RELAZIONE DI FINE TIROCINIO - Ingegneria Civile · creazione degli “experimental design”....
23
1 UNIVERSITÀ DEGLI STUDI DI “ROMA TRE” Dipartimento di Ingegneria Corso di Laurea Magistrale in Ingegneria delle Infrastrutture Viarie e Trasporti RELAZIONE DI FINE TIROCINIO Oggetto: Experimental designs e applicazione di modelli comportamentali Tutor Candidata Dott. Marialisa Nigro Eleonora Toniolo Matricola: 439601 Anno Accademico 2016/2017
-
Upload
nguyenhanh -
Category
Documents
-
view
250 -
download
1
Transcript of RELAZIONE DI FINE TIROCINIO - Ingegneria Civile · creazione degli “experimental design”....

1
UNIVERSITÀ DEGLI STUDI DI “ROMA TRE”
Dipartimento di Ingegneria
Corso di Laurea Magistrale in Ingegneria delle Infrastrutture Viarie e Trasporti
RELAZIONE DI FINE TIROCINIO
Oggetto: Experimental designs e applicazione di
modelli comportamentali
Tutor Candidata
Dott. Marialisa Nigro Eleonora Toniolo
Matricola: 439601
Anno Accademico 2016/2017

2
Sommario
1. PREMESSA .................................................................................................................. 3
2. INTRODUZIONE ......................................................................................................... 4
3. EXPERIMENTAL DESIGN ........................................................................................ 6
4. CASO DI STUDIO ....................................................................................................... 7
4.1. Processo di definizione del disegno sperimentale .................................................. 7
4.2. Applicazione Del Processo: ................................................................................. 11
5. ANALISI DEI DATI................................................................................................... 16
5.1. Multinomial Logit ....................................................................................................... 17
5.2. Mixed Logit ................................................................................................................. 19
6. CONCLUSIONI .......................................................................................................... 21
7. BIBLIOGRAFIA E SITOGRAFIA ............................................................................ 22

3
1. PREMESSA
La seguente relazione riassume gli obiettivi posti e raggiunti durante lo svolgimento del
tirocinio. Quest’ultimo si è svolto nel laboratorio di Trasporti del Dipartimento di
Ingegneria Civile dell’Università degli Studi di Roma Tre a partire dal giorno 1/07/17 al
giorno 31/10/17, per un totale di 100 ore corrispondenti a 4 CFU.
Il lavoro presentato si pone l’obiettivo di studiare uno dei possibili impatti dovuti
all’introduzione dei veicoli autonomi. Questi nuovi sistemi di trasporto non avendo la
necessità di essere guidati offrono all’utenza la possibilità di svolgere altre attività durante
il viaggio. Questo importante aspetto modifica in maniera inequivocabile la percezione del
tempo speso a bordo del mezzo, riducendone così il costo monetario ad esso associato. Si
genera quindi un fenomeno che può indurre i residenti dei centri abitati a rivalutare la
localizzazione della propria abitazione. Attraverso delle indagini di tipo Stated Preferences
si stima la quota di utenti che a valle dell’introduzione di tali veicoli sarà disposta a
trasferirsi verso la periferia, grazie all’ottimizzazione del costo opportunità del tempo di
viaggio. L’ambito di applicazione di tale studio è il contesto romano, per la precisione si è
scelto di condurre un’indagine parallela per la popolazione attualmente residente
all’interno dell’anello ferroviario e quella residente solo all’interno del Grande Raccordo
Anulare.

4
2. INTRODUZIONE
Il tema della mobilità del futuro, nelle sue declinazioni ed evoluzioni più tecnologicamente
avanzate, dalle strade intelligenti (smart road), ai veicoli connessi (connected vehicles),
alle infrastrutture stradali tecnologicamente avanzate, alle auto a guida autonoma
(automated cars), è al centro del dibattito più recente sulle prospettive della mobilità
intelligente. La vastità di ricerche, studi, annunci e notizie sui primi risultati ottenuti nei
test, annuncia che questo futuro della mobilità non è molto lontano.
Un’autovettura autonoma è un veicolo automatico che soddisfa le principali capacità di
trasporto di una macchina tradizionale, rilevando l'ambiente e la navigazione senza
intervento umano. I veicoli autonomi si avvalgono di tecniche come radar, lidar, GPS,
e visione artificiale. Sistemi di controllo avanzati interpretano gli input ricevuti per
selezionare i percorsi appropriati, avvistare gli ostacoli e la segnaletica rilevante. I veicoli
autonomi aggiornano le proprie mappe sulla base di input sensoriali, mantenendo la propria
posizione anche quando le condizioni cambiano o quando entrano in ambienti inesplorati.
Note le caratteristiche di queste nuove vetture è lecito supporre che numerosi sono i
benefici attesi dall’introduzione di massa dei veicoli totalmente autonomi: primo fra tutti è
l’aumento della sicurezza, infatti le principali cause di incidentalità stradale per l’80% sono
riconducibili ad errori umani (Fondazione Filippo Caracciolo, 2016). La guida distratta
risulta essere una delle più comuni concause di tali eventi incidentali, perciò affidando la
guida ad un sistema automatico, che risponde agli impulsi esterni in maniera tempestiva, si
riduce enormemente il rischio dei sinistri oppure se ne riduce la gravità. Se tutte le auto
circolanti fossero autonome ci sarebbe anche un risparmio di miliardi di euro per le spese
degli incidenti stradali. Gli Autonomous vehicles inoltre, grazie al nuovo sistema di guida,
garantiscono un’accelerazione e decelerazione più graduali in modo da abbattere i consumi
di carburante del 10% rispetto al pilota umano. Notevoli benefici sono stimati anche
riguardo la congestione del traffico, grazie alla riduzione dei tempi critici di manovra come
l’arresto, diminuisce infatti lo spazio di sicurezza tra i veicoli garantendo un’ottimizzazione
della capacità delle infrastrutture stradali. Le auto a guida autonoma miglioreranno quindi
le condizioni di viaggio non solo per chi già è in grado di guidare ma anche per coloro che

5
non lo sono, come i disabili, gli anziani e persino i più giovani, permettendo loro di
muoversi con un mezzo autonomamente.
Tra i numerosi benefici mostrati in letteratura emerge anche la questione relativa ai
parcheggi con la possibilità che si avrebbe di fruttare l’attuale spazio adibito agli stalli per
altri usi; gli Autonomous vehicles infatti non necessitano di essere parcheggiati nella sede
di destinazione del viaggio, ma potrebbero muoversi da soli in altre aree più distanti adibite
al parcheggio. Un’importante implicazione che i veicoli autonomi possono portare è quella
di una riduzione del valore monetario del tempo di viaggio a bordo del mezzo (in inglese
Value of Time, VoT). Come già noto il VoT è funzione del viaggio stesso, delle condizioni
di comfort, dell’affollamento a bordo, dalla motivazione dello spostamento e soprattutto
dalla possibilità di poter fruttare la durata del viaggio per qualsiasi attività. Per i mezzi
pubblici quest’ultima possibilità è già esistente, in essi però spesso ciò che grava
maggiormente è l’affollamento a bordo e/o le mancate condizioni di comfort richieste. In
questa ottica la possibilità di convertire in tempo produttivo la durata dello spostamento
con un mezzo privato potrebbe comportare un evidente impatto nella valutazione delle
durate stesse dei tragitti sistematici.
È lecito supporre che esista un forte legame tra le scelte localizzative residenziali e le
ripercussioni sul sistema di trasporto. Per comprendere tale correlazione è necessario
considerare non solo l’impatto della distribuzione delle attività urbane sulla domanda di
spostamento, ma anche l’impatto che la variazione dell’accessibilità di diverse zone può
avere sull’attrazione localizzativa nelle scelte residenziali. Il mercato degli immobili
italiani e dei finanziamenti per acquistarli sono tali da non rendere particolarmente agevoli
più cambi di residenza nel breve periodo. Perciò l’utente consapevole di questi vincoli,
pondera con la massima attenzione le sue scelte abitative. L’obiettivo di questo lavoro è
dunque di identificare e quantificare effettivamente quanto le variazioni sulle
caratteristiche del sistema di trasporto possano impattare sulle scelte residenziali. A tale
proposito si ritiene opportuno valutare la possibilità che si effettuino delle rivalutazioni
sulla localizzazione della propria abitazione per gli utenti già residenti nel centro città
grazie all’avvento dei veicoli autonomi. Il fenomeno che ci si aspetta è che avvenga uno
spostamento delle residenze verso la periferia dove il costo della vita risulta essere più

6
basso anche se i tempi di percorrenza degli itinerari sistematici si potrebbero allungare, ma
come già detto tale impatto sarà meno rilevante rispetto alla situazione attuale.
3. EXPERIMENTAL DESIGN
Le indagini di tipo SP (Stated Preference o Preferenze Dichiarate) descrivono le preferenze
dell’utenza su delle realtà ipotetiche, future, non ancora reali, a differenza delle RP
(Revealed Preference o Preferenze Rivelate) che descrivono invece i comportamenti degli
utenti nei contesti attuali. I vantaggi offerti da questo genere di indagini sono prima di tutto
relativi alla possibilità di investigare l’atteggiamento comune in contesti di scelta non
attualmente disponibili; in secondo luogo consentono di introdurre degli attributi di qualità
del servizio offerto non ancora presenti nella realtà; ed infine permettono di ottenere un
maggior numero di informazioni a parità di costo speso per le indagini, questo grazie alla
molteplicità dei contesti di scelta sottoposti agli intervistati. D’altra parte però questo
genere di approccio presenta distorsioni derivanti dalla possibile difformità tra le scelte
dichiarate e quelle effettive; possono mancare degli attributi rilevanti per il decisore; si
possono verificare problemi di comprensione di contesti irrealistici; ed infine l’intervistato
potrebbe risultare stanco se sottoposto ad un numero eccessivo di set di scelta.
Un esperimento di preferenze dichiarate è caratterizzato dalle alternative proposte
all’intervistato; gli attributi o i fattori che caratterizzano ogni alternativa; i livelli di
variazione di ogni attributo; la selezione dei contesti di scelta proposti, ossia gli scenari
creati come insieme di alternative tra le quali l’utente deve dichiarare la sua preferenza.
Operativamente è importante che gli scenari proposti siano il più possibile reali, cioè vicini
alla conoscenza e all’esperienza dell’utente. È inoltre importante offrire un numero
contenuto di opzioni alternative definite da pochi attributi e sottoporre ogni intervistato ad
un numero ridotto di scenari. La generazione di un indagine di questo tipo è basata sulla
creazione degli “experimental design”. Questi sono delle combinazioni di diversi valori
delle variabili (attributi o fattori), strutturati in modo tale da cogliere l’influenza che
ognuno degli attributi ha sulle scelte. Operativamente sono rappresentati da delle matrici

7
nelle quali compaiono i diversi livelli degli attributi (in ogni riga) per formare diverse
alternative (una per ogni colonna) da sottoporre ai rispondenti.
4. CASO DI STUDIO
Per svolgere questa tipologia di indagine si sono dovuti analizzare tutti i possibili design
disponibili in letteratura e nei manuali dei software a disposizione. A seguito di tale analisi
si è stabilito di utilizzare una particolare tipologia di design: il Bayesian D-Optimality.
Questa tipologia di progetto rientra nella categoria degli efficienti, ed in particolar modo
parte dalla definizione della probabilità di scelta di due o più alternative con l’obiettivo di
massimizzare il valore atteso di scelta delle opzioni realmente scelte.
Il progetto sperimentale Bayesiano si basa sulla conclusione Bayesiana per interpretare i
dati acquisiti durante lo studio pilota, permettendo di tener conto sia delle conoscenze
precedenti dei parametri da stimare, sia delle incertezze delle osservazioni. Il criterio del
D-Optimality si focalizza sulla minimizzazione del determinate della matrice di covarianza
delle stime dei coefficienti del modello, quindi vengono valutati tutti gli effetti che gli
attributi hanno sulle utilità. Questo genere di progetti si adatta bene in casi di studi pilota e
in studi che hanno l’obiettivo di definire gli effetti degli attributi sull’utilità e di identificare
i fattori incisivi per le scelte. Il criterio Bayesiano quindi lavora sull’ottimizzazione del
logaritmo del determinante della matrice di informazioni della massima verosimiglianza
degli stimatori dei parametri nel MNL. Per l’elaborazione di tale procedura si è scelto di
utilizzare il software JMP Statistical Discovery (from SAS) Version 13.
4.1. Processo di definizione del disegno sperimentale
DEFINIZIONE DEGLI ATTRIBUTI: La piattaforma DOE (Design of Experiments)
consente di stabilire le caratteristiche del piano di scelta: la definizione del numero degli
attributi, il loro nome, ruolo e i rispettivi livelli di variabilità.
GENERAZIONE DEL PIANO PILOTA: inizialmente non avendo delle stime dei
parametri a priori, si sceglie di ignorare le specifiche a priori e si generano dei piani neutrali

8
con tutti i parametri nulli. I piani neutrali sono stabiliti aventi eguale probabilità di scelta
per ogni alternativa, secondo la teoria proposta da Huber Zwerina (1996). Sempre in questa
fase si stabiliscono il numero di alternative per ogni scenario, il numero di scenari per ogni
questionario, il numero di questionari tipo e infine il numero di intervistati previsto.
AVVIO STUDIO PILOTA: una volta generato il piano pilota, gli scenari ricavati devono
essere somministrati ad un campione di utenti, mostrando loro ogni alternativa con i livelli
degli attributi opportunamente trasformati in frasi di senso compiuto e chiedendo loro di
scegliere l’alternativa preferita. Una volta ottenuti il numero di responsi stabilito si
riportano le scelte effettive sulla colonna degli indicatori di risposta, per fornire al
calcolatore i dati necessari sui quali avviare il processo di ottimizzazione.
ANALISI DELLO STUDIO PILOTA: dopo aver inserito gli indicatori di risposta si esegue
il modello per la prima volta, in modo da ottenere i report disponibili. La finestra dei report
di JMP offre di sapere:
a) Il valore del p-value dei parametri (la probabilità che ognuno di essi risulti uguale
a zero e sia quindi poco significativo per il modello di utilità);
b) Il valore del Log Valenza dato da: -log10(p-value), utile a ricavare una scala grafica
appropriata per valutare i valore del p-value;
c) La stima dei coefficienti ottenuta tramite il metodo della massima verosimiglianza
L(,θ) definita come segue:
𝐿(, 𝜃) =∏𝑃𝑗𝑖
𝑛
𝑖=1
(𝑖)(𝑉𝑗𝑖 , (𝑋𝑗
𝑖 , 𝛽)𝜃)
Dove la probabilità che l’i-esimo intervistato scelta l’alternativa j con k attributi è
data da:
𝑃𝑗𝑖 =
exp(∑ 𝛽𝑘𝑋𝑘)𝑘
∑ exp(𝑚𝑗=1 ∑ 𝛽𝑘𝑋𝑘)𝑘
Il software invece di massimizzare la funzione L(), preferisce minimizzare
− log[𝐿(𝛽)] seguendo una convergenza in gradiente. Più precisamente utilizza
−2 log[𝐿(𝛽)] in modo da ottenere una distribuzione che tende asintoticamente a 2.

9
d) L’indicatore -2log[L()] serve a valutare la bontà del modello rispetto ad altri, il
migliore risulta quello avente questo valore più basso.
e) L’indicatore AICc rappresenta il criterio informativo Akaike corretto. È funzione
dell’indicatore precedente e si definisce come segue:
𝐴𝐼𝐶𝑐 = −2 log[𝐿(𝛽)] + 2𝑘 +2𝑘(𝑘 + 1)
(𝑛 − 𝑘 − 1)
f) L’indicatore BIC rappresenta il criterio di informazioni Bayesiano ed è anch’esso
dipendente da -2log[L()]. Si definisce come segue:
𝐵𝐼𝐶 = −2 log[𝐿(𝛽)] + 𝑘𝑙𝑛(𝑛)
Dove k è il numero dei parametri stimati e n le osservazioni effettuate. In generale
l’indicatore BIC penalizza i modelli che presentano tanti parametri rispetto
all’AICc, così da suggerirne una riduzione.
g) L’indicatore (opzionale) −2 log[𝐿(𝛽)], calcolato secondo il metodo di correzione
della distorsione di Firth. La distorsione o bias è una modifica intenzionale o meno
del disegno e/o della conduzione di uno studio, dell’analisi e della valutazione dei
dati che incide sui risultati. È un errore dovuto a cause valutative o cognitive che
inducono a favorire alcuni esiti rispetto ad altri. Il metodo di Firth adottato da JMP
dimostra che il termine dominante della distorsione asintotica dello stimatore di
massima verosimiglianza può essere rimosso tramite un’appropriata modifica della
funzione di punteggio. Ciò si traduce in una correzione sistematica del meccanismo
che genera la stima di massima verosimiglianza, basando quest’equazione sulla
funzione di punteggio. La stima di massima verosimiglianza * del parametro si
ottiene come soluzione dell’equazione di verosimiglianza:
∇𝑙(𝜃) = 𝑈(𝜃) = 0
Per ridurre la distorsione asintotica dello stimatore di massima verosimiglianza si
effettua quindi una modifica della funzione di punteggio ricavata dalle volte in cui
la scelta attesa non corrisponde con quella effettiva. La stima di massima
verosimiglianza corretta * si ottiene come soluzione dell’equazione di
verosimiglianza basata sulla funzione di punteggio modificata:
𝑈∗(𝜃) = 0

10
h) La variabile test 2 rientra nella sezione “test del rapporto di verosimiglianza”.
Questa si ottiene sommando per ogni evento Ei il quadrato degli scarti tra le
frequenze teoriche e quelle osservate pesato rispetto alle frequenze teoriche:
2 =∑(𝑜𝑖 − 𝑒𝑖)
2
𝑒𝑖
𝑘
𝑖=1
Quindi se 2 = 0, le frequenze osservate coincidono esattamente con quelle
teoriche. Se invece 2 > 0, differiscono. Più grande è il valore di 2, più grande è
la discrepanza tra le frequenze osservate e quelle teoriche.
i) L’indicatore DF rappresenta i gradi di libertà del Chi-quadro test.
j) Ultimo indicatore è “Prob>Chi-quadro” che rappresenta la significatività del
parametro analogamente al p-value. Per essere ritenuto significativo un parametro
deve avere questa probabilità inferiore ad un valore soglia fissato pari a 0.05
(significatività del 95%).
Lo studio pilota è indispensabile per il processo di definizione del design finale, ma risulta
molto utile anche per le prime valutazioni. In relazione ai coefficienti stimati si effettua un
test informale: se si conosce a priori l’influenza positiva o negativa dell’attributo con un
particolare livello sull’utilità, si verifica la corrispondenza del segno atteso del parametro
con quello risultante dalle stima.
In secondo luogo grazie ai risultati del modello si possono effettuare delle osservazioni in
relazione alla significatività di ognuno dei fattori proposti nel modello. Se ci si accorge che
uno di questi risulta essere poco influente sulle scelte (p-value superiore a 0.05), dovrebbe
essere scartato o modificato.
GENERAZIONE DEL DESIGN FINALE: ottenuti i risultati dello studio pilota si salvano
i dati relativi alla stima e all’errore standard di ogni parametro per poterne ricavare quindi
l’errore quadratico. Si è così pronti per generare il design definitivo. Questo non sarà più
generato con utilità neutrali, ma si seguiranno le indicazioni ottenute dallo studio
precedente: si assumono come corrette le stime dei parametri a priori e gli errori quadratici
per la creazione della matrice di varianza a priori.

11
La creazione del piano prevede, come in precedenza, di specificare il numero di
alternative, scenari, indagini e rispondenti, che possono essere analoghi al disegno iniziale
oppure possono essere modificati se durante l’indagine pilota è emersa qualche difficoltà
(ad esempio un numero eccessivo di scenari da sottoporre ad ogni intervistato che è
risultato stanco e poco concentrato per rispondervi a tutti). Ottenuto il design questo va
convertito da matrici numeriche in tabelle contenenti i concetti relativi ai livelli di ogni
attributo in modo da essere compresi dagli utenti. Per evitare che durante la
somministrazione l’intervistato si focalizzi sull’ordine degli attributi, si procede
rimescolando l’ordine degli stessi nei diversi scenari proposti.
4.2. Applicazione Del Processo:
Nel caso di studio in questa fase si sono riscontrate delle difficoltà nella definizione degli
attributi e delle alternative per il contesto del cambio di residenza con l’introduzione dei
veicoli autonomi. Non essendo presente in letteratura uno studio affrontato nello stesso
modo, si è deciso di scindere le due condizioni (adozione del veicolo autonomo e cambio
di residenza). In modo particolare lo studio relativo all’accettabilità dei nuovi sistemi di
trasporto è stato effettuato applicando un experimental design, aggiungendo solo in seguito
le caratteristiche relative al cambio residenza.
Per la definizione della probabilità di diffusione dell’’utenza verso la periferia, si è stabilito
di utilizzare delle domande dirette: “Immaginando di essere in possesso di un veicolo
autonomo, sarebbe interessato a valutare una ri-localizzazione della sua residenza in
un’area all’esterno dell’Grande Raccordo Anulare?”; “Se sì, di quanto sarebbe disposto a
spostarsi?”; ecc.
DEFINIZIONE ATTRIBUTI: Gli attributi sono stati definiti sulla base di quanto è emerso
dall’analisi della letteratura in merito. Prima fra tutte le caratteristiche è la tipologia di
veicolo autonomo da adottare: oltre alla tradizionale automobile privata, oggi esistono altre
modalità di utilizzo quali il car-sharing e il ride-sharing. La prima consiste nella
condivisione del mezzo con altre persone senza la necessità di acquistarlo, ogni viaggio
viene effettuato privatamente dalla propria origine alla propria destinazione; la seconda

12
modalità è analoga alla prima ma con l’aggiunta della condivisione non solo del mezzo ma
anche del viaggio stesso: ogni corsa può essere effettuata con altre persone a bordo del
veicolo. Un’altra importante caratteristica di questo sistema di trasporto è la tipologia di
attività da poter compiere a bordo, che sia produttiva oppure no. Si è scelto di proporre
quindi tre livelli relativi a questo attributo in cui diminuisce progressivamente il livello di
redditività: “lavorare/leggere/studiare”, “guardare fuori dal finestrino/usare il cellulare”,
“dormire/riposare”. In fine un’altra caratteristica emersa in letteratura è la viabilità nella
quale utilizzare tali mezzi autonomi: urbana o extraurbana.
Figura 1: Livelli degli attributi
GENERAZIONE DEL PIANO PILOTA: si è stabilito di generare due sole alternative per
ogni scenario, tre scenari da sottoporre ad ogni intervistato, per un totale di quattro blocchi
di tre scenari diversi da sottoporre a diversi intervistati. Ottenendo così 12 scenari totali,
che non coprono tutte le combinazioni possibili che in questo caso sarebbero state 18 (= 21
∙ 32), ma solo i 2/3.
AVVIO DEL PIANO PILOTA: vengono così generate le matrici contenenti le
combinazioni dei livelli degli attributi delle due alternative, ad ogni valore numerico è
associato un livello tradotto in parole e frasi di senso compiuto per poter essere
somministrato all’utenza. È stato scelto di analizzare i risultati relativi ad un campione di
20 rispondenti, ai quali è stato chiesto solamente di scegliere l’alternativa preferita tra le
due per ognuno dei tre scenari.
Attività a bordo Livello
Leggere/Lavorare/Studiare 1
Guardare fuori dal finestrino/ Usare il cellulare 0
Dormire/Riposare -1
Tipologia di veicolo
Di proprietà privata 1
Condiviso (car-sharing) 0
A corse condivise (ride-sharing) -1
Viabilità
Urbana 1
Extraurbana -1

13
Figura 2: matrici del design per lo studio pilota, finestra di JMP
ANALISI DELLO STUDIO PILOTA: dopo aver ottenuto le 20 risposte stabilite, si sono
dovuti inserire gli indicatori di risposta nella rispettiva colonna. A valle dello studio pilota
si richiede di far partire il modello per valutarne i report. In questa fase è importante
effettuare i test prima citati della verifica del segno atteso dei coefficienti e del controllo
del valore del p-value per ogni attributo. In relazione a questo secondo test è emerso che
l’attributo “Tipologia di viabilità nella quale utilizzare il veicolo autonomo” è risultato
essere poco significativo per le scelte del primo campione di utenti. Ciò è dimostrato dal
valore del p-value maggiore di 0,05 (valore soglia), come si evince dalla Figura 3: report
studio pilota, finestra di JMP. Si è scelto quindi di eliminare questo attributo inserendone
un altro di maggiore significatività.
Dopo un’ulteriore analisi della letteratura, la scelta è ricaduta nella diversa “Gestione della
Circolazione”: in corsie preferenziali oppure in corsie condivise con i veicoli tradizionali.
Lo studio pilota quindi si è interrotto, ed è stato necessario riprendere il processo dal primo
step. Si è quindi generato un nuovo design pilota con i nuovi fattori e si è condotta una
nuova indagine su 20 intervistati. A seguito di ciò si sono valutati i risultati nella finestra
dei report per verificare la bontà del modello e la significatività degli attributi a valle della
modifica.

14
Figura 3: report studio pilota, finestra di JMP
Figura 4: definizione nuovi attributi, finestra di JMP
ANALISI DEL SECONDO STUDIO PILOTA: i risultati dell’indagine mostrano che
questo nuovo attributo influisce maggiormente sulle scelte effettuate, come mostrato dal
valore del p-value in Figura 5: report secondo studio pilota, finestra di JMP. Risulta
verificato anche il test del segno atteso dei parametri.

15
Figura 5: report secondo studio pilota, finestra di JMP
GENERAZIONE DEL DESIGN FINALE: inserendo le stime ottenute dal piano pilota per
la generazione di un nuovo piano (stima dei coefficienti e valori della matrice di varianza
pari agli errori quadratici), si ottiene il design finale. Come in precedenza si trasformano
le matrici di out-put in tabelle di senso compiuto che si uniscono alle altre domande redatte
per la creazione del questionario completo. Per evitare che ogni rispondente nella lettura
degli scenari si soffermasse sulla lettura di un unico attributo, è stato invertito l’ordine dei
fattori in ogni diverso scenario.
Avendo realizzato ben quattro blocchi/questionari da tre scenari ciascuno, si è stabilito di
ottenere un numero di responsi analogo per ogni blocco/questionario: per un totale di 200
interviste si è previsto di ottenere 50 responsi per ogni blocco.

16
5. ANALISI DEI DATI
A valle di uno studio sulle tecniche di stesura di un questionario, è stato stabilito di dividere
quest’ultimo in quattro sezioni: la prima nella quale vengono raccolti i dati socio-
demografici quali età, genere, grado di istruzione, condizione professionale, più alcune
informazioni sull’attuale residenza (dimensione dell’abitazione, titolo rispetto
all’immobile di residenza e numero di componenti familiari); nella seconda sezione sono
collezionate informazioni sugli attuali spostamenti sistematici, sulle attitudini di mobilità
e su una panoramica di pareri relativi alle condizioni di vita in aree urbane periferiche.
Nella terza parte è presente una breve descrizione del veicolo autonomo, vengono richieste
alcune opinioni al riguardo e alla fine di questa sezione viene indagata la disponibilità a
cambiare residenza ed entro quali distanze. Nell’ultimo settore del questionario, infine,
vengono mostrati i tre diversi scenari sul veicolo autonomo e richieste le preferenze per
ogni alternativa proposta.
Completata la redazione del questionario, nel mese di ottobre si è condotta l’indagine via
Internet avvalendosi di social network come Facebook, oppure inviandolo tramite e-mail.
Una parte delle interviste invece è stata ottenuta attraverso la modalità del Face-to-Face.
Dopo aver ottenuto tutti i dati necessari sono stati analizzati i possibili modelli per
rappresentare il comportamento dell’utenza in merito ai veicoli autonomi e al cambio di
residenza al di fuori del GRA. Per stimare la quota di utenza che rilocalizzerebbe la propria
residenza esternamente al GRA è stato valutato un modello senza le alternative
dell’experimental design. Questo ha permesso di valutare meglio le caratteristiche di questa
scelta soffermandosi solo su queste due alternative: Cambio Residenza e Non Cambio
Residenza. Rimane comunque il legame tra il cambio di residenza e l’adozione del veicolo
autonomo, infatti la domanda posta è: “Immaginando di essere in possesso di un veicolo
autonomo, grazie al quale durante il viaggio potrà svolgere qualsiasi altra attività
desidera, sarebbe interessato valutare la rilocalizzazione della sua residenza in un'area
all'esterno del GRA?”.

17
5.1. Multinomial Logit
È stato quindi sviluppato con il software BIOGEME un Binomial Logit per definire queste
due probabilità.
Figura 6: Struttura modello cambio residenza
Le funzioni di utilità sistematiche sono le seguenti:
VSì = Incidenza del AV + Propenso al cambio residenza
VNo = Residenza interna ad Anello Ferroviario + ASA CSA
L’attributo Incidenza del AV è relativo alla domanda posta a seguito della richiesta di
disponibilità al cambio residenza, nella quale si chiede quanto incide sulla scelta la
possibilità di poter usufruire di tale veicolo autonomo. Avendo imposto delle opzioni di
risposta questa risulta essere una variabile discreta, con quattro livelli disponibili: nessuna
risposta (nel caso si è risposto “No” al cambio residenza); “Incide molto”; “Incide poco”;
“Non incide affatto”. L’attributo Propenso al cambio residenza è relativo ai dati ottenuti
dalla domanda nella quale viene chiesto all’intervistato se ha mai pensato di cambiare
residenza. Anche questa è una variabile discreta in quanto le opzioni di scelta erano tre:
“Sì, spesso”, “A volte” e “Mai”. L’attributo Residenza interna all’Anello Ferroviario è una
variabile dummy, assume il valore 1 se l’utente risiede all’interno dell’anello ferroviario,
0 altrimenti.

18
Tabella 1: Report stima del modello cambio residenza
Come si nota dalla Tabella 1: Report stima del modello cambio residenzavengono verificate le
ipotesi dei segni degli attributi e i test di significatività del loro valore. Analizzando più nel
dettaglio i segni di ogni fattore, si nota che maggiore è l’incidenza del veicolo autonomo
sul cambio residenza e maggiore risulta l’utilità di effettuare questa scelta; analogo
ragionamento vale per la propensione al trasferimento; la residenza all’interno dell’anello
ferroviario invece risulta essere un’utilità per chi sceglie di non spostarsi verso la periferia,
chi abita invece solo all’interno del GRA è più propenso a spostarsi.
Avendo questo modello una struttura molto semplice, il rho-quadro risulta avere un ottimo
valore, pari a 0.848. La percentuale di volte in cui si descrive correttamente le scelte del
campione è del 95% con un errore nella stima della ripartizione tra le alternative dell’1%.
La probabilità media di scegliere l’alternativa 1 risulta pari al 34%, mentre quella di
scegliere l’alternativa 2 è pari al 66%.
Indicatori stimati da Biogeme Value Std err t-test p-value
Incidenza del AV 3.88 0.709 5.47 0
Residenza interna Anello Ferroviario 6.77 1.58 4.29 0
Propenso al cambio residenza 1.89 0.674 2.8 0.01
CSA 8.32 2.04 4.08 0
Correlatione di coefficienti Covariance Correlation t-test
Coeff1 Coeff2
Residenza interna Anello Ferroviario Incidenza del AV 0.944 0.844 2.75
Residenza interna Anello Ferroviario Propenso al cambio residenza 0.357 0.336 3.27
Propenso al cambio residenza CSA 1.26 0.919 -4.46
Residenza interna Anello Ferroviario CSA 1.22 0.379 -0.76*
Incidenza del AV CSA 0.983 0.681 2.71
Incidenza del AV Propenso al cambio residenza 0.244 0.51 2.91
Caratteristiche del modello Value
Number of observations 201
Null log-likelihood -139.32
Final log-likelihood -21.177
Likelihood ratio test 236.29
Rho-square 0.848
Adjusted rho-square 0.819
Out-put Simulate % ValidiRpMod
campione
RpMod
modelloErr
Alt
Sì 69 94% 34% 35% 1%
No 132 95% 66% 65% 1%
Totale 201 95% Errore medio 1%
Numerosità Campione

19
5.2. Mixed Logit
Per stimare l’esistenza o meno di un’eterogeneità casuale sulle preferenze e valutare quindi
un diverso atteggiamento dei rispondenti in funzione di alcune loro caratteristiche, è stato
applicato anche un Mixed Logit. Le funzioni di utilità sistematiche sono le seguenti:
VSì = Incidenza del AV { sigma } + Propenso al cambio residenza { sigma }
VNo = Residenza interna ad Anello Ferroviario { sigma } + ASA CSA
Analogamente al MNL le utilità sono definite dagli stessi attributi, con l’aggiunta di
parametri variabili secondo la stessa distribuzione di tipo normale. Come si nota dalla
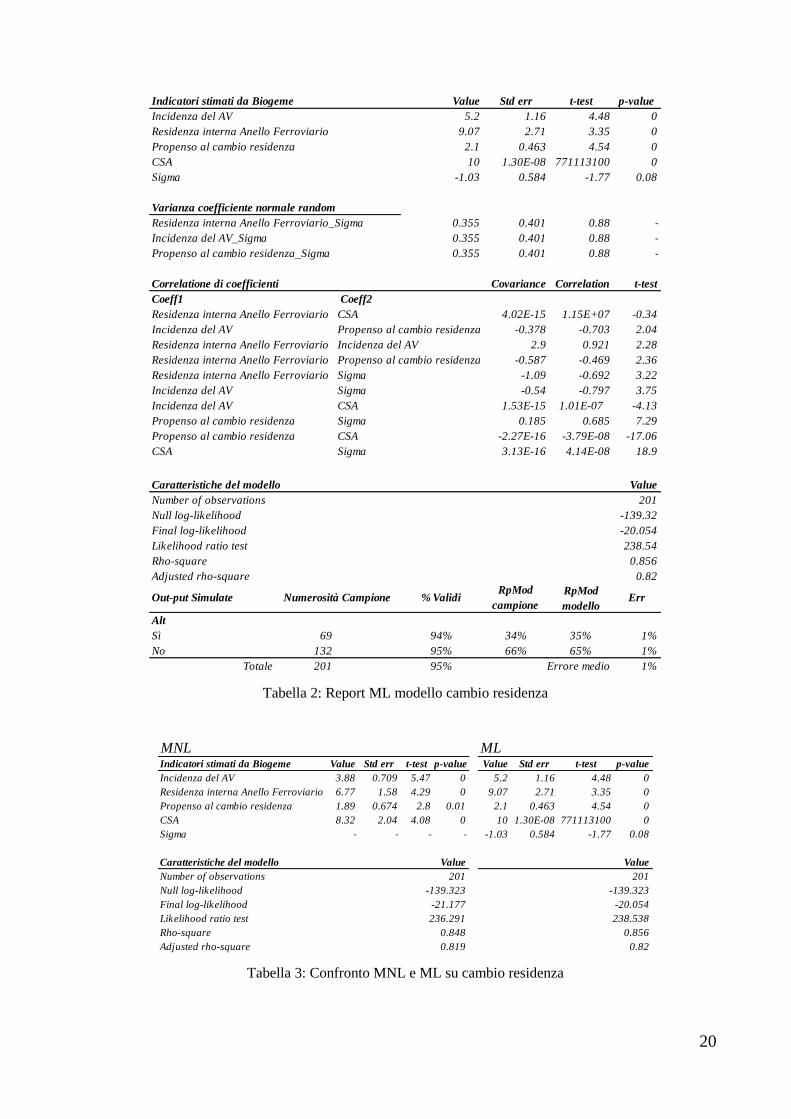
Tabella 2: Report ML modello cambio residenza i coefficienti β mantengono lo stesso segno del
MNL, diversi sono però i valori assoluti, pur mantenendo lo stesso ordine di grandezza. Il
rho-quadro con questo modello risulta migliore, arrivando ad un valore di 0.856. Non si
evincono differenze nei risultati della fase simulativa. La probabilità media di scegliere
l’alternativa 1 risulta pari al 35%, mentre quella di scegliere l’alternativa 2 è pari al 65%.
Le differenze tra il MNL e il ML sono sintetizzate nella Tabella 3: Confronto MNL e ML su
cambio residenza.
20
Tabella 2: Report ML modello cambio residenza
Tabella 3: Confronto MNL e ML su cambio residenza
Indicatori stimati da Biogeme Value Std err t-test p-value
Incidenza del AV 5.2 1.16 4.48 0
Residenza interna Anello Ferroviario 9.07 2.71 3.35 0
Propenso al cambio residenza 2.1 0.463 4.54 0
CSA 10 1.30E-08 771113100 0
Sigma -1.03 0.584 -1.77 0.08
Varianza coefficiente normale random
Residenza interna Anello Ferroviario_Sigma 0.355 0.401 0.88 -
Incidenza del AV_Sigma 0.355 0.401 0.88 -
Propenso al cambio residenza_Sigma 0.355 0.401 0.88 -
Correlatione di coefficienti Covariance Correlation t-test
Coeff1 Coeff2
Residenza interna Anello Ferroviario CSA 4.02E-15 1.15E+07 -0.34
Incidenza del AV Propenso al cambio residenza -0.378 -0.703 2.04
Residenza interna Anello Ferroviario Incidenza del AV 2.9 0.921 2.28
Residenza interna Anello Ferroviario Propenso al cambio residenza -0.587 -0.469 2.36
Residenza interna Anello Ferroviario Sigma -1.09 -0.692 3.22
Incidenza del AV Sigma -0.54 -0.797 3.75
Incidenza del AV CSA 1.53E-15 1.01E-07 -4.13
Propenso al cambio residenza Sigma 0.185 0.685 7.29
Propenso al cambio residenza CSA -2.27E-16 -3.79E-08 -17.06
CSA Sigma 3.13E-16 4.14E-08 18.9
Caratteristiche del modello Value
Number of observations 201
Null log-likelihood -139.32
Final log-likelihood -20.054
Likelihood ratio test 238.54
Rho-square 0.856
Adjusted rho-square 0.82
Alt
Sì 69 94% 34% 35% 1%
No 132 95% 66% 65% 1%
Totale 201 95% Errore medio 1%
RpMod
campione
RpMod
modelloErrOut-put Simulate Numerosità Campione % Validi
MLIndicatori stimati da Biogeme Value Std err t-test p-value Value Std err t-test p-value
Incidenza del AV 3.88 0.709 5.47 0 5.2 1.16 4.48 0
Residenza interna Anello Ferroviario 6.77 1.58 4.29 0 9.07 2.71 3.35 0
Propenso al cambio residenza 1.89 0.674 2.8 0.01 2.1 0.463 4.54 0
CSA 8.32 2.04 4.08 0 10 1.30E-08 771113100 0
Sigma - - - - -1.03 0.584 -1.77 0.08
Caratteristiche del modello Value Value
Number of observations 201 201
Null log-likelihood
Final log-likelihood
Likelihood ratio test
Rho-square 0.848 0.856
Adjusted rho-square 0.819 0.82
-139.323
-21.177
236.291
-20.054
238.538
MNL
-139.323

21
6. CONCLUSIONI
Il lavoro svolto durante il tirocinio mi ha permesso di approfondire le teorie dei modelli di
utilità aleatoria in particolar modo in relazione agli experimental designs. Questo nuovo
metodo di realizzazione ed analisi delle indagini seppur ricco di complesse teorie ed
assunti, è risultato essere un ottimo strumento di ricerca, per la sua peculiarità e specificità
nel tema degli esperimenti di scelta dichiarati.
Le già note conoscenze del software Biogeme mi hanno consentito di poter ulteriormente
approfondire i possibili modelli di analisi e conoscere la vastità di possibilità che esistono
nello studio di indagini. A seconda del modello scelto per l’applicazione, infatti, si
ottengono risultati distinti, di più modelli si è a conoscenza e migliore è la scelta effettuata
in quello da utilizzare, catturando di volta in volta per caratteristiche intrinseche di ogni
schema.

22
7. BIBLIOGRAFIA E SITOGRAFIA
[1] Levels Of Driving Automation Are Defined In New Sae International Standard J3016
(2016);
[2] Auto-matica: il futuro prossimo dell’auto: connettività e automazione (ACI 2017);
[3] Rico Krueger, Taha H. Rashidi, John M. Rose (2016). Preferences for shared
autonomous vehicles;
[4] Ramin Shabanpour, Seyedeh Niloufar Dousti Mousavi, Nima Golshani, Joshua Auld,
Abolfazl Mohammadian (2017). Consumer Preferences of Electric and Automated
Vehicles;
[5] Prateek Bansal, Kara M. Kockelman, Amit Singh (2016). Assessing public opinions of
and interest in new vehicle technologies: an Austin perspective;
[6] Roman Zakharenko (2016). Self-driving cars will change cities;
[7] Lewis M. Clements, Kara M. Kockelman (2017). Economic effects of automated
vehicles;
[8] Bayesian optimal designs for discrete choice experiments with partial profiles
Roselinde Kessels (2011);
[9] “Modelli per i sistemi di trasporto"(2006) a cura di Ennio Cascetta;
[10] Huber Zwerina (1996) Marketing Research Utility Balance;
[11] Bias Reduction of Maximum Likelihood Estimates Author(s): David Firth (1993);
[12] JMP® 13 Design of Experiments Guide, Second Edition. Cary, NC: SAS Institute Inc.
(2017);
[13] Stated Preference Analysis Of Travel Choices: The State Of Practice David A.
Hensher (1993);
[14] Making Better Decisions, Sheffield and Rotherham Bus Rapid Transit: Stated
Preference Research; Report for Arup and South Yorkshire Passenger Transport Executive
(2008);
[15] Stated Preference Survey for New Smart Transport Modes and Services: Design, Pilot
Study and New Revision; MIT Portugal Program. Lang Yang (2009);
[16] Discrete Choice Analysis, Moshe Ben-Akiva, Michel Bierlaire, Daniel McFadden,
Joan Walker, (2014);

23
[17] Bierlaire, M. BIOGEME: A free package for the estimation of discrete choice models,
Proceedings of the 3rd Swiss Transportation Research Conference, Ascona, Switzerland
(2003);
[18] Stefano Saracchi, Stefano Carrese, (Febbraio 2012). Modello di scelta per la
distribuzione delle residenze per la pianificazione della mobilità urbana.