
Linguiscacomputazionale* eapprocci*corpusbasedbosco/lingue2015/NLPcorpora-2015.pdf ·...
97
Linguis’ca computazionale e approcci corpusbased Cris%na Bosco Corso di Informa%ca applicata alla comunicazione mul%mediale 20142015
Transcript of Linguiscacomputazionale* eapprocci*corpusbasedbosco/lingue2015/NLPcorpora-2015.pdf ·...

Linguis'ca computazionale e approcci corpus-‐based
Cris%na Bosco
Corso di Informa%ca applicata alla comunicazione mul%mediale
2014-‐2015

Per definire un sistema di NLP occorre conoscerne i seguen% aspeA:
-‐ Input -‐ Algoritmi
-‐ Conoscenza linguis%ca -‐ Output
Sistemi di NLP

INPUT: modalità
Il sistema riceve in ingresso un input in linguaggio naturale
L’input può assumere diverse modalità: scriLo, parlato, gestuale o una mescolanza di queste tre modalità, che possono anche interagire tra loro.
Noi ci occuperemo specificamente di linguaggio scriLo, ma non va dimen%cata la complessità derivante dalle altre, come la sintesi del parlato e i problemi derivan% dal “rumore”, la percezione ed interpretazione della gestualità.

Un esempio: l’input nelle lingue dei segni e nel parlato
Nel caso delle lingue dei segni, l’input è gestuale e si deve tenere conto della gestualità delle mani, principale strumento per “segnare”, ma anche delle espressioni del viso, della posizione del capo, delle spalle, braccia, ecc.
Queste stesso componen% possono entrare in gioco anche quando il linguaggio è parlato … l’espressione del viso in mol% casi è una fondamentale chiave di interpretazione del significato del testo enunciato.

INPUT: lingua e genere
Il sistema riceve in ingresso un input in linguaggio naturale
L’input può contenere tes% di natura molto diversa tra loro a seconda di:
-‐ Lingua (francese, giapponese, swahili …)
-‐ Genere testuale (prosa giornalis%ca, TwiLer, poesia, romanzi, prosa scien%fica, manualis%ca tecnica, previsioni meteo …)

Il sistema deve anche avere gli algoritmi adegua' a u'lizzare la conoscenza e a produrre un determinato output.
Si deve pertanto assumere che le operazioni da fare sull’input siano ben definibili, e trovare un modo per definirle.
ALGORITMI

Quali sono le operazioni da fare sull’input?
Potrebbero essere le stesse che fanno gli esseri umani (intelligenza ar%ficiale forte) oppure differen% (intelligenza ar%ficiale debole).
In entrambi i casi possono esserci vari modi di produrre uno stesso output e il modo migliore può dipendere anche dall’input o dalla conoscenza.
ALGORITMI

I sistemi che traducono in modo automa%co adoLano approcci diversi, traducono direLamente dalla lingua target alla lingua sorgente oppure tramite la mediazione di interlingue.
Essi u%lizzano %pi di conoscenza diversa, dizionari, ontologie ecc. (e non tuLe queste basi di conoscenza sono disponibili per tuLe le lingue).
ALGORITMI: un esempio, la traduzione

Assumiamo che una lingua sia traLabile da un sistema che con%ene la conoscenza posseduta da un parlante di quella lingua.
Occorre equipaggiare il sistema con tale conoscenza.
CONOSCENZA LINGUISTICA

Il primo problema consiste nel delimitare la conoscenza necessaria alla comprensione del linguaggio.
Essa deve essere rappresentata in modo opportuno (dizionari, ontologie, corpora, memorie di traduzione, basi terminologiche …).
CONOSCENZA LINGUISTICA

Inoltre la conoscenza deve essere fornita al sistema in una forma adeguata.
Questo è un problema che è stato molto discusso e che è determinante per chi progeLa un sistema di NLP.
CONOSCENZA LINGUISTICA

Acquisizione della conoscenza
Un sistema che traLa il linguaggio deve avere a disposizione la conoscenza linguis%ca necessaria.
Ma come si meLe la conoscenza dentro un sistema?

Acquisizione della conoscenza
Esempio: che conoscenza occorre a un PoS tagger (analizzatore morfologico) per prendere in input
“il cane dorme in giardino” e res%tuire in output
“il ART, cane NOUN, dorme VERB, in PREP, giardino NOUN” ?

Acquisizione della conoscenza
output = il ART, cane NOUN, dorme VERB, in PREP, giardino NOUN
conoscenza =
ART (il), NOUN (cane, giardino), VERB (dorme), PREP (in)

Acquisizione della conoscenza
Esempio: che conoscenza occorre a un parser (analizzatore sintaAco) per prendere in input
“il cane dorme in giardino” e res%tuire in output
“[S [NP (il – cane)]
[VP (dorme) [PP (in – giardino)]]]” ?

Acquisizione della conoscenza
output = [S [NP (il – cane)] [VP (dorme) [PP (in – giardino)]]]
conoscenza =
art + noun = NP
verb + PP = VP
prep + noun = PP
NP + VP = S

Acquisizione della conoscenza
Dove si trova la conoscenza?
Le soluzioni sono 2:
1) conoscenza dentro il sistema – rule-‐based
2) conoscenza dentro un corpus di da% linguis%ci – corpus-‐based

Corpus versus rule-‐based
gramma%ca
lessico
…
SISTEMA

Corpus versus rule-‐based
gramma%ca
lessico
…
CORPUS
SISTEMA
apprendimento

Corpus versus rule-‐based In entrambi i casi si presuppone che il linguaggio sia governato da regole (da conoscere per traLarlo) MA: • nei sistemi corpus-‐based le regole sono apprese, nei rule-‐based sono date • nei sistemi corpus-‐based le regole sono probabilis%che, nei rule-‐based sono determinis%che

Corpus versus rule-‐based
Se le regole variano, ad es. da una lingua all’altra, da un genere testuale ad un altro, devono essere riscriLe in un sistema rule-‐based, ma non in uno corpus-‐based.

Approccio corpus-‐based
• U%lizzato dai linguis% dalla fine dell’800 e oggi molto diffuso
• Consiste nell’apprendere dal linguaggio le regole ed irregolarità del linguaggio

Approccio corpus-‐based
• A causa delle cri%che di Chomsky l’approccio corpus-‐based non è stato adoLato dalla linguis%ca computazionale che negli ul%mi 20 anni.
• Le cri%che che Chomsky porta a questo approccio sono riducibili a 2.

Approccio corpus-‐based
• Prima cri%ca:
Un corpus può adeguatamente rappresentare un linguaggio?
Il numero di frasi di un linguaggio è infinito, mentre un corpus ne con%ene comunque un numero finito, non tuLe, e distribuite in modo casuale.

Approccio corpus-‐based
• Risposta alla Prima cri%ca:
Un corpus può adeguatamente rappresentare un linguaggio se con%ene un campione sta%s%camente significa%vo di esso. Non occorre che contenga tuLe le frasi di un linguaggio, ma una sua porzione abbastanza ampia da contenere esempi di tuLe le struLure di tale linguaggio.

Approccio corpus-‐based
• Seconda cri%ca: Perché studiare il linguaggio tramite osservazione direLa invece che introspezione?
Nella nostra mente (grazie alla competence) sono presen% tuLe le struLure correLe del linguaggio, mentre lo stesso non può accadere in un corpus per quanto grande.

Approccio corpus-‐based
• Risposta alla Seconda cri%ca: Solo l’osservazione direLa ci può dare conto di come il linguaggio è realmente usato, del faLo che i parlan% riescono a comunicare tra loro nonostante errori e rumore.

Approccio corpus-‐based
La posizione di Chomsky è razionalis%ca e fondata su da% ar%ficiali e giudizi introspeAvi che sono espressione della nostra conoscenza interiorizzata del linguaggio (competence).
Al contrario l’approccio corpus-‐based è empiricista e fondato sull’osservazione di da% naturali che sono espressione empirica della conoscenza del linguaggio (performance).

Approccio corpus-‐based
• Il suo principale vantaggio è di offrire un concreto supporto alla soluzione del problema dell’ambiguità.
• Se una frase è ambigua, il sistema che la traLa ne costruisce più struLure alterna%ve. Analizzando un corpus possiamo scoprire quale ordine di preferenza dare alle alterna%ve.

Approccio corpus-‐based
• Si basa sull’idea che le co-‐occorrenze sono fon% importan% di informazioni sulla lingua
• Si ispira all’idea di apprendimento linguis%co umano, tramite esposizione a esempi e basato su criteri sta%s%ci

Approccio corpus-‐based
Esempio:
Nell’analisi sintaAca (parsing), di fronte all’ambiguità e quindi generazione di più struLure, per una singola frase, si ricavano dai da% linguis%ci i CRITERI per scegliere la migliore delle struLure generate

Approccio corpus-‐based
L’approccio corpus-‐based assume che buona parte del successo del linguaggio umano nella comunicazione dipende dall’abilità che gli esseri umani hanno nel ges%re ambiguità ed imprecisione in modo efficiente.

Approccio corpus-‐based
Gli esseri umani riescono infaA a cogliere la correLa interpretazione di un messaggio da un insieme di s%moli di varia natura (ad es. contestuali ed emo%vi) oltre che dalle parole e struLure che compongono il messaggio stesso.

Approccio corpus-‐based
L’approccio corpus-‐based offre inoltre la possibilità di sfruLare la conoscenza che va al di là delle parole e delle struLure che compongono il linguaggio.
È quindi un modo efficiente di acquisire la conoscenza sul linguaggio.

Approccio corpus-‐based
Si assume che un CORPUS C di un linguaggio L possa contenere (~tuLa) la conoscenza necessaria a traLare L, e si acquisisce la conoscenza da esso

Approccio corpus-‐based Il processo di apprendimento offre come risultato • la conoscenza delle regole ed irregolarità del linguaggio (non-‐ristreLo) • MA SOPRATTUTTO la percezione della frequenza delle struLure linguis%che

Approccio corpus-‐based In pra%ca per acquisire la conoscenza:
si prende un campione di linguaggio, cioè un insieme di frasi = CORPUS
si cercano nel corpus le struLure linguis%che e le loro probabilità = BASE di CONOSCENZA

Approccio corpus-‐based
In pra%ca un sistema corpus-‐based:
se incontra una struLura ambigua cerca nella base di conoscenza l’informazione u%le per costruire la rappresentazione più probabile della struLura

Approccio corpus-‐based Ma come funziona un sistema sta%s%co?
ad ogni struLura S del linguaggio il sistema associa un valore di probabilità
il valore di probabilità di S è dato dalla composizione delle probabilità delle par% di S

Approccio corpus-‐based Esempio:
“il cane dorme in giardino”
P(il–cane: NP) = 95%
P(in-‐giardino: PP) = 95%
P(cane-‐dorme: VP) = 5%
…

Approccio corpus-‐based
Ma come funziona un sistema sta%s%co?
la probabilità di ogni parte di una frase analizzata dipende dalla sua frequenza in un CORPUS di riferimento e dal modello sta%s%co u%lizzato

Approccio corpus-‐based
Ma come funziona un sistema sta%s%co?
Cosa è un modello probabilis%co ?
Serve a determinare come calcolare la probabilità di ogni risultato oLenuto dal sistema

Approccio corpus-‐based Ma come funziona un sistema sta%s%co?
Esempio di un modello probabilis%co molto usato:
i bi-‐grammi:-‐ per ogni coppia <a,b> di parole avremo una s%ma della probabilità che a e b siano associate sintaAcamente (a=il e b=cane ha maggiore probabilità di occorrere che a=il e b=gaLa)

Approccio corpus-‐based i bi-‐grammi di “il cane dorme in giardino”:
1-‐il cane
2-‐cane dorme
3-‐dorme in
4-‐in giardino
La probabilità di 1 sarà maggiore di quella di 2, quindi il sistema propone la costruzione di 1 invece che di 2.

Approccio corpus-‐based
A par%re dagli anni ‘90 si sono sviluppa% sistemi che apprendono la conoscenza da corpora di da% linguis%ci per mol%ssimi linguaggi.
Si è progressivamente affermata anche la necessità di ANNOTARE i da% linguis%ci e si sono costrui% i TREEBANK.

Approccio corpus-‐based
ALualmente i TREEBANK sono le risorse linguis%che più u%lizzate nel NLP.

Approccio corpus-‐based
Perché annotare i da% ?
L’informazione è presente in forma implicita anche nei da% non annota%.
Ma introdurre l’informazione in forma esplicita semplifica il processo di apprendimento, inoltre rende possibile la correzione.

Annotazione e treebank
Come annotare i da% ?
Solitamente si annotano le informazioni di %po morfologico e sintaAco, più raramente quelle seman%che

Annotazione e treebank
Come annotare i da% ?
Per ogni livello di annotazione vengono faLe delle scelte sia sulla teoria linguis%ca da prendere come riferimento sia sul modo in cui fisicamente mostrare i da%.

Annotazione e treebank
Quali da% annotare ?
Occorre scegliere i tes% da introdurre nel corpus in modo che siano rappresenta%vi del linguaggio che si vuole traLare.

Annotazione e treebank Quali da% annotare ?
un corpus é un campione significa%vo e rappresenta%vo di un linguaggio SE:
• con%ene frasi non ristreLe • è “bilanciato” rispeLo al genere, alla collocazione geografica e sociale, al tempo
• MA non rappresenta mai TUTTO il linguaggio nel suo complesso

Un progeLo reale: Turin University Treebank
• ObieAvo:
sviluppare una risorsa linguis%ca, una banca di alberi sintaAci per l’italiano

Fasi di sviluppo del progeLo
• Selezione dei tes% da annotare
• Definizione dello schema di annotazione
• Applicazione dello schema al corpus di tes% (validità e consistenza)

Selezione di tes' in TUT
• Giornali quo%diani (1.100 frasi = 18,044 tokens) • Codice civile (1.100 frasi = 28,048 tokens) • Acquis (201 frasi = 7,455 tokens) • Wikipedia (459 frasi = 14,746 tokens)
• Cos%tuzione Italiana, intera (682 frasi = 13,178 tokens)
• Totale 3.452 frasi = 102.000 token

TEXTS from PRAGUE newspapers, scientific and economic
journals
NEGRA newspaper Frankfurter Rundschau
PENN IBM manuals, nursing notes, newspapers (Wall Street Journal), telephone conversations
Selezione in altri treebank

Definizione dello schema di annotazione
• Scelta del formalismo
• Scelta delle informazioni e struLure da rappresentare

StruLura sintaAca: scelta tra 2 aspeA
• L’organizzazione delle unitá della frase (sintagmi e cons%tuent structure)
• La funzione degli elemen% della frase (relazioni gramma%cali e rela%onal structure)

Rela%onal structure
• Le parole della frase svolgono funzioni diverse
• Le funzioni sono espresse in termini di relazioni gramma%cali
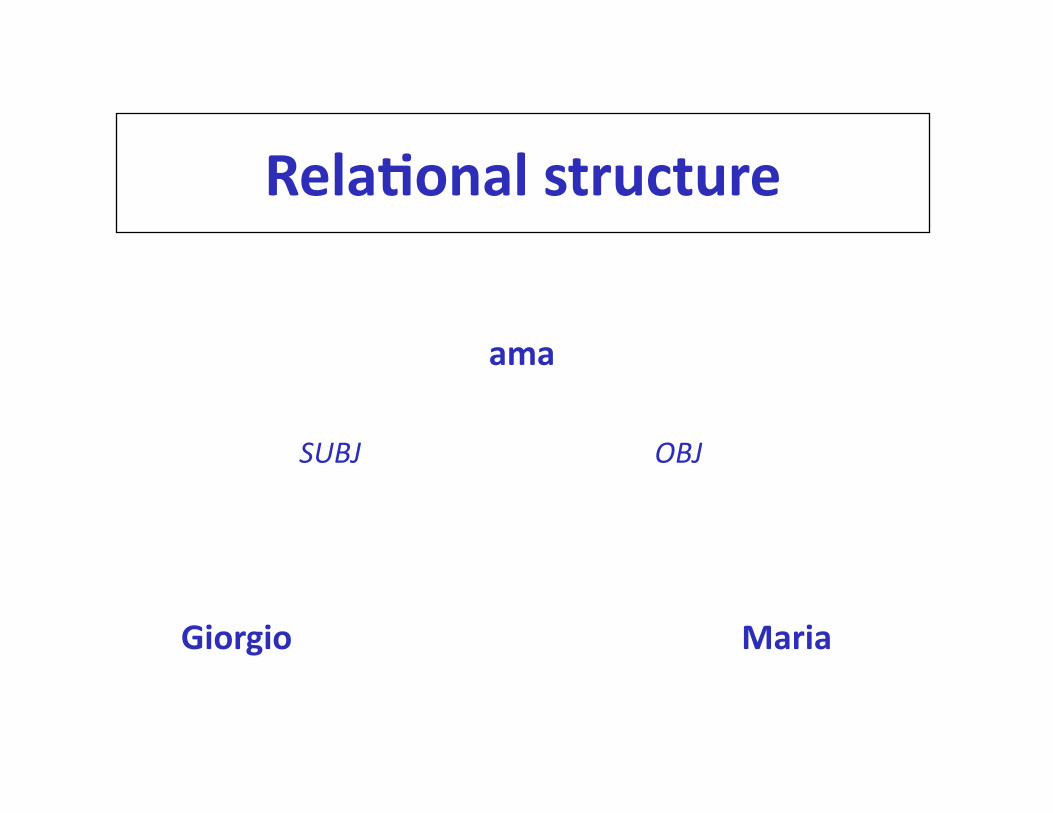
Giorgio
ama
Maria
SUBJ OBJ
Rela'onal structure

Cons%tuent structure
Le parole della frase sono organizzate in unità (cos%tuen%) che a loro volta sono oggeLo di una organizzazione (cons%tuent structure) in unità più grandi
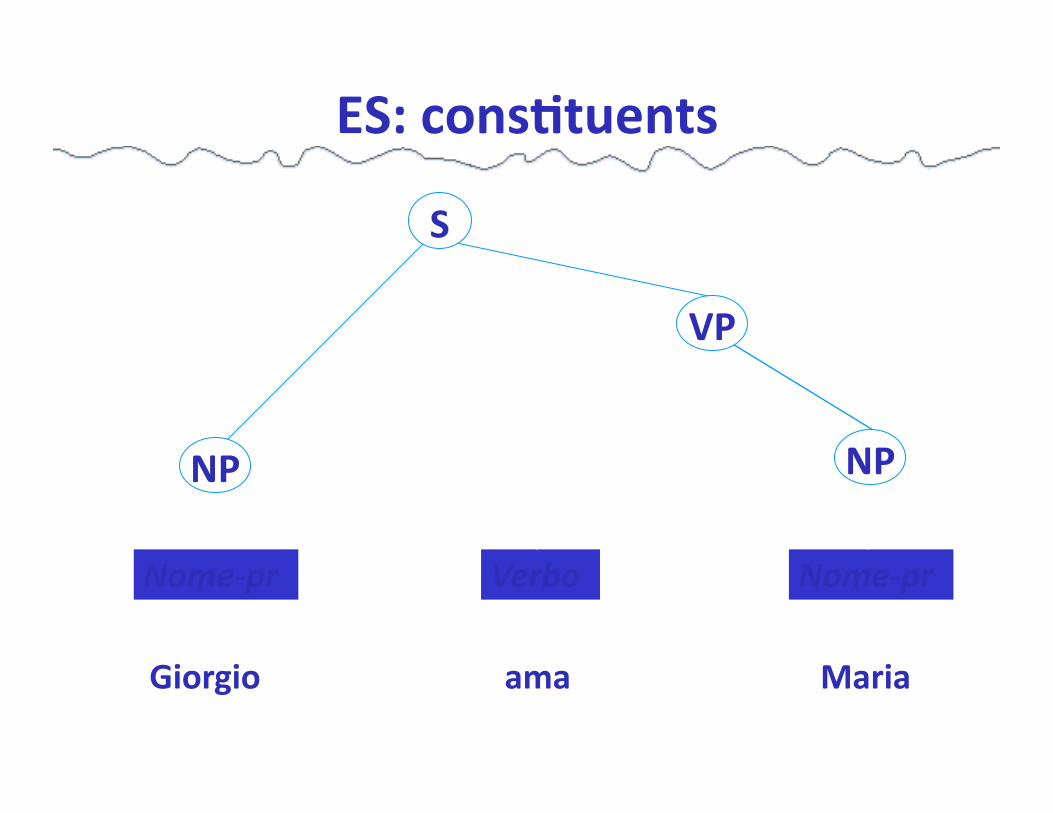
ES: cons'tuents
Giorgio ama Maria
Nome-‐pr Nome-‐pr Verbo
VP
S
NP NP

Cons%tuent structure
(S (NP ( NOME Giorgio)) (VP (VERBO ama) (NP (NOME Maria) ) )
)

Cons%tuent structure
Le relazioni tra le parole non sono tuLe uguali:
“Maria leggeva un libro in biblioteca”

ES: Penn annota'on
( S
( NP -‐ SBJ (PRP I) )
( ADVP -‐ TMP ( RB never) )
( VP (VBD had)
( NP (JJ many) (NNS clients) )
( NP -‐ ADV (DT a) ( NN day) ))
))
NP
VP
NP
ADVP
NP
S
SBJ
TMP
PRP
RB
VBD
NNS DT
NN DT ADV
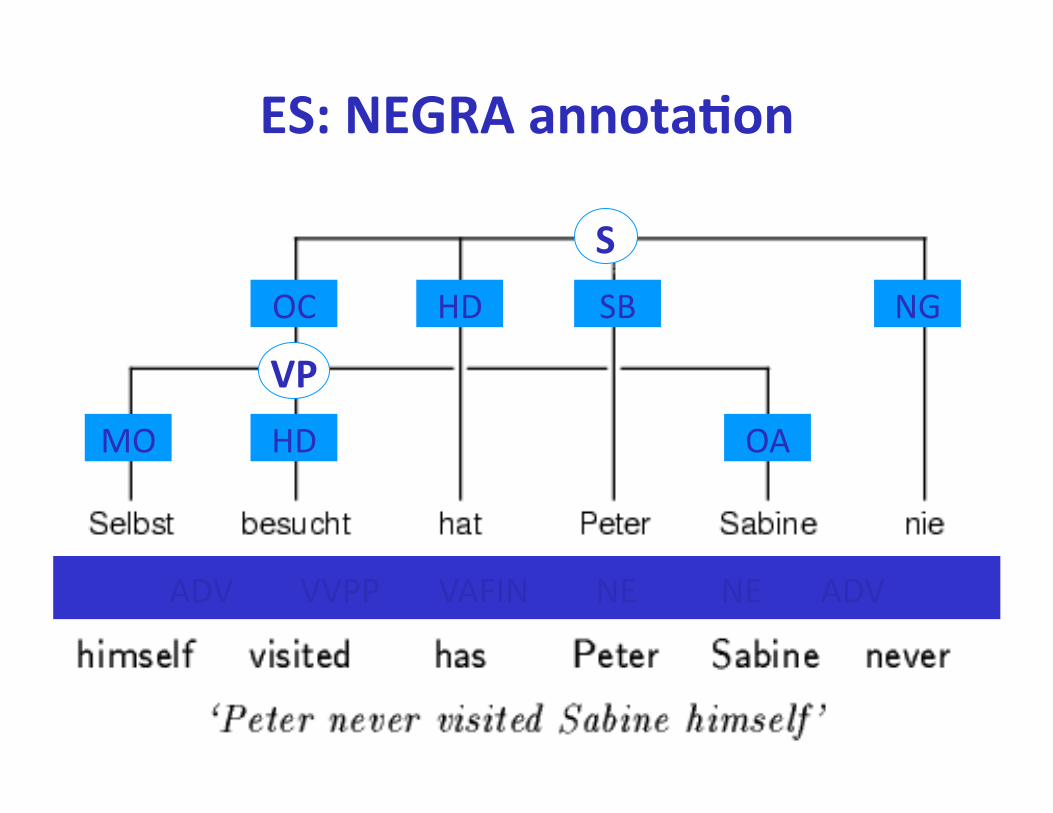
ES: NEGRA annota'on
S
VP
HD SB NG
MO HD OA
OC
ADV VVPP VAFIN NE NE ADV

Cos%tuen% e relazioni • La struLura relazionale include le informazioni rela%ve all’
organizzazione della frase in unità
• La struLura a cos%tuen% non include le informazioni rela%ve alla funzione delle parole
• La struLura relazionale è più compaLa

• Sia le relazioni che i cos%tuen% sono realizza% in modo diverso nelle diverse lingue
• La struLura relazionale include la struLura argomentale
Cos%tuen% e relazioni

La struLura argomentale
• relazioni gramma%cali
• ruoli seman%ci
• uguali o dis%n%?

Le relazioni gramma%cali
• Iden%ficabili da varie proprietà
• Diverse nelle varie lingue

Le relazioni gramma%cali
• Le relazioni sono realizzate diversamente nelle varie lingue, a seconda dell’uso di casi, inflessioni
give someone something dare a qualcuno qualcosa

MORPHO SYNT SEM PRAGUE semi-
automatic semi-automatic
semi-automatic
NEGRA automatic interactive (probabilistic)
PENN automatic automatic (skeletal)
Processo di annotazione

Processo di annotazione in TUT
• Part Of Speech tagging automa%co
• Correzione manuale del tagging
• Parsing interaAvo
• Verifica e revisione

Costruire un treebank
Per costruire validi sistemi di analisi del linguaggio occorrono i treebank.
InfaA è dimostrato che i sistemi di NLP che oLengono i migliori risulta% sono quelli che prendono le informazioni da treebank)

Costruire un treebank
Per costruire dei treebank occorrono validi sistemi di analisi del linguaggio.
È impossibile costruire treebank in modo esclusivamente manuale per mo%vi di tempo e di correLezza.

Costruire un treebank In pra%ca l’annotazione dei treebank è prodoLa da
sistemi automa%ci di analisi morfologica (-‐4%) e sintaAca (-‐10%)
+ annotatori umani che correggono le analisi prodoLe in modo automa%co
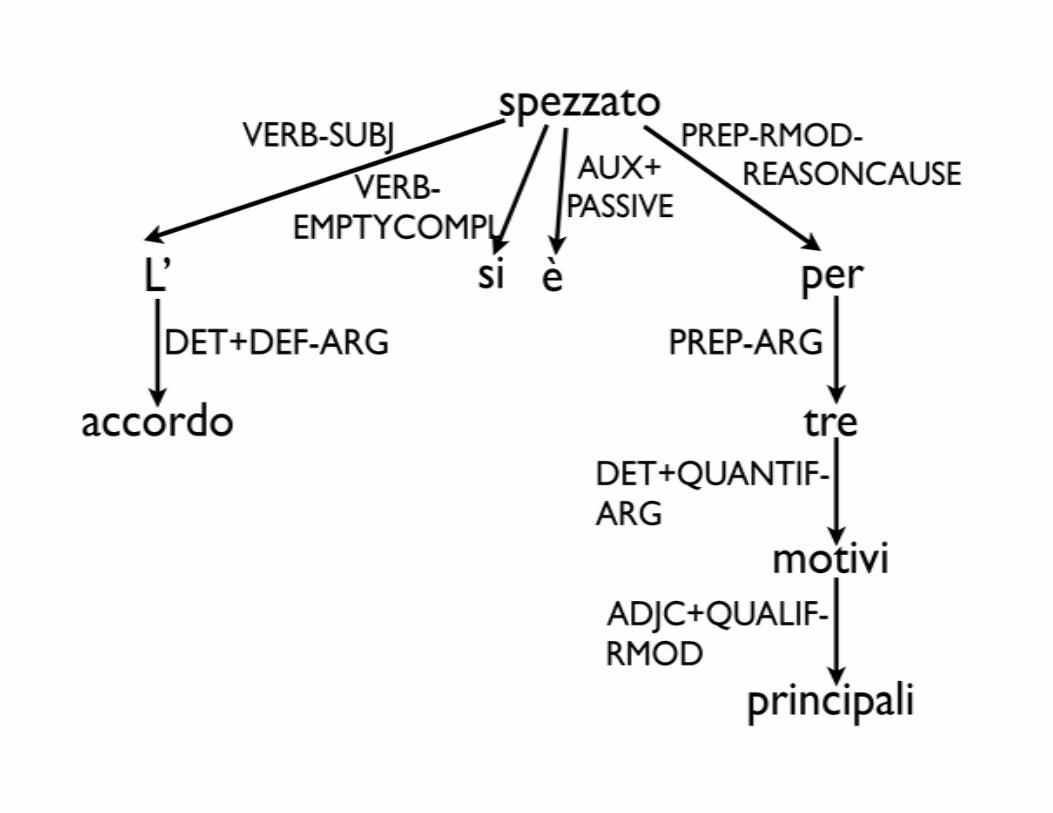
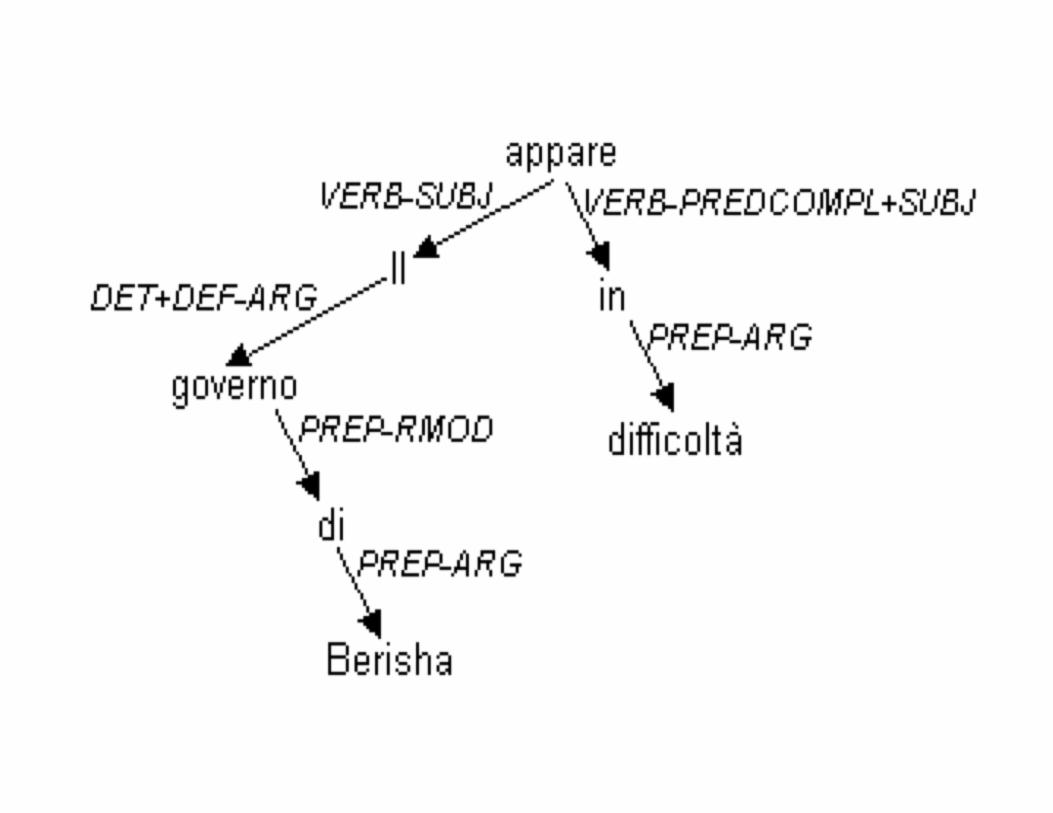

Ogni relazione di TUT può essere composta di 3 elemen%:
• Morfo-‐sintaAco: features che esprimono la categoria gramma%cale Verb, Noun, …
• Funzionale-‐sintaAco: relazioni sintaAche come Subject, Object
• Seman%co: relazioni seman%che come Loca%on, Time, Cause
Turin University Treebank (2)

1 In (IN PREP MONO) [7;PREP-‐RMOD-‐TIME]
2 quei (QUELLO ADJ DEMONS M PL) [1;PREP-‐ARG]
3 giorni (GIORNO NOUN COMMON M PL) [2;DET+DEF-‐ARG]
4 Sudja (|Sudja| NOUN PROPER) [7;VERB-‐SUBJ]
5 la (IL ART DEF F SING) [4;APPOSITION]
6 zingara (ZINGARO NOUN COMMON F SING) [5;DET+DEF-‐ARG]
7 annunciava (ANNUNCIARE VERB MAIN IND IMPERF TRANS 3 SING) [0;TOP-‐VERB]
8 il (IL ART DEF F SING) [7;VERB-‐OBJ]
9 fallimento (FALLIMENTO NOUN COMMON M SING FALLIRE INTRANS) [8;DET+DEF-‐ARG]
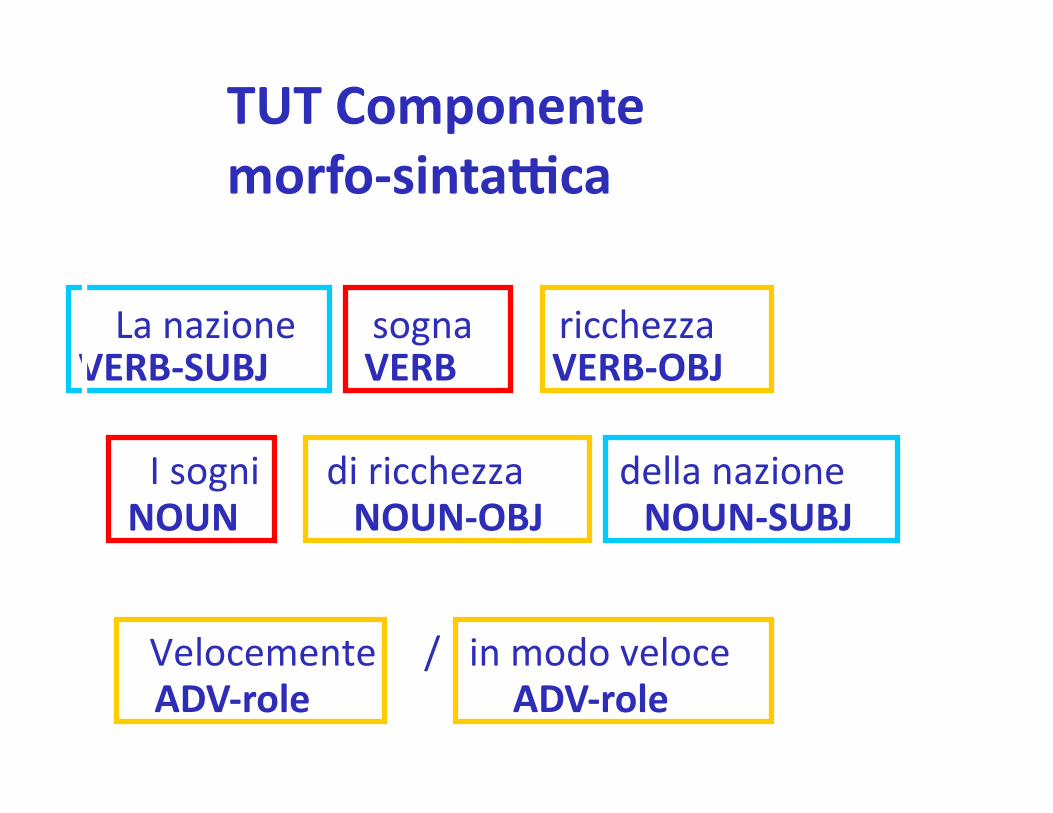
La nazione sogna ricchezza
I sogni di ricchezza della nazione
Velocemente / in modo veloce
VERB-‐SUBJ
NOUN-‐OBJ NOUN-‐SUBJ
VERB-‐OBJ VERB
NOUN
ADV-‐role ADV-‐role
TUT Componente morfo-‐sinta`ca

TUT Componente morfo-‐sinta`ca

• Da% 944 differen% Verbi per un totale di 4.169 occorrenze nel corpus di TUT
• Il 30% di ques% Verbi (e le struLure predica%ve argomentali ad essi associate) risulta presente anche in forma nominale
TUT Componente morfo-‐sinta`ca

Egli non è stato visto da nessuno
Egli non è stato visto da ieri
ARG
MOD
TUT Componente funzionale-‐sinta`ca
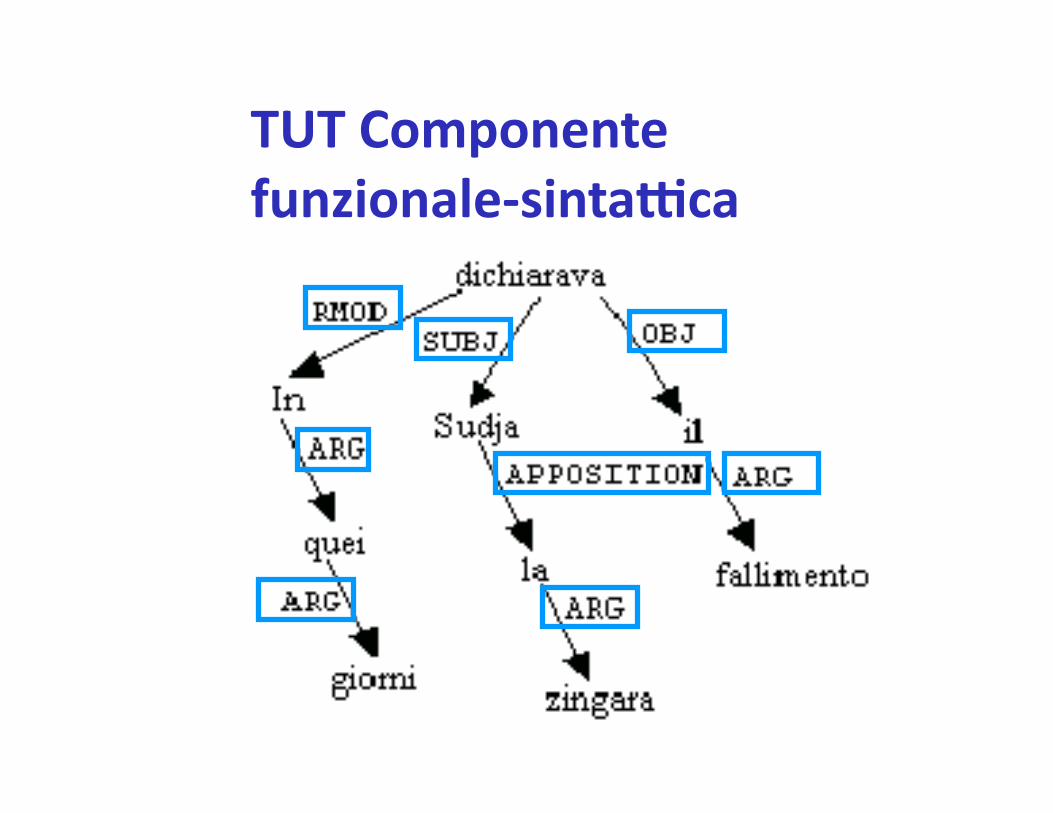
TUT Componente funzionale-‐sinta`ca

Da qui è par%to l’assalto
Succedeva dall’altra parte del mondo
I miliardi stanzia% dal 1991
Era impazzito dal dolore
Trarrà beneficio dalla bonifica
LOC+FROM
LOC+IN
TIME
REASONCAUSE
SOURCE
TUT Componente seman'ca
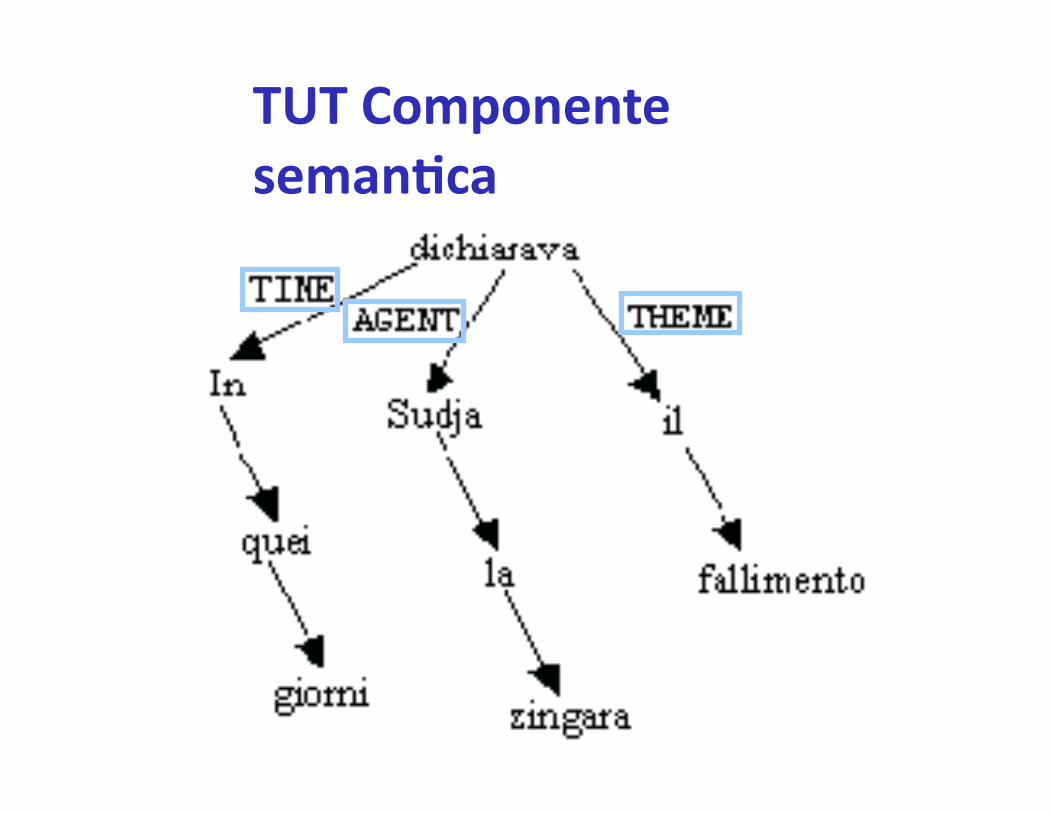
TUT Componente seman'ca

• Da% 600 sintagmi preposizionali introdoA dalla preposizione DA e che svolgono il ruolo di modificatori
• È stato rilevato che essi possono assumere i seguen% 7 differen% valori seman%ci: LOC+FROM, LOC+IN, LOC+METAPH, TIME, THEME, REASONCAUSE, SOURCE
TUT Componente seman'ca

1 In (IN PREP MONO) [7;PREP-‐RMOD-‐TIME]
2 quei (QUELLO ADJ DEMONS M PL) [1;PREP-‐ARG]
3 giorni (GIORNO NOUN COMMON M PL) [2;DET+DEF-‐ARG]
4 Sudja (|Sudja| NOUN PROPER) [7;VERB-‐SUBJ]
5 la (IL ART DEF F SING) [4;APPOSITION]
6 zingara (ZINGARO NOUN COMMON F SING) [5;DET+DEF-‐ARG]
7 annunciava (ANNUNCIARE VERB MAIN IND IMPERF TRANS 3 SING) [0;TOP-‐VERB]
8 il (IL ART DEF F SING) [7;VERB-‐OBJ]
9 fallimento (FALLIMENTO NOUN COMMON M SING FALLIRE INTRANS) [8;DET+DEF-‐ARG]

Applicare lo schema di annotazione a TUT significa che ogni sua frase:
• viene parsificata in modo automa%co dal parser TULE, sviluppato in parallelo con TUT • correLa da almeno 2 annotatori umani • verificata da tool automa%ci apposi% • soLoposta a conversioni e applicazione di altri sistemi

Ricadute del progeao TUT
U%lizzo in 3 diverse direzioni:
• Come raccolta di da% linguis%ci
• Come banco di prova per sistemi di NLP
• Come modello per lo sviluppo di altre risorse

• Come raccolta di da% linguis%ci TUT ha consen%to
• Studi sul comportamento dei verbi della lingua italiana (estrazione di conoscenza)
• Studio dell’ordine delle parole nella lingua italiana
Ricadute del progeao TUT
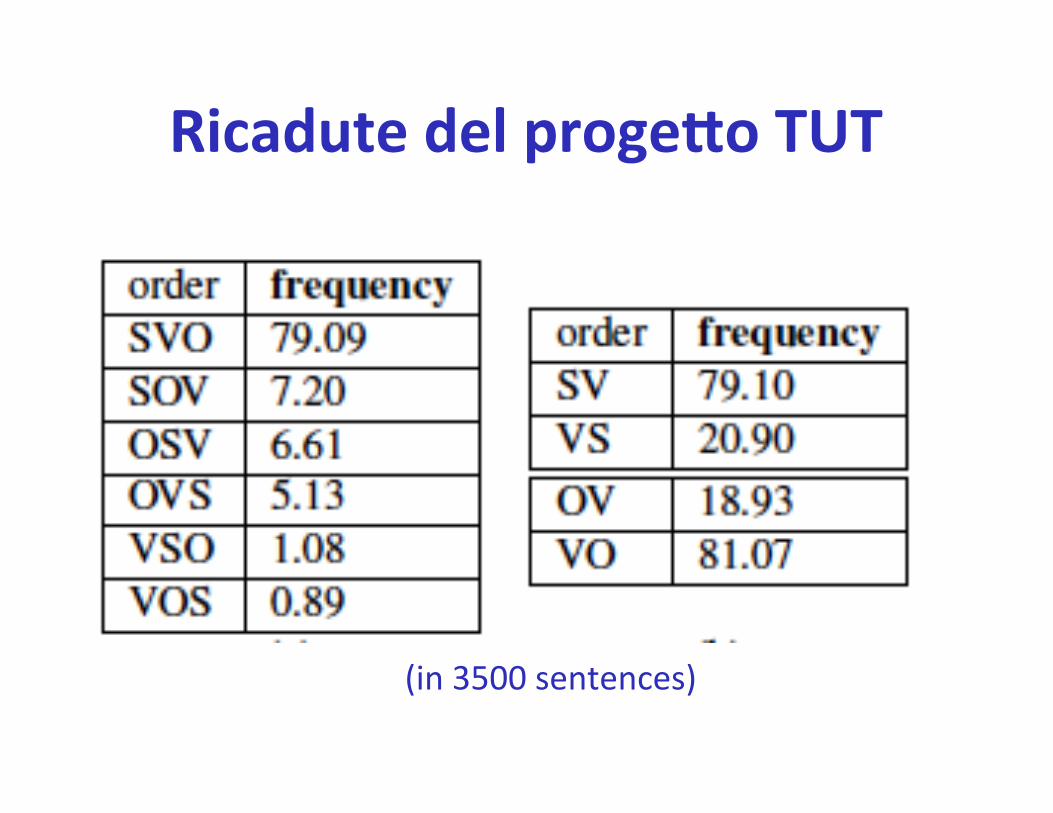
(in 3500 sentences)
Ricadute del progeao TUT

• Come banco di prova per sistemi di NLP TUT ha consen%to di raggiungere i risulta% allo stato dell’arte per il parsing dell’italiano, errore intorno al 10%
• TUT è il treebank di riferimento nelle compe%zioni per parser di italiano (Evalita 07, 09, 11, 14)
Ricadute del progeao TUT

• Come modello per lo sviluppo di altre risorse, TUT è u%lizzato in:
• in prospeAva cross-‐linguis%ca, è in corso di sviluppo un treebank parallelo per le lingue italiano, francese e inglese (ParTUT)
• per lo studio di fenomeni lega% all’espressione di sen%men%, opinioni ed emozioni, è in corso di sviluppo un corpus di tes% di TwiLer annotato morfologicamente (Sen%TUT)
Ricadute del progeao TUT

• INOLTRE: TUT è stato tradoLo in forma% di altri treebank grazie a tool di conversione automa%ca
• Questo ha reso possibile l’applicazione di strumen% sviluppa% per tali forma% ed il confronto tra paradigmi e modelli linguis%ci differen% nell’ambito del dibaAto su quale formato si rivela più adeguato per il NLP in generale e per le diverse lingue naturali
Ricadute del progeao TUT

Il Turin University Treebank (TUT), ParTUT e Sen%TUT sono tuA progeA
del Content Centered Compu%ng Group (C. Bosco, A. Mazzei, V. Lombardo, R. Damiano , V. PaA, M. SanguineA)
del Dipar%mento di Informa%ca dell’Università di Torino

Per ulteriori informazioni:
hLp://www.di.unito.it/~tutreeb


















