
Tool per il Data Warehousing: HIVE - Facoltà di Ingegneria · warehouse, ove lo scopo finale è il...
27
Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Basi di Dati Tool per il Data Warehousing: HIVE Anno Accademico 2013/2014 Candidato: Antonio Bosco matr. N 46001240
Transcript of Tool per il Data Warehousing: HIVE - Facoltà di Ingegneria · warehouse, ove lo scopo finale è il...

Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Basi di Dati
Tool per il Data Warehousing: HIVE
Anno Accademico 2013/2014 Candidato: Antonio Bosco matr. N 46001240

Un ringraziamento alla mia fantastica famiglia, che mi ha sempre incoraggiato e sostenuto, anche nei momenti difficili. Un ringraziamento alla mia inseparabile ragazza che ha sempre creduto in me. Questa vittoria la dedico a tutti loro.

Indice
Indice………………………………………………………………………………………………..III
Introduzione………………………………………………………………………………………….4
Capitolo 1: Data Warehouse……….…………………………………………………………….......5
1.1 Cos'è un Data Warehouse: definizione…………………………………………………….....5
1.1.1 Struttura di un Data Warehouse….……………………………………………………….6
1.1.2 Tipi di dati…………………….….……………………………………………………....8
1.2 Business Intelligence e Tecniche di analisi…..……………………………………………....9
1.2.1 OLAP ed analisi multidimensionale….…………………………………………………..9
Capitolo 2: BIG DATA………...….……….…………………………………………………….....11
2.1 Definizione e caratteristiche……………………………………………………....................11
2.2 Gestione Big Data..……………………………………………………………….................13
2.2.1 Limiti di gestione con gli RDMBS….…………………………………………………..13
2.2.2 Nuove tecnologie di gestione: NoSQL, MPP e MapReduce…………………………....14
Capitolo 3: Hive: SQL-HADOOP based DWH……………..…………………………………......16
3.1 Infrastruttura base di Hive: Hadoop…………………………………………………….......16
3.1.1 Hadoop distributed file system: HDFS………….…………………………………..….17
3.1.2 Hadopp MapReduce e YARN…....………………………………………………...…...18
3.2 HIVE: funzionamento e performance…..……………………………………………...…....20
3.2.1 Hive: funzionalità aggiuntive rispetto Hadoop….…………………………………...….20
3.2.2 Funzionamento ed utilizzo di Hive…………..….…………………………………...….20
3.3HIVE: performance e tempi di risposta....……………………………………………….......22
3.3.1 Hive vs Relational Data Warehouse………………………………………………...…..24
Conclusioni………………………………………………………………………………………....26
Bibliografia………………………………………………………………………………………....27

4
Introduzione
Sin dagli arbori dell’umanità, c'è sempre stata la necessità di “conservare” in un luogo
sicuro informazioni e dati, ai fini di riprodurli, consultarli o gestirli.
Tale affermazione era contenuta nella famosissima frase degli antichi latini : “Verba
volant, scripta manent”. Prima su registri cartacei, ora tutto in formato digitale. Il
compito di “archivio di dati”, nel quale le informazioni sono contenute in modo
strutturato, e collegate tra di loro attraverso un modello logico (nel più dei casi
relazionale), è adempiuto dai Database. L’esponenziale crescita di Internet ha
comportato un aumento dei dati da archiviare sul web (e nel mondo intero) di dimensioni
spropositate (ordine degli Zettabytes). L’utilizzo di un singolo database, con tecniche per
analisi dei dati di tipo OLTP, e cioè Online Transaction Processing è stata ritenuta
inefficiente con l’avvento di questo Data Set. Con il sopraggiungere di ciò che è chiamato
“BIG DATA” si è avuta la necessità di trovare un metodo nuovo e maggiormente
performante per riuscire ad “analizzare” questa ingente quantità di dati. Nasce così il
concetto di “DATA WAREHOUSE”. Un DWH è un archivio di dati, che nasce con lo scopo
di gestire un enorme data set per un’analisi di tipo OLAP, e cioè Online Analytical
Processing. Sono nati così software atti alla gestione di questi ingenti quantità di dati che
sfruttano la potenza di calcolo di nodi paralleli sulla rete per permettere l’analisi dei BIG
DATA. Architetture distribuite in parallelo sono offerte da MapReduce di Google, e dalla
sua implementazione open source Apache Hadoop, sul quale si basa APACHE HIVE.

5
Capitolo 1: Data WareHouse
Un Data Warehouse è un archivio informatico introdotto come strumento per le aziende
per facilitare l'utilizzo delle informazioni contenute nei loro archivi e per migliorare il
raggiungimento degli obiettivi aziendali.
1.1 Cos'è un Data WareHouse: definizione
Un Data Warehouse è un archivio di dati " integrato, variabile nel tempo, non volatile ed
orientato al soggetto" in supporto al processo decisionale aziendale [1]. Dalla definizione
si può appurare che un DWH deve essere:
Integrato: un sistema aziendale presenta diversi sistemi classici transazionali, i quali
forniscono i dati al nostro DWH. Questo implica che i dati presenti nel nostro
DWH sono estremamente disomogenei tra di loro. Ciò risulterebbe un problema
poichè potrebbe essere motivo di inconsistenza tra i dati. Proprio per questo, una
volta che i dati sono arrivati al DWH, devono essere "filtrati" in modo da
"integrarli" tra loro secondo particolari strutture di condifica e convenzioni sui
nomi al fine di renderli omogenei. Tutto ciò è trasparente al DSS ovvero al
processo decisionale aziendale.
Tempo variabile: i dati contenuti in un DWH corrispondono ad un ampio arco
temporale. Infatti essi si riferiscono ad un lungo periodo, generalmente molto
esteso (5 o 10 anni) nel quale sono immagazzinati tutti i dati provenienti dai
classici sistemi OLTP. Le informazioni sono, quindi, aggiornate fino ad una certa
data, creando una sorta di archivio "storico" dei dati aziendali, che poi è
analizzato dall'azienda. Ciò è in completa contrapposizione con i classici sistemi

6
transazionali nei quali i dati sono aggiornati quotidianamente e non hanno
informazioni sul passato.
Non volatilità: i dati inseriti in un DWH non sono modificabili. Ciò implica che è
possibile solo leggere i dati immagazzinati, rendendo notevolmente più semplice
l'architettura sotto questo punto di vista. Inoltre non sorgono più i problemi legati
all'inconsistenza referenziale dei dati dovuti ad aggiornamenti "errati"
(aggiornamento fantasma, perdita di aggiornamento, lettura sporca, lettura
inconsistente).
Orientata al soggetto: un DWH è orientato verso specifici topic aziendali, che
possono comprendere: utenti, prodotti, attività od anche esigenze specifiche di
una componente aziendale. Per questo il progetto di un DWH si focalizza
esclusivamente sul modello dei dati [2]. Quindi lo scopo non è quello di
normalizzare o di ridurre la ridondanza dei dati, come avviene nei normali DB
relazionali, ma quello di organizzarli in modo adeguato al fine di poterli rendere
consistenti per la produzione di informazioni utili ai fini aziendali.
Tale definizione è completamente esente dal concetto di infrastruttura di basso livello
che fornisce i dati al nostro sistema: un DWH è "indipendente" dall'architettura utilizzata
dai DB operazionali, questo lo rende anche indipendente dalla loro dislocazione fisica
(ecco perchè abbiamo anche DB esterni).
1.1.1 Struttura di un Data WareHouse
Un DWH è basato su un'architettura a livelli, solitamente cinque. Ogni livello comunica
solo con il livello immediatamente sottostante e fornisce i servizi al livello sovrastante. I
livelli sono divisi in questo modo [2]:
Data sources: corrispondono ai sistemi transazionali alla base del nostro DWH. Essi
provengono dall'ambiente operativo, e possono essere di svariato tipo.
Solitamente i dati vengono prelevati sia da sistemi interni che da sistemi esterni.

7
SI evince quindi, come il DWH sia un sistema "parassita", cioè che basa la sua
esistenza su sistemi sottostanti.
ETL: Extract, Transformation e Loading: E' il livello addetto all' estrazione dei dati
dal Data Sources. I sistemi transazionali del Data Sources sono di svariato tipo e
seguono convenzioni di codifica e formati differenti, quindi i dati devono essere
resi coerenti tra loro. Il livello ETL ha il compito di "estarre, integrare e filtrare " i
dati, in modo da "integrarli" e renderli omogenei tra loro.
Area staging: è il database che contiene i dati riconciliati ed integrati e costituisce
un modello di dati comune per l'azienda (stessa convenzione dei nomi, stessi
formati...). Solitamente è progettato come un sistema relazionale.
Warehousing Integration: tutti i dati del nostro DWH sono raggruppati qui. Vi
troviamo anche i cosidetti "Metadati" e cioè dati che contengono informazioni
aggiuntive sulla provenienza, il valore, la funzione e l'utilità delle informazioni
contenute nel DWH. Proprio per questo sono chiamati "data about data" cioè
fungono da catalogo per i reali dati.
Data Marts: nuclei indipendenti di dati "coesi" e "aggregati" relativi ad un
particolare soggetto, od area di business. Si collocano a valle di un DWH e ne
costituiscono un estratto indipendente dagli altri. Vengono utilizzati per
analizzare quel particolare soggetto che descrivono e prendere decisioni in base
al suo andamento passato.
Strumenti di analisi dei dati: i dati devono essere presentati all'utente finale il quale
ha la possibilità di consultarli ai fini (decisionali e/o statisci) aziendali.

8
1.1.2 Tipi di dati
In un DWH è possibile distinguere vari tipi di "dati" in base al loro arco di validità
temporale, al loro livello di dettaglio e alla loro funzione ai fini decisionali.
Sono quattro i tipi di dati principali [2]:
Dati attuali: sono i dati appena prelevati dai data sources e filtrati attraverso gli
ETL. L'attributo "attuale" indica che la loro validità è relativa all'interrogazione
corrente. Rispetto ai dati dei sistemi operazionali essi sono stati filtrati e
trasformati secondo convenzioni e formati standard nell'azienda.
Dati storici: sono i dati che non possono essere indicati come "attuali", ma
comunque rientrano nell'interesse temporale analizzato dall'azienda e quindi
sono conservati nel DWH. Essi sono memorizzati su devices fisici meno costosi ed
impegnativi, poichè meno richiesti rispetto ai primi.
Dati coesi ed aggregati: indicano i dati contenuti nei nuclei indipendenti dei data
marts. Hanno un elevato grado di coesione e servono per le interrogazioni relative
ad un determinato soggetto. Vengono creati per facilitare le richieste in
particolari ambiti decisionali, ma sono limitati rispetto all'imprevidibile numero di
richieste decisionali che un'azienda si trova ad affrontare, ma ciò non è un
problema perchè esse possono essere comunque realizzate attraverso i Dati
attuali e storici.
Metadati: non corrispondono a dati utili per l'azienda, ma sono delle informazioni
riguardo essi. Forniscono dettagli per il "query generation" (ad esempio
"Metastore" di Hive) ed il "data management". Presentano anche informazioni
sulla funzione di caricamento dei dati dal Data Sources, descrivendone la sorgente
di provenienza e le modifiche ad essi apportate. Sono anche utilizzati come
"catalogo relazionale" poichè descrivono come sono distribuiti i dati nel DWH.

9
1.2 Business Intelligence e Tecniche di analisi
"Per 'Business Intelligence' si intende quell'insieme di processi e tecnologie aziendali che
permettono di analizzare i dati, al fine di cercare le cause dei problemi di
un'organizzazione e gli eventuali fattori di successo, con lo scopo di incrementare il
vantaggio competitivo dell'azienda nel mercato" [3]. A supporto di questo processo ci
sono analisi OLAP e varie tecniche di analisi multidimensionale su sistemi Data
warehouse, ove lo scopo finale è il KDD (Knowdledge discovery in Database), ovvero la
conoscenza di alcuni aspetti di interesse attraverso i dati contenuti nel DWH. Una fase
rilevante di questo approccio è il "data mining", che indica l'insieme degli algoritmi
secondo i quali è possibile estrarre caratteristiche e regole dai dati archiviati. In poche
parole il Data mining permette di trovare le "regole nascoste" nelle informazioni e di
renderle visibili [2].
1.2.1 OLAP ed analisi multidimensionale
L'analisi multidimensionale consiste nel considerare i dati archiviati in un DWH e
trasformarli in informazioni multidimensionali, dove ogni dimensione riproduce un
soggetto di interesse per l'organizzazione. Dapprima vengono stabilite le "dimensioni di
interesse", in modo da creare un "(iper)-cubo multidimensionale", ove ogni dimensione
geometrica corrisponde ad una di esse. Creato il cubo multidimensionale, è possibile
effettuare analisi differenti in base a come esso viene analizzato. Indicate con (X,Y,Z) le
dimensioni del cubo, un qualsiasi attributo W può essere ricavato da (X,Y,Z) e corrisponde
ai dati di una cella del cubo f : (X,Y,Z) → W [4]. L'attributo W dipende dalle tre
dimensioni, quindi risulta essere un "sottocubo" (dicing). Spesso si fanno analisi
imponendo una delle dimensioni come costante ed analizzando solo le altre due. Questo
corrisponde al considerare degli attributi Q che sono delle "fette" (slicing) del cubo. Una
rappresentazione comune del cubo è quella che prende in essere le dimensioni: "tempo,
mercati geografici e prodotti" [2]. L'analisi di questo cubo permette di stabilire
l'andamento dell'organizzazione sulla base di queste tre variabili. Considerando una delle
dimensioni costante, si possono analizzare ad esempio l'andamento di vendite di un

10
prodotto nei mercati e nel periodo preso in considerazione (prodotto come dimensione
costante), oppure analisi su tutti i prodotti e in tutti i mercati (tempo costante), oppure
ancora conoscere tutte le vendite di un prodotto su un mercato di competenza (mercato
costante) [2]. Oltre alle operazioni di slicing e dicing abbiamo anche operazioni di
navigazione nel livello di dettaglio delle informazioni lungo una dimensione (drill-
down/Roll-up) ed inversione delle dimensioni (Pivot). Le implementazioni di queste
analisi dimensionali possono essere sia di tipo MOLAP (MULTIDIMENSIONAL OLAP) ove
vengono analizzati su una struttura dati a matrice sparsa tutti i possibili incroci derivanti
dalle analisi del cubo dimensionale, e sia di tipo ROLAP (RELATIONAL OLAP) che
corrisponde all'organizzazione dei dati su più tabelle relazionali (ad es. Schema a stella
basati su tabelle dei fatti e delle dimensioni). Per la Gartner Inc., multinazionale per la
consulenza strategica, i sistemi MOLAP sono utilizzati per la cosiddetta "Business View"
ovvero sull'analisi dell'andamento aziendale, mentre quelli ROLAP offrono la "System
View", cioè una visione più specifica del sistema impedendo l'integrazione e la
collaborazione dei progettisti ed i responsabili strategici dell'azienda [2].

11
Capitolo 2: Big Data
Per Big Data si intende una collezione di grandissime dimensioni di dati strutturati e non,
per la quale i convenzionali metodi di "estrapolazione, gestione ed analisi" in un tempo
ragionevole non risultano essere adeguati. L'idea alla base dei big data va ritrovata nella
necessità di analizzare, contemporaneamente, un data set molto esteso per ricavare
informazioni aggiuntive rispetto all'analisi di piccoli insiemi di dati. Questo permette
l'analisi degli "umori" dei mercati, analisi strategiche delle aziende ed altre analisi che
coinvolgono un ingente quantitativo di dati. Le dimensioni del dataset da analizzare
variano di giorno in giorno e si aggirano intorno agli Zettabytes (miliardi di TB). Ciò mette
alla luce che DBMS basati sul modello relazionale non sarebbero mai in grado di
analizzare tali tipi di informazioni, ma esiste la necessità di una parallelizzazione
dell'analisi e distribuzione del lavoro su più servers indipendendenti per arrivare a tempi
di analisi sufficientemente ragionevoli.
2.1 Definizione e caratteristiche
E' impossibile stimare una dimensione di riferimento, poiché questa cambia con una
grandissima velocità di giorno in giorno. Secondo una ricerca del 2001 [6], Doug Laney
definì il modello dei Big Data come un modello tridimensionale, chiamato "3V": nel
tempo aumenta il Volume dei dati, la Velocità e la loro Varietà. Successivamente si è
avuta la necessità di estendere tale definizione con un'ulteriore "V" intesa come
Veridicità di un dato. Ne risulta che le caratteristiche dei Big Data sono divise in
questo modo:

12
Volume: indica la dimensione del dataset. E' un parametro fondamentale poichè è
quello che ci fa capire se un insieme di dati è da considerarsi Big Data o meno. Le
dimensioni si aggirano dall'ordine dei Petabytes fino all'ordine degli Zettabytes.
Varietà: indica la varietà dei tipi dei nostri dati. E' un aspetto mutevole: i dati
provengono dalle più disparate fonti, ciò fornisce un insieme di dati altamente
variabile e non strutturati tra loro. Infatti nei Big Data abbiamo molteplici tipi di
dati da gestire (foto, video,audio,simulazioni 3D,dati geografici...). Tutti questi
dati sono naturalmente non strutturati, e difficilmente gestibili con sistemi
RDBMS.
Velocità: si riferisce alla velocità di generazione dei dati che di giorno in giorno
aumenta in modo spopositato.
La presente infografica, ne fornisce una visualizzazione visiva.
Ulteriori ricerche hanno evidenziato la necessità di considerare altre caratteristiche:
Veridicità: indica quanto è utile un dato, ossia la capacità di fornire informazioni
rilevanti ai fini dell'analisi decisionale;
Variabilità: indica il grado di "inconsistenza" tra i dati, cioè quanto essi presentano
"incoerenze" gli uni dagli altri.
Complessità: maggiore è la complessità, maggiore sarà lo sforzo necessario per
trarre informazioni utili dai nostri dati.
Queste caratteristiche rendono difficile la gestione dei Big Data con i sistemi relazionali
classici, e necessitano l'utilizzo di tecniche "ad hoc".

13
2.2 Gestione Big Data
L'idea alla base della gestione dei Big Data va ritrovata nell'intrinseca necessità di avere
una notevole potenza di calcolo per gestire quei dati. Tutto questo può essere garantito
solo distribuendo il carico dei dati su migliaia di servers e gestire in parallelo le analisi
degli stessi sui vari nodi.
2.2.1 Limiti di gestione con RDMBS
I problemi degli RDBMS nella gestione dei "Big Data" vanno ricercati proprio nelle
proprietà intrinseche di questi ultimi. Infatti, i limiti principali sono legati alle grandi
dimensioni (Volume) dei Big Data, al fatto che non sono strutturati (Variety), ed alla
velocità con la quale crescono (Velocity). Le dimensioni crescenti dei Big Data, che vanno
da qualche decina di Petabytes, fino all'ordine di grandezza degli ZettaBytes, rendono gli
RDBMS inadeguati per la loro gestione. Infatti i sistemi relazionali sono stati creati per
gestire un quantitativo di dati molto più piccolo, e questo potrebbe saturare le CPU dei
vari servers. Una soluzione, solo parziale, potrebbe essere quella di aumentare le unità di
CPU del management system centrale garantendo una maggiore "scalabilità verticale",
ma aumentando anche notevolmente il costo del sistema. Il secondo problema, relativo
alla "varietà" dei dati, è un limite difficilmente gestibile dagli RDBMS. Questi ultimi sono
basati su un'architettura formata da uno schema relazionale che risulta molto efficiente
con informazioni fortemente strutturate, ma la gestione dei dati non strutturati non
rientra nel loro ambito. Oggi i dati vengono creati in formato semi-strutturato o non
strutturato (social media, foto, video, audio, emails…), rendendo quindi molto
penalizzante l'utilizzo degli RDBMS per gestirli. Il terzo limite è legato alla velocità di
crescita dei dati. Infatti i sistemi relazionali possono gestire solo situazioni per lo più
statiche e non scenari di veloce crescita dei dati. Il grandissimo numero di dispositivi che
creano dati garantisce una velocità di produzione di essi spropositata e quindi non
gestibile da DBMS relazionali. Tutti questi problemi potrebbero trovare parziali soluzioni
riprogettando i sistemi relazionali con architetture in parallelo per gestire la velocità di
crescita e il grande volume dei dati. Tuttavia la memorizzazione distribuita dei dati

14
rimarrebbe ingestita, ed inoltre il problema dei dati "non strutturati" continuerebbe a
ledere sull'architettura degli RDBMS. Inoltre sorgono problemi anche riguardo le politiche
di sicurezza e consistenza dei dati dei sistemi relazionali: operazioni come "redo, undo,
ripresa a caldo e a freddo" sono inutilizzabili con una mole cosi elevata e dinamica di dati.
Quindi, gestire i "big data" con sistemi convenzionali risulta da un lato troppo costoso e
dall'altro addirittura inefficiente. Nuove tecnologie "ad hoc" sono state pensate per
risolvere queste problematiche.
2.2.2 Nuove Tecnologie di gestione: NoSQL, MPP e MapReduce
I Big Data necessitano di tecnologie più performanti per garantire la gestione di una
grandissima quantità di dati e dei tempi di risposta tollerabili. I limiti dei sistemi
relazionali ci suggeriscono che le tecnologie per gestire i Big Data dovrebbero essere
"scalabili orizzontalmente" e non dovrebbero essere legate allo schema relazionale.
Soluzioni che rispettano tali problematiche potrebbero essere quelle basate sul "Massive
parallel processing" (MPP relazionale e non, come Teradata), e tecnologie basate su file
system e database distribuiti (come Hadoop, Hive). NoSQL indica l'utilizzo di databases
non relazionali per la gestione dei dati. Esso è legato al "Teorema CAP" secondo il quale
"un sistema distribuito può rispettare solo due tra le seguenti tre proprietà: coerenza dei
dati, disponibilità di risposta, tolleranza ai guasti" [7]. Non avendo una struttura
relazionale, i DB NoSQL gestiscono i dati non strutturati per loro natura e quindi si
adattano bene per i Big Data trovando un trade-off tra consistenza, velocità e scalabilità.
L'MPP utilizza clusters di unità elaborative per processare i dati in parallelo, per poi unire
le risposte in un unico livello. Hadoop, e le sue implementazioni come Hive, utilizzano un
HDFS per distribuire i dati su un numero elevato di nodi, e MapReduce per processare in
parallelo le richieste e quindi garantire scalabilità e performance sul tempo di esecuzione.
MPP e MapReduce hanno molto in comune: entrambi utilizzano un numero elevato di
servers per processare le richieste in parallelo. Tuttavia MPP è costituito da clusters di
unità elaborative di "fascia alta" e specializzate per questi compiti, risulta quindi molto
costoso al crescere della mole di dati. I clusters Hadoop sono basati su unità di
15
elaborazione di "commodity" (comuni personal computers ad esempio) e quindi possono
crescere all'aumentare dei dati, senza quindi inficiare sui costi effettivi [8]. Un'ulteriore
differenza la si nota considerando che le funzioni di MapReduce sono scritte in Java e
sono quindi portabili e non legate ad uno schema preciso, come invece lo sono in MPP.
Infatti quest'ultimo metodo prevede un'interrogazione basata su query SQL, ed è quindi
soggetto alle limitazioni che ne derivano. Ne risulta una maggiore scalabilità a favore di
soluzioni basate su Hadoop, rispetto a soluzioni relazionali e/o basate su MPP. Di seguito
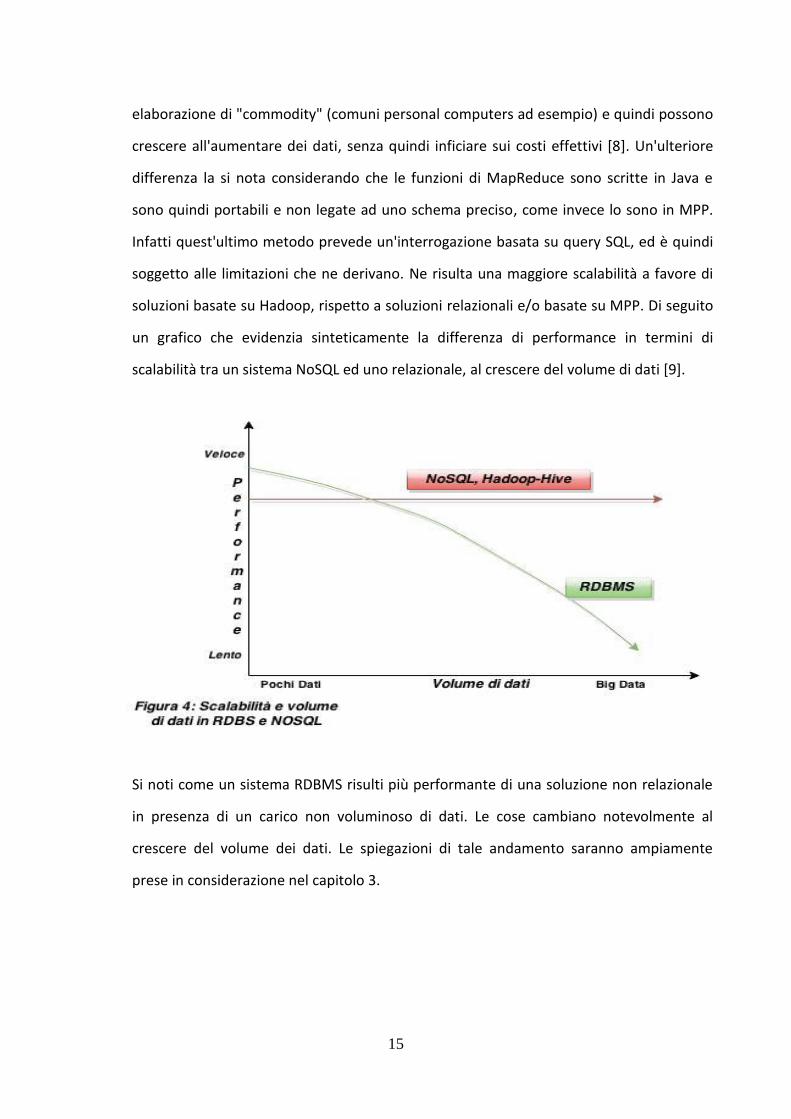
un grafico che evidenzia sinteticamente la differenza di performance in termini di
scalabilità tra un sistema NoSQL ed uno relazionale, al crescere del volume di dati [9].
Si noti come un sistema RDBMS risulti più performante di una soluzione non relazionale
in presenza di un carico non voluminoso di dati. Le cose cambiano notevolmente al
crescere del volume dei dati. Le spiegazioni di tale andamento saranno ampiamente
prese in considerazione nel capitolo 3.

16
Capitolo 3: Hive: SQL-HADOOP based DWH
Apache Hive è un tool per il data warehousing basato sull'infrastruttura Hadoop.
Esso permette di operare con grandi data sets attraverso query ad-hoc in un linguaggio
SQL-like. I dati utilizzati da Hive sono memorizzati nel File System HDFS di Hadoop, o in
file systems compatibili con esso. E' quindi scalabile, tollerante ai fallimenti e garantisce
un certo grado di parallelismo computazionale poichè le richieste, una volta arrivate
all'infrastruttura Hadoop, vengono distribuite sui vari nodi che compongono il cluster, e
vengono tradotte in funzioni MapReduce. Offre, in aggiunta alle funzionalità di Hadoop, i
bridges JDBC e ODBC, interfacce grafiche per l'utilizzo di Hive-QL e svariati drivers per
l'ottimizzazione delle query.
3.1 Infrastruttura base di Hive: Hadoop
Apache Hadoop è un framework per la gestione affidabile, scalabile e distribuita di grandi
quantità di dati. Esso traduce la richiesta di un singolo server, ad un intera collezione di
macchine che costituiscono i nodi del nostro cluster. Fu sviluppato da Apache e da
Yahoo! nel 2004, ed utilizza HDFS come file system distribuito per archiviare dati non
strutturati e sfrutta, invece, la potenza del paradigma MapReduce per parallelizzare
l'elaborazione. Hadoop ha un'architettura a livelli. E' composto da quattro moduli,
ognuno con un preciso compito: Hadoop common, Hadoop distributed file system,
Hadoop Yarn, Hadoop MapReduce.
Hadoop Common è il modulo che contiene le librerie utili al nostro software.

17
3.1.1 Hadoop distributed file system - HDFS
E' il file system di Hadoop, utilizzato quindi, anche da Hive, dato che è stato creato per
essere compatibile con diversi prodotti. Garantisce affidabilità, scalabilità e la
distribuzione dei files sui vari nodi. Esso deriva dal GFS, ovvero il Google File System. Una
particolarità che lo distingue da altri file system distribuiti è la possibilità di supportare un
hardware dei vari nodi anche non performante, e cioè macchine di "commodity". La
struttura del File System è gerarchica. Essa è formata da vari CLUSTERS HDFS. Ogni
cluster è composto da svariate macchine sulla rete. Ognuno di essi contiene un Server,
che è formato da una macchina nella quale gira un NameNode. Le altre macchine che
compongono il cluster, hanno un solo DataNode e i vari blocchi che compongono i files.
L'insieme "DataNode-Nodi" viene chiamato Rack. In ogni cluster ci sono svariati Racks.
Il Namenode è addetto all'apertura, chiusura, ed alla eventuale rinominazione di un file,
mentre i Datanodes sono addetti alla scrittura ed alla lettura dei file. Importantissimo
compito dei Datanodes, su direttiva del Namenode, è quello di applicare delle repliche
del file su più nodi, garantendone quindi un alto grado di tolleranza ai fallimenti (Faut-
tollerance): qualora un nodo fosse "out of service", la richiesta è subito trasferita ad un
nodo differente che presenta una replica di quel file. L'implementazione dei NameNodes
e DataNodes è in Java, garantendo un'interoreperibilità ed una portabilità su qualunque
macchina abbia una JVM. Ogni DataNode ha una socket aperta col NameNode ed è in
"polling" continuo chiedendo direttive sul da farsi, utilizzando un protocollo "block-
based" proprietario [10]. I Clients contattano i NameNodes, i quali impartiscono istruzioni
ai DataNodes che li hanno contattati. Il protocollo di comunicazione è basato su TCP/IP.
Ogni client ha una connessione TCP attiva con il NameNode e comunica con esso
attraverso un protocollo RPC proprietario (Remote protocol communication)[10]. Le
funzioni per i client sono quelle di un qualsiasi file system: crea, rimuovi, sposta,
rinomina, ma non modifica. Esso è anche compatibile con altri file system in rete. Pechè
HDFS è utilizzato come file system in tool per il datawarehousing, come HIVE? La
motivazione va ricercata nella sua naturale predisposizione a supportare file di
grandissime dimensioni, e nell'altissimo grado di tolleranza ai fallimenti.

18
Tool come HIVE, hanno bisogno di scrivere i file una sola volta (write-once), ma compiono
numerosissime operazioni di lettura (read-many), necessitando di essere soddisfatte in
un certo intervallo di tempo. HDFS divide i file in chunks (blocchi) di 64 MB, distribuendoli
nei vari nodi del cluster, e se possibile, ogni chunk su un DataNode, in modo da
incrementarne il parallelismo nei trasferimenti. La "fault tollerance" viene garantita dalla
presenza continua di messaggi, chiamati "Heartbeat" da parte dei DataNodes al
NameNode corrispondente: in assenza di tale notifica, il DataNode, con i relativi blocchi
di file, viene cancellato dalla gerarchia dell'HDFS, e quindi il NameNode non vi invierà più
alcuna richiesta. Se il numero di repliche dei blocchi persi è inferiore ad un valore
minimo, il NameNode provvede a crearne nuove repliche per riparare la situazione.
3.1.2 Hadoop MapReduce e YARN
Hadoop implementa il paradigma MapReduce per gestire la grande quantità di dati e
parallelizzare l'elaborazione. Strettamente collegata all'HDFS, su ogni nodo di ogni cluster
girano due processi, "Mapper" e "Reducer". Ogni blocco di file può essere visto
logicamente come composto da vari record di dati: ogni record viene "mappato" in una
tupla, od anzi, una coppia (chiave, valore) dal processo Mapper.
map(key1,value) -> list<key2,value2>
L'output può avere una chiave differente dall'ingresso, e possono esserci più tuple con la
stessa chiave.
L'insieme delle tuple di output, diventa l'input per il processo Reducer: esso riceve tutte
le tuple con la stessa chiave e le "riduce", cioè le aggrega in una lista.

19
reduce(key2, list<value2>) -> list<value3>
L'output di tale processo è un file contenente questo insieme di tuple ridotte. Il file di
output può ricevere ulteriori processi di MapReduce, concatenando queste operazioni.
La potenza di tale paradigma va ricercata nella possibilità di rendere le operazioni di MAP
e REDUCE praticamente indipendenti le une dalle altre e permettere quindi di aumentare
la parallelizzazione sui vari nodi del cluster. Le due entità principali del MapReduce di
Hadoop sono il processo "JobTracker" ed il processo "TaskTracker". La sequenza di
esecuzione è la seguente:
Client comunica i propri "Jobs" al JobTracker, comunicando anche le funzioni Map
e Reduce;
JobTracker contatta NameNode per conoscere la locazione dei dati;
JobTracker trova i TaskTrackers liberi più vicini ai dati;
TaskTrackers eseguono il lavoro, inviando periodicamente HeartBeat al JobTracker;
Il TaskTracker ha tanti slots quanti sono i Job che può servire. Ogni Job è impostato su
una JVM differente, in modo da evitare un singolo "point of failure" per l'intero sistema.
Differentemente accade per il JobTracker: se fallisce, tutti i jobs commissionati da esso
falliscono di conseguenza. Una revisione del paradigma appena illustrato è implementata
nel modulo YARN ("Yet Another Resource Negotiator"). Esso divide i compiti del
JobTracker in due moduli indipendenti: Resource Manager e Application Master. Il primo
si occupa di ricevere le richieste dai client e di allocare le giuste risorse per i vari Jobs,
mentre il secondo si occupa di monitorare le attività dei TaskTrackers e di ricevere quindi
gli HeartBeats da essi.

20
3.2 HIVE: funzionamento e performance
Hive è utilizzato per effettuare l'analisi di Big data in modo distribuito, affidabile e
scalabile utilizzando le potenzialità di Hadoop. Ma perchè Hive è così utilizzato? Cosa
offre Hive in più all'infrastruttura Hadoop sottostante? E quali sono i benefici in termini di
performance e tempo rispetto ad un DATA WAREHOUSE RDBMS based?
3.2.1 Hive: funzionalità aggiuntive rispetto Hadoop
Hive offre le piene funzionalità di Hadoop, e quindi può avvalersi di un file system
distribuito come HDFS e di una parallelizzazione dei lavori con MapReduce. Ma quindi, a
che scopo è stato creato? Interfacciarsi con Hadoop, prima, significava dover fornirgli le
funzioni di Map e Reduce, e quindi implementarle in Java. Sebbene i sistemi RDBMS
fossero praticamente incapaci di gestire tale mole di dati, per i problemi citati nel
capitolo 2, essi hanno una caratteristica che fa invidia a sistemi come Hadoop: la
presenza di un linguaggio, strutturato, semplice e potente come l'SQL. Hive sfrutta
proprio questa caratteristica . Infatti se da un lato si offrono le potenzialità di Hadoop,
dall'altro la presenza di una GUI permette di implementare l'interfacciamento con
l'utente attraverso un linguaggio SQL-like: HIVE-QL. Hive risulta quindi essere un
"traduttore" (Hive)SQL-MapReduce. Hive fornisce HiveQL per effettuare query sui
clusters Hadoop. In questo modo si sfrutta l'ecosistema Hadoop per risolvere i problemi
legati all'incapacità di gestione dei Big data da parte dei sistemi RDBMS e si utilizza la
comodità di un "linguaggio" simile all'SQL, tipico di sistemi relazionali.
3.2.2 Funzionamento ed utilizzo di Hive
Come detto, gli utenti utilizzano Hive con un'apposita Web GUI per sottomettere delle
istruzioni in Hive-QL. Questo offre gran parte delle potenzialità dell'SQL come "SHOW",
"DESCRIBE", "JOIN", "SELECT", "CREATE" [11]. Le query Hive-QL non sono trasformate in
istruzioni MapReduce traducendole in JAVA. Quando sono richiesti tasks MapReduce,
Hive fa uso di alcuni file scritti in XML che corrispondono ai moduli MAPPER e REDUCER e
qui ci sono le istruzioni di esecuzione delle funzioni Map e Reduce. Quindi le query Hive-
QL sono tradotte in un grafo MapReduce di Hadoop ed eseguite grazie ai moduli XML.
21
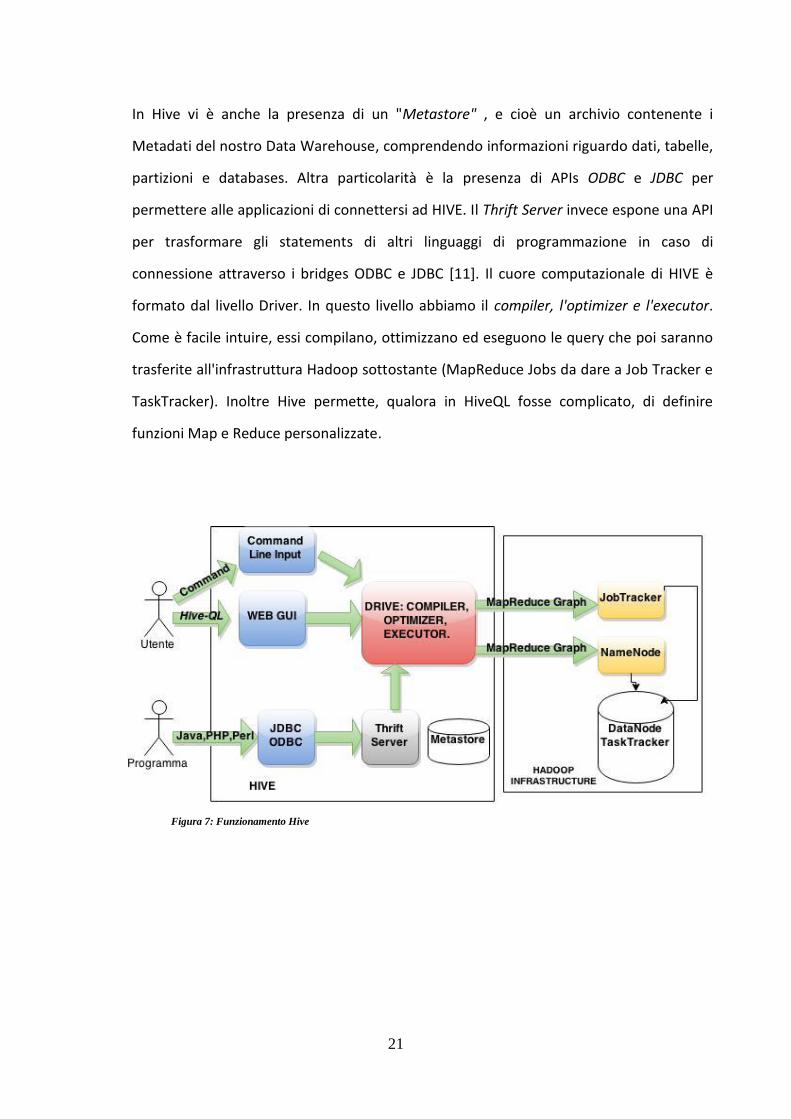
In Hive vi è anche la presenza di un "Metastore" , e cioè un archivio contenente i
Metadati del nostro Data Warehouse, comprendendo informazioni riguardo dati, tabelle,
partizioni e databases. Altra particolarità è la presenza di APIs ODBC e JDBC per
permettere alle applicazioni di connettersi ad HIVE. Il Thrift Server invece espone una API
per trasformare gli statements di altri linguaggi di programmazione in caso di
connessione attraverso i bridges ODBC e JDBC [11]. Il cuore computazionale di HIVE è
formato dal livello Driver. In questo livello abbiamo il compiler, l'optimizer e l'executor.
Come è facile intuire, essi compilano, ottimizzano ed eseguono le query che poi saranno
trasferite all'infrastruttura Hadoop sottostante (MapReduce Jobs da dare a Job Tracker e
TaskTracker). Inoltre Hive permette, qualora in HiveQL fosse complicato, di definire
funzioni Map e Reduce personalizzate.
Figura 7: Funzionamento Hive

22
3.3 Hadoop-Hive vs RDBMS: performance e tempi di risposta
Nel presente paragrafo, si vuole mettere a confronto la soluzione Hadoop-Hive in
relazione alla classica controparte RDBMS. Mentre da un lato, l'analisi di una query che
coinvolge Petabytes di dati è divisa (splits) in tanti tasks per ottimizzarne i tempi di
risposta, d'altro canto la gestione di query con basso carico computazionale risulta essere
un limite in termini di performance. Una elaborazione che comprende un notevole carico
di dati da analizzare, e quindi una grande ed efficiente velocità computazionale
impiegherebbe con un sistema relazionale centralizzato anche ore. Con Hive potrebbe
essere svolto in decine di minuti, dimostrando, ancora una volta, una forte scalabilità ed
un vantaggio irraggiungile nell'analisi di Big Data dai concorrenti relazionali [12]. Infatti,
ciò che rende Hive, e quindi Hadoop, adatto per i Big Data, è proprio la presenza della
distrubuzione del carico: l'utilizzo della parallelizzazione dei lavori su unità elaborative di
"commodity" permette di avere una potenza di calcolo ineguagliabile da un sistema
RDBMS. Inoltre la caratteristica che le singole unità siano dei "comuni" personal
computer permette una notevole scalabilità orizzontale, garantendo la possibilità di
aggiungere delle unità senza inficiare in modo considerevole sul costo.

23
Ricapitolando: Hive offre un'interfaccia SQL-Based, sfrutta l'esecuzione distribuita ed
efficiente in termini di velocità di Hadoop, risulterebbe quindi il tool perfetto per la
gestione dei dati? Come in ogni processo ingegneristico, la risposta dipende da vari
fattori. Hive, così come lo stesso Hadoop, e la maggior parte dei software basati su
MapReduce e distribuzione del lavoro, soffrono di un problema inverso rispetto a quello
degli RDBMS. Questa limitazione può essere riassunta in due parole: real-time. Hive non
è adatto all'esecuzione di query semplici che devono essere risolte "in tempo reale".
Infatti, mentre un sistema RDBMS, grazie alla sua forte schematizzazione ed alla sua
esecuzione centrale, permette di raggiungere tempi di esecuzione pressocchè a tempo
reale, si evidenziano invece forti limiti in tool come Hive. Query che in un sistema
relazionale impiegherebbero qualche manciata di millesimi per essere eseguite, con Hive
si potrebbero avere tempi notevolmente maggiori. Questo offre una latenza troppo
elevata per il sistema in questione. Da una ricerca effettuata analizzando gli utilizzatori di
Hadoop/Hive si evince che il 39% degli intervistati pensa che questa soluzione sia
perfetta per la loro azienda, il 37% lenta per task interattivi, ed il 30% eccessivamente
lenta per richieste real-time, comportando che il 30% di loro abbandoni questa soluzione
[12]. Le soluzioni basate su Hadoop, come Hive, non sono adatte per analisi real-time e
time-sensitive: "una query che necessita una velocità di 300 millisecondi per essere risolta
non potrà, almeno per il momento, essere eseguita da Hadoop" [13]. Le motivazioni di
questa latenza vanno ricercate proprio nelle proprietà di Hive. Mentre con
un'elaborazione complessa, c'è un beneficio immane nella suddivisione dei lavori sui vari
tasktrackers, con una query che coinvolge una mole bassa di dati si perde di efficienza
proprio quando il lavoro viene diviso, poichè "splittarlo" costa in termini di tempo. Infatti
mentre Hive suddivide il lavoro, fa partire dei tasktracker, un sistema relazionale ha già
svolto l'elaborazione richiesta. Tutto questo ci fa capire come Hive possa essere utilizzato
per analisi OLAP, e quindi analisi che coinvolgono un grande dataset: l'estrema scalabilità
dovuta alla distribuzione dei lavori e dei dati ne permette delle prestazioni
ragionevolmente ottimali (non perfette) rispetto alle controparti relazionali. Tuttavia per
analisi real-time Hive risulta inadatto e fortemente limitante.

24
3.3.2 HIVE vs RELATIONAL DATAWAREHOUSE
La parallelizzazione computazionale e la distribuzione dei dati non sono gli unici vantaggi
offerti da Hive. Infatti anche in datawarehouses tradizionali, come gli MPP, basati sul
"massive parallel processing", esiste la parallelizzazione, ma Hive offre comunque
benefici rispetto a questa soluzione. Uno dei punti forti di Hive, è proprio l'organizzazione
dei dati. Sebbene Hive sia un tool per il datawarehousing, esso offre una struttura ai dati
archiviati nell'HDFS. In Hive i dati sono organizzati nel seguente modo [11]:
Databases: indicano lo spazio dei nomi dei nostri dati, per evitare conflitti;
Tabelle: indicano un insieme omogeneo di dati che hanno lo stesso "schema",
possono essere non esterne o esterne.
Partizioni: in ogni tabella possono esserci più partizioni secondo una determinata
"chiave" o meglio "colonna". Le partizioni determinano il modo in cui i dati sono
effettivamente memorizzati all'interno delle directories dell'HDFS.
Clusters: i dati in ogni tabella possono essere divisi in "clusters" (o "buckets")
secondo una colonna della tabella o della partizione.
Il partizionamento ed il clustering, influenzano l'organizzazione fisica dei dati nell'HDFS,
segnando inevitabilmente i tempi delle analytic query, permettendo di "analizzare" solo i
dati che effettivamente interessano (attraverso il pruning). Il partizionamento definisce
delle "colonne virtuali" che sono derivate dalla nostra tabella e sono salvate in sotto-
directories della directory di quest'ultima. Se avessimo la seguente tabella:
"CREATE TABLE Occupazioni (id INT, Nome STRING, Lavoro STRING, Salario INT, Località
STRING)
PARTITIONED BY (Località STRING)
LOCATION '/user/staging/Occupazioni';"

25
si otterrebbero due partizioni in base alla colonna "Locazione": "Napoli" e "Milano". La
clausola "LOCATION" indica la locazione fisica nella quale sarà memorizzata la tabella.
All'interno della directory "Occupazioni" ci saranno due sotto-cartelle "Napoli" e
"Milano", contenenti le righe delle due partizioni, ovvero, rispettivamente, le righe che
hanno come Locazione "Napoli" e quelle come Locazione "Milano". All'atto di un'analisi:
" SELECT * FROM Occupazioni WHERE Localita='Napoli' ";
Hive non andrà a cercare le informazioni in tutte le sotto-directories di "Occupazioni",
ma taglierà fuori (pruning) quelle che non corrispondono ai nostri criteri, cioè "Milano".
L'analisi verrà fatta solo sulla directory "Napoli" e quindi solo su due righe, e non su tutta
la tabella, permettendo una notevole diminuzione del tempo di risposta della query. In
uno scenario con tabelle formate da migliaia di righe, il vantaggio diventa davvero
significante, permettendo un'analisi dei Big Data in modo molto più efficiente rispetto ad
un sistema DWH relazionale. Il bucketting funziona in un modo simile, solo che limita il
numero di buckets al tempo della creazione della tabella. Se avessimo avuto:
"CREATE TABLE Occupazioni (id INT, Nome STRING, Lavoro STRING, Salario INT, Località
STRING) CLUSTERED BY (Nome) INTO 20 BUCKETS";
ci sarebbero stati 20 buckets ognuno dei quali contenenti più righe. Tuttavia ogni riga
sarebbe stata rigorosamente inclusa in un solo bucket. Anche in questo caso lo scopo è
limitare l'analisi ai soli dati che realmente ci servono, analizzando solo i buckets
interessati, aumentando quindi le performance delle query. La differenza con il
partizionamento è che quest'ultimo può aumentare il numero di partizioni al crescere dei
dati, mentre il numero di buckets resta immutato nel tempo. Tutte le informazioni
riguardo l'organizzazione dei dati, la locazione delle partizioni e dei buckets sono
contenute nel database relazionale Metastore, che contiene tutti i metadati del nostro
sistema.

26
Conclusioni
In tale elaborato sono state trattate le problematiche legate all'utilizzo dei Big Data e
come sistemi come Hive possano essere più efficienti rispetto a sistemi relazionali
classici, nella loro gestione. Vengono prese in considerazione anche le opportunità che
sono offerte alle aziende grazie alla "Business Intelligence". Opportunità che stanno
diventando di giorno in giorno sempre più reali e significative e permettono alle
organizzazioni di guadagnare un notevole vantaggio competitivo nel mercato. E' per
questo che i finanziamenti riguardo i Big Data sono sempre in aumento, così come le
aziende che, affacciandosi al mondo del Business, adottano soluzioni basate su Hadoop o
su Hive. Tuttavia, Hive resta ancora limitato per quelle transazioni real time che lo
vedono sfavorevole in relazione ad una sua controparte relazionale. Infatti, come anche
accennato da Doug Cutting, creatore di Hadoop, queste soluzioni sono nate per degli
scopi differenti dagli RDBMS. Ma, così come Hive ha riempito il gap che negava ad
Hadoop l'utilizzo di un linguaggio comodo e potente come l'SQL, non è detto che con il
sopraggiungere di nuove tecnologie non si riescano a risolvere i problemi dell'analisi real-
time, così da unificare i due mondi in un'unica soluzione affidabile, veloce, scalabile e
poco costosa.

27
Bibliografia
[1] Bill Inmon, "Building in DataWarehouse", 1993
[2] A. Chianese, V. Moscato, A. Picariello, L. Sansone, "Basi di dati per la gestione
dell'informazione", McGraw-Hill, 247-255
[3] Hans Peter Luhn, 1958
[4] Wikipedia, http://it.wikipedia.org/wiki/Cubo_OLAP
[5] Snijders, C., Matzat, U., & Reips, U.-D (2012). 'Big Data': Big gaps of knowledge in the
field of Internet.International Journal of Internet Science, 7, 1-5.
[6] Douglas Laney, 3D Management: controlling Data Volume, Velocity and Variety,
Gartnier
[7] "Brewer's CAP theorem on distributed systems", www.royans.net
[8] Andrew Bust, http://www.zdnet.com/article/mapreduce-and-mpp-two-sides-of-the-
big-data-coin/
[9] "What is Hadoop and nosql", https://datajobs.com/what-is-hadoop-and-nosql
[10] "An Introduction to HDFS", http://www.ibm.com/developerworks/library/wa-
introhdfs/
[11] "Hive Wiki", https://cwiki.apache.org/confluence/display/Hive/Tutorial
[12]"Not Real Time", http://www.citeworld.com/article/2462886/big-data-
analytics/when-to-use-hadoop-and-when-not-to.html
[13] Claudia Perlich, Dstillery


















