
LA STIMA DELLA VARIANZA CAMPIONARIA DI INDICATORI...
22
Statistica Applicata Vol. 17, n. 4, 2005 529 LA STIMA DELLA VARIANZA CAMPIONARIA DI INDICATORI COMPLESSI DI POVERTÀ E DISUGUAGLIANZA Diego Moretti, Claudio Pauselli, Claudia Rinaldelli 1 Servizio Condizioni economiche delle famiglie, ISTAT, via Adolfo Ravà 150, 00142 Roma - [email protected], [email protected], [email protected] Riassunto In ISTAT è consuetudine calcolare gli errori di campionamento delle principali stime (frequenze, medie, totali) attraverso una procedura informatica basata sulla metodologia standard di stima della varianza campionaria. Tuttavia è sempre più frequente la produ- zione di stime complesse da un punto di vista funzionale per le quali non si può applicare direttamente la suddetta metodologia. A questo proposito si ricorda il caso delle misure complesse di povertà relativa stimate dall’indagine sui Consumi delle Famiglie; la valutazione degli errori campionari di tali stime è stato uno degli obiettivi metodologici affrontati dall’ISTAT nel periodo 2002-2003. L’indagine EU-SILC (Statistics on Income and Living Conditions) propone un problema analogo in quanto tra i parametri da stimare risiede una serie di indicatori complessi di povertà e disuguaglianza che dovranno essere trasmessi ad EUROSTAT con i corrispondenti errori di campionamento. Il presente lavoro ha lo scopo di illustrare gli studi attualmente effettuati per la valutazione dell’errore campionario di questi indicatori complessi e le soluzioni metodologiche finora individuate. Parole chiave: errore campionario – stima della varianza campionaria – equazioni stimanti – linearizzazione – tecniche di ricampionamento 1. INTRODUZIONE Lo scopo principale delle indagini campionarie eseguite dall’ISTAT è quello di stimare alcuni parametri di popolazioni e subpopolazioni di interesse; le stime costituiscono quindi il prodotto principale delle indagini campionarie. È comunque consuetudine accompagnare la presentazione delle stime di una indagine campionaria con una adeguata documentazione contenente informazioni 1 Il presente lavoro esprime le opinioni degli autori e non riflette necessariamente quelle dell’ISTAT.I paragrafi 1 e 2 sono da attribuire a Claudia Rinaldelli, i paragrafi 3, 3.1, 3.2, 4.1- 4.4, 5 e l’appendice 1 a Claudio Pauselli, l’appendice 2 a Diego Moretti.
Transcript of LA STIMA DELLA VARIANZA CAMPIONARIA DI INDICATORI...

Statistica Applicata Vol. 17, n. 4, 2005 529
LA STIMA DELLA VARIANZA CAMPIONARIA DI INDICATORICOMPLESSI DI POVERTÀ E DISUGUAGLIANZA
Diego Moretti, Claudio Pauselli, Claudia Rinaldelli1
Servizio Condizioni economiche delle famiglie, ISTAT, via Adolfo Ravà 150, 00142Roma - [email protected], [email protected], [email protected]
Riassunto
In ISTAT è consuetudine calcolare gli errori di campionamento delle principali stime(frequenze, medie, totali) attraverso una procedura informatica basata sulla metodologiastandard di stima della varianza campionaria. Tuttavia è sempre più frequente la produ-zione di stime complesse da un punto di vista funzionale per le quali non si può applicaredirettamente la suddetta metodologia. A questo proposito si ricorda il caso delle misurecomplesse di povertà relativa stimate dall’indagine sui Consumi delle Famiglie; lavalutazione degli errori campionari di tali stime è stato uno degli obiettivi metodologiciaffrontati dall’ISTAT nel periodo 2002-2003. L’indagine EU-SILC (Statistics on Incomeand Living Conditions) propone un problema analogo in quanto tra i parametri da stimarerisiede una serie di indicatori complessi di povertà e disuguaglianza che dovranno esseretrasmessi ad EUROSTAT con i corrispondenti errori di campionamento. Il presente lavoroha lo scopo di illustrare gli studi attualmente effettuati per la valutazione dell’errorecampionario di questi indicatori complessi e le soluzioni metodologiche finora individuate.
Parole chiave: errore campionario – stima della varianza campionaria – equazionistimanti – linearizzazione – tecniche di ricampionamento
1. INTRODUZIONE
Lo scopo principale delle indagini campionarie eseguite dall’ISTAT è quellodi stimare alcuni parametri di popolazioni e subpopolazioni di interesse; le stimecostituiscono quindi il prodotto principale delle indagini campionarie.
È comunque consuetudine accompagnare la presentazione delle stime di unaindagine campionaria con una adeguata documentazione contenente informazioni
1 Il presente lavoro esprime le opinioni degli autori e non riflette necessariamente quelledell’ISTAT.I paragrafi 1 e 2 sono da attribuire a Claudia Rinaldelli, i paragrafi 3, 3.1, 3.2, 4.1-4.4, 5 e l’appendice 1 a Claudio Pauselli, l’appendice 2 a Diego Moretti.

530 Moretti D., Pauselli C., Rinaldelli C.
ed indicatori per: a) mettere a conoscenza l’utente delle metodologie utilizzate nellarilevazione e nel processo dei dati; b) valutare le stime fornite ai fini di una lorocorretta utilizzazione.
Nell’ambito del punto b), gli errori di campionamento rivestono una partico-lare importanza. La loro conoscenza è infatti essenziale per una adeguata utilizza-zione delle stime prodotte, tenendo presente che esistono diverse categorie di utentiche si servono degli errori campionari per scopi più o meno approfonditi, dallavalutazione dell’attendibilità delle stime fino alla progettazione di nuove indagini(Zannella, 1989); per questo, l’ISTAT generalmente diffonde le principali stime daindagine campionaria insieme ad indicatori quali l’errore relativo di campionamen-to, l’errore assoluto di campionamento, l’intervallo di confidenza.
A tal fine è stata sviluppata una procedura informatica, basata sulla metodo-logia standard2 di stima della varianza campionaria, che è ampiamente utilizzatanelle indagini eseguite dall’ISTAT con riferimento alle tipologie di stime piùfrequentemente prodotte quali frequenze, medie, totali (Falorsi, Rinaldelli, 1998).
Tuttavia nel tempo si sta spostando sempre più l’attenzione verso la produzio-ne di stime complesse da un punto di vista funzionale per le quali non può esseredirettamente applicata la metodologia standard di calcolo degli errori di campio-namento.
A titolo di esempio, si ricorda il caso delle misure complesse di povertà relativastimate dall’indagine sui Consumi delle Famiglie; l’impegno assunto dall’ISTAT conil Ministero dell’Economia e delle Finanze per la fornitura di stime di povertà relativaa livello regionale, ha obbligato l’ISTAT a fronteggiare problemi di natura metodolo-gica piuttosto complessi, tra i quali proprio quello di stimare in maniera adeguata glierrori campionari delle suddette stime complesse (ISTAT, 2003). La valutazione deglierrori campionari delle misure di povertà relativa è stato uno dei più importanti obiettivimetodologici affrontati dall’ISTAT nel periodo 2002-2003 (Coccia et al., 2002; DeVitiis et al., 2003; Pauselli, Rinaldelli, 2004a - 2004b).
Il problema della valutazione degli errori campionari di stime complesse, perle quali non è possibile applicare la metodologia standard, si presenta nuovamentenell’ambito dell’indagine EU-SILC (Statistics on Income and Living Conditions).
2 Per metodologia standard si intende metodologia notoriamente diffusa e applicata. La lettera-tura sulla teoria del campionamento da popolazioni finite, fornisce, per i più importanti disegnidi campionamento, le formule per il calcolo della varianza degli stimatori frequentementeutilizzati nelle indagini; nel caso di stimatori lineari, vengono fornite le espressioni esatte, mentreper stimatori non lineari, ma di uso frequente, vengono messe a disposizione le espressioniapprossimate.

La stima della varianza campionaria di indicatori complessi di povertà e … 531
L’indagine EU-SILC, che verrà eseguita per Regolamento Comunitario dai PaesiMembri, ha come scopo principale la stima di statistiche su reddito, condizioni divita, povertà ed esclusione sociale (EC Regulation, 2003).
Tra queste statistiche risiedono indicatori di povertà e disuguaglianza,complessi da un punto di vista funzionale, che devono essere trasmessi adEUROSTAT con i corrispondenti errori di campionamento (EUROSTAT, 2004a).
Per risolvere il problema del tipo qui esposto, la letteratura propone duepossibili approcci (Wolter, 1985; Zannella, 1989; Särndal et al., 1992):a) ricavare, dove possibile, una espressione approssimata dell’indicatore complesso
attraverso metodi di linearizzazione; b) applicare le tecniche di ricampionamento.
Nel presente lavoro sono state applicate entrambe le metodologie citate in a)-b); infatti, gli errori campionari degli indicatori complessi qui trattati sono statistimati sia ricavando una espressione linearizzata degli indicatori medesimi3 siautilizzando la tecnica di ricampionamento BRR (Balanced Repeated Replication,Replicazioni Bilanciate Ripetute).
Il presente lavoro ha quindi lo scopo di illustrare gli studi e le applicazionieffettuati per la valutazione dell’errore campionario di questi indicatori complessi;in particolare, nel paragrafo 2 sono descritti gli indicatori complessi di povertà edisuguaglianza qui trattati; i paragrafi 3.1 e 3.2 sintetizzano rispettivamente lametodologia delle equazioni stimanti e il metodo di Taylor-Woodruff utilizzati perricavare le espressioni linearizzate degli indicatori complessi che sono poi riportatenei paragrafi 4.1-4.4; nel paragrafo 5, sono messi a confronto gli errori campionaridegli indicatori complessi ottenuti secondo le due metodologie sopra dette; l’ap-pendice 1 descrive la tecnica BRR utilizzata come approccio alternativo allalinearizzazione; infine, l’appendice 2 descrive l’implementazione informatica chesi è resa necessaria rispettivamente per: a) calcolare le espressioni linearizzate degliindicatori complessi; b) consentire l’applicazione della tecnica BRR.
2. GLI INDICATORI EU DI POVERTÀ E DISUGUAGLIANZADELL’INDAGINE EU-SILC
Riportiamo di seguito quattro degli indicatori EU di povertà e disuguaglianzaper i quali EUROSTAT richiede di fornire il valore degli errori di campionamento
3 Una volta ottenute le espressioni linearizzate degli indicatori complessi, queste sono state usatenella procedura informatica dell’ISTAT per stimare gli errori campionari degli indicatorimedesimi.

532 Moretti D., Pauselli C., Rinaldelli C.
(EUROSTAT, 2004a-2004b); questi indicatori sono stati oggetto dello studioillustrato nel presente lavoro:1) linea di povertà relativa (at Risk-of-Poverty Threshold), definita come il 60%
del valore mediano della distribuzione del reddito4:
RPT=60%*Medianared ; (1)
2) incidenza di povertà relativa (at Risk-of-Poverty Rate), definita come lapercentuale di individui (sul totale della popolazione) con reddito inferiore allalinea di povertà relativa:
RPRI w
w
k kk s
kk s
=∑∑ε
ε
* 100 (2)
dove k denota l’indice di individuo, s il campione rilevato, wk il coefficiente diriporto all’universo dell’individuo k, Ik variabile indicatrice così definita:
I se y RPT
akk=<1
0 lltrimenti
(3)
dove yk denota il valore della variabile reddito dell’individuo;3) indice di disuguaglianza della distribuzione del reddito, il coefficiente di Gini
(inequality income distribution), secondo la formulazione proposta daEUROSTAT per l’indagine EU-SILC (EUROSTAT, 2004b):
G
y w wk k kprima pers.
pers. k
k=
∑
100
2
*
* * *== =∑ −
prima pers.
ultima pers.
k k2
k prima pe
y w*rrs.
ultima pers.
kk prima pers.
ultima pers
w
∑
=
..
k kk prima pers.
ultima pers.
y w∑ ∑
−
=
* *
1
(4)
dove k è l’indice dell’unità, yk il valore della variabile reddito per la persona k, wkil coefficiente di riporto all’universo della persona k; per l’applicazione della (4) ivalori yk devono essere ordinati dal più piccolo al più grande;
4 Col termine reddito si intende ‘reddito disponibile equivalente’; per l’esatta definizione dellevariabili richiamate in questo paragrafo si veda EUROSTAT, 2004b.

La stima della varianza campionaria di indicatori complessi di povertà e … 533
4) il Gender Pay Gap (indice di disuguaglianza della retribuzione media orarialorda tra maschi e femmine):
GPG
y w
w
y w
w
y w
k kk M
kk M
k kk F
kk F
k kk
=
−∑∑
∑∑
ε
ε
ε
ε
εε
ε
M
kk M
w
∑∑
* 100 (5)
dove k denota l’indice di individuo, M l’insieme degli individui campione di sessomaschile lavoratori dipendenti con età compresa tra 16 e 64 anni con almeno x5 oredi lavoro settimanali, F l’insieme degli individui campione di sesso femminilelavoratori dipendenti con età compresa tra 16 e 64 anni con almeno x ore di lavorosettimanali, yk il valore della variabile retribuzione oraria lorda dell’individuo k, wkil coefficiente di riporto all’universo dell’individuo k.
3. LINEARIZZAZIONE: METODI
Gli indicatori (1), (2), (4) e (5) sono linearizzabili, i primi tre tramite il metododelle equazioni stimanti (descritto sinteticamente nel paragrafo 3.1) e il quarto conil metodo di Taylor–Woodruff (descritto nel paragrafo 3.2).
Il metodo delle equazioni stimanti permette di ottenere linearizzazioni diespressioni complesse quali quelle in uso nello studio della distribuzione dei redditie più generalmente nello studio della disuguaglianza sociale.
Per maggior chiarezza si introducono le notazioni che ricorreranno in seguito.Sia U = {1, 2,…, N} una popolazione finita di N elementi; sia i l’indice che distingueil generico elemento della popolazione; sia s ⊂ U un campione casuale di nelementi, ad ogni elemento i del campione è associato il coefficiente di riportoall’universo wi (s).
3.1 IL METODO DELLE EQUAZIONI STIMANTI
Nel descrivere il metodo si farà riferimento a quanto esposto in Kovacevic eBinder (1997); per maggiori approfondimenti sull’argomento si segnalano Bindere Kovacevic (1994), Godambe e Thompson (1986).
5 L’attuale valore di 15 ore settimanali è suscettibile di modifiche da parte di EUROSTAT.

534 Moretti D., Pauselli C., Rinaldelli C.
La stima del parametro θ di una popolazione infinita si può ottenere risolven-
do l’equazione di massima verosimiglianza Ulog f(y ; )
0iθθ
θ( ) = ∂
∂=∑ dove f(y;θ)
è la funzione di densità differenziabile.Nelle popolazioni finite il parametro θ può anche essere descritto come la
soluzione dell’equazione:
U u y ; 0ii 1
N
θ θ( ) = ( ) ==∑ (6)
che prende il nome di equazione stimante.La stima corretta dell’equazione stimante secondo Horwitz-Thompson da un
campione casuale s è:
U u y ;ii 1
N
θ θ( ) = ( ) ( )=∑ w si (7)
dove wi(s) =1/πi (πi è la probabilità di inclusione dell’unità i) se i è presente nelcampione s, 0 altrimenti.
La stima del parametro θN è θ ; soluzione dell’equazione stimante U θ( ) = 0.
u(yi; θ) prende il nome di funzione stimante ed è Gauss coerente (Godambe,Kale; 1991); ovvero noti tutti i valori della popolazione finita le stime del parametrosono uguali al valore del parametro.
L’equazione stimante è il punto di partenza per la stima della varianza di θ .La (6) può essere riscritta come:
0 U u(y ; )-u(y ; ) u(y ; )i i Ni 1
N
i Ni
= ( ) = +=∑θ θ θ θˆ
== =∑ ∑+ ( ) −
1
N
i i Ni 1
N
u(y ; )-u(y ; )w s w si i( ) θ θ 11 (8)
Sia R L’ultimo termine della (8); esso è di ordine o Nθ θ−( ) , diventa pertanto
trascurabile per θ θ→ N ; sviluppando u(y;θ ) intorno a θN tramite la forma di Young
del teorema di Taylor (Serfling, 1980) la (8) può essere riscritta come:
0 U -u y ;
oNi 1
Ni
NN
= ( ) = ( ) ∂ ( )∂
+ −(= =∑ˆ ˆ ˆ ˆθ θ θ
θθ
θ θθ θ
)) + +=∑u(y ; )w (s) Ri Ni 1
N
iθ (9)
Trascurando il termine R la differenza θ θ− N può essere approssimata come:

La stima della varianza campionaria di indicatori complessi di povertà e … 535
dove u y ; J u y ;*i N
1iθ θθ( ) = − ( )− e J
u y ;i
i 1
N
N
θθ θ
θθ
=∂ ( )
∂= =∑ .
Pertanto var var var w u y ;N i*
i Ns
ˆ ˆ .θ θ θ θ( ) = −( ) = ( )
∑
Poiché θN è sconosciuto lo si stima con θ (sua stima campionaria), in questo
caso: w s u y ;i*
is∑ ( ) ( ) =ˆ .θ 0
In molti casi, soprattutto per le stime non lineari, il parametro θ è multidimen-sionale ed è partizionabile in due componenti: la prima θN che è il parametro diinteresse (ad esempio il rapporto tra due totali) e la seconda λN i parametri didisturbo (ad esempio i due totali da mettere a rapporto).
In questo caso la forma funzionale cambia leggermente e la (6) diventa:
U ; U , ,U ,1 2θ λ θ λ θ λ( ) = ( ) ( ) .
Le stime dei parametri devono essere la soluzione all’equazione:
0,
,2
=( )( )
ˆ ˆ ˆ
ˆ ˆ ˆ
U
U
1 θ λ
θ λ (10).
Analogamente a quanto fatto nel caso unidimensionale si può arrivare ad unalinearizzazione dell’espressione complessa (per i dettagli si veda Kovacevic eBinder, 1977):
θ θ θ θ λ λ θ θ λ θ− ≈ − + −( )− − − −
N 11
11
1 2 2 11
1
1
2J J J J J J J J JJ U , J J J J J J11
1 N N 11
1 2 2 11
1θ θ λ λ θ θθ λ− − −
( ) + −ˆ
λλ θ λ( ) ( )−1
2 N NU ;ˆ (11)
dove
JU ;
11
;N N
θθ θ λ λ
θ λθ
=∂ ( )
∂ = =, matrice di ordine 1 x 1
JU ;
11
;N N
λθ θ λ λ
θ λλ
=∂ ( )
∂ = =, matrice di ordine 1 x k
JU ;
22
;N N
θθ θ λ λ
θ λθ
=∂ ( )
∂ = =, matrice di ordine k x 1

536 Moretti D., Pauselli C., Rinaldelli C.
JU ;
22
;N N
λθ θ λ λ
θ λλ
=∂ ( )
∂ = =, matrice di ordine k x k,
dove k sono i parametri di disturbo.
In molte applicazioni U ;2 θ λ( ) non dipende da θ quindi J2θ=0. Inoltre se le
derivate prime di u1(y,θ,λ) e u2(y,θ,λ) rispetto a θ sono indipendenti da λ la (11)può esser:e scritta in modo semplificato come:
ˆ ˆ ˆ ˆθ θ θ λ θ λλ λ θ− ≈ − ( )+ ( )
−N 1 N N 1 2 N N 1
1U , J J U ; J
== ( ) − ( ) + ( )−w s u y ; ; J J u y ; ;i 1 i N N 1 21
2 i N Nθ λ θ λλ λ
= ( ) ( )=
−
=
∑
∑i 1
N
11
ii 1
N*
i N N
J
w s u y ; ;
θ
θ λ .
(12)
La u* è la variabile linearizzata ricercata. La stima della varianza del totale di
questa variabile approssimerà la varianza della stima θ .
3.2 IL METODO DI TAYLOR – WOODRUFF
Per stimare la varianza di una funzione non lineare di più totali si utilizzal’approssimazione lineare di Taylor – Woodruff.
Sia θ =F(Y ,.........,Y )1 q un parametro funzione non lineare di q totali e sia
ˆ ˆ ˆθ = ( )F Y ,.....,Y1 q la relativa stima campionaria.
Si può dimostrare che in condizioni abbastanza generali (Zannella, 1989) che
si può approssimare θ θ− con la formula di Taylor, arrestando lo sviluppo aitermini di ordine lineare:
ˆ ˆθ θ− ≅ −( )=∑b Y Yj j jj 1
q
(13)
bF
YY Yj
jj j=
∂∂
=( ), ˆ .
Elevando al quadrato entrambi i membri della (13) e calcolando i loro valoriattesi si ottiene

La stima della varianza campionaria di indicatori complessi di povertà e … 537
MSE Var b b Cov Y ,Yji 1
q
j 1
q
i j iˆ ˆ ˆ ˆ ˆ ˆθ θ( ) ≅ ( ) ≅ (
==∑∑ )) (14).
Ovvero si può esprimere la varianza dell’espressione complessa di q totalicome combinazione lineare di q2 covarianze delle stime dei totali (sej=i si tratteràdelle varianze).
Il numero di stime di varianze e covarianze per ottenere la (14) aumenta inproporzione quadratica con il crescere del numero dei totali.
Per semplificare i calcoli, è possibile ricorrere alla trasformata di Woodruff
(Zannella, 1989), in questo caso la varianza di θ è approssimata dalla varianza dellastima del totale:
Z b Yjj 1
q
j==∑ ˆ
(15).
La (15) si ottiene dalla somma ponderata con i coefficienti di riporto
all’universo della variabile Z b Yi jj 1
q
ji==∑ (Yji è il valore che assume la variabile Yj
nell’unità i), questo permette di ridurre la dimensionalità del problema in quantocon questa trasformazione è necessario – al contrario di quanto accadeva con la (14)– soltanto calcolare la stima della varianza di un solo totale.
4. LA LINEARIZZAZIONE DEGLI INDICATORI EU
4.1 INCIDENZA DI POVERTÀ RELATIVA (RPR)
La stima della varianza dell’incidenza di povertà relativa descritta nelparagrafo 2, può essere linearizzata come mostrato da Berger e Skinner (2003) eDeville (1999). Sia la linea di povertà relativa una frazione di un quantile della
variabile Y (α = frazione, β = quantile): αYβ. Sia pαβ la proporzione di unità della
popolazione sotto tale linea di povertà. Un primo tipo di approssimazione (piùsemplice) è la seguente:
u1
NI y Y p1i i= ≤( )− α β αβ (16)
dove I y Yi ≤( )α β è una funzione indicatrice che assume valore 1 se y Yi ≤ α β 0
altrimenti.

538 Moretti D., Pauselli C., Rinaldelli C.
La (16) non tiene conto della variabilità della linea; ovvero si considera lostato di povertà come un attributo la cui presenza è funzione di una lineadeterminata in maniera esterna ai dati rilevati. In realtà la linea è funzione dei daticampionari ed è perciò essa stessa soggetta a variabilità campionaria. La logicadietro questo approccio è che per campioni di grandi dimensioni, cosa questaverificata in indagini condotte dall’ISTAT, la variabilità della linea è talmenteridotta da rendere trascurabile l’errore che si commette considerandola fissa. A taleconclusione si era anche arrivati nei lavori relativi alla povertà regionale stimatadell’indagine ISTAT sui consumi delle famiglie (De Vitiis et al., 2003; Rinaldelliet al., 2002; Rinaldelli, Pauselli, 2004a-2004b).
Per tener conto della variabilità della linea si può ricorrere al metodo delleequazioni stimanti ottenendo la variabile linearizzata (Deville, 1999):
u1
NI y Y p R I y Y2i i i= ≤( )− − ≤{ } −( )
α α ββ αβ αβ β (17)
Rf Y
f Yαββ
β
α= ( )
( ) (18)
dove f(x) rappresenta la densità della distribuzione nel punto x. La stima delladensità di una distribuzione stimata da un campione da popolazione finita è unproblema al quale la letteratura ha fornito diverse soluzioni: Deville (1999)suggerisce l’utilizzo di differenziazione numerica di semplice implementazione,Francisco e Fuller (1991) utilizzano la procedura di Woodruff (1952) per funzionidi quantili stimati. In questo lavoro si farà riferimento al metodo di Preston (1996)descritto qui di seguito:
ˆˆ ˆf y
Nbw K
y-y
bi
s
i( ) =
∈
∑1
i(19)
dove:
K x ) x-1( ) = −( exp( / )2 22 2
e b N= − −0 79 0 75 0 25
15. ( ˆ ˆ ). .Y Y (20)
Sostituendo nelle espressioni (18) e (19) le loro stime campionarie si ottiene:
u1
NI y p R I y2i i i= ≤( )− − ≤( )−( )
α α ββ αβ αβ β
ˆ ˆ ˆY Y
e

La stima della varianza campionaria di indicatori complessi di povertà e … 539
ˆ Y
Y.R
f
fαββ
β
α= ( )
( )4.2 COEFFICIENTE DI GINI
La linearizzazione da utilizzare per la stima della varianza del coefficiente diGini è (Kovacevic, Binder; 1997):
u2
NA y y y G 1i
*i i i= ( ) ( ) − +( )
ˆ
ˆ ˆ ˆ ˆµ
µ2
+ B
dove ˆ ˆ ˆA(y) F(y) (G 1)/2= − + e B(y) w y I y y /Ni is
i= ≥( )∑ .
ˆˆ
ˆG1
Nw 2F 1 yi i
si= −( )∑µ (stima campionaria dell’indice di Gini)
F w I y y /Ni i j i= ≤( )∑ e µ è la stima campionaria della media del carattere Y. Permaggiori dettagli sull’applicazione del metodo delle equazioni stimanti in questocaso si veda Kovacevic, Binder, 1997.
4.3 LINEA DI POVERTÀ RELATIVA (RPT)
Per la stima dell’errore della linea di povertà relativa descritto dalla (1) si faràriferimento alla approssimazione lineare utilizzata nella stima dell’errore di cam-pionamento di un quantile riportato in letteratura (Kovacevic, Binder, 1997;Wheeles, Shah, 1988; Sarndal et al., 1992).
Sia ζp un quantile p della variabile Y (ovvero I(y /N pii U
p∈∑ ≤ =ξ ) ); sia ζp la
sua stima campionaria (ovvero I y w /N pi pi s
i≤( ) =∈∑ ξ ). L’equazione stimante del
quantile ξ p è:
I(y /N-p 0.ii U
p∈∑ ≤ =ξ )
Applicando il metodo delle equazioni stimanti, descritto nel paragrafo 3.1, lalinearizzata che si ottiene è la seguente:
uNf
p-I yi
p
i p= ( ) ≤( )
1ˆ ˆ
ˆζ
ζ

540 Moretti D., Pauselli C., Rinaldelli C.
ˆ ˆf ζp( ) è la stima della densità della funzione di distribuzione del carattere nel punto
ζp .La funzione di densità è stimata con la (20). La stima dell’errore relativo di
campionamento6 della linea di povertà relativa è uguale a quella dell’errore dicampionamento relativo della mediana.
Per ottenere l’errore di campionamento assoluto della linea di povertà saràsufficiente moltiplicare l’errore di campionamento relativo della mediana per lastima della linea di povertà.
4.4 GENDER PAY GAP (GPG)
L’espressione (5) può essere più agevolmente espressa facendo questesostituzioni:
Y y wM k kk M
=∑ε
, Y y wF k kk F
=∑ε
, P wM kk M
=∑ε
, P wF kk F
=∑ε
. Poniamo inoltre
Y YPM
MM
= , Y YPF
FF
= , dove:
YM : è la retribuzione media oraria della popolazione maschile, con età tra i 16 e
i 64 anni, lavoratore dipendente;
YF : è la retribuzione media oraria della popolazione femminile, con età tra i 16 e
i 64 anni, lavoratore dipendente;
YM: è il totale della retribuzione oraria della popolazione maschile, con età tra i 16e i 64 anni, lavoratore dipendente;
YF: è il totale della retribuzione oraria della popolazione femminile, con età tra i16 e i 64 anni, lavoratore dipendente;
PM: è il totale della popolazione maschile lavoratore dipendente, con età tra i 16e i 64 anni, lavoratore dipendente;
PF: è il totale della popolazione femminile lavoratore dipendente, con età tra i 16e i 64 anni, lavoratore dipendente;
Il GPG può essere riscritto come θ = −1Y
YF
M
; la stima campionaria del GPG è:
6 Si ricorda che l’errore relativo è lo scarto quadratico medio dello stimatore sul valore attesodello stimatore. Una sua stima consistente si ottiene utilizzando la stima campionaria dell’erroredi campionamento assoluto e la stima campionaria utilizzata.

La stima della varianza campionaria di indicatori complessi di povertà e … 541
ˆˆ
ˆ .θ = −1Y
Y
F
M
La varianza di tale stima è:
Var Var VarF
M
F
M
M
F
ˆˆ
ˆ
ˆ
ˆ
ˆ
ˆθ( ) =
=
Y
Y
Y
Y
P
P
.
Per la stima della varianza è necessario linearizzare il rapporto di quattro totali
F Y ,Y ,P ,PY P
Y PF M F M
F M
M F
ˆ ˆ ˆ ˆˆ ˆ
ˆ ˆ( ) = facendo ricordo alla approssimazione lineare di Taylor –
Woodruff .Seguendo pertanto quanto descritto in Zannella (1989), la variabile linearizzata
è:
z b y b y b d b di 1 F 2 M 3 M 4 Fi i i i= + + +
dove:
bF
Y
P
Y P1F
M
M F
=∂∂
= ;bF
Y
Y
Y
P
P2M
F
M2
M
F
=∂∂
= − ;bF
P
Y
Y P3M
F
M F
=∂∂
= ;bF
P
Y
Y
P
P4F
F
M
M
F2
=∂∂
= − ;
dMi= 1 se i-esima unità campionaria è lavoratore dipendente con età compresa tra
i 16 e i 64 anni e di sesso maschile, 0 altrimenti; dFi= 1 se i-esima unità campionaria
è lavoratore dipendente con età compresa tra i 16 e i 64 anni e di sesso femminile,
0 altrimenti; yMi= retribuzione oraria se i-esima unità campionaria è lavoratore
dipendente con età compresa tra i 16 e i 64 anni e di sesso maschile, 0 altrimenti;
yFi= retribuzione oraria se i-esima unità campionaria è lavoratore dipendente con
età compresa tra i 16 e i 64 anni e di sesso femminile, 0 altrimenti.
5. APPLICAZIONE E RISULTATI
È stato stimato l’errore di campionamento con le variabili linearizzateillustrate nel paragrafo 4 e con la tecnica di ricampionamento BRR. Poiché i datidell’indagine EU-SILC non saranno disponibili prima del 2005, si è reso necessariosperimentare le linearizzazioni su dati il più possibile simili, per variabili e disegno
542 Moretti D., Pauselli C., Rinaldelli C.
di campionamento, a quelli che saranno rilevati nella futura indagine EU-SILC.A tale scopo sono stati utilizzati i dati del Panel Europeo delle Famiglie
(ECHP), indagine europea armonizzata su reddito e condizioni di vita dellefamiglie, articolata su otto onde annuali e basata su disegno a due stadi di selezionecon stratificazione delle unità primarie (comuni) (Falorsi et al., 1994).
In particolare sono stati utilizzati i dati dell’anno 1994 (file delle intervisteindividuali del 1994); la variabile considerata è il reddito equivalente calcolatocome rapporto tra il reddito familiare e l’ampiezza delle famiglie corretta secondola scala OECD modificata.
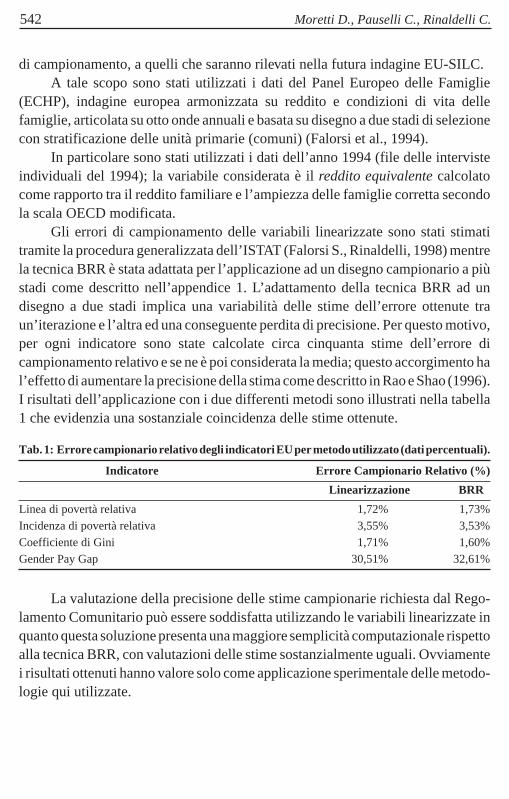
Gli errori di campionamento delle variabili linearizzate sono stati stimatitramite la procedura generalizzata dell’ISTAT (Falorsi S., Rinaldelli, 1998) mentrela tecnica BRR è stata adattata per l’applicazione ad un disegno campionario a piùstadi come descritto nell’appendice 1. L’adattamento della tecnica BRR ad undisegno a due stadi implica una variabilità delle stime dell’errore ottenute traun’iterazione e l’altra ed una conseguente perdita di precisione. Per questo motivo,per ogni indicatore sono state calcolate circa cinquanta stime dell’errore dicampionamento relativo e se ne è poi considerata la media; questo accorgimento hal’effetto di aumentare la precisione della stima come descritto in Rao e Shao (1996).I risultati dell’applicazione con i due differenti metodi sono illustrati nella tabella1 che evidenzia una sostanziale coincidenza delle stime ottenute.
Tab. 1: Errore campionario relativo degli indicatori EU per metodo utilizzato (dati percentuali).
Indicatore Errore Campionario Relativo (%)
Linearizzazione BRR
Linea di povertà relativa 1,72% 1,73%Incidenza di povertà relativa 3,55% 3,53%Coefficiente di Gini 1,71% 1,60%Gender Pay Gap 30,51% 32,61%
La valutazione della precisione delle stime campionarie richiesta dal Rego-lamento Comunitario può essere soddisfatta utilizzando le variabili linearizzate inquanto questa soluzione presenta una maggiore semplicità computazionale rispettoalla tecnica BRR, con valutazioni delle stime sostanzialmente uguali. Ovviamentei risultati ottenuti hanno valore solo come applicazione sperimentale delle metodo-logie qui utilizzate.

La stima della varianza campionaria di indicatori complessi di povertà e … 543
APPENDICE 1. LA TECNICA DI RICAMPIONAMENTO BRR
La tecnica BRR è stata ideata nei primi anni ’60 dal Bureau of Census; sidescriverà la tecnica nel caso base di un disegno campionario ad uno stadiostratificato per passare poi al caso generale di più stadi (Zannella, 1989).
Supponiamo che la popolazione sia suddivisa in H strati e che da ogni stratosiano estratte k=2 unità campionarie. Con la selezione casuale di una unità per stratosi ottiene un sottocampione chiamato replicazione di ampiezza pari alla metà delcampione originale.
Sia ah un coefficiente che assume valore +1 se la prima unità del genericostrato h appartiene alla replicazione, o –1 se invece è la seconda unità dello stratoa farne parte; allora l’insieme delle possibili replicazioni potrà essere descritto dauna matrice di dimensione 2H x H. Ogni cella di questa matrice assumerà valore +1o –1.
In questa matrice valgono le seguenti relazioni (Zannella, 1989):
arhr 1
2H
= 0 (h =1.....H)=∑ (a1.1)
a = 0 (h=1.....H)rh rkr
2H
a=∑
1
(a1.2)
La (a1.1) implica che le due unità campionarie sono presenti un ugualenumero di volte nell’insieme di tutte le replicazioni possibili; la (a1.2) che lecolonne della matrice sono tra loro ortogonali.
Sia θ la stima lineare del parametro di interesse calcolata sul campione totale
e sia θr la corrispondente stima calcolata sulla r-esima replicazione; si dimostra che(Zannella, 1989):
ˆ ˆθ θ==∑1
2H rr 1
2H
(a1.3)
Var1
2-
Hr 1
2H
rˆ ˆ ˆθ θ θ( ) = ( )∑
=
2
(a1.4)
In caso di stimatori non lineari la (a1.3) non è valida e la (a1.4) è una stimadella varianza.

544 Moretti D., Pauselli C., Rinaldelli C.
Appare evidente che il metodo applicato per tutte le possibili replicazionidiventa estremamente oneroso anche con un H piccolo (per H=30 si hanno poco piùdi un miliardo di replicazioni). Si rende necessario pertanto determinare unR << 2H; la scelta casuale delle replicazioni implicherebbe una stima della varianzacampionaria più elevata di quella ottenuta sull’insieme di tutte le replicazioni.
La soluzione a questo problema è stata fornita da McCarthy (McCarthy,1969a-1969b) con l’introduzione delle replicazioni bilanciate ripetute (BRR).
Un sottoinsieme di R replicazioni è bilanciato se vale:
a a 0 (h=1.....H, k h)rh rk
r 1
R
=
∑ = (a1.5)
Se inoltre vale:
arh
r 1
R
0 (h=1.....H)=
∑ = (a1.6)
si dice completamente bilanciato.La stima della varianza basata su R replicazioni bilanciate ripetute produce la
stessa stima basata su tutte le 2H replicazioni.Per costruire un sottoinsieme di replicazioni bilanciate si possono utilizzare
le matrici di Hadamard. Le matrici di Hadamard sono delle particolari matrici didescrizione delle replicazioni di ordine quadrato k. Ogni sottoinsieme di k’<kcolonne (con esclusione della colonna composta da tutti +1) della matrice soddisfale condizioni (a1.5) e (a1.6) ed è quindi completamente bilanciato; l’insieme di tuttele colonne soddisfa solo la condizione (a1.5) ed è quindi bilanciato (Zannella,1989).
La matrice di Hadamard di ordine 2 è:
+ ++ −
1 1
1 1
Sia M una matrice di Hadamard di ordine k; la procedura iterativa per lacostruzione di una matrice di ordine 2k è (Wolter, 1985):
M M
M M−
Da quanto detto precedentemente solo se la matrice di Hadamard generata è

La stima della varianza campionaria di indicatori complessi di povertà e … 545
maggiore del numero degli strati H, l’utilizzo di un suo sottoinsieme di H colonnegarantisce il bilanciamento delle replicazioni.
Oltre alla stima della varianza espressa da:
Var ˆ ˆ ˆr1 θ θ− θ( ) = ( )∑
=
1
R
2
r 1
R
(a1.7)
è possibile calcolare la stima alternativa:
Var ˆ ˆ ˆrc
2 θ θ− θ( ) = ( )=∑1
R
2
r 1
R
(a1.8)
dove θ cr è la stima del parametro calcolata sulla parte complementare del campione
alla r-esima replicazione (ovvero quella che si otterrebbe moltiplicando per –1 icoefficienti della matrice di descrizione delle replicazioni).
La media tra (a1.7) e (a1.8) fornisce una stima più precisa della varianzacampionaria.
Le indagini campionarie sulle famiglie eseguite dall’ISTAT sono general-mente a due stadi di selezione con stratificazione delle unità di primo stadio(comuni); è pertanto necessario l’adattamento della tecnica BRR.
L’adattamento ad un disegno complesso si svolge in quattro passi (Wolter,1985; Zannella, 1989):1) si considerano solo le unità di primo stadio (PSU), solo queste saranno incluse
nella replicazione;
2) nel caso in cui fosse presente una sola PSU per strato, si aggrega ad uno stratocontiguo; tale operazione, nota come collassamento, implica una sovrastimadella varianza;
3) nel caso in cui le PSU fossero più di due, si formano in modo casuale due pseudo-PSU in cui sono contenute le PSU dello strato;
4) negli strati autorappresentativi le famiglie campione sono considerate PSU esono suddivise in due pseudo-PSU secondo quanto descritto nel passo 3.
Una volta formate le pseudo-PSU e calcolato il numero di strati risultanti, siapplica la tecnica BRR.
546 Moretti D., Pauselli C., Rinaldelli C.
APPENDICE 2. IMPLEMENTAZIONE INFORMATICA
Come descritto nel paragrafo 1, è consuetudine dell’ISTAT fornire indicazio-ni riguardanti la precisione delle principali stime (frequenze, medie, totali) prodottedalle indagini campionarie. A tal fine è possibile utilizzare o la procedura informa-tica SGCE (Procedura di tipo generalizzato per il calcolo degli errori di campiona-mento) (Falorsi, Rinaldelli, 1998) o il software GENESEES (Software per ilcalcolo delle stime e degli errori campionari) (ISTAT, 2002).
Entrambe le procedure informatiche citate implementano la metodologiastandard di stima della varianza campionaria e sono state sviluppate in ambienteSAS a seguito degli studi e delle attività di alcuni ricercatori del Servizio StudiMetodologici dell’ISTAT negli anni ’80. La procedura SGCE risale agli anni ’90ed è il prototipo del software GENESEES disponibile dalla fine del 2001.
Tuttavia gli indicatori EU di povertà e di disuguaglianza considerati nonpossono essere direttamente trattati da queste due procedure informatiche che nonprevedono attualmente l’applicazione automatizzata di espressioni approssimatedi indicatori complessi.
Come descritto nei precedenti paragrafi, per gli indicatori considerati è statocalcolato l’errore di campionamento sia ricorrendo alla linearizzazione sia imple-mentando la tecnica di ricampionamento BRR (Pauselli, Rinaldelli, 2004a-2004b).
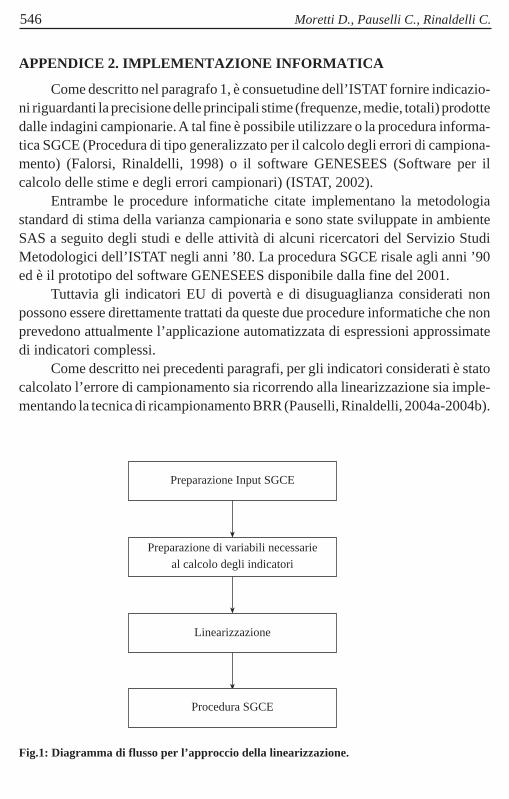
Fig.1: Diagramma di flusso per l’approccio della linearizzazione.
Preparazione Input SGCE
Preparazione di variabili necessarieal calcolo degli indicatori
Linearizzazione
Procedura SGCE

La stima della varianza campionaria di indicatori complessi di povertà e … 547
Preparazione Input
Collassamento degli strati
Costruzione delle pseudo-psu
Calcolo delle stime per ogni replicazione,utilizzando matrice di Hadamard
Calcolo dell’errore campionariodell’indicatore complesso
Fig. 2: Diagramma di flusso per l’approccio della tecnica BRR.
Secondo l’approccio della linearizzazione, si è reso necessario sviluppare inambiente SAS due procedure: la prima che predispone variabili necessarie alcalcolo degli indicatori; la seconda che consente l’applicazione delle linearizzazioniindividuate. A seguire queste due procedure, viene applicata la procedura informa-tica SGCE che stima gli errori campionari degli indicatori suddetti; si veda ildiagramma di flusso di figura 1.
Per il secondo approccio, basato sulla tecnica di ricampionamento BRR, sonostate sviluppate in ambiente SAS una serie di procedure per l’implementazionedella tecnica medesima, basandosi anche sulla esperienza maturata in precedentistudi di stimatori complessi (Pauselli, Rinaldelli, 2004a-2004b). Si veda il diagram-ma di flusso di figura 2 che descrive le operazioni necessarie alla applicazione della
tecnica BRR.

548 Moretti D., Pauselli C., Rinaldelli C.
RIFERIMENTI BIBLIOGRAFICI
BERGER Y.G., SKINNER C.J., 2003, Variance estimation for a low income proportion, AppliedStatistics, 52, part 4, pp. 457-468.
BINDER D.A., KOVACEVIC M.S., 1994, Estimating some measures of income inequality fromsurvey data: An application of the estimating equation approach, Survey Methodology, 21, pp.137-145.
COCCIA G., PANNUZI N., RINALDELLI C., VIGNANI D., 2002, Verso una misura della povertàregionale: problemi e strategie, Sesta Conferenza Nazionale di Statistica, Roma 6-8 Novembre2002, in : www.istat.it.
DEVILLE J.C., 1999, Variance Estimation for complex statistics and estimators: linearization andresidual techniques, Survey Methodology, vol. 25 n.2, pp 193-203.
DE VITIIS C., DI CONSIGLIO L., FALORSI S., PAUSELLI C., RINALDELLI C., 2003, Lavalutazione dell’errore di campionamento delle stime di povertà relativa, Documento presen-tato al Convegno sulla Povertà Regionale ed Esclusione Sociale, Roma 17 Dicembre 2003.
EUROSTAT, 2004a, Technical document on intermediate and final quality reports, Statistics onIncome and Living Conditions (EU-SILC), doc. EU-SILC 132/04.
EUROSTAT, 2004b, Common cross-sectional EU indicators based on EU-SILC; the gender pay gap,Statistics on Income and Living Conditions (EU-SILC), doc. EU-SILC 131/04.
FALORSI P.D., FALORSI S., RINALDELLI C., 1994, The estimation Method adopted in the firstwave of the Italian European Community Household Panel Survey, Documento interno,ISTAT.
FALORSI S., RINALDELLI C., 1998, Un software generalizzato per il calcolo delle stime e deglierrori di campionamento, Statistica Applicata, 10, 2, 217-234.
FRANCISCO C.A., FULLER W.A., 1991, Quantile estimation with complex survey design, Ann.Statist., 19, pp. 454-469.
GODAMBE V.P., THOMPSON M.E., 1986, Parameters of superpopulations and survey population:
their relationship and estimation, International Statistical Review, 54, 137-138.
GODAMBE V.P., KALE B.K., 1991, Estimating functions: an overview, in V.P. Godambe (ed.)
estimating functions, London: Oxford Statistical Science Series, 7.
ISTAT, 2002, GENESEES v1.0 Software per il calcolo delle stime e degli errori campionari,Manuale Utente e Aspetti Metodologici.
ISTAT, 2003, La povertà e l’esclusione sociale nelle regioni italiane, Statistiche in Breve, 17dicembre 2003, in: www.istat.it.
KOVACEVIC M.S., BINDER D.A., 1997, Variance estimation for measures of income inequalityand polarization – The estimating equations approach, Journal Official Statistics, Vol. 13 N.1, pp. 41-58.
MCCARTHY P.J., 1969a, Pseudoreplication: further evaluation and application of the balanced half-sample technique, Vital and Health Statistics, Series 2 n.31, National Center for HealthStatistics, Public Health Service, Washington, D.C.
MCCARTHY P.J., 1969b, Pseudoreplication: Half-Samples, Review of the International StatisticalInstitute, 37, 239-264.
PAUSELLI C., RINALDELLI C., 2004a, Stime di povertà relativa: la valutazione dell’errorecampionario secondo le Replicazioni Bilanciate Ripetute, Statistica Applicata, 16, 1, 89-101.

La stima della varianza campionaria di indicatori complessi di povertà e … 549
PAUSELLI C., RINALDELLI C., 2004b, La valutazione dell’errore di campionamento delle stimedi povertà relativa secondo la tecnica Replicazioni Bilanciate Ripetute, Collana ISTATContributi, n. 9, in : www.istat.it.
PRESTON I., 1996, Sampling distributions of relative poverty statistics, Applied Statistics, 45, pp.91-99.
RAO N.K., SHAO J., 1996, On balanced half-sample variance estimation in stratified randomsampling, Journal of American Statistical Association, vol. 91, n.433.
REGULATION (EC) No 1177/2003 of the EUROPEAN PARLIAMENT and of the COUNCIL of16 June 2003 concerning Community statistics on income and living conditions (EU-SILC),3.7.2003 L 165/1 Official Journal of the European Union.
RINALDELLI C., CESARINI A., COLOMBINI S., MASI A., 2002, Indagine sui consumi dellefamiglie – Calcolo e valutazione dell’attendibilità delle stime di frequenze assolute di povertà,Documento interno ISTAT.
SÄRNDAL C-E., SWENSSON B., WRETMAN J., 1992, Model assisted survey sampling, NewYork: Springer-Verlag.
SERFLING R.J., 1980, Approximations theorems of mathematical statistics, New York: Wiley ed.
WHELESS S.C., SHAH B.V., 1988, Results of a simulation for comparing two methods forestimating quantiles and their variances for data from a sample surveys Proceedings of theSurvey Research Methods Section, ASA.
WOLTER K. M., 1985, Introduction to variance estimation, New York: Springer-Verlag.
WOODRUFF R. S., 1952, Confidence intervals for medians and other position measures, J.Am.Statist. Ass., 47, 635-646.
ZANNELLA F., 1989, Tecniche di stima della varianza campionaria, Manuale di tecniche diindagine, Collana ISTAT Note e Relazioni, anno 1989, n. 1, vol.5.
VARIANCE ESTIMATION FOR RELATIVE POVERTYMEASURES AND INEQUALITY INDICATORS
Summary
Sampling errors of common estimates (frequencies, means, totals) are calculated inISTAT using a software procedure based on standard methodology for variance estimation.Nevertheless sampling errors for complex estimates are also required; the standardmethodology can not be applied to these estimates. A valid evaluation of the precision ofrelative poverty estimates (from Households Budget Survey) was one of the methodologicalaims at ISTAT in the period 2002-2003; this matter is migrating from the HouseholdsBudget survey to the EU-SILC survey (Statistics on Income and Living Conditions). Thispaper reports the studies to evaluate the sampling errors of a subset of EU complex relativepoverty and inequality indicators that will be estimated by EU-SILC survey.

550 Moretti D., Pauselli C., Rinaldelli C.


















