
Lezione B.4 Biginissimo su stima per intervalli e prova delle ipotesi
24
Lezione B.4 Biginissimo su stima per intervalli e prova delle ipotesi TQuArs – a.a. 2010/11 Tecniche quantitative per l’analisi nella ricerca sociale Giuseppe A. Micheli
-
Upload
lawrence-rich -
Category
Documents
-
view
21 -
download
0
description
TQuArs – a.a. 2010/11 Tecniche quantitative per l’analisi nella ricerca sociale Giuseppe A. Micheli. Lezione B.4 Biginissimo su stima per intervalli e prova delle ipotesi. In questa lezione. - PowerPoint PPT Presentation
Transcript of Lezione B.4 Biginissimo su stima per intervalli e prova delle ipotesi

Lezione B.4
Biginissimo su stima per intervalli e
prova delle ipotesi
TQuArs – a.a. 2010/11Tecniche quantitative per l’analisi nella ricerca sociale
Giuseppe A. Micheli

In questa lezione..
In questa lezione faremo una galoppata velocissima per dare almeno una idea di larga massima dei seguenti concetti base della teoria della stima:
• Campionamento e stima puntuale
• Stima per intervalli di confidenza
• Verifica di ipotesi statistiche

Rappresentazioni imperfette della realtà sociale
L’estrazione di un campione genera necessariamente una rappresentazione imperfetta della realtà sociale indagata, che si aggiunge alla non piena attendibilità degli strumenti di rilevazione, o errore di misurazione. Le conclusioni che si possono trarre sono circondate da un certo grado di incertezza.
ˆ ̂ Vero valore del parametro di interesse
Stima parametro determinata sul campione Errore totale della stima
In realtà non può essere determinato esattamente. Dobbiamo accettare il fatto che la conoscenza della realtà ha carattere inferenziale quindi incerto.
Tuttavia, l’applicazione di regole formali consente di definire l’incertezza definire l’incertezza che circonda le stime di interesse che circonda le stime di interesse (specificando l’errore totale di stima). Le regole formali consistono nell’adozione di metodi probabilistici per la selezione di un campione, che ne assicurino la “imparzialità”.La regola più semplice è che ogni unità di popolazione abbia la stessa probabilità di entrare a far parte del campione (c. casuale semplice).
Modello degli errori

Terminologia da non trascurare
PARAMETRO - E’ una misura statistica, solitamente una misura sintetica di posizione, di variabilità o di forma rilevata sulla popola-zione (la media, la varianza, l’indice di simmetria, la probabilità del veri-ficarsi di un dato evento e così via) Un parametro non può essere determinato in modo esatto, ma solo stimato, fatta eccezione dei casi in cui si effettuano indagini censuarie avvalendosi di strumenti di rilevazione immuni da errori di misurazione.
Sulla scia del caso concreto, chiariamoci una volta per tutte il significato di alcuni termini ricorrenti:
STIMA - Valore di una misura statistica associata a un particolare campione e-stratto. Quando selezioniamo uno speci-fico campione dalla popolazione e calco-liamo, ad esempio, la media aritmetica (ma anche altre misure) otteniamo un valore denominato stima del corri-spondente parametro della popolazione.
STIMATORI - Le statistiche sono invece delle funzioni delle osservazioni cam-pionarie, nel senso che esse dipendono dagli elementi del campione estratto dalla popolazione. I valori corrispondenti a tali statistiche sono dette stime corrette o distorte. Una statistica è ciò che il ricer-catore conosce, mentre un parametro è ciò che desidera conoscere.

L’estrazione campionariaConsideriamo di voler fare inferenza relativamente ad una certa caratteristica X. Supponiamo che nella popolazione tale caratteristica sia distribuita normalmente con media e varianza 2 e che una variabile idonea alla sua rappresentazione sia una variabile continua. Estraiamo allora dalla popolazione un campione casuale semplice con reimmissione di dimensione pari a n (ripetiamo cioè la singola prova/estrazione un numero n di volte).
Ogni estrazione, regolata dalle leggi del caso, corrisponde ad una variabile casuale (v. c.) con distribuzione pari a quella della
popolazione, quindi con media e deviazione standard [Xi N(, )]
Il campione nel suo complesso è l’insieme di n v.c. (X1, X2, …, Xn) tra loro indipendenti ed identicamente distribuite.
Se i valori campionari sono estratti da una popolazione con distribuzio-ne N(, ), allora la media campionaria ha distribuzione: N(, /n).
Chiamiamo errore standard (es) la deviazione standard della media campionaria

Stimatore non distorto di
Se dunque le Xi sono v.c. “estrazioni campionarie”, la distribuzione “media campionaria” ha media pari proprio alla media della popolazione:
Una statistica (o stimatore) è NON DISTORTA (o corretta) se la sua media entro la distribuzione di tutti i possibili campioni è proprio pari
al parametro della popolazione che si vuole stimare.
E’ uno stimatore corretto (o non distorto) della media della popolazione.
)()( nMEXE X
Possiamo allora lanciarci in una definizione più generale:
Se siamo quindi interessati a fare inferenza sulla media della popolazione (), una stima corretta per tale parametro è proprio la media campionaria X

Stime puntualiSi può verificare che lo stimatore media è migliore dello stimatore mediana, nel senso che, per esso, le fluttuazioni intorno al valore medio della popolazione (che è poi il parametro da stimare) generate dal processo di campionamento sono più piccole.La media campionaria è anch’essa una v.c. perché sono molteplici i modi di estrarre n unità (dimensione del campione) dalle N unità della popolazione (universo).La media della popolazione è un parametro fisso (anche se ignoto), mentre possiamo ottenere una diversa media campionaria per ogni diverso campione di n elementi che estraiamo dagli N della popolazione.
Il primo passo consiste quindi nel fare inferenza su un parametro della popolazione a partire da una sua stima corretta. Si parla in tal
caso di STIMA PUNTUALE (stima di un parametro di una popolazione data da un solo numero).

Un esempio numerico
Soffermiamoci con questo esempio sulla stima puntuale della media m. La po-polazione di riferimento è costituita da N = 6 studenti che frequentino un corso universitario. Per ciascuno di questi studenti è noto il voto ottenuto all’esame di Statistica Sociale, come riportato nella seguente tabella:
Supponiamo ora di estrarre un campione di 2 elementi, scegliendo un primo elemento e, senza reimmetterlo nella popolazione, estraendo un secondo elemento. Enumeriamo tutti i possibili 15 campioni di ampiezza 2 estraibili dalla nostra popolazione studentesca:
Il voto medio tra questi 6 studenti è 27,6667 28
Unità/studente A B C D E FVoto 25 28 27 30 30 26
N° Campione 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15A A A A A B B B B C C C D D EB C D E F C D E F D E F E F F25 25 25 25 25 28 28 28 28 27 27 27 30 30 3028 27 30 30 26 27 30 30 26 30 30 26 30 26 26
Voto medio campionario 26,5 26 27,5 27,5 25,5 27,5 29 29 27 28,5 28,5 26,5 30 28 28
Unità/studenti del campione
Voti osservati

Deviazione di Mn da
Se non conoscessimo il valore medio pari a 27,67 della popolazione - situazione in realtà molto usuale proprio per la rilevanza che hanno i metodi probabilistici di stima dei parametri - potremmo ricorrere ad uno dei 15 campioni, estrarlo e calcolarne il valore medio.Ci si accorge subito, però, che essendo la media (ignota) della popolazione pari a 27,67, le stime calcolate entro i 15 campioni possono risultare a volte molto vicine alla vera media, ma altre volte anche molto lontane. La tabella seguente mostra sinteticamente l’allontanarsi di ciascuna media campionaria dal valore della media m.Entità della deviazionedella mediacampionaria dallamedia dellapopolazione
Numerocampioni
< -2 2- 2 | -1 3-1| 0 40 00 | +1 4+1 | +2 2Totale 15
Neanche un campione su 15 porta a una valutazione esat-ta della media della popola-zione! Se siamo disposti ad accettare un errore al più di 2 unità ben 13 campioni su
15 soddisfano il livello di accuratezza richiesto.

La distribuzione campionaria di Mn
Ritorniamo alla tabella che riporta tutti i 15 possibili campioni. Non a caso abbiamo usato il rosso per distinguere l’ultima riga, corrispondente alle medie di ciascuno dei 15 campioni estratti.Queste medie variano da un campione all’altro. Esse determinano perciò una distribuzione campionaria di un particolare stimatore, qual è la media Mn, funzione delle osservazioni campionarie che di volta in volta si realizzano. Nella riga rossa la distribuzione è però presentata sotto forma di serie. Rivediamola in forma di seriazione, forse più consona al nostro modo di apprendere:
Verifichiamo la proprietà di correttezza dello stimatore Mn. Se calcoliamo la media tra tutte le 15 stime otteniamo:
1/15[(25,5x1) + (26x1) + (26,5x2) + (27x1) + (27,5x3) + (28x2) + (28,5x2) + (29x2) + (30x1)] 27,67 = E(Mn) = m
Media campionaria = Stima =
Mn
Numero campioni = Numerosità
assolute
Frequenza relativa
25,5 1 1/1526 1 1/15
26,5 2 2/1527 1 1/15
27,5 3 3/1528 2 2/15
28,5 2 2/1529 2 2/1530 1 1/15
Totale 15 1
Distribuzione della media campionaria Mn

Stima intervallare
Ognuna delle possibili medie campionarie di n unità può essere quindi considerata come un’osservazione ottenuta da una distribuzione normale con valore atteso proprio uguale a µ (e varianza pari a 2/n).
Ma noi disponiamo di un unico campione, e quindi di una sola media campionaria!! Estraiamo un’unica osservazione dalla di-stribuzione N(µ,2/n), e questa potrà trovarsi vicina al parametro di interesse (µ, valore centrale della distribuzione) ma anche relativa-mente lontana (collocandosi su una delle due code della normale).
Possiamo però puntare ad un obiettivo più modesto ma di grande utilità: costruire un intervallo che contiene µ non con certezza matematica ma con certezza probabilistica.
Dato che la distribuzione normale può teoricamente assumere valori che vanno da meno a più infinito, non siamo in grado di costruire nessun intervallo nel quale possiamo affermare essere contenuto con certezza µ.

L’L’intervallo di confidenzaintervallo di confidenza è un intervallo (ottenuto da dati campionari) che contiene, con prefissata probabilità (alta a piacere), l’ignoto parametro di interesse (es. ): Pr(Tinf Tsup)=1- dove 1-, detto “livello fiduciario” è la (prefissata) probabilità che l’intervallo contenga . Se la media campionaria si distribuisce secondo una N(,/n), la sua standardizzata seguirà una N(0,1).
Intervallo di confidenza
-4 -3 -2 -1 0 1 2 3 4
0,025 0,025
0,95
-1,96 +1,96
N(0, 1)
Supponiamo di volere un intervallo che contenga la media della popolazione con probabilità = 0,95.Nella N(0,1) a 1-=95% corrisponde l’area inclusa tra -1,96 e +1,96.La quantità (x -)/(/n) si distribui-sce proprio come una N(=,1). Allora:Pr-1,96 (x-)/(/n) +1,96 =0,95
Che può essere riformulato evidenziando l’intervallo intorno al parametro cercato:Prx-1,96(/n) x+1,96(/n) = 0,95 e più in generale
Pr[x-/2(/n)] [x+z/2(/n)] = 1-

Una controprovaSupponiamo di sapere che la spesa per un certo consumo (X) segua una distribuzione normale con =30 euro e =2,55. Commissioniamo, per avere una controprova, a 20 diverse società un’indagine basata su un campione casuale di 100 persone, dando però a ciascuno solo l’informazione che X segue una distribuzione normale con = 2,55 e che il livello di fiducia deve essere del 95% (1- =0,95). Ognuna delle 20 società ha gli stessi ingredienti di base: z/2 =1,96; = 2,55 ed n=100. Ciascuna delle 20 società estrarrà dalla popolazione un diverso campione, quindi la media campionaria varierà da società a società.
La prima società trova una media campionaria 30,24. Quindi il suo IDC() è 30,24 1,96(2,55/10)=[29,74; 30,74]. La seconda società trova una media 30,12, da cui IDC() = [29,62; 30,62]. E così via. Dato che la probabilità che l’IDC contenga è fissata pari al 95%, ci si può aspettare che 19 dei 20 intervalli (il 95%) contengano e solo per 1 campione estratto l’IDC corrispondente fallisca.In effetti, tutti e venti gli intervalli contengono =30, tranne uno (il campione 17).
29
30
31
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20

Rilasciare un’ipotesi senza senso: la distribuzione t di Student
Nel calcolare l’intervallo di confidenza per la media della popolazione , fin qui si è supposta la conoscenza della deviazione standard () della popolazione (2). Ipotesi improbabile! Se non è nota, la cosa più ovvia è sostituirvi uno stimatore la cosa più ovvia è sostituirvi uno stimatore “corretto” di “corretto” di . La teoria della stima ci dice che
s2x= (xi - Mn)2/(n-1)
è uno stimatore corretto della varianza della popolazione. (dove il denomina-tore (n-1) è ora un parametro importante, detto “gradi di libertà”, gl). Sostituendo s a nella standardizzazione di x per la costruzione dell’intervallo di confidenza, siottiene una nuova statistica:Questa misura segue una nuova legge di distribuzione detta t di Student:
(xi-) / (s/n) ~ t
0
-4 -3 -2 -1 0 1 2 3 4
Esempio: g.l. = 5
t* = 1,48
Area di probabilità = 10%
La distribuzione è simile alla Normale, ma più appiattita. Inoltre, per ogni valore di t si ha una curva diversa. Nella figura si è considerato un caso esemplificativo con 5 gradi di libertà, per facili-tare la lettura dei valori della tavola.

Tavola della curva t di StudentArea di probabilità
Gradi dilibertà
25% 10% 5% 2,5% 1% 0,5%1 1,00 3,08 6,31 12,71 31,82 63,662 0,82 1,89 2,92 4,30 6,96 9,923 0,76 1,64 2,35 3,18 4,54 5,844 0,74 1,53 2,13 2,78 3,75 4,605 0,73 1,48 2,02 2,57 3,36 4,036 0,72 1,44 1,94 2,45 3,14 3,717 0,71 1,41 1,89 2,36 3,00 3,508 0,71 1,40 1,86 2,31 2,90 3,369 0,70 1,38 1,83 2,26 2,82 3,25
10 0,70 1,37 1,81 2,23 2,76 3,1711 0,70 1,36 1,80 2,20 2,72 3,1112 0,70 1,36 1,78 2,18 2,68 3,0513 0,69 1,35 1,77 2,16 2,65 3,0114 0,69 1,35 1,76 2,14 2,62 2,9815 0,69 1,34 1,75 2,13 2,60 2,9516 0,69 1,34 1,75 2,12 2,58 2,9217 0,69 1,33 1,74 2,11 2,57 2,9018 0,69 1,33 1,73 2,10 2,55 2,8819 0,69 1,33 1,73 2,09 2,54 2,8620 0,69 1,33 1,72 2,09 2,53 2,8521 0,69 1,32 1,72 2,08 2,52 2,8322 0,69 1,32 1,72 2,07 2,51 2,8223 0,69 1,32 1,71 2,07 2,50 2,8124 0,68 1,32 1,71 2,06 2,49 2,8025 0,68 1,32 1,71 2,06 2,49 2,79

La t di Student e le sue proprietà formali
Non ci interessa in questa sede conoscere la legge di densità di probabilità di t. E’ sufficiente considerarne le sue proprietà:
1. La legge t varia con il numero dei gradi di libertà (g.l.). Varia cioè al variare dell’ampiezza del campione.
2. Per ogni valore di n, t ha comunque una distribuzione simmetrica campanulare intorno a una media = 0, cioè molto simile alla forma della N(0,1), ma più appiattita nel punto di massimo, e di conseguenza più dispersa sulle code.
3. Al crescere del numero dei g.l. la distribuzione t converge rapidamente a N(0,1). Praticamente già per n = 100 le distribuzioni coincidono, come si vede confrontando i valori critici per z e t per probabilità di fallimento = 5% e = 1%.

Confronto valori critici di t di Student e N(0,1)
Valori di t5% con g.l. pari ag.l. 5 10 15 20 25 30 60 120
Valoriz5%
t 2.57 2.23 2.13 2.09 2.06 2.04 2.00 1.98 1.96
Caso A) 1 - = 95%
Caso B) 1 - = 99%
Valori di t1% con g.l. pari ag.l. 5 10 15 20 25 30 60 120
Valoriz1%
t 4.03 3.17 2.95 2.85 2.79 2.75 2.66 2.62 2.57

Prender decisioni usando gli IDC
Cerchiamo di capire con un esempio se e come gli strumenti fino ad ora acquisiti possano essere utilizzati per prendere una decisione.
Un’azienda vuole effettuare un’indagine campionaria sul consumo di taluni prodotti, e si affida a voi per trovare una valida società per le ricerche di mercato che esegua l’indagine per conto dell’azienda stessa.Tra le società entrate in una prima selezione, una in particolare dichiara che il proprio staff è estremamente preparato: il voto medio di laurea (vml) dei dipendenti – dicono - è pari a 106 con deviazione standard = 8.Per non rischiare, decidete di verificare questa affermazione preparandovi a fare un test sul voto medio di laurea di un campione estratto casualmente di 25 persone dello staff. Il voto medio di laurea tra queste persone risulta pari a 100.E’ chiaro che il campione estratto ha un voto medio inferiore a quello dichiarato dalla società. Come spiegarlo? Due le spiegazioni possibili:
Ipotesi Nulla (H0: = 106 )l’affermazione della società è vera:
lo staff ha veramente un voto mediopari a 106. E’ capitato che
casualmente è stato estratto uncampione con voto medio più basso.
Ipotesi alternativa (H1: 106 ) l’affermazione della società è falsa:lo staff non ha un voto pari a 106
(il campione non proviene da una popolazione con voto di laurea 106)
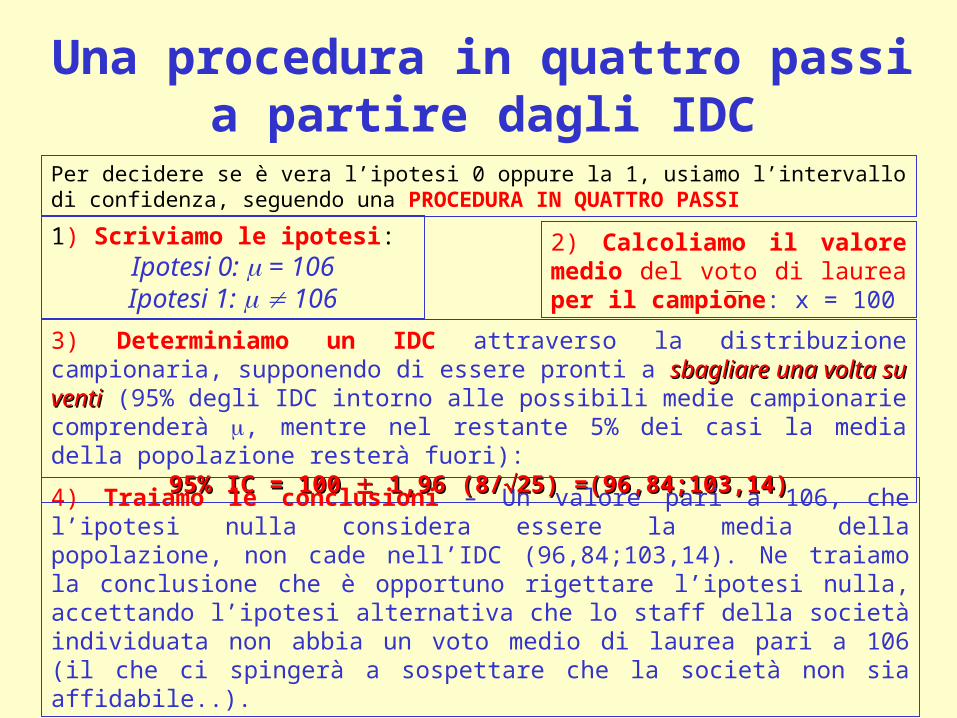
Una procedura in quattro passi a partire dagli IDC
Per decidere se è vera l’ipotesi 0 oppure la 1, usiamo l’intervallo di confidenza, seguendo una PROCEDURA IN QUATTRO PASSI
1) Scriviamo le ipotesi:Ipotesi 0: = 106Ipotesi 1: 106
2) Calcoliamo il valore medio del voto di laurea per il campione: x = 100
3) Determiniamo un IDC attraverso la distribuzione campionaria, supponendo di essere pronti a sbagliare una volta su ventisbagliare una volta su venti (95% degli IDC intorno alle possibili medie campionarie comprenderà , mentre nel restante 5% dei casi la media della popolazione resterà fuori):
95% IC = 100 95% IC = 100 1,96 (8/ 1,96 (8/25) =(96,84;103,14)25) =(96,84;103,14)
4) Traiamo le conclusioni – Un valore pari a 106, che l’ipotesi nulla considera essere la media della popolazione, non cade nell’IDC (96,84;103,14). Ne traiamo la conclusione che è opportuno rigettare l’ipotesi nulla, accettando l’ipotesi alternativa che lo staff della società individuata non abbia un voto medio di laurea pari a 106 (il che ci spingerà a sospettare che la società non sia affidabile..).

Da stima di Idc a verifica di ipotesi statistiche
Siamo passati quasi senza accorgercene dalla logica della costru-zione di un IDC centrato sulla media campionaria, rispetto al quale andiamo a vedere dove si colloca il valore ipotizzato in H0, alla logica della verifica di un’ipotesi, con la quale andiamo a vedere dove si colloca di fatto la media campionaria rispetto a una regione di accettazione centrata sul valore ipotizzato in H0.
Certo le due logiche portano a risultati analoghi, ma è prudente tenerle distinte (la prima ha carattere più generale, non essendo legata a una specifica ipotesi, come invece avviene con la regione di accettazione). Introduciamone allora terminologia e regole di funzionamento mediante un problema di ricerca
1) Il quesito di ricerca: Recenti indagini mostrano che i comportamenti dei giovani studenti universitari sono influenzati dal controllo esercitato dalla fami-glia nella vita quotidiana. Ci chiediamo allora se il living arrangement favorisce l’adozione di alcune condotte trasgressive (ad esempio l’andare in discoteca).
2) Riscrittura del problema di ricerca in ipotesi statistiche: Supponiamo che dai dati nazionali sulle ragazze che vivono coi genitori emerga un valore medio di X =numero medio di serate passate in discoteca in un mese pari a 3, con una deviazione standard x=3,3. Il quesito di ricerca si traduce nel confronto tra due ipotesi opposte formulate dal ricercatore:

L’osservazione empirica
In termini statistici le due ipotesi sono formulabili così:
Ipotesi 0: 3
Ipotesi 1: >3
3) L’osservazione empirica: Si imposta un ‘esperimento’ campionario per sce-gliere tra le due ipotesi. A tal fine si seleziona un campione di n=100 studen-tesse che frequentino corsi universitari in una sede lontana da casa dei genitori. Dai dati campionari risulta un numero medio di x=4 serate. Sapendo da dati nazionali che la deviazione standard è X=3,3 si ricava l’errore standard pari a x=X/n=0,33. Che conclusioni trarre sulla base del risultato dell’esperimento?
H1: tra le ragazze che per motivi di studio vivono per vari giorni all’anno lontano dal controllo dei genitori si manifestano compor-tamenti più liberi.
Con riferimento al quesito di ricerca sopra formulato le due idee ci dicono che:
H0: la congettura esposta non ha valore reale. Il valore osservato di X è dovuto solo al caso.
H1: esiste un’alternativa che è proprio la congettura che si vuole verificare o “provare”.
H0: tra le ragazze che per studio vivono per vari giorni all’anno lontano dal controllo dei genitori non si manifestano comporta-menti più liberi.
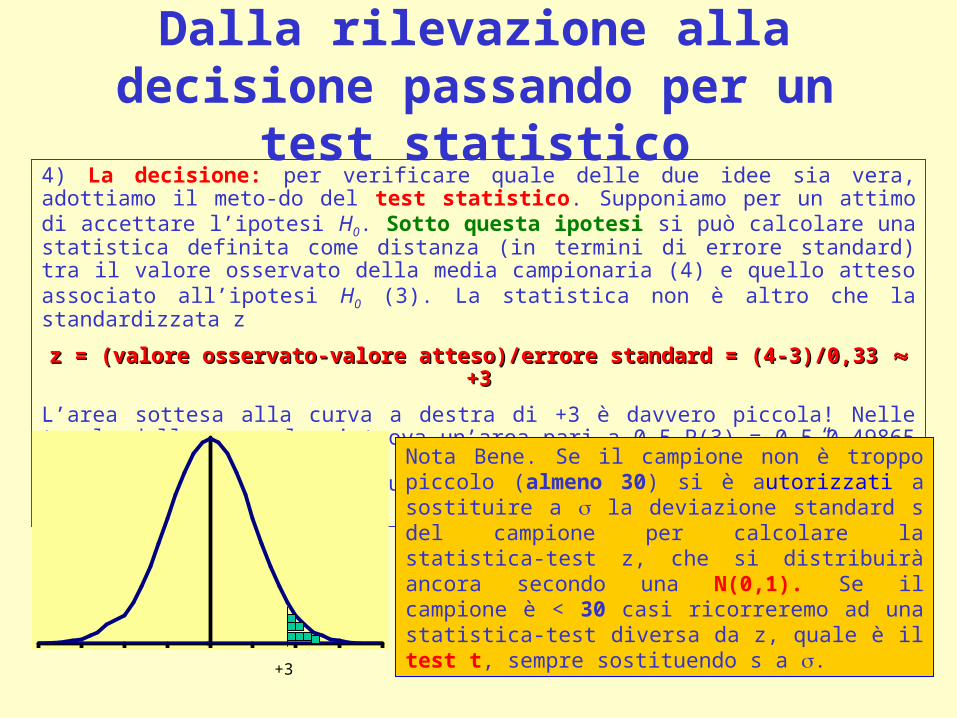
Dalla rilevazione alla decisione passando per un test statistico
4) La decisione: per verificare quale delle due idee sia vera, adottiamo il meto-do del test statistico. Supponiamo per un attimo di accettare l’ipotesi H0. Sotto questa ipotesi si può calcolare una statistica definita come distanza (in termini di errore standard) tra il valore osservato della media campionaria (4) e quello atteso associato all’ipotesi H0 (3). La statistica non è altro che la standardizzata z
z = (valore osservato-valore atteso)/errore standard = (4-3)/0,33 z = (valore osservato-valore atteso)/errore standard = (4-3)/0,33 +3 +3
L’area sottesa alla curva a destra di +3 è davvero piccola! Nelle tavole della nor-male si trova un’area pari a 0,5-P(3) = 0,5-0,49865 = 0,00135 = 1,35‰. Insomma l’evento “4 serate in discoteca” è così improbabile (poco più dell’uno permille) da fare rigettare l’ipotesi H0.
+3
Nota Bene. Se il campione non è troppo piccolo (almeno 30) si è autorizzati a sostituire a la deviazione standard s del campione per calcolare la statistica-test z, che si distribuirà ancora secondo una N(0,1). Se il campione è < 30 casi ricorreremo ad una statistica-test diversa da z, quale è il test t, sempre sostituendo s a .

P-value e valori critici
Utilizzando le tavole della N(0,1), è possibile segnalare alcuni valori critici della statistica-test z. Solitamente si scelgono per i valori 0,05; 0,01; 0,001.
Se il P-value o livello di significatività è la probabilità che il valore osservato della statistica-test cada al di fuori dei valori critici (cioè entro la regione di rifiuto), ipotizzando che valga l’ipotesi nulla, il livello di fiducia è il complemento ad 1 del livello di significatività: è la probabilità (1 - ) che la statistica-test cada entro la regione di accettazione, supponendo che sia vera l’ipotesi nulla.
P-valuePercentuale dell’area totale
compresa tra il valore medio (0) e il valore critico (z(1- )/2)
Valori critici
=5% (1-)/2=47,5% +1,96; -1,96 =1% (1-)/2=49,5% +2,58; -2,58
=0,1% (1-)/2=49,9% +3,3; -3,3-3,3 +3,3
-2,58 +2,58+1,96-1,96
La probabilità di osservare valori campionari molto distanti, in termini di errore standard, da quello atteso sotto l’ipotesi nulla (es. 1 permille) è chiamata livello di significatività osservato o P-value. Nell’esempio il P-value del test è 0,1%”. Ciò significa che in 1000 ripetizioni dell’esperimento (campione) solo una genererà un valore della statistica-test z (distanza tra valore osservato e atteso) come quello osservato o al limite più estremo. Se il P-value è piccolo c’è poca evidenza empirica a favore dell’ipotesi nulla, e questo comporta il rifiuto dell’ipotesi nulla.

Dizionario della prova di ipotesi
IPOTESI è una dichiarazione sul valore di un parametro osservato sulla popolazione.
IPOTESI NULLA (H0): è l’ipotesi del niente fuori dell’ordinario, del “no-difference”.
LIVELLO DI SIGNIFICATIVITÁ è la probabilità (più spesso 5% o 1%) che il valore osservato cada al di fuori dei valori critici (cioè nella REGIONE DI RIFIUTO), pur appartenendo alla popolazione ipotizzata in H0.
LIVELLO DI FIDUCIA è il complemento ad 1 del livello di significatività, e quindi esprime la probabilità (1-) che la statistica cada entro la regione di ACCETTAZIONE, quando sia vera l’ipotesi nulla.
Data la distribuzione campionaria nell’ipotesi H0, il fatto che la statistica campionaria standardizzata si collochi nella regione di rifiuto o in quella di accettazione porta a decidere se rifiutare o accettare l’ipotesi.
+3


















