Sviluppo di un sistema per l'interpretazione dei comandi ... · dizionario interno...
32
Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Fondamenti di sistemi dinamici Sviluppo di un sistema per l'interpretazione dei comandi basati sul riconoscimento vocale per l'interazione uomo-robot Anno Accademico 2016/17 Candidato: Davide Russo matr. N46002152
-
Upload
phungthien -
Category
Documents
-
view
217 -
download
0
Transcript of Sviluppo di un sistema per l'interpretazione dei comandi ... · dizionario interno...

Scuola Politecnica e delle Scienze di BaseCorso di Laurea in Ingegneria Informatica
Elaborato finale in Fondamenti di sistemi dinamici
Sviluppo di un sistema per l'interpretazione dei comandi basati sul riconoscimento vocale per l'interazione uomo-robot
Anno Accademico 2016/17
Candidato:
Davide Russo
matr. N46002152

[Dedica]

Indice
Indice..................................................................................................................................................IIIIntroduzione..........................................................................................................................................4Capitolo 1: Stato dell’arte.....................................................................................................................6Capitolo 2: Implementazione.............................................................................................................15
2.1 Verifica della raggiungibilità del server....................................................................................162.1 Richiesta HTTP al server..........................................................................................................172.2 Interpretazione dei comandi.....................................................................................................182.3 Codifica dei comandi................................................................................................................212.4 Creazione del messaggio..........................................................................................................232.5 Visualizzazione dei comandi....................................................................................................24
Capitolo 3: Casi di test.......................................................................................................................253.1 Primo: comando singolo semplice............................................................................................253.2 Secondo: comando singolo articolato.......................................................................................263.3 Terzo: comando fuori dal dominio delle funzioni eseguite dal robot.......................................273.4 Quarto: due comandi semplici..................................................................................................283.5 Quinto: comandi multipli.........................................................................................................293.6 Sesto: interazione sociale.........................................................................................................30
Conclusioni.........................................................................................................................................31Bibliografia.........................................................................................................................................32

Introduzione
Il lavoro svolto in questa tesi ha lo scopo di implementare un sistema per l'interpretazione
dei comandi inviati a un robot da un utente espressi in linguaggio naturale.
Tale sistema estende un lavoro già presentato nella tesi di laurea [1], al quale abbiamo
aggiunto diverse funzionalità in modo da superarne alcuni limiti, tra cui:
• l’analisi della frase pronunciata dall’utente era eseguita in maniera statica nel senso
che le parole della frase vengono analizzate senza eseguire alcuna analisi sintattica
delle stesse, ma semplicemente confrontando le radici di queste basandoci su un
dizionario interno all’applicativo e implementato dagli sviluppatori;
• la possibilità di esprimere un solo comando per volta;
• l’assenza di modulartità dell’algoritmo che comportava una particolare difficoltà
nell’aggiunta di comandi.
Quindi, gli obiettivi di questo lavoro di tesi sono:
• utilizzare un motore di Natural Language Processing in cloud per interpretare un
insieme di comandi richiesti da un operatore umano, in modo da permettere a questi
di richiedere un’azione interagendo attraverso il linguaggio naturale;
• implementare un sistema che permetta controllo e interazione sociale tra l'utente ed
il robot;
• implementare un sistema modulare, indipendente sia dalla piattaforma robotica
utilizzata (nel nostro caso RoDyMan sviluppato dal PRISMA Lab dell’Università
degli Studi di Napoli “Federico II”) che dal Natural Language Processor utilizzato;
Tale lavoro di tesi si divide in tre parti: inizialmente verranno introdotte le tecnologie
utilizzate, considerando sia il cuore dell’applicativo ovvero il Natural Language Processor,
sia l’area di applicazione di quest’ultimo cioè il Natural Language Processing. Verranno
descritte le soluzioni già esistenti in letteratura e quella utilizzata in questo lavoro di tesi,
motivandone la scelta. In una seconda parte verranno descritte le tecniche implementative
seguite durante lo sviluppo del sistema, e infine verranno discussi alcuni casi di test per
dimostrare come funziona il sistema implementato e gli obiettivi raggiunti.
4

Per quanto riguarda l’implementazione di tale sistema, esso è basato su tecnologia
Android, attraverso la programmazione in linguaggio Java e prevedendo un terminale
mobile (cellulare, tablet, etc…) che permette l’interazione tra l’utente la piattaforma
robotica.
Per quanto riguarda la lingua scelta per l’interazione tra l’uomo e il sistema implementato,
esso è l'inglese, a differenza di quello utilizzato nella precedente tesi, che era basata
sull’italiano. Questa scelta nasce principalmente dal fatto che la lingua utilizzata dal
Natural Language Processor utilizzato nel sistema implementato è appunto l’inglese.
In ogni caso il sistema implementato produce comunque lo stesso risultato in quanto
l’analisi del testo viene effettuata tramite l’analisi degli elementi sintattici del testo inserito
dall’utente e non delle parole stesse del testo.
5

Capitolo 1: Stato dell’arte
Natural Language Processing si riferisce al trattamento informatico (computer
processing) del linguaggio naturale, per qualsiasi scopo, indipendente dal livello di
approfondimento dell’analisi. Per linguaggio naturale si intende la lingua che usiamo nella
vita di tutti i giorni, come l’inglese, il russo, il giapponese, il cinese, ed è sinonimo di
linguaggio umano, principalmente per poterlo distinguere dal linguaggio formale, incluso
il linguaggio dei computer. Così com’è, il linguaggio naturale è la forma di comunicazione
più naturale e più comune, non solo nella sua versione parlata, ma anche in quella scritta.
Rispetto al linguaggio formale, il linguaggio naturale è molto più complesso, contiene
spesso sottintesi e ambiguità, il che lo rende molto difficile da elaborare.
Le teorie dietro l’area chiamata Natural Language Processing è la linguistica
computazionale che si focalizza su come diminuire il gap tra linguaggio naturale e
linguaggio formale, attraverso dei formalismi descrittivi di un linguaggio naturale.
Il Natural Language Processing si divide in due macro aree: il Natural Language
Understanding e il Natural Language Generation. Queste due macro aree sono una
l’opposta dell’altra: la prima ha come obiettivo lo studio delle comprensione da parte delle
macchine del linguaggio naturale; la seconda ha come obiettivo quello di studiare come le
macchine possono generare frasi in linguaggio naturale.
In generale il Natural Language Processing prevede diverse fasi nell’analisi di un testo che
ne fanno di esso una struttura su livelli. I livelli fondamentali su cui si basa l’elaborazione
dell’analisi di una frase sono [2]:
• lessico e morfologia, si occupa di effettuare l’analisi lessicale del testo posto in
input. Il testo viene “spezzettato” attraverso un processo di tokenizzazione,
formado una serie di token. In un Natural Language Processing ogni token è
associato ad una parola del testo. Per ogni token, tramite i processi di
Lemmatization e Morphological segmentation, vengono individuate tutte le parole
con significato, detti lemmi, che compongono il testo in input e ne fa l’analisi
morfologica, cioè individua il modo e il tempo dei verbi, se un nome è singolare o
6

plurale, etc.;
• sintassi, si occupa di effettuare l’analisi sintattica del testo posto in input. Vengono
cioè individuate tutte le parti del discorso, intesi come verbi, nomi, aggettivi,
avverbi, preposizioni, pronomi. Il processo che si occupa di marcare ogni parola
con la propria parte del discorso si chiama Part-of-speech tagging. Il processo, si
divide in due sotto-processi: il primo, detto shallow parsing, produce un albero
binario in cui vengono individuate le parti elementari cioè la parte nominale (NP) e
la parte verbale (VP), mentre il secondo, detto full parsing, produce un albero
sintattico in cui ogni parola viene marcata con il suo ruolo sintattico all’interno
della frase. Di seguito viene fatto un esempio, supponendo che il testo in ingresso
sia “Martina mangia la pizza”. Nell’esempio la stringa in ingresso è identificata con
S.
• semantica, si occupa di individuare il significato del testo. Non ci si spinge oltre
nella spiegazione, ma vale la pena citare il processo Named Entity Recognition che
è utilizzato per ricercare ed individuare gruppi di parole che possono formare
un’entità, intesa come nomi di persona, paesi, eventi, etc.;
7

• pragmatica, si occupa di individuare il contesto in cui è posto il testo e di elaborarlo
e utilizzarlo in funzione di esso.
Il Natural Language Processing è implementato con un Natural Language Processor, che è
un framework che racchiude tutti i processi utilizzati nei vari livelli.
Allo stato attuale della teconologia, un Natural Language Processor è presente in rete
come servizio cloud.
Il cloud computing è un paradigma di erogazione di risorse informatiche caratterizzate
dal fatto che queste risorse non sono collocate sul computer dell’utente ma su un server
remoto e sono accessibili dall’utente attraverso la rete. Questo paradigma è offerto a
partire da risorse che non vengono configurate e messe in opera dal fornitore apposta per
l'utente, ma gli sono assegnate, grazie a procedure automatizzate, a partire da un insieme
di risorse condivise con altri utenti lasciando all'utente la configurazione della risorsa.
Quando l'utente rilascerà la risorsa, essa verrà riconfigurata nello stato iniziale e rimessa a
disposizione nell’insieme condiviso delle risorse.
I servizi fondamentali messi a disposizione dal cloud computing sono:
• SaaS (Software as a Service), offre l’utilizzo di un software, installato su un
server remoto, usufruibile tramite API (Application Programming Interface)
accessibili via web;
• DaaS (Data as a Service), offre le funzionalità di una memoria di massa,
mettendo a disposizione dell’utente la gestione di dati disponibili in vari
formati, come se fossero in locale;
• HaaS (Hardware as a Service), offre l’utilizzo di risorse hardware atte
all’elaborazione di dati collocate, di solito, in un centro elaborazione dati
(CED) o data center cioè una struttura in cui sono presenti apparecchiature
fisiche come i server, per la gestione dell’elaborazione dei dati, e tutti gli
strumenti utili per il funzionamento di essi, come per esempio gruppi di
continuità e sistemi di raffreddamento;
Attualmente questi servizi sono raggruppati in due macro-servizi che sono:
8

• PaaS (Platform as a Service), offre, a differenza di Saas e Daas, una piattaforma
costituita da una serie di programmi e librerie utilizzabili dall’utente che
comprendono sia software che sistemi per la gestione di dati;
• IaaS (Infrastructure as a Service), offre risorse hardware, non solo in termini di
unità di elaborazione, ma anche in termini di dischi locali e infrastrutture di
rete.
L’applicazione del cloud computing alla robotica comporta una serie di vantaggi al punto
da creare una nuova branca della robotica, detta cloud robotics. I vantaggi ottenuti sono in
termini di potenza di calcolo e riduzione dei costi. Infatti è possibile creare dei robot a
basso costo, dotati però di un “cervello” costituito dai servizi del cloud compunting di cui
si cita il Machine Learning, Data Mining, Information Extraction, e altri. Questi servizi
sono utili nel campo della robotica per:
• la creazione di sistemi per la Human-Robot Interaction;
• utilizzare di Big Data, cioè dati raccolti e/o diffusi su reti accessibili e di grandi
dimensioni che possono consentire decisioni per problemi di classificazione o
rivelare modelli;• Internet of Things per la robotica.
Questi sistemi sono utilizzati per realizzare servizi del tipo:
• Autonomous mobile robots, cioè la possibilità di creare auto che “si guidano da
sole” in base alle immagini ricevute da GPS e comparate con quelle catturate
dall’auto tramite fotocamere, sensori;
• Cloud medical robots, un cloud che fa da assistenza ai medici attraverso l’accesso a
vari servizi come un archivio di malattie, cartelle cliniche elettroniche, un sistema
di gestione della salute del paziente, servizi di pratica, servizi di analisi, soluzioni
cliniche, sistemi esperti;
• Industrial robots, cioè robot utilizzati per la produzione di prodotti.
Un’azienda che si occupa di offrire il cloud computing è detta cloud provider. I maggiori
cloud provider esistenti al mondo sono, per esempio, Google, Amazon, IBM, Microsoft.
Tra i software offerti dal cloud compunting di queste aziende, troviamo anche il Natural
Language Processing. In particolare i prodotti che offrono questo tipo di servizio sono
9
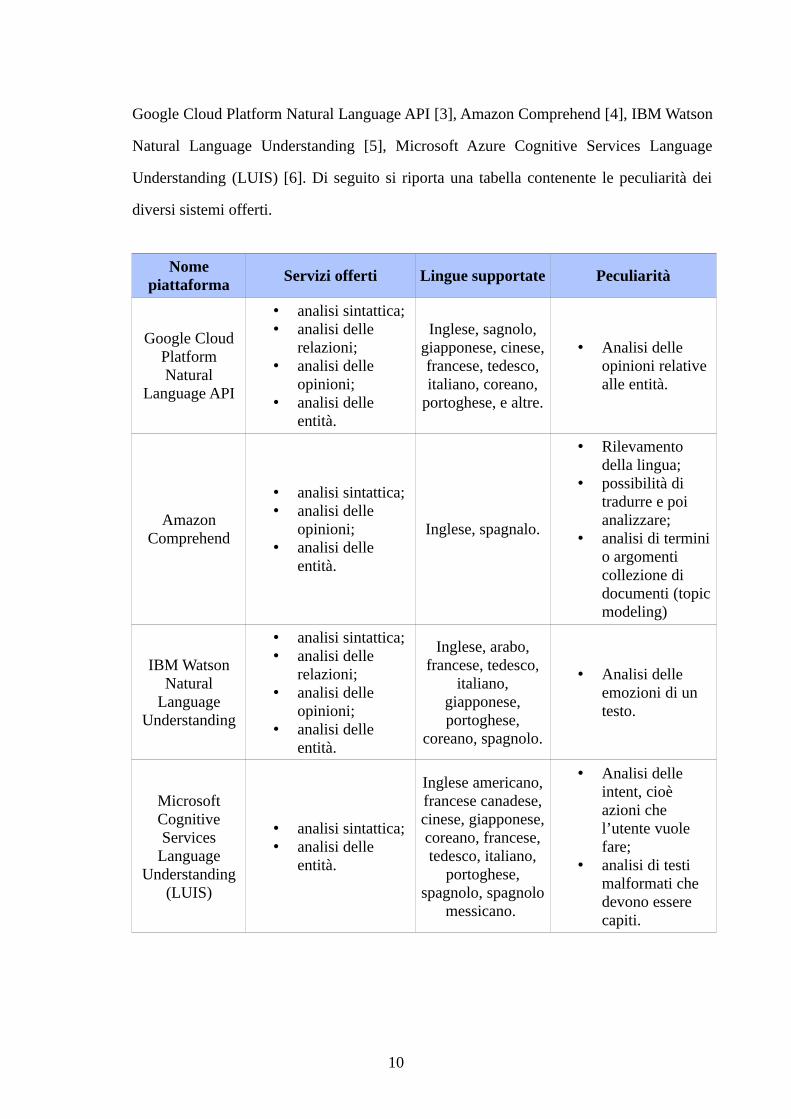
Google Cloud Platform Natural Language API [3], Amazon Comprehend [4], IBM Watson
Natural Language Understanding [5], Microsoft Azure Cognitive Services Language
Understanding (LUIS) [6]. Di seguito si riporta una tabella contenente le peculiarità dei
diversi sistemi offerti.
Nomepiattaforma
Servizi offerti Lingue supportate Peculiarità
Google CloudPlatformNatural
Language API
• analisi sintattica;• analisi delle
relazioni;• analisi delle
opinioni;• analisi delle
entità.
Inglese, sagnolo,giapponese, cinese,francese, tedesco,italiano, coreano,
portoghese, e altre.
• Analisi delle opinioni relative alle entità.
AmazonComprehend
• analisi sintattica;• analisi delle
opinioni;• analisi delle
entità.
Inglese, spagnalo.
• Rilevamento della lingua;
• possibilità di tradurre e poi analizzare;
• analisi di terminio argomenti collezione di documenti (topicmodeling)
IBM WatsonNatural
LanguageUnderstanding
• analisi sintattica;• analisi delle
relazioni;• analisi delle
opinioni;• analisi delle
entità.
Inglese, arabo,francese, tedesco,
italiano,giapponese,portoghese,
coreano, spagnolo.
• Analisi delle emozioni di un testo.
MicrosoftCognitiveServices
LanguageUnderstanding
(LUIS)
• analisi sintattica;• analisi delle
entità.
Inglese americano,francese canadese,cinese, giapponese,coreano, francese,tedesco, italiano,
portoghese,spagnolo, spagnolo
messicano.
• Analisi delle intent, cioè azioni che l’utente vuole fare;
• analisi di testi malformati che devono essere capiti.
10

Di seguito segue una lista di tabelle di costi per ogni cloud provider.
Google Cloud Platform Natural Language API
Servizio 0 → 5K 5K+ → 1M 1M+ → 5M 5M+ → 20M
Analisi delle entità Gratis $1.00 $0.50 $0.25
Analisi delle opinioni Gratis $1.00 $0.50 $0.25
Analisi sintattica Gratis $0.50 $0.25 $0.125
Analisi delle opinionirelative alle entità
Gratis $2.00 $1.00 $0.50
Il costo si riferisce a una spesa mensile per unità detta text record e rappresenta 1000
caratteri Unicode. Per oltre 20 milioni di text record, Google propone dei contratti
commerciali ad-hoc per il cliente.
Amazon Comprehend
Tipo di servizio 0 → 10M 10M → 50M Over 50M
NLP $0.0001 $0.00005 $0.000025
Amazon Comprehend
Tipo di servizio First 100 MB For every MB over 100
Topic modeling $1.00 $0.004
Il costo fa riferimento a una singola unità che consiste in 100 caratteri Unicode. Il minimo
di unità per poter usufruire dei servizi di Amazon è 3.
IBM Watson Natural Language Understanding
Tipo di contratto 0 → 30K
Lite Gratis
IBM Watson Natural Language Understanding
Tipo di contratto 0 → 250K 250K+ → 5M Over 5M
Standard $0.003 $0.001 $0.0005
11

Il costo fa riferimento a un canone mensile per unità della NLU che rappresenta 10000
caratteri. La Microsoft permette anche di stipulare contratti commerciali personalizzati.
Microsoft Cognitive Services Language Understanding (LUIS)
Servizio 0 → 10K Every 1000 transaction
over 10K
LUIS Gratis $1.50
Il costo fa riferimento ad un costo mensile. Per transaction s’intende una chiamata alle
API del sistema con query che contengono fino a 500 caratteri.
Il più idoneo per questo lavoro di tesi è Google Cloud Natural Language API in quanto le
API offerte si adattano perfettamente alla stesura di un’applicazione Android, ma a causa
dei costi, che si basano sul numero di query inviate e sul fatto che per accedere al servizio
serve una partita IVA, la scelta è ricaduta su una soluzione open-source chiamata
StanfordNLP. Questo Natural Language Processor è stato sviluppato da un team di
ricercatori della Stanford University. Di seguito si riportano in tabella le caratteristiche del
Natural Language Processor in esame.
Nomepiattaforma
Servizi offerti Lingue supportate Peculiarità
StafordNLP
• analisi sintattica;• analisi delle
opinioni;• analisi delle
entità.
Inglese, arabo,cinese, francese,
tedesco, spagnolo.• Open-source
Il servizio di Natural Language Processing è offerto in modo tale da poter installare un
server privato al fine di creare un’architettura client-server, dove il client fa delle richieste
al server, che vengono effettuate tramite protocollo HTTP e il server risponde con le
informazioni legate al testo messo in ingresso in formato JavaScript Object Notation
(JSON) [7].
JavaScript Object Notation è un formato dati adatto all’interscambio di essi
nell’architettura client-server. JSON prende origine dalla sintassi degli oggetti letterali in
12

JavaScript. Un oggetto letterale può essere definito così:
Si tratta di coppie di proprietà/valori separate dalla virgola a eccezione dell’ultima.
L’intero oggetto viene racchiuso tra parentesi graffe. A differenza di JavaScript, che può
contenere anche funzioni e valori complessi, JSON ammette solo valori semplici e
atomici, tra cui:
• stringhe;
• numeri;
• array;
• oggetti letterali;
• true, false;
• null.
La caratteristica principale di StanfordNLP che più salta all’occhio è che la lingua
utilizzata dal servizio è l’inglese, quindi tutti i comandi sono dati in lingua inglese.
Particolare attenzione vale la pena darla al servizio Part-of-speech tagging di StanfordNLP
utilizza il Penn Treebank tag set [8]. Questo set di tag è una legenda che esplicita la
semantica di ogni tag utilizzato dal servizio Part-of-speech. Di cui di seguito viene
mostrata la tabella.
Tag Description
CC Coordinating conjunction
CD Cardinal number
DT Determiner
EX Existential there
FW Foreign word
IN Preposition or subordinating conjunction
13
var JSON = { proprieta1: 'Valore', proprieta2: 'Valore', proprietaN: 'Valore'
}

JJ Adjective
JJR Adjective, comparative
JJS Adjective, superlative
LS List item marker
MD Modal
NN Noun, singular or mass
NNS Noun, plural
NNP Proper noun, singular
NNPS Proper noun, plural
PDT Predeterminer
POS Possessive ending
PRP Personal pronoun
PRP$ Possessive pronoun
RB Adverb
RBR Adverb, comparative
RBS Adverb, superlative
RP Particle
SYM Symbol
TO to
UH Interjection
VB Verb, base form
VBD Verb, past tense
VGD Verb, gerund or present participle
VBG Verb, past participle
VBN Verb, non-3rd person singular present
VBZ Verb, 3rd person singular present
WDT Wh-determiner
WP Wh-pronoun
WP$ Possessive wh-pronoun
WRB Wh-adverb
Di seguito verrà mostrato un esempio di applicazione di questa tabella supponendo di
avere in ingresso il testo “Take the bottle and take the glass”.
14

Capitolo 2: Implementazione
In questo capitolo verrà illustrato come l’applicazione Android realizza le funzionalità al
fine di raggiungere gli obiettivi richiesti.
Prima di analizzare l’algoritmo, verrà discussa l’architettura completa del sistema che
permette l’interazione tra l’operatore e la piattaforma robotica. Tale architettura è proposta
nella seguente figura.
Di seguito si descrive il funzionamento del sistema. L’utente inserisce il comando tramite
linguaggio naturale. L’applicativo trasforma in stringa il comando dell’utente e, attraverso
un’interfaccia di comunicazione, invia la stringa al Natural Language Processor. Dopo
l’elaborazione, la risposta del servizio ritorna all’applicativo, che, attraverso opportune
elaborazioni, individua i comandi espressi dall’operatore e crea un messaggio per il robot.
Successivamente quest’ultimo viene inviato al robot tramite su una rete che collega
l’applicativo al robot.
15

L’algoritmo utilizzato precedentemente per decidere quali comandi dovesse svolgere il
robot era statico, nel senso che l’analisi della frase dell’operatore non era fatta tramite
un’analisi sintattica ma attraverso la comparazione delle parole della frase con un
dizionario interno. Inoltre, come detto precedentemente prevedeva, l’interpretazione di un
singolo comando alla volta. Con questo lavoro di tesi si è voluto rivoluzionare l’algoritmo
di interpretazione dei comandi lasciando inalterati il modo in cui l’applicativo invia i
comandi al robot (un apposito thread che apre una comunicazione con il robot tramite una
socket di tipo UDP) e il modo in cui l’utente fornisce il comando all’applicativo (speech-
to-text fornito da Google come API per Android). In particolare quest’ultima funzionalità
dell’applicazione fornisce come output, sotto forma di stringa, il comando immesso
dell’utente. Si vuole far notare che il servizio speech-to-text non è esente da errore di
interpretazione. Da questo momento in poi si farà riferimento a questo risultato con il
termine “stringa”.
In particolare, si ricorda, che la stesura di questo nuovo algoritmo prevede che si possono
dare più comandi al robot e che ci sia una forma di conoscenza con esso.
L’algoritmo di interpretazione comandi si basa su cinque sotto-funzionalità:
1. verifica della raggiungibilità del server;
2. richiesta HTTP al server del Natural Language Processor;
3. interpretazione dei comandi;
4. codifica dei comandi;
5. creazione del messaggio;
6. visualizzazione dei comandi.
Ogni sottofunzionalità è implementata come metodo della classe MainActivity, tranne la
richiesta HTTP che è implementata con una classe apposita.
Nelle sezioni seguenti verranno descritte in dettaglio ogni sotto-funzionalità.
2.1 Verifica della raggiungibilità del serverQuesta prima sotto-funzionalità si occupa di contattare il server tramite il comando da
terminale ping. Infatti in Java sono presenti particolari tipi e metodi che permettono di
16

richiamare i comandi della Shell durante l’esecuzione di un programma. In particolare si
utilizzano il tipo Process e il metodo Runtime.getRuntime().exec(String command) della
libreria java.lang per adempiere all’obiettivo della sotto-funzionalità.
Il comando è utilizzato in modo tale che se esso va a buon fine, allora l’utente può dare il
comando al robot (in sostanza si apre la RecognizerIntent di Google), altrimenti viene
visualizzato un Toast, che è un tipo di notifica di Android che appare sotto forma di
riquadro in basso dello schermo, che dice all’utente che il server non è raggiungibile.
Il codice per implementare la sotto-funzionalità è presentato di seguito:
2.1 Richiesta HTTP al serverL’utente inserisce il proprio comando se la verifica della raggiungibilità va a buon fine, e,
tramite un processo di speech-to-text, quest’ultimo viene trasformato in stringa. La
seconda sotto-funzionalità si occupa di contattare il server, inviando la stringa appena
trasformata. Essa, come già detto, è implementata in una apposita classe Java, chiamata
HTTPRequest, che estende la classe AsyncTask, che permette l’esecuzione di operazioni in
background [9]. Il funzionamento è simile a un Thread, ma viene scelto AsyncTask perché,
a differenza di Thread, viene utilizzato per l’esecuzione di brevi task asincroni che devono
comunicare con un task principale.
La classe AsyncTask possiede un metodo Abstract chiamato doInBackground(Params…
params). Questo metodo viene sovrascritto con le istruzioni atte alla creazione di una
comunicazione HTTP. Ciò avviene tramite i costrutti URL e HttpURLConnection. Il primo
permette di dichiarare un puntatore ad una risorsa del World Wide Web intesa come
Uniform Resource Locator a partire da un indirizzo passato come parametro di tipo String
[10]. Il secondo permette di aprire una comunicazione con la URL dichiarata utilizzando il
protocollo HTTP [11]. Entrambi i tipi sono contenuti nella libreria java.net.
17
public boolean ping() throws IOException, InterruptedException { Process p1 = java.lang.Runtime.getRuntime().exec("ping -c 1 corenlp.run"); int returnVal = p1.waitFor(); return (returnVal==0);}

La caratteristica principale di HttpURLConnection è quella di poter utilizzare diversi
parametri per caratterizzare la connessione, come per esempio il comando da utilizzare
nella connessione HTTP, che nel nostro caso è POST in quanto la stringa contenente il
comando è inviata nel corpo del messaggio e non nell’header a differenza del comando
GET.
Una volta iniziata la comunicazione con il server vengono aperti due standard stream, uno
di input e l’altro di output, in cui si scrive il messaggio e si legge la risposta.
La connessione si chiude quando il server invia tutta la risposta.
Il codice utilizzato è presentato di seguito:
2.2 Interpretazione dei comandiQuesta sotto-funzionalità è il perno principale dell’applicativo. L’ipotesi principale su cui
si fonda è quella che ogni frase di senso compiuto, soprattutto per dare un comando, nella
maggior parte delle volte, è formata da verbo e complemento oggetto (es. prendi la
bottiglia). Il problema, quindi, che viene risolto è quello di dividere il verbo e il
complemento oggetto a cui si riferisce.
Questa sotto-funzionalità inoltre è quella che si occupa di costruire una forma di
18
protected String doInBackground(Void... params) { String jsonStr = ""; try { URL url = new URL("http://corenlp.run:80/"); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); //istruzioni per caratterizzare la connessione DataOutputStream wr = new DataOutputStream(conn.getOutputStream()); wr.write(command.getBytes(Charset.forName("UTF-8"))); wr.close(); BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream())); String temp; while ((temp = br.readLine()) != null) jsonStr += temp; br.close(); } catch (Exception e) { e.printStackTrace(); } return jsonStr;}

“conoscenza sociale” da parte del robot.
La sotto-funzionalità in esame è divisa ulteriormente in due parti: la prima ricerca un
eventuale nome di persona all’interno della stringa attraverso il servizio Named Entity
Recognition, mentre la seconda ricerca all’interno della stessa stringa ogni verbo e ogni
nome grazie al servizio Lemmatization e Part-of-speech tagging.
Si vuole ricordare come il server risponde con un messaggio in formato JSON, quindi sono
previste delle linee di codice che trasformano la stringa di risposta del server, tramite
appositi costrutti e tipi contenuti nella libreria org.json, in un JSONObject e di questo ne
viene estratto un JSONArray. Da quest’ultimo vengono estrapolate le informazioni
necessarie per l’elaborazione che vengono selezionate attraverso i tag utilizzati dal Part-of-
speech tagging del Natural Language Processor utilizzato. In particolare, in questa sotto-
funzionalità vengono utilizzati i tag VB e NN, che rispettivamente indicano un verbo alla
forma base e un nome singolare.
Il risultato di questa sotto-funzione sono due array di stringhe contenenti una tutti i verbi e
l’altra tutti i nomi trovati nella stringa.
Per ottenere una struttura omogenea, vengono inseriti in questi due array anche il nome di
persona eventualmente trovato e un verbo, che è stato chiamato “social”, per identificare
l’azione da far compiere al robot.
Il vantaggio di avere due array distinti sta nel fatto che in ogni posizione del vettore
contenente i verbi, in corrispondenza della stessa posizione (cioè nello stesso valore
dell’indice), c’è il complemento oggetto a cui fa riferimento, realizzando di fatto uno
“splitting intelligente” della stringa in cui ogni verbo è associato al relativo complemento
oggetto, venendo incontro all’ipotesi fatta, cioè è stata realizzata una struttura del tipo
verbo-complemento oggetto.
Si vuole far notare che per evitare conflitti tra le due parti della sotto-funzionalità, nella
seconda vengono saltate tutti i nomi di persona. È stato evidenziato, inoltre, come alcuni
verbi e/o oggetti possono creare alcune incomprensioni nell’interpretazione del comando,
per cui sono state scartate durante l’esecuzione della sotto-funzione. Esempi lampanti sono
il verbo “be” e “please” e il nome “place”, saltato poiché il sistema riconosce quest’ultimo
19

come nome e non come verbo.
Il codice fulcro della sotto-funzionalità è presentato di seguito:
20

2.3 Codifica dei comandiLa sotto-funzionalità in esame si occupa di verificare se i verbi e/o gli oggetti riconosciuti
sono rispettivamente funzioni che il robot svolge e/o oggetti che il robot vede e codifica il
comando, l’oggetto e un eventuale errore, che si verifica quando la verifica di verbo e/o
21
public void commandInterpreter(String response) { JSONObject responseJsonObj; JSONArray responseJsonArray; if (response != null) try { responseJsonObj = new JSONObject(response); Log.d("MAIN", responseJsonObj.toString()); responseJsonArray = responseJsonObj.getJSONArray("sentences"); for (int i = 0; i < responseJsonArray.getJSONObject(0).getJSONArray("tokens").length(); i++) { if (responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("ner").contains("PERSON")) { vb.add("social"); nn.add(responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("lemma")); } } for (int i = 0; i < responseJsonArray.getJSONObject(0).getJSONArray("tokens").length(); i++) { if (responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("lemma").equals("be") || (responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("lemma").equals("please")) || (responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("ner").equals("PERSON"))) continue; if (responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("pos").contains("VB")) { vb.add(responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("lemma")); if (responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("lemma").equals("stop")) nn.add("no obj"); } if (responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("pos").contains("NN")) nn.add(responseJsonArray.getJSONObject(0).getJSONArray("tokens").getJSONObject(i).getString("lemma")); } } catch (Exception e) { e.printStackTrace(); } else Log.d("MAIN", "STRINGA VUOTA");}

oggetto fallisce.
La verifica dei comandi e degli oggetti è un’operazione necessaria ai fini dell’obiettivo
finale poiché il robot non svolge ovviamente tutti comandi che si vogliono, ma ha un
dominio ristretto di funzioni preventivamente definito. In particolare i comandi eseguiti
dal robot sono di prendere, lasciare oggetti, conoscenza, di andare in una direzione e
fermarsi.
Una volta effettuata la verifica, il comando e/o l’oggetto vengono codificati secondo le
regole dettate da un protocollo di comunicazione, preventivamente accordato. Nello
specifico, il protocollo prevede tre bit di cui il primo indica la presenza di errori, il
secondo codifica il verbo e il terzo codifica l’oggetto. Si nota che se c’è un errore, gli altri
due bit sono posti a zero.
Per effettuare la verifica e la codifica, i verbi e gli oggetti sono stati inseriti in due strutture
dati HashMap, una per i verbi e l’altra per gli oggetti, della libreria java.util di tipo
<String, Integer> dichiarate in una classe Java del progetto, chiamata Dictionary. La
particolarità della struttura dati HashMap sta nel fatto che ogni elemento salvato è diviso
in due: un valore e una chiave. Nel nostro caso il valore, di tipo Integer rappresenta la
codifica del comando o dell’oggetto, mentre la chiave, di tipo String, è proprio il comando
o l’oggetto. All’interno dell’applicazione viene utilizzato il metodo containsKey(String
key), che prende una chiave come parametro e ne verifica la presenza nella HashMap, e il
metodo get(String key), che data una chiave in ingresso restituisce il valore associato.
Questi due metodi permettono, utilizzati in modo corretto, sia la verifica che la codifica, il
tutto in poche righe di codice.
Il risultato di questa sotto-funzionalità sono tre array di stringhe contenenti ognuno la
codifica rispettivamente di errori, verbi e oggetti.
Nel caso di nomi di persona, questi non vengono codificati, ma vengono lasciati inalterati
e mandati al robot così come sono.
Il codice per questa sotto-funzionalità è riportato di seguito.
22

2.4 Creazione del messaggioQuesta sotto-funzionalità si occupa di creare il messaggio da mandare al robot. Ciò che fa
è la concatenazione della tripla di elementi dei tre array creati dalla sotto-funzione che si
occupa della codifica, per ogni posizione dei vettori. La concatenazione è possibile grazie
al metodo append(String s) della classe StringBuilder.
Il risultato finale sarà una stringa di cifre. Si vuole far notare che nel caso di un nome di
persona, il messaggio mandato al robot non è formato da sole cifre ma anche di caratteri,
che appunto rappresentano il nome di persona.
Quando la creazione del messaggio è finita, viene abilitato l’invio della stringa da parte del
thread che si occupa della comunicazione con il robot, ponendo al valore True una
variabile Boolean addetta proprio alla verifica della presenza del messaggio.
Il codice utilizzato è riportato di seguito:
23
public void commandEncorder() { if ((vb.size() == 0) || (vb.size() != nn.size())) { error.add("1"); command.add("0"); object.add("0"); } else { for (int i = 0; i < vb.size(); i++) { String verb = vb.get(i); String obj = nn.get(i); String commandEncoded = diz.getCommandCoding(verb); String objEncoded = diz.getObjectCoding(obj); if (verb.equals("social")) { error.add("0"); command.add(commandEncoded); object.add(obj); } else if ((commandEncoded.equals("not find")) || (objEncoded.equals("not find"))) { error.add("1"); command.add("0"); object.add("0"); } else { error.add("0"); command.add(commandEncoded); object.add(objEncoded); } } }}

2.5 Visualizzazione dei comandiQuesta sotto-funzionalità non è importante ai fini dell’obiettivo finale, serve per capire il
risultato finale dell’applicazione, soprattutto da parte dell’utente. Si occupa di visualizzare
in due TextView, tipo particolare di Android con cui è possibile visualizzare un testo, la
stringa riconosciuta dalla RecognizerIntent e la sua elaborazione da parte dell’algoritmo,
sia sotto forma di comandi e/o oggetti riconosciuti sia sotto forma di codifica. In
particolare il protocollo di visualizzazione scelto prevede la seguente regola:
Nel capitolo successivo è possibile osservare nello specifico il risultato di tale sotto-
funzione attraverso i casi di test.
Il codice utilizzato è riportato di seguito:
24
public void commandCreator() { StringBuilder msg = new StringBuilder(); for (int i = 0; i < error.size(); i++) { msg.append(error.get(i)); } for (int i = 0; i < command.size(); i++) { msg.append(command.get(i)); } for (int i = 0; i < object.size(); i++) { msg.append(object.get(i)); } udpOutputData = msg.toString(); sendUdp = true;}
public void commandVisualizer() { StringBuilder res = new StringBuilder(); if (vb.size() == 0) for (int i = 0; i < error.size(); i++) vb.add("VB MISS"); if (nn.size() == 0) for (int i = 0; i < error.size(); i++) nn.add("OBJ MISS"); for (int i = 0; i < error.size(); i++) res.append("ERROR: ").append(error.get(i)).append(" COMMAND: ").append(command.get(i)).append(" - ").append(vb.get(i)).append(" OBJECT: ").append(object.get(i)).append(" - ").append(nn.get(i)).append("\n"); String result = res.toString(); mCommandOutputTv.setText(result);}
ERROR: ‘bit dell’errore’ COMMAND: ‘bit del comando’ – ‘comando’ OBJECT: ‘bit dell’oggetto’ – ‘oggetto’

Capitolo 3: Casi di test
In questo capitolo verranno mostrati vari casi di test per mostrare come l’applicativo
Android si comporta di fronte a diversi input.
Verranno esplicitati gli input e i gli output previsti, intesi come messaggio costruito da
mandare al robot.
3.1 Primo: comando singolo sempliceINPUT: “Take the bottle”
OUTPUT: 011
COMPORTAMENTO:
In questo test si è voluto testare un semplice comando al robot e, come previsto, il
messaggio di uscita verso esso è 011.
25

3.2 Secondo: comando singolo articolatoINPUT: “Would you please to take me the bottle?”
OUTPUT: 011
COMPORTAMENTO:
In questo secondo caso di test si vuole porre enfasi su quanto naturale è il linguaggio
utilizzato per dare il comando con l’aggiunta non solo del verbo e del complemento
oggetto ma anche di verbi ausiliari. L’uscita prevista coincide con quella reale, cioè 011.
26

3.3 Terzo: comando fuori dal dominio delle funzioni eseguite dal robotINPUT: “Do you like a pizza?”
OUTPUT: 100
COMPORTAMENTO:
In questo caso di test si è voluto testare il comportamento dell’applicativo in presenza di
un input al di fuori del dominio delle funzioni del robot. L’uscita reale è 100 ed è pari a
quella prevista.
27

3.4 Quarto: due comandi sempliciINPUT: “Take the bottle and take the glass”
OUTPUT: 011012
COMPORTAMENTO:
Come ripetuto, uno degli obiettivi dell’algoritmo è quello di poter elaborare una stringa
con all’interno più di un comando. In questo caso di test si verifica il corretto
funzionamento della funzionalità. Il messaggio reale in uscita è pari a quello atteso. Si
vuole far notare che l’algoritmo garantisce il corretto funzionamento anche in presenza di
congiunzioni.
28

3.5 Quinto: comandi multipliINPUT: “Take the bottle, take the glass and stop”
OUTPUT: 011012044
COMPORTAMENTO:
In questo caso di test, si testa il comportamento dell’algoritmo in presenza di una stringa
contenente più di due comandi. Il risultato finale è pari a quello atteso.
Si vuole far notare che il comando stop è stato inserito poiché il robot in futuro potrebbe
anche avere funzioni di movimento.
29

3.6 Sesto: interazione socialeINPUT: “I’m David”
OUTPUT: 05David
COMPORTAMENTO:
Come ripetuto, il robot prevede una sorta di interazione sociale che consiste nel
riconoscere il nome dell’utente nel caso in cui viene inserito nell’applicativo. Il
comportamento reale è pari a quello atteso. Particolare attenzione si pone sul messaggio in
uscita che risulta essere 05David, cioè come già detto il nome non è codificato quindi
viene mandato così com’è al robot.
30

Conclusioni
In questo lavoro di tesi abbiamo sviluppato un sistema per l’interpretazione dei comandi
tramite riconoscimento vocale. Gli obbiettivi prefissati erano:
• l’utilizzo di un Natural Language Processing per l’elaborazione del comando
dell’utente;
• rendere l’applicativo indipendente dal robot e dal Natural Language Processor e dal
linguaggio utilizzato;
• creare un’interazione sociale tra utente e robot.
Come si è visto nel capitolo in cui sono stati presentati i test, tali obiettivi sono stati
raggiunti, mostrando i risultati ottenuti seguendo l’implementazione proposta nel capitolo
2, utilizzando tecnologie mobile, basate su Android e Java e un motore di Natural
Language processing in cloud.
Tale Natural Language Processing utilizzato dal sistema implementato è fornito dalla
Stanford University, chiamato Standord NLP. Di tale risorsa sono stati utilizzati i servizi di
Named Entity Recognition, Lemmatization e Part-of-speech tagging in modo da
permettere l’interpretazione di più comandi alla volta e implementando oltre il possibile
controllo di una pattaforma robotica l’interazione sociale dell’utente con esso.
Possibili sviluppi futuri possono essere:
• la possibilità di poter “insegnare” al robot eventuali comandi attaverso tecniche di
Machine Learning (es. versare = prendere bottiglia + prendere bicchiere + girare
mano bottiglia);
• Effettuare un’analisi semantica della frase in modo da non dover necessariamente
specificare il dominio applicativo del nostro sistema.
31

Bibliografia
[1] Thomas Villacci, “Sviluppo di un framework per l’interazione uomo-robot basato
sulle tecnologie di sintesi e riconoscimento vocale”, Tesi triennale, 2017.
[2] Daniel Jurafsky and James H. Martin, “Speech and Language Processing: An
Introduction to Natural Language Processing, Speech Recognition, and Computational
Linguistics, Prentice-Hall, 2nd edition, 2008.
[3] Google Cloud Platform Natural Language API, https://cloud.google.com/natural-
language/.
[4] Amazon Comprehend, https://aws.amazon.com/comprehend/.
[5] IBM Watson Natural Language Understanding,
https://www.ibm.com/watson/services/natural-language-understanding/.
[6] Microsoft Azure Cognitive Services Language Understanding (LUIS),
https://azure.microsoft.com/it-it/services/cognitive-services/language-understanding-
intelligent-service/.
[7] Introduzione a JSON, https://www.json.org/json-it.html.
[8] Stanford Log-linear Part-Of-Speech Tagger,
https://nlp.stanford.edu/software/tagger.shtml.
[9] AsyncTask, https://developer.android.com/reference/android/os/AsyncTask.html.
[10] Classe URL, https://docs.oracle.com/javase/7/docs/api/java/net/URL.html.
[11] Classe, HttpURLConnection,
https://docs.oracle.com/javase/7/docs/api/java/net/HttpURLConnection.html.
32