
Lezione T8 Gli scheduler CPU di Linux - … · Algoritmo di scheduling (Round Robin; what else?)...
64
1 Lezione T8 Gli scheduler CPU di Linux Sistemi Operativi (9 CFU), CdL Informatica, A. A. 2013/2014 Dipartimento di Scienze Fisiche, Informatiche e Matematiche Università di Modena e Reggio Emilia http://weblab.ing.unimo.it/people/andreolini/didattica/sistemi-operativi
-
Upload
phamnguyet -
Category
Documents
-
view
218 -
download
0
Transcript of Lezione T8 Gli scheduler CPU di Linux - … · Algoritmo di scheduling (Round Robin; what else?)...

1
Lezione T8Gli scheduler CPU di LinuxSistemi Operativi (9 CFU), CdL Informatica, A. A. 2013/2014Dipartimento di Scienze Fisiche, Informatiche e MatematicheUniversità di Modena e Reggio Emiliahttp://weblab.ing.unimo.it/people/andreolini/didattica/sistemi-operativi

2
Quote of the day(Meditate, gente, meditate...)
“The design relies on the fact that interactive tasks, by their nature, sleep often.”
Con Kolivas (1977-)Anestesista, programmatoreIl pioniere del “desktop interattivo”

3
Parametri di progetto di uno scheduler(Repetita juvant)
Numero e formato delle code dei processi pronti.Algoritmo di scheduling per ciascuna coda.Criterio usato per spostare un processo in una coda con priorità maggiore.Criterio usato per spostare un processo in una coda con priorità minore.Criterio usato per scegliere la coda in cui inserire inizialmente un processo.

4
LINUX v1.2
5
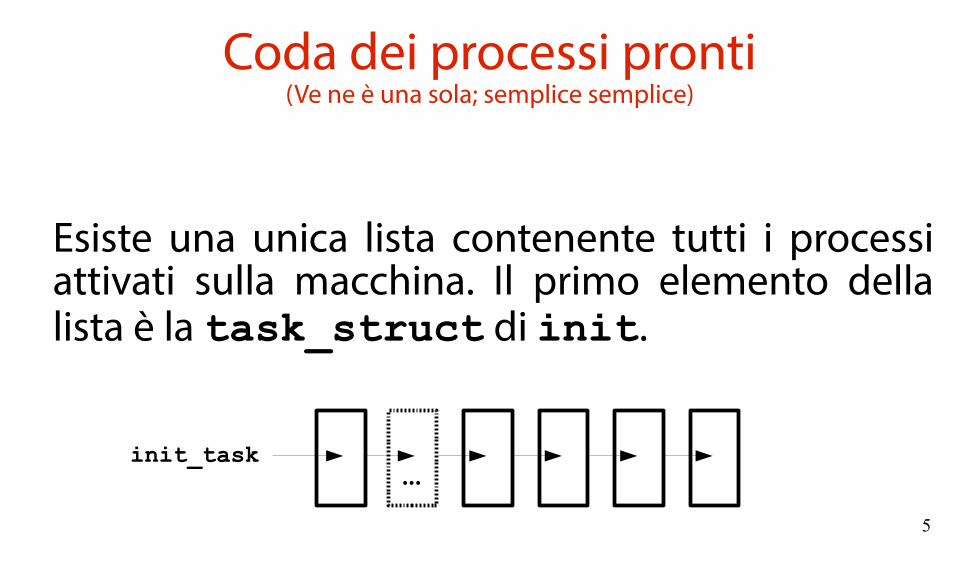
Coda dei processi pronti(Ve ne è una sola; semplice semplice)
Esiste una unica lista contenente tutti i processi attivati sulla macchina. Il primo elemento della lista è la task_struct di init.
...init_task

6
Definizione delle priorità(Priorità statica, the UNIX way)
Ogni processo ha una priorità statica (nice value o nice) (re)impostabile dall'utente.La priorità varia da -20 (priorità più alta) a +19 (priorità più bassa). Il valore di default è 10.
→ Schema classico delle priorità in UNIX.Non è prevista una modifica dinamica delle priorità da parte del kernel.

7
Algoritmo di scheduling(Round Robin; what else?)
L'algoritmo di scheduling pesca in modalità “round robin pesata” uno dei processi in TASK_RUNNING.
Un processo in attesa da più tempo viene favoritorispetto ad un processo che attende da meno tempo.A parità di attesa, un processo a priorità più alta vienefavorito rispetto ad un processo a priorità più bassa.
A tal scopo, ad ogni processo è associato un contatore, inizializzato al valore della priorità statica.

8
Aggiornamento del contatore(Round Robin; what else?)
Ad ogni invocazione di schedule(), l'intera lista è scandita ed i contatori aggiornati:
contatore = (contatore >> 1) + prioritySi sceglie il processo per cui contatore è massimo.

9
Modifica dinamica della priorità(Non pervenuta)
Non esiste alcun meccanismo per la modifica dinamica della priorità in funzione della natura del processo.L'unica priorità esistente è quella statica.La priorità iniziale del processo è:
il valore iniziale di default (10).oppure un valore impostato con il comando nice.

10
Problemi 1/3(Tanti, purtroppo)
L'algoritmo di scheduling è O(n) rispetto al numero di processi (una invocazione di schedule() una →scansione lineare della lista).
Che succede se schedule() è invocata migliaia divolte al secondo in un sistema server con migliaia diprocessi attivi?

11
Problemi 2/3(Tanti, purtroppo)
Non vi è alcuna differenziazione in classi; l'unico discriminante è una priorità statica.
Che succede se un processo muta spesso la proprianatura? Il programmatore deve reimpostare ogni volta la priorità statica a mano?Che succede ad un terminale interattivo che va incompetizione con uno script di make?

12
Problemi 3/3(Tanti, purtroppo)
Vi è una unica lista globale.L'accesso alla lista va “serializzato” per impedire lemodifiche concorrenti. I processori si “accodano”→per accedere alla lista. Le prestazioni non scalano→con il numero di processori.
Questo non è un vero problema, dal momento che Linux v1.12 non supporta sistemi SMP.

13
LINUX v2.2

14
Differenze rispetto allo scheduler v1.2(Classi di processi, goodness())
Lo scheduler del kernel v2.2 è una estensione di quello presente nella versione v1.2. Differenziazione dei processi in più classi tramite un
insieme più ampio di priorità.Introduzione di una funzione (goodness())per il calcolo della “bontà” di un processo (ovveroquanto è favorevole schedularlo).

15
Il nuovo schema di priorità(Da [-20, 19] a [0, 139])
Si usano 140 livelli di priorità.Livelli [0, 99]: usati da algoritmi di scheduling di tipo soft real time (SCHED_FIFO, SCHED_RR), che hanno sempre la precedenza sull'algoritmo standard.Livelli [100, 139]: corrispondono al vecchio intervallo [-20, 19] e sono utilizzati dall'algoritmo di scheduling di default (round robin pesato).

16
Classi di processi: SCHED_FIFO(Alta priorità)
Impostabili staticamente dall'utente all'avvio del processo.SCHED_FIFO: FCFS senza prelazione “soft real time”. Opera ad una priorità in [0, 99]. Un processo non si ferma se non quando termina o richiede I/O.
→ Occhio: pericolo di stallo della macchina in caso diciclo infinito!

17
Classi di processi: SCHED_RR(Alta priorità)
Impostabili staticamente dall'utente all'avvio del processo.SCHED_RR: RR “soft real time”. Opera ad una priorità in [0, 99].

18
Classi di processi: SCHED_OTHER(Bassa priorità)
Impostabili staticamente dall'utente all'avvio del processo.SCHED_OTHER: algoritmo di scheduling RR pesato (derivato da quello presente in v1.2).Opera ad una priorità in [100, 139] ed è pertanto sempre battuto da SCHED_FIFO o SCHED_RR.
→ Occhio: rischio di starvation in caso di esecuzionecon un processo CPU-bound soft real time!

19
Criterio di scelta del processo(Priorità + algoritmo)
Algoritmo multilivello.Passo 1: si individua il processo con priorità più alta nella lista dei processi.Passo 2: si applica l'algoritmo di scheduling associato al processo.

20
La funzione goodness()(Stima dell'interattività di un processo)
La funzione goodness() ritorna un peso (weight) nell'intervallo [-1000, 1000]. Il peso è usato per scegliere il processo da schedulare.
-1000: mai selezionare questo processo.1000: processo soft real time, da selezionare subito.
Algoritmo:Classe == SCHED_FIFO | SCHED_RR? Sì weight=1000→Processo gira su stesso processore? Sì weight += bonus→Processo usa le stesse aree di memoria?
Sì weight += bonus →weight += priorità processo

21
Problemi 1/2(Un po' meno)
L'algoritmo di scheduling è O(n) rispetto al numero di processi (una invocazione di schedule() una →scansione lineare della lista).
Che succede se schedule() è invocata migliaia divolte al secondo in un sistema server con migliaia diprocessi attivi?

22
Problemi 2/2(Un po' meno)
Vi è una unica lista globale.L'accesso alla lista va “serializzato” per impedire lemodifiche concorrenti. I processori si “accodano”→per accedere alla lista. Le prestazioni non scalano→con il numero di processori.
Questo comincia ad essere un problema, dal momento che Linux v2.2 supporta architetture SMP.

23
LINUX v2.4

24
Differenze rispetto allo scheduler v2.2(Classi di processi, goodness())
Lo scheduler del kernel v2.4 è una estensione di quello presente nella versione v2.2. Uso di una coda contenente solo processi in stato di
pronto.Uso di quanti di tempo variabili (time slice).Uso di un sistema di schedulazione a crediti.

25
Time slice(Quanto di tempo variabile)
Ciascun processo può eseguire al più per un intervallo di tempo calcolato dinamicamente (time slice).Il calcolo avviene mediante un sistema a crediti:
un credito 10ms di esecuzione.→un processo acquisisce un credito ogni volta che siblocca premio all'interattività.→dopo l'esecuzione di una time slice si scala un credito.nessun credito niente processore.→

26
Recrediting(Quanti crediti sono riassegnati ai processi?)
Quando tutti i processi in stato TASK_RUNNING hanno esaurito i crediti, il kernel ricalcola il credito per tutti i processi (recrediting).Algoritmo di aggiornamento:
next_credit = prev_credit / 2 + prioritySi cerca di ridurre il credito a disposizione dei processi per non farli eseguire troppo a lungo.Se il processo è interattivo il credito aumenta.→Se il processo non è interattivo il credito si →riduce.

27
Algoritmo di scheduling(Round Robin; what else?)
L'algoritmo di scheduling pesca il processo migliore tramite la funzione goodness(), in modo analogo al kernel v2.2.La funzione goodness() tiene ora in conto anche dei seguenti aspetti:
affinità al processore.crediti rimanenti.

28
Problemi 1/2(Pochi, ma grossi)
L'algoritmo di scheduling è O(n) rispetto al numero di processi.
Una invocazione di schedule() una scansione→lineare della run queue).Un recrediting una scansione lineare della run→queue.

29
Problemi 2/2(Pochi, ma grossi)
I processori sono inattivi durante il recrediting. → starvation dei processori (tanto più marcata
quanti più sono).

30
LINUX V2.5.49 - V2.6.22

31
Differenze rispetto allo scheduler v2.4(Parecchie; è una riscrittura da zero)
Obiettivi.Favorire i processi interattivi indipendentemente dal carico di lavoro applicato al processore.Scalare bene le prestazioni dello scheduler con
il numero di processi.il numero di processori.
32
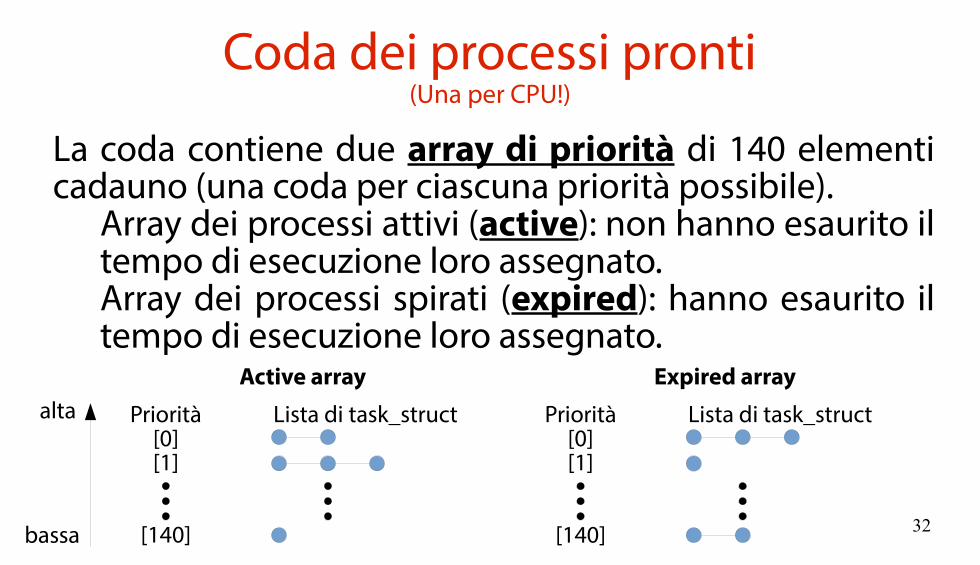
Coda dei processi pronti(Una per CPU!)
La coda contiene due array di priorità di 140 elementi cadauno (una coda per ciascuna priorità possibile).
Array dei processi attivi (active): non hanno esaurito iltempo di esecuzione loro assegnato.Array dei processi spirati (expired): hanno esaurito iltempo di esecuzione loro assegnato.
Priorità[0][1]
[140]
Active array
Lista di task_struct Priorità[0][1]
[140]
Expired array
Lista di task_struct
bassa
alta

33
for (p = init_task; p != init_task; p++) {if (p->prio != MAX)
p->prio++;if (p->prio > current->prio)
switch_to(p);}
Il difetto del Weighted Round Robin(L'algoritmo standard in pseudocodice O(n))→
Aging (per evitare lastarvation del processo)
Si schedula ilprimo processocon priorità piùalta trovato.
Il ciclo for cicla sull'intera lista dei processi e pesca quello a priorità più alta fra gli eseguibili.
→ Algoritmo O(n) rispetto al numero di processi.Bisogna cercare di evitare il ciclo for sull'intera lista.

34
Un algoritmo O(1) rispetto ai processi(Ricorda molto da vicino la tecnica del double buffering per i videogiochi)
1.Trovare in tempo O(1) la coda di priorità più elevata in active contenente la task_struct di un processo eseguibile.
2.Se non esiste una task_struct, tutti i processi sono spirati. Si scambiano gli array active ed expired (operazione fattibile in tempo O(1)) e si ripete 1.
3.Sia next=task_struct in cima alla coda di priorità più elevata (O(1)).
4.Si ricalcola la priorità di next (O(1).5.Si effettua un cambio di contesto a next (O(1)).6.Quando next ha usato la sua timeslice, lo si inserisce nella coda
di priorità opportuna nell'array expired (O(1)).7.Si invoca schedule() per schedulare un altro processo (O(1)).

35
Come risolvere il passo 1.(Come trovare la coda con priorità più elevata senza scandirle tutte)
Si usa una bitmap di 140 bit (5 interi a 32 bit).
bit i=1 →Nella coda i è presente la task_struct di un processoeseguibile.
bit i=0 →Nella coda i non è presente la task_struct di un processoeseguibile.
L'istruzione assembly bsfl (Intel) individua in tempo costante (O(1)) il primo bit non nullo in una bitmap.

36
Stima dell'interattività(Il kernel riconosce i processi interattivi)
Obiettivo della stima: aumentare in maniera dinamica la priorità di un processo interattivo.Criterio di interattività: frequenza di blocco processo.
Frequenza elevata: processo I/O-bound→Frequenza bassa: processo CPU-bound→
Implementazione: campo sleep_avg inserito nella task_struct del processo.
Run blocked: si sottrae a → sleep_avg il tempo diesecuzione dell'ultima timelice.Blocked run: si aggiunge a → sleep_avg il tempo diblocco (fino ad un massimo di 10ms).

37
Calcolo dinamico della priorità(Il processo esegue tanto spesso quanto richiesto dalla sua natura)
La funzione effective_prio(), definita nel file $LINUX/kernel/sched.c, calcola il boost di priorità da assegnare ad un processo in base alla sua interattività.Tale funzione assegna un bonus di priorità nell'intervallo [-5, +5].
Processo fortemente I/O-bound -5.→Processo fortemente CPU-bound +5.→

38
Calcolo dinamico della timeslice(Il processo esegue tanto tempo quanto richiesto dalla sua natura)
La durata della timeslice è:memorizzata nel campo time_slice dellatask_struct.calcolata dalla funzione task_timeslice() nelfile $LINUX/kernel/sched.c.
Tale funzione scala la priorità statica (PS) di un processo in un valore nell'intervallo [5ms, 800ms]: PS < 120 time_slice = (140 – PS) * 20→ PS ≥ 120 time_slice = (140 – PS) * 5→
39
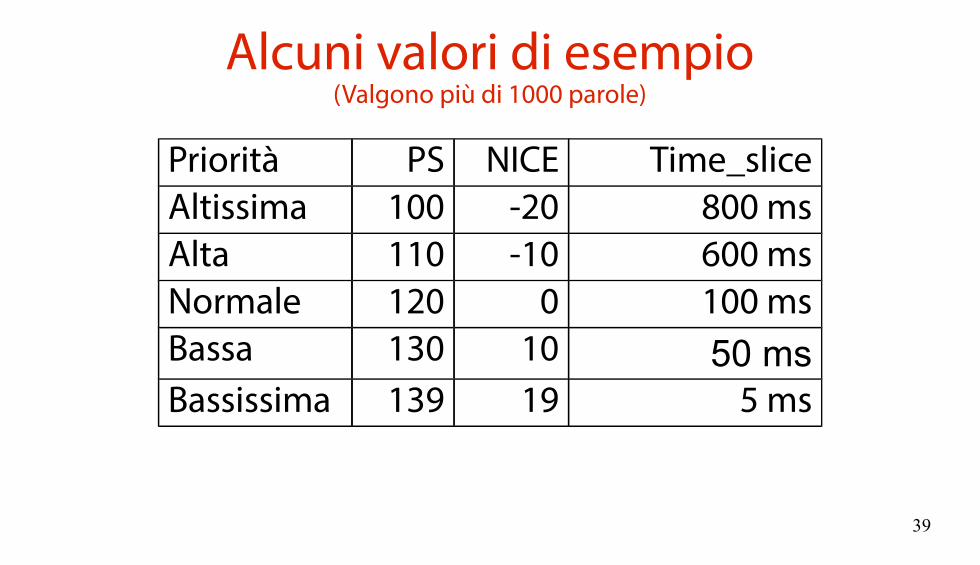
Alcuni valori di esempio(Valgono più di 1000 parole)
Priorità PS NICE Time_sliceAltissima 100 -20 800 msAlta 110 -10 600 msNormale 120 0 100 msBassa 130 10 50 msBassissima 139 19 5 ms

40
Una riflessione su sleep_avg(STOP! A che serve tutto questo? Qual è l'effetto sui processi?)
La metrica sleep_avg è molto accurata!Un processo che si blocca spesso, ma che esaurisce la sua timeslice continuamente, non riceve un bonus grande.
Effetto ricompensa per i processi interattivi.Effetto punizione per i processi non interattivi.
Un task che riceve un bonus di priorità lo perde se comincia ad abusare del processore.
Cambi di contesto non compensati da atteseprovocano la decrescita di sleep_avg e del bonus.

41
Una pecca dell'algoritmo O(1)(Un processo CPU-bound può rallentare un processo I/O-bound)
Scenario.Un processo CPU-bound ed un processo I/O-boundsono in competizione per il processore.Il processo I/O-bound termina la sua timeslice perprimo.Il processo CPU-bound continua a consumare la suatimeslice per molto più tempo.
→ Il processo CPU-bound blocca il processoI/O-bound almeno fino all'esaurimento dellasua timeslice!

42
Una euristica risolutiva(La classica “pezza”)
Se il processo è sufficientemente interattivo, al termine della sua timeslice
non viene spostato nell'array expiredviene reinserito nell'array active.
Rationale: reinserendo il processo interattivo nell'array di priorità active, esso continua ad essere rischedulato immediatamente.

43
Aggiornamento delle timeslice(Rimettiamo insieme tutti i pezzi)
scheduler_tick() in $LINUX/kernel/sched.c.Si decrementa time_slice nella task_struct delprocesso in esecuzione.Se time_slice == 0, la timeslice è spirata e bisognadecidere in che array piazzare la task_struct.Si invoca la macro TASK_INTERACTIVE() per capirese il task è sufficientemente interattivo.Si invoca la macro EXPIRED_STARVING() per capire sela runqueue ha processi in starvation.Se la runqueue non ha processi in starvation ed il task èsufficientemente interattivo, viene reinserito in active.

44
Problemi 1/2(I vecchi problemi sono spariti; ne sorgono di nuovi)
È complicato stimare l'interattività di un processo.I/O-bound deve essere schedulato più spesso.→CPU-bound deve essere schedulato meno spesso e→con timeslice più lunghe.
È complicato calcolare una giusta durata.Timeslice troppo piccola elevato aggravio legato al→cambio di contesto.Timeslice troppo grande scheduler degenera in→FIFO (bene per il batch, pessimo per l'interattivo).

45
Problemi 2/2(I vecchi problemi sono spariti; ne sorgono di nuovi)
La priorità è relativa mentre la timeslice è assoluta.
Due processi con NICE 0 ed 1: le timeslice sono di100ms e 95ms 5% di differenza.→Due processi con NICE 18 e 19: le timeslice sono di10ms e 5ms 100% di differenza!→
Sono state progettate diverse euristiche per affrontare questi problemi.Problema: le euristiche possono essere sfruttate per provocare Denial of Service (fatta l'euristica, trovato l'inganno!).

46
LINUX V2.6.23-

47
Differenze rispetto allo scheduler v2.5(Parecchie; è una riscrittura da zero)
Obiettivi.Semplificare lo scheduler, togliendo tutte le euristiche viste in precedenza.Rendere lo scheduler equo (fair) verso tutti i processi.Mantenere elevata l'interattività con gli utenti.
→ Completely Fair Scheduler (CFS)
48
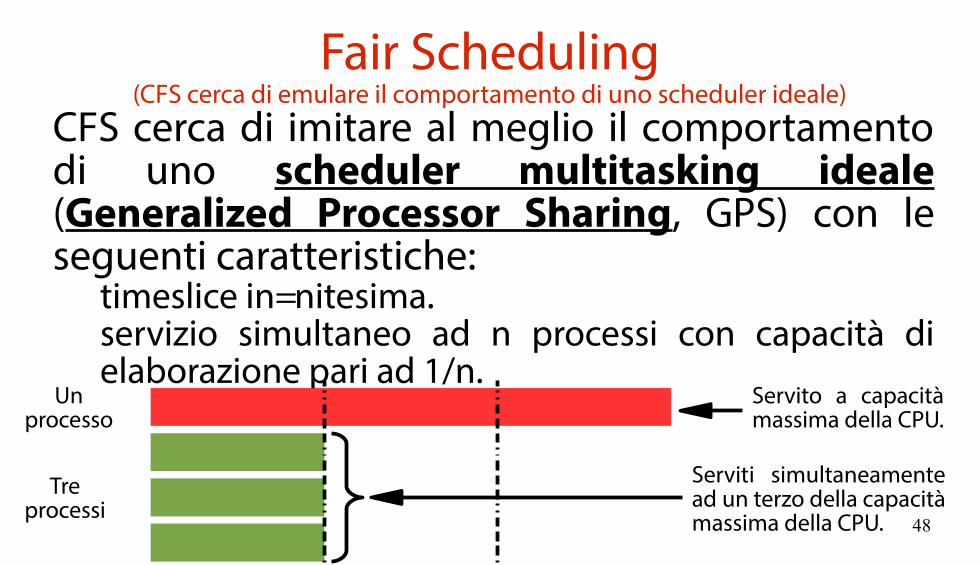
Fair Scheduling(CFS cerca di emulare il comportamento di uno scheduler ideale)
CFS cerca di imitare al meglio il comportamento di uno scheduler multitasking ideale (Generalized Processor Sharing, GPS) con le seguenti caratteristiche:
timeslice infinitesima.servizio simultaneo ad n processi con capacità dielaborazione pari ad 1/n.
Treprocessi
Unprocesso
Servito a capacitàmassima della CPU.
Serviti simultaneamentead un terzo della capacitàmassima della CPU.

49
Perché GPS?(Già, perché proprio GPS?)
GPS ha latenza di servizio minima. I processi non possono essere serviti più celermente di quanto non riesca a fare GPS.Perché non implementare direttamente GPS?

50
Problema(GPS non è implementabile)
GPS non è implementabile perché un processore non può servire simultaneamente più processi.
No, usare più processori non vale! GPS è definito soloper un processore.No, non si può ridurre la timeslice ad un valore quasinullo nell'algoritmo O(1). L'aggravio legato al cambiodi contesto ammazzerebbe le prestazioni.
→ Si deve implementare una approssimazione di GPS Ripensamento delle strutture dati.→

51
Strategia implementativa 1/3 (Cambia parecchio rispetto all'O(1))
Si cambia l'ordinamento della coda di pronto.Non più FIFO con priorità.I processi sono ordinati in base a quanta CPU hannoricevuto in meno rispetto a GPS.
→ In tal modo si può scegliere in maniera efficiente il processo con il maggior bisogno di CPU.

52
Strategia implementativa 2/3(Cambia parecchio rispetto all'O(1))
Non si usa una timeslice fissa per un processo.Si usa una sola timeslice, condivisa fra tutti i processi.
→ Una volta esaurita la timeslice, tutti i processidevono essere stati schedulati.
Ogni processo è schedulato almeno una volta nella→timeslice.
→Approssimazione della “schedulazionesimultanea” effettuata da GPS.

53
Strategia implementativa 3/3(Cambia parecchio rispetto all'O(1))
Non si usa Round Robin per la scelta del processo.Si sceglie il processo che ha ricevuto meno CPUrispetto a GPS.
→ CFS si comporta come GPS “a tratti”.

54
Scheduling latency(La timeslice condivisa da tutti i processi)
La scheduling latency è la timeslice unica condivisa fra tutti i processi.
Approssimazione di una timeslice infinitesima.Valore di default: 20ms ( applicazioni multimediali).→Tunable: /proc/sys/kernel/sched_latency_ns
Ciascun processo ottiene una uguale proporzione di timeslice.
timeslice(task)=sched_latency_ns/nr_tasks.timeslice(task) non può essere inferiore a 4ms.Tunable per regolare la timeslice minima:/proc/sys/kernel/sched_min_granularity_ns.

55
Priorità e pesi(Il peso quantifica la priorità nelle formule dello scheduler)
La priorità statica del processo (in [0, 139]) è usata per definire dei valori detti pesi (weight). I pesi servono per scalare le grandezze di un processo (fetta di timeslice associata, tempo di esecuzione effettivo) in funzione della sua priorità.I pesi sono calibrati sperimentalmente e decrescono con la priorità assoluta.
Priorità=0: peso massimoPriorità=139: peso minimo

56
Calcolo dinamico del quanto di tempo(Il processo esegue quanto gli serve, entro 20 ms.)
La timeslice è la scheduling latency media per processo, pesata con la frazione relativa del peso del processo considerato.
timeslice(task) = [ sched_latency_ns/nr_tasks ] *[ weight(task) / Σtasks weight (task) ]
Rationale: più è elevata la priorità, più è basso il valore di priorità assoluta, più è alto il peso, più aumenta la frazione di timeslice assegnata.

57
Il tempo virtuale(Scorre più o meno rapidamente a seconda della priorità)
Ciascun processo ha associato un tempo virtuale di esecuzione (virtual run time).
Campo vruntime della task_struct.Durante l'esecuzione di un processo, il tempo virtuale cresce:
normalmente alla priorità standard (120).più lentamente a priorità più alte (<120).più velocemente a priorità più basse (>120).

58
Aggiornamento del tempo virtuale(Scorre più o meno rapidamente a seconda della priorità)
Ad ogni rischedulazione viene ricalcolato il peso del processo uscente. Il valore vruntime è aumentato del tempo di esecuzione delta_exec in maniera proporzionale al rapporto fra la priorità standard e quella attuale.
vruntime = [vruntime+delta_exec] *[ weight(prio=120) / weight(prio) ]
Rationale: più elevata è la priorità assoluta, più è alto il peso, più lentamente cresce vruntime.

59
L'algoritmo di scheduling(Molto semplice)
Si sceglie il processo eseguibile il cui vruntime è minimo.Problema: vruntime può andare in overflow. In tal caso, il processo attuale è eseguito per sempre (vruntime è a 64 bit!).Soluzione: si sceglie il processo eseguibile per cui la differenza vruntime – min_vruntime è minima.
→ Tale differenza non è soggetta ad overflow.

60
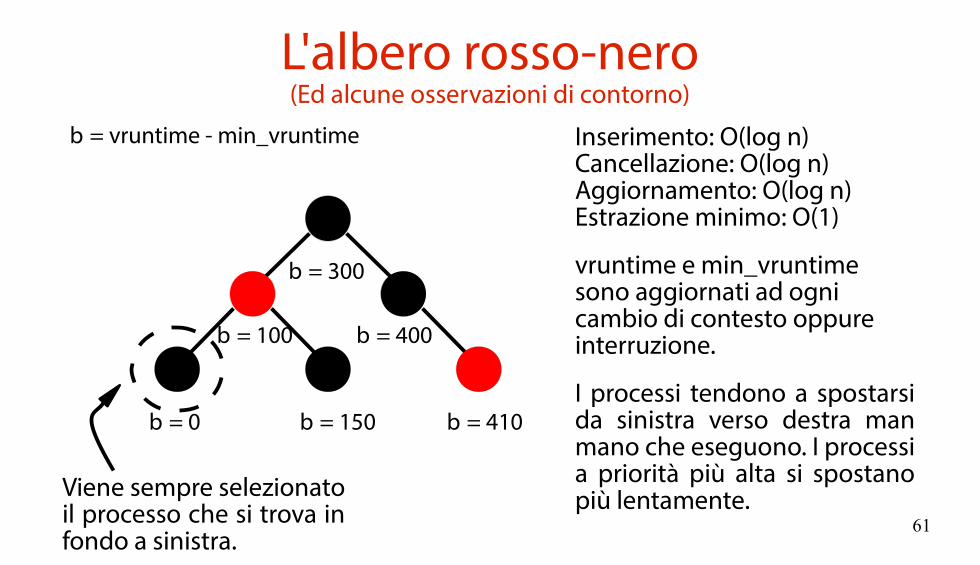
La “coda di pronto”(Non è più una coda!)
Come pescare efficientemente (O(1)) il processo con differenza vruntime – min_vruntime minima?Si usa un albero rosso-nero (red-black tree) di task_struct ordinate secondo la chiavevruntime – min_vruntime.
61
L'albero rosso-nero(Ed alcune osservazioni di contorno)
Δ = vruntime - min_vruntime
Δ = 0
Viene sempre selezionatoil processo che si trova infondo a sinistra.
Inserimento: O(log n)Cancellazione: O(log n)Aggiornamento: O(log n)Estrazione minimo: O(1)
vruntime e min_vruntimesono aggiornati ad ognicambio di contesto oppureinterruzione.
Δ = 150 Δ = 410
Δ = 400
Δ = 300
Δ = 100
I processi tendono a spostarsida sinistra verso destra manmano che eseguono. I processia priorità più alta si spostanopiù lentamente.

62
Fairness fra utenti diversi(Finora i processi sono stati considerati tutti appartenenti ad un utente)
Si supponga di avere 25 processi, di cui20 relativi ad un utente A.5 relativi ad un utente B.
CFS cerca di essere fair con tutti l'utente A →ottiene una fetta di CPU molto più consistente rispetto all'utente B.
→ Si rende necessario estendere i meccanismi di fairness a gruppi di processi.

63
Scheduling gerarchico(Si schedulano processi e gruppi di processi)
A partire dal kernel v2.6.24 è stato aggiunto il supporto per la schedulazione gerarchica (hierarchical scheduling).Si introduce una nuova struttura dati:
struct sched_entity(definita in $LINUX/include/linux/sched.h)
che rappresenta un gruppo di processi.Ogni entity ha un suo vruntime e un suo peso,calcolato in maniera analoga a quanto visto prima.
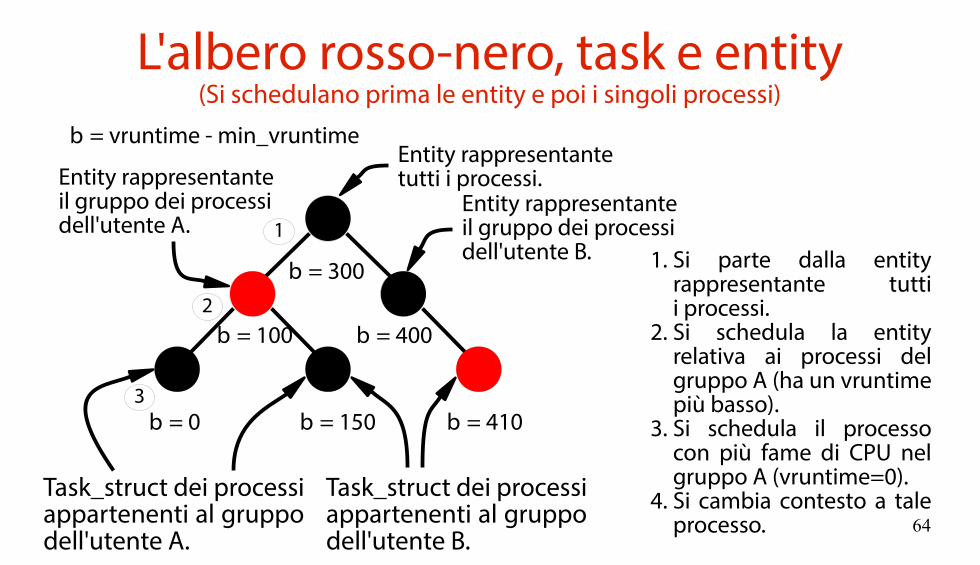
64
L'albero rosso-nero, task e entity(Si schedulano prima le entity e poi i singoli processi)
Δ = vruntime - min_vruntime
Δ = 0
Task_struct dei processiappartenenti al gruppodell'utente A.
Δ = 150 Δ = 410
Δ = 400
Δ = 300
Δ = 100
Entity rappresentantetutti i processi.Entity rappresentante
il gruppo dei processidell'utente A.
Entity rappresentanteil gruppo dei processidell'utente B.
Task_struct dei processiappartenenti al gruppodell'utente B.
1
2
3
1. Si parte dalla entityrappresentante tuttii processi.
2. Si schedula la entityrelativa ai processi delgruppo A (ha un vruntimepiù basso).
3. Si schedula il processocon più fame di CPU nelgruppo A (vruntime=0).
4. Si cambia contesto a taleprocesso.


















