
Microeconometria Day #wpage.unina.it/cembalo/microeconometria/Lez1_26Nov/Lez...Metodi e modelli...
41
Microeconometria Day # 1 L. Cembalo
Transcript of Microeconometria Day #wpage.unina.it/cembalo/microeconometria/Lez1_26Nov/Lez...Metodi e modelli...

MicroeconometriaDay # 1
L. Cembalo

Metodi e modelli statistici ed econometria - Microeconometria durata del corso: dal 26 Novembre 2018 al 7 Febbraio 2019
48 ore di lezioni
Regressione lineare multipla – OLS e temi avanzati
Rimozione delle ipotesi e test
Metodi di stima robusti e regressione quantile
Modelli con variabile dipendente qualitativa – Probit, Logit, Normit
Modello SUR (Seemingly Unrelated Regression)
STATA

Valutazione
Sistema di valutazione:
Esame intermedio (11/1/19) 30%
Esame finale 70%
Cameron A.C., and Trivedi P.K. Microeconometrics: Methods and Applications. Cambridge University Press.
Cameron A.C., and Trivedi P.K. Microeconometrics Using Stata. Stata Press
Gujarati D.N. Basic econometrics. Tata McGraw-Hill Education
3

Luigi [email protected]. 081 25 39056
http://wpage.unina.it/cembalo/microeconometria/
Microeconometria



Econometria: quale definizionese chiedessimo a una mezza dozzina di econometria cos’è l’econometria oterremmo, probabilmente, le seguenti risposte
è una scienza che verifica (test) la teoria economica è un insieme di strumenti usati per la previsione di valori futuri di variabili economiche è un processo che consente di modellizzare dati derivanti dal mondo reale è una scienza e un’arte che usa dati storici per dare suggerimenti di politica attraverso dati qualitativi e quantitativi
qual è, secondo voi, quella giusta?

Tutte le risposte sono corretteIn termini generali, l’econometria è la scienza e arte di usare la teoria economica combinata con tecniche statistiche per analizzare dati. L’econometria è usata in molti campi dell’economia, incluso la finanza, l’economia del lavoro, la macro e microeconomia, l’economia agraria, il marketing e l’economia politica. Anche le scienze sociali, le scienze politiche e la sociologia fanno uso di strumenti econometrici.



Premi Nobel
“per lo sviluppo di teoria e metodi per analizzare i selective samples”
“per lo sviluppo di teoria e metodi per analizzare i discrete choice”

b. 1937b. 1944
University of California Berkeley, CA, USA
University of Chicago Chicago, IL, USA
1/2 of the prize1/2 of the prizeDaniel L. McFaddenJames J. Heckman

Filosofia dello studio:
L’unico modo per imparare l’econometria è di usare computer e software su dati reali. Questo significa saper manipolare dati usando uno specifico software (STATA) in grado di far girare routine di ottimizzazione numerica e matematica.
Filosofia dell’econometria:
comprendere il data generating process è una condizione necessaria. Questo significa comprendere gli aspetti istituzionali della domanda di ricerca.
Citazione da Johnston p.499 If computers are essentially free goods, if “researchers” can plug in a data bank without any understanding of where the series come from or how they are constructed, if they can press buttons to implement computer programs whose contents they dimly understand, it then follows, as night follows the day, that some work of zero worth will emerge. Indeed, give the uncertainty inherent in the research process, compounded by the fallibility of the researcher, some outputs may err on the wrong side of zero and be positively dangerous.

Nell’econometria l’uso del termine “popolazione” è semplicemente una metafora. Un concetto più appropriato è quello del DGP: data-generating process or DGP. Per DGP si intende qualsivoglia meccanismo/processo in azione nel mondo reale, legato ad attività economiche, che generano numeri che fanno parte del nostro campione, cioè il meccanismo che il nostro modello econometrico intende descrivere
Data Generating Process

A data-generating process is the analog in econometrics of a population in biostatistics. Samples may be drawn from a DGP just as they may be drawn from a population. In both cases, the samples are assumed to be representative of the DGP or population from which they are drawn.
Davidson & MacKinnon
Data Generating Process

L’applicazione dei metodi econometrics richiede la complementarietà dell’uso della statistica e della teoria economica. Se si ritiene di voler generare risultati utili, ci sono altri ingredienti necessari che spesso non sono esplicitamente insegnati durante i corsi di econometria. Due tra i più importanti sono: (i) prendere familiarità con i dati; e (ii) la familiarità con l’ambiente istituzionale
Considerazione sui dati: Una massima spesso enunciata dice che i risultati dell’econometria sono tanto buoni quanto lo sono i dati utilizzati per le stime. La massima, comunque, implicitamente assume un altro concetto, ovvero come è possibile valutare la qualità dei dati. La mia esperienza mi dice che non c’è un approccio fisso o standard per valutare la qualità dei dati. In alcuni casi utilizzeremo delle tecniche statistiche, in altri verrà richiesta una valutazione più soggettiva. Il miglior consiglio è: sii curioso e non dare nulla per scontato.
la pulizia dei dati è comprendere i punti di forza e di debolezza dei dati non sono attività accessorie. Avere un database pulito è essenziale per le stime, l’inferenza e la previsione. Altrettanto importante è il processo di pulizia dei dati e la familiarizzazione con essi.
Conoscere i propri dati e il DGP

Conoscere i propri dati e il DGP
Institutional Setting: quasi tutti i problemi economici accadono in un particolare contesto istituzionale. Per istituzioni si intende l’insieme di regole, esplicite e implicite, che governano le attività economiche. Esplicite sono quelle regole stabilite dai sistemi legali e regolamentati da agenzie che implementano e controllano le regole. Sebbene le regole possono essere complesse, possono essere verificate se attentamente ricercate.
Le regole implicite, per loro natura, sono molto più complesse da comprendere. Per esempio i business models possono essere di diversa natura e difficilmente comprensibili a prima vista. Nel USA i contratti sono quasi sempre formali mentre in Italia no.

Il misterioso DGP:
A prescindere da quale problema si analizza è sempre utile porsi le seguenti domande al fine di comprendere il DGP.
Chi sono gli agenti economici di cui vogliamo studiare-spiegare-prevedere il comportamento?
Quali tipi di eteregeneità ci aspettiamo nell’osservazione della popolazione degli agenti?
Quali sono gli obiettivi degli agenti economici?
Come prendono le decisioni (quale processo decisionale) gli agenti?
Quali aspetti del comportamento possiamo osservare e quali no?
Quali eventi esogeni possono influenzare gli agenti economici?
Come sono raccolti i dati relativi al fenomeno economico oggetto di studio?
Quali sono le potenziali fonti di errore nella raccolta dei dati?
Qual’è il time-frame in cui i dati sono raccolti?
Conoscere i propri dati e il DGP
Prendi nota di queste e altre domande ogni volta che lavori con nuovi dati

Esperimenti, esiti e variabili casuali
Qual’è la fonte dei dati?
esperimenti controllati - dati sperimentali
esperimenti medici, esperimenti di laboratorio
uncontrolled experiments - dati non sperimentali
variabili socioeconomiche, prodotto nazionale lordo, tasso di interesse, prezzo di un bene, disponibilità a pagare, e così via

Tipologia di approccioCausal explanation
quello a cui di solito pensiamo Y=f(X,Z,beta)
il ricercatore è esogeno al DGP
Quasi experiment
osservazione
Experiment
DGP controllato
il ricercatore è endogeno al DGP

Casual explanationY = f(X, Z, beta)
Con questo approccio siamo interessati a identificare il ruolo di X attraverso la stima del vettore dei coefficienti beta
Tuttavia,
1. il livello di risposta di Y alla X (attraverso i coefficienti) dipenderà anche da Z e da altre potenziali variabili omesse nel modello di stima
2. La X deve essere esogena, ovvero non deve esserci: reverse causality, eterogeneità non osservata, sample selection
Tutto quanto non controllato influenza la stima di Y

EsperimentiUn esperimento è costruito e implementato dal ricercatore, ovvero il ricercatore è endogeno al DGP
Un esperimento necessita di una costruzione cosciente del gruppo “trattato” e di quello di “controllo” con una assegnazione casuale del trattamento
in questo modo il DGP è noto e condizionato dal ricercatore, nel bene e nel male!!!!!


Una delle sfide nelle ricerche economiche è di ottenere dati che sono consistenti con le variabili teoriche nei modelli economici e che sono utili nell’analizzare un problema economico
Esperimenti, esiti e variabili casuali
Una variabile casuale è una variabile il cui valore è incognito fino a quando non è osservata. Tuttavia, il valore di una variabile casuale non è perfettamente prevedibile a causa della cosiddetta variazione campionaria
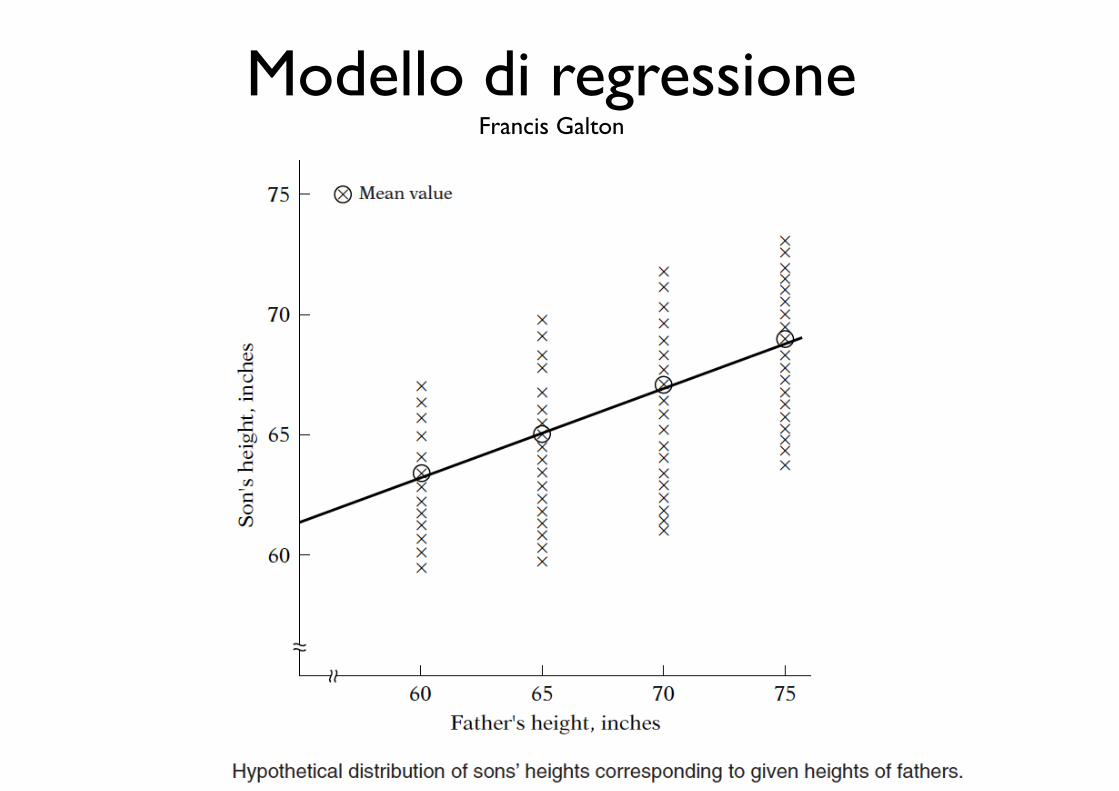
Modello di regressioneFrancis Galton
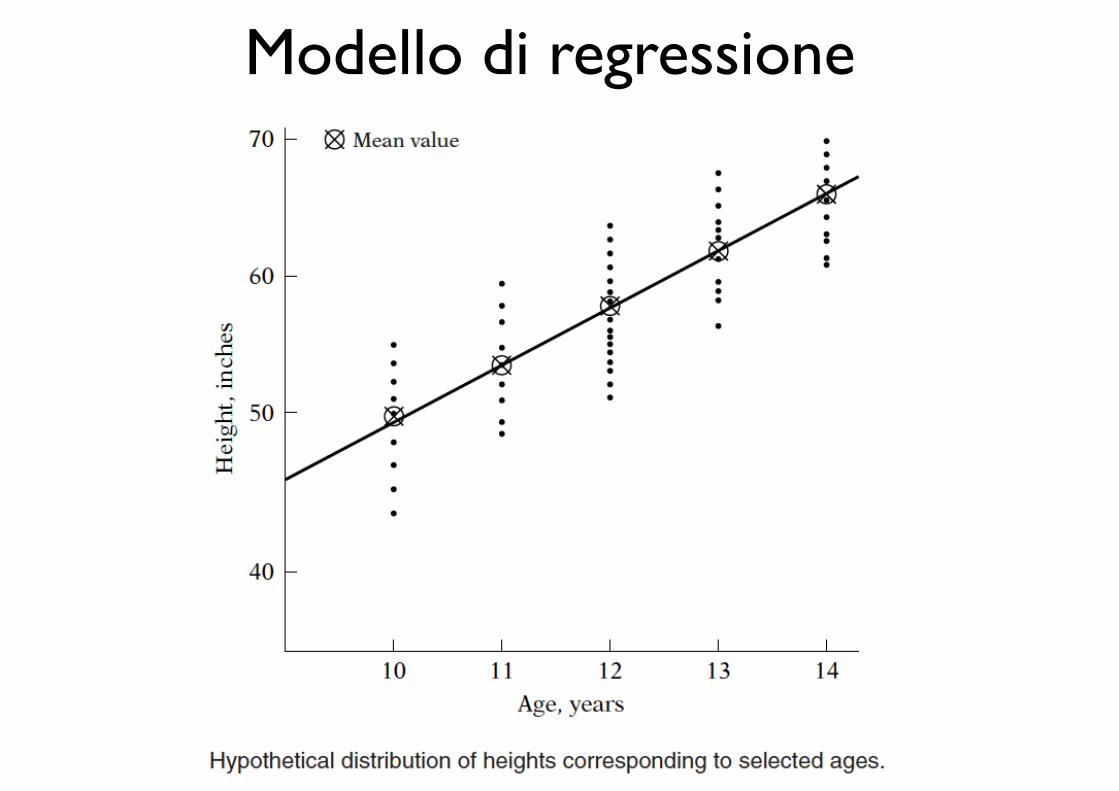
Modello di regressione
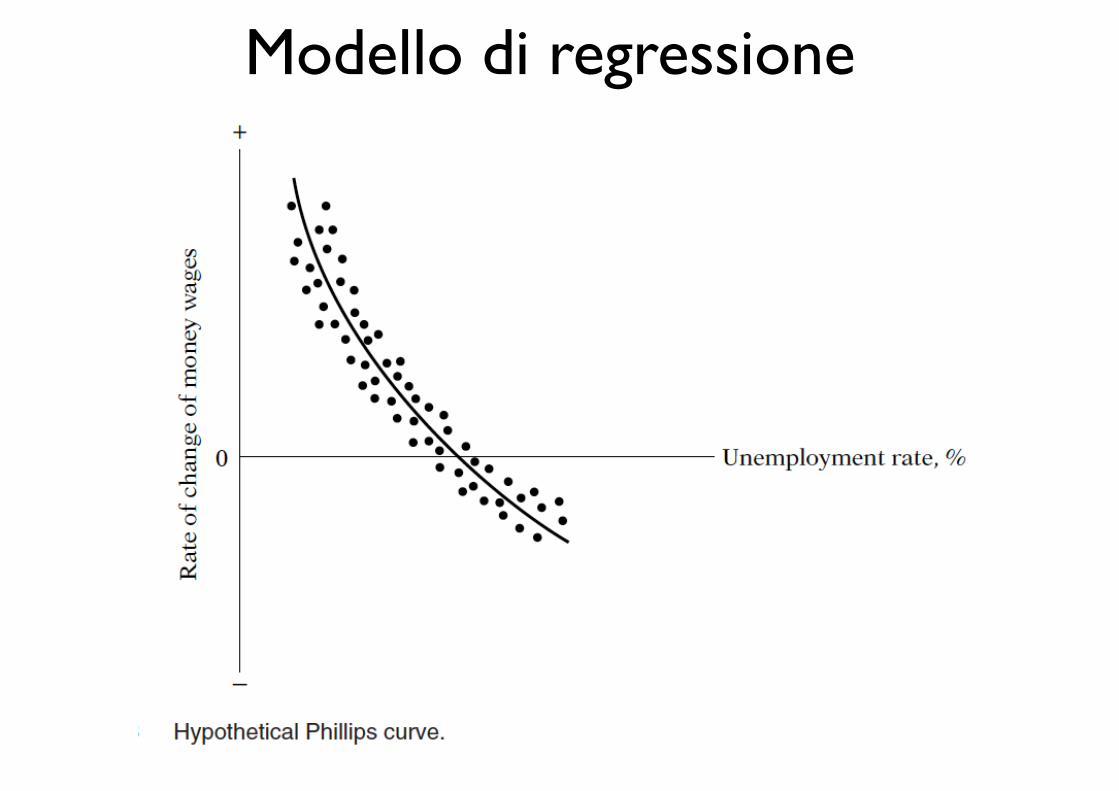
Modello di regressione
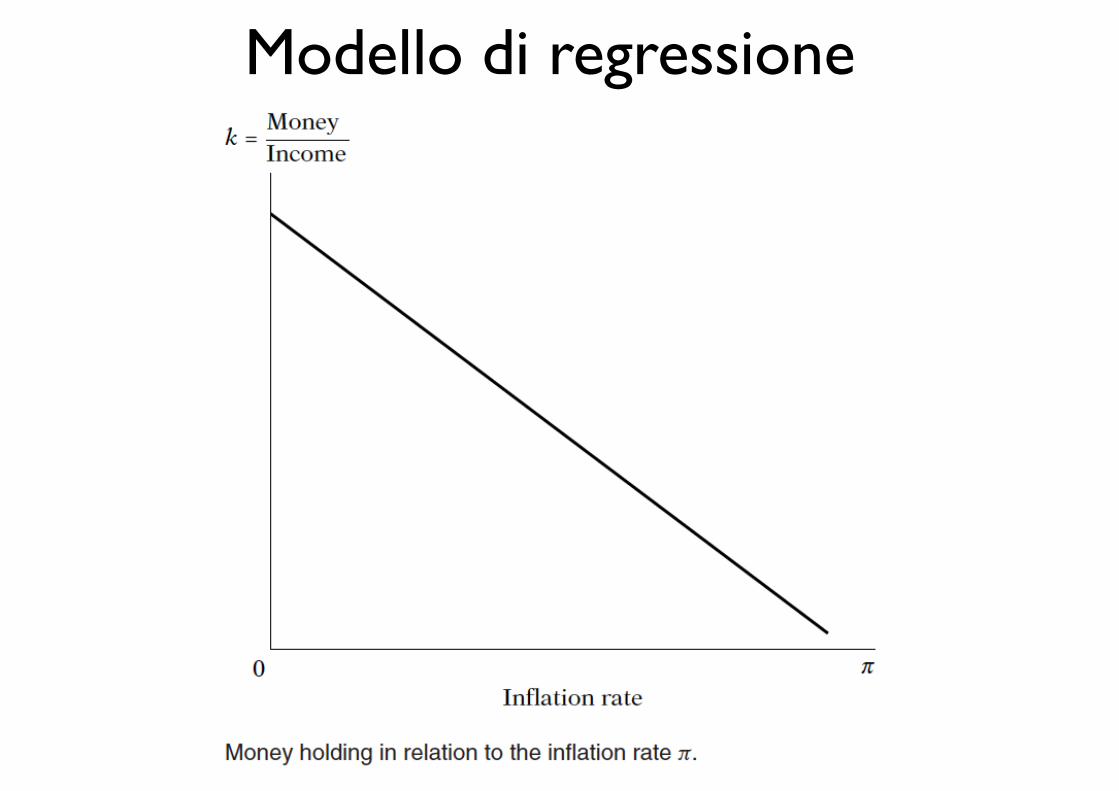
Modello di regressione

Modello di regressione relazioni statistiche vs deterministiche
Nelle relazioni statistiche tra variabili essenzialmente abbiamo a che fare con variabili casuali o stocastiche, ovvero variabili che hanno distribuzioni in probabilità. Una dipendenza funzionale o deterministica, invece, pur avendo a che fare con variabili, queste non sono casuali o stocastiche.
La legge di Newton sulla gravità dice: ogni particella nell’universo attrae ogni altra particella con una forza direttamente proporzionale al prodotto della loro massa e inversamente proporzionale al quadrato della loro distanza (deterministic)

Modello di regressione regressione vs causalità
La regression ha a che fare con la dipendenza di una variabile da altre variabili. Questo non necessariamente implica causalità. La causalità (decidere quale variabili dipende da un’altra), non ha a che fare con la statistica.Nella resa di una coltura non c’è alcuna ragione statistica per assumere che la pioggia non dipenda dalla resa di una coltura. Il fatto che noi decidiamo che è la resa a dipendere dalla quantità di pioggia (così come da tante altre variabili) è dovuto a considerazioni non-statistiche: il senso comune suggerisce che la relazione non può essere che questa, in quanto osserviamo che non possiamo controllare la piovosità variando la resa delle colture. In molti casi il puIn many cases the point to note is not da notare è che relazioni statistiche non possono avere logicamente una implicazione causale.

Modello di regressione regression vs correlation
Un concetto molto vicino a quello appena esposto riguarda l’analisi delle correlazioni dove l’obiettivo primario è di misurare l’intensità o il grado di associazione lineare tra due variabili.
La regressione e la correlazione hanno diverse differenze fondamentali have some che è bene che chiariamo. In una regressione c’è asimmetria nel modo col quale trattiamo la variabile dipendente da quella esplicativa. La variabile dipendente viene assunta essere statistica, casuale o stocastica, cioè avere una distribuzione in probabilità. Le variabili esplicative, invece, sono assunte come valori fissi (in campionamenti ripetuti)

Modello di regressione regression vs correlation
Nell’analisi delle correlazioni, invece, trattiamo ognuna delle variabili simmetricamente; non c’è differenza tra variabile dipendente e variabile esplicativa. Ad esempio, la correlazione tra i voti in matematica e statistica è la stessa di quella tra statistica e matematica. Inoltre, entrambe le variabili sono assunte come casuali. La maggior parte della teoria della correlazione è basata sull’assunzione di casualità, mentre la gran parte della teoria delle regressioni fa riferimento all’assunzione secondo la quale la variabile dipendente è stocastica mentre quelle esplicative sono fisse o non-stocastiche.

Modello di regressione singola terminologia

Modello di regressione singola tipi di dati
• Serie storiche
• Cross section
• Pooled data • elementi cross section nel tempo (serie storiche)
• Panel, longitudinal, o micropanel • tipi speciali di pooled data in cui la stessa unità (famiglia o impresa) è
osservata nel tempo
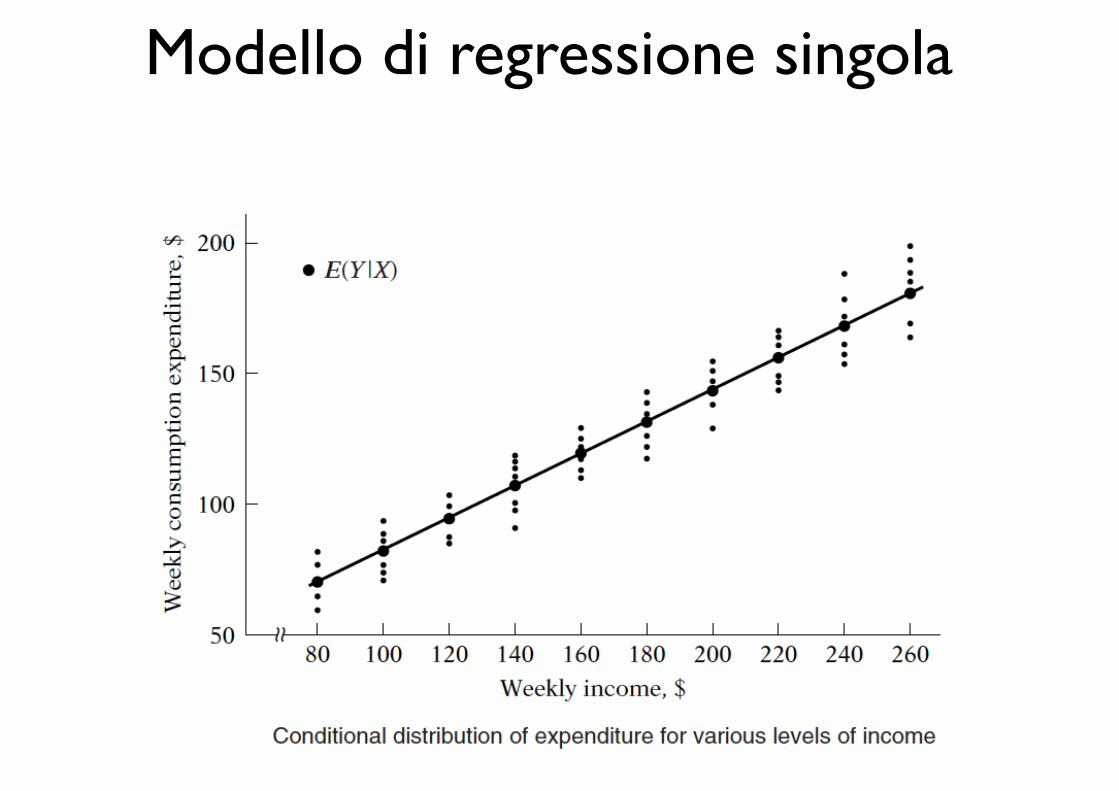
Modello di regressione singola
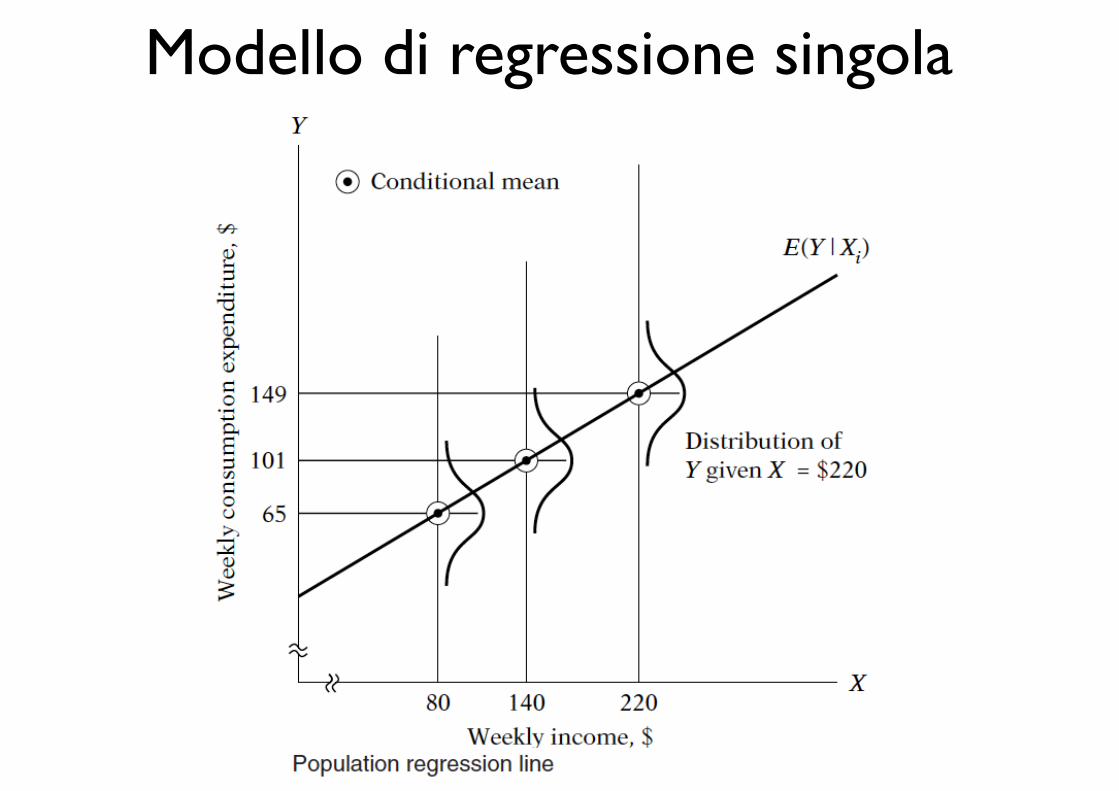
Modello di regressione singola
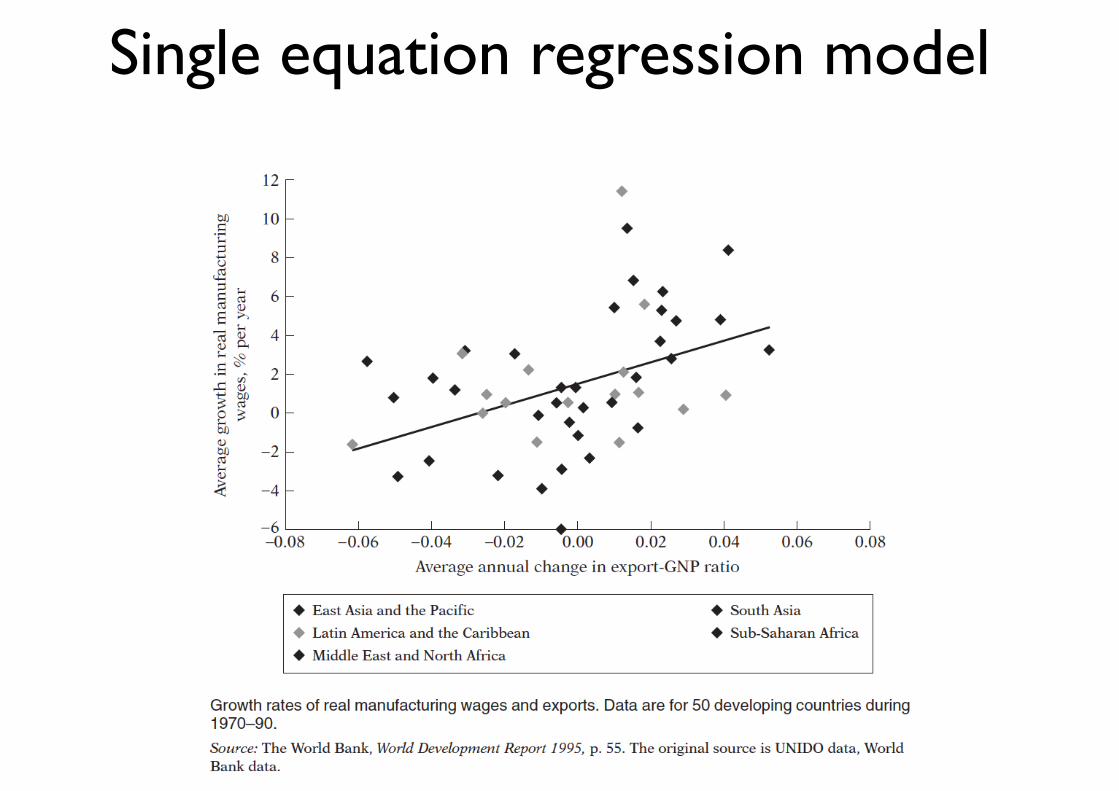
Single equation regression model
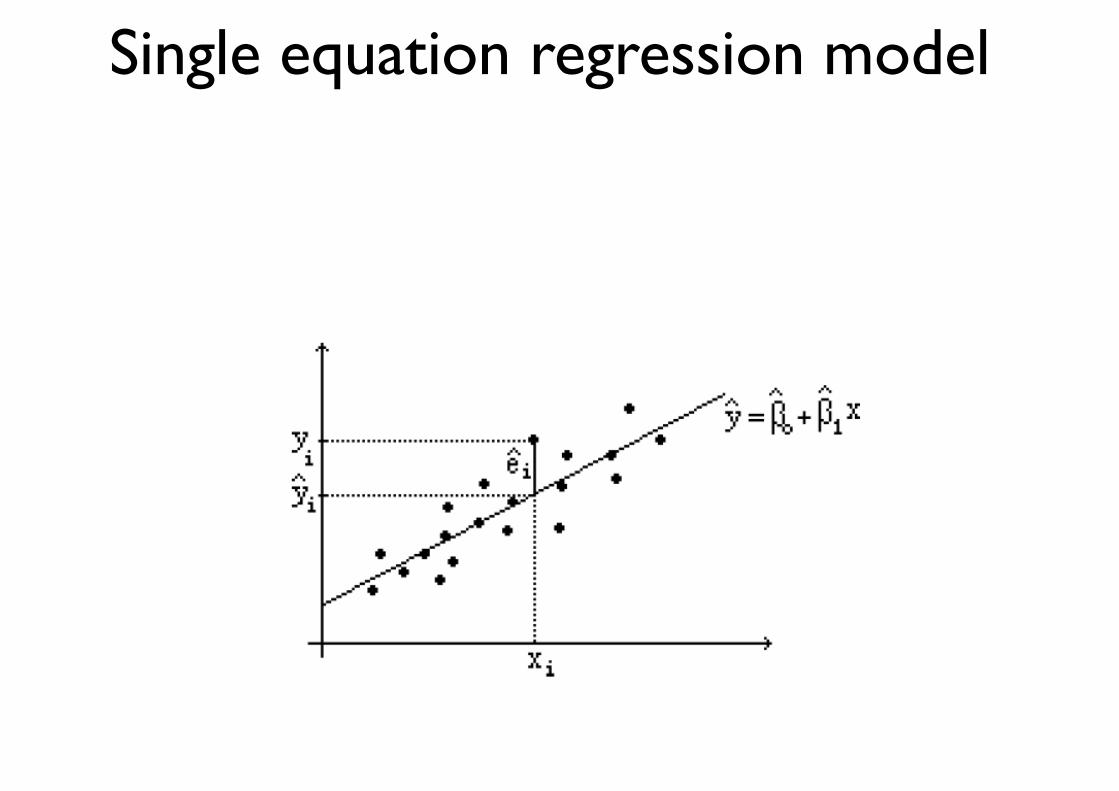
Single equation regression model
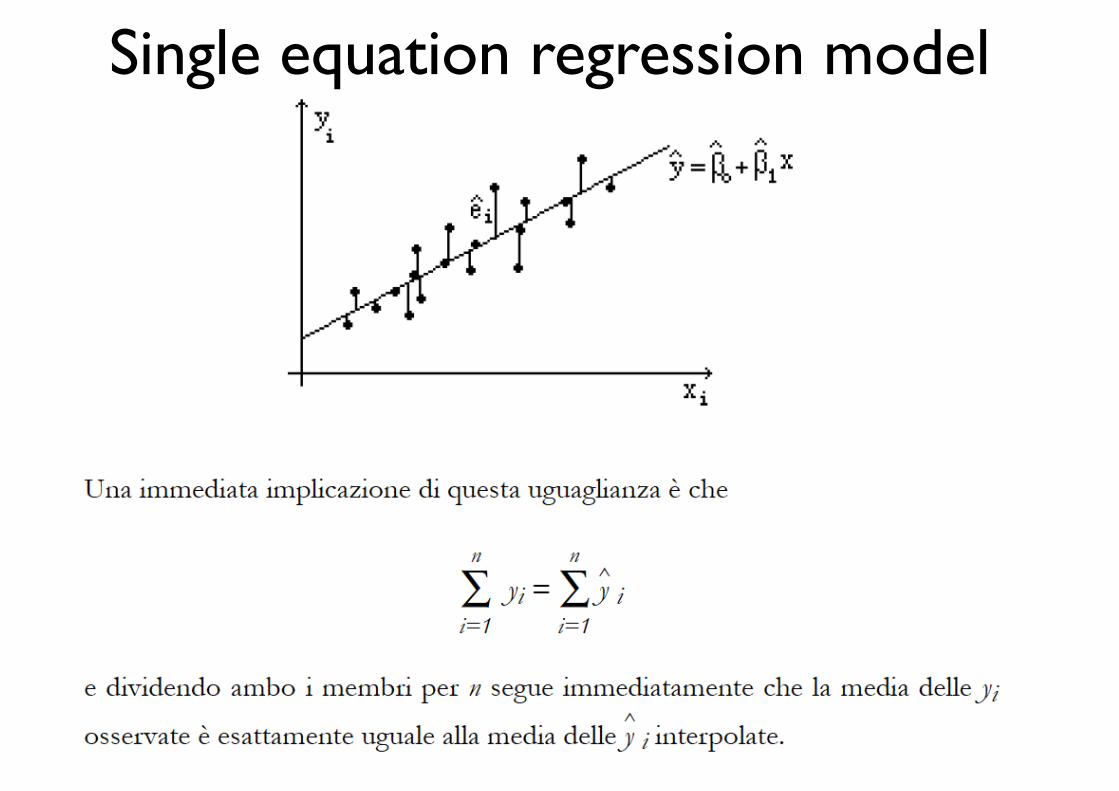
Single equation regression model


















