
Mercoledì, 21 Febbraio 2007 Giuseppe Manco Readings: Chapter 8, Han and Kamber
48
Clustering Mercoledì, 21 Febbraio 2007 Giuseppe Manco Readings: Chapter 8, Han and Kamber Chapter 14, Hastie , Tibshirani and Friedman Clustering Lecture 10 Lecture 10
-
Upload
cadence-fidel -
Category
Documents
-
view
25 -
download
0
description
Lecture 10. Clustering. Mercoledì, 21 Febbraio 2007 Giuseppe Manco Readings: Chapter 8, Han and Kamber Chapter 14, Hastie , Tibshirani and Friedman. Introduction K-means clustering Hierarchical clustering: COBWEB. Outline. Apprendimento supervisionato. Dati - PowerPoint PPT Presentation
Transcript of Mercoledì, 21 Febbraio 2007 Giuseppe Manco Readings: Chapter 8, Han and Kamber

Clustering
Mercoledì, 21 Febbraio 2007
Giuseppe Manco
Readings:Chapter 8, Han and Kamber
Chapter 14, Hastie , Tibshirani and Friedman
Clustering
Lecture 10Lecture 10

Clustering
OutlineOutline
• Introduction• K-means clustering• Hierarchical clustering: COBWEB

Clustering
Apprendimento supervisionatoApprendimento supervisionato
• Dati– Un insieme X di istanze su dominio multidimensionale
– Un funzione target c
– Il linguaggio delle ipotesi H
– Un insieme di allenamento D = {<x,c(x)>}
• Determinare– L’ipotesi h H tale che h(x) = c(x) per ogni x D
– Che sia consistente con il training set

Clustering
Supervised vs. Unsupervised LearningSupervised vs. Unsupervised Learning
• Supervised learning (classificazione)
– Supervisione: il training set contiene l’etichetta che indica la classe da apprendere
– I nuovi dati sono classificati sulla base di quello che si apprende dal training set
• Unsupervised learning (clustering)
– L’etichetta di classe è sconosciuta
– Le istanze sono fornite con l’obiettivo di stabilire se vi sono raggruppamenti (classi) tra i
dati

Clustering
Classificazione, ClusteringClassificazione, Clustering
Classificazione: Apprende un metodo per predire la classe dell’istanza da altre istanze pre-classificate
Clustering
ClusteringClustering
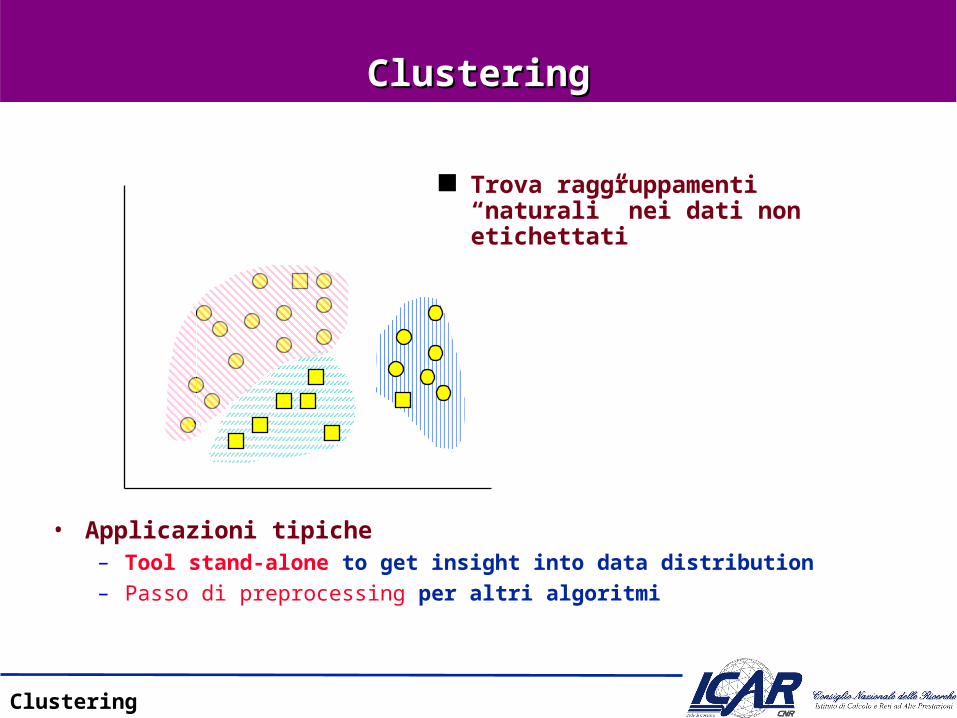
Trova raggruppamenti “naturali” nei dati non etichettati
• Applicazioni tipiche– Tool stand-alone to get insight into data distribution – Passo di preprocessing per altri algoritmi

Clustering
Clustering, clustersClustering, clusters
• Raggruppamento di dati in classi (clusters) che abbiano una significatività
– alta similarità intra-classe
– Bassa similarità inter-classe
• Qualità di uno schema di clustering
– La capacità di ricostruire la struttura nascosta
• similarità

Clustering
Similarità, distanzaSimilarità, distanza
• Distanza d(x,y)– Misura la “dissimilarità tra gli oggetti”
• Similarità s(x,y)– S(x,y) 1/d(x,y)
– Esempio
• Proprietà desiderabili
• Definizione application-dependent– Può richiedere normalizzazione
– Diverse definizioni per differenti tipi di attributi
),(),( yxdeyxs
),(),(),(
),(),(
0),(
0),(
jkkiji
ijji
ii
ji
ddd
dd
d
d
xxxxxx
xxxx
xx
xx
Clustering
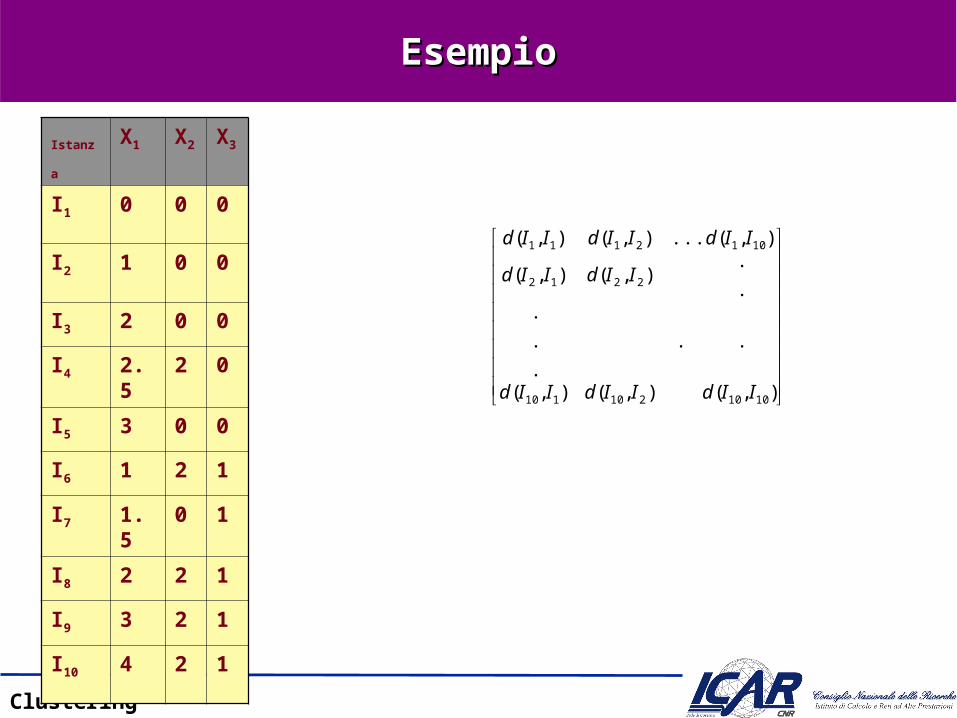
EsempioEsempio
Istanza X1 X2 X3
I1 0 0 0
I2 1 0 0
I3 2 0 0
I4 2.5 2 0
I5 3 0 0
I6 1 2 1
I7 1.5 0 1
I8 2 2 1
I9 3 2 1
I10 4 2 1
),(),(),(
..
.
.
..
.),(),(
),(...),(),(
1010210110
2212
1012111
IIdIIdIId
IIdIId
IIdIIdIId

Clustering
Similarità e dissimilarità tra oggettiSimilarità e dissimilarità tra oggetti
• La distanza è utilizzata per misurare la similarità (o dissimilarità) tra due istanze
• Distanza di Minkowski (Norma Lp):
– Dove x = (x1, x2, …, xd) e y = (y1, y2, …, yd) sono due oggetti d-dimensionali, e p è l’ordine
della distanza
• se p = 1, d è la distanza Manhattan
• Se p=
d
iii yxyxdist
1
),(
pd
i
p
ii yxyxdist/1
1
),(
iidi
yxyxdist 1
sup),(

Clustering
Similarità e dissimilarità tra oggetti [2]Similarità e dissimilarità tra oggetti [2]
• se p = 2, d è la distanza euclidea:
– Proprietà
• Translation-invariant
• Scale variant
• Varianti– Distanza pesata
– Distanza Mahalanobis
pd
i
p
iii yxwyxdist/1
1
),(
d
iii yxyxdist
1
2),(
)()(),( 1 yxyxyxdist T

Clustering
EsempioEsempio
00,93,67,658,14,57,655,48,112,6
0,900,95,853,65,45,854,55,48,1
3,60,905,850,98,15,855,44,55,4
7,655,855,8507,657,65185,855,857,65
8,13,60,97,65012,67,658,15,44,5
4,55,48,17,6512,607,650,93,68,1
7,655,855,85187,657,6505,855,857,65
5,44,55,45,858,10,95,8500,93,6
8,15,44,55,855,43,65,850,900,9
12,68,15,47,654,58,17,653,60,90
0124,5342,5567
1013,5231,5456
2102,5141,5345
4,53,52,502,52,541,51,52,5
3212,5052,5434
4342,5502,5123
2,51,51,542,52,502,53,54,5
5431,5412,5012
6541,5323,5101
7652,5434,5210
Euclidea
manhattan
mahalanobis
0123,201632,44951,802833,74174,5826
1012,522,23611,1182,449533,7417
2102,061612,44951,1182,23612,44953
3,20162,52,061602,06161,80282,44951,1181,1181,8028
3212,0616031,80282,44952,23612,4495
2,44952,23612,44951,8028302,0616123
1,80281,1181,1182,44951,80282,061602,06162,53,2016
32,44952,23611,1182,449512,0616012
3,741732,44951,1182,236122,5101
4,58263,741731,80282,449533,2016210

Clustering
Similarità e dissimilarità tra oggetti [3]Similarità e dissimilarità tra oggetti [3]
• Similarità del coseno
– Proprietà
• Translation variant• Scale invariant
• Similarità di Jaccard (Tanimoto)
• Similarità di Jaccard (Tanimoto)
yx
yxyxsim
T
),(
yxyx
yxyxsim
T
T
22),(
yx
yxyxsim
),(
Clustering
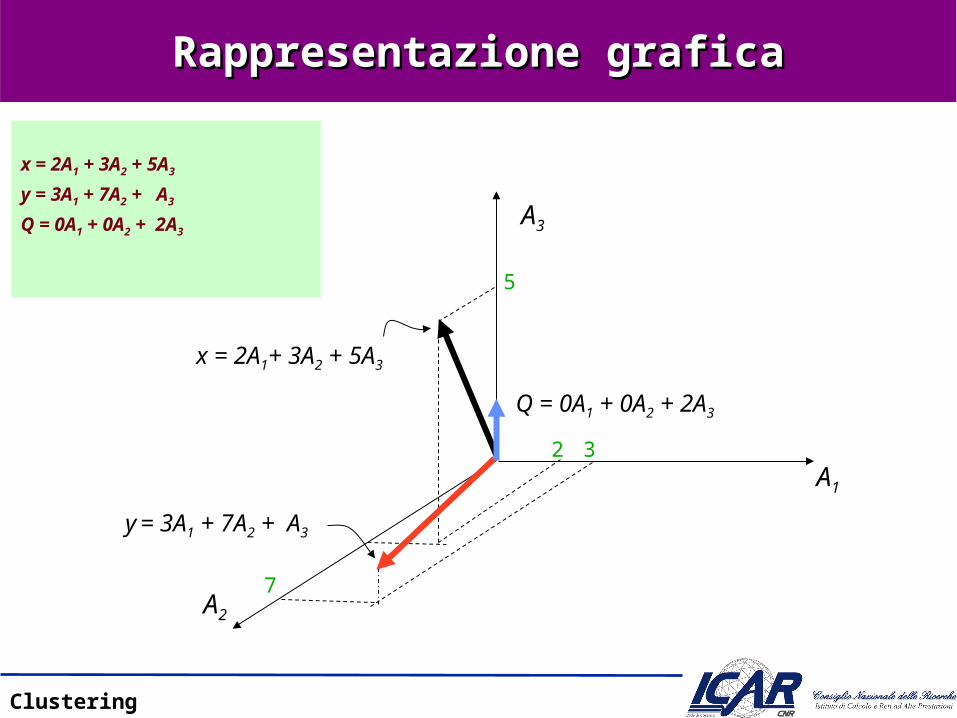
Rappresentazione graficaRappresentazione grafica
x = 2A1 + 3A2 + 5A3
y = 3A1 + 7A2 + A3
Q = 0A1 + 0A2 + 2A3A3
A1
A2
x = 2A1+ 3A2 + 5A3
y = 3A1 + 7A2 + A3
Q = 0A1 + 0A2 + 2A3
7
32
5

Clustering
Rappresentazione graficaRappresentazione grafica
euclidea Coseno Jaccard

Clustering
EsempioEsempio
0123,201632,44951,802833,74174,5826
1012,522,23611,1182,449533,7417
2102,061612,44951,1182,23612,44953
3,20162,52,061602,06161,80282,44951,1181,1181,8028
3212,0616031,80282,44952,23612,4495
2,44952,23612,44951,8028302,0616123
1,80281,1181,1182,44951,80282,061602,06162,53,2016
32,44952,23611,1182,449512,0616012
3,741732,44951,1182,236122,5101
4,58263,741731,80282,449533,2016210
00,0080,0540,150,190,120,040,120,120
0,00800,020,180,120,190,0390,190,190
0,0540,02200,260,040,330,060,330,330
0,150,180,2600,430,160,350,160,160
0,190,120,040,4300,590,170,590,590
0,120,190,330,160,5900,21000
0,0450,030,060,350,170,2100,210,210
0,120,190,330,160,5900,21000
0,120,190,330,160,5900,21000
0000000000
00,9440,7650,4060,50,6670,8120,4710,2220
0,94400,9170,4680,6670,6430,9020,50,250
0,7650,91700,4850,8750,50,8780,4440,250
0,4060,4680,48400,370,5810,3850,7060,5450
0,50,6670,8750,3700,250,6670,250,1670
0,6670,6430,50,5810,2500,6380,8570,4280
0,8120,9020,8780,3850,6670,63800,540,2860
0,4710,50,4440,7060,250,8570,54100,6670
0,2220,250,250,5450,1670,4290,2860,66700
0000000000
Euclidea
Jaccard
Coseno

Clustering
Attributi binariAttributi binari
• Distanza di Hamming
– Distanza Manhattan quando i valori possibili sono 0 o 1
• In pratica, conta il numero di mismatches
altrimenti0
se1),(
),(),(11
iiii
d
iii
d
iii
yxyx
yxyxyxdist

Clustering
Attributi binariAttributi binari
• Utilizzando la tabella di contingenza
• Coefficiente di matching (invariante, se le variabili sono simmetriche):
• Coefficiente di Jaccard (noninvariante se le variabili sono asimmetriche):
dcbacb yxd
),(
cbacb yxd
),(
pdbca
dcdc
baba
totale
totale
0
1
01
Oggetto x
Oggetto y

Clustering
Dissimilarità tra attributi binariDissimilarità tra attributi binari
• Esempio
– gender è simmetrico– Tutti gli altri sono asimmetrici– Poniamo Y e P uguale a 1, e N a 0
Name Gender Fever Cough Test-1 Test-2 Test-3 Test-4
Jack M Y N P N N NMary F Y N P N P NJim M Y P N N N N
75.0211
21),(
67.0111
11),(
33.0102
10),(
maryjimd
jimjackd
maryjackd

Clustering
Variabili NominaliVariabili Nominali
• Generalizzazione del meccanismo di variabili binarie
• Metodo 1: Matching semplice
– m: # di matches, p: # di attributi nominali
• metodo 2: binarizzazione
• Metodo 3: Jaccard su insiemi
pmpyxd ),(

Clustering
Combinare dissimilaritàCombinare dissimilarità
• x,y– xR, yR: attributi numerici
– xn, yn: attributi nominali
– Va garantita la stessa scala
),(),(),( nnRR yxdistyxdistyxdist

Clustering
Metodi di clusteringMetodi di clustering
• Una miriade di metodologie differenti:– Dati numerici/simbolici– Deterministici/probabilistici– Partizionali/con overlap– Gerarchici/piatti– Top-down/bottom-up

Clustering
Clustering per enumerazioneClustering per enumerazione
• Utilizzando come criterio
• Il numero di possibili clusterings sarebbe
• S(10,4)=34.105
Cx Cy
yxdistCw ),()(
nk
i
ik ii
k
kknS
1
)1(!
1),(

Clustering
L’algoritmo più semplice: K-meansL’algoritmo più semplice: K-means
• Algorithm K-Means(D, k)
– m D.size // numero di istanze
– FOR i 1 TO k DO
i random // scegli un punto medio a
caso
– WHILE (condizione di terminazione)
• FOR j 1 TO m DO // calcolo del cluster membership
• h argmin1≤i ≤kdist(xj, i)
C[h] xj
• FOR i 1 TO k DO
i
– RETURN Make-Predictor (w, P)
][
1
iCxj
i j
xn
Clustering
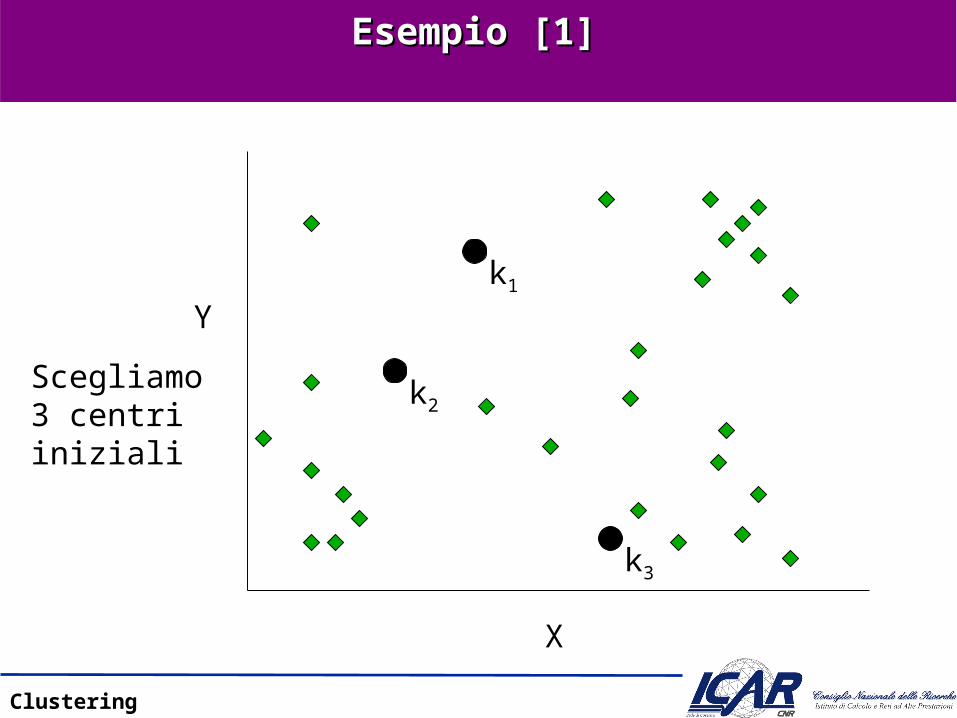
Esempio [1]Esempio [1]
k1
k2
k3
X
Y
Scegliamo3 centri iniziali
Clustering
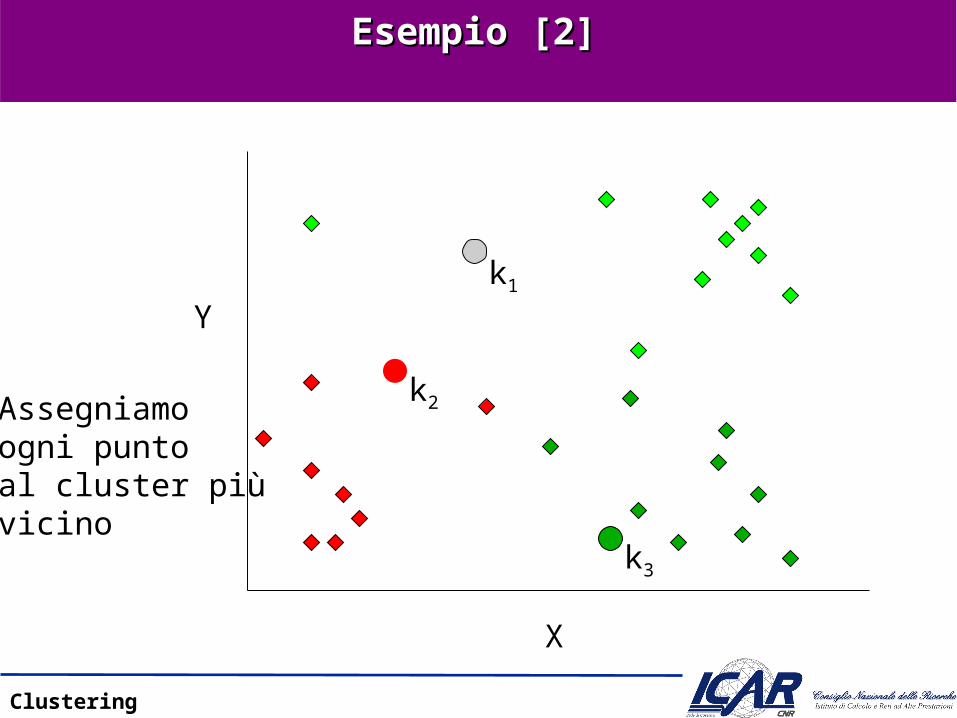
Esempio [2]Esempio [2]
k1
k2
k3
X
Y
Assegniamoogni puntoal cluster piùvicino

Clustering
Esempio [3]Esempio [3]
X
Y
Ricalcoliamoil centroide
k1
k2
k2
k1
k3
k3

Clustering
Esempio [4]Esempio [4]
X
Y
Riassegniamoi punti ai clusters
k1
k2
k3

Clustering
Esempio [5]Esempio [5]
X
Y
Punti riassegnati
k1
k3k2
Clustering
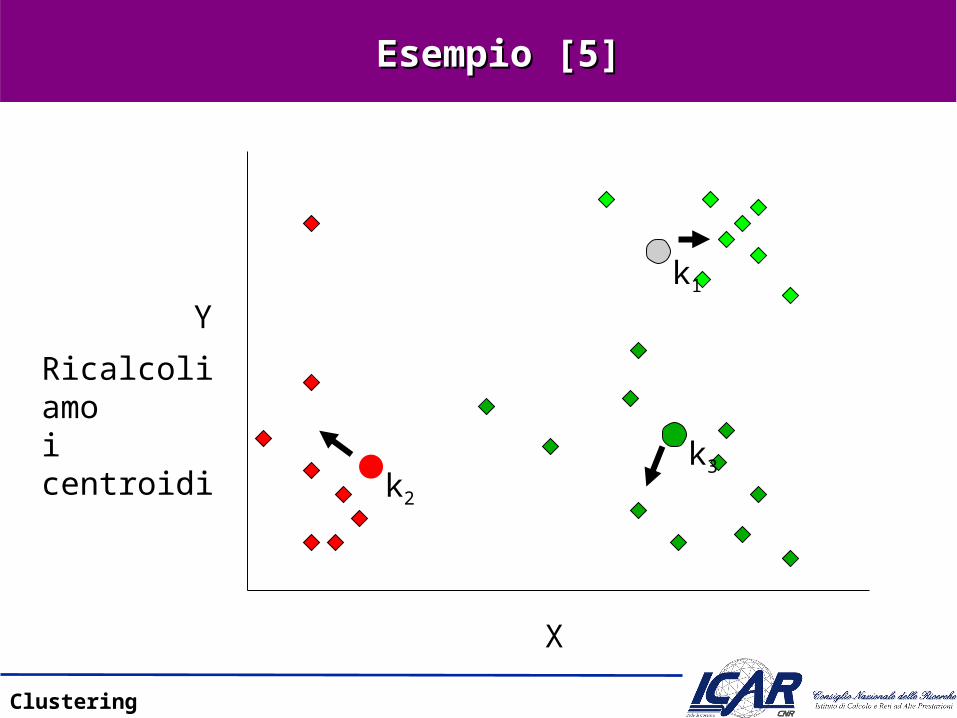
Esempio [5]Esempio [5]
X
Y
Ricalcoliamoi centroidi
k1
k3k2

Clustering
Esempio [7]Esempio [7]
X
Y
k2
k1
k3

Clustering
Quale criterio di stop?Quale criterio di stop?
• Cos’è il centroide?
• Misura della compattezza di un cluster
• Misura della compattezza del clustering
• Teorema– Ad una generica iterazione t,
Cx
cxdistCt ),()(cos
SC
ik
i
CtCCSt )(cos]),...,[(cos 1
)(cos)(cos 1 tt StSt
),(minarg yxdistCxXy
c

Clustering
Il metodo K-MeansIl metodo K-Means
• Vantaggi: Relativamente efficiente: O(tkn), dove n è il numero di oggetti, k il numero di
clusters e t il numero di iterazioni. Di solito, k, t << n.
• Al confronto: PAM: O(k(n-k)2 ), CLARA: O(ks2 + k(n-k))
• Converge ad un ottimo locale. L’ottimo globale può essere trovato ricorrendo a varianti
(ad esempio, basati su algoritmi genetici)
• Punti critici
– Applicabile solo quando il punto medio ha senso
• Attributi nominali?
– K va dato in input
• Qual’è il numero ottimale?
– Incapace di gestire outliers e rumore
– Non adatto a scoprire forme non convesse

Clustering
VariantiVarianti
• Selezione dei centri iniziali
• Strategie per calcolare i centroidi
• L’algoritmo k-modes (Huang’98)
– Dati categorici
– Usiamo le mode invece dei centroidi
– Usiamo Hamming
– L’update si basa sul cambiamento di frequenze
– Modelli misti: k-prototype

Clustering
VariantiVarianti
• K-medoids – invece del centroide, usa il punto mediano
– La media di 1, 3, 5, 7, 9 è
– La media di 1, 3, 5, 7, 1009 è
– La mediana di 1, 3, 5, 7, 1009 è
• Problema: come calcolare il medoide?
5205
5
),(minarg yxdistmCxCy
c

Clustering
Algoritmo PAMAlgoritmo PAM
1. Seleziona k oggetti m1, …, mk arbitrariamente da D
• m1, …, mk rappresentano i medoidi
2. Assegna ogni oggetto xD al cluster j (1 ≤ j ≤ k) che ne minimizza la distanza dal medoide– Calcola cost(S)current
3. Per ogni coppia (m,x)1. Calcola cost(S)xm
4. Seleziona la coppia (m,x) per cui cost(S)xm è minimale
5. Se cost(S)xm < cost(S)current
• Scambia m con x
6. Ritorna al passo 3 (2)

Clustering
Problemi con PAMProblemi con PAM
• Più robusto del k-means in presenza di rumore e outliers
– Un medoide è meno influenzato del centroide dalla presenza di outliers
• Efficiente su pochi dati, non scala su dati di grandi dimensioni.
– O(k(n-k)2 ) per ogni iterazione
• Alternative basate sul campionamento
– CLARA(Clustering LARge Applications)
– CLARANS

Clustering
Varianti al K-MedoidVarianti al K-Medoid
• CLARA [Kaufmann and Rousseeuw,1990]– Parametro addizionale: numlocal– Estrae numlocal campioni dal dataset– Applica PAM su ogni campione– Restituisce il migliore insieme di medoidi come output
– Svantaggi:
– L’efficienza dipende dalla dimensione del campione
– Non necessariamente un clustering buono sul campione rappresenta un clustering
buono sull’intero dataset
• Sample bias
• CLARANS [Ng and Han, 1994)– Due ulteriori parametri: maxneighbor e numlocal– Vengono valutate al più maxneighbor coppie (m,x)– La prima coppia (m,x) per cui cost(S)xm < cost(S)current è scambiata
• Evita il confronto con la coppia minimale– Si ripete la progedura numlocal volte per evitare il minimo locale.
• runtime(CLARANS) < runtime(CLARA) < runtime(PAM)

Clustering
Scelta dei punti inizialiScelta dei punti iniziali
• [Fayyad, Reina and Bradley 1998]– costruisci m campioni differenti da D– Clusterizza ogni campione, fino ad ottenere m stime per i k rappresentanti
• A = (A1, A2, …, Ak), B = (B1, B2, …, Bk), ..., M = (M1, M2, …, Mk)
– Clusterizza DS= A B … M m volte• utilizzando gli insiemi A, B, ..., M come centri iniziali
• Utilizza il risultato migliore come inizializzazione sull’intero dataset

Clustering
InizializzazioneInizializzazione
D Centri su 4 campioni
Centri effettivi

Clustering
Scelta del parametro kScelta del parametro k
• Iterazione– Applica l’algoritmo per valori variabili di k
• K=1, 2, …– Scegli il clustering “migliore”
• Come scegliere il clustering migliore?– La funzione cost(S) è strettamente decrescente
• K1> k2 cost(S1) < cost(S2)
• Indici di bontà di un cluster

Clustering
Indici di bontàIndici di bontà
• In generale, si valuta intra-similarità e intersimilarità
• a(x): distanza media di x dagli oggetti del cluster A cui x appartiene• b(x): distanza media di x dagli oggetti del secondo cluster B più prossimo a x• Coefficiente su x
– sx=-1: x è più prossimo agli elementi di B
– sx = 0: non c’è differenza tra A e B
– sx = 1: x è stato clusterizzato bene
• Generalizzazione sc
– Media dell’indice su tutti gli oggetti
– Valori bassi: clustering debole
– Valori alti: clustering robusto
)}(),(max{
)()(
xbxa
bbxasx
i ji i i Cx
jiCyC Cx Cy
yxdistyxdist ),()1(),(

Clustering
Minimum description LengthMinimum description Length
• Il principio del Minimum Description Length– Rasoio di Occam: le ipotesi più semplici sono più probabili
• (Il termine Pr(D) non dipende da M e può essere ignorato)
• Più alto è Pr(M|D), migliore è il modello
)Pr()|Pr()|Pr(
)Pr(
)Pr()|Pr()|Pr(
)Pr()|Pr(),Pr(
MMDDM
D
MMDDM
MMDDM

Clustering
Minimum Description Length, Numero ottimale di Minimum Description Length, Numero ottimale di clustersclusters
• Fissiamo un range possibile di valori per k– k = 1...K (con K abbastanza alto)
• Calcoliamo Pr(Mk|D) per ogni k
– Il valore k che esibisce il valore più alto è il migliore
• Problema: Come calcoliamo Pr(Mk|D)?

Clustering
Bayesian Information Criterion e Minimum Bayesian Information Criterion e Minimum Description LengthDescription Length
• Problema: calcolare
• Idea: adottiamo il trick del logaritmo
• Cosa rappresentano i due termini?
– = accuratezza del modello
– = complessità del modello
)Pr()|Pr( MMD
)Pr(log)|Pr(log)Pr()|Pr(log MMDMMD
)|Pr(log MD
)Pr(log M

Clustering
Bayesian Information CriterionBayesian Information Criterion
– = accuratezza del modello
• Assunzione: algoritmo K-Means, distanza euclidea
• La giustificazione è data dall’interpretazione “gaussiana” del clustering K-Means
)|Pr(log MD
)|()|(log)|(log)|Pr(log MDCostMxpMxpMD iii
i
k Cxkii
Cxkik
kik
ki
k
i
k
k
xdMxp
xd
Cxxd
Mxp
,)|(log
,
t.c.,
exp2
1)|(
22
2
2

Clustering
Bayesian Information CriterionBayesian Information Criterion
• = complessità del modello
– Intuitivamente, quanti più cluster ci sono, più il clustering è complesso• E quindi, meno è probabile
– Adottando un criterio basato sull’encoding (in bit) dell’informazione relativa i clusters, otteniamo
• Per ogni tuple nel dataset, codifichiamo a quale cluster appartiene
)Pr(log M
knM log)Pr(log

Clustering
Bayesian Information CriterionBayesian Information Criterion
• Codifica il costo di un clustering M fatto di k clusters– Direttamente proporzionale al costo del clustering dei dati
• Più i cluster sono omogenei, meno costoso è il clustering– Inversamente proporzionale al costo del modello
• Quanti meno clusters ci sono, meno costoso è il clustering• α è una costante di normalizzazione
– (serve a confrontare valori che potrebbero avere scale diverse)
knMDCostMBIC log)|()(














![Esercitazione 5 [modalit compatibilit ]staff.icar.cnr.it/manco/Teaching/datamining/wp-content/uploads/200… · Ce1 = [0,0.5,0.75] e Ce2 = [1,0.5,0.66] L’algoritmo continua ad iterare](https://static.fdocumenti.com/doc/165x107/5f4957ffd69f623c574bb63e/esercitazione-5-modalit-compatibilit-stafficarcnritmancoteachingdataminingwp-contentuploads200.jpg)


