
La voce e il computer - zavagna.it · SCUOLA DI Musica elettronica DISPENSA DEL CORSO DI STORIA...
63
CONSERVATORIO S TATALE DI MUSICA “B. MARCELLO” DI VENEZIA S CUOLA DI Musica elettronica DISPENSA DEL CORSO DI S TORIA DELLA MUSICA ELETTROACUSTICA 2 La voce e il computer Paolo Zavagna April 13, 2013
Transcript of La voce e il computer - zavagna.it · SCUOLA DI Musica elettronica DISPENSA DEL CORSO DI STORIA...

CONSERVATORIO STATALE DI MUSICA “B. MARCELLO” DI VENEZIA
SCUOLA DI Musica elettronica
DISPENSA DEL CORSO DI
STORIA DELLA MUSICA ELETTROACUSTICA 2
La voce e il computer
Paolo Zavagna
April 13, 2013

QUESTO DOCUMENTO, VERSIONE 0.6 DEL APRIL 13, 2013, INTERNO ALLA SCUOLA DI Musica
elettronica DEL CONSERVATORIO STATALE DI MUSICA “B. MARCELLO” DI VENEZIA, È DA
CONSIDERARSI RISERVATO E NON DIVULGABILE, ED È STATO SCRITTO UTILIZZANDO MikTex
2.9 E TeXnicCenter 1.0

Listening to the voices of the World,listening to the “inner” sounds of theimaginative mode, spans a wide range ofauditory phenomena. Yet all sounds are ina broad sense “voices” of things, ofothers, of the gods, and of myself. [. . . ] Aphenomenology of sound and voicemoves [. . . ] toward full significance,toward a listening to the voiced characterof the sounds of the World.
Don IhdeListening and Voice

ii

Indice
§1. Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . vii
I La voce e il computer 1
1 Bell laboratories 31.1 Parlare al telefono . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
§2. Ricerca ai Bell Laboratories . . . . . . . . . . . . . . . . . . . 3§3. Max Mathews . . . . . . . . . . . . . . . . . . . . . . . . . . 3§4. 2001 Odissea nello spazio . . . . . . . . . . . . . . . . . . . . 5
2 Voce sintetica e voce naturale 72.1 Daisy Bell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.0.1 A bycicle built for two di Max Mathews (1961) . . . . . . . . 72.2 Risset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
§5. Jean-Claude Risset . . . . . . . . . . . . . . . . . . . . . . . 7§6. Inharmonique . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Johan Sundberg . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13§7. Regole per la sintesi delle voce . . . . . . . . . . . . . . . . . 13
2.4 LPC o della codifica per predizione lineare . . . . . . . . . . . . . . . . . . . . 13§8. La codifica LPC . . . . . . . . . . . . . . . . . . . . . . . . . 13§9. Charles Dodge . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5 Gerald Bennet e Xavier Rodet . . . . . . . . . . . . . . . . . . . . . . . . . . 20§10. “Sintesi della voce cantata” . . . . . . . . . . . . . . . . . . 20
2.6 Michael McNabb, Dreamsong . . . . . . . . . . . . . . . . . . . . . . . . . . 21§11. Voci ed altri suoni . . . . . . . . . . . . . . . . . . . . . . . 21
2.7 FM o della modulazione di frequenza . . . . . . . . . . . . . . . . . . . . . . 23§12. John Chowning: biografia e percorso teorico . . . . . . . . . 23§13. Phoné di John Chowning . . . . . . . . . . . . . . . . . . . 23
2.8 Jonathan Harvey . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24§14. Cenni biografici . . . . . . . . . . . . . . . . . . . . . . . . 24§15. Mortuos Plango, Vivos voco . . . . . . . . . . . . . . . . . . 25
2.8.1 Descrizione del patch Pure Data di Miller Puckette per l’‘esecuzione’di Mortuos plango, vivos voco [Francesco Grani, a.a. 2011-12] . . . . . 27
§16. Il Patch mortuos.pd . . . . . . . . . . . . . . . . . . . . . . 27§17. Schermata principale del Patch . . . . . . . . . . . . . . . . 27§18. Subpatch pd startup . . . . . . . . . . . . . . . . . . . . . . 29§19. Subpatch pd analysis . . . . . . . . . . . . . . . . . . . . . . 30
iii

§20. Subpatch pd arrays . . . . . . . . . . . . . . . . . . . . . . . 31§21. Subpatch pd inputs . . . . . . . . . . . . . . . . . . . . . . . 31§22. Subpatch pd messpeak . . . . . . . . . . . . . . . . . . . . . 32§23. Subpatch pd box-control . . . . . . . . . . . . . . . . . . . . 34§24. Subpatch pd unpacker . . . . . . . . . . . . . . . . . . . . . 35§25. Subpatch pd osc-bank . . . . . . . . . . . . . . . . . . . . . 35
3 Trevor Wishart 393.1 Notizie biografiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
§26. Biografia, riconoscimenti e poco altro . . . . . . . . . . . . . 393.2 Audible Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
§27. Il frontespizio di Audible Design . . . . . . . . . . . . . . . . 403.3 On Sonic Art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
§28. Utterance . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40§29. “Il repertorio umano” . . . . . . . . . . . . . . . . . . . . . 42
3.4 La voce e il ciclo Voice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42§30. Catalogo delle opere vocali . . . . . . . . . . . . . . . . . . 42§31. Vox 5 (1986) . . . . . . . . . . . . . . . . . . . . . . . . . . 43§32. Globalalia . . . . . . . . . . . . . . . . . . . . . . . . . . . 45§33. Voiceprints . . . . . . . . . . . . . . . . . . . . . . . . . . . 46§34. Encounters in the Republic of Heaven . . . . . . . . . . . . . 47
Bibliografia 51
iv

Elenco delle figure
1.1.1 Graham Bell: era phonautograph e trascrizione parlato . . . . . . . . . . . . . 4(a) Ear Phonautograph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4(b) Tascrizione parlato di Bell 1875 . . . . . . . . . . . . . . . . . . . . . . 4
2.2.1 Strumento NOISE4 utilizzato da Risset in Inharmonique . . . . . . . . . . . . 9(a) Diagramma strumento . . . . . . . . . . . . . . . . . . . . . . . . . . . 9(b) Funzioni tabulate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.1 Tabella valori formanti voce tratta da Sundberg . . . . . . . . . . . . . . . . . 142.3.2 Grafico valori formanti voce tratto da Sundberg . . . . . . . . . . . . . . . . . 152.4.1 Modello semplificato di predizione lineare. . . . . . . . . . . . . . . . . . . . 162.4.2 Flusso del segnale durante l’analisi nella LPC. . . . . . . . . . . . . . . . . . . 162.4.3 Sintesi tramite LPC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
(a) Italiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17(b) Inglese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.4 Flusso dei dati ottenuti tramite LPC dall’analisi dei frames che compongono laparola “sit”. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4.5 Due pagine da In Celebration di C. Dodge . . . . . . . . . . . . . . . . . . . . 21(a) Pagina 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21(b) Pagina 9 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.6.1 Modi utilizzati in Dreamsong di McNabb . . . . . . . . . . . . . . . . . . . . 222.6.2 Melodie utilizzate in Dreamsong di McNabb . . . . . . . . . . . . . . . . . . . 222.6.3 Listato strumento SING per Dreamsong di McNabb . . . . . . . . . . . . . . . 232.8.1 Parziali campana cattedrale Winchester . . . . . . . . . . . . . . . . . . . . . 262.8.2 Frequenze attorno alle quali ruotano le otto sezioni del brano . . . . . . . . . . 272.8.3 Schermata principale di mortuos.pd . . . . . . . . . . . . . . . . . . . . . . . 282.8.4 Patcher pd startup. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.8.5 Patcher pd analysis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.8.6 Patcher pd arrays. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.8.7 Patcher pd inputs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.8.8 Patcher pd messpeak. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.8.9 Patcher pd box-control. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.8.10I subpatchers pd unpacker e pd osc-bank. . . . . . . . . . . . . . . . . . . . . 35
(a) Patcher pd unpacker . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35(b) Patcher pd osc-bank . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.8.11Patcher voice.pd. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2.1 Frontespizio Audible Design . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.4.1 Partitura diffusione Vox 5 di Wishart . . . . . . . . . . . . . . . . . . . . . . . 44
v

3.4.2 Partitura diffusione Globalalia di Wishart 1/4 . . . . . . . . . . . . . . . . . . 463.4.3 Partitura diffusione Globalalia di Wishart 2/4 . . . . . . . . . . . . . . . . . . 473.4.4 Partitura diffusione Globalalia di Wishart 3/4 . . . . . . . . . . . . . . . . . . 483.4.5 Partitura diffusione Globalalia di Wishart 4/4 . . . . . . . . . . . . . . . . . . 49
vi

§1. Introduzione
Il nucleo originario di questa dispensa è stato scritto in occasione del corso di Storia dellamusica elettroacustica 2 tenuto presso il Conservatorio Statale di Musica “B. Marcello” diVenezia nell’Anno Accademico 2011-2012. Il tema principale del corso è stato come la voce,in senso lato, sia stata ‘utilizzata’ dopo l’avvento delle tecnologie informatiche applicate allamusica. In seguito è stata aggiornata e arricchita di informazioni che via via sono state pubblicateo segnalate da colleghi e studenti.
La voce è il modo in cui la realtà ci parla: quella naturale e quella artificiale, quellaumana, animale, e quella di ogni altro elemento, autonomamente (perché emette da solo) oprovocatoriamente (perché genericamente ‘sollecitato’). Se assumiamo quanto scritto in esergo1
come linea guida, dobbiamo audire ai fenomeni sonori/musicali come all’ascolto di una o più‘voci’. Se tutti i suoni sono voci, allora i suoni sintetici prodotti con l’elaboratore sono le vocidei nuovi strumenti di ‘oggi’, che ci ‘spiegano’ le implicazioni tecnologiche del fare musica.
Che la voce abbia ampliato i suoi orizzonti ci è ben chiarito dal saggio di Hazel Smith, chemette in relazione l’uso della voce con i luoghi, l’identità e la comunità, resi ancor più ‘confusi’dalle possibilità di ibridazione offerte dalle tecnologie informatiche2.
Una voce che deve confrontarsi con ‘altri’ strumenti e con se stessa diventata ‘altro’ stru-mento, grazie anche a processi di analisi e di (ri)sintesi, che la immergono nel paesaggio insenso lato.
1La citazione è tratta da Ihde, Listening and Voice, p. 147.2Smith, “The Voice in Computer Music and its Relationship to Place, Identity, and Community”.
vii

viii

Parte I
La voce e il computer
1


Capitolo 1
Bell laboratories
1.1 Parlare al telefono
§2. Ricerca ai Bell Laboratories
Dal gennaio 1922 i Bell Laboratories pubblicano una rivista, «The Bell System TechnicalJournal», che tratta di tutte le innovazioni sia tecnologiche sia teoriche apportate nel campo dellatelefonia – e affini – e della fisica, in ogni sua branca. Gli studi di acustica ed elettroacustica sonoparticolarmente nutriti (troviamo, fin dal primo numero, scritti di Fletcher, Carson, Crandall,Sacia). In uno di questi studi, del 1925, si fa riferimento alle sperimentazioni di Bell con l’earphonautograph (si veda la Figura 1.1.1 (a)), di cui viene riprodotto un esempio di fonautogramma(qui in Figura 1.1.1 (b)1), e viene effettuata una ricerca su centosessanta registrazioni grafiche disuoni di vocali e di consonanti2. Il suono viene ancora ‘inciso’ in maniera meccanica, sebbene laparte di trasduzione relativa al microfono, soprattutto nei laboratori in quanto sedi di strumentidi misura, fosse già da tempo utilizzata.
§3. Max Mathews
Max Vernon Mathews (13 novembre 1926, Columbus, Nebraska, USA - 21 aprile 2011, SanFrancisco, CA, USA) è stato un pioniere nel mondo della computer music3.
Mathews studia ingegneria elettronica al California Institute of Technology e al Massachu-setts Institute of Technology, ricevendo un Sc. D. nel 1954. Lavorando ai Bell Labs, nel 1957Mathews scrive MUSIC, il primo programma ampiamente utilizzato per la generazione delsuono. Nel 1970, Mathews e Moore sviluppano il GROOVE (Generated Real-time OutputOperations on Voltage-controlled Equipment)4, primo sistema per la sintesi musicale comple-tamente sviluppato per la composizione interattiva e l’esecuzione in tempo reale, utilizzandominicomputer 3C/Honeywell DDP-245 o DDP-2246.
1In Crandall, “The Sounds of Speech”, p. 587.2In ibid.3Informazioni tratte da http://en.wikipedia.org/wiki/Max_Mathews.4Si veda Mathews e Moore, “GROOVE, a program to compose, store, and edit functions of time”.5Nyssim Lefford, Eric D. Scheirer, and Barry L. Vercoe. “An Interview with Barry Vercoe”. Experimental
Music Studio 25. Machine Listening Group, MIT Media Laboratory.6Bogdanov, Vladimir (2001). All music guide to electronica: the definitive guide to electronic music. Backbeat
Books.
3

4 CAPITOLO 1. BELL LABORATORIES
(a) Ear Phonauto-graph
(b) Tascrizione parlato di Bell 1875
Figura 1.1.1: L’Ear Phonautograph di Graham Bell e Clarence Blake (a) e trascrizione delparlato effettuata da Graham Bell nel 1875 – due anni prima dell’invenzione del fonografo –(b).
Sebbene il linguaggio MUSIC non fosse stato il primo tentativo di generare suoni con uncomputer (un computer australiano CSIRAC suonava già all’inizio del 1951)7, Mathews fu ilpadre di generazioni di ‘strumenti’ musicali digitali.
L’esecuzione della musica tramite computer nacque nel 1957 quando un IBM 704 a NYCsuonò una composizione di 17 secondi realizzata dal programma Music I che avevo scritto.Timbri e note non erano interessanti, ma l’innovazione tecnica si percepisce ancora. MusicI mi ha portato a Music II fino a V. Sullo stesso modello sono stati inoltre scritti Music 10,Music 360, Music 15, Csound e Cmix. Molti brani interessanti sono oggi eseguiti digital-mente. L’IBM 704 e i suoi fratelli erano macchine da studio, troppo lente per sintetizzaremusica in tempo reale. Gli algoritmi di Chowning con la FM e l’arrivo di processori digitaliveloci ed economici resero il tempo reale possibile e, ugualmente importante, conveniente[. . . ]
A partire dal programma GROOVE nel 1970, i miei interessi si sono focalizzati sull’esecu-zione dal vivo e su ciò che un computer può fare per aiutare un esecutore. Ho realizzatoun controller, il Radio-Baton, e un programma, il Conductor, per fornire nuove possibili-tà all’interpretazione ed esecuzione di partiture tradizionali. Oltre che per i compositoricontemporanei, questi sistemi si sono dimostrati interessanti anche per i solisti come unmodo per eseguire accomopagnamenti orchestrali. I cantanti spesso preferiscono suonare ipropri accompagnamenti. Recentemente ho aggiunto opzioni per l’improvvisazione che lorendono semplice nella scrittura di algoritmi compositivi. These can involve precomposedsequences, random functions, and live performance gestures. Gli algoritmi sono scritti inlinguaggio C. We have taught a course in this area to Stanford undergraduates for two years.Con nostra gradita sorpresa, agli studenti piace imparare e utilizzare il C. Primarily I believe
7Si veda Doornbusch, The music of CSIRAC: Australia’s first computer music. Un breve estratto di questotesto si può leggere in http://ww2.csse.unimelb.edu.au/dept/about/csirac/music/index.html.

1.1. PARLARE AL TELEFONO 5
it gives them a feeling of complete power to command the computer to do anything it iscapable of doing8.
Nel 1961, Mathews arrangiò l’accompagnamento della canzone “Daisy Bell” per unastraordinaria performance di voce umana sintetizzata al computer, utilizzando una tecnologiasviluppata da John Kelly e altri dei Bell Laboratories. Lo scrittore Arthur C. Clarke eracasualmente in visita dell’amico e collega John Pierce ai Bell Labs di Murray Hill al tempo diquesta notevole dimostrazione di sintesi vocale e ne fu così impressionato che in seguito disse aStanley Kubrick di utilizzarla in 2001: A Space Odyssey, nella scena chiave in cui il computerHAL 9000 canta mentre le sue funzioni cognitive vengono disabilitate9.
Mathews diresse il Centro di Ricerca Acoustical and Behavioral ai Bell Laboratories dal1962 al 1985, which carried out research in speech communication, visual communication,human memory and learning, programmed instruction, analysis of subjective opinions, physicalacoustics, and industrial robotics. Dal 1974 al 1980 fu Scientific Advisor dell’Institute deRecherche et Coordination Acoustique/Musique (IRCAM) di Parigi, e fino al 1987 è statoProfessor of Music (Research) alla Stanford University. He served as the Master of Ceremoniesfor the concert program of NIME-01, the inaugural conference on New Interfaces for MusicalExpression.
Mathews è stato membro dell’Accademia Nazionale delle Scienze, dell’Accademia Naziona-le dell’Ingegneria e socio dell’American Academy of Arts and Sciences, dell’Acoustical Societyof America, dell’IEEE, e dell’Audio Engineering Society. He held a Silver Medal in MusicalAcoustics from the Acoustical Society of America, and the Chevalier dans l’ordre des Arts etLettres, Republique Francaise.
La parte Max del software Max/MSP è così chiamata in onore di Mathews.
§4. 2001 Odissea nello spazio
Nel 1997 esce un libro curato da Stork, Hal’s Legacy10. In esso si rammentano i fondamentiscientifici di quella che era stata un’avventura fantascientifica: la stesura di un libro di Clarke,2001: A Space Odyssey e la realizzazione del film di Kubrick che porta lo stesso titolo. In questolibro troviamo in particolare un contributo relativo al computer e alla voce: Olive, ““The TalkingComputer”: Text to Speech Synthsis”. In esso viene abbozzata la storia delle ricerche riguardantila nascita della voce sintetica, con particolare attenzione al riconoscimento del testo e alla suasintesi vocale.
La voce di HAL, mentre viene disattivato, si ispira ad uno dei primi esperimenti di vocesintetica: l’arrangiamento della celebre canzone popolare A bycicle built for two.
8Note scritte in occasione dell’evento “Horizons in Computer Music”, 8-9 Marzo 1997, Indiana University.9Tratto da http://www.bell-labs.com/news/1997/march/5/2.html.
10Lo si può trovare in formato elettronico al seguente http://mitpress.mit.edu/e-books/Hal/.

6 CAPITOLO 1. BELL LABORATORIES

Capitolo 2
Voce sintetica e voce naturale
2.1 Daisy Bell2.1.0.1 A bycicle built for two di Max Mathews (1961)
La canzoncina arrangiata da Max Mathews (accompagnamento) e da John Larry Kelly Jr. eCarol Lochbaum (sintesi della voce), creata con un IBM 7094 ai Bell Laboratories, la si puòascoltare come traccia 6 di Aa. Vv. The Historical CD of Digital Sound Synthesis e fa parte diuna serie di lavori predisposti come dimostrazione delle possibilità della musica sintetica, fracui vi erano gli studi sulla voce. Non una vera e propria composizione, ma la trascrizione di uncelebre brano popolare, Daisy Bell, finalizzata alla diffusione ed esemplificazione dell’alloranuovo mondo della musica digitale. Da notare che il lavoro di Kelly e Lochbaum sulla voce nonsi basava sul vocoder ma su un modello di analogia col tratto vocale; non su un modello spettralebensì su un modello meccanico1. Lo stesso brano è stato oggetto di un progetto sviluppato sulweb, Bycicle Built for 2,000, in cui le voci di più di 2000 persone registrate direttamente dainternet vengono assemblate per realizzare una versione ‘globale’ della canzone. Nello stessoprogetto si può ascoltare una ricostruzione dell’originale per computer del 1962.
2.2 Risset§5. Jean-Claude Risset
Jean-Claude Risset2 nasce a Le Puy in Francia il 18 marzo 1938. Studia composizionecon André Jolivet, pianoforte con Robert Trimaille (allievo di Alfred Cortot) e fisica all’ÉcoleNormale Supérieure di Parigi. Si dedica alla ricerca scientifica presso il CNRS, all’InstitutÉlectronique Fondamentale di Pierre Grivet (1961-1971), ai Bell Laboratories nel New-Jersey(Stati Uniti), con Max Mathews e John Pierce nei periodi 1964-1965 e 1967-1969, durantei quali sviluppa lavori sulla sintesi dei suoni tramite computer e le sue applicazioni musicali(in particolare la simlazione dei suoni strumentali, le illusioni sonore e i paradossi musicali),a Orsay (1970-1971), quindi, a partire dal 1972, al Centro universitario di Marseille-Luminy,all’IRCAM (1975-1979) e infine al LMA (Laboratoire de Mécanique et d’Acoustique) delCNRS a Marseille, istituzione presso la quale rimane direttore di ricerca emerito.
1I risultati delle loro ricerche vennero pubblicati l’anno dopo la realizzazione di A bycicle built for two in Kellye Lochbaum, “Speech synthesis” e Kelly e Lochbaum, “Speech synthesis”.
2Notizie tratte da http://brahms.ircam.fr/jean-claude-risset.
7

8 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
Il suo percorso teorico nell’ambito della ricerca musicale informatica incomincia con l’analisie la risintesi dei suoni strumentali. Nel 1969 esce l’articolo, scritto con Max Mathews, “Analysisof instrument tones”, in cui vengono analizzati suoni di tromba.
In un saggio in forma di elenco, “Nouveaux gestes musicaux: quelques points de repèrehistoriques”, Risset ci segnala due importanti innovazioni in ambito vocale: nel 1921, i primiesperimenti di poemi fonetici di Haussmann e Schwitters (la cui Ursonate, del 1932, è un casoparticolare di gesto fonetico) e nel 1977, nel brano Interphone, di Michel Decoust, i gesti vocaliche vengono ‘impressi’ sul suono (ulteriori esempi di ibridazione sono Sud di Risset stesso, del1985, e Préfixes, di Michel Levinas, del 1991).
Sebbene in Sud la voce umana non venga direttamente utilizzata, l’idea di ibridazione ditimbri e altezze e l’imitazione del timbro vocale sono caratteristiche che segneranno anche leopere in cui Risset sfrutta la voce dal vivo: Inharmonique, del 1977, L’autre face, del 1983 eInvisible, del 1995, tutte opere per soprano e nastro magnetico.
§6. Inharmonique
Esemplare dell’utilizzo di voce e suoni sintetici è il brano Inharmonique, realizzato pressol’IRCAM nel 1972, per suoni sintetizzati tramite elaboratore e soprano e dedicato a Irène Jarsky.I suoni sono stati sintetizzati con il programma Music V e la prima esecuzione ha avuto luogo il25 aprile 1977. Il brano è suddiviso in otto sezioni3.
Un utilizzo avanzato del programma Music V prevede la possibilità da parte dell’autoredi realizzare dei ‘sottoprogrammi’ (le routines PLF, PLay First), che generano eventi sonoricomplessi invece di scrivere, come prevede la sintassi del software, ogni singola nota. Risset faampio uso di questa possibilità offertagli dal programma sviluppato da Mathews, che peraltroconosceva bene, avendo egli contribuito al suo sviluppo e soprattutto alla sua divulgazione conil catalogo (si veda 2.1.0.1).
La gran parte dei suoni sintetizzati sono, come il titolo rende evidente, di tipo inarmonico,non vi è cioè fra le varie componenti lo spettro un rapporto di numeri interi. In particolarepossiamo ascoltare suoni di campana, la cui sintesi additiva era stata uno degli esempi delcatalogo del 1969.
La suddivisione formale proposta da Lorrain viene accompagnata dai rispettivi nomi distrumenti utilizzati:
i. *NOISE4 (0”-50”);ii. +VOXN1, +RVP411 (58”-1’25”);
iii. +FM8, +LB1113, +LOSLO3, +PHASE6 (3’10”-4’33”);iv. BELHH4, HH3 (5’17”-6’10”);v. BELLSB (6’35”-8’12”);
vi. +BLLTX1 (9’15”-10’04”);vii. +BLTX1, +BLTX2, +PHASE7 (12’10”-13’11”);
viii. *IR, +IRR1, *IRR3, +IRR4 (13’11”-14’00”).
Possiamo vedere lo strumento NOISE4, il primo ad essere utilizzato da Risset per generarel’introduzione del brano, nella Figura 2.2.1 (a)4.
Di seguito riporto lo schema del flusso delle variabili dello strumento:
3Per un’analisi dettagliata si veda Lorrain, Analyse de la bande magnétique de l’oeuvre de Jean-Claude RissetInharmonique e Zattra, Studiare la computer music, pp. 282-299, che si basa gran parte sul lavoro di Lorrain.
4Tratta da Lorrain, Analyse de la bande magnétique de l’oeuvre de Jean-Claude Risset Inharmonique.
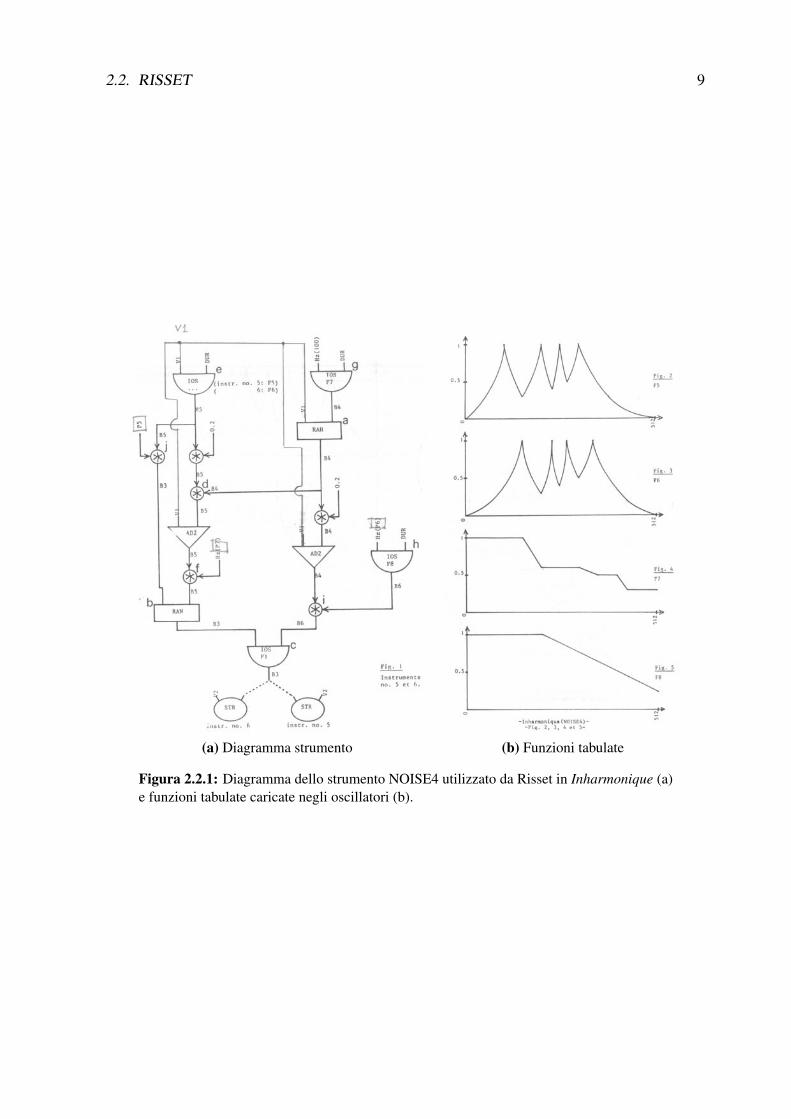
2.2. RISSET 9
(a) Diagramma strumento (b) Funzioni tabulate
Figura 2.2.1: Diagramma dello strumento NOISE4 utilizzato da Risset in Inharmonique (a)e funzioni tabulate caricate negli oscillatori (b).

10 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
DUR = 1/p3P5 = p4 * giampFact ; AmplitudeP6 = p5 ; center frequencyP7 = p6 ; bandwidthV1 = 1B5 oscili V1, DUR, 5B4 oscili 100, DUR, 7B4 randh V1, B4B3 = B5 * P5B5 = B5 * 0.2B5 = B5 * B4B5 = V1 + B5B5 = P7 * B5B3 randi B3, B5B6 oscili P6, DUR, 8B4 = B4 * 0.2B4 = V1 + B4B6 = B4 * B6B3 oscili B3, B6, 1outs1 B3endin
Ho evidenziato il flusso del segnale colorando alcune variabili in modo da poterne seguire ilpercorso all’interno dello strumento. Si noti che soltanto uno degli oscillatori – quello più inbasso – utilizza una forma d’onda (nel caso specifico un’onda sinusoidale) a frequenza audio;tutti gli altri sono utilizzati come ‘inviluppatori’ le cui quattro funzioni di inviluppo sono visibilinella Figura 2.2.1 (b).
Di seguito riporto lo strumento e la partitura Csound:
<CsoundSynthesizer><CsOptions></CsOptions><CsInstruments>; RISSET’S INHARMONIQUE (1977) - NOISE4.ORC; As described in Lorrain, Denis:; "Analyse de la bande magnetique de l’oeuvre de; Jean-Claude Risset - Inharmonique"; in Rapports IRCAM 26/80.; Csound version by Antonio de Sousa Dias; [email protected]#include "header_stereo"giamp_fact = 16 ; Amplitude factor (not in the original orchestra)
; GLISSANDI DE BRUIT
instr 5

2.2. RISSET 11
iDUR = 1/p3iP5 = p4 * giamp_fact ; AmplitudeiP6 = p5 ; center frequencyiP7 = p6 ; bandwidthiV1 = 1
aB5 oscili iV1, iDUR, 5aB4 oscili 100, iDUR, 7aB4 randh iV1, aB4aB3 = aB5 * iP5aB5 = aB5 * 0.2aB5 = aB5 * aB4aB5 = iV1 + aB5aB5 = iP7 * aB5aB3 randi aB3, aB5aB6 oscili iP6, iDUR, 8aB4 = aB4 * 0.2aB4 = iV1 + aB4aB6 = aB4 * aB6aB3 oscili aB3, aB6, 1outs1 aB3endin
instr 6
iDUR = 1/p3iP5 = p4 * giamp_factiP6 = p5iP7 = p6iV1 = 1
aB5 oscili iV1, iDUR, 5aB4 oscili 100, iDUR, 7aB4 randh iV1, aB4aB3 = aB5 * iP5aB5 = aB5 * 0.2aB5 = aB5 * aB4aB5 = iV1 + aB5aB5 = iP7 * aB5aB3 randi aB3, aB5aB6 oscili iP6, iDUR, 8aB4 = aB4 * 0.2aB4 = iV1 + aB4aB6 = aB4 * aB6aB3 oscili aB3, aB6, 1outs2 aB3

12 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
endin
</CsInstruments><CsScore>; RISSET’S INHARMONIQUE (1977) - NOISE4.SCO; As described in Lorrain, Denis:; "Analyse de la bande magnetique de l’oeuvre de; Jean-Claude Risset - Inharmonique"; in Rapports IRCAM 26/80.; Csound version by Antonio de Sousa Dias; [email protected]
f1 0 4096 10 1f5 0 512 5 0.0009765 100 1 50 .3 50 1 30 .4 20 1 20 .5 30 180 .3 132 .0009765f6 0 512 5 0.0009765 150 1 50 .3 30 1 20 .4 20 1 30 .5 40 190 .2 82 .0009765f7 0 512 7 1 150 1 50 .6 100 .6 50 .5 50 .5 30 .3 82 .3f8 0 512 7 1 200 1 312 .25
;P3 P2 P4 P5 P6 P7; AMP CF BWi5 0 14 187.5 1318 100i6 0 14 187.5 1108 100
i5 0 13.5 312.5 2349 200i6 0 13.5 312.5 2093 200
i5 0 13.3 187.5 3320 200i6 0 13.3 187.5 3321 200
i5 0 13.1 125 4186 400i6 0 13.1 125 4186 400
i5 0 13.0 62.5 5100 500i6 0 13.0 62.5 5100 500
i5 0 12.9 62.5 6000 600i6 0 12.9 62.5 6000 600
i5 0 12.7 62.5 6800 600i6 0 12.9 62.5 6999 699
i5 0 12.7 62.5 6800 600i6 0 12.7 62.5 6800 600

2.3. JOHAN SUNDBERG 13
e</CsScore></CsoundSynthesizer>
2.3 Johan Sundberg§7. Regole per la sintesi delle voce
Johan Sundberg, nato nel 1936 a Stoccolma, musicologo ed esperto di acustica, ha dedicatola ricerca di questi ultimi anni a temi legati alla voce. Fra i testi dedicati a questo argomentoricordo The Science of the Singing Voice, che raccoglie molti anni di ricerche sulla voce cantata.Nel contesto della tematica affrontata in questa dispensa, di particolare interesse ci pare essere unarticolo apparso nella raccolta Current Directions in Computer Music Research, in cui Sundbergsi sofferma sulla sintesi della voce cantata per mezzo di regole5. Il sintetizzatore utilizzato daSundberg permette di specificare cinque formanti e cinque larghezze di banda per ogni formante,le cui due più acute sono fisse a 150 Hz. Nella tabella riportata in Figura 2.3.1 possiamo notarei valori in Hertz delle cinque formanti seguiti dai volori in Hertz delle larghezze di banda deiprimi tre.
Nel grafico in Figura 2.3.2, oltre all’andamento nel tempo dei valori già visti nella tabella,possiamo notare anche il valore di altri due parametri determinanti per la sintesi della voce: ilrumore della glottide e quello della lingua (Figura 2.3.2, sotto).
2.4 LPC o della codifica per predizione lineare§8. La codifica LPC
La codifica Linear Predictive Coding è un metodo di sintesi dei suoni tramite analisi. Derivail nome dalla capacità di “predire” i valori dei campioni in uscita attraverso una combinazionelineare dei parametri di un filtro e dei campioni precedenti. I dati forniti dall’analisi sonomodificabili, manipolabili, rendendo questa tecnica particolarmente potente a fini musicali. Ivalori predetti vengono confrontati con i valori reali (si veda la Figura 2.4.1, modello semplificatodi funzionamento della stima del valore) e viene fatta una stima dell’errore di predizione.
Il flusso semplificato dell’analisi del segnale è riportato in Figura 2.4.2.Viene effettuata un’analisi frame by frame con una media di frames che varia fra 50 e 200 al
secondo; ogni frame è descritto da 24 parametri:
• ampiezza del residuo (RMS1)• ampiezza suono originale (RMS2)• rapporto tra le due ampiezze altezza• 19 coefficienti per il filtro solo poli (punti di risonanza) durata del frame
La sintesi avviene secondo un mdello del tratto vocale che prevede la parte di suono vocalico(‘intonato’) prodotta da un buzz e modificata da un filtro i cui parametri sono dati dai coefficientiestratti dall’analisi e la parte di suono consonantico (rumore) prodotta da un rumore bianco (siveda la Figura 2.4.3).
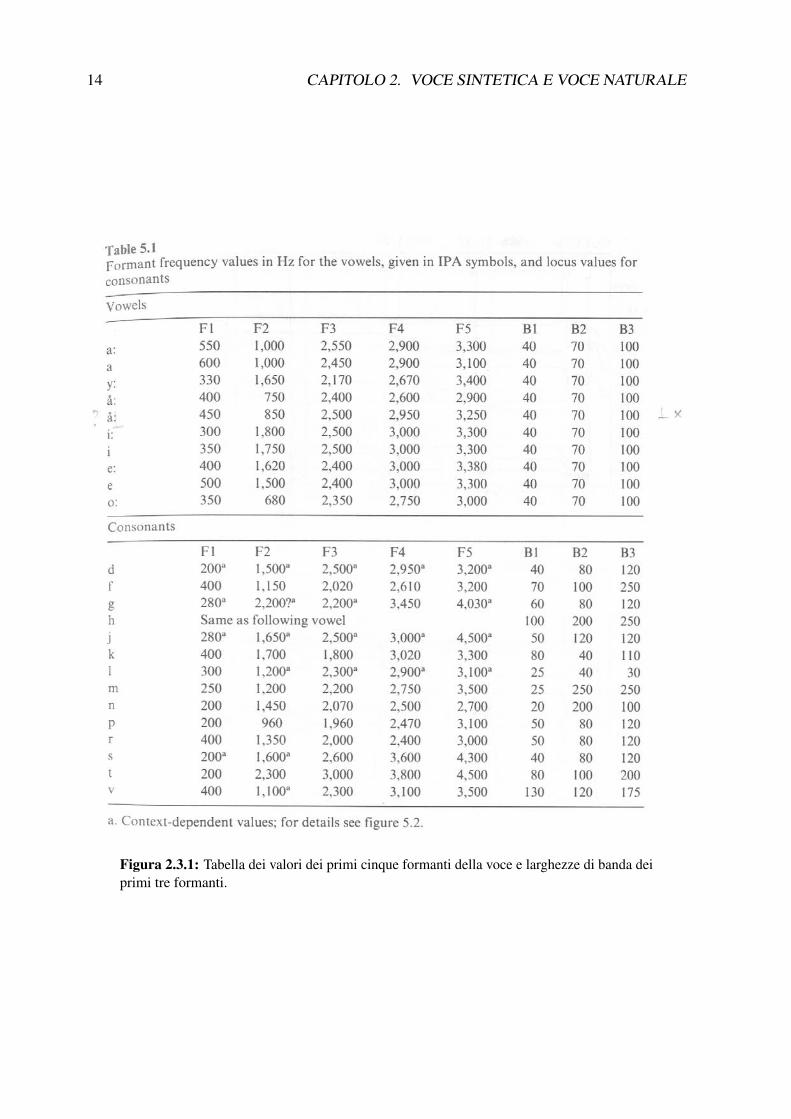
14 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
Figura 2.3.1: Tabella dei valori dei primi cinque formanti della voce e larghezze di banda deiprimi tre formanti.
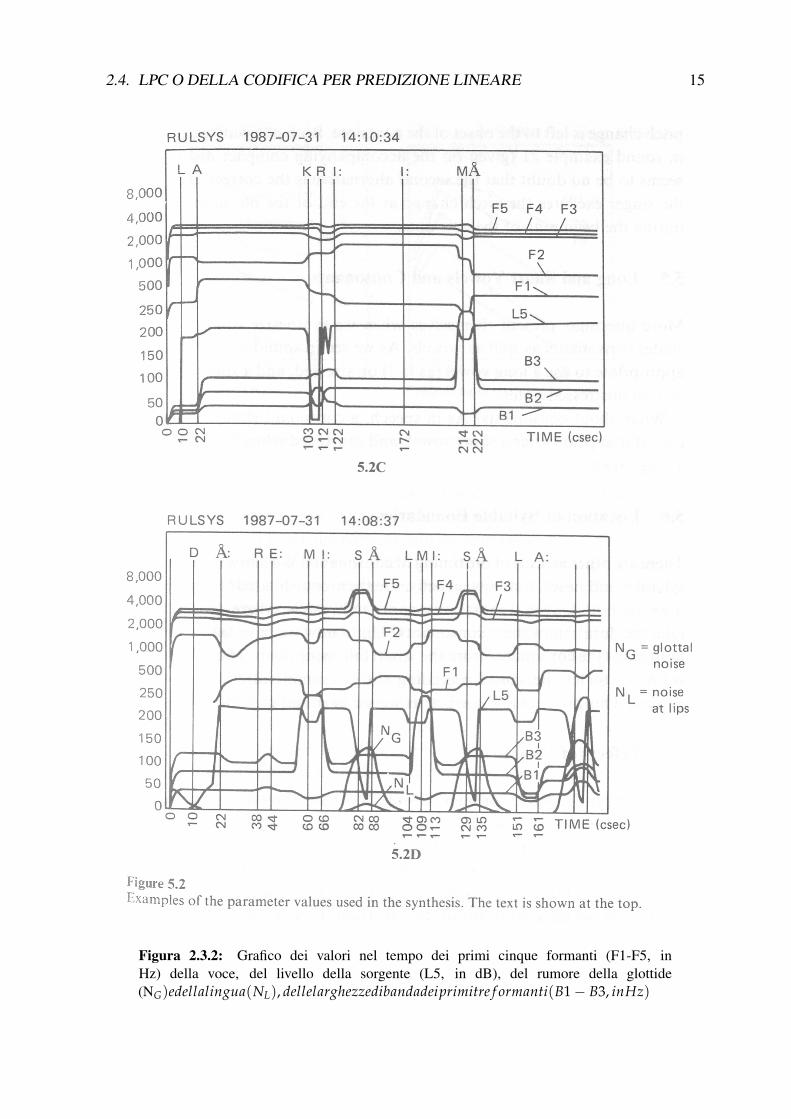
2.4. LPC O DELLA CODIFICA PER PREDIZIONE LINEARE 15
Figura 2.3.2: Grafico dei valori nel tempo dei primi cinque formanti (F1-F5, inHz) della voce, del livello della sorgente (L5, in dB), del rumore della glottide(NG)edellalingua(NL), dellelarghezzedibandadeiprimitre f ormanti(B1 − B3, inHz)

16 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
Figura 2.4.1: Modello semplificato di predizione lineare.
Figura 2.4.2: Flusso del segnale durante l’analisi nella LPC.

2.4. LPC O DELLA CODIFICA PER PREDIZIONE LINEARE 17
(a) Italiano (b) Inglese
Figura 2.4.3: Il flusso dei dati nel processo di sintesi per LPC.
I dati ottenuti dall’analisi della parola “sit” si possono vedere nella Figura 2.4.4. Si possononotare le colonne che contengono:
1. fonema;2. numero del frame;3. RMS del segnale originale;4. RMS del segnale residuo;5. errore di predizione;6. frequenza del suono in Hz;7. durata del frame in secondi.
Per effettuare le modifiche che si vogliono ottenere in fase di sintesi si analizza il listato deivalori di analisi frame per frame per individuare il testo. La forma generale di un comando pereditare i frame è: C, I1, I2, j, E1, E2, E3
• C carattere di controllo che indica l’istruzione;• I1 numero del primo frame sul quale effettuare l’operazione;• I2 numero dell’ultimo frame sul quale effettuare l’operazione;• j numero del parametro sul quale effettuare l’operazione;• E1, E2, E3 numeri con la virgola usati dagli operatori.
Ad esempio il comando T 175 196 0.2 indica l’istruzione T, Time, che assegna ai frames dal175 al 196 la durata di 0.2 secondi6.
§9. Charles Dodge
5Sundberg, “Synthesis of Singing by Rule”.6Per un elenco dei comandi utilizzati da Dodge nel programma di editing per la realizzazione di In Celebration
(cfr. §9) si veda Dodge, “In Celebration: the composition and its realization in synthetic speech”, pp. 69-73.

18 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
Figura 2.4.4: Flusso dei dati ottenuti tramite LPC dall’analisi dei frames che compongono laparola “sit”.

2.4. LPC O DELLA CODIFICA PER PREDIZIONE LINEARE 19
L’utilizzo della tecnica LPC è alla base di una serie di brani di Charles Dodge. Un gruppodi quattro brevi canti intitolato Speech Songs e una composizione dal titolo In Celebration.Realizzati i primi tra la fine del 1972 e il 1973 presso i Bell Telephone Laboratories e il secondonel 1975 presso il Columbia University Center of Computing Activities e i Nevis Laboratories,sono tutti basati su poesie di Mark Strand.
Il gruppo Speech Songs7 si avvale della collaborazione di Dodge con Joseph Olive, che stavasviluppando una tecnica di sintesi basata sul tracciamento dei formanti8.
Il testo delle quattro brevi poesie di Strand per Speech Songs è il seguente:
When I am with youWhen I am with you, I am two places at once.When you are with me, you have just arrivedWith a suitcase which you packWith one hand and unpack with the other.
He destroyed her imageHe destroyed her image and thus she was no longer.When he saw her in the streetHe knew he had seen her before,But couldn’t place himself.
A man sitting in a cafeteriaA man sitting in a cafeteriaHad one enormous earAnd one tiny one.Which was fake?
The days are aheadThe days are ahead1,926,346 to 1,926,345.Later the nights will catch up.9
Il brano In Celebration, basato su una poesia del 1973 dal medesimo titolo, sfrutta lepossibilità del parlato sintetico. Il testo della poesia è il seguente:
You sit in a chair, touched by nothing, feelingthe old self become the older self, imaginingonly the patience of water, the boredom of stone.You think that silence is the extra page,you think that nothing is good or bad, not eventhe darkness that fills the house while you sit watchingit happen. You’ve seen it happen before. Your friends
7Si veda l’articolo Dodge, “On Speech Songs”. Interessante, per una ricostruzione ‘moderna’ del primo deiquattro brani tramite Pd, l’articolo di Miller-Puckette reperibile al seguente URL: http://crca.ucsd.edu/~msp/Publications/icmc06-reprint.dir/.
8Olive, “Automatic Formant Tracking in a Newton-Raphson Technique”.9Tratto da http://www.sfcmhistory.com/Spitzer/History_204/notes/Notes_
Speech_Songs_2.htm.

20 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
move past the window, their faces soiled with regret.You want to wave but cannot raise your hand.You sit in a chair. You turn to the nightshade spreadinga poisonous net around the house. You tastethe honey of absence. It is the same whereveryou are, the same if the voice rots beforethe body, or the body rots before the voice.You know that desire leads only to sorrow, that sorrowleads to achievement which leads to emptiness.You know that this is different, that thisis the celebration, the only celebration,that by giving yourself over to nothing,you shall be healed. You know there is joy in feelingyour lungs prepare themselves for an ashen future,so you wait, you stare and you wait, and the dust settlesand the miraculous hours of childhood wander in darkness10.
La poesia è divisa in due parti: l’introduzione alla prima parte, “senza speranza, disperata,statica”11, caratterizzata dalla parola ricorrente “You”, tema unificante, prosegue con “sit in achair” e col coro scandito dalle parole “touched by nothing” e termina con “imagining only”, untema a tre voci molto utilizzato anche nel seguito; la seconda parte, scandita dalla ripresa del testo“You sit in a chair”, “pur continuando il tono della prima, sottolinea una certa consapevolezza”.
La partitura mescola simboli della notazione tradizionale con durate cronometriche e simbolidi andamenti generici del testo (si veda la Figura 2.4.5).
2.5 Gerald Bennet e Xavier Rodet§10. “Sintesi della voce cantata”
In un articolo12 presente nella raccolta Current Directions in Computer Music Research,Gerald Bennett e Xavier Rodet propongono i risultati di una ricerca in corso il cui inizio risalealla fine degli anni settanta e che ha portato alla realizzazione del software CHANT per lasintesi della voce tramite formanti. Nel rapport IRCAM n.35 del 1985, Rodet, Potard e Barrière,Chant, avevano già in parte illustrato il funzionamento della sintesi FOF (Fonctions d’Onde
10La poesia (p. 49) e la gran parte delle informazioni che seguono in questo paragrafo sono state tratte da Dodge,“In Celebration: the composition and its realization in synthetic speech”. “Tu siedi su una sedia, toccato da niente,sentendo / il vecchio te stesso diventare il più vecchio te stesso, immaginando / solo la pazienza dell’acqua, lanoia della pietra. / Tu pensi che il silenzio sia la pagina in più, / tu pensi che nulla sia buono o cattivo, nemmeno /l’oscurità che riempie la casa mentre seduto lo guardi / accadere. L’hai già visto accadere. I tuoi amici / si muovonooltre la finestra, le loro facce sporche di rammarico. / Vuoi salutarli ma non puoi alzare la mano. / Tu siedi su unasedia. Ti giri verso la morella stendendo / una rete velenosa attorno la casa. Assaggi / il miele dell’assenza. È lostesso ovunque / tu sei, lo stesso se la voce si decompone prima / del corpo, o il corpo si decompone prima dellavoce. / Sai che il desiderio porta solo al dolore, che il dolore / porta alla realizzazione che porta al vuoto. / Tu saiche questo è diverso, che questo / è la celebrazione, la sola celebrazione, / che col darti al nulla, / devi guarire. Saiche vi è felicità nel sentire / i polmoni prepararsi per un futuro cinereo, / così aspetti, fissi lo sguardo e aspetti, e lapolvere si deposita / e le ore miracolose della fanciullezza vagano nel buio.”
11Dodge, “In Celebration: the composition and its realization in synthetic speech”, p. 48.12Bennett e Rodet, “Synthesis of the singing voice”.

2.6. MICHAEL MCNABB, DREAMSONG 21
(a) Pagina 1 (b) Pagina 9
Figura 2.4.5: La prima e l’ultima pagina della partitura di In Celebration di Charles Dodge.
Formantiques) e le possibilità che questo tipo di sintesi aveva nell’utilizzo anche oltre la sintesivocale. I compositori citati in questo articolo che hanno utilizzato il software sono GeraldBennett, Conrad Cummings, Jean-Baptiste Barrière, Jonathan Harvey, Jukka Tiensuu, HarrisonBirstwistle, Kaija Saariaho, Michel Tabachnik, Gerard Grisey, Alejandro Vinao, Tod Machovere Marco Stroppa.
2.6 Michael McNabb, Dreamsong
§11. Voci ed altri suoni
“Dreamsong è stato composto e realizzato al CCRMA (Center for Computer Research inMusic and Acoustics) tra il 1977 e il 1978. L’intento di base del brano era di integrare uninsieme di suoni sintetizzati con un insieme di suoni naturali registrati digitalmente in modotale da formare un continuum di materiale sonoro disponibile.”13. Fra i cinque materiali sonoriessenziali utilizzati da McNabb vi sono
13McNabb, “Dreamsong: The Composition”, p. 36. La gran parte delle informazioni riportate in questo paragrafosono tratte da questo articolo.

22 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
1. voce cantata elaborata e risintetizzata;2. elaborazioni di parlato e di folla;
gli altri materiali sono3. modulazione di frequenza (FM) semplice;4. FM complessa;5. sintesi additiva.
I suoni vocali cantati sono del soprano Marilyn Barber: dieci note singole tenute e unglissando. La gran parte dei materiali armonici e melodici sono tratti dai due modi visibili nellaFigura 2.6.1
Figura 2.6.1: Modi utilizzati in Dreamsong da McNabb per ricavare tutte le altezze dimelodie e accordi.
Nella composizione vi sono due temi: uno primario (Figura 2.6.2, sopra), tratto da un sutraZen, e uno secondario (Figura 2.6.2, sotto)
Figura 2.6.2: Le due melodie utilizzate in Dreamsong da McNabb.
Interessanti alcuni configurazioni ritmiche. In particolare l’uso dei ritmi derivati dal calcolodelle subottave di alcune note chiave dei modi utilizzati. “Per esempio, a 102 secondi il tonoprincipale nel primo accordo oscillante è F, 349,23 Hz. Sei ottave sotto troviamo 5,457 Hz, cheha un periodo di 0,183 secondi. Questa è la frequenzxa con il quale l’accordo oscilla da canale acanale ed è quattro volte la frequenza delle campane sul si bemolle in sottofondo.”14
Il programma principale utilizzato è un discendente del Music V di Mathews, il MUS10, laversione di Leland Smith del MUSCMP di Tovar. Questa versione permette di specificare inlinguaggio Algol alcune routine, funzioni e vettori, che alleggeriscono (come le PLF in Music V)la scrittura della partitura e permettono di gestire eventi complessi grazie alla programmazione.Possiamo vedere il listato dello strumento SING nella (Figura 2.6.3)
14McNabb, “Dreamsong: The Composition”, pp. 36-37.

2.7. FM O DELLA MODULAZIONE DI FREQUENZA 23
Figura 2.6.3: Listato dello strumento SING, utilizzato per modellare una voce cantata insintesi additiva per Dreamsong da McNabb.
2.7 FM o della modulazione di frequenza§12. John Chowning: biografia e percorso teorico
John Chowning nasce nel 1934. Studia composizione a Parigi con Nadia Boulanger (’59-’62). Nel 1964 a Stanford lavora sotto la supervisione di Max Mathews. Applica la modulazionedi frequenza in banda audio (1967). Ha insegnato composizione e sintesi dei suoni a Stanforded è stato direttore del CCRMA (Center for Computer Research and Acoustics).
Il suo percorso teorico in ambito musicale vede tre tappe fondamentali:
1. la simulazione di sorgenti sonore in movimento15;2. la modulazione di frequenza (d’ora in poi FM)16;3. la sintesi della voce17.
La FM verrà utilizzata nei sintetizzatori commerciali della Yamaha a partire dal GS 1 e aseguire in tutta la serie aaXnn (dal TX81Z alla fortunata schiera di modelli del DX7).
§13. Phoné di John Chowning
John Chowning nel 1979 sviluppa la tecnica FM per la voce cantata (in particolare disoprano). Tra il dicembre 1979 e l’agosto 1980 soggiorna infatti all’IRCAM18, dove trovaJohan Sundberg19. Il modello base che utilizza è quello di una FM complessa a tre portanti euna modulante oppure quello con tre FM semplici, la cui frequenza modulante coincide con lafrequenza fondamentale (ovvero la nota cantata). I due anni successivi, trasferitosi a Stanford,vi realizza Phoné, che vedrà la prima esecuzione assoluta a Parigi fra il 17 e il 21 febbraio
15Chowning, “The simulation of moving sound sources”.16Chowning, “The Synthesis of Complex Audio Spectra by Means of Frequency Modulation”.17Si vedano Chowning, “Synthesis of the singing voice by frequency modulation” e Chowning, “Frequency
modulation synthesis of the singing voice”.18Gran parte delle informazioni biografiche sono tratte da Bossis, “Phoné”.19Si veda §7.

24 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
1981. Fra gli stimoli che Chowning aveva ricevuto troviamo il brano Dreamsong di MichaelMcNabb (si veda §11) e gli studi di Rodet e Bennet sulla sitesi della voce per il progetto CHANTall’IRCAM.
Da una prima analisi della voce cantata possiamo trarre alcune semplici conseguenze sullesue caratteristiche principali:
• il primo formante (per le voci femminili questo avviene sempre) coincide con la fonda-mentale;
• 2 o 3 picchi secondari nello spettro dipendono dalla vocale e dalla fondamentale;• la frequenza dei formanti dipende dalla fondamentale;• in fase di attacco solo l’ampiezza del primo formante è significativa, mentre l’ampiezza
degli altri diventa significativa nella fase quasi-stazionaria;• l’intensità delle formanti più acute al decrescere dell’intensità globale decresce più
rapidamente di quella delle formanti più gravi (e viceversa);• si nota una piccola ma distinguibile variazione d’altezza anche in assenza di vibrato.
In Phoné Chowning intende esplorare due estremi percettivi come polarità: brevi suonipercussivi e vocali cantate. Lo strumento FM che utilizza va da 2 a 6 portanti e 1 modulante.Carattere preponderante hanno le interpolazione timbriche e gli effetti’ per simulare la voce(vibrato, [. . . ]). Un esempio di interpolazione timbrica lo possiamo ascoltare nel passaggio dasuono di campana a voce per tornare nuovamente a suono di campana realizzato tramite attaccodi campana, vibrato tipicamente vocale, decadimento di campana.
2.8 Jonathan Harvey
§14. Cenni biografici
Nato a Warwickshire (UK) nel 1939, Jonathan Harvey viene invitato da Pierre Boulez alavorare all’IRCAM nei primi anni ottanta, dove realizza, fra gli altri, Mortuos Plango, VivosVoco per solo nastro, Bhakti (1982) per ensemble ed elettronica e il quartetto d’archi No.4, conlive electronics. Harvey ha anche composto per altre formazioni: orchestra (Tranquil Abiding(1998), White as Jasmine (1999) e Madonna of Winter and Spring (1986) – quest’ultimo eseguitodai Berliner Philharmoniker diretti da Simon Rattle nel 2006), camera (quattro quartetti d’archi,Soleil Noir/Chitra, e Death of Light, Light of Death del 1998) e opere per strumento solista. Hascritto svariate opere per coro senza accompagnamento ampiamente eseguite – così come unagrande cantata per il BBC Proms Millennium, Mothers shall not Cry (2000). La sua opera dachiesa Passion and Resurrection (l981) è stata il soggetto di un film per la televisione BBC, edè stato eseguito per diciassette volte di seguito. La sua opera Inquest of Love, commissionatada ENO, è stata eseguita per la prima volta under the baton di Mark Elder nel 1993 e ripresaal Theatre de la Monnaie di Brussels nel 1994. La sua terza opera, Wagner Dream (2006),commissionata dalla Nederlandse Oper e realizzata all’IRCAM, è stata eseguita la prima voltacon grande successo nel 2007. Il 2008 vede la prima di Messages (per il Rundfunkchor Berlin ei Berlin Philharmoniker) e Speakings (co-commissione fra BBC Scottish Symphony Orchestra,IRCAM e Radio France); Speakings è stato il culmine della sua residenza (2005-08) con la BBCScottish Symphony Orchestra, dalla quale sono nati anche Body Mandala (2006) e ...towards apure land (2005).

2.8. JONATHAN HARVEY 25
È dottore onorario delle università di Southampton, Sussex, Bristol, Birmingham e Hud-dersfield, è membro dell’Accademia Europaea e nel 1993 è stato premiato con il prestigiosopremio Britten per la composizione. Nel 2007 è stato premiato con il Premio Giga-Hertz peruna vita dedicata alla musica elettronica. Ha pubblicato due libri nel 1999, rispettivamentesull’ispirazione e sulla spiritualità. Uno studio di Arnold Whittall sulla sua musica è apparsonel 1999, pubblicato da Faber & Faber (e in francese dall’IRCAM) nello stesso anno. Dueanni dopo John Palmer ha pubblicato uno studio sostanziale: Jonathan Harvey’s Bhakti, EdwinMellen Press. Michael Downes ha pubblicato un libro su due sue opere nel 2009 con l’editoreAshgate. Harvey è stato professore di musica alla Sussex University tra il 1977 e il 1993 doveè attualmente professore onorario. È stato professore di musica alla Stanford University (US)tra il 1995 e il 2000, è membro onorario del St. John’s College, Cambridge ed è stato membrodell’Istituto di Studi Avanzati di Berlino nel 200920.
§15. Mortuos Plango, Vivos voco
Il brano di Jonathan Harvey Mortuos Plango, Vivos Voco21, per nastro a otto tracce, è statorealizzato all’IRCAM nel 1980 con l’assistenza tecnica di Stanley Haynes, il quale, parlandodelle tecniche di PV in un articolo del 1982, afferma che
[t]he evolution of the spectra can be modified either by changing the functions or bymultiplying them by modifying functions produced by oscillators within the computerinstrument. This gives the possibility of beginning with a recognizably instrumental orvocal sound and gradually shifting the amplitude and frequency of each harmonic componentto produce a new spectrum. The British composer Jonathan Harvey has exploited theseeffects in a number of pieces, creating instrumentlike tones whose harmonic componentsspread out in pitch and equalize in amplitude to come to rest on chords22.
Harvey utilizza il programma di analisi tramite FFT allora presente all’IRCAM, cheproveniva dal pacchetto S di analisi del suono interattiva sviluppato all’Università di Stanford23.
Harvey, cinque anni dopo la composizione di Mortuos Plango, Vivos Voco, parlando deltimbro e dopo aver fornito alcuni esempi di pratiche di compositori quali Boulez, Stockhausen,Ligeti, Grisey, Murail, li accomuna sostenendo che “they are all playing with the identity given toobjects by virtue of their having a timbre, in order to create ambiguity”24. Il senso di ambiguità,già accennato in “Identity and Ambiguity: The Construction and Use of Trimbral Transitions
20Copyright: Faber Music Ltd, dicembre 2009; notizie tratte da http://www.vivosvoco.com/biography.html.
21Un’introduzione al brano la si può leggere in Harvey, “Mortuos Plango, Vivos Voco: A Realization at IRCAM”,dal quale sono state tratte molte delle informazioni presenti in questo paragrafo. La prima esecuzione è avvenuta il30 novembre 1980 al Lille Festival. Per un’analisi del brano che ripercorre, con tecnologie attuali, il processo direalizzazione dei suoni tramite l’analisi delle registrazioni della campana e della voce si veda Dirks, An Analysis ofJonathan Harveys “Mortuos Plango, Vivos Voco”. Un buon esercizio di ‘ricostruzione’ informatica lo proponeMiller Puckette e lo si può trovare qui http://crca.ucsd.edu/~msp/pdrp/latest/files/doc/harvey/harvey.htm. Ad oggi, l’unica analisi di mia conoscenza che affronta il problema delladistribuzione del brano nello spazio è Zattra, Studiare la computer music, pp. 243-256. Un’edizione discograficastereofonica la si può trovare in Aa. Vv. Computer Music Currents 5. Di questa ‘ricostruzione’ si può trovare unadettagliata spiegazione in 2.8.1.
22Haynes, “The Computer as a Sound Processor: A Tutorial”, p. 14.23Harvey, “Mortuos Plango, Vivos Voco: A Realization at IRCAM”, p. 22.24Harvey, “The Mirror of Ambiguity”, pp. 178-179.

26 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
and Hybrids”, viene reso grazie a ibridazione fra timbri diversi, realizzabile tramite tecniche diphase-vocoding.
Particolare importanza è stata attribuita da Harvey, per approfondire il concetto di ambiguità,allo studio dei suoni di strumenti acustici, in particolare di culture lontane da quella occidentale.In un articolo scritto a quattro mani con Jan Vanenheede mentre lavorava all’IRCAM25, sebbenescritto nel 1985 e legato alla realizzazione del brano Bhakti (1982) per 15 esecutori e nastroquadrifonico, Harvey testimonia del suo interesse per l’“ambiguità” dei timbri strumentali, per latransizione fra un timbro e l’altro, per le possibilità di ibridazione timbrica, aspetti che lo avevanogià interessato nella composizione di Mortuos plango, vivos voco. Nella risintesi dei suonivocali viene tuttavia utilizzata una tecnica ‘granulare’ (la FOF, motore di sintesi del programmaCHANT sviluppato all’IRCAM26). La compresenza di tecniche sia di sintesi (granulare tramiteFOF) sia di sintesi per analisi (tramite filtro ad eterodina) evidenzia la diversità degli strumentiutilizzati dai compositori, e soprattutto la diversità dei parametri di controllo a loro disposizioneper generare nuovi mondi sonori: da un punto di vista compositivo ragionare sui parametri dellasintesi granulare o sui parametri di un banco di oscillatori significa creare suoni, strutture eprocessi musicali anche molto distanti fra loro.
I materiali concreti utilizzati da Harvey in Mortuos Plango, Vivos voco sono due: la voce delfiglio e la grande campana della cattedrale di Winchester, per la quale Harvey ha scritto moltamusica corale. Il testo letto e cantato dalla voce è l’iscrizione presente sulla campana: “HorasAvolantes Numero, Mortuos Plango: Vivos ad Preces Voco”27.
La fase di analisi del suono ha occupato una buona parte del lavoro di Harvey, in quanto daessa si sono ricavate molte informazioni per la costruzione del brano, utili sia alla sintesi deisuoni sia alle relazioni formali e alle scelte strutturali. Il suono della campana, analizzato mezzosecondo dopo l’inizio del rintocco tramite FFT, riporta i valori di altezza ‘trascritti’ in notazionetradizionale riprodotti in Figura 2.8.1.
8
Figura 2.8.1: Le parziali della campana della cattedrale di Winchester ottenute da Harveytramite FFT seguite dalla “strike note”.
“Le otto sezioni del lavoro, con le loro altezze centrali, sono strutturate attorno alle parzialimostrate nella Figura 2.8.2”28.
La sintesi e il mixaggio dei suoni sono stati realizzati con la versione dell’IRCAM del MusicV. La possibilità di controllare l’ampiezza di ogni singola parziale in fase di risintesi ha permessoad Harvey di variarne il decadimento singolarmente, ad esempio aumentando la durata di quelleacute, normalmente rapide, e diminuendo la durata di quelle gravi, normalmente lente. Harvey,alcuni anni dopo, sottolinea che “instead of making all the models with FOFs as we originallyintended, we finally had to use different types of synthesis for the models. So the bell, althoughbeing possible with pure FOFs is a pure additive synthesis instrument, to get a more precise
25Vandenheede e Harvey, “Identity and Ambiguity: The Construction and Use of Trimbral Transitions andHybrids”.
26Si veda Rodet, Potard e Barrière, Chant.27“Conto le ore che volano, piango i morti: i vivi chiamo alla preghiera”.28Harvey, “Mortuos Plango, Vivos Voco: A Realization at IRCAM”, p. 22.

2.8. JONATHAN HARVEY 27
Figura 2.8.2: Le note/frequenze, tratte dallo spettro della campana, attorno alle quali ruotanole otto sezioni del brano.
control over its time evolution”29, proprio ciò che aveva messo in pratica in Mortuos plango,vivos voco.
Un’interessante applicazione della risintesi è quella che prevede la distribuzione nellospazio ottofonico delle singole parziali ricavate dall’analisi del suono della campana, che“danno all’ascoltatore la curiosa sensazione di essere dentro la campana”30. La suddivisionespaziale dello spettro di un suono è a mio avviso uno degli aspetti centrali nella composizioneelettroacustica; di questo utilizzo ci fornisce una descrizione anche Robert Normandeau, quandoafferma che “what is unique in electroacoustic music is the possibility to fragment sound spectraamongst a network of speakers. [. . . W]ith multichannel electroacoustic music, timbre can bedistributed over all virtual points available in the defined space”31.
2.8.1 Descrizione del patch Pure Data di Miller Puckette per l’‘esecuzione’di Mortuos plango, vivos voco [Francesco Grani, a.a. 2011-12]
§16. Il Patch mortuos.pd
Il patch Pure Data descritto in questa sezione appartiene alla collezione di patches PDRepertory Project32, ideata e mantenuta dal ricercatore Miller Puckette creatore anche dell’am-biente di sviluppo Pure Data e di altri linguaggi di programmazione dedicati alla creazionemusicale. Scopo del PD Repertory Project – come dichiarato dall’autore nel file README.txtdella collezione – è quello di “realizzare l’ambiente esecutivo di brani del repertorio classico dimusica elettronica, [...] per permetterne una esecuzione più semplice [e] per poterne studiare ilfunzionamento [a scopo didattico]”.
§17. Schermata principale del Patch
In apertura è utile fornire un chiarimento: il patch33 mortuos.pd non esegue il brano MortuosPlango, Vivos Voco di Harvey; piuttosto permette di replicare il tipo di trasformazioni che
29Vandenheede e Harvey, “Identity and Ambiguity: The Construction and Use of Trimbral Transitions andHybrids”, p. 100.
30Harvey, “Mortuos Plango, Vivos Voco: A Realization at IRCAM”, p. 24.31Normandeau, “The visitors and the residents”, p. 62.32Puckette, PD Repertory Project, Version 12 2009. La collezione è scaricabile dal web ed è coperta da una
licenza Standard Improved BSD License (The Linux Information Project 2005). Il pacchetto compresso per ildownload è raggiungibile all’indirizzo: http://crca.ucsd.edu/~msp/pdrp/latest/files/doc/. La versione della collezione impiegata per redarre il presente documento è la numero 12, datata 24Settembre 2009 ed è eseguita all’interno dell’ambiente Pure Data Extended (PD Extended 2004, PD Community2003) versione 0.41.4-extended, recuperabile all’indirizzo: http://puredata.info/downloads/pd-extended/releases
33Il termine Patch è generalmente impiegato nel campo della musica elettronica al femminile; in questo lavoro èinvece utilizzato il genere maschile, per le motivazioni che seguono: con il termine Patch (trad. toppa, rattoppo,

28 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
Harvey ha impiegato per creare il proprio brano. In particolare il Patch esegue un morphingspettrale. È possibile scegliere di operare il morphing su un segnale audio in ingresso, oppure suun segnale audio preregistrato.
Figura 2.8.3: Schermata principale del Patch mortuos.pd.
Il patch principale è suddiviso in numerosi sottoprogrammi (subpatchers, si veda la Figu-ra 2.8.3) all’interno dei quali vengono eseguite in modo ordinato le operazioni dell’ambiente
pezza) si intende descrivere nel gergo informatico un software creato per modificare una specifica porzione delcodice di un altro software di cui sia noto un problema o un errore di programmazione (Wikipedia s.d.); in questosenso la Patch va a porre una “toppa” all’interno del software malfunzionante, ed è perciò sensato l’uso del termineal femminile. Anche nel campo della pirateria informatica, Patch assume il significato femminile di toppa o pezza,perché si tratta ancora una volta di un codice atto a modificare una precisa porzione di un programma legalmentelimitato, per renderlo illegalmente illimitato.
Nel gergo dei linguaggi di programmazione grafici (caso tipico nella musica elettronica) tuttavia con la parolaPatch si intende descrivere nel complesso l’insieme di istruzioni date all’ambiente di programmazione (ad es. PureData) per fargli eseguire l’insieme di operazioni volute dal programmatore. In definitiva, in questo contesto Patchnon significa toppa, e non indica alcun programma ‘minore’ necessario a modificare o ad aggiustare un programma‘maggiore’. In questo caso Patch significa Programma oppure di Algoritmo o ancora Codice sorgente o Sequenzadi istruzioni, tutti termini propriamente maschili. È per questo motivo che impiegheremo a nostra volta il maschilenella redazione del presente lavoro.

2.8. JONATHAN HARVEY 29
esecutivo. Centro nevralgico delle trasformazioni sonore è il subpatch pd osc-bank, che analiz-zeremo nel paragrafo ad esso dedicato. All’interno della schermata principale sono presenti ivari parametri di controllo che governano la creazione dei suoni e l’impostazione dei parametriche ne determinano le caratteristiche.
La prima operazione da fare, una volta avviato il patch, è cliccare sul segnale di bangcollegato al patcher score-editor.pd. In questo modo vengono richiamate una serie di istruzioniall’interno del patcher sequencer.pd che permettono di eseguire un piccolo brano musicale didimostrazione delle funzionalità del Patch. Editando i files di testo qlist1.txt e score1.txt (presentinella sottodirectory “score”) è possibile creare la propria sequenza di istruzioni da inviare alsequencer affinché esegua un brano musicale di nostra creazione. I patchers score-editor esequencer sono librerie comuni a tutta la collezione PD Repertory Project, perciò non verrannoanalizzati in dettaglio34.
Altri controlli presenti nella schermata principale sono:
• Live input: selezionando o deselezionando questo toggle si sceglie se operare il morphingspettrale tra diversi istanti o zone dello spettro del segnale in input, oppure del segnalepreregistrato bell.aiff ;
• i controlli di volume nelle variabili loop-amp e osc-amp: rispettivamente relativi all’am-piezza del segnale letto da file e del segnale audio generato dal banco di oscillatori delPatch;
• pick out partial: permette di scegliere una precisa parziale da ascoltare in “solo”;• gliss time: regola il tempo di glissando tra un set di frequenze/ampiezze del banco di
oscillatori ed il successivo (potremmo chiamarlo tempo di “morphing”);• find partial staring here: questa soglia opzionale comunica al banco di oscillatori di non
utilizzare tutte le frequenze al di sotto del numero impostato;• snapshot bang: messaggio da premere per “fotografare” il live input microfonico ed
effettuare dunque successivamente una transizione spettrale verso di lui impostando ilbanco di oscillatori sulle sue parziali.
§18. Subpatch pd startup
Come suggerisce il nome, questo subpatch viene caricato all’avvio del patch principalemortuos.pd con il duplice compito di:
34I patchers sequencer.pd e score-editor.pd si trovano all’interno della directory /lib della collezione PD RepertoryProject . In questa stessa posizione si trovano tutti gli oggetti da considerarsi librerie, ossia strumenti utilizzati dapiù Patchers senza che nessuno di essi ne detenga in qualche modo la paternità. Questo genere di suddivisione diun programma in due tipi di oggetti, quelli caratteristici del programma specifico e quelli comuni a più programmi,è molto utilizzato nello sviluppo informatico.
Facciamo un esempio: i programmi Gioco-a-Dadi e Gioco-a-Tombola eseguono tutti e due un’estrazione casualead ogni mossa del gioco, saranno perciò istruiti su un diverso set di numeri da estrarre (un numero alla volta, da 1a 90, nel programma della Tombola, e due numeri per volta, entrambi da 1 a 6, nel programma dei Dadi), ma ilmeccanismo atto a generare il caso nell’estrazione sarà unico, e lo potremmo chiamare random. Random è unalibreria. Chiamando ad esempio Random(1,1-90) (=“esegui una estrazione di un numro tra 1 e 90”) potremmogiocare ai dadi, mentre chiamando Random(2,1-6,1-6) (=“esegui due estrazioni, ognuna di un numero tra 1 e6”) potremmo ad esempio giocare ai Dadi. In ogni caso Random non apparterrà a nessuno dei due software inparticolare e lo posizioneremo in una directory (ad es. /lib) dove possa essere utilizzato da tutti i software che nefacciano richiesta. I Patchers score-editor.pd e sequencer.pd sono proprio librerie di questo tipo e sono impiegati datutti i Patchers della collezione PD Repertory Project che ne abbiano bisogno, pur senza appartenere a nessuno diessi in particolare.

30 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
• avviare il motore audio DSP di Pure Data• mandare il segnale di inizializzazione init che sortisce più effetti:
– all’interno di questo subpatch ordina il caricamento del file audio di default bell.aiffnella tabella di nome array5, che si trova nel patch principale (Nota: array5 misura88203 campioni, ossia 2 secondi di audio campionato a 44100 Hz, mentre bell.aiffcontiene 4 secondi di audio campionato a 44100 Hz. Viene perciò caricata in array5solo una porzione del file audio letto);
– nel subpatch pd osc-bank, in ognuno dei subpatchers voice N, attiva un messaggio direset che imposta momentaneamente a zero il valore dell’ampiezza su cui è intonatoil tale oscillatore N-esimo; ciò avviene per tutti gli oscillatori.
Figura 2.8.4: Patcher pd startup.
§19. Subpatch pd analysis
Questo subpatch riceve il segnale di input (ossia il campione audio memorizzato nellatavola array5 oppure il segnale microfonico dal live-input) dal patch pd inputs attraverso lavariabile audio input-signal e ne esegue ininterrottamente l’analisi delle parziali con lo strumentosigmund˜. Sigmund˜ è configurato in questo caso per produrre in uscita i picchi delle prime50 sinusoidi individuate dall’analisi, ordinate in ordine descrescente di ampiezza. In uscita dasigmund˜ si ottiene dunque, ad ogni snapshot bang, una lista di 5 numeri per riga:
1. numero d’ordine della sinusoide individuata;2. fequenza della sinusoide;3. ampiezza della sinusoide;4. componente cosinusoidale;5. componente sinusoidale;
Quando è inviato il messaggio snapshot bang dalla finestra principale vengono fatte passare leprime tre colonne (attraverso unpack) di ogni riga dell’output di sigmund˜ le quali si immettonoordinatamente in due tabelle come segue:
• in array1 viene caricata la lista delle frequenze delle componenti sinusoidali (con numerod’ordine, frequenza, ampiezza);
• in array2 viene caricata la lista delle ampiezze delle componenti sinusoidali (con numerod’ordine, frequenza, ampiezza).
§20. Subpatch pd arrays
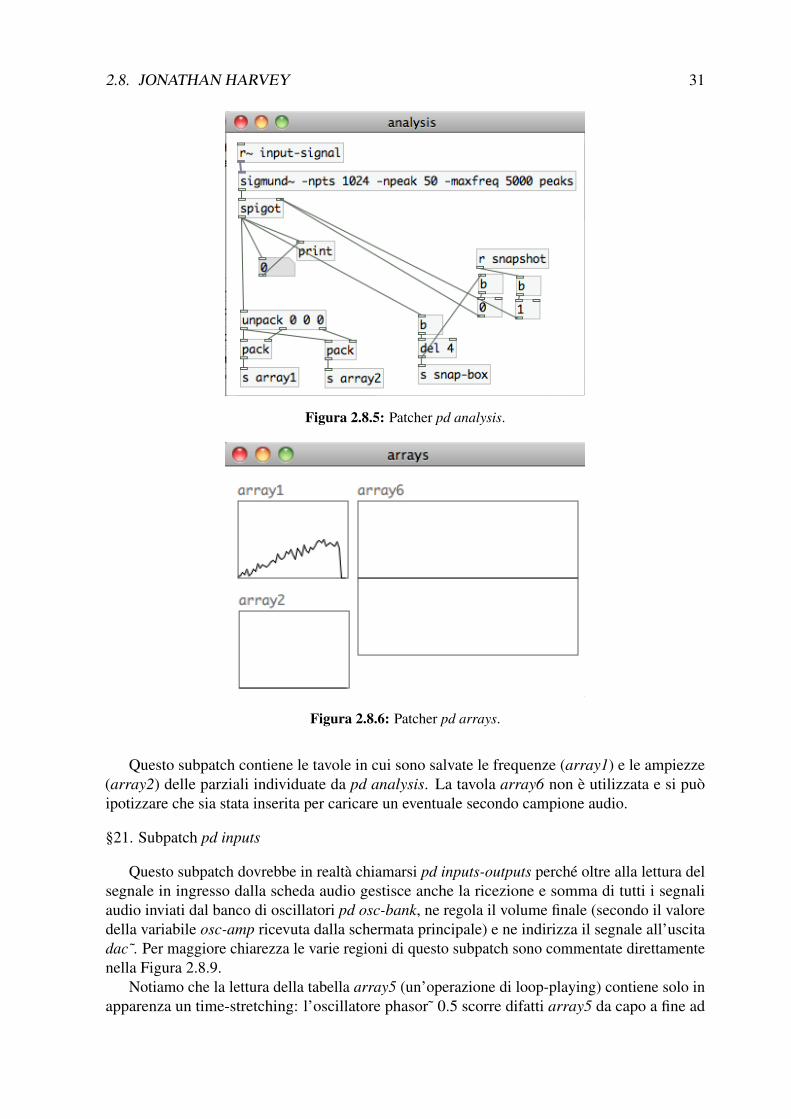
2.8. JONATHAN HARVEY 31
Figura 2.8.5: Patcher pd analysis.
Figura 2.8.6: Patcher pd arrays.
Questo subpatch contiene le tavole in cui sono salvate le frequenze (array1) e le ampiezze(array2) delle parziali individuate da pd analysis. La tavola array6 non è utilizzata e si puòipotizzare che sia stata inserita per caricare un eventuale secondo campione audio.
§21. Subpatch pd inputs
Questo subpatch dovrebbe in realtà chiamarsi pd inputs-outputs perché oltre alla lettura delsegnale in ingresso dalla scheda audio gestisce anche la ricezione e somma di tutti i segnaliaudio inviati dal banco di oscillatori pd osc-bank, ne regola il volume finale (secondo il valoredella variabile osc-amp ricevuta dalla schermata principale) e ne indirizza il segnale all’uscitadac˜. Per maggiore chiarezza le varie regioni di questo subpatch sono commentate direttamentenella Figura 2.8.9.
Notiamo che la lettura della tabella array5 (un’operazione di loop-playing) contiene solo inapparenza un time-stretching: l’oscillatore phasor˜ 0.5 scorre difatti array5 da capo a fine ad

32 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
Figura 2.8.7: Patcher pd inputs.
una velocità di 0.5 Hz. Essendo il frammento audio contenuto in array5 campionato a 44100 Hze la dimensione di array5 pari a ˜ 88200 campioni, operando su un DSP a 44100 Hz di clock, nerisulta una velocità di lettura pari a quella originale.
§22. Subpatch pd messpeak
Principalmente, questo subpatch lavora in modo conseguente al subpatch pd analysis. Quan-do pd analysis ha terminato di individuare le parziali, come richiestogli dall’invio di un segnaledi “snapshot bang” nella finestra principale, allora un segnale snap-box è inviato a pd mes-speak. A questo punto (alla ricezione di snap-box) vengono attivati i 20 subpatch dofreq ed i 20subpatch doamp.
I 20 patchers dofreq ([dofreq 0], [dofreq 1], . . . , [dofreq 19]) hanno ognuno il compito diaccedere alla tabella array1 – in cui sono memorizzate le frequenze delle parziali individuate dapd analysis – e di caricarne il valore (= la frequenza) contenuto nella posizione corrispondentealla variabile ricevuta come argomento, convertendo poi ogni frequenza in un valore MIDI

2.8. JONATHAN HARVEY 33
Figura 2.8.8: Patcher pd messpeak.
attraverso l’operatore ftom. Ad esempio dofreq 0 leggerà il primo valore contenuto nella tabellaarray1 (ad es. 327.9 Hz) e lo passerà in uscita come nota MIDI (nell’esempio 63.91).
Se nella finestra principale è impostato il valore find partial staring here, questo vienetrasmesso alla variabile shift1 che sposta in alto tutti i numeri d’ordine dei patchers dofreq iquali, in questo modo, leggeranno da array1 un set di frequenze posizionate dal valore sceltoper la parziale più bassa in poi.
Con la procedura descritta viene caricato nella variabile oscfreq un set di 20 parziali contiguetra quelle individuate dall’analisi del segnale live in ingresso. La variabile oscfreq è poi ricevutadal subpatcher pd unpacker che provvede a suddividere il vettore in singoli valori di frequenza,assegnandone ognuno alle variabili vf1, vf2, . . . , vfN che verranno caricate poi ognuna da unodei subpatch voice del banco di oscillatori pd osc-bank.
Similarmente a quanto descritto per i patchers dofreq avviene per i patchers doamp. Inquesto caso uno stesso tipo di percorso ed operazioni richiama dalla tabella array2 le ampiezzedelle parziali in uso per inviarle al banco di oscillatori attraverso le variabili va1, va2, . . . , vaN.
In sintesi dunque il subpatch pd messpeak preleva dagli array 1 e 2 la lista di frequenzeed ampiezze su cui impostare il banco di oscillatori ed invia i valori al banco di oscillatori pd

34 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
osc-bank ed al patcher pd box-control che permette di salvare e richiamare fino a due diversiset di frequenze ed ampiezze oltre a quella attualmente in uso. Prima di raggiungere però ilbanco di oscillatori, i due vettori oscfreq ed oscamp, passarenno attraverso pd unpacker che lisuddividerà in una serie di valori singoli con cui inizializzare ogni singola voce del banco dioscillatori.
§23. Subpatch pd box-control
Questo subpatch riceve la lista di valori di frequenze e di ampiezze delle parziali impiegatedal banco di oscillatori. Al click del messaggio save1 bang – nella finestra principale – vieneattivato l’oggetto pack che raduna le variabili vf1, . . . , vfN e va1, . . . , vaN rispettivamente neivettori box_f1 (vettore delle frequenze) e box_a1 (vettore delle ampiezze). Similarmente a quantodescritto per il messaggio save1 bang, cliccando il messaggio save2 bang la configurazioneattuale è memorizzata in un secondo set di vettori: box_f1 e box_a2; in questo modo è possibilesalvare in ogni momento fino a due set di parziali.
Per richiamare uno dei due set memorizzati, è sufficiente cliccare – sempre nella finestraprincipale – i messaggi recall1 bang o recall2 bang. Alla pressione, ad esempio, di “recall1bang” i vettori box_f1 e box_a1 vengono spediti alle variabili globali oscamp ed oscfreq (chesono ricevuti da pd unpacker).
Figura 2.8.9: Patcher pd box-control.

2.8. JONATHAN HARVEY 35
Per praticità, i vettori box_f1, box_f2 e box_a1, box_a2 non sono collocati all’interno dipd box-control, ma direttamente nella finestra principale. In questo modo è possibile avere unfeedback visivo immediato sul funzionamento delle operazioni di salvataggio. Inoltre, con unsemplice colpo d’occhio, è possibile avere informazione su quale set di valori sarà richiamatonel momento in cui premeremo recall1, oppure recall2, evitando così il caricamento di set divalori non desiderati o imprevisti.
§24. Subpatch pd unpacker
Questo subpatch si occupa di suddividere i vettori oscfreq ed oscamp nei singoli valori inessi contenuti. I venti valori contenuti in oscfreq sono indirizzati a venti variabili numerate inmodo progressivo: vf1, . . . , vf20, ed allo stesso modo i venti valori di ampiezza contenuti inoscamp sono smistati alle variabili va1, . . . , va20.
Le variabili vfX e vaX sono impegate dal banco di oscillatori pd osc-bank e dal subpatcherper il salvataggio delle scene pd box-control.
(a) Patcher pd unpac-ker
(b) Patcher pd osc-bank
Figura 2.8.10: I subpatchers pd unpacker e pd osc-bank.
§25. Subpatch pd osc-bank
All’interno di pd osc-bank sono radunati i venti oscillatori cosinusoidali [voice vf1 va1 1],[voice vf2 va2 2], . . . , [voice vf20 va20 20] intonati ognuno su una delle venti parziali armonichedel segnale live-input analizzato da pd analysis.
Ogni istanza del patch voice.pd richiamata in questo modo accetta in ingresso tre variabili:
• vf -i : frequenza a cui viene intonato l’oscillatore i-esimo;

36 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE
• va-i : ampiezza assegnata al segnale dell’oscillatore i-esimo;• i : numero di parziale generata dall’oscillatore i-esimo.
All’interno dell’i-esima istanza del patch voice.pd un oscillatore cosinusoidale viene intonatoalla frequenza i-esima e scalato all’ampiezza i-esima. La descrizione dettagliata del funziona-mento di voice.pd si trova direttamente in Figura 2.8.11 per una maggiore chiarezza. Quandouna certa parziale (pick out partial) è impostata in “solo” dalla finestra principale, tutti gli oscil-latori intonati su una parziale di numero d’ordine diverso da quella in solo, automaticamente simutano.
Ogni nuovo set di frequenze assegnato agli oscillatori viene raggiunto con un glissando trala frequenza precedente e la nuova ed è accompagnato da un portamento lineare dell’ampiezzadal valore precedente al nuovo. Queste operazioni di glissando hanno una durata impostata nellafinestra principale del Patch attraverso gliss time; nel caso in cui venga però impostato un tempotroppo breve, questo viene forzato al valore minimo di 20 ms per la transizione tra le successiveampiezze (non è invece forzato ad alcun valore minimo il tempo di transizione tra successivefrequenze. Ad esempio un gliss time = 2, comporterebbe un salto istantaneo del set di frequenze,accompagnato da un glissando di 20 ms tra le ampiezze precedenti e nuove).
Figura 2.8.11: Patcher voice.pd.

2.8. JONATHAN HARVEY 37
Il segnale audio di ogni oscillatore è inviato al bus audio osc-sum di cui viene poi regolato ilvolume globale nel patcher pd inputs che lo invia all’uscita fisica del dac˜, come abbiamo vistoall’inizio dell’analisi.
Considerando il risultato aggregato del banco di oscillatori pd osc-bank resteremo sorpresidal fascino sonoro del risultato; parleremo dunque di un effetto sonoro di morphing spettrale cheoffre notevoli suggestioni, specialmente impiegando la voce umana come segnale di live-input.Anche deselezionando il toggle live input nella finestra principale ed operando dei morphingspettrali sul campione audio contenuto in array5 è comunque possibile rendersi conto dellepotenzialità del metodo di morphing illustrato.

38 CAPITOLO 2. VOCE SINTETICA E VOCE NATURALE

Capitolo 3
Trevor Wishart
3.1 Notizie biografiche
§26. Biografia, riconoscimenti e poco altro
Compositore, insegnante, autore di saggi, ricercatore e sviluppatore di software per la musica,Trevor Wishart nasce a Leeds, in Gran Bretagna, nel 1946. Ha studiato ad Oxford, all’Universitàdi Nottingham e di York. Presso quest’ultima ha conseguito, nel 1973, il Dottorato in Com-posizione. La sua formazione avviene principalmente nell’ambito della musica tradizionalema la sua carriera di compositore si svolge soprattutto nella produzione di musica elettronicaanalogica e digitale. Wishart non ha mai occupato un posto ufficiale nel mondo accademico,che fosse un’Università o un Conservatorio, prediligendo una carriera indipendente. In annirecenti ha iniziato a collaborare come professore onorario all’Università di York1. Negli annidella formazione, tradizionale ed accademica, fu molto colpito dall’ascolto di alcuni lavorielettronici di Xenakis, Berio, Stockhausen e dei concretisti di Pierre Schaeffer. Un primo passoverso la musica elettronica avviene con l’acquisto di un modesto registratore a nastro magnetico,attraverso cui iniziò a registrare suoni industriali da utilizzare nelle sue composizioni. La suacarriera è stata valorizzata da numerosi riconoscimenti come il recente Giga-Herz Grand Prizerilasciato dallo ZKM (Zentrum für Kunst und Medientechnologie), il Golden Nica al Linz ArsElectronica, il premio Gaudeamus e l’Euphonie d’Or al Festival di Bourges. I suoi lavori sonostati commissionati da importanti istituzioni quali l’Ircam di Parigi, la Biennale di Parigi e laBBC Promenade Concerts2.
Compositore residente in Australia, Canada, Olanda, Berlino, USA, presso le università diYork, Cambridge e Birmingham. Attualmente Honorary Visiting Professor presso l’Universitàdi York e AHRB Research Fellow presso l’Università di Birmingham. Il suo libro Sounds Fundi giochi musicali educativi è stato tradotto e pubblicato in giapponese. È membro fondatoredella Composer’s Guild.
Nel 2010 ha partecipato come docente alla Session #14 dell’ILV (Institute for Living Voice)tenutasi a Venezia, presso la Fondazione “Giorgio Cini” e ospitata dal laboratorioarazzi, doveha eseguito, durante un concerto in cui si esibiva anche David Moss, il suo brano Globalalia.
1Si veda Vassilandonakis, “An Interview with Trevor Wishart”, p. 8.2Informazioni tratte da http://www.musicainformatica.it/argomenti/trevor_
wishart.php.
39

40 CAPITOLO 3. TREVOR WISHART
3.2 Audible Design§27. Il frontespizio di Audible Design
Il frontespizio del volume di Wishart Audible Design (si veda la Figura 3.2.1) è la sum-ma, in stile rinascimentale, di tutto il sapere a cui deve (dovrebbe) attingere il compositorecontemporaneo che fa uso delle tecnologie elettroacustiche ed informatiche.
Si possono notare in alto al centro sulla sinistra Max Mathews3, pioniere dell’informaticamusicale, che sovrasta le seguenti discipline:
• informatica;• electronica;• physica;• arithmetica;
mentre sempre in alto al centro sulla destra troviamo Pierre Schaeffer (Nancy, 14 agosto1910 - Aix-en-Provence, 19 agosto 1995), pioniere della musica acusmatica, che sovrasta leseguenti discipline:
• acousmatica;• psycho-acoustica;• acoustica;• musica;
tutte che confluiscono nella grande figura di matematico Jean Baptiste Joseph Fourier(Auxerre, 21 marzo 1768 - Parigi, 16 maggio 1830).
Quello che sto cercando è un modo per trasformare il materiale sonoro e fornire un risultatoche sia chiaramente simile alla sorgente ma anche chiaramente diverso4.
Il primo oggetto significante da un punto di vista musicale è la forma di una serie dicampioni, in particolare di un ciclo d’onda (una singola lunghezza d’onda di un suono)5.
3.3 On Sonic Art§28. Utterance
La terza e ultima parte del volume On Sonic Art di Trevor Wishart6 si intitola Utterance,termine che riveste vari significati: espressione, parola, pronuncia. In Wishart si possonoritrovare tutti questi significati, poiché in questa parte del libro egli ci parla di Espressione[Utterance] (cap. 11), Il repertorio umano (cap. 12), Oggetti fonemici (cap. 13), Flusso [stream]del linguaggio e paralinguaggio (cap. 14), Gruppo (cap. 15), inteso come insieme di singoliindividui (singole individualità) che si esprimono tramite la ‘vocalità’.
Inizialmente viene messa in evidenza l’‘universalità’ dell’espressione ‘vocale’, in quan-to comune anche agli animali in configurazioni variamente canore, segnaletiche, espressive,comunicative.
3Si veda §3.4In Wishart, Audible Design, p. 4.5In ibid., p. 17.6Wishart, On Sonic Art.

3.3. ON SONIC ART 41
Figura 3.2.1: Frontespizio del volume di Trevor Wishart autoprodotto Audible Design.

42 CAPITOLO 3. TREVOR WISHART
§29. “Il repertorio umano”
Wishart propone una tassonomia del comportamento e delle possibilità dell’organo vocaleumano. Una prima sistematizzazione l’aveva già abbozzata in un testo del 19797 e la ripropone,rivedendola e aggiornandola in seguito ad una serie di colloqui avuti con il lettrista Jean-PaulCurtay (autore, fra l’altro, di Curtay, La poésie lettriste), in On Sonic Art. L’analisi dei suonivocali effettuata da Wishart si limita a quelli relativi al tratto vocale. Il primo elemento didistinzione avviene fra suoni “intrinsecamente di breve durata” e “suoni che possono esseresostenuti”8
“Oscillatori e altre sorgenti”
• la glottide è la sorgente della normale voce umana cantata. La vibrazione della laringeproduce un suono che è normalmente iterato (es. 12.1). Ad una frequenza ‘normale’ divibrazione è percepito come un suono ad altezza definita (es. 12.2);
• la trachea. Se l’aria viene emessa con molta forza dai polmoni viene prodotto un suonograve che non è originato nella laringe ma in qualche zona sottostante (es. 12.3). Questosuono è la base della voce roca di “Satchmo”. Un effetto simile si può osservare nellatrachea sopra la laringe (es. 12.4). “Sebbene io non abbia un’evidenza medica direttache questi suoni siano prodotti dove io suggerisco, essi sono evidentemente distinti dallevibrazioni della glottide poiché è possibile combinarli con esse. Gli ess. 12.5-12.8illustrano il suono sotto la laringe, lo stesso combinato col suono della laringe, il suonosopra la laringe e lo stesso combinato col suono della laringe”9.
• subarmonici;• l’esofago;• la lingua;• le labbra;• le guance;
3.4 La voce e il ciclo Voice§30. Catalogo delle opere vocali
Quello che segue è il catalogo delle opere di Wishart in cui sono utilizzate le voci dal vivo.Fra il 1982 e il 1989 Wishart compone il Vox Cycle che comprende:
• Vox 1 del 1982 e della durata di 7’, per 4 voci amplificate e nastro a 4 tracce. Primaesecuzione degli Electric Phoenix alla Biennale di Parigi, La Villette, 1984;
• Vox 2 del 1984 e della durata di 12’, per 4 voci amplificate e nastro stereo. Primaesecuzione degli Electric Phoenix alla Biennale di Parigi, La Villette, 1984;
• Vox 3 del 1985 e della durata di 17’; per 4 voci amplificate e nastro di sincronizzazione.Commissionato dal Sound Art at Mobius. Prima esecuzione degli Electric Phoenix,Mobius Gallery, Boston USA nel 1985;
7Wishart, Book of Lost Voices.8“Sounds of intrinsecally short duration” e “sounds which can be sustained”; in Wishart, On Sonic Art, p. 263.9In ibid., pp. 264-265.

3.4. LA VOCE E IL CICLO VOICE 43
• Vox 4 del 1988 e della durata di 13’; per 4 voci amplificate e 4 voci su nastro, o 8 voci,e nastro (a 4 o 2 tracce). Prima esecuzione degli Electric Phoenix, all’HuddersfieldContemporary Music Festival nel 1988;
• Vox 6 del 1989 e della durata di 14’; per 4 voci amplificate e nastro. Prima esecuzionedegli Electric Phoenix, BBC Prom, Kensington Town Hall nel 1989.
Vox 5 è per solo nastro.Altre opere:
• Machine 2 (1970), durata variabile, per coro da camera e suoni di macchine ascoltati sunastro.
• Anticredos (1980) 19’. Per 6 voci amplificate e utilizzo di percussioni con parsimonia.Prima esecuzione degli Singcircle presso St John’s, Smith Square nel 1980;
• Birthrite (2000) per Soprano, Baritono, Basso, Tromba, Violino, Violoncello e nastro;• A Fleeting Opera per Soprano, Tenore, Basso, Tromba, Violino, Contrabbasso, in collabo-
razione con Max Couper. Prima esecuzione, membri della Royal Opera House e del RoyalBallet su due chiatte in movimento sul fiume Tamigi nella Central London in quanto partedel String of Pearls Festival, 2000;
§31. Vox 5 (1986)
Quinto di sei brani che compongono il Vox Cycle (1977-1986), Vox 5 è l’unico del ciclointeramente elettroacustico. Wishart descrive il brano, nelle sue linee generali, in un articolo del198810. “The sound transformations in Vox 5 were largely achieved using the Phase Vocoder”11.La genesi di questo brano ci fornisce molte indicazioni su come e dove, nei primi anni ottantadel secolo scorso, le tecnologie a disposizione dei compositori di musica elettroacustica stesseroevolvendosi. Nel 1979 Wishart, dopo aver esplorato a fondo le apparecchiature audio analogichee cercato un modo per realizzare con esse metamorfosi sonore, si rivolge all’IRCAM di Parigi– “at that time the only facility for advanced computer-music in Europe”12 – per realizzare unbrano. Durante il soggiorno di sei settimane scopre alcuni ‘strumenti’, fra i quali l’LPC (LinearPredictive Coding). A seguito di questa breve permanenza a Parigi viene invitato a realizzarele sue idee musicali ma, a causa di un rinnovamento delle apparecchiature, quando decide diriprendere il suo progetto compositivo dovrà aspettare il 1986 per poterlo mettere in opera.
It was suggested to me that the CARL Phase Vocoder (Moore, Dolson) might be a bettertool to use, but no-one at IRCAM at that time had inside knowledge of the workings of thisprogram, so I took apart the data files it produced to work out for myself what was going on.
I eventually developed a number of software instruments for the spectral transformationof sounds which were then used to compose Vox 5. These instruments massaged the datain the analysis files produced by the Phase Vocoder. The most significant of these werestretching the spectrum and spectral morphing - creating a seamless transition betweentwo different sounds which are themselves in spectral motion13.
10Wishart, “The Composition of Vox 5”. Una segmentazione analitica del brano è proposta da Williams, “Vox 5by Trevor Wishart”, in cui è riprodotta la ‘partitura’ per la diffusione redatta da Wishart e una partitura d’ascoltografica redatta dall’autore dell’articolo. Un’edizione discografica è Wishart, The Vox Cycle. La prima esecuzione èavvenuta nel 1987 a Parigi all’interno dell’INA/GRM Cycle Acousmatique di Radio France. Ne esiste anche unaversione quadrifonica.
11Wishart, Sound Composition, p. 63.12Ibid., p. 61.13Wishart, Computer Sound Transformation.

44 CAPITOLO 3. TREVOR WISHART
Possiamo vedere la ‘partitura’ per la diffusione redatta da Wishart in Figura 3.4.1.
Figura 3.4.1: Partitura per la diffusione di Vox 5 redatta dall’autore.
La novità fu dunque l’introduzione del PV, che Wishart studiò approfonditamente e con ilquale realizzò parte del software convogliato in seguito nel Composer Desktop Project14. Laconoscenza approfondita dei dati ricavati dall’analisi e la possibilità di manipolarli, modificarli,controllarli a piacere rendono per Wishart il PV uno strumento di lavoro adatto alla sua poetica.Ma soltanto dopo la programmazione degli ambienti di controllo dei dati sarà per lui possibile unuso veramente creativo di uno strumento così versatile come il PV. Wishart insiste sul continuofeedback fra dati ricavati dall’analisi, ascolto, dati generati per la sintesi. Sono momentidistinti di un processo teso alla composizione. Il sistema da lui utilizzato per realizzare Vox
14Si veda Composers Desktop Project. Per un riepilogo delle operazioni sullo spettro possibili con il CDP si vedainoltre Roads, Microsound, pp. 264-267. Sull’uso del PV da parte di Wishart si possono leggere, oltre al già citatocontributo su Vox 5, i suoi Audible Design, Computer Sound Transformation e l’articolo qui presente alle pp. ??-??.

3.4. LA VOCE E IL CICLO VOICE 45
5 “was an analysis-synthesis tool. You could run analysis on its own, synthesis on its own,or analysis+synthesis. The possibility to run analysis and synthesis separately allowed me towrite software to manipulate the analysis data, then to resynthesize the output”15. La continuamanipolazione dei dati e la continua verifica percettiva pongono questioni quali la tendenza allacategoricità della nostra percezione. Illustrando un esempio di morphing fra suono umano esuono animale (voce -> ronzìo di api), Wishart sottolinea che “we hear sounds either as a voiceor as a sound of bees. Hence there is a moment in the transformation, no matter how smooth,where aural recognition tends to suddenly switch from ‘It’s a voice’ to ‘No, it’s a bees!”’16.Calibrando e modificando adeguatamente i dati durante l’interpolazione fra i due spettri (quellodella voce e quello del ronzìo dell’ape), Wishart ottiene l’effetto di morphing desiderato. “Inthe Voice -> Bees morph the initial vocal sound is spectrally transposed. In this case, however,only a part of the spectrum is transposed”17. Nel brano Supernova questa separazione fra idue momenti di analisi e di sintesi risulta ancora più evidente, laddove i dati dell’analisi nonderivano da alcun suono18.
Nel suo lavoro artigianale di liuteria elettronica, Wishart si costruisce i propri strumenti,rendendoli parte integrante del processo compositivo.
§32. Globalalia
La pratica di redigere partiture per la diffusione dei suoi brani è stata resa publica da Wishartnel suo libro Sound Composition. In esso, infatti, le ultime pagine sono occupate dalle “partituredi diffusione, liberamente copiabili”19 delle seguenti opere:
• Red Bird;• Tongues of Fire;• Fabulous Paris;• Angel;• Division of Labour;• Imago;• Globalalia.
Di quest’ultima composizione riproduco nelle pagine seguenti la partitura per la diffusioneredatta da Wishart stesso20.
In questo brano “tutti i suoni utilizzati sono sillabe, editate da discorsi e selezionate da undatabase di oltre 8300 esempi. Globalalia, ‘the universal dance of human speech as revealed in20 tales from everywhere, spoken in tongues’, è stato commissionato da Folkmar Hein, per ilsuo sessantesimo compleanno, è dedicato alla memoria di Scheherezade, morta in circostanzesospette ad Abu Ghraib nel 2004, ed è stato premiato all’Inventionen nel 2004 a Berlino. Èstato composto utilizzando il software Composers Desktop Project tra il giugno del 2003 e ilgiugno 2004, a York e a Berlino, dove il compositore è stato Edgard Varèse Visiting Professordi Musica presso la Technical University, una specializzazione supportata dal DAAD”21.
15Comunicazione personale, e-mail del 4 aprile 2013.16Wishart, Sound Composition, p. 65.17The option to transpose only a part of the spectrum is a feature of the resulting CDP software. [Nota di
Wishart]. In Wishart, Sound Composition, p. 65.18Si veda questo stesso numero alle pp. ??-??.19Ibid., p. 178.20Wishart, Sound Composition, pp. 174-177.21Tratto dal programma di sala del concerto tenutosi presso la Fondazione “G. Cini” di Venezia il 10 ottobre
2010.

46 CAPITOLO 3. TREVOR WISHART
Figura 3.4.2: Pagina 1 della partitura per la diffusione di Globalalia redatta dall’autore.
§33. Voiceprints
“Sometimes, computer music composers manipulate the voice for the purposes of politicalintervention.”22. È il caso della raccolta di brani Voiceprints, che possiamo trovare nel CDWishart, Voiceprints. Le impronte vocali lasciate dalla principessa Diana e da Margareth Thatcherin Two Women o da Martin Luther King, Neil Armstrong ed Elvis Presley in American Tryptichsono testimoni di un suono ma anche del loro valore simbolico.
“Two Women è stato commissionato dal DAAD ed è stato eseguito per la prima volta duranteil concerto per il 50imo anniversario della musica concreta alla Parochialkirke di Berlino nelsettembre 1998, utilizzando il sistema di diffusione dell’Università tecnica di Berlino. American
22Smith, “The Voice in Computer Music and its Relationship to Place, Identity, and Community”, p. 281.

3.4. LA VOCE E IL CICLO VOICE 47
Figura 3.4.3: Pagina 2 della partitura per la diffusione di Globalalia redatta dall’autore.
Tryptich è stato commissionato dal governo francese per essere eseguito al GRM nel gennaiodel 2000 durante il Cycle Acousmatique presso Radio France a Parigi.”23.
§34. Encounters in the Republic of Heaven
In un libretto stampato in proprio, Wishart, Encounters in the Republic of Heaven, l’autoreracconta la genesi e i dettagli tecnici della nascita dell’opera. Completata nel settembre del2010, è stata eseguita in prima mondiale al SAGE, Gateshead, il 4 maggio 201124 ed è un’operaacusmatica su 8 canali in 4 atti. Realizzata con l’ambiente software Sound Loom/CDP, utilizzale seguenti tecniche:
23Wishart, Sound Composition, p. 99.24La prima italiana è avvenuta presso la sala concerti del Conservatorio Statale di Musica “B. Marcello” di
Venezia, il 21 dicembre 2012.

48 CAPITOLO 3. TREVOR WISHART
Figura 3.4.4: Pagina 3 della partitura per la diffusione di Globalalia redatta dall’autore.
• grain-extension, roughness-extension;• wavesets;• waveset-based loudness-enveloping;• waveset omission;• FOF detection;• peak extration;• retiming;• pitch tracking of speech;• pitch-contour of speech;• pitch-following filter;• pitch-focusing / harmonic field filter• spectral subtraction, tracing, blurring, hold;

3.4. LA VOCE E IL CICLO VOICE 49
Figura 3.4.5: Pagina 4 della partitura per la diffusione di Globalalia redatta dall’autore.
• time stretching / pitch shifting.
“Encounters è un’esplorazione della musica inerente al parlato quotidiano. Contrariamentea Globalalia, tuttavia, lo scopo del progetto fu di cogliere le caratteristiche musicali del parlatoa livello di frasi, la loro melodia e il loro ritmo e la sonorità delle voci individuali, quel qualcosadi indefinibile ma riconoscibile che ci permette di distinguere una persona da un’altra.”25.
25Wishart, Sound Composition, p. 131.

50 CAPITOLO 3. TREVOR WISHART

Biblio- sito- discografia
Aa. Vv. Composers Desktop Project. 2010. URL: http://www.composersdesktop.com/(visitato il 19/03/2013).
— Computer Music Currents 5. Computer Music Currents 5; WER 2025-2. CD. Mainz: Wergo,[1990].
— The Historical CD of Digital Sound Synthesis. Con pref. di John Pierce. Computer MusicCurrents 13. CD. Con libretto contenente saggi storici. Mainz: Wergo, 1995.
Bennett, Gerald e Xavier Rodet. “Synthesis of the singing voice”. In: Current Directions inComputer Music Research. A cura di Max V. Mathews e John R. Pierce. Cambridge: MITPress, 1989, 1944.
Bossis, Bruno. “Phoné”. In: John Chowning. Portraits polychromes. Paris: INA, 2007, pp. 103–105.
Chowning, John. “Frequency modulation synthesis of the singing voice”. In: Current Directionsin Computer Music Research. A cura di Max Mathews e John Pierce. Cambridge: MIT Press,1989, pp. 57–63.
— “Synthesis of the singing voice by frequency modulation”. In: Sound generation in winds,strings, and computers. A cura di J. Jansson e J. Sundberg. Stockholm: Royal Academy ofScience, 1980, pp. 4–13.
— “The simulation of moving sound sources”. In: Journal of the Audio Engineering Society19.1 (1971), pp. 2–6.
— “The Synthesis of Complex Audio Spectra by Means of Frequency Modulation”. In: Journalof the Audio Engineering Society 21.7 (set. 1973), pp. 526–534.
Clarke, Arthur C. 2001: A Space Odyssey. Polaris Production, 1968.Crandall, Irving B. “The Sounds of Speech”. In: The Bell System Technical Journal 4 (ott. 1925),
pp. 586–626.Curtay, Jean-Paul, cur. La poésie lettriste. Paris: Seghers, 1974.Dirks, Patricia Lynn. An Analysis of Jonathan Harveys “Mortuos Plango, Vivos Voco”. 2007.
URL: http://cec.sonus.ca/econtact/9_2/dirks.html (visitato il 24/06/2012).Dodge, Charles. “On Speech Songs”. In: Current Directions in Computer Music Research.
Cambridge, London: MIT Press, 1989, pp. 9–17.— “In Celebration: the composition and its realization in synthetic speech”. In: Composers and
the computer. A cura di Curtis Roads. Los Altos CA: Kaufmann, 1985, pp. 47–73.Doornbusch, Paul. The music of CSIRAC: Australia’s first computer music. Common Ground
Pub., 2005.Harvey, Jonathan. “Mortuos Plango, Vivos Voco: A Realization at IRCAM”. In: Computer Music
Journal 5.4 (1981), pp. 22–24.— “The Mirror of Ambiguity”. In: The Language of Electroacoustic Music. A cura di Simon
Emmerson. Houndmills e London: The Macmillian Press Ltd., 1986, pp. 175–190.
51

52 BIBLIO- SITO- DISCOGRAFIA
Haynes, Stanley. “The Computer as a Sound Processor: A Tutorial”. In: Computer Music Journal6.1 (1982), pp. 7–17.
Ihde, Don. Listening and Voice. Phenomenologies of Sound. 2a ed. New York: State Universityof New York Press, 2007.
Kelly, J. L. e C. C. Lochbaum. “Speech synthesis”. In: Proceedings of the Fourth InternationalCongress on Acoustics. Copenhagen, set. 1962, pp. 1–4.
— “Speech synthesis”. In: Proceedings of the Speech Communications Seminar. SpeechTransmission Lab. Stockholm: Royal Institute of Technology, set. 1962.
Koblin, Aaron e Massey. Daniel. Bycicle Built for 2,000. Over 2,000 human voices recorded viathe internet, assembled to sing Daisy Bell. 2009. URL: http://www.bicyclebuiltfortwothousand.com/ (visitato il 11/03/2013).
Lorrain, Denis. Analyse de la bande magnétique de l’oeuvre de Jean-Claude Risset Inharmoni-que. Rapport 26. Paris: IRCAM, 1980.
Mathews, Max Vernon e F. R. Moore. “GROOVE, a program to compose, store, and editfunctions of time”. In: Communications of the Association for Computing Machinery 13.12(1970), pp. 715–721.
Mathews, Max Vernon e John R. Pierce, cur. Current Directions in Computer Music Research.System Development Foundation Benchmark Series 2. Cambridge - London: MIT Press,1989.
McNabb, Michael. “Dreamsong: The Composition”. In: Computer Music Journal 5.4 (1981),pp. 36–53.
Normandeau, Robert. “The visitors and the residents”. In: Musica/Tecnologia 4.4 (2010). URL:http://www.fupress.net/index.php/mt/article/view/9108.
Olive, Joseph. “Automatic Formant Tracking in a Newton-Raphson Technique”. In: J. Acou.Soc. Am. 50.2 (1971), pp. 661–670.
Olive, Joseph P. ““The Talking Computer”: Text to Speech Synthsis”. In: Hal’s Legacy. 2001’SComputer As Dream and Reality. A cura di David G. Stork. 3a ed. [Firts edition 1997].Cambridge, London: Mit Press, 2000, pp. 101–129.
Risset, Jean-Claude. “Nouveaux gestes musicaux: quelques points de repère historiques”. In:Les nouveaux gestes de la musique. Marseille: Parenthèses, 1999, pp. 19–33.
Risset, Jean-Claude e Max Vernon Mathews. “Analysis of instrument tones”. In: Physics Today22.2 (1969), pp. 23–30.
Roads, Curtis. Microsound. Cambridge, London: The MIT Press, 2001.Rodet, Xavier, Yves Potard e Jean-Baptiste Barrière. Chant. De la synthèse de la voix a la
synthèse en général. Rapport 35. Paris: IRCAM, 1985.Smith, Hazel. “The Voice in Computer Music and its Relationship to Place, Identity, and
Community”. In: The Oxford Handbook of Computer Music. A cura di Roger Dean. Oxford:Oxford University Press, 2009, pp. 274–293.
Stork, David G., cur. Hal’s Legacy. 2001’S Computer As Dream and Reality. 3a ed. [Firts edition1997]. Cambridge, London: Mit Press, 2000.
Sundberg, Johan. “Synthesis of Singing by Rule”. In: Current Directions in Computer MusicResearch. Cambridge - London: MIT Press, 1989, pp. 45–55.
— The Science of the Singing Voice. Northern Illinois University Press, 1987.Vandenheede, Jan e Jonathan Harvey. “Identity and Ambiguity: The Construction and Use of
Trimbral Transitions and Hybrids”. In: ICMC Proceedings. Ann Arbor, MI: MPublishing,1985, pp. 97–102. URL: http://hdl.handle.net/2027/spo.bbp2372.1985.016.

BIBLIO- SITO- DISCOGRAFIA 53
Vassilandonakis, Yiorgos. “An Interview with Trevor Wishart”. In: Computer Music Journal33.2 (2009).
Williams, Tom. “Vox 5 by Trevor Wishart. The analysis of an electroacoustic tape piece”. In:Journal of Electroacoustic Music 7 (1993), pp. 6–13.
Wishart, Trevor. Audible Design. CD allegato. Orpheus the Pantomime, 1994.— Book of Lost Voices. Unpublished. York, 1979.— Computer Sound Transformation. A personal perspective from the U.K. Ott. 2000. URL:
http://www.composersdesktop.com/trnsform.htm (visitato il 16/02/2012).— Encounters in the Republic of Heaven. CD allegato con il remix stereo. In proprio, 2010.— On Sonic Art. A cura di Simon Emmerson. Contemporary music studies 12. CD allegato.
New York - London: Routledge, 1996.— Sound Composition. 2 CD allegati. In proprio, [2012].— “The Composition of Vox 5”. In: Computer Music Journal 12.4 (1988), pp. 21–27.— The Vox Cycle. OPT 904. CD. s. d.— Voiceprints. EMF 029. CD. 2000.Zattra, Laura. Studiare la computer music. Definizioni, analisi, fonti. Padova: libreriauniversita-
ria.it, 2011.


















