
informatica - - Università degli Studi di Cassino · Concetti di base • Unitàstatistica Minima...
63
Informatica Anno Accademico 2009/2010 Corso di Laurea Triennale in Infermieristica Dr. Bruno Federico Facoltà di Scienze Motorie Università di Cassino - [email protected]
-
Upload
truongthien -
Category
Documents
-
view
216 -
download
0
Transcript of informatica - - Università degli Studi di Cassino · Concetti di base • Unitàstatistica Minima...

Informatica
Anno Accademico 2009/2010Corso di Laurea Triennale in Infermieristica
Dr. Bruno FedericoFacoltà di Scienze MotorieUniversità di Cassino - [email protected]

2
Il ruolo della statistica nella ricerca scientifica
Dati elementari, dati sintetici e informazioni

Che cos’è la Statistica?
• È una metodologia generale per lo studio dei fenomeni collettivi e della variabilità di tali fenomeni
• È uno strumento essenziale per la scoperta di leggi e relazioni tra fenomeni�Svolge un ruolo fondamentale nella ricerca scientifica

Fasi del processo statistico
• La Statistica riguarda la raccolta, l’organizzazione, la presentazione, l’analisi e l’interpretazione dei dati allo scopo di fornire un supporto per la realizzazione di decisioni più efficaci
Raccolta Organizzazione Analisi Interpretazione

Dati Elementari
• il DATO è una descrizione originaria e non interpretata di un evento�è la materia prima del processo di costruzione delle informazioni
�è costituito da gruppi di simboli (lettere, numeri, caratteri speciali) che rappresentano quantità, azioni, cose, ecc.
� il DATO INIZIALE o ELEMENTARE è la rappresentazione oggettiva di fenomeni o eventi reali

Dati sintetici
• i dati sintetici sono equivalenti ad un “prodotto intermedio” di un processo produttivo� il processo di sintesi che permette di generare un dato sintetico a partire da più dati elementari modifica il potenziale informativo iniziale

Informazioni
• E’ INFORMAZIONE tutto ciò che produce variazione nel patrimonio conoscitivo di un soggetto� Il concetto di informazione fa riferimento al suo percettore, al suo utilizzatore
�L’ INFORMAZIONE è un dato che è stato sottoposto ad un processo che lo ha reso significativo per il destinatario e realmente importante per il suo processo decisionale presente o futuro
�L’ INFORMAZIONE è relativa: sussiste solo se destinata a qualcuno per qualche scopo

Raccolta ed organizzazione dei dati nella ricerca
• In ogni progetto di ricerca scientifica, le fasi di raccolta e organizzazione dei dati sono fondamentali
• Il ricercatore deve ad esempio definire quali siano le variabili di interesse, nonchéquali metodi di misura vanno adottati

Struttura di un archivio dei dati

Concetti di base
• Unità statistica� Minima unità da cui si raccolgono i dati in una indagine� Individuo�Famiglia�Regione�Squadra�Gara
• Variabile� Caratteristica che può assumere valori diversi nelle diverse unità statistiche�Altezza dei bambini di una classe�Peso degli atleti�Età dei pazienti di una clinica

Concetti di base
• Modalità�Valore assunto da una variabile in una determinata unità statistica
Individuo PesoGiorgio 80 kg
Mario 75 kg Modalità
Roberto 77 kg

Tipo di variabili
• Le variabili si possono distinguere in due gruppi�Variabili numeriche
�Discrete: es. n° figli, n° volte/die
�Continue: es. peso, altezza, …
�Variabili categoriche�Binomiali: es. genere�Nominali: es. tipo di sport, etnia�Ordinali: gravità del sintomo, titolo di studio

Organizzazione dei dati
• I dati raccolti in uno studio devono essere organizzati in maniera razionale
• Ogni riga rappresenta un’unità statistica• È importante avere un codice identificativo univoco per ogni osservazione (variabile id)

Organizzazione dei dati
• Ogni colonna riporta i diversi valori di una variabile

Un esempio di archivio di dati: Football
• Two identical footballs, one air-filled and one helium-filled, were used outdoors on a windless day at The Ohio State University's athletic complex. Each football was kicked39 times and the two footballs werealternated with each kick. The experimenterrecorded the distance traveled by each ball.
• Trial: Trial Number• Air: distance in yards for air-filled football • Helium: distance in yards for helium-filledfootball
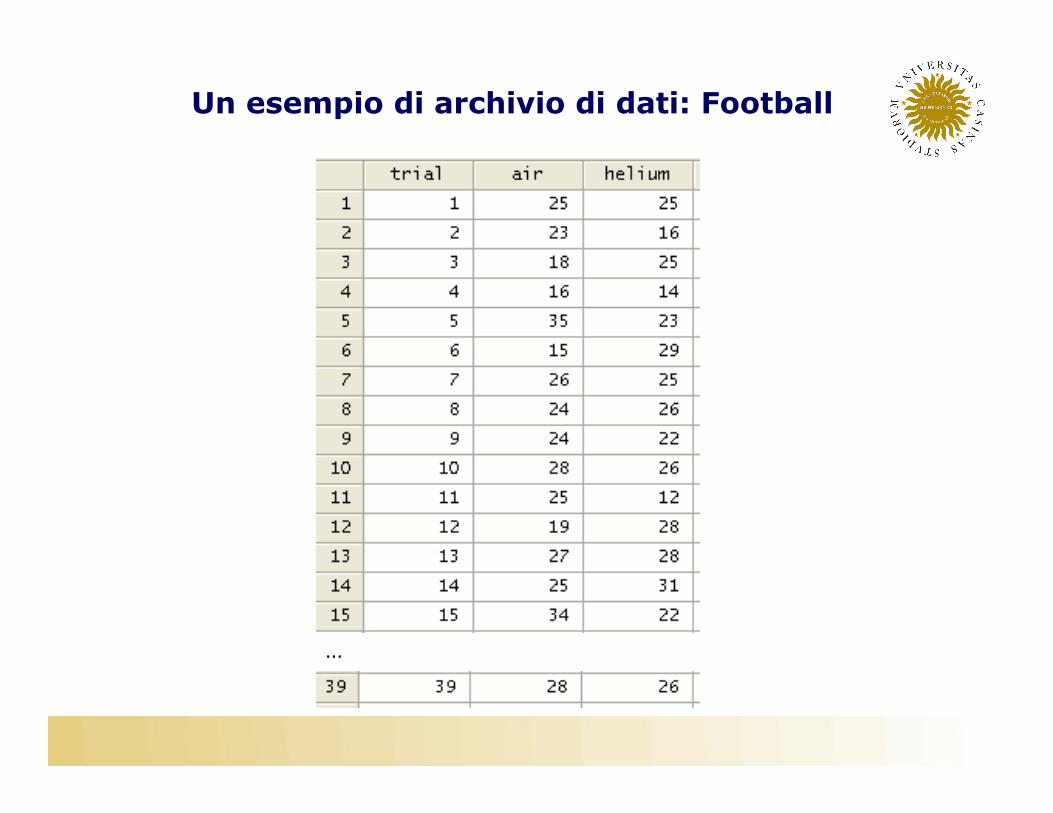
Un esempio di archivio di dati: Football
…

Uso di un codice identificativo
• Il codice identificativo è la “chiave” che permette di collegare le informazioni raccolte con i dati personali dell’individuo
• È univoco, ovvero ne esiste solo uno per ogni soggetto
• Il codice identificativo deve essere inserito sia sul modulo di raccolta dati (es. sulla prima pagina del questionario) che nell’archivio dei dati

Privacy
• Legge sulla privacy 196/2003• I dati sanitari sono dati “sensibili”• Bisogna adoperare delle precauzioni per evitare di diffondere queste informazioni
• È conveniente utilizzare un codice identificativo univoco, che non ha nessun significato al di fuori del progetto di lavoro
• Una volta assegnato il codice identificativo i dati personali possono essere rimossi e conservati separatamente

La legenda
• La legenda è il collegamento tra il questionario ed i dati inseriti nel computer
• Durante l’analisi dei dati le variabili vengono richiamate per nome�Devono avere un nome breve�Se le variabili registrate sono poche è meglio usare un nome che aiuti nel ricordare la variabile
�Se le variabili registrate sono molte (es. un questionario con centinaia di domande) è meglio usare nomi che derivano dal numero delle domande nel questionario (q1, q2, q3, …)

La legenda

Etichette delle variabili
• Alcuni software statistici consentono l’impiego di etichette per le variabili
storage display value
variable name type format label variable label
------------------------------------------------------------------
idnum int %3.0f cod. identificativo
datanas long %d data di nascita
artodom byte %1.0f lbl arto dominante

Etichette dei valori
•Alcuni software statistici consentono l’impiego di etichette dei valori nel caso di variabili categoriche
. tabulate artodom, nolabel
arto |
dominante | Freq. Percent Cum.
------------+-----------------------------------
1 | 305 84.49 84.49
2 | 47 13.02 97.51
3 | 9 2.49 100.00
------------+-----------------------------------
Total | 361 100.00

Etichette dei valori
• Alcuni software statistici consentono l’impiego di etichette dei valori nel caso di variabili categoriche
. tabulate artodom
arto |
dominante | Freq. Percent Cum.
------------+-----------------------------------
destro | 305 84.49 84.49
sinistro | 47 13.02 97.51
ambidestro | 9 2.49 100.00
------------+-----------------------------------
Total | 361 100.00

La gestione dei dati

Problemi nella gestione dei dati
• Quando si raccolgono, utilizzano e conservano dei dati, si possono verificare:�Errori�Perdita di tempo�Perdita di informazioni

Inserimento dei dati
• Per piccoli set di dati, si possono inserire i dati raccolti in un foglio di lavoro di Excel, ma, con grandi dataset, questo sistema diventa complesso e suscettibile di errori

Inserimento dei dati
• È meglio usare Epidata entry
• Prima di inserire i dati va definita la legenda
• Una frequente forma di errore è che la risposta giusta viene registrata nella domanda sbagliata� La risposta sull’arrossamento “dietro le ginocchia”viene registrata nel campo “sulle caviglie”
• Non inserire i dati tutti insieme
• Inserire i dati due volte� Correggere poi gli errori in entrambi gli archivi
• Una volta scoperto un errore, controllare i valori vicini

Ricerca degli errori
• Fai una stampa di:�Legenda�Elenco delle variabili�Tabelle di frequenza delle variabili
• Confronta la legenda originale con quella derivata dai dati inseriti
• Osserva le tabelle per evidenziare valori improbabili, massimo e minimo
• Osserva il numero delle osservazioni• Osserva se sono presenti dati incoerenti
�Maschi in gravidanza

Ricerca degli errori
• Una volta identificati valori sospetti, elenca i dati con il corrispondente id e controlla se sono corretti
• Se ci sono dati incoerenti (maschi in gravidanza)�Ricodifica i valori a valori mancanti
• Se ci sono dati mancanti�A volte puoi dedurre questi valori da altre informazioni per lo stesso soggetto (data imput)�Es. donna, con tre figli di 19, 6 e 1 anno
– Età??

Unione di archivi di dati
• Se hai raccolto dati sugli stessi soggetti in misurazioni successive, puoi unire i due files corrispondenti�merge
• Se hai raccolto informazioni su altri soggetti in un secondo momento , puoi unire i due files corrispondenti�append

Unione di archivi di dati
• Se hai raccolto dati sugli stessi soggetti in misurazioni successive, puoi unire i due files corrispondenti

Unione di archivi di dati
• Se hai raccolto informazioni su altri soggetti in un secondo momento, puoi unire i due files corrispondenti

Creazione di variabili derivate
• Evitare di fare calcoli• Puoi costruire delle nuove variabili a partire dalle informazioni registrate nel questionario� Indice di massa corporea
Un bambino di 10 anni, Peso=43 kg Altezza=1,43 m
43 kg
(1,43 m)2IMC = = 21 kg/m2

Back-up ed archiviazione
• Obiettivo del back up è quello di essere in grado di recuperare i dati ed i documenti in caso di distruzione o perdita di dati�È un’attività da svolgere di routine
• L’archiviazione ha luogo una o poche volte nell’arco della vita di un progetto

Un esempio di archivio di dati: Step
• An experiment was conducted by students at The Ohio State University in the fall of 1993 to explore the nature of the relationship between a person's heart rate and the frequency at which that person stepped up and down on steps of various heights.
• The response variable, heart rate, was measured in beatsper minute. There were two different step heights: 5.75 inches (coded as 0), and 11.5 inches (coded as 1). Therewere three rates of stepping: 14 steps/min. (coded as 0), 21 steps/min. (coded as 1), and 28 steps/min. (coded as2). This resulted in six possible height/frequencycombinations.

Un esempio di archivio di dati: Step
• Each subject performed the activity for three minutes. Subjects were kept on pace by the beat of an electricmetronome. One experimenter counted the subject's pulse for 20 seconds before and after each trial.
• The subject always rested between trials until her or hisheart rate returned to close to the beginning rate. Another experimenter kept track of the time spentstepping. Each subject was always measured and timedby the same pair of experimenters to reduce variability in the experiment.
• Each pair of experimenters was treated as a block.

Esempi di archivi di dati
• Order: the overall performance order of the trial
• Block: the subject and experimenters' block number
• Height: 0 if step at the low (5.75") height, 1 if at the high (11.5") height
• Frequency: the rate of stepping. 0 if slow (14 steps/min), 1 if medium (21 steps/min), 2 if high (28 steps/min)
• RestHR: the resting heart rate of the subject beforea trial, in beats per minute
• HR: the final heart rate of the subject after a trial, in beats per minute

Esempi di archivi di dati

Il software Epidata Entry

Il software Epidata
• Epidata Entry è un software gratuito utile per l’inserimento e la raccolta dati, scaricabile al sito www.epidata.dk
• È stato realizzato da Jens Lauritsen ed èattualmente disponibile in italiano la versione 3.1
• Consente di�Effettuare il controllo sui valori inseriti�Eseguire “salti” condizionali�Effettuare l’inserimento dei dati in doppio

Step per l’inserimento ed il controllo dei dati
1. Definizione del numero e del tipo di variabili (file *.qes)
2. Creazione della maschera per l’inserimento dei dati (file *.rec)
3. Aggiunta di eventuali controlli (file *.chk)4. Inserimento dei dati5. Documentazione6. Esportazione

Schermata di apertura

1. Definizione dati
• Si costruisce un file *.qes• Si introducono nell’ordine:
�Nome della variabile� Etichetta della variabile (opzionale)� Formato della variabile
� È possibile specificare il numero di caratteri per ogni variabile
• Si procede fino ad inserire tutte le variabili che si intendono raccogliere
• È possibile registrare le variabili categoriche utilizzando codici numerici� Attribuendo in seguito un’etichetta alle diverse modalità della variabile

1. Definizione dati
1. Definizione dati
Un esempio di database

2. Creazione file dati

3. Aggiunta controlli
• Epidata permette di:�Definire il range di valori ammissibili per ogni variabile (range)
�Ripetere lo stesso dato nelle osservazioni successive (repeat)
�Eseguire salti condizionali (jump)�Assegnare delle etichette ai valori delle variabili�Generare delle variabili derivate
3. Aggiunta controlli
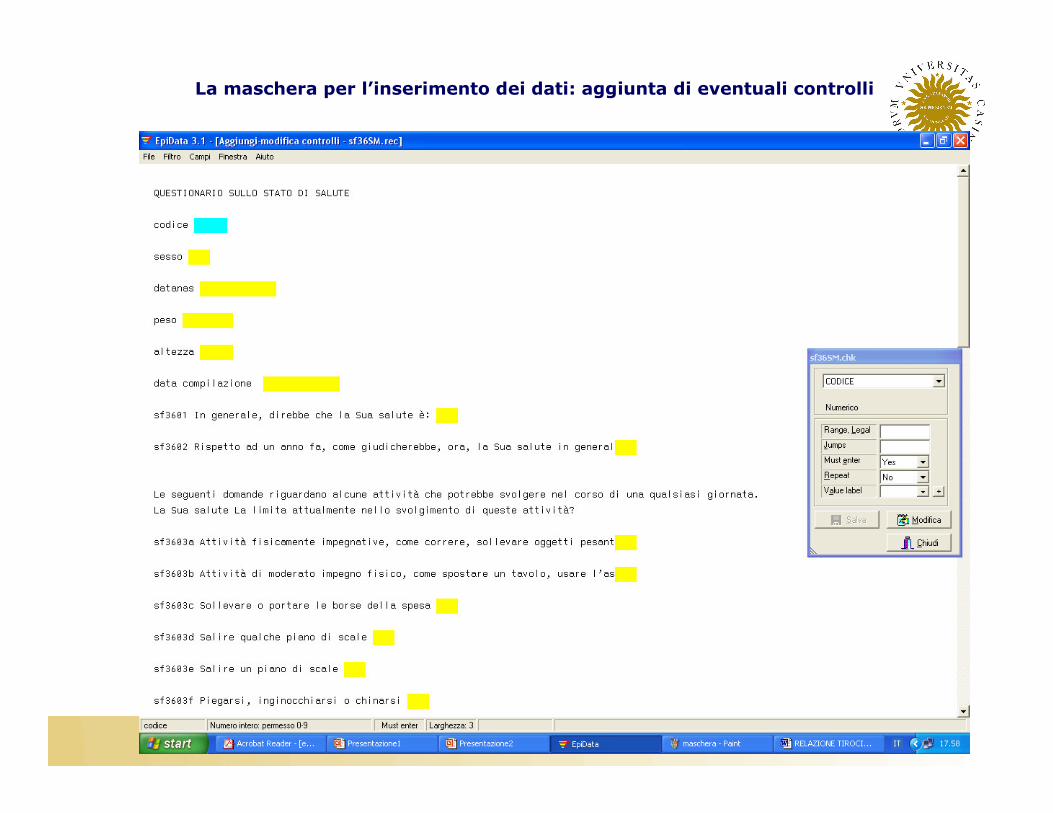
La maschera per l’inserimento dei dati: aggiunta di eventuali controlli
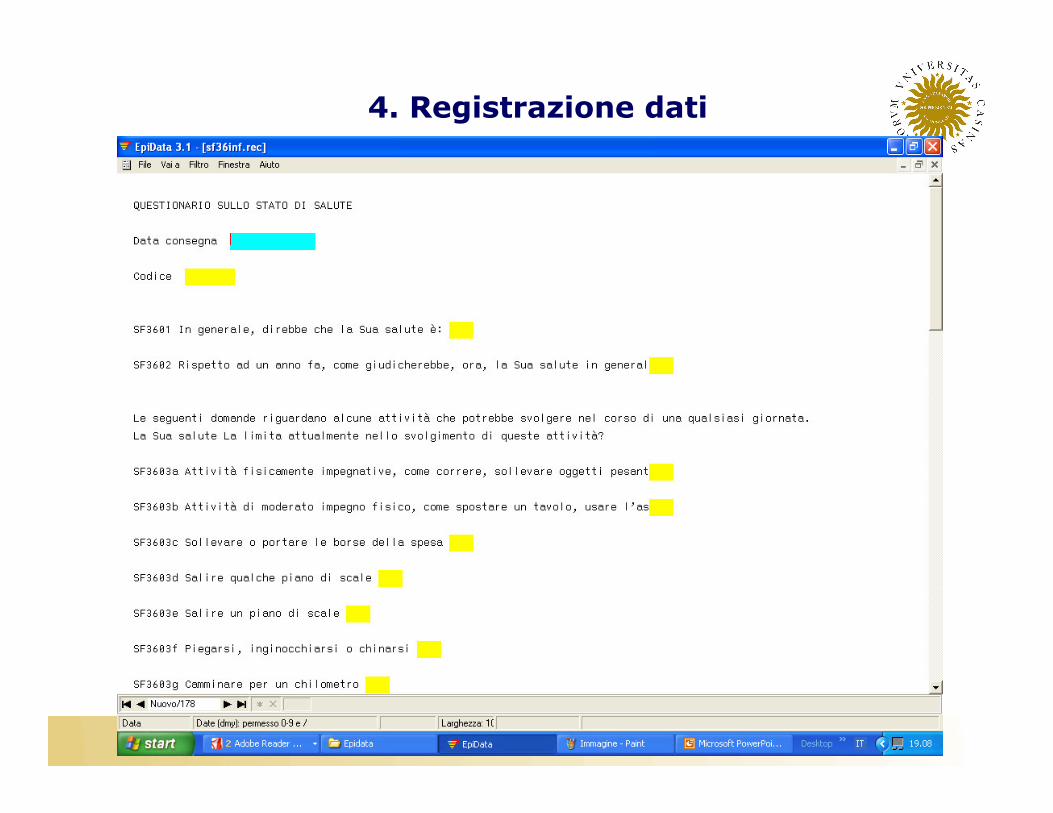
4. Registrazione dati

4. Registrazione dati
• È buona norma ripetere per due volte l’inserimento dei dati, poiché è sempre possibile che ci sia qualche errore nell’inserimento dei dati
• Epidata permette di realizzare il secondo inserimento dei dati in due modi:�Controllando istante per istante i dati inseriti�Controllando al termine del secondo inserimento

5. Documentazione
• Una volta completato l’inserimento dei dati, è buona regola calcolare delle statistiche descrittive per tutte le variabili inserite, allo scopo di verificare che non ci siano errori o dati anomali�Tabelle di frequenza�Range�Media�Deviazione standard

5. Documentazione
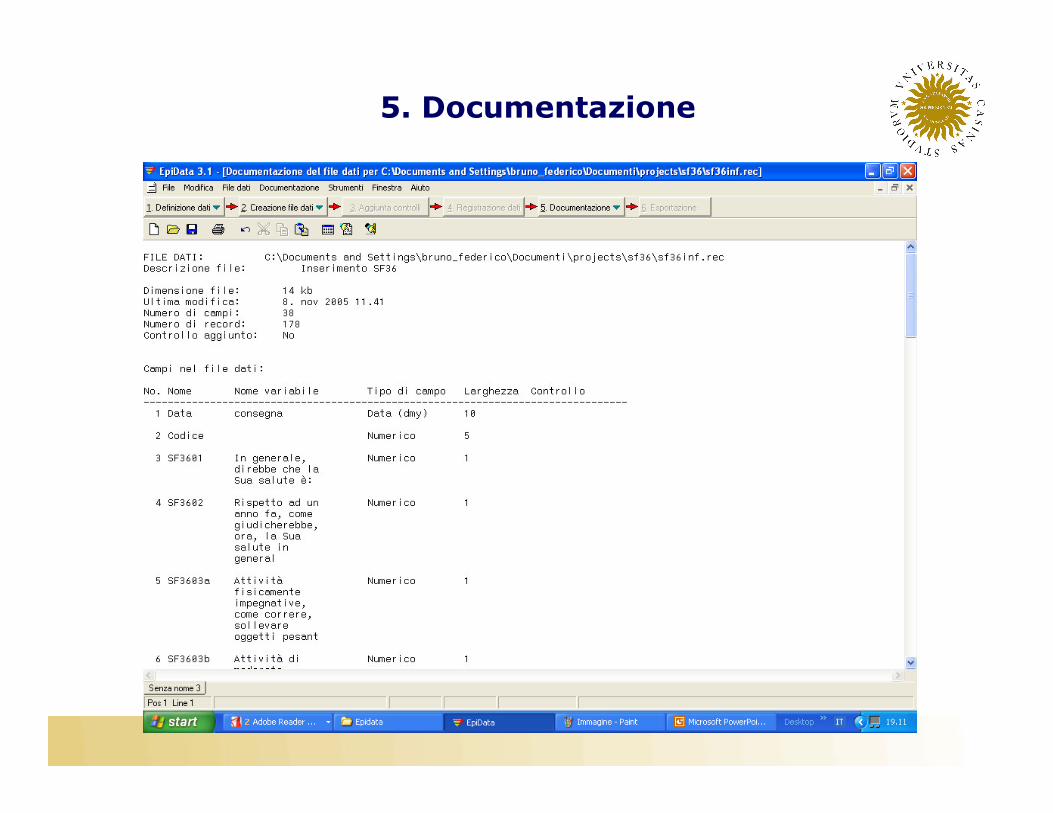
5. Documentazione
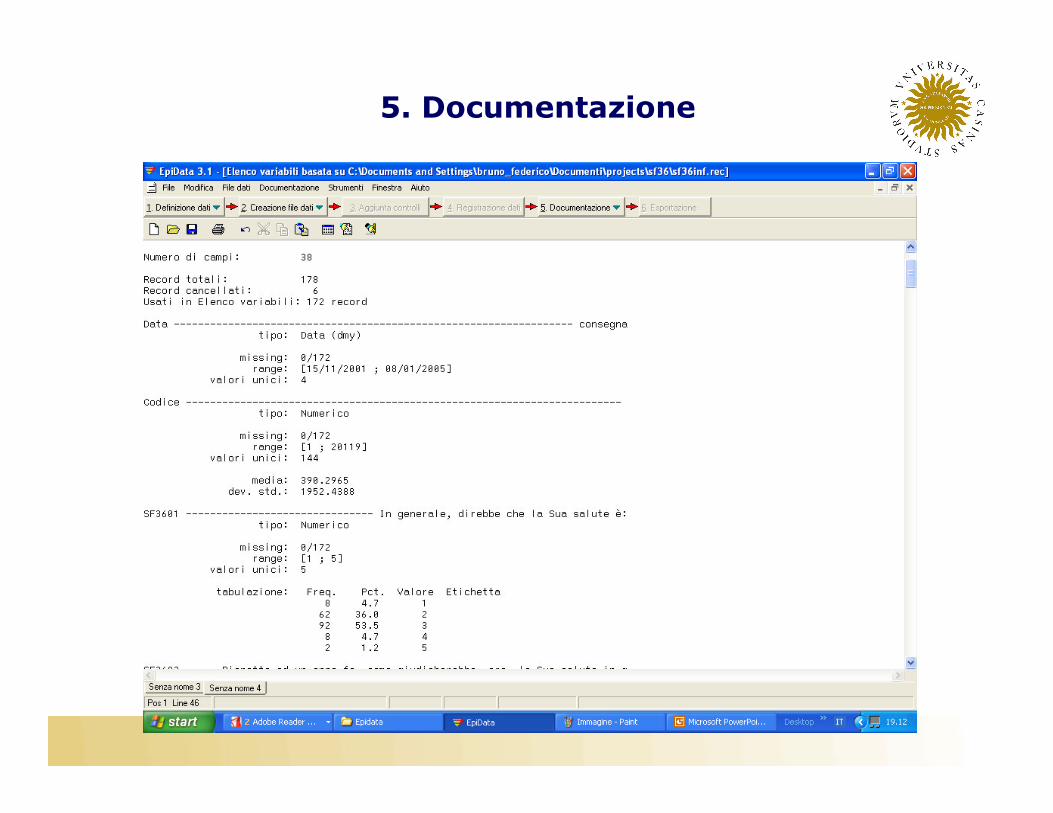
5. Documentazione

6. Esportazione dei dati
• Epidata permette di trasferire l’archivio dei dati verso una varietà di software per l’analisi dei dati�Excel, Stata, SAS, SPSS, …
• Epidata analysis è un altro software della famiglia di Epidata Entry ed è utile per l’analisi dei dati�È anch’esso gratuito
6. Esportazione dei dati

6. Esportazione dei dati

Esercitazione

61
Esercitazione
• Sei interessato a studiare il fenomeno dell’obesità infantile
• Hai raccolto, attraverso una scheda cartacea, dati socio-demografici, antropometrici e dati relativi alle abitudini di vita (sport praticati, tempo dedicato allo sport ed alla TV, numero di snack/die) di un grande campione di bambini di una scuola calcio
• Vuoi costruire un sistema elettronico di archiviazione dei dati per poi condurre l’analisi

62
Obiettivi dello studio
• Qual è la prevalenza dell’obesità e del sovrappeso in questa popolazione di giovani calciatori?
• Quali sono i fattori che determinano una più alta frequenza di obesità/sovrappeso in questa popolazione?
• Esiste una correlazione tra le informazioni ottenute dal BMI e quelle ricavate dalla plicometria in questa popolazione?
• Il tempo trascorso davanti alla televisione o giocando ai videogames è un fattore rilevante?
• Quali sono i fattori che determinano un maggiore cambiamento nel tempo nella frequenza di obesità/sovrappeso in questa popolazione ?
• …

63
Compito
1. costruire una maschera per l’inserimento dei dati con Epidata, definendo i diversi tipi di variabili (numeriche, categoriche, …)
2. definire delle etichette dei valori (es. 0=no, 1=sì)
3. inserire delle ripetizioni (ad es. per la data)
4. inserire dei salti condizionali (es. se il soggetto non ha avuto traumi, vai direttamente alla parte successiva dei genitori)
5. definire variabili derivate quali l’età e l’Indice di Massa Corporea


















