
G. Gallo 2006/2007 - di.unipi.itgallo/Books/SimulazioneMain_07_1.pdf · 6.2.2 variabili ausiliarie...
134
Note di Simulazione G. Gallo 2006/2007
-
Upload
duongkhuong -
Category
Documents
-
view
218 -
download
0
Transcript of G. Gallo 2006/2007 - di.unipi.itgallo/Books/SimulazioneMain_07_1.pdf · 6.2.2 variabili ausiliarie...

Note di Simulazione
G. Gallo
2006/2007

ii
c©2007 Giorgio GalloE possibile scaricare, stampare e fotocopiare il testo. Nel caso che se ne
stampino singole parti, si deve comunque includere anche la pagina inizialecon titolo ed autore.

Indice
Introduzione vii
1 Problemi e Modelli 11.1 Processi decisionali e modelli di simulazione . . . . . . . . . . 11.2 Classi di modelli di simulazione . . . . . . . . . . . . . . . . . 6
1.2.1 Modello Preda-Predatore . . . . . . . . . . . . . . . . . 61.2.2 Modello dell’officina . . . . . . . . . . . . . . . . . . . 91.2.3 Un problema di manutenzione . . . . . . . . . . . . . . 10
2 Simulazione discreta 132.1 Il sistema da modellare . . . . . . . . . . . . . . . . . . . . . . 13
2.1.1 Entita . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.1.2 Operazioni . . . . . . . . . . . . . . . . . . . . . . . . . 162.1.3 Cicli delle attivita . . . . . . . . . . . . . . . . . . . . . 17
2.2 UML: un linguaggio di modellazione . . . . . . . . . . . . . . 192.2.1 Esempi . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.3 Approcci alla simulazione . . . . . . . . . . . . . . . . . . . . 322.3.1 Simulazione per eventi . . . . . . . . . . . . . . . . . . 332.3.2 Simulazione per attivita . . . . . . . . . . . . . . . . . 352.3.3 Simulazione per processi . . . . . . . . . . . . . . . . . 40
3 Funzioni di distribuzione e test statistici 433.1 Variabili casuali . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.1.1 Distribuzioni discrete . . . . . . . . . . . . . . . . . . . 453.1.2 Distribuzioni continue . . . . . . . . . . . . . . . . . . 53
3.2 Stima di parametri . . . . . . . . . . . . . . . . . . . . . . . . 603.2.1 Media e varianza del campione . . . . . . . . . . . . . 603.2.2 Intervalli di confidenza . . . . . . . . . . . . . . . . . . 61
iii

iv INDICE
3.2.3 Massima verosimiglianza . . . . . . . . . . . . . . . . . 643.2.4 Stima dell’errore quadratico medio . . . . . . . . . . . 66
3.3 Test di ipotesi . . . . . . . . . . . . . . . . . . . . . . . . . . . 683.3.1 Test Chi-Quadro . . . . . . . . . . . . . . . . . . . . . 683.3.2 Test di Kolmogorov-Smirnov per distribuzioni continue 693.3.3 Il test della somma dei ranghi . . . . . . . . . . . . . . 71
3.4 Modelli di processi di arrivo . . . . . . . . . . . . . . . . . . . 72
4 Analisi e scelta dei dati di input 754.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 754.2 Distribuzioni empiriche . . . . . . . . . . . . . . . . . . . . . . 774.3 Analisi dei dati di input . . . . . . . . . . . . . . . . . . . . . 78
4.3.1 Indipendenza delle osservazioni . . . . . . . . . . . . . 784.3.2 Individuazione della distribuzione . . . . . . . . . . . . 794.3.3 Stima dei parametri della distribuzione . . . . . . . . . 80
4.4 Numeri pseudocasuali . . . . . . . . . . . . . . . . . . . . . . . 804.4.1 Numeri pseudocasuali con distribuzione uniforme . . . 814.4.2 Distribuzioni discrete . . . . . . . . . . . . . . . . . . . 824.4.3 Distribuzioni continue . . . . . . . . . . . . . . . . . . 84
5 Analisi dei dati di output 895.1 Analisi del transitorio . . . . . . . . . . . . . . . . . . . . . . . 895.2 Tecniche per la riduzione della varianza . . . . . . . . . . . . . 92
5.2.1 Variabili antitetiche . . . . . . . . . . . . . . . . . . . . 925.2.2 Condizionamento . . . . . . . . . . . . . . . . . . . . . 93
6 Dinamica dei sistemi 976.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 976.2 Modello Preda-Predatore . . . . . . . . . . . . . . . . . . . . . 98
6.2.1 Livelli e flussi . . . . . . . . . . . . . . . . . . . . . . . 996.2.2 variabili ausiliarie e costanti . . . . . . . . . . . . . . . 1006.2.3 Cicli causali . . . . . . . . . . . . . . . . . . . . . . . . 102
6.3 Ritardi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1046.3.1 Un problema di magazzino . . . . . . . . . . . . . . . . 1076.3.2 Diffusioni di inquinanti . . . . . . . . . . . . . . . . . . 1126.3.3 Inquinamento atmosferico ed effetto serra . . . . . . . . 1156.3.4 La matematica dei ritardi . . . . . . . . . . . . . . . . 120
Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125

INDICE v
Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125

vi INDICE

Introduzione
Con il termine simulazione si intende l’attivita del replicare per mezzo diopportuni modelli una realta gia esistente o da progettare, al fine di studiare,nel primo caso, gli effetti di possibili interventi o eventi in qualche modoprevedibili, o, nel secondo, di valutare diverse possibili scelte progettualialternative.
L’uso di modelli come strumento di aiuto nei processi decisionali e anticoe diffusissimo. Un tipico esempio e quello dei modelli a scala, usati soprat-tutto in fase di progettazione. Si tratta di modelli che replicano fedelmente,anche se a scala ridotta, la realta che si vuole rappresentare. Tipici modellidi questo tipo sono i plastici che vengono utilizzati nella progettazione ar-chitettonica, o i modelli di strutture che vengono utilizzati per studiare glieffetti di sollecitazioni, ad esempio di tipo sismico. Questi strumenti sonocaratterizzati da un notevole costo di realizzazione e da una grande rigiditadi uso, e pertanto sempre meno utilizzati in pratica.
Altri importantissimi modelli molto usati come strumenti decisionali, so-prattutto con lo sviluppo e la diffusione della Ricerca Operativa, sono i mo-delli analitici. Si tratta di modelli in cui la realta sotto esame viene rap-presentata per mezzo di variabili e relazioni di tipo logico/matematico. Aquesta classe appartengono, fra gli altri, i modelli di programmazione lineare(piu in generale di programmazione matematica) o i modelli di file d’attesa.Si tratta di modelli di notevole potenza, che consentono in molti casi di de-terminare, con un costo contenuto, una o piu soluzioni ottime (o comunquesoluzioni molto buone) per il problema considerato. Tuttavia al crescere del-la complessita e della dimensione dei problemi tali modelli diventano di usosempre piu difficile e costoso, ed in molti casi, per le loro stesse caratteristiche,inapplicabili.
La complessita di un processo decisionale ha diverse dimensioni: il nume-ro delle variabili, il tipo di relazioni che legano fra loro le variabili, il numero
vii

viii Introduzione
di obiettivi, il numero di attori, cioe di persone che hanno la possibilita diprendere decisioni o di influire su esse, ed infine il grado di incertezza con cuile grandezze in gioco e le relazioni fra le variabili sono conosciute. In generalesituazioni in cui il numero di obiettivi ed il numero di decisori e sufficiente-mente limitato (idealmente un obiettivo ed un unico decisore) ed in cui lerelazioni fra le variabili e le grandezze in gioco sono conosciute con sufficienteapprossimazione si prestano abbastanza bene all’uso di modelli di tipo ana-litico. Ovviamente purche il numero di variabili necessarie per descrivere larealta sotto esame non sia eccessivamente grande, dove i limiti nelle dimen-sioni dei problemi trattabili dipendono grandemente dalla complessita dellerelazioni che legano fra loro le variabili.
Qui faremo riferimento a processi decisionali caratterizzati da elevati li-velli di complessita, in cui l’uso di modelli analitici sia poco proponibile. Imodelli che presenteremo si differenziano da quelli di tipo analitico per l’u-so del calcolatore come strumento non solo di calcolo, come ad esempio neimodelli di programmazione matematica, ma anche di rappresentazione de-gli elementi che costituiscono la realta in studio e delle relazioni fra di essi.La corrispondenza tra realta e modello non e basata su una riduzione pro-porzionale delle dimensioni, ma e di tipo funzionale: ad ogni elemento delsistema reale corrisponde un oggetto informatico (una sottoprogramma, unastruttura di dati, . . . ) che ne svolge la funzione nel modello.
Rispetto alla sperimentazione diretta, costosissima e spesso praticamenteimpossibile, o a quella realizzata per mezzo di modelli a scala, la simulazioneha il vantaggio della grande versatilita, della velocita di realizzazione e del(relativamente) basso costo. E possibile attraverso la simulazione provare ra-pidamente politiche e scelte progettuali alternative e modellare sistemi anchedi grandissima complessita studiandone il comportamento e l’evoluzione neltempo.

Capitolo 1
Problemi e Modelli
1.1 Processi decisionali e modelli di simula-
zione
Il processo decisionale, cioe il processo attraverso cui, a partire dall’emergeredi una situazione che richiede una scelta o una azione, si arriva alla sceltadell’azione da intraprendere e poi alla sua realizzazione, e oggetto di studio insettori notevolmente diversi che vanno dall’ingegneria all’informatica, dallasociologia alla teoria della politica, dall’economia alle scienze gestionali.
Lo studio dei processi decisionali, la capacita di analizzarne e scompornei meccanismi, e soprattutto la messa a punto di strumenti sia metodologiciche tecnici di supporto e essenziale per pervenire a ‘buone’ decisioni. Spessoe il processo decisionale in se stesso che produce risultati significativi al di ladelle decisioni ed azioni alle quali esso porta; questo per la sua caratteristicadi essere un processo di apprendimento che in qualche modo cambia gli attoristessi in esso coinvolti.
In generale in un processo decisionale il punto di partenza e l’individua-zione di una realta problematica che richiede un cambiamento e quindi unadecisione. La realta cosı individuata viene analizzata in modo da evidenziareal suo interno il sistema da studiare ai fini della o delle decisioni da prendere;vengono cioe scelti quegli elementi che ci sembrano piu rilevanti, evidenziatele relazioni che li collegano, e definiti gli obiettivi da raggiungere. A questopunto si costruisce un modello formale che permetta di riprodurre (simulare)il sistema individuato, allo scopo di comprenderne il comportamento e diarrivare ad individuare le decisioni da prendere.
1

2 Capitolo 1. Problemi e Modelli
Realtà
Sistema Modello Simulazione
Decisioni
Figura 1.1. Processo decisionale
Il processo che abbiamo delineato parte quindi dalla realta ed arriva al-la o alle decisioni finali attraverso tre passi: l’individuazione del sistemada studiare, la costruzione del modello e la simulazione. Questo processo esinteticamente rappresentato in figura 1.1, dove e stata evidenziata la par-te che qui ci interessa, quella che va dalla definizione del sistema fino allasimulazione.
Esamineremo nel seguito piu in dettaglio i passi del processo decisionale.
Il sistema. La realta oggetto di indagine viene rappresentata attraver-so un sistema, cioe un insieme di elementi interagenti fra loro. Quella dirappresentare la realta come un sistema e una scelta, ed il risultato di ta-le rappresentazione e la conseguenza di una successione di scelte specifiche,tutte caratterizzate da un certo grado di arbitrarieta e quindi suscettibili direvisione nel corso del processo decisionale. La principale e piu critica sceltariguarda i confini del sistema, cioe quali elementi della realta debbano es-sere inseriti nel sistema che la rappresenta e quali invece lasciati fuori. Adesempio, nello studio del traffico privato in una area urbana dovro sceglierequale porzione della rete viaria considerare e dove disegnare i confini dell’areada studiare. Si tratta di scelte che riguardano aspetti fisici della realta chesembra non pongano rilevanti problemi: alcune strade secondarie sono chia-ramente poco rilevanti ai fini dei flussi principali di traffico, e appare naturale

1.1. Processi decisionali e modelli di simulazione 3
limitarsi a considerare l’area nella quale ci interessa conoscere la distribuzionedel traffico. In realta le scelte fatte anche su aspetti di questo tipo non sononeutre, e possono falsare i risultati ottenuti. La possibilita di usare alcunestrade apparentemente secondarie, ad esempio, puo avere effetti imprevistisulla distribuzione del traffico. Inoltre puo accadere che una parte dei veicoliin ingresso nell’area possa utilizzare piu punti di accesso, e la scelta dipendedalla distribuzione del traffico dentro l’area stessa; questo porta ad effetti sultraffico totale che possono non essere valutabili senza ampliare l’area sottoesame. Altre scelte riguardano quali variabili considerare e la definizionedelle relazioni fra le variabili o elementi del sistema. Naturalmente in questolavoro bisogna essere guidati dagli obiettivi che il nostro processo decisionaleha. Diversi obiettivi portano a rappresentazioni diverse della stessa realta.
E necessario tenere sempre presente lo scarto che esiste tra il sistema ela realta che esso rappresenta. Questo scarto puo essere maggiore o minore,ma e comunque ineludibile. La realta non e direttamente conoscibile se nonattraverso una ‘concettualizzazione’ da parte dell’osservatore, e l’ottica siste-mica e proprio lo strumento usiamo a questo scopo. Noi conosciamo la realtaattraverso il sistema con cui la rappresentiamo. Si tratta di una rappresen-tazione che dobbiamo essere sempre disponibili a rimettere in discussioni.Situazioni nuove ed impreviste ci potranno portare a rivedere il sistema cheabbiamo definito, arricchendolo e modificandolo.
Il modello. Il modello costituisce il modo con cui noi formalizziamo il si-stema che rappresenta la realta in esame. I modelli possono essere di tipodiverso, e possono essere sia quantitativi che qualitativi. Ad esempio, modelliclassici ed un tempo molto usati sono i cosiddetti modelli a scala. Si trattadi modelli fisici che rappresentano a scala ridotta un sistema. Tipici esempisono il plastico di un quartiere o di una intera citta, utilizzato per scelte ditipo architettonico o urbanistico, oppure il modello a scala della struttura diun edificio che viene utilizzato per valutare la risposta della struttura a sol-lecitazioni ad esempio di tipo sismico. Questi sono modelli di tipo analogico;la riduzione della scala viene fatta in modo che le caratteristiche di interessesi mantengano, eventualmente riducendosi nella loro intensita secondo scalascelta. Questi modelli con la diffusione dei calcolatori elettronici sono sempremeno usati.
Una altra classe di modelli e costituita dai modelli analitici. Si tratta dimodelli in cui il sistema viene formalizzato attraverso un insieme di variabili

4 Capitolo 1. Problemi e Modelli
e un insieme di relazioni matematiche che limitano e definiscono i valori chetali variabili possono assumere. Ad esempio una rete elettrica puo essere rap-presentata per mezzo di un opportuno sistema di equazioni, la cui soluzionefornisce i valori che variabili quali intensita di corrente e differenze di poten-ziale possono assumere. Molto spesso in questo tipo di modelli viene anchedefinito una funzione obiettivo da minimizzare o massimizzare. Si ricorrein questo caso ad algoritmi di ottimizzazione. Modelli analitici sono quel-li studiati nell’ambito della Programmazione Matematica (Bigi et al., 2003)oppure nell’ambito della teoria delle code.
I modelli a scala e quelli analitici sono, sia pure in forma diversa, mo-delli abbastanza ‘rigidi’ e caratterizzati da una limitata ricchezza espressiva.Possono essere usati per modellare sistemi ‘relativamente’ semplici1. Moltopoco rigidi e capaci di rappresentare una grande varieta di diverse situazionisono modelli qualitativi, quali ad esempio i diversi tipi di mappe cognitive chevengono utilizzate per rappresentare realta problematiche nell’ambito dellacosiddetta “Soft Operations Research”(Checkland, 1989; Rosenhead, 1989).
I modelli di simulazione, che sono quelli che piu ampiamente tratteremonel seguito, sono modelli che si differenziano da quelli di tipo analitico perl’uso del calcolatore come strumento non solo di calcolo, come ad esempio neimodelli di programmazione matematica, ma anche di rappresentazione deglielementi che costituiscono la realta in studio e delle relazioni fra di essi. Lacorrispondenza tra realta e modello non e basata su una riduzione proporzio-nale delle dimensioni, ma e di tipo funzionale: ad ogni elemento del sistemareale corrisponde un oggetto informatico (un sottoprogramma, una struttu-ra di dati, . . . ) che ne svolge la funzione nel modello. Questi modelli sonoparticolarmente flessibili consentendo di rappresentare e di studiare sistemimolto complessi, e dei quali conosciamo alcune caratteristiche solo attraversoanalisi di tipo statistico.
I modelli di simulazione sono in genere modelli dinamici, cioe includono ladimensione temporale, e hanno lo scopo di studiare l’andamento nel tempodi un sistema. Al contrario i modelli analitici sono spesso (anche se nonsempre) statici: forniscono la soluzione al problema studiato a partire dadati che descrivono il sistema in un dato istante o intervallo temporale2.
1In realta i modelli di Programmazione Matematica consentono di affrontare problemianche con milioni di variabili. Le difficolta nascono soprattutto quando si e in presenza diforti nonlinearita e di situazioni caratterizzate da incertezza.
2E bene avvertire il lettore che ogni tentativo di classificazione e necessariamente pro-blematica. La realta sfugge sempre ai nostri tentativi di racchiuderla in categorie predefi-

1.1. Processi decisionali e modelli di simulazione 5
La simulazione. La fase della simulazione vera e propria e quella con-clusiva, che portera poi alle decisioni finali. Innanzitutto il modello vienetradotto in un programma su calcolatore che viene fatto girare. In questomodo, analizzando il comportamento del modello e confrontandolo con i datiin nostro possesso sulla da cui eravamo partiti, e possibile verificare quantoil modello costruito rappresenti, correttamente rispetto ai nostri obiettivi3,la realta sotto studio. La correttezza puo essere vista da due punti di vistadiversi:
• Correttezza d’insieme (black box validity): gli output che il modelloproduce riflettono accuratamente quelli del sistema reale.
• Correttezza delle singole componenti del sistema (white box validity):le componenti del sistema sono consistenti con la realta e/o la teoriaesistente.
L’implementazione del modello puo essere realizzata con diversi strumen-ti. E possibile usare linguaggi general purpose quali Pascal, C, C++, per iquali esistono delle librerie di routines orientate alla simulazione. Esistonoanche diversi linguaggi specializzati, quali ad esempio SIMSCRIPT, MOD-SIM e GPSS. Una interessante alternativa e quella di ricorrere ad applicazionidi tipo interattivo per la simulazione quali, fra gli altri, Arena, Witness, Ex-tend e Micro Saint. Tali applicazioni sono di facile uso e quindi molto adattea costruire rapidamente modelli anche sofisticati, ma sono meno versatili epotenti dei linguaggi specializzati o di quelli general purpose. Per problemidi piccole dimensioni e anche possibile usare strumenti informatici di uso co-mune quali le spreadsheet. Tali strumenti possono essere utili quando si vuolerapidamente avere un’idea del funzionamento di una singola componente odi un sottosistema di un sistema complesso.
Una volta assicuratici della correttezza del modello inizia la parte con-clusiva e fondamentale del lavoro, quella della sperimentazione che porteraalle decisioni finali. Questa fase richiede l’uso di strumenti statistici, sia perl’analisi dei dati di partenza sia per la valutazione dei risultati della simu-lazione. A questi strumenti verra dedicato un ampio spazio nel seguito. La
nite, e questo vale anche per i modelli: esistono modelli analitici che tengono conto delledinamiche temporali, e d’altra parte alcuni modelli di simulazione sono essenzialmentestatici.
3Va sempre ricordato che un modello non e la realta, e che di conseguenza non ha sensoparlare di correttezza in se del modello; la correttezza e relativa agli scopi per cui abbiamocostruito il modello.

6 Capitolo 1. Problemi e Modelli
sperimentazione deve essere realizzata in modo che l’influenza dei diversi fat-tori sui risultati ottenuti sia chiaramente evidenziata. Bisogna sempre tenerepresente che, in ultima analisi, la simulazione e uno strumento conoscitivo.
1.2 Classi di modelli di simulazione
Un modello di simulazione puo essere deterministico o stocastico, discretoo continuo. Si parla di simulazione deterministica quando l’evoluzione neltempo del modello costruito e univocamente determinata dalle sue caratteri-stiche e dalle condizioni iniziali. Quando nel modello sono presenti grandezzealeatorie che a seconda del valore che assumono possono portare a diversicomportamenti si parla invece di simulazione stocastica. Con simulazionecontinua si intende una simulazione in cui il valore delle variabili coinvoltevaria in modo continuo nel tempo (anche se poi esse saranno in pratica va-lutate in istanti discreti). Si ha invece una simulazione discreta quando lostato del sistema studiato, e quindi il valore delle variabili relative, cambia inben definiti istanti di tempo. Illustreremo meglio questi concetti nel seguitoattraverso alcuni esempi.
1.2.1 Modello Preda-Predatore
In una isola sono presenti due popolazioni di animali, conigli e linci. Lavegetazione dell’isola fornisce ai conigli nutrimento in quantita che possiamoassumere illimitata, mentre sono i conigli l’unico alimento disponibile per lelinci. Possiamo considerare costante nel tempo il tasso di natalita dei conigli;questo significa che in assenza di predatori i conigli crescerebbero con leggeesponenziale. Il loro tasso di mortalita invece dipende dalla probabilita cheessi hanno di divenire preda di una lince e quindi dal numero di linci presentiper unita di superficie. Per quel che riguarda le linci, il tasso di mortalita ecostante, mentre il loro tasso di crescita dipende dalla disponibilita di ciboe quindi dal numero di conigli per unita di superficie presenti nell’isola. Sivuole studiare l’andamento della dimensione delle due popolazioni nel tempoa partire da una situazione iniziale (numero di conigli e di linci) data.
Per effettuare una simulazione di questo sistema biologico possiamo mo-dellarlo per mezzo del seguente sistema di equazioni alle differenze finite,dove x(t) e y(t) sono rispettivamente il numero dei conigli e delle linci altempo t:

1.2. Classi di modelli di simulazione 7
x(t + 1)− x(t) = Ncx(t)− F (y(t))x(t),
y(t + 1)− y(t) = −Mly(t) + G(x(t))y(t).
In questo modello sono sottese le seguenti ipotesi: (i) in assenza di pre-datori il numero dei conigli cresce secondo una legge esponenziale, cioe contasso costante; (ii) analogamente, in assenza di prede, il numero delle lincidecresce con tasso costante.
Nella figura 1.2 viene indicato l’andamento delle due popolazioni nel cor-so di 50 anni, avendo scelto l’anno come unita di tempo ed avendo postoNc=0.35, Ml=0.25, F (y) = 1.25(1− e
−35yS ) e G(x) = 0.5(1− e
−0.8xS ). Con S
si e indicata la superficie dell’isola, che si e assunta essere pari a 6000 ettari.I valori iniziali delle due popolazioni sono stati posti a 6000 per i conigli e a70 per le linci.
Questo modello deriva dal classico modello preda/predatore proposto dalmatematico italiano Vito Volterra4 nel 1926 per studiare le variazioni dialcune popolazioni di pesci nell’Adriatico, che, nella sua forma piu semplicesi presenta cosı:
dx(t)
dt= Ax(t)−Bx(t)y(t),
dy(t)
dt= −Cy(t) + Dx(t)y(t).
Chiaramente si tratta di un modello deterministico e di simulazione con-tinua. Infatti lo stato del sistema (dimensione delle due popolazioni) in ogniistante di tempo e univocamente determinato dato lo stato iniziale ed i para-metri del modello. Inoltre, almeno in principio, le variabili, cioe le dimensionidelle popolazioni, variano con continuita nel tempo. Il fatto che esse venganovalutate in un insieme discreto di istanti di tempo non e in contraddizione conquesto fatto. Chiaramente questa variabilita continua nel tempo e propriadel modello usato, non della realta che esso rappresenta. Avremmo potuto
4Il modello che noi abbiamo qui presentato puo essere considerato la discretizzazionedi una variante dell’originale modello di Volterra. In essa si e usato un intervallo didiscretizzazione pari ad 1. I risultati ottenuti dipendono da questa scelta; torneremo inseguito sugli effetti della scelta dell’intervallo di discretizzazione nel caso di modelli disimulazione basati su sistemi di equazioni alle differenze finite.

8 Capitolo 1. Problemi e Modelli
Figura 1.2. Andamento delle popolazioni nel tempo

1.2. Classi di modelli di simulazione 9
M1 M2
L1 4 6L2 0 5L3 3 8L4 4 0L5 6 3
Tabella 1.1. Tempi di lavorazione
scegliere un modello diverso in cui fossero evidenziati gli eventi delle catture,delle morti e delle nascite. Un tale modello sarebbe pero di difficile realiz-zazione in considerazione della dimensione del problema e non ci darebbe,ai fini dello studio dell’andamento della dimensione delle popolazioni, unainformazione piu accurata di quella fornita dal modello scelto.
1.2.2 Modello dell’officina
In un’officina ci siano 2 macchine M1 e M2, e all’inizio della giornata sianoin attesa di essere eseguiti 5 lavori, L1, L2, L3, L4 e L5. Nella tabella 1.1sono indicati i tempi richiesti dai lavori sulle macchine (in decine di minuti).Uno zero indica che un lavoro non richiede quella macchina. I lavori cherichiedono due macchine devono passare prima per M1 e poi per M2.
Supponiamo che si decida di eseguire i lavori assegnando a ciascuna mac-china, quando essa si rende disponibile, il primo lavoro eseguibile, nell’ordineda 1 a 5. Se allo stesso istante piu lavori sono eseguibili sulla stessa macchinasi eseguira quello con indice minore. Ci si chiede quale sia il tempo minimonecessario per completare tutti i lavori.
Gli eventi in cui si possono avere cambiamenti di stato nel sistema sono:
1. un lavoro si rende disponibile per una macchina;
2. una macchina inizia un lavoro;
3. una macchina termina un lavoro
La sequenza dei cambiamenti di stato nella simulazione e riportata nellatabella 1.2.

10 Capitolo 1. Problemi e Modelli
Tempo M1 M2
045711171922
Finisce IniziaL1
L1 L3
L3 L4
L4 L5
L5
Finisce IniziaL2
L2 L1
L1 L3
L3 L5
L5
Tabella 1.2. Cambiamenti di stato del sistema
Con la politica scelta sono quindi necessari 220 minuti per l’esecuzione ditutti i lavori.
Anche questo, come il precedente e un esempio di simulazione determi-nistica, ma al contrario di esso qui la simulazione e di tipo discreto; infattii cambiamenti di stato del sistema avvengono solamente in alcuni istanti, esono determinati dalle durate delle lavorazioni sulle macchine. Osserviamoche in questo esempio si e usata una tempificazione diversa da quella usatanell’esempio precedente. Invece di valutare lo stato del sistema ad intervalliregolari, il che avrebbe comportato un gran numero di valutazioni inutili, lo sie fatto solamente negli istanti in cui avviene effettivamente un cambiamentodi stato (tempificazione per eventi).
1.2.3 Un problema di manutenzione
Un server ha due unita disco. Un guasto ad uno dei dischi comporta laperdita delle informazioni in esso contenute e la necessita di ricorrere allecopie di back-up con relativa interruzione del servizio e costo di intervento.La riparazione di un disco costa 150 Euro, mentre la sua revisione, se ancorafunzionante, costa 50 Euro. Nella tabella 1.3 viene riportata la probabilita pi
di un guasto nell’iesimo mese dopo una riparazione o una revisione. Abbiamoassunto che la probabilita che il disco funzioni piu di 6 mesi senza guasti siatrascurabile. Con Pi sono state indicate le probabilita cumulate.
Attualmente i dischi vengono riparati ogni volta che si guastano, l’uno

1.2. Classi di modelli di simulazione 11
i pi Pi
1 0.05 0.052 0.15 0.203 0.20 0.404 0.30 0.705 0.20 0.906 0.10 1
Tabella 1.3. Probabilita delle durata di funzionamento dei dischi
indipendentemente dall’altro. Si vuole valutare la convenienza di effettuareuna politica congiunta: ogni qualvolta un disco si guasta, esso viene riparatoe l’altro, se ancora funzionante, viene revisionato.
Per ricorrere ad una simulazione dobbiamo essere in grado di generaregli “eventi guasto” in modo che rispettino le probabilita date. A questoscopo basta generare numeri (pseudo)casuali nell’intervallo [0, 1) e generarel’evento “guasto nel mese i” se il numero generato appartiene all’intervallo[Pi−1, Pi), avendo posto P0 = 0. Nella Tabella 1.4 sono indicati i risultatidella simulazione per le due politiche in esame. Con t e T vengono indicatirispettivamente l’intervallo tra due interventi successivi ed il tempo simulato.

12 Capitolo 1. Problemi e Modelli
Riparaz. separate Ripar. congiunteNum. Casuali t T t T
Disco A Disco B Disco A Disco B Disco A Disco B0.71 0.37 5 3 5 3 3 30.58 0.34 4 3 9 6 3 60.21 0.89 3 5 12 11 3 90.81 0.08 5 2 17 13 2 110.94 0.67 6 4 23 17 4 150.58 0.19 4 2 27 19 2 170.19 0.22 2 3 29 22 2 190.37 0.33 3 3 32 25 3 220.88 0.56 5 4 37 29 4 260.67 0.77 4 5 41 34 4 300.36 0.27 3 3 44 37 3 330.67 0.90 4 5 48 42 4 370.30 0.08 3 2 51 44 2 390.50 0.84 4 5 49 4 430.56 0.27 4 3 52 3 460.21 0.35 3 3 3 490.11 0.16 2 2 2 51
Tabella 1.4. Riparazione dischi: risultato della simulazione

Capitolo 2
Simulazione discreta
In questo capitolo presentiamo i concetti base per la costruzione di modellidi simulazione e i principali approcci alla simulazione discreta. La tratta-zione e in parte basata sul testo di Pidd (1998), al quale rimandiamo perapprofondimenti.
2.1 Il sistema da modellare
Come abbiamo gia visto nel precedente capitolo, in generale, in un progettodi simulazione il primo passo consiste nell’analizzare la realta nella quale ilproblema che si vuole affrontare e risolvere. Questa realta viene rappresen-tata come un sistema. Un sistema e un insieme di elementi e di relazionifar essi. L’aspetto piu rilevante di un sistema e che esso e qualcosa di piudell’insieme delle sue parti. Cioe il suo comportamento non puo essere appie-no conosciuto solamente analizzando separatamente il comportamento delleparti. E la struttura e la natura delle relazioni fra le parti che determina,secondo modalita a volte ‘apparentemente’ imprevedibili, il comportamentocomplessivo del sistema.
Come abbiamo evidenziato, il sistema non e la realta ma ne e una rappre-sentazione, in ultima analisi e una costruzione mentale. Sta a noi scegliereil livello di dettaglio del sistema che vogliamo definire. Questo livello dipen-dera dagli obiettivi del nostro studio, cioe dal tipo di problema che vogliamorisolvere. Ad esempio, se ci proponiamo di studiare il traffico di veicoli pri-vati allo scopo di definire politiche per la riduzione della congestione e deitempi di trasporto, non e rilevante ne il colore ne l’anno di produzione delle
13

14 Capitolo 2. Simulazione discreta
auto. Quest’ultimo dato potrebbe essere invece interessante se fossimo inte-ressati all’inquinamento prodotto dal traffico; in questo caso infatti l’anno diproduzione ci puo fornire indicazioni sulle emissioni del motore.
In generale una buona norma e che il livello di dettaglio sia il minimo,compatibilmente con le risposte che noi vogliamo ottenere dalla simulazione.Usualmente si parte da un modello semplice, con pochi elementi, e poi lo siraffina, aumentando man mano il grado di dettaglio, fino ad arrivare ad unmodello che sia soddisfacente rispetto ai nostri obiettivi.
Un elemento molto importante e il tipo di notazioni formali usato perrappresentare e descrivere il sistema. Innanzitutto le notazioni devono esseresufficientemente semplici e chiare da potere essere comprese facilmente datutti coloro che sono coinvolti sia esplicitamente che implicitamente nel pro-cesso di modellazione, cioe da quelli che spesso vengono chiamati portatoridi interessi. Si tratta non solo di chi avra il compito di prendere le decisionifinali e di farle eseguire, ma anche di dovra poi concretamente metterle inpratica, e di chi, operando nella realta sotto esame, detiene sia conoscenzeessenziali per la definizione e modellazione del sistema che i dati necessariper la sperimentazione. Un modello facilmente comprensibile permette unaverifica della sua correttezza da parte di tutti e quindi anche una maggio-re efficienza ed efficacia del processo di modellazione. Oltre che garantirechiarezza e semplicita, le notazioni devono essere anche sufficientemente ri-gorose da permettere una veloce ed efficiente implementazione del modelloper mezzo del software scelto.
In questo paragrafo descriveremo gli elementi formali che utilizzeremo percaratterizzare un sistema, introducendo anche le notazioni che verranno piufrequentemente usate. L’attenzione sara diretta al sistema fisico che si vuolemodellare, agli elementi che in esso compaiono, alle relazioni tra tali elementie alle attivita che vi si svolgono. Successivamente riesamineremo il processodi modellazione avendo come obiettivo l’implementazione di un simulatoredel sistema in esame.
I principali elementi che utilizzeremo per rappresentare un sistema sonole entita e le operazioni . Le prime descrivono cio che caratterizza un sistemada un punto di vista statico, mentre le seconde permettono di descrivernel’evoluzione nel tempo e di evidenziare le relazioni fra le sue parti.

2.1. Il sistema da modellare 15
2.1.1 Entita
Gli oggetti base del sistema da modellare sono le entita. Si tratta di ele-menti del sistema che vengono considerati individualmente, e del cui statosi mantiene informazione nel corso della simulazione. Tipiche entita sono ilpaziente che si presenta all’accettazione di un ospedale, il pezzo che vienelavorato in una catena di montaggio, oppure l’aereo in attesa di atterrare aun aereoporto.
Nel seguito distingueremo fra tipi di entita, o classi , e entita individualio oggetti1.
Attraverso una classe viene definito un tipo astratto di entita con le sueproprieta. Le proprieta sono costituite da un insieme di attributi che carat-terizzano tutte le entita che di quella classe sono istanziazioni. Ad esempioin un sistema costituito da uno sportello postale a cui si rivolgono clienti perrichiedere alcuni tipi di servizi, possiamo definire la classe cliente, caratte-rizzata da attributi quali: tipo e quantita di servizio richiesto, ora di arrivoallo sportello, . . . . Un oggetto della classe sara invece un particolare cliente,cioe ad esempio il cliente che si presenta allo sportello alle 11:32, con duebollettini di conto corrente da pagare. Pertanto ad un dato tipo di entitacorrispondera una sola classe ed un numero variabile, limitato o illimitato,di oggetti. Naturalmente la realta puo essere piu complessa, ad esempio conpiu sottoclassi della stessa classe.
Gli oggetti possono a volte essere raggruppati in insiemi . Ad esempio inun pronto soccorso ospedaliero possiamo considerare l’insieme degli infermie-ri. Nel corso delle operazioni del sistema, ciascuna attivita potra richiedereuno o piu infermieri; se il numero degli infermieri liberi non e sufficiente per losvolgimento dell’attivita, allora essa non potra iniziare finche non si rendanoliberi tanti infermieri quanti ne servono.
Alcune entita sono di tipo collettivo. Ad esempio un parcheggio con 100posti macchina puo essere rappresentato mediante la classe “posto macchi-na” con 100 istanze, cioe oggetti del tipo “posto macchina”. Ma, a menodi situazioni molto particolari, non ci interessera sapere se il singolo postomacchina e libero o occupato; ci basta invece sapere se ci sono posti liberi nelparcheggio e quanti ce ne sono. In questo caso il parcheggio viene considerato
1Cosı facendo prendiamo a prestito termini propri dell’informatica ed in particolaredella programmazione ad oggetti. Questa scelta e stata fatta per accentuare il fatto che iltipo di modellazione che stiamo presentando e orientata alla implementazione del modelloe quindi alla simulazione.

16 Capitolo 2. Simulazione discreta
come una unica entita collettiva: si dice allora che e una risorsa. Ovviamenteil decidere se una data entita sia o non sia da considerare una risorsa e unascelta che dipende da noi: al limite anche una entita individuale puo essereconsiderata come una risorsa di cardinalita 1. In generale si tratta di unascelta che deve essere guidata di considerazioni legate all’economia globaledel modello che si sta costruendo2.
Le entita possono essere permanenti o temporanee, attive o passive. Adesempio, nel caso di una coda a un botteghino teatrale, i clienti che arrivanosi mettono in coda ed escono dal sistema una volta serviti, possono essereconsiderati come entita temporanee e passive, mentre il botteghino svolgeil ruolo di entita permanente ed attiva. Comunque la distinzione e a voltearbitraria, dipendendo dalla percezione che ha del sistema colui che costruisceil modello e dalle sue scelte.
Infine una entita puo essere in uno stato di attesa oppure puo essereoccupata nello svolgimento di una qualche attivita. Uno stato del sistema edefinito come l’insieme degli stati delle entita che lo costituiscono.
2.1.2 Operazioni
Con il termine operazioni indichiamo tutto cio che attiene alla dinamicadel sistema e che fa sı che esso evolva passando da uno stato all’altro. Inparticolare parleremo di eventi , attivita e processi .
Eventi. Nei testi di Simulazione molto spesso con il termine evento si in-tende l’istante di tempo in cui avviene un cambiamento di stato del sistema.Qui lo intenderemo piuttosto come un fatto che produce un cambiamentodi stato nel sistema. Ad esempio la fine del servizio di un cliente ad unosportello fa sı che il cliente esca dal sistema e che l’impiegato allo sportellopassi dallo stato di occupato a quello di libero.
Attivita. Ognuna delle entita/oggetti presenti nel nostro sistema in ogniistante di tempo svolge delle attivita, avendo considerato anche l’attesa comeuna particolare attivita. Una attivita e qualcosa che si svolge fra due eventi
2Nella costruzione di un modello di simulazione e bene farsi guidare dal principio enun-ciato dal filosofo medievale Guglielmo da Ockham, meglio noto come il rasoio di Ockham:“Entia non sunt multiplicanda praeter necessitatem” (gli enti non vanno moltiplicati al dila di cio che e strettamente necessario).

2.1. Il sistema da modellare 17
e corrisponde ad uno stato di una o piu entita. Ad esempio l’attivita diservizio ad uno sportello si svolge tra l’evento di ‘inizio servizio’ e quello di‘fine servizio’, e coinvolge sia l’impiegato che opera allo sportello che il clienteche viene servito. Il primo svolge un ruolo attivo in questa attivita, mentreil secondo svolge un ruolo passivo.
Processi. I processi sono delle sequenze o cicli predefiniti di attivita (equindi di eventi). Ad esempio il passeggero di un aereo passa attraverso laseguente sequenza di attivita: arrivo al check-in, attesa in coda, check-in,arrivo al controllo di sicurezza, attesa in coda, controllo di sicurezza, attesaper la chiamata di imbarco, controllo alla porta d’imbarco, imbarco sull’aereo.
2.1.3 Cicli delle attivita
Un metodo molto usato per descrivere le transizioni da uno stato all’altro inun sistema e costituito dai cosiddetti cicli di attivita. In un ciclo di attivitagli stati vengono rappresentati come nodi in un grafo ed i passaggi da unostato all’altro come archi orientati. Si distingue fra stati attivi e stati passiviutilizzando due tipi diversi di rappresentazione grafica dei nodi: quadratiper rappresentare gli stati attivi e cerchi per rappresentare quelli passivi(figura 2.1). Spesso i due tipi di stati si alternano nello stesso ciclo: ad unostato attivo segue uno passivo e viceversa.
Attivo
Passivo
Figura 2.1. Rappresentazione degli stati
Riprendiamo l’esempio del servizio allo sportello gia utilizzato preceden-temente. In questo esempio, che consideriamo nella sua versione piu sem-plice, si hanno due classi, la classe ‘sportello’ e la classe ‘cliente’. La prima

18 Capitolo 2. Simulazione discreta
supponiamo abbia una sola istanziazione, avendo supposto l’esistenza di unsolo sportello, mentre la seconda ha un numero a priori illimitato di istan-ziazioni. Gli oggetti della classe cliente sono entita temporanee nel nostrosistema; infatti entrano nel sistema quando arrivano nell’ufficio e scompaionodal sistema dopo essere state servite. L’entita sportello e invece una entitapermanente.
I cicli delle attivita per le due classi sono quelli indicati nelle figure 2.2 e2.3. Osserviamo come il ciclo delle attivita ci permetta di evidenziare benenon solo gli stati veri e propri, ma anche le attivita ad essi associate e glieventi che segnano il passaggio dall’uno all’altro.
Servizio
Attesa
Figura 2.2. Il ciclo degli stati dell’addetto allo sportello
Combinando i cicli delle attivita delle diverse classi/entita presenti pos-siamo costruire il ciclo delle attivita del sistema, che riportiamo nella figura2.4.
In questo esempio abbiamo un solo tipo di cliente e questo rende partico-larmente semplice il ciclo delle attivita. Un esempio un po’ piu complesso equello del ‘botteghino del teatro’ utilizzato da Pidd (1998). In questo esem-pio il sistema e costituito dal botteghino di un teatro in cui vengono vendutii biglietti. L’addetto al botteghino (servente), oltre a vendere i biglietti aiclienti deve anche rispondere alle telefonate fornendo le informazioni richie-ste. Si hanno pertanto due code, una fisica di clienti, davanti allo sportello, eduna, virtuale, formata da chiamate in attesa (il sistema telefonico si supponeabbastanza sofisticato da consentirlo). Entrambe le code vengono processatecon una politica di tipo FIFO e i clienti hanno sempre la precedenza sullechiamate (mai rischiare di perdere un cliente pagante!). In questo caso ab-biamo tre classi di entita: cliente (un numero illimitato di entita temporanee

2.2. UML: un linguaggio di modellazione 19
Servizio
Attesa
Arrivo
Esterno
Figura 2.3. Il ciclo degli stati del cliente
e passive), chiamata (un numero illimitato di entita temporanee e passive),botteghino (una sola entita, permanente e attiva). I cicli delle attivita perle classi ‘cliente’ e ‘chiamata’ sono identici a quello di figura 2.3, mentre ilciclo delle attivita della classe ‘botteghino’ e quello riportato nella figura 2.5.Riprenderemo nel seguito questo esempio piu in dettaglio.
2.2 UML: un linguaggio di modellazione
Nel seguito, per rappresentare graficamente i modelli di simulazione useremola grafica e la sintassi del linguaggio per modellazione UML. Si tratta di unlinguaggio che pur essendo nato in altro contesto, quello della modellazionedi sistemi software, tuttavia per la sua versatilita si presta molto bene anchealla costruzione di modelli di simulazione. Ed in effetti gia da alcuni anniha fatto la sua comparsa anche in questo contesto. Per una introduzione allinguaggio UML rimandiamo al testo di Fowler (2000).
Le classi e gli oggetti che le istanziano vengono rappresentati per mezzodi rettangoli divisi in tre sezioni che contengono il nome della classe/entita,gli attributi e le operazioni. Per gli attributi viene spesso anche indicato iltipo di variabile che li definisce (intero, booleano, ...), mentre per le opera-zioni viene indicata la variabile il cui valore l’operazione calcola e il tipo ditale variabile. Una o entrambe le sezioni relative agli attributi ed alle ope-

20 Capitolo 2. Simulazione discreta
Servizio
Attesa
Arrivo
Esterno
Attesa
Figura 2.4. Il ciclo degli stati del sistema
razioni possono anche mancare. Nella figura 2.6 sono rappresentate le classidell’esempio dello sportello. Rispetto a quanto visto precedentemente abbia-mo aggiunto la classe ‘coda’ che ha una ben precisa relazione con la classecliente: gli oggetti della prima sono aggregazioni di oggetti della seconda.Questo fatto e graficamente rappresentato dal particolare simbolo usato perconnettere le due classi. Nella classe Impiegato abbiamo indicato come at-tributo una variabile booleana che e vera se l’impiegato e libero (in attesa)e falsa altrimenti3, ed una operazione che e quella di servire il cliente e cheprogramma la fine del servizio al tempo TC + t, dove TC e il tempo correntenella simulazione e t e il tempo di servizio del cliente che viene servito. Nellaclasse coda sono stati indicati un attributo, la lunghezza, variabile di tipointero, e due operazioni, Estrai() e Inserisci(). L’operazione Estrai() forni-
3Seguendo un uso diffuso nell’area della programmazione, abbiamo indicato la variabilecon la notazione nome.tipo, dove il primo e il nome della variabile, mentre il secondo e iltipo della variabile (un tempo nel nostro caso).

2.2. UML: un linguaggio di modellazione 21
Attesa
Serviziosportello
Rispostachiamate
Figura 2.5. Il ciclo degli stati del botteghino del teatro
sce il suo primo elemento, che nel nostro caso sara un oggetto di tipo Cliente,e lo cancella dalla coda; analogamente l’operazione Inserisci(Q) inserisce unoggetto di tipo Cliente nella coda. Un altro attributo importante potrebbeessere il tipo di gestione degli oggetti nella coda: FIFO, LIFO, . . . . La classeCliente ha come attributo il tempo di servizio, t.
Gli oggetti sono rappresentati con simboli simili a quelli usati per rappre-sentare le classi di cui sono istanziazioni. Naturalmente qui potremo averepiu copie dello stesso oggetto in dipendenza del numero di istanze presentinel sistema. Ad esempio se nel sistema avessimo due sportelli, nel diagrammaavremo due copie dell’oggetto sportello. Nella figura 2.7 e rappresentato ildiagramma degli oggetti presenti nel sistema costituito da un solo sportello.Ogni oggetto e caratterizzato dal suo nome e dalla classe alla quale appar-tiene, con la notazione “Nome: Classe”4. Come per le classi il rettangoloche li rappresenta puo contenere altre informazioni, quali gli attributi e leoperazioni che gli oggetti possono compiere.
4Per gli oggetti della classe Cliente abbiamo utilizzato i nomi C1, C2, . . . , e ne abbiamoindicati alcuni, l’uno sovrapposto all’altro, per indicare simbolicamente che il loro numeronon e a priori limitato.

22 Capitolo 2. Simulazione discreta
ImpiegatoLibero: Boolean = veroServi(t: Time)
CodaLunghezza.Integer = 0Estrai(): ClienteInserisci(c: Cliente )
Clientet: Time
*
Figura 2.6. Diagramma delle classi
I: Impiegato
C1: Cliente
C: Coda
Figura 2.7. Diagramma degli oggetti
Gli stati vengono rappresentati con i simboli di figura 2.8, dove sono in-dicati anche due stati speciali, quello iniziale e quello finale, ed il simbolousato per rappresentare le transizioni. Le transizioni hanno una etichettacostituita da tre sezioni (non tutte necessariamente presenti): evento, condi-zione ed azione. L’evento e il fatto che produce la transizione, la condizione,se verificata, e quella che fa sı che al verificarsi dell’evento effettivamente siabbia la transizione, mentre l’azione e l’oggetto della transizione stessa. Adesempio l’evento ‘fine del servizio’, se la condizione ‘coda non vuota’ e veri-ficata produce l’azione di chiamare il primo cliente in coda e di servirlo. Nelrettangolo arrotondato che rappresenta uno stato, nella zona sotto il nomedello stato possono essere indicate le diverse azioni che vengono effettuate

2.2. UML: un linguaggio di modellazione 23
nello stato.
Stato
evento [condizione]/azione
Figura 2.8. Stati e transizioni
Illustreremo ora l’uso del linguaggio UML attraverso la modellazione delproblema del botteghino teatrale presentato precedentemente. Il diagrammadelle entita e quello indicato in figura 2.9, dove sono indicate le classi e glioggetti che le istanziano. Attributo della classe cliente e il tipo, che e unavariabile booleana: puo assumere i valori p (cliente che si presenta di personaallo sportello) e t (cliente che chiama al telefono)5. Osserviamo la presenza didue code, una per ciascun tipo di cliente: Qp e la coda dei clienti che arrivanodi persona al botteghino, mentre Qt e la coda dei clienti che telefonano.
I: Impiegato
Ct1: Cliente
Qt: Coda Qp: Coda
Cp1: Cliente
ImpiegatoLibero: Boolean = VeroServi(t: Time)
CodaLunghezza.Integer = 0Estrai(): ClienteInserisci(c: Cliente )
Clientet: TimeTipo: p, t
*
Figura 2.9. Classi ed oggetti nell’esempio del botteghino teatrale
In figura 2.10 e riportato il diagramma degli stati per quel che riguardal’impiegato addetto allo sportello. Quando entra in servizio si trova nello
5Qui abbiamo scelto di avere una sola classe di clienti, distinguendo per mezzo di unattributo i due tipi di clienti. Ovviamente avremmo potuto in alternativa rappresentare iclienti per mezzo di una classe con due sottoclassi.

24 Capitolo 2. Simulazione discreta
stato di attesa, dal quale esce per iniziare un servizio non appena arrivi ilprimo cliente fisico oppure la prima telefonata. In questo caso l’evento chefa partire la transizione e l’arrivo del cliente e l’azione e l’inizio dell’attodi servire il cliente. Osserviamo che se arriva un cliente fisico, esso deveessere servito subito (i clienti successivi andranno in coda), mentre se arrivauna chiamata, essa verra servita solo se allo stesso tempo non e arrivato uncliente fisico6. Nel caso che l’addetto stia servendo un cliente, non appenail servizio finisce (evento FineServizio) verra controllata la lunghezza dellacoda Qp, e se non vuota (condizione) si iniziera a servire il primo cliente incoda Qp.Estrai(). L’operazione InizioServizio(Qp.Estrai()) esegue anchela cancellazione di Qp.Estrai() da Qp. Se poi Qp risulta vuota, si controllala coda Qt e, se non e vuota, si risponde alla prima chiamata in coda. Anchequi il cliente di cui si inizia il servizio viene cancellato dalla coda.
Attesa
Servizio
FineServizio[Qp.Lunghezza=0&Qt.Lunghezza>0]
FineServizio[Qp.Lunghezza>0]/InizioServizio(Qp.Pop())
FineServizio[Qp.Lunghezza=0&Qt.Lunghezza>0]/InizioServizio(Qt.Pop())
ArrivaCp/InizioServizio(Cp)
ArrivaCt/InizioServizio(Ct)
FineServizioInizioServizio()
Figura 2.10. Il Diagramma degli stati dell’impiegato nell’esempio delbotteghino teatrale
Il diagramma di figura 2.10 non contiene una descrizione completa di cio
6Questa relazione di precedenza non appare esplicitamente nel diagramma di figura2.10

2.2. UML: un linguaggio di modellazione 25
che accade nel nostro sistema. E infatti necessario anche descrivere gli sta-ti dei clienti, cosa che viene fatta in figura 2.11, con riferimento ai clientifisici; per gli altri il diagramma e nella sua struttura identico. Nel succes-sivo paragrafo vengono riportati alcuni esempi svolti con un certo livello didettagliodettaglio.
Attesa in coda Servizio FineServizioArrivaCp[Impiegato.Libero = Falso] /Qp.Inserisci(Cp)
FineServizio[Cp=Qp.Pop()]/IniziaServizio(Cp)
ArrivaCp [Impiegato.Libero = Vero]/IniziaServizio(Cp)
Figura 2.11. Diagramma degli stati del cliente nell’esempio del botteghinoteatrale
In realta si sarebbe potuto evitare di costruire un diagramma degli statianche per i clienti, anche se forse si sarebbe perso un po’ in leggibilita delmodello. I clienti infatti in questo esempio sono entita passive ed una ra-gionevole scelta puo essere quella di definire gli stati solamente per le entitaattive. Se avessimo deciso di fare cosı naturalmente avremmo dovuto arric-chire il diagramma degli stati per l’impiegato, ad esempio aggiungendo dueulteriori transizioni come in figura 2.12. Queste transizioni corrispondono al-l’arrivo dei clienti ed al loro inserimento in coda. Dal punto di vista formalee come se si desse all’impiegato anche il compito di gestire le code non soloper quel che riguarda le estrazioni ma anche gli inserimenti. In pratica sitratta di una operazione fittizia che richiede tempo nullo. La nostra sceltaqui, anche se a prezzo di una certa ridondanza, e stata guidata da esigenzedi chiarezza e leggibilita del modello.
Nel seguito saranno descritti alcuni esempi per i quali verranno presentatii diagrammi degli stati.
2.2.1 Esempi
Servizio piccoli prestiti
Si consideri una banca in cui il servizio dei piccoli prestiti funziona secondo leseguenti modalita. Il cliente si rivolge all’ufficio apposito, dove un impiegatoesamina la richiesta. Se questa rispetta un certo numero di criteri prefissati,viene approvata; altrimenti il cliente viene rinviato al funzionario responsabile

26 Capitolo 2. Simulazione discreta
Attesa
Servizio
FineServizio[Qp.Lunghezza=0&Qt.Lunghezza>0]
ArrivaCp/Qp.Inserisci(Cp) ArrivaCt/Qt.Inserisci(Ct)
FineServizio[Qp.Lunghezza>0]/InizioServizio(Qp.Pop())
FineServizio[Qp.Lunghezza=0&Qt.Lunghezza>0]/InizioServizio(Qt.Pop())
ArrivaCp/InizioServizio(Cp)
ArrivaCt/InizioServizio(Ct)
FineServizioInizioServizio()
Figura 2.12. Inclusione dell’operazione di inserimento in coda dei clienti nelDiagramma degli stati nell’esempio del botteghino teatrale
del servizio crediti. Il funzionario riesamina la pratica, rivede col clientel’importo del prestito e le eventuali condizioni, e quindi o approva la richiestaoppure la respinge definitivamente.
Ci sono in questo sistema tre classi di entita: cliente, impiegato e fun-zionario. Le entita cliente sono temporanee e passive: entrano nel sistemasecondo una data legge di probabilita, passano attraverso una o due code evengono servite dai relativi serventi, quindi escono dal sistema. Invece, le en-tita impiegato e funzionario sono permanenti ed attive. Nella figura 2.13 sonoindicate le tre entita. Abbiamo indicato qui un solo attributo per ciascunaclasse. Il cliente ha come attributo ‘Prestito approvato’, di tipo Booleano,che viene inizializzata a Falso. L’impiegato ed il funzionario hanno l’attri-buto, ‘Disponibile’ di tipo Booleano, che viene inizializzato al valore Vero,e che indica la disponibilita a servire un nuovo cliente; se il funzionario el’impiegato stanno servendo un cliente, allora e ‘Disponibile’=Falso.
Nella figura 2.14 e stato indicato il diagramma degli stati dei clienti. Unavolta arrivato, il cliente entra in coda e vi aspetta. La transizione avviene

2.2. UML: un linguaggio di modellazione 27
ClienteApprovato: Boolean
FunzionarioDisponibile: Boolean
ImpiegatoDisponibile: Boolean
Figura 2.13. Le entita
quando si verifica l’evento che l’impiegato si e reso libero ed e soddisfattala condizione che il cliente e il primo della coda. A questo punto il clientecambia di stato ed inizia il servizio (primo esame). In questo stato vengonoeffettuate le seguenti azioni: appena il servizio inizia l’attributo ‘Disponibile’dell’impiegato viene posto a Falso7, viene poi svolto il servizio ed infine siriporta al valore V ero l’attributo ‘Disponibile’. Poi, se il prestito e statoapprovato il cliente esce dal sistema, altrimenti passa alla seconda coda. Ipassaggi dalla seconda coda al secondo esame e poi l’uscita del cliente hannoun andamento analogo a quello relativo al primo esame.
Analogamente si possono costruire i diagrammi degli stati dell’impiegatoe del funzionario, che sono fra loro identici. In figura 2.15 e riportato quellodel funzionario8.
Il centro prelievi
Il centro prelievi di un ospedale e aperto nei giorni feriali dalle 7,30 alle 10.Anche qui abbiamo una classe clienti. Un cliente appena arrivato ritira unnumero da un’apposita macchinetta distributrice ed attende di essere chia-mato allo sportello per l’accettazione, dove presentera la richiesta di analisieffettuata dal suo medico curante. I clienti sono chiamati all’accettazione in
7In alcuni tipi di servizio questo e cio che avviene quando la luce sullo sportello cambiadi colore passando da verde a rossa.
8Qui abbiamo scelto di fare passare sempre nello stato Libero il funzionario dopo ognifine di servizio. Avremmo potuto invece, analogamente a quanto fatto nell’esempio delbotteghino teatrale, farlo rimanere nello stato di servizio fino allo svuotamento della coda.

28 Capitolo 2. Simulazione discreta
Prima Coda 1º esame
entry/Impiegato.Disponibile=Falsodo/Servizioexit/Impiegato.Disponibile=Vero
Seconda Coda
[Cliente.Approvato=Falso ]
2º esame
entry/Funzionario.Disponibile=Falsodo/Servizioexit/Funzionario.Disponibile=Vero
Funzionario.Disponibile=Vero [Cliente Primo in Coda ]/Inizio Servizio
Arrivo Cliente
Uscita Cliente
Impiegato.Disponibile=Vero [Cliente Primo in Coda ]/Inizio Servizio
[Cliente.Approvato=Vero ]
[Cliente.Approvato=Vero ]
[Cliente.Approvato=Falso ]
/Entra in coda
Created with Poseidon for UML Community Edition. Not for Commercial Use.
Figura 2.14. Servizio Piccoli Prestiti: Diagramma degli stati del cliente
ordine di numero crescente. Dopo l’accettazione il cliente si reca allo sportel-lo per il pagamento del ticket per poi mettersi in fila davanti all’ambulatorioin cui si effettuano i prelievi; se e esente dal ticket, si rechera direttamenteall’ambulatorio per il prelievo.
Le entita sono: i clienti, lo sportello per l’accettazione, lo sportello peril pagamento del ticket e l’ambulatorio per i prelievi. I clienti sono entitatemporanee e passive, in numero illimitato, caratterizzate da due attributi,Esente e Numero. Il primo indica se il cliente e esente o no dal pagamentodel ticket; si tratta di un attributo di tipo Boolean. Il secondo attributo eil numero che viene assegnato al cliente all’arrivo; questo numero servira perla coda dell’accettazione e per quella dei prelievi. Le altre entita sono inveceentita attive e permanenti; possono essere presenti in piu istanze: ad esempionell’ambulatorio possono esserci piu infermiere/i che effettuano i prelievi. Ildiagramma degli stati relativo ai clienti e riportato nella figura 2.16.
Il cliente, appena entrato nel sistema, riceve un numero, che corrispondeal suo ordine di arrivo, ed aspetta che il numero venga chiamato. A questopunto accede ad uno degli sportelli dell’accettazione, e interagisce con l’ad-detto, che, alla fine del servizio, gli da un foglio con tutti i dati degli esamirichiesti. Poi, se non e esente dal ticket, il cliente si mette in fila alla cassae quando si libera una cassa (numero di casse libere, NP, maggiore di zero)

2.2. UML: un linguaggio di modellazione 29
2º esame
entry/Funzionario.Disponibile=Falsodo/Servizioexit/Funzionario.Disponibile=Vero
Libero
[Servizio terminato][Coda non vuota]
Inizio orario servizio Fine orario servizio[Coda vuota ]Created with Poseidon for UML Community Edition. Not for Commercial Use.
Figura 2.15. Diagramma degli stati del funzionario
accede al pagamento; dopo di che passa alla coda 3. Qui vale il suo numeroiniziale, per cui quando il numero viene chiamato il cliente puo accedere alservizio prelievo.
In generale ci saranno disponibili piu sportelli per l’accettazione, piu cas-sieri per il pagamento e piu ambulatori per il prelievo. Nel diagramma nonabbiamo evidenziato questo fatto. Lo avremmo potuto fare espandendo cia-scuno degli stati relativi a servizi. Ad esempio, in figura 2.17 e indicatal’espansione dello stato Accettazione nell’ipotesi di due sportelli di servizio.Quando il numero viene chiamato viene anche indicato lo sportello relativoed il cliente chiamato accedera a quello sportello.
Possiamo immaginare che ci sia una classe Accettazione, che ha come at-tributo la variabile LN , ultimo numero chiamato, e come istanze le entitaSportello 1 e Sportello 2. Ciascuna delle due entita ha come attributo lavariabile booleana Disponibile. Quando una di queste entita si rende dispo-nibile chiama il numero successivo; la chiamata, che immaginiamo avvengaattraverso un display che porta oltre al numero chiamato anche quello dellosportello, viene letta dal cliente che si reca allo sportello.
Nella figura 2.18 abbiamo indicato il diagramma degli stati relativo all’ac-cettazione. Gli sportelli dell’accettazione aprono alle 7:30 e chiudono dopo le10:00 non appena e stato servito l’ultimo cliente arrivato. Durante l’apertura,non appena ci sia uno sportello disponibile, allora viene chiamato il numerosuccessivo. Con LN , variabile che all’inizio ha valore 0, abbiamo indicatoil numero dell’ultimo cliente chiamato al servizio, e con CMAX abbiamo in-dicato il numero dell’ultimo cliente arrivato. La condizione LN ≤ CMAXindica che il prossimo numero viene chiamato solo se ad esso corrisponde un

30 Capitolo 2. Simulazione discreta
Arrivo Cliente
Coda 1/Ricevi Numero Accettazione
Coda 2
[Cliente.Esente=Falso ]
Pagamento Ticket
NP > 0 [Cliente primo in coda ]
Coda 3
Pagamento completato
[Cliente.Esente=Vero ]
Prelievo
Cliente.Numero=NumeroChiamato
Uscita Cliente
Prelievo completato
Cliente.Numero=NumeroChiamato
Created with Poseidon for UML Community Edition. Not for Commercial Use.
Figura 2.16. Ciclo delle attivita dei clienti del Centro Prelievi
cliente in attesa. Dopo la chiamata inizia il servizio del cliente chiamato.Prima di iniziare le operazioni si rende non disponibile lo sportello9, ed allafine lo si rende di nuovo disponibile.
Un deposito per la distribuzione di merci
Una cooperativa di distribuzione ha un solo deposito, dove arrivano camionprovenienti dai produttori con le merci richieste, e da cui partono i furgonicon le merci destinate ai diversi supermercati appartenenti alla cooperativa.Ci sono 2 banchine per lo scarico dai camion e 4 per il carico dei furgoni.Ci sono 5 squadre di 2 addetti ciascuna, che provvedono a scaricare, metterein stock e caricare la merce sui furgoni. Esiste poi solo una via di accesso edi uscita, che consente il passaggio o di un camion (indipendentemente dalsenso di marcia) o di due furgoni (purche in senso opposto di marcia); nonc’e lo spazio perche passino contemporaneamente un camion ed un furgone.
Se l’obiettivo della simulazione e di studiare le attese dei camion e deifurgoni, possiamo pensare di considerare camion e furgoni come delle entita,
9Questa operazione potrebbe in pratica corrispondere al fatto che il display relativoallo sportello su cui era comparso il numero chiamato smetta di lampeggiare.
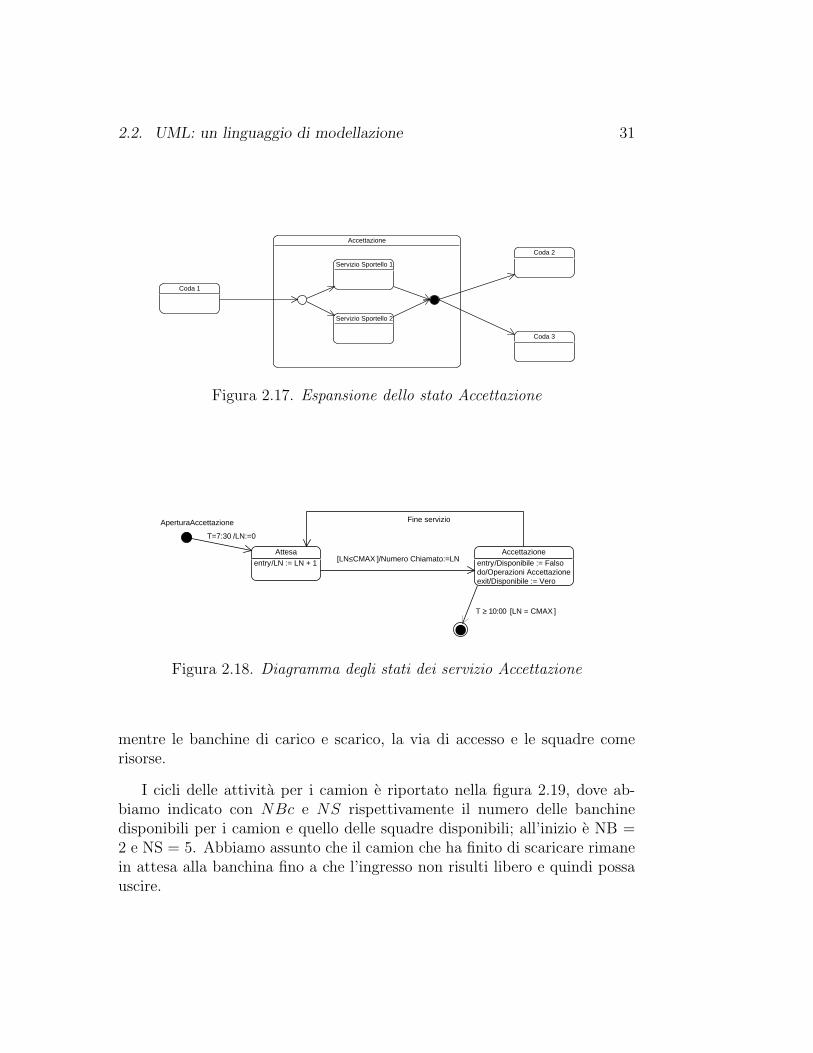
2.2. UML: un linguaggio di modellazione 31
Accettazione
Servizio Sportello 1
Servizio Sportello 2
Coda 2
Coda 1
Coda 3
Created with Poseidon for UML Community Edition. Not for Commercial Use.
Figura 2.17. Espansione dello stato Accettazione
Attesa
entry/LN := LN + 1
Accettazione
entry/Disponibile := Falsodo/Operazioni Accettazioneexit/Disponibile := Vero
[LN≤CMAX ]/Numero Chiamato:=LN
Fine servizioAperturaAccettazione
T=7:30 /LN:=0
Chiusura Accettazione
T ≥ 10:00 [LN = CMAX ]
Created with Poseidon for UML Community Edition. Not for Commercial Use.
Figura 2.18. Diagramma degli stati dei servizio Accettazione
mentre le banchine di carico e scarico, la via di accesso e le squadre comerisorse.
I cicli delle attivita per i camion e riportato nella figura 2.19, dove ab-biamo indicato con NBc e NS rispettivamente il numero delle banchinedisponibili per i camion e quello delle squadre disponibili; all’inizio e NB =2 e NS = 5. Abbiamo assunto che il camion che ha finito di scaricare rimanein attesa alla banchina fino a che l’ingresso non risulti libero e quindi possauscire.

32 Capitolo 2. Simulazione discreta
Arrivo Camion
Attesa ingresso/Entra in codaIngresso
entry/Ingresso := occupatodo/Entraexit/Ingresso := libero
NBc ≥ 1 [Primo in coda & Ingresso = libero ]
Attesa scarico
entry/NBc := NBc - 1
Scarico merce
entry/NS := NS - 1do/Operazioni di scaricoexit/NS := NS + 1
NS ≥ 1
Partenza Camion
Attesa uscita
exit/NBc := NBc + 1
Uscita
entry/Ingresso : occupatodo/Esciexit/Ingresso : libero
Ingresso = libero
Created with Poseidon for UML Community Edition. Not for Commercial Use.
Figura 2.19. Diagramma degli stati dei camion
2.3 Approcci alla simulazione
In generale in un programma di simulazione sono sempre presenti i seguentielementi:
• Controllore
• Tempo di simulazione
• Generatore dei dati di input
• Entita
• Eventi
• Attivita
• Stati
• Processi
Il controllore e la componente del sistema che gestisce la sequenza deglieventi e l’evolversi dello stato del sistema nel tempo. In particolare il control-lore ha il compito di fare avanzare il tempo di simulazione. Per quanto questafunzione sia presente in ogni modello, tuttavia il modo in cui essa viene svolta

2.3. Approcci alla simulazione 33
puo essere diverso. A diversi approcci alla simulazione corrispondono diversimodi di implementare il controllore. Un processo e una sequenza di stati edi transizioni da uno stato al successivo.
I diversi approcci corrispondono alla diversa enfasi che puo essere dataagli elementi. In generale una simulazione puo essere realizzata a partire daglieventi, dalle attivita, oppure dai processi. Ciascuno di questi tre approcci hasvantaggi e vantaggi. Nel seguito li presenteremo piu in dettaglio, servendocidi alcuni degli esempi visti precedentemente, e discuteremo i relativi meriti.
2.3.1 Simulazione per eventi
L’approccio basato sugli eventi ha una notevole importanza storica: i prin-cipali linguaggi orientati alla simulazione lo inglobano, anche se in generecome una delle opzioni. Permette di costruire programmi di simulazionemolto compatti ed efficienti, ma anche proprio per questo piu costosi dalpunto di vista della manutenzione e degli aggiornamenti.
Per modellare un simulatore per eventi abbiamo bisogno di introdurredelle nuove classi, che sono indicate nella figura 2.20.
Evento1
verificaCondizione():BoolEseguiAzione()
Evento1
verificaCondizione():BoolEseguiAzione()
Evento1
verificaCondizione():BoolEseguiAzione()
AgendaLunghezza: Int = 0Inserisci(e: Evento)Scandisci(t: Time): TimeEsegui(t: Time): Boolean
ControlloreTc: Time = 0cal: AgendaEsegui(end: Time)
Eventot: Time
VerificaCondizione():BooleanEseguiAzione()
Evento1t: TimeVerificaCondizione():BooleanEseguiAzione()
*
Figura 2.20. Diagramma delle classi in un simulatore per eventi
Oltre al controllore abbiamo la classe degli eventi (Evento), le diverseentita della classe (Evento1, Evento2, . . . ) ed il calendario degli eventiche devono avvenire (Agenda). La classe Agenda e caratterizzata da un

34 Capitolo 2. Simulazione discreta
attributo, Lunghezza, che fornisce il numero di eventi in essa contenuti, e datre operazioni: inserisci, che inserisce un nuovo evento; scandisci, che operauna scansione della lista al fine di determinare il tempo del prossimo evento;esegui, che, per ognuno degli eventi che avvengono al tempo corrente, necontrolla le condizioni e, se verificate, ne esegue le azioni.
Nel diagramma di figura 2.21 riportiamo la sequenza delle operazioni cheeffettua il controllore.
Tc = cal.scandisci(end)
cal.esegui(Tc)
[Tc < end]
[cal.Lunghezza = 0OR Tc = end]
Figura 2.21. Diagramma degli stati in un simulatore per eventi
Innanzitutto il controllore fa una scansione del calendario degli eventicalin modo da determinare il nuovo tempo corrente, TC , che viene posto alvalore del tempo in cui e previsto il primo degli eventi. Se questo temporisulta maggiore o uguale al tempo massimo, allora a TC viene attribuito ilvalore end e la simulazione termina. Invece se il tempo corrente e inferiore altempo massimo della simulazione, allora vengono eseguite le azioni relativeagli eventi di cal le cui condizioni sono verificate. Il calcolo del tempo correntee cio che fa avanzare il tempo di simulazione.
Nel caso del botteghino di teatro abbiamo tre tipi di eventi: ArrivaCp,ArrivaCt, FineServizio. Tutti e tre questi eventi agiscono, producendoazioni, sia sull’entita sportello che sulle entita di tipo cliente, anche se lofanno seguendo un ordine prestabilito. In particolare ArrivaCp agisce prima

2.3. Approcci alla simulazione 35
di ArrivaCt, nel caso i due eventi si verifichino nello stesso istante di tempo.Questo garantisce che un cliente fisico che arriva allo stesso tempo di unatelefonata venga servito prima.
Esaminiamo ora piu in dettaglio gli effetti dei tre eventi.
• ArrivaCp. Se L’impiegato e libero, allora l’evento fa iniziare il serviziodel cliente arrivato: l’impiegato passa allo stato di servizio, e lo stessoaccade per il cliente che non passa attraverso la coda.
• ArrivaCt. Se L’impiegato e libero, e non e arrivato contemporanea-mente un cliente fisico, allora l’evento fa iniziare il servizio del clientearrivato: l’impiegato passa allo stato di servizio, e lo stesso accade peril cliente che non passa attraverso la coda.
• FineServizio. Se l’impiegato non e libero, rimane nello stato di servi-zio ed inizia a servire il primo cliente della coda fisica, se ce ne sono,altrimenti risponde alla prima telefonata in coda. Se infine entrambe ledue code sono vuote, l’impiegato si mette in attesa, cambiando cosı distato. Contemporaneamente il cliente appena servito esce dal sistema,e il primo cliente in coda (nell’ordine fisica e telefonica), se esiste, passadallo stato di attesa a quello di servizio.
2.3.2 Simulazione per attivita
In questo approccio, a partire dal diagramma degli stati, si decompongono leattivita svolte nel sistema in attivita elementari. Queste attivita corrispon-dono agli eventi, cioe a quei fatti o azioni che portano ai cambiamenti di statodel sistema e che quindi danno origine alle transizioni. Il ruolo del controlloresara quello di gestire la lista delle attivita individuate in modo che venganoeseguite. Ogni attivita e caratterizzata dalla condizione che la fa avveniree dalle azioni che vengono corrispondentemente fatte, e viene rappresentatoper mezzo di una tabella in cui sono riportate le informazioni rilevanti.
Utilizzando anche qui la notazione UML, in figura 2.22 abbiamo indicatole principali classi ed entita presenti in un simulatore per attivita.
Oltre al controllore abbiamo la classe delle attivita (Attivita), le diverseentita della classe (Attivita1, Attivita2, . . . ) e la lista delle attivita (ListaAt-tivita). La classe delle attivita e caratterizzata da due attributi: il tempoal quale l’attivita deve essere realizzata e la condizione che la fa realizzare;uno solo dei due attributi sara sara presente in una data attivita. La lista

36 Capitolo 2. Simulazione discreta
ListaAttivitàL: Attività[n]
Sscandisci(t: Time): TimeEsegui(t: Time): Boolean
ControllorecurT: Time = 0lista: ListaAttivitàEsegui(end: Time)
Attivitàt:Timecondizione: Logic FormulaVerificaCondizione():BooleanEseguiAzione()
Evento1
verificaCondizione():BoolEseguiAzione()
Evento1
verificaCondizione():BoolEseguiAzione()
Evento1
verificaCondizione():BoolEseguiAzione()
Attività1t: TimeCondizione: Logic FormulaVerificaCondizione():BooleanEseguiAzione()
Figura 2.22. Diagramma delle classi in un simulatore per attivita
puo essere realizzata in diversi modi: il modo piu semplice e costituito da unvettore. Alla lista, che puo essere vista come un calendario delle attivita, so-no associate due operazioni: scandisci, che opera una scansione della lista alfine di determinare il tempo della prossima o delle prossime attivita eesegui,che esegue le attivita che vanno eseguite al tempo t e fornisce in output unavariabile booleana che e vera se tutte le attivita sono state eseguite.
Nel diagramma di figura 2.23 riportiamo la sequenza delle operazioni cheeffettua il controllore.
Innanzitutto il controllore fa una scansione della lista di attivita in mododa determinare il nuovo tempo corrente, TC , che viene posto al valore deltempo in cui e prevista la prima delle attivita da eseguire. Se questo temporisulta maggiore o uguale al tempo massimo, allora a TC viene attribuito ilvalore end e la simulazione termina. Invece se il tempo corrente e inferioreal tempo massimo della simulazione, allora vengono eseguite tutte le attivitadella lista le cui condizioni sono verificate (ciclo interno). Per fare questaoperazione e necessaria una nuova scansione della lista, che pero va esegui-ta piu volte: infatti l’esecuzione di una attivita puo rendere soddisfatte lecondizioni per un’altra fra quelle gia esaminate. L’operazione e completataquando una intera scansione della lista non porta alla esecuzione di nessunaattivita. Quando tutte le attivita da eseguire sono state completate il con-trollore va a calcolare il nuovo tempo corrente ed inizia un nuovo ciclo. Il

2.3. Approcci alla simulazione 37
Tc = lista.Scandisci(end)
done = lista.Esegui(Tc)
[Tc < end]
[done = falso][done = vero]
[Tc = end]
Figura 2.23. Diagramma delle operazioni effettuate dal controllore in unsimulatore per attivita
calcolo del tempo corrente e cio che fa avanzare il tempo di simulazione.Consideriamo l’esempio del botteghino di teatro e cerchiamo di indivi-
duare quali sono le attivita. Possiamo definire 6 attivita:
• a[1] Inizio servizio allo sportello
• a[2] Inizio servizio al telefono
• a[3] Fine servizio allo sportello
• a[4] Fine servizio al telefono
• a[5] Arrivo cliente allo sportello
• a[6] Arrivo cliente al telefono
Osserviamo come queste attivita siano attivita elementari e che non coin-cidano con le operazioni descritte nelle figure 2.10 e 2.11. Esse fanno piut-tosto riferimento all’inizio ed alla fine degli stati attivi. Le descriviamo piu

38 Capitolo 2. Simulazione discreta
in dettaglio di seguito, indicando per ogni attivita gli attributi (il tempo econdizione).
La prima attivita ha la struttura seguente:
Attivita a[1]: Inizio servizio allo sportelloAttributi -
I.Libero = vero & Qp.lunghezza > 0Azioni a[3].t := TC + Qp.Estrai().t; I.Libero := falso
In questo caso l’attributo tempo e vuoto, mentre la condizione e che allostesso tempo abbia valore vero l’attributo Libero dell’Impiegato I (I.Libero =vero) e risulti non vuota la coda (Qp.lunghezza > 0). Se la condizione everificata, si programma la fine del servizio al tempo corrente, TC , piu iltempo di servizio del cliente, cioe il suo attributo t, e si pone a falso il valo-re dell’attributo Libero dell’impiegato. Osserviamo che il cliente e ottenutoeffettuando l’operazione Estrai sulla coda Qp. Simile e la seconda attivita:
Attivita a[2]: Inizio servizio al telefonoAttributi -
I.Libero = vero & Qp.lunghezza = 0 & Qt.lunghezza > 0Azioni a[4].t := TC + Qt.Estrai().t; I.Libero := falso
La terza e la quarta attivita hanno le seguente struttura comune:
Attivita a[3]/a[4]: Fine servizioAttributi t
veroAzioni I.Libero := vero
Qui esiste un tempo al quale le attivita vanno realizzate, quello di fi-ne servizio calcolato dalle attivita a[1] o a[2], mentre la condizione e sem-pre verificata. L’unica azione che viene fatta e quella di rendere liberol’impiegato.
l’attivita a[5] e riportata di seguito. Non viene invece riportata la a[6]che e sostanzialmente identica.

2.3. Approcci alla simulazione 39
Attivita a[5]: Arrivo cliente fisicoAttributi t
veroAzioni Qp.Inserisci(nuovoCliente(rndp1())
a[5].t := TC + rndp2()
Qui le azioni sono due. Innanzitutto viene chiamato un generatore di nu-meri casuali (rndp1) che genera il cliente che arriva, con le sue caratteristiche;il cliente cosı generato viene inserito nella coda. Poi viene programmato ilprossimo arrivo, modificando il tempo della attivita. Anche qui si usa ungeneratore di numeri casuali (rndp2) per determinare l’intervallo di tempofra l’arrivo attuale ed il prossimo10.
In questo approccio abbiamo fatto la scelta di considerare attivita ele-mentari comportanti una singola operazione di cambiamento di stato. Adesempio, nel caso delle attivita “Arrivo cliente”, anche se la coda e vuota el’impiegato disponibile, si mette il cliente in coda; ci sara poi un’attivita ditipo “Inizio servizio” che si verifichera subito dopo (pero sempre nello stessoistante del tempo di simulazione) e che provvedera a fare iniziare il servizioestraendo il cliente dalla coda; per cui il tempo effettivo di permanenza in co-da e nullo. Ciascuna di queste attivita elementari e indipendente dalle altre.Questo ha il vantaggio di rendere abbastanza semplice l’aggiornamento o lamanutenzione di programmi di simulazione basati su questo approccio. Hapero un prezzo, l’effettuazione da parte del controllore di ripetute scansionidi una lista che puo essere notevolmente lunga.
Analizzando le attivita elementari si vede come esse possano essere con-siderate di due tipi, attivita condizionate e attivita programmate. Le primesono attivita che si verificano, indipendentemente dal valore del tempo disimulazione, ogni qualvolta siano verificate determinate condizioni logiche.Appartengono a questa classe nell’esempio del botteghino teatrale le attivitaa[1] ed a[2]. Infatti nella descrizione di queste attivita l’attributo tempo evuoto: lo svolgersi di esse dipende dallo stato complessivo del sistema. Leseconde invece sono destinate a svolgersi in tempi prefissati, indipendente-mente dallo stato del sistema. Sono di questo tipo nell’esempio le attivitaa[3], a[4], a[5], ed a[6].
Da questa osservazione segue che le scansioni ripetute di tutta la lista
10I generatori di numeri casuali, dei quali parleremo piu in dettaglio nel seguito servonoper realizzare nella simulazione dei tempi di arrivo e di servizio che abbiano le stesseproprieta statistiche di quelli reali.

40 Capitolo 2. Simulazione discreta
Tc = listaB.Scandisci(end)
done = listaC.Esegui(Tc)
[Tc < end]
[done = falso][done = vero]
[Tc = end]
listaB.Esegui(Tc)
Figura 2.24. Diagramma delle operazioni effettuate dal controllore nel metododelle tre fasi
delle attivita da parte del controllore portano a dei controlli non necessari.In effetti le attivita programmate possono essere scandite una sola volta,mentre le scansioni ripetute possono essere limitate alla parte della lista checontiene le attivita condizionate. Questo permette di rendere piu efficientile operazioni del controllore. Un approccio di questo tipo viene chiamatometodo delle tre fasi (Pidd, 1998). Il diagramma degli stati di un simulatoreche utilizzi il metodo delle tre fasi e indicato in figura 2.24, dove abbiamoindicato listaB e listaC rispettivamente la lista delle attivita programmatee quella delle attivita condizionate.
2.3.3 Simulazione per processi
In questo approccio tutti gli eventi del ciclo degli stati di una entita, con lerelative operazioni, vengono vengono accorpati in una sequenza detta proces-

2.3. Approcci alla simulazione 41
so. Un processo e sostanzialmente la sequenza delle operazioni descritte daldiagramma degli stati.
Nel caso del botteghino teatrale, ogni processo e relativo ad un cliente.Ad esempio il processo relativo ad un cliente fisico C puo essere pensatocome costituito dalle seguenti operazioni, in cui abbiamo usato le notazionigia introdotte a proposito della simulazione per attivita ed abbiamo indicatocon P (C)il processo che e esso stesso una entita del modello.
1. Arrivo del cliente C quando il tempo di simulazione e uguale al suotempo di arrivo, cioe TC = P (C).t.
2. Calcolo del tempo di arrivo , P (C ′).t del cliente successivo, C ′;
3. Generazione dell’entita C ′ e creazione del processo P (C ′);
4. Il processo P (C ′) viene posto in stato di attesa fino a che non risultiTC = P (C ′).t;
5. Il cliente C viene inserito nella prima coda, e viene posto in sta-to di attesa fino a quando non si trovi in testa alla coda e risultiImpiegato.Libero = vero;
6. Si pone Impiegato.Libero := falso, si pone P (C).Tempo Prossima Attivita=TC + C.t, e si pone il processo in stato di attesa fino a quandoTC = P (C).Tempo Prossima Attivita;
7. Si pone Impiegato.Libero := V ero e si interrompe il processo.
Un processo puo essere attivo oppure in attesa. In quest’ultimo caso, sipuo trattare di una attesa condizionata, quando la ripresa dell’attivita delprocesso dipende dal realizzarsi di condizioni esterne, oppure di un’attesaprogrammata, quando il tempo in cui il processo verra riattivato e predefi-nito. Nell’esempio c’e una attesa condizionata (operazione n.5) e due atteseprogrammate (operazioni n.4 e n.6).
Nell’esempio considerato, l’impiegato puo essere considerato come unarisorsa che viene utilizzata dai processi (clienti). In casi piu complessi sipossono avere diverse classi di entita e quindi tipi di processi che competonoper l’uso di risorse comuni. In questo caso si hanno processi che interagiscono,ciascuno condizionato dallo stato degli altri.

42 Capitolo 2. Simulazione discreta
In questo tipo di approccio, il programma di controllo deve mantenere unalista contenente, per ciascuna entita/processo due informazioni: il tempo diriattivazione (se conosciuto) ed il punto nel processo in cui la prossima riat-tivazione deve avvenire. Questa lista puo essere suddivisa in due sottoliste:quella degli eventi futuri, che contiene i processi in attesa non condizionataed il cui tempo di riattivazione e maggiore del tempo corrente; quella deglieventi correnti, che contiene i processi in attesa non condizionata che devo-no al tempo corrente essere riattivati, e tutti quelli in attesa condizionata.Questi ultimi stanno in questa lista, anche se non necessariamente verrannoriattivati, perche il riattivarsi di uno degli altri puo creare le condizioni perla loro riattivazione.
L’operazione tipica che il controllore effettua in questo tipo di approccioe:
(i) esegue una scansione della sottolista degli eventi futuri, in modo dadeterminare il nuovo tempo di simulazione che viene quindi aggiornato;
(ii) sposta dalla sottolista degli eventi futuri a quella degli eventi cor-renti le entita il cui tempo di riattivazione coincide con il nuovo tempo disimulazione;
(iii) esegue ripetute scansioni della sottolista degli eventi correnti, cercan-do di spingere ciascuna entita il piu avanti possibile nel suo processo (quan-do un’entita viene posta in attesa non condizionata, essa viene spostata allasottolista degli eventi futuri).
Naturalmente all’inizio il controllore deve inizializzare il sistema dando adesempio nel caso del botteghino valori vero all’attributo Libero dell’impiegatoe generando il primo cliente.
L’approccio per processi e porta a programmi di simulazione efficienticomputazionalmente. Esso richiede pero, soprattutto per modelli complessi,grande attenzione nella gestione delle interazioni tra processi: c’e ad esempioil rischio che si creino situazioni di stallo. Questo fatto e particolarmente cri-tico quando si debba intervenire su un modello gia esistente, per aggiornarloo modificarlo.

Capitolo 3
Funzioni di distribuzione e teststatistici
Presentiamo in questo capitolo i concetti e gli strumenti del Calcolo del-le Probabilita e della Statistica indispensabili per la costruzione e l’uso dimodelli di simulazione stocastica. La trattazione, che sara necessariamentemolto sintetica, e basata sul testo di Mood, Graybill e Boes ? e su quello diRoss ?, a cui rimandiamo per approfondimenti.
3.1 Variabili casuali
Uno spazio di probabilita e una tripla (Ω,F , P ), dove:
· Ω , lo spazio campione, e un insieme di elementi (tipicamente l’insiemedei possibili esiti di un esperimento);
· F , lo spazio degli eventi, e una famiglia di sottoinsiemi di Ω, caratteriz-zata delle seguenti proprieta :
i) Ω ∈ F ,ii) A ∈ F =⇒ Ω \ A ∈ F ,iii) A, B ∈ F =⇒ A ∪B ∈ F ;
· P : F →[0, 1], la funzione di probabilita, e una funzione reale avente leseguenti proprieta :
43

44 Capitolo 3. Funzioni di distribuzione e test statistici
i) P (A) ≥ 0,∀A ∈ F ,ii) P (Ω) = 1,iii) (A, B ∈ F) ∧ (A ∩B = ∅) =⇒ P (A ∪B) = P (A) + P (B);
Dalle proprieta sopra definite si possono derivare facilmente le seguenti:
A, B ∈ F =⇒ A ∩B ∈ F , e B \ A ∈ F ,P (Ω \ A) = 1− P (A),A ⊆ B =⇒ P (B \ A) = P (B)− P (A),P (A ∪B) = P (A) + P (B)− P (A ∩B)
Dato uno spazio di probabilita, (Ω,F , P ), una variabile casuale e unafunzione X: Ω → <, avente la proprieta che, per ogni reale r, ω ∈ Ω:X(ω) ≤ r ∈ F . L’uso dell’espressione “variabile casuale” non ha con-vincenti giustificazioni ed e causa di ambiguita; e comunque un’espressioneuniversalmente accettata e pertanto verra usata anche qui.
La funzione FX(x) = P (X ≤ x) = P (ω ∈ Ω : X(ω) ≤ x), definitasull’insieme dei reali, e detta funzione di distribuzione.
L’uso di variabili casuali e fondamentale nella simulazione stocastica. Neisistemi da simulare si presentano usualmente fenomeni non (facilmente) pre-vedibili apriori (arrivo di clienti ad uno sportello, quantita di pioggia in unadata stagione, guasti in un’apparecchiatura, . . . ). Tali fenomeni vengonorappresentati per mezzo di variabili casuali, delle quali, per mezzo di seriestoriche o di indagini campionarie, viene poi studiata la funzione di distribu-zione. Vengono quindi costruiti generatori di numeri casuali, aventi le stessedistribuzioni, che verranno usati nella simulazione per modellare i fenomenistessi.
Esempio 1 Ad uno sportello di banca assumiamo che si possano faresolamente tre operazioni, incasso di un assegno (operazione a), bonifico (ope-razione b) e versamento (operazione v), e che il singolo cliente faccia una soladi esse. Consideriamo come esperimento l’arrivo del prossimo cliente, comeesito dell’esperimento la richiesta di una delle operazioni, a, b e v, e comeevento il fatto che il cliente chieda una in un sottoinsieme delle operazioni(ad esempio la a o la v).
Poniamo allora Ω = a, b, v, F = 2Ω. Sia poi X la funzione cosı definita:

3.1. Variabili casuali 45
X(a) = 0,
X(b) = 1,
X(v) = 2.
La funzione X e una variabile casuale, infatti si ha:
r < 0 ω : X(ω) ≤ r = ∅,0 ≤ r < 1 ω : X(ω) ≤ r = a,1 ≤ r < 2 ω : X(ω) ≤ r = a, b,
2 ≤ r ω : X(ω) ≤ r = Ω.
Esempio 2 Si consideri il numero di pazienti che si presentano ad unambulatorio tra le 9 e le 10 di mattina, e poniamo Ω = 0, 1, 2, . . ., F = 2Ω,e X(ω) = ω (la funzione identita). La funzione X cosı definita e una variabilecasuale, infatti, per ogni reale r e
ω : X(ω) ≤ r = 0, . . . , brc ∈ F .
3.1.1 Distribuzioni discrete
Una variabile casuale e detta discreta, se l’insieme dei valori che puo assumeree numerabile. Sia (Ω,F , P ) uno spazio di probabilita, e X una variabilecasuale discreta che possa assumere i valori x1, x2, . . ., xk, . . .. Definiamo lafunzione di densita discreta:
fX(x) =
P (X = x), se x = xi, per qualche i = 1, 2, . . . ,0, altrimenti.
(3.1)
Le funzioni di densita e di distribuzione di X sono legate dalle seguentirelazioni:
FX(x) =∑xi≤x
fX(xi), (3.2)
fX(xi) = FX(xi)− limh→0+FX(xi − h). (3.3)

46 Capitolo 3. Funzioni di distribuzione e test statistici
La media di X, che sara indicata con µX , e definita dalla
E[X] =∑
i
xifX(xi). (3.4)
La media della variabile casuale Xr viene detta momento resimo di X eviene denotata come µr
X .La varianza X, indicata con σ2
X , e la media degli scarti quadratici rispettoalla media µX , e rappresenta una misura di dispersione di X. La sua radicequadrata, σX , e detta deviazione standard. La varianza e definita dalla
V ar[X] =∑
i
(xi − µX)2fX(xi), (3.5)
da cui e immediato derivare la
V ar[X] = E[X2]− (E[X])2. (3.6)
Se X e Y sono variabili casuali, e α ∈ <, allora valgono le seguentiproprieta:
E[α] = α,
E[αX] = αE[X],
E[X + Y ] = E[X] + E[Y ],
V ar[α] = 0,
V ar[αX] = α2V ar[X].
Se X e Y sono variabili casuali, la varianza della loro somma e data dalla:
V ar[X + Y ] = E[(X + Y − E[X + Y ])2]
= E[(X + Y − µX − µY )2]
= E[(X − µX)2 + (Y − µY )2 + 2(X − µX)(Y − µY )]
= σ2X + σ2
Y + 2Cov[X, Y ],
dove Cov[X, Y ] e la covarianza di X ed Y:
Cov[X,Y ] = E[(X − E[X])(Y − E[Y ])].

3.1. Variabili casuali 47
Se X ed Y sono indipendenti, allora la loro covarianza e nulla e si ha:
V ar[X + Y ] = V ar[X] + V ar[Y ].
Un ruolo rilevante nel legare fra loro media e varianza di una distribuzionehanno le Disuguaglianze di Chebyshef :
P (|X − µX | > rσX) ≤ 1/r2, (3.7)
P (|X − µX | < rσX) ≥ 1− 1/r2, (3.8)
dove r e un reale positivo.Introduciamo ora una funzione particolarmente importante ai fini della
determinazione di media e varianza di distribuzioni, la funzione generatricedei momenti :
mX(t) = E[etX ] = E[1 + Xt +1
2!(Xt)2 +
1
3!(Xt)3 + . . .] (3.9)
= 1 + µ1Xt +1
2!µ2Xt2 + . . . =
∞∑i=0
1
i!µiXti. (3.10)
dove la seconda uguaglianza deriva dall’espansione in della funzione etX . Ab-biamo assunto l’esistenza di un intervallo di ampiezza positiva, [−h, h], taleche per ogni t in esso contenuto la funzione mx(t) e definita..
E immediato verificare che risulta:
dr
dtrmX(0) = µrX . (3.11)
Nel seguito descriveremo brevemente alcune delle piu comuni funzioni didistribuzione. Dato un insieme S, con IS(x) indicheremo una funzione chevale 1 se x ∈ S e 0 altrimenti.
Distribuzione uniforme
Sia X una variabile casuale che assume i valori 1, 2, ..., n. Essa viene dettaavere una distribuzione uniforme se risulta:
fX(x) = fX(x; n) =
1n, x = 1, 2, ..., n
0, altrimenti=
1
nI1,2,...,n(x), (3.12)

48 Capitolo 3. Funzioni di distribuzione e test statistici
Si ha
E[X] =1
n
n∑i=1
i =(n + 1)n
2n=
n + 1
2;
V ar[X] = E[X2]− (E[X])2 =1
n
n∑i=1
i2 − (n + 1)2
4
=n(n + 1)(2n + 1)
6n− (n + 1)2
4=
n2 − 1
12;
mX(t) =1
n
n∑j=1
ejt.
Esempio La variabile casuale che rappresenta l’esito del lancio di undado ha distribuzione uniforme con n=6 (naturalmente nell’ipotesi che ildado non sia truccato).
Distribuzione binomiale
Consideriamo un esperimento che abbia due possibili esiti, che possiamochiamare S (successo) e F (fallimento), l’uno con probabilita p e l’altro conprobabilita q = 1 − p. Assumiamo ora di eseguire n volte l’esperimentoin modo che ciascun esito sia indipendente dagli altri, e consideriamo comevariabile casuale X il numero di volte in cui si ha un successo cioe in cuil’esito dell’esperimento e S.
Chiaramente e:
fX(x) = fX(x; n, p) =
(nx
)pxqn−x, x = 0, 1, 2, ..., n
0, altrimenti. (3.13)
La variabile casuale X viene detta avere una distribuzione binomiale.
mX(t) =n∑
i=0
eti
(n
i
)piqn−i =
n∑i=0
(n
i
)(pet)iqn−i = (q + pet)n. (3.14)
Possiamo pertanto calcolare la media e la varianza. Essendo
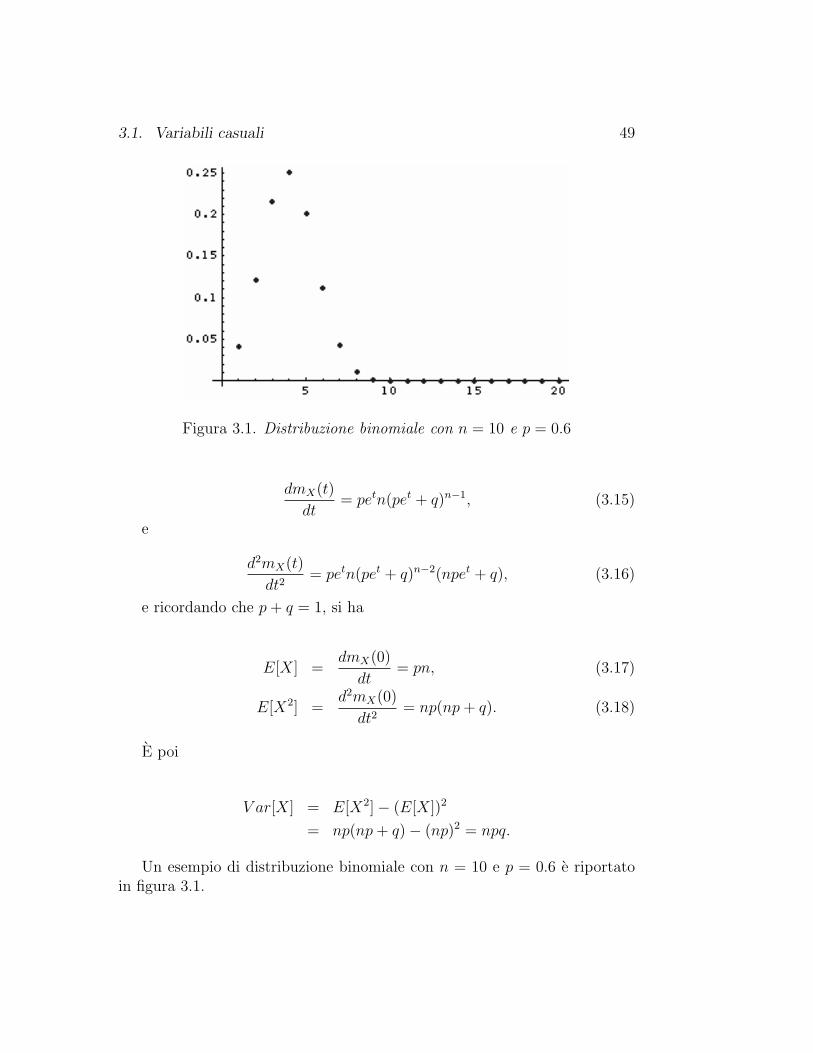
3.1. Variabili casuali 49
Figura 3.1. Distribuzione binomiale con n = 10 e p = 0.6
dmX(t)
dt= petn(pet + q)n−1, (3.15)
e
d2mX(t)
dt2= petn(pet + q)n−2(npet + q), (3.16)
e ricordando che p + q = 1, si ha
E[X] =dmX(0)
dt= pn, (3.17)
E[X2] =d2mX(0)
dt2= np(np + q). (3.18)
E poi
V ar[X] = E[X2]− (E[X])2
= np(np + q)− (np)2 = npq.
Un esempio di distribuzione binomiale con n = 10 e p = 0.6 e riportatoin figura 3.1.

50 Capitolo 3. Funzioni di distribuzione e test statistici
Nel caso particolare in cui n = 1 si parla di distribuzione di Bernoulli.Supponiamo ora di avere n realizzazioni di una variabile casuale con distri-buzione di Bernoulli. La probabilita di avere x di tali realizzazioni uguali ad1 e
(nx
)pxqn−x. Abbiamo cosı ottenuto una v.c. con distribuzione binomiale.
E possibile dimostrare che se X1, X2, . . . , Xm sono variabili casuali in-dipendenti, con distribuzione binomiale con parametri n1, n2, . . . , nm e p,allora la variabile casuale Y =
∑mi=1 Xi ha una distribuzione binomiale con
parametri n =∑m
i=1 ni.
Oserviamo infine che la distribuzione binomiale e simmetrica se e solo sep = 0.5
Una applicazione interessante della distribuzione binomiale si ha nel con-trollo di qualita: il numero di pezzi difettosi in un lotto di dimensione n,assumendo che sia p la probabilita che un pezzo abbia dei difetti, ha unadistribuzione binomiale con parametri n e p.
Esempio Nel volo Roma-Milano delle 16 della compagnia aerea AirPa-dania ci sono disponibili 80 posti. La probabilita che un viaggiatore prenotatonon si presenti alla partenza sia indicata con p. Assumiamo che il valore dip dipenda dalla fascia oraria e dal tipo di volo, ma che per dato volo sialo stesso per ogni passeggero. Avendo gia 80 prenotazioni, la AirPadania,per decidere che politica di “overbooking” seguire, vuol sapere quale e ladistribuzione di probabilita della v.c. X = numero di viaggiatori che nonsi presentano. Il presentarsi o non presentarsi di un singolo viaggiatore puoessere visto come il realizzarsi di una v.c. con distribuzione di Bernoulli.Pertanto la X ha una distribuzione binomiale con n = 80.
Distribuzione geometrica
Supponiamo di effettuare una sequenza di esperimenti identici ed indipen-denti, ciascuno dei quali ha come esito S (successo) con probabilita p e F(fallimento) con probabilita q = 1− p. Consideriamo come variabile casualeX il numero di fallimenti prima di ottenere un successo. Abbiamo allora chee
P [X = k] = p(1− p)k, k = 0, 1, 2, . . .
La funzione generatrice dei momenti e data da:

3.1. Variabili casuali 51
mX(t) =∞∑i=0
eitp(1− p)i = p
∞∑i=0
[et(1− p)]i.
e se assumiamo che essa sia definita in un intorno sufficientemente piccolodello 0 per cui risulti et(1− p) < 1, allora e1
mX(t) =p
1− et(1− p).
Possiamo ora calcolare la media e la varianza:
E[X] = m′X(0) =
1− p
p;
V ar[X] = E[X2]−E[X]2 = m′′X(0)−E[X]2 =
(1− p)(2− p)
p2−(1− p)2
p2=
1− p
p2.
Distribuzione di Poisson
Consideriamo eventi che accadono nel tempo, quali l’arrivo di clienti ad unosportello (di telefonate ad un centralino, ...); sia ν il numero medio di occor-renze dell’evento nell’unita di tempo, e supponiamo che valgano le seguentiproprieta.
• La probabilita di avere esattamente una occorrenza in un intervallo ditempo di ampiezza h opportunamente piccola (h 1) e νh+o(h), dovecon o(h) viene indicato un infinitesimo di ordine superiore rispetto adh.
• La probabilita di piu di un’occorrenza in un intervallo di ampiezza h eun o(h).
• I numeri di occorrenze in intervalli disgiunti sono indipendenti.
Una sequenza temporale di eventi che abbiano le proprieta indicate sopraviene anche detta un Processo di Poisson.
Dato un processo di Poisson, consideriamo la variabile casuale X ugualeal numero di eventi che si verificano in un dato intervallo (0, t). Dividiamo
1Ricordiamo che, per le proprieta della serie geometrica, se a < 1, allora e∑∞
i=0 ai =1
1−a .

52 Capitolo 3. Funzioni di distribuzione e test statistici
Figura 3.2. Distribuzione di Poisson
l’intervallo in n intervallini di ampiezza tn. La probabilita di avere esatta-
mente una occorrenza in un dato intervallino, a meno di un infinitesimo diordine superiore rispetto a t
n, e ν t
n, e per la proprieta dell’indipendenza,
abbiamo che la probabilita di k occorrenze e, a meno di un infinitesimo diordine superiore data dalla
P [X = k] =
(n
k
) (νt
n
)k (1− νt
n
)n−k
=n(n− 1)...(n− k + 1)
k!nk(νt)k
(1− νt
n
)n (1− νt
n
)−k
−−−→n→∞
(νt)ke−νt
k!.
Abbiamo cosı ricavato una distribuzione molto usata, nota come distri-buzione di Poisson.
fX(x) = fX(x; λ) =
e−λλx
x!, x = 0, 1, 2, ...
0, altrimenti, (3.19)
Esempi di distribuzioni di Poisson con λ = 2 e λ = 5 sono riportati infigura 3.2.
Calcoliamo la funzione generatrice dei momenti

3.1. Variabili casuali 53
mX(t) = e−λ
∞∑i=0
(etλ)i
i!= eλ(et−1), (3.20)
dove l’uguaglianza deriva dal fatto che e∑∞
i=0ai
i!= ea.
Si ha allora
dmX(t)
dt= λeλ(et−1)+t, (3.21)
d2mX(t)
dt2= λeλ(et−1)+t(λet + 1), (3.22)
da cui
E[X] =dmX(0)
dt= λ, (3.23)
E[X2] =d2mX(0)
dt2= λ(λ + 1). (3.24)
Possiamo quindi calcolare la varianza:
V ar[X] = E[X2]− E[X]2 = λ(λ + 1)− λ2 = λ. (3.25)
Questa distribuzione fornisce un ragionevole modello per molti fenomenicasuali in cui si vuole descrivere il numero di volte che un dato evento avvienenell’unita di tempo, ad esempio numero di arrivi ad uno sportello nell’unitadi tempo.
3.1.2 Distribuzioni continue
Una variabile casuale, X, e detta continua se esiste una funzione reale fX
tale che per ogni x reale :
FX(x) =
∫ x
−∞fX(u)du,
dove fX e la funzione di densita di probabilita, o piu semplicemente lafunzione di densita.
Per i punti x in cui la FX(x) e differenziabile, vale la:

54 Capitolo 3. Funzioni di distribuzione e test statistici
fX(x) =dFX(x)
dx.
E quindi possibile data l’una delle due funzioni, densita o distribuzione,trovare l’altra.
Nel caso di variabili continue, la media della variabile X viene definitacome segue
E[X] = µX =
∫ ∞
−∞xfX(x)dx.
Di conseguenza si definiscono la varianza, i momenti e la funzione gene-ratrice dei momenti, per cui valgono le proprieta gia viste a proposito delledistribuzioni discrete:
V ar[X] = E[(X − µX)2] = E[X2]− (E[X])2,
µrX = E[Xr],
mX(t) = E[etX ]
Le proprieta della funzione generatrice dei momenti sono simili a quelledella funzione generatrice dei momenti per il caso discreto.
Distribuzione uniforme
Una variabile casuale, X, e uniformemente distribuita nell’intervallo reale[a, b] se e caratterizzata dalle seguenti funzioni di densita e distribuzione
fX(x) = fX(x; a, b) =1
b− aI[a,b](x),
FX(x) =
(x− a
b− a
)I[a,b](x) + I(b,∞)(x),
Si ha allora

3.1. Variabili casuali 55
E[X] =
∫ b
a
x
b− adx =
b + a
2,
V ar[X] = E[X2]− (E[X])2 =
∫ b
a
x2
b− adx−
(a + b
2
)2
=b3 − a3
3(b− a)− (a + b)2
4=
(b− a)2
12,
mX(t) =
∫ b
a
etx 1
b− adx =
ebt − eat
(b− a)t
La distribuzione uniforme gioca un ruolo particolarmente importante nel-la simulazione. Usualmente infatti si parte da generatori di variabili casualiuniformi per derivare le diverse distribuzioni che servono. Osserviamo che inquesto caso la funzione generatrice dei momenti non e definita nello 0.
Distribuzione normale
Una distribuzione di particolare importanza sia dal punto di vista della teoriache da quello delle applicazioni pratiche e la distribuzione normale:
fX(x) = fX(x; µ, σ) =1√2πσ
e−(x−µ)2
2σ2 ,
dove i parametri µ e σ sono rispettivamente la media e la deviazione standard;infatti e
mX(t) = E[etX ] = etµE[et(X−µ)]
= etµ
∫ ∞
−∞
1√2πσ
et(x−µ)e−(x−µ)2
2σ2 dx
= etµ
∫ ∞
−∞
1√2πσ
e−(x−µ)2−2σ2t(x−µ)
2σ2 dx
= eµt+σ2t2
2
∫ ∞
−∞
1√2πσ
e−(x−µ−σ2t)2
2σ2 dx.
Osserviamo che l’integrale fornisce l’area sotto la curva che definisce ladensita di una variabile casuale normale con media µ− σ2t e varianza σ2, epertanto vale 1. Si ha allora
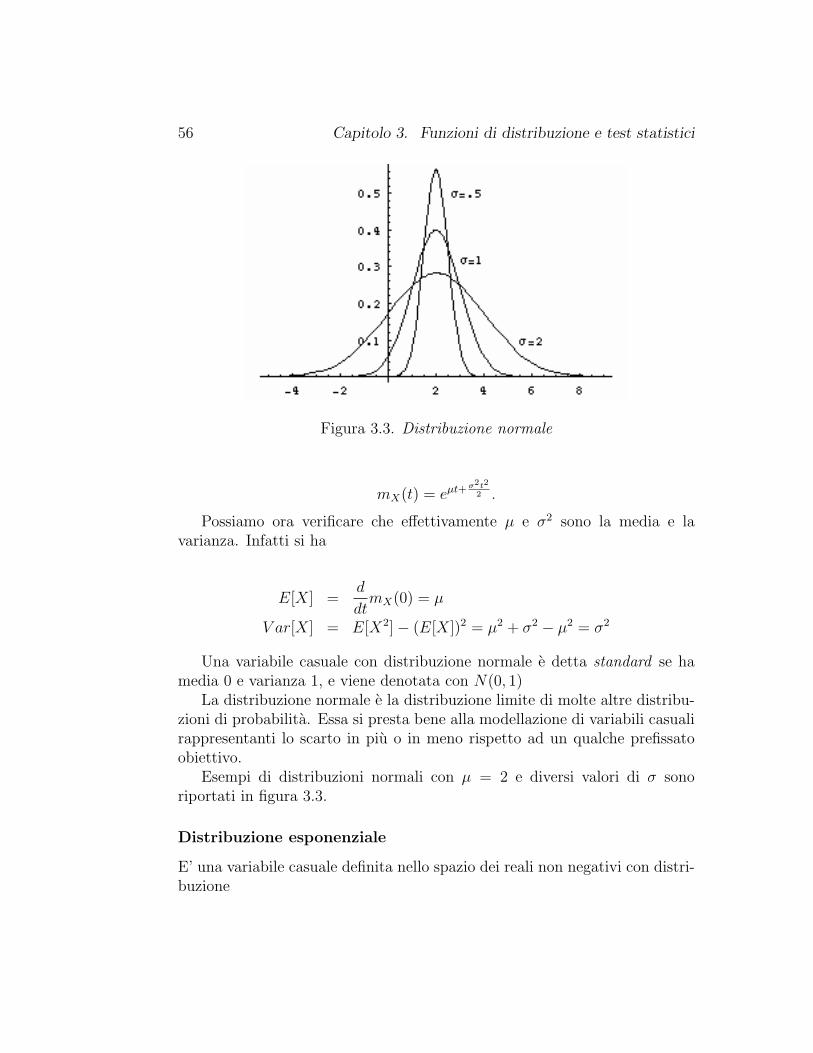
56 Capitolo 3. Funzioni di distribuzione e test statistici
Figura 3.3. Distribuzione normale
mX(t) = eµt+σ2t2
2 .
Possiamo ora verificare che effettivamente µ e σ2 sono la media e lavarianza. Infatti si ha
E[X] =d
dtmX(0) = µ
V ar[X] = E[X2]− (E[X])2 = µ2 + σ2 − µ2 = σ2
Una variabile casuale con distribuzione normale e detta standard se hamedia 0 e varianza 1, e viene denotata con N(0, 1)
La distribuzione normale e la distribuzione limite di molte altre distribu-zioni di probabilita. Essa si presta bene alla modellazione di variabili casualirappresentanti lo scarto in piu o in meno rispetto ad un qualche prefissatoobiettivo.
Esempi di distribuzioni normali con µ = 2 e diversi valori di σ sonoriportati in figura 3.3.
Distribuzione esponenziale
E’ una variabile casuale definita nello spazio dei reali non negativi con distri-buzione
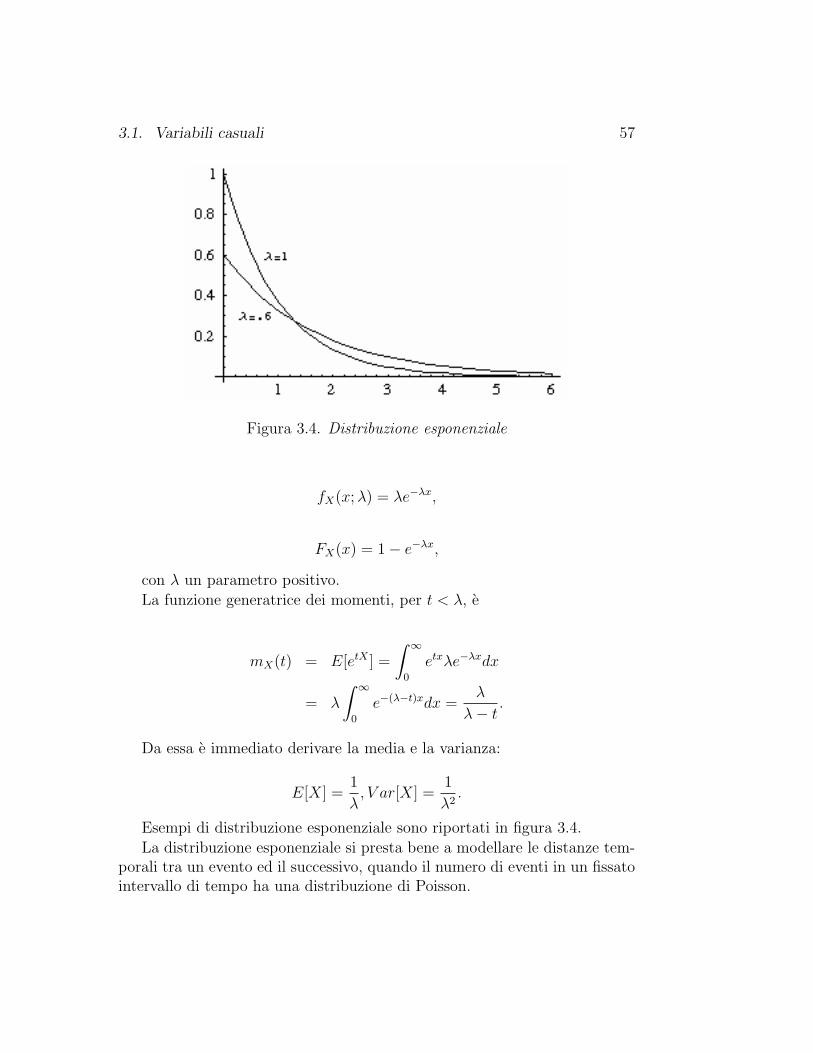
3.1. Variabili casuali 57
Figura 3.4. Distribuzione esponenziale
fX(x; λ) = λe−λx,
FX(x) = 1− e−λx,
con λ un parametro positivo.
La funzione generatrice dei momenti, per t < λ, e
mX(t) = E[etX ] =
∫ ∞
0
etxλe−λxdx
= λ
∫ ∞
0
e−(λ−t)xdx =λ
λ− t.
Da essa e immediato derivare la media e la varianza:
E[X] =1
λ, V ar[X] =
1
λ2.
Esempi di distribuzione esponenziale sono riportati in figura 3.4.
La distribuzione esponenziale si presta bene a modellare le distanze tem-porali tra un evento ed il successivo, quando il numero di eventi in un fissatointervallo di tempo ha una distribuzione di Poisson.

58 Capitolo 3. Funzioni di distribuzione e test statistici
Consideriamo un evento le cui occorrenze nel tempo hanno una distri-buzione di Poisson. Supponendo che si sia appena verificata un’occorren-za, chiamiamo con X la variabile casuale “tempo da attendere prima dellaoccorrenza successiva”. E allora
P [X > t] = P [nessuna occorrenza fino al tempo t] = e−νt,
e di conseguenza
FX(t) = P [X ≤ t] = 1− e−νt, t ≥ 0.
Una caratteristica importante della distribuzione esponenziale e che, perogni coppia (s, t) di reali positivi, vale la
P [X > s + t|X > s] = P [X > t]. (3.26)
Infatti e
P [X > s + t|X > s] =P [X > s + t]
P [X > s]=
e−λ(s+t)
e−λs= e−λt = P [X > t].
Si parla in questo caso di proprieta di assenza di memoria. Per capirne ilsenso assumiamo di avere un processo di Poisson e che sia passato il tempos dall’ultimo evento verificatosi. Ci si chiede quale sia la probabilita chepassi ancora almeno un tempo t prima che si verifichi il prossimo evento. Laproprieta di assenza di memoria per la distribuzione esponenziale ci dice chela probabilita cercata e indipendente dal valore di s: possiamo cioe fare comese il processo iniziasse nel momento in cui ci troviamo.
Vale inoltre la seguente proprieta:
P [cX ≤ x] = P [X ≤ x
c] = 1− e
λcx
Cioe se X e una variabile casuale esponenziale con parametro λ, alloracX e una variabile casuale esponenziale con parametro λ
c.
Distribuzione Gamma
Siano X1, X2, . . . , Xn variabili casuali indipendenti con distribuzione espo-nenziale e parametro λ. Consideriamo la nuova variabile casuale

3.1. Variabili casuali 59
Yn =n∑
i=1
Xi.
Per studiare la funzione di distribuzione di Yn, osserviamo che ciascunaXi puo essere pensata come il tempo intercorso fra due eventi successivi in unprocesso poissoniano con λ occorrenze in media nell’unita di tempo. Allorala probabilita che Yn sia minore o uguale a t e pari alla probabilita che neltempo t si verifichino almeno n eventi, cioe:
FYn(t) = P [Yn ≤ t] =∞∑
j=n
(λt)je−λt
j!.
Possiamo calcolare ora la funzione di densita:
fYn(t) = F ′Yn
(t) =∞∑
j=n
λj(λt)j−1e−λt − λ(λt)je−λt
j!
= λe−λt(∞∑
j=n
(λt)j−1
(j − 1)!−
∞∑j=n
(λt)j
j!) = λe−λt (λt)n−1
(n− 1)!.
Questa distribuzione viene chiamata distribuzione Gamma con parametrin e λ.
Esempi di distribuzione Gamma sono riportati in figura 3.5.La media e la varianza sono date dalle:
E[Yn] =n
λ, V ar[Yn] =
n
λ2.

60 Capitolo 3. Funzioni di distribuzione e test statistici
Figura 3.5. Distribuzione Gamma con λ = 1.
3.2 Stima di parametri
3.2.1 Media e varianza del campione
Siano X1, X2, ..., Xn v.c. indipendenti con una data distribuzione F , e conE[Xi] = µ e V ar[Xi] = σ2, i = 1, . . . , n.
la quantita
Xn =1
n
n∑i=1
Xi,
e detta media campionaria, ed e uno stimatore di µ; puo quindi essere usataper stimare questo parametro, quando esso non sia noto. Osserviamo che sitratta di uno stimatore corretto, infatti e
E[Xn] = µ.
Per valutare la bonta di Xn come stimatore osserviamo che risulta
V ar[Xn] =1
nσ2,
e pertanto lo stimatore e tanto piu accurato quanto piu grande e n.Uno stimatore corretto della varianza σ2 e
S2n =
∑ni=1(Xi −Xn)2
n− 1.

3.2. Stima di parametri 61
Infatti si ha:
(n− 1)E[S2n] = E[
n∑i=1
(Xi −Xn)2]
=n∑
i=1
E[X2i ]− nE[X
2
n].
Dalla (3.6) si ha che
E[X2i ] = V ar[Xi] + E[Xi]
2,
e pertanto
(n− 1)E[S2n] =
n∑i=1
(V ar[Xi] + E[Xi]2)− n(V ar[Xn] + E[Xn]2)
= nσ2 + nµ2 − nσ2
n− nµ2
= (n− 1)σ2.
Abbiamo cosı mostrato che e E[S2n] = σ2.
3.2.2 Intervalli di confidenza
Ci proponiamo ora di ottenere una valutazione della bonta della stima diµ fornita dalla media campionaria Xn. La possibilita di valutare la bontadella stima e importante al fine di determinare il valore di n che consente distimare µ con la voluta accuratezza.
Per il teorema del limite centrale, per n opportunamente grande, e
√n
Xn − µ
σ
·∼ N(0, 1),
dove·∼ N(0, 1) significa: “e approssimativamente distribuito come una nor-
male standard”.La stessa cosa vale se sostituiamo σ, che non conosciamo, con la sua stima
Sn.Sia Z una v.c. normale standard; per ogni α ∈ (0, 1) sia zα il valore per
cui e

62 Capitolo 3. Funzioni di distribuzione e test statistici
P (Z > zα) = α.
Abbiamo allora
P (−zα/2 < Z < zα/2) = 1− α,
e quindi
P (−zα/2 <√
nXn − µ
Sn
< zα/2) ≈ 1− α,
o equivalentemente, moltiplicando per -1,
P (−zα/2 <√
nµ−Xn
Sn
< zα/2) ≈ 1− α,
da cui
P (Xn − zα/2Sn√n
< µ < Xn + zα/2Sn√n
) ≈ 1− α,
Abbiamo cosı trovato che, con probabilita 1 − α, il valore µ incognito sitrova nell’intervallo Xn ± zα/2
Sn√n. Si dira allora che abbiamo una stima di µ
con un intervallo di confidenza del 100(1− α)%.
Ad esempio, essendo P (Z < 1.96) = 0.975, si ha che la probabilita che lamedia campionaria Xn differisca da µ di piu di 1.96 Sn√
ne circa 0.05.
Supponiamo ora di volere stimare la media di una variabile casuale X, lacui distribuzione non e nota, in modo che la probabilita che di fare un erroremaggiore di d sia pari ad α, con d ed α valori prefissati.
Se c e il reale per cui risulta P (Z < c) = 1− α/2, si generano successiverealizzazioni di X fino ad averne un numero k tale che risulti c Sk√
k< d. E
comunque opportuno che tale valore non sia inferiore a 30.
Per realizzare in modo efficiente il calcolo e opportuno disporre di formulericorsive per il calcolo di Xk e di S2
k . Tale formula e facilmente derivabile perla media:

3.2. Stima di parametri 63
Xk+1 =1
k + 1
k+1∑j=1
Xj
= Xk −Xk +kXk + Xk+1
k + 1
= Xk +Xk+1 −Xk
k + 1.
Per quel che riguarda la varianza, possiamo scrivere:
S2k+1 =
k+1∑j=1
(Xj −Xk+1)2
k
=k∑
j=1
(Xj −Xk + Xk −Xk+1)2
k+
(Xk+1 −Xk+1)2
k
=k∑
j=1
(Xj −Xk)2 + (Xk −Xk+1)
2 + 2(Xj −Xk)(Xk −Xk+1)
k
+(Xk+1 −Xk+1)
2
k
= (1− 1
k)S2
k + (Xk −Xk+1)2 +
(Xk+1 −Xk+1)2
k,
dove l’ultima uguaglianza deriva dal fatto che e∑k
j=1(Xj −Xk) = 0.Essendo
Xk+1 −Xk+1 =(k + 1)Xk+1 −
∑k+1j=1 Xj
k + 1
=kXk+1 −
∑kj=1 Xj
k + 1
=kXk+1 −
∑kj=1[(k + 1)Xj − kXj]
k + 1
= k(Xk+1 −Xk),

64 Capitolo 3. Funzioni di distribuzione e test statistici
si ha
S2k+1 = (1− 1
k)S2
k + (1 + k)(Xk+1 −Xk)2.
3.2.3 Massima verosimiglianza
Sia X1, X2, . . . , Xn il campione che assumiamo provenga da una distribuzionecon funzione di densita fθ(x), dove con θ si e indicato il parametro checaratterizza la distribuzione (o il vettore dei parametri, nel caso ve ne sianopiu di uno). Allora, nell’ipotesi che le osservazioni siano indipendenti, unamisura della probabilita di avere ottenuto proprio quel campione da unapopolazione con la distribuzione data e fornita dalla funzione
L(θ) = fθ(X1)fθ(X2) . . . fθ(Xn)
che e detta funzione di verosimiglianza.Il metodo della massima verosimiglianza consiste nello scegliere come
stimatore il valore di θ che massimizza L(θ).Osserviamo che, nel caso di distribuzioni discrete, L(θ) e proprio la proba-
bilita di avere ottenuto il campione X1, X2, . . . , Xn. E diverso invece il casodi distribuzioni continue, per le quali la probabilita di un particolare insiemefinito di valori e comunque nulla. In questo caso possiamo pero affermare chela probabilita che l’estrazione casuale di un elemento da una popolazione conla distribuzione data sia un valore compreso in un’intorno di raggio ε/2 di Xi
e approssimativamente εfθ(Xi), con un’approssimazione tanto piu accurataquanto piu piccolo e ε. Pertanto L(θ) e approssimativamente proporzionalealla probabilita dell’estrazione di un campione di n elementi, Y1, Y2, . . . , Yn,con Yi ∈ [Xi − ε, Xi + ε], i = 1, 2, . . . , n, e con ε opportunamente piccolo.
Esempi
Stima del parametro λ in una distribuzione esponenziale. Sup-poniamo di volere stimare con il metodo della massima verosimiglianza ilparametro λ di una esponenziale. Si ha
L(λ) = (λe−λX1)(λe−λX2) . . . (λe−λXn)= λne−λ
Pni=1 Xi
= λne−λnXn

3.2. Stima di parametri 65
La derivata di L(λ) e
dL
dλ= nλn−1e−λnXn − λnnXne
−λnXn
e, uguagliando a 0, si ottiene
λ =1
Xn
che era quello che ci si aspettava essendo la media media campionaria unostimatore corretto di 1/λ, la media della distribuzione.
Stima dei parametri di una distribuzione uniforme. Assumiamoche x1 ≤ x2 ≤ · · · ≤ xn siano realizzazioni di una v.c. X uniforme, dellaquale non conosciamo ne gli estremi ne l’ampiezza dell’intervallo.
Dalle proprieta della distribuzione uniforme sappiamo che
σ2 =(b− a)2
12⇒ b− a = 2
√3σ,
e quindi possiamo scrivere la funzione di densita come segue
f(x; µ, σ) =1
2√
3σI[µ−
√3σ,µ+
√3σ](x).
La funzione di massima verosimiglianza e allora
L(µ, σ; x1, x2, . . . , xn) =n∏
i=1
1
2√
3σI[µ−
√3σ,µ+
√3σ](xi)
=
(1
2√
3σ
)n
I[µ−√
3σ,xn](x1)I[x1,µ+√
3σ](xn)
=
(1
2√
3σ
)n
I[µ−x1√
3,+∞]
(σ)I[xn−µ√3
,+∞](σ).
La funzione L(µ, σ) vale(
12√
3σ
)n
nell’area che si trova, in figura 3.6, si
al di sopra delle due rette e 0 altrove. Il massimo si ha allora quando σ eminimo, cioe in corrispondenza dell’incrocio fra le rette:
µ =xn + x1
2σ =
xn − x1
2√
3.

66 Capitolo 3. Funzioni di distribuzione e test statistici
xnx1µ
!
!
x1"
3
xn
!
3
! =µ ! x1"
3! =xn ! µ"
3
Figura 3.6. Le rette al di sopra delle quali la funzione di verosimiglianza havalore positivo
3.2.4 Stima dell’errore quadratico medio
Siano X1, X2, ..., Xn v.c. indipendenti con distribuzione F . Indichiamo conθ(F ) un parametro della distribuzione F che si vuole stimare (media, varian-za, ...) e con g(X1, X2, ..., Xn) lo stimatore che si vuole utilizzare. Definiamol’Errore Quadratico Medio:
EQM(F, g) = EF [(g(X1, X2, ..., Xn)− θ(F ))2].
Il problema che ci poniamo e la stima di EQM(F, g). Osserviamo che Fnon e nota e quindi EF [(g(X1, X2, ..., Xn)− θ(F ))2] non puo essere determi-nata per via analitica.
Supponiamo di disporre di una realizzazione (x1, x2, ..., xn) delle v.c. X1,X2, ..., Xn, e definiamo la variabile casuale discreta Xe che assume i valorix1, x2, ..., xn con funzione di distribuzione:
Fe(x) =|i : xi ≤ x|
n.
In pratica ordiniamo le xi
x(1), x(2), . . . , x(n),
dove x(i) indica l’iesima osservazione in ordine crescente di valore.

3.2. Stima di parametri 67
Si ha allora
Fe(x) =
0, se x < x(1)jn, se x(j) ≤ x < x(j+1)
1, se x(n) ≤ x
La distribuzione Fe puo essere considerata una stima empirica della F ;infatti, per la legge dei grandi numeri, e
Fe(x) −−−→n→∞
F (x).
Allora θ(Fe) e una approssimazione di θ(F ), e
EQM(Fe, g) = EFe [(g(X1, X2, ..., Xn)− θ(Fe))2]
e una approssimazione di EQM(F, g). Poiche Fe e nota, sia θ(Fe) cheEQM(Fe, g) sono calcolabili e quindi e possibile avere una approssimazionedi EQM(F, g) tanto piu buona quanto piu e grande n.
In pratica pero il calcolo di EQM(Fe) puo risultare notevolmente oneroso.Infatti e
EQM(Fe) =∑
y∈x1,x2,...,xnn
(g(y)− θ(Fe))2
nn,
dove con x1, x2, ..., xnn abbiamo indicato l’insieme di tutti i vettori ad ncomponenti i cui elementi possono assumere valori nell’insieme x1, x2, ..., xn.
In pratica vengono generati k vettori y ∈ x1, x2, ..., xnn, y1, y2, ..., yk, esi pone
EQM(Fe) 'k∑
i=1
(g(yi)− θ(Fe))2
k.
Questo modo di procedere si giustifica col fatto che le (g(yi) − θ(Fe))2
possono essere considerate come valori assunti da variabili casuali indipen-denti con media EQM(Fe), e quindi la loro media e una stima corretta diEQM(Fe).

68 Capitolo 3. Funzioni di distribuzione e test statistici
3.3 Test di ipotesi
3.3.1 Test Chi-Quadro
Siano date n variabili casuali discrete, X1, X2, . . . , Xn, assumenti valori 1, 2,. . . , k. Assumiamo tali variabili identicamente distribuite e sia X una v.c.che rappresenti ciascuna di esse.
Vogliamo validare la correttezza della seguente ipotesi H0 (ipotesi nulla)
H0 : P [X = i] = pi, i = 1, ..., k
dove p1, p2, ..., pk sono valori dati con somma 1.Definiamo le nuove v.c. Ni = |j : Xj = i| , i = 1, ..., k. Sotto l’ipotesi
H0, Ni ha distribuzione binomiale con parametri n e pi, per ogni i, e quindiha media npi. Consideriamo ora la grandezza
T =k∑
i=1
(Ni − npi)2
npi
Chiaramente piu grande e T meno e probabile che l’ipotesi H0 sia cor-retta. Per valori di n grandi T ha approssimativamente una distribuzioneChi-Quadro con k − 1 gradi di liberta. E quindi
PH0 [T ≥ t] ∼= P [χ2k−1 ≥ t]
Se e t il valore assunto da T , P [χ2k−1 ≥ t] fornisce la probabilita di errore
nel caso che si decida di scartare l’ipotesi H0. Valori che vengono conside-rati ragionevoli per rigettare l’ipotesi sono P [χ2
k−1 ≥ t] = 0.05 (oppure piuconservativamente 0.01).
Una piu accurata approssimazione del valore PH0 [T ≥ t] puo essere otte-nuta per mezzo di una simulazione. Si generano a questo scopo le variabilicasuali T (1), T (2), ..., T (r), ciascuna con la distribuzione di T sotto l’ipotesiH0, e si pone
PH0 [T ≥ t] ∼=∣∣j : T (j) ≥ t
∣∣r
Al crescere di r migliora la bonta dell’approssimazione.Consideriamo ora il caso in cui X1, X2, . . . , Xn siano variabili indipen-
denti identicamente distribuite e l’ipotesi H0 sia che abbiano una comunedistribuzione continua F data.

3.3. Test di ipotesi 69
Possiamo ricondurci al caso precedente suddividendo l’insieme dei possi-bili valori assunti dalle Xi in k intervalli distinti
(−∞, x1), (x1, x2), ..., (xk−2, xk−1), (xk−1, +∞).
Si considerano quindi le v.c. discrete Xdi con Xd
i = i se Xi si trova nel-l’intervallo (xi−1, xi), e l’ipotesi H0 diviene P [Xd
i = i] = F (xi) − F (xi−1),i = 1, . . . , k.
Si pone il problema di come scegliere gli intervalli in modo da garantire lavalidita del test. Una ragionevole scelta e quella di intervalli equiprobabili,cioe tali che risulti F (x1)−F (x0) = F (x2)−F (x1) = . . . = F (xk)−F (xk−1), etali che il numero di osservazioni che ricade in ciascuno di essi non sia troppopiccolo (ad esempio non inferiore a 5)2.
3.3.2 Test di Kolmogorov-Smirnov per distribuzionicontinue
Il caso in cui X1, X2, . . . , Xn sono variabili indipendenti identicamente di-stribuite e l’ipotesi H0 che vogliamo valutare e che abbiano una comunedistribuzione continua F data, puo essere trattato in modo diretto e piu ef-ficiente. A questo scopo utilizziamo l’approssimazione empirica Fe della F ,costruita come gia visto nel paragrafo 3.2.4:
Fe(x) =|i : Xi ≤ x|
n
Se l’ipotesi H0 e corretta allora Fe(x) e una buona approssimazione diF (x). Una misura dello scostamento e
D = maxx |Fe(x)− F (x)| .Dati i valori osservati x1, . . . , xn di X1, . . . , Xn, ricaviamo il valore osser-
vato d di D. Essendo
MaxxFe(x)− F (x) = Max j
n− F (x(j)) : j = 1 . . . n,
MaxxF (x)− Fe(x) = MaxF (x(j))−j − 1
n: j = 1 . . . n,
si ha
2Per una trattazione piu approfondita di questo punto rinviamo a ?.

70 Capitolo 3. Funzioni di distribuzione e test statistici
d = max
j
n− F (x(j)), F (x(j))−
j − 1
n: j = 1, . . . n
.
Se conoscessimo la probabilita PF (D ≥ d) nell’ipotesi che la distribuzionevera sia F , avremmo la probabilita di fare un errore se decidessimo di rigettareH0.
Osserviamo che
PF [D ≥ d ] = P
[Maxx
∣∣∣∣ |i : Xi ≤ x|n
− F (x)
∣∣∣∣ ≥ d
]= P
[Maxx
∣∣∣∣ |i : F (Xi) ≤ F (x)|n
− F (x)
∣∣∣∣ ≥ d
]= P
[Maxx
∣∣∣∣ |i : Ui ≤ F (x)|n
− F (x)
∣∣∣∣ ≥ d
]dove U1, U2, . . . , Un sono variabili casuali indipendenti uniformi in (0.1).
La prima uguaglianza deriva dal fatto che la funzione F e monotona crescente;la seconda dal fatto che se X e una v.c. con distribuzione continua F , alloraF (X) e una v.c. uniforme in (0, 1). Infatti, ponendo Y = F (X) si haP [Y ≤ y] = P [X ≤ F−1(y)] = y.
La distribuzione di D sotto H0 non dipende quindi da F ed e
P [D ≥ d ] = P
[Max0≤y≤1
∣∣∣∣ |i : Ui ≤ y|n
− y
∣∣∣∣ ≥ d
].
Possiamo allora stimare P [D ≥ d ] iterando il seguente procedimento:
1. Si generano u1, u2, . . . , un, uniformi in (0, 1),
2. Si calcola Max0≤y≤1
∣∣∣ |i:ui≤y|n
− y∣∣∣ = Max
jn− u(j), u(j) − j−1
n:j = 1, ..., n
.
Si ripete piu volte e si prende come valore per P [D ≥ d ] la proporzionedi volte in cui il valore trovato risulta ≥ d.
Se P [D ≥ d] e sufficientemente basso (es. 0.05) l’ipotesi viene rigettata,altrimenti viene accettata.

3.3. Test di ipotesi 71
3.3.3 Il test della somma dei ranghi
Consideriamo una grandezza rilevante del sistema che si vuole modellare, esiano date m osservazioni, Y1, Y2, . . . , Ym, di questa grandezza (ad esempioi tempi totali di attesa in m giorni). Sotto opportune ipotesi le Yi possonoessere considerate come v.c. identiche e indipendenti.
Siano X1, X2, . . . , Xn i valori forniti dalla simulazione per la stessa gran-dezza in n esecuzioni del modello. Anche le Xi saranno v.c. identicamentedistribuite e indipendenti, con distribuzione F (in generale non nota). L’ipo-tesi H0 da verificare e che anche le Yi abbiano la stessa distribuzione, cioe che
X1, X2, . . . , Xn, Y1, Y2, . . . , Ym
siano v.c. identicamente distribuite e indipendenti.Operiamo come segue: ordiniamo le X1, . . . , Xn, Y1, . . . , Ym in ordine cre-
scente di valore e per i = 1, . . . , n sia Ri il rango di Xi, cioe la sua posizionenella lista ordinata.
Ad esempio se le sequenze sono:X : 20, 15, 38, 40, 35, 31
Y : 25, 30, 29, 34.Si haR1 = 2, R2 = 1, R3 = 9, R4 = 10, R5 = 8 e R6 = 6.Consideriamo ora la quantita
R =n∑
i=1
Ri
(R = 36 nell’esempio precedente)Chiaramente un valore troppo piccolo o troppo grande di R falsificherebbe
con alta probabilita l’ipotesi H0. Supponendo di ritenere accettabile unaprobabilita α (ad es. 0.05) di sbagliare nel rigettare l’ipotesi, rigetteremo H0
se risulta2 min PH0 [R ≤ r] , PH0 [R ≥ r] ≤ α.
Si pone allora il problema di determinare la distribuzione di R. PonendoFn,m(r) = PH0 [R ≤ r], vale la seguente equazione ricorsiva
Fn,m(r) =n
n + mFn−1,m(r − n−m) +
m
n + mFn,m−1(r),

72 Capitolo 3. Funzioni di distribuzione e test statistici
con
F1,0(r) =
0, se r < 11, se r ≥ 1
F0,1(r) =
0, se r < 01, se r ≥ 0
Si ha allora un sistema di equazioni ricorsive che consente di calcolareFn,m(r) e quindi la distribuzione di R.
In pratica il calcolo di Fn,m(r) utilizzando la formula ricorsiva risultamolto oneroso. Si ricorre allora ad una approssimazione di Fn,m(r).
E possibile dimostrare che
R− n(n+m+1)2√
nm(n+m+1)12
e, approssimativamente, per n ed m grandi, una normale standard, N(0, 1).Pertanto e
P [R ≤ r] ∼= P [Z ≤ r∗]con Z una v.c. N(0, 1) e
r∗ =r − n(n+m+1)
2√nm(n+m+1)
12
.
3.4 Modelli di processi di arrivo
In molti casi ci si trova ad analizzare sistemi caratterizzati da arrivi di en-tita, come ad esempio nel caso dei clienti che arrivano ad un ufficio postale.Abbiamo gia visto come la distribuzione di Poisson svolga un ruolo rilevantein questi casi. Si parla in situazioni di questo tipo di processi di Poisson e sidistingue tra due tipi di processi, quelli stazionari e quelli non stazionari.
Nel seguito descriveremo brevemente i due tipi di processi, indicando conλ il numero medio di arrivi nell’unita di tempo, e con N(t) il numero di arrivinell’intervallo temporale [0, t].
Un processo di Poisson si dice stazionario quando valgono le seguentiproprieta:
1. arriva un individuo alla volta, cioe non ci sono arrivi di gruppi diindividui;

3.4. Modelli di processi di arrivo 73
2. il numero di arrivi nell’intervallo (t, t+s], N(t+s)−N(t), e indipendenteda N(u), per ogni u ∈ [0, t];
3. la distribuzione di N(t+s)−N(t) e indipendente da t per ogni (t, s) ≥ 0.
Secondo quanto abbiamo gia visto nel paragrafo 3.1.1, gli arrivi in questeipotesi sono rappresentabili per mezzo di una variabile casuale con distribu-zione di Poisson, cioe:
P [N(t + s)−N(t) = k] =eλs(λs)k
k!, k = 0, 1, 2, . . . , t, s ≥ 0.
Ricordiamo che, come abbiamo gia visto, i tempi di interarrivo sono v.c. condistribuzione esponenziale e media λ.
In molti casi reali il numero medio di arrivi nell’unita di tempo non eindipendente dal tempo: il numero di clienti che si presenta ad uno spor-tello non e in media lo stesso in ogni intervallo temporale. Possiamo allorasostituire alla costante λ una funzione del tempo λ(t). In questo caso si par-la di processo di Poisson non stazionario. Un tale processo e definito dalleseguenti condizioni:
1. arriva un individuo alla volta, cioe non ci sono arrivi di gruppi diindividui;
2. il numero di arrivi nell’intervallo (t, t+s], N(t+s)−N(t), e indipendenteda N(u), per ogni u ∈ [0, t].
La distribuzione degli arrivi e sempre poissoniana, ma con parametrovariabile. Si ha allora:
P [N(t + s)−N(t) = k] =eb(t,s)b(t, s)k
k!, k = 0, 1, 2, . . . , t, s ≥ 0.
Indicando con Λ(t) la media di N(t), cioe
Λ(t) = E[N(t)],
possiamo scrivereb(t, s) = Λ(t + s)− Λ(t).

74 Capitolo 3. Funzioni di distribuzione e test statistici
Nel caso in cui Λ(t) e differenziabile si ha
λ(t) =dΛ(t)
dt,
e quindi
b(t, s) = Λ(t + s)− Λ(t) =
∫ t+s
t
λ(y)dy.
Per potere stimare la funzione λ(t) e necessario disporre delle serie tem-porali corrispondenti a piu giorni. Si supponga di conoscere gli arrivi inun intervallo di tempo T per n giorni. Assumiamo che non ci sia moti-vo di ritenere che il comportamento degli arrivi sia diverso da un giornoall’altro. Dividiamo l’intervallo T in p intervallini di uguale ampiezza ∆,[t1, t2], [t2, t3], . . . , [tp, tp+1].
Sia xij il numero di arrivi nell’intervallo i del giorno j. Possiamo alloracalcolare la media del numero di arrivi in ciascuno degli intervallini:
xi =
∑j xij
n,
e di conseguenza costruire una approssimazione della funzione λ(t):
λ(t) =xi
∆, t ∈ [ti, ti+1], i = 1, 2, . . . , p.
Naturalmente ∆ non dovra essere troppo piccolo, altrimenti risulterebbepriva di senso la media xi, ne troppo grande, altrimenti non si riuscirebbe acatturare la variabilita di λ(t).
In diversi casi i clienti arrivano a gruppi. Tipico e il caso degli arrivi ad unristorante. In questo caso possiamo pensare di operare a due livelli. Ad unprimo livello consideriamo i gruppi come gli individui che arrivano. L’arrivodei gruppi puo essere considerato come un processo di tipo poissoniano, eN(t) e il numero dei gruppi che arrivano entro il tempo t.
Definiamo poi, per ogni gruppo i, la variabile casuale discreta, Bi, che puoassumere valori 1, 2, . . . . Tale variabile definisce la cardinalita del gruppo.Il numero di arrivi individuali entro il tempo t e allora dato dalla:
X(t) =
N(t)∑i=1
Bi, t ≥ 0.

Capitolo 4
Analisi e scelta dei dati di input
4.1 Introduzione
Per l’esecuzione di una simulazione e necessario disporre di dati di input chesiano una adeguata rappresentazione di cio che accadra in realta nel sistemaoggetto di studio. Ad esempio se stiamo simulando il funzionamento di unambulatorio per un periodo di un anno, avremo bisogno di generare perogni giorno un flusso di clienti, che per caratteristiche (tipo di trattamentorichiesto) e per distribuzione temporale, sia il piu realistico possibile.
In generale le caratteristiche dell’input possono essere rappresentate permezzo di opportune variabili casuali (ad esempio la v.c. tempo di interarrivofra due clienti successivi), e possiamo ragionevolmente supporre che su que-ste variabili siano disponibili dei dati sperimentali; dati raccolti durante ilfunzionamento del sistema da simulare, se gia esistente, oppure dati relativia sistemi simili nel caso che la simulazione riguardi un sistema da realizzare.
Possiamo pensare, in prima istanza, a tre approcci alternativi di uso deidati disponibili per la preparazione dell’input della simulazione.
1. I dati disponibili vengono utilizzati direttamente nella simulazione.
2. I dati disponibili vengono usati per costruire una funzione di distribu-zione empirica che verra poi usata per generare l’input della simulazio-ne.
3. Si utilizzano tecniche statistiche per derivare dai dati una funzionedi distribuzione teorica che rappresenti bene il loro andamento e per
75

76 Capitolo 4. Analisi e scelta dei dati di input
stimarne i parametri; questa distribuzione sara poi usata nella simula-zione.
Il primo approccio ha senso nel caso in cui sia facile raccogliere grandiquantita di dati rappresentativi delle effettive condizioni di funzionamentodel sistema sotto esame. Se, ad esempio, stiamo studiando la politica di ge-stione degli accessi ad una memoria a dischi in un sistema di calcolo, possiamofacilmente disporre di lunghe sequenze di queries rilevate nel funzionamentodi sistemi di calcolo esistenti, sotto diverse condizioni di uso. Tuttavia conquesto approccio c’e sempre il rischio di riprodurre solamente cio che e av-venuto nel passato, perdendo la possibilita di valutare il funzionamento delsistema in condizioni diverse e non previste.
Il secondo approccio e in genere preferibile, essendo meno condizionatodalla abbondanza dei dati disponibili. Questo approccio e particolarmenteutile in fase di validazione del modello, quando si vogliono confrontare glioutput del modello e quelli del sistema reale.
Se si riesce a stimare una distribuzione teorica che rappresenti bene i datiosservati, allora il terzo approccio e preferibile per le seguenti ragioni:
• Una distribuzione empirica puo mostrare irregolarita (dovute ad esem-pio al numero limitato di dati), mentre una distribuzione teorica tendea “regolarizzare” i dati.
• Al contrario di una distribuzione empirica, una distribuzione teoricaconsente di generare valori delle variabili casuali che siano al di fuoridell’intervallo dei valori osservati.
• Una distribuzione teorica costituisce un modo molto compatto perrappresentare i valori dei dati di input, mentre l’uso di distribuzioniempiriche richiede il mantenimento in memoria di grandi quantita didati.
Sia che si usi una distribuzione empirica oppure una distribuzione teorica(ad esempio una di quelle viste nel paragrafo 3.1), e necessario disporre dellacapacita di generare numeri casuali con la voluta distribuzione. Ad esempionel problema della riparazione e manutenzione dei dischi (paragrafo 1.2.3)abbiamo assunto la disponibilita di una sequenza di numeri casuali unifor-memente distribuiti tra 0 ed 1 che ci e servito per generare una sequenzadi numeri tra 1 e 6 aventi la funzione di probabilita richiesta. Nel prossimoparagrafo verra mostrato come si puo derivare una distribuzione empirica dai

4.2. Distribuzioni empiriche 77
dati disponibili. Successivamente affronteremo il problema della individua-zione della distribuzione che corisponde ai dati e della generazione di variabilicasuali con la distribuzione scelta.
4.2 Distribuzioni empiriche
Supponiamo di disporre di un insieme di osservazioni di una data variabilecasuale, X1, X2, . . . , Xn, e di volere costruire a partire da esse una distri-buzione continua. Supponiamo che i valori siano tutti distinti, ed indichia-mo con X(i) la iesima osservazione in ordine crescente di valore, cioe siaX(1) < X(2) < . . . < X(n).
1
Consideriamo gli n − 1 intervalli del tipo [X(i), X(i+1)), ed assumiamoche la distribuzione all’interno dell’ intervallo i sia uniforme con densita
1(n−1)(X(i+1)−X(i))
, con i = 1, 2, . . . , n− 1.
Allora la distribuzione empirica continua F e data dalla:
F (x) =
0 , x < X(1),i−1n−1
+(x−X(i))
(n−1)(X(i+1)−X(i)), X(i) ≤ x < X(i+1), i = 1, . . . , n− 1,
1 , X(n) ≤ x.
Ad esempio le osservazioni 0.6, 1, 3.4, 2, 2.5, 4, 3.2 danno origine alladistribuzione empirica di figura 4.1.
Osserviamo che la distribuzione empirica cosı costruita e diversa da quellaintrodotta nel precedente capitolo. La differenza sta nel fatto che questa di-stribuzione, a differenza di quella, e continua, e presumibilmente approssimameglio la distribuzione cercata, permettendo di avere valori di F (x) distintie crescenti all’interno di ciascun intervallo [xj, xj+1).
In certi casi non si dispone di singole osservazioni, ma si conosce sola-mente quante osservazioni cadono in ciascuno di k intervalli contigui, [a0, a1),[a1, a2), . . . , [ak−1, ak). In questo caso possiamo ragionevolmente assumere ladistribuzione in ciascun intervallo uniforme con densita ni/n(ai−ai−1), doven e il numero totale delle osservazioni e ni e il numero di esse che cadononell’iesimo intervallo.
1Nel caso in cui alcuni valori fossero coincidenti possiamo riportarci al caso di valoridistinti con tecniche di perturbazione, cioe modificando alcuni di essi (in piu o in meno)di quantita opportunamente piccole.

78 Capitolo 4. Analisi e scelta dei dati di input
Figura 4.1. Distribuzione empirica
4.3 Analisi dei dati di input
4.3.1 Indipendenza delle osservazioni
Una ipotesi essenziale nelle stime di parametri discusse nel precedente capi-tolo e che le osservazioni siano indipendenti. Questa e un’ipotesi che nellarealta puo non essere soddisfatta. Ad esempio, se rileviamo i tempi di atte-sa in una coda di clienti successivi abbiamo delle osservazioni strettamentecorrelate.
Siano X1, X2, . . . , Xn le nostre osservazioni. Un’idea della loro indipen-denza la possiamo ottenere analizzando la correlazione fra le diverse os-servazioni2. Indichiamo con ρj la stima del coefficiente di correlazione fra
2Ricordiamo che, date due variabili casuali X e Y , il loro coefficiente di correlazione e

4.3. Analisi dei dati di input 79
osservazioni distanti j posizioni nella sequenza:
ρj =
∑n−ji=1 (Xi −Xn)(Xi+j −Xn)
(n− j)S2n
Chiaramente nel caso di osservazioni indipendenti ci si aspetta che ρj siamolto prossimo a zero. L’esame del grafico di ρj al variare di j da una buonaidea dell’indipendenza delle osservazioni. Una conferma puo essere ottenutaesaminando il grafico che si ottiene riportando su un piano i punti (Xi, Xi+1),per i = 1, 2, . . . , n−1. In caso di osservazioni indipendenti i punti dovrebberorisultare distribuiti casualmente sul piano; invece in presenza di correlazioniessi appariranno concentrati intorno a rette con pendenza positiva o negativaa seconda del tipo di correlazione.
4.3.2 Individuazione della distribuzione
Il passo successivo, una volta verificata l’indipendenza delle osservazioni, equello della individuazione del tipo di distribuzione da scegliere per la varia-bile di input sotto esame. Tale individuazione puo essere ottenuta in certicasi da una conoscenza a priori del tipo di fenomeno da cui la variabile ca-suale deriva. Un tipico esempio sono le considerazioni svolte a proposito delladistribuzione di Poisson.
Piu spesso si ricorre alla stima di opportuni parametri che ci fornisconoun’idea delle caratteristiche della distribuzione ed all’esame dell’andamentodelle osservazioni per mezzo di grafici.
Un confronto della media e della mediana puo farci capire se e ragionevoleo no considerare la distribuzione simmetrica (come ad esempio nel caso dellanormale): infatti nel caso di distribuzioni continue simmetriche media e me-diana coincidono. Nel caso di distribuzioni discrete cio non e vero quando ilnumero di valori distinti che la variabile puo assumere e pari. Ricordiamo chela mediana di una variabile casuale X con distribuzione FX e il piu piccolovalore x per cui risulta FX(x) ≥ 0.5. Dobbiamo naturalmente sempre tenerepresente che noi disponiamo solo di stime dei parametri, pertanto non pos-siamo aspettarci che anche nel caso di distribuzioni continue e simmetrichele stime della media e della varianza siano esattamente uguali.
Parametri che misurano la variazione di una v.c. sono il rapporto σ/µ edil rapporto σ2/µ. Il primo ha la caratteristica di essere uguale ad 1 per la
ρXY = Cov[X,Y ]σXσY
, dove Cov[X, Y ] = E[(X − µX)(Y − µY )] e la covarianza di X e Y .

80 Capitolo 4. Analisi e scelta dei dati di input
distribuzione esponenziale e < 1 per la gamma con n > 1, mentre il secondoe 1 per la distribuzione di Poisson e < 1 per la binomiale. Una stima di taliparametri puo quindi dare utili indicazioni.
Infine e molto utile tracciare un istogramma dei valori assunti dalla va-riabile casuale nel campione di cui disponiamo. A questo scopo si suddividel’intervallo tra il minimo ed il massimo dei valori assunti in intervalli disgiun-ti di uguale ampiezza, [b0, b1), [b1, b2), . . . , [bk−1 − bk), con ∆ = bk − bk−1. Sidefinisce quindi la funzione h(x):
h(x) =
0, se x < b0
hj, se bj−1 ≤ x < bj, j = 1, 2, . . . , k0, se bk ≤ x
dove hj e il numero di osservazioni che cadono nel jesimo intervallo diviso ilnumero totale di osservazioni.
Il grafico della funzione h(x) puo dare una buona idea del tipo di distri-buzione che ha la variabile casuale in esame.
Nel caso di variabili discrete si puo ottenere lo stesso effetto tracciando suun grafico i punti (nj/n, xj), dove xj e il jesimo valore assunto nel campionedalla variabile casuale, nj e il numero di occorrenze di tale valore, e n e lacardinalita del campione.
4.3.3 Stima dei parametri della distribuzione
Una volta individuata la distribuzione e necessario determinarne i parametri.Ad esempio se la distribuzione e una esponenziale, allora bisogna determinareil valore di λ. Uno degli approcci piu usati per la determinazione dei para-metri di una distribuzione e quello della massima verosimiglianza presentatocapitolo 3.
Una volta stimati i parametri, una verifica di quanto la distribuzionescelta approssima la distribuzione dei dati nel campione puo essere effettuatacon uno dei test visti nel capitolo 3.
4.4 Numeri pseudocasuali
Il problema che affrontiamo qui e quello dei metodi che possono essere usatiper generare sequenze di numeri casuali. Metodi meccanici caratterizzati da

4.4. Numeri pseudocasuali 81
un’intrinseca casualita, quali il lancio di un dado, possono portare alla pro-duzione di numeri casuali con la voluta distribuzione. Tali metodi pero sonoimpraticabili nella simulazione, dove si richiede la generazione in tempi mol-to piccoli di lunghe sequenze di numeri. Si ricorre pertanto alla generazionesu calcolatore di numeri cosiddetti pseudocasuali. Si tratta di sequenze dinumeri generati deterministicamente, e quindi “per nulla casuali”, ma aventiproprieta statistiche che approssimano bene quelle di sequenze di numeri real-mente casuali. Si tratta quindi di sequenze che all’analisi statistica risultanoindistinguibili da sequenze di numeri casuali.
4.4.1 Numeri pseudocasuali con distribuzione unifor-me
Esistono diverse tecniche per generare numeri pseudocasuali con distribu-zione uniforme. I metodi piu frequentemente usati sono i cosiddetti metodicongruenziali. In questi metodi una sequenza viene generata per mezzo dellaseguente formula:
Xi+1 = aXi + c (mod m).
Se c e zero, il metodo viene detto moltiplicativo, altrimenti si parla dimetodo misto. Un generatore di questo tipo genera al piu m numeri distinti(m-1 se c = 0, poiche lo zero non puo apparire nella sequenza generata),nell’intervallo [0, m− 1], e la sequenza generata e periodica. Il generatore haperiodo pieno se ha periodo m, e quindi genera tutti i numeri compresi tra 0e m-1. Dividendo poi i numeri generati per m, si ottengono numeri compresinell’intervallo [0,1).
Naturalmente ogni valore nell’intervallo deve avere la stessa probabilitadi essere presente. Si vuole inoltre che tutti i numeri, le coppie e le tripleabbiano la stessa probabilita di comparire in qualsiasi porzione della sequen-za generata. Il primo numero della sequenza, X0, e detto il seme. La sceltadel seme e importante al fine di assicurare che la sequenza abbia un periodosufficientemente lungo. Ad esempio nel caso di un generatore moltiplicativo(c = 0), X0 ed m devono essere primi fra loro. Sempre nel caso di gene-ratori moltiplicativi, delle scelte che garantiscono delle sequenze con buoneproprieta statistiche sono, nel caso di macchine a 32 bit, m = 231 − 1 ea = 75 = 16, 807.

82 Capitolo 4. Analisi e scelta dei dati di input
Esempio Usando un generatore moltiplicativo e a = 3, X0 = 3 e m = 7si ha:
X1 = 9(mod 7) = 2
X2 = 6(mod 7) = 6
X3 = 18(mod 7) = 4
X4 = 12(mod 7) = 5
X5 = 15(mod 7) = 1
X6 = 3(mod 7) = 3
X7 = 9(mod 7) = 2
La disponibilita nei linguaggi di programmazione piu usati ed in partico-lare in quelli orientati alla simulazione di ottimi generatori di numeri casualicon distribuzione uniforme permette di considerare uno studio piu appro-fondito dei generatori di numeri pseudocasuali e dei metodi statistici peranalizzarne la qualita come al di la degli obiettivi del corso. Per un appro-fondimento dell’argomento rimandiamo ai testi di Law e Kelton ? e di Knuth?.
Nel seguito vedremo come, a partire da una sequenza di numeri pseudo-casuali distribuiti uniformemente nell’intervallo [0, 1), sia possibile generarenumeri pseudocasuali con la distribuzione voluta.
4.4.2 Distribuzioni discrete
Inversione
Sia Y una variabile casuale discreta, che puo assumere i valori y1 < y2 < y3
< . . . , e siano
fY (yi) = pi,
FY (yi) =∑j≤i
pj.
le corrispondenti funzioni di densita e distribuzione.Sia U una variabile casuale uniforme in [0, 1). A partire da essa definiamo
la variabile casuale X:
X(U) = Maxyi : U ∈ [FY (yi−1), FY (yi)],

4.4. Numeri pseudocasuali 83
avendo posto FY (y0) = 0.Abbiamo cosı costruito una variabile casuale che ha la stessa distribuzione
della variabile Y a partire da una distribuzione uniforme. Infatti e:
P [X = yi] = P [FY (yi−1) ≤ U < FY (yi)] = pi,
dove l’ultima uguaglianza deriva dal fatto che U e uniforme in [0, 1).E possibile allora dato una sequenza si numeri compresi tra 0 ed 1, con
distribuzione uniforme, generare una corrispondente sequenza di numeri ap-partenenti ad un dato insieme discreto, con una prefissata distribuzione diprobabilita.
In pratica dal punto di vista computazionale si sfrutta il fatto che per le di-stribuzione discrete esprimibili analiticamente come quelle viste nel paragrafo3.1.1 e
P [X = i + 1] = a(i + 1)P [X = i],
P [X ≤ i + 1] = P [X ≤ i] + P [X = i + 1],
dove a(i) una opportuna funzione.Ad esempio, nel caso di una distribuzione di Poisson,
a(i) = λ/i.
Un algoritmo generale di inversione itera le seguenti operazioni, che adogni iterazione forniscono un numero casuale con la voluta distribuzione.
k := 0,
P := P [X = 0],
S := P,
Estrai u ∈ [0, 1] (variabile pseudocasuale uniforme),
While(u > S) do
k := k + 1,
P := a(k)P,
S := S + P,
Restituisci k.

84 Capitolo 4. Analisi e scelta dei dati di input
Distribuzione di Poisson
Oltre al metodo di inversione del precedente paragrafo, si puo usare la rela-zione fra distribuzione di Poisson e distribuzione esponenziale.
Ricordiamo che, se X una v.c. con distribuzione di Poisson e media λ,e Y una v.c. con distribuzione esponenziale e media 1/λ, allora la primafornisce il numero di eventi nell’unita di tempo e la seconda il tempo fra unevento ed il successivo.
Possiamo allora generare una sequenza di numeri pseudocasuali con di-stribuzione esponenziale, y1, y2, ..., e fermarci non appena risulti
k+1∑1
yi > 1 ≥k∑1
yi;
Si pone x1 = k, e si ripete generando successivamente x2, x3, ....
Abbiamo cosı ottenuto una sequenza di numeri pseudocasuali con distri-buzione di Poisson.
4.4.3 Distribuzioni continue
Inversione
Sia Y una variabile casuale continua, con funzioni di densita e distribuzionefY e FY , rispettivamente.
Sia U una variabile casuale uniforme in [0, 1). A partire da essa, definiamola variabile casuale X = F−1
Y (U). Cioe, per ogni valore u assunto da U , ilcorrispondente valore di X e x = F−1
Y (u).
Si ha allora
FX(x) = P [X ≤ x] = P [F−1Y (U) ≤ x]
= P [U ≤ FY (x)] = FY (x);
La terza uguaglianza deriva dal fatto che la funzione di distribuzione emonotona e pertanto [F−1
Y (U) ≤ x] ⇒ [FY (F−1Y (U)) ≤ FY (x)]. L’ultima
uguaglianza deriva dal fatto che U e uniforme.
Abbiamo cosı costruito una variabile casuale che ha la stessa distribuzio-ne della variabile Y a partire da una distribuzione di probabilita uniforme.E possibile allora data una sequenza si numeri compresi tra 0 ed 1, con

4.4. Numeri pseudocasuali 85
distribuzione uniforme, generare una corrispondente sequenza di numeri ap-partenenti ad un dato insieme discreto, con una prefissata distribuzione diprobabilita.
Ad esempio supponiamo di volere costruire una sequenza di numeri pseu-docasuali con distribuzione esponenziale.
Se Y e una variabile casuale con distribuzione esponenziale, e
FY (y) = 1− e−λy,
e quindi
F−1Y (x) = −1
λln(1− x).
Pertanto se U e una v.c. con distribuzione uniforme in [0,1), allora
X = F−1Y (U) = −1
λln(1− U)
e una v.c. con distribuzione esponenziale che assume valori [0,∞).Data una sequenza di numeri pseudocasuali con distribuzione uniforme in
[0, 1), possiamo allora derivare una sequenza con distribuzione esponenziale.
Distribuzione normale
Siano X1, X2, ..., Xn, v.c. indipendenti, aventi la stessa distribuzione, con:
E[Xi] = µ, V ar[Xi] = σ2, i = 1, ..., n.
Consideriamo la v.c.
Xn =1
n
n∑i=1
Xi,
con
E[Xn] = µ, V ar[Xn] =1
nσ2.
Introduciamo ora la variabile casuale
Zn =Xn − E[Xn]√
V ar[Xn]=
Xn − µ
σ/√
n,
che, per il Teorema del limite centrale, al crescere di n, tende ad una v.c. condistribuzione normale standard, N(0, 1).

86 Capitolo 4. Analisi e scelta dei dati di input
Se le Xi sono distribuite in modo uniforme fra 0 e 1, si ha che µ = 12
eσ2 = 1
12, e quindi:
Zn =Xn − 1
2
1/√
12n. (4.1)
Pertanto per ottenere una variabile normale standard bastera generaresequenze di n numeri casuali con distribuzione uniforme ed utilizzare poi la(4.1). In pratica un ragionevole valore per n e 12. Se poi si vuole ottenere unav.c. con media µ e varianza σ2, bastera moltiplicare per σ il valore ottenutoe sommare µ.
Quest’approccio alla generazione di distribuzioni normali non forniscebuoni risultati ne dal punto di vista della qualita delle sequenze di numerigenerati ne da quello della efficienza computazionale.
E preferibile il metodo che viene brevemente descritto nel seguito, dettometodo polare (per una trattazione piu approfondita rimandiamo a ? e ?).
Definiamo le due variabili casuali
V1 = 2U1 − 1,
V2 = 2U2 − 1,
dove U1 e U2 sono v.c. uniformi in [0, 1). Chiaramente V1 e V2 sarannouniformi in (-1, 1).
Data una sequenza di coppie (V1, V2), tratteniamo solo quelle per cui eV 2
1 +V 22 ≤ 1. Avremo cosı costruito una v.c. a due dimensioni uniformemente
distribuita nel cerchio unitario di raggio 1.Ponendo S = V 2
1 + V 22 , si ha che le variabili casuali X e Y cosı definite:
X = V1
√−2 lg S
S
Y = V2
√−2 lg S
S
sono v.c. normali indipendenti con media 0 e varianza 1.
Metodo della reiezione
Si tratta di un metodo di semplice implementazione che permette di generaresequenze di numeri casuali, x1, x2, ..., xn, ..., aventi una data funzione di den-sita, fX . Si assume che tale funzione sia limitata e definita in un intervalloprefissato [a, b]:

4.4. Numeri pseudocasuali 87
0 ≤ fX(x) ≤ M, per a ≤ x ≤ b
fX(x) = 0, altrove.
Vogliamo costruire una sequenza di numeri casuali, x1, x2, ..., xn, ..., aventiquesta funzione di densita.
Si puo procedere iterando la seguente operazione, partendo con i = 1:
1. si genera una coppia di numeri pseudocasuali uniformi (r, s) con r ∈[a, b], e s ∈ [0, M ];
2. se 0 ≤ s ≤ fX(r), allora si pone xi = r.

88 Capitolo 4. Analisi e scelta dei dati di input

Capitolo 5
Analisi dei dati di output
Una fase essenziale di ogni studio di simulazione e l’analisi dei risultati dellasimulazione stessa. Supponiamo di avere costruito il modello di un sistema esiano Y1, Y2, . . . , Ym i dati di output che ci interessa studiare. Ad esempio Yi
rappresenti la lunghezza di una coda alla fine dell’iesimo intervallo di tempoin cui e stata suddivisa la giornata. Chiaramente Yi puo essere pensata comeuna variabile casuale. La difficolta qui sta nel fatto che le variabili casualiY1, Y2, . . . , Ym non sono in generale indipendenti; quindi i metodi visti neiprecedenti capitoli non possono essere direttamente utilizzati.
Se supponiamo pero di avere effettuato n diversi run di simulazioni uti-lizzando diverse sequenze di numeri pseudocasuali, abbiamo diverse sequenzedi realizzazioni delle variabili casuali Y1, Y2, . . . , Ym:
y11, . . . , y1i, . . . , y1m
y21, . . . , y2i, . . . , y2m...
...yn1, . . . , yni, . . . , ynm
(5.1)
Una sequenza y1i, y2i, . . . , yni puo essere vista come una sequenza di rea-lizzazioni di n variabili casuali identicamente distribuite e indipendenti; ciopermette l’utilizzazione delle tecniche di analisi studiate.
5.1 Analisi del transitorio
Un problema di notevole importanza in una simulazione e quello della sceltadelle condizioni iniziali. A questo proposito e essenziale distinguere tra si-
89

90 Capitolo 5. Analisi dei dati di output
stemi con terminazione e sistemi di cui siamo interessati al comportamentoa regime.
Ad esempio lo sportello di una banca che apre alle 8,30 e chiude alle13,30 e un tipico esempio di sistema del primo tipo. Si tratta di un sistemain cui l’andamento della coda dei clienti ha un andamento intrinsecamentevariabile: si parte all’inizio con nessun cliente in coda, e alla chiusura non siaccettano piu clienti e si esaurisce la coda. E proprio a questa variabilita chesiamo interessati.
Diverso e il caso di un sistema di produzione continuo, in cui siamo inte-ressati ad analizzare, ad esempio, il tempo richiesto a regime perche un pezzovenga prodotto, oppure l’intervallo di tempo (sempre a regime) tra l’arrivo diun ordine e la spedizione del prodotto ordinato. In questo caso il transitoriopuo falsare in modo rilevante i risultati del modello.
Ad esempio, supponiamo di essere interessati al tempo medio di attesa,a regime, di fronte ad una data macchina di una linea di produzione, cheindicheremo con d. Siano Y1, Y2, . . . , Ym, i valori del parametro che si vuolestimare ottenuti tramite una simulazione. Se indichiamo con Y la variabilecasuale ‘tempo di attesa a regime’, abbiamo
d = E[Y ] = limj→∞E[Yj].
Una stima di d possiamo ottenerla usando la media campionaria
Y m =
∑mj=1 Yj
m,
dove m e il numero di osservazioni di cui disponiamo.Nell’effettuare la simulazione dobbiamo scegliere le condizioni iniziali del
sistema. Ad esempio, se decidiamo di iniziare la simulazione col sistemascarico, sara Y1 = 0. Cio ovviamente si riflette sulla stima ottenuta falsandola.Si potrebbe pensare di partire da una situazione il piu possibile simile a quellache si ha a regime, ma questo sposta solo il problema essendo proprio questasituazione quella che noi vogliamo stimare.
Una possibile soluzione e allora quella di non considerare nella stima leprime osservazioni, quelle che sono piu influenzate dalle condizioni iniziali.La media viene allora stimata dalla
Y ml =
∑mj=l+1 Yj
m− l,

5.1. Analisi del transitorio 91
dove l e il numero di osservazioni che vengono scartate, quelle cioe che cor-rispondono alla fase del transitorio. Il problema e quello di una correttascelta di l; infatti, un valore troppo basso rischia di portare ad una stima incui si risente delle condizioni iniziali, mentre un valore troppo alto porta asimulazioni eccessivamente costose.
Non esistono regole sicure per l’individuazione del transitorio. Una ra-gionevole procedura e riportata nel seguito.
1. Si effettuano n repliche della simulazione, ciascuna di lunghezza m; siayij l’osservazione jesima della iesima replica.
2. Costruiamo la sequenza Y 1, Y 2, . . . , Y m, con Y j =Pn
i=1 yij
n. Risulta
E[Y j]=E[Yj], e V ar[Y j]=V ar[Yj]/n.
3. Sostituiamo ora alla sequenza Y 1, Y 2, . . . , Y m, la nuova sequenzaY 1(k), Y 2(k), . . . , con k ≤ bm/2c, e
Y j(k) =
Pj−1
h=−(j−1)Y j+h
2j−1, j = 1, . . . , kPk
h=−k Y j+h
2k+1j = k + 1, . . . ,m− k.
4. Scegliere infine quel valore di l oltre il quale la sequenza Y j(k) apparegiunta a convergenza.
Si tratta, come si vede facilmente, di un approccio basato sulla ispezioneda parte dell’esperto, ma dopo avere sottoposto i dati ad un trattamento cheha lo scopo fondamentale di ridurne la varianza. Tale trattamento consisteprima in una media fra dati corrispondenti nelle diverse repliche, poi nellasostituzione di ognuno dei dati cosı ottenuti con la media fra esso e i datiimmediatamente precedenti e quelli immediatamente seguenti.
Grande cura bisognera avere nella scelta dei parametri m, n e k. Ilprimo dovra essere sufficientemente grande da risultare molto maggiore delvalore aspettato per l e tale da permettere nella simulazione un numeroelevato di occorrenze di tutti gli eventi, anche di quelli poco probabili. Per ilsecondo puo essere opportuno di partire inizialmente con 5 o 10 repliche perpoi aumentare tale valore se necessario. Infine k va scelto sufficientementegrande da rendere regolare il grafico della Y j(k), ma non cosı grande danon permettere di distinguere bene il transitorio. Ovviamente nella scelta efondamentale il ruolo dell’esperienza di chi effettua la simulazione.

92 Capitolo 5. Analisi dei dati di output
Esercizio Una linea di produzione consiste di una cella di lavorazio-ne ed una stazione di ispezione, in serie. I pezzi semilavorati arrivano allacella con tempi di interarrivo esponenziali con media 1 minuto. I tempi dilavorazione nella cella sono uniformi nell’intervallo [0.65, 0.70] (in minuti). Itempi di ispezione sono uniformi in [0.75, 0.80]. Il 10% dei pezzi risultanodifettosi e sono rimandati alla cella per essere lavorati di nuovo. La cellae soggetta ad interruzioni nella lavorazione a causa di guasti; l’intervallo ditempo fra un guasto ed il successivo ha legge esponenziale con media 6 ore,ed il tempo di riparazione e uniforme nell’intervallo [8, 12] (in minuti). Sivoglia determinare la produzione oraria (numero di pezzi) a regime. Si usil’approccio precedentemente descritto per l’individuazione del transitorio.
5.2 Tecniche per la riduzione della varianza
Tipico obiettivo di uno studio di simulazione e la stima di uno o piu parame-tri. La bonta della stima che si ottiene sara tanto migliore quanto minore sarala varianza dello stimatore usato. Nel seguito presenteremo alcune tecnicheper la riduzione della varianza.
5.2.1 Variabili antitetiche
Supponiamo di volere stimare θ = E[X], e supponiamo di avere generato duevariabili casuali, X1 e X2, identicamente distribuite con media θ. E allora
V ar
[X1 + X2
2
]=
1
4(V ar[X1] + V ar[X2] + Cov[X1, X2]) (5.2)
Se le due variabili casuali X1 e X2 fossero correlate negativamente, attra-verso il loro uso potremmo ottenere una sostanziale riduzione della varianza.
Supponiamo che la variabile casuale X di cui vogliamo stimare la mediasia una funzione di m numeri casuali, uniformi in [0,1):
X = h(U1, U2, . . . , Um). (5.3)
Si puo allora usare X come X1 e porre
X2 = h(1− U1, 1− U2, . . . , 1− Um). (5.4)

5.2. Tecniche per la riduzione della varianza 93
Essendo 1 − U anch’essa una variabile casuale uniforme in [0,1), X2 hala stessa distribuzione di X, ed essendo 1 − U negativamente correlata conU , si puo provare che, se h e una funzione monotona, allora anche X1 ed X2
sono correlate negativamente.
Esempio Consideriamo una coda, e sia Di il tempo di attesa in codadell’iesimo cliente. Supponiamo di volere stimare θ = E[X], avendo indicatocon X il tempo di attesa totale dei primi n clienti:
X = D1 + · · ·+ Dn. (5.5)
Indicando con Ti l’iesimo tempo di interarrivo e con Si l’iesimo tempodi servizio. Possiamo allora scrivere
X = h(T1, . . . , Tn, S1, . . . , Sn), (5.6)
dove h puo ragionevolmente essere assunta monotona.Siano F e G le distribuzioni di T e di S rispettivamente, e supponiamo
di usare il metodo dell’inversione per generare tali variabili casuali a partireda 2n numeri casuali uniformi:
Ti = F−1(Ui), Si = G−1(Un+i), i = 1, . . . , n. (5.7)
Una variabile casuale “antitetica” con la stessa distribuzione di X e ot-tenibile effettuando una seconda simulazione usando i numeri casuali 1−Ui,i = 1, . . . , 2n.
5.2.2 Condizionamento
Sia X una v.c. di cui si voglia stimare la media θ = E[X], e sia Y un’altrav.c.. Assumiano nel seguito che sia X che Y siano v.c. discrete; il caso div.c. continue e analogo e viene lasciato per esercizio al lettore.
Definiamo ora la nuova variabile casuale Z funzione di Y :
Z = E[X|Y = y] =∑
x
xP [X = x|Y = y]
=∑
x
xP [X = x, Y = y]
P [Y = y].

94 Capitolo 5. Analisi dei dati di output
Facciamo vedere che la media di Z e proprio il valore θ cercato:
E[Z] =∑
y E[X|Y = y]P [Y = y] =∑
y
∑x
xP [X = x, Y = y]
=∑
x x∑
y P [X = x, Y = y] =∑
x
xP [X = x] = E[X] = θ.
Analizziamo la varianza di Z. Abbiamo che e
V ar[X|Y = y] = E[(X − E[X|Y = y])2|Y = y]
= E[X2|Y = y]− (E[X|Y = y])2.
Si ha allora:
E[V ar[X|Y = y]] = E[E[X2|Y = y]− (E[X|Y = y])2]
= E[X2]− E[(E[X|Y = y])2],
V ar[Z] = E[Z2]− (E[Z])2
= E[(E[X|Y = y])2]− (E[X])2,
e sommando membro a membro si ottiene
E[V ar[X|Y = y] + V ar[Z] = E[X2]− (E[X])2 = V ar[X], (5.8)
da cui
V ar[Z] = V ar[X]− E[V ar[X|Y = y]] ≤ V ar[X]. (5.9)
Quindi la v.c. Z ha la stessa media di X con una varianza minore (ouguale): puo allora essere conveniente usare Z per la stima di θ.
Esempio Si voglia stimare, come nell’esempio precedente, la somma deitempi di attesa in una coda
θ = E[∑
i
Wi], (5.10)
dove Wi e il tempo di attesa dell’iesimo cliente. Si assume una politica ditipo FIFO.

5.2. Tecniche per la riduzione della varianza 95
Sia Ni il numero dei clienti presenti nel sistema all’istante di arrivo delcliente iesimo, cioe il numero dei clienti in attesa piu l’eventuale cliente cheviene servito. Supponiamo anche che i tempi di servizio siano esponenzialicon media µ.
Introduciamo allora la nuova v.c. Z =∑
i E[Wi|Ni]. Essendo
E[Wi|Ni] = Niµ, (5.11)
si ha quindi
θ = E[Z] = E[∑
i
Niµ]. (5.12)
Pertanto l’uso delle Ni invece delle Wi consente di ottenere uno stimatorecon minore varianza e quindi piu accurato.
Osserviamo che abbiamo usato la proprieta della distribuzione esponen-ziale per cui se il tempo di servizio e esponenziale con media µ, anche il temponecessario per completare, a partire da un tempo fissato (quello dell’arrivodel cliente iesimo), il servizio e esponenziale con la stessa media (assenza dimemoria della distribuzione esponenziale).

96 Capitolo 5. Analisi dei dati di output

Capitolo 6
Dinamica dei sistemi
6.1 Introduzione
Riprendiamo il modello Preda-Predatore visto nel primo capitolo. Comeabbiamo osservato, in questo modello cio che ci interessa non e l’informazioneriguardante le singole prede e i singoli predatori. Siamo piuttosto interessatia seguire l’evoluzione nel tempo delle due popolazioni a livello aggregato;le due variabili di stato principali sono pertanto il numero delle linci ed ilnumero dei conigli.
Un’altro aspetto interessante di questo modello e la presenza di effetti diretroazione per cui la variazione in un senso di una variabile puo portare,attraverso catene di tipo causa-effetto ad ulteriori variazioni nella stessa di-rezione o in direzione opposta. Un tipico esempio e quello della figura 6.1dove la freccia che va da una variabile ad un’altra indica che una variazionedell’una produce una variazione dell’altra variabile, ed il segno accanto allafreccia indica il tipo di variazione. Ad esempio un aumento del numero deiconigli produce un aumento della disponibilita di cibo per le linci, che a suavolta produce una diminuizione del tasso di mortalita.
Modelli caratterizzati da variabili di tipo aggregato e da cicli di retroa-zione possono essere trattati per mezzo delle tecniche della Dinamica deiSistemi, oggetto di questo capitolo. Per un approfondimento delle tecnichedella Dinamica dei Sistemi rimandiamo al testo di Sterman ?.
Nel seguito riprenderemo il modello Preda-Predatore, descrivendone unaversione piu completa di quella semplificata vista nel primo capitolo, edattraverso esso introdurremo i principali concetti della Dinamica dei Sistemi.
97

98 Capitolo 6. Dinamica dei sistemi
conigli linci
disponibilità di cibo per le linci
+mortalità delle linci-
-
mortalità dei conigli+
-
Figura 6.1.
6.2 Modello Preda-Predatore
Il modello Preda-Predatore e stato sviluppato dal matematico italiano VitoVolterra (1860-1940) per studiare un fenomeno che era stato evidenziato dallozoologo Umberto D’Ancona.1
Analizzando le statistiche relative alla pesca nel nord dell’Adriatico, D’An-cona aveva osservato che durante gli ultimi anni della prima guerra mondialee negli anni immediatamente seguenti si era verificato un sostanziale aumen-to della percentuale dei predatori (Selaci) pescati. L’unica circostanza cheappariva collegabile a questo incremento era la diminuzione dell’attivita dipesca causata dalle attivita belliche.
Il modello proposto da Volterra aveva proprio lo scopo di studiare questofenomeno. Qui presenteremo un modello di Dinamica dei Sistemi che e so-stanzialmente equivalente a quello di Volterra e puo esserne considerato unaversione approssimata. Questo modello ci servira per introdurre i principaliconcetti della Dinamica dei Sistemi.
1Le equazioni che stanno alla base del modello sono oggi note come equazionidi Volterra-Lotka, dallo statistico americano Alfred J. Lotka che le aveva derivateindipendentemente e contemporaneamente, anche se in una forma meno generale.

6.2. Modello Preda-Predatore 99
Prede
Predatori
Nascite Prede Morti Prede
Nascite Predatori Morti Predatori
Figura 6.2. Livelli e Flussi
6.2.1 Livelli e flussi
Componenti fondamentali di un modello di Dinamica dei Sistemi sono levariabili di livello (o semplicemente livelli) e le variabili di flusso (o sempli-cemente flussi). Le prime rappresentano grandezze che mantengono il lorovalore anche in condizione statiche, cioe nell’ipotesi che si blocchi lo scorreredel tempo. Le seconde sono invece variabili che rappresentano delle variazioninell’unita di tempo, e che quindi assumerebbero valore nullo se bloccassimolo scorrere del tempo. Nel nostro caso sono variabili di livello le cardinalitadelle due popolazioni, Prede e Predatori. Sono invece variabili di flusso ilnumero di individui delle due popolazioni che nascono e muoiono nell’unitadi tempo, Nascite Prede, Morti Prede, Nascite Predatori e Morti Predatori.
Dal punto di vista grafico i livelli vengono rappresentati per mezzo direttangoli (che richiamano dei serbatoi), con canali di input e di output,mentre i flussi vengono rappresentati per mezzo di valvole su questi canali.Un esempio di rappresentazione grafica per il nostra problema e fornito infigura 6.2, dove le nuvole rappresentano la realta esterna al sistema sottoconsiderazione.
Dal punto di vista analitico possiamo rappresentare le relazioni fra livellie flussi attraverso equazioni del tipo
Livello(t + ∆t) = Livello(t) + (FlussoInput(t)− FlussoOutput(t))∆t (6.1)
dove con FlussoInput e FlussoOutput si sono indicate le variazioni per unitadi tempo, in aumento ed in diminuzione rispettivamente, della variabile Li-vello, mentre con ∆t si e indicato l’intervallo di tempo tra una valutazionedelle variabili e la successiva nel processo di simulazione. L’equazione esprime

100 Capitolo 6. Dinamica dei sistemi
il fatto che il valore della variabile Livello al tempo t + ∆t e uguale al valoreal tempo t piu la variazione totale che si e verificata nell’intervallo di tempo[t, t + ∆t]. Osserviamo che le variabili FlussoInput(t) e FlussoOutput(t)rappresentano le variazioni medie unitarie nell’intervallo [t, t + ∆t], pertantol’equazione 6.1 descrive tanto piu accuratamente l’andamento della variabi-le Livello quanto piu e piccolo il valore di ∆t. Sul problema della sceltadell’intervallo di tempo nei modelli di Dinamica dei Sistemi torneremo inseguito.
Nel problema in esame le equazioni che descrivono l’andamento nel tempodelle variabili di livello sono:
Prede(t + ∆t) = Prede(t)+(Nascite Prede(t)−Morti Prede(t))∆t,
Predatori(t + ∆t) = Predatori(t)+(Nascite Predatori(t)−Morti Predatori(t))∆t.
(6.2)
6.2.2 variabili ausiliarie e costanti
Le equazioni 6.2 consentono di descrivere l’andamento dei livelli, cioe nelnostro caso delle popolazioni delle prede e dei predatori, una volta note lecondizioni iniziali (la dimensione delle popolazioni al tempo t = 0) e unavolta che siano state esplicitate le natalita e mortalita delle due popolazioniin funzione del tempo. A questo scopo abbiamo bisogno di introdurre dellenuove grandezze: variabili ausiliarie e costanti.
Consideriamo innanzitutto le prede: assumendo che l’ambiente in cuivivono (il mare nel caso che stiamo esaminando) fornisca loro tutto il nutri-mento necessario, possiamo assumere un tasso di natalita costante, e pertantoporre
Nascite Prede(t) = A · Prede(t)
dove A e una costante che rappresenta il tasso di natalita delle prede.La diminuzione delle prede e dovuta principalmente a due effetti, uno
interno all’ecosistema, l’azione dei predatori, e l’altro esterno, la pesca.Il numero di prede catturate da predatori nell’unita di tempo puo essere
assunto come proporzionale al numero dei possibili incontri, che e dato dalprodotto del numero delle prede per il numero dei predatori:
Prede Catturate(t) = B · Incontri Prede Predatori,

6.2. Modello Preda-Predatore 101
dove eIncontri Prede Predatori = Prede(t) · Predatori(t).
Per quel che riguarda la pesca, possiamo assumere che nell’unita di tempovenga pescata una frazione ε della popolazione esistente:
Prede Pescate(t) = ε · Prede(t).
Si ha allora:
Morti Prede = Prede Catturate(t) + Prede Pescate(t).
Consideriamo ora i predatori. Possiamo assumere che, in mancanza diprede e di azioni esterne, i predatori si estinguano con tasso di mortalitacostante:
Mortalita Predatori(t) = C · Predatori(t)
dove C e una costante che rappresenta il tasso di mortalita dei predatori.Alle morti dovute a mancanza di cibo si aggiungono quelle dovute alla
pesca. Nell’ipotesi che la proporzione di pesci pescati non dipenda dal tipodi pesce si ha:
Predatori Pescati(t) = ε · Predatori(t).
Possiamo allora scrivere:
Morti Predatori = Mortalita Predatori(t) + Predatori Pescati(t).
Per quel che riguarda la crescita dei predatori, essa dipende dalla dispo-nibilita di preda e quindi e proporzionale al numero di incontri tra predee predatori; cio viene rappresentato per mezzo della seguente equazione chelega le nascite dei predatori al numero di incontri che esse hanno con le prede:
Nascite Predatori(t) = D · Prede(t) · Predatori(t).
In generale le costanti B e D saranno diverse: la sparizione di una predanon comporta immediatamente la nascita di un predatore.

102 Capitolo 6. Dinamica dei sistemi
Dal punto di vista grafico il modello e rappresentato in figura 6.3, dovele frecce indicano le dipendenze funzionali tra le diverse variabili.
Prede
Predatori
Nascite Prede Morti Prede
Nascite Predatori Morti Predatori
A
B
D
Prede CatturatePrede Pescate
Predatori Pescati
Mortalità Predatori
Incontri Prede Predatoriepsilon
C
Figura 6.3. Il modello Predatore-Preda
6.2.3 Cicli causali
Le frecce nel modello che abbiamo costruito, sia che corrispondano a flussifisici o a passaggi di informazioni, rappresentano delle relazioni cusa-effetto.Ad esempio la freccia che va dalla variabile di flusso Nascite Prede alla va-riabile di livello Prede indica che il valore della prima ha un effetto sul valoredella seconda; questo effetto e di segno positivo, nel senso che un aumentodella prima comporta un aumento della seconda, anzi un rafforzamento dellasua crescita. Anche la freccia che va dalla seconda alla prima, pur non rap-presentando un flusso fisico, descrive una relazione causale di tipo positivo:

6.2. Modello Preda-Predatore 103
all’aumentare della popolazione, in assenza di altri elementi, corrisponde unaumento delle nascite per unita di tempo. Le due frecce insieme individuanoun ciclo di retroazione positiva: ad un aumento della popolazione corrispondeun aumento delle nascite e quindi un ulteriore aumento della popolazione.
Ci possono essere relazioni con segno negativo, cioe rappresentanti unarelazione tra due variabili in cui ad un aumento del valore della prima corri-sponde una diminuizione del valore della seconda oppure una riduzione dellasua velocita di crescita. Se in un ciclo appare un numero dispari di tali rela-zioni, allora tutto il ciclo e di segno negativo, e si parla di retroazione nega-tiva. Ad esempio il Ciclo “Prede-Incontri Prede Predatori-Prede Catturate-Morti Prede-Prede” e un ciclo con segno negativo, infatti la relazione “Mor-ti Prede-2 e di tipo negativo perche ad un aumento delle morti di una po-polazione, la popolazione diminuisce di numero, oppure si rafforza una suaeventualmente gia esistente decrescita, oppure infine si rallenta la sua even-tuale crescita. Osserviamo che un ciclo causale, perche possa contribuireall’evoluzione del sistema nel tempo, dovra contenere almeno una variabiledi livello ed una variabile di flusso.
In un modello sono in genere presenti molti cicli causali ed una analisidel loro segno e essenziale per una piena comprensione del comportamentodel sistema che si sta studiando.
Nella figura 6.43 e riportato l’andamento del numero delle prede e delnumero dei predatori in una simulazione in cui si e assunto che l’attivita dipesca terminasse alla 250.esima settimana, e che prima della terminazione ilnumero di pesci pescati nell’unita di tempo fosse pari all’1% della popolazionetotale dei pesci (ε = 0.01). In linea con quanto osservato si ha che il numerodei predatori aumenta, mentre decresce il numero delle prede. Il risultato eche la proporzione dei predatori cresce in modo significativo.
Questo andamento che non e immediatamente intuitivo si spiega con il fat-to che un aumento dell’attivita di pesca fa crescere la mortalita dei predatoriattraverso due catene causa-effetto concordanti: da un lato c’e l’effetto diret-to della pesca, dall’altro c’e quello indiretto dovuto al fatto che diminuisconole prede. Invece l’effetto dell’aumento dell’attivita della pesca sulle predeavviene attraverso due catene causa-effetto discordi: da un lato aumenta lamortalita a causa della pesca stessa, ma dall’altro la mortalita diminuisce
2A questa relazione causa-effetto non corrisponde nella figura 6.3 in una freccia cheva dalla variabile di flusso “Morti Prede” al livello “Prede”; questa relazione e invecerappresentata dalla freccia che va nella direzione opposta.
3Osservare che le scale sono diverse per le due popolazioni.

104 Capitolo 6. Dinamica dei sistemi
400,000600
300,000450
200,000300
100,000150
00
0 50 100 150 200 250 300 350 400 450 500
Prede
Predatori
Settimane
Figura 6.4. Effetto della cessazione della pesca sull’andamento dellepopolazioni delle prede e dei predatori.
perche diminuiscono i predatori. Questo spiega il fatto che nella curve dellafigura 6.4 appare, quando finisce l’attivita di pesca, una diminuzione delleprede ed un aumento dei predatori.
6.3 Ritardi
Nei modelli di dinamica dei sistemi le catene ed i cicli causali, come abbiamovisto, giocano un ruolo molto importante. La loro presenza rende spessodifficile da prevedere il comportamento di un sistema. Cio e tanto piu veroin quanto gli effetti non si verificano immediatamente dopo le azioni cheli causano; ci sono molto spesso ritardi nel manifestarsi degli effetti, e ciopuo rendere particolarmente difficile da analizzare e spesso controintutitivoil comportamento di un sistema.
Ad esempio in una linea di produzione ci troviamo di fronte ad un flussodi pezzi che entrano in celle in cui vengono lavorati e ad un corrispondenteflusso di pezzi finiti che escono: fra l’entrata di un pezzo nella cella e lasua uscita passa un tempo dato R. Quando viene lanciata una campagnapubblicitaria per la vendita di un nuovo prodotto passa in genere un certo
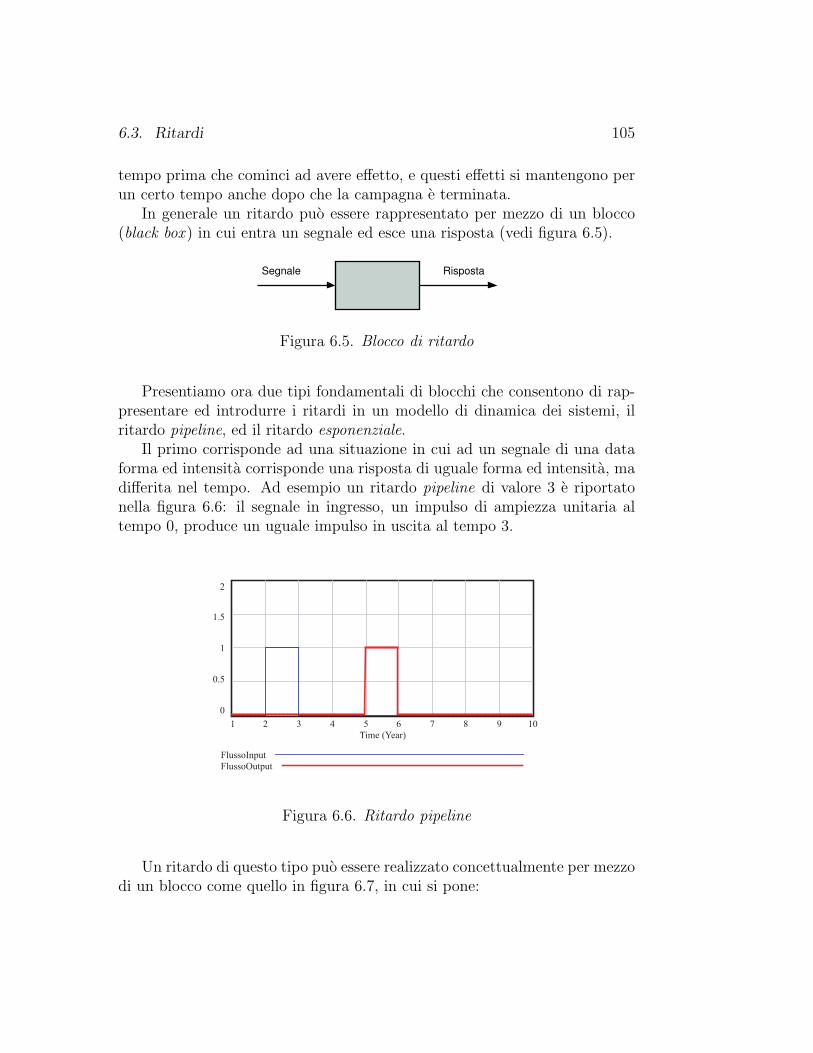
6.3. Ritardi 105
tempo prima che cominci ad avere effetto, e questi effetti si mantengono perun certo tempo anche dopo che la campagna e terminata.
In generale un ritardo puo essere rappresentato per mezzo di un blocco(black box ) in cui entra un segnale ed esce una risposta (vedi figura 6.5).
RispostaSegnale
Figura 6.5. Blocco di ritardo
Presentiamo ora due tipi fondamentali di blocchi che consentono di rap-presentare ed introdurre i ritardi in un modello di dinamica dei sistemi, ilritardo pipeline, ed il ritardo esponenziale.
Il primo corrisponde ad una situazione in cui ad un segnale di una dataforma ed intensita corrisponde una risposta di uguale forma ed intensita, madifferita nel tempo. Ad esempio un ritardo pipeline di valore 3 e riportatonella figura 6.6: il segnale in ingresso, un impulso di ampiezza unitaria altempo 0, produce un uguale impulso in uscita al tempo 3.
2
1.5
1
0.5
0
1 2 3 4 5 6 7 8 9 10Time (Year)
FlussoInput FlussoOutput
Figura 6.6. Ritardo pipeline
Un ritardo di questo tipo puo essere realizzato concettualmente per mezzodi un blocco come quello in figura 6.7, in cui si pone:

106 Capitolo 6. Dinamica dei sistemi
FlussoOutput(t) = FlussoInput(t−R), (6.3)
dove R e il valore del ritardo4.
LivelloFlussoInput FlussoOutput
R
Figura 6.7. Blocco di ritardo pipeline: FlussoOutput(t) = FlussoInput(t−R)
Nel caso del ritardo esponenziale la situazione e diversa: il blocco funzionada livello, accumulando le quantita in ingresso (segnale) e fornendo in uscita(risposta) un flusso unitario pari al valore del livello diviso per un coefficientedi ritardo. La situazione e illustrata nella figura 6.8, dove un segnale iningresso che vale 1 al tempo 0, e 0 dal tempo 1 in poi, produce in uscitauna risposta smorzata che tende asintoticamente a zero. Nella figura sonopresentate le risposte per due valori di ritardo, 3 e 6. Nel primo caso larisposta sale al valore 1/3 per poi decrescere asintoticamente a 0, mentre nelsecondo caso sale al valore 1/6 per poi decrescere. Come si vede piu grande eil ritardo piu smorzata e la risposta e piu lentamente il suo effetto si annullanel tempo. Un ritardo di questo tipo puo essere rappresentato per mezzo delblocco di figura 6.9, in cui si pone:
FlussoOutput(t) = Livello(t)/R, (6.4)
dove R e il valore del ritardo.Altri tipi di ritardi possono essere ottenuti mettendo in serie piu blocchi
di ritardo esponenziale. Particolarmente usato e il ritardo del terzo ordine
4In Vensim questo tipo di ritardo e realizzato per mezzo della funzione DELAYFIXED(Input, R, Output(0)).
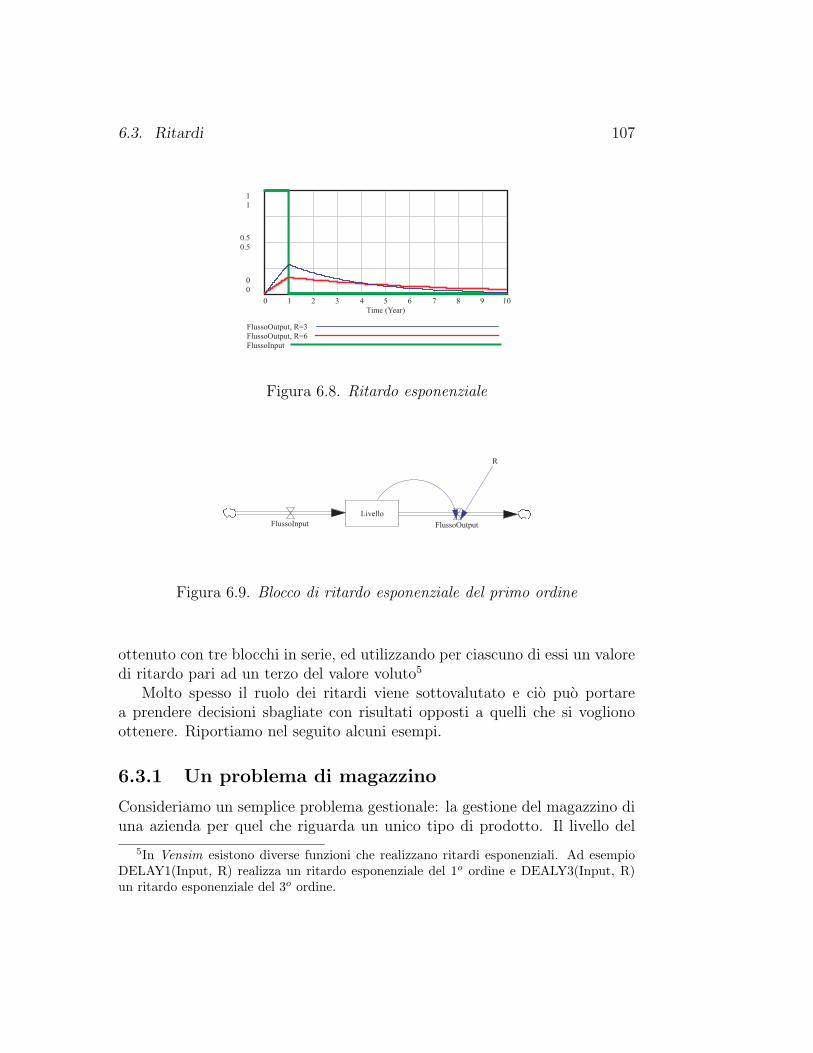
6.3. Ritardi 107
1 1
0.5 0.5
0 0
0 1 2 3 4 5 6 7 8 9 10Time (Year)
FlussoOutput, R=3 FlussoOutput, R=6 FlussoInput
Figura 6.8. Ritardo esponenziale
LivelloFlussoInput FlussoOutput
R
Figura 6.9. Blocco di ritardo esponenziale del primo ordine
ottenuto con tre blocchi in serie, ed utilizzando per ciascuno di essi un valoredi ritardo pari ad un terzo del valore voluto5
Molto spesso il ruolo dei ritardi viene sottovalutato e cio puo portarea prendere decisioni sbagliate con risultati opposti a quelli che si voglionoottenere. Riportiamo nel seguito alcuni esempi.
6.3.1 Un problema di magazzino
Consideriamo un semplice problema gestionale: la gestione del magazzino diuna azienda per quel che riguarda un unico tipo di prodotto. Il livello del
5In Vensim esistono diverse funzioni che realizzano ritardi esponenziali. Ad esempioDELAY1(Input, R) realizza un ritardo esponenziale del 1o ordine e DEALY3(Input, R)un ritardo esponenziale del 3o ordine.

108 Capitolo 6. Dinamica dei sistemi
magazzino (numero di pezzi del prodotto in stock) puo essere rappresentatoda un livello, con le vendite come flusso in uscita, e il numero dei nuovi pezziprodotti in ingresso. Livello e flussi sono rappresentati nella figura 6.10,che rappresenta il nucleo di partenza del modello che vogliamo costruire. In
MagazzinoPezzi prodotti Pezzi venduti
Domanda
Q
S
Ordini
Figura 6.10. Il magazzino con i flussi in ingresso e uscita
questo modello abbiamo assunto la Domanda come una variabile esogena, edabbiamo indicato con Q la quantita (il lotto) che viene ordinato ogni voltache si decide di rifornire il magazzino e con S il livello di stock raggiunto ilquale si decide di fare un nuovo ordine. Immaginiamo che in questo modellosemplificato un ordine venga fatto all’inizio di un periodo e che i nuovi pezziarrivino all’inizio del successivo. Supponiamo poi di avere una domandacostante di 10 pezzi alla settimana (l’unita di tempo scelta), di decideredi riordinare quando il livello di magazzino e tale da potere soddisfare ladomanda solamente per una settimana, che il valore scelto per Q sia 100, eche questo sia anche il valore del livello iniziale del magazzino pari a Q. Larelazione fra gli ordini ed il livello del magazzino e data dalla:
Ordini = IF THEN ELSE(Magazzino ≤ S, Q, 0).
Effettuando allora una simulazione su 50 settimane si ha l’andamento6 indi-cato in figura 6.11.
6L’andamento riportato nel grafico e un po’ falsato dall’effetto dell’interpolazione neltracciamento del grafico. Ad esempio, alla fine della nona settimana il livello ha raggiuntoil valore 10 che fa partire un nuovo ordine e nel corso della decima settimana il magazzinosi svuota completamente e l’arrivo del nuovo lotto lo porta all’inizio dell’undicesima setti-mana al valore 100. A causa dell’interpolazione nel grafico il livello invece di arrivare a 0,cresce dal livello 10 al livello 100 nel corso della decima settimana.
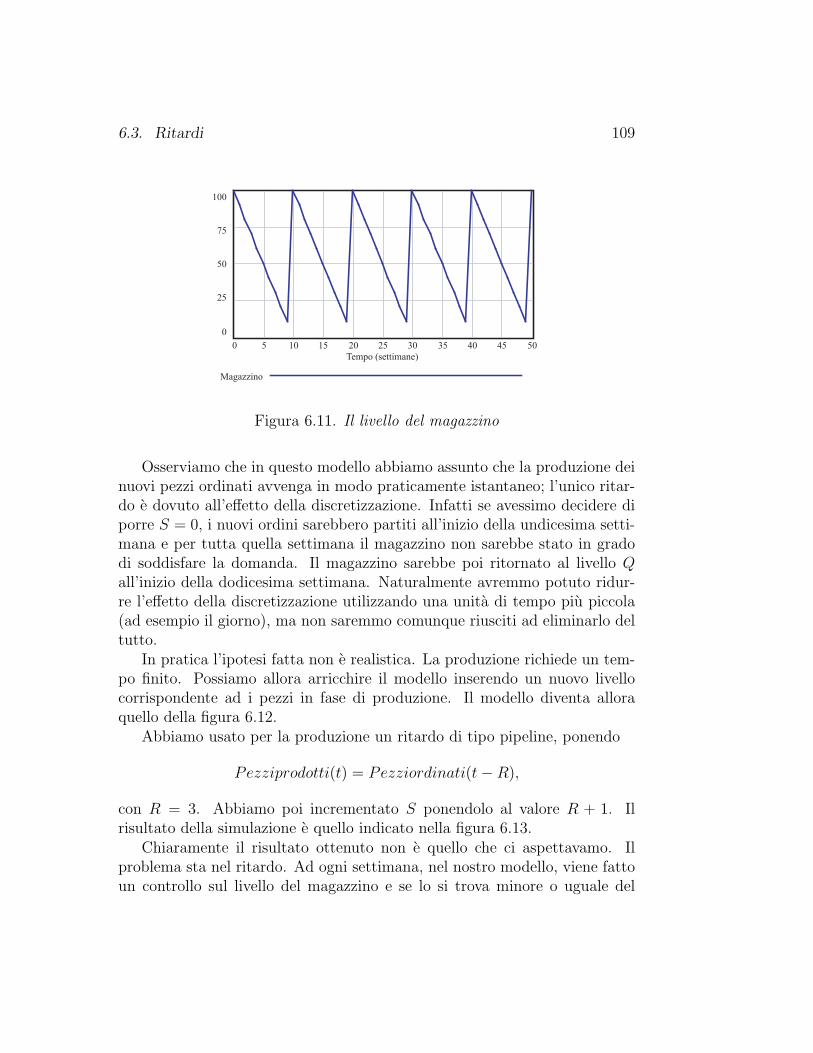
6.3. Ritardi 109
100
75
50
25
0
0 5 10 15 20 25 30 35 40 45 50Tempo (settimane)
Magazzino
Figura 6.11. Il livello del magazzino
Osserviamo che in questo modello abbiamo assunto che la produzione deinuovi pezzi ordinati avvenga in modo praticamente istantaneo; l’unico ritar-do e dovuto all’effetto della discretizzazione. Infatti se avessimo decidere diporre S = 0, i nuovi ordini sarebbero partiti all’inizio della undicesima setti-mana e per tutta quella settimana il magazzino non sarebbe stato in gradodi soddisfare la domanda. Il magazzino sarebbe poi ritornato al livello Qall’inizio della dodicesima settimana. Naturalmente avremmo potuto ridur-re l’effetto della discretizzazione utilizzando una unita di tempo piu piccola(ad esempio il giorno), ma non saremmo comunque riusciti ad eliminarlo deltutto.
In pratica l’ipotesi fatta non e realistica. La produzione richiede un tem-po finito. Possiamo allora arricchire il modello inserendo un nuovo livellocorrispondente ad i pezzi in fase di produzione. Il modello diventa alloraquello della figura 6.12.
Abbiamo usato per la produzione un ritardo di tipo pipeline, ponendo
Pezziprodotti(t) = Pezziordinati(t−R),
con R = 3. Abbiamo poi incrementato S ponendolo al valore R + 1. Ilrisultato della simulazione e quello indicato nella figura 6.13.
Chiaramente il risultato ottenuto non e quello che ci aspettavamo. Ilproblema sta nel ritardo. Ad ogni settimana, nel nostro modello, viene fattoun controllo sul livello del magazzino e se lo si trova minore o uguale del

110 Capitolo 6. Dinamica dei sistemi
Magazzino
Pezzi venduti
Domanda
Q S
Ordini
ProduzionePezzi prodottiPezzi ordinati
R
Figura 6.12. Il modello ampliato
valore della soglia S, si fa un ordine di Q unita. Quello che accade e cheper il ritardo, fatto il primo ordine, la settimana successiva non sono ancoraarrivati i pezzi richiesti e quindi si procede ad un altro ordine e cosı viafino ad accumulare 4 ordini di Q pezzi di seguito. Questo porta il livellodel magazzino a crescere come indicato nella figura. Il modello va alloramodificato; basta aggiungere la nuova condizione che l’ordine viene fattosolo se non ci sono pezzi correntemente in produzione7:
Ordini = IF THEN ELSE(Magazzino ≤ S : AND : Produzione = 0, Q, 0).
Effettuando di nuovo la simulazione si riottiene, come ci aspettavamo,l’andamento riportato in figura 6.11.
Nelle simulazioni effettuate abbiamo considerato la domanda come co-stante e da questo valore abbiamo fatto dipendere il valore di soglia, sceltoin modo tale da garantire il soddisfacimento della domanda fra il momento incui viene effettuato l’ordine e quello in cui i pezzi ordinati arrivano in magaz-zino. Nel caso di domanda variabile puo essere utile introdurre il concetto diDomanda attesa, che ci servira per la determinazione di S, e che puo essereanche usata per la determinazione del valore di Q che finora abbiamo consi-derato come variabile esogena. Se C e la copertura massima del magazzino,cioe il numero di settimane di vendite che il lotto da ordinare dovra garantire,possiamo porre S = (R+1)×Domanda attesa e Q = C×Domanda attesa. Il
7Abbiamo qui usato la sintassi propria di Vensim.

6.3. Ritardi 111
400
300
200
100
0
0 5 10 15 20 25 30 35 40 45 50Tempo (settimane)
Magazzino
Figura 6.13. Il livello del magazzino nel modello ampliato
calcolo della domanda attesa puo essere fatto per mezzo di una media delledomande passate attraverso la formula:
Yi+1 =n∑
k=0
akYi−k, (6.5)
dove con Yi e con Yi abbiamo indicato rispettivamente la domanda e la do-manda attesa al tempo i, mentre gli ak sono dei coefficienti positivi con∑n
k=0 ak = 1. Chiaramente piu grande e il valore di n scelto maggiore e ilpeso che si da all’andamento passato della domanda. Un caso limite e quelloin cui considero solo l’intervallo di tempo precedente ponendo n = 0 e a0 = 1;in questo case si considera come domanda attesa al tempo i la domanda altempo i− 1. E ragionevole che gli ak siano decrescenti al crescere di k, cioeche si dia meno importanza alle osservazioni piu lontane nel tempo.
Una tecnica che viene spesso usata per effettuare una stima di una gran-dezza a partire dai valori che essa ha assunto nel passato e quella del co-siddetto Exponential Smoothing. In questa tecnica si utilizza la formula 6.5,ma portando n ad infinito, cioe considerando idealmente un infinito numerodi osservazioni, ed utilizzando i coefficienti ai = α(1 − α)i, i = 0, 1, . . . , con

112 Capitolo 6. Dinamica dei sistemi
0 < α < 1. Poiche si ha che8
∞∑k=0
(1− α)k =1
α,
i coefficienti hanno somma unitaria.Possiamo allora scrivere:
Yi+1 = α∞∑
k=0
(1− α)kYi−k
= αYi + α∞∑
k=1
(1− α)kYi−k
= αYi + (1− α)α∞∑
k=0
(1− α)kYi−k−1
= αYi + (1− α)Yi.
Si ha allora:
Yi+1 − Yi − α(Yi − Yi). (6.6)
La 6.6 puo essere realizzata per mezzo di un livello, Y , con αY comeOnput e αY come Input. In pratica esistono delle funzioni predefinite cherealizzano l’Exponential Smoothing.
6.3.2 Diffusioni di inquinanti
In Olanda, fra gli anni 1960 e 1990, fu abbondantemente usato, nelle col-tivazioni di patate e di bulbi, un disinfettante del suolo, il DCPe (1-2 Di-cloropropene) contenente un inquinante, il 1-2 Dicloropropano (DCPa), cheha una vita molto lunga e filtra nel terreno fino a raggiungere, dopo moltotempo (alcuni decenni) le falde acquifere, inquinandole. Pertanto anche sel’uso del DCPe e stato bandito nel 1990, ci si aspetta nei prossimi anni uninquinamento molto consistente (superiore ai livelli accettabili) delle falde9.
Una situazione come questa puo essere rappresentata per mezzo del mo-dello di figura 6.14. In questo modello gli elementi principali sono due livelli
8Si tratta di una serie geometrica.9Questo esempio e stato ripreso da Meadows et al. Meadows et al. (1992).

6.3. Ritardi 113
ed un blocco di ritardo pipeline fra di essi; i due livelli realizzano essi stes-si dei ritardi di tipo esponenziale. L’inquinante entra nel sistema (flusso diingresso a sinistra) e viene immagazzinato nel terreno, dove in parte vieneassimilato o assorbito attraverso processi naturali ed in parte percola versogli strati intermedi del terreno. Nel terreno una percentuale dell’inquinantesi decompone e scompare (la decomposizione e un processo che avviene conun ritardo esponenziale), mentre un’altra parte scende nelle falde sottostantiattraverso un processo di percolazione (anche qui un ritardo esponenziale).Il processo di percolazione dura un certo tempo (ritardo pipeline), dopo diche l’inquinante raggiunge la falda acquifera, dove si accumula e man manoviene liberato attraverso processi di decadimento naturale: anche qui il flussoin uscita e proporzionale alla quantita immagazzinata in falda, e quindi si hadi nuovo un ritardo esponenziale.
Inquinante insuperficie
Inquinante intransito
Inquinante nellefalde
Inquinante usato Percolazione1 Percolazione2Decomposizione
in acqua
Decomposizionenel terreno
Figura 6.14. Un modello di diffusione di inquinanti
Nella figura 6.15 e stato riportato un tipico andamento nel tempo dellaconcentrazione dell’inquinante nelle falde acquifere confrontato con le curvedell’inquinante usato e di quello rilasciato nel terreno. Qui abbiamo suppo-sto l’uso di una quantita costante di inquinante dall’istante 0 per 10 anni,dopo di che l’uso dell’inquinante e stato interrotto. E interessante osservarecome la presenza di inquinante in falda continui ad aumentare anche dopol’interruzione del suo uso, e come solo dopo diversi anni il suo livello comin-ci a decrescere. Al di la del fatto che i numeri usati possano essere piu omeno realistici e del fatto che il modello sia troppo generico per rappresen-tare bene un qualche particolare tipo di inquinante, esso ci fa comprendere

114 Capitolo 6. Dinamica dei sistemi
bene l’effetto dei ritardi, che in maggiore o minore quantita sono comunquesempre presenti in situazioni del tipo che abbiamo illustrato. Tra l’altro lafigura presenta un andamento molto simile a quello riportato con riferimentoal caso del DCPa dagli autori precedentemente citati.
40
30
20
10
0
0 5 10 15 20 25 30 35 40 45 50Tempo (anni)
Inquinante in faldaInquinante usato
40
30
20
10
0
0 5 10 15 20 25 30 35 40 45 50Tempo (anni)
Inquinante in faldaInquinante usato
Figura 6.15. Diffusione dell’inquinante
Un caso simile, sempre riportato dagli stessi autori, e quello che riguardai PCB (PolyChlorinated Biphenyls). Si tratta di materiali chimici, stabili,oleosi, non infiammabili, usati principalmente per il raffreddamento di com-ponenti elettriche, capacita e trasformatori. Dal 1929 sono state prodottecirca 2 milioni di tonnellate di PCB, il quale e stato in genere eliminato do-po l’uso in discariche nel terreno, nelle fogne o anche in acqua. Nel 1966uno studio sulla diffusione del DDT nell’ambiente porto a scoprire anche lapresenza dei PCB in praticamente ogni componente dell’ecosistema, dall’at-mosfera alla catena del cibo. La maggior parte dei PCB sono poco solubiliin acqua, ma solubili nei grassi ed hanno una vita molto lunga. Si muovonolentamente nel terreno e in acqua, fino a che non si inseriscono in qualcheforma di vita, dove si accumulano nei tessuti grassi ed aumentano in con-centrazione man mano che si muovono in alto nella catena alimentare. Sitrovano in pesci carnivori, uccelli e mammiferi marini, nei grassi umani edanche nel latte umano. Interferiscono col sistema immunitario ed endocrino,in particolare con la riproduzione e lo sviluppo del feto. Negli anni ‘70 lasua produzione ed il suo uso sono stati proibiti in molti paesi. Tuttavia nel

6.3. Ritardi 115
1992 ancora circa il 70% del PCB prodotto era o in uso oppure contenuto inapparecchiature elettriche abbandonate. Del rimanente 30% solamente l’1%era gia apparso nella catena alimentare. Anche qui i danni provocati dall’u-so di un materiale inquinante saranno ancora evidenti molto tempo dopo ladecisione di abbandonare l’uso di quel prodotto.
6.3.3 Inquinamento atmosferico ed effetto serra
Un caso che evidenzia bene come l’interagire di flussi e di livelli porti aritardi e quello dell’effetto serra. Riportiamo nella figura 6.16 un modellosemplificato dei rapporti fra ciclo del carbonio e riscaldamento globale.
ConcentrazioneCO2 in
atmosfera
Temperatura
Variazioneconcentrazione CO2
Decadimento
Variazionitemperatura
Temperatura diequilibrio
Concentrazione CO2preindustriale
Temperaturapreindustriale
Ritardo
Tempo di vita inatmosfera
K
Emissioni CO2
Figura 6.16. Un modello semplificato del ciclo del carbonio e dellatemperatura globale
I fenomeni connessi sono abbastanza complessi, ma possiamo cercare didelinearne gli elementi fondamentali in modo semplice. La temperatura sullasuperficie terrestre - terra, strati inferiori dell’atmosfera e fascia superioredei mari (la zona dei 50-100 metri in cui si concentra la vita marina) - edeterminata pricipalmente dal bilancio fra le radiazioni solari (energia che

116 Capitolo 6. Dinamica dei sistemi
entra per radiazione) e l’energia che viene radiata indietro nello spazio. Laterra e una massa calda circondata da uno spazio freddo ed emette radiazionila cui distribuzione di frequenza ed intensita dipende dalla sua temperaturasuperficiale. Piu calda e la terra maggiore e il flusso di energia che vieneemessa per radiazione verso lo spazio: si crea un effetto di feedback negativo,per cui le radiazioni solari in arrivo scaldano la terra, facendone aumentare latemperatura superficiale, fino al punto in cui l’energia emessa per radiazionebilancia quella ricevuta; a questo punto la temperatura non cresce piu.
La quantita di energia emessa verso lo spazio dipende pure dalla compo-sizione dell’atmosfera. I cosiddetti gas serra, tra cui principalmente l’anidri-de carbonica (biossido di carbonio), assorbono una parte di questa energia.Quindi un aumento nella concentrazione dei gas serra fa aumentare la tem-peratura della terra fino a che essa non raggiunga un valore che permette dinuovo il bilanciamento tra energia in arrivo ed energia in uscita. Va osserva-to che i gas serra svolgono un ruolo fondamentale: sono essi che riducono leradiazioni di quel che serve per mantenere una temperatura media di circa 150C, necessaria per la vita sulla terra. In assenza di gas serra la temperaturamedia superficiale sarebbe di circa -17 0C.
Diversi processi naturali di natura biochimica e geotermica hanno causatonel tempo fluttuazioni di concentrazione di anidride carbonica nell’atmosfe-ra. Oggi le attivita umane hanno raggiunto una scala tale da avere effettiparticolarmente rilevanti: le emissioni di gas serra sono andate crescendoin modo esponenziale dall’inizio della rivoluzione industriale. Conseguente-mente la concentrazione di questi gas nell’atmosfera e anch’essa cresciutaesponenzialmente. La concentrazione nell’atmosfera di CO2, che era primadell’era industriale di circa 280 ppm (parti per milione), e ora di 370 ppm etende a crescere10.
Attualmente c’e uno sbilancio nelle radiazioni di circa 2.4 w/m2, cioe laradiazione solare in arrivo supera di questa quantita la radiazione emessadalla terra. Da qui il continuo aumento della temperatura: secondo l’IPCCla temperatura media e cresciuta nel ventesimo secolo fra 0.4 ed 0.8 0C. Ilriscaldamento e stato accompagnato, fra gli altri fenomeni, dal ritirarsi deighiacciai, dalla dimuzione dello spessore dei ghiacci artici, e da un aumentodell’ordine di 10-20 cm del livello dei mari.
10L’IPCC (Intergovernmental Panel on Climate Change), un’agenzia promossa dall’Onu,afferma: La presente concentrazione di CO2 non e mai stata superata negli ultimi 420.000anni e molto probabilmente neppure negli ultimi 20 milioni di anni. L’attuale tasso dicrescita non ha pari almeno negli ultimi 20.000 anni ?

6.3. Ritardi 117
Nel modello della figura 6.16, abbiamo utilizzato due livelli, uno per rap-presentare la concentrazione di CO2 nell’atmosfera e l’altro per rappresentarela temperatura. Abbiamo poi supposto l’esistenza di un effetto di ritardoesponenziale per il decadimento dell’anidride carbonica atmosferica, per cui,da un lato ci sono le emissioni industriali di CO2 e dall’altra il suo decadi-mento, smorzato sulla base di una stima della sua vita media nell’atmosfera.Abbiamo assunto come base il livello di concentrazione preindustriale11 ecome vita media 100 anni, per cui il decadimento avviene secondo la legge:
Decadimento =CCO2 − Cpi
100,
dove CCO2 e la concentrazione di CO2 e Cpi il suo livello preindustriale.Cioe, essendo di 100 anni il tempo medio di permanenza nell’atmosfera diuna molecola di anidride carbonica, il numero medio di molecole che in mediascompaiono ogni anno e approssimativamente un centesimo di quelle presentiin atmosfera12. Naturalmente qui abbiamo assunto l’anno come unita ditempo.
Abbiamo poi assunto che gli incrementi della temperatura di equilibriorispetto alla temperatura media preindustriale siano crescenti con il rapportofra la concentrazione di CO2 ed il suo valore preindustriale secondo una leggedel tipo:
T (CCO2) = Tpi + K lnCCO2
Cpi
,
dove T (CCO2) e la temperatura di equilibrio in funzione della concentrazionedi CO2, Tpi e il suo livello preindustriale e K e un coefficiente di proporzio-nalita. Per temperatura di equilibrio intendiamo quella che, per dati livellidi concentrazione di CO2, consente di realizzare l’equilibrio fra radiazioni inentrata e radiazioni in uscita.
L’effettiva temperatura, indicata con il secondo livello del modello, crescequando essa e piu bassa di quella di equilibrio e decresce quando e piu alta;anche qui pero c’e un effetto di smorzamento e quindi un ritardo.
11Il livello preindustriale viene qui considerato come un dato, anche se e esso stesso ilrisultato di un equilibrio fra bioemissioni e decadimento nell’atmosfera.
12Il fatto di considerare qui non tutta la quantita di anidride carbonica presente, masolamente la frazione dovuta alle emissioni industriali, CCO2 − Cpi, e dovuto al fatto che,per semplicita, abbiamo considerato la quantita di gas presente a regime in atmosfera acausa delle bioemissioni una costante, cioe una variabile esogena.
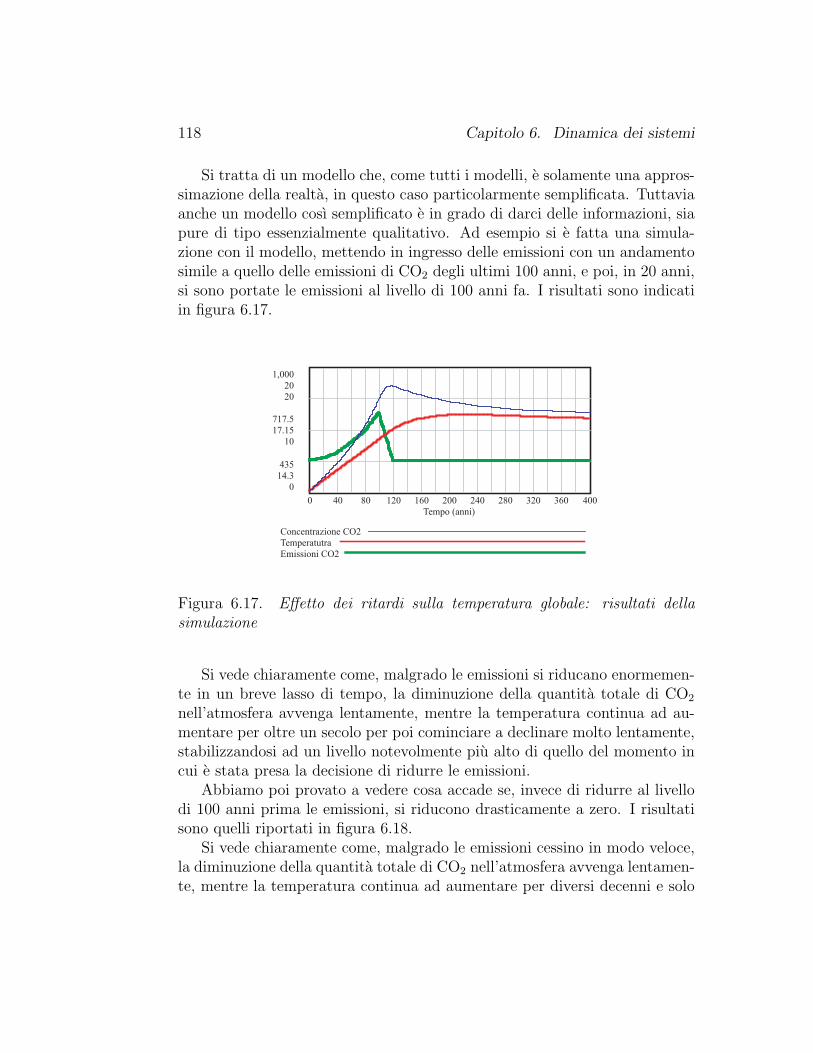
118 Capitolo 6. Dinamica dei sistemi
Si tratta di un modello che, come tutti i modelli, e solamente una appros-simazione della realta, in questo caso particolarmente semplificata. Tuttaviaanche un modello cosı semplificato e in grado di darci delle informazioni, siapure di tipo essenzialmente qualitativo. Ad esempio si e fatta una simula-zione con il modello, mettendo in ingresso delle emissioni con un andamentosimile a quello delle emissioni di CO2 degli ultimi 100 anni, e poi, in 20 anni,si sono portate le emissioni al livello di 100 anni fa. I risultati sono indicatiin figura 6.17.
1,000
2020
717.517.15
10
43514.3
0
0 40 80 120 160 200 240 280 320 360 400Tempo (anni)
Concentrazione CO2TemperatutraEmissioni CO2
Figura 6.17. Effetto dei ritardi sulla temperatura globale: risultati dellasimulazione
Si vede chiaramente come, malgrado le emissioni si riducano enormemen-te in un breve lasso di tempo, la diminuzione della quantita totale di CO2
nell’atmosfera avvenga lentamente, mentre la temperatura continua ad au-mentare per oltre un secolo per poi cominciare a declinare molto lentamente,stabilizzandosi ad un livello notevolmente piu alto di quello del momento incui e stata presa la decisione di ridurre le emissioni.
Abbiamo poi provato a vedere cosa accade se, invece di ridurre al livellodi 100 anni prima le emissioni, si riducono drasticamente a zero. I risultatisono quelli riportati in figura 6.18.
Si vede chiaramente come, malgrado le emissioni cessino in modo veloce,la diminuzione della quantita totale di CO2 nell’atmosfera avvenga lentamen-te, mentre la temperatura continua ad aumentare per diversi decenni e solo

6.3. Ritardi 119
1,000
2020
717.517.15
10
43514.3
0
0 40 80 120 160 200 240 280 320 360 400Tempo (anni)
Concentrazione CO2TemperatutraEmissioni CO2
Figura 6.18. Effetto dei ritardi sulla temperatura globale: risultati dellasimulazione
dopo piu di un secolo ritorna ai valori che aveva nel momento in cui si erapresa la decisione di azzerare le emissioni.
Per quanto il modello usato sia molto semplificato, i risultati ottenutisono consistenti con quelli forniti dai ben piu sofisticati modelli usati dall’I-PCC, che riportiamo in figura 6.19. In questo caso le emissioni sono stateridotte ad un livello sostenibile, in modo da garantire una stabilizzazione del-la temperatura. La stabilizzazione pero, proprio per effetto dei ritardi, nonavviene subito, ma solo dopo un rilevante lasso di tempo in cui la temperatu-ra continua ad aumentare. Questo comporta una temperatura di equilibrioconsistentemente piu alta di quella esistente nel momento in cui e stata presala decisione di ridurre le emissioni.
Il tenere in conto l’effetto dei ritardi nel modello e molto importante nelprendere decisioni: quando si decidera di intervenire potra essere troppo tar-di! Questo e proprio quello che rischia di accadere se consideriamo che nellaConferenza di Kyoto del 1997, 38 paesi industrializzati si sono accordati a ri-durre le emissioni a . . . circa il 95% dei livelli del 1990 entro il 2012. Anche seil trattato di Kyoto fosse realizzato completamente, le emissioni continuereb-bero a superare la capacita di assorbimento e la concentrazione nell’atmosferadei gas serra continuerebbe ad aumentare. E comunque la probabilita cheesso venga effettivamente messo in pratica sono limitatissime dato che gli Usa

120 Capitolo 6. Dinamica dei sistemi
Figura 6.19. Inerzia della temperatura globale rispetto alle variazioni delleemissioni di anidride carbonica (IPCC 2001)
non lo hanno ratificato e che l’unica azione che intendono portare avanti sem-bra sia quella di ridurre le emissioni per unita di prodotto, senza porre perolimiti al volume totale delle attivita economiche che producono emissioni digas serra.
6.3.4 La matematica dei ritardi
Riprendiamo il ritardo esponenziale del primo ordine e l’equazione 6.4. Que-sta equazione e la discretizzazione della seguente equazione differenziale li-neare del primo ordine:

6.3. Ritardi 121
dL(t)
dt+
L(t)
R= I(t). (6.7)
Il primo membro della 6.7 ricorda la derivata di un prodotto di cui L(t)sia uno dei fattori. Ed in effetti moltiplicando il primo ed il secondo membroper e
tR si ottiene
etR
dL(t)
dt+ e
tR
L(t)
R= e
tR I(t), (6.8)
che puo essere riscritta come segue
d[etR L(t)]
dt= e
tR I(t). (6.9)
Assumiamo che la funzione L(t) sia definita sull’insieme dei reali nonnegativi (t ≥ 0). Possiamo allora integrare primo e secondo membro della6.9 fra 0 e t, ottenendo∫ t
0
d[esR L(s)]
dsds =
∫ t
0
esR I(s)ds, (6.10)
da cui
etR L(t)− L(0) =
∫ t
0
esR I(s)ds. (6.11)
Possiamo allora ricavare L(t)
L(t) = L(0)e−tR + e−
tR
∫ t
0
esR I(s)ds. (6.12)
Consideriamo ora 2 casi, quello in cui si ha un input costante con valoreunitario e quello in cui l’input e un impulso unitario di durata 1.
Caso 1 - I(t) = 1, t ∈ [0, +∞].In questo caso si ha ∫ t
0
esR I(s)ds = R(e
tR − 1),
e quindi sostituendo nella 6.12 si ottiene
L(t) = L(0)e−tR + R(1− e−
tR ),
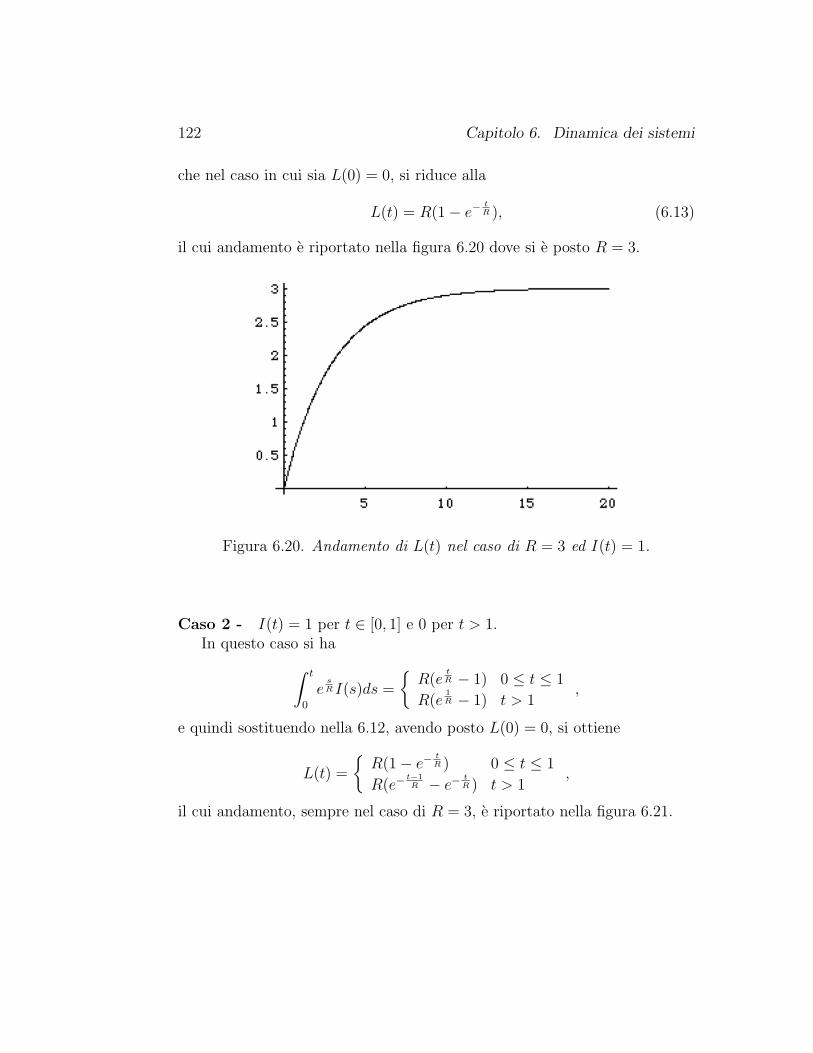
122 Capitolo 6. Dinamica dei sistemi
che nel caso in cui sia L(0) = 0, si riduce alla
L(t) = R(1− e−tR ), (6.13)
il cui andamento e riportato nella figura 6.20 dove si e posto R = 3.
Figura 6.20. Andamento di L(t) nel caso di R = 3 ed I(t) = 1.
Caso 2 - I(t) = 1 per t ∈ [0, 1] e 0 per t > 1.In questo caso si ha∫ t
0
esR I(s)ds =
R(e
tR − 1) 0 ≤ t ≤ 1
R(e1R − 1) t > 1
,
e quindi sostituendo nella 6.12, avendo posto L(0) = 0, si ottiene
L(t) =
R(1− e−
tR ) 0 ≤ t ≤ 1
R(e−t−1R − e−
tR ) t > 1
,
il cui andamento, sempre nel caso di R = 3, e riportato nella figura 6.21.
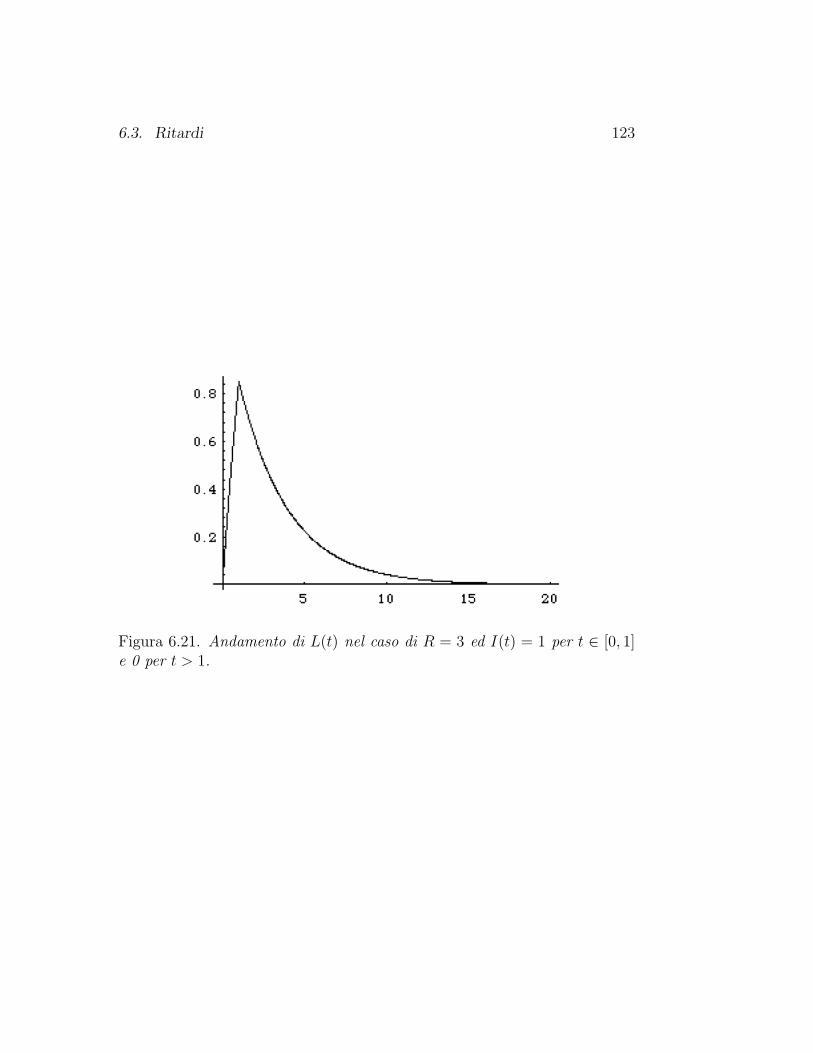
6.3. Ritardi 123
Figura 6.21. Andamento di L(t) nel caso di R = 3 ed I(t) = 1 per t ∈ [0, 1]e 0 per t > 1.

124 Capitolo 6. Dinamica dei sistemi

Bibliografia
Giancarlo Bigi, Antonio Frangioni, Giorgio Gallo, Stefano Pallottino, andMaria Grazia Scutella. Appunti di Ricerca Operativa. SEU - ServizioEditoriale Universitario Pisano, 2003.
Peter Checkland. Soft systems methodology. In Jonathan Rosenhead, editor,Rational analysis for a problematic world. J. Wiley, 1989.
M. Fowler. UML Distilled. Addison-Wesley, 2000.
Donella H. Meadows, Dennis L. Meadows, and Jørgen Randers. Beyondthe Limits. Confronting global collapse. Envisioning a sustainable future.Chelsea Green Publishing Company, 1992.
Michael Pidd. Computer Simulation in Management Science. McGraw-Hill,1998.
Jonathan Rosenhead, editor. Rational analysis for a problematic world. J.Wiley, 1989.
125

126 BIBLIOGRAFIA



![capitolo03 rivisto.ppt [modalità compatibilità] · quadrati fra variabili 3-2 due variabili. ... Calcolate le misure delle relazioni tra variabili correlazione 3-55. Title: Microsoft](https://static.fdocumenti.com/doc/165x107/606f5cad56f3616a2c7e043c/capitolo03-modalit-compatibilit-quadrati-fra-variabili-3-2-due-variabili.jpg)














