
raccolta di materiale didattico per il corso di diritto ...
52
Università Mediterranea di Reggio Calabria Facoltà di Giurisprudenza Corso di Laurea Magistrale in Giurisprudenza raccolta di materiale didattico per il corso di diritto dell’informatica Melchiorre Monaca seminario tecnico 2015/2016
Transcript of raccolta di materiale didattico per il corso di diritto ...

Università Mediterranea di ReggioCalabria
Facoltà di Giurisprudenza
Corso di Laurea Magistrale in Giurisprudenza
raccolta di materiale didatticoper il corso di
diritto dell’informatica
Melchiorre Monaca
seminario tecnico
2015/2016

Testi di riferimento
• Alessio Plebe, Melchiorre MonacaIntroduzione all’informatica delle conoscenzeEditori Riuniti University Press 2010 - ISBN13: 9788864732152
• Andrew S. Tanenbaum, David J. WetherallReti di calcolatori - V edizionePearson 2011 - ISBN13: 9788871926407
• AgID - Agenzia per l’Italia Digitale - Firme Elettronichehttp://www.agid.gov.it/agenda-digitale/infrastrutture-architetture/firme-elettroniche
• AgID - Agenzia per l’Italia Digitale - Posta Elettronica Certificatahttp://www.agid.gov.it/agenda-digitale/infrastrutture-architetture/posta-elettronica-certificata

Indice
Premessa 1
1 Reti di calcolatori 2
1.1 Dagli albori militari alla fisica delle alte energie . . . . . . . . 31.2 Stipulare intese su come comunicare . . . . . . . . . . . . . . . 6
1.2.1 Pensare a strati . . . . . . . . . . . . . . . . . . . . . . 111.3 Dalle intese ad Internet . . . . . . . . . . . . . . . . . . . . . . 15
1.3.1 Consegnare i dati . . . . . . . . . . . . . . . . . . . . . 161.3.2 Comunicazione efficace . . . . . . . . . . . . . . . . . . 351.3.3 Le Applicazioni . . . . . . . . . . . . . . . . . . . . . . 38
2 Sicurezza 45
Bibliografia 46
i

Premessa
Con questa raccolta s’intende fornire allo studente una sorta di “traccia”,un percorso che guidi lo studio attraverso le tematiche discusse a lezio-ne, trasmettendo il “lessico minimo” indispensabile alla comprensione degliargomenti trattati nel modulo giuridico di questa stessa materia.
È stato evidentemente necessario semplificare - forse ai limiti del lecito -i contenuti qui riassunti: il lettore più interessato alla materia potrà appro-fondire gli argomenti di suo interesse sui testi di riferimento consigliati e suilavori originali citati in bibliografia.
1

Capitolo 1Reti di calcolatori
Una rete di telecomunicazioni è un sistema che fornisce servizi relativi altrasferimento di informazioni ad una popolazione di utenti distribuiti geo-graficamente. Le reti di telecomunicazioni sono vicine alla nostra esperienzaquotidiana di uomini moderni: basti pensare alla rete telefonica, alla retepostale, alle reti per diffusione radio e TV, alle reti telematiche.
Alcune di queste reti sono di nuova concezione e quindi utilizzano tecno-logie avanzate, tipicamente del settore elettronico (e in qualche caso anchedella fotonica), mentre altre, come la rete postale, sono state in funzione perquasi due secoli e si basano su strumenti molto più tradizionali, quali i mezzidi trasporto.
Sappiamo inoltre che in tempi remoti sono esistite reti di telecomunicazio-ni basate su tecnologie diverse, come torri d’avvistamento e segnali luminosio bandiere (i castelli della Valle d’Aosta, la Grande Muraglia Cinese), segnalidi fumo (caratteristici degli indiani americani), o segnali acustici (i tam-tamdella giungla). Inoltre, verso la fine del secolo scorso erano state attivate retitelegrafiche basate su segnalazioni ottiche, utilizzando tralicci su cui eranomontati pannelli mobili azionabili dal basso e visibili da lontano.
È evidente una rilevante differenza tra le reti citate ad esempio: le retiper diffusione radio e TV, i segnali di fumo ed i tam-tam costituiscono reti adiffusione e unidirezionali: l’informazione viene distribuita da una sorgente
2

1.1. Dagli albori militari alla fisica delle alte energie 3
a chiunque disponga di un apparato ricevitore, quindi a ogni utente dellarete, indipendentemente dalla sua identità. Non è inoltre possibile per lagran maggioranza degli utenti, che dispongono solo di un apparato ricevente,inviare informazioni ad altri. Le reti telematiche, la rete telefonica, il sistemapostale, sono invece reti a selezione e bidirezionali: sono caratterizzate dallapossibilità per la sorgente dell’informazione di scegliere a quali interlocutoriquesta deve essere trasferita. In questo caso tutti gli utenti sono attrezzatisia per trasmettere sia per ricevere.
1.1 Dagli albori militari alla fisica delle alte
energie
Internet, la rete delle reti che è divenuta il nostro principale strumento diricerca, collaborazione ed interazione sociale, una realtà consolidata per illettore oggi venticinquenne, ha radici lontane nella storia dell’Informatica.Riesaminare insieme i passi remoti della sua storia è un esercizio utile edistruttivo su come stimoli storici e sociali, idee geniali e tecnologia possonoessere fusi per creare qualcosa di unico e così influente da cambiare lo stiledi vita di due terzi della popolazione mondiale.
Come spesso accade, il primo impulso alla realizzazione di un sistemad’interconnessione di calcolatori su scala geografica fu di origine militare. La“mamma” di Internet fu infatti ARPANET, una rete costruita negli anni ’70a scopo militare, pensata per condividere online il tempo di utilizzazione deicomputer tra i diversi centri di elaborazione dati dell’ARPA (Advanced Re-search Projects Agency), che eseguivano ricerche scientifiche a lungo termineper conto del Dipartimento della Difesa degli Stati Uniti. Un’impresa non dapoco, dato che all’epoca non esistevano standard per la costruzione di calco-latori ed i “supercomputer” erano isolati e basati su sistemi incompatibili traloro.
Il progetto è principalmente dovuto alla caparbietà di Bob Taylor, diret-tore della divisione informatica dell’ARPA, alle idee rivoluzionarie di Joseph

1.1. Dagli albori militari alla fisica delle alte energie 4
Licklider, all’epoca coordinatore dell’IPTO (Information Processing Tech-niques Office) [1, 2, 3] ed alla teorizzazione delle reti a commutazione dipacchetto1, proposta da Leonard Kleinrock [4] come argomento per la suatesi di dottorato al Massachusetts Institute of Technology (MIT).
Tali e tanti sono gli eventi che si susseguono nel corso di un decennio, chesi ritiene opportuno elencarne la sequenza:
1961 (luglio) Leonard Kleinrock del MIT pubblica Information flow in largecommunication nets [4] sulla teoria del packet switching
1962 (agosto) Licklider & Wesley Clark del MIT pubblicano On-line mancomputer communication [5] che forse può essere considerato il primoarticolo sul concetto di internet
1962 (ottobre) J.C.R. Licklider diviene direttore dell’IPTO
1964 Leonard Kleinrock pubblica il libro Communication net [6], nel qualedescrive rigorosamente il funzionamento di una rete basata sul packetswitching
1964 (marzo) Paul Baran della RAND Corporation descrive, in una serie dimemoranda per la USAF, una rete di comunicazione capace di resisteread un attacco termonucleare basata sul packet switching [7]
1964 (settembre) Ivan Sutherland diviene il nuovo direttore dell’IPTO
1965 (ottobre) Lawrence Roberts (MIT) e Thomas Marrill (CCA) effettuanoil primo collegamento con tecnologia packet switching fra il TX-2 deiLincoln Labs a Lexington e l’AN/FSQ-32 della SDC a Santa Monica
1966 (agosto) Robert Taylor diventa il terzo direttore dell’IPTO ed assumeLawrence Roberts per coordinare il progetto
1967 (aprile) Wesley Clark suggerisce di utilizzare una sottorete di minicom-puter, tutti uguali e compatibili tra di loro, dedicata esclusivamente allaricezione e trasmissione dei dati. Suggerisce di chiamare questi com-puter IMP (Interface Message Processors). È la svolta concettuale che
1contrapposte alla commutazione di circuito, tipica dei sistemi di telefonia analogici

1.1. Dagli albori militari alla fisica delle alte energie 5
permetterà di superare i problemi legati all’eterogeneità dei computerdell’epoca
1967 (ottobre) DonaldW. Davies, che lavora al National Physical Laboratory(UK), pubblica i risultati delle sul packet switching, svolte in modo deltutto indipendente dai ricercatori americani [8]
1967 (ottobre) Lawrence Roberts presenta il disegno della futura rete [9]
1968 (agosto) Lawrence Roberts invia a 140 società la “Request For Propo-sals” (RFP) per la realizzazione degli IMP della rete ARPANET; albando rispondono la BBN e la Raytheon, ma non IBM e AT&T chegiudicano il progetto improponibile: la fornitura è affidata alla BBN
1968 (ottobre) Leonard Kleinrock viene assunto al Network MeasurementCenter (UCLA)
1969 (aprile) restano ancora da definire le caratteristiche che deve avere l’in-terfaccia tra i singoli calolatori e gli IMP, che sono pubblicate da BobKahn
1969 (aprile) Steve Crocker scrive il primo Request For Comment (RFC)che tratta l’host-to-host protocol [10]: da questo momento tutti i pro-tocolli di rete saranno formalizzati in documenti di questo tipo e gliRFC saranno il principale strumento di collaborazione e sviluppo dellacomunità di ricerca nell’ambito delle reti di calcolatori [11].
Finalmente, nell’ottobre 1969 viene stabilito il primo collegamento dacomputer a computer fra l’Università della California di Los Angeles e loStanford Research Institute: nasce il primo link ARPANET. I centri colle-gati si susseguono con ritmo incalzante ed alla fine del 1971 la rete conta già15 nodi, che diventano 37 alla fine del 1972; da allora la crescita è esponen-ziale. È il periodo nel quale viene formalizzato da Crocker il protocollo NCP(Network Control Program) [12], che stabilisce le regole per la connettivitàalla base di ARPANET.
La svolta determinante avviene però nel 1974 con la pubblicazione dell’R-FC 675, dal significativo titolo “Specification of Internet Transmission Control

1.2. Stipulare intese su come comunicare 6
Program” [13], dove appare per la prima volta il termine “Internet”. Nel 1978Cerf, Postel e Crocker aggiugono al TCP il protocollo IP (Internet Protocol)[14], mettendo a punto il definitivo modello su cui ancor oggi opera Internet,il TCP/IP [15].
Parallelamente nascono le prime applicazioni: Telnet, per la gestione re-mota di terminali, FTP per la trasmissione di file, E-Mail per la posta elettro-nica: sono tutte applicazioni basate sulla linea di comando, con un’interfacciaostica e riservata al personale tecnico e ricercatore. Il primo tentativo di “in-terfaccia universale” alle risorse di rete è Gopher2, ma la vera rivoluzionearriva con l’implementazione dell’interfaccia grafica e del mouse nei sistemioperativi.
Questi due elementi rendono possibile la nascita del World Wide Web(1990), un sistema per la condivisione di informazioni in ipertesto, sviluppa-to da Tim Berners-Lee [16] presso il CERN di Ginevra, pensato per facilitarela condivisione di informazioni scientifiche nella comunità dei fisici nucleari.Il sistema si basa sul protocollo HTTP [17] e sul linguaggio HTML: per stan-dardizzare quest’ultimo, Berners-Lee fonda il World Wide Web Consortium(W3C), che tuttora si occupa di definire gli standard per il web3.
Il resto è cronaca: l’avvento della “banda per tutti” (broadband) e, soprat-tutto, il DNS (Domain Name System), i motori di ricerca, i social network,la necessità di generare contenuti in modo collaborativo e semanticamentepregnante hanno portato alla nascita di quello che adesso è definito Web 2.0[18].
1.2 Stipulare intese su come comunicare
Si vuole iniziare suggerendo una riflessione su cosa “si nasconde” dietro unasemplice telefonata. Quando si solleva il microtelefono, prima di compiere
2la prima applicazione di rete basata su menu descrittivi a struttura gerarchica,realizzati mediante un’architettura di tipo client server
3una curiosità: il computer usato da Berners-Lee per realizzare il primo server web erabasato sul sistema operativo NeXT, realizzato da Steve Jobs prima di rientrare alla Apple

1.2. Stipulare intese su come comunicare 7
qualsiasi azione, l’apparecchio telefonico controlla se è attivo il segnale dilinea e restituisce un feedback sonoro: in modo totalmente trasparente per ilchiamante, il telefono ha verificato l’esistenza di un collegamento fisico con larete telefonica e la disponibilità di un canale per iniziare la comunicazione. Ilpasso successivo è la composizione del “numero di telefono”, cioè dell’indirizzodel destinatario della telefonata. Val la pena notare che tale indirizzo èrigidamente codificato (infatti non può essere scelto dall’utente finale, maviene assegnato dal provider dei servizi telefonici), è univoco (non possonoesistere due utenti con lo stesso numero) ed ha una struttura gerarchica:un prefisso internazionale, un prefisso nazionale, un eventuale prefisso dicentralino e, infine, l’identificativo del telefono chiamato.
Composto il numero, il segnale sarà instradato attraverso la rete telefonicamondiale e la richiesta di iniziare la comunicazione arriverà a destinazione: inaltre parole, il telefono del destinatario squillerà e inizierà la conversazione. . .
. . . O no?In realtà (pur supponendo che il telefono chiamato sia perfettamente funzio-nante) possono verificarsi almeno tre casi:
• l’essere umano che si vuole contattare non è in casa o non vuole rispon-dere
• l’apparecchio del destinatario è utilizzato per un’altra conversazione
• il destinatario risponde
Le tre situazioni saranno gestite in modo diverso. Nel primo caso, proba-bilmente, dopo un pò d’attesa, sarà chi chiama a chiudere la comunicazione;nel secondo caso si otterrà il tipico segnale di “occupato”. Se invece si è fortu-nati, il destinatario, attivato il proprio microtelefono, risponderà col classico“. . . pronto. . . ” o con un’altra frase convenzionale, a quel punto anche il chia-mante, per iniziare la conversazione, userà un’espressione analoga. Durantetutta la telefonata, il sistema telefonico si occuperà di garantire che ciascunsuono pronunziato giunga a destinazione velocemente, nella giusta sequenzae senza disturbi. Alla fine della telefonata sorge un problema, spesso causa

1.2. Stipulare intese su come comunicare 8
d’imbarazzo tra gli interlocutori: chi chiude per primo? Questa situazio-ne capita, come si vedrà,anche nella gestione della connessione tra apparatifisici.
Infine, durante tutta la telefonata, non ci siamo minimamente preoccupatidel tipo di telefono posseduto dal nostro interlocutore (fisso, cellulare, cord-less, isdn, analogico): in realtà l’eterogeneità dei dispositivi da far comunicareaggiunge complessità e deve essere opportunamente gestita.
L’esempio precedente, sia pur semplicistico e limitato, evidenzia la com-plessità insita nel problema di mettere in comunicazione due entità remote(end point) variamente collegate.
Realizzare una rete di calcolatori richiede risorse e competenze in variambiti disciplinari, che vanno dalla progettazione e costruzione dei dispositivifisici, al disegno e realizzazione del software che gestisce i servizi.
Pensare di codificare la materia in un blocco monolitico è dunque impro-ponibile: è invece opportuno tentare di scomporre la problematica in unaserie d’obiettivi specifici, il più possibile indipendenti l’uno dall’altro.
Il primo, ovviamente, è la connettività fisica tra gli apparati, necessariaaffinché qualsiasi forma di comunicazione possa avvenire. Si noti, ancora unavolta, la necessità di collegare alla stessa rete dispositivi di tipo diverso (peresempio PC e telefoni cellulari), su un ampio range di distanze (stampare undocumento mediante la stampante dipartimentale è differente dal consultareun sito Web) e con esigenze di prestazioni diverse (lo streaming di un filmrichiede una “velocità” della rete molto maggiore rispetto alla trasmissione diun messaggio e-mail).
Un altro aspetto fondamentale è l’indirizzamento, cioè la necessità dipoter identificare univocamente ciascun apparato (host) presente sulla re-te. Come nel caso della telefonata, alla caratteristica d’univocità si deveassociare la possibilità di conferire allo spazio d’indirizzamento una strutturagerarchica. Ancora, su una rete complessa, come, ad esempio, quella mon-diale, è necessario poter determinare il percorso che i dati devono seguireper arrivare a destinazione nel modo più efficiente possibile: occorre cioè un

1.2. Stipulare intese su come comunicare 9
meccanismo di instradamento del traffico.Tuttavia, il collegamento più veloce ed efficiente servirebbe a poco se i dati
trasmessi non fossero correttamente interpretabili dal destinatario: occorrequalcosa che presieda al trasporto dei dati e che gestisca la connessione dimodo che questi possano essere ricevuti in modo completo e senza errori daentrambe le parti. Infine occorre codificare le applicazioni che la rete deveerogare, i servizi, la loro interfaccia verso l’utente finale.
In sintesi (e semplificando) chi progetta reti di calcolatori dovrà tenerconto di queste caratteristiche:
• Collegamento fisico
• Indirizzamento
• Instradamento
• Trasporto dei dati e gestione della connessione
• Applicazioni
Adesso si passerà a formalizzare quanto detto fin qui: per ridurre la com-plessità di progetto, le reti sono, in generale, organizzate a livelli, ciascunocostruito sopra il precedente. Lo scopo di un livello è offrire servizi ai livellipiù alti, nascondendo i dettagli sull’implementazione. Le due macchine chedevono comunicare prendono il nome di host : il livello n su un host “conver-sa” col livello n su un’altro host. Le regole e le convenzioni che governano laconversazione sono collettivamente indicate col termine protocollo di livellon. Si parla, in questo caso di “conversazione tra pari” e le entità (processi) cheeffettuano tale conversazione si chiamano peer entity (entità di pari livello).
In realtà non c’è un trasferimento diretto dal livello n di host A al livellon di host B. Ogni livello di host A passa i dati, assieme a delle informazionidi controllo, al livello sottostante; questo procedimento prende il nome di in-capsulamento e ne discuteremo ampiamente più avanti. Questo meccanismoè evidenziato in Fig. 1.1. Al livello 1 c’è il mezzo fisico, attraverso il qualei dati vengono trasferiti da host A ad host B. Quando arrivano a host B, i

1.2. Stipulare intese su come comunicare 10
Livello 6
Livello 5
Livello 6
Livello 5
Protocollo di livello 6
Protocollo di livello 5
Host A Host B
Interfaccia Interfaccia
Figura 1.1: Comunicazione peer to peer tra livelli
dati sono trasmessi da ogni livello (a partire dal livello 1) a quello superiore,fino a raggiungere il livello n.
Fra ogni coppia di livelli adiacenti è definita un’interfaccia, che caratte-rizza le operazioni primitive che possono essere richieste al livello sottostanteed i servizi che possono essere offerti dal livello sottostante. Una buona pro-gettazione delle interfacce tra i livelli consente di minimizzare la quantità ela complessità delle informazioni da trasferire e non preclude la possibilità diaggiornare l’implementazione del livello con l’evolversi della tecnologia.
Si noti che, in questo schema, un servizio definisce quali operazioni illivello è pronto ad eseguire per conto dei propri utenti (il livello superiore equello inferiore), ma non dice nulla su come tali operazioni dovranno essererealizzate.
Di quest’ultimo aspetto si occupano i protocolli, cioè insiemi di regoleche governano il formato ed il significato dei blocchi di informazione, deipacchetti o dei messaggi che vengono scambiati dalle peer entity di un datolivello. Le entità utilizzano i protocolli per formalizzare le definizioni deipropri servizi. Esse sono libere di modificarli in futuro, purché non cambino iservizi erogati, implementando così la totale indipendenza della realizzazionedi ciascun livello rispetto agli altri.

1.2. Stipulare intese su come comunicare 11
In questo modo si ottengono due vantaggi importanti: il primo è che pos-sono dialogare fra loro anche host aventi caratteristiche (processore, sistemaoperativo, costruttore) diverse, il secondo è che ciascun livello si occuperàdi un aspetto specifico in modo indipendente dall’implementazione dei livellisottostanti; per esempio, una pagina web potrà essere interpretata corretta-mente dal browser indipendentemente dal fatto che il fruitore stia utilizzandoun computer desktop collegato alla rete dell’Università o il suo portatile col-legato via radio tramite un hot spot dell’aeroporto. L’insieme dei livelli e deirelativi protocolli di una specifica implementazione è detto architettura direte.
1.2.1 Pensare a strati
Nelle pagine seguenti verranno esaminate in parallelo due formalizzazioni del-la struttura a strati fin qui presentata: un modello di riferimento, l’ISO/OSIed un’architettura di rete, il TCP/IP. La sostanziale differenza tra i due è cheil modello ISO/OSI si limita a specificare cosa dovrebbe fare ciascun livello,ma non specifica con precisione i servizi ed i protocolli che devono essereusati e, dunque, non può essere considerato un’architettura di rete. Tutta-via la sua rilevanza storica e concettuale lo rende il fulcro di ogni modernaimplementazione di rete.
L’OSI (Open Systems Interconnection) Reference Model [19] è il fruttodel lavoro della ISO (International Standard Organization), ed ha lo scopodi:
• fornire uno standard per la connessione di sistemi aperti, cioè in gradodi colloquiare gli uni con gli altri;
• fornire una base comune per lo sviluppo di standard per l’interconnes-sione di sistemi;
• fornire un modello rispetto a cui confrontare le varie architetture direte.

1.2. Stipulare intese su come comunicare 12
Esso non include la definizione di protocolli specifici (che sono stati definitisuccessivamente, in documenti separati). I principi di progetto che sono statiseguiti durante lo sviluppo del modello OSI schematizzano fedelmente quantoesposto nel paragrafo precedente:
• ogni livello deve avere un diverso strato di astrazione;
• ogni livello deve avere una funzione ben definita;
• i limiti dei livelli devono essere scelti in modo da minimizzare il pas-saggio delle informazioni attraverso le interfacce;
• il numero dei livelli deve essere abbastanza ampio per permettere afunzioni distinte di non essere inserite forzatamente nel medesimo livellosenza che sia necessario e abbastanza piccolo per permettere che learchitetture non diventino pesanti e poco maneggevoli.
Sono individuati e formalizzati sette livelli, numerati a partire dal basso:fisico, data link, network, trasporto, sessione, presentazione, applicazione(Fig. 1.2).
I livelli più bassi, da quello fisico a quello di trasporto, si occupano dellaconsegna dei dati tra gli host, mentre quelli più alti si occupano della loroelaborazione e realizzano perciò le applicazioni di rete. Non si espliciteràadesso il significato ed il ruolo del singolo livello: essi diverranno più chiarinel seguito della trattazione.
Come avviene in pratica la comunicazione tra un livello e quello sotto-stante? Si supponga di dover spedire una lettera: redatto il messaggio suun foglio di carta, si metterà quest’ultimo in una busta, sulla quale vienescritto l’indirizzo del mittente e del destinatario. L’addetto della compagniapostale ritirerà la busta e la porterà al centro di smistamento della città dipartenza, dove la lettera sarà messa in un sacco indirizzato alla città di de-stinazione. Il sacco sarà caricato via via sugli opportuni mezzi di trasporto(non importa quali e quanti) e giungerà al centro di smistamento della cittàdi destinazione. Qui sarà aperto e la nostra busta sarà consegnata al postinoper la consegna finale. Il postino leggerà l’indirizzo e consegnerà la lettera

1.2. Stipulare intese su come comunicare 13
Application
Presentation
Session
Transport
Network
Data Link
Physical
Figura 1.2: I livelli del modello di riferimento ISO/OSI

1.2. Stipulare intese su come comunicare 14
payload headertrailer
PDU livello n payload headertrailer
PDU livello n-1
Figura 1.3: Incapsulamento dei dati nel livello sottostante
al destinatario. Il destinatario, letto l’indirizzo, aprirà la busta e leggerà ilmessaggio. É importante notare che soltanto il mittente ed il destinatarioelaborano le informazioni contenute nella lettera, tutti gli altri protagonistidella consegna si limitano a leggere l’indirizzo sulla busta (o sul sacco) ereindirizzano la missiva alla tappa successiva.
Nelle reti di comunicazione avviene qualcosa d’analogo: i dati dell’appli-cazione vengono incapsulati nei livelli sottostanti fino ad arrivare al livellofisico; durante il percorso vengono “aperte” solo le “buste” relative ai livelli chesi occupano dell’instradamento del messaggio e solo sull’host di destinazionei dati dell’applicazione vengono elaborati.
In altri termini, ciascun livello dell’host mittente incapsula i dati (payload)del livello superiore premettendo un’intestazione (header) ed, eventualmente,posponendo dei codici di controllo (trailer); a sua volta, il pacchetto cosìcostruito diventa payload del livello sottostante (Fig. 1.3).
Lungo il percorso attraverso i nodi della rete vengono elaborati ed even-tualmente modificati solo gli header dei livelli che si occupano della trasmis-sione. Soltanto sull’host di destinazione saranno elaborati gli header relativiad ogni livello, fino alla consegna dei dati all’applicazione. Ad esempio,un router, che è un apparato che realizza l’instradamento dei dati, “aprirà”soltanto le “buste” fino al livello 3, che contiene le informazioni necessarie.Ciascun livello avrà una propria Protocol Data Unit (PDU), composta da

1.3. Dalle intese ad Internet 15
header, payload e trailer, che realizza l’incapsulamento. In particolare, èutile, per riferimento nel prosieguo della trattazione, conoscere i nomi dellePDU dei primi quattro livelli:
1. Livello fisico: bit
2. Livello data link: frame
3. Livello network: pacchetto
4. Livello trasporto: TPDU (Transport Protocol Data Unit)
1.3 Dalle intese ad Internet
Il TCP/IP (Transmission Control Protocol / Internet Protocol) [15] è l’ar-chitettura di rete che costituisce il fondamento della trasmissione dati inInternet.
Rispetto al modello ISO/OSI condensa i livelli fisico e data-link in un uni-co livello (host-to-network) ed i tre livelli applicativi in un più generico appli-cation (Fig. 1.4). Essendo nato principalmente per realizzare servizi Internet,formalizza in modo rigoroso i due livelli di networking (Internet e transport)definendone le funzionalità, lo spazio d’indirizzamento e le caratteristiche deiprotocolli. Il livello più basso non è specificato nell’architettura, che prevededi utilizzare i protocolli disponibili per le varie piattaforme hardware e con-formi agli standard, purché consentano agli host di inviare pacchetti IP sullarete. Il livello applicativo è quello sul quale poggiano le applicazioni Internetche oggi tutti conoscono (posta elettronica, web, trasferimento file).
I protocolli che implementano le funzionalità del TCP/IP sono forma-lizzati in una serie di documenti denominati RFC (Request For Comment)[10, 11]: sono documenti aperti, nel senso che la descrizione di un protocol-lo esposta in ciascuno di essi potrà essere migliorata con la pubblicazionedi un RFC successivo. Si descriverà di seguito sommariamente il ruolo diciascun livello (usando la nomenclatura della pila ISO/OSI) evidenziandoesempi d’implementazione nell’ambito del TCP/IP.

1.3. Dalle intese ad Internet 16
Application
Presentation
Session
Transport
Network
Data Link
Physical
Application
Transport
Internet
Host to Network
ISO/OSI TCP/IP
Figura 1.4: Lo stack TCP/IP
1.3.1 Consegnare i dati
Il livello fisico attiene la trasmissione di bit “grezzi” su un canale di comu-nicazione. Gli aspetti di progetto sono volti a garantire la congruenza deibit ricevuti con quelli trasmessi; le specifiche sono, in massima parte, rela-tive alle caratteristiche meccaniche, elettriche e procedurali delle interfaccedi rete (componenti che connettono l’elaboratore al mezzo fisico) e alle ca-ratteristiche del mezzo fisico stesso. La misura della “velocità” pura di unarete è data dalla quantità di dati che è possibile trasmettere nell’unità ditempo e spesso viene indicata con il nome di banda. L’unità di misura èil bit/s (attenzione, bit non byte), con i vari multipli: kilo, Mega, Giga. Inteoria (ed in conformità col Sistema Metrico Internazionale) i multipli citatidovrebbero essere potenze di 10 (un kilo=1000), ma la matematica in base 2e la tradizione portano spesso ad inpiegare come moltiplicatore 210 = 1024.
In realtà, fatto comunque salvo il principio “. . . più banda c’è meglio è. . . ”,spesso le prestazioni di una rete dipendono da altri fattori. Per esempio è au-spicabile che una transazione bancaria vada, sia pur lentamente, a buon fine,piuttosto che precipitare rapidamente in uno stato impredicibile. Oppure,nel caso di trasmissione di voce in tempo reale (una telefonata su Internet),

1.3. Dalle intese ad Internet 17
non è fondamentale che la banda sia elevata: è molto più importante che labanda richiesta per la telefonata (piccola, dell’ordine dei 16Kb/s) sia erogatacon costanza nel tempo (jitter basso) di modo che le due parti possano perce-pire il parlato con fluidità. La destinazione d’uso della rete da realizzare e lasua estensione geografica giocano un ruolo fondamentale nei processi decisio-nali relativi alla progettazione; è allora utile suddividere le reti in categorie,ovviamente in modo del tutto indicativo. Una possibile classificazione è laseguente:
• PAN (personal area network): è una rete informatica utilizzata perpermettere la comunicazione tra diversi dispositivi in ambito dome-stico; le tecnologie più utilizzate sono generalmente wireless (WiFi,Bluetooth), ma talvolta vengono usati anche cavi (Ethernet, USB, Fi-reWire). Il classico esempio è costituito dal router WiFi, utilizzato perla connessione ad Internet.
• LAN(local area network): è costituita da computer collegati tra loroall’interno di un ambito fisico delimitato (un’azienda, un campus uni-versitario); il cablaggio è costituito da un livello di distribuzione in fibraottica e da punti d’accesso realizzati con cavo in rame. La banda tipicaè dell’ordine del Gb/s.
• MAN (metropolitan area network): è un’infrastruttura in fibra otticao, più raramente, wireless (WiMax ) che realizza dorsali a larga bandache collegano i principali centri della vita sociale, politica e culturaledella città.
• WAN (wide area network): realizza l’interconnessione tra le reti me-tropolitane, l’esempio tipico è Internet stessa.
La scelta del mezzo trasmissivo, cioè il supporto fisico che consente ilcollegamento degli host, è un elemento di fondamentale importanza nellarealizzazione di una rete effettivamente funzionante; tale scelta è dettatasia da considerazioni tecniche (distanza massima tra due apparati, larghez-za di banda, ostacoli di natura geografica), sia da motivazioni di carattere

1.3. Dalle intese ad Internet 18
economico-sociale (la diffusione del mezzo sul territorio, gli elevati costi el’impatto sociale ed ambientale di alcune tecnologie).
Schematizzando, si usano mezzi fisici di quattro tipologie diverse: cavoelettrico, onde radio, fibra ottica, laser. Sulle classiche reti su doppino tele-fonico (dette anche POTS, plain old telephone system) è possibile realizzarereti con diverse tecnologie. Nel decennio scorso era frequente l’uso di modemper codificare segnali digitali sopra le comuni linee telefoniche analogiche: laconnessione era on-demand e la velocità limitata a circa 56Kb/s. Il grandevantaggio di questa tecnologia è che non richiede modifiche alla rete distri-butiva esistente. Una prima evoluzione furono le linee ISDN, costituite dadue canali telefonici (in realtà ne serve un terzo, di controllo) in tecnolo-gia digitale. La velocità massima di 128Kb/s veniva raggiunta sfruttandodue connessioni in parallelo su canali da 64Kb/s. Ma la tecnologia che haconsentito la diffusione di massa (broadband) della connettività domestica è,senza alcun dubbio, l’ADSL (asymmetric digital subscriber line): essa richie-de l’installazione di nuovi apparati di commutazione nelle centrali telefoniche,chiamati DSLAM, e l’utilizzo di filtri negli impianti telefonici domestici perseparare le frequenze utilizzate per la trasmissione dati da quelle per la co-municazione vocale. La banda erogata è asimmetrica, tipicamente 7Mb/s indownload e 384Kb/s in upload, ma ormai tutti gli operatori telefonici offronocollegamenti a velocità maggiore.
Tra i candidati a sostituire il doppino per la distribuzione domestica deiservizi di telecomunicazioni, si possono citare le fibre ottiche e le infrastrut-ture della TV via cavo (diffusa soprattutto negli USA), il trasporto di datisulla rete elettrica, le reti wireless e le reti satellitari (utili in aree disagiate).Per realizzare le LAN si usano in genere particolari cavi (UTP), costituiti daquattro doppini, ed interfacce di rete Ethernet : la particolare tecnica rea-lizzativa li rende meno sensibili alle interferenze, consentendo di raggiungerevelocità dell’ordine del Gb/s. Con tecnologie più costose, tipicamente uti-lizzate dai provider, si raggiungono velocità di 40Gb/s per il singolo link sufibra ottica.

1.3. Dalle intese ad Internet 19
Stella Anello
Bus
Figura 1.5: Topologia a stella, anello, bus
Il modo in cui i componenti di una rete sono collegati tra di loro, nelsenso della disposizione ideale che questi hanno, viene definito generalmenteattraverso quella che è nota come topologia di rete. Le reti punto a punto(point-to-point) consistono in un insieme di coppie di elaboratori connessitra loro in vario modo (stella, anello, albero). Per passare da una sorgen-te ad una destinazione, l’informazione deve attraversare diversi elaboratoriintermedi. Si ha una rete a stella quando tutti i componenti periferici sonoconnessi a un nodo principale in modo indipendente dagli altri; in tal modotutte le comunicazioni passano per il nodo centrale e sono gestite completa-mente da questo. Si ha una rete ad anello quando tutti i nodi sono connessitra loro in sequenza, in modo da formare un anello ideale, dove ognuno haun contatto diretto solo con il precedente e il successivo; la comunicazioneavviene (semplificando) a senso unico e ogni nodo ritrasmette i dati che nonsono ad esso destinati al nodo successivo. Le reti broadcast (o bus) invecesono formate da un unico mezzo fisico, condiviso da più elaboratori, sul qualei messaggi inviati da un host vengono ricevuti da tutti gli altri. All’internodel messaggio vi è una parte relativa all’indirizzo del destinatario (elaborataa livello 2), in modo che tutte le altre macchine in ascolto possano scartare ilmessaggio in arrivo. Un esempio di una tale rete è la comune Ethernet [20].

1.3. Dalle intese ad Internet 20
Un problema tipico delle reti a bus è l’allocazione del canale trasmissivo.Si pensi ad una normale conversazione tra esseri umani: capita talvolta
che i due interlocutori inizino a parlare contemporaneamente. Di solito sigenera una situazione d’imbarazzo che conduce ad un istante di silenzio, poi,dopo un intervallo casuale, uno dei due interlocutori riprende a parlare e laconversazione può aver luogo.
Analogamente, nel caso in cui il mezzo fisico è condiviso da più di duehost, la trasmissione simultanea da parte di due di essi genera una sovrap-posizione del segnale elettrico che inficia la trasmissione: è stata generatauna collisione. Gli host che condividono il mezzo trasmissivo appartengonodunque allo stesso dominio di collisione: è evidente che maggiore è il numerodi macchine appartenenti al dominio di collisione, più elevata è la probabilitàche le collisioni abbiano luogo. Una buona regola nella progettazione dellereti è quindi far sì che i domini di collisione siano di dimensioni limitate.
Ciò non è possibile al mero livello fisico: occorre un protocollo, collocatonella parte bassa del livello 2, che consenta l’allocazione del canale trasmissivoall’host che vuole trasmettere. Si esamina ora il più diffuso, tipico delle retiethernet: il CSMA/CD. CSMA/CD è l’acronimo inglese di Carrier SenseMultiple Access with Collision Detection, ovvero accesso multiplo tramiterilevamento della portante e delle collisioni. L’algoritmo è il seguente:
1. L’adattatore di rete sistema il messaggio in un buffer;
2. Se il canale è inattivo procede alla trasmissione, se è occupato attendeprima di ritrasmettere;
3. Mentre trasmette, l’adattatore controlla la rete (è questo il vero e pro-prio collision detection), se non riceve segnali da altri adattatori consi-dera il messaggio spedito, altrimenti è avvenuta una collisione, quindiva interrotta la trasmissione;
4. Se l’adattatore riceve, durante una trasmissione, un segnale da un altroadattatore, arresta la trasmissione e trasmette un segnale di disturbo(jam);

1.3. Dalle intese ad Internet 21
5. Dopo aver abortito la trasmissione attende un tempo casuale e ritra-smette.
Evidentemente un approccio di questo genere è poco efficiente perché compor-ta un elevato numero di ritrasmissioni, ma le reti a bus hanno il considerevolevantaggio dell’economicità e, per questo, sono ormai le più diffuse.
Quando si vogliono unire due o più reti (o anche degli elaboratori singoli)per formarne una sola più grande, occorre utilizzare dei nodi speciali connessisimultaneamente a tutte le reti da collegare. Il ripetitore è un componenteche collega due reti fisiche intervenendo al primo livello ISO/OSI. In questosenso, il ripetitore non filtra in alcun caso i pacchetti dati, ma rappresentasemplicemente un modo per allungare un tratto di rete oltre il limite impostodal singolo cavo passivo. Il ripetitore tipico è l’HUB, ovvero il concentratoredi rete.
Da quanto detto risulta evidente che non può esistere un dispositivo dilivello 1 in grado di interrompere un dominio di collisione; inoltre il lettoreattento avrà notato che non è ancora emerso alcun tipo di meccanismo d’in-dirizzamento. Per ottenere questi risultati (ed altro ancora) occorre salire dilivello.
Il bridge o switch è un dispositivo di livello 2 che mette in connessionedue (o più) reti. Limitandosi a intervenire nei primi due livelli del modelloISO-OSI, il bridge è in grado di connettere tra loro solo reti fisiche dellostesso tipo. Il bridge più semplice duplica ogni frame nelle altre reti a cui èconnesso; quello più sofisticato è in grado di determinare gli indirizzi dei nodiconnessi nelle varie reti, ottimizzando il traffico. Nell’ottica dell’allocazionedel canale trasmissivo, è interessante notare che l’inserimento di un bridgetra due segmenti di una rete a bus divide il dominio di collisione (Fig. 1.6).
Il livello data link ha il compito di offrire una comunicazione affidabile edefficiente a due macchine adiacenti, cioé connesse fisicamente da un canale dicomunicazione. Si occupa dunque di fare da tramite tra il livello 1 (fisico),che realizza la mera connettività ed il livello 3 (network), che instrada il

1.3. Dalle intese ad Internet 22
Application
Presentation
Session
Transport
Network
Data Link
Physical
Application
Presentation
Session
Transport
Network
Data Link
Physical
Data Link
Physical Physical
BRIDGE
Figura 1.6: Collegamento a livello 2 mediante un bridge
traffico dati sulla rete geografica. È il livello sovrano delle LAN e attendealle seguenti incombenze principali:
• Frammentazione
• Controllo dell’errore
• Controllo di flusso
• Indirizzamento di livello 2
Un problema da non sottovalutare nella trasmissione dei dati a livello fisi-co è costituito dall’inaffidabilità del mezzo trasmissivo: per farsene un’ideabasti pensare all’effetto che possono avere collisioni, interferenze e cadutedi tensione sui collegamenti in rame. Per questo motivo è opportuno che illivello 2 si occupi di minimizzare il danno, organizzando i dati da trasmet-tere in piccoli “contenitori”, i frame; in questo modo, un’eventuale problemacomporterà la ritrasmissione di una piccola quantità d’informazione e non ditutto il contenuto della comunicazione. Questa operazione prende il nome diframmentazione.
Frammentati i dati, occorrerà prevedere un protocollo di controllo dell’er-rore, di solito basato sulla creazione di una checksum, una stringa generatacon un opportuno algoritmo applicato al payload del frame. Questa sarà

1.3. Dalle intese ad Internet 23
calcolata dall’host trasmittente ed accodata al frame: l’host ricevente prov-vederà, ricevuto il frame, al ricalcolo della checksum, mediante il medesimoalgoritmo, la confronterà con quella trasmessa e scarterà tutti i frame corrotti.
Per ogni frame correttamente ricevuto sarà inviata all’host trasmittenteuna “ricevuta di ritorno” (acknowledgement o, più semplicemente, ack): tuttii frame per i quali non arriverà, entro un tempo limite, un ack al mittentesaranno ritrasmessi. Questo procedimento per il controllo del flusso è mol-to efficiente e consente, tra l’altro, di adeguare la velocità di trasmissioneall’effettiva capacità di elaborazione del singolo host.
Infine, il livello 2 provvede a fornire una prima forma d’indirizzamento, inmodo da evitare che host non coinvolti nella comunicazione siano comunquecostretti ad elaborare a livelli più alti i dati ricevuti prima di scartarli.
Lo standard di livello 2 attualmente più diffuso è Ethernet. È una tecno-logia nata molto presto, è più economica e facile da usare rispetto ai sistemiconcorrenti, funziona bene e genera pochi problemi ed è adeguata all’utilizzocon TCP/IP; col passare del tempo lo standard si è aggiornato ed oggi con-sente velocità di trasmissione dell’ordine del Gb/s. Fornisce al livello di reteun servizio senza alcuna contrattazione iniziale ed il frame viene inviato nel-la LAN in modalità broadcast. Quando sarà ricevuto da tutti gli adattatoripresenti sulla LAN, quello che vi riconoscerà il suo indirizzo di destinazionelo elaborerà (ed i dati saranno consegnati al livello 3), mentre tutti gli altrilo scarteranno. La gestione delle collisioni e dell’occupazione simultanea delcanale di trasmissione viene gestita mediante il CSMA/CD.
Nelle reti più recenti si tende ad evitare completamente il problema dellecollisioni, collegando ciascun host ad un bridge multiporta (switch) cosicchéil dominio di collisione a cui appartiene ciascun host risulta essere popolatoda due sole schede di rete: quella dell’host e la singola porta dello switch allaquale è collegato.
Gli indirizzi sono tutti a 6 byte in quanto Ethernet definisce uno schemad’indirizzamento a 48 bit [21]: ogni nodo collegato, quindi, ha un indirizzoEthernet univoco di questa lunghezza. Esso corrisponde all’indirizzo fisico

1.3. Dalle intese ad Internet 24
preambleSFD
destinationaddress
sourceaddress
lenght/type data payload FCS
bytes7 1 6 6 4 46 - 1500 4
Figura 1.7: Struttura a blocchi di un frame Ethernet
della macchina ed è associato all’hardware (MAC address). Il MAC addressviene, di solito, rappresentato in forma esadecimale: per esempio, il MACaddress della scheda di rete del calcolatore col quale vengono redatte questepagine è 00:0d:93:45:f4:22.
In figura 1.7 è mostrata la struttura a blocchi di un frame Ethernet: sinoti la presenza del MAC address sorgente e del MAC address destinazione.Inoltre il payload del frame ha dimensioni massime di 1500 Bytes, quindiil protocollo frammenterà i dati ricevuti dal livello 3 in blocchi di questadimensione.
Per poter realizzare la consegna dei dati da un protocollo di livello 3, comenel caso del protocollo IP che viene descritto più avanti, ad un protocollodi livello 2, occorre un modo per definire un abbinamento tra gli indirizzidi questo protocollo superiore e gli indirizzi fisici delle interfacce utilizzateeffettivamente, secondo le specifiche del livello inferiore.
Le interfacce Ethernet hanno un sistema di indirizzamento composto da48 bit. Quando con un protocollo di livello network si vuole contattare unnodo, identificato quindi da un indirizzo di livello 3, se non si conosce l’indi-rizzo Ethernet, ma ammettendo che tale nodo si trovi nella rete fisica locale,viene inviata una richiesta circolare (broadcast di livello 2, indirizzo di desti-nazione FF:FF:FF:FF:FF:FF) secondo il protocollo ARP (Address ResolutionProtocol). La richiesta ARP è ascoltata da tutte le interfacce connesse a quel-la rete fisica e ogni nodo passa tale richiesta al livello 3, che quindi leggerà ilpayload del frame, in modo da verificare se l’indirizzo richiesto corrispondeal proprio.
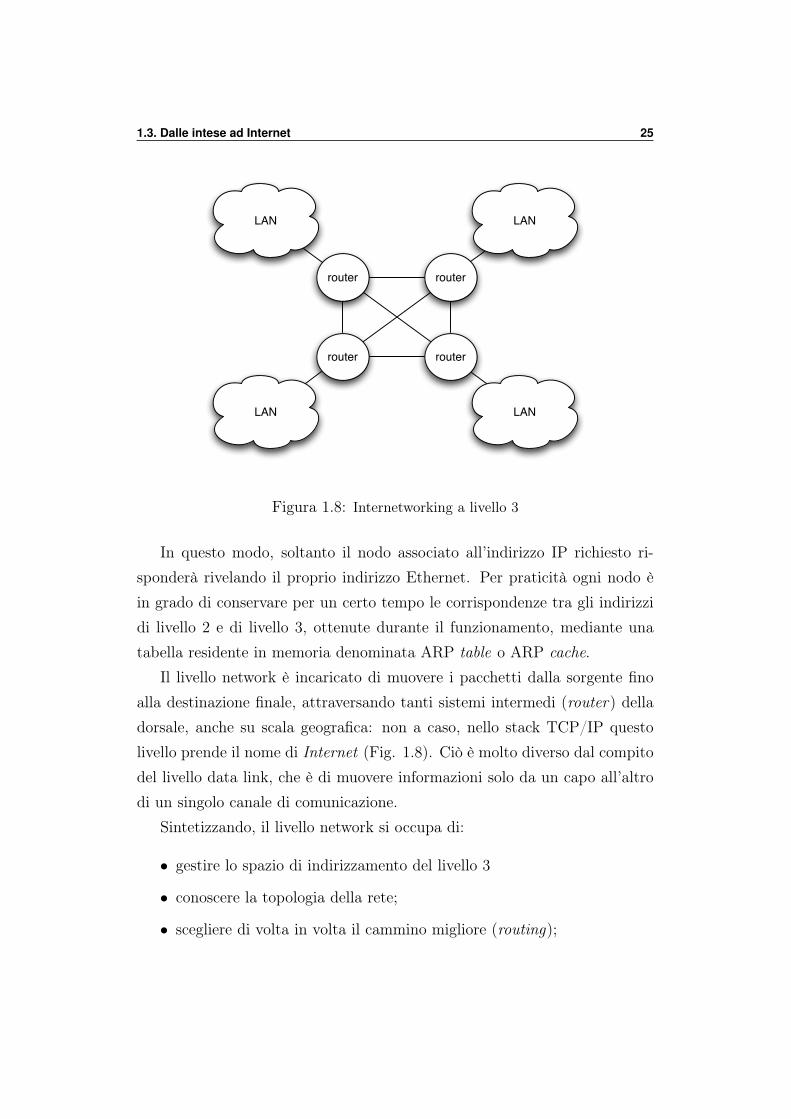
1.3. Dalle intese ad Internet 25
LAN
router
router router
router
LAN
LAN LAN
Figura 1.8: Internetworking a livello 3
In questo modo, soltanto il nodo associato all’indirizzo IP richiesto ri-sponderà rivelando il proprio indirizzo Ethernet. Per praticità ogni nodo èin grado di conservare per un certo tempo le corrispondenze tra gli indirizzidi livello 2 e di livello 3, ottenute durante il funzionamento, mediante unatabella residente in memoria denominata ARP table o ARP cache.
Il livello network è incaricato di muovere i pacchetti dalla sorgente finoalla destinazione finale, attraversando tanti sistemi intermedi (router) delladorsale, anche su scala geografica: non a caso, nello stack TCP/IP questolivello prende il nome di Internet (Fig. 1.8). Ciò è molto diverso dal compitodel livello data link, che è di muovere informazioni solo da un capo all’altrodi un singolo canale di comunicazione.
Sintetizzando, il livello network si occupa di:
• gestire lo spazio di indirizzamento del livello 3
• conoscere la topologia della rete;
• scegliere di volta in volta il cammino migliore (routing);

1.3. Dalle intese ad Internet 26
• gestire le problematiche derivanti dalla presenza di più reti diverse(internetworking).
IP (Inter-networking Protocol) [14] è il protocollo di livello 3 della suiteTCP/IP, nato per interconnettere reti eterogenee per tecnologia, prestazioni,gestione.
Gli indirizzi IP versione 4, cioè quelli tradizionali, sono composti da unasequenza di 32 bit, suddivisi convenzionalmente in quattro gruppetti di 8bit, rappresentati in modo decimale e separati da un punto. Per esempio,l’indirizzo IP del computer (host) in cui risiede il file che contiene questeparole è il seguente:
82.55.113.23
ed è stato assegnato alla mia scheda ADSL dal provider di telecomunicazionial quale sono connesso. Questo tipo di rappresentazione è definito comenotazione decimale puntata. L’esempio seguente corrisponde all’indirizzo1.2.3.4:
00000001.00000010.00000011.00000100
All’interno di un indirizzo del genere si distinguono due parti: l’indirizzodi rete e l’indirizzo del nodo particolare. Il meccanismo è simile a quellodel numero telefonico in cui la prima parte del numero, il prefisso, definiscela zona ovvero il distretto telefonico, mentre il resto identifica l’apparecchiotelefonico specifico di quella zona. Come per i numeri telefonici, sulla retemondiale l’indirizzo IP di ogni singolo host non può essere duplicato, cioènon possono esistere due apparati di rete con lo stesso indirizzo; per questomotivo esistono delle organizzazioni a livello mondiale (INTERNIC, RIPE)che si occupano di rilasciare gli IP ai provider che ne fanno richiesta. Inpratica viene rilasciato un indirizzo di rete in funzione del numero di nodida connettere. In questo indirizzo una certa quantità di bit nella parte finalesono azzerati: ciò significa che quella parte finale può essere utilizzata per gliindirizzi specifici dei nodi.

1.3. Dalle intese ad Internet 27
Considerando l’esempio precedente, un possibile indirizzo di rete potrebbeessere 1.2.3.0, cioè:
00000001.00000010.00000011.00000000
In tal caso, si potrebbero utilizzare gli ultimi 8 bit (quindi 28 = 256 indi-rizzi) per i vari nodi. Ma l’indirizzo di rete non può identificare un nodo inparticolare, quindi il numero di indirizzi possibili per gli host diventa 255.
Inoltre, un indirizzo in cui i bit finali lasciati per identificare i nodi sianotutti a uno, identifica, per convenzione del protocollo, un indirizzo broadcast,cioè un indirizzo per la trasmissione a tutti i nodi di quella rete. Nell’esempioprecedente, 1.2.3.255
00000001.00000010.00000011.11111111
rappresenta simultaneamente tutti gli indirizzi che iniziano con
00000001.00000010.00000011
cioè che hanno lo stesso prefisso di rete.In pratica, il livello 3 di tutti gli host della sottorete valuterà un pacchetto
che ha come destinazione l’indirizzo di broadcast e passerà il payload di quelpacchetto al livello 4. Di conseguenza, un indirizzo broadcast non può essereutilizzato per identificare un singolo nodo ed il numero di indirizzi possibiliper gli host dell’esempio scende a 254.
Il meccanismo utilizzato per distinguere la parte dell’indirizzo che identi-fica la rete è quello della maschera di rete o netmask. La maschera di rete èun numero di 32 bit, che viene abbinato all’indirizzo IP con l’operatore boo-leano AND4. La netmask sarà dunque costituita da tanti uno quanti sono ibit che si vuole dedicare alla parte di rete e da tutti zero per la parte host.Nell’esempio precedente, nel quale si sono usati 24 bit per la parte di rete, lanetmask sarà:
11111111.11111111.11111111.000000004l’operatore AND fornisce in uscita 1 solo se i due valori in ingresso sono entrambi 1

1.3. Dalle intese ad Internet 28
cioè, in notazione decimale, 255.255.255.0 .Il procedimento è il seguente: si definisce la netmask e la si applica all’in-
dirizzo ip, il numero che si ottiene è l’indirizzo della rete: questa operazionenon è soltanto una mera speculazione accademica, ma viene utilizzata in pra-tica dai router per calcolare la sottorete di destinazione dei singoli pacchettial fine di instradare il traffico nel modo corretto. Nell’esempio precedente siha:
00000001.00000010.00000011.00000100 1.2.3.4 (host)11111111.11111111.11111111.00000000 255.255.255.0 (mask)00000001.00000010.00000011.00000000 1.2.3.0 (net)
In base al valore dei primi bit, gli indirizzi IP vengono suddivisi in classi,ciascuna con una netmask convenzionale, per esempio la classe A è costituitada indirizzi il cui primo bit vale 0 e ha una netmask convenzionale di 8 bit,cioè 255.0.0.0. In tabella 1.1 è riportata la classificazione completa.
Classe Leading bits Inizio intervallo Fine intervalloA 0 0.0.0.0 127.255.255.255
B 10 128.0.0.0 191.255.255.255
C 110 192.0.0.0 223.255.255.255
D 1110 224.0.0.0 239.255.255.255
E 240.0.0.0 255.255.255.255
Tabella 1.1: Classi d’indirizzamento IP
Si può notare che l’esempio scelto (net 1.2.3.0 con 24 bit di parte direte) non è conforme alla tabella, infatti l’indirizzo 1.2.3.0, convertito incifre binarie, inizia con uno 0 e quindi appartiene alla classe A, che ha 8 bitdedicati alla rete. Non è un errore: estendendo la netmask si può suddividereuna rete in sottoreti più piccole e ciò è molto utile, perché il numero di IPdiversi ottenibili con 32 bit è grande, ma finito (232) e non avrebbe sensoassegnare, per esempio, una intera classe C (254 indirizzi utili) ad una rete

1.3. Dalle intese ad Internet 29
Application
Presentation
Session
Transport
Network
Data Link
Physical
Application
Presentation
Session
Transport
Network
Data Link
Physical
Network
Data Link
Physical
Data Link
Physical
ROUTER
Figura 1.9: Instradamento a livello 3 mediante un router
di un piccolo ufficio con 4 computer5. L’operazione appena descritta prendeil nome di subnetting e, purtroppo, non è supportata da tutti gli standarde protocolli. Gli ambienti in cui è possibile gestire il subnetting vengonodefiniti classless, mentre i contesti nei quali non si può derogare dalla rigidadivisione in classi prendono il nome di classfull. In ambiente classless si puògeneralizzare la definizione di indirizzo di net e di broadcast di una sottorete:l’indirizzo della net sarà quello con tutti i bit della parte host posti a 0,mentre il broadcast avrà tutti i bit della parte host posti ad 1.
Un pacchetto IP avrà un header che conterrà l’indirizzo sorgente e l’in-dirizzo di destinazione, oltre a vari campi di controllo sui quali non ci sof-fermeremo. L’header sarà analizzato dal livello 3 dell’host: se il pacchettoha un indirizzo di destinazione uguale quello del nodo che lo sta esaminando(oppure la destinazione è l’indirizzo di broadcast della sottorete) il payloaddel pacchetto verrà consegnato al livello 4 dell’host; in tutti gli altri casi ilpacchetto sarà scartato. Per interconnettere due (o più) reti, intervenendo alterzo livello del modello ISO-OSI, è necessario un router ; esso è in grado diinstradare i pacchetti IP indipendentemente dal tipo di reti fisiche connesseeffettivamente (Fig. 1.9).
5con una parte di rete di 29 bit si ottengono 23 − 2 = 6 indirizzi utili, resta al lettorel’incombenza di calcolare il valore della netmask opportuna

1.3. Dalle intese ad Internet 30
A
B
C
D
E
IJ
G
F
H
A
B
C
D
E
IJ
G
F
H
Figura 1.10: Costruzione del Sink Tree
L’instradamento dei pacchetti attraverso le reti connesse al router avvienein base a una tabella di instradamento che può anche essere determinata inmodo dinamico, in presenza di connessioni ridondanti; questo procedimentoprende il nome di routing. Un algoritmo di routing è quella parte del softwaredi livello network che decide su quale linea d’uscita instradare un pacchettoche è arrivato al router. Da un algoritmo di routing desideriamo:
• correttezza (deve muovere il pacchetto nella giusta direzione);
• semplicità (l’implementazione non deve essere troppo complicata);
• robustezza (deve funzionare anche in caso di cadute di linee e/o guastidei router e di riconfigurazioni della topologia);
• stabilità (deve convergere, e possibilmente in fretta);
• ottimalità (deve scegliere la soluzione globalmente migliore).
Esiste un cosiddetto principio di ottimalità per cui se il router j è nelcammino migliore fra i e k, allora anche il cammino ottimo fra j e k è sullastessa strada. Se così non fosse, ci sarebbe un altro cammino fra j e k
migliore di quello che è parte del cammino ottimo fra i e k, ma allora cisarebbe anche un cammino migliore fra i e k. Una diretta conseguenza èche l’insieme dei cammini ottimi da tutti i router a uno specifico router didestinazione costituisce un albero, detto sink tree per quel router (Fig. 1.10).

1.3. Dalle intese ad Internet 31
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area * - candidate default, U - per-user static route, o - ODR P - periodic downloaded static route
Gateway of last resort is 172.31.255.253 to network 0.0.0.0
C 192.168.101.0/24 is directly connected, Vlan1C 192.167.101.0/24 is directly connected, Vlan1O 192.167.106.0/24 [110/5] via 172.31.200.22, 00:49:56, Vlan902 192.167.107.0/24 is variably subnetted, 3 subnets, 3 masksO 192.167.107.0/27 [110/6] via 172.31.200.86, 00:49:56, Vlan910O 192.167.107.64/26 [110/18] via 172.31.200.86, 00:49:56, Vlan910O 192.167.107.128/25 [110/5] via 172.31.200.38, 00:49:56, Vlan904O 192.167.105.0/24 [110/3] via 172.31.200.70, 00:49:56, Vlan908O 192.167.110.0/24 [110/5] via 172.31.200.13, 00:49:56, Vlan901..........
Figura 1.11: Esempio di tabella di routing
In sostanza, gli algoritmi di routing calcolano i sink tree relativi a tuttii possibili router di destinazione, e quindi instradano i pacchetti esclusiva-mente lungo tali alberi. Ciascun router della rete conserverà una tabella dirouting, generata a partire dal sink tree, che conterrà, per ogni sottorete didestinazione conosciuta dal router, l’indicazione della "rotta" (route) da farseguire ai pacchetti, cioè l’interfaccia tramite la quale instradare il traffico ol’IP del next hop (il salto successivo) sul percorso per raggiungere la sotto-rete di destinazione (Fig. 1.11). Eventualmente, se il protocollo è evoluto,la tabella di routing conterrà altre informazioni, come il "peso" della rotta(metrica), il protocollo di routing che l’ha comunicata al router, una marcatemporale, etc.
Un’ultima osservazione: un router, specie se realizza un nodo di Internet,non può conoscere direttamente rotte per ogni destinazione possibile, perchéla tabella di routing dovrebbe avere dimensioni (e quindi un’occupazione diRAM) enormi ed i tempi di aggiornamento sarebbero improponibili.

1.3. Dalle intese ad Internet 32
Il problema è di facile soluzione: alle rotte verso specifiche destinazioni siaggiunge anche la rotta verso la sottorete 0.0.0.0, che, convenzionalmente,indica la destinazione “sconosciuta”. Questa particolare rotta viene indicatacome “default route” o “ last resort”: attraverso di essa il router instraderàtutto il traffico diretto a destinazioni non esplicitamente presenti nella tabelladi routing.
Quando la rete cresce fino contenere decine di migliaia di nodi, diventatroppo gravoso mantenere in ogni router la completa topologia. Il routing vaquindi impostato in modo gerarchico, come succede nei sistemi telefonici. Larete viene divisa in zone (spesso dette regioni): all’interno di una regione valequanto visto finora, cioè i router (detti router interni) sanno come arrivare atutti gli altri router della regione; viceversa, quando un router interno devespedire qualcosa a un router di un’altra regione sa soltanto che deve farlopervenire a un particolare router, detto router di confine (border router), chepossiederà la rotta per il next hop verso la destinazione.
Il modo più semplice per implementare il routing è stabilire a priori ipercorsi ottimali sulla rete e scrivere la tabella di routing direttamente nellaconfigurazione dei router. Questo approccio, di tipo statico, ha il vantag-gio della semplicità (non bisogna implementare sui router un software checalcoli le rotte, questo calcolo è gia stato fatto dall’amministratore di rete),ma richiede che l’amministratore conosca completamente la topologia dellarete, in modo da poter calcolare i percorsi migliori. Inoltre l’amministratoredovrà materialmente scrivere la routing table d’ogni router e cambiarla espli-citamente ogni volta che è apportata una modifica alla topologia (un nuovonodo, un guasto, la caduta di un circuito, un cambiamento negli indirizziIP). Uno schema di questo tipo si adatta bene a piccole realtà, collegate areti più grandi mediante un solo router di frontiera, che avrà anche il ruolodi last resort gateway. Nelle moderne reti si usano algoritmi dinamici, chesi adattano automaticamente ai cambiamenti della rete. Questi algoritminon sono eseguiti solo all’avvio della rete, ma rimangono in esecuzione suirouter durante il normale funzionamento e aggiornano le rotte ad intervalli

1.3. Dalle intese ad Internet 33
temporali regolari o a seguito di variazioni di topologia.Gli algoritmi di routing dinamico sono sostanzialmente di due tipi: distan-
ce vector e link state. Nel primo ogni router mantiene una tabella (vector)contenente un elemento per ogni altro router destinazione. Ogni elementodella tabella contiene la “distanza” (numero di hop, ritardo, ecc.) che losepara dal router in oggetto e la linea in uscita da usare per arrivarci. Ilprotocollo distance vector più diffuso è il RIP. Per i suoi vicini immedia-ti il router stima direttamente la distanza dei collegamenti corrispondenti,mandando speciali pacchetti ECHO e misurando quanto tempo ci mette larisposta a tornare. A intervalli regolari ogni router manda la sua tabella atutti i vicini, e riceve quelle dei vicini. Quando un router riceve le nuove in-formazioni, calcola una nuova tabella scegliendo, fra tutte, la concatenazionemigliore con quest’ordine: se stesso→ vicino immediato→ router remoto didestinazione.
Ovviamente, la migliore è la concatenazione che produce la minore sommadi distanza fra il router stesso ed un suo vicino immediato (viene dalla misu-razione diretta) e la distanza fra quel vicino immediato ed il router remoto didestinazione (viene dalla tabella ricevuta dal vicino immediato). L’algoritmodistance vector routing funziona piuttosto bene, ma è molto lento nel reagirealle cattive notizie, cioè quando un collegamento va giù. Ciò è legato al fattoche i router non conoscono la topologia della rete e basano le loro scelte solosulle tabelle che vengono loro fornite dai router adiacenti.
Si è cercato di ovviare con un approccio diverso, che ha dato origineal link state routing. L’idea di base è che ogni router controlla lo statodei collegamenti fra se stesso e i suoi vicini immediati (misurando il ritardodi ogni linea) e distribuisce tali informazioni a tutti gli altri; sulla base ditali informazioni, ogni router ricostruisce localmente la topologia completadell’intera rete e calcola il cammino minimo verso tutti gli altri. I passi daseguire sono:
1. scoprire i vicini e identificarli;
2. misurare il costo (ritardo o altro) delle relative linee;

1.3. Dalle intese ad Internet 34
3. costruire un pacchetto con tali informazioni;
4. mandare il pacchetto a tutti gli altri router;
5. dopo aver ricevuto gli analoghi pacchetti che arrivano dagli altri router,costruire la topologia dell’intera rete;
6. calcolare il cammino più breve verso tutti gli altri router
7. redigere la tabella di routing e copiarla nella RAM.
Quando il router si avvia, invia un pacchetto HELLO su tutte le lineein uscita. In risposta riceve dai vicini i loro indirizzi (univoci in tutta larete). Inviando vari pacchetti ECHO, misurando il tempo di arrivo dellarisposta (diviso 2) e mediando su vari pacchetti si deriva il ritardo della linea.Si costruisce un pacchetto con identità del mittente, numero di sequenzadel pacchetto, età del pacchetto, lista dei vicini con i relativi ritardi. Lacostruzione e l’invio di tali pacchetti si verifica tipicamente a intervalli regolario quando accade un evento significativo (es.: una linea va giù o torna su). Ladistribuzione dei pacchetti è la parte più delicata, perché errori in questa fasepossono portare qualche router ad avere idee sbagliate sulla topologia, conconseguenti malfunzionamenti. Combinando tutte le informazioni arrivate,ogni router costruisce il sink tree della subnet e calcola il cammino minimoverso tutti gli altri router (l’algoritmo si chiama SPF, Shortest Path First[22]); con queste informazioni costruisce la propria tabella di routing.
Il vantaggio di questo approccio è che, all’occorrenza di una variazionedello stato della rete, è sufficiente che il router che la percepisce direttamentemandi una segnalazione a tutti gli altri, che, in modo autonomo, provvede-ranno a modificare le proprie tabelle di routing in conseguenza dell’eventosegnalato. Il link state routing è molto usato attualmente su reti di gran-di dimensioni: esempi di protocolli che implementano algoritmi di tipo linkstate sono: OSPF (Open Shortest Path First), che è il più usato, ed IS-IS(Intermediate System-Intermediate System), progettato per DECnet e poiadottato da OSI. La sua principale caratteristica è di poter gestire indirizzi

1.3. Dalle intese ad Internet 35
di diverse architetture (OSI, IP, IPX) per cui può essere usato in reti misteo multiprotocollo.
1.3.2 Comunicazione efficace
Fin qui si sono esaminati livelli, dispositivi e protocolli che, sinergicamente,ci consentono di realizzare la connettività, cioè la possibilità di scambiare datitra due host, indipendentemente dalla loro distanza. Quel che ora occorreè uno strato che simuli la connessione diretta tra le due macchine, un cavovirtuale che nasconda al livello applicativo la complessità della rete fisicasottostante e che si occupi di organizzare e consegnare i dati affinchè sianofruibili dalle applicazioni. Il livello di Trasporto fa proprio questo, nellospecifico sovrintende alle seguenti operazioni:
• offre servizi ai livelli applicativi;
• controlla la connessione;
• controlla il flusso dei dati;
• riordina le TPDU (Transport Protocol Data Unit).
La PDU di questo livello prende il nome di TPDU (Transport PDU) el’indirizzamento, nel TCP/IP, è gestito mediante i numeri di porta.
Porta Protocollo Applicazione21 FTP File transfer23 Telnet Remote Login25 SMTP e-mail80 HTTP World Wide Web110 POP3 Remote e-mail- access
Tabella 1.2: Indirizzi del livello di trasporto
Come si vede dalla tabella in Fig. 1.2, ciascun numero di porta identi-fica un servizio applicativo diverso: il port number è qundi il tramite con i

1.3. Dalle intese ad Internet 36
host1
host2
SYN (SEQ = x)
SYN (SEQ = y, ACK = x+1))
(SEQ = x+1, ACK = y+1)
Figura 1.12: Three-way handshake
livelli applicativi superiori. Un servizio applicativo sarà quindi identificatodall’indirizzo IP dell’host che lo eroga e dal numero di porta che identifica ilservizio stesso. Questa coppia di valori prende il nome di socket.
Un altro obiettivo del livello di trasporto è il riordino dei TPDU: il livellonetwork si occupa, infatti, soltanto della consegna dei pacchetti, ma non ga-rantisce che essi siano consegnati nell’ordine con il quale sono stati trasmessi.Ai fini della corretta ricostruzione dell’informazione è dunque necessario cheil livello 4 si occupi di caricare il payload dei pacchetti ricevuti in un buffer eli consegni al livello 5 nell’ordine corretto. A questo livello è di fondamentaleimportanza la distinzione tra due tipologie di servizi: servizi affidabili orien-tati alla connessione (tipici di questo livello), servizi datagram senza gestionedella connessione (poco usati in questo livello).
Il TCP [15] è il protocollo di livello 4 che si occupa di realizzare unaconnessione nell’ambito della suite TCP/IP. Il protocollo TCP è stato pro-gettato per fornire un flusso di byte affidabile, da sorgente a destinazione, suuna rete eterogenea e si occupa di:
• accettare dati dal livello application;

1.3. Dalle intese ad Internet 37
• spezzarli in segment, il nome usato per i TPDU (dimensione massima64 Kbyte, tipicamente circa 1.500 byte);
• consegnarli al livello network, eventualmente ritrasmettendoli;
• ricevere segmenti dal livello network;
• rimetterli in ordine;
• consegnare i dati, in ordine, al livello application.
Esso realizza la connessione mediante un three-way handshake: l’host 1invia all’host 2 un messaggio contenente la richiesta di iniziare la connessio-ne ed un numero (sequence number) di sequenza; l’host 2 risponde con una“ricevuta di ritorno”, contenente, a sua volta, un segnale di inizializzazione(SYN) con un proprio sequence number ed un segnale di acknowledgement(ACK) con il sequence number contenuto nel messaggio dell’host 1, aumen-tato di una unità. Come si vede dalla figura 1.12, il processo continua conuna operazione analoga da parte dell’host 1, finché la connessione è attivata.Durante tutta la connessione i due host si scambieranno periodici messaggi diacknowledgement, in modo da effettuare il controllo della connessione. Il ri-lascio della connessione avviene mediante un messaggio di conclusione (FIN)al quale segue, normalmente, un messaggio di conferma della chiusura. Perevitare problemi alla disconnessione, spesso si stabilisce un tempo di timeoutdopo il quale la connessione viene comunque considerata chiusa.
Il livello transport della suite TCP/IP fornisce anche UDP, un protocollonon connesso e non affidabile, utile per inviare dati senza stabilire connessioni(ad esempio per applicazioni client-server, streaming video). L’header di unsegmento UDP è molto semplice e contiene essenzialmente la porta sorgente,la porta destinazione, la lunghezza del segmento ed una checksum, il calcolodella quale può essere disattivato, tipicamente nel caso di traffico in temporeale (come voce e video) per il quale è in genere più importante mantenereun’elevato tasso di arrivo dei segmenti piuttosto che evitare i rari errori chepossono accadere.

1.3. Dalle intese ad Internet 38
Root
.it .edu .gov .org
aaa.it bbb.it ccc.it
root
top level
zone
Figura 1.13: Gerarchia DNS
1.3.3 Le Applicazioni
In questo modello di architettura, sopra il livello transport c’è il livello ap-plication, nel quale viene effettivamente svolto il lavoro utile per l’utente. Inquesto livello si trovano diverse tipologie di oggetti:
• protocolli di supporto a tutte le applicazioni, come il DNS (DomainName System, RFC 1034 e 1035);
• protocolli di supporto ad applicazioni di tipo standardizzato, come FTP(File Transfer Protocol, RFC 959) per il trasferimento di file, SMTPe POP3 (Simple Mail Transfer Protocol, RFC 821 e Post Office Pro-tocol, RFC 1225) per la posta elettronica, HTTP (HyperText TransferProtocol, RFC 1945) alla base del World Wide Web (WWW);
• applicazioni proprietarie.
DNS
Il DNS è un servizio di livello applicativo che mette in relazione gli indirizzi IPcon delle stringhe di testo strutturate in modo gerarchico: i nomi di dominio(domain name), organizzati ad albero in domini, sottodomini (eventualmentealtri sottodomini di livello inferiore. . . ), fino ad arrivare a identificare il nododesiderato6 (Fig. 1.13).
6www.unime.it è l’host di nome www, appartenente al dominio unime.it

1.3. Dalle intese ad Internet 39
Il servizio, corrispondente alla porta 53 sia TCP (zone tranfer) che UDP(request), è erogato da nodi (name server) che si occupano di risolvere i nomiin indirizzi numerici IP e viceversa.
La gerarchia dei server rispecchia abbastanza fedelmente quella dei nomidi dominio, implementando almeno tre livelli: i root server, i top level do-main server, i server di zona; una siffatta struttura permette di delegare al“proprietario” del dominio la gestione dei nomi degli host della propria zona(hostname), mantenendo comunque possibile la risoluzione del nome da ognipunto della rete mediante richieste ai nodi superiori dell’albero.
La posta elettronica (e-mail) è uno dei servizi per i quali è nata la rete; èbasata sul paradigma della posta tradizionale ed il suo utilizzo ne ripropo-ne i passaggi, dalla composizione del messaggio, alla spedizione, all’iter diconsegna, alla ricezione e lettura. Il servizio è realizzato mediante una seriedi protocolli, ciascuno dedicato ad una particolare funzionalità; il cuore delsistema è il protocollo SMTP (simple mail transfer protocol, porta 25 TCP),che agisce da mail transport agent (MTA) e si occupa di ricevere i messaggie trasportarli sulla rete fino al server (MTA) del destinatario.
La gestione delle mailbox moderne è demandata ai protocolli POP3 (postoffice protocol, porta 110 TCP) ed IMAP7 (Internet Message Access Protocol,porta 143 TCP), che agiscono da mail user agent, consentendo all’utentefinale di comporre, leggere, eliminare e spedire messaggi (via MTA).
Il singolo messaggio di posta elettronica ha un formato piuttosto semplice,che prevede un’intestazione (header) ed un corpo (body), separati da una lineavuota. Le linee che compongono l’header sono codificate in modo stringente,perché contengono i campi necessari al corretto instradamento del messaggio:
• To: indirizzo e-mail di uno o più destinatari, nella forma, a tutti nota,user@dominio.
7la gestione e-mail via web, alla quale siamo abituati, è realizzata tramite questoprotocollo

1.3. Dalle intese ad Internet 40
• From: indirizzo e-mail del mittente
• Cc: indirizzo di uno o più destinatari per conoscenza;
• Bcc: come Cc, ma gli indirizzi non sono visibili al destinatario
• Subject : Argomento del messaggio
ed altri campi di gestione del messaggio, la cui descrizione non è qui essen-ziale.
Per ragioni storiche e di compatibilità, il formato previsto per i messaggidi posta elettronica è di “solo testo”, costituito dai caratteri che compongono ilcodice ASCII; ciò renderebbe impossibile inviare allegati (immagini, filmati,documenti), in genere codificati in formato binario. Per superare questalimitazione viene utilizzato lo standard MIME (Multipurpose Internet MailExtension, RFC 1341 e 1521), che si occupa di codificare (encode), allegare(attach) e decodificare (decode) gli allegati.
WORLD WIDE WEB
Il servizio, nato nel 1989 al CERN di Ginevra [17], è erogato dal protocolloHTTP (hypertext transfer protocol, porta 80 TCP) e prevede un’architettu-ra basata su client (i browser) che interrogano pagine, scritte in linguaggioHTML, rese disponibili da server (siti) distribuiti su tutta la rete mondiale.L’architettura prevede uno spazio d’indirizzamento basato su URL (UniformResource Locator), sequenze di caratteri che identificano univocamente unarisorsa, nella forma:
protocol://<user:pass@>host<:port></path><?query>
In tabella 1.3 sono riportati alcuni esempi.Gli unici elementi indispensabili sono il protocollo e l’hostname del server
da raggiungere; i campi opzionali user e password servono all’autenticazioneper la consultazione di risorse private, il campo port è la porta del TCP(eventualmente diversa dalla 80 standard), il path è il percorso diretto tramiteil quale è possibile raggiungere una risorsa senza passare dalla pagina iniziale

1.3. Dalle intese ad Internet 41
Nome Uso Esempiohttp Hypertext (html) http://www.unime.itftp FTP ftp://files.unime.itgopher Gopher gopher://gopher.unime.it/libsmailto e-mail mailto:[email protected]
Tabella 1.3: Esempi di URL
(home page) e, infine, il campo query è utile per passare parametri a paginedinamiche, costruite a richiesta, mediante linguaggi di programmazione (peresempio il Python), basandosi sui dati presenti in un datatabase.
Questa forma di gestione degli indirizzi è molto potente e permette di col-legare contenuti presenti su pagine e server diversi mediante hyperlink, basatisulla URL della risorsa da referenziare; ciò consente la “navigazione Internet”(browsing) con le modalità da tutti sperimentate nella vita quotidiana.
SEARCH ENGINES
Fin dagli inizi del Web un utente si trova più frequentemente a voler cercareinformazioni di cui ignora la provenienza, piuttosto che accedere ad una pa-gina di cui possiede già la URI. Quest’ultimo è tutt’altro che un evento raro,ancora oggi la navigazione comprende sempre accedere a pagine usuali, incui si ha interesse a verificare l’aggiornamento delle informazioni contenute,si pensi al sito di una Facoltà universitaria o ancor più alle versioni on-linedi quotidiani. Purtuttavia il primo caso, in cui si ha in mente il genere diconoscenze desiderate ma non la loro fonte, perlomeno non sotto forma diURI, è di importanza prevalente nella fruizione della rete.
Una maniera inizialmente pratica di affrontare il sistema fu quella deglielenchi di risorse, pagine Web di per se scarse di contenuto, ma ricche dilink ad altre pagine, selezionate manualmente ed eventualmente corredatesingolarmente di un breve commento. è una soluzione che richiede un grandesforzo umano, ed è impiegata esclusivamente per settori ristretti, dove an-

1.3. Dalle intese ad Internet 42
cora oggi costituisce la forma più precisa e preziosa di ausilio alla ricerca.è evidentemente impraticabile come modo generalizzato di cercare nel Web.Il metodo che si è andato invece affermando è quello dei cosiddetti motoridi ricerca, search engine, sistemi che l’utente interroga mediante una serie diparole, che reputa significative dei contenuti che cerca, e restituiscono elenchidi link a pagine selezionate automaticamente, sulla base di una semplice veri-fica del contenere quelle parole (dette keywords, parole chiave). Attualmenteesiste un migliaio circa di diversi motori di ricerca, ma in questa sezione siprenderà in esame solo quello che da alcuni anni si è andato affermando comeil più popolare dei motori di ricerca: Google. La sua fama è ben motivatarisultando effettivamente il più efficiente sulla base di valutazioni oggettive[23].
Ci sono comunque degli elementi del sistema Google che sono comuni allamaggior parte degli altri motori di ricerca. Ciò che l’utente vede abitual-mente, la pagina con la form per scrivere parole, è l’interfaccia del compo-nente searcher del sistema, quello che effettua le ricerche per gli utenti. Inrealtà questo sottosistema non cerca proprio nulla su internet, ma funzionatotalmente su database interni al motore di ricerca, generati dagli altri com-ponenti. L’insieme degli archivi interni, denominato semplicemente index, ècostruito dal software che si chiama appunto indexer, il quale pure lavoracompletamente off-line, su un altro enorme database, il repository, dove so-no immagazzinate in formati compressi tutte le pagine Web conosciute dalmotore di ricerca. Infine il repository è costruito dal crawler, il programmache effettivamente recupera copie delle pagine da internet.
Quest’ultima operazione è di gran lunga la più lenta, perché richiede l’ef-fettiva navigazione attraverso la rete. è effettuata da tante copie dello stessoprogramma che lavorano in parallelo su computer distribuiti, raggiungendovelocità dell’ordine di migliaia di documenti scaricati al secondo. Pur conquesto ritmo, se si tiene conto che attualmente il volume di documenti con-trollati da Google è di diversi miliardi, il tempo di attraversamento dell’interarete è di decine di giorni. Mediamente uno stesso sito è rivisitato dai crawler

1.3. Dalle intese ad Internet 43
links
searcher
pageRank
URL server crawler
indexer
index
repository
lexicon
Figura 1.14: Uno schema generale dell’architettura di Google, o di un motore di
ricerca analogo.
circa una volta al mese.L’indexer passa in rassegna tutte le pagine archiviate nel repository e ne
estrae diverse caratteristiche importanti per la ricerca. Anzitutto produce leliste dei cosiddetti hits, che sono parole con abbinato il numero di volte in cuicompaiono nel documento, e la loro posizione. Inoltre riserva un trattamen-to particolare al testo contenuto nei tag A, che viene immagazzinato comeparziale descrizione della pagina cui rimanda il link, e naturalmente vieneinoltre archiviata la URI del link stesso. Queste informazioni sono quelle chepoi, processate dal URL Server, andranno ad informare il crawler su dovereperire da internet le pagine. Ma un uso particolare in Google è quello cheverrà spiegato al paragrafo successivo. Uno schema complessivo del sistemaè in Fig. 1.14.
Il searcher tipicamente non effettua nulla di complesso, ma semplicementecerca nell’index tutte le pagine che contengono le parole scritte dall’utente.Vi sono pochissimi accorgimenti opzionali che possono raffinare la ricerca, deltipo di imporre che le parole siano consecutive. Il risultato è che abitualmente

1.3. Dalle intese ad Internet 44
una ricerca sia esaudita da diverse migliaia di documenti. Aggiungere parolechiave non sempre migliora la situazione, e facilmente si passa da un numeromolto elevato a nessun documento, quando le parole sono evidentemente pococompatibili. La strategia che può cambiare radicalmente la soddisfazionenella ricerca di conoscenze è nell’assegnare in qualche modo un punteggio allepagine trovate, e presentarle nell’ordine corrispondente. Siccome chi navigadifficilmente si prende la briga di esaminare il contenuto di più di qualchedecina di pagine recuperate, è evidente quanto sia essenziale che compaianoal primo posto quelle, tra molte migliaia, veramente rilevanti.
Le strategie dei primi motori di ricerca erano basate su semplici valuta-zioni rispetto alle parole cercate: per esempio aveva maggior punteggio unapagina che conteneva un numero maggiore di hit o un rapporto tra hit e nu-mero complessivo di parole vantaggioso. Data l’importanza capitale per siticommerciali di comparire in cima agli elenchi dei motori di ricerca, criteridi questo genere hanno innescato rapidamente distorsioni aberranti, comepagine web ingigantite da parole invisibili (per es. scritte in colore biancosu sfondo bianco), ripetute migliaia di volte. Lo stesso fenomeno si potrebberipetere per qualunque criterio estratto dalla pagina stessa, è evidente cheun’oggettività non poteva che scaturire da elementi esterni al documento,non controllabili da chi progetta la propria pagina.
Così come l’intero Web è derivato da un primo uso accademico, anche ilmetodo introdotto da Google, denominato PageRank [24], è preso in prestitodal modello di valutazione degli articoli scientifici in sede accademica: tramitele citazioni che riceve l’articolo stesso. Analogamente, il metodo PageRankassegna un punteggio ad ogni pagina Web in base a quante altre pagine hannolink a essa diretti, pesando il contributo di questi link mediante il punteggiodi quelle altre pagine. In altre parole, un documento è ritenuto importantese ci sono altri documenti in cui compare come link, ma lo è ancor di più sequesti documenti sono importanti.

Capitolo 2Sicurezza
Per lo studio delle problematiche riguardanti la Sicurezza Informatica, la Fir-ma digitale e la Posta Elettronica Certificata lo studente è invitato ad usare
come traccia le slides del corso, approfondendo i contenuti mediante lalettura dei seguenti documenti:
• AgID - Agenzia per l’Italia Digitale - Firme Elettronichehttp://www.agid.gov.it/agenda-digitale/infrastrutture-architetture/firme-elettroniche
• AgID - Agenzia per l’Italia Digitale - Posta Elettronica Certificatahttp://www.agid.gov.it/agenda-digitale/infrastrutture-architetture/posta-elettronica-certificata
45

Bibliografia
[1] Joseph C.R. Licklider. Man-computer symbiosis. IRE Transactions onHuman Factors, 1:4–11, 1960.
[2] J. C. R. Licklider. Man-computer partnership. International Scienceand Technology, May 1965.
[3] J. C. R. Licklider and Robert W. Taylor. The computer as acommunication device. Science and Technology, April 1968.
[4] Leonard Kleinrock. Information Flow in Large Communication Nets.Proposal for a ph.d. thesis, MIT, May 1961.
[5] J. C. R. Licklider and Wesley Clark. On-line man-computer communica-tion. In Proceedings of the May 1-3, 1962, spring joint computer confe-rence San Francisco, California, AIEE-IRE ’62 (Spring), pages 113–128,New York, NY, USA, May 1962. ACM.
[6] Leonard Kleinrock. Communication Nets: Stochastic Message Flow andDesign. McGraw-Hill, New York, 1964.
[7] Paul Baran. On distributed communications. Memoranda for Uni-ted States Air Force Project, RAND Corporation, Santa Monica (CA),august 1964.
46

Bibliografia 47
[8] D. W. Davies, K. A. Bartlett, R. A. Scantlebury, and P. T. Wilkinson.A digital communication network for computers giving rapid responseat remote terminals. In Proceedings of the first ACM symposium onOperating System Principles, SOSP ’67, pages 2.1–2.17, New York, NY,USA, 1967. ACM.
[9] Lawrence G. Roberts. Multiple computer networks and intercomputercommunication. In Proceedings of the first ACM symposium on Opera-ting System Principles, SOSP ’67, pages 3.1–3.6, New York, NY, USA,October 1967. ACM.
[10] S. D. Crocker. Host software, 1969.
[11] E. Krol. Hitchhikers guide to the internet, 1989.
[12] S. D. Crocker. New host-host protocol, 1970.
[13] V. Cerf, Y. Dalal, and C. Sunshine. Specification of internet transmissioncontrol program, 1974.
[14] J. Postel. Internet protocol, 1981.
[15] J. Postel. Internet message protocol, 1980.
[16] T. J. Berners-Lee, R. Cailliau, and J.-F. Groff. The World-Wide Web.Computer Networks and ISDN Systems, 25:454–459, 1992.
[17] T. Berners-Lee, R. Fielding, and H. Frystyk. Hypertext transfer protocol– http/1.0, 1996.
[18] D. DiNucci. Fragmented future. Print, 53(4):32, 1999.
[19] C. ISO. Information technology - open systems interconnection - basicreference model. International Standard 7498, ISO/IEC, United States,November 1994.
[20] A. G. Malis. Arpanet 1822l host access protocol, 1981.

Bibliografia 48
[21] J. Postel and J. K. Reynolds. Standard for the transmission of ipdatagrams over ieee 802 networks, 1988.
[22] Edsger W. Dijkstra. A note on two problems in connexion with graphs.Numerische Mathematik, 1(1):269–271, December 1959.
[23] Yi Shang and Longzhuang Li. Precision evaluation of search engines.World Wide Web: Internet and Web Information Systems, 5:159–173,2002.
[24] Sergey Brin and Lawrence Page. The anatomy of a large-scale hyper-textual Web search engine. Computer Networks and ISDN Systems,30:107–117, 1998.

Typeset with LATEX


















