
Econometria Applicata - Scienze Statistiche
110
Econometria Applicata Tommaso Proietti Dipartimento di Scienze Statistiche Universit`a di Udine
Transcript of Econometria Applicata - Scienze Statistiche

Econometria Applicata
Tommaso ProiettiDipartimento di Scienze Statistiche
Universita di Udine

Indice
1 Descrizione e Previsione di Serie Temporali 61.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2 Analisi esplorativa delle serie temporali . . . . . . . . . . . . . . . . . 7
1.2.1 La trasformazione logaritmica e le differenze della serie . . . . 81.2.2 Le sintesi della distribuzione del fenomeno . . . . . . . . . . . 101.2.3 Autocorrelazione . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.3 Il modello classico di scomposizione di una serie temporale . . . . . . 131.4 Stima del modello . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.4.1 Test di ipotesi e di significativita su un singolo coefficiente . . 201.4.2 Misura della bonta dell’adattamento . . . . . . . . . . . . . . 21
1.5 Previsione mediante modelli deterministici . . . . . . . . . . . . . . . 211.6 Previsione mediante livellamento esponenziale . . . . . . . . . . . . . 221.7 Previsione mediante il metodo di Holt-Winters . . . . . . . . . . . . . 231.8 Procedura di Holt-Winters stagionale . . . . . . . . . . . . . . . . . . 25
2 I modelli ARIMA 262.1 Premessa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.2 Generalita sui processi stocastici . . . . . . . . . . . . . . . . . . . . . 262.3 Momenti campionari . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.4 Il teorema di Wold . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.5 Autocorrelazione parziale . . . . . . . . . . . . . . . . . . . . . . . . . 282.6 L’algebra dell’operatore L . . . . . . . . . . . . . . . . . . . . . . . . 302.7 Processi Autoregressivi . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.7.1 Processo AR(1) . . . . . . . . . . . . . . . . . . . . . . . . . . 312.7.2 Processo AR(2) . . . . . . . . . . . . . . . . . . . . . . . . . . 322.7.3 Processo AR(p) . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.8 Processi media mobile . . . . . . . . . . . . . . . . . . . . . . . . . . 342.8.1 Processo MA(1) . . . . . . . . . . . . . . . . . . . . . . . . . . 342.8.2 Processo MA(q) . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.9 Processi misti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.10 Non stazionarieta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
1

2.11 Stagionalita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.12 L’approccio di Box e Jenkins . . . . . . . . . . . . . . . . . . . . . . . 38
2.12.1 Identificazione . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.12.2 Stima . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.12.3 Verifica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.13 Previsione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3 Analisi non parametrica delle serie temporali 443.1 Le medie mobili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.2 Effetto fase ed effetto ampiezza . . . . . . . . . . . . . . . . . . . . . 453.3 L’effetto di Slutzky-Yule . . . . . . . . . . . . . . . . . . . . . . . . . 463.4 Polinomi locali; filtri di Macaulay . . . . . . . . . . . . . . . . . . . . 47
3.4.1 Varianza e distorsione . . . . . . . . . . . . . . . . . . . . . . 493.5 Medie mobili aritmetiche semplici . . . . . . . . . . . . . . . . . . . . 49
3.5.1 Componente stagionale di periodo s pari . . . . . . . . . . . . 503.6 Composizione di mm aritmetiche . . . . . . . . . . . . . . . . . . . . 503.7 Lisciamento e filtri di Henderson . . . . . . . . . . . . . . . . . . . . . 513.8 Il trattamento delle estremita della serie . . . . . . . . . . . . . . . . 51
4 La destagionalizzazione delle serie temporali 524.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.2 La procedura X-12-ARIMA . . . . . . . . . . . . . . . . . . . . . . . 544.3 Il filtro di destagionalizzazione (Enhanced X-11) . . . . . . . . . . . . 55
4.3.1 Prima fase: stime iniziali . . . . . . . . . . . . . . . . . . . . . 564.3.2 Seconda fase: fattori stagionali e destagionalizzazione . . . . . 574.3.3 Terza fase: stima finale delle componenti . . . . . . . . . . . . 59
4.4 Le proprieta teoriche del filtro . . . . . . . . . . . . . . . . . . . . . . 594.5 Correzione dei valori anomali nell’X-11 . . . . . . . . . . . . . . . . . 614.6 Le componenti di calendario . . . . . . . . . . . . . . . . . . . . . . . 624.7 Diagnostica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.7.1 Test di stagionalita . . . . . . . . . . . . . . . . . . . . . . . . 634.7.2 Nuova diagnostica su stagionalita residua e l’effetto del n.
giorni lavorativi . . . . . . . . . . . . . . . . . . . . . . . . . . 644.7.3 Test di casualita dei residui I(3)
t . . . . . . . . . . . . . . . . . 644.7.4 Bonta della destagionalizzazione . . . . . . . . . . . . . . . . . 654.7.5 Diagnostiche basate sulla stabilita delle stime . . . . . . . . . 65
5 Analisi Econometrica di Dati non Stazionari 715.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.2 Stazionarieta ed integrazione . . . . . . . . . . . . . . . . . . . . . . . 725.3 Il test di Dickey e Fuller . . . . . . . . . . . . . . . . . . . . . . . . . 75
2

5.4 Il test ADF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 775.5 Trend e RW nelle serie economiche . . . . . . . . . . . . . . . . . . . 785.6 Persistenza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.7 Integrazione stagionale . . . . . . . . . . . . . . . . . . . . . . . . . . 835.8 Test di integrazione stagionale . . . . . . . . . . . . . . . . . . . . . . 865.9 Critiche all’applicazione dei test per radici unitarie . . . . . . . . . . 875.10 Le implicazioni econometriche . . . . . . . . . . . . . . . . . . . . . . 88
5.10.1 Modello nei livelli . . . . . . . . . . . . . . . . . . . . . . . . . 895.10.2 Modello nelle differenze . . . . . . . . . . . . . . . . . . . . . . 895.10.3 Regressione tra serie detrendizzate . . . . . . . . . . . . . . . 90
5.11 Modelli con meccanismo a correzione dell’errore . . . . . . . . . . . . 915.12 Cointegrazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6 I Modelli Strutturali per l’Analisi delle SerieTemporali 996.1 L’approccio modellistico e la classe dei modelli strutturali . . . . . . . 996.2 Trend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1016.3 La modellazione del ciclo economico . . . . . . . . . . . . . . . . . . . 1026.4 Componente stagionale . . . . . . . . . . . . . . . . . . . . . . . . . . 1036.5 Il trattamento statistico del modello e la stima delle componenti . . . 103
6.5.1 La rappresentazione nello spazio degli stati . . . . . . . . . . . 1046.5.2 Il filtro di Kalman . . . . . . . . . . . . . . . . . . . . . . . . 1056.5.3 Verosimiglianza e inizializzazione del filtro . . . . . . . . . . . 1066.5.4 Smoothing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1076.5.5 Diagnostica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
6.6 Componenti di calendario . . . . . . . . . . . . . . . . . . . . . . . . 1086.7 Altre specificazioni della componente stagionale . . . . . . . . . . . . 108
3

Elenco delle tabelle
4.1 Filtro di Henderson: pesi hj per le m.m a 9, 13, 17 e 23 termini . . . 58
4

Elenco delle figure
1.1 Grafico di quattro serie temporali. . . . . . . . . . . . . . . . . . . . 91.2 Distribuzione dei rendimenti sul mercato azionario di Londra (FTSE). 121.3 Correlogramma della trasformazione ∆12 ln yt della serie delle vendite
(variazioni relative su base annua). . . . . . . . . . . . . . . . . . . . 14
4.1 Destagionalizzazione della serie Airline. . . . . . . . . . . . . . . . 534.2 Pesi e funzioni di trasferimento per il filtro X-11 default . . . . . . . 684.3 Pesi e funzioni di trasferimento per il filtro X-11 con filtro di Hender-
son a 17 termini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.4 Serie BDIGENGS: livello degli ordini e della domanda dall’interno
per il totale industria (saldi), ISCO. . . . . . . . . . . . . . . . . . . 70
5

Capitolo 1
Descrizione e Previsione di SerieTemporali
1.1 Introduzione
Una serie temporale costituisce una sequenza di osservazioni su un fenomeno y ef-fettuate in istanti o intervalli (rispettivamente per le variabili di stock e di flusso) ditempo consecutivi e solitamente, anche se non necessariamente equispaziati (stock)o della stessa lunghezza (flussi). Un esempio di una variabile di stock e costituito dalprezzo di un prodotto, mentre un esempio di flusso e rappresentato dalle vendite diun particolare bene realizzate in un intervallo di tempo. Una tipologia intermedia ecostituita dalle medie temporali di uno stock (prezzi medi in un periodo di tempo).
Denotando con t = 1, . . . , T il tempo, indicheremo tale sequenza yt; il tempo eil criterio ordinatore che non puo essere trascurato, per cui occorre conoscere anchela posizione dell’osservazione lungo la dimensione temporale. Generalmente, si usarappresentare la coppia di valori (t, yt) su diagramma cartesiano, con un grafico atratto continuo, come se il fenomeno fosse rilevato con continuita.
L’analisi univariata delle serie temporali, oggetto del presente capitolo, si pro-pone di interpretare il meccanismo dinamico che ha generato la serie e di prevederele realizzazioni future del fenomeno: in queste operazioni l’informazione che vienesfruttata riguarda esclusivamente la coppia (t, yt), t = 1, . . . , T . Il punto fondamen-tale e che il passato ed il presente contengono informazioni rilevanti per prevederel’evoluzione futura del fenomeno.
Si puo ritenere che l’analisi univariata sia troppo limitativa; solitamente si di-spone di informazioni su fenomeni collegati a quello da prevedere e che andreb-bero opportunamente incorporate al fine di migliorare la performance del modellodi previsione. Cio nonostante, essa e un utile benchmark che consente di validarealternative piu sofisticate.
6

1.2 Analisi esplorativa delle serie temporali
L’analista aziendale e interessato a seguire nel tempo l’evoluzione dei fenomeni eco-nomici di interesse, quali la produzione e le vendite, le scorte di magazzino, i flussituristici, le quote di mercato etc. Molto spesso l’interesse non e incentrato sul valoreassoluto del fenomeno, ma piuttosto sulle variazioni relative, vale a dire sui tassi dicrescita.
In tal caso l’analista puo assumere un istante o intervallo temporale di riferi-mento (detto base), che viene mantenuto fisso, e valutare la dinamica del fenomenorelativamente alla base. Sia ad es. y0 il valore delle vendite di un particolare beneal tempo base: il numero indice (percentuale) delle vendite al tempo t e fornito da
i0t = 100yt
y0,
mentre il tasso di variazione relativo e dato dal complemento a 100, i0t − 100; cosı,se i04 = 105.2, il valore delle vendite nel periodo t = 4 e superiore a quello del tempobase per una quota pari al 5.2%.
Altre volte e utile raffrontare il valore del fenomeno con quello del tempo prece-dente, considerando gli indici a base mobile e le variazioni percentuali
it−1,t = 100yt
yt−1, it−1,t − 100 = 100
yt − yt−1
yt−1
Un problema sorge quando il fenomeno e complesso, vale a dire risulta dallacombinazione di piu fenomeni elementari; si pensi alla costruzione di un indice deiprezzi di vendita di un’impresa che produce beni differenziati (ad es. cioccolatini,caramelle, panettoni etc.). Una soluzione pratica consiste nel costruire un indice ditipo Laspeyres:
I0t = 100∑
k pktqk0∑
k pk0qk0= 100
∑
k(pkt/pk0)pk0qk0∑
k pk0qk0
dove pkt rappresenta il prezzo del prodotto k al tempo t e qkt la quantita vendutacorrispondente.
Se il fenomeno e stagionale, presentando delle oscillazioni ricorrenti e periodichenell’arco dell’anno (le vendite sono piu elevate nel mese di dicembre per effetto delNatale), ha senso calcolare i tassi di variazione relativa con riferimento allo stessoperiodo dell’anno precedente, al fine di ottenere una valutazione non influenzatadalla stagionalita. Nel caso di osservazioni mensili:
it−12,t = 100yt
yt−12, it−12,t − 100 = 100
yt − yt−12
yt−12
Uno dei piu efficaci strumenti esplorativi e senza dubbio il grafico della serie (edelle sue trasformazioni), il quale puo immediatamente rivelare alcuni fatti stilizzati,
7

come la presenza e la natura del trend, della stagionalita, di fluttuazioni di breveperiodo, di valori anomali o rotture strutturali (si veda [?], cap. 3, per alcune”questioni di stile” concernenti le rappresentazioni grafiche delle serie temporali).
La figura 1.1 mette in luce che fenomeni diversi possono mostrare comporta-menti molto differenziati: la prima serie, formata da 135 misurazioni del diametrodi componenti di un pistone prodotte ad intervalli di tempo regolari, si manifestapiuttosto ”irregolare”, fluttuando attorno ad un valore medio (linea tratteggiata)che puo essere assunto costante. La seconda e la serie semestrale dei contratti pertelefonia cellulare e presenta un evidente trend di natura esponenziale. La terzariguarda le vendite effettuate da una societa anonima ed ha periodicita mensile; levendite mostrano un trend crescente, ma il fatto nuovo, non osservabile nelle altreserie, e la presenza di una forte stagionalita, tale che il massimo annuale si ha incorrispondenza del mese di novembre ed il minimo in quello di maggio. Inoltre,l’ampiezza delle fluttuazioni stagionali cresce al crescere del trend. L’ultima serierappresenta il logaritmo dei prezzi giornalieri di chiusura sul mercato azionario diLondra (FTSE); torneremo tra breve su questa serie.
1.2.1 La trasformazione logaritmica e le differenze della se-rie
Con riferimento all’ultima serie abbiamo utilizzato la trasformazione logaritmica;esistono almeno due buone ragioni che possono giustificarne l’impiego. In primoluogo essa stabilizza la variabilita della serie, quando questa si riveli crescente alcrescere del trend: questa circostanza si verifica per la serie delle vendite, la cuitrasformazione logaritmica non possiede piu la caratteristica segnalata precedente-mente riguardo alle fluttuazioni stagionali, che presenteranno ampiezza costante. Ineffetti, se la serie puo essere pensata come il risultato dell’interazione moltiplicativadi piu componenti, mediante la trasformazione logaritmica si rende tale relazionepuramente additiva.
In generale, si consideri una variabile casuale yt con media µt e varianza σ2µ2t ;
si desidera determinare la trasformazione f(yt) tale che Var[f(yt)] sia costante.L’approssimazione di Taylor del primo ordine attorno a µt della funzione f(yt) e:
f(yt) ≈ f(µt) + f ′(µt)(yt − µt)
e, pertanto, Var[f(yt)] ≈ f ′(µt)2µ2t σ
2. Occorre dunque scegliere la funzione in modotale che:
f ′(µt) =1µt
,
da cui discende che la trasformazione richiesta e quella logaritmica (d ln y/dy = 1/y),per cui f(·) = ln(·).
8
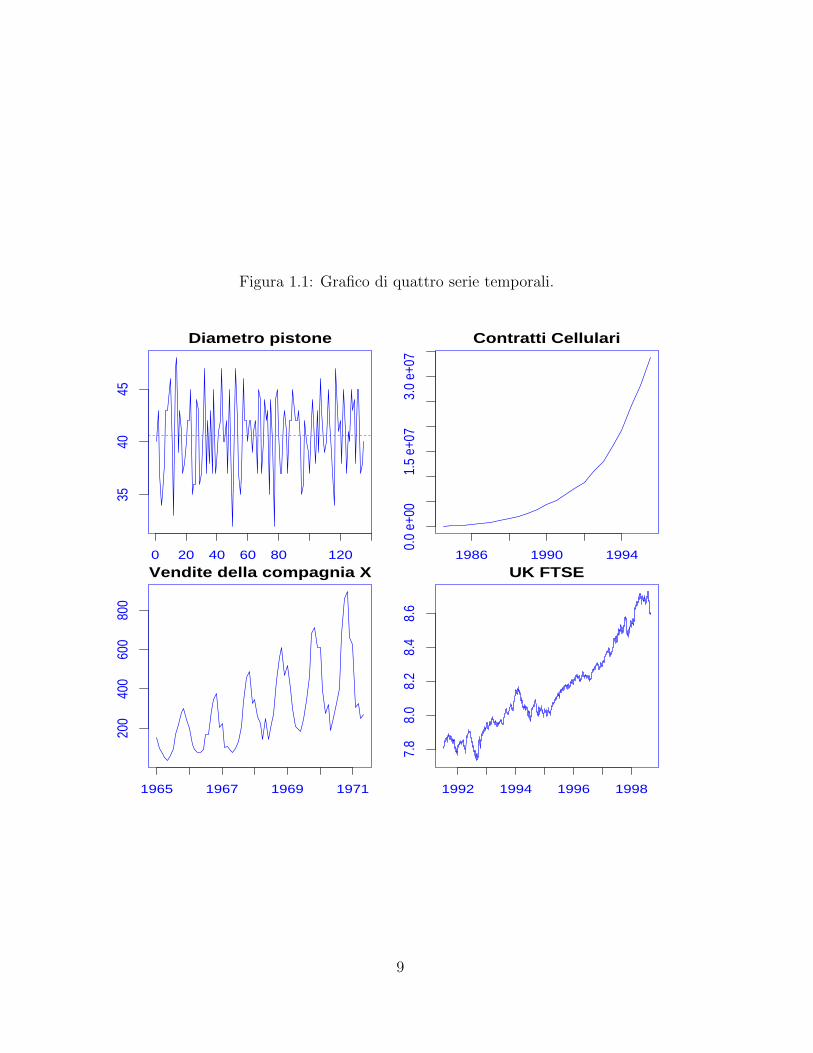
Figura 1.1: Grafico di quattro serie temporali.
Diametro pistone
0 20 40 60 80 120
3540
45
Contratti Cellulari
1986 1990 1994
0.0
e+00
1.5
e+07
3.0
e+07
Vendite della compagnia X
1965 1967 1969 1971
200
400
600
800
UK FTSE
1992 1994 1996 1998
7.8
8.0
8.2
8.4
8.6
9

La seconda ragione attiene all’impiego della trasformazione in congiunzione alledifferenze della serie. Infatti, definendo
∆k ln yt = ln yt − ln yt−k,
si ha che le differenze k-esime costituiscono un’approssimazione della variazionerelativa del fenomeno dal tempo t− k al tempo t, ovvero:
∆kyt ≈yt − yt−k
yt−k.
Per comprendere la natura dell’approssimazione si prenda, senza perdita digeneralita, il caso k = 1 (differenze prime logaritmiche):
∆ ln yt = ln(
yt
yt−1
)
= ln(
1 +∆yt
yt−1
)
= ln(1 + rt)
dove rt = ∆yt/yt−1 e il tasso di variazione relativo rispetto al tempo precedente. Losviluppo in serie di Taylor della funzione ln(1 + rt) attorno al punto rt = 0 risulta:
ln(1 + rt) = rt −12r2t +
13r3t + · · · ,
per cui si puo affermare che ∆ ln yt rappresenta l’approssimazione di Taylor del primoordine della variazione relativa. La bonta dell’approssimazione dipende dall’ordinedi grandezza di quest’ultima.
1.2.2 Le sintesi della distribuzione del fenomeno
Le sintesi del fenomeno effettuate mediante le medie e le varianze
• Media: y = T−1 ∑Tt=1 yt
• Varianza: S2 = T−1 ∑Tt=1(yt − y)2
o altre statistiche descrittive (asimmetria, curtosi, etc.), che consideriamo nel pro-sieguo della discussione, hanno significato solo se sono stabili nel tempo.
Nel caso di variabili univariate siamo soliti andare a guardare la distribuzionedei valori mediante la stima della densita della stessa (cfr. appendice ??). Questasintesi potrebbe non avere molto senso nel caso di serie temporali data la forteinterdipendenza nel tempo, e sarebbe sicuramente non informativa per tutte le serieconsiderate ad eccezione della prima. In effetti, lo stima della distribuzione di unfenomeno assume che le osservazioni a nostra disposizione costituiscano un campionecasuale proveniente da un’unica popolazione di valori, e risulta oltremodo difficileritenere che la distribuzione del fenomeno sia costante nel caso della serie delle
10

vendite, per il quale si osserva che in media il fenomeno e crescente e ha movimentistagionali.
Cio non implica che lo studio della distribuzione sia del tutto privo di rilievoanche con riferimento ad una trasformazione della serie. Si consideri, ad esempio,la serie dei rendimenti (log return),
rt = ∆ ln yt = ln yt − ln yt−1,
calcolata con riferimento alla serie FTSE e presentata nel primo pannello della fi-gura 1.2. Il grafico dei rendimenti contro i valori ritardati di un periodo mostra,nella sostanza, che rt e incorrelato con rt−1 (questo implicherebbe che la conoscenzadel passato non e di aiuto per predire il futuro); tuttavia, si osservano dei periodiin cui la volatilita della serie e piu pronunciata, ed effettivamente, se consideriamola distribuzione dei rendimenti mediante l’istogramma e una stima non parametricadella densita si nota la presenza del fenomeno noto come leptocurtosi: la distribuzio-ne presenta un addensamento delle frequenze sui valori centrali e sulle code rispettoal caso normale (l’ultimo riquadro riporta, accanto alla stima non parametrica, ladensita di una variabile casuale normale con media e varianza poste uguali a quelleosservate per i rendimenti rt); questo implica che la possibilita di osservare eventiestremi e maggiore.
Due misure di sintesi molto utili al fine di caratterizzare la natura della distri-buzione sono l’indice di asimmetria:
skewness =1T
T∑
t=1
(yt − yS
)3,
e di curtosi:
curtosi =1T
T∑
t=1
(yt − yS
)4.
Se la distribuzione e simmetrica il primo indice e pari a zero, mentre il valore teoricodi riferimento per il secondo e quello assunto sotto l’ipotesi di distribuzione normale,pari a 3; valori superiori indicano che la distribuzione e leptocurtica.
Al fine di testare dal punto di vista formale la conformita con la distribuzionenormale si puo utilizzare il test di Jarque e Bera [?], il quale e basato sulla statistica:
JB =T6
[
skewness2 +14(curtosi− 3)2
]
che, sotto l’ipotesi nulla di normalita, ha distribuzione χ2 con 2 gradi di liberta.Un ausilio grafico finalizzato alla valutazione di conformita con la distribuzione nor-male e il cosiddetto qqplot che costituisce il diagramma a dispersione dei quantilidella distribuzione empirica della serie osservata con quelli teorici della distribuzionenormale con stessa media e varianza; esso puo essere ottenuto in R utilizzando lafunzione qqnorm(). Se la distribuzione del fenomeno e normale i punti si dispongonolungo una linea retta.
11

Figura 1.2: Distribuzione dei rendimenti sul mercato azionario di Londra (FTSE).
Rendimenti FTSE
1992 1994 1996 1998
−0.0
40.
000.
020.
04
−0.04 0.00 0.02 0.04
−0.0
40.
000.
020.
04
rt versus rt−1
Distr. Rendimenti
−0.04 0.00 0.02 0.04
010
2030
4050
6070
−0.04 0.00 0.02 0.04
010
2030
4050
6070
Confronto distribuzione normale
12

1.2.3 Autocorrelazione
I fenomeni aziendali presentano una cosiddetta dipendenza temporale, o autocorrela-zione, nel senso che il presente dipende dal passato; un semplice modo per verificarese la serie e autocorrelata consiste nel rappresentare in un diagramma a dispersioneyt e yt−1 (la serie ritardata di un periodo - in generale definiamo la serie ritardatadi k periodi slittando la serie originaria k periodi in avanti, di modo che al tempo tviene associato il valore yt−k); se si ottiene una nuvola di punti che si muove attornoad una retta inclinata positivamente, allora si dice che yt presenta autocorrelazionepositiva e che quanto piu il valore registrato nel periodo precedente e elevato, tantopiu e lecito attendersi un valore positivo ed alto per il tempo corrente; viceversa nelcaso di autocorrelazione negativa. Il coefficiente di correlazione tra yt e yt−1 misural’intensita del legame della serie con il passato. Si parla inoltre di autocorrelazionedi ordine k se yt e correlato con yt−k.
L’autocovarianza campionaria a lag, o ritardo, k e calcolata come segue:
ck = T−1T
∑
t=1(yt − y)(yt−k − y)
si osservi che a stretto rigore gli scarti dalla media delle osservazioni ritardate do-vrebbero essere calcolati con riferimento alla media delle T −k osservazioni yt−k, t =k + 1, . . . , T ; tuttavia, se T e sufficientemente elevato e il fenomeno non presentatendenza, questa non differisce dalla media globale. Il coefficiente di autocorrela-zione al medesimo ritardo e fornito da ρk = ck/c0. Osserviamo che a denominatoredovremmo avere il prodotto degli scarti quadratici medi di yt, t = 1, . . . , T , e diyt−k, t = k + 1, . . . , T ; anche in questo caso, sotto certe condizioni, il secondo nondifferisce da
√c0 = S.
La tipologia di rappresentazione grafica che viene comunemente impiegata perrappresentare le autocorrelazioni e il correlogramma, un diagramma ad aste checontiene in ascissa i valori consecutivi del ritardo k e in ordinata i valori delle auto-correlazioni corrispondenti. Un esempio e fornito dalla figura 1.3 ed e stato prodottodalla funzione acf() della libreria ts di R.
La dipendenza del fenomeno dal passato e fortemente legata alla possibilita diprevedere le realizzazioni future dalla conoscenza del comportamento nel tempo.
1.3 Il modello classico di scomposizione di unaserie temporale
Le serie temporali relative a fenomeni economico-aziendali presentano delle carat-teristiche comuni, che sono state identificate come trend, ciclo, stagionalita (per
13
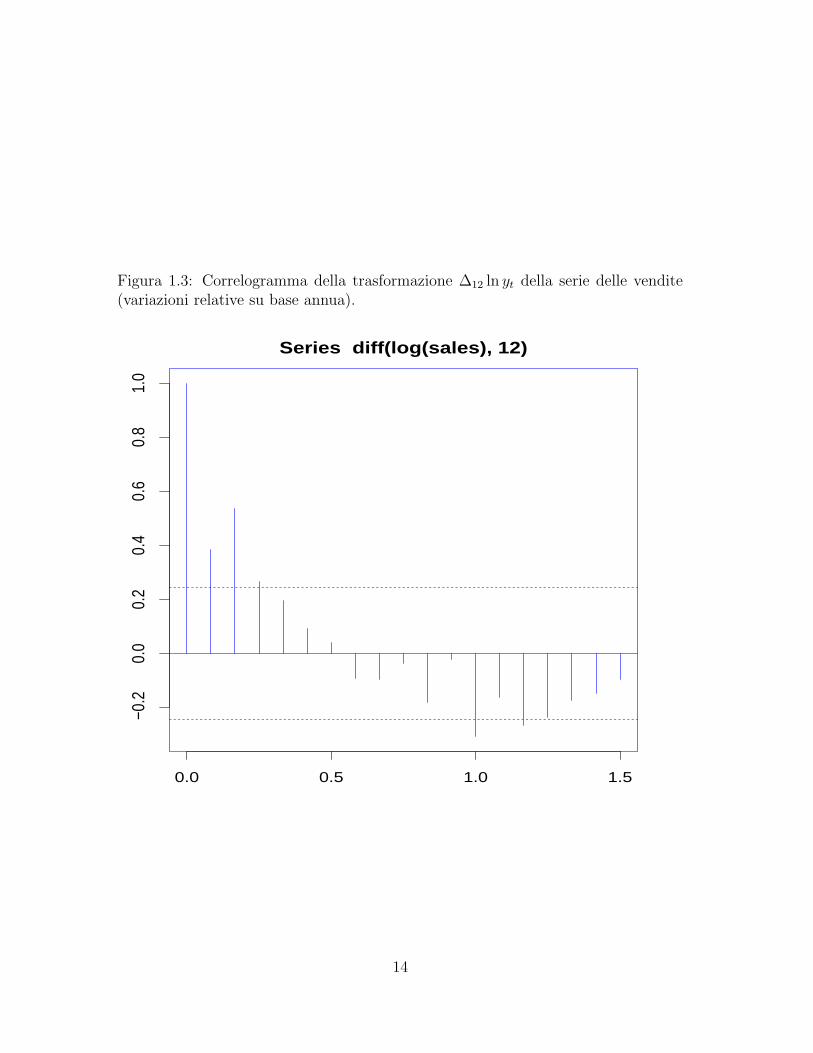
Figura 1.3: Correlogramma della trasformazione ∆12 ln yt della serie delle vendite(variazioni relative su base annua).
0.0 0.5 1.0 1.5
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
Series diff(log(sales), 12)
14

osservazioni subannuali); questi “segnali” possono essere contaminati da oscillazio-ni che a prima vista appaiono non strutturate e che possono essere identificatecome puramente casuali. L’analisi classica prende le mosse da questa naturale con-statazione, proponendo i seguenti modelli di scomposizione della serie temporale(rispettivamente modello additivo e modello moltiplicativo):
yt = µt + ψt + γt + εt
yt = µtψtγtεt(1.1)
dove, in generale, le componenti hanno natura deterministica ad eccezione di quellairregolare; quest’ultima viene intesa come una componente puramente casuale, nonprevedibile dalla conoscenza delle sue realizzazioni passate e che si sovrappone aisegnali senza avere una sistematicita. Nel caso additivo, un modello statistico percatturare queste caratteristiche postula che εt sia una sequenza di realizzazioni divariabili casuali normali identicamente e distribuite in maniera indipendente conmedia nulla e varianza costante; in simboli, εt ∼ NID(0, σ2). Una versione piudebole non richiede la normalita, ma si limita ad assumere che εt, t = 1, . . . , T sianovariabili causali incorrelate a media nulla e varianza costante. Nel seguito faremoriferimento esclusivo al modello di scomposizione additivo, al quale si puo ricondurreil modello moltiplicativo in seguito all’applicazione della trasformazione logaritmica.
Il simbolo µt denota la componente tendenziale (trend), espressione della di-namica di lungo periodo della serie, generalmente rappresentata da una funzionedeterministica (ad es. un polinomio) del tempo, t:
• Trend costante (di grado 0): µt = β0
• Trend lineare: µt = β0 + β1t
• Trend quadratico: µt = β0 + β1t + β2t2
• Trend logistico (per fenomeni caratterizzati da un livello di saturazione):
µt =β0
1 + β1 exp(−β2t)
• Trend esponenziale: µt = exp(β0 + β1t)
La componente di breve periodo, detta anche ciclo, e denotata con ψt ed erappresentata da una funzione trigonometrica:
ψt = α cos(λt) + β sin(λt)
dove λ ∈ [0, π] rappresenta la frequenza angolare, tale che il periodo dell’oscillazionee pari a P = 2π/λ e α e β determinano l’ampiezza dell’oscillazione (A =
√α2 + β2).
La componente stagionale coglie le oscillazioni sistematiche della serie che hannoperiodo uguale all’anno; Hylleberg, [?] propone la seguente definizione:
15

Seasonality is the systematic, although not necessarily regular, intra-year movement caused by the changes of the weather, the calendar, andtiming of decisions, directly or indirectly through the production andconsumption decisions made by the agents of the economy. These deci-sions are influenced by endowments, the expectations and preferences ofthe agents, and the production techniques available in the economy.
Harvey [?] fornisce una definizione incentrata sul problema della previsione, cheindividua la stagionalita nella componente della serie che estrapolata si ripete co-stantemente per ogni periodo di tempo pari all’anno (periodicita) ed ha somma nullasu quel periodo. Sebbene vi sia sufficiente consenso attorno a queste definizioni, chelasciano aperta la possibilita che la componente stagionale evolva nel tempo, unaspetto altrettanto importante e la loro traduzione operativa.
Supponiamo che la serie temporale sia osservata con periodicita s (dove s denotail numero di stagioni in un anno, vale a dire s = 4 per dati trimestrali, s = 12 per datimensili, s = 52 per dati settimanali, etc.) e denotiamo con γt l’effetto stagionale altempo t. Ci sono due approcci equivalenti alla modellazione di un pattern stagionaledeterministico (vale a dire invariante nel tempo): nel dominio temporale, mediantel’introduzione di particolari variabili indicatrici dette dummy stagionali; nel dominiofrequenziale, mediante una combinazione lineare di funzioni trigonometriche, seno ecoseno in particolare. Secondo il primo approccio,
γt =s
∑
j=1δjDjt (1.2)
dove Djt e una dummy stagionale, Djt = 1 nella stagione j e 0 altrimenti, e icoefficienti δj misurano l’effetto associato al corrispondente periodo dell’anno. Se laserie contiene anche una componente tendenziale e il modello di scomposizione e deltipo
yt = β0 + β1t +s
∑
j=1δjDjt + εt,
si incontra immediatamente una difficolta, consistente nel fatto che il modello non eidentificato, poiche esiste dipendenza lineare tra i regressori (infatti la somma delles dummy stagionali e pari all’unita e questo effetto viene confuso con l’intercetta).A tale problema si rimedia vincolando i coefficienti δj ad avere somma nulla; talerestrizione consente di identificare il modello (1.1) quando e presente il terminedi intercetta e, sotto l’ipotesi che la componente irregolare sia abbia distribuzioneεt ∼ NID(0, σ2), il modello (1.1) puo essere stimato mediante i minimi quadrati(MQ) vincolati (cfr. [?]).
Invece di vincolare i coefficienti δj ad avere somma nulla, si possono utilizzarestrategie alternative che rendono praticabili le stime dei MQ ordinari.
16

• Una parametrizzazione equivalente si ottiene ponendo Djt = 1, t = j, mods, Djt = 0, t 6= j mod s, Djt = −1, t = s, mod s (vale a dire ponendoDjt = Djt −Dst per j = 1, . . . , s− 1) e stimando il modello
yt = β0 + β1t +s−1∑
j=1δjDjt + εt
L’effetto stagionale associato alla stagione s si ottiene come segue:
δs = −s−1∑
j=1δj
• Una soluzione consiste nell’eliminare l’intercetta, stimando il modello
yt = β1t +s
∑
j=1δ∗j Djt + εt
dove δ∗j = δj +β0, mediante i MQO. Ottenute le stime dei parametri, si ottieneβ0 = 1/s
∑
δ∗j e δj = δ∗j − β0.
• Alternativamente, possiamo modellare la stagionalita introducendo soltantos− 1 dummy del tipo Djt, ad es. escludendo l’ultima:
yt = β†0 + β1t +s−1∑
j=1δ†jDjt + εt
In tal caso, β†0 + δ†j = β0 + δj, j = 1, . . . , s − 1, e β†0 = β0 + δs; sommandorispetto a j si ottiene:
β0 = β†0 +1s
s−1∑
j=1δ†j
e successivamente si possono ricavare gli effetti originari δj.
Il modello trigonometrico e formulato nei termini di s−1 effetti associati all’ampiezzadi s/2 onde cicliche definite alle frequenze 2πj/s, j = 1, 2, . . . , s/2: per s pari,
γt =s/2∑
j=1[αj cos(λjt) + βj sin(λjt)] (1.3)
La proprieta condivisa da tutte queste parametrizzazioni e che la somma deglieffetti stagionali su s unita temporali consecutive e identicamente nulla:
s−1∑
j=0γt−j = 0.
17

1.4 Stima del modello
Il modello di scomposizione deterministico puo essere rappresentato come segue:
yt = b1xt1 + . . . + bkxtk + εt = x′tb + εt, t = 1, . . . , T,
con x′t = [xt1, xt2, . . . , xtk] e b e un vettore contenente i k coefficienti di regres-sione. Ad esempio, il modello con trend lineare e s dummy stagionali ha x′t =[t,D1t, . . . , Dst] e b = [β1, δ∗1, . . . , δ
∗s ]′, mentre il modello trend quadratico piu irrego-
lare, yt = β0 + β1t + β2t2 + εt presenta xt = [1, t, t2]′ e b = [β0, β1, β2]′.Le T equazioni lineari possono essere riscritte in forma matriciale
y = Xb + ε,
con y = [y1, . . . , yt, . . . , yT ]′ e X = [x1, x2, . . . ,xT ]′. Il nostro obiettivo e stimare iparametri incogniti (i coefficienti b e σ2), fare inferenze, per verificare se soddisfanole conoscenze a priori o altri vincoli, verificare che il modello costituisca una validainterpretazione della realta e prevedere le osservazioni future.
Sia b una stima di b. In corrispondenza possiamo definire il vettore dei residui(o scarti tra i valori osservati, y, e i valori interpolati, y = Xb):
e = y −Xb.
Lo stimatore dei minimi quadrati (ordinari) si ottiene minimizzando la somma deiquadrati dei residui:
S(b) = e′e = (y −Xb)′(y −Xb) = y′y − 2b′X ′y + b
′X ′Xb
Le condizioni del primo ordine:∂S(b)
∂b= 0
forniscono le cosiddette equazioni normali:
X ′Xb = X ′y,
le quali costituiscono un sistema di k equazioni in k incognite che ammette unasoluzione unica se la matrice X ha rango k: in tal caso la matrice (X ′X) e nonsingolare e la soluzione e
b = (X ′X)−1X ′y =( T
∑
t=1xtx′t
)−1 T∑
t=1xtyt.
18

Le condizioni del secondo ordine affinche la soluzione individui un minimo dellafunzione S(b) richiedono che la matrice hessiana sia definita positiva: cio si verificain quanto
∂2S(b)
∂b∂b′ = 2(X ′X) > 0.
Il vettore dei valori predetti dal modello di regressione e dei residui del sonoforniti rispettivamente da y = Xb, con elemento generico yt = x′tb, e da e =y − y = y −Xb, con elemento generico et = yt − x′tb.
y = Xb + e = y + e
Sostituendo b = (X ′X)−1X ′y in S(b) si ottengono le seguenti espressioni equi-valenti per la somma dei quadrati dei residui:
e′e = y′y − b′X ′Xb
= y′(I −X(X ′X)−1X ′)y= y′y − b
′X ′y
= y′y − y′Xb
Si osservi che se la prima colonna di X e il vettore unitario, i (il modello contieneil termine di intercetta), le equazioni normali
X ′e = X ′(y −Xb) = 0,
implicano che :
• i residui dei minimi quadrati hanno somma (media) nulla: i′e = 0 e sonoortogonali rispetto alle variabili indipendenti.
• L’iperpiano di regressione passa per il centroide y = x′b
• La media dei valori predetti, y = Xb, coincide con la media dei valoriosservati.
Proprieta statistiche in campioni finiti Se si assume che E(ε) = 0, lo stimatoreb e corretto:
E(b) = E[(X ′X)−1X ′y] = b + E[(X ′X)−1X ′ε] = b,
e ha matrice di covarianza:
Var(b) = σ2(X ′X)−1
19

Inoltre, sotto l’assunzione di sfericita degli errori, E(εε′) = σ2I, si puo dimostrareche esso presenta varianza minima all’interno della classe degli stimatori lineari.Tale risultato e noto come teorema di Gauss-Markov.
Lo stimatore e inoltre una combinazione lineare di y e quindi di ε. Se si assumeche ε sia distribuito normalmente, b ∼ N(b, σ2(X ′X)−1). Tale risultato viene uti-lizzato per la costruzione di statistiche test per la verifica di ipotesi sui coefficientib. Senza l’assunzione di normalita la distribuzione degli stimatori MQO non e nota;tuttavia, in campioni di grandi dimensioni, si puo invocare il teorema del limitecentrale per trattare b come approssimativamente normale.
Stima di σ2 e della varianza di b Uno stimatore corretto di di σ2 e
s2 =e′e
T − k=
∑Tt=1 e2
t
T − k.
La radice quadrata, s, e denominata errore standard della regressione. Il risultatoviene utilizzato per ottenere una stima della matrice di covarianza delle stime OLS:Var(b) = s2(X ′X)−1.
1.4.1 Test di ipotesi e di significativita su un singolo coeffi-ciente
Sotto l’assunzione di normalita e stato desunto il risultato b ∼ N(b, σ2(X ′X)−1).Se aii denota l’elemento i-esimo sulla diagonale principale di (X ′X)−1:
bi − bi
σ√
aii∼ N(0, 1).
Inoltre, si puo mostrare che (T −k)s2/σ2 ∼ χ2n−k e che tale statistica e distribuita in
maniera indipendente da b. Applichiamo ora il noto risultato per cui dividendo unavariabile casuale normale standardizzata per la radice di una v.c. χ2
n−k indipendentedivisa per il numero dei gradi di liberta si ottiene una v.c. tn−k:
t =bi − bi
s√
aii∼ tn−k
Il risultato puo essere utilizzato per testare ipotesi su un singolo coefficiente eper costruire intervalli di confidenza. Il test di H0 : bi = 0 e anche detto test disignificativita.
20

1.4.2 Misura della bonta dell’adattamento
Qualora il modello contenga un intercetta possiamo ottenere una misura sintetica(scalare) della capacita esplicativa del modello che assume valori compresi tra 0 e1; in particolare, possiamo calcolare la quota di varianza della serie spiegata dallevariabili esplicative incluse nel modello di regressione. La misura in questione prendeil nome di R-quadro ed e fornita dalla seguente espressione:
R2 = 1−∑
t e2t
∑
t(yt − y)2 .
1.5 Previsione mediante modelli deterministici
Al fine di illustrare la previsione effettuata mediante un modello deterministico discomposizione della serie temporale, consideriamo il seguente modello:
yt = β0 + β1t + εt = b′xt + εt
dove b = (β0, β1)′, xt = (1, t)′ e εt ∼ NID(0, σ2). Sia inoltre b il vettore che contienele stime MQO. Il valore predetto al tempo t = 1, . . . , T, e ottenuto come segue:yt = b
′xt = E[yt|xt]; la previsione l periodi in avanti e fornita da:
yT+l = b′xT+l
dove xT+l = (1, T + l)′.Tale previsione e “corretta” nel senso che l’errore di previsione ha valore atteso
nullo:E[yT+l − yT+l] = E[(b− b)′xT+l + εT+l] = 0
ed ottimale, nel senso che minimizza l’errore quadratico medio di previsione (questae una conseguenza del teorema di Gauss-Markov). Infine, la varianza dell’errore diprevisione risulta pari a:
Var[yT+l − yT+l] = E[(b− b)′xT+l + εT+l]2 = 0= σ2
[
1 + x′T+l(X′X)−1xT+l
]
dove X e la matrice T × 2 la cui riga t e data da x′t. Essa puo essere stimatasostituendo σ2 = SSE/(T − 2) nell’espressione precedente.
Modello livello + irregolare : nel caso particolare in cui yt = β0 + εt, yT+l =β0 = y, dove y = T−1 ∑
yt. Inoltre,
Var(yT+l − yT+l) = σ2(
1 +1T
)
21

con σ2 = (T−1)−1 ∑
(yt−y)2. L’intervallo di confidenza all’(1−α)% per la previsioneyT+l e:
y ± tα/2,T−1σ
√
1 +1T
,
dove tα/2,T−1 e il percentile della distribuzione t di Student con T−1 gradi di liberta.
1.6 Previsione mediante livellamento esponenzia-le
In ambito aziendale sono spesso richieste previsioni a breve termine di un grannumero di serie (vendite disaggregate per tipo di bene prodotto) per la pianificazionedella produzione e del magazzino. Un insieme di procedure di previsione ad hoc estato introdotto in questo contesto, caratterizzate da semplicita computazionale eda immediatezza interpretativa, come dovrebbe essere per tecniche di applicazioneroutinaria.
Consideriamo un fenomeno che oscilla attorno ad un valore medio approssimati-vamente costante, e supponiamo di disporre di informazioni sino al tempo t incluso:y1, y2, . . . , yt. Ci proponiamo ora di prevedere il valore del fenomeno un periodoin avanti, al tempo t + 1.
Una previsione elementare puo essere costruita a partire dalla media aritmeticasemplice delle osservazioni disponibili:
yt+1|t = y =1t(yt + yt−1 + · · ·+ y2 + y1)
Si noti che tutte le osservazioni, anche le piu lontane nel tempo, ricevono un pesocostante pari a 1/t.
Potrebbe essere desiderabile ponderare le osservazioni in ragione della loro di-stanza dal tempo corrente, assumendo che le osservazioni piu recenti presentinoun contenuto informativo piu elevato a fini previsivi. Cio conduce a formulare laprevisione come segue:
yt+1|t = w0yt + w1yt−1 + w2yt−2 + · · ·
dove wj, j = 0, 1, 2, . . . e un insieme di coefficienti di ponderazione decrescenti alcrescere di j e a somma unitaria:
∑
j wj = 1. Al fine di ottenere l’effetto desideratosi puo prendere wj = λ(1− λ)j, dove λ e una costante di livellamento compresa tra0 e 1. In tal caso i pesi seguono una progressione geometrica di ragione (1− λ):
w0 = λ, w1 = λ(1− λ), w2 = λ(1− λ)2, . . .
(ad es. se λ = 0.8, w0 = 0.8, w1 = 0.16, w2 = 0.032, per cui il peso dato all’ultimaosservazione e molto piu elevato di quello assegnato alle osservazioni precedenti, che
22

diventa molto piccolo gia a partire dalla terzultima osservazione; nel caso in cuiλ = 0.1, i pesi risultano nell’ordine 0.1, 0.09, 0,081,. . . , presentando una variazionemolto piu limitata).
Riscriviamo ora la previsione dopo aver sostituito l’espressione per wj:
yt+1|t = λyt + λ(1− λ)yt−1 + λ(1− λ)2yt−2 + · · ·
analogamente, se disponessimo soltanto delle osservazioni fino al tempo t − 1 siavrebbe:
yt|t−1 = λyt−1 + λ(1− λ)yt−2 + λ(1− λ)2yt−3 + · · ·Moltiplicando quest’ultima espressione per (1− λ) e sottraendo membro a membrosi ottiene:
yt+1|t − (1− λ)yt|t−1 = λyt,
ovveroyt+1|t = λyt + (1− λ)yt|t−1
o equivalentementeyt+1|t = yt|t−1 + λ(yt − yt|t−1)
Si ottengono due formule ricorsive che forniscono la previsione un periodo inavanti in funzione del valore corrente della serie, yt, del valore previsto al tempoprecedente, yt|t−1, e della costante λ. La seconda espressione indica che nel for-mulare la previsione al tempo corrente modifichiamo la previsione precendente inproporzione all’errore di previsione che abbiamo commesso nel prevedere yt. Perl’inizializzazione delle formule ricorsive sono state avanzate diverse proposte: le piufamose sono y1|0 = y1, y1|0 = s−1 ∑s
t=1 yt, la media delle prime s osservazioni (es.s = 6).
Questo modo di effettuare le previsioni viene detto livellamento esponenziale. Ilproblema fondamentale sta nella determinazione di λ. Essa puo essere effettuataminimizzando la somma dei quadrati degli errori di previsione:
minλ
S(λ) =T
∑
t=1(yt − yt|t−1)2
cio puo essere effettuato mediante una ricerca a griglia nell’intervallo (0,1). Si no-ti che per λ = 1, yt+1|t = yt e la previsione coincide con l’ultima osservazionedisponibile. Viceversa, per λ tendente a 0 si assegna lo stesso peso alle osservazioni.
1.7 Previsione mediante il metodo di Holt-Winters
Un fenomeno che presenta un trend lineare puo essere interpretato mediante ilmodello trend piu irregolare:
yt = α + βt + εt, t = 1, 2, . . . , T.
23

I coefficienti α e β possono essere stimati mediante il metodo dei minimi quadrati eil modello puo essere utilizzato per prevedere il fenomeno un periodo in avanti:
yt+1|t = α + β(t + 1) = α + βt + β;
in generaleyt+l|t = α + β(t + l) = α + βt + lβ;
Le previsioni si muovono lungo una retta, e il modello potrebbe rivelarsi scarsamenteflessibile se il fenomeno presenta un trend locale. In tal caso ha senso estrapolare latendenza indicata dai dati piu vicini al tempo corrente.
Ora, ponendo mt = α + βt, si ha che mt rappresenta il livello del trend al tempot, mentre bt = β rappresenta l’incremento (costante), vale a dire la quantita cheoccorre aggiungere a mt per ottenere yt+1|t; pertanto,
yt+1|t = mt + bt
Si noti che mt (livello) e bt (incremento) possono essere riscritti nei termini di unaformula ricorsiva:
mt = mt−1 + bt−1
bt = bt−1
con valori iniziali m0 = α e b0 = β. Risulta evidente che le osservazioni non giocanoalcun ruolo nell’aggiornamento dei valori di mt e bt.
Le formule precedenti possono essere generalizzate in maniera flessibile mediantele formule di Holt & Winters:
yt+1|t = mt + bt
mt = λ0yt + (1− λ0)(mt−1 + bt−1)bt = λ1(mt −mt−1) + (1− λ1)bt−1
la prima equazione fornisce la nuova stima del livello come media ponderata dell’ul-tima osservazione e della previsione effettuata al tempo precedente ed e pertantoanaloga all’equazione di aggiornamento del livellamento esponenziale; l’equazioneper l’aggiornamento di bt opera una media ponderata tra il valore precedente e ladifferenza tra il livello al tempo t e al tempo t− 1.
La previsione l periodi in avanti giace su una retta
yt+1|t = mt + lbt
con origine in mt e coefficiente angolare bt. Quando una nuova osservazione si rendedisponibile, queste quantita vengono aggiornate.
24

Le due costanti di livellamento, λ0 e λ1, sono comprese tra 0 e 1 e possono esseredeterminate minimizzando la somma dei quadrati degli errori di previsione
S(λ0, λ1) =T
∑
t=2(yt − yt|t−1)2
Dalla relazione mt−1 + bt−1 = yt|t−1, dopo qualche passaggio algebrico, possiamoriscrivere:
mt = mt−1 + bt−1 + λ0et|t−1
bt = bt−1 + λ0λ1et|t−1
dove et|t−1 = yt− yt|t−1. La tecnica di previsione nota come livellamento esponenzialedoppio e un caso particolare del metodo di Holt & Winters, per cui si fanno dipendereλ0 e λ1 da un unico parametro, ω:
λ0 = 1− ω2, λ1 =1− ω1 + ω
Per quanto riguarda l’inizializzazione delle formule ricorsive, si possono prenderem2 = y2 e b2 = y2 − y1.
1.8 Procedura di Holt-Winters stagionale
Consideriamo ora una serie stagionale di periodo s e prendiamo a riferimento ilmodello di scomposizione moltiplicativo: yt = ytgt, dove yt denota la serie destagio-nalizzata e gt e un fattore stagionale che misura l’espansione o la contrazione delfenomeno nelle stagioni dell’anno. La previsione l = 1, 2, . . . , s, periodi in avanti altempo t sara: yt+l|t = (mt + btl)gt+l−s,
mt = λ0(yt/gt) + (1− λ0)(mt−1 + bt−1)bt = λ1(mt −mt−1) + (1− λ1)bt−1
gt = λs(yt/mt) + (1− λs)gt−s
con λs ∈ (0, 1). L’inizializzazione puo avvenire al tempo t = s prendendo ms =s−1 ∑s
k=1 yk (in alternativa si puo prendere la media geometrica delle prime s osser-vazioni), bs = 0, gj = yj/ms, j = 1, 2, . . . , s.
Nel caso additivo si avranno le seguenti formule ricorsive:
mt = λ0(yt − gt) + (1− λ0)(mt−1 + bt−1)bt = λ1(mt −mt−1) + (1− λ1)bt−1
gt = λs(yt −mt) + (1− λs)gt−s
25

Capitolo 2
I modelli ARIMA
2.1 Premessa
Prenderemo in considerazione quello che, forse con terminologia inappropriata, econosciuto come approccio “moderno” delle serie temporali, il cui elemento di dif-ferenziazione sta nel considerare la serie yt come realizzazione finita di un processostocastico. Il problema inferenziale e risalire da yt al processo generatore e, in talecontesto, la modellistica ARIMA semplifica il problema mediante una restrizionedella classe dei processi stocastici. La pretesa e quella di fornire una rappresenta-zione unitaria ad una vasta gamma di fenomeni reali; ovviamente, la generalita vaa scapito della possibilita di interpretare il modello in termini di variabili latenti,per cui nell’ambito dell’approccio moderno, si sono affermati i cosiddetti approc-ci “strutturali”. Il riferimento bibliografico piu rilevante per questo capitolo e lamonografia di Box, Jenkins e Reinsel [?]
2.2 Generalita sui processi stocastici
Un processo stocastico,Yt, puo essere definito come una successione ordinata divariabili casuali Yt indicizzate dal parametro t appartenente ad un insieme parame-trico T . Poiche nel seguito ci limiteremo a considerare la classe dei processi stocasticicontinui a parametro discreto, avremo T = 1, 2, . . . e Yt = Y1, Y2, . . ..
Il p.s. e noto se e nota la funzione di ripartizione P (Y1 ≤ a1, Y2 ≤ a2, . . . , YT ≤aT ) per ogni T -upla (a1, . . . , aT ); in altre parole, se e nota la densita congiunta di ognievento nello spazio reale a T dimensioni. Nelle applicazioni si dispone, per ogni t, diuna singola realizzazione della v.c. yt, per cui il processo inferenziale presenterebbecomplicazioni insuperabili se non venissero imposte due classi di restrizioni sullecaratteristiche del processo: la stazionarieta e l’ergodicita.
In particolare, diremo che un processo stocastico e stazionario in senso forte se
26

la distribuzione di probabilita congiunta di Yt, Yt+1, . . . , Yt+r e indipendente da t,∀r. Condizione necessaria e sufficiente perche cio si verifichi e che tutti i momentidella v.c. multipla Yt, Yt+1, . . . , Yt+r siano finiti ed indipendenti da t. La strutturadinamica e dunque invariante nel tempo. Ora, per un p.s. gaussiano la densitacongiunta dipende esclusivamente dal vettore delle medie delle v.c. Yt, Yt+1, . . . , Yt+r
e dalla loro matrice di covarianza; pertanto, esso e stazionario se i suoi momenti finoal secondo sono finiti ed indipendenti da t, vale a dire
E(Yt) = µE(Yt − µ)2 = γ(0) < ∞
E[(Yt − µ)(Yt−k − µ)] = γ(k) < ∞
∀t, k, dove γ(k) denota l’autocovarianza tra Yt e Yt−k, che si assume essere funzioneesclusivamente di k. Si noti che come conseguenza della stazionarieta la funzione diautocovarianza e simmetrica rispetto a k: γ(k) = γ(−k). Un p.s. non gaussiano icui momenti µ e γ(k) sono indipendenti da t si dice stazionario in senso debole (incovarianza). In tal caso la stazionarieta in covarianza non implica quella in sensoforte, ma e generalmente sufficiente per ottenere i risultati piu rilevanti.
Utili strumenti per la caratterizzazione di un processo stazionario nel dominiotemporale e frequenziale sono la funzione di autocorrelazione (FAC) e la densitaspettrale; la prima e definita ρ(k) = γ(k)/γ(0), k = 0, 1, . . . , mentre la seconda da
f(ω) =12π
[
γ(0) + 2∞∑
k=1
γ(k) cos ωk]
,
dove ω e la frequenza in radianti che assume valori in [0, π]. E’ immediato dimostrareche la FAC gode delle seguenti proprieta: i) ρ(0) = 1, ii) |ρ(k)| < 1, iii) ρ(k) = ρ(−k).
White Noise (WN). Il processo stazionario piu elementare e costituito da una se-quenza di variabili casuali incorrelate a media nulla e varianza costante: esso e deno-minato white noise, e viene indicato con εt ∼ WN(0, σ2), dove E(εt) = 0, E(ε2
t ) = σ2
e E(εtεt−k) = 0 per k 6= 0.
2.3 Momenti campionari
Dalla sezione precedente e emerso che un processo stazionario (in senso debole) ecompletamente caratterizzato dai parametri µ e γ(k). A partire da una realizzazionefinita, ytT
t=1 possiamo costruire le seguenti statistiche:
• Media campionaria: y = µ = T−1 ∑Tt=1 yt
• Varianza campionaria: γ(0) = T−1 ∑Tt=1(yt − y)2
27

• Autocovarianza campionaria a lag k: γ(k) = T−1 ∑Tt=1(yt − y)(yt−k − y)
Se il p.s. e ergodico queste statistiche convergono (in media quadratica) ai mo-menti del processo, rispettivamente µ, γ(0) e γ(k). L’ergodicita richiede invece chela “memoria” del processo sia limitata cosı che eventi distanti nel tempo abbiano unbasso grado di dipendenza; si dimostra che un p.s. gaussiano stazionario e ergodicose ∞
∑
k=0
|γ(k)| < ∞.
La funzione di autocorrelazione viene stimata mediante il rapporto: ρ(k) =γ(k)/γ(0); il grafico ad aste delle coppie (k, ρ(k)) e noto come correlogramma; comevedremo in seguito esso rappresenta uno degli strumenti cardine per l’identificazionedel processo stocastico che ha generato la serie.
Per un processo WN, tale che ρ(k) = 0, ∀k 6= 0, vale inoltre il risultato che ρ(k)ha distribuzione asintotica normale con media nulla e varianza pari a T−1. Talerisultato viene solitamente utilizzato al fine di costruire bande di confidenza appros-simate al 95% attorno allo zero per valutare la significativita delle autocorrelazionistimate: queste sono giudicate non significativamente diverse da zero se sono interneall’intervallo [−2/
√T , 2/
√T ].
2.4 Il teorema di Wold
Alla classe dei processi stazionari si applica un importante risultato noto come teo-rema di Wold: esso afferma che ogni p.s. stazionario (in senso debole) puo esserescomposto in due processi stocastici mutualmente incorrelati, uno dei quali e linea-re deterministico, c(t), mentre l’altro (indeterministico) e una sequenza infinita divariabili causali incorrelate (processo lineare):
Yt = c(t) + εt + ψ1εt−1 + ψ2εt−2 + · · · ,
con∑ |ψj| < ∞ e E[c(t)εt−j] = 0, ∀t, j. Il termine εt e WN e rappresenta l’errore di
previsione uniperiodale: εt = Yt−E(Yt|Yt−1, Yt−2, . . .), ed e anche detto innovazione.Un processo e deterministico se puo essere previsto senza errore a partire dai
valori passati di Yt; solitamente la parte deterministica corrisponde alla media delprocesso, c(t) = µ. Come vedremo, il teorema consente di derivare la classe deiprocessi ARMA, imponendo particolari restrizioni sull’insieme dei coefficienti ψj.
2.5 Autocorrelazione parziale
Il coefficiente di autocorrelazione parziale e una misura dell’associazione lineare traYt e Yt−k “depurata” della correlazione dovuta alle v.c. intermedie Yt−1, . . . , Yt−k+1.
28

Consideriamo un processo stazionario Yt, assumendo c(t) = 0 nella rappresenta-zione di Wold, e proponiamoci di costruire il miglior previsore lineare non distor-to di Yt sulla base della conoscenza di Yt−1, Yt−2, . . . , Yt−k; denotato con X t−1 =[Yt−1, Yt−2, . . . , Yt−k]′ il vettore contenente il set informativo di riferimento, si dimo-stra che il previsore ottimale e
φ′X t−1 = φk1Yt−1 + φk2Yt−2 + · · ·+ φkkYt−k, (2.1)
dove il vettore dei coefficienti della combinazione lineare, φ = [φk1, φk2, . . . , φkk]′, siottiene dalla relazione E[(Yt − φ′X t−1)X ′
t−1] = 0, che fornisce
φ = E[X t−1X ′t−1]
−1E[X t−1Yt].
Il coefficiente associato a Yt−k, φkk, e detto coefficiente di autocorrelazione parzia-le a ritardo k, poiche fornisce una misura del legame lineare tra le v.c. al netto dellacorrelazione esistente con le v.c. intermedie. Tale interpretazione e dovuta al fattoche φkk = ∂Yt/∂Yt−k. Analogamente, si definisce il coefficiente di autocorrelazioneparziale come il coefficiente di correlazione lineare tra Yt − E(Yt|Yt−1, . . . , Yt−k+1) eYt−k.
Si noti che la matrice E[X t−1X ′t−1] contiene le autocovarianze ed e una matrice
di Toeplitz, tale che, cioe l’elemento di posto (i, j) e pari a γ(|i − j|), mentre ilvettore E[X t−1Yt] = [γ(1), γ(2), . . . , γ(k)]′. Pertanto, i coefficienti φkj possono essereottenuti in maniera equivalente dal sistema di equazioni seguente, detto sistema diYule-Walker (si premoltiplica (2.1) per E[X t−1X ′
t−1] e si dividono entrambi i membriper γ(0)):
ρ(1)ρ(2)
...ρ(k − 1)
ρ(k)
=
1 ρ(1) · · · ρ(k − 2) ρ(k − 1)ρ(1) 1 · · · ρ(k − 3) ρ(k − 2)...
... . . . ......
ρ(k − 2) ρ(k − 3) · · · 1 ρ(1)ρ(k − 1) ρ(k − 2) · · · ρ(1) 1
φk1
φk2...φk,k−1
φkk
ovvero, ρ = Pφ. La soluzione per φkk si ottiene applicando la regola di Cramer:
φkk =|P ∗||P |
dove P ∗ si ottiene sostituendo l’ultima colonna di P con ρ.Il grafico dei valori φ00, φ11, φ22, . . . , φkk contro k, viene detto correlogramma
parziale, mentre la sequenza φkk e la funzione di autocorrelazione parziale (FACP).Ovviamente, φ00 = 1 e φ11 = ρ(1).
29

2.6 L’algebra dell’operatore L
Uno strumento molto importante e l’operatore ritardo (lag), L, che, applicato ad Yt,produce il valore ritardato di un periodo Yt−1:
LYt = Yt−1
In generale, LkYt+r = Yt+r−k, k = 0,±1, . . .. Un polinomio di ordine m nell’operatoreritardo e definito come segue:
α(L) = 1 + α1L + α2L2 + · · ·+ αmLm
Le radici del polinomio si ottengono ponendo α(L) = 0 e risolvendo rispetto a L.Le radici saranno reali o complesse coniugate: si dice che esse giacciono al di fuoridel (sul) cerchio di raggio unitario se il loro modulo e superiore (uguale) a 1. Inparticolare, definendo il polinomio infinito
ψ(L) = 1 + ψ1L + ψ2L2 + · · ·
possiamo riscrivere la rappresentazione di Wold in maniera piu sintetica: Yt = c(t)+ψ(L)εt.
Importanti operatori (filtri) lineari possono essere definiti in funzione di L; diparticolare rilievo e l’operatore differenza, ∆ = 1− L, tale che ∆Yt = Yt − Yt−1. Ledifferenze di ordine d sono date ∆dYt; ad esempio, per d = 2, ∆2Yt = (1 − 2L +L2)Yt = Yt − 2Yt−1 + Yt−2. Nel caso di processi mensili, la variazione rispetto allostesso mese dell’anno precedente viene detta differenza stagionale:
∆12Yt = (1− L12)Yt = Yt − Yt−12
2.7 Processi Autoregressivi
Dal teorema di Wold abbiamo appreso che qualunque processo stazionario puo essereespresso come una combinazione lineare di processi WN; tuttavia, la struttura deiritardi in εt e di ordine infinito, e non possiamo ambire a stimare infiniti parametria partire da una realizzazione finita. In questa sezione mostreremo che notevoleparsimonia nel numero dei parametri richiesti per descrivere la struttura dinamicadel processo e resa possibile dall’introduzione dei processi autoregressivi.
Un processo autoregressivo di ordine p, AR(p), e definito come segue:
Yt = m + φ1Yt−1 + φ2Yt−2 + · · ·+ φpYt−p + εt
con εt ∼ WN(0, σ2). Nel seguito assumeremo m = 0 e riscriveremo il processoφ(L)Yt = εt, dove φ(L) = 1 − φ1L − · · · − φpLp e il polinomio autoregressivo diordine p.
30

2.7.1 Processo AR(1)
Il processo autoregressivo del primo ordine e tale che Yt si ottiene moltiplicando perun coefficiente φ il valore precedente Yt−1 ed aggiungendo un p.s. εt ∼ WN(0, σ2):
Yt = φYt−1 + εt
Il processo e stazionario se |φ| < 1; infatti, mediante sostituzione successiva si ottienela rappresentazione di Wold:
Yt = εt + φεt−1 + · · ·+ φkεt−k + · · · ;
la successione (geometrica) dei pesi ψj = φj risulta convergente se e solo se vale φgiace nell’intervallo (−1, 1). Infatti,
∑ |φ|j = 1/(1 − |φ|). Si noti che in tal casole realizzazioni passate della v.c. εt hanno un peso geometricamente decrescente alcrescere della loro distanza dal tempo corrente (funzione di risposta all’impulso):
∂Yt
∂εt−j= φj −→j→∞ 0
La condizione di stazionarieta puo essere riferita alle radici del polinomio φ(L) =1 − φL: in particolare, il p.s. e stazionario se e solo se la radice del polinomio,ottenuta risolvendo per L l’equazione 1− φL = 0, e in modulo superiore all’unita.
Deriviamo ora i momenti del processo quando φ e nella regione di stazionarieta:
E(Yt) = 0γ(0) = Var(Yt) = E(Y 2
t ) = E[(φYt−1 + εt)Yt]= φγ(1) + σ2
poiche E(Ytεt) = E[(εt + φεt−1 + · · ·)εt] = σ2.
γ(1) = E(YtYt−1) = E[(φYt−1 + εt)Yt−1]= φγ(0)
poiche E(Yt−1εt) = E[(εt−1 + φεt−2 + · · ·)εt] = 0. Sostituendo l’espressione per γ(1)in quella per γ(0) si ottiene:
γ(0) =σ2
1− φ2
γ(2) = E(YtYt−2) = E[(φYt−1 + εt)Yt−2]= φγ(1)= φ2γ(0)
In generale,γ(k) = φkγ(0), e, ricordando la definizione di FAC, ρ(k) = φk. Pertantola FAC di un p.s. AR(1) e una successione geometrica decrescente di ragione φ. Perquanto concerne la FACP, basta riflettere su fatto che, dato Yt−1, Yt e incorrelatocon Yt−2, . . . , per comprendere che φkk = 0 per k > 1. Inoltre, φ11 = ρ(1) = φ.
31

Note i) Se m 6= 0, E(Yt) = m/(1−φ); ii) Per φ = 1 si ottiene il p.s. non stazionarioYt = Yt−1 + εt, noto come random walk (passeggiata aleatoria). E’ facile vedere chele innovazioni passate hanno tutte peso unitario ed i momenti dipendono dal tempo:ad es. la varianza e lineare in t, Var(Yt) = tσ2.
2.7.2 Processo AR(2)
Il processo autoregressivo del secondo ordine e generato dall’equazione:
Yt = m + φ1Yt−1 + φ2Yt−2 + εt
Per processi di ordine superiore al primo e piu semplice definire la condizione distazionarieta con riferimento alle radici del polinomio φ(L): si dimostra infatti cheYt e stazionario se le radici di 1 − φ1L − φ2L2 = 0 sono in modulo superiori ad1. Nel caso in questione si ha che ψ(L) = φ(L)−1 e pertanto i coefficienti dellarappresentazione di Wold possono essere ottenuti eguagliando i termini associatialle potenze di L in ψ(L)(1 − φ1L − φ2L2) = 1. Ne consegue che essi sono fornitidalla formula ricorsiva ψj−φ1ψj−1−φ2ψj−2 = 0 con valori iniziali ψ0 = 1 e ψ1 = φ1.Si verifica, appunto, che
∑
j |ψj| e convergente se e solo se φ(L) = 0 per |L| > 1.La condizione di stazionarieta impone i seguenti vincoli sullo spazio parametrico
(φ1, φ2): i) φ1+φ2 < 1 ii) φ2−φ1 < 1 e iii) φ2 > −1, per cui la regione di stazionarietadei parametri (φ1, φ2) e interna al triangolo di vertici (-2,-1),(2,-1),(0,1). Inoltre, siavra una coppia di radici complesse coniugate quando φ2
1 + 4φ2 < 0.Se Yt e stazionario (e gaussiano), esso e completamente caratterizzato dai mo-
menti:
• Valore atteso: E(Yt) = µ = m/(1− φ1 − φ2).
• La funzione di autocovarianza e data dalla formula ricorsiva
γ(k) = φ1γ(k − 1) + φ2γ(k − 2), k = 2, 3, . . .
con valori iniziali:
γ(0) =(1− φ2)σ2
(1 + φ2)([(1− φ2)2 − φ21]
(2.2)
e γ(1) = φ1γ(0)/(1− φ2).
• La FAC e data dalla formula ricorsiva
ρ(k) = φ1ρ(k − 1) + φ2ρ(k − 2), k = 2, 3, . . .
con valori iniziali: ρ(0) = 1 e ρ(1) = φ1/(1−φ2). Il comportamento della FACe tale che ρ(k) → 0 per k →∞; se le radici del polinomio AR sono complessela FAC percorre un’onda ciclica smorzata.
32

• La FACP e tale che φkk = 0 per k > 2; cio e intuitivo dal momento che, datiYt−1 e Yt−2, Yt e incorrelato con Yt−3, Yt−4, etc.
Il risultato per γ(k) e derivabile nella maniera seguente: supposto m = 0,
γ(0) = E[(φ1Yt−1 + φ2Yt−2 + εt)Yt]= φ1γ(1) + φ2γ(2) + σ2
γ(1) = E[(φ1Yt−1 + φ2Yt−2 + εt)Yt−1]= φ1γ(0) + φ2γ(1)
γ(2) = E[(φ1Yt−1 + φ2Yt−2 + εt)Yt−2]= φ1γ(1) + φ2γ(0)
· · · · · · · · ·γ(k) = E[(φ1Yt−1 + φ2Yt−2 + εt)Yt−k]
= φ1γ(k − 1) + φ2γ(k − 2)
dalla seconda equazione si ricava γ(1), e sostituendo nella terza equazione si fadipendere γ(2) soltanto da γ(0) (e dai parametri AR); sostituendo le espressionitrovate nella prima equazione si ottiene il risultato (2.2).
Esempio: Consideriamo il processo AR(2) con m = 0, φ1 = 1.1, φ2 = −0.18 eσ2 = 1: le radici dell’equazione (1 − 1.1L + 0.18L2) sono reali ed in modulo superioread uno: L1 = 1.1 e L2 = 5 (L = (1.1 ±
√
1.12 − 4(.18))/(2 × 0.18)). Per esercizio sicalcoli ρ(k) per k = 1, 2, 3.
2.7.3 Processo AR(p)
I risultati ottenuti precedentemente possono essere generalizzati al caso AR(p), (1−φ1L− · · · − φpLp)Yt = m + εt, nel modo seguente:
• Yt e stazionario se le p radici del polinomio φ(L) sono in modulo superioriall’unita.
• Il valore medio del processo e µ = m/φ(1), dove φ(1) = 1− φ1 − · · · − φp. Sipuo riscrivere Yt − µ = φ1(Yt−1 − µ) + · · ·+ φp(Yt−p − µ) + εt.
• La funzione di autocovarianza si ottiene moltiplicando l’espressione precedenteper (Yt−k − µ) e prendendo il valore atteso.
γ(k) = φ1γ(k − 1) + · · ·+ φpγ(k − p), per k > 0γ(k) = φ1γ(k − 1) + · · ·+ φpγ(k − p) + σ2, per k = 0
• La FAC da luogo al sistema di equazioni di Yule-Walker:
ρ(k) = φ1ρ(k − 1) + φ2ρ(k − 2) + · · ·+ φpρ(k − p), k = 1, 2, . . . , p
• La FACP di un processo AR(p) e identicamente nulla per k > p
33

2.8 Processi media mobile
I processi media mobile (MA) si ottengono dalla rappresentazione di Wold assumen-do ψj = θj, j ≤ q e ψj = 0, j > q. Pertanto,
Yt = µ + εt + θ1εt−1 + θ2εt−2 + · · ·+ θqεt−q
dove εt ∼ WN(0, σ2). Il termine MA viene dal fatto che Yt e una somma ponderatadei valori piu recenti di εt. Si noti che un processo MA soddisfa sempre la condizione∑
j |ψj| < ∞ ed e dunque sempre stazionario. A differenza del caso AR la parsimonianel numero dei parametri necessari per descrivere la struttura dinamica del processoe ottenuta troncando i coefficienti ψj ad un ritardo prefissato.
2.8.1 Processo MA(1)
Il processo MA del primo ordine e fornito dall’espressione:
Yt = µ + εt + θεt−1 = µ + (1 + θL)εt
E(Yt) = µ + E(εt) + θE(εt−1) = µγ(0) = E[(Yt − µ)2] = E[(εt + θεt−1)2] = E(ε2
t ) + 2θE(εtεt−1) + θ2E(ε2t−1)
= σ2(1 + θ2)γ(1) = E[(Yt − µ)(Yt−1 − µ)] = E[(εt + θεt−1)(εt−1 + θεt−2)]
= θσ2
γ(k) = 0, k > 1
La FAC e identicamente nulla a partire da k = 2:
ρ(0) = 1ρ(1) = θ
1+θ2
ρ(k) = 0, k > 1
La FACP non si annulla mai, ma tende esponenzialmente a zero secondo l’anda-mento dettato dal parametro θ.
Invertibilita Il MA(1) e invertibile se |θ| < 1. Nel seguito restringeremo la nostraattenzione alla classe dei processi MA(q) invertibili, per cui opereremo opportunerestrizioni nello spazio dei parametri MA. Per motivare la scelta, inizieremo col mo-strare che per ogni rappresentazione MA(1) invertibile esiste una rappresentazioneMA(1) non invertibile, di parametro |θ| > 1, che possiede gli stessi momenti. Siconsideri dunque il processo
Yt = µ + εt + θεt−1
34

con θ = 1/θ e εt ∼ WN(0, σ2). Si verifica immediatamente che γ(0) e γ(1) sono egualia quelle del processo Yt = µ+εt+θεt−1 con σ2 = θ2σ2; inoltre, ρ(1) = θ−1/(1+θ−2) =θ/(1 + θ2). I due processi hanno identiche proprieta e dunque sarebbe impossibilediscriminarli a partire da una serie storica. Tale problema di identificazione vienerisolto appunto vincolando il parametro θ nell’intervallo (-1,+1). Il vincolo appa-re arbitrario, ed ha comunque una giustificazione pratica. Il termine invertibilitaderiva dalla possibilita di riscrivere il processo come un AR(∞) con coefficienti πj
convergenti:
Yt + π1Yt−1 + π2Yt−2 + · · ·+ πkYt−k + · · · = m + εt,∞∑
j=1|πj| < ∞
Nel caso in questione la sequenza πj = (−θ)j e convergente se e solo se |θ| < 1.
2.8.2 Processo MA(q)
Il processoYt = µ + εt + θ1εt−1 + · · ·+ θqεt−q
e sempre stazionario; e invertibile se le soluzioni dell’equazione
(1 + θ1L + θ2L2 + · · ·+ θqLq) = 0
sono in modulo superiori ad 1.
E(Yt) = µγ(0) = E[(Yt − µ)2] = E[(εt + θ1εt−1 + · · ·+ θqεt−q)2]
= (1 + θ21 + · · ·+ θ2
q)σ2
γ(k) = E[(εt + θ1εt−1 + · · ·+ θqεt−q)(εt−k + θ1εt−k−1 + · · ·+ θqεt−q−k)= (θk + θ1θk+1 + θ2θk+2 + · · ·+ θq−kθq)σ2
γ(k) = 0, k > q
Pertanto, la FAC e identicamente nulla per k > q. La PACF non si annulla mai etende a zero al crescere di k.
Esercizio: calcolare la FAC per il processo MA(2): Yt = (1 + 2.4L + 0.8L2)ut,ut ∼ NID(.5, 1). Indicare inoltre se il processo e invertibile.
2.9 Processi misti
Il processo Yt = µ +∑∞
j=0 ψjεt−j puo essere rappresentato in maniera parsimoniosada un processo ARMA(p, q), il quale puo essere pensato come una generalizzazione
35

di un p.s. AR(p) con innovazioni che seguono un processo MA(q), ovvero come unprocesso MA(q) che dipende ulteriormente dai suoi p valori passati.
Yt = m + φ1Yt−1 + φ2Yt−2 + · · ·+ φpYt−p + εt + θ1εt−1 + · · ·+ θqεt−q
ovvero, φ(L)Yt = m + θ(L)εt.Le condizioni sotto le quali il processo e stazionario sono le stesse per le quali
il processo AR e stazionario, vale a dire le p radici del polinomio φ(L) devonoessere esterne al cerchio di raggio unitario. Il processo e invertibile se le q radici delpolinomio θ(L) sono esterne al cerchio di raggio unitario.
La FAC e la FACP presentano un comportamento che rappresenta una misturadi quelli che caratterizzano processi puramente AR e MA: in particolare, esse non siannullano mai; la FAC tende a 0 a partire dal lag q, mentre la FACP a partire dallag p.
Il processo ARMA stazionario ed invertibile e identificabile se non esistono fattoricomuni: ad es. il processo ARMA(1,1), (1 − αL)Yt = (1 − αL)εt, e equivalente aYt ∼ WN(0, σ2).
2.10 Non stazionarieta
Definizione: Ordine di integrazione. Il processo Yt e integrato di ordine d, e scrive-remo Yt ∼ I(d), se le differenze d-esime, ∆dYt, ammettono una rappresentazione diWold stazionaria e invertibile.
In altre parole applicando d volte l’operatore differenza, ∆ = 1− L, si ottiene
∆dYt = µ + ψ(L)εt,∞∑
j=0|ψj| < ∞
Es.: Yt = 2Yt−1 − Yt−2 + εt + θεt−1, Yt ∼ I(2) ⇐⇒ |θ| < 1 ;L’esempio piu elementare di p.s. non stazionario e il random walk, definito dalla
relazione Yt = Yt−1 + εt; esso e tale che le sue differenze prime sono WN. Il processo∆Yt = µ + εt e detto RW con drift. Mediante sostituzione successiva si ha:
Yt = Y0 + µt + εt + εt−1 + · · ·+ ε1,
che mostra che l’innovazione εt−k ha effetti persistenti sul livello della serie (vieneper intero accumulata, o integrata, nel livello).
Al fine di estendere la classe dei processi che possono essere trattati si introduce laclasse dei processi ARIMA(p, d, q), tali che le differenze d-esime seguono un modelloARMA(p, q) stazionario e invertibile:
φ(L)∆dYt = µ + θ(L)εt
36

2.11 Stagionalita
Serie osservate con cadenza subannuale (mensile o trimestrale) possono manifestareun comportamento periodico, con oscillazioni che hanno ciclo annuale. Tipico e ilcaso della produzione industriale, caratterizzata da una caduta in corrispondenzadel mese di agosto, e delle vendite al minuto, che hanno un’impennata in dicembre.La stagionalita si ritrova nella funzione di autocorrelazione con valori alti a ritardistagionali (k = 12, 24, 36... per serie mensili).
Per catturare tali dinamiche occorre estendere adeguatamente la classe dei pro-cesssi ARIMA. Puo darsi il caso che le differenze stagionali del processo, ∆sYt = Yt−Yt−s(s = 4, 12) siano non stagionali ed ammettano una rappresentazione ARIMA(p, d, q).In tal caso si dice che Yt e integrato stagionalmente di ordine 1. Estendendo taleconcetto, Yt e integrato stagionalmente di ordine D se occorre applicare D voltel’operatore ∆s.
Un processo AR stagionale del primo ordine e:
Yt = ΦYt−s + εt, |Φ| < 1
e facile mostrare che la FAC assume la forma: ρ(k) = Φk/s per k = s, 2s, 3s, .., ede zero altrimenti. La condizione di stazionarieta e ovviamente riferita alle radicidel polinomio (1 − ΦLs) = (1 − ΦL)(1 + ΦL + ΦL2 + · · · + ΦLs−1). In generale, ilmodello ARIMA puo essere generalizzato al fine di includere coefficienti AR e MA aritardi stagionali. Tuttavia, la rappresentazione piu in auge ha natura moltiplicativae conduce al processo ARIMA(p, d, q)× (P, D,Q)s:
φ(L)Φ(Ls)∆d∆Ds Yt = µ + θ(L)Θ(Ls)εt
dove Φ(Ls) = 1−Φ1Ls−Φ2L2s−· · ·−ΦP LPs, e il polinomio AR stagionale in Ls diordine P , e Θ(Ls) = 1 + Θ1Ls + Θ2L2s + · · ·+ ΘQLQs e il polinomio MA stagionaledi ordine Q. Un caso di particolare rilevanza (per le serie temporali economiche) eil cosidetto processo Airline: ARIMA(0, 1, 1)× (0, 1, 1)s
(1− L)(1− Ls)Yt = (1 + θL)(1 + ΘLs)εt,
con |θ| < 1, |Θ| < 1. Per tale processo la funzione di autocovarianza presenta lasemplice struttura:
γ(0) = (1 + θ2)(1 + Θ2)σ2
γ(1) = θ(1 + Θ2)σ2
γ(k) = 0 per k = 2, . . . , s− 2γ(s− 1) = θΘσ2
γ(s) = Θ(1 + θ2)σ2
γ(s + 1) = θΘσ2
γ(k) = 0 per k > s + 1
37

Esercizio: calcolare la FAC per il processo MA stagionale: Yt = εt+.8εt−12. Mostrareche esiste un processo non invertibile caratterizzato dalla medesima FAC.
2.12 L’approccio di Box e Jenkins
Nelle sezioni precedenti abbiamo cominciato ad avere una certa familiarita con iprocessi stocastici; essi dovrebbero essere riconoscibili in base alle loro proprieta,espresse dalla FAC e dalla FACP. Ora, le serie temporali, che costituiscono unarealizzazione di tali processi, dovrebbero rispecchiarne le proprieta, fermo restandoche la limitatezza dell’intervallo di osservazione puo in concreto alterarne alcune.
Box e Jenkins hanno proposto una metodologia per l’adattamento di un modelloARIMA alla serie temporale, yt, che consiste nell’iterare il seguente schema a trefasi: i) identificazione del modello; ii) stima e iii) verifica.
2.12.1 Identificazione
La fase di identificazione mira in primo luogo a determinare la trasformazione dellaserie che induce la stazionarieta in media, varianza e covarianza. Es. trasformazionedi Box-Cox. Nelle serie temporali macroeconomiche e usuale la trasformazione zt =∆ ln yt, che corrisponde approssimativamente al tasso di variazione del fenomeno:
∆yt ≈yt − yt−1
yt−1
Successivamente si passa a selezionare il modello ARMA (gli ordini p e q) sullabase della FAC, ρ(k), e FACP φkk della serie trasformata. I correlogrammi fornisco-no lo strumento piu importante di identificazione; dal confronto dei correlogrammistimati con quelli teorici che caratterizzano i p.s. al variare degli ordini p e q siottengono indicazioni circa i medesimi. Ad esempio, se ρ(k) ha un salto a ritardoq, oltre il quale e prossima a zero, si identifica un processo MA(q). L’ordine di unprocesso AR e piu difficile a determinarsi a partire dalla sola FAC, ma soccorre laFACP.
2.12.2 Stima
La stima avviene mediante il metodo della massima verosimiglianza (MV), sotto l’as-suzione di normalita delle osservazioni; una semplificazione si ottiene condizionandorispetto alle prime p+ q osservazioni, poiche in tal caso il problema si riconduce allaminimizzazione di una somma dei quadrati dei residui. Nel caso dei processi ARle stime di MV condizionate sono equivalenti a quelle dei minimi quadrati ottenute
38

dalla regressione di yt su p valori ritardati. In tal caso esiste una soluzione esplicitaper le stime. Ad esempio, nel caso di un AR(1) senza costante,
φ =∑T
t=2 yt−1yt∑T
t=2 yt−1
Analogamente, il sistema di equazioni di Yule-Walker: φ = P−1
ρ, dove φ =[φ1, . . . , φp]′, fornisce stime consistenti dei parametri autoregressivi di un processopuro AR(p).
Nel caso di processi MA o misti la somma dei quadrati dei residui e non linearenei parametri θ e la minimizzazione utilizza algoritmi iterativi, non esistendo unasoluzione esplicita. Ad esempio, nel caso di un MA(1), la funzione obiettivo e datada S =
∑
ε2t =
∑
(yt − θεt−1)2; ora, εt−1 dipende a sua volta da θ, per cui ∂S/∂θ epari alla somma dei termini
−(
εt−1 + θ∂εt−1
∂θ
)
.
2.12.3 Verifica
• Test di significativita dei parametri
• Analisi dei residui
et =1− φ1L− · · · − φpLp
1 + θ1L + · · ·+ θqLqyt
Si tratta di sottoporre a verifica tre proprieta: normalita, omoschedasticita eincorrelazione. Un test formale di normalita e quello di Bowman e Shenton,basato sulla statistica N = N1 + N2, avente distribuzione χ2(2). N1 e il testper l’asimmetria dei residui che fa riferimento al momento terzo rispetto allamedia: N1 = (T − 1)b1/6, dove
√b1 e il momento terzo centrato di et, ed ha
distribuzione asintotica χ2(1). N2 = (T − 1)(b2 − 3)2/24, dove b2 rappresentail momento quarto centrato, e il statistica test per la presenza di curtosi e sidistribuisce secondo una χ2(1).
Per la presenza di eteroschedasticita possono essere utilizzati metodi grafici etest formali; se si sospetta che vi sia stato un cambiamento ad un tempo t∗,si puo spezzare il campione in due sottoperiodi e testare l’ipotesi che σ2 siauguale nei due sottoperiodi, mediante un opportuno test F .
Per testare l’autocorrelazione dei residui, oltre al consueto test DW, solita-mente si costruisce il correlogramma globale ρe(k), e parziale φe,kk, e si valutala presenza di valori che fuoriescono dalle bande di confidenza al 5% (±2/
√T ).
39

La statistica test per l’ipotesi nulla H0 : ρε(1) = · · · = ρε(m) = 0 e fornitadalla statistica di Ljung-Box, Q(m), basata su m autocorrelazioni dei residui.
Q(m) = T (T + 2)m
∑
j=1(T − j)−1ρ2
e(j)
Sotto H0, Q(m) si distribuisce come una v.c. χ2 con m − (p + q) gradi diliberta.
• Bonta dell’adattamento: se la serie e non stazionaria e l’ordine di differen-ziazione e d = 1, il coefficiente di determinazione viene calcolato come segue:R2
D = 1−SSE/SSD, dove SSE = (T − 1)σ2 e SSD e la somma dei quadratidelle differenze prime corrette della media. Il coefficiente, che puo anche ri-sultare negativo, indica se l’adattamento e migliore o peggiore di un sempliceARIMA(0,1,0).
Spesso, soprattutto quando si ha a che fare con modelli misti, si procedeper tentativi, scoprendosi che diversi modelli sono compatibili, nel senso chegenerano residui WN. La scelta tra di essi puo essere effettuata mediante uncriterio di informazione: per dati ordini massimi p∗, q∗, si stimano tutti i p∗q∗
modelli di ordine inferiore e si sceglie quello che
min
AIC(p, q) = ln σ2 + 2p + q
T
,
oppure
min
BIC(p, q) = ln σ2 + ln Tp + q
T
.
2.13 Previsione
Data la disponibilita della serie temporale fino al tempo T , ci proponiamo ora diprevedere il fenomeno l periodi in avanti. Il set informativo a cui facciamo riferimentoe denotato FT = y1, y2, . . . , yT−1, yT
Sfrutteremo il risultato fondamentale secondo il quale il previsore ottimale diyT+l e il suo valore atteso condizionato all’informazione FT :
yT+l|T = E[yT+l|FT ]
L’ottimalita va intesa nel senso che yT+l minimizza l’errore quadratico medio diprevisione. Inoltre, l’errore di previsione, yT+l − yT+l|T , ha valore atteso nullo evarianza che denotiamo Var(yT+l|T ).
La funzione di previsione verra ottenuta sotto le seguenti assunzioni:
1. εt ∼ NID(0, σ2)
40

2. I parametri φ1, . . . , φp, θ1, . . . , θq, µ, σ2 sono noti
3. Si dispone di una realizzazione infinita: FT = yT , yT−1, . . . , y1, y0, y−1, . . .:
L’assunzione 1 e piu forte di εt ∼ WN(0, σ2) poiche postula l’indipendenza (oltrel’incorrelazione) tra le v.c. εt; la seconda implica che i parametri sono stimati senzaerrore. La terza assunzione assume rilievo quando si ha a che fare con processi MAo misti ed implica che le realizzazioni passate e corrente della v.c. εt sono note. Adesempio, per un MA(1) essa consente di “invertire” il modello al fine di ottenereεt = yt/(1 + θL); al tempo T ,
εT = yT − θεT−1 = yT − θyT−1 + θ2yT−2 − θ3yT−3 + . . . =∞∑
j=0(−θ)jyT−j
e pertanto E(εT |FT ) = εT e noto, poiche dipende dai valori passati di y. Nella prati-ca, in cui si dispone esclusivamente di un campione finito, la sequenza εt e generataricorsivamente ipotizzando ε0 = 0: ε1 = y1 − θε0 = y1; ε2 = y2 − θy1; . . . , εT =yT − θεT−1.
La previsione da modelli ARIMA viene effettuata applicando le seguenti regolegenerali, che discendono direttamente dalle assunzioni precedenti:
yT+j|T = yT+j per j ≤ 0
εT+j|T =
εT+j per j ≤ 00 per j > 0
Infatti, quando j > 0, il miglior previsore lineare non distorto dei valori futuri di εt
e la media incondizionata, εT+j|T = E[εT+j|FT ] = 0.L’assunzione 1 implica che l’intervallo di confidenza al 95% attorno al valore
previsto e fornito da:
yT+l = yT+l|T ± 1.96[Var(yT+l|T )]1/2
Previsione da un modello AR(1): yt = φyt−1 + εt
yT+1|T = E[yT+1|FT ]= φE[yT |FT ] + E[εT+1|FT ]= φyT ;
yT+2|T = E[yT+2|FT ]= φE[yT+1|FT ] + E[εT+2|FT ]= φE[(φyT + εT+1)|FT ] + E[εT+2|FT ]= φ2yT ;
In generale, le previsioni seguono la formula ricorsiva yT+l|T = φyT+l−1|T , con va-lore iniziale (l = 0) pari all’ultimo valore osservato, yT . Nei termini di quest’ultimo,yT+l|T = φlyT .
41

Calcoliamo ora la varianza dell’errore di previsione:
Var(yT+1|T ) = E[(yT+1 − yT+1|T )2]= E[(φyT + εT+1 − φyT )2]= σ2;
Var(yT+2|T ) = E[(yT+2 − yT+2|T )2]= E[(φ2yT + φεT+1 + εT+2 − φy2
T )2]= σ2(1 + φ2);
Var(yT+l|T ) = E[(yT+l − yT+l|T )2]= σ2(1 + φ2 + φ4 + · · ·+ φ2(l−1));
Pertanto,
liml→∞
Var(yT+l|T ) =σ2
1− φ2
Previsione da un modello ARIMA(0,1,1) Consideriamo il modello ∆yt =εt + θεt−1:
yT+1|T = E[yT+1|FT ]= E[yT |FT ] + E[εT+1|FT ] + θE[εT |FT ]= yT + θεt;
yT+2|T = E[yT+2|FT ]= E[yT+2|FT ] + E[εT+2|FT ] + θE[εT+1|FT ]= yT+1|T = yT + θεt;
Per l > 1,yT+l|T = yT+l−1|T = yT + θεt e la funzione di previsione e costante. Siverifica facilmente che se −1 < θ < 0 si effettua un livellamento esponenziale, vale adire il valore previsto e una media ponderata dei valori passati della serie, con pesidecrescenti secondo i termini di una progressione geometrica di ragione −θ:
yT+l|T = (1 + θ)T−1∑
j=0(−θ)jyT−j
Analogamente si dimostra che le previsioni dal modello
∆2yt = (1 + θ1L + θ2L2)εt
sono equivalenti a quelle dello schema di Holt & Winters, sotto particolari restrizionisui parametri θ1 e θ2.
Esercizio: Calcolare le previsioni l = 1, 2, 3 periodi in avanti effettutate a partire daimodelli di seguito elencati
yt = 0.5− .7yt−1 + εt, εt ∼ WN(0, .1)
∆yt = 0.5− .7∆yt−1 + εt, εt ∼ WN(0, .1)
42

yt = 0.2 + εt + .4εt−1, εt ∼ WN(0, .1)
∆yt = 0.2 + εt − .4εt−1, εt ∼ WN(0, .1)
noto che yT = .40, yT−1 = .35 e εT = 0.001, εT−1 = −0.031. Calcolare inoltre la varian-za dell’errore di previsione.
43

Capitolo 3
Analisi non parametrica delle serietemporali
3.1 Le medie mobili
Una media mobile (mm) non e altro che una media aritmetica semplice o ponderatadi k osservazioni consecutive della serie temporale. In maniera piu formale possiamodefinirla come una trasformazione lineare della serie che puo essere rappresentatacome combinazione lineare delle potenze positive e negative dell’operatore ritardo,L.
M =m2∑
i=−m1
wiLi
Pertanto, Myt = w−m1yt−m1 + · · ·+ w0yt + · · ·+ wm2yt+m2 .Il numero delle osservazioni consecutive, m1 + m2 + 1 e denominato ordine della
mm. Una mm si dice centrata qualora m1 = m2 = m; in tal caso
M = L−m(w−m + w−m+1L + · · ·+ wmL2m) = L−mw(L)
dove w(L) e un polinomio di grado 2m in L, detto polinomio associato alla mm.Inoltre, una mm centrata e simmetrica se w−i = wi, i = 1, . . . ,m; il polinomioassociato e simmetrico e L−mw(L) = Lmw(L−1).
Valgono le seguenti proprieta: a) la composizione di due mm e ancora una mm;b) la composizione di due mm centrate e ancora una mm centrata; c) l’insieme dellemm simmetriche e chiuso rispetto alla composizione.
Nullita di una media mobile Si chiama nullita (spazio nullo) di una mediamobile M l’insieme delle serie temporali yt tali che Myt = 0:
Myt = w−myt−m + · · ·+ wmyt+m = 0, ∀t
44

ovvero w(L)yt = 0. Gli elementi dello spazio nullo sono le soluzioni dell’equazionecaratteristica w(r) = 0. Esempio: si consideri la serie −1, 1,−1, 1,−1, 1; la mediamobile asimmetrica (1 + L)yt genera NA, 0, 0, 0, 0, 0.
Invarianza e nucleo Una serie temporale e invariante rispetto alla mm M se esolo se Myt = yt; le serie invarianti soddisfano
Myt = w−myt−m + · · ·+ wmyt+m = yt
e si ottengono a soluzione dell’equazione alle differenze finite [w(L)− Lm]yt = 0.La mm preserva i polinomi di grado non superiore a p se r = 1 e una radice di
molteplicita p+1 dell’equazione caratteristica w(r)−rm = 0. In tal caso il polinomio[w(L)− Lm] contiene il fattore ∆p+1.
Si consideri ad esempio m = 2, wi = 1/5, i = 0,±1,±2; si ha [w(L) − Lm] =(1/5)[(1− L2) + (L− L2) + (L3 − L2) + (L4 − L2)] = (1/5)(1− L)2(1 + 3L + L2), ilquale contiene la radice 1 con molteplicita 2.
Teorema Una mm preserva una serie costante se e solo se w(1) = 1, vale a direm
∑
i=−mwi = 1
Teorema Una mm simmetrica che preserva la costante preserva anche i polinomidi primo grado. Sia yt = a + bt; Myt = Ma + Mbt = a + bMt, ma Mt = w−m(t −m) + · · ·+ w0t + · · ·wm(t + m) = t.
Teorema Il nucleo di una composizione di medie mobili e dato dall’intersezionedei nuclei delle mm componenti. Pertanto il prodotto di due mm che preservanoentrambe i polinomi di grado non superiore a p preserva anche esso tali polinomi.
3.2 Effetto fase ed effetto ampiezza
L’applicazione di una media mobile ad una serie determina due effetti: si viene amodificare l’ampiezza delle fluttuazioni (ad es. i punti di massimo e di minimorisultano amplificati o attenuati) e si determina uno spostamento di fase, vale a direuno spostamento dell’oscillazione lungo l’asse dei tempi.
Dato il generico filtro lineare W (L), si chiama funzione di risposta frequenzialeil termine W (e−ıλ) che si ottiene sostituendo eıλ = cos λ + ı sin λ a L.
L’effetto relativo all’ampiezza e misurato dal guadagno (gain), il cui quadrato edenominato funzione di trasferimento
|W (e−iλ)| = [W (e−iλ)W (eiλ)]1/2.
45

Infatti, data la serie yt, con spettro fy(λ), la densita spettrale di W (L)yt e pari a|W (e−iλ)|2fy(λ). Il guadagno (o la funzione di trasferimento) fornisce informazioniimportanti sull’operativita del filtro; ad esempio se e 1 attorno alle frequenze basse,la mm preserva il trend; se e zero o prossimo a zero in un intorno di alcune frequenzeil filtro elimina le componenti oscillatorie corrispondenti a quelle frequenze.
La fase e rappresentata da
Ph(λ) = arctan[
−W †(λ)W ∗(λ)
]
dove W †(λ) e la parte reale di W (e−ıλ) mentre W ∗(λ) e la parte immaginaria.La categoria dei filtri bidirezionali simmetrici presenta l’importante caratteristica
di lasciare inalterata la posizione dei punti di svolta delle fluttuazioni dal momentoche la loro fase e nulla ∀λ: infatti essi ammettono la rappresentazione
W (L) = w0 +m
∑
j=1wj(L + L−1); W (e−ıλ) = w0 + 2
m∑
j=1wj cos λj
Pertanto, la parte immaginaria della funzione di risposta e nulla e la funzione di faseassume valore 0 (nessuno spostamento di fase) o π (inversione di fase) se W (e−ıλ) enegativa (caso irrilevante). Il guadagno della media mobile e in questo caso G(λ) =|w0 + 2
∑mj=1 wj cos λj|.
3.3 L’effetto di Slutzky-Yule
Il filtraggio di un processo εt ∼ WN(0, σ2) mediante una mm M conduce ad unprocesso Mεt con media nulla e varianza
Var(Mεt) = σ2m
∑
j=−mw2
j
Il rapporto Var(Mεt)/σ2 rappresenta il fattore di inflazione della varianza, che seinferiore all’unita misura il lisciamento indotto dalla mm. Il processo Mεt sara oraautocorrelato e presentera in generale 2m autocorrelazioni diverse da zero.
In relazione al filtro utilizzato possono prodursi ciclicita spurie evidenziate dallapresenza di un massimo relativo nella funzione di trasferimento del filtro. Ai fini delcalcolo approssimato del periodo si puo utilizzare la formula 2π/(arccos ρ(1)) doveρ(1) e l’autocorrelazione a ritardo 1 di Mεt. L’effetto di Slutzky-Yule e funzionecrescente del fattore di inflazione della varianza.
46

3.4 Polinomi locali; filtri di Macaulay
Una importante classe di mm si ottiene dall’adattamento di un polinomio a 2h + 1termini consecutivi di una serie; il polinomio stimato viene utilizzato per stima-re il trend nella modalita centrale. Dal momento che la stima dei coefficientidel polinomio risulta lineare nelle osservazioni, anche la stima del trend linea-re. yt = m(t) + εt, dove m(t + j) ≈ mt(j) (approssimazione polinomiale locale),mt(j) = β0 + β1j + · · ·+ βpjp, j = −h, . . . , h.
L’obiettivo e quello di ottenere un lisciamento (smoothing) della serie, rimuoven-do le fluttuazioni irregolari e isolando una stima del trend ovvero del valore attesodi yt. L’ idea di fondo e che tale valore atteso varia debolmente nel tempo e che per-tanto possa essere approssimato (nel senso dell’approssimazione di Taylor di ordinep) localmente da un polinomio, che costituisce una funzione di t piuttosto lisciata econ derivate continue fino ad un certo ordine.
I coefficienti wj della mm possono essere ottenuti adattando alla serie un po-linomio locale (su intervalli di lunghezza 2h + 1) attraverso l’ottimizzazione di uncriterio che fa riferimento alla “fedelta” dell’approssimazione.
minh
∑
i=−h
[yt+j − (β0 + β1j + · · ·+ βpjp)]2
La stima del trend al tempo t si ottiene come mt = b0, dove b0 e lo stimatore di β0
e dal momento che gli stimatori dei MQ sono lineari nelle osservazioni si ha
mt =h
∑
j=−h
wjyt+j.
Questa quantita fornisce a secondo membro i pesi di una mm centrata che preservalocalmente un polinomio di grado p. Se si denota con C la matrice del disegno
C =
1 −h (−h)2 · · · (−h)p
1 −(h− 1) [−(h− 1)]2 · · · [−(h− 1)]p...
...... · · · ...
1 0 0 · · · 0...
...... · · · ...
1 h− 1 (h− 1)2 · · · (h− 1)p
1 h h2 · · · hp
e con y = [yt−h, . . . , yt+h]′, sotto l’ipotesi εt ∼ WN(0, σ2), lo stimatore dei minimiquadrati ordinari di b = [b0, . . . , bp]′ risulta
b = (C ′C)−1C ′y;
47

i coefficienti della mm sono forniti dalla prima riga della matrice (C ′C)−1C ′.
mt = b0 = e′1b = e′1(C′C)−1C ′y = w′y
dove w′ = e′1(C′C)−1C ′, e, denotando con c(ij) il generico elemento della matrice
(C ′C)−1 si ha
mt =p
∑
l=1
c(1l)h
∑
j=−h
jlyt+j
dalla quale si evidenzia c(11) = w0 e in generale
wj = c(11) + c(12)j + · · · c(1p)jp =p
∑
l=1
c(1l)jl
Pertanto,mt = e′1b = e′1(C
′C)−1C ′y = w′y
Proprieta:
1. La media mobile ottenuta mediante questo argomento preserva ovviamente ipolinomi di grado p: se infatti yt = m(t), con mt(j) = β0 +β1j+ · · ·+βpjp, j =−h, . . . , h, allora mt = m(t): basta porre y = Cβ, β = [β0, . . . , βp]′; seguemt = w′(Cb) = e1β = β0 = yt. Si noti che w′C = e1 implica:
[h
∑
j=−h
wj = 1,h
∑
j=−h
jlwj = 0, l = 1, . . . , p
e pertanto preserva tutti i polinomi di grado inferiore a p. La somma deicoefficienti e unitaria e pertanto viene preservata la costante.
2. Simmetria: wj = w−j; consegue dal disegno simmetrico dei punti temporalipresi in considerazione.
3. I pesi giacciono su un polinomio di grado k. Si confronti la formula precedente,dove k = [p/2], dove [p/2] = p/2 per p pari e [p/2] = (p − 1)/2 per p dispari.Pertanto se p = 0, 1 i pesi sono costanti; per p = 2, 3 giacciono su una retta
4. Le medie calcolate con riferimento ai polinomi di ordine pari sono le stesse diquelle calcolate per p + 1. Questo dovuto al fatto che la somma delle potenzedispari di i e identicamente nulla per effetto della simmetria.
5.
w′w =h
∑
j=−h
w2j = e′1(C
′C)−1C ′C(C ′C)−1e1 = e′1(C′C)−1e1 = w0
il primo elemento dell’inversa che pari a w0 Il fattore di inflazione della varianzae pari a w0 (
∑
w2i = w0)
48

Esercizio: dimostrare che se m = k, k = [q/2], dove [q/2] = q/2 per q pari e= (q − 1)/2 per q dispari, (t) = ht(0) = yt.
3.4.1 Varianza e distorsione
Dalla teoria dei MQO Var(mt) = σ2w0 dal momento che il primo elemento dellamatrice (CC)−1 corrisponde a w0. Per dato q, si dimostra che la varianza decresceal crescere di m, mentre per dato m essa cresce con k, k = [q/2], dove [q/2] = q/2per q pari e = (q − 1)/2 per q dispari. Essa pertanto rimane inalterata se si passadal grado q pari al grado q + 1. (questo si dimostra con il fatto che la mm e il trendestratto coincidono).
La distorsione e nulla se E(yt) e esattamente un polinomio di grado p, altrimenti
E(yt −mt) = h(t)−m
∑
i=−mwih(t + i).
Tra la distorsione e la varianza esiste il trade-off per cui all’aumentare di m dimi-nuisce la varianza ma aumenta la distorsione.
3.5 Medie mobili aritmetiche semplici
Una mm aritmetica semplice e tale che wi = w = 1/(2m + 1); essa si ottiene perp = 0, 1, vale a dire quando il polinomio locale e una semplice costante o una retta,nel qual caso le equazioni normali forniscono a0 = (2m + 1)−1 ∑m
i=−m yt+i.Le mm semplici possono essere anche derivate a soluzione del seguente problema
di ottimo vincolato: minimizzare il coefficiente di inflazione della varianza sotto ilvincolo di somma ad uno dei coefficienti:
minm
∑
i=−mw2
i , s.v.m
∑
i=−mwi = 1.
La soluzione fornisce appunto wi = 1/(2m + 1) (media aritmetica semplice).Il polinomio caratteristico associato alla mm e
w(L) =1
2m + 1(1 + L + · · ·+ L2m) =
(1− L2m+1)(2m + 1)(1− L)
,
e la nullita della mm. e rappresentata dai processi periodici di periodo 2m + 1(dispari).
Il nucleo della mm e rappresentato dalle sequenze costanti e lineari, ma nonda quelle quadratiche: se si considera infatti yt = a + bt + ct2 si ha che Myt =a + bt + ct2 + cm(m + 1)/3.
49

Il guadagno e fornito da
G(λ) =1
2m + 1
∣
∣
∣
∣
∣
1 + 2m
∑
i=1cos(λi)
∣
∣
∣
∣
∣
=1
2m + 1
∣
∣
∣
∣
∣
sin(m + 1/2)λsin(λ/2)
∣
∣
∣
∣
∣
ed e nullo per λ = (2πj)/(2m + 1), j = 1, . . . , 2m. Se applicata ad un processoWN, il fattore di inflazione della varianza e pari a (2m + 1)−1 e la funzione diautocorrelazione di Mεt e una linea retta inclinata negativamente.
3.5.1 Componente stagionale di periodo s pari
La mm aritmetica di un numero pari di termini (s = 4, 12) non e centrata rispettoalla modalita temporale di riferimento. Possiamo infatti costruire le due mm:
y∗1t =1
2m(yt−m + · · ·+ yt+m−1); y∗2t =
12m
(yt−m+1 + · · ·+ yt+m)
con m = s/2. Al fine di ottenere una mm centrata in t possiamo prendere
y∗t =12(y∗1t + y∗2t) =
12m
(.5yt−m + yt+m+1 + · · ·+ yt+m−1 + .5yt+m)
Il polinomio associato e w(L) = (2s)−1(1 + L)S(L) = (2s)−1(1 + L)∆s/(∆), conS(L) = 1 + L + · · ·+ Ls−1.
3.6 Composizione di mm aritmetiche
La composizione di mm aritmetiche consente di derivare una famiglia di mm diagevole calcolo che costituiscono buone approssimazioni di mm piu sofisticate. Adesempio, se desiderassimo una mm che preservi i polinomi di grado uno e che eliminiun pattern stagionale con ampiezza linearmente crescente, si puo applicare due volteuna mm a s termini:
M = 1s(L
s + · · ·+ L + 1 + L−1 + · · ·+ L−s+1)× 1s(L
s−1 + · · ·+ L + 1 + L−1 + · · ·+ L−s)= 1
s2 (Ls + 2Ls−1 + · · ·+ (s− 1)L + s + (s− 1)L−1 + · · ·+ 2L−s+1 + L−s)
Il polinomio caratteristico e proporzionale a S(L)2.Tuttavia, le mm aritmetiche consentono di preservare i polinomi di grado non
superiore al primo. Le mm di Spencer superano questa limitazione. In particolareesse, pur essendo caratterizzate da una struttura di coefficienti molto semplice, eli-minano una componente stagionale di periodo s con ampiezza variabile in manieralineare, etc..
50

3.7 Lisciamento e filtri di Henderson
In un paragrafo precedente abbiamo desunto le mm aritmetiche come soluzione delproblema di minw′w sotto il vincolo w′i = 1. Un criterio alternativo e basato sullaminimizzazione della forma quadratica w′Ωw, dove w′ = (w−m, . . . , w0, . . . , wm e Ω euna matrice simmetrica e definita positiva. Nel caso delle medie mobili di HendersonΩ = D3′D3, D e la matrice tale che Dw = (w−m, w−m+1 − w−m, . . . , wm − wm−1)′.
minm
∑
i=−m+3(∆3wi)2, s. v. C ′w = c
dove i vincoli sono relativi alla preservazione dei polinomi di ordine p.∑
iwi = 1,
∑
ijwi = 0, j = 1, 2, . . . , p (3.1)
Al fine di comprendere la natura dei vincoli, consideriamo una polinomiale diordine p:
yt =p
∑
j=1βjtt
Affinche sia
Myt =m
∑
i=−mwiyt+i =
m∑
i=−mwi
p∑
0j=1βj(t + i)j,
devono essere soddisfatte le relazioni (3.1). Il lisciamento della mm viene misuratodalla somma dei quadrati delle differenze terze dei coefficienti; questa quantita enulla se essi si dispongono lungo una parabola.
La soluzione e fornita da w = Ω−1C(C ′Ω−1C)−1c. Per p = 2, ponendo k = m+2:
wi =315[(k + 1)2 − i2](k2 − i2)[(k + 1)2 − i2)(3k2 − 16− 11i2)
8k(k2 − 1)(4k2 − 1)(4k2 − 9)(4k2 − 25)
Tali medie non elimininano la stagionalita, sebbene per una scelta opportuna di mse ne puo ridurre significativamente l’ampiezza.
3.8 Il trattamento delle estremita della serie
I due approcci fondamentali per il trattamento delle estremita della serie sono diseguito schematizzati:
1. Impiego di medie mobili asimmetriche per t = T −m + 1, . . . , T a 2m, 2m −1,m + 1 termini. Pertanto, gli ultimi m termini della serie sono soggetti arevisione quando una nuova osservazione si rende disponibile.
2. Estrapolazione (e retropolazione) della serie: yT+l|T , l = 1, . . . , m.
Se le previsioni sono lineari i due approcci sono equivalenti.
51

Capitolo 4
La destagionalizzazione delle serietemporali
4.1 Introduzione
La stagionalita rappresenta una delle maggiori fonti di variabilita dei fenomeni azien-dali. La sua rilevanza induce a ritenere che essa sia di autonomo interesse; tutta-via, esistono argomenti sufficientemente fondati ed istituzionalmente riconosciutiche inducono ad isolarla e rimuoverla da una serie storica al fine di evidenziaresegnali meno appariscenti, ma altrettanto significativi dal punto di vista interpre-tativo, identificabili con la componente ciclica e la componente di lungo periodo, otendenziale.
Una procedura di destagionalizzazione, come la X-12-ARIMA, oggetto del pre-sente capitolo, si fonda sul presupposto che non sussistano interazioni tra le com-ponenti di una serie temporale, ed in particolare tra la stagionalita e le altre com-ponenti; sotto queste ipotesi mira a eliminare una sovrastruttura dovuta a fattoriistituzionali, di calendario e climatici, legati all’alternarsi delle stagioni e diversi daquelli che presiedono alla componente di ciclo-trend, che possono essere legati alleaspettative degli operatori, al clima economico prevalente, alla diffusione delle inno-vazioni tecnologiche, e cosı via. Il grado di realismo di tale assunzione e stato ed etuttora oggetto di un ricco ed approfondito dibattito.
Un punto fermo rimane comunque il fatto che la disponibilita di informazionistatistico-economiche destagionalizzate costituisce un fabbisogno informativo dif-fuso, soprattutto da parte degli utilizzatori meno esperti o semplicemente menointeressati all’analisi statistica delle serie temporali, e sanzionato dai regolamenticomunitari, che invitano gli Istituti di Statistica dei paesi membri a produrre seriedestagionalizzate in maniera routinaria, secondo determinati standard qualitativi.
Al fine di illustrare l’operativita di una procedura di destagionalizzazione faremoriferimento ad una serie mensile molto famosa nella letteratura, la serie Airline,
52

Figura 4.1: Destagionalizzazione della serie Airline.
50 55 60
200
300
400
500
600
Serie originaria
50 55 60
5
5.5
6
6.5Trasformazione logaritmica
50 55 60
200
300
400
500Serie destagionalizzata
50 55 60
200
300
400
500
600
Serie originaria e ciclo-trendairline TRairline
relativa al numero dei passeggeri di una linea aerea nel periodo Gennaio 1941 -Dicembre 1961. Da essa prende il nome il modello Airline introdotto nel capitoloprecedente, dal momento che questo ben si adatta alla serie e in generale presenta unbuon adattamento per un ampio spettro di fenomeni economici che presentano trende stagionalita. La figura 4.1 evidenzia la presenza di un trend crescente e di unastagionalita abbastanza regolare, che tuttavia presenta un ampiezza delle oscillazionicrescente al crescere del trend: siamo in presenza di una situazione tipica in cuila trasformazione logaritmica elimina questa ultima caratteristica, come mostra ilsecondo pannello.
Il modello della classe ARIMA adattato alla serie risulta:
∆∆12 ln yt = (1− 0.40L)(1− 0.56L12)εt,
con σ2 = 0.013, e supera tutti i test diagnostici. Gli ulteriori pannelli della figura4.1 mostrano rispettivamente la serie destagionalizzata ottenuta come output dellaprocedura X-12, che come vedremo usa il modello ARIMA soltanto strumentalmente,al fine di ottenere estensioni della serie mediante previsione, e la componente di ciclo-trend. Le due differiscono dal momento che la prima contiene anche una stima dellacomponente irregolare, fornendo dunque un segnale meno lisciato.
Quello che la serie destagionalizzata consente di evidenziare e che non era palesea prima vista e la presenza di alcune flessioni cicliche, di natura temporanea, inparticolare nell’anno 1958.
53

4.2 La procedura X-12-ARIMA
La procedura X-12-ARIMA e stata sviluppata dal Census Bureau degli Stati Uniticon l’intento di sostituire la versione precedente, nota come X-11-ARIMA, che harappresentato a lungo la procedura di destagionalizzazione impiegata da soggettiistituzionali. Essa, distribuita in via sperimentale mediante il sito
ftp://ftp.census.gov/pub/ts/x12a/,
assieme al manuale ed al paper illustrativo (Findley et al., 1996), contiene elementidi continuita rispetto alla precedente versione, ma anche forti punti di rottura. Lanovita essenziale e rappresentata dal modulo RegARIMA, che va a sovrapporsi alnucleo originale della procedura X-11-ARIMA e che riporta su basi inferenziali iltrattamento di aspetti che precedentemente ricevevano soluzioni ad hoc.
In particolare, RegARIMA consente di adattare alla serie Yt modelli del tipo
φ(L)Φ(Ls)∆d∆Ds
(
yt −K
∑
k=1
βkxkt
)
= θ(L)Θ(Ls)εt, (4.1)
dove yt = f(Yt/dt) e la trasformazione di Box-Cox della serie Yt corretta dei fattoridt (ad es. per il diverso numero dei giorni lavorativi).
Le variabili esogene xk sono a) predefinite; b) definite dall’utente. Tra le primetroviamo, oltre alle dummy stagionali, quelle per la diversa lunghezza dei mesi, perl’effetto degli anni bisestili, per il numero dei giorni lavorativi, distintamente pervariabili di flusso e di stock, per la Pasqua e altre festivita mobili; per i valorianomali additivi, cambiamenti di livello, rampe temporanee. Inoltre, per quantoconcerne il trattamento automatico dei valori anomali, si assiste all’introduzionedelle procedure di forward addition e backward deletion.
Findley et al. (1996) descrivono le procedure di selezione della trasformazionepreliminare della serie, del modello ARIMA (nel caso si usi l’opzione automatica), distima dei parametri, etc.. Queste operazioni rientrano nella metodologia standard enon vengono discusse ulteriormente. In effetti, RegARIMA costituisce un pacchettoapplicativo che puo essere utilizzato autonomamente per l’identificazione, stima everifica di modelli ARIMAX secondo la metodologia di Box & Jenkins, trascendendodall’impiego funzionale all’estrapolazione della serie per l’applicazione in sequenzadel filtro X-11-enhanced.
Dopo aver realizzato l’aggiustamento preliminare e la previsione e retropolazionedella serie, si applica una versione arricchita del filtro X-11 che verra descritta inmaniera piu approfondita nei paragrafi che seguono. L’arricchimento ha riguarda-to la possibilita di specificare medie mobili di Henderson e stagionali di qualsiasilunghezza, la ridefinizione delle medie mobili asimmetriche e l’introduzione dellascomposizione “pseudo-additiva”.
54

Si noti che X-12, incorporando il modulo X-11, consente l’impiego delle pre-esistenti tecniche di aggiustamento per i valori anomali e per le componenti dicalendario, seppure il loro impiego appare ovviamente non opportuno.
La fase di diagnosi della bonta della destagionalizzazione conclude la procedura.In realta viene evidenziato un feedback con le fasi precedenti, poiche alcuni effettipotrebbero essere individuati soltanto in questa sede. Gli strumenti diagnostici dinuova introduzione sono: sliding spans, revision histories, la stima della densitaspettrale dei residui del modello regARIMA per l’individuazione della stagionalitaresidua e delle componenti di calendario.
4.3 Il filtro di destagionalizzazione (Enhanced X-11)
I modelli di scomposizione della serie storica Yt, t = 1, . . . , T , utilizzati dallaprocedura sono i seguenti:
Modello Scomposizione Serie destagionalizzataMoltiplicativo (default) Yt = Tt × St × It At = Tt × It
Additivo Yt = Tt + St + It At = Tt + It
Log-additivo lnYt = Tt + St + It At = exp(Tt + It)Pseudo-additivo Yt = Tt(St + It − 1) At = Tt × It
La scomposizione pseudo-additiva e applicabile nei riguardi di serie che assumonovalori comunque non negativi, ma prossimi allo zero in alcune stagioni. Il modellolog-additivo fornisce stime della componente tendenziale distorte verso il basso; pertale motivo si applica una correzione ad hoc atta ad assicurare che la media annuadella serie destagionalizzata coincida con quella della serie originaria.
Nella schematizzazione del filtro che segue presenteremo una esemplificazioneriferita ai modelli moltiplicativo (M) e additivo (A) applicati su dati mensili, s = 12.
La procedura X-11 risulta divisa in tre fasi ed e iterata tre volte, (iterazioni B,C, D): le prime due iterazioni sono dedicate all’identificazione e alla stima finale deivalori anomali, nel caso in cui l’aggiustamento preliminare non sia effettuato conregARIMA; l’ultima alla destagionalizzazione in senso stretto sulla serie corretta1.Di seguito descriveremo esclusivamente l’iterazione D; i riferimenti utilizzati sonoprevalentemente Findley et al. (1996) e Ghysels et al. (1995).
1In realta una prima iterazione, A, e dedicata all’aggiustamento preliminare della serie effettuatacon pesi a priori per i diversi giorni di calendario specificati dall’utente.
55

4.3.1 Prima fase: stime iniziali
1. Stima iniziale del trend-ciclo, T (1)t , mediante media mobile centrata a 12
termini (m.m. 2× 12):T (1)
t = C(L)Yt
con C(L) = 124(1+L)S(L)L−6 = 1
12
(
12L
−6 + L−5 + · · ·+ L−1 + 1 + L + · · ·+ L5 + 12L
6)
Yt.La media mobile in questione elimina una stagionalita deterministica diperiodo pari a 12 mesi, preservando le altre componenti.
2. Stima iniziale della componente stagionale-irregolare, SI(1)t , (rapporti - o dif-
ferenze - SI):(M) SI(1)
t = Yt
T (1)t
(A) SI(1)t = Yt − T (1)
t = SM(L)Yt
doveSM(L) = 1− C(L).
La divisione o sottrazione della stima preliminare del trend ciclo fornisce unastima iniziale della componente stagionale-irregolare.
3. La serie SI(1)t e suddivisa in 12 gruppi mensili. Si procede a perequare i rappor-
ti applicandovi una media mobile a 5 termini (m.m. 3× 3) separatamente perciascun mese, dando luogo ad una stima preliminare dei cd. fattori stagionali(seasonal factors),
S(1)t = M1(L)SI(1)
t
con
M1(L) =19(L−12 + 1 + L12)2 =
19L−24 +
29L−12 +
39
+29L12 +
19L24.
Le medie mobili mirano a eliminare la componente irregolare dalla componentestagionale-irregolare.
4. Si ottengono i fattori stagionali iniziali, S(1)t , le cui somme annuali sono pari
rispettivamente a 12 (M) e a zero (A).
(M) S(1)t = S(1)
t
C(L)S(1)t
(A) S(1)t = SM(L)S(1)
t
Questa operazione effettua la centratura dei fattori stagionali.
56

5. Stima iniziale della serie destagionalizzata, A(1)t :
(M) A(1)t = Yt
S(1)t
(A) A(1)t = Yt − S(1)
t
La divisione per i fattori stagionali (M) o la sottrazione dei medesimi (A)genera una stima della serie destagionalizzata.
4.3.2 Seconda fase: fattori stagionali e destagionalizzazione
1. La stima intermedia della componente trend-ciclo, T (2)t , viene calcolata appli-
cando una m.m. di Henderson alla serie A(1)t ;
T (2)t = Hm(L)A(1)
t
con Hm(L) = hmL−m + · · ·+ h1L−1 + h0 + h1L + · · ·+ hmLm.
Il filtro di Henderson riproduce un trend cubico e puo essere derivato equi-valentemente: (a) minimizzando la varianza delle differenze terze della seriefiltrata (∆3T (2)
t ); (b) minimizzando la somma dei quadrati delle differenze ter-ze dei coefficienti della media mobile; (c) adattando alla serie un trend cubicocon i minimi quadrati ponderati, minimizzando la somma dei quadrati delledifferenze terze dei pesi. Cfr Kenny & Durbin, 1982, JRSS, A, 145. Vedi ancheKendall 1973. I valori tipici di m sono 4, 6 e 11, dando luogo a m.m. di 2m+1termini. I coefficienti hj possono essere ricavati dall’applicazione dell’algorit-mo presentato in Findley et al. (1996, Appendice A): essi sono riportati nellatabella 1 per alcuni valori di m.
La scelta di m e resa automatica dalla procedura Variable Trend Cycle Routine:si considera inizialmente m = 6, T (2)
t = H6(L)A(1)t ; il rapporto It = A(1)
t /T (2)t ,
o la differenza It = A(1)t − T (2)
t , rappresenta una stima preliminare della com-ponente irregolare. Denotando con T la media campionaria di |∆Tt| e con Iquella di |∆It|, si costruisce il rapporto R = T /I, che rappresenta una misura,anche se abbastanza rozza, di lisciamento del trend (R−1 misura di roughness);la routine sceglie m = 4 se R−1 < 1.0 e m = 6 se 1.0 ≤ R−1 < 3.5.
2. Nuova stima dei rapporti SI:
(M) SI(2)t = Yt/T
(2)t
(A) SI(2)t = Yt − T (2)
t
3. Con riferimento ai 12 gruppi mensili dei rapporti SI si calcolano stime preli-minari dei fattori stagionali, S(2)
t , mediante media mobile 3× 5:
S(2)t = 1
15(L−36 + 2L−24 + 3L−12 + 3 + 3L12 + 2L24 + L36)SI(2)
t
= M2(L)SI(2)t
57

Pesij m = 4 m = 6 m = 8 m = 110 .33114 .24006 .18923 .14406
±1 .26656 .21434 .17639 .13832±2 .11847 .14736 .14111 .12195±3 -.00987 .06549 .09229 .09740±4 -.04072 .00000 .04209 .06830±5 -.02786 .00247 .03893±6 -.01935 -.01864 .01343±7 -.02037 -.00495±8 -.00996 -.01453±9 -.01569±10 -.01092±11 -.01453
Tabella 4.1: Filtro di Henderson: pesi hj per le m.m a 9, 13, 17 e 23 termini
doveM2(L) =
115
(L−12 + 1 + L12)(L−24 + L−12 + 1 + L12 + L24)
L’opzione default effettua la scelta della media mobile 3 × r, r = 3, 5, 9, inmaniera e automatica, mediante il sottoprogramma Seasonal-Factor CurveRoutine:
(a) Si calcola una m.m. a 7 termini dei rapporti SI(2)t mese per mese, S(p)
t =M2(L)SI(2)
t , considerando gli anni per i quali si dispone di un set dirapporti completo.
(b) Si ottiene la stima della componente irregolare, I(p)t , dal rapporto o dif-
ferenza tra SI(2)t e S(p)
t .
(c) Separatamente per ciascun mese si calcola il cd Moving Seasonality Ratio,MSR, fornito dal rapporto tra la media aritmetica di |∆I(p)
t | e quella di|∆S(p)
t | (MSR rappresenta dunque una misura di “roughness” del patternstagionale), e la scelta di r e effettuata come segue: r = 3 se MSR ≤ 2.5;r = 5 se 3.5 ≤ MSR ≤ 5.5; r = 9 se MSR ≥ 6.5; negli altri casisi ridetermina MRS escludendo l’ultimo anno di osservazioni; se nessuncriterio e applicabile si continua con l’esclusione di un anno alla volta finoad un massimo di cinque, e se non si ottiene una risposta si prende r = 5.
58

4. Si effettua la centratura dei fattori stagionali:
(M) S(2)t = S(2)
t
C(L)S(2)t
(A) S(2)t = SM(L)S(2)
t
5. Destagionalizzazione:
(M) A(2)t = Yt/S
(2)t
(A) A(2)t = Yt − S(2)
t
La stima preliminare della componente irregolare si consegue rispettivamentecome I(2)
t = A(2)t /T (2)
t e I(2)t = A(2)
t − T (2)t .
4.3.3 Terza fase: stima finale delle componenti
1. La stima finale della componente tendenziale viene calcolata applicando unam.m. di Henderson alla serie A(2)
t ;
T (3)t = Hm(L)A(2)
t
L’ordine del filtro viene determinato ex novo dalla variable trend cycle routine,la quale ora consente la scelta m = 11 qualora R−1 ≥ 3.5.
2. La stima finale della componente irregolare e fornita ripettivamente da I(3)t =
A(2)t /T (3)
t e I(3)t = A(2)
t − T (3)t .
La scomposizione finale risulta:
(M) Yt = T (3)t × S(2)
t × I(3)t
(A) Yt = T (3)t + S(2)
t + I(3)t
4.4 Le proprieta teoriche del filtro
Prescindendo dal trattamento dei valori anomali e dalla limitazione temporale dellaserie, che richiede la modifica dei filtri alle estremita della serie, il filtro X-11 e unasequenza di medie mobili che da luogo ad un filtro lineare2 applicato a Yt, le cuiproprieta sono state approfondite nel dominio temporale e frequenziale.
Sebbene dal punto di vista operativo la scomposizione moltiplicativa sia utilizzatapiu di frequente, le proprieta del filtro sono state investigate nel caso additivo (Wallis,
2Per una diversa opinione si veda Ghysels et al. (1996).
59

1974, Ghysels e Perron, 1993). Ovviamente, i risultati possono essere estesi al casomoltiplicativo, via il caso log-additivo.
Seguendo l’approccio di Ghysels e Perron (1993), scriviamo:
A(2)t = νX−11(L)Yt
dove
νX−11(L) = 1−SM(L)M2(L)+SM(L)M2(L)Hm(L)−SM3(L)M1(L)M2(L)Hm(L)
Analogamente, possono essere desunti i filtri per l’estrazione delle componenti:
T (3)t = Hm(L)νX−11(L)Yt
S(2)t = [1− νX−11(L)]Yt
I(3)t = [1−Hm(L)]νX−11(L)Yt
Da ciascuna di queste rappresentazioni e possibile derivare i pesi applicati alla serieYt per estrarre la componente; inoltre, la funzione di trasferimento del filtro consentela comprensione degli aspetti principali dell’operativita del filtro. Se wj rappresentail peso associato al j-esimo ritardo, il guadagno del filtro e dato da G(λ) = w0 +2
∑Jj=1 wj cos(λj).Le figure 1 e 2 mettono in luce tre aspetti fondamentali del filtro:
• il filtro e relativamente insensibile a variazioni della lunghezza delle medie mo-bili fondamentali; il filtro e pertanto ad hoc e non si adatta alle caratteristichedella serie, dando luogo alla possibilita di sovra o sotto aggiustamento;
• il filtro non e idempotente: se applicato alla serie destagionalizzata genera lacomponente stagionale S∗t = [1 − νX−11(L)]νX−11(L)Yt 6= [1 − νX−11(L)]Yt =S(2)
t ;
• il filtro puo estrarre stagionalita spuria.
Al fine di illustrare la scarsa flessibilita del filtro, consideriamo il problema di de-stagionalizzare la serie mensile di fonte ISCO BDIGENGS che rappresenta il livellodegli ordini e della domanda dall’interno per il totale industria (saldi). La serie vienepresentata nella figura 4.4 assieme allo pseudospetto in decibels (10× log10 f(λ)) sti-mato con una finestra di Daniell, che mette in evidenza, tra l’altro, la concentrazionedi potenza attorno alle frequenze stagionali.
L’aggiustamento stagionale realizzato dalla procedura X-12 viene messo a con-fronto con quello effettuato da SEATS a partire dal modello ARIMA (3, 1, 0) ×(1, 0, 0)12. La scelta dell’ordine del polinomio AR non stagionale (p = 3) e impostadai limiti di SEATS; la diagnostica fornisce comunque un quadro sostanzialmente
60

accettabile. Il coefficiente AR stagionale e pari a -.57 e sottintende un modello distagionalita stazionario. La procedura X12 e stata applicata con la specificazioneadditiva.
Il grafico delle serie destagionalizzate ed il loro pseudospettro sono riportate nel-la figura 4.4; si noti che il pattern stagionale estratto da X12 e notevolmente piustabile di quello estratto da SEATS. Lo pseudospettro mette in luce che il primodomina il secondo, con la conseguenza che la serie destagionalizzata con SEATS sipresentera piu liscia (Froeb e Koyak, 1995) e che il fenomeno della sovraddifferen-ziazione, percepibile dai minimi relativi alle frequenze stagionali, ha una rilevanzaminore per SEATS.
4.5 Correzione dei valori anomali nell’X-11
La correzione dei valori anomali costituisce una delle fonti di non linearita del filtroX-11. Sebbene tale operazione possa essere effettuata in via preliminare all’appli-cazione del filtro X-11 mediante regARIMA, qui di seguito descriviamo la routineoriginaria, ricordando che viene applicata nelle due iterazioni della procedura, B eC, le cui fasi sono identiche a quelle descritte nella sezione 1.
La routine entra in azione alla fine della prima fase, in cui si ottiene I(1)t =
SI(1)t − S(1)
t . Con riferimento a I(1)t si calcola la deviazione standard mobile σI per
sottoperiodi di 5 anni (60 osservazioni mensili consecutive). I valori della componen-te irregolare dell’anno centrale che escono dai limiti 2.5σI sono rimossi e le deviazionistandard ricalcolate; queste sono poi reimpiegate per ottenere la seguente funzioneponderatrice:
wt =
1 se 0 ≤ |I(1)t | ≤ 1.5σI
2.5− |I(1)t |σI
se 1.5σI < |I(1)t | ≤ 2.5σI
0 se |I(1)t | > 2.5σI
Per le osservazioni tali che wt < 1 i corrispondenti rapporti (o differenze) SI sonosostituiti dalla media di wtSI(1)
t e dei due valori precedenti e successivi piu viciniriferiti allo stesso mese con peso unitario. Successivamente vengono ricalcolati ecentrati i fattori stagionali.
La procedura viene impiegata anche all’inizio della seconda fase, con la correzionedei rapporti SI, facendo riferimento a I(2∗)
t = SI(2)t − S(2)
t . Inoltre viene applicatacon riferimento a I(2)
t = A(1)t /T (2)
t (M) o I(2)t = A(1)
t −T (2)t (A): a) al fine di escludere
i valori estremi dall’analisi delle componenti di calendario; b) prima di ottenere lestime finali (fase 3) in corrispondenza dei valori wt < 1, A(2)
t viene rimpiazzato dallamedia di wtA
(2)t e due valori precedenti e successivi piu vicini con peso unitario.
61

Infine, nella fase finale, con riferimento a I(3)t , i pesi sono calcolati per ottenere i
fattori di correzione da applicare alle osservazioni originarie:
Ft =1 + (I(3)
t − 1)wt
I(3)t
=I(3)t wt + (1− wt)
I(3)t
=I∗tI(3)t
Vengono calcolati i cosidetti valori estremi (extreme values) come reciproco deifattori di correzione Ft: Ot = F−1
t .
4.6 Le componenti di calendario
Consideriamo innanzitutto l’effetto della diversa lunghezza dei mesi; a tal fine deno-tiamo il numero dei giorni di calendario nel mese t con Nt; questo non costituisce uneffetto puramente stagionale, avendo periodo pari a 4 anni per la presenza dell’annobisestile; sopra un ciclo di 4 anni la media di Nt e pari a N = 365.25/12 = 30.4375, erappresenta la componente di livello in Nt. Sempre a partire da Nt possiamo definirela variabile stagionale: N∗
t = Nt se t 6= 2 modulo 12 e N∗t = 28.5 se t = 2 mod 12
(mese di febbraio). Pertanto N∗t e periodica con periodo pari a 12 mesi. L’effetto
della lunghezza del mese puo essere visto come composto da trend, N , stagionalita,ed un residuo “ciclico”; nel caso moltiplicativo:
Nt = NN∗
t
NNt
N∗t
(4.2)
mentre nel caso additivo:
Nt = N + (N∗t − N) + (Nt −N∗
t )
La componente residua e dovuta alla presenza dell’anno bisestile (leap year effect)ed ha valori non nulli solo nel mese di febbraio.
Denotiamo ora con Djt il numero delle volte in cui il j-esimo giorno della settima-na (Lunedı, . . . , Domenica), entra nel mese t e con δj l’effetto corrispondente (il tassomedio di attivita relativo al giorno j); si avra pertanto Nt =
∑
j Djt, δ =∑7
j=1 δj/7.L’effetto cumulato nel mese t sara dato da
TDt =7
∑
j=1δjDjt = δNt +
6∑
j=1(δj − δ)(Djt −D7t) (4.3)
La seconda componente misura l’effetto legato alla composizione dei diversi mesi;essa ha somma nulla sopra un numero di mesi che contiene un numero intero disettimane, e pertanto non interferisce con la componente trend; la prima e dovutaalla diversa lunghezza dei mesi e per la sua presenza TDt conterra una componentedi livello e una componente stagionale.
62

Dal momento che nel modello di scomposizione della serie sono gia presenti lecomponenti trend e stagionalita, questi possono essere scorporati da TDt dividendo(caso moltiplicativo) - sottraendo (caso additivo) - per δN∗
t :
(M) TD∗t = Nt
N∗t
+∑6
j=1 δ∗jDjt−D7t
N∗t
(A) TD∗t = δ(Nt −N∗
t ) +∑6
j=1 δ∗j (Djt −D7t)
Si ottiene pertanto che TD∗t misura l’effetto dei giorni lavorativi e degli anni bisestili
(componente ciclica di Nt). Se si desidera rimuovere soltanto l’effetto trend, si divideo si sottrae per δN . L’effetto corrispondente misura, oltre agli effetti in TD∗
t l’effettostagionale della diversa lunghezza del mese.
La procedura X-11 stima gli effetti TD a partire da una stima preliminare dellacomponente irregolare e stima i coefficienti δ∗j nel modello It = TD∗
t + et mediantei MQO. X-12 li stima direttamente sulla serie Yt, utilizzando il modello additivo,nella fase regARIMA preliminare all’aggiustamento. L’evidenza empirica si rive-la a favore di questa seconda strategia (Chen et al., 1995). Nel caso si adotti latrasformazione logaritmica della serie la stima degli effetti TD mediante il modelloadditivo rappresenta un’approssimazione di Taylor del primo ordine (Findley et al.,1996). Pertanto, i regressori predefiniti nella spec: REGRESSION sono le sei varia-bili Djt −D7t e lom= Nt − N o leap year= Nt −N∗
t . Si noti che se D > 0 in (4.1),l’effetto lom e lom piu leap year coincidono. L’aggiustamento puo essere effettuatoin maniera preliminare in sede di trasformazione di Yt −→ Yt/dt, con dt = Nt/Nt oNt/N∗
t .X-12 offre l’opzione automatica per determinare se includere gli effetti TD nel
modello (4.1): effettua la stima del modello in presenza degli effetti (dt = Nt/N∗t e
regressori Djt − D7t) ed in loro assenza e si seleziona il modello che fornisce il piupiccolo AIC.
4.7 Diagnostica
4.7.1 Test di stagionalita
Una successione di test di stagionalita sono applicati nel corso della procedura:a) Test FS per l’assenza di stagionalita nei rapporti o differenze SI(1)
t , propor-zionale al rapporto tra la varianza tra i mesi e la varianza entro i mesi dei rapportiSI; si suggerisce il livello di significativita .001.
b) Test FM per l’assenza di stagionalita evolutiva applicato alla serie |SI(2)t | nel
caso additivo e |SI(2)t − 100| nel caso moltiplicativo: la varianza totale e scomposta
in varianza tra i mesi, varianza tra gli anni e varianza residua; il test e proporzionaleal rapporto tra la varianza tra gli anni e la varianza residua.
63

c) Test congiunto per la presenza di stagionalita non identificabile. Vengono presiin considerazione i test FS, FM ed il test nonparametrico di Kruskal-Wallis (KW)3.Si dice che la stagionalita e identificabile quando FS e KW sono significativi, mentreFM cade nella zona di accettazione. Si e in presenza di stagionalita non identificabilequalora: il test FS non risulta significativo al livello .001; FS e FM sono significativirispettivamente al livello .001 e .05, e la media aritmetica tra T1 = 7/(FM − FS) eT2 = 3FM/FS e non inferiore all’unita. Non si esclude la presenza di stagionalitaidentificabile qualora FS e significativo, il test FM e non significativo e T1, T2 < 1 oKW non e significativo.
d) Test FS per l’assenza di stagionalita residua applicato alla serie completa edagli ultimi tre anni di A(2)
t − A(2)t−s/4 (nel caso trimestrale ∆A(2)
t ).
4.7.2 Nuova diagnostica su stagionalita residua e l’effettodel n. giorni lavorativi
La presenza di stagionalita residua viene studiata stimando la densita spettrale deiresidui alle frequenze stagionali con riferimento agli anni piu recenti (default: ulti-mi 8 anni). X-12-ARIMA produce automaticamente queste stime per le differenzeprime della serie destagionalizzata e per la stima finale della componente irregolare.Viene effettuato il confronto con le due frequenze immediatamente vicine e se questesono inferiori di un dato margine, il programma produce il messaggio che i picchisono “visually significant”. Gli stimatori spettrali sono due: il periodogramma e lostimatore autoregressivo con 30 ritardi.
Analogamente, per valutare la presenza di effetti legati ai giorni della settimana,si valuta la significativita dei picchi alle frequenze 2π × .348 e 2π × .432.
4.7.3 Test di casualita dei residui I(3)t
a) Un test non parametrico di autocorrelazione del primo ordine e fornito dallastatistica ADR (Average Duration of Run), la quale misura il numero medio divariazioni mensili consecutive nella stessa direzione. Per serie mensili di oltre diecianni valori esterni all’intervallo [1.36, 1.75] sono da considerare significativi.
3Il test di Kruskal-Wallis e un’alternativa al test F parametrico dell’analisi della varianza chenon richiede l’assunzione di normalita e che sfrutta soltanto l’ordinamento delle osservazioni.
KW =12
T (T + 1)
s∑
j=1
R2j
nj− 3(T + 1)
dove Rj e la somma dei ranghi (per rango intendendosi il numero d’ordine dell’osservazione nel-l’ordinamento non decrescente) per la stagione j e nj e il numero degli anni in cui si presentala stagione j (solitamente nj = n = T/s). Sotto l’ipotesi nulla di assenza di stagionalita e diindipendenza dei rapporti SI, KW ∼ χ2 con s− 1 gradi di liberta.
64

b) Periodogramma cumulativo normalizzato e test di Kolmogorov-Smirnov
4.7.4 Bonta della destagionalizzazione
Undici grandezze diagnostiche sono previste con la finalita di valutare la bonta delladestagionalizzazione: M1: misura sintetica del contributo relativo della componenteirregolare I2
t /Y 2t . M2: misura sintetica del contributo relativo della componente
irregolare alla varianza della serie, resa stazionaria rimuovendo un trend lineare(versione additiva e log-additiva) o esponenziale (versione moltiplicativa); M3 =R−1, (cfr. Variable Trend Cycle Curve Routine); M4 = ADR (Average Durationof Run); M5: numero di mesi richiesto affinche |∆T (3)
t | > |∆I(3)t |; M6 = MSR
(Moving Seasonality Ratio); M7 = 100FM/FS (stagionalita variabile rapportata allastagionalita stabile); M8 misura della variabilita tra gli anni di S(2)
t ; M9 trend linearemedio nei fattori stagionali finali, S(2)
t ; M10 e M11 sono identici alle due misureprecedenti, ma sono calcolate solo per gli anni piu recenti.
Il campo di variazione e [0, 3] e la regione di accettazione [0, 1]. Le stati-stiche M1-M11 sono poi aggregate in un’unica misura sintetica della bonta delladestagionalizzazione, Q.
4.7.5 Diagnostiche basate sulla stabilita delle stime
Un metodo di destagionalizzazione e detto stabile se la serie destagionalizzata none suscettibile di variazioni significative con l’aggiunta di nuove osservazioni. Lastabilita e una caratteristica desiderabile per la previsione a breve termine ed eappetibile per i produttori di dati e per il policy maker.
Le quantita diagnostiche disponibili in X-12-ARIMA si basano sulla revisioninella serie At con l’aggiunta di nuove osservazioni. Sia At|j la stima della seriedestagionalizzata che utilizza le osservazioni fino al tempo j; quando j = t abbiamoil cd. concurrent estimator (CE), mentre nel caso j = T abbiamo la stima piurecente (more recent estimator), MR. Nel caso della scomposizione moltiplicativaviene fornito l’indice di revisione da CE a MR:
Rt|T = 100×At|T − At|t
At|t
e per dati J0 e J1, viene fornita la sequenza Rt|T per J0 ≤ t ≤ J1 (revision history-RH). Per la scelta di J0 si suggerisce un numero di periodi almeno pari alla lunghezzadel filtro stagionale.
Dal momento che spesso l’interesse si appunta sulle variazioni relative del fenome-no, piuttosto che sul suo livello assoluto, X-12 prende in considerazione anche l’indice
65

di revisione relativo al tasso di variazione uniperiodale della serie destagionalizzata:
R∆t|j = 100×
At|j − At−1|j
At−1|t,
e la corrispodente RH. Un ulteriore impiego delle RH e la determinazione del numerodi anni su cui estendere la serie per previsione, come argomentano Findley et al.(1996).
Recentemente, Findley et alii (1990) hanno proposto le cd. sliding span dia-gnostics. Queste si fondano sul confronto tra i dati destagionalizzati prendendo inconsiderazione gruppi mobili di osservazioni (spans) che si sovrappongono mediantel’aggiunta sequenziale di un anno di osservazioni alla volta e l’eliminazione dell’annoiniziale. Le stime At sono giudicate affidabili se non variano sensibilmente da ungruppo all’altro.
Si supponga di considerare K(= 4) gruppi di lunghezza pari ad N anni; suciascuno viene applicata la procedura di destagionalizzazione e si denoti con S(k)
t ilfattore stagionale associato al k-esimo gruppo, k = 1, . . . , K. La lunghezza deglispan risulta uguale a quella minima necessaria per l’applicazione dei filtri MA dellaprocedura X-11 e risultera pertanto pari a N = 6, 8, 11 rispettivamente nei casi incui si scelgano le medie mobili 3× 3, 3× 5, 3× 9 per perequare i fattori stagionali.
Si dice che il fattore stagionale al tempo t e inaffidabile se
Smaxt =
maxk S(k)t −mink S(k)
t
mink S(k)t
> .03
Poiche l’obiettivo della destagionalizzazione e quello di ottenere misure delle varia-zioni mensili, si propone di valutare altresı
MMmaxt = max
k
∆A(k)t
A(k)t
−mink
∆A(k)t
A(k)t
> .03
Al fine di cogliere se l’instabilita riguarda periodi contigui o stagioni particolari,la stima della variazione relativa su base annua e giudicata inaffidabile se
Y Y maxt = max
k
∆12A(k)t
A(k)t
−mink
∆12A(k)t
A(k)t
> .03
Misure sintetiche possono essere ottenute mediante la percentuale di mesi confattori stagionali non affidabili, S(%), con variazioni relative mensili inaffidabili(MM(%)) e variazioni annuali innaffidabili (Y Y (%)). Se ad esempio S(%) > 25 laserie non dovrebbe essere destagionalizzata.
Per un efficace giudizio critico su queste statistiche, vedasi Maravall (1996). Inpoche parole, la loro utilita sarebbe ristretta alla scelta tra la destagionalizzazione
66

diretta o indiretta (mediante le serie componenti) di un aggregato e nella selezionedella lunghezza del filtro. Piu oscuro il ruolo nella decisione se aggiustare o meno toutcourt, poiche l’instabilita e una proprieta della serie e non (soltanto) della proceduradi destagionalizzazione.
67

Figura 4.2: Pesi e funzioni di trasferimento per il filtro X-11 default
68

Figura 4.3: Pesi e funzioni di trasferimento per il filtro X-11 con filtro di Hendersona 17 termini
69

Figura 4.4: Serie BDIGENGS: livello degli ordini e della domanda dall’interno peril totale industria (saldi), ISCO.
BDIGENGS
Time
1986 1988 1990 1992 1994 1996
-50
-40
-30
-20
-10
010
frequency
spec
trum
0 1 2 3 4 5 6
-10
010
20
Series: bdigen Smoothed Periodogram
bandwidth= 0.0571957 , 95% C.I. is ( -4.41115 , 9.00983 )dB
X12: Comp. Stagionale
Time
1986 1988 1990 1992 1994 1996 1998
-8-6
-4-2
02
4
SEATS: Comp. Stagionale
Time
1986 1988 1990 1992 1994 1996
-10
-50
5
S.Dest. X12:____, SEATS:....
Time
1986 1988 1990 1992 1994 1996
-40
-30
-20
-10
010
frequency
spec
trum
0 1 2 3 4 5 6
-10
010
20
Series: bdigen.adj Smoothed Periodogram
bandwidth= 0.0819443 , 95% C.I. is ( -3.85117 , 6.96677 )dB bandwidth= 0.0819443 , 95% C.I. is ( -3.85117 , 6.96677 )dB
70

Capitolo 5
Analisi Econometrica di Dati nonStazionari
5.1 Introduzione
Buona parte dell’informazione statistica, soprattutto in campo macroeconomico, eorganizzata in senso temporale; la cosiddetta Econometria delle serie storiche, pro-ponendosi di stimare relazioni esistenti tra variabili osservate nel tempo, ha dedicatoun’attenzione crescente alle proprieta dinamiche del processo generatore dei dati.Cio ha portato, nel corso dell’ultimo decennio, ad una profonda rivisitazione dellebasi statistiche della modellistica econometrica che ha fatto leva sui concetti di inte-grazione e cointegrazione, introdotti al fine di interpretare una delle caratteristicheprincipali delle serie macroeconomiche: l’assenza di stazionarieta.
Di questi aspetti ci occuperemo ora con il seguente programma: nel paragrafo2 verra introdotta la particolare forma di non stazionarieta legata alla presenzadi integrazione; di questa vengono illustrati gli effetti sulla dinamica dei processie sulle inferenze statistiche. Si discute quindi come condurre dei test parametriciper verificarne la presenza in una serie storica (par. 3 e 4). Il par. 5 considera leimplicazioni dal punto di vista interpretativo mediante la contrapposizione di dueteorie relative alla dinamica di lungo periodo del sistema economico. Per processiintegrati la dinamica viene descritta come la reazione del sistema ad innovazioni ditipo casuale; di qui l’interesse a misurare la persistenza degli shock (par. 6). I par. 7e 8 trattano l’estensione del concetto di integrazione a processi di natura stagionalee introducono il test HEGY di integrazione stagionale. Si passera poi all’ambitobivariato al fine di discutere gli effetti dell’integrazione sulle inferenze che possonoessere tratte da un modello a ritardi distribuiti (par. 10). Verranno quindi introdottidue concetti complementari: il meccanismo a correzione dell’errore di equilibrio e lacointegrazione, i quali presuppongono l’esistenza di una relazione di lungo periodotra le serie esaminate (par 11-12).
71

5.2 Stazionarieta ed integrazione
Un processo stocastico puo essere definito come una sequenza di variabili casualiyt indicizzate da un parametro t appartenente ad un insieme parametrico T .Poiche nel seguito ci limiteremo a considerare la classe dei processi stocastici continuia parametro discreto, avremo T = 0, 1, . . .. Nelle applicazioni econometriche sidispone, per ogni t, di una singola realizzazione della v.c. yt, per cui il processoinferenziale presenterebbe complicazioni insuperabili se non venissero imposte dueclassi di restrizioni sulle caratteristiche del processo: la stazionarieta e l’ergodicita.
In particolare, diremo che un processo stocastico e stazionario in senso debole sei suoi momenti fino al secondo sono finiti ed indipendenti da t, vale a dire E(yt) = µ,E(yt−µ)2 = γ0 e E[(yt−µ)(yt−k−µ)] = γk = γ−k, ∀t, k, dove γk denota la covarianzatra yt e yt−k che si assume essere funzione esclusivamente di k. L’ergodicita richiedeinvece che la “memoria” del processo sia limitata cosı che eventi distanti nel tempoabbiano un basso grado di dipendenza.
Utili strumenti per la caratterizzazione di un processo stazionario sono la funzio-ne di autocorrelazione e densita spettrale; la prima e definita ρk = γk/γ0, k = 0, 1, . . .mentre la seconda da
f(ω) =12π
[
γ0 + 2∞∑
k=1
γk cos ωk]
,
dove ω e la frequenza in radianti che assume valori in [0, π].Il processo stazionario piu elementare e costituito da una sequenza di variabili
casuali incorrelate a media nulla e varianza costante: esso e denominato white noise,ed indicato con εt ∼ WN(0, σ2), dove E(εt) = 0, E(ε2
t ) = σ2 e E(εtεt−k) = 0 perk 6= 0.
Alla classe dei processi in questione si applica un importante risultato noto cometeorema di Wold: esso afferma che ogni processo stazionario puo essere scompo-sto in due processi stocastici stazionari e mutualmente incorrelati, uno dei quali edeterministico mentre l’altro (indeterministico) e il processo lineare:
zt = εt + C1εt−1 + C2εt−2 + · · · ,
con∑
C2k < ∞.
Consideriamo ora un processo autoregressivo del primo ordine (AR(1)):
yt = φyt−1 + εt t = 1, 2, . . . , T
con εt ∼ WN(0, σ2); e noto allora che se il processo e stazionario, vale a dire se|φ| < 1, lo stimatore dei minimi quadrati
φ =
T∑
t=2ytyt−1
T∑
t=2y2
t−1
(5.1)
72

e√
T -consistente ed inoltre√
T (φ− φ) →d N(
0, (1− φ2))
.
E’ immediato constatare che questo risultato non e piu valido se φ = 1. Inquesto caso, noto nella letteratura anglosassone come random walk (RW), yt e non-stazionaria perche risulta Var(yt) = tσ2; cio puo essere visto risolvendo l’equazionealle differenze finite
yt = yt−1 + εt.
Sotto specifiche ipotesi riguardanti i valori iniziali, εs = 0 per s ≤ 0 e y0 noto (nonstocastico), si ottiene infatti la soluzione
yt = y0 +t−1∑
j=0εt−j. (5.2)
La natura di tale processo (la varianza linearmente crescente) implica che essopossa vagare indefinitamente lontano dal valore iniziale con il procedere del tempo;1
in altre parole, diversamente dal processo autoregressivo stazionario descritto prima,non gode della proprieta di “regressione” verso la media (mean reversion). Si notianche che yT+l = E(yT+l|yT ) = yT ; pertanto tutta l’informazione sul comportamentodel processo e contenuta nell’ultima realizzazione.
Il random walk e inoltre un processo dalla memoria lunga in quanto il pesodelle realizzazioni passate della v.c. εt nella determinazione del presente rimaneinalterato, mentre nel caso del processo autoregressivo stazionario decade in manieraesponenziale. Dalla (2) emerge infatti che la derivata parziale di yt rispetto a εt−k epari a uno, indipendentemente dal valore di k.
Il RW e un esempio di processo integrato del primo ordine, ovvero, con notazionesintetica, yt ∼ I(1); introduciamo dunque la seguente definizione:
Def. Ordine di integrazione: il processo yt e integrato di ordine d, e scriveremoyt ∼ I(d), se le differenze d-esime ∆dyt ammettono una rappresentazione di Woldstazionaria e invertibile.
In altre parole applicando d volte l’operatore differenza, ∆ = 1−L, si ottiene unprocesso stazionario ed invertibile, per il quale vale la tradizionale teoria asintotica.
Es. 1: yt = 2yt−1 − yt−2 + εt + θεt−1, yt ∼ I(2) ⇐⇒ |θ| < 1 ;Es. 2: yt = β0 +β1t+β2t2 +εt non e I(2), bensı I(0) con trend deterministico di secondo
grado.1Notiamo, per inciso, che nel caso |φ| > 1 siamo in presenza di un processo non stazionario
(esplosivo) la cui varianza cresce esponenzialmente con t.
73

Il comportamento dei processi integrati differisce da quello dei processi stazio-nari anche per un altro aspetto; la presenza di un termine costante in un modelloautoregressivo non ha conseguenze drammatiche sulle sue proprieta temporali:
yt = µ + φyt−1 + εt t = 1, 2, . . . , T
yt e infatti un processo stazionario attorno a m = E(yt) = µ/(1 − φ), ed e notoche m e φ possono essere stimati in maniera (asintoticamente) indipendente; inoltrei momenti di ordine superiore al primo non sono affetti dalla presenza della me-dia, la quale si configura come un parametro di disturbo eliminabile prendendo inconsiderazione il processo scarti dalla media.
Vediamo invece cosa accade nel caso φ = 1: il processo
∆yt = µ + εt t = 1, 2, . . . , T
e ancora I(1), ma le sue realizzazioni sono notevolmente diverse da quelle di un RW;mediante sostituzione successiva troviamo infatti che
yt = y0 + µt +t−1∑
j=0εt−j
e che pertanto il valor medio del processo e un trend lineare deterministico attorno alquale le oscillazioni si fanno sempre piu accentuate.2 Tuttavia, in una realizzazionefinita il comportamento di detto processo puo essere non troppo dissimile da quellodi un processo stazionario attorno ad un trend lineare, e cio e tanto piu vero quantopiu Var(εt) e bassa. Quanto ottenuto nel caso del RW e generalizzabile nella manieraseguente: se yt ∼ I(d) senza drift allora yt contiene un trend polinomiale di ordined− 1; se invece yt ∼ I(d) con drift, yt contiene un trend polinomiale di ordine d.
In molte circostanze ha rilievo determinare l’ordine di integrazione di una variabi-le. Un caso molto noto riguarda la trasformazione da adottare preliminarmente allaspecificazione di un modello ARMA al fine di ottenere la stazionarieta. Tuttavia, co-me vedremo nel seguito, l’ordine di integrazione possiede un contenuto informativoautonomo sulle proprieta dinamiche della serie.
Si potrebbe tentare il ricorso ai tradizionali strumenti di identificazione qualiil correlogramma, ma quest’ultimo presenta una serie di limiti atti a sconsigliarnel’impiego. Dal punto di vista teorico la funzione di autocovarianza del RW non tendea zero rapidamente, risultando Cov(yt, yt−τ ) = E[(yt − y0)(yt−τ − y0)] = σ2|t − τ |;pertanto, quando t e elevato relativamente a τ il processo e altamente autocorrelato.Tuttavia in realizzazioni “brevi” il correlogramma stimato potrebbe erroneamenteindurre ad accettare l’ipotesi di stazionarieta.
Lo scopo dei paragrafi successivi e appunto quello di analizzare il problema dalpunto di vista dell’inferenza parametrica introducendo una batteria di test per laverifica delle ipotesi concernenti l’ordine di integrazione di una serie.
2Il processo e denominato Random Walk with Drift; si noti che se yt e espresso in logaritmi ildrift rappresenta il tasso medio di crescita.
74

5.3 Il test di Dickey e Fuller
Fuller (1976, p. 367) ha studiato le proprieta dello stimatore (1) sotto l’ipotesiφ = 1, vale a dire quando il meccanismo generatore dei dati e un RW.
Un primo risultato riguarda la proprieta di superconsistenza dello stimatore:nell’ipotesi che y0 = 0 e εt ∼ NID(0, σ2)
φ− 1 = Op(T−1)
il che significa che quando il valore vero e φ = 1, la stima converge in probabilita atale valore piu rapidamente che nel caso stazionario. Il risultato e dovuto al fattoche al crescere di T il denominatore cresce, relativamente al numeratore, ad un ritmosuperiore rispetto al caso stazionario.
Malgrado φ sia (super)consistente, non gode tuttavia della proprieta di corret-tezza asintotica e la sua distribuzione non e normale, ma asimmetrica a sinistra:questo implica che la stima di φ e distorta verso il basso e che se ci fidassimo cie-camente delle stime dei minimi quadrati saremo indotti a rifiutare l’ipotesi di unaradice unitaria piu spesso del dovuto.
La distribuzione di φ non e standard; la tavola 8.5.1 del libro di Fuller (p. 371)fornisce i percentili della funzione di ripartizione della v.c T (φ−1) ottenuti attraversola simulazione Monte-Carlo sotto l’ipotesi φ = 1 per le dimensioni campionarieT = 25, 50, 100, 250, 500 e ∞.
L’ipotesi nulla puo essere testata facendo ricorso alla statistica
τ =φ− 1
s
( T∑
t=2y2
t−1
)12
,
con s2 pari alla somma dei quadrati dei residui, che sotto H0 non e piu distribuitacome una t di Student. La distribuzione e riportata nella tavola 8.5.2, p. 373 dellibro di Fuller.
Un’altra rilevante differenza dal caso stazionario, che abbiamo avuto modo dirilevare nel paragrafo precedente, e relativa alla circostanza che, sotto H0 : φ = 1,la distribuzione non e invariante rispetto alla presenza di un termine costante: inquesto caso il modello di riferimento e
yt = µ + φµyt−1 + εt t = 1, 2, . . . , T
e le tavole sopra citate riportano i percentili delle distribuzioni empiriche di T (φµ−1)e della statistica τµ = (φµ − 1)/se(φµ).
Dickey e Fuller (DF) tabulano i valori di τµ nell’ipotesi che il processo generatoredei dati abbia, oltre a φµ = 1, µ = 0. Pertanto, il solo fatto che il modello stimatocontenga un termine costante ha effetto sulla distribuzione di τµ anche quando µ = 0.
75

Tuttavia se il processo generatore ha un termine ha effettivamente µ 6= 0, ed ilmodello stimato include un termine costante, si dimostra che τµ −→d N(0, 1). Taleapparente anomalia si spiega, euristicamente, col fatto che il processo in questionee asintoticamente dominato dal trend deterministico (dovuto all’accumulazione deltermine costante).
Se si rigetta H0 allora yt e un processo stazionario con media che puo anchenon risultare significativa in base al canonico test t (poiche vale la tradizionaleteoria asintotica). Quando invece e accettata l’ipotesi di radice unitaria diventarilevante accertarsi se il drift assume un valore significativamente diverso da zero.Ora, la distribuzione asintotica del t test associato al parametro µ sotto l’ipotesi nulla(φµ = 1), che indichiamo con ταµ, non e normale, sebbene sia ancora simmetrica. Untest bidirezionale dell’ipotesi µ = 0 puo essere basato sulla distribuzione empiricatabulata da Dickey e Fuller (1981). Qualora risulti che µ 6= 0 allora la distribuzionedi τµ tende asintoticamente ad una normale standard, per cui la zona di accettazionesara piu ridotta rispetto alla distribuzione DF. Se invece il test τµ non e significativosi prende come modello generatore ∆yt = εt.
Infine potremmo essere interessati a testare la presenza di una radice unitarianel modello
yt = µ + βt + φτyt−1 + εt t = 1, 2, . . . , T (5.3)
La terza parte della tavola di DF presenta i percentili della distribuzione della sta-tistica test associata a yt−1, ττ , simulata per φτ = 1 e β = 0: in questo caso ladistribuzione di ττ cessa di dipendere da µ, ma dipende da β, e se β 6= 0 torna adessere asintoticamente normale.
Come nel caso precedente, se la presenza di una radice unitaria e accettata, ladistribuzione del test t sui coefficienti µ e β non e standard (ed e tabulata da Dickeye Fuller, cfr. τατ e τβτ ). Allora, tenuto fermo che φ = 1, se risulta significativo iltest τβτ , la statistica ττ associata a yt−1 nel modello di partenza ha distribuzioneasintotica normale e pertanto si fara riferimento alle tavole ordinarie per decidere seaccettare H0 o meno; qualora esso risulti non significativo allora yt ∼ I(1).
Al fine di minimizzare il rischio di inferenze non corrette, rischio dovuto allapresenza di parametri di disturbo che sotto determinate condizioni cambiano le pro-prieta distributive delle statistiche test, viene generalmente suggerita una proceduratop down che parte dalla specificazione piu generale (3) allo scopo di valutare inprimo luogo l’impatto di β e poi quello di µ sulle inferenze circa la presenza di radiciunitarie.
Es. 3. Applichiamo il test di DF alla serie trimestrale relativa al tasso si disoccupazione,Italia 1970Q1-1990Q4.
ln yt = 0.3077 +0.0020t +0.8165 ln yt−1(0.1129) (0.0008) (0.0699)
Si ottiene ττ = (0.8165− 1)/0.0699 = −2.62 e τβτ = 2.411. Pertanto si accetta H0 : φ = 1
76

con β = 0. Si noti infine che τατ = 2.73 e molto prossimo al valore critico al 10%, suggerendoche un RW+drift puo essere un valido punto di partenza.
In sintesi il test di Dickey e Fuller ha la seguente struttura:
Modello H0 H1 Statistica testyt = φyt−1 + εt φ = 1 φ < 1 τyt = µ + φµyt−1 + εt φµ = 1 φµ < 1 τµ
yt = µ + βt + φτyt−1 + εt φτ = 1 φτ < 1 ττ
Si noti che i valori delle statistiche test possono essere derivati immediatamente dallestatistiche t relative ai coefficienti di yt−1 nelle regressioni:3
∆yt = φ∗yt−1 + εt
∆yt = µ + φ∗µyt−1 + εt
∆yt = µ + βt + φ∗τyt−1 + εt
in questa parametrizzazione l’ipotesi nulla implica che il coefficiente di regressionedi yt−1 e pari a zero e cio puo essere testato ricorrendo ai valori tabulati da Dickeye Fuller (si ha ad es. φ∗ = φ− 1).
Es. 4. Per i dati dell’esempio precedente:
∆ln yt = 0.3077 +0.0020t −0.1835 ln yt−1(0.1129) (0.0008) (0.0699)
e pertanto ττ = −0.1835/0.0699 = −2.62.
Per verificare l’ipotesi yt ∼ I(d) per d > 1 si effettua un test DF sulle differenzed-esime; ovviamente l’alternativa e che la serie sia integrata di ordine d− 1.
5.4 Il test ADF
I modelli finora considerati sono eccessivamente semplificati; in particolare si e sup-posto che la v.c. εt sia incorrelata nel tempo e omoschedastica. Ci si e chiesti alloracome modificare le inferenze sulle radici unitarie in presenza di autocorrelazione edeteroschedasticita.
Phillips e Perron (1988) propongono di operare opportune modifiche non para-metriche alle statistiche test considerate precedentemente al fine di non alterare laloro distribuzione asintotica.
La via alternativa proposta da Said e Dickey (1984) si fonda sull’idea di appros-simare un processo lineare mediante un processo autoregressivo di ordine adeguato.
3E’ sufficiente sottrarre yt−1 da ambo i membri.
77

Supponiamo allora che yt ∼ AR(p) e proponiamoci di testare la presenza di unaradice unitaria nel polinomio autoregressivo. Cio puo essere effettuato notando chee sempre possibile riscrivere φ(L) = 1− φ1L− . . .− φpLp come
φ(L) = φ(1)L + ∆φ†(L)
dove φ†(L) = 1− φ†1L− . . .− φ†p−1Lp−1 e il polinomio autoregressivo di ordine p− 1
il cui termine generico e φ†j = −p∑
i=j+1φi.
Se ad esempio prendiamo in considerazione il modello φ(L)yt = εt, la presenzadi una radice unitaria nel polinomio autoregressivo comporta che φ(1) = 0; pertantoe possibile riparametrizzare il modello autoregressivo nella maniera seguente:
∆yt = φ∗yt−1 +p−1∑
j=1φ†j∆yt−j + εt, (5.4)
dove φ∗ = −φ(1) =∑p
j=1 φj−1. La procedura test consiste nel verificare la presenzadi una radice unitaria nella regressione “aumentata” (4) attraverso l’usuale impiegodella statistica t associata con yt−1, la cui distribuzione e asintoticamente indipen-dente dai parametri φ†j e pertanto coincide con quella tabulata da Fuller; il test perla presenza di una radice unitaria prende il nome di Augmented Dickey-Fuller test.
Il problema lasciato aperto dall’ADF riguarda ovviamente la determinazione del-l’ordine p del polinomio autoregressivo, che appare piuttosto arbitraria. Si suggeriscedi partire da un ordine sufficientemente elevato, con riserva di ridurlo se i coefficientidel polinomio autoregressivo φ†(L) non risultino significativi; per questi ultimi valela tradizionale teoria asintotica: le stime MQO sono consistenti, hanno distribu-zione normale e sono efficienti (se l’ordine p e correttamente specificato). Occorrecomunque controllare che i residui della (4) risultino sbiancati.
Es. 5. Per la serie del PIL italiano a prezzi 1985 (1970:q1,1993:q1) e stato stimato ilmodello:
∆ln yt = .8176+0.0004t−0.0689 ln yt−1+0.5250∆ ln yt−1+.1159∆ ln yt−2+−.1805∆ ln yt−3
dal quale risulta che ττ = −2.00 e τβτ = 1.80, portando all’accettazione di H0 con β = 0.
5.5 Trend e RW nelle serie economiche
L’ordine di integrazione di una variabile economica ha rilevanti implicazioni di na-tura interpretativa. La questione e stata originariamente sollevata da Nelson e Plos-ser (1982), i quali esaminano alcune macrovariabili statunitensi alla luce della con-trapposizione di due processi/modelli miranti entrambi ad interpretare l’assenza distazionarieta nelle serie economiche:
78

1. Processi TS (trend-stationary): processi la cui componente evolutiva di lungoperiodo e esprimibile nei termini di una funzione deterministica del tempo e lacui componente di breve periodo e rappresentata da un processo stazionario amedia nulla:
yt = f(t) + ct (5.5)
nel caso di trend lineareyt = α + δt + ct (5.6)
dove ct ha una rappresentazione ARMA(p, q) stazionaria e invertibile. Nellungo periodo il fenomeno ha un’evoluzione deterministica nella cui determi-nazione il presente ed il passato non hanno alcun ruolo, mentre l’informazionerilevante per la previsione e la posizione nel tempo.
2. Processi DS (difference-stationary): processi per i quali le differenze d-esimedella variabile yt ammettono una rappresentazione ARMA stazionaria ed in-vertibile. La controparte del processo TS (6) e dunque:
(1− L)yt = µ + νt (5.7)
α(L)νt = γ(L)εt (5.8)
Al fine di stabilire il collegamento tra le due classi di processi, si supponga chect e νt siano WN e si noti che mediante sostituzione successiva nella (7) si ottiene:
yt = y0 + µt +t−1∑
j=0εt−j.
A questo punto e evidente come entrambi i processi possano essere scritti intermini di una funzione lineare del tempo t; tuttavia emergono due importanti dif-ferenze: in primo luogo il termine costante (intercetta) dipende nel secondo casodalla storia del processo (e il valore iniziale), mentre e un parametro fisso nel pri-mo; in secondo luogo le deviazioni dalla componente lineare sono stazionarie per ilprocesso TS ma non lo sono per quello DS, la cui varianza aumenta indefinitamenteal crescere di t.
Da cio consegue che mentre le previsioni dal modello TS non sono influenzate,nel lungo periodo, dagli shock casuali provenienti da εt, quelle del modello DS con-serveranno l’influenza dei fatti storici intervenuti; inoltre la varianza dell’errore diprevisione cresce senza limiti.
Al fine di discriminare tra i due tipi di processo si noti che entrambi sono sonocasi particolari di
φ(L)yt = µ + βt + εt;
ovvero il processo e DS se∑p
j=1 φj = 1 e β = 0.
79

Adottando quindi la reparametrizzazione del paragrafo precedente, in particola-re:
∆yt = µ + βt + φ∗τyt−1 +p−1∑
j=1φ†j∆yt−j + εt,
si effettua un test ADF dell’ipotesi φ∗τ = 0 e β = 0. Nel caso di accettazionedell’ipotesi nulla si concludera che la serie appartiene alla categoria DS.
Nelson e Plosser applicarono questo test ad insieme di serie economiche statu-nitensi, concludendo che, ad eccezione del tasso di disoccupazione, la totalita delleserie risulta DS.
Es. 6. Per la serie del PNL Statunitense dal 1910 al 1970 risulta:
∆ ln yt = 0.8035 + 0.0056t− 0.1734 ln yt−1 + 0.4250∆ ln yt−1
dal quale ττ = −2.93 e τβτ = 3.01, portando all’accettazione dell’ipotesi nulla H0 : φ∗ = 1,con β = 0.
Questi risultati mettevano in discussione la maniera tradizionale di rappresentarela non stazionarieta, consistente nel pensare la serie nei termini della somma di duecomponenti ortogonali, ciclo e trend, quest’ultimo rappresentato da una funzionedel tempo (una funzione lineare o quadratica, una logistica). La conseguenza piurilevante, dal punto di vista interpretativo, e che viene a cadere la tradizionaledistinzione tra forze che determinano il comportamento del sistema nel breve periodoe forze che determinano le fluttuazioni cicliche: quando infatti il processo generatoree integrato le innovazioni sono persistenti, influendo sulla dinamica di lungo periodo.
Si osservi anche che differenziando un processo TS si ottiene un termine di di-sturbo che e strettamente non invertibile e che pertanto non ammette una rappre-sentazione autoregressiva. Viceversa, l’eliminazione di un trend lineare medianteregressione di yt su una costante e il tempo t, a lungo adottata come una trasfor-mazione preliminare all’analisi econometrica strutturale, da luogo ad un processostazionario se e solo se yt ∈ TS.
Nelson e Kang (1984) hanno approfondito le conseguenze derivanti dal conside-rare un processo DS alla stregua di uno TS: supponiamo che ad un processo yt ∈ DSvenga ugualmente adattato un trend lineare e proponiamoci di considerare cosa av-viene alle tradizionali statistiche di regressione. Allora abbiamo che gli scostamentida un trend lineare sono forniti da
yt − α− βt = (y0 − α)− (µ− β)t +t−1∑
j=0εt−j.
Il termine di errore e allora fortemente autocorrelato (un RW) e le stime degli erroristandard e le statistiche t per la significativita dei parametri sono distorte e portanoad esagerare la significativita dei parametri. Anche il coefficiente di determinazione
80

R2 risultera elevato, ma la bonta dell’adattamento e soltanto illusoria, poiche siha un caso di regressione spuria. Inoltre, e cio assume una rilevanza particolareper l’analisi del ciclo economico, i residui dal trend mostrano periodicita del tuttoartificiali4.
La scomposizione di Beveridge-Nelson Beveridge e Nelson (1981) hanno mo-strato che un processo DS ammette un’unica scomposizione additiva in una com-ponente tendenziale, generata da un processo random walk, e in una componenteciclica, generata da un processo stazionario. Il risultato prende le mosse dalla defini-zione del trend come previsione di lungo periodo della serie; il suo rilievo, attestatodal numero dei lavori che nel corso degli anni 80 e 90 hanno fatto riferimento adesso, deriva dal fatto che il trend e intrinsecamente stocastico, risultando dall’effettocumulato della propagazione di shock. In tal modo BN forniscono la chiave interpre-tativa in senso strutturale di un modello ARIMA(p, 1, q). Per l’estensione a processiI(2) e a processi integrati stagionalmente, si veda Proietti (1995).
Gli autori partono dalla considerazione della rappresentazione di Wold di unprocesso DS, ∆yt = m+C(L)εt = m+wt, dove si e posto wt = C(L)εt. La previsionel periodi in avanti, yt+l|t = E[yt+l|Yt], e fornita dall’equazione alle differenze delprimo ordine: yt+l|t = yt+l−1|t + m + wt+l|t, la cui soluzione generale e
yt+l|t = yt + lm +l
∑
i=1wt+i|t.
Beveridge e Nelson procedono dunque alla definizione della componente perma-nente o trend, µt, con approccio predittivo, come il valore che yt assumerebbe se sigiacesse sul sentiero di lungo periodo, o, in maniera equivalente, come il valore cor-rente della serie piu “all forecastable future changes in the series beyond the meanrate of drift” (Beveridge and Nelson, 1981, p. 156). Pertanto,
µt = liml→∞
[yt+l|t − lm] = yt + Ut,
con
Ut = liml→∞
[ l∑
i=1wt+i|t
]
=∞∑
i=1
∞∑
j=0Ci+jεt−j =
∞∑
j=0
∞∑
k=j+1
Ck
εt−j = −C∗(L)εt (5.9)
dove C∗(L) = [C(L) − C(1)]/∆ =∞∑
j=0C∗
j Lj, C(1) =
∞∑
j=0Cj, e C∗
j = −∞∑
k=j+1Ck,
j = 0, 1, . . ..4I due autori conducono un’analisi di simulazione dalla quale emerge che la funzione di autocor-
relazione dei residui oscilla con un periodo pari approssimativamente a 2T/3 e pertanto i residuimostreranno un ciclo lungo interamente spurio.
81

In conclusione, il trend e generato da un RW con drift costante, m, e varianzadelle innovazioni (detta anche “size of the RW”) C(1)2σ2: ∆µt = m + C(1)εt. Lacomponente transitoria e definita in maniera residuale come ψt = yt − µt = −Ut.
5.6 Persistenza
Si e gia accennato al fatto che le innovazioni casuali hanno effetti persistenti sui pro-cessi DS; riprendiamo dunque la rappresentazione di Wold di un processo integratodel primo ordine:
∆yt = m + C(L)εt,
dove C(L) =∞∑
j=1CjLj, con C0 = 1 e
∑
C2j < ∞. Il coefficiente Ck associato alla
potenza k-esima dell’operatore ritardo misura l’effetto su ∆yt di uno shock unitariorealizzatosi k periodi precedenti. L’effetto cumulato su yt dopo k periodi di tempoe invece 1 + C1 + · · ·+ Ck; facendo dunque tendere k all’infinito si ha che l’impattodi uno shock unitario nel lungo periodo e pari alla somma dei coefficienti dellarappresentazione MA, vale a dire C(1).
In maniera equivalente
C(1) = limk→∞
∂E(yt+k|It)∂εt
,
dove It denota l’informazione accumulata fino al tempo t, si interpreta come larevisione nella previsione di lungo periodo della serie dovuta ad uno shock unitariooccorso al tempo t. Cio ha portato Campbell e Mankiw (1987) a suggerire l’adozionedi C(1) come misura di persistenza. La stima parametrica si ottiene a partire dallarappresentazione MA(∞) di un processo ARMA adattato alle differenze prime dellaserie analizzata.
Cochrane (1986) ha invece proposto una misura di persistenza non parametricadenominata rapporto di varianze normalizzato poiche si fonda sulla statistica
Vk =1k
Var(yt − yt−k)Var(yt − yt−1)
, k = 1, 2, . . . .
Facendo uso dell’identita ∆k = 1−Lk = ∆Sk(L), dove Sk(L) = 1+L+· · ·+Lk−1,possiamo riscrivere il numeratore come segue:
Var(yt − yt−k) = Var(k−1∑
j=0∆yt−j)
=k−1∑
j=0Var(∆yt) + 2
k−1∑
i=0
k−1∑
j=i+1Cov(∆yt−i, ∆yt−j)
= kγ0 + 2k−1∑
j=1(k − j)γj;
82

Pertanto,
Vk = 1 + 2k−1∑
j=1
(
k − jk
)
ρj,
e per k tendente ad infinito si ottiene:
V = limk→∞ Vk
= 1 + 2∞∑
j=1ρj
= 2πf(0)γ0
;
il che mostra che tra V e la densita spettrale a frequenza ω = 0 esiste una relazionedi diretta proporzionalita.
Se il processo generatore dei dati e un RW, ρτ = 0, τ > 0 implica Vk = 1; inmaniera equivalente si ha Var(yt−yt−k) = kσ2 e Var(yt−yt−1) = σ2. D’altra parte, seil processo e TS, Var(yt− yt−k) non cresce linearmente (tende piuttosto a 2Var(yt)),cosicche Vk tende a zero. Questi due casi possono essere assunti a riferimento pergiudicare se un processo sia piu o meno persistente. In particolare, si parlera diun processo altemente persistente qualora per esso Vk risulti tendere ad un valoresuperiore all’unita; al contrario il processo sara giudicato a bassa persistenza se Vk
si attesta su un valore inferiore all’unita.La stima del rapporto di Cochrane a partire da una serie storica puo avvenire
sostituendo le autocorrelazioni stimate a quelle teoriche, cosı da ottenere:
Vk = 1 + 2k−1∑
j=1
(
k − jk
)
ρj.
Si noti che Vk corrisponde alla stima della densita spettrale a frequenza zero utiliz-zando la finestra di Bartlett.
Le due misure di persistenza sono legate dalla relazione:
C(1) =
√
V γ0
σ2
il che parrebbe suggerire una certa sostituibilita tra di esse. In realta esse risultanodifficilmente conciliabili, poiche i modelli ARIMA stimati in base al criterio della par-simonia tendono ad enfatizzare il ruolo delle componenti ad alta frequenza, alle spe-se delle correlazioni di lungo periodo, le quali sono indicative di un comportamentomean reverting.
5.7 Integrazione stagionale
Finora abbiamo considerato la non-stazionarieta legata alla presenza del trend, valea dire della componente di lungo periodo. E’ noto tuttavia che altre componenti
83

oscillatorie di periodo piu breve possono indurre non-stazionarieta: la presenza diuna componente stagionale rappresenta il caso piu frequente nelle serie storicheeconomiche. Consideriamo a titolo di esempio il processo
(1 + L)yt = εt, t = 1, . . . , T
che supponiamo valido per dati semestrali. E’ immediato verificare che yt non estazionario in quanto E(yt) = (−1)ty0 e la varianza cresce linearmente al cresceredi t; ed infatti rileviamo che il polinomio autoregressivo possiede la radice -1. Inquesto caso il processo oscilla con periodo pari all’anno e l’ampiezza delle oscillazionie determinata dalle realizzazioni della v.c. εt.
Al fine di effettuare una trattazione adeguata di questa tipologia di processistocastici si rende necessaria un’estensione del concetto di integrazione (cfr. Engleet al., 1989):
Def. Ordine di integrazione Sia yt un processo lineare indeterministico; allora sidira che yt e un processo integrato di ordine d a frequenza λ, e si scrivera yt ∼ Iλ(d),se lo (pseudo-)spettro di potenza, f(ω), assume la forma:
f(ω) ∝ (ω − λ)−2d,
in un intorno di λ.
Secondo questa definizione il random walk e un processo integrato del primoordine alla frequenza λ = 0, mentre il processo (1 + L)yt = εt e integrato del primoordine a frequenza π. Infatti, considerando lo sviluppo della funzione coseno in seriedi Taylor del secondo ordine si ha
cos ω = cos λ− (ω − λ) sin λ− (ω − λ)2
2+ o[(ω − λ)2],
dove o(.) denota un infinitesimo di ordine inferiore all’argomento. Poiche lo spettrodi un RW e [4π(1 − cos ω)]−1σ2, si ottiene f(0) ∝ (ω − λ)−2. Allo stesso modo siverifica che lo spettro del processo yt = (1 + L)−1εt a frequenza π e proporzionale a(ω − λ)−2.
Consideriamo ora un processo che e osservato s volte l’anno, con s pari (tipi-camente s = 4 per dati trimestrali e 12 per dati mensili); tale processo e dettostagionale se possiede uno spettro caratterizzato dalla concentrazione di potenzaattorno alle frequenze stagionali λj = 2πj/s, j = 1, . . . , s/2.
Esistono diversi modi in cui puo scaturire il comportamento stagionale; si sup-porra che siano tutti casi particolari del seguente processo generatore:
ψ(L)yt = µt + εt, t = 1, . . . , T, (5.10)
84

dove ψ(L) e un polinomio in L di grado p e εt ∼ WN(0, σ2); la stagionalitadeterministica e ascrivibile alla componente
µt =s
∑
j=1µjSjt + βt
dove le Sjt sono dummies stagionali che assumono valore 1 nella stagione j e zeroaltrove; µj sono le medie stagionali.
Il processo yt e stazionario se le radici di ψ(L) giacciono tutte al di fuori delcerchio di raggio unitario ed e stagionale se il polinomio possiede radici complesseconiugate a frequenze stagionali; ad esempio il processo generato da yt = ψyt−4 + εt
con |ψ| < 1 ha uno spettro che assume il massimo (2π)−1σ2ε/(1− ψ)2 alle frequenze
0, π/2 e π in corrispondenza delle radici ψ−1/4, ±iψ−1/4 e −ψ−1/4 rispettivamente.Se ψ → 1 lo spettro e infinito alle stesse frequenze.
Quando le radici del polinomio autoregressivo giacciono sul cerchio unitario, epossibile adottare la fattorizzazione:
ϕ(L)φ(L)yt = µt + εt (5.11)
dove ϕ(L) e un polinomio AR le cui radici sono unitarie in modulo e φ(L) e unpolinomio AR stazionario di ordine q. yt e dunque un processo stagionale integratose il suo spettro e illimitato alle frequenze stagionali λj = 2πj/s. I casi piu rilevantisono elencati di seguito: (i) ϕ(L) = S(L) = 1 + L + · · · + Ls−1, l’operatore disomma stagionale; (ii) ϕ(L) = ∆s = 1 − Ls, l’operatore differenza stagionale; (iii)ϕ(L) = ∆∆s = (1− L)(1− Ls).
Consideriamo il processo (10) nel caso (i) con s = 4 (dati trimestrali): l’operatoredi somma stagionale puo essere fattorizzato come S(L) = (1 + L)(1 + iL)(1 − iL),da cui si evince che le radici di S(L) sono ±i e -1; in corrispondenza lo spettro dipotenza e illimitato alla frequenza fondamentale π/2 e all’armonica π. Pertanto, duecicli si combinano in maniera moltiplicativa e sono responsabili del comportamentostagionale: il primo ha un periodo pari all’anno, mentre il secondo ha un periodopari a due trimestri 5.
Le proprieta dinamiche di un processo stagionale integrato differiscono notevol-mente da quello di uno stazionario: in primo luogo gli shocks sono persistenti ehanno un impatto permanente sul pattern stagionale; inoltre, la varianza cresceman mano che ci allontaniamo dal tempo iniziale.
L’operatore differenza stagionale ∆4 = ∆S(L) ha quattro radici unitarie: 1, -1 ela coppia ±i; pertanto e anche integrato di ordine 1 a frequenza 0. Infine, nel casoϕ(L) = ∆∆4 = ∆2S(L) il processo e I0(2), Iπ/2(1) e Iπ(1).
5In generale S(L) ha (s − 2)/2 coppie di radici complesse coniugate alle frequenze λj =2πj/s, j = 1, . . . , s/2 e la radice -1 2π/s.
85

Per tutti questi casi abbiamo bisogno di una notazione piu compatta: a tal pro-posito introduciamo la seguente definizione, anch’essa dovuta a Engle et al. (1989):
Def. Integrazione stagionale yt e integrato stagionalmente di ordine d0 e ds, e sidenota yt ∼ SI(d0, ds), se ∆d0S(L)dsyt e stazionario e invertibile.
Secondo questa definizione il processo ∆∆syt = µ + θ(L)εt e SI(2, 1) se θ(L) eun polinomio invertibile.
5.8 Test di integrazione stagionale
Il problema del’integrazione stagionale e sorto con qualche ritardo rispetto a quel-lo dell’integrazione a frequenza zero, cio essendo legato alla disponibilita di datidestagionalizzati. Tuttavia e stato recentemente provato che l’utilizzo di dati de-stagionalizzati, in relazione alla natura del filtro di aggiustamento, puo modificarele inferenze sulle radici unitarie a frequenza zero nel senso di dare piu supportoall’ipotesi nulla di integrazione.
Nella tradizione del test DF, Dickey, Hasza e Fuller (DHF) (1984) hanno sugge-rito un test basato sulla regressione
(1− Ls)yt = πsyt−s + εt, s = 2, 4, 12
La statistica test per H0 : πs = 0 e la statistica t associata al parametro πs. DHFforniscono i percentili della distribuzione corrispondente, che possono essere utilizza-ti per testare H0 contro l’alternativa πs < 0 (che implica che il processo consideratoe generato da un processo stagionale autoregressivo stazionario del primo ordine.Valori ritardati di ∆syt possono essere aggiunti al lato destro dell’equazione al finedi sbiancare i residui senza alterare la distribuzione asintotica del test. Come nelcaso del test DF puo essere presa in considerazione la presenza di componenti deter-ministiche quali un intercetta, un trend lineare, e dummy stagionali: ovviamente ladistribuzione non e invariante rispetto alla componente di volta in volta considerata.
Il test DHF non soddisfa appieno in quanto costituisce un test congiunto operatosu tutte le frequenze sia stagionali che non (H0 : yt ∼ SI(1, 1) contro H1 : yt ∼SI(0, 0)). Il test proposto per dati trimestrali6 da Hylleberg, Engle, Granger and Yoo(test HEGY) consente invece di esaminare l’integrazione a ciascuna delle frequenzestagionali e a frequenza zero.
Gli autori suppongono che i dati siano generati da un processo autoregressivo diordine finito ψ(L)yt = µt+εt. Poniamoci dunque il problema di testare l’ipotesi yt ∼
6Per l’estensione a dati mensili si veda Beaulieu e Miron (1993).
86

SI(1, 1); ricordando che l’operatore differenza stagionale ammette la fattorizzazione∆4 = (1−L)(1 + L)(1 + iL)(1− iL), si dimostra che, espandendo il polinomio ψ(L)attorno alle radici unitarie 1, -1 e ±i si puo riscrivere:
φ(L)∆4yt = π1Z1,t−1 + π2Z2,t−1 + π3Z3,t−2 + π4Z3,t−1 + µt + εt, (5.12)
dove Z1t = S(L)yt, Z2t = −(1− L + L2 − L3)yt e Z3t = −(1− L2)yt.La trasformazione che genera Z1t rimuove le radici unitarie stagionali; quella che
genera Z2t rimuove quelle a frequenza zero e π/2, lasciando un processo integratosotto H0 soltanto a frequenza π; infine Z3t e un processo integrato a π/2.
L’utilita della rappresentazione (11) e legata alla relazione tra le radici unitariedi ψ(L) e i parametri πi (i = 1, 2, 3, 4): in particolare ψ(1) = 0 implica π1 =0 cosicche la presenza di una radice unitaria a frequenza zero puo essere testatacontro π1 < 0 (corrispondente alla alternativa stazionaria ψ(1) > 0); analogamenteψ(−1) = 0 (una radice unitaria a frequenza π) implica π2 = 0, mentre l’alternativadi stazionarieta ψ(−1) > 0 implica π2 < 0. Infine, l’ipotesi che la serie sia Iπ/2(1)comporta che entrambi π3 e π4 siano nulli.
L’equazione (11) puo essere stimata mediante i minimi quadrati e le statistichet associate ai parametri πi (i = 1, 2, 3, 4) possono essere impiegate per testare lapresenza di radici unitarie alle frequenze corrispondenti. Dal momento che H0 :(π3 = 0)∩(π4 = 0) e bidimensionale, HEGY suggeriscono di utilizzare una statisticaF per un test congiunto sulla significativita dei due parametri. Alternativamente sipuo prima condurre un test t bidirezionale dell’ipotesi π4 = 0 e, qualora non risultisignificativo, testare π3 = 0 contro l’alternativa π3 < 0.
HEGY hanno tabulato la distribuzione dei test t unidirezionali sui parametriπ1, π2 and π3, per il test t bidirezionale su π4 e per il test F dell’ipotesi (π3 =0)∩ (π4 = 0). La distribuzione cambia a seconda del nucleo deterministico presentenel modello di regressione: i. µt = 0, ii. µt = µ, iii. µt =
∑sj=1 µjSjt, iv. µt = µ+βt,
v. µt =∑s
j=1 µjSjt + βt (si vedano le tavole 1a e 1b a pag. 227). Si noti che ladistribuzione ′t′ : π1 e piu ”sensibile” alla presenza dei termini di trend ed intercettapiuttosto che alla presenza di dummy stagionali; per le altre statistiche test valel’opposto.
Quando un processo e integrato stagionalmente e possibile misurare la persi-stenza delle innovazioni sul pattern stagionale mediante opportune estensioni delrapporto di varianze normalizzato di Cochrane, come mostrato in Proietti (1996).
5.9 Critiche all’applicazione dei test per radici uni-tarie
E’ noto che l’accettazione dell’ipotesi nulla non esclude che l’alternativa sia vera.Nel caso in questione la potenza dei test per la presenza di radici unitarie (1 −
87

P (H0|H1)) e estremamente bassa riflettendo la circostanza che in campioni finiti edifficile discriminare un processo con una radice unitaria da uno con radice 1−δ, δ >0 qualsiasi.
Le realizzazioni possono essere virtualmente identiche per dimensioni campiona-rie non elevatissime e pertanto sia i metodi basati sui momenti che sulla funzione diverosimiglianza non riescono a discernere le due situazioni. Cochrane (1991) portaalle estreme conseguenze questo punto mostrando che per ogni processo DS esiste uncorrispondente processo stazionario le cui inferenze parametriche (e quindi anche itest per le radici unitarie) sono arbitrariamente vicine a quelle condotte sul processoDS.
Perron mostra che cambiamenti di regime e la presenza di punti di rottura nellaserie (break e shift strutturali) possono comportare l’accettazione dell’ipotesi DSquando il meccanismo generatore sia TS e riformula la distribuzione delle statistichetest per tener conto della possibilita che la non stazionarieta sia da attribuire allapresenza di suddetti shocks. In altre parole e possibile che una serie sia stazionariaattorno ad un trend “segmentato”, rappresentabile da una spezzata che incorpori levariazioni del livello ed i cambiamenti del tasso di crescita, mentre non lo sia rispettoad un trend lineare.
Schwert (1989) e Pantula (1991) contestano l’idea che governa l’ADF consistentenell’approssimare il processo generatore con un AR di ordine finito e citano l’evi-denza delle principali serie macroeconomiche studiate che sarebbero bene adattateda un modello IMA(1,1). Se il parametro MA e vicino all’unita, allora una rap-presentazione autoregressiva finita non e adeguata e i due autori dimostrano chel’impiego dei valori critici tabulati da Dickey e Fuller porta erroneamente a rigettarela presenza di una radice unitaria. In effetti si realizza una quasi-cancellazione deglioperatori AR e MA, che lascia un processo virtualmente non distinguibile dal WN.
5.10 Le implicazioni econometriche
Supponiamo che yt e xt siano entrambe I(1) e che esista una relazione causaleunidirezionale x → y; ci proponiamo allora di stimare una relazione econometrica tral’endogena y e l’esogena x. L’ordine di integrazione delle variabili non e indifferentee concorre a determinare diversi modi di formalizzare la relazione tra le due variabilidal punto di vista econometrico.
Partiamo dalla seguente rappresentazione (ADL(r, s) Autoregressive DistributedLag):
α(L)zt = µ + β(L)vt + ξt
dove α(L) = 1 − α1L − . . . − αrLr e β(L) = β0 + β1L + . . . + βsLs; quest’ultimaincorpora un ampio spettro di modelli dinamici (modelli a ritardi distribuiti, modelliautoregressivi, modelli con funzione di trasferimento) a seconda della specificazione
88

dei polinomi α(L) e β(L), delle assunzioni sul termine di errore e delle trasformazioniadottate su yt e xt per ottenere rispettivamente zt e vt. Il modello ADL e stabile sele radici del polinomio α(L) giacciono tutte al di fuori del cerchio di raggio unitario;tale proprieta e importante per l’esistenza di una soluzione di lungo periodo.
Nel seguito non ci proponiamo di effettuare una rassegna delle numerose spe-cificazioni esistenti nella letteratura econometrica; ci limiteremo ad esporre alcunipunti fondamentali per l’analisi successiva.
5.10.1 Modello nei livelli
In questo caso si ha zt = yt e vt = xt. Consideriamo per semplicita il caso diregressione statica:
yt = µ + βxt + εt, εt ∼ WN(0, σ2),
in cui si ipotizza una dipendenza istantanea tra le due variabili; la presenza diintegrazione puo dar luogo al fenomeno che prende il nome di regressione spuria:se yt e xt sono generate da due random walk indipendenti la stima dei MQO di βpuo risultare significativamente diversa da zero; inoltre si otterra un coefficiente dideterminazione R2 alto in presenza di un DW estremamente basso e prossimo a zero.
Pertanto nella stima di relazioni in livelli tra processi integrati si va incontro alrischio che il “buon adattamento” del modello ai dati sia del tutto illusoria. Nevale il ricorso agli usuali test statistici in quanto la correlazione seriale esistente neiresidui implica che i livelli di significativita dei test t ed F non risultino piu corretti.Il fenomeno ha trovato una spiegazione formale in campo asintotico grazie a Phillips(1985), il quale ha dimostrato che per T →∞ il test DW tende a zero, R2 all’unitae che le usuali statistiche test divergono, con la conseguenza che la probabilita dirifiutare H0 : β = 0 cresce al crescere di T .
Questo risultato e piuttosto sconfortante dal punto di vista della teoria econo-mica, la quale formula delle relazioni tra variabili in livello. Tuttavia non tutto eperduto, come vedremo successivamente.
5.10.2 Modello nelle differenze
Considerati i problemi posti dalla regressione statica in livelli si potrebbe pensare diformulare una relazione econometrica tra le variazioni delle variabili; la differenzia-zione dei dati e una delle trasformazioni che viene solitamente suggerita per aggirareil problema:
∆yt = µ + β∆xt + εt
Si noti che se le due variabili sono generati da RW indipendenti, la differenzia-zione consente di eliminare il problema di regressione spuria, poiche per il test t
89

dell’ipotesi β = 0 vale la tradizionale teoria distributiva. Tuttavia, anche questoapproccio non va esente da critiche: innanzitutto non contiene alcuna relazione suilivelli, per cui, se esiste una relazione di equilibrio di lungo periodo y = cx, essa nonpuo essere incorporata nel modello: infatti quando il sistema raggiunge lo stato diequilibrio stazionario, yt = ye e xt = xe, entrambe le differenze prime sono nulle.
E’ inoltre possibile che la differenziazione dia luogo ad un termine di errorestrettamente non invertibile, da cui consegue che per approssimare la dinamica delsistema e necessario un polinomio autoregressivo di ordine molto elevato, cosa chepotrebbe violare il principio di parsimonia.
5.10.3 Regressione tra serie detrendizzate
La nonstazionarieta puo essere incorporata nel modello introducendo un trend li-neare tra i regressori:
yt = α + γt + βxt + εt.
Tale procedura ha qualche probabilita di successo solo se le variabili sono pro-cessi TS; un importante risultato, noto come teorema di Frisch e Waugh, ha infattistabilito che inserire un trend lineare equivale ad effettuare una regressione staticatra serie detrendizzate mediante l’eliminazione di un trend lineare. Pertanto se levariabili sono generate da RW indipendenti si incorre in una regressione spuria poi-che la detrendizzazione ha effetto solo sul nucleo deterministico, lasciando inalteratoquello stocastico.
Un possibile rimedio alla regressione spuria puo consistere nell’inclusione di valoriritardati delle variabili esplicative e della dipendente; nel caso dei RW indipendenti,ad esempio, aggiungendo tra i regressori il valore ritardato di entrambe le variabili,
yt = µ + αyt−1 + β0xt + β1xt−1 + εt,
esiste la combinazione con α = 1, β0 = β1 = 0, tale che εt ∼ I(0). Si puo dimostrareche le stime MQO sono consistenti per tutti i parametri e che i test t delle ipotesi β0 =0 e β1 = 0 hanno distribuzione asintotica normale. Il test F dell’ipotesi congiunta,al pari del test t dell’ipotesi α = 1, ha tuttavia distribuzione limite nonstandard.Tuttavia, almeno in parte la teoria asintotica gaussiana viene recuperata.
Possiamo concludere dunque che nel generico modello ADL, se non esiste almenoun punto nello spazio dei parametri tale che εt e stazionario, la stima MQO puo darluogo a risultati spuri nel senso sopra precisato.
90

5.11 Modelli con meccanismo a correzione dell’er-rore
Il modello ADL(r, s) in livelli
α(L)yt = µ + β(L)xt + εt
con α(L) = 1− α1L− . . .− αrLr, β(L) = β0 + β1L + . . . + βsLs e εt ∼ WN(0, σ2),puo essere riparametrizzato nella forma “a correzione dell’errore”, il cui significatoemergera tra non molto.
Mediante la stessa tecnica adottata precedentemente riscriviamo α(L) = α(1)L+∆α†(L), β(L) = β(1)L+∆β†(L), dove α†(L) e β†(L), sono polinomi di ordine r− 1e s− 1 rispettivamente (di primo termine 1 e β0).
Sostituendo e riordinando i termini otteniamo:
α†(L)∆yt = µ− α(1)(yt−1 − cxt−1) + β†(L)∆xt + εt, (5.13)
ovvero:α†(L)∆yt = −α(1)(yt−1 −m− cxt−1) + β†(L)∆xt + εt,
dove m = µ/α(1) e c = β(1)/α(1) e il moltiplicatore totale che puo essere valida-mente interpretato come il coefficiente di risposta di lungo periodo della relazione diequilibrio (statico) tra y e x; se le variabili sono espresse in logaritmi c rappresental’elasticita di lungo periodo di y rispetto a x. In equilibrio yt = ye e xt = xe: sosti-tuendo si ottiene la relazione di equilibrio y = cx; e evidente che yt−1− cxt−1 misural’entita del disequilibrio realizzatosi nel periodo precedente; il primo termine a se-condo membro si configura pertanto come un “meccanismo di correzione dell’errore”(MCE).
La parametrizzazione con MCE presenta alcuni pregi: il primo, di natura inter-pretativa, consiste nel combinare opportunamente la dinamica di breve periodo concon le proprieta di equilibrio di lungo periodo suggerite dalla teoria economica. Levariazioni di y dipendono non soltanto dalle variazioni di x ma anche dall’entita deldisequilibrio al tempo precedente. A titolo esemplificativo consideriamo un modelloADL(1, 1), che ammette la parametrizzazione MCE:
∆yt = µ + (α1 − 1)(yt−1 − cxt−1) + β0∆xt + εt,
con c = (β0 +β1)/(1−α1); se il modello e stabile (|α1| < 1) allora il secondo termineal secondo membro gioca un rilevante ruolo stabilizzatore: qualora nel periodo pre-cedente y si fosse rivelata superiore (inferiore) al suo livello di equilibrio statico cx,il tasso di crescita di y risulterebbe diminuito (aumentato), contribuendo a riportarela y verso il sentiero di equilibrio.
91

Es. 7: L’evidenza empirica suggerisce che nel lungo periodo l’elasticita del consumo totaleCt rispetto al reddito Yt e costante. Tuttavia la funzione keynesiana del consumo aggregatopostula che l’elasticita sia decrescente; in realta la teoria economica e in contraddizione conl’evidenza empirica solo apparentemente se si considera che la funzione keynesiana e valevolenel breve periodo.
La rappresentazione MCE consente di conciliare la relazione di lungo periodo C = kY ν ,dove ν rappresenta l’elasticita di lungo periodo, supposta costante, con la dinamica di breveperiodo (nella parametrizzazione con MCE derivata dall’ADL(1, 1) si avrebbe β0 < 1).
Un altro rilevante vantaggio di natura piu strettamente econometrica sta nelfatto che le variabili originarie yt, yt−1, . . . , yt−r, xt, xt−1, . . . , xt−s costituiscono uninsieme fortemente collineare, mentre la forma con MCE realizza un notevole ridi-mensionamento della multicollinearita. Se εt ∼ WN(0, σ2) allora, supposto noto c,i coefficienti possono essere stimati in maniera consistente ed efficiente mediante iMQO.
5.12 Cointegrazione
Generalmente, combinazioni lineari di variabili integrate di ordine d risultano in-tegrate dello stesso ordine; esistono casi, che sono poi quelli veramente rilevantidal punto di vista della teoria econometrica, in cui particolari combinazioni linearipresentano un ordine di integrazione inferiore a quello delle serie di partenza.
Torniamo al caso piu semplice, in cui le variabili sono I(1): puo esistere unacombinazione lineare che sia stazionaria e diremo che le variabili sono cointegrateperche i movimenti di lungo periodo presenti in ciascuna si eliminano. Cio vieneattribuito al fatto che esiste una relazione di equilibrio statico tra di esse e che la lorodinamica non puo discostarsi troppo (esiste in altre parole una tendenza comune).
Def. Cointegrazione: I processi yt e xt sono detti cointegrati di ordine d e b,0 < b ≤ d, e scriveremo ut = [yt xt]′ ∼ CI(d, b), se:
• entrambi i processi sono I(d);
• ∃ λ = [λ1 λ2]′ tale che λ′ut ∼ I(d− b).
La definizione precedente esclude la possibilita di cointegrazione tra processi chemostrano diversi ordini di integrazione; questo non ci meraviglia perche ad es. unprocesso I(1) ed uno I(0) hanno proprieta temporali notevolmente difformi atte adescludere la possibilita di un andamento solidale. Pertanto la verifica statistica dellacointegrazione e sempre preceduta dall’analisi dell’integrazione delle serie componen-ti il sistema. λ prende il nome di vettore di cointegrazione ed e definito unicamentea meno di una normalizzazione (in genere si prendera [1 − c], c = −λ2/λ1)
92

La cointegrazione e un occorrenza piu eccezionale che abituale nelle serie storichereali; la sua presenza implica ed e implicata dall’esistenza di un trend comune: siawt ∼ I(1), εxt e εyt due processi I(0) e si supponga che i dati siano generati dalmeccanismo seguente: xt = wt + εxt e yt = cwt + εyt ; pertanto yt− cxt = εyt − cεxt ∼I(0).
Riconoscere l’esistenza di cointegrazione ha importanti conseguenze sotto il pro-filo della modellistica, come emerge da un fondamentale risultato noto come teoremadi rappresentazione di Granger (Engle e Granger 1987), il quale afferma, tra l’altro,che se due serie sono cointegrate esse ammettono sempre una rappresentazione conMCE:
∆yt = µ1 + ρ1zt−1 +∑
k
α1k∆yt−k +∑
k
β1k∆xt−k + d(L)ε1t
∆xt = µ2 + ρ2zt−1 +∑
k
α2k∆yt−k +∑
k
β2k∆xt−k + d(L)ε2t
dove zt−1 = yt−1−cxt−1 (si noti che nella combinazione lineare stazionaria puo esserepresente un termine costante se la relazione di equilibrio non e di stretta propor-zionalita: y = m + cx; in questo caso si ha zt−1 = yt−1 −m − cxt−1; ovviamente itermini costanti µ1 e µ2 scompaiono in quanto incorporati nella relazione di equili-brio) e |ρ1|+ |ρ2| 6= 0; l’ultima condizione assicura che il termine con MCE compaiain almeno una delle due relazioni.
La precedente proposizione puo essere rovesciata nel senso che se ut ammetteuna rappresentazione con MCE, le variabili sono cointegrate. Si noti che poiche(yt, xt) ∼ I(1) e (ε1t, ε2t) ∼ I(0) tutti i termini della rappresentazione sono stazionarie per i relativi coefficienti vale la tradizionale teoria asintotica.
Nel paragrafo precedente abbiamo supposto che il vettore di cointegrazione fos-se noto (molto spesso viene assunto c = 1, vale a dire che vi sia omogeneita trale due variabili). In realta, il fondamentale problema statistico-econometrico po-sto dalla teoria della cointegrazione e duplice: si tratta di verificare l’esistenza dicointegrazione tra le variabili e di stimare il vettore di cointegrazione. I due puntisono strettamente collegati, per cui partiamo dal secondo; nel seguito ci limiteremoa descrivere la procedura suggerita da Engle e Granger (1987), che si articola in duestadi:
1. Stima del vettore di cointegrazione attraverso regressione statica e verificadell’ipotesi di cointegrazione
2. Stima dei parametri della forma con MCE assumendo zt nonstocastico.
La procedura descritta e improntata alla massima semplicita: entrambi gli stadirichiedono l’impiego dei MQO.
L’idea fondamentale e quella di ottenere la stima del vettore di cointegrazioneregredendo la variabile il cui coefficiente e normalizzato all’unita sulle rimanenti; nel
93

caso bivariato:yt = m + cxt + εt (5.14)
per verificare l’ipotesi di cointegrazione si controlla che i residui ottenuti siano I(0).Come e possibile che un processo generatore estremamente semplice, quale la
regressione statica di yt su una costante e xt fornisca informazioni tanto importantisul comportamento di lungo periodo del sistema considerato? La risposta sta nelleproprieta della regressione statica tra variabili cointegrate: e stato infatti dimostra-to (Stock, 1987) che la stima del vettore di cointegrazione e (super)consistente e,pur essendo distorta, la distorsione tende a scomparire, al crescere del periodo cam-pionario, piu rapidamente del caso di regressione tra variabili stazionarie, essendodi ordine T−1. Un’altra interessante proprieta consiste nella possibilita di ignorareil problema della presenza di non contemporaneita tra x e y, per cui non c’e bi-sogno di introdurre nella (13) valori ritardati della variabile dipendente e/o dellaindipendente.
Questi risultati paiono confortanti; eppure vanno interpretati con qualche circo-spezione in quanto hanno valenza asintotica; per le realizzazioni finite comunementedisponibili fare affidamento su di essi puo anche essere fuorviante: e stato mostrato,mediante simulazione, che in campioni finiti la distorsione nella stima del vettore dicointegrazione puo permanere elevata anche per valori grandi di T e che declina adritmo meno elevato di quello teorico. La distorsione deriva dall’omissione delle varia-bili esprimenti la dinamica di breve periodo, il cui peso, trascurabile asintoticamente,puo essere rilevantissimo in campioni finiti.
Si consideri poi che le inferenze su c non sono quelle usuali poiche, seppure lastima dei parametri della (13) sia consistente, lo stesso non vale per la stima dell’er-rore standard, precludendo la possibilita di verificare ipotesi di interesse economicosui coefficienti della regressione statica 7.
La verifica dell’ipotesi di cointegrazione si effettua contestualmente alla stimadella (13). Per la precisione l’ipotesi sottoposta a verifica e che yt e xt non sianocointegrate, nel qual caso una radice unitaria e presente nei residui della regressione(13), e per testarla Engle e Granger propongono una batteria di test: il primo e il cd.CRDW (Cointegrating Regression Durbin-Watson), rappresentato dal DW calcolatosui residui et della regressione statica; sotto l’ipotesi nulla εt ∼ I(1) la statistica DWe pari a 0, per cui il test e significativo se CRDW risulta significativamente maggioredi zero. I valori critici non sono quelli tabulati da Durbin e Watson, ma sono fornitida Sargan e Bhargava (1983).
7Va considerato poi che, nel caso bivariato, esistono due vettori di cointegrazione, il primo [1 c]′
ottenuto dalla (13), il secondo [c 1] ottenuto dalla regressione “inversa” xt = m + cyt. In campionifiniti c 6= 1/c; tuttavia se esiste cointegrazione si avra che R2 −→ 1 e, tenuto conto della relazioneR2 = cc, si ha anche c −→ 1/c.
94

Un secondo gruppo di test fa capo alle statistiche DF e ADF per testare lapresenza di radici unitarie: se l’ipotesi nulla viene rifiutata si puo concludere che yt
e xt sono cointegrate.A questo scopo si considera la statistica t per φ∗ = 0 nella regressione:
∆et = φ∗et−1 + ut
ovvero, per tener conto dell’autocorrelazione dei residui si considera
∆et = φ∗et−1 +∑
jγj∆et−j + ut.
In entrambe e assente l’intercetta poiche se essa e presente nella regressione di coin-tegrazione i residui hanno media nulla e l’inclusione di un termine costante ha effettitrascurabili sulle statistiche test.
Purtroppo la distribuzione delle statistiche test non e quella tabulata da Dickeye Fuller e faremo riferimento ad essa come distribuzione EG: ad es. per T = 100 ilvalore critico unidirezionale al livello di significativita del 5% sarebbe pari a −2.89per la distribuzione DF e −3.17 per la distribuzione EG.
In effetti se il vettore di cointegrazione fosse noto a priori non sorgerebberodifficolta di sorta, poiche i test di radice unitaria su zt seguirebbero la distribuzionedi DF. Il problema e invece posto dal fatto che il vettore di cointegrazione e stimatoa partire dai dati: i MQO, minimizzando la varianza dei residui, agiranno in mododa far apparire i residui stazionari anche quando non lo sono e il test DF indurra alrifiuto di H0 troppo spesso.
Ovviamente anche per il test EG si ripresenta il problema della dipendenza daparametri di disturbo, per cui la distribuzione varia a seconda che la regressionedi cointegrazione (ovvero la regressione ADF sui residui) sia stimata in presenza diun termine costante e/o di trend. L’inclusione di un trend lineare avrebbe senso sesi volesse eliminare la dipendenza del test EG dal termine costante m e qualora sidesiderasse testare l’ipotesi che le serie non sono cointegrate anche dopo l’estrazionedi un trend lineare da ognuna. I valori critici dipendono inoltre dal numero divariabili esogene impiegate nel modello statico.
I due autori considerano infine un’altra batteria di test basati sulla stima delmodello con MCE e di modelli autoregressivi vettoriali; per essi si segnala che godonodi una potenza estremamente piu bassa del test EG e pertanto hanno una valenzalimitata. Per maggiori dettagli si rimanda comunque ad Engle e Granger (1987) ea Banerjee et al. (1993).
Per quanto concerne il secondo stadio EG dimostrano che il fatto di stimare ilvettore di cointegrazione non ha conseguenze sulle proprieta distributive delle stimedei coefficienti della forma con MCE: pertanto la stimatore a due stadi del modellocon MCE, ottenuto assumendo (m, c) stimati tramite la (13) come il valore vero,
95

ha la stessa distribuzione asintotica dello stimatore MV che impiega m, c; inoltre lestime degli errori standard sono consistenti.
Es. 8: Questo esempio e tratto da Engle e Granger e riguarda i consumi per beni nondurevoli e il reddito disponibile pro capite a prezzi costanti dal 1947Q1 al 1981Q2. Dall’analisidi integrazione scaturisce che le serie sono I(1), mentre la regressione di cointegrazione fornisce:ct = m + 0.23yt con R2 = 0.99, CRDW = 0.465 che risulta significativamente diverso dazero; inoltre il test EG risulta pari a −4.3 ed e significativo all’1% portando al rifiuto dell’ipotesidi assenza di cointegrazione. Il modello con MCE stimato risulta:
∆ct = −0.14zt−1 + 0.068∆yt−1.
Il coefficiente del consumo nella regressione di yt su una costante e ct e pari a 4.3, che coincidecol reciproco di 0.23. Anche in questo caso l’ipotesi di non cointegrazione e rifiutata e il termineche incorpora il MCE e significativo. Nelle situazioni di questo tipo nessuna delle due variabilie esogena ed esiste feedback.
Riferimenti bibliografici
Beaulieu J.J. e Miron J.A. (1993). Seasonal Unit Roots in Aggregate U.S. Data, Journalof Econometrics, 55, 305-328.
Banerjee, A., Dolado J., Galbraith J.W. e Henry D.F. (1993). Co-Integration, Error-Correction, and the Econometric Analysis of Non-Stationary Data., Oxford Univer-sity Press.
Beveridge, S. and Nelson, C.R. (1981), A New Approach to the Decomposition of EconomicTime Series into Permanent and Transitory Components with Particular Attentionto the Measurement of the ‘Business Cycle’. Journal of Monetary Economics, 7,151-174.
Campbell, J.Y. e Mankiw, N.S. (1987). Are Output Fluctuations Transitory? QuarterlyJournal of Economics, 102, 857-880.
Cochrane J. (1988). How Big is the Random Walk Component in GNP? Journal of PoliticalEconomy, 96, 893-920.
Cochrane J. (1991). A Critique of the Application of Unit Root Tests, Journal of EconomicDynamics and Control, 15, 275-284.
Dickey D.A. e Fuller W. A. (1981). Likelihood Ratio Statistics for Autoregressive TimeSeries with a Unit Root, Econometrica, 49, 1057-1077.
Dickey, D.A., D.P. Hasza e W.A. Fuller (1984): “Testing for Unit Roots in Seasonal TimeSeries.” Journal of the American Statistical Association, Vol. 79, No. 386, pp.355-67.
96

Engle, R.F., C.W.J. Granger e J.J. Hallman (1989): “Merging Short- and Long-Run Fo-recasts. An Application of Seasonal Cointegration to Monthly Electricity SalesForecasting.” Journal of Econometrics, Vol. 40, pp. 45-62.
Engle R.F. e Granger C.W.J. (1987). Co-integration and Error Correction: Representation,Estimation and Testing, Econometrica, 55, 251-276.
Fuller W. A. (1976). Introduction to Statistical Time Series, New York, Wiley.
Hylleberg, S., R.F. Engle, C.W.J. Granger e B.S. Yoo (1990): “Seasonal Integration andCointegration.” Journal of Econometrics, Vol. 44, pp. 215-38.
Nelson C.R. e Kang H. (1984). Pitfalls in the Use of Time as an Explanatory Variable,Journal of Business and Economic Statistics, 2, 73-82.
Nelson C.R. e Plosser C.I. (1982). Trends and Random Walks in Macroeconomic TimeSeries: some Evidence and Implications, Journal of Monetary Economics, 10, 139-162.
Pantula S.G. (1991). Asymptotic Distribution of the Unit Root Tests when the Process isNearly Stationary, Journal of Business and Economic Statistics, 9, 63-71.
Perron P. (1989). The Great Crash, the Oil Shock and the Unit Root Analysis, Econome-trica, 57, 1361-1402.
Phillips P.C.B. e Perron P. (1988). Testing for a Unit Root in Time Series Regression,Biometrika, 75, 335-346.
Proietti, T. (1995). The Beveridge-Nelson Decomposition. Properties and Extensions.Journal of the Italian Statistical Society, 4, 1, 101-124.
Proietti, T. (1996). Persistence of Shocks on Seasonal Processes. Journal Applied Econo-metrics, 11, 383-398.
Said S.E. e Dickey D.A. (1984). Testing for Unit Roots in Autoregressive Moving AverageModels of Unknown Order, Biometrika, 71, 599-607.
Sargan J.D. e Barghava A. (1983). Testing Residuals from Least Squares Regression forBeing Generated by the Gaussian Random Walk, Econometrica, 51, 153-174.
Schwert G.W. (1989). Test for Unit Roots: a Monte Carlo Investigation, Journal ofBusiness and Economic Statistics, 7, 147-159.
Stock J.H. (1987). Asymptotic Properties of Least Squares Estimators of CointegratingVectors, Econometrica, 55, 1035-1056.
Opere generali:
97

Banerjee, A., Dolado J., Galbraith J.W. e Henry D.F. (1993). Co-Integration, Error-Correction, and the Econometric Analysis of Non-Stationary Data., Oxford Univer-sity Press.
Cappuccio, N. e Orsi R. (1991). Econometria, Il Mulino, Bologna.
Engle R.F. e Granger C.W.J. (a cura di) (1991). Long Run Economic Relationships -Readings on Cointegration, Oxford University Press.
J.D. Hamilton (1994). Time Series Analysis, Princeton University Press, New Jersey.
Hatanaka M. (1996). Time-Series-Based Econometrics. Unit Roots and Cointegration,Oxford University Press.
Johansen S. (1995). Likelihood-based inference in cointegrated vector autoregressive models,Oxford University Press.
98

Capitolo 6
I Modelli Strutturali per l’Analisi delle SerieTemporali
6.1 L’approccio modellistico e la classe dei mo-delli strutturali
La classe dei modelli strutturali racchiude un insieme, piu vasto di quanto si possaritenere a prima vista, di approcci il cui tratto comune va ritrovato nella speci-ficazione diretta del modello di scomposizione della serie temporale in termini dicomponenti non osservabili, identificabili con trend, ciclo, stagionalita etc.; in cioesso raccoglie l’eredita dell’analisi classica. Nel seguito ci limiteremo a descrivere leproposte piu importanti, dando particolare rilievo ai modelli strutturali di Harvey edei suoi collaboratori, che tra l’altro forniscono un metodo di destagionalizzazionecompetitivo con X-12-ARIMA e TRAMO-SEATS.
L’approccio ha molti punti in comune con quello AMB (Arima Model Based) diMaravall, che trova la sua implementazione nel software TRAMO-SEATS, corren-temente utilizzato dall’Istituto Nazionale di Statistica italiano ai fini della destagio-nalizzazione delle serie temporali; in particolare, entrambi prendono le mosse dallarappresentazione a componenti latenti di tipo ARIMA, detta UCARIMA, in cui tut-te le componenti e, per aggregazione, la serie stessa, yt, hanno una rappresentazioneARIMA:
yt =K
∑
k=0
ykt =K
∑
k=0
θk(L)∆k(L)φk(L)
ξkt (6.1)
con ξkt ∼ NID(0, σ2k).
Le assunzioni comuni ai due approcci sono le seguenti:
• I polinomi φk(L), θk(L) e ∆k(L) non presentano radici comuni; lo stesso valeper φk(L) e φh(L), θk(L) e θh(L), ∆k(L) e ∆h(L), ∀h, k = 0, . . . , K.
99

• I polinomi φk(L) sono stazionari e di ordine pk.
• I polinomi θk(L) sono invertibili (anche se non strettamente invertibili) e diordine qk.
• Le radici dei polinomi ∆k(L) giacciono tutte sul cerchio di raggio unitario.
• le innovazioni ξkt sono mutualmente incorrelate.
Tali assunzioni implicano che yt ammette una rappresentazione lineare di tipoARIMA (forma ridotta o forma osservabile):
yt =θ(L)
∆(L)φ(L)ξt
con ξt ∼ NID(0, σ2). L’invertibilita della rappresentazione per yt e assicuratadall’assunzione che i polinomi MA θk(L) non possiedono radici comuni.
Dal momento che esistono infiniti modi di scomporre yt secondo la (6.1), si richie-de l’introduzione di un insieme di restrizioni nella rappresentazione delle componen-ti. Nel caso dei modelli strutturali si fa riferimento ad Hotta (1983), che ha fornitouna condizione necessaria e sufficiente per l’identificabilita della scomposizione: peralmeno K componenti si richiede che pk + dk ≥ qk + 1. L’approccio strutturale,pertanto, identifica le componenti restringendo l’ordine dei polinomi MA.
L’approccio AMB assegna il noise ad una sola componente e rende le altre noninvertibili (Maravall e Planas,1994), imponendo le restrizioni:
• pk + dk ≥ qk per almeno K componenti
• per le medesime componenti il minimo della densita spettrale e zero (noninvertibilita a determinate frequenze).
Le componenti per le quali vale la seconda condizione sono dette canoniche; in sintesi,si richiede che segnali quali il trend, la stagionalita ed il ciclo, non contengano rumoreseparabile.
Per l’approccio AMB il punto di partenza e rappresentato dalla forma ridottadel modello, che e vincolante per la caratterizzazione dinamica delle componen-ti: si procede all’identificazione e stima del modello ARIMA per yt e si ottieneuna rappresentazione delle componenti consistente con la forma ridotta. Nell’ap-proccio strutturale, invece, quest’ultima non gioca alcun ruolo fondamentale nellaspecificazione del modello di scomposizione, che e definito a priori dal ricercatore.
La linearita della rappresentazione (6.1) implica che le scomposizioni consentitesono l’additiva e la log-additiva. Il modello default e costituito dal cosidetto ModelloStrutturale di Base (MSB)
yt = µt + γt + εt, t = 1, . . . , T, (6.2)
100

dove µt e il trend, γt e la componente stagionale e εt ∼ WN(0, σε2). Maravall (1987)
ha mostrato la prossimita col modello Airline, il quale ultimo costituisce l’anello dicongiunzione ed il riferimento comune delle varie tecniche di destagionalizzazione.La specificazione delle componenti e discussa nelle sezioni successive.
Il modello puo essere esteso al fine di comprendere effetti di calendario, ciclistocastici stazionari e un nucleo di regressione, che consente l’inclusione di variabiliesogene, valori ritardati della variabile indipendente e variabili di intervento.
6.2 Trend
Un trend lineare deterministico, µt = α + βt, puo essere rappresentato in manieraricorsiva come segue: µt = µt−1 + βt−1, βt = βt−1, con µ0 = α e β0 = β. Al fine diottenere un trend stocastico possiamo introdurre degli shock casuali nelle equazioniche definiscono µt e βt. Questa e la genesi del modello lineare locale:
µt = µt−1+ βt−1+ ηt
βt = βt−1+ ζt(6.3)
dove ηt e ζt sono due WN incorrelati con media nulla e varianza rispettivamente ση2
e σζ2. Qualora σζ
2 = 0 il modello e una passeggiata aleatoria con drift costante:µt = µt−1 + β + ηt; quando ση
2 = 0 si ha il cosidetto modello IRW (IntegratedRandom Walk) privilegiato da Young (1990) e Kitagawa e Gersch (1984), in quantofornisce un trend caratterizzato da un grado di lisciamento piu elevato. Il filtro diHodrick & Prescott si ottiene nel caso particolare in cui ση
2 = 0 e σζ2 = qσε
2, perq = 1/1600. Infine, quando entrambe le varianze sono nulle, µt e un processo linearedeterministico. Nel modello con damped slope la seconda equazione e sostituita dalprocesso AR(1) stazionario:
βt = ρβt−1 + ζt, con ρ ∈ (0, 1)
Supponiamo che la serie yt abbia una rappresentazione trend + irregolare:
yt = µt + εt, εt ∼ WN(0, σε2)
dove µt e un trend lineare locale (6.3) e si assume che εt sia incorrelato con ηt e ζt.E’ immediato verificare che
∆2yt = ∆ηt + ζt−1 + ∆2εt
e che pertanto E(∆2yt) = 0. La funzione di autocovarianza, γ(k) = E(∆2yt∆2yt−k), etale che γ(0) = 2ση
2+σζ2+6σε
2, γ(1) = −ση2−4σε
2, γ(2) = σε2 e γ(k) = 0, k > 2, che
implica che yt ∼ ARIMA(0, 2, 2). La struttura del modello implica forti restrizioninello spazio parametrico dei parametri MA: in particolare, la FAC a ritardo 1 ecompresa tra -2/3 e 0 e quella a ritardo 2 tra 0 e 1/6. Infine, la funzione di previsionerealizza uno smorzamento esponenziale del tipo di quello tipico della procedura diHolt & Winters.
101

6.3 La modellazione del ciclo economico
Un ciclo deterministico, ψt = A1 cos λct + A2 sin λct, dove λc ∈ [0, π] rappresenta lafrequenza angolare e (A2
1 + A22)
1/2 l’ampiezza dell’oscillazione, puo essere scritto informa ricorsiva:
[
ψt
ψ∗t
]
=[
cos λc sin λc
− sin λc cos λc
] [
ψt−1
ψ∗t−1
]
con [ψ0, ψ∗0] = [A1, A2].La versione stocastica del modello si ottiene introducendo un fattore di smor-
zamento, ρ, che assume valori nell’intervallo [0,1], e due disturbi stocastici mutual-mente incorrelati e a varianza comune, κt, κ∗t :
[
ψt
ψ∗t
]
= ρ[
cos λc sin λc
− sin λc cos λc
] [
ψt−1
ψ∗t−1
]
+[
κt
κ∗t
]
con κt ∼ WN(0, σ2κ) e κ∗t ∼ WN(0, σ2
κ).La forma ridotta e un modello ARMA(2,1) con radici del polinomio AR com-
plesse, di modulo ρ−1 e fase λc:
(1− 2ρ cos λcL + ρ2L2)ψt = (1− ρ cos λcL)κt + ρ sin λcLκ∗t ,
ad eccezione del caso λc → 0, π, in cui il modello si riduce ad un AR(1) di parametrorispettivamente positivo e negativo.
Una rappresentazione equivalente si ottiene facendo variare nel tempo i coeffi-cienti A1 e A2 che definiscono l’ampiezza dell’oscillazione:
ψt = [cos λt, sin λt]At, At = [A1t, A2t]′
A1,t = ρA1,t−1 + κ1t
A2,t = ρA2,t−1 + κ2t
dove κ1t ∼ WN(0, σ2κ) e κ2t ∼ WN(0, σ2
κ).La possibilita di modellare il ciclo appare appetibile per le serie temporali econo-
miche; tuttavia e sperimentato che la destagionalizzazione e relativamente insensibileall’introduzione del ciclo. In effetti, se il periodo del ciclo e sufficientemente elevato(ad es. e superiore a tre anni) il filtro di estrazione della componente stagionale hauna funzione di trasferimento pressoche nulla in corrispondenza delle frequenze cicli-che e l’estrazione del ciclo interagisce essenzialmente con la componente tendenziale,che risulta piu lisciata: generalmente quelle che vengono descritte come fluttuazionicicliche vengono assorbite dalla componente βt.
102

6.4 Componente stagionale
La componente stagionale, di periodo pari a s, ha due rappresentazioni fondamentali:dummy e trigonometrica. La prima e tale che S(L)γt = ωt, dove ωt ∼ WN(0, σω
2)e S(L) = 1 + L + · · · + Ls−1, mentre nella seconda l’effetto stagionale risulta dallacombinazione di s/2 cicli stocastici integrati del primo ordine definiti alle frequenzestagionali λj = 2πj/s, j = 1, . . . , s/2:
γt =s/2∑
j=1γit (6.4)
dove[
γjt
γ∗jt
]
=[
cos λj sin λj
− sin λj cos λj
] [
γj,t−1
γ∗j,t−1
]
+[
ωj,t
ω∗jt
]
, (6.5)
(1 + L)γ s2 ,t = ω s
2 ,t (6.6)
ωjt e ω∗jt costituiscono un set di WN mutualmente incorrelati con varianza comuneσ2
ω. Si mostra che S(L)γt ha rappresentazione MA(s− 2).La formulazione trigonometrica e preferibile in termini di lisciamento, poiche
da luogo ad una componente che evolve meno rapidamente della corrispondenteformulazione dummy. La restrizione di eguaglianza delle varianze degli shock edi sovraidentificazione e puo essere rimossa (Bruce e Jurke (1996), Bell (1992)).L’evidenza mostra che rimuovendo tale restrizione migliora in maniera significatival’adattamento del modello, soprattutto nel caso mensile, quando ad es. la frequenzafondamentale ha un ruolo piu importante delle armoniche. Tuttavia, cio richiede lastima di s/2 parametri in luogo di uno, con corrispondente allungamento del tempocomputazionale e problemi di convergenza.
6.5 Il trattamento statistico del modello e la sti-ma delle componenti
La rappresentazione del modello nello spazio degli stati apre la via al trattamentostatistico del modesimo. Ad essa si applica il filtro di Kalman (FK) che costitui-sce l’algoritmo fondamentale per il calcolare della funzione di verosimiglianza me-diante la tecnica di scomposizione in errori di previsione uniperiodali. La verosimi-glianza e massimizzata numericamente ricorrendo all’algoritmo di Broyden-Fletcher-Goldfarb-Shanno. Stime iniziali possono essere ottenute mediante l’algoritmo EM.
103

6.5.1 La rappresentazione nello spazio degli stati
Sia yt una serie temporale multivariata che contiene N elementi; essa e collegata adun vettore m× 1 di componenti latenti attraverso l’equazione di misurazione:
yt = Ztαt + dt + εt, t = 1, 2, . . . , T, (6.7)
dove Zt e una matrice N ×m, dt e un vettore N × 1 di grandezze deterministiche(esogene rispetto al sistema), αt e il vettore di stato, e εt ∼ NID(0, H t).
Il modello dinamico che genera gli stati e fornito dalla equazione di transizione:
αt = T tαt−1 + ct + Rtηt, t = 1, 2, . . . , T, (6.8)
dove T t e la matrice di transizione (m × m), ct e un vettore m × 1 di grandezzedeterministiche, ηt ∼ NID(0, Qt), un vettore g× 1 di disturbi stocastici, e Rt e unamatrice m× g.
La specificazione del modello e completata dall’assunzione che il vettore di statoiniziale abbia media a0 = E(α0) e matrice di covarianza P 0 = Cov(α0) e che α0, εt
e ηt siano mutualmente incorrelate per ogni t. Le matrici Zt, dt, H t,T t, ct,Rt, Qt,dette matrici del sistema, hanno natura non stocastica e per i modelli strutturali danoi considerati sono invarianti nel tempo (Zt = Z, etc.).
Es. Modello ARIMA(p, d, q) Consideriamo il modello
φ(L)∆dyt = µ + θ(L)ξt, ξt ∼ WN(0, σ2)
e sia m = max(p, q+1). Denotando φ = [φ1, φ2, . . . , φm]′ and θ = [1, θ1, θ2, . . . , θm−1]′;il modello ARMA(p, q) per ∆dyt puo essere rappresentato nello spazio degli statidefinendo un vettore m× 1 che segue la seguente equazione di transizione:
αt = Tαt−1 + c + Rξt,
dove R = θ,
T =[
φ∣
∣
∣
∣
∣
Im−1
0′
]
,
c = [µ, 0, . . . , 0]′, Im−1 e la matrice identita di ordine (m − 1) e 0 e un vettore(m− 1)× 1 di 0.
L’equazione di misurazione seleziona il primo elemento di αt: pertanto, definendoZ = [1,0′], si ha
∆dyt = Zαt.
Infine, a0 = (Im − T )−1c e P 0 soddisfa l’equazione P 0 = TP 0T ′ + σ2RtR′t.
104

6.5.2 Il filtro di Kalman
Il filtro di Kalman e un algoritmo ricorsivo che calcola il valore atteso del vettoredi stato al tempo t, αt, condizionato all’informazione disponibile al tempo t − 1,Y t−1 = y1,y2, . . . ,yt−1, che denoteremo at|t−1 = E(αt|Y t−1), assieme al suoerrore quadratico medio di stima, P t|t−1 = E[(αt − at|t−1)(αt − at|t−1)′|Y t−1].
Tale valore atteso rappresenta lo stimatore ottimale di αt sulla base di Y t−1, nelsenso che minimizza l’errore quadratico medio di stima nella classe degli stimatorilineari in yt. Sotto l’ipotesi di normalita, lo stimatore e ottimale tout court.
Il filtro, inoltre, aggiorna la stima di αt quando l’informazione corrente, yt, siaggiunge al set informativo e consente il calcolo della funzione di verosimiglianzamediante la scomposizione in errori di previsione.
Ai fini della derivazione del filtro supponiamo di trovarci al tempo t − 1 e diconoscere, sulla base del set informativo Y t−1, lo stimatore ottimale di αt−1 con-dizionato a Y t−1, che denotiamo at−1 = E(αt−1|Y t−1), e la matrice di covarianzadell’errore di stima: P t−1 = E[(αt−1 − at−1)(αt−1 − at−1)′|Y t−1].
Proponiamoci di prevedere un periodo in avanti il vettore di stato e di calcolarela matrice di covarianza del corrispondente errore di previsione; dall’equazione ditransizione:
at|t−1 = T tat−1 + ct
P t|t−1 = T tP t−1T ′t + RtQtR
′t
(6.9)
Le equazioni (6.9) sono denominate equazioni di predizione. Consideriamo ora ilproblema di prevedere yt un periodo in avanti: dalla (6.7) si ottiene:
yt|t−1 = E(yt|Y t−1) = Ztat|t−1 + dt
e, denotando con νt l’errore di previsione, νt = yt −Ztat|t−1 − dt, si ha
E(νt|Y t−1) = 0, F t = Cov(νt) = E(νtν ′t|Y t−1) = ZtP t|t−1Z ′t + H t
Supponiamo ora di trovarci al tempo t e di aver acquisito la piu recente osser-vazione yt. E’ a questo punto possibile aggiornare la stima del vettore di statoutilizzando il set informativo Y t. Cio da luogo alle equazioni di aggiornamento:
at = at|t−1 + P t|t−1Z ′tF
−1t νt
P t = P t|t−1 − P t|t−1Z ′tF
−1t ZtP t|t−1
(6.10)
Derivazione delle equazioni di aggiornamento Si parte dalla considerazionedella distribuzione congiunta yt e αt condizionata a Y t−1:
ytαt
∣
∣
∣
∣
∣
Y t−1,∼ N
[(
Ztat|t−1 + dt
T tat−1 + ct
)
,
(
ZtP t|t−1Z′t + Ht ZtP t|t−1
P t|t−1Z′t P t|t−1
)]
105

Al fine di ottenere il risultato si sfrutta un noto teorema per il quale la distribuzionedi αt|Y t−1, condizionata a yt ha valore atteso:
E(αt|Y t) = E(αt|Y t−1) + Cov(αt,yt|Y t−1)[Cov(yt|Y t−1)]−1(yt − E(yt|Y t−1))
che produceat = at|t−1 + P t|t−1Z
′tF
−1t νt
Inoltre,
Cov(αt|Y t) = Cov(αt|Y t−1)− Cov(αt, yt|Y t−1)[Cov(yt|Y t−1)]−1Cov(yt,αt|Y t−1)
che fornisce la seconda equazione di aggiornamento nella (6.10).Il filtro di Kalman puo anche essere scritto compattando la fase di aggiornamento
del filtro: dati i valori iniziali a1|0, P 1|0,
νt = yt −Ztat − dt, F t = ZtP t|t−1Z ′t + H t
Kt = T t+1P t|t−1Z ′tF
−1t ,
at+1|t = T t+1at|t−1 + Ktνt + ct, P t+1|t = T t+1(P t|t−1 − P t|t−1Z ′tF
−1t ZtP t|t−1)T ′
t+1 + Rt+1Qt+1R′t+1
6.5.3 Verosimiglianza e inizializzazione del filtro
Le matrici del sistema dipendono da un insieme di parametri Ψ. La funzione didensita congiunta delle osservazioni,
L(y1, . . . ,yT ;Ψ) =T∏
t=1f(yt|Y t−1)
dovef(yt|Y t−1) = (2π)N/2|F t|−1/2 exp
(
−12νtF−1
t νt
)
Pertanto
ln L = −12
(
NT ln 2π +T
∑
t=1ln |F t|+
T∑
t=1νtF−1
t νt
)
La massimizzazione rispetto ai parametri incogniti puo essere effettuata medianteun algoritmo numerico.
Tale espressione fornisce la verosimiglianza solo se a0 e P 0 sono noti, come av-viene nel caso in cui αt e stazionario. Quando αt contiene d elementi non stazionari,si puo mostrare che le prime d osservazioni possono essere utilizzate per ottenere imomenti della distribuzione di αd e pertanto, considerando dette osservazioni comefisse,
ln L = −12
N(T − d) ln 2π +T
∑
t=d+1
ln |F t|+T
∑
t=d+1
νtF−1t νt
106

Ai fini computazionali, una soluzione approssimata consiste nell’inizializzare il filtromediante un diffuse prior: supponendo senza perdita di generalita che i primi m1
elementi siano non stazionari, si pone
a0 =[
0m1
a20
]
,[
κIm1 00 P m2
]
dove κ e un numero sufficientemente “elevato”. DeJong (1991) ha introdotto un filtrodi Kalman modificato che supera elegantemente il problema dell’inizializzazione eche consente di calcolare la funzione di verosimiglianza esatta.
6.5.4 Smoothing
L’operazione che prende il nome di smoothing mira ad ottenere stime delle com-ponenti condizionate all’intero set di osservazioni, Y T . Il tradizionale algoritmo dismoothing ad intervallo fisso (dal momento che opera su un set di dati fisso) e quel-lo di Anderson e Moore (1979), ed e fornito dalle seguenti formule retro-ricorsive,inizializzate con aT |T = aT e P T |T = P T :
at|T = at + P ∗t (at+1|T − T t+1at)
P t|T = P t + P ∗t (P t+1|T − P t+1|t)P ∗′
t
dove at|T = E(αt|Y T ), P t|T = E[(αt − at|T )(αt − at|T )′|Y T ] e P ∗t = P tT ′
t+1P−1t+1|t.
Si noti che l’algoritmo deve essere preceduto da un’applicazione del filtro di Kal-man, passo nel quale le stime aggiornate e le matrici P t+1|t devono essere tenutein memoria. Inoltre, si richiede l’inversione di queste ultime. Cio e inefficiente dalpunto di vista computazionale e in letteratura sono disponibili versioni piu efficientiper le quali rimandiamo a DeJong (1989) e Koopman (1993).
Ai fini della destagionalizzazione, la serie aggiustata e ottenuta per sottrazionedalla serie delle stime smoothed della componente stagionale:
at = yt − γt|T .
6.5.5 Diagnostica
Le innovazioni (standardizzate) del FK sono utilizzate in sede di verifica del mo-dello e per la valutazione della bonta dell’adattamento. A tal fine vengono impie-gati gli stessi strumenti diagnostici che sono utilizzati dalla modellistica ARIMA, ilcorrelogramma, il periodogramma, il test di Ljung-Box, etc.
107

6.6 Componenti di calendario
Dagum & Quenneville (1995) e Durbin & Quenneville (1997) considerano la seguenteestensione del modello strutturale di base:
yt = µt + γt + TDt + εt, (6.11)
dove
TDt =6
∑
i=1δit(Dit −D7t)
Dit e il numero dei giorni di tipo i nel mese e gli effetti sono variabili nel temposecondo un rw:
δit = δi,t−1 + νit, νt ∼ WN(0, σ2ν)
tale che νit, i = 1, . . . , 6 sono mutualmente incorrelati. Poiche puo apparire eccessivoche gli effetti abbiano una variazione di periodo in periodo, si puo semplificare ilmodello ponendo: δit = δi,t−s + νt. L’evidenza empirica mostra che la formulazionedeterministica e generalmente appropriata.
6.7 Altre specificazioni della componente stagio-nale
La destagionalizzazione cambia al variare della specificazione della componente sta-gionale. Il modello di Harrison e Stevens (1971) ha la rappresentazione γt = x′tχt,dove xt e un vettore s × 1 di selezione con 1 nella posizione corrispondente allaj-esima stagione e 0 altrove, mentre χt e un vettore s × 1 che segue la seguenteequazione di transizione:
χt = χt−1 + Ωt, con Ωt ∼ WN(
0, σ2ω[Is − (i′sis)
−1isi′s])
La forma ridotta e tale che S(L)γt ha una rappresentazione MA(s− 2). La densitaspettrale e monotonicamente decrescente da 0 a π e, a differenza della specificazionetrigonometrica non presenta un massimo relativo alla frequenza π. Conseguente-mente, si ottiene una componente stagionale piu lisciata (Proietti, 1997).
Den Butter e Fase (1991) propongono la seguente specificazione:
γt = γt−s −1sS(L)γt−1 + ωt
che puo essere riscritta
(1− ρs)S(L)γt = ωt, con ρs =s− 1
s
108

Le proprieta di lisciamento sono abbastanza simili a quelle del modello di Harrisone Stevens, anche se S(L)γt ha rappresentazione AR(1).
Il vincolo imposto dall’identificabilita del modello esclude la possibilita di rap-presentare la componente stagionale con il modello γt = γt−s + ωt o con modelli lacui parte AR contiene il fattore ∆s (Engle, 1976). Altre estensioni per modellarel’eteroschedasticita stagionale e per trend stagionali sono disponibili.
109


















