
nico/corsi/aa/clu
51
Clustering Corso di Apprendimento Automatico Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari 3 febbraio 2009 Corso di Apprendimento Automatico Clustering
-
Upload
nicola-fanizzi -
Category
Documents
-
view
214 -
download
1
description
Clustering 3 febbraio 2009 Dipartimento di Informatica Università degli Studi di Bari Corso di Apprendimento Automatico Clustering k -MEANS e sue generalizzazioni: k -MEDOIDS e FUZZY k -MEANS Modello misto EM Clustering Bayesiano Clustering incrementale Clustering basato su probabilità Clustering gerarchico Corso di Apprendimento Automatico Clustering
Transcript of nico/corsi/aa/clu

Clustering
Corso di Apprendimento AutomaticoLaurea Magistrale in Informatica
Nicola Fanizzi
Dipartimento di InformaticaUniversità degli Studi di Bari
3 febbraio 2009
Corso di Apprendimento Automatico Clustering

Sommario
IntroduzioneClustering iterativo basato su distanza
k -MEANS e sue generalizzazioni: k -MEDOIDS e FUZZYk -MEANS
Clustering gerarchicoClustering incrementaleClustering basato su probabilità
Modello mistoEMClustering Bayesiano
Corso di Apprendimento Automatico Clustering

Introduzione
Le tecniche di clustering sono utili nei casi in cuinon ci siano classi da predireScopo: dividere le istanze in gruppi naturaliI cluster possono essere:
disgiunti vs. sovrappostideterministici vs. probabilisticipiatti vs. gerarchici
Gli algoritmi possono anche essere:divisivi vs. agglomerativi
I cluster ottenuti con K-MEANS, presentato in seguito, sonodisgiunti, deterministici e piatti
Trattazioni sul clustering: [Jain and Dubes, 1988][Kaufman and Rousseeuw, 1990]
Corso di Apprendimento Automatico Clustering

Rappresentazione I
Rappresentazione Diagramma di Vennsemplice 2D (cluster sovrapposti)
Corso di Apprendimento Automatico Clustering

Rappresentazione II
Assegnazione probabilistica Dendrogramma
Corso di Apprendimento Automatico Clustering

Prossimità I
Molti algoritmi si basano su nozioni di similarità o prossimitàMatrice:
D = (dij)i=1,...,N j=1,...,N
In genere D è simmetrica e ∀i = 1, . . . ,N : dii = 0
Date p misure xih sulle istanze (i = 1, . . . ,N e h = 1, . . . ,p), sidefiniscono p funzioni di (dis)similarità dh sull’h-esimo attributo,ad es. dh(xih, xjh) = (xih − xjh)2
Per cui la dissimilarità tra le istanze di indice i e j :
D(xih, xjh) =∑
h
dh(xih, xjh)
Corso di Apprendimento Automatico Clustering

Prossimità II
attributi quantitativi: d(xi , xj) = l(|xi − xj |)oppure la correlazione ρ(xi , xj)
attributi ordinali:supponendo che si possano assumere M valori, questipossono essere mappati su: i−1/2
M , per i = 1, . . . ,Me quindi usare misure quantitative
attributi categorici:supponendo che si possano assumere M valori,si può costruire una matrice L simmetrica a diagonali nullee tale che Lrs = 1 per r 6= so usare altre loss function
Corso di Apprendimento Automatico Clustering

Prossimità III
Combinazione delle misure di dissimilarità
D(xi , xj) =∑
h
wh · dh(xih, xjh)
con∑
h wh = 1
Per la scelta dei pesi: wh = 1/shcon
sh =1
N2
∑i
∑j
(xih − xjh)2 = 2 · varh
varh stima sul campione della varianza dell’attributo h-esimo
Corso di Apprendimento Automatico Clustering

Prossimità IV
Valori mancanti per un certo attributo:eliminare le istanze
abbondanza di dati
considerare la media dei valori dell’attributooppure la medianao la moda
considerare il valore mancante un ulteriore valore speciale
Corso di Apprendimento Automatico Clustering

k -MEANS
Clusterizzare dati in k gruppi (k predefinito):1 Scegliere k centroidi
es. casualmente2 Assegnare le istanze ai cluster
basandosi sulla distanza dai centroidi3 Ri-calcolare i centroidi dei cluster4 Tornare al passo 1
fino ad avverare un criterio di convergenza
Corso di Apprendimento Automatico Clustering

k -MEANS – osservazioni I
L’algoritmo minimizza la distanza quadratica delle istanzedai centroidiI risultati possono variare significativamente
a seconda della scelta dei centri iniziali
può rimanere intrappolato in un minimo locale
Per incrementare la probabilità di trovare un ottimo globale:far ripartire l’algoritmo con una diversa scelta di centroidiPuo essere applicato ricorsivamente con k = 2BISECTING k -MEANS
Corso di Apprendimento Automatico Clustering

k -MEANS – osservazioni IIcentroidi iniziali partizione iniziale
iterazione #2 iterazione #20
Corso di Apprendimento Automatico Clustering

Calcolo veloce delle distanze I
Si possono usare kD-trees o ball trees
Costruire l’albero, che rimane statico, per tutte le istanze
In ogni nodo: immagazzinare il numero delle istanze e lasomma di tutte le istanzeAd ogni iterazione, scendere nell’albero e trovare a qualecluster ogni nodo appartenga
La discesa si può fermare non appena si trovi un nodo cheappartiene interamente ad un particolare clusterUsare delle statistiche conservate in ogni nodo percalcolare nuovi centri:
somma dei vettori, numero di punti, . . .
Corso di Apprendimento Automatico Clustering

Calcolo veloce delle distanze II
Esempio
Corso di Apprendimento Automatico Clustering

Quanti cluster ?
Come scegliere k in k -MEANS ?Possibilità:
Scegliere k che minimizzi la distanza quadratica dai centrimediata da un processo di cross-validationUsare una distanza quadratica penalizzata sui dati ditraining (es. usando un criterio MDL)Applicare k -MEANS ricorsivamente con k = 2 eusare un criterio di stop (es. basato su MDL)
I centroidi iniziali per i sotto-cluster possono essere sceltilungo le direttrici di massima varianza nel cluster(lontane dal centroide del cluster padre un’unitaà dideviazione standard in ogni direzione)Implementato nell’algoritmo X-MEANS[Moore and Pelleg, 2000], nel quale si usa il BIC (BayesianInformation Criterion [Kass and Wasserman, 1995]) invecedel MDL
Corso di Apprendimento Automatico Clustering

k -MEDOIDS I
Generalizzazione del k -MEANS
in caso non si possano definire centroidi
Si utilizzano diversi rappresentanti dei cluster {mi , . . . ,mk}
medoide del cluster Cj :istanza del cluster che minimizza la distanza media dagli altri
mj = argminxr∈Cj
∑xs∈Cj
D(xr , xs)
Corso di Apprendimento Automatico Clustering

k -MEDOIDS II
Algoritmo k -MEDOIDS
Inizializzare i medoidi: {mj}j=1,...,k
Ripetere1 Minimizzare l’errore totale assegnando ogni istanza al
medoide (corrente) più vicino:Per i = 1, . . . ,N eseguire
C(i)← argmin1≤j≤k
D(xi ,mj )
2 Ricalcolare medoidi:Per j = 1, . . . , k eseguire
mj ← argminxr∈Cj
∑xs∈Cj
D(xr , xs)
Fino alla convergenza
Corso di Apprendimento Automatico Clustering
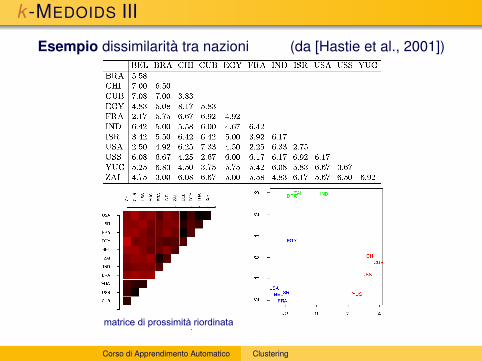
k -MEDOIDS III
Esempio dissimilarità tra nazioni (da [Hastie et al., 2001])
matrice di prossimità riordinata
Corso di Apprendimento Automatico Clustering

FUZZY k -MEANS I
Generalizzazione del k -MEANS:grado di appartenenza ad al cluster i-esimo in [0,1]Corrisponde a P(Cj |xi , θ) (normalizzate)
Si utilizzano diversi rappresentanti dei cluster {µ1, . . . , µk}
Funzione obiettivo da minimizzare:
L =∑
i
∑j
(P(Cj |xi , θ))b‖xi − µj‖2
Annullando le derivate di ∂L/∂µj e ∂L/∂P̂j si ha:
µj =
∑i(P(Cj |xi))bxi∑i(P(Cj |xi))b P(Cj |xi) =
(1/dij)1
b−1∑r (1/dir )
1b−1
dij = ‖xi−µj‖2
Corso di Apprendimento Automatico Clustering

FUZZY k -MEANS II
Algoritmo k -MEDOIDS
Inizializzare: µj e P(Cj |xi) per i = 1, . . . ,N, j = 1, . . . , kRipetere la classificazione delle istanze in base alprototipo più vicino
1 ricalcolare ogni µj2 ricalcolare le probabilità P(Cj |xi )
e normalizzarle
fino alla convergenza (nessun cambiamento)
Corso di Apprendimento Automatico Clustering

Clustering gerarchico I
Algoritmitop-down (divisivi): partono da un gruppo unico e lodividono ad ogni livello; il gruppo da dividere è quello menocoesobottom-up (agglomerativi): si parte da gruppi compostidalle singole istanze e che vengono fusi via viagruppi con la più alta similarità
In genere questi algoritmi non richiedono k ma una misuradi dissimilarità tra gruppiDegli N − 1 livelli scegliere quello con il clustering più”naturale”; sono state proposte molte statistiche[Bezdek and Pal, 1998, Halkidi et al., 2001]
Dunn, Hubert, Davies-Bouldin, Silhouette, Gap, . . .
Corso di Apprendimento Automatico Clustering

Clustering gerarchico II
Corso di Apprendimento Automatico Clustering

Approcci agglomerativi I
ad ogni livello occorre scegliere i cluster da fonderedati due cluster Ci e Cj la loro dissimilarità si basa suquella dei loro elementi:
single linkage (SL)
dSL(Ci ,Cj ) = minxi∈Ci ,xj∈Cj
d(xi , xj )
complete linkage (CL)
dCL(Ci ,Cj ) = maxxi∈Ci ,xj∈Cj
d(xi , xj )
average group linkage (GL)
dGL(Ci ,Cj ) =1
|Ci ||Cj |∑
xi∈Ci ,xj∈Cj
d(xi , xj )
Corso di Apprendimento Automatico Clustering

Approcci agglomerativi II
Corso di Apprendimento Automatico Clustering

Approcci divisivi I
meno investigati dei precedentialgoritmi ricorsivi ricavabili da k -means (k -medoids):
ad ogni livello si individua il cluster meno coeso da divideresi applica un algoritmo per dividere questo cluster in ksotto-clusterfino ad avere diviso tutti i cluster o altro criterio di stop
scelta del cluster da dividere:massimo diametro [Kaufman and Rousseeuw, 1990]:
∆(C) = maxxi ,xj∈C
d(xi , xj )
massima dissimilarità media:
d̄(C) =1|C|
∑xi∈C,xj∈C
d(xi , xj )
Corso di Apprendimento Automatico Clustering

Approcci divisivi II
Corso di Apprendimento Automatico Clustering

Approcci incrementali
Approccio euristicoCOBWEB [Fisher, 1987]CLASSIT [Gennari et al., 1997]
Formare incrementalmente una gerarchia di clusterInizialmente:
l’albero consiste in un nodo-radice vuotoQuindi:
Aggiungere istanze una alla voltaAggiornare l’albero appropriatamente ad ogni passaggioPer l’aggiornamento: trovare la foglia destra per un’instanzaPuò comportare la ristrutturazione dell’albero
Decisioni sull’aggiornamento basate sul criterio di categoryutility
Corso di Apprendimento Automatico Clustering

Category Utility
Category utility [Gluck and Corter, 1985]Loss function quadratica definita dalle probabilita condizionate:
CU(C1, . . . ,Ck ) =
∑l P(Cl)
∑i∑
j(P(ai = vij | Cl)2 − P(ai = vij)
2)
k
Ogni istanza in una diversa categoria=⇒ il numeratore diventa:
n −∑
i∑
j P(ai = vij)2 ← massimo
↑numero di attributi
Corso di Apprendimento Automatico Clustering

Ristrutturazione: fusione e suddivisione
Evitare la dipendenza dall’ordine di presentazione delle istanzeFusione
Calcolare la CU per tutte le coppie di nodi (costoso)Trovare un nodo-ospite per la nuova istanza tra nodi allostesso livello: annotare nodo migliore + seconda scelta
nodo migliore: posto per l’istanza(a meno che non si preferisca costruire un cluster proprio)considerare la fusione del nodo ospite + seconda scelta
Suddivisioneidentificare il miglior nodo-ospitefusione svantaggiosaconsiderare la suddivisione del nodo migliore
Corso di Apprendimento Automatico Clustering

Esempio I
ID Outlook Temp. Humidity Windya Sunny Hot High Falseb Sunny Hot High Truec Overcast Hot High Falsed Rainy Mild High Falsee Rainy Cool Normal Falsef Rainy Cool Normal Trueg Overcast Cool Normal Trueh Sunny Mild High Falsei Sunny Cool Normal Falsej Rainy Mild Normal Falsek Sunny Mild Normal Truel Overcast Mild High True
m Overcast Hot Normal Falsen Rainy Mild High True
Corso di Apprendimento Automatico Clustering

Esempio II
ID Outlook Temp. Humidity Windya Sunny Hot High Falseb Sunny Hot High Truec Overcast Hot High Falsed Rainy Mild High Falsee Rainy Cool Normal Falsef Rainy Cool Normal Trueg Overcast Cool Normal Trueh Sunny Mild High Falsei Sunny Cool Normal Falsej Rainy Mild Normal Falsek Sunny Mild Normal Truel Overcast Mild High True
m Overcast Hot Normal Falsen Rainy Mild High True
FusioneFusione
Corso di Apprendimento Automatico Clustering

Esempio III
ID Outlook Temp. Humidity WindyA Sunny Hot High FalseB Sunny Hot High TrueC Overcast Hot High FalseD Rainy Mild High False
Corso di Apprendimento Automatico Clustering

Attributi Numerici
Si assume una distribuzione normale:f (a) = 1√
(2π)σexp(− (a−µ)2
2σ2 )
quindi∑
j P(ai = vij)2 ⇔
∫f (ai)
2dai = 12√πσi
pertanto
CU(C1,C2, . . . ,Ck ) =P
l P(Cl )P
iP
j (P(ai=vij |Cl )2−P(ai=vij )
2)
k
diventa CU(C1,C2, . . . ,Ck ) =
Pl P(Cl )
12√
π
Pi (
1σil− 1
σi)
k
Problema: una sola instanza in un nodo porta a varianzanullaminima varianza pre-specificata
parametro acuity:misura dell’errore in un singolo campione
Corso di Apprendimento Automatico Clustering
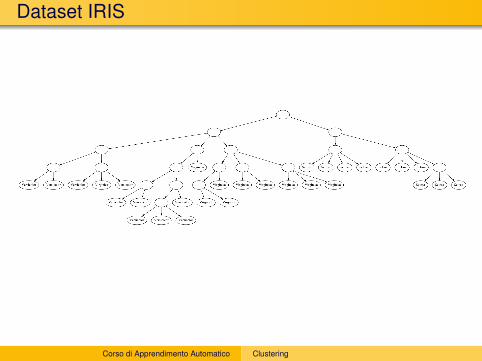
Dataset IRIS
Corso di Apprendimento Automatico Clustering

Cut-off
Corso di Apprendimento Automatico Clustering

Clustering probabilistico
Problemi dell’approccio euristico:Suddivisione in k cluster ?Ordine degli esempi ?Sono sufficienti le operazioni di ristrutturazione ?Il risultato raggiunge almeno localmente la minima categoryutility?
Prospettiva probabilistica =⇒cercare i cluster più verosimili date le osservazioniInoltre: un’istanza appartiene ad ogni clustercon una certa probabilità
Corso di Apprendimento Automatico Clustering

Composizioni finite
Si modellano i dati usando una composizione (mixture) didistribuzioniOgni cluster corrisponde ad una distribuzione
governa le probabilità dei valori degli attributi per quelcluster
Finite mixtures: numero finito di clusterLe singole distribuzioni sono (di solito) NormaliSi combinano le distribuzioni usando pesi relativi ai cluster
Corso di Apprendimento Automatico Clustering

Modello composto a 2-classi
Corso di Apprendimento Automatico Clustering

Uso del modello composto
Probabilità che l’istanza x appartenga al cluster A:
P(A | x) =P(x | A)P(A)
P(x)=
f (x ;µA, σA)pA
P(x)
conf (x ;µ, σ) = 1√
2πσexp(− (x−µ)2
2σ2 )
Probabilità di un’istanza dati i cluster:
P(x | {C1, . . . ,Ck}) =∑
i
P(x | Ci)P(Ci)
Corso di Apprendimento Automatico Clustering

Imparare i cluster
Si assuma:di conoscere che il numero di cluster k
Imparare i cluster ?determinare i loro parametriossia medie e deviazioni standard
Criterio di valutazione:Probabilità dei dati di training dati i cluster
Algoritmo EMtrova un massimo locale della likelihood
Corso di Apprendimento Automatico Clustering

Algoritmo EM I
EM = Expectation-Maximization
Generalizza K-MEANS in senso probabilisticoProcedura iterativa:
passo E expectation:Calcolare la probabilità di appartenenza ai cluster per ogniistanzapasso M maximization:Stimare i parametri della distribuzione a partire dallleprobabilità determinate
Immagazzinare le probabilità come pesi delle istanze
Stop quando il miglioramento è trascurabile
Corso di Apprendimento Automatico Clustering

Algoritmo EM II
Stimare i parametri dalle istanze pesate
µA =w1x1 + w2x2 + · · ·+ wnxn
w1 + w2 + · · ·+ wn
σA =w1(x1 − µ)2 + w2(x2 − µ)2 + · · ·+ wn(xn − µ)2
w1 + w2 + · · ·+ wn
Stop quando si satura la log-likelihoodLog-likelihood:∑
i
log(pAP(xi | A) + pBP(xi | B))
Corso di Apprendimento Automatico Clustering

Estensione del modello composto
Più di due distribuzioni: facileParecchi attributi: facile – assumendone l’indipendenzaAttributi correlati: difficile
modello congiunto: distribuzione normale bivariatacon una matrice di covarianza (simmetrica)n attributi: serve stimare n + n(n + 1)/2 parametri
Corso di Apprendimento Automatico Clustering

Altre estensioni
Attributi nominali: facile se indipendentiAttributi nominali correlati: difficile
Due attributi correlati =⇒ ν1ν2 parametri
Valori mancanti: facilePossibilità di usare altre distribuzioni diverse dalla normale:
log-normale se è dato un minimo predeterminatolog-odds se limitato superiormente ed inferiormentePoisson per attributi che rappresentano conteggi interi
Usare la cross-validation per stimare k
Corso di Apprendimento Automatico Clustering

Clustering Bayesiano
Problema: tanti parametri =⇒ EM soffre disovradattamentoApproccio Bayesiano: si attribuisce ad ogni parametro unadistribuzione di probabilità a priori
Si incorpora la probabilità a priori nel computo totale dellalikelihoodSi penalizza l’introduzione di parametri
Es. lo stimatore di Laplace per attributi nominaliSi può anche avere una probabilità a priori sul numero diclusterImplementazione: AUTOCLASS
[Cheeseman and Stutz, 1995]
Corso di Apprendimento Automatico Clustering

Discussione
Diminuisce la dipendenza tra attributi ?passo di pre-elaborazioneEs. usare l’analisi delle componenti principali
Si può usare per completare i valori mancantiPrincipale vantaggio del clustering probabilistico:
Si può stimare la likelihood dei datiusabile poi per confrontare modelli differenti in modoobiettivo
Corso di Apprendimento Automatico Clustering

Clustering concettuale
In una seconda fase succesiva al clustering (nonsupervisionato) è possibile interpretare i cluster tramitel’apprendimento supervisionato
passo di post-elaborazione: conceptual clustering[Stepp and Michalski, 1986]
Ogni cluster rappresenta una classe di istanze per la qualecostruire un concetto in forma insensionale
Per ogni clusteres. positivi istanze del clusteres. negativi istanze degli altri cluster disgiunti
Corso di Apprendimento Automatico Clustering

Fonti
A.K. Jain, M.N. Murty, P.J. Flynn: Data Clustering: AReview. ACM Computing Surveys, 31(3), 264–323, 1999I. Witten & E. Frank: Data Mining: Practical MachineLearning Tools and Techniques, Morgan KaufmannR. Duda, P. Hart, D. Stork: Pattern Classification, WileyT. Hastie, R. Tibshirani, J. Friedman: The Elements ofStatistical Learning, SpringerT. M. Mitchell: Machine Learning, McGraw Hill
Corso di Apprendimento Automatico Clustering

Bibliografia I
Bezdek, J. and Pal, N. (1998).Some new indexes of cluster validity.IEEE Transactions on Systems, Man, and Cybernetics, 28(3):301–315.
Cheeseman, P. and Stutz, J. (1995).Bayesian classification (AutoClass): Theory and results.In Fayyad, U., Piatetsky-Shapiro, G., Smyth, P., and Uthurusamy, R.,editors, Advances in Knowledge Discovery and Data Mining, pages153–180. AAAI Press.
Fisher, D. (1987).Knowledge acquisition via incremental conceptual clustering.Machine Learning, 2(2):139–172.
Gennari, I., Langley, P., and Fisher, D. (1997).Models of incremental concept formation.Artificial Intelligence, 40:11–61.
Corso di Apprendimento Automatico Clustering

Bibliografia II
Gluck, M. and Corter, J. (1985).Information, uncertainty, and utility of categories.In Proceedings of the Annual Conference of the Cognitive ScienceSociety, pages 283–287. Lawrence Erlbaum.
Halkidi, M., Batistakis, Y., and Vazirgiannis, M. (2001).On clustering validation techniques.Journal of Intelligent Information Systems, 17(2-3):107–145.
Jain, A. and Dubes, R. (1988).Algorithms for Clustering Data.Prentice Hall, Englewood Cliffs, NJ.
Kass, R. and Wasserman (1995).A reference bayesian test for nested hypotheses and its relationship tothe Schwarz criterion.Journal of the American Statistical Association, 90:928–934.
Corso di Apprendimento Automatico Clustering

Bibliografia III
Kaufman, L. and Rousseeuw, P. (1990).Finding Groups in Data: an Introduction to Cluster Analysis.John Wiley & Sons.
Moore, A. and Pelleg, D. (2000).X-means: Extending k-means with efficient estimation of the number ofclusters.In Kaufmann, M., editor, Proceedings of the 17th InternationalConference on Machine Learning, pages 727–734.
Stepp, R. E. and Michalski, R. S. (1986).Conceptual clustering of structured objects: A goal-oriented approach.Artificial Intelligence, 28(1):43–69.
Corso di Apprendimento Automatico Clustering


















