
MANLIO ROSSI DORIA Collana a cura del Centro per la...
222
«MANLIO ROSSI -DORIA» Collana a cura del Centro per la Formazione in Economia e Politica dello Sviluppo Rurale e del Dipartimento di Economia e Politica Agraria dell’Università di Napoli Federico II 4
Transcript of MANLIO ROSSI DORIA Collana a cura del Centro per la...

«MANLIO ROSSI-DORIA»
Collana a cura del Centro per la Formazionein Economia e Politica dello Sviluppo Rurale
e del Dipartimento di Economia e Politica Agrariadell’Università di Napoli Federico II
4

Nella stessa collana:
1. Qualità e valorizzazione nel mercato dei prodotti agroalimentari tipici, a cura diF. de Stefano, 2000.
2. L’economia agrobiologica in Campania: un difficile percorso, a cura di F. deStefano, G. Cicia e T. del Giudice, 2000.
3. Istituzioni, capitale umano e sviluppo del Mezzogiorno, a cura di M.R. Carrilloe A. Zazzaro, 2001.
4. Introduzione alla statistica per le applicazioni economiche. Vol. I, Statisticadescrittiva, C. Vitale 2002.
In preparazione:
O. W. MAIETTA, L’analisi quantitativa dell’efficienza. Tecniche di base edestensioni recenti.

COSIMO VITALE
INTRODUZIONE
ALLA STATISTICA
PER LE APPLICAZIONI
ECONOMICHE
Volume primo
STATISTICA DESCRITTIVA
Edizioni Scientifiche Italiane

VITALE COSIMO
Introduzione alla statistica per le applicazioni economiche. Vol. IStatistica descrittiva.Collana: «Manlio Rossi-Doria», a cura del Centro per la Formazionein Economia e Politica dello Svilupppo Rurale e del Dipartimento diEconomia e Politica Agraria dell’Università di Napoli Federico II, 4Napoli: Edizioni Scientifiche Italiane, 2002pp. X+210; cm 24ISBN© 2002 by Edizioni Scientifiche Italiane s.p.a.80121 Napoli, via Chiatamone 700185 Roma, via dei Taurini 27
Internet: www.esispa.comE-mail: [email protected]
I diritti di traduzione, riproduzione e adattamento totale o parziale econ qualsiasi mezzo (compresi i microfilm e le copie fotostatiche)sono riservati per tutti i Paesi.


INDICE
Premessa
CAPITOLO 1Rilevazioni statistiche e distribuzioni di frequenza
1.1 Introduzione 11.2 La classificazione delle rilevazioni statistiche 2
Rilevazione di popolazioniRilevazione per campione
1.3 Le distribuzioni di frequenza semplici 71.4 La rappresentazione grafica delle distribuzioni di frequenza 12
Le rappresentazioni ad asteLe rappresentazioni con torteLe rappresentazioni a nastriGli istogrammi di frequenze
1.5 Frequenze relative e frequenze relative cumulate 18La funzione di ripartizione
CAPITOLO 2Indici statistici descrittivi
2.1 Introduzione 252.2 Alcuni indici di posizione o locazione 26
La media aritmeticaLa media troncataLa medianaI quartiliLa modaLa media geometrica
2.3 Alcuni indici di variabilità 57L'intervallo di variazioneLa varianzaI momenti di ordine r

IndiceVI
Il coefficiente di variazioneLo scostamento semplice medioLo scostamento semplice medianoLa differenza tra quartiliL'entropia di ShannonL'indice di mutabilità di Gini
2.4 Alcuni indici sulla forma 71Alcuni indici di asimmetriaL'indice di curtosi
CAPITOLO 3La concentrazione
3.1 Introduzione 833.2 Il concetto di concentrazione 84
Il caso discreto o discretizzatoIl caso per classi di modalità
3.3 Alcuni indici di concentrazione 91L'indice di concentrazione di GiniIl rapporto di concentrazioneL'indice d del Gini
3.4 Alcune considerazioni sulla concentrazione dei redditi 96
CAPITOLO 4Le distribuzioni di frequenza doppie
4.1 Introduzione 1034.2 Distribuzioni semplici derivate da una doppia 105
Le marginaliLe condizionate
4.3 L'indipendenza fra caratteri 110Indipendenza assolutaIndipendenza in media
4.4 La correlazione lineare 124La covarianzaLa disuguaglianza di SchwarzIl coefficiente di correlazione
CAPITOLO 5Introduzione all'analisi delle serie storiche
5.1 Introduzione 1395.2 Alcune rappresentazioni grafiche delle serie storiche 141
Rappresentazione sul tempoRappresentazione gambo-foglie

Indice VII
Rappresentazione box-plot5.3 Alcune trasformazioni delle serie storiche 147
La serie degli indiciLa serie delle differenze
5.4 Gli indici dei prezzi 165Indici dei prezzi composti o ponderatiLa deflazione delle serie monetarie
CAPITOLO 6L’interpolazione lineare
6.1 Introduzione 1756.2 Il modello lineare semplice 1776.3 La stima dei parametri del modello 179
Misura della bontà di adattamentoAnalisi dei residui
6.4 Modello non lineare 201Modello non lineare nelle esplicativeModello non lineare ma linearizzabileModello non linearizzabile
Bibliografia 205 Indice analitico 207


PREMESSA
Queste lezioni, dedicate agli allievi del secondo anno dei corsi di laurea in Economia e Commercio e in Economia Aziendale, forniscono i primi rudi-menti di quella disciplina che va sotto il nome di Statistica. Raccoglie, rielabora-te e corrette, le lezioni tenute negli anni accademici 1990-98 presso la Facoltà di Economia dell'Università di Salerno. In tal senso sono grato agli studenti che, autonomamente, e con grande dispendio di energia, hanno seguito, registrato e trascritto quelle lezioni.
Il corso si compone di tre parti:
(a) la prima immediatamente applicabile a fenomeni reali è dedicata alla stati-stica descrittiva e fornisce gli strumenti ed i metodi più noti e semplici da utilizzare in molte pratiche applicazioni. Questa parte è composta dal pri-mo dei due volumi;
(b) la seconda, di tipo essenzialmente strumentale nella economia generale del corso, presenta alcuni elementi di calcolo delle probabilità e di variabili ca-suali. A questa parte sono dedicati i capitoli del secondo volume;
(c) la terza riporta elementi di inferenza statistica (stime e test delle ipotesi) e di regressione lineare ed è coperta dai rimanenti capitoli del secondo volu-me.
Ho cercato di esporre il tutto in modo semplice e discorsivo e di corre-
darlo con esempi riferiti a fenomeni di tipo socio-economico in modo da ren-dere più facile l'apprendimento e più immediata l'applicabilità degli strumenti presentati.
Fisciano, febbraio 2002 L'Autore


Capitolo 1
RILEVAZIONI STATISTICHE E DISTRIBUZIONI DI FREQUENZA 1.1 Introduzione
La statistica studia non i singoli fenomeni in quanto tali, ma insiemi di fenomeni, collettivi statistici, all'interno dei quali cerca di individuare eventuali re-golarità. Inoltre, si interessa della raccolta e della catalogazione delle informazio-ni e dell'analisi di tali informazioni tramite strumenti elaborati dalla statistica stessa. La raccolta di informazioni con procedure elaborate dalla statistica per-mette di ottenere le informazioni di base: le rilevazioni statistiche.
Una rilevazione statistica è la raccolta di informazioni, su uno o più feno-meni, in un dato tempo ed in un dato luogo, con metodi forniti dalla statistica e su cui possono essere usati, per la relativa analisi, strumenti statistici.
Da questo punto di vista la statistica è una disciplina strumentale a tutte le altre. In pratica, non vi è campo dell'umano sapere in cui non si raccolgono ed elabo-rano informazioni con gli strumenti forniti dalla statistica.
Le rilevazioni statistiche possono essere classificate in diverse categorie. Naturalmente, esistono differenti modi di raggrupparle, qui di seguito verranno proposte alcune classificazioni (fra le tante possibili) che tengano conto dei di-versi strumenti analitici a cui rilevazioni appartenenti a classi diverse possono essere diversamente sottoposte. In altri termini, dato che rilevazioni con carat-teristiche qualitative diverse possono essere analizzate con strumenti statistici differenti, si cercherà di presentare una classificazione che tenga conto di questi aspetti.

Capitolo 1 2
1.2 La classificazione delle rilevazioni statistiche
A seconda della estensione delle rilevazioni statistiche si può distinguere fra:
rilevazione di popolazioni rilevazione di campioni RILEVAZIONE DI POPOLAZIONI
Il fenomeno di interesse viene osservato sull'intera popolazione, ove
per popolazione si intende l'insieme, definito in un dato luogo ed in un determi-nato tempo, di elementi qualsiasi (persone, animali, cose ecc.) che hanno in comune una o più caratteristiche prefissate.
Naturalmente, prima di effettuare una rilevazione di una popolazione bi-
sogna definire gli oggetti (persone, animali, cose ecc.) su cui vengono raccolte le informazioni, questi oggetti prendono il nome di unità di rilevazione. Una volta definita l'unità di rilevazione è necessario definire gli aspetti, i caratteri, i feno-meni dell'unità di rilevazione su cui si vuole raccogliere informazione ed una scala di misura delle caratteristiche di interesse.
Di solito si suppone che i fenomeni che si analizzano siano indipendenti dalla scala di misura utilizzata. Così, se si è interessati all'altezza di date persone misurarla in metri o in centimetri, a meno di trascurabili problemi di arroton-damento, dovrebbe fornire risultati simili. In realtà, questa assunzione è vera solo per fenomeni regolari. Infatti, negli anni settanta si è scoperto che esistono molti fenomeni in natura per cui questa supposizione è falsa. Così se si misura la lunghezza del sistema vascolare di dati individui si ottengono risultati molto diversi a seconda che si utilizzi, come unità di misura, il millimetro o il micron e questo dipende, essenzialmente, dal fatto che il carattere considerato è molto "irregolare" ha, in termini più precisi, una struttura frattale. Nel seguito, per semplicità di esposizione, non terremo conto di questa ulteriore complicazione e supporremo che i fenomeni da noi analizzati siano invarianti rispetto alla sca-la di misura utilizzata.

Rilevazioni statistiche e distribuzioni di frequenza 3
Esempio di popolazione. I vari punti rappresentano le unità di rilevazioni da cui è costituita la popo-lazione.
Da questo punto di vista una popolazione può, anche, essere definita come
l'insieme di tutte le unità di rilevazione in un determinato momento ed in un dato luogo.
Si osservi che possono essere definite anche delle popolazioni fittizie,
ipotetiche. Esempio 1
Tutti i possibili redditi che una data persona avrebbe potuto guadagnare in un determinato anno. Quando si rileva un’intera popolazione si effettua quello che viene chiamato censimento. Naturalmente, non è possibile effettuare censimenti per popolazioni ipotetiche o per popolazioni costituite da infinite unità di rilevazione. RILEVAZIONE PER CAMPIONE
Le rilevazioni campionarie sono rilevazioni parziali, più precisamente:
per campione si intende un sotto insieme di unità di rilevazione scelte, con un definito criterio, da una data popolazione.
Le informazioni vengono, naturalmente, acquisite solo sulle unità della
popolazione che fanno parte del campione selezionato. Esistono diversi modi per scegliere un campione da una popolazione ciò

Capitolo 1 4
dà luogo a differenti tipi di campioni, in particolare distinguiamo fra: campione ragionato campione casuale.
I campioni ragionati sono ottenuti fissando una ben definita regola e sce-gliendo tutte le unità di rilevazione della popolazione che soddisfano quella re-gola.
Naturalmente, in tal caso, ripetendo l'operazione di campionamento a
parità di condizioni (stessa regola ed identica popolazione), si ottiene sempre un campione costituito esattamente dalle stesse unità di rilevazioni.
Esempio 2 Supponiamo di avere la popolazione costituita da tutte le famiglie (questa è l'unità di
rilevazione) residenti in Campania al 31/12/1992. Come regola di estrazione fissiamo la seguente: tutte le famiglie residenti in Campania al 31/12/1992 con più di sei componenti. Si ottiene in tal modo il campione (sotto insieme della popolazione data) costituito da tutte le famiglie residenti al 31/12/1992 in comuni della Campania costituite da sette o più com-ponenti.
Come è facile intuire, se si ripete l'estrazione dalla stessa popolazione utilizzando la stessa regola si ottiene sempre lo stesso risultato.
Un aspetto negativo di questo tipo di campioni è che i risultati ottenuti non sono, in generale, estensibili all'intera popolazione e questo perché i cam-pioni ragionati non sono di solito rappresentativi della popolazione da cui sono stati estratti.
I campioni casuali sono ottenuti scegliendo dalla popolazione le unità di rilevazione con un meccanismo casuale. Cioè affidandosi ad un arbitro neutrale quale è la sorte, il caso di modo che ogni unità di rilevazione ha la stessa pro-babilità di far parte del campione.
In queste condizioni, se si ripete l'operazione di campionamento non si
ottiene lo stesso risultato, in altre parole il risultato dell'estrazione è incerto, so-lo probabile. Ma proprio perché nella scelta delle unità di rilevazioni si è utiliz-zato un arbitro neutrale, quale è il caso, i risultati ottenuti da questi campioni

Rilevazioni statistiche e distribuzioni di frequenza 5
possono essere estesi, entro certi limiti, all'intera popolazione. Il numero delle unità di rilevazione che compongono il campione viene
detto numerosità campionaria. Esempio 3
Assegniamo a ciascuna delle unità di rilevazione della popolazione definita nell'esem-pio 2 un numero progressivo. Scriviamo detti numeri su dei foglietti che vengono immessi in un'urna. Mescoliamo i biglietti nell'urna così costituita e quindi scegliamo un bigliettino. Ri-petiamo l'estrazione n volte. Si ottiene così un campione casuale di n famiglie della popola-zione data. Notiamo che se si ripete l'operazione di campionamento non c'è certezza di otte-nere le stesse famiglie.
Nel seguito, non verrà trattato il delicato problema del piano di campio-na-mento, cioè di come costruire un campione che sia il meno costoso ma il più rappresentativo possibile della popolazione. Di queste problematiche se ne occu-pa in modo sistematico una branca della statistica che va sotto il nome di Teoria dei Campioni.
Fino ad ora abbiamo visto che le rilevazioni statistiche si classificano in rilevazioni su popolazioni (i noti censimenti ne sono un esempio) e rilevazioni su campioni. Ma le rilevazioni statistiche possono anche essere distinte in: rilevazione semplice rilevazione multipla.
Una rilevazione statistica è detta semplice quando per ogni unità di rileva-zione si assumono informazioni su un solo carattere.
Esempio 4
Se sulla popolazione (o sul campione) di cui abbiamo trattato negli esempi 2 e 3 rile-viamo informazioni su un solo carattere, per esempio la professione o il titolo di studio del capofamiglia, si ottiene una rilevazione semplice. La stessa cosa se della famiglia rileviamo il numero dei componenti, o il reddito annuo familiare, o il luogo di residenza.
Una rilevazione statistica è detta multipla quando per ogni unità di rileva-zione si assumono informazioni simultaneamente su più di un carattere.

Capitolo 1 6
Esempio 5 Se sulla popolazione (o sul campione), di cui abbiamo trattato negli esempi 2 e 3, ri-
leviamo contemporaneamente informazioni sulla professione del capofamiglia, il numero dei componenti e il reddito annuo familiare si ottiene una rilevazione statistica tripla.
Nel seguito particolare rilievo, fra le rilevazioni multiple, verrà dato a quelle doppie, cioè a quelle rilevazioni in cui le informazioni si raccolgono (su popolazione o campione) su coppie di caratteri di ciascuna unità di rilevazione. L'importanza delle rilevazioni multiple è che queste, oltre a fornire informazio-ni sui singoli caratteri, forniscono informazioni sui possibili legami esistenti fra i diversi caratteri considerati e quindi permettono di capire se esistono e di che natura ed entità sono le relazioni fra i diversi caratteri presi in considerazione.
Le rilevazioni statistiche (siano esse relative a popolazioni o a campioni) possono essere anche classificate in rapporto al tipo di carattere che viene rile-vato. Si hanno così le rilevazioni che generano: variabili mutabili.
Una rilevazione statistica prende il nome di variabile se il carattere su cui si raccolgono informazioni è misurabile.
Si noti che i caratteri misurabili, cioè le variabili, possono essere sempre
ordinati in modo "naturale" e che detti caratteri si riferiscono a delle quantità in questo senso si parla anche di carattere quantitativo. Inoltre, le variabili posso-no essere sia discrete che continue a seconda che il carattere può assumere, teori-camente, una infinità continua di valori o solo un numero finito o numerabile.
Una rilevazione statistica prende il nome di mutabile se il carattere su cui si raccolgono informazioni non è misurabile.
Si osservi che le mutabili si riferiscono a qualità del carattere preso in
considerazione. Si tenga conto che le mutabili, a differenza delle variabili, non necessariamente ammettono un ordinamento naturale. Se una mutabile non ammette un ordinamento naturale viene detta sconnessa.

Rilevazioni statistiche e distribuzioni di frequenza 7
Esempio 6 Nella rilevazione dell'esempio 4 i caratteri professione del capofamiglia e titolo di studio del capofamiglia danno luogo a mutabili, la prima sconnessa, la seconda ordinabi-le. Viceversa, i caratteri numero di componenti per famiglia e reddito annuo fami-liare danno luogo a variabili la prima discreta e la seconda continua.
Le mutabili, a differenza delle variabili, sono sempre discrete. Esiste un solo carattere qualitativo che è misurabile, continuo e quindi ordinabile ed è il tempo. Lo schema della classificazione qui proposta è riportato nella figura che segue:
Una classificazione delle rilevazioni statistiche
Un diverso modo di classificare le rilevazioni statistiche tiene conto della dinamicità nel tempo, nello spazio o nello spazio-tempo, o della staticità della rilevazione. Nel seguito analizzeremo alcune rilevazioni statiche riportate sotto forma di distribuzioni di frequenza e delle rilevazioni dinamiche di tipo quantitati-ve che evolvono nel tempo dette anche serie storiche. 1.3 Le distribuzioni di frequenza semplici
In questa prima parte del corso consideriamo quelle rilevazioni statisti-che che riguardano intere popolazioni per cui i risultati che si ottengono, a me-no di errori di misurazione che considereremo trascurabili, sono certi. In altri termini, in questa prima parte del corso supporremo di muoverci in un mondo

Capitolo 1 8
deterministico, un universo in cui tutto è certo anche se incognito per nostra ignoranza. Questo è il mondo della Statistica descrittiva.
Data una rilevazione statistica riguardante un determinato carattere pos-seduto dalle unità di rilevazione di una definita popolazione, le diverse deter-minazioni (o modi) che il carattere assume nelle unità di rilevazione prendono il nome di modalità del carattere. Il numero, di solito indicato con N, delle unità di rilevazione della popolazione considerata prende il nome di numerosità della popolazione. Esempio 7
Nel caso dell'esempio 2 in cui la popolazione era costituita dalle famiglie residenti in Campania al 31/12/1992, se il carattere preso in considerazione fosse la professione del capofamiglia, le modalità sarebbero costituite dalle diverse posizioni professionali dei residenti in Campania (esempio: contadino, artigiano, operaio, impiegato, professionista, ecc.); se il carattere preso in considerazione fosse la numerosità della famiglia allora le modalità sarebbe-ro costituite dalle diverse numerosità di quelle famiglie (esempio: 1, 2, 3, ...., k, ove k è il numero dei componenti della famiglia più numerosa della popolazione); se il carattere fosse il titolo di studio del capo famiglia allora le modalità sarebbero i diversi titoli di studio di quei capifamiglia (esempio: senza titolo, licenza elementare, licenza media, licenza media superio-re, laurea). Esempio 8
Supponiamo che la nostra popolazione sia costituita da N=16 persone e che il carat-tere d’interesse sia l'altezza di queste persone espressa in centimetri; inoltre, supponiamo che le 16 misurazioni delle altezze abbiano dato luogo ai 16 numeri seguenti:
173 154 165 160 160 155 165 173 170 180 165 160 154 180 173 165
In tal caso le modalità del carattere altezza nella popolazione data sono costituite dai seguen-ti sette numeri:
154 155 160 165 170 173 180 Se il carattere di interesse della nostra popolazione fosse il colore degli occhi e dalla no-stra rilevazione risultasse:
N V M V V N V M M M N V M V M M

Rilevazioni statistiche e distribuzioni di frequenza 9
ove si è posto N=colore nero, M=colore marrone, V=colore chiaro, allora le modalità della rilevazione sarebbero date dai seguenti tre simboli:
N, M, V.
Se contiamo quante volte si presenta, nella popolazione data, ciascuna modalità a ognuna di queste viene associato un numero intero positivo detto frequenza. In altri termini:
le modalità di una distribuzione di frequenze sono le diverse determinazioni che il carattere di interesse assume nella popolazione, le frequenze sono il numero di volte che si presentano le diverse modalità.
Nel seguito indicheremo con una delle ultime lettere maiuscole dell'alfabe-
to latino la generica rilevazione statistica quantitativa e con la corrispondente lettera minuscola la generica modalità. Così se indichiamo con X una rilevazio-ne statistica quantitativa avremo che xi indicherà la sua modalità i-esima. Se il fenomeno è una qualità utilizzeremo una delle prime lettere dell'alfabeto latino. Così se si indica con A la generica rilevazione qualitativa, la sua i-esima modali-tà sarà indicata con ai. In ogni caso useremo il simbolo ni, i=1, 2, ..., k, per in-dicare la frequenza associata alla i-esima modalità sia essa una quantità o una qualità. Naturalmente sarà sempre
N = n1+ n2 + ... + nk = ∑=
k
iin
1
Se l'ordine con cui le osservazioni vengono acquisite è irrilevante ai fini
dell'analisi che si vuole condurre si dice che vi è scambiabilità fra le unità di rile-vazione del fenomeno. In tal caso esiste una corrispondenza biunivoca fra rile-vazione statistica e distribuzione di frequenza nel senso che tutte le informa-zioni contenute nella prima sono conservate nella seconda e viceversa. La ge-nerica distribuzione di frequenza quantitativa X assumerà le modalità x1, x2, ..., xk con rispettive frequenze n1, n2, ..., nk, mentre la generica distribuzione di fre-quenza qualitativa A assumerà le modalità a1, a2, ..., ak con simili frequenze. Entrambe possono essere indicate con una tabella composta da due colonne e precisamente:

Capitolo 1 10
Variabile Mutabile xi ni ai ni
x1 n1 a1 n1
x2 n2 a2 n2
… … … … xk nk ak nk
N N
ove si suppone che le xi siano state ordinate in modo crescente per cui risulta x1 < x2 < ... < xk. Esempio 9
Riprendendo i casi riportati nell'esempio 8, le relative distribuzioni di frequenza sono date rispettivamente da:
xi ni ai ni
154 2 N 3
155 1 V 6 160 3 M 7 165 4 16 170 1 173 3 180 2
16
Nel primo caso il carattere è una quantità e quindi è ordinabile, nel secondo caso è una qualità sconnessa e quindi l'ordinamento presentato è del tutto soggettivo.
Si osservi che la generica frequenza ni è sempre un numero intero non negativo visto che indica quante volte si presenta ciascuna modalità. Al contra-rio, come già detto, le modalità possono essere sia delle quantità, sia delle quali-tà. Quando le modalità del carattere sono delle qualità si dice che nella rileva-zione del fenomeno si è usata una scala nominale dato che le modalità sono nomi o aggettivi. Ricordiamo che i caratteri quantitativi possono essere sia discreti che continui anche se quando vengono effettivamente misurati la misurazione avviene sempre nel discreto. I caratteri qualitativi possono essere sia non ordi-nabili (è la maggior parte dei casi) che ordinabili.
Negli esempi 8 e 9 abbiamo derivato due distribuzioni di frequenza ot-

Rilevazioni statistiche e distribuzioni di frequenza 11
tenute da una popolazione molto piccola dato che era composta solo da 16 u-nità di rilevazione. In molti fenomeni socioeconomici spesso si analizzano po-polazioni composte da migliaia, se non da milioni, di unità di rilevazione e non ha molto senso, da un punto di vista pratico, riportare la lista di tutte le modali-tà che il dato fenomeno assume. In questi casi, anche se sono noti i dati relativi a tutte le modalità assunte nella popolazione, le modalità vengono raggruppate con un qualche criterio di solito soggettivo per formare quelle che vengono chiamate classi di modalità. Esempio 10
Distribuzione di frequenza della popolazione residente (dati in migliaia di unità) in Calabria al 31 dicembre 1981 per classi di età (fonte ISTAT)
Classi di età Residenti (in migliaia) xi xi+1 ni
0 15 587 15 25 350 25 45 511 45 65 390
>65 241 2079
Nella prima riga della tabella il simbolo 0—|15 sta ad indicare che i residenti in Calabria al 31/12/81 con una età, in anni compiuti, da 0 (escluso) a 15 anni (incluso) erano 587.000, quelli che avevano una età da 15 (escluso) a 25 anni (incluso) erano 350.000 e così via. Osserviamo che l'ultima classe, quella indicata con il simbolo >65, è una classe aperta superiormente cioè una classe in cui non è indicato l'estremo superiore. In questo caso quell'ultima classe sta ad indicare che coloro che avevano più di 65 anni di età erano 241.000.
Le classi aperte si possono incontrare sia come classe finale, è il caso del-l'esempio riportato, che come classe iniziale o per entrambe. Osserviamo che il simbolo xi—| xi+1 sta a significare che in quella classe le unità di rilevazione che hanno un carattere minore o uguale ad xi sono escluse mentre sono incluse immediatamente dopo xi fino ad xi+1 compreso. In altri termini, l'estremo infe-riore è escluso mentre quello superiore è incluso. Naturalmente, se avessi utilizzato la scrittura xi|—xi+1 sarebbe stato incluso l'estremo inferiore della classe, mentre

Capitolo 1 12
sarebbe stato escluso quello superiore. Le classi di modalità vengono utilizzate non solo per scrivere in modo più compatto distribuzioni di frequenza con ca-rattere continuo, ma anche quelle con carattere discreto come, per esempio, il numero dei figli per famiglia, oppure il numero di aziende per addetti, o il nu-mero di comuni per provincia.
Abbiamo già sottolineato che quando una rilevazione statistica viene tra-sformata in una distribuzione di frequenza si distrugge l'ordine in cui le osser-vazioni vengono acquisite e questo fa, in generale, perdere informazioni a me-no che le unità di rilevazione non siano scambiabili rispetto al problema in ana-lisi. La trasformazione di una rilevazione statistica in una distribuzione di fre-quenza per classi di modalità distrugge ancora di più informazioni e la perdita di informazioni è tanto più elevata quanto più ampie sono le rispettive classi; questo è particolarmente vero se vi sono classi aperte. Infatti, non è mai possi-bile risalire dalla distribuzione di frequenza per classi di modalità a quella con tutte le modalità distinte, mentre è, ovviamente, sempre possibile fare il vice-versa. 1.4 La rappresentazione grafica delle distribuzioni di frequenza
Le rappresentazioni grafiche, in generale e quelle delle rilevazioni stati-stiche in particolare, servono solo a dare un’idea sintetica e complessiva del fe-nomeno. Fenomeni a volte anche molto complessi per numerosità di variabili o di osservazioni o di entrambi possono essere efficacemente sintetizzati con una adeguata rappresentazione grafica. Da questo punto di vista i grafici non dico-no nulla di più di ciò che è già contenuto nelle osservazioni. Per quanto ci ri-guarda, le varie rappresentazioni grafiche delle distribuzioni di frequenza fanno solo cogliere aspetti globali del fenomeno anche se si perdono alcuni dettagli. Da questo punto di vista se i grafici sono ben fatti sono un utile strumento di sintesi dei fenomeni in studio.
Data la seguente distribuzione di frequenza:
xi ni
x1 n1
x2 n2
… … xk nk
N in cui il carattere si è supposto ordinabile per cui risulta x1 < x2 < ... < xk, esi-stono vari modi per rappresentarla graficamente, qui di seguito ne presentere-mo alcune di largo uso ma semplici da costruire.

Rilevazioni statistiche e distribuzioni di frequenza 13
LE RAPPRESENTAZIONI AD ASTE
In questo caso si considera un sistema di assi cartesiani e si riportano su di esso le coppie di punti (xi, ni). Di solito la scala sui due assi è diversa ed i punti così ottenuti spesso si uniscono con una spezzata. Si ottiene così un gra-fico come quello riportato nella figura che segue:
Esempio 11
Riprendiamo la prima distribuzione di frequenza riportata nell'esempio 9. Il relativo grafico ad aste è riportato nella figura seguente.
LE RAPPRESENTAZIONI CON TORTE
In questo caso la rappresentazione è fatta su un cerchio che viene diviso

Capitolo 1 14
in tanti settori quante sono le modalità. L'ampiezza di ciascun settore è propor-zionale a ciascuna frequenza nel senso che a modalità con frequenza doppia rispetto ad un'altra modalità sarà attribuito un settore circolare doppio rispetto all'altro e così via. Nella figura che segue è riportato un esempio generico di una tale rappresentazione.
Esempio 12
Consideriamo la prima distribuzione di frequenza dell'esempio 9 la sua rappresenta-zione a torta è riportata nella figura
Nella figura che segue riportiamo la rappresentazione a torta della seconda distribuzione di frequenza dell'esempio 9.

Rilevazioni statistiche e distribuzioni di frequenza 15
Dall'esempio precedente segue che le rappresentazioni a torte possono
essere utilizzate per qualsiasi tipo di distribuzioni di frequenza siano esse quan-titative o qualitative, con modalità distinte o per classi di modalità. In altri ter-mini, questo tipo di rappresentazione è abbastanza generale da poterlo utilizza-re per qualsiasi tipo di distribuzioni di frequenza. LE RAPPRESENTAZIONI A NASTRI
Si tratta di una rappresentazione simile a quella ad aste con la differenza che le barre vengono ordinate secondo l'ampiezza delle frequenze ciò vuol dire che questo tipo di rappresentazione può essere utilizzato per qualsiasi tipo di distribuzione di frequenza indipendentemente dal fatto che il carattere sia ordi-nabile, misurabile, sconnesso. Esempio 13
Consideriamo la seconda distribuzione riportata nell'esempio 9 il cui carattere, come abbiamo sottolineato, è una qualità non ordinabile, in tal caso la relativa rappresentazione a nastri è riportata nella figura
Come si può notare da questa rappresentazione, la larghezza dei nastri è la stessa per le tre modalità, il loro ordinamento è fatto sulla base dell'ammontare delle frequenze e l'unica cosa che varia è la lunghezza delle barre che è funzione dell'ammontare delle frequenze. Esempio 14
Consideriamo la seguente distribuzione di frequenze rappresentante i laureati in Ita-

Capitolo 1 16
lia nel 1990 distinti per gruppo disciplinare
Gruppo disciplinare laureati N° Scientifico 11.607 Medico 11.167 Ingegneria 11.740 Agrario 2.642 Economico 12.556 Politico-sociale 4.571 Giuridico 13.666 Letterario 17.862 Diplomi 3.670 Totale 89.481
La relativa rappresentazione a nastri è riportata nella figura seguente
GLI ISTOGRAMMI DI FREQUENZA
Questo tipo di rappresentazione viene costruito nel caso in cui la distri-buzione è per classi di modalità. Infatti, nel caso in cui il carattere è per classi di modalità e si voglia tener conto nella rappresentazione grafica della diversa am-piezza delle classi non è più possibile rappresentarle con barre come è stato fat-to nell'esempio 11. In una situazione del genere non si sa in quale punto della classe va posizionata la relativa barra. Per superare questo inconveniente si so-stituiscono le barre con dei rettangoli che hanno per base l'ampiezza di ciascu-

Rilevazioni statistiche e distribuzioni di frequenza 17
na classe e per area l'ammontare della relativa frequenza. Per calcolare l'altezza, tenendo conto della formula delle aree dei rettangoli: A = b h, e ricordando che nel nostro caso per il generico rettangolo relativo alla classe xi xi+1, risulta Ai = ni, bi = xi+1 - xi, avremo che la relativa altezza, detta anche intensità della classe, è
hi = nibi
.
In conclusione, gli istogrammi di frequenza si utilizzano per le distribu-
zioni il cui carattere è per classi di modalità. Si costruiscono tanti rettangoli quante sono le classi. Detti rettangoli hanno per base le ampiezze delle relative classi, per area l'ammontare delle corrispondenti frequenze e per altezza il rap-porto fra la frequenza della relativa classe e l'ampiezza della stessa classe. Quan-to fino ad ora detto è chiarito nell'esempio che segue. Esempio 15
Supponiamo di avere la seguente distribuzione di frequenza il cui carattere è per classi di modalità:
xi —|xi+1 ni bi = xi+1 - xi hi=ni/bi 0 —|2 3 2-0=2 3/2=1.500 2 —|5 4 5-2=3 4/3=1.333
5 —|10 5 10-5=5 5/5=1.000 10—|20 3 20-10=10 3/10=0.300
Totale 15
i valori di bi ed hi sono riportati nella stessa tabella mentre il relativo istogramma è riportato nella figura che segue

Capitolo 1 18
1.5 Frequenze relative e frequenze relative cumulate
Data una generica distribuzione di frequenza, il numero ni di volte per cui si verifica la i-esima modalità o classe di modalità è detta anche frequenza as-soluta
. Dalle frequenze assolute è possibile derivare le frequenze relative, indicate di solito con fi, definite come il rapporto fra ciascuna frequenza assoluta e la somma di tutte le frequenze assolute:
fi = niN .
Si osservi che mentre le frequenze assolute sono dei numeri interi posi-
tivi quelle relative sono delle percentuali: fi rappresenta la percentuale delle uni-tà di rilevazione che appartengono alla i-esima modalità o classe di modalità. E' facile verificare che la somma delle frequenze relative è pari ad uno, infatti:
f1 + f2 + ... + fk = n1N +
n2N + ... +
nkN =
n1+n2+...+nkN =
NN = 1.
Una caratteristica fondamentale delle frequenze relative è di essere indi-
pendenti dalla numerosità del fenomeno (numero delle unità di rilevazione ap-partenenti alla popolazione che si analizza) e quindi possono essere utili per confrontare distribuzioni di frequenza con le stesse modalità o classi di modali-tà rilevate in luoghi o tempi diversi. Le frequenze relative di una distribuzione di frequenza possono essere sempre calcolate indipendentemente dal carattere che si analizza sia esso discreto o continuo, sia quantitativo o qualitativo. La rappresentazione grafica di una distribuzione di frequenze relative ha lo stesso andamento di quella in cui si utilizzano le frequenze assolute dato che nella de-

Rilevazioni statistiche e distribuzioni di frequenza 19
rivazione delle fi non si è fatto altro che un cambiamento di scala (divisione per una costante).
Nella tabella seguente è riportata una tipica distribuzione di frequenza, derivata da una qualche rilevazione statistica, in cui sono indicate sia le fre-quenze assolute che quelle relative:
xi ni fi
x1 n1 f1 = n1N
x2 n2 f2 = n2N
x3 n3 f3 = Nn3
… … …
xk nk fk = nkN
N 1
Dalle frequenze relative è possibile derivare le frequenze relative cumulate. Perché abbia senso derivare questo tipo di frequenze è necessario ordinare preventi-vamente le modalità del carattere della distribuzione di frequenza; questo implica che tale frequenze ha senso calcolarle solo se il carattere è ordinabile. In parti-colare, nel caso di variabili l'ordinamento è fatto in senso crescente.
Le frequenze relative cumulate, indicate di solito con Fi, sono definite come
il rapporto fra la somma delle prime i frequenze assolute e la somma di tutte le frequenze assolute:
Fi = Nnnn i+++ ...21 .
Si noti che è sempre
Fk = f1 + f2 + ... + fk = 1 e risulta
0 ≤ F1 ≤ F2 ≤ ... ≤ Fk = 1
in altri termini, le frequenze relative cumulate sono non decrescenti.

Capitolo 1 20
Supponiamo che il carattere considerato sia una variabile e che le relative modalità siano state ordinate per cui risulta: x1 < x2 < ... < xk in tal caso Fi rappresenta la percentuale del carattere posseduto fino alla modalità xi inclusa.
Nella tabella seguente è riportata una tipica distribuzione di frequenze in cui sono indicate le frequenze assolute, quelle relative e quelle relative cumula-te:
xi ni fi Fi
x1 n1 f1 = n1N F1= f1 =
n1N
x2 n2 f2 = n2N F2= f1+f2 =
n1+n2N
x3 n3 f3 = n3N F3= f1+f2+f3 =
n1+n2+n3N
… … … ……………
xk nk fk = nkN Fk= f1+f2+...+fk=
n1+n2+...+nkn =1
N 1 Esempio 16
Nella tabella seguente è riportata la distribuzione di frequenza dei redditi lordi men-sili di 20 soggetti, arrotondati al milioni di lire più vicino, con le corrispondenti frequenze relative e relative cumulate:
xi ni fi Fi
2 2 220 = 0.10 0.10
5 6 620 = 0.30 0.40
6 4 420 = 0.20 0.60
7 3 320 = 0.15 0.75
10 3 320 = 0.15 0.90
11 2 220 = 0.10 1
20 1 Se poniamo la nostra attenzione sulla terza modalità, cioè su x3, risulta x3 = 6 a cui corri-

Rilevazioni statistiche e distribuzioni di frequenza 21
sponde n3 = 4 questo vuol dire che 4 delle 20 persone considerate guadagnano 6 milioni al mese; f3 = 0.2 questo vuol dire che il 20% del collettivo considerato (in questo caso composto da 20 persone) guadagnano 6 milioni al mese; F3 = 0.60 cioè il 60% del collettivo guada-gna fino a 6 milioni al mese.
Fra le frequenze relative e le frequenze relative cumulate esiste una corri-spondenza biunivoca nel senso che note tutte le frequenze relative si possono de-rivare tutte le frequenze relative cumulate e viceversa. In simboli questo si indi-ca nel modo seguente:
{Fi, i=1,...,k} ⇔ {fi, i=1,...,k}
La dimostrazione di questa affermazione è abbastanza semplice. Abbia-mo già visto che note le fi è possibile derivare le Fi tramite la seguente:
Fi = f1+ f2 +...+ fi, i=1,..,k;
viceversa, note le Fi è possibile derivare le fi tramite la seguente:
fi = Fi - Fi-1 = (f1 + f2 +...+ fi-1+ fi) - (f1+ f2+...+ fi-1), i=1,...,k.
La rappresentazione grafica delle frequenze relative cumulate prende il nome di funzione di ripartizione. LA FUNZIONE DI RIPARTIZIONE
L'esempio che segue serve a chiarire come viene costruita una funzione di ripartizione. Esempio 17
La funzione di ripartizione relativa alla distribuzione di frequenze dell'esempio 16 è riportata nella figura che segue

Capitolo 1 22
L'altezza di ciascun gradino corrisponde alla frequenza relativa delle rispettive modalità. Se un gradino è molto alto vuol dire che la corrispondente frequenza è elevata e quindi la relativa modalità è molto frequente. In questo caso la frequenza più elevata (corrispondente al gradino più alto) è la seconda e cioè x2 = 5.
Se la distribuzione di frequenza è per classi di modalità si può ugualmen-te costruire la funzione di ripartizione ponendo sull'asse delle ordinate le classi di modalità. In questo caso però, il grafico non può essere a gradini dato che non è possibile sapere in quali punti della classe le frequenze sono concentrate. Per superare questo ostacolo si suppone che le frequenze appartenenti a cia-scuna classe siano uniformemente ripartite all'interno di dette classi e quindi che le frequenze cumulate crescano secondo delle spezzate che uniscono i pun-ti con coordinate (xi, Fi-1) ed (xi+1, Fi). Naturalmente, l'interpretazione della funzione di ripartizione che ne risulta rimane esattamente la stessa. Nell'esem-pio seguente viene costruita la funzione di ripartizione quando il fenomeno è per classi di modalità. Esempio 18
Supponiamo che la rilevazione dei redditi mensili (in milioni di lire) di 20 soggetti abbia dato luogo alla seguente distribuzione di frequenze il cui carattere è riportato per classi di modalità:
xi —|xi+1 ni fi Fi
0 —|1 2 0.1 0.1 1 —|3 4 0.2 0.3 3 —|5 8 0.4 0.7
5 —|10 4 0.2 0.9 10 —|20 2 0.1 1.0
20 1.0 La funzione di ripartizione di questa distribuzione di frequenze è riportata nella figura se-
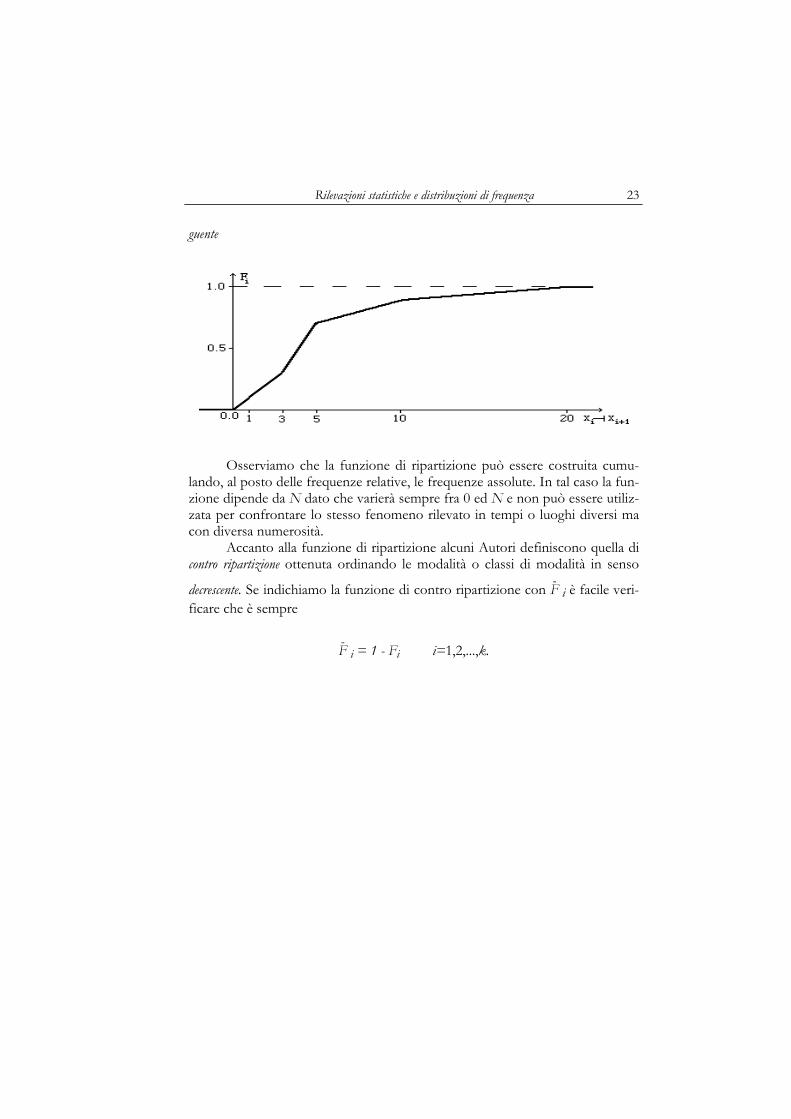
Rilevazioni statistiche e distribuzioni di frequenza 23
guente
Osserviamo che la funzione di ripartizione può essere costruita cumu-lando, al posto delle frequenze relative, le frequenze assolute. In tal caso la fun-zione dipende da N dato che varierà sempre fra 0 ed N e non può essere utiliz-zata per confrontare lo stesso fenomeno rilevato in tempi o luoghi diversi ma con diversa numerosità.
Accanto alla funzione di ripartizione alcuni Autori definiscono quella di contro ripartizione ottenuta ordinando le modalità o classi di modalità in senso
decrescente. Se indichiamo la funzione di contro ripartizione con F- i è facile veri-ficare che è sempre
F- i = 1 - Fi i=1,2,...,k.


Capitolo 2 INDICI STATISTICI DESCRITTIVI 2.1 Introduzione
Nel capitolo precedente abbiamo presentato alcune delle rappresenta-zioni tipiche delle distribuzioni di frequenza, in questo verranno illustrati alcuni degli indici più utilizzati per la sintesi di una distribuzione. Sintetizzare un dato fenomeno, in particolare una distribuzione di frequenza, in uno o pochi valori è utile per cogliere alcuni degli aspetti globali del fenomeno in studio e per po-ter effettuare immediati confronti fra fenomeni diversi o lo stesso fenomeno rilevato in posti o tempi diversi. Naturalmente, ogni qual volta si effettua una sintesi di un dato fenomeno si perdono informazioni: possono assumere lo stesso valore di sintesi distribuzioni molto diverse fra di loro. In tal senso, gli indici che tratteremo non avranno la pretesa di rappresentare esattamente una distribuzione, ma solo alcuni limitati aspetti di questa. Il problema, quindi, è di capire se tale perdita di informazioni è irrilevante rispetto agli obiettivi che il ricercatore si pone.
Di indici statistici descrittivi di una distribuzione di frequenza ne esiste una casistica molto vasta, qui presenteremo quelli che sono di più largo uso e di facile interpretazione mettendone in evidenza le eventuali proprietà che li carat-terizzano. Osserviamo, infine, che la quasi totalità degli indici che tratteremo sono utilizzabili solo per fenomeni il cui carattere è una quantità cioè è misura-bile. Inoltre, per comodità di esposizione distingueremo fra tre classi di indici statistici descrittivi in funzione dell'aspetto della rilevazione che si vuole evi-denziare: (a) indici di posizione o locazione: Servono per individuare il valore o la modalità del carattere più rappresentativo
della distribuzione di frequenza;
(b) indici di variabilità: Servono sia a valutare fino a che punto un dato indice di locazione è rap-

Capitolo 2 26
presentativo della distribuzione, sia a misurare la variabilità, l’oscillazione del fenomeno in studio;
(c) indici di forma: Servono per fornire alcune informazioni su aspetti della forma grafica della
distribuzione di frequenza. 2.2 Alcuni indici di posizione o locazione
Abbiamo già sottolineato che questi indici servono a localizzare una data distribuzione di frequenza, cioè ad individuare quel valore o modalità del carat-tere che meglio rappresenta l'intera distribuzione ed in questo senso la sintetizza.
Di indici che soddisfano una tale esigenza ne esistono molti, quello più noto ed utilizzato è la media aritmetica. LA MEDIA ARITMETICA
Questo indice, detto più semplicemente media, è quello più utilizzato nel-le pratiche applicazioni sia per la sua semplicità di calcolo, sia per la sua imme-diata interpretazione. La media aritmetica può essere calcolata solo se il caratte-re del fenomeno è una variabile cioè per fenomeni quantitativi. Vedremo che se le modalità del carattere sono distinte allora questo indice viene calcolato in modo esatto, se il carattere pur essendo una quantità è riportato per classi di modalità allora il calcolo dell'indice può essere effettuato solo in via approssi-mata.
La media aritmetica viene di solito indicata con uno dei seguenti simboli:
A : iniziale della parola Aritmetica
M : iniziale della parola Media
µ : equivalente della lettera m nella lingua greca
E(X) : iniziale della parola Expectation, mentre X indica la particolare di-stribuzione che si analizza
x : indica la media aritmetica calcolata sul campione. Nel seguito, per indicare la media aritmetica, useremo indifferentemente i sim-boli µ ed E(X) per indicare la media calcolata su popolazioni e x per indicare la media calcolata sul campione.
Data la generica distribuzione di frequenza X le cui modalità quantitative sono tutte distinte:

Indici statistici descrittivi 27
xi ni
x1 n1
x2 n2
… … xk nk
N
la media aritmetica di X è data da:
µ = x1n1+x2n2+...+xknk
N =
∑i=1
k xini
N = ∑i=1
k xi
niN = ∑
i=1
k xi fi
Nell’espressione della media le quantità fi = niN engono denominate pesi dato
che rappresentano, per l'appunto, il peso che ciascuna modalità xi ha sul calco-lo di µ; per questo motivo µ viene anche detta media aritmetica ponderata. Nel ca-so particolare in cui tutte le N modalità xi sono distinte, per cui risulta n1 = n2 = ... = nN =1, l'espressione della media aritmetica si riduce alla seguente:
µ = x1+x2+...+xN
N = 1N ∑
i=1
N xi
che viene anche chiamata media aritmetica semplice. Naturalmente, anche quando le modalità non sono tutte distinte queste possono essere sempre enumerate distintamente ed utilizzare questa formula per il calcolo della media. Mostriamo ora con un esempio come si calcola concretamente la media aritmetica. Esempio 1
Supponiamo di aver osservato una popolazione di 20 soggetti di cui si è rilevato il reddito lordo mensile espresso in milioni di lire e di aver ottenuto la seguente distribuzione di frequenze:

Capitolo 2 28
xi ni
2 2
5 4
7 6 8 4
10 4 20
Per calcolare la media aritmetica basta aggiungere alla tabella della distribuzione di frequen-ze una nuova colonna: quella dei prodotti, xini, fra ciascuna modalità e la rispettiva frequen-za
xi ni xini 2 2 4 5 4 20 7 6 42 8 4 32 10 4 40 20 138
che permette di ottenere immediatamente il calcolo della media
µ = 1N ∑
i=1
k xini =
13820 = 6.9
Le 20 osservazioni della distribuzione di frequenza, sopra riportate, possono essere indicate distintamente ottenendo: 2 5 7 8 10 2 5 7 8 10 5 7 8 10 5 7 8 10 7 7 cioè 20 valori xi alcuni dei quali si ripetono secondo la rispettiva frequenza. Naturalmente, in questo caso il calcolo della media è dato semplicemente dal rapporto fra la somma delle modalità diviso il numero delle modalità:

Indici statistici descrittivi 29
µ = x1+x2+...+xN
N = 1N ∑
i=1
N xi =
= 2+2+5+5+5+5+7+7+7+7+7+7+8+8+8+8+10+10+10+10
20 =
= 120 138 = 6.9
La media aritmetica gode di alcune importanti proprietà che la rendono,
in molti casi, particolarmente utile per effettuare sintesi di distribuzioni di fre-quenze. Proprietà della media aritmetica: 1) La media aritmetica rappresenta, da un punto di vista fisico, il baricentro
delle distribuzioni di frequenze cioè quel valore che lascia invariata l'in-
tensità totale ∑i=1
k xini della distribuzione. Analiticamente questo vuole di-
re che è sempre:
∑i=1
k xini = ∑
i=1
k µni
Infatti, dalla formula della media aritmetica e ricordando che N = ∑i=1
k ni
si ricava
∑i=1
k xini = µN = µ ∑
i=1
k ni = ∑
i=1
k µni
che dimostra quanto affermato. 2) La media aritmetica è sempre compresa fra la più piccola e la più grande
delle modalità del carattere. In altre parole, se è x1 ≤ x2 ≤ ... ≤ xk risulta sempre:

Capitolo 2 30
x1 ≤ µ ≤ xk ⇔ x1 ≤ 1N ∑
i=1
k xini ≤ xk.
Dimostriamo che è sempre
1N ∑
i=1
k xini ≥ x1
che equivale a dimostrare
∑i=1
k xini - x1N ≥ 0
Quest'ultima espressione si può scrivere:
∑i=1
k xini - x1N = ∑
i=1
k xini - x1 ∑
i=1
k ni =
∑i=1
k xini - ∑
i=1
k x1 ni = ∑
i=1
k (xi - x1) ni ≥ 0
Dove l'ultima disuguaglianza deriva dal fatto che si è posto x1 ≤ x2 ≤ ... ≤ xk. Una dimostrazione del tutto simile si ha per µ ≤ xk.
3) La somma degli scarti dalla media (ove per scarto dalla media s'intendo-no le differenze xi - µ) per le rispettive frequenze è sempre nulla. In sim-boli:
∑i=1
k (xi - µ) ni = 0
Infatti:
∑i=1
k (xi - µ) ni = ∑
i=1
k (xini - µ ni) = ∑
i=1
k xini - ∑
i=1
k µni =

Indici statistici descrittivi 31
= ∑i=1
k xini - µ ∑
i=1
k ni = ∑
i=1
k xini - µ N =
= ∑i=1
k xini -
1N ∑
i=1
k xini N = ∑
i=1
k xini - ∑
i=1
k xini = 0
Tutto questo vuol dire che la somma degli scarti negativi e positivi dalla
media aritmetica si compensano e ciò è una ulteriore giustificazione del fatto che la media aritmetica rappresenta il baricentro della distribuzione di frequenze.
4) La media aritmetica è l'unico valore che rende minima la somma dei qua-
drati degli scarti ponderati con le rispettive frequenze. In formule questa affermazione diviene:
∑i=1
k (xi - µ) 2ni ≤ ∑
i=1
k (xi - a) 2ni
qualsiasi sia la costante a. Osserviamo che se poniamo
f(a) = ∑i=1
k (xi - a) 2ni
per a = µ risulta
f(µ) = ∑i=1
k (xi - µ) 2ni
e la disuguaglianza che bisogna provare diviene f(µ) ≤ f(a) per ogni a rea-
le. Da un punto di vista geometrico la f(a), vista come funzione di a, è l'e-quazione di una parabola con il vertice rivolto verso il basso ed il cui mi-nimo, bisogna dimostrare, si raggiunge per a=µ.
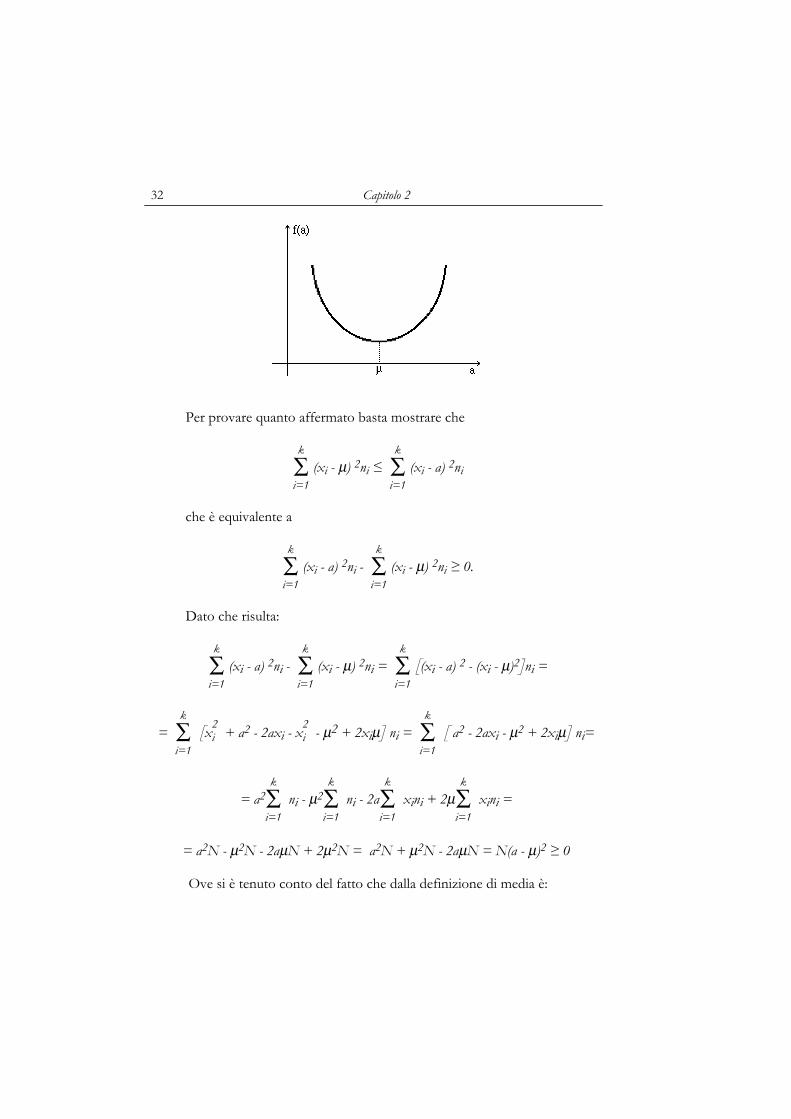
Capitolo 2 32
Per provare quanto affermato basta mostrare che
∑i=1
k (xi - µ) 2ni ≤ ∑
i=1
k (xi - a) 2ni
che è equivalente a
∑i=1
k (xi - a) 2ni - ∑
i=1
k (xi - µ) 2ni ≥ 0.
Dato che risulta:
∑i=1
k (xi - a) 2ni - ∑
i=1
k (xi - µ) 2ni = ∑
i=1
k [(xi - a) 2 - (xi - µ)2]ni =
= ∑i=1
k [x2
i + a2 - 2axi - x2i - µ2 + 2xiµ] ni = ∑
i=1
k [ a2 - 2axi - µ2 + 2xiµ] ni=
= a2∑i=1
k ni - µ2∑
i=1
k ni - 2a∑
i=1
k xini + 2µ∑
i=1
k xini =
= a2N - µ2N - 2aµN + 2µ2N = a2N + µ2N - 2aµN = N(a - µ)2 ≥ 0
Ove si è tenuto conto del fatto che dalla definizione di media è:

Indici statistici descrittivi 33
∑i=1
k xini = Nµ.
In questo modo abbiamo dimostrato l'affermazione fatta. Una dimo-
strazione alternativa si può ottenere utilizzando l'operatore derivata e ri-cordando che una funzione f(a) raggiunge il minimo in un dato punto se la sua derivata prima è nulla in quel punto e la derivata seconda è positi-va:
f '(a) = 0 , f "(a) > 0 in a = µ.
Ricordando l'espressione di f(a) risulta immediatamente:
f '(a) = - 2∑i=1
k (xi - a) ni = 0
da cui si ricava
- 2∑i=1
k (xi - a) ni = 0 ⇔ ∑
i=1
k (xi - a) ni = 0 ⇔ ∑
i=1
k xini - aN = 0 ⇔ a = µ
Inoltre, la derivata seconda, qualsiasi sia a, è data da:
f "(a) = -2 (-1)∑i=1
k ni = 2N >0
e quindi effettivamente in a=µ la funzione f(a) raggiunge il suo minimo assoluto.
5) La media della trasformazione lineare di una distribuzione di frequenza è
uguale alla trasformazione lineare della media. Da un punto di vista anali-tico questa affermazione vuole dire che data la distribuzione di frequenza X con media aritmetica µx se consideriamo la nuova distribuzione di frequenza Y = a +bX ottenuta da X tramite una trasformazione lineare, allora la media della nuova distribuzione di frequenza Y è data da
µy = a + bµx
Notiamo che passare dalla distribuzione X alla Y significa sottoporre il

Capitolo 2 34
fenomeno X ad un cambiamento di unità di misura. Dato che la retta è una funzione monotona (sempre crescente o sempre decrescente) è sempre possibile ritornare dalla Y alla X, in altri termini tutte le informa-zioni contenute nella X sono contenute nella Y e viceversa.
Distribuzione X Distribuzione Y
xi ni yi=a+bxi ni
x1 n1 y1 =a+bx1 n1
x2 n2 y2= a+bx2 n2
… … … … xk nk yk=a+bxk nk
N N
Dimostriamo che la media di una trasformazione lineare è uguale alla trasforma-zione lineare delle medie. Ricordando che per definizione è
µx = 1N∑
i=1
k xini ⇔ Nµx = ∑
i=1
k xini
avremo
µy = 1N∑
i=1
k yini =
1N ∑
i=1
k (a+bxi) ni =
= a 1N∑
i=1
k ni + b
1N∑
i=1
k xini = a + bµx
che dimostra quanto affermato.
Nelle pagine precedenti ho introdotto il concetto di media aritmetica ed illustrato le proprietà di cui gode questo indice di posizione e precisamente: 1) media aritmetica = baricentro della distribuzione di frequenza 2) min(xi) ≤ µ ≤ max(xi)
3) ∑i=1
k (xi - µ) ni = 0
4) ∑i=1
k (xi - µ) 2ni ≤ ∑
i=1
k (xi - a) 2ni per ogni a reale

Indici statistici descrittivi 35
5) se Y= a + bX allora µy = a + bµx Queste proprietà insieme alla facilità di calcolo di questo indice lo ren-
dono uno dei più noti ed usati. La media aritmetica ha però un difetto: è for-temente influenzata dall'esistenza di valori anomali (eccezionali o outliers) cioè modalità eccezionalmente grandi o eccezionalmente piccole rispetto alle restan-ti modalità della distribuzione di frequenza. L'origine di questi valori ecceziona-li può essere la più diversa: errori di trascrizione o di rilevazione, modalità ap-partenenti a popolazioni diverse da quella che si vuole analizzare, ecc. Esempio 2
Supponiamo di aver rilevato i redditi lordi mensili, espressi in milioni di lire, di 15 soggetti ottenendo i risultati riportati nella seguente distribuzione di frequenza:
xi ni
1 2
2 3
4 5 5 4
100 1 15
se calcoliamo la media aritmetica di questa distribuzione abbiamo
µ = 2+6+20+20+100
15 = 14815 ≈ 9.8
Otteniamo così un valore medio che non è rappresentativo né dei primi 14 individui che han-no un reddito compreso fra un milione e cinque milioni, né del quindicesimo individuo che ha un reddito di 100 milioni mensili. Questo effetto è dovuto alla presenza di quest'ultimo sog-getto che è chiaramente eccezionale rispetto agli altri 14 presi in considerazione. Se dalla di-stribuzione eliminiamo questo individuo ottenendo la nuova
xi ni
1 2
2 3
4 5 5 4
14 e calcoliamo la relativa media risulta

Capitolo 2 36
µ = 2+6+20+20
14 = 4814 ≈ 3.4
Come si nota dall'esempio sopra riportato, una volta individuati ed eli-minati i relativi valori eccezionali la media aritmetica diviene effettivamente rappresentativa della distribuzione di frequenza. In conclusione si può afferma-re che la media aritmetica ha un grave difetto: non è un indice robusto.
Un indice si dice robusto se è poco influenzato dall'esistenza di valori ec-cezionalmente grandi o eccezionalmente piccoli nella rilevazione statistica presa in considerazione.
Vediamo ora come si può calcolare la media aritmetica se la distribuzio-
ne è riportata per classi di modalità. Dato che non è possibile, in tal caso, sape-re a quali valori di ciascuna classe imputare le frequenze, il calcolo della media può essere ottenuto solo in via approssimata sostituendo a ciascuna classe un valore che in qualche modo la rappresenti. Questa operazione implica necessa-riamente un’approssimazione che è tanto maggiore quanto più le classi sono ampie. Un modo molto semplice di ottenere valori rappresentativi delle classi è quello di sostituirle con i rispettivi:
valori centrali di ciascuna classe. Quello della generica classe xi —| xi+1 è dato da:
ci = xi + xi+1
2 ; i=1,...,k
In tal modo, la media aritmetica è data approssimativamente da:
µ ≈ 1N ∑
i=1
k ci ni.
Si noti che la media calcolata rispetto alle modalità fittizie ci ha tutte le
proprietà ed i limiti che abbiamo illustrato. Nel caso in cui la prima, l'ultima o entrambe le classi sono aperte, per
poter calcolare la media è necessario chiudere queste classi. Nel caso in cui è la

Indici statistici descrittivi 37
prima classe ad essere aperta questa, di solito, può essere chiusa facilmente da-to che per molti fenomeni esiste un limite naturale dato dallo zero come avvie-ne per le età, i redditi, i consumi, gli investimenti ecc. Per fenomeni come peso e altezza e nel caso in cui sia la classe superiore ad essere aperta un limite natu-rale spesso non esiste e la scelta va fatta soggettivamente caso per caso. Una valida e più coerente alternativa alla procedura qui delineata consiste nel calcolo di una media troncata. LA MEDIA TRONCATA
La media troncata si ottiene eliminando le prime e le ultime classi della di-stribuzione di frequenza, sotto il vincolo che le frequenze cancellate nelle prime classi siano uguali a quelle cancellate nelle ultime, e calcolando la media aritme-tica sulla distribuzione così ridotta.
Così, data la seguente distribuzione di frequenza la cui ultima classe è aperta
xi —| xi+1 ni fi x1 —| x2 n1 f1 x2 —| x3 n2 f2 x3 —| x4 n3 f3
… … … xk-1 —| xk nk-1 fk-1
> xk nk fk N 1
se risulta f1 = fk allora è possibile eliminare nel calcolo della media la prima clas-se di modalità (x1 —| x2) e l'ultima (> xk) e calcolare la media aritmetica sulle classi centrali evidenziate nella tabella precedente. Naturalmente, se risulta f1 > fk si elimina l'ultima classe, mentre la prima rimane ma con una frequenza pari a f1- fk. Nel caso in cui sia fk > f1 si elimina la prima e l'ultima classe ed inoltre la frequenza della seconda classe si riduce a f2 -(fk-f1) facendo attenzione che sia f2 -(fk-f1) ≥ 0; se risulta f2 -(fk-f1) < 0 allora si eliminano le prime due classi e l'ul-tima mentre la frequenza della terza classe si riduce a f3 - (fk - f1 - f2) facendo attenzione che sia f3 - (fk - f1 - f2) ≥ 0, e così via.
Si osservi che la media troncata può essere calcolata, ovviamente, anche

Capitolo 2 38
per distribuzioni di frequenze il cui carattere è quantitativo e non diviso in clas-si. Inoltre, tale indice è robusto dato che elimina per costruzione le modalità o classi di modalità che si trovano agli estremi (piccole e grandi). Naturalmente, come avviene per la media aritmetica, la media troncata non può essere calcola-ta per distribuzioni di frequenze il cui carattere è una qualità anche se ordinabi-le. Esempio 3
Consideriamo il caso riportato nell'esempio 2 e calcoliamo la media troncata ponendo come condizione l'eliminazione dell'ultima modalità. Visto che risulta fk = 1 < f1 = 2 per fare in modo che le frequenze eliminate siano bilanciate, la distribuzione troncata diviene
xi ni
1 1
2 3
4 5 5 4
13 e la relativa media troncata, che indichiamo con µT risulta pari a
µT = )( 45543211131 ×+×+×+× =
4713 ≈ 3.615
Un altro indice di posizione molto utilizzato nelle pratiche applicazioni è
la mediana. LA MEDIANA
A differenza della media aritmetica, che è invariate rispetto all'ordina-mento delle modalità o classi di modalità, per poter calcolare la mediana è ne-cessario ordinare in modo crescente le modalità o le classi di modalità del carat-tere.
La mediana è quella modalità che bipartisce la distribuzione di frequenza il cui carattere è stato ordinato in senso crescente. Cioè quella modalità tale che il 50% delle frequenze stanno al di sopra ed il 50% al di sotto.

Indici statistici descrittivi 39
Di solito la mediana si indica con i simboli Me oppure µe. Nel seguito utilizze-remo il primo di questi. Esempio 4
Supponiamo che nella rilevazione del numero dei componenti di 15 famiglie si sia a-vuto il risultato seguente:
1; 3; 5; 2; 4; 3; 2; 1; 4; 4; 3; 1; 5; 4; 2. Per poter calcolare la mediana è necessario ordinare il carattere, che in questo caso è dato dal numero dei componenti di ciascuna delle 15 famiglie, in senso non decrescente ottenendo:
1 1 1 2 2 2 3 3 3 4 4 4 4 5 5
Modalità che bipartisce la distribuzione
Come si può notare, la modalità che bipartisce la distribuzione è quella che è stata
racchiusa in un cerchio dato che al di sotto ed al di sopra di tale valore cadono lo stesso nume-ro di modalità. Questo vuol dire che in tal caso è
Me = 3.
Le 15 osservazioni le possiamo riscrivere sotto forma di distribuzione di frequenza ottenendo la tabella seguente ove nell'ultima colonna sono state riportate le frequenze cumulate indicate con Ni
xi ni Ni 1 3 3 2 3 6 3 3 9 4 4 13 5 2 15 15
Osserviamo che la mediana, per definizione, è quella modalità che stacca alla sua si-
nistra il 50% delle frequenze, cioè N2 % . In questo caso si ha
N2 =
152 = 7.5 e la me-
Prima frequenza cumulata che supera 7.5

Capitolo 2 40
diana sarà data dalla prima modalità xi la cui relativa frequenza cumulata supera 7.5. Nel nostro esempio, come indicato dalla freccia, tale modalità è pari a 3 per cui risulta
Me = 3.
Nel caso precedente il calcolo della mediana è risultato piuttosto sempli-ce dato che la numerosità N era dispari. Vediamo ora cosa succede se N è pari. Il tutto è illustrato nell'esempio che segue. Esempio 5
Supponiamo che le famiglie intervistate siano 14 e che i risultati ottenuti sull’ampiezza del loro nucleo familiare siano i seguenti
1; 3; 5; 2; 4; 3; 2; 4; 4; 4; 1; 5; 4; 2 ordinando questi numeri si ottiene
Come si vede, le modalità centrali della distribuzione sono due: quella di posto 2N e quella
di posto 2N +1. In questo caso la modalità di posto
2N è pari a 3 mentre quella di posto
2N +1 è pari a 4 e la mediana, per convenzione, si pone pari alla media di queste due
modalità, cioè:
Me = 3+4
2 = 3.5
In definitiva, data la generica distribuzione di frequenza
modalità centrali della distribuzione
1 1 2 2 2 3 3 4 4 4 4 4 5 5 3 4
2N 1
2+N

Indici statistici descrittivi 41
xi ni Ni x1 n1 N1= n1 x2 n2 N2=n1+n2 x3 n2 N3=n1+n2+n3 ... ... ............ xk nk Nk=N N
si distinguono due casi: 1) N è dispari: in tale caso la mediana è la prima modalità la cui frequenza cumulata su-
pera N2 ; in altri termini la mediana è quella modalità che, dopo averle ordi-
nate in senso non decrescente, occupa il posto 2
1+N -esimo. Osserviamo che
essendo N dispari, N+1 è sempre divisibile per due; 2) N è pari: in tal caso per calcolare la mediana bisogna individuare la modalità che
occupa il posto 2N -esimo, la modalità successiva che occupa il posto
(2N +1)-esimo ed ottenere la mediana come semi somma di questi due
valori:
Me = xi + xi+1
2
In molti casi può accadere che sia xi = xi+1 e naturalmente risulta Me = xi. Esempio 6
Supponiamo di avere osservato un qualche fenomeno che ha dato luogo alla seguente distribuzione di frequenza ove nelle ultime due colonne sono state riportate, rispettivamente, le frequenze cumulate e le frequenze relative cumulate

Capitolo 2 42
xi ni Ni Fi 2 2 2 0.1 3 4 6 0.3 5 4 10 0.5 7 6 16 0.8 10 4 20 1.0 20
In questo caso, essendo
N2 =
202 = 10,
le due modalità di riferimento sono xi = 5 individuato in corrispondenza di Ni = 10 ed il successivo xi+1 = 7. Avremo così
Me = 5+7
2 = 6.
Questo è uno dei pochi casi in cui la mediana non coincide con una delle modalità del fenome-no analizzato.
Se la distribuzione fosse stata la seguente
xi ni Ni Fi 2 2 2 0.1 3 4 6 0.3 5 6 12 0.6 7 6 18 0.9 10 2 20 1.0 20
allora avremmo avuto xi = xi+1 = 5 dato che la prima modalità che è uguale o supera N/2 è data proprio dal valore 5. Avremmo così Me = 5.
Ovviamente, invece che le frequenze cumulate, possono essere prese come mezzo per individuare la mediana le frequenze relative cumulate in tal caso il termine di riferimento non è più N/2 ma 0.5. Osserviamo ancora che la mediana è un particolare caso di media troncata: si ottiene quando nel calcolo della media troncata si eliminano il 50% dei valori piccoli ed il 50% dei valori

Indici statistici descrittivi 43
grandi. La mediana, al contrario della media aritmetica, è un indice robusto nel
senso che risente molto poco dell'esistenza di valori eccezionalmente grandi o piccoli nella distribuzione. Tutto questo è illustrato nell'esempio che segue. Esempio 7 Riprendiamo la distribuzione dell'esempio 2
xi ni Ni 1 2 2 2 3 5 4 5 10 5 4 14
100 1 15 15
ed essendo N/2 = 15/2 = 7.5 segue immediatamente che è Me = 4. Se dalla distribuzione eliminiamo la modalità anomala x5 = 100 otteniamo
xi ni Ni 1 2 2 2 3 5 4 5 10 5 4 14 15
e risulta ancora Me = 4 che dimostra la robustezza di questo indice. E' interessante osserva-re che la media aritmetica di questa seconda distribuzione è µ = 3.83 che è vicino alla me-diana ed alla media troncata calcolata nell'esempio 3.
Mostriamo ora come si calcola, anche se in via approssimata, la mediana quando il carattere è per classi di modalità. In tal caso è necessario individuare in primo luogo la classe mediana, cioè quella classe che contiene il 50% delle fre-quenze relative cumulate. Questa classe si individua facilmente. Infatti, basta considerare la prima classe per cui la rispettiva frequenza relativa cumulata su-pera o uguaglia 0.5. Se supponiamo che la prima classe per cui Fi≥0.5 è la (xi; xi+1] è evidente che la mediana cadrà in questa classe

Capitolo 2 44
Questo vuole dire che la mediana è uguale ad xi più qualcosa. Se si formula l'ipo-tesi semplificatrice che le frequenze della classe (xi; xi+1] si distribuiscono uni-formemente in essa, è possibile impostare la seguente proporzione
(Me - xi) : (xi+1 - xi) = (0.5 - Fi-1): (Fi - Fi-1)
ed ottenere un valore approssimato per la mediana
Me ≈ xi +(xi+1 - xi) 0.5 - Fi-1Fi - Fi-1
Quanto detto può essere illustrato graficamente nella figura che segue
Si osservi che nel caso particolare in cui è Fi = 0.5 allora risulta Me = xi+1 co-me si può anche derivare dalla formula sopra presentata per il calcolo della me-diana. Il calcolo della mediana può anche essere fatto utilizzando al posto delle frequenze relative cumulate Fi le frequenze assolute cumulate Ni utilizzando la corrispondente formula
Me = xi + (xi+1 - xi)
12 N - Ni-1
Ni - Ni-1
Si osservi che questa formula è ottenuta dalla precedente moltiplicando il nu-meratore ed il denominatore della frazione per N, notare che Ni è la prima fre-

Indici statistici descrittivi 45
quenza cumulata che supera 2N . Illustriamo quanto abbiamo detto con un e-
sempio. Esempio 8
Consideriamo la seguente distribuzione di frequenza il cui carattere è per classi di modalità ed in cui abbiamo riportato le frequenze relative fi e le corrispondenti frequenze rela-tive cumulate Fi e le frequenze assolute cumulate Ni:
xi —| xi+1 ni fi Fi Ni 0 —| 1 3 0.20 0.20 3 1 —| 5 5 0.33 0.53 8 5 —| 7 4 0.27 0.80 12 7 —| 15 3 0.20 1.00 15
15 1 La prima frequenza relativa cumulata che supera 0.5 è F2 = 0.53 in corrispondenza della quale vi è la classe mediana 1 —| 5 al cui interno si troverà la mediana che, utilizzando la formula sopra riportata e ricordando che in questo caso è
xi = 1, xi+1 = 5, Fi = 0.53, Fi-1 = 0.2,
sarà data approssimativamente da:
Me ≈ 1 + (5 - 1) 0.5 - 0.20.53 - 0.2 = 4.6.
Utilizzando la seconda formula, tenuto conto che in questo caso risulta
N2 = 7.5, Ni = 8, Ni-1 = 3,
avremo ovviamente lo stesso risultato:
Me ≈ 1 + (5 - 1) 7.5 - 38 - 3 = 4.6

Capitolo 2 46
Esempio 9
Supponiamo di avere rilevato un fenomeno X ottenendo la seguente distribuzione di frequenza
xi ni fi Fi Ni 2 2 0.1 0.1 2 3 4 0.2 0.3 6 5 4 0.2 0.5 10 7 6 0.3 0.8 16 10 4 0.2 1.0 20 20 1.0
Dato che N = 20 è pari si ha immediatamente che la mediana è compresa fra la 10° e la 11° posizione e quindi fra le modalità 5 e 7, per convenzione si pone
Me = 5 + 7
2 = 6.
La funzione di ripartizione di questa distribuzione di frequenza è riportata nella figura se-guente da cui emerge ancora che la mediana è un valore indeterminato fra 5 e 7 che per con-venzione può essere posto pari alla media di queste due modalità.

Indici statistici descrittivi 47
Supponiamo ora di avere ottenuto la seguente distribuzione di frequenza
xi ni fi Fi Ni 1 2 0.15 0.15 2 2 3 0.21 0.36 5 3 3 0.21 0.57 8 4 4 0.28 0.85 12 5 2 0.15 1.00 14 14 1.0
Anche in questo caso N=14 è pari per cui la mediana è compresa fra la 7° e la 8°
posizione a cui corrisponde la stessa modalità 3, pertanto avremo
Me = 3 + 3
2 = 3.
Tutto questo si evince immediatamente dalla relativa funzione di ripartizione riporta-
ta qui di seguito.
Abbiamo visto che una proprietà della mediana è di essere robusta ri-

Capitolo 2 48
spetto alla presenza di valori eccezionali, un'altra proprietà, che non dimostre-remo, è che la somma degli scarti in valore assoluto dalla mediana, ponderati con le relative frequenze, è un minimo rispetto a qualsiasi altro valore reale, in simboli:
∑i=1
k |xi - Me|ni ≤ ∑
i=1
k |xi - a|ni
per qualunque a reale.
Con la stessa logica con cui è stata calcolata la mediana è possibile calco-lare altri indici che prendono il nome di quartili. I QUARTILI
Il primo quartile, di solito indicato con Q1, è quel valore al di sotto del quale cade il 25% delle frequenze ed al di sopra il 75%;
il terzo quartile, di solito indicato con Q3, è quel valore al di sotto del qua-le cade il 75% delle frequenze ed al di sopra il 25%.
Per quanto detto la mediana, che sarà sempre compresa fra Q1 e Q3,
prende anche il nome di secondo quartile e viene anche indicata per similitudine con Q2. I tre indici Q1, Q2, Q3, per come sono costruiti, dividono una distribu-zione di frequenza in quattro parti uguali da cui il nome di quartili.
Un modo operativo per calcolare i quartili si basa sul fatto che la media-na, Me = Q2, divide una distribuzione di frequenza in due sotto distribuzioni in ciascuna delle quali ricade, per costruzione, lo stesso numero di unità di rileva-zioni. Ebbene, Q1 non è altro che la mediana della prima sotto distribuzione (da x1 incluso a Me escluso) e Q3 la mediana della seconda sotto distribuzione (da Me escluso a xn incluso). Il calcolo pratico dei quartili si effettua con la stes-
sa tecnica usata per la mediana solo che per Q1 il termine di riferimento è N4 e
per Q3 è 3N4 . Naturalmente, se per il calcolo dei quartili si utilizzano le fre-
quenze relative cumulate i valori di confronto sono 0.25 per Q1 e 0.75 per Q3 così come 0.50 lo è per la mediana.
Una distribuzione di frequenza può essere sintetizzata con cinque numeri notevoli:

Indici statistici descrittivi 49
x1: minima modalità della distribuzione Q1: primo quartile della distribuzione Q2 = Me: mediana della distribuzione Q3: terzo quartile della distribuzione xk: massima modalità della distribuzione.
Questi cinque numeri possono anche essere usati per costruire un parti-colare grafico che prende il nome di box-plot (grafico a scatola)
come illustrato nella figura seguente
Il box-plot è un modo alternativo per rappresentare e contemporanea-mente sintetizzare, visto che si basa solo su cinque numeri caratteristici, una distribuzione di frequenza e può essere costruito se il carattere è una quantità sia esso riportato in classi di modalità o meno. Spesso il box-plot è molto utile per confrontare distribuzioni di frequenze relative allo stesso fenomeno rileva-to in tempi o luoghi diversi. In tale caso i diversi box-plot vengono affiancati per poterne dare una lettura d'insieme (box-plot paralleli). Esempio 10
Calcoliamo i quartili della distribuzione di frequenza di cui all'esempio 5 e costruia-mo il relativo box-plot.
xi ni Ni Fi 2 2 2 0.10 3 4 6 0.30 5 5 11 0.55 7 5 16 0.80 10 4 20 1.00 20

Capitolo 2 50
Da questa distribuzione si ricavano immediatamente i cinque valori caratteristici:
x1 = 2 Q1 = 3 Q2 = 5 Q3 = 7 xk = 10
che permettono di ottenere il relativo box-plot riportato nella figura seguente.
Vediamo ora come possono essere utilizzati i quartili per individuare l'e-sistenza di eventuali valori eccezionali presenti in una distribuzione di frequen-za. A tale proposito definiamo i seguenti due valori cardine:
h1= Q1 - 1.5(Q3 - Q1); H2 = Q3 + 1.5(Q3 - Q1).
Tutte le modalità, se esistono, più piccole di h1 sono valori eccezionalmente piccoli;
tutte le modalità, se esistono, più grandi di H2 sono valori eccezionalmente grandi.
I cardini sono parte integrante del box-plot e vanno sempre calcolati ed
indicati se h1 è più grande di x1 ed H2 più piccolo di xk. Nella stessa figura vanno indicati sempre gli eventuali valori eccezionali. L'esempio che segue mo-stra come va costruito un box-plot. Esempio 11 Supponiamo di avere la seguente distribuzione di frequenza
e quindi
2 3 5 7 18
2 4 6 6 2
xi
ni

Indici statistici descrittivi 51
x1 = 2 Q1 = 3 Q2 = 5 Q3 = 7 xk = 18
h1 = 3-1.5(7-3) = -3 H2 = 7+1.5(7-3) = 13
Come si poteva intuire, nella distribuzione data non vi sono valori eccezionalmente piccoli, ma ve ne sono due eccezionalmente grandi con modalità pari a 18. Questo è messo chiaramente in luce nel relativo box-plot ove sono indicati i due valori eccezionali con due a-sterischi. Notare che in questo caso si è riportato solo il cardine superiore H2 .
*
Un indice che può essere calcolato per qualsiasi distribuzione di fre-quenza indipendentemente dalle caratteristiche del carattere rilevato, cioè sia esso una variabile o una mutabile ordinabile o sconnessa, è la moda. LA MODA
Di solito tale indice viene indicato con il simbolo Mo e può essere defini-to come segue: la moda è quella modalità del carattere a cui corrisponde la massima frequenza della distribuzione:
Mo = {xi: ni = max)
Naturalmente, dato che la moda è un indice molto generale, le informa-
zioni che fornisce su una distribuzione di frequenza sono poche. Esempio 12
Supponiamo che la rilevazione di un particolare carattere in una popolazione abbia dato luogo alla seguente distribuzione di frequenza

Capitolo 2 52
xi ni xini Ni Fi 7 3 21 3 0.143 8 5 40 8 0.380 15 4 60 12 0.570 18 7 126 19 0.905 21 2 42 21 1.000 21 289
La moda, la mediana e la media di questa distribuzione sono date rispettivamente da:
Mo = 18; Me = 15; µ = 13.7619.
Come si può notare, in questo caso, i tre indici sono abbastanza differenti fra di loro, come d'altra parte era da attendersi dato che ciascuno di loro mette in rilievo particolari aspet-ti della distribuzione in studio.
Se il carattere è per classi di modalità bisogna porre l'attenzione non sul-le frequenze ni ma sulle intensità di ciascuna classe hi (le altezze dei rettangoli nell'istogramma della distribuzione) individuando così la relativa classe modale all'interno della quale cade la moda, questa verrà ottenuta solo in via approssi-mata.
La classe modale di una distribuzione, il cui carattere è per classi di modali-tà, è data da:
classe modale = { xi —| xi+1: hi = max}.
dove hi è l'intensità della classe e, come abbiamo visto, è data da
hi = nibi
= ni
xi+1 - xi
Se la classe modale individuata è xi —| xi+1 risulterà xi ≤ Mo ≤ xi+1. Un
metodo utilizzato per ottenere, anche se in via approssimata, un valore per la moda è di considerare il valore centrale della classe modale:
Mo ≈ xi + xi+1
2

Indici statistici descrittivi 53
Questa approssimazione si basa sull'ipotesi che le frequenze si distribuiscano uniformemente nella classe modale ed il suo valore centrale le rappresenta, in media, molto bene. Esempio 13
Supponiamo di avere rilevato un fenomeno il cui carattere, quantitativo, sia riportato per classi di modalità ottenendo la seguente distribuzione di frequenza
xi —| xi+1 ni hi 1 —| 3 2 1.000 3 —| 7 5 1.250 7 —| 15 7 0.875 15 —| 20 8 1.600
22 da cui si ha immediatamente che, essendo l'intensità massima del carattere pari a h4 = 1.6, la classe modale è data da 15 —| 20 e la moda sarà approssimativamente pari a
Mo ≈ 15 + 20
2 = 17.5.
Supponiamo ora che la distribuzione sia data da
xi —| xi+1 ni hi 1 —| 3 2 1.000 3 —| 7 5 1.250 7 —| 15 7 0.875 15 —| 22 8 1.143 22
Come si può notare, questa nuova distribuzione è molto simile alla precedente l'unica
differenza fra le due è l'estremo superiore dell'ultima classe che nella prima era pari a 20 e nella seconda è 22. Questa lieve differenza implica però che la classe modale della seconda distribuzione è data da 3 —| 7 per cui sarà 3 < Mo < 7 e la relativa moda sarà data, approssimativamente, da
Mo ≈ 3 + 7
2 = 5.
che è un valore molto diverso dal precedente. Questo esempio ci mostra come la moda sia un

Capitolo 2 54
indice poco robusto e sensibile al modo in cui le classi di modalità vengono costruite.
Un ultimo indice di locazione che tratteremo in questo corso, ma di in-dici di locazione ne esiste una larga schiera spesso dimenticati ed inutilizzati, è la media geometrica. LA MEDIA GEOMETRICA
E' un indice che viene utilizzato, essenzialmente, quando il carattere del-la distribuzione è un tasso (tasso di interesse, di produzione, di sviluppo ecc.) e viene indicato con µG. Questo indice ha senso utilizzarlo solo se il fenomeno, oltre ad essere una quantità, è strettamente positivo per le ragioni che vedremo più innanzi. Data la generica distribuzione di frequenza X le cui modalità quan-titative sono tutte distinte e strettamente positive:
xi ni
x1 n1
x2 n2
… … xk nk
N
la media geometrica della distribuzione di frequenza sopra riportata è definita nel modo seguente:
µG = N
xn11 x
n22 ... x
nkk
La media geometrica può essere anche scritta in termini di frequenze
relative, infatti
µG = N nk
nn kxxx ...2121 = ( ) Nn
knn kxxx
/121 ...21 = x 1
1f x 2
2f ... x kf
k =
= ∏i=1
k xfi
i
La media geometrica ha una serie di caratteristiche alcune delle quali so-
no qui di seguito illustrate:

Indici statistici descrittivi 55
1) se una delle modalità fosse pari a zero, la media geometrica sarebbe
sempre pari a zero indipendentemente dal valore assunto dalle altre mo-dalità. Inoltre, se una delle modalità fosse negativa ed N dispari la radice non esisterebbe nel campo dei numeri reali. Per questi motivi la media geometrica viene utilizzata per caratteri misurabili positivi. Osserviamo ancora che questa media, come già visto per la media aritmetica e la mo-da, è indipendente dall'ordinamento delle modalità del carattere.
2) Mentre la media aritmetica può essere definita come quel valore che so-
stituito a ciascuna modalità xi ne lascia immutata la somma, cioè:
∑i=1
k xi ni = ∑
i=1
k µ ni = Nµ
la media geometrica è quel valore che sostituito a ciascuna modalità xi ne
lascia immutato il prodotto, cioè:
∏i=1
k xni
i = ∏i=1
k µni
G = µNG
3) Si può dimostrare che è sempre
x1 ≤ µG ≤ xk 4) Si può dimostrare che (caso particolare della disuguaglianza di Jensen)
µG ≤ µ con l'uguaglianza se e solo se risulta x1 = x2 = ... = xk = µ. 5) La media geometrica, così come abbiamo visto per la media aritmetica,
non è un indice robusto e quindi è fortemente influenzata dalla presenza di valori eccezionali.
6) Fra la media aritmetica e quella geometrica esiste un altro rilevante lega-me:
il logaritmo della media geometrica è uguale alla media aritmetica dei logaritmi:
log(µG) = ∑i=1
k fi log(xi)
Infatti, risulta immediatamente

Capitolo 2 56
log (µG) = log
∏=
ifi
k
ix
1= ∑
i=1
k log ( )if
ix = ∑i=1
k fi log(xi)
Come si può notare, l'ultima espressione è proprio la media aritmetica,
non degli xi, ma del loro logaritmo. Quest'ultima proprietà suggerisce di calcolare la media geometrica come l'espo-nenziale della media aritmetica dei logaritmi:
µG =)ixlog(if
k
ie∑=1
Esempio 14
Supponiamo che nella rilevazione di un carattere di una popolazione di 14 unità sia stata ottenuta la seguente distribuzione di frequenze:
xi ni Ni xi ni log(xi) ni log(xi) 2 2 2 4 0.6931 1.3863 3 3 5 9 1.0986 3.2958 5 4 9 20 1.6094 6.4378 6 3 12 18 1.7917 5.3753 8 2 14 16 2.0794 4.1589 14 67 20.6541
da cui si ricava immediatamente
∑i=1
k fi lg(xi) =
1N ∑
i=1
k ni lg(xi) =
20.654114 = 1.4753
e quindi
µG = exp
∑=
)xlg(f iik
i 1= exp(1.4753) = 4.3723
Per gli altri indici di locazione si ottiene:
µ = 6714 = 4.7857

Indici statistici descrittivi 57
Me = 5 Mo = 5 Si osservi che, come previsto dalla teoria, risulta µG < µ.
Se la distribuzione è per classi di modalità, la media geometrica può esse-re calcolata in via approssimata sostituendo a ciascuna classe il suo valore cen-trale, ci, e quindi utilizzando la formula:
µG ≈ exp
∑=
)clog(f iik
i 1
2.3 Alcuni indici di variabilità
Abbiamo visto che gli indici di posizione individuano il valore o la mo-dalità che può essere considerata più rappresentativa della data distribuzione di frequenza. Una volta calcolato un indice di posizione è necessario anche elabo-rare un qualche indice che ci dia informazione sul grado di rappresentatività del-l'indice di locazione considerato. Questo aspetto è legato alla variabilità del fe-nomeno preso in considerazione, ove: la variabilità di una distribuzione di frequenza X è la sua attitudine ad assumere differenti modalità.
Data la generica distribuzione di frequenza X:
xi ni
x1 n1
x2 n2
… … xk nk
N essa è tanto più variabile quanto più diverse e distanti fra di loro sono le moda-lità che assume. Da questo punto di vista gli indici di variabilità devono essere tutti non negativi ed aumentare all'aumentare della variabilità del fenomeno. Il massimo della variabilità si ha quando i caratteri sono polarizzati ai due estremi, cioè una parte delle unità di rilevazione assume la modalità più piccola possibile

Capitolo 2 58
x1, e le restanti unità di rilevazione assumono la massima possibile xk. L'assenza di variabilità si ottiene quando tutte le modalità del carattere sono uguali fra di loro, cioè se x1 = x2 = ... = xk = µ. Di indici che misurano la variabilità di un carattere ne sono stati elaborati una larga classe, qui di seguito verranno pre-sentati quelli più noti ed usati nelle pratiche applicazioni. L'INTERVALLO DI VARIAZIONE
E' il più semplice e, per molti aspetti, grossolano indice di variabilità. Di solito viene indicato con il simbolo IV, più precisamente questo indice può essere definito nel modo seguente: l'intervallo di variazione (range) è dato dalla differenza fra la più grande e la più piccola modalità del carattere:
IV = xk - x1
E' sempre IV ≥0 ed è nullo se e solo se x1 = xk che equivale a dire che
tutte le modalità sono uguali fra di loro. Come abbiamo già sottolineato, è un indice molto grossolano perché nel suo calcolo tiene conto solo delle due mo-dalità estreme disinteressandosi di ciò che avviene nel corpo della distribuzio-ne. Per questo motivo distribuzioni anche molto diverse fra di loro possono presentare lo stesso valore di IV come illustrato nella figura seguente. Da que-sta si evince che le due distribuzioni, pur avendo un andamento molto diverso e quindi una variabilità nettamente differente, hanno lo stesso valore di IV.
L'indice IV è un indice assoluto, è funzione dell'unità di misura utilizzata per rilevare il fenomeno, e quindi non può essere usato per confrontare la va-riabilità di distribuzioni misurate con differente unità di misura. Un modo per

Indici statistici descrittivi 59
relativizzare tale indice, cioè renderlo indipendente dall'unità di misura, è
IVr = xk - x1|x1|
Un secondo e più usato indice di variabilità è la varianza. LA VARIANZA
Più precisamente, questo indice viene indicato con uno dei seguenti simboli σ2, var(X), E[(X-µ)2], S2, s2. Di solito, i simboli σ2, var(X), E[(X-µ)2] vengono usati per indicare la varianza in una popolazione, mentre S2, s2 sono usati per indicare la varianza di campioni casuali.
La varianza di una distribuzione di frequenza X è data:
σ2 = var(X) = 1N ∑
i=1
k (xi - µ) 2ni
Come si può notare, la varianza di X non è altro che la media dei qua-drati degli scarti, per questo motivo si ha che σ2 ≥ 0 e risulta σ2 = 0 se e solo se tutte le modalità sono uguali fra di loro e quindi coincidenti con la media: x1 = x2 = ... = xk = µ.
La varianza, non solo misura la variabilità del fenomeno, ma indica fino a che punto µ è rappresentativo della distribuzione data.
Per poter calcolare la varianza è necessario in primo luogo calcolare la media e, da un punto di vista pratico, può essere utile costruire una tabella del tipo:
xi ni xini (xi-µ)2 (xi-µ)2ni x1 n1 x1n1 (x1-µ)2 (x1-µ)2n1 x2 n2 x2n2 (x2-µ)2 (x2-µ)2n2 ... ... ... ... ... xk nk xknk (xk-µ)2 (xk-µ)2nk
N ∑ xini ∑ (xi-µ) 2ni

Capitolo 2 60
ove la terza colonna permette di calcolare la media (dividendo la somma di tale colonna per N) e l'ultima la varianza (dividendo la somma di tale colonna per N).
La varianza può essere espressa sotto una diversa forma:
σ2 = 1N∑ (xi-µ) 2ni =
1N∑ (x2
i - 2xiµ + µ2) ni =
= 1N∑ x2
i ni - 2µ 1N∑ xini + µ2
1N∑ ni =
= 1N∑ x2
i ni - 2µ2 + µ2 = 1N∑ x2
i ni - µ2
Se indichiamo 1N∑ x2
i ni = µ2 la varianza si può anche ottenere come
σ2 = var(X) = µ2 - µ2
L'indice µ2 è detto momento secondo della distribuzione di frequenza ed è la
media aritmetica dei quadrati delle modalità, esso è anche indicato con E(X2). In definitiva
varianza = media dei quadrati - quadrato della media =
= µ2 - µ2 = E(X2) - [E(X)]2
Notiamo che, essendo per costruzione σ2 ≥ 0, si avrà
µ2 ≥ µ2
la quantità µ2 viene anche chiamata media quadratica ed utilizzata come uno degli indici di posizione.
Da un punto di vista pratico la varianza di una distribuzione X può an-che essere calcolata utilizzando la formula σ2 = µ2 - µ2 e quindi adottando lo

Indici statistici descrittivi 61
schema seguente:
xi ni xini x2i ni
x1 n1 x1n1 x21 n1
x2 n2 x2n2 x22 n2
... ... ... ... xk nk xknk x2
k nk
N ∑ xini ∑ x 2i ni
ove la terza colonna permette di calcolare la media (somma della colonna divi-so N) e l'ultima il momento secondo (somma della colonna diviso N).
Generalizzando il concetto di momento secondo è possibile definire i momenti di ordine r. I MOMENTI DI ORDINE r
Il momento di ordine r, che di solito si indica con il simbolo µr o con E(Xr), è la media delle potenze r-esime delle modalità:
µr = E(Xr) = 1N ∑
i=1
k xr
i ni per r=1,2,....
Si osservi che se è r=1 si ottiene la media aritmetica, se è r=2 si ottiene il
momento secondo utile, come visto, per il calcolo della varianza. Da questo punto di vista la media aritmetica viene detta anche momento primo.
Naturalmente, affinché la varianza possa essere calcolata è necessario che il carattere sia misurabile e quindi dia luogo ad una variabile. Se il carattere è per classi di modalità la varianza può essere calcolata solo in via approssimata sostituendo a ciascuna classe di modalità il suo valore centrale ci ed ottenendo:
σ2 ≈ 1N ∑
i=1
k (ci - µ) 2ni.
Vediamo alcune caratteristiche della varianza:

Capitolo 2 62
1) Dato che la varianza è definita come media degli scarti al quadrato, è un indice che dipende dall'unità di misura al quadrato. In altri termini, se per esempio il fenomeno è misurato in quintali la sua varianza è espressa in quintali al quadrato, se il fenomeno è misurato in centimetri la sua va-rianza è misurata in centimetri quadri e così via. Per evitare questo in-conveniente come misura della variabilità si considera lo
scarto quadratico medio definito come la radice quadrata (positiva) della va-rianza:
σ = σ2 = 1N ∑
i=1
k (xi - µ)2ni = µ2 - µ2
Questo indice è espresso nella stessa unità di misura del fenomeno e viene anche chiamato deviazione standard (standard deviation).
2) La varianza, come pure lo scarto quadratico medio, sono indici poco ro-busti cioè fortemente influenzati dall'esistenza di valori eccezionali esi-stenti nella distribuzione.
3) Data la distribuzione X con media µx e varianza σ2x se costruiamo la
nuova distribuzione Y = a +bX si ha che
σ2y = b2σ2
x Infatti, ricordando che in questo caso risulta µy = a +bµx, avremo
σ2y =
1N∑
i=1
k (yi - µy) 2ni =
1N∑
i=1
k (a+bxi - a - bµx) 2ni =
1N ∑
i=1
k (bxi - bµx) 2ni = b2 1
N ∑i=1
k (xi - µx) 2ni = b2σ2
x
che dimostra quanto abbiamo affermato.
Da una distribuzione di frequenza X con media µx e varianza σ2x è
sempre possibile derivare una nuova distribuzione, chiamiamola Z, con media

Indici statistici descrittivi 63
zero e varianza pari ad uno.
Questa distribuzione prende il nome di standardizzata ed è definita come
Z = X - µx
σx
Facciamo vedere che effettivamente Z ha sempre media zero e varianza
uno. Notiamo che Z si può anche scrivere come
Z = - µxσx
+ 1
σx X
Questo vuole dire che Z è una particolare trasformazione lineare della X con le costanti a e b date rispettivamente da
a = - µxσx
; b = 1
σx
e quindi per quanto detto in precedenza risulta:
µz = a + bµx = - µxσx
+ 1
σx µx = 0
σ2z = b2σ2
x = 1
σ2x σ2
x = 1
Osserviamo che la distribuzione Z, per come è stata costruita, è indi-
pendente dall'unità di misura utilizzata per rilevarla ed è proprio per questo che viene chiamata standardizzata. Questo vuole dire che se vogliamo confrontare due distribuzioni con differente unità di misura si può ricorrere alle rispettive standardizzate. Nell'esempio che segue mostriamo come da una distribuzione data si ottiene la sua standardizzata. Esempio 15 Deriviamo la distribuzione standardizzata dalla seguente

Capitolo 2 64
xi ni xini x2
i ni 0 1 0 0 2 2 4 8 3 4 12 36 5 3 15 75 10 31 119
da cui
µx = 3.1 σ x = 11.9 - 9.61 = 1.5133
E quindi la standardizzata della distribuzione considerata è data da:
zi ni 0-3.1
1.5133 = - 2.0485 1 2-3.1
1.5133 = - 0.7269 2 3-3.1
1.5133 = - 0.0661 4 5-3.1
1.5133 = 1.2555 5
10 Osserviamo che la media e la varianza di Z risultano rispettivamente pari a
µz = -0.0002 σ2z = 0.9999
invece che zero ed uno come atteso e questo per le inevitabili approssimazioni di calcolo che bisogna in generale fare.
Se la distribuzione data è per classi di modalità e si vuole derivare la rela-tiva standardizzata, questa può essere ricavata solo in via approssimata calco-lando la media e lo scarto quadratico medio sostituendo a ciascuna classe il proprio valore centrale e quindi standardizzando gli estremi di ciascuna classe. Così se µx e σx sono media e scarto quadratico medio ottenuti in modo ap-prossimato come sopra detto, la generica classe xi —| xi+1 si trasformerà nella standardizzata zi —| zi+1 ove si è semplicemente posto:

Indici statistici descrittivi 65
zi = xi - µx
σx zi+1 =
xi+1 - µxσx
Questa operazione verrà ripetuta per ciascuna delle k classi della distribuzione. Esempio 16
Supponiamo di avere osservato un fenomeno X su una popolazione di 12 unità e de-rivato la distribuzione, per classi di modalità, riportata qui di seguito.
xi —| xi+1 ni ci cini c2i c2i ni 0 —| 1 2 0.5 1.0 0.25 0.50 1 —| 3 4 2.0 8.0 4.00 16.00 3 —| 7 5 5.0 25.0 25.00 125.00 7 —| 10 1 8.5 8.5 72.25 72.25 12 42.5 213.75
Da cui si ottiene immediatamente:
µ = 42.512 = 3.5417 µ2 =
213.7512 = 17.8125
σ2 = µ2 - µ2 = 17.8125 - (3.5417)2 = 5.2689
σ = 5.2689 = 2.2954
La relativa standardizzata sarà ottenuta standardizzando gli estremi di ciascuna classe:
zi —| zi+1 ni -1.542 —| -1.107 2 -1.107 —| -0.236 4 -0.236 —| 1.507 5 1.507 —| 2.814 1
12 Osserviamo che in questo caso risulta µz ≈ 0.0054 e σ2
z ≈ 0.9923 invece che gli attesi valori di zero ed uno teorici e ciò per le inevitabili approssimazioni che si è costretti a fare nei calcoli.

Capitolo 2 66
Abbiamo visto che sia la varianza che lo scarto quadratico medio sono
degli indici assoluti, cioè dipendenti dall'unità di misura del fenomeno, e quindi non possono essere utilizzati per confrontare la variabilità di distribuzioni con differente unità di misura. Per ovviare a questo inconveniente si definisce il co-efficiente di variazione. IL COEFFICIENTE DI VARIAZIONE
Questo è un indice di variabilità relativo, viene di solito indicato con CV e definito nel modo seguente:
il coefficiente di variazione è dato dal rapporto fra lo scarto quadratico medio ed il valore assoluto della media:
CV = µσ
Per come è stato costruito, l'indice è sempre non negativo ed indipen-
dente dall'unità di misura utilizzata per rilevare il fenomeno. Non è però un in-dice robusto dato che è funzione di due indici che sono sensibili all'esistenza dei valori eccezionali nella distribuzione. Inoltre, non è definito se la media del fenomeno è zero e tende ad essere infinitamente grande se la media del feno-meno tende ad essere molto piccola. LO SCOSTAMENTO SEMPLICE MEDIO
Un differente indice di variabilità, poco usato nelle applicazioni, indicato di solito con il simbolo Sµ, è
lo scostamento semplice medio definito come la media degli scarti, in valore assolu-to, dalla media:
Sµ = 1N ∑
i=1
k |xi - µ|ni
Questo indice è espresso nella stessa unità di misura del fenomeno con-
siderato. Non è un indice robusto ed è funzione, come detto, dell'unità di mi-

Indici statistici descrittivi 67
sura del fenomeno. L'indice può essere relativizzato nel modo seguente:
Srµ = Sµ
|µ|
LO SCOSTAMENTO SEMPLICE MEDIANO
Anche questo indice è poco usato nelle pratiche applicazioni, di solito è indicato con SM ed è definito nel modo seguente:
lo scostamento semplice mediano è la media degli scarti, in valore assoluto, dalla mediana:
SM = 1N ∑
i=1
k |xi - Me|ni
E' un indice non robusto ed è funzione dell'unità di misura del fenome-
no. L'indice può essere relativizzato considerando
SrM = SM
|Me|
Inoltre, per quanto abbiamo detto sulla mediana, risulta sempre
SM ≤ Sµ
LA DIFFERENZA TRA QUARTILI
Un indice di variabilità legato ai quartili di una distribuzione di frequen-za, e quindi robusto rispetto all'esistenza di valori eccezionali, è:
la differenza tra quartili definita da
DQ = Q3 - Q1
Questo indice è espresso nella stessa unità di misura del fenomeno ed è

Capitolo 2 68
dato dall'ampiezza del box nella rappresentazione box-plot. L'indice può essere facilmente relativizzato in modo da poter confrontare agevolmente la variabili-tà di distribuzioni rilevate con differente unità di misura:
DQr = Q3 - Q1|Q2|
Naturalmente, l'indice DQr è robusto rispetto all'esistenza di valori eccezionali. Esempio 17 Consideriamo la distribuzione di frequenza dell'esempio 11. Abbiamo già visto che
Q1 = 3 Q2 = Me = 5 Q3 = 7 inoltre
µ = 6.6 Si ottiene così:
DQ = 7 - 3 = 4; DQr = 7 - 3
5 = 0.8
Inoltre:
xi ni xini |xi - µ|ni |xi -Me|ni 2 2 4 9.2 6 3 4 12 14.4 8 5 5 25 8.0 0 7 5 35 2.0 10 10 2 20 6.8 10 18 2 36 22.8 26 20 132 63.2 60
e risulta Sµ = 3.16 SM = 3.0 per cui Srµ = 0.479 SrM = 0.6.
Se il carattere della distribuzione è una qualità gli indici sopra definiti non possono essere utilizzati per misurare la variabilità esistente nel carattere. In questi casi sono stati definiti una serie di indici che misurano la diversità delle modalità del carattere prendendo in considerazione le frequenze della distribu-

Indici statistici descrittivi 69
zione e tenendo conto del fatto che un carattere è tanto più variabile quanto più numerose e diverse sono le modalità. Se il carattere si riduce ad una sola modalità vuole dire che vi è la minima diversità nella popolazione data rispetto a quel carattere. La variabilità è tanto più elevata quanto più numerose sono le modalità. Gli indici così definiti vengono di solito chiamati indici di mutabilità perché applicabili a caratteri non quantitativi (le mutabili). Naturalmente, vo-lendo, questi indici possono essere utilizzati per misurare la variabilità anche di distribuzioni di frequenza il cui carattere è una variabile. L'ENTROPIA DI SHANNON
Questo indice misura il disordine, l'eterogeneità esistente in un sistema ed è stato ripreso da un concetto fisico legato al secondo principio della termodi-namica.
L'indice di entropia di Shannon di una data distribuzione di frequenza X è definito da:
H = - ∑i=1
k fi log(fi)
Come è facile verificare, risulta H = 0 se tutte le modalità sono uguali;
infatti, in tal caso si ha che una sola frequenza relativa, diciamo per semplicità la f1, è pari ad uno mentre le altre k-1 sono pari a zero questo vuole dire che l'indice, ricordando che log(1) = 0, diviene
H = - 1 log(1) = 0.
Viceversa, l'indice è massimo se tutte le frequenze sono uguali fra loro: fi
= 1k per i=1,2,...,k, e l'indice di Shannon diviene
H = - k 1 k log
k1 = log(k)
Questo ci permette di definire un indice di entropia relativo dato da

Capitolo 2 70
0 ≤ Hr = - )klog(
)flog(f iik
1i∑= ≤ 1
Più Hr è vicino a zero minore è la disomogeneità del carattere, più è vicino ad uno maggiore è la disomogeneità del fenomeno. L'INDICE DI MUTABILITA' DI GINI
Anche questo è un indice che viene utilizzato per misurare la disomoge-neità di un carattere qualitativo.
L'indice di mutabilità del Gini di una data distribuzione X è dato da:
MG = 1- ∑i=1
k f 2
i
Il valore minimo di questo indice vale zero e si ottiene se il carattere assume una sola modalità per cui tutte le frequenze relative sono nulle eccetto quella dell'unica modalità assunta che vale uno:
MG = 1 - 12 = 0.
Viceversa, l'indice è massimo se le modalità assumono tutte le stesse
frequenze (caso di equipresenza delle diverse modalità): fi = 1k per i=1,2,...,k, e
l'indice di Gini diviene
MG = 1 - k 1k2 =
k-1k
Questo ci permette di ottenere un indice di mutabilità relativa dato semplice-mente da
0 ≤ MGr =
−
−∑=
2
11
1 ik
if
kk ≤ 1

Indici statistici descrittivi 71
Più MGr è vicino a zero minore è la disomogeneità del carattere, più è vicino ad uno maggiore è la disomogeneità del fenomeno. Esempio 18
Supponiamo che la distribuzione di una popolazione di 25 adulti rispetto al titolo di studio conseguito sia la seguente:
Titolo di studio ni fi Nessun titolo 1 0.04 Elementare 3 0.12 Media Inferiore 11 0.44 Media Superiore 6 0.24 Laurea 4 0.16 25 1.00
si ha immediatamente
Hr = - 1
log(5) [0.04 log(0.04) + 0.12 log(0.12) + 0.44 log(0.44) +
0.24 log(0.24) + 0.16 log(0.16)] = 1.380141.60944 = .8575
MGr = 54 [1- (0.04)2 - (0.12)2 - (0.44)2 - (0.24)2 - (0.16)2]
= 54 0.7072 = 0.884
2.4 Alcuni indici sulla forma
Nelle pagine precedenti abbiamo illustrato alcuni indici di posizione e di variabilità, in questo paragrafo tratteremo di indici che forniscono informazioni sintetiche su alcuni aspetti della forma di una distribuzione di frequenza. In particolare, tratteremo della: asimmetria di una distribuzione di frequenza rispetto al suo centro di gravità che abbiamo visto coincidere con la media aritmetica; curtosi di una distribuzione di frequenza, cioè il suo maggiore o minore ap-piattimento rispetto ad una distribuzione tipo detta normale.

Capitolo 2 72
ALCUNI INDICI DI ASIMMETRIA
E' noto che una generica funzione g(x) è simmetrica rispetto ad un valo-re θ se risulta:
g(θ - x) = g(θ + x)
per ogni x nell'insieme di definizione di g(x). Nel nostro caso, come abbiamo sopra accennato, il parametro θ è la media aritmetica. L'importanza di sapere se una data distribuzione è più o meno vicina al caso di simmetria misurandola con degli indici è dovuto, fra l'altro, al fatto che se una distribuzione di fre-quenza è perfettamente simmetrica allora, come è facile capire, risulta:
µ = Me cioè media e mediana coincidono. Se la distribuzione, oltre ad essere perfetta-mente simmetrica è anche unimodale (cioè possiede una sola moda) allora si ha
µ = Me = Mo
In altri termini, una distribuzione simmetrica è una distribuzione molto regolare. In pratica, però, è difficile trovare distribuzioni che siano esattamente simme-triche per cui diventa importante individuare indici che misurano quanto la di-stribuzione data si discosta dal caso ideale di simmetria. Naturalmente esistono diversi indici di asimmetria, qui di seguito ne presenteremo solo alcuni. C'è da dire che tutti gli indici qui presentati possono essere utilizzati solo se il carattere del fenomeno è una variabile. Un primo indice di asimmetria è:
la differenza interquartile data da
DIr = (Q3 - Q2) - (Q2 - Q1)(Q3 - Q2) + (Q2 - Q1) .
E' un indice di facile calcolo, è robusto, è relativo cioè indipendente
dall'unità di misura utilizzata per rilevare il fenomeno oggetto di studio. Se DIr > 0 vuole dire che risulta (Q3 - Q2) > (Q2 - Q1) e quindi il box-
plot assume una forma tipo quella riportata nella figura seguente ed in tal caso

Indici statistici descrittivi 73
si dice che la distribuzione ha una asimmetria positiva: la coda di destra della di-stribuzione è più lunga, marcata della coda di sinistra.
Il grafico della distribuzione di frequenza assumerà allora una forma come quella della figura che segue.
Se DIr < 0 vuole dire che (Q3 - Q2) < (Q2 - Q1) e quindi il box-plot ha una struttura come quella qui di sotto riportata. In tal caso si dice che la distri-buzione è asimmetrica negativa: la coda di sinistra della distribuzione è più marcata di quella di destra.
Il relativo grafico della distribuzione di frequenza assumerà un aspetto simile a quello riportato nella figura seguente.

Capitolo 2 74
Un secondo indice di asimmetria, di solito indicato con γ1, è
il coefficiente di asimmetria dato da
γ1 = 1
Nσ3 ∑i=1
k (xi - µ) 3ni
Anche γ1 è un indice relativo, ma non è robusto e misura di quanto la di-
stribuzione data è lontana dal caso di simmetria. In particolare: se γ1 > 0 la distribuzione è asimmetrica positiva, se γ1 < 0 la distribuzione è asimmetrica negativa, se la distribuzione è simmetrica risulta γ1 = 0, ma non è vero il viceversa.
L'indice γ1 può essere espresso in termini dei primi tre momenti della distribuzione:
γ1 = 1
σ3N ∑i=1
k (xi - µ) 3ni =
1σ3N ∑
i=1
k [x3
i - 3x2i µ+ 3xiµ2 - µ3]ni
=
−+− ∑∑∑∑
====i
k
iii
k
iii
k
iii
k
in
Nnx
Nnx
Nnx
N 1
3
1
22
1
3
13
1131311 µµµσ
= [ ]33233 331
µµµµµσ
−+− = [ ]3233 231
µµµµσ
+−
L'indice γ1 può essere calcolato anche nel caso in cui il carattere è per classi di

Indici statistici descrittivi 75
modalità sostituendo a ciascuna classe il relativo valore centrale. Se osserviamo che
3i
3i
3
3i z
x)x(=
−
=−
σµ
σµ
risulta immediatamente
γ1 = )x(N
ik
iµ
σ−∑
=13
1 3ni = 1N ∑
i=1
k z3
i ni = E(Z3)
e quindi il coefficiente di asimmetria non è altro che il momento terzo della di-stribuzione standardizzata. Notiamo che se una distribuzione è perfettamente simmetrica allora tutti i momenti di ordine dispari della sua standardizzata sono nulli. Il primo di questi momenti è sempre nullo, qualsiasi sia la distribuzione di partenza, per la proprietà della media aritmetica che la somma degli scarti dalla media è sempre pari a zero. Questo vuol dire che per verificare se una distribu-zione è asimmetrica basta controllare cosa succede al momento terzo della connessa standardizzata cioè a γ1.
Un terzo modo per misurare l'asimmetria in una distribuzione si basa sul fatto che mentre la media aritmetica è fortemente influenzata dalla presenza di valori molto grandi o molto piccoli (che cadono rispettivamente nella coda di destra ed in quella di sinistra della distribuzione), la mediana è poco sensibile alla presenza dei valori eccezionali. Questo vuole dire che un indice di asimme-tria relativo può essere dato da:
ASr = µ - Me|Me|
Infatti, se la distribuzione è simmetrica allora si ha che µ=Me e quindi ASr ri-sulta pari a zero; se la distribuzione è asimmetrica positiva vuole dire che le modalità grandi (sono nella coda di destra) hanno una preponderanza su quelle piccole (che sono nella coda di sinistra) questo implica che µ è attratta nella coda di destra per cui tende ad essere µ > Me e l'indice ASr risulta essere posi-tivo. Un risultato inverso si ottiene se la distribuzione è asimmetrica negativa cioè ASr tende ad essere negativo. L'INDICE DI CURTOSI
La curtosi è un secondo aspetto caratterizzante la forma di una distribu-

Capitolo 2 76
zione di frequenza. Questo aspetto riguarda la pesantezza, lo spessimento o più o meno marcato delle code di una distribuzione rispetto ad una tipica detta nor-male, o di Gauss, o degli errori accidentali. Di questa distribuzione tratteremo più approfonditamente nell'ambito della parte del corso che riguarda il Calcolo delle Probabilità e l'Inferenza. Qui osserviamo che una distribuzione normale assume tutti i valori della retta reale, è perfettamente simmetrica ed unimodale intorno al proprio centro di asimmetria che è la sua media. Questo vuole dire che per una normale risulta
µ = Me = Mo
Ha un unico asintoto che coincide con l'asse delle x e due flessi nei punti:
x1 = µ - σ ; x2 = µ + σ
La distribuzione normale ha un unico massimo per x = µ ed in tale punto la distribuzione vale
12πσ2
Infine, nell'intervallo [µ-σ; µ+σ] cadono circa il 68% dei casi, nell'intervallo [µ-2σ; µ+2σ] cadono circa il 95% dei casi, nell'intervallo [µ-3σ; µ+3σ] cadono circa il 99% dei casi. Questo vuole dire che anche se teoricamente la distribu-zione può assumere valori nell'intervallo (-∞; +∞) in realtà quasi tutti i casi ca-dono nell'intervallo [µ-4σ; µ+4σ] e quasi nulla cade nelle code al di fuori di questo intervallo. In altri termini, la distribuzione normale ha code molto sottili, poco spesse. Naturalmente, dalla distribuzione normale si può derivare la nor-male standardizzata che, per costruzione ha media zero e varianza unitaria. Nella figura che segue è riportata la distribuzione di due normali: quella a sini-stra è la normale standardizzata (ha µ = 0 e σ = 1) quella a destra ha µ = 2 e σ = 1. Dato che le due normali hanno la stessa varianza, hanno anche una forma esattamente uguale l'unica differenza è che la prima è centrata sullo zero e la seconda sul due.

Indici statistici descrittivi 77
Per stabilire il tipo di curtosi che una distribuzione osservata X possiede si standardizza ottenendo la distribuzione osservata Z e si confronta il suo gra-fico con quello della normale standardizzata. Più precisamente:
la distribuzione X è detta leptocurtica se la sua standardizzata Z ha code più spesse di quelle della normale standardizzata;
la distribuzione X è detta platicurtica se la sua standardizzata ha code me-no spesse di quelle della normale standardizzata;
la distribuzione X è detta mesocurtica se la sua standardizzata ha code di uguale spessore di quelle della normale standardizzata.
Nelle due figure che seguono sono riportati due casi tipici: rispettiva-
mente di distribuzione leptocurtica e platicurtica.

Capitolo 2 78
Una volta chiarito il concetto di curtosi, definiamo un indice che misuri fino a che punto una distribuzione è più o meno lontana dal caso di normalità.
L'indice di curtosi di una distribuzione di frequenza X è dato da
γ2 = 1
N σ4∑i=1
k (xi - µ) 4 ni - 3.
L'indice γ2 viene anche chiamato di disnormalità perché misura fino a che
punto una distribuzione osservata è distante dal caso di normalità. La costante 3 figurante nella formula di γ2 deriva dal fatto che per la normale si dimostra che il momento quarto standardizzato vale esattamente 3.
L'indice γ2 può anche essere scritto come:
γ2 = 1
N σ4 ∑i=1
k (xi - µ) 4 ni - 3 =
−
∑= σ
µik
i
xN 1
1 4ni - 3 =
= 1N ∑
i=1
k z4
i ni - 3 = E(Z4) - 3
Il coefficiente di curtosi non è altro che il momento quarto della standardizzata osservata meno la costante 3, che è il momento quarto della normale standar-

Indici statistici descrittivi 79
dizzata; pertanto:
γ2 = momento quarto della standardizzata osservata -
momento quarto della normale standardizzata
L'interpretazione di questo indice è la seguente:
se risulta γ2 > 0 allora la distribuzione X è leptocurtica, se risulta γ2 < 0 allora la distribuzione X è platicurtica.
Se in una distribuzione osservata X si ha contemporaneamente γ1 ≈ 0, γ2 ≈ 0 allora X può essere approssimata abbastanza bene da una distribuzione normale con media e varianza pari a quella della distribuzione osservata.
L'indice di curtosi può essere espresso anche in funzione dei primi quat-tro momenti della distribuzione osservata X. Infatti, dato che
1N ∑
i=1
k (xi - µ) 4 ni =
1N ∑
i=1
k (x4
i - 4x3i µ + 6x2
i µ2 - 4xiµ3 + µ4) ni =
= µ4 - 4µ3µ + 6µ2µ2 - 4µ4 + µ4 = µ4 - 4µ3µ + 6µ2µ2 - 3µ4
avremo:
γ2 = 1σ4 [µ4 - 4µ3µ + 6µ2µ2 - 3µ4] - 3
L'indice γ2 è indipendente dall'unità di misura del fenomeno visto che è basato sulla distribuzione standardizzata, ma poco robusto. Se il carattere è per classi di modalità l'indice di curtosi può essere calcolato solo in via approssimata so-stituendo a ciascuna classe il relativo valore centrale. Esempio 19
Mostriamo con un esempio come si calcolano i due indici γ1 e γ2 definiti in questo paragrafo.

Capitolo 2 80
xi ni xini x2
i ni x3i ni x4
i ni 0 1 0 0 0 0 2 2 4 8 16 32 3 4 12 36 108 324 5 3 15 75 375 1875 10 31 119 499 2231
Nella tabella le ultime quattro colonne sono state ottenute a partire dalle prime due e permet-tono di calcolare:
µ = 3110 = 3.1 Q1 =2 Q2=3 Q3=5
µ2 = 11910 = 11.9 µ3 =
49910 = 49.9 µ4 =
223110 = 223.1
da cui si ricava: σ2 = 2.29 σ = 1.51327
ASr= 0.13 = 0.033 DIr =
2-12+1 = 0.333
γ1 = 1
3.465399 [49.9 - 110.67 + 59.582] = - 0.3428
come si può notare i tre indici di asimmetria danno risultati contraddittori e questo è dovuto al fatto che la distribuzione è vicina al caso di simmetria;
γ2 = 1
5.2441 [223.1 - 618.76 + 686.154 - 277.0563] - 3 = - 0.4375
che vuole dire che la distribuzione osservata è leggermente platicurtica.
Se indichiamo con {µr, r=1,2,...} tutti i momenti di una distribuzione X, si può dimostrare che fra X e {µr, r=1,2,...} esiste, in generale, una corrispon-denza biunivoca nel senso che, sotto condizioni molto generali, da {µr, r=1,2,...} si può risalire ad X e viceversa. Questo vuol dire che se di X conside-

Indici statistici descrittivi 81
riamo solo i suoi primi quattro momenti non conosciamo tutto della struttura di X, ma molte delle sue caratteristiche dato che avremo informazioni su: la sua localizzazione tramite µ1, la sua variabilità tramite σ2, la sua asimmetria tramite γ1, la sua curtosi tramite γ2. In genere, il vettore (µ1, σ2, γ1, γ2) viene chiamato vettore caratteristico della distribuzione X.


Capitolo 3 LA CONCENTRAZIONE 3.1 Introduzione
Un importante aspetto di una rilevazione statistica, e quindi della con-nessa distribuzione di frequenza, con carattere quantitativo è quello della concen-trazione.
Un fenomeno è tanto più concentrato quanto più una piccola frazione delle unità di rilevazione della popolazione possiede una elevata quantità del caratte-re.
Da un punto di vista logico ha senso parlare di concentrazione solo per
fenomeni trasferibili da una unità di rilevazione all'altra. Il concetto di concentra-zione, infatti, è legato a quello di possesso di beni. Questo vuole dire che ogni qual volta vengono applicati gli strumenti che descriveremo in questo capitolo è necessario in primo luogo verificare che il carattere di cui si tratta sia trasferibi-le, cioè che quote di carattere possono essere tolte, almeno teoricamente, ad una unità di rilevazione ed assegnate ad altre. In genere, un carattere trasferibile è una quantità positiva e nel seguito supporremo che, non solo la distribuzione di frequenza è una variabile, ma che sia non negativa e che il relativo carattere possegga le caratteristiche della trasferibilità. Sono trasferibili caratteri come il reddito, la popolazione, il possesso di terra, gli investimenti, mentre non sono trasferibili, generalmente, le qualità come la professione, titolo di studio ecc., ma anche quantità strettamente connesse alle unità di rilevazione come il peso, l'altezza, l'età.
La concentrazione può variare fra due casi estremi:
assenza di concentrazione massima concentrazione

Capitolo 3 84
3.2 Il concetto di concentrazione
Questi casi estremi sono, in pratica, solo teorici dato che ben difficil-mente si possono riscontrare nelle pratiche applicazioni. Servono però come termine di paragone per stabilire se un caso concreto si avvicina all'uno o all'al-tro estremo.
Si ha concentrazione nulla quando tutte le unità di rilevazione della popola-zione posseggono lo stesso ammontare del carattere
Quando la concentrazione è nulla tutte le N osservazioni sono uguali fra di loro e si ottiene semplicemente:
x1 = x2 = ... = xN = µ
In questo caso si parla anche di equiripartizione del carattere dato che tutti gli N soggetti lo posseggono con la stessa intensità. Ad esempio, si ha equiri-partizione del reddito in una data popolazione se tutti i soggetti hanno lo stesso ammontare di reddito; si parla di equiripartizione del possesso di terra in una data popolazione se tutti i componenti di quella popolazione posseggono la stessa estensione di terreno. L’equiripartizione è equivalente ad assenza di va-riabilità, come facilmente si verifica. Da questo punto di vista vi sono chiare connessioni fra variabilità e concentrazione di un carattere.
Nel caso di equiripartizione la distribuzione di frequenza associata alla rilevazione diviene semplicemente:
xi ni µ N N
Si ha massima concentrazione quando una sola unità di rilevazione della po-polazione possiede tutto l'ammontare del carattere e le rimanenti unità non ne posseggono: x1 = ... = xN-1=0, xN = Nµ.
Se è µ la media della popolazione, nel caso di concentrazione massima la
distribuzione di frequenza derivata da quella rilevazione statistica diviene

La concentrazione 85
xi ni 0 N-1
Νµ 1 N
Come si può vedere, nel caso di concentrazione massima, le modalità del
carattere si polarizzano sui due valori 0 ed Nµ = ∑=
k
iii nx
1 questo vuole dire che
anche la variabilità del fenomeno è elevata e risulta
σ2 = Nµ2 - µ2 = (N-1)µ2.
Come abbiamo già sottolineato, nelle pratiche applicazioni è ben diffici-le, se non impossibile, trovare fenomeni la cui concentrazione è esattamente nulla o è esattamente massima. In genere, si hanno casi con distribuzioni com-prese fra questi due estremi. Si pone, pertanto, il problema di misurare la con-centrazione esistente in una data distribuzione relativa ad un carattere trasferibi-le. Consideriamo, perciò, una generica rilevazione statistica relativa ad un carat-tere trasferibile discreto o discretizzato riferibile ad una popolazione composta da N unità di rilevazione in cui le osservazioni x1, x2, ..., xN siano state ordinate in senso crescente ottenendo
x(1) ≤ x(2), ≤ .... ≤ x(N)
ove con x(i) abbiamo indicato la rilevazione che occupa il posto i-esimo nell'or-dinamento in senso non decrescente. Vogliamo elaborare degli indici che per-mettano di misurare il grado di concentrazione esistente in questa generica rile-vazione. Inoltre, vogliamo che tale indice sia relativo di modo che possa essere facilmente confrontabile con quello derivato da rilevazioni espresse con diversa unità di misura e differente numerosità.
Per rendere gli indici indipendenti dalla numerosità N della popolazione si considerano al posto delle frequenze assolute le frequenze relative cumulate che, per motivi storici, nell'ambito della concentrazione vengono indicate con pi:
pi = 1N ∑
j=1
i 1 =
iN i=1, 2, ..., N
Si osservi che fra le pi (nei due capitoli precedenti e nei seguenti indicate
con Fi) esiste la seguente relazione

Capitolo 3 86
pi = pi-1 + 1N = pi-1 + fi
e dato che è sempre 1N ≥ 0 si ha 0 ≤ p1 ≤ p2 ≤ ... ≤ pN = 1. Come già sappia-
mo, pi è una percentuale: la percentuale cumulata dei primi i possessori del carattere e risulta indipendente dalla numerosità N della popolazione.
Per rendere gli indici indipendenti dall'unità di misura del fenomeno, al posto delle x(i) consideriamo le percentuali cumulate del carattere dei primi i possessori che si indicano di solito con qi
qi = 1
Nµ ∑j=1
i xj =
x1 + x2 +...+ xiNµ i=1,2,...,N
Fra le qi esistono le seguenti relazioni:
qi = qi-1 + xi
Nµ = qi-1 + fi xiµ
e dato che µN
x i ≥ 0 risulta immediatamente 0 ≤ q1 ≤ q2≤ ... ≤ qN = 1. Si os-
servi che è sempre pN = qN = 1. Da un punto di vista operativo, al posto della rilevazione di partenza con
modalità xi si ha una nuova rilevazione composta dalle coppie qi e pi
xi x(i) pi qi
x1 x(1) 1N
x(1)Nµ
x2 x(2) 2N
x(1)+x(2)Nµ
x3 x(3) 3N
x(1)+x(2)+x(3)Nµ
… … … … xN x(N) 1 1
Vediamo ora cosa succede alle N coppie (pi, qi) nei due casi estremi di
concentrazione nulla e di concentrazione massima. Nel caso di concentrazione

La concentrazione 87
nulla abbiamo visto che è xi = x(i) = µ per i=1,2,...,N questo vuole dire:
qi = 1
Nµ ∑j=1
i x(j) = µ
Nµ ∑j=1
i 1 =
1N ∑
j=1
i 1 = pi i=1,...,N.
In conclusione:
nel caso di concentrazione nulla si ha sempre
pi = qi , i=1,2,...,N
Nel caso di massima concentrazione avremo x(1) = x(2) = ... x(N-1) = 0 e
questo vuole dire
qi = 1
Nµ ∑j=1
i x(j) =
1Nµ ∑
j=1
i 0 = 0 i=1,2,...N-1.
In conclusione
nel caso di concentrazione massima si ha
qi = 0 per i=1,2,...,N-1, mentre qN = 1
In generale, fra le pi e le qi esiste la seguente relazione pi ≥ qi che è equi-
valente a pi - qi ≥ 0, per i=1,2,...,N. Infatti,
pi - qi = ∑=
i
jN 111
- ∑=
i
j)j(x
N 1
1µ
= ∑=
−
i
j
)j(xN 1
11µ
=
= ∑=
−i
j)j( )x(
N 1
1 µµ
Ricordiamo che:

Capitolo 3 88
1) la somma di tutti gli N scarti dalla media è sempre nulla:
∑i=1
N (xi - µ) = ∑
i=1
N (µ - xi) = ∑
i=1
N (µ - x(i)) = 0
cioè scarti positivi e scarti negativi si compensano;
2) le x(i) sono ordinate in senso non decrescente; 3) il carattere della distribuzione, perché sia trasferibile, è sempre non negativo,
il che implica µ > 0.
Le prime due caratteristiche fanno si che gli scarti non negativi siano sempre ai primi posti, mentre quelli negativi agli ultimi questo implica che sia sempre
∑j=1
i (µ - x(j)) ≥ 0
dato che nella sommatoria vi sono o solo scarti non negativi, o tutti gli scarti non negativi e solo alcuni di quelli negativi che non possono compensare tutti i positivi. La terza caratteristica fa si che sia sempre 1/Nµ > 0 tutto questo di-mostra che pi ≥ qi.
Se il fenomeno è rilevato per classi di modalità risulta inevitabilmente raggruppato in k<N classi ordinate in senso crescente. A ciascuna classe è ne-cessariamente associata la relativa frequenza ni. In tal caso l'espressione per le pi diviene
pi = ∑j=1
i nj N ; i=1,2,...,k,
mentre quella di qi può essere ottenuta solo in via approssimata sostituendo a ciascuna classe xi —| xi+1 il proprio valore centrale ci ed ottenendo
qi ≈ ∑j=1
i cjnj Nµ ; i=1,2,...,k.
Le qi possono essere ottenute in modo esatto se accanto alle classi ed alle
relative frequenze sono riportate le intensità del carattere ricadente in ciascuna

La concentrazione 89
classe. Le coppie (pi, qi) possono essere riportate su un sistema di assi cartesiani
ed ottenere una rappresentazione grafica del fenomeno concentrazione. A tale proposito bisogna distinguere i due casi: IL CASO DISCRETO O DISCRETIZZATO
Quando il fenomeno non è rilevato per classi di modalità, le N coppie di punti (pi, qi) vengono unite da una spezzata, detta spezzata di Lorenz, a gradini così come è stato fatto per la funzione di ripartizione. In tal caso si ha una si-tuazione simile a quella rappresentata nella figura seguente
IL CASO PER CLASSI DI MODALITA'
Se il fenomeno è per classi di modalità, sotto l'ipotesi che all'interno di ciascuna classe il fenomeno si distribuisce uniformemente, le k coppie di punti (pi, qi) vengono unite da segmenti di retta crescenti che formano una curva concava che costituisce la spezzata di Lorenz. Nella figura seguente sono riporta-te le caratteristiche generali della spezzata di Lorenz nel caso in cui il fenomeno è per classi di modalità.

Capitolo 3 90
Sia che il fenomeno sia o non sia per classi di modalità, nel caso di con-centrazione nulla abbiamo visto che è pi = qi e la spezzata di Lorenz coincide con la diagonale del quadrato di lato unitario come evidenziato nella figura che segue.
In altri termini, la diagonale del quadrato di lato unitario coincide con il caso di equiripartizione e viene detta retta di equiripartizione.
Nel caso di concentrazione massima abbiamo visto che tutte le qi sono nulle esclusa l'ultima che è pari ad uno. La spezzata di Lorenz coincide, sostan-zialmente, con i cateti del triangolo rettangolo definito al di sotto della diagona-le del quadrato di lato unitario come evidenziato nella figura che segue

La concentrazione 91
In conclusione possiamo affermare che la spezzata di Lorenz: - si trova al di sotto della diagonale del quadrato di lato unitario; - è sempre non decrescente; - ha la concavità rivolta verso l'alto.
3.3 Alcuni indici di concentrazione
Presentiamo ora degli indici capaci di misurare la concentrazione di una distribuzione di frequenza, questi indici saranno calcolati in funzione delle pi e qi.
L'INDICE DI CONCENTRAZIONE DEL GINI
Questo indice, di facile calcolo e di immediata interpretazione, viene di solito usato quando la distribuzione non è per classi di modalità, si basa sul fatto che pi ≥ qi per i=1,2,...,N-1 e che pN = qN = 1, più precisamente:
l'indice di concentrazione del Gini è indicato con Rg e dato da
Rg = i
N
i
ii
N
i
p
)qp(
∑
∑−
=
−
=−
1
1
1
1
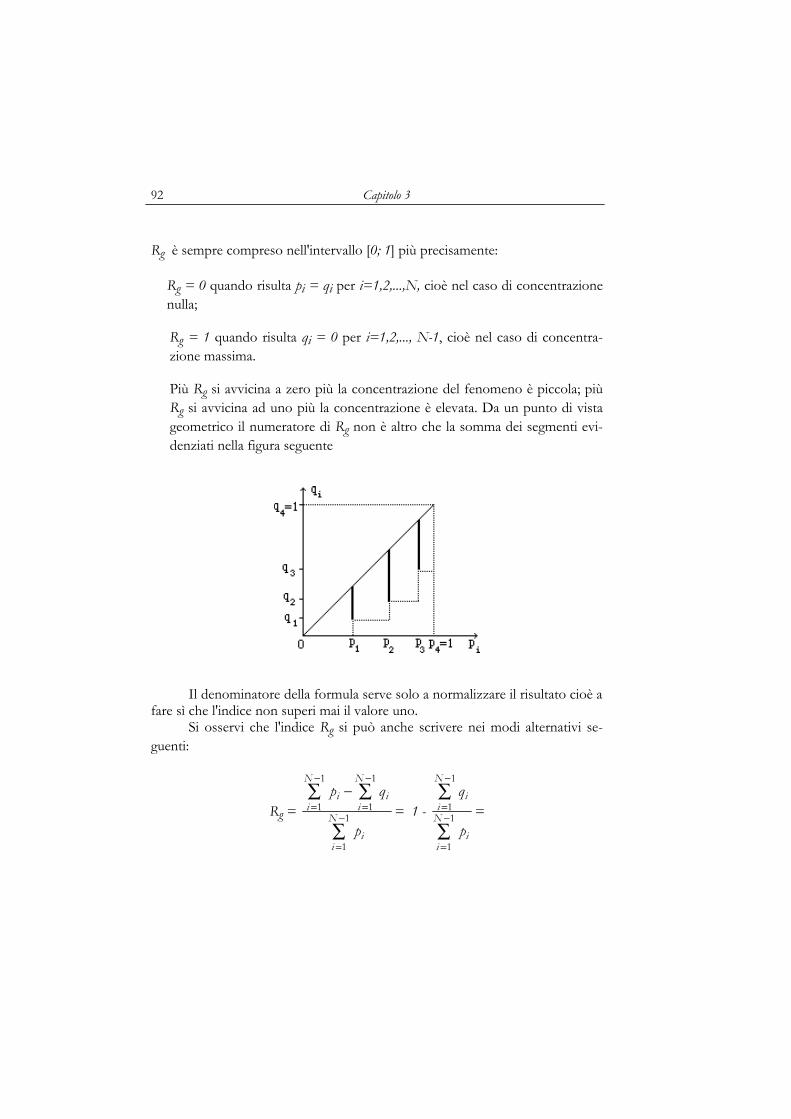
Capitolo 3 92
Rg è sempre compreso nell'intervallo [0; 1] più precisamente: Rg = 0 quando risulta pi = qi per i=1,2,...,N, cioè nel caso di concentrazione
nulla; Rg = 1 quando risulta qi = 0 per i=1,2,..., N-1, cioè nel caso di concentra-
zione massima. Più Rg si avvicina a zero più la concentrazione del fenomeno è piccola; più
Rg si avvicina ad uno più la concentrazione è elevata. Da un punto di vista geometrico il numeratore di Rg non è altro che la somma dei segmenti evi-denziati nella figura seguente
Il denominatore della formula serve solo a normalizzare il risultato cioè a fare sì che l'indice non superi mai il valore uno.
Si osservi che l'indice Rg si può anche scrivere nei modi alternativi se-guenti:
Rg = i
N
i
i
N
ii
N
i
p
qp
∑
∑∑−
=
−
=
−
=−
1
1
1
1
1
1 = 1 - i
N
i
i
N
i
p
q
∑
∑−
=
−
=1
1
1
1 =
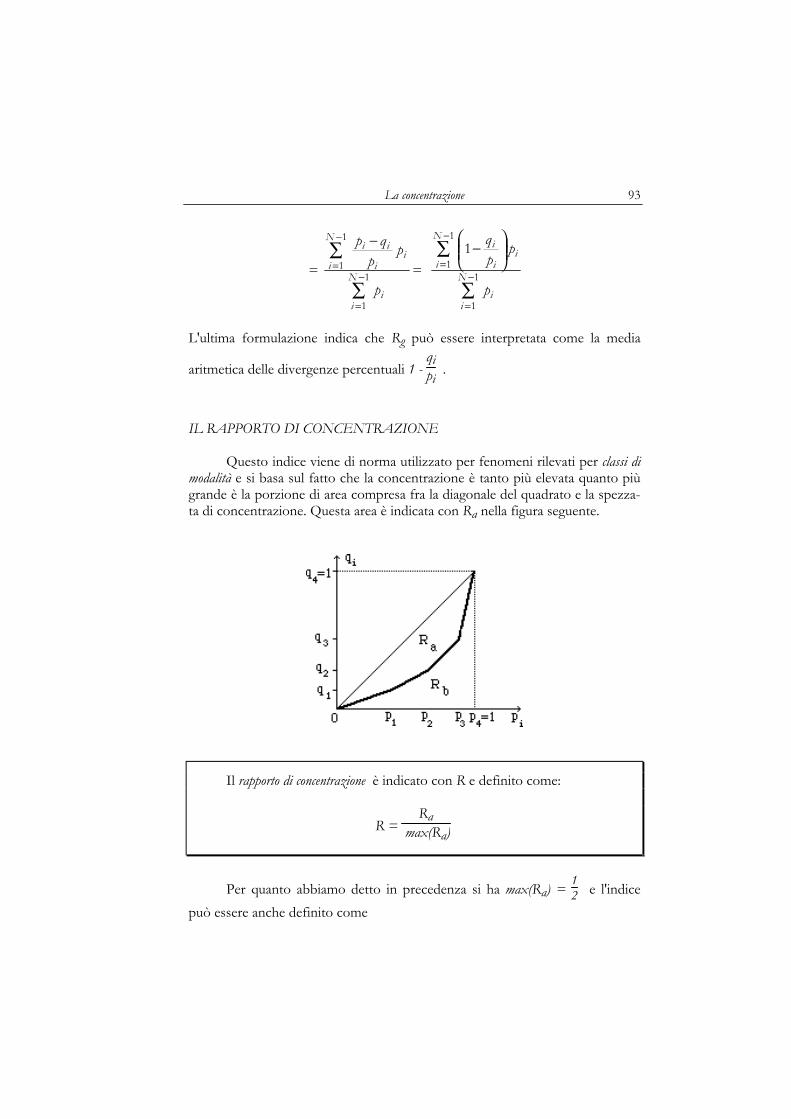
La concentrazione 93
= i
N
i
ii
iiN
i
p
pp
qp
∑
∑−
=
−
=
−
1
1
1
1 = i
N
i
ii
iN
i
p
ppq
∑
∑−
=
−
=
−
1
1
1
11
L'ultima formulazione indica che Rg può essere interpretata come la media
aritmetica delle divergenze percentuali 1 - qipi
.
IL RAPPORTO DI CONCENTRAZIONE
Questo indice viene di norma utilizzato per fenomeni rilevati per classi di modalità e si basa sul fatto che la concentrazione è tanto più elevata quanto più grande è la porzione di area compresa fra la diagonale del quadrato e la spezza-ta di concentrazione. Questa area è indicata con Ra nella figura seguente.
Il rapporto di concentrazione è indicato con R e definito come:
R = Ra
max(Ra)
Per quanto abbiamo detto in precedenza si ha max(Ra) = 12 e l'indice
può essere anche definito come

Capitolo 3 94
R = 2 Ra
D'altro lato, dalla figura precedente, si ha Ra = 12 - Rb ed avremo
R = 1 - 2 Rb.
Rb è facilmente calcolabile come somma delle aree Ai di k trapezi come
evidenziato nella figura seguente
Otteniamo così
Rb = 2
0pq0 11 ))(( −++
2ppqq 1221 ))(( −+
+
+ 2
ppqq 2332 ))(( −++ ... +
2ppqq 1kkk1k ))(( −− −+
=
= ))(( 1jjj1jk
1jppqq
21
−−=
−+∑ = )( j1jk
1jqq
21 +−
=∑ fj
ove si è posto po = qo = 0 e si è tenuto conto del fatto che pj = pj-1 + fj. In con-clusione si ha che il rapporto di concentrazione può essere calcolato con la se-guente

La concentrazione 95
R = 1 - 2Rb = 1 - )( j1jk
1jqq +−
=∑ fj
L'INDICE δ DEL GINI
Questo indice nasce dalla relazione pi ≥ qi e dal fatto che 0≤ pi, qi ≤1 che è equivalente a 1-pi ≤ 1 - qi. Ma allora esiste una costante δi ≥ 1 per cui si ha:
1 - pi = (1-qi)δi i = 1,2,...,N-1
La costante δi viene interpretata come una misura puntuale (relativa alla i-esima modalità o classe di modalità del fenomeno) della concentrazione. δi può essere derivata facilmente considerando i logaritmi di entrambi i membri dell'ultima espressione ottenendo:
log(1 - pi) = δi log(1 - qi)
da cui si ricava
δi = log(1 - pi)log(1 - qi) i = 1,2,...,N-1
Partendo da questa relazione Gini propose di utilizzare come misura globale della concentrazione (in particolare di quella riguardante i redditi) il seguente indice δ:
δ =
∑i=1
N-1 log(1 - pi)
∑i=1
N-1 log(1 - qi)
L'indice δ è pari ad uno se e solo se nella distribuzione si ha assenza di
concentrazione. Generalmente, sarà δ > 1 e l'indice è tanto più elevato quanto più forte è la concentrazione.
Un altro modo per ottenere un indice globale di concentrazione parten-

Capitolo 3 96
do dai singoli δi è quello di considerarne la media:
δ = 1
N-1 ∑i=1
N-1 δi
I due ultimi indici, δ eδ , sono poco utilizzati nelle pratiche applicazioni
perché non sono normalizzati, cioè non variano fra zero ed uno come gli altri due visti in precedenza. 3.4 Alcune considerazioni sulla concentrazione dei redditi
Vediamo cosa succede nella concentrazione quando nella distribuzione X, che supponiamo per semplicità dei redditi discretizzati (per esempio appros-simati al milione di lire, oppure alle centomila lire), avvengono particolari varia-zioni.
Supponiamo in primo luogo che X, in virtù di qualche provvedimento governativo, diventi Y = a + X. Questo vuole dire che tutte le modalità di Y sono aumentate (se risulta a > 0, per esempio per aumenti di stipendi in cifra fissa) o diminuite (se risulta a < 0, per esempio per l'introduzione di una tassa in cifra fissa) della stessa quantità. Ciò implica che dalla rilevazione X si è passati alla Y e precisamente
X: x1, x2, ...., xN
Y: a+x1, a+x2, ..., a+xN
In altri termini, se prima un individuo aveva reddito xi, dopo il suo red-dito è diventato yi = a+xi, pertanto se risulta a > 0 vi è una diminuzione della concentrazione, viceversa se è a < 0 la concentrazione aumenta. Per rendersi conto di questo fatto consideriamo due individui, diciamo A e B, e supponiamo che il reddito di A sia 1000 e quello di B sia 100 questo vuole dire che fra i red-
diti di questi individui vi è un rapporto di 10 = 1000100 : il reddito di A è 10 volte
quello di B. Supponiamo che il reddito di entrambi aumenti dello stesso am-montare a=10 in tal modo il nuovo reddito di A sarà 1010 e quello di B solo
110 mentre il rapporto fra i due si ridurrà 1010110 = 9.1818 che implica una di-
minuzione delle distanze relative fra i redditi dei due individui e quindi della concentrazione. Naturalmente, si avrà una situazione inversa se vi è una dimi-

La concentrazione 97
nuzione del reddito in cifra fissa. Infatti, se è a = -10, il nuovo reddito di A sarà
990 e quello di B sarà 90 ed il rapporto fra i due crescerà a 99090 = 11 che impli-
ca un aumento della concentrazione. Quanto detto lo possiamo dimostrare formalmente considerando come misura della concentrazione l'indice Rg ed in-dicando con pix e qix le quantità che si riferiscono alla rilevazione X e con piy e qiy quelle che si riferiscono alla Y. Osserviamo ora che risulta sempre, visto che gli N individui sono sempre gli stessi, prima e dopo la variazione intervenuta
pix = piy i = 1,2,...,N
Inoltre, sappiamo che µy = a + µx e l'indice di concentrazione relativo alla rilevazione Y si può scrivere
Rgy = iy
N
i
iyiy
N
i
p
)qp(
∑
∑−
=
−
=−
1
1
1
1 =
ix1N
1i
iyix1N
1i
p
)qp(
∑
∑−
=
−
=−
.
D'altro lato si ha:
pix - qiy = ∑=
−i
j)j(y
y)y(
N 1
1 µµ
= )xaa()a(N )j(x
i
jx−−+
+ ∑=
µµ 1
1 =
= )x()a(N )j(x
i
jx−
+ ∑=
µµ 1
1 = µx
a+µx (pix - qix)
ove l'ultimo risultato è stato ottenuto ricordando quanto dimostrato nel para-grafo 3.2. Sostituendo l'ultima espressione in Rgy diviene:
Rgy = ix
k
i
iyiy
k
i
p
)qp(
∑
∑−
=
−
=−
1
1
1
1 =
ix1k
1i
ixixx
x1k
1i
p
)qp(a
∑
∑−
=
−
=−
+ µµ
= µx
a+µx Rgx .
Come si vede avremo che Rgy < Rgx se è a > 0 mentre Rgy > Rgx se è

Capitolo 3 98
a<0. Supponiamo ora che sia Y = aX, con a costante positiva. Questo vuole
dire che il nuovo reddito Y è cresciuto (se è a>1) o decresciuto (se è a<1) pro-porzionalmente al vecchio. In tal caso i rapporti fra i vecchi ed i nuovi redditi so-no rimasti immutati come pure la loro concentrazione. Le due rilevazioni di-ventano rispettivamente
X: x1, x2, ...., xN
Y: ax1, ax2, ..., axN Mentre
µy = aµx; piy = pix i=1,2,...,N
e quindi
qiy = 1
Nµy ∑j=1
i y(j) =
1Naµy
∑j=1
i ax(i) =
1Naµy
a ∑j=1
i x(i) = qix i=1,2,...,N
di conseguenza si ha Rgy = Rgx indipendentemente dal valore di a. Esempio 1
Supponiamo di avere una popolazione di 20 individui e di avere rilevato il reddito lordo mensile di ciascuno di essi arrotondato al milione più vicino. Si vuole analizzare la con-centrazione della distribuzione dei redditi così ottenuti. Le osservazioni originarie e le elabo-razioni necessarie per ottenere i risultati richiesti sono riportati nella tabella seguente. Nella prima colonna di detta tabella sono state riportate le osservazioni originarie, nella seconda le stesse osservazioni ordinate in senso non decrescente, nella terza sono riportate le frequenze cumulate, nella quarta le frequenze cumulate relative, nella quinta le percentuali cumulate del carattere, nella sesta e nella settima gli elementi per calcolare l'indice δ di Gini, nella penul-tima il rapporto fra la settima e l'ottava colonna, nell'ultima gli elementi per calcolare il rap-porto di concentrazione come se il fenomeno fosse per classi di modalità. xi x(i) i pi qi log(1-pi) log(1-qi) δi (qi-1+qi)/20
5 2 1 0.05 0.0144 -0.05129 -0.01459 3.5154 0.00072 2 2 2 0.10 0.0289 -0.10536 -0.02940 3.5837 0.00217 7 5 3 0.15 0.0652 -0.16251 -0.06744 2.4096 0.00471 7 5 4 0.20 0.1014 -0.22314 -0.10697 2.0860 0.00833 2 5 5 0.25 0.1376 -0.28768 -0.14812 1.9422 0.01195

La concentrazione 99
5 5 6 0.30 0.1739 -0.35667 -0.19105 1.8669 0.01557 8 7 7 0.35 0.2246 -0.43078 -0.25442 1.6931 0.01992 7 7 8 0.40 0.2753 -0.51082 -0.32208 1.5860 0.02500 10 7 9 0.45 0.3260 -0.59783 -0.39464 1.5149 0.03007 7 7 10 0.50 0.3768 -0.69314 -0.47290 1.4657 0.03514 5 7 11 0.55 0.4275 -0.79850 -0.55781 1.4315 0.04021 8 7 12 0.60 0.4782 -0.91629 -0.65058 1.4084 0.04529 10 8 13 0.65 0.5362 -1.04982 -0.76836 1.3663 0.05072 7 8 14 0.70 0.5942 -1.20397 -0.90189 1.3349 0.05652 8 8 15 0.75 0.6521 -1.38629 -1.05604 1.3127 0.06231 10 8 16 0.80 0.7101 -1.60943 -1.23837 1.2996 0.06811 5 10 17 0.85 0.7826 -1.89711 -1.52606 1.2431 0.07463 7 10 18 0.90 0.8550 -2.30258 -1.93150 1.1921 0.08188 8 10 19 0.95 0.9275 -2.99573 -2.62458 1.1414 0.08913 10 10 20 0.09637 138 9.50 7.6884 -17.5790 -13.25688 33.3935 0.81884
in tal modo si ottengono le seguenti misure di concentrazione
Rg = 1 - 7.688378
9.50 = 0.190697
R = 1- 0.8188378 = 0.1811622
δ = -17.57929-13.25471 = 1.326267
δ = 33.4297
19 = 1.759458
che indicano una modesta presenza di concentrazione dei redditi di quella popolazione di 20 soggetti analizzati. La spezzata di Lorenz è riportata nella figura seguente che conferma quanto è emerso dagli indici sopra riportati.

Capitolo 3 100
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0p p
q
Nel caso in cui il fenomeno è per classi di modalità, come spesso avviene nelle pratiche applicazioni, gli indici sopra presentati possono essere calcolati solo in via approssimata sostituendo alle relative classi i propri valori centrali. Questa sostituzione permette di ottenere, come già accennato, dei valori ap-prossimati delle qi. Le qi possono essere calcolate in modo esatto se accanto alle classi ed alle frequenze sono riportate anche le intensità del fenomeno relative a ciascuna classe. Esempio 2
Supponiamo di aver rilevato il fatturato annuo, in miliardi di lire, di 40 piccole aziende di un dato settore in una determinata regione ottenendo i risul-tati seguenti
classi: xi —|xi+1 1 —|3 3 —|6 6 —|10 10 —|15 15 —|20 frequenze: ni 5 7 12 10 6 40 intensità: 9 34 88 124 95 350
Vogliamo costruire la curva di Lorenz di questo fenomeno e calcolare la relativa con-centrazione. Notiamo che la cifra figurante nella riga delle intensità vuol dire che le 5 aziende della classe 1—|3 fatturano complessivamente 9 miliardi all'anno, le 7 aziende della classe 3—|6 fatturano complessivamente 34 miliardi all'anno, e così via. Il fatturato annuo totale delle 40 aziende considerate è pari a 350 miliardi di lire. Nella tabella che segue riportiamo i dati necessari per poter costruire il grafico richiesto ed il relativo rapporto di concentrazione

La concentrazione 101
classi: xi —|xi+1 1 —|3 3 —|6 6 —|10 10 —|15 15 —|20
frequenze: ni 5 7 12 10 6 40 intensità: 9 34 88 124 95 350
pi 5/40 12/40 24/40 34/40 1 qi 9/350 43/350 131/350 255/350 1
(qi-1+qi)fi 0.00321 0.02600 0.14914 0.27571 0.25929 0.71335 Da cui si ottiene immediatamente che è
R = 1-0.71315 = 0.28665
mentre la spezzata di Lorenz è riportata nella figura che segue.
0.0
0.2
0.4
0.6
0.8
1.0
0.2 0.4 0.6 0.8 1.0
q
p
i
i


Capitolo 4 LE DISTRIBUZIONI DI FREQUENZA DOPPIE 4.1 Introduzione
Data una popolazione composta da N unità di rilevazione, se per ognu-na di queste si rilevano contemporaneamente i due caratteri X ed Y, si ottiene la rilevazione doppia:
(x1, y1), (x2, y2), ........, (xN, yN) L'importanza delle rilevazioni doppie, e di quelle multiple in generale in cui si rilevano contemporaneamente s caratteri per ogni unità, risiede nel fatto che in tal modo non solo si hanno informazioni su ciascun carattere preso singolar-mente, ma se ne ottengono sulle possibili relazioni che intercorrono fra i carat-teri dati.
I caratteri presi in considerazione possono essere entrambi quantitativi, entrambi qualitativi o uno quantitativo e l'altro qualitativo. Inoltre, se i caratteri sono delle quantità queste possono essere sia discrete che continue ed anche, ovviamente, per classi di modalità. Una tipica rilevazione statistica doppia può essere, se le unità di rilevazione sono scambiabili, equivalentemente rappresen-tata da una distribuzione di frequenza doppia, di solito indicata con (X, Y) per sotto-lineare che si stanno analizzando simultaneamente i due caratteri X ed Y. Que-sta viene riportata in una tabella a doppia entrata come quella di seguito sche-matizzata
Y\X x1 x2 x3 … xk y1 n11 n21 n31 … nk1 n.1 y2 n12 n22 n32 … nk2 n.2 y3 n13 n23 n33 … nk3 n.3 … … … … … … … yh n1h n2h n3h … nkh n.h n1. n2. n3. … nk. N

Capitolo 4 104
La tabella a doppia entrata è formata da h righe, tante quante sono le di-verse modalità o classi di modalità assunte dal carattere Y, e k colonne, tante quante sono le diverse modalità o classi di modalità assunte dal carattere X. I simboli nij, i=1,2,...,k, j=1,2,...,h, rappresentano le frequenze relative alla coppia di caratteri (xi, yj) cioè quante volte fra le N unità di rilevazione osservate si presenta la coppia di valori (xi, yj). Ovviamente alcune delle nij possono essere pari a zero e questo vuole significare che nel collettivo non esiste nessuna unità di rilevazione che assume quella coppia di determinazioni dei caratteri. Inoltre: ni. rappresenta la somma delle frequenze della i-esima colonna, i=1,2,...,k n.j rappresenta la somma delle frequenze della j-esima riga, j=1,2,...,h N rappresenta la somma totale delle frequenze che ovviamente
corrisponde alla numerosità della popolazione (numero delle unità di rilevazione della popolazione).
In simboli:
ni. = ∑j=1
h nij n.j = ∑
i=1
k nij
N = ∑i=1
k ∑
j=1
h nij = ∑
j=1
h n.j = ∑
i=1
k ni.
Esempio 1
Supponiamo che di una popolazione di 119 individui si è rilevato contemporanea-mente il peso, espresso in chilogrammi, e l'altezza, espressa in centimetri ottenendo la seguente distribuzione doppia (H, P):
P\H 150 155 160 170 180 40 5 7 3 1 0 16 45 6 10 4 1 1 22 50 3 5 7 6 2 23 60 2 5 8 7 3 25 75 1 0 5 4 7 17 90 0 0 1 5 10 16 17 27 28 24 23 119
Come si vede, nella prima riga della tabella vengono indicate le modalità assunte dal
primo carattere, in questo caso l'altezza, nella prima colonna vengono indicate le modalità

Le distribuzioni di frequenza doppie
105
assunte dal secondo carattere, in questo caso il peso, nelle altre caselle vengono indicate le fre-quenze. In particolare: il valore 16 posto all'incrocio fra la prima riga e l'ultima colonna sta ad indicare che
vi sono 16 persone che pesano 40 chili, indipendentemente dalla loro altezza; il valore 28 posto all'incrocio fra la quarta colonna e l'ultima riga sta ad indicare che
vi sono 28 individui che sono alti 160 centimetri indipendentemente dal loro peso; il valore 7 posto all'incrocio fra la penultima colonna e la sesta riga sta ad indicare
che vi sono 7 individui che sono alti 180 centimetri e pesano 75 chilogrammi; il valore 0 posto all'incrocio fra la penultima colonna e la seconda riga sta ad indica-
re che non vi sono, nel collettivo, individui che sono alti 180 centimetri e contempora-neamente pesano 40 chilogrammi. L'interpretazione dei dati figuranti nelle altre caselle della tabella è del tutto simile a
quanto sin qui accennato.
Quando si analizzano simultaneamente più fenomeni è necessario defi-nire anche quali di questi sono da considerare causa e quali effetti. Queste in-formazioni, che sono essenzialmente logiche, non possono essere ottenute con strumenti statistici. Così, se si considera la distribuzione doppia (Peso, Altezza) è noto che fra di loro esistono relazioni di simultaneità nel senso che il peso influenza l'altezza e viceversa, e gli strumenti statistici servono solo a confermare e misurare tali relazioni. Se i fenomeni presi in considerazione sono (Reddito, Consumo) è noto che sono i Redditi ad influenzare i Consumi, ma di solito non vale il viceversa: in questo caso il reddito è la causa o una delle cause che influenza il consumo. Se i due caratteri sono (Altezza del padre, Altezza del primogenito) chiaramente è il primo carattere la causa ed il secondo l'effetto e non esiste strumento statistico che possa fornire una tale informazione. In con-clusione, quando si analizzano più fenomeni congiuntamente, bisogna per pri-ma cosa chiedersi se l'analisi ha senso logicamente e se è logicamente fondato individuare i caratteri da considerare cause e quelli da ritenere effetti ed even-tualmente se esiste una doppia relazione fra di essi come visto nel caso (Peso, Altezza). 4.2 Distribuzioni semplici derivate da una doppia
Data una distribuzione doppia (X,Y) da questa si possono derivare delle distribuzioni semplici che descrivono aspetti particolari della doppia.

Capitolo 4 106
LE MARGINALI
Dalla distribuzione (X,Y) è possibile sempre derivare la distribuzione della sola X e quella della sola Y. Queste distribuzioni vengono dette marginali della doppia perché si trovano ai margini della tabella doppia che descrive la (X,Y).
Le marginali X ed Y della distribuzione doppia sono date rispettivamente da:
xi ni. yj n.j x1 n1. y1 n.1
x2 n2. y2 n.2
x3 n3. y3 n.3 … … … … xk nk. yh n.h
N N Esempio 2
Data la distribuzione (H,P) vista nell'esempio 1, le sue marginali sono, rispettiva-mente, le seguenti:
hi ni. pj n.j 150 17 40 16
155 27 45 22
160 28 50 23 170 24 60 25 180 23 75 17
119 90 16
119
Osserviamo che nota la distribuzione doppia è sempre possibile derivare le sue marginali. Note le marginali, in generale, non è possibile risalire alla dop-pia visto che la conoscenza delle marginali nulla ci dice sugli eventuali legami esistenti fra X ed Y e quindi sulle caselle all'interno della tabella a doppia entra-ta che descrive (X,Y). Naturalmente, tutti gli strumenti di analisi che sono stati

Le distribuzioni di frequenza doppie
107
presentati nei capitoli recedenti possono essere utilizzati sulle singole distribu-zioni marginali della doppia. Esempio 3
Consideriamo la distribuzione del personale di ricerca in Italia nel 1990 per qualifica e settore d'impiego
Settore di impiego Qualifica Ammin. pubblica Imprese
Ricercatori 46346 31530 77876 Tecnici 19019 23285 42304 Altro 12056 12681 24737 77421 67496 144917
Le due marginali di questa distribuzione doppia sono date rispettivamente da:
Qualifica n.j Settore di impego ni. Ricercatori 77876 Ammin. pubblica 77421 Tecnici 42304 Imprese 67496 Altro 24737
144917 144917
Come si rileva è impossibile risalire dalle due marginali alla tabella doppia che le ha generate. LE CONDIZIONATE
Le distribuzioni condizionate sono particolari distribuzioni di frequenza semplici derivate dalla doppia sotto la condizione di un vincolo imposto ad uno dei caratteri. Più in generale, data una popolazione P (nel nostro caso le N unità di rilevazione da cui è stata ottenuta la distribuzione doppia (X,Y)), im-porre su P una condizione vuol dire effettuare una restrizione di P, più preci-samente, considerare la sotto popolazione P* di P che soddisfa la condizione posta (nel nostro caso il vincolo imposto ad uno dei due caratteri). La popola-zione P* sarà contenuta o al più sarà uguale a quella da cui è stata derivata. Inoltre, P* può anche essere vuota se la condizione imposta non può essere ve-rificata. Per esempio, data la popolazione di tutti gli italiani ad una certa data, se

Capitolo 4 108
consideriamo tutti gli italiani maschi a quella data abbiamo ottenuto una popo-lazione condizionata dal vincolo di essere maschi. Ovviamente la seconda po-polazione è contenuta nella prima. Graficamente la situazione è illustrata nella figura che segue.
Data una distribuzione di frequenza doppia (X,Y), si possono derivare due classi di condizionate:
le condizionate X dato che Y ha assunto una data modalità, di solito queste di-stribuzioni si indicano con (X|Y=yj) j=1,2,...,h;
le condizionate Y dato che X ha assunto una data modalità, di solito queste di-stribuzioni si indicano con (Y|X=xi) i=1,2,...,k
Di distribuzioni del tipo (X|Y=yj) ve ne sono h e coincidono con cia-
scuna riga della tabella doppia:
xi|Y=y1 ni1 xi|Y=y2 ni2 xi|Y=yh nih x1 n11 x1 n12 x1 n1h x2 n21 x2 n22 x2 n2h … … … … … … xk nk1 xk nk2 xk nkh n.1 n.2 n.h
Allo stesso modo, di distribuzioni condizionate (Y|X=xi) ve ne sono k e coin-cidono con ciascuna colonna della distribuzione doppia:

Le distribuzioni di frequenza doppie
109
yj|X=x1 n1j yj|X=x2 n2j yj|X=xk nkj
y1 n11 y1 n21 y1 nk1 y2 n12 y2 n22 y2 nk2 … … … … … … yh n1h yh n2h yh nkh n1. n2. nk.
Le distribuzioni condizionate, così come le marginali, si possono derivare da qualsiasi
distribuzione doppia siano i caratteri delle qualità o delle quantità, per classi di modalità o meno. Esempio 3
Deriviamo le condizionate (H|P=pj) relative alla distribuzione doppia riportata nell'esempio 1:
hi|P=40 ni1 hi|P=45 ni2 hi|P=50 ni3 150 5 150 6 150 3 155 7 155 10 155 5 160 3 160 4 160 7 170 1 170 1 170 6
16 180 1 180 2 22 23
hi|P=60 ni4 hi|P=75 ni2 hi|P=90 ni3 150 2 150 1 160 1 155 5 160 5 170 5 160 8 170 4 180 10 170 7 180 7 16 180 3 17
25 La distribuzione (H|P=40) rappresenta la distribuzione della sotto popolazione costituita da 16 dei 119 soggetti che hanno peso pari a 40 chilogrammi; la distribuzione (H|P=45) rappresenta la distribuzione della sotto popolazione costituita da 22 dei 119 soggetti che hanno peso pari a 45 chilogrammi, e così via. In modo del tutto simile si derivano le condi-zionate del tipo (P|H=hi).
Si osservi che se sono note tutte le condizionate appartenenti ad una delle due classi è nota la tabella e quindi la distribuzione doppia. Questo vuol dire che esiste una corrispondenza biunivoca fra distribuzione doppia e tutte le sue con-

Capitolo 4 110
condizionate. Si osservi, infine, che non sempre logicamente ha senso derivare le condizionate di tutte e due le classi. Così, nella distribuzione doppia (Altezza padre, Altezza primogenito) ha senso considerare solo la classe delle condizio-nate del tipo (Altezza primogenito|Altezza padre). 4.3 L'indipendenza fra caratteri
Abbiamo più volte sottolineato come una distribuzione di frequenza doppia, oltre a fornire informazione sui due caratteri presi in considerazione (tramite le distribuzioni marginali), fornisce informazioni sugli eventuali legami esistenti fra detti caratteri. Naturalmente, qui si analizza la dipendenza o l'indi-pendenza statistica, cioè quella che può essere rilevata e misurata con strumenti statistici. Da questo punto di vista è indispensabile, ogni volta che si applicano questi strumenti, chiedersi in primo luogo se logicamente fra i due caratteri possa esistere un eventuale legame. Solo se la risposta è affermativa, o quanto meno dubbia si può procedere alla rilevazione e misura della dipendenza.
Data la distribuzione doppia (X, Y) si dice che fra X ed Y vi è indipenden-za assoluta se non esiste alcun tipo di legame sia fra X ed Y che fra Y ed X.
In altri termini, l'indipendenza assoluta è di tipo reciproco per cui se X
non dipende da Y, anche Y non dipende da X. Si possono, infatti, avere casi per cui mentre X dipende da Y, Y è indipendente da X. Un esempio di questo tipo è fornito dalla distribuzione doppia (Altezza padre, Altezza primogenito) in cui la seconda variabile dipende dalla prima, mentre la prima è indipendente dalla seconda. Quando si ha indipendenza in coppie di fenomeni di quest'ulti-mo tipo si dice che fra di loro esiste una indipendenza relativa. Un diverso tipo di indipendenza è quella in media:
i due caratteri X ed Y sono indipendenti in media se in media non esiste nessun legame fra di loro.
INDIPENDENZA ASSOLUTA
In generale, quando si parla di indipendenza fra due caratteri X ed Y si intende quella assoluta: X è indipendente da Y ed Y è indipendente da X. Ov-viamente, se X ed Y sono assolutamente indipendenti lo sono anche in media.

Le distribuzioni di frequenza doppie
111
Di solito non è vero il viceversa. Nel seguito analizzeremo essenzialmente l'in-dipendenza assoluta e faremo un breve cenno a quella in media.
Data una distribuzione doppia (X, Y) rappresentata dalla relativa tabella a doppia entrata, per verificare, statisticamente, se X ed Y sono dipendenti o indipendenti basta analizzare tutte le distribuzioni condizionate di una delle due classi, cioè o solo quelle della classe (X|Y=yj), o solo quelle della classe (Y|X=xi). Per ogni distribuzione condizionata così ottenuta vengono conside-rate le frequenze relative. Da questo punto di vista diremo che:
i due caratteri X ed Y sono assolutamente indipendenti se tutte le distribuzione condizionate di frequenza relative (X|Y=yj), j=1,2,...,h, sono uguali fra di loro.
In altri termini, consideriamo le distribuzioni condizionate (X|Y=y1),
(X|Y=y2), ..., (X|Y=yh) e consideriamo le distribuzioni delle frequenze relati-ve:
xi|Y=y1 ni1n.1
xi|Y=y2 ni2n.2 xi|Y=yh
nihn.h
x1 n11n.1
x1 n12n.2
x1
n1hn.h
x2 n21n.1
x2 n22n.2
x2 n2hn.h
… … … … … …
xk nk1n.1
xk nk2n.2
xk nkhn.h
1 1 1
I due caratteri X ed Y sono assolutamente indipendenti se queste h di-stribuzioni sono esattamente uguali. In tal caso al variare delle modalità assunte dalla Y la distribuzione della X, condizionata a tali modalità, rimane sempre la stessa per cui Y non esercita alcuna influenza statistica sulla X. Naturalmente se questo è vero si ha anche che le k distribuzioni condizionate delle frequenze relative (Y|X=xi), i=1,2,...,k, sono uguali. Ma se le frequenze relative delle di-stribuzioni condizionate (X|Y=yj) sono identiche, per forza di cose dovranno coincidere con le frequenze relative della distribuzione della marginale X. In altri termini, tutte le colonne delle frequenze relative di queste due distribuzioni

Capitolo 4 112
dovranno essere uguali:
xi|Y=yj nijn.j
xi ni.N
x1 n1jn.j
x1 n1.N
x2 n2jn.j
x2 n2.N
… … … …
xk nkjn.j
xk nk.N
1 1 per j=1,2,...,h.
In definitiva, possiamo affermare che
i due caratteri X ed Y sono assolutamente indipendenti se e solo se risulta nijn.j
= ni.N per i=1,...,k; j=1,...,h
Quest'ultima espressione può anche essere scritta:
nij = ni. n.j
N i=1,...,k; j=1,...,h
Nelle pratiche applicazioni è ben difficile osservare distribuzioni in cui,
per tutte le coppie (i,j), sia verificata l'ultima uguaglianza sopra riportata. D'altro lato, quella equazione permette di derivare la distribuzione doppia teorica sotto l'ipotesi d'indipendeza. Se con nij intendiamo le frequenze effettivamente osservate in una data distribuzione doppia (X,Y) e con:
n*ij =
ni. n.jN i=1,...,k; j=1,...,h
le frequenze ottenute sotto l'ipotesi di indipendenza, allora X ed Y sono asso-lutamente indipendenti se e solo se la tabella relativa alla distribuzione osserva-

Le distribuzioni di frequenza doppie
113
ta coincide, casella per casella, alla tabella teorica d'indipendenza costruita utilizzan-do l'ultima eguaglianza. Se dividiamo ambo i membri dell'ultima espressione per N otteniamo le frequenze relative della doppia e delle marginali:
nijN =
ni. n.jN N i =1,...,k; j=1,...,h
cioè:
fij = fi. f.j
Questo vuol dire che X ed Y sono assolutamente indipendenti se e solo se cia-scuna frequenza relativa della doppia è uguale al prodotto delle corrispondenti frequenze relative delle marginali. Esempio 4
Su una popolazione di 49 unità di rilevazione abbiamo osservato i due caratteri X ed Y ottenendo la distribuzione osservata seguente
Y\X x1 x2 x3 y1 5 4 3 12 y2 7 5 2 14 y3 6 2 4 12 y4 8 1 2 11 26 12 11 49
la relativa tabella d'indipendenza è:
Y\X x1 x2 x3
y1 49
1226× 49
1212× 49
1211× 12
y2 49
1426× 49
1412 × 49
1411× 14
y3 49
1226× 49
1212 × 49
1211× 12
y4 49
1126× 49
1112 × 49
1111× 11
26 12 11 49 E dato che le due tabelle non coincidono casella per casella, per esempio a fronte della fre-

Capitolo 4 114
quenza n11 = 5 figurante nella tabella osservata si ha n*11 = 6,367 in quella di indipen-
denza, vuol dire che fra la X e la Y vi è una qualche dipendenza che bisognerà misurare con qualche indice per stabilirne la sua intensità. Osserviamo, inoltre, che le frequenze delle due marginali X ed Y, nella tabella osservata ed in quella di indipendenza, sono esattamente le stesse. Questa uguaglianza la mostreremo formalmente più avanti.
Vediamo ora come può essere costruito un indice di indipendenza, che ci permetta di stabilire fino a che punto si è vicini o lontani dal caso teorico di indipendenza. Questo indice dovrà essere pari a zero nel caso di perfetta indi-pendenza fra X ed Y (la tabella osservata e la tabella teorica sono coincidenti) ed essere positivo e crescente man mano che ci si allontana dal caso di perfetta indipendenza (la tabella osservata è molto diversa da quella teorica costruita sotto l'ipotesi di indipendenza).
Y\X x1 x2 x3 … xk y1 n11 n21 n31 … nk1 n.1 y2 n12 n22 n32 nk2 n.2 y3 n13 n23 n33 … nk3 n.3 … … … … … … … yh n1h n2h n3h nkh n.h n1. n2. n3. nk. N
Y\X x1 x2 x3 … xk
y1 Nnn .. 11
Nnn .. 12
Nnn .. 13 …
Nnn ..k 1 n.1
y2 Nnn .. 21
Nnn .. 22
Nnn .. 23
Nnn ..k 2 n.2
y3 Nnn .. 31
Nnn .. 32
Nnn .. 33 …
Nnn ..k 3 n.3
… … … … … … …
yh Nnn h..1
Nnn h..2
Nnn h..3
Nnn h..k n.h
n1. n2. n3. nk. N
Osserviamo che le frequenze marginali delle due tabelle sono esattamen-
Tabella osservata
Tabella di indipendenza

Le distribuzioni di frequenza doppie
115
te le stesse. Infatti, la somma delle frequenze della j-esima riga della tabella di indipendenza è data da:
n1. n.jN +
n2. n.jN +
n3. n.jN + ... +
nk. n.jN =
= n.j n1. + n2. + n3. + ... + nk.
N = n.j
Le stesse considerazioni valgono per la somma di ciascuna colonna della
tabella di indipendenza. A questo punto possiamo definire un indice capace di misurare la diversi-
tà esistente fra tabella osservata e tabella teorica.
Data la distribuzione doppia (X, Y) l'indice di indipendenza di Pizzetti-Pearson, che di solito si indica con χ2 e si legge chi-quadrato, è dato da
χ2 = ∑i=1
k ∑
j=1
h
[nij - n*ij]2
n*ij
Come si può notare, quest'indice è: - sempre non negativo; - nullo se e solo se la tabella osservata e quella d'indipendenza coincidono; - cresce al crescere della diversità delle due tabelle; - può essere utilizzato per qualsiasi tipo di carattere dato che non dipende dalle
modalità dei due fenomeni analizzati. L'indice χ2 non è normalizzato, cioè non varia in un intervallo finito, dato che è funzione della numerosità N della popolazione. Infatti, risulta:
χ2 = *ij
*ijijh
j
k
i n]nn[ 2
11
−∑∑==
= *ij
*ijij
*ijijh
j
k
i nnnnn 222
11
−+∑∑==
=
=
−+∑∑
==ij
*ij*
ij
ijh
j
k
inn
nn
22
11= *
ij
ijh
j
k
i nn2
11∑∑==
+ N - 2N =

Capitolo 4 116
= ∑i=1
k ∑
j=1
h
n2ij
ni. n.jN
- N = N
−∑∑
==1
2
11 j..i
ijh
j
k
i nnn
che dimostra quanto avevamo affermato. Si osservi che quest'ultima formula-zione spesso è utile, rispetto alla definizione precedente, per calcolare l'indice χ2 dato che per il suo uso non è necessario derivare la tabella teorica di indi-pendenza. Esempio 5
Abbiamo osservato i due caratteri X ed Y su una popolazione di 20 unità e abbia-mo ottenuto la distribuzione doppia seguente
Y\X x1 x2 x3 y1 5 3 3 11 y2 4 2 3 9 9 5 6 20
Calcoliamo l'indice d'indipendenza χ2. In questo caso la tabella di indipendenza è:
Y\X x1 x2 x3
y1 2099
2055
2060 11
y2 2081
2045
2054 9
9 5 6 20 Se per il calcolo dell'indice di indipendenza utilizziamo la formula
χ2 = ∑i=1
k ∑
j=1
h
[nij - n*ij]2
n*ij
si ottiene:

Le distribuzioni di frequenza doppie
117
χ2 = (5-4.95)2
4.95 + (3-2.75)2
2.75 + (3-3.3)2
3.3 + (4-4.05)2
4.05 + (2-2.25)2
2.25 +
+ (3-2.7)2
2.7 = 0.1122.
Se si utilizza la formula
χ2 = N
−∑∑
==1
2
11 j..i
ijh
j
k
i nnn
si ottiene ovviamente lo stesso risultato:
χ2 = 20
−+++++ 1
549
454
8116
669
559
9925 = 0.1122
Possiamo così affermare che fra i due caratteri considerati vi è dipendenza, ma a questo punto non possiamo dire nulla sull'intensità di tale legame. Per poter stabilire la forza di questo legame è necessario derivare un indice normalizzato.
Il modo più semplice per normalizzare un indice è quello di dividerlo per il suo massimo se esiste finito. Nel nostro caso, fissata l'ampiezza N della popolazione, si può dimostrare (la dimostrazione non viene riportata per brevi-tà) che è;
max(χ2) = N[min(h, k) - 1]
ove, come sappiamo, è
h=numero delle modalità del carattere Y (numero delle righe della tabella), k=numero delle modalità del carattere X (numero delle colonne della tabel-la), min(h,k)=numero più piccolo fra h e k.
Questo ci permette di definire

Capitolo 4 118
l'indice d'indipendenza di Cramér dato da:
Φ2 = χ2
max(χ2) =
∑i=1
k ∑j=1
h
n2ij
ni. n.j - 1
min(h, k) - 1
Questo è un indice che varia nell'intervallo [0, 1]: vale zero se fra X ed Y
vi è perfetta indipendenza, vale 1 se fra X ed Y vi è la massima dipendenza possibile. Spesso al posto dell'indice di Cramér Φ2 si preferisce utilizzare la ra-dice quadrata positiva di questo perché riesce a misurare in modo meno distor-to la dipendenza esistente fra i caratteri dati:
Φ = Φ2
ovviamente risulta ancora 0 ≤ Φ ≤ 1. Esempio 6 Riprendendo la distribuzione doppia riportata nell'esempio 5 si ha immediatamente che
χ2 = 0.1122; max(χ2) = 20[min(2, 3) -1] = 20[2 - 1] = 20 che implica:
Φ2 = 0.1122
20 = 0.00561; Φ = 0.0749
Possiamo così affermare che fra i due caratteri dell'esempio 5 esiste una trascurabile dipen-denza. INDIPENDENZA IN MEDIA
Trattiamo qui di seguito, brevemente, del concetto della dipendenza in media fra due caratteri. A tal proposito supponiamo di avere una distribuzione di frequenza doppia (X,Y) in cui almeno uno dei due caratteri sia misurabile e possa essere considerato logicamente funzione dell'altro. Senza perdere in ge-neralità, supponiamo che tale carattere sia X. La generica distribuzione X con-dizionata da Y=yj sappiamo che è

Le distribuzioni di frequenza doppie
119
xi|Y=yj nij
x1 n1j x2 n2j … … xk nkj n.j
Al variare di j=1,2,...,h si ottengono tutte le h distribuzioni (X|Y=yj)
condizionate. Dato che, per ipotesi, X è una variabile è possibile calcolare per ciascuna di quelle condizionate la relativa media, la j-esima delle quali indichia-mo con µx|j, j=1,2,...,k. Possiamo, quindi, dire che:
il carattere X è indipendente in media dal carattere Y se µx|j è costante al variare di j, cioè se le h distribuzioni condizionate (X|Y=yj) hanno tutte la stessa media aritmetica coincidente con quella della marginale X:
µx|1 = µx|2 = ... = µx|h = µx
Se anche il carattere Y è una variabile si può considerare un sistema car-
tesiano di riferimento su cui rappresentare le h coppie di punti (yj, µx|j), j=1,2,...,h ottenendo un grafico come quello idealizzato nella figura seguente.
Questo grafico, non solo mette immediatamente in evidenza l'esistenza di legami in media fra X ed Y, ma permette di avere un'idea della forma di tali legami. Si osservi che se X ed Y sono indipendenti tutte le distribuzioni condi-zionate di frequenza relative (X|Y=yj) sono uguali fra di loro ed uguali alla di-stribuzione marginale X. Ma allora anche le loro relative medie aritmetiche sa-ranno uguali. Questo vuole dire che l'indipendenza assoluta implica quella in

Capitolo 4 120
media, ma non vale, in generale, il viceversa. Esempio 7
Consideriamo la distribuzione di frequenza riportata nell'esempio 1 e verifichiamo se esiste dipendenza in media (dipendenza in senso statistico, ovviamente) di H in funzione di P. Per far questo calcoliamo le medie di ciascuna riga della tabella ed otteniamo
µh|1 = 16
1170316071555150 ×+×+×+× = 155.3125
µh|2 = 22
118011704160101556150 ×+×+×+×+× = 156.3636
µh|3 = 23
21806170716051553150 ×+×+×+×+× = 161.9565
µh|4 = 25
31807170816051552150 ×+×+×+×+× = 163.4
µh|5 = 17
7180417051601150 ×+×+×+× = 170
µh|6 = 16
1018051701160 ×+×+× = 175.625
Come si può notare da queste medie e dal grafico seguente l'altezza è fortemente influenzata, in media, dal relativo peso.
Naturalmente nel caso in cui Y è un carattere quantitativo ed ha senso logico supporre Y in funzione di X è possibile derivare le distribuzioni condi-zionate (Y|X=xi), le relative medie condizionate:
µy|1, µy|2, ..., µy|k
e verificare la dipendenza in media che esiste fra Y ed X. Data la distribuzione di frequenza doppia (X, Y), la generica media con-

Le distribuzioni di frequenza doppie
121
dizionata di (X|Y=yi) è data da
µx|j = 1n.j
∑i=1
k xi nij, j = 1,2,...,h
Dimostriamo che la media delle h medie condizionate µx|j è uguale alla
media della marginale X, in simboli E(µx|j) = µx.
Infatti,
E(µx|j) = ∑=
k
iN 1
1 µx|j n.j =
∑∑==
iji
k
ij
h
jnx
.nN 11
11 n.j =
∑∑==
k
i
h
jN 11
1 xi nij = ∑=
k
iN 1
1 xi ∑=
h
j 1nij = ∑
=
k
iN 1
1 xi ni. = µx
Indichiamo ora con var(µx|j) la varianza delle h medie condizionate si ha immediatamente
var(µx|j) = 1N ∑
j=1
h (µx|j - µx) 2 n.j
Dimostriamo che la varianza delle h medie condizionate è sempre minore o uguale della varianza della marginale X, in simboli
var(µx|j) ≤ var(X) Infatti,
var(X) = 1N ∑
i=1
k (xi - µx) 2 ni. =
1N ∑
i=1
k (xi - µx) 2 ∑
j=1
h nij =
= 1N ∑
j=1
h ∑i=1
k (xi - µx|j + µx|j - µx) 2nij =

Capitolo 4 122
= 1N ∑
j=1
h ∑i=1
k (xi - µx|j) 2nij +
1N ∑
j=1
h ∑i=1
k (µx|j - µx) 2nij +
+ 2N ∑
j=1
h ∑i=1
k (µx|j - µx)(xi - µx|j) nij
il primo di questi addendi è sicuramente non negativo, il secondo coincide con la varianza delle medie condizionate, mentre il terzo è, come mostreremo nel seguito, identicamente nullo. In definitiva risulta
var(X) = A2 + 1N ∑
i=1
k (µx|j - µx) 2nij = A2 + var(µx|j)
che dimostra quanto affermato. Nella conclusione qui sopra riportata si è tenu-to conto del fatto che
1N ∑
j=1
h ∑i=1
k (µx|j - µx)(xi - µx|j) nij =
= 1N ∑
i=1
k xi ∑
j=1
h µx|j nij -
1N ∑
j=1
h xj.jx n µµ −2
1N ∑
i=1
k xi ni. +
+ µx 1N ∑
j=1
h µx|j n.j =
= 1N ∑
j=1
h µx|j n.j
1n.j
∑i=1
k xi nij -
1N ∑
j=1
h j.jx n2µ - µxµx + µx µx =
= 1N ∑
j=1
h j.jx n2µ -
1N ∑
j=1
h j.jx n2µ - µxµx + µx µx = 0
La relazione var(µx|j) ≤ var(X) permette di definire un indice relativo che
misura l'influenza che Y esercita in media su X, più precisamente

Le distribuzioni di frequenza doppie
123
la connessione di X in funzione di Y è data da
ηx|y = var(µx|j)var(X)
per costruzione varia nell'intervallo zero ed uno: più è bassa l'influenza che Y esercita su X, più detto indice è vicino a zero; viceversa, più è elevata la dipen-denza di X da Y più quell'indice si avvicina ad uno.
Naturalmente, se ha senso logico la relazione da X ad Y è possibile an-che derivare un indice ηy|x che misura l'influenza che X esercita su Y. Esempio 8
Riprendiamo la distribuzione di frequenza doppia del peso e delle altezze riportata negli esempi 1 e 7. La distribuzione delle medie condizionate delle altezze rispetto ai pesi e quella della marginale altezza sono riportate, rispettivamente, nelle tabelle seguenti
µh|j n.j H ni. 155.3125 16 150 17 156.3636 22 155 27 161.9565 23 160 28 163.4000 25 170 24 170.0000 17 180 23 175.6250 16 119
119 Risulta immediatamente
E(µh|j) = 163.319317 E(X) = 163.319328
come si può notare queste due medie, a meno degli inevitabili arrotondamenti, sono uguali come previsto dalla teoria. Per le varianze si ha
Var(µh|j) = 44.6609 Var(X) = 106.4190
e, come atteso la prima è nettamente inferiore alla seconda. In tal modo si ottiene
ηH|P = 0.648

Capitolo 4 124
che indica una consistente influenza di P su H. 4.4 La correlazione lineare
Quando entrambi i caratteri della distribuzione doppia sono delle varia-bili è possibile elaborare, oltre agli indici riportati nel paragrafo precedente, un indice capace di misurare l'eventuale legame lineare esistente fra X ed Y. Suppo-niamo a tal fine di aver rilevato su una popolazione di ampiezza N i due carat-teri quantitativi e di aver ottenuto la distribuzione di frequenza (X,Y). Uno dei legami più semplici che si può ipotizzare fra questi caratteri è quello lineare. Il legame lineare, oltre a permettere una semplice ed immediata interpretazione, può rappresentare una prima approssimazione di legami più complessi.
Fra X ed Y esiste un legame lineare se al variare di una delle due variabili l'altra cresce o decresce, in media, secondo una retta.
Se al crescere di X l'altra variabile, in media, cresce come una retta si di-ce che fra X ed Y esiste un legame lineare positivo.
Se al crescere di X l'altra variabile decresce, in media, come una retta si dice che fra X ed Y esiste un legame lineare negativo.
Nella ricerca di un legame lineare esistono due casi limite che servono come termine di paragone per poter stabilire, come faremo più avanti, il grado del legame lineare esistente fra due variabili:
il perfetto legame lineare quando al crescere della X la Y cresce o decresce esattamente come una retta, questo caso si ha se
X = a + bY
con a, b costanti reali e b≠0;
l'incorrelazione quando al crescere o decrescere della X la Y, in media, ri-mane costante.
Data una distribuzione doppia (X, Y) con X ed Y delle variabili per le quali ha senso logico supporre fra di loro un legame, un indice per misurare l'esistenza di legami lineari fra X ed Y è covarianza. LA COVARIANZA Questo indice è di solito indicato con cov(X,Y), σxy, E[(X-µx)(Y-µy)], e con Sxy nel caso di rilevazioni campionarie ed è definita da:

Le distribuzioni di frequenza doppie
125
σxy = 1N ∑
i=1
k ∑
j=1
h (xi - µx)(yj - µy) nij = ∑
i=1
k ∑
j=1
h (xi - µx)(yj - µy) fij
ove con µx abbiamo indicato la media aritmetica della marginale X
µx = 1N ∑
i=1
k xini.
e con µy la media aritmetica della marginale Y
µy = 1N ∑
j=1
h yjn.j
La covarianza misura come X ed Y covariano, è un indice espresso nel prodotto delle unità di misura usate per rilevare X ed Y e quindi non può essere utilizza-to per stabilire quanto è forte l'eventuale legame lineare esistente fra le due va-riabili.
Come si vede dalla formula sopra riportata, la covarianza non è altro che la media dei prodotti degli scarti ponderati con le rispettive frequenze. La cova-rianza è un indice che può teoricamente assumere qualsiasi valore da -∞ a +∞. Più precisamente: se è σxy > 0 allora fra X ed Y esiste un legame lineare positivo; se è σxy < 0 allora fra X ed Y esiste un legame lineare negativo; se è σxy = 0 allora X ed Y sono incorrelate (non esiste legame lineare). Vediamo ora di dare una interpretazione grafica dei tre casi sopra elencati: Caso di σxy > 0
Si ottiene quando a scarti della X corrispondono, in media, scarti dello stesso segno della Y. Se tali scarti vengono riportati in un sistema di assi carte-

Capitolo 4 126
siani si ha una situazione simile a quella illustrata nella figura seguente
La maggior parte di tali scarti sono situati nel primo (entrambi gli scarti
sono positivi) e nel terzo quadrante (entrambi gli scarti sono negativi), la mag-gior parte del prodotto di tali scarti, avendo segno concorde, saranno positivi. Caso di σxy < 0
Si ottiene quando a scarti della X corrispondono, in media, scarti di se-gno opposto della Y. Riportando detti scarti in un sistema di assi cartesiani si ha una situazione simile a quella illustrata nella figura seguente
La maggior parte degli scarti si trova nel secondo (primo scarto negativo e secondo positivo) e nel quarto quadrante (primo scarto positivo e secondo negativo) e la maggior parte del prodotto di tali scarti saranno negativi.

Le distribuzioni di frequenza doppie
127
Caso di σxy = 0
Gli scarti suddetti sono distribuiti in modo simmetrico nei quattro qua-dranti. Un caso di σxy = 0 è schematizzato nella figura che segue ove gli scarti sono distribuiti paritariamente e simmetricamente nei quattro quadranti per cui la media dei loro prodotti sarà pari a zero.
Come si nota da questa figura, il fatto che sia σxy = 0 vuol dire solo che fra X ed Y non esiste legame lineare, ma fra i due caratteri potrebbe esistere, come in questo caso, un forte o addirittura perfetto legame di tipo non lineare. In altri termini
l'indipendenza fra X ed Y implica assenza di qualsiasi legame e quindi incorrelazio-ne. L'incorrelazione, in generale, non implica l'indipendenza.
Dimostriamo formalmente che se X ed Y sono indipendenti necessa-
riamente devono essere incorrelati. Dalla definizione di covarianza abbiamo
σxy = 1N ∑
i=1
k ∑
j=1
h (xi - µx)(yj - µy) nij
Introduciamo in questa formula la condizione di indipendenza che, ricordiamo,
equivale a nij = ni. n.j
N , otteniamo

Capitolo 4 128
σxy = 1N ∑
i=1
k ∑
j=1
h (xi - µx)(yj - µy)
ni. n.jN =
= 1N ∑
i=1
k (xi - µx) ni.
1N ∑
j=1
h (yj - µy) n.j = 0 × 0 = 0
e questo per una delle proprietà della media aritmetica (la somma degli scarti dalla media, ponderati con le relative frequenze, è sempre nulla).
L'indice σxy può anche essere espresso sotto una forma diversa e preci-samente
σxy = 1N ∑
i=1
k ∑
j=1
h (xi - µx)(yj - µy) nij =
= 1N ∑
i=1
k ∑
j=1
h (xiyj - µxyj - µyxi + µx µy) nij =
= 1N ∑
i=1
k ∑
j=1
h xi yjnij - µx
1N ∑
i=1
k ∑
j=1
h yjnij +
- µy 1N ∑
i=1
k ∑
j=1
h xinij + µxµy
1N ∑
i=1
k ∑
j=1
h nij =
= µxy - µx 1N ∑
j=1
h yj∑
i=1
k nij - µy
1N ∑
i=1
k xi∑
j=1
h nij + µx µy =
= µxy - µx 1N ∑
j=1
h yjn.j - µy
1N ∑
i=1
k xini. + µx µy =
= µxy - µxµy - µyµx + µx µy = µxy - µxµy
ove si è posto:

Le distribuzioni di frequenza doppie
129
µxy = 1N ∑
i=1
k ∑
j=1
h xi yjnij
che rappresenta la media dei prodotti (detto anche momento primo misto) delle modalità delle due variabili e viene spesso indicato con i simboli
µ11, E(XY).
In definitiva si può affermare che
la covarianza fra X ed Y è data dalla differenza fra la media dei prodotti ed il prodotto delle medie delle marginali:
σxy = µxy - µx µy = E(XY) - E(X)E(Y)
Osserviamo che se almeno una delle medie delle marginali è nulla la
covarianza coincide con il momento primo misto: σxy = µxy = E(XY). Esempio 9
Su una popolazione di 22 elementi sono stati osservati due caratteri quantitativi otte-nendo la seguente distribuzione doppia
Y\X 0 1 4 1 5 2 0 7 2 3 4 1 8 3 1 1 5 7 9 7 6 22
Si vuole calcolare la covarianza esistente fra queste due variabili. Notiamo che la
maggior parte delle frequenze della distribuzione doppia sono concentrate lungo la diagonale principale della tabella. Questo implica che il legame lineare esistente fra i due caratteri deve essere positivo pertanto è attesa una covarianza positiva fra i due fenomeni. Dalla seconda formula della covarianza si ottiene:
µxy = 1N ∑
i=1
k ∑
j=1
h xi yjnij =
122 [1×0×5 + 1×1×2 + 1×4×0 + 2×0×3

Capitolo 4 130
+ 2×1×4 + 2×4×1+ 3×0×1 + 3×1×1 + 3×4×5] = 8122
µx = 122 [0×9 + 1×7 + 4×6] =
3122 µy =
122 [1×7 + 2×8 + 3×7] =
4422
e quindi risulta:
σxy = 8122 -
3122
4422 =
1922 > 0
Possiamo così affermare che fra i due caratteri dell'esempio esiste una legame lineare positivo, nel senso che al crescere di una delle due variabili l'altra in media cresce. Nel grafico che segue abbiamo riportato le coppie di valori (xi, yj) ove il peso delle frequenze è rappresentato dalla diversa grandezza dei pallini. Da questo grafico emerge il legame lineare positivo esistente fra le due variabili visto che i pallini più grossi sono ben rappresentati da una retta crescente.
Supponiamo ora di avere una distribuzione doppia (X, Y) in cui la covarianza sia data da σxy e le medie e varianze delle marginali rispettivamente
da µx, µy, σ2x , σ2
y . Consideriamo la nuova distribuzione
V = a + bX +cY
ove a, b, c sono costanti reali qualsiasi. Dimostriamo che
σ2v = b2 σ2
x +c2 σ2y + 2bc σxy
Infatti, per definizione abbiamo che la distribuzione semplice V assume
modalità pari a vij = (a+bxi +cyj) e corrispondenti frequenze nij per i=1,...,k; j=1,...,h. Questo vuol dire che

Le distribuzioni di frequenza doppie
131
µv = ∑∑==
h
j
k
iN 11
1 vijnij = )cybxa(N ji
h
j
k
i++∑∑
== 11
1 nij =
= a ∑∑==
h
j
k
iN 11
1 nij + b ∑∑==
h
j
k
iN 11
1 xinij + c ∑∑==
h
j
k
iN 11
1 yjnij =
= a 1N N + b ∑
=
k
iN 1
1 xi
∑=
ij
h
jn
1+ c ∑
=
h
jN 1
1 yj
∑=
ij
k
in
1=
= a + b ∑=
k
iN 1
1 xini. + c ∑=
h
jN 1
1 yj n.j = a +bµx + cµy
D'altra parte si ha che
σ2v =
1N ∑
i=1
k ∑j=1
h (vij - µv) 2nij =
1N ∑
i=1
k ∑j=1
h (a+bxi+cyj - a -bµx - cµy) 2nij =
= 1N ∑
i=1
k ∑j=1
h [ b(xi - µx)+c(yj - µy)]2nij =
= 1N ∑
i=1
k ∑j=1
h [b2(xi - µx)2+c2(yj - µy)2 + 2bc(xi - µx)(yj - µy)]nij =
= b2 1N ∑
i=1
k (xi - µx) 2
∑=
ij
h
jn
1+ c2
1N ∑
j=1
h (yj - µy) 2
∑=
ij
k
in
1+
+ 2bc 1N ∑
i=1
k ∑j=1
h (xi - µx)(yj - µy) nij =
= b2 1N ∑
i=1
k (xi - µx) 2ni.+ c2
1N ∑
j=1
h (yj - µy) 2n.j +

Capitolo 4 132
+ 2bc 1N ∑
i=1
k ∑j=1
h (xi - µx)(yj - µy) nij =
= b2 σ2
x +c2 σ2y + 2bc σxy
che dimostra quanto avevamo affermato. Da questa uguaglianza segue imme-diatamente che se X ed Y sono incorrelate (ed a maggior ragione se sono indi-pendenti) si ha immediatamente
σ2v = b2 σ2
x +c2 σ2y
Naturalmente, detto risultato può essere esteso, con una procedura simile, alla somma di un numero qualsiasi di distribuzioni di frequenza. Vediamo ora di derivare un indice che misuri i legami lineari e sia relativo (cioè
indipendente dall'unità di misura utilizzato per rilevare le due variabili) e normalizzato (cioè che vari in un intervallo finito) in modo da poter fornire indicazioni sull'intensità dei legami lineari esistenti fra i due caratteri. A que-sto proposito, è possibile dimostrare la disuguaglianza di Schwarz.
LA DISUGUAGLIANZA DI SCHWARZ
Questa disuguaglianza, detta anche di Cauchy - Schwarz,è data da:
σ2xy ≤ σ2
x σ2y ⇔ [cov(X,Y)]2 ≤ var(X) var(Y)
La disuguaglianza sopra riportata può anche essere scritta come
E[(X-µx)(Y-µy)]2 ≤ E[(X-µx)2] E[(Y-µy)2]
che nel caso in cui entrambe le medie delle due marginali sono nulle diventa
[E(XY)]2 ≤ E(X2) E(Y2)
Senza perdere in generalità, si può sempre fare in modo che le medie delle due marginali siano nulle utilizzando le variabili scarto dalle rispettive me-die. In tal modo, basta dimostrare che l'ultima disuguaglianza è vera per dimo-strare la disuguaglianza di Cauchy - Schwarz. Infatti, qualsiasi sia la costante a ri-

Le distribuzioni di frequenza doppie
133
sulta
E[(Y-aX)2] ≥ 0 visto che si tratta di una media di quadrati. Inoltre
E[(Y-aX)2] = E(Y2 + a2X2 - 2aXY) = E(Y2) + a2E(X2) - 2aE(XY) =
= a2E(X2) + [E(XY)]2
E(X2) - [E(XY)]2
E(X2) - 2a E(XY)E(X2) E(X2) + E(Y2) =
= a2E(X2) + [E(XY)]2[E(X2)]2 E(X2) - 2a
E(XY)E(X2) E(X2) + E(Y2) -
[E(XY)]2E(X2) =
= E(X2)
+− 22
2
22 2
)]X(E[)]XY(E[
)X(E)XY(Eaa +
−
)X(E)]XY(E[)Y(E 2
22 =
= E(X2)
−
)X(E)XY(Ea 2
2 +
−
)X(E)]XY(E[)Y(E 2
22 ≥ 0
Questa disuguaglianza vale qualsiasi sia la costante a reale. In particolare pos-siamo porre
a = E(XY)E(X2)
ed ottenere
−
)X(E)]XY(E[)Y(E 2
22 ≥ 0
che è equivalente a
[E(XY)]2 ≤ E(X2) E(Y2) e questo dimostra quanto asserito.
Una volta dimostrato che è sempre 0 ≤ σ2xy ≤ σ2
x σ2y dividendo ambo i
membri di questa disuguaglianza per σ2x σ2
y si ottiene

Capitolo 4 134
0 ≤ σ2
xy
σ2x σ2
y ≤ 1
Considerando la radice quadrata si ottiene, infine
- 1 ≤ σxy
σx σy ≤ 1
Questa relazione può essere più facilmente dimostrata ricordando che, qualsiasi siano le costanti a, b, c in V = a + bX + cY, è sempre
σ2v = b2 σ2
x +c2 σ2y + 2bc σxy ≥ 0
ed è valida, in particolare, per b = - σy, c = σx che implicano
σ2y σ2
x + σ2x σ2
y - 2 σy σx σxy ≥ 0
da cui si ha immediatamente
σxyσx σy
≤ 1
Allo stesso per b=σy, c = σx si ottiene
σ2y σ2
x + σ2x σ2
y - 2 σy σx σxy ≥ 0
e quindi la disuguaglianza
σxyσx σy
≥ -1
Combinando insieme queste due ultime disuguaglianze si ha il risultato cercato.

Le distribuzioni di frequenza doppie
135
IL COEFFICIENTE DI CORRELAZIONE
Il coefficiente di correlazione, di solito indicato con ρxy, corr(X,Y), rxy, è dato da
ρxy = corr(X,Y) = σxy
σx σy =
cov(X,Y)var(X)var(Y)
Come si può notare, il coefficiente di correlazione ρxy è un indice nor-
malizzato che varia nell'intervallo [-1, 1] e misura, oltre all'esistenza dei legami lineari fra X ed Y, anche la loro intensità. Più in particolare: 1) più ρxy assume un valore vicino a - 1 più il legame lineare è forte e negativo; 2) più ρxy assume un valore vicino a 1 più il legame lineare è forte e positivo; 3) più ρxy assume un valore vicino a zero più il legame lineare è trascurabile. Nel caso particolare in cui è ρxy = 1 allora fra X ed Y vi è un perfetto legame lineare positivo e risulta
X = a + bY
con b > 0 indipendentemente dalla costante a. Nel caso particolare in cui è ρxy = -1 allora fra X ed Y vi è un perfetto legame lineare negativo e risulta
X = a + bY
con b < 0 ed indipendentemente dalla costante a. Nel caso particolare in cui si abbia ρxy = 0 allora fra X ed Y non esiste legame lineare e diremo che le due variabili sono incorrelate. Esempio 10
Consideriamo la distribuzione presentata nell'esempio 8 e calcoliamo il coefficiente di correlazione di questa distribuzione doppia. Abbiamo già visto che è
σxy = 1922 µx =
3122 µy =
4422
Inoltre abbiamo

Capitolo 4 136
µ2x = 1N ∑
i=1
k x2
i ni. = )( 61671221 ×+× =
10322
µ2y = 1N ∑
j=1
h y2
j n.j = )( 798471221 ×+×+× =
10222
e quindi
σ2x =
10322 -
2231 2
= 1305484 σ2
y = 10222 -
2244 2
= 711
In definitiva avremo
ρxy =
1922
1305484
711
= 0.6593
Possiamo così affermare che fra X ed Y esiste un discreto legame lineare positivo.
Consideriamo ora una generica distribuzione doppia (X, Y), ove X ed Y sono delle variabili, e sottoponiamo entrambe a trasformazione lineare:
V = a + bX U = c +dY in modo da ottenere la nuova distribuzione doppia (V, U). Vediamo quali rela-zioni passano fra il coefficiente di correlazione ρxy di X ed Y ed il coefficiente
di correlazione ρvu di V ed U. Se indichiamo con µx, µy, µv, µu,σ2x , σ2
y , σ2v ,
σ2u medie e varianze di X, Y, V ed U sappiamo che sono vere le relazioni se-
guenti:
µv = a + bµx σ2v = b2σ2
x
µu = c + dµy σ2u = d2σ2
y Inoltre, si ha che
σvu = 1N ∑
i=1
k ∑
j=1
h (vi - µv)(uj - µu) nij =

Le distribuzioni di frequenza doppie
137
= 1N ∑
i=1
k ∑
j=1
h (a+bxi -a- bµx)(c+dyj -c- dµy) nij =
= 1N ∑
i=1
k ∑
j=1
h (bxi - bµx)(dyj - dµy) nij =
= bd 1N ∑
i=1
k ∑
j=1
h (xi - µx)(yj - µy) nij = bd σxy
Avremo così
ρvu = σvu
σv σu =
bd σxy|bd|σx σy
= bd
|bd| ρxy
Più precisamente
ρvu =
<−>
00
dbsedbse
xy
xy
ρρ
In altri termini, una trasformazione lineare non cambia, a meno del segno, il coefficiente di correlazione. Nel caso in cui uno o entrambi i caratteri, pur essendo quantitativi, sono per
classi di modalità, la covarianza, e quindi il coefficiente di correlazione, può essere ottenuto in modo approssimato sostituendo, come al solito, a ciascu-na classe il relativo valore centrale.
La covarianza, e quindi il relativo coefficiente di correlazione, può essere calco-lato direttamente dalla rilevazione statistica doppia senza passare per la connessa distribuzione di frequenza doppia. Infatti, data la rilevazione dop-pia:
(x1, y1), (x2, y2), ..., (xN, yN)
si ottiene immediatamente
σxy = 1N ∑
i=1
N (xi - µx)(yi - µy) .


Capitolo 5 INTRODUZIONE ALL'ANALISI DELLE SERIE STORI-CHE 5.1 Introduzione
Osservare e misurare, per quanto possibile, ad intervalli regolari i feno-meni che interessano l'attività economica, sociale e scientifica degli uomini af-fonda le sue radici nel lontano passato: per esempio è noto che già gli antichi egiziani osservavano e misuravano regolarmente le piene del Nilo, i raccolti a-gricoli connessi e ne traevano conseguenti interpretazioni e previsioni. Negli anni, ed in particolare in questi ultimi, si è affermata una branca della statistica che tratta proprio dello studio di fenomeni rilevati ad intervalli costanti nel tempo: l'analisi statistica delle serie storiche. Naturalmente questa analisi può essere affrontata a vari livelli di raffinatezza, qui utilizzeremo un approccio e-splorativo-descrittivo che non richiede sofisticati strumenti analitici: nelle no-stre analisi, infatti, useremo essenzialmente le quattro operazioni dell'aritmetica.
Questo tipo di approccio ci permette di ottenere una massa di informa-zioni non molto lontana da quella ottenibile usando strumenti più elaborati. Un ruolo determinante in questo approccio è l'uso sistematico di grafici e dia-grammi che, mettendo in evidenza gli aspetti più rilevanti dei fenomeni analiz-zati, permettono di trarre immediate conclusioni ed effettuare eventuali con-fronti.
La raccolta delle informazioni su uno o più fenomeni, molto spesso, av-viene con sistematicità ad intervalli abbastanza regolari nel tempo. Questo permette, non solo di descrivere i fenomeni oggetto di studio assieme alle loro interrelazioni ma anche di analizzarne l'evoluzione nel tempo e, eventualmente, riprodurne il meccanismo fisico adattandovi appropriati modelli statistici. Fra le altre cose, tale approccio permette di evidenziare le componenti essenziali che soggiacciono all'evoluzione del fenomeno.
Più in generale, si può constatare come le informazioni così accumulate

Capitolo 5 140
vengono utilizzate per i fini più disparati che in modo diverso tendono a condi-zionare i futuri comportamenti individuali e sociali. Tali comportamenti a loro volta si ripercuotono sui fenomeni oggetto di studio in un circolo ininterrotto, ma che è essenziale analizzare per capire la struttura interna dei fenomeni che ci circondano.
Dato un fenomeno A di cui si misura la caratteristica X, se questa misurazione viene effettuata, a partire dal tempo iniziale c, N volte con cadenza s, si ottiene la successione di valori
Xc, Xc+s, ...., Xc+(N-1)s
che prende il nome di serie storica con cadenza s.
Di solito è irrilevante conoscere c per cui possiamo supporre c=1 e de-
scrivere la serie storica più semplicemente nel modo seguente
X1, X2, ...., XN = {Xt; t=1,2, ..., N}
esplicitando il periodo di misurazione e la cadenza. Se il fenomeno oggetto di studio, invece che sul tempo, è osservato sul piano lungo una data direzione, le metodologie che illustreremo per le serie storiche possono essere estese anche a queste particolari serie spaziali.
Nello studio di una serie storica, che nel seguito indicheremo più sempli-cemente con Xt, ha un ruolo fondamentale l'ordinamento temporale, nel senso che gli N valori osservati, di cui Xt si compone, sono ordinati rispetto a t e per ciò non sono scambiabili. Infatti, lo scambio delle osservazioni distrugge le infor-mazioni sulla evoluzione del fenomeno nel tempo. Per derivare particolari in-formazioni su Xt possiamo rimuovere la condizione di non scambiabilità. In tal caso le informazioni che si ottengono non possono concernere l'evoluzione del fenomeno, ma solo aspetti globali e sintetici di questo. Se sul fenomeno A si misurano più caratteristiche simultanee, per esempio se ne considerano k, si ottiene una serie storica k-pla:
Xt =
kt
t
t
X...
XX
2
1
, t=1, 2, ..., N.
In questo caso è possibile non solo analizzare l'evoluzione delle singole serie,

Introduzione all'analisi delle serie storiche 141
ma anche le interrelazioni che esistono fra queste ed in particolare quelle che intercorrono fra tutte le coppie Xit ed Xjt, per i≠j. Esempio 1
Qui di seguito riportiamo le prime 36 osservazioni con cadenza mensile riguardante: Mt morti in Italia per ogni 1000 abitanti, Dt numero dei detenuti adulti nelle carceri italia-ne, PEt produzione di energia elettrica e gas in Italia.
Mt Dt PEt t 10.4 25.665 13.005 1 9.9 26.984 11.521 2 11.0 26.196 12.278 3 9.6 27.013 11.577 4 8.8 27.593 11.899 5 8.7 26.346 11.330 6 8.9 26.545 12.045 7 8.9 26.831 10.059 8 8.1 28.851 11.754 9 9.0 29.557 12.558 10 9.6 30.085 11.924 11 10.2 27.672 12.189 12 11.6 30.557 12.743 13 11.4 31.754 11.843 14 9.8 31.099 12.181 15 9.1 32.815 11.520 16 9.2 32.534 11.323 17 8.8 32.285 11.227 18
Mt Dt PEt t 8.6 31.448 11.596 19 8.6 31.413 9.167 20 8.5 32.307 11.532 21 9.5 32.604 12.561 22 9.5 33.155 12.399 23 10.4 29.429 12.758 24 13.6 30.886 13.064 25 11.4 31.938 12.933 26 10.7 32.557 13.430 27 9.7 31.431 12.580 28 9.2 32.661 12.595 29 8.9 31.936 12.376 30 9.1 30.673 13.064 31 8.7 30.601 10.534 32 8.1 30.718 13.001 33 9.1 30.591 13.617 34 9.9 30.496 13.699 35 10.8 28.556 14.489 36
Analogamente alle distribuzioni di frequenza, anche le serie storiche pos-sono essere sintetizzate utilizzando gli indici descrittivi che abbiamo già studia-to nei capitoli precedenti. Questo permette di confrontare, fra le altre cose, il comportamento globale di serie diverse. Dobbiamo osservare che questi indici, in generale, prescindono dalla condizione di non scambiabilità delle osserva-zioni e quindi, di solito, non servono per valutare l'evoluzione delle serie nel tempo. 5.2 Alcune rappresentazioni grafiche delle serie storiche
Le rappresentazioni di fenomeni con grafici e figure risultano estrema-mente utili dato che permettono di cogliere, in modo immediato, gli aspetti più rilevanti. D'altro lato, è possibile elaborare rappresentazioni differenti a secon-da delle caratteristiche particolari che si vogliono mettere in evidenza. Questo

Capitolo 5 142
implica che la stessa serie storica può essere rappresentata in modi diversi; qui di seguito consideriamo quelle più comuni ed informative.
RAPPRESENTAZIONE SUL TEMPO Il modo più utile e rapido per rappresentare l'evoluzione di una serie storica è
la rappresentazione sul tempo. Data la serie Xt, t=1,2,...,N, si considerano le N cop-pie (t, Xt), si rappresentano in un piano cartesiano ponendo sulle ascisse il tem-po t e sulle ordinate le osservazioni Xt, si uniscono con una spezzata gli N pun-ti così individuati.
Questa rappresentazione di Xt, non solo è rapida ed agevole da costruire,
ma permette di evidenziare l'evoluzione della serie mettendo in rilievo molte delle sue caratteristiche più rilevanti ed in particolare: (a) l'esistenza di un eventuale trend, cioè dell'andamento di fondo di Xt, e sua
tipologia (crescente, decrescente, lineare, quadratico, esponenziale ecc.); (b) l'esistenza di un eventuale ciclo, cioè di fluttuazioni periodiche che si presen-
tano più o meno regolarmente ogni certo numero di anni; (c) l'esistenza, per serie osservate con cadenza inferiore all'anno (serie settima-
nali, mensili, trimestrali ecc.) di un'eventuale stagionalità, cioè di fluttuazioni più o meno regolari che si presentano in ciascun anno di osservazione.
Questo tipo di rappresentazione grafica permette, anche, di confrontare
l'evolversi di due o più serie, in pratica non più di tre per evitare di costruire grafici confusi, riportando semplicemente le serie date sullo stesso sistema di assi. Naturalmente, perché ciò abbia senso è necessario che le serie considerate siano confrontabili ed in particolare: (i) che vi sia fra di loro un qualche nesso logico, (ii) che le serie siano misurate nella stessa unità di misura, (iii) che l'ordine di grandezza delle misure non sia molto differente. Se le due ultime condizioni non sono soddisfatte si può preventivamente ed opportunamente trasformarle, così come vedremo nel prossimo paragrafo, prima di effettuare il relativo confronto grafico.

Introduzione all'analisi delle serie storiche 143
Esempio 2 La figura seguente riporta i grafici sul tempo relativi a Mt, Dt, PEt, osservate nel
periodo gennaio 1972 - dicembre 1982 e le cui prime 36 osservazioni sono state riportate nell'esempio 1. Dalle dette figure rileviamo che: (a) la serie Mt è sostanzialmente stazionaria in media (non cresce né decresce sistematica-
mente nel periodo di osservazione), possiede una marcata stagionalità con picchi netti nei mesi invernali e depressioni meno nette in quelli estivi. Inoltre si evidenziano due valori ec-cezionalmente elevati nei mesi di gennaio del 3° e del 5° anno di osservazione;
(b) la serie Dt ha un andamento molto irregolare e può essere distinta in tre sottoserie: la prima con un trend crescente, la seconda essenzialmente stazionaria in media, la terza (dopo una repentina caduta dovuta agli effetti di una amnistia) di nuovo crescente. Non si evince stagionalità di rilievo;
(c) la serie PEt evidenzia una forte e regolare stagionalità in tutto il periodo di osservazione, un trend crescente nei primi cinque anni di osservazione ed una sostanziale stazionarietà in media nel restante periodo.
t
t

Capitolo 5 144
t
RAPRESENTAZIONE GAMBO-FOGLIE La rappresentazione
gambo-foglie (stem-leaves), a differenza di quella illustrata precedentemente, di-strugge l'ordinamento temporale del fenomeno visto che viene costruita sulla serie ordinata,
ma permette di evidenziare aspetti che la rappresentazione con la spezzata sul tempo maschera. In realtà, questo tipo di rappresentazione è utile costruirla, più che su Xt, su sue particolari componenti.
Per illustrare la procedura di costruzione di questo diagramma utilizzia-mo un esempio. A tale fine supponiamo che il fenomeno osservato nel tempo t=1,2,...,70 dia luogo alla seguente serie storica: 103 120 124 109 103 107 107 115 103 114 119 115 119 103 124 117 120 105 110 110 96 133 121 105 96 112 116 110 98 123 91 97 111 127 132 115 132 97 119 96 112 103 94 114 115 109 110 98 120 110 119 122 115 99 122 105 99 128 117 127 116 102 103 117 121 127 117 110 100 103
Dato che la serie oscilla fra 91 e 133 i suoi valori sono al massimo di tre cifre, pertanto possiamo indicare come foglie l'ultima cifra di ciascuno di tali numeri e come gambi le prime due cifre. In tal modo i gambi sono dati da 9, 10, 11, 12, 13 e se accanto a questi elementi poniamo, leggendo le osservazioni per riga, le unità (cioè le foglie) otteniamo il diagramma seguente.

Introduzione all'analisi delle serie storiche 145
9 66817764899 10 3937733553952303 11 54959700260159245009576770 12 04401370228717 13 322 gambi foglie Se ordiniamo gli elementi delle foglie in senso crescente, otteniamo la rappre-sentazione grafica finale che, come detto, prende il nome di diagramma gambo-foglie 9 14666778899 10 0233333335557799 Me 11 00000012244555556677779999 12 00011223447778 13 223
Dall'esame di questo diagramma è facile calcolare i quartili. In particola-re, dato che è N=70, segue immediatamente che la mediana è compresa fra il 35-esimo ed il 36-esimo elemento per cui avremo
Me = Q2 = 112+112
2 =112;
viceversa Q1 è la mediana delle prime 35 osservazioni e quindi corrisponde alla 18-esima, mentre Q3 è la mediana delle ultime 35 osservazioni e corrisponde alla 52-esima. In definitiva avremo
Q1 = 103; Me = Q2 = 112; Q3 = 119.
In generale, se i valori della serie Xt sono costituiti da più di tre cifre, si utilizzano solo le prime due o tre per costruire la rappresentazione gambo-foglie. Le foglie del diagramma sono pari alla numerosità della serie, in questo caso 70. Questo vuole dire che tutti gli elementi della serie vengono conservati nel diagramma, ciò che viene perso è l'ordinamento temporale. Il numero di gambi può essere diminuito o aumentato a seconda delle esigenze. Per esempio, nel caso sopra riportato al gambo 9 sono state attribuite tutte le seconde cifre comprese fra 90 e 99, al gambo 10 tutte le terze cifre comprese fra 100 e 109, al gambo 11 tutte le terze cifre comprese fra 110 e 119 e così via. Ma è possibile ridurre il numero dei gambi associando un maggior numero di foglie. Per e-sempio se indichiamo con:

Capitolo 5 146
9+ il gambo a cui vengono associate tutte le ultime cifre comprese fra 90 e 104; 11+ il gambo a cui vengono associate tutte le ultime cifre comprese fra 105 e 119; 12+ il gambo a cui vengono associate tutte le ultime cifre comprese fra 120 e 134; otteniamo il diagramma seguente: 9+ 14666778899023333333 11+ 555779900000012244555556677779999 12+ 00011223447778223
Naturalmente, con una logica simile è possibile aumentare il numero dei gambi, distribuendo fra di essi le 70 foglie. In pratica, per potere utilmente in-terpretare la rappresentazione, si costruiscono diagrammi con almeno 5 gambi. La rappresentazione del diagramma, invece che per orizzontale, come è stato fatto nell'esempio, può essere riportata in verticale scrivendo i gambi su una riga e le relative foglie come colonne sovrastanti tale riga. RAPPRESENTAZIONE BOX-PLOT Una particolare rappresentazione grafica che sintetizza la serie ordinata, già illu-strata e commentata per le distribuzioni di frequenza, è la rappresentazione a scatola o box-plot. Per la sua costruzione, ricordiamo, che si procede nel modo seguente: (a) si ordina la serie storica osservata e da questa si derivano i cinque valori ca-
ratteristici:
X(1); Q1; Q2; Q3; X(N);
(b) fissata una scala, si utilizzano questi cinque numeri per costruire il grafico

Introduzione all'analisi delle serie storiche 147
Questo grafico sintetizza la serie osservata in cinque valori, pertanto vie-
ne spesso utilizzato per confrontare serie diverse, rese omogenee per l'unità di misura, o per sintetizzare e confrontare componenti di Xt. Ricordiamo che ac-canto ai cinque punti X(1), Q1, Q2, Q3, X(N) ne vengono sempre calcolati altri due dati rispettivamente da:
h1 = Q1 - 1.5(Q3 - Q1); H2 = Q1 + 1.5(Q3 - Q1)
e quindi vengono individuati con un asterisco, se esistono, tutti i valori di Xt inferiori ad h1 e superiori ad H2. I dati segnati con l'asterisco vengono conside-rati eccezionalmente piccoli, se inferiori ad h1, ed eccezionalmente grandi, se superiori ad H2, rispetto all'andamento complessivo del fenomeno. Per esem-pio, se si ha una situazione come quella descritta dalla figura seguente
vuole dire che in Xt vi sono tre valori eccezionalmente grandi. Una volta in-dividuati dei valori eccezionali si cerca di risalire alle cause che li hanno gene-rati. 5.3 Alcune trasformazioni delle serie storiche
Il più delle volte, nell'analisi di una serie storica, non si è interessati ai singoli valori che assume, ma alla sua evoluzione nel tempo; ciò vuole dire che una serie può essere convenientemente trasformata conservando tutte le in-formazioni sulla sua evoluzione. Così se, per esempio, si vogliono confrontare più serie logicamente legate fra di loro è necessario trasformarle preventiva-mente in qualche modo per eliminare la diversa unità di misura usata nella rile-vazione del fenomeno. Esistono diversi modi di trasformare una serie storica ciascuno dei quali è funzionale a determinati scopi. Le più note trasformazioni sono: dalla serie Xt alla serie degli indici, che indichiamo con IXt, oppure alla serie delle differenze, che indichiamo con ∇Xt.

Capitolo 5 148
LA SERIE DEGLI INDICI
Data la serie storica Xt osservata per t=1,2,...,N, si chiama serie indice a base fissa t=r la seguente
serie:
rIXt = XtXr
, t=1,2,...,N.
Spesso rIXt viene moltiplicata per 100 per esprimerla come una
percentuale. La serie indice a base fissa è una serie adimensionale, cioè indipendente
dall'unità di misura del fenomeno. La serie indice a base fissa, dato che è otte-nuta da quella originaria dividendo ciascun suo valore per la stessa costante Xr, detta anche base della serie, conserva l'andamento della serie originaria. Tutto questo implica che se si vuole confrontare l'evoluzione di più serie misurate con unità di misura diverse, basta confrontare le rispettive serie degli indici con base tutte allo stesso tempo t=r. Da un punto di vista interpretativo, rIXt misu-ra la variazione che è intervenuta nel fenomeno rispetto al tempo base r, più in particolare:
rIXt
⇔<⇔=⇔>
r ad t da negativa variazione una stata è vi1r ed t fra variazione alcuna stata è vi non1r ad t da positiva variazione una stata è vi1
Nota la serie degli indici rIXt e nota la base Xr della serie si può sempre
risalire alla serie originaria, infatti risulta
rIXt Xr = XtXr
Xr = Xt, t=1, 2, ..., N;
questo mostra la corrispondenza biunivoca esistente fra {Xt} ed {rIXt, Xr}. In altri termini, la serie degli indici a base fissa, nota la base, contiene tutte le in-formazioni della serie originaria. Di solito, nelle pratiche applicazioni, la base viene fissata al tempo r=1 oppure al tempo r=N.
Nota la serie indice a base r, cioè rIXt, è possibile cambiare base (slitta-mento della base) passando, per esempio alla base s. Per fare questo basta divide-

Introduzione all'analisi delle serie storiche 149
re ciascun elemento di rIXt per il suo s-esimo elemento, cioè per rIXs. Infatti, dato che per definizione è
rIXt = XtXr
; rIXs = XsXr
si ha immediatamente
rIXtrIXs
= XtXr
: XsXr
= XtXr
XrXs
= XtXs
= sIXt, t=1,2,...,N
Qui di seguito mostriamo come si costruisce una serie indice a base fissa.
Esempio 3
Supponiamo di volere confrontare l'evoluzione della serie PEt, che rappresenta la pro-duzione di energia elettrica e gas in Italia vista nell'esempio 1, con la serie rIPRt, che è la se-rie indice a base fissa della produzione in Italia. Per fare questo trasformiamo la serie PEt nella serie indice a base fissa r=1 dividendo ciascun elemento di PEt per PE1 = 13.005. Inoltre, per potere fare il confronto, cambiamo la base di rIPRt portandola a r=1. Per fare questo dividiamo ciascun elemento di rIPRt per rIPR1= 108.1. I primi dodici valori delle serie originarie e degli indici sono riportati nella tabella che segue
Serie indici a base fissa per PEt e rIPRt
t PEt rIPRt 1IPEt 1IPRt t PEt rIPRt 1IPEt 1IPRt
1 13.005 108.1 1.000 1.000 2 11.521 117.9 0.886 1.091 3 12.278 119.2 0.944 1.103 4 11.577 121.8 0.890 1.127 5 11.899 128.7 0.915 1.191 6 11.330 127.5 0.871 1.179
7 12.045 122.2 0.926 1.130 8 10.059 68.4 0.773 0.633 9 11.754 133.7 0.904 1.237 10 12.558 130.1 0.966 1.204 11 11.924 134.6 0.917 1.245 12 12.189 128.6 0.937 1.190
I grafici di 1IPEt e di 1IPRt sono riportati nelle figure seguenti, ove, per poterli con-frontare, si è usata la stessa scala sull'asse delle ordinate:

Capitolo 5 150
1IPRt
t
1IPEt
t
Dal confronto dei due grafici notiamo che: (i) la stagionalità di IPR è molto più marcata di quella di IPE; (ii) in tutta la serie IPR vi è un modesto trend crescente a cui si sovrappone un ciclo che si
ripete ogni 5 anni circa, mentre IPE mostra un trend crescente solo per i primi cinque anni di osservazioni e non riusciamo, almeno in questa fase dell'analisi, ad intravedere al-cun ciclo;
(iii) IPR cresce più velocemente di IPE, infatti pur partendo entrambe dallo stesso valore pari ad 1, la prima raggiunge un massimo di 1.411, mentre il massimo della seconda è pari a solo 1.267. Questo implica che, a parità di produzione, vi è stato un risparmio di ener-gia.
Data la serie Xt, t=1,2,...,N,

Introduzione all'analisi delle serie storiche 151
la serie degli indici a base mobile si ottiene dividendo ciascun elemento di Xt per quello immediatamente precedente Xt-1. In simboli
t-1IXt = Xt
Xt-1 per t=2,3,...,N.
Di solito t-1IXt viene moltiplicata per 100 per esprimerla come una per-
centuale. Gli indici sopra definiti vengono detti anche concatenati e come si vede
immediatamente nella serie t-1IXt si perde la prima informazione: essa è costi-tuita solo da N-1 valori. A differenza di rIXt, che misura le variazioni che inter-vengono fra il periodo corrente t e quello base r, la serie t-1IXt misura le varia-zioni che intercorrono fra il periodo corrente t e quello immediatamente prece-dente t-1 e quindi mette in evidenza variazioni di breve periodo.
Dato {t-1IXt, X1} possiamo sempre risalire iterativamente ad Xt tramite la seguente
t-1IXt Xt-1 = Xt
Xt-1 Xt-1 = Xt, per t=2, 3, ..., N;
questo implica che tutte le informazioni di Xt sono contenute in {t-1IXt, X1} e viceversa.
Dall'indice a base mobile t-1IXt possiamo sempre risalire a quello a base fissa 1IXt e viceversa. Infatti, se consideriamo che l'indice a base fissa al tempo 1, 1IX1, è sempre pari ad uno e che l'indice a base fissa al tempo 2, 1IX2, coin-cide con quello a base mobile si ha che, nota la serie a base mobile, si ottiene quella a base fissa tramite la seguente
1IX2 2IX3 3IX4 ...t-1IXt = X2X1
X3X2
X4X3
... Xt
Xt-1 =
XtX1
= 1IXt,
t = 2,3,...,N.
Naturalmente, una volta ottenuto 1IXt possiamo ottenere una serie con base fissa diversa dal tempo 1 ricorrendo al relativo cambio di base. Viceversa, nota la serie a base fissa, otteniamo quella a base mobile utilizzando la seguente

Capitolo 5 152
1IXt1IXt-1
= XtX1
: Xt-1X1
= XtX1
X1Xt-1
= t-1IXt, t = 2,3,...,N.
Questo vuole dire che tutte le informazioni contenute nella serie a base fissa sono contenute in quella a base mobile e viceversa.
Nell'esempio che segue vediamo come si calcola una serie a base mobile con la relativa rappresentazione grafica. Esempio 4
Qui di seguito calcoliamo e riportiamo i primi dodici valori della serie a base mobile per la produzione di energia elettrica e gas e la serie a base mobile derivata da quella a base fissa rIPRt. Inoltre, delle due serie a base mobile così calcolate riportiamo e commentiamo i relativi grafici .
Indici a base mobile calcolati per la serie PEt e rIPRt. t PEt rIPRt t-1IPEt t-1IPRt t PEt rIPRt t-1IPEt t-1IPRt 1 13.005 108.1 ---- ----- 2 11.521 117.9 0.886 1.091 3 12.278 119.2 1.066 1.011 4 11.577 121.8 0.943 1.022 5 11.899 128.7 1.028 1.057 6 11.330 127.5 0.952 0.991
7 12.045 122.2 1.063 0.958 8 10.059 68.4 0.835 0.560 9 11.754 133.7 1.169 1.954 10 12.558 130.1 1.068 0.973 11 11.924 134.6 .950 1.035 12 12.189 128.6 1.022 0.955
t

Introduzione all'analisi delle serie storiche 153
t
Dall'analisi dei grafici delle due figure ricaviamo alcune informazioni di estremo inte-
resse: (a) mentre la serie originaria mostrava un trend crescente più o meno accentuato, nella serie
degli indici a base mobile tale trend è praticamente scomparso; (b) la stagionalità presente nella serie originaria continua ad essere presente in quella degli
indici a base mobile.
Generalizzando quanto abbiamo visto nell'esempio, possiamo conclude-re che
se in Xt vi è trend e stagionalità, in generale, nella serie degli indici a base mobi-le t-1IXt rimane solo la stagionalità mentre scompare il relativo trend.
Quanto abbiamo detto fino ad ora può essere esteso al caso in cui si vo-
glia misurare le variazioni che intercorrono fra Xt ed Xt-s costruendo la serie degli indici a base mobile s
t-sIXt = XtXt-s
, per t = s+1, s+2,...,N
La costruzione di una tale serie è utile quando i dati, raccolti con cadenza
infra-annuale, per esempio s all'anno, presentano un andamento stagionale di periodo s, nel senso che in Xt vi è un'onda ciclica, più o meno regolare, che si esaurisce in ciascun anno. Così, se i dati sono mensili, e quindi se ne raccolgono 12 all'anno, si ha s=12, per dati trimestrali se ne raccolgono 4 all'anno e risulta s=4, se i dati sono bimestrali se ne raccolgono 6 all'anno e si ha s=6. In questi casi si è spesso interessati a confrontare i dati distanziati s tempi in modo da eliminare il peso che la stagionalità esercita sull'evoluzione della serie. Così, per

Capitolo 5 154
dati mensili si è interessati a valutare le variazioni che intervengono fra un mese e lo stesso mese dell'anno precedente, per cui si costruisce la serie degli indici a base mobile 12:
t-12IXt = Xt
Xt-12 , per t=13, 14,...,N.
Si può verificare che se in Xt vi è stagionalità di periodo s tale stagionalità scompare nella serie degli indici t-sIXt. Esempio 5
Consideriamo la serie PEt, abbiamo visto che in questa vi è un modesto trend crescen-te, almeno nella prima parte della serie, ed una accentuata stagionalità. In questo caso, dato che si tratta di una serie mensile, risulta s=12 e la rappresentazione grafica di t-12IPEt è riportata nella figura seguente.
t-12IPEt
t
Come possiamo notare, dalla serie degli indici è stato eliminato sia il trend che la stagionalità presente in quella originaria. LA SERIE DELLE DIFFERENZE
Una trasformazione alternativa a quella vista in precedenza è la trasfor-mazione differenze. Qui di seguito illustreremo diversi tipi di differenze molto utilizzate nelle pratiche applicazioni e ne analizzeremo le proprietà più rilevanti.
Data una serie storica Xt, t=1,2,...,N,

Introduzione all'analisi delle serie storiche 155
la serie delle differenze, dette anche differenze assolute o differenze prime, è data dal-la seguente
Zt = Xt - Xt-1, t=2,3,...,N
Per dire che la serie Zt è la differenza di Xt si usa anche la simbologia se-guente
Zt = ∇Xt, t=2,3,...,N;
Osserviamo che nella serie degli indici a base mobile si confronta Xt con l'os-servazione precedente Xt-1 tramite il rapporto, mentre nella serie delle differen-ze prime il confronto avviene utilizzando la differenza. Nella serie delle diffe-renze si perde la prima informazione X1. Inoltre, noto {Zt, X1} si può, iterati-vamente, derivare Xt tramite la seguente:
Xt = Zt + Xt-1, t=2,3,...,N; questo vuole dire che tutte le informazioni contenute in Xt sono pure contenu-te in {Zt, X1}. Infine, nella serie delle differenze è assente l'eventuale trend li-neare esistente in Xt. Esempio 6
Il grafico delle differenze prime di PEt è riportato nella figura seguente
∇PEt
t

Capitolo 5 156
Abbiamo più volte osservato che questa serie è composta sostanzialmente da due sottoserie: la prima relativa ai primi cinque anni di osservazione e la seconda relativa ai restanti sei anni. Queste due serie hanno una struttura sostanzialmente differente come è evidenziato nella ta-bella che segue.
Confronto fra le due sottoserie che compongono la serie ∇PEt.
∇PEt ∇PE1t ∇PE2t Medie 0.014 0.041 -0.008 Scarti quadratici medi 1.224 1.124 1.342
In questa tabella con ∇PE1t abbiamo indicato la serie delle differenze relative alle osserva-zioni dei primi cinque anni e con ∇PE2t quelle relative ai rimanenti sei anni. Da questi dati emerge la diversa struttura delle due sottoserie. In particolare, la prima sottoserie è meno va-riabile della seconda; ciò emerge anche dai box-plot delle due sotto serie e dai rispettivi grafici riportati qui di seguito
t
Grafico della sottoserie ∇PE1t
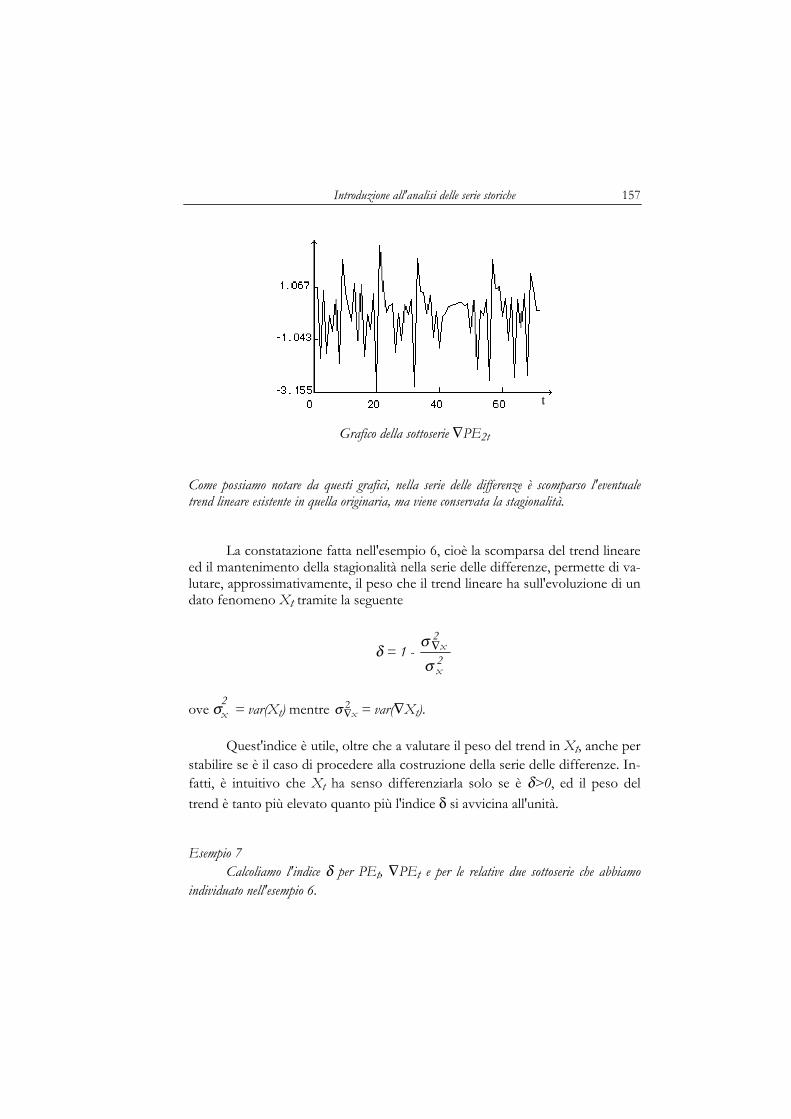
Introduzione all'analisi delle serie storiche 157
t
Grafico della sottoserie ∇PE2t
Come possiamo notare da questi grafici, nella serie delle differenze è scomparso l'eventuale trend lineare esistente in quella originaria, ma viene conservata la stagionalità.
La constatazione fatta nell'esempio 6, cioè la scomparsa del trend lineare ed il mantenimento della stagionalità nella serie delle differenze, permette di va-lutare, approssimativamente, il peso che il trend lineare ha sull'evoluzione di un dato fenomeno Xt tramite la seguente
δ = 1 - 2x
2x
σ
σ ∇
ove σ2
x = var(Xt) mentre 2x∇σ = var(∇Xt).
Quest'indice è utile, oltre che a valutare il peso del trend in Xt, anche per
stabilire se è il caso di procedere alla costruzione della serie delle differenze. In-fatti, è intuitivo che Xt ha senso differenziarla solo se è δ>0, ed il peso del trend è tanto più elevato quanto più l'indice δ si avvicina all'unità. Esempio 7
Calcoliamo l'indice δ per PEt, ∇PEt e per le relative due sottoserie che abbiamo individuato nell'esempio 6.

Capitolo 5 158
PEt ∇PEt PE1t ∇PE1t PE2t ∇PE2t
σ2 2.322 1.535 1.615 1.241 1.457 1.777
δ ----- .339 ----- .232 ----- -.219 La serie delle differenze Zt = ∇Xt può essere utilizzata per individuare e misu-rare l'esistenza di valori eccezionali in Xt che spesso sono mascherati dalla presen-za del trend. In pratica, si considerano eccezionali quei valori di Xt che presen-tano ambedue le caratteristiche seguenti:
− si discostano sostanzialmente, in positivo o in negativo, dalla tendenza di fondo di Xt;
− la loro presenza è dovuta a fattori specifici, contingenti e non sistematici e quindi non sono legati alla legge di evoluzione di Xt. In tale ottica non sono da considerare eccezionali le fluttuazioni, anche rilevanti, dovute alla stagionalità o al ciclo-trend. In particolare, se al tempo s vi è un valore eccezionalmente grande in Xt e si
costruisce il grafico sul tempo della serie delle differenze Zt questo presenterà due picchi uno per t=s ed uno per t=s+1. In particolare, Zs sarà eccezionalmen-te grande, Zs+1 sarà eccezionalmente piccolo e risulterà |Zs| ≈|Zs+1|. Se in Xt, per t=s, vi è un valore eccezionalmente piccolo, quanto abbiamo detto continua a valere con l'unica differenza che Zs risulta piccolo mentre Zs+1 grande. Una conferma dell'esistenza di valori eccezionali si ottiene costruendo il box-plot di Zt. Se in Xt, per t=s, vi è un valore eccezionale il box-plot di Zt fornirà due va-lori estremi situati uno nella coda di sinistra ed uno in quella di destra. La stessa cosa si dovrà evidenziare nel diagramma gambo-foglie di Zt. Ovviamente, se nella serie vi sono più valori eccezionali la situazione sopra descritta si ripeterà di conseguenza. Se il numero dei valori eccezionali è elevato rispetto al numero N delle osservazioni della serie, in pratica se si supera il 20% delle osservazioni di Xt, vuole dire che questi valori non sono più "eccezionali" ma costituiscono una caratteristica del fenomeno. In tal caso si rende necessario indagare sulle cause che li generano oltre che sulla loro struttura e distribuzione.
Una volta stabilito che Xs è un valore eccezionale di Xt, possiamo valu-tare il suo effetto sull'evoluzione della serie confrontando
var(Zt) = 1
N-1 ∑t=2
N (Zt -µz) 2

Introduzione all'analisi delle serie storiche 159
con il contributo alla variabilità del valore eccezionale dato da
As = 1
N-1 [(Zs - µz)2 + (Zs+1 - µz)2], ottenendo
Asvar(Zt)
che misura quanta parte della variabilità di Zt è dovuta alla presenza del valore eccezionale Xs. Gli esempi seguenti chiariscono quanto abbiamo fino ad ora affermato. Esempio 8
Consideriamo la serie Mt. Abbiamo già intravisto che in questa esistono due valori eccezionalmente elevati. Per meglio metterli in evidenza presentiamo la serie delle differenze ∇Mt ed il relativo box-plot
t
Dal grafico di ∇Mt emerge come la stagionalità presente nella serie originaria sia ancora riscontrabile in quella delle differenze, mentre i due valori eccezionali sono diventati molto netti, ciò è confermato in modo inequivocabile anche dal relativo box-plot.

Capitolo 5 160
Esempio 9 Consideriamo la serie mensile dei Depositi in conto corrente e postale rilevata nel pe-
riodo gennaio 1972 - dicembre 1982 (espressa in centinaia di migliaia di miliardi di lire) che indichiamo con DCt. Questa serie, riportata nella figura seguente, mostra un marcato trend di tipo esponenziale e si intravede, specie negli ultimi anni, una modesta componente stagiona-le. Inoltre, da una prima analisi del grafico della serie non sembra che in questa siano riscon-trabili valori eccezionali.
t
Se della serie DCt consideriamo la serie delle differenze e ne costruiamo la rappresentazione sul tempo otteniamo il grafico seguente che ci riserva qualche sorpresa
t
Infatti: (a) i picchi che si riscontrano alle osservazioni t=52 e t=53 mostrano chiaramente che
DC52 è un valore eccezionalmente basso rispetto all'andamento complessivo del fenomeno; (b) nella serie vi è una componente stagionale che era sostanzialmente mascherata dal trend; (c) emerge chiaramente l'evoluzione di tipo esponenziale del fenomeno.
L'uso delle differenze può essere utile per mettere in evidenza e valutare i cambiamenti di livello, dovuti a specifici fattori, che avvengono in una data serie

Introduzione all'analisi delle serie storiche 161
storica. Per essere più precisi, supponiamo che nella serie Xt sia avvenuta una variazione del suo livello medio complessivo a partire dalla osservazione Xs+1. Questo vuole dire che: - se il cambiamento di livello è positivo, allora il grafico di Zt presenta un valore
eccezionalmente basso, dovuto all'aumento del livello in Xt; - se il cambiamento di livello è in negativo, lo stesso grafico presenta un valore
eccezionalmente alto, dovuto ad una diminuzione del livello in Xt.
Un modo per valutare il peso del cambio del livello sulla evoluzione della serie è dato dal seguente indice
δ*s =
Lsvar(Zt)
ove si è posto
Ls = 1
N-1 (Zs - µz) 2,
che misura quanta parte della variabilità di Zt è dovuta al cambiamento di livello in t=s. L'esempio seguente illustra i concetti riportati. Esempio 10
Consideriamo la serie Dt e da questa deriviamo quella delle differenze ∇Dt, il suo grafico è riportato nella figura seguente
t
Come possiamo notare dal grafico, la serie presenta una struttura molto complessa e, fra l'al-tro, vi è un valore eccezionalmente basso in corrispondenza della 92-esima osservazione dovu-ta alla netta caduta del livello avvenuta a partire da D92 da attribuire ad una amnistia con-

Capitolo 5 162
cessa in quel mese dal governo.
Di una serie storica possono essere calcolate, invece che le differenze prime, le differenze di ordine superiore applicando iterativamente la procedura della differenziazione. In particolare,
la serie delle differenze seconde derivata da Xt è data da
Vt = ∇2Xt = ∇Zt = Zt - Zt-1 = (Xt - Xt-1) - (Xt-1 - Xt-2) = = Xt - 2Xt-1 + Xt-2
Nella serie Vt si perdono le prime due osservazioni
Le serie, specie quelle economiche, che vengono rilevate con cadenza in-fra-annuale sono influenzate spesso dalla stagionalità. In questo caso, se si vuo-le isolare e valutare il peso di questo aspetto sulla evoluzione della serie è ne-cessario ricorrere alla serie delle differenze stagionali. Più precisamente, se il periodo stagionale è s, la serie alle differenze stagionali è data da
Zt = ∇sXt = Xt - Xt-s, t= s+1, s+2, ..., N
ove ∇s è la differenza stagionale, e risulta s=12 per serie mensili, s=6 per serie bimestrali, s=4 per serie trimestrali, s=2 per serie semestrali ecc. Se per sempli-cità di esposizione supponiamo che sia s= 12, derivare Zt = ∇12Xt significa calcolare le variazioni intervenute fra un mese e lo stesso mese dell'anno prece-dente (fra gennaio e gennaio precedente, febbraio e febbraio precedente e così via).
Una caratteristica della serie Zt = ∇12Xt è che se in Xt vi sono onde pe-riodiche annuali o di sottomultipli dell'anno, queste scompaiono da Zt, ma la differenza stagionale elimina dalla serie anche buona parte dell'eventuale trend in essa presente. Inoltre, se Xk è un valore eccezionalmente grande, rispetto all'andamento generale di Xt, allora nella serie delle differenze stagionali Zt= ∇sXt vi è un valore eccezionalmente grande in Zk ed uno eccezionalmente pic-colo in Zk+s, cioè s osservazioni dopo.
Per valutare, in prima approssimazione, l'incidenza della stagionalità sulla evoluzione della serie possiamo utilizzare l'indice
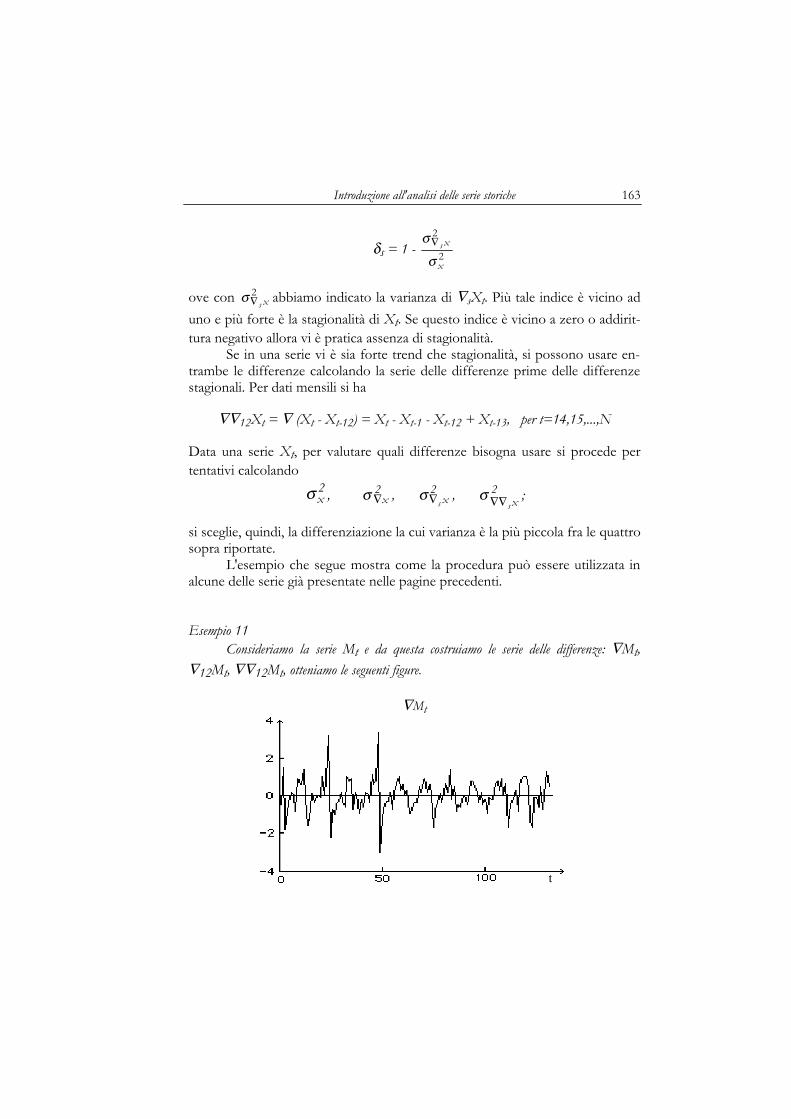
Introduzione all'analisi delle serie storiche 163
δs = 1 - 2
2
x
xs
σ
σ∇
ove con 2xs∇σ abbiamo indicato la varianza di ∇sXt. Più tale indice è vicino ad
uno e più forte è la stagionalità di Xt. Se questo indice è vicino a zero o addirit-tura negativo allora vi è pratica assenza di stagionalità.
Se in una serie vi è sia forte trend che stagionalità, si possono usare en-trambe le differenze calcolando la serie delle differenze prime delle differenze stagionali. Per dati mensili si ha
∇∇12Xt = ∇ (Xt - Xt-12) = Xt - Xt-1 - Xt-12 + Xt-13, per t=14,15,...,N
Data una serie Xt, per valutare quali differenze bisogna usare si procede per tentativi calcolando
2xσ , 2
x∇σ , 2xs∇σ , 2
xs∇∇σ ;
si sceglie, quindi, la differenziazione la cui varianza è la più piccola fra le quattro sopra riportate.
L'esempio che segue mostra come la procedura può essere utilizzata in alcune delle serie già presentate nelle pagine precedenti. Esempio 11
Consideriamo la serie Mt e da questa costruiamo le serie delle differenze: ∇Mt, ∇12Mt, ∇∇12Mt, otteniamo le seguenti figure.
∇Mt
t

Capitolo 5 164
∇12Mt
t
∇∇12Mt
Dall'analisi di queste figure notiamo che: (a) l'uso della differenza prima non elimina la stagionalità, ma mette in evidenza l'esistenza
di valori eccezionali; (b) l'uso della differenza dodici elimina la stagionalità e rende ancora più chiara l'esistenza
dei due valori eccezionali presenti nella serie; (c) l'uso congiunto della differenza prima e della differenza stagionale non produce alcun mi-
glioramento interpretativo sulla serie Mt ma raddoppia i picchi dovuti ai valori ecceziona-li.
Se per Mt, ∇Mt, ∇12Mt, ∇∇12Mt calcoliamo la relativa varianza otteniamo i ri-sultati riportati nella tabella seguente.

Introduzione all'analisi delle serie storiche 165
Varianze e indice ∇ per le serie delle differenze relative a Mt.
Mt ∇Mt ∇12Mt ∇∇12Mt σ2 1.241 .755 .661 .948 δ ----- .392 .467 .236
Da questi dati risulta confermato che la differenza stagionale è quella appropriata e che la stagionalità spiega circa il 46% della variabilità di Mt. Notiamo ancora che la media di ∇12Mt è pari a -.005 e che i quattro valori derivati dai due eccezionali sono pari rispettiva-mente a -2, 3.5, -4.2, 3.3 per cui l'incidenza di tali valori sulla varianza di ∇12Mt è data da
A = 1
120 [(-2+.005)2+(3.5-.005)2+(-4.2+.005)2+(3.3+.005)2] = .373
che rapportata alla varianza di ∇12Mt dà .373/.616 = .606. Questo vuole dire che più del 60% della varianza di ∇12Mt è dovuta all'esistenza dei due valori eccezionali. Ciò implica che se Mt viene depurata da tali valori l'incidenza della stagionalità sulla sua evoluzione ri-sulta molto più rilevante. 5.4 Gli indici dei prezzi
Nel caso in cui il carattere osservato è il prezzo, Pt per t=1,2,...,N, di un dato bene e della serie dei prezzi si costruiscono i relativi indici, siano essi a ba-se fissa o a base mobile, si parla di indici dei prezzi. Le variazioni che mettono in rilievo gli indici dei prezzi sono una misura dell'inflazione. La serie degli indici dei prezzi al tempo t in base x, di solito, viene indicata più semplicemente come:
xIt = PtPx
Naturalmente, tutte le analisi ed interpretazioni viste nelle pagine precedenti valgono sia per la serie Pt che per quella degli indici.
Nel caso dei prezzi, la serie degli indici a base fissa misura le variazioni storiche che si sono verificate nei prezzi, mentre quella a base mobile misura le variazioni congiunturali. Come già visto in generale, le due serie sono comples-sivamente equivalenti e quindi forniscono, da prospettive diverse, la stessa quantità di informazione sull'evoluzione dei prezzi del bene considerato.
Spesso, quando si analizzano le variazioni di un sistema di prezzi si è interessati a misurare le variazioni complessive dei prezzi di più beni rilevati in tempi e luoghi diversi. Questo porta alla costruzione degli

Capitolo 5 166
INDICI DEI PREZZI COMPOSTI O PONDERATI
Come già osservato, molto spesso nelle analisi economiche si è interessa-ti a studiare le variazioni dei prezzi di più beni o, addirittura, di un intero mer-cato. Lo strumento idoneo per ottenere tali misure sono appunto gli indici dei prezzi composti. Questi vengono anche chiamati sintetici oppure ponderati. A tale proposito supponiamo di avere rilevato i prezzi di k beni Bi, i=1,2,...,k, in n tempi diversi. Si osservi che alcuni di questi k beni possono essere piazze diver-se in cui è rilevato il prezzo dello stesso bene. Questi nk prezzi possono essere elencati in una tabella come quella qui di seguito riportata
t\B B1 B2 B3 … Bk 1 P11 P12 P13 … P1k 2 P21 P22 P23 … P2k 3 P31 P32 P33 … P3k
… … … … … … n Pn1 Pn2 Pn3 … Pnk
ove nel generico prezzo Pti il primo indice t=1,2,...,n rappresenta il tempo, men-tre il secondo indice i=1,2,...,k rappresenta il diverso bene o piazza su cui il prezzo è stato rilevato. Così P11 indica il prezzo del bene B1 rilevato al tempo t=1; P23 indica il prezzo del bene B3 rilevato al tempo t=2 e così via.
Abbiamo visto che nel caso in cui gli n prezzi si riferivano allo stesso be-ne, il relativo indice xIt era definito come rapporto fra prezzo del bene al tempo t e prezzo al tempo x. Questo tipo di procedura non può essere più utilizzata nel caso si voglia misurare la variazione congiunta dei prezzi di più beni. In tal caso per risolvere il problema si confrontano non i singoli prezzi ma medie di prezzi. Così, se indichiamo con µ(P)t la media dei k prezzi al tempo t e con µ(P)x la media dei prezzi al tempo x la variazione media dei prezzi fra il tempo x e quello t ci fornisce il relativo indice sintetico:
indice dei prezzi composto
xIt = µ(P)tµ(P)x
= media dei prezzi al tempo tmedia dei prezzi al tempo x
A questo punto è necessario capire il tipo di media da prendere in consi-

Introduzione all'analisi delle serie storiche 167
derazione. Notiamo intanto che le medie devono essere ponderate per tenere conto della diversa importanza che i vari beni hanno nel mercato che si analizza e devono essere sensibili alle variazioni dei prezzi. Visto che si tratta di indici di prezzi di beni, il modo più ovvio per tenere conto nella costruzione delle medie del diverso peso è quello di considerare come pesi le quantità che indicheremo con qti. Queste saranno le quantità consumate, cioè quelle scambiate fra imprese e famiglie, se l'indice deve misurare le variazioni dei prezzi al consumo, le quantità prodotte se l'indice deve misurare le variazioni dei prezzi alla produzione, le quan-tità scambiate fra imprese se l'indice riguarderà le variazioni dei prezzi all'ingros-so, ecc.
Si osservi che, se rilevare sistematicamente i prezzi di beni e per tutto il territorio nazionale richiede una organizzazione capillare ed un forte impegno finanziario, ancora più complicato è rilevare le quantità siano esse quelle con-sumate, prodotte o scambiate. Per questi motivi, di solito, vengono considerati come pesi alternativamente: le quantità relative all'anno base le quantità relative all'anno corrente
Se si considerano come pesi le quantità relative all'anno base si ottiene
l'indice di Laspeyres
xILt =
∑i=1
k Pti qxi
∑i=1
k qxi
∑i=1
k Pxi qxi
∑i=1
k qxi
=
∑i=1
k Pti qxi
∑i=1
k Pxi qxi
Come si può notare, per il calcolo dell'indice è necessario rilevare i prezzi in tutti i tempi in cui si calcola e le sole quantità relative al periodo scelto come base. Ovviamente, se si cambia periodo base bisogna rilevare delle nuove quantità.

Capitolo 5 168
tità. Si osservi che Pxi qxi rappresenta il valore dell'i-esimo bene al tempo x
scelto come base. Questo vuole dire che l'indice di Laspeyres si può anche formulare nel modo seguente:
xILt =
Valore al tempo t delle merci relative al tempo xValore al tempo x delle merci relative al tempo x
cioè come rapporto fra valori delle merci che entrano nella composizione (in termini tecnici paniere) dell'indice. Esempio 12
Se si vuole calcolare 3IL1 si ha
3IL1 =
∑i=1
k P1i q3i
∑i=1
k P3i q3i
= P11 q31 + P12 q32 +... + P1k q3kP31 q31 + P32 q32 +... + P3k q3k
e come si vede, nell'indice sono coinvolte la prima e la terza riga della tabella dei prezzi sopra presentata e la riga delle quantità relative al tempo base. Allo stesso modo avremo che
3IL2 =
∑i=1
k P2i q3i
∑i=1
k P3i q3i
= P21 q31 + P22 q32 +... + P2k q3kP31 q31 + P32 q32 +... + P3k q3k
ed in tal caso nella costruzione dell'indice sono coinvolte la seconda e la terza riga della tabella dei prezzi e la stessa riga delle quantità. Se si utilizzano come pesi le quantità dell'anno corrente si ottiene

Introduzione all'analisi delle serie storiche 169
l'indice di Paasche
xIPt =
∑i=1
k Pti qti
∑i=1
k qti
∑i=1
k Pxi qti
∑i=1
k qti
=
∑i=1
k Pti qti
∑i=1
k Pxi qti
Dato che l'indice di Paasche pondera con le quantità dell'anno corrente,
ogni volta che si calcola un indice, anche se non si cambia base, è necessario rilevare le quantità. Questo vuol dire che l'indice di Paasche è più costoso dell'in-dice di Laspeyres. Esempio 13
Se si vuole calcolare 3IP1 si ha
3IP1 =
∑i=1
k P1i q1i
∑i=1
k P3i q1i
= P11 q11 + P12 q12 +... + P1k q1kP31 q11 + P32 q12 +... + P3k q1k
e come si vede, nell'indice sono coinvolte la prima e la terza riga della tabella dei prezzi sopra presentata e la prima riga delle quantità relative al tempo corrente. Allo stesso modo avremo che

Capitolo 5 170
3IP2 =
∑i=1
k P2i q2i
∑i=1
k P3i q2i
= P21 q21 + P22 q22 +... + P2k q2kP31 q21 + P32 q22 +... + P3k q2k
ed in tal caso nella costruzione dell'indice sono coinvolte la seconda e la terza riga della tabella dei prezzi e la seconda riga delle quantità relative al tempo corrente. Come si può notare, ogni volta che si calcola un indice è necessario disporre delle quantità relative al tempo a cui l'indice si riferisce.
Anche l'indice di Paasche può essere interpretato come rapporto fra va-lori. Infatti, il numeratore dell'indice esprime il valore delle merci al tempo cor-rente, mentre il denominatore rappresenta il valore delle stesse merci valutate con i prezzi del tempo scelto come base:
xIPt =
Valore al tempo t delle merci relative al tempo tValore al tempo x delle merci relative al tempo t
Per gli indici composti, come per quelli semplici, si derivano con una
tecnica del tutto simile quelli a base fissa e quelli a base mobile. Inoltre, è pos-sibile passare, anche se tecnicamente la cosa risulta più complicata dato che bi-sogna tener conto dei coefficienti di raccordo pubblicati dall'ISTAT, da una ba-se all'altra.
I due indici composti sopra illustrati (Laspeyres e Paasche), anche se so-no derivati con una ponderazione molto diversa, in pratica presentano lievi dif-ferenze numeriche. Per questo motivo si utilizza, quasi sempre, visto che è quello meno oneroso, l'indice di Laspeyres. Da un punto di vista teorico, però, i due indici presentano proprietà statistiche contrapposte: il primo tende a sotto-valutare gli aumenti di prezzi (tendenziosità negativa), mentre il secondo tende a sopravvalutarli (tendenziosità positiva). Per ovviare a questo inconveniente è stato proposto, con poca fortuna visto che è raramente usato, un ulteriore indi-ce composto:
l'indice ideale di Fisher definito come media geometrica dei due indici sopra men-zionati:
xIFt = xIL
t xIPt

Introduzione all'analisi delle serie storiche 171
Se negli indici che abbiamo presentato si scambiano i prezzi con le quan-tità, se in altri termini si è interessati alle variazioni delle quantità utilizzando i prezzi come pesi, si ottengono indici di quantità come, per esempio, l'indice della produzione industriale. LA DEFLAZIONE DELLE SERIE MONETARIE
Gli indici dei prezzi servono, oltre che a misurare le variazioni intervenu-te nei prezzi di uno (indici semplici) o più beni (indici composti), a ridurre una serie monetaria ad una serie a prezzi costanti. Questo tipo di procedura prende il nome di deflazione. Le serie monetarie sono quelle serie che sono espresse in u-nità di conto come: redditi, risparmi, consumi, investimenti, debito pubblico ecc.
Per capire perché è utile in molti casi trasformare una serie monetaria da prezzi correnti a prezzi costanti, supponiamo di avere, a fini puramente esplica-tivi dato che la logica si estende ad una qualsiasi serie monetaria, la serie dei redditi rilevati in n tempi diversi:
R1, R2, R3, ..., Rn
Supponiamo ora che il mercato sia composto da un solo bene ed indichiamo con Pt e qt, t=1,2,...,n, i prezzi e le quantità acquistate con quei redditi. Ovvia-mente avremo che:
R1 = P1 q1, R2 = P2 q2, R3 = P3 q3, ..., Rn = Pn qn
e come si vede, le eventuali variazioni intervenute nei prezzi sono da attribuire sia alle variazioni dei prezzi che a quelle delle quantità. In molti casi, per esem-pio se si è interessati a sapere se la capacità di acquisto è aumentata o meno nel tempo, è importante sapere quanto delle variazioni è da attribuirsi alle quantità. Per far questo basta esprimere quei redditi con il prezzo di un dato anno. E' proprio questa tecnica che prende il nome di deflazione.
Supponiamo che si voglia esprimere quei redditi con il prezzo P3 co-struendo la serie a prezzi costanti del tempo 3. Per far questo è necessario con-siderare la serie degli indici dei prezzi a base fissa con base al tempo t=3 ed ot-tenere la serie deflazionata nel modo seguente:
R*1 =
R13I1
, R*2 =
R23I2
, R*3 =
R33I3
, ..., R*n =
Rn3In

Capitolo 5 172
E' facile verificare che la nuova serie R*t , t=1,...,n, così ottenuta è espressa con il
prezzo P3. Infatti, ricordando che
3It = PtP3
, t=1,...,n
si ha immediatamente
R*1 =
R13I1
= P1 q1 P3P1
= P3 q1
R*2 =
R23I2
= P2 q2 P3P2
= P3 q2
R*3 =
R33I3
= P3 q3 P3P3
= P3 q3
..........................................
R*n =
Rn3In
= Pn qn P3Pn
= P3 qn
ed i nuovi redditi sono espressi tutti con i prezzi del terzo tempo. In generale, se si vuole esprimere questa serie a prezzi costanti con i prezzi del tempo x bi-sogna considerare:
R*t =
RtxIt
= Pt qt PxPt
= Px qt; t=1,2,...,n
Per esprimere la serie Rt a prezzi costanti Px, basta dividere Rt per l'indice a base fissa xIt, t=1,2,...,n.
In realtà, su un mercato non esiste un solo bene, ma ne esistono k per
cui risulta:
Rt = ∑i=1
k Pti qti , t=1,2,..., n
in tal caso si avrà che

Introduzione all'analisi delle serie storiche 173
per esprimere la serie Rt a prezzi costanti del tempo x, basta dividere Rt per l'in-
dice composto di Paasche a base fissa xIPt , t=1,2,...,n.
Infatti, avremo
R*t =
Rt
xIPt =
∑i=1
k Pti qti
∑i=1
k Pti qti
∑i=1
k Pxi qti
= ∑i=1
k Pxi qti, t=1,2,...,n
Le variazioni che interverranno nella serie R*
t sono da attribuire esclusi-vamente alle quantità dato che i prezzi sono sempre gli stessi. Il particolare in-dice dei prezzi che viene utilizzato per effettuare la deflazione viene detto deflat-tore. La scelta del deflattore è in funzione del tipo di serie da rendere a prezzi costanti. Così, se si tratta del reddito disponibile delle famiglie come deflattore bisogna considerare l'indice composto dei prezzi al consumo, se la serie da de-flazionare è quella dei profitti aziendali allora l'indice da usare come deflattore sarà quello dei prezzi all'ingrosso e così via.
Naturalmente, se al posto dell'indice di Paasche si utilizza quello di La-speyres, che è meno costoso dell'altro, si ottiene una deflazione approssimata.


Capitolo 6 L'INTERPOLAZIONE LINEARE 6.1 Introduzione
In questo capitolo conclusivo affrontiamo il problema, di grande rile-vanza pratica, riguardante l'esistenza di una relazione fra una data variabile (va-riabile endogena o dipendente) ed una o più variabili (variabili esplicative o indipenden-ti). Il legame è del tipo cause-effetto che supponiamo di tipo unidirezionale: sono le variabili esplicative che causano quella dipendente, ma non è ammesso, logi-camente, il viceversa. Da un punto di vista formale, se indichiamo con Y la va-riabile dipendente e con X1, X2, ..., Xk le k variabili esplicative che entrano nel problema si suppone che sia
Y = f(X1, X2, ..., Xk; β) (1)
ove f( ) è una qualche funzione nota a meno del vettore di parametri β. Più precisamente: X1, X2, ..., Xk sono le cause Y è l'effetto β è un vettore di parametri incogniti f( ) è una funzione nota
Se si escludono fenomeni di tipo fisico, ed anche in quell'ambito la cosa è discutibile, è ben difficile sostenere che fra cause ed effetto vi sia una perfetta relazione matematica. Di solito su Y, oltre alle k variabili esplicative (X1, X2, ..., Xk) individuate, esercitano la loro influenza tutta una serie di micro-cause di difficile o impossibile osservazione che chiamiamo scarto per indicare aspetti irrilevanti che possono essere scartati, eliminati. Queste micro-cause possono essere rappresentate da una variabile non osservabile, che chiamiamo errore o scarto, e che indichiamo con e. Un modo molto semplice per includere in Y

176 Capitolo 6
l'influenza di e è quello di sommare questa variabile scarto nella (1) ottenendo
Y = f(X1, X2, ..., Xk; β) + e (2) Esempio 1
Indichiamo con R il reddito individuale di un certo insieme di soggetti, con C i relativi consumi, dalla teoria economica sappiamo che ha senso scrivere
C = f(R) + e
In altri termini, con questa relazione diciamo che i consumi individuali sono una qualche funzione del reddito individuale a cui si somma una variabile scarto che può essere identificata con i diversi gusti, la diversa religione, errori di misurazione ecc.
Indichiamo con D la domanda di un dato bene, P il prezzo unitario di quel bene, R il reddito del consumatore, Pc il prezzo unitario di un bene complementare, Ps il prezzo uni-tario di un bene sostitutivo, sappiamo dalla teoria economica che ha senso la relazione seguen-te
D = f(P, R, Pc, Ps) + e
Indichiamo con CA il consumo di carburante e con CI la cilindrata di date autovet-ture, ha senso scrivere la relazione seguente
CA = f(CI) + e.
Nella (2), per procedere oltre, esplicitiamo la forma funzionale di f( ) e
quindi ci poniamo così in un ambito parametrico (le uniche incognite sono i parametri β presenti nel modello). Si potrebbe anche utilizzare un approccio più complesso, che in questa sede non viene presentato, in cui la forma fun-zionale f( ) è essa stessa incognita (caso non parametrico) e da stimare. Per semplificare ancora gli sviluppi ed i risultati teorici, nel seguito supporremo che f( ) sia lineare e di conseguenza parleremo di modello lineare.
Nel caso in cui vi sia una sola variabile esplicativa ed f( ) è lineare si parla di modello lineare semplice, se le variabili esplicative sono più di una si parla di modello lineare multiplo. Tratteremo in modo diffuso del modello lineare semplice avvertendo che, almeno da un punto di vista concettuale, tutto ciò che viene detto per questo caso vale per quello, più interessante da un punto di vista applicativo, multiplo. La scelta di analizzare e presentare in modo detta-gliato il modello lineare semplice è che in tal caso molti sviluppi formali si semplificano ed i relativi calcoli applicativi possono essere eseguiti anche con una semplice calcolatrice tascabile. D'altro lato, almeno concettualmente, fare-

Il modello lineare 177
mo vedere come questi sviluppi si generalizzano al caso multiplo e presentere-mo in tal senso anche qualche applicazione a fenomeni reali. 6.2 Il modello lineare semplice
Poniamo ora la nostra attenzione al caso di un modello di regressione li-neare semplice. In altri termini, supponiamo che per i fenomeni che si stanno studiando si può ritenere valido un modello di regressione lineare semplice e quindi che sia
Y = βo + β1X + e (3)
con: Y la variabile dipendente che descrive il fenomeno di interesse, X l'unica variabile esplicativa (causa) di Y, e la variabile scarto non osservabile, βo e β1 due parametri incogniti e da stimare.
Osserviamo che nella (3) βo + β1X rappresenta l'equazione di una retta ove βo è la relativa intercetta mentre β1 è il coefficiente angolare. Per poter procedere alla stima dei parametri incogniti del modello (3) è necessario avere informazioni sulle due variabili osservabili Y ed X. A tale proposito supponia-mo di disporre di n coppie di osservazioni effettuate sulla coppia di fenomeni (X, Y) ottenendo la seguente rilevazione statistica:
(x1, y1), (x2, y2), ..., (xn, yn).
Naturalmente, queste n coppie di osservazioni possono essere analizzate con gli strumenti della statistica descrittiva di cui abbiamo parlato nei capitoli iniziali ed in particolare possono dare luogo ad una distribuzione di frequenza doppia ed ai relativi indici descrittivi ivi presentati.
Se il modello (3) è vero, e tale lo riteniamo fino a prova contraria, allora sarà vero per ogni coppia di osservazioni ottenendo
y1 = βo + β1 x1 + e1 y2 = βo + β1 x2 + e2
........................ yn = βo + β1 xn + en
ove e1 è il valore della variabile scarto non osservabile associata alla prima cop-pia di osservazioni, e2 è il valore della variabile scarto non osservabile associata alla seconda coppia di osservazioni, ....., en è il valore della variabile casuale scar-

178 Capitolo 6
to non osservabile associata alla n-esima coppia di osservazioni. Ovviamente, le n coppie di osservazioni potrebbero anche costituire una serie storica doppia osservata in n tempi diversi sulla stessa unità di rilevazione in tal caso anche ei, i=1,2,...,n, risulta ordinata nel tempo. Esempio 2 Nel caso del consumo in funzione del reddito, il modello lineare diviene
C = βo + β1R + e
ed avendo a disposizione le n coppie di osservazioni (ci, ri) avremo:
ci = βo + β1ri + ei i=1,2, ..., n
Se le n coppie di osservazioni (ci, ri) sono state ottenute intervistando gli n individui di una data popolazione allora queste sono scambiabili e le informazioni contenute nella rilevazione doppia sono equivalenti a quella della distribuzione di frequenza doppia ad essa associata. Se le n coppie di osservazioni si riferiscono sempre alla stessa unità di rilevazione (lo stesso indi-viduo, oppure la stessa regione, oppure lo stesso paese) osservata in n tempi diversi, di solito equispaziati, allora si ha una serie storica doppia le cui coppie di rilevazioni non sono scam-biabili pena la perdita di informazioni sull'evoluzione temporale del fenomeno.
Una volta formulato il modello e ottenute le n coppie di osservazioni è necessario stimare i parametri incogniti. Per fare questo sembra plausibile che gli scarti, in media, non abbiano alcuna influenza sul fenomeno Y e quindi che risulti
ne...ee n21 +++
= 0
che equivale a supporre che sia
e1+e2+...+en =0 (4)
Da quanto è stato detto fino ad ora, rileviamo che in complesso i para-metri da stimare sono βo, β1.
Se il modello lineare fosse stato multiplo, per esempio con le tre variabili esplicative X, Z V, avremmo dovuto avere n quadruple di informazioni (yi, xi, zi, vi), i=1,2,...,n, e per ciascuna di esse sarebbe risultato

Il modello lineare 179
yi = βo + β1xi + β2zi + β3 vi + ei i=1,2,…,n (5)
In questo caso sarebbero quattro i parametri da stimare e precisamente: βo, β1, β2, β3.
Ritornando al caso semplice, tenuto conto dell'ipotesi (4) si ha immediatamente
E(Yi) = βo + β1xi, i=1,2,...,n
questo vuol dire che Y, in media, è una funzione lineare della X. 6.3 La derivazione dei parametri del modello
Dato il modello lineare semplice, utilizzando le n informazioni campio-narie, stimiamo i due parametri βo e β1. Per far questo utilizziamo il Metodo dei Minimi Quadrati.
Per capire come opera logicamente questo metodo di stima nel caso del modello di regressione consideriamo la rappresentazione grafica a scatter delle coppie di valori osservati (xi, yi), i=1,2,...,n. In altri termini, riportiamo su un sistema di assi cartesiani le n coppie di punti osservati, si otterrà una rappresen-tazione tipo quella riportata nella figura seguente. Il problema che si vuole af-frontare è di adattare agli n punti la retta "ottimale" il che equivale a scegliere la coppia di parametri ottimali (βo, β1) che descrivono tale retta. Come è ben noto, in n punti passano infinite rette e quella "ottimale" deve essere scelta secondo una qualche funzione obiettivo.

180 Capitolo 6
Il metodo dei minimi quadrati, in sigla OLS (Ordinary Least Squares), sceglie, fra le infinite rette possibili, quella che minimizza la somma dei quadrati degli scarti.
Questo vuol dire che nel metodo dei minimi quadrati il criterio obiettivo per la scelta della retta "ottimale" è la minimizzazione della somma dei quadrati degli scarti. Traduciamo quanto detto qui sopra in espressioni algebriche in modo da poter ottenere delle formule operative per le stime dei due parametri della retta in questione. Dalla relazione ipotizzata
yi = βo + β1xi + ei, i=1,2,...,n
si ricavano gli n scarti:
ei = yi - βo - β1xi, i=1,2,...,n
e quindi la somma dei loro quadrati:
∑i=1
n e2i = ∑
i=1
n (yi - βo - β1xi) 2
e fra le infinite coppie (βo, β1) e quindi fra le infinite corrispondenti rette pos-sibili scegliamo quella che minimizza l'ultima espressione,
cioè quella per cui risulta
∑i=1
n e2i = ∑
i=1
n (yi - βo - β1xi) 2 = minimo(βo, β1)
La soluzione del problema di minimo per la ricerca dei valori da attribui-
re a βo e β1 è un problema prettamente matematico che in questo caso ha una soluzione piuttosto semplice. Infatti, per trovare questo minimo basta conside-
rare le derivate prime di ∑ e2i rispetto alle due incognite βo e β1, uguagliarle a zero, risolvere il relativo sistema di equazioni lineari. Più precisamente:

Il modello lineare 181
)xy( i1oin
1ioββ
β−−
∂∂ ∑
=
2 = 2 )1)(xy( i1oin
1i−−−∑
=ββ =
= -2 ∑i=1
n (yi - βo - β1xi) = 0
)xy( i1oin
1i1ββ
β−−
∂∂ ∑
=
2 = 2 ∑i=1
n (yi - βo - β1xi)(-xi) =
= -2 ∑i=1
n (yi - βo - β1xi) xi = 0.
Da cui, dividendo ambo i membri delle due equazioni per -2, deriviamo il se-guente sistema lineare nelle due incognite βo e β1:
=−−
=−−
∑
∑
=
=
0
0
11
11
iioin
i
ioin
i
x)xy(
)xy(
ββ
ββ
che posto
x = 1n ∑
i=1
n xi y =
1n ∑
i=1
n yi
mxy = 1n ∑
i=1
n xiyi m2x =
1n ∑
i=1
n x2
i
può essere scritto
=−−=−−
0nmxnnm0xnnyn
x21oxy
1oββ
ββ

182 Capitolo 6
Dividendo ambo i membri delle due equazioni per n, ricavando βo dalla prima equazione e sostituendolo nella seconda si può scrivere
−−−=
= x21)x1xy
x1omy(xm
yββ
ββ
Posto Sxy = mxy - x- y- : covarianza di (X, Y) sulle n coppie di osservazioni (xi, yi) S2
x = m2x - x- 2 : varianza di X sulle n osservazioni xi si ottiene
=−=
2x1xy
1oSS
xyβ
ββ
Risolvendo rispetto ai due parametri incogniti si ha infine che
le stime dei minimi quadrati dei parametri della retta sono
β^ 1 = Sxy
S2x
, β^ o = y- - β^ 1 x
L'equazione della retta che minimizza la somma dei quadrati degli scarti è
data da
y = β^ o + β^ 1 x
Osserviamo che:
(a) β^ 1 e β^ o non sono i valori veri βo e β1 che sono funzioni anche dei valori non osservabili di e, ma quelli ottenuti sulla base delle n coppie di osserva-zioni (xi, yi), i = 1, 2, ..., n
(b) la retta di regressione passa sempre per il punto medio ( x , y ), infatti
sostituendo al posto di β^ o si ottiene

Il modello lineare 183
β^ o + β^ 1 x = (y- - β^ 1 x ) + β^ 1 x = y
(c) in corrispondenza di ciascuna xi osservata è possibile individuare la relativa
yi interpolata, che indichiamo con y i, situata sulla retta:
y i = β^ o + β^ 1 xi, i=1,2,..,n (d) dai valori osservati yi e da quelli interpolati y i possiamo derivare gli scarti,
che indichiamo con e i, dati da
e i = yi - y i i=1,2,..,n
(e) se ricordiamo che una delle proprietà della media aritmetica è quella di mi-nimizzare la somma dei quadrati degli scarti ci rendiamo subito conto che la retta ottenuta con il metodo dei minimi quadrati è proprio una media ed è presumibile che i relativi parametri abbiano le stesse proprietà della media;
(f) una conseguenza di quanto detto al punto (e) è che la somma degli scarti in-terpolati è sempre nulla: la somma degli scarti positivi è pari alla somma de-gli scarti negativi. La dimostrazione formale di questa affermazione è sem-plice, infatti
∑i=1
n e i = ∑
i=1
n (yi - yi) = ∑
i=1
n [yi - ( β^ o + β^ 1 xi)] =
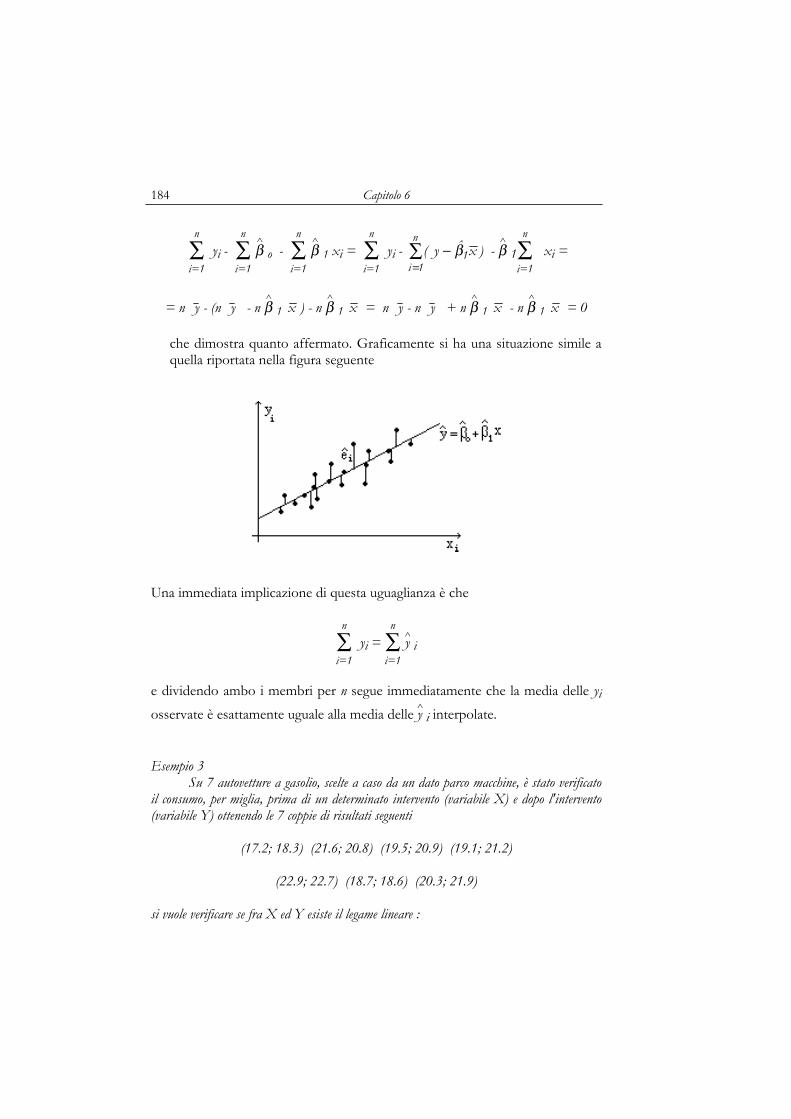
184 Capitolo 6
∑i=1
n yi - ∑
i=1
n β^ o - ∑
i=1
n β^ 1 xi = ∑
i=1
n yi - ∑
=−
n
1i1 )xˆy( β - β^ 1∑
i=1
n xi =
= n y - (n y - n β^ 1 x ) - n β^ 1 x = n y - n y + n β^ 1 x - n β^ 1 x = 0
che dimostra quanto affermato. Graficamente si ha una situazione simile a quella riportata nella figura seguente
Una immediata implicazione di questa uguaglianza è che
∑i=1
n yi = ∑
i=1
n y i
e dividendo ambo i membri per n segue immediatamente che la media delle yi osservate è esattamente uguale alla media delle y i interpolate. Esempio 3
Su 7 autovetture a gasolio, scelte a caso da un dato parco macchine, è stato verificato il consumo, per miglia, prima di un determinato intervento (variabile X) e dopo l'intervento (variabile Y) ottenendo le 7 coppie di risultati seguenti
(17.2; 18.3) (21.6; 20.8) (19.5; 20.9) (19.1; 21.2)
(22.9; 22.7) (18.7; 18.6) (20.3; 21.9) si vuole verificare se fra X ed Y esiste il legame lineare :
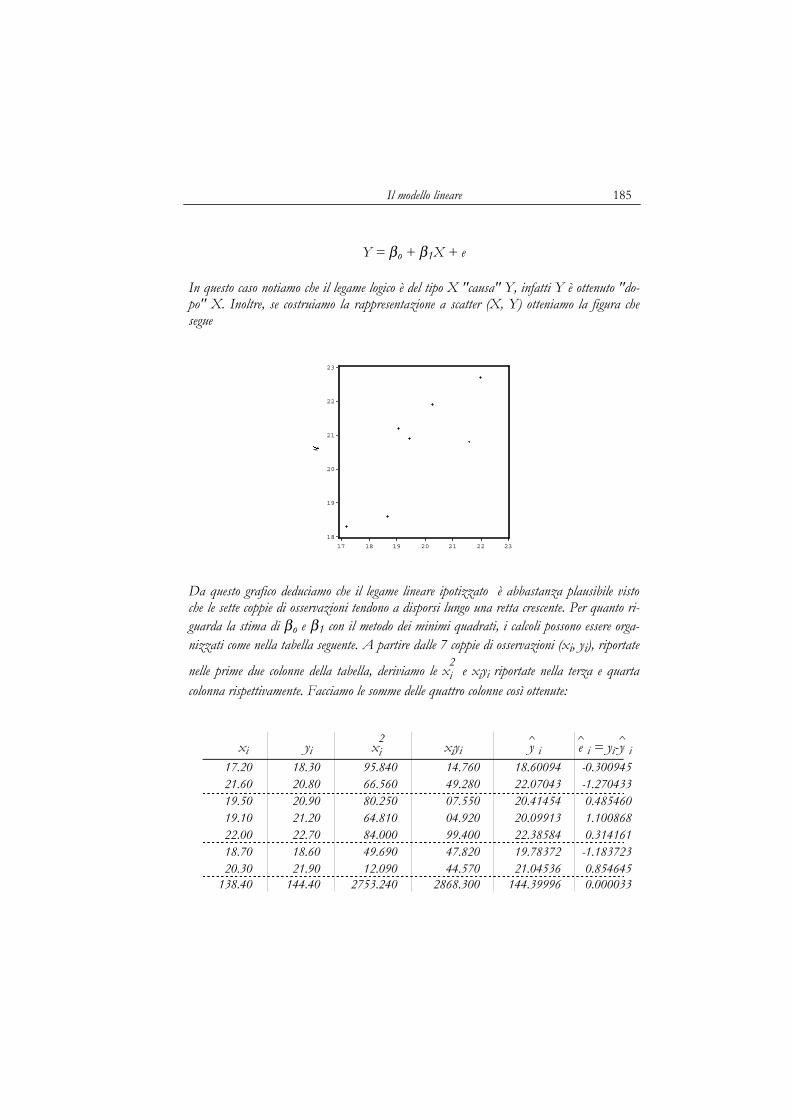
Il modello lineare 185
Y = βo + β1X + e
In questo caso notiamo che il legame logico è del tipo X "causa" Y, infatti Y è ottenuto "do-po" X. Inoltre, se costruiamo la rappresentazione a scatter (X, Y) otteniamo la figura che segue
18
19
20
21
22
23
17 18 19 20 21 22 23
Y
Da questo grafico deduciamo che il legame lineare ipotizzato è abbastanza plausibile visto che le sette coppie di osservazioni tendono a disporsi lungo una retta crescente. Per quanto ri-guarda la stima di βo e β1 con il metodo dei minimi quadrati, i calcoli possono essere orga-nizzati come nella tabella seguente. A partire dalle 7 coppie di osservazioni (xi, yi), riportate
nelle prime due colonne della tabella, deriviamo le x2i e xiyi riportate nella terza e quarta
colonna rispettivamente. Facciamo le somme delle quattro colonne così ottenute:
xi yi x2i xiyi y i e i = yi-y i
17.20 18.30 95.840 14.760 18.60094 -0.300945 21.60 20.80 66.560 49.280 22.07043 -1.270433 19.50 20.90 80.250 07.550 20.41454 0.485460 19.10 21.20 64.810 04.920 20.09913 1.100868 22.00 22.70 84.000 99.400 22.38584 0.314161 18.70 18.60 49.690 47.820 19.78372 -1.183723 20.30 21.90 12.090 44.570 21.04536 0.854645 138.40 144.40 2753.240 2868.300 144.39996 0.000033

186 Capitolo 6
Dalla tabella deriviamo immediatamente:
x = 138.4
7 = 19.771429 y = 144.4
7 = 20.62857
m2x = 2753.24
7 = 393.32001 mxy = 2868.3
7 = 409.75715
S2
x = 2.4106 Sxy = 1.9008
che ci permettono di ottenere le stime cercate
β^ 1 = 0.78852 β^ o = 5.0384
Una volta ottenute le stime dei due parametri deriviamo le stime della variabile dipendente:
i10i xˆˆy ββ +=
y 1 = β^ o+β^ 1x1 = 5.0384 + (0.78852)17.20 = 18.600944
y 2 = β^ o+β^ 1x2 = 5.0384 + (0.78852)21.6 = 22.070432 .......................................................................................
y 7 = β^ o+β^ 1x7 = 5.0384 + (0.78852)20.3 = 21.045356 Ottenuti i valori stimati iy (penultima colonna della tabella sopra riportata) deriviamo le
stime dei residui e i = yi-y i riportate nell'ultima colonna della citata tabella. Osserviamo, infine, che teoricamente dovrebbe risultare
∑ y i = ∑ yi ∑ e i = 0
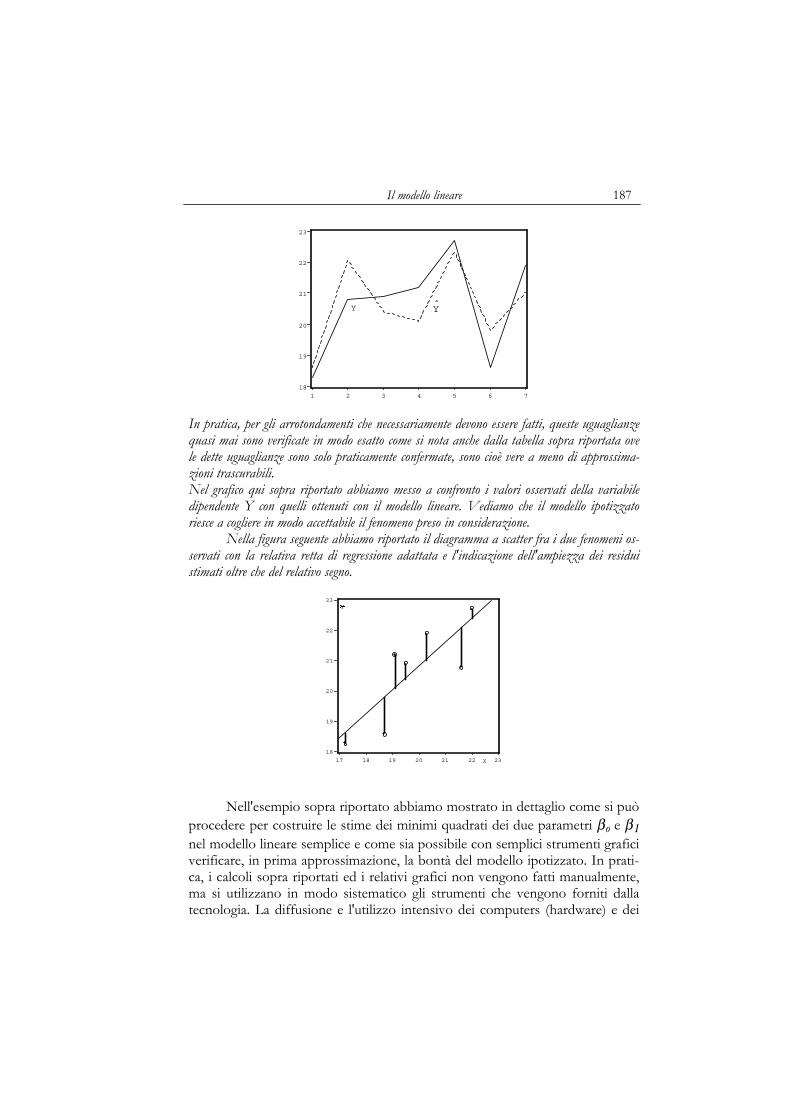
Il modello lineare 187
1 2 3 4 5 6 718
19
20
21
22
23
Y Y^
In pratica, per gli arrotondamenti che necessariamente devono essere fatti, queste uguaglianze quasi mai sono verificate in modo esatto come si nota anche dalla tabella sopra riportata ove le dette uguaglianze sono solo praticamente confermate, sono cioè vere a meno di approssima-zioni trascurabili. Nel grafico qui sopra riportato abbiamo messo a confronto i valori osservati della variabile dipendente Y con quelli ottenuti con il modello lineare. Vediamo che il modello ipotizzato riesce a cogliere in modo accettabile il fenomeno preso in considerazione.
Nella figura seguente abbiamo riportato il diagramma a scatter fra i due fenomeni os-servati con la relativa retta di regressione adattata e l'indicazione dell'ampiezza dei residui stimati oltre che del relativo segno.
18
19
20
21
22
23
17 18 19 20 21 22 23
Y
X
Nell'esempio sopra riportato abbiamo mostrato in dettaglio come si può procedere per costruire le stime dei minimi quadrati dei due parametri βo e β1 nel modello lineare semplice e come sia possibile con semplici strumenti grafici verificare, in prima approssimazione, la bontà del modello ipotizzato. In prati-ca, i calcoli sopra riportati ed i relativi grafici non vengono fatti manualmente, ma si utilizzano in modo sistematico gli strumenti che vengono forniti dalla tecnologia. La diffusione e l'utilizzo intensivo dei computers (hardware) e dei

188 Capitolo 6
relativi programmi di calcolo (software) permettono di effettuare queste elabo-razioni in modo preciso e veloce. Naturalmente l'utilizzatore deve sapere cosa l'elaboratore sta calcolando e come i risultati vanno interpretati. Tutto questo è ancora più rilevante quando il modello utilizzato è di regressione multipla (le va-riabili esplicative sono più di una) e le relative elaborazioni bisogna necessaria-mente effettuarle con tali strumenti avanzati. Teniamo conto che nelle pratiche applicazioni molto spesso il modello è di tipo multiplo. In questo caso la pro-cedura di stima è una semplice generalizzazione di quella vista ma, ripetiamo, i calcoli diventano molto più lunghi e complessi e quindi non eseguibili se non con gli strumenti informatici ormai largamente disponibili.
Per rimanere nel concreto, supponiamo che il modello di cui vogliamo stimare i parametri è quello riportato nella (5)
yi = βo + β1xi + β2zi + β3vi + ei, i=1,2,..,n in questo caso è necessario risolvere il seguente problema di minimo
∑i=1
n e2i = ∑
i=1
n (yi - βo - β1xi - β2zi - β3vi) 2 = minimo(βo, β1, β2, β3)
che si ottiene risolvendo rispetto a (βo, β1, β2, β3) il seguente sistema non o-mogeneo di quattro equazioni lineari che ammetterà, sotto l'ipotesi che fra le tre variabili esplicative non vi siano perfetti legami lineari, una ed una sola solu-zione:
=−−−−−=∂∂
=−−−−−=∂
∂
=−−−−−=∂∂
=−−−−−=∂∂
∑∑
∑∑
∑∑
∑∑
==
==
==
==
02
02
02
02
13210
1
2
3
13210
1
2
2
13210
1
2
1
13210
1
2
0
in
iiiii
n
ii
in
iiiii
n
ii
n
iiiiii
n
ii
n
iiiii
n
ii
v)vzxy(e
z)vzxy(e
x)vzxy(e
)vzxy(e
βββββ
βββββ
βββββ
βββββ
Nell'esempio che segue stimeremo un modello di regressione con tre va-riabili esplicative e ne commenteremo i relativi risultati.

Il modello lineare 189
Esempio 4 Nella tabella seguente riportiamo i tassi relativi ai Nati vivi (NV), Matrimonialità
(MTR), Mortalità (MRT), in Cerca di prima occupazione (CPO) relativi al 1993 per le venti regioni italiane:
NV MTR MRT CPO NV e Piemonte 7.5 4.9 11.4 2.507 8.024250 - 0.524250 Valle d'Aosta 7.4 4.8 10.1 1.201 8.094782 - 0.694782 Lombardia 8.4 4.7 9.0 1.739 8.341146 0.058853 Trentino-Alto A. 10.5 5.2 9.0 0.879 9.181734 1.318266 Veneto 8.2 5.0 9.1 1.495 8.847956 - 0.647956 Friuli-Ven. Giu. 7.2 4.4 12.5 1.581 6.582482 0.617518 Liguria 6.5 4.7 13.8 3.055 6.915501 - 0.415501 Emilia-Romagna 7.1 4.4 11.4 1.503 6.938589 0.161411 Toscana 7.0 4.6 11.5 2.468 7.413622 - 0.413622 Umbria 7.9 5.0 11.2 2.927 8.336814 - 0.436813 Marche 8.2 4.7 10.2 2.199 8.001959 0.198041 Lazio 9.7 4.9 8.9 4.835 9.162971 0.537028 Abruzzo 9.4 4.8 9.8 3.955 8.556788 0.843211 Molise 9.2 4.9 10.3 5.622 8.800165 0.399834 Campania 13.4 6.3 7.8 11.030 13.01526 0.384737 Puglia 11.7 6.1 7.5 7.281 12.23962 - 0.539623 Basilicata 9.4 5.5 8.3 7.199 10.81801 - 1.418008 Calabria 10.9 5.4 8.0 9.527 11.03327 - 0.133274 Sicilia 12.4 5.7 9.1 8.389 11.08948 1.310516 Sardegna 9.3 5.0 8.1 7.006 9.905586 - 0.605586 Italia 9.4 5.1 9.5 4.602 9.400000 0.000000 Le variabili sopra riportate sono state ottenute tramite le seguenti:
NV = numero nati vivi nel 1993
popolazione media nel 1993 × 1000
MTR = numero matrimoni nel 1993popolazione media nel 1993 × 1000
MRT = numero morti nel 1993
popolazione media nel 1993 × 1000

190 Capitolo 6
CPO = n° cerca 1° occupazione nel 1993
popolazione nel 1993 × 100
Osserviamo che utilizziamo dati relativi e non assoluti visto che vogliamo capire se esiste un legame fra NV (l'effetto) e MTR, MRT, CPO (le cause) e questo ha senso solo se elimi-niamo la diversa numerosità di popolazione esistente fra le diverse regioni italiane. Per i fe-nomeni in studio ipotizziamo che il seguente modello lineare
NV = βo + β1MTR + β2MRT + β3CPO + e
sia idoneo a spiegare il fenomeno Nati vivi per le diverse regioni italiane. Da un punto di vi-sta logico ci attendiamo che: (a) fra Matrimoni e Nati vivi vi sia un legame lineare positivo (questo ci fa attendere un
β1>0) visto che è logico supporre un aumento del tasso di natalità in corrispondenza del-l'aumento del tasso di matrimonialità;
(b) il legame sia negativo fra Morti e Nati vivi (valore atteso di β2 < 0) dato che in una popolazione matura, come quella italiana, la mortalità è alta perché la popolazione è più vecchia e quindi la natalità è più bassa;
(c) siamo molto scettici a ipotizzare un legame diretto ed immediato fra in Cerca di prima occupazione e Nati vivi anche se non può essere escluso del tutto dato che chi è giovane e non ha un lavoro difficilmente si sposa e mette al mondo figli (valore atteso β3 > 0). In margine, notiamo la forte dicotomia che esiste fra le regioni del centro-nord e quelle del sud.
I legami a coppie (NV, MTR), (NV, MRT), (NV, CPO) sono riportati negli scatter se-guenti
5
8
10
13
15
4.0 4.5 5.0 5.5 6.0 6.5
NV
MTR

Il modello lineare 191
che confermano le ipotesi fatte, in particolare emerge un legame lineare non marginale fra NV e CPO.
Le stime dei quattro parametri con il metodo dei minimi quadrati sono rispettiva-mente:
β^ o = 2.1456; β^ 1 = 1.9073; β^ 2 = - 0.3331; β^ 3 = 0.0131
ed il segno dei valori stimati è quello atteso. Queste stime ci hanno permesso di ottenere i va-lori stimati di NV tramite la seguente
NV^ = 2.1456 + 1.9073 MTR - 0.3331MRT + 0.0131CPO ed i relativi residui stimati e . I valori di NV^ e di e sono riportati nelle ultime due co-lonne della tabella. Nella figura che segue abbiamo riportato i grafici dei valori osservati e stimati della variabile dipendente NV, per le 20 regioni ed il relativo scatter. I risultati sem-brano complessivamente accettabili.
5 10 15 206
7
8
9
10
11
12
13
14
NV
NV
5
8
10
13
15
5 8 10 13 15
NV
MRT5
8
10
13
15
0 25 50 75 100 125
NV
CPO

192 Capitolo 6
5
8
10
13
15
5 8 10 13 15
NV
NV
Una volta stimati i parametri βi del modello di regressione è necessario derivare anche σ2 la varianza delle ei. Sembra ovvio che questo parametro debba essere ottenuto a partire dagli scarti interpolati
e i = yi - y i, i=1,2,...,n.
Nel caso del modello di lineare semplice, yi = βo + β1xi, la somma dei quadrati degli scarti dalla media è data da
∑i=1
n (yi - yi) 2 = ∑
i=1
n e 2
i
Si può dimostrare che un
valore accettabile per σ2, nel caso del modello lineare semplice, è dato da
s2 = 1
n-2 ∑i=1
n e 2
i .
Con ragionamenti del tutto simili si ottiene un valore per σ2 nel caso di model-lo lineare multiplo. Così per il modello lineare definito nella (5) un valore accet-tabile per σ2 è data da

Il modello lineare 193
s2 = 1
n-4 ∑i=1
n e 2
i
Esempio 5
La stima di σ2 nel caso visto nell'esempio 3 è data da
s2 = 5.382467
5 = 1.076493
La stima di σ2 nel caso visto nell'esempio 4 è data da
s2 = 9.61101
16 = 0.600688.
MISURA DELLA BONTÁ DI ADATTAMENTO
Definiamo in primo luogo uno strumento che ci permette di misurare l'accostamento tra i dati osservati e quelli stimati e quindi di stabilire se global-mente il modello di regressione stimato descrive in modo accettabile le osserva-zioni che si hanno a disposizione. In altre parole, vogliamo calcolare un indice che ci indica fino a che punto il modello di regressione lineare stimato, nella sua globalità, approssima i dati osservati.
Consideriamo, per il momento, il caso della regressione lineare semplice. In questo contesto la situazione ottimale si ha quando tutte le n coppie (xi, yi) osservate sono allineate lungo una retta che, ovviamente, coincide con quella di regressione per cui i relativi residui osservati e i sono tutti identicamente nulli. Viceversa il caso peggiore si ha quando tutte le n coppie osservate (xi, yi) sono disperse nel piano (X, Y) e risulta del tutto irrealistica l'approssimazione con una retta. Le due situazioni qui richiamate sono schematizzate nelle figure se-guenti
194 Capitolo 6
1) Caso ottimale 2) Caso peggiore
Nelle pratiche applicazioni ben difficilmente si hanno situazioni estreme come quelle sopra illustrate e sorge la necessità di misurare fino a che punto si è vicini al caso ottimale o a quello peggiore. A tale scopo si costruisce un indice di correlazione multipla, che si indica con R2, e misura l'intensità del legame lineare esistente fra la variabile dipendente Y e quelle esplicative X1, X2, ..., Xk. Prima di definire questo nuovo indice dimostriamo che è sempre
∑i=1
n e^ i (y i - y
- ) = 0
Infatti,
∑i=1
n e^ i (y i - y
- ) = ∑i=1
n (yi - yi)(yi - y
-) =
= ∑i=1
n (yi - β^ o - β
^1xi)(β
^o + β^ 1xi - β
^o - β
^1x- ) = β^ 1∑
i=1
n (yi - β^ o - β
^1xi)(xi - x
- ) =
= β^ 1∑i=1
n (yixi - β
^oxi - β
^1x2
i - yi x- + β^ ox
- + β^ 1xi x- ) =
= β^ 1(∑i=1
n yixi - β
^ o∑i=1
n xi - β
^ 1∑i=1
n x
2i - x- ∑
i=1
n yi + n β^ ox
- + β^ 1 x- ∑i=1
n xi) =
= β^ 1(n mxy - n β^ o x- - n β^ 1m2x - n x- y- + n β^ ox
- + β^ 1 x- 2) =

Il modello lineare 195
= β^ 1n [mxy - x- y- - β^ 1(m2x - x- 2)] = β^ 1 n (Sxy - β
^ 1S2x ) =
= β^ 1 n
− 2
2 xx
xyxy S
S
SS = 0
Tenendo conto di questo risultato si ha immediatamente
∑i=1
n (yi - y
-) 2 = ∑i=1
n (yi - yi + yi - y
-) 2 = ∑i=1
n [e i + (y i - y
- )]2 =
= ∑i=1
n [e2
i + (y i - y- )2 + 2 e i (y i - y
- )] = ∑i=1
n e2
i + ∑i=1
n (yi - y
-) 2
Se dividiamo il primo e l'ultimo membro di quest'ultima uguaglianza per n si ottiene
1n ∑
i=1
n (yi - y
-) 2 = 1n ∑
i=1
n e2
i + 1n ∑
i=1
n (yi - y
-) 2
o equivalentemente
S2y = S
2e + S
2y
In altri termini,
se il modello di regressione è lineare ed è stimato con il metodo dei minimi quadrati, allora la varianza stimata delle y osservate è sempre uguale alla varian-za dei residui stimati più la varianza delle y teoriche.
Se dividiamo ambo i membri dell'ultima uguaglianza per S2
y si ottime
1 = S
2e
S2y +
S2y
S2y

196 Capitolo 6
Siamo ora in condizione di dare la seguente definizione
l'indice R2 è dato da
R2 = S
2y
S2y = 1 -
S2e
S2y
e misura la percentuale della variabilità di Y spiegata dal modello di regressione adattato ad Y.
Da quanto abbiamo appena detto è facile verificare che è sempre
0 ≤ R2 ≤ 1
Per meglio illustrare il significato di questo indice, analizziamo i due casi estre-mi: R2 = 0 ed R2 = 1. Caso di R2 = 0.
R2 = 0 è equivalente a S2y = 0, cioè
1n ∑
i=1
n (yi - y
-) 2 = 0
che equivale a
(y 1 - y- ) = (y 2 - y- ) = ... = (y n - y- ) = 0 da cui infine
y 1= y 2= ... = y n = y- .
In altri termini, nel caso di R2 = 0 tutti i valori interpolati sono uguali fra di lo-ro e coincidono con la propria media. Nel caso della regressione lineare sem-plice si ha una situazione come quella schematizzata nella figura seguente

Il modello lineare 197
y-
Quanto detto si verifica se e solo se risulta β 1 = 0 e quindi β o = y- , ma questo vuol dire che al variare di X la Y, in media, non varia. In altri termini, in un ca-so del genere la variabile esplicativa X non esercita, in media, alcuna influenza su Y per cui il modello considerato non è accettabile e va riformulato. Queste considerazioni possono essere estese al caso multiplo con k ≥ 2 variabili espli-cative. Infatti, si può dimostrare che R2 = 0 è equivalente a β 1 = β 2 = .... = β
k = 0 e quindi β o = y- . Questo vuol dire che, in media, nessuna delle k variabili esplicative X1, X2, ..., Xk esercita una influenza su Y, di conseguenza il model-lo utilizzato è inaccettabile a va riformulato. Caso di R2 = 1
R2 = 1 è equivalente a S2e = 0 che a sua volta è equivalente a
∑i=1
n e 2
i = 0.
Questo si verifica se e solo se risulta e 1 = e 2 = ... = e n = 0. In definitiva, si ha R2 = 1 se e solo se tutti i residui osservati sono identicamente nulli, ma que-sto è equivalente a dire che tutte le y osservate sono coincidenti con quelle teo-riche e quindi risulta yi = y i per i=1,2,...,n. In altri termini, le yi osservate sono tutte allineate lungo una retta che coincide necessariamente con quella di re-gressione. Graficamente si ha una situazione come quella descritta nella figura seguente

198 Capitolo 6
y = + xβ βο 1^^^
Questo risultato vale, con identica interpretazione, anche quando si hanno k ≥ 2 variabili esplicative.
Nelle pratiche applicazioni molto difficilmente si otterrà uno dei casi li-mite sopra illustrati, ma si avranno valori di R2 interni all'intervallo [0; 1]. Tali valori limite sono utili per meglio interpretare questo indice: più R2 è vicino ad uno più il modello è globalmente accettabile, più R2 è vicino a zero più il mo-dello globalmente è da rifiutare. Per esempio, se in una data applicazione risulta R2 = 0.86 vuol dire che l'86% della varianza di Y è spiegato dal modello di re-gressione lineare, mentre il restante 14% è spiegato dai residui. Esempio 6 Riprendiamo l'esempio 3, abbiamo visto che il modello da prendere in considerazione è
Y =β0 + β1X + e
in tal caso si ottiene R2 = 0.592. Questo vuol dire che il 59.2% della variabilità di Y è spiegato dal modello di regressione utilizzato, mentre il restante 40.8% è dovuto ai residui. Riprendiamo l'esempio 4, siamo arrivati alla conclusione che abbia senso il modello
NV =β0 + β1MTR + β2MRT + β3CPO + e
in tal caso si ottiene R2 = 0.846. In altri termini, la variabilità di NV è spiegata per l'84.6% dal modello suddetto, mentre il restante 15.4% è spiegato dai residui e quindi da fattori accidentali.
Facciamo ora vedere che R2 è una generalizzazione del coefficiente di correlazione già analizzato. Più precisamente mostriamo che nel caso di regres-

Il modello lineare 199
sione lineare semplice R2 coincide con la correlazione stimata al quadrato:
R2 = r2 = S2
xy
S2xS2
y
Partendo dalla definizione di R2 si ha
R2 = S
2y
S2y ,
ma nel caso della regressione semplice, tenendo conto delle espressioni di iy ,
y- e β^ 1 si ha sempre
S2y =
1n ∑
i=1
n (yi - y
-) 2 = 1n ∑
i=1
n (β^ o + β^ 1xi - β
^o - β
^1 x
- ) 2 =
β^ 21
1n ∑
i=1
n (xi - x
- ) 2 = β^ 21 S2
x = S2
xy
S4x
S2x =
S2xy
S2x
Sostituendo quest'ultima nella formula di R2 si ottiene il risultato cercato. ANALISI DEI RESIDUI
Un secondo modo per stabilire se il modello adattato ai dati può essere accettato e quindi utilizzato, oppure va rifiutato e quindi riformulato è quello di analizzare i residui stimati. Se nei residui stimati vi è ancora una qualche strut-tura è evidente che il modello selezionato non riesce a catturare completamente l'evoluzione del fenomeno e quindi va riformulato e ristimato. Se le n osserva-zioni di cui si dispone sono relative a serie storiche, oppure posseggono un qualche altro ordinamento naturale, un modo di verificare se nei residui vi è una qualche struttura è quello di costruire i due grafici come qui di seguito in-dicato. Primo grafico

200 Capitolo 6
In un sistema di assi cartesiani si riportano le coppie di punti (i, e i), se nei residui stimati vi è una qualche ulteriore struttura questa dovrebbe emerge-re dal relativo grafico. Nella figura che segue è riportato il tipico caso in cui fra i residui esiste una ulteriore struttura che il modello non è riuscito a catturare. Infatti, in questo grafico a residui positivi tendono a susseguirsi residui positivi ed a quelli negativi ancora residui negativi.
Secondo grafico In un sistema di assi cartesiani si rappresentano le coppie (e i, e i-1), se
nei residui vi è una qualche struttura allora questa dovrebbe emergere dal grafi-co ed il relativo modello dovrebbe essere riformulato. Nella figura che segue viene riportato il tipico caso in cui fra i residui esiste una ulteriore struttura di cui è necessario tenere conto.
In questo caso si può notare come la maggior parte dei punti siano concentrati nel primo e nel terzo quadrante.
Se le osservazioni di cui si dispone non posseggono un ordinamento na-

Il modello lineare 201
turale, un modo per verificare se nei residui vi è una qualche ulteriore struttura è quella di costruire uno scatter rappresentando le n coppie di osservazioni (e i, yi). Se il modello utilizzato non è idoneo a rappresentare la variabile dipendente Y nello scatter sopra citato deve essere visibile una qualche struttura.
Le due figure qui sopra riportate si riferiscono agli scatter ( ie , yi) e ( ie , NVi) connessi alle stime dei modelli di regressione degli esempi 3 e 4. Come si può notare, in questi non si intravedono strutture apparenti e quindi i modelli utilizzati possono essere considerati idonei per rappresentare i fenomeni in stu-dio. 6.4 Modello non lineare
Le analisi che abbiamo fatto nei paragrafi precedenti sono relative al ca-so in cui la relazione esistente fra la variabile dipendente Y e quelle esplicative (X1, X2, ..., Xk) sia di tipo lineare. Molto spesso, considerazioni teoriche, evi-denze empiriche o entrambe portano a formulare modelli non lineari. In questi casi è necessario distinguere fra tre situazioni alternative, qui di seguito somma-riamente illustrate, che implicano soluzioni diverse. MODELLI NON LINEARI NELLE ESPLICATIVE
Questo è il caso più semplice da affrontare dato che la stima dei suoi parametri e la relativa verifica non si discosta sostanzialmente da quello lineare già conosciuto. Per essere più chiari supponiamo che per esempio sia
6
8
10
12
14
-2 -1 0 1 2RESID18
19
20
21
22
23
-2 -1 0 1 2RESID

202 Capitolo 6
conosciuto. Per essere più chiari supponiamo che per esempio sia
Y = βo + β1eX + β2V2 + a ove a è la variabile residuo. Come si può notare, questo modello è lineare nei parametri incogniti, ma è non lineare nelle due variabili esplicative X e V. D'al-tra parte, se poniamo
eX = X*, V2 = V* cioè lavoriamo sull'esponenziale della variabile X e sui quadrati della variabile V, otteniamo il nuovo modello
Y = βo + β1X* + β2V* + a che risulta lineare nei parametri e nelle nuove variabili esplicative X*, V* e tut-to quanto illustrato per il modello lineare continua a valere per questo partico-lare modello non lineare. MODELLI NON LINEARI MA LINEARIZZABILI
In molti casi un modello non lineare nei parametri può essere ricondotto a quello lineare con una semplice trasformazione monotona. In tal modo i ri-sultati illustrati nelle pagine precedenti valgono per il modello trasformato e dato che la trasformazione è di tipo monotona, è sempre possibile risalire al modello originario. Qui di seguito presentiamo tre modelli non lineari nei pa-rametri incogniti e la relativa trasformazione monotona che li riconduce al caso lineare:
Y = βo e(β1X + β2V) a
Y = βo Xβ1Vβ2 a
Y = 1
βo+β1X+e
ove con a abbiamo indicato la variabile scarto ed Y è strettamente positivo. Questi modelli possono essere ricondotti facilmente alla forma lineare, rispetti-

Il modello lineare 203
vamente, con le trasformazioni seguenti:
log(Y) = log(βo) + β1X + β2V + log(a)
log(Y) = log(βo) + β1 log(X) + β2 log(V)+ log(a)
1Y = βo+β1X+e.
MODELLI NON LINEARIZZABILI
Esistono molti modelli di regressione non lineari e non linearizzabili con semplici trasformazioni monotone. Così, se è
Y = βo + Xβ1 + Vβ2 + a
il modello è non lineare nei parametri e non è facilmente linearizzabile. In tal caso per procedere è necessario utilizzare una stima non lineare dei minimi quadrati dato che bisogna minimizzare l'espressione seguente
∑i=1
n [yi - βo - X
β1 - Vβ2] = min(βo, β1, β2).
Esistono algoritmi numerici abbastanza affidabili all'interno di pacchetti
applicativi per computer che permettono di ottenere le relative stime. In tal ca-so, però, gli strumenti di verifica del modello che abbiamo qui illustrato non sono più validi.


Bibliografia
BOLDRINI M. (1968) Statistica, Giuffrè, MilanoCALVELLI A., QUINTANO C. (1982) La Statistica. Elementi di Metodologia ed
Applicazioni in Campo Sociale ed Economico, Liguori Editore, NapoliCASTELLANO V. (1968) Istituzioni di Statistica, Ed. Ilardi, RomaCECCHI C. (1995) I Numeri indici, Cacucci, BariCHIEPPA M., RIBECCO N., VITALE C. (1994) Teoria e Metodi Statistici, ESI NapoliDEL VECCHIO F. (1996) Elementi di Statistica per la Ricerca Sociale, Cacucci, BariGIRONE G SALVEMINI T. (1984) Lezioni di Statistica, vol. I, Cacucci, BariGIUSTI F. (1983) Introduzione alla Statistica, Loescher Editore, TorinoGIUSTI F., GUERRIERI G. (1980) Elementi di Statistica, Cacucci, BariJALLA E. (1980) Per un'Analisi Statistica degli Aggregati Economici, Giappichelli, TorinoLANDENNA G. (1984) Fondamenti di Statistica Descrittiva, Il Mulino, BolognaLETI G. (1983) Statistica Descrittiva, Il Mulino, BolognaNADDEO A. (1981) Statistica di Base, Edizioni Kappa, RomaNADDEO A., LANDENNA G. (1986) Metodi Statistici nella Ricerca Scientifica e Industriale,
Franco Angeli, MilanoPICCOLO D., VITALE C. (1984) Metodi Statistici per l'Analisi Economica, Il Mulino,
BolognaPREDETTI A. (1978) I Numeri Indici. Teoria e Pratica, Giuffré, MilanoSALVEMINI T. (1970) Lezioni di Statistica, vol. I, Cacucci, BariSCARDOVI I. (1980) Appunti di Statistica, vol. I, Edizioni Patron, BolognaTUKEY J.W. (1971) Esploratory Data Analysis, Addison-Wesley, ReadingVAJANI L. (1974) Statistica Descrittiva, ETAS Libri, MilanoVITALI O. (1991) Statistica per le Scienze Applicate, vol. I, Cacucci, BariZENGA M. (1988) Introduzione alla Statistica Descrittiva, Vita e Pensiero, Milan


Indice analitico
207
INDICE ANALITICO
A Asimmetria; 71; 74; 80
negativa; 73 positiva; 73
B Baricentro; 29; 31; 34 Base
slittamento; 148 Box-plot; 48; 68; 72; 146; 158 C Carattere; 2; 6; 9; 10; 22; 38; 43; 70;
83; 103; 115; 165 Cardine; 52 Classe
aperta; 12; 13 intensità; 18 mediana; 53 modale; 55 modalità; 55
Coefficiente asimmetria; 74; 75
Collettivo statistico; 21
Concentrazione massima; 83; 91 nulla; 84 dei redditi; 96
Connessione; 123 Correlazione
coefficiente; 135-137 Covarianza; 124; 125; 127; 129; 130;
137; 182 Curtosi
leptocurtica; 77; 79 mesocurtica; 77 platicurtica; 77; 79
D Deflattore; 173 Deflazione; 171; 173 Deviazione standard; 62 Differenza
tra quartili; 72 interquartile; 72
Differenze assolute; 155 prime; 155; 162 seconde; 162 stagionali; 162
Distribuzione di frequenza; 9; 12-23;
Disuguaglianza di Cauchy-Schwarz; 132 Jensen; 52
E Entropia; 69 F Frequenza
assoluta; 18 relativa; 18 relativa cumulata; 43; 45
G Gambo-foglie; 144; 145; 158 Gini; 70; 91; 95; 98 Grafico
aste; 13 barre; 15-17 box-plot; vedi Box-plot funzione di contro ripartizione; 23 funzione di ripartizione; 21-23 gambo-foglie; vedi Gambo-foglie istogramma; 17; 52

Indice analitico 208
nastri; 15 scatola; vedi Box-plot stem-leaves; vedi Gambo-foglie torta; 14
I Incorrelazione; 124; 127 Indice
base fissa; 148; 149; 151; 165; 170 base mobile, 151; 170 base mobile s; 153 composto; 170 deflattore; 173 Gini; vedi Gini ideale; 170 prezzi; 165 quantità; 170
Indici descrittivi asimmetria; 71 cncentrazione; 91 concentrazione δ; 95 curtosi; 76; 78; 79 forma; 26 locazione; 53; 56 mutabilità; 69 posizione; 25; 57; 60; 71 variabilità; 25; 57
Indipendenza assoluta; 110; 111; 119 fra caratteri; 110 indice; 114; 115; 116 in media; 118 relativa; 110
Intensità della classe; 17 Intervallo di variazione; 58 L Laspeyres; 167-170 Livello
cambiamento di; 161 Lorenz; 89-91; 99-101
M Media
geometrica; 53-57; 170 ponderata; 27 proprietà; 29 robustezza, 35 semplice; 27 troncata; 37
Mediana; 38-48; 52; 67; 72; 75; 145 classe; 43; 45 robustezza; 43
Metodo dei minimi quadrati; 180, 182, 185,
187, 191, 195, 203 Moda; 51-55; 72
classe; 52; 53 Modalità; 8- 20; Modello di regressione
lineare; 177; 179; 188; 192; 193; 195; 196; 198
O Ordinamento
statistico; 6; 10 P Paasche; 169; 170; 172; 173 Popolazione
condizionata; 2-6; 8; 9 R Rapporto
di concentrazione; 93; 94; 99; 101 T Trasformazione
lineare; 33; 34; 63; 136; 137 V Variabilità; 25; 26; 57 Varianza; 59-62; 66; 76; 79; 121-125


Questo volume è stato impressonel mese di marzo dell’anno 2002
presso la Buona Stampa s.p.a., Ercolanoper le Edizioni Scientifiche Itasliane s.p.a., Napoli
Stampato in Italia/ Printed in Italy



















