Dna e Sintesi Proteica
9
Click here to load reader
-
Upload
luigi-borgese -
Category
Documents
-
view
16 -
download
0
Transcript of Dna e Sintesi Proteica

LA MOLECOLA DEL DNA
Il DNA (Acido DesossiriboNucleico) è un acido nucleico, composto chimico di grande importanza,
presente in tutti gli organismi viventi, portatore dell'informazione genetica e depositario dei caratteri
ereditari. Da esso ha origine l'importantissima sintesi proteica, alla quale partecipa un altro acido
nucleico, l' RNA (Acido RiboNucleico).
Esistono tre principali tipi di RNA: RNA messaggero o mRNA, RNA ribosomico o rRNA, e l'RNA
di trasporto o tRNA. I tre tipi di acido ribonucleico interagiscono tra di loro provvedendo alle
sintesi proteiche della cellula.
Gli acidi nucleici sono lunghi polinucleotidi, ossia polimeri lineari, formati dall'unione di molte
unità denominate nucleotidi.
I nucleotidi sono a loro volta costituiti da tre componenti molecolari: una molecola di zucchero a
cinque atomi di carbonio, un gruppo fosfato e una molecola appartenente ad una gruppo di cinque
basi che definiscono cinque tipi diversi di nucleotidi: due basi puriniche, adenina e guanina e tre
basi pirimidiniche, timina, uracile e citosina. Nel DNA lo zucchero è il desossiribosio e le due basi
pirimidiniche sono solo timina e citosina . Nell'RNA sono presenti invece uracile e citosina.
Una lunga serie di nucleotidi si associa per formare una catena polinucleotidica che è costituita da
uno scheletro di gruppi fosfato e zuccheri alternati dal quale si irradiano lateralmente le basi
puriniche e pirimidiniche.
1

STRUTTURA DEL DNA
La definizione della struttura a doppia elica del DNA è da attribuirsi a J.D. Watson e F.H.C. Crick
che nel 1953 pubblicarono sulla rivista Nature il loro modello strutturale, modello che rappresenta
una delle più importanti scoperte scientifiche del ventesimo secolo e che di fatto costituisce la pietra
miliare della moderna biologia molecolare.
Secondo questo modello, il DNA è composto da due catene polinucleotidiche che decorrono in
direzione opposta e sono avvolte a spirale a formare una doppia elica. Le due catene sono legate fra
loro mediante ponti idrogeno fra le basi.
La molecola è quindi formata da due assi laterali costituiti dai residui fosforici e di desossiribosio
alternati e da una porzione interna costituita dall' accoppiamento delle basi. Le due catene sono di
polarità opposta, cioé le posizioni 3' e 5' delle molecole di desossiribosio in una catena sono
orientate in direzione opposta a quella delle molecole della catena complementare.
L' accoppiamento delle basi sulle due catene è altamente specifico, nel senso che l'adenina di una
catena può appaiarsi soltanto con la timina della catena opposta mediante un doppio ponte idrogeno.
La guanina di una catena si appaia con la citosina della catena opposta mediante tre ponti idrogeno.
Questa proprietà delle due catene affrontate prende il nome di complementarità e le due catene sono
dette complementari.
Nonostante la relativa fragilità dei ponti idrogeno che legano ciascuna coppia di basi, ogni molecola
di DNA contiene un numero tale di coppie di basi, da impedire che la catena possa separarsi
spontaneamente in condizioni fisiologiche.
Le due catene della doppia elica possono essere considerate come una coppia di modelli, positivo e
negativo, ognuno dei quali specifica il rispettivo complemento per la sintesi di una catena
complementare che quindi sarà identica alla catena opposta. In tal modo le due molecole di DNA
figlie prodotte risultano identiche alla doppia elica madre. Il meccanismo di duplicazione del DNA
risulta così essere semiconservativo, in quanto delle due catene originarie una è conservata in
ciascuna delle due cellule figlie e l'altra è di nuova sintesi
2

MECCANISMO MOLECOLARE DI DUPLICAZIONE
Il DNA è costituito da due catene polinucleotidiche avvolte a spirale a formare una doppia elica.
Le due catene sono collegate tra loro mediante ponti idrogeno tra le basi appaiate, sono
complementari e antiparallele, cioè le posizioni 3' e 5' delle molecole di desossiribosio in una catena
sono orientate in direzione opposta a quella delle molecole della catena complementare. Nella
terminologia corrente, un'estremità di ciascuna catena è comunemente indicata come terminazione
5' e quella opposta come terminazione 3'.
Il processo di duplicazione o replicazione del DNA è stato postulato da Watson e Crick nel 1953 e
successivamente confermato sperimentalmente con metodi biochimici. Secondo il modello
semiconservativo la duplicazione comporta le seguenti fasi:
Progressivo svolgimento delle due catene polinucleotidiche avvolte a spirale
Separazione delle catene per apertura dei ponti idrogeno tra basi complementari appaiate,
che le rende quindi libere di interagire con quelle dei nucleotidi presenti nell'ambiente
Sintesi, ad opera dell'enzima DNA polimerasi, su ogni catena separata di una catena nuova
complementare. Ognuna delle due catene parentali funziona da modello o stampo per la
sintesi di una catena nuova mediante appaiamento di nucleotidi complementari ai propri.
La DNA polimerasi può agire in una sola direzione, polimerizzando la molecola neoformata
dall'estremità 5' a quella 3'. Dato che le due catene del DNA sono antiparallele, la catena che
termina con 5' si replica con la formazione di piccoli frammenti nella direzione 5' 3' che si
riuniscono fra loro in un tempo successivo ad opera di un altro enzima, la polinucleotide ligasi
SINTESI PROTEICA
3

Ogni cellula, ogni organismo, ogni specie è caratterizzata dalle proprie proteine: durante la sintesi
ogni cellula costruisce, infatti, delle proteine specifiche, che sono diverse da specie a specie, da
individuo a individuo (il trapianto di un organo da un individuo all’altro riesce difficile proprio per
questo motivo) e, spesso, nello stesso individuo sono diverse da un tipo di cellula all ’altra. In altre
parole, ogni cellula manifesta nella sintesi delle proteine un’individualità propria.
La sostanza che presiede alla sintesi delle proteine, è il DNA; mentre le proteine vengono
sintetizzate sui ribosomi presenti sul reticolo endoplasmatico e nel citoplasma.
Il codice viene trascritto: la sintesi dell’RNA
Sebbene le differenze strutturali fra DNA e RNA siano modeste, le funzioni espletate dai due acidi
nucleici sono notevolmente diverse: il DNA è il depositario dell’informazione genetica, l’RNA è
l’intermediario mediante il quale l’informazione, presente nel DNA, viene utilizzata per la
costruzione di proteine.
Il processo di sintesi delle proteine inizia con l’apertura della doppia elica del DNA; a mano a mano
che la doppia catena del DNA si apre, le basi di uno dei filamenti agiscono come uno stampo per la
sintesi della molecola di RNA: ad esse aderiscono i nucleotidi complementari a quelli del DNA, che
grazie alla presenza di enzimi specifici si legano tra loro. La molecola del RNA è dunque costituita
da una singola catena di nucleotidi, disposti secondo una sequenza di basi complementare alla
sequenza esistente sulla molecola di DNA che ha funzionato da stampo.
La molecola dell’RNA formatasi sullo stampo del DNA è detta RNA messaggero, o mRNA;
terminata la trascrizione, essa si stacca dal filamento del DNA, che riassume la forma di doppia
elica.
La proteina e' realizzata
Per arrivare alla sintesi di una proteina, quella voluta dalla sequenza scritta in codice sulla molecola
del DNA, la molecola dell’RNA messaggero deve ora essere tradotta.
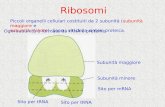
Il processo di traduzione coinvolge altri due tipi di RNA: l’RNA ribosomiale (RNAr), che
costituisce quelle microstrutture cellulari che già riconosciamo con il nome di ribosomi, e l’RNA di
trasporto (RNAt).
4

Il riconoscimento di un amminoacido da parte del suo RNA di trasporto, è un compito che viene
svolto con la massima precisione. Un enzima specifico per ogni amminoacido, infatti, attiva
l’amminoacido stesso, sia per farlo combinare con il proprio RNA di trasporto, sia per renderlo
disponibile per la sintesi proteica.
La sintesi di una molecola proteica avviene quando i ribosomi, scorrendo sull’RNA messaggero,
leggono il codice nella sequenza richiesta dal codice stesso e accolgono gli RNA di trasporto.
Gli RNA di trasporto, una volta portati a destinazione gli amminoacidi, tornano liberi e possono di
nuovo prendere dal citoplasma altri amminoacidi specifici richiesti da ulteriori procesi di sintesi.
La sintesi procede in tre fasi: inizio, crescita e termine del polipeptide.
L'inizio della sintesi vede i ribosomi legarsi al codone di inizio dell'mRNA, che indica il punto in
cui l'mRNA comincia a codificare la proteina. Questo codone è generalmente AUG (adenina-
uracile-guanina), ma codoni diversi sono frequenti nei procarioti. Negli eucarioti l'amminoacido
corrispondente al codone di inizio è la metionina.
Il tRNA iniziatore accoppia le sue basi con quelle del codone di avvio e si lega al sito P del
ribosoma. La subunità maggiore forma quindi un complesso con quella minore. A questo punto
avviene la crescita. Un nuovo tRNA entra sul sito A del ribosoma ed accoppia le sue basi con
quelle dell'mRNA. L'enzima peptidil transferasi crea un legame peptidico tra gli amminoacidi
vicini. Appena questo accade, l'amminoacido sul sito P si stacca dal suo tRNA e si lega al tRNA sul
sito A. Il ribosoma quindi si muove lungo l'mRNA spostando il tRNA dal sito A al sito P liberando
nel contempo il tRNA vuoto. Questo processo è noto come traslocazione.
Questo processo continua finché il ribosoma non incontra uno dei tre possibili codoni di arresto
(stop), dove avviene il termine. La crescita della proteina si interrompe e la proteina viene liberata
nel citoplasma.
La sintesi delle proteine può avvenire molto rapidamente. Questo avviene perché più ribosomi
possono legarsi ad un filamento di mRNA consentendo quindi la costruzione simultanea di più
proteine.
Negli eucarioti la traduzione avviene nel citoplasma mentre la trascrizione avviene nel nucleo
cellulare.
5

CODICE GENETICO
È un sistema di corrispondenza tra basi azotate del DNA e amminoacidi.
Tale sistema nel corso della sintesi proteica permette l'interpretazione delle informazioni contenute
nella molecola di acido nucleico e la loro trasformazione in un precisa indicazione della sequenza
che gli amminoacidi devono avere nella proteina che è in via di formazione.
In particolare, il codice genetico è formato da 64 triplette (o codoni), ossia da 64 combinazioni di
tre basi azotate, ad esempio AAC, ATA, TCG e così via.
A ogni tripletta corrisponde un amminoacido: considerando le triplette degli esempi citati, gli
amminoacidi corrispondenti sono la leucina, la tirosina e la serina. Poiché gli amminoacidi sono
venti, e le possibili triplette sono 64, ne deriva che diverse triplette devono corrispondere a uno
stesso amminoacido.
Vi sono tre triplette non-senso, che cioè non corrispondono ad alcun amminoacido e che pongono
termine alla sintesi proteica, e una tripletta che costituisce un segnale di inizio della sintesi.
Il codice genetico viene definito universale, in quanto è comune a tutti i viventi, dagli animali alle
piante, ai batteri; tale sistema di decodificazione delle istruzioni contenute nel genoma è presente
anche nei virus; esso è anche detto ridondante, per il fatto che a un solo amminoacido possono
corrispondere diverse triplette.
Ricapitoliamo le caratteristiche del codice genetico:
È a triplette
Viene letto in modo continuo
È degenerato
Ha segnali di inizio e fine
È universale
6