
Algoritmo probabilistico di tipo montecarlo per il list decoding

POLITECNICO DI TORINO Facoltà di Ingegneria dell’Informazione
Tesi di Laurea
Interfaccia intelligente per motori di ricerca
Candidato:
Andrea Amburatore Relatori:
ing. Fulvio Corno ing. Laura Farinetti
Aprile 2002

I
SOMMARIO
CAPITOLO I 1
INTRODUZIONE 1
OBIETTIVI 1
SISTEMA DI RICERCA TRASPARENTE 6
Architettura di un motore di ricerca classico 8
Architettura di un motore di ricerca trasparente 9
STRUTTURA DEI CAPITOLI 12
CAPITOLO II 13
RAPPRESENTAZIONE INFORMAZIONI 13
INFORMATION RETRIEVAL 13
CONCETTI DI BASE 15
MODELLO BOOLEANO 17
MODELLO VETTORIALE 19
Calcolo dei pesi delle parole chiave dei documenti 22
MODELLO PROBABILISTICO 26
SOLUZIONE ADOTTATA 31
CAPITOLO III 33
IL LIVELLO APPLICATIVO 33
ALGORITMO PRIMARIO DEL MOTORE DI RICERCA 33
ALGORITMO DI GESTIONE DEI VETTORI V_ABSTRACT 41
Processo di ricerca appena avviato 41
Processo di ricerca a regime 41
CALCOLO DEL NUOVO PESO_VETTORE 47
CALCOLO DEL NUOVO VETTORE UTENTE 49
CRITERI DI DECISIONE PER I DOCUMENTI DA MOSTRARE 53
FEEDBACK DELL’UTENTE 55
CAPITOLO IV 57
IMPLEMENTAZIONE 57

II
DATA BASE 57
Tabelle 59
STRUTTURE DATI 62
Vettore utente 62
Lifo 62
Media 67
LIVELLO APPLICATIVO 70
Index.php 70
Moise.php 72
Functions.php 81
CAPITOLO V 84
VALUTAZIONE DEL SISTEMA 84
INTRODUZIONE 84
CONCETTI TEORICI SULLA VALUTAZIONE DI UN SISTEMA DI IR 86
VALUTAZIONE DEL SISTEMA DI IR 89
USABILITÀ 95
CAPITOLO VI 97
CONCLUSIONI 97
APPENDICE A 99
FONTI DI DOCUMENTAZIONE 101

Capitolo I - Introduzione
1
Capitolo I Introduzione
Obiettivi
Lo sviluppo di Internet e delle tecnologie multimediali ed essa associate
hanno aperto nuove potenzialità riguardo la possibilità di accedere ad una vasta
quantità di informazioni.
Tuttavia il continuo aumento delle informazioni su scala globale presenti
sulla rete non è sufficiente a permettere ad un utente senza una certa esperienza
di accedere a tali informazioni o più precisamente al sottogruppo di
informazioni che gli interessano.
Nonostante l’enorme quantità di informazioni disponibili su ogni argomento
immaginabile, la capacità di reperire informazioni dipende dall’efficacia dei
cosiddetti motori di ricerca.
I motori di ricerca sono servizi che tipicamente ricevono come input parole
chiave, inserite dall’utente e restituiscono le pagine web (o i documenti più in
generale) relative alle parole chiave immesse dall’utente.
In realtà molto spesso, affinché la ricerca sia fruttuosa, l’utente oltre ad una
certa esperienza in campo informatico deve formulare richieste complesse (tanto
più l’informazione da ricercare è specifica) seguendo sintassi non sempre ovvie.
Questi vincoli rendono spesso frustrante la ricerca di informazioni in un
campo di cui non si conosca discretamente il lessico fondamentale.
Capitolo I - Introduzione
2
Un tipico motore di ricerca infatti si basa su un form, generalmente
costituito da un text-box, nel quale si inserisce la parola o le parole che
dovrebbero identificare il maggior numero di documenti di interesse per
l’utente. Una volta inserite le parole chiave l’utente invia la richiesta che il
motore vero e proprio elabora, solitamente comparando quelle parole con il
breve testo presente nei meta-tag delle pagine registrate dal motore, o
analizzando la frequenza delle parole chiave all’interno delle pagine che
costituiscono il sito.
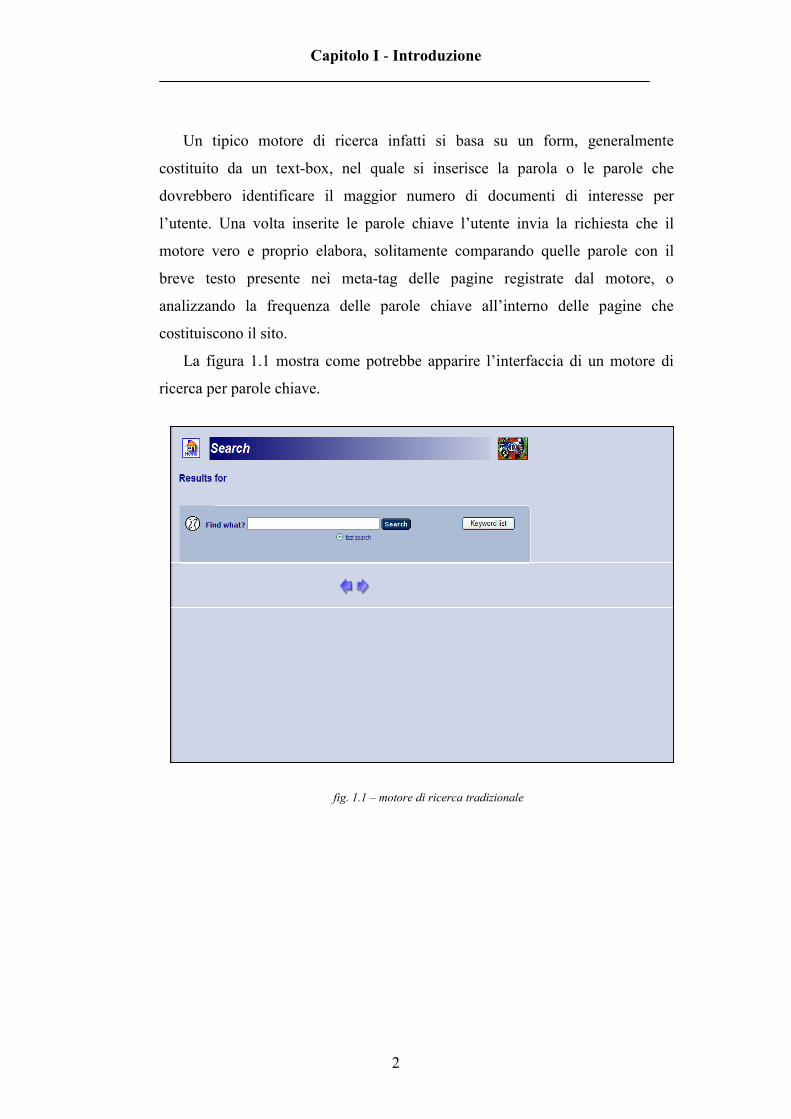
La figura 1.1 mostra come potrebbe apparire l’interfaccia di un motore di
ricerca per parole chiave.
fig. 1.1 – motore di ricerca tradizionale

Capitolo I - Introduzione
3
Analizzando i sistemi di archiviazione e di consultazione presenti su Internet
emerge una cronica incapacità di interazione con utenti inesperti.
La tecnica usata dai motori di ricerca attuali, come precedentemente
accennato, si basa su un insieme di parole chiave (eventualmente organizzate in
modo gerarchico), l’utente deve avere quindi una discreta conoscenza del
campo in esame, conoscere in definitiva i termini specifici dell’argomento che
si ricerca. Per fare un esempio, se un genitore dovesse fare una ricerca su un
archivio relativo alle disabilità, raramente adotterebbe nomi scientifici che un
motore di ricerca attuale tanto gradirebbe per focalizzare la ricerca su un
sottoinsieme di documenti relativi all’argomento ricercato. Il motore di ricerca
che si vede immettere dal genitore termini molto generici probabilmente
restituirebbe come output della ricerca tutti i documenti in suo possesso, non
avendo ricevuto delle parole chiave sufficientemente specifiche per restringere
la ricerca ad un sottogruppo dei documenti presenti in archivio.
I produttori di informazioni nei motori di ricerca attuali, solitamente, non
inseriscono oltre al documento ulteriori informazioni (che potrebbero aiutare la
sua reperibilità), è tipicamente il motore di ricerca che periodicamente legge i
nuovi documenti aggiunti e a seconda di vari criteri (la frequenza delle parole
nei documenti) ne stabilisce le parole chiave. Servirebbero invece delle meta-
informazioni ovvero delle informazioni sulle informazioni, capaci di classificare
accuratamente ciascun documento. Queste meta-informazioni devono essere
inserite dalla stessa persona o team di persone che hanno creato il documento,
attraverso un’interfaccia semplice ed intuitiva che consenta l’inserimento di
queste meta-informazioni senza una conoscenza specifica dei data base e della
loro struttura e modelli di inserimento. Questo può avvenire attraverso la
compilazione di pagine che consentono, per mezzo di una serie di domande, di
catalogare il documento.
Al fine di rendere le informazioni contenute nell’archivio accessibili anche
alla fascia di utenza allargata, è necessario realizzare un’interfaccia di
consultazione intelligente, che sia in grado di guidare l’utente nella sua ricerca,

Capitolo I - Introduzione
4
proponendo percorsi di consultazione alternativi, fino ad indicare uno o più
documenti potenzialmente di suo interesse.
Il requisito principale è la necessità di un modello circolare
dell’informazione, in cui l’utente compie delle selezioni tra le informazioni
proposte dalla macchina, mentre la macchina propone nuove informazioni
basandosi su quanto selezionato dall’utente.
Il modello proposto in questa tesi si basa sulla disponibilità di una serie di
testi introduttivi, integrati mediante collegamenti ipertestuali, che invoglino
l’utente a leggere dei brevi brani sui diversi argomenti tratti dall’archivio. Tali
sommari che noi chiameremo abstract sono collegati fino a formare un unico
ipertesto, per cui l’utente può leggere le descrizioni che più da vicino
corrispondono ai suoi interessi.
Il livello applicativo dell’interfaccia intelligente osserva l’utente mentre
seleziona i collegamenti ipertestuali, ricavando informazioni sulle tematiche che
gli interessano. Ogni volta che l’utente segue un collegamento, ovvero seleziona
un link, fornisce al sistema l’indicazione che esso gli interessa più degli altri
collegamenti presenti nella stessa pagina.
Sulla base di queste informazioni, quando l’interesse dell’utente risulta
sufficientemente definito, il livello applicazione formula delle interrogazioni al
data base restituendo i documenti che più si avvicinano al suo interesse.
Il funzionamento di un motore di ricerca per abstract, oggetto della tesi in
questione, si basa dunque su un modello circolare in cui l’utente è tenuto a
leggere dei brevi documenti ovvero gli abstract e a selezionare i link di
maggiore interesse. Procedendo con le selezioni il livello applicazione del
motore di ricerca modella l’interesse dell’utente, nel corso della sua evoluzione
e lo confronta con i documenti presenti nel data base.
Esempio:
Se un utente compie una ricerca attraverso un motore di ricerca per abstract
relativo al mondo dello sport e dopo una serie di selezioni di abstract risulta
avere un interesse orientato verso la “sicurezza”, si può dedurre che all’utente

Capitolo I - Introduzione
5
possono interessare documenti che trattano la sicurezza nello sport (per esempio
nella Formula 1) e dunque gli verranno proposti tutti i documenti relativi
all’argomento.
Si può obiettare che per trovare documenti o pagine web che trattino la
sicurezza nello sport o più precisamente nella Formula 1 sia sufficiente
utilizzare un qualsiasi motore di ricerca e inserire come parole chiave: sport
sicurezza o Formula 1 sicurezza.
Questa affermazione è sicuramente corretta ma in un ambito in cui non si
conosca in maniera approfondita il lessico (ovvero i termini tecnici) e questo è
particolarmente vero quando si fanno ricerche in campo scientifico e non si ha
una sufficiente cultura in merito, risulta molto più comodo navigare attraverso
una serie di documenti introduttivi che consentano al livello applicazione di
“modellare” l’interesse dell’utente e all’utente stesso di scegliere tra i
documenti proposti che dovrebbero rispecchiare il proprio interesse.
Devono dunque essere progettate delle precise strutture dati, di cui si
parlerà nei capitoli successivi, per poter memorizzare l’interesse di un utente e
precisi algoritmi per paragonare questo interesse con l’argomento dei documenti
al fine di visualizzare quelli che potrebbero interessare l’utente.
L’implementazione del motore di ricerca è invece l’ultimo degli aspetti che
verrà analizzato, accennando solo quando strettamente necessario, prima del
capitolo relativo a questo argomento, ai dettagli implementativi.
Per concludere, l’obiettivo del motore di ricerca è rivolto alla realizzazione
di un’applicazione che dia i mezzi per accedere, in un archivio tematico, a vari
documenti senza una conoscenza specifica del lessico settoriale, semplicemente
navigando in una serie di testi introduttivi, lasciando che sia il livello
applicazione e il sistema di information retrieval a mostrarci i documenti di
interesse.
Capitolo I - Introduzione
6
Sistema di ricerca trasparente
L’obiettivo principale del motore di ricerca trasparente è dunque di
nascondere all’utente il complesso processo di selezione delle parole chiave per
la costruzione della cosiddetta query string che deve essere inserita nel text-box
di input dei motori di ricerca classici.
In un sistema di ricerca trasparente l’interfaccia presentata all’utente non
indica, al primo sguardo, che un processo di ricerca è stato iniziato.
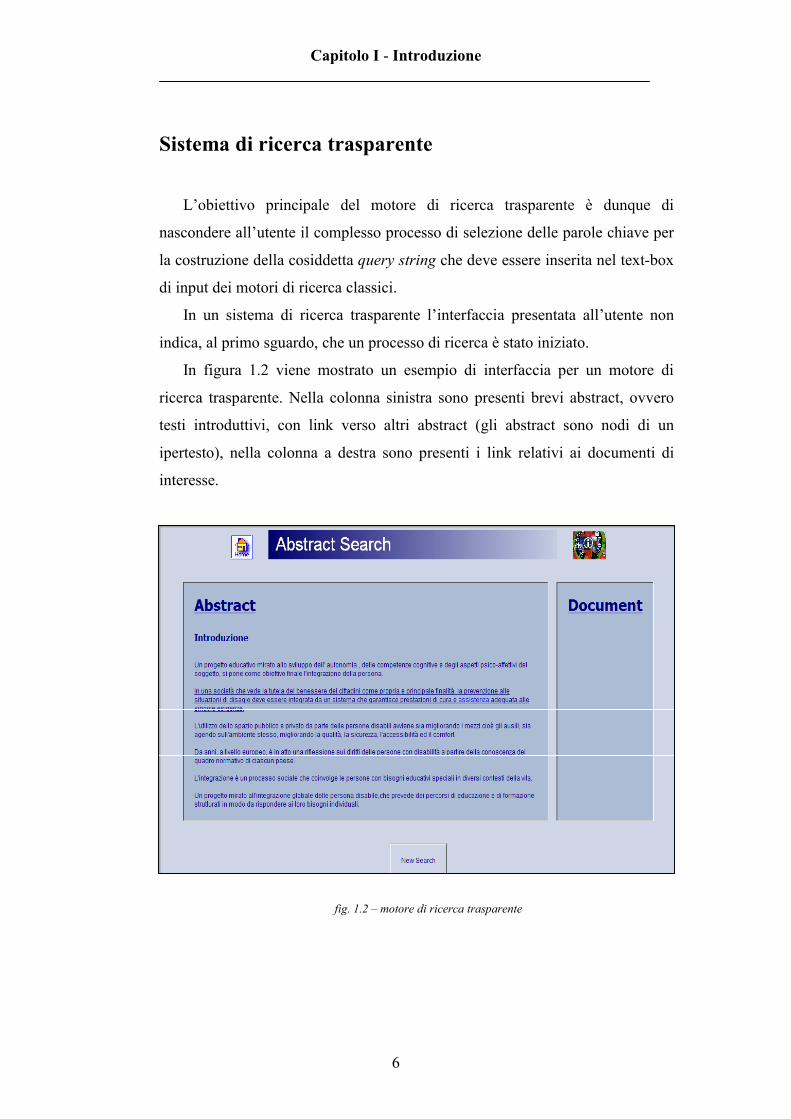
In figura 1.2 viene mostrato un esempio di interfaccia per un motore di
ricerca trasparente. Nella colonna sinistra sono presenti brevi abstract, ovvero
testi introduttivi, con link verso altri abstract (gli abstract sono nodi di un
ipertesto), nella colonna a destra sono presenti i link relativi ai documenti di
interesse.
fig. 1.2 – motore di ricerca trasparente

Capitolo I - Introduzione
7
All’inizio della ricerca l’area alla destra della pagina è vuota dato che
nessun documento incontra ancora l’interesse dell’utente, in questo modo
l’utente non viene distratto da documenti che possono non interessarlo.
Quest’area è riempita direttamente dal livello applicativo del motore di ricerca
che dinamicamente costruisce la lista dei puntatori ai documenti di maggiore
interesse per l’utente.
L’utente quindi non deve mai inserire del testo nel motore di ricerca e
l’interfaccia propone possibili scelte basate sulle informazioni correntemente
disponibili. Tutti i termini specifici (che necessitano di un lessico specifico)
sono contestualizzati, ovvero non appaiono mai da soli (come in una lista di
parole chiave) ma sono sempre parte di una frase completa che aiuta a
comprenderne il significato.
La contestualizzazione dell’informazione è uno dei maggiori miglioramenti
di questo tipo di interfaccia utente.
In qualunque momento l’utente può scegliere se continuare nella
navigazione, ovvero proseguire a selezionare nuovi abstract dalla pagina di
sinistra per raffinare il suo interesse, o aprire i documenti proposti.
Un tipico modo di procedere consiste nel navigare attraverso la selezione di
nuovi abstract e dopo una serie di scelte analizzare la parte destra
dell’interfaccia al fine di selezionare i documenti di interesse.
Nei capitoli successivi verranno illustrate le strutture dati e gli algoritmi che
stanno sotto il sistema qui brevemente presentato, ma prima di procedere, nelle
pagine successive verranno mostrate le differenze a livello architetturale tra un
sistema di ricerca classico e uno con ricerca trasparente.
Capitolo I - Introduzione
8
Architettura di un motore di ricerca classico
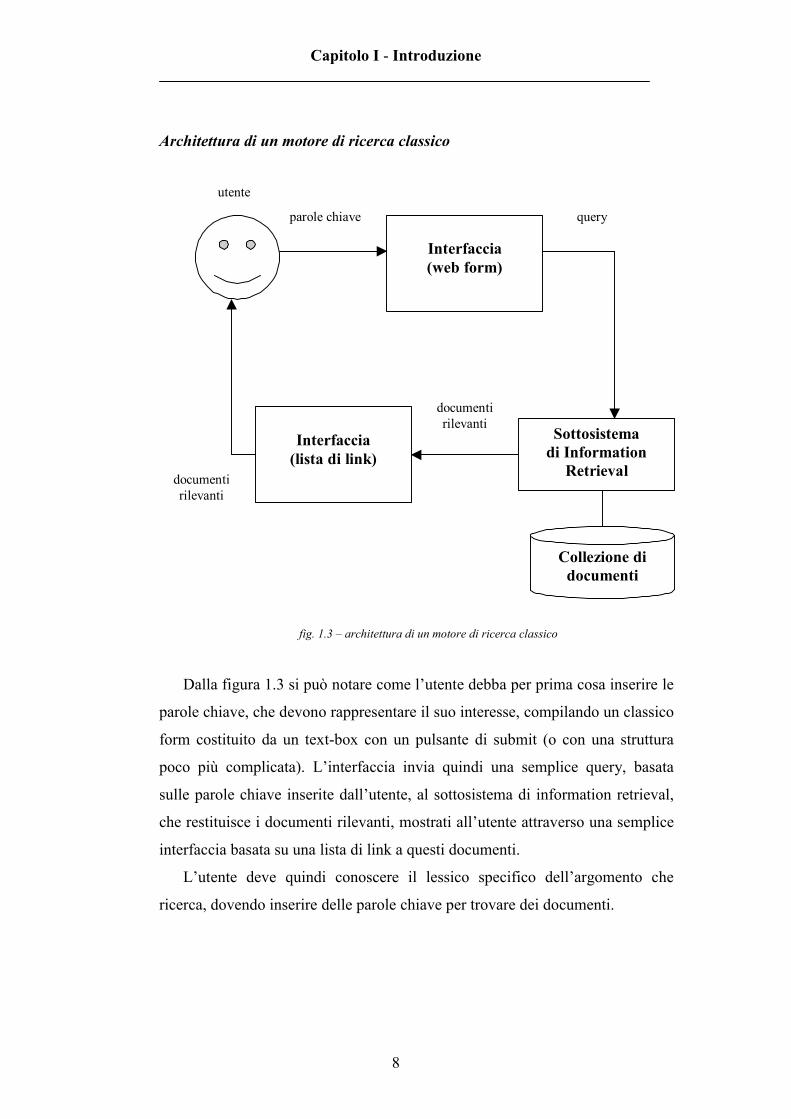
fig. 1.3 – architettura di un motore di ricerca classico
Dalla figura 1.3 si può notare come l’utente debba per prima cosa inserire le
parole chiave, che devono rappresentare il suo interesse, compilando un classico
form costituito da un text-box con un pulsante di submit (o con una struttura
poco più complicata). L’interfaccia invia quindi una semplice query, basata
sulle parole chiave inserite dall’utente, al sottosistema di information retrieval,
che restituisce i documenti rilevanti, mostrati all’utente attraverso una semplice
interfaccia basata su una lista di link a questi documenti.
L’utente deve quindi conoscere il lessico specifico dell’argomento che
ricerca, dovendo inserire delle parole chiave per trovare dei documenti.
Sottosistema di Information
Retrieval
Collezione di documenti
utente
Interfaccia (web form)
Interfaccia
(lista di link)
parole chiave query
documenti rilevanti
documenti rilevanti
Capitolo I - Introduzione
9
Architettura di un motore di ricerca trasparente
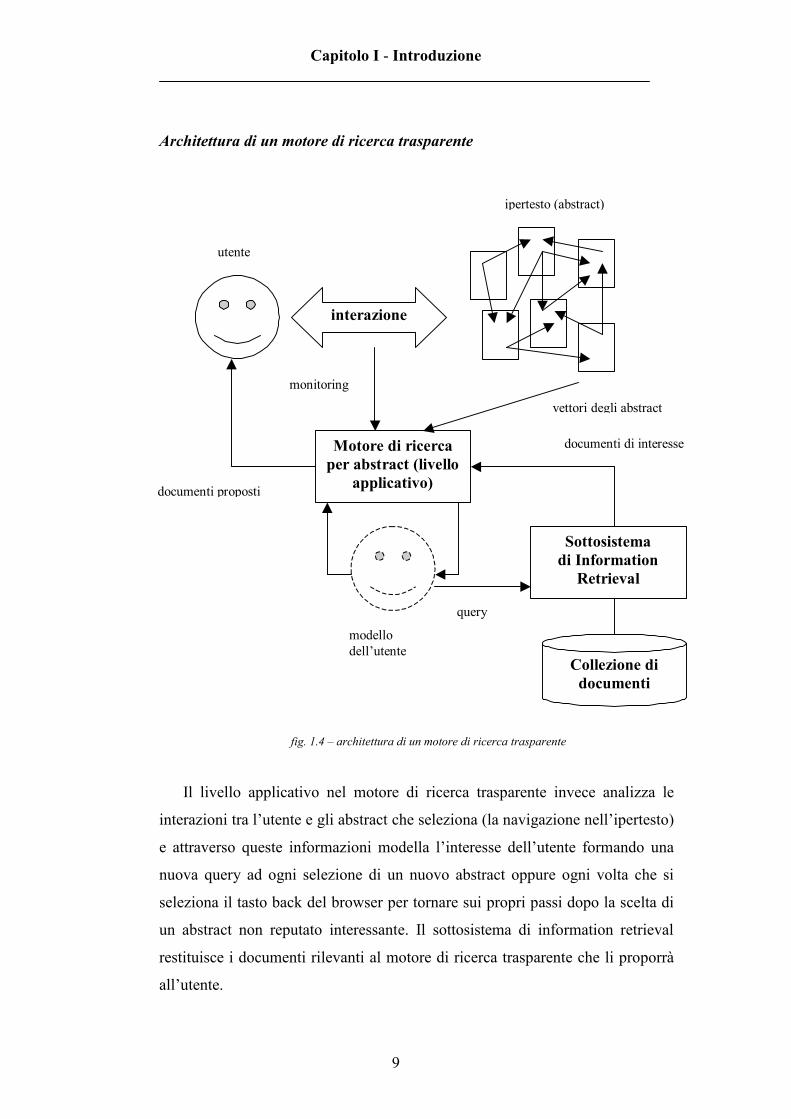
fig. 1.4 – architettura di un motore di ricerca trasparente
Il livello applicativo nel motore di ricerca trasparente invece analizza le
interazioni tra l’utente e gli abstract che seleziona (la navigazione nell’ipertesto)
e attraverso queste informazioni modella l’interesse dell’utente formando una
nuova query ad ogni selezione di un nuovo abstract oppure ogni volta che si
seleziona il tasto back del browser per tornare sui propri passi dopo la scelta di
un abstract non reputato interessante. Il sottosistema di information retrieval
restituisce i documenti rilevanti al motore di ricerca trasparente che li proporrà
all’utente.
interazione
Motore di ricercaper abstract (livello
applicativo)
Sottosistema di Information
Retrieval
Collezione di documenti
utente
ipertesto (abstract)
monitoring
modello dell’utente
vettori degli abstract
query
documenti di interesse
documenti proposti

Capitolo I - Introduzione
10
In questo modo l’utente non deve inserire nessuna parola chiave dato che il
suo interesse si forma con la navigazione negli abstract e non deve conoscere
neanche il lessico dell’argomento che ricerca perché negli abstract i termini più
specifici sono contestualizzati.
Il sistema appena descritto si può dividere, a livello architetturale, in tre livelli
(layer)
User Interface (UI) : consiste di una finestra in cui vengono visualizzati gli
abstract e di una in cui vengono mostrati i documenti di interesse. Gli abstract
sono dei brevi testi introduttivi, relativi a vari argomenti, costituiti da link verso
altri abstract. L’utente interagisce con questa interfaccia in due modi possibili:
• interazione con gli abstract: l’utente naviga tra gli abstract
selezionando i link di suo interesse o eventualmente tornando sulle sue
scelte selezionando il tasto back del browser.
• interazione con i documenti: l’utente seleziona tra i documenti proposti
quelli di suo interesse.
Application Layer : il livello applicativo osserva (operazione di monitoring) le
interazioni tra l’utente e la user interface o più precisamente tra l’utente e gli
abstract e ad ogni nuova selezione di un link o del tasto back del browser, tiene
conto di questa nuova azione nell’ “affinare” la rappresentazione dell’interesse
dell’utente (si parlerà in seguito di quali strutture dati si sono usate per creare il
modello dell’utente).
Information Retrieval (IR) : il livello applicativo, ad ogni interazione dell’utente
con l’interfaccia, invia una query al livello di IR che paragonerà la struttura dati
che contiene il modello dell’interesse dell’utente alle strutture dati relative ai
vari documenti presenti nel data base del sistema. Anche i documenti infatti
devono essere rappresentati attraverso una struttura dati che ne modelli il
contenuto, confrontabile con quella dell’interesse dell’utente al fine di poterle

Capitolo I - Introduzione
11
paragonare per discriminare tra i documenti quelli che più si avvicinano
all’interesse dell’utente.
Il livello IR quindi, ricevuta la query dal livello applicativo restituisce a
quest’ultimo (che restituisce alla UI) i documenti di interesse.

Capitolo I - Introduzione
12
Struttura dei capitoli
• Capitolo II – Rappresentazione informazioni tratta del livello più basso del
motore di ricerca, ovvero il livello di Information Retrieval, presentando le
alternative possibili e la soluzione adottata.
• Capitolo III – Livello applicativo approfondisce il livello del motore di
ricerca che modella l’interesse dell’utente nel corso della navigazione tra gli
abstract.
• Capitolo IV – Implementazione tratta dei dettagli implementativi del motore
di ricerca.
• Capitolo V – Valutazione del sistema tratta della valutazione delle
performance del sistema di retrieval e dell’usabilità del sistema stesso
paragonandolo con un motore di ricerca tradizionale.
• Capitolo VI – Conclusioni trae le conclusioni relative al progetto.

Capitolo II - Rappresentazione informazioni
13
Capitolo II Rappresentazione informazioni
Information Retrieval
In questo capitolo si discute relativamente al più “basso” dei livelli
architetturali esposti al termine del primo capitolo. Si tratta del layer relativo al
processo di Information Retrieval.
Quest’ultimo è un processo di ranking (ordinamento) dei documenti che
sono presenti nel sistema in base a una query che rappresenta l’interesse
dell’utente.
Prima di discutere dei possibili modelli per rappresentare il problema
dell’IR e di quello utilizzato per la realizzazione del motore di ricerca oggetto
della presente tesi, verrà esposta di seguito una definizione formale di un
modello di IR:
Definizione Un modello di IR è una quadrupla [D, Q, F, R(qi, dj)] dove
(1) D è un insieme di viste logiche (o rappresentazioni) dei documenti
nella collezione presente nel sistema.
(2) Q è un insieme di viste logiche (o rappresentazioni) relative
all’information need dell’utente.

Capitolo II - Rappresentazione informazioni
14
(3) F è un framework per modellare le rappresentazioni dei documenti,
delle query e le loro relazioni.
(4) R(qi, dj) è una funzione di ranking (ordinamento) che associa un
numero reale ad una query qi ∈ Q e alla rappresentazione di un
documento dj ∈ D. Tale ranking definisce un ordine tra i documenti
rispetto alla query qi.
Prima di costruire un modello è necessario pensare alle rappresentazioni dei
documenti e dell’information need dell’utente (interesse dell’utente). Date
queste rappresentazioni si può ideare il framework nel quale possono essere
modellate.
Si descriveranno nel successivo paragrafo i concetti base per comprendere i
tre principali modelli di IR ovvero quello booleano, quello vettoriale e quello
probabilistico.

Capitolo II - Rappresentazione informazioni
15
Concetti di base
I modelli classici relativi all’information retrieval descrivono ogni
documento (ma anche gli abstract e l’information need dell’utente) attraverso un
insieme di parole chiave rappresentative.
Una parola chiave è una parola che riveste una certa importanza nella
descrizione del contenuto dei documenti.
Le varie parole chiave hanno una rilevanza variabile nel descrivere il
contenuto dei documenti.
Una parola chiave presente molto frequentemente in un determinato
documento e che compare in maniera sporadica negli altri assume una grande
importanza nel descrivere il suddetto documento.
Una parola chiave che compare poco (o è assente) oppure è presente in una
certa misura ma lo è anche negli altri documenti del sistema, non assume una
grande importanza nel descrivere il suddetto documento.
Al fine di descrivere il contenuto di un documento è dunque necessario
associare un peso numerico ad ogni sua parola chiave.
Chiamiamo ki la parola chiave i-esima, dj sia il documento j-esimo e wi,j ≥0
sia un peso associato alla coppia (ki, dj). Questo peso quantifica l’importanza
della parola chiave nel descrivere il contenuto del documento.
Definizione Sia t il numero delle parole chiave nel sistema e ki una generica
parola chiave. K={k1, …, kt} è l’insieme di tutte le parole chiave. Un peso
wi,j>0 è associato ad ogni parola chiave ki di un documento dj. Per una parola
chiave che non appare nel documento (o che non lo rappresenta minimamente)
wi,j=0. Al documento dj è associato un vettore di parole chiave dj, rappresentato
da dj=(w1,j,w2,j, …, wt,j). Infine sia gi la funzione che restituisce il peso associato
alla parola chiave ki (esempio gi(dj)=wi,j).

Capitolo II - Rappresentazione informazioni
16
Si può notare che per rappresentare il contenuto di un documento (o di un
abstract o dell’information need dell’utente) è sufficiente associargli un vettore
che lega ad ogni parola chiave un certo peso in corrispondenza della sua
frequenza nel testo o seguendo altri criteri più complessi.

Capitolo II - Rappresentazione informazioni
17
Modello Booleano
Il modello booleano è un semplice modello di IR basato sulla teoria degli
insiemi e sull’algebra booleana. Siccome il concetto di insieme è relativamente
intuitivo, il modello booleano offre un framework che è facile da comprendere
da un utente comune di sistemi di IR.
Le query sono rappresentate da espressioni booleane che hanno una precisa
semantica. Il modello booleano per la sua semplicità ricevette grande attenzione
in passato.
Sfortunatamente il modello booleano soffre di vari problemi.
In primo luogo la strategia di retrieval di questo modello è basata su un
criterio di decisione binario (un documento è classificato come rilevante o non
rilevante) senza “sfumature” intermedie.
In secondo luogo, avendo le espressioni booleane una precisa semantica,
spesso non è semplice trasformare un concetto come l’interesse dell’utente
(information need) in un’espressione booleana.
Nonostante questi problemi il modello booleano continua ad essere il
modello dominante tra i sistemi di data base commerciale ed è un ottimo punto
di partenza per altri modelli.
Il modello booleano considera che le parole chiave sono presenti o assenti in
un documento. Come risultato di questa considerazione le parole chiave
assumono pesi binari: wi,j ∈ {0,1}.
Una query q è composta da parole chiave collegate da tre operatori (not,
and, or). Una query è quindi un’espressione booleana che può essere
rappresentata come una disgiunzione di vettori congiuntivi (forma DNF).
I vettori con i pesi binari del modello booleano nella forma DNF prendono il
nome di componenti congiuntive di qdnf.
Definizione Nel modello booleano, i pesi delle parole chiave sono tutti binari
wi,j ∈ {0,1}. Una query q è una espressione booleana convenzionale.
Chiamiamo qdnf la forma normale disgiuntiva della query q. Sia qcc ognuna

Capitolo II - Rappresentazione informazioni
18
delle componenti congiuntive di qdnf. La relazione di somiglianza di un
documento dj alla query q è definita come
altrimentiqgdgqqqse
qdsim ccijikdnfccccj
i
0))()(,()(|.1
),(�
�
��� =∀∧∈∃=
Se sim(dj,q)=1 allora il modello booleano “predice” che il documento dj è
rilevante in relazione alla query q, altrimenti la predizione è che il documento
non sia rilevante.
Il modello booleano predice che un documento è rilevante oppure no. Non
c’è nessuna nozione di match parziale alle condizioni della query.

Capitolo II - Rappresentazione informazioni
19
Modello Vettoriale
Il modello vettoriale riconosce che l’utilizzo di pesi binari nella
rappresentazione dell’interesse dell’utente è eccessivamente limitante e associa
alle parole chiave, che possono essere viste come gli assi di un sistema
cartesiano nel quale sono rappresentati i vettori, pesi non binari (reali positivi).
Le proiezioni del vettore sugli assi, che altro non sono se non i pesi delle
parole chiave, sono utilizzati nel calcolo del cosiddetto grado di somiglianza
(degree of similarity) tra ogni documento memorizzato nel sistema ed il vettore
che rappresenta l’interesse dell’utente.
Ordinando i documenti in ordine decrescente per grado di somiglianza
(quindi maggiore è questo valore più i vettori sono simili), il modello vettoriale
prende in considerazione anche quei documenti che “matchano” il vettore utente
solo parzialmente.
Definizione Per il modello vettoriale, il peso wi,j associato alla parola chiave i-
esima (ki) del documento j-esimo (dj) è positivo e non binario. Analogamente
per ciò che concerne il vettore utente possiamo chiamare wi,q il peso associato
alla parola chiave i-esima (ki), ricordando che anche in questo caso wi,q ≥ 0.
Il vettore utente q è definito come q = (w1,q, w2,q, …, wt,q) dove t è il numero di
parole chiave nel sistema.
Analogamente il vettore relativo al documento dj è rappresentato da dj = (w1,j,
w2,j, …, wt,j).
Il modello vettoriale dunque si propone di valutare il grado di somiglianza
tra il documento j-esimo e l’interesse dell’utente attraverso la correlazione tra i
vettori dj e q.
Questa correlazione può essere quantificata attraverso il coseno dell’angolo
compreso tra i due vettori.
Capitolo II - Rappresentazione informazioni
20
∑∑
∑
==
=
⋅
⋅=
⋅
×=
t
iqi
t
iji
t
iqiji
j
jj
ww
ww
qd
qdqdsim
1,
2
1,
2
1,,
),(�
�
�
�
Dove |dj| e |q| sono il modulo del vettore del documento j-esimo e del
vettore utente.
Poiché wi,,j ≥ 0 e wi,q ≥ 0, il risultato della formula precedente assume un
valore compreso tra 0 e 1, tanto maggiore quanto più si “assomigliano” vettore
utente e vettore documento.
Essendo infatti i pesi delle parole chiave, ovvero le proiezioni del vettore
sugli assi del sistema, positive, l’angolo tra i due vettori che rispettano questa
regola sarà minore o uguale a 90° e dunque il coseno risultante sarà un valore
compreso tra 0 e 1.
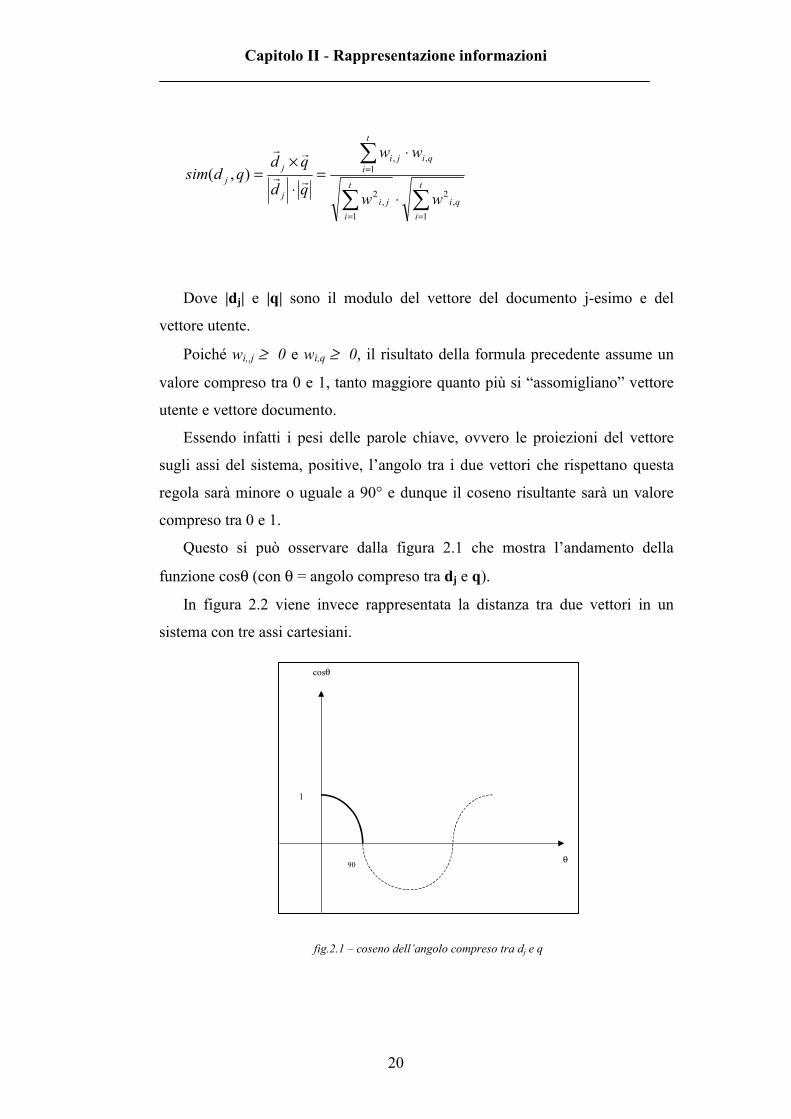
Questo si può osservare dalla figura 2.1 che mostra l’andamento della
funzione cosθ (con θ = angolo compreso tra dj e q).
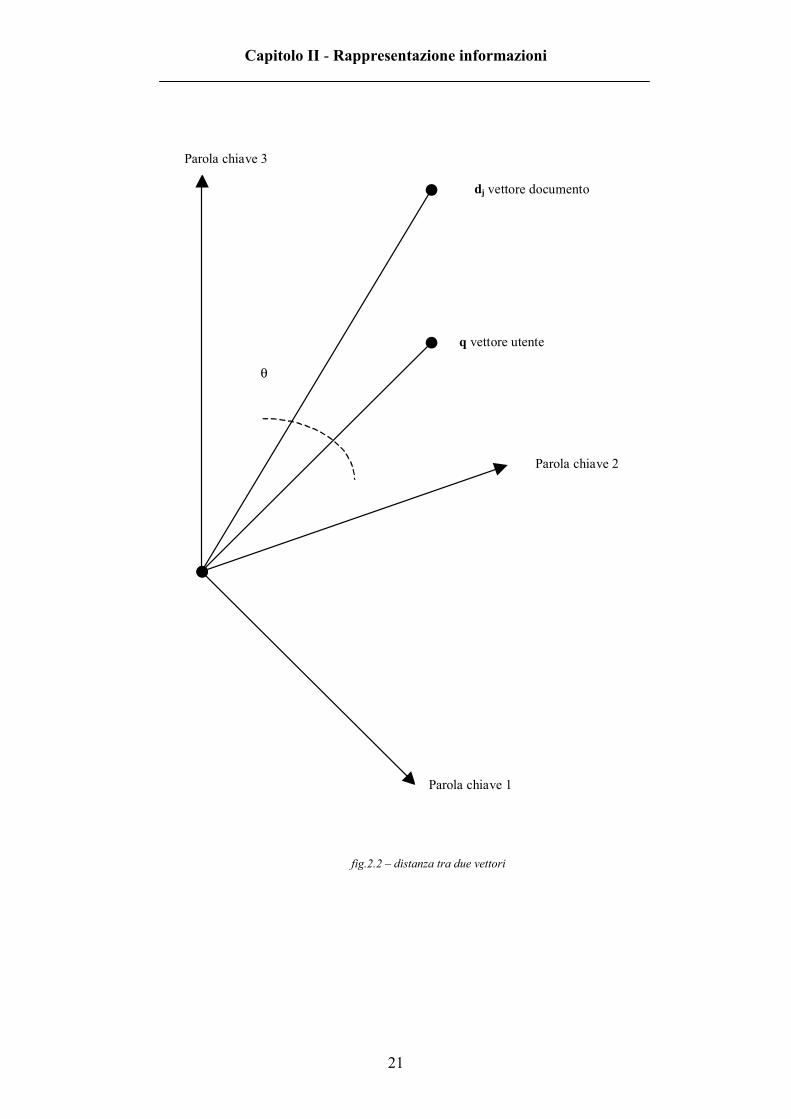
In figura 2.2 viene invece rappresentata la distanza tra due vettori in un
sistema con tre assi cartesiani.
fig.2.1 – coseno dell’angolo compreso tra dj e q
θ
1
90
cosθ
Capitolo II - Rappresentazione informazioni
21
fig.2.2 – distanza tra due vettori
Parola chiave 1
Parola chiave 2
Parola chiave 3
q vettore utente
dj vettore documento
θ

Capitolo II - Rappresentazione informazioni
22
Calcolo dei pesi delle parole chiave dei documenti
Un argomento di cui non si è ancora parlato è relativo a come si calcolino
per i documenti i vettori che li descriveranno (ovvero i pesi delle parole chiave).
Verrà ora descritto il meccanismo attraverso il quale si definisce il vettore
relativo ai documenti, trattando l’implementazione di quest’ultimo nei capitoli
successivi.
Esistono varie tecniche per calcolare il peso delle parole chiave. Si parlerà
ora di una delle possibili soluzioni che si fonda sul principio del clustering.
Data una collezione C di oggetti e una vaga descrizione di un set A,
l’obiettivo di un semplice algoritmo di clustering può essere quello di separare
la collezione C in due set: un primo composto da oggetti collegati al set A ed un
secondo costituito da oggetti non collegati al set A.
Con il termine “vaga descrizione” si intende che non si è in possesso di
informazioni complete per decidere in maniera precisa quali oggetti siano e
quali invece no nel set A. Per esempio una persona potrebbe cercare un set A
costituito dalle auto che hanno un prezzo simile a quello di un determinato
modello. Dato che il termine “simile” non ha un significato chiaro, non c’è una
precisa ed unica descrizione del set A.
Si può pensare ai documenti come ad una collezione C di oggetti e
all’interesse dell’utente come ad una vaga descrizione di un set A di oggetti. In
questo scenario il problema dell’information retrieval può essere ridotto al
problema di determinare quali documenti sono nel set A e quali no.
In un problema di clustering, due importanti compiti devono essere risolti:
primo si devono determinare quali siano le caratteristiche che meglio
descrivono gli oggetti nel set A, secondo si deve determinare quali siano le
caratteristiche che meglio distinguono gli oggetti nel set A dai rimanenti oggetti
nella collezione C.
Il primo insieme di caratteristiche dà una descrizione dell’intra-cluster
similarity, mentre il secondo descrive l’inter-cluster dissimilarity. I migliori
algoritmi di clustering cercano di bilanciare questi due effetti.

Capitolo II - Rappresentazione informazioni
23
Nel modello vettoriale, l’intra-clustering similarity è quantificata dalla
misura grezza della frequenza di un termine ki (parola chiave i-esima)
all’interno di un documento dj.
Questa frequenza è tipicamente chiamata fattore tf (term frequency factor) e
dà una misura di quanto la parola chiave i-esima descriva il documento j-esimo.
Invece l’inter-cluster dissimilarity misura l’inverso della frequenza di un
termine ki tra i documenti della collezione.
Questo fattore è tipicamente chiamato frequenza inversa del documento o
fattore idf (inverse document frequency factor).
La motivazione per l’uso di un fattore idf è da ricercare nel fatto che i
termini (le parole chiave) che appaiono in molti documenti non sono utili per
distinguere un documento rilevante da uno che non è di interesse. Il miglior
schema per dare pesi alle parole chiave del documento cerca di bilanciare questi
due effetti.
Definizione Sia N il numero totale dei documenti nel sistema e sia freqi,j la
frequenza grezza del termine ki nel documento dj (il numero delle volte che il
termine ki appare nel testo del documento dj). Allora la frequenza normalizzata
fi,j del termine ki nel documento dj è data da:
jll
jiji freq
freqf
,
,, max
=
dove il massimo è calcolato su tutte le parole chiave che sono menzionate nel
testo del documento dj. Se il termine ki non appare nel testo del documento dj
allora fi,j=0 (fi,j al massimo può raggiungere il valore 1 proprio in base alla
normalizzazione fatta). Sia idfi la frequenza inversa del documento per la
parola chiave ki, dato da:
∑=
= N
nni
i
f
Nidf
1,
log
Uno dei migliori modi conosciuti di pesare le parole chiave usa pesi che sono
dati da:

Capitolo II - Rappresentazione informazioni
24
∑=
⋅= N
nni
jiji
f
Nfw
1,
,, log
o da una variazione di questa formula. Questa strategia di peso delle parole
chiave prende il nome di schema tf-idf.
Perché viene usato il fattore idf nella formula che si usa per assegnare i
pesi?
Si supponga di avere una parola chiave i-esima che appare frequentemente
negli N documenti presenti nel sistema. Se il vettore utente ha una forte
componente relativa alla suddetta parola chiave, l’algoritmo di calcolo del
degree of similarity, non avendo utilizzato nella fase di associazione dei pesi il
coefficiente idf, reputerà interessanti tutti i documenti (mentre proprio per la
forte componente della parola chiave in tutti i documenti non li avrebbe dovuti
prendere in considerazione).
Esempio
In un motore di ricerca per abstract relativo al mondo dello sport ci sarà
sicuramente calcio tra le varie parole chiave.
Cercando informazioni sulle caratteristiche di un pallone da calcio, tra le
varie parole chiave del vettore utente, avrebbe sicuramente grande rilievo la
parola chiave calcio. Se non si usasse il coefficiente idf (che normalizza i pesi in
base alla frequenza di una certa parola chiave in tutti i documenti), il motore di
ricerca inserirebbe tutti i documenti relativi al mondo del calcio tra quelli
interessanti, essendo la suddetta parola chiave presente quasi ovunque e in
maniera frequente, dato che il motore di ricerca è tematico.
Ovviamente tutti questi documenti non interesserebbero e verrebbe meno
l’utilità di un motore di ricerca per abstract.
Il coefficiente idf premia dunque le parole chiave che appaiono in pochi
documenti, infatti se una parola chiave è presente in piccola misura in un
documento e non è presente negli altri, l’idf di questa parola chiave sarà un

Capitolo II - Rappresentazione informazioni
25
valore molto grande, essendo la sommatoria degli fi,n piccola. Per questo motivo
moltiplicando fi,k (essendo k il documento con la componente della parola
chiave i-esima) per idfi, ottengo un valore molto grande che esalta il fatto che
quel documento abbia una componente della parola chiave i-esima (anche se
piccola in origine) mentre gli altri non l’hanno.
Si ricordi che è possibile ed in una certa misura auspicabile, correggere il
peso delle parole chiave con informazioni provenienti dallo stesso autore che
può inserirle attraverso delle copertine che contengono meta-informazioni sul
contenuto dei documenti atte a classificarli.
Tali copertine contengono dunque informazioni che vengono inserite dagli
stessi autori dei documenti per catalogarli e “definirli” in maniera opportuna.

Capitolo II - Rappresentazione informazioni
26
Modello Probabilistico I modelli probabilistici sono caratterizzati dall’applicazione formale della
teoria delle probabilità alla logica dell’information retrieval; i documenti della
collezione in esame vengono ordinati in base alla probabilità che essi soddisfino
le richieste dell’utente.
Alcuni studiosi (Cooper - Maron) hanno formulato negli anni ’60 il
cosiddetto probability ranking principle: tale enunciato afferma che se un
sistema di IR restituisce i documenti esaminati in ordine decrescente della loro
probabilità di essere rilevanti e se tale probabilità è calcolata il più
accuratamente possibile, allora l’effectiveness (che misura la bontà del sistema
di IR) ottenibile con tale sistema è la migliore ottenibile sulla base dei dati a
disposizione.
Tutta la teoria del probabilistic retrieval si basa sul teorema di Bayes o
teorema della probabilità delle cause, di cui viene data di seguito una brevissima
trattazione.
Teorema di Bayes
A volte non tutti i possibili eventi sono direttamente osservabili: in tal caso
la probabilità marginale P(A) è indicata come probabilità a priori. Qualora
l’evento A sia in qualche modo legato ad un secondo evento B, che invece
possiamo osservare, la probabilità condizionata P(A|B) prende il nome di
probabilità a posteriori perché, a differenza di quella a priori, rappresenta un
valore di probabilità valutata dopo la conoscenza di B.
Fig 2.3 - Insieme degli eventi per la teoria di Bayes

Capitolo II - Rappresentazione informazioni
27
In generale, però, si conosce solamente P(A) e P(B|A) (queste ultime sono
dette probabilità condizionate in avanti), e per calcolare P(A|B) occorre
conoscere anche P(B). Quest’ultima quantità si determina saturando la
probabilità congiunta P(A|B) rispetto a tutti gli eventi marginali Ai possibili:
∑ ∑==i i
iii APABPABPBP )(*)|(),()(
a patto che i vari Ai siano mutuamente esclusivi ed esaustivi dello spazio
degli eventi.
L’ultima relazione permette di enunciare il teorema preannunciato, che
mostra come ottenere le probabilità a posteriori a partire da quelle a priori e
da quelle condizionate in avanti:
∑=
kkk
iii APABP
APABPBAP)(*)|(
)(*)|()|(
Il modello probabilistico è simile al modello vettoriale in quanto i
documenti e le query vengono rappresentati mediante vettori; la differenza sta
nel fatto che, anziché recuperare i documenti basandosi sulla loro similarità con
la query, il modello probabilistico ordina i documenti in base alla probabilità
che essi siano rilevanti per la query. Questa probabilità viene calcolata
utilizzando un insieme di documenti per i quali è noto a priori se siano rilevanti
oppure no.
In pratica i pesi associati alle parole chiave che costituiscono la collezione
vengono calcolati basandosi sulla loro distribuzione nei documenti che vengono
osservati come campione. Se si assume che le distribuzioni dei vari termini
siano tra di loro indipendenti, il che non è in realtà del tutto vero, la probabilità
che un documento sia rilevante rispetto ad una query può essere calcolata
sommando i pesi associati ai termini comuni tra tale documento e la query; tali
pesi indicano infatti la probabilità che i termini della query compaiano in un
documento rilevante, ma non in uno non rilevante.

Capitolo II - Rappresentazione informazioni
28
Il problema che ci si trova a dover affrontare può quindi essere espresso nei
seguenti termini: si supponga di avere un documento descritto dalla
presenza/assenza delle parole chiave ricavate dalla collezione in esame;
possiamo rappresentarlo mediante un vettore binario
),...,,( 21 nXXXD =�
dove Xi = 0 o 1 indica rispettivamente l’assenza o la presenza del termine i-
esimo. La seconda assunzione che si fa è che ci siano due eventi tra di loro
mutuamente esclusivi, ossia:
E1 = il documento esaminato è rilevante
E2 = il documento esaminato NON è rilevante
In base alle convenzioni qui presentate, si può dire che per ogni documento
D è di interesse calcolare P(E1|D) oppure, analogamente P(E2|D).
Si è già detto che in aiuto viene il teorema di Bayes, il quale dice che per
distribuzioni discrete si ha:
)()(*)|(
)|(DP
EPEDPDEP ii
i = i=1,2
Da questa formula deriva la regola di decisione di Bayes, che si può così
sintetizzare:
[ ]rilevantenonDrilevanteDDEPDEP , )|()|( 21 →> (1)
Ad ogni termine si assegnano dei cosiddetti “odds of relevance”,
letteralmente delle “probabilità di rilevanza” in base alle loro frequenze
nell’insieme di documenti conosciuti preso come campione.
Una volta calcolati gli odds of relevance associati alle varie parole chiave
bisogna utilizzarli per calcolare la probabilità che un certo documento sia
rilevante; a tale scopo si utilizzano le seguenti equazioni:

Capitolo II - Rappresentazione informazioni
29
( )∏=term
termdoc oddsodds
relnon
relterm odds
oddsodds
=
5.05.0
+−+=rn
roddsrel nei documenti rilevanti
5.05.0
+−+=rn
rodds relnon nei documenti non rilevanti
r = numero di documenti contenenti il termine in esame
n = numero di documenti rilevanti o non rilevanti nella collezione
Tutte le relazioni prese in esame sono state ricavate applicando una serie di
trasformazioni alla relazione (1); da questa Robertson e Sparck Jones hanno
derivato la formula per calcolare il peso delle parole chiave che porta il loro
nome e che ricorre frequentemente in letteratura
++−−+−
+−+
=
5.05.05.0
5.0
log
rRnNrnrR
r
Wi
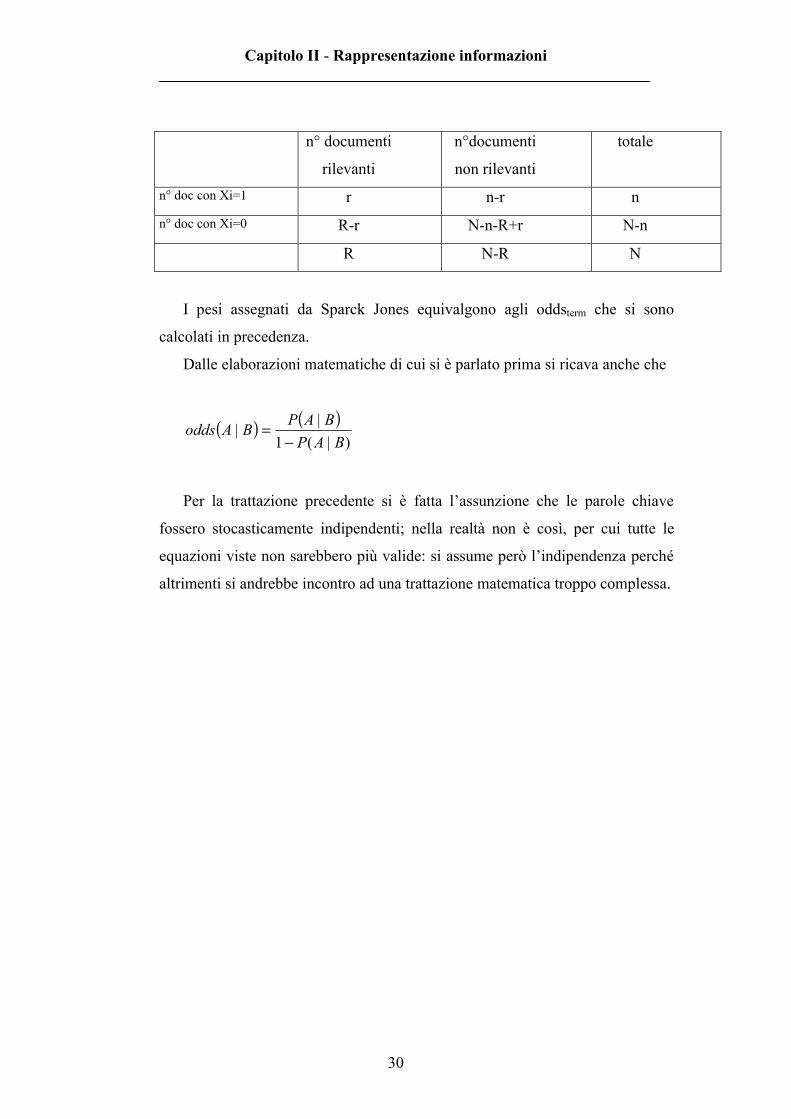
Il significato dei vari simboli è indicato nella tabella seguente, che viene
indicata come contingency table relativa al generico termine Xi nel campione di
documenti di riferimento (dove Xi = 1 o 0 indica come al solito la presenza o
l’assenza del termine):
Capitolo II - Rappresentazione informazioni
30
n° documenti
rilevanti
n°documenti
non rilevanti
totale
n° doc con Xi=1 r n-r n n° doc con Xi=0 R-r N-n-R+r N-n
R N-R N
I pesi assegnati da Sparck Jones equivalgono agli oddsterm che si sono
calcolati in precedenza.
Dalle elaborazioni matematiche di cui si è parlato prima si ricava anche che
( ) ( ))|(1
||BAP
BAPBAodds−
=
Per la trattazione precedente si è fatta l’assunzione che le parole chiave
fossero stocasticamente indipendenti; nella realtà non è così, per cui tutte le
equazioni viste non sarebbero più valide: si assume però l’indipendenza perché
altrimenti si andrebbe incontro ad una trattazione matematica troppo complessa.

Capitolo II - Rappresentazione informazioni
31
Soluzione adottata
Tra le soluzioni esposte nei paragrafi precedenti si è esclusa in prima battuta
quella che fa uso del modello probabilistico per motivi legati all’estrema
complessità del modello matematico che ne sta alla base. I concetti e le formule
espresse nel paragrafo relativo a questo modello si fondavano sull’assunzione
dell’indipendenza stocastica delle parole chiave, si rendeva pertanto necessaria
la presenza di un modello più accurato che sarebbe risultato troppo complesso
da utilizzare.
L’incertezza dunque restava tra il modello booleano e quello vettoriale.
Il modello booleano, però, a fronte di una maggiore semplicità concettuale
presentava diversi problemi che avrebbero minato l’efficienza del motore di
ricerca.
Il modello booleano infatti dà una predizione di rilevanza o non rilevanza
per ogni documento, non esiste la nozione di match parziale alle condizioni
della query che invece è presente nel modello vettoriale.
Il più grande vantaggio del modello booleano dunque è da ricercarsi nel
chiaro formalismo che “sta dietro” al modello stesso e la sua estrema semplicità
concettuale.
Il più grande svantaggio risiede nel fatto che un’operazione di retrieval può
proporre troppo pochi documenti o troppi (proprio per l’assenza del matching
parziale).
I maggiori vantaggi relativi al modello vettoriale sono invece:
(1) il suo schema di peso delle parole chiave che migliora le
performance del processo di retrieval
(2) la sua strategia di matching parziale che consente al motore di
proporre documenti che approssimino le condizioni della query
(3) La formula di ranking (ordinamento) che ordina i documenti in base
al loro grado di somiglianza alla query.

Capitolo II - Rappresentazione informazioni
32
A fronte dei vantaggi appena esposti si è deciso di scegliere il modello
vettoriale a scapito di quello booleano che comunque rimane un metodo di
information retrieval usato ancora in molte situazioni.

Capitolo III - Il livello applicativo
33
Capitolo III Il livello applicativo
Algoritmo primario del motore di ricerca
In questo capitolo si discuterà degli algoritmi che “muovono” il livello
applicativo del motore di ricerca per abstract.
Si seguirà, nella trattazione, un approccio TOP-DOWN, parlando prima
degli algoritmi più generici (che sono anche quelli fondamentali), accennando
quando necessario a quelli più specifici che verranno descritti in un secondo
momento.
Ciò che verrà descritto ora è il cuore del motore di ricerca, ovvero lo schema
base della pagina che costituisce il livello applicativo dell’intero progetto.
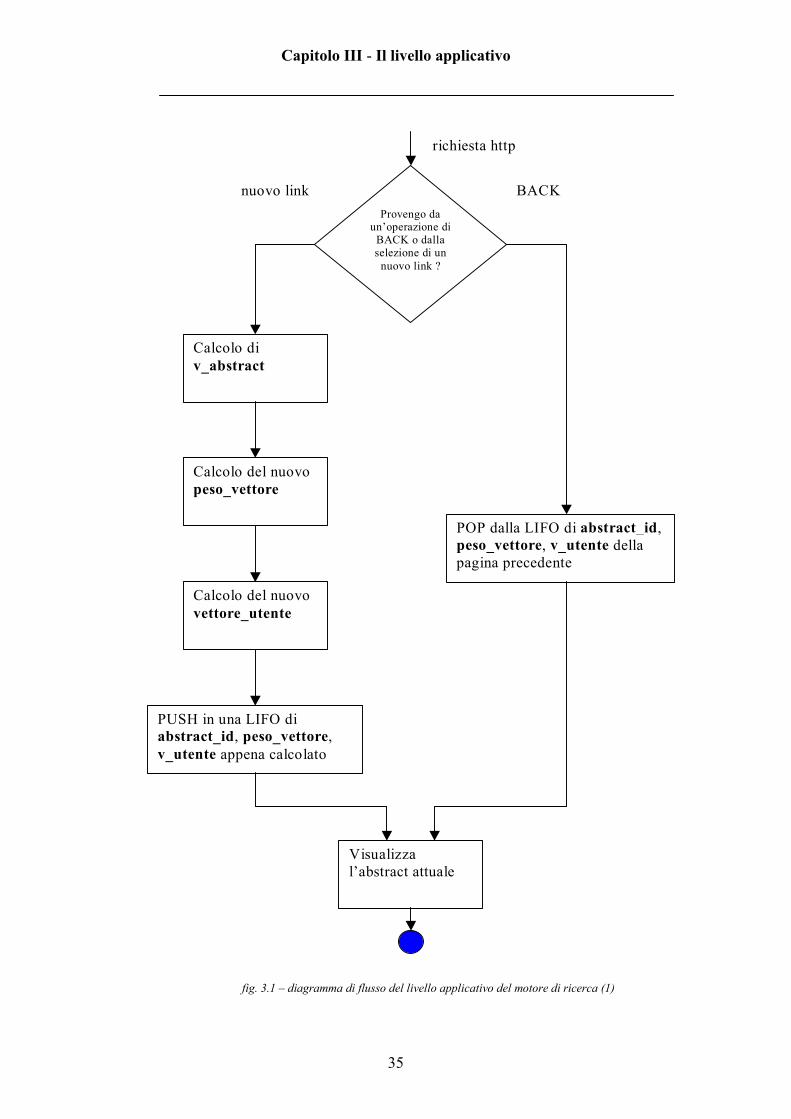
Nelle figure 3.1 e 3.2 sono mostrati i diagrammi di flusso (ovvero gli schemi
a blocchi) che descrivono ad alto livello il funzionamento del livello applicativo
del progetto.
Quando si parlerà di variabili o di strutture dati, verrà fatto sempre in modo
molto generale per svincolare la comprensione dell’algoritmo (o meglio degli
algoritmi) dalla sua implementazione pratica che verrà analizzata in dettaglio
nel capitolo successivo, nel quale si parlerà anche di come vengano
implementate le strutture dati e di quale soluzione, a livello di data base, si sia
fatto uso per la memorizzazione dei dati.

Capitolo III - Il livello applicativo
34
L’intero progetto è costituito da una serie di pagine WEB scritte usando
l’HTML 4.0 ed il linguaggio PHP (simile al più noto, in ambito commerciale,
ASP usato nei server Microsoft).
Capitolo III - Il livello applicativo
35
fig. 3.1 – diagramma di flusso del livello applicativo del motore di ricerca (1)
Provengo da un’operazione di
BACK o dalla selezione di un
nuovo link ?
Calcolo di v_abstract
Calcolo del nuovo peso_vettore
Calcolo del nuovo vettore_utente
PUSH in una LIFO di abstract_id, peso_vettore, v_utente appena calcolato
POP dalla LIFO di abstract_id, peso_vettore, v_utente della pagina precedente
Visualizza l’abstract attuale
richiesta http
nuovo link BACK
Capitolo III - Il livello applicativo
36
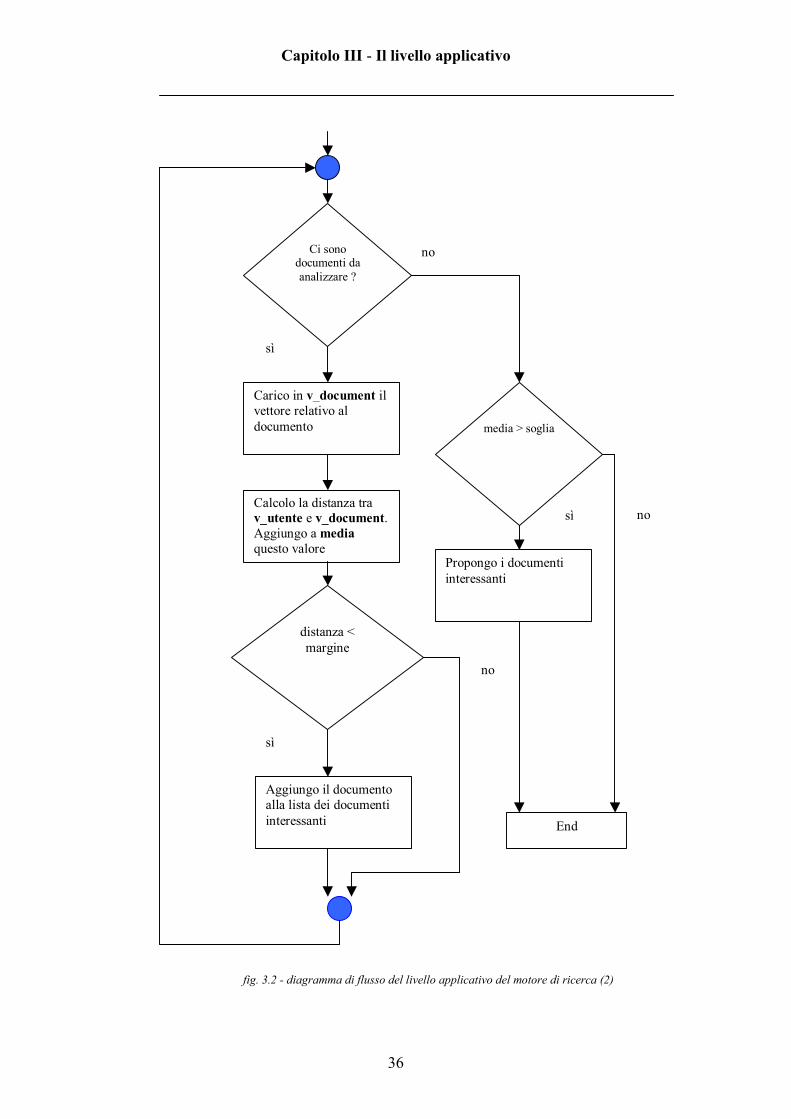
fig. 3.2 - diagramma di flusso del livello applicativo del motore di ricerca (2)
Carico in v_document il vettore relativo al documento
Calcolo la distanza tra v_utente e v_document.Aggiungo a media questo valore
Ci sono documenti da analizzare ?
distanza < margine
Aggiungo il documento alla lista dei documenti interessanti
Propongo i documenti interessanti
sì
sì
no
no
media > soglia
sì
End
no

Capitolo III - Il livello applicativo
37
Si ricorda a scopo informativo che a ogni argomento qui trattato in maniera
volutamente concisa verrà dedicato un paragrafo di approfondimento che
spiegherà in modo dettagliato ciò che qui viene appena accennato.
L’algoritmo inizia con una richiesta http alla pagina web che rappresenta il
livello applicativo del motore di ricerca.
In questa richiesta sono presenti una serie di campi qui di seguito elencati:
• abstract_id : l’identificativo del nuovo abstract da visualizzare.
• abstract_old : l’identificativo dell’abstract precedentemente visualizzato.
• frase_id : il numero di frase selezionato nell’abstract vecchio.
• url_tempo : una variabile che serve per scoprire se si è selezionato BACK
dal browser al fine di visualizzare la pagina precedente.
La prima operazione che viene eseguita è relativa all’appurare se nella
pagina precedente si sia selezionato un link (un altro abstract) o il pulsante
BACK del browser.
Questa operazione avviene attraverso il confronto della variabile url_tempo
con la variabile tempo.
La variabile di sistema tempo viene incrementata ogni volta che viene
caricata la pagina web del motore di ricerca e viene passata come parametro:
url_tempo=tempo nei link verso i nuovi abstract. Il livello applicativo confronta
queste due variabili e deduce, dalla loro differenza, che si è selezionato il tasto
BACK.
Esempio
Si supponga di essere al tempo T ovvero tempo=T. Nella finestra di sinistra
viene visualizzato l’abstract corrente nel quale i collegamenti agli altri abstract
avranno tra i parametri url_tempo=tempo (=T). Nel momento in cui viene
caricata la pagina successiva, dopo la selezione di un link tra quelli disponibili,
viene confrontata la variabile di sessione tempo con url_tempo, che in questo

Capitolo III - Il livello applicativo
38
caso coincide; tempo viene incrementata, la nuova pagina viene caricata e i
collegamenti verso i nuovi abstract avranno tra i parametri url_tempo=tempo
(=T+1). Se invece di selezionare un link si fosse selezionato il tasto BACK del
browser, recuperando l’url della pagina precedente dalla cronologia, non ci
sarebbe più questa uguaglianza tra le variabili e il sistema si accorgerebbe che la
pagina precedente si è selezionato BACK e non un link.
Caso 1 : selezione di un abstract
Se non si proviene da un’operazione di BACK, viene caricato in una
variabile v_abstract il vettore dell’abstract selezionato a cui si sottraggono i
vettori degli abstract non selezionati nella pagina precedente, ridotti di un
fattore di proporzionalità. Quest’operazione viene eseguita perché selezionando
un abstract piuttosto che un altro viene espressa una precisa preferenza verso un
argomento rispetto a tutti gli altri presenti nella pagina.
Ora che si è in possesso di v_abstract si può calcolare il nuovo vettore
utente, facendo una media pesata tra il vecchio vettore (a cui viene associato un
peso pari a peso_vettore) e v_abstract.
Il motivo per cui viene calcolata questa media risiede nel fatto che nella
costruzione del nuovo vettore utente si tiene conto sia della storia passata,
rappresentata dal vecchio vettore utente, che della selezione attuale,
rappresentata da v_abstract. Ciò che si è calcolato in questo modo è il nuovo
vettore utente che verrà memorizzato in una struttura LIFO attraverso
un’operazione di PUSH insieme ad altre variabili che sono: abstract_id ed il
peso_vettore usato per calcolare il nuovo vettore_utente e che varia di selezione
in selezione.
Caso 2 : selezione del tasto BACK
Il fatto di selezionare il pulsante BACK indica che l’utente si aspettava di
trovare qualcosa che in realtà non ha trovato nel nuovo abstract, è logico quindi
che non solo gli venga riproposta la pagina precedente, ma che a livello

Capitolo III - Il livello applicativo
39
applicazione vengano effettuate delle operazioni per riportare il vettore utente
allo stato precedente.
Viene eseguita un’operazione di POP e quindi si memorizzano nelle
variabili abstract_id, v_utente e peso_vettore i valori relativi alla pagina
precedentemente visualizzata, ponendo il sistema in una situazione di coerenza
ovvero riportandolo nell’esatto stato dal quale si proveniva.
Esempio
Si supponga di provenire dalla pagina con abstract_id = 28 al tempo t = 10.
In seguito viene effettuata la selezione dell’abstract 32 e si arrivia al tempo t =
11. Se a questo punto si seleziona il tasto BACK del browser, verrà visualizzata
nuovamente la pagina 28 e verranno estratte dalla LIFO le variabili relative al
tempo t = 10, riportando il sistema esattamente nello stato precedente, proprio
come se la scelta di visualizzare la pagina 28 non fosse mai avvenuta.
Sezione comune al caso 1 e al caso 2
Sia che provenga da un’operazione di BACK sia che provenga da
un’operazione di selezione di un nuovo abstract, ci si trova ora nella parte
comune in cui viene visualizzato l’abstract corrente.
L’informazione che viene usata è semplicemente abstract_id, attraverso la
quale si accede al data base e viene visualizzato il contenuto dell’abstract
relativo.
Relativamente al secondo diagramma di flusso, in figura 3.2, si può notare
che il livello applicazione scandisce in ciclo tutti i documenti presenti nel data
base.
Per ogni documento viene recuperato dal data base il suo vettore interesse
(che rappresenta il contenuto del documento) e viene memorizzato in
v_document.

Capitolo III - Il livello applicativo
40
Viene dunque calcolato un “grado di somiglianza” tra v_utente e
v_document, che viene aggiunto a media (un oggetto istanziato da una struttura
dati di cui si parlerà in seguito) e se questo grado risulta anche maggiore di un
certo margine, l’id del documento, il titolo e la distanza dal v_utente vengono
inseriti in una struttura atta a contenere i documenti interessanti.
Una volta scanditi tutti i documenti verranno mostrati quelli che avranno
grado di somiglianza al di sopra di una certa soglia, sempre che media non
assuma un valore troppo grande (ci sarebbero altrimenti troppi documenti
interessanti).
Il livello applicazione prevede due soglie relativamente al grado di
somiglianza tra il vettore utente e i vettori relativi ai documenti:
Best match � documenti che possono essere di vero interesse per l’utente
Related link � documenti che pur non essendo molto “vicini” a livello di
contenuto al vettore utente possono comunque interessare il lettore.
Ogni singolo argomento a cui si è accennato in questo paragrafo verrà
approfondito in quelli successivi per dare una visione più dettagliata di come si
comporta il motore di ricerca.

Capitolo III - Il livello applicativo
41
Algoritmo di gestione dei vettori v_abstract
Una volta stabilito che si proviene dalla selezione di un nuovo abstract e non
da un’operazione di BACK, si pone il problema di calcolare il nuovo vettore
utente che deve tener conto della selezione del nuovo abstract.
Come si vedrà in seguito ad ogni selezione di un nuovo abstract, il vettore
utente viene ricalcolato in base alla scelta fatta dall’utente facendo una media
pesata tra il vecchio vettore utente e il vettore v_abstract (che rappresenta il
“contenuto” trattato dall’abstract).
Ora però si porrà l’attenzione sui procedimenti relativi al calcolo di
v_abstract.
Per prima cosa si deve fare un importante distinguo in base al fatto che
l’abstract visualizzato sia il primo (si è appena “avviato” il motore di ricerca) o
ci si trovi a “regime” (ovvero si provenga da un altro abstract).
Processo di ricerca appena avviato
L’operazione che viene fatta consiste nel caricare il vettore relativo
all’abstract di partenza nella variabile v_abstract. Il vettore degli abstract è
memorizzato nel data base di supporto insieme ad altre informazioni necessarie
al funzionamento del motore di ricerca come meglio verrà descritto nel capitolo
successivo che ne descrive l’implementazione pratica.
Processo di ricerca a regime
In questo caso invece si proviene da un abstract dal quale si è selezionato un
link (un collegamento) verso un altro abstract.
A differenza del caso precedente ora si proviene da una pagina nella quale si
è espressa una preferenza precisa.
Si era di fronte ad un testo introduttivo nel quale erano presenti vari
collegamenti ad altri testi e tra questi si è scelto un collegamento preferendolo a
tutti gli altri.

Capitolo III - Il livello applicativo
42
Questo significa che in v_abstract non si vuole solo memorizzare
l’informazione che si è scelto un determinato abstract, ma che se ne è scelto uno
preferendolo agli altri.
Questa informazione può essere memorizzata sottraendo al vettore
dell’abstract selezionato il passo precedente quelli degli abstract non selezionati.
Esempio:
Si è in presenza di un abstract in cui si parla di farmaci e viene selezionato
un abstract che ha come titolo sport e doping.
Nella stessa pagina c’erano molti link relativi appunto all’uso lecito di
farmaci nelle varie attività sportive.
Selezionando sport e doping e memorizzando in v_abstract solo il vettore
relativo all’abstract selezionato che aveva un vettore con forti componenti
relative agli assi “farmaci” “sport” e “droghe”, si troverebbero nella pagina
successiva, tra i documenti di interesse, anche quelli che riguardano
l’assunzione regolare di farmaci nello sport.
Sottraendo invece al vettore relativo all’abstract selezionato quello degli
altri abstract presenti nella pagina da cui si proviene (soluzione adottata), la
componente farmaci verrà notevolmente indebolita e verranno mostrati i
documenti in cui sono centrali gli argomenti “sport” e “droghe”.
Selezionando infatti un link piuttosto che un altro si esprime il proprio
interesse verso quell’argomento rispetto agli altri.
Se ci sono cinque link che parlano di sport e farmaci, ma solo uno che parla
di doping e viene selezionato quello è ovvio che l’utente sia interessato ai
documenti che trattano l’argomento uso illecito di sostanze (per esempio nel
modo del calcio) piuttosto che a quelli che parlano in generale di farmaceutica
applicata allo sport.
Ora che si è dato un esempio chiarificatore si può proseguire analizzando i
problemi che si incontrano usando questo tipo di soluzione.

Capitolo III - Il livello applicativo
43
In primo luogo è possibile che in un abstract siano presenti argomenti molto
differenti tra loro e che dunque si debba andare a sottrarre dal vettore
dell’abstract scelto il valore degli altri link che hanno argomenti diversi e quindi
componenti su assi che il vettore ha nulli, portandoli a valori negativi.
La soluzione che si è scelta a questo problema è semplice quanto efficace:
una volta calcolato v_abstract vengono eliminate le componenti negative
sostituendole con componenti nulle.
Di seguito si presenterà un'altra considerazione che si può fare considerando
quanto fin qui detto: se siamo in presenza di un abstract con molti link ad
altrettanti abstract nella pagina da cui si proviene, una volta selezionato il link
nel quale si vuole andare, per calcolare il nuovo v_abstract si dovrebbe
memorizzare il vettore dell’abstract scelto e togliere i vettori degli altri abstract.
Così facendo si renderebbe presto il v_abstract un vettore nullo, togliendo
molti valori dalle componenti del vettore di partenza.
Anche in questo caso la soluzione pare molto semplice: posso usare un
fattore di riduzione, che in realtà altro non è che un coefficiente (un numero
compreso tra 0 e 1 estremi esclusi) che va a moltiplicare i vettori degli abstract
che devono essere sottratti al vettore dell’abstract selezionato, riducendone il
peso.
Questo ragionamento è sicuramente corretto ma bisogna fare due
precisazioni.
Per prima cosa gli abstract devono essere tra loro normalizzati in modo tale
da essere confrontabili non solo a livello di “distanza angolare” ma anche a
livello di modulo.
In secondo luogo si deve rendere il fattore di riduzione dipendente dal
numero di abstract che si devono togliere da quello selezionato.
Per fare ciò è necessario dividere tale fattore per il numero di link presenti
nella pagina precedente (ovvero la pagina nella quale ho selezionato il link di

Capitolo III - Il livello applicativo
44
destinazione), rendendolo tanto più piccolo, tanto maggiore è il numero degli
abstract da sottrarre a quello selezionato.
Si può capire ora perché sia necessario inserire nella richiesta http anche l’id
dell’abstract precedente.
Serve infatti sia per poter sottrarre gli abstract non selezionati (i cui
identificativi sono memorizzati nel data base e vi si può accedere tramite
l’identificativo del vecchio abstract) sia per calcolarne il loro numero.
Esempio
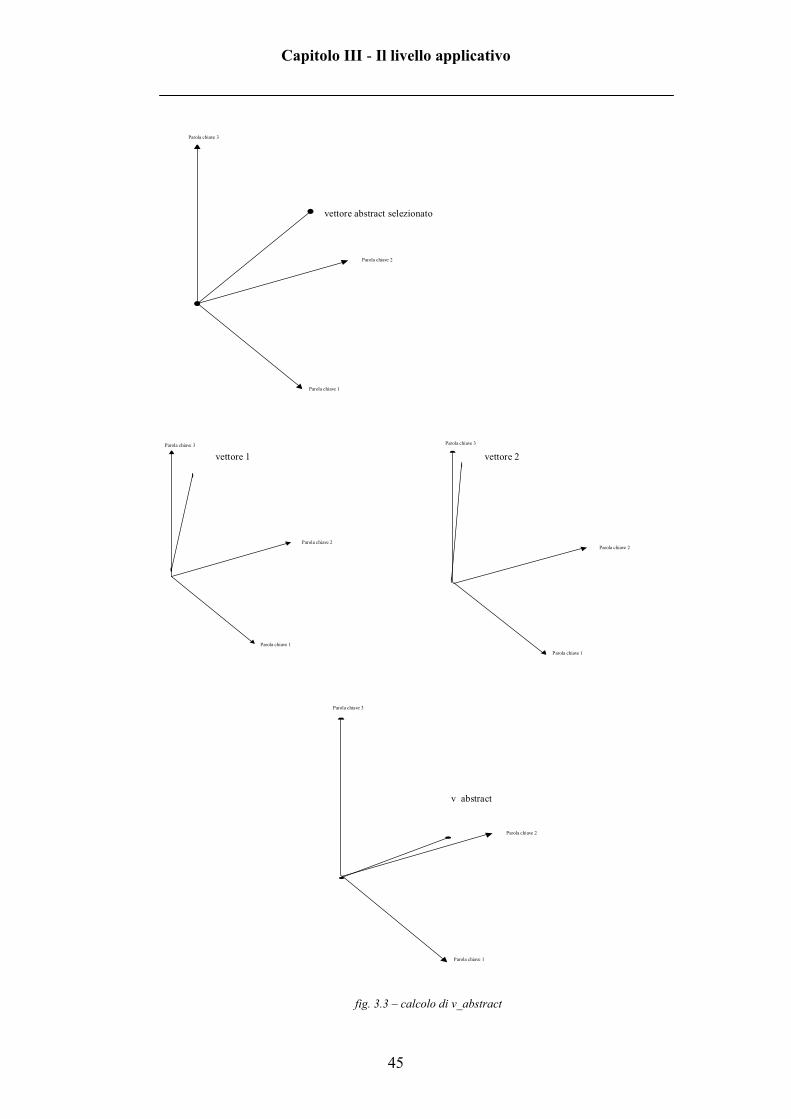
url =motore_di_ricerca?abstract_id=a1&abstract_old=a2…
v1 = vettore associato all’abstract a1
v2…vn = vettori relativi agli abstract non selezionati nell’abstract a2 (quello di
partenza), questi vettori li trovo accedendo ad una particolare tabella del data
base attraverso l’indicativo dell’abstract a2.
1−=
ncalfa con c costante che assume un valore compreso tra 0 e 1
)...(_ 21 nvvalfavabstractv ++⋅−=
In figura 3.3 è presente un esempio visivo relativo al calcolo della variabile
v_abstract.
Capitolo III - Il livello applicativo
45
fig. 3.3 – calcolo di v_abstract
Parola chiave 1
Parola chiave 2
Parola chiave 3
vettore abstract selezionato
Parola chiave 1
Parola chiave 2
Parola chiave 3 vettore 1
Parola chiave 1
Parola chiave 2
Parola chiave 3
vettore 2
Parola chiave 1
Parola chiave 2
Parola chiave 3
v_abstract

Capitolo III - Il livello applicativo
46
Si è dunque illustrato il procedimento per calcolare v_abstract, si può ora
passare a spiegare la legge che regola l’evoluzione della variabile peso_vettore
al fine di avere le basi per poi spiegare come viene calcolato il nuovo vettore
utente, partendo da quello vecchio e dalle variabili a cui si è appena accennato.
Capitolo III - Il livello applicativo
47
Calcolo del nuovo peso_vettore
La prima domanda che ci si può porre è relativa all’effettiva utilità della
variabile peso_vettore.
In parte si è già risposto a questa domanda dicendo che serve al calcolo del
nuovo vettore utente, partendo da quello vecchio e dall’abstract correntemente
visualizzato.
Il modo esatto in cui viene calcolato il nuovo vettore utente sarà comunque
argomento del prossimo paragrafo.
In questo paragrafo si discuterà invece di come il peso_vettore varia al
“trascorrere del tempo”, ovvero di selezione in selezione degli abstract da
visualizzare.
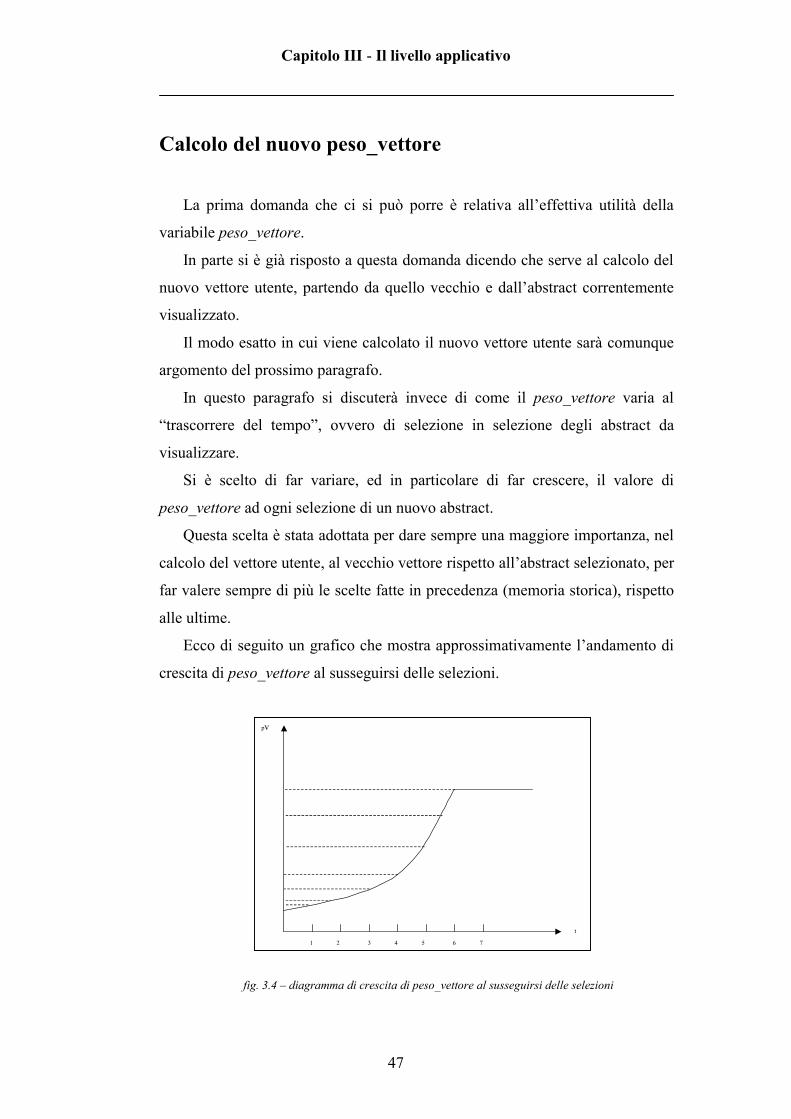
Si è scelto di far variare, ed in particolare di far crescere, il valore di
peso_vettore ad ogni selezione di un nuovo abstract.
Questa scelta è stata adottata per dare sempre una maggiore importanza, nel
calcolo del vettore utente, al vecchio vettore rispetto all’abstract selezionato, per
far valere sempre di più le scelte fatte in precedenza (memoria storica), rispetto
alle ultime.
Ecco di seguito un grafico che mostra approssimativamente l’andamento di
crescita di peso_vettore al susseguirsi delle selezioni.
fig. 3.4 – diagramma di crescita di peso_vettore al susseguirsi delle selezioni
pv
t
1 2 3 4 5 6 7

Capitolo III - Il livello applicativo
48
La formula che regola la crescita di peso_vettore è qui di seguito esposta:
( )2
1 1__ += −tt vettorepesovettorepeso
Si può subito notare che la legge che regola la crescita di peso_vettore sia di
tipo quadratico (anche se con delle modifiche).
I valori che la variabile può assumere vanno da 9 ad 81, valore per cui la
variabile satura (ovvero raggiunto il quale non cresce più).
Il prossimo paragrafo mostrerà come viene utilizzata la variabile
peso_vettore al fine di calcolare il nuovo vettore utente.

Capitolo III - Il livello applicativo
49
Calcolo del nuovo vettore utente
Riassumendo quanto esposto nei paragrafi precedenti abbiamo visto che alla
selezione di un abstract a1 al tempo t-1, il livello applicazione, al tempo t,
esegue una serie di operazioni:
• calcola il valore v_abstract usando il vettore relativo all’abstract a1 e
sottraendogli i vettori degli abstract che non sono stati scelti al tempo
t-1 (ovviamente attenuati grazie al coefficiente di riduzione, che
dipende dal numero di abstract non selezionati nella pagina
precedente).
• incrementa il valore di peso_vettore, seguendo la formula descritta nel
paragrafo precedente.
• calcola il nuovo vettore utente usando il vettore utente al tempo t-1,
v_abstract e il peso_vettore.
Ecco di seguito la formula che unisce tutti questi ingredienti per il calcolo
del nuovo vettore utente:
100_)_100(__
_ 1 abstractvvettorepesoutentevvettorepesoutentev tttt
⋅−+⋅= −
Ciò che viene fatto è una media pesata tra il vecchio vettore utente a cui
viene associato un peso pari a peso_vettore/100 e v_abstract a cui viene
associato il peso (100 – peso_vettore)/100.
Il nuovo vettore utente dipenderà dunque dalla storia passata rappresentata
da v_utente (al tempo t-1) e dalla selezione effettuata, rappresentata da
v_abstract.
Il modello di crescita del valore di peso_vettore può essere considerato
simile al modello di apprendimento di un essere umano.

Capitolo III - Il livello applicativo
50
Il bambino nei suoi primi mesi di vita è una “spugna” che recepisce dal
mondo esterno ogni genere di input.
Le esperienze che si fanno in tenera età sono quelle che maggiormente
forgiano l’uomo.
Proprio seguendo questo modello, il valore di peso_vettore (ovvero del peso
associato al vettore utente) cresce al susseguirsi delle selezioni.
Durante le prime selezioni il valore di peso_vettore è molto piccolo, facendo
quindi diventare molto grande (100 – peso_vettore) che viene associato al
vettore v_abstract.
All’inizio della navigazione quindi, non essendo ancora il vettore_utente
formato (non avendo l’utente avuto modo di esprimere i propri interessi),
assumeranno grande importanza le prime scelte effettuate e quindi la
componente v_abstract.
Successivamente al crescere di peso_vettore l’ago della bilancia per la
definizione del nuovo v_utente si sposterà verso il v_utente vecchio rendendo
sempre minore (fino a saturazione di peso_vettore) il contributo di v_abstract, e
sempre più influenti le scelte fatte all’inizio.
Risulta necessario mostrare le differenze nel calcolo del nuovo vettore
utente usando prima un peso_vettore fisso e successivamente uno che varia
seguendo la legge che abbiamo esposto nel paragrafo precedente.
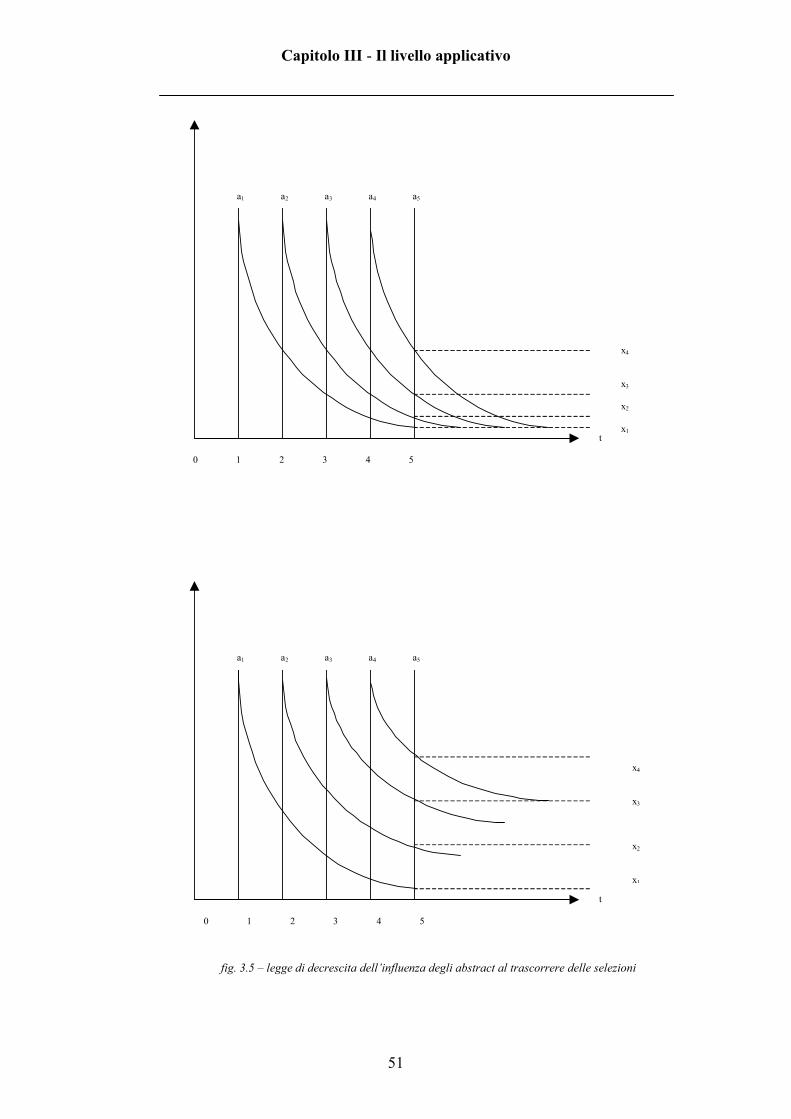
La figura 3.5 rappresenta l’importanza dei vari abstract nel calcolo del
vettore utente al susseguirsi delle selezioni (all’avanzare del tempo), sia nel caso
di peso_vettore constante sia nel caso che segua la legge esposta.
Capitolo III - Il livello applicativo
51
fig. 3.5 – legge di decrescita dell’influenza degli abstract al trascorrere delle selezioni
t
t
a1
a1
a2
a2
a3
a3
a4
a4
a5
a5
x4 x3 x2 x1
x4 x3 x2 x1
0 1 2 3 4 5
0 1 2 3 4 5

Capitolo III - Il livello applicativo
52
Le curve rappresentano la legge di decrescita dell’importanza dell’abstract
da cui partono nel calcolo del vettore utente al trascorrere del tempo.
Da come si può notare, analizzando i due grafici di figura 3.5 e soffermando
l’attenzione al tempo t=5 (per esempio), mentre nel caso di peso_vettore
costante, l’importanza dell’abstract a5 nella costruzione del nuovo vettore utente
risulta notevole rispetto a quella degli abstract precedenti, nel caso di
peso_vettore variabile (usando la formula precedentemente descritta) aumenta
l’influenza degli altri abstract.
Questo lo si può notare dal fatto che x1, x2, x3 e x4 assumano valori maggiori
nel secondo grafico.
In questo modo si dà maggiore importanza alle prime scelte, quelle che per
intenderci dovrebbero definire l’interesse “base” dell’utente, rispetto alle ultime,
che invece dovrebbero solo raffinarlo.

Capitolo III - Il livello applicativo
53
Criteri di decisione per i documenti da mostrare
Si è analizzato in precedenza come calcolare il nuovo vettore utente
partendo da quello vecchio, da peso_vettore e da v_abstract, nel capitolo
relativo alla rappresentazione delle informazioni si è invece descritto
l’algoritmo per confrontare il vettore utente e v_document dei documenti
presenti nel sistema. Ora non resta che descrivere i criteri che si sono seguiti per
mostrare i documenti di interesse.
Una volta confrontato il vettore utente con i vettori di tutti i documenti del
sistema, siamo in possesso del cosiddetto grado si somiglianza (degree of
similarity) per ogni documento.
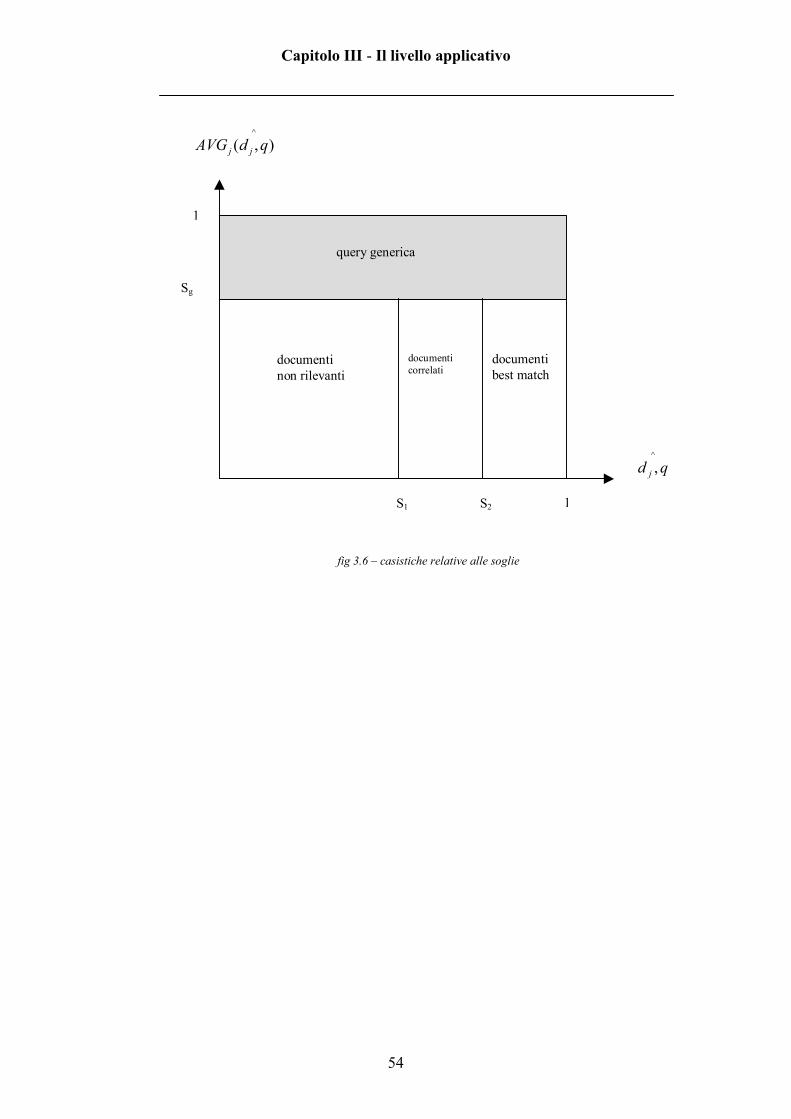
Il motore di ricerca possiede due soglie: una più stretta, dal valore maggiore
(sempre compreso tra 0 e 1 comunque) e una più lasca, dal valore minore. Il
degree of similarity dei documenti viene paragonato con queste soglie e se
maggiore (ovvero interessante) viene inserito tra i documenti best match o
related link a seconda del grado di somiglianza col vettore utente attuale.
La prima operazione che viene eseguita dal motore di ricerca però consiste
nel confrontare la media di tutti i degree of similarity dei documenti analizzati
con una determinata soglia. Se la media è maggiore della suddetta soglia non
verranno mostrati documenti neanche se “interessanti” rispetto ai criteri a cui si
è precedentemente accennato (ovvero sono all’interno delle cosiddette soglie di
interesse).
La motivazione di questo comportamento è da ricercare nel fatto che se la
media del grado di somiglianza tra il vettore utente e i vettori di tutti i
documenti presenti nel sistema è grande, ci sarebbero troppi documenti da
visualizzare il che significa che il vettore utente è troppo generico.
In figura 3.6 vengono rappresentate tutte le situazioni in cui ci si può
trovare: s1 e s2 sono le soglie related link e best match, sg è la soglia relativa alla
media delle distanze.
Capitolo III - Il livello applicativo
54
fig 3.6 – casistiche relative alle soglie
documenti non rilevanti
documenti correlati
documenti best match
1
^, qd j
),(^
qdAVG jj
1S1 S2
Sg
query generica

Capitolo III - Il livello applicativo
55
Feedback dell’utente
In questo paragrafo si discuterà brevemente del problema del term-
reweighting.
Essendo i vettori dei documenti “tipicamente” compilati dagli autori stessi o
ricavati da parser che analizzano la frequenza delle parole chiave al loro interno,
è possibile che un documento di interesse per molti utenti non venga trovato
dove lo si aspetterebbe.
Per fare un esempio un utente, navigando attraverso una serie di abstract, si
aspetta di trovare un certo documento (o una certa tipologia di documenti) che
invece non trova.
Se questo fenomeno si verifica per molti utenti allora l’ipotesi e che il
documento che gli utenti cercavano abbia un vettore che non corrisponde al suo
reale contenuto.
Si è adottata a questo proposito una semplice soluzione di term-reweighting
che si basa sull’assunzione che un utente seleziona il tasto BACK del browser
quando è arrivato ad un abstract (con un determinato vettore utente) e non ha
trovato il documento desiderato.
Il sistema di term-reweighting a questo punto memorizza il vettore utente in
una struttura dati e lascia navigare l’utente fino a che non selezioni uno o più
documenti.
La supposizione che viene fatta e che i documenti così selezionati l’utente si
aspettava di trovarli al momento in cui ha selezionato per la prima volta il tasto
BACK.
Il sistema associerà dunque il vettore utente che si aveva al momento della
prima selezione del tasto BACK ai documenti selezionati.
Per ogni documento il sistema calcolerà un vettore m, media di tutti i vettori
utenti associati al documento stesso.
A questo punto se la media dei degree of similarity tra il vettore m e tutti gli
altri (che hanno contribuito al calcolo della media e relativi allo stesso
documento) è sopra una certa soglia ciò sta a significare che questi vettori si

Capitolo III - Il livello applicativo
56
assomigliano tra di loro, ovvero molti utenti avevano un vettore interesse molto
simile quando si aspettavano di trovare il documento.
Il sistema a questo punto propone la procedura di term-reweighting che
consiste nel cambiare il peso delle parole chiave del vettore del documento con
il peso delle parole chiave del vettore m relativo a quel documento.

Capitolo IV - Implementazione
57
Capitolo IV Implementazione
Data Base
Il data base è usato per memorizzare, attraverso tabelle, informazioni sui
vettori relativi ai documenti e informazioni relative agli abstract.
Le tabelle sono state implementate in modo tale da potersi “appoggiare” ad
un generico data base contenente documenti di varia natura.
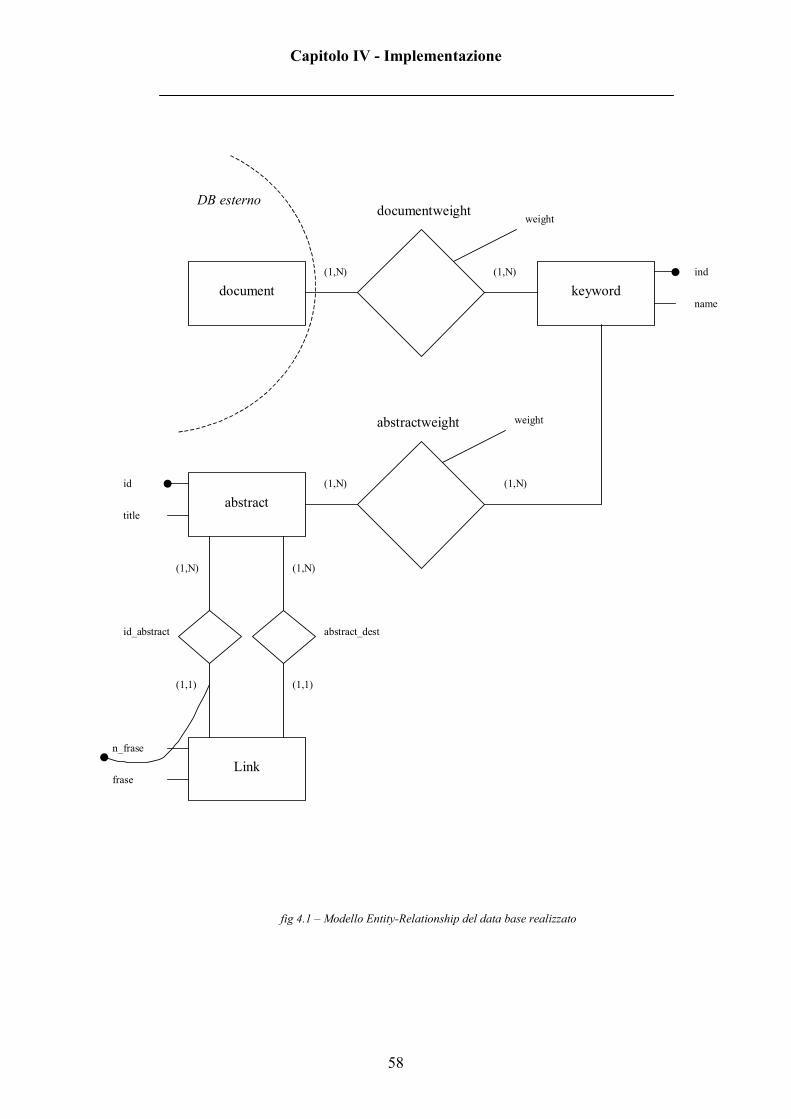
In figura 4.1 viene mostrato il diagramma E-R (Entity-Relationship) relativo
al data base che si è implementato e come quest’ultimo si leghi ad una tabella
document “esterna” (facente parte di un data base già esistente).
Nel sottoparagrafo successivo verranno analizzate più in dettaglio le tabelle
di cui si è appena accennato.
Capitolo IV - Implementazione
58
fig 4.1 – Modello Entity-Relationship del data base realizzato
document
keyword
abstract
Link
documentweight
abstractweight
weight
weight
ind
name
id
title
n_frase
frase
id_abstract abstract_dest
(1,N) (1,N)
(1,N) (1,N)
(1,1)
(1,N)
(1,1)
(1,N)
DB esterno

Capitolo IV - Implementazione
59
Tabelle
Di seguito verranno descritte brevemente le tabelle che implementano il data
base di supporto al motore di ricerca.
keyword
Le parole chiave possono essere viste come gli assi di un sistema cartesiano
sul quale sono presenti i vettori di cui si è accennato in precedenza.
CREATE TABLE keyword (
ind int(11) NOT NULL DEFAULT '0' auto_increment,
name char(200) ,
PRIMARY KEY (ind)
);
La tabella keyword contiene le parole chiave nel cui “spazio” vengono
rappresentati i vettori utente e quelli relativi ai documenti e agli abstract. Esiste
un identificativo per ogni parola chiave attraverso il quale vi si fa riferimento
nelle tabelle.
documentweight
Questa tabella, definendo i pesi delle parole chiave per ogni documento,
rappresenta i vettori relativi ai documenti.
CREATE TABLE documentweight (
document_id int(11) NOT NULL DEFAULT '0' ,
keyword_ind int(11) NOT NULL DEFAULT '0' ,
weight float(10,2) ,
PRIMARY KEY (document_id,keyword_ind)
);

Capitolo IV - Implementazione
60
La tabella documentweight codifica la relazione tra un documento e una
parola chiave e le associa un peso. La j-esima parola chiave (keyword_ind = j)
relativa al documento i-esimo (documenti_id = i) avrà dunque un peso pari a
weight (un valore floting point maggiore di zero).
abstract
CREATE TABLE abstract (
id int(11) NOT NULL DEFAULT '0' auto_increment,
title char(200) NOT NULL DEFAULT '0' ,
PRIMARY KEY (id)
);
La tabella abstract contiene un identificativo relativo all’abstract (id) e il
titolo di quest’ultimo (title).
abstractweight
Questa tabella, definendo i pesi delle parole chiave per ogni abstract,
rappresenta i vettori relativi agli abstract.
CREATE TABLE abstractweight (
abstract_id int(11) NOT NULL DEFAULT '0' ,
keyword_ind int(11) NOT NULL DEFAULT '0' ,
weight float(10,2) DEFAULT '0.00' ,
PRIMARY KEY (abstract_id,keyword_ind)
);
La tabella abstractweight codifica la relazione tra un abstract e una parola
chiave e le associa un peso. La j-esima parola chiave (keyword_ind = j) relativa

Capitolo IV - Implementazione
61
all’abstract i-esimo (abstract_id = i) avrà dunque un peso pari a weight (un
valore floting point maggiore di zero).
link
CREATE TABLE link (
id_abstract int(11) NOT NULL DEFAULT '0' ,
n_frase int(11) NOT NULL DEFAULT '0' ,
frase blob ,
abstract_dest int(11) ,
PRIMARY KEY (id_abstract,n_frase)
);
La tabella link, infine, contiene per ogni abstract le frasi che lo costituiscono
(più un identificativo di frase) e per ogni frase l’identificativo dell’abstract di
destinazione (se presente) a cui la frase fa riferimento.
id_abstract n_frase Frase abstract_dest A1 1 Frase numero 1 che porta all’abstract A2 A2
A1 2 Frase numero 2 che porta all’abstract A4 A4
A1 3 Frase numero 3 che porta all’abstract A8 A8
fig 4.2 – rappresentazione della tabella link
Abstract 1 (A1) Frase numero 1 che porta all’abstract A2 Frase numero 2 che porta all’abstract A4 Frase numero 3 che porta all’abstract A8
Abstract 2 (A2) …
Abstract 4 (A4) …
Abstract 8 (A8) …

Capitolo IV - Implementazione
62
Strutture Dati
Questo paragrafo è dedicato all’implementazione delle strutture dati del
motore di ricerca.
Esistono varie strutture dati, memorizzate come variabili di sessione PHP,
ma tre di queste assumono particolare importanza all’interno del livello
applicativo.
La prima modella l’interesse dell’utente attraverso un vettore, le altre due
sono la classe lifo, e la classe media.
Vettore utente
L’interesse dell’utente è modellato semplicemente attraverso un vettore (un
array) il cui numero di elementi è dato dalla variabile di sessione
NUM_EL_VETTORE che contiene il numero di assi cartesiani (le parole chiave)
sui quali viene rappresentato il vettore utente.
Un esempio può essere dato dal seguente vettore utente
v_utente = (1.12, 4, 0, 0, 2, 2, 2.4, 8)
In questo caso il numero di assi cartesiani del sistema di riferimento è otto,
ovvero ci sono otto parole chiave a cui viene associato un peso per indicare
l’interesse verso queste ultime da parte dell’utente.
Lifo
La terminologia LIFO significa Last In First Out, ovvero l’ultimo elemento
aggiunto alla “lista” (con un’operazione detta PUSH) è il primo a venir
restituito quando si effettua una operazione di “estrazione” (detta POP). Il
meccanismo è molto simile a quello della pila di piatti, l’ultimo elemento posto
sulla pila è il primo a venir preso quando c’è bisogno di un piatto.
Si tratta di una struttura di supporto utile per memorizzare tre campi dati:

Capitolo IV - Implementazione
63
id � l’identificativo univoco dell’abstract.
v_utente � il vettore utente (in continua evoluzione).
pv � il peso del vettore utente usato nel calcolo del vettore utente stesso. Il
peso indica l’importanza che ha il vettore utente rispetto al vettore dell’abstract
correntemente visualizzato al fine di calcolare il nuovo vettore utente.
Queste tre informazioni vengono inserite nella LIFO ogni qual volta viene
selezionato un nuovo abstract.
Ci si può chiedere perché sia necessario salvare ad ogni passo un’istantanea
di queste tre variabili, quando sarebbe molto più semplice usare singole
variabili.
La risposta risiede in una considerazione fatta nel capitolo 3: ogni qual volta
si seleziona il tasto BACK per visualizzare l’abstract precedente si deve
memorizzare nel vettore utente corrente il valore di quello al tempo t-1 (facendo
l’ipotesi di essere al tempo t) per questo motivo è utile mantenere la “storia” dei
vettori utente durante la navigazione attraverso gli abstract.
Mantenendo queste informazioni ed in più il peso del vettore per ogni
selezione si ha la storia dei passi fatti per giungere alla situazione attuale.
In figura 4.3 viene mostrato un esempio relativo alle operazioni svolte dalla
LIFO.
Capitolo IV - Implementazione
64
fig.4.3 – esempio di lifo
id = 4 v_utente pv = 16
id = 8 v_utente pv = 25
id = 28 v_utente pv = 36
clicco sul link 32
id = 4 v_utente pv = 16
id = 8 v_utente pv = 25
id = 28 v_utente pv = 36
t=3
id = 32 v_utente pv = 49
t=4
clicco su BACK
id = 4 v_utente pv = 16
id = 8 v_utente pv = 25
id = 28 v_utente pv = 36
id = 32 v_utente pv = 49
t=5
clicco sul link 52
id = 4 v_utente pv = 16
id = 8 v_utente pv = 25
id = 28 v_utente pv = 36
id = 52 v_utente pv = 49
t=6

Capitolo IV - Implementazione
65
Ecco di seguito l’implementazione pratica della classe lifo:
class lifo_class {
var $pos;
var $nv;
var $id;
var $vector;
var $pv;
function lifo_class ($NUM_EL_VETTORE)
{
$this->pos = 0;
$this->nv = $NUM_EL_VETTORE;
}
function add_element ($id, $vect, $pv)
{
$this->pos++;
$this->id[$this->pos] = $id;
for ($i = 1; $i <= $this->nv; $i++)
$this->vector[$this->pos][$i] = $vect[$i];
$this->pv[$this->pos] = $pv;
}
function remove_element ()
{
if ($this->pos < 1)
printf ("Can't remove");
else
$this->pos--;
}
function get_element (&$id, &$vector, &$pv)
{
if ($this->pos >= 1)
{
$id = $this->id[$this->pos];

Capitolo IV - Implementazione
66
for ($i = 1; $i <= $this->nv; $i++)
$vector[$i] = $this->vector[$this->pos][$i];
$pv = $this->pv[$this->pos];
}
else
$id = "INTRODUCTION";
}
}
Il costruttore della classe riceve come parametro NUM_EL_VETTORE una
variabile di sistema che contiene il numero di parole chiave (assi del sistema di
riferimento) da cui è costituito il vettore utente. Viene inoltre azzerata la
variabile pos, che indica la posizione corrente nella lifo.
La lifo viene rappresentata da tre variabili: id, pv e v_utente.
Per comprendere il modo in cui è stata implementata viene mostrato di
seguito un esempio:
• id[1], pv[1], v_utente[1][n] rappresentano le tre variabili di sistema al
passo 1.
• id[2], pv[2], v_utente[2][n] rappresentano le tre variabili di sistema al
passo 2.
Si può notare come la variabile v_utente sia in realtà una matrice e non un
array come le altre variabili. Mentre per id e pv le informazioni da memorizzare
sono singole e quindi vengono “trasformate” in array per implementare la lifo,
v_utente è un array è verrà dunque “trasformato” in matrice.
L’operazione di PUSH viene implementata attraverso la funzione
add_element, a cui vengono passati come parametri l’id dell’abstract
correntemente visualizzato, il vettore utente ed il suo peso (peso_vettore).

Capitolo IV - Implementazione
67
La funzione add_element incrementa pos e memorizza nei vari vettori (in
posizione pos) le variabili suddette.
L’operazione di POP viene implementata attraverso le funzioni
remove_element, che decrementa pos, a meno che non sia inferiore al valore 1, e
dalla funzione get_element a cui vengono passati come parametri tre variabili by
reference, sulle quali vengono scritte id, pv e v_utente della lifo alla posizione
pos (decrementata nella funzione precedentemente esposta).
Media
Si tratta di una classe general pourpose, ovvero che può essere usata in
maniera versatile per diverse applicazioni.
Come si deduce dal nome, la struttura dati effettua la media degli elementi
che vengono inseriti.
Si può immaginare che in questo contenitore vengano inseriti dei dati (nel
caso specifico i dati sono semplicemente delle variabili intere) e che restituisca
la media di ciò che è stato inserito ogni volta che viene richiesto.
Può quindi essere istanziato un oggetto di questa struttura dati ogni qual
volta serva il calcolo della media di determinati valori.
Un’applicazione di media risiede per esempio nel calcolo della media delle
distanze tra i vettori argomento dei documenti e il vettore interesse dell’utente.
Il motore mostrerà i cosiddetti documenti di interesse solo se sono verificate
due condizioni, ovvero il grado di somiglianza tra questi documenti e il vettore
interesse dell’utente è all’interno di un certo margine e se la media dei gradi di
somiglianza tra tutti i vettori dei documenti e quello dell’utente non è troppo
grande. Quest’ultima condizione è dovuta al fatto che se si avesse una media dei
degree of similarity troppo grande si avrebbero troppi documenti da mostrare e
non si avrebbe dunque la precisione richiesta nel mostrare i documenti di
interesse.

Capitolo IV - Implementazione
68
Questa condizione può verificarsi ad esempio quando il vettore utente è
ancora molto generico (all’inizio della navigazione per esempio) o quando le
scelte relative agli abstract da visualizzare sono state rivolte verso argomenti
disparati.
In questo modo il vettore utente non definisce un preciso interesse e non è
quindi utile che venga mostrato alcun documento.
Ecco l’implementazione della classe media_class:
class media_class {
var $tot_element;
var $num_element;
function media_class ()
{
$this->tot_element = 0;
$this->num_element = 0;
}
function add_value ($value)
{
$this->tot_element += $value;
$this->num_element++;
}
function return_media ()
{
if ($this->num_element != 0)
return ($this->tot_element / $this->num_element);
else
return 0;
}
}
Il costruttore azzera il valore di tot_element, che contiene la somma di tutti i
valori inseriti in un oggetto istanziato da questa classe, e num_element, che

Capitolo IV - Implementazione
69
invece contiene l’informazione relativa al numero di elementi presenti
nell’oggetto.
La funzione add_value, come facilmente si può intuire dal nome, inserisce
un nuovo valore nell’oggetto media. Viene aggiunto a tot_element il valore
passato come parametro della funzione e viene incrementato il valore di
num_element.
Se per esempio si fossero inseriti in un oggetto istanziato da questa classe
questi cinque valori: 28, 2, 38, 102, 98 si avrebbe:
tot_element = 268
num_element = 5
La funzione return_media, restituisce la media dei valori inseriti: dividendo
il valore presente in tot_element, ovvero la somma di tutti i valori inseriti
nell’oggetto media per num_element, il numero di valori inseriti, si ottiene la
media di questi ultimi.
Ritornando all’esempio precedente, ciò che viene fatto è:
media = tot_element / num_element
media = 268 / 5
media = 53,6
Un’ultima nota è relativa al caso in cui si richiami la funzione return_media
senza aver inserito prima alcun valore. In questo caso num_element assume il
valore zero e il risultato sarebbe un errore di divisione per zero.
Contro questa evenienza si è inserito il codice:
if ($this->num_element != 0)
return ($this->tot_element / $this->num_element);
else
return 0;

Capitolo IV - Implementazione
70
Livello applicativo
In questo paragrafo si discuterà della realizzazione pratica degli algoritmi
trattati nel capitolo precedente.
Si discuterà relativamente ai file:
• index.php in cui vengono inizializzate le variabili di sessione
• moise.php centro del livello applicativo del motore di ricerca
• functions.php in cui sono realizzate le funzioni di supporto per
moise.php
Trattando l’implementazione del motore di ricerca, si ometteranno quelle
parti di codice non essenziali che renderebbero solo più complessa la
comprensione degli argomenti.
Index.php
In index.php vengono inizializzate tutte le variabili di sessione che verranno
usate nel corso del programma. La funzione session_register (), infatti, consente
di associare ad ogni utente un set di variabili (memorizzate sul server) che
vengono richiamate da ogni pagina che utilizzi la funzione session_start ()
prima del codice HTML.
Per fare un esempio, se in una pagina si effettua la chiamata
session_register (“prova”), e nelle pagine successive, richiamando sempre
session_start () all’inizio del codice, viene modificata la variabile, ogni utente
del sistema alla fine avrà un proprio valore nella variabile prova, creando un
concetto di sessione.
Ecco parte del codice di index.php:
<?
include ("classi.php");

Capitolo IV - Implementazione
71
session_start ();
session_register ("NUM_EL_VETTORE", "v_utente", "peso_vettore",
"margine_best_match", "margine_related_documents", "margine_media", "lifo", "alfa");
inizializzazione delle variabili di sessione
?>
<html>
<head>
…
<meta http-equiv="Refresh" content="0;
url=moise.php?abstract_selected=6&abstract_old=INTRODUCTION&url_tempo=0">
…
</head>
</html>
Le variabili che vengono inizializzate sono:
NUM_EL_VETTORE, v_utente e peso_vettore di cui si è già estesamente
parlato.
Margine_best_match e margine_related_link sono due margini relativi ai
documenti da visualizzare (le soglie di cui si è parlato nel penultimo paragrafo
del capitolo 3). Come si è visto se il degree of similarity tra il v_utente e il
vettore di interesse dei documenti è superiore ai margini suddetti, il documento
entrerà a far parte dei related link (documenti correlati) o dei best match
(documenti interessanti), sempre che la media dei degree of similarity non sia
superiore a margine_media (troppi documenti interessanti).
Su lifo e alfa si è già parlato estesamente nel capitolo sugli algoritmi e
relativamente a tempo si può dire che si tratta di una variabile utilizzata per
individuare eventuali selezioni del tasto BACK del browser.
Di interesse risulta infine l’ultima riga HTML del file index.php:
<meta http-equiv="Refresh" content="0;
url=moisel.php?abstract_selected=6&abstract_old=INTRODUCTION&url_tempo=0">

Capitolo IV - Implementazione
72
Questo tag HTML indica di caricare la pagina moise.php, con i vari
parametri di cui si parlerà nel prossimo sottoparagrafo,
url=moise.php?abstract_selected=6&abstract_old=INTRODUCTION&url_tempo=0 dopo
zero secondi di attesa content="0;…".
Moise.php
Moise.php rappresenta il nucleo del livello applicativo del motore di ricerca.
Una richiesta http verso questa pagina è effettuata attraverso questa sintassi:
http://server/moise.php?abstract_selected=ID&abstract_old=ID_OLD&n_frase_selected=
NF&url_tempo=TMP
I parametri di questa richiesta sono:
• abstract_selected rappresenta l’identificativo dell’abstract il cui link
l’utente ha selezionato al passo precedente (rappresenta insomma
l’abstract da visualizzare)
• abstract_old rappresenta invece l’identificativo dell’abstract
visualizzato il passo precedente. L’utilità di mantenere questa
informazione insieme a n_frase_selected risiede nel fatto che serve per
accedere agli identificativi di tutti gli abstract linkati nella pagina
precedente al fine di calcolare il vettore v_abstract. Avendo
l’identificativo dell’abstract vecchio e il numero di frase (relativo
all’abstract selezionato), si può accedere alla tabella link e alla tabella
abstractweight e calcolare v_abstract seguendo la formula spiegata il
capitolo precedente.
• url_tempo è una variabile che viene confrontata con la variabile di
sistema tempo al fine di capire se il passo precedente si è selezionato il
tasto BACK del browser o no.
Segue ora una descrizione della pagina seguendo un approccio top-down:

Capitolo IV - Implementazione
73
<html>
<meta http-equiv="Pragma" content="no-cache">
<meta http-equiv="Cache-Control" content="no-cache">
…
<body>
<table>
<tr> <td> <center>
intestazione
</center> </td> </tr>
<tr> <td>
<div> Abstract </div>
<? 1 - Codice relativo alla visualizzazione dell’abstract selezionato e al calcolo del v_utente
?>
</td>
<td>
<div> Document </div>
<?
2 - Codice relativo alla visualizzazione dei documenti interessanti: confronto tra il vettore
utente calcolato precedentemente e i vettori relativi ad i documenti
?>
</td> </tr>
<tr> <td >
<center>
pulsante per effettuare una nuova ricerca
</center>
</td> </tr>
</table>
</body>
</html>

Capitolo IV - Implementazione
74
Come si può notare dal codice e dalla figura 1.2, la pagina è divisa in
quattro sezioni.
Nella prima, quella superiore, è presente il logo del motore di ricerca, in
quella a sinistra è presente la pagina relativa agli abstract, in quella a destra
vengono visualizzati i documenti collegati (se presenti) e nell’ultima, quella
inferiore, è presente il bottone per iniziare una nuova ricerca.
Si analizza ora il blocco contrassegnato da 1 nel codice precedente, ovvero il
codice relativo alla visualizzazione degli abstract e al calcolo del vettore utente:
Blocco 1
Caso 1 Si proviene da un’operazione di BACK
if ($tempo != $url_tempo)
{
/* Decremento tempo per portarlo a quello dell'url precedente */
$tempo -= 2;
/* Prendo dalla lifo l'id dell'abstract corrente e il vettore peso dell'utente */
$lifo->remove_element ();
$lifo->get_element ($abstract_selected, $v_utente, $peso_vettore);
}
Se nella pagina precedente si è selezionato il tasto BACK del browser, la
variabile di sistema tempo non coinciderà più con la variabile url_tempo, perché
al passo precedente si è incrementato tempo ma avendo selezionato BACK si è
ripresa dalla cronologia delle pagine visitate quella “vecchia” che aveva un
url_tempo minore.

Capitolo IV - Implementazione
75
Questo sistema funziona anche in virtù del codice HTML di seguito esposto
che impedisce di riprendere dalla cache la pagina web precedente e la fa
ricaricare ex-novo:
<meta http-equiv="Pragma" content="no-cache">
<meta http-equiv="Cache-Control" content="no-cache">
Tornando al programma l’operazione che viene fatta è quella di
decrementare di due unità la variabile tempo per riportarla al valore di
url_tempo (per le selezioni successive) ed estrarre dalla lifo i valori relativi al
vecchio abstract (che dovrà essere mostrato nel corso del programma) al vettore
utente e al peso del vettore.
Caso 2.1 Si proviene dalla selezione di un abstract
Se invece non si proviene da un’operazione di BACK ci si può trovare in
due situazioni: o si è a “regime” o si proviene da index.php. Di seguito è
presente il codice che descrive il primo caso:
if (strcmp ($abstract_old, "INTRODUCTION"))
{
/* Mi calcolo il coefficente che dividerà il peso degli abstract
non selezionati la volta precedente */
$query = select * from link where id_abstract=$abstract_old
$riduttore_alfa = 0;
while ($row = riga di $query)
if ($row->abstract_dest != NULL)
$riduttore_alfa++;
$alfa_effettivo = $alfa / $riduttore_alfa;
/* Mi calcolo il nuovo vettore abstract */
/* Passo 1 : Carico in v_abstract il vettore dell'abstract selezionato */

Capitolo IV - Implementazione
76
$query = select * from abstractweight where abstract_id=’$abstract_selected’
while ($row = riga di $query)
$v_abstract[$row->keyword_ind] = $row->weight;
/* Passo 2 : Sottraggo da v_abstract i vettori degli abstract presenti come LINK
nella pagina dalla quale provengo attenuati di un fattore */
$query = select * from link where id_abstract=$abstract_old
while ($row = riga di $query)
if (($row->n_frase != $n_frase_selected) && ($row->abstract_dest != NULL))
{
$query2 = select * from abstractweight where abstract_id='$row-> abstract_dest'
while ($row2 = riga di $query2)
$v_abstract[$row2->keyword_ind] -= ($alfa_effettivo * $row2->weight);
}
/* Passo 3: Elimino i valori negativi di v_abstract */
for ($i = 1; $i <= count ($v_abstract); $i++)
if ($v_abstract[$i] < 0)
$v_abstract[$i] = 0;
}
Ciò che viene fatto nel caso 2.1 (ed ovviamente anche nel caso 2.2 se si
proviene dalla pagina index.php) è semplicemente calcolare v_abstract.
Al passo 1 viene caricato il vettore relativo all’abstract selezionato, al passo
2 si sottraggono a questo vettore i vettori degli abstract non selezionati la pagina
precedente, attenuati di un fattore alfa_effettivo che viene calcolato in base al
numero di collegamenti presenti nel vecchio abstract,
alfa_effettivo = alfa / (n di link dell’abstract precedentemente visitato)
(gli id degli abstract non selezionati si reperiscono dalla tabella link,
possedendo l’informazione relativa al vecchio abstract selezionato e al numero

Capitolo IV - Implementazione
77
di frase selezionata il passaggio precedente). Al passo 3 infine si eliminano le
componenti negative di v_abstract.
Caso 2.2 Si proviene da index.php
/* Mi calcolo il nuovo vettore abstract */
$query2 = select * from abstractweight where abstract_id='$abstract_selected'
while ($row2 = riga di $query2)
$v_abstract[$row2->keyword_ind] = $row2->weight;
In questo caso il calcolo di v_abstract risulta notevolmente semplificato in
virtù del fatto che si tratta della prima pagina visualizzata e quindi non si deve
sottrarre al vettore del primo abstract quello degli abstract non selezionati la
pagina precedente (non esistendo una pagina precedente).
Parte comune al caso 2.1 e 2.2 (calcolo di v_utente usando v_abstract calcolato
il passo 2.1 o 2.2)
/* Salvo il peso del vettore corrente */
$peso_vettore = incrementa ($peso_vettore);
/* Calcolo il nuovo vettore utente */
nuovo_vettore ($v_utente, $v_abstract, $peso_vettore, $NUM_EL_VETTORE);
/* Salva nella lifo l'id dell'abstract corrente , il vettore peso dell'utente
ed il peso del vettore utente */
$lifo->add_element ($abstract_selected, $v_utente, $peso_vettore);
Il calcolo del nuovo vettore utente viene effettuato attraverso la funzione
nuovo_vettore (dopo aver incrementato il peso_vettore). Il vettore utente così

Capitolo IV - Implementazione
78
calcolato sarà confrontato nel blocco 2 di moise.php con i vettori relativi ai
documenti presenti nell’archivio al fine di mostrare all’utente quelli di interesse.
L’identificativo dell’abstract corrente, il vettore utente (appena calcolato) e
il peso_vettore (usato nel calcolo del vettore utente) vengono salvati nella LIFO
al fine di essere recuperati nel caso di eventuali operazioni di BACK.
Parte comune al CASO 1 e al CASO 2 (visualizzazione dell abstract)
/* Incrementa tempo */
$tempo++;
/* Visualizza il titolo dell'abstract */
…
/* Visualizza l'abstract */
$query = select * from link where id_abstract='$abstract_selected'
while ($row = carico riga di $query)
{
if ($row->abstract_dest != NULL)
printf ("<a class='collegamento' href='moise.php?
abstract_selected=$row-> abstract_dest &
abstract_old=$abstract_selected &
n_frase_selected=$row-> n_frase&url_tempo=$tempo'>
$row->frase </a>");
else
printf ("$row->frase");
}
L’ultima operazione che viene effettuata, sia che si provenga da una
operazione di BACK o dalla selezione di un abstract, consiste nel visualizzare
l’abstract selezionato, reperendo le informazioni relative alle frasi da
visualizzare e ai link ai quali puntano le suddette frasi dalla tabella link.

Capitolo IV - Implementazione
79
Come si può notare la variabile tempo viene incrementata e aggiunta ai link
verso i nuovi abstract attraverso url_tempo=$tempo nell’url del link di
destinazione (per implementare il meccanismo di riconoscimento del tasto
BACK di cui si è precedentemente parlato).
Blocco 2
if ($peso_vettore > 16)
{
$array_documenti_title = array ();
$array_documenti_id = array ();
$array_documenti_dist = array ();
$media_dist = new media_class ();
$query = select * from file where language = 'italian'
while ($row = carico riga di $query)
{
/* Carico il vettore documenti */
$query2 = select * from documentweight where document_id = '$row-> document_id'
while ($row2 = carico riga di $query2)
$v_documenti[$row2->keyword_ind] = $row2->weight;
/* Calcolo la distanza tra v_utente e v_documenti */
$dist = calcola_distanza ($v_utente, $v_documenti, $NUM_EL_VETTORE);
/* Aggiungi la distanza al calcolo della media */
$media_dist->add_value ($dist);
/* Se il valore è maggiore di margine_related_documents allora lo inserisco
nella lista dei documenti */

Capitolo IV - Implementazione
80
if ($dist > $margine_related_documents)
{
$query3 = select * from document where id = '$row->document_id'
$row3 = mysql_fetch_object ($query3);
$array_documenti_title[] = $row3->title;
$array_documenti_id [] = $row->document_id;
$array_documenti_dist[] = $dist;
}
}
Nel secondo blocco le operazioni effettuate si possono dividere
concettualmente in due parti: nella prima, il cui codice è stato appena mostrato
viene calcolata la distanza tra il vettore utente (calcolato nel blocco 1) e i vettori
dei documenti, inserendo il titolo, l’identificativo e la stessa distanza in tre
vettori distinti (da notare che alla posizione n di questi tre vettori ci sono dati
relativi all’n-esimo documento). L'idea è di avere pochi documenti da mostrare
in modo da avere documenti che siano interessanti per l'utente e che questi non
siano in numero esagerato.
Relativamente alla seconda parte del blocco 2, se c’è almeno un documento
interessante e la media dei degree of similarity è inferiore a una certa soglia, si
ordinano i tre vettori di cui si è parlato precedentemente in maniera decrescente
dal più interessante a quello meno interessante, in base al valore presente in
$array_documenti_dist (mantenendo comunque le “relazioni” tra i tre vettori
ovvero mantenendo il loro ordinamento relativo: $array_documenti_id[$i],
$array_documenti_title[$i], $array_documenti_dist[$i] faranno riferimento ad
un unico documento anche dopo la procedura di ordinamento).
if ((count ($array_documenti_title) != 0) &&
($media_dist->return_media () < $margine_media))
{

Capitolo IV - Implementazione
81
array_multisort ($array_documenti_dist, SORT_DESC, $array_documenti_title,
$array_documenti_id);
printf ("<table>");
printf ("<tr> <td class='scuro'> <div class='blue_text'> Best Match </div> <br>");
for ($i = 0; $i < count ($array_documenti_title); $i++)
if ($array_documenti_dist[$i] > $margine_best_match)
visualizzo il link al documento
printf ("</td> </tr>");
printf ("<tr> <td class='scuro'> <div class='blue_text'> Related Documents </div> <br>");
for ($i = 0; $i < count ($array_documenti_title); $i++)
if (($array_documenti_dist[$i] < $margine_best_match) &&
($array_documenti_dist[$i] > $margine_related_documents))
visualizzo il link al documento
printf ("</td> <tr>");
printf ("</table>");
}
}
Si analizza ora, per concludere la panoramica sull’implementazione del
motore di ricerca, il file functions.php.
In moise.php si sono infatti utilizzate alcune funzioni di cui verrà data una
breve descrizione di seguito.
Functions.php
incrementa: questa funzione riceve come parametro la variabile peso_vettore e
restituisce il nuovo peso vettore (incrementato secondo la regola discussa nel
capitolo relativo agli algoritmi).
Ecco di seguito la formula di incremento:

Capitolo IV - Implementazione
82
( )
+= − 81,1_min_
2
1tt vettorepesovettorepeso
ed il codice che implementa il suddetto algoritmo:
function incrementa ($peso_vettore)
{
$valore = pow (sqrt ($peso_vettore) + 1, 2);
if ($valore < 100)
return $valore;
else
return $peso_vettore;
}
nuovo_vettore: questa funzione calcola il nuovo vettore utente partendo da
quello vecchio (v_1), da v_abstract (v_2), dal peso_vettore (pv) e da
NUM_EL_VETTORE (num_iterazioni). Da notare è che v_1 è passato by
reference proprio perché la funzione scrive su questa variabile il risultato del
calcolo effettuato.
Ecco di seguito la formula utilizzata:
100_)_100(__
_ 1 abstractvvettorepesoutentevvettorepesoutentev tttt
⋅−+⋅= −
ed il codice che implementa suddetto algoritmo:
function nuovo_vettore (&$v_1, $v_2, $pv, $num_iterazioni)
{
for ($count = 1; $count <= $num_iterazioni; $count++)
$v_1[$count] = ($pv * $v_1 [$count] + (100 - $pv) * $v_2[$count]) / 100;
}

Capitolo IV - Implementazione
83
calcola_distanza: questa funzione calcola il degree of similarity tra il vettore
utente e i vettori dei documenti (questa operazione viene ripetuta per ogni
documento).
Ecco la formula utilizzata:
∑∑
∑
==
=
⋅
⋅=
⋅
×=
t
iqi
t
iji
t
iqiji
j
jj
ww
ww
qd
qdqdsim
1,
2
1,
2
1,,
),(�
�
�
�
ed il codice che la implementa:
function calcola_distanza ($v_1, $v_2, $num_iterazioni)
{
$tot1 = 0;
$tot2 = 0;
$tot3 = 0;
for ($count = 1; $count <= $num_iterazioni; $count++)
{
$tot1 += $v_2[$count] * $v_1[$count];
$tot2 += pow ($v_2[$count], 2);
$tot3 += pow ($v_1[$count], 2);
}
$dist = $tot1 / (sqrt ($tot2) * sqrt ($tot3));
return $dist;
}
In cui:
tot1 è uguale alla sommatoria di wi,,j x wi,q per i che va da 1 a t
tot2 alla sommatoria di w2i,,j per i che va da 1 a t
tot3 alla sommatoria di w2i,q per i che va da 1 a t.

Capitolo V - Valutazione del sistema
84
Capitolo V Valutazione del sistema
Introduzione
Prima dell’implementazione finale di un motore di ricerca deve essere
condotta una valutazione del sistema stesso.
Le misure più comuni per valutare le prestazioni di un sistema sono il tempo
e lo spazio. Più breve è il tempo di risposta e più piccolo è lo spazio usato,
migliore è considerato il sistema.
In un sistema progettato per provvedere a funzioni di data retrieval, infatti, il
tempo di risposta e lo spazio richiesto sono tipicamente metriche di grande
interesse nel valutare il sistema. Tra i vari parametri di cui si tiene conto sono
presenti: i ritardi dovuti al canale di comunicazione e gli overhead introdotti dai
vari livelli software che sono tipicamente presenti. Ci si riferisce a questa forma
di valutazione attraverso la definizione di valutazione di performance.
In un sistema di information retrieval ci sono però altre metriche di
maggiore interesse. Il sistema di information retrieval richiede la valutazione
della qualità del cosiddetto answer set, ovvero viene misurata la precisione con
la quale vengono restituiti documenti dopo una query dell’utente. Questo tipo di
valutazione prende il nome di valutazione delle performance di retrieval.

Capitolo V - Valutazione del sistema
85
In questo capitolo si discuterà proprio di quest’ultimo argomento e
dell’usabilità del sistema ovvero della sua facilità di utilizzo.
La valutazione delle performance di retrieval si basa tipicamente su:
• Una collezione di documenti di prova
• Un insieme di “richieste di informazione” (query descrittive)
• Un insieme di documenti rilevanti (selezionati da specialisti) per ogni
esempio di richiesta di informazione.
Data una strategia di retrieval S, la valutazione quantifica la somiglianza tra
l’insieme dei documenti proposti da S e l’insieme dei documenti proposti dagli
specialisti. Questo fornisce una stima della bontà della strategia di retrieval S.
Come banco di prova per questo progetto si sono usati documenti relativi al
progetto MOISE, rivolto alla distribuzione di informazioni relative
all’esperienza con bambini con bisogni educativi speciali in differenti scuole di
varie nazioni.

Capitolo V - Valutazione del sistema
86
Concetti teorici sulla valutazione di un sistema di IR
Si consideri una richiesta di informazione d’esempio I (di una collezione di
prova) e l’insieme di documenti rilevanti R. Sia |R| il numero di documenti in
questo insieme. Si assuma che una data strategia (che deve essere valutata)
processi la richiesta I e generi un answer set A. Sia |A| il numero di documenti
in questo insieme. Sia infine |Ra| il numero di documenti nell’intersezione
dell’insieme R e A. In figura 6.1 vengono illustrati questi 3 insiemi.
fig 5.1 – Esempio di richiesta di informazione
Due importanti concetti che devono essere illustrati al fine di comprendere i
metodi di valutazione delle performance di un sistema di retrieval sono le
misure di recall e precision.
Documenti Rilevanti |R|
Answer Set |A|
Documenti Rilevanti nell’Answer Set |Ra|
Collezione

Capitolo V - Valutazione del sistema
87
Recall è la parte dei documenti rilevanti (l’insieme R) che è stata generata
da un processo di retrieval.
RR
recall a=
Precision è la parte di documenti generati da un processo di retrieval
(l’insieme A) che è rilevante.
AR
precision a=
Recall e Precision sono i parametri che verranno usati per giudicare la
“bontà” del sistema di retrieval implementato.
Esempio
Si supponga che sia stata formulata una query q. Si assuma che un insieme
Rq contenente i documenti rilevanti per q sia stato definito (da esperti).
Rq = {d3, d5, d9, d25, d39, d44, d56, d71, d89, d123}
Si consideri ora l’algoritmo di retrieval che è stato progettato e deve essere
giudicato. Si assuma che questo algoritmo restituisca per la query q questo
answer set (i documenti con un asterisco al fianco sono quelli presenti anche
nell’insieme Rq):
1. d123 * 6. d9 * 11. d38
2. d84 7. d511 12. d48
3. d56 * 8. d129 13. d250
4. d6 9. d187 14. d113
5. d8 10. d25 * 15.d3 *

Capitolo V - Valutazione del sistema
88
Per il suddetto esempio si ottiene:
Recall = 5/10 = 0,5 (50%)
Precision = 5/15 = 0,33 (33%)
Maggiori sono i valori, maggiore è la qualità del motore di ricerca.
Un’ultima considerazione è relativa al fatto che queste misure non tengono
conto del fatto che il sistema di retrieval restituisce i documenti ordinandoli per
degree of similarity. Questa considerazione richiederebbe dei parametri di
valutazione più complessi che non verranno presi in considerazione.

Capitolo V - Valutazione del sistema
89
Valutazione del sistema di IR
La valutazione del sistema di IR attraverso i parametri di cui si è trattato nel
paragrafo precedente richiederebbe la presenza di un data base estremamente
fornito di documenti e abstract su cui navigare. L’assenza di una quantità
adeguata di questi ultimi e la mancanza di un gruppo di tester porterà ad una
valutazione non precisa ed accurata del sistema, ma fornirà comunque i mezzi
necessari per impostare future valutazioni (avendo a disposizione maggiori
informazioni).
Gli esempi di seguito esposti sono stati fatti settando i valori delle soglie con
questi valori:
margine_best_match = 0.7
margine_related_documents = 0.6
margine_media = 0.5
Come metriche di valutazione si sono usate le misure di recall, precision e il
numero di click necessari per ottenere le informazioni cercate (minore è il
numero di selezioni di abstract per ottenere i documenti cercati, migliore è il
sistema).
Nell’ appendice A è presente un elenco di tutti i documenti e di tutti gli
abstract presenti nel data base usato come studio.
Esempio 1
query descrittiva:
Si vogliono cercare informazioni relative alla possibilità di lavorare in modo
autonomo, pur avendo bisogni speciali.
documenti scelti dall’esperto:
• Progetto Attivamente

Capitolo V - Valutazione del sistema
90
• Esperienza con il computer per conquistare autonomia, competenze e
lavorare in gruppo
utente 1:
navigazione: introduzione, accessibilità, integrazione, BACK, autonomia,
autonomia lavorativa
documenti proposti:
• Esperienza con il computer per conquistare autonomia, competenze e
lavorare in gruppo (86,9%)
n.click = 5
recall = 50%
precision = 100%
utente 2:
navigazione: introduzione, autonomia, autonomia lavorativa
documenti proposti:
• Esperienza con il computer per conquistare autonomia, competenze e
lavorare in gruppo (92,8%)
n.click = 2
recall = 50%
precision = 100%

Capitolo V - Valutazione del sistema
91
fig 5.2 – schermata finale dell’esempio 1
Esempio 2
query descrittiva:
Si vogliono cercare informazioni relative all’integrazione nella società di
persone con bisogni educativi speciali.
documenti scelti dall’esperto:
• Servizio educativo assistenziale di integrazione scolastica
• Integrazione degli interventi
• Progetto accoglienza, inserimento, integrazione di alunni
extracomunitari
• Esempio di integrazione per sordità
utente 1:
navigazione: introduzione, assistenza, integrazione sociale

Capitolo V - Valutazione del sistema
92
documenti proposti:
• Progetto accoglienza, inserimento, integrazione di alunni
extracomunitari (79%)
• Esempio di integrazione per sordità (68,8%)
• Progetto calamaio (60,5%)
• Abilità sociali (53,1%)
n.click = 2
recall = 50%
precision = 50%
utente 2:
navigazione: introduzione, educazione, socializzazione
documenti proposti:
• Progetto accoglienza, inserimento, integrazione di alunni
extracomunitari (77,7%)
• Esempio di integrazione per sordità (68,2%)
• Progetto calamaio (60,2%)
n.click = 2
recall = 50%
precision = 66,67%

Capitolo V - Valutazione del sistema
93
fig 5.3 – schermata finale dell’esempio 2
Esempio 3
query descrittiva:
Si vogliono cercare informazioni relative all’autonomia funzionale.
documenti scelti dall’esperto:
• Diagnosi funzionale
utente 1 = utente 2:
navigazione: introduzione, autonomia, autonomia funzionale
documenti proposti:
• Diagnosi funzionale
n.click = 2
Capitolo V - Valutazione del sistema
94
recall = 100%
precision = 100%
fig 5.4 – schermata finale dell’esempio 3
Come conclusione possiamo mostrare i dati medi relativi a questi
esperimenti pur essendo consci del fatto che per un’analisi più approfondita
servano un maggior numero di documenti e di information request:
recall = 66,67%
precision = 86,11%

Capitolo V - Valutazione del sistema
95
Usabilità
Per verifica di usabilità si intende la valutazione della facilità con la quale
un utente di fronte ad un sistema riesce a portare a termine un task (la ricerca di
uno o più documenti nel caso di studio della tesi).
La prima considerazione che si può fare è relativa all’assenza di un numero
sufficiente di documenti per portare a termine una valutazione di questo tipo.
Partendo da questo presupposto si possono però fare delle considerazioni
relative al confronto tra un sistema di ricerca tradizionale ed un sistema di
ricerca trasparente (oggetto della tesi).
La ricerca attraverso un motore di ricerca tradizionale da parte di un utente
che sta cercando informazioni in un campo relativamente sconosciuto è
tipicamente frustrante dato che usare termini generici (quelli tipicamente usati
da persone non esperte che non posseggono il lessico di base relativo
all’argomento cercato) può portare o ad un risultato infruttuoso o alla
presentazione dei documenti cercati “seppelliti” in una serie di documenti che
non sono di interesse reale all’utente. Inoltre studi di usabilità mostrano che la
maggior parte degli utenti trova difficoltà nel formulare query con più di una
parola e nell’usare gli operatori booleani and/or.
Questo causa una situazione simile alla sindrome della schermata nera
(“black screen” syndrome) che bloccò molti utenti ai tempi del vecchio sistema
operativo MS-DOS. Gli utenti capivano le potenzialità della macchina ma non
avevano modo di esprimerle dato che la macchina aspettava l’inserimento delle
“parole giuste” (esiste quindi un’analogia tra i comandi MS-DOS e le query
string).
I sistemi attuali per eliminare la composizione esplicita delle query string
sono tipicamente basati su directory, che sono però difficili da gestire e la cui
gerarchia potrebbe non incontrare le aspettative dell’utente relativamente
all’ordinamento gerarchico delle informazioni.
Il sistema di ricerca trasparente implementa un’interfaccia che non necessita
dell’inserimento di una query string di input esplicita e implicitamente la

Capitolo V - Valutazione del sistema
96
“deriva” dai percorsi seguiti dall’utente nella navigazione attraverso l’ipertesto
costituito dagli abstract.
L’utente naviga attraverso un insieme di abstract in cui ogni termine
“complesso” è contestualizzato dalla presenza di una frase descrittiva e
selezionando un link di interesse esprime una preferenza che il motore di ricerca
userà per modellare l’interesse dell’utente e creare in modo trasparente una
query string. Ecco che l’utente non si trova mai abbandonato e incapace di
esprimere una preferenza come invece succede nei motori di ricerca attuali.
Questa facilità nel comporre in modo trasparente una richiesta può essere
considerato come un fattore positivo relativamente all’usabilità del sistema.

Capitolo VI - Conclusioni
97
Capitolo VI Conclusioni
Il progetto presentato in questa tesi è relativo alla costruzione di una
interfaccia di ricerca trasparente (Transparent Search Interface) che consenta a
utenti non esperti di accedere a documenti di interesse tra quelli presenti in una
collezione tematica.
Minore è l’esperienza dell’utente, sia dal punto di vista dell’abilità col
computer sia dal punto di vista della conoscenza (tipicamente a livello di
lessico) dell’argomento che deve essere cercato, maggiormente sofisticata deve
essere l’interfaccia utente. Questa maggior complessità è dovuta al fatto che
l’interfaccia di ricerca trasparente, in modo invisibile, memorizza e aggiorna il
modello dell’interesse dell’utente e interagisce con il sottosistema di
Information Retrieval per trovare i documenti rilevanti, mentre l’utente naviga
attraverso un ipertesto di brevi abstract. I documenti rilevanti vengono
presentati all’utente appena il modello dell’utente risulta definito.
Come banco di prova per questo progetto si sono usati documenti relativi al
progetto MOISE, rivolto alla distribuzione di informazioni relative
all’esperienza con bambini con bisogni educativi speciali in differenti scuole di
varie nazioni. Attraverso un’interfaccia di questo tipo i problemi tecnici e
culturali relativi alle interfacce di ricerca tradizionali basate su parole chiave
cercano di essere risolti attraverso una semplice ed efficace metafora: una

Capitolo VI - Conclusioni
98
navigazione aperta attraverso ipertesti al fine di modellare l’interesse
dell’utente.
Allo stato attuale il progetto risulta completo e funzionante (relativamente al
caso di studio preso in esame), ma al fine di poterlo usare in maniera più diffusa
necessita di un meccanismo “universale” per definire il “contenuto dei
documenti” (i vettori relativi ai documenti). Questo meccanismo può essere
implementato attraverso l’inserimento da parte degli autori dei documenti di
metainformazioni attraverso delle pagine web (copertine) che ne descrivano il
contenuto. Attualmente questa procedura è eseguita attraverso un parser (in
lingua italiana) che descrive il “contenuto del documento” attraverso la
frequenza delle parole chiave al suo interno.

99
Appendice A Documenti e Abstract
Documenti presenti nel DB di prova
Servizio educativo assistenziale di integrazione scolastica Progetto Calamaio La bambina che non voleva tornare a scuola Il caso di Marco Progetto attivamente Protocollo in uso Presentazione Cooperativa Animazione Valdocco Plan of continuity Verso la comunicazione Integrazione degli interventi Abilità sociali Recupero e sviluppo di conoscenze Esperienza con il computer per conquistare autonomia,competenze e lavorare in gruppo Alice nel paese dei sogni Viaggio a Parigi Il giornalino piu pazzo del mondo Il piacere della lettura e della scrittura: incontro con la poesia Il piacere della lettura e della scrittura: incontro con la fiaba Progetto accoglienza, inserimento, integrazione di alunni extracomunitari Attività in lingua italiana con bimbo cinese Diagnosi funzionale Protocollo d'uso Profilo dinamico funzionale Piano educativo personalizzato Esempio di integrazione per sordità

100
Abstract presenti nel DB di prova
Autonomia sociale Autonomia relazionale Autonomia funzionale Indicatori di verifica e valutazione Reperimento di risorse Introduzione Progetto educativo Autonomia Obiettivo Assistenza Accessibilità Ausili Disabilità Quadro normativo e diritti Bisogni educativi speciali Educazione Formazione handicap Autonomia lavorativa Autonomia personale/motoria Indipendenza Carità e beneficienza Prestazioni e servizi Integrazione sociale Qualità della vita Protesi Ortesi Informatica applicata Progetti Integrazione Sviluppo delle conoscenze Cambiamento Menomazione

101
Fonti di documentazione
Un testo relativo all’information retrieval è:
R.Baeza-Yates, B.Ribero-Neto “Mordern Information Retrieval”, Addison
Wesley / ACM Press
Un sito che fornisce documentazione esauriente circa il protocollo http è:
http://www.w3.org/Protocols/
Il sito ufficiale di Php è:
http://www.php.net
Il sito ufficiale di MySQL è:
http://www.mysql.com
Il sito ufficiale del progetto MOISE è:
http://www.euromoise.net
Un sito in cui vengono forniti tutorial ed esempi relativamente all’HTML, al
PHP e a MySQL è:
http://www.html.it


















