
Lezione03 - Banche datidocente.unife.it/matteo.ramazzotti/bioinfo/03 - Databanks.pdf · Banche...
30
Banche dati
Transcript of Lezione03 - Banche datidocente.unife.it/matteo.ramazzotti/bioinfo/03 - Databanks.pdf · Banche...

Banche dati

Banche dati
Si possono raggruppare in varie categorie in base al tipo di dato biologico che raccolgono e organizzano, ma ce ne sono alcune che sono da considerarsi fondamentali:
- banche dati di sequenze nucleotidiche (dette anche primarie)
- banche dati di espressione genica
- banche dati proteiche
Su queste se ne impiantano molte altre, che articolano le varie informazioni a seconda dei casi e degli scopi della banca dati e su cui è possibile effettuare ricerche in modo molto mirato.
In questo corso verranno trattate le banche dati proteiche anche se non bisogna dimenticare che molti dati sulle
proteine derivano dalle banche dati primarie, cioè quelle nucleotidiche.

Banche dati: un po’ di storia
• Inizio anni 70: nasce la tecnologia del DNA ricombinante, che permette di manipolare le sequenze nucleotidiche e di capire la struttura, la funzione e l’organizzazione del DNA.
• Fine anni 70: pubblicazione dei primi dati genomici, con le prime sequenze nucleotidiche codificanti liberamente accessibili attraverso i rudimenti della rete disponibili a quel tempo tra le varie università.
• 2001: il Consorzio Pubblico Internazionale e la Celera Genomicsforniscono dati del genoma umano completo, aprendo la strada ai progetti di sequenziamento a tappeto.
Successivamente, l’approccio biotecnologico ha fornito una serie imponente di dati di natura proteomica grazie all’analisi spettrometricae all’elettroforesi 2-D, ed una serie altrettanto vasta di dati di trascrittomica grazie alla tecnologia dei microarray.

Insieme ai dati nasce l’esigenza di sistemi di archiviazione e di ritrovamento facili e esaustivi, in modo da averli a disposizione in ogni istante, dato che
sebbene ci siano tantissime informazioni, ognuna deve essere convalidata e confermata, essendo per la maggior parte dati grezzi non rielaborati.
una banca dati è il posto dove cercare i dati da cui partire per una ricerca, non il suo punto di arrivo.
Banche dati: significato
Conoscere il dato non significa capire il dato, serve sempre un approccio sperimentale classico perché questo sia veramente
utile.

1965: Margareth Dayhoff compila un atlante di proteine omologhestudiando le relazioni tra le sequenze primarie
1970: l’atlante viene reso pubblico in versione elettronica nella banca dati NBRF
=> nasce la prima banca dati proteica.
Ancora non ci sono dati di sequenziamento nucleotidico nella banca, sono tutti dati di natura biochimica classica, ma
l’idea di rendere disponibili in modo libero dei dati accumulati e organizzati è alla base del concetto che muove gli organizzatori e i curatori delle banche dati, e che muove anche i fondi per la loro gestione.
I pionieri

Banche dati: infrastrutture
EMBNet, nata nel 1988 come rete europea a supporto della ricerca bio-molecolare, oggi conta 41 nodi nazionali in paesi europei ed extraeuropei (in Italia il nodo è a Bari).
APBioNet (Asian-Pacific BiologicNetwork), gemelleta con EMBNet, con un’organizzazione analoga.
Oggi le due banche dati primarie più importanti sono accessibili dai centri
EBI (Cambridge, UK) : EMBL data-library
NCBI (USA) : GenBank

1981: nasce nel Laboratorio Europeo di Biologia Molecolare ad Heidelberg (Germania) l’EMBL-datalibrary, 519 entries con sequenze di DNA e RNA, autore Kurt Stueber
1982: nasce una banca dati simile negli USA, darà vità alla GenBank, autore Walter Goad
1986: nel National Institute of Genetics in Mishima (Giappone) nasce un mirror della GenBank, la DDBJ
1992: i tre centri si consorziano nell’ INSDC (International Nucleotide Sequence Database Collaboration) stabilendo regole comuni per la gestione delle banche dati.
Banche dati primarie
http://www.ddbj.nig.ac.jp/
http://www.embl.de/
http://www.ncbi.nlm.nih.gov/
http://www.insdc.org/

Banche dati primarie: i numeri
DDBJ release 80.0
EMBL release 102
GenBank release 176
0.00E+00
2.00E+07
4.00E+07
6.00E+07
8.00E+07
1.00E+08
1.20E+08
1.40E+08
3 -1982
53 -1987
67 -1991
82 -1994
97 -1996
112 -1999
127 -2001
142 -2004
157 -2006
172 -2009
Release - Date
Entr
ies
0
2E+10
4E+10
6E+10
8E+10
1E+11
1.2E+11
Bas
e Pa
irs
Entries Base Pairs

Organizzazione di un database biologico
L’oggetto principale è la ENTRY, una unità riconoscibile grazie ad un identificatore univoco, che possiede una descrizione organizzata in campi standardizzati riconoscibili grazie ad HEADERS (o qualifiers) univoci nella banca dati.
es. Identificatore -----------------
Autore -----------------
Data -----------------
ecc.
Ogni banca dati presenta 2 versioni delle entries:
Flat-file: un file di testo semplice, formattato, non interattivo.
HTML : pagina web interattiva, di facile consultazione.

Banche dati primarieLe banche dati primarie sono la “sorgente” di tutte le altre banche dati, servono regole ferree e condivise affinché si possano sincronizzare “on a daily basis”.
Per questo nasce il concetto di Feature Table
http://www.insdc.org/documents/feature_table.html

La feature table INSDCNiente è lasciato al caso (almeno nelle intenzioni) nel definire uno standard condiviso per la condivisione delle informazioni tra banche dati: oltre che ai campi (Feature keys) e ai valori (qualifiers) anche il numero di spazi e la formattazione del testo ha una definizione rigorosa.
Feature keys(66)
Qualifiers (/xxx=)(154)

“In 2005 the International Nucleotide Sequence Database Collaboration (INSDC) introduced the lat_onqualifier that allows to describe precisely where the sequenced specimen was collected. The mapabove shows the geographical distribution of samples annotated so far.”
L’importanza dei “qualifier”I qualifier indicano che tipo di informazione si trova in un dato campo. Neesistono attualmente 154, alcuni davvero curiosi…

Formattazione dei flat filesUna formattazione così rigorosa assicura il corretto funzionamento dei programmi che eseguono il cosiddetto “parsing” dell’informazione.
EMBL GenBank

Interattività e dati incrociati
L’interattività ha un ruolo centrale per una banca dati, perché permette di navigare tra le sue entries e quelle di altri database.
Sia i flat-file sia le pagine web sono ricchi di cross-references, riferimenti che mandano ad altre banche dati generiche o specializzate.

Qualifier: /db_xref="database:identifier"
Definition: database cross-reference: pointer to related informationin another database
Scope: all feature keys
Value format: "database:identifier" where database is the name of the database containing related information, and identifier is the internal identifier of the related information according to the namingconventions of the cross-referenced database.
Examples:
cross reference to GDB identifier: /db_xref="GDB:39999" cross reference to Swiss-Prot entry: /db_xref="Swiss-Prot:P12345"
Incrociare i dati: il qualifier /db_xrefAl fine di mantenere una uniformità rigorosa, anche le cross-referencessono pre-classificate: il campo /db_xref serve a “puntare” banche dati esterne affidabili e verificate (es. non si può puntare wikipedia…).
Detto questo però ogni consorzio però è libero di puntare ciò che vuole: le /db_xref sono ufficiali, le altre no…

Banche dati EMBL
Banche dati DDBJ

Banche dati NCBI

Banche dati nucleotidiche più utilizzate

Banche dati genomiche più utilizzate
http://www.ncbi.nlm.nih.gov/sites/genome
http://gib.genes.nig.ac.jp/
http://www.ensembl.org/index.html

Uso delle guide, fondamentale…Le banche dati non possono essere relegata ad una lezione: sono entitàcomplesse e ognuna ha le sue peculiarità. Non è nemmeno possibile mandare a memoria i dettagli di utilizzo di ogni banca dati.
La cosa più utile è abituarsi a consultare le guide online, ogni banca dati che si rispetti ne ha una…

Genome browser EMBLMolto complesso, piuttosto intuitivo, fornisce delle mappe clickabili dei cromosomi che vengono zoomati fino ad arrivare al dettaglio dei geni, sei CDS e delle sequenze, che alla fine possono essere scaricate.

Genome browser NCBIRelativamente semplice, tramite lo zoom è possibile aumentare o diminuire il dettaglio. Clickando sui link si aggiungono dettagli e si punta alla sequenza o al contesto cromosomico.

Genome browser DDBJIl più semplice (e il meno annotato), forse troppo semplice. Muovendosi sulla mappa grafica si scorre il cromosoma evidenziando CDS, RNA e “altro” utilizzando un’utile legenda a blocchi colorati.

Banche dati tassonomiche
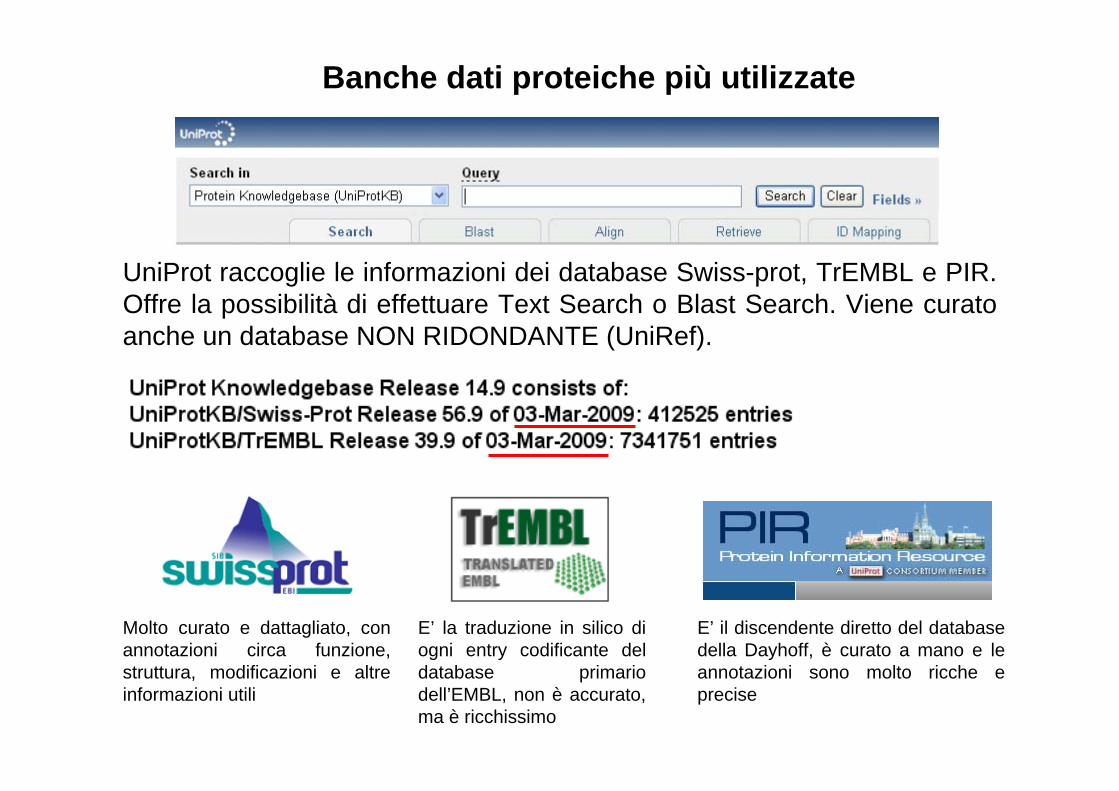
Banche dati proteiche più utilizzate
UniProt raccoglie le informazioni dei database Swiss-prot, TrEMBL e PIR. Offre la possibilità di effettuare Text Search o Blast Search. Viene curato anche un database NON RIDONDANTE (UniRef).
Molto curato e dattagliato, con annotazioni circa funzione, struttura, modificazioni e altre informazioni utili
E’ la traduzione in silico di ogni entry codificante del database primario dell’EMBL, non è accurato, ma è ricchissimo
E’ il discendente diretto del database della Dayhoff, è curato a mano e le annotazioni sono molto ricche e precise

Ma quante proteine sono note oggi?
> 410.000 verificate
(Swiss-Prot)
> 7.000.000 predette
(TrEMBL)

Banche dati proteiche più utilizzate
E’ un database di famiglie e domini proteici comprensiva di pattern e motivi (signatures) che identificano e rendono riconoscibili e classificabili le proteine. La ricerca in prosite comprende anche altri database strutturali e di classificazione.
una signature formattata, definita anche pattern, permette di indicare con precisione le sequenze tipiche e le loro varianti.

Integr8 è una immensa raccolta di proteine catalogate per organismo di appartenenza e permette analisi inter-proteomiche mediante opportuni programmi di confronto.
Pfam è una raccolta di proteine allineate e di profili generati con i modelli nascosti di Markov (HMM) che descrivono quasi tutte le famiglie e i domini proteici conosciuti. Da qui è possibile una analisi dettagliata sfruttando le risorse disponibili nel server del Sanger Institute per l’analisi familiare delle proteine.
Banche dati proteiche più utilizzate

Database di Protein Fingerprints, cioèpattern caratteristici di certe famiglie proteiche
Database di domini proteici generato in modo automatico da Swiss-Prot e TrEMBL
Database di architetture proteicheannotate per organismo e per famiglia
Database di strutture tridimensionali di proteine altre componenti proteiche
Banche dati proteiche più utilizzate


















