Linguistica Computazionale - elearning.humnet.unipi.it · l Fonte di dati primaria per la...
30
28 settembre 2016 Linguistica Computazionale
Transcript of Linguistica Computazionale - elearning.humnet.unipi.it · l Fonte di dati primaria per la...

28 settembre 2016
Linguistica Computazionale

2
Il linguista computazionale:
§ raccoglie dati linguistici § usa metodi formali (logici, matematici, statistici, ecc.) e strumenti
informatici per analizzare i dati raccolti e ricostruire l’organizzazione e struttura del linguaggio
Dati linguistici l Dati linguistici
l i prodotti del linguaggio che sono oggetto di un processo di analisi (computazionale) e che formano l’evidenza empirica per lo sviluppo di modelli e teorie linguistiche l come funziona il linguaggio, qual è la sua organizzazione,
come viene usato, come viene appreso

3
intuizioni linguistiche dati linguistici “controllati”
raccolti in contesti “sperimentali” e in situazioni “idealizzate”
testi prodotti dai parlanti dati linguistici “ecologici”
osservazioni “naturali” degli usi linguistici in contesti e situazioni reali
Dati linguistici l Le fonti dei dati linguistici
l “Intuizioni linguistiche” dei parlanti l es. giudizi di grammaticalità, giudizi semantici, ecc.
§ la frase “L’uomo correva velocemente” è grammaticale? § la parola “cane” è più semanticamente simile a “gatto” oppure a “treno”?
l testi prodotti dai parlanti l testo = qualsiasi prodotto dell’attività linguistica dei parlanti
elaborato o trascritto come sequenza di caratteri

4
Dati linguistici controllati l Fonte di dati primaria per la linguistica formale
“razionalista” di derivazione chomskiana e per la psicolinguistica l obiettivo dell’indagine linguistica è ricostruire le conoscenze che i
parlanti hanno della lingua (competenza) indipendentemente dal modo in cui la usano (esecuzione o performance) l i fenomeni tipici dell’uso linguistico sono considerati “rumore” da
cui è necessario fare astrazione
l Fonte di dati primaria per la linguistica computazionale e Intelligenza Artificiale di Ia generazione l sistemi generalmente in grado di operare in ambienti circoscritti
(toy models)

5
Dati linguistici controllati l Limiti e problemi dei dati controllati
l le intuizioni dei parlanti non sono sempre “chiare e distinte” l “la ragazza che ci sono uscito ieri” (???) l “c’è la maggior parte di noi che non leggono abbastanza” (???)
l esperimenti “in vitro” l eccessivo grado di idealizzazione e astrazione rispetto all’uso
effettivo del linguaggio l i sistemi computazionali sono scarsamente adattabili e
“robusti” l difficoltà a gestire testi reali che contengono rumore
§ errori di digitalizzazione, errori grammaticali, forme linguistiche substandard, ecc.
l (da Twitter) § “Ah dimenticavo, ma tutta sta caciara per fare un governo Monti ? Mai na
sorpresa dentro sto paese.” § “sto anche facendo pausa con yogurt...ottimo parlare di ste cose...
Solocosebelle e buone!!!yeeesss ma venite in camper?”

6
(Dal lat. corpus, “corpo”, pl. corpora) Un corpus è una collezione di testi selezionati e organizzati in
maniera tale da soddisfare specifici criteri che li rendono funzionali per le analisi linguistiche
Dati linguistici “ecologici”
l I corpora rappresentano fonti di dati linguistici “ecologici”, ovvero raccolti nei loro “habitat naturali” l lingua scritta
l libri (saggistica, narrativa, poesia, ecc.), giornali, riviste, pagine Web, produzioni “effimere” (e-mail, pubblicità, chat, tweet, ecc.
l lingua parlata (trascritta) l notiziari radio-televisivi, conversazioni telefoniche, conversazioni
faccia-a-faccia, ecc.
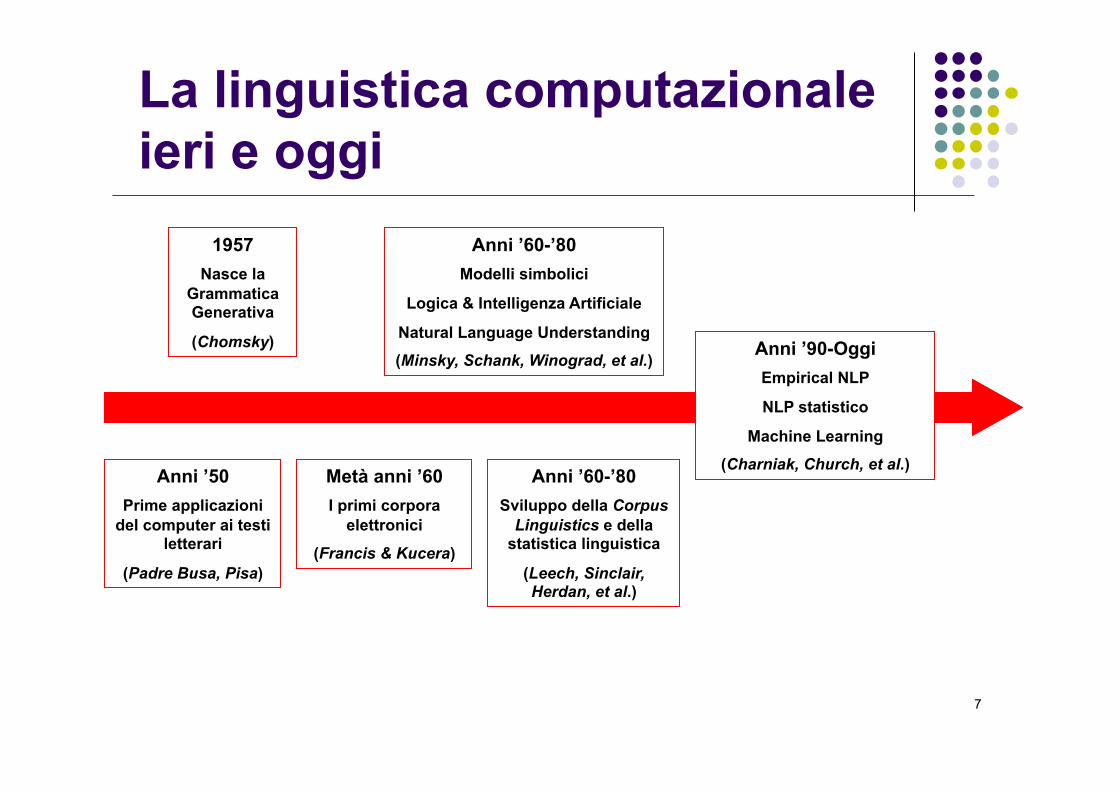
7
Anni ’50 Prime applicazioni
del computer ai testi letterari
(Padre Busa, Pisa)
1957 Nasce la
Grammatica Generativa
(Chomsky)
Anni ’60-’80 Modelli simbolici
Logica & Intelligenza Artificiale
Natural Language Understanding
(Minsky, Schank, Winograd, et al.)
Metà anni ’60 I primi corpora
elettronici
(Francis & Kucera)
Anni ’60-’80 Sviluppo della Corpus
Linguistics e della statistica linguistica
(Leech, Sinclair, Herdan, et al.)
Anni ’90-Oggi Empirical NLP
NLP statistico
Machine Learning
(Charniak, Church, et al.)
La linguistica computazionale ieri e oggi

8
Corpora Strumenti e applicazioni di NLP
sviluppo
valutazione
I corpora testuali rappresentano la principale (anche se non esclusiva) fonte di dati in linguistica computazionale
Corpora e linguistica computazionale
sviluppo e valutazione di modelli e applicazioni
creazione di corpora annotati

9
corpus = corpus elettronico i testi sono in formato digitale (machine-readable)
Corpora elettronici l L’avvento dell’era informatica ha rivoluzionato la
natura, ruolo e uso dei corpora l Il computer permette di:
l immagazzinare quantità di dati testuali prima inimmaginabili
l interrogare in maniera avanzata il contenuto del corpus l compiere nuove forme di elaborazione e computazione sui
dati lingustici

10
The rich variety of corpora reflects the diversity of their designers’ objectives
Atkins et al. (1992): 5
Tipologia ed uso
l Principali usi dei corpora l applicativo
l tipico del NLP e dell’ingegneria del linguaggio, per progettare strumenti: § dotati di conoscenze linguistiche direttamente ricavate da dati rappresentativi
di un certo dominio o varietà di linguaggio § “robusti” e ben adattati al linguaggio reale
l analitico l per fondare analisi e descrizioni linguistiche sull’effettiva
distribuzione delle costruzioni e fenomeni all’interno di un linguaggio, al fine di valutare ipotesi teoriche sulla sua forma ed organizzazione

11
Ogni corpus è per sua definizione il risultato di un’opera di selezione
i criteri che guidano questa scelta determinano la natura stessa del corpus e condizionano lo spettro dei suoi usi possibili
Tipologia ed uso
l Parametri rilevanti per classificare i corpora l generalità l modalità l cronologia l lingua l integrità dei testi l codifica digitale dei testi

12
Tipi di corpora generalità l corpus specialistico
l orientato alla descrizione di una particolare varietà del linguaggio (sublanguage) o a un ristretto dominio applicativo l linguaggio giornalistico l linguaggio infantile l linguaggio giuridico, medico, ecc. l linguaggio dei controllori di volo, ecc.
l corpus generale o di riferimento (reference corpus) l trasversale rispetto alle diverse varietà di un linguaggio L l plurifunzionale l orientato a rappresentare tutti gli aspetti caratteristici di L,
proponendosi come risorsa di riferimento per la descrizione di L l può essere organizzato in vari sottocorpora specializzati per
varietà di L

13
Tipi di corpora modalità l corpus di scritto
l solo testi di linguaggio scritto l corpus di parlato
l solo trascrizioni di linguaggio parlato l corpus misto
l testi scritti e trascrizioni di parlato (in proporzioni variabili) l speech database (corpus audio)
l campioni di linguaggio parlato in forma di segnale acustico (più eventualmente la trascrizione ortografica)
l corpus multimediale (audio-video) l testi scritti, video, parlato in forma di segnato acustico, ecc.

14
Tipi di corpora cronologia e lingua l corpus sincronico
l descrive un particolare stadio del linguaggio (i testi appartengono tutti ad una stessa finestra temporale)
l corpus diacronico l descrive il mutamento linguistico (i testi appartengono a diverse
finestre temporali) l corpus monolingue
l contiene testi di una sola lingua l corpus bi/plurilingue
l corpus parallelo – lo stesso testo è rappresentato (in traduzione) in più di una lingua l corpus allineato – ciascuna frase (parola) della lingua L1 è
esplicitamente collegata col suo traducente nella lingua L2 l corpus comparabile – testi in più lingue (non in traduzione)
appartenenti alle stesse tipologie (ciascuna lingua è rappresentata da testi diversi)

15
Tipi di corpora integrità e codifica dei testi l Un corpus può contenere testi interi o porzioni di
testi di lunghezza prefissata
l Corpora codificati l i testi sono arricchiti con etichette (codici) che ne rendono
esplicite vari tipi di informazione (es. struttura testuale, composizione, ecc.)
l Corpora annotati l le informazioni codificate sul testo riguardano la struttura
linguistica del testo a livelli diversi di rappresentazione (es. morfologica, sintattica, semantica, ecc.)

16
Evoluzione della dimensione dei corpora
corpora di prima generazione anni 60-70 milioni di parole
corpora di seconda generazione anni 80-90 decine di milioni di parole 2000-oggi centinaia di milioni di parole
corpora di ultima generazione oggi - … miliardi di parole
Dimensione del corpus l Numero di parole (token) contenute nel corpus
l numero di ore di registrazione, per corpora di parlato
l Regola generale: “The larger, the better!”

17
Corpora di prima generazione Brown Corpus l Il primo corpus computazionale in formato elettronico, iniziato nel
1961 l Francis e Kucera (Brown University) l corpus standard di American English contemporaneo
l Dimensione l 1 milione di parole tratte da materiale pubblicato nel 1961 appartenente
a vari generi l Tratti caratteristici:
l generale l sincronico l monolingue
l Registrato su 100.000 schede perforate e trasferito su nastri magnetici nel 1964. Disponibile su CD-ROM
l Modello di riferimento per tutti i corpora di prima generazione

18
Corpora di prima generazione Brown Corpus

19
Corpora di seconda generazione British National Corpus (BNC)
l Corpus del British English (1991-1994) l creato da un consorzio accademico (Oxford, Lancaster, ecc.) ed editoriale
(Oxford University Press, Longman, ecc.) l Dimensione:
l 100 milioni di parole l Tratti caratteristici
l generale l monolingue l sincronico l misto
l 90% testi scritti di vari generi l 10% testi di parlato trascritto (conversazioni spontanee)
l codificato e annotato l http://www.natcorp.ox.ac.uk/

20
Corpora di seconda generazione PAROLE l Corpora multilingue comparabili per 14 lingue europee
l catalano, danese, finlandese, francese, francese belga, greco, inglese, irlandese, italiano, norvegese olandese, portoghese, svedese, tedesco
l tutti i corpora sono stati costruiti secondo criteri e specifiche uniformi l PAROLE-Italiano (1996-1998)
l realizzato presso l’ILC-CNR (Pisa) l Dimensione:
l 21 milioni di parole tratte da testi scritti di vari generi (libri, giornali periodici, miscellanee)
l attualmente portate a ca. 100 milioni l Tratti caratteristici
l generale l sincronico l (internamente) monolingue l codificato l http://www.ilc.cnr.it/pisystem/demo/demo_dbt/demo_corpus/index.htm

21
Corpora di seconda generazione PAROLE

22
Corpora di seconda generazione La Repubblica l Corpus monolingue dell’italiano giornalistico
l SSLiMIT Forlì (Baroni et al. 2004) l http://dev.sslmit.unibo.it/corpora/corpus.php?
path=&name=Repubblica l Dimensione
l ca. 326 milioni di parole l Tratti caratteristici:
l generale come dominio tematico, ma specialistico come tipologia testuale
l scritto l monolingue l annotato
l il corpus è lemmatizzato e annotato a livello morfosintattico

23
Corpora di parlato l Map Task Corpus (1992)
l University of Edimburgh (HCRC) e University of Glasgow l 18 h, 128 dialoghi semi-spontanei “task-oriented” (map-task),
trascritti e comprensivi di segnale acustico l http://www.hcrc.ed.ac.uk/maptask/maptask-description.html
l Archivio di Varietà di Italiano Parlato (AVIP) (2001) l 3,5 h, 44 dialoghi semi-spontanei “task-oriented” (map-task) (39
prodotti da adulti e 5 da bambini), trascritti l registrazioni effettuate a Pisa, Napoli e Bari
l C-ORAL-ROM l corpus audio della lingua parlata spontanea. Il corpus è
comparabile con altri corpora per spagnolo, francese e portoghese
l registrazioni audio per un totale di 300.000 parole, trascritte

24
Corpora paralleli l Canadian Hansard Corpus (2001)
l 1,3 milioni di frasi francesi-inglesi allineate a livello di frase, tratte dagli atti del Parlamento Canadese

25
Corpora paralleli l European Parliament Proceedings Parallel Corpus (1996-2011)
l estratti dagli atti del Parlamento Europeo l include versioni allineate a livello di frase in 21 lingue europee (l’inglese
è la lingua pivot) l francese, italiano, spagnolo, portoghese, inglese, olandese, tedesco,
danese, svedese, greco, finlandese, etc. l la sezione italiana contiene ca. 52 milioni di parole
l finalizzato alla traduzione automatica statistica l http://www.statmt.org/europarl/index.html

26
Corpora paralleli Europarl Corpus
<SPEAKER ID=2 LANGUAGE=”IT" NAME="Evans, Robert J"> Signora Presidente, intervengo per una mozione d'ordine. Come avrà letto sui giornali o sentito alla televisione, in Sri Lanka si sono verificati numerosi assassinii ed esplosioni di ordigni.
<SPEAKER ID=2 NAME="Evans, Robert J"> Madam President, on a point of order. You will be aware from the press and television that there have been a number of bomb explosions and killings in Sri Lanka.

27
Corpora specialistici l Switchboard Corpus (1992)
l 2.400 conversazioni telefoniche registrate in varie regioni degli USA e trascritte (ca. 3 milioni di parole)
l applicazioni: Automatic Speech Recognition (ASR), Speaker Identification, ecc.
l Child Language Data Exchange (CHILDES) (B. MacWhinney) l database di interazioni conversazionali di bambini in fase di
apprendimento linguistico o di soggetti con patologie del linguaggio
l finalità: studio dell’apprendimento linguistico l “meta-corpus”:
l sistema per la raccolta, trascrizione e trattamento di di dati linguistici
l collezione di dati aperta l http://childes.psy.cmu.edu/

28
Corpora multimodali l Human Speechome Project (Deb Roy, MIT Media Lab)
l 10 ore al giorno di registrazione continua audio-video di un bambino dalla nascita a 3 anni nella sua abitazione
l ca. 90K ore di video e 140K ore di audio registrazioni, parzialmente trascritte in modo automatico l “To study a corpus of this scale and richness, current methods of
developmental cognitive science are inadequate” (Roy 2009)

29
I corpora oggi l I corpora generali più recenti ospitano spesso proporzioni variabili di
parlato trascritto l Esiste un numero crescente di corpora audio e corpora multilingui
(soprattutto paralleli allineati), e specialistici l Il numero di lingue per le quali esistono corpora di varie tipologie è
in continuo aumento l Si preferisce includere in un corpus testi interi per garantire la
massima naturalezza dei dati linguistici estraibili l I testi sono riccamente codificati e sempre più estensivamente
annotati l Strumenti informatici sofisticati (basi di dati, interfacce di ricerca,
ecc.) potenziano la fruibilità dei dati linguistici nei corpora

30
Corpora di grandi dimensioni e di varie tipologie esistono per un numero crescente di lingue
Collezioni di corpora
l Agenzie per la distribuzione di corpora l Language Data Consortium (LDC)
l http://www.ldc.upenn.edu/ l European Language Resources Association (ELRA)
l http://www.elra.info/
l Consultazione on-line di corpora (a pagamento) l Sketchengine (http://www.sketchengine.co.uk)