j)k = ∑α ∑β pα(β)k ∀ j’ ≠ j* (5)
Ove:
α assume i valori associati ai corner di Old che si trovano nell’intorno del corner j-
esimo ed α≠1.
In pratica definisce un area attorno a P(xi , yi ) ∈ Old e raccoglie i corners in esso
contenuti. β scandisce i candidati dalla lista di P (xα,yα) di Old che hanno una
disparità d simile a quella di

Capitolo 2 Il flusso ottico 48
P(xi , yi ) , ovvero:
β : || d - d’|| ≤ θ
Quindi, mentre α scorre le liste dei corner di Old vicini a Pi, da queste stesse liste
vengono estratte le probabilità dei candidati che hanno una disparità simile a quella
del corner (i , j).
Con la definizione data è ovviamente sempre vero che qi(j)k ≥ 0, ove l’uguaglianza
si verifica se e solo se non esistono dei corner attorno a Pi con disparità simile a d.
Al contrario, il valore sarà tanto maggiore quanto più i corner attorno confermano
l’ipotesi di disparità (in sostanza il gruppo da forza al singolo).
Il valore di qi(j)k viene utilizzato quale base di partenza per il calcolo della
probabilità pi(j)k+1, la quale deve essere normalizzata e deve tenere conto
dell’elemento j*.
Si procede in due fasi, nella prima si calcola una probabilità non normalizzata
diversa per gli elementi j-esimi e per j*:
ψi(j)k+1 = pi(j)k (A +B ψi(j)k+1 ) ∀ j’ ≠ j* (6)
ψi(j*)k+1 = pi(j*)k
Nella seconda fase si normalizza ottenendo il risultato voluto:
pi(j)k+1 = ψi(j)k+1 / ∑j’ ψi(j’)k+1 (7)
I parametri A e B nelle (6) sono costanti positive che modulano le caratteristiche di
risposta del modello matematico. Gli autori suggeriscono i valori A= 0.3 e B=3. Il
loro significato è abbastanza semplice: A ritarda la soppressione delle probabilità

Capitolo 2 Il flusso ottico 49
associate ai candidati poco probabili (assicurando che ψi(j)k+1 non si annulli anche
se pi(j)k vale zero).
Questo è importante nel caso particolare dei corner situati sulle regioni di confine
degli oggetti.
Per questi corner, infatti ,vi saranno un certo numero di corner ‘compagni’ che
confermano la disparità corretta ed altri (quelli appartenenti ad altri oggetti o allo
sfondo) che la valutano errata (dal loro punto di vista).
In questi casi conviene quindi che non vengano mai incontrate probabilità di valore
zero.
Il valore B è invece importante in quanto determina la velocità di convergenza della
distribuzione delle probabilità verso il suo stato finale. Nella (7) la sommatoria a
denominatore viene eseguita entro la lista Li appartenente al corner j-esimo di Old.
Osserviamo infine che la probabilità associata all’elemento di disparità indefinita
pi(j*) risulta influenzata unicamente dalla (7), ovvero dalla normalizzazione.
Avviene allora che la probabilità di j*cresce solo se vale la condizione:
∑j ψi(j)k+1 < ∑j pi(j)k ∀ j’ ≠ j*
Negli altri casi la pi(j*) decresce o rimane invariata.
Riassumendo, l’algoritmo funziona come segue: si estraggono i corner dalle
immagini, per ogni corner di Old si genera una lista di corner di New che sono
nelle vicinanze. Ad ogni candidato di queste liste viene assegnata una probabilità
iniziale di successo (cioè di corrispondenza con il padrone della lista) tramite le
formule (1), (2), (3),(4). Successivamente le probabilità vengono elaborate
iterativamente tramite le (5),(6),(7) sino a che entro ogni lista la distribuzione di
queste probabilità non raggiunge una condizione di stazionarietà,
Barnard e Thompson hanno osservato che, dopo poche iterazioni, la maggior parte
dei candidati ha una probabilità molto bassa. Per aumentare l’efficienza
dell’algoritmo è bene eliminarli riducendo così le dimensioni delle liste. Ad ogni
iterazione si esegue dunque una verifica e si eliminano tutti i candidati la cui
probabilità è scesa al di sotto di 0.01 (valore suggerito dagli autori).

Capitolo 2 Il flusso ottico 50
L’algoritmo risolve quindi un problema di convergenza numerica in cui il numero
di iterazioni non può essere previsto a priori. Gli autori indicano comunque la
possibilità di arrestarsi dopo solo dieci iterazioni a patto di applicare una soglia alle
probabilità. Il loro suggerimento è quello di limitare le iterazioni (a dieci appunto) e
poi di accettare come candidato quello la cui probabilità supera lo 0.7.
Evidentemente, se più corner in una lista superano la soglia, non è possibile
assegnare la disparità, così come se nessuno dei candidati raggiunge la soglia
(banalmente anche in caso in cui la lista si trovi con il solo j*).
In queste situazioni si assegna pi(j*) ed il corner P(xi , yi ) viene definito
“unmatchable” ovvero non accoppiabile.
2.2.6 Vantaggi e svantaggi degli algoritmi di Matching Vorrei sottolineare il fatto che questo tipo di soluzione presenta dei vantaggi, in
termini di costi di elaborazione, nei confronti della stima del movimento mediante il
flusso ottico. Infatti tramite l’applicazione di maschere opportunamente studiate,
alla sequenza di immagini in esame e precedentemente elaborata, è possibile
ottenere una valutazione del movimento ed in particolare del flusso ottico
qualitativamente accurata in tempi di calcolo sufficientemente brevi. Soprattutto se
si pensa che la maggior parte, se non la totalità, di queste operazioni utilizzano dei
dati di tipo intero. Sarà questa la strada che seguirò nel proseguimento di questo
lavoro. Un altro vantaggio non trascurabile, che si può rivelare anche svantaggioso
in taluni casi, è il fatto che utilizzando le tecniche descritte in questo paragrafo il
calcolo del movimento si può facilmente concentrare su alcuni oggetti della scena
trascurando il resto, situazione importante nei casi di inseguimento e/o di
catalogazione degli enti presenti o che ci si aspetta siano presenti nella scena.
L’obbiezione più importante che può essere sollevata nei riguardi delle procedure
evidenziate è la loro “inesattezza” formale, dovuta alle semplificazioni richieste per
poter essere in grado di ottenere una soluzione senza dover affrontare una quantità
di calcoli eccessiva

CAPITOLO 3 Il sensore omnidirezionale

Capitolo 3 Il sensore omnidirezionale 51
3.1 “Vedere” a 360° con il sensore catadiottrico
Con l’aumentare delle prestazioni dei calcolatori ed il diminuire dei costi di
equipaggiamento video, risulta efficace impiegare sistemi di visione di alta qualità
nei processi di navigazione di robot autonomi.
Così come la navigazione dei robot si muove verso ambienti via via più semplici,
aumenta di pari passo il bisogno di sensori che descrivano in modo completo tali
ambienti.
La tendenza attuale della di ricerca è quella di “sollevare” il calcolatore da
elaborazioni di dati in input provenienti da diverse sorgenti visive (e per questo di
complessa manipolazione), compensando con un unico sensore (o 2 per la visione
stereo) che diano informazioni sufficientemente dettagliate sull’ambiente
circostante.
Questo richiede l’utilizzo di sensori visivi che diano una informazione più “globale”
(anche se meno precisa e particolareggiata) sulla scena in cui il robot è immerso, e
permettano quindi di ottenere una veloce descrizione, magari sommaria ma più
direttamente traducibile in azione.
Purtroppo, le telecamere convenzionali hanno, nella maggior parte dei casi, un
campo visivo piuttosto limitato, e questo risulta essere spesso restrittivo per
l’applicazione immediata.
Si può accrescere il campo visivo utilizzando specchi in congiunzione alle
tradizionali telecamere.
Per sensore catadiottrico si intende la combinazione di lenti e specchi posizionati in
configurazioni appropriatamente studiate per ottenere un campo visivo molto
superiore rispetto a quello del sensore effettivamente utilizzato. E’ per questo che i
catadiottri vengono utilizzati in ambienti dinamici come ad esempio quello della
competizione Robocup ([Asada et al., 1998], [Marquez e Lima, 2000], [Bonarini et
al., 2000]).

Capitolo 3 Il sensore omnidirezionale 52
Il termine catadiottrico deriva da “diottrica”, la disciplina degli elementi rifrangenti
(le lenti) e da “catottrica”, la disciplina delle superfici riflettenti (gli specchi).
Esistono molteplici esempi a questo riguardo: la sorveglianza, l’acquisizione di
modelli per la realtà virtuale, la stima del proprio movimento, la pianificazione e
l’auto-localizzazione dei robot.
Per quanto riguarda quest’ultima infatti, anziché utilizzare la tecnica della
triangolazione dopo aver selezionato i marker di riferimento, si può semplicemente
misurare l’angolo di azimuth rispetto a tali marker e, grazie all’utilizzo di sensori
omnidirezionali, tale misura diviene più immediata.
Se si vuole espandere il campo visivo in maniera isotropa, la migliore delle
soluzioni è probabilmente quella di adottare specchi convessi con un asse di
simmetria centrale (quindi a sezione tipicamente conica, sferica, ellittica o
parabolica) e, in effetti quasi tutti i sistemi impiegati sono di questo tipo ([Svoboda
e Pajdla, 2000], [Hicks e Bajcsy, 1999]).
Posizionando l’asse ottico della telecamera in verticale e facendolo coincidere con
l’asse di simmetria dello specchio si ottiene un campo visivo estesoin tutte le
direzioni.
Fig. 3.1

Capitolo 3 Il sensore omnidirezionale 53
L’impiego di catadiottri, quindi, ha il vantaggio di raccogliere, in una sola
immagine, un’informazione riguardante una vasta area, evitando i complessi
meccanismi di controllo generalmente impiegati nella visione attiva; tuttavia vanno
anche evidenziati due nuovi problemi connessi con questa scelta:
1. la riflessione della telecamera e del robot sullo specchio fa sì che la parte
centrale dell’immagine, ossia quella caratterizzata da maggiore risoluzione e
minori distorsioni, sia generalmente occupata dall’immagine riflessa del
robot e non sia quindi utilizzabile per descrivere la scena circostante.
2. l’utilizzo congiunto di una telecamera e di uno specchio concavo determina
il sommarsi di effetti distorcenti di cui risulta spesso difficile trovare la
legge e quindi compensare l’effetto.
Tutti questi aspetti fanno sì che tramite il catadiottro si possano ottenere
informazioni adeguate per un’analisi di massima di un’ampia scena (facilitando ad
esempio l’auto-localizzazione, l’individuazione di oggetti ed elementi di possibile
interesse per l’applicazione, eccetera), ma non sufficientemente dettagliate per
un’analisi approfondita dei particolari (ad esempio per l’individuazione di ostacoli).
3.2 Progettazione del sensore omnidirezionale HOPS
Il principale problema della progettazione del sensore omnidirezionale è il disegno
della superficie riflettente [Ishiguro , 2001].
Si riporta qui di seguito il metodo di progettazione usato presso i laboratori
dell’Università di Parma [Adorni et al 2002].
L’approccio è stato di tipo “trial and error” (fig. 3.2) supportato da programmi di
simulazione di ambienti 3D.
Per testare i differenti profili possibili dello specchio si è utilizzato un programma
di rendering per la creazione di ambienti foto-realistici .

Capitolo 3 Il sensore omnidirezionale 54
Si è simulato uno specchio, dalla forma assomigliante ad un paraboloide
“schiacciato” e dalla superficie totalmente riflettente, posizionato su di un piano
mappato con alcune rette orizzontali e verticali , sul quale giacevano solidi
rappresentanti robot e palle.
Grazie a questa simulazione si è potuta avere una visione generale degli effetti
distorcenti dello specchio (e quantificarli),così da poter variare alcuni parametri:
profilo dello specchio e posizione della telecamera.
Fig. 3.2
A questo punto non restava altro che scegliere un campo di applicazione
abbandonando la generalità delle specifiche e concentrandosi sull’ottimizzazione
per l’ambiente RoboCup.
Infatti, prima di progettare il profilo dello specchio, è consigliabile definire per
quale scopo è progettato.
Per esempio : un sistema di visione per la localizzazione di ostacoli non necessiterà
di riconoscere oggetti a grande distanza, viceversa, un sistema di localizzazione
avrà bisogno di un’estensione visiva considerevole.

Capitolo 3 Il sensore omnidirezionale 55
E’ stato quindi realizzato un prototipo sperimentale di sensore costituito da due
sensori visivi: un sensore catadiottrico per la visione omnidirezionale, e una
normale telecamera posta frontalmente per la visione stereo. A questo sistema è
stato dato il nome HOPS: Hybrid Omnidirectional/Pin-hole Sensor. Dove , con il
termine Pin-Hole si intende quel modello che trascura in prima approssimazione
l’effetto distorcente che ogni telecamera provoca sull’immagine. Come si può
osservare nelle figure 3.3, la struttura è costituita fondamentalmente da un cilindro
in plexiglass, un ripiano circolare interno ad esso, uno specchio fissato sulla
sommità del cilindro, due telecamere a CCD. Questo sistema è simile a quello
descritto in [Clérentin et al., 2000], anche se in questo caso il catadiottro è
combinato con un sensore visivo che, utilizzato come tale e non come range-sensor,
fornisce informazioni più ricche utilizzabili in diverse applicazioni.
Nel caso specifico dell’applicazione sviluppata si utilizza la combinazione delle
immagini acquisite dai due sensori visivi per la ricerca di ostacoli nell’area frontale
al robot.
Fig. 3.3

Capitolo 3 Il sensore omnidirezionale 56
Nel prototipo realizzato, per la parte che costituisce il catadiottro, una delle due
telecamere è fissata al centro del ripiano circolare ed è orientata verticalmente verso
lo specchio in maniera tale da far coincidere il suo asso ottico con l’asse dello
specchio. Inoltre il ripiano circolare interno possiede un grado di libertà che gli
permette di essere posizionato a diverse altezze. La seconda telecamera è invece
posizionata sul ripiano di plexiglass che poggia sopra lo specchio, orientata in modo
tale da inquadrare l’area di fronte al sistema. Sia la base del sistema che il ripiano
della telecamera superiore sono entrambi dotati di un sistema per l’orientamento
della struttura costituito da quattro coppie vite-molla utilizzate come regolatori di
posizione tra due ripiani di plexiglass. Tramite la regolazione di queste è possibile
orientare il piano della base dello specchio e il ripiano della telecamera superiore in
modo che essi risultino paralleli al piano del pavimento, ottenendo quindi anche la
verticalità dell’asso ottico del catadiottro.
3.2.1 Specifiche adottate per la realizzazione del profilo dello specchio
Per applicazione in ambiente RoboCup sono state definite le seguenti specifiche:
• Minimizzare l’ingombro dello specchio minimizzandone il raggio. In questo
modo si rende più leggera l’intera struttura del sensore e meccanicamente
più stabile il robot.
• Disegnare un profilo dello schermo atto a ridurre l’area di immagine
contenente informazioni inutili (riflessione del robot sullo specchio).
• Estensione radiale del campo visivo là dove si pensa siano le informazioni
rilevanti.
• Cercare di mantenere una risoluzione alta in un’area di interesse “strategico”
nelle vicinanze del robot.

Capitolo 3 Il sensore omnidirezionale 57
3.2.2 Lo specchio
La soluzione è stata quella di adottare uno specchio con la regione centrale sferica,
che riduce l’effetto di occlusione da parte del corpo del robot, e una parte esterna
conica che permette di ottenere un migliore compromesso fra campo visivo e
risoluzione.
Occorre ora fare una precisazione : nel 199, presso il Politecnico di Milano, è stato
realizzato un primo progetto dello specchio la cui forma (in fig. 3.4 ne si è riportata
la sezione) era data dall’intersezione (con tangenza) di un cono ed una sfera .
Raggio sfera = 6,6 cm
Angolo di apertura del cono = 117°
Raggio della base del cono = 8,9 cm
Altezza totale dello specchio = 4,3 cm
Purtroppo, le tecnologie di lavorazione dell’alluminio utilizzate per la realizzazione
di specchi per catadiottri, introducono spesso delle imprecisioni sia per quanto
riguarda il profilo dello specchio che per la sua regolarità superficiale: nel nostro
caso solo una regione centrale e una esterna dello specchio possono essere
considerate corrispondenti al progetto, mentre tutta la regione intermedia è una
regione di passaggio dal profilo della sfera a quello del cono. Si sono inoltre
osservate imprecisioni anche dal punto di vista della simmetria assiale (ossia la
sezione perpendicolare all’asse non è perfettamente circolare ma piuttosto
leggermente ellittica) e delle irregolarità locali a livello della superficie riflettente.

Capitolo 3 Il sensore omnidirezionale 58
Nel 2001, in collaborazione con l’Università di Parma, è stato realizzato presso
l’Università di Ulm in Germania lo specchio utilizzato in questa tesi per l’analisi del
flusso ottico.
Le migliorie apportate rispetto alla precedente versione sono state notevoli.
La superficie esterna è composta da ottone ricoperto galvanicamente da Nichel.
Per la realizzazione, è stata utilizzata una macchina a controllo numerico con
risoluzione 20µ di modo da rendere ancora più continuo il profilo dello specchio del
quale sono state considerevolmente ridotte le dimensioni:
Fig. 3.5
Il principale miglioramento risiede nella regione che, in figura 3.5, è stata indicata
con il termine “Zona di collasso”.
In tale regione, infatti, anzichè mantenere il profilo sferico come nella precedente
versione, un intorno della zona a derivata prima nulla della calotta sferica collassa
in un cono al fine di annullare quasi del tutto l’occlusione dovuta al Robot sulla
parte centrale dell’immagine.

Capitolo 3 Il sensore omnidirezionale 59
3.3 Cenni sulla calibrazione e sulla rimozione prospettica di un sensore ominidirezionale
Un’eccellente lavoro riguardante questo argomento è stato svolto dall’Ing.
Bolognini durante la sua tesi di laurea basata principalmente sulla calibrazione del
sensore HOPS descritto in precedenza; per questo motivo si rimanda il lettore
interessato ad un approfondimento, alla lettura di tale tesi.
In questa sede mi limiterò a descrivere le principali tecniche di calibrazione,
argomento correlato con la mia tesi.
Il processo di formazione dell’immagine di una scena su una superficie implica che,
tra tutti i raggi luminosi riflessi o emessi dagli oggetti presenti nella scena, sia
possibile eseguire una selezione, in maniera che, idealmente, la luce proiettata su
diversi punti della superficie di formazione dell’immagine provenga da diversi
punti dello spazio della scena e, viceversa, diversi punti dello spazio proiettino luce
su diversi punti della superficie. Lo scopo del processo è quindi produrre sulla
superficie un’ immagine che sia una rappresentazione sufficientemente buona della
scena.
L’ottica di tutte le telecamere produce una distorsione delle immagini, generalmente
distinta in una componente radiale e una tangenziale, di solito trascurabile. In quasi
tutte le telecamere con angoli di apertura non superiori agli 80°, questo effetto di
distorsione è comunque molto limitato e un primo modello grossolano dell’ottica
può anche trascurarlo.
Analizziamo ora il fenomeno che va sotto il nome di effetto prospettico.
Trascurando la distorsione delle lenti (adottando quindi il cosiddetto modello pin-
hole per l’ottica della telecamera), l’effetto prospettico è il processo di proiezione
degli oggetti tridimensionali della scena reale nelle corrispondenti forme sulla
superficie di formazione dell’immagine.
In particolare questa proiezione si chiama proiezione geometrica planare, ed è

Capitolo 3 Il sensore omnidirezionale 60
caratterizzata dal fatto che la proiezione avviene su un piano e che le linee di
proiezione sono delle rette. La retta di proiezione di ogni punto della scena dello
spazio oggetto o passa per uno specifico punto detto centro di proiezione e da qui
interseca il piano di proiezione, se si tratta di una proiezione prospettica, o è
parallela ad un asse di proiezione unico per tutti i punti, se si tratta di una proiezione
ortografica.
La proiezione prospettica è un processo che determina la perdita di molte
informazioni: da un mondo tridimensionale si passa a una descrizione
bidimensionale, quindi le informazioni su dimensione, profondità e posizione
relativa degli oggetti si perdono.

Capitolo 3 Il sensore omnidirezionale 61
Si tratta di un processo non lineare e non reversibile che va a sommarsi a quello
delle distorsioni introdotte dall’ottica.
Un passo fondamentale verso il recupero di almeno una parte delle informazioni
perse durante il processo di formazione dell’immagine è la cosiddetta calibrazione
del sensore visivo. Nel caso più generale e classico questa consiste nel ricavare le
caratteristiche ottico-geometriche interne della telecamera, inerenti al modello
adottato della telecamera stessa (dette parametri intrinseci), e quelle esterne, cioè
l’orientazione ed il posizionamento della telecamera nello spazio (dette parametri
estrinseci). A partire da una precisa conoscenza di questi parametri e dall’utilizzo di
informazioni sull’ambiente di lavoro, o derivanti da sistemi di visione
stereoscopica, o derivanti ad esempio da sequenze di immagini, risulta possibile
recuperare informazioni sulla profondità, la distanza relativa e la forma degli
oggetti. Insomma si può cercare di aggiungere tridimensionalità alla conoscenza che
si ha della scena osservata. Tra le innumerevoli tecniche proposte in letteratura per
la calibrazione di telecamere, la principale è probabilmente quella di Tzai [Tzai,
1997].
Un modo di impiegare le informazioni sul sistema ottico ricavate dalla sua
calibrazione è quello che va sotto il nome di prospettiva inversa (IPM, Inverse
Perspective Mapping). Come descritto nello studio del processo di formazione
dell’immagine, le immagini fornite da una qualsiasi telecamera danno una
rappresentazione molto distorta della realtà: si ha una componente di distorsione
legata all’ottica della telecamera, ma soprattutto una distorsione geometrica legata
al processo di proiezione prospettica. La prospettiva inversa è un tecnica che vuol
rimappare le informazioni presenti nell’immagine I su una nuova immagine
rettificata R che dia una rappresentazione non distorta di ciò che appare su un
qualunque piano P preso come riferimento.

Capitolo 3 Il sensore omnidirezionale 62
Questa mappatura può essere così descritta:
Dati (k,m) come coordinate del pixel dell’immagine I che rappresenta il
punto (x,y) del piano P (ed è questa la relazione (k(x,y),m(x,y)) che la
calibrazione deve individuare) e I(k,m) la sua intensità, (i,j) le coordinate
del pixel dell’immagine rettificata R che rappresenta lo stesso punto (x,y)
del piano P e R(i,j) la sua intensità, a parte traslazioni nei sistemi di
riferimento,
i = round(x / Sens),
j = round(y / Sens),
R(i(x) , j(y)) = I(k(x,y) , m(x,y))
Dove Sens è la lunghezza del lato della regione quadrata di superficie del
piano P rappresentata da un pixel dell’immagine R.
Nel caso della navigazione, in cui questo piano di riferimento è tipicamente il piano
del pavimento, il risultato di questa operazione è la generazione di una mappa
dell’ambiente a livello pavimento: questa immagine sembrerà una fotografia
scattata dall’alto verso il basso ad una altezza considerevole da un obbiettivo privo
di distorsioni.
Fig. 3.6a Fig. 3.6b

Capitolo 3 Il sensore omnidirezionale 63
La figura 3.6b corrisponde alla 3.6a dopo l’applicazione della rimozione prospettica
tramite calibrazione empirica (descritta nel successivo paragrafo). Come detto in
precedenza , la nuova immagine sembra essere stata acquisita da un altezza
maggiore e si può notare come, in vicinanza del robot, si mantenga una buona
risoluzione mentre nell’area distante dal centro dell’immagine, la risoluzione vada
via via diminuendo.
Diamo, ora, una breve descrizione (non è infatti scopo di questa tesi) delle 2
principali tecniche di calibrazione presenti in letteratura.
3.3.1 Calibrazione geometrica o esplicita
Questa tecnica di calibrazione utilizza un modello molto simile a quello classico
impiegato da Tzai [Tzai, 1996].
Tramite la costruzione di un modello geometrico del sensore visivo, fondato sulla
conoscenza della posizione e dell’orientazione reciproca della telecamera e dello
specchio, dei parametri intrinseci della telecamera, della forma dello specchio, della
posizione e orientazione del piano di riferimento per l’inversione prospettica, il
modello permette di calcolare la relazione tra pixel dell’immagine e punti del piano
di riferimento. Per la telecamera si utilizza un modello pin-hole, ipotizzando che la
distorsione introdotta dall’ottica sia sferica e trascurando un’eventuale componente
tangenziale. In particolare, tra i parametri intrinseci della telecamera, solo gli angoli
di apertura e il coefficiente di distorsione radiale dell’ottica risultano essere rilevanti
ai fini del modello.
Ciò che si deve conoscere per applicare un algoritmo di calibrazione di questo tipo
è:
l’equazione radiale della forma dello specchio, che include anche l’altezza
di questo dal piano di riferimento;

Capitolo 3 Il sensore omnidirezionale 64
il coefficiente di distorsione dell’ottica;
la dimensione in pixel delle immagini acquisite;
l’angolo di apertura dell’ottica;
l’altezza del centro ottico dal piano di riferimento.
Questo algoritmo ha il vantaggio di suddividere tutti i componenti del catadiottro e
di analizzarli separatamente, in modo tale che la modifica di uno di essi o la
riorganizzazione nello spazio del sistema comporti solamente la necessità di
misurare i nuovi valori assunti dai parametri del modello (ad esempio l’altezza dello
specchio dal suolo, il coefficiente di distorsione di questa, l’equazione della forma
dello specchio) per ottenere una nuova calibrazione del sistema. D’altro canto non
sempre è possibile conoscere con precisione questi parametri e inoltre il sistema è
molto sensibile anche a piccoli errori in alcuni di questi.
3.3.2 Calibrazione empirica o implicita
Invece di creare un modello articolato che descrive separatamente tutte le parti del
sistema fisico (la telecamera con i suoi parametri intrinseci, lo specchio e la sua
forma, il posizionamento reciproco di questi, il piano di riferimento, eccetera), per
cercare di ovviare ai problemi visti nella tecnica geometrica, si è sviluppato un
algoritmo che anziché basarsi su un modello analitico, si fonda su basi strettamente
empiriche.
Si raccolgono un numero predefinito di punti campione di cui è nota la distanza dal
centro del sistema (che solitamente coincide con il robot).
I punti campione dovranno essere rappresentativi di tutte le regioni di interesse del
campo visivo, ed essere concentrati più densamente nelle regioni di maggior
importanza: la precisione locale dell’inversione prospettica sarà infatti
proporzionale a questa densità.

Capitolo 3 Il sensore omnidirezionale 65
Operando, poi, una semplice interpolazione lineare fondata sulle posizioni dei punti
campione, si riesce a rimappare tutta l’area di interesse dell’immagine sulla
superficie .
L’Ing. Bolognini, nel lavoro di tesi, ha scelto di utilizzare campioni presi da otto
direttrici equidistanti angolarmente.
Per quanto riguarda la rilevazione delle coppie di campioni, questa è un’operazione
che viene fatta con l’ausilio di un pattern di regioni bianche e nere che si alternano
regolarmente lungo una direzione (si veda l’immagine in figura 3.6a).
Dall’osservazione dell’immagine di figura 3.6b, si può notare come in molte regioni
siano presenti ancora notevoli distorsioni locali (si noti ad esempio la base della
porta sulla destra dell’immagine). Queste distorsioni sono da attribuire in gran parte
alla linearità dell’interpolazione utilizzata: usare un’interpolazione lineare equivale
ad approssimare la forma dello specchio tramite un insieme di quadrilateri, superfici
piane che accostate generano una superficie a gradiente discontinuo.
Esiste una terza tecnica di calibrazione (si veda tesi dell’Ing. Bolognini) che
permette di ridurre questi effetti distorcenti tramite una correzione basata su
polinomi approssimanti ma della quale non ci occuperemo in quanto è
un’estensione di quella empirica.

CAPITOLO 4 L’algoritmo SPY

Capitolo 4 L’algoritmo SPY 66
4.1 Applicazione ad un caso: ambiente RoboCup
RoboCup è un progetto internazionale per promuovere l’intelligenza artificiale
applicata ai robot puntando sul gioco del calcio come campo di ricerca.
Varie tecnologie vengono applicate a questo progetto: acquisizione di immagini,
elaborazione ed interpretazione dati in real-time e strategie di decisione .
Scindendo l’aspetto puramente meccanico di RoboCup, da quello elettronico ed
informatico possiamo affermare che quest’ultimo si basa principalmente sulla
visione artificiale in ambienti fortemente dinamici .
Si è pensato, quindi, di applicare lo studio del movimento tramite sensori
omnidirezionali al caso specifico delle competizioni tra Robot intelligenti e di
calibrare il sensore, rimuovendo la prospettiva, rispetto al piano rappresentato dal
campo da calcio delle competizioni RoboCup. (si veda Cap. 3)
Questo tipo di applicazione ha imposto dei vincoli che hanno influenzato le scelte
fatte durante la creazione del programma SPY. Tutto ciò verrà ampiamente
descritto nel corso di questo capitolo.
4.2 I vincoli imposti
In questo paragrafo saranno illustrate tutte le specifiche richieste per la soluzione al
problema .
• L’Algoritmo deve poter lavorare in real-time (ad esempio per applicazioni
in ambiente RoboCup).
• E’ necessario poter scegliere se analizzare i dati on-line (real-time) o off-
line per un analisi approfondita.
• I risultati devono essere affidabili in un intorno considerevole del sensore
visivo.

Capitolo 4 L’algoritmo SPY 67
• L’analisi del movimento deve poter rilevare spostamenti in qualsiasi
direzione .
• Devono essere presenti parametri che consentano di variare la sensibilità
dell’algoritmo al movimento.
• E’ necessario un potente filtraggio del rumore associato all’acquisizione ed
agli errori nel calcolo dei vettori di flusso ottico.
Come descritto nell’introduzione, lo studio del flusso ottico tramite sensore
omnidirezionale, richiedeva scelte assai differenti da quelle adottate ad esempio
dall’Ing. Maris , dall’Ing. Ampollini nelle loro tesi o da Barnard & Thompson.
Essi, infatti, hanno sviluppato algoritmi operanti su immagini piane, indipendenti,
quindi, da tutto ciò che è l’ IPM (Cap. 3).
Analizziamo ora, alcune delle specifiche sopraelencate.
Lavorare in real-time (o on-line) è indispensabile per il caso delle competizioni
RoboCup nelle quali il contesto è un ambiente dinamico dove sono presenti oggetti
fermi (campo da calcio cromaticamente uniforme e righe del campo) o in
movimento (palla ed altri robot). Questo aspetto del problema ha richiesto di
valutare la velocità di acquisizione-elaborazione di SPY.
Al fine di testare la qualità dell’algoritmo, si rende necessario poter lavorare anche
off-line: acquisendo 2 immagini significative e visualizzandone il flusso ottico al
variare di alcuni parametri, si può trovare la combinazione ideale dei valori che
questi parametri devono assumere per poi utilizzarli on-line.
Questo strumento di calibrazione dell’algoritmo ha permesso di migliorare la
qualità e l’affidabilità dei dati forniti in output da SPY.
L’aspetto dell’affidabilità è critico in questo contesto, in quanto le decisioni prese
dal robot si basano sulle posizioni di altri oggetti (fermi o in movimento) ricavabili
dai vettori di flusso ottico.
Uno dei problemi incontrati è relativo alla risoluzione delle immagini acquisite dal
robot : questa, una volta rimossa la prospettiva dall’immagine, diminuisce
allontanandosi dal robot stesso. Ecco perché una volta definito l’algoritmo si è reso
necessario testarne la validità al variare della posizione degli oggetti considerati .

Capitolo 4 L’algoritmo SPY 68
Se le risorse a mia disposizione si fossero concentrate sull’individuazione del
movimento in una direzione preferenziale, come accade nelle applicazioni per il
riconoscimento di targhe (vedi tesi di Ampollini), si sarebbe ottenuta una maggior
densità di vettori di flusso ottico ma si sarebbe altresì snaturato lo scopo per il quale
è stato costruito il sensore HOPS; è stato quindi necessario sviluppare operatori di
rivelazione del movimento che operassero in tutte le direzioni a scapito della
velocità di elaborazione e della densità dei dati da analizzare.
4.2.1 Le scelte strumentali Elenchiamo i componenti meccanici, hardware e software utilizzati in questa tesi:
• Sensore omnidirezionale HOPS nella versione utilizzante lo specchio
costruito presso l’Università di Ulm
• 2 Framegrabber BT 878 montati sul robot “ Galavron ”
• Video for Linux come interfaccia tra il framegrabber e la memoria del
computer.
• Ambiente di sviluppo/programmazione : Linux / C, C++ con compilatore
GNU g++.
• Librerie grafiche QT2 Trolltech integrate con quelle standard di Linux.
• Computers : un PC AMD K6 350MHz ed un PC Pentium III 600 .
Fig. 4.1

Capitolo 4 L’algoritmo SPY 69
In figura 4.1 vengono rappresentati schematicamente gli elementi usati per lo
svolgimento del lavoro.
In realtà la maggior parte delle prove effettuate off-line sono state svolte con una
configurazione che prevedeva il framegrabber installato sul PC. La lentezza del
trasferimento dati tra il computer+framegrabber montato sul robot ed un display per
la visualizzazione dei risultati ha reso impossibile le prove on-line direttamente da
Galvron. Per questa ragione all’esecuzione di SPY viene caricata in memoria una
sequenza di 10 immagini significative (visualizzabile sull’interfaccia grafico del
programma) che simula un processo on-line.
4.3 L’algoritmo
Per la descrizione, si supponga di avere acquisito 2 immagini che chiameremo Old
e New, di averle trasformate (ove necessario) in immagini a 256 livelli di grigio (8
bit per pixel) e di averle depositate nella memoria del computer sottoforma di
matrice bidimensionale.
Le parti costituenti il “cuore” dell’algoritmo sono le seguenti:
1. Filtraggio in ingresso del rumore associato ai frame Old e New.
2. Estrazione dei contorni.
3. Rimozione prospettica.
4. Ottimizzazione della fase 6 tramit rilevamento dei 15 codici più
rappresentativi da associare a tutti i pixel di uno dei 2 frame .
5. Sottrazione del fondo tramite un confronto tra istogrammi.
6. Codifica soft 3×3.
7. Estrazione del flusso ottico tramite matching .
8. Filtraggio finale del rumore fatto sui vettori di flusso ottico.

Capitolo 4 L’algoritmo SPY 70
4.3.1 Filtraggio del rumore associato ai frame in ingresso
La teoria sugli operatori di filtraggio è stata descritta nel Cap. 1. In questa sede
saranno illustrate le scelte fatte ed i motivi che mi hanno condotto ad esse.
Per testare le prestazioni dei tre filtri vengono caricate, nella memoria del
calcolatore, 2 acquisizioni consecutive della medesima scena pertanto Old coincide
con New.
E’ stato verificato l’effetto del filtraggio controllando l’immagine dei contorni e a
posteriori, i valori di flusso ottico.
Fig. 4.2
In figura 4.2 è mostrato come il rumore unitamente alle variazioni di luminosità
“sporchi” le zone interne ai bordi.
Un buon filtraggio agisce sull’estrazione dei contorni nel seguente modo:
Produce contorni sottili
Per oggetti cromaticamente uniformi, tutta la regione di pixel all’interno dei
contorni dovrebbe risultare bianca, quindi ad un livello di grigio pari a 255.
Il numero di pixel neri entro tale regione (indice appunto di rumore)
dovrebbe essere limitato.

Capitolo 4 L’algoritmo SPY 71
Da questa prima analisi, il filtro più accurato è risultato (come prevedibile) il filtro
Unsharp Masking con gaussiana.
Soddisfacenti sono state le prestazioni con il filtro Gaussiano e sufficienti quelle
con il filtro quantizzatore a due bit di soppressione.
Successivamente si sono analizzate le immagini di flusso ottico .
Avendo, infatti, caricato in memoria 2 acquisizioni della medesima scena, se il
sistema fosse esente da rumore aleatorio, ci si aspetterebbe un flusso ottico uguale a
zero ovunque (nulla si è mosso). Successivamente, scrivendo su file di testo tutti i
vettori di flusso ottico, ho potuto valutare al variare dell’operatore di filtraggio,
quanti pixel presentavano valori di flusso diversi da 0 , quindi in che quantità il
rumore aveva agito sull’immagine.
I risultati sono riportati nella seguente tabella:
Tipo di filtro n° pixel totali n° pixel con f.o. ≠ 0
Unsharp Masking + gauss. 512×384 = 196608 19
Gaussiano 512×384 = 196608 25
Quantizzatore a 2 bit 512×384 = 196608 35
Quantizzatore a 3 bit 512×384 = 196608 27
Una prima stesura dell’algoritmo prevedeva l’utilizzo del filtro Unsharp Masking.
Tuttavia, procedendo con il lavoro, si è realizzato che il rallentamento dovuto
all’utilizzo di questo operatore (causato dai calcoli in virgola mobile) era accettabile
per un’analisi off-line ma, se sommato ai tempi di calcolo delle altre parti
dell’algoritmo, insostenibile per il real-time.
Si è scelto, perciò, di utilizzare il filtro quantizzatore a 3 bit di soppressione, il
quale richiede una semplice operazione di shift a destra di 3 posizioni della
“parola” rappresentante il livello di grigio.
Ciò che si perde in termini di qualità a causa dell’utilizzo di questo operatore verrà
compensato (o quasi) tramite l’ultimo passo dell’algoritmo: il filtraggio finale del
rumore fatto sui vettori di flusso ottico.

Capitolo 4 L’algoritmo SPY 72
4.3.2 Estrazione dei contorni
Nell’algoritmo sviluppato, il processo di segmentazione viene fuso con quello di
estrazione dei contorni.
L’operazione di estrazione degli edge è alla base di molte applicazioni nel campo
della visione artificiale; da essa dipende la consistenza dei dati elaborati ed
un’immagine dei contorni “pulita” porta a risultati migliori.
Si rende per questo necessaria un’accurata scelta sul tipo di estrattore da utilizzare
tra quelli descritti in letteratura (vedi Cap. 1); scelta che, in questo caso, è stata
dettata semplicemente da osservazioni su vari tipi di immagini riportate nelle figure
1.4, 1.5, 1.6 e 1.7 del Cap. 1.
L’importanza di questo passo e le conseguenze che esso provoca sul resto delle
operazioni dell’algoritmo è fondamentale.
Non esiste, infatti, un’estrattore migliore in assoluto ma la scelta dipendende dal
tipo di immagine e dalla dinamica dei livelli di grigio; per questo motivo ho scelto
di rendere disponibili tutti e 4 gli operatori di estrazione dei contorni potendo
altresì agire in tempo reale sul valore di soglia e utilizzare, a seconda del contesto,
quello ottimale per lo scopo.
4.3.3 Rimozione Prospettica IPM
L’algoritmo SPY lavora correttamente su immagini piane e su quelle acquisite
dal sensore omnidirezionale HOPS montato sul robot “Galavron” .
Dopo aver operato sull’immagine tramite filtraggio del rumore ed estrazione dei
contorni, nel caso specifico di immagini omnidirezionali è previsto l’utilizzo
dell’IPM (descritta nel Cap. 3) riferita ad esempio al piano coincidente con il campo
da calcio delle competizioni RoboCup.
Ricordo che una delle principali informazioni che il flusso ottico contiene è di tipo
spaziale ossia: SPY deve poter affermare con un margine di errore minimo che, ad

Capitolo 4 L’algoritmo SPY 73
esempio, il pixel di coordinate (235,178) si è spostato in (237, 180). Quindi,
conoscendo a priori la risoluzione dell’immagine ( a quanti cm o mm corrisponde un
pixel) ottengo lo spostamento fisico cui viene sottoposto il pixel e, ripetendo il
calcolo per tutti i punti che hanno variato la loro posizione appartenenti ad un
determinato oggetto della scena, riesco a stimare di quanto si sia spostato un
oggetto tra un frame (Old) ed il successivo (New).
Per applicare questo principio alle immagini fortemente distorte acquisite con
HOPS, occorre “ricostruire” l’ambiente che circonda il sensore. Di questo si occupa
l’IPM la quale elimina, in gran parte, la distorsione introdotta dallo specchio del
sensore omnidirezionale, fornendo in uscita un’immagine piana e “raddrizzata” in
cui le coordinate reali di ogni punto della scena vengono ricavate tramite la distanza
in pixel dal centro del robot.
Fig. 4.3a Fig. 4.3b
In figura 4.3a è mostrata l’immagine (con prospettiva) acquisita dal sensore ibrido
omnidirezionale (nell’algoritmo la rimozione prospettica viene eseguita
sull’immagine dei contorni ma il principio non cambia).
Si può notare una forte distorsione, ad esempio, sulle linee bianche del campo da
calcio ed alla base delle pareti laterali.
In figura 4.3b è stata rimossa la prospettiva, l’immagine è raddrizzata e si intuisce
un aspetto critico dopo questa applicazione: nell’allontanarsi dal centro

Capitolo 4 L’algoritmo SPY 74
dell’immagine (il robot) la risoluzione tende a calare. Questo fenomeno determinerà
un’incongruenza tra i dati misurati sperimentalmente e quelli forniti da SPY su
oggetti posizionati là dove la risoluzione è bassa. Uno scopo di questa tesi era
quantificare tale errore, tentare di correggerlo e stimare a quale distanza dal robot i
dati diventano inaffidabili.
Come viene eseguita l’IPM :
La rimozione della prospettiva si basa su una mappatura dell’ambiente circostante
al robot ottenuta mediante calibrazione semi-empirica del sensore HOPS (si veda
Cap. 3).
L’output di questa calibrazione è la Look-up-Table ; una tabella sotto forma di file
di testo la quale, per ogni pixel dell’immagine con prospettiva, fornisce la posizione
del corrispondente pixel appartenente all’immagine con prospettiva rimossa.
Le specifiche per una corretta applicazione dell’IPM tramite la tabella Look-up-
Table sono:
• Grabbaggio di immagini tramite BT878 ad una risoluzione di 512×384.
• Risoluzione dell’immagine con prospettiva rimossa : 307×307
• Coordinate in pixel del centro del robot 153×153
Non essendo argomento principale di questa tesi mi limiterò a descrivere il metodo
formato della Look-up-Table, utile per l’algoritmo sviluppato:
La prima riga, ad esempio, sta a significare che il pixel di
coordinate (193,10), dell’immagine con prospettiva rimossa,
corrisponde al pixel (305,25) dell’immagine originaria.
Il numero 1 a fianco indica che il pixel appartiene alla zona
dell’immagine interna al cerchio visibile in figura 4.3a e
4.3b. Se vi fosse il numero 0 vorrebbe dire che il punto in
questione dell’immagine originaria è esterno a tale circonferenza così come sarà
esterno nell’immagine con prospettiva rimossa.

Capitolo 4 L’algoritmo SPY 75
SPY è stato quindi dotato di uno switch per consentire la scelta di eseguire o meno
la rimozione prospettica a seconda che, rispettivamente, si lavori con il robot o con
immagini piane.
4.3.4 Estrazione dei 15 codici significativi
A questo punto, il rumore è filtrato, i contorni estratti e, ove necessario si è
applicata la rimozione prospettica.
Avendo optato per un algoritmo basato sul MATCHING di elementi significativi
dell’immagine, si imponeva una scelta su quali fossero questi elementi.
Tra tutte le possibili assegnazioni, si è scelto di confrontare, tra Old e New, le forme
di un intorno 3×3 centrato su ogni pixel dell’immagine codificando queste forme
tramite un numero binario a 9 bit.
Si è così mantenuta una stretta analogia con l’algoritmo proposto da Maris .
Si può notare dalla figura 4.4 come, focalizzando l’attenzione su un singolo punto,
si possa isolare un intorno 3×3 di ogni pixel dell’immagine dei contorni.
Fig. 4.4

Capitolo 4 L’algoritmo SPY 76
Definendo rows il numero di righe e cols il numero di colonne della matrice
bidimensionale nella quale ogni elemento è un pixel dell’immagine, si scorre il
singolo frame dall’alto a sinistra (rows = 1, cols =1 ) fino ad arrivare in basso a
destra (rows = Image_Height-1, cols = Image_Width-1) centrando una maschera
3×3 su ogni pixel al quale verrà associato un codice (un numero intero) secondo la
seguente regola:
Si scorre la maschera partendo dal punto 0 dove è presente il pixel al quale si sta
assegnando il codice fino al punto 8; si assegna valore logico “0” al pixel a livello
di grigio pari a 255 (bianco) o valore logico “1” se si trova un pixel nero.
Il codice sarà rappresentato dal numero decimale corrispondente.
Esempio:
Essendo rappresentato da un numero binario a 9 bit, il codice si potrà presentare in
512 combinazioni diverse, assumendo valori ∈ [0 , 511].
E’ importante a questo punto, osservare come l’algoritmo di Maris sia stato
sviluppato e successivamente testato su immagini piane e cromaticamente semplici;
l’idea di base rimane la stessa, ossia il confronto viene fatto sugli stessi elementi ma
Maris ed Ampollini, non dovendo agire su immagini fortemente distorte, hanno

Capitolo 4 L’algoritmo SPY 77
imposto un vincolo alle possibili combinazioni di 1 e 0 che il codice poteva
assumere.
“Da studi statistici, effettuati su immagini piane, si dimostra come tra le 512 forme
del codice,ne risultino significative solo 15 le quali sono quasi sempre le stesse per
ogni immagine.” [Maris].
I 15 valori ricavati da Maris vengono riportati di seguito:
480 312 270 387 483 504 318 399 497 380 287 455 290 392 511.
In realtà dovrei riportare anche il codice 0 (intorno di pixel bianchi) ma ai fini di
calcolo del flusso ottico non è rilevante.
Una prima stesura dell’algoritmo prevedeva l’utilizzo di questa teoria grazie alla
quale si alleggeriva il carico computazionale.
Testando SPY su immagini piane, ho potuto riscontrare eccellenti risultati che
tuttavia peggioravano notevolmente al momento di utilizzo delle immagini distorte
acquisite tramite HOPS.
Ho quindi dedotto che l’ipotesi di Maris, nel caso di tali immagini, non fosse
rigorosamente valida.
E’ stata quindi studiata la statistica, su un insieme considerevole di acquisizioni,
sulla frequenza di ripetizione ed i valori con cui le combinazioni dei codici si
presentavano nelle immagini distorte.
I risultati vengono riportati di seguito:
Tipo di immagine Codici
Omnidirez. senza IPM 28 193 318 483 7 112 399 504 415 18 69 432 447 507 380
Omnidirez. con IPM 28 483 318 7 193 112 504 399 116 16 392 69 432 495 381
Si può notare una differenza superiore al 50% in entrambi i casi rispetto ai codici di
Maris.
In teoria ci si dovrebbe aspettare che i codici dell’immagine alla quale viene
applicata l’IPM coincidano approssimativamente con i 15 fissi elencati in
precedenza in quanto, in entrambi i casi, si tratta di osservazioni su immagini piane.

Capitolo 4 L’algoritmo SPY 78
Probabilmente questa discrepanza nasce dalle forti distorsioni introdotte dallo
specchio presenti in minima parte nell’immagine raddrizzata e da una risoluzione
non uniforme su tutta l’immagine con IPM.
Tengo a precisare che i codici riportati in tabella, variano anche al variare del tipo
di estrattore dei contorni selezionato.
Tutto ciò ha comportato la seguente scelta:
Si estraggono i 15 codici ( da Old o da New) che si presentano con maggior
frequenza, memorizzandoli in un array lineare in ordine decrescente insieme al
numero di volte col quale si presentano nell’immagine.
L’utilizzo di quest’ultimo dato verrà chiarito più avanti.
Abbandonando del tutto l’idea di 15 codici fissi ho reso l’algoritmo più pesante ma
certamente ho migliorato la validità dei dati per lo scopo al quale questa tesi mira.
Ci si potrebbe, a questo punto, porre le seguenti domande: è necessario (lavorando
on-line ad esempio) ricavare i codici per ogni coppia di Old e New ? Non sarebbe
sufficiente trovare questi codici per le prime 2 o 3 coppie di immagini ?
Precisiamo che, a meno di drastici cambiamenti di oggetti o di sfondo, i 15 codici
rimarranno circa gli stessi.
La scelta di ricavare continuamente i codici o meno sarà motivata nel seguente
paragrafo.
4.3.5 Sottrazione del fondo tramite confronto tra istogrammi
Lavorando on-line ci si imbatte in un fastidioso fenomeno indipendente dal rumore
aleatorio o dall’algoritmo utilizzato: quando di una scena si visualizza lo sfondo,
in teoria si dovrebbe osservare una situazione dinamicamente stabile (nulla si
muove) ⇒ flusso ottico uguale a zero ovunque.

Capitolo 4 L’algoritmo SPY 79
In realtà non è così; infatti, a causa di impercettibili movimenti di tutte le parti del
sensore, accade che, nonostante nulla si sia mosso, Old e New non siano
esattamente la stessa immagine.
Visualizzando il flusso ottico si noterà visivamente del rumore (che per
convenzione viene chiamato rumore di oscillazione del sensore) inteso come pixel
in movimento (anche significativo) in direzioni casuali aventi vettori di flusso ottico
diversi da zero i quali si sommeranno “visivamente” a quelli utili nel momento in
cui un generico oggetto si muoverà nella scena.
E’ stata applicata allora un tecnica di sottrazione del fondo sfruttando i 15 codici
trovati in precedenza che vado ora ad illustrare.
Si estraggono, dall’immagine dello sfondo, i 15 codici significativi
memorizzandoli in un array lineare in ordine decrescente (in analogia a quanto
fatto per le immagini Old o New).
E’ inoltre indispensabile, ricavare un istogramma della frequenza con cui ognuno
dei 15 codici si presenta nell’immagine.
Questi codici sono rappresentativi di ciò che tra Old e New è rimasto immobile e
forniranno agli istogrammi delle immagini in movimento un contributo pressoché
costante.
Una volta estratti i 15 codici di Old o New procedo alla sottrazione degli
istogrammi.
I codici che sopravviveranno a questa differenza, tramite opportune regole di
selezione, saranno quelli che userò nella successiva fase dell’algoritmo.
Queste regole devono essere dettate dal buon senso; ricordando che il contributo
portato ad esempio da una palla (posta nel campo da calcio dei robot) in termini di
numero di presenze di un determinato codice sarà certamente modesto rispetto a
quello portato dall’immagine di fondo a quello stesso codice.
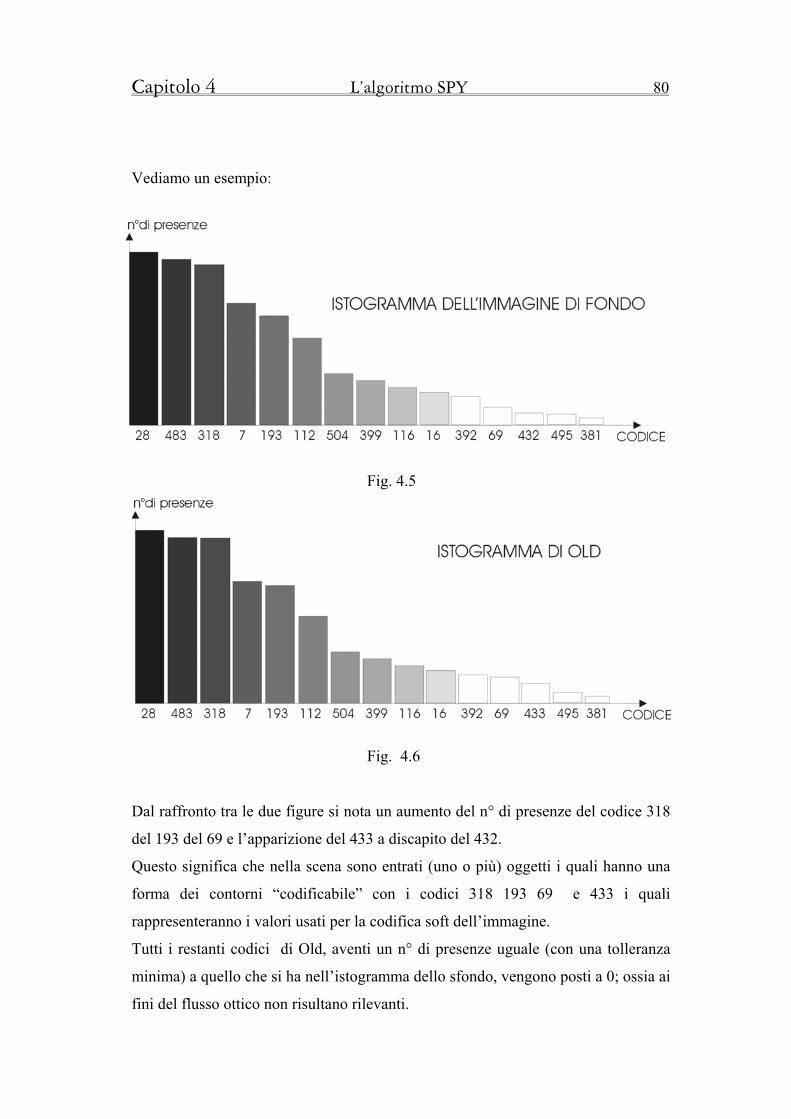
Capitolo 4 L’algoritmo SPY 80
Vediamo un esempio:
Fig. 4.5
Fig. 4.6
Dal raffronto tra le due figure si nota un aumento del n° di presenze del codice 318
del 193 del 69 e l’apparizione del 433 a discapito del 432.
Questo significa che nella scena sono entrati (uno o più) oggetti i quali hanno una
forma dei contorni “codificabile” con i codici 318 193 69 e 433 i quali
rappresenteranno i valori usati per la codifica soft dell’immagine.
Tutti i restanti codici di Old, aventi un n° di presenze uguale (con una tolleranza
minima) a quello che si ha nell’istogramma dello sfondo, vengono posti a 0; ossia ai
fini del flusso ottico non risultano rilevanti.

Capitolo 4 L’algoritmo SPY 81
Vantaggi:
• Il match viene eseguito su un numero di codici (che da questo punto in
avanti chiamerò “sopravvissuti”) certamente inferiore a 15. Dato che i
passaggi sul calcolo delle corrispondenze, vengono ripetuti iterativamente su
ogni pixel dell’immagine, si ottiene un buon guadagno di velocità di
elaborazione.
• L’analisi visiva dei vettori di flusso ottico dovuti al rumore di oscillazione
del sensore, ha confermato una riduzione di questi pari a circa il 40 %.
Svantaggi:
• Quello che si guadagna sulla velocità di esecuzione grazie al risparmio di
codici utilizzati, si perde abbondantemente a causa della continua estrazione
dei 15 codici di Old o di New.
• La fase di sottrazione degli istogrammi richiede inoltre del tempo
computazionale tutt’altro che trascurabile.
La soluzione migliore, riguardo alla scelta se ricavare o meno in modo continuo i 15
codici significativi per poi applicare la sottrazione del fondo tramite istogrammi, è
sembrata quella di dotare SPY di uno switch per permettere all’operatore di attivare
questo processo nel momento ad esempio, di un considerevole cambiamento della
scena.

Capitolo 4 L’algoritmo SPY 82
4.3.6 Codifica Soft 3×3
E’ il passo finale prima di eseguire il matching.
Si costruisce, in memoria, una matrice bidimensionale “COD” che dovrà contenere
i codici di ogni pixel, si attraversano entrambe le immagini Old e New (dall’angolo
in alto a sinistra fino a quello in basso a destra), si applica una maschera 3×3
centrata iterativamente su ogni pixel e si confronta il codice con quelli restanti dalla
sottrazione degli istogrammi secondo le seguenti regole:
1. Si parte operando un confronto a “distanza 0” il che vuol dire che solo se il
valore decimale del codice del pixel (i , j) di Old o di New coincide con uno
dei codici sopravvissuti, assegnerò all’elemento COD[i,j] il valore di tale
codice, uscendo dall’iterazione , saltando il passo n°2 e centrando la
maschera 3×3 sul successivo pixel.
2. Se il confronto a distanza 0 non dovesse rivelare la presenza di alcun codice
valido, ripeto il procedimento ma questa volta a “distanza 1”. Ciò significa
fare la somma degli XOR bit a bit tra il numero binario rappresentante il
codice di Old o New e quello rappresentante in ordine decrescente uno dei
codici sopravvissuti .La prima di queste somme equivalente ad 1 rappresenta
una corrispondenza valida a distanza 1 ⇒ si esce dal ciclo di iterazione e si
memorizza il risultato in COD [i,j].
3. Nel caso di “mancata corrispondenza” (anche il confronto a distanza 1
fallisce) si assegna il valore 0 a COD [i,j]
4. Quando il processo è completato per ogni pixel si pongono a valore 0 tutti
gli elementi del contorno della matrice COD ossia la prima ed ultima riga e
la prima ed ultima colonna.
Ciò è dovuto al fatto di aver applicato una maschera 3×3 ai pixel; ragion per
cui non si poteva centrare tale maschera sugli elementi con rows = 0 cols = 0
e con rows = Image_Height e cols = Image_Width.

Capitolo 4 L’algoritmo SPY 83
Vediamo un esempio di tentativo riuscito a distanza 0:
Vediamo un esempio di tentativo riuscito a distanza 1:
Il nome Soft abbinato a questa codifica deriva dal fatto di accettare come valide
anche corrispondenze a distanza diversa da 0 (in caso contrario infatti si sarebbe
chiamata Codifica Hard).
La scelta è dettata dal fatto di voler evitare di perdere informazioni utili sul singolo
pixel; utilizzando infatti una codifica di tipo Hard, si sarebbero posti a zero troppi

Capitolo 4 L’algoritmo SPY 84
elementi della matrice COD ottenendo un numero di vettori di flusso ottico diversi
da zero troppo basso per un’analisi del movimento della scena.
Si applica quindi un fattore di tolleranza su questa selezione; bisogna accettare il
fatto che nel movimento compiuto da Old a New, il singolo pixel può avere
cambiato la forma del suo intorno.
4.3.7 Estrazione del flusso ottico
Paradossalmente, è il processo più semplice dell’intero algoritmo.
Si hanno a disposizione 2 matrici bidimensionali contenenti i codici : COD_Old e
COD_New.
E’ necessario crearne altre due di dimensioni rows × cols chiamando OFX quella
che conterrà le componenti orizzontali del flusso ottico e OFY quella che conterrà
le componenti verticali.
Per ricavare il flusso, è necessario eseguire il MATCHING tra COD_Old e
COD_New attraversando COD_Old dal pixel di cordinate rows = a e cols = b
fino a quello di cordinate rows = Image_Height - a e cols = Image_Width – b
dove a e b dipendono dal tipo di operatore usato per eseguire il matching .
Durante questo processo iterativo, vengono assegnati (per ogni elemento della
matrice COD_Old) i valori di OFX e OFY secondo la seguente regola:
1. Una maschera, chiamata operatore, viene centrata sull’elemento (i , j) di
COD_New.
2. Si attraversa l’operatore con spostamenti predefiniti. Questa operazione
termina nel momento in cui si individua il primo match valido:
COD_New [i ± yoffset , j ± xoffset ] ≡ COD_Old [i , j] .
If ( yoffset > Ky ) and ( xoffset > Kx )

Capitolo 4 L’algoritmo SPY 85
⇒ OFX [i , j] = xoffset ; OFY [i , j] = yoffset
dove Ky e Kx dipendono dal tipo di operatore utilizzato.
Nel caso si trovasse un match valido entro un rettangolo di dimensioni Kx e
Ky (i quali assumono valori piccoli rispetto alle dimensioni dell’operatore):
OFX [i , j] = 0 ; OFY [i , j] = 0
Ossia si considera non rilevante lo spostamento del pixel (i , j) .
Ipotizzo questo scostamento come dovuto in primo luogo al rumore di
oscillazione del sensore o a qualsiasi altra fonte di rumore.
3. Nel caso non si trovino match validi entro il campo di azione
dell’operatore:
OFX [i , j] = 0 ; OFY [i , j] = 0 .
Si riporta a questo punto un’esempio di match valido con le seguenti caratteristiche
: COD_Old [i , j] = 28, Kx = 2 , Ky = 3 , operatore di tipo 5×6R .
La convenzione adottata sui nomi degli operatori segue le seguenti regole: il primo
numero indica l’altezza in pixel , il secondo numero indica la larghezza e la lettera o
la parola posta alla fine del nome si riferisce al metodo di scorrimento
dell’operatore (in questo caso ad esempio , R indica una scansione dell’operatore da
sinistra a destra) .

Capitolo 4 L’algoritmo SPY 86
⇒ OFX [i , j] = 2 ; OFY [i , j] = -1.
Il pixel (i , j) di Old al quale era stato assegnato un codice = 28 , viene individuato
in (j + 2 , i – 1).
Nelle stesse ipotesi precedenti vediamo ora un esempio di match non valido a causa
del limitato scostamento dalla posizione di Old .

Capitolo 4 L’algoritmo SPY 87
Il pixel con codice = 28 è individuato entro il rettangolo di dimensioni Kx e Ky per
cui : OFX [i , j] = 0 ed OFY [i , j] = 0 .
Riportiamo infine, un ultimo esempio di match non valido:
In questo caso il pixel è uscito dal campo di azione dell’operatore prescelto; ci
troviamo, quindi, in una situazione di “perdita del pixel”.
Questo tipo di situazione può essere facilmente evitata allungando (in riferimento
all’esempio precedente) la forma della maschera dell’operatore.
La soluzione proposta va però a discapito della velocità di esecuzione del matching
il quale verrà eseguito su un numero di pixel crescente con l’aumentare delle
dimensioni (sia verticali che orizzontali) .
Occorre, quindi, ponderare la scelta del tipo di operatore a seconda della scena e
della direzione del movimento da analizzare.
Verranno illustrati dettagliatamente, in seguito, gli operatori sviluppati sulla base di
osservazioni su numerose coppie di immagini Old e New.

Capitolo 4 L’algoritmo SPY 88
4.3.8 Filtraggio finale del rumore sui vettori di flusso ottico
Ricordiamo brevemente le operazioni di filtraggio del rumore fino a qui svolte:
Applicazione del filtro quantizzatore (a 3 bit di soppressione) ad Old e New
per un filtraggio del rumore aleatorio.
Sottrazione del fondo tramite un confronto tra istogrammi per eliminare il
rumore di oscillazione del sensore.
Eliminazione di scostamenti piccoli dei pixel rispetto alla loro posizione in
Old.
Nel visualizzare il flusso ottico, purtroppo, si è verificato come una discreta
componente di rumore si sommasse ai dati in uscita da SPY.
Venivano infatti riconosciuti degli spostamenti (anche rilevanti) di pixel isolati in
zone dove, in teoria, nulla nella scena si era mosso.
E’ ragionevole pensare che un oggetto di dimensioni non infinitesime del quale si
rileva lo spostamento fornisca, in un intorno della sua posizione in Old, una densità
di vettori di flusso ottico molto maggiore rispetto a quella dovuta a pixel isolati
descritta in precedenza come fonte di rumore.
Si è quindi optato per un filtraggio ulteriore da applicare ai valori di flusso ottico
presenti nelle due matrici OFX ed OFY secondo il seguente schema:
puntando all’elemento (i , j) di OFX e di OFY viene contato il numero di elementi
in un intorno 3×3 di (i , j) che hanno OFX o OFY diversi da zero. Se tale numero
risulta essre < di una determinata soglia (è stato empiricamente determinato che 3
può essere considerato un valore ragionevole) si annulla il flusso ottico per
l’elemento (i , j) .
Grazie a quest’ultima operazione, la componente di rumore descritta in precedenza
risulta notevolmente diminuita rendendo l’immagine del flusso ottico più “pulita”
ed i dati maggiormente affidabili.

Capitolo 4 L’algoritmo SPY 89
Il valore di soglia citata in precedenza (che da ora in avanti sarà chiamata intensità
del filtraggio finale), entro il quale si annulla il flusso ottico, è stato reso variabile
da un minimo di 0 (nessun filtraggio) ad un massimo di 5.
4.4 Gli operatori di MATCHING
Un paragrafo a parte meritano la scelta e la descrizione degli operatori di matching
sviluppati; da essi infatti dipende una precisa individuazione del movimento.
L’operatore ideale è quello che stima il movimento in una direzione nota a priori;
conoscendo infatti la direzione con la quale un oggetto della scena si muove ricavo
la forma adatta dell’operatore da applicare.
Queste ipotesi divengono inapplicabili nel caso di analisi in tempo reale di
movimento omnidirezionale.
Nel caso specifico di questa tesi (sensore omnidirezionale) occorre riconoscere
spostamenti di oggetti in tutte le direzioni; si perderebbe altrimenti il vantaggio
dovuto all’utilizzo del sensore ibrido HOPS.
Per questo motivo, per una prima analisi dell’algoritmo vengono utilizzati gli
operatori precedentemente progettati da Maris ma per il corretto funzionamento di
SPY sono state progettate in seguito maschere assai differenti con metodi di
scansione adatti allo scopo.
Occorre sempre tenere presente il compromesso tra precisione dell’operatore e
velocità di esecuzione dell’algoritmo; una maschera di elevate dimensioni ha il
vantaggio di rilevare spostamenti in pixel considerevoli ossia “vede” oggetti veloci
ma, dovendo eseguire il matching su molti pixel, (date appunto le dimensioni)
diminuisce l’efficienza dell’algoritmo.
Gli operatori che verranno illustrati sono stati dimensionati ed utilizzati all’interno
dell’algoritmo, dopo numerose prove effettuate su coppie di immagini Old e New.
Capitolo 4 L’algoritmo SPY 90
• Operatore 7×15R :
E’ preciso nel rilevare il movimento verso destra ; sui primi elementi ha una
scansione a chiocciola per poi divenire lineare (dall’alto al basso) su tutto il resto
della maschera.
La sua portata è di 14 pixel in lunghezza e di 3 in altezza ed il numero di
pixel su cui esegue il matching è pari a 104.
Ottimo per un’analisi off-line al fine di settare alcuni dei parametri citati nei
paragrafi precedenti ma inadatto per lavorare on-line con le immagini
acquisite da HOPS.
Si omette di riportare l’operatore 7×15L in quanto risulta essere speculare
rispetto al 7×15R.
• Operatore 11×11 a chiocciola:

Capitolo 4 L’algoritmo SPY 91
Su tutta l’area ha una scansione di tipo chiocciola; è in grado di rilevare il
movimento in qualsiasi direzione. Esegue il matching su 120 elementi ed ha una
portata max. di 5 pixel in tutte le direzioni.
Non è stato ritenuto utile estendere le dimensioni di questo operatore di modo
da aumentarne la portata. Infatti per fare ciò, si rendeva necessario passare ad un
operatore di tipo 13×13 il che comportava un matching su 168 elementi.
Quindi per aumentare la portata di un solo pixel in tutte le direzioni sarebbe
stato necessario eseguire il confronto su 48 elementi in più rispetto all’ 11×11 ;
considerando questo incremento per ogni pixel dell’immagine si sarebbe
introdotto un ritardo non trascurabile nella catena dell’algoritmo.
• Operatore 21×21 Explosion:
Questo operatore raddoppia la propria portata rispetto al precedente (10
pixel in tutte le direzioni) mantenendo a 160 il numero di elementi su cui
fare il match .
Tutto ciò a discapito della precisione e della densità dei vettori di flusso
ottico. Come si nota dalla figura, infatti, il match viene eseguito solo sui
quadrati anneriti partendo dal nucleo centrale (il pixel (i , j) ) e spostandosi
verso l’esterno. Si perde una discreta parte di informazione sullo

Capitolo 4 L’algoritmo SPY 92
spostamento di un oggetto di piccole dimensioni ma mediamente su oggetti
come palle o altri robot, il flusso dati è sufficiente per stimare il movimento.

CAPITOLO 5 Programma, test e risultati

Capitolo 5 Programma, test e risultati 92
5.1 Il programma SPY
Durante la definizione dell’algoritmo, si è evidenziata l’importanza di disporre di
uno strumento dal quale ottenere informazioni sulla qualità e sulla correttezza di ciò
che si stava progettando.
Per tale motivo, il programma è nato come “banco di prova” per le intuizioni e le
supposizioni riguardo all’argomento del progetto sviluppato; vale a dire che SPY
viene progettato in una prima stesura , per lavorare off-line .
Con questo tipo di utilizzo è risultato possibile valutare l’importanza di alcuni dei
parametri usati nell’algoritmo e la necessità di poterli settare (in relazione alla
scena) .
Una volta analizzate le numerose problematiche incontrate e corretti gli errori di
una prima stesura, si è progettata la sezione di programma da utilizzare in processi
on-line.
Si procederà qui di seguito con una breve descrizione del sorgente di SPY al fine di
motivare alcune delle scelte adottate.
Fig. 5.1

Capitolo 5 Programma, test e risultati 93
In figura 5.1 vengono rappresentate schematicamente le principali componenti del
programma:
Image rappresenta la classe base per la gestione delle immagini, è fornita di
metodi per : lettura delle dimensioni, conversione da e verso i formati ppm e pgm,
filtraggio del rumore, estrazione dei contorni, estrazione dei 15 codici
rappresentativi , l’estrazione dei “codici sopravvissuti” e rimozione prospettica.
OptcialFlow una volta costruiti i due oggetti immagine Old e New vengono
inviati come parametri ad un oggetto Flow appartenente alla classe OpticalFlow la
quale è fornita di metodi per : matching tra Old e New, memorizzazione dei vettori
di flusso ottico nelle due matrici OFX ed OFY, filtraggio dei vettori di flusso e
memorizzazione dei dati su file di testo.
Framegrabber questa classe si occupa dell’acquisizione delle immagini e del
loro salvataggio nella memoria del calcolatore. Viene utilizzata in modo continuo
solo nei processi on-line.
Graphic integrata con le librerie grafiche QT2, questa classe si occupa della
gestione dell’interfaccia grafica di SPY, di collegare ogni switch o slider inserita
con il corrispondente evento e, all’esecuzione del programma, di caricare in
memoria alcune strutture di default tra cui la Look-up-Table.
Main dentro al sorgente principale vi sono le due Thread per la gestione del
programma. Al momento dell’esecuzione, questi due processi osservano
automaticamente ciò che accade sull’interfaccia grafica dato che il parametro
passato alle Thread è un oggetto appartenente alla classe Graphic.
SPY viene dotato di un selezionatore che permette di scegliere se analizzare il
flusso ottico in real-time ed utilizzare le chiamate all’interno della Thread “on-
line” oppure a telecamere spente utilizzando quelle della Thread “off-line”.
Riportiamo in figura 5.2 uno schematico diagramma di flusso del programma:

Capitolo 5 Programma, test e risultati 94
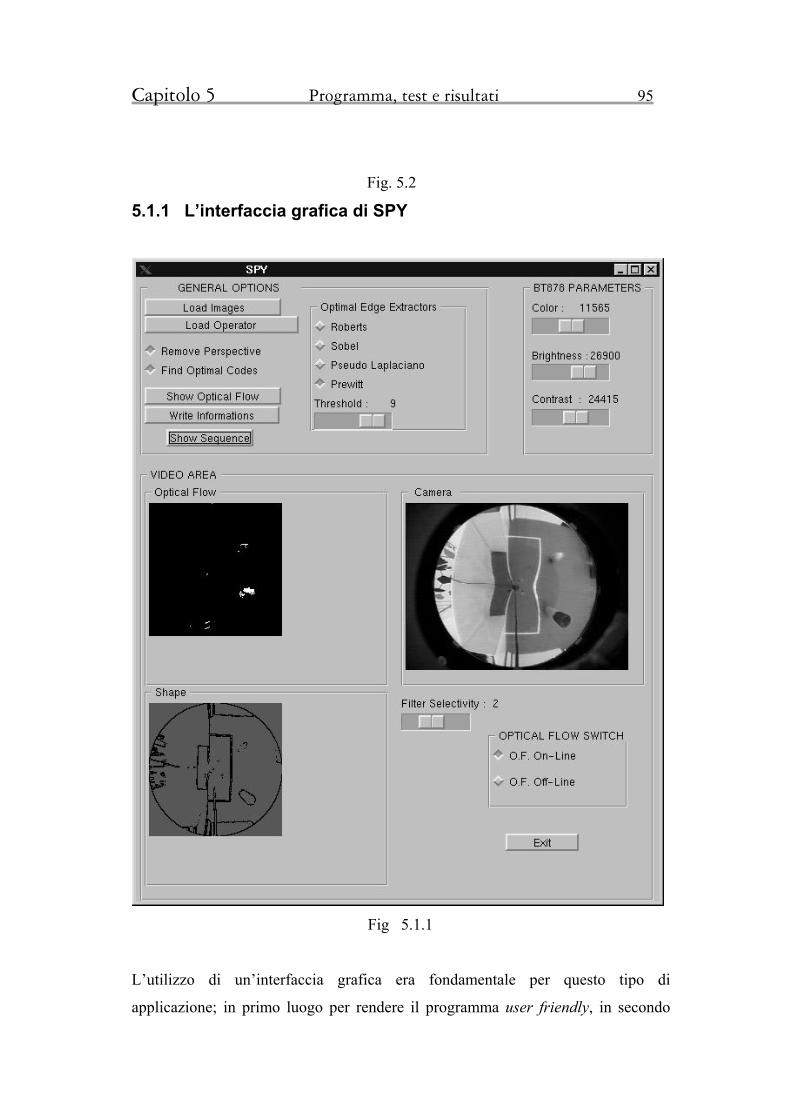
Capitolo 5 Programma, test e risultati 95
Fig. 5.2
5.1.1 L’interfaccia grafica di SPY
Fig 5.1.1
L’utilizzo di un’interfaccia grafica era fondamentale per questo tipo di
applicazione; in primo luogo per rendere il programma user friendly, in secondo

Capitolo 5 Programma, test e risultati 96
perché troppi erano i parametri da settare “in console” ed infine perché non vi era
altra soluzione per una modalità di tipo on-line.
L’interfaccia viene creata grazie all’uso di librerie complesse ma efficaci: le QT2.
Esse vengono applicate ad un ambiente di programmazione Linux/C++.
Come si nota da figura 5.1.1 vengono distinte 3 zone: “GENERAL OPTIONS”,
“BT878 PARAMETERS” e “VIDEO AREA”.
General Options Comprende i pulsanti utilizzabili off-line, per il
caricamento delle immagini e degli operatori, per l’abilitazione dell’IPM e
dell’estrazione dei 15 codici significativi e per la scrittura dei dati su file di
testo. Compare un settore chiamato “Optimal Edge Extractor” nel quale è
possibile selezionare il tipo di estrattore e la soglia da utilizzare.
BT878 parameters Consente di settare luminosità, contrasto ed intensità
cromatica con i quali il framegrabber acquisisce le immagini.
Video Area sono presenti tre finestre, una per la visualizzazione del
flusso ottico, una per visualizzare l’immagine dei contorni ed una, attivata
quando si lavora on-line, per visualizzare in real-time la scena vista dal
sensore.
Sono inoltre presenti: una slider per variare l’intensità del filtraggio finale ed uno
switch per selezionare la modalità di esecuzione (on-line o off-line).
5.1.2 Le caratteristiche dinamiche del programma Considerando attentamente le specifiche viste nel Cap. 4 ( par. 4.2), si è preferito
optare per una gestione dinamica dell’allocazione della memoria sull’intero
programma.
I primi test venivano effettuati su immagini acquisite da telecamere piane (di
difficile reperimento) aventi dimensioni differenti; ragion per cui non si poteva
prescindere dalle dimensioni delle immagini analizzate.

Capitolo 5 Programma, test e risultati 97
Al fine di svincolare il programma da continui aggiornamenti sul cambiamento di
larghezza o altezza delle immagini, si è preferito dotare la classe Image di un
metodo per la lettura delle dimensioni, allocando successivamente un’area di
memoria dinamica .
Pertanto SPY è in grado di lavorare con immagini di qualsiasi dimensione, a
colori o a livelli di grigio, piane, fortemente distorte o con prospettiva rimossa.
Questa scelta è stata pagata in termini di aumento notevole della complessità nel
gestire la memoria a causa (ma non solo) delle frequenti chiamate alle funzioni new
e delete del C++.
5.2 Primi test visivi su immagini piane
Per valutare visivamente la validità dell’algoritmo si sono analizzate inizialmente
delle immagini piane in formato pgm con livelli di grigio pressoché uniformi su
vaste aree dell’immagine.
Grazie a questi primi test è stato possibile studiare il modo di agire degli estrattori
dei contorni e quali fossero i valori di soglia ottimali per ognuno di essi.
Occorre fare una precisazione: quando si parla di immagini piane ci si riferisce
implicitamente ad immagini acquisite da telecamere piane e non, ad esempio da
sensori omnidirezionali.
Nella realtà anche in questo tipo di immagini una piccola parte di distorsione è
presente ma, utilizzando un modello di studio approssimato, si può qualitativamente
stimare il flusso ottico.
Riportiamo in successione 2 prove su due scene a complessità differente:
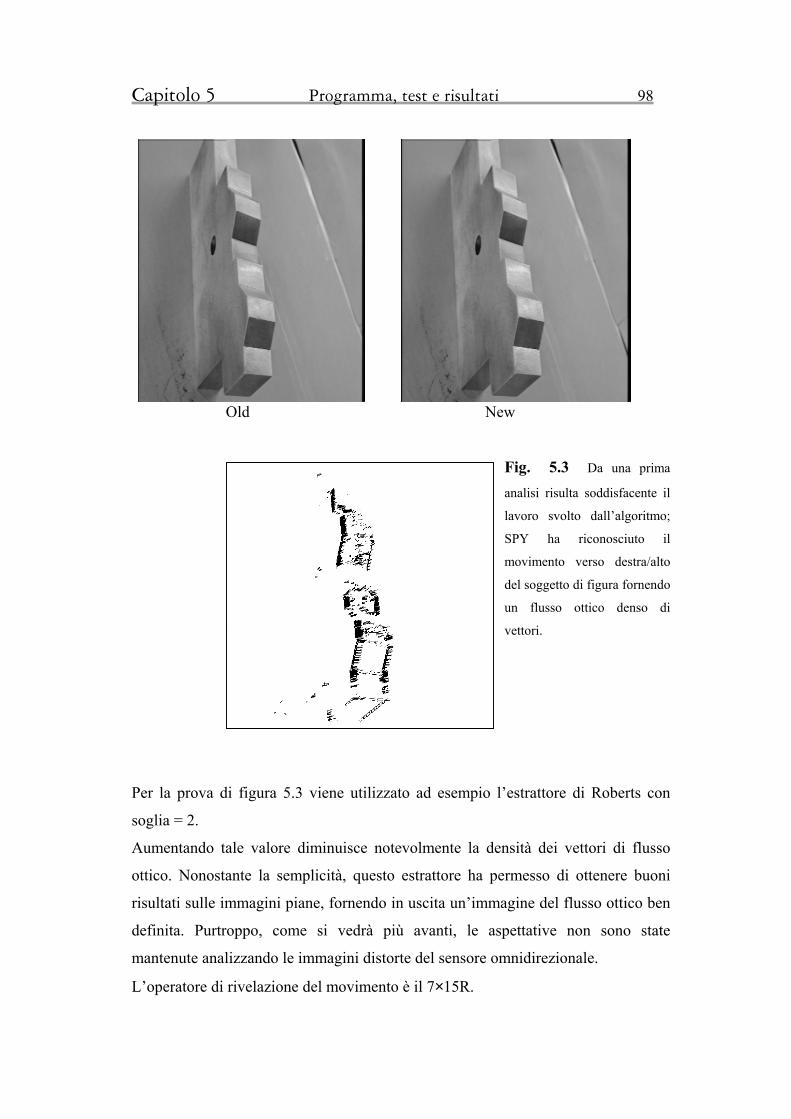
Capitolo 5 Programma, test e risultati 98
Old New
Fig. 5.3 Da una prima
analisi risulta soddisfacente il
lavoro svolto dall’algoritmo;
SPY ha riconosciuto il
movimento verso destra/alto
del soggetto di figura fornendo
un flusso ottico denso di
vettori.
Per la prova di figura 5.3 viene utilizzato ad esempio l’estrattore di Roberts con
soglia = 2.
Aumentando tale valore diminuisce notevolmente la densità dei vettori di flusso
ottico. Nonostante la semplicità, questo estrattore ha permesso di ottenere buoni
risultati sulle immagini piane, fornendo in uscita un’immagine del flusso ottico ben
definita. Purtroppo, come si vedrà più avanti, le aspettative non sono state
mantenute analizzando le immagini distorte del sensore omnidirezionale.
L’operatore di rivelazione del movimento è il 7×15R.

Capitolo 5 Programma, test e risultati 99
Rimanendo nell’ambito delle immagini piane ho testato SPY su scene
maggiormente complesse, nelle quali apparivano numerosi oggetti in movimento:
Old New
Fig. 5.4: Il programma rivela un
movimento di traslazione rigida della
scena da sinistra a destra; dovuto ad
uno spostamento della telecamera
nella direzione opposta.
Anche in questo caso ottengo una buona stima del movimento ed un’alta densità di
vettori di flusso.
Per l’esecuzione di questa prova si è utilizzato l’estrattore di Prewitt con soglia 9.
Questo operatore è risultato essere il miglior compromesso qualità/velocità di
elaborazione sia su immagini piane che su immagini acquisite dal robot.
L’operatore di rivelazione del movimento è l’ 11×11 chiocciola.

Capitolo 5 Programma, test e risultati 100
5.3 Test su immagini acquisite dal sensore HOPS
In input vi sono immagini in formato ppm (a colori), verrà stimato il movimento e
si confronteranno i risultati ottenuti mantenendo l’effetto prospettico con quelli
ottenuti mediante rimozione prospettica.
A differenza delle prove eseguite sulle precedenti immagini, in questo caso si
applica la tecnica di estrazione dei 15 codici rappresentativi, la sottrazione dello
sfondo tramite differenza di istogrammi ed il filtraggio finale del rumore sui vettori
di flusso ottico.
Aspetto critico: l’immagine con prospettiva rimossa, mantiene su tutta la sua area,
una risoluzione di 2 cm per pixel; questo significa che per le zone vicine al centro
dell’immagine vi sarà un numero rilevante di pixel a mappare una certa area,
mentre allontanandosi dal robot, per mappare la stessa area mantenendo la
medesima risoluzione, aumenterà la larghezza del singolo pixel.
Questo fattore impedisce a qualsiasi estrattore dei contorni di lavorare
correttamente a distanze dal robot superiori ad un certo valore il quale è stato
determinato sperimentalmente dalle prove svolte in laboratorio.
Prima di passare alla descrizione dei test effettuati occorre descrivere le modalità di
svolgimento di tali prove ed i parametri di giudizio utilizzati.
Si acquisiscono due immagini Old e New su cui verrà eseguito il match; per i casi
significativi vengono riportate l’immagine dei contorni e (nel caso si applichi
l’IPM) l’immagine Old con prospettiva rimossa.
Il risultato è l’immagine di flusso ottico.
Alla fine di ogni prova verrà compilata una tabella contenente i seguenti parametri:
L’oggetto che ha compiuto lo spostamento.
Distanza dal robot : intesa come distanza dal baricentro dell’oggetto al
centro del robot.

Capitolo 5 Programma, test e risultati 101
Spostamento effettivo: viene misurato ed indica di quanto si sia spostato
l’oggetto rispetto alla sua posizione iniziale.
Spostamento misurato con rimozione prospettica a priori: dopo aver
rimosso la prospettiva e ricavato le matrici OFX ed OFY, SPY scriverà su
file di testo gli spostamenti di ogni pixel ricavati grazie all’algoritmo di
matching. Trattandosi dell’analisi di corpi rigidi, si può stimare un
movimento medio in pixel dell’intero oggetto, ricavando lo scostamento
effettivo in cm (1 pixel = 2 cm).
Spostamento misurato con rimozione prospettica a posteriori: l’IPM
viene eseguita dopo aver calcolato il flusso ottico.
Il programma è dotato di una funzione di conversione grazie alla quale è in
grado di applicare una rimozione prospettica ( basata sulla stessa look-up
table) agli elementi delle matrici OFX ed OFY per poi scrivere i risultati su
file di testo. Ad esempio:
applicando l’IPM a priori: il pixel [100,100] (che corrisponde al pixel
[89,102] dell’immagine acquisita) si è mosso di 5 pixel in verticale e di 5 in
orizzontale cambiando coordinate in (105,105) (che corrisponde al pixel [96,
109] dell’immagine acquisita).
Applicando l’IPM a posteriori : il pixel [89 , 102] si è mosso di 7 pixel in
verticale e di 7 in orizzontale cambiando coordinate in [96 ,109]; leggendo
la Look_up_Table ricaverò le coordinate in Old ed in New del pixel mosso
ossia [100,100] e [105,105].
Errore: è la differenza tra lo spostamento ricavato da SPY e quello
effettivamente misurato.
Si precisa che il segno ‘–‘ davanti al valore dello spostamento sta ad indicare un
avvicinamento al robot mentre spostamenti positivi implicano allontanamento.
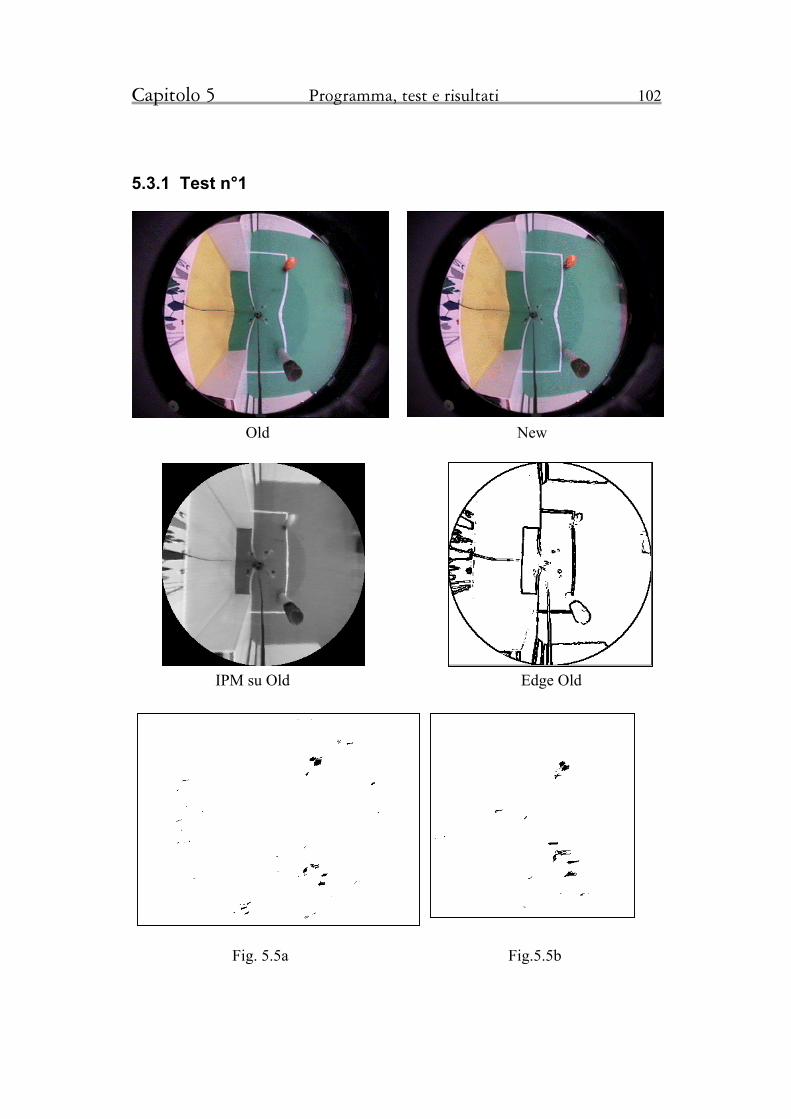
Capitolo 5 Programma, test e risultati 102
5.3.1 Test n°1
Old New
IPM su Old Edge Old
Fig. 5.5a Fig.5.5b

Capitolo 5 Programma, test e risultati 103
Settaggi delle grandezze utilizzati per il test riportato in figura 5.5 :
• Estrattore di Prewitt con soglia 9.
• Intensità del filtraggio sui vettori di flusso ottico = 2.
• Operatore di rivelazione del movimento di tipo 11×11 chiocciola.
• Soggetti in movimento nella scena: palla e cestino.
La prima compie un movimento destra/alto mentre il secondo trasla rigidamente
verso destra.
Nonostante l’utilizzo di un estrattore avente soglia di valore elevato (aumentando
perciò la selettività) , si può notare come una parte del contorno della palla e della
base del cestino vengano “persi”. Questo è dovuto principalmente all’aspetto critico
citato in precedenza sulla risoluzione uniforme, unitamente al non netto distacco del
livello di grigio della palla o della base del cestino da quello del campo.
Il risultato riportato in figura 5.5a viene ottenuto mantenendo la prospettiva; si può
notare una discreta presenza di rumore di oscillazione, imputabile al contorno
circolare della base su cui appoggia la telecamera.
Nell’immagine di flusso ottico riportata in figura 5.5b il fenomeno viene eliminato
dalla rimozione prospettica grazie alla quale la stessa circonferenza risulta
delineata perfettamente (vedi metodo di lettura della Look-up-Table Cap.4 par.
4.3.3).
Oggetto Distanza
dal robot
Spostamento
effettivo
Spost. IPM
a priori
Spost. IPM
a posteriori
Errore
palla 150 cm + 20 cm + 18 cm + 17 cm 2 - 3
cestino 120 cm + 20 cm + 22 cm + 21 cm 2 - 1

Capitolo 5 Programma, test e risultati 104
5.3.2 Test n°2 Old New
Edge Old Edge New
Fig. 5.6
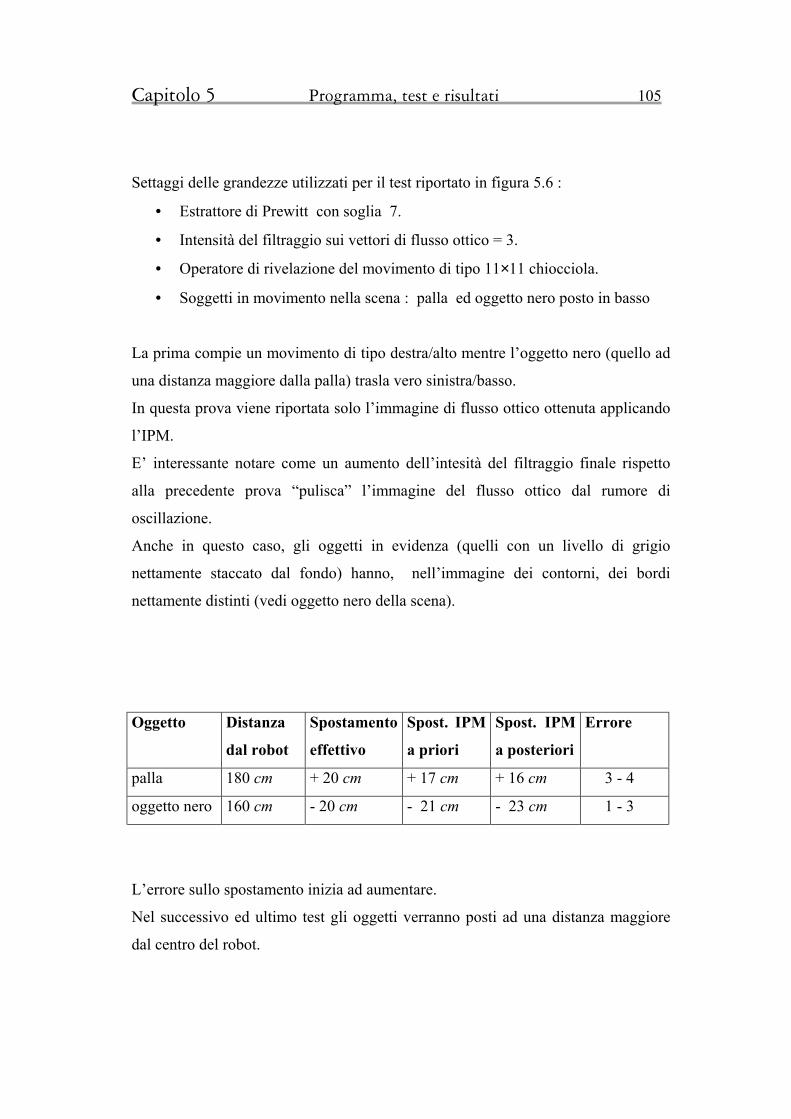
Capitolo 5 Programma, test e risultati 105
Settaggi delle grandezze utilizzati per il test riportato in figura 5.6 :
• Estrattore di Prewitt con soglia 7.
• Intensità del filtraggio sui vettori di flusso ottico = 3.
• Operatore di rivelazione del movimento di tipo 11×11 chiocciola.
• Soggetti in movimento nella scena : palla ed oggetto nero posto in basso
La prima compie un movimento di tipo destra/alto mentre l’oggetto nero (quello ad
una distanza maggiore dalla palla) trasla vero sinistra/basso.
In questa prova viene riportata solo l’immagine di flusso ottico ottenuta applicando
l’IPM.
E’ interessante notare come un aumento dell’intesità del filtraggio finale rispetto
alla precedente prova “pulisca” l’immagine del flusso ottico dal rumore di
oscillazione.
Anche in questo caso, gli oggetti in evidenza (quelli con un livello di grigio
nettamente staccato dal fondo) hanno, nell’immagine dei contorni, dei bordi
nettamente distinti (vedi oggetto nero della scena).
L’errore sullo spostamento inizia ad aumentare.
Nel successivo ed ultimo test gli oggetti verranno posti ad una distanza maggiore
dal centro del robot.
Oggetto Distanza
dal robot
Spostamento
effettivo
Spost. IPM
a priori
Spost. IPM
a posteriori
Errore
palla 180 cm + 20 cm + 17 cm + 16 cm 3 - 4
oggetto nero 160 cm - 20 cm - 21 cm - 23 cm 1 - 3
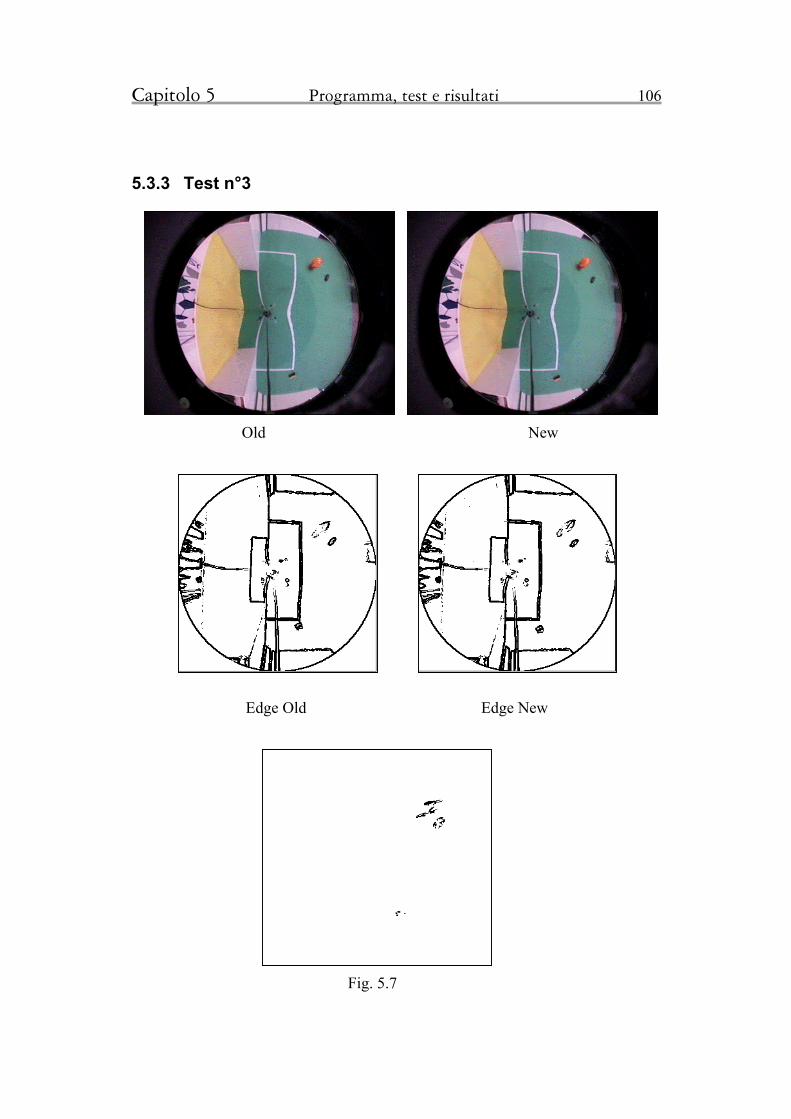
Capitolo 5 Programma, test e risultati 106
5.3.3 Test n°3
Old New
Edge Old Edge New
Fig. 5.7

Capitolo 5 Programma, test e risultati 107
Settaggi delle grandezze utilizzati per il test riportato in figura 5.7 :
• Estrattore di Prewitt con soglia 8.
• Intensità del filtraggio sui vettori di flusso ottico = 3.
• Operatore di rivelazione del movimento di tipo Explosion.
• Soggetti in movimento nella scena : palla ed entrambi gli oggetti neri .
La prima compie un movimento di tipo alto/destra , l’oggetto nero vicino ad essa si
muove a destra mentre quello ad una distanza maggiore trasla vero il basso.
Rispetto alla prova precedente è cambiato il tipo di operatore di matching;
l’operatore Explosion ha mostrato i propri pregi e difetti, è riuscito infatti ad
individuare un movimento di tipo omnidirezionale ma ha perso una discreta
quantità di informazione sul movimento di uno degli oggetti neri (quello a distanza
maggiore dalla palla).
Questo conferma quanto detto nel Cap. 4 a proposito di questo operatore: l’utilizzo
è consigliato per oggetti di dimensioni non piccole.
Oggetto Distanza
dal robot
Spostamento
effettivo
Spost. IPM
a priori
Spost. IPM
a posteriori
Errore
palla 220 cm + 20 cm + 15 cm +14 cm 5 - 6
oggetto nero
vicino alla
palla
240 cm
+ 20 cm
+ 10 cm
+ 12 cm
10 – 8
Oggetto nero
distante dalla
palla
160 cm
+20 cm
+21 cm
+20 cm
1 - 0

Capitolo 5 Programma, test e risultati 108
5.3.4 Conclusioni riguardo alle prove effettuate sulle immagini del sensore.
Nella realtà sono state effettuate altre prove di cui le tre riportate sono risultate le
più significative.
Tramite i test di laboratorio si è cercato di quantificare due parametri interessanti
per la valutazione del progetto: la presenza del rumore associato all’immagine di
flusso ottico (in funzione dell’intensità di filtraggio finale) e l’errore commesso sui
valori dei vettori del flusso in funzione della distanza dal robot (quest’ultimo viene
riportato nelle tabelle ).
Per il primo dei due valori, ho semplicemente ricavato (tramite scrittura del flusso
ottico su file di testo) il numero di pixel con flusso ottico diverso da zero non
appartenenti ad un oggetto realmente in movimento.
I risultati ottenuti vengono riportati nei seguenti grafici:
Fig. 5.8 : utilizzando ad
esempio un filtraggio con
intensità pari a 2, il numero
medio di pixel rumore è
compreso tra 20 e 25.
Il grafico è ottenuto mediante applicazione dell’estrattore di Prewitt con soglia pari
a 7.

Capitolo 5 Programma, test e risultati 109
Fig. 5.9
E’ evidente un miglioramento su ogni valore dell’intensità di filtraggio finale.
Aumentando la soglia, aumenta la selettività dell’estrattore riducendo in tal modo il
numero di pixel rumore ma di pari passo anche l’accuratezza con cui vengono
descritti i bordi degli oggetti in movimento.
Un aumento smisurato del valore di soglia, porterebbe alla dannosa perdita di pixel
sul contorno di tali oggetti.
Aggiungendo in seguito, un filtraggio pesante, si potrebbe addirittura non rilevare
movimento o quantomeno confondere i pixel degli oggetti in moto (ridotti a poche
unità) con il rumore di oscillazione che li circonda.
Ponderata deve essere anche la scelta dell’operatore di matching.
L’operatore Exlosion, ad esempio, ha una perdita di informazione intrinseca sul
movimento dell’oggetto di 441
160441 − ≅ 64% nel peggiore dei casi.
Ancora una volta occorre cercare il giusto compromesso tra soglia – tipo di
operatore di matching – intensità di filtraggio.
Al fine di ricavare un buon settaggio di tutte le variabili in gioco è stato considerato
come parametro di valutazione il rapporto tra n° pixel utili e n° totale dei pixel che
hanno variato la loro posizione (il quale comprende anche quelli

Capitolo 5 Programma, test e risultati 110
rumore) al variare della soglia, dell’intensità di filtraggio e del tipo di operatore di
matching.
Il solo parametro che si è preferito mantenere costante, durante le prove effettuate,
è il tipo di estrattore dei contorni.
Come è evidente nei test, si è optato per l’utilizzo di quello che, sulla base di
numerose prove ripetute, ha fornito visivamente (ed in termini di prestazioni) i
migliori risultati: l’estrattore di Prewitt.
In ogni casella viene riportato il valore del rapporto citato in precedenza:
Tab. 1
Tab. 2
Tab. 3

Capitolo 5 Programma, test e risultati 111
Osservando i risultati delle tre tabelle è chiaro come la miglior combinazione di
parametri al fine di ottimizzare il rapporto ‘pixel utili/pixel totali’ sia:
Estrattore di Prewitt con soglia = 9, intensità di filtraggio finale = 2 ed operatore di
matching = 7×15R.
Occorre precisare che quest’ultimo tipo di operatore essendo ‘monodirezionale’
(rileva infatti, solo movimenti da sinistra a destra) è inutilizzabile in ambiente
Roboup nel quale non si hanno a priori informazioni sulla direzione del movimento.
Utilizzando l’operatore di tipo 11×11 chiocciola (tabella 2), si ottengono discreti
risultati tuttavia inferiori rispetto al caso di tabella 1.
Essendo un’operatore di rilevamento di spostamenti omnidirezionali infatti, l’
11×11 chiocciola include anche il movimento in tutte le direzioni dei pixel rumore a
differenza del precedente il quale operava intrinsecamente una sorta di filtraggio sui
pixel rumore che si spostavano verso sinistra.
Infine, in tabella 3 si riportano i risultati ottenuti con l’operatore Explosion.
Si nota una diminuzione complessiva del rapporto ‘pixel utili/pixel totali’ rispetto a
quelli delle due tabelle precedenti. Con buona probabilità ciò è dovuto alla modesta
quantità di pixel su cui questo operatore esegue il matching causando un brusco
calo dei pixel rumore ma soprattutto del numero di pixel utili dei quali Explosion ha
rilevato il movimento.
Si conclude questa fase di valutazione dei test effettuati e conseguentemente della
qualità dell’algoritmo sviluppato, con la valutazione dell’errore medio misurato
come differenza tra spostamento effettivo e spostamento ricavato dal programma su
movimenti di 20 cm, in funzione della distanza dal robot.
Questa grandezza è di fondamentale importanza in quanto fornisce una stima delle
zone (corone circolari di figura 5.10) in cui i dati si possono considerare affidabili.
Non è stato ritenuto utile effettuare le misure al variare dell’operatore di matching
in quanto si può affermare con buona approssimazione che l’errore medio non
dipende dal modo di rivelazione del movimento.

Capitolo 5 Programma, test e risultati 112
In figura 5.10 viene riportato l’andamento dell’errore.
Fig. 5.10
Si distinguono tre zone fondamentali di incertezza:
1. [0 – 150] Zona ad incertezza trascurabile entro la quale, l’errore su uno
spostamento di 20 cm si mantiene sotto l’unità.
2. [150 – 200] Zona di incertezza minima.
3. [200 – 250] Zona di incertezza considerevole nella quale si commette un
errore medio fino al 65% nel peggiore dei casi.
In conclusione, per applicazioni in ambiente RoboCup, il programma appare fornire
dati attendibili fino a circa 220 cm dal centro del robot.
Nelle immagini con prospettiva rimossa, si ottiene un’estensione visiva di 330 cm
dal centro del robot quindi SPY riesce a coprire in modo affidabile i 2/3 dell’intero
campo visivo.

Capitolo 5 Programma, test e risultati 113
5.4 Stima della velocità e del tempo di esecuzione
L’ultimo parametro su cui il progetto è stato valutato corrisponde alla velocità con
cui SPY ricava i valori di flusso ottico lavorando on-line.
Ricordo che l’algoritmo entra in funzione nell’istante in cui l’immagine Old viene
memorizzata in una matrice bidimensionale allocata dinamicamente in memoria.
Si è quindi valutato quale fosse il ritardo ideale con cui effettuare la seconda
acquisizione al fine di ottenere New.
Il tempo di acquisizione del frame grabber (tempo che intercorre dal comando di
acquisizione alla memorizzazione dell’immagine) è ≅ 251 sec; tempo nel quale (in
ambiente RoboCup) risulterebbe immobile la totalità della scena.
Non avrebbe quindi alcun senso, grabbare consecutivamente Old e New
(risulterebbero quasi come la stessa immagine) . E’ necessario introdurre un ritardo
tra la prima e la seconda acquisizione al fine di rendere significativo lo scostamento
tra le due immagini.
Tra tutte le possibili soluzioni, in figura 5.11 viene riportata quella che ha fornito i
risultati migliori :
Fig. 5.11

Capitolo 5 Programma, test e risultati 114
in cui il blocco Trasf. Memoria si occupa di trasferire il contenuto del buffer lineare
in una matrice bidimensionale.
Lo schema a blocchi di figura simula una situazione di lavoro a “pieno carico” ossia
nella quale sia l’IPM che l’estrazione dei codici sono attivate.
Si definisce tempo di esecuzione totale il tempo che intercorre tra la visualizzazione
di un messaggio di fine ciclo ( opportunamente inserito alla fine della funzione che
scrive i vettori di flusso ottico dentro OFX ed OFY) ed il successivo.
Per effettuare il test di velocità e stimare il tempo di esecuzione totale , il computer
Canone ( AMD K6 350 MHz) è stato collegato al sensore visivo esterno alla Pal. 1
presso la Facoltà di Ingegneria dell’Università di Parma lanciando successivamente
SPY in modalità on-line.
Grazie all’uso di un contatore (inserito nello stesso punto del programma dove si
trova il messaggio di fine ciclo) e di un cronometro manuale , si misura quante volte
appare il messaggio di fine ciclo in ‘ x ‘ minuti.
Il risultato è il seguente:
in 10 minuti (600 sec.), Spy ha compiuto 928 estrazioni di flusso ottico a pieno
carico sfruttando le risorse di un processore a 350MHz.
Su tale piattaforma hardware, il programma è in grado di compiere un’estrazione di
flusso ottico in circa 0.64 sec.
E’ necessario comprendere se questo dato sia indice di una possibile reale
applicazione on-line in ambiente RoboCup; a tal proposito analizziamo un caso
specifico.
Si supponga di usare un’operatore di matching di tipo Explosion il quale ha un
campo d’azione di 20 pixel in tutte le direzioni il che equivale a 40 cm di
spostamento massimo riconoscibile da tale operatore.
Il sistema “fallisce” (non vede movimento) se un oggetto compie 40 cm in un tempo
inferiore a 0.64 sec ossia se l’oggetto in questione possiede una velocità superiore a
62 cm / s .

Capitolo 5 Programma, test e risultati 115
Supponendo che un moderno processore ad 1.5GHz incrementi la velocità di
elaborazione di un fattore maggiore di 4 (il calcolo è molto approssimativo) rispetto
al processore utilizzato per i test si riesce ad ottenere una velocità massima alla
quale è ancora possibile riconoscere il movimento di circa 2,5 m/s.

CONCLUSIONI
Gran parte degli obbiettivi preposti sono stati raggiunti; è stato realizzato un
programma elastico, facilmente interfacciabile con qualsiasi altro tipo di progetto
riguardante questo argomento o quantomeno correlato con la stima del movimento.
Le prestazioni sono soddisfacenti ed i dati risultano affidabili su un’area circolare
centrata sul robot di dimensioni piuttosto estese.
L’ ”anello debole” della catena dell’algoritmo rimane la parte di estrazione dei
codici e di sottrazione del fondo la quale appesantisce il carico computazionale
dell’elaboratore ed introduce ritardo sull’intero processo di elaborazione.
Possibili sviluppi futuri: gli aspetti tuttora migliorabili degli algoritmi di stima del
flusso ottico basati su matching sono limitati apparentemente all’estrazione dei
contorni e al filtraggio del rumore.
I margini di miglioramento in questa direzione di studio del movimento con
tecniche convenzionali, appaiono comunque limitati, occorre quindi dotare
algoritmi come quello di Marris, quello sviluppato in questa tesi, quello di
Ampollini o di Barnard & Thompson, di componenti “intelligenti” fornite ad
esempio di moduli basati su reti neurali o algoritmi genetici, in analogia a quanto
fatto recentemente da: Zhang & Lu (2000), Williams & Hanson (1998).
Queste componenti potranno ad esempio determinare delle euristiche, in grado di
scegliere (on-line) il miglior operatore di matching da utilizzare per quel preciso
contesto, imparando ed ottimizzando le proprie prestazioni sulla base di prove
ripetute.

Bibliografia Adorni G., Cagnoni S., Mordonini M. An efficient perspective effect removal
technique for scene interpretation. Proc. Asian Conference on Computer Vision,
pagg. 601-605. 2000a.
Adorni G., Cagnoni S., Mordonini M. Cellular automata based inverse perspective
transform as a tool for indoor robot navigation. LNCS. AI*IA99:Advances in
Artificial Intelligence, n.1792, pagg. 345-355. Springer. 2000b.
Ampollini P., Flusso ottico e stima del movimento, Facoltà di Ingegneria, Università
di Parma, Tesi di Laurea, 2001
Ballard D.H., Brown C.M. Computer Vision. Prentice-Hall, Englewood Cliffs,1982.
Barnard S.T. e Thomson W.B. Analisis of Images, IEEE P.A.M.I., vol.6
Black M.J. e Anandan P. A Framework for the Robust Estimation of Optical Flow.
In International Conference on Computer Vision, 1993.
Bolognini L. Progetto e Realizzazione di un Sensore Ibrido Omnidirezionale/pin-
hole e suo Impiego per Compiti di Navigazione di Robot Autonomi, Facoltà di
Ingegneria, Università di Parma, Tesi di Laurea, 2001
Bonarini A.,Aliverti P.,Lucioni M. An omnidirectional vision system for fast
tracking for mobile robots. IEEE Transactions on Instrumentation and
Measurement, 49(3), 509-512. 2000.
Brady M. Artificial Intelligence and Robotics. Artificial Intelligence and Robotics,
vol. 26, pagg. 79-121. 1985.
Camus T. Calculating Time-to-Contact Using Real-Time Quantized Optical Flow.
Technical report n° 14 presso il Max-Planck-Institut für biologische kybernetik.
Faugeras O. Three Dimensional Computer Vision: A Geometric Viewpoint. The

MIT Press, Cambridge, MA. 1993.
Golland P. Use of Color for Optical Flow Estimation. Master of Science in
Computer Science. Israel Institute of Technology, 1995.
Gonzalez R.C., Woods R.E. Digital Image processing. Addison Westley. 1992.
Horn B.K.P. e Schunk B.G. Determining Optical Flow. Artificial Intelligence,
August, 1981.
Kasturi R. Ramesh C.F. Computer Vision Principles IEEE , Washington,
Brussels, Tokyo 1991.
Klaus B., Horn P. Robot Vision. The MIT Press. Cambridge, Massachusetts. 1986.
Maris G. Analisi di Sequenze di Immagini mediante Stima dei Vettori di Flusso:
Studio di un Caso su Architettura Cellulare, Facoltà di Ingegneria, Università di
Parma,Tesi di Laurea 1996
Marr D. Vision: A computational Investigation into the Human Representation and
Processing of Visual Information. W. H. Freeman, New York. 1982.
Otha N. Optical flow detection by color images. In Proceeding of IEEE
International Conference on Image Processing, Pan Pacific, Singapore, 1989.
Schunk B.G. e Horn B.K.P. Constraints on Optical Flow Computation. In Pattern
Recognition and Image Processing, August 1991
Tistarelli M. Multiple Constraints to Compute Optical Flow. Reprint from
“IEEE Transactions on Pattern Analysis and Machine Intelligence”. Vol. 18, No.
12, December 1996.
Tzai R.Y. A Versatile Camera Calibration Technique for High-Accuracy 3D
Machine Vision Metrology Using Off-the-Shelf TV Cameras and Lenses. IEEE
Journal of Robotics and Automation, vol. RA-3, No.4, pagg. 323-344. Agosto 1997.