
“La Sapienza” · 2009-01-31 · Appendice A. Codice NetLogo ..... 146 A1 – Il codice NetLogo...
179
Università degli Studi di Roma “La Sapienza” Facoltà di Economia Corso di Laurea Specialistica in Economia Politica Roma, aprile 2008 Agente Rappresentativo ed Agenti Eterogenei. Un Approccio Computazionale Candidato Jakob Grazzini Relatore Correlatore Prof. Enrico Marchetti Prof. Nicola Acocella ANNO ACCADEMICO 2006/2007
Transcript of “La Sapienza” · 2009-01-31 · Appendice A. Codice NetLogo ..... 146 A1 – Il codice NetLogo...

Università degli Studi di Roma
“La Sapienza”
Facoltà di Economia
Corso di Laurea Specialistica in Economia Politica
Roma, aprile 2008
Agente Rappresentativo ed Agenti Eterogenei. Un Approccio Computazionale
Candidato
Jakob Grazzini
Relatore Correlatore
Prof. Enrico Marchetti Prof. Nicola Acocella
ANNO ACCADEMICO 2006/2007

2
Indice
Introduzione ...................................................................................... 6
Capitolo I. L’agente rappresentativo .................................................... 8
1. La nascita dell’agente rappresentativo...................................................... 8
2. L’agente rappresentativo moderno ......................................................... 11
2.1 La critica di Lucas .......................................................................... 12
2.2 La tradizione Walrasiana ................................................................ 15
2.3 La microfondazione ......................................................................... 18
3. Agente rappresentativo: ipotesi necessarie ............................................. 19
3.1 Il problema dell’aggregazione .......................................................... 20
Capitolo II. Critiche all’agente rappresentativo .................................. 25
1.Critica all’agente rappresentativo marshalliano ....................................... 25
2.Superamento della Critica di Lucas e la Tradizione Walrasiana............... 28
3.Una critica formale all’agente rappresentativo ......................................... 31
3.1 Agenti versus Agente: il problema dell’aggregazione ........................ 33
3.2 Incoerenza dell’agente rappresentativo in presenza di politiche economiche ..................................................................................... 37
3.3 Inconsistenza Paretiana .................................................................. 40
3.4 Difficoltà nell’analisi empirica ........................................................ 42
Capitolo III. L’interazione tra gli agenti ............................................. 46
1. Interazione ............................................................................................. 46
2. Membership Theory ............................................................................... 49
3. La teoria ................................................................................................ 54
3.1 Un modello ..................................................................................... 57
4. Reti: come si formano i gruppi sociali..................................................... 59
4.1 Il mondo piccolo .............................................................................. 61
5. La segregazione: come si formano i gruppi sociali .................................. 65
6. Stima dei parametri di interazione: problema di identificazione e autoselezione. ................................................................................. 71
6.1 Il problema di identificazione .......................................................... 71
6.2 Autoselezione .................................................................................. 73
7. Le indagini empiriche ............................................................................. 75

3
Capitolo IV. Un approccio computazionale all’economia .................... 83
1.La simulazione ad agenti ........................................................................ 83
2. Simulazione e metodologia tradizionale .................................................. 84
2.1 Generalizzazione e stima ................................................................. 86
2.2 Linguaggio condiviso ....................................................................... 89
3. Le caratteristiche dei modelli di simulazione ad agenti ........................... 91
4. Gli agenti ............................................................................................... 91
4.1 L’apprendimento, gli agenti “intelligenti” ......................................... 96
4.2 Le Reti Neurali Artificiali ................................................................. 97
4.3 Algoritmi Genetici ......................................................................... 103
4.4 La selezione .................................................................................. 109
4.5 Il cross-over e la mutazione .......................................................... 110
4.6 Risultati della simulazione ............................................................ 112
4.7 L’importanza di cross-over e mutazione ........................................ 113
4.8 Teorema fondamentale degli algoritmi genetici .............................. 118
4.9 Modelli con algoritmi genetici ........................................................ 123
5. Complessità ed Emergenza .................................................................. 127
Capitolo V. Alcune applicazioni di economia computazionali ........... 131
1.Modello con agenti non intelligenti ........................................................ 131
2. Modello di fragilità finanziaria .............................................................. 137
3. Conclusione ......................................................................................... 145
Appendice A. Codice NetLogo .......................................................... 146
A1 – Il codice NetLogo per la rappresentazione del mondo piccolo ............ 146
A2 – Il codice NetLogo del modello di segregazione ................................... 147
A3 – Il codice NetLogo di una Rete Neurale Artificiale ............................... 149
A4 – Il codice NetLogo del modello economico con algoritmi genetici ........ 154
A5 – Il codice NetLogo del modello di borsa simulato ................................ 157
A6 – Il codice NetLogo del modello di fragilità finanziaria ........................ 161
Appendice B. Differenze di reddito tra i quartieri romani. ................ 164
Bibliografia ..................................................................................... 169

4
Si ringraziano per la disponibilità ed il preziosissimo aiuto:
Prof. Enrico Marchetti, Università degli Studi di Napoli "Parthenope",
Dipartimento di Studi Economici
Prof. Pietro Terna, Università degli Studi di Torino, Dipartimento di Scienze
Economiche e Finanziarie
Prof. Nigel Gilbert, University of Surrey, CRESS – Centre for Research in Social
Simulation

5
“In many systems, the situation is such that under some conditions chaotic
events take place. That means that given a particular starting point it is
impossible to predict outcomes. This is true even in some quite simple
systems, but the more complex a system, the more likely it is to become
chaotic. It has always been assumed that anything as complicated as
human society would quickly become chaotic and, therefore,
unpredictable. What I have done, however, is to show that, in studying
human society, it is possible to choose a starting point and to make
appropriate assumption that will suppress the chaos, and will make it
possible to predict the future, not in full detail, of course, but in broad
sweeps; not with certainty, but with calculable probabilities.”
(Hari Seldon)1
1 Isaac Asimov, 1988 (edizione 1996), Prelude to Foundation, HarperCollinsPublishers, London, p.23

6
Introduzione Il sistema economico è un aggregato di miriadi di agenti eterogenei che
interagiscono tra loro. L’idea espressa nella proposizione precedente è stata il
fondamento su cui si è sviluppato il presente lavoro. Affermare che il sistema
economico è un sistema complesso non è una definizione vuota, bensì ha
grandi conseguenze sui metodi utilizzati per l’analisi economica. Il
comportamento aggregato in un sistema complesso infatti ha proprietà spesso
non deducibili dalle proprietà degli elementi che compongono il sistema.
Ignorando interazione ed emergenza l’analisi economica, tramite l’ipotesi
dell’agente rappresentativo, può commettere ciò che in filosofia è chiamato
fallacy of composition (Delli Gatti et al. 2006). Ipotizzare la possibilità di
rappresentare il sistema economico tramite l’agente rappresentativo significa
attribuire al sistema economico nel suo complesso le stesse proprietà che
caratterizzano gli agenti che lo compongono. Tale metodologia di studio può
avere successo solo se la relazione funzionale tra le variabili è lineare e se non
esiste alcuna interazione diretta tra gli elementi che compongono il sistema.
Rifiutare le precedenti ipotesi implica riconoscere che i sistemi economici sono
appunto dei sistemi complessi, nei quali il fenomeno dell’ emergenza impedisce
l’impiego di un approccio puramente “riduzionistico”. Nel primo capitolo
cerchiamo di comprendere quali motivi hanno portato alla nascita dell’agente
rappresentativo. In particolare si evidenzia la necessità di una
microfondazione della macroeconomia, in base alla quale sono i singoli agenti
che tramite le loro azioni determinano le regolarità macroeconomiche, sono le
proprietà micro degli agenti a determinare le proprietà macro del sistema. Ciò
che si critica dunque non è la necessità della microfondazione dell’analisi,
bensì il modo in cui tale microfondazione è stata proposta. L’agente
rappresentativo si rivela come una pseudo-microfondazione (Kirman 1992) e la
critica a questo concetto viene dettagliata nel secondo capitolo. Una
caratteristica importante che impedisce l’utilizzo dell’agente rappresentativo è
la presenza di interazione tra gli agenti. L’interazione viene studiata nel terzo
capitolo in cui si valuterà anche l’effettiva importanza dell’interazione nei fatti
economici. La soluzione proposta al problema nel quarto capitolo sono i
modelli basati su agenti (ABM – Agent Based Models). Tramite i modelli

7
computazionali si riesce a ricreare la complessità propria dei sistemi
economici, e a studiare come le proprietà aggregate emergano dalle proprietà
degli agenti. Il ricercatore ha il compito di costruire il modello e di osservarne i
risultati, ma l’analisi complessiva dei vari problemi economici in oggetto può
essere condotta in due diverse direzioni. Da una parte è possibile osservare il
risultato delle ipotesi imposte sugli agenti eseguendo le simulazioni; dall’altra
è possibile partire dalle regolarità macroeconomiche per cercare di
comprendere quali ipotesi riescono a riprodurre tali regolarità. Una
caratteristica importante dei modelli ad agenti è la possibilità di implementare
algoritmi di apprendimento che simulano la razionalità limitata degli agenti, in
particolare verranno discusse le Reti Neurali Artificiali e gli Algoritmi Genetici,
presentando inoltre due semplici modelli che ne illustrano le caratteristiche.
Nel quinto capitolo vengono forniti due ulteriori esempi di modelli basati su
agenti, in particolare una simulazione del mercato azionario con agenti Zero
Intelligence, ed un modello in cui il ciclo economico è provocato dall’interazione
tra le imprese ed il sistema finanziario.

8
Capitolo I L’agente rappresentativo
1. La nascita dell’agente rappresentativo La nascita del concetto di agente rappresentativo avviene nei Principles of
Economics di Alfred Marshall. Quando Marshall per la prima volta espose la
sua idea di agente rappresentativo limitò il concetto alla sola impresa
rappresentativa. L’obiettivo era quello di studiare le condizioni di offerta dei
sistemi economici, ed in particolare di costruire una curva che mettesse in
relazione prezzi del bene e quantità offerta del bene. In sintesi, il desiderio di
Marshall era quello di costruire una curva di offerta. Marshall pensò anche di
estendere il concetto di agente rappresentativo alla teoria del consumo,
creando un moderno consumatore rappresentativo (Hartley 1997), ma decise
di accantonare il progetto:
I think the notion of representative firm is capable of extension to labour; and I
have had some idea of introducing that in to my discussion of standard rates of
wages. But I don’t feel sure I shall: and I almost think I can say what I want to
more simply in another way
(Marshall in Pigou 1956, p.437)
La definizione di impresa rappresentativa data da Marshall è la seguente:
We shall have to analyse carefully the normal cost of producing a commodity,
relatively to a given aggregate volume of production; and for this purpose we
shall have to study the expenses of a representative producer for that aggregate
volume. On the one hand we shall not want to select some new producer just
struggling into business, who works under many disadvantages, and has to be
content for a time with little or no profits, but who is satisfied with the fact that
he is establishing a connection and taking the first steps towards building up a
successful business; nor on the other hand shall we want to take a firm which
by especially long sustained ability and good fortune has got together a vast
business, and huge well ordered workshops that give it a superiority over
almost all its rivals. But our representative firm must be one which had a fairly

9
long life, and fair success, which is managed with normal ability, and which
has normal access to the economies, external and internal, which belong to that
aggregate volume of production; account being taken of the class of goods
produced, the conditions of marketing them and the economic environment
generally.
(Marshall, 1920 [1961], vol. 1, p. 317)
L’impresa rappresentativa entra nel ragionamento durante l’analisi dei
costi di produzione. Marshall era infatti convinto che l’offerta di un dato bene
dipendesse dal costo di produzione di tale bene. Il sistema economico è
costituito da una grande varietà di imprese, sia dal punto di vista
dell’esperienza che dal punto di vista della dimensione. Data l’esistenza di
economie di scala, le diverse imprese possono portare al mercato lo stesso
bene a costi largamente diseguali. Il problema fondamentale divenne perciò la
scelta del costo di riferimento, ossia quale, tra la grande varietà di costi,
dovesse essere quello preso in considerazione per la costruzione della curva di
offerta. Marshall si rese conto che in un sistema economico esistono diversi
tipi di impresa; le imprese giovani che tentano di entrare nel mercato si
possono accontentare di profitti negativi (o nulli) con la speranza di
conquistare quote di mercato e di ottenere profitti positivi nel futuro. Il prezzo
di offerta perciò non potrà essere quello di queste imprese. D’altro canto
esistono anche imprese che grazie all’esperienza acquisita nel tempo riescono
ad ottenere profitti positivi. Il prezzo di offerta dovrà perciò essere inferiore al
prezzo delle imprese giovani e superiore ai prezzi delle imprese più anziane.
Avendo solo queste informazioni è impossibile definire esattamente una curva
di offerta. L’impresa rappresentativa di Marshall serviva esattamente a tale
scopo. La definizione di impresa rappresentativa si concretizza nell’impresa il
cui costo di produzione è esattamente uguale al prezzo dell’industria, ossia è
l’impresa che ottiene profitti nulli. L’impresa rappresentativa marshalliana è
molto simile alla definizione di impresa di equilibrio in un mercato competitivo.
Infatti Pigou utilizzò una costruzione molto simile chiamandola “impresa di
equilibrio” (Pigou, 1928). Ecco cosa scrive Pigou a proposito dell’impresa
rappresentativa marshalliana:

10
Marshall's statements about his "representative firm" show that this is conceived
as an "equilibrium firm" but it is also something more. It is a firm of, in some
sense, average size. Marshall pictures it as a "typical" firm, built on a scale to
which actual firms tend to approximate; for some purposes he suggests that it
might be well to picture to ourselves several different typical firms, one, for
example, in the company form, another, probably smaller, in the private
business form.
(Pigou 1928, nota 1)
Similitudine che può essere resa ancora più chiara dal seguente passo dello
stesso Marshall:
Let us call to mind the “representative firm”, whose economies of production,
internal and external, are dependent on the aggregate volume of production of
the commodity that it makes; and, postponing all further study of the nature of
this dependence, let us assume that the normal supply price of any amount of
that commodity may be taken to be its normal expenses of production (including
gross earnings of management) by that firm. That is, let us assume that this is
the price the expectation of which will just suffice to maintain the existing
aggregate amount of production; some firms meanwhile rising and increasing
their output, and others falling and diminishing theirs; but the aggregate
production remaining unchanged. A price higher than this would increase the
growth of the rising firms, and slacken, though it may not arrest, the decay of
falling firms; with the net result of an increase in the aggregate production.
(Marshall, 1920 [1961], vol. 1, p. 342)
L’impresa rappresentativa immaginata da Marshall aveva una
connotazione piuttosto differente dall’impresa rappresentativa moderna. Lo
scopo è naturalmente quello di rappresentare una categoria di agenti, ma
piuttosto che una rappresentatività statistica è una rappresentatività
economica. L’impresa rappresentativa Marshalliana non è l’impresa costruita
dividendo il prodotto totale per il numero delle imprese; non è una “super”
impresa che produce l’intero reddito (Hartley 1997). Lo scopo, nell’idea di
Marshall, era quello di riuscire ad astrarsi dalle diversità delle imprese

11
presenti nell’economia, senza dover assumere una totale omogeneità delle
imprese stesse; grazie ad essa riesce a studiare le condizioni di equilibrio della
produzione totale in un settore industriale, senza richiedere
contemporaneamente che le imprese che fanno parte di tale settore debbano
essere tutte in equilibrio. È importante sottolineare come la costruzione
dell’impresa rappresentativa aveva uno scopo ben preciso, e che mai si è
andati oltre tale scopo. Marshall utilizza l’impresa rappresentativa solamente
come una nozione astratta in grado di superare le asperità del reale, non ha
mai visto ne utilizzato l’impresa rappresentativa come una entità con vita
propria. La nozione di rappresentatività di Marshall è piuttosto limitata dal
punto di vista del concetto moderno di agente rappresentativo; nonostante
questo ha ricevuto pesanti critiche dagli autori contemporanei (in particolare
Robbins 1928).
2. L’agente rappresentativo moderno Le critiche piovute sull’impresa rappresentativa marshalliana furono
talmente feroci da decretarne la scomparsa. Il concetto di agente
rappresentativo “moderno” venne reintrodotto negli anni ’70 con la Nuova
Macroeconomia Classica. Hoover (1988) individua tre basi, considerate la
chiave per comprendere la nuova macroeconomia classica: le decisioni degli
agenti sono basate su grandezze reali; gli agenti sono sempre in equilibrio; gli
agenti possiedono aspettative razionali. In realtà, nessuna delle precedenti
chiavi di lettura implica necessariamente l’introduzione dell’agente
rappresentativo (Hartley 1997), ed in effetti la stessa discussione che Hoover
dedica all’agente rappresentativo occupa solo una parte molto ridotta.
La difficoltà a trovare letteratura che giustifichi in modo compiuto e
rigoroso l’utilizzo dell’agente rappresentativo, obbliga a tracciarne le
caratteristiche principali prendendo spunto da autori critici, gli unici, sembra,
ad essere interessati alle basi e ai ragionamenti che sostengono a livello teorico
l’agente rappresentativo. In particolare prenderemo le mosse da Hartley (1997)
e da Grabner (2002)2 i quali criticano l’utilizzo dell’agente rappresentativo, non
senza però aver cercato di capire le motivazioni che hanno spinto la scienza
economica ad usare in modo così massiccio i modelli con agente 2 Grabner 2002 è in effetti una rielaborazione del libro di Hartley.

12
rappresentativo. In particolare si possono trovare due ordini di ragionamento.
Il primo è la critica di Lucas. Il secondo si ricollega alla tradizione Walrasiana,
ed alla ricerca di modelli di equilibrio generale per studiare i fenomeni
economici. Data la scarsità di letteratura al riguardo, Hartley (1997) procede
collezionando lavori ed articoli adatti a giustificare l’agente rappresentativo.
Normalmente i modelli ad agente rappresentativo presuppongono
semplicemente che il lettore sappia perché l’agente rappresentativo sia
utilizzato ed utilizzabile, senza scendere in dettagli teorici che lo giustifichino.
2.1 La critica di Lucas Una parte importante della letteratura macroeconomica si è sviluppata
basandosi su modelli puramente macroeconomici. Per capire come nasca
l’esigenza di introdurre l’agente rappresentativo sembra naturale andare a
cercare nel lavoro che spiega come risolvere un tale modello. Hansen e Sargent
(1980) descrivono i metodi di soluzione per modelli relativamente complicati
che utilizzano l’agente rappresentativo. L’introduzione dell’articolo citato lascia
pochi dubbi sulle motivazioni che spingono gli autori allo studio di tali modelli:
This paper describes research which aims to provide tractable procedures for
combining econometric methods with dynamic economic theory for the purpose
of modeling and interpreting economic time series. That we are short of such
methods was a message of Lucas’s (1976) criticism of procedures for
econometric policy evaluation. Lucas pointed out that agents’ decision rules, e.g.
dynamic demand and supply schedules, are predicted by economic theory to
vary systematically with change in the stochastic process facing agents. This is
true according to virtually any dynamic theory that attributes some degree of
rationality to economic agents, e.g. various version of rational expectation and
Bayesian learning hypothesis. The implication of Lucas’s observation is that
instead of estimating the parameters of decision rules, what should be
estimated are the parameters of agents’ objective functions and of the random
processes they faced historically”.
(Hansen and Sargent, 1980, p. 7)

13
La critica di Lucas (Lucas 1976) si incentra sull’osservazione che i
comportamenti e le decisioni degli agenti economici non possono rimanere
invariati al variare delle politiche adottate. Un sistema economico al tempo t
può essere definito in modo molto semplice tramite una variabile endogena , un vettore di variabili esogene , ed un vettore di shock casuali indipendenti
identicamente distribuiti . Il moto di tale economia può essere descritto con:
1 = , , ,
Dove è la variabile endogena nel periodo + 1. La funzione e il vettore di
parametri derivano dalle regole decisionali degli agenti nell’economia, e
queste decisioni sono, teoricamente, ottimali data la situazione affrontata da
ogni agente. Come afferma lo stesso Lucas, non è assolutamente detto che le
informazioni su e siano facili da ottenere, ma è ipotesi centrale nella teoria
economica (precedente a Lucas) che una volta che essi sono conosciuti (anche
approssimativamente), essi rimarranno stabili sotto ogni variazione del
comportamento della serie . Ad esempio, supponiamo di disporre di un
modello , affidabile, e di volerlo utilizzare per accertare le conseguenze di
diverse regole di politica economica e fiscale, ossia diverse scelte di
comportamento da parte delle autorità economiche per i periodi futuri. Se si
ipotizzasse che la struttura dell’economia sia indipendente dalle diverse scelte
di politica economica, o in altre parole che la struttura dell’economia non vari
sistematicamente con le diverse scelte, il confronto tra le politiche potrebbe
essere effettuato semplicemente simulando le politiche economiche e
comparando i risultati ottenuti. Il problema è secondo Lucas che “everything
we know about dynamic economic theory indicates that this presumption is
unjustified” (Lucas 1976, p. 25). In un contesto in cui gli agenti massimizzano
la propria utilità, trovare una regola decisionale ottimale costante al variare
dei parametri è impossibile. Solo problemi triviali in cui gli agenti possono
ignorare il futuro possono essere formulati in questo modo. Lo stesso
ottenimento del modello , , presuppone che gli agenti abbiano delle
opinioni sul comportamento futuro delle variabili che li interessano. Supporre
la costanza di , con politiche economiche alternative significa supporre
che le opinioni degli agenti rispetto al comportamento degli shock economici

14
sono invarianti quando il comportamento degli shock è effettivamente
cambiato. Senza questa ipotesi estrema le simulazioni di politica economica
effettuate con modelli economici invarianti sono inutili (Lucas 1976 p.25).
Per riformulare in modo corretto il sistema economico dobbiamo imporre
la dipendenza di dalle scelte di politica economica. Supponendo che
2 = , ,
Dove G è una funzione nota, è un vettore di parametri dato, e è il vettore
dei disturbi casuali. Allora la struttura dell’economia può essere scritta come
segue:
3 = , , ,
Dove il parametro decisionale è funzione del parametro che governa le
politiche. Il problema econometrico in questo contesto diventa la stima di . In questo tipo di modello le variazioni di politica economica vanno ad
influenzare sia il comportamento della serie che le decisioni degli agenti.
Se la critica di Lucas sottolinea un aspetto teorico molto interessante,
non indica la soluzione. Essa afferma che si deve stimare la funzione ma
non dice come farlo. La risposta venne dal tentativo di andare oltre le curve
macroeconomiche, o come scrisse Sargent “Beyond Demand and Supply
Curves in Macroeconomics”:
…the private decision rules change systematically with descriptions of the
dynamic environment and of government rules, a successful theoretical analysis
requires understanding the way in which optimizing agents make their decision
rules depend on the dynamic environment in general. The econometric ideal of
discovering objects that are structural, in the sense that they are invariant with
respect to the class of policy interventions to be analyzed, imposes that criterion
for success. The upshot is that the analysts attention is directed beyond
decision rules to the objective functions that agents are maximizing and the
constraints that they are facing, and which lead them to choose the decision
rules that they do.
(Sargent 1982, p. 383)

15
L’analisi da parte della nuova macroeconomia classica tenta di superare la
critica di Lucas andando a studiare le funzioni obiettivo degli agenti. Se
inseriamo nel modello la funzione di utilità degli agenti, possiamo predire la
risposta ad eventuali variazioni di politica economica. In altre parole,
conoscendo le reazioni di ogni individuo ed ogni impresa alla politica
economica possiamo dedurne il risultato aggregato. Il risultato è l’agente
rappresentativo. Data l’impossibilità analitica di trattare ogni agente in modo
indipendente, si studia un agente rappresentativo, e come Marshall con la sua
impresa rappresentativa, si cerca di dare risposte a quesiti che rimarrebbero
nascosti nei meandri matematici di un modello con agenti eterogenei. Come
scrive Hartley:
Representative agent models are thus an attempt to model rigorously the
structural relationships in an economy. If we cannot simply start with
macroeconomic equations, then we need to start with microeconomic agents. The
first step is to write down the problem faced by the microeconomic agent in
terms of fundamental parameters. This agent is assumed to be representative,
and the solution to this problem is assumed to hold for the macroeconomy.
(Hartley 1997 p.26)
Il problema è capire se effettivamente la soluzione di un modello ad agente
rappresentativo è valido anche per l’aggregato, ossia se il passaggio da
“microfondare” ad “agente rappresentativo” è consentito e corretto.
2.2 La tradizione Walrasiana Una seconda ragione che sembra aver portato all’utilizzo dell’agente
rappresentativo è il desiderio di costruire modelli di equilibrio generale
walrasiano. Come scrivono Kydland e Prescott:
By general equilibrium we mean a framework in which there is an explicit and
consistent account of the household sector as well as the business sector. To
answer some research questions, one must also include a sector for the
government, which is subject to its own budget constraint. A model within this
framework is specified in terms of the parameters that characterise preferences,

16
technology, information structure, and institutional arrangements. It is these
parameters that must be measured, and not some set of equations. The general
equilibrium language has come to dominate in business cycle theory, as it did
earlier in public finance, international trade, and growth. This framework is
well-designed for providing quantitative answers to questions of interest to the
business cycle student.
(Kydland and Prescott 1991, p. 168)
La meta dell’economia politica è perciò di sviluppare un modello completo
dell’economia, ed è proprio questa concentrazione sul modello a creare il
legame con Walras, il quale sostiene la creazione di modelli “puri”, privi delle
complicazioni del mondo reale 3 . Sviluppare modelli puri significa basare
l’intera costruzione sulla logica. Dato che il mondo reale rimane sullo sfondo, è
impossibile dare prove e controprove di tipo empirico, la logica deve essere la
struttura che tiene in piedi i modelli. Data una certa condizione, lo scienziato
economista deve chiedersi la conseguenza necessaria della data condizione. Il
fatto che l’economia è una scienza sociale rafforza la necessità di basare
modelli e conclusioni sulla logica e sul pensiero piuttosto che sull’evidenza
empirica:
Being denied a sufficiently secure experimental base, economic theory has to
adhere to the rules of logical discourse and must renounce the facility of internal
inconsistency. A deductive structure that tolerates a contradiction does so under
the penalty of being useless, since any statement can be derived flawlessly and
immediately from that contradiction. 4
(Debreu 1991, pp. 2-3)
Gli economisti devono partire da basi che sappiamo essere vere per poi
costruire rigorosamente e logicamente il modello economico. Elementi di
economia politica pura (1874 [1974]) di Walras ed i lavori di Arrow e Debreu
3 Il concetto richiama la metodologia di Galileo Galilei del “difalcare gli impedimenti”: “…quando il
filosofo geometra vuol riconoscere in concreto gli effetti dimostrati in astratto, bisogna che difalchi gli
impedimenti della materia” (Galilei, 1632 [1970], p.266) 4 Vale infatti la legge logica del “ex falso quodlibet”. ex falso quodlibet (ossia: "dal falso (segue una)
qualsiasi cosa (scelta) a piacere") indica nella logica classica un principio logico che stabilisce come da un enunciato contraddittorio consegue logicamente qualsiasi altro enunciato. (da Wikipedia)

17
sono esempi di questo approccio. I modelli sviluppati non hanno nessuna
intenzione di permettere prove empiriche, lo scopo è di spiegare le vere
relazioni che intercorrono tra le variabili economiche, depurandole dai disturbi
del reale grazie alla rigorosa dimostrazione logica di premesse e conclusioni5.
L’economia diventa perciò una scienza teorica nella definizione aristotelica,
che prescinde dagli aspetti particolari, andando alla ricerca delle cause
necessarie. Naturalmente l’economia non è riducibile ad una scienza
puramente logica, tuttavia la parte empirica rimane in secondo piano, come
rappresentazione inesatta dell’esatta teoria economica. Il problema di questo
approccio è la sua difficoltà. La ricchezza di un modello walrasiano completo è
immensa. Il numero di agenti e di beni presenti nell’economia rende quasi
impossibile una analisi efficiente degli effetti di politica economica e delle
imperfezioni dei mercati. È richiesta una semplificazione, e la semplificazione è
l’agente rappresentativo:
Rather than carrying along the number of firms and the number of households
as additional parameters, which is a nuisance, we use the standard device of
“representative” agents. The substantive aspect of this device is to build in the
assumption that all firms are alike and all households are alike, while
technically it serves to eliminate the need to carry along the numbers of each
kind of unit.
(Sargent 1979, nota 4, p. 371)
Con l’agente rappresentativo si riacquista il controllo dei metodi matematici
inutilizzabili nei modelli ad agenti eterogenei e la possibilità di sfruttare il
teorema fondamentale dell’ economia del benessere (Hartley 1997). In una
economia con agente rappresentativo diventa relativamente semplice risolvere
il problema affrontato dal pianificatore sociale. Per trovare l’ottimo paretiano si
5Ossia per sillogismi: “Sillogismo è propriamente un discorso (lógos) in cui, posti alcuni elementi, risulta
per necessità, a causa degli elementi stabiliti, qualcosa di differente da essi. Si ha così anzitutto dimostrazione, quando il sillogismo è costituito e deriva da elementi veri e primi. ... Dialettico è poi il sillogismo che conclude da elementi plausibili (éndoxa). ... Eristico è infine il sillogismo costituito da elementi che sembrano plausibili, pur non essendolo, e anche quello che all'apparenza deriva da elementi plausibili o presentatisi come tali “ (Aristotele, Topici I, 100 a18-b25).

18
ha bisogno semplicemente della massimizzazione dell’utilità dell’agente
rappresentativo. In conclusione, l’agente rappresentativo sembra essere lo
strumento che permette lo sviluppo dei modelli economici di tipo walrasiano.
La rigorosità logica è ridotta allo studio del singolo agente rappresentante la
categoria di interesse, per lo studio degli aspetti ritenuti importanti per la
comprensione del sistema economico. Grazie ad esso si possono costruire una
grande varietà di modelli economici con cui studiare le scelte della totalità
degli agenti. Il problema rimane quello di capire se è possibile considerare
l’insieme delle scelte degli agenti operanti in un sistema economico come la
scelta di un singolo agente massimizzante, se la ricchezza del modello
walrasiano è mantenuta dall’agente rappresentativo. Dobbiamo comprendere
se studiare la scelta dell’agente rappresentativo è sufficiente per capire ed
analizzare la scelta dell’aggregato di agenti.
2.3 La microfondazione La microfondazione è la risposta alle esigenze esposte. Il bisogno di
coerenza tra i modelli macroeconomici e le teorie microeconomiche è
soddisfatto grazie alla microfondazione dei modelli macroeconomici: basare le
regolarità macroeconomiche sulle scelte degli agenti che compongono
l’aggregato. Oltre ad avere una teoria economica coerente, è però necessario
poter trarre benefici dall’analisi economica. Un modello eccessivamente
complesso, soprattutto in un’epoca in cui il computer non era a disposizione di
ogni ricercatore, significava un modello difficile da risolvere e difficile da
interpretare. A risolvere la situazione è l’agente rappresentativo, un agente che
abbia caratteristiche tali da operare scelte equivalenti alla massa di agenti che
si vuole rappresentare:
It is tedious and difficult to try to understand the motivations of millions of
diverse individuals. It is here that the representative agent comes to the rescue.
By rigorously modeling the decision-making process of a single agent and
assuming these rules hold in the aggregate, we simultaneously bypass the need
to model millions of different agents while still grounding our macroeconomic
model in microeconomics
(Hartley, 1997, p.29)

19
L’agente rappresentativo diviene il modo di uscire dal dilemma coerenza-rigore
(per cui è necessaria la microfondazione) vs utilità-trattabilità (che richiede la
riduzione del sistema economico). La necessità di avere una teoria economica
corretta deve essere coniugata con l’esigenza della trattabilità, in modo che la
teoria economica possa essere utile, oltre che rigorosa. Il problema centrale
diviene, come è già stato detto, capire se l’agente rappresentativo è soluzione al
dilemma sopra affermato, in particolare se la trattabilità dei modelli economici
non sia raggiunta a scapito del rigore teorico.
Le ipotesi necessarie affinché l’aggregato di agenti si comporti come un
singolo agente massimizzante sarà l’argomento del prossimo paragrafo.
3. Agente rappresentativo: ipotesi necessarie Il passaggio dall’idea della microfondazione all’agente rappresentativo
non è assolutamente banale. La correttezza di un tale passaggio dipende dalla
capacità di aggregare la miriade di agenti facenti parte di un sistema
economico, nel singolo agente che deve rappresentare le scelte della collettività
come aggregato. La questione, come si è detto, non è banale e richiede la
specificazione di particolari ipotesi sul comportamento degli agenti. In primo
luogo non devono esistere interazioni dirette tra gli agenti6. Tutto ciò che si
trova al di fuori della funzione obiettivo viene annullato dall’aggregazione delle
preferenze. L’agente rappresentativo cattura il comportamento tipico in un
dato momento e ne congela le caratteristiche; i parametri delle funzioni
obiettivo sono costanti e non esiste alcun rapporto tra le variazioni
dell’ambiente7 in cui operano gli agenti e le preferenze8 dell’agente. Dal punto
di vita matematico, il comportamento aggregato dei singoli agenti deve essere
equivalente al comportamento di un singolo agente massimizzante, agente che
verrà scelto al fine di rappresentare la collettività. Un primo modo per ottenere
una simile relazione tra le proprietà degli individui e il comportamento
aggregato è ipotizzare che tutti gli agenti siano identici. Tale ipotesi
semplificatrice, anche se spesso usata nei modelli macroeconomici, è
chiaramente irreale. Una strada alternativa e più rigorosa è quella di imporre
6 “…there is no direct interaction among economic units” (Delli Gatti et al. 2006, p.5)
7 Con ambiente si intende l’insieme degli agenti e delle istituzioni che compongono il sistema
economico. 8 Con preferenze si intende in generale la funzione obiettivo che determina le scelte dell’agente.

20
particolari ipotesi sulle funzioni obiettivo degli agenti. Dal famoso articolo di
Gorman (1953) si sono susseguiti diversi lavori contenenti condizioni
aggiuntive per la consistenza dell’aggregazione. L’aspetto fondamentale non è
quale ipotesi si impone per rendere coerenti le scelte della collettività con le
scelte dell’agente rappresentativo, bensì è affrontare il problema
dell’aggregazione. Ipotizzare agenti identici o ipotizzare agenti con specifiche
caratteristiche è invariante dal punto di vista del modello, ma è importante dal
punto di vista teorico.
3.1 Il problema dell’aggregazione Seguendo Lewbel (1989) supponiamo di avere una economia in cui tutti
gli individui possiedono funzioni di domanda 9 (derivate dalla funzione di
utilità) della forma:
4 = + + , ,
Dove è la domanda individuale per il bene , è il vettore dei prezzi, è il
reddito dell’individuo, è il parametro delle preferenze che può variare tra gli
individui, è una funzione qualsiasi di , , e , e , e sono funzioni che
dipendono dai prezzi. L’equazione (4) è la forma più generale di domanda
avente curva di Engel lineare nel reddito ed una funzione del reddito. Tale
forma è utile per l’aggregazione, dato che tutti gli effetti non lineari sono
incorporati nel termine . La domanda aggregata, o pro-capite, ossia la
domanda dell’agente rappresentativo, è ottenuta prendendo la media
dell’equazione (4). Per studiare come la domanda aggregata differisca dalla
domanda del consumatore rappresentativo, possiamo definire una funzione !
come la soluzione dell’equazione:
9 Lewbel prende in considerazione il problema dell’aggregazione delle funzioni di domanda. Come
afferma Grabner (2002), non riferendosi direttamente al lavoro di Lewbel: “To a large part this is due to the fact that aggregation is much less problematic for firms since they are not subject to budget constraints (only technological ones) and thus no wealth effects exist. Only substitution effects along the production frontier occur when prices change. This allows for exact aggregation of production sets and the formulation of a joint profit maximization problem, the solution of which perfectly corresponds to decentralized actions”. È da notare che non essendo le imprese individui, ma gruppi di individui, si può sollevare il problema dell’aggregazione anche all’interno delle imprese stesse (Hartley 1997).

21
5 #, , ! = $%, , &
Dove $∙ denota l’operatore valore atteso sulla distribuzione delle variabili tra
tutti gli individui dell’economia, e # = $# è il reddito medio. La
differenziabilità e la monotonocità locale della funzione rispetto a è
sufficiente a garantire l’esistenza di !. È da notare che ! dipende da e dalla
distribuzione di e tra gli individui dell’economia. Sia ( = $%&, ossia la
domanda media pro capite del bene . Utilizzando l’operatore di valore atteso
sull’equazione (4) ed utilizzando la (5) otteniamo:
6 ( = + # + #, , !
La quale assomiglia molto alla (4). Infatti, se *+, … , - è la funzione di utilità
di un individuo (con preferenze ) che porta all’equazione (4), allora la
domanda pro capite nell’economia sarà uguale alla domanda che deriva dalla
massimizzazione di *.(, … , (- soggetta al vincolo ∑ ( = #. In altre parole,
la domanda aggregata dell’economia dovrà essere pari alla domanda del
consumatore rappresentativo avente preferenze ! . Il problema che sorge
nell’interpretazione della (5) come la domanda del consumatore
rappresentativo, deriva dal fatto che ! dipende in generale da e #, rendendo
non legittima la sua inclusione in una funzione di utilità. Sono necessarie due
ipotesi per rendere ! indipendente da prezzi e reddito medio: la prima riguarda
la forma delle funzioni di domanda e di utilità degli individui, la seconda
riguarda la distribuzione del reddito tra gli individui. Le funzioni che
permettono di rendere le preferenze del consumatore rappresentativo
indipendenti dai prezzi sono elencate dal Teorema 1 in Lewbel (1989)10. Per
quanto riguarda la dipendenza dal reddito medio, definiamo 0 la proporzione
di individui della popolazione aventi reddito pari a = 1#; sia 2 l’insieme di
tutti i valori di 1 = /# presenti nella popolazione (tutti i valori di s per cui
0 ≠ 0; e sia l’insieme di tutti i 0 con 1 ∈ 2. Ogni distribuzione discreta può
essere parametrizzata in questo modo. Si dice che la distribuzione è “mean
scaled” se non dipende da # . Intuitivamente, supponendo costante nel
10
Le funzioni sono: Hometetiche, Quasi-Homotetiche, PIGL, PIGLOG, Quadratic, extendend PIGL, extended PIGLOG, LINLOG

22
tempo, se dovesse variare il reddito medio # di una certa percentuale 7, allora
il reddito di ogni individuo deve variare della stessa percentuale 7. Questo è un
caso particolare. Più in generale le variazioni della distribuzione devono essere
proporzionali, ossia la distribuzione relativa deve rimanere costante. L’ipotesi
di “mean scaling” perciò non impone restrizioni alla distribuzione ma ai
cambiamenti della distribuzione. Lewbel (1989) dimostra che l’ipotesi di “mean
scaling” rende le preferenze dell’agente rappresentativo indipendenti dalla
distribuzione del reddito permettendo l’aggregazione, naturalmente rimanendo
nei confini delle forme funzionali elencate nel teorema 1 dello stesso articolo di
Lewbel.
I diversi approcci adottati per lo studio del problema di aggregazione
hanno condotto sempre a risultati simili: senza ipotesi piuttosto restrittive
sulle funzioni che delineano il comportamento degli agenti e sulla
distribuzione delle caratteristiche tra gli agenti, la funzione aggregata contiene
un errore sistematico. Può essere interessante seguire il lavoro di Keller
(1980), nel quale tale errore viene individuato grazie all’approssimazione di
Taylor. Supponiamo che tutti gli individui abbiano una funzione di
comportamento della forma:
7 = % , … , 9 & ≡ %;&
Dove è la quantità di interesse, ; = , … , 9′ è il vettore delle caratteristiche
individuali che determinano il comportamento dell’agente. Tali caratteristiche
possono essere individuate come il reddito, la ricchezza e le preferenze. Per
ipotesi ; è continua e derivabile fino all’ordine <. Le caratteristiche degli
individui sono distribuite tra gli individui = 1, … , = secondo la funzione di
densità congiunta >, … , 9 . Supponiamo che la distribuzione abbia i
momenti centrali esistenti almeno fino al terzo. Il momento primo è definito
come:
8 ;@ = A ;>;B;
Ricordando che ; è un vettore. La matrice delle varianze e covarianze C è:

23
9 D = A; − ;@; − ;@′>;B;
Dove l’integrale della matrice è definito come matrice di integrali. La matrice D è di ordine F × F. Noi siamo interessati al comportamento aggregato
10 H = I = = ∙ J = = A ;>;B;9K
O, in termini pro capite,
11 J ≡ H= = A ;>;B;
Si può dimostrare che il comportamento aggregato pro capite, J, definito nella
(11) può essere approssimato nel modo seguente11:
12 J ≈ ;@ + 12 7M@ D Dove ;@ è il comportamento individuale (7) calcolato nel punto ;@ , come
definito nella (8), M@ è l’hessiano della funzione ; , e D è la matrice delle
varianze e covarianze come definita nella (9); 7 è l’operatore traccia. Inoltre si
può dimostrare che l’approssimazione è esatta se vengono rispettate alcune
condizioni sulla funzione di comportamento individuale ; o sulla funzione
di distribuzione >12. A prescindere dalle dimostrazioni che possono essere
trovate in Keller (1980), è interessante notare come la (12) mostra l’errore
commesso quando si aggrega. Se la funzione di comportamento ; non è
lineare (ossia se l’hessiano è diverso da zero) e se le caratteristiche degli agenti
11
Intuitivamente la (12) si ottiene calcolando il comportamento individuale definito nella (6) attorno alla media ;@ utilizzando l’approssimazione di Taylor del secondo ordine. In parole povere l’approssimazione di Taylor del secondo ordine di attorno al vettore ;@. La sostituzione di tale approssimazione di Taylor nella (11) permette di ottenere la (12). Per approfondire Lewbel (1989, p. 560) 12
Le condizioni di approssimazione esatta sono: a)la funzione ; è quadratica (le derivate terza e superiori si annullano) b) la distribuzione congiunta >; è simmetrica attorno alla media e la funzione ; è di terzo grado. La dimostrazione intuitiva è che rispettando le condizioni a) o b) si annullano i termini successivi al secondo dell’approssimazione di Taylor, rendendo l’approssimazione esatta.

24
non sono identiche tra loro (la matrice D è diversa da zero) si commette sempre
un errore quando si aggregano le funzioni di comportamento semplicemente
prendendo in considerazione le caratteristiche medie degli agenti (utilizzando
;@ come funzione dell’agente rappresentativo) . Il secondo termine della (12)
“…can be used as a first-order approximation of the aggregation error made
when aggregate behavior per capita is approximated by the behavior of the
average individual (with characteristics x), as is often done.”
(Keller, 1980, p.561)
Nel caso non valgano le condizione di approssimazione esatta date da Keller,
all’errore sottolineato deve essere aggiunto l’errore insito nell’approssimazione
di Taylor, errore che spesso è significativo.

25
Capitolo II Critiche all’agente rappresentativo
1.Critica all’agente rappresentativo marshalliano Nel primo paragrafo del capitolo precedente è stata descritta la nascita
dell’impresa rappresentativa. Marshall, nel tentativo di costruire una curva di
offerta ebbe il problema di decidere quale impresa dovesse essere il riferimento
per costruire tale curva. Il problema nasce dalla consapevolezza di trovarsi in
un mondo che presenta eterogeneità. Le imprese di una stessa industria
possono differire in diversi aspetti, ed offrire uno stesso bene a prezzi diversi.
L’impresa rappresentativa è l’impresa che ha una vita abbastanza lunga, un
successo non eccessivo e diretta con abilità normale (Marshall 1920 [1961])13.
Il principale critico nei confronti dell’impresa rappresentativa marshalliana fu
Robbins:
The Marshallian conception of a Representative Firm has always been a
somewhat unsubstantial notion. Conceived as an afterthought […] it lurks in the
obscurer corners of Book V [of Principles] like some pale visitant from the world
of the unborn waiting in vain for the comforts of complete tangibility. Mr. Keynes
has remarked that, “this is the quarter in which in my opinion the Marshall
analysis is least complete and satisfactory and where there remains most to
do.”14
(Robbins 1928, p. 387)
Il primo punto della critica di Robbins, e altri contemporanei di Marshall,
riguardava l’utilità dell’impresa rappresentativa. Dato lo scopo dell’impresa
rappresentativa, di superare le difficoltà nell’analisi dell’offerta quando i
produttori sono eterogenei (Robins 1928, p.391), la questione di interesse è
comprendere se effettivamente l’impresa rappresentativa risponde alle esigenze
13
In Marshall, deve essere una impresa “which had a fairly long life, and fair success, which is managed
with normal ability..”. Vedere citazione a pagina 2 14
J. M. Keynes, Alfred Marshall, 1842-1924 , The Economic Journal, Vol. 34, No. 135. (Sep., 1924), pp. 311-372. Citato in Robbins 1928.

26
che ne richiedono la nascita. La risposta di Robbins a tale questione è
inequivocabile:
There is no more need for us to assume a representative firm or representative
producer, than there is for us to assume a representative piece of land, a
representative machine, or a representative worker
Robbins (1928,p.393)
Robbins non è il solo a criticare Marshall; Sraffa, introducendo il concetto di
concorrenza monopolistica (Wolfe 1954), afferma che l’equilibrio è in generale
determinato anche in assenza di una impresa rappresentativa, e che tale
equilibrio normalmente non avrà un unico prezzo; produttori diversi
chiederanno per beni simili prezzi differenti. Il ragionamento di Sraffa porta
all’inutilità dell’impresa rappresentativa: l’esigenza di stabilire un’unica curva
di offerta per una data industria è semplicemente sbagliata (Hartley 1997).
La critica non si limita a contestare l’utilità dell’impresa rappresentativa
nell’analisi economica, bensì vuole dimostrare anche la sua incapacità di
rappresentare vari fatti economici. Un problema piuttosto importante si
manifesta quando si tenta di rappresentare la crescita economica. Marshall
(1920 [1961]) afferma che la crescita dell’industria poteva essere rappresentata
da una crescita proporzionale dell’impresa rappresentativa, tale crescita però
riesce a tenere conto solo dell’aumento di dimensione media delle imprese già
esistenti nel sistema economico. L’impresa rappresentativa nasconde il
progresso causato dal fenomeno della divisione del lavoro, riconosciuta come
forza fondamentale di progresso economico da Adam Smith. Come gli spilli
venivano prima prodotti da un solo artigiano e poi da più individui, così i beni
che prima venivano prodotti da una sola impresa saranno successivamente
prodotti da più imprese, ognuna delle quali produce solo una parte del
prodotto complessivo. La divisione del lavoro è un concetto problematico per
l’impresa rappresentativa:
With the extension of the division of labor among industries the representative
firm, like the industry of which it is a part, loses its identity. Its internal
economies dissolve into the internal and external economies of the more highly

27
specialized undertakings which are its successors, and are supplemented by
new economies.
(Young 1928, p. 538)
L’impresa rappresentativa è perciò inadatta a tenere conto di una qualsiasi
crescita produttiva che non sia semplicemente un allargamento del processo
produttivo già esistente. Il problema non si presenta solo in caso della
continua riorganizzazione del processo produttivo. La crescita può essere
infatti causata da un aumento della produzione delle imprese esistenti, ovvero
da un aumento del numero delle imprese esistenti. Se ad accadere è
quest’ultimo evento, il quale è sicuramente non meno probabile del primo,
l’impresa rappresentativa smette di essere significativa. Il prodotto
dell’economia cresce mentre l’impresa rappresentativa rimane immutata,
celando di nuovo un evento economico fondamentale. Sotto tali condizioni
l’impresa rappresentativa non solo è non necessaria ma diviene anche
fuorviante (Robbins 1928, p.398).
La critica che Robbins ritiene fondamentale riguarda però la capacità
dell’impresa rappresentativa di nascondere l’eterogeneità dei fattori produttivi,
in particolare dell’abilità manageriale. L’ipotesi implicita che tutti gli
imprenditori abbiano una abilità media conduce ai limiti più gravi della teoria
di Marshall. Se il prezzo di mercato di una certa industria è pari al prezzo
dell’impresa rappresentativa, e si ammette la presenza di una sorta di
arbitraggio, si deve imporre implicitamente che gli imprenditori abbiano tutti
l’abilità (o minimo l’abilità ) pari all’abilità dell’imprenditore rappresentativo. Il
prezzo di mercato non tende a soddisfare l’imprenditore marginale, bensì
l’imprenditore medio, rendendo impossibile la vita economica dell’imprenditore
marginale. Se si analizza il settore produttivo nel suo complesso sembra ovvio
che in ogni data situazione la posizione dell’abilità manageriale è esattamente
identica alla posizione degli altri fattori produttivi: le terre migliori sono
limitate quanto gli uomini migliori (Robbins 1928)15. L’ipotesi che il prezzo di
mercato si adegui al prezzo dell’imprenditore medio è impossibile. Non può
accadere semplicemente perché in tal caso gli imprenditori meno abili
dell’imprenditore medio uscirebbero dal mercato, rendendo impossibile
15
O come afferma Robbins: The best land and the best men are limited (Robbins, 1928, p.401)

28
all’imprenditore medio essere medio. Il concetto è espresso in una forma
migliore da Robbins (1928, p.402):
Mr. Henderson16 should reflect that if all entrepreneurs were at least of average
managerial ability, they would at once cease to be average.
Robbins (1928, p.402)
L’insieme di tali critiche, con in testa il famoso (e qui più volte citato)
lavoro di Robbins è fatale all’impresa rappresentativa di Marshall. Nonostante
non mancassero i difensori, l’impresa rappresentativa vide la sua fine.
Nell’analisi di Wolfe (1954) uno dei motivi fondamentali nel distrarre la scienza
economica dall’impresa rappresentativa fu lo sviluppo delle teorie della
concorrenza imperfetta e della concorrenza monopolistica (Wolfe 1954, p.339).
2. Superamento della Critica di Lucas e la Tradizione Walrasiana
Seguendo la strada indicata da Robbins nella sua critica all’impresa
rappresentativa marshalliana, possiamo iniziare la critica all’agente
rappresentativo “moderno” cercando di comprendere se il suo utilizzo abbia
effettivamente dato una risposta alle esigenze che ne hanno indotto la nascita.
L’esigenza di microfondare i modelli macroeconomici deriva originariamente
dal tentativo di superare la Critica di Lucas e di costruire modelli che fossero
coerenti con la tradizione Walrasiana.
La critica di Lucas, come è stato notato nel capitolo precedente, presenta
una interessante questione teorica senza indicarne la soluzione. La scienza
economica ha tentato di superare la critica di Lucas andando a studiare quella
parte del sistema economico che sembrava invariante ai cambiamenti di
politica economica. Sono state così definite delle equazioni strutturali, ossia
equazioni che non variano con le decisioni delle autorità politiche ma sono
formate dai parametri “profondi”: tecnologie e preferenze. Riuscire ad
16
La critica di Robbins è indirizzata a Mr. Henderson “as the product of Marshallian influence”. In particolare critica “Supply and Demand” di Henderson.

29
identificare tali parametri profondi e a separarli da quelli variabili può essere
una impresa molto difficile. Il primo problema da affrontare è comprendere se
effettivamente esistano parametri economici invarianti. Lucas, in particolare,
considera appropriato tenere costanti i parametri di preferenza e le tecnologie
nella speranza, vana secondo Hartley (1997), che tali parametri siano
effettivamente costanti. Anche supponendo l’esistenza di parametri invariabili
rimane il problema fondamentale di come riconoscerli e di come stimarli:
we need to recognize explicitly that what we call an agent’s deep taste or
technology parameters are actually merely approximations of the truly deep
parameters and, thus, can vary with regime.
(Hartley 1997,p.36)
I parametri economici non sono delle costanti che possono essere fissate, la
loro esistenza sembra effimera in quanto non è possibile stimarli e non è
possibile identificarli. I modelli con agente rappresentativo tengono costanti
parametri che non possono essere immaginati costanti in quanto ogni
comportamento economico si forma attraverso l’interazione tra agente e
ambiente circostante. L’agente rappresentativo nel tentativo, probabilmente
riuscito, di semplificazione dell’economia tralascia aspetti fondamentali
dell’economia. In Hartley (1997) si trova una lunga dissertazione riguardo alla
costanza di parametri che effettivamente non possono essere ritenuti costanti.
Se Lucas critica la teoria economica in quanto non prende in considerazione
fattori che vengono influenzati dalle politiche economiche, allora lo stesso
approccio dell’agente rappresentativo può essere criticato in quanto nella sua
semplificazione tende a mantenere invarianti parametri che difficilmente
possono essere ritenuti tali. Il punto non è che sia impossibile concepire questi
parametri; bensì che i parametri utilizzati in molti modelli ad agente
rappresentativo non possono ragionevolmente essere supposti costanti
(Hartley 1997). Sembra centrale anche la dimensione temporale considerata,
richiedendo in tal caso una attenta qualificazione temporale dell’analisi. È
importante sottolineare però che l’ambiente in cui operano gli agenti dipende
fortemente dalle azioni degli agenti stessi. Imponendo l’ipotesi dell’agente
rappresentativo si elimina un fattore essenziale nella determinazione

30
dell’ambiente economico: l’interazione tra gli agenti. Pur supponendo
l’invarianza dei coefficienti relativamente ad un dato arco temporale non è
possibile prescindere dall’effetto che l’ambiente economico ha sulla lunghezza
di tale arco temporale. La reazione che gli agenti hanno nei confronti delle
politiche economiche non riguarda solamente la variazione del proprio
comportamento, ma può comprendere anche le determinanti di tale
comportamento. Tali reazioni divengono allora non lineari e non comprensibili
attraverso la finzione dell’agente rappresentativo.
Il tratto distintivo dell’approccio Walrasiano alla teoria economica è, come
abbiamo visto, quello di una scienza teorica nel senso aristotelico. Data la
scarsa possibilità di sperimentare empiricamente le vere relazioni che formano
la struttura base dell’economia, si deve indagare l’economia attraverso la
logica. Si pongono ipotesi essenziali che riteniamo vere e partendo da esse si
costruisce la teoria economica tramite sillogismi. Se le ipotesi sono false, falsa
è la conclusione che costruiamo a partire da tali ipotesi. Eliminando le
asperità del reale si arriva alla struttura vera dell’economia. La questione che
si pone è comprendere quali complicazioni siano eliminabili e quali no. Se un
ricercatore vuole studiare il sistema economico è costretto a porre alcune
ipotesi che permettano di analizzare l’oggetto di studio. Le ipotesi imposte però
hanno una influenza significativa sui risultati per le motivazioni esposte sopra.
Ipotesi errate portano a risultati sbagliati. È di vitale importanza allora la
distinzione tra le ipotesi che sono irrilevanti dal punto di vista del risultato e
quelle ipotesi che invece hanno influenza sulla struttura fondamentale del
sistema economico. Se è possibile imporre le ipotesi irrilevanti è assolutamente
sbagliato imporre ipotesi che modificano il sistema economico nei suoi
fondamenti (Hartley 1997). E’ evidente che nella realtà esiste eterogeneità sia
tra le persone che tra le imprese. Seguendo il ragionamento precedente,
utilizzare l’ipotesi di agente rappresentativo nell’approccio walrasiano implica
imporre l’ ipotesi che le caratteristiche fondamentali dell’economia non siano
influenzate dal fatto che gli agenti economici differiscono uno dall’altro. Se tale
ipotesi è vera, allora l’utilizzo dell’agente rappresentativo è legittimo. Se tale
ipotesi è falsa, allora l’utilizzo dell’agente rappresentativo in un modello di tipo
walrasiano è ingiustificato:

31
Now, we know that in the actual world people are different. If we believe that
the representative agent assumption is useful in a Walrasian model, we must
also believe that our actual economy would not look very different than a world
composed of clones or identical robots.
(Hartley 1997, p.66)
Come si diceva in precedenza l’agente rappresentativo semplifica di molto
l’analisi; la domanda allora è se ha valore un’analisi semplice ma sbagliata,
rispetto ad una analisi complicata e meno limpida nelle conclusioni ma che
cerca di avvicinarsi maggiormente alla realtà delle relazioni economiche.
3. Una critica formale all’agente rappresentativo “A modern economy presents a picture of millions of people, either as
individuals or organized into groups and firms, each pursuing their own
disparate interests in a rather limited part of the environment.” (Kirman 1992, p.117)
Il lavoro fondamentale di Kirman (1992) per la critica all’agente
rappresentativo inizia con una constatazione ovvia, ma non per questo meno
importante. Un sistema economico è formato da milioni di decisori individuali,
ognuno dei quali persegue il proprio fine interagendo direttamente con le altre
entità, creando l’emergenza17 di un comportamento collettivo. La possibilità di
rappresentare tale comportamento collettivo con un singolo agente
massimizzante è il problema fondamentale affrontato. Certamente l’agente
rappresentativo semplifica di molto l’analisi, certamente rende comprensibili i
risultati. La domanda è se ha effettivamente valore un risultato semplice e
comprensibile nel momento in cui esso è sbagliato. Capire se il risultato è
sbagliato è la meta.
L’ordine apparente derivante dall’interazione degli agenti economici è
solitamente spiegato con la “mano invisibile” di Adam Smith. Nonostante gli
interessi conflittuali degli individui, il risultato del perseguimento dei propri
17
Emergenza è la traduzione del termine inglese “emergence”. Da Wikipedia: “…emergence refers to the way complex systems and patterns arise out of a multiplicity of relatively simple interactions”. (http://en.wikipedia.org/wiki/Emergence)

32
fini egoistici è socialmente soddisfacente. Il mercato è il meccanismo che
provvede alla coordinazione delle azioni individuali. Il paradosso è che i
modelli macroeconomici che tentano di dare una rappresentazione della realtà
economica (anche semplificata) non possiedono nessuna attività che necessiti
di una tale coordinazione. Questo perché normalmente assumono che le scelte
di tutti gli agenti di un dato settore possono essere considerati come la scelte
di un solo agente massimizzante il cui comportamento coincide con le scelte
eterogenee degli individui (Kirman 1992). Ciò che si vuole tentare di mostrare
nel presente capitolo, seguendo l’articolo di Kirman (1992), è che
this reduction of the behavior of a group of heterogeneous agents even if they
are all themselves utility maximizers, is not simply an analytical convenience as
often explained, but is both unjustified and leads to conclusions which are
usually misleading and often wrong.
(Kirman 1992, p.117)
La critica all’agente rappresentativo prenderà spunto dalle questioni
poste nell’articolo di Kirman. In primo luogo non esistono giustificazioni
formali plausibili per l’ipotesi che la collettività si comporti come un agente
massimizzante. La massimizzazione individuale non implica razionalità
collettiva, non esiste una relazione diretta tra il comportamento individuale ed
il comportamento aggregato. Secondo, anche se accettassimo che le scelte
aggregate possano essere rappresentate dalla scelta di un singolo agente, la
reazione dell’agente rappresentativo ad una variazione dei parametri del
modello originario può non essere la stessa della reazione della collettività che
esso rappresenta. In terzo luogo, anche se fossimo nella situazione in cui le
prime due critiche fossero inapplicabili, può accadere che dati due stati del
mondo, l’agente rappresentativo ne preferisca uno quando tutti gli agenti
rappresentati preferiscono l’altra. Non si può perciò utilizzare l’agente
rappresentativo per le analisi di economia del benessere. Infine, i modelli ad
agente rappresentativo hanno particolari svantaggi quando sono impiegati in
analisi empiriche. La somma di comportamenti semplici di tanti individui
eterogenei può creare dinamiche complesse, mentre la costruzione di un
singolo individuo per rappresentare tali dinamiche complesse, può portare a

33
dover ipotizzare per l’individuo comportamenti “particolari”. Inoltre, dato che
l’agente rappresentativo è frutto di una particolare ipotesi sui comportamenti
individuali, il test empirico di un modello ad agente rappresentativo prova le
due ipotesi congiunte: la particolare ipotesi che si sta tentando di verificare e
l’ipotesi di agente rappresentativo.
3.1Agenti versus Agente: il problema dell’aggregazione Il problema fondamentale che si presenta con l’utilizzo dell’agente
rappresentativo è il “problema dell’aggregazione”. Come è stato visto nel
capitolo precedente, per ottenere una aggregazione rigorosa delle preferenze
degli agenti, devono essere imposte ipotesi molto restrittive sulle funzioni che
rappresentano il comportamento degli agenti e sulla distribuzione del reddito.
Il metodo di aggregazione delle preferenze influisce sia sulle reazioni
dell’agente rappresentativo, le quali possono contenere errori rispetto alla
somma delle reazioni degli agenti (Keller 1980), sia sul comportamento
aggregato dell’economia: l’esistenza, o l’assenza, di equilibri unici e stabili. La
questione non è di poco conto. I modelli con agente rappresentativo spesso
richiedono che l’equilibrio economico sia unico e stabile. La stabilità assicura
una giustificazione all’ipotesi di equilibrio; se l’equilibrio è stabile infatti,
l’ipotesi che l’economia si trovi effettivamente in un punto così particolare è
plausibile. L’equilibrio, a sua volta, è fondamentale per assicurare legittimità
all’analisi di statica comparata, cioè per valutare gli effetti di eventuali
variazioni di parametri e/o di variabili esogene. Queste proprietà dipendono
dalle caratteristiche della funzione di eccesso di domanda aggregata. Se le
ipotesi normalmente imposte sulle funzioni di eccesso di domanda individuale
assicurano tali proprietà, non è affatto detto che tali proprietà si conservino
nel passaggio alla funzione aggregata. Nell’assenza di risultati precisi sulla
relazione tra comportamento individuale e comportamento aggregato, il modo
più semplice di procedere è di assumere che l’intera economia si comporti
come un singolo individuo. Un modo per giustificare tale ipotesi è assumere
che, se gli individui godono di certe proprietà, allora anche l’aggregato deve

34
godere delle stesse proprietà. L’errore di composizione (fallacy of composition18)
è evidente. Affinché sia possibile utilizzare un agente rappresentativo, senza
commettere errori, è necessario imporre le ipotesi ben precise a cui si è
accennato prima, e di cui si è trattato nel capitolo precedente. Come afferma
Lewbel, al termine del suo lavoro sull’aggregazione delle preferenze:
“It is a fact that the use of a representative consumer assumption in most macro
work is an illegitimate method of ignoring valid aggregation concerns.”
(Lewbel 1989, p.631)
Supponendo soddisfatte le condizioni formali richieste per l’esistenza
dell’agente rappresentativo, rimane il problema accennato in precedenza
riguardo alla mancanza di interazione diretta tra gli agenti. Per superare il
problema normalmente si suppone che l’economia si trovi costantemente in
equilibrio. In questo modo tutte le attività individuali, l’arbitraggio coinvolto
nella ricerca di opportunità profittevoli, riflettono i movimenti attorno
all’equilibrio. Di conseguenza il singolo individuo rappresentativo sarebbe
solamente una finzione che descrive in modo soddisfacente l’evoluzione
fondamentale dell’economia (Kirman 1992).
Affinché si possa analizzare l’economia come un sistema che si trova
sempre nell’intorno dell’equilibrio, si deve ipotizzare e dimostrare che
l’economia è un sistema stabile e con un unico equilibrio. Se il sistema
economico non godesse di tali proprietà, l’agente rappresentativo sarebbe solo
un modo per garantire stabilità e unicità dell’equilibrio, non garantite dal
sistema sottostante. In altre parole, l’agente rappresentativo piuttosto che
rappresentare gli agenti economici diviene un vincolo agli agenti economici.
Entrambe le proprietà di stabilità ed unicità dell’equilibrio rivestono un
ruolo fondamentale. Senza la stabilità, lo stesso concetto di equilibrio perde
notevolmente importanza:
If economists successfully devise a correct general equilibrium model, even if it
can be proved to possess an equilibrium solution, should it lack the institutional 18
Definizione di Wikipedia: “A fallacy of composition arises when one infers that something is true of the whole from the fact that it is true of some part of the whole.” (http://en.wikipedia.org/wiki/Fallacy_of_composition)

35
backing to realize an equilibrium solution, then that equilibrium solution will
amount to no more than a utopian state of affairs which bears no relation
whatsoever to the real economy.
(Morishima 1984, citato in Kirman 1989, p. 127)
Senza un equilibrio unico sarebbe impossibile utilizzare l’analisi di statica
comparata. Il modo più diretto per trovare le condizioni necessarie affinché il
sistema goda di stabilità ed unicità dell’equilibrio è di imporre ipotesi a livello
di comportamento individuale.
Supponiamo di avere una economia di puro scambio, e supponiamo di
imporre le ipotesi normalmente adottate per il consumatore individuale. Ogni
agente avrà curve di indifferenza “well behaved” e una dotazione iniziale
positiva di tutti i beni. Da questa combinazione di preferenze e dotazioni è
derivata la funzione di domanda individuale, e di conseguenza, sottraendo le
dotazioni iniziali, la funzione di eccesso di domanda individuale. Sommando
su tutti gli individui otteniamo la funzione di eccesso di domanda per l’intera
economia. Sotto alcune condizioni19, tre proprietà saranno trasmesse dalla
funzione di eccesso di domanda individuale alla funzione di eccesso di
domanda aggregata: continuità; il valore dell’eccesso di domanda deve essere
zero per tutti i valori positivi dei prezzi, ossia che il vincolo di bilancio per
l’economia deve essere soddisfatto (Legge di Walras); e che la funzione di
eccesso di domanda è omogenea di grado zero (contano solo i prezzi relativi).
Purtroppo queste sono anche le uniche proprietà che si trasmettono dalle
funzioni individuali alla funzione aggregata (Kirman 1992). In particolare a
livello aggregato può non essere soddisfatto l’assioma debole delle preferenze
rivelate, ossia può avvenire che la collettività sceglie x quando è disponibile y
in una data situazione e sceglie y quando è disponibile x in un’altra situazione
19
Agenti con curve di indifferenza “well behaved”, dotazione iniziale positiva di tutti i beni. Da queste deriva una funzione di domanda “well-behaved” ed una funzione di eccesso di domanda. Sommando tutti gli individui otteniamo l’eccesso di domanda aggregato. Se vengono considerati solo i prezzi maggiori di N, con N > 0 allora tre proprietà si trasmettono dalla funzione di eccesso di domanda individuale alla funzione di eccesso di domanda aggregata: continuità, legge di Walras, omogeneità di grado zero. (Kirman 1992) La continuità della funzione di eccesso di domanda aggregato potrebbe essere ottenuta anche in caso di non continuità delle funzioni individuali se gli agenti sono molti e se le loro preferenze sono disperse. (Varian 1992)

36
(Varian 1992). Questo non può avvenire per individui che soddisfano le ipotesi
standard:
Aggregate community demand might violate revealed preference axioms that
would be satisfied if there were just one consumer. As a result, representative
consumer models could misrepresent the effects of changes in endowments,
technology or policy on prices and aggregate consumption.
(Jerison 2006, p.1)
Inoltre, affinché l’equilibrio sia unico devono essere soddisfatte una delle due
seguenti condizioni: tutti i beni presenti nell’economia sono sostituti lordi per
ogni vettore di prezzo; vale il teorema dell’unicità dell’equilibrio. La seconda
condizione permette un risultato più generale, ma è difficilmente giustificabile
economicamente (Varian 1992) 20. Le condizioni descritte valgono però solo per
le funzioni di eccesso di domanda aggregate. I risultati di Sonnenschein,
Debreu e Mantel mostrano che è impossibile ipotizzare caratteristiche degli
agenti (quali preferenze, dotazioni etc.) tali da garantire l’unicità e la stabilità
dell’equilibrio a livello aggregato (Fagiolo e Roventini 2008). Kirman e Koch
(1986) mostrano che anche se gli agenti fossero quasi identici21 (preferenze
uguali e dotazioni quasi uguali), l’unicità e la stabilità non possono essere
recuperate. Hildenbrand e Kirman esprimono chiaramente il concetto nel
passo seguente:
“… There are no assumptions on the isolated individuals which will give us the
properties of aggregate behavior which we need to obtain uniqueness and
stability. Thus we are reduced to making assumptions at the aggregate level,
which cannot be justified, by the usual individualistic assumptions. This
problem is usually avoided in the macroeconomic literature by assuming that the
20
Formalmente le due condizioni sono: Beni sostituti lordi implicano unicità dell’equilibrio: Se tutti i beni sono sostituti lordi per tutti i prezzi, allora se P∗ è il vettore di prezzi di equilibrio, P∗ è l’unico vettore di prezzi di equilibrio. Unicità dell’equilibrio. Supponiamo R sia una funzione di eccesso di domanda continuamente
differenziabile sul simplesso dei prezzi con RS>0 quando P = 0 . Se la matrice – URP∗ ha determinanti positivi per tutti gli equilibri, allora esiste un solo equilibrio. −URP∗ è il negativo della matrice jacobiana degli eccessi di offerta, tolte l’ultima riga e l’ultima colonna; se esistono k beni, la matrice sarà di ordine V − 1 × V − 1. 21
Nel caso fossero identici si comporterebbero come un singolo individuo

37
economy behaves like an individual. Such an assumption cannot be justified in
the context of the standard economic model and the way to solve the problem
may involve rethinking the very basis on which this model is founded
(Hildenbrand e Kirman 1988, p. 239)
Trovare le ipotesi che permettono l’unicità dell’equilibrio e la stabilità globale
di tale equilibrio è perciò molto difficile. L’ipotesi che il sistema economico
possa essere rappresentato dalle decisioni di un singolo agente massimizzante,
sembra essere un modo per evitare le complessità dell’economia22. Piuttosto
che una innocente ipotesi semplificatrice, esso è il meccanismo che permette
di aggirare difficoltà altrimenti insormontabili. E’ tuttavia vero che, date le
ipotesi normali sulle funzioni degli individui, l’equilibrio generale di Debreu
possiede equilibri unici locali e stabilità locale (Debreu 1970)23. Se l’economia
partisse da un equilibrio stabile e avvenisse un cambiamento piccolo, potrebbe
verificarsi uno spostamento ad un equilibrio vicino all’equilibrio iniziale, ovvero
l’economia potrebbe tornare all’equilibrio iniziale, riducendo l’importanza del
problema di unicità. Purtroppo tale argomento è pieno di trappole ed in ogni
caso non viene normalmente utilizzato dai macroeconomisti (Kirman 1992,
p.123).
3.2 Incoerenza dell’agente rappresentativo in presenza di politiche economiche
Supponiamo che le condizioni adatte alla costruzione dell’agente
rappresentativo siano soddisfatte, ossia che le scelte della comunità di agenti
che formano il sistema economico equivalgano effettivamente alla scelta di un
agente massimizzante. Anche nel presente caso l’agente rappresentativo può 22
Concetto affermato nel passo citato di Hildenbrand e Kirman e confermato in Kirman (1992): “By
making such an assumption directly, macroeconomists conveniently circumvent these difficulties”
(Kirman 1992, p.122) 23
“A mathematical model which attempts to explain economic equilibrium must have a nonempty set of
solutions. One would also wish the solution to be unique. This uniqueness property, however, has been
obtained only under strong assumptions, and, as we will emphasize below, economies with multiple
equilibria must be allowed for. Such economies still seem to provide a satisfactory explanation of
equilibrium as well as a satisfactory foundation for the study of stability provided that all the equilibria of
the economy are locally unique. But if the set of equilibria is compact (a common situation), local
uniqueness is equivalent to finiteness. One is thus led to investigate conditions under which an economy
has a finite set of equilibria.” (Debreu 1970,p. 387)

38
portare ad errori nell’analisi economica. Nei modelli con agente
rappresentativo, l’analisi di scelte di politica economica vengono effettuate
inserendo le variazioni dei parametri economici nel modello, e valutando il
nuovo equilibrio. La procedura descritta implica però una nuova ipotesi: la
politica economica adottata non influisce sulla rappresentatività dell’agente
rappresentativo. L’agente rappresentativo non rappresenta solo l’economia in
un dato istante, ma rappresenta anche la reazione degli agenti economici a
variazioni di politica economica. Il riconoscimento di tale ipotesi avviene
normalmente tramite la locuzione “ignorando le conseguenze distributive”
(Kirman 1992). La questione è che normalmente le politiche economiche
influenzano in modo diverso agenti diversi, e spesso è proprio la variazione
della distribuzione ad essere l’obiettivo delle politiche. Nel caso in cui la
politica economica influenza diversamente gli agenti economici, può accadere
che l’agente rappresentativo costruito prima della variazione non rappresenti
più il sistema economico dopo la variazione. Il problema deve essere affrontato:
“As a modeling strategy, ignoring the sensitivity of aggregators to policy changes
seems no more compelling than ignoring the dependence of expectations on the
policy regime. “
(Geweke 1985,p.206)
Geweke (1985) mostra come il modo con cui si aggregano le entità
microeconomiche influisce fortemente sui risultati macroeconomici. Egli
analizza il processo di aggregazione del comportamento di una singola impresa
per ottenere la relazione macroeconomica. Il modello è disegnato in modo da
avere aggregazione esatta, ogni impresa decide la produzione con tre diverse
regole decisionali: con la funzione di offerta; con la funzione di domanda dei
fattori produttivi; o tramite la funzione di produzione. Geweke studia la
reazione del modello e degli agenti in caso di variazione della politica
economica. Il risultato è molto diverso rispetto a come le imprese sono
disegnate; la stessa politica economica produce risultati diversi per le stesse
imprese se viene adottato un diverso modo di descrivere la regola decisionale.
Riprendiamo un esempio molto semplice da Hartley (1997), per visualizzare il

39
problema. Supponiamo di studiare un mondo con due agenti, i quali hanno le
seguenti funzioni di consumo:
W = 0,8 H
WX = 0,4HX
Lo scopo è di definire un agente rappresentativo con una funzione W = YH che
sia in grado di mostrare la relazione tra consumo aggregato e reddito
aggregato. Inizialmente entrambi i consumatori hanno lo stesso reddito di 100,
perciò il reddito aggregato è di 200 e il consumo aggregato è di 120. L’agente
rappresentativo (come agente medio) di conseguenza ha un reddito di 100 e
un consumo di 60 ed Y = 0.6 . Supponiamo ora di effettuare una politica
redistributiva, togliendo 50 al consumatore 1 per aggiungerli al reddito del
consumatore 2. Dato che il reddito aggregato è rimasto invariato, il nostro
modello dovrà predire un consumo invariato di 120. In realtà, andando ad
analizzare il comportamento individuale si scopre che il consumo aggregato è
sceso a 100. Lo stesso accade se avvenisse un aumento di reddito aggregato di
100. Il modello ad agente rappresentativo predice un consumo aggregato di
180, quando in realtà si pone il problema di come è stato distribuito il reddito
aggiuntivo. Se l’aumento di reddito fosse ripartito equamente tra i due agenti,
il nostro modello riuscirebbe a prevedere il consumo aggregato corretto.
Dipendendo dalla distribuzione del reddito aggiuntivo il consumo aggregato
effettivo può variare tra 160, (se l’intero reddito aggiuntivo è del consumatore
2) a 200 (se il reddito aggiuntivo è interamente del consumatore 1). Nel
sistema economico modificato è naturalmente possibile costruire un nuovo
agente rappresentativo, il quale però sarà differente da quello originale dato
che le scelte di quest’ultimo, dopo la variazione intervenuta, non coincidono
più con la scelta aggregata (Kirman 1992). Tale possibilità richiede però che
l’agente rappresentativo sia effettivamente costruito partendo dagli agenti,
come deve essere affrontato il problema dell’aggregazione esplicitando le
ipotesi sui comportamenti individuali, così per riuscire a costruire agenti
rappresentativi coerenti anche in caso di variazioni dei parametri
dell’economia si devono considerare gli agenti rappresentati. Il modello
precedente è semplicissimo e, conoscendo gli agenti, semplice da correggere; la

40
questione che si pone è se effettivamente sia utile utilizzare l’agente
rappresentativo se si devono in ogni caso prendere in considerazione le
reazioni dei singoli agenti. Usare l’agente rappresentativo può essere
problematico, se si prescinde dagli agenti rappresentati può diventare erroneo.
In particolare nell’ultimo esempio proposto, l’errore derivante dall’uso
dell’agente rappresentativo è quantitativo, mentre le relazioni qualitative
rimangono invariate (all’aumentare del reddito aggregato aumenta il consumo
aggregato). Lo scopo del precedente esempio non è dimostrare che l’agente
rappresentativo sia sempre fonte di errore, bensì è insinuare il dubbio che lo
studio del sistema economico (decisamente più complesso dell’esempio
proposto) non possa essere effettuato con strumenti che non solo possono
portare all’errore, ma che neppure sono in grado di segnalare tale errore.
3.3 Inconsistenza Paretiana L’approccio dell’agente rappresentativo può contenere un errore fatale
anche nel caso in cui si vogliano utilizzare modelli con agente rappresentativo
per una valutazione di economia del benessere. È possibile che dati due stati
del mondo a e b, l’individuo rappresentativo preferisca strettamente lo stato a
allo stato b, mentre tutti gli agenti “rappresentati” preferiscono strettamente lo
stato b allo stato a:
“Even when aggregate community demand satisfies the strong axiom and
therefore is indistinguishable from the demand of a single competitive consumer,
the single-consumer model might not be adequate for evaluating efficiency. The
representative consumer can be Pareto inconsistent, preferring an aggregate
situation A to B even though all the actual consumers in the community prefer B
to A.”
(Jerison 2006, p.2)
La capacità rappresentativa di un singolo agente dipende da quali comunità e
da quali politiche o eventi vengono analizzati. Se tutti gli agenti sono
competitivi e identici allora esiste un modello ad agente rappresentativo
“positivo” che riesce a descrivere la comunità ed è pareto consistente,
rendendo possibili giudizi di benessere per tutte le politiche e gli eventi
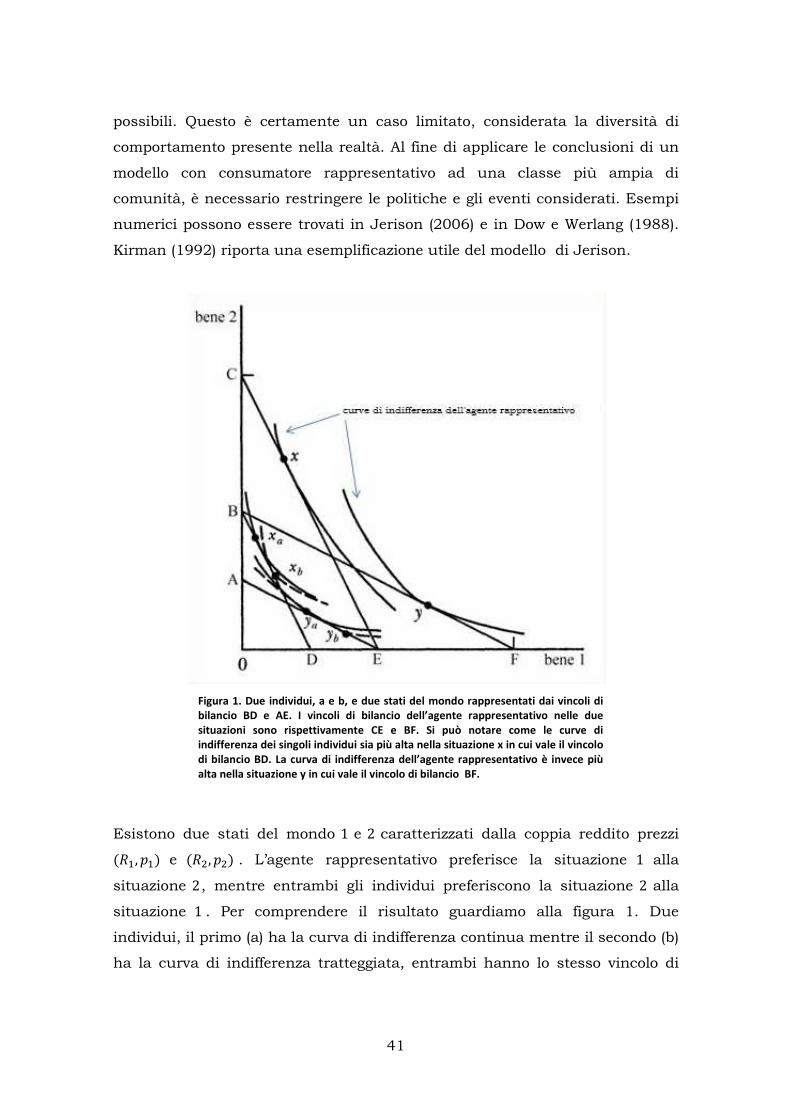
41
possibili. Questo è certamente un caso limitato, considerata la diversità di
comportamento presente nella realtà. Al fine di applicare le conclusioni di un
modello con consumatore rappresentativo ad una classe più ampia di
comunità, è necessario restringere le politiche e gli eventi considerati. Esempi
numerici possono essere trovati in Jerison (2006) e in Dow e Werlang (1988).
Kirman (1992) riporta una esemplificazione utile del modello di Jerison.
Figura 1. Due individui, a e b, e due stati del mondo rappresentati dai vincoli di bilancio BD e AE. I vincoli di bilancio dell’agente rappresentativo nelle due situazioni sono rispettivamente CE e BF. Si può notare come le curve di indifferenza dei singoli individui sia più alta nella situazione x in cui vale il vincolo di bilancio BD. La curva di indifferenza dell’agente rappresentativo è invece più alta nella situazione y in cui vale il vincolo di bilancio BF.
Esistono due stati del mondo 1 e 2 caratterizzati dalla coppia reddito prezzi
[, P e [X, PX . L’agente rappresentativo preferisce la situazione 1 alla
situazione 2, mentre entrambi gli individui preferiscono la situazione 2 alla
situazione 1 . Per comprendere il risultato guardiamo alla figura 1. Due
individui, il primo (a) ha la curva di indifferenza continua mentre il secondo (b)
ha la curva di indifferenza tratteggiata, entrambi hanno lo stesso vincolo di

42
bilancio AE, ed effettuano la scelta \ e ]. Quando il vincolo di bilancio è dato
da ^U le loro scelte sono \ e ] . La loro scelta aggregata nella prima
situazione è data da che si trova sul vincolo di bilancio aggregato ^, e nel
secondo caso è data da , che si trova sul vincolo di bilancio aggregato W$. Ora
è facile vedere che l’individuo rappresentativo, le cui curve di indifferenza sono
date dalle curve indicate nella figura 1, fa effettivamente la scelta che
corrisponde alla somma delle scelte di e . Nonostante ciò, l’individuo
rappresentativo preferisce lo stato allo stato , mentre l’individuo preferisce
lo stato \ allo stato \, e l’individuo preferisce lo stato ] allo stato ]. Perciò
inferire le preferenze sociali dalle preferenze dell’individuo rappresentativo, ed
utilizzarle per effettuare scelte di politica economica, è illegittimo. (Kirman
1992, p.124). Jerison così conclude il suo lavoro sul “consumatore non
rappresentativo”:
The Pareto inconsistencies of positive representative consumers in
macroeconomics may be small, but this does not extend the applicability of such
models very far. A typical community does not have a positive representative
consumer at all. Furthermore, even if there is a Pareto consistent representative
consumer, its preferences need not be useful for policy evaluation. The
representative consumer's preferences are a special form of compensation
criterion. They attach greater weight to richer consumers who consume more. It
is possible that the representative consumer agrees with only a tiny minority of
the community in its evaluation of the relevant policy alternatives. For these
reasons, it may not be appropriate to identify a representative consumer's
preferences with social welfare even if doing so entails no logical inconsistency.
(Jerison 2006, p.19)
3.4 Difficoltà nell’analisi empirica I problemi di aggregazione descritti precedentemente non possono non
creare problemi all’analisi empirica dei modelli economici, la quale è
notoriamente irta di specifiche difficoltà. La natura dei fenomeni studiati è tale
da rendere l’economia una scienza non sperimentale: non è possibile
invalidare (o validare) una teoria sulla base di “esperimenti”. In primo luogo
perché la nozione stessa di esperimento è estranea all’economia: non è infatti

43
possibile creare (o ricreare) condizioni ambientali controllate per studiare
fenomeni economici in modo che le condizioni sperimentali stesse abbiano
validità con riferimento al mondo reale24. In secondo luogo è spesso difficile
isolare il fenomeno stesso di interesse. Questo implica che la teoria economica
ha un ruolo fondamentale. Se gli agenti economici sono eterogenei; se le
interazioni tra agenti hanno un effetto sui risultati economici; se i
comportamenti degli agenti non sono formalizzabili con una funzione del tipo
richiesto dalle condizioni di Lewbel (1989) in altre parole se la comunità di
agenti non si comporta come un unico agente massimizzante allora è evidente
che le prove empiriche di modelli con agente divengono problematiche.
Quando si verifica empiricamente un modello con agente rappresentativo si
stanno effettivamente verificando due ipotesi congiunte: la particolare
relazione economica che il modello intende verificare e l’ipotesi che le scelte
dell’aggregato possano essere descritte dal singolo agente massimizzante
(Kirman 1992). Summers (1991), ad esempio, discute il lavoro di Hansen e
Singleton (1982, 1983) nel quale risulta il rifiuto di una particolare relazione
tra consumo e “asset pricing”. Date le ipotesi con cui è stato costruito il
modello (agente rappresentativo, funzioni di utilità separabile additiva e
avversione relativa al rischio costante CRRA), ciò che viene rifiutato potrebbe
essere il modo stesso in cui il modello è costruito:
“…they provide little insight into whether the reason for the theory's failure is
central to its logical structure or is instead a consequence of auxiliary
assumptions made in testing it. […] Any test of the representative consumer
model involves a test of whatever assumption is made about these issues and a
dozen similar ones. ”
(Summers 1991,p.135)
Altro esempio interessante si trova in Kirman (1992) e riguarda
l’apparentemente strana reazione del consumo ai cambiamenti del reddito
(excess smoothing del consumo). Se il settore del consumo è visto come un
singolo individuo, la reazione di tale individuo a variazioni del reddito corrente 24
Naturalmente esiste l’economia sperimentale. In questo caso si intende la ricreazione di ambienti controllati complessi nei quali studiare i fenomeni economici di interesse esattamente come avvengono nella realtà.

44
sembra essere minore di quanto predetto dall’ipotesi di reddito permanente.
Quando avviene uno shock imprevisto sul reddito corrente, l’agente modifica la
sua stima del reddito permanente, modificando di conseguenza anche i suoi
consumi. L’entità della variazione dipende dalla percezione che l’agente ha
dello shock: quale parte della variazione del reddito corrente è permanente e
quale transitoria. Quah (1990) dimostra che è sempre possibile costruire un
agente rappresentativo che decomponga gli shock in modo da rendere le
osservazioni empiriche consistenti con l’ipotesi di reddito permanente.
Naturalmente tale decomposizione è completamente arbitraria. Un modo per
risolvere il problema è la variazione dell’approccio utilizzato. I modelli ad
agente rappresentativo devono ipotizzare comportamenti dell’agente
rappresentativo stesso che potrebbero sembrare strani. Diebold e Rudebusch
(1991) ad esempio tenta di risolvere il problema costruendo un agente
rappresentativo che prende in considerazione possibili variazioni del reddito
nel lungo periodo. Ai comportamenti complessi dell’agente rappresentativo si
contrappongono i modelli che tentano l’approccio al problema con agenti
eterogenei. Se si aggregano agenti eterogenei e miopi, che analizzano il loro
processo di reddito in un modo molto più semplice, si riesce ad ottenere il
risultato desiderato di excess smoothing del consumo. Clarida (1991)
costruisce un modello con agenti eterogenei, ognuno dei quali soddisfa l’ipotesi
di reddito permanente, di consumption smoothing e di risparmio per la
vecchiaia. In particolare l’eterogeneità inserita nel modello riguarda l’età degli
agenti, con l’ipotesi che dati < periodi di vita, solo per i primi _ < < l’agente
ottiene reddito da lavoro. Egli ottiene a livello aggregato il tipo di reazione a
variazioni di reddito effettivamente osservata e conclude:
…the representative agent PIH [permanent income hypothesis] may be
misleading because it does not account for the demographic consideration that
makes permanent per capita shocks transitory from the point of view of any
individual, and it does not incorporate the empirically relevant implication of this
fact.
(Clarida 1991, p.865-866)

45
Lippi (1988) analizza il modello di Davidson et al. (1978), il quale stima
l’equazione consumo-reddito per il Regno Unito e utilizza una equazione a
ritardi infiniti. Lippi mostra che il comportamento aggregato può non derivare
da una complicata massimizzazione dell’agente rappresentativo, bensì può
essere riprodotto grazie all’aggregazione di agenti eterogenei, i cui
comportamenti dipendono da variabili con un solo ritardo, o dalle sole variabili
correnti. Invece di proporre agenti rappresentativi con programmi di
massimizzazione dinamica sempre più complicati, si possono sviluppare
modelli con agenti eterogenei, rendendo le ipotesi più semplici e i risultati
ancora coerenti. Le parole di Lippi (1988):
“Independently of the dynamic shape of the corresponding microequation, we
have shown that the dependent lagged variable, as well as the independent
lagged variable, are likely to occur in the macroequations. Therefore the usual
interpretation of the macroequations, being based on the representative agent,
may be responsible for an overstating of the importance of dynamic
microbehaviors. In fact, simple static or almost static microbehavior have been
seen to be a possible microbackground for dynamically complex macroequation.”
(Lippi 1988,p.585)
Attestato che le condizioni per l’esatta aggregazione sono molto
stringenti, e che i modelli ad agente rappresentativo commettono un errore, la
letteratura si è occupata di tentare la “misura” 25 di tale errore. L’entità
dell’errore provocato dall’aggregazione errata delle preferenze dipende dalla
situazione e dal metodo di analisi; in alcuni casi è rilevante, in altri meno.
Gupta (1969), ad esempio, studiando il mercato del lavoro, trova che “[the]
empirical exercise demonstrated that the problem of aggregation bias can be
serious and lead to some disturbing results” (Gupta 1969, p.72)
25
Effettivamente “The largest problem in assessing the size of aggregation error is the inability to measure it” (Hartley 1997, p. 135). Per questo motivo sono state poste le virgolette.

46
Capitolo III L’interazione tra gli agenti
1. Interazione L’approccio dell’agente rappresentativo è segnato da diversi limiti.
Riferendoci ai capitoli precedenti possiamo giudicare tali limiti come una
semplificazione, le cui ipotesi fortemente limitanti possono essere viste come il
prezzo per ottenere (e sottolineare) relazioni economiche effettivamente
significative. Oppure possiamo ritenere le ipotesi riguardo alle forme funzionali
e alla distribuzione del reddito (Capitolo I) talmente stringenti, da limitare la
capacità di comprensione del sistema economico analizzato. Esiste una
questione a cui si deve rispondere in ogni caso: le interazioni tra gli agenti26
sono significative per la spiegazione del sistema economico?
Se si ammettono interazioni significative tra gli agenti è ovvio che diviene
impossibile rappresentare un sistema economico con un agente
rappresentativo. L’agente rappresentativo nasconde ed elimina le interazioni
dirette tra gli agenti (Delli Gatti et al. 2006) e diviene completamente inutile
quando tali interazioni divengono importanti. Si deve però notare che
l’economia politica, dalla prospettiva dell’equilibrio generale, ha sempre
considerato le interazioni non di mercato come prive di interesse economico;
ciò che si trova fuori dal mercato è un ostacolo al corretto funzionamento dei
mercati (non completezza dei mercati), e al raggiungimento dell’ottimo sociale
(Manski 2000). Le interazioni significative sono solo le interazioni economiche,
che passano esclusivamente attraverso il meccanismo indiretto di mercato e
dei prezzi:
Mainstream economics has always been fundamentally concerned with a
particular endogenous effect: how an individual's demand for a product varies
26
Con interazioni tra gli agenti si intende il concetto economico di esternalità. La diversa denominazione è stata adottata solamente per porre maggiore enfasi sull’importanza che ricopre la presenza di più agenti eterogenei che si influenzano a vicenda, ma rimane possibile leggere la presenza di interazione tra gli agenti come la presenza di esternalità tra gli agenti.

47
with price, which is partly determined by aggregate demand in the relevant
market
(Manski 1993, p.531)
Il problema delle interazioni tra gli agenti è relativamente recente. Negli
anni ’70 la teoria economica allarga le proprie competenze non abbandonando
il rigore che la rende particolare tra le scienze sociali. Sviluppi della
microeconomia27, dell’economia del lavoro28 e della macroeconomia29 danno
slancio alla nuova fase (Manski 2000). Le interazioni sociali, da eliminare
piuttosto che da studiare, sono secondo Kirman la fonte dei problemi della
macroeconomia:
“The problem30 seems to be embodied in what is an essential feature of a
centuries long tradition in economics, that of treating individual as acting
independently of each other.”
(Kirman 1989,p.137)
Che le interazioni tra gli agenti esistano è un dato di fatto, riscontrabile
quotidianamente. L’aspetto interessante è capire se tali interazioni siano
significative economicamente. Uno studio coerente delle interazioni sociali
richiede una chiara concettualizzazione del processo di interazione. Il sistema
economico è formato da agenti, i quali prendono decisioni. Lo studio
dell’economia può allora essere concettualizzato come lo studio delle decisioni
di agenti economici dotati di preferenze, che formano aspettative e sono
sottoposti a vincoli. Le preferenze sono formalizzate in una funzione di utilità,
le aspettative da una distribuzione soggettiva di probabilità, e i vincoli da un
insieme di scelte possibili. Il processo di interazione interessante in termini
27
In particolare lo sviluppo della teoria dei giochi non cooperativi nello studio dei mercati e di altre interazioni 28
Lo sviluppo di una economia del lavoro che prende in considerazione anche problemi di carattere sociale 29
Sviluppo della teoria della crescita endogena, del concetto di esternalità dinamica del capitale sociale 30
Il problema a cui si riferisce Kirman è: “…if one examines carefully the terminology employed in the
macroeconomic literature one constantly finds reference to 'the equilibrium' or 'the natural rate' and
moreover a discussion as to how long the economy wiIl take to return to the equilibrium. The underlying
assumptions of uniqueness and stability are clear, yet as should be clear by now such assumptions have
no theoretical justification.” (Kirman 1989,p.137)

48
economici riguarda perciò gli agenti, definiti come unità elementari di scelta
(ossia scelgono, compiono azioni), e le influenze che le scelte di ogni agente
hanno sulle scelte degli altri agenti. In particolare tale influenza dovrà
concretizzarsi su uno dei tre fattori che permette la scelta: i vincoli, le
aspettative e le preferenze (Manski 2000).
Le interazioni che influenzano i vincoli degli agenti sono normalmente
interazioni indirette. L’esempio classico è un’economia in cui esistono
consumatori ed imprese price-taking. Le decisioni degli agenti nel loro
aggregato determinano domanda e offerta aggregata e di conseguenza i prezzi,
influenzando a loro volta l’insieme di scelta degli agenti. Altra forma di
interazione nei vincoli è la congestione. Immaginando agenti con vicoli
temporali, la scelta degli agenti di usufruire di un certo servizio influenza la
possibilità di altri agenti di utilizzare lo stesso servizio. Mercato e congestione
sono esempi di interazioni “negative”, più agenti scelgono un certo bene, meno
è disponibile tale bene per gli altri agenti, influenzando perciò l’insieme delle
scelte. È possibile però immaginare anche esempi di interazione “positiva” sui
vincoli. Se gli agenti intraprendono ricerca e sviluppo, possono generare
interazioni positive. Nuove tecnologie possono aumentare l’insieme di scelta
dell’agente, e nel caso in cui la nuova tecnologia divenga di dominio pubblico
si allarga l’insieme di scelta di tutti gli agenti.
L’analisi economica suppone che gli agenti, affrontando problemi
decisionali, si formino delle aspettative sui risultati possibili derivanti da ogni
scelta. Le aspettative di ogni agente dipendono dal suo personale bagaglio di
informazioni e credenze che gli permetterà di effettuare previsioni più o meno
precise. Ogni agente nelle sue previsioni prende in considerazione tutte le
informazioni disponibili, e cercherà di trarre vantaggio dall’osservazione delle
azioni e dei relativi risultati di altri agenti. Le azioni degli agenti in questo
modo assumono importanza non solo per gli agenti che compiono l’azione, ma
anche per gli agenti che osservano tale azione, si crea in questo modo una
interazione tra le aspettative.
L’interazione sulle preferenze avviene quando la preferenza rispetto a
situazioni alternative di un agente dipende dalle azioni di altri agenti.
L’economia neoclassica del consumo ha sempre considerato gli agenti come
interessati esclusivamente al proprio consumo.

49
It is a commonplace that preferences are influenced by other people's
consumption, but this insight has never been incorporated into demand analysis
in a satisfactory way.
(Pollak 1976)
Semplici esempi di interazione sulle preferenze sono il modello di Pollak
(1976), in cui il consumo degli agenti dipende dal consumo (corrente o del
periodo precedente) degli altri agenti, oppure lo schema di creazione delle
convenzioni sociali sviluppato da Young (1996). Le convenzioni sociali sono il
frutto dell’azione e dell’interazione di miriadi di agenti e difficilmente non
influenzano le relazioni economiche:
“conventions regulate much of economic and social life, yet they have received
surprisingly little attention from economists. By a convention, we mean a pattern
of behavior that is customary, expected and self-enforcing”
(Young 1996,p.105)
Le convenzioni infatti influenzano le variabili economiche direttamente (“The
economic significance of conventions is that they reduce transaction cost.”
Young 1996, p.105), ed indirettamente attraverso l’effetto che esse hanno sulle
scelte degli agenti. Riprendendo l’esempio di Young sulle convenzioni di guida,
l’utilità di guidare a destra o a sinistra è evidentemente influenzata dalle scelte
del resto della popolazione.
Le interazioni tra gli agenti influenzano direttamente i parametri di scelta
degli agenti, influenzando, come si è detto, vincoli, attese e preferenze. È
importante sottolineare che in presenza di interazioni sociali le scelte degli
agenti sono ancora scelte razionali (Durlauf 2003, p.5).
2. Membership Theory Tema centrale nello studio delle interazioni sociali è capire tra quali
agenti avvengono le interazioni. È plausibile supporre che l’interazione non
avvenga globalmente, è difficile infatti immaginare agenti che interagiscano
con tutti gli agenti dell’economia. La forza dell’interazione tra l’azione di un

50
dato agente e le preferenze di un altro agente dipende dalla “distanza”31 tra i
due agenti coinvolti (Pollak 1976, p.312). Rispetto al fenomeno che si vuole
studiare, può allora essere utile introdurre il concetto di gruppo sociale, ed
analizzare il rapporto che si instaura tra gruppo ed agente. La teoria
dell’appartenenza, o “Membership Theory”, studia gli effetti dell’interazione
all’interno dei gruppi e sottolinea l’influenza diversa che gruppi diversi hanno
sui propri membri (Durlauf 2002)32. Il meccanismo di interazione in presenza
di gruppi non differisce dai meccanismi di interazione sociale più generali. Nei
modelli di appartenenza ogni agente effettua delle scelte basandosi sulle
proprie preferenze, sulle previsioni degli effetti delle sue azioni e nel rispetto
dei suoi vincoli; la novità si trova nell’analisi di come i gruppi influenzano tali
parametri di scelta (Durlauf 2002). I comportamenti possono essere influenzati
dalle caratteristiche e dai comportanti dei membri veterani dello stesso gruppo
(“role model effects”), oppure dai comportamenti di altri appartenenti
(contemporanei) allo stesso gruppo (“peer group effects”)(Durlauf 2002). Il
comportamento imitativo alla base dei “peer effects” e “role model effects”
dipende perciò da fattori psicologici ed economici: interdipendenza nei vincoli
tra gli individui (il costo, sia economico che psicologico, di un certo
comportamento dipende dal comportamento adottato dagli altri);
interdipendenza nella trasmissione delle informazioni (il comportamento di
altri altera l’informazione sugli effetti del proprio comportamento);
interdipendenza delle preferenze. L’interazione agisce perciò esattamente nello
modo indicato nel paragrafo precedente, l’aspetto interessante diviene la
caratterizzazione dei gruppi e lo studio delle influenze diverse che ogni gruppo
ha sui propri membri. Le società umane possono essere divise in miriadi di
gruppi diversi, e uno dei temi fondamentali nello studio dei modelli con
interazione sociale è scegliere quali tra questi gruppi hanno rilevanza
economica, ossia quali gruppi hanno la capacità di influire sui parametri
31
La variabile che determina l’interazione può essere la distanza geografica, culturale etc. Maggiori sono le possibilità di contatto tra i due agenti maggiore è la forza dell’influenza tra i due agenti. 32
La definizione di Durlauf: “The memberships theory of inequality is nothing more than an approach to
understanding socioeconomic outcomes that focuses on the way in which various socioeconomic
groupings affect individuals. Individuals, of course, can be categorized by any number of groupings. The
basis of the memberships theory is that at least some of these memberships have powerful influences on
individual outcomes.” (Durlauf 2002, p.3)

51
decisionali dell’agente. Il gruppo deve essere inteso in senso lato, si può
immaginare una vicinanza geografica degli agenti, e probabilmente è il
concetto più immediato33, ma il gruppo può essere inteso anche come classe
sociale, etnica, censuaria e culturale. Nel trattare con i diversi tipi di
classificazione, è importante distinguere per quali gruppi l’appartenenza è
esogena, quali sesso ed etnia, e per quali è endogena, come il quartiere nel
quale si vive, la scuola che si frequenta, i colleghi di lavoro; in ognuno di
questi casi l’appartenenza al gruppo è determinata come parte del più generale
sviluppo economico e sociale (Durlauf 2002). La distinzione tra i gruppi
endogeni ed esogeni è importante perché per una teoria dell’appartenenza
completa si deve conoscere sia l’influenza che i gruppi hanno sugli individui,
sia il modo in cui si formano tali gruppi; in particolare i gruppi endogeni
generano ineguaglianza persistente nel momento in cui si formano a causa di
un qualche tipo di segregazione, gruppi differenti influenzano infatti in modo
diverso i propri membri. I modelli con interazione sociale hanno prestato
particolare attenzione alla segregazione economica e razziale. La segregazione
razziale è stata modellizzata da Schelling nel 1978, egli analizza come la
segregazione possa emergere in contesti in cui gli agenti abbiano una
preferenza ad avere propri simili nella zona in cui abitano. La segregazione
economica è causata, secondo Durlauf (1996), dalla finanza pubblica locale e
dalle interazioni sociali. In questi modelli le famiglie preferiscono avere dei
vicini ricchi per l’effetto che ciò ha sulla fiscalità locale e per la loro influenza
sul quartiere. In termini economici i quartieri ricchi hanno esternalità positive
verso i propri membri mentre i quartieri poveri hanno esternalità negative sui
propri membri.
Quando gli agenti sono parte di gruppi sociali e quando il comportamento
di un membro di un gruppo è dipendente dal comportamento di altri, si viene
a creare un grado di libertà nel comportamento del gruppo come aggregato.
Dipendenze contemporanee nel comportamento implicano che i membri di un
gruppo si comporteranno in modo simile. Questo significa che esistono
equilibri multipli, e il raggiungimento di un equilibrio particolare dipende da
quale comportamento collettivo si è sviluppato all’interno del gruppo. Il 33
In effetti “social interaction effect” e “neighborhood effect” sono in questa letteratura sinonimi, proprio a causa dell’importanza che assume il concetto di interazione geografica per la sua influenza, ad esempio, sulla trasmissione delle informazioni.

52
discorso è molto simile alle convenzioni studiate da Young (1996), nel periodo
iniziale, quando non esisteva una convenzione, era ugualmente possibile si
stabilisse di guidare a destra o a sinistra. Il fatto che si sia scelto un lato della
strada è dovuto ad una serie di comportamenti che si sono auto-rinforzati e
propagati nella società creando la convenzione. Le interazioni sociali
incorporate nei “peer effects” e nei “role model effects”, se abbastanza forti
possono, in alcuni contesti particolari, produrre trappole della povertà. Le
trappole della povertà sono definite da un insieme di comportamenti
socialmente indesiderabili, i quali si auto rinforzano all’interno del gruppo
sociale. La trappola della povertà può essere intesa come una situazione in cui
una comunità povera rimane povera per molti periodi o generazioni. Le
interazioni sociali intertemporali forniscono esattamente questo tipo di
dipendenza. Affinché i meccanismi di interazione producano trappole della
povertà deve accadere che ad un dato livello di interazione sociale, gli incentivi
privati allo sforzo per evitare la povertà siano sufficientemente deboli (Durlauf
2002). Gli equilibri socialmente indesiderabili possono esistere solo quando le
opportunità economiche sono basse. Il problema dell’abbandono scolastico,
basso nei quartieri ricchi, alto in quelli poveri, non può essere spiegato solo
con il dato che nei quartieri ricchi il numero di laureati è (fortuitamente) alto, e
che di conseguenza l’interazione sociale porta a replicare il risultato nelle
generazioni. Il problema è che nei quartieri ricchi il numero di laureati è alto
perché le prospettive economiche derivanti da una laurea sono molto migliori
delle prospettive affrontate da uno studente di un quartiere povero (Durlauf
2002). La novità e la forza della “Membership Theory” non sta nella sua abilità
nel creare modelli con trappole della povertà, bensì nella spiegazione che
riesce a fornire sulle cause delle trappole della povertà, ossia come è possibile
che le situazioni di degrado siano perpetuate per lunghi periodi di tempo
(Durlauf 2002). Come scrive Akerlof, parlando delle interazioni sociali che
avvengono nei sistemi economici:
“…social decisions to include dependence of individuals' utility on the utility or
the actions of others. Except under rare circumstances, such interactions
produce externalities. These externalities typically slow down movements

53
toward socially beneficial equilibria but in the most extreme cases they will
create long-run low-level equilibrium traps that are far from socially optimal.”
(Akerlof 1997, p.1005)
Simile può essere la spiegazione delle divergenze di crescita che si registrano
tra i diversi paesi (Durlauf 2003a). Il disaccordo tra la teoria della crescita di
Solow, che prevede la convergenza delle economie nel lungo periodo, e le
osservazioni empiriche, dove è evidente la divergenza tra paesi ricchi e paesi
poveri (Milanovic 2006), hanno dato un forte impulso alla letteratura sulle
interazioni tra gli agenti. Le trappole della povertà, spiegate grazie alla
“Membership Theory” (Durlauf 2002), possono facilmente essere estese da
parti della società di un dato paese, alla situazione di gruppi di paesi che non
riescono a svilupparsi.
Il limite fondamentale della letteratura sulle interazioni sociali è che non
prende in considerazione gli effetti che possono avere sui comportamenti del
gruppo gli atteggiamenti di agenti esterni al gruppo (Durlauf 2002). L’effetto è
stato studiato in particolare per la situazione degli Afro Americani negli USA.
Se da una parte la “Memebership Theory” ha aiutato a capire le persistenti
differenze che esistono nel livello di reddito e di posizione sociale, andando al
di là della sola discriminazione razziale, dall’altra il cosiddetto “stigma razziale”
non è stato minimamente preso in considerazione dalla teoria (Durlauf 2002).
Sull’agente, oltre alle influenze del gruppo di appartenenza, agiscono effetti
che possono derivare dall’esterno: il giudizio che il resto del mondo ha
sull’agente influenza il giudizio che l’agente stesso ha di sé stesso. Una
importante prova su come la comunità afro americana è influenzata dagli
atteggiamenti degli altri può essere rintracciata nel lavoro di Steele (1997). Egli
ha selezionato un campione casuale di studenti neri e bianchi e li ha
sottoposti ad una serie di test. In alcuni casi ha detto agli studenti che si
trattava di test di intelligenza, in altri che si trattava semplicemente di
risolvere problemi. L’esperimento ha evidenziato un notevole calo di
prestazioni da parte degli studenti neri quando messi di fronte al test di
intelligenza. La differenza di prestazioni è, nell’interpretazione di Steele, un
effetto dell’ansia causata dalla discriminazione razziale sulle vittime di tale
discriminazione: lo stigma razziale.

54
3. La teoria I modelli teorici che incorporano interazioni sociali devono spiegare due
questioni fondamentali:
i) come i comportamenti individuali vengono influenzati dal comportamento
del gruppo di appartenenza;
ii) come si formano i gruppi.
Naturalmente lo studio delle influenze all’interno dei gruppi può essere
generalizzata al caso in cui la società venga considerata come un gruppo
unico, o nel caso vengano studiati fenomeni di interazione che non abbiano
bisogno della definizione di gruppi sociali. Per analizzare le caratteristiche dei
modelli con interazioni sociali utilizziamo un formalizzazione presente in
Durlauf (2003). Modelli di questo tipo possono essere trovati anche in Manski
(1993), Brock e Durlauf (2001), Blume e Durlauf (2005).
Consideriamo = agenti membri di uno stesso gruppo sociale denotato con
< . Ogni individuo effettua una scelta a , con a ∈ Ωc , dove Ωc rappresenta
l’insieme di scelte possibili dell’individuo . Si suppone che il gruppo di
appartenenza sia noto34. Questa ipotesi rappresenta una limitazione, dato che
la formazione dei gruppi dovrebbe essere endogena al modello. La limitazione è
dovuta all’esigenza di ottenere un modello con trattabilità analitica, e potrà
essere superato con l’introduzione di metodi di analisi che coinvolgano
simulazioni computazionali 35 . L’obiettivo dell’analisi è la descrizione della
decisione individuale in funzione delle caratteristiche individuali e del gruppo
di appartenenza. In particolare è interessante comprendere come le
caratteristiche del gruppo di appartenenza influenzino la decisione. Definiamo
a-,d come il vettore delle scelte degli individui diversi da appartenenti al
gruppo. Dalla prospettiva della decisione individuale possiamo distinguere
quattro fattori che influenzano la scelta: definiamo # il vettore delle
caratteristiche note dell’individuo ; N il vettore di caratteristiche casuali
dell’individuo , possono essere considerate come le caratteristiche non note
dell’individuo; H- il vettore delle caratteristiche del gruppo <; !ea-,d l’attesa 34
Durlauf (2003) chiama il gruppo di appartenenza “neighborhood”. L’espressione più generale “gruppo sociale” sta a sottolineare che le interazioni non avvengono solo tra agenti in prossimità geografica, ma come si è affermato, l’interazione può avvenire tra agenti che, in generale, abbiano contatti tra loro. 35
Tratteremo di questo tipo di approccio nel prossimo capitolo.

55
soggettiva dell’individuo rispetto al comportamento degli altri appartenenti al
gruppo, e può essere descritta come una funzione di probabilità su tali
comportamenti. I fattori descritti faranno parte della funzione che determina le
scelte individuali. Seguendo Manski (1993) possiamo definire !ea-,d come
l’effetto endogeno del gruppo: “endogenous effects, wherein the propensity of an
individual to behave in some way varies with the behaviour of the group.”
(Manski 1993, p. 532); H- come l’effetto contestuale (o esogeno): exogenous
(contextual) effects, wherein the propensity of an individual to behave in some
way varies with the exogenous characteristics of the group. (Manski 1993, p.
532) e N l’effetto di correlazione: “correlated effects, wherein individuals in the
same group tend to behave similarly because they have similar individual
characteristics or face similar institutional environments.” (Manski 1993, p.533).
Normalmente, nello studio delle interazioni sociali, l’effetto di correlazione
viene supposto pari a zero (viene trattato come un fattore casuale con media
zero). Quando l’effetto di correlazione è diverso da zero significa che gli
individui si comportano in modo simile, non solo a causa degli effetti endogeno
e contestuale, ma a causa della somiglianza delle loro caratteristiche non
osservabili (incluse in N). Il problema verrà analizzato nel paragrafo 6.2, dato
che ha conseguenze importanti sulla stima econometrica degli effetti di
interazione sociale. L’effetto endogeno e l’effetto contestuale sono gli elementi
che definiscono gli effetti dell’interazione sociale sul comportamento
dell’individuo. Un esempio di Manski (1993) chiarisce il significato ed il ruolo
dell’effetto contestuale e dell’effetto endogeno. Consideriamo i risultati
scolastici di uno studente. Esiste un effetto endogeno se i risultati individuali
tendono a variare al variare del risultato medio degli studenti della scuola, del
gruppo etnico o del gruppo di amici dello studente preso in considerazione.
Esiste un effetto esogeno se i risultati scolastici variano ad esempio con la
composizione socio-economica del gruppo di amici dello studente36.
Dati gli elementi che incidono sull’utilità dell’individuo, possiamo
determinarne la scelta tramite la massimizzazione dell’utilità:
36
L’effetto di correlazione viene spiegato nel modo seguente: “There are correlated effects if youths in
the same school tend to achieve similarly because they have similar family backgrounds or because they
are taught by the same teachers.” (Manski 1993, p.533). L’effetto correlazione è un effetto che implica comportamenti simili a prescindere dall’appartenenza del gruppo sociale, o, in altre parole, può essere l’effetto non osservato che spiega l’appartenenza ad un dato gruppo sociale.

56
1 a = arg Yi∈Ωj k la, #, N , H-, !e%a-,d&m
Per chiudere il modello occorre descrivere come sono determinate le attese
dell’individuo rispetto al comportamento degli altri. In Durlauf (2003) si
ipotizza che l’attesa sia razionale, nel senso che utilizza tutte le informazioni a
sua disposizione:
2 !e%a-,d& = !%adnN , H-, #o , !oe%a-,do& ∀q&
È da notare che nella formalizzazione adottata, l’incertezza sul
comportamento medio del gruppo si trova nell’impossibilità dell’agente di
osservare la componente casuale No per agenti diversi da se stesso. L’ipotesi
che i comportamenti individuali siano influenzati dall’attesa di comportamento
degli altri membri del gruppo è solo una convenienza analitica adottata in
Durlauf (2003). Lo stesso termine può essere formalizzato diversamente
rispetto alle ipotesi sul grado di conoscenza che ogni agente ha dell’ambiente
circostante. Inoltre può essere sostituito dal comportamento effettivo (non
quello atteso) dei membri del gruppo osservabili dall’individuo 37. Ad esempio
in Pollak (1976) l’effetto endogeno è rappresentato dal comportamento di
consumo corrente o passato degli altri agenti.
Affinché le implicazioni delle interazioni sociali siano interessanti deve
poter avvenire un processo auto-rinforzante nelle scelte dei membri di un dato
gruppo. Questo significa che ipotizzando una funzione di utilità differenziabile
due volte, le derivate parziali seconde di k rispetto al comportamento
dell’agente e rispetto al comportamento atteso degli altri agenti devono essere
positive. 38 Se vale (ed è sufficientemente forte) la condizione di auto
rinforzamento delle decisioni, si crea un grado di libertà nella determinazione
dei risultati individuali e aggregati; l’auto rinforzamento implica infatti che gli
individui si comportano in modo simile senza specificarne il comportamento
37
Si veda ad esempio la definizione di effetto endogeno data da Manski riportata nella pagina precedente. 38
La condizione può essere generalizzata richiedendo la proprietà di complementarietà delle decisioni individuali e delle decisioni attese degli altri membri del gruppo. Vedi Durlauf (2003).

57
effettivo (Durlauf 2003). In questo caso le interazioni sociali rendono possibile
la presenza di equilibri multipli, importanti per spiegare le trappole della
povertà (paragrafo 2) e per spiegare la possibilità di osservare comportamenti
aggregati diversi in presenza di condizioni iniziali simili.
Un modo interessante per visualizzare l’effetto delle interazioni sociali è
formalizzare la scelta dell’individuo come una funzione lineare:
3 a = V + # + BH- + r!e%a-,d& + N
Dove V e r sono scalari e e B sono vettori. In particolare se r e B sono
diversi da zero otteniamo una scelta individuale dipendente dalle interazioni
sociali:
The statement that social interactions matter is equivalent to the statement that
at least some element of the union of the parameters in d and J is nonzero. The
statement that contextual social interactions are present means that at least one
element of d is nonzero. The statement that endogenous social interactions
matter requires that J is nonzero.
(Blume e Durlauf 2005,p.7)
Questo tipo di formalizzazione è utilizzata in Blume e Durlauf (2005) e in
Manski (1993) per studiare il problema dell’identificazione delle interazioni
sociali, problema che verrà affrontato nel paragrafo 6.1. Per il momento
l’utilità della funzione lineare è limitata alla facile visualizzazione degli effetti
dell’interazione sociale.
3.1 Un modello
Glaeser, Sacerdote, Scheikman (1996) analizzano la varianza del tasso di
criminalità tra diverse zone degli Stati Uniti. Ciò che colpisce gli autori è che
l’alta differenza del tasso di criminalità tra le diverse zone non sembra legato ai
fattori socioeconomici che caratterizzano tali zone. Essi ipotizzano che il
comportamento individuale dipenda fortemente dal comportamento degli altri
membri del gruppo sociale, in questo caso dagli abitanti dello stesso quartiere.

58
I risultati empirici di Glaeser et al. (1996) sono consistenti con l’esistenza di
una tale interazione tra gli agenti (Glaeser et al. 1996, p.508).
Consideriamo un mondo in cui esistono 2< + 1 agenti, i quali devono
effettuare una scelta binaria che corrisponde a “essere criminale” o “essere
onesto” (nel modello rispettivamente -1 e 1). Gli agenti sono per ipotesi di tre
tipi indicizzati da s ∈ 0,1,2 . L’eterogeneità degli agenti è imposta da una
distribuzione dei tre tipi di agente nella popolazione. Tenendo la
formalizzazione di Durlauf (2003), la funzione di utilità degli agenti può essere
formalizzata come:
4 k = Vta + rtaad
Gli agenti sono disposti in uno spazio unidimensionale circolare39. Dalla
(5) è evidente che la loro utilità dipende dai parametri che caratterizzano il tipo
di agente, dalla propria scelta e dalla scelta dell’agente alla sinistra.
L’interazione è perciò univoca, ad ogni agente interessa solo la scelta
dell’agente che lo “precede”. L’agente influenza l’agente + 1 ed è influenzato
dall’agente − 1 . L’agente di tipo 0 massimizza l’utilità scegliendo sempre
a = −140; questo equivale ad affermare che il tipo 0 ha una funzione di utilità
con V < 0 e r = 0 ; esso non è influenzato dalla scelta dell’agente vicino.
Simmetricamente l’agente di tipo 1, sceglie sempre a = 141; questo equivale ad
imporre V > 0 e r = 0 nella funzione di utilità. Anche in questo caso r = 0 rende
evidente l’indipendenza dell’azione dell’agente del tipo 1 dalla scelta dell’agente
a lui prossimo. L’agente di tipo 2 invece sceglie sempre l’azione scelta dal
proprio vicino, il ché equivale a dire che nella sua funzione di utilità V = 0 e
r > 0 . Il risultato del modello dipende naturalmente dalla distribuzione dei
diversi tipi di agenti nella popolazione. L’obiettivo del modello è di mostrare
come la volatilità del tasso di criminalità sia alto in presenza di interazione
sociale, ed in particolare in presenza dell’effetto endogeno nella definizione di
Manski (1993). Supponiamo allora che ogni agente ha una probabilità
positiva Pu di essere del tipo 0 ed una probabilità positiva P di essere del tipo
39
In questo modo ogni agente ha affianco a sé due agenti 40
“diehard lawbreakers” in Glaeser, Sacerdote, Scheikman 1996 41
“diehard law-abiders” in Glaeser, Sacerdote, Scheikman 1996

59
1. La probabilità di essere di tipo 0, 1, o 2 è indipendente tra gli agenti.
Poniamo che v = Pu + P e che P = P Pu +⁄ P . Glaeser, Sacerdote e
Scheikman (1996) dimostrano che al limite (per < che tende a infinito), la
varianza del comportamento medio nella popolazione è:
5 xX = P1 − P2 − vv
Date le quote di popolazione il comportamento medio è definito, ma
l’interazione sociale influenza la dispersione del comportamento medio nella
popolazione. Osserviamo ad esempio che se non c’è interazione sociale, ossia
tutti gli agenti sono del tipo 0 o 1, la varianza si ridurrebbe a P1 − P42 .
Aumentando la quota di popolazione del tipo 2, ossia aumentando l’interazione
tra i comportamenti degli agenti, la varianza aumenta fino a tendere ad infinito
quando v tende a 0. La presenza di interazione sociale moltiplica l’effetto di
shock idiosincratici e causa un aumento della varianza del comportamento
medio osservato. Il risultato aggregato del quartiere preso in considerazione
dipende dal numero di agenti di tipo 2 e dal loro posizionamento. Le stesse
condizioni iniziali (la stessa quota di agenti 0 e 1) possono far emergere, grazie
alle interazioni tra agenti, un quartiere in maggioranza criminali o un
quartiere in maggioranza lavoratori.
4. Reti: come si formano i gruppi sociali È difficile trovare una definizione univoca di gruppo sociale, e ciò rende il
loro studio complicato. D’altra parte la definizione delle reti di interazione tra
gli agenti è necessaria, in quanto le strutture di interazione possono essere
fondamentali per comprendere il comportamento aggregato del sistema 43 .
Nonostante si trovino spesso modelli in cui si suppone noto il gruppo sociale di
appartenenza, per uno studio approfondito delle interazioni sociali è
necessario definire una teoria della formazione dei gruppi sociali. In poche
parole è necessario che in un modello di interazione sociale, la dimensione e la
42
In questo caso infatti v = 1 43
“I modelli ad agenti interagenti fanno sì che le componenti microscopiche di un sistema, gli agenti, si incontrino formando delle strutture di interazione che possono anche essere molto rilevanti per il comportamento macroscopico del sistema” (Fioretti 2006, p.137)

60
composizione dei gruppi sociali sia endogena. Il problema, facile da spiegare, è
naturalmente di difficile soluzione. Supponendo di poter definire un gruppo
sociale come un insieme di agenti connessi direttamente ed indirettamente tra
loro, possiamo utilizzare la teoria dei grafi. Gli agenti e V sono detti
direttamente connessi se essi possono comunicare direttamente tra loro, ossia
se esiste un collegamento diretto. Due agenti e V sono detti indirettamente
connessi se esiste un percorso che connette l’agente con l’agente V (passando
eventualmente per connessioni dirette con altri agenti). Seguendo Durlauf
(2003) analizziamo i risultati della teoria dei grafi stocastici, “random graph
theory”. Il teorema di Erdos Renyi, ripreso in Palmer (1985), in Durlauf (2003)
e in Fioretti (2006) ci permette di ottenere la dimensione dei gruppi sociali in
relazione con la probabilità che si creino connessioni tra gli agenti.
Supponiamo di avere < agenti (nodi), supponiamo inoltre che la probabilità che
due agenti qualsiasi e q siano connessi direttamente è pari a P< e che le
connessioni dirette siano distribuite in modo indipendente. Se valgono le
ipotesi descritte e poniamo P< = <⁄ , con ∈ ℛ , allora valgono le seguenti
proposizioni (la dimostrazione si trova in Palmer 1985):
i. Se < 1, allora al crescere di <, il gruppo sociale più ampio (perciò l’insieme
più ampio di agenti connessi tra loro) avrà una dimensione di ordine log <.
Dato che log < < <, all’aumentare della dimensione del grafo, diminuisce la
dimensione relativa della componente più ampia
ii. Se = 1 , allora al crescere di < , il gruppo sociale più ampio avrà
dimensione di ordine <X | . Dato che log < < <X | < < , all’aumentare della
dimensione del grafo, diminuisce la dimensione relativa del gruppo sociale
più ampio.
iii. Se > 1 , allora al crescere di < , il gruppo sociale più ampio avrà
dimensione di ordine < . La componente più grande cresce come la
popolazione.
L’aspetto interessante è la transizione di fase che avviene quando P< supera un certo limite. In particolare quando < 1 la popolazione è divisa in
gruppi sociali relativamente piccoli, quando invece > 1 emerge un gruppo
sociale grande, ciò che nella letteratura dei grafi è noto come “la componente
gigante” (Palmer 1985, Durlauf 2003, Fioretti 2006). Bollobas e Thomason

61
(1987) mostrano come la transizione di fase evidenziata sia un risultato di
portata generale; l’improvvisa emersione di una componente gigante è una
caratteristica comune a tutti i grafi stocastici (Fioretti 2006,p.138).
Purtroppo le ipotesi necessarie per la proposizione precedente, in
particolare omogeneità delle probabilità di connessione tra gli agenti, limitano
l’applicabilità dei grafi stocastici alle interazioni sociali ed alle analisi
economiche (Durlauf 2003).
4.1 Il mondo piccolo Una struttura di grafo particolare, studiata in Watts e Strogatz (1998), è
la cosiddetta struttura a “mondo piccolo” (“small world”). La caratteristica
fondamentale di tale struttura è il basso numero di passaggi necessari per la
comunicazione tra due nodi casuali del grafo. La struttura a mondo piccolo
venne scoperta per la prima volta in un esperimento di Stanley Milgram nel
1967, descritto in Fioretti (2006). Milgram consegnò ai partecipanti
dell’esperimento una busta indirizzata ad uno sconosciuto. Tale busta doveva
essere consegnata ad un conoscente, e di conoscente in conoscente. Ogni
passaggio doveva essere documentato con una apposita annotazione
all’interno della busta. L’esperimento sarebbe finito quando le buste sarebbero
arrivate al destinatario (ricordiamo che tale destinatario era sconosciuto al
primo partecipante). Solo la metà delle buste arrivò a destinazione, il fatto
sorprendente fu però che le buste che arrivarono impiegarono solo pochi
passaggi (quasi sempre meno di sei passaggi). Il risultato è interessante perché
implica che il grafo rappresentante le relazioni umane ha una forma
particolare. Le conoscenze di ogni individuo sono normalmente locali, un grafo
corrispondente a conoscenze esclusivamente locali però non riuscirebbe a
spiegare il basso numero di passaggi riscontrati nell’esperimento di Milgram.
Un grafo casuale potrebbe invece spiegare il fenomeno, ma richiederebbe che
le conoscenze di ogni individuo siano uniformemente distribuite su tutto il
globo terrestre, il ché è naturalmente impossibile. L’unico modo per spiegare il
risultato dell’esperimento è ipotizzare un grafo con una prevalenza di
connessioni locali (accettando il fatto che normalmente le conoscenze siano
locali), con qualche nodo con connessioni lontane. La struttura a mondo
piccolo nasce quindi dalla presenza contemporanea di agglomerati di nodi con

62
molte relazioni locali, e connessioni sparse a lunga distanza (Fioretti 2006).
Per caratterizzare quantitativamente il grafo con struttura mondo piccolo
seguiamo Fioretti (2006). Prendiamo in considerazione un grafo = F, ~, con
F l’insieme dei nodi e ~ l’insieme degli archi. Sia < il numero di nodi del grafo
. Per misurare l’agglomerazione dei nodi con connessioni locali utilizziamo il
coefficiente di agglomerazione (“clustering coefficient” in Watts e Strogatz
1998). Per ∀ sia ⊆ l’insieme di nodi direttamente connessi con il nodo . Sia ℎ il numero di archi presenti in e V il numero di nodi presenti in . Il numero di archi necessari affinché ogni nodo di sia collegato con tutti gli
altri nodi di è VV − 1 2⁄ . Definiamo allora coefficiente di agglomerazione
del nodo :
W = ℎVV − 1 2⁄ 1 V ≥ 2 0 7 Y<
Definiamo il coefficiente di agglomerazione del grafo come la media dei
coefficienti di agglomerazione dei suoi nodi:
W = 1< I W-
K
Per misurare le relazioni a lunga distanza del grafo utilizziamo la
lunghezza del cammino caratteristico (path lenght in Watts e Strogatz 1998).
Per ogni coppia di nodi , q ∈ , sia Bo il numero di connessioni minimo
necessarie per collegare i due nodi (path lenght):
= 1<< − 1 I I Bo-
oK-
K
Dove nella seconda sommatoria q ≠ . Date le due misure possiamo distinguere
le diverse strutture di grafi:

63
a) i grafi con connessioni esclusivamente locali sono caratterizzate da W e
grandi;
b) i grafi con struttura mondo piccolo sono caratterizzati da W grande e piccolo;
c) i grafi stocastici sono caratterizzati da W piccolo e piccolo.
La struttura a mondo piccolo è definita in Watts e Strogatz (1998) come
una combinazione tra le reti con collegamenti esclusivamente locali, che loro
chiamano “regular lattices”, e i grafi stocastici:
We find that these systems can be highly clustered, like regular lattices, yet
have small characteristic path lengths, like random graphs. We call them ‘small-
world’ networks, by analogy with the small-world phenomenon44
(Watts e Strogatz 1998, p.440)
Supponiamo di avere un grafo di < nodi, ognuno connesso ad un numero di
nodi più vicini. Supponiamo inoltre che ogni connessione di ogni nodo abbia
una probabilità P di riconnettersi con un nodo casuale, e una probabilità
1 − P di rimanere invariato. Quando P = 0 il grafo è regolare ed è un grafo con
connessioni esclusivamente locali, quando P = 1, il grafo è stocastico. Il mondo
piccolo emerge quando 0 < P < 145. Watts e Strogatz (1998) mostrano che la
struttura a mondo piccolo emerge grazie al diverso comportamento del
coefficiente di agglomerazione e del cammino caratteristico al variare di P .
Dato il grafo = F, ~ e variando solamente la probabilità di riconnessione
degli archi, Watts e Strogatz mostrano che P/0 diminuisce più in fretta di
WP/W0, dove 0 e W0 sono rispettivamente i valori di e W nel grafo con
P = 0, creando la caratteristica alta agglomerazione e bassa distanza media tra
i nodi. La struttura a mondo piccolo riguarda diverse reti reali, in particolare le
connessioni tra gli attori sul sito internet imdb (www.imdb.com), importante
44
Dove con small-world phenomenon si riferiscono ad esempio all’esperimento di Milgram descritto in precedenza 45
Non esiste una soglia critica come nel teorema di Erdos-Renyi: “the transition to a small world is
almost undetectable” (Watts e Strogatz 1998, p. 441)

64
per l’analogia esistente con la società umana46; la rete elettrica degli Stati Uniti
occidentali, la rete neurale del verme Caenorhabditis elegans (Watts e Strogatz
1998), e la rete internet considerando i siti nodi e i link connessioni (Fioretti
2006). La configurazione delle reti a mondo piccolo non è solo una curiosità né
un modello meramente ideale, essa descrive al contrario molte reti osservabili
in natura47 (Watts e Strogatz 1998, p. 441). Nella figura 2 è rappresentato un
grafo con 20 nodi e 40 archi. Il grafo è costruito in modo che ogni nodo sia
direttamente connesso con i quattro nodi più vicini (due alla sua destra e due
alla sua sinistra). Da sinistra verso destra sono rappresentate le tre situazioni
P = 0, P = 0.2, P = 1.
Figura 2. La struttura a mondo piccolo creata con NetLogo. A sinistra una struttura con connessioni esclusivamente locali, a destra una struttura con connessioni completamente casuali ed al centro la struttura a mondo piccolo visualizzata come una sorta di intersezione tra le caratteristiche della struttura a connessioni locali e della struttura a connessioni casuali.
È possibile notare come nel primo caso le connessioni siano solo locali (per
costruzione), nel secondo caso le connessioni siano locali, con alcuni agenti
con connessioni lontane (mondo piccolo) e nel terzo caso le connessioni siano
completamente casuali. Il processo è stato programmato con NetLogo 48
seguendo le istruzioni di Watts e Strogatz (1998).
46
The graph of film actors is a surrogate for a social network, with the advantage of being much more
easily specified (Watts e Strogatz 1998, p. 441). 47
A conferma di ciò è interessante anche vedere che lo schema delle connessioni di Facebook è molto simile ad una struttura a mondo piccolo (vedere il sito http://nexus.ludios.net/). I Social Network su internet (Facebook, Flickr etc.) sono molto interessanti in quanto sono la riproduzione più fedele delle connessioni nelle società umane. Un progetto di ricerca sullo studio delle reti sociali tramite i siti come Facebook e Flickr è in corso al CRESS (Centre for Reasearch in Social Simulation, http://cress.soc.surrey.ac.uk/). 48
Appendice A1 per il codice.

65
5. La segregazione: come si formano i gruppi sociali Uno studio interessante che riguarda la formazione endogena dei gruppi
sociali è il famoso modello di segregazione di Schelling (1978). Lo studio di
Schelling è stimolato da un problema che 26 anni più tardi è ancora di grande
attualità negli Stati Uniti49:
“residential segregation remains a striking feature of the urban landscape in
many large metropolitan areas with significant black populations.”
(Sethi e Somanathan 2004,p.1297)
Nel modello di segregazione si studia, grazie ad un modello ad automi
cellulari50, come evolve la segregazione territoriale dati due tipi di agenti che
preferiscono vivere in zone in cui non siano minoranza. In primo luogo dunque
è da sottolineare che nel modello di segregazione si analizza la formazione di
quartieri segregati, dando una nozione territoriale al concetto di gruppo
sociale. In particolare Schelling considera una popolazione di agenti bianchi e
neri distribuiti casualmente su un piano. La caratterizzazione degli agenti è
generale, l’analisi può riguardare una qualsiasi distinzione dicotomica della
popolazione: maschi e femmine, professori e studenti in un bar universitario,
bianchi e neri (Schelling 1978). Gli agenti vogliono occupare una zona in cui
almeno il 50% dei vicini è del suo stesso colore.
Figura 3. Il vicinato dell'agente che si trova nella zona nera è l'insieme di agenti residenti nelle zone rosse.
49
Un lavoro empirico che si occupa (anche) di verificare la segregazione etnica negli Stati Uniti è Borjas (1995). 50
Per una introduzione agli automi cellulari nello studio delle scienze sociali vedere Gilbert e Troitzsch (2005)

66
Per vicini si intende agenti che occupano i quadrati adiacenti alla zona
dell’agente preso in considerazione. Nella figura 3, se l’agente preso in
considerazione si trova nella zona nera, i suoi vicini sono gli agenti che si
trovano nelle zone rosse. Ogni zona può essere occupata da un solo agente. La
funzione di utilità dell’agente può perciò essere formalizzata come:
= 0 1 < 0.51 1 ≥ 0.5
Dove ∈ 0,1 è la quota di agenti simili all’agente tra i suoi vicini. Gli agenti
hanno la possibilità di muoversi di zona in zona. Questo accade se valgono
entrambe le seguenti condizioni: la zona corrente è abitata in prevalenza da
agenti di etnia diversa < 0.5; esiste una zona adiacente libera. Può essere
aggiunta una terza condizione: esiste una zona adiacente libera che sia più
soddisfacente. Questa condizione potrebbe rappresentare l’ipotesi che lo
spostamento sia costoso, e lo si effettua solo se apporta un miglioramento. La
terza condizione, limitando gli spostamenti riduce la segregazione, senza però
eliminarla. Il risultato di Schelling è che la popolazione si segrega in zone di
colore omogeneo, nonostante la preferenza non richieda segregazione, ossia gli
agenti sono contenti di vivere in zone in cui la popolazione è divisa
esattamente a metà tra i due tipi (o in generale in zone in cui non siano
minoranza). Il risultato dipende dall’interazione tra le scelte degli agenti:
“What is instructive about the experiment is the “unraveling” process. Everybody
who selects a new environment affects the environment of those he leaves and
those he moves among. There is a chain reaction.”
(Schelling 1978,p.151)
Ogni agente che si sposta influenza l’utilità degli agenti che lascia e degli
agenti che incontra, creando la reazione a catena. Il modello è stato simulato
con NetLogo, programma sviluppato appositamente per la simulazione
sociale51. La figura 4 mostra lo stato iniziale. Gli agenti occupano il 70% delle
51
Il programma è scaricabile gratuitamente sul sito: http://ccl.northwestern.edu/netlogo/ . Il codice per permettere la riproduzione del modello di trova nell’appendice A2.

67
zone disponibili, in modo da dare loro la possibilità di muoversi, inoltre essi
sono divisi al 50% tra agenti di colore celeste e agenti di colore blu. Nello stato
iniziale il grado di omogeneità medio delle zone è intorno al 50%52.
Figura 4. Situazione iniziale.
Iniziando la simulazione, già dopo 24 periodi otteniamo l’equilibrio, inteso
come lo stato in cui gli agenti non hanno più la possibilità (o la volontà) di
muoversi. Questo avviene quando ogni agente si trova in un vicinato di suo
gradimento e/o non ha la possibilità di muoversi. Come è evidente dalla figura
5, la popolazione si è divisa in diversi cluster di colore omogeneo. La
percentuale media di omogeneità sale velocemente fino ad arrivare vicina
all’80% (Figura 6). Omogeneità che è ben al di sopra della soglia richiesta dagli
agenti per essere soddisfatti.
52
La distribuzione degli agenti di colori diversi tra le zone è casuale, perciò il gradi di omogeneità può variare intorno al 50%.

68
Figura 5. Situazione al periodo 24. Si nota come si siano formate isole di agenti di colore omogeneo
Figura 6. Il grafico rappresenta la percentuale media di omogeneità per ogni agente. In equilibrio il modello ha una omogeneità dell’80%.
Per rendere visivamente ancora più chiaro il modello supponiamo che gli
agenti occupino solo il 50% delle zone (per renderli ancor più liberi di
muoversi) e che preferiscano vivere non isolati, ossia non solo non vogliono

69
essere minoranza, ma preferiscono vivere in una zona che comprenda almeno
qualche agente53 (Figura 7).
Figura 7. Nella figura a sinistra lo stato iniziale, nella figura a destra una configurazione di equilibrio del modello. Qui sono perfettamente visibili le isole si agenti omogenei.
Il risultato del modello di Schelling mostra in modo chiaro che fenomeni
aggregati possono derivare, in presenza di interazioni sociali, da agenti le cui
caratteristiche sono diverse dalle caratteristiche risultanti dall’aggregazione54.
Interessante è la generalizzazione di Granovetter e Soong (1988), in cui si
inseriscono funzioni che descrivono le preferenze degli agenti e funzioni
dinamiche che descrivono la variazione della composizione del vicinato preso
in considerazione. Mentre nel modello di Schelling (1978) tutti gli agenti hanno
la stessa tolleranza nei confronti della quota di agenti diversi nel vicinato, in
Granovetter e Soong (1988) tale tolleranza varia nella popolazione, riuscendo a
costruire una funzione del tipo ]0.25 = 0.65. In questo caso si afferma che il
65% degli agenti bianchi è disposto ad abitare in un quartiere con una quota
di bianchi pari o superiore al 25%. Essi riescono così a trovare una
formalizzazione analitica della segregazione:
53
La nuova condizione implica che l’agente vuole avere almeno una certa quota di vicini. In particolare, se il numero di zone vicine abitate è inferiore al 50% l’agente si sposta, alla ricerca di una zona in cui almeno il 50% delle zone è abitata, e gli abitanti di tali zone sono almeno per il 50% simili a lui. Questa opzione viene considerata dopo la prima solo perché richiede una ipotesi in più rendendo più opaco un procedimento molto semplice e potente. 54
“We can at least persuade ourselves that certain mechanism could work, and that observable
aggregate phenomena could be compatible with types of “molecular movement” that could not closely
resemble aggregate outcomes that they determine”.(Schelling 1978,p.152)

70
“We showed that Thomas Schelling's models can be expressed in terms of our
system of two coupled difference equations, permitting an exact mathematical
account of his results and such important generalizations as the incorporation of
preferences for integration and the extension to more than two groups.”
(Granovetter e Soong 1988,p.103)
Esistono tuttavia delle limitazioni a questo tipo di modello 55 . In
particolare, è importante riuscire ad inserire una fondazione microeconomica
più rigorosa, in modo da incorporare altri fattori che possano influenzare la
scelta della zona dove vivere, fattori che sono esattamente ciò che viene
studiato dalla teoria dei “Neighborhoods Effect” (Durlauf 2003). Sethi e
Somanathan (2004), partendo dalla constatazione che la differenza di reddito
dei gruppi etnici è diminuita e che la segregazione è rimasta alta, costruiscono
un modello di segregazione che si sviluppa lungo due variabili: appartenenza
etnica e reddito. Essi trovano che anche quando la differenza di reddito è
piccola esistono equilibri multipli, alcuni dei quali sono di alta segregazione.
La segregazione non è limitata a fattori etnici, ma si sviluppa spesso
anche per fattori puramente economici. Il modello in Durlauf (1996) ne è un
esempio interessante. Importanti ai fini delle interazioni sociali, sono le
differenze tra le esternalità che possono esistere tra quartieri ad alto reddito e
quartieri a basso reddito. L’esistenza di effetti di “role model” positivi dati dagli
individui anziani del quartiere che hanno avuto successo, possono rendere
grande la differenza tra i diversi quartieri (Durlauf 1996). Nel modello di
Durlauf, le famiglie più ricche hanno l’incentivo ad isolarsi per garantire un
più alto livello di educazione per i figli (sia per finanziamento locale, sia per
l’effetto positivo supposto di una comunità ad alto reddito). Quando le forze
che creano omogeneità dei quartieri emergono, le famiglie povere verranno
isolate nei quartieri più poveri56. Tale isolamento può indurre persistente (o
permanente) povertà tra quelle famiglie che non riescono a generare un
55
Oltre a quella ovvia riconosciuta dallo stesso Schelling: “The results of course are only suggestive,
because few of us live in square cells on a checkerboard”
(Schelling 1971,p.151) 56
Nell’appendice B si trova un confronto tra i redditi medi nei quartieri romani.

71
investimento in educazione tale da permettere ai figli di evadere da lavori che
producono bassi redditi (Durlauf 1996).
6. Stima dei parametri di interazione: problema di
identificazione e autoselezione.
Studiare e stimare i parametri che caratterizzano l’interazione sociale è
un compito difficile. In particolare esistono due problemi importanti
nell’analisi dell’interazione sociale: il problema di identificazione ed il problema
dell’autoselezione.
6.1 Il problema di identificazione Il problema dell’identificazione è stato studiato per la prima volta da
Manski (1993), definendolo come il problema di “riflessione”57. Il problema
dell’identificazione (o “riflessione”) tenta di comprendere sotto quali condizioni
è possibile identificare econometricamente le interazioni sociali. Il tema è stato
affrontato da Manski (1993), Durlauf (2003), Blume e Durlauf (2005).
Seguendo Blume e Durlauf (2005) e Manski (1993) studiamo il problema di
identificazione nell’ambito di un modello lineare:
6 a = V + # + BH- + r!e%a-,d& + N
La (6) è la stessa funzione del paragrafo 3. L’obiettivo è stimare i
parametri V, , B e r . Riprendendo la terminologia di Manski (1993), H-
rappresenta l’effetto contestuale, !e%a-,d& rappresenta l’effetto endogeno e N rappresenta l’effetto di correlazione. Il problema di identificazione si verifica a
causa della difficoltà a separare l’effetto endogeno e l’effetto contestuale, dato
che i due tipi di effetto si muovono insieme. Per chiudere il modello (6) è
necessario specificare delle ipotesi sulle aspettative dell’individuo rispetto al
comportamento atteso degli altri membri del gruppo. Supponiamo valgano
attese razionali. L’agente conosce la forma lineare del modello, il valore di # di
57
La metafora dello specchio: “The term reflection is appropriate because the problem is similar to that
of interpreting the almost simultaneous movements of a person and his reflection in a mirror. Does the
mirror image cause the person's movements or reflect them? An observer who does not understand
something of optics and human behaviour would not be able to tell.” (Manski 1993,p.532)

72
tutti gli agenti, il valore di H-, e l’attesa di comportamento di equilibrio del
gruppo. Gli agenti non possono osservare la scelta degli altri agenti ed il
termine casuale N . Allora l’attesa dell’individuo sul comportamento degli
agenti nel suo gruppo sociale, supponendo che il valore atteso di N = 0, sarà:
7 !e%a-,d& = !- = V + #- + BH-1 − r = V + BH-1 − r + #-1 − r
Dove #- è la media delle caratteristiche individuali nel gruppo sociale <, e
H- è l’effetto contestuale, ossia l’effetto delle caratteristiche del gruppo sociale
sul comportamento degli individui che ne fanno parte. Dato che le aspettative
sono razionali e tutti gli agenti hanno a disposizione le stesse informazioni,
l’attesa della (7) vale per tutti i membri del gruppo sociale <, possiamo perciò
scrivere !- . Dalla (7) si nota come l’attesa del comportamento medio dei
membri del gruppo sociale dipenda linearmente dalla media delle
caratteristiche individuali, #-, e dall’effetto contestuale H-. In questo contesto,
se il ricercatore non dispone delle informazioni sulle caratteristiche specifiche
degli agenti membri del gruppo sociale, #, e delle caratteristiche contestuali, il
modello lineare di interazione sociale non è identificato, si verifica il problema
di “riflessione” (Manski 1993). Per vedere meglio il problema supponiamo che
l’effetto contestuale sia determinato dalle caratteristiche medie dei membri del
gruppo sociale, H- = #-. La (7) si riduce in questo caso a:
8 !- = V + + BH-1 − q
Da cui è evidente che il regressore !- è linearmente dipendente dagli altri
regressori, ed in questo caso particolare da H- . Perciò se si osserva che la
scelta dell’individuo è correlata con l’attesa del comportamento medio nel
gruppo sociale, la (8) indica che tale correlazione può essere dovuta al fatto
che !- semplicemente “rifletta” il ruolo dell’effetto contestuale nell’influenzare
le decisioni individuali. La conclusione di Manski (1993):
Inference on endogenous effects is not possible unless the researcher has prior
information specifying the composition of reference groups. If this information is

73
available, the prospects for inference depend critically on the population
relationship between the variables defining reference groups and those directly
affecting outcomes. Inference is difficult to impossible if these variables are
functionally dependent or statistically independent. The prospects are better if
the variables defining reference groups and those directly affecting outcomes are
"moderately" related in the population.”
(Manski 1993,p.532)
Il problema si pone con gravità minore se l’attesa del comportamento
medio (fattore endogeno) non è linearmente dipendente dal fattore contestuale.
Condizione necessaria affinché questo avvenga è che il termine #- 1 − r sia
non linearmente dipendente da H-, ossia se esiste almeno un regressore in # il cui valore medio di gruppo non appare in H- (Blume e Durlauf 2005). Inoltre,
mentre il problema di identificazione è naturale nei modelli lineari, il risultato
non è necessariamente generalizzabile ad altre strutture quali ad esempio il
modello di scelta binaria di Brock e Durlauf (2001). (Blume e Durlauf 2005,
Durlauf 2003)
6.2 Autoselezione Dato che l’appartenenza ad un dato gruppo sociale non è stocastica,
nasce il problema dell’autoselezione. Infatti in molti contesti l’appartenenza ad
una dato gruppo sociale è essa stessa una variabile di scelta. La decisione di
una famiglia di abitare in una data zona non è casuale, bensì dipende dalle
caratteristiche della zona presa in considerazione, dal reddito, e dal tipo di
residenti della zona. La scelta del gruppo sociale di appartenenza è, nella
maggior parte dei casi, endogena, ossia dipende dalle caratteristiche
individuali degli agenti. I gruppi sociali perciò non sono campioni casuali della
popolazione e nello studio empirico dei comportamenti individuali e dei gruppi
sociali è necessario prendere in considerazione il problema dell’autoselezione.
Uno studio empirico che non prenda in considerazione la possibilità
dell’autoselezione, troverà risultati che sovrastimano la presenza di effetti di
interazione sociale (Evans Oates and Schwab 1992, Durlauf 2003, Blume e
Durlauf 2005). Intuitivamente, la presenza di effetti di interazione sociale viene

74
sovrastimata perché si considerano parte dell’influenza delle interazioni
sociali, comportamenti che derivano in realtà dalle caratteristiche non
osservabili degli agenti. Per fare un esempio prendiamo in considerazione un
gruppo di giovani studenti poco studiosi. Se il gruppo di amici si è formato a
causa della comune tendenza a studiare poco, e non si prende in
considerazione tale fattore, il loro basso rendimento verrà imputato agli effetti
del gruppo. In realtà tali studenti non sono poco studiosi perché gruppo, bensì
sono gruppo perché poco studiosi. Riferendoci ancora al modello descritto
dalla (6), l’autoselezione perciò implica che il valore atteso della componente
casuale di scelta (che comprende tutte le componenti non osservabili), N ,
possa essere diverso da zero (ricordiamo che in Manski (1993), la componente
N è la componente di correlazione). Formalizzando il comportamento degli
individui nei termini dell’equazione (6) in presenza di auto selezione, il termine
N deve essere diviso tra una componente sistematica ed una componente
casuale. Il termine N dipende anche dal gruppo sociale di cui fa parte
l’individuo :
8 a = V + # + BH- + rY- + $ lN# , H-, ∈ < m +
Dove < , è il gruppo di appartenenza dell’individuo . Una soluzione a
tale problema è possibile trovarla in Heckman (1979), in Durlauf (2003), e in
Blume e Durlauf (2005) (i quali riprendono le argomentazioni di Heckman) e in
Evans, Oates, and Schwab (1992). Heckman studia l’errore che deriva da una
specificazione errata del campione. Se i gruppi sociali sono formati a seguito di
processi endogeni, il gruppo sociale non può essere considerato come un
campione casuale della società58. Per risolvere il problema, Heckman propone
l’introduzione di un nuovo regressore che sia capace di stimare le variabili che,
quando omesse dalla regressione, danno luogo all’errore di specificazione59.
Seguendo l’approccio di Heckman una stima consistente della (8) richiede una
58
Sample selection bias may arise in practice for two reasons. First, there may be self selection by the
individuals or data units being investigated. Second, sample selection decisions by analysts or data
processors operate in much the same fashion as self selection. (Heckman 1979,p.154) 59
…it is sometimes possible to estimate the variables which when omitted from a regression analysis
give rise to the specification error. The estimated values of the omitted variables can be used as
regressors so that it is possible to estimate the behavioral functions of interest by simple methods. (Heckman 1979,p. 154)

75
stima consistente del termine $ lN# , H-, ∈ < m, il quale verrà poi incluso
come regressore aggiuntivo nella (8) (Durlauf 2003). È interessante l’indagine
proposta da Evans, Oates, and Schwab (1992). Essi studiano l’influenza delle
interazioni sociali sulla probabilità di gravidanze adolescenziali. In particolare
stimano tali influenze in due modelli distinti (naturalmente con gli stessi dati),
il primo è un modello in cui il gruppo sociale è esogeno. Nel secondo modello
considerano il gruppo sociale endogeno, stimando anche il gruppo di
appartenenza e costruendo un modello ad equazioni simultanee. Il risultato è
eclatante: nel primo modello esiste un’influenza significativa delle interazioni
sociali, influenze che spariscono60 nel secondo modello. Nel campione preso in
esame, l’effetto che nel primo modello viene attribuito al gruppo di
appartenenza, può, nel secondo modello, essere attribuito alle scelte della
famiglia. Questo non significa che le influenze delle interazioni sociali non
esistano, bensì indica l’importanza che l’autoselezione ha sui risultati empirici
(Evans, Oates, and Schwab 1992,p.969).
7. Le indagini empiriche Esiste un’ampia letteratura che studia empiricamente l’esistenza degli
effetti di interazione sociale, e tale letteratura tende a dimostrare che gli effetti
delle interazioni sociali sono statisticamente significativi ed importanti (Akerlof
1997, p. 1007). È importante però leggere ogni indagine empirica con le
avvertenze indicate nei paragrafi precedenti. Data l’estensione della letteratura
illustreremo solo una rassegna dei risultati principali61
Esperimenti
È interessante l’esperimento di Sherif et al (1961) conosciuto come il
Robber Cave Experiment e descritto in Durlauf (2003). Sherif e collaboratori
hanno portato un gruppo di ragazzi di classe sociale media ad un campo a
Robbers Cave Oklahoma. Per le prime due settimane di campo, le interazioni
tra i ragazzi non sono state controllate dagli sperimentatori. Dopo le due
60
In the standard model presented in Section III, we find a moderate and statistically significant peer
group effect on teenage pregnancy. In the expanded model presented in Section IV, this effect disappears
completely! (Evans, Oates, and Schwab 1992,p.969) 61
Cfr. Durlauf (2003),

76
settimane il gruppo è stato diviso in modo casuale in due gruppi (casualità
parziale: sono stati attenti a dividere le amicizie nate prima della divisione). I
due gruppi sono stati impegnati in gare e giochi competitivi; Sherif et al. (1961)
documenta come questi gruppi siano diventati presto fonte di forte senso di
identità. I membri di ogni gruppo hanno sviluppato stereotipi negativi, in
termini di intelligenza e onestà, sui membri del gruppo concorrente. Questo
esperimento rende evidente come l’appartenenza ad una comunità, anche
assegnata casualmente, può influenzare la cognizione e il comportamento nei
confronti degli altri.
Un altro esperimento interessante è stato condotto da Falk e Ichino
(2003). Falk e Ichino assumono un gruppo casuale di individui. Organizzano le
persone assunte in modo casuale in gruppi di dimensione diverse (da soli o in
coppia) ed affidano loro il compito di riempire buste, con un compenso
indipendente dal lavoro effettivamente svolto. Vengono studiate due situazioni.
Nella prima due lavoratori lavorano insieme nella stessa stanza. In questa
situazione è possibile che i componenti della coppia siano influenzati dal
comportamento del proprio compagno, ossia è possibile che vi siano influenze
di “peer group”. Falk ed Ichino parlano di influenze positive tra lavoratori se il
prodotto di influenza sistematicamente il prodotto di q e viceversa, portando i
membri della coppia a livelli di produzione simili. Nella seconda situazione i
lavoratori vengono fatti lavorare da soli. Questa seconda parte dell’esperimento
serve da controllo, gli effetti di interazione sono esclusi per costruzione dato
che i lavoratori lavorano da soli nelle stanze. Il prodotto in questo caso rivela la
produttività in caso di assenza di influenze derivanti dall’interazione. Il
confronto tra i livelli di produttività emergenti dalle due situazioni permette a
Falk ed Ichino di affermare o meno l’esistenza di effetti di interazione tra il
lavoratori. I loro risultati confermano che tali interazioni esistono. In primo
luogo si riscontra una forte omogeneità della produttività nelle coppie, a fronte
di una forte eterogeneità della produttività tra le coppie. Confrontando lo
scarto quadratico medio della produttività nelle coppie e nelle coppie simulate
formate dai lavoratori singoli “We show that peer effects are large and highly
significant” (Falk e Ichino 2003,p.5). Inoltre anche se gli incentivi economici
sono identici, il prodotto medio dei lavoratori è superiore quando lavorano in
coppia rispetto a quando lavorano singolarmente. Infine emerge che le

77
interazioni influenzano gli agenti in modo diverso, in particolare aumenta la
produttività dei lavoratori meno produttivi. Anche se è difficile trasportare
questi risultati nei modelli di interazione sociale studiati convenzionalmente,
sicuramente rafforza l’idea generale che le influenze sociali hanno un ruolo
importante nella determinazione dei comportamenti (Durlauf 2003).
Studi econometrici
Dal lavoro pionieristico di Datcher (1982) si è sviluppata una ricca
letteratura empirica diretta all’affermazione degli effetti delle interazioni
sociali. La gran parte della letteratura sembra trovare conferme all’esistenza di
effetti delle interazioni sociali, anche se molti lavori subiscono l’influenza dei
pregiudizi degli autori (Durlauf 2003). Esistono tuttavia diverse problematiche
riguardanti la sistematicità dei lavori econometrici, le variabili misurate e il
metodo stesso di misura cambiano rendendo difficile il confronto tra i risultati
(Mayer e Jencks 1989; Ginther, Havemann, Wolfe 2000). Questo implica anche
la difficoltà di trasferire i risultati in modelli teorici microfondati. Inoltre sono
stati spesso sottovalutati i problemi di identificazione e autoselezione e non è
stata controllata sistematicamente la robustezza dei risultati (Durlauf 2003).
In poche parole, nonostante la grande mole di lavoro econometrico, le prove
sugli effetti delle interazioni sociali ottenute non sempre possono essere
ritenute decisive.
Datcher (1982) studia le differenze di reddito tra neri e bianchi, ed
ipotizza che tali differenze possano derivare da differenze nei quartieri e nelle
attitudini dei genitori. Il modello statistico di Datcher può essere rappresentato
con il seguente sistema ricorsivo:
2 = u + + XX +
H = u + # + X#X + |2 + X
Dove Y è il logaritmo del reddito, S è il numero di anni di scolarizzazione,
# e sono, rispettivamente, le variabili esplicative del reddito e della
scolarizzazione. Supponendo $X|# , 2 = 0, $| = 0 e la covarianza tra X e
nulla, Datcher utilizza il metodo dei minimi quadrati. I tentativi precedenti
di esaminare l’effetto del background individuale sui risultati erano limitati a

78
stimare l’impatto della famiglia. Modelli che utilizzano solo queste variabili non
riescono però ad avere una accurata visione delle differenze etniche negli
effetti di interazione sociale, dato che trascurano importanti caratteristiche dei
quartieri nei quali abitano gli agenti (Datcher 1982). Per ottenere una stima
accurata degli effetti delle diverse comunità e famiglie sui risultati dei membri,
si dovrebbero possedere misure effettive dei beni che la famiglia e la comunità
usano per produrre il capitale umano dei giovani. Purtroppo tali misure non
esistono, perciò Datcher inserisce nella regressione le seguenti variabili proxy:
educazione del padre, educazione della madre, reddito della famiglia,
dimensione della zona di origine, regione di origine, numero di fratelli, reddito
medio del quartiere e percentuale di abitanti bianchi nel quartiere. I risultati
dell’analisi di Datcher confermano l’importanza della qualità del quartiere di
residenza nella generazione di differenze nella scolarizzazione e nel reddito sia
all’interno dei gruppi etnici, sia tra gruppi etnici. Sia il reddito medio che la
composizione etnica dei quartieri contribuisce alla differenza tra i gruppi
etnici. Come è stato detto, questo è il primo di una lunga serie di lavori che
hanno tentato di accertare gli effetti che i gruppi sociali hanno sugli individui
tramite studi econometrici. In Durlauf (2003) è possibile trovare un lungo
elenco di lavori e risultati, risultati generalmente a favore dell’esistenza delle
interazioni sociali, ma risultati che come si è detto mancano in qualche caso di
una base solida. Drewianka (2003) è interessante in quanto prende
direttamente in considerazione il problema di riflessione di Manski (1993).
Drewianka (2003) scopre che vi sono effetti di interazione sociale nella ricerca
del partner. Nonostante i problemi di identificazione e autoselezione, sotto
alcune condizioni gli effetti di interazione sociale “can be both quantifiable and
consequential” (Drewianka 2003,p.422). Borjas (1995) oltre a confermare
l’esistenza di effetti dovuti al quartiere dove si abita, è interessante in quanto
dimostra empiricamente l’esistenza di segregazione etnica62. Borjas esamina la
percentuale di popolazione proveniente da una data etnia sull’intera
popolazione statunitense, e la confronta con la percentuale media di vicini
simili delle stessa etnia scoprendo che la seconda è molto più ampia (Borjas
1995,p.368). Ad esempio, la popolazione di origine italiana negli Stati Uniti era 62
“I conclude the descriptive analysis of the Census data by documenting that ethnic residential
segregation exists across a number of demographic and skill groups” (Borjas 1995, p.370)

79
nel 1970 il 2,8% sul totale della popolazione. L’immigrato italiano “tipico”
abitava nello stesso anno in quartieri in cui la percentuale di italiani arrivava
al 12,1%.
Quasi esperimenti
Una alternativa importante all’utilizzo di dati osservati può essere l’uso
dei dati in cui il governo interviene sulle scelte degli individui per valutare gli
effetti delle interazioni sociali. Questo tipo di interventi vengono chiamati
“quasi esperimenti” (Durlauf 2003). L’idea è che l’intervento definisce gruppi di
individui che ricevono o non ricevono un trattamento. Un esempio di questo
tipo di intervento è il programma Gautreaux. Nel 1967 Dororthy Gautreaux ha
fatto causa alla Chicago Housing Autorithy, affermando che il collocamento
delle famiglie povere in quartieri poveri era una forma di discriminazione. Una
sentenza consensuale tra le parti in causa ha portato ad un programma
abitativo che sostanzialmente assegnava un gruppo di famiglie ad altre parti
della città e un altro gruppo alle zone residenziali appena fuori Chicago. Il
sociologo James Rosebaum ha organizzato e condotto interviste con le famiglie
coinvolte nel programma per determinare gli effetti di abitare nelle zone
residenziali sulle famiglie povere. Egli mostra come le famiglie trasferite nelle
zone più ricche della città abbiano subìto un miglioramento delle condizioni di
vita. Descriviamo caratteristiche e risultati seguendo Rosebaum (1995). Il
programma Gautreaux permette ai partecipanti di evitare le normali barriere
che impediscono alle famiglie dei quartieri poveri di abitare in quartieri a
medio reddito, fornendo sussidi che permettono di vivere in appartamenti in
zone residenziali a medio reddito allo stesso costo delle case popolari (“public
housing”). Le zone residenziali con una quota di bianchi inferiore al 70% sono
escluse dalla sentenza, mentre zone ad altissimo costo sono escluse dai fondi
limitati del programma. Inoltre la tipologia delle famiglie partecipanti avevano
tre limiti: dovevano avere meno di quattro figli, non avere debiti eccessivi e
tenere la casa in modo soddisfacente. Questi tre limiti tuttavia hanno ristretto
l’insieme delle famiglie eleggibili solo del 30%. Tutte le famiglie partecipanti
erano a basso reddito, ed avevano vissuto buona parte delle loro vite in
quartieri cittadini poveri. La procedura di selezione ha creato le condizioni per
un quasi esperimento. Tutte le famiglie provenivano da quartieri poveri a

80
maggioranza nera (normalmente da progetti abitativi pubblici), alcuni spostati
in quartieri residenziali a medio reddito e maggioranza bianca altri in altri
quartieri neri a basso reddito. In linea di principio i partecipanti hanno la
possibilità di scegliere dove traslocare, ma in pratica essi sono assegnati alle
diverse zone in modo quasi-casuale. Questo perché le offerte di alloggio
alternativo erano rifiutabili, ma non venivano mai rifiutate data la bassa
probabilità di ottenere nuove offerte. Di conseguenza le preferenze delle
famiglie, di traslocare in quartieri residenziali o in altri quartieri urbani, non
aveva influenza su dove le famiglie sono effettivamente andate a vivere. Le
famiglie sono state perciò divise in due gruppi: un gruppo viene traslocato in
zone residenziali a medio reddito (gruppo sperimentale), un altro gruppo viene
traslocato in altri quartieri cittadini a basso reddito (gruppo di controllo). La
procedura di selezione evita l’autoselezione (iniziale), e permette ai due gruppi
di avere caratteristiche molto simili. Lo studio degli effetti del cambiamento
delle condizioni di vita ha avuto luogo tramite una indagine su 332 adulti, di
cui 95 intervistati in modo dettagliato. Il primo studio sui bambini ha avuto
luogo su un campione casuale di bambini in età scolare (da 8 a 18 anni) da
ognuna delle 114 famiglie nel 1982, ed un secondo studio sugli stessi bambini
nel 1989, quando erano ormai adolescenti o adulti, esaminando i loro risultati
scolastici e lavorativi.
I risultati
In primo luogo in Rosebaum (1995) vengono analizzati gli effetti del
trasloco sugli adulti. È da premettere che data la provenienza da ambienti a
basso reddito, gli adulti potevano avere problemi di tipo motivazionale, che
avrebbero potuto incidere negativamente sui loro risultati. La discriminazione
da parte dei datori di lavoro, le poche abilità acquisite a causa di lunghi
periodi di disoccupazione, e la frequentazione di scuole di bassa qualità inoltre
potevano impedire l’inserimento nel mercato del lavoro delle zone residenziali a
medio reddito. Nonostante queste difficoltà Rosebaum (1995) trova
miglioramenti nelle condizioni lavorative degli adulti traslocati nelle zone
suburbane rispetto agli adulti traslocati in zone a basso reddito. Durante le
interviste coloro che avevano traslocato in zone a medio reddito hanno
evidenziato come le maggiori opportunità lavorative, la maggiore percezione di

81
sicurezza e la presenza di una comunità in gran parte lavorativa avevano
aiutato ad ottenere un lavoro. In particolare, la presenza di “role model” e
norme sociali “positive” avevano spinto gli intervistati alla ricerca di un lavoro,
confermando le teorie che affermano l’importanza delle interazioni sociali sulla
vita degli individui (Durlauf 2003).
I risultati ottenuti sui giovani in età scolare sono stati più chiari. In
primo luogo deve essere sottolineato come le difficoltà delle condizioni iniziali
siano importanti anche per i giovani in età scolare. La bassa preparazione
delle scuole di bassa qualità dei quartieri poveri ha reso effettivamente difficile
l’adattamento alle aspettative più alte da parte dei docenti e ai programmi più
avanzati delle scuole nei quartieri residenziali (riscontrati in voti più bassi per
gli studenti traslocati nelle zone residenziali). Nel 1982, dopo sei anni nelle
zone residenziali, le loro condizioni erano però già migliorate. Inoltre genitori e
alunni hanno espresso un alto apprezzamento per la qualità educativa, come è
possibile evincere anche dalle interviste di Rosebaum ai genitori coinvolti63.
Nel 1989 venne fatta una nuova indagine sugli stessi soggetti, e risultò
un notevole miglioramento dei risultati scolastici e lavorativi rispetto al
campione di controllo dei residenti nelle zone povere della città. Il tasso di
abbandono scolastico era stato del 5% nelle zone residenziali ed il 20% nelle
zone cittadine. I voti, nonostante la maggiore difficoltà delle scuole residenziali,
erano uguali tra i due campioni. Il 54% dei ragazzi delle zone residenziali era
iscritto al college contro il 21% dei ragazzi delle zone cittadine. Inoltre tra
coloro che non frequentavano il college, il 75% dei giovani delle zone
residenziali aveva un lavoro a tempo pieno contro il 41% dei giovani delle zone
cittadine. I risultati erano stati talmente promettenti che ci fu un aumento
nello sforzo sperimentale attraverso il programma “Moving to Opportunity”
(MTO), il quale venne intrapreso dal 1994 in cinque città: Baltimora, Boston,
Chicago, Los Angeles e New York (Rosebaum e Harris 2001, Durlauf 2003). Il
programma prevedeva la distribuzione di buoni per la casa ad un campione
63
Un esempio riportato in Rosebaum: “The move affected my child’s education for the better. I even
tested it out… [I] let her go to summer school by my mother’s house [in Chicago] for about a month…She
was in fourth grade at that time…Over in the city, they were doing third grade work; what they were
supposed to be doing was fourth grade. The city curriculum seemed to be one to three years behind the
suburban schools”
(citato in Rosebaum 1995,p.241)

82
casuale di famiglie; il gruppo di famiglie sussidiate è stato ulteriormente diviso
casualmente in famiglie con buoni non vincolati (conosciuti come gruppo
Sezione 8) e buoni che potevano essere usati solo in zone con tassi di povertà
inferiori al 10% (conosciuto come il gruppo Sperimentale). I risultati sono stati
interessanti; si è infatti riscontrata una forte riduzione tra i giovani di queste
famiglie dell’incidenza di problemi comportamentali e di problemi di salute (sia
per la Sezione 8 che per il gruppo Sperimentale). I risultati per gli adulti sono
stati meno significativi. Si è rilevato un aumento delle ore lavorate, aumento
che è stato del 35% più forte nelle famiglie della Sezione 8; è stato trovato una
sostanziale diminuzione dei problemi legati alla depressione per le famiglie del
gruppo Sperimentale, mentre da questo punto di vista non c’è stato
miglioramento nelle condizioni della Sezione 8.
È importante sottolineare le limitazioni dei “quasi-esperimenti” dell’MTO.
Il più importante, sottolineato anche da Rosebaum (1995), è la mancanza di
dati su coloro che hanno abbandonato il programma. Esistono due motivazioni
per le quali il programma veniva abbandonato. In primo luogo il miglioramento
delle condizioni poteva portare a redditi che superavano il limite necessario a
far parte dei programmi abitativi pubblici. In questo caso gli effetti riscontrati
nell’MTO sarebbero sottostimati. In secondo luogo è possibile che le famiglie si
siano trovate a disagio nelle nuove residenze ed abbiano deciso di tornare nei
quartieri di origine. In questo caso ci troveremmo di nuovo di fronte ad
autoselezione: solo i migliori sono rimasi nel programma, sovrastimando gli
effetti del miglioramento delle condizioni del quartiere. Inoltre deve essere
riconosciuto che parte dei miglioramenti possa essere dovuto all’aumento di
reddito associato con i sussidi (Durlauf 2003). Infine esiste una questione di
generalizzazione. Non è possibile applicare il programma Gauetraux su larga
scala. Traslocare un grande numero di famiglie povere in quartieri ad alto
reddito, farebbe probabilmente traslocare i residenti del quartiere, abbassando
la qualità del quartiere (può essere visto come un effetto simile all’effetto a
catena del modello di Schelling) e rendendo inutile il trasloco (Durlauf 2003).

83
Capitolo IV Un approccio computazionale all’economia
1.La simulazione ad agenti L’esigenza di microfondare i modelli macroeconomici, pur essenziale per
produrre una teoria macro coerente e significativa, si è scontrata con le
difficoltà di formalizzazione matematica dell’economia. Il sistema economico è
infatti un sistema complesso (Tesfatsion 2005) in cui le scelte degli agenti
hanno influenze dirette sulle scelte degli altri agenti e sull’ambiente in cui
operano gli agenti; se la matematica ha i pregi dell’eleganza e della facile
comprensione delle relazioni descritte, essa ha i difetti della difficoltà di analisi
e della scarsa flessibilità. Riuscire a formalizzare matematicamente un sistema
economico, completo delle sue interrelazioni, è pressoché impossibile; da
questa impossibilità nasce l’agente rappresentativo. Come è stato argomentato
nel capitolo II, l’agente rappresentativo non è però una semplice convenienza
analitica, ma è il modo di rendere trattabile un sistema che trattabile non è,
rendendo lineare un sistema non lineare, e supponendo isolati agenti che non
sono isolati. Queste semplificazioni e modificazioni del quadro d’analisi
portano a risultati spesso fuorvianti ed errati (Kirman 1992). Pertanto la
convinzione che per lo studio dell’economia sia fondamentale basarsi sullo
studio degli agenti microeconomici, rende necessario superare la “pseudo-
microfoundations”64 ricercando una microfondazione appropriata. È necessaria
una costruzione dei modelli economici partendo da una prospettiva “bottom-
up”, incentrando l’analisi sulle caratteristiche micro dei sistemi economici, in
contrasto con la natura “top-down” della macroeconomia tradizionale (Fagiolo
e Roventini 2008). Abbandonare l’ipotesi dell’agente rappresentativo porta a
dover considerare la complessità dell’economia. La complessità dei sistemi
economici è enorme, e tale complessità è dovuta al fatto che i sistemi
64
“It should be clear by now that the assumption of a representative individual is far from innocent; it is
the fiction by which macroeconomists can justify equilibrium analysis and provide pseudo-
microfoundations. I refer to these as pseudo-foundations, since the very restrictions placed on the
behavior of the aggregate system are those which are obtained in the individual case and, as we have
seen, there is no formal justification for this.” (Kirman 1992, p.125)

84
economici sono formati da miriadi di individui, ognuno con uno scopo ed una
volontà autonoma, il cui comportamento si traduce in un comportamento
aggregato che spesso può essere completamente diverso da quello deducibile
dalle caratteristiche delle singole componenti (Terna 2006). L’esempio più
utilizzato per visualizzare il problema è il formicaio. Il comportamento semplice
delle singole formiche si aggrega in un comportamento complesso del
formicaio. Nessuna formica (probabilmente) si rende conto dell’effetto del
proprio comportamento sul comportamento aggregato, così come nessun
agente economico si rende conto della propria influenza sui risultati
aggregati65. La “mano invisibile” di Adam Smith può allora essere considerata
come una proprietà emergente del sistema economico e come tale deve essere
studiata: quando un equilibrio esiste esso è raggiunto grazie alle scelte
individuali degli agenti economici (Testfatsion 2005, Axtell 2005). Le proprietà
aggregate del sistema economico non sono deducibili dalla semplice
osservazione degli elementi che lo compongono, le interazioni interne svolgono
un ruolo determinante, esse infatti rendono differente il sistema dalla somma
degli elementi: avviene il fenomeno dell’emergenza. L’esigenza di una
microfondazione appropriata, lo sviluppo dei computer e di nuovi linguaggi di
programmazione, hanno permesso di sviluppare un approccio computazionale
all’economia, aprendo la strada allo studio dell’economia concepita come
sistema complesso (Gilbert 2004). Grazie agli strumenti informatici è infatti
possibile superare i problemi di trattabilità analitica di modelli che
incorporano la complessità, basare i modelli sugli agenti e sulle loro
interrelazioni. La simulazione ad agenti permette la creazione di società
“artificiali” in cui possono essere rappresentati direttamente individui ed
organizzazioni, ed in cui può essere osservato l’effetto delle loro interazioni
(Gilbert 2004).
2. Simulazione e metodologia tradizionale Il riferimento costante all’informatica è prova dell’importanza che ha lo
sviluppo del software nella simulazione ad agenti. Lo strumento della
simulazione sembra indispensabile per inserire interazioni ed eterogeneità nei
modelli economici (Leombruni e Richiardi 2005, p.104). Nel dibattito sulla 65
“L’economia è il risultato dell’azione umana, ma non è un progetto degli uomini” (Terna 2006, p. 23)

85
validità scientifica della simulazione come strumento di indagine e di
rappresentazione della teoria, si arrivò alla definizione della simulazione come
strumento diverso ed autonomo dalla matematica e dalla descrizione
puramente verbale con Ostrom (1988). Ostrom (1988) descrive la simulazione
come il terzo sistema simbolico diverso dal sistema matematico e dal sistema
verbale66. La simulazione non deve sostituire la matematica e la descrizione
verbale dei modelli, bensì li deve integrare con la sua nuova e diversa capacità
descrittiva (Holand e Miller 1991, p.366). Alcuni tipi di simulazione
permettono di superare i limiti della descrizione matematica e verbale
aumentando enormemente le potenzialità esplicative (Fontana 2006). I modelli
matematici hanno il grande pregio della calcolabilità67, le regole di analisi
proprie della matematica permettono infatti di trarre informazioni dal modello,
fornendo inoltre un linguaggio universale grazie al quale ogni risultato può
essere confermato o contestato. D’altra parte la matematica appare troppo
rigida, soprattutto quando l’oggetto dell’analisi è il comportamento umano. La
descrizione verbale, a sua volta, permette la flessibilità e il dettaglio precluse
alla matematica, perdendone però quasi sempre il rigore. Date le
caratteristiche della simulazione, Ostrom (1988) ne afferma la superiorità
rispetto agli altri due sistemi simbolici, in quanto riesce ad essere intersezione
dell’espressione verbale e della matematica. Ogni teoria esprimibile con i primi
due sistemi simbolici può essere espressa anche con il terzo sistema
simbolico. La simulazione computazionale può essere usata per rappresentare
sia il linguaggio naturale che le costruzioni matematiche 68 (Ostrom 1988,
p.383).
Dal punto di vista strettamente economico, la perdita della rigidità della
matematica, se da una parte permette lo studio di fenomeni innegabilmente
interessanti come l’eterogeneità e le interazioni, dall’altra mette in discussione
una metodologia di studio affermata da tempo. La matematica permette di
66
Vedi anche Holand e Miller (1991), Axelrod (1997), Gilbert e Terna (2000), Fontana (2006). 67
La calcolabilità dei modelli economici è in realtà non sempre garantita (vedere ad esempio Rustem e Velupillai (1990)). Nel testo ci riferiamo ai modelli calcolabili, che abbiano perciò imposto le ipotesi necessarie a rendere l'analisi matematica completa 68
Naturalmente poi è compito del ricercatore capire quale sia il sistema simbolico più efficiente per esporre la propria teoria (Ostrom 1988). La “superiorità” del terzo sistema simbolico si trova nella capacità di esprimere teorie esprimibili negli altri due sistemi simbolici. La scelta della simulazione deve avvenire quando si trattano sistemi complessi, caso in cui i sistemi simbolici tradizionali sono inadatti (Ostrom 1988).

86
dimostrare proposizioni valide per intere classi di funzioni ed ipotesi, mentre la
simulazione manca decisamente di questa possibilità. Riferendoci però alle
discussioni dei capitoli precedenti, la trattabilità matematica è garantita da
ipotesi molto restrittive, che restringono di conseguenza anche la portata dei
risultati. Spesso inoltre i modelli economici differiscono tra loro per le ipotesi
adottate, ipotesi che naturalmente influiscono sui risultati, rendendo valide le
conclusioni solo per le corrispondenti ipotesi. In ogni caso, anche se si ripone
cieca fiducia nell’eleganza matematica, vale sicuramente la pena dare la
possibilità ai modelli di simulazione ad agenti di esprimere i propri pregi per
essere poi valutati. Secondo Leombruni e Richiardi (2005) il “mainstream” è
ancora scettico nei confronti della simulazione69. In particolare le critiche si
rivolgono alla difficoltà di interpretazione e generalizzazione dei modelli; e la
difficoltà di stima. Seguendo Leombruni e Richiardi (2005) discutiamo tali
critiche.
2.1 Generalizzazione e stima Un fraintendimento frequente riguardo le simulazioni è che esse non
offrono un insieme di equazioni che possano facilmente essere interpretate e
generalizzate. In effetti la simulazione consiste di equazioni definite,
stocastiche o deterministiche, che definiscono la dinamica aggregata del
sistema (Holland e Miller 1991) 70 . Inoltre l’eventuale equilibrio unico del
sistema è una funzione nota dei parametri strutturali e delle condizioni
iniziali. Leombruni e Richiardi (2005) dimostrano che l’unica differenza tra un
modello “tradizionale” ed un modello con simulazione ad agenti è il grado di
conoscenza che si ha rispetto alle funzioni che costituiscono il modello. La
costruzione di un modello di simulazione implica infatti l’individuazione di un
obiettivo di studio; si costruisce il modello di interesse attraverso un processo
di astrazione motivato teoricamente, e si osserva il comportamento del modello
confrontandolo con i fatti stilizzati (Gilbert e Terna 2000). La differenza tra
modello tradizionale e modello di simulazione si trova solamente nell’ultima
69
“despite the upsurge in ABM research witnessed in the past 15 years the methodology is still left aside
in a standard economist’s toolbox” (Richiardi e Leombruni 2005, p. 104) 70
“The precision of the definitions also opens AAA [Artificial Adaptive Agents] models to mathematical
analysis” (Holland e Miller 1991, p.366).

87
fase, dove si sostituisce all’analisi matematica la simulazione informatica. I
modelli tradizionali ed i modelli con simulazione ad agenti sono perciò
sostanzialmente simili. La diversa tecnica di analisi delle implicazioni teoriche
del modello richiede una maggiore attenzione nei modelli di simulazione, dove
essendo il computer ad effettuare i calcoli sono possibili errori nel codice di
programmazione non riconoscibili dai risultati della simulazione71. Seguendo
Leombruni e Richiardi (2005), supponiamo che in ogni periodo , un individuo
, ∈ 1, … < , possa essere descritto da una variabile di stato , ∈ ℛ .
Supponiamo inoltre che l’evoluzione della variabile di stato possa essere
descritta dall’equazione alle differenze
1 , = >%, , d,; &
Possono variare tra i diversi individui sia la forma funzionale > che i parametri
, inoltre può esistere una dipendenza con la variabile di stato degli individui
diversi da . Specificato il comportamento di ogni individuo, formalizzato da
, , è possibile definire le caratteristiche aggregate del sistema, le quali
dipenderanno naturalmente dalle variabili di stato di tutti gli individui facenti
parte del sistema:
2 H = 1%,, X,, … , -,&
La questione diviene perciò capire se è possibile risolvere la (2) per ogni ,
indipendentemente da quale forma funzionale > si adotti, e la risposta è che
una soluzione può sempre essere trovata iterativamente risolvendo ogni
termine , nella (2) usando la (1):
Hu = 1%,u, X,u, … , -,u& H = 1%,, X,, … , -,& = 1 l >%,u, d,u; &, … , >-%-,u, d-,u; -&m 71
Con l’analisi matematica si scoprono necessariamente eventuali incoerenze del modello. Con i modelli di simulazione è possibile ottenere risultati plausibili con modelli incoerenti teoricamente. Questo naturalmente invalida i risultati, è perciò necessaria un’attenzione particolare nella fase di costruzione e codificazione del modello.

88
≡ %,u, … , -,u; , … , -&
Perciò possiamo scrivere:
3 H = %,u, … , -,u; , … , -&
La legge di moto (3) permette di ottenere H in ogni periodo unicamente
conoscendo le condizioni iniziali ed il valore dei parametri, ed in alcuni casi
potrebbe convergere ad una funzione indipendente da o perfino indipendente
dalle condizioni iniziali. La formalizzazione adottata è adatta a descrivere sia
un modello “tradizionale” che un modello di simulazione. La differenza
sostanziale si trova nelle forme funzionali. Se il modello è tradizionale, si
semplifica molto l’analisi grazie all’ipotesi dell’agente rappresentativo,
eliminando l’eterogeneità e l’interazione tra gli agenti (i pedici e d,). La legge
di moto aggregata si riduce al moto della variabile di stato di un solo individuo
(l’individuo rappresentativo) rendendo analiticamente trattabile il modello. Nel
caso di un modello di simulazione ad agenti, le relazioni del modello non
vengono semplificate e l’analisi diviene analiticamente complessa. Al crescere
di ed < l’espressione per può facilmente ostacolare la trattabilità analitica,
ed impedire la risoluzione algebrica. La simulazione si presenta perciò come lo
strumento che permette di superare le difficoltà analitiche del modello 72
(Fagiolo e Roventini 2008). È importante sottolineare che i modelli ad agenti
sono solo un mezzo per lo studio dell’economia in assenza delle ipotesi
semplificatrici tradizionali. In ogni caso la (3) esiste ed è possibile
approssimarla utilizzando i dati artificiali prodotti dalla simulazione. Per
ottenere l’approssimazione di ∙ si può specificare una forma funzionale
H = %,u, … , -,u; , … , -, & da approssimare ai dati prodotti dalla
simulazione, dove rappresenta i coefficienti di ∙ . Ad esempio se si
suppone che ∙ sia lineare, esisteranno due coefficienti, l’intercetta ed il
coefficiente angolare, che possono essere stimati con i dati artificiali. Stimando
è possibile arrivare ad una conoscenza degli effetti delle variabili e parametri
72
Strumento non è inteso come mero metodo di calcolo. Il termine strumento è utilizzato in modo più ampio che comprende anche l’esposizione della teoria, ed in particolare l’esposizione dei risultati (vedi Ostrom 1988).

89
su H molto simile a quella a cui si giunge interpretando le derivate di un
modello tradizionale (Leombruni e Richiardi 2006). Due sono le critiche
principali, in primo luogo ∙ è una funzione arbitraria, ed in secondo luogo
la stima di dipende dai risultati specifici della simulazione. È possibile che al
variare dei parametri la simulazione dia risultati completamente diversi. Il
metamodello ∙ fornirebbe allora una descrizione povera del sistema. Per
quanto riguarda il primo punto, si hanno a disposizione tutti i metodi statistici
che si usano quando si analizzano dati reali, con la differenza che in questo
caso si conosce perfettamente la struttura fondamentale del modello. Per
quanto riguarda il secondo punto invece è possibile obiettare che quello che
vale per il modello simulato, vale anche per la realtà. Il processo di
generazione dei dati reali è infatti sconosciuto, ed i fatti stilizzati possono
essere un risultato particolare di tale processo di generazione, rivelandosi
fallace da un momento all’altro (Leombruni e Richiardi 2006). Il metamodello
intende dare la possibilità di analizzare gli effetti dei parametri sui risultati. È
possibile effettuare tale analisi globalmente o localmente, in uno spazio dei
parametri conosciuto a priori come lo spazio di interesse. In conclusione il
problema di conoscere il comportamento del mondo simulato, di cui il
ricercatore è l’unico dio, e di trarne conseguentemente implicazioni di validità
generale risulta sostanzialmente risolvibile. (Leombruni e Richiardi 2006,
p.57).
L’approssimazione ∙ del modello di simulazione può essere utilizzata
per conoscere la differenza tra i risultati del modello simulato e la realtà.
Applicando la stessa approssimazione del modello simulato ai dati reali, e
stimando il coefficiente utilizzando i dati reali è possibile confrontare i
coefficienti stimati con i dati reali con i coefficienti stimati con i dati artificiali
(Leombruni e Richiardi 2006). In questo modo è possibile verificare la validità
della simulazione.
2.2 Linguaggio condiviso Lo studio dei modelli di simulazione ad agenti è relativamente recente. Il
primo esempio, presentato nel capitolo precedente, è il modello di segregazione

90
di Schelling (Schelling 1978)73 nel quale, come è stato mostrato, l’interazione
tra gli agenti da vita a proprietà emergenti non direttamente deducibili
dall’osservazione delle caratteristiche degli agenti stessi. Un problema esposto
in diversi lavori (Axelrod 1997, Gilbert e Troitzsch 2005, Goldstone e Janssen
2005, Leombruni e Richiardi 2006, Fontana 2006), forse causato anche dalla
relativa novità delle simulazioni nelle scienze sociali, è l’esigenza di adottare
un sistema di comunicazione condiviso su metodi e risultati ottenuti nei
modelli di simulazione. Mentre nella modellistica “tradizionale” esiste un
protocollo metodologico, comunemente accettato ed utilizzato dalle riviste
scientifiche come metro di valutazione, un’idea condivisa sulle caratteristiche
che dovrebbe avere un buon modello di simulazione non è ancora emersa
(Leombruni e Richiardi 2006). Per Goldstone e Janssen (2005) i lavori di
simulazione ad agenti hanno sofferto di poca sistematicità nella ricerca.
Questo problema sembra collegato in parte alla difficoltà di inserire spiegazioni
esaurienti, riguardo al modello teorico e all’algoritmo di simulazione, negli
spazi tradizionalmente utilizzati per la diffusione degli articoli: conferenze,
riviste specializzate e libri (Axelrod 1997). I risultati dei modelli di simulazione
dipendono fortemente dai dettagli del modello, rendendo poco agevole la
spiegazione e la replicabilità dello stesso, a cui si aggiunge la mancanza di un
linguaggio comune che sia in grado di facilitare l’esposizione dei risultati
(Fontana 2006). La modellistica tradizionale può basare le proprie premesse e
confrontare i propri risultati affidandosi ad una letteratura precedente molto
estesa, creando le basi per una discussione teorica più proficua. E’ necessario
perciò sviluppare metodologie e classificazioni condivise74 75, e possibilmente
rendere disponibile il codice del modello in modo da permettere la replicazione
dei risultati. L’analisi del modello dovrebbe collegarsi alla letteratura
tradizionale e della simulazione, mentre l’algoritmo dovrebbe essere
implementato su piattaforme condivise (freeware o open source, come Repast,
73
Schelling in realtà non usa il computer ma carta e penna (e una scacchiera). In Schelling è però sottolineata la caratteristica fondamentale dei modelli ad agenti, ossia la costruzione completamente basata sugli agenti. 74
Con le parole di Goldstone e Janssen (2005) è necessaria la creazione di una “Lingua Franca” per la simulazione ad agenti. 75
Un passo avanti importante è stato fatto con la nascita del JASSS, Journal of artifical societies and
social simulation, edito dal dipartimento di sociologia dell’Università del Surrey, e specializzato nella simulazione sociale.

91
Swarm o NetLogo)76 che gestendo parte delle funzionalità tecniche rende più
intellegibile il codice e più confrontabili i modelli (Leombruni e Richiardi 2006).
L’implementazione della teoria nell’algoritmo è infatti un passaggio
fondamentale per controllare la validità dei risultati e per avviare discussioni
sulla teoria stessa, nello stesso modo in cui le equazioni matematiche e le
dimostrazioni dei teoremi mettono in luce limiti e pregi dei modelli a cui si
riferiscono. Uno dei principi della simulazione ad agenti viene chiamata KISS
(Keep It Simple, Stupid!); il principio implica che la costruzione deve essere il
più semplice possibile, lasciando che siano i risultati ad essere complessi
(Axelrod 1997)77, “However, there must be a compromise between simplification
and expressiveness, determined by the results produced by the model” (Hassan,
Antunes e Arroyo 2008, p.1). Risultati significativi e realistici devono essere
ottenuti cercando di mantenere semplice il modello; il principio KISS è vitale
sia per il ricercatore che deve comprendere cosa accade effettivamente nel
modello (specialmente in presenza di risultati sorprendenti), sia per una facile
comprensione da parte del resto della comunità scientifica.
3. Le caratteristiche dei modelli di simulazione ad agenti Come emerso dai primi paragrafi, la simulazione ha tre caratteristiche
fondamentali che ricorrono nella discussione: gli agenti, la complessità e
l’emergenza (Page 2005).
4. Gli agenti Il sostantivo “agente”, deriva dal verbo latino “agere”, che significa agire,
fare, operare 78 . La caratteristica fondamentale dell’agente è esattamente
questa, è l’elemento che all’interno dei modelli di simulazione agisce
influenzando se stesso, gli altri agenti, e l’ambiente in cui si trova. Per la
76
I siti di riferimento sono rispettivamente: http://repast.sourceforge.net/ ; http://www.swarm.org ; http://ccl.northwestern.edu/netlogo/ . 77
“The complexity of agent-based modeling should be in the simulated results, not in the assumption of
the model” (Axelrod 1997, p. 6) 78
www.etimo.it

92
definizione di agente riprendiamo Woldridge e Jennings (1995)79 . Il modo più
generale in cui il termine agente viene utilizzato è per denotare un programma
informatico (e più di rado un hardware) che ha le seguenti proprietà:
autonomia, gli agenti operano senza l’intervento diretto del ricercatore ed
hanno una sorta di controllo sulle proprie azioni e sul proprio stato interno;
abilità sociale, gli agenti interagiscono con altri agenti (e talvolta con umani)
tramite una qualche forma di linguaggio di comunicazione; reattività, gli agenti
percepiscono l’ambiente circostante (che può comprendere il mondo fisico, un
utente tramite un’interfaccia grafica, un insieme di altri agenti, internet, o la
combinazione di esse) e ad esso reagiscono; attività, gli agenti non agiscono
semplicemente in risposta all’ambiente, essi sono in grado di esibire
comportamenti diretti ad un obiettivo prendendo l’iniziativa. (Wooldridge e
Jennings 1995, p.3)
L’agente, nell’ambito della simulazione sociale, è dunque un oggetto
software80 in un ambiente virtuale, con regole che permettono l’interazione con
gli altri agenti e con l’ambiente. L’autonomia degli agenti implica che qualsiasi
situazione affrontata nel modello deve essere risolta grazie alle regole
implementate nella fase di costruzione del modello. L’intervento umano è di
creazione ed osservazione, non di guida; l’agente reagisce a stimoli esterni
provenienti da altri agenti (simulando le interazioni sociali) e provenienti
dall’ambiente. Inoltre gli agenti hanno (o possono avere) un comportamento
finalistico, cioè volto ad un obiettivo da raggiungere. L’aspetto primario è
dunque l’autonomia con cui gli agenti agiscono e reagiscono; la costruzione
degli agenti è la parte fondamentale della simulazione sociale, in quanto sono
gli agenti e il loro comportamento aggregato l’oggetto di studio. La definizione
di regole e l’autonomia degli agenti garantiscono che gli effetti osservati a
livello aggregato siano effettivamente prodotti dalle regole del singolo agente.
Wooldridge e Jennings (1995) offre anche una “Stronger Notion of Agency”81: ne
fanno parte gli agenti che in aggiunta alle proprietà precedentemente elencate,
79
Una definizione più compatta si trova in Jennings (2000): “ An agent is an encapsulated computer
system that is situated in some environment and that is capable of flexible, autonomous action in that
environment in order to meet its design objectives.” 80
Per questo sono preferiti normalmente linguaggi di programmazione Object Oriented, in particolare Java (ad esempio in Repast e Swarm) e Objective C (in Swarm). NetLogo, programma costruito su java, ha un linguaggio anch’esso orientato agli oggetti. 81
La definizione precedente è infatti “A Weak Notion of Agency” (Wooldridge e Jennings 1995)

93
sono costruiti utilizzando concetti che normalmente sono applicati alla
descrizione di esseri umani, quali l’intelligenza o addirittura le emozioni
(Wooldridge e Jennings 1995). La definizione forte di agente permette perciò di
parlare di cooperazione tra gli agenti e di apprendimento (Remondino 2006),
concetti importanti nella simulazione delle scienze sociali, dato che lo scopo
della simulazione è di simulare, anche se in modo semplificato, il
comportamento umano. Comportamento che è decisamente arduo da decifrare
e formalizzare:
“Imagine how hard physics would be if electrons could think”
(Murray Gell-Mann, in Page 1999, p.2)
La frase citata, attribuita al premio Nobel per la fisica Murray Gell-Mann, dà
l’idea delle sfide che affrontano le simulazioni ad agenti nelle scienze sociali. Il
comportamento degli agenti, ossia le regole da dare agli agenti, non sono
oggettive. Il comportamento umano nella società può essere formalizzato nei
modi più diversi, rispetto alle convinzioni del ricercatore e rispetto all’obiettivo
della ricerca. Gli agenti possono rappresentare imprese, lavoratori,
consumatori, agenti economici in generale, i quali hanno uno scopo economico
e delle variabili interne che possono essere opinioni, aspettative ed intenzioni.
Il principio fondante dei modelli basati su agenti, abbiamo visto, è il KISS.
Mantenere semplice il modello permette di ottenere risultati facilmente
comprensibili, e spesso significativamente aderenti alla realtà. Comportamenti
semplici a livello micro producono comportamenti complessi a livello macro,
non c’è perciò bisogno di approfondire ulteriormente il processo di
formulazione della decisione. Un esempio è il modello di Schelling, in cui le
regole di comportamento sono semplicissime, gli agenti sono miopi, non hanno
aspettative di nessun genere, e reagiscono solo alla variabile ambientale
“percentuale di agenti simili nel vicinato”. Vale il criterio di sufficienza
generativa di Epstein (Boero et al. 2006) per cui il compito dei modelli di
simulazione ad agenti è di trovare le regole micro sufficienti a generare il
fenomeno macro di interesse. Il comportamento di un agente sociale può in
questo caso essere approssimato a quello di unità più elementari di materia, i
cui obiettivi possono essere rappresentati da un ridotto numero di regole e da

94
una funzione di fitness, arrivando fino ad agenti adattivi, in cui gli agenti
tendono ad aumentare il valore della propria funzione di fitness. I modelli che
seguono il principio di semplicità sono chiamati da Boero et al. (2006) modelli
“emergentisti”. Sono i modelli che studiano le proprietà emergenti di primo
ordine, l’effetto del comportamento dei singoli agenti sul comportamento
aggregato. Una delle conseguenze della diversa struttura mentale tra particelle
di materia inanimata e umani è l’eventuale reazione all’emergenza:
While emergent phenomena can also be found in physical systems, a feature of
human societies which makes then unique is that people can recognise (and
therefore respond to) the emergent features. For example, households not only
often cluster in segregated neighbourhoods, but these neighbourhoods are
named and can acquire reputations that further affect the behaviour of those
living there and others such as employers who may stereotype the inhabitants.
(Gilbert 2004, p.3)82
Confermando il grande interesse che hanno i modelli con agenti semplici, può
accadere che sia necessario, e utile, programmare agenti più complessi, che
riescano ad essere descrittivi del comportamento economico o sociale. Se il
precedente tipo di simulazione ad agenti segue il principio KISS, i modelli con
agenti più complessi seguono il principio KIDS (“Keep It Descriptive, Stupid”).
Questo tipo di modelli consente di studiare il legame tra proprietà emergenti
dalle interazioni fra agenti e meccanismi cognitivo-simbolici di
contestualizzazione sociale dell’azione, ovvero “l’immergenza” (Boero et al.
2006, p. 91). In tali sistemi, i cui agenti sono detti “deliberativi” (Remondino
2006), esiste una doppia influenza tra agenti e proprietà emergenti, e tra
proprietà emergenti ed agenti. Essi hanno perciò la capacità di “ragionare” e di
apprendere. La complessità degli agenti può allora arrivare a risolvere
problemi, non rispondono a regole fisse bensì a regole di apprendimento,
riuscendo in questo modo ad adottare scelte diverse di fronte a problemi
differenti. Si possono inoltre descrivere opinioni, aspettative, intenzioni degli
agenti. La complessità degli agenti può allora arrivare alla descrizione quasi
realistica delle scelte umane, seguendo i risultati dell’economia
82
Si veda anche Gilbert (2002)

95
comportamentale (Camerer e Loewenstein 2004), o introducendo una nuova
classe di agenti che fonde in sé le conoscenze delle scienze sociali, delle
scienze cognitive, e dell’informatica: gli agenti BDI (Beliefs, Desires,
Intentions). Tali agenti sviluppano le scelte basandosi sulla logica modale e sui
mondi possibili, ma hanno avuto fino ad ora uno sviluppo principalmente
teorico, a causa della loro difficile applicazione software (Remondino 2006).
Buona parte dei modelli economici sono “emergentisti”. La finalità degli
economisti computazionali è infatti principalmente quella di dimostrare come
non sia necessario presupporre agenti dotati di razionalità perfetta, agenti
rappresentativi e un sistema di informazioni complete per generare e
comprendere dinamiche economiche interessanti (Boero et al. 2006). Su tali
agenti semplici è possibile inoltre implementare algoritmi di apprendimento
che simulino la razionalità limitata degli agenti. È possibile grazie a tali
algoritmi, eliminare l’ipotesi irrealistica di razionalità perfetta, e l’ipotesi
altrettanto irrealistica di completa irrazionalità, e basare la razionalità limitata
degli agenti economici su fenomeni di adattamento ed imitazione. Gli agenti
possono perciò imparare dalle proprie azioni, e in alcuni casi dalle azioni degli
altri agenti presenti nel sistema simulato; possono essere definiti agenti
“adattivi”, i quali non hanno la capacità di “ragionamento”, o di formazione di
reputazione, ma riescono ad imparare dai propri errori, seguendo l’evoluzione
dell’ambiente. Gli agenti adattivi sono definiti in Holland e Miller (1991) come
agenti alle cui azioni può essere assegnato un valore (utilità, fitness o simili) e
che si comportano in modo da aumentare tale valore nel tempo83. I modelli
“immergentisti” sono più completi, ma di più difficile codificazione e
comprensione. Questo tipo di modelli vengono per lo più utilizzati nello studio
delle interazioni di agenti sociali, in cui diviene ad esempio fondamentale,
l’effetto che la proprietà emergente ha sui singoli agenti.
83
Holland e Miller (1991) sostengono che i sistemi economici siano sistemi complessi adattivi. In particolare, nei sistemi complessi : “An agent in such a system is adaptive if it satisfies an additional pair
of criteria: the actions of the agent in its environment can be assigned a value (performance, utility,
payoff, fitness, or the like); and the agent behaves so as to increase this value over time.” (Holland e Miller 1991, p. 365)

96
4.1 L’apprendimento, gli agenti “intelligenti” Una delle ipotesi fondamentali dell’analisi economica è la razionalità degli
agenti. L’essenza dell’Homo economicus è definita dal metodo razionale che
esso usa per le sue scelte (Persky 1995) 84 . Allo scopo di semplificare la
trattazione analitica dei modelli macroeconomici, gli economisti spesso
ipotizzano che gli agenti siano perfettamente razionali, ossia che riescano a
prevedere esattamente l’evolversi del sistema di cui fanno parte 85 . Come
affermano Fagiolo e Roventini (2008, p. 12), gli agenti devono avere una sorta
di razionalità “olimpica” ed avere libero accesso all’intero insieme di
informazioni. Il paradosso è evidente, dato che un agente perfettamente
razionale deve conoscere il modello dell’economia meglio di quanto lo conosca
un econometrico (Sargent 1993) 86 . Accettando l’ipotesi di razionalità
dell’agente economico, ma rifiutando l’ipotesi di onniscienza, è possibile
sostituire l’ipotesi di razionalità perfetta, con l’ipotesi di razionalità limitata.
L’obiettivo dell’agente economico è effettuare la migliore scelta possibile e
spesso ciò gli viene impedito dalle scarse informazioni che ha sul sistema nel
quale si trova. La razionalità dell’agente economico allora si limita alla
capacità di imparare dalle esperienze, evitando di commettere gli stessi errori,
e continuando imperterrito nella ricerca della soluzione migliore. Tentativi ed
errori è il paradigma dell’agente adattivo, il quale trae informazioni sul proprio
ambiente e si adatta ad esso. L’apprendimento degli agenti può essere diviso in
due macrocategorie, rispetto al livello a cui avviene l’apprendimento:
l’apprendimento individuale e l’apprendimento sociale (Vriend 2000). Con
l’apprendimento individuale gli agenti apprendono esclusivamente dalla
propria esperienza, l’apprendimento sociale invece comprende l’apprendimento
per imitazione, ossia anche grazie alle esperienze degli altri membri del
sistema economico. Vriend (2000) dimostra come i due tipi di apprendimento
abbiano dinamiche molto diverse. La scelta del livello di apprendimento non è 84
Persky 1995 confronta l’homo economicus moderno, identificato esclusivamente dalla razionalità, con il concetto più ampio dato da J. S. Mill in “On the Definition of Political Economy and on the Method of Investigation Proper to It”: Mill's economic man has four distinct interests: accumulation, leisure, luxury
and procreation (Persky 1995, p. 223) 85
Devono perciò (i) conoscere il modello dell’economia, (ii)devono riuscire a risolvere qualunque tipo di problema affrontino senza commettere errori, e (iii) devono conoscere gli altri agenti e sapere che si comportano anch’essi seguendo i primi due punti. (Fagiolo e Roventini 2008) 86
“When implemented numerically, or econometrically, rational expectations models impute much more
knowledge to the agents within the model than is possessed by an econometrician” (Sargent 1993, p. 3)

97
ininfluente al livello dei risultati del modello, e dipende naturalmente da cosa
debbano imparare gli agenti. Esistono scelte che possono essere imitate e
scelte che non possono essere imitate; se gli agenti sono eterogenei le scelte
migliori per ogni agente potrebbero essere diverse rendendo impossibile un
apprendimento sociale.
Un vantaggio dell’economia computazionale è di poter attingere alle
scienze informatiche, in particolare dall’intelligenza artificiale, per
implementare nei modelli l’apprendimento. Gli algoritmi di apprendimento più
conosciuti ed utilizzati nelle scienze sociali sono le Reti Neurali Artificiali
(“Artificial Neural Net”), gli Algoritmi Genetici (“Genetic Algorithm”)87 (Ferraris
2006). Entrambi gli algoritmi si basano, come è evidente dai nomi, su analogie
con i sistemi di apprendimento naturali. Nei prossimi paragrafi saranno
esposte le principali caratteristiche delle Reti Neurali Artificiali e degli
Algoritmi Genetici. L’esposizione degli Algoritmi Genetici sarà più approfondita
per la grande importanza che tali metodi di apprendimento hanno iniziato ad
assumere nella letteratura economica. Le Reti Neurali sono un metodo di
apprendimento molto potente che permette anche un certo grado di
generalizzazione dell’apprendimento stesso. Il difetto delle Reti Neurali risiede
nel complicato processo di apprendimento, decisamente meno intuitivo
rispetto al processo degli algoritmi genetici.
4.2 Le Reti Neurali Artificiali Le reti neurali umane sono composte da circa 100 miliardi di neuroni. I
neuroni comunicano tramite una densa rete di connessioni che trasporta
impulsi elettrochimici. Ogni neurone ottiene un impulso da un certo numero
di altri neuroni, e se il segnale è sufficientemente forte a sua volta spedirà un
impulso ai neuroni ad esso collegati. L’apprendimento ha luogo quando
particolari connessioni tra neuroni si rafforzano, facilitando la trasmissione tra
tali neuroni. Le reti neurali artificiali si basano sullo stesso principio,
naturalmente molto semplificato (Gilbert e Troitzsch 2005). Le reti neurali
artificiali sono composte da tre o più strati (“layer”) di neuroni, disposte in
87
Per chi fosse interessato Wikipedia possiede voci incredibilmente estese, complete di bibliografia, per le voci “Artificial intelligence”, “Artificial Neural Network”, “Genetic Algorithm”.

98
modo tale che ogni strato sia connesso con lo strato successivo. Ogni
connessione ha associato un peso, le connessioni simboleggiano le dendriti
umane ed il peso ne simula l’efficienza. Il primo strato di neuroni è chiamato
“input layer”, è lo strato per cui passano gli stimoli provenienti dall’esterno
(per convenzione tale strato viene disegnato sulla sinistra, vedere figura 8).
L’ultimo strato di neuroni è chiamato “output layer”, il quale emette la riposta
della rete agli stimoli. Nel mezzo sono situati uno o più strati di “hidden layer”.
Figura 8. Una rete neurale artificiale
Gli stimoli in uscita dai neuroni vengono detti “attivazioni”. L’attivazione dei
neuroni input è direttamente lo stimolo esterno. Tale stimolo viene trasmesso
tramite le connessioni al primo (spesso unico) strato di neuroni nascosti. Tali
neuroni sommano gli stimoli derivanti da tutte le sue connessioni in entrata,
ponderandole per il peso della connessione. L’impulso risultante viene
trasformato in modo non lineare per ottenere un valore tra 0 e 1. Normalmente
per tale operazione si fa uso della funzione sigmoide, dove è l’attivazione ed
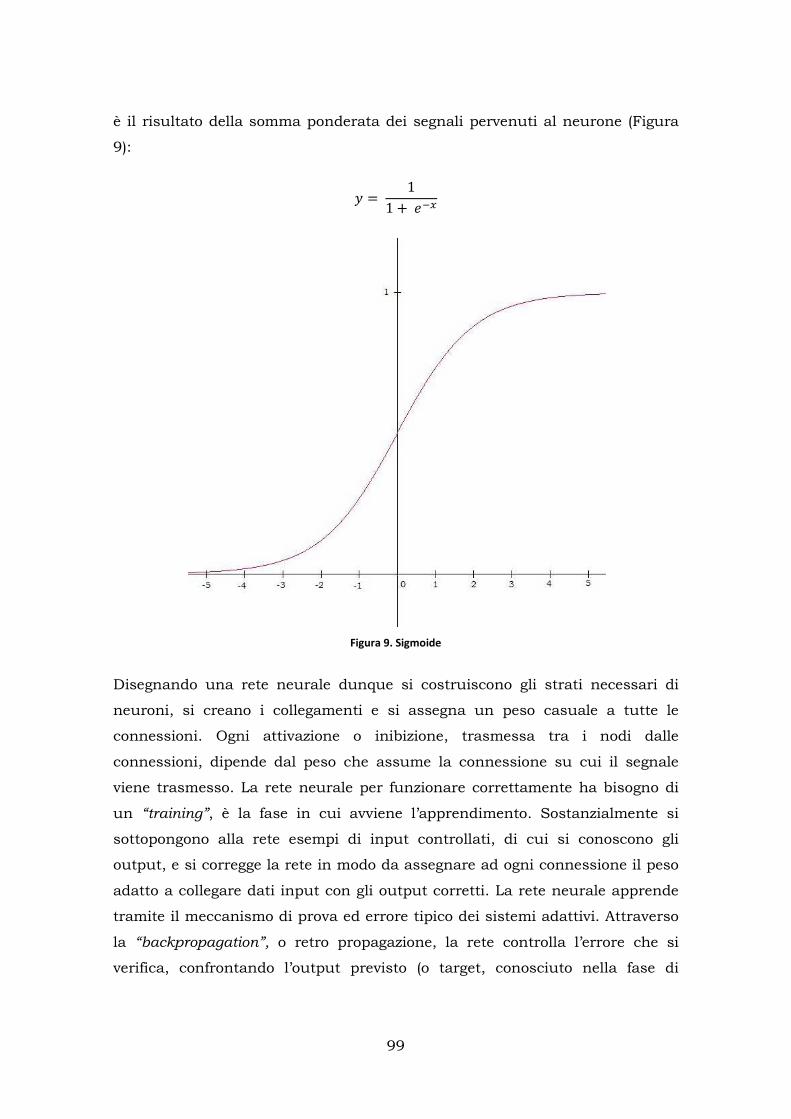
99
è il risultato della somma ponderata dei segnali pervenuti al neurone (Figura
9):
= 11 + d
Figura 9. Sigmoide
Disegnando una rete neurale dunque si costruiscono gli strati necessari di
neuroni, si creano i collegamenti e si assegna un peso casuale a tutte le
connessioni. Ogni attivazione o inibizione, trasmessa tra i nodi dalle
connessioni, dipende dal peso che assume la connessione su cui il segnale
viene trasmesso. La rete neurale per funzionare correttamente ha bisogno di
un “training”, è la fase in cui avviene l’apprendimento. Sostanzialmente si
sottopongono alla rete esempi di input controllati, di cui si conoscono gli
output, e si corregge la rete in modo da assegnare ad ogni connessione il peso
adatto a collegare dati input con gli output corretti. La rete neurale apprende
tramite il meccanismo di prova ed errore tipico dei sistemi adattivi. Attraverso
la “backpropagation”, o retro propagazione, la rete controlla l’errore che si
verifica, confrontando l’output previsto (o target, conosciuto nella fase di

100
training) con l’output effettivo. L’eventuale errore viene propagato dai neuroni
di output verso gli strati precedenti, correggendo i pesi delle connessioni.
La costruzione di una rete neurale
In Gilbert e Troitzsch (2005) sono presentate alcune regole per la
costruzione delle reti neurali. Dopo il lavoro di codificazione di input ed output
è necessario decidere il numero di neuroni in ciascuno strato e la legge di
misurazione dell’errore. Il numero di neuroni di input ed output dipende da
come sono stati codificati i dati. Ad esempio gli input sono codificati in quattro
categorie saranno necessari quattro neuroni di input. Il numero di neuroni
nascosti dipende dalla complessità del problema affrontato. Esiste una regola
generale per cui il numero di neuroni nascosti non deve mai eccedere il doppio
del numero di neuroni di input (Gilbert e Troitzsch 2005). La misurazione
dell’errore, fondamentale per l’apprendimento della rete neurale, avviene
normalmente misurando la semplice differenza tra l’output effettivo e l’output
target, misurata per ogni unità di output. L’errore misurato viene poi utilizzato
per correggere i pesi delle connessioni, la correzione del singolo peso avviene
sulla base di una quota denominata “learning rate”. Inoltre può spesso essere
utile misurare l’errore totale della rete neurale; normalmente si usa la radice
quadrata della somma degli errori al quadrato di ogni neurone di output.
Grazie alla misura dell’errore totale è possibile visualizzare l’apprendimento
della rete. Può accadere che gli errori non scompaiano completamente, in
questo caso è possibile che la rete si trovi in una situazione in cui la
minimizzazione dell’errore è solamente locale. Nonostante siano state proposte
diverse soluzioni al problema del minimo locale, l’unica procedura affidabile è
di ripetere la fase di training diverse volte, utilizzando la stessa rete con
condizioni iniziali casuali. Se l’insieme di pesi rimane lo stesso è possibile
trarre la conclusione che il minimo in cui la rete si trova è un minimo globale
(Gilbert e Troitzsch 2005).
Per una spiegazione più chiara presentiamo una rete neurale artificiale
molto semplice, costruita con NetLogo88.
88
Vedere l’appendice A3 per il codice.

101
Figura 10. Rete Neurale con NetLogo.
Nella figura 10 è rappresentata la rete neurale costruita, in cui, seguendo la
convenzione, a sinistra sono i nodi di input, a destra i nodi di output e al
centro i nodi nascosti. Supponiamo di voler insegnare ad una rete neurale a
riconoscere il numero decimale corrispondente ad un dato numero binario. In
primo luogo è necessario codificare il problema in termini adeguati all’utilizzo
dello schema di rete neurale. Nel caso in esame, l’input è binario, perciò
direttamente integrabile nella rete neurale tramite segnali 1, 0 da trasmettere
ai neuroni di input. L’output è un numero decimale; nel modello che
presentiamo la codificazione del numero decimale avviene in relazione a quali
e a quanti neuroni output ricevono il segnale con una certa intensità.
L’algoritmo costruito ha lo scopo di convertire tutti i numeri binari di quattro
cifre in numeri decimali. I nodi di input sono perciò quattro ed hanno il
seguente ordine nel numero binario: (nodo3, nodo 2, nodo 1, nodo 0).
L’insieme dei numeri decimali possibili è F = 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15, e sono rappresentati dai nodi di output colorando di blu i nodi di output che
hanno un numero inferiore o uguale al numero binario di input (vedere la
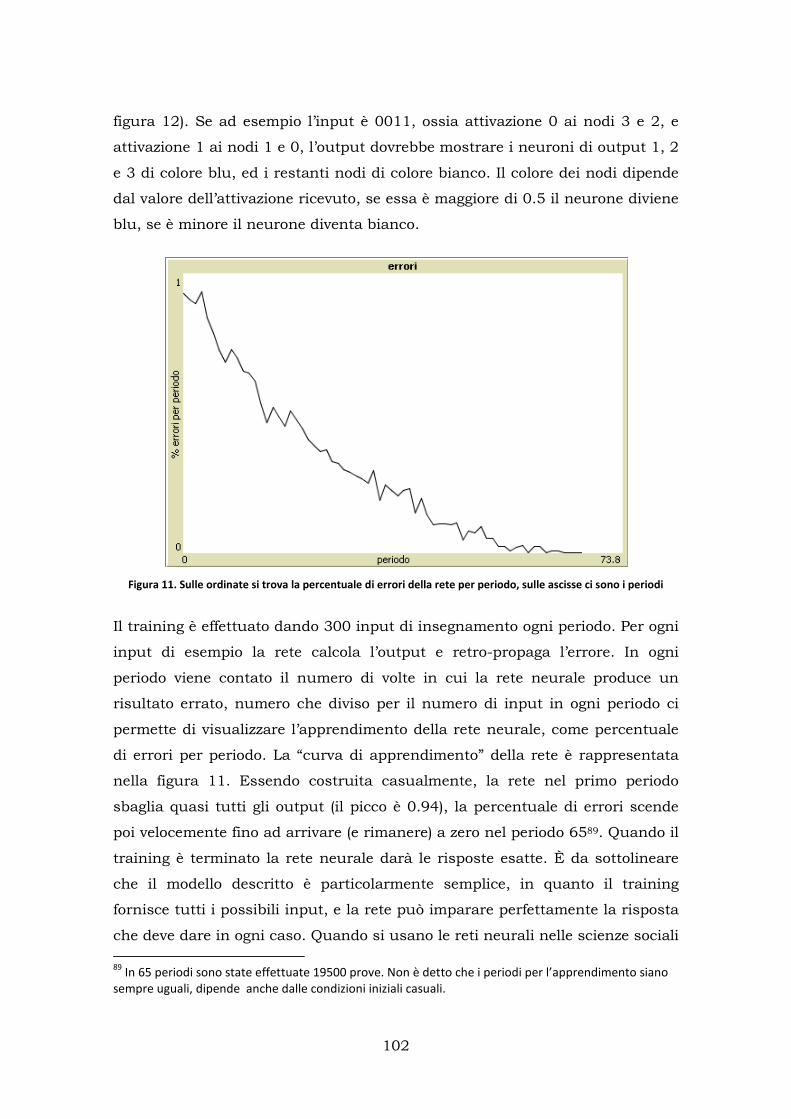
102
figura 12). Se ad esempio l’input è 0011, ossia attivazione 0 ai nodi 3 e 2, e
attivazione 1 ai nodi 1 e 0, l’output dovrebbe mostrare i neuroni di output 1, 2
e 3 di colore blu, ed i restanti nodi di colore bianco. Il colore dei nodi dipende
dal valore dell’attivazione ricevuto, se essa è maggiore di 0.5 il neurone diviene
blu, se è minore il neurone diventa bianco.
Figura 11. Sulle ordinate si trova la percentuale di errori della rete per periodo, sulle ascisse ci sono i periodi
Il training è effettuato dando 300 input di insegnamento ogni periodo. Per ogni
input di esempio la rete calcola l’output e retro-propaga l’errore. In ogni
periodo viene contato il numero di volte in cui la rete neurale produce un
risultato errato, numero che diviso per il numero di input in ogni periodo ci
permette di visualizzare l’apprendimento della rete neurale, come percentuale
di errori per periodo. La “curva di apprendimento” della rete è rappresentata
nella figura 11. Essendo costruita casualmente, la rete nel primo periodo
sbaglia quasi tutti gli output (il picco è 0.94), la percentuale di errori scende
poi velocemente fino ad arrivare (e rimanere) a zero nel periodo 6589. Quando il
training è terminato la rete neurale darà le risposte esatte. È da sottolineare
che il modello descritto è particolarmente semplice, in quanto il training
fornisce tutti i possibili input, e la rete può imparare perfettamente la risposta
che deve dare in ogni caso. Quando si usano le reti neurali nelle scienze sociali 89
In 65 periodi sono state effettuate 19500 prove. Non è detto che i periodi per l’apprendimento siano sempre uguali, dipende anche dalle condizioni iniziali casuali.

103
è possibile che si debba effettuare il training con un sottoinsieme dei possibili
input. Il rendimento della rete in questo caso dipenderà dal grado di generalità
e completezza del training iniziale (Ferraris 2006) e normalmente riuscirà a
riconoscere input che non siano identici agli input di insegnamento. Per
questo motivo le reti neurali sono state usate per il riconoscimento della
scrittura manuale. Nonostante il training preveda il riconoscimento solo di
una parte delle possibili calligrafie, la rete neurale è in grado di riconoscere
anche nuove calligrafie. Questo perché le reti neurali possiedono una capacità
di generalizzazione (Gilbert e Troitzsch 2005). Nella figura 12 è rappresentata
la schermata di NetLogo, in cui è stato effettuato un test dopo aver concluso il
training.
Figura 12. Schermata di NetLogo. Il training è finito ed è stato inserito il numero binario 1 0 1 1, convertito in modo esatto dalla rete neurale nel numero decimale 11
4.3 Algoritmi Genetici Gli algoritmi genetici sono basati sull’analogia con l’evoluzione delle
specie di Darwin90. In natura gli esseri viventi competono per le risorse scarse,
e per la riproduzione. Saranno gli individui migliori a tramandare le proprie
caratteristiche alle generazioni future, e saranno gli individui meno adatti
all’ambiente a sparire. Data una popolazione di DNA differenti, la selezione
naturale opera per selezionare i DNA migliori, questi DNA si accoppiano
90
Per una introduzione agli algoritmi genetici vedere anche Goldberg (1989)

104
subendo cross-over e mutazione, dando vita alla generazione successiva di
DNA. Grazie alla ricombinazione dei DNA (cross-over) e alla mutazione, ogni
generazione ha elementi di diversità che permettono la continuazione della
ricerca del DNA migliore. I nuovi DNA possono perciò rappresentare
caratteristiche completamente nuove, le quali possono sopravvivere alla
selezione, operando un progresso della specie, oppure possono sparire in
favore di DNA migliori. L’algoritmo genetico è un algoritmo euristico adattivo di
ricerca che imita le caratteristiche essenziali della selezione naturale (Gilbert e
Troitzsch 2005):
Simply stated, genetic algorithms are probabilistic search procedures designed
to work on large spaces involving states that can be represented by strings
(Holland e Goldberg 1988, p.95)
Venne sviluppato da Holland (1975) come metodo di studio dell’adattamento,
l’ottimizzazione e l’apprendimento (Holland e Miller 1991). Gli algoritmi
genetici operano su una popolazione di agenti, le cui caratteristiche sono
codificate in una stringa (normalmente binaria). Ogni elemento della stringa
rappresenta un gene, il genoma (l’insieme dei geni) caratterizza un genotipo (la
composizione genetica individuale), il quale si esprime nel fenotipo (in natura
le caratteristiche dell’individuo, nelle scienze informatiche un numero o una
strategia). Nelle scienze sociali, ed in particolare nei modelli economici, gli
algoritmi genetici sono utilizzati per riprodurre la razionalità limitata degli
agenti.
Le caratteristiche fondamentali dell’algoritmo genetico sono la misura di
fitness, la quale misura quanto una data strategia è adatta all’ambiente in cui
si trovano gli agenti, e gli operatori genetici, che comprendono selezione, cross-
over e mutazione. Per chiarire le caratteristiche degli algoritmi genetici
presentiamo un semplicissimo modello economico, descritto in Dawid e Kopel
(1998), in cui le imprese scelgono la produzione grazie ad un algoritmo
genetico.
Il modello “cobweb” descrive un equilibrio temporaneo dei prezzi di
mercato in un mercato singolo con un ritardo nell’offerta; dato che la
produzione richiede tempo, la decisione rispetto alla quantità da produrre deve

105
essere presa prima dell’osservazione dei prezzi di mercato. Nello stesso modello
verranno ipotizzati prima agenti perfettamente razionali e poi agenti con
razionalità limitata le cui decisioni verranno simulate con gli algoritmi genetici.
Supponiamo che l’economia in esame sia composta da < imprese price-taker in
un mercato competitivo che producono un bene omogeneo. Denotiamo la
quantità prodotta dall’impresa nel periodo con , . Ogni impresa ha la
stessa funzione di costo
%,& = + ,X , > 0 , > 0 0 , = 0
Dove rappresenta i costi fissi di breve periodo. Gli imprenditori non
conoscono il prezzo di mercato del prossimo periodo quando devono decidere
la quantità prodotta, ma hanno un prezzo atteso pari a P,e . Basandosi su tale
attesa, l’impresa sceglie un livello di produzione che massimizzi i suoi
profitti. Ossia massimizza la seguente funzione di profitto:
1 Π%P,e , ,& = P,e , − − ,X , > 00 , = 0
La condizione del primo ordine della funzione di profitto per un produzione
non nulla è
2 BΠB = P,e − 2 = 0
Da cui
3 = P,e2
Sostituendo la (3) nella (1) otteniamo:
4 P,e = 2

106
Se il prezzo atteso è maggiore della (4) i profitti attesi sono positivi, e la
produzione è pari alla (3). Se il prezzo atteso è uguale alla (4) il profitto atteso
massimo è zero ed il prodotto ottimo è = ⁄ , o = 0 (si ricordi che sono
costi fissi di breve periodo e che il costo di non produrre è zero). Se il prezzo
atteso è inferiore alla (4) il profitto atteso è negativo e le imprese rinunciano
alla produzione. Formalizzando, la scelta ottimale dell’impresa è data da
5 ∗%P,e & = P,e
2 P,e > 2 0, ⁄ P,e = 2 0 P,e < 2
Il prezzo che si verificherà effettivamente nel periodo , è il prezzo di equilibrio
tra domanda e offerta, e sarà determinato dalla funzione di domanda inversa
6 P = − I ,-
K
Con , > 0 . Affinché il profitto atteso sia positivo per almeno qualche
combinazione di prezzo e produzione deve essere rispettata la condizione
7 < X4
Altrimenti non esisterebbe nessun incentivo per le imprese ad entrare nel
mercato 91 . Supponiamo che la (7) sia soddisfatta. In un equilibrio con
aspettative perfettamente razionali, l’attesa di prezzo delle imprese sarà uguale
al prezzo che effettivamente verrà osservato, ossia P = P,e per ogni , e tutte
le imprese prendono la stessa decisione ottimale ∗%P,e & = ∗ per ogni , con
∗ ∈ ∗P. Seguendo la (5) dobbiamo distinguere due casi. Supponiamo in
91
La condizione (7) implica che quando la produzione nel mercato è zero il prezzo è maggiore di 2
rendendo la produzione conveniente. Elimina perciò la possibilità di un equilibrio in cui tutte le imprese producono zero. Si ottiene ponendo pari a zero la produzione di tutte le imprese nella (6) ed imponendo
che P = > 2.

107
primo luogo che il prezzo atteso sia maggiore di 2 . Allora dalla (5)
otteniamo che P,e = 2∗%P,e & , sapendo che P,e = P possiamo scrivere che
P = 2∗P. Inserendo questo risultato nella funzione di domanda inversa (6)
otteniamo, sapendo che tutte le imprese prendono la stessa decisione ottimale
∗P, la seguente relazione:
8 − < ∗P = 2∗P
Da cui troviamo la produzione di equilibrio
9 ∗ = ∗P = 2 + <
E dalla (3) il prezzo di equilibrio
10 P∗ = 22 + <
La (10) è maggiore di 2 se
11 < X2 + <X
D’altra parte se assumiamo che il prezzo sia inferiore a 2 otteniamo P∗ = ,
il quale è minore di 2 se
> X4
Che contraddice la condizione (7). Nel modello possono accadere due
situazioni diverse, dipendendo dal livello dei costi fissi: se la (11) è soddisfatta
esiste un unico equilibrio con aspettative razionali con prezzo di equilibrio
dato dalla (10) e produzione di equilibrio data dalla (9). Se la condizione (11)
non è soddisfatta (ma vale la (7)) non esiste nessun equilibrio nel modello.

108
Quando le imprese producono ∗ sono incentivate ad uscire dal mercato.
Quando la produzione diminuisce però il prezzo sale sopra la soglia di
profittabilità e le imprese sono incentivate ad entrare nel mercato (per una
trattazione dello stato senza equilibrio vedere Dawid e Kopel (1998)).
Supponiamo che i parametri assumano i seguenti valori:
= 5, = 0.25, = 1, = 5
Dove = <. È facile verificare che le condizioni (7) e (11) sono soddisfatte,
perciò esiste un equilibrio unico in cui la produzione è
∗ = ∗P∗ = 2 + = 57 = 0,714
Supponiamo di eliminare l’ipotesi di aspettative razionali e sostituiamo la
scelta degli agenti con una strategia determinata dagli algoritmi genetici. Ogni
impresa deve decidere di produrre una quantità di prodotto compresa tra
[0, \]92. La strategia delle imprese sarà codificata in una stringa binaria di DNA.
In particolare, data una stringa V , il prodotto è dato da V = \ dove
= ∑ 2doVq oK Vq ∈ 0,1 è il valore del j-esimo bit nella stringa k ed è la
lunghezza totale della stringa di DNA, che nel nostro caso è 10. sarà perciò
compreso tra
V = 0 0 0 0 0 0 0 0 0 0 → = 0
V = 1 1 1 1 1 1 1 1 1 1 → = 0,99902343893
Ogni stringa di DNA rappresenta una strategia produttiva, il risultato di ogni
strategia produttiva dipende dalla strategia adottata dalle altre imprese. Esiste
perciò una interazione indiretta tra le imprese. All’aumentare della produzione 92
è la produzione che condurrebbe il prezzo a 0 (vedi funzione di domanda inversa), può perciò
essere utilizzata come produzione massima. 93
Il valore di quando la stringa è formata da solo 1 è pari alla serie geometrica ∑ -K¢ = £d¤¥¦d .
Nel caso in esame la serie geometrica ha la seguente forma:
I 2 = 2du − 2u−1 = 0,999023438d
Kdu

109
totale si riduce il prezzo cambiando la strategia ottima delle imprese.
L’algoritmo genetico opera sulle imprese cercando la strategia migliore.
Riprendendo le argomentazioni di Vriend (2000), l’algoritmo genetico è una
forma di apprendimento sociale, è il sistema di imprese, oltre all’impresa
singola ad apprendere la strategia migliore. Il numero di geni in ogni stringa
non è decisivo per il successo dell’algoritmo genetico, determina invece lo
spazio in cui l’algoritmo genetico cerca il massimo (Arifovic et al. 1997).
4.4 La selezione Fondamentale nella codificazione delle strategie in stringhe genetiche è la
creazione di una misura di fitness. Sarà infatti la fitness a permettere la
selezione delle strategie migliori. La selezione opera in modo da dare una
probabilità maggiore di passare alla nuova generazione alle stringhe con
risultati migliori (Holland e Miller 1991). La misura più semplice di probabilità
proporzionale all’efficienza della stringa è
12 P7 = > <11∑ > <11oo
La probabilità di ogni impresa di essere selezionata è pari al rapporto tra la
fitness dell’impresa e la somma delle fitness di tutte le imprese presenti nel
sistema (“roulette wheel selection”94, Golberg 1989). Un altro meccanismo di
selezione è il “tournament selection”95. In questo tipo di selezione, ogni stringa
si confronta con un’altra stringa casuale nella popolazione, la stringa vincitrice
viene selezionata (Gilbert e Troitzsch 2005). Nel semplice modello economico
la misura di fitness più naturale è il profitto. È il profitto a misurare la
capacità di una impresa di adattarsi all’ambiente e di sopravvivere. Nel caso in
cui la strategia fosse errata le imprese potrebbero però incorrere in profitti
negativi. Perciò per poter utilizzare la formula (12) è necessario traslare la
funzione dei profitti in modo che sia sempre maggiore o uguale a zero. La
funzione di fitness sarà perciò:
94
“[Selection] operates like a biased roulette wheel. Each string is allocated a slot sized in proportion to
its fitness” (Arifovic 1995, p.226) 95
Utilizzato ad esempio in Arifovic (1997)

110
13 >§ = Π%P§, V& + + l\mX
Dove > indica la funzione di fitness per la stringa V, e § indica lo stato della
popolazione, ossia le stringhe presenti nelle altre imprese del sistema
economico. Il profitto dipende dal prezzo, il quale a sua volta dipende dalla
produzione totale (caratterizzata da § ), e dalla produzione dell’impresa, la
quale dipende direttamente dalla stringa V. Per traslare la funzione di fitness
si è aggiunto il massimo costo possibile per l’impresa, in questo modo se
l’impresa producesse il massimo quando il prezzo è zero, ossia se avesse il
profitto minimo ottenibile nel sistema descritto, la sua fitness sarebbe zero.96 È
da notare che sia la selezione probabilistica che la “tournament selection” non
scelgono la stringa migliore in assoluto ma le stringhe migliori nella
popolazione. Questo perché durante l’evoluzione del sistema è possibile che la
stringa migliore del periodo sia un massimo locale piuttosto che globale. Il
sistema scarterebbe perciò stringhe forse destinate a diventare le migliori,
riducendo l’efficienza dell’algoritmo genetico (Gilbert e Troitzsch 2005). Dal
punto di vista economico, la selezione può essere visto come l’imitazione da
parte delle imprese con risultati peggiori delle strategie delle imprese con
risultati migliori.
4.5 Il cross-over e la mutazione L’operatore genetico più importante è il cross-over (Gilbert e Troitzsch
2005). Il processo di cross-over viene eseguito in tre passi. In primo luogo
viene selezionata casualmente una coppia dalle stringhe derivanti dalla
selezione. Viene poi selezionato casualmente un punto di cross-over per ogni
coppia, ed infine con una probabilità P¨, vengono scambiate tra le due stringhe
originali i due segmenti alla destra del punto di cross-over creando due nuove
stringhe frutto della combinazione delle stringhe originali (Holland e Miller
1991).
96
In realtà il fitness sarebbe ≅ 0 dato che come è stato notato sopra le stringhe non possono ottenere il valore 1, ma solo un valore approssimato di 1

111
Figura 13. Cross-over singolo. Le stringhe risultato del cross-over saranno uguali alle stringhe originali con le parti a destra del punto di cross-over scambiate.
Si ritiene che per una maggiore efficienza dell’algoritmo genetico la probabilità
di cross-over debba essere maggiore di 0,5 (Bullard e Duffy 1998)97. Il processo
descritto è il cross-over singolo, è possibile immaginare anche un cross-over
che taglia le stringhe in due punti distinti, creando due segmenti e
scambiando questi due segmenti tra le stringhe. Esperimenti sui diversi tipi di
cross-over dimostrano che il tipo di cross-over scelto non è critico per i
risultati, importante è solo che l’operatore di cross-over mantenga un certo
numero di geni adiacenti per la generazione successiva (Gilbert e Troitzsch
2005). L’importanza di questi segmenti di geni è che essi rappresentano valori
di parametri che l’algoritmo genetico ha scoperto e selezionato, perciò parti di
codice di successo che vengono tramandati alla generazione successiva. Il
cross-over perciò riesce a creare diversità nella popolazione, mantenendo i
segmenti di geni selezionati.
L’ultimo operatore genetico è la mutazione. La mutazione cambia con
una certa probabilità ogni gene di ogni stringa risultante dal cross-over.
Quando la popolazione si evolve, vi sarà la tendenza di alcune stringhe di
diventare predominanti nella popolazione grazie alla selezione. Senza la
mutazione tali geni rimarrebbero immutati, e se tali geni fossero un massimo
locale, l’algoritmo genetico non riuscirebbe a svolgere propriamente
97
Non è raro trovare corss-over certi, ossia con una probabilità di cross-over pari ad 1, è il caso anche del modello costruito da Bullard e Duffy (1998)

112
l’ottimizzazione. Se l’ambiente è in evoluzione, un algoritmo genetico senza
mutazione e senza cross-over potrebbe trovare un massimo in un certo
periodo della simulazione, e a causa dell’omogeneità delle stringhe rimarrebbe
intrappolato in tale massimo impendendo l’adattamento delle strategie
all’evoluzione dell’ambiente. Dal punto di vista economico il cross-over può
essere interpretato come l’imitazione di parte delle strategie delle altre
imprese, mentre la mutazione può essere vista come la sperimentazione di
nuove strategie. I valori da dare alla probabilità di cross-over e mutazione non
sono univocamente determinati. In Goldberg (1989) viene dato il valore di 0,6
alla probabilità di cross-over e 0,0333 alla probabilità di mutazione, ma più in
generale si suggerisce:
“…that good GA [Genetic Algorithm] performance requires the choice of a high
cross-over probability, a low mutation probability (inversely proportional to the
population size), and a moderate population size”
(Goldberg 1989, p.71)
4.6 Risultati della simulazione Utilizziamo nel modello descritto nei paragrafi precedenti gli algoritmi
genetici98. Eliminiamo perciò l’ipotesi di razionalità perfetta e forniamo ad ogni
impresa una stringa di DNA che evolverà grazie agli algoritmi genetici.
Supponiamo di avere 1000 imprese ognuna con una stringa iniziale casuale. I
parametri della funzione di costo e della funzione di domanda sono = 5, = 0.25, = 1, = 5
Essendo = < = 5, = 0.005.Gli algoritmi genetici operano con la selezione
probabilistica descritta precedentemente, con una probabilità di cross-over di
0.6 ed una probabilità di mutazione di 0.002. Nel modello la tecnologia di
produzione delle imprese è la stessa. Ciò che rende diverse le imprese sono le
aspettative. Esse infatti formulano diverse aspettative di prezzo, differenti dalle
aspettative razionali, e su queste basano le loro strategie di produzione. Le
regole di selezione, cross-over e mutazione cercano di cogliere i meccanismi di
apprendimento degli agenti.
98
Il modello è stato scritto con NetLogo. Il codice si trova nell’appendice A4
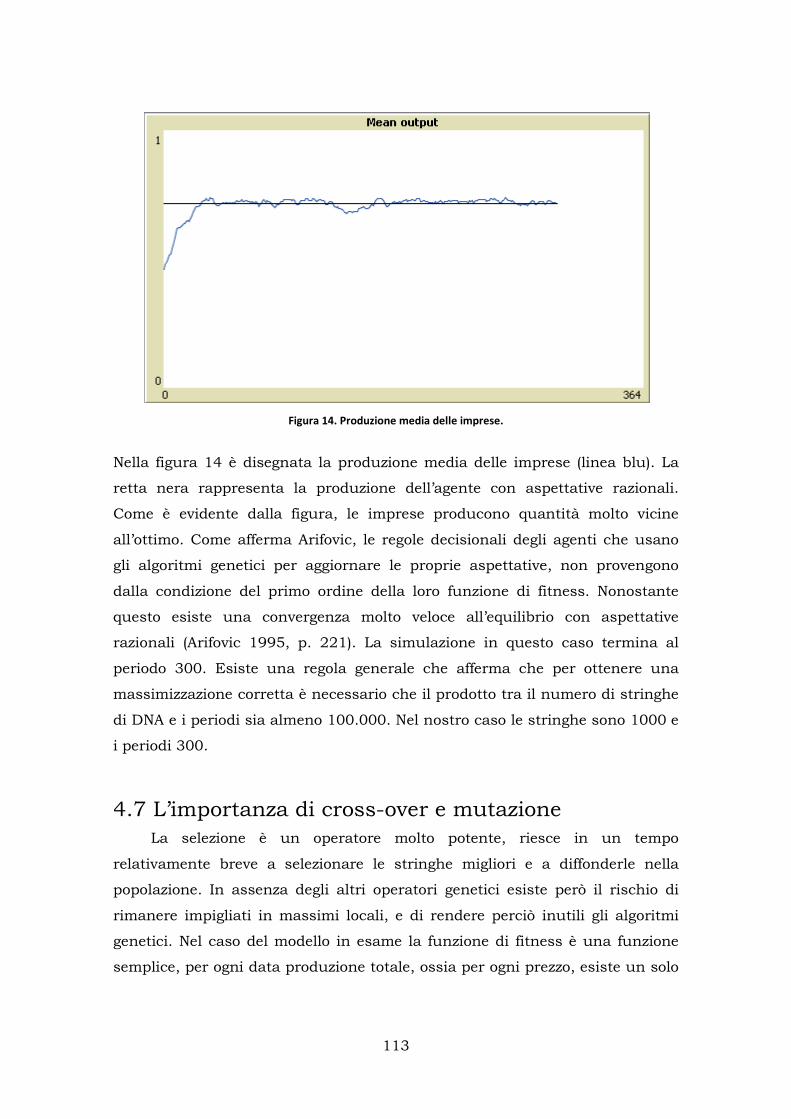
113
Figura 14. Produzione media delle imprese.
Nella figura 14 è disegnata la produzione media delle imprese (linea blu). La
retta nera rappresenta la produzione dell’agente con aspettative razionali.
Come è evidente dalla figura, le imprese producono quantità molto vicine
all’ottimo. Come afferma Arifovic, le regole decisionali degli agenti che usano
gli algoritmi genetici per aggiornare le proprie aspettative, non provengono
dalla condizione del primo ordine della loro funzione di fitness. Nonostante
questo esiste una convergenza molto veloce all’equilibrio con aspettative
razionali (Arifovic 1995, p. 221). La simulazione in questo caso termina al
periodo 300. Esiste una regola generale che afferma che per ottenere una
massimizzazione corretta è necessario che il prodotto tra il numero di stringhe
di DNA e i periodi sia almeno 100.000. Nel nostro caso le stringhe sono 1000 e
i periodi 300.
4.7 L’importanza di cross-over e mutazione La selezione è un operatore molto potente, riesce in un tempo
relativamente breve a selezionare le stringhe migliori e a diffonderle nella
popolazione. In assenza degli altri operatori genetici esiste però il rischio di
rimanere impigliati in massimi locali, e di rendere perciò inutili gli algoritmi
genetici. Nel caso del modello in esame la funzione di fitness è una funzione
semplice, per ogni data produzione totale, ossia per ogni prezzo, esiste un solo
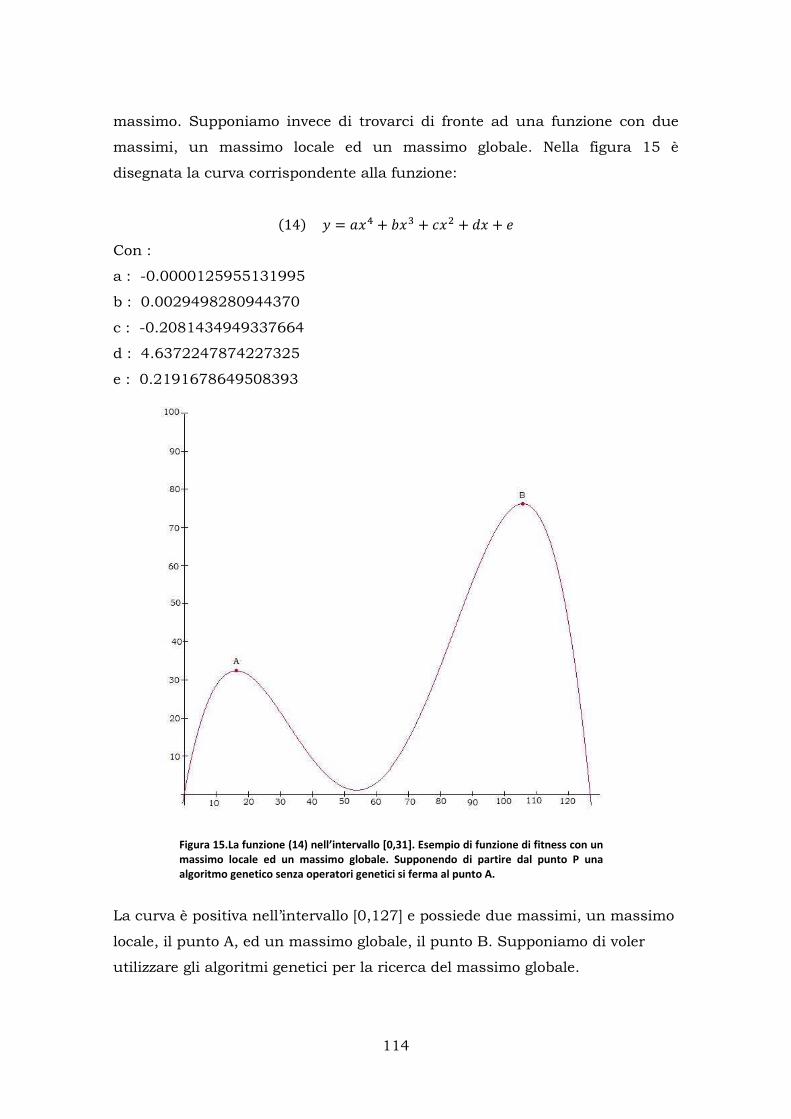
114
massimo. Supponiamo invece di trovarci di fronte ad una funzione con due
massimi, un massimo locale ed un massimo globale. Nella figura 15 è
disegnata la curva corrispondente alla funzione:
14 = ª + | + X + B +
Con :
a : -0.0000125955131995
b : 0.0029498280944370
c : -0.2081434949337664
d : 4.6372247874227325
e : 0.2191678649508393
Figura 15.La funzione (14) nell’intervallo [0,31]. Esempio di funzione di fitness con un massimo locale ed un massimo globale. Supponendo di partire dal punto P una algoritmo genetico senza operatori genetici si ferma al punto A.
La curva è positiva nell’intervallo [0,127] e possiede due massimi, un massimo
locale, il punto A, ed un massimo globale, il punto B. Supponiamo di voler
utilizzare gli algoritmi genetici per la ricerca del massimo globale.

115
Costruiamo un algoritmo genetico con 1000 stringhe99, formate ognuna
da sette geni. L’algoritmo genetico è perciò codificato in modo da estendere la
ricerca a tutto l’intervallo [0, 127] 100, lo stesso intervallo in cui la curva è
maggiore di zero. Normalmente nello stato iniziale le stringhe sono
completamente casuali. In questo caso riduciamo l’ampiezza della casualità
delle stringhe imponendo a tutte le stringhe di iniziare nell’intervallo [0,15].
Questo significa che i primi tre bit (geni) saranno zero, mentre i restanti
saranno casuali. Nella simulazione seguente prenderemo in considerazione
due casi: uno con operatori genetici ed uno senza. Quando presente la
probabilità di cross-over è 0.6, la probabilità di mutazione è 0.002; entrambe
le simulazioni terminano nel periodo 200.
Figura 16. Sopra gli algoritmi genetici con cross-over e mutazione, sotto gli algoritmi genetici senza cross-over e mutazione. La linea nera rappresenta la fitness dell'algoritmo con fitness massimo nella popolazione. Entrambe le simulazioni partono da una fitness pari alla fitness massima presente nello spazio iniziale. Nella figura a destra è evidente come l’algoritmo scopra la presenza di un massimo globale diverso da quello in cui si trova.
99
Per costruire il codice di questo algoritmo genetico è sufficiente riferirsi al codice del modello economico e cambiare le parti necessarie. L’unica variazione fondamentale è la funzione di fitness che deve essere sostituita con la curva (14). 100
Ogni DNA codifica un numero binario di 7 cifre. L’intervallo di ricerca in binario è tra 0000000 e 1111111

116
Nella figura 16 è disegnata l’evoluzione del fitness nel caso in cui siano
operativi cross-over e mutazione e nel caso in cui siano esclusi. È’ evidente
come nel primo caso, l’algoritmo si sposta dal massimo in A al massimo in B.
La condizione iniziale è costruita in modo che l’algoritmo genetico trovi subito
il massimo locale in A. Dopo un certo numero di periodi (che varia ad ogni
simulazione) l’algoritmo genetico riesce sempre a trovare il massimo globale.
Nel secondo caso, quando vengono esclusi il cross-over e la mutazione,
l’algoritmo rimane (rimarrà per sempre) nel minimo locale in A. Questo perché
senza cross-over e mutazione (in particolare senza mutazione) l’algoritmo
genetico non riesce ad effettuare la ricerca in tutto lo spazio, ma solo nello
spazio già selezionato (in questo caso artificialmente, ma è ovvia l’estensione al
caso in cui è l’algoritmo genetico stesso a selezionare le stringhe
corrispondenti ad un massimo, per poi scoprire che tale massimo è locale).
L’algoritmo genetico nel secondo caso non funziona.
Sperimentiamo ora l’assenza degli operatori genetici nel modello
economico presentato in precedenza, nel caso in cui avvenga una variazione
dei parametri economici. Supponiamo ad esempio che nel periodo 250 vi sia
un aumento (imprevisto) dei costi variabili da 1 ad 1.5. Dato che gli altri
parametri rimangono invariati, la produzione ottima dell’agente razionale si
sposta da «¬ = 0,714 a
∗ = ∗P∗ = 2 + = 58 = 0,625
Dato che nello stato iniziale le stringhe sono completamente casuali, nella
popolazione è rappresentato tutto lo spazio di strategie possibili. La selezione
opera selezionando le stringhe migliori e conduce la produzione media delle
imprese attorno all’ottimo dell’agente con aspettative razionali. Quando
avviene la variazione del parametro la produzione ottima si sposta in basso.
In presenza di cross-over e selezione l’algoritmo genetico riesce a spostare la
produzione media raggiungendo l’ottimo in un numero di periodi relativamente
basso (figura 17). Quando gli operatori genetici sono esclusi invece l’algoritmo
genetico non riesce ad ottimizzare la produzione (figura 18).

117
Figura 17. Variazione dei costi variabili nel periodo 250. la linea blu rappresenta il prodotto medio delle imprese, la retta nera rappresenta la produzione dell'impresa perfettamente razionale. Sono attivi tutti gli operatori genetici
Figura 18. Stessa situazione della figura precedente. In questo caso però sono stati esclusi il cross-over e la mutazione.
Come è stato affermato in precedenza, la selezione probabilistica adottata
riesce a mantenere un certo grado di diversità nella popolazione. La selezione
opera in modo da selezionare le stringhe più vicine al nuovo ottimo
abbassando la produzione media, ma non riesce a raggiungere il nuovo ottimo.
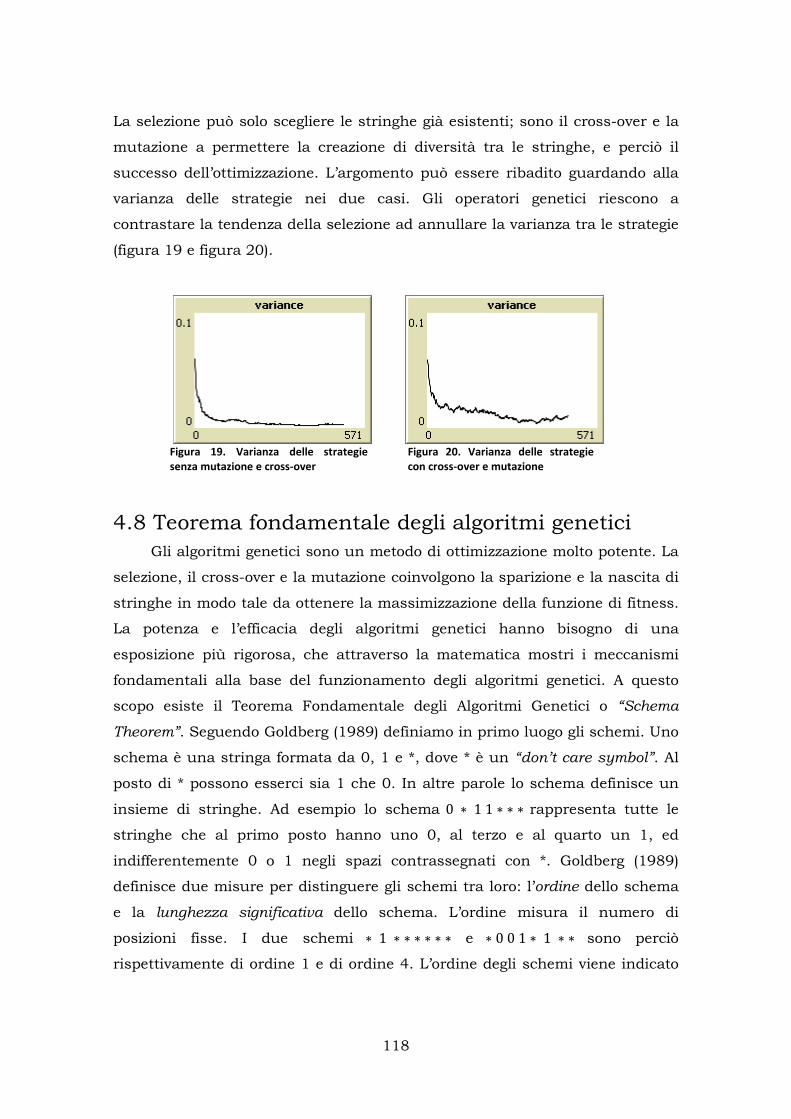
118
La selezione può solo scegliere le stringhe già esistenti; sono il cross-over e la
mutazione a permettere la creazione di diversità tra le stringhe, e perciò il
successo dell’ottimizzazione. L’argomento può essere ribadito guardando alla
varianza delle strategie nei due casi. Gli operatori genetici riescono a
contrastare la tendenza della selezione ad annullare la varianza tra le strategie
(figura 19 e figura 20).
Figura 19. Varianza delle strategie senza mutazione e cross-over
Figura 20. Varianza delle strategie con cross-over e mutazione
4.8 Teorema fondamentale degli algoritmi genetici Gli algoritmi genetici sono un metodo di ottimizzazione molto potente. La
selezione, il cross-over e la mutazione coinvolgono la sparizione e la nascita di
stringhe in modo tale da ottenere la massimizzazione della funzione di fitness.
La potenza e l’efficacia degli algoritmi genetici hanno bisogno di una
esposizione più rigorosa, che attraverso la matematica mostri i meccanismi
fondamentali alla base del funzionamento degli algoritmi genetici. A questo
scopo esiste il Teorema Fondamentale degli Algoritmi Genetici o “Schema
Theorem”. Seguendo Goldberg (1989) definiamo in primo luogo gli schemi. Uno
schema è una stringa formata da 0, 1 e *, dove * è un “don’t care symbol”. Al
posto di * possono esserci sia 1 che 0. In altre parole lo schema definisce un
insieme di stringhe. Ad esempio lo schema 0 ∗ 1 1 ∗ ∗ ∗ rappresenta tutte le
stringhe che al primo posto hanno uno 0, al terzo e al quarto un 1, ed
indifferentemente 0 o 1 negli spazi contrassegnati con *. Goldberg (1989)
definisce due misure per distinguere gli schemi tra loro: l’ordine dello schema
e la lunghezza significativa dello schema. L’ordine misura il numero di
posizioni fisse. I due schemi ∗ 1 ∗ ∗ ∗ ∗ ∗ ∗ e ∗ 0 0 1 ∗ 1 ∗ ∗ sono perciò
rispettivamente di ordine 1 e di ordine 4. L’ordine degli schemi viene indicato

119
con ®, dove H rappresenta lo schema. La seconda misura è la lunghezza
significativa (“defining lenght”) dello schema H, denotata con ¯®. La misura
prende in considerazione la distanza tra la prima e l’ultima posizione fissa. Lo
schema ∗ 0 0 1 ∗ 1 ∗ ∗ ad esempio avrà lunghezza significativa ¯ = 4, dato che
la prima posizione fissa si trova in 2 e l’ultima in 6, e ¯ = 6 − 2; la lunghezza
significativa di ∗ 1 ∗ ∗ ∗ ∗ ∗ ∗ è invece ¯ = 0 . Le misure definite sono importanti
per distinguere i diversi tipi di schema e per misurare l’effetto che selezione,
cross-over e mutazione hanno sui diversi tipi di schemi.
L’effetto della selezione è relativamente semplice da determinare.
Supponiamo di essere nel periodo , e che nella popolazione vi siano Y
stringhe di un particolare schema H, possiamo scrivere Y = Y ®, .
Supponiamo che la selezione avvenga in modo probabilistico, perciò la
probabilità che una particolare stringa nella popolazione sia selezionata è
pari a P = > ∑ >o⁄ , dove > rappresenta il valore del fitness della generica stringa
. Allora il numero atteso di stringhe appartenenti allo schema ® , se la
popolazione totale di stringhe è <, possiamo scriverla come:
Y®, + 1 = Y®, ∙ < ∙ >®∑ >o
Dove >®è la fitness media delle stringhe appartenenti allo schema H nel
periodo . Dato che la fitness media dell’intera popolazione può essere scritta
come >° = ∑ >o <⁄ , possiamo riscrivere il numero atteso di stringhe appartenenti
allo schema H nel periodo + 1 come:
Y®, + 1 = Y®, ∙ >®>°
In altre parole lo schema cresce se la sua fitness media è maggiore della
fitness media della popolazione, e decresce se la sua fitness media è minore
della fitness media della popolazione.
Per comprendere come un dato schema sia influenzato dal cross-over
consideriamo una particolare stringa e due schemi di una popolazione di
stringhe con 7 geni:

120
~ = 0 1 1 1 0 0 0
® = ∗ 1 ∗ ∗ ∗ ∗ 0
®X = ∗ ∗ ∗ 1 0 ∗ ∗
Evidentemente la stringa ~ fa parte sia dello schema ® che dello schema ®X.
Supponiamo che la stringa ~ sia stata scelta come compagno di cross-over per
un’altra stringa della popolazione, e supponiamo che il punto di cross-over,
casuale sia 3, ossia le stringhe si scambieranno i geni alla destra del terzo
gene:
~ = 0 1 1 | 1 0 0 0
® = ∗ 1 ∗ | ∗ ∗ ∗ 0
®X = ∗ ∗ ∗ | 1 0 ∗ ∗
Se l’altra stringa con cui viene effettuato il cross-over è diversa da ~ , lo
schema ® viene distrutto dato che le posizioni fisse verranno posizionate in
stringhe diverse. Essendo su parti opposte del punto di cross-over, lo schema
viene diviso in due e distrutto. Lo schema ®X invece sopravvivrà, dato che le
posizioni fisse si trovano dalla stessa parte del punto di cross-over. Qualsiasi
sia la stringa partner del cross-over, darà sicuramente vita ad una stringa
appartenente allo schema ®X , dato che una delle parti del cross-over è
completamente libera di assumere qualsiasi valore. Se il punto di cross-over
viene scelto come una variabile casuale uniforme tra tutte le posizioni possibili
nella stringa, è evidente che lo schema ® ha una probabilità di essere
distrutto pari al rapporto tra la lunghezza significativa e la lunghezza totale
dello schema. Lo schema viene infatti distrutto se il punto di cross-over si
trova tra due posizioni fisse, la probabilità che questo avvenga aumenta
all’aumentare della lunghezza significativa:
P± =¯(®)
( − 1)=
5
6
La probabilità di distruzione dello schema ®X è invece:

121
P± = ¯®X − 1 = 16
La probabilità che il punto di cross-over si trovi esattamente tra il gene 4 e il
gene 5 è 1 rispetto alla numerosità dell’insieme di tutti i possibili punti di
cross-over pari a 6. Più in generale possiamo costruire una probabilità minima
di sopravvivenza P0 per ogni schema. Dato che uno schema qualsiasi
sopravvive se il punto di cross-over si trova al di fuori della lunghezza
significativa, la probabilità di sopravvivenza sarà pari a
P0 = 1 − ¯® − 1
Dove naturalmente P0 = 1 − P± . Se il cross-over viene esso stesso eseguito
casualmente, la probabilità di sopravvivenza è data da:
P0 = 1 − P¨ ∙ ¯® − 1
Dove P¨ è la probabilità che il cross-over avvenga. Consideriamo ora l’effetto di
selezione e cross-over e scriviamo l’espressione che denota il numero atteso di
stringhe appartenenti ad un dato schema nel periodo + 1. Supponendo che le
operazioni di cross-over e di selezione siano indipendenti otteniamo:
Y®, + 1 ≥ Y®, ∙ >®>° ²1 − P¨ ∙ ¯® − 1³
Il numero di stringhe dello schema H nel periodo + 1 sarà pari al numero
atteso di stringhe selezionate moltiplicato per la probabilità di sopravvivenza di
tali stringhe al cross-over.
L’ultimo operatore da prendere in considerazione è la mutazione. La
mutazione è una alterazione casuale di un gene con probabilità P¢ . La
probabilità di sopravvivere per uno schema è equivalente alla probabilità che
le sue posizioni fisse non subiscano la mutazione. Moltiplicando la probabilità
che la mutazione non avvenga 1 − P¢ per se stesso, per un numero di volte

122
pari all’ordine dello schema ®, otteniamo la probabilità che lo schema non
venga distrutto dalla mutazione, 1 − P¢´µ . Per valori molto piccoli di
P¢ P¢ << 1 , la probabilità di sopravvivenza dello schema può essere
approssimata dall’espressione 1 − ®P¢. Il teorema fondamentale degli
algoritmi genetici afferma perciò che il numero atteso di stringhe appartenenti
ad uno schema H, con selezione, cross-over e mutazione è dato dalla seguente
equazione101:
Y®, + 1 ≥ Y®, ∙ >®>° ²1 − P¨ ∙ ¯® − 1 − ®P¢³ Gli schemi corti, con basso ordine e alta fitness ricevono una proporzione di
“rappresentanti” nella generazione successiva crescente (Goldberg 1989). Lo
Schema Theorem rende analiticamente evidente ciò che avviene nel computer
quando si esegue un algoritmo genetico. La selezione è l’operatore
fondamentale per l’aumento delle stringhe con fitness alta nella popolazione.
Tale aumento può essere visualizzato con un esempio in Goldberg (1989).
Supponiamo di avere uno schema H con una fitness >® = 1 + >°°102 .
Possiamo riscrivere l’equazione alle differenze, con la sola selezione, come
segue:
Y®, + 1 = Y®, >° + >°>° = 1 + ∙ Y®,
Iniziando nel periodo = 0, e supponendo che il valore di rimanga invariato,
otteniamo l’equazione:
Y®, = Y®, 0 ∙ 1 +
L’effetto della riproduzione è ora quantitativamente chiaro; la riproduzione
permette un aumento (diminuzione) esponenziale del numero di
rappresentanti degli Schemi con una fitness maggiore (minore) della media
(Goldberg 1989, p.30). Naturalmente, nell’esecuzione effettiva di un algoritmo
101
Si ignora il termine Y®, ∙ ¶µ¶° ∙ P¨ ∙ ·µ d ∙ ®P¢. In Goldeberg (1989): “Ignoring small cross-
product terms”. 102
Dato che la fitness non può essere negativa deve valere > −1
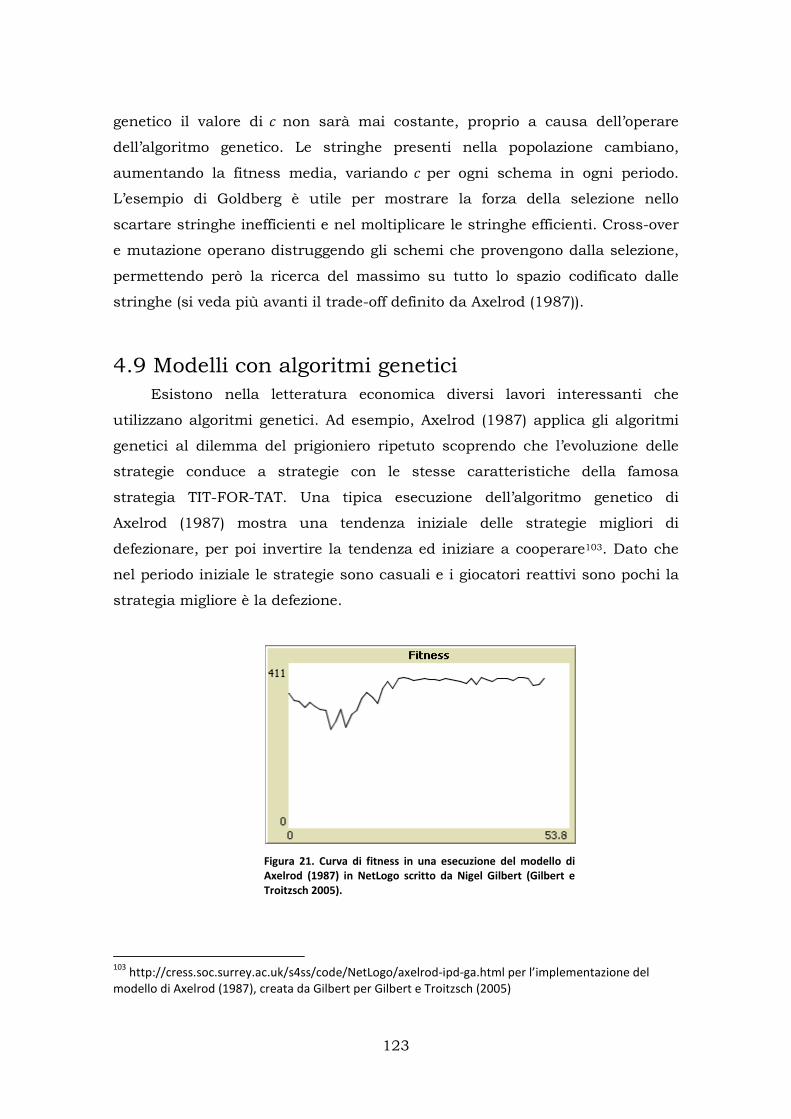
123
genetico il valore di non sarà mai costante, proprio a causa dell’operare
dell’algoritmo genetico. Le stringhe presenti nella popolazione cambiano,
aumentando la fitness media, variando per ogni schema in ogni periodo.
L’esempio di Goldberg è utile per mostrare la forza della selezione nello
scartare stringhe inefficienti e nel moltiplicare le stringhe efficienti. Cross-over
e mutazione operano distruggendo gli schemi che provengono dalla selezione,
permettendo però la ricerca del massimo su tutto lo spazio codificato dalle
stringhe (si veda più avanti il trade-off definito da Axelrod (1987)).
4.9 Modelli con algoritmi genetici Esistono nella letteratura economica diversi lavori interessanti che
utilizzano algoritmi genetici. Ad esempio, Axelrod (1987) applica gli algoritmi
genetici al dilemma del prigioniero ripetuto scoprendo che l’evoluzione delle
strategie conduce a strategie con le stesse caratteristiche della famosa
strategia TIT-FOR-TAT. Una tipica esecuzione dell’algoritmo genetico di
Axelrod (1987) mostra una tendenza iniziale delle strategie migliori di
defezionare, per poi invertire la tendenza ed iniziare a cooperare103. Dato che
nel periodo iniziale le strategie sono casuali e i giocatori reattivi sono pochi la
strategia migliore è la defezione.
Figura 21. Curva di fitness in una esecuzione del modello di Axelrod (1987) in NetLogo scritto da Nigel Gilbert (Gilbert e Troitzsch 2005).
103
http://cress.soc.surrey.ac.uk/s4ss/code/NetLogo/axelrod-ipd-ga.html per l’implementazione del modello di Axelrod (1987), creata da Gilbert per Gilbert e Troitzsch (2005)

124
Quando si iniziano a sviluppare strategie che rispondono alla
cooperazione quando trovano cooperazione, iniziano a nascere strategie
reattive che guadagnano dalla mutua cooperazione ma non si fanno ingannare
da un giocatore che defeziona. La curva di utilità dei giocatori perciò
inizialmente decresce (defezione), per poi invertire la tendenza ed iniziare a
crescere (inizia la cooperazione) (Axelrod 1987 p. 11, Gilbert e Troitzsch 2005
p.248).
Un modello interessante che utilizza gli algoritmi genetici è possibile
trovarlo in Arifovic (1995). Il modello rappresenta una economia in cui vi sono
due generazioni sovrapposte, e studia il comportamento degli algoritmi genetici
in economie con moneta del tipo “fiat money”, confrontando i risultati con
altri algoritmi di apprendimento. Le stringhe codificano il consumo degli agenti
nel primo periodo, determinando il risparmio. Le dotazioni di ogni periodo
sono date ed i prezzi dipendono dall’offerta di moneta e dal risparmio
complessivo nel periodo. Vengono considerate due regole di politica
economica, una in cui l’offerta di moneta è costante, l’altra con un deficit
costante dell’autorità di politica economica finanziato con il signoraggio. Nel
primo scenario, con offerta di moneta costante, la simulazione converge ad un
unico equilibrio stazionario con livello dei prezzi costanti. Il risultato è
consistente con i modelli che utilizzano l’insieme dei prezzi dei periodi
precedenti per la previsione e con gli esperimenti con soggetti umani. Nel
secondo scenario, con deficit costante finanziato con signoraggio, gli algoritmi
genetici convergono ad un equilibrio con bassa inflazione, equilibrio che
risulta instabile nei modelli con perfetta razionalità, e localmente stabile con
l’apprendimento dei minimi quadrati con bassi deficit. Il tasso di inflazione
registrato negli esperimenti con soggetti umani converge anch’esso al un tasso
di equilibrio con bassa inflazione. Gli algoritmi genetici riescono a catturare
meglio le fluttuazioni del tasso di inflazione registrate nelle economie
sperimentali (Arifovic 1995). Un modello simile a quello di Arifovic (1995) è
Bullard e Duffy (1998), i quali estendono lo studio ad una economia con <
generazioni sovrapposte. In questo caso la stringa genetica rappresenta la
strategia utilizzata per prevedere il prezzo nei periodi futuri, e quindi
impostare il consumo ottimo rispetto a tale attesa (non direttamente il
consumo del primo periodo, la diversità è dovuta anche all’esigenza di

125
modellare agenti che vivono < periodi). La stringa genetica utilizzata, formata
da 21 geni, indica quali periodi devono essere presi in considerazione nella
regola di previsione. Sono possibili tre risultati: una convergenza delle
aspettative e del sistema verso una situazione di bassa inflazione, una
convergenza verso una situazione di alta inflazione, nessuna convergenza. A
differenza del modello di Arifovic (1995) in cui ogni agente sceglieva la propria
strategia solo alla nascita (“nonoverlapping information”, ossia coloro che
tramandano la propria strategia muoiono subito dopo averla tramandata), in
Bullard e Duffy (1998) la strategia di previsione del prezzo viene aggiornata ad
ogni periodo della simulazione; gli agenti perciò hanno la possibilità di
emulare gli altri agenti presenti (vivi) nell’economia. Un aspetto molto
interessante dal punto di vista dell’algoritmo genetico utilizzato è l’aggiunta di
un passaggio ai tre studiati nei paragrafi precedenti. Oltre a selezione, cross-
over e mutazione, Arifovic (1995) introduce l’elezione (confermata in Bullard e
Duffy (1998)). L’elezione è un particolare operatore genetico che opera dopo
selezione, cross-over e mutazione, e che, confrontando le stringhe originali con
le stringhe derivanti da cross-over e mutazione, sceglie la stringa con una
fitness migliore. Nelle parole di Arifovic che ha sviluppato l’elezione:
It is a form of an elitist selection procedure which reduces the effects of the
mutation operator over the course of a simulation
(Arifovic 1995, nota 5, p. 227)
Per chiarire come funziona l’elezione ne descriviamo l’uso fatto in Arifovic
(1995). Supponiamo che su una popolazione di stringhe sia stata effettuata la
selezione delle stringhe migliori. Le stringhe vengono accoppiate casualmente,
viene effettuato il cross-over e la mutazione creando due nuove stringhe.
L’elezione confronta la fitness effettiva delle stringhe originali e la fitness
potenziale delle stringhe nuove (ossia misura la fitness prodotta dalla strategia
nella situazione ambientale in cui hanno operato le stringhe originali). Le due
stringhe migliori (entrambe le originali, scartando le due stringhe nuove,
oppure entrambe le nuove, o, ancora una delle nuove ed una delle originali)
saranno le stringhe tramandate alla nuova generazione. L’elezione è un
passaggio interessante in quanto, mantenendo l’elemento innovatore della

126
mutazione, evita che stringhe inefficienti vengano inserite nella popolazione. In
qualche modo si supera il trade-off intrinseco agli algoritmi genetici,
sottolineato da Axelrod (1987). All’aumentare della probabilità di mutazione
migliora l’esplorazione dello spazio in cui si massimizza, ma peggiora la
possibilità di sfruttare le strategie già presenti nella popolazione (Axelrod
1987, p.15) 104 . È da verificare però che non vi siano effetti perversi
sull’evoluzione della popolazione influenzando l’ambiente dove vive l’agente. Il
fatto che alcune stringhe inferiori non vedono la luce può avere effetti
sull’evoluzione dell’ambiente e perciò sul processo di massimizzazione
dell’utilità. Se ad esempio utilizzassimo l’elezione nel modello di Axelrod
(1987), potrebbe accadere che la massimizzazione divenga inefficiente. Come
abbiamo visto nel modello di Axelrod nei periodi iniziali la strategia migliore è
la defezione. Il fatto che nella popolazione nascano stringhe, non ancora
ottime, che comprendano un certo grado di cooperazione, rende le strategie di
cooperazione vantaggiose. Se tali stringhe non vedessero la luce potremmo
rimanere in una situazione di perenne defezione, proprio a causa dell’elezione.
Quando le strategie degli altri agenti influiscono direttamente sulla funzione di
fitness è possibile che l’elezione abbia effetti perversi.
Un modello interessante, sia per le implicazioni economiche che per
l’implementazione degli algoritmi genetici, è illustrato in Arifovic et al. (1997).
È noto che tutte le economie attualmente industrializzate sono partite da
situazioni di stagnazione e bassa crescita (Maddison 1982). Inoltre
considerando i dati recenti, è evidente un’ampia e persistente differenza di
reddito tra paesi poveri e paesi ricchi (Milanovic 2006). Il limite dei modelli di
crescita endogena, che tentano di spiegare la non convergenza dei sistemi
economici, è che non riescono a comprendere come un dato sistema
economico possa passare da uno stato di stagnazione e bassa crescita, ad uno
stato di alta crescita. Arifovic et al. (1997) tenta di dare una risposta al
problema costruendo un modello economico con esternalità del capitale
sociale, in cui le scelte degli agenti sono codificate da un algoritmo genetico.
Gli agenti sono eterogenei e vivono per due periodi. In ogni periodo esistono
perciò F agenti “giovani” ed F agenti “anziani”. Gli agenti possono decidere 104
“there is an inherent tradeoff for a gene pool between exploration of possibilities (best done with a
high mutation rate), and exploitation of the possibilities already contained in the current gene pool (best
done with a low mutation rate)” (Axelrod 1987, p.15)

127
quanto tempo dedicare alla formazione da giovani e quanto risparmiare.
L’utilità dipende dal consumo. L’esternalità si riflette sul capitale umano
tramite una funzione di produzione di capitale umano che include il livello
medio di capitale umano nell’economia. All’aumentare del capitale umano già
presente nell’economia, aumenta la produttività di ogni unità di tempo
dedicata alla formazione. Nel modello sono possibili due equilibri, un equilibrio
con bassa crescita caratterizzato da una scelta di investimento in formazione
nullo, ed un equilibrio con alta crescita in cui gli agenti scelgono di investire
una parte positiva della propria dotazione di tempo in formazione. Il risultato
mostra come economie che partono da situazioni iniziali identiche (a parte il
random seed che caratterizza le stringhe iniziali), sperimentano la transizione
in periodi molto diversi della simulazione. Nel momento in cui gli agenti
iniziano ad investire in formazione si avvia un circolo virtuoso che porta
l’economia ad ottenere alti livelli di crescita. Uno degli aspetti interessanti del
modello è come Arifovic implementa nell’algoritmo genetico la doppia scelta a
disposizione degli agenti. Ogni agente possiede una stringa unica di 30 geni.
La scelta di formazione e risparmio deve essere tramandata alle generazioni
future congiuntamente, è perciò appropriata la scelta della stringa unica. Tale
stringa rappresenta nei primi 15 geni la scelta della quantità di tempo da
dedicare alla formazione, e negli ultimi 15 geni la scelta di risparmio. La
selezione avviene con la “tournament selection” confrontando le prestazioni
delle strategie codificate nella stringa unica. Il cross-over avviene considerando
le due sottostringhe da 15 geni separate. Gli agenti avranno perciò due punti
di cross-over casuali, il primo tra i primi 15 geni ed il secondo tra gli ultimi 15,
e si scambieranno i geni come il cross-over tradizionale, considerando le
sottostringhe come stringhe separate. La mutazione avviene, come di
consueto, dando una data probabilità ad ogni gene di mutare.
5. Complessità ed Emergenza Una definizione precisa di complessità non è immediata. Autorevoli
scienziati, come ad esempio Gell–Mann (1995), hanno messo in luce la
difficoltà di una definizione chiara, quantitativa e generale del concetto di
complessità – e paradossalmente, anche il concetto di semplicità sembra
piuttosto difficile da definire accuratamente. La complessità è un concetto che

128
appare in diverse discipline, dalla fisica alla biologia, dalla sociologia
all’economia; tale estensione del concetto crea ulteriori difficoltà 105 . Nella
definizione di complessità data in questo capitolo (vedere in particolare
Testfatsion 2005, p.4 e Terna 2006, p.20) si pone particolare risalto alla
composizione di un sistema complesso, formato da una miriade di elementi
che interagendo creano regolarità aggregate che non sono direttamente
deducibili dalle proprietà delle unità elementari del sistema. Diverse definizioni
di complessità possono essere trovate in Fromm (2004), ed un lavoro
interessante sul dibattito è Rosser (1999)106. Senza entrare in un dibattito
ampio e… complesso, si vuole sottolineare un elemento centrale dei sistemi
complessi e di grande importanza per lo studio dell’economia come sistema
complesso: l’emergenza.
Nella definizione data da Gilbert (2004) un fenomeno aggregato è
emergente quando può essere descritto e caratterizzato usando termini e
misure che sono inappropriate o impossibili da applicare sulle singole
componenti (Gilbert 2004, p. 3). L’emergenza è perciò quel fenomeno che
caratterizzando i sistemi complessi ne impedisce uno studio riduzionistico. A
causa delle dinamiche interne al sistema, le proprietà del sistema a diversi
livelli di aggregazione sono diverse, impedendo lo studio isolato delle unità
elementari. Se si accetta la definizione del sistema economico come un sistema
complesso, è necessario adottare strumenti adatti allo studio dei sistemi
complessi: la simulazione ad agenti (Fromm 2004107, Terna 2006). Dato che le
proprietà del sistema economico variano al variare del livello di osservazione,
non è possibile indurre dalle proprietà degli elementi le proprietà
dell’aggregato, e non è possibile dedurre dalle proprietà aggregate le proprietà
degli elementi. L’unico modo per ottenere una descrizione della realtà è tentare
di riprodurre i fenomeni complessi reali attraverso la simulazione ad agenti,
osservando come le proprietà emergenti si formano a partire dalle proprietà
105
Ulteriori rispetto alle normali difficoltà di definizione dei concetti. Come afferma Murray Gell-Mann, esiste diffidenza tra i ricercatori ad utilizzare nomenclature create da altri ricercatori: It is worth
remarking for readers of this journal that John Holland, for example, uses a different set of terms to
describe some of the same ideas. […] Both of us are conforming to the old saying that a scientist would
rather use someone else's toothbrush than another scientist's nomenclature. 106
Un riferimento ormai fondamentale per lo studio della complessità come ricerca interdisciplinare è il Santa Fe Insitute. http://www.santafe.edu/ 107
“The right kind of tools to model and simulate complex system are Multi Agent Systems and Cellular Automata” (Fromm 2004, p.16). Gli automi cellulari sono un particolare tipo di Multi Agent System.

129
elementari delle unità che formano il sistema. Tramite la costruzione di
modelli ad agenti è possibile disegnare un mondo microeconomico che faccia
emergere le variabili macroeconomiche (o meglio le relazioni tra le variabili
macroeconomiche) osservate.
Il concetto di emergenza non è esente da dibattito. La definizione data da
Gilbert (2004) è una definizione che può comprendere due concetti distinti di
emergenza: l’emergenza forte e l’emergenza debole. Definizioni di questi due
concetti di emergenza sono date in Chalmers (2006):
We can say that a high-level phenomenon is strongly emergent with respect to a
low-level domain when the high-level phenomenon arises from the low-level
domain, but truths concerning that phenomenon are not deducible even in
principle from truths in the low-level domain […] We can say that a high-level
phenomenon is weakly emergent with respect to a low-level domain when the
high-level phenomenon arises from the low-level domain, but truths concerning
that phenomenon are unexpected given the principles governing the low-level
domain.
(Chalmers 2006, p. 1)
Chalmers (2006) sostiene che esiste solamente un tipo di emergenza forte: la
consapevolezza di sé (“consciousness”); il sistema cervello, formato da
meccanismi ed unità elementari riconosce se stesso e riesce a creare una
rappresentazione di se stesso. Tale emergenza è completamente inspiegabile
guardando agli elementi costitutivi del cervello. Come afferma in modo critico
Bedau (1997):
Although strong emergence is logically possible, it is uncomfortably like magic.
How does an irreducible but supervenient downward causal power arise, since
by definition it cannot be due to the aggregation of the micro-level potentialities?
Such causal powers would be quite unlike anything within our scientific ken.
(Bedau 1997, p. 4)
L’emergenza debole è il concetto fondamentale per lo studio dei sistemi
complessi normalmente studiati (economia, sociologia, fisica etc.). La

130
differenza fondamentale è la rilevanza scientifica dei due concetti di
emergenza. L’emergenza debole infatti è riconducibile alle parti che
compongono il sistema, ed è per questo analizzabile. Le proprietà tra i diversi
livelli del sistema sono diverse (vale perciò la definizione di Gilbert), ma tali
proprietà aggregate (emergenti) non sono altro che il risultato delle proprietà
micro del sistema. Le proprietà aggregate, emergenti semplici, possono essere
ricondotte al livello di unità elementari e possono essere riprodotte tramite la
simulazione108. La distinzione non ha interesse meramente filosofico. Il fatto
che i sistemi economici facciano parte dei sistemi caratterizzati da emergenza
debole permette di comprendere tali proprietà emergenti. Se il fine ultimo
dell’economia è comprendere i fatti economici, per controllarli e prevederli, la
caratteristica dell’emergenza debole permette di sperare in un futuro in cui gli
eventi aggregati possano essere compresi grazie alla comprensione dei
fenomeni micro.
Although perhaps unfamiliar, the idea of a macrostate being derived "by
simulation" is straightforward and natural. Given a system's initial condition
and the sequence of all other external conditions, the system's microdynamic
completely determines each successive microstate of the system.
(Badau 1997, p. 6)
La discussione è importante inoltre perché richiama le affermazioni di
Lembruni e Richiardi (2005), riportate nel paragrafo 2.1. La simulazione non è
magia, i risultati sono diretta e necessaria conseguenza della costruzione del
modello di simulazione, e per questo è possibile verificare quali siano le leggi
che provocano un dato risultato. La simulazione, se utilizzata in modo
scientifico e rigoroso, è uno strumento che apre orizzonti completamente nuovi
alla ricerca economica e non solo.
108
La definizione di emergenza semplice di Bedau: “Macrostate P of S with microdynamic D is weakly
emergent iff P can be derived from D and S 's external conditions but only by simulation” (Bedau 1997, p. 6)

131
Capitolo V Alcune applicazioni di economia computazionale
1.Modello con agenti non intelligenti
I modelli ad agenti sono producono risultati rilevanti sia nelle loro
versioni più complesse, in cui si utilizzano specifici algoritmi di intelligenza
artificiale per implementare la razionalità limitata109, sia nelle versioni più
semplici in cui gli agenti seguono regole estremamente semplificate per
decidere la propria strategia. Uno dei primi lavori che studiano il
comportamento di agenti non intelligenti in un mercato è Gode e Sunder
(1993). Gli agenti vengono chiamati “Zero-Intelligence” (ZI) perché le loro azioni
sono puramente casuali. Quando si trovano però davanti al vincolo imposto
dal mercato (che il prezzo di offerta sia superiore o uguale al costo ed il prezzo
di domanda inferiore o uguale al valore) il comportamento di questi agenti
casuali assomiglia sorprendentemente al comportamento di veri agenti umani.
L’efficienza dei mercati con agenti non intelligenti si avvicina molto
all’efficienza 110 massima dimostrando che la razionalità degli agenti gioca
spesso un ruolo di secondo piano rispetto al funzionamento delle istituzioni
del mercato (Gode e Sunder 1993), o come scrive Testfatsion (2005):
Gode and Sunder concluded that the high market efficiency they observed in
their experiments derived from the structural and institutional aspects of the
auction and not from the learning capabilities of the auction traders per se.
(Testfatsion 2005, p.24)
Sono le regole che governano gli scambi a rendere efficiente il mercato. Il
risultato è interessante, ed è stato analizzato anche nell’ambito delle
simulazioni di borsa (Terna 2000a, Farmer et al. 2005) dove l’inserimento di
109
Come afferma Sargent (1993): “Ironically, when we economists make people in our models more
bounded in their rationality and more diverse in their understanding of the environment, we must be
smarter, because our models become larger and more demanding econometrically and mathematically” (Sargent 1993, p. 2) 110
L’efficienza del mercato viene calcolata sommando il profitto totale di tutti gli agenti diviso il profitto massimo ottenibile (ossia la somma del surplus dei consumatori e dei produttori).

132
regole che governano gli scambi permette l’emergenza di andamenti
interessanti dei prezzi. Ispirandoci a Terna (2000a) svilupperemo un mercato
azionario simulato con agenti ZI. Si vedrà come, nonostante gli agenti agiscano
in modo casuale, emergano bolle e crash tipiche del mercato di borsa. In Terna
(2000a) si distinguono quattro macro categorie per i modelli ad agenti: i) agenti
“senza mente” operanti in un ambiente non strutturato; ii) agenti “senza
mente” operanti in un ambiente strutturato, iii) agenti “con mente” operanti in
un ambiente non strutturato; iv) agenti “con mente” operanti in un ambiente
strutturato. Applicando questa categorizzazione al mercato di borsa è possibile
verificare come nel primo caso il comportamento emergente sia completamente
caotico (Terna 2000b). La nostra intenzione è costruire un modello di borsa in
cui gli agenti siano “senza mente” ma il mercato sia strutturato. La struttura
del mercato consiste in un meccanismo (“book”) che registra gli ordini di
offerta e di vendita degli agenti, con relativi prezzi, ed esegue gli ordini se trova
un controparte compatibile. Gli agenti in questo modello sono completamente
miopi (o meglio Zero Intelligence): conoscono solamente l’ultimo prezzo di
transazione, scelgono casualmente se comprare o vendere, fissano il loro
prezzo moltiplicando il prezzo vigente per un coefficiente casuale. La struttura
del mercato permette l’emergenza di un andamento del prezzo con bolle e
crash senza la necessità di spiegazioni esogene. Il modello consiste di
i) 100 agenti che scelgono con probabilità P = 0,5 di comprare o
vendere una azione;
ii) un registro che esegue le transazioni se esistono domande o offerte
compatibili, e le registra in caso contrario;
iii) una variabile casuale uniforme tra 0,9 e 1,1 che gli agenti usano per
decidere il prezzo di acquisto o di vendita (se V è il coefficiente, il
prezzo sarà V ∗ * Y P7RR);
iv) un prezzo base al di sotto del quale gli agenti tendono a comprare
più che vendere (al di sotto di 0.3 la percentuale di agenti che
compra supera quella di agenti che vendono).
Il prezzo iniziale è pari ad 1 (prezzi iniziali diversi danno risultati qualitativi
identici). Il codice NetLogo del modello si trova nell’appendice A5. Nelle figure
22 e 23 sono rappresentati i prezzi ad ogni transazione ed il prezzo a fine
giornata.
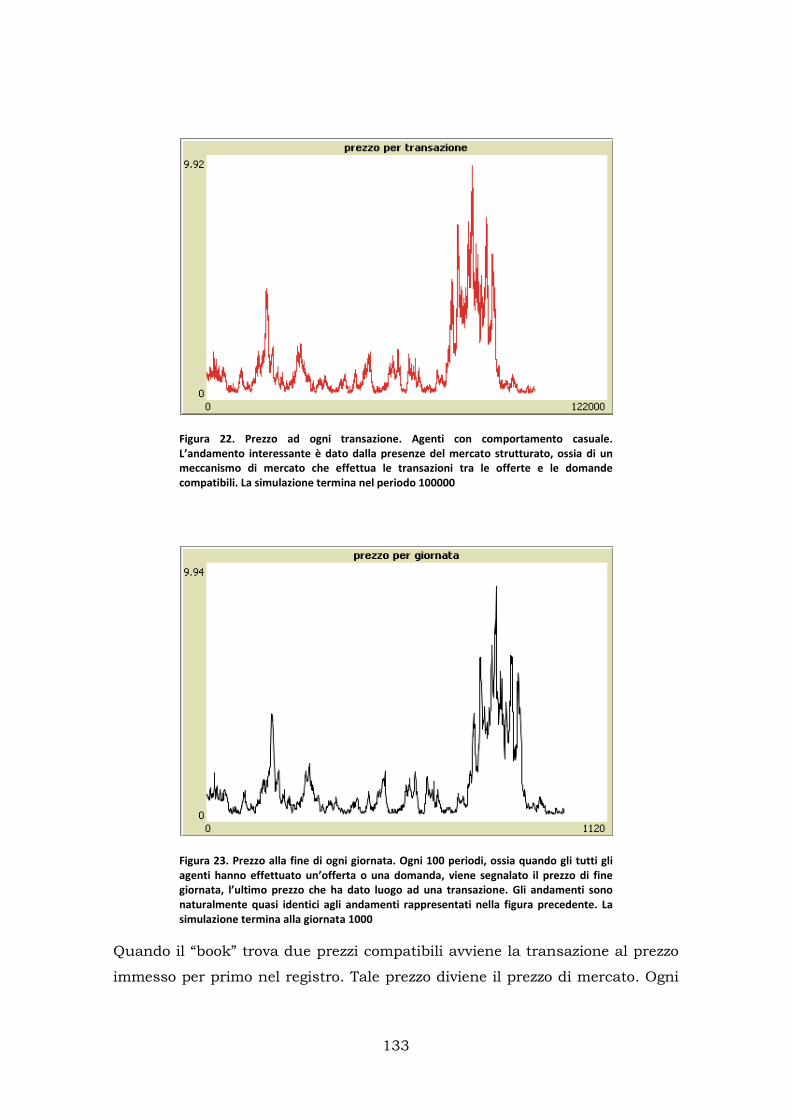
133
Figura 22. Prezzo ad ogni transazione. Agenti con comportamento casuale. L’andamento interessante è dato dalla presenze del mercato strutturato, ossia di un meccanismo di mercato che effettua le transazioni tra le offerte e le domande compatibili. La simulazione termina nel periodo 100000
Figura 23. Prezzo alla fine di ogni giornata. Ogni 100 periodi, ossia quando gli tutti gli agenti hanno effettuato un’offerta o una domanda, viene segnalato il prezzo di fine giornata, l’ultimo prezzo che ha dato luogo ad una transazione. Gli andamenti sono naturalmente quasi identici agli andamenti rappresentati nella figura precedente. La simulazione termina alla giornata 1000
Quando il “book” trova due prezzi compatibili avviene la transazione al prezzo
immesso per primo nel registro. Tale prezzo diviene il prezzo di mercato. Ogni
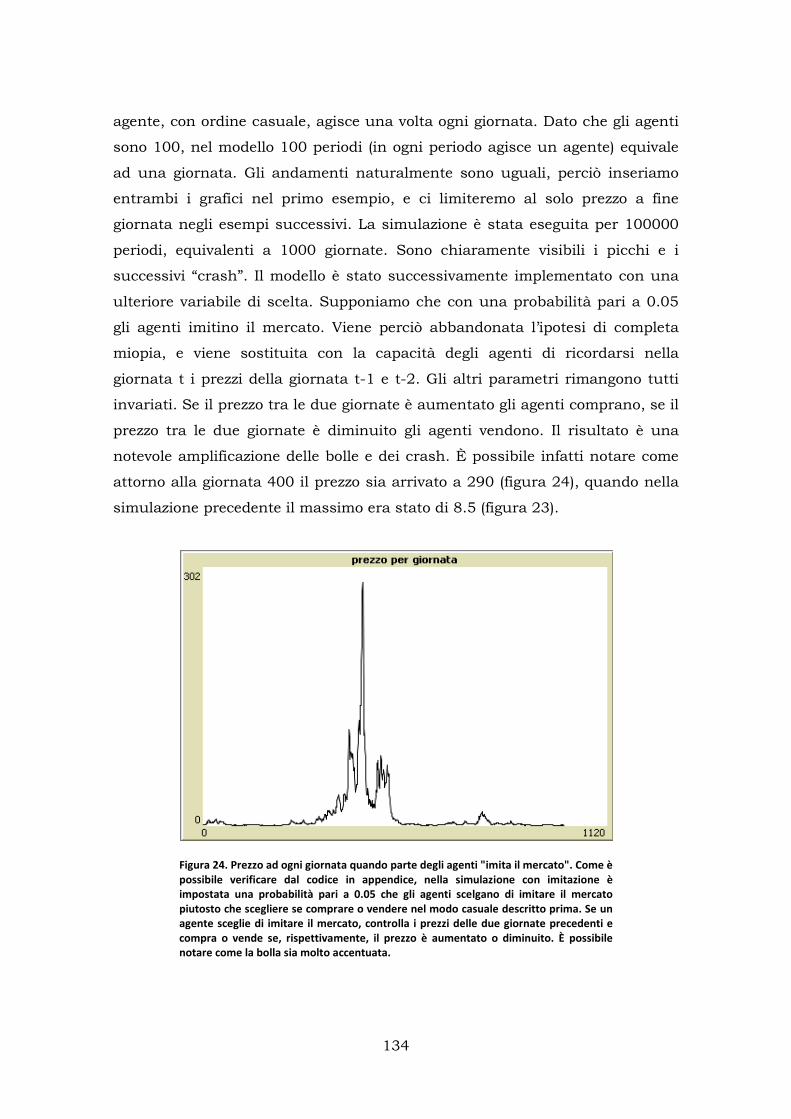
134
agente, con ordine casuale, agisce una volta ogni giornata. Dato che gli agenti
sono 100, nel modello 100 periodi (in ogni periodo agisce un agente) equivale
ad una giornata. Gli andamenti naturalmente sono uguali, perciò inseriamo
entrambi i grafici nel primo esempio, e ci limiteremo al solo prezzo a fine
giornata negli esempi successivi. La simulazione è stata eseguita per 100000
periodi, equivalenti a 1000 giornate. Sono chiaramente visibili i picchi e i
successivi “crash”. Il modello è stato successivamente implementato con una
ulteriore variabile di scelta. Supponiamo che con una probabilità pari a 0.05
gli agenti imitino il mercato. Viene perciò abbandonata l’ipotesi di completa
miopia, e viene sostituita con la capacità degli agenti di ricordarsi nella
giornata t i prezzi della giornata t-1 e t-2. Gli altri parametri rimangono tutti
invariati. Se il prezzo tra le due giornate è aumentato gli agenti comprano, se il
prezzo tra le due giornate è diminuito gli agenti vendono. Il risultato è una
notevole amplificazione delle bolle e dei crash. È possibile infatti notare come
attorno alla giornata 400 il prezzo sia arrivato a 290 (figura 24), quando nella
simulazione precedente il massimo era stato di 8.5 (figura 23).
Figura 24. Prezzo ad ogni giornata quando parte degli agenti "imita il mercato". Come è possibile verificare dal codice in appendice, nella simulazione con imitazione è impostata una probabilità pari a 0.05 che gli agenti scelgano di imitare il mercato piutosto che scegliere se comprare o vendere nel modo casuale descritto prima. Se un agente sceglie di imitare il mercato, controlla i prezzi delle due giornate precedenti e compra o vende se, rispettivamente, il prezzo è aumentato o diminuito. È possibile notare come la bolla sia molto accentuata.
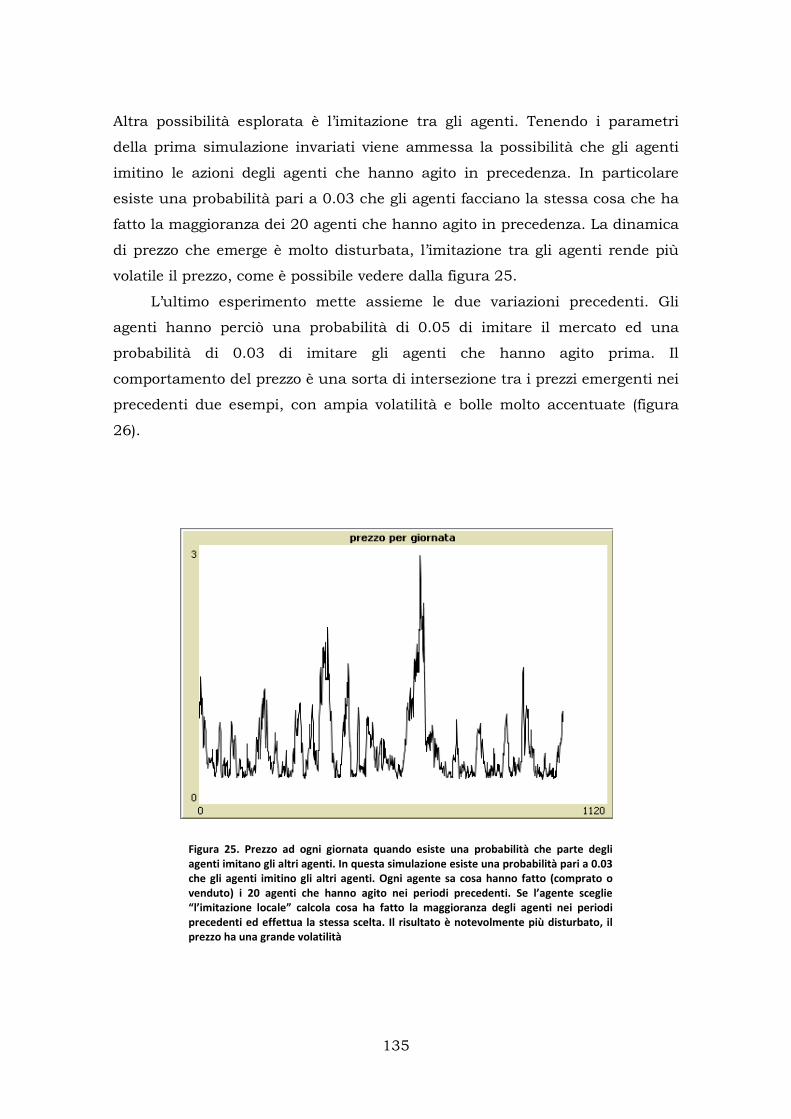
135
Altra possibilità esplorata è l’imitazione tra gli agenti. Tenendo i parametri
della prima simulazione invariati viene ammessa la possibilità che gli agenti
imitino le azioni degli agenti che hanno agito in precedenza. In particolare
esiste una probabilità pari a 0.03 che gli agenti facciano la stessa cosa che ha
fatto la maggioranza dei 20 agenti che hanno agito in precedenza. La dinamica
di prezzo che emerge è molto disturbata, l’imitazione tra gli agenti rende più
volatile il prezzo, come è possibile vedere dalla figura 25.
L’ultimo esperimento mette assieme le due variazioni precedenti. Gli
agenti hanno perciò una probabilità di 0.05 di imitare il mercato ed una
probabilità di 0.03 di imitare gli agenti che hanno agito prima. Il
comportamento del prezzo è una sorta di intersezione tra i prezzi emergenti nei
precedenti due esempi, con ampia volatilità e bolle molto accentuate (figura
26).
Figura 25. Prezzo ad ogni giornata quando esiste una probabilità che parte degli agenti imitano gli altri agenti. In questa simulazione esiste una probabilità pari a 0.03 che gli agenti imitino gli altri agenti. Ogni agente sa cosa hanno fatto (comprato o venduto) i 20 agenti che hanno agito nei periodi precedenti. Se l’agente sceglie “l’imitazione locale” calcola cosa ha fatto la maggioranza degli agenti nei periodi precedenti ed effettua la stessa scelta. Il risultato è notevolmente più disturbato, il prezzo ha una grande volatilità
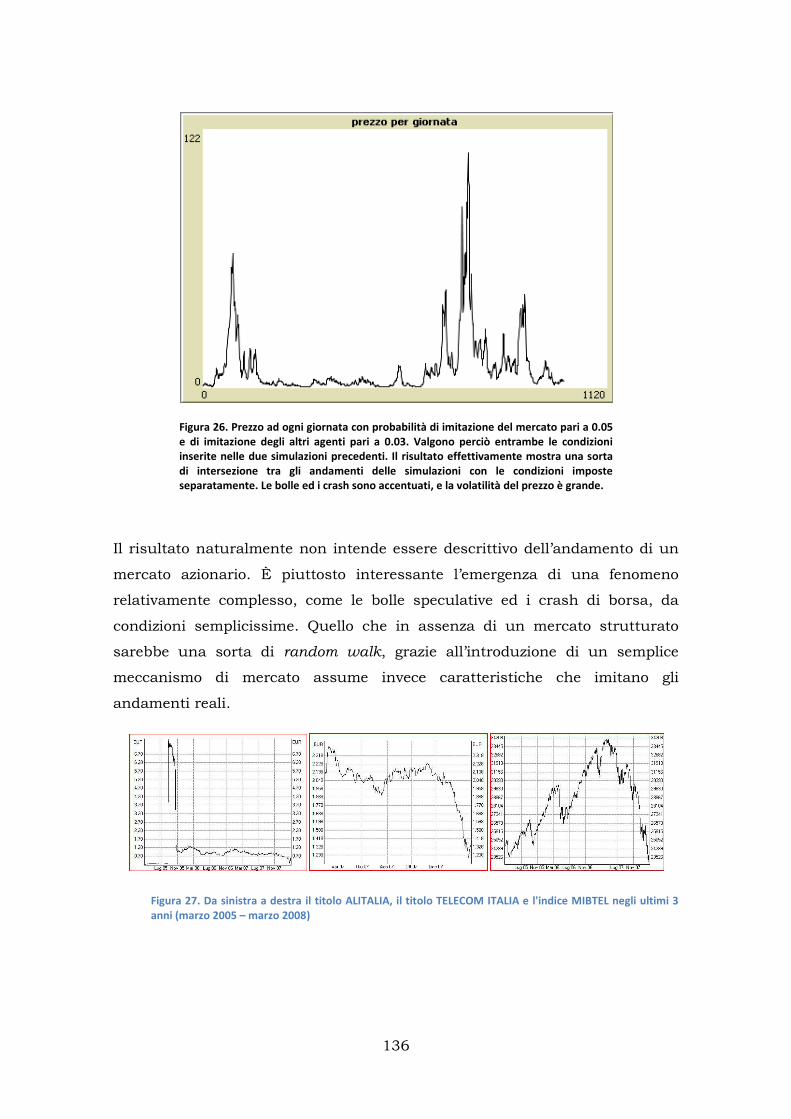
136
Figura 26. Prezzo ad ogni giornata con probabilità di imitazione del mercato pari a 0.05 e di imitazione degli altri agenti pari a 0.03. Valgono perciò entrambe le condizioni inserite nelle due simulazioni precedenti. Il risultato effettivamente mostra una sorta di intersezione tra gli andamenti delle simulazioni con le condizioni imposte separatamente. Le bolle ed i crash sono accentuati, e la volatilità del prezzo è grande.
Il risultato naturalmente non intende essere descrittivo dell’andamento di un
mercato azionario. È piuttosto interessante l’emergenza di una fenomeno
relativamente complesso, come le bolle speculative ed i crash di borsa, da
condizioni semplicissime. Quello che in assenza di un mercato strutturato
sarebbe una sorta di random walk, grazie all’introduzione di un semplice
meccanismo di mercato assume invece caratteristiche che imitano gli
andamenti reali.
Figura 27. Da sinistra a destra il titolo ALITALIA, il titolo TELECOM ITALIA e l'indice MIBTEL negli ultimi 3 anni (marzo 2005 – marzo 2008)

137
Per un confronto con la realtà proponiamo l’andamento del titolo ALITALIA, del
titolo TELECOM ITALIA e dell’indice MIBTEL degli ultimi tre anni (figura 27).
Ribadendo che il modello non può essere descrittivo della realtà, è possibile
notare come l’andamento irregolare e la presenza di picchi sia abbastanza
simile alle simulazioni effettuate. Gli andamenti di borsa sono sicuramente
influenzati da tante variabili. È possibile però intravedere, a prescindere
dall’andamento generale, piccole bolle e crash riconducibili più che altro ad
atteggiamenti speculativi, i quali sono sorprendentemente ben imitati dal
comportamento degli agenti ZI in un mercato strutturato.
Per ottenere descrizioni più appropriate del mercato di borsa è necessaria
una descrizione più fedele del comportamento degli agenti. In Terna (2000c) ad
esempio si sviluppa un modello di simulazione di borsa con reti neurali. Le reti
neurali, come mostrato nei paragrafi precedenti, hanno la capacità di imparare
quali azioni siano le azioni corrette da intraprendere dati gli input. In questo
caso gli input possono riguardare il comportamento del prezzo e degli altri
agenti (Terna 2000b, Terna 2000c). Un lavoro famoso che tenta di riprodurre
un mercato di borsa con agenti adattivi, sviluppato nell’ambito del progetto del
Santa Fe Institute, si può trovare in Palmer et al. (1994), in Arthur et al.
(1997) e in LeBaron (2002). Gli articoli citati riprendono lo stesso modello in
diverse fasi di sviluppo. Gli agenti nel mercato azionario simulato del Santa Fe
Institute scelgono le proprie strategie grazie ad un sistema a classificatori. Il
sistema a classificatori è una particolare forma di apprendimento individuale
derivante dagli algoritmi genetici (Arthur et al. 1997). Senza dilungarsi nella
spiegazione dei sistemi a classificatori possiamo affermare che tale metodo di
apprendimento prevede una stringa condizione, la quale attiva una stringa
azione. Gli input del mercato codificati nella stringa condizione determinano
l’azione effettiva dell’agente. L’apprendimento avviene con un algoritmo
genetico che agisce sulle stringhe azione. Grazie alle tecniche di intelligenza
artificiale è possibile riprodurre alcuni andamenti dei mercati azionari e i
comportamenti umani.
2. Modello di fragilità finanziaria In Delli Gatti et al. (2005, 2006) si trova un modello basato su agenti in
cui si studiano le fluttuazioni macroeconomiche. Il modello originale è stato

138
costruito nell’ambiente software Swarm, mentre nel presente lavoro ne
proponiamo una versione riscritta in NetLogo il cui codice si trova in
appendice A6 (nel codice possono essere trovati anche i valori assegnati ai
parametri del modello). In ogni periodo operano due mercati: il mercato per il
bene omogeneo prodotto dalle imprese ed il mercato del credito con cui le
imprese finanziano i propri investimenti. Si suppone che la domanda sia
sempre pari all’offerta, le imprese riescono perciò sempre a vendere tutto il
prodotto. Si suppone inoltre che le imprese possano finanziarsi solo tramite il
credito bancario e l’autofinanziamento. La domanda di credito dipende dalla
spesa in investimenti, la quale dipende dal tasso di interesse bancario. Il
credito totale è un multiplo del capitale proprio della banca, il quale è
negativamente influenzato dall’eventuale fallimento delle imprese con la
conseguente insolvenza. L’interazione tra le imprese attraverso il mercato
finanziario permette agli shock casuali che colpiscono le singole imprese di
propagarsi ed amplificarsi. Se avvengono fallimenti di imprese importanti, le
risorse del sistema bancario si riducono propagando l’effetto nell’intera
economia; la diminuzione dell’offerta di credito causa condizioni più gravose
sulle imprese rimaste in vita, mettendo in pericolo le imprese non sane.
Le imprese
In ogni periodo esiste un numero finito di imprese indicate con =1, … , F, ognuna collocata su un’ “isola”. Il numero totale delle imprese (quindi
delle isole) dipende dal periodo a causa del processo endogeno di entrata ed
uscita delle imprese dal mercato. Ogni impresa produce H grazie all’unico
fattore di produzione, il capitale , con la funzione di produzione lineare
H = ¹ . La produttività del capitale (¹) è costante ed uniforme tra tutte le
imprese, inoltre il capitale non si deprezza. La domanda di bene in ogni isola è
influenzata da shock reali idiosincratici B. Dato che l’arbitraggio tra le isole è
imperfetto, gli shock di domanda nel mercato di ogni impresa si riflettono
direttamente sul prezzo, il quale è casuale attorno al prezzo medio con
distribuzione = * , in cui $* = 1 e la varianza è finita. L’ipotesi di
arbitraggio imperfetto implica che uno shock di domanda positivo per una
data impresa faccia aumentare il suo prezzo di vendita. Lo stock di capitale di
ogni impresa = ~ + , è pari alla somma tra il capitale proprio

139
dell’impresa al tempo , ~, e del prestito ricevuto dalle banche nel periodo , . . Gli obblighi di pagamento delle imprese sul prestito nel periodo sono
7, dove 7 è il tasso di interesse reale. Supponendo per semplicità che 7 sia anche il profitto reale sul capitale proprio ~ , abbiamo che per ogni
impresa il costo del finanziamento è pari a 7 + ~ = 7 . Se i costi
variabili sono proporzionali ai costi di finanziamento per un fattore > 0 ,
allora avremo che il profitto in termini reali è dato da:
1 v = *H − 7 = *¹ − 7
e il profitto atteso è pari a $v = ¹ − 7 . Nel modello il fallimento di una impresa avviene se il valore netto
dell’impresa diventa negativo. La legge dinamica del valore netto è
2 ~ = ~d + v
Usando la (1) e la (2) otteniamo che il fallimento avviene se
3 * < 1¹ º7 − ~d » ≡ *J
La probabilità di fallimento 7¶ viene incorporata direttamente nella funzione
di costo dell’impresa dato che il fallimento rappresenta un costo (crescente
all’aumentare della dimensione dell’impresa). Supponiamo che * sia
distribuita uniformemente in (0,2) e che il costo del fallimento sia quadratico,
W¶ = HX con > 0, la funzione obiettivo dell’impresa diventa
4 Γ = ¹ − 7 − ¹2 %7 X − ~d &
Dalla condizione del primo ordine111, lo stock di capitale ottimale è
5 ± = ¹ − 7¹7 + ~d27 111
Dato che > 0 ed 7 > 0 la condizione del secondo ordine per un massimo è rispettata.
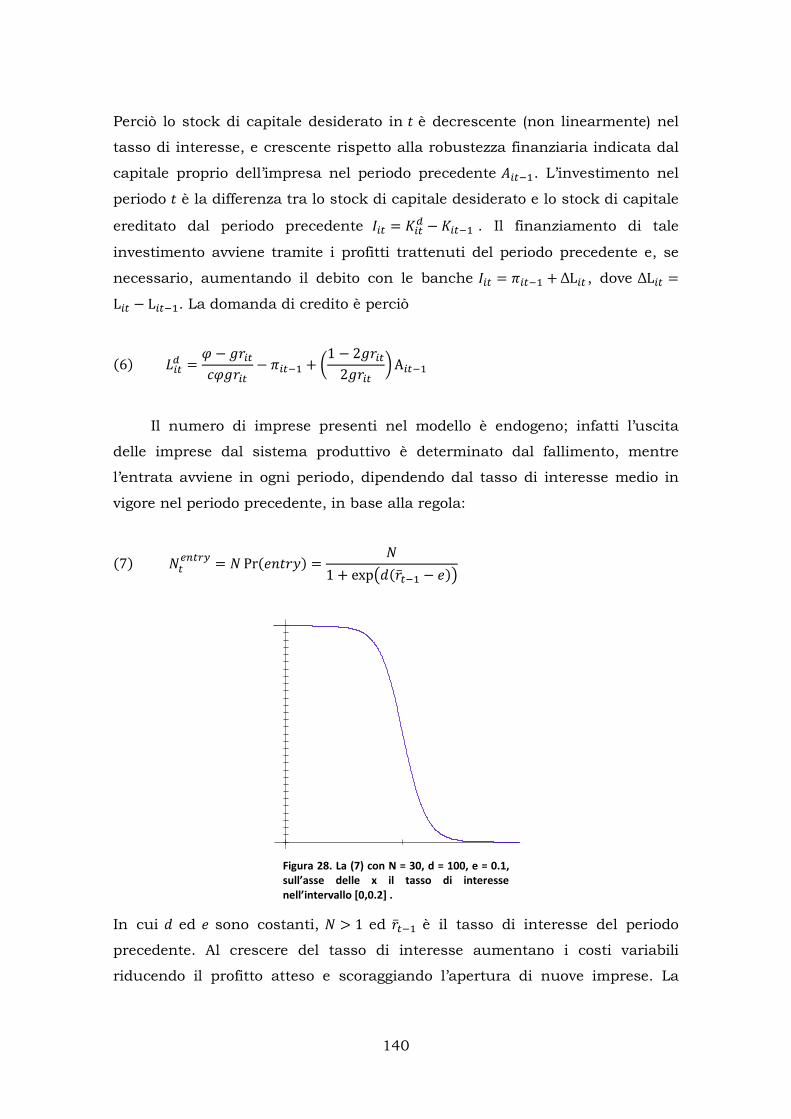
140
Perciò lo stock di capitale desiderato in è decrescente (non linearmente) nel
tasso di interesse, e crescente rispetto alla robustezza finanziaria indicata dal
capitale proprio dell’impresa nel periodo precedente ~d. L’investimento nel
periodo è la differenza tra lo stock di capitale desiderato e lo stock di capitale
ereditato dal periodo precedente = = ± − d . Il finanziamento di tale
investimento avviene tramite i profitti trattenuti del periodo precedente e, se
necessario, aumentando il debito con le banche = = vd + ∆L , dove ∆L =L − Ld. La domanda di credito è perciò
6 ± = ¹ − 7¹7 − vd + º1 − 2727 » Ad
Il numero di imprese presenti nel modello è endogeno; infatti l’uscita
delle imprese dal sistema produttivo è determinato dal fallimento, mentre
l’entrata avviene in ogni periodo, dipendendo dal tasso di interesse medio in
vigore nel periodo precedente, in base alla regola:
7 Fe-¾¿ = F Pr<7 = F1 + exp%B7°d − &
Figura 28. La (7) con N = 30, d = 100, e = 0.1, sull’asse delle x il tasso di interesse nell’intervallo [0,0.2] .
In cui B ed sono costanti, F > 1 ed 7°d è il tasso di interesse del periodo
precedente. Al crescere del tasso di interesse aumentano i costi variabili
riducendo il profitto atteso e scoraggiando l’apertura di nuove imprese. La

141
dimensione delle imprese nascenti sarà pari alla media delle imprese già
presenti nel mercato e la quota di capitale proprio sarà pari alla quota di
capitale proprio media delle imprese nel mercato.112
Il settore bancario
Il bilancio del settore bancario è 0 = $ + U, dove 0 è l’offerta totale di
credito, $ è il capitale proprio della banca e U i depositi, che nel modello sono
determinati come residuo. Per determinare il livello aggregato dell’offerta di
credito, imponiamo una regola prudenziale alle banche per cui 0 = $d Ä⁄ ,
dove Ä è il coefficiente di rischio ed è costante. Quindi maggiore è la salute
finanziaria delle banche maggiore sarà l’offerta di credito. I finanziamenti sono
stanziati ad ogni impresa in base all’ipoteca che esse offrono, la quale è
proporzionale alla dimensione e al capitale proprio, seguendo la regola:
8 0 = 0 dd + 1 − 0 ~d~d
Con d = ∑ d9ÅƦK , ~d = ∑ ~d9ÅƦK e 0 < < 1 . Il tasso di interesse di
equilibrio per l’impresa è determinato dall’equilibrio tra la domanda di credito
(6) e l’offerta di credito (7)
9 7 = 2 + ~d2 l 1¹ + vd + ~dm + 20Vd + 1 − d
Dove Vd e d sono rispettivamente pari a ÇÈÅƦÇÅƦ e
ÉÈÅƦÉÅƦ . Sotto l’ipotesi che il
capitale proprio sia remunerato ad un tasso pari al tasso di interesse medio
sui prestiti 7°, e che i depositi vengano remunerati con un tasso di interesse
pari a 7°1 − a il profitto delle banche è
10 vÊ = I 70 −∈9Å
7°%1 − aUd + $d& 112
In questo caso ci siamo leggermente discostati dal modello originale in cui le due grandezze appena elencate venivano poste grazie ad una variabile casuale uniforme attorno alla moda delle imprese nel mercato

142
La differenza tra il tasso di interesse medio ed il tasso di interesse a cui
vengono remunerati i depositi dipende da a, il quale può essere interpretato
come il coefficiente che denota il grado di concorrenza nel settore bancario,
maggiore è a maggiore è la differenza tra i tassi di interesse e minore è la
concorrenza nel settore bancario. All’aumentare del parametro a aumentano i
profitti del settore bancario.
Quando un’impresa fallisce, il capitale proprio diviene negativo e l’intero
settore bancario subisce una perdita pari alla differenza tra il debito totale
accumulato fino al periodo e il capitale accumulato, = − = −~ (~ < 0 se l’impresa è fallita). Perciò è il debito non restituito da parte
dell’impresa . Il capitale proprio della banca evolve secondo la legge
11 $ = vÊ + $d − I ,d∈ΩËƦ
Dove l’ultimo termine rappresenta la somma dei debiti non restituiti alla banca
(ΩÌd è l’insieme delle imprese fallite in − 1). Attraverso il settore bancario,
shock endogeni che portano al fallimento delle imprese influenzano l’intero
sistema. Un aumento del debito non restituito provoca una diminuzione
dell’offerta di credito, aumentando i costi finanziari delle imprese (aumenta il
tasso di interesse). Inoltre la distribuzione del capitale proprio delle imprese
influenza il valore medio del tasso di interesse che a sua volta influenza i
profitti delle banche e potenzialmente l’offerta di credito. Perciò le imprese si
influenzano a vicenda tramite il settore bancario. In particolare l’interazione è
globale e avviene attraverso una variabile di settore, che nel nostro caso è il
bilancio del settore bancario
La simulazione
La simulazione è stata fatta per 1000 periodi. Il capitale iniziale delle
imprese è 100, il capitale proprio è 20 ed il capitale di debito è 80. Il prezzo
varia attorno al prezzo medio grazie ad una variabile casuale uniforme
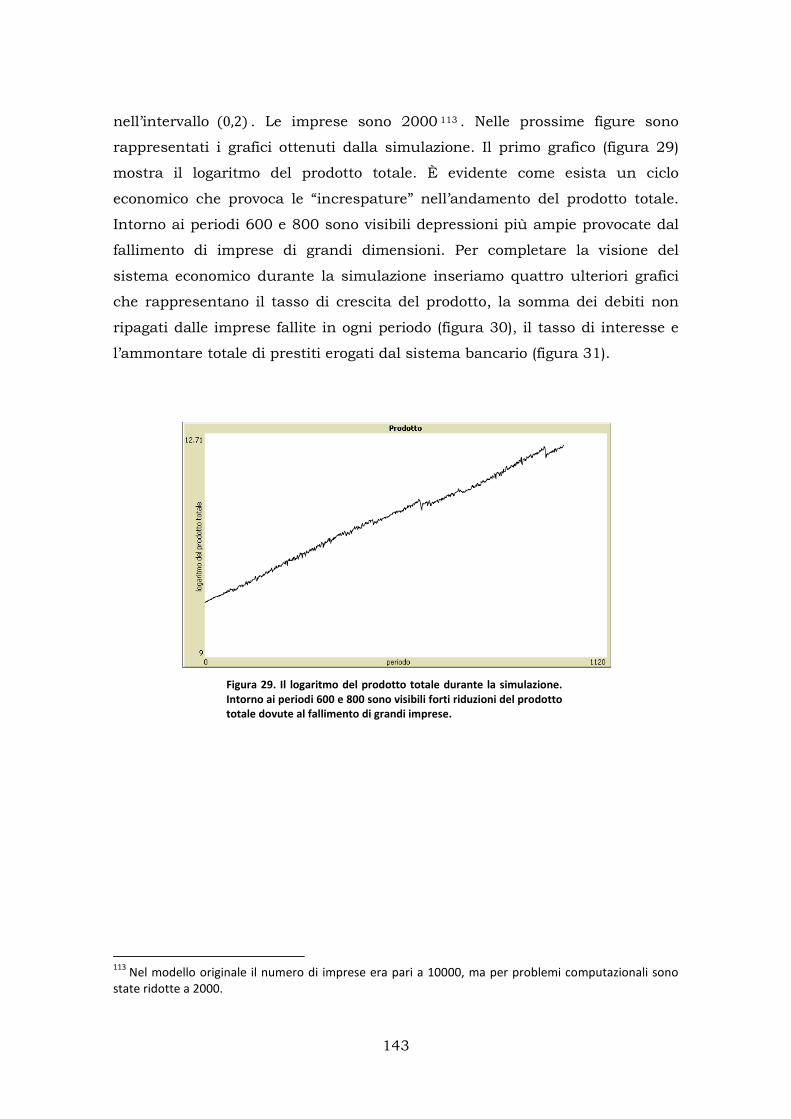
143
nell’intervallo 0,2 . Le imprese sono 2000 113 . Nelle prossime figure sono
rappresentati i grafici ottenuti dalla simulazione. Il primo grafico (figura 29)
mostra il logaritmo del prodotto totale. È evidente come esista un ciclo
economico che provoca le “increspature” nell’andamento del prodotto totale.
Intorno ai periodi 600 e 800 sono visibili depressioni più ampie provocate dal
fallimento di imprese di grandi dimensioni. Per completare la visione del
sistema economico durante la simulazione inseriamo quattro ulteriori grafici
che rappresentano il tasso di crescita del prodotto, la somma dei debiti non
ripagati dalle imprese fallite in ogni periodo (figura 30), il tasso di interesse e
l’ammontare totale di prestiti erogati dal sistema bancario (figura 31).
Figura 29. Il logaritmo del prodotto totale durante la simulazione. Intorno ai periodi 600 e 800 sono visibili forti riduzioni del prodotto totale dovute al fallimento di grandi imprese.
113
Nel modello originale il numero di imprese era pari a 10000, ma per problemi computazionali sono state ridotte a 2000.
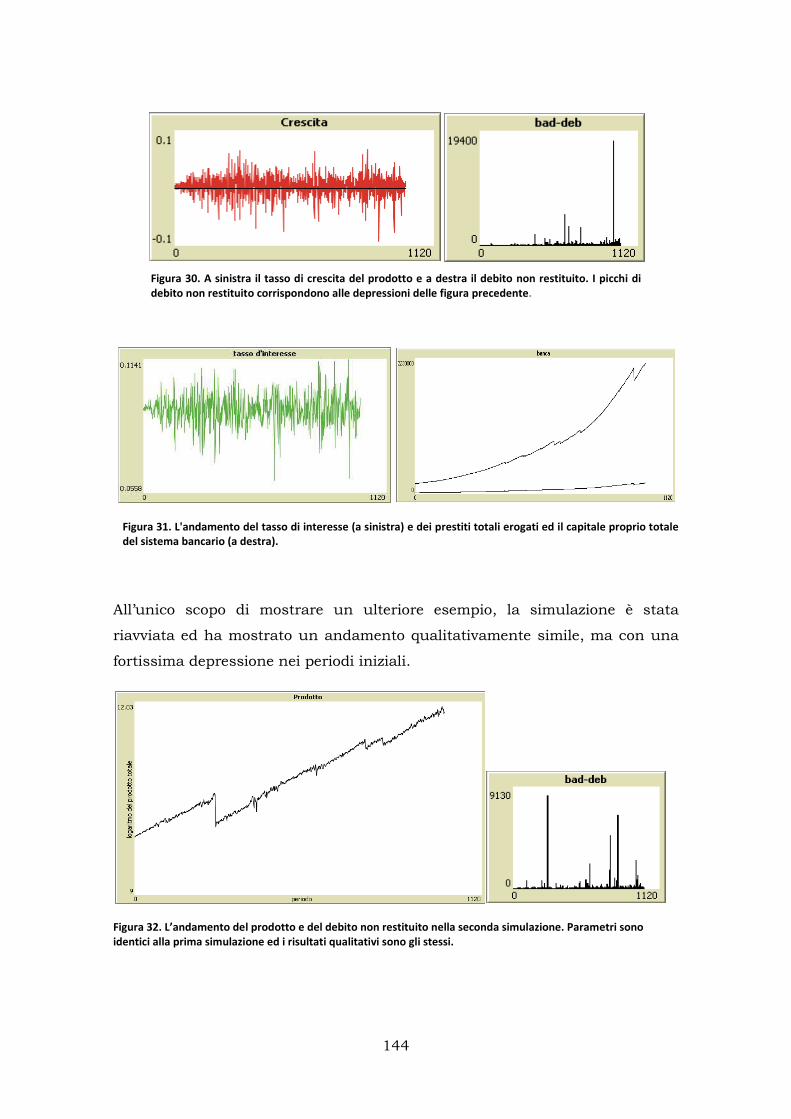
144
Figura 30. A sinistra il tasso di crescita del prodotto e a destra il debito non restituito. I picchi di debito non restituito corrispondono alle depressioni delle figura precedente.
Figura 31. L'andamento del tasso di interesse (a sinistra) e dei prestiti totali erogati ed il capitale proprio totale del sistema bancario (a destra).
All’unico scopo di mostrare un ulteriore esempio, la simulazione è stata
riavviata ed ha mostrato un andamento qualitativamente simile, ma con una
fortissima depressione nei periodi iniziali.
Figura 32. L’andamento del prodotto e del debito non restituito nella seconda simulazione. Parametri sono identici alla prima simulazione ed i risultati qualitativi sono gli stessi.

145
Della seconda simulazione si riportano solamente l’andamento del prodotto
totale e il grafico che mostra il quantitativo di risorse non restituite al sistema
bancario in ogni periodo (figura 32).
3. Conclusione L’analisi svolta nei precedenti capitoli ha mostrato come l’alternativa
all’agente rappresentativo sia realistica e realizzabile. Le interessanti
possibilità che si aprono grazie all’uso della computazione in economia
richiedono ulteriori sforzi di ricerca al fine di comprendere a fondo il sistema
economico in quanto sistema complesso. Lo sviluppo di metodologie comuni e
di linguaggi di comunicazione comprensibili è tuttavia fondamentale per
rendere l’approccio basato su agenti un complemento dell’approccio
puramente matematico. Si richiede perciò ai ricercatori uno sforzo ulteriore
per la creazione della lingua franca che permetta la comunicazione e la
comprensione dei risultati anche a coloro che non hanno esperienze di
programmazione. Sono inoltre cruciali per la diffusione dell’approccio ABM lo
sviluppo di linguaggi di programmazione semplici ed indirizzati alle scienze
sociali, la creazione di centri di ricerca multidisciplinare sulla complessità
(come ad esempio il Santa Fe Institute), e l’edizione di riviste dedicate
specificatamente alla simulazione nelle scienze sociali (come ad esempio
JASSS, Journal of Artificial Societies and Social Simulation). Questi sforzi
hanno dato un forte impulso alla ricerca nel settore. Il mio progetto di ricerca
inizia con questa Tesi di laurea e guarda alla prospettiva di un
approfondimento post-laurea, che riveli l’efficacia (o meno) dell’approccio
computazione alle scienze economiche

146
Appendice A
Codice NetLogo È possibile richiedere i file delle simulazioni seguenti all’indirizzo: [email protected]
A1-Codice NetLogo per la rappresentazione del mondo
piccolo di Watts e Strogatz 1998. globals [n] to setup ca set-default-shape turtles "circle" create-turtles 20 ask turtles [set size 0.5] layout-circle (sort turtles) max-pxcor - 1 ask turtles [set color white] set n 0 while [n < count turtles - 2] [ask turtle n [create-link-with turtle (n + 1) create-link-with turtle (n + 2)] set n n + 1] ask turtle 18 [create-link-with turtle 19 create-link-with turtle 0] ask turtle 19 [create-link-with turtle 0 create-link-with turtle 1] ask links [set color red] end to rewire ask links [if random-float 1 < p [let nodo1 end1 let nodo2 one-of turtles with [ (self != nodo1) and (not link-neighbor? nodo1)] ask nodo1 [create-link-with nodo2] die]] end Per utilizzare il programma scaricare NetLogo dal sito http://ccl.northwestern.edu/netlogo/, copiare il codice nella sezione “Procedures”. Andare alla sezione “Interface” creare due bottoni e chiamarli “setup” e “rewire”. Creare uno Slider, imporre 1 come valore massimo, 0.01 con increment e 0 in value. Editare il grafico con gli agenti e deselezionare “Word wraps horizontally” e “Word wraps vertically”.

147
A2 – Il codice NetLogo del modello di segregazione breed [a ] breed [b ] a-own [u mine-rate neigh-rate] b-own [u mine-rate neigh-rate] patches-own [a-rate b-rate] to setup ca ask n-of (%-occupati * count patches) patches [sprout 1] ask turtles [set color white] ask n-of (0.5 * count turtles) turtles [set breed a set color blue] ask turtles with [color = white] [set breed b] ask a [set color blue] ask b [set color cyan + 2] ask patches [if any? turtles-on neighbors [set a-rate count a-on neighbors / count turtles-on neighbors]] ask patches [if any? turtles-on neighbors [set b-rate count b-on neighbors / count turtles-on neighbors]] do-plot end to go utility move do-plot tick end to utility ask a [ifelse count a-on neighbors >= similar-wanted * count turtles-on neighbors [set u 1][set u 0]] ask b [ifelse count b-on neighbors >= similar-wanted * count turtles-on neighbors [set u 1][set u 0]] end to move ask patches [if any? turtles-on neighbors [set a-rate count a-on neighbors / count turtles-on neighbors]]
ask patches [if any? turtles-on neighbors [set b-rate count b-on neighbors / count turtles-on neighbors]]

148
ask a [set mine-rate [a-rate] of patch-here] ask b [set mine-rate [b-rate] of patch-here]
ask a [if any? neighbors with [a-rate > similar-wanted and not any? turtles-on
self] and mine-rate < similar-wanted [move-to one-of neighbors with [a-rate > 0.5 and not any? turtles-on self]]]
ask b [if any? neighbors with [b-rate > similar-wanted and not any? turtles-on self] and mine-rate < similar-wanted [move-to one-of neighbors with [b-rate > 0.5 and not any? turtles-on self]]]
;; le istruzioni sopra e sotto sono due alternative per supporre il movimento
degli agenti. Le istruzioni ;sopra suppongono che l’agente si muova solo se esiste una locazione migliore nel suo vicinato e non è ;soddisfatto con il suo vicinato. L’agente si muoverà in una di queste locazioni migliori. Le istruzioni sotto ;invece implicano che l’agente, se non soddisfatto con il vicinato corrente, si muova in ogni caso.
ask a [if mine-rate < similar-wanted and any? neighbors with [not any?
turtles-on self][move-to one-of neighbors with [not any? turtles-on self]]] ask b [if mine-rate < similar-wanted and any? neighbors with [not any?
turtles-on self][move-to one-of neighbors with [not any? turtles-on self]]] ; quest’ultima parte di codice serve ad ottenere la visualizzazione più chiara
descritta nel testo. È possibile ;rimuoverla senza conseguenze sul funzionamento del modello.
ask turtles [if count turtles-on neighbors / count neighbors < 0.5 [move-to one-of neighbors with [not any? turtles-on self]]] end to do-plot set-current-plot "%-similar" set-current-plot-pen "mine rate" plot mean [mine-rate] of turtles end Per la riproduzione del modello scaricare NetLogo dal sito http://ccl.northwestern.edu/netlogo/ Copiare il codice nella sezione “Procedures”. Andare nella sezione “Interface” ed eseguire le seguenti azioni:
- Creare un bottone e nominarlo “setup”. Quando il bottone sarà cliccato richiamerà la procedura di setup del codice
- Creare un bottone e nominarlo “go”. Quando il bottone sarà cliccato richiamerà la procedura go del codice

149
- Nel codice il numero di zone occupate dagli agenti è scritto come %-occupati. Lo scopo è rendere l’utilizzatore capace di variare tale variabile senza dover cambiare il codice. Creare uno “Slider”, nominarlo %-occupati, scrivere 1 nello spazio “maximum”, 0.01 nello spazio “increment”, e 0.7 nello spazio “value”. Quest’ultimo è il valore di default che prenderà la variabile %-occupati.
- Nel codice la preferenza di abitanti simili minima degli agenti è indicata da “similar-wanted”. Lo scopo è lo stesso del precedente punto. Creare uno slider nominato “similar-wanted”, scrivere 1 nello spazio “maximum”, 0.01 nello spazio “increment”, e 0.5 nello spazio “value”. Quest’ultimo è il valore di default che prenderà la variabile similar-wanted.
- Il codice prevede un grafico che descriva la variabile “mine-rate”. È la percentuale di agenti simili nel vicinato per ogni agente. Il plot descrive il valore medio di questa variabile. Creare un plot, nominare il plot “%-similar”, inserire il valore 1 nello spazio Ymax, cliccare su Rename e scrivere “mine rate”.
- Se si desidera la percentuale media di vicini omogenei esatta è possibile creare un Monitor, e scrivere: mean [mine-rate] of turtles. Autore: Jakob Grazzini, 2007.
A3. Il codice NetLogo di una Rete Neurale Artificiale breed [input-nodes input-node] ;;tre tipi di neuroni, input, nascosti e output breed [hidden-nodes hidden-node] breed [output-nodes output-node] links-own [weight] ;i link possiedono un'unica variabile, il peso del collegamento globals [errore target-answer] ; errore servirà a calcolare gli errori della rete per sapere quando il training è ;finito, target answer serve nella retro propagazione del segnale. input-nodes-own [activation error] output-nodes-own [activation error] hidden-nodes-own [activation error] ; i neuroni hanno due variabili, l'attivazione, che rappresenta il messagio che ;devono spedire tramite i loro link, e l'errore che servirà durante la retro ;propagazione. to setup
ca

150
set-default-shape turtles "circle" setup-input-nodes setup-output-nodes setup-hidden-nodes setup-links do-plot
end to setup-input-nodes create-input-nodes 1 [setxy -14 9 set label who]
create-input-nodes 1 [setxy -14 3 set label who] create-input-nodes 1 [setxy -14 -3 set label who] create-input-nodes 1 [setxy -14 -9 set label who] ask input-nodes [set size 2] ask input-nodes [set color blue]
end to setup-output-nodes
create-output-nodes 1 [setxy 12 9 set label "1"] create-output-nodes 1 [setxy 12 6 set label "2"] create-output-nodes 1 [setxy 12 3 set label "3"] create-output-nodes 1 [setxy 12 0 set label "4"] create-output-nodes 1 [setxy 12 -3 set label "5"] create-output-nodes 1 [setxy 12 -6 set label "6"] create-output-nodes 1 [setxy 12 -9 set label "7"] create-output-nodes 1 [setxy 14 9 set label "8"] create-output-nodes 1 [setxy 14 6 set label "9"] create-output-nodes 1 [setxy 14 3 set label "10"] create-output-nodes 1 [setxy 14 0 set label "11"] create-output-nodes 1 [setxy 14 -3 set label "12"] create-output-nodes 1 [setxy 14 -6 set label "13"] create-output-nodes 1 [setxy 14 -9 set label "14"] create-output-nodes 1 [setxy 13 -11 set label "15"] ask output-nodes [set color red]
end to setup-hidden-nodes
create-hidden-nodes 1 [setxy -1 10] create-hidden-nodes 1 [setxy -1 6] create-hidden-nodes 1 [setxy -1 2] create-hidden-nodes 1 [setxy -1 -2] create-hidden-nodes 1 [setxy -1 -6] create-hidden-nodes 1 [setxy -1 -10] ask hidden-nodes [set color green]

151
end to setup-links
connect-all input-nodes hidden-nodes connect-all hidden-nodes output-nodes
end ; colleghiamo i neuroni input con i neuroni nascosti ed i neuroni nascosti con i neuroni ;output grazie a link direzionati. to connect-all [nodes1 nodes2]
ask nodes1 [ create-links-to nodes2 [ set weight random-float 0.2 - 0.1 ] ]
end ;;iniziamo il training della rete. al solo scopo di avere una misura dell'apprendimento della ;rete. Ripetiamo in ogni periodo un numero "esempi-periodo" di esperimenti to train
set errore 0 repeat esempi-periodo [ask input-nodes [set activation random 2] propagate back-propagate ] set errore errore / esempi-periodo
;; ogni periodo conta la percentuale di esempi andati male tick do-plot
end to propagate
ask hidden-nodes [set activation new-activation] ask output-nodes [set activation new-activation] ask output-nodes [ifelse activation > 0.5 [set color blue][set color white]]
end to-report new-activation
report sigmoid sum [[activation] of end1 * weight] of my-in-links end

152
;; l'attivazione dei nodi input dipende dall'input, l'attivazione degli altri nodi è la somma ;delle attivazioni che viaggiano sui collegamenti in entrata (my-in links), pesato con la ;forza dei collegamenti ed inserito nella funzione sigmoide. to-report sigmoid [input]
report 1 / (1 + e ^ (- input)) end to back-propagate
let target [activation] of input-node 0 * 2 ^ 0 + [activation] of input-node 1 * 2 ^ 1 + [activation] of input-node 2 * 2 ^ 2 + [activation] of input-node 3 * 2 ^ 3 ; per la retro propagazione definisco il risultato target show target
if target = 0 [set target-answer [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] if target = 1 [set target-answer [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] if target = 2 [set target-answer [1 1 0 0 0 0 0 0 0 0 0 0 0 0 0]] if target = 3 [set target-answer [1 1 1 0 0 0 0 0 0 0 0 0 0 0 0]] if target = 4 [set target-answer [1 1 1 1 0 0 0 0 0 0 0 0 0 0 0]] if target = 5 [set target-answer [1 1 1 1 1 0 0 0 0 0 0 0 0 0 0]] if target = 6 [set target-answer [1 1 1 1 1 1 0 0 0 0 0 0 0 0 0]] if target = 7 [set target-answer [1 1 1 1 1 1 1 0 0 0 0 0 0 0 0]] if target = 8 [set target-answer [1 1 1 1 1 1 1 1 0 0 0 0 0 0 0]] if target = 9 [set target-answer [1 1 1 1 1 1 1 1 1 0 0 0 0 0 0]] if target = 10 [set target-answer [1 1 1 1 1 1 1 1 1 1 0 0 0 0 0]] if target = 11 [set target-answer [1 1 1 1 1 1 1 1 1 1 1 0 0 0 0]] if target = 12 [set target-answer [1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]] if target = 13 [set target-answer [1 1 1 1 1 1 1 1 1 1 1 1 1 0 0]] if target = 14 [set target-answer [1 1 1 1 1 1 1 1 1 1 1 1 1 1 0]] if target = 15 [set target-answer [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]]
(foreach target-answer (sort output-nodes)[
ask ?2 [set error activation * (1 - activation) * (?1 - activation) ] ]) ;; date le due liste target answer ed i nodi output messi in ordine, ho bisogno che il primo ;elemento della lista target sia uguale all'attivazione. ?1 - activation è la differenza tra il ;target e l'attivazione del nodo corrispondente ?2 ask hidden-nodes [

153
set error activation * (1 - activation) * sum [weight * [error] of end2] of my-out-links ] ;; l'errore si propaga indietro verso i neuroni nascosti ask links [ set weight weight + learning-rate * [error] of end2 * [activation] of end1 ] ; e va a modificare il peso dei collegamenti. if target != count output-nodes with [color = blue] [set errore errore + 1] end to test ;; il TEST, l'utente può inserire un numero binario e provare la rete. clear-output ask input-node 0 [set activation input-0] ask input-node 1 [set activation input-1] ask input-node 2 [set activation input-2] ask input-node 3 [set activation input-3] propagate output-print "il valore dovrebbe essere" output-print [activation] of input-node 0 * 2 ^ 0 + [activation] of input-node 1 * 2 ^ 1 + [activation] of input-node 2 * 2 ^ 2 + [activation] of input-node 3 * 2 ^ 3 output-print "il risultato della rete neurale è" output-print count output-nodes with [color = blue] ifelse ([activation] of input-node 0 * 2 ^ 0 + [activation] of input-node 1 * 2 ^ 1 + [activation] of input-node 2 * 2 ^ 2 + [activation] of input-node 3 * 2 ^ 3) = count output-nodes with [color = blue] [output-print "CORRETTO :-)"] [output-print "SBAGLIATO :-("] end to do-plot set-current-plot "errori" set-current-plot-pen "errore" if ticks > 0 [plot errore] end Autore: Jakob Grazzini 2008.

154
Si ringrazia il professor Uri Wilensky per aver messo il suo modello di rete neurale a disposizione su internet sul sito http://ccl.northwestern.edu/netlogo/models/ArtificialNeuralNet
Per riprodurre la simulazione creare i bottoni go e setup come sopra. Creare un grafico con il titolo “errori” ed il nome della penna “errore”. Creare uno slider con il nome esempi-periodo, impostare il valore iniziale a 300, creare uno slider con il nome learning-rate ed impostare il valore iniziale a 0.03, e creare 4 chooser con i nomi input-0; input-1; input-2; input-3, ed impostare i valori a 0 e 1, saranno questi che ci permetteranno di fare il test inserendo un numero bianrio. Riferirsi anche alla figura 12 a pagina 104.
A4-Codice NetLogo del modello economico con algoritmi genetici TURTLES-OWN [dna x y pex fitness pr n new couple couplen whocouple m cross-point altro-dna] globals [p c d alfa; costi fissi beta; costi variabili a ; intercetta domanda-inversa b ; slope domanda-inversa ] to setup ca create-turtles 1000 ask turtles [setxy random-xcor random-ycor] ask turtles [set color white] ask turtles [set dna (list random 2 random 2 random 2 random 2 random 2 random 2 random 2 random 2 random 2 random 2)] ask turtles [set x item 0 dna * 2 ^ -1 + item 1 dna * 2 ^ -2 + item 2 dna * 2 ^ -3 + item 3 dna * 2 ^ -4 + item 4 dna * 2 ^ -5 + item 5 dna * 2 ^ -6 + item 6 dna * 2 ^ -7 + item 7 dna * 2 ^ -8 + item 8 dna * 2 ^ -9 + item 9 dna * 2 ^ -10 ] set alfa 0.25 set beta 1 set a 5 set b 0.005 ask turtles [set y a / (1000 * b) * x] ;a / gamma * x set p a - b * sum [y] of turtles

155
ask turtles [set pex a - b * count turtles * y] ask turtles [set fitness pex * y - alfa - y ^ 2 + alfa + beta * ( a / (b * 1000))^ 2 ] end to go if ticks = 500 [stop] if ticks = 250 [set beta 1.5] ;set b var-p-y ;set beta variable-cost selection cross-over mutation ;; upgrade parameters ask turtles [set x item 0 dna * 2 ^ -1 + item 1 dna * 2 ^ -2 + item 2 dna * 2 ^ -3 + item 3 dna * 2 ^ -4 + item 4 dna * 2 ^ -5 + item 5 dna * 2 ^ -6 + item 6 dna * 2 ^ -7 + item 7 dna * 2 ^ -8 + item 8 dna * 2 ^ -9 + item 9 dna * 2 ^ -10 ] ask turtles [set y a / (1000 * b) * x] set p a - b * sum [y] of turtles ask turtles [set pex a - b * count turtles * y] ask turtles [set fitness p * y - alfa - beta * y ^ 2 + alfa + beta * (a / (1000 * b))^ 2] do-plot tick end to selection ask turtles [set n 0] ask turtles [set pr fitness / sum [fitness] of turtles] while [sum [n] of turtles < 1000] [ask turtles [if random-float 1 < pr [set n n + 1]]] ask turtles [if sum [n] of turtles > 1000 [ask n-of (sum [n] of turtles - 1000) turtles with [n > 0][set n n - 1]]] ask turtles [hatch n[set new true]]; setxy random-xcor random-ycor]] ask turtles [if count turtles with [new = true] > 500[set d count turtles with [new = true] - 1000 ask n-of d turtles [die]]] ask turtles with [new != true][die]

156
ask turtles [set new false] end to cross-over ;prima di tutto formo le coppie. sono casuali e danno il valore ad una ;variabile in modo da essere riconoscibili. gli agenti con lo stesso valore di ;couplen sono una coppia set c 1 while [count turtles with [couple != true] > 2][ask n-of 2 turtles with [couple != true][set couple true set couplen c] set c c + 1] ;dico agli agenti il nome del loro partner ask turtles [set whocouple [who] of one-of other turtles with [couplen = [couplen] of myself]] ;le coppie devono stabilire un cross point. Tutti estraggono un numero a ;caso da 0 a 9, uno dei due si adegua all'altro. set c 1 while [c < max [couplen] of turtles][ask turtles with [couplen = c][set cross-point random 10] ask one-of turtles with [couplen = c] [set cross-point [cross-point] of turtle whocouple set c c + 1]] ;show [cross-point] of turtles with [couplen = 10] ;show [dna] of turtles with [couplen = 10] ;show [whocouple] of turtles with [couplen = 10] ;dico agli agenti il dna del partner. se facessi girare direttamente l'istruzione ;successiva, il corss over averrebbe effetivamente solo per ;uno dei due agenti, in quanto quando tocca all'altro il primo ha il suo ;stesso codice genetico dal punto di cross verso destra. ;quindi "salvo" il codice del partner in una variabile in modo che ognuno ;possa fare il suo cross-over. ask turtles [set altro-dna [dna] of turtle whocouple] ;finalmente il cross-over vero e proprio, ogni agente rispetto al cross-point ;scambia gli ultimi n geni. set c 1 ask turtles [if random-float 1 < 0.6 [if cross-point = 9 [set dna replace-item 0 dna (item 0 altro-dna)] if cross-point >= 8 [set dna replace-item 1 dna (item 1 altro-dna)] if cross-point >= 7 [set dna replace-item 2 dna (item 2 altro-dna)] if cross-point >= 6 [set dna replace-item 3 dna (item 3 altro-dna)] if cross-point >= 5 [set dna replace-item 4 dna (item 4 altro-dna)] if cross-point >= 4 [set dna replace-item 5 dna (item 5 altro-dna)] if cross-point >= 3 [set dna replace-item 6 dna (item 6 altro-dna)] if cross-point >= 2 [set dna replace-item 7 dna (item 7

157
altro-dna)] if cross-point >= 1 [set dna replace-item 8 dna (item 8 altro-dna)] if cross-point >= 0 [set dna replace-item 9 dna (item 9 altro-dna)]]] ask turtles [set couplen 0] ask turtles [set couple false] end to mutation ask turtles [while [m <= 9][if random-float 1 < 0.002 [set dna replace-item m dna (1 - item m dna) ]set m m + 1]] ask turtles [set m 0] end to do-plot set-current-plot "Mean output" set-current-plot-pen "y" plot mean [y] of turtles set-current-plot-pen "exy" plot a / (2 * beta + 1000 * b) set-current-plot "variance" set-current-plot-pen "variance" plot variance [x] of turtles end Autore: Jakob Grazzini, 2007 Per eseguire la simulazione creare i bottoni setup e go come sopra, creare un plot con il titolo "Mean output" ed il nome della penna “y”. Creare un altro plot con titolo “variance” e nome della penna “variance”
A5- Codice NETLOGO del modello di borsa simulato ;Terna (2000a). Our (un)realistic market emerges from the behavior of myopic
agents that: (i) know only
;the last executed price, (ii) choose randomly, in a balanced way, the buy or
sell side and (iii) fix
;their limit price by multiplying the previously executed price times a random coefficient ;supponiamo ora che gli agenti conoscano i prezzi dei periodi t-1 e t-2 (giorni, non transazioni) e che si comportino

158
;imitando il mercato. Se il prezzo nelle ultime due giornate è aumentato ;comprano di più, se il prezzo nelle ultime due giornate e diminuito vendono di ;più ;ora mettiamo la probabilità di imitare il mercato pari a zero, ed inseriamo la probabilità positiva di imitare gli altri agenti nel mercato. globals [price ;prezzo a cui avviene lo scambio agente-azione buyer seller b trade ;variabili globali con scopo semplicemente funzionale al codice book-p-buyer book-p-seller ;registro (book) di prezzi proposti per la vendita e l'acquisto record-price ;registro dei prezzi delle giornate precedenti per l'imitazione di mercato. Da ricordare che una giornata è pari a 100 periodi record-azione ;registro azione agenti codificate con 1 = acquisto 0 = vendita. Se la media è maggiore di 0.5 la maggioranza degli agenti ha scelto di acquistare! ] turtles-own [p fatto] to setup ca set-default-shape turtles "person" create-turtles 100 ask turtles [setxy random-xcor random-ycor] ask turtles [if xcor = 0 and ycor = 0 [setxy random-xcor random-ycor]] ask turtles [set color white] ask patch 0 0 [set pcolor red set plabel "book"] ask turtles [set fatto false] set book-p-buyer [] set book-p-seller [] set record-price [1 1] set record-azione [1 0] set price 1 do-plot end to go if ticks = 100000 [stop] if ticks mod 100 != 0 [ set agente-azione one-of turtles with [fatto = false] ;; per inserire l'imitazione ;del mercato, inseriamo una nuova probabilità. se il prezzo è superiorie a 0 ask agente-azione [ifelse price > 0.30 [ ifelse random-float 1 < probabilita-imitazione-mercato [imita-mercato] ;;la probabilità di imitare il mercato. [ifelse random-float 1 < probabilita-imitazione-locale [local-imitation] [ifelse random-float 1 < 0.5 [buy][sell]]]

159
] [ifelse random-float 1 < 0.8 [buy][sell]]]] if ticks mod 100 = 0 [set record-price (lput price record-price) if length record-price > 2 [set record-price remove-item 0 record-price] show record-price set book-p-buyer [] set book-p-seller [] ask turtles [set fatto false]] ;show book-p-buyer show book-p-seller if length record-azione > 20 [set record-azione remove-item 0 record-azione]
tick
do-plot
end
to buy
set buyer agente-azione
set record-azione (lput 1 record-azione)
ask buyer [set trade false]
ask buyer [let k random-float 0.2 + 0.9 set p price * k]
set b 0
ask buyer [while [b < length book-p-seller][if item b book-p-seller < p [set price item b book-p-seller set book-p-seller remove-item b book-p-seller set fatto true set b length book-p-seller set trade true]
set b b + 1]]
ask buyer [if trade = false [set book-p-buyer (lput p book-p-buyer) set book-p-buyer sort-by [?1 > ?2] book-p-buyer]] ;sort al contrario
ask buyer [set fatto true]
end to sell set seller agente-azione set record-azione (lput 0 record-azione) ask seller [set trade false] ask seller [let k random-float 0.2 + 0.9 set p price * k] set b 0 ask seller [while [b < length book-p-buyer][if item b book-p-buyer > p [set price item b book-p-buyer set book-p-buyer remove-item b book-p-buyer set fatto true

160
set b length book-p-buyer set trade true] set b b + 1]] ask seller [if trade = false [set book-p-seller (lput p book-p-seller) set book-p-seller sort book-p-seller]] ask seller [set fatto true] end to imita-mercato ask agente-azione [let variazione-prezzo (item 1 record-price - item 0 record-price) ifelse variazione-prezzo >= 0 [buy] [sell]] end to local-imitation ask agente-azione [if mean record-azione > 0.5 [buy ]] ;se la maggioranza degli ultimi 20 agenti ha comprato, l'agente compra ask agente-azione [if mean record-azione < 0.5 [sell]] ;se la maggioranza degli ultimi 20 agenti ha venduto, l'agente vende ask agente-azione [if mean record-azione = 0.5 [ifelse random-float 1 < 0.5 [buy] [sell] ] ; se esattamente la metà degli agenti ha scelto di vendere e l'altra metà di comprare l'agente scegli casualmente se vendere o comprare ] end to do-plot set-current-plot "prezzo per transazione" set-current-plot-pen "price" plot price set-current-plot "prezzo per giornata" set-current-plot-pen "price" if ticks mod 100 = 0 [plot price] set-current-plot "proposte di acquisto-proposte di vendita" set-current-plot-pen "differenza" plot (length book-p-buyer - length book-p-seller) set-current-plot-pen "0" plot 0 end Autore: Jakob Grazzini, 2008

161
Per eseguire la simulazione, creare i bottoni setup e go come sopra. Creare 3 grafici, il primo con titolo “prezzo per transazione” e penna “price”; il secondo con il titolo “prezzo per giornata” e penna “price”; il terzo “proposte di acquisto-proposte di vendita” e penna “price”.
A6 - Codice NetLogo del modello di fragilità
finanziaria. Il modello originale si trova in Delli Gatti et al. (2005, 2006). globals [bad-deb Lb Eq v lambda c g phi profitb omega D da entry N et at prodotto prodotto-1 t falliti averager] turtles-own [ profit A b L K-1 K u r y ] to setup ca create-turtles 2000 ask turtles [ setxy random-xcor random-ycor set color white set A 20 set L 80 set K 100] set Eq 12800 set v 0.08 set lambda 0.3 set phi 0.1 set g 1.1 set c 1 set omega 0.004 set N 30 set da 100 set et 0.1 do-plot end to go if ticks = 1000 [stop] set prodotto-1 prodotto ask turtles [if A + profit < 0 [set b -1 * (A + profit)]] set falliti count turtles with [A + profit < 0] set bad-deb sum [b] of turtles

162
ask turtles [if A + profit < 0 [die]] new-entry set Lb Eq / v set D Lb - Eq ;; Le imprese ask turtles [ set u random-float 2 set L (lambda * K / sum [K] of turtles + (1 - lambda)* A / sum [A] of turtles)* Lb set r (2 + A) / (2 * c * g * (1 / (phi * c) + profit + A) + 2 * c * g * L) set K-1 K set K (phi - g * r)/(c * phi * g * r)+ A / (2 * g * r) set A K - L set y phi * k set profit u * y - g * r * K ] set prodotto sum [y] of turtles if ticks > 0 [set t (prodotto - prodotto-1) / prodotto-1] ;; Settore bancario set averager sum [r * L] of turtles / lb set profitb (sum [r * L] of turtles) - averager * ((1 - omega) * D + Eq) set Eq Eq + profitb - bad-deb tick do-plot end to new-entry set entry floor (N * (1 + e ^ (da *(averager - et)))^ (-1)) ask n-of entry patches [sprout 1 [set k random-normal mean [k] of turtles 1 set at mean [ A / K] of turtles set A at * k set phi 0.1]] end to do-plot set-current-plot "Prodotto" set-current-plot-pen "prodotto" if ticks > 0 [plot ln prodotto] set-current-plot "banca" set-current-plot-pen "Lb" plot lb set-current-plot-pen "Eq" plot Eq

163
set-current-plot "bad-deb" set-current-plot-pen "D" plot bad-deb set-current-plot "Crescita" set-current-plot-pen "C" plot t set-current-plot-pen "0" plot 0 set-current-plot "tasso d'interesse" set-current-plot-pen "i" if ticks > 0 [plot averager] end Autore: Jakob Grazzini, 2008
Per eseguire la simulazione, creare i bottoni setup e go, e creare 5 plot con le seguenti caratteristiche: titolo “prodotto” e penna ”prodotto”; titolo banca e penna “Lb” seconda penna “Eq”: titolo “bad-deb” e penna “D”; titolo “Crescita” e penna “C” seconda penna “0”;titolo “tasso d’interesse”, penna “i”

164
Appendice B
Differenze di reddito tra i quartieri romani.
Uno studio approfondito della configurazione per reddito delle zone di Roma
può essere fatto solo dopo una lunga e dispendiosa raccolta di dati. Ciò che mi
propongo di fare è mostrare, con un semplice intento esemplificativo, come le
differenze tra i redditi medi registrati nei quartieri di Roma siano imputabili a
segregazione economica all’interno della città. I dati in mio possesso
provengono da uno studio della Regione Lazio e descrivono il reddito medio nei
quartieri romani. Le zone sono divise con criterio amministrativo piuttosto che
rispetto alle comunità che vi abitano, ma dal punto di vista della segregazione
è possibile ottenere qualche risultato.
Utilizzando il teorema del limite centrale, la distribuzione delle medie
campionarie è approssimabile ad una normale standardizzata. Siano i
quartieri i campioni di popolazione che vogliamo studiare. Se la popolazione
romana fosse distribuita casualmente dovremmo trovare che l’intervallo di
confidenza costruito attorno alla media campionaria (alla media di una
quartiere) contiene la media effettiva della popolazione. In altre parole, se il
quartiere Parioli non fosse abitato prevalentemente da famiglie ricche,
dovremmo trovare che facendo inferenza sulla media del reddito dei Parioli, il
parametro reale “media di reddito della popolazione” si dovrebbe trovare
nell’intervallo di confidenza costruito attorno alla media campionaria dei
Parioli. Si può vedere la questione anche dal punto di vista del test di ipotesi:
poniamo di avere la media del campione Parioli e la media della popolazione
Roma, voglio verificare che Parioli fa effettivamente parte della popolazione
Roma; dato che io so che Parioli è parte di Roma, se la verifica rifiuta l’ipotesi
nulla posso affermare che esiste segregazione economica a Roma. Purtroppo
per costruire l’intervallo di confidenza necessario avrei bisogno della varianza
dei redditi a Roma, dato che non ho a disposizione. Il ragionamento che verrà
fatto sarà inverso: quale dovrebbe essere la varianza dei redditi a Roma
affinché l’intervallo di confidenza attorno alla media campionaria contenga il
parametro della popolazione?

165
Costruiamo l’intervallo di confidenza al 95%
#∗ − 1,96 ∙ x √< , #∗ + 1,96 ∙ x √<
Dove #∗ è la media campionaria, 1,96 è il valore critico sulla tavola della
normale standardizzata, x è lo scarto quadratico medio, < è la popolazione
campionaria. I dati sono
#∗ = 28.641 € (media reddito del quartiere Parioli)
< = 14000 (popolazione parioli)
! = 19615 € (è il reddito medio di Roma, Fonte Regione Lazio)
da ciò segue che
#∗ − 1,96 ∙ x √< = !
x = #∗ − ! ∙ √< 1,96
x = 28.641 − 19615 ∙ √14000 1,96
x = 9026 ∙ 118,32 1,96 = 544875,67
Lo scarto quadratico medio nella distribuzione del reddito a Roma dovrebbe
essere di 544875,67 € un valore evidentemente troppo alto per essere
verosimile. La conclusione dell’analisi è che è plausibile che l’alto reddito
medio ai Parioli sia frutto di una segregazione economica. Non è possibile
estendere la conclusione all’intera città di Roma; esistono quartieri ricchi
(come i Parioli) e quartieri poveri (la Borghesiana ha un reddito che non
raggiunge la metà del reddito dei Parioli), ed esistono molti quartieri intermedi
dove popolazioni di fasce di reddito diverse coesistono.

166
Classifica dei quartieri di Roma in base al reddito disponibile pro capite
al 2003. Fonte Regione Lazio, Istituto Guglielmo Tagliacarne.
1 RM Pinciano, Parioli
28.641
2 RM Salario Trieste
27.615
3 RM Centro Storico (rioni)
25.067
4 RM Della Vittoria (quartiere), Flaminio
24.895
5 RM Tor di Valle, Torrino, Eur
24.861
6 Tor di Quinto (sub.), Tor di Quinto (quartiere)
24.655
7 RM Monte Sacro (quartiere)
23.728
8 RM Casal Boccone, Monte Sacro Alto
23.396
9 RM Torricola, Appio Pignatelli, Ardeatino
23.263
10 RM Gianicolense (quartiere)
22.786
11 RM Trionfale (sub.), Ottavia, Della Vittoria (sub.), Tomba di Nerone, Grottarossa
21.831
12 RM Isola Farnese, La Storta, La Giustiniana
21.726
13 RM Primavalle, Aurelio (quartiere), Trionfale
21.463
14 RM Appio Latino
20.817
15 RM Cecchignola, Giuliano Dalmata, Fonte Ostiense
20.747
16 RM Lido di Ostia
19.269
17 RM Collatino, Tiburtino, Nomentano
19.193
18 RM Ostia Antica, Casal Palocco, Acilia N, Acilia S, Castel Fusano, Mezzocammino
19.120
19 RM Portuense (quartiere), Ostiense
18.516
20 RM Marcigliana, Val Melaina, Tor San Giovanni, Castel Giubileo
18.454
21 RM Capannelle, Appio Claudio
17.991

167
22 RM Castel Porziano, Castel di Decima, Tor de' Cenci, Vallerano, Castel di Leva
17.938
23 RM Torre Maura, Don Bosco, Tuscolano
17.353
24 RM Magliana Vecchia, Portuense (sub.), La Pisana, Gianicolense sub.
16.936
25 RM San Basilio, Ponte Mammolo
16.748
26 RM Prima Porta, Labaro
16.732
27 RM Pietralata
16.694
28 RM Prenestino Centocelle, Prenestino Labicano
15.880
29 RM Tor Cervara, Tor Sapienza, Torre Spaccata, Alessandrino
15.798
30 RM Santa Maria di Galeria, Cesano
15.383
31 RM Casalotti, Aurelio (sub.)
15.276
32 RM Castel di Guido, Ponte Galeria
14.913
33 RM Lunghezza, Acqua Vergine, San Vittorino
14.293
34 RM Settecamini
13.985
35 RM Torre Angela, Torrenova, Torre Gaia, Casal Morena, Aeroporto di Ciampino
13.950
36 RM Borghesiana 13.949
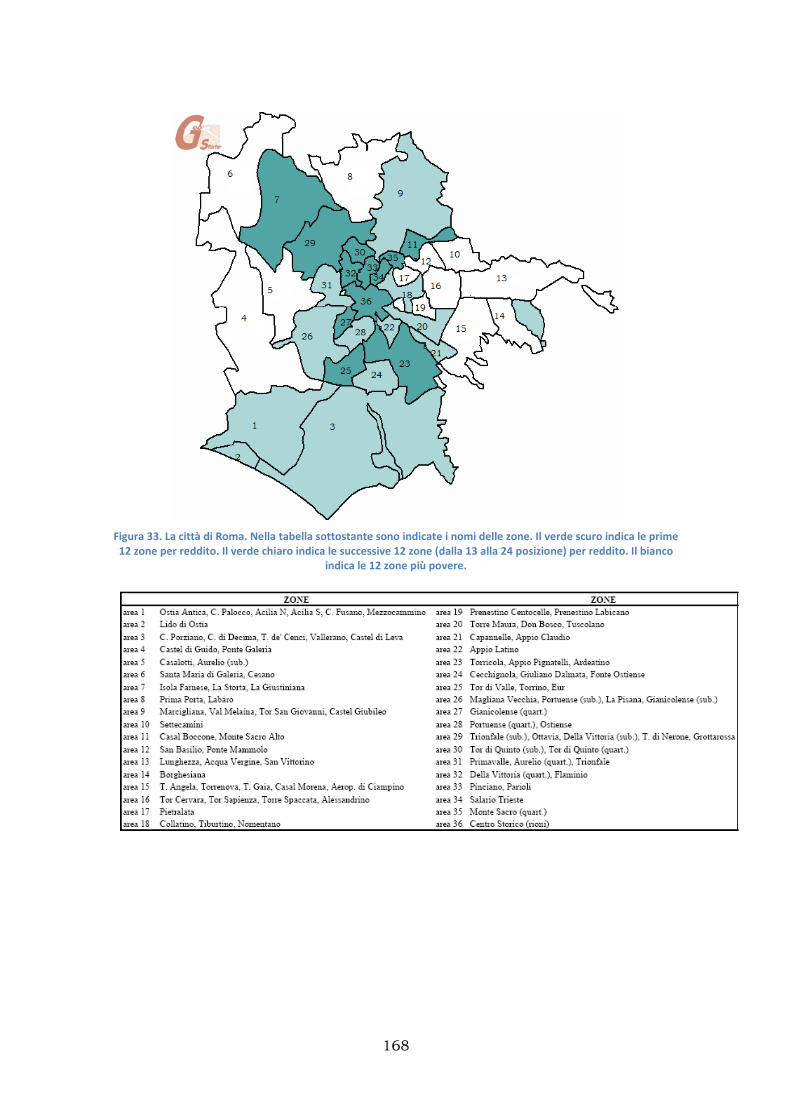
168
Figura 33. La città di Roma. Nella tabella sottostante sono indicate i nomi delle zone. Il verde scuro indica le prime 12 zone per reddito. Il verde chiaro indica le successive 12 zone (dalla 13 alla 24 posizione) per reddito. Il bianco
indica le 12 zone più povere.

169
Bibliografia Akerlof, George A. 1997, Social Distance and Social Decisions, Econometrica, vol. 65 (5), pp. 1005-1027 Arifovic, Jasmina , James Bullard John Duffy 1997, The Transition from Stagnation to Growth: An Adaptive Learning Approach, Journal of Economic Growth, vol. 2 (2), pp. 185-209 Arifovic, Jasimina 1995, Genetic Algorithms and Inflationary Economies, Journal of Monetary Economics, vol. 36, pp. 219-243 Arthur, W. Brian, John H. Holland, Blake LeBaron, Richard Palmer e Paul Tayler 1997, Asset Pricing Under Endogenous Expectations in an Artificial Stock Market, in W. B. Arthur, S. Durlauf & D. Lane, eds, ‘The Economy as an Evolving Complex System II’, Addison-Wesley, Reading, MA, pp. 15–44. Una versione precedente alla pubblicazione dello stesso articolo è disponibile sul sito: http://www.econ.iastate.edu/tesfatsi/ahlpt96.pdf Arthur, W. Brian 1999, Complexity and the Economy, Science, New Series, vol. 284 (5411), pp. 107-109 Axelrod, Robert 1987, The Evolution of Strategies in the Iterated Prisoner’s Dilemma, in Lawrence Davis (ed.), Genetic Algorithms and Simulated Annealing, London : Pitman e Los Altos, CA: Morgan Kaufmann. Axelrod, Robert, 1997, Advancing the Art of Simulation in the Social Sciences, in Rosaria Conte, Rainer Hegselmann and Pietro Terna (eds.), Simulating Social Phenomena (Berlin: Springer, 1997), pp. 21-40. Axtell, Robert 2005, The complexity of Exchange, The Economic Journal, 115 (June), F193–F210. Bedau, Mark A. 1997, Weak Emergence, Philosophical Perspective: Mind, Causation and World, vol (11), pp. 375-399. Disponibile all’indirizzo: http://academic.reed.edu/philosophy/faculty/bedau/pdf/emergence.pdf Blume, Lawrence E., Steven N. Durlauf 2005, Identifyng Social Interactions: A Review, Working Paper 2005-12, University of Wisconsin. Disponibile all’indirizzo: http://www.ssc.wisc.edu/econ/archive/wp2005-12.pdf Bollobàs, Béla, Andrew Thomason 1987, Threshold Functions, Combinatorica, vol. 7 (1), pp.35-38

170
Boero, Riccardo, Marco Castellani e Flaminio Squazzoni 2006, Processi Cognitivi e Studio delle Proprietà Emergenti nei Modelli ad Agenti, in Pietro Terna, Riccardo Boero, Matteo Morini e Michele Sonnessa, 2006, Modelli per la complessità. La simulazione ad agenti in economia, Bologna, Il mulino Borjas, George J. 1995, Ethnicity, Neighborhoods and Human-Capital Externalities, The American Economic Review, vol. 85 (3), pp. 365-390 Brock, William A., Steven N. Durlauf 2001, Discrete Choice with Social Interactions, The Review of Economic Studies, vol. 68 (2), pp. 235-260 Bullard, James, John Duffy 1998, A model of learning and emulation with artificial adaptive agents, Journal if Economic Dynamics and Control, vol.22, p.179-207 Camerer, F. Colin e George Loewenstein 2004, Behavioral Economics: Past, Present, Future in Colin F. Camerer, George Loewenstein e Matthew Rabin, 2004 Advances in Behavioral Economics. New York: Russel Sage Foundation; Princeton university press. Chalmers, David J., 2006, Strong and Weak Emergence, in P. Clayton and P. Davis (ed.), The Re-emergence of Emergence, Oxford, Oxford University Press. Disponibile all’indirizzo: http://consc.net/papers/emergence.pdf Clarida, Richard H. 1991, Aggregate Stochastic Implications of the Life Cycle Hypothesis, The Quarterly Journal of Economics, Vol. 106 (3), pp. 851-867. Datcher, Linda 1982, Effects of Community and Family Background on Achievement, The Review if Economics Studies, vol. 63 (1), pp.32-41 Davidson, J. E. H., D. F. Hendry, F. Srba, S. Yeo 1978, Econometric Modelling of the Aggregate Time-Series Relationship Between Consumers' Expenditure and Income in the United Kingdom, Economic Journal, vol. 88 (352), pp. 661-692. Dawid, Herbert, Michael Kopel 1998, On economic applications of genetic algorithm: a model of cobweb type, Journal of Evolutionary Economics, vol. 8, pp. 297-315 Debreu, Gerard 1970, Economies with a Finite Set of Equilibria, Econometrica, vol.38 (3), pp.387-392 Debreu, Gerard 1991, The Mathematization of Economic Theory, American Economic Review, vol.81 (1), pp. 1 - 7

171
Delli Gatti, Domenico, Corrado Di Guilmi, Edoardo Gaffeo, Gianfranco Giulioni, Mauro Gallegati, Antonio Palestrini 2005, A New Approach to Business Fluctuations: Heterogeneous Interacting Agents, Scaling Laws and Financial Fragility, Journal of Economic Behavior and Organization, vol. 56, pp.489-512 Delli Gatti, Domenico, Edoardo Gaffeo, Mauro Gallegati, Gianfranco Giulioni, Antonio Palestrini 2006, Emergent Macroecomics. An Agent Based Approach to Business Fluctuation. Disponibile sul sito: http://www.dea.unian.it/gallegati/Emergent_Macroeconomics.pdf Diebold, Francis X., Glenn D. Rudebusch 1991, Is Consumption Too Smooth? Long Memory and the Deaton Paradox, The Review of Economics and Statistics, Vol. 73 (1), pp. 1-9. Dow, James, Sergio Riberio da Costa Werlang, 1988, The consistency of welfare judgments with a representative consumer, Journal of Economic Theory 44, 269-280. Drewianka, Scott 2003, Estimating Social Effects in Matching Markets: Externalities in Spousal Search, The Review of Economics and Statistics, vol. 85 (2), pp. 409-423 Durlauf, Steven N. 1996, A Theory of Persistent Income Inequality, Journal of Economic Growth, vol. 1 (1), pp. 75-93 Durlauf, Steven N. 2002, Groups, Social Influences and Inequality: A Memberships Theory Perspective on Poverty Traps, Working Paper 2002-18, University of Wisconsin. Disponibile all’indirizzo: http://www.ssc.wisc.edu/econ/archive/wp2002-18.pdf Durlauf, Steven N. 2003, Neighborhoods Effect, Working Paper 2003-17, University of Wisconsin. Diponibile all’indirizzo: http://www.ssc.wisc.edu/econ/archive/wp2003-17.htm Durlauf, Steven N. 2003a, The Convergence Hypothesis After 10 Years, Working Paper 2003-06, University of Wisconsin. Disponibile all’indirizzo: http://www.ssc.wisc.edu/econ/archive/wp2003-06.pdf Evans, William N., Wallace E. Oates, Robert M. Schwab 1992, Measuring Peer Group Effects: A Study of Teenage Behavior, The Journal of Political Economy, vol.100 (5), pp.966-991

172
Fagiolo, Giorgio e Andrea Roventini 2008, On Scientific Status of Economic Policy: A Tale of Alternative Paradigms, Working Paper , Sant’Anna School of Advanced Studies Falk, Armin, Andrea Ichino 2003, Clean Evidence and Peer Pressure, IZA Discussion Paper no. 732 Farmer, J. Doyne, Paolo Patelli, Ilija I. Zovko 2005, The Predictive Power of Zero Intelligence in Financial Markets, Proceedings of the National Academy of Sciences of the United States of America 102 (6) pp. 2254-2259. Disponibile all’indirizzo: http://www.santafe.edu/~baes/jdf/papers/zero.pdf Ferraris, Gianluigi 2006, Apprendimento: reti neurali, algoritmi genetici, sistemi a classificatore, in Pietro Terna, Riccardo Boero, Matteo Morini e Michele Sonnessa, 2006, Modelli per la complessità. La simulazione ad agenti in economia, Bologna, Il mulino Fioretti, Guido 2006, La struttura delle comunicazioni tra agenti, in Pietro Terna, Riccardo Boero, Matteo Morini e Michele Sonnessa, 2006, Modelli per la complessità. La simulazione ad agenti in economia, Bologna, Il mulino Fontana, Magda 2006, Uso della simulazione in economia, in Pietro Terna, Riccardo Boero, Matteo Morini e Michele Sonnessa, 2006, Modelli per la complessità. La simulazione ad agenti in economia, Bologna, Il mulino Fromm, Jochen 2004, The Emergence of Complexity, Kassel University Press. Disponibile all’indirizzo: http://www.upress.uni-kassel.de/online/frei/978-3-89958-069-3.volltext.frei.pdf Galilei, Galileo 1632 [1970], Dialogo Sopra i Due Massimi Sistemi del Mondo, a cura di Roberto Sosio, 1970, Torino: Einaudi. Disponibile all’indirizzo: http://www.letteraturaitaliana.net/pdf/Volume_6/t333.pdf Gell-Mann, Murray 1995, What is complexity?, Complexity, Vol. 1 (1), disponibile all’indirizzo: http://www.santafe.edu/~mgm/complexity.html Geweke, John 1985, Macroeconometric Modeling and Theory of the Representative Agent, The American Economic Review, Vol. 75 (2), Papers and Proceedings of the Ninety-Seventh Annual Meeting of the American Economic Association. pp. 206-210. Gilbert, Nigel 2002, Varieties of Emergence, working paper, CRESS, University of Surrey

173
Gilbert, Nigel 2004 Agent-Based Social Simulation: Dealing with Complexity, Working Paper, CRESS, University of Surrey Gilbert, Nigel, Pietro Terna 2000, How to build and use agent-based models in social Science, Mind & Society, vol I (1), pp. 57-72 Gilbert, Nigel, Klaus G. Troitzsch 2005, Simulation for the social scientist (Second ed.). Open University Press, Buckingham. Ginther, Donna, Robert Haveman, Barbara Wolfe 2000, Neighoborhood Attributes as Determinants of Children’s Outcomes: How Robust Are the Relationships?, The Journal of Human Resources, vol. 35 (4), pp.603-642 Glaeser, Edward L., Bruce Sacerdote, José A. Scheinkman 1996, Crime and Social Interaction, The Quarterly Journal of Economics, vol. 111 (2), pp.507-548 Gode, Dhananjay, Shyam Sunder 1993, Allocative Efficiency of Markets with Zero-Intelligence Traders: Market as a Partial Substitute for Individual Rationality, The Journal of Political Economy, vol. 101 (1) pp. 110-137 Goldberg, David E. 1989, Genetic Algorithms in search, optimization, and machine learning, Addison-Wesley Publishing Company, New York Goldstone, Robert L. e Marco A. Janssen 2005, Computational Models of Collective Behavior, Trends in Cognitive Sciences, Vol. 9 (9),pp. 424-430 Gorman, William M. 1953, Community Preference Fields, Econometrica, vol. 21, pp. 63- 80. Grabner, Michael 2002, Representative Agents and the Microfoundations of Macroeconomics, University of California. Disponibile all’indirizzo: http://www.econ.ucdavis.edu/graduate/mgrabner/research/microfoundations.pdf Granovetter, Mark, Roland Soong 1988, Threshold Models of Diversity: Chinese Restaurants, Residential Segregation, and the Spiral of Silence, Sociological Methodology, vol. 18 (1988), pp.69-104 Gupta, Kanhaya Lal 1969, Aggregation in Economics: A Theoretical and Empirical Study, Rotterdam: Rotterdam University Press. Hansen, Lars Peter, Kenneth J. Singleton 1982, Generalized instrumental variables estimation of nonlinear rational expectations models. Econometrica 50 (5), pp.1269-86

174
Hansen, Lars Peter, Kenneth J. Singleton, 1983, Stochastic consumption, risk aversion, and the temporal behavior of asset returns. Journal of Political Economy 91 (2), pp.249-265 Hansen, Lars Peter, Thomas J. Sargent 1980, Formulating and Estimating Dynamic Linear Rational Expectations Models, Journal of Economic Dynamics and Control, vol. 2, pp. 7- 46 Hartley, James E., 1996, Retrospectives: The Origins of the Representative Agent, The Journal of Economic Perspectives, Vol. 10 (2), pp. 169-177 Hartley, James A. 1997, Representative Agent in Macroeconomics, Routledge, Florence, KY, USA Hassan, Samer, Luis Antunes e Millàn Arroyo 2008, Deepening the Demographic Mechanisms in a Data-Driven Social Simulation of Moral Values Evolution. In Proceedings of the Multi-Agent-Based Simulation Workshop 2008, Lecture Notes in Artificial Intelligence, Lisbon. Springer. Heckman, James J. 1979, Sample Selection Bias as a Specification Error, Econometrica, vol.47 (1), pp. 153-161 Hildenbrand, W., Alan P. Kirman 1988, Equilibrium Analysis, Amsterdam: North-Holland Holland, John H.1975, Adaptation in natural and artificial systems. University of Michigan Press, Ann Arbor Holland, John H., David E. Goldberg, 1988, Machine Learning 3, pp. 95-99 Holland, John H., John H. Miller 1991, Artificial Adaptive Agents in Economic Theory, The American Economic Review, Vol. 81 (2), Papers and Proceedings of the Hundred and Third Annual Meeting of the American Economic Association. (May, 1991), pp. 365-370. Hoover, Kevin D., 1988, The New Classical Macroeconomics: A Sceptical Inquiry, Oxford: Basil Blackwell. Jennings, Nicolas R., 2000, On agent-based software engineering, Artificial Intelligence 117, pp. 277-296 Jerison, Michael 2006, Nonrepresentative Representative Consumer, Discussion Paper 06-08, University of New York at Albany, Department of Economics

175
Keller, Wouter J., 1980, Aggregation of Economic Relations: A Note, De Economist, vol. 128 (4), pp. 558-562 Kirman, Alan P. 1989, The Intrinsic Limit of Modern Economic Theory: The Emperor has no Clothes, The Economic Journal, vol. 99 (395), pp.126-139 Kirman, Alan P. 1992, Whom or What Does the Representative Individual Represent?, The Journal of Economic Perspectives, Vol. 6 (2) pp. 117-136 Kirman, Alan P., K. J. Koch 1986, Market Excess Demand in Exchange Economies with Identical Preferences and Collinear Endowments, The Review of Economic Studies, Vol. 53 (3), pp. 457-463. Kydland, Finn E., Edward C. Prescott, 1991 The Econometrics of the General Equilibrium Approach to Business Cycles, Scandinavian Journal of Economics, vol. 93 (2), pp. 161-178. LeBaron, Blake 2002, Building the Santa Fe Artificial Stock Market, Working Paper, Brandeis University, disponibile sul sito: http://people.brandeis.edu/~blebaron/wps/sfisum.pdf Leombruni, Roberto e Matteo Richiardi 2005, Why are economists sceptical about agent-based simulations?, Physica A 355 103–109 Leombruni, Roberto e Matteo Richiardi 2006, Una risposta alle critiche: le metodologie per la definizione dei modelli di simulazione in Pietro Terna, Riccardo Boero, Matteo Morini e Michele Sonnessa, 2006, Modelli per la complessità. La simulazione ad agenti in economia, Bologna, Il mulino Lewbel, Arthur 1989, Exact Aggregation and A Representative Consumer, The Quarterly Journal of Economics, Vol. 104 (3), pp. 621-633. Lippi, Marco 1988, On the Dynamic Shape of Aggregated Error Correction Models, Journal of Economic Dynamics and Control, vol. 12 (2-3), 561-585. Lucas, Robert Jr. 1976, Econometric Policy Evaluation: A Critique, in Karl Brunner and Allan H. Meltzer (eds) The Phillips Curve and Labor Markets, Carnegie-Rochester Conference Series on Public Policy, vol. 1, Amsterdam: North-Holland, pp. 19- 46. Disponibile all’indirizzo: http://pareto.uab.es/mcreel/reading_course_2006_2007/lucas1976.pdf Maddison, Angus 1982, Phases of Capitalist Development, New York: Oxford University Press.

176
Manski, Charles F. 1993, Identification of Endogenous Social Effects: The Reflection Problem, The Review of Economic Studies, Vol. 60 (3), pp. 531-542. Manski, Charles F. 2000, Economic Analysis of Social Interactions, The Journal of Economic Perspectives, Vol. 14 (3), pp. 115-136. Marshall, Alfred 1920 [1961], Principles of Economics, 9th edn, London: Macmillan. Mayer, Susan E., Cristopher Jencks 1989, Growing up in Poor Neighborhoods: How Much Does it Matter?, Science, New Series, vol. 243 (4897), pp. 1441-1445 Milanovic, Branko 2006 Worlds Apart – Measuring International and Global Inequality, Princeton University Press Ostrom Thomas M. 1988, Computer Simulation: the Third Symbol System, Journal of Experimental Social Psychology, vol. 24 (5), pp. 381-392 Palmer, Edgar M. 1985, Graphical Evolution . An Introduction to the Theory of Random Graphs, New York: Wiley. Palmer, Richard, W. Brian Arthur, John H. Holland, Blake LeBaron e Paul Tayler, 1994, Artificial economic life: A simple model of a stock market, Physica D, vol. 75, pp.264–274 Page, Scott 1999, Computational Models from A to Z, Complexity, vol. 5 (1) pp.35-41 Page, Scott 2005, Agent Based Models, working paper, Center for the Study of Complex Systems, University of Michigan Persky, Joseph 1995, Retrospectives: The Ethology of Homo Economicus. Journal of Economic Perspectives, 9(2), 221-231 Pigou, Arthur C. 1928, “An Analysis of Supply”, Economic Journal, vol. 38 (150), June: pp. 238-57. Pigou, Arthur C. (ed.) 1956, Memorials of Alfred Marshall, New York: Kelly & Millman. Pollak, Robert A. 1976, Interdependent Preferences, The American Economic Review, vol. 66 (3), pp.309-320

177
Quah, Danny 1990, Permanent and Transitory Movements in Labor Income: An Explanation for "Excess Smoothness" in Consumption, The Journal of Political Economy, Vol. 98 (3), pp. 449-475. Remondino, Marco 2006, Gli agenti dall’Informatica alle Scienze Cognitive e alle Applicazioni in Pietro Terna, Riccardo Boero, Matteo Morini e Michele Sonnessa, 2006, Modelli per la complessità. La simulazione ad agenti in economia, Bologna, Il mulino Robbins, Lionel 1928, The Representative Firm, The Economic Journal, vol.38 (151), pp.387-404 Rosebaum, James E. 1995, Changing the Geography of Opportunity by Expanding Residential Choice: Lessons from the Gautreaux Program, Housing Policy Debate, vol. 6 (1), pp.231-269 Rosebaum, Emily, Laura E. Harris 2001, Residential Mobility and Opportunities: Early Impacts of the Moving to Opportunity Demonstration Program in Chicago, Housing Policy Debate, vol. 12 (2), pp. 321-346 Rosser, J. Barkley Jr. 1999, On the complexities of Complex Economic Dynamic, Journal of Economic Perspectives, vol. 13 (4), pp. 169-192 Rustem, Berc, Kumaraswamy Velupillai 1990, Rationality, Computability and Complexity, Journal of Economic Dynamics and Control, vol. 14, pp.419-432 Sargent, Thomas J. 1979, Macroeconomic Theory, New York: Academic Press. Sargent, Thomas J. 1982, Beyond Demand and Supply Curves in Macroeconomics, American Economic Review, vol 72 (2), pp. 382-389 Sargent, Thomas J. 1993, Bounded Rationality in Macroeconomics, Clarendon Press, Oxford Schelling, C. Thomas 1978, Micromotives and Macrobehavior, New York: Norton. Sethi, Rajiv, Rohini Somanathan 2004, Inequality and Segregation, Journal of Political Economy, vol. 112 (6), pp. 1296-1321

178
Sherif, M., O. Harvey, B. White, W. Hood, e C. Sherif 1961, Intergroup Conflict and Cooperation: The Robbers Cave Experiment, Norman: Institute of Group Relations, University of Oklahoma, reprinted by Wesleyan University Press, 1988.
Steele, Claude M. 1997, A Threat in the Air: How Stereotypes Shape the Intellectual Identities and Performances of African Americans, American Psychologist, vol. 52, pp.613-629. Summers, Lawrence H. 1991, The Scientific Illusion in Empirical Macroeconomics, The Scandinavian Journal of Economics, Vol. 93 (2), Proceedings of a Conference on New Approaches to Empirical Macroeconomics pp. 129-148. Terna, Pietro 2000a, SUM: a Surprising (Un)realistic Market: Building a Simple Stock Market Structure with Swarm, presentato a CEF 2000, Barcelona, June 5-8 Terna, Pietro 2000b, The "mind or no mind" dilemma in agents behaving in a market, in G. Ballot e G. Weisbuch (eds.), Applications of Simulation to Social Sciences. Paris, Hermes Science Publications. Terna, Pietro 2000c, Economic Experiments with Swarm: a Neural Network Approach to the Self-Development of Consistency in Agents' Behavior, in F. Luna and B. Stefansson (eds.), Economic Simulations in Swarm: Agent-Based Modelling and Object Oriented Programming. Dordrecht and London, Kluwer Academic Terna Pietro, 2006, Modelli ad Agenti: Introduzione, in Pietro Terna, Riccardo Boero, Matteo Morini e Michele Sonnessa, 2006, Modelli per la complessità. La simulazione ad agenti in economia, Bologna, Il mulino Testfatstion, Leigh 2005, Agent-Based Computational Economics: a Constructive Approach to Economic Theory, in K. L. Judd and L. Tesfatsion (editors), 2005, Handbook of Computational Economics, Volume 2:Agent-Based Computational Economics, Handbooks in Economics Series, North-Holland Varian, Hal R., 1992, Microeconomic Analysis Third Edition, New York: W.W. Norton & Co Vriend, Nicolaas J. 2000, An illustration of the essential difference between individual and social learning, and its consequences for computational analyses, Journal of Economic Dynamics and Control, vol.24, pp. 1-19

179
Walras, Leon 1874 [1974], Elementi di Economia Politica Pura, Torino : Unione tipografico-editrice torinese, 1974. Watts, D.J. , S.H. Strogatz, (1998), Collective dynamics of small-world networks, Nature vol. 393 (6684), pp. 409-410 Wolfe, J.N. 1954, The Representative Firm, The Economic Journal, vol.64 (254), pp.337-349 Wooldridge, Michael e Nick Jennings 1995, Intelligent Agents: Theory and Practice, Knowledge Engineering Review, vol. 10 (2), pp.115-152 Young, Allyn A. 1928, Increasing Returns and Economic Progress, The Economic Journal, Vol. 38 (152), pp. 527-542. Young, H. Peyton 1996, The Economics of Convention, The Journal of Economic Perspectives, vol.10 (2), pp. 105-122


















