
Progetto e valutazione di un repository distribuito per la...
73
Transcript of Progetto e valutazione di un repository distribuito per la...

Facoltá di Ingegneria dell'informazione, informatica e
statisticaDipartimento di informatica e sistemistica �Antonio Ruberti�
Tesi di Laurea Magistrale in Ingegneria Informatica
Dicembre 2010
Progetto e valutazione di un repository distribuito per la
memorizzazione di dati di contesto in sistemi domotici avanzati
Umberto Carlo de Matteis
Matricola: 800673
Relatore: Prof. Leonardo Querzoni Controrelatore: Prof. Massimo Mecella

ii
Ai miei genitori,a chi ha creduto in me
e a chi continuerá a farlo

Indice
Introduzione 1
Scenario d'uso: Mike e i suoi amici 3
1 La memorizzazione dei dati di contesto 5
1.1 Introduzione alle applicazioni context-aware . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2 Il problema della memorizzazione dei dati di contesto . . . . . . . . . . . . . . . . . . . . . . . 61.3 Stato dell'arte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.1 Studio di casi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8Framework and Toolkit for Context-Aware Applications . . . . . . . . . . . . . . . . . 8CR Architecture for SCE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 L'architettura del sistema SM4All 13
2.1 Architettura generale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2 User layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.3 Composition layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.1 Context Awarness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.2 Context Storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4 Pervasive layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3 Architettura generale del repository del contesto 21
3.1 Funzionalitá e principi generali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2 Organizzazione interna del repository . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.3 ContextRepository . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3.1 Store . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.3.2 Query . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.3.3 DHT class loading . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.4 ContextStorage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303.5 DHT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.5.1 Distributed Hash Table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.5.2 Pastry [10] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.5.3 FreePastry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.6 Sviluppo e installazione nuovi tipi di sensori . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.7 Sviluppare e installare nuovi sensori di un vendor . . . . . . . . . . . . . . . . . . . . . . . . . 353.8 Tipi di sensori attualmente implementati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.8.1 Sensori di temperatura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.8.2 Sensori di pressione sanguigna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.9 Driver dei sensori attualmente implementati . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.9.1 Driver del sensore di temperatura Slurp . . . . . . . . . . . . . . . . . . . . . . . . . . 393.9.2 Driver del sensore di pressione sanguigna Slurp . . . . . . . . . . . . . . . . . . . . . . 41
3.10 Deployment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
iii

iv INDICE
4 Valutazione delle prestazioni 454.1 Descrizione del sistema usato per la valutazione . . . . . . . . . . . . . . . . . . . . . . . . . . 454.2 Test eseguiti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.2.1 Test con sei nodi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Test S 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Test S 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51Test S 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.2.2 Test a un nodo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51Test U 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51Test U 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57Test U 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58Test U 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
5 Conclusioni 61

Elenco delle �gure
1.1 Esempio di con�gurazione dei componenti di un Context Toolkit . . . . . . . . . . . . . . . . 101.2 Architettura di Smart Collaborative Environment . . . . . . . . . . . . . . . . . . . . . . . . . 111.3 Architettura del modulo di Context Repository di SCO (1) . . . . . . . . . . . . . . . . . . . 12
2.1 Architettura di rete di SM4All . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2 Architettura dei componenti di SM4All . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3 Component diagram del Composition layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.4 Schema a blocchi dei componenti del composition layer . . . . . . . . . . . . . . . . . . . . . . 162.5 Struttura del modulo di Context Awarness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.6 Component diagram del modulo di Context awarness . . . . . . . . . . . . . . . . . . . . . . . 172.7 Use case del sotto�modulo di Context Repository . . . . . . . . . . . . . . . . . . . . . . . . . 182.8 Funzionamento del modulo di context storage . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.9 Use case del pervasive layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.10 Architettura del pervasive layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.1 Dipendenza dei sotto-moduli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.2 Interfaccia del modulo Context Repository . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.3 Class diagram della struttura dati per lo store . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.4 Sequence diagram generale di un'operazione di store . . . . . . . . . . . . . . . . . . . . . . . 253.5 Sequence diagram di un'operazione di normalizzazione . . . . . . . . . . . . . . . . . . . . . . 253.6 Sequence diagram del parsing di un XML di store . . . . . . . . . . . . . . . . . . . . . . . . . 263.7 Class diagram della struttura dati per le query . . . . . . . . . . . . . . . . . . . . . . . . . . 273.8 Sequence diagram generale di un'operazione di query . . . . . . . . . . . . . . . . . . . . . . . 283.9 Sequence diagram del parsing di un XML di query . . . . . . . . . . . . . . . . . . . . . . . . 293.10 Interfaccia del modulo Context Storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303.11 Interfaccia del modulo DHT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.12 Esempio di uso di una DHT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.13 Esempio di routing di un messaggio in Pastry . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.14 Pseudo-codice dell'algoritmo di routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.1 Sequence diagram del bundle MethodLogging . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.2 Tempo di esecuzione test S 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 494.3 Utilizzo della memoria test S 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 504.4 Tempo di esecuzione test S 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.5 Utilizzo della memoria test S 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.6 Tempo di esecuzione test S 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.7 Utilizzo della memoria test S 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.8 Tempo di esecuzione test U 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.9 Utilizzo della memoria test U 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.10 Tempo di esecuzione test U 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.11 Utilizzo della memoria test U 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.12 Tempo di esecuzione test U 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 584.13 Utilizzo della memoria test U 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.14 Tempo di esecuzione test U 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
v

vi ELENCO DELLE FIGURE
4.15 Utilizzo della memoria test U 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59

Elenco delle tabelle
2.1 Descrizione dell'use case di store . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2 Descrizione dell'use case di retrieve . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1 Test E�ettuati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
vii

viii ELENCO DELLE TABELLE

Ringraziamenti
Vorrei prima di tutto ringraziare i miei genitori, che mi hanno sempre sostenuto sia nei momenti di felicitáche in quelli un po meno felici. Sono stati sempre con me sia nel bisogno che nella vittoria.
Un grande ed a�ettuoso ringraziamento a Ludovica Orestano, sempre presente a riempire di musica epoesia questi ultimi quattro anni. Oltre che un Maestro impareggiabile é un'amica fantastica.
Un caloroso e vivo ringraziamento al mio relatore, professor Leonardo Querzoni, per la sua grandeprofessionalitá, per i suoi incoraggiamenti e per la paziente disponibilitá dimostratami sempre.
ix

x Ringraziamenti

Introduzione
L'obiettivo di questo elaborato é quello di illustrare il modulo di memorizzazione e ricerca di dati di contestonell'ambito del progetto SM4All.
Per ben comprendere lo scopo e l'importanza di questo progetto si andranno a de�nire prima il concettodi contesto e come questo é attualmente gestito (capitolo 1), successivamente si illustrerá il progetto nel qualeil presente modulo andrá a posizionarsi (capitolo 2). Una volta data una de�nizione ed una collocazione,si passerá all'illustrazione della sua architettura (capitolo 3), ai test delle sue prestazioni (capitolo 4) e alleconclusioni raggiunte (capitolo 5).
Per poter meglio comprendere gli scenari resi possibili dalla gestione del contesto, in particolare in unambiente domotico, viene adesso illustrato un possibile scenario di utilizzo di un tale sistema.
1

2 Introduzione

Scenario d'uso: Mike e i suoi amici
Mike sta per terminare la sua giornata lavorativa e, prendendosi una pausa comincia a programmare il suotempo per l'imminente serata.
É venerdí e pensa che sarebbe una buona idea organizzare una cena per gli amici.Come un buon ospite, gradirebbe poter piani�care una piacevole riuscita della serata ma non ha or-
ganizzato niente nel corso della settimana e non puó farlo neanche adesso perché ancora occupato inu�cio.
Il tempo per predisporre il tutto é poco, cosí decide di connettersi remotamente alla sua casa e dareun'occhiata alla sua videoteca.
Si accorge che é sprovvista di �lm adatti alla serata, cosí decide di usare il servizio di download automaticodi �lms. Questo servizio é programmato con le sue preferenze e la sua funzione principale é di connettersiad una videoteca on-line per cercare, tramite vari parametri, un �lm che può essere interessante per i suoiospiti e di procedere alla sua acquisizione e al pagamento.
Mike comincia la ricerca e trova tre �lm che crede potrebbero essere graditi, ma non vuole essere lui il soloa decidere. Preferisce lasciare la possibilitá di scegliere anche ai suoi invitati, cosí usando la sua applicazioneinvia un sondaggio tramite sms.
I numeri di telefono dei suoi amici vengono reperiti mediante l'interrogazione del sistema domotico. Nelsondaggio gli amici possono votare uno dei �lm scelti da Mike, il �lm che otterrá piú voti sará automati-camente scaricato. In caso di paritá o di mancata risposta entro un tempo determinato toccherá lui lascelta.
Il sistema domotico é con�gurato con le sue credenziali di pagamento, puó quindi direttamente procederead esso senza l'aggiunta di ulteriori dati. Il �lm viene automaticamente scaricato su un hard disk portatile.Mike ha preferito questa impostazione per avere la possibilitá di portarlo anche in viaggio qualora fossenecessario.
Finito il suo lavoro lascia l'u�cio e riesce ad arrivare a casa giusto in orario per preparare la cena, manon ha molto tempo. É necessario che sappia il numero di persone che hanno aderito al suo invito. Il suocellulare é collegato (via bluetooth) agli speacker di casa, in questo modo il servizio Follow me combinato congli speakers e microfoni distribuiti nelle varie stanze della casa gli consentono di muoversi nei vari ambienticontinuando le conversazioni a mani libere.
Telefona a Bob, tornato recentemente dall'Africa, che quella sera vorrá far vedere le foto della suavacanza a lui e ai suoi amici. Mike gli suggerisce di memorizzare le sue foto nel suo cellulare, cosí saráfacile vederle sullo schermo del televisore. Quando Mike si sposta in cucina, lo speaker di quell'ambientenon si attiva. Il sistema domotico si accorge del guasto e genera un report. Nel frattempo automaticamenteil sistema domotico attiva la soluzione di default di alzare il volume dello speaker piú vicino, posizionatonel soggiorno, in questo modo Mike puó ancora ascoltare la conversazione leggendo il report generato dalsistema successivamente.
Ci saranno molte persone che devono arrivare, e Mike é cosí occupato in cucina che chiede a sua sorellaMaria di aiutarlo quando arriveranno gli ospiti rispondendo al citofono e aprendo la porta di casa. Maria éuna studentessa universitaria, il giorno dopo ha un di�cile esame, quindi, non è del tutto disponibile. Perconsentire a Mike di sentire la musica, studia con le cu�e. Per poter sentire il campanello della porta, accedeal suo account del sistema domotico programmandolo per far lampeggiare le luci in caso qualcuno arrivi.
Tutto é pronto, l'unica cosa che rimane da fare é scegliere una playlist musicale per la cena.
3

4 Scenario d'uso: Mike e i suoi amici
Mentre il cibo é in cottura, Mike va in soggiorno per preparare la playlist. Ascoltando la musica si distraee non pone la dovuta attenzione ai fornelli. Come risultato si genera un piccolo incendio. Fortunatamenteil sistema domotico si accorge dell'evento e attiva gli estintori. Contemporaneamente il sistema domotico siaccorge anche che l'incendio é localizzato solo in cucina, cosí chiude con meccanismo automatico le portedi accesso e apre le �nestre per far fuoriuscire il fumo. Ferma anche la riproduzione musicale nel soggiornoeseguendo un segnale di allarme. Appena il fuoco viene domato il brano precedentemente interrotto vienerimesso in esecuzione. Dopo mezz'ora e una veloce pulizia in cucina, gli invitati cominciano ad arrivare.
Contemporaneamente all'arrivo degli ospiti, Mike seleziona la �modalitá festa�. la musica sará in ese-cuzione in tutte le stanze eccetto quella di Maria, ed in soggiorno il volume sará stato programmato piúbasso per non disturbare la conversazione dei commensali.

Capitolo 1
La memorizzazione dei dati di contesto
1.1 Introduzione alle applicazioni context-aware
Per poter correttamente parlare delle applicazioni context-aware è utile cominciare dalla de�nizione delconcetto di contesto e di come esso sia stato de�nito in letteratura.
Possibili precedenti de�nizioni sono:
� La situazione nel suo insieme, gli scenari o gli ambienti rilevanti a qualche evento o personalitá(Webster's Dictionary)
� Luoghi, identitá delle persone e oggetti vicini e i cambiamenti a queste entitá (Schilit e Theimer, 1994)
� Luoghi, identitá delle persone attorno l'utente, l'orario, la stagione, la temperatura etc. (Brown, Bovey& Cher, 1997)
� Posizione dell'utente, l'ambiente, l'identitá e l'orario (Ryan, Pascoe & Morse, 1997)
� Stato emotivo dell'utente, l'attenzione, luoghi, data e orario, oggetti e persone nell'ambiente dell'utente(Dey, 1998)
� Informazioni su un individuo ed il suo ambiente circostante che possano essere usate per dedurre i modicon i quali il sistema possa servirlo al meglio (Norman H. Cohen, James Black, Paul Castro, MariaEbling, Barry Leiba, Archan Misra, Wolfgang Segmuller, 2004)
� Insieme di variabili che possano essere di interesse per un agente e che in�uenzi le sue azioni (Bolchiniet al. 2009)
Queste de�nizioni son di di�cile aiuto nella decisione di cosa classi�care come contesto o meno.Una de�nizione piú aggiornata di quel che é la context awarness (che tiene conto di: dove si trova l'utente,
con chi é e che risorse ha nelle vicinanze) é stata enunciata da Dey & Abowd nel 2000 ed é la seguente:
Contesto: qualunque informazione che puó essere usata per caratterizzare la situazione delleentitá (persone, posti, oggetti) che siano considerate rilevanti per l'interazione tra un utente eun'applicazione, utente e applicazione inclusi. Il contesto é tipicamente il luogo, l'identitá e lostato delle persone, gruppi e oggetti �sici e virtuali.
Uno degli scopi di un'applicazione context-aware é quello di determinare cosa un utente stia cercando difare, il che é di�cile da determinare direttamente. Questa é la ragione per la quale la de�nizione data é dicarattere cosí generale.
I dati di cui un'applicazione context-aware raccoglie, per la de�nizione data, possono sia essere raccoltiin modo manuale (li fornisce l'utente) che automatica (é il sistema stesso ad acquisirli).
Secondo Dey e Abowd i dati di contesto possono essere categorizzati in 4 gruppi:
5

6 CAPITOLO 1. LA MEMORIZZAZIONE DEI DATI DI CONTESTO
1. Dati relativi all'identitá delle entitá in ogetto
2. Dati relativi alla posizione di suddette entitá
3. Dati relativi allo stato nel quale si trovano
4. Dati relativi al tempo
Essi peró possono essere anche categorizzati nel modo seguente:
Contesto computazionale - Il contesto che ha a che fare con gli aspetti tecnici riferiti alle capacitáelaborative e delle risorse.
Contesto �sico - Il contesto che tiene in considerazione tutti quegli aspetti che rappresentano il mondoreale (temperatura, pressione, illuminazione, etc.).
Contesto temporale - Il contesto che riguarda la dimensione temporale del mondo reale: eventi sporadicio periodici.
Contesto dell'utente - Il contesto che pone attenzione sugli aspetti �sociali� dell'utente: chi conosce,quello che vuole comunicare etc.
1.2 Il problema della memorizzazione dei dati di contesto
La memorizzazione dei dati di contesto deve a�rontare vari problemi.Il primo di questi é il problema di un orario globale condiviso tra tutte le entitá del sistema. Come si é
evinto dalle de�nizioni di contesto, l'orario é un attributo sempre presente in quanto permette di compararee combinare i vari dati di contesto generati dai vari actors del sistema. Il problema da a�rontare é il fatto chei vari dispositivi facenti parte dell'ambiente possono non essere ben sincronizzati fra loro rendendo quindinecessario usare algoritmi di clock-synchronization, i quali aggiungono sia complessitá alla progettazionecomplessiva del sistema che riduzione delle prestazioni globali in quanto costosi da eseguire.
Altro aspetto da tenere in considerazione é il fatto che debba esser presente una cronologia completa deidati raccolti. Questo perché anche se un singolo dato puó non essere interessante al momento, esso potráforse in un futuro servire se messo in relazione a dati raccolti successivamente. Questo aspetto porta allaneccessitá di dover ben progettare sia le funzioni di storage del componente atto al context retrieval perrendere e�ciente e il meno possibile oneroso il recupero dei dati memorizzati (soprattutto in presenza diuna gran quantitá di essi; per esempio memorizzando ogni informazione sotto un indice ben preciso che sialegato ad esso in modo di poter facilitare la ricerca di informazioni logicamente correlate), che le tecnologie(database distribuiti, overlay networks strutturate o meno etc. etc.) con le quali memorizzare le informazioni.
I sistemi che dovranno interagire con un context repository dovranno necessariamente gestire una quantitádi dispositivi diversi tra loro, quali sensori (a loro volta suddivisibili nei loro sottotipi: temperatura, pressioneetc. etc.), attuatori e altri tipi.Ogni dispositivo dovrá essere in grado di memorizzare o richiedere i dati chelo interessano in uno speci�co formato.
Progettando un context repository, quindi, si dovrá necessariamente mettere in conto la grande etero-geneitá dei dati che esso dovrá gestire e che dovranno essere compresi da tutti i dispositivi rilevanti.
Altro problema legato all'eterogeneitá dei dati di contesto risiede nella varietá dei suoi attributi. Unipotetico dato di contesto relativo ad un sensore di temperatura, ad esempio, ha come minimo tre attributi(data, luogo e valore), ma si puó tranquillamente pensare ad altri dati che abbiano piú di tre campi (unsensore di pressione sanguigna, per esempio, che ne ha come minimo cinque). Con questi tipi di dato conmolteplici attributi eterogenei tra un dato e l'altro, il compito di progettazione della funzionalitá di ricercanon é a�atto banale.
Un componente atto alla memorizzazione e ricerca di tali dati dovrá tenere conto di informazioni chealla sua progettazione non siano ancora stati de�niti, o che, anche se appartenenti alla stessa tipologia (per

1.3. STATO DELL'ARTE 7
esempio di un sensore di temperatura), di�eriscano in quanto generati da prodotti di vendor di�erente (unsensore di temperatura prodotto dall'azienda A piuttosto che dall'azienda B).
Una modalitá di risoluzione di quest'ultima problematica potrebbe essere quella di imporre un formatostandard dei dati delle varie tipologie, ma approccio del genere, se da una parte elimina le di�coltá legatealla gestione di diversi formati incompatibili fra loro, dall'altra ne mina la �essibilitá.
Nel presente progetto si é scelto un approccio a cavallo tra le due soluzioni. Alla de�nizione di nuovi tipidi dato o si impone un formato standard per quella tipologia e non si richiede al vendor funzioni di letturadelle informazioni di sua pertinenza, o si lascia libero il vendor imponendogli, peró, la scrittura di un pezzodi codice che possa decodi�care la sua sezione.
Altra problematica da gestire riguarda la limitata potenza elaborativa e capacitá di immagazzinamentodati che i dispositivi del sistema avranno a disposizione. Nel progettare il sistema di storage si dovráscrivere detto modulo in modo tale da essere leggero sia in termini di spazio di memorizzazione usato che dielaborazioni e�ettuate.
In aggiunta agli aspetti precedentemente esposti, un altro aspetto da tenere in considerazione é la modalitácon la quale e�ettuare le interrogazioni.
Una possibile soluzione potrebbe essere quella di recapitare la query ad ogni nodo presente nel sistema,stará poi ai nodi contenenti i risultati desiderati il recapitare le informazioni cercate al nodo generatoredella query. Questo approccio, se da una parte é di facile implementazione e richiede bassa capacitá dicomputazione locale, dall'altra aumenta l'overhead dell'utilizzo della rete recapitando la query anche ai nodiche non contengono i dati voluti. Considerazione ancor piú valida tenendo presente la dinamicitá intrinsecadel sistema.
La soluzione trovata nella presente discussione, invece, assegna ad ogni nodo una ben speci�ca e speci�cataparte dei dati di contesto, di modo che alla richiesta da parte dell'applicazione di una certa categoria di dati(per esempio tutti i dati dei sensori di temperatura relativi al salotto che superino i 26 gradi), il nodo chericeve la query sappia (puó calcolare) quali sono i nodi che abbiano memorizzati i dati richiesti. Per garantirela completezza dei dati (ossia per fare in modo che nel momento che un nodo esce dal sistema i dati che essoconteneva siano lo stesso disponibili), i dati sono memorizzati sotto indici (chiavi). La tabella contenente lacorrispondenza tra indici e nodo responsabile per essi é dinamica e distribuita (si utilizza una DHT). Questovuol dire che quando un nodo esce dal sistema, i dati che esso conteneva e gli indici che gestiva vengonopresi in consegna dal nodo logicamente successivo.
1.3 Stato dell'arte
Sono state soventemente cercate e trovate soluzioni atte alla memorizzazione dei dati di contesto, per garantireda una parte a�dabilitá dei dati e dall'altra facilitá di gestione.
Nel progetto �A peer-to-peer architecture for context lookup�1 si é scelto un approccio totalmente peer-to-peer, nel quale le informazioni di contesto sono categorizzate secondo un'ontologia comune e per ognicategoria viene creata una overlay network distinta. Ogni nodo che localmente contiene dati di contestorelativi a una o piú categorie viene connesso a tutte le overlay networks relative.
Per eseguire una memorizzazione, il dato viene posto nell'overlay network di cui la sua categoria ap-partiene, per quanto riguarda le query, invece, il nodo richiedente invia la richiesta all'overlay network chegestisce il tipo di dato richiesto. Questo approccio, se da una parte con un basso grado di categorie diverseo�re alta e�cienza, dall'altro, all'aumentare delle categorie gestite (e quindi delle overlay networks) il costodi mantenimento e di gestione dei nodi diviene molto oneroso. Per a�rontare questa problematica i nodivengono a loro volta categorizzati in una loro overlay network ring-based.
Nel presente progetto, invece, l'overlay network usata é unica per tutti i tipi di dato e per tutti i nodi. Tipiuguali di dati (sia come tipologia del dispositivo di appartenenza che come valore eventualmente associato)vengono gestiti dallo stesso nodo. In questo modo si evitano le complessitá insite nella gestione di svariate
1vedi bibliogra�a [3]

8 CAPITOLO 1. LA MEMORIZZAZIONE DEI DATI DI CONTESTO
overlay (una per ogni tipo di dato), e si mantiene e�ciente la gestione di tipologie di dato similari in quantoesse vengono gestite da speci�ci e ben determinabili nodi del sistema.
In �A scalable distributed RDF repository based on A Structured Peer-to-Peer Network�2 Cai et al.propongono un repository distribuito che memorizza ogni dato in tre nodi di una rete che estende Chordapplicando una funzione hash condivisa. Le query sono quindi indirizzate verso i nodi che gestiscono i daticon le chiavi relative alla query stessa.
Nello studio �GChord: Indexing for multi-attribute query in P2P system with low maintenance cost�3 sié posta l'attenzione sulla gestione dei dati multi-attributo. Scopo del sistema descritto é di ricercare datimulti-attributo (chiamate MAQ, Multi-Attribute Query) in un sistema P2P completamente decentralizzato.Il sistema, basato su Chord, assegna indici in codice di Gray per ogni attributo, il che tramite la creazione diun multicast tree generato da un algoritmo che si basa sulle mappe di Karnaugh rende le ricerche di queryespresse come congiunzione di insiemi di predicati molto e�cienti.
Come in questo studio, anche nel presente progetto si memorizzano i dati sotto indici calcolati in base(anche) degli attributi. Al contrario, per la parte della ricerca si ha una generazione in locale degli indicidegli attributi in base ai quali interrogare la DHT senza l'uso di multicast tree.
Lo studio riportato nel testo �PePeR: A distributed range addressing space for peer-to-peer systems�4
a�ronta la modalità di query partizionando lo spazio dei dati dei singoli attributi dei dati da gestire nei diversinodi presenti nel sistema. Ogni nodo é responsabile di una partizione del dominio di uno o piú attributi.Nodi vicini memorizzano intervalli contigui di tale partizionamento. In questo modo per rispondere ad unaquery si interrogano solo i nodi i quali siano responsabili del range di intervalli cercati. Viveversa gli approccibasati su overlay networks non strutturate (come in Gnutella5 o Freenet6), nelle quali le query devono esserein ogni caso recapitate ad ogni nodo del sistema, hanno la potenzialitá di ospitare qualsiasi tipo di dato.
L'approccio adottato in �Tree Vector Indexes: E�cient range queries for dynamic content on peer-to-peernetworks�7, invece, unisce i due aspetti:
1. per eseguire una query esegue un algoritmo BFS8 nell'overlay network del quale il nodo fa parte;
2. guida poi questa ricerca attraverso l'uso di uno spanning tree e avendo una rappresentazione degliattributi dei dati speci�ca.
1.3.1 Studio di casi
In questa sezione andremo ad analizzare casi di particolare interesse riguardanti applicazioni pre-esistenti dicontext awarnes e/o repository
A conceptual Framework and a Toolkit for Supporting the Rapid Prototyping of Context-Aware Applications (bibl. [1])
Nello studio succitato si puó evincere un approccio al problema usando componenti software chiamatiWidget.Detto studio astrae il contesto in cinque componenti:
2vedi bibliogra�a [4]3vedi bibliogra�a [5]4vedi bibliogra�a [6]5vedi bibliogra�a [7]6vedi bibliogra�a [8]7vedi bibliogra�a [9]8Breadth First Search

1.3. STATO DELL'ARTE 9
Context Widget
Come i widget associati alle interfacce utenti nascondono lo speci�co dispositivo di input utilizzato dalprogrammatore dell'applicazione, cosí i context widget producono i seguenti bene�ci:
� Provvedono ad una separazione tra il dato in se e come esso sia stato generato, nanscondendo in questomodo la complessitá di gestione di un speci�co sensore.
� Astraggono l'informazione del contesto per renderla idonea ai bisogni dell'applicazione. Per esempioun widget che tiene traccia del posizionamento di un utente in un edi�cio o in una cittá noti�cal'applicazione solo quando l'utente si muove da una stanza all'altra, o da una strada ad un'altra, nonriportando movimenti meno signi�cativi all'applicazione.
� Producono componenti software riusabili e personalizzabili . Un widget che monitora la posizione diun utente puó essere usato in svariate situazioni, e in aggiunta puó essere utilizzato in aiuto di altriwidget per produrre comportamenti piú avanzati.
Una possibile critica all'utilizzo di widget é il fatto che essi nascondono i dettagli di come il dato vengaraccolto. I context widget in studio forniscono un'interfaccia comune e non nascondono i dettagli sottostanti,ma li rendono disponibili solo su speci�ca richiesta. In modo simile all'approccio adottato nel presenteprogetto nel quale, come illustrato in dettaglio nel capitolo 3, si é scelto di rappresentare le informazioni deisensori in XML standard con una sezione a completa discrezione del sensore ma con l'obbligo di fornire undriver (che si potrebbe equiparare al widget) che uniformi, nelle operazioni di query e store, quello speci�coXML ad altri dello stesso tipo. Questo approccio consente di trattare informazioni ricevute dalla stessatipologia di sensori in modo omogeneo non precludendo, peró, l'utilizzo di informazioni speci�che di undeterminato vendor di venire utilizzate in computazioni successive alla ricerca. Oltre che nella gestione delcontesto, detta separazione tra dispositivo (eterogeneo) e suo componente di controllo (standard all'internodel sistema) é usata anche nel pervasive layer come spiegato nella sezione 2.4.
La metodologia di acquisizione dati puó essere sia di tipo pull (é l'applicazione a richiedere i dati) che ditipo push (é il widget attraverso un call-back a noti�care all'applicazione l'arrivo di un particolare dato).
Un'altra di�erenza tra un widget di un'interfaccia utente e un context widget é il loro ciclo di vita.Mentre il widget di una GUI nasce e muore nell'ambito dell'applicazione che lo ha generato, il ciclo di vitadi un context widget presuppone che la sua esecuzione sia indipendente dalle applicazioni che lo andrannoad usare, in quanto esso puó essere usato da piú applicazioni e deve mantenere una completa cronologia deidati che va a gestire.
Interpreters
Gli interpreters hanno il ruolo di alzare il livello d'astrazione dei dati acquisiti.Il posizionamento, per esempio, puó esser espresso ad un basso livello come coordinate geogra�che, mentre
associate dette coordinate ad una sorgente cartogra�ca il dato ad alto livello diverrebbe il nome della strada.Altro esempio puó essere, avendo due dati a basso livello quali il numero di occupanti di una stanza ed
il livello di rumorositá in quella stanza, il dato ad alto livello inferito é che in quella stanza é in essere unmeeting.
Detto processo di inferenza é da attribuirsi agli interpreters. Mentre precedentemente i loro compiti eranoassolti a livello applicativo, aver separato detto processo in un componente piú a basso livello ha permessoche esso possa esser riusato da piú applicazioni e widget.

10 CAPITOLO 1. LA MEMORIZZAZIONE DEI DATI DI CONTESTO
Figura 1.1: Esempio di con�gurazione dei componenti di un Context Toolkit
Aggregators
Gli Aggregators hanno il compito di raccogliere piú pezzi di informazioni contestuali in un unico repository.Essi raccolgono informazioni logicamente coerenti tra loro e le rendono accessibili attraverso un singolocomponente software. Questo compito facilita il ruolo degli interpreters facendo si che essi possano accedereai vari pezzi dei dati di contesto da un singolo punto di accesso. Nel progetto correntemente in esame,in modalitá analoga, si é scelto un approccio di una overlay network strutturata (DHT, nella fattispecePastry) che consente la memorizzazione ed il recupero dei dati da qualsiasi nodo facente parte dell'overlaynetwork. Detta overlay network é accessibile tramite un unico componente software (detto Context awarness,analizzato nella sezione 2.3.1) le cui istanze vengono eseguite una per ogni nodo del sistema.
Services
Detti componenti software hanno il compito di eseguire generiche azioni per conto delle applicazioni. Uncontext service é analogo ad un context widget. Mentre questi ultimi hanno il compito di raccogliere infor-mazioni sullo stato di un ambiente da sensori, i context services hanno il compito di controllo o modi�ca disuddetto stato tramite attuatori in modo o sincrono o asincrono.
Discoverers
Compito dei discoverers é quello di mantenere un registro di quali capacitá esistano nel framework elencandoquali context widget, interpreters, aggregators e services siano presenti e di come raggiungerli.
Nel progetto SM4All detto servizio é eseguito nel pervasive layer, come spiegato nella sezione 2.4.Un esempio di con�gurazione dei componenti sopra elencati si puó vedere nella �gura 1.1

1.3. STATO DELL'ARTE 11
Figura 1.2: Architettura di Smart Collaborative Environment
Context Repository Architecture for Smart Collaborative Environment (bibl [2])
Nello studio succitato il problema viene a�rontato suddividendo la memorizzazione dei dati in due partilogiche:
� Dati che devono essere localizzati nei dispositivi mobili del sistema (detti �Cooperative Sensors�e�Cooperative Objects�)
� Dati che possono essere memorizzati in un repository centrale (detto �Backend Server�)
Suddetta architettura é mostrata in �gura 1.2.La soluzione di storage usata per la memorizzazione dei dati per i sensori e gli ogetti é l'implementazione
di uno spazio di tuple distribuito, un database ontologico per i palmari degli utenti e una soluzione di contextrepository per il backend server.
Spazio di tuple
Uno spazio di tuple é una memoria associativa condivisa tra tutti i nodi del sistema, i quali dedicano partedel loro spazio di archiviazione locale all'immagazzinamento dei dati condivisi. Il risultato di ogni operazionesullo spazio di memoria locale ad un nodo viene visto da ogni altro nodo del sistema.
Database ontologico
Un database ontologico é un normale database che si appoggia per le sue operazioi ad un'ontologia. Ilprincipale componente dell'ontologia usata in questo studio é un'entitá. Esempi di entitá possono essere:utenti, sale riunioni, ristoranti etc. Le informazioni del contesto per una speci�ca entitá possono esseresuddivise in:
� Informazioni relative all'ambiente
� Informazioni relative alla dimensione spaziotemporale
� Informazioni relative alle operazioni da e�ettuare

12 CAPITOLO 1. LA MEMORIZZAZIONE DEI DATI DI CONTESTO
Figura 1.3: Architettura del modulo di Context Repository di SCO (1)
Queste informazioni sono gestite tramite ontologie.Ogni entitá interagisce con le altre tramite i propri �Agenti� dei quali fanno parte: i �ltri, gli interpreti
e i cosí detti �decision maker�. Dette parti hanno compito di: aiutare l'utente a cercare i risultati voluti,interpretare le informazioni memorizzate in diverso formato e prendere decisioni sulle prossime operazionida eseguire basandosi sulla conoscenza acquisita e sulle regole imposte dall'utente.
Context Repository sul backend server
Nel server di backend le informazioni pervenute dagli altri oggetti del sistema saranno memorizzate in ordinecronologico. Esso deve includere il supporto a computazioni complesse e alla predizione dei comportamentidell'utente. Moduli software detti �Context Mergers� avranno il compito di raccogliere le debite informazionida memorizzare dagli altri oggetti del sistema e integrarle nello spazio di memorizzazione locale. Ogniinformazione acquisita dará luogo all'esecuzione di un agente di predizione che avrá il compito di capire edeseguire l'operazione seguente da mettere in atto.
L'architettura di questo componente é mostrata in �gura 1.3.La suddetta soluzione presuppone un unico componente (il backend server) atto alla gestione di tutti
i dati del sistema, componente a cui i vari dispositivi (sensori, attuatori, PDA, etc.) devono rifornire deidati che hanno raccolto e richiedere quelli di cui hanno bisogno. Considerando questi aspetti, con questasoluzione da una parte si son dovuti implementare componenti software atti al solo scopo di context merging(reperimento ed unione dei dati di contesto generati dalle varie fonti), il che aumenta la complessitá globaledel sistema, mentre dall'altra identi�ca il backend server come �single point of failure�. Se detto componentesubisce malfunzionamenti o cali di performance dovuti, per esempio, al troppo carico, il sistema nella suainterezza funziona in modo erratico (nel caso in cui non si é predisposta una qualche politica di fault-tollerance del backend server, il che peró porta ad un maggiore overhead sia in termini progettuali che intermini prestazionali del sistema).

Capitolo 2
L'architettura del sistema SM4All
2.1 Architettura generale
Scopo dell'architettura di SM4ALL é di integrare vari dispositivi in modo trasparente per sempli�care l'ac-cesso ai servizi esposti da detti dispositivi e comporre dinamicamente questi servizi per o�rire all'utente�nale funzionalitá piú complesse e un'esperienza di ambiente domotico piú ricca.
A causa delle di�erenti tecnologie impiegate dai dispositivi che interaggiranno in SM4All, l'architetturasi a�da ad un layer astratto di comunicazione rappresentato dallo standard UPnP. L'utilizzo di questaastrazione porta notevoli vantaggi nella forma di:
� Compatibilitá tra di�erenti standard di comunicazione (WiFi, ZigBee, Bluethooth, etc.)
� Rilevazione di nuovi dispositivi
� Gestione dei guasti o rimozione dei dispositivi
La �gura 2.1 dá una vista ad alto livello di un possibile deployment di un sistema SM4All, dove dispositivilargamente di�erenti interagiscono usando i loro diversi standard di comunicazione attraverso un gatewayUPnP. Il gateway rappresenta l'interfaccia tra il sistema pervasivo e il resto del middleware di SM4All.
Adesso che il ruolo del middleware di SM4All con la sua architettura globale é stato chiari�cato, daremoal lettore una visione d'insieme dei componenti architetturali (una cui visone puó esser evinta dalla �gura2.2) che costituiscono il sistema, focalizzandoci successivamente sul sottosistema per la gestione del contesto.
User layer Questo layer é destinato all'interazione con l'utente �nale e con l'amministratore, realizzato condiverse UI.
Composition layer Questo layer ha come compito principale il ricevimento di comandi di alto livello dagliutenti attraverso il layer di interfaccia e di raggiungere i corrispondenti complessi compiti controllandol'esecuzione dei servizi di basso livello o�erti dai dispositivi impiegati.
Pervasive layer Rappresenta il livello �sico dell'architettura e i componenti software necessari per astrarlo
Segue una breve analisi dei componenti di User layer e Pervasive layer (che non riguardano speci�cata-mente il progetto in esame) e un'analisi un pó' piú approfondita del componente Composition layer (di cuiquesto progetto implementa un suo sub-componente).
13

14 CAPITOLO 2. L'ARCHITETTURA DEL SISTEMA SM4ALL
Figura 2.1: Architettura di rete di SM4All
Figura 2.2: Architettura dei componenti di SM4All

2.2. USER LAYER 15
Figura 2.3: Component diagram del Composition layer
2.2 User layer
Compito di questo componente é quello di interfacciare il sistema con gli individui e/o entitá che andrannoad interagire con esso.
Per fornire un front-end quanto piú slegato a speci�che tecnologie (quali possono essere thin client svilup-pati in Java, .net o con altri metodi), le quali andrebbero a minare l'apertura del sistema blindandolo conprotocolli proprietari e necessitá di dover installare componenti software proprietari sui dispositivi di inter-faccia, si é scelto di utilizzare web servers che consentano di usare lo standard HTTP per interfacciarsi colsistema.
Implementando un SOA1, il middleware SM4All non impone l'utilizzo di uno speci�co linguaggio diprogrammazione (quale potrebbero essere PHP piuttosto che ASP.NET o Java servlets/JSP) per il webserver.
Altra problematica da tenere in considerazione é che mentre tutto il sistema SM4All é inserito all'internodi una sola rete, chi la deve utilizzare deve essere in grado anche di accederci da fuori di quella rete (peresempio quando si connette al sistema fuori dalla casa). Gli approcci attuati per risolvere questa situazionesono di due tipo: o aprire speci�che porte su router/modem e connettersi dall'esterno ad esse, oppure esporreun PC tra il router della casa ed il modem ed a�dare ad esso il ruolo di proxy.
2.3 Composition layer
Il composition layer (il cui component diagram é illustrato in �gura 2.3 e uno schema a blocchi in �gura 2.4)é formato dai seguenti componenti:
Synthesis: riceve dal livello superiore l'obiettivo da raggiungere. Detto obiettivo dovrá esser espletatotramite le informazioni di contesto presenti nel sistema. Per poter ottemperare al suo compito, ilcomponente scinde il target �nale in una collezione di servizi che dovranno essere invocati per ottenerelo scopo voluto.
Orchestration Engine: ha la responsabilitá di eseguire i servizi indicati dal componente di Synthesisattraverso le interfacce che i dispositivi mettono a disposizione.
Semantic Repository: memorizza le meta-informazioni e la descrizione dei servizi o�erti dai dispositivi
Rule Maintenance Engine: ha il compito di prender decisioni per il componente Synthesis, e di tenerein considerazione i cambiamenti del mondo reale, aiutato dal modulo di context awareness.
1Service Oriented Application

16 CAPITOLO 2. L'ARCHITETTURA DEL SISTEMA SM4ALL
Figura 2.4: Schema a blocchi dei componenti del composition layer
Context awareness: esporta le funzionalitá di raccolta, analisi ed aggregazione del contesto dal Pervasivelayer. Esso o�re anche un'interfaccia per memorizzare e richiedere dati di contesto.
Location: tiene traccia della locazione dei dispositivi.
Segue un'analisi del modulo di Context awarness
2.3.1 Context Awarness
La struttura di questo modulo é illustrata in �gura 2.5. Il progetto in esame in questo documento vienerappresentato nei componenti Context processing e Context Repository. Nel primo (che nel presente progettoviene rinominato in Context Repository, analizzato nella sezione 3.3) nelle operazioni di store i dati in ingressovengono processati per ricavare le informazioni utili per una loro corretta memorizzazione, mentre in quelledi query il loro processamento é teso alla creazione delle informazioni necessarie al reperimento dei datidi interesse. Il secondo (suddiviso in due moduli chiamati Context Storage e DHT ed analizzati nellesezioni 3.4 e 3.5) puó venire utilizzato esclusivamente dal componente di Context processing e serve alla solamemorizzazione �sica dei dati, con la funzionalitá di reperimento di essi tramite le informazioni create dalcomponente di Context processing.
Il contesto, per le applicazioni da noi desiderate, pué essere categorizzato in:
System context: si riferisce all'hardware usato, la larghezza di banda e i di�erenti dispositivi disponibilied accessibili dall'utente.
User context: é alla base di tutta la gestione del contesto. Esso viene collezionato nella forma del suopro�lo e rappresenta le sue preferenze riguardo tutto l'ambiente domotico. Le informazioni riguardantiil contesto dell'utente scorrono nel sistema, servendo come linea guida del servizio di context-awarenesse scopo del composition service
Physical context: si riferisce alle informazioni riguardanti l'ambiente �sico dove é localizzato l'utente, qualila temperatura, il livello di rumore, l'illuminazione etc.
Le informazioni sul contesto possono esser recuperate dai sensori, aggiunte staticamente dall'amminis-tratore del sistema o immesse direttamente dall'utente o da altri componenti dell'architettura.

2.3. COMPOSITION LAYER 17
Figura 2.5: Struttura del modulo di Context Awarness
Figura 2.6: Component diagram del modulo di Context awarness
Per la gestione del contesto sono necessari i seguenti passi:
Context analysis and composition Le informazioni raccolte dai sensori devono essere analizzate e com-poste in modo da poterle interpretare e ragionare su di esse. Le informazioni date dai sensori devonoessere aggregate a quelle fornite dagli utenti e dagli altri componenti per costruire una vista completadel contesto generale.
Context management Le informazioni sul contesto devono essere aggregate e organizzate per poter fornireagli altri componenti informazioni piú ad alto livello.
Context retrieval Per poter utilizzare le informazioni di contesto, esse devono poter esser richieste aqualche componente. Per questo motivo ci dev'essere nel sistema qualche componente atto a questaprocedura.
Altri requisiti sono: la dinamicitá (le applicazioni disponibili sono eterogenee, imprevedibili e frequente-mente (s)collegate), scalabilitá (il sistema deve prevedere un gran numero di dispositivi connessi e diinformazioni da gestire) e a�dabilitá (il sistema deve tenere in conto guasti a dispositivi).

18 CAPITOLO 2. L'ARCHITETTURA DEL SISTEMA SM4ALL
Figura 2.7: Use case del sotto�modulo di Context Repository
Use Case ID: CR1Nome Use Case: Store Context DataActors: ContextRepository clientDescrizione: Un'informazione di contesto da inserireTrigger: L'operazione deve essere invocata direttamente dall'actorPrecondizioni: NessunaPostcondizioni: Una copia del dato fornito dall'actor é presente nel
repositoryFlusso di esecuzione normale:
1. Il dato é fornito dall'actor
2. Il dato é gestito internamente dal repository perprepararlo alla memorizzazione
3. Una o piú copie del dato sono memorizzate nelrepository
Eccezioni: -Inclusioni: -
Tabella 2.1: Descrizione dell'use case di store
In �gura 2.6 é mostrato il component diagram del componente di Context awarness.Si andrá ad analizzare il sotto-modulo denominato �Context Storage�(anche denominato Context Repos-
itory).
2.3.2 Context Storage
Detto modulo deve esportare due funzionalitá:
1. Memorizzare i dati di contesto
2. Eseguire interrogazioni sui dati memorizzati
Funzionalitá illustrate nello use case in �gura 2.7 le cui descrizione sono mostrate nelle tabelle 2.1 e 2.2.In �gura 2.8 é illustrato a grandi linee la modalitá di funzionamento del sottomodulo.I dati da memorizzare sono indicizzati secondo un mapping che data l'informazione reale del sensore
ne associa una discreta secondo valori prestabiliti (detta operazione é e�ettuata da un componente dettoMapper), per poi essere usata (da un componente detto Hasher) assieme alle informazioni sulla locazioneper calcolare la chiave sotto la quale memorizzare l'XML originario. Quest'operazione permette, in fase diricerca, di recuperare dal layer di memorizzazione �sica solo i dati corrispondenti alle sole chiavi di interesse,chiavi calcolate localmente al nodo che richiede la ricerca secondo la query in ingresso.

2.3. COMPOSITION LAYER 19
Use Case ID: CR2Nome Use Case: Retrieve Context DataActors: ContextRepository clientDescrizione: I dati precedentemente memorizzati devono essere recu-
perati per successive computazioniTrigger: L'operazione deve essere invocata direttamente dall'actorPrecondizioni: Una query nel formato correttoPostcondizioni: NessunaFlusso di esecuzione normale:
1. L'actor fornisce una query
2. Il repository elabora la query per consentire di reperirei risultati corretti
3. I risultati corretti vengono restituiti dall'actor
Eccezioni: -Inclusioni: -
Tabella 2.2: Descrizione dell'use case di retrieve
Figura 2.8: Funzionamento del modulo di context storage

20 CAPITOLO 2. L'ARCHITETTURA DEL SISTEMA SM4ALL
Figura 2.9: Use case del pervasive layer
Figura 2.10: Architettura del pervasive layer
I dati vengono poi memorizzati in una DHT ad anello ove ogni nodo é responsabile di un insieme dichiavi.
2.4 Pervasive layer
Scopo del pervasive layer é quello di integrare in modo trasparente network e dispositivi (sensori o attuatori)eterogenei tra loro fornendo alle applicazioni accesso a detti dispositivi attraverso interfacce standard enascondendo le diverse tecnologie sulle quali son basati i dispositivi reali.
Detto layer ha la responsabilitá di individuare nuovi dispositivi, registrare dispositivi che si connettonoal sistema o deregistrare quelli che si disconnettono ed eseguire servizi speci�ci dei dispositivi.
Uno use case del pervasive layer é illustrato in �gura 2.9, mentre un diagramma della sua architettura émostrato in �gura 2.10.

Capitolo 3
Architettura generale del repository del
contesto
3.1 Funzionalitá e principi generali
Lo scopo del modulo di repository (precedentemente indicato come context storage) del contesto é dimemorizzare dati provenienti dai livelli superiori e fare ricerche tra i dati memorizzati.
I dati da memorizzare sono in formato XML e rappresentano le informazioni riguardanti generici sensoriposti in una casa.
Le informazioni sono suddivise in
� Casa di appartenenza
� Stanza della casa dove si trova il sensore
� Informazioni speci�che del sensore
Ogni XML memorizzato é nel seguente formato
<?xml version="1.0" encoding="UTF-8"?>
<Device>
<Home_ID datatype="integer">1</Home_ID>
<Location datatype="enumeration">LocationName</Location>
<Sensor>
<SensorName>
<!-- sensor data -->
</SensorName>
</Sensor>
</Device>
La sezione interna al tag Sensor é aperta al formato deciso dallo speci�co vendor in quanto ogni tipo disensore avrá di�erenti informazioni da memorizzare (valore di temperatura in caso di sensore di temperatura,pressione sistolica, diastolica e battito cardiaco in caso di sensore di pressione etc. etc.) e ogni vendor didispositivi di sensori potrá memorizzare i dati nella forma da lui voluta.
Per consentire una piú rapida ricerca delle informazioni, i dati memorizzati sono immagazzinati sottoindici speci�ci.
21

22 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
Figura 3.1: Dipendenza dei sotto-moduli
Detti indici sono calcolati partendo sia dalle informazioni di locazione del sensore (casa e stanza) che daintervalli di valori discreti delle informazioni del sensore.
Come esempio, analizzando il caso di un sensore di temperatura, il valore di temperatura viene suddivisoin piú intervalli e ogni valore che andrá memorizzato dovrá esser fatto ricadere in uno e uno solo di dettiintervalli.
Fornendo un caso concreto, se i valori discreti fossero
10, 15, 20, 25, 30, 35
e il valore reale del sensore fosse 27, l'indice relativo al valore del sensore sarebbe 25.In questo modo nel reperimento di un dato dal sistema si leggono solo le informazioni reperite tramite le
chiavi di interesse, ignorando i dati super�ui.Per fare in modo che il sistema possa essere in grado di calcolare la chiave sotto la quale memorizzare
l'informazione si deve essere in grado di leggere la sezione dell'XML riguardante le informazioni del sensore,per questo motivo é necessario avere un driver per ogni sensore che sia in grado di leggere la sua parterelativa e di poter fornire al sistema il suo valore normalizzato.
Visto che si deve essere in grado di fornire al sistema tutte le chiavi sotto le quali ricercare i risultaticercati, si deve avere un altro driver in grado di leggere l'XML contenente la query di ricerca e di restituirele suddette chiavi.
3.2 Organizzazione interna del repository
Per poter sviluppare il sistema in oggetto si é scelto di suddividerlo in due sotto-moduli: il primo si occupadi tutta la logica di business legata alla memorizzazione e ricerca dei dati (ContextRepositoryBundle) e ilsecondo é dedito solo all'immagazzinamento dei dati (DHTBundle).
Come soluzione di immagazzinamento si é scelta una hash table distribuita (DHT) (nella sua declinazionedi Pastry) che accetta come dati da memorizzare ogetti java di tipo Serializable mentre i dati che a noi servonodi memorizzare e ricercare sono di tipo o String o byte-code dei driver dei sensori. Per questo motivo si éprogettato un layer intermedio che traduca i dati della logica di business nel formato accettato dalla DHT eviceversa. Detto modulo é stato chiamato Context Storage.
La dipendenza dei moduli che formano il sistema é mostrata nella �gura 3.1.Segue un'analisi dei suddetti sotto-moduli

3.3. CONTEXTREPOSITORY 23
Figura 3.2: Interfaccia del modulo Context Repository
3.3 ContextRepository
Le funzioni primarie di questo sotto-modulo sono rappresentate da due metodi
1. storeContextData
2. retrieveContextData
L'interfaccia che esso implementa é illustrata in �gura 3.2Le richieste di store e retrieve sono rappresentate da un �le XML nel seguente formato:
<?xml version="1.0" encoding="UTF-8"?>
<Device>
<Home_ID datatype="integer">1</Home_ID>
<Location datatype="enumeration">LocationName</Location>
<Sensor>
<SensorName>
<!-- sensor data -->
</SensorName>
</Sensor>
</Device>
La sezione dell'XML interna al tag <Sensor> é a discrezione del vendor dello speci�co sensore cherichiede lo store (o la query) e che si fa riconoscere dal nome del tag successivo. Nella DHT viene inseritoautomaticamente dal sistema un insieme di �le XML con le liste di mapping tra i nomi dei sensori e le classiatte a gestire le richieste da essi e�ettuate nel seguente modo:
<?xml version="1.0" encoding="UTF-8"?>
<DomainSchema>
<Sensor name="SensorName"
class="SensorClassName"
filter="SensorFilterClassName" />
</DomainSchema>
Nella DHT, gli XML memorizzati, rappresentanti i dati dei sensori, sono mappati con chiavi calcolate daicampi Home e Location insieme al tipo di sensore e al suo valore normalizzato seguendo la seguente formula:
K = h(home, location, sensorType, normalizedSensorV alue)
La versione normalizzata del valore del sensore si calcola partendo da una lista di valori discreti possibili perquel dato tipo di sensore, detto mapping tra il tipo di sensore e i valori ammessi per esso é presente nellaDHT in vari XML (ogni XML puó contenere il mapping di un o piú tipi di sensori) nel seguente formato:

24 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
<?xml version="1.0" encoding="UTF-8"?>
<values>
<Sensor type="SensorTypeName">
<!-- Lista dei valori normalizzati degli attributi del sensore -->
</Sensor>
</values>
3.3.1 Store
Quando un client invoca il metodo storeContextData passando come argomento l'XML da memorizzare,detto XML tramite un parser viene convertito in una struttura dati il cui class diagram é riportato in �gura3.3.
Figura 3.3: Class diagram della struttura dati per lo store
Il parser legge il nome del sensore dall'XML e carica dalla DHT la classe atta a gestire lo speci�cosensore di quel vendor e tramite re�ection istanzia l'oggetto relativo. Successivamente crea un altro XMLcontenente solo la parte dell'XML originario che riguarda il sensore e lo passa come argomento al metodoreadXML(String xml).
Ogni tipo di sensore é rappresentato da una classe astratta ATipoDiSensore implementante la classeastratta ASensor che le classi dei vendor (se necessario, vedere sezione 3.6) devono estendere (solitamentele classi dei vendor non devono estendere ASensor, ma estendere la classe astratta rappresentante il tipo disensore che vanno a gestire).
Una volta creata questa struttura dati, essa viene passata ad un oggetto Mapper che reperisce i valoriconsentiti per quel tipo di sensore e li passa al sensore. Solo dopo aver e�ettuato (da parte del mapper) lachiamata del metodo normalize sull'oggetto del sensore, ci si aspetta di ricevere il valore normalizzato diesso (leggibile tramite il metodo getNormalizedValue). Eseguita la normalizzazione, la struttura dati vienepassata ad un oggetto Hasher il cui compito è calcolare la chiave sotto la quale poi viene memorizzato l'XMLoriginario nella DHT sottostante.
Il processo di store é illustrato nei sequence diagram di �gure 3.4, 3.6 e 3.5.

3.3. CONTEXTREPOSITORY 25
Figura 3.4: Sequence diagram generale di un'operazione di store
Figura 3.5: Sequence diagram di un'operazione di normalizzazione

26 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
Figura 3.6: Sequence diagram del parsing di un XML di store

3.3. CONTEXTREPOSITORY 27
3.3.2 Query
Per l'operazione di query, all'invocazione del metodo retrieveContextData l'XML in input viene usato per lacreazione della struttura dati in �gura 3.7 dove l'�HomeFilter �rappresenta la casa della quale si é interessati, il
Figura 3.7: Class diagram della struttura dati per le query
LocationFilter ha il compito di stabilire se una Location é o meno accettata dalla query in essere (attualmentele uniche operazioni sono o di uguaglianza (la Location é accettata solo se é uguale a quella richiesta nellaquery) o di accettarle tutte (mettendo nel campo Location dell'XML un asterisco)) e il SensorFilter chedata una Home e una Location ricerca tutti gli XML nella DHT che soddis�no i valori richiesti.
Per poter e�ettuare una query che non abbia vincoli sulla location del sensore, é necessario per il sistemaessere a conoscenza di tutte le stanze che compongono una casa, per questo motivo nella dht é memorizzatoun XML che le elenca tutte; detto XML é nel seguente formato:
<?xml version="1.0" encoding="UTF-8"?>
<Home>
<Home_ID>1</Home_ID>
<Location>Kitchen</Location>
<Location>Living Room</Location>
<!-- lista delle altre location della casa -->
</Home>
In modo similare alla parte dello store, anche in questo caso l'oggetto SensorFilter é vendor-dependentin quanto la query puó esser espressa in qualsiasi formato il vendor voglia. Similarmente allo store, il parseruna volta letto dall'XML il nome del �ltro istanzia la classe presa dal mapping precedentemente espostopassandogli come parametro del metodo readXML(String xml) solo la parte dell'XML originario riguardantequel sensore. Di conseguenza anche per la parte del �ltro esistono tante classi astratte quanti i tipi di sensorida dover gestire; classi che devono essere estese dai vendor.
Mentre il parsing della parte dell'XML del sensore é vendor dependent, la modalitá con la quale la classe(astratta) ASensorFilter ricerca le informazioni nella DHT é standardizzata e si puó illustrare nel seguentemodo:
1. Recuperare dalla classe �glia tutte le chiavi con le quali cercare i risultati nella DHT
2. Per ogni risultato trovato a partire dalle chiavi generate
(a) Se il risultato trovato ha gli stessi campi Home, Location ed il suo sensore é accettato dalla classe�glia (per eliminare i casi di collisione di chiavi) aggiungere il risultato all'insieme dei risultatitrovati

28 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
Figura 3.8: Sequence diagram generale di un'operazione di query

3.3. CONTEXTREPOSITORY 29
Figura 3.9: Sequence diagram del parsing di un XML di query

30 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
Figura 3.10: Interfaccia del modulo Context Storage
Il processo di query é illustrato nei sequence diagram di �gure 3.8 e 3.9.Oltre alle due funzionalitá sopra elencate, il sotto-modulo di ContextRepository consente altresí l'istal-
lazione delle classi dei driver dei sensori, la memorizzazione dell'XML di mapping dei valori e l'XML delloschema della casa.
3.3.3 DHT class loading
Come evinto dai precedenti paragra�, a run-time é richiesto di poter accedere alla parte dell'XML sia distore che di query che é vendor-dependent e di cui il vendor deve fornire il driver. Il modulo di contextrepository si aspetta di trovare detto driver, rappresentato da due classi (una per la gestione degli store,l'altra per la gestione delle query), nella DHT sotto forma di byte-code java. Per poter permettere questocomportamento si é sviluppato un class loader modi�cato che alla richiesta del parser dei due tipi di XMLdi caricare la classe del driver esegue i seguenti passaggi:
1. Se la classe cercata é stata precedentemente giá caricata nella corrente esecuzione del nodo restituiscel'instanza giá caricata, altrimenti
2. Cerca nella cartella �SensorClasses� se quella classe era giá stata richiesta da un'esecuzione precedente,in caso a�ermativo la restituisce, altrimenti
3. Cerca il driver nella DHT, se la trova la copia nella cartella �SensorClasses� e la restituisce, altrimenti
4. Lancia una eccezione ClassNotFoundException.
Per lo sviluppo e l'installazione di nuovi tipi di sensore vedere la sezione 3.6, mentre per lo sviluppo einstallazione di nuovi driver vedere la sezione 3.7.
3.4 ContextStorage
Il sotto-modulo ContextStorage (la cui interfaccia é illustrata in �gura 3.10) é un adapter tra una DHT che ac-cetta tuple <String,Serializable> e il sotto-modulo ContextRepository che necessita di tuple <String,String>e in aggiunta di poter istallare classi nella DHT.
Per quanto riguarda la funzionalità di store, l'unica operazione eseguita da ContextStorage é il forwardingdella richiesta alla DHT sottostante con gli stessi parametri ricevuti in input, in quanto la classe Stringimplementa Serializable.
Al contrario, per quanto riguarda la funzione lookup ContextStorage prende dalla DHT tutti i risultatidati dalla chiave in input e ritorna soltanto quelli che sono String.

3.5. DHT 31
Figura 3.11: Interfaccia del modulo DHT
Figura 3.12: Esempio di uso di una DHT
Per consentire la memorizzazione e il reperimento del byte-code viene utilizzata una classe che contieneil nome della classe da memorizzare e un array di byte che rappresenta il byte-code, la chiave sotto la qualeviene memorizzato il byte-code é il nome della classe.
3.5 DHT
Il sotto-modulo DHT (la cui interfaccia é illustrata in �gura 3.11) espone le funzionalitá di store e lookup dituple <String,Serializable>. La DHT presa in esame é Pastry nella sua declinazione open source FreePastry.
Prima di entrare in dettaglio nel modulo DHT é conveniente una de�nizione su cos'é una DHT e Pastrye una breve illustrazione del loro funzionamento.
3.5.1 Distributed Hash Table
Una Distributed Hash Table é un tipo di �le system distribuito che, similarmente ad una tavola hash,memorizza le informazioni sotto un id calcolato, comunemente, come hash del dato. La responsabilitá dimantenere la corrispondenza tra le chiavi ed i valori é distribuita ai nodi del sistema, di modo che uncambiamento nell'insieme dei partecipanti causi le minime incoerenze possibili. Un esempio di distributedhash table puó esser visto in �gura 3.12.
Una DHT deve garantire le seguenti proprietá
Decentralizzazione: i nodi possono entrare, usare e uscire dal sistema senza alcun coordinamento centrale.
Scalabilitá: il sistema deve funzionare correttamente ed e�centemente anche con centinaia o migliaia dinodi.

32 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
Tolleranza ai guasti: il sistema deve poter supplire a guasti dei nodi.
Per poter raggiungere detti obiettivi ogni nodo, comunemente, si coordina con un ridotto numero dipartecipanti (solitamente nell'ordine di O(log(n)), ove n é il numero totale dei nodi).
Il funzionamento generico di una DHT si puó descrivere, in caso di store, nel seguente modo:
1. Il nodo che riceve il dato da memorizzare dall'aplicazione calcola, tramite una funzione di hash, h =H(dato) e comunica al sistema il messaggio put(h, dato)
2. Il messaggio, tramite un servizio di routing interno al sistema, viene recapitato al nodo responsabiledei dati con hash h
3. Detto nodo memorizza il dato
Similarmente, in caso di query i passaggi sono:
1. L'applicazione comunica ad un nodo del sistema l'hash h del quale vuole reperire il dato
2. Il nodo immette nel sistema un messaggio get(h)
3. Tramite il servizio di routing del sistema, il messaggio viene recapitato al nodo responsabile dei daticon hash h
4. Detto nodo comunica al nodo richiedente il dato richiesto
Per garantire performances accettabili bisogna trovare un compromesso tra numero di passaggi necessariche un messaggio deve fare e numero di nodi conosciuti da un generico nodo; meno passaggi deve fare unmessaggio piú veloce esso raggiunge la sua destinazione e maggiore deve essere il numero dei nodi conosciutida un generico nodo, ma piú vicini conosce un nodo, piú overhead é necessario per la gestione di entrate ouscite dalla DHT.
3.5.2 Pastry [10]
Pastry é un tipo di DHT speci�catamente progettato per avere una elevata scalabilitá e buone performance.Ogni nodo ha un identi�cativo di 128 bits generato casualmente. Dato un messaggio ed una chiave, Pastry
lo recapita all'id numericamente piú vicino alla chiave in meno di dlog2b Ne passaggi (b é un parametro dicon�gurazione usualmente con�gurato a 4). Il recapito dei messaggi é garantito �n tanto che l/2 o piú nodicon id adiacenti non si guastino simultaneamente (l é un parametro tipicamente con�gurato a 16). Le tabellenecessarie in ogni nodo hanno solo (2b−1)∗dlog2b Ne+ l righe, dove ogni riga associa ad ogni id l'IP relativo.All'arrivo di un nuovo nodo sono richiesti uno scambio di O(log2b N) messaggi.
Ogni nodo mantiene: una tabella di routing, un neighborhood set e un leafset. La tabella di routing associagli id con speci�ci pre�ssi agli IP. Il leafset contiene gli l/2 id minori e gli l/2 maggiori numericamente all'iddel nodo corrente. Il neighborhood set contiene gli id e gli IP di M nodi vicini (secondo una metrica diprossimitá) al nodo corrente.
Un esempio di routing di un messaggio nell'anello é mostrato in �gura 3.13.L'algoritmo in pseudo-codice di routing di un messaggio é mostrato in �gura 3.14, e all'arrivo di un
messaggio con chiave D arrivato al nodo A, segue la sefuente notazione:
Ril Il dato nella tabella di routing R alla colonna i, 0 ≤ i < 2b e riga l, 0 ≤ l < b128/bc.
Li l'i-esimo id piú vicino nel leafset L, −b|L| /2c ≤ i ≤ b|L| /2c, dove gli indici negativi indicano id inferiorie quelli positivi i superiori.
Dl il valore dell'l-esimo carattere nella chiave D
shl(A,B) la lunghezza del pre�sso condiviso tra A e B, in caratteri

3.5. DHT 33
Figura 3.13: Esempio di routing di un messaggio con chiave d46a1c dal nodo 65a1fc
Figura 3.14: Pseudo-codice dell'algoritmo di routing

34 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
3.5.3 FreePastry
FreePastry é un'implementazione open source di Pastry.Le funzioni che FreePastry espone per le lookup e gli store sono asincrone. Mentre per l'implementazione
dello store questa modalitá é inin�uente, per implementare la lookup il thread del modulo DHT invocantela funzione lookup della libreria FreePastry si sincronizza con il thread lanciato da FreePastry stesso tramiteun ogetto CyclicBarrier.
Alle funzioni di store e lookup di FreePastry si deve passare come parametro un oggetto implementantel'interfaccia Continuation i cui metodi (receiveResult e receiveException) vengono eseguiti alla �ne dell'op-erazione invocata (rispettivamente in caso di successo o di fallimento). L'invocazione dei metodi di store elookup comporta la creazione (da parte della libreria) di un thread che andrá a servire la richiesta, mentreil thread invocante continuerá con le istruzioni successive.
Per memorizzare un'informazione in FreePastry si deve necessariamente creare una classe che esten-da la classe del framework �ContentHashPastContent� le cui variabili di istanza devono implementarel'interfaccia �Serializable�. Nel caso in esame la classe implementata ha come variabile di istanza un�HashSet<Serializable>� in quanto in caso di piú store con medesima chiave piú oggetti devono esserememorizzati. Per consentire di poter memorizzare un secondo oggetto su uno preesistente con medesimachiave si é dovuto fare overriding del metodo �checkInsert� il cui compito é quello di decidere in caso dicollisione di chiavi quale oggetto debba esser memorizzato nella DHT.
3.6 Sviluppo e installazione nuovi tipi di sensori
Per sviluppare nuovi tipi di sensori bisogna creare classi che implementino le classi astratte ASensor delpackage contextrepository.domain.interfaces e ASensorFilter del package contextrepository.�lters ed even-tualmente renderle disponibili ai vendors. Dette classi saranno astratte e lasceranno astratti i metodi relativial formato dei dati rappresentati in caso si voglia lasciare a discrezione dei singoli vendor la sezione relativanegli XML di store e di query, altrimenti saranno classi concrete che implementeranno tutti i metodi dellesuper-classi in caso si voglia bloccare la rappresentazione degli XML in un formato pre-stabilito (e dovrannovenire installate nella DHT come fossero driver).
La classe astratta ASensor ha il seguente scheletro:
public abstract class ASensor<T>{
public abstract void normalize(Map<String,List<String>> val);
public abstrat T getValue();
public abstract void readXML(String xml);
public abstract String getSensorType();
public abstract String getNormalizedValue();
//Metodo che restituisce il valore numerico in values
//più vicino al comparable comp
protected String getNormVal(List<String> values,
Comparable<Number> comp){
//Implementazione del metodo
}

3.7. SVILUPPARE E INSTALLARE NUOVI SENSORI DI UN VENDOR 35
}
La classe che implementerá il tipo di sensore dovrá obbligatoriamente implementare in modo �nal ilmetodo getSensorType e preferibilmente i metodi getNormalizedValue() e normalize(. . . ).
La classe astratta ASensorFilter ha il seguente scheletro:
public abstract class ASensorFilter {
public abstract boolean acceptSensor(ISensor<?> sens);
public abstract List<String> getKeys(
Map<String,List<String>> mapper);
public abstract ISensor<?> getSensor();
public abstract void readXML(String xml);
}
La classe che andrá ad estendere detta classe dovrá implementare in modo �nal i metodi acceptSensor egetKeys.
Nel caso si siano sviluppate classi astratte, il jar ottenuto da dette classi deve essere copiato in ogni deviceche abbia bisogno di gestire interrogazioni o memorizzazioni riguardanti quel tipo di sensore nella cartella�sensor_types�, non é necessario spegnere il nodo.
3.7 Sviluppare e installare nuovi sensori di un vendor
Per sviluppare un nuovo tipo di sensore é necessario avere disponibile sia il jar �ContextRepositoryBundle.jar �che il jar del tipo di sensore che si sta sviluppando contenente le classi astratte che si è obbligati ad estendere.Ogni vendor dovrá creare sia una classe che estenda la classe astratta ATipoDiSensore, sia una seconda classeche estenda la classe astratta ATipoDiSensoreFilter, dette classi dovranno avere costruttori pubblici a zeroargomenti.
Per installare i driver bisogna invocare su un nodo del sistema il metodo installClasses del sotto-modulocontext repository passandogli come argomento il nome logico del sensore, il nome esteso della classe deldriver e del �ltro. Il sistema stesso si preoccuperá di aggiungere il mapping tra nome del sensore e classi digestione. Il jar contenente il byte-code delle classi deve esser messo nella cartella �sensor_driver�del nodoche installa il driver nel sistema (dopo l'installazione potrá venir cancellato).
3.8 Tipi di sensori attualmente implementati
Sono stati �n ora implementati due tipi di sensori: sensori di temperatura e sensori di pressione sanguignea.Segue analisi dei due tipi.

36 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
3.8.1 Sensori di temperatura
Detti tipi di sensori hanno un solo attributo (la temperatura) e l'XML contenente i suoi valori soglia é nelformato
<?xml version="1.0" encoding="UTF-8"?>
<values>
<Sensor type="Temperature">
<value type="Temperature">10,15,20,25,30,35</value>
</Sensor>
</values>
Per la gestione di detto sensore sono state sviluppate due classi astratte: ATemperatureSensor e ATem-peratureSensorFilter.
La prima ha il seguente scheletro:
public abstract class ATemperatureSensor<T extends Number>
extends ASensor<T> implements Comparable<Number>{
public static final String SENSOR_TYPE="Temperature";
public static final String VALUE_NAME="Temperature";
public final String getSensorType(){
//Corpo del metodo
}
public final String getNormalizedValue(){
//Corpo del metodo
}
public final void normalize(Map<String,List<String>> valu) {
//Corpo del metodo
}
}
Detta classe delega l'implementazione alla classe �glia dei metodi getValue e readXML della super-classeASensor e del metodo compareTo(Number n) dell'interfaccia Comparable<Number>. Si é scelta l'imple-mentazione dell'interfaccia Comparable per poter collocare l'istanza corrente di un sensore di temperaturarispetto ad altre istanze della stessa classe in fase di ricerca.
L'implementazione della classe astratta ATemperatureSensorFilter ha il seguente scheletro:
public abstract class ATemperatureSensorFilter extends ASensorFilter{
protected enum TEMPERATURE_OPERATION{
GREATER,LESS,EQUAL
}
protected abstract ATemperatureSensorFilter.TEMPERATURE_OPERATION
getOperation();
@Override

3.8. TIPI DI SENSORI ATTUALMENTE IMPLEMENTATI 37
public final boolean acceptSensor(ASensor<?> sens) {
//Corpo del metodo
}
@Override
public final List<String> getKeys(Map<String,
List<String>> allValues) {
//Corpo del metodo
}
}
Detto metodo delega alla classe �glia l'implementazione dei metodi getSensor e readXML dichiaratinella super-classe ASensorFilter e del metodo getOperation dichiarato in questa stessa classe. Quest'ultimometodo ha lo scopo di avere conoscenza dell'operazione che l'XML di query correntemente analizzato imponedi fare, che possono essere di trovare temperature maggiori, uguali o minori di un certo valore. Detteoperazioni sono codi�cate nell'enumerazione TEMPERATURE_OPERATION.
Il metodo di generazione delle chiavi per un sensore di temperatura funziona nel seguente modo:
1. Richiesta alla classe �glia di un'istanza del driver
2. Richiesta dell'operazione da eseguire alla classe �glia (maggiore, minore o uguale)
3. Normalizzazione del valore della ricerca
4. Per ogni valore concesso per quel tipo di sensore:
(a) Se il valore in esame é maggiore del valore normalizzato e sono di interesse i valori maggiori
i. Aggiungere la chiave trovata all'insieme delle chiavi da restituire
(b) Se il valore in esame é uguale al valore normalizzato e sono di interesse i valori uguali
i. Aggiungere la chiave trovata all'insieme delle chiavi da restituire
(c) Se il valore in esame é minore del valore normalizzato e sono di interesse i valori minori
i. Aggiungere la chiave trovata all'insieme delle chiavi da restituire
3.8.2 Sensori di pressione sanguigna
Detti tipi di sensori hanno tre attributi (pressione sistolica, pressione diastolica e pulsazioni cardiache) el'XML contenente i suoi valori soglia é nel formato:
<?xml version="1.0" encoding="UTF-8"?>
<values>
<Sensor type="BloodPressure">
<value type="Systolic">100,110,120,130,140,150,170,180,190,200</value>
<value type="Diastolic">40,50,60,70,80,90,100,110</value>
<value type="Hearth">30,40,50,60,70,80,90,100,110,120</value>
</Sensor>
</values>
Per la gestione di detto tipo di sensore sono state implementate due classi astratte: ABloodPressureSensore ABloodPressureSensorFilter.
Lo scheletro della prima é:

38 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
public abstract class ABloodPressureSensor
<S extends Number, D extends Number, H extends Number>
extends ASensor<ABloodPressureSensor.BloodPressure<S,D,H>>{
public static class BloodPressure
<S extends Number, D extends Number, H extends Number>{
//Classe rappresentante i valori del sensore
}
public static final String SENSOR_TYPE="BloodPressure";
public static final String SYSTOLIC_VALUE_NAME="Systolic";
public static final String DIASTOLIC_VALUE_NAME="Diastolic";
public static final String HEART_VALUE_NAME="Hearth";
public final String getSensorType() {
//Corpo del metodo
}
public final String getNormalizedValue() {
//Corpo del metodo
}
public final void normalize(Map<String, List<String>> val) {
//Corpo del metodo
}
public abstract int compareSystolic(Number n);
public abstract int compareDiastolic(Number n);
public abstract int compareHeart(Number n);
}
Detta classe delega l'implementazione alla classe �glia dei metodi: getValue e readXML dichiarati nellasuper-classe ASensor e dei metodi compareSystolic, compareDiastolic e compareHeart dichiarati in questastessa classe. Questi ultimi tre metodo hanno la funzione di porre una speci�ca istanza di questo sensore aconfronto con altre istanze (in fase di ricerca) i suoi attributi di pressione (sistolica e diastolica) e pulsazione.
Lo scheletrodella classe ABloodPressureSensorFilter é la seguente:
public abstract class ABloodPressureSensorFilter extends ASensorFilter{
protected enum OPERATION{
GREATER,LESS,EQUAL,NONE
}
protected static class BloodPressureOperation{
//Classe rappresentante l'operazione da effettuare
}
@Override
public final boolean acceptSensor(ASensor<?> sens) {
//Corpo del metodo
}

3.9. DRIVER DEI SENSORI ATTUALMENTE IMPLEMENTATI 39
@Override
public final List<String> getKeys(Map<String,List<String>> disValues) {
//Corpo del metodo
}
protected abstract BloodPressureOperation getOperation();
}
Detta classe delega alla classe �glia l'implementazione dei metodi: getSensor e readXML dichiarati nellasuper-classe ASensorFilter e getOperation dischiarato in questa stessa classe. Quest'ultimo metodo ha loscopo di sapere l'operazione da e�ettuare dichiarata dall'XML di query (congunzione delle operazioni dae�ettuare sui tre attributi).
Il metodo di generazione delle chiavi per un sensore di temperatura funziona nel seguente modo:
1. Richiesta alla classe �glia di un'istanza del driver
2. Richiesta alal classe �glia dell'operazione da e�ettuare
3. Normalizzazione del driver
4. Dati i valori concessi per l'attributo di pressione sistolica recupero di quelli pertinenti coerenti conl'operazione da e�ettuare
5. Dati i valori concessi per l'attributo di pressione diastolica recupero di quelli pertinenti coerenti conl'operazione da e�ettuare
6. Dati i valori concessi per l'attributo di pulsazione cardiaca recupero di quelli pertinenti coerenti conl'operazione da e�ettuare
7. E�ettuare il prodotto cartesiano dei tre insiemi precedentemente calcolati
8. Per ogni elemento del prodotto cartesiano, aggiungere detto elemento alle chiavi di ricerca
3.9 Driver dei sensori attualmente implementati
Sono stati implementati i driver dei sensori di temperatura e di pressione di un ipotetico e �ttizio vendorSlurp. Segue una breve analisi di detti driver.
3.9.1 Driver del sensore di temperatura Slurp
Detto driver é composto da due classi: SlurpTemperatureSensor e SlurpTemperatureSensorFilter.La prima classe ha il seguente scheletro:
public class SlurpTemperatureSensor
extends ATemperatureSensor<Float>{
private float temp;

40 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
public SlurpTemperatureSensor() {
}
public SlurpTemperatureSensor(float val) {
//Corpo del metodo
}
public Float getValue(){
//Corpo del metodo
}
public void readXML(String xml){
//Corpo del metodo
}
public int compareTo(Number arg0) {
//Corpo del metodo
}
}
Detta classe gestisce XML del tipo:
<?xml version="1.0" encoding="UTF-8"?>
<SlurpTemperatureSensor>
<Temp_value datatype="float">26.5</Temp_value>
</SlurpTemperatureSensor>
ove la temperatura é rappresentata come �oat.Lo scheletro della classe SlurpTemperatureSensorFilter é:
public class SlurpTemperatureSensorFilter
extends ATemperatureSensorFilter{
@Override
protected TEMPERATURE_OPERATION
getOperation() {
//Corpo del metodo
}
@Override
public void readXML(String xml){
//Corpo del metodo
}
@Override
public ASensor<?> getSensor() {
//Corpo del metodo
}
}
e si aspetta XML nel formato:
<?xml version="1.0" encoding="UTF-8"?>

3.9. DRIVER DEI SENSORI ATTUALMENTE IMPLEMENTATI 41
<SlurpTemperatureSensor>
<Temp_value datatype="float">operazioneEValore</Temp_value>
</SlurpTemperatureSensor>
ove il campo �operazioneEValore�é:
� Un valore di tipo �oat per operazioni di uguaglianza rispetto a quel valore
� Un valore di tipo �oat con pre�sso �gt�(per esempio �gt23.7�) per operazioni di maggioranza rispetto aquel valore
� Un valore di tipo �oat con pre�sso �lt�(per esempio �lt23.7�) per operazioni di minoranza rispetto aquel valore
3.9.2 Driver del sensore di pressione sanguigna Slurp
Detto driver é composto da due classi: SlurpBloodPressureSensor e SlurpBloodPressureSensorFilter.La prima classe ha scheletro:
public class SlurpBloodPressureSensor
extends ABloodPressureSensor<Float, Float, Float>{
private BloodPressure<Float,Float,Float> val;
SlurpBloodPressureSensor(float sys, float dias, float ht) {
//Corpo del metodo
}
public SlurpBloodPressureSensor(){
}
@Override
public int compareSystolic(Number n) {
//Corpo del metodo
}
@Override
public int compareDiastolic(Number n) {
//Corpo del metodo
}
@Override
public int compareHeart(Number n) {
//Corpo del metodo
}
public BloodPressure<Float, Float, Float> getValue() {
//Corpo del metodo
}
public void readXML(String xml) {

42 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
//Corpo del metodo
}
}
e si aspetta XML del tipo:
<?xml version="1.0" encoding="UTF-8"?>
<SlurpBloodPressureSensor>
<Systolic>125</Systolic>
<Diastolic>60</Diastolic>
<Heart>69</Heart>
</SlurpBloodPressureSensor>
ove il dominio degli attributi é �oat.La classe SlurpBloodPressureSensorFilter ha scheletro:
public class SlurpBloodPressureSensorFilter
extends ABloodPressureSensorFilter{
public SlurpBloodPressureSensorFilter(){
//Corpo del metodo
}
@Override
protected BloodPressureOperation getOperation() {
//Corpo del metodo
}
@Override
public ASensor<?> getSensor() {
//Corpo del metodo
}
public void readXML(String xml) {
//Corpo del metodo
}
}
e si aspetta XML del tipo:
<?xml version="1.0" encoding="UTF-8"?>
<SlurpBloodPressureSensor>
<Systolic>operazioneEValore</Systolic>
<Diastolic>operazioneEValore</Diastolic>
<Heart>operazioneEValore</Heart>
</SlurpBloodPressureSensor>
dei tag Systolic, Diastolic e Heart ne é obbligatoria la presenza almeno di uno, in caso di assenza di un tagsi assume che la query riguardi l'intero range di valori per quell'attributo. Il campo �operazioneEValore�hail seguente formato:
� Un valore di tipo �oat per operazioni di uguaglianza rispetto a quel valore
� Un valore di tipo �oat con pre�sso �gt�(per esempio �gt23.7�) per operazioni di maggioranza rispetto aquel valore

3.10. DEPLOYMENT 43
� Un valore di tipo �oat con pre�sso �lt�(per esempio �lt23.7�) per operazioni di minoranza rispetto aquel valore
3.10 Deployment
Il progetto appena esaminato é stato pensato per l'utilizzo in un framework OSGi, detto framework éutilizzato per il caricamento e la rimozione di moduli (detti �bundles�) a run-time. Detti moduli possonoessere o interfacce esportate o servizi messi a disposizione (o una combinazione dei due). I bundle cheesportano servizi devono avere un ogetto che implementi l'interfaccia BundleAvtivator il cui metodo �start()�verrá invocato all'avvio del bundle stesso e il cui metodo �stop()� allo stop del medesimo. Ogni �le jar peressere un bundle dovrá avere nel suo manifest le seguenti righe:
Bundle-Version: Versione del bundle
Bundle-Name: Nome del bundle
Bundle-ManifestVersion: 2
Bundle-Activator: Classe che implementi BundleActivator
Import-Package: Packages esterni a java.* a cui il bundle possa accedere
Export-Package: Packages che questo bundle esporta
Bundle-ClassPath: Eventuali risorse (interne al jar) che il bundle può utilizzare
Bundle-SymbolicName: Nome del bundle
I bundles riguardanti questo progetto sono:
ContextRepositoryInterface Bundle che esporta l'interfaccia del context repository
ContextRepositoryBundle Bundle che esporta il servizio context repository
ContextStorageInterface Bundle che esporta l'interfaccia del context storage
ContextStorageBundle Bundle che esporta il servizio context storage
DHTInterface Bundle che esporta l'interfaccia della DHT
DHTBundle Bundle che esporta il servizio della DHT
Per poter avviare il progetto, installare i bundles in una speci�ca implementazione di OSGi e avviarli.A�nché il nodo avviato possa memorizzare i dati relativi dei sensori il cui comando di memorizzazione
sia stato invocato su un altro nodo, basta avviare nell'ordine solo i bundles DHTInterface, ContextRepos-itoryInterface, ContextStorageInterface, ContextStorageBundle e DHTBundle. Mentre per fare in modo dipoter invocare il metodo di memorizzazione (o di ricerca) sul nodo occorre avviare (successivamente) ancheContextRepositoryBundle avendo cura che nella cartella �sensor_types� nella working directory ci siano leclassi (in un archivio jar o nei �le .class posizionati nella struttura del package nel quale sono dichiarati)rappresentanti i tipi di sensori che quel nodo dovrá gestire (che possono essere aggiunti anche a run-time incaso quel nodo debba gestire altri tipi).
Per poter con�gurare le proprietá di avvio della DHT, il bundle DHTBundle si aspetta nella workingdirectory un �le chiamato �PastryPortConf.conf� con i parametri di avvio nel seguente formato:
BindHost#IP o nome del computer locale
BindPort#porta locale sulla quale attestare la DHT
Host#IP o nome del computer del nodo di boot

44 CAPITOLO 3. ARCHITETTURA GENERALE DEL REPOSITORY DEL CONTESTO
BootPort#porta sulla quale è attestata la DHT del nodo di boot
PersistentStorage#grandezza in bytes della memoria su disco
CacheSize#grandezza in bytes della memoria cache in RAM
Replicas#numero di repliche per dato
Ogni parametro é opzionale, se non presente viene usato il suo valore di default.I valori di default perogni singolo parametro sono mostrati nella seguente tabella
BindHost localhostBindPort 9000Host localhostBootPort 9000PersistentStorage 4194304CacheSize 524288Replicas 3
L'ordine dei parametri nel �le é irrilevante e se lo stesso �le non é presente vengono utilizzati tutti i valoridi default.

Capitolo 4
Valutazione delle prestazioni
Per la misurazione delle prestazioni di questo progetto si sono tenute in considerazione le due seguentimetriche
1. Tempo di esecuzione
2. Memoria ocupata
4.1 Descrizione del sistema usato per la valutazione
Per essere in grado di poter e�ettuare dette misurazioni si é sviluppato un bundle OSGi il cui compito é,dato da un �le XML con:
1. il nome del servizio;
2. i nomi dei metodi;
3. il nome dei logger da utilizzare.
Il bundle (chiamato MethodLoggerBundle), una volta letto il nome del servizio di cui fare il monitoraggio,lo recupera tramite il framework e crea un'istanza della classe java.lang.re�ect.Proxy che implementa tuttele interfacce giá implementate dal servizio da monitorare.
L'invocation handler all'invocazione di un metodo, se detto metodo non é da monitorare, chiama traspar-entemente il metodo relativo del servizio, altrimenti prima dell'invocazione, avvia i logger desiderati e altermine dell'esecuzione del metodo da parte del servizio, li ferma. Uno schema del suo funzionamento éillustrato in �gura 4.1.
Alla �ne di ogni esecuzione di un metodo da monitorare, i risultati ottenuti vengono memorizzati in unoggetto java.util.Map. Detto oggetto é esposto tramite un servizio che il bundle registra su OSGi.
Ulteriormente al succitato bundle se ne é sviluppato un altro (chiamato TestContextRepository) che eseguematerialmente il test, questo bundle legge dal �le �TestProperties.conf� i parametri con i quali e�ettuare iltest su quel speci�co nodo nel formato
TestName#NomeDelTest
NumberStore#NumeroDiStorePerIlNodoCorrente
StorePerSecond#FrequenzaDiStore
NumberQuery#NumeroDiRetrievePerIlNodoCorrente
QueryPerSecond#FrequenzaDiRetrieve
45

46 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI
Una volta letto il �le con le con�gurazioni, avvia un logger che, tramite un thread distinto, ogni secondofa una �fotogra�a� dello stato corrente della memoria utilizzata e comincia a fare le operazioni di store.
Terminati gli store inizia a fare le retrieve, per poi fermare il thread di logging della memoria.Gli XML di store e di query sono generati randomicamente per ogni operazione e�ettuata ipotizzando
l'esistenza di due stanze (Kitchen e Living room) e due sensori (SlurpTemperatureSensor e SlurpBloodPres-sureSensor descritti nella sezione 3.9).
Una volta �nite le retrieve, viene richiesto al bundle MethodLoggerBundle il Map con i risultati di og-ni singola operazione e per ognuna di esse viene scritto un �le in cui ogni riga ha il valore dell'orolo-gio di sistema sia di quando é iniziato il metodo che il valore di quando é terminato. Se per esem-pio fosse stato chiamato due volte il metodo store e tre il metodo retrieve, avremmo 2 �les: il primo(�Test-NomeDelTest-ContextRepository-store.txt�) contenente due righe, in cui ogni riga avrebbe una cop-pia �valoreInizio-valoreFine�, e un secondo �le (�Test-NomeDelTest-ContextRepository-retrieve.txt�) con trerighe con i relativi valori.
Oltre ai due �le con il tempo di esecuzione, se ne genera un terzo che ha per ogni riga una terna�TempoDiMisurazione-MemoriaHeapUsata-MemoriaNonHeapUsata�. Detto �le rappresenta la fotogra�a del-la memoria utilizzata (heap e stack) durante l'esecuzione di tutte le operazioni di store e retrieve, unafotogra�a al secondo.
Per l'analisi dei risultati sono stati importati i �le di output di ciascun nodo in un �le excel, tramite ilquale si son creati i gra�ci.
I metodi che sono stati monitorati sono:
1. storeContextData del modulo di context repository
2. retrieveContextData del modulo di context repository
Per eseguire i test si sono utilizzate sei macchine virtuali localizzate su quattro server distinti collegati inLAN.
Il sistema operativo utilizzato é Linux nella sua distribuzione di Ubuntu (mentre il progetto é statosviluppato e provato su sistema operativo Microsoft® Windows® 7).
Si é avviato l'ambiente Java aumentando la memoria massima utilizzabile heap a 512MB e sono statiusati i seguenti parametri per la DHT
PersistentStorage 5242880CacheSize 1048576Replicas 0
4.2 Test eseguiti
Sono stati eseguiti due categorie di test, la prima categoria con sei nodi, mentre la seconda con un nodo solo.Le descrizioni dei test e�ettuati sono in tabella 4.1.
4.2.1 Test con sei nodi
Test S 1
I tempi di esecuzione del metodo di store per ogni nodo é illustrato in �gura 4.2(a).In detta �gura, l'asse delle ascisse rappresentano i millisecondi mentre le ordinate rappresentano il numero
di esecuzioni portate a termine in quell'intervallo.La �gura 4.2(b) mostra la distribuzione complessiva delle store compiute da tutti e sei i nodi.

4.2. TEST ESEGUITI 47
Figura 4.1: Sequence diagram del bundle MethodLogging

48 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI
S 1 Numero di nodi 6Store per nodo 1700Frequenza di store 10Retrieve per nodo 1700Frequenza di retrieve 10
S 2 Numero di nodi 6Store per nodo 16700Frequenza di store 10Retrieve per nodo 1700Frequenza di retrieve 10
S 3 Numero di nodi 6Store per nodo 1700Frequenza di store 1Retrieve per nodo 1700Frequenza di retrieve 1
U 1 Numero di nodi 1Store per nodo 1000Frequenza di store 10Retrieve per nodo 10000Frequenza di retrieve 10
U 2 Numero id nodi 1Store per nodo 10000Frequenza di store 10Retrieve per nodo 10000Frequenza di retrieve 10
U 3 Numero di nodi 1Store per nodo 1000Frequenza di store 1Retrieve per nodo 10000Frequenza di retrieve 1
U 4 Numero di nodi 1Store per nodo 10000Frequenza di store 1Retrieve per nodo 10000Frequenza di retrieve 1
Tabella 4.1: Test E�ettuati
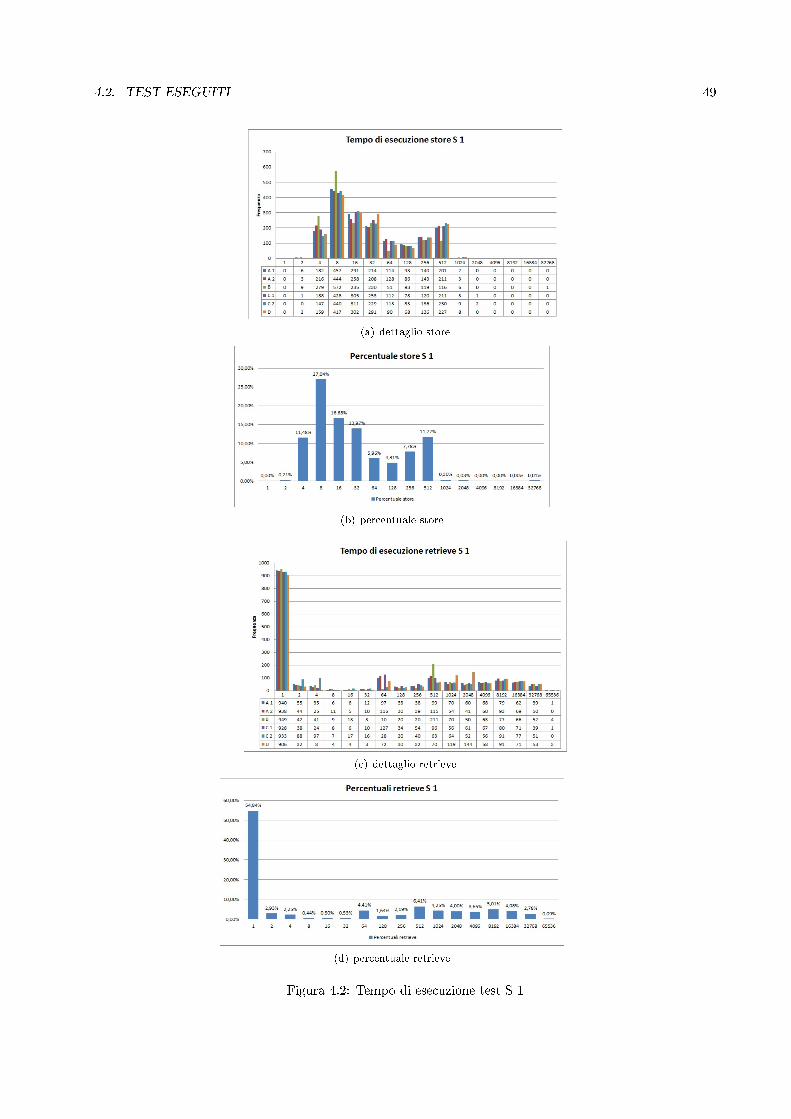
4.2. TEST ESEGUITI 49
(a) dettaglio store
(b) percentuale store
(c) dettaglio retrieve
(d) percentuale retrieve
Figura 4.2: Tempo di esecuzione test S 1

50 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI
La �gura 4.2(c) mostra il dettaglio del tempo di esecuzione dell'operazione di retrieve per i sei nodi, lacui distribuzione complessiva é illustrata in �gura 4.2(d).
L'utilizzo della memoria per il test S 1 é illustrato nelle �gure 4.3(a), 4.3(b), 4.3(c), 4.3(d), 4.3(e) e 4.3(f).
(a) Utilizzo della memoria test S 1 nodo A 1 (b) Utilizzo della memoria test S 1 nodo A 2
(c) Utilizzo della memoria test S 1 nodo B (d) Utilizzo della memoria test S 1 nodo C 1
(e) Utilizzo della memoria test S 1 nodo C 2 (f) Utilizzo della memoria test S 1 nodo D
Figura 4.3: Utilizzo della memoria test S 1
In questo test la maggioranza delle operazioni di store (55, 2%) é completata nell'intervallo tra 4 e 16millisecondi, mentre nel caso delle retrieve la concentrazione maggiore (54, 84%) si attesta in 1 millisecondo.Da questo si evince che le operazioni di store sono mediamente piú onerose da eseguire rispetto alle retrieve.
La presenza nel gra�co di retrieve di una coda tra i 64 e i 32768 millisecondi (38, 42%) potrebbe suggerirel'esecuzione di piú operazioni e�ettuate in modo concorrente sui nodi remoti alla macchina e�ettuante laquery. Il diverso utilizzo della memoria riscontrato sui diversi server potrebbe implicare da una parte unapolarizzazione delle informazioni memorizzate verso un nodo piuttosto che verso un altro (FreePastry attuaun meccanismo di caching delle informazioni memorizzate) e dall'altra una diversa distribuzione delle querydi ricerca (e quindi di risultati ottenuti rispetto ai dati memorizzati) di ogni nodo.
Altro fattore da tenere in considerazione é la di�erente durata del test delle diverse macchine, i nodiche hanno avuto bisogno di piú tempo rispetto agli altri hanno piú informazioni riguardanti l'utilizzo dellamemoria, e quindi, nel gra�co il compattamento di questi dati potrebbe comportare la diversa forma visibiledella curva.

4.2. TEST ESEGUITI 51
Test S 2
Analogamente al precedente test, il tempo di esecuzione in dettaglio e in percentuale dell'operazione di storesono illustrati in �gure 4.4(a) e 4.4(b).
Le �gure 4.4(c) e 4.4(d) illustrano la distribuzione dei tempi di esecuzione dell'operazione di retrieveottenuta nel test S 2.
Nelle �gure 4.5(a), 4.5(b), 4.5(c), 4.5(d), 4.5(e) e 4.5(f), invece, é mostrato l'utilizzo della memoria.Con il numero di informazioni memorizzate di un ordine di grandezza superiore rispetto al test S 1,
il comportamento del test S 2 mostra una relativa similitudine nei risultati del tempo di esecuzione. Ciósigni�ca che aumentando il numero di informazioni memorizzate, il comportamento del sistema non subiscesostanziali cambiamenti dimostrandone la scalabilitá. La coda presente sempre nell'operazione di retrieve trai 512 e i 16384 millisecondi (sempre nell'ordine del 30%) puó ancora rappresentare le operazioni concorrentisu nodi remoti al nodo interrogante.
Il maggior numero di informazioni, invece, é rispecchiato nel maggior utilizzo di memoria.La parte di crescita continua rispecchia il sempre maggior numero di dati memorizzati nelle operazioni di
store (piú dati vengono memorizzati piú memoria cache é necessaria), mentre l'andamento altalenante evintopuó esser dato dai risultati (eliminati con andamento periodico dal garbage collector) trovati nelle query.
Test S 3
La distribuzione del tempo di esecuzione per l'operazione di store é mostrata in �gure 4.6(a) e 4.6(b).Per l'operazione di retrieve, la distribuzione é illustrata in �gure 4.6(c) e 4.6(d).L'utilizzo della memoria per il test S 3 é fatto vedere nelle �gure 4.7(a), 4.7(b), 4.7(c), 4.7(d), 4.7(e) e
4.7(f).Confrontando questo test con il test S 1 (dal quale si di�erenzia solo per la frequenza con la quale sono
eseguite le operazioni) si puó evincere uno spostamento verso sinistra della curva di distribuzione del tempodi esecuzione.
Questo puó ra�orzare la tesi della motivazione addotta per la presenza di code nella parte destra deigra�ci di retrieve del test S 1. É chiaro che eseguendo le operazioni piú distanziate tra loro, il numerodi operazioni concorrenti diminuisce. La scarsa quantitá di operazioni presenti nella �coda� testimoniacomunque l'e�cienza della soluzione adottata.
4.2.2 Test a un nodo
I test successivi prevedono, al contrario di quelli sopra esposti, l'utilizzo di un solo nodo nel sistema.
Test U 1
In �gure 4.8(a) e 4.8(b) é illustrata la distribuzione del tempo di esecuzione dell'operazione di store.La distribuzione del tempo di esecuzione per l'operazione di retrieve é illustrato in �gure 4.8(c) e 4.8(d).In �gura 4.9 viene illustrato l'utilizzo della memoria per detto test.In questo test la maggioranza delle operazioni di store si posiziona nell'intervallo 4 e 8 millisecondi,
andandosi quasi a annullare negli intervalli successivi (tra i 16 e i 512 millisecondi il numero di store édel 3, 7%), il che fa supporre che la presenza di store negli intervalli maggiori di 16 millisecondi presentinei test di tipo S siano da ricondurre a memorizzazioni remote rispetto al nodo richiedente. Anche lacollocazione della coda della retrieve, prima posizionata tra 512 e 32768 millisecondi, adesso é spostata verso

52 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI
(a) dettaglio store
(b) percentuale store
(c) dettaglio retrieve
(d) percentuale retrieve
Figura 4.4: Tempo di esecuzione test S 2

4.2. TEST ESEGUITI 53
(a) Utilizzo della memoria test S 2 nodo A 1 (b) Utilizzo della memoria test S 2 nodo A 2
(c) Utilizzo della memoria test S 2 nodo B (d) Utilizzo della memoria test S 2 nodo C 1
(e) Utilizzo della memoria test S 2 nodo C 2 (f) Utilizzo della memoria test S 2 nodo D
Figura 4.5: Utilizzo della memoria test S 2

54 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI
(a) dettaglio store
(b) percentuale store
(c) dettaglio retrieve
(d) percentuale retrieve
Figura 4.6: Tempo di esecuzione test S 3

4.2. TEST ESEGUITI 55
(a) Utilizzo della memoria test S 3 nodo A 1 (b) Utilizzo della memoria test S 3 nodo A 2
(c) Utilizzo della memoria test S 3 nodo B (d) Utilizzo della memoria test S 3 nodo C 1
(e) Utilizzo della memoria test S 3 nodo C 2 (f) Utilizzo della memoria test S 3 nodo D
Figura 4.7: Utilizzo della memoria test S 3

56 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI
(a) dettaglio store (b) percentuale store
(c) dettaglio retrieve (d) percentuale retrieve
Figura 4.8: Tempo di esecuzione test U 1
Figura 4.9: Utilizzo della memoria test U 1

4.2. TEST ESEGUITI 57
(a) dettaglio store (b) percentuale store
(c) dettaglio retrieve (d) percentuale retrieve
Figura 4.10: Tempo di esecuzione test U 2
Figura 4.11: Utilizzo della memoria test U 2
sinistra nell'intervallo tra i 32 e i 2048 millisecondi. Il che é coerente con l'interpretazione fornita per ilposizionamento della coda in quell'intervallo.
L'utilizzo della memoria é sempre crescente in quanto c'é un progressivo aumento di dati memorizzati e,successivamente, di dati trovati nella fase di retrieve.
Test U 2
La distribuzione del tempo di esecuzione dell'operazione di store del test U 2 é illustrata in �gure 4.10(c) e4.10(d).
Le �gure 4.10(c) e 4.10(d) rappresentano la distribuzione del tempo di esecuzione dell'operazione diretrieve.
L'utilizzo di memoria é visualizzato in �gura 4.11.All'aumentare dei dati memorizzati la curva di distribuzione si appiattisce verso gli estremi, evidenziando
una �siologica maggior richesta di computazione all'aumentare delle informazioni nel sistema. Da notare che,al contrario del test S 2 il quale anch'esso memorizza lo stesso ordine di grandezza di informazioni (poco piú

58 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI
(a) dettaglio store (b) percentuale store
(c) dettaglio retrieve (d) percentuale retrieve
Figura 4.12: Tempo di esecuzione test U 3
di 10000), la maggioranza degli store (52%) si posiziona sotto i 4 millisecondi. Il che é facilmente spiegabileconsiderando che il test U 2 non contempla la presenza di nodi remoti.
La presenza maggiore dei dati nel sistema é causa anche dell'andamento molto altalenante mostratonell'utilizzo della memoria, piú dati presenti implicano piú risultati trovati in fase i query, e quindi piúmemoria utilizzata per tenerli in memoria, memoria che viene periodicamente liberata dal garbage collector.
Test U 3
Nelle �gure 4.12(a) e 4.12(b) si puó osservare la distribuzione del tempo di esecuzione dell'operazione distore.
La distribuzione del tempo di esecuzione dell'operazione di retrieve si puó evincere nelle �gure 4.12(c) e4.12(d).
Mentre in �gura 4.13 si evince lo stato della memoria durante il test.Una minor frequenza di store rispetto al test U 1 porta al posizionamento della quasi totalitá delle
operazioni di store nell'intervallo tra i 4 e gli 8 millisecondi, mentre non condiziona l'andamento dellamemoria, che é paragonabile al test U 1.
Test U 4
La sua distribuzione del tempo di esecuzione dell'operazione di store si puó vedere in �gure 4.14(a) e 4.14(b).L'operazione di retrieve in �gure 4.14(c) e 4.14(d).L'occupazione di memoria é illustrata in �gura 4.15.Per la comparazione di questo test con il test U 2 valgono considerazioni analoge a quelle e�ettuate per
la comparazione dei test U 1 con il test U 3.

4.2. TEST ESEGUITI 59
Figura 4.13: Utilizzo della memoria test U 3
(a) dettaglio store (b) percentuale store
(c) dettaglio retrieve (d) percentuale retrieve
Figura 4.14: Tempo di esecuzione test U 4
Figura 4.15: Utilizzo della memoria test U 4

60 CAPITOLO 4. VALUTAZIONE DELLE PRESTAZIONI

Capitolo 5
Conclusioni
Il seguente lavoro è stato realizzato con l'intento di sviluppare nuove soluzioni nell'ambito della contextawarness, ma come evidenziato in questo elaborato, la corretta gestione della memorizzazione dei dati dicontesto é un'area particolarmente ricca di problemi e di s�de da a�rontare, in quanto le variabili da tenerein considerazione sono tante e strettamente interdipendenti tra di loro.
Credo non esista una soluzione che soddis� tutti i requisiti richiesti non apportando alcun svantaggio.In questo progetto ho cercato di sviluppare un sistema quanto piú �essibile possibile, aperto a futuri
nuovi aggiornamenti e che possa risultare il piú scalabile.Come evinto nel capitolo 4, la presente soluzione soddisfa il vincolo delle ridotte capacitá elaborative
richieste a questo tipo di applicazioni.L'utilizzo di una DHT consente di ottenere le richieste di dinamicitá e scalabilitá del sistema mentre
l'utilizzo dell'indicizzazione dei dati consente il soddisfacimento delle speci�che di e�cienza nelle query. Lapossibilitá o�erta ai vendor di poter scrivere la loro parte dei dati dei sensori a loro piacimento, al contempo,consente sia la gestione di dati multi-attributo che la futura estensione del sistema per la gestione di sensorinon previsti al tempo della progettazione.
Vivere in un edi�cio intelligente signi�ca prima di tutto comoditá e controllo: la casa �pensa�, interpretaogni desiderio di comfort e lo realizza senza che si muova un dito.
La scelta di questo tipo di impianti comporta una scelta �loso�ca di fondo: �ducia nei confronti del-l�elettronica e delle sue possibilitá.
Penso di poter prevedere che, dopo alcuni anni di reticenza, tutti gli impianti di un certo livello verrannoeseguiti con una massiccia dipendenza dall�elettronica.
Viviamo in un'epoca in cui l'automazione é sempre più incalzante. La domotica quale scienza interdis-ciplinare che si occupa dello studio delle tecnologie per migliorare la qualitá della vita nella casa ed altrovesará l'obiettivo per la realizzazione di un sistema che consentirá a qualsiesi persona anche colpita da de�citsensoriali o ridotte capacità motorie di poter condurre una vita quanto più possibile autonoma.
É l'applicazione tecnologica del futuro peraltro non tanto lontano.
61

62 CAPITOLO 5. CONCLUSIONI

Bibliogra�a
[1] Anid K. Day, Gregory D. Abows and Daniel Salber: A conceptual framework and a toolkitfor supporting the rapid prototyping of context aware application
[2] S. M. Faisal, Mohammad Rezwanul Huq and A. S. M. Ashique Mahmood: Contextrepository architecture for Smart Collaborative Environment
[3] Tao Gu, Edmond Tan, Hung Keng Pung and Daqing Zhang: A peer-to-peer architecturefor context lookup
[4] M. Cai and M. Frank: RDFPeers: A scalable distributed RDF repository based on AStructured Peer-to-Peer Network
[5] Minqi Zhou, Rong Zhang, Weining Qian, Aoying Zhou: GChord: Indexing for multi-attribute query in P2P system with low maintenance cost
[6] Antonios Daskos, Shahram Ghandeharizadeh and Xinghua An:PePeR: A distributed rangeaddressing space for peer-to-peer systems
[7] Gnutella, http://gnutella.wego.com
[8] Freenet http://freenetproject.org/
[9] M. Marzolla, M. Mordacchini, S. Orlando: Tree Vector Indexes: E�cient range queriesfor dynamic content on peer-to-peer networks
[10] Antony Rowstron and Peter Druschel: Pastry: Scalable, decentralized object location androuting for large-scale peer-to-peer systems.
63


















