
dispense mate 1415 - cide.univr.itcide.univr.it/aperetti/matematica/dispense_mate_1415.pdf · A....
411
Dispense del Corso di Matematica 2014/15 Sede di Vicenza Alberto Peretti Dipartimento di Scienze economiche Universit`a degli Studi di Verona 8 settembre 2014 Indice Introduzione 9 1 Motivazioni e obiettivi 9 1.1 Definizioni, Teoremi, ... ............................................ 9 1.2 Simbologia di base ............................................... 10 1.3 Simboli logici .................................................. 10 2 Insiemi 12 2.1 Intersezione, Unione, Differenza, Complementare .............................. 13 2.2 Insieme delle parti ............................................... 14 2.3 Insiemi numerici fondamentali ......................................... 14 2.4 Intervalli della retta reale ........................................... 17 3 Sommatorie e altro 18 3.1 Simbolo di somma (sommatorie) ....................................... 18 3.1.1 Cambio di variabile in una sommatoria ............................... 20 3.1.2 Doppia sommatoria .......................................... 20 3.1.3 Scambio dei simboli di una doppia sommatoria ........................... 22 3.1.4 Qualche utile formula ......................................... 22 3.2 Simbolo di prodotto (produttorie) ...................................... 23 4 Calcolo combinatorio 23 4.1 Permutazioni di n elementi .......................................... 23 4.2 Disposizioni di n elementi di classe k ..................................... 24 4.3 Combinazioni di n elementi di classe k .................................... 25 4.4 Il binomio di Newton .............................................. 26 5 Tabella riassuntiva dei simboli principali 28 Parte I 29 I-1 Polinomi 31 1 Prodotti e potenze notevoli 31 2 Divisione tra polinomi 32 2.1 Regola di Ruffini ................................................ 34 3 Fattorizzazione di un polinomio 35 4 Teorema di Ruffini 38 1
-
Upload
dangnguyet -
Category
Documents
-
view
296 -
download
21
Transcript of dispense mate 1415 - cide.univr.itcide.univr.it/aperetti/matematica/dispense_mate_1415.pdf · A....

Dispense del Corso di Matematica 2014/15
Sede di Vicenza
Alberto Peretti
Dipartimento di Scienze economiche
Universita degli Studi di Verona
8 settembre 2014
Indice
Introduzione 9
1 Motivazioni e obiettivi 91.1 Definizioni, Teoremi, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.2 Simbologia di base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.3 Simboli logici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Insiemi 122.1 Intersezione, Unione, Differenza, Complementare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2 Insieme delle parti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3 Insiemi numerici fondamentali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4 Intervalli della retta reale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Sommatorie e altro 183.1 Simbolo di somma (sommatorie) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.1 Cambio di variabile in una sommatoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.1.2 Doppia sommatoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.1.3 Scambio dei simboli di una doppia sommatoria . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.1.4 Qualche utile formula . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Simbolo di prodotto (produttorie) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4 Calcolo combinatorio 234.1 Permutazioni di n elementi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.2 Disposizioni di n elementi di classe k . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.3 Combinazioni di n elementi di classe k . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.4 Il binomio di Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5 Tabella riassuntiva dei simboli principali 28
Parte I 29
I-1 Polinomi 31
1 Prodotti e potenze notevoli 31
2 Divisione tra polinomi 322.1 Regola di Ruffini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3 Fattorizzazione di un polinomio 35
4 Teorema di Ruffini 38
1

INDICE 2
5 Completamento del quadrato 38
6 Soluzioni degli esercizi 40
I-2 Potenze, Radicali e Logaritmi 44
1 Potenze e Radicali 441.1 Potenze con esponente naturale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 441.2 Potenze con esponente intero . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 441.3 Radicali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451.4 Proprieta dei radicali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451.5 Operazioni con i radicali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 461.6 Potenze con esponente razionale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 481.7 Potenze con esponente irrazionale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2 Logaritmi 502.1 Definizione di logaritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 502.2 Proprieta dei logaritmi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3 Soluzioni degli esercizi 53
I-3 Equazioni e Disequazioni 56
1 Generalita sulle equazioni 56
2 Equazioni di primo grado 58
3 Equazioni di secondo grado 58
4 Equazioni intere di grado superiore al secondo 60
5 Equazioni razionali (o fratte) 61
6 Generalita sulle disequazioni 62
7 Disequazioni di primo e di secondo grado 63
8 Sistemi di equazioni e di disequazioni di primo e secondo grado 65
9 Disequazioni intere di grado superiore al secondo 66
10 Disequazioni razionali (o fratte) 68
11 Equazioni e disequazioni irrazionali 69
12 Equazioni e disequazioni esponenziali 71
13 Equazioni e disequazioni logaritmiche 73
14 Equazioni e disequazioni con valori assoluti 75
15 Soluzioni degli esercizi 77
I-4 R2 ed R3 – Piano e spazio cartesiani 82
1 Prodotto cartesiano di due insiemi 82
2 Rappresentazione di R2 sul piano cartesiano 82
3 Sottoinsiemi di R2 e regioni del piano cartesiano 83
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

INDICE 3
4 R3 e sua rappresentazione nello spazio cartesiano 86
5 Soluzioni degli esercizi 86
I-5 Elementi di geometria analitica 88
1 Rette nel piano 881.1 Rette passanti per un punto assegnato . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 891.2 Retta passante per due punti assegnati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 901.3 Rette parallele e rette perpendicolari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
2 Parabole 92
3 Circonferenze 96
4 Ellissi 99
5 Iperboli 101
6 Soluzioni degli esercizi 105
Parte II 109
II-1 Funzioni 111
1 Il concetto di funzione 111
2 Funzione composta 115
3 Funzione inversa 117
4 Restrizione e prolungamento di una funzione 119
5 Soluzioni degli esercizi 119
II-2 Numeri reali 122
1 Alcune considerazioni iniziali 122
2 Struttura di ordine e struttura algebrica di R 122
3 Insiemi limitati ed estremi di un insieme 123
4 Proprieta metriche dei numeri reali 125
5 Cenni di topologia in R 127
6 Soluzioni degli esercizi 129
II-3 Funzioni reali di variabile reale 131
1 Grafico di una funzione reale 131
2 Funzioni elementari 1322.1 Funzione potenza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1322.2 Funzione esponenziale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1332.3 Funzione logaritmica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
3 Immagine ed estremo superiore di una funzione reale 134
4 Controimmagine o immagine inversa di una funzione reale 135
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

INDICE 4
5 Proprieta delle funzioni reali 136
6 Altri esempi di funzioni, non elementari 1386.1 Funzioni definite a tratti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1396.2 Funzione valore assoluto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1396.3 Funzione parte intera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
7 Grafici di funzioni e curve nel piano 140
8 Soluzioni degli esercizi 142
9 Appendice – Trasformazioni grafiche elementari 147
II-4 Limiti 156
1 I vari casi di limite 1561.1 Limite finito al finito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
1.1.1 Limite per x→ a+ (limite destro) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1561.1.2 Limite per x→ b− (limite sinistro) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1561.1.3 Limite per x→ c (limite bilatero) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
1.2 Limite finito all’infinito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1571.3 Limite infinito al finito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1571.4 Limite infinito all’infinito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
2 Alcuni teoremi sui limiti 159
3 Limiti di funzioni elementari 161
4 Algebra dei limiti 162
5 Confronti tra funzioni 1665.1 Confronti tra infiniti e infinitesimi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1685.2 Principi di eliminazione/sostituzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
6 Un limite fondamentale 172
7 Soluzioni degli esercizi 172
II-5 Funzioni continue 179
1 Funzioni continue: definizioni e prime proprieta 179
2 Continuita delle funzioni elementari 180
3 Funzioni continue in un intervallo. Teorema di Weierstrass 181
4 Limiti di funzioni composte 184
5 Limiti notevoli 187
6 Soluzioni degli esercizi 189
II-6 Derivate 194
1 Definizione di derivata 194
2 Calcolo di derivate 1972.1 Derivate di funzioni elementari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1982.2 Regole di derivazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
3 Il teorema del valor medio (di Lagrange) 201
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

INDICE 5
4 Studio del comportamento locale di una funzione 202
5 Il teorema di De l’Hopital 203
6 Derivate successive 206
7 Funzioni convesse 207
8 Formula di Taylor 2098.1 Alcuni sviluppi notevoli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
8.1.1 Funzione esponenziale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2108.1.2 Funzione logaritmica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2108.1.3 Funzione potenza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
9 Soluzioni degli esercizi 211
10 Appendice – Studio di funzione 216
II-7 Integrale indefinito 226
1 Primitive 226
2 Tecniche di integrazione I 2272.1 Linearita dell’integrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2272.2 Integrali quasi immediati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 228
3 Tecniche di integrazione II 2303.1 Formula di integrazione per parti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2303.2 Integrazione per sostituzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
4 Soluzioni degli esercizi 234
II-8 Integrale di Riemann 237
1 Definizione di integrale di Riemann 237
2 Condizioni di esistenza dell’integrale di Riemann 239
3 Proprieta dell’integrale di Riemann 239
4 Calcolo dell’integrale 2404.1 La funzione integrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2414.2 Il teorema fondamentale del calcolo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2414.3 Integrale di una f definita a tratti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2434.4 Funzione integrale di una f definita a tratti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
5 L’integrale di Riemann generalizzato 2455.1 Integrale generalizzato su intervallo non limitato . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2455.2 Criteri di convergenza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
6 Soluzioni degli esercizi 249
II-9 Successioni e serie 254
1 Successioni 2541.1 Limite di una successione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
2 Serie 2562.1 La serie armonica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2582.2 La serie geometrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

INDICE 6
3 Criteri per serie a termini non negativi 2603.1 Criteri del confronto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2613.2 Criterio del rapporto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
3.2.1 Lo sviluppo in serie di ex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2633.3 Criterio della radice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263
4 Criteri per serie a termini di segno non costante 264
5 Soluzioni degli esercizi 266
Parte III 271
III-1 Spazi vettoriali Rn 273
1 La struttura di spazio vettoriale 273
2 Dipendenza e indipendenza lineare 275
3 Base e dimensione di uno spazio vettoriale 277
4 Sottospazi 278
5 Prodotto interno 281
6 Soluzioni degli esercizi 285
III-2 Trasformazioni lineari e matrici 289
1 Trasformazioni lineari 289
2 Matrici 294
3 Immagine di una trasformazione lineare 299
4 Inversione di una trasformazione lineare 301
5 Soluzioni degli esercizi 303
III-3 Determinante e rango 305
1 Determinante di una matrice 305
2 Calcolo della matrice inversa 310
3 Calcolo del rango 312
4 Soluzioni degli esercizi 316
III-4 Sistemi di equazioni lineari 322
1 Sistemi di equazioni lineari 322
2 Alcuni risultati generali 3232.1 Il teorema di Rouche – Capelli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3232.2 Il teorema e la regola di Cramer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
3 Il calcolo delle soluzioni nel caso generale 324
4 Soluzioni degli esercizi 331
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

INDICE 7
Parte IV 343
IV-1 Funzioni reali di piu variabili 345
1 Insiemi in Rn 3451.1 Simmetrie degli insiemi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348
2 Funzioni da Rn a R 3502.1 Simmetrie di una funzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3532.2 Insiemi di livello e curve di livello . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3542.3 Restrizione di una funzione ad una curva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355
3 Limite 357
4 Continuita 358
5 Soluzioni degli esercizi 359
IV-2 Forme quadratiche 364
1 Forme quadratiche 364
2 Segno di una forma quadratica 3652.1 Il metodo dei minori principali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 366
3 Soluzioni degli esercizi 370
IV-3 Derivate delle funzioni di piu variabili 375
1 Derivate parziali 375
2 Regole di derivazione 379
3 Derivabilita e continuita 381
4 Differenziabilita 381
5 Derivate seconde e teorema di Schwarz 382
6 Soluzioni degli esercizi 384
IV-4 Massimi e minimi delle funzioni di piu variabili 388
1 Massimi e minimi liberi 388
2 Massimi e minimi vincolati 394
3 Soluzioni degli esercizi 400
4 Appendice – Interpolazione con il metodo dei Minimi quadrati 406
Indice analitico 409
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

Alcune note sulle dispense
Questo documento raccoglie tutte le dispense originarie del corso di Matematica. Per comodita qui continuo achiamare “dispensa” ognuna delle parti che costituiva inizialmente una dispensa a se stante.
Ogni dispensa riporta nel titolo la relativa parte del corso (in numero romano) e un numero progressivo. Ognidispensa e divisa in un certo numero di sezioni. A volte una sezione contiene delle sottosezioni.
Vi sono di tanto in tanto alcuni esempi, che dovrebbero aiutare a comprendere le nozioni appena esposte. Invito glistudenti a considerare con attenzione le nozioni teoriche prima di affrontare gli esempi. Cercare di imparare l’esempiopensando che esso sia una valida e completa alternativa alla nozione teorica e un classico grave errore.
Alcune sezioni contengono esercizi proposti, che sono indicati da scritture come Esercizio 0.1
Di questi esercizi viene fornita la soluzione nell’ultima sezione di ogni dispensa. A proposito degli esercizi svolti,raccomando di cercare autonomamente la soluzione, prima di andare a vedere quella proposta. Nel caso lo studenteabbia prodotto una risoluzione in tutto o in parte diversa da quella proposta e un ottimo esercizio quello di riesaminareattentamente le due alternative per capire se sono entrambe valide (e puo succedere) oppure se sono stati commessierrori. Sono grato a chi mi segnalera eventuali errori presenti nelle dispense.
Le dispense sono state scritte in LATEX.1 I grafici sono stati prodotti con il package PSTricks.2
1Si tratta, oltre a tutti gli altri pregi, di un free software. Chi fosse interessato puo averne una valida descrizione ad esempio alla paginahttp://www.latex-project.org/.
2Chi e interessato puo saperne di piu ad esempio collegandosi alla pagina http://tug.org/PSTricks/.

1 MOTIVAZIONI E OBIETTIVI
INTRODUZIONE
9
Introduzione
1 Motivazioni e obiettivi
Ho raccolto gli argomenti di questo corso in un certo numero di dispense, disponibili in rete.�
Le dispense sono scaricabili in due formati diversi. Nella pagina del corso trovi un file per ogni dispensa. Nellepagine e–learning le trovi tutte raccolte in un unico file, corredate da un indice generale ed un indice analitico, chepossono agevolarne la consultazione.
�
L’esperienza maturata in questi ultimi anni mi porta alla convinzione che molti studenti arrivino a frequentare ilcorso di Matematica con molte carenze su argomenti basilari che dovrebbero essere stati acquisiti alla scuola secondaria.Non sempre la colpa e interamente degli studenti. Sicuramente incide un purtroppo diffuso disordine con cui la materiaviene spesso svolta alla scuola secondaria, anche a causa di continui avvicendamenti di insegnanti diversi.
In questo corso mi trovo quindi il non facile compito di portare in primo luogo gli studenti al livello che dovrebberoavere alla fine della scuola secondaria e, successivamente, portarli ad approfondire gli argomenti tipici di un corsouniversitario.
Nei corsi successivi (Statistica in particolare, poi Matematica finanziaria e alcuni insegnamenti dell’area economica)sono richieste alcune semplici nozioni di matematica di base e a volte anche argomenti piu avanzati. Si pone quindiil problema che studenti poco attrezzati sulle basi devono affrontare in poco tempo anche questioni piu delicate, coni risultati che si possono intuire. Spesso accade che l’unico modo che rimane allo studente per superare l’ostacolo equello di imparare a memoria le cose, senza realmente capire la sostanza.
Con questo corso cerco quindi di raggiungere questo doppio obiettivo: richiamare le basi, facendo in modo chequeste restino acquisite, arrivando poi a toccare anche argomenti piu avanzati.
Ovviamente tra le basi e gli argomenti avanzati ci sono molte conoscenze che stanno nel mezzo e che devonologicamente essere affrontate (la matematica e una sequenza di conoscenze, in cui le precedenti sostengono quelle cheseguono).
Devo riuscire a fare questo in una cinquantina di ore di lezioni, diciamo teoriche, e 36 ore di esercitazioni.Penso che l’unico modo di riuscire nell’intento sia quello di affrontare i vari argomenti con un grado di dettaglio
piu blando rispetto a quanto si faceva fino a qualche tempo fa, puntando soprattutto a dare agli studenti conoscenzeoperative, piu che profondita teorica. Certamente la teoria non puo essere tralasciata e anzi molti studenti continue-ranno ad avere l’impressione che ci sia “tanta teoria”, ma vi assicuro che ho fatto il possibile per rendere operativi iconcetti. Piu di cosı, non sarebbe piu matematica.
Ho diviso il corso in quattro parti, in base alle affinita degli argomenti.La prima parte riguarda questioni che dovreste avere gia visto alla scuola secondaria. Non e solo un ripasso: questi
argomenti fanno parte integrante del programma del corso di Matematica.3
Non serve che vi dica ora quali sono gli argomenti delle quattro parti, li vedremo un po’ alla volta.4
In questa lezione introduttiva ho raccolto alcuni concetti preliminari elementari, un po’ di simbologia altrettantoelementare, qualche esempio di uso del simbolo di sommatoria e qualche nozione di calcolo combinatorio.
Cominciamo con qualche riga di carattere piu generale e poi un po’ di simbologia essenziale. Ovviamente con ilprocedere del corso verranno via via definiti altri nuovi simboli.
1.1 Definizioni, Teoremi, . . .
Avete senz’altro gia incontrato questi termini, ma desidero parlarne brevemente per fare un po’ di chiarezza e sgombrareil campo da possibili equivoci. La matematica non e fatta di formule e non e certamente fatta di calcolo. Il calcolo eil prodotto piu “volgare” della matematica, il prodotto di quotidiano utilizzo.
Il grosso della matematica e fatto di risultati teorici relativi a oggetti tipicamente altrettanto teorici. Questirisultati si chiamano teoremi (quelli importanti). Un teorema e un risultato che si puo dimostrare, a partire daconcetti e risultati precedentemente definiti e dimostrati. I concetti vengono definiti appunto attraverso le definizioni.
3Dopo anni in cui, anche in altre sedi universitarie, ho provato a ripassare questi argomenti, in precorsi o altro, dandoli poi per scontatie non richiedendo quindi agli studenti di provarmi che essi sono stati acquisiti, da quando sono a Vicenza mi sono deciso ad inserire taliargomenti nel programma d’esame, nella speranza che gli studenti capiscano che sono cose da studiare (o ristudiare) con molta attenzione.Spero con questo di evitarvi un sacco di problemi in seguito.
4Il programma completo e disponibile in rete nella pagina del corso.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MOTIVAZIONI E OBIETTIVI
INTRODUZIONE
10
La matematica definisce rigorosamente ogni concetto che studia, qualche volta si limita ad ammetterne l’esistenza,molte volte ne fissa alcune proprieta. Quando un concetto e stato definito non lo si puo piu modificare, non si puodire “pensavo che avesse anche quest’altra proprieta”. Se e cosı occorre cambiare la sua definizione.
I teoremi dimostrano che, date certe ipotesi (ben precise anch’esse), allora valgono certe conseguenze, che si diconola tesi del teorema. E fondamentale capire che quelle conseguenze valgono in quelle ipotesi: non si puo credereche si abbiano le stesse conseguenze senza quelle ipotesi o in altre ipotesi. E un classico errore, che molti studenticommettono, ricordare magari bene la tesi di un teorema ma dimenticare in quali ipotesi essa e vera. Troverete spessodetto “si puo dimostrare che . . . ”. Ho scelto di non presentare le dimostrazioni dei teoremi (tranne pochissimi casi).Scelta drastica, forse criticabile, ma purtroppo il numero di ore del corso e finito e oltretutto di due sole cifre.
In queste dispense troverete qua e la anche proposizioni : sono risultati, non cosı importanti da essere chiamatiteoremi, ma della stessa natura, cioe affermazioni che possono essere dimostrate.
Nell’esposizione ho sparso moltissime osservazioni e molti esempi : e importante che li affrontiate con la stessaattenzione con cui affrontate il resto.
Un consiglio: non limitatevi a leggere queste dispense. Fatelo pure in una prima fase, per avere un’idea di checosa c’e, ma poi ricominciate daccapo con la volonta di riflettere su quanto leggete, facendovi continuamente domandeper capire anche quello che non c’e scritto. E stato uno dei miei obiettivi quello di corredare definizioni, teoremi,procedimenti di calcolo, . . . con molti spunti di riflessione che solitamente non si trovano nei testi di matematicaperche ritenuti forse ovvi e quindi “lasciati al lettore”. E non e per mancanza di fiducia nei vostri confronti, ma soloperche in questi ultimi anni mi sono reso conto che non e proprio possibile (oltre che corretto) pensare che gli studentiarrivino da soli a porsi questioni che sono magari ovvie, ma per chi lavora con la matematica da vent’anni.
La matematica, oltre che di teoremi, definizioni, . . . e fatta anche di simbologia. Meglio, non e che quest’ultimasia essa stessa matematica, ma e per cosı dire il linguaggio con cui vengono spesso espresse le nozioni matematiche. Edoveroso richiamare ora qualche prima notazione indispensabile.
1.2 Simbologia di base
Tra un po’ richiamero la simbologia riguardante gli insiemi. Prima pero focalizzo l’attenzione sui simboli di disugua-glianza, che talvolta non sono intesi correttamente dagli studenti.
• Il simbolo “<” significa “minore”; se scrivo a < b significa che il numero a e minore del numero b
• Il simbolo “≤” significa “minore o uguale”; se scrivo a ≤ b significa che il numero a e minore oppure uguale alnumero b. Attenzione: la disuguaglianza a ≤ b e vera quindi se a < b oppure se a = b. 5
• Analogamente con i simboli “>” e “≥”, che significano rispettivamente “maggiore” e “maggiore o uguale”.
Osservazione Talvolta, scrivendo a < b, si legge “a strettamente minore di b”, per far notare che non sono uguali.Si dice anche che e una disuguaglianza stretta. Invece a ≤ b e una disuguaglianza larga.
Se scrivo x > 0, posso leggere “x maggiore di zero” oppure “x positivo”. Se scrivo x ≥ 0, posso leggere “x maggioreo uguale a zero” oppure “x non negativo”.
Osservazione Abituatevi a saper leggere ed utilizzare questi simboli nei due versi: se voglio dire ad esempio che ae maggiore o uguale a b, posso scrivere indifferentemente a ≥ b oppure b ≤ a.
1.3 Simboli logici
Sono molto comodi per una scrittura piu sintetica alcuni simboli, che chiamero simboli logici.A volte usero i simboli logici di congiunzione e disgiunzione “∧” e “∨”. Sono i celebri and/or, molto utilizzati
anche in informatica.Il simbolo ∧ significa e (congiunzione forte), il simbolo ∨ significa o (oppure) (congiunzione debole).Ad esempio, se n e un numero naturale,6 scrivendo
n > 5 ∧ n < 10
affermo che n e maggiore di 5 e nello stesso tempo minore di 10, quindi che e compreso tra 6 e 9 (ossia puo essere 6,7, 8 oppure 9). Scrivendo
n < 10 ∨ n > 10
5Quindi, ad esempio, le due scritture 2 < 3 e 2 ≤ 3 sono vere entrambe.6I numeri naturali, che formano il primo insieme numerico fondamentale, sono 1,2,3,4,. . . .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MOTIVAZIONI E OBIETTIVI
INTRODUZIONE
11
affermo che n e minore oppure maggiore di 10 (quindi che n non e 10). La scrittura equivale quindi a n 6= 10. Si notiche, invece, se scriviamo n < 10 ∧ n > 10, chiediamo che n sia minore e nello stesso tempo maggiore di 10, cosa cherisulta impossibile.
A volte faro uso di altri due importanti simboli (detti quantificatori): “∃” e “∀”.Il simbolo ∃ vuol dire “esiste almeno un”;7 il simbolo ∀ vuol dire “per ogni”.Avverto subito che confondere questi due simboli (e cioe confondere il significato di cio che si afferma) costituisce
un grave errore in matematica, come dovrebbe essere anche nella vita di tutti i giorni.8
Tra poco vediamo qualche esempio di utilizzo dei quantificatori in proposizioni di carattere matematico. Vediamoneprima pero qualche esempio nella vita comune.
Consideriamo la proposizione “in TV c’e almeno un programma che mi piace”. E evidente che c’e di mezzo ilquantificatore ∃. Qual e la negazione di tale proposizione? Naturalmente e: “non c’e alcun programma che mi piace”,e cioe che “tutti i programmi non mi piacciono,”9 dove chiaramente si ha a che fare con il quantificatore ∀.
Se ritengo falsa la proposizione “in TV mi piacciono tutti i programmi”, e perche “c’e almeno un programma chenon mi piace”;10 anche qui notiamo che i due quantificatori si scambiano: nella prima c’e il ∀, nella negazione c’e l’∃.
Qualche esempio matematico di utilizzo dei simboli logici lo presentero piu avanti (devo prima fornire un veloceripasso sulla simbologia degli insiemi e sugli insiemi numerici fondamentali, cosa che faro tra breve).
E opportuno ora riflettere brevemente su qualche esempio di implicazione, dato che nel seguito incontreremo nume-rosi casi in cui un risultato matematico rilevante viene espresso attraverso un’implicazione. Non essere perfettamenteconsapevoli di che cosa significa implicazione puo portare a gravi fraintendimenti.
Il simbolo “=⇒” significa “implica”.Se scrivo P =⇒ Q, dove P e Q sono due proprieta di un certo oggetto, due condizioni, in generale due proposizioni,
significa che la proprieta P implica la proprieta Q, cioe che se P e vera, allora e vera anche Q.Se dico “vado al mare se non piove” sto affermando che “se non piove allora vado al mare”. Ci sono altri modi
equivalenti per esprimere questa affermazione, modi classici della matematica. Uno di questi e dire che “non piove” econdizione sufficiente perche io vada al mare, e cioe: perche io vada al mare basta che non piova.
Si rifletta un po’ per capire che cio equivale a dire che “se non vado al mare allora piove”.11
Altra proposizione puo essere “vado al mare solo se fa bello”. Qui “fa bello” e condizione necessaria perche iovada al mare, cioe ci vado solo in questo caso. Equivale a dire che “se vado al mare allora necessariamente fa bello”.Equivale anche a dire che “se non fa bello allora non vado al mare”.
Si faccia attenzione che “se non piove vado al mare” non equivale a dire “se piove allora non vado al mare”: inaltre parole la prima vuol dire che se non piove ci vado sicuramente, ma potrei anche andarci se piove.
Gli esempi illustrano questa situazione generale: se indichiamo con P e Q due condizioni, due proprieta, dueproposizioni, etc. e con nonP e nonQ le rispettive negazioni, allora nell’implicazione
P =⇒ Q
possiamo dire che:
• P e condizione sufficiente per la verita di Q
• Q e condizione necessaria per la verita di P 12
• L’implicazione equivale all’implicazione (detta contronominale) nonQ =⇒ nonP .
Osservazione Naturalmente, come conseguenza di questo ultimo punto, se vale l’implicazione P =⇒ nonQ, essaequivale a Q =⇒ nonP . 13
Se, oltre a valere P =⇒ Q, vale anche l’implicazione inversa, cioe Q =⇒ P , si dice che vale la doppia implicazione, oche una e vera se e solo se e vera l’altra, e si scrive P ⇐⇒ Q. In questo caso quindi si dice anche che una e condizionenecessaria e sufficiente per l’altra.
In matematica si incontrano spesso proposizioni che sono implicazioni (e le piu importanti si chiamano teoremi).Vediamo qualche semplice esempio di implicazioni matematiche.
7Per dire esiste soltanto un si scrive ∃!.8E ben diverso dire (e fare): mi lavo tutti i giorni dell’anno oppure mi lavo almeno un giorno dell’anno.9Mi raccomando, non si pensi che la negazione sia “c’e almeno un programma che non mi piace”.
10Analogamente a prima, non si deve pensare che la negazione sia “dei programmi non ce n’e uno che mi piaccia”.11Si tratta di un’implicazione logica, non di implicazione causale: l’ultima implicazione non significa che se non vado al mare allora causo
la pioggia.12Si potrebbe dire anche “P e vera solo se e vera Q”.13Se piove allora non vado al mare equivale a dire se vado al mare allora non piove. Ovviamente si tratta sempre di implicazioni logiche,
non di implicazioni di causa: cioe l’ultima implicazione non significa che se vado al mare allora faccio sı che non piova.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 INSIEMI
INTRODUZIONE
12
Esempi Si consideri l’implicazione seguente, relativa ai numeri naturali:
n e divisibile per 4 =⇒ n e divisibile per 2.
Essa e certamente vera, dato che se un numero e divisibile per 4, significa che e un multiplo di 4, e quindi e multiplodi 2. Ovviamente non vale l’implicazione inversa, dato che ad esempio 6 e divisibile per 2 ma non per 4.14
Si consideri l’implicazione, relativa ad un numero naturale n:
n e pari =⇒ n2 e pari.
Si tratta di un’implicazione vera, in quanto, se n e divisibile per 2 allora n2 e divisibile per 4 e quindi e pari. Valeanche il viceversa? Non e immediato come prima, ma la risposta e sı. Si provi a trovare una giustificazione rigorosa.Possiamo scrivere quindi
n e pari ⇐⇒ n2 e pari (e quindi anche n e dispari ⇐⇒ n2 e dispari).
Si considerino le due implicazioni, relative ai numeri naturali:15
n e primo =⇒ n2 + 1 e primo oppure n e primo =⇒ n2 + 2 e primo
E facile trovare un controesempio per entrambe, e quindi verificare che sono false. Invece l’implicazione
n e primo =⇒ 1 · 2 · 3 · . . . · n+ 1 e primo
e vera. Si provi a trovare una giustificazione rigorosa.
2 Insiemi
Ora vediamo alcune nozioni di base riguardanti gli insiemi. Non esiste una vera e propria definizione formale diinsieme. Il concetto si assume “intuitivo”: si tratta di un qualunque gruppo di oggetti, numeri, etc. Gli oggetti checostituiscono un insieme si dicono gli elementi dell’insieme. Gli elementi si indicano solitamente con lettere minuscole,gli insiemi con lettere maiuscole. Si dice allora che un elemento a appartiene all’insieme A e si scrive, come noto,
a ∈ A.
La scritturaa, b ∈ A
dice che a e b sono elementi dell’insieme A. Per dire che c non e elemento di A, cioe che c non appartiene ad A, siscrive
c /∈ A.Talvolta (non sempre) e possibile definire un insieme elencando i suoi elementi. Ad esempio, se voglio dire che
l’insieme A e costituito dagli elementi a, b, c, d e che l’insieme B e costituito dai numeri naturali da 1 a 10, possoscrivere
A = {a, b, c, d} e B = {1, 2, 3, . . . , 10}. 16
Nel secondo caso non vengono elencati proprio tutti gli elementi, intendendo con i puntini che anche tutti i numeri(naturali) compresi tra 3 e 10 fanno parte dell’insieme B.
Se l’insieme e infinito17 non e possibile definirlo elencando tutti i suoi elementi. Possiamo pero ad esempio ancorascrivere
N = {1, 2, 3, 4, . . .},intendendo con i puntini tutti i numeri naturali che vengono dopo il 4. Questa puo essere presa quale ”definizioneintuitiva” dell’insieme dei numeri naturali.
E comodo definire anche un insieme che non ha elementi: si chiama insieme vuoto e si indica con il simbolo ∅.14Questo, cioe il 6, viene detto un controesempio. Si tratta di un esempio che prova che una certa affermazione non e vera, in questo
caso l’affermazione “n e divisibile per 2 =⇒ n e divisibile per 4”. Ovviamente basta un solo controesempio per provare che un certo fattonon e vero.
15Si ricordi che un numero naturale n maggiore di uno e primo se e divisibile solo per 1 e per n. I primi numeri primi sono 2,3,5,7,11,13,. . .16Attenzione che l’ordine in cui scrivo gli elementi non e rilevante, quindi {a, b, c, d} = {d, c, b, a}.17Un insieme e finito se ha un numero finito di elementi, e infinito se ne ha infiniti.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 INSIEMI
INTRODUZIONE
13
Un insieme si puo definire indicando una o piu proprieta dei suoi elementi. Ad esempio la scrittura
A = {n ∈ N : n ≤ 100} 18
dice che l’insieme A e dato da tutti i numeri naturali che sono minori o uguali di 100. E molto piu comodo che nonelencare tutti i numeri naturali da 1 a 100. Si poteva anche, come visto, scrivere A = {1, 2, 3, . . . , 100}.
Altro esempio: si ha{n ∈ N : n2 < 100} = {1, 2, 3, 4, 5, 6, 7, 8, 9}.
Si faccia sempre attenzione alla differenza tra < e ≤.Se A e B sono due insiemi, puo succedere che A sia contenuto in B, cioe che ogni elemento di A appartenga anche
a B. Si dice allora che A e sottoinsieme di B e si scrive
A ⊂ B.
Esempio Ad esempio abbiamo che {3, 4, 5} ⊂ N. L’insieme vuoto e sottoinsieme di qualunque altro insieme, quindi,se A e un insieme, possiamo scrivere ∅ ⊂ A.
Se scriviamo A = B intendiamo che i due insiemi sono uguali e questo significa che si ha contemporaneamenteA ⊂ B e B ⊂ A, cioe che ogni elemento di A sta anche in B e viceversa ogni elemento di B sta anche in A.
Osservazione Tutti i simboli visti finora possono essere usati nei due versi. Quindi si puo trovare talvolta scrittoA ∋ a (vuol dire a ∈ A), oppure A ⊃ B (vuol dire B ⊂ A).
2.1 Intersezione, Unione, Differenza, Complementare
Definizione Dati due insiemi A e B, di chiama intersezione di A e B l’insieme degli elementi che appartengonoad A e a B, cioe ad entrambi. Si scrive
A ∩B = {x : x ∈ A e x ∈ B}.
Definizione Dati due insiemi A e B, di chiama unione di A e B l’insieme degli elementi che appartengono ad Aoppure a B, cioe ad almeno uno dei due. Si scrive
A ∪B = {x : x ∈ A oppure x ∈ B}.
Esempio A titolo di esempio, se
A = {n ∈ N : n ≤ 10} e B = {n ∈ N : n ≥ 5}
alloraA ∩B = {5, 6, 7, 8, 9, 10} e A ∪B = N.
Puo succedere che due insiemi non abbiano elementi in comune. In questo caso si scrive A ∩ B = ∅. Ad esempio,si ha
{n ∈ N : n e dispari} ∩ {n ∈ N : n e divisibile per 6} = ∅.
Definizione Se A e B sono insiemi, si chiama differenza A \B l’insieme degli elementi di A che non appartengonoa B.
Esempio Se A e l’insieme dei numeri naturali pari e B e l’insieme dei naturali divisibili per 6, allora A\B e l’insiemedei numeri naturali che sono divisibili per 2 ma non per 3.
Se voglio scrivere i numeri naturali diversi da 1 posso scrivere N \ {1}.Definizione Se A e un sottoinsieme dell’insieme X , si chiama insieme complementare di A (in X) l’insieme deglielementi di X che non appartengono ad A.
Esempio Ad esempio, nell’insieme N, il complementare dei numeri pari e l’insieme dei numeri dispari. Il comple-mentare dei numeri primi e l’insieme fatto dai numeri che si possono scrivere come prodotto di due numeri entrambimaggiori di 1.
Il complementare di X in X e l’insieme vuoto ed il complementare del vuoto e tutto l’insieme X .
18La scrittura si legge cosı: A e l’insieme degli n appartenenti ad N tali che n e minore o uguale di 100. In particolare i due punti “:” sileggono con “tale/i che”.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 INSIEMI
INTRODUZIONE
14
Osservazione Si puo dire che il complementare di A in X e l’insieme differenza X \ A. Per indicare l’insiemecomplementare di A in X possiamo scrivere X \A oppure usare il simbolo Ac, sottintendendo l’insieme X che contieneA.
Sono interessanti due formule che riguardano l’unione, l’intersezione e il complementare di insiemi, le cosiddetteleggi di De Morgan. Esse dicono che
(A ∩B)c = Ac ∪Bc e (A ∪B)c = Ac ∩Bc.
Sostanzialmente affermano che il complementare dell’intersezione e uguale all’unione dei complementari e che ilcomplementare dell’unione e uguale all’intersezione dei complementari. E un utile esercizio verificare la validita diqueste formule attraverso la rappresentazione degli insiemi con i soliti diagrammi.
2.2 Insieme delle parti
Definizione Dato un insieme A, si chiama insieme delle parti di A l’insieme di tutti i sottoinsiemi di A.19
Osservazione L’insieme delle parti di A e detto anche insieme potenza di A, e si indica con PA o con 2A. Ilmotivo della seconda notazione viene illustrato tra breve.
Esempio Se A = {1, 2, 3}, allora si ha
PA ={
∅, {1}, {2}, {3}, {1, 2}, {1, 3}, {2, 3}, A}
.
Si osservi la notazione: occorrono le parentesi graffe esterne, dato che PA e un insieme, e le parentesi graffe interne,dato che gli elementi di PA sono a loro volta insiemi.
Osservazione L’insieme delle parti si dice anche insieme potenza perche, se A e un insieme di n elementi, alloraPA ha esattamente 2n elementi (nell’esempio precedente PA ha 8 = 23 elementi). Per questo motivo PA vieneindicato anche con 2A.
Esempio Si puo considerare l’insieme delle parti di un insieme infinito, come ad esempio le parti di N, cioe l’insiemedi tutti i sottoinsiemi di N. 20 Ad esempio l’insieme dei numeri pari e un elemento di 2N.
2.3 Insiemi numerici fondamentali
Molto spesso in questo corso avremo a che fare con insiemi numerici, cioe insiemi i cui elementi sono numeri. Ab-biamo gia incontrato e usato l’insieme N dei numeri naturali. Completiamo le definizioni degli altri insiemi numericifondamentali.
Altro importante insieme numerico e l’insieme dei numeri interi:
Z = {. . . ,−3,−2,−1, 0, 1, 2, 3, . . .}.
Possiamo dire che N ⊂ Z.L’insieme dei numeri razionali si puo invece definire come
Q ={m
n: m,n ∈ Z e n 6= 0
}
. 21
Si tratta dei numeri detti anche frazioni, che avete incontrato gia alle scuole elementari. L’insieme Q e un insiemeabbastanza ricco di proprieta.22
Per sviluppare pero concetti matematici ad un buon livello le frazioni non sono sufficienti, per un motivo non deltutto evidente nella vita di tutti i giorni, ma noto peraltro all’uomo da piu di duemila anni. Cerco di evidenziare talemotivo senza scendere troppo in profondita.
19Si ricordi che, dato un insieme A, esso, tra i suoi sottoinsiemi, ha l’insieme vuoto e l’insieme A stesso. Possiamo quindi scrivere ∅ ∈ PA,dato che ∅ ⊂ A e analogamente A ∈ PA, dato che A ⊂ A. Si noti che qui la convenzione di indicare con lettere minuscole gli elementidell’insieme non puo essere rispettata, dato che gli elementi dell’insieme delle parti sono insiemi.
20Ovviamente l’insieme delle parti di N ha infiniti elementi.21La scrittura si legge: Q e l’insieme delle frazioni m
nin cui m ed n sono numeri interi ed n non e zero.
22Si pensi ad esempio che in Q la divisione si puo quasi sempre fare, mentre non e cosı in Z. Oppure, ma la questione e solo apparentementediversa, un’equazione di primo grado ha sempre soluzione se questa la cerchiamo in Q, mentre questo non e vero in Z.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 INSIEMI
INTRODUZIONE
15
Una delle funzioni pratiche piu comuni dei numeri e la possibilita che essi ci danno di fare delle misure dellecose, cioe di quantificare alcune caratteristiche degli oggetti che ci circondano. Tale necessita nacque fin dagli alboridell’umanita, non appena alcuni nostri progenitori dovettero contare ad esempio il numero di pecore in loro possesso.E fin qui bastavano i numeri naturali. Quando i nostri antenati non furono piu nomadi ma cominciarono a coltivareil terreno, ecco che nacque la necessita di misurare l’estensione di un campo. E qui la questione e gia molto piucomplicata.
Se vogliamo misurare le lunghezze, non e evidente che le frazioni non bastano. Pero i matematici antichi si poseroquesta domanda: se un quadrato ha il lato che misura 1 (non importa che sia un palmo, una yarda o un metro),quanto misura la sua diagonale? Non e difficile provare (chi e curioso venga a ricevimento a chiedermelo) che nonci sono frazioni che possano esprimere tale misura. Uno puo accontentarsi e dire: misura circa 1,41 (palmi, yarde ometri). Il matematico si chiede qual e il valore esatto e per esprimere tale valore ha inventato i numeri reali.23
I numeri reali, che peraltro voi avete gia incontrato alla scuola secondaria, completano, per cosı dire, i numerirazionali e ci permettono di esprimere in modo esatto le misure (delle lunghezze, delle aree, dei volumi). Ribadisco chei numeri reali sono uno strumento teorico, astratto; di essi si possono pero dare ottime approssimazioni con numerirazionali.
Per scendere un po’ piu in concreto e cercare di “vedere” un numero reale,24 posso ricordare che i numeri razionalisono quelli che si possono scrivere in forma decimale (con la virgola per intenderci) con un numero finito di cifre dopola virgola o con un numero infinito di cifre ma che si ripetono periodicamente da un certo punto in poi (i cosiddettinumeri periodici).
I numeri reali invece sono rappresentabili con infinite cifre dopo la virgola,25 senza che ci siano periodicita. Deinumeri
√2, π, e, che sono tra i numeri reali piu famosi, si puo dare una rappresentazione decimale soltanto approssimata,
nel senso che non si possono conoscere tutte le loro cifre decimali.L’insieme dei numeri reali si indica con R. Sulla struttura dei reali diremo piu avanti. Le loro proprieta piu
importanti dovrebbero pero essere note agli studenti dalla scuola secondaria.
Insiemi numerabili e insiemi non numerabili
Qui tocchiamo soltanto una questione difficile. Ne parlo, anche se brevemente, perche questa sara una questioneimportante quando incontrerete nel corso di Statistica la teoria della Probabilita.
L’insieme N e un insieme infinito, cosı come lo e l’insieme R. Puo sembrare strano chiedersi quale tra i due insiemiha piu elementi, ma e una domanda sensata e difficile. Occorre precisare pero come possiamo fare per stabilire qualedei due insiemi e piu numeroso. Con gli insiemi finiti e facile: basta confrontare il numero di elementi dell’uno conquello dell’altro. Con gli insiemi infiniti possiamo dire che hanno “lo stesso numero di elementi” se possiamo metterein corrispondenza biunivoca gli elementi di un insieme con quelli dell’altro.26 Se questo non e possibile allora unodei due insiemi e piu numeroso dell’altro.
Prendiamo in considerazione ad esempio i numeri naturali (N) e l’insieme dei naturali pari, che indico con P.Sono due insiemi infiniti. Consideriamo la corrispondenza che associa ad ogni numero naturale il suo doppio e adogni numero pari la sua meta. Non e difficile convincersi che si tratta di una corrispondenza biunivoca tra N e P.Conclusione: i numeri naturali sono tanti quanti i numeri pari. La cosa puo per certi versi sembrare strana, dato che epur vero che i numeri pari sono un sottoinsieme dei numeri naturali. Ma questo e perche noi siamo abituati ad insiemifiniti, per i quali non puo succedere che, se B e sottoinsieme di A, ci sia una corrispondenza biunivoca tra A e B. Pergli insiemi infiniti puo quindi essere che un insieme e in corrispondenza biunivoca con una sua parte.
Definizione Gli insiemi che possono essere messi in corrispondenza biunivoca con l’insieme N dei naturali si diconoinsiemi numerabili. Gli insiemi infiniti che non possono essere messi in corrispondenza biunivoca con l’insieme N sidicono insiemi non numerabili.27
Veniamo ora alle cose piu interessanti. Si puo dimostrare che N e Z possono essere messi in corrispondenzabiunivoca, e quindi i naturali sono tanti quanti gli interi.28
23Che i numeri reali esistano veramente o che siano un’invenzione e una domanda mal posta.24Noi in effetti non vediamo i numeri, nemmeno quelli naturali, vediamo la loro rappresentazione. Il numero naturale e un concetto,
un’idea, e cosı (a maggior ragione) i numeri interi, razionali, reali, . . . .25Sarebbe meglio dire “sarebbero rappresentabili”, dato che non possiamo in concreto scrivere infinite cifre decimali. Nemmeno con il
calcolatore piu potente al mondo sara mai possibile rappresentare un numero reale non razionale fornendo tutte le sue cifre decimali. Nelcalcolo usiamo sempre approssimazioni dei numeri reali, cioe usiamo in realta solo numeri razionali.
26Vuol dire che ad ogni elemento del primo insieme possiamo associare un elemento del secondo e, viceversa, ad ogni elemento del secondopossiamo associare uno del primo. Dobbiamo questa idea, cioe questo modo di confrontare gli insiemi infiniti, al grande matematico tedescoGeorg Cantor, il padre della moderna teoria degli insiemi.
27Gli elementi di un insieme numerabile possono essere elencati, cioe disposti uno dopo l’altro, quelli non numerabili no, cioe un qualunquetentativo di elencarli ne lascia fuori alcuni.
28Una semplice legge di corrispondenza biunivoca tra i naturali e gli interi e ad esempio
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 INSIEMI
INTRODUZIONE
16
Anche N e Q possono essere messi in corrispondenza biunivoca, come prova una celebre dimostrazione di Cantor.Quindi in altre parole Z e Q sono insiemi numerabili, al pari di N
Invece N ed R non possono essere messi in corrispondenza biunivoca, come prova un’elegantissima e brevissimadimostrazione di Cantor.29
Il fatto che l’insieme R non sia numerabile rende piu complicate le cose ad esempio quando si vuole definire laprobabilita. Pero definirla sui reali e in certi campi assolutamente necessario.
Considerando che Q e un sottoinsieme di R, che Q e numerabile ed R invece e non numerabile, si intuisce chela non numerabilita di R e dovuta alla non numerabilita dei numeri reali che non sono razionali: questi si chiamanonumeri irrazionali.
Ora per concludere questa sezione vediamo ancora qualche esempio di uso dei simboli logici.
• Per definire l’inclusione tra insiemi possiamo scrivere
B ⊂ A significa che ∀b ∈ B, b ∈ A
(si legge: “per ogni b appartenente a B, b appartiene ad A”).
• La proposizione∃x ∈ R : x2 = −1
si legge: “esiste almeno un x reale tale che x2 e uguale a −1”, ed e chiaramente falsa. La sua negazione, che eovviamente vera, e: ∀x ∈ R, x2 6= −1.
Osservazione Continuo ad utilizzare i due punti con il significato di “tale che”. Faro sempre uso di questanotazione.
• La proposizione∀x ∈ R, x2 > 0
si legge: “per ogni x reale, x2 e positivo”, ed e falsa. La sua negazione e: ∃x ∈ R : x2 ≤ 0.30 La negazione evera, dato che la rende vera x = 0.
• La proposizione∃r ∈ Q : r2 = 2
si legge: “esiste almeno un r razionale tale che r2 e uguale a 2”, e dovrebbe essere noto allo studente che e falsa.
• Invece la proposizione∀r ∈ Q, r2 ∈ Q,
che si legge: “per ogni r razionale, r2 e ancora razionale”, e vera.
• La proposizione∃x ∈ R : x /∈ Q
si legge: “esiste almeno un x reale che non e razionale”, ed e vera (tutti i numeri irrazionali ne sono un esempio).
• La proposizione∃!x ∈ R : x /∈ Q
si legge: “esiste un solo x reale che non e razionale”, ed e appunto falsa (gli irrazionali sono infiniti).
• La proposizione∀r ∈ Q, r ∈ R
si legge: “per ogni r razionale, r e anche reale”, ed e vera.
f(n) =
{n/2 se n e pari
−(n− 1)/2 se n e dispari.
1 2 3 4 5 6 7 . . .l l l l l l l0 1 −1 2 −2 3 −3 . . .
29La dimostrazione usa il fatto che una possibile rappresentazione dei reali e quella degli allineamenti decimali (periodici e non periodici).Se tale rappresentazione viene fatta in base 2, cioe usando solo le cifre 0 e 1, ad ogni reale e associata una sequenza (spesso infinita) di 0 e1. Bene, Cantor dimostra che i numeri naturali non si possono mettere in corrispondenza biunivoca con le sequenze di 0 e 1.
30Si noti e si ricordi bene che la negazione di x > 0 e x ≤ 0, dato che sono tre le possibilita: x positivo, negativo o nullo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 INSIEMI
INTRODUZIONE
17
• Si consideri la proposizione∀n ∈ N ∃m ∈ N : m > n.
Essa e vera e dice in pratica che i numeri naturali sono infiniti. Quale sarebbe la sua negazione?31
• Infine la proposizione∀n ∈ N e ∀y ∈ R, y ≥ 0 ∃!x ∈ R, x ≥ 0 : xn = y
si legge: “per ogni numero naturale n e per ogni y reale non negativo, esiste un unico reale non negativo x cheelevato alla n mi da y”. La proposizione e vera ed e cio su cui si fonda la definizione, che rivedremo piu avanti,di radice n-esima di un numero reale non negativo.
Quali ulteriori esempi di utilizzo dei simboli logici, rivediamo alcune definizioni insiemistiche viste poco fa.
⊲ Intersezione di insiemi. Possiamo definire l’intersezione di A e B con
A ∩B = {x : x ∈ A ∧ x ∈ B}
(si legge: A ∩B e l’insieme degli x tali che x sta in A e anche in B).
⊲ Unione di insiemi. Possiamo definire l’unione di A e B con
A ∪B = {x : x ∈ A ∨ x ∈ B}
(si legge: A ∪B e l’insieme degli x tali che x sta in A oppure in B).
⊲ Differenza di insiemi. Possiamo scrivere
A \B = {x : x ∈ A ∧ x /∈ B}
(si legge: A \B e l’insieme degli x tali che x sta in A ma non sta in B).
Da ultimo, un paio di implicazioni. Si consideri l’implicazione
A ∪B = A =⇒ B ⊂ A.
Essa e vera, in quanto puo essere dimostrata.32
Lo studente dimostri che vale in realta la doppia implicazione, cioe A ∪B = A⇐⇒ B ⊂ A.Si consideri l’implicazione
x < 10 =⇒ x2 < 100.
Qui occorre chiarire una cosa fondamentale: in quale insieme numerico consideriamo l’implicazione. Lo studenteosservi che, se la consideriamo in N (cioe se x ∈ N), l’implicazione e vera mentre, se la consideriamo in R (o anchesolo in Z), essa e falsa e invito gli studenti a trovare un controesempio.
2.4 Intervalli della retta reale
Anticipo una notazione riguardante particolari sottoinsiemi di R: gli intervalli. Nel corso, parlando di sottoinsiemi diR, avremo quasi sempre a che fare con intervalli.
Supponiamo che a e b siano due numeri reali fissati, con a ≤ b. Per indicare gli intervalli, usero le seguenti notazioni,con il significato a fianco riportato:
• (a, b) = {x ∈ R : x > a ∧ x < b} = {x ∈ R : a < x < b}
• [a, b] = {x ∈ R : x ≥ a ∧ x ≤ b} = {x ∈ R : a ≤ x ≤ b}
• [a, b) = {x ∈ R : x ≥ a ∧ x < b} = {x ∈ R : a ≤ x < b}31La negazione, che e falsa, sarebbe che c’e un n maggiore o uguale di tutti gli altri numeri naturali, e cioe in simboli:
∃n ∈ N : ∀m ∈ N si ha m ≤ n.
Si noti che la negazione si ottiene scambiando i quantificatori e scrivendo la negazione delle condizioni presenti (∀ diventa ∃, ∃ diventa ∀ em > n diventa m ≤ n.)
32Se A ∪ B = A, allora A ∪ B ⊂ A, e quindi ogni elemento dell’insieme A ∪ B, sia che stia in A, sia che stia in B, deve appartenere adA, e questo prova che B ⊂ A.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOMMATORIE E ALTRO
INTRODUZIONE
18
• (a, b] = {x ∈ R : x > a ∧ x ≤ b} = {x ∈ R : a < x ≤ b}
• (a,+∞) = {x ∈ R : x > a}
• [a,+∞) = {x ∈ R : x ≥ a}• (−∞, b) = {x ∈ R : x < b}
• (−∞, b] = {x ∈ R : x ≤ b}
• (−∞,+∞) = R
Osservazione Si faccia attenzione che +∞ e −∞ non rappresentano numeri reali. Non c’e quindi il numero reale+∞ o il numero reale −∞ e non si puo scrivere x = +∞ o x = −∞.
Osservazione Gli intervalli non costituiscono tutti i possibili sottoinsiemi di R, cioe in altre parole ci sono sottoin-siemi di R che non sono intervalli (come dovrebbe essere ovvio). Esempi di sottoinsiemi di R che non sono intervallisono
N , Z , Q , (0, 1) ∪ (1, 2). 33
Si noti che l’intersezione di due intervalli e sempre un intervallo (oppure l’insieme vuoto), mentre l’unione di dueintervalli puo essere un intervallo oppure no. Anche la differenza di due intervalli puo essere un intervallo oppure no.Lo studente provi a costruire alcuni esempi e ragionare su quanto affermato.
Osservazione Gli intervalli del tipo
(a, b) , [a, b] , [a, b) , (a, b]
sono intervalli limitati. Quelli del tipo
(a,+∞) , [a,+∞) , (−∞, b) , (−∞, b) , (−∞,+∞)
sono intervalli illimitati. Non ci si confonda tra i concetti di illimitato e infinito. Potremmo dire che limitato/illimitatosi riferisce all’“estensione” dell’insieme mentre finito/infinito si riferisce al numero dei suoi elementi. Un intervallo[a, b] (se a < b) e ad esempio limitato e infinito. Un intervallo del tipo [a,+∞) invece e illimitato e infinito.
3 Sommatorie e altro
In questa sezione presento una notazione importante in matematica e in genere in tutte le sue applicazioni. E unanotazione formale molto utile, con la quale e bene prendere un po’ di confidenza: il simbolo di somma e le scritturedette sommatorie. Gli studenti le utilizzeranno intensamente in particolare nel corso di Statistica. Dedico qualcheriga anche all’analogo simbolo di prodotto.
3.1 Simbolo di somma (sommatorie)
Il simbolon∑
i=m
ESPRESSIONEi
con m,n naturali e n ≥ m, si legge “sommatoria per i che va da m a n di ESPRESSIONEi”.Indica che si deve procedere alla somma dei valori dell’espressione (ESPRESSIONEi) che segue il simbolo e che
dipende dall’indice i, per i valori indicati dell’indice. Quindi
n∑
i=m
ESPRESSIONEi = ESPRESSIONEm + ESPRESSIONEm+1 + . . .+ ESPRESSIONEn.
Ad esempio
4∑
i=1
ai = a1 + a2 + a3 + a4 ,5∑
i=3
i
1 + 2i=
3
1 + 6+
4
1 + 8+
5
1 + 10=
3
7+
4
9+
5
11=
920
693.
33Si noti che quest’ultimo e l’unione di due intervalli, non un intervallo: sono due cose diverse.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOMMATORIE E ALTRO
INTRODUZIONE
19
Le quantita ai e i1+2i , che figurano nelle precedenti scritture, si dicono l’argomento della sommatoria, mentre la
variabile i, che prende i valori naturali successivi indicati nel simbolo, si dice indice della sommatoria.Al posto di i si possono trovare altre lettere: h, j, k,m, n, . . ..Quando l’argomento e costante (indipendente dall’indice), come ad esempio in
∑ni=1 a, la scrittura indica la somma
di un certo numero di addendi uguali, cioe il prodotto dell’argomento per il numero di addendi. Cosı ad esempioabbiamo
n∑
i=1
a = a+ a+ . . .+ a︸ ︷︷ ︸
n volte
= na oppuren∑
i=m
a = a+ a+ . . .+ a︸ ︷︷ ︸
n−m+ 1 volte
= (n−m+ 1)a.34
Nel caso in cui l’argomento contenga una parte costante sono possibili semplificazioni o riscritture della sommatoria.Ad esempio con
N∑
k=1
axk (l’argomento e la costante a per xk),
volendo questo dire ax1 + ax2 + . . .+ axN , e possibile raccogliere la costante a e fare a(x1 + x2 + . . .+ xN ). Quindipossiamo scrivere direttamente
N∑
k=1
axk = a
N∑
k=1
xk (a si porta fuori del segno di sommatoria).
Attenzione pero che invece conN∑
k=1
(a+ xk),
che significa (a+ x1) + (a+ x2) + . . .+ (a+ xN ) si ha invece
N∑
k=1
(a+ xk) = Na+
N∑
k=1
xk.
E chiaro che in generale possiamo scrivere
N∑
k=1
(ak + bk) =
N∑
k=1
ak +
N∑
k=1
bk (proprieta commutativa dell’addizione).
Si noti che invece non possiamo fare lo stesso se l’argomento e il prodotto di ak per bk. Cioe non vale l’uguaglianza
N∑
k=1
(akbk) =N∑
k=1
ak ·N∑
k=1
bk.
E facile convincersi di questo: ad esempio non e vero che sia a1b1 + a2b2 = (a1 + a2)(b1 + b2).
Osservazione A volte, se non e rilevante riportare gli estremi dell’indice, quindi i valori che l’indice assume (o questisono sottintesi), si puo scrivere la sommatoria semplicemente ad esempio con
∑
k xk.
L’uso del simbolo di somma ha lo scopo di sintetizzare scritture che potrebbero essere lunghe e noiose da scrivereper esteso: puo quindi ad esempio servire ad “accorciare” la scrittura di un polinomio di grado n, quando n e grandeoppure quando n e generico.35
Un polinomio di grado n nella variabile x e un’espressione del tipo
Pn(x) = a0 + a1x+ a2x2 + . . .+ anx
n , con an 6= 0, 36
dove a0, a1, a2, . . . , an sono numeri reali fissati, quindi noti, e x e una “variabile” i cui valori sono in un insiemenumerico, in genere R.
34Il numero di interi compresi tra m ed n e dato da n−m+ 1.35Naturalmente per poter fare questo occorre che i coefficienti del polinomio si possano scrivere attraverso una funzione dell’indice.36Se fosse an = 0 il polinomio non sarebbe piu di grado n.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOMMATORIE E ALTRO
INTRODUZIONE
20
Usando il simbolo di somma si puo scrivere
Pn(x) =
n∑
i=0
aixi , con an 6= 0.
Ad esempio
1 + 2x+ 3x2 + 4x3 + . . .+ 101x100 =
100∑
k=0
(k + 1)xk
oppure, che e lo stesso,101∑
h=1
hxh−1 (vedi la sottosezione che segue).
3.1.1 Cambio di variabile in una sommatoria
Approfitto di questo esempio per presentare una tecnica che a volte incontrerete, quello che si puo chiamare un cambiodi variabile in una sommatoria. Consideriamo l’espressione
N∑
n=1
nxn+1.
Se poniamo n+ 1 = k, da cui otteniamo n = k − 1, la sommatoria diventa
N+1∑
k=2
(k − 1)xk.
3.1.2 Doppia sommatoria
Potrete incontrare nei vostri studi anche scritture come la seguente, in cui figurano una doppia sommatoria e un doppioindice:
n∑
i=1
n∑
j=1
ai,j ,n∑
i=1
m∑
j=0
ai,j .
L’argomento della doppia sommatoria, cioe il termine ai,j , sta ad indicare un’espressione che dipende sia da i sia daj (potrebbe essere ad esempio qualcosa come i+ j oppure i
i+j ).
La doppia sommatoria comporta che per ogni valore di i da 1 ad n (l’indice esterno) occorre sviluppare la secondasommatoria per j da 1 ad n (o per j da 0 ad m). Quindi ad esempio
3∑
i=1
6∑
j=4
ai,j =
3∑
i=1
(ai,4 + ai,5 + ai,6)
= (a1,4 + a1,5 + a1,6) + (a2,4 + a2,5 + a2,6) + (a3,4 + a3,5 + a3,6).
Osservazione Nel primo caso, anziche scrivere le due sommatorie∑n
i=1
∑nj=1 ai,j , si puo anche accorciare la scrittura
con∑n
i,j=1 ai,j . Nel secondo caso questo non si puo fare perche i valori che assume l’indice j non sono gli stessi
dell’indice i. A volte si tralascia la virgola tra i e j e si scrive∑n
i=1
∑nj=1 aij . Non si tratta pero del prodotto tra i e
j.
Un caso interessante di uso della doppia sommatoria, caso che lo studente ritrovera nel corso di Statistica, e ilseguente:
n∑
i=1
n∑
j=1
xiyj .
Si osservi che nella sommatoria interna (quella di indice j), la quantita xi e costante, in quanto non dipende dall’indice(che e j). Allora, come gia visto prima, possiamo portare xi fuori dalla sommatoria interna e scrivere
n∑
i=1
n∑
j=1
xiyj =
n∑
i=1
xi
n∑
j=1
yj
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOMMATORIE E ALTRO
INTRODUZIONE
21
Ora pero possiamo osservare che nell’argomento della sommatoria esterna la quantita costituita dalla sommatoria inj e costante e quindi questa quantita puo essere portata fuori dalla sommatoria in i. Si ottiene quindi
n∑
i=1
n∑
j=1
xiyj =
n∑
i=1
xi
n∑
j=1
yj
=
n∑
i=1
xi
n∑
j=1
yj, (1)
cioe il prodotto delle due sommatorie.Lo studente potrebbe verificare tutto questo ad esempio nel caso particolare di n = 2, cioe con
∑2i=1
∑2j=1 xiyj,
svolgendo anzitutto la scrittura di doppia sommatoria e poi verificando che quanto scritto e il prodotto delle duesommatorie.
Altra situazione caratteristica e la seguente. Consideriamo un quadrato del tipo
(N∑
k=1
xk
)2
.
Osservando che ovviamente(
N∑
k=1
xk
)2
=
(N∑
k=1
xk
)
·(
N∑
k=1
xk
)
,
ci troviamo nella stessa situazione vista poco fa, precisamente si tratta di un caso particolare del termine di destradell’equazione (1). Quindi si puo intanto scrivere
(N∑
k=1
xk
)2
=
N∑
i=1
N∑
j=1
xixj .
Ora osserviamo che l’argomento della doppia sommatoria, al variare degli indici tra 1 ed N , a volte e il prodottodi x con lo stesso indice (xi · xi), le altre volte invece e il prodotto di x con indici diversi (xi · xj con i 6= j). Allorapossiamo evidenziare questo scrivendo
(N∑
k=1
xk
)2
=
N∑
i=1
N∑
j=1
xixj =
N∑
i=1
x2i +
N∑
i,j=1i6=j
xixj . (2)
Nell’ultima sommatoria di destra la scrittura significa ovviamente che gli indici variano tra 1 ed N , con l’ulterioreprecisazione che devono assumere valori diversi.
Ma ora possiamo anche osservare che in questa ultima (doppia) sommatoria, essendo il prodotto commutativo, tuttii termini sono in realta presenti due volte (ad esempio il termine x1x2 e uguale al termine x2x1) e quindi possiamoanche scrivere
(N∑
k=1
xk
)2
=
N∑
i=1
N∑
j=1
xixj =
N∑
i=1
x2i + 2
N∑
i,j=1i<j
xixj . (3)
Forse per “visualizzare” il tutto puo essere utile riferirsi alla seguente tabella:
x1x1 x1x2 . . . x1xNx2x1 x2x2 . . . x2xN...
.... . .
...xNx1 xNx2 . . . xNxN
ossia
x21 x1x2 . . . x1xNx2x1 x22 . . . x2xN...
.... . .
...xNx1 xNx2 . . . x2N
La doppia sommatoria∑N
i=1
∑Nj=1 xixj significa operare la somma di tutti gli elementi senza particolari ulteriori
trasformazioni. La scrittura di destra della (2) significa fare prima la somma “sulla diagonale” dei quadrati e poi ditutti gli altri elementi fuori dalla diagonale. Infine la scrittura di destra della (3) significa fare la somma dei quadrati,e per il resto sommare i termini che sulla tabella stanno “sopra la diagonale”, moltiplicando per 2 il risultato.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOMMATORIE E ALTRO
INTRODUZIONE
22
3.1.3 Scambio dei simboli di una doppia sommatoria
Qualche studente potrebbe farsi questa bella domanda: e possibile in generale scambiare i due simboli di una doppiasommatoria? Provate a convincervi, con qualche caso particolare, che la risposta e sı.37
Quindi possiamo dire che in generale vale che
n∑
i=1
m∑
j=1
ai,j =
m∑
j=1
n∑
i=1
ai,j .
Un’altra utile formula, sempre in tema di cambio dell’ordine di sommatorie, e la seguente:
n∑
i=1
n∑
j=i
ai,j =
n∑
j=1
j∑
i=1
ai,j .38 (4)
Si noti che la particolarita di questa situazione e che nella doppia sommatoria di sinistra l’indice della sommatoriainterna (j) dipende da quello della sommatoria esterna (i). Si noti che anche in questo caso lo scambio tra le duesommatorie e possibile, ma non negli stessi termini immediati del caso piu semplice.39
Non e difficile convincersi della validita della formula (4), basta ad esempio utilizzare una “tabella” in cui figurano,opportunamente disposti, tutti i termini della doppia sommatoria. La tabella potrebbe essere la seguente:
a11 a12 a13 . . . a1na22 a23 . . . a2n
a33 . . . a3n. . .
...ann
Ogni riga “perde” un elemento in quanto l’in-dice interno inizia da un valore che cresce conl’indice esterno. Quindi la seconda riga ini-zia da 2 (da j = 2), la terza da 3 e cosıvia, l’ultima da n e quindi contiene un soloelemento.
Ci si rende conto della validita della (4) osservando che la doppia sommatoria di sinistra corrisponde alla somma deglielementi “per riga” (cioe sommo prima gli elementi della prima riga, poi quelli della seconda, e cosı via) mentre ladoppia sommatoria di destra corrisponde alla somma degli elementi “per colonna”.
3.1.4 Qualche utile formula
Vediamo ancora qualche utile formula in cui si fa uso del simbolo di sommatoria.
(a) La somma dei primi N numeri naturali :
S =
N∑
n=1
n =N(N + 1)
2.
La formula si puo facilmente dimostrare col metodo di Gauss:40
S = 1 + 2 + 3 + . . . + (N − 1) + Nma anche, per la proprieta commutativa,
S = N + (N − 1) + (n− 2) + . . . + 2 + 1
Sommando membro a membro le due uguaglianze si ha
2S = (N + 1) + (N + 1) + . . .+ (N + 1)︸ ︷︷ ︸
N volte
e quindi
S =N(N + 1)
2.
37Non e difficile intuire che c’e di mezzo la proprieta commutativa dell’addizione.38Gli studenti incontreranno anche questa situazione nel corso di Statistica.39Nel caso precedente i e j vanno entrambi da 1 ad n. Qui i va da 1 ad n ma j va da i ad n. Dopo lo scambio delle sommatorie troviamo
che j va da 1 ad n mentre i va da 1 a j.40Si narra che Gauss ricavo questa formula quando aveva appena 9 anni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO COMBINATORIO
INTRODUZIONE
23
(b) Puo essere utile anche la formula che da la somma dei primi N quadrati dei numeri naturali. Questa e
N∑
n=1
n2 =N(N + 1)(2N + 1)
6.
La dimostrazione di tale risultato non e cosı immediata.
(c) E interessante anche la somma dei primi N cubi dei numeri naturali :
N∑
n=1
n3 =N2(N + 1)2
4=
(N(N + 1)
2
)2
=
(N∑
n=1
n
)2
.
Quindi la somma dei primi N cubi dei naturali e il quadrato della somma semplice dei primi N naturali.
3.2 Simbolo di prodotto (produttorie)
Quanto detto per le sommatorie si puo ripetere, opportunamente adattato, per il simbolo di prodotto.
n∏
i=1
ai = a1 · a2 · . . . · an.
Ad esempion∏
i=1
2 = 2 · 2 · . . . · 2︸ ︷︷ ︸
n volte
= 2n.
Anche il simbolo di prodotto si puo trovare ripetuto, o anche abbinato al simbolo di somma. Ad esempio
3∏
i=1
5∏
k=4
(i + k) =
3∏
i=1
(i+ 4)(i+ 5) = (1 + 4)(1 + 5)(2 + 4)(2 + 5)(3 + 4)(3 + 5) = 5 · 6 · 6 · 7 · 7 · 8 = 70560
o ancora2∑
i=1
3∏
k=1
i
k=
2∑
i=1
(i
1· i2· i3
)
=
2∑
i=1
i3
6=
1
6+
8
6=
3
2.
E forse il caso di osservare che, mentre (come per le somme) i doppi simboli di prodotto si possono scambiare,non e cosı quando abbiamo somme di prodotti (o prodotti di somme). Lo studente provi a verificarlo nell’esempio quisopra.
4 Calcolo combinatorio
Possiamo dire che il Calcolo combinatorio e quel settore della matematica che studia la disposizione degli elementidi un insieme e soprattutto il numero delle possibili disposizioni. Ad esempio rientrano nel calcolo combinatorio ledomande: “dato un insieme di n persone, in quanti modi queste si possono disporre in una fila allo sportello?” oppure“quante sono le possibili targhe automobilistiche che posso formare con due lettere iniziali dell’alfabeto inglese, seguiteda tre cifre e seguite ancora da altre due lettere dell’alfabeto inglese?”
Passo subito a dare le prime definizioni.
4.1 Permutazioni di n elementi
Consideriamo un insieme di n elementi.
Definizione Si chiama permutazione degli n elementi un qualunque modo di posizionare tutti gli n elementi inuna sequenza.
Non e difficile capire che il numero delle permutazioni di n elementi e dato da
1 · 2 · 3 · . . . · n.
Tale numero si indica con il simbolo n! e si legge “fattoriale di n” (o anche “n fattoriale)”. Se indichiamo con Pn
il numero delle permutazioni di n elementi, possiamo allora scrivere Pn = n!.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO COMBINATORIO
INTRODUZIONE
24
Si puo visualizzare la “formazione” delle permutazioni, ad esempio con 3elementi a,b,c attraverso l’albero riportato qui a fianco. Partendo dalla radicedell’albero (a sinistra) i primi rami rappresentano la scelta del primo elementodella permutazione (quindi a,b oppure c). Fatta la scelta del primo elemento, isecondi rami rappresentano la scelta del secondo elemento della permutazione.Ovviamente se al primo posto abbiamo scelto a, al secondo posto la scelta etra b e c. I rami di terzo livello rappresentano la scelta dell’ultimo elementodella permutazione, scelta che con tre soli elementi e naturalmente obbligata.Cosı ci si rende conto facilmente di come con n elementi il numero delle per-mutazioni sia dato dal fattoriale di n. Infatti il primo elemento lo possiamoscegliere in n modi, il secondo in n− 1 modi, e cosı via, il penultimo in 2 modie l’ultimo in un solo modo. Abbiamo quindi il prodotto dei primi n numerinaturali.
a
b abcc
c acbb
ba bac
c
c bcaa
c a cabb
bcba
a
Esempio In un ufficio postale ci sono 10 persone e un solo sportello aperto. In quanti modi le 10 persone possonodisporsi in fila allo sportello?
Risposta: il numero e quello delle permutazioni di 10 elementi, cioe 10! (che risulta essere uguale a 3.628.800).41
Esempio In quanti modi 10 persone si possono disporre attorno ad un tavolo rotondo? A volte nelle questioni dicalcolo combinatorio non e facile dare una risposta in quanto la domanda non e formulata con sufficiente chiarezza.Sulla domanda che ho appena posto ad esempio si potrebbe replicare: “Ma ritieni uguali due disposizioni in cui ognunoha gli stessi vicini, cioe lo stesso vicino di destra e lo stesso vicino di sinistra?”42 Se la risposta alla replica e no, allorala risposta alla domanda iniziale e facile: la situazione e la stessa della fila allo sportello e i possibili modi sono tantiquanti le permutazioni di 10 elementi. Se invece la risposta alla replica e sı, il numero dei modi e minore ed e un po’piu complicatalo trovare la risposta. In questo caso il numero e
(n− 1)!.
Lo si puo capire in piu modi diversi. Ne propongo due.Fissiamo l’attenzione su uno di quelli seduti al tavolo e consideriamo le possibili sequenze di coloro che sono seduti
alla sua destra (o sinistra, e ovviamente lo stesso). Il primo vicino lo possiamo scegliere in n − 1 modi, il successivoin n − 2 modi e cosı via fino al vicino di sinistra, che possiamo scegliere in un solo modo. Quindi complessivamenteabbiamo
(n− 1) · (n− 2) · . . . · 2 · 1 modi, e cioe (n− 1)! modi.
Un secondo modo di ragionare e quello di pensare a tutte le possibili disposizioni attorno al tavolo, ritenendo diversedue disposizioni anche se l’ordine dei vicini e lo stesso. Queste come detto sono n!. Ora, considerata una certadisposizione, per trovare tutte quelle a questa equivalenti basta pensare di far spostare le persone tutte insieme,mantenendo gli stessi vicini (facciamo “ruotare” la disposizione). Di queste rotazioni ne possiamo trovare n, compresaquella inizialmente scelta. Pertanto il numero n! va diviso per n e si ottiene come prima (n− 1)!.
Osservazione Ricordo che la definizione di fattoriale, anche se da un punto di vista combinatorio la cosa non haalcun senso concreto, viene estesa anche ad n = 0. Si pone infatti (per definizione) 0! = 1.
4.2 Disposizioni di n elementi di classe k
Consideriamo il solito insieme di n elementi e sia k un numero naturale minore di n.
Definizione Si chiama disposizione semplice degli n elementi di classe k un qualunque modo di posizionarein una sequenza k elementi degli n, senza mai ripetere un elemento gia utilizzato.
Se abbiamo ad esempio 5 elementi e k = 3 possiamo scegliere in 5 modi il primo posto, in 4 modi il secondo e in 3modi il terzo. In generale il numero delle disposizioni semplici di n elementi di classe k e dato da
n · (n− 1) · (n− 2) · . . . · (n− k + 1).
Indichero tale numero con il simbolo Dn,k, quindi abbiamo
Dn,k = n · (n− 1) · (n− 2) · . . . · (n− k + 1).
Esempio Quanti sono i numeri interi di 5 cifre distinte, utilizzando le cifre da 1 a 9?
41Ci si accorge presto che il fattoriale di n cresce molto rapidamente al crescere di n, molto piu in fretta ad esempio di n2.42Si pensi che in due disposizioni in cui ognuno ha gli stessi vicini una persona potrebbe essere seduta in sedie diverse.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO COMBINATORIO
INTRODUZIONE
25
Risposta: sono tante quante le disposizioni semplici di 9 elementi di classe 5 e cioe
D9,5 = 9 · 8 · 7 · 6 · 5 = 15.120.
Osservazione Se prendessimo k = n, ogni disposizione semplice sarebbe anche una permutazione e viceversa, equindi potremmo scrivere Dn,n = Pn.
Osservazione Si noti che
Dn,k · (n− k)! = n!43 da cui Dn,k =n!
(n− k)! e cioe Dn,k =Pn
Pn−k.
Di quest’ultima relazione, ricavata per cosı dire algebricamente, c’e un’interpretazione “combinatoria”. Infatti ognidisposizione di classe k si puo pensare ottenuta da una permutazione degli n elementi eliminando gli ultimi n−k elementidella permutazione. Dato che ci sono Pn−k permutazioni che permutano gli ultimi n− k elementi e mantengono fermii primi k, ecco che il numero di disposizioni si ottiene dal quoziente Pn/Pn−k.
Consideriamo ancora un insieme di n elementi e sia k un qualunque numero naturale.
Definizione Si chiama disposizione con ripetizione degli n elementi di classe k un qualunque modo diposizionare in una sequenza k elementi degli n, anche eventualmente ripetendo elementi gia utilizzati.
Se abbiamo ad esempio 3 elementi e k = 2 possiamo scegliere in 3 modi il primo posto e ancora in 3 modi ilsecondo, come visualizza l’albero qui sotto
a
aa
a
ab
b
ac
c
b
ba
a
bb
b
bc
c
c
ca
a
cb
b
cc
c
In generale il numero delle disposizioni con ripetizione di n elementi di classe k e dato da
n · n · . . . · n︸ ︷︷ ︸
k volte
= nk
Indichero tale numero con il simbolo D(r)n,k, quindi abbiamo
D(r)n,k = nk.
Esempio Quante sono le sequenze di testa/croce che si possono ottenere lanciando una moneta 5 volte?Risposta: sono tante quante le disposizioni con ripetizione di 2 elementi di classe 5 e cioe
D(r)2,5 = 25 = 32.
Esempio Quante sono le possibili schedine del Totocalcio (relative ad una data giornata)?Risposta: sono tante quante le disposizioni con ripetizione di 3 elementi di classe 13 e cioe
D(r)3,13 = 313 = 1.594.323.
4.3 Combinazioni di n elementi di classe k
Consideriamo ancora il solito insieme di n elementi e sia k un numero naturale minore di n.
Definizione Si chiama combinazione degli n elementi di classe k una qualunque scelta di k elementi degli n,senza tenere conto dell’ordine in cui i k elementi compaiono.
Osservazione Un modo equivalente di formulare la definizione e quello di utilizzare un concetto che abbiamo in-contrato nella sezione precedente: una combinazione e sostanzialmente un sottoinsieme dell’insieme dato, quindi unacombinazione di classe k e semplicemente un sottoinsieme di k elementi.
43InfattiDn,k · (n− k)! = n · (n− 1) · (n− 2) · . . . · (n− k + 1)
︸ ︷︷ ︸
Dn,k
· (n− k) · (n− k − 1) · . . . · 1︸ ︷︷ ︸
(n−k)!
= n!.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO COMBINATORIO
INTRODUZIONE
26
Un modo abbastanza semplice per stabilire quante sono le combinazioni di n elementi di classe k e pensare che lacombinazione di classe k formata da certi assegnati k elementi raccoglie per cosı dire tutte le disposizioni formate congli stessi k elementi (le disposizioni, pur avendo gli stessi elementi, sono diverse a causa dell’ordine in cui gli elementicompaiono). Quindi basta chiedersi quante sono le disposizioni formate con k elementi assegnati. Sono ovviamente lepermutazioni di questi, e quindi sono k!. Allora il numero delle combinazioni di classe k si ottiene dividendo il numerodelle disposizioni (semplici) di classe k per il numero delle permutazioni di k elementi, quindi si ha
Cn,k =Dn,k
Pk=n · (n− 1) · (n− 2) · . . . · (n− k + 1)
k!.
Questo quoziente si indica con il simbolo(nk
), e viene detto coefficiente binomiale. Il nome di coefficienti
binomiali (detti anche numeri di Pascal), proviene dal fatto che queste quantita compaiono nello sviluppo dellapotenza del binomio (a+ b)n, come vedremo tra poco.
Possiamo quindi scrivere
Cn,k =
(n
k
)
=n · (n− 1) · (n− 2) · . . . · (n− k + 1)
k!.
Osservazione Una (parziale) verifica di questo risultato: se consideriamo i sottoinsiemi formati da un solo elemento,questi sono evidentemente n. La formula qui sopra, per k = 1, fornisce infatti Cn,1 =
(n1
)= n
1! = n.44
Osservazione Da come abbiamo ottenuto il numero delle combinazioni, appare scontato che Dn,k sia divisibile perPk, o che in altre parole il coefficiente binomiale sia un numero intero. Partendo pero dalla definizione di
(nk
)questo
fatto non e poi cosı ovvio.
Esempio Quante sono le possibili cinquine di carte da un mazzo di 52? Se sottintendiamo che l’ordine non conta,cioe una cinquina e caratterizzata solo dalle carte presenti, sono tante quante le combinazioni di 52 elementi di classe 5,ossia tanti quanti i sottoinsiemi di 5 elementi dell’intero mazzo di carte. Quindi sono
(525
)= 52·51·50·49·48
5! = 2.598.960.
Osservazione Come fatto con il fattoriale, anche con i coefficienti binomiali si estende (per convenzione) la validitadella formula al caso k = 0 e si pone
(n0
)= 1.
I coefficienti binomiali hanno alcune classiche proprieta. Lo studente ne vedra poi anche altre nel corso di Statistica.Qui ne presento soltanto un paio.
Se nel quoziente che definisce il coefficiente binomiale(nk
)moltiplichiamo sopra e sotto (cioe, meglio, numeratore
e denominatore) per (n− k)! otteniamo
(n
k
)
=n · (n− 1) · (n− 2) · . . . · (n− k + 1)
k!=n · (n− 1) · (n− 2) · . . . · (n− k + 1)(n− k)!
k!(n− k)! =n!
k!(n− k)! ,
che e un altro possibile modo di scrivere il coefficiente binomiale.Proprieta interessante e la seguente proprieta di “simmetria” del coefficiente binomiale:
(n
k
)
=
(n
n− k
)
.
La dimostrazione di questa e assolutamente banale se usiamo l’ultima scrittura ottenuta del coefficiente binomiale. Piuinteressante e cercarne una giustificazione di tipo combinatorio. Si trova che anche cosı la giustificazione e immediata:basta pensare che per ogni sottoinsieme di k elementi che possiamo individuare, ne resta individuato immediatamenteuno di n− k elementi (lo studente dovrebbe intuire che e quello che abbiamo chiamato il complementare). Quindi ilnumero dei possibili sottoinsiemi di k elementi e uguale al numero dei possibili sottoinsiemi di n− k elementi.
4.4 Il binomio di Newton
Richiamo questo argomento, anche per l’uso che lo studente ne fara nel corso di Statistica.
44Con questo non intendo assolutamente dire che abbiamo dimostrato la validita della relazione trovata. Abbiamo solo verificato che inun caso particolare (quello dei sottoinsiemi di un solo elemento) la formula funziona. Potremmo dire che abbiamo verificato una condizionenecessaria per la validita della formula. Non e pero sufficiente che essa valga in un caso particolare. La validita della formula sta nelprocedimento (generale) che abbiamo seguito in precedenza. Quale altro caso particolare di verifica della formula possiamo osservare che,se consideriamo i sottoinsiemi di n elementi, cioe k = n, evidentemente ce n’e uno solo, e infatti dalla formula si ha Cn,n =
(nn
)= n!
n!= 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO COMBINATORIO
INTRODUZIONE
27
Per la potenza n-esima di un binomio a+ b (da cui il nome di coefficienti binomiali) vale la seguente formula, dettaformula del binomio di Newton:
(a+ b)n =
(n
0
)
an +
(n
1
)
an−1b1 + . . .+
(n
k
)
an−kbk + . . .+
(n
n
)
bn
=n∑
k=0
(n
k
)
an−kbk. (5)
Non e difficile capire la validita della formula. Intanto pensiamo che
(a+ b)n = (a+ b) · (a+ b) · . . . · (a+ b)︸ ︷︷ ︸
n volte
.
Ora immaginiamo di svolgere il prodotto.45 Si tratta della “somma di tanti prodotti” (si usa la proprieta distributivadella moltiplicazione rispetto all’addizione): in questa lunga addizione troveremo un termine an, poi ci sono terminidel tipo an−1b, poi gli an−2b2 e cosı via fino agli a2bn−2, gli abn−1 e infine il bn. Possiamo esprimerli tutti nella formaan−kbk, con k = 0, 1, 2, . . . , n − 2, n − 1, n. Questo era abbastanza semplice. La parte difficile e capire quanti sonoi termini dello stesso tipo (tecnicamente si chiamano monomi simili). Consideriamo i monomi del tipo an−kbk, chesono quelli ottenuti scegliendo nei fattori (a + b), k volte b e n − k volte a. Equivale a scegliere, in un insieme din elementi, un sottoinsieme di k elementi, quelli diciamo dove scegliamo b, poi in tutti gli altri n − k scegliamo a.Pertanto i monomi simili del tipo an−kbk sono tanti quanti questi sottoinsiemi, sono cioe
(nk
). Ecco spiegati anche i
coefficienti della sommatoria (5).
In precedenza, parlando di insieme delle parti, ho anticipato che le parti di un insieme non vuoto di n elementisono 2n. Ora siamo in grado di dimostrare questo fatto. Lo si puo fare usando la formula del binomio.
Il numero complessivo di sottoinsiemi di un insieme di n elementi e dato da
n∑
k=0
(n
k
)
=
n∑
k=0
(n
k
)
1n−k1k = (1 + 1)n = 2n.
Esercizi
• In quanti modi 10 persone possono mettersi in coda ad uno sportello?
• Quante sono le sestine che possono essere estratte al SuperEnalotto?46
• In quanti modi posso disporre 20 libri in uno scaffale che ne contiene solo 10?
45Lo studente provi a farlo con diciamo n = 3, cioe provi a svolgere il prodotto di (a+ b)(a + b)(a + b).46Il SuperEnalotto estrae 6 numeri da un’urna che contiene da 1 a 90. I numeri, una volta estratti, non sono rimessi nell’urna (e un
particolare importante). Non teniamo conto del Jolly e del SuperStar. Teniamo conto invece del fatto che, qualunque sia il risultatotrovato, non conviene giocare!
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 TABELLA RIASSUNTIVA DEI SIMBOLI PRINCIPALI
INTRODUZIONE
28
5 Tabella riassuntiva dei simboli principali
Ecco una tabella che raccoglie i principali simboli utilizzati.
Insiemi numerici
N insieme dei numeri naturali, N = {1, 2, 3, 4, . . .}N0 N ∪ {0}, cioe insieme dei naturali con lo zero
Z insieme dei numeri interi, Z = {. . . ,−3,−2,−1, 0, 1, 2, 3, . . .}Q insieme dei numeri razionali, Q =
{mn : m,n ∈ Z e n 6= 0
}
R insieme dei numeri reali
Insiemi
∅ insieme vuoto l’insieme che non ha elementi
∈ appartiene a ∈ A, l’elemento a appartiene all’insieme A
/∈ non appartiene a /∈ A, l’elemento a non appartiene all’insieme A
⊂ sottoinsieme B ⊂ A, l’insieme B e sottoinsieme di A
∩ intersezione tra insiemi A ∩B e l’insieme degli elementi che stanno in A e in B
∪ unione tra insiemi A ∪B e l’insieme degli elementi che stanno in A o in B
\ differenza tra insiemi A \B e l’insieme degli elementi che stanno in A ma non in B
PA o 2A insieme delle parti di A e l’insieme di tutti i sottoinsiemi di A
Simboli logici
∧ e P ∧Q, proposizione formata da “P e Q”
∨ o P ∨Q, proposizione formata da “P oppure Q”
∃ esiste esiste almeno un . . .
∀ per ogni per ogni . . .
=⇒ implica P =⇒ Q, proposizione formata da “P implica Q”
⇐⇒ se e solo se P ⇐⇒ Q, “P implica Q e viceversa”
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

Parte I
Nella prima parte del corso di Matematica ripassiamo un po’ di argomenti che gia avete incontrato alla ScuolaSecondaria.
Ecco un sintetico elenco di quanto vedremo in questa parte del corso.
• Richiami sui polinomi
• Richiami su potenze, radicali e logaritmi
• Richiami su equazioni e disequazioni
• Richiami sui concetti fondamentali legati alla rappresentazione nel piano cartesiano
• Richiami di geometria analitica


1 PRODOTTI E POTENZE NOTEVOLI
POLINOMI
31
I-1 Polinomi
In questa prima lezione parliamo di polinomi. Sono argomenti che avete gia incontrato alla scuola secondaria: prodottinotevoli, la divisione di due polinomi, la regola di Ruffini, la fattorizzazione dei polinomi, il teorema di Ruffini.A queste note, necessariamente schematiche, e bene che lo studente affianchi un testo di matematica per la scuolasecondaria, per poter eventualmente rivedere in questo gli argomenti che dovessero presentare difficolta e per svolgerequalche esercizio aggiuntivo.
1 Prodotti e potenze notevoli
Ricordiamo che si dice monomio nella variabile x un’espressione algebrica del tipo a · xk (di solito si scrive sempli-cemente axk), dove a e in genere un numero reale e k e un numero intero non negativo. L’esponente k e il grado delmonomio.Un monomio nelle variabili x, y e invece un’espressione algebrica del tipo axmyn, dove ancora a e un numero reale e med n sono numeri interi non negativi. Possiamo avere monomi in un qualunque numero di variabili, come ad esempio−2xy3z2t4. Il grado di un monomio in piu variabili e dato dalla somma degli esponenti delle variabili in esso presenti.Quindi il grado del polinomio appena indicato e 10. Il fattore numerico che precede le lettere e il coefficiente: semanca vale +1 o −1 a seconda del segno che precede le lettere.Si dice polinomio una somma47 di piu monomi. Ovviamente si potra specificare polinomio nelle variabili x, y, . . . se imonomi che lo costituiscono sono nelle variabili x, y, . . .. Si dice grado del polinomio il massimo dei gradi dei monomiche figurano in esso. Ad esempio, il polinomio
−x4 + 2x3 − 1
3x+ 1 e un polinomio di grado 4.
Ancora, il polinomioxyz − 2y2z2 + 3x2z3
e di grado 5, dato che i monomi sono rispettivamente di grado 3,4,5.Siano A,B,C polinomi.48 Si hanno allora i seguenti prodotti e potenze notevoli :
(A+B)(A−B) = A2 −B2
(A+B)2 = A2 + 2AB +B2
(A−B)2 = A2 − 2AB +B2
(A+B)(A2 −AB +B2) = A3 +B3
(A−B)(A2 +AB +B2) = A3 −B3
(A+B)3 = A3 + 3A2B + 3AB2 +B3
(A−B)3 = A3 − 3A2B + 3AB2 −B3
(A+B + C)2 = A2 + 2AB + 2AC +B2 + 2BC + C2.
Osservazione Lo studente si abitui subito a saper leggere un’identita in entrambi i versi. Quindi, ad esempio, nellaprima sappia riconoscere una “somma per una differenza”, riscrivendola come differenza di quadrati, o viceversa sappiavedere una differenza di quadrati, per scriverla come somma per differenza. La questione puo apparire banale e ovviama lo e, appunto, solo in apparenza.Consiglio agli studenti di svolgere autonomamente qualche esercizio in merito, utilizzando un qualunque testo dellascuola secondaria.
Esercizio 1.1 Calcolare i prodotti
(a) (1− t)(2− t+ t3) (b) (4x+ 5y)(4x− 5y) (c)
(1
2x+
2
3y
)(
3x− 1
2y
)
.
47Dicendo somma generalmente si intende somma o differenza, dato che la differenza e la somma del primo addendo con l’opposto delsecondo.
48Qui, come avviene spesso in matematica, si indica con una lettera un intero oggetto. L’oggetto ora e un polinomio. Quindi A,B, Crappresentano interi polinomi. Si noti inoltre che non scrivo ad esempio A(x): se scrivessi A(x) vorrebbe dire che mi riferisco soltanto apolinomi in una variabile, mentre qui le uguaglianze che seguono sono valide per polinomi in un numero qualunque di variabili.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 DIVISIONE TRA POLINOMI
POLINOMI
32
Esercizio 1.2 Calcolare le potenze
(a) (2z − 3t)2 (b)
(2
3x− 1
2
)2
(c) (2− y)3.
Esercizio 1.3 Calcolare i prodotti
(a) (3− 2x2)(3 + 2x2) (b) (1− y)(1 + y + y2).
Esercizio 1.4 Calcolare le potenze
(a) (1− x+ t)2 (b) (y − 3z)3.
2 Divisione tra polinomi
Quello che voglio qui richiamare e il procedimento euclideo di divisione tra due polinomi (in una variabile). Anzituttodividere un polinomio P (x) per un polinomio D(x) (D sta per divisore) significa determinare altri due polinomi Q(x)e R(x) (Q sta per quoziente e R sta per resto) tali che valga la seguente scrittura
P (x) = D(x) ·Q(x) +R(x).
Occorre subito dire che questo in generale non e sempre possibile. La divisione e possibile se e solo se il grado di P emaggiore o uguale del grado di D. In tal caso esiste un procedimento che permette di trovare i polinomi Q(x) e R(x).Ora richiamo in dettaglio tale procedimento, e lo faccio direttamente su di un esempio. Prendiamo
P (x) = 8x2 − 2x− 5 e D(x) = 2x− 3.
Occorre anzitutto scrivere i polinomi P (x) e D(x), ordinandoli per potenze decrescenti (i nostri sono gia ordinati),separati da barre, come qui sotto indicato:
8x2 −2x −5 2x −3
Ora si divide il monomio di grado massimo di P (x) (cioe 8x2) per il monomio di grado massimo del divisore D(x)(cioe 2x) e si scrive il risultato (4x) sotto quest’ultimo:
8x2 −2x −5 2x −34x
Ora si moltiplica il 4x per 2x e per −3 e si scrivono i risultati cambiati di segno, a sinistra, sotto i monomi dello stessogrado di P (x), tracciando poi sotto una riga:
8x2 −2x −5 2x −3−8x2 +12x 4x
Ora si sommano (in colonna) i monomi dello stesso grado a sinistra e si riporta il risultato sotto alla riga primatracciata:
8x2 −2x −5 2x −3−8x2 +12x 4x
// 10x −5
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 DIVISIONE TRA POLINOMI
POLINOMI
33
Ora si ripete il procedimento con il polinomio trovato sotto a sinistra e il divisore D(x), iniziando dalla divisione deimonomi di grado massimo. Il risultato (+5) si scrive a destra, a fianco di 4x. Quindi si ottiene:
8x2 −2x −5 2x −3−8x2 +12x 4x +5
// 10x −5
Ora si moltiplica il +5 per quanto c’e nella riga sopra e si riporta il risultato cambiato di segno a sinistra, facendo poila somma e scrivendo sotto il risultato:
8x2 −2x −5 2x −3−8x2 +12x 4x +5
// 10x −5−10x +15
// +10
A questo punto il procedimento ha termine, in quanto il polinomio trovato sotto a sinistra (10) non si puo piu dividereper il divisore D(x), in quanto il suo grado e minore di quello di quest’ultimo. Il polinomio quoziente si trova sotto ildivisore e il polinomio resto e invece quello in fondo a sinistra. Quindi nel nostro caso si ha Q(x) = 4x+5 e R(x) = 10e vale quindi la scrittura
8x2 − 2x− 5 = (2x− 3)(4x+ 5) + 10.
Vediamo un altro esempio. Vogliamo dividere P (x) = x3− x+1 per D(x) = x+1. In questo caso nel polinomio P (x)“manca” il monomio di grado 2 (in realta nessuno ci impedisce di scrivere P (x) = x3 + 0x2 − x+ 1). Conviene alloralasciare un po’ di spazio (o anche scrivere appunto 0x2) tra x3 e −x. Si ottiene:
x3 −x +1 x +1
−x3 −x2 x2 −x// −x2 −x +1
+x2 +x
// // +1
Quindi Q(x) = x2 − x e R(x) = 1 e vale la scrittura
x3 − x+ 1 = (x + 1)(x2 − x) + 1.
In qualche caso risulta R(x) = 0. Allora si dice che il polinomio P (x) e divisibile per il polinomio D(x) e ovviamenterisulta P (x) = D(x)Q(x).Questo succede ad esempio nel seguente caso. Dividiamo il polinomio P (x) = x4 + x3 + 2x2 + x+ 1 per il polinomioD(x) = x2 + x+ 1. Si ottiene
x4 +x3 +2x2 +x +1 x2 +x +1
−x4 −x3 −x2 x2 +1
// // x2 +x +1
−x2 −x −1// // //
Quindi Q(x) = x2 + 1 e R(x) = 0 e vale la scrittura
x4 + x3 + 2x2 + x+ 1 = (x2 + x+ 1)(x2 + 1).
Esercizio 2.1 Dati P (x) = x4 + x3 − x2 + x− 1 e D(x) = x2 + 1, trovare quoziente e resto della divisione di P
per D.
Esercizio 2.2 Dati P (x) = 2x3 − 3x2 + 5x − 1 e D(x) = 2x + 1, trovare quoziente e resto della divisione di P
per D.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 DIVISIONE TRA POLINOMI
POLINOMI
34
2.1 Regola di Ruffini
Quando il polinomio divisore D(x) e del tipo x+ a (di primo grado con coefficiente di x uguale a 1), il procedimentoeuclideo puo essere sostituito dal procedimento detto regola di Ruffini, semplificazione formale di quello euclideo.Anche qui descriviamo il metodo su di un esempio, uno di quelli visti poco fa, con P (x) = x3 − x+ 1 e D(x) = x+ 1.Si comincia scrivendo i coefficienti di P (x) su una riga e, sulla riga sotto, piu a sinistra, la radice del polinomio divisoreD(x);49 quindi si tracciano tre righe, due verticali e una orizzontale, come nello schema qui sotto
1 0 −1 1
−1
Ora si trascrive il primo coefficiente della prima riga sulla terza riga, lo si moltiplica per la radice del divisore inseconda riga (−1) e si riporta il risultato in seconda riga, terza colonna, sotto lo 0:
1 0 −1 1
−1 −11
Si sommano gli elementi nella terza colonna e si riporta il risultato (−1) in terza riga. Poi si moltiplica quest’ultimoper la radice del divisore in seconda riga e si riporta il risultato in seconda riga, quarta colonna:
1 0 −1 1
−1 −1 1
1 −1
Si sommano gli elementi nella quarta colonna e si riporta il risultato (0) in terza riga. Si moltiplica quest’ultimo perla radice del divisore in seconda riga e si riporta il risultato in seconda riga, quinta colonna. Infine si sommano glielementi della quinta colonna:
1 0 −1 1
−1 −1 1 0
1 −1 0 1
Il procedimento e terminato. Ora basta ricostruire i polinomi quoziente e resto sulla base dei coefficienti. Il polinomioquoziente si legge sulla terza riga, tra le due barre verticali. Nel nostro caso si tratta di un polinomio di secondogrado (P (x) e di grado 3 e D(x) di grado 1), quindi il polinomio quoziente e Q(x) = x2 − x. Il polinomio resto e unacostante:50 e la costante che si trova in basso a destra nella terza riga e ultima colonna.Pertanto si ha, come prima
x3 − x+ 1 = (x + 1)(x2 − x) + 1.
Vediamo un altro esempio: dividiamo P (x) = 2x3 − 5x2 + 3x− 2 per il polinomio D(x) = x− 2. La regola di Ruffiniporta a trovare la tabella
2 −5 3 −22 4 −2 2
2 −1 1 0
In questo caso il resto e 0, quindi il polinomio P (x) e divisibile per D(x). Si ha quindi
2x3 − 5x2 + 3x− 2 = (x− 2)(2x2 − x+ 1).
Ancora un esempio: dividiamo P (x) = x4−x2+1 per il polinomio D(x) = x+10. La regola di Ruffini porta a trovarela tabella
1 0 −1 0 1
−10 −10 100 −990 9900
1 −10 99 −990 9901
49Una radice (o uno zero) di un polinomio e un valore che, sostituito alla variabile x, annulla il polinomio stesso. Quindi, nel caso delpolinomio divisore D(x) = x+ a, l’unica radice e −a.
50E sempre una costante quando si applica la regola di Ruffini, dato che il divisore e di primo grado e quindi il resto e di grado zero, cioecostante.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 FATTORIZZAZIONE DI UN POLINOMIO
POLINOMI
35
Si ha quindix4 − x2 + 1 = (x+ 10)(x3 − 10x2 + 99x− 990) + 9901.
Quale ulteriore esempio, possiamo mettere a confronto i due procedimenti visti per la divisione dei polinomi:
(4x3 − x2 + 5x− 8) : (x− 1).
Procedimento euclideo Regola di Ruffini
4x3 −x2 +5x −8 x −1−4x3 +4x2 4x2 +3x +8
// +3x2 +5x −8−3x2 +3x
// +8x −8−8x +8
// //
4 −1 5 −81 4 3 8
4 3 8 0
Allora Q(x) = 4x2 + 3x+ 8 e R(x) = 0. Quindi entrambi i procedimenti portano a scrivere:
(4x3 − x2 + 5x− 8) : (x− 1) = 4x2 + 3x+ 8,
oppure4x3 − x2 + 5x− 8 = (4x2 + 3x+ 8)(x− 1).
Esercizio 2.3 Dividere P (x) = x4 − x3 + x− 1 per D(x) = x− 1 utilizzando la regola di Ruffini.
Esercizio 2.4 Dividere P (x) = 3x3 + 2x2 + x per D(x) = x+ 3 utilizzando la regola di Ruffini.
3 Fattorizzazione di un polinomio
Fattorizzare o scomporre un polinomio significa scriverlo come prodotto di fattori, cioe come prodotto di due o piupolinomi. La cosa puo essere utile in molti casi, come ad esempio per risolvere equazioni e disequazioni, per semplificarele frazioni algebriche, ed in svariate altre occasioni.Si richiamano qui, attraverso alcuni esempi, le principali regole, che lo studente dovrebbe gia conoscere: se cosı nonfosse, sara utile rivedere l’argomento su testi di scuola secondaria.
1. Raccoglimento semplice. Consiste nel mettere in evidenza (raccogliere), come primo fattore, un monomiodivisore del polinomio.
Esempi
• 2x4 − 8x2 + 10x = 2x(x3 − 4x+ 5)
• 3x2y − 9xy2 + 6xyz = 3xy(x− 3y + 2z)
• 4a(3x− y) + 5b(3x− y) = (3x− y)(4a+ 5b)
•32x
2y − 16x
3y + 74xy
3 = 112xy(18x− 2x2 + 21y2).
Osservazione Nell’ultimo esempio, raccogliendo 112xy invece di 1
2xy, si ottiene tra parentesi un polinomio concoefficienti interi, il che puo facilitare una successiva fattorizzazione. Lo studente cerchi di arrivare da solo allaregola generale con cui, dato un polinomio a coefficienti frazionari, un raccoglimento porta ad un polinomio acoefficienti interi.
2. Scomposizione di binomi
(a) Differenza di quadrati: A2 −B2 = (A−B)(A+B).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 FATTORIZZAZIONE DI UN POLINOMIO
POLINOMI
36
Esempi
• x2 − 16 = (x− 4)(x+ 4)
• 4x2 − 9y2 = (2x− 3y)(2x+ 3y)
• 3y3 − 12y = 3y(y2 − 4) = 3y(y − 2)(y + 2).
• a4 − 16b4 = (a2 − 4b2)(a2 + 4b2) = (a− 2b)(a+ 2b)(a2 + 4b2)
•52x
3y2 − 25x = 1
10x(25x2y2 − 4) = 1
10x(5xy − 2)(5xy + 2)
Osservazioni Nel quarto esempio il fattore finale (a2+4b2) non e stato scomposto, perche e somma di duequadrati e ricordiamo che la somma di due quadrati non e fattorizzabile. Nel quinto esempio e stato fattoanzitutto un raccoglimento: si e raccolto 1
10x per avere poi coefficienti interi (vedi osservazione precedente).
(b) Somma e differenza di cubi:
A3 +B3 = (A+ B)(A2 −AB +B2).
A3 −B3 = (A− B)(A2 +AB +B2).
Esempi
• 27x3 − 1 = (3x− 1)(9x2 + 3x+ 1)
• 8a3 + b3 = (2a+ b)(4a2 − 2ab+ b2)
• x3y3 − 27 = (xy − 3)(x2y2 + 3xy + 9)
• 2x4 + 16x = 2x(x3 + 8) = 2x(x+ 2)(x2 − 2x+ 4)
• 2x4y − 14xy
4 = 14xy(8x
3 − y3) = 14xy(2x− y)(4x2 + 2xy + y2)
3. Scomposizione di trinomi
(a) Quadrati di binomi:
A2 + 2AB +B2 = (A+B)2.
A2 − 2AB +B2 = (A−B)2.
Esempi
• x2 − 8x+ 16 = x2 − 2 · 4 · x+ 42 = (x− 4)2
• 4a2 + 4a+ 1 = (2a)2 + 2 · 2a · 1 + 12 = (2a+ 1)2
•12x
3 − 3x2y + 92xy
2 = 12x(x
2 − 6xy + 9y2) = 12x(x − 3y)2
(b) Trinomi particolari: x2 + (m+ n)x+m · n = (x+m)(x+ n).
Esempi
• x2 + 4x+ 3 = x2 + (1 + 3)x+ 1 · 3 = (x + 1)(x+ 3)
• x2 − 7x+ 12 = x2 + (−3− 4)x+ (−3)(−4) = (x− 3)(x− 4)
• x2 + 4x− 5 = x2 + (5− 1)x+ 5 · (−1) = (x+ 5)(x− 1)
Osservazione La scomposizione di trinomi di questo ultimo tipo puo essere naturalmente ottenuta facendoricorso alle equazioni di secondo grado.
4. Scomposizione di quadrinomi
(a) Raccoglimento parziale o doppio raccoglimento:
am+ bm+ an+ bn = m(a+ b) + n(a+ b) = (m+ n)(a+ b).
am− bm+ an− bn = m(a− b) + n(a− b) = (m+ n)(a− b).Esempi
• 2x− 2y − x2 + xy = 2(x− y)− x(x − y) = (x − y)(2− x)• 3ab2 + 6b− 2a2b− 4a = 3b(ab+ 2)− 2a(ab+ 2) = (ab+ 2)(3b− 2a)
•12x
2 + 32xy +
13x+ y = 1
2x(x + 3y) + 13 (x+ 3y) = 1
6 (3x+ 2)(x+ 3y)
(b) Cubi di binomi:
A3 + 3A2B + 3AB2 +B3 = (A+B)3.
A3 − 3A2B + 3AB2 −B3 = (A−B)3.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 FATTORIZZAZIONE DI UN POLINOMIO
POLINOMI
37
Esempi
• x3 + 3x2 + 3x+ 1 = (x)3 + 3(x)2 · 1 + 3 · x · 12 + 13 = (x+ 1)3
• 8x3 − 12x2y + 6xy2 − y3 = (2x)3 − 3(2x)2y + 3(2x)y2 − y3 = (2x− y)3• 2a4 − 12a3 + 24a2 − 16a = 2a(a3 − 6a2 + 12a− 8) = 2a(a− 2)3
(c) Differenza di quadrati:
A2 + 2AB +B2 − C2 = (A+B)2 − C2 = (A+B − C)(A+B + C).
A2 − 2AB +B2 − C2 = (A−B)2 − C2 = (A−B − C)(A−B + C).
A2 −B2 − 2BC − C2 = A2 − (B + C)2 = (A−B − C)(A+B + C).
A2 −B2 + 2BC − C2 = A2 − (B − C)2 = (A−B + C)(A+B − C).
Esempi
• x2 + 2x+ 1− y2 = (x+ 1)2 − y2 = (x + 1− y)(x+ 1 + y)
• 4a2 − b2 + 6b− 9 = (2a)2 − (b2 − 6b+ 9) = (2a)2 − (b − 3)2 = (2a− b + 3)(2a+ b − 3)
• x2 + 2xy + y2 − 1 = (x+ y)2 − 12 = (x+ y − 1)(x+ y + 1)
• 9a2 − 4x2 + 4x− 1 = 9a2 − (2x− 1)2 = (3a− 2x+ 1)(3a+ 2x− 1)
Esercizio 3.1 Fattorizzare i polinomi
(a) 4x2 − 4x+ 1 (b) 4x2 − 9 (c) z4 + z6.
Esercizio 3.2 Fattorizzare i polinomi
(a) 4p2 − 20pq + 25q2 (b)8
3x2 − 8
3x+
2
3.
Esercizio 3.3 Fattorizzare i polinomi
(a) x3 − 2x2 + x (b) 4x2y2 − 4xyzt+ z2t2.
Esercizio 3.4 Fattorizzare i polinomi
(a) 3x2 − 3
4(b) a2b2 − 4t2.
Esercizio 3.5 Fattorizzare il polinomio
x4y2t2 − z4t2.
Esercizio 3.6 Fattorizzare il polinomio
1− p4q4.
Esercizio 3.7 Fattorizzare i seguenti polinomi
(a) 2x3y2 − x4y3 + 3x2y5
(b) 81x2y4 − 64z6
(c) 92z
2t3 − 2t
(d) 13x
4y3 + 2x2y2z + 3yz2
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 COMPLETAMENTO DEL QUADRATO
POLINOMI
38
4 Teorema di Ruffini
Ricordiamo, perche utile in varie occasioni, il seguente importante
Teorema (di Ruffini): se un polinomio P (x) si annulla per x = a, con a numero reale qualsiasi, allora P (x) edivisibile per il binomio (x− a).Ad esempio, sia P (x) = 3x3 − 2x2 − 16. Poiche risulta P (2) = 0, si puo affermare che P (x) e divisibile per il binomio(x − 2). Infatti si verifica facilmente che
(3x3 − 2x2 − 16) : (x − 2) = (3x2 + 4x+ 8)
e percio3x3 − 2x2 − 16 = (x− 2)(3x2 + 4x+ 8).
Osservazione L’esempio mostra come sia possibile, se sono verificate le ipotesi del teorema di Ruffini, scomporreun polinomio che con le normali regole di scomposizione dei polinomi non si saprebbe fattorizzare.La ricerca degli eventuali numeri a che rendono nullo il polinomio P (x) (come detto si chiamano radici o zeri di P (x))e che portano alla sua scomposizione va fatta tenendo presente quanto segue:
• se ci sono zeri interi, allora essi vanno cercati tra i divisori del termine noto di P (x);
• se ci sono zeri frazionari del tipo mn , allora i possibili m vanno cercati tra i divisori del termine noto di P (x) ed
i possibili n 6= 1 vanno cercati tra i divisori del coefficiente del termine di grado massimo di P (x).
Osservazione Si rifletta attentamente su quanto appena detto: un polinomio non ha necessariamente zeri interio frazionari. Se pero ci sono zeri interi o frazionari, quanto detto permette di restringerne la ricerca ad un numerosolitamente ragionevole di tentativi.Vediamo un esempio. I possibili zeri interi di P (x) = 6x3 − 5x2 − 2x+ 1 sono fra gli elementi dell’insieme {−1, 1}. Ipossibili zeri frazionari di P (x) sono fra gli elementi dell’insieme { 12 ,− 1
2 ,13 ,− 1
3 ,16 ,− 1
6}.Si trova che gli zeri sono 1, − 1
2 e 13 . Pertanto
51
P (x) = 6(x− 1)
(
x+1
2
)(
x− 1
3
)
= 6(x− 1)
(2x+ 1
2
)(3x− 1
3
)
= (x− 1)(2x+ 1)(3x− 1).
Un altro esempio. Se consideriamo il polinomio P (x) = x3+x+1, gli eventuali zeri interi e razionali stanno nell’insieme{−1, 1}, ma si vede subito che nessuno di questi due valori e uno zero di P (x). A questo punto possiamo dire e cheP (x) non ha zeri interi o razionali. Puo avere zeri non razionali, ma i metodi in nostro possesso non ci consentono peril momento ne di dire che sicuramente ci sono ne tanto meno di trovarli.
Osservazione Chiaramente, dopo aver trovato con il teorema di Ruffini che un polinomio e divisibile per un fattore(x − a), si puo effettuare la divisione attraverso la regola di Ruffini.
Esercizio 4.1 Quali dei seguenti polinomi sono divisibili per (x − 1)?
3x2 − 2x+ 1 5x3 + 2x− 7 x12 − x6 + x− 1.
Esercizio 4.2 Dopo aver verificato che il polinomio P (x) = x5 − 2x3 − 1 e divisibile per (x+ 1), trovare con la
regola di Ruffini il polinomio quoziente.
5 Completamento del quadrato
Concludo questi primi richiami con un metodo che verra utilizzato piu avanti e che puo risultare utile in molti casi. Sitratta di mettere in evidenza, in un polinomio di secondo grado, un quadrato aggiungendo e togliendo opportunamenteuna quantita. Non formalizzo la questione, ma mi limito ad illustrare il metodo in qualche caso particolare.Consideriamo il polinomio
x2 − 4x+ 1.
51Si faccia attenzione! Se il coefficiente del termine di grado massimo e diverso da 1 (in questo caso e 6) occorre tenere conto di questocoefficiente nella fattorizzazione del polinomio.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 COMPLETAMENTO DEL QUADRATO
POLINOMI
39
Esso non e il quadrato di un binomio, ma in esso possiamo dire che si nasconde il quadrato di un binomio, a menodi una quantita additiva costante.52 Possiamo vedere nel primo monomio il quadrato di x e nel secondo monomioil doppio prodotto di x per −2. Il polinomio dato non e lo sviluppo del quadrato di un binomio perche il suo terzomonomio (+1) non e il quadrato di −2. Ma allora, aggiungendo e togliendo tale quadrato, cioe 4, otteniamo
x2 − 4x+ 1 = x2 − 4x+ 4− 4 + 1 = (x− 2)2 − 3.
Anticipo che questo metodo lo useremo per risolvere le equazioni di secondo grado. Infatti l’equazione
x2 − 4x+ 1 = 0
equivale a questo punto all’equazione (x− 2)2 − 3 = 0, cioe (x− 2)2 = 3, la cui soluzione e immediata.53
Vediamo qualche altro esempio.
• Con il polinomio x2 + 6x− 2 possiamo scrivere
x2 + 6x− 2 = x2 + 6x+ 9− 9− 2 = (x+ 3)2 − 11.
• Con il polinomio x2− 3x+2 si presenta un piccolo problema: il secondo monomio (−3x) non sembra un doppioprodotto. In realta lo e: basta pensare che −3x = 2
(− 3
2
)x.54 Allora possiamo scrivere
x2 − 3x+ 2 = x2 − 3x+9
4− 9
4+ 2 =
(
x− 3
2
)2
− 1
4.
• Con il polinomio x2 + x+ 1 possiamo dunque scrivere
x2 + x+ 1 = x2 + x+1
4− 1
4+ 1 =
(
x+1
2
)2
+3
4.
• Se x2 ha un coefficiente diverso da 1, possiamo prima raccogliere tale coefficiente e poi seguire il metodo diprima. Ad esempio, con il polinomio 3x2 + 6x+ 9 possiamo fare
3x2 + 6x+ 9 = 3(x2 + 2x+ 3) = 3(x2 + 2x+ 1− 1 + 3) = 3((x+ 1)2 + 2
).
• Ancora, con il polinomio 2x2 − x+ 1 possiamo fare
2x2 − x+ 1 = 2
(
x2 − 1
2x+
1
2
)
= 2
(
x2 − 1
2x+
1
16− 1
16+
1
2
)
= 2
[(
x− 1
4
)2
+7
16
]
.
• Analogamente
3x2 + 2x− 1 = 3
(
x2 +2
3x− 1
3
)
= 3
(
x2 +2
3x+
1
9− 1
9− 1
3
)
= 3
[(
x+1
3
)2
− 4
9
]
.
• Quale ultimo esempio, e chiaro che il metodo puo essere applicato anche con un polinomio di secondo grado indue variabili x, y, privo del monomio in xy. Si consideri il polinomio
x2 + y2 − 10x+ 12y + 60.
Possiamo applicare il completamento del quadrato sia alla x sia alla y e scrivere
x2 + y2 − 10x+ 12y + 60 = x2 − 10x+ 25 + y2 + 12y + 36− 25− 36 + 60 = (x − 5)2 + (y + 6)2 − 1.
Lo studente ricordi questo esempio: ci sara utile quando parleremo di circonferenze.
Esercizio 5.1 Completare i quadrati nei polinomi
(a) x2 + 2x− 3 (b) x2 + 8x+ 1
(c) x2 + x+ 1 (d) x2 − 5x− 2
52A meno di una quantita additiva costante significa che il quadrato che otteniamo differisce dal polinomio originario soltanto per unaquantita indipendente dalla variabile del polinomio, quindi costante.
53La soluzione di (x− 2)2 = 3 e x− 2 = ±√3, cioe x = 2±
√3.
54Ogni numero e doppio della sua meta.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
POLINOMI
40
6 Soluzioni degli esercizi
Esercizio 1.1
(a) Si applica la proprieta distributiva e si ha
(1− t)(2 − t+ t3) = 2− t+ t3 − 2t+ t2 − t4 = 2− 3t+ t2 + t3 − t4.
(b) Abbiamo la somma di due monomi per la rispettiva differenza. Il risultato e la differenza dei quadrati:
(4x+ 5y)(4x− 5y) = 16x2 − 25y2.
(c) Con la proprieta distributiva si ha
(1
2x+
2
3y
)(
3x− 1
2y
)
=3
2x2 − 1
4xy + 2xy − 1
3y2 =
3
2x2 +
7
4xy − 1
3y2.
Esercizio 1.2
(a) E il quadrato di un binomio:(2z − 3t)2 = 4z2 − 12zt+ 9t2.
(b) E ancora il quadrato di un binomio:
(2
3x− 1
2
)2
=4
9x2 − 2
3x+
1
4.
(c) E il cubo di un binomio:(2− y)3 = 8− 12y + 6y2 − y3.
Esercizio 1.3
(a) Qui si potrebbe svolgere il prodotto applicando come in precedenza la proprieta distributiva. Pero si puo anchericonoscere che si tratta della differenza di due monomi per la rispettiva somma. Quindi si ha
(3− 2x2)(3 + 2x2) = 9− 4x4.
(b) Anche nel secondo si puo riconoscere un caso caratteristico: la scomposizione della differenza di due cubi. Quindi
(1− y)(1 + y + y2) = 1− y3.
Esercizio 1.4
(a) Il primo e il quadrato di un trinomio:
(1 − x+ t)2 = 1 + x2 + t2 − 2x+ 2t− 2xt.
(b) Il secondo e il cubo di un binomio:
(y − 3z)3 = y3 − 9y2z + 27yz2 − 27z3.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
POLINOMI
41
Esercizio 2.1
Con la divisione di Euclide si ottiene il seguente schema:
x4 +x3 −x2 +x −1 x2 +1
−x4 −x2 x2 +x −2x3 −2x2 +x −1−x3 −x
−2x2 −12x2 +2
1
Quindi il quoziente e Q(x) = x2 + x− 2 e il resto R(x) = 1. Vale cioe l’identita
x4 + x3 − x2 + x− 1 = (x2 + 1)(x2 + x− 2) + 1.
Esercizio 2.2
Con la divisione di Euclide si ottiene il seguente schema:
2x3 −3x2 +5x −1 2x +1
−2x3 −x2 x2 −2x + 72
−4x2 +5x −1+4x2 +2x
7x −1−7x − 7
2
− 92
Quindi il quoziente e Q(x) = x2 − 2x+ 72 e il resto R(x) = − 9
2 . Vale cioe l’identita
2x3 − 3x2 + 5x− 1 = (2x+ 1)
(
x2 − 2x+7
2
)
− 9
2.
Esercizio 2.3
Ecco la tabella:1 −1 0 1 −1
1 1 0 0 1
1 0 0 1 0
La tabella dice che il quoziente della divisione e il polinomio Q(x) = x3 +1 e il resto e zero. Quindi possiamo scrivereche x4 − x3 + x− 1 = (x− 1)(x3 + 1), come si trova facilmente anche fattorizzando il polinomio iniziale.
Esercizio 2.4
Ecco la tabella:3 2 1 0
−3 −9 21 −663 −7 22 −66
La tabella dice che il quoziente della divisione e il polinomio Q(x) = 3x2 − 7x+ 22 e il resto e −66. Quindi possiamoscrivere che 3x3 + 2x2 + x = (x+ 3)(3x2 − 7x+ 22)− 66.
Esercizio 3.1
(a) Si ha 4x2 − 4x+ 1 = (2x− 1)2; poi (b) 4x2 − 9 = (2x− 3)(2x+ 3) e infine (c) z4 + z6 = z4(1 + z2).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
POLINOMI
42
Esercizio 3.2
(a) Si ha4p2 − 20pq + 25q2 = (2p− 5q)2.
(b) Si ha8
3x2 − 8
3x+
2
3=
2
3(4x2 − 4x+ 1) =
2
3(2x− 1)2.
Esercizio 3.3
Per la (a) si hax3 − 2x2 + x = x(x2 − 2x+ 1) = x(x − 1)2.
Per la (b) si ha4x2y2 − 4xyzt+ z2t2 = (2xy − zt)2.
Esercizio 3.4
(a) Si ha
3x2 − 3
4=
3
4(4x2 − 1) =
3
4(2x− 1)(2x+ 1).
(b) Si haa2b2 − 4t2 = (ab− 2t)(ab+ 2t).
Esercizio 3.5
Si hax4y2t2 − z4t2 = t2(x4y2 − z4) = t2(x2y − z2)(x2y + z2).
Esercizio 3.6
Si ha1− p4q4 = (1 − p2q2)(1 + p2q2) = (1− pq)(1 + pq)(1 + p2q2).
Esercizio 3.7
Si ha
(a) 2x3y2 − x4y3 + 3x2y5 = x2y2(2x− x2y + 3y3)
(b) 81x2y4 − 64z6 = (9xy2 − 8z3)(9xy2 + 8z3)
(c) 92x
2t3 − 2t = 12 t(9x
2t2 − 4) = 12 t(3xt− 2)(3xt+ 2)
(d) 13x
4y3 + 2x2y2z + 3yz2 = 13y(x
4y2 + 6x2yz + 9z2) = 13y(x
2y + 3z)2.
Esercizio 4.1
Ricordo che un polinomio P e divisibile per (x − 1) se e solo se risulta P (1) = 0. Indicando allora con P1, P2 e P3 itre polinomi nell’ordine, sono divisibili per (x − 1) soltanto i polinomi P2 e P3, dato che P2(1) = P3(1) = 0, mentreP1(1) 6= 0.
Esercizio 4.2
Dato che P (−1) = 0, il polinomio P e divisibile per (x+ 1). Con la regola di Ruffini si ha:
1 0 −2 0 0 −1−1 −1 1 1 −1 1
1 −1 −1 1 −1 0
Pertanto il polinomio quoziente e Q(x) = x4 − x3 − x2 + x− 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
POLINOMI
43
Esercizio 5.1
Si ha
(a) x2 + 2x− 3 = x2 + 2x +1 −1 −3 = (x+ 1)2 − 4
(b) x2 + 8x+ 1 = x2 + 8x +16 −16 +1 = (x+ 4)2 − 15
(c) x2 + x+ 1 = x2 + x + 14 − 1
4 +1 =(x+ 1
2
)2+ 3
4 .
(d) x2 − 5x− 2 = x2 − 5x + 254 − 25
4 −2 =(x− 5
2
)2 − 334 .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 POTENZE E RADICALI
POTENZE, RADICALI E LOGARITMI
44
I-2 Potenze, Radicali e Logaritmi
1 Potenze e Radicali
In questa sezione parliamo di altri argomenti che sono stati affrontati nella scuola secondaria. Anche qui lo studente,in caso senta la necessita di approfondire qualche argomento, puo affiancare a queste pagine un testo gia utilizzato inprecedenza.
1.1 Potenze con esponente naturale
Richiamo qui alcuni concetti che dovrebbero essere gia largamente noti allo studente.Se a e un numero reale fissato, si dice potenza di base a ed esponente naturale n (n = 1, 2, 3, . . .), il numero
andef= a · a · a · . . . · a︸ ︷︷ ︸
n volte
, se n > 1
o il numero a stesso, se n = 1.Ecco alcune proprieta delle potenze appena definite.Qualunque sia il numero a e qualunque siano i naturali m, n, si ha:
1. am · an = am+n
2. (am)n = (an)m = am·n
Con a 6= 0 e n > m, si ha ancora:
3. an : am = an
am = an−m
Qualunque siano i numeri a e b e il naturale n:
4. (a · b)n = an · bn
Qualunque siano a e b 6= 0, qualunque sia n, si ha infine:
5. (a : b)n = an : bn =(ab
)n.
Osservazione Ribadisco un’osservazione gia fatta nella sezione precedente: lo studente si abitui a saper utilizzarequeste regole “nei due versi”: tutte le identita qui sopra possono essere utilizzate da sinistra a destra o da destra asinistra.
1.2 Potenze con esponente intero
Il concetto di potenza, definita poco fa con esponente naturale, si puo generalizzare al caso dell’esponente intero.Questa prima generalizzazione si ottiene ponendo
a0def= 1 , se a 6= 0 ; a−n def
=
(1
a
)n
=1
an, se a 6= 0.
dove n e un numero naturale.Attenzione che la scrittura 00 non viene definita e resta per ora (lo sara anche nel seguito) priva di significato.Con le definizioni appena viste abbiamo definito le potenze con esponente intero, cioe il simbolo az, con z ∈ Z. Questepotenze hanno, per effetto della definizione data, le stesse proprieta delle potenze con esponente naturale.
Osservazione La terza proprieta delle potenze con esponente naturale richiede che sia n > m. Con l’introduzionedel concetto di potenza ad esponente intero, la medesima proprieta puo essere applicata anche se n ≤ m.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 POTENZE E RADICALI
POTENZE, RADICALI E LOGARITMI
45
1.3 Radicali
Cominciamo con una definizione fondamentale.Si dice radice n-esima (n ∈ N, n ≥ 2) di un numero reale a ≥ 0 quel numero reale b, pure lui non negativo, la cuipotenza di esponente n e uguale ad a: tale numero viene indicato col simbolo n
√a. 55
In simboli quindi:
se a ≥ 0 e n ∈ N, n ≥ 2, allora scrivere b = n√a, con b ≥ 0, significa che bn = a.
Ad esempio,√4 = 2, perche 22 = 4. Attenzione che scrivere
√4 = −2 (o
√4 = ±2), in base alla definizione data, non
ha alcun senso. Quindi la radice n-esima di un numero non negativo e unica ed e un numero non negativo.
Osservazione Al simbolo n√a si puo dare significato anche quando a < 0, ma solo con n dispari (n = 3, 5, . . .):56 in
questo caso il simbolo n√a indica il numero reale negativo b, tale che bn = a. Si vede facilmente che, se a < 0 ed n e
dispari, allora n√a = − n
√−a. Quindi ad esempio 3√−8 = − 3
√8 = −2.
Nessun significato viene attribuito al simbolo n√a, quando a < 0 ed n = 2, 4, . . .; nessun significato ha pure il simbolo
0√a, qualunque sia a. Quindi scritture come
√−4, 0√5, 4√−1, 0√−2, sono prive di significato.
1.4 Proprieta dei radicali
Premettiamo alle proprieta dei radicali un richiamo importante: dato un numero reale x, si definisce valore assolutoo modulo di x la quantita
|x| def={
x se x ≥ 0
−x se x < 0.
Osservazione Dalla definizione segue che |x| e una quantita sempre non negativa e nulla se e solo se x = 0.
1. Proprieta fondamentali.
Dalle definizioni del simbolo n√a, con a ≥ 0, oppure con a < 0, seguono facilmente le due seguenti proprieta:
(a) n√bn =
{b , se n e dispari|b| , se n e pari
Si noti che n√bn e definita qualunque sia b, dato che, se n e pari, allora bn ≥ 0, e, se n e dispari, la radice e
comunque definita, essendo di indice dispari.
(b) ( n√a)n = a. (e chiaro che, se n e pari, deve essere a ≥ 0.)
Ad esempio:3√23 = 2 ; 3
√
(−2)3 = −2 ;4√24 = 2 ; 4
√
(−2)4 = | − 2| = 2
( 3√2)3 = 2 ; ( 3
√−2)3 = −2 ; ( 4
√2)4 = 2.
Lo stesso se il radicale ha per argomento una quantita che contiene una variabile x.
Ad esempio:√x2 = |x|, ∀x ; 4
√
(x− 1)4 = |x− 1|, ∀x ; 3√
(x+ 2)3 = x+ 2, ∀x ;(√x)2 = x, ma solo con x ≥ 0 ; ( 3
√x+ 1)3 = x+ 1, ∀x.
Osservazione Lo studente rifletta su questi esempi e presti sempre attenzione in questi casi: queste situazionisono spesso fonte di classici gravi errori.
2. Proprieta invariantiva
Questa proprieta e quella che permette, nei casi che ora discutiamo, di moltiplicare (o dividere, quando possibile)l’indice del radicale e l’esponente del radicando57 per uno stesso numero naturale, maggiore 1. In formule e quellache si esprime scrivendo
mk√ank = m
√an.
55La definizione e giustificata dal fatto che si puo dimostrare che in R, dato un numero a ≥ 0 e un n ∈ N, esiste un unico numero b ≥ 0tale che bn = a. Come d’uso, anziche 2
√a scriviamo
√a.
56Questo perche se a < 0 e n ∈ N, n dispari, esiste un unico numero b < 0 tale che bn = a.57Radicando e cio che sta sotto il segno di radice.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 POTENZE E RADICALI
POTENZE, RADICALI E LOGARITMI
46
Qui pero in generale occorre fare attenzione, in quanto se ad esempio scrivo
6√
(−1)2 = 3√−1,
commetto evidentemente un errore: i due membri dell’uguaglianza non possono essere uguali, dato che a sinistraho una quantita positiva, mentre a destra ne ho una negativa. Possiamo allora dire che la proprieta invariantivavale certamente se a ≥ 0, in quanto in questo caso non usciamo dalla definizione originaria di radice n-esima,quella che opera solo con quantita positive.
Se la vogliamo applicare anche con a < 0, possiamo dire che con n pari non ci sono problemi: infatti m√an e
certamente positivo, per definizione, e anchemk√ank e positivo, dato che anche nk e pari.
Con a < 0 ed n dispari, m√an e negativo e quindi intanto dovremo avere m dispari; poi anche
mk√ank dovra
essere negativo, e quindi k dovra essere anche lui dispari.
Infine, con a < 0, n dispari e k pari, la proprieta come e scritta sopra non vale, ma la possiamo sostituire con la
mk√ank = m
√
|a|n,
e, scritta cosı, vale anche se m e pari.
Un consiglio allo studente: non si cerchi di imparare a memoria tutti i casi. Volendo semplificare un radicaleapplicando questa proprieta si valuti caso per caso, e ci si chieda se, con la semplificazione, si rischia di cambiareil segno dell’espressione o di far perdere il suo significato.
Ad esempio:6√23 =
√2 ; 6
√
(−5)2 = 3√
| − 5| = 3√5 ;
9√
(−2)3 = 3√−2 = − 3
√2 ; 4
√
(−3)2 =√
| − 3| =√3.
Osservazione La proprieta invariantiva consente di semplificare i radicali (abbassandone l’indice), oppure ditrasformare due o piu radicali con indice diversi in altri con indice uguale (condizione questa per confrontare dueradicali, o per moltiplicarli, o per dividerli). Ad esempio:
• La disuguaglianza√2 < 3√3 e certamente vera dato che, applicando la proprieta invariantiva ai due membri,
si ottiene 6√8 < 6√9.
• Volendo semplificare la frazione3√2
4√2possiamo scrivere
3√2
4√2=
12√24
12√23
= 12
√24
23 = 12√2. Lo stesso calcolo si puo
eseguire, come vedremo tra un po’, utilizzando le potenze con esponente frazionario.
• Per semplificare il radicale 9√
(−2)6, come gia visto, possiamo scrivere
9√
(−2)6 = 3√
(−2)2 =3√4.
• La quantita 4√
(x− 2)2 equivale a√
|x− 2|. Attenzione che in questo caso, dato che l’argomento del
radicale contiene la variabile x, non possiamo essere certi del segno di (x− 2): quindi, dato che 4√
(x− 2)2
e certamente non negativo, occorre usare il valore assoluto.
•6√x3 =
√x. Qui non dobbiamo usare il valore assoluto, in quanto l’espressione a sinistra e definita per
x ≥ 0, e anche√x e definita sulle x non negative. Sarebbe opportuno in questi casi evidenziare dove e
valida l’uguaglianza, scrivendo quindi6√x3 =
√x, con x ≥ 0. Scrivere invece
6√x3 =
√
|x|, senza precisaredove la considero, puo dare origine ad errori, dato che l’espressione a sinistra e definita per x ≥ 0, mentrequella a destra e definita in tutto R.
• Invece dobbiamo scrivere 6√
(x+ 1)2 = 3√
|x+ 1|, valida in tutto R.
1.5 Operazioni con i radicali
1. Addizione (o sottrazione) di due radicali.
In generale, la somma (o la differenza) di due radicali non e esprimibile con un solo radicale, anche se gli addendisono radicali con lo stesso indice. Quindi, ad esempio
√2 +
3√3 =
6√8 +
6√9,
ma a questo punto non possiamo scriverlo come un unico radicale. Grave errore sarebbe scrivere ad esempio6√8 + 6√9 = 6√17.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 POTENZE E RADICALI
POTENZE, RADICALI E LOGARITMI
47
Sono ovviamente applicabili le consuete regole del raccoglimento: ad esempio
2√5−√5 +
1
2
√5 =
(
2− 1 +1
2
)√5 =
3
2
√5.
2. Moltiplicazione (o divisione) di due radicali.
Il prodotto (o il quoziente) di due radicali puo sempre essere espresso mediante un solo radicale: se i fattoridella moltiplicazione (o i termini della divisione) hanno lo stesso indice, anche il prodotto (o il quoziente) avraquell’indice e per radicando il prodotto (o il quoziente) dei radicandi.
Quindi, in simboli, si ha:
n√a · n√b =
n√a · b ,
n√a
n√b= n
√a
b,
dove pero accorre anche qui fare attenzione all’ambito di validita. Se a ≥ 0, b ≥ 0 non ci sono problemi(chiaramente dovra essere b > 0 nella seconda). Se a oppure b sono negativi, dovra essere n dispari.
Possiamo anche qui estendere la validita nel caso che a e b siano entrambi negativi e n pari, scrivendo
n√
|a| · n√
|b| = n√a · b.
Ad esempio si ha:√2 ·√5 =√10 ; 3
√−5 · 3
√2 = 3√−10 = − 3
√10.
Se i fattori (o il dividendo e il divisore) sono radicali con indici diversi, occorre ridurli prima allo stesso indice,per avere il prodotto (o il quoziente) espresso con un unico radicale, facendo sempre attenzione, come visto,nell’applicare la proprieta invariantiva.
Ad esempio:√2 · 3√−5 = −
√2 · 3√5 = − 6
√8 · 6√25 = − 6
√200.
Errato sarebbe invece fare:√2 · 3√−5 =
6√23 · 6
√
(−5)2 = 6√8 · 6√25 = 6
√200.
3. Potenza di un radicale.
Per elevare un radicale a potenza con esponente naturale (o intero) basta elevare a potenza il suo radicando. Insimboli:
( n√a)k =
n√ak.
Naturalmente le due quantita devono essere definite (quindi ad esempio, se k < 0, deve essere a 6= 0).
Ad esempio: ( 3√2)2 = 3
√4 ; ( 3
√−5)2 = 3
√25.
Notare che invece ( 4√−2)2 = 4
√4 non e corretta, dato che 4
√−2 non ha significato.
Quindi, attenzione prima di applicare questa proprieta ad un radicale il cui argomento contiene una variabile.Si devono anzitutto porre le corrette condizioni di esistenza.
Esempi:(√x− 2)2 = x− 2 , per x ≥ 2;
invece: ( 3√x− 2)3 = x− 2 , qualunque sia x.
4. Radice di un radicale.
La radice di un radicale puo, in generale, diventare un radicale semplice, avente per indice il prodotto degli indicied il medesimo radicando: fare pero attenzione come sempre. Quindi, in simboli:
n
√
m√a = nm
√a.
Se a ≥ 0, non ci sono problemi. Se a < 0, occorre che n ed m siano entrambi dispari.
Osservazione Un fattore numerico esterno ad un radicale potra sempre essere pensato come un radicale.Attenzione pero che un fattore negativo non puo essere scritto come radicale di indice pari.
Vediamo alcuni esempi:
• 3 4√2 =
4√34 · 4√2 = 4√162.
• −2 3√5 = 3
√
(−2)3 · 3√5 = 3√−40 = − 3
√40.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 POTENZE E RADICALI
POTENZE, RADICALI E LOGARITMI
48
• −2 4√3 non si puo scrivere come 4
√
(−2)4 · 4√3. Occorre fare −2 4
√3 = − 4
√24 · 4√3 = − 4
√48.
Vediamo altri esempi significativi, in cui si applicano le proprieta viste finora.
•4√36 =
4√34 · 32 = 3 4
√9.
•3√
(−5)10 = 3√
(−5)9(−5) = | − 5|3 · 3√
| − 5| = 125 3√5.
Qui occorre usare i moduli dato che la quantita iniziale e positiva.
•3√
(−2)7 = 3√
(−2)6(−2) = (−2)2 · 3√
(−2) = −(−2)2 · 3√2 = −4 3
√2.
In questo caso la quantita iniziale e negativa, e tali devono restare anche i membri delle uguaglianze sucessive.
5. Razionalizzazione dei termini di una frazione.
Sfruttando la proprieta invariantiva delle frazioni e possibile rendere razionale il denominatore (o il numeratore)di una espressione fratta, che sia irrazionale, naturalmente a scapito dell’altro termine.
Richiamiamo con esempi i casi piu semplici e utili: lo studente eventualmente approfondisca l’argomento,rivedendo quanto gia sa dalla scuola secondaria.
1◦ caso: 32√2. Per rendere razionale il denominatore moltiplichiamo numeratore e denominatore per
√2.
Quindi: 32√2·√2√2= 3
√2
4 .
2◦ caso: 53 4√2. Per rendere razionale il denominatore moltiplichiamo numeratore e denominatore per
4√23.
Quindi: 53 4√2·
4√23
4√23
= 5 4√8
6 .
3◦ caso:√5−
√2
3 . Qui razionalizziamo il numeratore: basta moltiplicare numeratore e denominatore per
(√5 +√2).
Quindi:√5−
√2
3 = (√5−
√2)(
√5+
√2)
3(√5+
√2)
= 5−23(
√5+
√2)
= 1√5+
√2.
Altro esempio: xx+
√x= x
x+√x· x−
√x
x−√x= x(x−√
x)x2−x , precisando pero che il tutto ha senso per x > 0 e x 6= 1,
affinche sia definito il radicale iniziale, non sia nullo il denominatore della frazione iniziale e non sia nulla laquantita (x−√x) per cui abbiamo moltiplicato.
4◦ caso: 32− 3
√2. In questo caso il fattore che razionalizza il denominatore e (4 + 2 3
√2 + 3√4) (ricordare che
(a− b)(a2 + ab+ b2) = a3 − b3). Quindi:
3
2− 3√2=
3
2− 3√2· (4 + 2 3
√2 + 3√4)
(4 + 2 3√2 + 3√4)
=3(4 + 2 3
√2 + 3√4)
8− 2=
4 + 2 3√2 + 3√4
2.
1.6 Potenze con esponente razionale
Dati i numeri naturali m,n, con n > 1, e il numero non negativo a, si definisce potenza di a con esponente razionalemn il valore del radicale n
√am. In simboli:
am/n def= n√am , con a ≥ 0.
Se l’esponente e razionale negativo, −mn , e a > 0, sempre per definizione, si ha:
a−m/n def=
1
am/n=
1n√am
.
Per le definizioni date, i simboli am/n e a−m/n rappresentano sempre numeri non negativi. Essi godono di tutte leproprieta delle potenze con esponente naturale.Non e possibile estendere direttamente la definizione data se la base e negativa: si pensi ad esempio che questoporterebbe a scrivere (−2)3/4 = 4
√
(−2)3, e questo non ha senso. Anche nei casi che sembrano meno pericolosi, adesempio con m ed n entrambi dispari, ci sono problemi: si pensi che (−2)1/3 = 3
√−2 potrebbe anche andare, ma, dato
che 13 = 2
6 , avremmo (−2)1/3 = (−2)2/6 = 6√
(−2)2, e questo non puo sussistere, dato che iniziamo con una quantitanegativa e finiamo con una positiva.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 POTENZE E RADICALI
POTENZE, RADICALI E LOGARITMI
49
1.7 Potenze con esponente irrazionale
Ricordo che e possibile definire anche la potenza con esponente irrazionale, cioe la potenza del tipo
bα , dove b ∈ R, b > 0 e α e un numero reale irrazionale.
Non entro nei dettagli della definizione, che lo studente forse ha gia incontrato alla scuola secondaria. Ricordo soltantole uniche due cose che in qualche modo potranno servirci: quando l’esponente e (o puo essere) un numero irrazionale,come d’altro canto e stato gia con gli esponenti razionali, la definizione viene data solo con base positiva. Anche perquesto tipo di potenze valgono le consuete proprieta. Inoltre bα (con b > 0 e α irrazionale) e una quantita comunquepositiva.Pertanto hanno un senso, e sono numeri reali positivi, le scritture
2√2 , 3π , π−π =
1
ππ, 2x, con x ∈ R
ma non sono invece definite le quantita
(−2)√2 , (−π)π , (−3)x, con x ∈ R.
Quindi, scrivendo ad esempio
(x + 3)√2,
dovremo precisare che deve essere x > −3.Osservazione Prima di passare ai logaritmi, qualche parola per raccomandare allo studente di prestare sempreattenzione per non interpretare in modo errato le notazioni. Desidero soffermarmi in particolar modo sulla scrittura
amn
,
che rischia di essere male interpretata. Si ricordi che amn
= a(mn) e non am
n
= (am)n.
Quindi ad esempio 232
= 29 = 1024 e invece 232 6= (23)2 = 82 = 64. Ancora, nello stesso modo, non si creda che 2x
2
voglia dire (2x)2, e cioe 22x. Invece, se potesse servire, vale 2x2
= 2x·x.
Esercizio 1.1 Si scriva√8 come potenza in base 2 e 3
√81 come potenza in base 3.
Esercizio 1.2 Si scriva 432
come potenza in base 2.
Esercizio 1.3 E vero che
21/x e uguale a21
2x?
Esercizio 1.4 Come si puo anche scrivere 2−1/x? E e1−xx ?
Esercizio 1.5 Come si puo scrivere3√x5 in forma di potenza?
Esercizio 1.6 Si scriva√x+
√x5
x√x
come somma di due potenze.
Esercizio 1.7 E vero che6√a3 e definita qualunque sia a? Per quali valori posso dire che
6√a3 =
√a?
Esercizio 1.8 E vero che8√a4 e uguale a
√a qualunque sia a?
Esercizio 1.9 Si riscriva ex + e−x raccogliendo prima ex e poi e−x.
Esercizio 1.10 Si riscriva ex + e1/x raccogliendo e1/x.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 LOGARITMI
POTENZE, RADICALI E LOGARITMI
50
2 Logaritmi
2.1 Definizione di logaritmo
Anche la definizione di logaritmo e le relative proprieta dovrebbero essere gia note agli studenti. Coloro che invece travoi incontrassero questo termine per la prima volta sono invitati a consultare qualche testo di scuola secondaria in cuitale argomento viene trattato.Rivediamo comunque gli aspetti essenziali, cominciando dalla definizione di logaritmo.
Definizione Se b e un numero reale positivo diverso da 1 e a e un numero reale positivo, si dice logaritmo in base bdi a quel numero reale y tale che by = a. In simboli
logb a = y significa che by = a, con b > 0, b 6= 1 e a > 0.
Quindi logb a e l’esponente che devo dare a b per ottenere a. Si dice che b e la base del logaritmo e che a e l’argomento.
Ci sono alcuni casi particolari, che e bene ricordare:
• logb 1 = 0, qualunque sia la base b (0 < b 6= 1), dato che b0 = 1;
• logb b = 1, qualunque sia b (0 < b 6= 1), dato che b1 = b.
Vediamo qualche esempio.
• log2 8 = 3, poiche 23 = 8;
• log10 100 = 2, poiche 102 = 100;
• log214 = −2, poiche 2−2 = 1
4 ;
• log10110 = −1, poiche 10−1 = 1
10 ;
• log1/2 4 = −2, poiche(12
)−2= 4;
• logb(b2) = 2, poiche b2 = b2 (ovviamente con 0 < b 6= 1);
• log1/b b = −1, poiche(1b
)−1= b (anche qui con 0 < b 6= 1);
Dagli esempi risulta evidente che il valore del logaritmo puo essere anche negativo (quindi l’argomento deve esserepositivo, ma poi il valore del logaritmo puo avere segno qualunque). Anzi, riguardando gli esempi si intuisce che:
• se la base b e maggiore di 1, allora
il logaritmo e positivo quando l’argomento e maggiore di 1, il logaritmo e negativo quando l’argomento e minoredi 1 (il logaritmo vale 0 se l’argomento vale 1);
• se la base b e minore di 1, allora
il logaritmo e positivo quando l’argomento e minore di 1, ed e negativo quando l’argomento e maggiore di 1(anche qui il logaritmo vale 0 se l’argomento vale 1).
2.2 Proprieta dei logaritmi
Dalla definizione di logb a si deducono immediatamente due proprieta fondamentali:
logb(by) = y , con 0 < b 6= 1 e blogb a = a , con 0 < b 6= 1, a > 0.
La prima si puo giustificare a parole cosı: logb(by) e l’esponente che devo dare a b per ottenere by: si tratta chiaramente
di y. Anche la seconda e banale: se logb a e l’esponente che dato a b mi fa trovare a, allora evidentemente blogb a e a.Queste due identita sono molto utili perche consentono di scrivere un numero reale rispettivamente come logaritmo inuna certa base di qualche cosa e come potenza in una certa base di qualcos’altro.58
Ad esempio, se vogliamo scrivere 10 come logaritmo in base 2 e come potenza in base 2, basta scrivere
10 = log2(210) e 10 = 2log2 10.
58Le due proprieta sono utili nella risoluzione delle equazioni logaritmiche ed esponenziali.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 LOGARITMI
POTENZE, RADICALI E LOGARITMI
51
Per quanto riguarda i numeri negativi, sara certamente possibile scriverli come logaritmi, ma non come potenze conbase positiva. Cosı, volendo scrivere −2 come logaritmo in base 10 bastera fare
−2 = log10(10−2) = log10
1
100.
Non si puo invece scrivere −2 come potenza in base 10.Ecco ora le altre proprieta dei logaritmi. Queste possono essere dimostrate facilmente, applicando le proprieta dellepotenze e le due identita fondamentali appena viste.
• logb(xy) = logb x+ logb y , con x > 0, y > 0 e 0 < b 6= 1;
• logbxy = logb x− logb y , con x > 0, y > 0 e 0 < b 6= 1;
• logb(xa) = a logb x , con x > 0 e 0 < b 6= 1.
A dimostrazione della prima, basta provare che elevando b alla quantita di destra si ottiene xy: infatti
blogb x+logb y = blogb x · blogb y = xy.
Per la seconda le cose sono molto simili:
blogb x−logb y =blogb x
blogb y=x
y.
Anche per la terza e lo stesso:ba logb x =
(blogb x
)a= xa.
Lo studente faccia attenzione a queste proprieta: si noti che esse sono state enunciate con argomenti dei logaritmitutti positivi (come e ovvio).Da notare che peraltro la validita di queste proprieta puo essere estesa ricorrendo all’uso del valore assoluto. Possiamoinfatti dire che per le prime due valgono queste proprieta piu generali:
• logb(xy) = logb |x|+ logb |y| , con xy > 0 e 0 < b 6= 1;
• logbxy = logb |x| − logb |y| , con xy > 0 e 0 < b 6= 1;
Per quanto riguarda la terza, possiamo osservare che, se la potenza xa richiede che sia x > 0 (come ad esempio nelcaso di a irrazionale), allora non c’e da modificare nulla. Se invece xa e definita anche per x < 0 (come ad esempio sefosse a numero naturale pari), allora possiamo scrivere
• logb(xa) = a logb |x| , con x 6= 0 e 0 < b 6= 1
(la condizione x 6= 0 va comunque precisata, poiche il logaritmo di 0 non esiste).
A volte puo essere utile ricordare anche la formula del cambio di base di un logaritmo. Se conosciamo il logaritmo inuna certa base b di un numero positivo x, come possiamo esprimere il logaritmo in una diversa base c ?Scrivendo x come potenza in base c otteniamo
x = clogc x,
da cui, applicando i logaritmi in base b ad entrambi, abbiamo
logb x = logb clogc x = logc x · logb c,
da cui
logc x =logb x
logb c,
che e appunto la nota formula del cambio di base: se conosciamo i logaritmi in base b la formula ci dice come calcolareil logaritmo in base c.Da notare che, nel caso particolare x = b, si ha l’altra importante identita
logc b =1
logb c.
Osservazione Occorre fare sempre molta attenzione nell’applicare le proprieta dei logaritmi.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 LOGARITMI
POTENZE, RADICALI E LOGARITMI
52
Ad esempio, la quantita log5[x(x − 1)
]e definita per x > 1 oppure x < 0, valori per cui l’argomento del logaritmo e
positivo.59 Non possiamo pero scrivere che in tutto questo insieme vale la
log5[x(x − 1)
]= log5 x+ log5(x − 1),
dato che solo per x > 1 esistono entrambi i logaritmi a destra (per x < 0 il nessuno dei due logaritmi di destra esiste).Quindi dobbiamo scrivere
log5[x(x − 1)
]= log5 x+ log5(x− 1) , per x > 1.
Se vogliamo scrivere qualcosa che valga in tutto l’insieme in cui e definito il log5[x(x − 1)
]dobbiamo scrivere
log5[x(x − 1)
]= log5 |x|+ log5 |x− 1| , per x > 1 oppure x < 0.
Forse ancora piu pericolosa e la terza proprieta dei logaritmi. Ad esempio, in presenza della quantita log3(x − 2)4 eforte la tentazione di scrivere
log3(x− 2)4 = 4 log3(x− 2).
Questa pero e errata, dato che la quantita a sinistra esiste per qualunque x 6= 2, mente quella a destra richiede x > 2.Anche qui le cose vanno a posto scrivendo
log3(x− 2)4 = 4 log3 |x− 2| , con x 6= 2.
Osservazione Solitamente come base dei logaritmi si utilizza il numero e (detto numero di Neper). Si tratta di unnumero reale irrazionale, un valore approssimato del quale e il numero razionale 2.718 (cioe 2718
1000 ).Di solito i logaritmi in base 10 si dicono logaritmi decimali, mentre quelli in base e si dicono logaritmi naturali. Nelseguito usero quasi sempre i logaritmi naturali: scrivendo “ln” intendero logaritmo naturale, cioe in base e. Basidiverse saranno esplicitamente indicate (log2, log10, etc.).
Osservazione Concludo questa lezione con qualche parola ancora sulle notazioni, che possono essere talvolta fontedi equivoco ed errore. Non si confondano le due scritture
logb xn e lognb x.
La prima sta per logb(xn), cioe il logaritmo di xn. La seconda significa (logb x)
n, cioe la potenza n-esima del logaritmodi x. Frequente errore di alcuni studenti e applicare in modo scorretto una delle proprieta dei logaritmi e scriverelognb x = n logb x, scambiando lognb x con logb(x
n).
Esercizio 2.1 Calcolare log218 e log3
10√9.
Esercizio 2.2 Calcolare log√21
3√16.
Esercizio 2.3 Che cosa significa x = logy z?
Esercizio 2.4 Scrivere come logaritmo in base 2 i seguenti numeri:
0 , 1 , 2 ,1
4, −1
2.
Esercizio 2.5 Scrivere come potenza in base 2 i seguenti numeri:
√2 , 3 ,
√3 ,
1
3, e.
Esercizio 2.6 Scrivere come logaritmo in base e i seguenti numeri:
1 , 2 , −1 ,1
2, −1
3.
59Non abbiamo ancora ripassato le disequazioni, ma questa e molto semplice: il prodotto x(x− 1) e positivo per “valori esterni a 0 e 1”,cioe per x minore di 0 oppure per x maggiore di 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
POTENZE, RADICALI E LOGARITMI
53
Esercizio 2.7 Scrivere, se possibile, come potenza in base e i seguenti numeri:
√e ,
13√e
, 2 ,1
2, −1
3.
Esercizio 2.8 Il numero log2 3 e positivo o negativo?
Esercizio 2.9 E vero che il logaritmo di un numero minore di 1 e sempre negativo?
Esercizio 2.10 E vero che log4(x4) = 4 log4 x per ogni x?
Esercizio 2.11 E vero che log4(x4) = 2 log4(x
2) per ogni x diverso da zero?
Esercizio 2.12 Scrivere x come potenza in base z. Per quali valori di x e z ha senso l’uguaglianza?
Esercizio 2.13 Scrivere t come logaritmo in base y. Per quali valori di t e y ha senso l’uguaglianza?
3 Soluzioni degli esercizi
Esercizio 1.1
Si ha√8 =√23 = (23)1/2 = 23/2 e 3
√81 = (34)1/3 = 34/3.
Esercizio 1.2
Attenzione qui: 432
significa 49 (e non 642) e quindi 218.
Esercizio 1.3
Certo che no. La quantita 21/x non si puo trasformare usando quella proprieta delle potenze. Si ricordi che 21
2x significa21−x.
Esercizio 1.4
Il primo, cioe 2−1/x, si puo scrivere anche come 121/x
. Invece per e1−xx si puo scrivere
e1−xx = e
1x−1 = e1/x · e−1 =
e1/x
e.
Esercizio 1.5
Si puo scrivere x5/3.
Esercizio 1.6
Si ha √x+√x5
x√x
=
√x
x√x+
√x5
x√x=
1
x+x5/2
x3/2= x−1 + x.
Esercizio 1.7
La6√a3 e definita soltanto per a ≥ 0. Quindi la prima risposta al quesito e no. L’uguaglianza
6√a3 =
√a e vera dove
sono definite entrambe le quantita, e cioe per a ≥ 0.
Esercizio 1.8
No. La prima quantita e definita per ogni a, mentre la seconda solo per a ≥ 0. La validita dell’uguaglianza e limitataquindi agli a ≥ 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
POTENZE, RADICALI E LOGARITMI
54
Esercizio 1.9
Si haex + e−x = ex(1 + e−2x)
eex + e−x = e−x(e2x + 1).
Esercizio 1.10
Si haex + e1/x = e1/x(ex−1/x + 1).
Approfitto dell’occasione per mettere in guardia da un possibile fraintendimento in questo tipo di scritture: se scrivo
ex−1/x , ad esponente c’e x− 1x e non x−1
x .
Se voglio scrivere la seconda con la frazione in linea devo scrivere e(x−1)/x.
Esercizio 2.1
Si ha log218 = log2 2
−3 = −3 e log310√9 = log3 9
1/10 = log3 31/5 = 1/5.
Esercizio 2.2
Si ha
log√2
13√16
= log√2
13√24
= log√2 2−4/3 = log√2((
√2)−8/3) = −8/3.
Esercizio 2.3
In base alla definizione di logaritmo x = logy z significa che yx = z.
Esercizio 2.4
Si ha:
0 = log2 1 , 1 = log2 2 , 2 = log2 4 ,1
4= log2 2
1/4 = log24√2 , −1
2= log2 2
−1/2 = log21√2
Esercizio 2.5
Si ha:
√2 = 21/2 , 3 = 2log2 3 ,
√3 = 2log2
√3 = 2
12log2 3 ,
1
3= 2log2
13 = 2− log2 3 , e = 2log2 e
Esercizio 2.6
Si ha:
1 = ln e , 2 = ln e2 , −1 = ln e−1 = ln1
e,
1
2= ln e1/2 = ln
√e , −1
3= ln e−1/3 = ln
13√e
Esercizio 2.7
Si ha: √e = e1/2 ,
13√e= e−1/3 , 2 = eln 2 ,
1
2= eln 1/2 = e− ln 2.
Per quanto riguarda l’ultimo (−1/3), e impossibile scrivere come potenza di base positiva un numero negativo.
Esercizio 2.8
E maggiore di 1, quindi certamente positivo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
POTENZE, RADICALI E LOGARITMI
55
Esercizio 2.9
No. E vero solo se la base del logaritmo e maggiore di 1.
Esercizio 2.10
No. La prima espressione e definita per ogni x diverso da 0, la seconda solo per x > 0. L’uguaglianza e vera per x > 0.Possiamo scrivere log4(x
4) = 4 log4 |x|, e questa vale per ogni x diverso da 0.
Esercizio 2.11
Sı, e vero. Infatti log4(x4) = log4(x
2)2 = 2 log4(x2) (ovviamente se x 6= 0).
Esercizio 2.12
Si ha x = zlogz x e la scrittura ha senso per z > 0 e z 6= 1 e per x > 0.
Esercizio 2.13
Si ha t = logy(yt) e la scrittura ha senso per y > 0 e y 6= 1 e per qualunque t.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 GENERALITA SULLE EQUAZIONI
EQUAZIONI E DISEQUAZIONI
56
I-3 Equazioni e Disequazioni
1 Generalita sulle equazioni
Un’equazione e un’uguaglianza tra due espressioni. Possiamo avere equazioni in una variabile (detta anche incognita)o anche equazioni in due o piu variabili.
Esempi Sono equazioni in una variabile le seguenti uguaglianze:
2x+ 1 =1
2x− 1 ; x2 + x+ 1 = 0 ; 1 +
1
y2= 0 ; e−t2 = 2 ; 1 + ln z =
√1 + z.
Esempi Sono equazioni in due variabili le seguenti uguaglianze:
x− y + 1 = 0 ; x2 + y2 = 1 ; 4x2 + 9y2 = 1 ; t+1
z2= 1.
I valori (solitamente reali) che, sostituiti alle variabili, rendono vere le uguaglianze, si dicono soluzioni (o anche radici)dell’equazione.Risolvere un’equazione significa trovare l’insieme delle sue soluzioni, cioe tutte le sue soluzioni.
EsempiL’equazione x2 − 1 = 0 ha per soluzioni −1 e 1, quindi l’insieme delle sue soluzioni e {−1, 1}.L’equazione x2 + 1 = 0 non ha nessuna soluzione (tra i numeri reali).L’equazione: x− y + 1 = 0 ha come soluzione (1, 2), ma anche (−1, 0) e molte altre.60
L’equazione x2 + y2 = 0 ha l’unica soluzione (0, 0), quindi l’insieme delle sue soluzioni va indicato con {(0, 0)}.Un’equazione che non ha soluzioni si dice impossibile. L’insieme delle soluzioni di un’equazione impossibile e quindil’insieme vuoto. Ad esempio, come appena visto, l’equazione x2+1 = 0 e impossibile. Anche 2
√x = − 1
x2 e impossibile(infatti il numero non negativo 2
√x non puo essere uguale al numero, certamente negativo, − 1
x2 ).
Un’equazione che abbia almeno una soluzione si dice possibile. Tra le equazioni possibili si distinguono di solito quelleindeterminate, che hanno infinite soluzioni. Infine, le equazioni che sono vere per qualsiasi valore della (delle) variabile(variabili) per cui hanno significato i due membri dell’equazione stessa, vengono dette identita.
EsempiL’equazione: x2 + 2x− 3 = 0 e possibile, dato che e vera per x1 = 1 oppure per x2 = −3.L’equazione: 3 + |x|
x = 4 e indeterminata, perche vera per ogni x positivo (ma non per x ≤ 0).
L’equazione√x2 = |x| e un’identita, essendo vera per ogni valore di x.
Anche l’equazione 2+√x√
x= 2
√x
x + 1 e un’identita, essendo vera per ogni valore positivo di x ed essendo i due membri
dell’equazione definiti solo per le x positive.
Avremo spesso a che fare anche con sistemi di equazioni. Un esempio di sistema di equazioni e la scrittura
{x3 + x− 2 = 0
x2 − 1 = 0.
Si tratta in questo caso di un sistema di due equazioni in una sola variabile. Una soluzione del sistema e un valoreche, sostituito alle variabili, rende vere tutte le equazioni del sistema. Nel nostro esempio una soluzione del sistema eil valore 1 (ed e l’unica soluzione).Risolvere un sistema di equazioni significa trovare tutte le sue soluzioni. E chiaro che l’insieme delle soluzioni di unsistema e l’intersezione degli insiemi delle soluzioni delle equazioni che costituiscono il sistema. E quindi evidente che,se una delle equazioni del sistema e impossibile, allora il sistema e impossibile. Non vale il viceversa: il sistema puoessere impossibile anche se nessuna delle equazioni lo e.Possiamo avere sistemi di un numero qualunque di equazioni, in un numero qualunque di variabili.
Torniamo alle equazioni, per affrontare gradualmente l’argomento di come si risolvono.
60La notazione che qui si usa e quella di indicare la soluzione di un’equazione in due variabili come coppia di numeri reali. La coppia deinumeri reali a e b viene indicata col simbolo (a, b). Non si confonda l’insieme {−1, 1} con la coppia (−1, 1).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 GENERALITA SULLE EQUAZIONI
EQUAZIONI E DISEQUAZIONI
57
Due equazioni si dicono equivalenti quando hanno lo stesso insieme di soluzioni, cioe quando ogni soluzione dell’unae anche soluzione dell’altra e viceversa.
Esempio Sono equazioni equivalenti le seguenti:
x− 1
x= 2 e x2 − 2x− 1 = 0
(insieme di soluzioni {1−
√2, 1−
√2})
o anche √x = 2 e x = 4
(unica soluzione: 4
).
Non sono equazioni equivalenti invece:
x+1
x− 2= 2 +
1
x− 2e x = 2,
(anche se la seconda “si ottiene immediatamente dalla prima”) perche la soluzione 2 della seconda non e soluzionedella prima.61
Per trasformare un’equazione in altra equivalente si hanno le seguenti regole (comunemente dette principi di equivalenzadelle equazioni):
1. Principio di addizione.
Aggiungendo ai due membri di un’equazione uno stesso numero, o una medesima espressione, che non perdasignificato nell’insieme di risoluzione dell’equazione e che comunque non alteri tale insieme, si ottiene un’equazioneequivalente alla precedente.62
Osservazione Se si aggiunge ai due membri di un’equazione una qualsiasi costante o espressione che risultasempre definita, come ad esempio (x2+1) o 2
x2+3 , si sara sicuri di avere un’equazione equivalente alla precedente;
non si sara altrettanto certi di avere un’equazione equivalente se si aggiungono espressioni, come 1x o x
x−2 , chepossono alterare l’insieme dove si cercano le soluzioni dell’equazione.
2. Principio di moltiplicazione.
Moltiplicando (o dividendo) ambo i membri di un’equazione per uno stesso numero non nullo o per una medesimaespressione, che non diventi nulla e non perda significato nell’insieme di risoluzione dell’equazione, si ottieneun’equazione equivalente a quella data.
Osservazione Si potra quindi moltiplicare ambo i membri di un’equazione per una costante diversa da zero,o per una espressione sempre diversa da zero, come ad esempio (x2 + 2x+ 3) o 1
x2+√2e si sara certi di ottenere
un’equazione equivalente a quella che si aveva; si potra, in qualche caso, moltiplicare i due membri anche perespressioni come (x − 1) o 1
x , oppure√x, se cosı facendo non si altera l’insieme in cui si cercano le soluzioni.
Nell’esempio di poco fa delle due equazioni che non sono equivalenti succede proprio questo: togliendo ad amboi membri dell’equazione x+ 1
x−2 = 2 + 1x−2 la quantita 1
x−2 si modifica l’insieme in cui l’equazione e definita.
Talvolta per risolvere un’equazione, cioe per trovare tutte le sue soluzioni, basta trasformarla, mediante i due principi ocon opportune modifiche algebriche, in altre equivalenti e piu semplici, che possano piu facilmente suggerire le eventualisoluzioni cercate.63
Facciamo qualche esempio.
Esempio Si abbia l’equazione x(1+x)3 = x2
3 − 1. Moltiplicando ambo i membri per 3, si ha l’equazione equivalente
x(1 + x) = x2 − 3,
che puo anche scriversix+ x2 = x2 − 3;
aggiungiamo ora ad ambo i membri −x2 (o trasportiamo x2 dal primo al secondo membro, cambiandolo di segno); siha, in ogni caso, l’equazione equivalente
x = −3.Quest’ultima suggerisce subito che la soluzione cercata e −3.
61Il motivo e che passando dalla prima equazione alla seconda, togliendo ad ambo i membri la quantita frazionaria, si altera l’insieme incui e definita l’equazione iniziale, rendendo cosı possibile una soluzione che non puo essere accettata.
62E in uso spesso il seguente modo di dire: nell’equazione (ad esempio) 2x + 3 = 0, “porto a destra il 3” e ottengo 2x = −3. Non c’enessun problema nel dire cosı; si ricordi pero che significa aggiungere ad ambo i membri dell’equazione −3.
63Abbiamo detto “talvolta”, dato che in generale puo non essere cosı semplice. Anzi diciamo subito che, a parte qualche particolaretipologia di equazioni, che ora vedremo, non c’e un metodo generale per trovare le soluzioni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 EQUAZIONI DI SECONDO GRADO
EQUAZIONI E DISEQUAZIONI
58
2 Equazioni di primo grado
Qui ci limitiamo a pochi richiami, dato che si tratta di un argomento che lo studente deve gia conoscere.Le equazioni di primo grado sono quelle i cui due membri sono entrambi polinomi di primo grado o costanti. Si possonosempre ricondurre alla forma
ax+ b = 0 , con a 6= 0, 64
che porta all’unica soluzione: x = −b/a.Lo studente eventualmente si eserciti con qualche esempio preso da testi di scuola secondaria.
3 Equazioni di secondo grado
Anche qui pochi richiami delle cose essenziali.Sono equazioni di secondo grado quelle i cui due membri sono riducibili a polinomi di secondo grado (o ad uno disecondo e l’altro di grado inferiore). Con i principi di equivalenza le equazioni di secondo grado si possono semprericondurre alla forma
ax2 + bx+ c = 0 , con a 6= 0. 65 (6)
Vediamo come si risolvono. Consideriamo prima i seguenti casi particolari:
(i) a 6= 0, b = c = 0. L’equazione (6) diventaax2 = 0,
e questa ha ovviamente per soluzione soltanto x = 0.
(ii) a 6= 0, b 6= 0, c = 0. L’equazione (6) diventa:ax2 + bx = 0.
Scomponendo in fattori il primo membro, si puo scrivere
x(ax + b) = 0.
La legge dell’annullamento del prodotto66 da le soluzioni x1 = 0, x2 = −b/a.
Esempio L’equazione3x2 − x = 0
si puo scrivere come x(3x− 1) = 0 e quindi ha le soluzioni x1 = 0, x2 = 1/3.
(iii) a 6= 0, b = 0, c 6= 0. L’equazione (6) diventaax2 + c = 0.
Se i coefficienti a, c sono concordi l’equazione risulta impossibile. Se invece a, c sono discordi, le soluzionidell’equazione sono x1 =
√
−c/a, x2 = −√
−c/a.In pratica, in questo caso, il procedimento risolutivo, e semplicemente il seguente: da ax2 + c = 0 si ricavax2 = −c/a e, successivamente, essendo −c/a > 0, x1,2 = ±
√
−c/a.
Osservazione Approfitto dell’occasione per fare un’osservazione di carattere “tipografico”. Talvolta e comodoscrivere una frazione “in linea”, cioe ad esempio scrivere a
b come a/b. Pero attenzione: se vi capitera di farlo
dovete ricordare che, volendo ad esempio scrivere a+bc dovete scrivere (a + b)/c e non a + b/c, che invece vuol
dire a+ bc . Ancora:
12x si deve scrivere 1/(2x), perche 1/2x vuol dire 1
2x. La notazione in linea puo quindi esserecomoda ma talvolta puo complicare leggermente le cose, dato che puo richiedere parentesi che altrimenti nonsono necessarie.
Esempio L’equazione3x2 − 4 = 0
si puo scrivere come x2 = 4/3 e quindi ha le soluzioni x1 = −√
4/3, x2 =√
4/3, cioe x1,2 = ±2/√3.
64Se a = 0 la cosa diventa banale: con b 6= 0 l’equazione e impossibile, mentre con b = 0 e un’ovvia identita.65Se e a = 0 si ricade nel caso precedente dell’equazione di primo grado e, con b 6= 0, l’unica soluzione sarebbe x = −c/b.66La legge dell’annullamento del prodotto e una proprieta valida nei numeri reali. Dice che se il prodotto di due numeri e zero allora
deve necessariamente essere zero uno dei due numeri. La cosa puo sembrare banale e siamo abituati a darla per scontata. Ci sono perostrutture algebriche in cui questa legge non vale e quando parleremo piu avanti di matrici constateremo che e proprio cosı.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 EQUAZIONI DI SECONDO GRADO
EQUAZIONI E DISEQUAZIONI
59
(iv) Esaminiamo infine il caso a 6= 0, b 6= 0, c 6= 0. Il procedimento risolutivo porta a scrivere successivamente leseguenti equazioni equivalenti alla (6):
4a2x2 + 4abx+ 4ac = 0 (si sono moltiplicati i due membri per 4a);4a2x2 + 4abx+ 4ac+ b2 − 4ac = b2 − 4ac (si e aggiunto ai due membri b2 − 4ac).
Si noti che abbiamo usato il completamento del quadrato. Quest’ultima puo anche scriversi
(2ax+ b)2 = b2 − 4ac.
Ora:
⊲ se b2 − 4ac < 0, si ha un’uguaglianza impossibile;
⊲ se b2 − 4ac = 0, si ha pure 2ax+ b = 0 e quindi l’equazione ha la sola soluzione x = − b2a ;
⊲ se b2 − 4ac > 0, il procedimento risolutivo porta a due equazioni di primo grado
2ax+ b =√
b2 − 4ac e 2ax+ b = −√
b2 − 4ac,
le cui soluzioni sono rispettivamente
x1 =−b+
√b2 − 4ac
2a, x2 =
−b−√b2 − 4ac
2a. (7)
In pratica, per risolvere un’equazione di secondo grado completa, conviene esaminare preliminarmente la quantita∆ = b2 − 4ac, detta discriminante dell’equazione.
⊲ Se ∆ < 0, l’equazione (6) risulta impossibile.
⊲ Se ∆ = 0, si ha la sola soluzione x = − b2a .
⊲ Se ∆ > 0, vi sono due soluzioni, che si ottengono mediante le formule (7).
Esempi
• L’equazione 3x2 + 7x+ 2 = 0, avendo ∆ = b2 − 4ac = 25, ha le due soluzioni
x1 =−7−
√25
6= −2 , x2 =
−7 +√25
6= −1
3.
• L’equazione 4x2 − 12x+ 9 = 0, avendo ∆ = b2 − 4ac = 0, ha l’unica soluzione
x = − b
2a= 3/2. 67
• L’equazione 6x2 − 7x+ 3 = 0, avendo ∆ = b2 − 4ac = −23 < 0, non ha soluzioni.
Osservazione (Formula ridotta). Nel caso generale (caso (iv)), se il coefficiente del termine in x e pari si puo usareuna formula semplificata (detta ridotta). Lo studente, adattando gli stessi passaggi usati prima, provi a ritrovarequesta formula, valida per un’equazione del tipo ax2 + 2bx+ c = 0.
Le soluzioni sono: x1,2 =−b+
√b2 − aca
.
Si notino le differenze con la formula generale: il coefficiente della x viene diviso per 2, nel discriminante compare acanziche 4ac e infine a denominatore compare a anziche 2a.
Osservazione Le equazioni di primo e secondo grado sono le uniche per cui si hanno procedimenti standard dirisoluzione. Nella loro semplicita sono di fondamentale importanza, dato che ad esse si fa sempre ricorso, sia perrisolvere equazioni di altro tipo sia per risolvere le disequazioni.
Esercizio 3.1 Risolvere le equazioni (di primo e secondo grado)
(a) 2− 3x = 4 (b) 2x2 + 3x− 2 = 0 (c) x2 + 2x− 15 = 0.
67Ovviamente 4x2 − 12x+ 9 = 0 equivale a (2x− 3)2 = 0, da cui la soluzione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 EQUAZIONI INTERE DI GRADO SUPERIORE AL SECONDO
EQUAZIONI E DISEQUAZIONI
60
4 Equazioni intere di grado superiore al secondo
Ci sono vari tipi di equazioni di grado superiore al secondo che possono essere risolti in modo elementare.Vediamo quelle che si incontrano piu frequentemente.
(i) Equazioni binomie. Prendono questo nome le equazioni del tipo:
axn + b = 0 , con a 6= 0, b 6= 0.
Quando n = 1 o n = 2 l’equazione binomia, essendo rispettivamente di primo o di secondo grado, rientra nei casigia visti. Quando n = 3 si ha l’equazione binomia ax3 + b = 0, che ha sempre una sola soluzione: x = 3
√
−b/a.
Esempio E equazione binomia di terzo grado la seguente:
2x3 − 16 = 0,
che si riduce facilmente alla forma x3 = 8, e questa ha l’unica soluzione x = 3√8, cioe x = 2.
Quando n = 4 e i coefficienti di ax4 + b = 0 sono concordi, l’equazione non ha alcuna soluzione; se invece a e bsono discordi, come nel caso in cui n = 2, si hanno due soluzioni opposte: x1 = − 4
√
−b/a, x2 = + 4√
−b/a.
Esempio l’equazione: 3x4 + 12 = 0 e impossibile, mentre 12x
4 − 3 = 0, che equivale a x4 = 6, ha le soluzioni
opposte x1,2 = ± 4√6.
(ii) Equazioni trinomie. Sono le equazioni del tipo ax2n + bxn + c = 0, con a 6= 0, b 6= 0, c 6= 0 e n > 1. Si possonoconsiderare come equazioni di 2◦ grado nella variabile xn (infatti ax2n + bxn + c = a(xn)2 + bxn + c):
⊲ se ∆ = b2 − 4ac > 0, esse equivalgono alle due equazioni binomie:
xn =−b−
√∆
2ae xn =
−b+√∆
2a,
che possono dare nel complesso nessuna, due o quattro soluzioni;
⊲ se ∆ = 0, si ha una sola equazione binomia: xn = −b/2a, che puo dare nessuna, una o due soluzioni;
⊲ se ∆ < 0, non si ha nessuna soluzione.
Vediamo qualche esempio.
• L’equazione 3x4 − 4x2 − 4 = 0 e trinomia (biquadratica). Essa equivale alle equazioni binomie seguenti:
x2 =4−√64
6= −2
3e x2 =
4 +√64
6= 2.
La prima non ha soluzioni, perche − 23 < 0, mentre la seconda ha per soluzioni i numeri x1,2 = ±
√2. Tali
valori sono le soluzioni dell’equazione data.
• L’equazione 4x4 − 4x2 + 1 = 0 e pure biquadratica. Essa equivale all’equazione
(2x2 − 1)2 = 0 cioe x2 =1
2.
Quest’ultima fornisce le due soluzioni x1,2 = ±1/√2, che sono le soluzioni dell’equazione data.
• L’equazione x6 − 7x3 − 8 = 0 e trinomia; pensata come equazione di 2◦ grado nella variabile x3, da le dueequazioni binomie
x3 =7−√81
2= −1 e x3 =
7 +√81
2= 8,
le cui rispettive soluzioni sono x1 = −1 e x2 = 2: queste sono le soluzioni dell’equazione data.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 EQUAZIONI RAZIONALI (O FRATTE)
EQUAZIONI E DISEQUAZIONI
61
(iii) Equazioni generali di grado superiore al secondo. Occorre subito dire che per queste non ci sono metodi generalidi risoluzione.68 L’equazione si puo scrivere nella forma Pn(x) = 0, dove Pn(x) e un polinomio di grado n > 2.Si possono risolvere se si e in grado di fattorizzare il polinomio in fattori al piu di secondo grado, in altre parolese siamo in grado di trovare gli zeri del polinomio, e questo sappiamo che non e in generale un problema facile.In questi casi e di fondamentale importanza l’uso del teorema di Ruffini, visto in precedenza.
Vediamo qui alcuni esempi.
• Consideriamo l’equazione di terzo grado x3 + x− 2 = 0. Si vede facilmente che 1 e uno zero del polinomioa primo membro. Questo dice che il polinomio e divisibile per x − 1 e con la regola di Ruffini si ottienel’equazione equivalente (x−1)(x2+x+2) = 0. Ora il polinomio x2+x+2 non e ulteriormente fattorizzabile infattori di primo grado dato che il discriminante e negativo. Quindi l’equazione data ha soltanto la soluzionex = 1.
• Consideriamo l’equazione di terzo grado x3 − 3x + 2 = 0. Anche qui 1 e uno zero del polinomio a primomembro. Si ottiene l’equazione equivalente (x−1)(x2+x−2) = 0. Ora il polinomio x2+x−2 ha gli zeri 1 e−2. Allora l’equazione equivalente e (x− 1)2(x+2) = 0 e pertanto le soluzioni sono x1 = 1 e x2 = −2. Peresprimere il fatto che 1 “annulla due volte” l’equazione, si dice che 1 e soluzione doppia, o di molteplicita2, mentre −2 e soluzione semplice, o di molteplicita 1.
• L’equazione x3− 6x2+11x− 6 = 0, dopo aver osservato che 1 e zero del polinomio a primo membro e dopoaver diviso tale polinomio per x− 1, e equivalente alla (x− 1)(x2− 5x+6) = 0. Il polinomio x2− 5x+6 hacome zeri 2 e 3, e quindi l’equazione si puo scrivere come (x− 1)(x− 2)(x− 3) = 0. In questo caso abbiamotre soluzioni distinte: x1 = 1, x2 = 2 e x3 = 3.
• Per evidenziare che le cose possono non essere sempre cosı semplici, consideriamo l’equazione di quartogrado x4 +x− 2 = 0 (equazione trinomia, ma non biquadratica). Anche qui 1 e zero del polinomio a primomembro e si ottiene facilmente l’equazione equivalente (x− 1)(x3 + x2+ x+2) = 0. Quindi una soluzione ex1 = 1. Pero ora, cercando radici intere o razionali del polinomio x3+x2+x+2 si vede subito che non se netrovano. Non ci sono metodi elementari per poter proseguire (in realta, con metodi che verranno sviluppatipiu avanti in questo corso, potremo dire senza troppa fatica che almeno un altro zero reale esiste, anzi chene esiste un altro soltanto e che e negativo, ma per trovarlo con una formula occorrerebbe parecchia faticain piu).
• Con l’equazione x4−x3+x−1 = 0 le cose sono piu semplici. Evidentemente 1 e una radice del polinomio. Siottiene l’equazione equivalente (x−1)(x3+1) = 0. Le soluzioni dell’equazione data sono quindi due: x1 = 1e x2 = −1. Si poteva anche fattorizzare il polinomio iniziale con un doppio raccoglimento: x4−x3+x−1 =x3(x− 1) + x− 1 = (x− 1)(x3 + 1).
Lo studente svolga autonomamente altri esempi, prendendoli dai soliti testi di scuola secondaria.
Esercizio 4.1 Risolvere le equazioni (intere di grado superiore al secondo)
(a) 3x3 + 1 = 0 (b) 4x4 − 1 = 0
(c) x4 − 6x2 + 8 = 0 (d) x6 − 3x3 + 2 = 0
(e) x4 − 2x2 − 3 = 0 (f) x3 + 3x2 − 4 = 0
5 Equazioni razionali (o fratte)
Ricordiamo che un’equazione si dice fratta, quando l’incognita compare in essa, almeno una volta, anche a denomi-natore; e possibile allora che qualche valore non possa essere soluzione, perche annulla qualche denominatore: e beneindividuare subito tali valori ed indicarli.Questo e il primo caso in cui affrontiamo equazioni le cui soluzioni non vanno cercate nell’insieme di tutti i numerireali, ma in un sottoinsieme di questi. Nelle equazioni intere viste finora non ci sono motivi per escludere a priori alcunivalori reali, precludendoli per cosı dire alle soluzioni che stiamo cercando. In altre parole i polinomi che compaiononelle equazioni intere sono definiti per tutti i valori reali e quindi le soluzioni vanno cercate in tutto R.
68Per la verita ci sono formule generali per le equazioni di terzo e quarto grado, ma sono piuttosto complicate. Uno dei grandi risultatidella matematica (Galois, 1800) e che invece per le equazioni di quinto grado (e superiore) non esistono formule risolutive generali.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 GENERALITA SULLE DISEQUAZIONI
EQUAZIONI E DISEQUAZIONI
62
Con le equazioni fratte invece possiamo (e dobbiamo) escludere a priori gli eventuali valori che annullano i denominatori.Sicuramente le soluzioni non potranno assumere questi valori.
Esempio Volendo risolvere l’equazione 1x−1 = 1
x+2 occorre anzitutto avere ben chiaro che i valori 1 e 0 non potrannoin alcun caso essere soluzione. Sarebbe bene in questi casi fare uso della scrittura di sistema, scrivendo cioe
{1
x−1 = 1x + 2
x 6= 1 e x 6= 0.
Solitamente si dice che x 6= 1 e x 6= 0 sono le condizioni di esistenza. Si intende che sono le condizioni sotto le qualiesistono (cioe sono definite, hanno senso) tutte le quantita in gioco nell’equazione iniziale. Tenendo conto di questecondizioni si puo trasformare l’equazione fratta in una equazione equivalente intera.Il sistema diventa
{1
x−1 − 1x − 2 = 0
x 6= 1 e x 6= 0cioe
{x−(x−1)−2x(x−1)
x(x−1) = 0
x 6= 1 e x 6= 0cioe
{2x2 − 2x− 1 = 0
x 6= 1 e x 6= 0.
Si noti che nel passare dal secondo al terzo sistema ho moltiplicato ambo i membri dell’equazione per il denominatore:lo posso fare perche, come specificato nelle condizioni di esistenza, esso e diverso da zero.
Le soluzioni dell’ultima equazione sono x1,2 = 1∓√3
2 . Sono entrambe accettabili, come soluzioni dell’equazione iniziale,perche soddisfano le condizioni di esistenza.
Esempio Analogamente, volendo risolvere l’equazione fratta
1
x+ 1+
2
x=
2
x2 + x,
si scrivera il sistema {1
x+1 + 2x = 2
x(x+1)
x 6= 0 e x 6= −1e successivamente
{1
x+1 + 2x − 2
x(x+1) = 0
x 6= 0 e x 6= −1 cioe
{x+2(x+1)−2
x2+x = 0
x 6= 0 e x 6= −1 cioe
{3x = 0
x 6= 0 e x 6= −1.
La soluzione dell’ultima equazione e x = 0, ma questa non rispetta le condizioni di esistenza e quindi si deve concludereche l’equazione data e impossibile.
Osservazione Si noti che in entrambi gli esempi per risolvere l’equazione abbiamo portato tutte le incognite asinistra, abbiamo ridotto allo stesso denominatore e abbiamo annullato il numeratore della frazione. Questa e unaprocedura generale per risolvere questo tipo di equazioni, senza dimenticare le condizioni di esistenza. Si ricordi cheuna frazione, quando esiste, si annulla se e solo se si annulla il suo numeratore.
Esercizio 5.1 Risolvere le equazioni (fratte)
(a)1
x+ 2 = 0 (b)
x
x+ 1+ 1 =
1
x(c)
1
x2= x.
Prima di affrontare gli altri tipi di equazioni e necessario rivedere come si risolvono le prime semplici disequazioni.
6 Generalita sulle disequazioni
Le disequazioni sono disuguaglianze tra espressioni in cui sono presenti delle variabili. Se A(x) e B(x) rappresentanoad esempio espressioni nella variabile x, sono disequazioni le seguenti scritture:
A(x) > B(x) , A(x) < B(x) , A(x) ≥ B(x) , A(x) ≤ B(x),
dove ovviamente, come capita spesso, una delle due espressioni puo essere una costante.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 DISEQUAZIONI DI PRIMO E DI SECONDO GRADO
EQUAZIONI E DISEQUAZIONI
63
Ad esempio sono disequazioni le seguenti scritture:
x2 − 5x > 3 ;x
x+ 1<x+ 2
x; 1 + x >
lnx
x.
Le disequazioni, come le equazioni, possono essere vere o false a seconda dei valori che si attribuiscono alle variabili.I numeri che, sostituiti alle variabili, rendono vera una disequazione, si dicono le soluzioni della disequazione. Risolvereuna disequazione significa, come prima, trovare tutte le sue soluzioni.Con le disequazioni capita piu di frequente, rispetto alle equazioni, che le soluzioni siano infinite (cioe che l’insiemedelle soluzioni sia un insieme infinito). Per indicare l’insieme delle soluzioni si possono usare disequazioni “immediate”del tipo
x < a , x ≥ b , a ≤ x < b , . . .
oppure si puo usare una notazione insiemistica, scrivendo cioe chi e l’insieme S delle soluzioni, come in
S = {x ∈ R : x < a} , S = {x ∈ R : x ≥ b} , S = {x ∈ R : a ≤ x < b} , . . .
o anche, con le notazioni degli intervalli,
S = (−∞, a) , S = [b,+∞) , S = [a, b) , . . . .
A volte anche le disequazioni sono prive di soluzioni, e allora si dicono impossibili, oppure sono identicamente vere,quando ogni numero e soluzione.
Esempio E impossibile la disequazione x2 < −√x ed e identicamente vera la x2 + 1 > − 1x2 , come e facile capire.69
Due disequazioni, analogamente a quanto detto per le equazioni, sono equivalenti quando hanno il medesimo insiemedi soluzioni.Esistono, anche per le disequazioni, principi di equivalenza che sono alla base dei vari procedimenti risolutivi, e sono:
1. Principio di addizione.
Aggiungendo ad ambo i membri di una disequazione uno stesso numero o una medesima espressione (che nonalteri l’insieme di risoluzione della disequazione) si ottiene una disequazione equivalente.
Ad esempio, 3x− 4 > 1 e equivalente a 3x > 5, perche ottenuta dalla prima aggiungendo ad ambo i membri 4.
2. Principio di moltiplicazione.
Moltiplicando (o dividendo) ambo i membri di una disequazione per uno stesso numero positivo o una medesimaespressione, che si mantenga pure positiva per ogni valore attribuibile alla variabile e non alteri l’insieme dirisoluzione, si ottiene una disequazione equivalente alla data. Se il fattore per cui si moltiplica (o si divide) enegativo, allora, per ottenere una disequazione equivalente occorre invertire il verso della disequazione.
Esempio La disequazione x−12 > x
3 e equivalente alla 3(x − 1) > 2x, ottenuta moltiplicando ambo i membridella prima per 6. Questa, a sua volta, applicando il principio di addizione, diventa x > 3, che fornisce quindi lesoluzioni della disequazione data.
Esempio Nella disequazione x+32x < 1
4 invece occorre fare attenzione. Oltre alla presenza di un denominatoreche puo annullarsi, non possiamo semplicemente moltiplicare, come fatto prima, ambo i membri per 4x, datoche x puo essere negativo. E necessario quindi uno studio piu attento, che richiede di tenere conto del segno dix. Vedremo presto come si procede in questi casi.
7 Disequazioni di primo e di secondo grado
(i) Sono disequazioni di primo grado quelle che possono ricondursi ad una delle forme:
ax+ b > 0 , ax+ b ≥ 0 , ax+ b < 0 oppure ax+ b ≤ 0 , a 6= 0.
69La prima e impossibile perche il primo membro e certamente non negativo e il secondo non positivo. Si noti che non e impossibileinvece la x2 ≤ −√
x, dato che ha la soluzione x = 0. La seconda e identicamente vera (lo e nell’insieme in cui e definita, cioe per x 6= 0)dato che il primo membro e certamente positivo e il secondo negativo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 DISEQUAZIONI DI PRIMO E DI SECONDO GRADO
EQUAZIONI E DISEQUAZIONI
64
⊲ Se a > 0, queste hanno rispettivamente per soluzione:
x > −b/a , x ≥ −b/a , x < −b/a , x ≤ −b/a(con a < 0 si potra sempre, cambiando il segno dei due membri e il verso della disuguaglianza, ricondursial caso precedente).
⊲ Se fosse invece a = 0 e b > 0, le disequazioni sarebbero di grado zero e avremmo le prime due identicamentevere e le seconde due impossibili.
⊲ Con a = 0 e b < 0 la situazione s’inverte: le prime due risultano impossibili e le seconde due identicamentevere.
Esempi
• La disequazione 4(x+ 2)− 5 < 2(x+ 3) equivale alla 4x+ 3 < 2x+ 6; col principio di addizione si ottiene4x− 2x < −3 + 6, ossia 2x < 3; col principio di moltiplicazione si ha infine x < 3/2.
L’insieme delle soluzioni, di questa e della disequazione data, e quindi S = (−∞, 32 ), che si puo rappresentaregraficamente con
bcS
R3/2• La disequazione 5 − 4x ≤ 0 equivale alla 4x ≥ 5, cioe alla x ≥ 5/4. L’insieme delle soluzioni e quindiS = [ 54 ,+∞) che si puo rappresentare con
b
5/4
S
R
Osservazione Si notino, nei due disegni, queste convenzioni: uso il “pallino vuoto” per dire che il numeronon fa parte dell’insieme delle soluzioni e il “pallino pieno” per dire che invece il numero appartiene all’in-sieme delle soluzioni. Analogamente il tratto continuo indica un intervallo di soluzioni, mentre il tratteggioindica un intervallo in cui non ci sono soluzioni.
•x+22 > 4 + 1
2x; moltiplicando ambo i membri per 2, la disequazione diventa x + 2 > 8 + x; trasportando itermini si ha x− x > 8− 2, ossia 0 > 6, che e falsa. La disequazione data e quindi impossibile.
•x+35 + x
4 > 9x−120 ; moltiplicando ambo i membri per 20 si ha 4(x + 3) + 5x > 9x − 1; questa diventa
9x+ 12 > 9x− 1, ossia 0 > −13, vera per qualunque valore della variabile. La disequazione data e percioidenticamente vera.
(ii) Sono disequazioni di secondo grado quelle che possono ricondursi ad una delle forme:
ax2 + bx+ c > 0 , ax2 + bx+ c ≥ 0 , ax2 + bx+ c < 0 oppure ax2 + bx+ c ≤ 0 , a 6= 0.
Si puo pensare che sia a > 0 (in caso contrario sara conveniente cambiare il segno dei termini e il verso delladisuguaglianza). Il numero ∆ = b2−4ac (il discriminante dell’equazione associata) potra risultare positivo, nulloo negativo. Si presentano allora i seguenti casi:
⊲ Se ∆ > 0, ci sono due numeri distinti x1 < x2 per cui ax2 + bx+ c = 0. In questo caso:
ax2 + bx+ c > 0 ha per soluzioni x < x1, x > x2, cioe S = (−∞, x1) ∪ (x2,+∞);
ax2 + bx+ c ≥ 0 ha per soluzioni x ≤ x1, x ≥ x2, cioe S = (−∞, x1] ∪ [x2,+∞);
ax2 + bx+ c < 0 ha per soluzioni x1 < x < x2, cioe S = (x1, x2);
ax2 + bx+ c ≤ 0 ha per soluzioni x1 ≤ x ≤ x2, cioe S = [x1, x2]
(come noto si dice che le soluzioni sono per valori esterni o interni alle due radici).
⊲ Con ∆ = 0, l’equazione ax2 + bx+ c = 0 ha un’unica soluzione x1 = − b2a . In questo caso:
ax2 + bx+ c > 0 ha per soluzioni ogni x 6= − b2a , quindi possiamo scrivere S = R \ {− b
2a};ax2 + bx+ c ≥ 0 ha per soluzioni ogni x reale, quindi S = R;
ax2 + bx+ c < 0 e invece impossibile, quindi S = ∅;ax2 + bx+ c ≤ 0 ha per soluzione solo x = − b
2a , quindi S = {− b2a}.
⊲ Infine con ∆ < 0, l’equazione ax2 + bx+ c = 0 non ha soluzioni reali e quindi:
ax2 + bx+ c > 0 e identicamente vera, quindi S = R;
ax2 + bx+ c ≥ 0 e pure identicamente vera, quindi S = R;
ax2 + bx+ c < 0 e impossibile, quindi S = ∅;ax2 + bx+ c ≤ 0 e pure impossibile, quindi S = ∅.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 SISTEMI DI EQUAZIONI E DI DISEQUAZIONI DI PRIMO E SECONDO GRADO
EQUAZIONI E DISEQUAZIONI
65
Esempi
• 2x2 − 5x+ 3 > 0. ∆ = 25− 24 = 1 > 0, gli zeri sono x1 = 1, x2 = 3/2.
Soluzioni: x < 1 oppure x > 3/2 bc bc
1 3/2
RS = (−∞, 1) ∪ (32 ,+∞)
• 2x2 − 4x+ 2 < 0. ∆ = 16− 16 = 0, unico zero: x1 = 1.
Soluzioni: nessuna, quindi disequazione impossibile, S = ∅
• 2x2 − 4x+ 2 ≤ 0.
Soluzioni: x = 1 b
1
RS = {1}
• 2x2 − 4x+ 3 > 0. ∆ = 16− 24 < 0, nessuno zero.
Soluzioni: ogni numero, quindi disequazione identicamente vera, S = R
• 3x2 − 5x− 12 ≤ 0. ∆ = 25 + 144 = 169, zeri: x1,2 = 5∓136 , ossia x1 = − 4
3 , x2 = 3.
Soluzioni: − 43 ≤ x ≤ 3 b b
−4/3 3
RS = [− 4
3 , 3]
Esercizio 7.1 Risolvere le disequazioni (di primo e secondo grado)
(a) 1− 3x < 5 (b) x2 − x− 6 ≥ 0
(c) 4 + 3x− x2 > 0 (d) 9x2 + 12x+ 4 ≤ 0
8 Sistemi di equazioni e di disequazioni di primo e secondo grado
Abbiamo gia visto rapidamente in precedenza che i sistemi di equazioni (o di disequazioni) altro non sono che insiemidi due o piu equazioni (o disequazioni) nelle stesse variabili (incognite).E abbiamo detto che risolvere un sistema di equazioni (o di disequazioni) significa cercare tutte le soluzioni comunialle equazioni (o alle disequazioni) che lo compongono: queste, se ci sono, sono costituite in genere da numeri (coppie,terne, . . . ordinate di numeri, se ci sono piu incognite) che verificano tutte le equazioni (o le disequazioni) del sistema.Vediamo ora qualche caso particolare di sistema.
(i) Sistemi di equazioni di 1◦ grado. Ricordiamo che il grado di un sistema di equazioni intere e dato dalprodotto dei gradi delle sue equazioni, quindi si dice sistema di 1◦ grado o lineare ogni sistema le cui equazionisiano tutte di 1◦ grado, rispetto al complesso delle incognite.
Le equazioni che compongono un sistema hanno spesso tante incognite quante sono le sue equazioni, ma sipotranno incontrare anche sistemi in cui cio non accade.
Esempio il sistema{
2x+ y = 1
x− y = 2ha due equazioni e due incognite.
Esso ha pero una sola soluzione: la coppia (1,−1). (Attenzione: non si deve dire che il sistema ha due soluzioniperche si trovano due valori: la soluzione e una sola, ed e una coppia di valori).
Altro esempio e il sistema{
2x+ y − z = 0
x− y + 2z = 3.
Questo ha due equazioni, ma tre incognite. Alla risoluzione, in generale, dei sistemi di equazioni lineari saradedicata una parte del programma, piu avanti.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 DISEQUAZIONI INTERE DI GRADO SUPERIORE AL SECONDO
EQUAZIONI E DISEQUAZIONI
66
(ii) Sistemi di disequazioni di 1◦ grado in una variabile. Le soluzioni si ottengono risolvendo separatamentele singole disequazioni che compongono il sistema e cercando poi le soluzioni comuni, aiutandosi eventualmentecon una rappresentazione grafica.
Si abbia, per esempio, il sistema di disequazioni
{x+ 2 ≥ 0
x− 1 < 0che equivale a
{x ≥ −2x < 1. bc
1
b
−2
Dal grafico delle soluzioni delle singole disequazioni si deduce facilmente che le soluzioni del sistema sono tuttie soli gli x ∈ R per cui sia −2 ≤ x < 1. Si osservi che, per ricavare l’insieme delle soluzioni del sistema dagliinsiemi delle soluzioni delle due disequazioni, abbiamo fatto l’intersezione.
Il sistema di tre disequazioni
x− 1 ≥ 0
2− x ≥ 0
x− 2 > 0
equivale a
x ≥ 1
x ≤ 2
x > 2.
b
1 b
2bc2
Si vede subito che non ci sono soluzioni comuni e quindi il sistema non ha soluzioni.
Un esempio di sistema con disequazioni di primo e secondo grado:
{x2 − 1 ≥ 0
x+ 1 ≥ 0.
La prima disequazione ha per soluzioni l’insieme S1 = (−∞,−1]∪ [1,+∞), la seconda l’insieme S2 = [−1,+∞).Rappresentiamo graficamente:
x2 − 1 ≥ 0:x+ 1 ≥ 0:
b b
−1 1b
−1Risulta evidente che le soluzioni sono date dall’insieme S = {−1} ∪ [1,+∞).
Possono anche presentarsi sistemi cosiddetti “misti”, come il seguente
x ≥ 0
x < 2
x2 − 4x+ 3 = 0.
Il sistema e formato da due disequazioni e da una equazione di 2◦ grado, le cui soluzioni sono i numeri x1 = 1e x2 = 3. Queste pero, confrontate con le soluzioni delle disequazioni, portano a concludere che solo x1 = 1 esoluzione del sistema, essendo l’altra, x2 = 3, incompatibile con la condizione: x < 2.
Graficamente si hax ≥ 0:x < 2:x2 − 4x+ 3 = 0:
b
0 bc
2b b
1 3
S = {1}
9 Disequazioni intere di grado superiore al secondo
Sono le disequazioni che possono ricondursi alle forme
P (x) > 0 , P (x) ≥ 0 , P (x) < 0 oppure P (x) ≤ 0,
dove P (x) e un polinomio in una variabile di almeno terzo grado.Come accade per le corrispondenti equazioni, la prima cosa da fare (e forse anche quella che puo risultare piu difficile)e la fattorizzazione del polinomio P (x), di cui abbiamo gia detto. Supponiamo quindi di aver gia fattorizzato ilpolinomio. Vediamo come si puo procedere su di un paio di esempi.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 DISEQUAZIONI INTERE DI GRADO SUPERIORE AL SECONDO
EQUAZIONI E DISEQUAZIONI
67
Esempi
• (x2 + 1)(x − 1) ≥ 0. Qui si puo osservare che solo il secondo fattore puo cambiare di segno, dato che il primoe strettamente positivo per ogni x. Allora una disequazione equivalente e semplicemente x − 1 ≥ 0, che ha persoluzioni x ≥ 1, cioe l’intervallo [1,+∞).
Avremmo anche potuto risolvere la disequazione trasformandola in un doppio sistema, osservando che il prodottodi due quantita e maggiore o uguale a zero se e solo se sono entrambe non negative oppure entrambe non positive:
{x2 + 1 ≥ 0
x− 1 ≥ 0oppure
{x2 + 1 ≤ 0
x− 1 ≤ 0,
Lo studente provi a risolvere i due sistemi e ad ottenere per questa strada le soluzioni gia trovate prima.
• (x−1)2(x+1) ≤ 0. Attenzione qui. Il primo fattore e non negativo, ma puo annullarsi. Possiamo intanto osservareche i valori che annullano i singoli fattori, e cioe x = 1 e x = −1, sono soluzioni, dato che la disuguaglianzaprevede anche l’uguale a zero. In secondo luogo, anche in questo caso il primo fattore non cambia segno (cioe,dove non e nullo e positivo). Allora le soluzioni sono date dall’insieme (−∞,−1] ∪ {1}.Anche qui avremmo potuto risolvere la disequazione trasformandola nel doppio sistema:
{(x− 1)2 ≥ 0
x+ 1 ≤ 0oppure
{(x − 1)2 ≤ 0
x+ 1 ≥ 0.
Il primo sistema fornisce l’intervallo (−∞,−1], il secondo l’unico punto 1.
Si noti che, se la disequazione fosse stata (x − 1)2(x + 1) < 0, le soluzioni x = 1 e x = −1 non sarebbero stateaccettabili e quindi avremmo avuto per soluzioni soltanto (−∞,−1).
• (x+ 2)(x+ 1)(x− 3) < 0. Osserviamo intanto che i valori che annullano i singoli fattori, e cioe x = −2, x = −1e x = 3, non sono soluzioni. Qui ora conviene studiare il segno dei tre fattori. Un consiglio: studiate sempre ilsegno positivo dei fattori, anche se la disequazione e con il “<”, come in questo caso. Si ha:
segno di x+ 2:
segno di x+ 1:
segno di x− 3:
segno del prodotto:
bc
−2− + + +
bc
−1− − + +
bc
3
− − − +
bc
−2bc
−1bc
3
− + − +
Nei tre assi sono riportati i segni dei tre fattori70 e sotto c’e il segno del prodotto dei tre fattori, in base allesolite regole sul “prodotto dei segni”. A questo punto si torna a considerare la disequazione iniziale: anzitutto,come gia detto, si osserva che gli estremi degli intervalli, che annullano i fattori e quindi il prodotto, non sonoaccettabili; poi si considera che la richiesta era di avere un prodotto minore di zero. Quindi si prendono comesoluzioni gli intervalli in cui compare il segno “−”, cioe S = (−∞,−2) ∪ (−1, 3).
Osservazione Si noti che lo studio separato del segno dei fattori puo essere utilizzato in ogni caso in cui serveconoscere il segno di un prodotto o di un quoziente. Utile esercizio che lo studente puo fare e la risoluzione di unadisequazione di 2◦ grado con lo studio del segno dei due fattori.
Esercizio 9.1 Risolvere le disequazioni (intere di grado superiore al secondo)
(a) x3 − 3x2 + 2x ≥ 0 (b) x3 + x2 < 0
(c) x3 − x4 > 0 (d) x4 − x2 ≥ 0
70Se studiate sempre il segno positivo dei fattori dovete semplicemente riportare il segno + nell’insieme delle soluzioni trovate: adesempio, con il primo fattore si ha x+ 2 > 0 per x > −2 e quindi dobbiamo riportare il segno + a destra di −2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 DISEQUAZIONI RAZIONALI (O FRATTE)
EQUAZIONI E DISEQUAZIONI
68
10 Disequazioni razionali (o fratte)
Le disequazioni che possono ricondursi alle forme
P (x)
Q(x)> 0 ,
P (x)
Q(x)≥ 0 ,
P (x)
Q(x)< 0 oppure
P (x)
Q(x)≤ 0,
dove P (x) e Q(x) sono polinomi in una variabile vengono dette disequazioni razionali (o fratte). Queste disequazionivanno affrontate tenendo anzitutto presente che possono richiedere condizioni di esistenza (il denominatore non si deveannullare). Successivamente si possono risolvere o studiando il segno dei due fattori (e considerando che il segno delquoziente coincide con il segno del loro prodotto) oppure ricorrendo come gia visto ai due sistemi.
Esempi
• Consideriamo la disequazione frattax+ 2
x− 1≥ 0. Anzitutto notiamo che i due termini della frazione (numeratore
e denominatore) si annullano rispettivamente in x = −2 e x = 1: il valore x = 1 non e certamente soluzione,dato che annulla il denominatore. Poi, considerando che la disequazione e con il “maggiore o uguale”, possiamodire che x = −2 e soluzione. Infine studiamo il segno dei due termini. Si ha il seguente schema:
segno di x+ 2:
segno di x− 1:
segno del quoziente:
b
−2− + +
bc
1
− − +
b
−2bc
1
+ − +
Quindi le soluzioni sono date dall’insieme S = (−∞,−2] ∪ (1,+∞).
Si poteva anche scrivere il doppio sistema
{x+ 2 ≥ 0
x− 1 > 0oppure
{x+ 2 ≤ 0
x− 1 < 0.
• Consideriamo la disequazione1
x− 1≥ x− 1
x. Anzitutto notiamo che deve essere x 6= 0 e x 6= 1. Successivamente
“portiamo tutto a primo membro” e otteniamo
1
x− 1− x− 1
x≥ 0 cioe
x− x2 + 2x− 1
x(x − 1)≥ 0 cioe ancora
x2 − 3x+ 1
x(x− 1)≤ 0
(nell’ultimo passaggio ho cambiato il segno del numeratore, cambiando il verso della disuguaglianza, per averedue fattori di 2◦ grado con coefficiente del termine quadratico positivo).71 Ora posso intanto trovare gli zeri delpolinomio a numeratore:
x1,2 =3±√9− 4
2=
3±√5
2.
Osservo allora che gli zeri del polinomio a numeratore sono soluzioni, mentre gli zeri del denominatore (0 e 1)non lo sono. Ora studio il segno dei due termini:
segno di x2−3x+1:
segno di x(x − 1):
segno del quoziente:
b3−
√5
2
b3+
√5
2
+ + − − +
bc
0bc
1
+ − − + +
b3−
√5
2
b3+
√5
2
bc
0bc
1
+ − + − +
Attenzione ora: per decidere quali dobbiamo prendere come soluzioni dobbiamo riferirci all’ultima disequazioneottenuta prima dello studio del segno. Anche se la disequazione iniziale era con il ≥, quella che dobbiamoconsiderare e con il ≤ e quindi quelli che ci interessano sono gli intervalli dove c’e il segno −. Le soluzioni sono
pertanto date dall’insieme S =(
0, 3−√5
2
]
∪(
1, 3+√5
2
]
.
Si poteva anche procedere con il doppio sistema (provare a svolgere i calcoli):
{x2 − 3x+ 1 ≥ 0
x(x− 1) < 0oppure
{x2 − 3x+ 1 ≤ 0
x(x − 1) > 0.
71Questo non e necessario. Si poteva anche lasciare la frazione com’era e studiare il segno dei due fattori. Occorre pero fare attenzionea non fare pasticci quando si studia il segno di un polinomio di secondo grado con coefficiente del termine quadratico negativo!
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

11 EQUAZIONI E DISEQUAZIONI IRRAZIONALI
EQUAZIONI E DISEQUAZIONI
69
• Nell’introduzione alle disequazioni avevamo considerato, senza poi risolvere, la disequazionex+ 3
2x<
1
4, osser-
vando che il moltiplicare ambo i membri per 2x (per renderla intera) e sbagliato in quanto cosı facendo non sitiene conto del segno di x. Si tratta di una disequazione fratta e adesso sappiamo risolverla. Portando tutto aprimo membro si ottiene:
x+ 3
2x− 1
4< 0 cioe
2x+ 6− x4x
< 0 cioex+ 6
4x< 0.
Ora, con i metodi visti, si ottiene facilmente S = (−6, 0).Si poteva procedere anche in altro modo. Presento la tecnica perche la stessa puo essere utile in altre situazioni.
Riconsideriamo la disequazione nella forma iniziale
x+ 3
2x<
1
4.
Dopo aver osservato che certamente x = 0 non e soluzione, si possono distinguere due casi: x > 0 oppure x < 0.
Se x > 0 possiamo moltiplicare ambo i membri per 4x, mantenendo il verso della disuguaglianza; se x < 0,possiamo moltiplicare ancora tutto per 4x, ma cambiando il verso della disuguaglianza.
Allora possiamo esprimere tutto con due sistemi:
{4x > 0
2(x+ 3) < xoppure
{4x < 0
2(x+ 3) > x.
Attenzione che entrambi i sistemi, a priori, possono fornire soluzioni. Per ottenere le soluzioni complessivedovremo poi fare, come in precedenza, l’unione dei due insiemi.
Il primo sistema in questo caso e impossibile (il suo insieme di soluzioni e ∅) ed il secondo ha per soluzione−6 < x < 0. Quindi l’intervallo (−6, 0) e l’insieme delle soluzioni della disequazione, come gia trovato.
Esercizio 10.1 Risolvere le disequazioni (fratte)
(a) x+1
x− 1≥ 1 (b)
2
x+ x ≥ 3 (c)
x
1− x2 ≥ x.
11 Equazioni e disequazioni irrazionali
Si dicono irrazionali quelle equazioni e disequazioni che presentano la variabile, almeno in un termine, sotto un segnodi radice (che puo essere quadrata, terza, . . . ).Per esempio, sono irrazionali l’equazione e la disequazione seguenti:
2x+√x = 1 ;
1√x+ 1
>√x− 2.
Anzitutto occorre ricordare che solitamente queste equazioni/disequazioni richiedono condizioni di esistenza, dato chele radici di indice pari vogliono argomenti non negativi. Non cosı le radici di indice dispari, che sono definite anchecon argomenti negativi.Per risolvere poi le equazioni e le disequazioni irrazionali si deve far ricorso ad un terzo principio di equivalenza invirtu del quale si puo sostituire ad una equazione (o disequazione) irrazionale quella che si ottiene elevando i duemembri allo stesso esponente naturale, ma ricordando quanto segue:
• se n e dispari, l’equazione A(x) = B(x) e equivalente all’equazione (A(x))n = (B(x))n;
• se n e pari e se A(x) e B(x) sono maggiori o uguali a zero, l’equazione A(x) = B(x) e equivalente all’equazione(A(x))n = (B(x))n.
Analogamente, per le disequazioni:
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

11 EQUAZIONI E DISEQUAZIONI IRRAZIONALI
EQUAZIONI E DISEQUAZIONI
70
• se n e dispari, la disequazione A(x) > B(x) e equivalente alla disequazione (A(x))n > (B(x))n;
• se n e pari e se A(x) e B(x) sono maggiori o uguali a zero, la disequazione A(x) > B(x) e equivalente alladisequazione (A(x))n > (B(x))n.
Osservazione Quindi, detto in parole molto povere con la speranza che questo faciliti gli studenti a ricordare questopunto delicato e fonte di molti errori: se le radici sono di indice dispari le cose sono semplici; se le radici sono di indicepari invece occorre fare piu attenzione e la risoluzione dell’equazione/disequazione e piu elaborata.
Vediamo, attraverso alcuni esempi, come si procede in pratica.
• Consideriamo l’equazione 3√3x+ 5 = x + 1. La radice e di indice dispari. L’equazione equivale alla 3x + 5 =
(x+ 1)3, che si ottiene elevando al cubo i due membri.72 Quest’ultima diventa
x3 + 3x2 − 4 = 0 , che ha per soluzioni x1 = −2, x2 = 1.
• Consideriamo l’equazione√2x+ 3 = x+ 1. Qui anzitutto c’e la condizione di esistenza 2x+ 3 ≥ 0, dato che la
radice e di indice pari. Poi si ragiona sul segno di x+ 1: non ci possono essere soluzioni se x + 1 < 0, dato cheinvece certamente
√2x+ 3 ≥ 0. Quindi possiamo limitarci a considerare il caso x+1 ≥ 0. Tenendo conto allora
di tutte le condizioni espresse, possiamo elevare al quadrato. Otteniamo quindi il sistema
2x+ 3 ≥ 0
x+ 1 ≥ 0
2x+ 3 = (x+ 1)2che equivale a
x ≥ −3/2x ≥ −1x2 = 2.
Delle due soluzioni dell’equazione (x1,2 = ±√2), soltanto quella positiva (x2 =
√2) soddisfa anche le disequazioni
(infatti −√2 < −1) e pertanto la soluzione dell’equazione data e
√2.
Mostriamo ora come si procede per risolvere le disequazioni.
•3√x3 + 3x− 2 < x− 1. Non ci sono condizioni di esistenza. Elevando alla terza, la disequazione equivale alla
x3 + 3x− 2 < (x− 1)3,
che a sua volta diventa 3x2− 1 < 0. Pertanto le soluzioni cercate sono − 1√3< x < 1√
3(oppure S = (− 1√
3, 1√
3)).
•
√x− 1 < x − 3. Condizione di esistenza del radicale: x − 1 ≥ 0; poi si osserva che, se il secondo membro e
negativo, non ci possono essere soluzioni, dato che il primo membro e certamente non negativo; quando il secondomembro e non negativo, possiamo elevare al quadrato.
Quindi questa disequazione equivale al sistema
x− 1 ≥ 0 (assicura l’esistenza del radicale)x− 3 ≥ 0 (assicura la non negativita del secondo membro)x− 1 < (x− 3)2 (equivale, per le condizioni poste, alla disequazione data).
La terza disequazione e verificata da x < 2, x > 5. Il sistema precedente diventa percio
x ≥ 1x ≥ 3x < 2 ∨ x > 5
b
1 b
3bc
2bc
5Dal grafico si deduce che le soluzioni della disequazione data sono i valori x > 5, cioe S = (5,+∞).
•
√3x2 + 4x+ 2 > 5 − 2x. La condizione di esistenza e 3x2 + 4x + 2 ≥ 0. Questa volta, se il secondo membro e
negativo, abbiamo certamente soluzioni, dato che il primo e non negativo. Pertanto il sistema
{3x2 + 4x+ 2 ≥ 0
5− 2x < 0
72Si ricorda anche che in questo caso non ci sono condizioni di esistenza da porre: infatti le radici di indice dispari sono definite per ognivalore dell’argomento.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

12 EQUAZIONI E DISEQUAZIONI ESPONENZIALI
EQUAZIONI E DISEQUAZIONI
71
fornisce un primo insieme di soluzioni S1: osservando che la prima disequazione e identicamente vera, avendo∆ < 0, le soluzioni di questo sono x > 5
2 , quindi S1 = (52 ,+∞).
Se invece il secondo membro e non negativo, possiamo elevare al quadrato, ottenendo cosı il sistema:
{5− 2x ≥ 0
3x2 + 4x+ 2 > (5 − 2x)2che equivale a
{x ≤ 5/2
x2 − 24x+ 23 < 0.
La disequazione di secondo grado e verificata dagli x tali che 1 < x < 23; quindi le soluzioni del sistema sono1 < x ≤ 5
2 , e pertanto S2 = (1, 52 ]. Di conseguenza si puo affermare che le soluzioni della disequazione data sonocostituite dall’insieme S1 ∪ S2 = (52 ,+∞) ∪ (1, 52 ] = (1,+∞).
Esercizio 11.1 Risolvere le equazioni (irrazionali)
(a) x− 1 =√x (b) 1−
√x− 1 = x.
Esercizio 11.2 Risolvere le disequazioni (irrazionali)
(a) x−√1− x < 3 (b) x ≤ 1−
√x+ 1 (c)
√
1− x2 > x.
12 Equazioni e disequazioni esponenziali
Si dicono esponenziali quelle equazioni (e disequazioni) che presentano l’incognita ad esponente di una o piu potenzedi base positiva assegnata.Ad esempio, sono esponenziali le equazioni
3x = 2 , 2x+1
2 = 2x + 3
e le disequazioni2x > 5 , 51−
√x < 1 + x.
Alcune equazioni e disequazioni esponenziali si possono risolvere scrivendo ambo i membri come potenze nella stessabase. Poi occorre tenere presenti le proprieta delle potenze ed un principio di equivalenza, in virtu del quale ad unauguaglianza (o disuguaglianza) tra potenze di ugual base si puo sempre sostituire l’uguaglianza (o una disuguaglianzaappropriata) tra gli esponenti.Abbiamo detto disuguaglianza appropriata dato che, nel passare agli esponenti, occorre considerare se la base emaggiore o minore di 1. Se la base e maggiore di 1 il verso della disuguaglianza si conserva mentre, se la base e minoredi 1, il verso della disuguaglianza va cambiato.Si tenga anche conto del fatto che le potenze presenti nell’equazione (disequazione) possono non avere inizialmentela stessa base: e allora opportuno operare in modo che diventino potenze nella stessa base (abbiamo gia visto inprecedenza come si puo scrivere un qualunque numero reale positivo come potenza in una data base).
Illustriamo, attraverso esempi, come si procede in alcuni casi.
• 3x2−2x = 27. Potendo vedere i due membri dell’equazione come potenze nella stessa base (27 = 33), possiamo
considerare l’equazione equivalente x2 − 2x = 3, che ha per soluzioni x1 = −1, x2 = 3. Questi valori sono lesoluzioni dell’equazione data.
• 3x =√3x2−x. In questo caso si puo procedere cosı: l’equazione si puo scrivere 3x = 3
x2−x2 , da cui x = x2−x
2 ,cioe x2 − 3x = 0, che ha per soluzioni x1 = 0 e x2 = 3.
• 32x = 5. Scriviamo 5 come potenza di base 3: 32x = 3log3 5. Quindi otteniamo
2x = log3 5, da cui x = 12 log3 5, che e l’unica soluzione dell’equazione data.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

12 EQUAZIONI E DISEQUAZIONI ESPONENZIALI
EQUAZIONI E DISEQUAZIONI
72
• 32x − 11 · 3x + 18 = 0. Questa equazione appartiene ad una tipologia particolare: si tratta di un’equazioneesponenziale riconducibile ad un’equazione di secondo grado. Ponendo 3x = t si ha infatti l’equazione in t
t2 − 11t+ 18 = 0,
le cui soluzioni sono t1,2 = 11∓72 , cioe t1 = 2, t2 = 9. Queste permettono di scomporre l’equazione data nelle due
equazioni esponenziali3x = 2 , 3x = 9,
che portano alle soluzionix1 = log3 2 , x2 = 2.
Vediamo ora, con qualche esempio, come si procede nella risoluzione delle disequazioni: diciamo subito che i procedi-menti sono analoghi a quelli delle equazioni, con qualche attenzione in piu relativamente al verso della disuguaglianza.
• 2x2+2x > 8. Potendo vedere i due membri come potenze di 2 (8 = 23), ed essendo 2 > 1, si puo passare alla
disuguaglianza tra gli esponenti, conservando il verso: si ha cosı x2+2x > 3. Le soluzioni di questa disequazionesono per x < −3 oppure x > 1. Queste sono le soluzioni anche della disequazione data.
• (12 )x2+2x > 1
8 . Essendo ora la base delle potenze 12 < 1, passando al confronto degli esponenti, per avere una
disequazione equivalente si dovra cambiare il verso della disuguaglianza. Quindi si ha x2+2x < 3, le cui soluzionisono per −3 < x < 1.
• 2 · 3x − 3x+1 + 1 > 0. Qui la strada non e quella di scrivere subito tutto come potenza in base 3.73 Usandoinvece altre proprieta delle potenze la disequazione si puo riscrivere come 2 · 3x − 3 · 3x + 1 > 0, cioe 3x < 1. Lesoluzioni sono quindi le x < 0.
Questo esempio mostra che per questo tipo di disequazioni non c’e un metodo generale, che forse si poteva vederenei tipi di disequazioni incontrate in precedenza. Qui lo studente deve, con l’esperienza, arrivare ad impararealcuni metodi possibili.
• 22x − 2x+1 < 3. Osservando che 2x+1 = 2 · 2x e che 22x = (2x)2, la disequazione data si puo scrivere
(2x)2 − 2 · 2x − 3 < 0. Poniamo ora 2x = t. Otteniamo t2 − 2t− 3 < 0.
Gli zeri del trinomio sonot1,2 = 1∓
√4 cioe t1 = −1, t2 = 3.
Le soluzioni della disequazione nella variabile t sono −1 < t < 3. Tornando alla variabile x si puo quindi scrivere−1 < 2x < 3, che equivale al sistema
{2x > −1 (vera per ogni x)
2x < 3 (vera per x < log2 3).
Le soluzioni della disequazione data sono percio i valori
x < log2 3.
Osservazione Metto in guardia da un possibile (e purtroppo frequente) grave errore. Consideriamo la disequazione3x + 32x ≤ 1. Osservando che 1 = 30, essa si puo certamente riscrivere come 3x + 32x ≤ 30, ma ora sarebbe un’ideasciagurata passare direttamente agli esponenti trascurando le basi, cioe considerare x+2x ≤ 0. Quello che in pratica sifa quando i due membri della disequazione sono potenze nella stessa base non si puo fare se ci sono somme o differenzedi potenze (anche se nella stessa base). La disequazione proposta si puo invece correttamente ricondurre, come giavisto, ad una disequazione di secondo grado.
Esercizio 12.1 Risolvere le equazioni (esponenziali)
(a) 2 + 3 · 4x = 5 (b) 2x−1 = 3 (c) ex2−1 − 2 = 0.
Esercizio 12.2 Risolvere le disequazioni (esponenziali)
(a) 22x−1 ≥ 4x (b) e2x+3 ≤ 1 (c) 31+2x − 8 · 3x − 3 > 0.
73Si potrebbe anche scrivere 3log3 2+x − 3x+1 + 30 > 0, ma a questo punto non andiamo da nessuna parte.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

13 EQUAZIONI E DISEQUAZIONI LOGARITMICHE
EQUAZIONI E DISEQUAZIONI
73
13 Equazioni e disequazioni logaritmiche
Si dicono logaritmiche quelle equazioni (e disequazioni) che presentano l’incognita nell’argomento di uno o piu logaritmiin una base assegnata.Per esempio, sono logaritmiche le equazioni
log2 x = 4 ; log10(x2 + 1) = 2 · log10 x
e le disequazioni
ln(2x− 3) > lnx ; log1/22x− 1
x− 1< 2.
Come gia detto, adotto la convenzione di indicare con ln il logaritmo naturale, cioe in base e. Per quanto riguardala risoluzione delle eventuali equazioni e disequazioni logaritmiche in base e basta ricordare che e e un numero realemaggiore di 1.Per risolvere le equazioni e le disequazioni logaritmiche occorre anzitutto porre le condizioni di esistenza: infatti ilogaritmi esistono solo se i rispettivi argomenti sono positivi. Successivamente, analogamente a quanto si fa conquelle esponenziali, alcune si possono risolvere scrivendo ambo i membri dell’equazione/disequazione come logaritminella stessa base. Infine, ricordando le proprieta dei logaritmi, si fa ricorso al principio di equivalenza in virtu delquale si puo sostituire un’uguaglianza (o una disuguaglianza) tra logaritmi con l’uguaglianza (o una disuguaglianzaappropriata, facendo attenzione al verso) tra gli argomenti. Le considerazioni sul verso sono le stesse di prima: se labase dei logaritmi e maggiore di 1 il verso rimane quello che e mentre, se la base dei logaritmi e minore di 1, il versova cambiato.Quindi in generale, per la presenza delle condizioni di esistenza, un’equazione (o una disequazione) logaritmica sirisolve affrontando un sistema di equazioni e disequazioni.Mostro anche qui come si procede attraverso alcuni esempi.
• log2 x = 3. Anzitutto la condizione di esistenza: deve essere x > 0. Poi occorre scrivere il secondo membro comelogaritmo in base 2, e questo si fa ricordando che 3 = log2 2
3. L’equazione diventa log2 x = log2 8. Il sistemaequivalente e allora
{x > 0
x = 8.
La soluzione cercata e quindi x = 8.
• log3(2x+1) = 1. La condizione di esistenza e 2x+1 > 0, che vuol dire x > − 12 . Poi si puo passare all’uguaglianza
tra gli argomenti dei logaritmi. L’equazione equivale quindi al sistema{
2x+ 1 > 0
log3(2x+ 1) = log3 3cioe
{x > − 1
2
2x+ 1 = 3cioe
{x > − 1
2
x = 1.
La soluzione x = 1 del sistema e anche la soluzione dell’equazione data.
• lnx = ln(x2 − 2). Le condizioni di esistenza chiedono che sia x > 0 e x2 − 2 > 0. Poi si uguagliano direttamentegli argomenti dei logaritmi. L’equazione e quindi equivalente al sistema
x > 0
x2 − 2 > 0
x = x2 − 2
cioe
x > 0
x2 > 2
x2 − x− 2 = 0.
L’equazione ha per soluzioni x = −1 e x = 2, ma soltanto quella positiva soddisfa tutte le condizioni. Quindi lasoluzione dell’equazione proposta e x = 2.
• log3(x+1) = 1+log3(x−2). Essendo 1 = log3 3, l’equazione si puo riscrivere come log3(x+1) = log3 3+log3(x−2).Ricordando le proprieta dei logaritmi questa diventa log3(x + 1) = log3[3(x− 2)].74 Allora l’equazione equivaleal sistema
x+ 1 > 0
x− 2 > 0
log3(x + 1) = log3[3(x− 2)]
ossia
x > −1x > 2
x+ 1 = 3(x− 2)
ossia
{x > 2
x = 7/2
(si noti, nel penultimo, che la disequazione x > −1 e inutile, dato che sicuramente verificata dovendo ancheessere x > 2). La soluzione cercata e percio x = 7/2.
74Anche qui grave errore sarebbe “eliminare i logaritmi”, cioe passare da log3(x+ 1) = log3 3 + log3(x− 2) a x+ 1 = 3 + x− 2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

13 EQUAZIONI E DISEQUAZIONI LOGARITMICHE
EQUAZIONI E DISEQUAZIONI
74
Vediamo ora alcune disequazioni. Il modo di procedere e analogo a quello visto per le equazioni, con qualche attenzionein piu per il verso delle disequazioni, che in qualche caso dovra essere invertito (se le basi dei logaritmi dovessero essereminori di 1).
• log2 x < −3. Poiche −3 = log2(1/8), la disequazione proposta potra scriversi, nella condizione di esistenza, come
{x > 0
log2 x < log2(1/8)e quindi
{x > 0
x < 18
e questo ha come soluzioni tutti gli x compresi tra 0 e 18 . Si tratta naturalmente dell’insieme S = (0, 18 ), qui
raffigurato:bc
0bc
1/8
• log1/3(x+1) ≥ log1/3(x2+1). Qui abbiamo gia logaritmi nella stessa base, base che pero e minore di 1, e quindi
occorre cambiare il verso quando si passa agli argomenti. Si noti anche che l’argomento del logaritmo di destrae sempre positivo. La disequazione equivale quindi al sistema
{x+ 1 > 0
x+ 1 ≤ x2 + 1ossia
{x > −1x2 − x ≥ 0.
Possiamo aiutarci con un grafico:
x > −1:x2 − x ≥ 0:
bc
−1 b
0b
1L’insieme delle soluzioni e percio S = (−1, 0] ∪ [1,+∞).
• ln(x− 1) > 1 + ln(x+2). Tenendo conto delle condizioni di esistenza, del fatto che 1 = ln e e delle proprieta deilogaritmi, la disequazione equivale al sistema
x− 1 > 0
x+ 2 > 0
x− 1 > e(x+ 2).
ossia
x > 1
x > −2x < − 1+2e
e−1 .
Dopo aver osservato che la seconda disequazione e inutile e che si ha evidentemente − 1+2ee−1 < 0, possiamo
concludere che la disequazione data e impossibile.
• Consideriamo infine la disequazione log23 x + log3 x − 6 ≥ 0.75 C’e come sempre la condizione di esistenza (quix > 0). Questa disequazione, come le analoghe esponenziali viste prima, e riconducibile ad una disequazione disecondo grado. Possiamo porre log3 x = t e la nostra disequazione diventa t2 + t− 6 ≥ 0. Essa ha per soluzionit ≤ −3 oppure t ≥ 2 che, tornando alla variabile x, significano
log3 x ≤ −3 oppure log3 x ≥ 2.
Esse a loro volta equivalgono a
{x > 0
x ≤ 1/27oppure
{x > 0
x ≥ 9.
Le soluzioni sono quindi S = (0, 127 ] ∪ [9,+∞).
Esercizio 13.1 Risolvere le equazioni (logaritmiche)
(a) 3 + 2 lnx = 1 (b) 1 + log2(x+ 1) = 0 (c) 1− ln2 x = 0.
Esercizio 13.2 Risolvere le disequazioni (logaritmiche)
(a) ln(x+ 1) > 2 (b) ln2 x− 1 < 0 (c) 1 + ln3 x ≤ 0.
75Ricordo che la scrittura log2b x sta per (logb x)2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

14 EQUAZIONI E DISEQUAZIONI CON VALORI ASSOLUTI
EQUAZIONI E DISEQUAZIONI
75
14 Equazioni e disequazioni con valori assoluti
Ricordiamo anzitutto la definizione di valore assoluto (o modulo) di un numero reale r:
|r| def={
r se r ≥ 0
−r se r < 0.
Quindi, per esempio, |5| = 5, |0| = 0, | − 2| = 2.Trattandosi di argomento tradizionalmente ostico per molti studenti, faccio osservare (la cosa discende direttamentedalla definizione appena vista) che, nel caso siamo alla presenza dell’espressione |A(x)|, dove A(x) e una qualunqueespressione nella variabile x, avremo
|A(x)| ={
A(x) se A(x) ≥ 0
−A(x) se A(x) < 0.
Avverto gli studenti che la mancata comprensione di come si ottiene l’espressione di |A(x)| e spesso causa di gravierrori.76 Pertanto avremo ad esempio
|x− 2| ={
x− 2 se x ≥ 2
−x+ 2 se x < 2.
Il senso e lo scopo della definizione di valore assoluto dovrebbero essere chiari: ottenere una quantita comunque nonnegativa, anche se la quantita data e non positiva. Possiamo quindi dire che, in generale,
|A(x)| ≥ 0 , per tutte le x per cui A(x) esiste.
Osservazione Per risolvere equazioni e disequazioni con valori assoluti e conveniente tener bene presente l’equiva-lenza delle seguenti scritture, che si dimostrano facilmente usando la definizione:
• |A(x)| = k, con k ≥ 0, se e solo se A(x) = k oppure A(x) = −k;
• |A(x)| > k, con k ≥ 0, se e solo se A(x) < −k oppure A(x) > k;
• |A(x)| < k, con k ≥ 0, se e solo se −k < A(x) < k. 77
Se invece k < 0, allora l’equazione |A(x)| = k e impossibile, la disequazione |A(x)| > k e identicamente vera(ovviamente nell’insieme in cui A(x) esiste) e la disequazione |A(x)| < k e impossibile.Ecco qualche semplice esempio in cui applichiamo quanto appena detto.
• Consideriamo l’equazione |2x2 − 3| = 5. Essa equivale a
2x2 − 3 = −5 oppure 2x2 − 3 = 5 cioe x2 = −1 oppure x2 = 4.
La prima e impossibile e la seconda fornisce le due soluzioni x1 = −2 e x2 = 2.
• Consideriamo l’equazione |x−1x | = 2. L’equazione equivale a
x− 1
x= 2 oppure
x− 1
x= −2,
che equivalgono, a loro volta, ai sistemi
{x 6= 0
x− 1 = 2xoppure
{x 6= 0
x− 1 = −2x.
Le soluzioni di questi sono rispettivamente x1 = −1 e x2 = 1/3. I valori cosı trovati sono le soluzioni anchedell’equazione proposta.
76L’errore che tradizionalmente molti studenti commettono e quello di scrivere
|A(x)| ={
A(x) se x ≥ 0
−A(x) se x < 0,
ritenendo che sia il segno di x (anziche quello di A(x)) a determinare la scelta tra le due possibili espressioni.77La doppia disequazione −k < A(x) < k equivale ovviamente al sistema
{A(x) > −k
A(x) < k.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

14 EQUAZIONI E DISEQUAZIONI CON VALORI ASSOLUTI
EQUAZIONI E DISEQUAZIONI
76
• La disequazione |x− 2| ≤ 1 equivale a −1 ≤ x− 2 ≤ 1, cioe a 1 ≤ x ≤ 3, che sono le soluzioni.
• La |x+ 3| ≥ 4 equivale a x+ 3 ≥ 4 oppure x+ 3 ≤ −4, cioe x ≥ 1 oppure x ≤ −7.• La |x2 − 1| ≤ 3 equivale a −3 ≤ x2 − 1 ≤ 3, cioe −2 ≤ x2 ≤ 4. Ora quest’ultima equivale a x2 ≤ 4, dato che laprima disequazione (cioe x2 ≥ −2) e sempre verificata.78 Le soluzioni di x2 ≤ 4 sono ovviamente −2 ≤ x ≤ 2.
Si faccia sempre attenzione poi a casi come i seguenti:
• La disequazione |x− 1| ≥ 0 e sempre verificata, quindi ha per soluzioni tutto R.
• A differenza della precedente la disequazione |x− 1| > 0 non e vera per ogni x: essa infatti non vale per x = 1.Quindi le sue soluzioni sono R \ {1} (o se preferite (−∞, 1) ∪ (1,+∞)).
• La disequazione |x+ 2| ≤ 0 e verificata solo per x = −2, quindi ha per soluzioni l’insieme {−2}.• La disequazione |x+ 2| < 0 non e mai verificata, quindi ha per soluzioni l’insieme vuoto.
Vediamo ora in alcuni esempi come si procede quando, essendoci valori assoluti, non ci si trova nei casi gia visti.
• Consideriamo l’equazione x2 = |x − 1|. Possiamo distinguere i due casi possibili relativi al valore assoluto(x− 1 ≥ 0 oppure x− 1 < 0). Si scrivono quindi i sistemi
{x− 1 ≥ 0
x2 = x− 1oppure
{x− 1 < 0
x2 = −(x− 1). 79
Questi si possono riscrivere come{x ≥ 1
x2 − x+ 1 = 0oppure
{x < 1
x2 + x− 1 = 0.
L’equazione del primo sistema non ha radici reali, mentre la seconda ha le due radici x1,2 = −1±√5
2 . Esse sonoentrambe soluzioni del secondo sistema, dato che sono entrambe minori di 1. Quindi l’insieme delle soluzioni
dell’equazione iniziale e S = {−1−√5
2 , −1+√5
2 }.• Consideriamo la disequazione |x + 3| − 2x ≥ 5. Anche qui si distinguono i due casi possibili relativi al valoreassoluto (x+ 3 ≥ 0 oppure x+ 3 < 0). Si traduce quindi la disequazione nei sistemi
{x+ 3 ≥ 0
x+ 3− 2x ≥ 5oppure
{x+ 3 < 0
−x− 3− 2x ≥ 5.
Si noti che, quando si tolgono i valori assoluti, le uniche espressioni che vengono modificate sono quelle che primaerano in valore assoluto, tutto il resto rimane inalterato. Otteniamo quindi
{x ≥ −3x ≤ −2 oppure
{x < −3x ≤ − 8
3 .
Le soluzioni del primo sistema sono S1 = [−3,−2], le soluzioni del secondo sono S2 = (−∞,−3), e quindi lesoluzioni complessive (l’unione di S1 ed S2) sono date dall’insieme S = S1 ∪ S2 = (−∞,−2].
• Consideriamo la disequazione |x2− 1| ≥ x. Distinguendo i due casi relativi al segno di x2− 1 otteniamo i sistemi{x2 − 1 ≥ 0
x2 − 1 ≥ x oppure
{x2 − 1 < 0
1− x2 ≥ x,cioe {
x2 − 1 ≥ 0
x2 − x− 1 ≥ 0oppure
{x2 − 1 < 0
x2 + x− 1 ≤ 0.
Le soluzioni del primo sistema sono date dall’insieme S1 = (−∞,−1]∪[ 1+√5
2 ,+∞), quelle del secondo dall’insieme
S2 = (−1, −1+√5
2 ]. Pertanto le soluzioni della disequazione data sono costituite dall’unione
S1 ∪ S2 =(
−∞, −1+√5
2
]
∪[1+
√5
2 ,+∞)
.
78Si tenga sempre conto che una doppia disequazione significa un sistema tra le due disequazioni.79Si noti che, nel caso l’argomento del valore assoluto sia negativo, si sostituisce il valore assoluto con l’opposto dell’argomento.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

15 SOLUZIONI DEGLI ESERCIZI
EQUAZIONI E DISEQUAZIONI
77
• Consideriamo la disequazione |x−1x | > 2. Si tratta di un caso del tipo |A(x)| > k. Allora possiamo dire che tale
disequazione equivale ax− 1
x< −2 oppure
x− 1
x> 2.
Queste equivalgono alle disequazioni
3x− 1
x< 0 oppure
−x− 1
x> 0.
Aiutandoci con i soliti schemi abbiamo
segno di 3x− 1:
segno di x:
segno quoziente:
bc
1/3
− − +
bc
0
− + +
bc
0bc
1/3
+ − +
Segno di −x− 1:
Segno di x:
Segno quoziente:
bc
−1+ − −
bc
0
− − +
bc
−1bc
0
− + −
Il primo sistema ha soluzioni S1 = (0, 13 ) e il secondo ha soluzioni S2 = (−1, 0). Quindi le soluzioni delladisequazione iniziale sono l’insieme S = S1 ∪ S2 = (−1, 0) ∪ (0, 13 ) (o se si vuole (−1, 13 ) \ {0}).
Esercizio 14.1 Risolvere le equazioni (con valore assoluto)
(a) 1− |x+ 1| = x (b) x2 + 2 = |3x|.
Esercizio 14.2 Risolvere le disequazioni (con valore assoluto)
(a) |x|+ 2x ≤ x2 (b) 2|x+ 1| − x ≥ 3.
15 Soluzioni degli esercizi
Esercizio 3.1
(a) L’equazione di primo grado ha per soluzione x = − 23 .
(b) L’equazione di secondo grado ha per soluzioni x = −3±√25
4 , cioe 12 oppure −2.
(c) Si puo applicare la formula ridotta. Si ottengono le radici x = −1±√16, cioe −5 oppure 3.
Esercizio 4.1
(a) L’equazione si puo scrivere come x3 = − 13 , da cui si ricava x = − 1
3√3.
(b) L’equazione equivale alla x2 = 12 e questa ha per soluzioni x = ± 1√
2.
(c) L’equazione equivale alle due equazioni di secondo grado x2 = 4 oppure x2 = 2, che hanno per soluzioni x = ±2oppure x = ±
√2.
(d) L’equazione equivale alle due equazioni di terzo grado x3 = 1 oppure x3 = 2, che hanno per soluzioni x = 1 oppurex = 3√2.
(e) L’equazione equivale alle due equazioni di secondo grado x2 = 3 oppure x2 = −1. La seconda non ha soluzioni,mentre la prima ha per soluzioni x = ±
√3.
(f) Si puo osservare che il polinomio P (x) = x3 +3x2 − 4 si annulla per x = 1 e quindi e divisibile per (x− 1). Con laregola di Ruffini si trova il quoziente, che risulta essere x2+4x+4, e quindi l’equazione equivale alla (x−1)(x+2)2 = 0,che ha per soluzioni x = 1 oppure x = −2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

15 SOLUZIONI DEGLI ESERCIZI
EQUAZIONI E DISEQUAZIONI
78
Esercizio 5.1
(a) La prima equivale a (deve essere x 6= 0)
1 + 2x
x= 0 , che ha per soluzione x = −1
2.
(b) Nella seconda deve essere x 6= 0 e x 6= −1. L’equazione equivale a
x
x+ 1+ 1− 1
x= 0 cioe
x2 + x(x + 1)− (x+ 1)
x(x + 1)= 0 cioe
2x2 − 1
x(x+ 1)= 0.
Si hanno le due soluzioni x = ± 1√2.
(c) Nella terza deve essere x 6= 0. Per tali valori, moltiplicando ambo i membri per x2 si ottiene x3 = 1. Quindi lasoluzione e x = 1.
Esercizio 7.1
(a) La disequazione si puo riscrivere come 3x > −4 e quindi ha per soluzioni le x > − 43 .
(b) Le radici del polinomio sono x = −2 e x = 3 e la disequazione e verificata per valori esterni e quindi per x ≤ −2oppure per x ≥ 3.(c) Conviene riscrivere la disequazione nella forma x2 − 3x− 4 < 0. Le radici del polinomio sono x = −1 e x = 4 e ladisequazione e verificata per valori interni. Quindi le soluzioni sono per −1 < x < 4.(d) Il polinomio e un quadrato e la disequazione si puo scrivere nella forma (3x + 2)2 ≤ 0. C’e l’unica soluzionex = − 2
3 .
Esercizio 9.1
(a) La disequazione equivale a x(x − 1)(x − 2) ≥ 0. Studiando il segno dei tre fattori si trova che la disequazionee soddisfatta per 0 ≤ x ≤ 1 oppure per x ≥ 2. Possiamo scrivere le soluzioni in questa forma oppure, usando gliintervalli, scrivere che le soluzioni sono date dall’insieme S = [0, 1] ∪ [2,+∞).(b) La disequazione equivale alla x2(x+ 1) < 0. Qui possiamo osservare che x = 0 non e soluzione e quindi possiamodividere tutto per x2, che e certamente positivo. Allora le soluzioni sono per x < −1.Alternativamente si potevano usare i due sistemi: la disequazione equivale a
{x2 > 0
x+ 1 < 0∪
{x2 < 0
x+ 1 > 0.
Il secondo sistema e impossibile e quindi dal primo risultano le soluzioni trovate prima.(c) La disequazione equivale alla x3(1− x) > 0. Questa equivale ai due sistemi
{x3 > 0
1− x > 0∪
{x3 < 0
1− x < 0cioe
{x > 0
x < 1∪
{x < 0
x > 1.
Le soluzioni (dal primo soltanto) sono per 0 < x < 1, cioe l’intervallo (0, 1).(d) La disequazione equivale alla x2(x2 − 1) ≥ 0. Attenzione qui: anzitutto osserviamo che 0 e soluzione. Poi, conx 6= 0, possiamo dividere per x2, che e positivo, e restiamo con x2 − 1 ≥ 0, che ha per soluzioni i valori esterni a −1 e1. Le soluzioni sono quindi l’insieme S = (−∞,−1] ∪ {0} ∪ [1,+∞).Si poteva anche seguire un’altra strada: la disequazione x2(x2 − 1) ≥ 0 equivale ai due sistemi
{x2 ≥ 0
x2 − 1 ≥ 0∪
{x2 ≤ 0
x2 − 1 ≤ 0.
Il primo sistema fornisce le soluzioni esterne a −1 e 1. Il secondo sistema (attenzione!) fornisce la soluzione isolata 0.
Esercizio 10.1
(a) La disequazione equivale al sistema
{
x 6= 1
x+ 1x−1 − 1 ≥ 0
cioe
{
x 6= 1x(x−1)+1−x+1
x−1 ≥ 0cioe
{
x 6= 1x2−2x+2
x−1 ≥ 0.
Dato che il numeratore della frazione e sempre positivo, le soluzioni sono le x > 1, cioe l’intervallo (1,+∞).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

15 SOLUZIONI DEGLI ESERCIZI
EQUAZIONI E DISEQUAZIONI
79
(b) La disequazione equivale al sistema
{x 6= 02x + x− 3 ≥ 0
cioe
{
x 6= 0x2−3x+2
x ≥ 0.
Gli zeri del polinomio di secondo grado sono 1 e 2. Studiando il segno del numeratore e del denominatore e rispettandola condizione di esistenza si trova che le soluzioni sono l’insieme S = (0, 1] ∪ [2,+∞).(c) La disequazione equivale al sistema
{
x 6= ±1x
1−x2 − x ≥ 0cioe
{
x 6= ±1x3
1−x2 ≥ 0.
Dallo studio del segno nella disequazione fratta si ottengono le soluzioni x < −1 oppure 0 ≤ x < 1, che si possonoesprimere anche con S = (−∞,−1) ∪ [0, 1).
Esercizio 11.1
(a) Possibili soluzioni si hanno solo con x ≥ 0. Inoltre deve anche essere x ≥ 1, perche altrimenti il primo membro enegativo. Elevando al quadrato, l’equazione equivale quindi al sistema
{x ≥ 1
x2 − 2x+ 1 = xcioe
{x ≥ 1
x2 − 3x+ 1 = 0.
Le soluzioni dell’equazione di secondo grado sono x = 3±√5
2 , ma solo x = 3+√5
2 e soluzione del sistema.
Quindi la soluzione e x = 3+√5
2 .(b) Per risolvere la seconda possiamo riscriverla nella
√x− 1 = 1− x.
Deve essere x ≥ 1 per l’esistenza della radice. Inoltre per avere soluzioni deve anche essere x ≤ 1, perche altrimenti ilsecondo membro e negativo. Quindi rimane x = 1. che e in effetti soluzione.Si faccia attenzione che elevando ambo i membri al quadrato nell’ultima equazione si ottiene
x− 1 = 1− 2x+ x2 cioe x2 − 3x+ 2 = 0,
che ha le soluzioni x = 1 oppure x = 2, ma la seconda non e accettabile.
Esercizio 11.2
Sono disequazioni irrazionali.(a) La prima si puo riscrivere come √
1− x > x− 3.
L’argomento della radice non puo essere negativo; si puo elevare al quadrato ma con entrambi i membri non negativi.Si puo inoltre osservare che se il secondo membro e negativo la disuguaglianza e certamente vera (il primo membro enon negativo mentre il secondo e negativo). Quindi la disequazione equivale al sistema
1− x ≥ 0
x− 3 ≥ 0
1− x > x2 − 6x+ 9
∪{
1− x ≥ 0
x− 3 < 0cioe
x ≤ 1
x ≥ 3
x2 − 5x+ 8 < 0
∪{x ≤ 1
x < 3.
Il primo sistema e impossibile (la disequazione di secondo grado non ha soluzioni) e quindi le soluzioni sono (date dalsecondo sistema) tutte le x ≤ 1, cioe l’intervallo (−∞, 1].(b) La seconda disequazione si puo riscrivere come
√x+ 1 ≤ 1− x.
Come prima dobbiamo avere l’argomento della radice non negativo e possiamo elevare al quadrato solo se entrambi imembri sono non negativi. Si puo inoltre osservare che se il secondo membro e negativo la disuguaglianza e certamentefalsa. Quindi la disequazione equivale al solo sistema
x+ 1 ≥ 0
1− x ≥ 0
x+ 1 ≤ 1− 2x+ x2cioe
x ≥ −1x ≤ 1
x2 − 3x ≥ 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

15 SOLUZIONI DEGLI ESERCIZI
EQUAZIONI E DISEQUAZIONI
80
Con l’aiuto di un semplice grafico si trova facilmente che le soluzioni sono date dall’intervallo [−1, 0].(c) La terza disequazione equivale ai sistemi
1− x2 ≥ 0
x ≥ 0
1− x2 > x2∪
{1− x2 ≥ 0
x < 080
I due sistemi equivalgono a{
0 ≤ x ≤ 1
x2 < 1/2∪ −1 ≤ x < 0
cioe0 ≤ x < 1/
√2 ∪ −1 ≤ x < 0.
Queste si possono anche scrivere piu semplicemente con −1 ≤ x < 1/√2, e cioe anche con S =
[−1, 1/
√2).
Esercizio 12.1
(a) L’equazione equivale alla 3 · 4x = 3 e questa alla 4x = 1, la cui soluzione e x = 0.(b) Basta scrivere 2x−1 = 2log2 3, da cui x− 1 = log2 3 e quindi x = 1 + log2 3.(c) Possiamo scrivere
ex2−1 = 2 cioe ex
2−1 = eln 2 cioe x2 − 1 = ln 2 cioe x = ±√1 + ln 2.
Esercizio 12.2
Sono disequazioni esponenziali.(a) Nella prima (non ci sono condizioni di esistenza) possiamo scrivere ambo i membri in base 2 ricordando che4x = (22)x = 22x. Quindi la disequazione equivale a
22x−1 ≥ 22x cioe 2x− 1 ≥ 2x cioe − 1 ≥ 0
che e evidentemente falsa. Le soluzioni sono dunque l’insieme vuoto.(b) La seconda equivale a e2x+3 ≤ e0 e quindi a 2x+ 3 ≤ 0, cioe x ≤ − 3
2 .(c) La terza si puo riscrivere come
3 · 32x − 8 · 3x − 3 > 0.
Ponendo ora 3x = t ci si riconduce ad una disequazione di secondo grado:
3t2 − 8t− 3 > 0,
che ha per soluzioni t < − 13 oppure t > 3. Allora, risostituendo 3x al posto di t
3x < −1
3oppure 3x > 3.
La prima non ha ovviamente soluzioni. La seconda equivale a x > 1. Queste sono le soluzioni della disequazione data.
Esercizio 13.1
(a) C’e la condizione di esistenza x > 0. L’equazione equivale poi alla 2 lnx = −2 e questa alla lnx = −1. L’ultima sipuo riscrivere lnx = ln 1
e ed e vera per x = 1e , che rispetta la condizione di esistenza.
(b) Nella condizione di esistenza x > −1 l’equazione equivale a log2(x+ 1) = −1, cioe log2(x+ 1) = log212 . Quindi la
soluzione e x = − 12 .
(c) Le soluzioni vanno cercate tra le x positive. Si ha ln2 x = 1, cioe lnx = ±1. Da lnx = 1 si ottiene x = e e dalnx = −1 si ottiene x = e−1 = 1/e. Le soluzioni sono quindi x = e, x = 1/e.
80Si noti che tutte le soluzioni del secondo sistema sono accettabili, dato che nelle condizioni scritte nel secondo sistema il primo membroe non negativo, mentre il secondo e negativo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

15 SOLUZIONI DEGLI ESERCIZI
EQUAZIONI E DISEQUAZIONI
81
Esercizio 13.2
Disequazioni logaritmiche. Non bisogna dimenticare le condizioni di esistenza, che consistono nel porre l’argomentodel logaritmo maggiore di zero.(a) La prima equivale dunque al sistema
{x+ 1 > 0
ln(x+ 1) > ln e2cioe
{x > −1x+ 1 > e2
cioe
{x > −1x > e2 − 1.
Le soluzioni sono dunque date dall’intervallo (e2 − 1,+∞).(b) La seconda equivale al sistema
{x > 0
ln2 x < 1cioe
{x > 0
−1 < lnx < 1cioe
{x > 01e < x < e.
Le soluzioni sono dunque date dall’intervallo (1e , e).(c) La terza equivale al sistema
{x > 0
ln3 x ≤ −1 cioe
{x > 0
lnx ≤ −1 cioe
{x > 0
x ≤ 1/e.
Le soluzioni sono quindi 0 < x ≤ 1/e, cioe l’intervallo (0, 1/e].
Esercizio 14.1
(a) Ricordando che |x + 1| coincide con x + 1 se x ≥ −1 e invece coincide con −x − 1 se x < −1, allora la primaequazione e equivalente ai due sistemi
{x ≥ −11− x− 1 = x
∪{x < −11 + x+ 1 = x
cioe
{x ≥ −12x = 0
∪{x < −12 = 0.
Ovviamente l’unica soluzione e x = 0.(b) Nella seconda, ricordando che |3x| coincide con 3x se x ≥ 0 e invece coincide con −3x se x < 0, l’equazione datae equivalente ai due sistemi
{x ≥ 0
x2 − 3x+ 2 = 0∪
{x < 0
x2 + 3x+ 2 = 0.
Si trova facilmente che le possibili soluzioni sono quattro: x = 1, x = 2, x = −1, x = −2.
Esercizio 14.2
(a) Come sempre, distinguendo il segno di x:
{x ≥ 0
x+ 2x ≤ x2 ∪{x < 0
−x+ 2x ≤ x2
cioe {x ≥ 0
x(x− 3) ≥ 0∪
{x < 0
x(x− 1) ≥ 0.
Il primo sistema ha soluzioni x = 0 oppure x ≥ 3, mentre il secondo ha soluzioni x < 0. L’unione dei due insiemi epertanto l’insieme S = (−∞, 0] ∪ [3,+∞).(b) Distinguendo questa volta il segno di x+ 1, si hanno i due sistemi
{x+ 1 ≥ 0
2(x+ 1)− x ≥ 3∪
{x+ 1 < 0
−2(x+ 1)− x ≥ 3
cioe {x ≥ −12x+ 2− x ≥ 3
∪{x < −1−2x− 2− x ≥ 3
cioe
{x ≥ −1x ≥ 1
∪{x < −1x ≤ − 5
3 .
Le soluzioni sono pertanto date dall’insieme S = (−∞,− 53 ] ∪ [1,+∞).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 RAPPRESENTAZIONE DI R2 SUL PIANO CARTESIANO
R2 ED R3 – PIANO E SPAZIO CARTESIANI
82
I-4 R2 ed R3 – Piano e spazio cartesiani
1 Prodotto cartesiano di due insiemi
Dati due insiemi A e B, definiamo prodotto cartesiano di A e B, e lo indichiamo con A×B, l’insieme di tutte le coppieordinate del tipo (a, b), dove a ∈ A e b ∈ B. Formalmente
A×B ={
(a, b) : a ∈ A ∧ b ∈ B}
. 81
Si faccia attenzione che le coppie sono ordinate, quindi l’ordine in cui considero gli elementi e rilevante. Gli elementiche costituiscono la coppia si dicono le componenti della coppia.Vediamo qualche esempio.
• Siano A = {a, b, c} e B = {1, 2}. Allora
A×B ={
(a, 1), (a, 2), (b, 1), (b, 2), (c, 1), (c, 2)}
.
A ribadire che l’ordine e importante, si noti che ad esempio (a, 2) appartiene ad A×B, ma (2, a) no.
• Siano C = {a, b, c, d, e, f, g, h} e R = {1, 2, 3, 4, 5, 6, 7, 8}. Allora
C ×R ={
(a, 1), (a, 2), . . . , (h, 7), (h, 8)}
.
E il modo che si usa nel gioco degli scacchi per identificare laposizione di un pezzo sulla scacchiera. Ad esempio il re biancosi trova all’inizio della partita in posizione (e, 1), gli alfieri neriin posizione (c, 8) e (f, 8) e i pedoni neri in posizione (x, 7), conx ∈ C (C sta per colonne e R sta per righe).
8rmblkans7opopopop60Z0Z0Z0Z5Z0Z0Z0Z040Z0Z0Z0Z3Z0Z0Z0Z02POPOPOPO1SNAQJBMR
a b c d e f g h
• Z × Z e chiaramente il prodotto cartesiano di Z per se stesso. Si tratta di tutte le (infinite) coppie ordinate acomponenti intere.
• Un fondamentale esempio di prodotto cartesiano e R×R, che si indica anche con R2, cioe l’insieme delle coppieordinate di numeri reali.
2 Rappresentazione di R2 sul piano cartesiano
Rb
0b
1b
r
x
y
b
1
b1
b A
b B b (a, b)
a
b
R2
Cosı come R puo essere rappresentato sulla retta cartesiana, analogamente possiamo rappresentare R2 sul piano, dettopiano cartesiano.
81La notazione (a, b) e purtroppo la stessa che si usa per indicare un intervallo di R. Risulta in genere chiaro dal contesto se si staparlando di intervalli o di coppie ordinate.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOTTOINSIEMI DI R2 E REGIONI DEL PIANO CARTESIANO
R2 ED R3 – PIANO E SPAZIO CARTESIANI
83
In un piano geometrico consideriamo due rette cartesiane ortogonali.82 Rappresentiamo l’elemento (0, 0) con il puntodi intersezione delle due rette, che chiameremo origine del sistema cartesiano. Rappresentiamo poi i due elementi(1, 0) e (0, 1) con i due punti unita sulle due rette.83
La corrispondenza tra gli elementi di R2 e i punti del piano (e viceversa) e ora immediata. Per rappresentare unacoppia (a, b) basta rappresentare a sull’asse delle x (punto A nella figura), b sull’asse delle y (punto B), tracciare laperpendicolare all’asse delle x passante per A e la perpendicolare all’asse delle y passante per B; l’intersezione delledue perpendicolari e il punto che rappresenta la coppia (a, b).Viceversa, dato un punto del piano, tracciando le perpendicolari ai due assi troviamo due punti (A sull’asse x e Bsull’asse y), determiniamo i numeri reali che tali punti rappresentano sulle due rette cartesiane (siano rispettivamentea e b) e abbiamo la coppia (a, b) che corrisponde al punto da cui siamo partiti.Abbiamo cosı definito una corrispondenza biunivoca (ad ogni elemento di R2 corrisponde un punto del piano e viceversa)tra gli elementi di R2 e i punti del piano cartesiano. Capitera a volte di identificare gli elementi di R2 con le relativerappresentazioni.
3 Sottoinsiemi di R2 e regioni del piano cartesiano
Ovviamente i sottoinsiemi di R2 possono avere una loro rappresentazione sul piano cartesiano. Vediamo alcuni casisemplici e significativi.
Consideriamo il sottoinsieme di R2 definito da
Y ={
(x, y) ∈ R2 : x = 0}
.
La sua rappresentazione consiste dei punti di ascissa zero: sono tutti i punti dell’assey (per questo l’insieme si chiama Y ). In modo analogo l’insieme
X ={
(x, y) ∈ R2 : y = 0}
viene rappresentato dall’asse x.
X
Y
x
y
a
Ya
b Xb
x
y L’insiemeYa =
{
(x, y) ∈ R2 : x = a}
viene rappresentato dalla retta parallela all’asse y e passante per il punto (a, 0). Alvariare di a si ottengono tutte le rette verticali.L’insieme
Xb ={
(x, y) ∈ R2 : y = b}
e rappresentato da una retta parallela all’asse x (quindi orizzontale) e passante per ilpunto (0, b).
L’insiemeC+
x ={
(x, y) ∈ R2 : x ≥ 0}
e un semipiano (la parte destra del piano cartesiano, compreso il “bordo”). Lo si puo chiamaresemipiano delle x non negative. C+
x contiene l’insieme Y (cioe Y ⊂ C+x ). x
y
C+x
x
y
A+x
Anche l’insiemeA+
x ={
(x, y) ∈ R2 : x > 0}
e un semipiano. Lo si puo chiamare semipiano delle x positive. A+x non contiene nessun punto
dell’insieme Y , dato che A+x non contiene il bordo (quindi Y ∩ A+
x = ∅).
82Si tratta di due rette perpendicolari, cioe che intersecandosi formano nel piano quattro angoli retti.83Come noto si e soliti servirsi di una retta orizzontale, chiamata asse delle ascisse e di una retta verticale, chiamata asse delle ordinate.
L’elemento (1, 0) viene rappresentato sull’asse delle ascisse, mentre (0, 1) sull’asse delle ordinate. Chiameremo spesso, come di consueto,asse delle x l’asse delle ascisse e asse delle y l’asse delle ordinate.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOTTOINSIEMI DI R2 E REGIONI DEL PIANO CARTESIANO
R2 ED R3 – PIANO E SPAZIO CARTESIANI
84
Analogamente gli insiemi
C+y =
{
(x, y) ∈ R2 : y ≥ 0}
e A+y =
{
(x, y) ∈ R2 : y > 0}
sono semipiani (la parte superiore del piano cartesiano). Li chiamere-mo rispettivamente semipiano delle y non negative e semipiano delle ypositive.
x
y
C+y
x
y
A+y
Lo studente, per analogia, scriva la definizione degli insiemi
C−x , A−
x , C−y , A−
y .
L’insiemeQ1 =
{
(x, y) ∈ R2 : x ≥ 0, y ≥ 0}
viene detto primo quadrante. x
y
Q1
Gli insiemi
Q2 ={
(x, y) ∈ R2 : x ≤ 0, y ≥ 0}
, Q3 ={
(x, y) ∈ R2 : x ≤ 0, y ≤ 0}
, Q4 ={
(x, y) ∈ R2 : x ≥ 0, y ≤ 0}
vengono detti, rispettivamente, secondo, terzo e quarto quadrante. Ovviamente ci sono anche le versioni “senza ilbordo” e quelle con soltanto una parte del bordo.
Come in R abbiamo definito gli intervalli, cosı possiamo fare in R2. Anche qui si tratta di unafamiglia abbastanza generale di sottoinsiemi. Gli intervalli in R2 sono i prodotti cartesiani degliintervalli di R. Quindi, se I e J sono due intervalli di R, e un intervallo di R2 l’insieme
R = I × J.
Vediamo quali possibili sottoinsiemi di R2 possono prendere origine dalla definizione.
I
J
x
y
⊲ R = [x1, x2]× [y1, y2] e quello che solitamente si chiama rettangolo.
⊲ R = (x1, x2)× (y1, y2) e ancora un rettangolo, ma senza il bordo.
⊲ Anche R = [x1, x2)× (y1, y2] e un rettangolo. E privo del “bordo di destra” e del “bordo di sotto”.
⊲ Il prodotto cartesiano di intervalli non limitati di R porta a intervalli non limitati di R2 (basta che uno dei duesia non limitato), come ad esempio R = [a,+∞)× (−∞, b).
| |
||
x1 x2
y1
y2
x
y
| |
||
x1 x2
y1
y2
x
y
| |
||
x1 x2
y1
y2
x
y
|
a
b
x
y
Molti dei sottoinsiemi visti nei punti precedenti sono in realta intervalli. Sono intervalli infatti ad esempioC+
x , A−x , A
+y , C
−y , dato che
C+x = [0,+∞)× R
A−x = (−∞, 0)× R
A+y = R× (0,+∞)
C−y = R× (−∞, 0].
Anche i quadranti sono intervalli. Infatti ad esempio si puo scrivere
Q1 = [0,+∞)× [0,+∞) e Q2 = (−∞, 0)× [0,+∞).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOTTOINSIEMI DI R2 E REGIONI DEL PIANO CARTESIANO
R2 ED R3 – PIANO E SPAZIO CARTESIANI
85
Ovviamente anche in R2, come in R, ci sono sottoinsiemi che non sono intervalli: ad esempio Z × Z, che e l’insiemedei punti a coordinate intere, non e un intervallo. Un cerchio non e un intervallo, dato che non si puo scrivere comeprodotto cartesiano di due intervalli di R.Concludiamo questa prima parte con qualche considerazione circa la simmetria dei sottoinsiemi di R2.Un insieme S ⊂ R2 e simmetrico rispetto alle x se
(x, y) ∈ S ⇒ (−x, y) ∈ S.Un insieme S ⊂ R2 e simmetrico rispetto alle y se
(x, y) ∈ S ⇒ (x,−y) ∈ S.Nelle figure qui sotto sono rappresentati a sinistra un insieme simmetrico rispetto alle x e a destra due insiemisimmetrici rispetto alle y.
x
y
x
y
Altro esempio di insieme simmetrico rispetto alle x e il rettangolo R = [−1, 1] × [0, 1]. Altro esempio di insiemesimmetrico rispetto alle y e la retta di equazione x = 1.
Osservazione Si noti che nella nostra definizione simmetrico rispetto alle x vuol dire simmetrico rispetto all’asse y(e viceversa per l’altro).Ci sono insiemi che sono simmetrici sia rispetto alle x sia rispetto alle y. Ad esempio il quadrato Q = [−1, 1]× [−1, 1].Si faccia attenzione che per definire la simmetria sia rispetto alle x sia rispetto alle y non si puo dire
(x, y) ∈ S ⇒ (−x,−y) ∈ S.Infatti l’unione del primo e terzo quadrante e un insieme che soddisfa questa implicazione ma non e simmetrico nerispetto alle x ne rispetto alle y. Si intuisce che la simmetria definita dall’implicazione qui sopra e una simmetriarispetto all’origine.Se la simmetria rispetto all’origine non implica la contemporanea simmetria rispetto alle x e rispetto alle y, e veroinvece il viceversa, che cioe la contemporanea simmetria rispetto alle x e rispetto alle y implica la simmetria rispettoall’origine. Lo studente cerchi di convincersi di tutto questo costruendosi opportuni esempi.
Esercizio 3.1 Si descriva il sottoinsieme A di R2 definito da
A ={
(x, y) ∈ R2 : x < −1}
.
Lo si esprima poi attraverso un prodotto cartesiano.
Esercizio 3.2 Si descriva il sottoinsieme A di R2 definito da
A ={
(x, y) ∈ R2 : −1 ≤ x ≤ 1 ∧ y < 1}
.
Lo si esprima poi attraverso un prodotto cartesiano.
Esercizio 3.3 Si descriva il sottoinsieme A di R2 definito dal prodotto cartesiano
A = (−∞, 1]× (0,+∞).
Esercizio 3.4 Si descriva il sottoinsieme A di R2 definito dall’intersezione dei due insiemi
A1 = (−∞, 0]× [−1,+∞) e A2 = [0,+∞)× (−∞, 1].
Esercizio 3.5 Si descriva il sottoinsieme A di R2 definito dall’unione dei due insiemi
A1 = (−∞, 0]× [0,+∞) e A2 = [−1,+∞)× (−∞, 1].L’insieme A si puo scrivere attraverso un prodotto cartesiano?
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
R2 ED R3 – PIANO E SPAZIO CARTESIANI
86
4 R3 e sua rappresentazione nello spazio cartesiano
La definizione di prodotto cartesiano di due insiemi si puo facilmente estendere al prodotto cartesiano di un numeroqualunque di insiemi. Quindi, se A, B e C sono tre insiemi, si definisce prodotto cartesiano di A, B e C, e si indicacon A×B × C, l’insieme di tutte le terne ordinate del tipo (a, b, c), dove a ∈ A, b ∈ B e c ∈ C. Formalmente
A×B × C ={
(a, b, c) : a ∈ A, b ∈ B, c ∈ C}
.
In tutta generalita, se A1, A2, . . . , An sono n insiemi, si definisce prodotto cartesiano di A1, A2, . . . , An, e si indica conA1 ×A2 × . . .×An, l’insieme di tutte le n-uple ordinate del tipo (a1, a2, . . . , an), dove a1 ∈ A1, a2 ∈ A2, . . . , an ∈ An.Formalmente
A1 ×A2 × . . .×An ={
(a1, a2, . . . , an) : a1 ∈ A1, a2 ∈ A2, . . . , an ∈ An
}
.
Un esempio di prodotto cartesiano di tre insiemi e ovviamente R×R×R = R3, l’insieme delle terne ordinate di numerireali.Non e difficile intuire che R3 si puo rappresentare nello spazio cartesiano. Non ripeto la costruzione della corrispondenzabiunivoca che associa ad ogni elemento di R3 un punto dello spazio e viceversa, dato che e del tutto analoga a quellavista per R2.
Nello spazio cartesiano si hanno tre rette ortogonali che si incontrano inun punto, detto anche qui origine del sistema cartesiano (che rappresenta laterna (0, 0, 0)). Gli assi sono generalmente indicati con le lettere x, y, z (otalvolta x1, x2, x3). La raffigurazione del sistema cartesiano nello spazio e ladisposizione degli assi sono quelli che si vedono nella figura qui a fianco.
z
y
xVediamo brevemente qualche sottoinsieme di R3.
• L’insiemeA =
{
(x, y, z) ∈ R3 : x = 0}
e rappresentato nello spazio cartesiano dal piano che contiene gli assi y e z (sinteticamente il piano y, z).
• L’insiemeB =
{
(x, y, z) ∈ R3 : y = b}
e rappresentato nello spazio cartesiano dal piano, parallelo al piano x, z, e che passa per il punto (0, b, 0).
• L’insiemeC =
{
(x, y, z) ∈ R3 : z ≥ 0}
e rappresentato dal semispazio delle z non negative, cioe il semispazio che sta al di sopra del piano x, y, que-st’ultimo compreso. Naturalmente la disuguaglianza z > 0 definirebbe lo stesso semispazio, ma privo del pianox, y (cioe senza il bordo).
• Se vogliamo indicare l’asse z dobbiamo scrivere l’insieme{
(x, y, z) ∈ R3 : x = 0 ∧ y = 0}
={
(0, 0, z) : z ∈ R
}
(cioe l’insieme dei punti in cui x e y sono nulli e z e un qualunque numero reale).
Si possono poi definire facilmente gli intervalli in R3, come prodotti cartesiani di tre intervalli di R.
5 Soluzioni degli esercizi
Esercizio 3.1
Si tratta di un semipiano: la parte di piano che sta alla sinistra della retta di equazione x = −1, bordo escluso.L’espressione attraverso un prodotto cartesiano e
A = (−∞,−1)× R.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
R2 ED R3 – PIANO E SPAZIO CARTESIANI
87
Esercizio 3.2
Ricordo che la scrittura −1 ≤ x ≤ 1 ∧ y < 1 significa −1 ≤ x ≤ 1 e nello stesso tempo y < 1. Si tratta quindi dellaparte di piano che sta alla destra della retta di equazione x = −1, alla sinistra della retta di equazione x = 1 e al disotto della retta di equazione y = 1. Il bordo e solo in parte compreso (bordo laterale compreso, bordo superiore no).L’espressione attraverso un prodotto cartesiano e
A = [−1, 1]× (−∞, 1).
Esercizio 3.3
Si tratta della parte di piano che sta alla sinistra della retta di equazione x = 1 e al di sopra della retta di equazioney = 0. Per quanto riguarda il bordo, quello laterale fa parte dell’insieme A, quello inferiore no.
Esercizio 3.4
Si tratta di un segmento: quello di estremi (0,−1) e (0, 1).
Esercizio 3.5
Ci sono vari modi per descrivere A. Uno e il seguente: A e dato dai punti del piano che non appartengono ne all’insieme(0,+∞)× (1,+∞) ne all’insieme (−∞,−1)× (−∞, 0) (fare attenzione alle parentesi: qui devono essere tutte tonde).L’insieme A non si puo scrivere con un prodotto cartesiano dato che A non e un intervallo. Si osservi quindi chel’unione di due intervalli non e necessariamente un intervallo (e cosı sia in R sia in R2). Lo studente rifletta ora suiseguenti quesiti e arrivi da solo a dare le risposte:
• l’unione di due intervalli di R2 puo essere un intervallo? Si costruiscano situazioni in cui questo accade;
• quando l’unione di due intervalli di R e un intervallo? Si distinguano condizioni sufficienti e condizioni necessarie.
• quanto trovato in risposta alla seconda domanda vale anche in R2?
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 RETTE NEL PIANO
ELEMENTI DI GEOMETRIA ANALITICA
88
I-5 Elementi di geometria analitica
In questa lezione trattiamo alcuni argomenti della cosiddetta geometria analitica. Sono argomenti che rientrano neiprogrammi della scuola secondaria.Il problema che affrontiamo e questo: se consideriamo un’equazione in due incognite (mettiamo x e y), possiamoattenderci che tale equazione abbia certe soluzioni, che sono da intendersi come coppie (ordinate) di numeri reali,quelle che solitamente rappresentiamo con (x, y). Se noi ora rappresentiamo nel piano cartesiano le soluzioni dellanostra equazione, avremo ovviamente un sottoinsieme del piano. La domanda e: che tipo di sottoinsieme del pianosi trova in corrispondenza della nostra equazione? La risposta (ovvia) e che il tipo di sottoinsieme dipende dal tipodi equazione. Per scoprire un po’ di piu sulla questione iniziamo con le equazioni piu semplici, le equazioni di primogrado.
1 Rette nel piano
Ricordiamo che sono equazioni di primo grado in due incognite quelle che si possono ridurre alla forma
ax+ by + c = 0 , con a, b, c numeri reali fissati, a, b non entrambi nulli.
Esaminiamo intanto alcuni casi particolari.
• Se a = 0 e b 6= 0, allora possiamo riscrivere l’equazione nella forma
y = −cb
e quindi le soluzioni della nostra equazione sono tutte le coppie in cui la seconda componente vale appunto− c
b . Si tratta quindi di tutte le coppie del tipo (x,− cb ), dove x puo essere un numero reale qualunque. La
rappresentazione sul piano di tale insieme e la retta di ordinata − cb , quindi una retta orizzontale.
• Se b = 0 e a 6= 0, allora riscriviamo l’equazione nella forma
x = − ca;
le soluzioni sono le coppie di prima componente − ca , cioe delle coppie del tipo (− c
a , y), dove y puo essere unnumero reale qualunque. Quindi la rappresentazione sul piano di tale insieme e la retta di ascissa − c
a , cioe unaretta verticale.
Se invece a 6= 0 e b 6= 0, abbiamo il caso generale.Si puo verificare facilmente che la rappresentazione dell’insieme di soluzioni dell’equazione in questo caso e ancora unaretta, questa volta “obliqua”.Pertanto le equazioni di primo grado definiscono (individuano) rette. Vedremo subito che vale anche il viceversa.
Osservazioni Ricordiamo che, data l’equazione nel caso generale ax + by + c = 0, e possibile riscrivere l’equazionenelle due forme (equivalenti)
y = −abx− c
be x = − b
ay − c
a.
Solitamente si preferisce la prima forma in quanto “esprime esplicitamente y in funzione di x” (cioe l’ordinata infunzione dell’ascissa), e per pura questione di abitudine preferiamo fare questo piuttosto che il contrario. Ma tra breveimpareremo a fare altrettanto naturalmente anche la rappresentazione di x in funzione di y.La scrittura esplicita di y in funzione di x nel caso dell’equazione di primo grado si puo quindi dare nella forma
y = mx+ q
(ovviamente basta porre −ab = m e − c
b = q). Importante e l’interpretazione geometrica delle quantita m e q (o di −ab
e − cb se si preferisce):
⊲ m e detto coefficiente angolare della retta ed e legato all’angolo (da cui l’aggettivo “angolare”) che la retta formacon l’asse x, ossia alla pendenza della retta: se m > 0 la retta e “bassa a sinistra e alta a destra” (tra un po’vedremo come definire meglio questa proprieta), mentre se m < 0 accade il contrario (non puo essere in questocaso m = 0 perche a 6= 0).
Inoltre tanto piu e grande il valore di m, tanto piu pendente (ripida) e la retta.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 RETTE NEL PIANO
ELEMENTI DI GEOMETRIA ANALITICA
89
⊲ q e legato alla posizione del punto di intersezione della retta con l’asse y (si dice l’ordinata all’origine della retta):se q = 0 la retta incontra l’asse y nell’origine, se q > 0 tale punto di intersezione sta al di sopra dell’origine, seq < 0 tale punto sta al di sotto dell’origine. Tanto piu grande e il valore di q, tanto piu lontano dall’origine laretta incontra l’asse y.
Si osservi anche che la forma esplicita (y = mx+ q) non si puo ottenere se b = 0. Abbiamo visto prima che si trattain questo caso di una retta verticale e si noti che ci sarebbe qualche problema a definire la pendenza di tali rette.
Cerchiamo di capire perchem ha il significato che e stato detto. Possiamo anzitut-to osservare che dall’equazione y = mx+ q possiamo ricavare, se x 6= 0, che m = y−q
x .Aiutandoci con la figura qui a fianco, vediamo allora che questo quoziente altro non eche il rapporto tra la variazione delle ordinate sulla retta e la variazione delle ascissecorrispondenti nel passare dal punto di ascissa zero al punto di ascissa x.
q
x
y } y − q}
x
P
Q
x1 x2
y1
y2 } y2 − y1}
x2 − x1x
yPiu in generale (figura a sinistra), e il rapporto tra la variazione delle ordi-
nate e la variazione delle ascisse nel passaggio da un qualunque punto P sullaretta ad un altro punto Q sulla retta. Infatti, supponendo che i due punti siano(x1, y1) e (x2, y2), deve valere il sistema
{y1 = mx1 + q
y2 = mx2 + q
che, togliendo alla seconda equazione la prima, porta a y2 − y1 = m(x2 − x1),e cioe m =
y2 − y1x2 − x1
. 84
1.1 Rette passanti per un punto assegnato
Per un punto assegnato (x0, y0) passano ovviamente infinite rette. Ora che sappiamoil significato del parametro m, possiamo facilmente scrivere l’equazione di queste rette.Non e difficile capire che l’equazione e
y − y0 = m(x− x0). 85
b
x0
y0
x
y
Osservazione In realta l’equazione scritta da tutte le rette passanti per (x0, y0), ad eccezione di quella verticale,che ha equazione x = x0.Dovrebbe ora essere chiaro che possiamo determinare anche il parametro m se abbiamo un’informazione in piu, chepotrebbe essere o la conoscenza diretta della pendenza oppure il passaggio per un altro punto del piano.
Esempio Scrivere l’equazione delle rette passanti per il punto (−1, 2). Senza molti commenti, si tratta dell’equazioney − 2 = m(x+ 1).Siamo pronti per trovare l’equazione della retta per due punti.
84Questo vale se x1 6= x2 naturalmente, ma e un’ipotesi “accettabile”: se fosse x1 = x2 i due punti sarebbero allineati verticalmente equindi la retta avrebbe equazione x = x1.
85Ci si arriva o pensando che e m = y−y0x−x0
, oppure pensando che il punto (x0, y0) e soluzione dell’equazione (entrambi i membri sono
nulli) e si tratta certamente dell’equazione di una retta di pendenza m. Tutte le condizioni sono dunque rispettate.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 RETTE NEL PIANO
ELEMENTI DI GEOMETRIA ANALITICA
90
1.2 Retta passante per due punti assegnati
Supponiamo che i due punti siano (x1, y1) e (x2, y2). La condizione di passaggioper il primo punto porta a scrivere l’equazione
y − y1 = m(x − x1),
ma sappiamo anche che m = y2−y1
x2−x1. Quindi si trova
y − y1 =y2 − y1x2 − x1
(x− x1). 86
b
b
x1 x2
y1
y2 } y2 − y1}x2 − x1
x
y
Osservazione Anche qui l’equazione scritta esclude un caso possibile: infatti vale solo se x1 6= x2. Nel caso si abbiax1 = x2, cioe punti con la stessa ascissa, la retta e ovviamente verticale e la sua equazione e x = x1 (o x = x2).
1.3 Rette parallele e rette perpendicolari
Vediamo ora due semplici questioni, legate sempre ai coefficienti angolari delle rette: in particolare parliamo di retteparallele e rette perpendicolari.
• Rette parallele in forma esplicita hanno lo stesso coefficiente angolare.
Vediamo un’applicazione di questo fatto in un semplice esercizio: scrivere l’equazione della retta parallela allaretta di equazione 2x− y+1 = 0 e passante per il punto (3, 2). Scriviamo la retta in forma esplicita: y = 2x+1.La retta parallela avra allora equazione esplicita del tipo y = 2x+ q. Imponendo il passaggio per il punto (3, 2)si deve avere 2 = 2 · 3 + q, da cui q = −4. L’equazione cercata e quindi y = 2x − 4. Si poteva anche osservaredirettamente che si tratta della retta di pendenza 2 passante per il punto (3, 2) e quindi e la retta di equazioney − 2 = 2(x− 3).
• Rette perpendicolari in forma esplicita hanno coefficienti angolari m e m′ legati dalla relazione mm′ = −1 (dacui m′ = −1/m).
Vediamo anche qui un’applicazione in un esercizio: scrivere l’equazione della retta perpendicolare alla retta diequazione 2x − y + 1 = 0 e passante per il punto (3, 2). La retta in forma esplicita e y = 2x + 1. La rettaperpendicolare avra equazione esplicita del tipo y = − 1
2x+ q. Imponendo il passaggio per il punto (3, 2) si deveavere 2 = − 1
2 · 3 + q, da cui q = 72 . L’equazione cercata e quindi y = − 1
2x+ 72 .
Osservazione Se e abbastanza naturale capire che rette parallele hanno la stessa pendenza, non e forse altrettantonaturale capire la relazione che lega le pendenze di due rette perpendicolari, a parte forse il fatto che se uno deicoefficienti angolari e positivo, l’altro deve essere negativo.
Per il momento allora abbiamo visto che le equazioni di primo grado individuano nel piano delle rette. Ci si chiede aquesto punto se vale anche il viceversa, se cioe ogni retta del piano sia l’insieme delle soluzioni di un’equazione di primogrado. La risposta e affermativa, ma la corrispondenza tra equazioni di primo grado e rette non e biunivoca, come sipotrebbe inizialmente pensare: un’equazione individua una sola retta, ma la stessa retta e soluzione di molte (infinite)equazioni. Questo e naturale, dato che una certa equazione ne ha infinite altre equivalenti ad essa. Ad esempio le dueequazioni
x− 2y + 3 = 0 e − 2x+ 4y − 6 = 0
sono equivalenti, cioe hanno lo stesso insieme di soluzioni e cioe individuano la stessa retta.87
Possono essere utili e istruttivi due tipi di esercizi: data un’equazione, disegnare la retta che rappresenta le sue soluzionie, data una retta nel piano, trovare un’equazione che la individui.Vediamo il tutto su di un esempio. Consideriamo l’equazione di prima, x − 2y + 3 = 0. Vogliamo disegnare la rettacorrispondente.
86E chiaro che se avessimo utilizzato la condizione di passaggio per il secondo punto avremmo trovato l’equazione y−y2 = y2−y1x2−x1
(x−x2),
che e formalmente diversa dall’altra, ma che individua la stessa retta.87La seconda si ottiene dalla prima moltiplicando ambo i membri per −2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
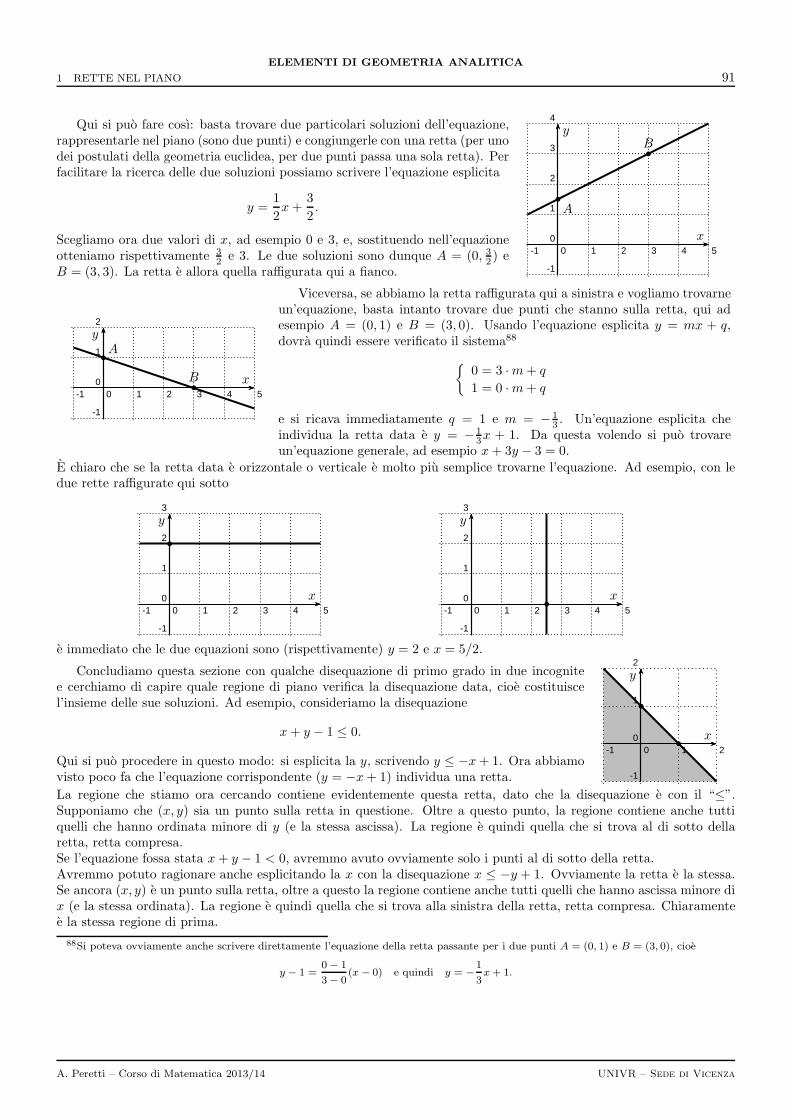
1 RETTE NEL PIANO
ELEMENTI DI GEOMETRIA ANALITICA
91
Qui si puo fare cosı: basta trovare due particolari soluzioni dell’equazione,rappresentarle nel piano (sono due punti) e congiungerle con una retta (per unodei postulati della geometria euclidea, per due punti passa una sola retta). Perfacilitare la ricerca delle due soluzioni possiamo scrivere l’equazione esplicita
y =1
2x+
3
2.
Scegliamo ora due valori di x, ad esempio 0 e 3, e, sostituendo nell’equazioneotteniamo rispettivamente 3
2 e 3. Le due soluzioni sono dunque A = (0, 32 ) eB = (3, 3). La retta e allora quella raffigurata qui a fianco.
-1 0 1 2 3 4 5
-1
0
1
2
3
4
x
y
b
A
bB
-1 0 1 2 3 4 5
-1
0
1
2
x
y
b A
bB
Viceversa, se abbiamo la retta raffigurata qui a sinistra e vogliamo trovarneun’equazione, basta intanto trovare due punti che stanno sulla retta, qui adesempio A = (0, 1) e B = (3, 0). Usando l’equazione esplicita y = mx + q,dovra quindi essere verificato il sistema88
{0 = 3 ·m+ q
1 = 0 ·m+ q
e si ricava immediatamente q = 1 e m = − 13 . Un’equazione esplicita che
individua la retta data e y = − 13x + 1. Da questa volendo si puo trovare
un’equazione generale, ad esempio x+ 3y − 3 = 0.
E chiaro che se la retta data e orizzontale o verticale e molto piu semplice trovarne l’equazione. Ad esempio, con ledue rette raffigurate qui sotto
-1 0 1 2 3 4 5
-1
0
1
2
3
x
y
b
-1 0 1 2 3 4 5
-1
0
1
2
3
x
y
b
e immediato che le due equazioni sono (rispettivamente) y = 2 e x = 5/2.
Concludiamo questa sezione con qualche disequazione di primo grado in due incognitee cerchiamo di capire quale regione di piano verifica la disequazione data, cioe costituiscel’insieme delle sue soluzioni. Ad esempio, consideriamo la disequazione
x+ y − 1 ≤ 0.
Qui si puo procedere in questo modo: si esplicita la y, scrivendo y ≤ −x+ 1. Ora abbiamovisto poco fa che l’equazione corrispondente (y = −x+ 1) individua una retta.
-1 0 1 2
-1
0
1
2
x
y
b
b
La regione che stiamo ora cercando contiene evidentemente questa retta, dato che la disequazione e con il “≤”.Supponiamo che (x, y) sia un punto sulla retta in questione. Oltre a questo punto, la regione contiene anche tuttiquelli che hanno ordinata minore di y (e la stessa ascissa). La regione e quindi quella che si trova al di sotto dellaretta, retta compresa.Se l’equazione fossa stata x+ y − 1 < 0, avremmo avuto ovviamente solo i punti al di sotto della retta.Avremmo potuto ragionare anche esplicitando la x con la disequazione x ≤ −y + 1. Ovviamente la retta e la stessa.Se ancora (x, y) e un punto sulla retta, oltre a questo la regione contiene anche tutti quelli che hanno ascissa minore dix (e la stessa ordinata). La regione e quindi quella che si trova alla sinistra della retta, retta compresa. Chiaramentee la stessa regione di prima.
88Si poteva ovviamente anche scrivere direttamente l’equazione della retta passante per i due punti A = (0, 1) e B = (3, 0), cioe
y − 1 =0− 1
3− 0(x− 0) e quindi y = −1
3x+ 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 PARABOLE
ELEMENTI DI GEOMETRIA ANALITICA
92
-1 0 1 2 3
-2
-1
0
1
x
y
b
b
Un altro esempio. La disequazione e
x− 2y − 2 < 0.
L’equazione corrispondente individua la retta rappresentata qui a sinistra. Esplicitia-mo la x scrivendo x < 2y + 2. Si tratta dei punti che stanno alla sinistra della rettain figura. Esplicitando la y avremmo ottenuto y > 1
2x− 1, cioe la regione al di sopradella retta.
Esercizio 1.1 Si scriva l’equazione della retta passante per i punti (0, 1) e (2,−1).
Esercizio 1.2 Si scriva l’equazione della retta per il punto (2,−1) e parallela alla retta di equazione 2x+3y = 5.
Esercizio 1.3 Si scriva l’equazione della retta perpendicolare alla retta di equazione x + 3y + 2 = 0 e passante
per il punto (2, 1).
Esercizio 1.4 Si descriva l’insieme del piano dei punti soluzione della disequazione 3x− 2y + 4 < 0.
Abbiamo visto tutto per quanto riguarda le equazioni (e disequazioni) di primo grado.Passiamo alle equazioni di secondo grado, sempre in due incognite. Qui le cose in realta si farebbero molto piucomplicate, se volessimo affrontare il problema nella sua generalita. Non arriveremo infatti a considerare il caso piugenerale, che e rappresentato dall’equazione
ax2 + by2 + cxy + dx+ ey + f = 0. (8)
Esamineremo soltanto alcuni casi particolari dell’equazione scritta qui sopra, che ci porteranno ad alcune particolaricurve nel piano.
2 Parabole
1. Consideriamo in (8) il caso particolare
ax2 + dx+ ey + f = 0 , con a 6= 0. 89 (9)
Mancano due dei tre termini di secondo grado e resta il termine in x2. Qui si possono presentare due casirilevanti: e = 0 oppure e 6= 0.
Se e = 0, allora l’equazione equivale aax2 + dx+ f = 0.
Ora, se questa equazione in una sola variabile non ha soluzioni, essa non individua nulla nel piano.
Se ha una sola soluzione x0, definisce la retta (verticale) di equazione x = x0.
Se ha due soluzioni distinte x1 e x2, definisce una coppia di rette parallele verticali di equazione x = x1 e x = x2.
Il caso e 6= 0 e piu interessante, dato che si ottiene una nuova curva nel piano, che si chiama parabola.90
Possiamo esplicitare facilmente la y in funzione della x e, ridenominando opportunamente i coefficienti, possiamoscrivere l’equazione nella forma
y = ax2 + bx+ c , con a 6= 0, (10)
da cui si vede che nelle parabole c’e una relazione di tipo quadratico tra la x e la y.
89Con a = 0 si tornerebbe all’equazione di primo grado.90Lo studente interessato puo andare a rivedere le proprieta geometriche della parabola in un testo di scuola secondaria.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 PARABOLE
ELEMENTI DI GEOMETRIA ANALITICA
93
Per cogliere qualche proprieta in piu della parabola possiamo scrivere
y = ax2 + bx+ c
= a(x2 + b
ax+ ca
)
(completamento del quadrato) = a(
x2 + bax+ b2
4a2 − b2
4a2 + ca
)
= a[(x+ b
2a
)2+ c
a − b2
4a2
]
= a(x+ b
2a
)2 −(
b2
4a − c)
= a(x+ b
2a
)2 − b2−4ac4a .
Questo dovrebbe far capire che la parabola presenta una simmetria rispetto alla retta (verticale) di equazionex = − b
2a , che prende il nome di asse della parabola. L’intersezione tra la parabola e il suo asse si chiama vertice
della parabola, che ha coordinate (− b2a ,− b2−4ac
4a ). Le parabole di equazione (9) hanno l’asse parallelo all’asse y.
Esempio Consideriamo l’equazione y = 2x2+4x+5. Procedendo con il completamento del quadrato si ottiene
y = 2(x2 + 2x+ 5
2
)= 2
(x2 + 2x+ 1 + 3
2
)= 2(x+ 1)2 + 3.
Il vertice della parabola e il punto (−1, 3), l’asse e la retta di equazione x = −1.
Osservazioni Prima di vedere qualche altro esempio, vediamo qual e il significato geometrico dei coeffi-cienti. Consideriamo per semplicita direttamente l’equazione esplicita (10). Il significato del coefficiente c esemplicemente, come per le rette, l’ordinata all’origine della parabola.
Il significato invece del coefficiente a e duplice: il suo segno dice se la parabola ha la concavita91 rivolta versol’alto o verso il basso (se il coefficiente e positivo la concavita e verso l’alto, il contrario se negativo). Il valoreassoluto del coefficiente dice invece qual e la curvatura della parabola: piu e grande e piu la parabola e stretta,per cosı dire.
x
y
a > 0a < 0
Importanti per tracciare un grafico della parabola sono anche le eventuali intersezioni con gli assi.
Se consideriamo l’equazione (10), le ascisse delle eventuali intersezioni con l’asse x (le ordinate di quella con lay la conosciamo gia) sono le eventuali soluzioni dell’equazione di secondo grado (in una incognita)
ax2 + bx+ c = 0
e sappiamo che possono essere due, una o nessuna.
2. Consideriamo ora in (8) l’altro caso particolare
by2 + dx+ ey + f = 0 , con b 6= 0. (11)
Qui mancano ancora due dei tre termini di secondo grado, ma stavolta resta il termine in y2.
La discussione procede come prima. Si possono presentare due casi: d = 0 oppure d 6= 0.
Se d = 0, l’equazione equivale aby2 + ey + f = 0.
Se questa equazione in una sola variabile non ha soluzioni, essa non definisce nulla nel piano.
91La concavita della parabola dice, in parole povere, da che parte la parabola si piega.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 PARABOLE
ELEMENTI DI GEOMETRIA ANALITICA
94
Se ha una sola soluzione y0, definisce la retta (orizzontale) di equazione y = y0.
Se ha due soluzioni distinte y1 e y2, definisce una coppia di rette parallele orizzontali di equazione y = y1 ey = y2.
Se invece d 6= 0, si ottiene ancora una parabola e si dovrebbe intuire facilmente cio che succede: questa voltae possibile esplicitare direttamente la x in funzione della y e, ridenominando opportunamente i coefficienti,possiamo scrivere
x = ay2 + by + c. (12)
E ancora una parabola poiche il tipo di curva e determinato solamente dal tipo di legame che c’e tra le dueincognite (qui ancora un legame di tipo quadratico). Quello che cambia e solo l’ordine delle variabili: e come seavessimo scambiato la x con la y. E si intuisce che questo scambio porta a “rovesciare” la parabola, portando ilsuo asse ad essere parallelo all’asse x questa volta.
Le parabole di equazione (11) hanno appunto l’asse parallelo all’asse x.
Osservazioni L’interpretazione geometrica dei coefficienti e analoga al caso precedente, tenendo conto ov-viamente dello scambio degli assi. Quindi, avendo a che fare con l’equazione esplicita (12), basta tradurre leconsiderazioni precedenti scambiando gli assi. Il coefficiente c e ora l’ascissa all’origine della parabola, mentre adice da che parte e la concavita (a destra se positivo e a sinistra se negativo), oltre alla curvatura.
x
y
a > 0a < 0
Importanti anche qui, per tracciare un grafico della parabola, sono le eventuali intersezioni con gli assi.
Considerando l’equazione (12), le ordinate delle eventuali intersezioni con l’asse y sono le eventuali soluzionidell’equazione di secondo grado
ay2 + by + c = 0,
anche qui due, una o nessuna.
Rivediamo il tutto in un paio di esempi.
• Consideriamo l’equazione
x+ y2 − 1 = 0 , che diventa x = −y2 + 1 in forma esplicita.
Si tratta di una parabola con asse parallelo all’asse x, con la concavita rivoltaverso sinistra, ascissa all’origine 1 (quindi passa per il punto (1, 0)). Le inter-sezioni con l’asse y sono nei due punti (0, 1) e (0,−1), dato che −1 e 1 sono lesoluzioni dell’equazione −y2 + 1 = 0. L’asse della parabola coincide con l’assex e il vertice della parabola e il punto (1, 0). -2 -1 0 1 2
-2
-1
0
1
2
x
y
• L’equazione
5x2 − 5x− y = 0 diventa y = 5x(x− 1) in forma esplicita.
Si tratta di una parabola con asse parallelo all’asse y, con la concavita rivoltaverso l’alto, ordinata all’origine 0 (quindi passa per l’origine); ha intersezionicon l’asse x nei due punti (0, 0) e (1, 0). L’asse di simmetria e la retta diequazione x = 1
2 e il vertice e nel punto (12 ,− 54 ).
-3 -2 -1 0 1 2 3-2
-1
0
1
2
3
4
x
y
Osservazione Lo studente attento avra notato che abbiamo parlato solo di parabole con asse di simmetria paralleloagli assi. Naturalmente ci sono nel piano anche parabole con asse “obliquo”. Di queste non parleremo, anche se conuna teoria piu generale di quella vista potremmo essere in grado di riconoscere l’equazione anche di queste.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 PARABOLE
ELEMENTI DI GEOMETRIA ANALITICA
95
Non e difficile capire quale sia la regione di piano individuata da una disequazione del tipo
y ≥ ax2 + bx+ c oppure y > ax2 + bx+ c.
Si tratta della regione che sta al di sopra della parabola di equazione y = ax2 + bx+ c. Ladifferenza tra i due insiemi e che il primo contiene i punti che stanno sulla parabola, mentreil secondo no.
x
y
x
y Dovrebbe essere chiaro qual e la regione individuata dalle disequazioni
y ≤ ax2 + bx+ c oppure y < ax2 + bx+ c.
Si tratta della parte di piano che sta al di sotto della parabola di equazione data, con lasolita precisazione riguardante il bordo dell’insieme.
Se invece consideriamo una disequazione del tipo
x ≥ ay2 + by + c oppure x > ay2 + by + c
abbiamo la regione che sta alla destra della parabola di equazione x = ay2 + by + c. x
y
x
y
Infine la regione individuata dalle disequazioni
x ≤ ay2 + by + c oppure x < ay2 + by + c
e quella che sta alla sinistra della parabola di equazione data.
Esempi
• La disequazione 2x2− y+1 ≥ 0 equivale a y ≤ 2x2 +1 e quindi ha per soluzione l’insieme dei punti del piano aldi sotto della parabola di equazione y = 2x2 +1. Tale parabola ha asse verticale, concavita rivolta verso l’alto enon ha intersezioni con l’asse x. I punti sulla parabola sono soluzioni (cioe la regione contiene il bordo).
• La disequazione y − 2 + x2 > 0 equivale a y > 2 − x2 e quindi ha per soluzione l’insieme dei punti del piano aldi sopra della parabola di equazione y = 2− x2. Tale parabola ha asse verticale, concavita rivolta verso il bassoe interseca l’asse x nei punti di ascissa x1 = −
√2 e x2 =
√2. I punti sulla parabola non sono soluzioni.
• La disequazione x+ y2 − 1 ≥ 0 equivale a x ≥ 1− y2 e quindi ha per soluzione l’insieme dei punti del piano alladestra della parabola di equazione x = 1− y2. Tale parabola ha asse orizzontale, concavita rivolta verso sinistrae interseca l’asse y nei punti di ordinata y1 = −1 e y2 = 1. I punti sulla parabola sono soluzioni.
• La disequazione x + 2 − 3y2 < 0 equivale a x < 3y2 − 2 e quindi ha per soluzione l’insieme dei punti del pianoalla sinistra della parabola di equazione x = 3y2 − 2. Tale parabola ha asse orizzontale, concavita rivolta verso
destra e interseca l’asse y nei punti di ordinata y1 = −√
23 e y2 =
√23 . I punti sulla parabola non sono soluzioni.
Esercizio 2.1 Si consideri la curva del piano definita dall’equazione x2 + 2y − 1 = 0. Tale curva passa per
l’origine? E passa per il punto (2,− 32 )? Si descriva poi tale curva.
Esercizio 2.2 Si consideri la curva del piano definita dall’equazione 3x − 2y2 + 1 = 0. Tale curva passa per
l’origine? Si descriva poi tale curva e si indichi un punto del primo quadrante che sta sulla curva.
Esercizio 2.3 Si descrivano in modo sufficientemente completo e si disegnino le regioni di piano individuate
dalle disuguaglianze:
(a) y + 2x2 − 3 < 0 (b) x2 + x− y − 2 ≤ 0 (c) 2x− y2 + 4 ≥ 0
Esercizio 2.4 Si disegnino nel piano le curve di equazione x2 + 4x+ 4 = 0 e di equazione y2 − 4y + 3 = 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CIRCONFERENZE
ELEMENTI DI GEOMETRIA ANALITICA
96
3 Circonferenze
-2 -1 0 1 2 3 4-2
-1
0
1
2
3
4
x
y
bC r
Ricordiamo intanto che la distanza euclidea di due punti del piano (x1, y1) e (x2, y2) e datada d =
√
(x1 − x2)2 + (y1 − y2)2 (teorema di Pitagora).La circonferenza di centro il punto (x0, y0) e raggio r ≥ 0 e l’insieme dei punti del piano chedistano r dal centro. Ad esempio qui a sinistra e raffigurata una circonferenza di centro ilpunto (1, 1) e raggio 2.Ricordando questa definizione geometrica si vede facilmente (utilizzando la distanza euclideain R2) che i punti di tale circonferenza soddisfano l’equazione
(x − x0)2 + (y − y0)2 = r2. (13)
E chiaro che un’equazione di questo tipo individua una (e solo quella) circonferenza e ormai dovrebbe essere altrettantochiaro che questa non e l’unica equazione le cui soluzioni sono i punti di quella circonferenza.92
Come gia visto per le rette e per le parabole, si possono presentare due tipi di problemi anche qui, e cioe: datauna circonferenza nel piano, con centro e raggio noti, scriverne l’equazione oppure, data un’equazione, disegnare lacirconferenza, cioe rappresentare le soluzioni di quell’equazione.Il primo problema e molto piu semplice. Scrivere l’equazione, nota la circonferenza, e in effetti molto facile dato che,conoscendo il centro (x0, y0) ed il raggio r, devo solo scrivere la (13). Quindi, ad esempio, se il centro e (−2, 1) e ilraggio e 3, l’equazione della circonferenza e (x+ 2)2 + (y − 1)2 = 9.Puo sembrare che anche il problema inverso sia ugualmente facile ed in effetti lo e se l’equazione data e nella forma(13). Ma puo essere che l’equazione non sia nella forma (13) e che sia parte dell’esercizio capire se puo essere riscrittanella forma (13). E chiaro che, quando saremo riusciti a scrivere la nostra equazione nella forma (13), tracciare lacirconferenza sara banale, dato che l’equazione dice chi e il centro e chi e il raggio.Affrontiamo cosı la questione: quali equazioni possono essere l’equazione di una circonferenza? Ad esempio, un’equa-zione di primo grado non puo essere l’equazione di una circonferenza. E chiaro che solo le equazioni di secondo gradopossono esserlo. Ma possiamo scoprire di piu, semplicemente svolgendo i calcoli nella (13). Si ottiene l’equazione(equivalente)
x2 − 2x0x+ x20 + y2 − 2y0y + y20 = r2.
Se vogliamo descrivere a parole le caratteristiche di un’equazione di questo tipo possiamo dire che: e un’equazionedi secondo grado con coefficienti uguali nei termini x2 e y2 (non e detto che questi coefficienti siano necessariamenteuguali ad 1: si ricordi che ci sono infinite equazioni equivalenti) e manca il termine xy. Queste sono le equazionicandidate ad individuare una circonferenza. Pero attenzione che prima di affermare che di circonferenza si trattaoccorre che si verifichi un altro fatto.Ma vediamo il tutto, compreso come si puo procedere in pratica, su qualche esempio.
• Consideriamo l’equazionex2 + y2 = 2.
Essa definisce certamente la circonferenza di centro l’origine e raggio r =√2 e non c’e molto da aggiungere.
• Consideriamo l’equazionex2 + y2 − 2x+ 2y − 2 = 0.
Puo avere per soluzioni i punti di una circonferenza. Si puo procedere per completamento dei quadrati, facendolosia sulle x sia sulle y. Otteniamo93
(x2 − 2x+ 1)− 1 + (y2 + 2y + 1)− 1− 2 = 0 cioe (x− 1)2 + (y + 1)2 = 4.
Solo ora possiamo dire che e in effetti l’equazione di una circonferenza, precisamente di centro (1,−1) e raggio 2.
• Consideriamo l’equazionex2 + y2 + 4x− 6y + 14 = 0.
Anche questa e una buona candidata ad essere una circonferenza. Con il completamento dei quadrati otteniamo94
x2 + 4x+ 4 + y2 − 6y + 9 + 14 = 13 cioe (x + 2)2 + (y − 3)2 = −1.92Si ricordi che esistono infinite equazioni equivalenti alla (13).93Per completare il quadrato sulle x devo aggiungere 1 e lo stesso per il quadrato sulle y. Naturalmente devo anche togliere le quantita
aggiunte.94Aggiungo 4 per completare il quadrato sulle x e 9 per il quadrato sulle y. Anziche togliere 13 a sinistra posso aggiungerlo a destra.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CIRCONFERENZE
ELEMENTI DI GEOMETRIA ANALITICA
97
Questa volta non e una circonferenza (il −1 che c’e a destra dovrebbe essere il quadrato del raggio).
Possiamo dire che quest’ultima equazione, che e equivalente alla nostra iniziale, non ha nessuna soluzione, datoche non puo mai essere vera. Quindi essa non definisce nulla nel piano, o se si preferisce definisce l’insieme vuoto.
• Consideriamo l’equazionex2 + y2 + 6y + 9 = 0.
Anche questa puo essere una circonferenza. I quadrati sono gia completi e possiamo riscrivere
x2 + (y + 3)2 = 0.
Nemmeno questa volta e una circonferenza, oppure qui possiamo dire che e una circonferenza degenere (raggionullo). L’unica soluzione di questa equazione e un solo punto del piano (il centro della circonferenza), cioe(0,−3).
Quelli visti sono i tre casi che si possono presentare quando si ha un’equazione che puo definire una circonferenza.Vediamo ancora qualche utile esempio.
• Consideriamo l’equazionex2 + y2 + x− 3y − 3
2 = 0.
Possiamo facilmente ottenere i doppi prodotti dove apparentemente non ci sono con
x2 + y2 + 2 · 12x− 2 · 32y − 32 = 0
e, completando i quadrati,
x2 + 2 · 12x+ 14 + y2 − 2 · 32y + 9
4 − 32 = 10
4 cioe(x+ 1
2
)2+(y − 3
2
)2= 4.
Si tratta della circonferenza di centro il punto (− 12 ,
32 ) e raggio 2.
• L’equazione36x2 + 36y2 − 36x+ 48y − 11 = 0
risulta una candidata a definire una circonferenza. Completiamo i quadrati, ottenendo
36x2 − 36x+ 9 + 36y2 + 48y + 16− 11 = 25 cioe (6x− 3)2 + (6y + 4)2 = 36.
Attenzione qui. Per riconoscere meglio centro e raggio conviene riscrivere
36(x− 1
2
)2+ 36
(y + 2
3
)2= 36 cioe
(x− 1
2
)2+(y + 2
3
)2= 1.
Si tratta allora della circonferenza di centro il punto (12 ,− 23 ) e raggio 1.
Si poteva anche, ripartendo dall’equazione iniziale, dividere tutto per 36 eliminando quindi il problema delcoefficiente diverso da 1. Si ottiene, completando poi i quadrati,
x2 + y2 − x+ 43y − 11
36 = 0 , x2 − x+ 14 + y2 + 4
3y +49 = 1
4 + 49 + 11
36 ,(x− 1
2
)2+(y + 2
3
)2= 1.
• Consideriamo l’equazione9x2 + 9y2 + 2x− 3y − 1 = 0,
che e candidata a definire una circonferenza. Completiamo i quadrati, ottenendo
9x2 + 2 · 3x · 13 + 19 + 9y2 − 2 · 3y · 12 + 1
4 = 1 + 19 + 1
4 cioe(3x+ 1
3
)2+(3y − 1
2
)2= 49
36 .
Attenzione che ora, prima di concludere, occorre “portare il 3 fuori dai quadrati”. Si poteva anche dividere peril coefficiente 9 all’inizio: si ottiene
x2 + y2 + 29x− 1
3y − 19 = 0 , x2 + 2
9x+ 181 + y2 − 1
3y +136 = 1
9 + 181 + 1
36 ,(x+ 1
9
)2+(y − 1
6
)2= 49
324 .
Si tratta quindi della circonferenza di centro il punto (− 19 ,
16 ) e raggio 7
18 .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CIRCONFERENZE
ELEMENTI DI GEOMETRIA ANALITICA
98
Osservazione Possiamo vedere la questione in questo modo: la tecnica del completamento del quadrato permettedi scoprire se la nostra circonferenza si ottiene come traslazione di una circonferenza con centro nell’origine. Infatti,consideriamo le due equazioni
x2 + y2 = r2 e (x− x0)2 + (y − y0)2 = r2.
La prima e la circonferenza di centro l’origine e raggio r e la seconda la circonferenza di centro (x0, y0) e raggio r.Quindi la seconda si ottiene attraverso una traslazione nel piano della prima, che porta l’origine nel punto (x0, y0).La stessa interpretazione la possiamo utilizzare anche con le parabole. Infatti, considerando le due equazioni
y = ax2 e y = a(x− x0)2,
possiamo vedere che la seconda parabola si ottiene con una traslazione della prima, traslazione che anche qui portal’origine nel punto (x0, y0).Ad esempio, se abbiamo l’equazione x2 + x− y+1 = 0 e la riscriviamo come y = x2 + x+1, completando il quadratosulle x possiamo ottenere
y = x2 + x+ 14 − 1
4 + 1 cioe y =(x+ 1
2
)2+ 3
4 e infine y − 34 =
(x+ 1
2
)2.
Ora si capisce che la parabola in questione si ottiene dalla parabola di equazione y = x2 con una traslazione che portail vertice dall’origine al punto (− 1
2 ,34 ). Faccio osservare che cosı riusciamo a ricavare esattamente come e fatta la
parabola.
Per quanto riguarda l’insieme individuato da una disequazione del tipo
(x− x0)2 + (y − y0)2 ≤ r2 oppure (x− x0)2 + (y − y0)2 < r2
e immediato capire che si tratta della regione interna alla circonferenza di equazione (x−x0)2+(y−y0)2 = r2 (la solitadifferenza per quanto riguarda la disuguaglianza di minore o di minore o uguale). Ovvio che invece le disequazioni
(x− x0)2 + (y − y0)2 ≥ r2 oppure (x− x0)2 + (y − y0)2 > r2
individuano la regione esterna alla circonferenza.
x
y
x
y
Esempi
• La disequazione x2 + y2 < 3 ha come soluzione l’insieme dei punti interni al cerchio95 di centro (0, 0) e raggior =√3.
• La disequazione (x + 1)2 + y2 ≥ 9 ha come soluzione la regione esterna alla circonferenza di centro (−1, 0) eraggio r = 3, compresa la circonferenza stessa.
• Consideriamo le due disequazioni (x− 1)2 + (y + 1)2 ≥ 0 e (x − 1)2 + (y + 1)2 > 0.
La prima e ovviamente verificata in ogni punto del piano (la somma di due quantita non negative e chiaramentenon negativa), mentre le soluzioni della seconda sono tutti i punti del piano ad eccezione pero del punto (1,−1),che rende nullo il primo membro.
• Consideriamo le due disequazioni (x+ 2)2 + y2 ≤ 0 e (x+ 2)2 + y2 < 0.
La seconda non e verificata in nessun punto del piano (come si diceva prima la somma di due quantita nonnegative e non negativa), mentre la prima ha un’unica soluzione, data dal punto (−2, 0), che rende nullo il primomembro.
95Come vedremo meglio piu avanti, si definisce in modo rigoroso il significato di punto interno ad un insieme. Anticipo qui che dicendopunti interni al cerchio si intendono tutti i punti del cerchio che non stanno sul bordo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 ELLISSI
ELEMENTI DI GEOMETRIA ANALITICA
99
Esercizio 3.1 Si scriva l’equazione della circonferenza di centro il punto (3,−2) e raggio 4.
Esercizio 3.2 Si descriva in modo sufficientemente completo e si disegni la curva di equazione x2+(y+1)2 = 3.
Che regione di piano soddisfa poi la disuguaglianza x2 + (y + 1)2 ≤ 3?
Esercizio 3.3 Si disegni la regione di piano individuata dalla disuguaglianza x2 + y2 − x+ 4y < 0.
4 Ellissi
Altre equazioni di secondo grado rilevanti sono quelle che si possono scrivere nella forma
x2
a2+y2
b2= 1. 96 (14)
Questo tipo di equazioni definiscono un altro particolare tipo di curva nel piano che si chiama ellisse.
La (14) definisce un’ellisse con centro nell’origine e vedremo tra breve l’equazionedell’ellisse con centro in un punto qualunque.
Non e difficile trovare le intersezioni dell’ellisse con gli assi cartesiani: se poniamox = 0 nella (14), otteniamo y = ±b e quindi l’ellisse incontra l’asse y nei punti (0,−b)e (0, b); se poniamo invece y = 0 nella (14), otteniamo x = ±a e quindi l’ellisseincontra l’asse x nei punti (−a, 0) e (a, 0).
I numeri a e b (entrambi positivi) si dicono i semiassi dell’ellisse. Il loro significatogeometrico dovrebbe essere chiaro guardando la figura a fianco.
x
y
a−a
b
−b
Osservazioni Si noti che l’ellisse ha due assi di simmetria. Nel caso dell’equazione (14) gli assi di simmetria sonogli assi cartesiani.Si noti anche che a e b sono i semiassi rispettivamente sulle x e sulle y. Se a e molto piu grande rispetto a b l’ellisserisulta molto allungata lungo le x (cioe orizzontalmente), mentre lo e lungo le y (verticalmente) se b e grande rispettoad a. Se invece a e b non sono molto diversi tra loro l’ellisse tende ad assomigliare ad una circonferenza (se a = b ineffetti si tratta di una circonferenza di raggio r = a).
C’e una forma piu generale che possiamo vedere senza troppa fatica in piu, dato che abbiamo gia visto l’analogocon le circonferenze. Dopo aver confrontato l’equazione di una circonferenza con centro l’origine con quella di unacirconferenza con centro in un punto diverso dall’origine, non e difficile intuire che in generale l’equazione di un’ellissecon centro (x0, y0) e
(x− x0)2a2
+(y − y0)2
b2= 1. 97
Disegnare un’ellisse noto il centro e i due semiassi e praticamente immediato, come e immediata la scrittura della
relativa equazione. Ad esempio l’equazione dell’ellisse di centro (1,−2) e semiassi 3 e 4 e (x−1)2
9 + (y+2)2
16 = 1.Come per le circonferenze, un po’ piu elaborato puo essere il problema inverso, cioe scoprire se una certa equazione el’equazione di un’ellisse.Vediamo anche qui qualche esempio.
• Le due equazioni
x2 +y2
4= 1 e
(x+ 1)2
9+ y2 = 1
definiscono rispettivamente un’ellisse di centro l’origine e semiassi 1 e 2 e un’ellisse di centro (−1, 0) e semiassi3 e 1. Sono raffigurati qui sotto.
96Qui conviene dire che pensiamo a e b positivi.97Lo studente avra intuito che questa equazione, come accadeva prima con le parabole, non e del tutto generale, nel senso che non
definisce tutte le possibili ellissi del piano, ma soltanto quelle con assi di simmetria paralleli agli assi cartesiani.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 ELLISSI
ELEMENTI DI GEOMETRIA ANALITICA
100
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
2
3
x
y
-5 -4 -3 -2 -1 0 1 2 3-2
-1
0
1
2
x
y
• L’equazione4x2 + 9y2 − 36 = 0
e candidata ad essere l’equazione di un’ellisse (lo studente cerchi di darsene una ragione). Per riconoscere iparametri dell’ellisse basta portare a destra il 36 e dividere tutto per 36:
4x2 + 9y2 = 36 ,x2
9+y2
4= 1.
Quindi e l’ellisse di centro (0, 0) e semiassi a = 3 e b = 2.
• L’equazione2x2 + y2 − 2y = 0
e candidata ad essere l’equazione di un’ellisse (lo studente cerchi di darsene una ragione). Completando ilquadrato su y la possiamo riscrivere come
2x2 + y2 − 2y + 1 = 1 e cioex2
1/2+ (y − 1)2 = 1.
Si tratta quindi dell’ellisse di centro (0, 1) e semiassi a = 1√2e b = 1.
• L’equazione4x2 + 8x+ y2 + 6y + 9 = 0
e candidata ad essere l’equazione di un’ellisse. Completando il quadrato su x (quello su y e gia completo) lapossiamo riscrivere come
4x2 + 8x+ 4 + y2 + 6y + 9 = 4 e cioe (2x+ 2)2 + (y + 3)2 = 4.
Dividendo tutto per 4 si ottiene
(x + 1)2 +(y + 3)2
4= 1,
che e l’equazione dell’ellisse di centro (−1,−3) e semiassi a = 1 e b = 2.
Per quanto riguarda le disequazioni, il caso e analogo a quello delle circonferenze: l’insieme individuato da unadisequazione del tipo
x2
a2+y2
b2≤ 1 oppure
x2
a2+y2
b2< 1,
e la regione interna all’ellisse di equazione x2
a2 + y2
b2 = 1, mentre le disequazioni
x2
a2+y2
b2≥ 1 oppure
x2
a2+y2
b2> 1
individuano la regione esterna all’ellisse.
x
y
x
y
Esercizio 4.1 Si descriva in modo sufficientemente completo e si disegni la curva di equazione 2x2+3(y−1)2 = 1.
Che regione di piano soddisfa poi la disuguaglianza 2x2 + 3(y − 1)2 > 1?
Esercizio 4.2 Si disegni la regione del piano formata dalle soluzioni della disuguaglianza x2 + 4y2 − 8y < 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 IPERBOLI
ELEMENTI DI GEOMETRIA ANALITICA
101
5 Iperboli
Vediamo ancora tre tipi di equazioni, per la verita diverse tra loro, ma che definiscono lo stesso tipo di curva: l’iperbole.
1. L’equazione di secondo gradoxy = c
definisce una curva nel piano che prende il nome di iperbole equilatera.
Qui ci sono due semplici casi possibili: c > 0 o c < 0 (il caso c = 0 e banale e l’iperbole degenera in una coppiadi rette: infatti l’equazione xy = 0 definisce gli assi cartesiani).
• Se c > 0, l’iperbole e raffigurata sotto a sinistra. Come si vede e una curva che presenta un aspetto nuovorispetto a tutte quelle viste finora, e cioe costituita da due parti distinte, detti rami dell’iperbole. Se c > 0,i rami occupano il primo e il terzo quadrante. L’origine e il centro dell’iperbole.
Piu grande e il valore di c e piu l’iperbole e “lontana” dall’origine.98
Ci sono due assi di simmetria: le rette di equazione y = x e y = −x (tratteggiate in figura).
• Se c < 0, l’iperbole e raffigurata sotto a destra. I rami dell’iperbole occupano il secondo e il quartoquadrante.
Anche qui, piu grande e il valore di |c| e piu l’iperbole e lontana dall’origine.99
Ci sono anche qui gli stessi assi di simmetria di prima: le rette di equazione y = x e y = −x.
x
y
√c
√c
c > 0
x
y
−√
|c|
√|c|
c < 0
In entrambi i casi gli assi cartesiani hanno una rilevanza particolare per l’iperbole. Sono infatti rettealle quali i rami dell’iperbole “tendono ad avvicinarsi”. Si chiamano gli asintoti dell’iperbole. Si noti chel’iperbole non interseca mai i suoi asintoti.
Non dovrebbe essere difficile intuire ora che cosa definisce un’equazione del tipo
(x− x0)(y − y0) = c.
Si tratta ancora di un’iperbole, simile a quella dell’equazione xy = c, ma traslata in modo che il centrosia nel punto (x0, y0). Gli asintoti sono ora, anziche gli assi cartesiani, le due rette di equazione x = x0 ey = y0. A seconda del segno di c si possono avere i due casi raffigurati qui sotto:
x
y
x0
y0
c > 0
x
y
x0
y0
c < 0
2. Anche un’equazione del tipox2
a2− y2
b2= 1 100 (15)
definisce un’iperbole, qui a fianco raffigurata.101
98I punti dell’iperbole piu vicini all’origine sono i punti (−√c,−√
c) e (√c,√c).
99I punti dell’iperbole piu vicini all’origine sono ora i punti (−√
|c|,√
|c|) e (√
|c|,−√
|c|).100Anche qui intendiamo a e b positivi.101In effetti per dare una buona definizione di iperbole si dovrebbero dare le sue proprieta geometriche, come d’altro canto anche per leparabole e le ellissi, cioe per tutte le coniche. Gli studenti che alla scuola secondaria hanno studiato geometria euclidea dovrebbero avervisto queste proprieta. Qui non entro nel merito.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 IPERBOLI
ELEMENTI DI GEOMETRIA ANALITICA
102
Si noti che, come fatto prima con l’ellisse, possiamo cercare le intersezioni
con gli assi cartesiani. Ponendo x = 0 si ottiene − y2
b2 = 1, che e impossibile.Quindi questo tipo di iperbole non ha intersezioni con l’asse y.
Ponendo invece y = 0 si ottiene x2
a2 = 1, cioe x2 = a2, che ha per soluzionix = ±a. L’iperbole interseca l’asse x nei punti (−a, 0) e (a, 0).
Si noti che, come la figura cerca di illustrare, anche in questo caso l’iperboleha due asintoti (le rette tratteggiate in figura), che pero questa volta non sonogli assi cartesiani. Si puo vedere che gli asintoti sono le rette di equazioney = b
ax e y = − bax.
102 L’origine e il centro dell’iperbole.L’iperbole, in questo caso, ha negli assi cartesiani due assi di simmetria.
x
y
a−a
b
−b
3. Infine anche l’equazione del tipox2
a2− y2
b2= −1 (16)
definisce un’iperbole, qui sotto raffigurata. Qui si dovrebbe intuire che c’e di mezzo soltanto uno scambio tra xe y (come visto con le parabole).103
Se cerchiamo le intersezioni con gli assi cartesiani, ponendo x = 0 si ottiene
− y2
b2 = −1, cioe y2 = b2, da cui y = ±b: l’iperbole interseca l’asse y nei punti(0,−b) e (0, b).
Ponendo invece y = 0 si ottiene x2
a2 = −1, che e impossibile. Quindi questotipo di iperbole non ha intersezioni con l’asse x.
Anche in questo caso l’iperbole ha due asintoti (le rette tratteggiate infigura), che non sono gli assi cartesiani, bensı come prima le rette di equazioney = b
ax e y = − bax.
Anche in questo caso l’iperbole ha negli assi cartesiani due assi di simmetria.
x
y
−a a
b
−b
Possiamo avere anche con questi tipi di iperboli il “caso traslato”.
Le equazioni
(x− x0)2a2
− (y − y0)2b2
= 1 e(x− x0)2
a2− (y − y0)2
b2= −1
definiscono iperboli, analoghe a quelle viste prima, ma traslate rispetto all’ori-gine. Quella che prima era l’origine e ora il punto (x0, y0). A fianco e raffiguratoad esempio il caso di sinistra.
x
y
x0
y0
Chiudiamo con qualche considerazione sulle possibili disequazioni.Consideriamo una disequazione del tipo
xy ≥ c oppure xy > c.
Esaminiamo i vari casi possibili:
• Se c = 0 le disequazioni individuano il primo e terzo quadrante (cioe l’insieme che si ottiene come unione delprimo e del terzo quadrante).104 La corrispondente figura e sotto a sinistra.
• Se c > 0 come visto i due rami dell’iperbole di equazione xy = c stanno nel primo e terzo quadrante. L’equazionedivide il piano in tre regioni illimitate. Una sola di queste contiene gli asintoti dell’iperbole: conveniamo dichiamare regione interna all’iperbole questa regione, che contiene gli asintoti. La disequazione xy > c individuaallora la regione esterna all’iperbole, l’unione cioe delle due regioni che non contengono gli asintoti. Nel caso
102Basta guardare la figura: la pendenza positiva dell’asintoto si trova facendo il quoziente tra variazione in ordinata e variazione inascissa e quindi b/a. Se b e grande rispetto ad a, e quindi b/a e grande, allora l’iperbole e molto “aperta”, mentre se succede il contrariol’iperbole e “schiacciata”.103Infatti l’equazione si puo anche riscrivere come y2
b2− x2
a2 = 1, forma in cui e evidente lo scambio tra x e y rispetto alla forma precedente.104La disequazione xy ≥ 0 e verificata in tutti i punti (x, y) del piano in cui le due componenti hanno lo stesso segno, o entrambe positiveo entrambe negative, quindi nel primo oppure nel terzo quadrante. Ovviamente l’unica differenza tra xy ≥ 0 e xy > 0 e che il bordo ecompreso nelle soluzioni della prima ma non in quelle della seconda.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 IPERBOLI
ELEMENTI DI GEOMETRIA ANALITICA
103
che stiamo ora esaminando, cioe relativo alla disequazione xy > c, con c positivo, si tratta di una regione che econtenuta in parte nel primo e in parte nel terzo quadrante. La corrispondente figura e sotto al centro.
L’unica differenza tra le due disequazioni xy ≥ c e xy > c e ovviamente che la prima individua una regione checontiene il bordo (cioe i punti dell’iperbole), mentre la seconda individua una regione che non contiene il bordo.
• Se c < 0 i rami dell’iperbole di equazione xy = c stanno nel secondo e quarto quadrante e la disequazioneindividua la regione interna all’iperbole, cioe in questo caso quella che contiene l’origine.105 La corrispondentefigura e sotto a destra.
x
yxy ≥ 0
x
y
xy ≥ c,con c > 0
x
yxy ≥ c,con c < 0
Invece con le disequazionixy ≤ c oppure xy < c
si ha
• Se c = 0 la disequazione individua il secondo e quarto quadrante.
• Se c > 0 l’iperbole sta nel primo e terzo quadrante e la disequazione individua la regione interna all’iperbole,cioe quella che contiene l’origine.
• Se c < 0 l’iperbole sta nel secondo e quarto quadrante e la disequazione individua la regione esterna all’iperbole,cioe quella che sta in parte nel secondo e in parte nel quarto quadrante.
x
y
xy ≤ 0
x
y
xy ≤ c,con c > 0
x
y
xy ≤ c,con c < 0
Facile intuire a questo punto come si rappresentano i casi di disequazione in cui l’iperbole e traslata.
Con gli altri tipi di iperboli si hanno questi casi.
Le disequazioni
x2
a2− y2
b2≥ 1 oppure
x2
a2− y2
b2> 1
individuano la regione esterna all’iperbole, cioe quella che non contiene il centro (comenella figura a fianco), mentre le disequazioni
x2
a2− y2
b2≤ 1 oppure
x2
a2− y2
b2< 1
individuano la regione interna all’iperbole, cioe quella che contiene il centro.
x
y
105Dico in questo caso perche si intuisce che con altri tipi di iperboli, specialmente quando ci sono traslazioni, la posizione dell’originepuo non avere piu lo stesso significato. Se diciamo invece “la regione che contiene il centro”, possiamo usare la stessa espressione anche neicasi con traslazioni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 IPERBOLI
ELEMENTI DI GEOMETRIA ANALITICA
104
x
yCon le disequazioni
x2
a2− y2
b2≥ −1 oppure
x2
a2− y2
b2> −1
si ha la regione che contiene il centro (come nella figura a fianco), mentre infine conle disequazioni
x2
a2− y2
b2≤ −1 oppure
x2
a2− y2
b2< −1
si ha la regione che non contiene il centro.
Se siamo in presenza di un’iperbole “traslata”, le situazioni sono le stesse, tenendo conto della traslazione.
Non e ovviamente facile ricordare tutti questi casi. Ma c’e un trucco per capire facilmente in quale dei casi ci sitrova: dopo aver disegnato l’iperbole basta verificare la disuguaglianza che abbiamo davanti in un punto qualunque,per comodita ad esempio nell’origine: se la disuguaglianza e vera, l’origine e compresa nella regione e quindi anchetutta la regione che si trova “dalla stessa parte dell’origine” rispetto all’iperbole. Se invece la disuguaglianza non everificata nell’origine, allora si tratta dell’altra regione, cioe di quella che non contiene l’origine.
Esempio Consideriamo la disequazione x2 − y2
2 ≤ −1.L’equazione corrispondente individua un’iperbole con rami al di sopra e al di sotto dell’o-
rigine. Possiamo anche osservare che gli asintoti hanno pendenza ±√2, quindi un po’ piu di
1. Dato che l’origine non soddisfa la disuguaglianza (0 ≤ −1 e falso), la regione individuatadalla disequazione e quella che sta al di sopra o al di sotto dei due rami dell’iperbole. Taleregione inoltre contiene i punti dell’iperbole, dato che la disuguaglianza e di minore o uguale.
x
y
−2
√2
−√2
x
yOsservazione Il metodo qui utilizzato per stabilire quale regione soddisfa una disequazio-ne data (cioe verificare la disequazione stessa in un punto particolare) e in realta un metododel tutto generale, che puo essere applicato con qualsiasi tipo di equazione.Ad esempio, con la disequazione x− y2 +2 < 0, dopo aver capito che il bordo e la parabolacon asse parallelo all’asse x raffigurata a fianco, per stabilire che la regione individuatadalla disequazione e quella che sta a sinistra della parabola basta osservare che l’origine nonsoddisfa la disequazione stessa.
Per la scelta del punto in cui verificare la disuguaglianza l’unica avvertenza e di non andare a prendere un puntoche sta sul bordo della regione, cioe un punto che soddisfi l’equazione associata. Ad esempio, con la disequazione(x − 1)2 + (y − 1)2 ≤ 2, verificare la disuguaglianza stessa nell’origine non sarebbe una buona idea, dato che l’originesta sulla circonferenza che e il bordo della regione.
Esercizio 5.1 Quale curva del piano individua l’equazioney2
2− x
2
3= 1? Si disegni poi la regione delle soluzioni
della disuguaglianzay2
2− x2
3≤ 1.
Esercizio 5.2 Quale curva del piano individua l’equazione 2x2− y2 = 1? Si disegni poi la regione delle soluzioni
della disuguaglianza 2x2 − y2 > 1.
Esercizio 5.3 Quale curva del piano individua l’equazione x2 − 4y2 = 0? Si disegni poi l’insieme delle soluzioni
dalla disuguaglianza x2 − 4y2 > 0?
Esercizio 5.4 Che curva individua l’equazione x(y − 1) = 1? Si disegni poi l’insieme delle soluzioni della
disuguaglianza x(y − 1) ≥ 1 e della disuguaglianza x(y − 1) ≤ 0.
Esercizio 5.5 Che curva individua l’equazione 2x2 + 2y2 − 4x+ 3y = 0? Si disegni poi l’insieme delle soluzioni
della disuguaglianza 2x2 + 2y2 − 4x+ 3y < 0?
Esercizio 5.6 Quale sottoinsieme del piano soddisfa la disuguaglianza x2 + y2 − 2x + 4y + 5 ≤ 0? E la
disuguaglianza x2 + y2 − 2x + 4y + 5 ≥ 0? E la disuguaglianza x2 + y2 − 2x + 4y + 5 > 0? E la disuguaglianzax2 + y2 − 2x+ 4y + 5 < 0?
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
ELEMENTI DI GEOMETRIA ANALITICA
105
6 Soluzioni degli esercizi
Esercizio 1.1
Basta applicare la formula: e ancora piu semplice pero aiutarsi con un grafico, dal quale si vede subito che l’equazioneesplicita e y = 1− x.
Esercizio 1.2
Si puo procedere cosı: l’equazione esplicita della retta assegnata e y = 53 − 2
3x. Il coefficiente angolare della rettacercata e allora m = − 2
3 e quindi l’equazione cercata e y + 1 = − 23 (x− 2).
Esercizio 1.3
Si puo procedere cosı: l’equazione esplicita e y = − 13x − 2
3 . Il coefficiente angolare della retta perpendicolare e alloram = 3 e quindi l’equazione cercata e y − 1 = 3(x− 2).
Esercizio 1.4
La disequazione equivale alla 2y > 3x+ 4 e questa alla y > 32x+ 2. L’insieme e il semipiano che sta al di sopra della
retta di equazione y = 32x + 2, retta di pendenza 3
2 e di altezza all’origine 2 (quindi passa per il punto (0, 2)). Taleretta non fa parte dell’insieme in questione.
Esercizio 2.1
La curva di equazione x2 + 2y − 1 = 0 non passa per l’origine, dato che il punto (0, 0) non soddisfa l’equazione stessa(infatti sostituendo i valori risulta −1 = 0). La curva passa invece per il punto (2,− 3
2 ), dato che tale punto soddisfal’equazione stessa.Si tratta di una parabola con asse parallelo all’asse y e concavita rivolta verso il basso: l’equazione esplicita e y =− 1
2x2 + 1
2 e il vertice e nel punto (0, 12 ). La parabola incontra l’asse x nei punti (−1, 0) e (1, 0).
Esercizio 2.2
La curva in questione non passa per l’origine, dato che il punto (0, 0) non soddisfa l’equazione data.Si tratta di una parabola con asse parallelo all’asse x e concavita rivolta verso destra: l’equazione esplicita e x = 2
3y2− 1
3e il vertice e nel punto (− 1
3 , 0). La parabola incontra l’asse y nei punti (0,− 1√2) e (0, 1√
2). Un punto del primo quadrante
che sta sulla curva e ad esempio il punto (1,√2).
Esercizio 2.3
(a) La disequazione equivale alla y < −2x2 + 3 e individua la parte di piano che sta al di sotto della parabola diequazione y = −2x2 + 3, parabola con asse parallelo all’asse y, concavita verso il basso e con vertice nel punto (0, 3).La parabola non fa parte della regione (vedi figura in appendice alla fine della dispensa).(b) La disequazione equivale alla y ≥ x2 + x − 2 e individua la parte di piano che sta al di sopra della parabola diequazione y = x2 + x− 2, parabola con asse parallelo all’asse y, concavita verso l’alto e che incontra l’asse x nei punti(−2, 0) e (1, 0). La parabola fa parte della regione (vedi figura in appendice).(c) L’equazione 2x− y2+4 = 0, cioe x = 1
2y2− 2, definisce una parabola con asse parallelo all’asse x, concavita rivolta
verso destra, vertice nel punto (−2, 0) e passante per i punti (0,−2) e (0, 2). La disuguaglianza individua pertanto laregione che si trova alla destra di tale parabola, bordo compreso (vedi figura in appendice).
Esercizio 2.4
Con l’equazione x2 + 4x+ 4 = 0 attenzione a non cadere nel tranello. Anche se c’e un quadrato qui le parabole nonc’entrano. L’equazione x2+4x+4 = 0 equivale alla (x+2)2 = 0, che e verificata se e solo se x = −2. Questa definiscela retta (verticale) di ascissa −2.L’equazione y2 − 4y + 3 = 0 ha per soluzioni y = 3 oppure y = 1, quindi la curva del piano che viene individuata eformata da una coppia di rette (orizzontali) di ordinate 1 e 3. I due grafici sono riportati alla fine nell’appendice.
Esercizio 3.1
L’equazione e (x − 3)2 + (y + 2)2 = 16.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
ELEMENTI DI GEOMETRIA ANALITICA
106
Esercizio 3.2
L’equazione individua la circonferenza di centro il punto (0,−1) e raggio r =√3.
La disequazione proposta individua la regione interna alla circonferenza, bordo compreso (quindi la regione e il cerchiodi centro il punto (0,−1) e raggio r =
√3). Si osservi che la regione si estende, sulle x, da −
√3 a√3 e, sulle y, da
−1−√3 a −1 +
√3 (vedi figura in appendice).
Esercizio 3.3
Consideriamo l’equazione x2 + y2 − x+ 4y = 0 e completiamo i quadrati. Si ha
x2 − x+ 14 + y2 + 4y + 4 = 1
4 + 4 e cioe (x − 12 )
2 + (y + 2)2 = 174 .
Si tratta quindi della circonferenza di centro (12 ,−2) e raggio r =√172 . Si noti che la circonferenza passa per l’origine.
La disuguaglianza individua la parte interna a tale circonferenza, bordo escluso (vedi figura in appendice).
Esercizio 4.1
L’equazione individua l’ellisse di centro il punto (0, 1) e semiassi a = 1/√2 (sulle x) e b = 1/
√3 (sulle y). L’ellisse si
estende quindi, sulle x, da −1/√2 a 1/
√2 e, sulle y, da 1− 1/
√3 a 1 + 1/
√3.
La disequazione proposta individua la regione esterna all’ellisse e non comprende i punti che stanno sull’ellisse (vedifigura in appendice).
Esercizio 4.2
Consideriamo l’equazione x2 + 4y2 − 8y = 0. Completando il quadrato sulle y abbiamo
x2 + 4y2 − 8y + 4 = 4 cioe x2 + (2y − 2)2 = 4 cioe x2
4 + (y − 1)2 = 1.
L’equazione individua quindi l’ellisse di centro il punto (0, 1) e semiassi a = 2 (sulle x) e b = 1 (sulle y). Le soluzioniriempiono la parte interna all’ellisse. Il bordo, cioe l’ellisse, e escluso.
Esercizio 5.1
L’equazione individua un’iperbole, di asintoti le rette di equazione y = ±√2√3x. I due rami dell’iperbole incontrano
l’asse y e non l’asse x. La disuguaglianza individua la regione, limitata dall’iperbole, che contiene l’origine, bordocompreso (vedi figura in appendice).
Esercizio 5.2
L’equazione individua un’iperbole, di asintoti le rette di equazione y = ±√2x. I due rami dell’iperbole incontrano
l’asse x (nei punti di ascissa ± 1√2). La disuguaglianza individua la regione, limitata dall’iperbole, che non contiene
l’origine. Il bordo e escluso (vedi figura in appendice).
Esercizio 5.3
L’equazione x2 − 4y2 = 0 equivale alla (x − 2y)(x + 2y) = 0, che quindi a sua volta equivale a x − 2y = 0 oppurex+ 2y = 0. Si tratta di una coppia di rette, di equazione esplicite y = x
2 e y = −x2 .
La disuguaglianza x2 − 4y2 > 0 equivale ai sistemi
{x− 2y > 0
x+ 2y > 0oppure
{x− 2y < 0
x+ 2y < 0
cioe {y < x
2
y > −x2
oppure
{y > x
2
y < −x2 .
La regione e quella compresa tra le due rette e che contiene l’asse x (per la verita non lo contiene tutto, dato che,essendo la disuguaglianza stretta, l’origine non e soluzione, come non lo sono i punti che stanno sulle due rette) (vedifigura in appendice).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
ELEMENTI DI GEOMETRIA ANALITICA
107
Esercizio 5.4
Si tratta di un’iperbole di centro il punto (0, 1) e asintoti le rette di equazione x = 0 e y = 1. Queste rette dividono ilpiano in quattro quadranti. I rami dell’iperbole occupano i quadranti in alto a destra e in basso a sinistra.La disuguaglianza x(y − 1) ≥ 1 individua la regione, limitata dall’iperbole, che non contiene il centro. Il bordo ecompreso (vedi figura in appendice).La disuguaglianza x(y− 1) ≤ 0 individua invece l’unione di due quadranti: quello in alto a sinistra e quello in basso adestra dei quattro in cui resta diviso il piano dagli asintoti dell’iperbole. Il bordo e compreso (vedi figura in appendice).
Esercizio 5.5
Dividendo tutto per 2 l’equazione si puo riscrivere come x2 + y2 − 2x + 32y = 0 ed e candidata ad individuare una
circonferenza. Completando i quadrati si ottiene
x2 − 2x+ 1 + y2 + 32y +
916 − 1− 9
16 = 0 cioe (x− 1)2 + (y + 34 )
2 = 2516 .
Quindi si tratta della circonferenza di centro (1,− 34 ) e raggio r = 5
4 (e si noti che la circonferenza passa per l’origine).La disequazione individua la regione interna alla circonferenza, bordo escluso. La regione si estende, sulle x, da 1− 5
4a 1 + 5
4 e, sulle y, da − 34 − 5
4 a − 34 + 5
4 (vedi figura in appendice).
Esercizio 5.6
Occorre intanto completare i quadrati nell’equazione corrispondente:
x2 − 2x+ 1 + y2 + 4y + 4− 5 + 5 = 0 cioe (x− 1)2 + (y + 2)2 = 0.
L’equazione individua un solo punto del piano: (1,−2).La prima disequazione individua allora questo stesso punto. La seconda disequazione individua tutto il piano, la terzatutto il piano ad esclusione del punto (1,−2) e la quarta l’insieme vuoto.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
6 SOLUZIONI DEGLI ESERCIZI
ELEMENTI DI GEOMETRIA ANALITICA
108
Appendice – Grafici
Questi sono i grafici richiesti, con l’indicazione del relativo esercizio.
√3/2−
√3/2
3
x
y
Esercizio 2.3a
1−2 x
y
Esercizio 2.3b
−2
2
−2
x
y
Esercizio 2.3c
−2 x
y
Esercizio 2.4a
1
3
x
y
Esercizio 2.4b
b −1
−1 +√3
−1−√3
−√3
√3
x
y
Esercizio 3.2
b−2
1/2
x
y
Esercizio 3.3
b 1
1 + 1/√3
1− 1/√3
−1/√2 1/
√2 x
y
Esercizio 4.1
b 1
−2 2
2
x
y
Esercizio 4.2
√2
−√2
x
y
Esercizio 5.1
1/√2−1/
√2 x
y
Esercizio 5.2
x
y
Esercizio 5.3
1
x
y
Esercizio 5.4a
1
x
y
Esercizio 5.4b
b
−1/4 9/41/2
−2
1
−3/4
x
y
Esercizio 5.5
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

Parte II
Nella seconda parte del corso di Matematica affrontiamo argomenti che fanno parte di quello che i matematici chiamanoAnalisi matematica.106
Alcuni di voi, tipicamente coloro che provengono dai Licei Scientifici o dagli Istituti Tecnici, hanno gia incontratoalcuni di questi argomenti. Termini come limiti, derivate, integrali sono certamente famigliari a molti di voi. Costoronon pensino tuttavia di sapere gia molto perche, lo dico in tutta franchezza, questo e vero solo in pochi casi.
Ecco un sintetico elenco di quanto vedremo in questa parte del corso.
• Il concetto di funzione in generale
• Una sintesi della struttura di R, con le principali proprieta che ci serviranno nel seguito
• Le principali proprieta delle funzioni reali, cioe a valori reali
• Il concetto di limite e le sue modalita di calcolo
• Il concetto di continuita e le proprieta delle funzioni continue
• Il concetto di derivata e le proprieta delle funzioni derivabili
• L’integrale indefinito
• L’integrale di Riemann e l’intergrale di Riemann generalizzato
• Le successioni e le serie
Ogni tanto troverete sulla sinistra di un paragrafo, come in questo, il segnale stradale di “doppia curva”. Si tratta diconsiderazioni, osservazioni ed esempi di piu difficile comprensione: anche se in una prima lettura le potete tralasciare,consiglio pero di tenerne conto quando lo studio si fara piu approfondito.
106Precisamente quella che di solito viene detta Analisi matematica I, o Analisi I, come dicono confidenzialmente gli studenti della Facoltadi Scienze.


1 IL CONCETTO DI FUNZIONE
FUNZIONI
111
II-1 Funzioni
In questa dispensa affrontiamo il concetto di funzione, nella sua generalita. Successivamente, nelle dispense cheseguono, ci concentreremo in particolare sulle funzioni reali.
1 Il concetto di funzione
Qui definiamo un concetto assolutamente fondamentale in matematica: il concetto di funzione.Siano X e Y due insiemi. Una funzione f da X a Y e una legge, una corrispondenza che associa ad ogni elementodi X uno ed un solo elemento di Y . Quindi per ogni x ∈ X esiste uno ed un solo y ∈ Y associato ad x. Tale y siindica con il simbolo f(x) e si puo chiamare il valore della funzione f in x.Formalmente si scrive f : X → Y per dire appunto che
∀x ∈ X ∃! y ∈ Y : y = f(x)
(la scrittura si legge: per ogni x che appartiene ad X esiste un unico y in Y tale che y e uguale ad f(x)).L’insieme X di dice il dominio della funzione f , l’insieme Y si dice il codominio della funzione f . Si dice anche che lafunzione f e da X ad Y , oppure definita in X a valori in Y .Se voglio definire una funzione particolare devo specificare il suo dominio, il suo codominio e la legge di corrispondenza.Ad esempio, se scrivo f : N→ N, con f(n) = n+1, intendo considerare la funzione f , definita in N, a valori in N, cheassocia ad ogni numero naturale il numero stesso aumentato di uno.
Per indicare una funzione in generale si puo scrivere semplicemente f ; se c’e la necessita diindicarne dominio e codominio scrivo f : X → Y . A volte si usano le notazioni y = f(x)oppure x 7→ f(x), che pero non specificano dominio e codominio; x si chiama l’argomentodella funzione f e f(x) e detto a volte anche l’immagine di x attraverso la funzione f .Nella figura a fianco e rappresentata una funzione dall’insieme X = {a, b, c, d} all’insiemeY = {e, f, g, h, i}. d
c
b
a
i
h
g
f
e
X Y
Qualche esempio:
• La scrittura f : N → N, con f(n) = 2n, ∀n ∈ N definisce la funzione f dall’insieme dei numeri naturalinell’insieme dei numeri naturali che associa ad ogni naturale il suo doppio.
• La scrittura f : N×N→ N, con f(m,n) = m+ n, ∀m,n ∈ N definisce la funzione f dall’insieme delle coppie dinumeri naturali nell’insieme dei numeri naturali che associa ad ogni coppia la somma delle due componenti.
• Un altro esempio e la funzione f : N → N0, che associa ad ogni n ∈ N il numero dei divisori di n.107 In questocaso non e cosı semplice la formulazione della legge di corrispondenza.
Altre definizioni importanti. Supponiamo di avere una funzione f : X → Y .
Definizione Se A ⊂ X si chiama immagine di A attraverso fl’insieme
f(A) ={f(a) : a ∈ A
}. 108
X Y
A f(A)
Osservazioni L’immagine di A e quindi l’insieme degli elementi f(a), al variare di a nell’insieme A; si trattadell’insieme dei valori che la funzione puo assumere in corrispondenza degli elementi dell’insieme A ed e chiaramenteun sottoinsieme di Y , quindi f(A) ⊂ Y .Si osservi, come caso particolare, che f({x}) = {f(x)}, per ogni x ∈ X , cioe l’immagine dell’insieme {x} e l’insieme ilcui unico elemento e f(x).Nell’altro caso particolare A = X l’immagine di X attraverso f , cioe f(X), e detta anche l’immagine di f . Si trattadell’insieme di tutti i valori che la funzione puo assumere. Non e detto che tale insieme sia tutto l’insieme Y .
107Accordiamoci sul fatto che 1 non e un divisore di alcun numero naturale e che nessun numero e divisore di se stesso. Ecco perche hoscritto che il codominio e N0, cioe i naturali con lo zero: infatti f(1) = 0. Abbiamo anche, per capire come funziona, f(2) = 0 (2 e divisibileper 1 e per se stesso), f(3) = 0 e cosı per tutti i numeri primi, che sono appunto divisibili solo per 1 e per se stessi. Invece f(4) = 1 (il 2),f(6) = 2 (il 2 e il 3), . . . , f(100) = 7 (2,4,5,10,20,25,50), . . . . Questa funzione ha valore zero sui numeri primi e solo su questi.108Quindi, se x ∈ X con f(x) indichiamo l’immagine di x attraverso f , ed e un elemento di Y ; se A ⊂ X, con f(A) indichiamo l’immaginedi A attraverso f , ed e un sottoinsieme di Y .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 IL CONCETTO DI FUNZIONE
FUNZIONI
112
Definizione Se B ⊂ Y si chiama controimmagine (o immagineinversa) di B attraverso f l’insieme
f−1(B) ={x ∈ X : f(x) ∈ B
}.
X Y
f−1(B) B
Osservazione E tradizionalmente un concetto difficile per molti studenti. La controimmagine di un insieme B (B eun sottoinsieme di Y ) e quindi l’insieme degli elementi di X la cui immagine sta in B. Ovviamente quindi f−1(B) ⊂ X .Nel caso particolare B = Y la controimmagine di Y , cioe f−1(Y ) e uguale ad X , dato che tutti gli elementi di Xhanno corrispondente in Y . Si noti anche che ovviamente la controimmagine di {f(x)} contiene x, ma in generale essapuo contenere anche altri elementi oltre ad x, dato che possono esserci altri elementi che hanno per immagine f(x).Si rifletta infatti che una cosa e dire che ad ogni x ∈ X corrisponde un solo f(x) (e tutte le funzioni hanno questaproprieta), altra cosa e dire che dato un y ∈ Y esso sia il corrispondente di un solo x ∈ X .Qualche esempio su immagine e controimmagine.
• Data la funzione f : N → N, con f(n) = 2n, l’immagine della funzione (cioe l’immagine di tutto il dominio,come abbiamo visto) e l’insieme dei numeri naturali pari. L’immagine dell’insieme A = {1, 2, 3, 4, 5} e l’insiemedei numeri naturali pari minori o uguali a 10 e possiamo scrivere quindi f(A) = {2, 4, 6, 8, 10}. L’immaginedei naturali dispari e ancora l’insieme dei naturali pari. Come si vede, l’immagine di una funzione, non enecessariamente uguale al codominio.
La controimmagine dell’insieme B = {10, 11, 12, 13, 14, 15} e l’insieme {5, 6, 7} e scriveremo quindi f−1(B) ={5, 6, 7}. La controimmagine dell’insieme dei numeri dispari e l’insieme vuoto.
• Data la funzione f : N→ N, con f(n) = n2, l’immagine dell’insieme A = {1, 2, 3, 4, 5} e l’insieme {1, 4, 9, 16, 25}.L’immagine della funzione e evidentemente l’insieme dei naturali che sono quadrati, quindi anche qui solo unaparte dei naturali.
La controimmagine dell’insieme B = {n ∈ N : n ≤ 100} e l’insieme {n ∈ N : n ≤ 10}. La controimmaginedell’insieme dei numeri pari e l’insieme dei numeri pari, mentre la controimmagine dei dispari e data dai dispari:questo perche il quadrato di un numero pari e un numero pari, mentre il quadrato di un numero dispari e unnumero dispari.
• Data la funzione f : N× N→ N, con f(m,n) = m+ n, l’immagine dell’insieme
A ={(1, 1), (1, 2), (2, 1), (1, 3), (3, 1)
}e l’insieme {2, 3, 4}.
L’immagine della funzione e l’insieme N \ {1}. 109
La controimmagine dell’insieme B = {10} e l’insieme
{(1, 9), (2, 8), (3, 7), (4, 6), (5, 5), (6, 4), (7, 3), (8, 2), (9, 1)
}.
Vediamo ora due proprieta che possono avere le funzioni.
Definizioni Diciamo che la funzione f : X → Y e iniettiva se ad elementi distinti di X associa elementi distinti diY . Formalmente, f e iniettiva se
∀t, z ∈ X , t 6= z ⇒ f(t) 6= f(z).
Diciamo invece che la funzione f : X → Y e suriettiva se la sua immagine coincide con il codominio. Formalmente, fe suriettiva se
f(X) = Y.
Diciamo infine che f e biiettiva se e contemporaneamente iniettiva e suriettiva.
a
b
c
d
e
f
g
funzione iniettivaa
b
c
d
e
f
g
funzione non iniettivaa
b
c
d
e
f
g
funzione suriettivaa
b
c
d
e
f
g
funzione non suriettiva
109Ricordo che \ e il simbolo di differenza tra insiemi: N \ {1} e l’insieme dei naturali diversi da 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 IL CONCETTO DI FUNZIONE
FUNZIONI
113
A commento delle rappresentazioni qui sopra, la prima da sinistra illustra una funzione iniettiva poiche a elementidistinti associa elementi distinti. La seconda non e iniettiva perche gli elementi a e c hanno la stessa immagine e.La terza e suriettiva perche tutti gli elementi del codominio, che e {e, f, g}, sono immagine di qualche elemento deldominio. Infine la quarta non e suriettiva perche l’elemento e del codominio non e immagine di alcun elemento deldominio. Possiamo anche notare che solo la prima e iniettiva e solo la terza e suriettiva.
Osservazioni Una funzione e iniettiva se e solo se per ogni y ∈ Y l’immagine inversa di {y} contiene al piu unelemento. Questo significa infatti che non ci sono elementi in X che hanno la stessa immagine.Una funzione e suriettiva se e solo se per ogni y ∈ Y l’immagine inversa di {y} contiene almeno un elemento. Questosignifica infatti che ogni elemento di Y e immagine di qualche elemento di X e quindi che f(X) = Y .Quindi una funzione e biiettiva se e solo se per ogni y ∈ Y l’immagine inversa di {y} contiene esattamente un (uno euno solo) elemento.Vediamo qualche esempio con le funzioni che abbiamo gia usato prima.
• Data la funzione f : N→ N, con f(n) = 2n, essa e iniettiva, dato che numeri naturali distinti hanno ovviamenteimmagini distinte. La funzione non e suriettiva dato che, come gia osservato, la sua immagine e formata dai solinumeri pari, che non sono tutti i numeri naturali. Quindi questa funzione non e biiettiva.
• Anche la funzione f : N→ N, con f(n) = n2, e iniettiva ma non suriettiva.
• La funzione f : N × N → N, con f(m,n) = m+ n, non e ne iniettiva, ne suriettiva. Infatti le due coppie (1, 2)e (2, 1) hanno la stessa immagine 3. 110 La funzione non e nemmeno suriettiva dato che, come gia osservato,l’immagine e N \ {1} e non tutto N.
• Un esempio di funzione biiettiva e invece la funzione f : Z → Z, con f(z) = z + 1. Essa e iniettiva dato cheaggiungendo 1 a due numeri interi distinti si ottengono interi distinti. Essa e anche suriettiva dato che l’immaginee tutto l’insieme Z. 111
Osservazione Se una funzione f : X → Y non e suriettiva, c’e un modo abbastanza semplice e “indolore” per“renderla suriettiva”. Basta modificare quello che viene dichiarato il suo codominio, sostituendolo con l’immaginedella funzione f , cioe quello che abbiamo indicato con f(X). Infatti, se scriviamo f : X → f(X), senza modificarenient’altro, avremo certamente una funzione suriettiva, dato che ora, per la definizione data, l’immagine coincide conil codominio. Cosı, ad esempio, la funzione f(n) = 2n sara suriettiva se come suo codominio dichiaro l’insieme deinaturali pari.
Esempi Chiudo questa sezione con qualche esempio di funzioni che per alcuni aspetti hanno qualche elemento dinovita. Lo studente ricordi questi esempi perche nel corso di Statistica, piu precisamente nella definizione di probabilita,queste situazioni si presentano.Il concetto di funzione e stato definito in questa dispensa nella sua generalita, e intendo che una funzione puo esseredefinita in un qualunque insieme (e avere valori in un qualunque insieme), non soltanto in un insieme di numeri (N, Z,. . . ).112
Qui voglio presentare il caso di una funzione definita sui sottoinsiemi di un insieme dato. Consideriamo un insiemequalunque A. Possiamo definire una funzione su alcuni sottoinsiemi di A (o su tutti i sottoinsiemi di A, cioe sull’insiemedella parti di A). Ad esempio, sia A un insieme finito (cioe con un numero finito di elementi). Definiamo la funzione
ϕ : PA→ N0 definita da ϕ(B) = numero di elementi di B.
La funzione ϕ associa quindi ad ogni sottoinsieme B di A il numero di elementi del sottoinsieme. Si noti che l’ipotesiche A sia finito e importante, altrimenti saremmo in difficolta nel dare un valore ai sottoinsiemi infiniti (si potrebbeanche scrivere: numero di elementi = +∞, ma = +∞ non e un numero). Si noti anche che sono costretto ad utilizzarecome codominio l’insieme N0, anziche l’insieme N. Perche?113
110Si ricordi che la funzione e iniettiva se le immagini sono distinte per ogni scelta di valori distinti nel dominio. Quindi basta trovare unsolo controesempio, cioe un caso in cui questo non si verifica, per provare che la funzione non e iniettiva.111Per provare questo basta ad esempio dimostrare che, dato un qualunque numero intero t esiste almeno una controimmagine, cioe unintero z tale che z + 1 = t. Tale intero e ovviamente t− 1. Si noti che la stessa legge di corrispondenza definita in N anziche in Z (cioe lafunzione f : N → N, con f(n) = n+ 1) e iniettiva ma non suriettiva!112Cosı potremmo pensare ad esempio ad una funzione definita sull’insieme dei residenti nella provincia di Vicenza, funzione ad esempioche associa a ciascuno la sua data di nascita. Tale funzione e definita su un insieme non numerico e ha valori in un insieme non numerico,almeno non nel senso di numeri naturali, interi, . . . .113Dato che la funzione ϕ e definita sull’insieme delle parti di A, cioe su ogni sottoinsieme di A, e che tra i sottoinsiemi di A c’e anchel’insieme vuoto, che ha zero elementi, non potrei usare N, che non contiene lo zero.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 IL CONCETTO DI FUNZIONE
FUNZIONI
114
Ci si potrebbe chiedere se questa funzione ϕ e iniettiva o suriettiva, ma lo lascio come facile esercizio a chi legge.
Altro esempio potrebbe essere il seguente. Definiamo la funzione
ψ : PN→ N0 definita da ψ(B) =
{minB se B 6= ∅
0 se B = ∅,
intendendo con minB, ma e facile intuirlo, il minimo dell’insieme B.114 Anche qui lascio allo studente l’esercizio distabilire se questa funzione ψ e iniettiva o suriettiva.
Esercizio 1.1 Data la funzione
f : N→ N , con f(n) = n2 + 1 , per ogni n ∈ N, si determini
(a) l’immagine dell’insieme {1, 2, 3};
(b) l’immagine di f ;
(c) l’insieme f−1({1, 2, 3}), cioe la controimmagine dell’insieme {1, 2, 3}.
(d) La funzione f e biiettiva?
Esercizio 1.2 Data la funzione
f : Z→ Z , con f(z) = z2 + 1 , per ogni z ∈ Z, si determini
(a) l’immagine dell’insieme {1, 2, 3};
(b) l’insieme f−1({1, 2, 3}), cioe la controimmagine dell’insieme {1, 2, 3}.
(c) E vero che f(N) = f(Z)? La funzione f e biiettiva?
Esercizio 1.3 Data la funzione
f : Z→ Z , con f(z) = |z| − 10 , per ogni z ∈ Z,
si determini
(a) l’immagine dell’insieme {0, 1, 2, 3};
(b) l’immagine di f ;
(c) l’insieme f−1({0, 1, 2, 3}), cioe la controimmagine dell’insieme {0, 1, 2, 3};
(d) l’insieme f−1(N), cioe la controimmagine dell’insieme N.
Esercizio 1.4 Data la funzione
f : N→ N , con f(n) =
{n2 se n e pari
n se n e dispari,
si determini
(a) l’immagine dell’insieme {1, 2, 3};
(b) la controimmagine dell’insieme {n ∈ N : n ≤ 10}.114Qui per la verita do per scontato che ogni sottoinsieme non vuoto di numeri naturali abbia minimo, cioe un elemento minore o ugualea tutti gli altri.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONE COMPOSTA
FUNZIONI
115
2 Funzione composta
Siano X , T e Y tre insiemi e siano f e g due funzioni, con
f : X → T e g : T → Y.
Prima di dare una definizione formale di funzione composta, cerco di dare l’idea. Dato un qualunque elemento x ∈ X ,applicando la funzione f possiamo ottenere l’elemento f(x) ∈ T . A questo ora possiamo applicare la funzione g,ottenendo cosı l’elemento g(f(x)) ∈ Y . Pertanto veniamo cosı a definire una funzione che ad ogni x ∈ X associa unelemento in Y . Essa prende il nome di funzione composta di f e g e si indica col simbolo g ◦ f . Si noti l’ordine in cuivengono scritte le due funzioni: scrivendo g ◦ f (che equivale a g(f)) vuol dire che prima opera f e poi opera g.
Ecco la definizione formale: si chiama funzione composta di f e g la funzioneg ◦ f : X → Y , definita da
(g ◦ f)(x) = g(f(x)) , per ogni x ∈ X .X T Y
f g
g ◦ fOsservazioni Si noti che, nella funzione composta g ◦ f , i valori attraverso la prima (nel nostro caso la f) diventanogli argomenti della seconda (la g). Il simbolo “◦” e appunto il simbolo di composizione tra funzioni.Si noti ancora che nella nostra definizione il codominio della prima funzione (la f) coincide col dominio della seconda(la g). La cosa e rilevante: questo consente di scrivere g(f(x)), dato che f(x) appartiene certamente al dominio dig. Invece potrebbe non avere significato la scrittura f(g(x)), dato che g(x) ∈ Y e Y potrebbe non avere nulla a chefare con X , che e il dominio di f . Quindi l’ordine di composizione delle funzioni e fondamentale. Possiamo dire che lacomposizione tra funzioni e un esempio di operazione (tra funzioni) non commutativa.
Vediamo ora qualche esempio sulla composizione.
• Siano f : N→ N, con f(n) = n+ 1 e g : N→ N, con g(n) = n2.
Possiamo costruire la funzione composta g ◦ f , che avra per dominio N e per codominio N. La sua espressione eper definizione
(g ◦ f)(n) = g(f(n)) = (n+ 1)2 , per ogni n ∈ N.
In questo caso si puo costruire anche la funzione composta (f ◦ g)(n) = f(g(n)) = n2 + 1, anch’essa da N ad N.Si noti che le due espressioni delle funzioni composte non sono uguali.
• Siano f : Z→ N, con f(z) = z2 + 1 e g : N→ Z, con g(n) = (−1)n.Possiamo costruire la funzione composta g ◦ f , che avra per dominio Z e per codominio Z. La sua espressione eper definizione
(g ◦ f)(z) = g(f(z)) = (−1)f(z) = (−1)z2+1 , per ogni z ∈ Z.
Anche in questo caso possiamo costruire pure la funzione composta f ◦ g, dato che il codominio di g e il dominiodi f coincidono. La funzione composta f ◦ g avra per dominio N e per codominio N. La sua espressione e perdefinizione
(f ◦ g)(n) = f(g(n)) = (g(n))2 + 1 = ((−1)n)2 + 1 = (−1)2n + 1 = 2 , per ogni n ∈ N.
Come si vede g ◦ f e f ◦ g sono due funzioni diverse, sia perche sono definite tra insiemi diversi, sia perche hannoespressioni diverse (g ◦ f vale 1 o −1, mentre f ◦ g vale sempre 2).
Quindi in generale ricordare che primo: non e detto si possa fare la composizione in entrambi i sensi e secondo:quando anche si puo fare, puo portare a funzioni completamente diverse tra loro.
• Indichiamo con P l’insieme dei naturali pari, cioe {2, 4, 6, . . .} e siano f : P→ P, con f(p) = p2
2 e g : P→ N, cong(p) = p
2 .115
115Le due definizioni di f e g meritano un commento, per capire che sono entrambe “ben poste”. Se p e un numero pari, allora p2 e
divisibile per 4 e di conseguenza p2
2e divisibile per 2, cioe e pari (e quindi posso scrivere f : P → P). Per quanto riguarda la funzione g, se
p e pari, allora p2e certamente un numero naturale (non necessariamente pari) e quindi posso scrivere g : P → N. Si rifletta sul fatto che
occorre sempre chiedersi se una data definizione sia ben posta, in quanto potrebbe sfuggire qualche “dettaglio” che invece la rende priva disenso. Un esempio di definizione “mal posta” e f : N → N, con f(n) = n
2: infatti, se n e dispari, n
2non e un numero naturale.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONE COMPOSTA
FUNZIONI
116
Possiamo costruire la funzione composta g ◦ f , che avra per dominio P e per codominio N. La sua espressione eper definizione
(g ◦ f)(p) = g(f(p)) =p2/2
2=p2
4, per ogni p ∈ P.
Non e invece possibile costruire la funzione composta f ◦ g. Possiamo constatarlo in due modi. Il primo e moltosemplice: consideriamo p = 2 e cerchiamo di calcolare (f ◦ g)(2) = f(g(2)). Dato che g(2) = 1, non possiamocalcolare f(1) in quanto 1 non e pari.
Il secondo modo e forse piu generale: dato che g(p) = p2 , f(g(p)) avrebbe espressione f(
p2 ) =
(p/2)2
2 = p2/42 = p2
8 ,ma se p e pari non necessariamente p2 e divisibile per 8 e quindi in qualche caso la f non la posso calcolare.
• Siano f : N→ Z, con f(n) = (−1)n e g : Z→ Q, con g(z) = zz+1. 116
Possiamo costruire la funzione composta g ◦ f , che avra per dominio N e per codominio Q. La sua espressione eper definizione
(g ◦ f)(n) = g(f(n)) = [f(n)]f(n)+1 = [(−1)n](−1)n+1 , per ogni n ∈ N.
Possiamo vedere facilmente che, per n pari (g ◦ f)(n) = 11+1 = 1 e per n dispari (g ◦ f)(n) = (−1)−1+1 = 1.Quindi la funzione composta e la funzione che vale 1 per ogni numero naturale.
In questo caso non si puo costruire la funzione composta f ◦ g, dato che il codominio della g e l’insieme deinumeri razionali, mentre il dominio di f e l’insieme dei naturali.
Possiamo anche osservare che l’espressione della funzione composta f ◦ g si puo formalmente scrivere, ed e(f ◦ g)(z) = (−1)zz+1
, ma che tale scrittura puo perdere di significato: si pensi ad esempio al suo significato perz = −2.
Osservazione Riflettendo sulla definizione di funzione composta si puo osservare che essa puo essere definita in unasituazione leggermente piu generale, quella in cui il codominio della prima funzione e contenuto nel dominio dellaseconda.
fg
X T
V
Y
Siano allora f : X → T e g : V → Y e sia T ⊂ V .La funzione g ◦ f : X → Y , definita come prima da (g ◦ f)(x) = g(f(x)),e la funzione composta di f e g.Questo puo essere utile in alcuni casi per definire la funzione compostain questa situazione piu generale. Ad esempio, con le funzioni
f : Z→ Z, con f(z) = 2z + 1 e g : Z→ N, con g(z) = 2|z|,
si puo certamente costruire la funzione composta g ◦ f , con dominio Z e codominio N ed espressione
(g ◦ f)(z) = g(f(z)) = 2|f(z)| = 2|2z+1| , per ogni z ∈ Z.
Ma tenendo in considerazione quanto detto poco fa possiamo anche costruire la funzione composta f ◦ g, con dominioZ e codominio Z ed espressione
(f ◦ g)(z) = f(g(z)) = 2g(z) + 1 = 2 · 2|z| + 1 = 2|z|+1 + 1 , per ogni z ∈ Z.
Esercizio 2.1 Date le funzioni
f : Z→ N , con f(z) = z2 + 2
eg : N→ N , con g(n) = 2n+ 1,
si scrivano le espressioni delle funzioni composte f ◦ g e g ◦ f ;
116Si osservi che la potenza zz+1 e sempre definita ed e un numero razionale. Ad esempio si ha g(0) = 01 = 0, g(−1) = (−1)0 = 1 eg(−2) = (−2)−1 = − 1
2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 FUNZIONE INVERSA
FUNZIONI
117
Esercizio 2.2 Date le funzioni
f : Z→ Z , con f(z) = |z|e
g : Z→ Z , con g(t) = t2,
(a) si scrivano le espressioni delle funzioni composte f ◦ g e g ◦ f ; le due funzioni coincidono?
(b) Qual e l’immagine dell’insieme {−2,−1, 0, 1, 2} attraverso le due funzioni composte?
(c) Qual e la controimmagine dell’insieme {−2,−1, 0, 1, 2} attraverso le due funzioni composte?
3 Funzione inversa
Il concetto di funzione inversa di una data funzione f e forse abbastanza intuitivo. Se la f e definita in X a valori inY , la sua funzione inversa e un’altra funzione, definita invece nel codominio Y e con valori in X ; non solo, ma se laf associa ad un qualunque x ∈ X il valore f(x) nell’insieme Y , allora l’inversa deve associare a questo f(x) di nuovol’elemento x. Questa e in effetti l’idea.La domanda importante che ci si deve porre subito e se tutte le funzioni abbiano una funzione inversa, se cioel’inversione sia una cosa “automatica” che si puo fare con tutte le funzioni.Ci si rende conto abbastanza facilmente che non e cosı. Restando ancora sul terreno dell’intuitivo, si pensi ad esempioad una funzione che non e iniettiva, che cioe associa a due elementi diversi x1, x2 dell’insieme X lo stesso valorey ∈ Y . Si capisce che, nel cercare una funzione che da Y ci riporta in X avremo difficolta nell’associare a questo y unvalore, dato che dovremo scegliere tra x1 e x2. E non possiamo dire: scegliamo ad esempio x1, e x2 lo assoceremo aqualcos’altro, dato che nessun altro valore di Y veniva associato ad x2 (si ricordi che una funzione associa agli elementidel dominio un solo valore nel codominio).Ecco, cosı ragionando, abbiamo anche intuito la condizione affinche una funzione possa avere una funzione inversa: lafunzione deve essere iniettiva.Per la verita occorrerebbe anche un’altra proprieta, ma abbiamo gia visto che questa in pratica si puo sempre averecon un semplice espediente. Se la funzione f non e suriettiva significa che non tutti gli elementi di Y sono valori chela funzione assume. Pertanto, se vogliamo che l’inversa sia definita su tutto Y , questa inversa non potremo costruirla.Quindi la f deve anche essere suriettiva. Ma abbiamo gia osservato in precedenza che per avere una funzione suriettivabasta dichiarare un codominio coincidente con l’immagine della funzione stessa. Quindi la vera proprieta che non puomancare per avere la funzione inversa e l’iniettivita, salvo fare pesanti modifiche sul dominio. Quando una funzioneha una funzione inversa, si dice che e invertibile.Fornisco qui di seguito un modo piu rigoroso di definire la funzione inversa. Gli studenti, avendo appena visto checosa significa “in pratica”, cerchino di riflettere anche sull’approccio rigoroso.
Se X e un insieme, la funzione che ad ogni x ∈ X associa l’elemento x stesso si chiamafunzione identita su X . La indichiamo con il simbolo iX . Pertanto
iX : X → X e iX(x) = x , ∀x ∈ X.
Si tratta di una funzione molto semplice, che puo essere definita in un qualunque insieme.E la funzione che in pratica non trasforma nulla, facendo corrispondere ad ogni elementol’elemento stesso.
x
X
Veniamo ora alla definizione di funzione inversa.Sia f : X → Y . La funzione f si dice invertibile se esiste una funzione g : Y → X tale che
g ◦ f = iX e f ◦ g = iY .X Y
f
g
Osservazione Si tratta di una definizione non operativa: non ci dice come fare per riconoscere se una funzione einvertibile oppure no. L’invertibilita di una f dipende dall’esistenza o meno di un’altra funzione, la g. La richiesta chesi fa sulla g e che la composizione con la f , nei due versi, dia come risultato la funzione identita, sia su X sia su Y .Se f e invertibile, la funzione g si chiama funzione inversa di f e si indica col simbolo f−1. 117
Come gia detto, alcune funzioni sono invertibili, altre non lo sono. Il risultato generale e il seguente:
Proposizione La funzione f : X → Y e invertibile se e solo se f e biiettiva.
117Il simbolo e lo stesso gia usato per indicare la controimmagine. La pero definiva un insieme, qui definisce una funzione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 FUNZIONE INVERSA
FUNZIONI
118
Vediamo alcuni esempi.
• Abbiamo gia visto prima che la funzione f : Z → Z, con f(z) = z + 1 e biiettiva. Troviamo la sua funzioneinversa. Preso un qualunque t ∈ Z, l’elemento z ∈ Z tale che f(z) = z+1 = t e evidentemente z = t− 1. Quindila funzione inversa e la g(t) = t− 1, con g : Z→ Z.
• La funzione f : Z → Z, con f(z) = −z e biiettiva, essendo iniettiva e suriettiva (facile esercizio). Quindi essa einvertibile. La sua funzione inversa e evidentemente la funzione stessa, dato che f(f(z)) = f(−z) = −(−z) = zper ogni z ∈ Z.
• Abbiamo visto che la funzione f : N → N, con f(n) = 2n non e biiettiva in quanto non e suriettiva. Se perocome codominio prendiamo l’insieme P dei numeri pari, cioe poniamo f : N → P, con f(n) = 2n, allora lafunzione f e biiettiva e quindi invertibile. La sua funzione inversa e naturalmente la funzione g : P → N, cong(p) = p
2 . Questo esempio mostra che l’invertibilita di una funzione puo dipendere dal dominio o dal codominioche scegliamo. Infatti qui abbiamo fatto diventare la funzione suriettiva cambiando il suo codominio.
• (Esempio difficile) Anche la funzione f : N → Z, con f(n) = 14 (−1)n(2n+ (−1)n − 1) e biiettiva (lo si verifichi
distinguendo i due casi n pari ed n dispari e costruendo una tabella che riporti n e f(n) per i primi valori di n).Pertanto e invertibile. La funzione inversa e la funzione g : Z→ N definita da
g(z) =
2z z > 0
1− 2z z < 0
1 z = 0.
Torneremo con altri esempi quando esamineremo le funzioni di R in R.
Esercizio 3.1 Data la funzione
f : N→ N , con f(n) =
{n+ 1 se n e dispari
n− 1 se n e pari,
si determini
(a) l’immagine dell’insieme {1, 2, 3, 4}; e vero che per ogni A ⊆ N l’immagine di A e A?
(b) l’immagine di f ;
(c) la controimmagine dell’insieme {1, 2, 3}.
(d) La funzione f e invertibile?
Esercizio 3.2 Data la funzione
f : N→ N , con f(n) =
{n/2 se n e pari
(n+ 1)/2 se n e dispari,
si determini
(a) l’immagine dell’insieme {1, 2, 3, 4};
(b) l’immagine di f ;
(c) la controimmagine dell’insieme {1, 2, 3, 4}.
(d) La funzione f e invertibile?
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI
119
4 Restrizione e prolungamento di una funzione
Anche qui do prima l’idea dei concetti che voglio esporre. Talvolta c’e la necessita o la convenienza di considerare unafunzione in una parte del suo dominio: si parlera allora di una restrizione della funzione stessa. Altre volte, data unafunzione, sara utile considerarne un’altra che e definita esattamente come la prima nel dominio di questa, e inoltre edefinita anche in qualche altro punto: parleremo di prolungamento. Ecco le definizioni formali.
• Data una qualunque funzione f : X → Y , se A e un sottoinsieme di X , si definisce restrizione di f all’insiemeA la funzione
f∣∣A: A→ Y , con f
∣∣A(a) = f(a), per ogni a ∈ A
(f∣∣Asi legge f ristretta all’insieme A).
Si tratta della funzione, definita su un sottoinsieme del dominio di f , che nei punti di tale insieme coincide conf . Un paio di esempi:
⊲ Data la funzione f : R→ R, con f(x) = x2, la sua restrizione all’intervallo [0,+∞) e la funzione
g : [0,+∞)→ R , con g(x) = x2, per ogni x ≥ 0.
⊲ Data la funzione f : (0,+∞)→ R, con f(x) = (1 + 1x)
x, la sua restrizione all’insieme N e la funzione
g : N→ R , con g(n) =(1 + 1
n
)n, per ogni n ∈ N.
L’utilita di questo concetto sta nel fatto che, rinunciando ad una parte del dominio della f , si puo ottenere unafunzione che ha qualche proprieta in piu rispetto ad f . Si consideri il primo esempio: la funzione x 7→ x2, definitain tutto R, non e invertibile (non e iniettiva). Se pero prendiamo la sua restrizione in [0,+∞) e prendiamo questostesso intervallo come codominio, la funzione risulta invertibile.
• Data una qualunque funzione f : X → Y , se A e un insieme che contiene X (cioe X ⊂ A), si definisceprolungamento di f all’insieme A la funzione
h : A→ Y , con h(x) = f(x), per ogni x ∈ X . 118
Si noti che, essendo X ⊂ A, ogni x che sta in X sta anche in A. Si tratta di una funzione, definita in un insiemepiu grande di X , che ristretta ad X coincide con f . Anche qui un paio di esempi:
⊲ Data la funzione f : N→ R, con f(n) = 1n , un suo prolungamento all’insieme N0 (i naturali con lo zero) e,
ad esempio, la funzione
f0 : N0 → R , con f0(n) =
{1/n n ∈ N
0 n = 0.
⊲ Data la funzione f : R \ {0} → R, con f(x) = x2
x , un suo prolungamento a tutto R e la funzione
h : R→ R , con g(x) = x, per ogni x ∈ R.
Si noti, in quest’ultimo esempio, che sarebbe errato pensare che l’espressione x2
x definisca gia una funzione
in tutto R, in quanto x2
x = x. Infatti, x2
x = x solo se x 6= 0.
5 Soluzioni degli esercizi
Esercizio 1.1
(a) Dato che f(1) = 2, f(2) = 5 e f(3) = 10, l’immagine dell’insieme {1, 2, 3} e
{2, 5, 10}.118Avremmo potuto anche dire h : A → Y , tale che h|X = f .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI
120
(b) Una scrittura generale dell’immagine di f , che possiamo indicare con f(N), e
f(N) = {n2 + 1 : n ∈ N},
cioe l’insieme dei numeri naturali che si possono scrivere come n2 + 1, dove n e un qualche numero naturale.Certo questa non dice molto. Possiamo anche elencare i primi elementi di questo insieme, e cioe scrivere
f(N) = {2, 5, 10, 17, 26, 37, . . .}.
(c) Sono i naturali che hanno per immagine 1,2 oppure 3: quindi (soltanto 2 puo essere immagine di qualcosa)
f−1({1, 2, 3}) = {1}.
(d) La funzione non e biiettiva, dato che non e suriettiva: infatti, come si vede sopra, l’immagine di f non coincidecon tutto l’insieme N.
In questa sezione spesso le domande chiedono di fornire insiemi. Gli insiemi possono essere talvolta scrittiindicando tutti gli elementi dell’insieme (questo ovviamente si puo fare solo se l’insieme e finito, cioe ha unnumero finito di elementi). Altre volte puo essere preferibile l’altra notazione, quella che definisce un insiemeattraverso una proprieta dei suoi elementi.
Esercizio 1.2
Si noti che la legge che definisce la funzione f e la stessa dell’esercizio precedente, cambiano invece gli insiemi tra cuie definita la funzione, che ora sono Z e Z.
(a) Chiaramente e lo stesso insieme del punto (a) di prima, dato che N ⊂ Z: {2, 5, 10}.
(b) f−1({1, 2, 3}) e questa volta l’insieme {−1, 0, 1}, infatti f(0) = 1 e f(−1) = f(1) = 2.
(c) Non e vero che f(N) = f(Z). Infatti f(Z) = f(N) ∪ {1}. La funzione non e biiettiva, per lo stesso motivo diprima.
Esercizio 1.3
(a) f({0, 1, 2, 3}) = {−10,−9,−8,−7}.
(b) f(Z) = {z ∈ Z : z ≥ −10}.
(c) f−1({0, 1, 2, 3}) = {±10,±11,±12,±13}.
(d) f−1(N) = {±11,±12,±13, . . .} = {z ∈ Z : |z| ≥ 11}.
Esercizio 1.4
(a) f({1, 2, 3}) = {1, 3, 4}.
(b) f−1({n ∈ N : n ≤ 10}) = {1, 2, 3, 5, 7, 9}.
Esercizio 2.1
Consideriamo prima f ◦ g. E una funzione da N a N. Si ha
(f ◦ g)(n) = f(g(n)) = f(2n+ 1) = (2n+ 1)2 + 2 = 4n2 + 4n+ 3.
Consideriamo ora g ◦ f . E una funzione da Z a N. Si ha
(g ◦ f)(z) = g(f(z)) = g(z2 + 2) = 2(z2 + 2) + 1 = 2z2 + 5.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI
121
Esercizio 2.2
(a) Entrambe le funzioni composte, cioe f ◦ g e g ◦ f , sono funzioni da Z in Z. Poi
(f ◦ g)(z) = f(g(z)) = f(z2) = |z2|
e(g ◦ f)(z) = g(f(z)) = g(|z|) = |z|2.
Le due espressioni, pur essendo formalmente diverse, coincidono (ricordare la definizione di valore assoluto).
(b) (f ◦ g)({−2,−1, 0, 1, 2}) = {0, 1, 4}. Ovviamente l’altra e uguale.
(c) (f ◦ g)−1({−2,−1, 0, 1, 2}) = {−1, 0, 1} e l’altra e uguale.
Esercizio 3.1
In questo caso puo essere utile costruire una tabella che riporti n e f(n) per i primi valori di n. Cosı facendo si capiscecome opera la funzione.
(a) f({1, 2, 3, 4}) = {1, 2, 3, 4}.Non e vero che per ogni A ⊆ N l’immagine di A e A (come invece succede per l’insieme {1, 2, 3, 4}. Infatti adesempio f({1, 2, 3}) = {1, 2, 4}.
(b) L’immagine di f e f(N) = N.
(c) f−1({1, 2, 3}) = {1, 2, 4}.
(d) La funzione f e invertibile, dato che e sia iniettiva sia suriettiva. Non fornisco una dimostrazione formale.Diciamo solo semplicemente che dalla tabella dei valori, una volta capito come opera la funzione, risultano verequeste sue due proprieta: valori distinti hanno immagini distinte (la funzione e quindi iniettiva); tutti i numerinaturali del codominio sono immagine di qualche naturale del dominio (cioe f(N) = N e quindi f e suriettiva).
Esercizio 3.2
Anche qui puo essere utile la tabella dei primi valori.
(a) f({1, 2, 3, 4}) = {1, 2}.
(b) L’immagine di f e N.
(c) La controimmagine dell’insieme {1, 2, 3, 4} e l’insieme {n ∈ N : n ≤ 8}.
(d) La funzione f non e invertibile, dato che, pur essendo suriettiva, non e iniettiva: infatti ad esempio f(1) =f(2) = 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 STRUTTURA DI ORDINE E STRUTTURA ALGEBRICA DI R
NUMERI REALI
122
II-2 Numeri reali
Prima di affrontare gli argomenti delle dispense successive e bene vedere alcuni concetti che riguardano le proprietadei numeri reali e dei sottoinsiemi di numeri reali.Almeno in parte dovrebbero essere proprieta note allo studente. Occorre pero riprenderle attentamente, in quanto sitratta di aspetti di non immediata acquisizione.
1 Alcune considerazioni iniziali
Prima di entrare nel formalismo, voglio proporre qualche spunto di riflessione. Alla scuola secondaria avete giaincontrato i numeri reali. In effetti, ad esempio, tutte le equazioni che avete visto prima di arrivare all’universita le aveterisolte nell’insieme dei numeri reali. Quindi non sono una novita, anzi il rischio e quello di dare per scontato che stiamolavorando con i numeri reali, senza riflettere mai sulle proprieta profonde che essi hanno, che li contraddistinguonodagli altri insiemi numerici, e che noi utilizziamo senza accorgercene.Tali proprieta emergono invece appena incontriamo le definizioni che presto arrivano.Allora voglio in qualche modo prepararvi. Vi propongo, per cominciare, questa domanda: qual e il numero reale piuvicino ad 1 (1 escluso, ovviamente)? Se avessi chiesto: qual e il numero intero piu vicino ad 1, non ho dubbi cheavreste subito pensato a 0 e 2, correttamente. Ma se si tratta dei numeri reali?La risposta e semplicemente che non esiste un numero reale piu vicino a 1. Se fissate l’attenzione su di un numeroreale “molto vicino a 1”,119 ne trovate subito un altro ancora piu vicino, quindi non c’e “quello piu vicino”.Ma gli studenti portati alla matematica diranno subito: questa non e una novita, succede anche nei numeri razionali.Infatti e vero. Questo non e un fatto strano, tipico soltanto dei numeri reali. Non c’e la frazione piu vicina ad 1.120
Altra domanda: quanti reali ci sono tra 1 e 2? Questo lo sapete tutti, ce ne sono infiniti. E quanti numeri razionali?Lo stesso, infiniti (spero non abbiate dubbi su questo).121 Quindi anche questa e una proprieta che hanno entrambi.Ancora possiamo dire che tra due numeri reali qualunque (o razionali, e lo stesso) possiamo sempre trovare infinitialtri numeri reali e infiniti altri numeri razionali. Anche qui non ci sono fatti nuovi, apparentemente tutto quello chesuccede nei reali succede anche nei razionali. E allora dove sta la differenza? Perche alla scuola secondaria vi hannofatto lavorare con i numeri reali?Dovreste saper dare una risposta, che peraltro non e per nulla “evidente”: sono piu di duemila anni che l’uomo si eaccorto che le frazioni non sono, per certi aspetti, sufficienti. La risposta non ve la do qui, perche la troviamo prestonelle righe qui sotto, espressa in modo rigoroso.
2 Struttura di ordine e struttura algebrica di R
Iniziamo ricordando in quali proprieta consiste la struttura di ordine e la struttura algebrica dei numeri reali.122
Con struttura di ordine si intende la seguente proprieta.In R c’e una relazione, che si indica con il simbolo <, tale che
• se x, y ∈ R, allora vale una e una sola tra le tre relazioni
x < y, x = y, y < x;
• (proprieta transitiva) se x, y, z ∈ R, x < y e y < z, allora x < z.
Valendo tali proprieta, si dice che R e un insieme ordinato. La scrittura x ≤ y come noto significa “x < y oppurex = y”; e noto anche che la scrittura y > x significa x < y.
Con struttura algebrica dei reali si intende l’insieme delle seguenti proprieta.
(i) In R e definita un’operazione di addizione, tale che
• (A1) (proprieta commutativa) a+ b = b+ a, ∀a, b ∈ R;
• (A2) (proprieta associativa) (a+ b) + c = a+ (b+ c), ∀a, b, c ∈ R;
119Riflettete che la dicitura “molto vicino a . . .”non ha, tra l’altro, alcun senso.120La frazione (cioe il numero razionale) 99
100e “molto vicino ad 1”, ma 999
1000lo e di piu e 9999
10000ancora di piu . . . .
121A proposito, chi mi sa indicare una formula che, date due frazioni, mi permette di trovare una frazione compresa tra le due? Questodovrebbe convincere che tra due frazioni ce ne sono infinite.122Con il termine struttura si intende un insieme di proprieta di un certo oggetto matematico.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 INSIEMI LIMITATI ED ESTREMI DI UN INSIEME
NUMERI REALI
123
• (A3) c’e in R un elemento, detto zero e indicato con 0, tale che a+ 0 = a, ∀a ∈ R;
• (A4) per ogni reale a c’e un altro reale, detto opposto di a ed indicato con −a, tale che a+ (−a) = 0.
(ii) In R e definita un’operazione di moltiplicazione, tale che
• (M1) (proprieta commutativa) a · b = b · a, ∀a, b ∈ R;
• (M2) (proprieta associativa) (a · b) · c = a · (b · c), ∀a, b, c ∈ R;
• (M3) c’e in R un elemento, detto uno e indicato con 1, tale che a · 1 = a, ∀a ∈ R;
• (M4) per ogni reale a 6= 0 c’e un altro reale, detto reciproco di a ed indicato con a−1, tale che a · a−1 = 1.
(iii) Valgono inoltre le seguenti proprieta:
• (D) (proprieta distributiva123) (a+ b) · c = a · c+ b · c, ∀a, b, c ∈ R;
• (CO1) per ogni y, z ∈ R tali che y < z, e per ogni x ∈ R, si ha che x+ y < x+ z;
• (CO2) per ogni x, y ∈ R tali che x > 0 e y > 0, si ha che xy > 0.
Le sigle che vedete a fianco delle varie proprieta sono di facile interpretazione, ad eccezione delle ultime due dovefigura il CO. Questa sigla sta per “corretto ordinamento”. Sono due proprieta che coinvolgono nello stesso tempo sial’ordinamento sia le operazioni algebriche.Le proprieta relative alla struttura algebrica fanno di R un campo commutativo (cioe ogni insieme numerico che haquelle proprieta viene chiamato campo commutativo). Le proprieta relative alla struttura algebrica e alla struttura diordine fanno di R un campo commutativo ordinato.
Osservazione Anche l’insieme Q dei numeri razionali e un campo commutativo ordinato. Infatti tutte le proprietascritte sopra valgono anche nei numeri razionali.
3 Insiemi limitati ed estremi di un insieme
Prima di arrivare alla novita di R rispetto a Q, occorrono alcune definizioni.
Definizione Un sottoinsieme non vuoto S ⊂ R si dice superiormente limitato se esiste un elemento b ∈ R taleche
b ≥ x, ∀x ∈ S.L’elemento b si chiama limitazione superiore (o maggiorante) di S.
Osservazione Attenzione a non fare confusione tra quello che sta in S, che e un sottoinsieme di R, e quello che stain R, e quindi non necessariamente in S. Il maggiorante puo non appartenere ad S.
Esempio Se consideriamo l’insieme S = (−∞, 1], un suo maggiorante e b = 2. A questo punto e chiaro che dimaggioranti di S, se ce n’e uno, ce ne sono infiniti. Nel nostro esempio tutti i numeri naturali sono maggioranti di S,anche 1. Tra questi 1 e l’unico che appartiene ad S.Un sottoinsieme non vuoto S ⊂ R si dice invece inferiormente limitato se esiste un elemento a ∈ R tale che
a ≤ x, ∀x ∈ S.
L’elemento a si chiama limitazione inferiore (o minorante) di S.Un sottoinsieme non vuoto di R si dice poi limitato se e sia superiormente sia inferiormente limitato.
Esempi I numeri naturali sono un insieme inferiormente limitato, ma non superiormente limitato in R. I numerirazionali compresi tra −1 e 2 sono un sottoinsieme limitato di R.
Osservazione Nel caso esistano limitazioni superiori per un insieme e ragionevole chiedersi se ci sia una minimalimitazione superiore (analogamente per l’esistenza di una massima limitazione inferiore). Qui sta la vera differenzatra i numeri reali e i numeri razionali. Si puo dimostrare che per ogni insieme di numeri reali superiormente limitatoesiste, tra i numeri reali, una minima limitazione superiore. Con i numeri razionali questo non e vero.Tralasciando ogni dimostrazione formale di tale esistenza, possiamo dare ora una definizione fondamentale.
123Si dovrebbe dire piu completamente proprieta distributiva della moltiplicazione rispetto all’addizione. Si noti che non vale un’analogaproprieta distributiva dell’addizione rispetto alla moltiplicazione, che sarebbe (a · b) + c) = (a+ c) · (b+ c).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 INSIEMI LIMITATI ED ESTREMI DI UN INSIEME
NUMERI REALI
124
Definizione Sia S un sottoinsieme non vuoto e limitato superiormente di R. Si chiama estremo superiore di Sla minima delle limitazioni superiori di S. Si scrive allora β = supS.
|
β|
b|||
S
Osservazione Se β e estremo superiore dell’insieme S e se β ∈ S, si dice che β e massimo di S (o che S ha massimo)e si scrive β = maxS. E chiaro che non sempre il massimo di un insieme esiste, dato che puo capitare che β /∈ S, cioeche l’estremo superiore non appartenga ad S.
Riporto anche la definizione di estremo inferiore, che peraltro si intuisce facilmente.
Definizione Sia S un sottoinsieme non vuoto e limitato inferiormente di R. Si chiama estremo inferiore di S lamassima delle limitazioni inferiori di S. Si scrive allora α = inf S.
|
α|
a| | |
S
Se α ∈ S, si dice che α e minimo di S (o che S ha minimo) e si scrive α = minS.
Tornando al fatto che nei numeri razionali puo non esserci la minima limitazione superiore, preciso che questo significaquanto segue: ci sono sottoinsiemi superiormente limitati di numeri razionali per cui non esiste, tra i numeri razionali,una minima limitazione superiore. Per citare il classico esempio a questo riguardo basta considerare l’insieme
S ={r ∈ Q : r2 < 2
},
cioe l’insieme dei razionali il cui quadrato e minore di 2. Tale insieme non ha (nell’insieme dei razionali) estremosuperiore.124
Quindi l’insieme Q, pur avendo la stessa struttura algebrica e la stessa struttura d’ordine di R, non ha un’altraproprieta importante che invece ha R. Questo e un “brutto difetto” per l’insieme Q, una sorta di incompletezza,mentre R si dice per questo completo.125
Alcuni esempi sul concetto di estremo superiore.
• Siano A = {x ∈ R : x ≤ 0} = (−∞, 0] e B = {x ∈ R : x < 0} = (−∞, 0). Osserviamo che:
⊲ 1 e un maggiorante sia di A sia di B, quindi entrambi gli insiemi sono limitati superiormente.
⊲ Sia per A sia per B 0 e la minima tra le limitazioni superiori, quindi supA = supB = 0. Poiche 0 ∈ A, siha che 0 e il massimo di A; dato che 0 /∈ B, allora B non ha massimo.
b
0|||
Abc
0|||
B
Non esiste invece l’estremo inferiore dei due insiemi (entrambi sono limitati superiormente ma non limitatiinferiormente).
• Consideriamo in generale il caso degli intervalli.
Se l’intervallo, chiamiamolo I, e illimitato superiormente (inferiormente) allora non esiste il suo estremo superiore(inferiore).
Per un intervallo limitato I, di estremi a, b (con a < b), non e difficile capire che in ogni caso si ha
a = inf I e b = sup I
e non ha importanza se gli estremi fanno parte oppure no dell’intervallo.
Possiamo precisare che, se l’estremo appartiene all’intervallo, esso e massimo o minimo, a seconda dei casi.Quindi, ad esempio, possiamo scrivere
inf[a, b) = a , min[a, b) = a , sup[a, b) = b , e l’intervallo non ha massimo.
124Un modo equivalente, forse piu famigliare allo studente, per esprimere lo stesso concetto e dire che non esiste alcun numero razionaleil cui quadrato e uguale a 2, cioe tra i razionali la radice di 2.125Per usare un’immagine poco matematica, ma che forse aiuta a cogliere il concetto, i numeri reali coprono con continuita la retta, nonci sono spazi liberi, se prendiamo un qualunque punto sulla retta lı c’e un numero reale. Invece i numeri razionali, le frazioni, formanoun insieme “pieno di spazi vuoti”. Ma attenzione, pieno di spazi vuoti non vuol dire che ci sono degli intervalli vuoti: ricordate sempreche tra due razionali, per quanto vicini, ce ne sono infiniti altri, quindi non ci sono intervalli privi di numeri razionali, ma nonostantequesto i razionali non formano quello che intuitivamente pensiamo dicendo un continuo di punti. La teoria della probabilita direbbe chela probabilita di “colpire”un numero razionale scegliendo a caso un punto sulla retta e zero. Cio che colma i vuoti lasciati dalle frazionisono i numeri che non sono frazioni, cioe i numeri irrazionali : razionali e irrazionali formano i numeri reali, ma ricordate che il grosso, e ilmerito della completezza, va ai numeri non razionali.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 PROPRIETA METRICHE DEI NUMERI REALI
NUMERI REALI
125
• Sia C ⊂ R, con
C ={
1n : n ∈ N
}
={
1, 12 ,13 ,
14 ,
15 , . . .
}
. bc bbbbb
0 112
13
14
15
. . .
R
Osserviamo che:
⊲ C e superiormente limitato (2 e un maggiorante); la minima limitazione superiore e 1, che risulta essere ilmassimo dell’insieme;
⊲ C e inferiormente limitato (−1 e un minorante); la massima limitazione inferiore e 0, quindi inf C = 0.Questo perche un qualunque numero positivo a non e piu una limitazione inferiore, dato che possiamosempre trovare una frazione 1/n che e minore di a;
⊲ 0 non e il minimo di C, dato che 0 /∈ C (quindi C non ha minimo).
• Sia D ⊂ R, con
D ={
1− 1n : n ∈ N
}
={
0, 12 ,23 ,
34 ,
45 , . . .
}
. b b b b b bc
0 12
23
3445
1. . .
R
La figura illustra che le frazioni del tipo 1 − 1n = n−1
n sono tutte minori di 1 e si avvicinano ad 1 al crescere din. Possiamo osservare che:
⊲ D e inferiormente limitato (−1 e un minorante). La massima limitazione inferiore e 0, che appartiene a D.Quindi 0 e il minimo di D;
⊲ dato che ogni elemento di D e minore di 1, allora 1 e un maggiorante di D;
⊲ 1 e anche la minima tra le limitazioni superiori, quindi 1 e l’estremo superiore di D. Questo perche anchequi risulta chiaro che un qualunque numero minore di 1 non puo essere ancora una limitazione superiore.
Osservazione Se A e un insieme non limitato superiormente possiamo dire che non esiste il suo estremo superioreo possiamo anche scrivere supA = +∞. Analogamente, se B e un insieme non limitato inferiormente diciamo che nonesiste il suo estremo inferiore o scriviamo inf B = −∞.Si tenga comunque sempre presente che +∞ e −∞ non sono numeri reali.
Esercizio 3.1 Per ciascuno dei seguenti insiemi (considerati come sottoinsiemi di R), si dica se l’insieme e
superiormente/inferiormente limitato, si indichino, se esistono, un maggiorante e un minorante, si indichino l’estremosuperiore e l’estremo inferiore e infine si indichino, se esistono, il massimo e il minimo.
(a) (−∞, 1] (b) (0,+∞)
(c) (−∞, 0) ∪ [1,+∞) (d) [−1, 2)
(e) N (f) Z
(g) {x ∈ R : x3 < 2} (h) {x ∈ R : x2 − 2x+ 1 > 0}
4 Proprieta metriche dei numeri reali
Ricordiamo intanto una definizione molto importante.
Definizione Si dice valore assoluto o modulo di un numero reale x la quantita
|x| def={
x se x ≥ 0
−x se x < 0.
Non e difficile dimostrare che valgono le proprieta seguenti: se x, y ∈ R, allora
(i) |x| ≥ 0 per ogni x e |x| = 0 se e solo se x = 0;
(ii) |xy| = |x| |y| per ogni x, y (in particolare | − x| = |x|);
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 PROPRIETA METRICHE DEI NUMERI REALI
NUMERI REALI
126
(iii) (disuguaglianza triangolare) |x+ y| ≤ |x|+ |y| per ogni x, y.
Osservazione Le prime due sono immediate. Per la terza, si puo osservare che in generale si ha t ≤ |t|, per ogni treale, e che ovviamente t2 = |t|2, per ogni t reale. Allora si ha
(x+ y)2 = x2 + y2 + 2xy
≤ x2 + y2 + 2|xy|= (|x|+ |y|)2,
da cui segue la disuguaglianza triangolare (si ricordi che, se a e positivo, sono equivalenti t2 ≤ a2 e |t| ≤ a).Utilizzando la definizione di valore assoluto di un numero reale possiamo definire l’importante concetto di distanza inR.
Definizione Chiamiamo distanza euclidea di due numeri reali x e y il numero reale non negativo
d(x, y)def= |x− y|.
Possiamo anche definire la distanza di un numero reale da un insieme di numeri reali: siano E ⊂ R non vuoto e x ∈ R.Chiamiamo distanza di x da E il numero
d(x,E)def= inf
{|x− y| : y ∈ E
}. 126
Ad esempio, la distanza di x = 1 dall’intervallo (2,+∞) e 1.Possiamo anche definire l’ampiezza di un insieme: se E ⊂ R non vuoto, possiamo dire che
ampiezza di Edef= sup
{|x− y| : x, y ∈ E
}.
Se ad esempio E e l’intervallo (a, b), si ha che l’ampiezza di E e b− a.127Se E e l’intervallo (a,+∞), l’ampiezza di E e +∞.
Osservazioni
• Se E = {y}, allora d(x,E) = |x− y| = d(x, y).
• Osserviamo che, se x ∈ E, allora d(x,E) = 0.
Viceversa, d(x,E) = 0 non implica che x appartenga a E. Ad esempio, d(0, (0, 1]
)= 0, ma 0 /∈ (0, 1].
Osservazione Se a e un numero reale positivo, si ha
|t| < a⇐⇒ t ∈ (−a, a).
Infatti
|t| < a⇐⇒{t ≥ 0
t < aoppure
{t < 0
−t < a⇐⇒ −a < t < a⇐⇒ t ∈ (−a, a). 128
Naturalmente, sempre se a e positivo, vale che |t| ≤ a⇐⇒ t ∈ [−a, a].Lo studente si abitui a questo punto a chiedersi: l’ipotesi e che a sia positivo; perche questa ipotesi? E se togliamoquesta ipotesi, il risultato resta valido? Se no, come si modifica?129
Osservazione Se a e un numero reale positivo, si ha
• |t| > a⇐⇒ t ∈ (−∞,−a) ∪ (a,+∞)
• |t| ≥ a⇐⇒ t ∈ (−∞,−a] ∪ [a,+∞).
126Si noti che non poniamo d(x,E)def= min{|x− y| : y ∈ E}. Questo perche il minimo potrebbe anche non esistere.
127Si osservi che il risultato non cambia se si tratta di un qualunque intervallo di estremi a e b, cioe [a, b], [a, b), oppure (a, b].128Approfitto dell’occasione per ricordare ancora che la disuguaglianza |t| < a, con a positivo, equivale alla t2 < a2. Attenzione chel’elevamento al quadrato di ambo i membri di una disequazione e un’“operazione pericolosa”, nel senso che porta ad una disequazioneequivalente se ambo i membri sono non negativi. Qui lo sono: |t| per la proprieta (i) e a per ipotesi.129Se a = 0 la disuguaglianza |t| < 0 e impossibile, come conseguenza della proprieta (i). Se a < 0 la disuguaglianza |t| < a e a maggiorragione impossibile. Nel caso della disuguaglianza larga, se a = 0 la |t| ≤ 0 equivale a t = 0 mentre nel caso di a < 0 la |t| ≤ a e impossibile.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CENNI DI TOPOLOGIA IN R
NUMERI REALI
127
Lo studente provi a dimostrare queste doppie implicazioni e poi, come fatto prima, si chieda come cambierebbero lecose se fosse a ≤ 0.
Osservazione Se x e un qualunque numero reale e se r e un numero reale positivo, vale l’implicazione
y ∈ (x− r, x+ r)⇐⇒ |y − x| < r. b
x|
x+ r|
x− r
r︷ ︸︸ ︷
|
y R
Lo si puo vedere come immediata conseguenza di quanto visto nell’osservazione precedente,130 oppure facendo passaggianaloghi a quelli appena fatti:
y ∈ (x− r, x+ r)⇐⇒ x− r < y < x+ r ⇐⇒ −r < y − x < r ⇐⇒ |y − x| < r.
5 Cenni di topologia in R
La definizione di distanza in R consente di dare altre importanti definizioni, che rientrano in quella che si chiamatopologia di R.
Definizione
⊲ Se x ∈ R, chiamiamo intorno di x di raggio r, con r > 0, l’intervallo
(x− r, x+ r) ={y ∈ R : |x− y| < r
}, b
xbc
x+ rbc
x− rR
cioe l’insieme dei reali che distano da x meno di r.
⊲ Chiamiamo intorno di +∞ ogni intervallo del tipo (a,+∞), dove a e un numero reale.
⊲ Chiamiamo infine intorno di −∞ ogni intervallo del tipo (−∞, b), dove b e un numero reale.
Osservazione Ribadisco ancora una volta che, anche se abbiamo definito i loro intorni, +∞ e −∞ non sono numerireali.E utile definire anche gli intorni destri e gli intorni sinistri. Saranno infatti questi che useremo per primi nella definizionedi limite.
Definizione
⊲ Se x ∈ R, chiamiamo intorno destro di x di raggio r, con r > 0, l’intervallo
[x, x+ r) ={y ∈ R : x ≤ y < x+ r
}, b
xbc
x+ r
R
cioe l’insieme dei reali maggiori o uguali ad x, che distano da x meno di r.
⊲ Se x ∈ R, chiamiamo invece intorno sinistro di x di raggio r, con r > 0, l’intervallo
(x− r, x] ={y ∈ R : x− r < y ≤ x
}. b
xbc
x− rR
Passiamo alle definizioni topologiche.
Definizione Sia A ⊂ R e sia x ∈ R.
⊲ Diciamo che x e interno ad A se esiste almeno un intorno di x interamente contenuto in A;
⊲ Diciamo che x e esterno ad A se x e interno al complementare di A;131
⊲ Diciamo che x e di frontiera per A se ogni intorno di x contiene punti di A e punti del complementare di A.
⊲ Diciamo che x e di accumulazione per A se ogni intorno di x contiene infiniti punti di A.
⊲ Diciamo che x e isolato in A se x ∈ A ed esiste almeno un suo intorno che non contiene alcun punto di Aeccetto x;
130Infatti |y − x| < r ⇐⇒ y − x ∈ (−r, r) ⇐⇒ y ∈ (x− r, x+ r).131Ricordo che il complementare di A e l’insieme dei numeri reali che non appartengono ad A.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CENNI DI TOPOLOGIA IN R
NUMERI REALI
128
Osservazioni Un punto interno all’insieme A appartiene necessariamente ad A.Un punto esterno all’insieme A appartiene certamente al complementare di A, e quindi non puo appartenere ad A.Un punto di frontiera per un insieme A puo appartenere o non appartenere all’insieme. Lo stesso vale per i punti diaccumulazione. I punti di frontiera di A sono i punti che non sono ne interni ne esterni ad A.Un punto isolato di A e un punto di A che pero non ha altri punti di A “nelle immediate vicinanze”.
Esempio Consideriamo l’intervallo A = [0, 1].
• Il numero reale 13 e interno ad A. Infatti il suo intorno (0, 23 ) e interamente contenuto in A.
• I punti interni ad A sono i punti dell’intervallo (0, 1). Infatti, se x ∈ (0, 1), ponendo r = min(x, 1 − x),132
certamente l’intorno di x di raggio r e interamente contenuto in A.
• Il numero reale −1 e esterno ad A, dato che il suo intorno (− 32 ,− 1
2 ) e interamente contenuto nel complementaredi A, e quindi −1 e interno al complementare. I punti esterni ad A sono i punti dell’insieme (−∞, 0)∪ (1,+∞).
• Il punto 0 e di frontiera per A: infatti ogni suo intorno e un intervallo del tipo (−r, r), e quindi contiene puntidi A e punti del complementare di A. Anche il punto 1 e di frontiera per A.
• In A non ci sono punti isolati. Un esempio di insieme con un punto isolato e l’insieme A∪{2}: il punto 2 e isolatoin tale insieme, dato che il suo intorno (1, 3) non contiene alcun punto dell’insieme ad eccezione di 2 stesso.
• Il punto 1 e di accumulazione per A: infatti ogni intorno di 1 contiene infiniti punti di A. Anche 0 e di accumu-lazione per A, ma anche ogni altro punto di A e di accumulazione per A. L’insieme dei punti di accumulazioneper A e l’insieme A stesso.
Sulle definizioni appena viste si basano altre definizioni importanti.
Definizione
⊲ Un insieme A ⊂ R si dice aperto se ogni punto di A e interno ad A.
⊲ Un insieme C ⊂ R si dice chiuso se il suo complementare e aperto.
Osservazioni Si puo vedere facilmente che gli insiemi aperti sono quelli che non contengono i propri punti di frontiera,mentre gli insiemi chiusi sono quelli che contengono tutti i propri punti di frontiera. Attenzione a non pensare cheogni insieme sia necessariamente o aperto o chiuso: ci sono insiemi che non sono ne aperti ne chiusi. Vedi negli esempiche seguono.
Esempi
• Ancora con l’insieme A = [0, 1], dato che i punti di frontiera sono 0 e 1 e che questi appartengono ad A, alloraA e chiuso.
• In generale gli intervalli del tipo [a, b] sono chiusi. Infatti i punti di frontiera di [a, b] sono a e b ed appartengonoall’intervallo.
Anche l’intervallo [a,+∞) e chiuso. Infatti l’unico suo punto di frontiera, a, sta nell’intervallo. Lo stesso dicasiper (−∞, b]. Quindi si noti che chiuso non vuol dire limitato.
• Invece gli intervalli del tipo (a, b) sono aperti. Infatti, se x ∈ (a, b), poniamo r = min(x − a, b − x). Alloral’intorno (x− r, x+ r) di x e interamente contenuto in (a, b) e quindi x e interno all’intervallo.
Anche gli intervalli del tipo (a,+∞) e (−∞, b) sono aperti.
• Esistono insiemi che non sono ne aperti ne chiusi: gli intervalli del tipo (a, b] oppure [a, b) sono un esempio.
• Ci sono insiemi che non hanno punti interni. Ogni insieme finito, cioe formato da un numero finito di elementi, eprivo di punti interni.133 Il fatto di avere infiniti elementi non garantisce pero che l’insieme abbia punti interni:ad esempio, l’insieme N contiene infiniti elementi ma non ha nessun punto interno. L’insieme N e fatto tutto dipunti isolati, che sono anche di frontiera, quindi in particolare e chiuso.
132La scrittura significa che r e il minimo tra x e 1− x.133Si pensi al fatto che un intorno ha sempre infiniti elementi, e quindi un insieme che ha un punto interno deve necessariamente contenereinfiniti elementi.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
NUMERI REALI
129
Esercizio 5.1 Scrivere un intorno circolare di t = −1.
Esercizio 5.2 Esistono intorni di +∞ che contengono numeri reali negativi?
Esercizio 5.3 Esistono intorni di +∞ che non contengono numeri interi?
Esercizio 5.4 Dire se le seguenti affermazioni sono vere o false.
(a) 0 e interno a (−1, 0]
(b) 0 e esterno a (−1, 0)
(c) 0 e di frontiera sia per (−1, 0] sia per (−1, 0)
(d) 0 e di accumulazione sia per (−1, 0] sia per (−1, 0)
(e) Dati i due insiemi A = (−∞, 0] ∪ [1, 2] e B = [0,+∞), 0 e punto isolato dell’insieme A ∩B.
Esercizio 5.5 Indicato con A l’insieme delle soluzioni della disequazione x3 − x2 − x + 1 ≤ 0, si classifichino i
punti di A, specificando quali sono interni, quali esterni, quali di frontiera, quali di accumulazione e quali isolati.
6 Soluzioni degli esercizi
Esercizio 3.1
(a) L’intervallo (−∞, 1] e superiormente limitato e inferiormente non limitato. Un maggiorante e ad esempio t = 2,ma anche t = 1. L’estremo superiore e 1, che e anche il massimo.
(b) L’intervallo (0,+∞) e inferiormente limitato e superiormente non limitato. Un minorante e ad esempio t = −1,ma anche t = 0. L’estremo inferiore e 0. L’insieme non ha minimo.
(c) L’insieme (−∞, 0) ∪ [1,+∞) non e ne superiormente ne inferiormente limitato. Non ci sono maggioranti ominoranti. Possiamo anche dire che il sup e l’inf sono rispettivamente +∞ e −∞.
(d) L’intervallo [−1, 2) e limitato (sia superiormente sia inferiormente). Un maggiorante e ad esempio t = 3, e unminorante e ad esempio t = −5. L’estremo superiore e 2, l’estremo inferiore e −1 (scriviamo sup[−1, 2) = 2 einf[−1, 2) = −1). L’intervallo ha minimo (−1) ma non ha massimo.
(e) L’insieme N e inferiormente limitato e superiormente non limitato. Un minorante e ad esempio t = 0. L’estremoinferiore e 1, che e anche minimo di N.
(f) L’insieme Z non e ne superiormente ne inferiormente limitato. Non ci sono maggioranti o minoranti. Possiamoscrivere supZ = +∞ e inf Z = −∞. L’insieme Z non ha ne massimo ne minimo.
(g) L’insieme {x ∈ R : x3 < 2}, cioe l’insieme delle soluzioni della disequazione x3 < 2, e l’intervallo (−∞, 3√2). Tale
insieme e limitato solo superiormente e non ha massimo. Si ha sup(−∞, 3√2) = 3
√2.
(h) L’insieme {x ∈ R : x2 − 2x+ 1 > 0} e l’insieme delle soluzioni della disequazione x2 − 2x+ 1 > 0 e coincide conl’insieme A = (−∞, 1) ∪ (1,+∞). Tale insieme non e limitato e quindi si ha supA = +∞ e inf A = −∞.
Esercizio 5.1
Ad esempio, un intorno circolare di t = −1 e l’intervallo (−2, 0), ma anche (−3, 1) oppure (− 32 ,− 1
2 ).
Esercizio 5.2
Certo, ad esempio (−1,+∞).
Esercizio 5.3
No. Ogni intorno di +∞ e un intervallo del tipo (a,+∞). Dato che certamente esistono interi maggiori di a, qualunquesia a, questi stanno in questo intervallo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
NUMERI REALI
130
Esercizio 5.4
(a) 0 non e interno a (−1, 0]: non esiste infatti alcun intorno circolare di 0 che sia tutto contenuto nell’intervallo.
(b) 0 non e esterno a (−1, 0): infatti il complementare di (−1, 0) e (−∞,−1] ∪ [0,+∞) e 0 non e interno a taleinsieme.
(c) 0 e di frontiera sia per (−1, 0] sia per (−1, 0): infatti ogni intorno circolare di 0 contiene punti dell’insieme e delsuo complementare. Questo vale sia per (−1, 0] sia per (−1, 0), in quanto non dipende dall’appartenenza di 0 aidue intervalli.
(d) 0 e di accumulazione sia per (−1, 0] sia per (−1, 0): ogni intorno circolare di 0 contiene infiniti punti dell’insieme,sia in un caso sia nell’altro (anche qui non dipende dall’appartenenza di 0 all’insieme).
(e) L’intersezione di A e B e l’insieme {0} ∪ [1, 2]. Allora 0 e punto isolato di tale insieme: esiste cioe almeno unintorno circolare di 0 che dell’insieme contiene soltanto il punto 0 stesso (ad esempio l’intorno circolare (−1, 1)).
Esercizio 5.5
Occorre anzitutto trovare l’insieme A risolvendo la disequazione. Il polinomio x3 − x2 − x+ 1 si fattorizza facilmentenel prodotto (x+1)(x− 1)2 e quindi la disequazione data equivale alla (x+1)(x− 1)2 ≤ 0, che ha per soluzioni x = 1oppure le x ≤ −1. Quindi A = (−∞,−1]∪{1}. Allora l’insieme dei punti interni e I = (−∞,−1), l’insieme dei puntiesterni e E = (−1, 1)∪ (1,+∞), l’insieme dei punti di frontiera e F = {−1, 1}, l’insieme dei punti di accumulazione eA = (−∞,−1] e infine l’insieme dei punti isolati e J = {1}.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 GRAFICO DI UNA FUNZIONE REALE
FUNZIONI REALI DI VARIABILE REALE
131
II-3 Funzioni reali di variabile reale
In questa dispensa studiamo un caso particolarmente rilevante di funzioni, quelle definite nell’insieme R dei numerireali (o suoi sottoinsiemi), a valori ugualmente in R. Quindi, con le notazioni viste in precedenza, si tratta dellefunzioni
f : A ⊂ R→ R,
cioe delle cosiddette funzioni reali (cioe con codominio reale) di variabile reale (cioe con dominio reale).Nei casi che considereremo l’insieme A sara sempre per noi o un intervallo di R o un’unione finita di intervalli.134
Esistono, come vedremo, strumenti analitici molto potenti per studiare questo tipo di funzioni.
1 Grafico di una funzione reale
Data una funzione f : A ⊂ R → R, si definisce grafico di f un sottoinsieme del prodotto cartesiano R × R = R2,precisamente il sottoinsieme
Gf ={(x, y) ∈ R2 : y = f(x), x ∈ A
}.
Detto a parole, il grafico di una funzione f e l’insieme delle coppie di numeri reali in cui la seconda componente (la y)e il valore che la funzione f assume nella prima componente (la x).Trattandosi di un sottoinsieme di R2, il grafico di una funzione si puo rappresentare nel piano cartesiano. Talerappresentazione consente di dare della funzione un’immagine grafica molto efficace, quello che si chiama appunto ilgrafico della funzione. Una volta disegnato il suo grafico, risultano praticamente evidenti le proprieta e gli aspetti piuimportanti della funzione.
x
f(x)
Non l’ho fatto in figura, ma solitamente l’asse orizzontale viene indicatocon x e quello verticale con y, e sono sicuramente familiari allo studentele diciture “asse delle x” e “asse delle y”. Siamo abituati a rappresentarequindi sull’asse orizzontale l’argomento della funzione e sull’asse verticalei suoi valori. Metto in guardia gli studenti sul fatto che molti errorivengono commessi perche non e chiaro “che cosa sta sull’asse x e checosa sta invece sull’asse y”.
Data una funzione, non e difficile ottenere alcuni punti del suo grafico: bastainfatti calcolare il valore della funzione per qualche valore della x e si ottengonoi corrispondenti punti nel grafico.Ad esempio, data la funzione f : R→ R, con f(x) = x2, calcolando
f(0) = 0 , f(1) = 1 , f(−1) = 1 , f(12
)= 1
4 , f(2) = 4
si possono ottenere i seguenti 5 punti del grafico di f :
(0, 0) , (1, 1) , (−1, 1) ,(12 ,
14
), (2, 4).
b
b
b
b
−1 1/2 1 2
1
1/4
4
x
y
Ottenere pero il grafico di una funzione per punti non e un buon modo di procedere. Ci sono metodi molto piu efficaci,come vedremo.
Esercizio 1.1 Per ciascuna delle seguenti funzioni si determini il relativo dominio (insieme di definizione).135
(a) f(x) =3√1− x1 + x
(b) f(x) =√lnx
(c) f(x) =1√
1− ex (d) f(x) = ln(1−√x
)
(e) f(x) =1
1− lnx(f) f(x) =
√
1− ln2 x
(g) f(x) =√
1− |1− x| (h) f(x) = ln(1− lnx
)
134Un sottoinsieme di R e unione finita di intervalli se e unione di un numero finito di intervalli. Abbiamo gia osservato in precedenza checi sono sottoinsiemi di R che non rientrano in questa tipologia, che non sono cioe ne intervalli, ne unioni finite di intervalli, ad esempio Z.135Si tratta di trovare qual e il piu grande sottoinsieme di R in cui la funzione risulta definita, cioe ha senso l’espressione analitica chedefinisce f .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
2 FUNZIONI ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
132
Esercizio 1.2 Per ciascuna delle seguenti funzioni si dica che curva del piano e il relativo grafico.
(a) f(x) = 1− x+ x2 (b) f(x) =1
x− 1
(c) f(x) =x− 1
x− 2(d) f(x) =
√4− x2
(e) f(x) = 1−√
2− (x− 1)2 (f) f(x) = −√1− 2x2
(g) f(x) =√x2 + 3 (h) f(x) = −
√x2 − 2
2 Funzioni elementari
Con il termine funzioni elementari intendero le funzioni potenza, le funzioni esponenziali e le funzioni logaritmiche.
2.1 Funzione potenza
Viene definita attraverso l’espressione f(x) = xα, con α 6= 0. Il dominio e le proprieta della funzione potenza dipendonodall’esponente α. Ricordando quanto detto nella prima parte sulla definizione di potenza, occorre distinguere alcunicasi, a seconda dell’insieme cui appartiene appunto l’esponente α.
• Se α ∈ N, la funzione potenza e definita su tutto R.
• Se α ∈ Z, α < 0, la funzione potenza e definita in R \ {0}.
• Se α ∈ Q oppure α ∈ R \Q, la funzione potenza e definita in R+, cioe in (0,+∞).
Fornisco qui sotto i grafici delle funzioni potenza, limitandomi a tracciarli in (0,+∞).
x
f(x) α > 1
0 < α < 1
α = 1
1
1
x
f(x)
α < 0
1
1
Si puo osservare che la funzione potenza in (0,+∞) e crescente se α > 0, mentre e decrescente se α < 0.I grafici in tutto R, quando la funzione e definita anche sui reali negativi, si possono ottenere facilmente in base aconsiderazioni sulla simmetria: se α ∈ N, la funzione xα e pari se α e pari, e invece e dispari se α e dispari.
Lo stesso se α ∈ Z, con α < 0, dato che in questi casi xα =1
x−α.
Facciamo ora alcune considerazioni sull’invertibilita della funzione potenza.
• Consideriamo la funzione potenza f : R → R, con f(x) = x2. La funzione f non e invertibile, dato che non einiettiva. Se pero considero la sua restrizione all’intervallo [0,+∞) ottengo una funzione iniettiva, che e dunqueinvertibile qualora consideri come suo codominio la sua immagine, che e [0,+∞). Quindi la funzione
f : [0,+∞)→ [0,+∞) , con f(x) = x2
e invertibile e la sua funzione inversa e la
f−1 : [0,+∞)→ [0,+∞) , con f−1(y) =√y = y1/2. 136
136Qui si e preferito indicare l’argomento della funzione inversa con la lettera y, per mantenere le notazioni usate precedentemente nellatrattazione generale della funzione inversa. E chiaro che non sarebbe cambiato nulla usando la x anche per l’argomento di f−1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
133
• Consideriamo la funzione potenza f : R → R, con f(x) = x3. La funzione f e invertibile, dato che e iniettiva esuriettiva. La sua funzione inversa e la funzione
f−1 : R→ R , con f−1(y) = 3√y. 137
• Consideriamo la funzione potenza f : (0,+∞)→ R, con f(x) = xα, con α reale non razionale (potrebbe essere
ad esempio x√2). La funzione e iniettiva ma non suriettiva, dato che comunque il valore della potenza e positivo.
Basta pero semplicemente cambiare il codominio di f in (0,+∞): la funzione f : (0,+∞) → (0,+∞), conf(x) = xα, e invertibile e la sua funzione inversa e
f−1 : (0,+∞)→ (0,+∞) , con f−1(y) = y1/α.
2.2 Funzione esponenziale
Funzione esponenziale di base b e la funzione f : R→ R, con f(x) = bx. 138
Ecco i grafici della funzione esponenziale.
x
f(x)
b > 1
1
x
f(x)
0 < b < 1
1
Si osservi che la funzione esponenziale di base b e crescente in tutto R se b > 1, mentre e decrescente in tutto R seb < 1. Assume comunque valori sempre positivi. La sua immagine in entrambi i casi e l’intervallo (0,+∞).Tutte queste proprieta della funzione esponenziale si potrebbero dimostrare rigorosamente.La funzione esponenziale di base b, con dominio tutto R e codominio (0,+∞), e invertibile. La sua funzione inversa ela funzione logaritmica, sempre di base b. 139
2.3 Funzione logaritmica
Funzione logaritmica di base b e la funzione f : (0,+∞)→ R, con f(x) = logb x.140
x
f(x)b > 1
1 x
f(x)0 < b < 1
1
Si osservi che la funzione logaritmica di base b e crescente nel suo dominio se b > 1, mentre e decrescente nel suodominio se 0 < b < 1. Puo assumere tutti i valori reali. La sua immagine in entrambi i casi e quindi tutto R.La funzione logaritmica di base b e invertibile e la sua funzione inversa e ovviamente la funzione esponenziale.
137Si noti che qui dovremmo evitare di scrivere f−1(y) = y1/3, dato che la potenza con esponente razionale e stata definita solo con basepositiva. Volendo scrivere il radicale come potenza sarebbe piu opportuno scrivere
f−1(y) =
{y1/3 y ≥ 0
−|y|1/3 y < 0.
138Il numero b deve essere positivo. Il caso b = 1 e poco significativo, dato che si ottiene una funzione costante.139Questo deriva da relazioni gia note. Infatti, se poniamo f(x) = bx e g(y) = logb y, abbiamo
(g ◦ f)(x) = g(f(x)) = g(bx) = logb(bx) = x, ∀x ∈ R
e(f ◦ g)(y) = f(g(y)) = blogb y = y, ∀y ∈ (0,+∞).
Pertanto le due funzioni sono una inversa dell’altra.140Il numero b, cioe la base del logaritmo, deve essere positivo e diverso da 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IMMAGINE ED ESTREMO SUPERIORE DI UNA FUNZIONE REALE
FUNZIONI REALI DI VARIABILE REALE
134
3 Immagine ed estremo superiore di una funzione reale
Come gia visto per le funzioni nel caso generale, l’immagine di f e l’insieme dei valori(ora reali) che la funzione puo assumere al variare del suo argomento.Se f : A ⊂ R→ R e una funzione reale, la sua immagine e l’insieme
f(A)def={f(x) : x ∈ A
}. 141
bc
bc
abc
bc
bAb
bc
f(A)
x
y
Se lo studente sta pensando alla rappresentazione, faccio notare che l’immagine della funzione, essendo un insieme divalori, dobbiamo pensarlo rappresentato nell’asse y. Nella figura qui sopra e rappresentato il caso di un insieme Adato da un intervallo aperto (a, b). Si noti che nel caso considerato l’immagine f(A) non e un intervallo aperto (main altri casi puo esserlo, dipende da come e fatta la funzione). Nell’esempio rappresentato l’immagine e un intervallochiuso in basso e aperto in alto.Un numero reale y sta nell’immagine di f se esiste un valore x ∈ A tale che f(x) = y.Utilizzando questa considerazione non e difficile trovare l’immagine delle funzioni nei due esempi che seguono.
• f : R→ R, con f(x) = x2. Osservando che se y ≥ 0, l’equazione x2 = y ha soluzione mentre se y < 0, l’equazionex2 = y non ha soluzione, si deduce che l’immagine di f e l’intervallo [0,+∞).
• f : R→ R, con f(x) = x3. Osservando che, qualunque sia y ∈ R, l’equazione x3 = y ha soluzione, si deduce chel’immagine di f e tutto R.
Osservazione Abbiamo parlato finora di immagine di tutta la funzione, cioe di tutto il suo dominio. Lo studentericordera che si puo definire l’immagine anche di un sottoinsieme del dominio.
Esercizio 3.1 Per le funzioni elementari seguenti si determinino le immagini a fianco indicate.
(a) f(x) = x2: l’immagine di f , f(0, 1),142 f [−1, 2], f(−1,+∞);
(b) f(x) = 2x: l’immagine di f , f(0, 1), f(−1, 2), f(−∞, 1);(c) f(x) = log2 x: l’immagine di f , f(0, 1), f(12 , 2), f(1,+∞).
Di particolare importanza e il concetto di estremo superiore e di estremo inferiore di una funzione reale. Datauna funzione f : A ⊂ R→ R, si definisce
supx∈A
f(x) = sup fdef= sup f(A) = sup
{f(x) : x ∈ A
}
e analogamente
infx∈A
f(x) = inf fdef= inf f(A) = inf
{f(x) : x ∈ A
}.
Non sono necessari molti commenti: l’estremo superiore (inferiore) di una funzione non e altro che l’estremo superiore(inferiore) della sua immagine.Puo succedere che l’immagine di f non sia superiormente limitata: si puo scrivere allora sup f = +∞. Se l’immaginedi f non e inferiormente limitata si puo scrivere inf f = −∞.Nel primo dei due esempi visti sopra, l’inf della funzione x2 e 0, mentre il sup e +∞. Nel secondo, per la funzione x3,si ha sup f = +∞ e inf f = −∞.Altri esempi: per la funzione f : [−1, 2] → R, con f(x) = x2 si ha sup f = 4 e inf f = 0; per la funzione f :(−2,−1) ∪ (0, 1)→ R, con f(x) = x2 si ha sup f = 4 e inf f = 0.
Puo succedere che una funzione reale abbia massimo (o minimo). Se la sua immagine ha massimo (o minimo),questo viene detto il massimo (o minimo) della funzione (si indicano con max f e con min f).La funzione f : R→ R, con f(x) = x2, ha minimo e si ha min f = 0; invece non ha massimo.La funzione f : R→ R, con f(x) = x3, non ha ne massimo ne minimo.La funzione f : [−1, 2] → R, con f(x) = x2, ha massimo e minimo e si ha max f = 4 e min f = 0; infine la funzionef : (−2,−1) ∪ (0, 1)→ R, con f(x) = x2, non ha ne massimo ne minimo.
141Trattandosi dell’insieme degli f(x), con x ∈ A, e chiaramente un sottoinsieme del codominio.142In tutti questi esercizi scrivo ad esempio f(0, 1) per semplicita, anziche f((0, 1)) come sarebbe forse piu corretto. La scrittura indical’immagine dell’intervallo (0, 1) attraverso la funzione f .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CONTROIMMAGINE O IMMAGINE INVERSA DI UNA FUNZIONE REALE
FUNZIONI REALI DI VARIABILE REALE
135
Esercizio 3.2 Si determinino gli estremi (estremo inferiore ed estremo superiore) delle seguenti funzioni. Si
precisi inoltre se i valori trovati sono il massimo e/o il minimo della funzione.
(a) f : [1,+∞)→ R, con f(x) = x2 (b) f : (−∞, 0)→ R, con f(x) = x2
(c) f : (−∞, 0)→ R, con f(x) = ex (d) f : [2, 4)→ R, con f(x) = log2 x
(e) f : R→ R, con f(x) =1
2x(f) f : R \ {0} → R, con f(x) =
1
x3
(g) f : (0,+∞)→ R, con f(x) = 3−x (h) f : (1,+∞)→ R, con f(x) = lnx
4 Controimmagine o immagine inversa di una funzione reale
Parlando di funzioni in generale abbiamo visto la definizione di controimmagine(immagine inversa) di un insieme attraverso una funzione. Ricordo che, datauna funzione f : A ⊂ R → R e dato un sottoinsieme B ⊂ R, si chiamacontroimmagine di B attraverso f l’insieme
f−1(B)def={x ∈ A : f(x) ∈ B
}. 143
Fissato quindi un certo insieme di valori (cioe B), la sua controimmagine e datadagli x tali che f(x) e uno dei valori fissati. a b
A
B
f−1(B)
bc bc
bcbc
b
bc
bc b b bc
x
y
Attenzione. Il concetto di controimmagine e tradizionalmente ostico a molti studenti. Vediamo qualche esempio.
Esempi
• f : R→ R, con f(x) = x2.
Se ad esempio B = (−∞, 0), si ha f−1(B) = ∅: per nessun x si puo avere x2 < 0. Se B = (−∞, 0], si haf−1(B) = {0}: solo x = 0 ha un quadrato che sta in B. Se B = (−∞, 1), si ha f−1(B) = (−1, 1): si tratta inpratica di risolvere la disequazione x2 < 1, che come noto ha per soluzioni −1 < x < 1. Se B = [−1, 4], si haf−1(B) = [−2, 2]. Se B = (0, 4], si ha f−1(B) = [−2, 0) ∪ (0, 2]. Fare sempre attenzione al tipo di parentesi.
• f : R→ R, con f(x) = x3.
Se ad esempio B = (−∞, 0), si ha f−1(B) = (−∞, 0), dato che le soluzioni di x3 < 0 sono le x < 0. SeB = [−1, 1], si ha f−1(B) = [−1, 1], dato che −1 ≤ x3 ≤ 1 se e solo se −1 ≤ x ≤ 1. Se B = (−8, 8), si haf−1(B) = (−2, 2).
Esercizio 4.1 Per le funzioni elementari seguenti si determinino le immagini e le controimmagini a fianco indicate.
(a) f(x) = x2: f [1, 2], f [−2, 1], f−1(−1, 1), f−1(1, 2] 144
(b) f(x) = x3: f(−∞, 1), f(−3, 2), f−1(−1, 2), f−1(2, 3)
(c) f(x) =√x: f(1, 2), f(3,+∞), f−1(−1, 1), f−1(−∞, 4)
(d) f(x) = 1x : f(1, 2), f(−∞,−1), f−1(−1,+∞), f−1(−3, 4)
(e) f(x) = 2x: f(−1, 2), f(0,+∞), f−1(−∞, 0], f−1(−∞, 2)
(f) f(x) = log2 x: f(1, 4), f(0, 16), f−1(1,+∞), f−1(−∞,−1)143Non si faccia confusione: B e un sottoinsieme del codominio e la sua controimmagine e invece un sottoinsieme del dominio.144Anche qui scrivo f−1(1, 2] per semplicita, anziche f−1((1, 2]), che sarebbe piu corretto. La notazione indica la controimmaginedell’intervallo (1, 2].
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 PROPRIETA DELLE FUNZIONI REALI
FUNZIONI REALI DI VARIABILE REALE
136
5 Proprieta delle funzioni reali
Per le funzioni reali esistono alcune proprieta rilevanti.
(i) Una proprieta importante e la monotonia, che si distingue in alcune particolari tipologie, che ora definiamo.
Sia f : I ⊂ R→ R, dove I e un intervallo (e importante che la funzione sia definita in un intervallo).
• La funzione f e crescente se
∀x1, x2 ∈ I, x1 < x2 ⇒ f(x1) < f(x2).
• La funzione f e non decrescente se
∀x1, x2 ∈ I, x1 < x2 ⇒ f(x1) ≤ f(x2).
• La funzione f e decrescente se
∀x1, x2 ∈ I, x1 < x2 ⇒ f(x1) > f(x2).
• La funzione f e non crescente se
∀x1, x2 ∈ I, x1 < x2 ⇒ f(x1) ≥ f(x2).
x
funzione crescente
x
funzione non decrescente
Osservazione A volte, per rimarcare la differenza tra funzione crescente e non decrescente si dice, per la prima,“strettamente crescente” o anche “crescente in senso stretto”. Chiaramente una funzione crescente e anche nondecrescente, ma il viceversa puo essere falso, come nell’esempio di destra qui sopra. Detto in parole povere, unafunzione crescente “cresce sempre”, mentre una non decrescente puo ad esempio essere in alcuni tratti costante.
(ii) Ovviamente tutte le proprieta gia viste nel caso generale possono essere proprieta delle funzioni reali. Cosı adesempio l’iniettivita e suriettivita: le definizioni sono ovviamente le stesse.
(iii) Particolare importanza ha l’invertibilita. Sussiste anche qui naturalmente il risultato, del tutto generale, cheuna funzione e invertibile se e solo se e contemporaneamente iniettiva e suriettiva.
(iv) Altre proprieta rilevanti sono le simmetrie. Noi consideriamo solo due particolari tipi di simmetria.
Sia A ⊂ R un insieme simmetrico rispetto all’origine, cioe un insieme con la proprieta che
se x ∈ A, allora −x ∈ A.
Alcuni esempi di insiemi simmetrici rispetto all’origine sono:
|
0bc
0bc
−1bc
1|
0b
−1b
1|
0
R R \ {0} (−1, 1) (−∞,−1] ∪ [1,+∞)
Sia ora f : A→ R, con A simmetrico rispetto all’origine.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 PROPRIETA DELLE FUNZIONI REALI
FUNZIONI REALI DI VARIABILE REALE
137
• La funzione f e pari (o simmetrica rispetto all’asse delle ordinate) se
f(−x) = f(x), ∀x ∈ A.
• La funzione f e dispari (o simmetrica rispetto all’origine) se
f(−x) = −f(x), ∀x ∈ A.
Sapere che una funzione ha una simmetria di qualche tipo puo facilitare il disegno del suo grafico. Se ad esempioso che la funzione f e pari e conosco il suo grafico sui reali positivi, allora il grafico sui reali negativi si ottienefacilmente per simmetria dal primo: si tratta appunto del grafico simmetrico rispetto all’asse delle ordinate.
x
funzione pari
x
funzione dispari
Esempi Sono pari tutte le funzioni del tipo x → xp, dove p e un numero naturale pari; sono dispari tutte lefunzioni del tipo x→ xd, dove d e un numero naturale dispari (la denominazione deriva da questo).
La funzione x→√1 + x2 e pari, dato che
√
1 + (−x)2 =√1 + x2 per ogni x ∈ R.
La funzione x→ 3√x e dispari, dato che 3
√−x = − 3√x per ogni x ∈ R.
Esercizio 5.1 Le seguenti funzioni sono invertibili nel loro dominio. Si determini l’espressione della relativa
funzione inversa.
(a) f(x) = e1−x (b) f(x) = 1− 2x+1 (c) f(x) = 1 + ln(1 + 2x)
(d) f(x) = 3√1 + x (e) f(x) = 2 ln(x3 + 1) (f) f(x) = ln (1 + 3
√x)
Esercizio 5.2 Si provi che le seguenti funzioni sono simmetriche e si dica quale tipo di simmetria presentano.
(a) f(x) = x2 + x4 (b) f(x) = x3 − x5 (c) f(x) = ln(1 + x2)
(d) f(x) =x
1 + x2(e) f(x) =
x3
ln(1 + x4)(f) f(x) =
1− ex1 + ex
Osservazione Un’osservazione prima di chiudere questo paragrafo. Parlando di proprieta delle funzioni reali, unadistinzione che spesso si fa e che incontreremo nel seguito e quella tra proprieta locali e proprieta globali. Una proprietadi una funzione f si dice locale se vale in un intorno di un punto x del dominio di f .145 Si dice invece globale se valein tutto il dominio di f .Le proprieta viste in questo paragrafo, la monotonia, l’iniettivita, la suriettivita, l’invertibilita, la simmetria, sonotutte di carattere globale.Tipicamente, per dimostrare una proprieta globale sono necessarie ipotesi forti, per dimostrare una proprieta localebastano ipotesi piu deboli.
A proposito di proprieta locali o globali, possiamo dare qui alcune definizioni importanti. Abbiamo visto in precedenzain questo capitolo la definizione di massimo e di minimo di una funzione. I concetti di massimo e di minimo sonoconcetti globali, perche riguardano tutto il dominio della funzione: in realta riguardano l’immagine, ma questa dipendea sua volta da tutto il dominio.Intanto diamo questa
145L’intorno potrebbe essere piccolissimo, anche se abbiamo gia osservato che questa espressione e priva di ogni significato. Rendecomunque l’idea spero.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 ALTRI ESEMPI DI FUNZIONI, NON ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
138
Definizione Data una funzione f : I ⊂ R→ R, si chiama punto di massimo globale di f ogni punto in cui essaassume il suo massimo.146 Se xM ∈ I e punto di massimo globale di f vale allora la seguente proprieta:
f(xM ) ≥ f(x), per ogni x ∈ I.
( )IxM
M
x
y
Analogamente per i punti di minimo globale.
Esempio Per la funzione f : R → R, con f(x) = (x − 1)2, il punto x = 1 e punto di minimo globale. Non si facciamai confusione: se dico punto di minimo globale alludo alle x, mentre se dico minimo alludo ai valori della funzione.Nel nostro caso l’immagine di f e l’intervallo [0,+∞) e quindi il minimo di f e zero, mentre il punto in cui f assumeil valore zero e x = 1.
Ora pero si puo definire una particolare situazione, in genere interessante e possibilmente significativa, di massimoo minimo, ma non globali. In pratica possiamo pensare ad un punto x0 in cui la funzione abbia massimo, malimitatamente ad un intorno di x0.Ecco la definizione formale:
Definizione Data una funzione f : I ⊂ R → R, si chiama punto di massimo locale di f ogni punto x0 ∈ I taleche esista un intorno (x0 − δ, x0 + δ) contenuto in I per cui
f(x0) ≥ f(x), per ogni x ∈ (x0 − δ, x0 + δ). 147
( )I x0
f(x0)
( )x0−δ x0+δ x
y
Osservazioni Ci possono essere punti che sono di massimo (minimo) locale ma non di massimo (minimo) globale.148
Si veda la figura qui sopra. In generale non e detto che ogni funzione abbia punti di massimo, e questo vale sia perquelli globali sia per quelli locali. In particolare non e detto che, se non ne ha di globali, ne abbia necessariamentedi locali. Si pensi ad esempio ad una funzione strettamente monotona in un intervallo aperto, che non ha punti dimassimo di nessun tipo e nemmeno di minimo.
6 Altri esempi di funzioni, non elementari
Qui vediamo alcune funzioni che non rientrano tra quelle appena viste.
146Quindi, se poniamo M = max f , ogni punto xM ∈ I in cui si abbia f(xM ) = M e punto di massimo globale. L’aggettivo globale si usaproprio per rimarcare che si tratta di una proprieta globale e anche per distinguerlo da quello che segue.147Sarebbe bene formulare la proprita del punto di massimo locale scrivendo
f(x0) ≥ f(x), per ogni x ∈ (x0 − δ, x0 + δ) ∩ I,
per consentire anche agli estremi dell’intervallo di poter essere punti di massimo locale. Si pensi al caso di un intervallo chiuso. Alterna-tivamente si potrebbe precisare che l’intorno puo essere un intorno destro se x0 coincide col primo estremo dell’intervallo e un un intornosinistro se x0 coincide col secondo.148Invece, se un punto e di massimo (minimo) globale allora e anche di massimo (minimo) locale. Facile da capire. Lo studente cerchi difarsene una ragione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 ALTRI ESEMPI DI FUNZIONI, NON ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
139
6.1 Funzioni definite a tratti
E opportuno famigliarizzarsi subito con funzioni che non sono elementari ma che lo sono su particolari intervalli delloro dominio. Vediamo subito un semplice esempio. Si consideri la funzione
f(x) =
0 x ≤ −1x2 −1 < x < 0
1− x 0 ≤ x < 1
lnx x ≥ 1.
Questa funzione si dice definita a tratti, intendendo che e definita con espressioni diverse (tutte elementari in questocaso) su particolari intervalli del suo dominio, che nel complesso e tutto R.Ricordando i grafici delle funzioni elementari, il grafico di f si ottiene facilmente (e dato dai tratti piu marcati):
b b
bbc
bc
−1 1
1
x
f(x)
Unico doveroso commento. Che cosa significano i “pallini pieni” e “pallini vuoti”? Il pallino pieno in corrispondenzadi x = −1 sta ad indicare che il valore della funzione f in corrispondenza di x = −1 (cioe f(−1)) e 0 (attenzione che ilvalore si legge sulle y). Il pallino vuoto in corrispondenza di x = −1 sta ad indicare che il valore di f in corrispondenzadi x = −1 non e 1. Analogamente per x = 0: il valore di f(0) e 1 e non 0. In x = 1 il valore della funzione e 0 (ilpallino vuoto non c’e o non si vede, dato che e sovrapposto a quello pieno).
6.2 Funzione valore assoluto
Sappiamo gia che cos’e il valore assoluto di un numero reale. Possiamo definire la funzione valore assoluto semplice-mente ponendo
f(x) = |x|.Ricordando la definizione di valore assoluto di x abbiamo che
f(x) =
{x x ≥ 0
−x x < 0.
Si tratta quindi di una funzione definita a tratti. Il grafico e naturalmente questo:
x
f(x)
6.3 Funzione parte intera
Sebbene non importante come la precedente, vediamo anche la funzione parte intera, che potra servire piu avanti inqualche esempio. Definiamo, per ogni x ∈ R,
f(x) = ⌊x⌋ def= max
{z ∈ Z : z ≤ x
}. 149
149La parte intera di x e il piu grande numero intero minore o uguale ad x. Alcuni esempi: se x e un numero intero, ovviamente la suap.i. coincide con x (e questo e l’unico caso in cui i due coincidono); ⌊ 1
2⌋ = 0, ⌊e⌋ = 2, ⌊π⌋ = 3, ⌊−e⌋ = −3, . . ..
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 GRAFICI DI FUNZIONI E CURVE NEL PIANO
FUNZIONI REALI DI VARIABILE REALE
140
Per ottenere il grafico della funzione parte intera si puo osservare che, dato un qualunque numero intero z, se x ∈[z, z + 1), allora ⌊x⌋ = z. 150 Quindi la funzione e costante sugli intervalli del tipo [z, z + 1), e quindi il grafico dellafunzione parte intera e il seguente (e sempre dato dai tratti piu marcati):
x
f(x)
b bc
b bc
b bc
b bc
b bc
−2 −11 2
−2
−1
1
2
Osservazione Anche la funzione parte intera e una funzione definita a tratti, l’unica differenza (peraltro di notevoleimportanza teorica) e che per definirla sugli intervalli occorre un numero infinito di intervalli.
Esempio Fornisco un altro esempio di funzione, che utilizza la parte intera, e che piu avanti ci sara utile. Si consideri
f(x) = x− ⌊x⌋.
Ricordando, come appena visto, che se x ∈ [z, z + 1), allora ⌊x⌋ = z, abbiamo
f(x) = x− z , se x ∈ [z, z + 1),
e cioe f(x) vale x in [0, 1), vale x− 1 in [1, 2), vale x− 2 in [2, 3), e cosı via. Quindi il grafico e il seguente:
x
f(x)
b
bc
b
bc
b
bc
b
bc
b
bc
b
bc
−2 −1 1 2
1
7 Grafici di funzioni e curve nel piano
Abbiamo detto all’inizio di questa sezione che il grafico di una funzione f : A ⊂ R→ R e il sottoinsieme Gf del pianodefinito da
Gf ={(x, y) ∈ R2 : y = f(x), x ∈ A
}.
Abbiamo poi visto, nei numerosi esempi di funzioni elementari, che i grafici sono generalmente certe curve nel piano.Puo sorgere la domanda se le curve nel piano che abbiamo studiato nella sezione di geometria analitica della primaparte del corso siano tutte grafici di opportune funzioni reali. La risposta e negativa e il motivo risiede nella definizionestessa di funzione. Infatti, se f e una funzione, per ogni x ∈ R (o per ogni x ∈ A, se f e definita in A) esiste un solof(x). In altre parole, se f e una funzione, il suo grafico deve avere questa proprieta: ogni retta verticale del piano puoincontrare il grafico di f al piu in un punto.151
Se chiamiamo per comodita proprieta caratteristica dei grafici quella appena enunciata, si vede subito che ad esempio,parlando di parabole, non tutte hanno la proprieta caratteristica: infatti solo quelle con asse parallelo all’asse y hannotale proprieta, le altre no. Le parabole con asse parallelo all’asse x non sono quindi grafici di funzioni reali.152
Allora ad esempio,
150Si noti la parentesi in z + 1: e tonda, cioe escludo z + 1 dall’intervallo. Infatti ⌊z + 1⌋ = z + 1 e non z.151Significa quindi che lo incontra o in nessun punto o in un punto solo. Dobbiamo prevedere infatti che la funzione non sia definita intutto R e quindi che ci siano rette di equazione x = t che non incontrano mai il grafico: sono quelle per cui t non sta nel dominio di f .152Stiamo parlando ovviamente di funzioni da x a y, cioe di funzioni che rappresentiamo come di consueto utilizzando l’asse delle ascisseper la variabile e l’asse delle ordinate per i valori della funzione. Se rappresentassimo una funzione usando l’asse y per la variabile e l’assex per i valori, sarebbero le parabole con asse parallelo all’asse x ad essere grafici di funzioni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 GRAFICI DI FUNZIONI E CURVE NEL PIANO
FUNZIONI REALI DI VARIABILE REALE
141
• il grafico della funzionef : R→ R, con f(x) = x2 + 1
e una parabola nel piano, precisamente la parabola di equazione esplicita y = x2 + 1 o equazione generalex2 − y + 1 = 0 se si preferisce.
• la parabola di equazione x + y2 + 1 = 0 non e grafico di alcuna funzione reale (salvo, come si diceva nella notapoco fa, uno scambio degli assi).
• E che dire del grafico della funzione
f : (−∞,−1]→ R, con f(x) =√−x− 1 ?
La presenza di una radice quadrata sembrerebbe precludere legami con le parabole. Se pero eleviamo al quadratonell’equazione y =
√−x− 1 otteniamo x + y2 + 1 = 0, che e l’equazione della parabola del punto precedente.
Attenzione pero. Anzitutto occorre osservare, come indicato nella definizione di f , che la funzione non e definitain tutto R, ma solo in (−∞,−1]. Inoltre i valori che la funzione assume sono soltanto valori non negativi. Eevidente allora che il grafico non puo essere tutta la parabola, ma e una parte di questa, la parte che sta al disopra (meglio non al di sotto) dell’asse delle x.153
Le circonferenze non sono mai grafici di funzioni reali, dato che ci sono rette verticali che incontrano la circonferenzain due punti. Lo stesso dicasi per le ellissi. Pero puo accadere quello che abbiamo appena visto con le parabole: siconsideri la funzione
f : [−1, 1]→ R, con f(x) =√1− x2.
L’equazione y =√1− x2, elevando al quadrato, diventa x2 + y2 = 1, che e l’equazione della circonferenza con centro
l’origine e raggio 1. Come prima pero il grafico non e tutta la circonferenza, perche l’equivalenza tra le due equazionisussiste solo con y ≥ 0. Quindi il grafico della funzione e una semicirconferenza, quella che sta sul semipiano delle ynon negative.Ovviamente anche la semicirconferenza che sta sul semipiano delle y non positive e grafico di una funzione (ha laproprieta caratteristica): e la funzione
f : [−1, 1]→ R, con f(x) = −√1− x2.
In generale le funzioni definite da
f(x) = y0 +√
r2 − (x− x0)2 oppure f(x) = y0 −√
r2 − (x− x0)2
(il caso precedente e un caso paricolare della prima di queste due, con x0 = 0, y0 = 0 e r = 1) hanno per grafico unasemicirconferenza, di centro il punto (x0, y0) e raggio r. Si noti che entrambe sono definite quando r2− (x− x0)2 ≥ 0,cioe se (x− x0)2 ≤ r2, cioe |x− x0| ≤ r: si tratta dell’intervallo [x0 − r, x0 + r].Per quanto riguarda le iperboli, si possono in realta presentare due casi, in base alle tipologie di iperboli che abbiamostudiato in precedenza. La funzione
f : R \ {0} → R, con f(x) =1
x
ha per grafico un’iperbole. Infatti e definita per x 6= 0 e per tali valori l’equazione y = 1x equivale alla xy = 1, che e
l’equazione di un’iperbole. Piu in generale, in questa tipologia rientrano tutte le funzioni del tipo
f : R \ {x0} → R, con f(x) = y0 +c
x− x0.
Infatti l’equazione y = y0+c
x−x0equivale alla (x−x0)(y− y0) = c, che e l’equazione di un’iperbole. Il caso precedente
e un caso particolare di questo, con x0 = 0, y0 = 0 e c = 1.Anche la funzione definita da
f(x) =√
x2 − 1
ha legami con un’iperbole: infatti elevando al quadrato otteniamo x2 − y2 = 1, che sappiamo essere l’equazione diun’iperbole. Pero anche qui il grafico non coincide con tutta l’iperbole. E non si tratta in questo caso di uno deidue rami, come forse si potrebbe pensare. Ricordando quanto visto nella geometria analitica, l’iperbole di equazione
153Come si risolve allora la questione: se l’equazione y =√−x− 1 equivale alla x + y2 + 1 = 0, perche il grafico e soltanto una parte
della parabola? Il fatto e che non e vero che l’equazione y =√−x− 1 equivalga alla x+ y2 + 1 = 0! L’equivalenza sussiste solo se ambo i
membri sono non negativi, cioe se y ≥ 0, ed ecco che i conti tornano.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI VARIABILE REALE
142
x2 − y2 = 1 interseca l’asse x e non l’asse y (i suoi rami stanno a destra e a sinistra dell’origine, per cosı dire): ilgrafico della funzione e la parte di iperbole che sta nel semipiano delle y non negative ed e fatto di due parti distinte.Si noti che la funzione e definita quando x2 − 1 ≥ 0, cioe nell’insieme (−∞,−1] ∪ [1,+∞).Per finire, anche la funzione
f : R→ R, con f(x) =√x2 + 1
ha legami con un’iperbole: elevando al quadrato otteniamo x2 − y2 = −1, che e ancora l’equazione di un’iperbole,che questa volta ha i due rami sopra e sotto l’origine. Il grafico di f questa volta coincide con uno dei due ramidell’iperbole, quello che sta sopra l’origine.
8 Soluzioni degli esercizi
Esercizio 1.1
(a) f(x) =3√1− x1 + x
. Le condizioni per l’esistenza della funzione sono date soltanto dalla presenza del denominatore:
la radice e una radice terza e quindi e definita per ogni valore per cui e definito il suo argomento. Quindi ildominio (o campo di esistenza) di f e l’insieme R \ {−1} = (−∞,−1) ∪ (−1,+∞).
(b) f(x) =√lnx. Qui il dominio e determinato da due condizioni di esistenza, che devono valere contemporanea-
mente: l’argomento del logaritmo deve essere positivo e l’argomento della radice (questa volta di indice pari)deve essere non negativo. Il dominio e dato allora dalle soluzioni del sistema
{x > 0
lnx ≥ 0cioe
{x > 0
x ≥ 1.
Si tratta quindi dell’intervallo [1,+∞).
(c) f(x) =1√
1− ex . Il dominio e determinato da due condizioni di esistenza: l’argomento della radice deve essere
non negativo e il denominatore deve essere diverso da zero: sintetizzando, l’argomento della radice deve esserestrettamente positivo. Quindi il dominio e dato dalle soluzioni della disequazione
1− ex > 0, cioe ex < 1, cioe x < 0.
Pertanto il dominio e l’intervallo (−∞, 0).
(d) f(x) = ln(1 − √x
)Le condizioni di esistenza sono due: argomento della radice non negativo e argomento del
logaritmo positivo. Quindi abbiamo il sistema
{x ≥ 0
1−√x > 0cioe
{x ≥ 0√x < 1.
Pertanto il dominio e l’intervallo [0, 1).
(e) f(x) =1
1− lnxLe condizioni sono: argomento del logaritmo positivo e denominatore diverso da zero. Quindi
abbiamo il sistema {x > 0
1− lnx 6= 0cioe
{x > 0
lnx 6= 1cioe
{x > 0
x 6= e.
Pertanto il dominio e l’insieme (0, e) ∪ (e,+∞).
(f) f(x) =√
1− ln2 x. Le condizioni sono: argomento del logaritmo positivo e argomento della radice non negativo.Quindi abbiamo il sistema
{x > 0
1− ln2 x ≥ 0cioe
{x > 0
ln2 x ≤ 1cioe
{x > 0
−1 ≤ lnx ≤ 1cioe
{x > 0
e−1 ≤ x ≤ e.
Pertanto il dominio e l’intervallo [e−1, e].
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI VARIABILE REALE
143
(g) f(x) =√
1− |1− x|. La condizione e soltanto che l’argomento della radice sia non negativo. Quindi abbiamola disequazione
1− |1− x| ≥ 0, cioe |1− x| ≤ 1.
Questa equivale a−1 ≤ x− 1 ≤ 1, cioe 0 ≤ x ≤ 2.
Pertanto il dominio e l’intervallo [0, 2].
(h) f(x) = ln(1 − lnx
). Le condizioni sono la positivita degli argomenti dei due logaritmi. Quindi abbiamo il
sistema {x > 0
1− lnx > 0cioe
{x > 0
lnx < 1cioe
{x > 0
x < e.
Pertanto il dominio e l’intervallo (0, e).
Esercizio 1.2
(a) f(x) = 1− x+ x2 ha per grafico la parabola di equazione y = 1− x+ x2 (basta porre y = f(x)).
(b) f(x) =1
x− 1ha per grafico l’iperbole di equazione (x− 1)y = 1, di asintoti le rette di equazione x = 1 e y = 0.
(c) Osserviamo che possiamo scrivere f(x) = x−1x−2 = x−2+1
x−2 = 1 + 1x−2 . La funzione f(x) =
x− 1
x− 2ha allora per
grafico l’iperbole di equazione (x− 2)(y − 1) = 1, di asintoti le rette di equazione x = 2 e y = 1.
(d) L’equazione y =√4− x2 porta alla x2 + y2 = 4, che e l’equazione della circonferenza di centro l’origine e raggio
2. Pero attenzione: quest’ultima ha per soluzione anche punti con y < 0, mentre la precedente no. Questoperche elevando al quadrato introduciamo nuove soluzioni (in altre parole le due equazioni non sono equivalenti).Consapevoli di questo fatto, possiamo concludere che il grafico di f e allora la parte di circonferenza che sta sulsemipiano delle y ≥ 0, cioe una semicirconferenza.
(e) L’equazione y = 1 −√
2− (x− 1)2 porta alla (x − 1)2 + (y − 1)2 = 2, che e l’equazione della circonferenza di
centro (1, 1) e raggio√2. Il grafico di f e allora la corrispondente semicirconferenza che sta sul semipiano delle
y ≤ 1.154
(f) L’equazione y = −√1− 2x2 porta alla 2x2 + y2 = 1,155 che e l’equazione dell’ellisse di centro (0, 0) e semiassi
a = 1√2e b = 1. Il grafico di f e allora la corrispondente semiellisse che sta sul semipiano delle y ≤ 0.
(g) L’equazione y =√x2 + 3 porta alla y2 − x2 = 3, che e l’equazione di un’iperbole con rami al di sopra e al di
sotto dell’origine. Il grafico di f e allora il ramo superiore dell’iperbole.
(h) L’equazione y = −√x2 − 2 porta alla x2 − y2 = 2, che e l’equazione di un’iperbole con rami a sinistra e a destra
dell’origine. Il grafico di f e la parte di iperbole che sta nel semipiano delle y non positive.
Esercizio 3.1
Per aiutarsi nelle risposte lo studente e invitato a disegnarsi un grafico delle funzioni.
(a) Con f(x) = x2 l’immagine di f e [0,+∞). Poi
f(0, 1) = (0, 1) , f [−1, 2] = [0, 4] , f(−1,+∞) = [0,+∞).
(b) Con f(x) = 2x l’immagine di f e (0,+∞). Poi
f(0, 1) = (1, 2) , f(−1, 2) = (1
2, 4) , f(−∞, 1) = (0, 2).
(c) Con f(x) = log2 x l’immagine di f e (−∞,+∞). Poi
f(0, 1) = (−∞, 0) , f(1
2, 2) = (−1, 1) , f(1,+∞) = (0,+∞).
154Infatti, riscrivendo la prima come√
2− (x− 1)2 = 1− y, si puo osservare che deve essere 1− y ≥ 0, cioe y ≤ 1.155Elevando direttamente al quadrato, oppure riscrivendo
√1− 2x2 = −y e poi elevando al quadrato si ottiene appunto 2x2 + y2 = 1. Si
noti che se eleviamo al quadrato l’equazione originaria abbiamo certamente il secondo membro non positivo, e quindi deve essere y ≤ 0.Se invece eleviamo al quadrato la
√1− 2x2 = −y dobbiamo osservare che −y ≥ 0, cioe ancora y ≤ 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI VARIABILE REALE
144
Esercizio 3.2
Anche qui un grafico puo essere molto utile.
(a) Dal grafico della funzione (si tratta della restrizione della funzione x 7→ x2 all’intervallo [1,+∞)) si vedefacilmente che
infx∈[1,+∞)
f(x) = minx∈[1,+∞)
f(x) = f(1) = 1
esup
x∈[1,+∞)
f(x) = +∞.
L’immagine della funzione e l’intervallo [1,+∞).
(b) Questa volta si tratta della restrizione x 7→ x2 all’intervallo (−∞, 0) e si vede facilmente che
infx∈(−∞,0)
f(x) = 0 (min f non esiste)
esup
x∈(−∞,0)
f(x) = +∞.
L’immagine della funzione e l’intervallo (0,+∞).
(c) Si tratta della restrizione della funzione esponenziale all’intervallo (−∞, 0). L’immagine e l’intervallo (0, 1).Quindi
infx∈(−∞,0)
f(x) = 0 (min f non esiste)
esup
x∈(−∞,0)
f(x) = 1 (max f non esiste).
(d) Si tratta della restrizione della funzione logaritmica (base 2) all’intervallo [2, 4). L’immagine e l’intervallo [1, 2).Quindi
infx∈[2,4)
f(x) = 1 = min f
esup
x∈[2,4)
f(x) = 2 (max f non esiste).
(e) La funzione e la funzione esponenziale di base 12 (oppure e la funzione x 7→ 2−x se si preferisce). Dal grafico si
vede cheinf f = 0 e sup f = +∞.
(f) E una funzione potenza con esponente intero negativo (f(x) = x−3). Si tratta di una funzione dispari, nonlimitata ne inferiormente ne superiormente. Quindi
inf f = −∞ e sup f = +∞.L’immagine della funzione e l’insieme (−∞, 0) ∪ (0,+∞).
(g) Ancora una funzione esponenziale (f(x) =(13
)x), o meglio la restrizione di questa all’intervallo (0,+∞).
L’immagine della funzione e l’intervallo (0, 1). Si ha quindi
supx∈(0,+∞)
f(x) = 1
einf
x∈(0,+∞)f(x) = 0.
Non esistono ne il massimo ne il minimo di f .
(h) Si tratta della restrizione della funzione x 7→ lnx (base e) all’intervallo (1,+∞). L’immagine della funzione el’intervallo (0,+∞) e quindi si ha
infx∈(1,+∞)
f(x) = 0
esup
x∈(0,+∞)
f(x) = +∞.
Il valore 0 non e il minimo: il minimo non esiste.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI VARIABILE REALE
145
Esercizio 4.1
Per aiutarsi nelle risposte lo studente e invitato a disegnarsi un grafico delle funzioni.
(a) Con f(x) = x2 abbiamo:
f [1, 2] = [1, 4] , f [−2, 1] = [0, 4] , f−1(−1, 1) = (−1, 1) , f−1(1, 2] = [−√2,−1) ∪ (1,
√2].
(b) Con f(x) = x3 abbiamo:
f(−∞, 1) = (−∞, 1) , f(−3, 2) = (−27, 8) , f−1(−1, 2) = (−1, 3√2) , f−1(2, 3) = (
3√2,
3√3).
(c) Con f(x) =√x abbiamo:
f(1, 2) = (1,√2) , f(3,+∞) = (
√3,+∞) , f−1(−1, 1) = [0, 1) , f−1(−∞, 4) = [0, 16).
(d) Con f(x) = 1x abbiamo:
f(1, 2) = (12 , 1) , f(−∞,−1) = (−1, 0) , f−1(−1,+∞) = (−∞,−1) ∪ (0,+∞)
e infine f−1(−3, 4) = (−∞,− 13 ) ∪ (14 ,+∞).
(e) Con f(x) = 2x abbiamo:
f(−1, 2) = (12 , 4) , f(0,+∞) = (1,+∞) , f−1(−∞, 0] = ∅ , f−1(−∞, 2) = (−∞, 1).
(f) Con f(x) = log2 x abbiamo:
f(1, 4) = (0, 2) , f(0, 16) = (−∞, 4) , f−1(1,+∞) = (2,+∞) , f−1(−∞,−1) = (0, 12 ).
Esercizio 5.1
In questi esercizi non ci poniamo il problema se la funzione sia invertibile (l’invertibilita e data per ipotesi). Vogliamosoltanto trovare l’espressione della funzione inversa.
(a) f(x) = e1−x. Si puo procedere cosı: poniamo y = e1−x e ricaviamo x in funzione di y. Si ottiene
1− x = ln y, quindi x = 1− ln y.
Questa e l’espressione della funzione inversa. Si potrebbe anche scrivere f−1(y) = 1 − ln y (si puo seguire laconsuetudine di indicare con y l’argomento della funzione inversa). Lo studente e invitato a riflettere su: dominioe immagine di f e dominio e immagine di f−1.
(b) f(x) = 1−2x+1. Poniamo y = 1−2x+1; si ricava 2x+1 = 1−y, quindi x+1 = log2(1−y) e infine x = log2(1−y)−1.Quindi l’espressione della funzione inversa e f−1(y) = log2(1 − y)− 1.
(c) f(x) = 1 + ln(1 + 2x). Poniamo y = 1 + ln(1 + 2x), da cui ln(1 + 2x) = y − 1, quindi 1 + 2x = ey−1, quindi2x = ey−1 − 1 e infine x = 1
2 (ey−1 − 1). Si ha allora f−1(y) = 1
2 (ey−1 − 1).
(d) f(x) = 3√1 + x. Poniamo
y = 3√1 + x, quindi 1 + x = y3, quindi x = y3 − 1.
Pertanto f−1(y) = y3 − 1.
(e) f(x) = 2 ln(x3 + 1). Poniamo
y = 2 ln(x3 + 1), quindi x3 = ey/2 − 1, quindi x =3√
ey/2 − 1.
Pertanto f−1(y) =3√ey/2 − 1.
(f) f(x) = ln (1 + 3√x). Poniamo
y = ln(1 + 3√x), quindi 1 + 3
√x = ey, quindi 3
√x = ey − 1, quindi x = (ey − 1)3.
Pertanto f−1(y) = (ey − 1)3.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI VARIABILE REALE
146
Esercizio 5.2
(a) La funzione f(x) = x2 + x4 e pari, dato che f(−x) = (−x)2 + (−x)4 = x2 + x4 = f(x).
(b) La funzione f(x) = x3 − x5 e dispari, dato che f(−x) = (−x)3 − (−x)5 = −x3 + x5 = −f(x).
(c) La funzione f(x) = ln(1 + x2) e pari, dato che f(−x) = ln(1 + (−x)2) = ln(1 + x2) = f(x).
(d) La funzione f(x) = x1+x2 e dispari, dato che f(−x) = −x
1+(−x)2 = − x1+x2 = −f(x).
(e) La funzione f(x) = x3
ln(1+x4) e dispari, dato che f(−x) = (−x)3
ln(1+(−x)4) = − x3
ln(1+x4) = −f(x).
(f) Quest’ultima e un po’ meno immediata. Con f(x) = 1−ex
1+ex si ha
f(−x) = 1− e−x
1 + e−x= (moltiplicando sopra e sotto per ex) =
ex − 1
ex + 1= −1− ex
1 + ex.
Quindi f e dispari.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
147
9 Appendice – Trasformazioni grafiche elementari
In questa appendice espongo alcune tecniche utili per ottenere grafici di funzioni che sono semplici trasformazioni difunzioni elementari. In particolare, data una funzione f di cui conosciamo il grafico, impareremo a disegnare il graficodelle funzioni
(a) x 7→ −f(x) (b) x 7→ |f(x)| (c) x 7→ f(x) + k
(d) x 7→ f(−x) (e) x 7→ f(|x|) (f) x 7→ f(x+ k)
(g) x 7→ kf(x) (h) x 7→ f(kx)
dove k e una costante, cioe un numero reale.
(a) Grafico di x 7→ −f(x).Detto a parole, basta capovolgere il grafico di f facendone il simmetrico rispetto all’asse x. Ecco un disegno cheillustra la trasformazione:156
x 7→ f(x)
x
x 7→ f(x)
x 7→ −f(x)
x
Esempio Grafico di g(x) = 1− x. Dato che g(x) = −(x− 1), si ha:
1
−1x
y
x 7→ x− 1
1
1
−1x
y
x 7→ x− 1
x 7→ 1− x
Esempio Grafico di g(x) = − lnx.
1 x
y x 7→ lnx
1 x
yx 7→ lnx
x 7→ − lnx
Esempio Grafico di g(x) = −ex.
1
x
y
x 7→ ex
−1x
y
x 7→ ex
x 7→ −ex
156Di norma, quando un grafico si ottiene da un altro con una qualche trasformazione, riporto tratteggiato il grafico precedente. Quandolo spazio me lo consente riporto anche l’espressione analitica della funzione relativa al grafico tratteggiato.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
148
(b) Grafico di x 7→ |f(x)|.Detto a parole: dove la funzione e positiva la si lascia com’e, dove e negativa si capovolge il grafico come fattoin precedenza. Il tutto segue dalla definizione di valore assoluto, che ricordo ancora una volta:
|f(x)| ={
f(x) f(x) ≥ 0
−f(x) f(x) < 0.
Ecco un disegno che illustra la trasformazione:
x 7→ f(x)
x
x 7→ f(x)
x 7→ |f(x)|
x
Esempio Grafico di g(x) = |x− 1|.
1
−1x
y
x 7→ x− 1
1
1
−1x
y
x 7→ |x− 1|
Esempio Grafico di g(x) = |x2 − 1|.
1−1
−1
x
yx 7→ x2 − 1
1−1
1
−1
x
yx 7→ |x2 − 1|
Esempio Grafico di g(x) = | lnx|.
1 x
y x 7→ lnx
1 x
yx 7→ | lnx|
Esempio Grafico di g(x) = 1|x| . La funzione e ovviamente x 7→
∣∣ 1x
∣∣.
x
yx 7→ 1
x
x
yx 7→ 1
|x|
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
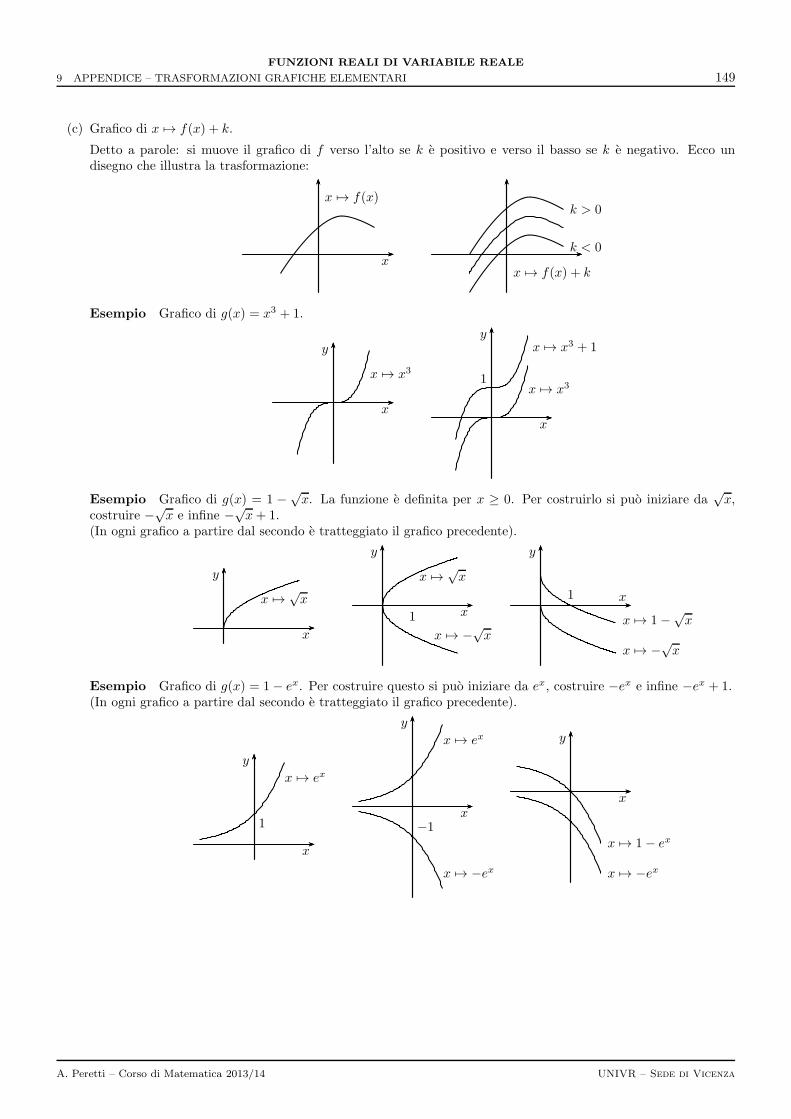
9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
149
(c) Grafico di x 7→ f(x) + k.
Detto a parole: si muove il grafico di f verso l’alto se k e positivo e verso il basso se k e negativo. Ecco undisegno che illustra la trasformazione:
x 7→ f(x)
x
k > 0
k < 0
x 7→ f(x) + k
Esempio Grafico di g(x) = x3 + 1.
x
y
x 7→ x3 1
x
y
x 7→ x3
x 7→ x3 + 1
Esempio Grafico di g(x) = 1 − √x. La funzione e definita per x ≥ 0. Per costruirlo si puo iniziare da√x,
costruire −√x e infine −√x+ 1.(In ogni grafico a partire dal secondo e tratteggiato il grafico precedente).
x
y
x 7→ √x1 x
y
x 7→ √x
x 7→ −√x
1 x
y
x 7→ −√x
x 7→ 1−√x
Esempio Grafico di g(x) = 1− ex. Per costruire questo si puo iniziare da ex, costruire −ex e infine −ex + 1.(In ogni grafico a partire dal secondo e tratteggiato il grafico precedente).
1
x
y
x 7→ ex
−1x
y
x 7→ ex
x 7→ −ex
x
y
x 7→ −exx 7→ 1− ex
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
150
(d) Grafico di x 7→ f(−x).Detto a parole: basta capovolgere il grafico di f facendone il simmetrico rispetto all’asse y (basta pensare chela funzione f(−x) assume in x lo stesso valore che la funzione f assume in −x). Ecco un disegno che illustra latrasformazione:
x 7→ f(x)
x
x 7→ f(x)x 7→ f(−x)
x
Esempio Grafico di g(x) = e−x.
1
x
y
x 7→ ex
1
x
y
x 7→ ex
x 7→ e−x
Esempio Grafico di g(x) = ln(−x). Ovviamente la funzione e definita sulle x negative.
1 x
yx 7→ lnx
−1 x
yx 7→ lnx
x 7→ ln(−x)
Esempio Grafico di g(x) = −x3. Si noti che la funzione si puo ottenere sia come x 7→ −(x3), e quindi con unribaltamento del grafico di x3 rispetto all’asse x sia come x 7→ (−x)3 e quindi con un ribaltamento della stessarispetto all’asse y. Il risultato e ovviamente lo stesso.
x
y
x 7→ x3
x
y
x 7→ x3
x 7→ −x3
Esempio Grafico di g(x) =√−x. La funzione e definita per x ≤ 0.
x
y
x 7→ √x
x
y
x 7→ √xx 7→ √−x
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
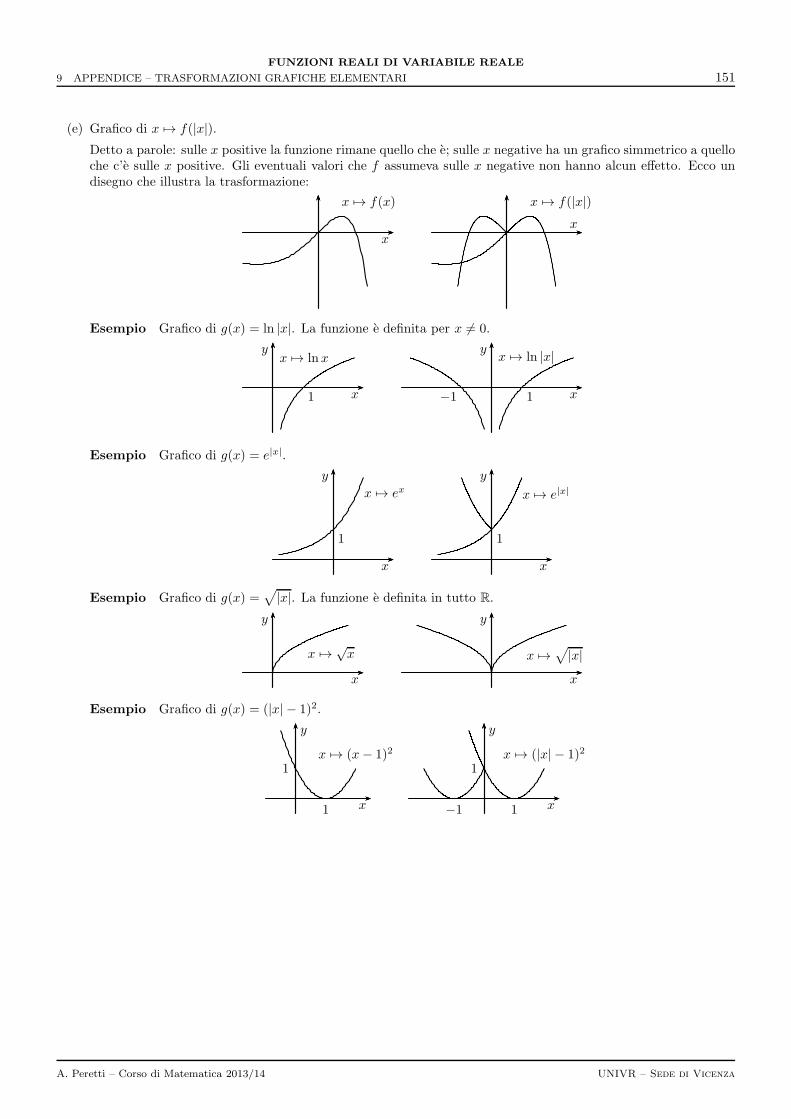
9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
151
(e) Grafico di x 7→ f(|x|).Detto a parole: sulle x positive la funzione rimane quello che e; sulle x negative ha un grafico simmetrico a quelloche c’e sulle x positive. Gli eventuali valori che f assumeva sulle x negative non hanno alcun effetto. Ecco undisegno che illustra la trasformazione:
x 7→ f(x)
x
x 7→ f(|x|)x
Esempio Grafico di g(x) = ln |x|. La funzione e definita per x 6= 0.
1 x
yx 7→ lnx
1−1 x
yx 7→ ln |x|
Esempio Grafico di g(x) = e|x|.
1
x
y
x 7→ ex
1
x
y
x 7→ e|x|
Esempio Grafico di g(x) =√
|x|. La funzione e definita in tutto R.
x
y
x 7→ √xx
y
x 7→√
|x|
Esempio Grafico di g(x) = (|x| − 1)2.
1
1 x
y
x 7→ (x− 1)2
1−1
1
x
y
x 7→ (|x| − 1)2
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
152
(f) Grafico di x 7→ f(x+ k).
Detto a parole: si muove il grafico di f verso sinistra se k e positivo e verso destra se k e negativo.157 Ecco undisegno che illustra la trasformazione:
x 7→ f(x)
x
k > 0 k < 0
x 7→ f(x+ k)
x
Esempio Grafico di g(x) = ln(x+ 1). La funzione e definita per x > −1.
1 x
yx 7→ lnx
−1 x
yx 7→ lnx
x 7→ ln(x+ 1)
Esempio Grafico di g(x) =√x− 1. La funzione e definita per x ≥ 1.
x
y
x 7→ √x
1 x
y x 7→ √x
x 7→√x− 1
Esempio Grafico di g(x) = 1x−1 . La funzione e definita per x 6= 1.
x
y
x 7→ 1x
1 x
y
x 7→ 1x−1
Esempio Grafico di g(x) = ex+1.
1
x
y
x 7→ ex
1
e
x
y
x 7→ ex
x 7→ ex+1
157Attenzione. Non e come potrebbe sembrare: se k e positivo il grafico va spostato verso sinistra. Non e difficile capire il perche. Siconsideri ad esempio x 7→ f(x+ 1): questa funzione assume in x il valore che f assume in x+ 1, quindi e chiaro che il grafico di f(x+ 1) espostato a sinistra rispetto al grafico di f .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
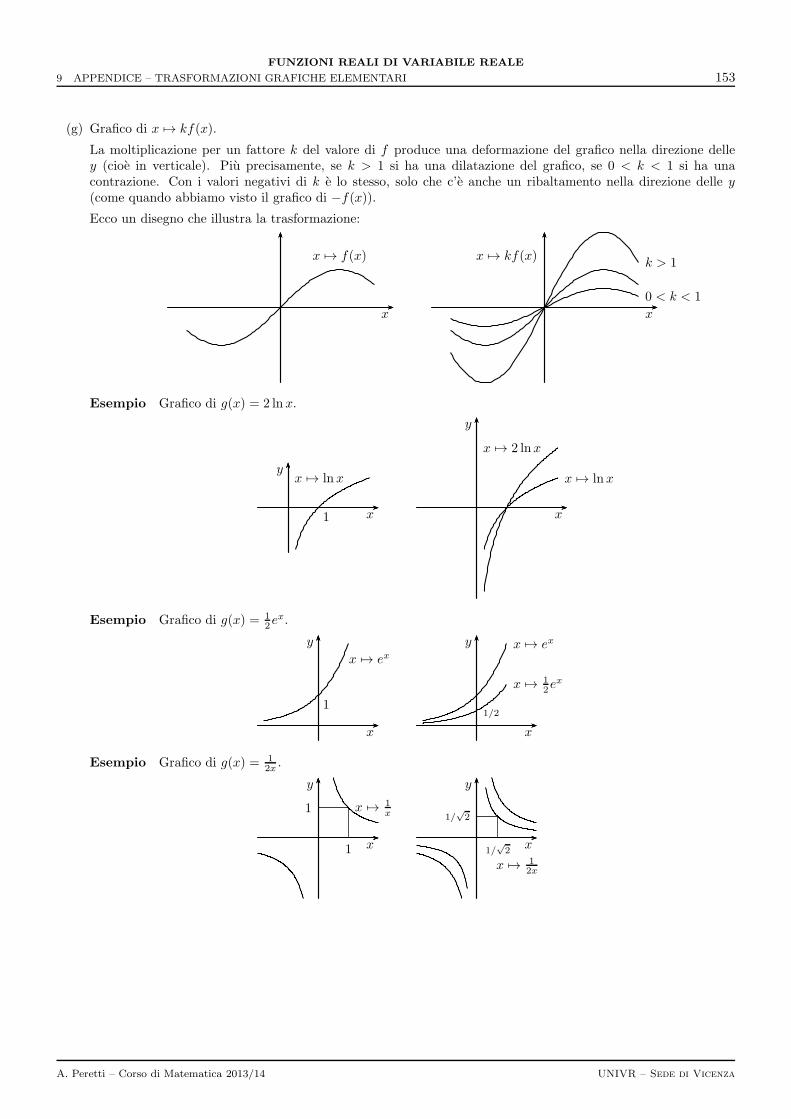
9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
153
(g) Grafico di x 7→ kf(x).
La moltiplicazione per un fattore k del valore di f produce una deformazione del grafico nella direzione delley (cioe in verticale). Piu precisamente, se k > 1 si ha una dilatazione del grafico, se 0 < k < 1 si ha unacontrazione. Con i valori negativi di k e lo stesso, solo che c’e anche un ribaltamento nella direzione delle y(come quando abbiamo visto il grafico di −f(x)).Ecco un disegno che illustra la trasformazione:
x 7→ f(x)
x
x 7→ kf(x)k > 1
0 < k < 1
x
Esempio Grafico di g(x) = 2 lnx.
1 x
yx 7→ lnx
x
y
x 7→ lnx
x 7→ 2 lnx
Esempio Grafico di g(x) = 12e
x.
1
x
y
x 7→ ex
1/2
x
y x 7→ ex
x 7→ 12e
x
Esempio Grafico di g(x) = 12x .
1
1
x
y
x 7→ 1x
1/√2
1/√2
x
y
x 7→ 12x
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
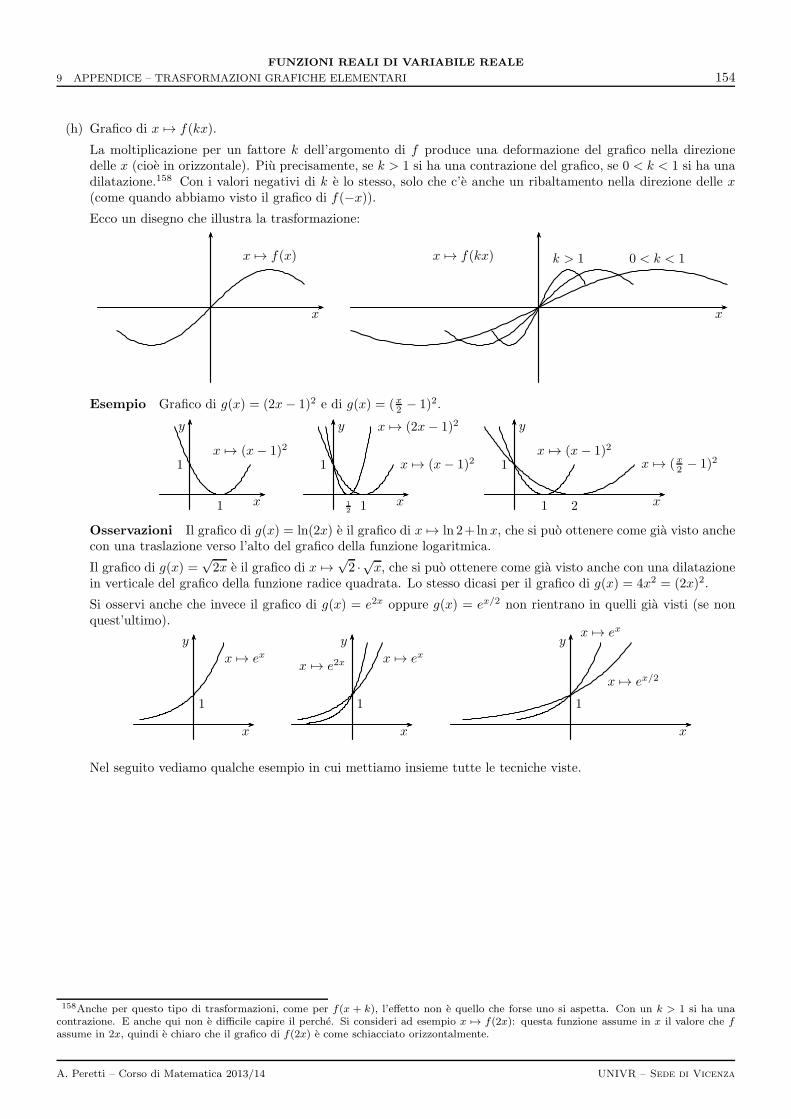
9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
154
(h) Grafico di x 7→ f(kx).
La moltiplicazione per un fattore k dell’argomento di f produce una deformazione del grafico nella direzionedelle x (cioe in orizzontale). Piu precisamente, se k > 1 si ha una contrazione del grafico, se 0 < k < 1 si ha unadilatazione.158 Con i valori negativi di k e lo stesso, solo che c’e anche un ribaltamento nella direzione delle x(come quando abbiamo visto il grafico di f(−x)).Ecco un disegno che illustra la trasformazione:
x 7→ f(x)
x
x 7→ f(kx) k > 1 0 < k < 1
x
Esempio Grafico di g(x) = (2x− 1)2 e di g(x) = (x2 − 1)2.
1
1 x
y
x 7→ (x− 1)2
112
1
x
y
x 7→ (x− 1)2
x 7→ (2x− 1)2
1 2
1
x
y
x 7→ (x− 1)2
x 7→ (x2 − 1)2
Osservazioni Il grafico di g(x) = ln(2x) e il grafico di x 7→ ln 2+ lnx, che si puo ottenere come gia visto anchecon una traslazione verso l’alto del grafico della funzione logaritmica.
Il grafico di g(x) =√2x e il grafico di x 7→
√2 ·√x, che si puo ottenere come gia visto anche con una dilatazione
in verticale del grafico della funzione radice quadrata. Lo stesso dicasi per il grafico di g(x) = 4x2 = (2x)2.
Si osservi anche che invece il grafico di g(x) = e2x oppure g(x) = ex/2 non rientrano in quelli gia visti (se nonquest’ultimo).
1
x
y
x 7→ ex
1
x
y
x 7→ exx 7→ e2x
1
x
yx 7→ ex
x 7→ ex/2
Nel seguito vediamo qualche esempio in cui mettiamo insieme tutte le tecniche viste.
158Anche per questo tipo di trasformazioni, come per f(x + k), l’effetto non e quello che forse uno si aspetta. Con un k > 1 si ha unacontrazione. E anche qui non e difficile capire il perche. Si consideri ad esempio x 7→ f(2x): questa funzione assume in x il valore che fassume in 2x, quindi e chiaro che il grafico di f(2x) e come schiacciato orizzontalmente.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
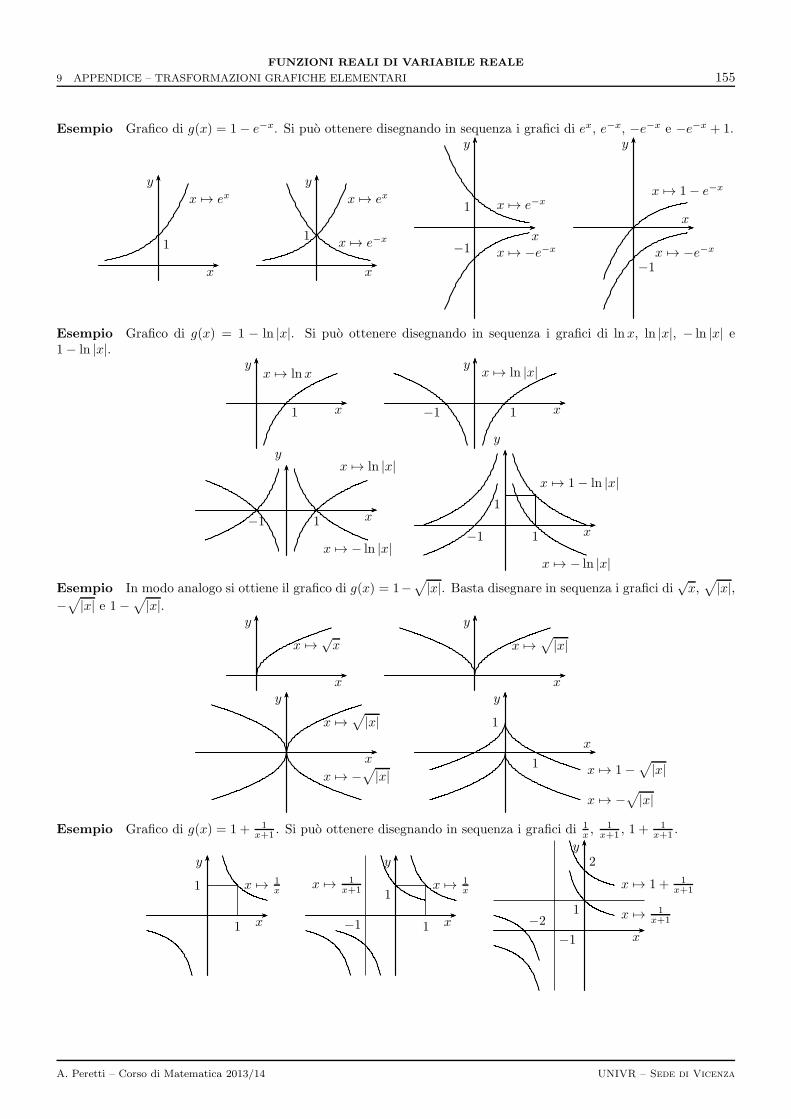
9 APPENDICE – TRASFORMAZIONI GRAFICHE ELEMENTARI
FUNZIONI REALI DI VARIABILE REALE
155
Esempio Grafico di g(x) = 1− e−x. Si puo ottenere disegnando in sequenza i grafici di ex, e−x, −e−x e −e−x + 1.
1
x
y
x 7→ ex
1
x
y
x 7→ ex
x 7→ e−x
1
−1x
y
x 7→ e−x
x 7→ −e−x
−1
x
y
x 7→ −e−x
x 7→ 1− e−x
Esempio Grafico di g(x) = 1 − ln |x|. Si puo ottenere disegnando in sequenza i grafici di lnx, ln |x|, − ln |x| e1− ln |x|.
1 x
yx 7→ lnx
1−1 x
yx 7→ ln |x|
1−1 x
yx 7→ ln |x|
x 7→ − ln |x|1−1
1
x
y
x 7→ − ln |x|
x 7→ 1− ln |x|
Esempio In modo analogo si ottiene il grafico di g(x) = 1−√
|x|. Basta disegnare in sequenza i grafici di√x,√
|x|,−√
|x| e 1−√
|x|.
x
y
x 7→ √x
x
y
x 7→√
|x|
x
y
x 7→√
|x|
x 7→ −√
|x|
x
y
1
1
x 7→ −√
|x|
x 7→ 1−√
|x|
Esempio Grafico di g(x) = 1 + 1x+1 . Si puo ottenere disegnando in sequenza i grafici di 1
x ,1
x+1 , 1 +1
x+1 .
1
1
x
y
x 7→ 1x
1
1
−1 x
y
x 7→ 1x
x 7→ 1x+1
−1−2
1
2
x
y
x 7→ 1x+1
x 7→ 1 + 1x+1
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 I VARI CASI DI LIMITE
LIMITI
156
II-4 Limiti
Il concetto di limite e fondamentale. Importanti concetti matematici che seguono sono definiti attraverso il concettodi limite. Nonostante questa rilevanza, in queste dispense rinuncio a dare la definizione rigorosa di tale concetto. Milimito a presentare, con l’ausilio grafico, le varie situazioni possibili.Vediamo in seguito alcuni limiti di funzioni elementari e successivamente presento alcune tecniche di calcolo dei limiti,valide piu in generale. Finisco con l’importante questione del confronto tra funzioni e con un limite fondamentale.
1 I vari casi di limite
Cerchiamo di capire subito il significato concreto di quello che vogliamo definire. Se abbiamo una funzione, puosuccedere che non possiamo calcolare il valore che essa assume in corrispondenza di tutti i numeri reali, per il semplicefatto che, come abbiamo visto, ci sono funzioni che non sono definite in tutto R.Supponiamo ad esempio che la funzione f sia definita in un intervallo e che non sia definita in un punto, chiamiamoloc, di tale intervallo, pur essendo definita in prossimita di c, cioe in tutti i punti di un intorno di c. Non possiamocalcolare f(c), pero possiamo chiederci: se la variabile x della nostra funzione si avvicina “infinitamente” al punto c(e questo lo puo fare perche f e definita attorno a c), a quale valore, se c’e, si avvicina il valore di f(x)? Questo valoree appunto il limite per x che tende a c della funzione f .Vediamo i diversi casi che si possono presentare. Considereremo soltanto funzioni definite su intervalli, che potrannoessere limitati o illimitati.
1.1 Limite finito al finito
Si parla di limite finito al finito quando il valore a cui tende la variabile x e un numero reale ed il limite e pure unnumero reale (non abbiamo quindi a che fare con infiniti).
1.1.1 Limite per x→ a+ (limite destro)
Sia f : (a, b)→ R, con (a, b) intervallo limitato di R.
Definizione Si scrivelim
x→a+f(x) = ℓ , con ℓ ∈ R
se, quando la variabile x si avvicina ad a da valori piu grandi di a (possiamo dire piusemplicemente “da destra”), il corrispondente valore di f(x) si avvicina al valore ℓ.
a b
ℓ
ℓ−ε
ℓ+ε
()
a+δ)bc
bc
bc
bc
x
y
Qualche commento.
Osservazione Si osservi che nella scrittura di limite l’eventuale valore f(a) (dico eventuale perche la funzionepotrebbe non essere definita in a e quindi non aver nessun valore in a) non compare, quindi non e rilevante. Sonorilevanti solo i valori x vicini ad a e i corrispondenti valori di questi x.Adesso vediamo gli altri casi.
1.1.2 Limite per x→ b− (limite sinistro)
Sia sempre f : (a, b)→ R, con (a, b) intervallo limitato di R.
Definizione Si scrivelim
x→b−f(x) = ℓ , con ℓ ∈ R
se, quando la variabile x si avvicina a b da valori piu piccoli di b (possiamo dire piusemplicemente “da sinistra”), il corrispondente valore di f(x) si avvicina al valore ℓ.
Osservazione Anche in questo caso non e rilevante l’eventuale valore f(b). a b
ℓ
ℓ−ε
ℓ+ε
()
b−δ(bc
bc
bc
bc
x
y
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 I VARI CASI DI LIMITE
LIMITI
157
1.1.3 Limite per x→ c (limite bilatero)
Sia (a, b) un intervallo e sia c ∈ (a, b). Sia poi f : (a, b) \ {c} → R. 159
Definizione Si scrive
limx→c
f(x) = ℓ , con ℓ ∈ R
se, quando la variabile x si avvicina a c, da destra e da sinistra, il corrispondentevalore di f(x) si avvicina al valore ℓ.
a b
ℓ
c
ℓ−ε
ℓ+ε
()
c−δ c+δ( )bc
bc
bc
bc
bc
bc
x
y
Osservazione Si osservi che qui, analogamente a quanto fatto prima con i limiti da destra e da sinistra, non erilevante l’eventuale valore f(c).Di solito il limite bilatero si chiama semplicemente limite. Quindi, dicendo limite, si allude al limite bilatero.
Osservazione Ribadisco che, dicendo “limite”, senza precisare se limite destro o limite sinistro, si intende limite dadestra e da sinistra.Si potrebbe dimostrare rigorosamente, ma e abbastanza facile intuirlo, che il limite esiste se e solo se esistono esono uguali il limite destro e il limite sinistro. Puo essere comodo talvolta (e lo faremo tra breve) calcolare il limitecalcolando separatamente il limite destro e il limite sinistro.
1.2 Limite finito all’infinito
Si parla di limite finito all’infinito quando la variabile tende a +∞ o a −∞ e il limite e un numero reale.Sia f : (a,+∞)→ R.
Definizione Si scrive
limx→+∞
f(x) = ℓ , con ℓ ∈ R
se, quando la variabile x assume valori che tendono a +∞, i corrispondentivalori di f(x) si avvicinano al valore ℓ.
a
ℓ
ℓ−ε
ℓ+ε
()
δ(bc
bc
x
y
Definizione Se f : (−∞, b)→ R, si scrive
limx→−∞
f(x) = ℓ , con ℓ ∈ R
se, quando la variabile x assume valori che tendono a −∞, i corrispondenti valori dif(x) si avvicinano al valore ℓ.
b
ℓ
ℓ−ε
ℓ+ε(
)
δ) bc
bc
x
y
Osservazione Se il limite di una funzione, per x→ c (c finito o infinito), e zero, si dice che la funzione e infinitesimao che e un infinitesimo, per x→ c. Attenzione. Se affermiamo che una funzione e infinitesima dobbiamo sempre direanche per x che tende a quale valore. Attenzione ancora: una funzione e infinitesima per x che tende a qualche cosase il suo limite e zero, a prescindere da cio a cui tende x (x puo tendere anche all’infinito).Possiamo quindi dire che la funzione f(x) = 1
x e infinitesima a +∞ e a −∞, e che la funzione esponenziale f(x) = ex
e infinitesima a −∞.
1.3 Limite infinito al finito
Si parla di limite infinito al finito quando la variabile tende ad un numero reale e il limite e +∞ o −∞. Anche qui c’eovviamente la possibilita di un limite solo da destra o solo da sinistra. Ecco la definizione nel caso del limite bilatero.
159La scrittura (a, b) \ {c}, come lo studente dovrebbe ricordare, indica l’intervallo (a, b) privato del punto c. Quindi si considera unafunzione che e definita in (a, c) ∪ (c, b), e cioe puo non essere definita nel punto c.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 I VARI CASI DI LIMITE
LIMITI
158
Definizione Si scrivelimx→c
f(x) = +∞
se, quando la variabile x si avvicina a c, da destra e da sinistra, i corrispondenti valoridi f(x) tendono a +∞.
a bc
ε (
c−δ c+δ( )bc
bc
bc
bc
bc
x
y
Naturalmente possiamo avere i casi di limite da destra e da sinistra.
limx→a+
f(x) = +∞
se, quando la variabile x si avvicina ad a da destra, i corrispondenti valori di f(x)tendono a +∞ (rappresentato qui a fianco), e
limx→b−
f(x) = +∞
se, quando la variabile x si avvicina a b da sinistra, i corrispondenti valori di f(x)tendono a +∞.
a b
ε (
a+δ)bc bc
bc
x
y
Poi abbiamo il caso del limite −∞.
Definizione Si scrivelimx→c
f(x) = −∞
se, quando la variabile x si avvicina a c, da destra e da sinistra, i corrispondenti valori di f(x) tendono a −∞.
Osservazione Se scrivessimo invece limx→0
1
x, senza precisare se da destra o da sinistra, dovremmo dire che tale limite
non esiste. Tra breve vediamo meglio questo aspetto.
1.4 Limite infinito all’infinito
Si parla di limite infinito all’infinito quando la variabile tende a +∞ o −∞ e il limite e +∞ o −∞. Dei quattro casipossibili ne vediamo solo uno, e lascio allo studente il compito di considerare gli altri casi.
Definizione Si scrivelim
x→+∞f(x) = −∞
se, quando la variabile x assume valori che tendono a +∞, i corrispondenti valori dif(x) tendono a −∞.
a
ε )
δ(bc
bcx
y
Osservazione Se il limite di una funzione, per x → c (c anche infinito), e +∞ o −∞, si dice che la funzione einfinita o che e un infinito, per x→ c. Attenzione anche qui. Occorre sempre precisare per x che tende a quale valore.E ancora, la funzione e un infinito se il suo limite e infinito, a prescindere da cio a cui tende x (x puo tendere anchea zero o a un qualunque numero reale).Possiamo quindi, ad esempio, dire che la funzione f(x) = 1
x e infinita in 0+ e in 0− (cioe per x che tende a zero dadestra o da sinistra), che la funzione f(x) = 1
x2 e infinita per x→ 0, e che la funzione logaritmica f(x) = lnx e infinitaper x→ 0+. Ancora: la funzione logaritmica e la funzione esponenziale sono degli infiniti per x→ +∞.
Le definizioni di limite finiscono qui, salvo un approfondimento che vediamo subito ma che non comporta sostanzialinovita rispetto a quanto visto finora.Si tratta di una situazione che puo risultare a volte importante nel calcolo dei limiti. Abbiamo visto all’inizio ilcaso di limite finito al finito, in cui la funzione tende ad un certo valore reale ℓ quando la sua variabile tende ad uncerto valore reale c. Mentre abbiamo considerato i due casi che la variabile tenda al valore c da destra o da sinistra(x→ c+ e x→ c−), non abbiamo distinto i casi in cui la funzione tende al suo limite da destra o da sinistra (data larappresentazione che solitamente facciamo delle funzioni, che porta a riportare i valori della funzione sull’asse verticale,sarebbe forse piu opportuno dire dall’alto o dal basso), cioe da valori piu grandi o piu piccoli.Ecco, ora vediamo come si interpretano graficamente queste due situazioni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 ALCUNI TEOREMI SUI LIMITI
LIMITI
159
Diremo che la funzione f tende al limite ℓ da valori piu grandi, e scriveremo
limx→c
f(x) = ℓ+,
se, quando la variabile x si avvicina a c, da destra e da sinistra, il corrispondente valore di f(x) si avvicina al valore ℓda valori piu grandi di ℓ.Diremo invece che la funzione f tende al limite ℓ da valori piu piccoli, e scriveremo
limx→c
f(x) = ℓ−,
se, quando la variabile x si avvicina a c, da destra e da sinistra, il corrispondente valore di f(x) si avvicina al valore ℓda valori piu piccoli di ℓ.
Osservazione Possiamo naturalmente definire il limite da valori piu grandi o piu piccoli anche se la x tendeall’infinito. Sarebbe bene che lo studente provasse a rappresentarsi graficamente questi casi.
Esempi Vediamo qualche esempio (lo studente si convinca di quanto scrivo attraverso un disegno dei vari grafici).
• Si halim
x→0+x3 = 0+ e lim
x→0−x3 = 0− mentre lim
x→0−x2 = 0+.
• Si halim
x→1+lnx = 0+ e lim
x→1−lnx = 0−.
• Si halim
x→−∞ex = 0+.
• Si halim
x→1+x2 = 1+ e lim
x→(−1)+x2 = 1−.
Osservazione Le prime non pongono grossi problemi (lo studente puo cercare di darsene una ragione ricordando ilgrafico delle funzioni coinvolte). Attenzione all’ultima. Non e un errore di chi scrive: il limite a 1+ di x2 e 1+ e illimite della stessa funzione a (−1)+ e 1−. Anche qui per convincersene basta il grafico. Quindi attenzione quando cisono elevamenti al quadrato di quantita negative.
Osservazione La domanda che a questo punto gli studenti fanno e: ma se il limite e, mettiamo, zero occorre sempreprecisare se e uno 0+ o uno 0−? La domanda e certamente lecita. Va detto anzitutto che ad una domanda diretta(tipo i limiti degli esempi qui sopra), se il limite e 0+ non e sbagliato dire che il limite e 0. Dire che e 0+ e un’ulterioreprecisazione. In qualche caso concreto di calcolo di limite (ne vedremo piu avanti) per concludere correttamente enecessario capire se un limite (di una parte della funzione) e da valori piu grandi o piu piccoli.La risposta alla domanda e quindi: non sempre, ma in qualche caso sı. Non vi posso pero dare una regola generale.Occorre vedere caso per caso. Di solito si procede cosı: si prova a calcolare il limite usando semplicemente 0; se nonsi riesce a concludere si cerca di precisare se e uno 0+ o uno 0−.
2 Alcuni teoremi sui limiti
Viste le diverse situazioni di limite, ora e intanto opportuno sgombrare il campo da un possibile fraintendimento.Non si deve pensare che, data una funzione f e dato un punto c in cui abbia senso fare il limite, esista sempre illimx→c f(x). In altre parole il limite puo non esserci (cioe non esistere). Sarebbe il caso che io fornissi un esempio diquesta affermazione. Si potrebbero scomodare le funzioni trigonometriche, ma non ne abbiamo mai parlato e non lofaro solo per dare un esempio di non esistenza del limite.Si consideri la funzione
f(x) =
{1 x ∈ N
0 x /∈ N.
E una funzione, definita sui numeri reali, che assume valore 1 se l’argomento e un numero naturale e assume il valorezero se l’argomento invece non e un numero naturale. Lo studente ne disegni il grafico e cerchi di convincersi che il
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
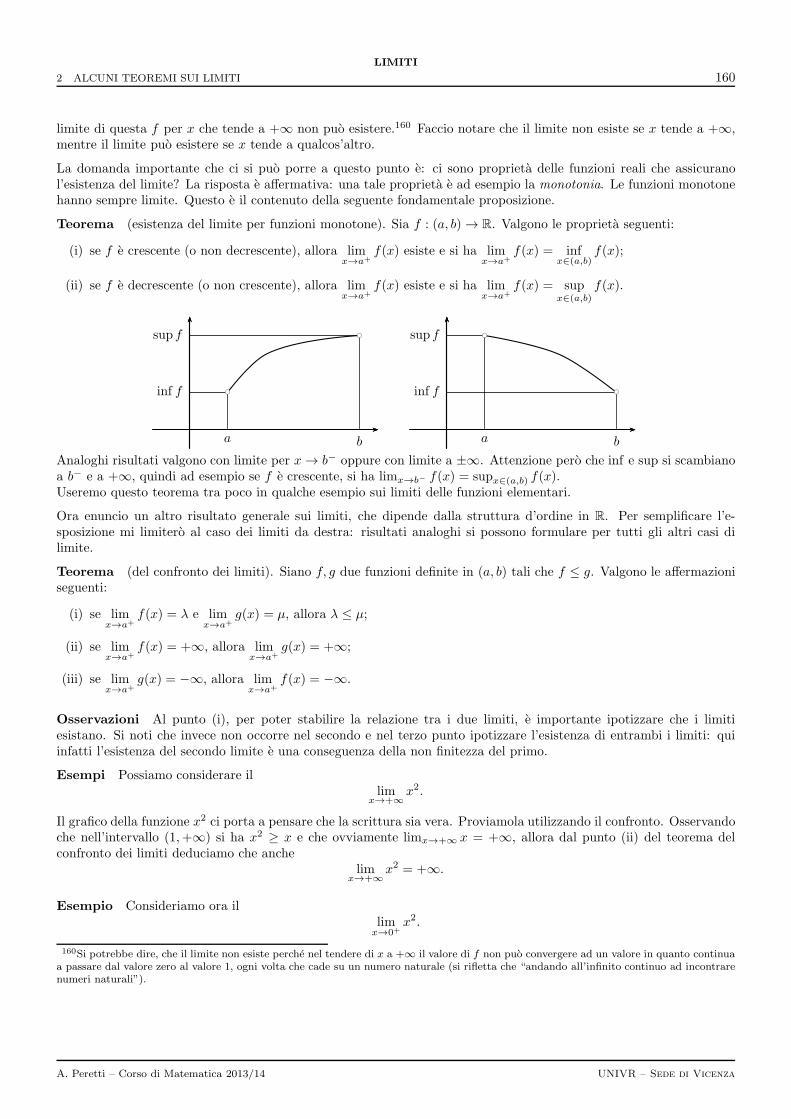
2 ALCUNI TEOREMI SUI LIMITI
LIMITI
160
limite di questa f per x che tende a +∞ non puo esistere.160 Faccio notare che il limite non esiste se x tende a +∞,mentre il limite puo esistere se x tende a qualcos’altro.
La domanda importante che ci si puo porre a questo punto e: ci sono proprieta delle funzioni reali che assicuranol’esistenza del limite? La risposta e affermativa: una tale proprieta e ad esempio la monotonia. Le funzioni monotonehanno sempre limite. Questo e il contenuto della seguente fondamentale proposizione.
Teorema (esistenza del limite per funzioni monotone). Sia f : (a, b)→ R. Valgono le proprieta seguenti:
(i) se f e crescente (o non decrescente), allora limx→a+
f(x) esiste e si ha limx→a+
f(x) = infx∈(a,b)
f(x);
(ii) se f e decrescente (o non crescente), allora limx→a+
f(x) esiste e si ha limx→a+
f(x) = supx∈(a,b)
f(x).
bc
bc
a b
inf f
sup f
a b
bc
bcinf f
sup f
Analoghi risultati valgono con limite per x→ b− oppure con limite a ±∞. Attenzione pero che inf e sup si scambianoa b− e a +∞, quindi ad esempio se f e crescente, si ha limx→b− f(x) = supx∈(a,b) f(x).Useremo questo teorema tra poco in qualche esempio sui limiti delle funzioni elementari.
Ora enuncio un altro risultato generale sui limiti, che dipende dalla struttura d’ordine in R. Per semplificare l’e-sposizione mi limitero al caso dei limiti da destra: risultati analoghi si possono formulare per tutti gli altri casi dilimite.
Teorema (del confronto dei limiti). Siano f, g due funzioni definite in (a, b) tali che f ≤ g. Valgono le affermazioniseguenti:
(i) se limx→a+
f(x) = λ e limx→a+
g(x) = µ, allora λ ≤ µ;
(ii) se limx→a+
f(x) = +∞, allora limx→a+
g(x) = +∞;
(iii) se limx→a+
g(x) = −∞, allora limx→a+
f(x) = −∞.
Osservazioni Al punto (i), per poter stabilire la relazione tra i due limiti, e importante ipotizzare che i limitiesistano. Si noti che invece non occorre nel secondo e nel terzo punto ipotizzare l’esistenza di entrambi i limiti: quiinfatti l’esistenza del secondo limite e una conseguenza della non finitezza del primo.
Esempi Possiamo considerare illim
x→+∞x2.
Il grafico della funzione x2 ci porta a pensare che la scrittura sia vera. Proviamola utilizzando il confronto. Osservandoche nell’intervallo (1,+∞) si ha x2 ≥ x e che ovviamente limx→+∞ x = +∞, allora dal punto (ii) del teorema delconfronto dei limiti deduciamo che anche
limx→+∞
x2 = +∞.
Esempio Consideriamo ora illim
x→0+x2.
160Si potrebbe dire, che il limite non esiste perche nel tendere di x a +∞ il valore di f non puo convergere ad un valore in quanto continuaa passare dal valore zero al valore 1, ogni volta che cade su un numero naturale (si rifletta che “andando all’infinito continuo ad incontrarenumeri naturali”).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 LIMITI DI FUNZIONI ELEMENTARI
LIMITI
161
Anche qui lo stesso: il grafico ci porta a dire che il limite e 0, ma proviamolo utilizzando il confronto. Possiamo direche nell’intervallo (0, 1) si ha x2 ≥ 0 e x2 ≤ x. 161 Il limite in questione esiste in quanto la funzione x 7→ x2 e monotona(crescente) in (0, 1). 162 Per il punto (i) del terorema del confronto possiamo dire allora che
limx→0+
x2 ≥ 0 e anche limx→0+
x2 ≤ limx→0+
x = 0.
Quindi il limite cercato e zero.
3 Limiti di funzioni elementari
In questa sezione, rinunciando a verificare i limiti attraverso una definizione formale, mi limito a dare alcuni risultatibasandomi sui grafici delle funzioni elementari, che abbiamo visto nella dispensa precedente sulle funzioni reali. Lostudente cerchi di capire che quanto ora diro e ben lontano dall’essere una dimostrazione. Occorrerebbe naturalmentedimostrare che i grafici gia visti sono effettivamente quelli corretti.Faro anche uso del teorema di esistenza del limite per funzioni monotone, visto nella sezione precedente, per illustrarequanto puo essere comodo il suo utilizzo.
• Cominciamo con una funzione elementare molto semplice, una funzione costante f(x) = k, il cui grafico e unaretta orizzontale di ordinata k. Si ha naturalmente lim
x→cf(x) = k, dove c e un qualunque valore reale o anche un
infinito.
• Consideriamo f(x) = x, il cui grafico e la retta bisettrice del primo e terzo quadrante. Si ha limx→c
x = c.
Con il teorema di esistenza e molto semplice. La funzione e crescente e possiamo procedere cosı. Consideriamoun intervallo (c, b) (con c < b); per il teorema di esistenza possiamo affermare che lim
x→c+x = inf
x∈(c,b)x = c.
Consideriamo ora un intervallo (a, c) (con a < c); per il teorema di esistenza possiamo affermare che limx→c−
x =
supx∈(a,c)
x = c. Pertanto limite destro e limite sinistro esistono e sono uguali, e quindi c e il valore del limite.
Si ha anche limx→+∞
x = supx∈R
x = +∞ e limx→−∞
x = infx∈R
x = −∞.
• Consideriamo f(x) = x2, il cui grafico e come noto una parabola con vertice nell’origine. Si ha limx→c
x2 = c2.
Supponiamo che sia c > 0. Possiamo affermare che esiste un intervallo (c − δ, c+ δ) in cui x 7→ x2 e crescente.Quindi si ha
limx→c+
f(x) = infc<x<b
x2 = c2 e limx→c−
f(x) = supa<x<c
x2 = c2.
Pertanto otteniamo la tesi. Lo studente adatti la dimostrazione nel caso c < 0 e nel caso c = 0.163
Si ha anche limx→+∞
x2 = limx→−∞
x2 = +∞.
• Con la funzione f(x) = x3 le cose non sono molto diverse, anzi sono piu semplici in quanto la funzione e oracrescente in tutto R. Si ha quindi lim
x→cx3 = c3.
Si ha inoltre limx→+∞
x3 = +∞ e limx→−∞
x3 = −∞.
• Si intuisce che per tutte le funzioni potenza vale il risultato
limx→c
xα = cα. 164
Inoltre, se α > 0, si ha limx→+∞
xα = +∞; se α < 0, si ha limx→+∞
xα = 0. Ancora, se α < 0, si ha limx→0+
xα = +∞(basta ricordare il grafico delle funzioni potenza).
161Si osservi che la prima disuguaglianza vale in realta in tutto R, mentre la seconda vale solo in [0, 1].162In effetti si puo provare che il limite e zero anche con il teorema si esistenza per funzioni monotone.163Attenzione che con c = 0 la funzione non e monotona in un intorno di c. Occorre quindi procedere separatamente con il limite destroe il limite sinistro.164Si ricordi che la funzione potrebbe essere definita solo in [0,+∞) o in (0,+∞), ma che comunque si tratta di una funzione monotona.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 ALGEBRA DEI LIMITI
LIMITI
162
• Per la funzione esponenziale f(x) = bx si puo dimostrare che
limx→c
bx = bc.
Inoltre, se b > 1, si ha limx→+∞
bx = +∞ e limx→−∞
bx = 0; se b < 1, si ha limx→+∞
bx = 0 e limx→−∞
bx = +∞ (ricordare
il grafico della funzione esponenziale).
• Per la funzione logaritmica f(x) = logb x, definita in (0,+∞), si ha
limx→c
logb x = logb c.
Inoltre, se b > 1, si ha limx→+∞
logb x = +∞ e limx→0+
logb x = −∞; se b < 1, si ha limx→+∞
logb x = −∞ e
limx→0+
logb x = +∞ (ricordare il grafico della funzione logaritmica).
4 Algebra dei limiti
Ecco un teorema molto utile nel calcolo dei limiti. Lo enuncio con riferimento al caso del limite destro, ma comesempre risultati analoghi valgono in tutti gli altri casi.
Teorema Siano f, g : (a, b)→ R, e supponiamo che sia
limx→a+
f(x) = λ e limx→a+
g(x) = µ , con λ, µ ∈ R (cioe numeri reali finiti).
Valgono le affermazioni seguenti:
(i) limx→a+
(f(x) + g(x)
)= λ+ µ (limite della somma);
(ii) limx→a+
(f(x)g(x)
)= λµ (limite del prodotto);
(iii) se µ 6= 0, allora limx→a+
f(x)
g(x)=λ
µ(limite del quoziente).
Osservazione C’e poco da aggiungere. Se i limiti sono finiti, per fare il limite di una somma si fa la somma deilimiti, per il limite del prodotto il prodotto dei limiti e per il limite del quoziente il quoziente dei limiti, sempre che ildenominatore non si annulli. Da questo teorema sono pero esclusi molti casi, ad esempio quelli in cui uno (o tutti edue) i limiti siano infiniti. Ma non solo: e se ho un quoziente e il denominatore tende a zero?Per riuscire a risolvere qualche caso, fornisco ora alcune regole di calcolo, peraltro abbastanza “naturali”.Se nel calcolo del nostro limite ci troviamo di fronte ad una delle situazioni indicate, il risultato e quello indicato (ℓrappresenta sempre un limite finito):
(i) se ℓ ∈ R,
ℓ+ (+∞) = +∞ , ℓ+ (−∞) = −∞ 165 ,ℓ
−∞ = 0 ,ℓ
+∞ = 0
(ii) se ℓ ∈ R e ℓ > 0,ℓ · (+∞) = +∞ , ℓ · (−∞) = −∞
(iii) se ℓ ∈ R e ℓ < 0,ℓ · (+∞) = −∞ , ℓ · (−∞) = +∞
(iv) inoltre(+∞) + (+∞) = +∞ , (−∞) + (−∞) = −∞
e(+∞) · (+∞) = +∞ , (+∞) · (−∞) = −∞ , (−∞) · (−∞) = +∞.
165Valendo la proprieta commutativa, sussistono anche le analoghe regole “scambiate”: (+∞) + ℓ = +∞ e (−∞) + ℓ = −∞. Lo stessoper quanto riguarda le regole che seguono sui prodotti.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 ALGEBRA DEI LIMITI
LIMITI
163
Si potrebbe ora dimostrare che non e invece possibile definire regole nei seguenti casi:166
(−∞) + (+∞) , 0 · (+∞) , 0 · (−∞) ,ℓ
0,±∞0
,±∞±∞
(solite considerazioni sulla commutativita).Per la verita, per i due casi
ℓ
0, con ℓ 6= 0, e
±∞0,
se riusciamo a stabilire “il segno dello zero a denominatore”, possiamo dare una regola, che si puo esprimere in formasintetica (e impropria) ma efficace, con le scritture:
ℓ > 0
0+= +∞ ,
ℓ < 0
0+= −∞ ,
ℓ > 0
0−= −∞ ,
ℓ < 0
0−= +∞
e+∞0+
= +∞ ,−∞0+
= −∞ ,+∞0−
= −∞ ,−∞0−
= +∞.
Chiamiamo infine forma indeterminata (f.i) uno qualunque dei casi che restano, e che per comodita riscrivo:
(−∞) + (+∞) , 0 · (±∞) ,0
0,±∞±∞ .
In realta ci sono altre forme indeterminate, che non riguardano pero le operazioni algebriche fondamentali. Questealtre forme, che potremmo chiamare forme indeterminate esponenziali, sono:
(0+)0 , (+∞)0 , 1±∞.
Esse, come vedremo piu avanti, si possono ricondurre alle precedenti.
Esempi
• Consideriamo il limitelimx→1
(ex + lnx).
La funzione esponenziale tende ad e per x→ 1 e la funzione logaritmica tende a 0. Non si tratta quindi di unaforma indeterminata e risulta
limx→1
(ex + lnx) = e+ 0 = e.
• limx→0+
(x+ lnx) = 0 + (−∞) = −∞.
• limx→1
(x lnx) = 1 · 0 = 0.
• limx→0+
((x+ 1) lnx) = 1 · (−∞) = −∞.
• limx→1
lnx
x=
0
1= 0.
• limx→−∞
ex
x=
0
−∞ = 0.
Nel caso si presenti una delle forme indeterminate, come si diceva il risultato del limite non e prevedibile. A titolo diesempio, consideriamo i tre limiti
limx→+∞
x+ 1
x, lim
x→+∞x+ 1
x2e lim
x→+∞x2 + 1
x.
Sono tutti della forma (indeterminata) +∞+∞ .
Ma per il primo
limx→+∞
x+ 1
x= (divido sopra e sotto per x) = lim
x→+∞1 + 1/x
1=
1 + 0
1= 1,
166Questo perche ci sono casi che rientrano tutti, ad esempio, nella prima tipologia e che danno risultati diversi. Quindi il risultato none prevedibile o, che e lo stesso, non si puo fornire una regola generale.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 ALGEBRA DEI LIMITI
LIMITI
164
per il secondo
limx→+∞
x+ 1
x2= (divido sopra e sotto per x) = lim
x→+∞1 + 1/x
x=
1 + 0
+∞ =1
+∞ = 0
e per il terzo
limx→+∞
x2 + 1
x= (divido sopra e sotto per x) = lim
x→+∞x+ 1/x
1=
+∞+ 0
1=
+∞1
= +∞.
Quindi la stessa forma indeterminata +∞+∞ puo dare origine a risultati diversi.
Osservazione Se riconsideriamo i limiti limx→0+
1
xe lim
x→0−
1
x, gia visti in precedenza con la definizione, ora possiamo
osservare che rientrano in quelli che sappiamo risolvere con le regole del calcolo, dato che
limx→0+
1
x=
1
0+= +∞ e lim
x→0−
1
x=
1
0−= −∞.
Si tratta di un caso in cui la conoscenza del segno dello zero a denominatore consente di stabilire il risultato.
Esempio Quale altro esempio di situazione in cui e importante l’idea di limite da valori piu grandi o piu piccoli,consideriamo il
limx→1−
(x
x− 1+
ex
ex − e
)
.
Si tratta di una forma del tipo 10 + e
0 ed e quindi importante stabilire il segno degli zeri a denominatore. Possiamoscrivere che
limx→1−
(x− 1) = 1− − 1 = 0− e limx→1−
(ex − e) = e− − e = 0−.
Pertanto si ha
limx→1−
(x
x− 1+
ex
ex − e
)
=1
0−+
e
0−= (−∞) + (−∞) = −∞.
Vediamo ora qualche esempio di calcolo di forme indeterminate.
• limx→+∞
(x2 − x). Si tratta di una f.i. +∞−∞. Si ha
limx→+∞
(x2 − x) = limx→+∞
(x(x − 1)) = (+∞) · (+∞− 1) = (+∞) · (+∞) = +∞.
Lo studente provi a risolverlo raccogliendo invece x2. Lo studente ancora verifichi che il limite a −∞ non einvece una f.i.
• La stessa tecnica consente di calcolare il limite agli infiniti di un qualunque polinomio. Vediamo ad esempio illim
x→+∞(2x3 − 3x2 + 5x− 1). Si tratta di una f.i. in quanto e presente una differenza di infiniti. Si ha
limx→+∞
(2x3 − 3x2 + 5x− 1) = limx→+∞
(
x3(
2− 3
x+
5
x2− 1
x3
))
= (+∞) · (2− 0 + 0− 0) = (+∞) · 2 = +∞.
Lo studente provi a calcolare il limite a −∞.
Osservazione A questo punto dovrebbe essere chiaro che il limite all’infinito di un polinomio e dato dal limiteall’infinito del suo monomio di grado massimo. Quindi i polinomi del tipo P (x) = axn + . . . (cioe con monomio digrado massimo axn) e a > 0 tendono a +∞ per x→ +∞ e a −∞ tendono a −∞ se n e dispari e a +∞ se n e pari.Passiamo al quoziente di due polinomi.
• limx→+∞
x3 + x− 1
2x2 − x+ 1. Si tratta di una f.i. (+∞)/(+∞). Si ha
limx→+∞
x3 + x− 1
2x2 − x+ 1= lim
x→+∞x3(1 + 1/x2 − 1/x3)
x2(2− 1/x+ 1/x2)= lim
x→+∞x(1 + 1/x2 − 1/x3)
2− 1/x+ 1/x2=
+∞ · 12
= +∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 ALGEBRA DEI LIMITI
LIMITI
165
• limx→+∞
x− 1
x2 + x+ 2. Si tratta di una f.i. (+∞)/(+∞). Si ha
limx→+∞
x− 1
x2 + x+ 2= lim
x→+∞x(1 − 1/x)
x2(1 + 1/x+ 2/x2)= lim
x→+∞1− 1/x
x(1 + 1/x+ 2/x2)=
1
+∞ · 1 = 0.
• limx→+∞
x2 − x3x2 + 1
. Si tratta ancora di una f.i. (+∞)/(+∞). Si ha
limx→+∞
x2 − x3x2 + 1
= limx→+∞
x2(1 − 1/x)
x2(3 + 1/x2)= lim
x→+∞1− 1/x
3 + 1/x2=
1
3.
Osservazione Questi tre esempi dovrebbero insegnare molto: una regola generale per trovare il limite di un quozientedi polinomi. Tutto dipende dal grado dei due polinomi. Lo studente trovi da solo la regola.Il raccoglimento risolve a volte forme indeterminate date dalla differenza di infiniti, ma non sempre. Sono da ricordarei seguenti esempi.
• limx→+∞
(x−√x). Si tratta di una f.i. +∞−∞. Si ha
limx→+∞
(x −√x) = limx→+∞
(x(1 − x−1/2)) = +∞ · 1 = +∞.
Si poteva anche fare
limx→+∞
(x−√x) = limx→+∞
(√x(√x− 1)) = (+∞) · (+∞) = +∞.
• limx→+∞
(
x−√
2x2 + 1)
. Si tratta ancora di una f.i. +∞−∞. Si ha
limx→+∞
(
x−√
2x2 + 1)
= limx→+∞
(
x
(
1−√2x2 + 1
x
))
= limx→+∞
(
x
(
1−√
2 +1
x2
))
= +∞ · (−1) = −∞.
• limx→+∞
(
x−√
x2 + 1)
. Si tratta ancora di una f.i. +∞−∞. Procedendo come prima si ha
limx→+∞
(
x−√
x2 + 1)
= limx→+∞
(
x
(
1−√x2 + 1
x
))
= limx→+∞
(
x
(
1−√
1 +1
x2
))
= +∞ · 0.
Come si vede questa volta cosı non si riesce ad eliminare la forma indeterminata. Occorre cambiare metodo. Sipuo razionalizzare.167 Moltiplicando sopra e sotto per la somma, cioe per (x+
√x2 + 1), si ha
limx→+∞
(
x−√
x2 + 1)
= limx→+∞
(x−√x2 + 1)(x+
√x2 + 1)
x+√x2 + 1
= limx→+∞
x2 − x2 − 1
x+√x2 + 1
=−1+∞ = 0.
Esercizio 4.1 Si calcolino i seguenti limiti usando l’algebra dei limiti.
(a) limx→2−
x
2− x (b) limx→−∞
2
1− x(c) lim
x→0+
1 + x
x(d) lim
x→−∞x
1 + 1/x
(e) limx→+∞
1 + 1/x
1 + x2(f) lim
x→+∞1 + e−x
1 + ex
(g) limx→0+
1 + x
lnx− 1(h) lim
x→0+
1/x
1− ex
(i) limx→0+
1/x
ln(1 + x)(j) lim
x→+∞(x+ ln(1 + 1/x))
(k) limx→0+
(x− lnx) (l) limx→1−
x
lnx
167Quando si ha una somma (differenza) di quantita sotto radice che danno origine ad una f.i., moltiplicando numeratore e denominatoreper la differenza (somma) si riesce ad eliminare le radici dal numeratore. Le radici compaiono a denominatore, ma non piu in formaindeterminata.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CONFRONTI TRA FUNZIONI
LIMITI
166
Esercizio 4.2 I seguenti limiti sono forme indeterminate. Si calcolino con opportuni raccoglimenti.
(a) limx→+∞
x− 1
1 + 2x(b) lim
x→−∞1− x21 + x2
(c) limx→+∞
x+ 1
1 + x3(d) lim
x→−∞x2 + x+ 1
x+ 1
(e) limx→0+
x+ x2
x2 + x3(f) lim
x→1+
x2 − 1
x2 − 3x+ 2
(g) limx→+∞
x+√x
x2 − 3√x
(h) limx→0+
x+√x
x2 − 3√x
(i) limx→+∞
x1/2 + x3/5
x4/3 + x3/2(j) lim
x→0+
x1/2 + x3/5
x4/3 + x3/2
(k) limx→+∞
(2x−√x
)(l) lim
x→+∞
(
2x−√
4x2 − 1)
(m) limx→−∞
(
x+√
|x|)
(n) limx→−∞
(
x+√
x2 + 1)
5 Confronti tra funzioni
Sono estremamente utili nel calcolo dei limiti i seguenti risultati.
Proposizione Valgono le proprieta:
1. limx→+∞
xα
bx= 0 per ogni α > 0 e b > 1;
2. limx→+∞
(logb x)p
xα= 0 per ogni b > 1, p > 0 e α > 0.
Osservazione Occorre anzitutto motivare le condizioni poste sui parametri α, b, p: il primo limite non sarebbesignificativo con α ≤ 0 e b > 1 (o con α ≥ 0 e b < 1), dato che non si tratterebbe di forme indeterminate. Considerazionianaloghe nel secondo limite. Le condizioni poste fanno sı che si tratti di limiti di quozienti tra funzioni dello stessotipo, cioe in questo caso tra infiniti (quindi di forme indeterminate del tipo +∞
+∞ ).
Osservazione Ovviamente, nel caso si presentino i limiti
limx→+∞
bx
xαe lim
x→+∞xα
(logb x)p
nelle stesse ipotesi sui parametri, il risultato e +∞ per entrambi.168
Osservazione I due punti della proposizione raccolgono molti casi particolari: si noti che la prima vale per ogni αmaggiore di 0 e per ogni b maggiore di 1, e la seconda e pure vera qualunque sia la scelta di b > 1, p e α positivi.
Esempi
• Il limx→+∞
x2
exvale zero, dato che e un caso particolare della prima (con α = 2, b = e).
Anche il limx→+∞
3√x
2xvale zero (con α = 1/3, b = 2).
• Il limx→+∞
lnx
xvale zero, essendo un caso particolare della seconda (con b = e, p = 1, α = 1).
Anche il limx→+∞
ln2 x√x
= limx→+∞
(lnx)2√x
vale zero (con b = e, p = 2, α = 1/2).
168Dato che possiamo scrivere
limx→+∞
bx
xα= lim
x→+∞
1
xα/bx=
1
0+= +∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CONFRONTI TRA FUNZIONI
LIMITI
167
Osservazione (importante) Consideriamo il primo dei due risultati appena visti, e cioe il fatto che
limx→+∞
xα
bx= 0.
Le due funzioni xα (una funzione potenza) e bx (una funzione esponenziale) tendono entrambe all’infinito per x chetende all’infinito. Il risultato del limite, cioe zero, ci da un’informazione che ha un’interpretazione interessante: seil quoziente tra due infiniti tende a zero significa che l’infinito che sta a numeratore e piu debole di quello che staa denominatore. In altre parole la funzione potenza tende all’infinito piu lentamente della funzione esponenziale. Eribadisco anche che, in virtu dell’osservazione precedente, questo fatto e generale, nel senso che una qualunque funzionepotenza e, all’infinito, un infinito piu debole di un qualunque infinito di tipo esponenziale.Si noti che il secondo risultato, e cioe il fatto che
limx→+∞
(logb x)p
xα= 0
ci dice invece che una qualunque funzione logaritmica e, all’infinito, un infinito piu debole di un qualunque infinito ditipo potenza.
I risultati appena visti suggeriscono una tecnica generale per effettuare un “confronto” tra due funzioni. Mi spiegomeglio. Supponiamo di avere due funzioni che ad esempio risultino infiniti per x che tende a +∞. Ha senso chiedersiquale delle due tenda all’infinito piu rapidamente. Un metodo molto efficace per stabilirlo e calcolare il limite per x chetende a +∞ del quoziente delle due funzioni. Come avviene per i confronti potenza/esponenziale e logaritmo/potenzaappena visti, potremo dire che, se il risultato del limite e zero, allora l’infinito a numeratore e piu debole dell’infinitoa denominatore (o, equivalentemente, che l’infinito a denominatore e piu forte dell’infinito a numeratore).Riflettendo brevemente si intuisce ora che questa tecnica e molto piu generale di quanto possa sembrare a prima vista.Infatti, per prima cosa x puo tendere a qualsiasi valore (ad esempio posso voler confrontare due infiniti per x che tendea −∞, a zero, uno, o qualsiasi altro valore). Secondo, posso anche usarla per confrontare due quantita che tendono azero.169 Prima di continuare vediamo un semplice esempio di confronto di infiniti all’infinito. Vogliamo confrontarela 3√x con la
5√x2, per x che tende a +∞. Quello che uno dovrebbe intuire facilmente, e cioe che l’infinito piu forte e
quello dato dalla potenza con esponente maggiore, e confermato dalla tecnica appena esposta. Se calcoliamo il limite
limx→+∞
3√x
5√x2
= limx→+∞
x1/3
x2/5= lim
x→+∞x−1/15 = lim
x→+∞1
x1/15=
1
+∞ = 0
possiamo concludere che 3√x e un infinito piu debole di
5√x2 (e infatti 1
3 <25 ).
Ora un confronto tra infiniti per x che tende a zero. Vogliamo confrontare la 1/√x con la 1/ 3
√x, per x che tende a
zero (da destra, per ovvi motivi). Basta calcolare il
limx→0+
1/√x
1/ 3√x= lim
x→0+
3√x√x= lim
x→0+
x1/3
x1/2= lim
x→0+x−1/6 = lim
x→0+
1
x1/6=
1
0+= +∞.
Ora attenzione alla conclusione. Dato che il quoziente tende all’infinito significa che il numeratore (cioe 1/√x) e un
infinito piu forte del denominatore (1/ 3√x).
Torniamo ora al confronto tra due quantita che tendono a zero. Consideriamo un semplice esempio di confronto tradue potenze, ad esempio x3 e x2, per x che tende a zero. Se calcoliamo il
limx→0
x3
x2= lim
x→0x = 0,
il risultato e quindi banalmente zero. Il significato questa volta e il seguente: se il quoziente di due quantita infinitesime(cioe che tendono a zero) tende a zero, significa che il numeratore tende a zero piu velocemente del denominatore.Quindi x3 e piu rapido nel tendere a zero rispetto ad x2, per x che tende a zero.Riassumendo: se il quoziente di due infiniti tende a zero allora il numeratore tende all’infinito piu lentamente deldenominatore; se il quoziente di due infinitesimi tende a zero allora il numeratore tende a zero piu velocemente deldenominatore.Tutto questo fornisce una buona tecnica per operare dei confronti tra le funzioni.
Possiamo formalizzare un po’ quanto appena trovato, fornendo alcune definizioni che possono aiutare a ricordaremeglio il concetto.
169Mi raccomando, non si faccia confusione tra il valore a cui tende x e il valore a cui tende la funzione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CONFRONTI TRA FUNZIONI
LIMITI
168
5.1 Confronti tra infiniti e infinitesimi
Supponiamo di voler confrontare due funzioni f e g, per x che tende ad un certo valore c, che puo essere o finito o±∞.170
Definizione
(i) Se limx→c
f(x)
g(x)= 0, diciamo che f e trascurabile rispetto a g, per x che tende a c.
(ii) se limx→c
f(x)
g(x)= 1, diciamo che f e equivalente a g, per x che tende a c.
(iii) se limx→c
f(x)
g(x)e finito, diverso da zero, diciamo che f e dello stesso ordine di grandezza di g, per x che tende
a c.
Osservazioni Si osservi che (banalmente), se f e equivalente a g per x → c, allora si ha anche che f e dello stessoordine di grandezza di g, per x→ c.Ancora, se f1 ed f2 sono trascurabili rispetto ad f , per x → c, allora anche f1 ± f2 e trascurabile rispetto ad f , perx→ c (lo studente dimostri queste semplici affermazioni).Si dimostra facilmente anche che se f1 e trascurabile rispetto ad f , per x→ c, allora f + f1 e equivalente ad f .Possiamo ribadire quanto gia esposto in precedenza in termini di queste nuove definizioni. Possiamo dire che:
• Per x→ +∞, xα e trascurabile rispetto a bx, per ogni α positivo e per ogni b > 1;
• Sempre per x→ +∞, lnp x e trascurabile rispetto a xα per ogni p e α positivi.
Quindi, ad esempio, abbiamo che x3 e trascurabile rispetto a 2x, per x → +∞, e ln4 x e trascurabile rispetto a√x,
sempre per x→ +∞.Non ci si dimentichi del significato veramente interessante dei risultati sui confronti tra potenze, esponenziali e logaritmi(che chiamero d’ora in avanti confronti standard): una qualunque potenza, per quanto elevata, e trascurabile rispettoad un esponenziale, per quanto “debole” e un logaritmo, anche se elevato ad una qualunque potenza, e trascurabilerispetto ad una potenza, per quanto bassa.
Altri esempi, importanti nel calcolo dei limiti, sono i seguenti:
• Confronto all’infinito tra due potenze. Consideriamo due potenze xa e xb, con 0 < a < b. Si ha
xa e trascurabile rispetto a xb, per x→ +∞.171
Quindi, ad esempio, si ha che x2 e trascurabile rispetto a x3, per x→ +∞.
• Confronto in zero tra due potenze. Consideriamo ancora due potenze xa e xb, con 0 < a < b, questa volta perx→ 0+. In questo caso si ha
xb e trascurabile rispetto a xa, per x→ 0+. 172
Quindi, ad esempio, si ha che x2 e trascurabile rispetto ad x, per x→ 0.
170Ovviamente, e lo sottintendo per non appesantire, le due funzioni dovranno essere definite in prossimita di c.171Segue dalla definizione:
limx→+∞
xa
xb= lim
x→+∞
1
xb−a= 0,
dato che b− a > 0.172Anche questa volta segue dalla definizione:
limx→0+
xb
xa= lim
x→0+xb−a = 0,
dato che b− a > 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CONFRONTI TRA FUNZIONI
LIMITI
169
Osservazione Ripeto: attenzione a non confondere i due casi: all’infinito tra due potenze e trascurabile quella conesponente minore, mentre in zero e trascurabile quella con esponente maggiore. Pertanto diremo ad esempio
√x e trascurabile rispetto a x e x1/3 e trascurabile rispetto a x1/2, per x→ +∞,
mentrex e trascurabile rispetto a
√x e x1/2 e trascurabile rispetto a x1/3, per x→ 0+.
Negli ultimi esempi visti avevamo sempre a che fare con funzioni infinite all’infinito e infinitesime in zero. Per ribadireche nel confronto e rilevante il valore della funzione piu che il punto a cui tende x, consideriamo il confronto delle duefunzioni 1
x e 1√x. Si osservi che le due funzioni sono infinitesime all’infinito e infinite in zero.
Dato che limx→+∞
1/x
1/√x= lim
x→+∞
√x
x= lim
x→+∞1√x= 0 allora
1
xe trascurabile rispetto a
1√x, per x→ +∞
e
dato che limx→0+
1/√x
1/x= lim
x→0+
√x = 0 allora
1√x
e trascurabile rispetto a1
x, per x→ 0+.
Vediamo altri esempi interessanti di confronti.
• Proviamo che√x3 + x2 + x+ 1 e equivalente a x3/2 per x→ +∞.
limx→+∞
√x3 + x2 + x+ 1√
x3= lim
x→+∞
√
x3 + x2 + x+ 1
x3= lim
x→+∞
√
1 +1
x+
1
x2+
1
x3= 1.
Lo studente dimostri questa regola generale: la radice n-esima di un polinomio e equivalente alla radice n-esimadel termine di grado massimo del polinomio stesso (intendo quando x tende all’infinito).
• Proviamo che ln(x2 + x+ 1) e equivalente a ln(x2) per x→ +∞. Infatti
limx→+∞
ln(x2 + x+ 1)
ln(x2)= lim
x→+∞
ln[
x2(1 + 1/x+ 1/x2)]
ln(x2)= lim
x→+∞ln(x2) + ln(1 + 1/x+ 1/x2)
ln(x2)= 1.
• Attenzione che non e vero invece che ex2+x+1 e equivalente a ex
2
per x→ +∞. Infatti
limx→+∞
ex2+x+1
ex2= lim
x→+∞ex
2+x+1−x2
= limx→+∞
ex+1 = +∞.
Osservazione Si potrebbe dimostrare (ma serve la definizione formale di limite) che vale il seguente risultato: se fe g sono due funzioni positive definite in [a,+∞) e se f(x) e trascurabile rispetto a g(x) per x → +∞, allora da uncerto punto in poi f e minore di g (e questo fa forse capire meglio perche in questo caso f si dica trascurabile rispettoa g).Il fatto che una certa proprieta (come ad esempio f(x) < g(x)) valga da un certo punto in poi si esprime dicendo chela proprieta vale definitivamente. Quindi possiamo dire che se f(x) e trascurabile rispetto a g(x) per x→ +∞, allorasi ha definitivamente f(x) < g(x).
5.2 Principi di eliminazione/sostituzione
Sono molto utili nella pratica del calcolo dei limiti i seguenti risultati, che chiameremo principi di eliminazio-ne/sostituzione. Essi in certo qual modo danno una giustificazione del perche alcune quantita sono state chiamatetrascurabili rispetto ad altre.
(i) (eliminazione) Se f1 e trascurabile rispetto a f per x→ c, allora
limx→c
(
f(x) ± f1(x))
= limx→c
f(x)
(ii) (sostituzione) Se f1 e equivalente a f e g1 e equivalente a g per x→ c, allora
limx→c
(
f1(x) · g1(x))
= limx→c
(
f(x) · g(x))
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CONFRONTI TRA FUNZIONI
LIMITI
170
(iii) (sostituzione) Se f1 e equivalente a f e g1 e equivalente a g per x→ c, allora
limx→c
f1(x)
g1(x)= lim
x→c
f(x)
g(x)
(iv) (eliminazione) f1 e trascurabile rispetto a f e g1 e trascurabile rispetto a g per x→ c, allora
limx→c
f(x) ± f1(x)g(x) ± g1(x)
= limx→c
f(x)
g(x)
Osservazione Si noti che allora le funzioni trascurabili si possono a tutti gli effetti trascurare nel calcolo del limite(almeno nelle situazioni previste dai principi). Funzioni invece equivalenti possono essere sostituite ad altre. Si notiun fatto molto importante: le quantita trascurabili si trascurano quando sono sommate o sottratte ad altre (nonmoltiplicate) e quantita equivalenti prendono il posto di altre quando ci sono prodotti o quozienti (e non addizioni osottrazioni).
Esempio Consideriamo illim
x→+∞(x3 − 3x2 + 2x+ 1).
Osservando che −3x2 + 2x+ 1 e trascurabile rispetto a x3 per x→ +∞,173 si ha
limx→+∞
(x3 − 3x2 + 2x+ 1) = limx→+∞
x3 = +∞.
Abbiamo applicato il punto (i) (principio di eliminazione). Il limite peraltro lo sapevamo gia calcolare con unraccoglimento.Piu in generale, con un generico polinomio, possiamo dire che
limx→±∞
(anxn + an−1x
n−1 + . . .+ a0) = limx→±∞
anxn.
Esempio Consideriamo illim
x→+∞(x2 − 2x −√x).
Osservando che x2 e trascurabile rispetto a 2x e√x e trascurabile rispetto a 2x, per x→ +∞, allora, per il punto (i)
(principio di eliminazione) si halim
x→+∞(x2 − 2x −√x) = lim
x→+∞(−2x) = −∞.
Esempio Dovendo calcolare il
limx→+∞
x3 + x− 1
x4 − x2 + 1,
e osservando che x−1 e trascurabile rispetto a x3 per x→ +∞ e che −x2+1 e trascurabile rispetto a x4 per x→ +∞,applicando il punto (iv) (principio di eliminazione) possiamo scrivere
limx→+∞
x3 + x− 1
x4 − x2 + 1= lim
x→+∞x3
x4= lim
x→+∞1
x= 0.
Si noti che anche questo limite lo sapevamo gia calcolare con raccoglimenti. Pero come si vede col principio dieliminazione le cose sono molto piu veloci.Anche in questo caso, con il quoziente di due polinomi in generale, possiamo dire che
limx→±∞
anxn + an−1x
n−1 + . . .+ a0bmxm + bm−1xm−1 + . . .+ b0
= limx→±∞
anxn
bmxm,
da cui si perviene immediatamente al risultato.
Esempio Consideriamo il
limx→+∞
x+ x2
x+√x.
173Il polinomio di secondo grado e somma di funzioni tutte trascurabili rispetto ad x3.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 CONFRONTI TRA FUNZIONI
LIMITI
171
Osservando che x e trascurabile rispetto a x2 e√x e trascurabile rispetto a x per x→ +∞, ancora con il punto (iv)
(principio di eliminazione) abbiamo
limx→+∞
x+ x2
x+√x= lim
x→+∞x2
x= +∞.
Esempio Se abbiamo il
limx→0+
x− x2x−√x
possiamo osservare che x2 e trascurabile rispetto a x, per x→ 0+ e x e trascurabile rispetto a√x, per x→ 0+. Quindi
per punto (iv) (principio di eliminazione) si ha
limx→0+
x− x2x−√x = lim
x→0+
x
−√x = limx→0+
(−√x) = 0.
Esempio Dovendo calcolare il
limx→+∞
x− lnx
x2 + 2x,
osservando che lnx e trascurabile rispetto a x per x → +∞ e che x2 e trascurabile rispetto a 2x per x → +∞,applicando il punto (iv) (principio di eliminazione) possiamo scrivere
limx→+∞
x− lnx
x2 + 2x= lim
x→+∞x
2x= 0 (confronto standard potenza/esponenziale).
Esempio Se abbiamo il
limx→+∞
x+ 1
ln(ex + 1),
osservando che x+ 1 e equivalente a x per x→ +∞ e che ln(ex + 1) e equivalente a ln ex per x→ +∞, applicando ilpunto (iii) (principio di sostituzione) possiamo scrivere
limx→+∞
x+ 1
ln(ex + 1)= lim
x→+∞x
ln ex= lim
x→+∞x
x= 1.
Esempio Se abbiamo il
limx→+∞
√x2 + 1
ln(x3 + 1)
possiamo osservare che√x2 + 1 e equivalente a x e ln(x3 + 1) e equivalente a ln(x3), per x→ +∞, e quindi
limx→+∞
√x2 + 1
ln(x3 + 1)= lim
x→+∞x
ln(x3)= lim
x→+∞x
3 lnx= +∞ (dal confronto standard potenza/logaritmica).
Abbiamo applicato il punto (iii) (principio di sostituzione).
Esempio Se abbiamo il
limx→+∞
((
e−x +1
x
)
ln(1 + x)
)
(f.i. del tipo 0 · (+∞)),
possiamo osservare che e−x+ 1x e equivalente a 1
x , per x→ +∞, dato che e−x e trascurabile rispetto a 1x (lo si verifichi).
Inoltre ln(1+x) e equivalente a lnx, sempre per x→ +∞. Quindi, applicando il punto (ii) (principio di sostituzione),possiamo scrivere
limx→+∞
((
e−x +1
x
)
ln(1 + x)
)
= limx→+∞
1
xlnx = lim
x→+∞lnx
x= 0 (confronto standard logaritmica/potenza).
Esempio Se abbiamo il
limx→+∞
(
e1−x 3√
x2 + 1)
(f.i. del tipo 0 · (+∞)),
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 SOLUZIONI DEGLI ESERCIZI
LIMITI
172
osservando che 3√x2 + 1 e equivalente a x2/3, per x → +∞ e applicando il punto (ii) (principio di sostituzione),
possiamo scrivere
limx→+∞
(
e1−x 3√
x2 + 1)
= limx→+∞
(
e · e−x · x2/3)
= e · limx→+∞
x2/3
ex= 0 (confronto standard potenza/esponenziale).
Osservazione Ribadisco un punto molto importante e delicato. Il principio di eliminazione dice sostanzialmente chequantita trascurabili si possono trascurare. Attenzione pero a non dare a questa affermazione una validita del tuttogenerale, come puo far credere questo modo di presentare la questione. La validita e quindi l’applicabilita del principioe limitata ovviamente ai casi previsti nell’enunciato. Faccio un esempio: il principio non dice che, nel caso io abbia
un prodotto di due quantita, di cui una trascurabile, io possa trascurare quest’ultima. Quindi se ho limx→+∞
x√x
x+ 1, non
posso trascurare√x, che pure e trascurabile rispetto ad x all’infinito, e concludere che il limite e 1. Il limite infatti e
+∞, come si trova facilmente dividendo numeratore e denominatore per x, o piu semplicemente dal confronto tra ledue potenze.
Osservazione Lo stesso dicasi per i casi che usano l’equivalenza: in un prodotto (o quoziente) posso sostituire ad una
quantita un’altra quantita ad essa equivalente. La cosa non vale se ho una somma. Si consideri il limx→+∞
(
x−√
x2 + x)
.
Se, dopo aver osservato che√x2 + x e equivalente a x, per x → +∞, applico il principio di sostituzione e concludo
che il limite e 0, commetto un errore.174
Esercizio 5.1 Si riconsiderino gli esercizi proposti 4.2. e, quando possibile, li si calcolino usando i principi di
eliminazione/sostituzione.
Esercizio 5.2 Si calcolino i seguenti limiti con i principi di eliminazione/sostituzione.
(a) limx→+∞
√x+ 2x
3√x+ lnx
(b) limx→+∞
√x− ln3 x
ex + lnx
(c) limx→+∞
√x+ x3/2 + lnx
x10 + 10x(d) lim
x→+∞x1/3 + 2x + lnx
x1/2 + 3x + lnx
(e) limx→0+
x2 − xx+√x
(f) limx→0+
x2 +√x3
x− 3√x2
6 Un limite fondamentale
In questa breve sezione mi limito ad enunciare un limite molto importante. Si ha
limx→±∞
(
1 +1
x
)x
= e.
Osservazione Il limite si presenta nella forma 1±∞, che e indeterminata, in quanto si puo scrivere
(
1 +1
x
)x
= eln(1+1x )
x
= ex ln(1+ 1x)
e l’esponente e della forma (±∞) · 0.
7 Soluzioni degli esercizi
174Infatti si ha invece, razionalizzando,
limx→+∞
(
x−√
x2 + x)
= limx→+∞
x2 − x2 − x
x+√x2 + x
= limx→+∞
−x
x+√x2 + x
= limx→+∞
−1
1 +√
1 + 1/x= −1
2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 SOLUZIONI DEGLI ESERCIZI
LIMITI
173
Esercizio 4.1
(a) limx→2−
x
2− x =2
0+= +∞. Essendo x minore di 2, la quantita 2− x e positiva.
(b) limx→−∞
2
1− x =2
+∞ = 0.
(c) limx→0+
1 + x
x=
1
0+= +∞.
(d) limx→−∞
x
1 + 1/x=−∞1 + 0
= −∞.
(e) limx→+∞
1 + 1/x
1 + x2=
1+ 0
1 +∞ =1
+∞ = 0.
(f) limx→+∞
1 + e−x
1 + ex=
1 + 0
1 +∞ = 0. Si ricordi il grafico di ex e quello di e−x = 1ex = (1e )
x.
(g) limx→0+
1 + x
lnx− 1=
1
−∞− 1= 0.
(h) limx→0+
1/x
1− ex =+∞
1− 1+=
+∞0−
= −∞. Qui forse e opportuno qualche commento in piu. E importante stabilire
il segno dello zero a denominatore, in quanto determina il segno dell’infinito. Si puo ragionare cosı: per x→ 0+
ex > 1, quindi ex → 1+. Questo significa che ex tende a 1 ma da valori piu grandi di 1. Allora il denominatoretende a 0 ma da valori negativi, da cui la conclusione.
(i) limx→0+
1/x
ln(1 + x)=
+∞0+
= +∞. Anche qui e importante stabilire il segno dello zero a denominatore. Per x→ 0+
1 + x→ 1+ e quindi il ln(1 + x) tende a 0, ma da valori positivi.
(j) limx→+∞
(x+ ln(1 + 1/x)) = +∞+ ln 1 = +∞+ 0 = +∞. Questo invece e un caso in cui non e rilevante stabilire
il segno dello zero, dato che c’e l’infinito.
(k) limx→0+
(x− lnx) = 0− (−∞) = +∞.
(l) limx→1−
x
lnx=
1
0−= −∞.
Esercizio 4.2
(a) limx→+∞
x− 1
1 + 2x. E una forma indeterminata (f.i.) del tipo +∞
+∞ . Possiamo scrivere
limx→+∞
x− 1
1 + 2x= lim
x→+∞x(1 − 1/x)
x(1/x+ 2)= lim
x→+∞1− 1/x
1/x+ 2=
1− 0
0 + 2=
1
2.
(b) limx→−∞
1− x21 + x2
. E una f.i. del tipo −∞+∞ . Possiamo scrivere
limx→−∞
1− x21 + x2
= limx→−∞
x2(1/x2 − 1)
x2(1/x2 + 1)= lim
x→−∞1/x2 − 1
1/x2 + 1=
0− 1
0 + 1= −1.
(c) limx→+∞
x+ 1
1 + x3. Sempre f.i. del tipo +∞
+∞ . Dividendo numeratore e denominatore per x si ottiene
limx→+∞
x+ 1
1 + x3= lim
x→+∞1 + 1/x
1/x+ x2=
1 + 0
0 +∞ =1
+∞ = 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 SOLUZIONI DEGLI ESERCIZI
LIMITI
174
(d) limx→−∞
x2 + x+ 1
x+ 1. Ancora f.i. del tipo +∞
−∞ . Dividendo numeratore e denominatore per x si ottiene
limx→−∞
x2 + x+ 1
x+ 1= lim
x→−∞x+ 1 + 1/x
1 + 1/x=−/infty+ 1 + 0
1 + 0=−/infty
1= −∞.
(e) limx→0+
x+ x2
x2 + x3. E una f.i. del tipo 0
0 . Possiamo dividere numeratore e denominatore ad esempio per x. Si ottiene
limx→0+
x+ x2
x2 + x3= lim
x→0+
1 + x
x+ x2=
1 + 0
0+=
1
0+= +∞.
Si osservi che e importante stabilire che a denominatore si tratta di uno 0+. Si poteva anche dividere numeratoree denominatore ad esempio per x2. Si ottiene in tal caso
limx→0+
x+ x2
x2 + x3= lim
x→0+
1/x+ 1
1 + x=
+∞+ 1
1 + 0=
+∞1
= +∞.
(f) limx→1+
x2 − 1
x2 − 3x+ 2. F.i. del tipo 0
0 . Qui si possono fattorizzare i polinomi:
limx→1+
x2 − 1
x2 − 3x+ 2= lim
x→1+
(x− 1)(x+ 1)
(x− 1)(x− 2)= lim
x→1+
x+ 1
x− 2= −2.
(g) limx→+∞
x+√x
x2 − 3√x. F.i. del tipo +∞
+∞ . Dividendo numeratore e denominatore ad esempio per x si ottiene
limx→+∞
x+√x
x2 − 3√x= lim
x→+∞1 + x−1/2
x− x−2/3=
1 + 0
+∞− 0= 0.
(h) limx→0+
x+√x
x2 − 3√x. La funzione e la stessa dell’esercizio precedente, ma questa volta il limite e per x→ 0+. E una
f.i. del tipo 00 . Lo studente puo verificare che dividendo sopra e sotto per x, come fatto prima, non si risolve la
f.i. Si puo dividere invece per√x (lo si verifichi) oppure per 3
√x. In quest’ultimo caso si ottiene
limx→0+
x+√x
x2 − 3√x= lim
x→0+
x2/3 + x1/6
x5/3 − 1=
0
−1 = 0.
Questi ultimi due esercizi insegnano che la scelta di che cosa raccogliere, o equivalentemente per quale fattoredividere numeratore e denominatore, non e in genere arbitraria, nel senso che una puo risolvere la f.i. e un’altrano.
(i) limx→+∞
x1/2 + x3/5
x4/3 + x3/2. F.i. del tipo +∞
+∞ . Anche qui si puo intuire che se dividessimo sopra e sotto per il termine di
grado minimo (cioe x1/2) non risolveremmo la f.i. (lo si verifichi). Se dividiamo invece per il termine di gradomassimo, x3/2, sı: infatti si ottiene
limx→+∞
x1/2 + x3/5
x4/3 + x3/2= lim
x→+∞x−1 + x−9/10
x−1/6 + 1=
0
1= 0.
Puo essere un utile esercizio provare a dividere per altri termini.
(j) limx→0+
x1/2 + x3/5
x4/3 + x3/2. Stessa funzione dell’esercizio precedente, ma questa volta per x→ 0+. F.i. del tipo 0
0 . Questa
volta dividendo sopra e sotto per il termine di grado massimo (cioe x3/2) non si risolve la f.i. (lo si verifichi).Dividendo invece per il termine di grado minimo, x1/2, sı. Infatti si ha
limx→0+
x1/2 + x3/5
x4/3 + x3/2= lim
x→0+
1 + x1/10
x5/6 + x=
1
0+= +∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 SOLUZIONI DEGLI ESERCIZI
LIMITI
175
(k) limx→+∞
(2x−√x
). F.i. del tipo +∞−∞. Raccogliendo
√x si ha
limx→+∞
(2x−√x
)= lim
x→+∞
(√x(2√x− 1)
)= +∞.
Si poteva anche raccogliere x. Lo si verifichi.
(l) limx→+∞
(
2x−√
4x2 − 1)
. Questo esempio, peraltro simile per molti aspetti al precedente, in realta e piu
complicato da risolvere. Raccogliendo x si ha
limx→+∞
(
2x−√
4x2 − 1)
= limx→+∞
(
x
(
2−√
4x2 − 1
x2
))
= limx→+∞
(
x
(
2−√
4− 1
x2
))
e questa e ancora una f.i., del tipo +∞ · 0. E necessaria una razionalizzazione:
limx→+∞
(
2x−√
4x2 − 1)
= limx→+∞
(2x−√4x2 − 1)(2x+
√4x2 − 1)
2x+√4x2 − 1
= limx→+∞
4x2 − 4x2 + 1
2x+√4x2 − 1
= limx→+∞
1
2x+√4x2 − 1
= 0.
(m) limx→−∞
(
x+√
|x|)
. Questa e una f.i. del tipo −∞+∞ e si ricordi che |x| = −x per le x negative (quindi se x
come in questo caso tende a −∞). Basta un raccoglimento:
limx→−∞
(
x+√
|x|)
= limx→−∞
(x+√−x)
= limx→−∞
(
x
(
1 +
√−xx
))
(attenzione!) = limx→−∞
(
x
(
1−√
−xx2
))
= limx→−∞
(
x
(
1−√
−1x
))
= −∞.
Attenzione nel terzo passaggio! Quando si porta sotto radice x, essendo x negativo, occorre cambiare il segnodavanti alla radice. Per capire il motivo di cio si rifletta attentamente sulla seguente affermazione:
se x < 0 allora x = −√x2.
(n) limx→−∞
(
x+√
x2 + 1)
. Anche questa e una f.i. del tipo −∞ +∞. Qui un raccoglimento non e sufficiente per
uscire dalla f.i. E necessaria invece una razionalizzazione:
limx→−∞
(
x+√
x2 + 1)
= limx→−∞
(x +√x2 + 1)(x −
√x2 + 1)
x−√x2 + 1
= limx→−∞
x2 − x2 − 1
x−√x2 + 1
=−1−∞ = 0.
Esercizio 5.1
(a) limx→+∞
x− 1
1 + 2x. Si puo osservare che a numeratore 1 e trascurabile rispetto ad x, per x→ +∞ e a denominatore
1 e trascurabile rispetto a 2x, per x→ +∞. Quindi, per il principio di eliminazione,
limx→+∞
x− 1
1 + 2x= lim
x→+∞x
2x=
1
2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 SOLUZIONI DEGLI ESERCIZI
LIMITI
176
(b) limx→−∞
1− x21 + x2
. Osservando che 1 e trascurabile rispetto ad x2, per x→ +∞, si ha
limx→−∞
1− x21 + x2
= limx→−∞
−x2x2
= −1.
(c) limx→+∞
x+ 1
1 + x3. Osservando che 1 e trascurabile sia rispetto ad x, sia rispetto ad x3, per x→ +∞, si ha
limx→+∞
x+ 1
1 + x3= lim
x→+∞x
x3= lim
x→+∞1
x2= 0.
(d) limx→−∞
x2 + x+ 1
x+ 1. A numeratore x + 1 e trascurabile rispetto ad x2 e a denominatore 1 e trascurabile rispetto
ad x. Quindi per il principio di eliminazione si ha
limx→−∞
x2 + x+ 1
x+ 1= lim
x→−∞x2
x= lim
x→−∞x = −∞.
(e) limx→0+
x+ x2
x2 + x3. Osservando che, per x → 0+, x2 e trascurabile rispetto ad x e x3 e trascurabile rispetto ad x2,
possiamo scrivere
limx→0+
x+ x2
x2 + x3= lim
x→0+
x
x2= lim
x→0+
1
x= +∞.
(f) limx→1+
x2 − 1
x2 − 3x+ 2. In questo caso i principi di eliminazione/sostituzione non sono applicabili. Infatti non ci sono
quantita trascurabili rispetto ad altre. Il limite deve essere calcolato come visto in precedenza.
(g) limx→+∞
x+√x
x2 − 3√x. All’infinito sono trascurabili le potenze con esponente piu basso. Quindi a numeratore
√x e
trascurabile rispetto ad x e a denominatore 3√x e trascurabile rispetto ad x2. Per il principio di eliminazione si
ha
limx→+∞
x+√x
x2 − 3√x= lim
x→+∞x
x2= lim
x→+∞1
x= 0.
(h) limx→0+
x+√x
x2 − 3√x. A zero sono trascurabili le potenze con esponente piu alto. Quindi a numeratore x e trascurabile
rispetto a√x e a denominatore x2 e trascurabile rispetto a 3
√x. Per il principio di eliminazione si ha
limx→0+
x+√x
x2 − 3√x= lim
x→0+
√x
− 3√x= lim
x→0+(−x1/6) = 0.
(i) limx→+∞
x1/2 + x3/5
x4/3 + x3/2. Si trascurano le potenze con esponente piu basso e quindi per il principio di eliminazione si
ha
limx→+∞
x1/2 + x3/5
x4/3 + x3/2= lim
x→+∞x3/5
x3/2= lim
x→+∞1
x9/10= 0.
(j) limx→0+
x1/2 + x3/5
x4/3 + x3/2. Si trascurano le potenze con esponente piu alto e quindi per il principio di eliminazione si ha
limx→0+
x1/2 + x3/5
x4/3 + x3/2= lim
x→0+
x1/2
x4/3= lim
x→0+
1
x5/6= +∞.
(k) limx→+∞
(2x−√x
). Basta osservare che, per x→ +∞,
√x e trascurabile rispetto ad x e quindi
limx→+∞
(2x−√x
)= lim
x→+∞(2x) = +∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 SOLUZIONI DEGLI ESERCIZI
LIMITI
177
(l) limx→+∞
(
2x−√
4x2 − 1)
. Volendo qui provare ad applicare il principio di eliminazione occorre anzitutto capire
se una delle due quantita e trascurabile rispetto all’altra. Se le confrontiamo, se cioe calcoliamo il limite delquoziente, si scopre subito che sono equivalenti.175 Quindi il principio di eliminazione non e applicabile. Il limitesi puo calcolare soltanto con i passaggi visti in precedenza (la razionalizzazione).
(m) limx→−∞
(
x+√
|x|)
. Ricordando che |x| = −x sulle x negative, possiamo poi osservare che√
|x| = √−x e
trascurabile rispetto ad x, per x→ −∞.176 Quindi
limx→−∞
(x+√−x)= lim
x→−∞x = −∞.
(n) limx→−∞
(
x+√
x2 + 1)
. Anche in questo caso nessuna delle due quantita e trascurabile rispetto all’altra. (Si
provi che√x2 + 1 e equivalente a −x per x→ −∞). Per risolvere il limite occorre la razionalizzazione.
Esercizio 5.2
In tutti i casi di limite all’infinito e utile ricordare le seguenti proprieta fondamentali:
xα e trascurabile rispetto a bx, per x→ +∞, per ogni α in R e per ogni b > 1
elnp x e trascurabile rispetto a xα, per x→ +∞, per ogni p in R e per ogni α > 0.
(a) limx→+∞
√x+ 2x
3√x+ lnx
. Per x→ +∞ si ha che
√x e trascurabile rispetto a 2x e lnx e trascurabile rispetto a 3
√x
e quindi
limx→+∞
√x+ 2x
3√x+ lnx
= limx→+∞
2x
3√x= +∞. 177
(b) limx→+∞
√x− ln3 x
ex + lnx. A numeratore e a denominatore e trascurabile il logaritmo. Quindi
limx→+∞
√x− ln3 x
ex + lnx= lim
x→+∞
√x
ex= 0.
(c) limx→+∞
√x+ x3/2 + lnx
x10 + 10x. A numeratore la radice e il logaritmo sono trascurabili rispetto ad x3/2, e a denomina-
tore e trascurabile la potenza. Quindi
limx→+∞
√x+ x3/2 + lnx
x10 + 10x= lim
x→+∞x3/2
10x= 0.
175Infatti
limx→+∞
2x√4x2 − 1
= limx→+∞
√
4x2
4x2 − 1= 1.
176Infatti
limx→−∞
√−x
x= lim
x→−∞
(
−√
−x
x2
)
= limx→−∞
(
−√
− 1
x
)
= 0.
177Dato che limx→+∞
3√x
2x= 0, allora
limx→+∞
2x
3√x
= limx→+∞
13√x/2x
=1
0+= +∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 SOLUZIONI DEGLI ESERCIZI
LIMITI
178
(d) limx→+∞
x1/3 + 2x + lnx
x1/2 + 3x + lnx. A numeratore la potenza e il logaritmo sono trascurabili rispetto all’esponenziale, e a
denominatore lo stesso. Quindi
limx→+∞
x1/3 + 2x + lnx
x1/2 + 3x + lnx= lim
x→+∞2x
3x= lim
x→+∞
(2
3
)x
= 0.
(e) limx→0+
x2 − xx+√x.
Questo e i seguenti sono casi invece di limite per x → 0 e le quantita in gioco sono tutte infinitesime.178 Quibisogna ricordare che, almeno nei confronti tra potenze, valgono le seguenti relazioni:
xa e trascurabile rispetto a xb, per x→ 0+, se a > b.
Quindi qui sono trascurabili le potenze di esponente piu elevato. Quindi nel nostro limite abbiamo: x2 etrascurabile rispetto a x e x e trascurabile rispetto a
√x, per x→ 0+, e si ha
limx→0+
x2 − xx+√x= lim
x→0+
−x√x= lim
x→0+(−√x) = 0.
(f) limx→0+
x2 +√x3
x− 3√x2
. Qui si ha che x2 e trascurabile rispetto a√x3 e x e trascurabile rispetto a
3√x2, per x → 0+.
Quindi
limx→0+
x2 +√x3
x− 3√x2
= limx→0+
x3/2
−x2/3 = limx→0+
(−x5/6) = 0.
178Ricordo che in generale possiamo avere anche quantita infinitesime con x che tende all’infinito o quantita infinite con x che tende azero (si pensi ad esempio a 1
xcon x → ±∞ oppure sempre 1
xcon x → 0+ o x → 0−).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 FUNZIONI CONTINUE: DEFINIZIONI E PRIME PROPRIETA
FUNZIONI CONTINUE
179
II-5 Funzioni continue
1 Funzioni continue: definizioni e prime proprieta
Definizione Supponiamo che siano a, b ∈ R e f : [a, b)→ R. Diciamo che f e continua in a da destra se
limx→a+
f(x) = f(a).
In modo analogo, se f : (a, b]→ R, diciamo che f e continua in b da sinistra se
limx→b−
f(x) = f(b).
Se infine f : (a, b) → R e a < x0 < b, diciamo che f e continua in x0 se e continua in x0 da destra e da sinistra,quindi se
limx→x0
f(x) = f(x0).
Una funzione non continua in qualche punto (eventualmente da destra o da sinistra) si dice discontinua in quel punto(eventualmente da destra o da sinistra).
| |
b
a b
f(a)
| |
b
bc
a b
f(a)
| |
b
a b
f(b)
| |
b
bc
a b
f(b)
| |
b
a bx0
f(x0)
| |
b
bc
a bx0
f(x0)
Le figure qui sopra rappresentano nell’ordine: una funzione continua in a da destra, una discontinua in a da destra,una continua in b da sinistra, una discontinua in b da sinistra, una continua in x0 e infine una discontinua in x0. Siosservi che l’ultima e discontinua in x0 perche e discontinua in x0 da destra, mentre e continua in x0 da sinistra.
Osservazione Una funzione discontinua in a da destra e comunque definita in a; analogamente una funzione discon-tinua in b da sinistra e definita in b e una funzione f discontinua in x0 e comunque definita in x0, cioe esiste il valoref(x0). Quindi attenzione che non ha senso chiedersi se, ad esempio, la funzione f(x) = lnx e continua o discontinuain zero (da destra), dato che in zero la funzione non e definita. Nel caso una funzione sia definita in un punto, la suacontinuita in quel punto dipende quindi dal fatto che il limite della funzione in quel punto sia uguale al valore cheessa assume in quel punto.
Esempi
• Sia f : R→ R la funzione definita da f(x) =
{1 se x = 0
0 se x 6= 0. bc
b1
x
E evidente che limx→0−
f(x) = 0 = limx→0+
f(x); poiche f(0) = 1, f non e continua in 0 ne da destra, ne da sinistra.
• Sia g : R→ R la funzione definita da g(x) =
{1 se x ≥ 0
0 se x < 0. bc
b1
x
E evidente che limx→0−
g(x) = 0 e che limx→0+
g(x) = 1; poiche g(0) = 1, g e continua in 0 da destra, ma non da
sinistra.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 CONTINUITA DELLE FUNZIONI ELEMENTARI
FUNZIONI CONTINUE
180
• Sia h : R→ R la funzione definita da h(x) =
{1/x se x > 0
0 se x ≤ 0. b
x
E evidente che limx→0−
h(x) = 0 e che limx→0+
h(x) = +∞; poiche h(0) = 0, h e continua in 0 da sinistra, ma non da
destra.
Definizione Supponiamo che siano a, b ∈ R e che f : [a, b) → R. Diciamo che f ha una discontinuita di primaspecie, o che ha un salto, in a da destra se lim
x→a+f(x) ∈ R (quindi e un numero reale finito) e
limx→a+
f(x) 6= f(a).
Se f e discontinua in a da destra e non ha una discontinuita di prima specie, diciamo che f ha una discontinuita diseconda specie in a da destra.In modo analogo si danno le definizioni di discontinuita di prima e di seconda specie da sinistra.
• Siano f , g e h le funzioni definite negli esempi visti sopra: f ha in 0 una discontinuita di prima specie sia dadestra sia da sinistra, g ha una discontinuita di prima specie da sinistra, h ha in 0 una discontinuita di secondaspecie da destra.179
• Le stesse funzioni f , g e h degli esempi in tutti i punti diversi da zero sono continue.
• La funzione f : R→ R definita da
f(x) =
{1 se x ∈ Q
0 se x /∈ Q
si chiama funzione di Dirichlet. Essa e discontinua in ogni punto di R. Infatti, preso un qualunque punto x, inogni intorno di x ci sono valori razionali e valori non razionali; quindi in ogni intorno di x ci sono punti in cuila funzione vale 0 e punti in cui la funzione vale 1. Pertanto non puo esistere il limite in x. Si tratta quindi tral’altro di discontinuita tutte di seconda specie.
La continuita, che e stata definita in un punto, si estende in modo naturale a tutto un intervallo, con la seguente
Definizione Siano I un intervallo e f : I → R. Si dice che f e continua in I se e continua in ogni punto di I(continua da destra nell’estremo sinistro di I se I e chiuso a sinistra, e continua da sinistra nell’estremo destro di I seI e chiuso a destra). L’insieme di tutte le funzioni continue in I (i matematici dicono la classe delle funzioni continuein I) viene indicata con C (I). Scrivendo quindi f ∈ C (I) si afferma che la funzione f e continua nell’intervallo I.
2 Continuita delle funzioni elementari
Si pone ora il problema se quelle che abbiamo chiamato funzioni elementari, e ricordo che si tratta delle potenze,delle esponenziali e delle logaritmiche, che sono tra le funzioni piu importanti e piu utilizzate in concreto, abbiano laproprieta ora definita, cioe siano continue. In base a quanto gia visto nella dispensa precedente non e difficile dareuna risposta.Nella dispensa sui limiti abbiamo visto che
limx→c
xα = cα , limx→c
bx = bc , limx→c
logb x = logb c.180
Questo allora ci dice che
Proposizione Le funzioni elementari sono continue nei rispettivi intervalli in cui sono definite.
179L’esempio della funzione h illustra una discontinuita che e di seconda specie per la presenza di un limite infinito. Si puo avere anchediscontinuita di seconda specie se un limite non esiste. Le distinzione tra prima e seconda specie nasce da questa considerazione: un salto(discontinuita di prima specie) e una “patologia” semplice della funzione (i limiti sono comunque finiti), mentre la seconda specie e una“patologia” piu grave, data dal fatto che la funzione e illimitata o addirittura dal fatto che non ha limite.180Si noti che quello che compare a destra nelle tre identita, cioe cα, bc e logb c, e il valore della funzione nel punto c, cioe f(c).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 FUNZIONI CONTINUE IN UN INTERVALLO. TEOREMA DI WEIERSTRASS
FUNZIONI CONTINUE
181
Puo sorgere ora la questione se anche la somma (o la differenza, o il prodotto, o il quoziente) di due o piu funzionielementari sia ancora una funzione continua.Ricordando i teoremi dell’algebra dei limiti (limite di una somma/prodotto/quoziente e somma/prodotto/quozientedei limiti) e naturale attendersi che la somma di funzioni continue sia una funzione continua e che lo stesso valga anchecon le altre operazioni algebriche. Vale infatti la seguente
Proposizione Siano f e g funzioni continue in un certo insieme. Allora f + g, f − g e fg sono continue in taleinsieme; anche f/g, nei punti dell’insieme in cui e definita, e continua.181
Osservazione Pertanto possiamo dire che ad esempio la funzione f(x) = x2 + ex e continua in tutto R perchesomma di funzioni elementari, che sono continue. La funzione g(x) =
√x ln x e continua in (0,+∞) perche prodotto
di funzioni elementari. La funzione h(x) = lnxx−1 e continua in (0,+∞) \ {1} perche quoziente di funzioni elementari.
Osservazione Visto che somme/prodotti/quozienti di funzioni continue sono funzioni continue, e naturale chiedersise anche la composizione di funzioni continue porti a funzioni continue. La risposta e anche qui affermativa, ma lovediamo tra un po’.
Esercizio 2.1 Si dica se le seguenti funzioni sono continue nel rispettivo dominio o se ci sono punti di disconti-
nuita, eventualmente precisando di che tipo di discontinuita si tratta.
(a) f : R→ R, con f(x) =
{1− x x 6= 1
1 x = 1
(b) f : R→ R, con f(x) =
{1− x2 x < 0
x2 x ≥ 0
(c) f : R→ R, con f(x) =
{1/x2 x 6= 0
0 x = 0
(d) f : [0,+∞)→ R, con f(x) =
1/ lnx x 6= 0, x 6= 1
0 x = 0
0 x = 1
Esercizio 2.2 Data la funzione
f(x) =
{e−ax x ≤ 1
x+ 1 x > 1,
si trovi per quali valori del parametro reale a la funzione f e continua in tutto R.
Esercizio 2.3 Data la funzione
f(x) =
{x2 + x+ a x < 0
(x − a)2 x ≥ 0,
si trovi per quali valori del parametro reale a la funzione f e continua in tutto R.
3 Funzioni continue in un intervallo. Teorema di Weierstrass
Le funzioni continue in un intervallo hanno proprieta globali interessanti, che sono descritte nel teorema seguente.
Teorema (fondamentale delle funzioni continue in un intervallo). Siano a, b ∈ R e sia f continua nell’intervallo [a, b].Allora l’insieme dei valori che f assume e anch’esso un intervallo chiuso e limitato.182
Osservazioni E importante osservare che se togliamo anche soltanto una delle ipotesi del teorema, la tesi puo esserefalsa. E un utile esercizio verificarlo e lo vediamo.Le ipotesi del teorema sono quattro: che la f sia continua, che sia definita in un intervallo, che tale intervallo sia chiusoe che tale intervallo sia limitato.
181La precisazione e doverosa dato che il quoziente non e definito dove g si annulla.182Potremmo scrivere quindi che f
([a, b]
)e un intervallo chiuso e limitato, ricordando che f([a, b]) indica l’immagine della funzione f , cioe
l’insieme dei valori che essa assume.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 FUNZIONI CONTINUE IN UN INTERVALLO. TEOREMA DI WEIERSTRASS
FUNZIONI CONTINUE
182
• Rimuoviamo la prima ipotesi e consideriamo ad esempio f : [0, 1]→ R definita da
f(x) =
{0 se x = 0
1 se 0 < x ≤ 1;b
bc b
1
1
x
f non e in C([0, 1]
), in quanto non e continua in 0. La tesi e falsa dato che f
([0, 1]
)= {0, 1} e questo non e un
intervallo.
• Rimuoviamo la seconda ipotesi e consideriamo ad esempio f : [0, 1]∪[2, 3]→ R definitada f(x) = x. La funzione e continua nel suo insieme di definizione, tale insieme echiuso e limitato, ma non e un intervallo. La tesi e falsa dato che l’immagine di f e[0, 1] ∪ [2, 3], che non e appunto un intervallo. b
b
b
b
| | |
|
|
|
1 2 3
1
2
3
x
• Rimuoviamo la terza ipotesi e consideriamo ad esempio f : (0, 1] → R definita da f(x) = 1/x. La funzionee continua e l’intervallo in cui e definita e limitato ma non chiuso. La tesi e falsa dato che l’immagine di f e[1,+∞), che non e limitato (lo studente si disegni il grafico della funzione).
• Rimuoviamo la quarta ipotesi e consideriamo ad esempio f : [1,+∞)→ R definita da f(x) = 1/x. La funzionee continua e l’intervallo in cui e definita e chiuso ma non limitato. La tesi e falsa dato che l’immagine di f e(0, 1], che non e chiuso (lo studente si disegni il grafico della funzione).
Il teorema fondamentale delle funzioni continue in un intervallo ha come conseguenze alcune proposizioni che spessovengono formulate come altrettanti teoremi.Sia f una funzione continua nell’intervallo [a, b].
(i) Teorema dei valori intermedi. Se f(a) < y < f(b), cioe se y e un qualunque valore compreso tra f(a) e f(b),allora esiste c ∈ (a, b) tale che f(c) = y.
(ii) Teorema degli zeri. Se f(a) e f(b) hanno valori di segno opposto (potremmo scrivere f(a) · f(b) < 0), alloraesiste c ∈ (a, b) tale che f(c) = 0.
(iii) Teorema di Weierstrass. Esiste almeno un punto xM nell’intervallo [a, b] in cui la funzione f assume il suovalore massimo ed almeno un punto xm in cui f assume il suo valore minimo.
Osservazioni Tutte e tre le proposizioni hanno come ipotesi fondamentale che la funzione sia definita in un intervallochiuso e limitato e che sia continua in tale intervallo.Il teorema dei valori intermedi dice sostanzialmente che, nelle ipotesi fatte, la funzione assume tutti i valori compresitra i valori che la funzione assume agli estremi dell’intervallo [a, b].Il teorema degli zeri afferma che, nelle ipotesi fatte, se la funzione assume valori di segno opposto agli estremi, allorac’e almeno un punto in cui essa si annulla.
Osservazioni Il teorema degli zeri e un caso particolare della proprieta dei valori intermedi, dato che, se f(a)·f(b) <0, allora f(a) < 0 < f(b) e quindi dalla (ii) si ricade nella (i).
Osservazioni Possiamo anche qui vedere che, cadendo alcune ipotesi, la tesi puo essere falsa. Lo facciamo conriferimento al teorema di Weierstrass, ma lo studente puo provare a farlo con gli altri. Si diceva che le ipotesi sonoquattro: funzione continua, definita in un intervallo, intervallo chiuso e intervallo limitato. In realta con il teoremadi Weierstrass una delle ipotesi puo cadere senza conseguenze, quella che il dominio sia un intervallo.183 Si pensi alsecondo esempio visto in precedenza sul teorema fondamentale: il dominio non e un intervallo ma la tesi di Weierstrassvale, dato che la funzione ha massimo e minimo (max f = 3 (e xM = 3) e min f = 0 (e xm = 0)). Le altre ipotesiinvece non possono cadere. Vediamolo.
• Funzione non continua: si consideri la funzione f : [0, 1]→ R definita da
f(x) =
1 se x = 0
2(1− x) se 0 < x < 1
1 se x = 1.
b b
bc
bc
1
1
2
x
183Attenzione che invece con il teorema degli zeri e il teorema dei valori intermedi nessuna delle ipotesi puo cadere: lo studente lo verifichisu qualche esempio.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
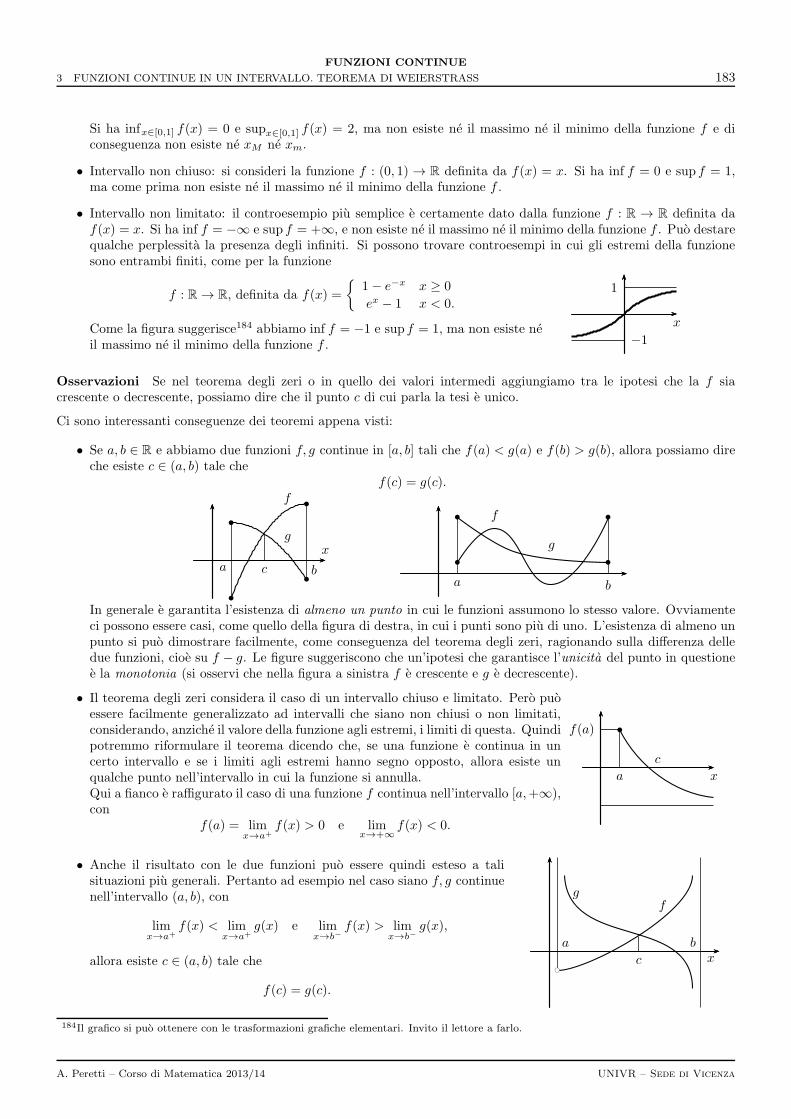
3 FUNZIONI CONTINUE IN UN INTERVALLO. TEOREMA DI WEIERSTRASS
FUNZIONI CONTINUE
183
Si ha infx∈[0,1] f(x) = 0 e supx∈[0,1] f(x) = 2, ma non esiste ne il massimo ne il minimo della funzione f e diconseguenza non esiste ne xM ne xm.
• Intervallo non chiuso: si consideri la funzione f : (0, 1) → R definita da f(x) = x. Si ha inf f = 0 e sup f = 1,ma come prima non esiste ne il massimo ne il minimo della funzione f .
• Intervallo non limitato: il controesempio piu semplice e certamente dato dalla funzione f : R → R definita daf(x) = x. Si ha inf f = −∞ e sup f = +∞, e non esiste ne il massimo ne il minimo della funzione f . Puo destarequalche perplessita la presenza degli infiniti. Si possono trovare controesempi in cui gli estremi della funzionesono entrambi finiti, come per la funzione
f : R→ R, definita da f(x) =
{1− e−x x ≥ 0
ex − 1 x < 0.
Come la figura suggerisce184 abbiamo inf f = −1 e sup f = 1, ma non esiste neil massimo ne il minimo della funzione f .
1
−1x
Osservazioni Se nel teorema degli zeri o in quello dei valori intermedi aggiungiamo tra le ipotesi che la f siacrescente o decrescente, possiamo dire che il punto c di cui parla la tesi e unico.
Ci sono interessanti conseguenze dei teoremi appena visti:
• Se a, b ∈ R e abbiamo due funzioni f, g continue in [a, b] tali che f(a) < g(a) e f(b) > g(b), allora possiamo direche esiste c ∈ (a, b) tale che
f(c) = g(c).
b
b
b
b
ca b
f
gx
b
b
b
b
a b
f
g
In generale e garantita l’esistenza di almeno un punto in cui le funzioni assumono lo stesso valore. Ovviamenteci possono essere casi, come quello della figura di destra, in cui i punti sono piu di uno. L’esistenza di almeno unpunto si puo dimostrare facilmente, come conseguenza del teorema degli zeri, ragionando sulla differenza delledue funzioni, cioe su f − g. Le figure suggeriscono che un’ipotesi che garantisce l’unicita del punto in questionee la monotonia (si osservi che nella figura a sinistra f e crescente e g e decrescente).
• Il teorema degli zeri considera il caso di un intervallo chiuso e limitato. Pero puoessere facilmente generalizzato ad intervalli che siano non chiusi o non limitati,considerando, anziche il valore della funzione agli estremi, i limiti di questa. Quindipotremmo riformulare il teorema dicendo che, se una funzione e continua in uncerto intervallo e se i limiti agli estremi hanno segno opposto, allora esiste unqualche punto nell’intervallo in cui la funzione si annulla.Qui a fianco e raffigurato il caso di una funzione f continua nell’intervallo [a,+∞),con
f(a) = limx→a+
f(x) > 0 e limx→+∞
f(x) < 0.
b
a
f(a)
c
x
• Anche il risultato con le due funzioni puo essere quindi esteso a talisituazioni piu generali. Pertanto ad esempio nel caso siano f, g continuenell’intervallo (a, b), con
limx→a+
f(x) < limx→a+
g(x) e limx→b−
f(x) > limx→b−
g(x),
allora esiste c ∈ (a, b) tale che
f(c) = g(c).
bc
a b
c
gf
x
184Il grafico si puo ottenere con le trasformazioni grafiche elementari. Invito il lettore a farlo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 LIMITI DI FUNZIONI COMPOSTE
FUNZIONI CONTINUE
184
• Se con le due funzioni si assume che f sia crescente e che g sia decrescente, il punto c e unico, cioe l’equazione
f(x) = g(x)
ha una e una sola soluzione in (a, b).
A titolo di esempio, vediamo come puo essere utilizzato tutto questo nella soluzione di un’equazione. Lo studenteha gia visto svariati esempi di equazioni e ha imparato a risolvere classi particolari di equazioni, come le intere diprimo e secondo grado, intere di grado maggiore del secondo (a patto di riuscire a fattorizzare il polinomio), razionali,irrazionali, esponenziali, logaritmiche. Ha anche gia visto pero che non esistono metodi generali per risolvere unaqualunque equazione. Davanti alla “semplice” equazione
x+ lnx = 0,
i metodi imparati non servono, dato che l’equazione non rientra nei tipi studiati. In realta non esiste un metodoesatto per risolvere tale equazione. Soltanto con metodi numerici approssimati e possibile trovare una soluzione, cioeun numero razionale “non troppo lontano” dalla soluzione esatta. In generale e gia tanto riuscire a sapere se una dataequazione ha almeno una soluzione.
Grazie alle conseguenze del teorema fondamentale delle funzioni continue in unintervallo e pero spesso possibile dire molto, come ora vediamo proprio sull’equazioneproposta. Scriviamo l’equazione come
lnx︸︷︷︸
f(x)
= −x︸︷︷︸
g(x)
e poniamo f(x) = lnx e g(x) = −x.
Consideriamo le due funzioni nell’intervallo (0,+∞). Si ha
limx→0+
f(x) = limx→0+
ln x = −∞ e limx→0+
g(x) = limx→0+
(−x) = 0,
mentre
limx→+∞
f(x) = limx→+∞
lnx = +∞ e limx→+∞
g(x) = limx→+∞
(−x) = −∞.
bc1
Per quanto visto sopra possiamo dire che esiste almeno una soluzione dell’equazione data nell’intervallo (0,+∞).Osservando inoltre che f e crescente e che g e decrescente, possiamo affermare che la soluzione e unica. Ripetendo leconsiderazioni precedenti nell’intervallo (0, 1), si puo dire che la soluzione e appunto compresa tra 0 e 1, come la figurasuggerisce. La soluzione pero non si puo trovare in modo esatto.
Esercizio 3.1 Data la funzione
f : [0, 1]→ R, con f(x) =
1 x = 0
−x2 − 2x+ 1 0 < x < 1
−2 x = 1,
si verifichi che ad essa e applicabile il teorema degli zeri e si verifichi la validita della tesi del teorema.
Esercizio 3.2 Data la funzione
f : [0, 1]→ R, con f(x) =
1/2 x = 0
|x− 1| − 1/2 0 < x < 1
−1/2 x = 1,
si verifichi che e ad essa applicabile il teorema di Weierstrass e si verifichi la validita della tesi del teorema.
4 Limiti di funzioni composte
In questa sezione vediamo un risultato che riguarda il limite della funzione composta, da cui seguono un’importanteconseguenza sulla continuita della funzione composta e un metodo operativo per il calcolo del limite. La questione
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 LIMITI DI FUNZIONI COMPOSTE
FUNZIONI CONTINUE
185
e sostanzialmente questa: se ho un’espressione composta del tipo g(f(x)), per calcolare il limite di questa per x chetende a qualche cosa posso calcolare prima il limite della funzione interna e poi di questo calcolare il valore attraversola funzione esterna?
Proposizione Siano f : (a, b)→ R, sia g un’altra funzione e supponiamo che esista la funzione composta g(f(x)).185
Valgono le proprieta seguenti:
(i) se limx→b−
f(x) = ℓ (ℓ ∈ R) e se g e continua in ℓ, allora limx→b−
g(f(x)
)= g(ℓ)
(ii) se limx→b−
f(x) = λ = ±∞, allora limx→b−
g(f(x)
)= lim
y→λg(y).
Valgono risultati analoghi per limiti da destra e bilateri e con intervalli non limitati (cioe con limiti per x→ ±∞).
Osservazione La proposizione sostanzialmente afferma che nelle condizioni esposte e possibile calcolare il limitedi una funzione composta calcolando prima il limite della funzione interna e successivamente quello della funzioneesterna.
Osservazione La proposizione sul limite di funzioni composte e il fondamento teorico di quello che, nelle tecnichedi calcolo dei limiti, si chiama comunemente cambio di variabile (o sostituzione). Ne vediamo qui un paio di esempi.
Esempi
• Semplice esempio di applicazione del punto (i) e il
limx→+∞
e1/x.
Il limite della funzione interna e limx→+∞
1x = ℓ = 0. La funzione esterna (g(y) = ey) e continua in ℓ = 0 e pertanto
il limite vale e0 = 1.
• Altro semplice esempio di applicazione del punto (i) e il
limx→−∞
ln
(
1 +1
x
)
.
Il limite della funzione interna e limx→−∞
(1 + 1
x
)= ℓ = 1. La funzione esterna (g(y) = ln y) e continua in ℓ = 1 e
pertanto il limite vale ln 1 = 0.
• Consideriamo il
limx→+∞
1 + lnx
1− lnx.
Si tratta di una f.i. del tipo (+∞)/(−∞). Effettuando il cambio di variabile y = lnx il limite diventa
limy→+∞
1 + y
1− y = −1.
Il limite si poteva peraltro calcolare anche dividendo numeratore e denominatore per ln x. Si osservi che ci siamomossi nell’ambito del punto (ii) della proposizione. La funzione f e la funzione x 7→ lnx, λ = +∞ e la funzioneesterna g e la funzione y 7→ 1+y
1−y .
• Consideriamo illim
x→0+x ln x.
Si tratta di una f.i. del tipo 0 · (−∞). Il limite puo essere riscritto nella forma limx→0+
lnx
1/x(ora f.i. (−∞)/(+∞)).
Effettuando il cambio di variabile y = 1x (da cui x = 1
y ) il limite diventa
limy→+∞
ln 1y
y= lim
y→+∞− ln y
y= 0 (confronto standard).
Ci siamo mossi ancora nell’ambito del punto (ii) della proposizione. La funzione f e la funzione x 7→ 1/x,
λ = +∞ e la funzione esterna g e la funzione y 7→ ln(1/y)y .
185Ricordo che affinche esista la funzione composta g(f(x)) occorre che i valori della f appartengano al dominio della g. La funzione gdeve quindi essere definita in un intervallo che contiene f((a, b)), che e l’immagine della funzione f .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 LIMITI DI FUNZIONI COMPOSTE
FUNZIONI CONTINUE
186
Molti limiti si possono ricondurre, come l’ultimo, al confronto tra funzioni potenza–esponenziale–logaritmica. Riportotali confronti, che continuo a chiamare per comodita confronti standard :
limx→+∞
xα
bx= 0 e lim
x→+∞(logb x)
p
xα= 0,
dove α > 0, b > 1 e p > 0.Si tratta dei noti confronti a +∞ tra le funzioni elementari potenza, esponenziale e logaritmica. Metto nuovamentein guardia lo studente: occorre fare attenzione sia alle funzioni sia al valore a cui tende x (+∞). In altre parole, none detto che un quoziente tra una potenza ed una esponenziale sia un confronto standard, e quindi abbia limite zero.
Ad esempio, nel caso del limx→−∞
x2
ex , non si tratta nemmeno di una forma indeterminata e il limite e +∞.
Vediamo alcuni limiti che, con un cambio di variabile, si riconducono ai confronti standard.
• Consideriamo il limx→0+
xe1/x. Si tratta di una f.i. del tipo 0 · (+∞). Con la sostituzione 1x = y il limite diventa
limy→+∞
1
y· ey = lim
y→+∞ey
y
(confronto standard) = +∞.
• Consideriamo il limx→0−
e1/x
x. Si tratta di una f.i. del tipo 0/0. Qui si puo usare un po’ di astuzia per intuire
quale e la sostituzione piu opportuna. La piu naturale sarebbe come prima porre 1x = y, la quale pero, dato che
x→ 0−, porterebbe a y → −∞ e non avremmo piu un confronto standard.186 Invece con la sostituzione 1x = −y
(da cui x = − 1y ), il limite diventa
limy→+∞
e−y
−1/y = − limy→+∞
y
ey
(confronto standard) = 0.
Ora riprendo in considerazione le “forme indeterminate esponenziali”, delle quali abbiamo detto l’esistenza ma di cuinon abbiamo ancora visto esempi. Esse, come anticipato nel capitolo sui limiti, sono le forme del tipo:
(0+)0 , (+∞)0 , 1±∞. 187
Vediamo come ci si comporta per affrontare questi casi in alcuni esempi.
• Consideriamo illim
x→0+xx.
Si tratta di una f.i. del tipo (0+)0. Il trucco, valido anche con tutte le altre forme di questo tipo, e quello discrivere la funzione come potenza in base e. Quindi qui scriviamo xx in base e, ricordando le cose dette all’iniziodel corso parlando di logaritmi.188 Allora nel nostro caso otteniamo
limx→0+
xx = limx→0+
ex lnx.
Abbiamo visto poco fa in uno degli esempi precedenti che il limite della funzione interna, cioe x 7→ x lnx, perx→ 0+, e ℓ = 0. La funzione esterna, l’esponenziale, e continua in ℓ = 0 e quindi, applicando il punto (i) dellaproposizione sul limite della funzione composta, possiamo concludere che il limite vale e0 = 1.
186Con la sostituzione 1x= y avremmo
limy→−∞
ey
1/y= lim
y→−∞yey,
che non e un confronto standard e che richiede un ulteriore cambio di variabile.187Si noti che in questi casi, trattandosi di forme esponenziali in cui sia la base sia l’esponente sono variabili, e quindi numeri reali, occorreche la base sia positiva: questo e il motivo dello 0+ e del +∞ nei primi due.188Si ricordi che un qualunque numero reale positivo r si puo scrivere come potenza in una qualunque base. Se vogliamo scrivere r comepotenza in base e basta scrivere r = eln r . Quindi xx = elnxx
= ex lnx.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 LIMITI NOTEVOLI
FUNZIONI CONTINUE
187
• Consideriamo illim
x→+∞x1/x.
Si tratta di una f.i. del tipo (+∞)0. Con lo stesso trucco usato poco fa possiamo scrivere
limx→+∞
x1/x = limx→+∞
e1x lnx = lim
x→+∞e
lnxx = e0 = 1
(ad esponente abbiamo ovviamente usato il confronto standard logaritmo/potenza).
Esempi di limiti nella forma indeterminata esponenziale del tipo 1±∞ li vediamo nella sezione successiva.
Prima di chiudere questa sezione torniamo su di una questione toccata in precedenza ma non ancora risolta. Se cioela composizione di funzioni continue sia anch’essa una funzione continua. Lo studente non dovrebbe avere difficoltanel riconoscere che questo significa, per definizione di continuita in un punto, poter affermare che
limx→c
g(f(x)) = g(f(c))
nelle ipotesi che c sia un punto in cui f e continua e che g sia continua in f(c).E del tutto immediato vedere che la validita di questa uguaglianza deriva dalla Proposizione sul limite della funzionecomposta, e piu precisamente che e sufficiente il punto (i): infatti la continuita della funzione interna f garantisce cheesista il limite ℓ = f(c), la funzione esterna g e continua in tale valore e quindi si ha proprio
limx→c
g(f(x)) = g(ℓ) = g(f(c)).
Allora, come caso particolare, possiamo affermare che la composta di funzioni elementari e ancora una funzionecontinua, in tutto il dominio in cui essa e definita.
Esempi La funzione f(x) = ex2
e continua in tutto R, dato che e composta di una potenza (interna) e di unaesponenziale. La funzione g(x) = ln
√x e continua in (0,+∞), essendo composta di una potenza (interna) e di una
logaritmica. La funzione h(x) =√lnx e continua in [1,+∞), essendo composta di una logaritmica (interna) e di una
potenza.
Osservazione In generale allora possiamo dire che non solo le funzioni elementari, ma anche le somme, i prodotti,i quozienti e le composizioni di queste sono funzioni continue.
Esercizio 4.1 Si calcolino i seguenti limiti.
(a) limx→+∞
x− ln x
x+ ln x(b) lim
x→0
ex2
ln(e+ x3)
(c) limx→0−
1 + e1/x
e1/x + ln(x+ e)(d) lim
x→−∞1 + ex
2
1 + e1/x
(e) limx→+∞
(
e1−√x +√1 + lnx
)
(f) limx→+∞
ln(1 + e−x)√1 + ex
(g) limx→+∞
ln(1 +√x)√
x(h) lim
x→0+
(x2 lnx
)
(i) limx→0+
(
xe1/x)
(j) limx→+∞
(
xe−x2)
5 Limiti notevoli
Come conseguenza del limite fondamentale (enunciato alla fine della lezione sui limiti) e attraverso l’utilizzo del cambiodi variabile possiamo trovare altri limiti notevoli. Vediamo qui i piu importanti.Ricordo che il limite fondamentale e:
limx→±∞
(
1 +1
x
)x
= e.
Si noti che il limite si presenta come una f.i. esponenziale del tipo 1±∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 LIMITI NOTEVOLI
FUNZIONI CONTINUE
188
• Risultalim
x→0+(1 + x)1/x = e.
E una f.i. del tipo 1+∞. Ponendo 1x = y (da cui x = 1
y ) si ottiene
limx→0+
(1 + x)1/x = limy→+∞
(
1 +1
y
)y
.
Il limite e quindi ricondotto al limite fondamentale. Il valore del limite e quindi e. Stesso risultato si ottieneanche per x→ 0−, per cui possiamo dire che il limite, per x→ 0, e e .
• Chiamero limite notevole logaritmico il seguente. Si ha
limx→0
ln(1 + x)
x= 1.
E una f.i. del tipo 0/0. Ponendo 1x = y (da cui x = 1
y ) si ottiene
limx→0
ln(1 + x)
x= lim
y→+∞
(
y · ln(
1 +1
y
))
= limy→+∞
ln
(
1 +1
y
)y
= ln e = 1.
Qui, oltre al cambio di variabile, abbiamo anche fatto uso del punto (i) della proposizione sul limite della funzionecomposta.
In generale, se il logaritmo e in base b, il limite e
limx→0
logb(1 + x)
x=
1
ln b.
• Chiamero limite notevole esponenziale il seguente. Si ha
limx→0
ex − 1
x= 1.
Con il cambio di variabile ex − 1 = y, da cui x = ln(1 + y), si ottiene
limx→0
ex − 1
x= lim
y→0
y
ln(1 + y)= lim
y→0
1ln(1+y)
y
.
Il limite e quindi ricondotto al limite notevole precedente. Il valore del limite e quindi 1.
Se la funzione esponenziale e in base b, cioe se il limite e limx→0
bx − 1
x, con lo stesso cambio di variabile e con il
limite notevole logaritmico in base b si ottiene che il limite e ln b.
• Chiamero limite notevole potenza il seguente. Si ha
limx→0
(1 + x)b − 1
x= b.
La risoluzione di questo e piu elaborata e non vediamo i passaggi. Lo studente ricordi semplicemente ilrisultato.189
189Per chi vuole provare, un cambio di variabile che porta sulla strada giusta e 1 + x = ey , da cui x = ey − 1. Il limite diventa
limx→0
(1 + x)b − 1
x= lim
y→0
eby − 1
ey − 1
ma qui non tolgo il piacere di arrivare da soli alla conclusione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
FUNZIONI CONTINUE
189
Osservazione E bene ricordare i limiti notevoli visti e saperli riconoscere. E bene anche imparare a ricondurrealcuni limiti ai limiti notevoli.Vediamo per finire un ultimo esempio di limite che si riconduce a quello fondamentale.Si tratta del limite
limx→±∞
(
1 +b
x
)x
, con b numero reale.
Lo si puo intanto riscrivere nella forma
limx→±∞
[(
1 +b
x
)x/b]b
= limx→±∞
[(
1 +1
x/b
)x/b]b
.
Viene quindi ricondotto al limite fondamentale con il cambio di variabile x/b = y. Si ha
limx→±∞
[(
1 +1
x/b
)x/b]b
= limy→±∞
[(
1 +1
y
)y]b
= eb.
Faccio notare che, potendo essere b un numero reale qualunque, quali casi particolari di questo limite abbiamo adesempio
limx→±∞
(
1 +2
x
)x
= e2 oppure limx→±∞
(
1− 1
x
)x
=1
e.
6 Soluzioni degli esercizi
Esercizio 2.1
(a) f : R→ R, con f(x) =
{1− x x 6= 1
1 x = 1.
Un grafico rende subito evidente la discontinuita di questa funzione. Procediamo comunque analiticamente. Siha f(1) = 1 per definizione, mentre
limx→1
f(x) = limx→1
(1− x) = 0.
Quindi, essendo i valori dei limiti diversi dal valore della funzione nel punto, f e discontinua in 1. Possiamodire che in 1 c’e una discontinuita di tipo salto, da destra e da sinistra. Talvolta questo tipo di discontinuitaviene denominato discontinuita eliminabile.190 In tutti gli altri punti di R la funzione e continua, essendo unpolinomio.
(b) f : R→ R, con f(x) =
{1− x2 x < 0
x2 x ≥ 0.
Anche qui lo studente e invitato a disegnare il grafico della funzione e a rispondere alla domanda sulla base diconsiderazioni grafiche.
Possiamo dire che la funzione e continua in R \ {0}, cioe in tutti i punti diversi da zero: si tratta infatti dipolinomi.
Nel punto x = 0 non possiamo usare lo stesso argomento, dato che la f e sı un polinomio sia a destra sia asinistra, ma non lo stesso polinomio! Quindi per studiare la continuita nel punto x = 0 dobbiamo procedere conla definizione. Si ha f(0) = 0 (si usa la seconda espressione, quella per x ≥ 0). Poi
limx→0−
f(x) = limx→0−
(1− x2) = 1
elim
x→0+f(x) = lim
x→0+x2 = 0.
Questo ci dice che la funzione e continua in 0 da destra, ma discontinua da sinistra e che da sinistra c’e un salto.
Si poteva anche evitare il calcolo del limite da destra, osservando che la funzione coincide con x2 in [0,+∞) equindi e certamente continua in 0 da destra, essendo un polinomio.
190Significa che la discontinuita puo essere eliminata semplicemente cambiando la definizione della funzione nel punto. Nel nostro caso,se ridefiniamo il valore della f in 1 con f(1) = 0, otteniamo una funzione continua in 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
FUNZIONI CONTINUE
190
(c) f : R→ R, con f(x) =
{1/x2 x 6= 0
0 x = 0.
Anche qui un grafico illustra subito la situazione. Possiamo dire che la funzione e continua in R\{0}, trattandosidi una funzione potenza.
Studiamo la continuita in x = 0. Si ha f(0) = 0 per definizione. Poi
limx→0−
f(x) = limx→0+
f(x) = limx→0
1
x2= +∞.
Pertanto f e discontinua in 0 e c’e una discontinuita di seconda specie, sia da destra sia da sinistra.
(d) f : [0,+∞)→ R, con f(x) =
1/ lnx x 6= 0, x 6= 1
0 x = 0
0 x = 1.
In questo caso la funzione e definita in [0,+∞). Possiamo dire che e certamente continua in (0, 1) ∪ (1,+∞),cioe in tutti i reali non negativi diversi da 0 e da 1 (quoziente di funzioni continue). Occorre studiare ora lacontinuita in x = 0 e x = 1.
In x = 0 si ha f(0) = 0 e
limx→0+
f(x) = limx→0+
1
lnx=
1
−∞ = 0.
Quindi f e continua in 0 da destra.
In x = 1 si ha f(1) = 0. Poi
limx→1−
f(x) = limx→1−
1
lnx=
1
0−= −∞
e
limx→1+
f(x) = limx→1+
1
lnx=
1
0+= +∞.
Quindi f non e continua in 1 e ha una discontinuita di seconda specie, sia da destra sia da sinistra.
Esercizio 2.2
La funzione f e certamente continua per x 6= 1, qualunque sia il valore di a, ed e continua in 1 da sinistra, dato che ela restrizione di una funzione elementare. Occorre studiare la continuita in x = 1 da destra. Si ha
f(1) = e−a e limx→1+
f(x) = limx→1+
(x+ 1) = 2.
Pertanto f e continua in 1 da destra se e solo se e−a = 2, cioe per a = − ln 2.
Esercizio 2.3
La funzione f e certamente continua per x 6= 0, qualunque sia il valore di a, ed e continua in 0 da destra, dato che ela restrizione di una funzione elementare. Occorre studiare la continuita in x = 0 da sinistra. Si ha
f(0) = a2 e limx→0−
f(x) = limx→0−
(x2 + x+ a) = a.
Pertanto f e continua in 0 da sinistra se e solo se a2 = a, cioe per a = 0 oppure a = 1.
Esercizio 3.1
Un teorema e applicabile se sono verificate le ipotesi previste dal teorema. Quindi qui si chiede di verificare che:
(i) la funzione in questione e definita in un intervallo chiuso e limitato;
(ii) in tale intervallo e continua;
(iii) assume valori opposti agli estremi dell’intervallo.
(i) La funzione e chiaramente definita in [0, 1], che e chiuso e limitato.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
FUNZIONI CONTINUE
191
(ii) La funzione e certamente continua in (0, 1), cioe in tutti i punti dell’intervallo diversi dagli estremi (e unpolinomio). Occorre ora vedere se e continua in 0 e in 1.
In 0 si ha f(0) = 1 elim
x→0+f(x) = lim
x→0+(−x2 − 2x+ 1) = 1.
Quindi f e continua in 0 da destra.
In 1 si ha f(1) = −2 elim
x→1−f(x) = lim
x→1−(−x2 − 2x+ 1) = −2.
Quindi f e continua in 1 da sinistra. Pertanto abbiamo provato che f e continua in [0, 1].
(iii) Abbiamo gia visto che f(0) = 1 e f(1) = −2, quindi anche la terza ipotesi e soddisfatta. Qui finisce la verificadelle ipotesi e possiamo dire che il teorema degli zeri e applicabile.
Ora l’esercizio chiede di verificare la tesi, che certamente deve essere vera, dato che le ipotesi sono soddisfatte. La tesidel teorema degli zeri dice che c’e almeno un punto dell’intervallo (0, 1) (punto interno quindi) in cui la funzione valezero. Qui basta considerare l’equazione f(x) = 0, cioe
−x2 − 2x+ 1 = 0
e risolverla. Si trovano le soluzionix1 = −1 +
√2 e x2 = −1−
√2.
La prima appartiene a (0, 1) e quindi la tesi e verificata.
Esercizio 3.2
Si tratta di verificare che la funzione e definita in un intervallo chiuso e limitato e che in tale intervallo e continua.La funzione e definita in [0, 1], che e chiuso e limitato. E sicuramente continua in (0, 1), essendo composta di funzionicontinue. Occorre verificare la continuita in 0 e in 1.In 0 si ha f(0) = 1/2 e
limx→0+
f(x) = limx→0+
(|x − 1| − 1/2) = 1/2.
Quindi f e continua in 0 da destra.In 1 si ha f(1) = −1/2 e
limx→1−
f(x) = limx→1−
(|x − 1| − 1/2) = −1/2.
Quindi f e continua in 1 da sinistra. Pertanto f e continua in [0, 1] e le ipotesi del teorema di Weierstrass sonoverificate.La tesi del teorema dice che ci sono punti nell’intervallo [0, 1] in cui la funzione assume il valore massimo e il valoreminimo. Si puo osservare che, in [0, 1], f(x) = |x− 1| − 1/2 = 1− x− 1/2 = 1/2− x. La funzione e quindi decrescentenell’intervallo in cui e definita. Allora il valore massimo viene necessariamente assunto nel primo estremo e il valoreminimo nel secondo estremo. Con le notazioni che ho usato nella dispensa di questa sezione potremmo scrivere cM = 0e cm = 1. Attenzione a non confondere mai il punto di massimo, cioe il punto in cui la funzione assume il valoremassimo (punto che sta nel dominio di f), con il massimo, che e invece il valore massimo, cioe il massimo dell’immaginedi f (e sta quindi nel codominio di f).
Esercizio 4.1
(a) limx→+∞
x− lnx
x+ lnx. La funzione logaritmica e trascurabile, per x → +∞, rispetto alla funzione x. Quindi, per il
principio di eliminazione, si ha
limx→+∞
x− lnx
x+ lnx= lim
x→+∞x
x= 1.
(b) limx→0
ex2
ln(e+ x3). Nel quoziente sono presenti funzioni composte. Si usano quindi i risultati visti sul limite della
funzione composta. Ricordando che, per x→ 0, x2 e x3 tendono a zero, si ha semplicemente
limx→0
ex2
ln(e + x3)= lim
x→0
e0
ln e= 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
FUNZIONI CONTINUE
192
(c) limx→0−
1 + e1/x
e1/x + ln(x+ e). Anche qui con il limite della funzione composta: per x→ 0−, 1/x→ −∞ e quindi
limx→0−
e1/x = limt→−∞
et = 0.
Pertanto
limx→0−
1 + e1/x
e1/x + ln(x+ e)=
1 + 0
0 + 1= 1.
(d) Possiamo scrivere
limx→−∞
1 + ex2
1 + e1/x=
1 + e+∞
1 + e0=
+∞2
= +∞.
(e) Abbiamo
limx→+∞
(
e1−√x +√1 + lnx
)
= e−∞ +∞ = 0 +∞ = +∞.
(f) Qui abbiamo
limx→+∞
ln(1 + e−x)√1 + ex
=ln(1 + 0)√1 +∞ =
0
+∞ = 0.
(g) limx→+∞
ln(1 +√x)√
x. Forma indeterminata (+∞)/(+∞). Qui facciamo un cambio di variabile. Poniamo
√x = y.
Si ha
limx→+∞
ln(1 +√x)√
x= lim
y→+∞ln(1 + y)
y.
E ancora ovviamente una f.i. e si intuisce che il numeratore e trascurabile rispetto al denominatore (la presenzadi 1 nel logaritmo non cambia il modo con cui il logaritmo tende all’infinito). Pero per ricondurci esattamenteal confronto standard, cioe ln y/y, possiamo usare un altro cambio di variabile ponendo ora 1 + y = z (da cuiy = z − 1). Si ha allora
limy→+∞
ln(1 + y)
y= lim
z→+∞ln z
z − 1= lim
z→+∞ln z
z= 0. 191
Anziche usare un secondo cambio di variabile si poteva seguire invece una via algebrica e fare cosı:
limy→+∞
ln(1 + y)
y= lim
y→+∞ln(y(1 + 1/y))
y= lim
y→+∞ln y + ln(1 + 1/y)
y= lim
y→+∞
(ln y
y+
ln(1 + 1/y)
y
)
.
Il primo e il confronto standard tra un logaritmo e una potenza e sappiamo che il risultato del limite e zero. Ilsecondo non e una f.i., dato che e 0/∞. Quindi il risultato e 0.
(h) limx→0+
(x2 lnx
). F.i. del tipo 0 · (−∞). Anche qui un cambio di variabile. Riscriviamo prima
limx→0+
(x2 lnx
)= lim
x→0+
lnx
1/x2.
Ora poniamo 1/x = y. Il limite diventa quindi
limx→0+
lnx
1/x2= lim
y→+∞ln(1/y)
y2= lim
y→+∞− ln y
y2= 0,
per il confronto standard tra logaritmo e potenza.
(i) limx→0+
(
xe1/x)
. F.i. del tipo 0 · ∞. Cambio di variabile: poniamo 1/x = y. Il limite diventa
limx→0+
(
xe1/x)
= limy→+∞
(1
yey)
= limy→+∞
ey
y= +∞,
per il confronto standard tra esponenziale e potenza.
191Nel penultimo passaggio a denominatore la costante e trascurabile rispetto a z. Il risultato segue poi dal confronto standard tra unlogaritmo e una potenza.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
FUNZIONI CONTINUE
193
(j) limx→+∞
(
xe−x2)
. F.i. del tipo +∞ · 0. Possiamo riscrivere
limx→+∞
x
ex2 .
Ora poniamo x2 = y. Il limite diventa
limx→+∞
x
ex2 = limy→+∞
√y
ey= 0,
per il solito confronto standard tra esponenziale e potenza.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DEFINIZIONE DI DERIVATA
DERIVATE
194
II-6 Derivate
1 Definizione di derivata
Definizione Sia I un intervallo aperto e sia f : I → R. Sia poi x0 ∈ I. Si chiama rapporto incrementale di fcon punto iniziale x0 il quoziente
f(x)− f(x0)x− x0
, con x ∈ I, x 6= x0.
Osservazione Si chiama ovviamente rapporto incrementale in quanto e il rapporto di due incrementi,192 e cioe dellavariazione dei valori di f (rispetto a f(x0)) e della variazione dei valori della variabile (rispetto ad x0).
Osservazione Nel rapporto incrementale x0 (il punto iniziale) e fissato, mentre x e variabile. Naturalmente ilrapporto incrementale e definito per x diverso da x0. Non ha nessuna importanza se x e maggiore o minore di x0, ilrapporto incrementale e definito sempre attraverso la stessa formula.
Osservazione Qual e il significato geometrico di questo rapporto? Quando si rapporta (si divide) una variazionein ordinata con una variazione in ascissa si ottiene una variazione in ordinata per unita di variazione in ascissa. Inmatematica, o meglio in geometria analitica, si dice anche pendenza. Se ho quindi due punti nel piano e calcolo ilrapporto delle variazioni, ottengo la pendenza: di che cosa? naturalmente della retta che passa per quei due punti.Quindi il rapporto incrementale fornisce la pendenza della retta che passa per i due punti (vedi figura pagina seguente)(x0, f(x0)
)e(x, f(x)
). C’e un termine piu tecnico per indicare la volgare pendenza, ma e esattamente lo stesso, ed e il
coefficiente angolare, perche e chiaro che c’e una dipendenza diretta tra la pendenza della retta e la misura dell’angoloche essa forma con l’asse delle x. Ultima cosa: chiaramente la pendenza di cui parliamo dipende da x.
Osservazione Il rapporto incrementale si puo anche scrivere in una forma leggermente diversa ma equivalente:
f(x0 + h)− f(x0)h
, con x0 + h ∈ I, h 6= 0.
Semplicemente vuol dire chiamare h quello che prima era x− x0 (vedi figura a destra nella pagina seguente).
x0 x
f(x0)
f(x)
x0 x0 + h
f(x0)
f(x0 + h)
}h
Veniamo ora ad una definizione assolutamente fondamentale.
Definizione Siano a, b ∈ R e sia f : (a, b)→ R. Sia poi x0 ∈ (a, b). Diciamo che f e derivabile da destra in x0 seil limite
limx→x+
0
f(x)− f(x0)x− x0
e un numero reale, cioe esiste ed e finito.
In questo caso chiamiamo derivata destra di f in x0 tale numero, che viene indicato con la scrittura f ′+(x0). Si ha
quindi
f ′+(x0) = lim
x→x+
0
f(x)− f(x0)x− x0
.
Si dice analogamente che f e derivabile da sinistra in x0 se il limite
limx→x−
0
f(x)− f(x0)x− x0
e un numero reale, cioe esiste ed e finito.
In questo caso tale numero si chiama derivata sinistra di f in x0, e viene indicato con la scrittura f ′−(x0).
192Sarebbe forse meglio dire variazioni e quindi rapporto variazionale, ma ormai lo hanno chiamato cosı. In ogni modo non si pensi cheincremento voglia dire quantita positiva: puo essere anche un decremento, cioe una quantita negativa.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DEFINIZIONE DI DERIVATA
DERIVATE
195
Se f : (a, b) → R e derivabile da sinistra e da destra in x0, e f′−(x0) = f ′
+(x0), diciamo che f e derivabile in x0 echiamiamo derivata di f in x0 il valore comune dei due limiti.Possiamo quindi dire che la derivata di f in x0 e il
limx→x0
f(x)− f(x0)x− x0
, se questo e finito.
La derivata di f in x0 si indica con f ′(x0), o anche con Df(x0) o condf
dx(x0).
Osservazione Se utilizziamo la seconda forma del rapporto incrementale possiamo scrivere la derivata come
f ′(x0) = limh→0
f(x0 + h)− f(x0)h
,
che in pratica si ottiene dall’altra forma con il cambio di variabile x− x0 = h.
Osservazione Si noti che nella definizione di derivata l’intervallo in cui e definita la f e aperto e che quindi il puntox0 e interno all’intervallo. Se l’intervallo fosse chiuso, diciamo [a, b], non possiamo parlare quindi di derivata in a e inb, ma possiamo pero parlare di derivata destra in a e derivata sinistra in b.
Esempi
• Sia f(x) = mx+ q. Allora per ogni x0 ∈ R si ha f ′(x0) = m.
Infatti
limx→x0
f(x)− f(x0)x− x0
= limx→x0
mx+ q −mx0 − qx− x0
= limx→x0
m(x− x0)x− x0
= m.
Lo studente provi a rifare i calcoli usando la seconda forma (quella con h), anche negli esempi che seguono.
• Sia f(x) = x2. Allora per ogni x0 ∈ R si ha f ′(x0) = 2x0.
Infatti
limx→x0
f(x)− f(x0)x− x0
= limx→x0
x2 − x20x− x0
= limx→x0
(x− x0)(x + x0)
x− x0= lim
x→x0
(x+ x0) = 2x0.
• Sia f(x) = x3. Allora per ogni x0 ∈ R si ha f ′(x0) = 3x20.
Infatti
limx→x0
f(x)− f(x0)x− x0
= limx→x0
x3 − x30x− x0
= limx→x0
(x− x0)(x2 + xx0 + x20)
x− x0= lim
x→x0
(x2 + xx0 + x20) = 3x20.
• Sia f : R→ R definita da
f(x) =
{1 x > 0
0 x ≤ 0.
bc
b
1
Se x0 > 0, allora limx→x0
f(x)− f(x0)x− x0
= limx→x0
1− 1
x− x0= 0.
Se x0 < 0 in modo simile, si ha limx→x0
f(x)− f(x0)x− x0
= limx→x0
0− 0
x− x0= 0. Quindi, f ′(x0) = 0 per ogni x0 6= 0.
Vediamo ora come vanno le cose in x0 = 0. Si ha
limx→0−
f(x)− f(0)x− 0
= limx→0−
0− 0
x= 0,
e quindi f ′−(0) = 0, ma
limx→0+
f(x) − f(0)x− 0
= limx→0+
1− 0
x= +∞,
e quindi la funzione non e derivabile in 0 da destra. Quindi la derivata in 0 non esiste.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DEFINIZIONE DI DERIVATA
DERIVATE
196
Esercizio 1.1 Scrivere il rapporto incrementale delle seguenti funzioni, con punto iniziale x0 indicato.
(a) f(x) = ln2 x, con x0 = e (b) f(x) =1
1 + x, con x0 = 1
(c) f(x) =
{x ln(1/x) x 6= 0
0 x = 0, con x0 = 0 (d) f(x) =
{x2 x ≤ 1
ex x > 1, con x0 = 1
Osservazione Come fatto prima con il rapporto incrementale, cerchiamo ora ilsignificato geometrico della derivata di una funzione f in un punto x0. Se il rapportoincrementale e la pendenza della retta passante per i due punti
(x0, f(x0)
)e(x, f(x)
),
si intuisce che, facendo il limite per x→ x0, tale retta “tende” alla retta che (vedi lafigura a fianco) la geometria chiama retta tangente al grafico di f nel punto
(x0, f(x0)
).
x0 ←− x
f(x0)
|
b
a|
bb
Non mi dilungo su che cosa sia rigorosamente la retta tangente, pensando che lo stu-dente ne abbia gia un’idea abbastanza precisa. Ovviamente il significato geometricosi puo adattare nel caso in cui si parli ad esempio di derivata destra nel primo estremodell’intervallo o di derivata sinistra nel secondo estremo: si trattera della pendenzadella semitangente (semiretta tangente) destra o sinistra rispettivamente nei punti(a, f(a)
)e(b, f(b)
)(vedi figura a fianco).
Lo studente cerchi di intuire, pensando a qualche grafico particolare, che l’esistenza della derivata (ossia la derivabilitadi f in un punto) e strettamente legata all’esistenza della retta tangente in quel punto. In altre parole non e detto checi sia sempre la retta tangente.
Proposizione Sia f : (a, b)→ R e sia x0 ∈ (a, b). Se f e derivabile in x0 da destra (da sinistra), allora f e continuain x0 da destra (da sinistra). Quindi se f e derivabile in x0 allora f e continua in x0.
DimostrazioneConsideriamo il caso della derivabilita da destra; il caso della derivabilita da sinistra e analogo.Supponiamo che f sia derivabile in x0 da destra. Significa che
limx→x+
0
f(x)− f(x0)x− x0
= ℓ.
Ma allora
limx→x+
0
(f(x)− f(x0)
x− x0− ℓ)
= 0 e cioe limx→x+
0
f(x)− f(x0)− ℓ(x− x0)x− x0
= 0.
Pertanto il numeratore e trascurabile rispetto al denominatore per x → x+0 . Ma questo, come sappiamo, dato che ildenominatore tende a zero, comporta che anche il numeratore tende a zero, e quindi che f(x)−f(x0)→ 0 per x→ x+0 .Questo non e che un modo equivalente di dire che f(x)→ f(x0) per x→ x+0 , e cioe che f e continua da destra in x0.
Osservazione Se quindi funzioni derivabili sono necessariamente continue, esistono pero funzioni continue in unpunto ma non derivabili in tale punto. Ad esempio, la funzione f(x) = |x| e continua in 0, ma e facile verificare che
f ′−(0) = −1 6= 1 = f ′
+(0),
e dunque f non e derivabile in 0.
Osservazione Dalla proposizione segue anche che se una funzione non e continua in un punto, allora in quel puntonon e nemmeno derivabile.
Osservazione Come gia detto nella dimostrazione, la scrittura
limx→x+
0
f(x)− f(x0)− ℓ(x− x0)x− x0
= 0
significa che f(x)−f(x0)−ℓ(x−x0) e trascurabile rispetto a x−x0 per x→ x+0 , e quindi possiamo dire che f(x)−f(x0)e uguale a ℓ(x− x0) a meno di questa quantita trascurabile.In questo si puo leggere il seguente profondo risultato: se f e derivabile in x0, la variazione della funzione f (cioef(x)−f(x0)) e bene approssimata da una funzione lineare (cioe ℓ(x−x0)) della variazione della variabile indipendente,o in altre parole la variazione di f e sostanzialmente proporzionale alla variazione della x (cioe x − x0). Infatti lavariazione di f e uguale ad ℓ(x−x0) piu una quantita trascurabile rispetto alla variazione della variabile indipendente.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 CALCOLO DI DERIVATE
DERIVATE
197
Possiamo vedere in tutto questo l’aspetto geometrico: se una funzione e derivabile in unpunto x0, una retta e una buona approssimazione del grafico di f nelle vicinanze del punto(x0, f(x0)). Delle infinite rette passanti per tale punto una soltanto e quella che ha questaproprieta. Dalla proposizione si vede che tale retta ha equazione y = f(x0) + ℓ(x− x0),cioe
y = f(x0) + f ′(x0)(x − x0). x0
f(x0)
Questa e quindi l’equazione della retta tangente al grafico della funzione f nel punto (x0, f(x0)).
Vediamo ora alcune situazioni specifiche, anche da un punto di vista geometrico.
Definizioni
• Se f : (a, b) → R e derivabile da sinistra e da destra in x0, e f′−(x0) 6= f ′
+(x0), diciamo che f ha un puntoangoloso in x0.
• Se f e continua in x0, limx→x−
0
f(x)− f(x0)x− x0
6= limx→x+
0
f(x)− f(x0)x− x0
, e almeno uno di questi due limiti e infinito,
diciamo che f ha un punto di cuspide in x0.
• Se f e continua in x0 e limx→x0
f(x)− f(x0)x− x0
vale +∞ oppure −∞, diciamo che x0 e un punto a tangente verticale.
Punto angoloso Punto di cuspide Punto a tangente verticale
Esempi
• La funzione f(x) = |x| ha un punto angoloso in 0.
Infatti, f e continua in 0 193 ef ′−(0) = −1 6= 1 = f ′
+(0).
• La funzione f(x) =√
|x| ha un punto di cuspide in 0.
Infatti, f e continua in 0 (composta di funzioni continue) e
limx→0+
f(x)− f(0)x− 0
= limx→0+
√x
x= lim
x→0+
1√x= +∞
mentre
limx→0−
f(x)− f(0)x− 0
= limx→0−
√−xx
= limx→0−
(
−√
−xx2
)
= limx→0−
(
−√
−1x
)
= −∞.
• La funzione f(x) = 3√x ha in 0 un punto a tangente verticale. Infatti, f e continua in 0 e
limx→0
f(x)− f(0)x− 0
= limx→0
3√x
x= lim
x→0
13√x2
= +∞.
2 Calcolo di derivate
La derivabilita di una funzione e stata definita in un punto. Si puo pero estendere facilmente ad un intervallo. Diamoallora intanto queste definizioni.
193Si noti che per un punto angoloso x0 la continuita nel punto stesso, anche se non esplicitamente prevista dalla definizione, e comunqueuna conseguenza delle altre ipotesi: infatti se la funzione deve essere derivabile da destra e da sinistra in x0, allora e anche continua dadestra e da sinistra, e quindi continua, in x0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 CALCOLO DI DERIVATE
DERIVATE
198
Definizione Sia I un intervallo e sia f : I → R. Diciamo che f e derivabile in I se f e derivabile in ogni puntodi I, con la precisazione che se l’intervallo comprende un estremo, diciamo che f e derivabile in tale intervallo se ederivabile nei punti interni e nell’estremo e derivabile da destra se e il primo e da sinistra se e il secondo.194
E chiaro ora che, se una funzione e derivabile in tutti i punti dell’intervallo, diciamo (a, b), in cui e definita, noipossiamo pensare alla nuova funzione che, ad ogni x dell’intervallo (a, b) associa la derivata in x, cioe f ′(x). In simbolisi tratta della funzione
x 7→ f ′(x), per ogni x ∈ (a, b).
Questa e la funzione derivata di f nell’intervallo (a, b), ma la si continua a chiamare semplicemente derivata.Si pone ora questa domanda: ci sono metodi, in particolare ci sono formule che, data l’espressione di una funzione f ,mi forniscano, senza usare la definizione punto per punto, l’espressione della sua derivata f ′ in tutto l’intervallo?Adesso ci procuriamo queste formule, e naturalmente partiamo dalle funzioni elementari. Successivamente daremoregole che permettono di derivare funzioni costruite a partire da funzioni elementari, mediante l’uso delle quattrooperazioni e della composizione di funzioni.
2.1 Derivate di funzioni elementari
E chiaro che l’unica via e quella, per il momento, di usare la definizione di derivata. Quindi calcoliamo, con ladefinizione, la derivata di alcune funzioni elementari. Faremo uso dei limiti notevoli studiati alla fine della lezione sullefunzioni continue.
• Funzione potenza. Consideriamo la funzione f : (0,+∞)→ R, definita da f(x) = xα. 195 Si ha f ′(x) = αxα−1
per ogni α in R, e ora lo dimostriamo.
Calcoliamo la derivata in un generico x0 > 0. Si ha (per esercizio si provi la forma con h):
limx→x0
xα − xα0x− x0
=xα0x0
limx→x0
(x/x0)α − 1
(x/x0)− 1
(ponendo x/x0 = 1 + y) = xα−10 lim
y→0
(1 + y)α − 1
y
= αxα−10 ,
ricordando il limite notevole potenza.
Consideriamo ora una funzione potenza definita anche in zero.196 Per quanto riguarda la sua derivabilita (dadestra) in x = 0 si tratta di calcolare il limite
limx→0+
xα
x= lim
x→0+xα−1.
Tale limite esiste finito se e solo se α ≥ 1, nel qual caso vale 1 se α = 1 e vale 0 se α > 1.
Osservazione Quindi, ad esempio, la funzione f(x) =√x, definita in [0,+∞), in x = 0 non e derivabile (da
destra). Ricordando il grafico, e facile accorgersi che la retta tangente (semitangente) e verticale e coincide conla parte positiva dell’asse y.
• Funzione esponenziale. Consideriamo la funzione f : R→ R, definita da f(x) = bx. Si ha f ′(x) = bx ln b.
Lo dimostro usando questa volta la forma con h. In un generico x0 ∈ R abbiamo
limh→0
bx0+h − bx0
h= bx0 lim
h→0
bh − 1
h= bx0 ln b,
ricordando il limite notevole esponenziale.
Osservazione Come caso particolare, assolutamente fondamentale, si ha che D(ex) = ex.
194Quindi, ad esempio, se dico che la funzione f : [0,+∞) → R, con f(x) =√x, e derivabile in [0, 1), intendo che e derivabile in (0, 1) e
derivabile da destra in 0 (cosa che tra l’altro e falsa). Si osservi che e quanto abbiamo fatto con la continuita: la continuita viene primadefinita in un punto e poi estesa a tutto l’intervallo se la funzione e continua in tutti i punti dell’intervallo.195Non includo lo zero nell’intervallo di definizione, e tanto meno i numeri negativi, perche sappiamo che la funzione potenza non e in talivalori definita qualunque sia α (ad esempio non e definita in zero se α = −1 e non e definita sui negativi se α = 1/2).196Ricordo che la funzione potenza e definita in x = 0 solo se α > 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 CALCOLO DI DERIVATE
DERIVATE
199
• Funzione logaritmica. Consideriamo la funzione f : (0,+∞)→ R, definita da f(x) = logb x. Si ha f′(x) =
1
x ln b,
per ogni x > 0. Anche questa volta uso la forma con h. Fissato x0 > 0 si ha
limh→0
logb(x0 + h)− logb x0h
= limh→0
logbx0+hx0
h
= limh→0
logb
(
1 + hx0
)
h
(dividendo sopra e sotto per x0) =1
x0limh→0
logb
(
1 + hx0
)
h/x0
=1
x0 ln b,
ricordando il limite notevole logaritmico.
Osservazione Come caso particolare si ha che D(ln x) = 1x .
2.2 Regole di derivazione
Per le funzioni derivabili valgono risultati analoghi a quelli visti per le funzioni continue, che cioe somme, prodotti equozienti di funzioni derivabili sono funzioni derivabili.Supponiamo che I sia un intervallo, che x0 ∈ I e che f, g : I → R siano derivabili in x0.Si puo allora dimostrare che
• f + g e fg sono derivabili in x0 e
(f + g)′(x0) = f ′(x0) + g′(x0);
(fg)′(x0) = f ′(x0) g(x0) + f(x0) g′(x0).
Queste forniscono le regole di derivazione rispettivamente di una somma e di un prodotto di due funzioni. Comesi vede per la somma si tratta di una regola quasi naturale, per il prodotto no, dato che la derivata del prodottonon e il prodotto delle derivate.
Esempi Abbiamo
D(
lnx+√x)
=1
x+
1
2√x
eD(xex)= 1 · ex + xex = ex + xex.
• se g(x0) 6= 0, allora f/g e derivabile in x0 e si ha
(f
g
)′(x0) =
f ′(x0) g(x0)− f(x0) g′(x0)[g(x0)]2
.
Questa fornisce la regola di derivazione del quoziente di due funzioni.
Esempio Abbiamo
D
(lnx
x
)
=1x · x− lnx · 1
x2=
1− lnx
x2.
Immediate conseguenze dei risultati appena esposti sono:
• Se α ∈ R, allora D(αf) = αDf .
Quindi, in parole povere, le costanti possono essere “portate fuori” dal simbolo di derivazione. Pertanto, perderivare ad esempio la funzione x 7→ 2 lnx si fara D(2 lnx) = 2D(lnx) = 2
x .
• D
(1
g
)
= −Dgg2
.
Questa formula si dimostra o con la derivata del quoziente o con la derivata della funzione composta, che vediamo
subito. Cosı, dovendo derivare la funzione x 7→ 1/ lnx si puo fare direttamente D( 1lnx ) = −
1/xln2 x
= − 1x ln2 x
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 CALCOLO DI DERIVATE
DERIVATE
200
• Utilizzando la formula della derivata della funzione potenza e le regole di derivazione di somma e prodotto siottiene che
D( n∑
k=0
ak xk)
=
n∑
k=1
kak xk−1,
con la quale si possono derivare tutti i polinomi.
Esempio Se devo derivare il polinomio P (x) = 2x3 − 4x2 + 5x− 3, si ha P ′(x) = 6x2 − 8x+ 5.
• Vale da ultimo la seguente importante regola di derivazione della funzione composta.
Siano f : (a, b)→ R e g : (c, d)→ R. Supponiamo che x ∈ (a, b) e che f(x) ∈ (c, d). Se f e derivabile in x e g ederivabile in f(x), allora la funzione composta g ◦ f e derivabile in x e
(g ◦ f)′(x) = g′(f(x)
)f ′(x).
Quindi la derivata della funzione composta si calcola con il prodotto delle derivate.
Esempi
• D(ln2 x
)= 2 lnx ·D(lnx) = 2 lnx · 1x .
• D(√x2 + 1
)= 1
2√x2+1
·D(x2 + 1) = 12√x2+1
· 2x.
• D(
3√lnx)
= D(
ln1/3 x)
= 13 ln
−2/3 x ·D(lnx) = 13 ln
−2/3 x · 1x = 1
3x3√ln2 x
.
• D(e−x2)
= e−x2 ·D(−x2) = −2xe−x2
.
• D(ln(x2 + x+ 1)
)= 1
x2+x+1 ·D(x2 + x+ 1) = 1x2+x+1 · (2x+ 1).
• D(
1ln x
)= D
(ln−1 x
)= − ln−2 x ·D(ln x) = − 1
ln2 x· 1x .
La regola si applica ovviamente anche a casi di composizione di tre (o piu) funzioni, come ad esempio
• D(ln2(1 + 2x)
)= 2 ln(1 + 2x) · 1
1+2x · 2 oppure D(
e√
1/x)
= e√
1/x · 1
2√
1/x· (− 1
x2 ).
Esercizio 2.1 Calcolare le funzioni derivate delle seguenti funzioni, usando le regole di derivazione.
(a) f(x) = x2 lnx (b) f(x) =1− x1 + x2
(c) f(x) = x√1 + x2 (d) f(x) = ln(x+ ex)
(e) f(x) = (x2 + ex)2 (f) f(x) =√x2 lnx
(g) f(x) =x+ e2x
x+ ln(2x)(h) f(x) = ln2(x+ lnx)
(i) f(x) =1
x+ e−x(j) f(x) = ln(x ln x)
Esercizio 2.2 Scrivere l’equazione della retta tangente ai grafici delle seguenti funzioni, nei punti di ascissa x0indicata.
(a) f(x) = x+ lnx, con x0 = 1 (b) f(x) = xex, con x0 = 1
(c) f(x) = x+√x, con x0 = 4 (d) f(x) =
√1− x2, con x0 = 1/2
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL TEOREMA DEL VALOR MEDIO (DI LAGRANGE)
DERIVATE
201
3 Il teorema del valor medio (di Lagrange)
Ecco ora due importanti risultati sulle funzioni derivabili in un intervallo.
Teorema (del valor medio, o di Lagrange). Se f e continua in [a, b] e derivabile in (a, b), allora esiste un puntoc ∈ (a, b) tale che
f ′(c) =f(b)− f(a)
b− a .
Teorema (di Rolle). Se f e continua in [a, b], derivabile in (a, b) e se f(a) = f(b), allora esiste c ∈ (a, b) tale che
f ′(c) = 0.
Non vediamo la dimostrazione di questi due teoremi. Vediamo invece qualche osservazione e tra breve le interpretazionigeometriche dei due risultati.
Osservazione Si noti che le ipotesi dei due teoremi chiedono che la funzione sia continua nell’intervallo chiuso ederivabile nei punti interni di tale intervallo. Quindi non e richiesta la derivabilita negli estremi. In altre parole la tesie vera anche per funzioni che non sono derivabili in a e/o in b.
Un esempio di funzione continua in un intervallo chiuso, derivabile nei punti interni ma nonderivabile agli estremi e la
f : [−1, 1]→ R definita da f(x) =√
1− x2,
il cui grafico e la semicirconferenza, di centro l’origine e raggio 1, che sta nel primo e secondoquadrante
−1 1
1
x
y
Osservazione Ricordando che la derivabilita implica la continuita, si potrebbe pensare che la derivabilita in (a, b) siasufficiente a garantire la continuita in [a, b]. Questo e falso: la derivabilita in (a, b) garantisce certamente la continuitain (a, b), ma non la continuita anche agli estremi. Si consideri ad esempio la funzione f : [0, 1]→ R definita da
f(x) =
1 se x = 0
x se 0 < x < 1
0 se x = 1. bc
b
b
bc
1
1
x
y
Essa e derivabile e quindi continua in (0, 1), ma non e continua agli estremi. Questo stesso esempio prova anche chenon possiamo rinunciare alla continuita agli estremi dell’intervallo se vogliamo che la tesi del teorema di Lagrange siavera. Infatti, con questa funzione si ha f(b)− f(a) = f(1)− f(0) = −1, mentre f ′(x) = 1 per ogni x ∈ (0, 1).
Osservazione Sull’interpretazione geometrica del teorema del valor medio. Con-
sideriamo l’identita contenuta nella tesi del teorema: f ′(c) = f(b)−f(a)b−a . Possiamo
intanto osservare che il quoziente e un rapporto incrementale, quello relativo a tuttol’intervallo [a, b]. Quindi, ricordando che la derivata in un punto ha il significato dipendenza della retta tangente al grafico e che il rapporto incrementale significa invecependenza della retta passante per gli estremi, la tesi del teorema dice che c’e un puntoc interno all’intervallo [a, b] tale che la tangente al grafico nel punto corrispondente ac e parallela alla retta per gli estremi del grafico.
c
b
b
a b
x
c1 c2a b
b b
x
Osservazione Non e difficile capire che il teorema di Rolle e un caso particolare diquello di Lagrange. Infatti, se alle ipotesi del teorema di Lagrange aggiungiamo chef(a) = f(b), allora la tesi del teorema del valor medio dice che c’e un punto c in cuif ′(c) = 0, che e appunto la tesi del teorema di Rolle. E non e difficile dare anchea Rolle un significato geometrico: se la funzione assume lo stesso valore agli estremidell’intervallo (e se ovviamente soddisfa le ipotesi di continuita e derivabilita) allorac’e almeno un punto interno all’intervallo [a, b] in cui la retta tangente e orizzontale(nella figura qui a fianco ce ne sono due).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 STUDIO DEL COMPORTAMENTO LOCALE DI UNA FUNZIONE
DERIVATE
202
4 Studio del comportamento locale di una funzione
Come conseguenze del teorema di Lagrange si hanno alcuni importanti risultati che consentono di studiare il compor-tamento locale di una funzione, cioe le proprieta che la funzione ha in prossimita di alcuni punti del suo dominio.Ma procediamo con ordine. Anzitutto richiamo un’importante definizione, gia incontrata nella sezione sulle funzionireali.
Definizione Sia I un intervallo e sia f : I → R. Sia poi x0 ∈ I. Ri-cordo che x0 e un punto di massimo locale (risp. punto di minimolocale) di f , se esiste un intorno (x0 − δ, x0 + δ) di x0, contenuto in I,tale che
f(x0) ≥ f(x) (risp. f(x0) ≤ f(x)) ∀x ∈ (x0 − δ, x0 + δ). x0
f(x0)
( )I
( )x0−δ x0+δ
x
Ricordo anche che, se x0 e un estremo di I, l’intorno puo essere destro o sinistro. Vale il seguente importante risultato:
Proposizione Sia f : I → R e sia x0 ∈ I. Se f e derivabile in x0 e x0 e un punto di massimo o di minimo locale perf interno ad I, allora f ′(x0) = 0.
Osservazione Ci sono alcune cose da osservare. Senza l’ipotesi sulla derivabilita di f la tesi puo non essere vera.In altre parole, la proposizione “in un punto di massimo o di minimo una funzione ha derivata nulla”, senza l’ipotesidi derivabilita della funzione, e falsa. Si consideri ad esempio la funzione f(x) = |x|. Essa ha in 0 un punto di minimoma in 0 la derivata non e nulla, dato che non esiste. Secondo: occorre dire “punto interno”. Per convincersene bastapensare ad esempio alla funzione f : [0, 1]→ R, data da f(x) = 1 − x. Il primo estremo 0 e punto di massimo locale(anche globale in questo caso), ma la derivata non e zero (nemmeno la derivata destra e zero).
Osservazione La proposizione appena enunciata fornisce un metodo per la ricerca dei punti di massimo e di minimodi una funzione derivabile. Essa dice che tali punti vanno cercati tra quelli che annullano la derivata della funzione(detti solitamente punti stazionari). Attenzione che la proposizione non afferma che i punti stazionari sono punti dimassimo o di minimo, dice il viceversa. Quindi, dopo aver trovato i punti stazionari, annullando la derivata, si dovrastabilire se questi sono o no di massimo o di minimo (potrebbero non essere ne di massimo ne di minimo197).Vediamo subito come si fa. Intanto abbiamo questi altri risultati:
Proposizione Siano I un intervallo aperto e f : I → R, con f derivabile in I. Valgono le proprieta seguenti:
• se f ′ > 0 in I, allora f e crescente in I; se f ′ ≥ 0, allora f e non decrescente in I;
(se f ′ < 0 in I, allora f e decrescente in I; se f ′ ≤ 0, allora f e non crescente in I);
• se f ′ e identicamente nulla in I, allora f e costante in I.
Osservazione Il primo di questi risultati fornisce un metodo molto potente e comodo per studiare la monotonia(cioe la crescenza o decrescenza) di una funzione (derivabile, naturalmente). E largamente utilizzato infatti nello studiodi funzione. Il secondo risultato invece inverte la gia nota proprieta che la derivata di una funzione costante e nulla.
Osservazione Abbiamo a questo punto tutti i risultati teorici che ci servono per studiare l’“andamento” di unafunzione: il segno della derivata prima ci permette di dire in quali intervalli essa cresce e in quali decresce. Dove laderivata si annulla abbiamo punti stazionari, cioe punti dove la pendenza e zero. Per capire se questi sono punti dimassimo o di minimo bastera vedere qual e il segno della derivata in prossimita: se la derivata e positiva a sinistra enegativa a destra del punto stazionario avremo un punto di massimo (locale), se invece la derivata e negativa a sinistrae positiva a destra avremo un punto di minimo (sempre locale). Puo anche succedere che la derivata sia positiva (onegativa) sia a sinistra sia a destra del punto stazionario. In questi casi il punto stazionario non e ne di massimo nedi minimo locale. Riassumo il tutto in uno schema.
segno di f ′: |
x0
0+ −|
x0
segno di f ′: |
x0
0− +
|
x0
segno di f ′: |
x0
0+ +
|
x0
segno di f ′: |
x0
0− −|
x0
Quale applicazione di quanto appena detto, vediamo un semplice esempio di studio di funzione.
197Si pensi alla funzione f(x) = x3, che ha derivata nulla in zero ma e crescente e quindi non ha ne massimi ne minimi.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 IL TEOREMA DI DE L’HOPITAL
DERIVATE
203
• Vogliamo studiare la funzione f(x) = 4x3 − x4.Cominciamo col dire che essa e definita in tutto R (e un polinomio). Possiamo anche affermare subito che essae continua e derivabile in tutto il suo dominio, essendo somma di funzioni continue e derivabili.
Calcoliamo ora i limiti agli estremi del dominio. Trattandosi di tutto R, i limiti da studiare sono gli infiniti.
limx→+∞
f(x) = −∞ e limx→−∞
f(x) = −∞.
Si puo a questo punto studiare se la funzione si annulla per qualche valore di x, risolvendo l’equazione f(x) = 0.198
Si ha4x3 − x4 = 0 se e solo se x3(4− x) = 0
e quindi la funzione si annulla in 0 e in 4.
Possiamo ora studiare il segno della funzione. Si ha
4x3 − x4 > 0 se e solo se x3(4− x) > 0
e si trova che questo e vero per 0 < x < 4. La funzione e dunque positiva in (0, 4) e quindi negativa in(−∞, 0) ∪ (4,+∞).
Studiamo allora l’andamento della funzione, cioe la monotonia, e cerchiamo se ci sono punti di massimo o diminimo locale. Calcoliamo intanto la derivata:
f ′(x) = 12x2 − 4x3 = 4x2(3− x).
Ci sono due punti stazionari, 0 e 3. Per capire qual e la natura di questi punti, studiamo il segno della derivata.Si ha evidentemente
f(x) > 0 nell’insieme (−∞, 0) ∪ (0, 3)
e invecef(x) < 0 nell’intervallo (3,+∞).
Pertanto possiamo affermare che la funzione e crescente in (−∞, 0), crescente in (0, 3) e decrescente in (3,+∞).Quindi 3 e un punto di massimo locale, mentre 0 non e ne di massimo ne di minimo locale. Possiamo oraosservare che f(0) = 0 e f(3) = 27. Siamo ora in grado di tracciare un grafico sommario.
3
4
27
Tra breve vedremo che ci sono altre proprieta analitiche che permettono di individuare altre proprieta geometrichedelle funzioni.
Esercizio 4.1 Dire in quali sottoinsiemi dei rispettivi domini le seguenti funzioni sono crescenti o decrescenti.
(a) f(x) = x3 − 6x2 + 9x+ 1 (b) f(x) = x+ ln(1 + x2)
(c) f(x) = x− ex+1 (d) f(x) = x+ 1/x
5 Il teorema di De l’Hopital
Ecco ora un risultato molto utile nel calcolo dei limiti.
Teorema (di De l’Hopital). Siano f, g : (a, b)→ R derivabili con g′(x) 6= 0 in (a, b).
198In questo caso e facile trovare le soluzioni dell’equazione e poi della corrispondente disequazione, ma in generale la cosa puo non essereper nulla agevole in quanto, come abbiamo detto, non esistono metodi del tutto generali per risolvere le equazioni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 IL TEOREMA DI DE L’HOPITAL
DERIVATE
204
• Se limx→a+
f(x) = 0 = limx→a+
g(x), ed esiste il limx→a+
f ′(x)
g′(x), allora
limx→a+
f(x)
g(x)= lim
x→a+
f ′(x)
g′(x);
• se limx→a+
f(x) e limx→a+
g(x) sono infiniti ed esiste il limx→a+
f ′(x)
g′(x), allora
limx→a+
f(x)
g(x)= lim
x→a+
f ′(x)
g′(x).
Come sempre analoghi risultati valgono per il limite da sinistra e per il limite bilatero. Il risultato vale anche sel’intervallo e illimitato e i limiti sono per x→ +∞ o per x→ −∞.
Osservazione Il teorema di De l’Hopital fornisce una regola molto comoda per calcolo dei limiti che si presentanonelle forme indeterminate 0/0 o ∞/∞. Ribadisco che il teorema e applicabile solo in questi casi. Sostanzialmenteil teorema dice che in presenza di tali limiti, se le funzioni sono derivabili, anziche calcolare il limite del quozientesi puo cercare di calcolare il limite del quoziente delle derivate: se questo esiste, allora esso coincide con il limitecercato. Per la verita si noti che nell’enunciato c’e l’ipotesi che la derivata del denominatore non si annulli: anche senei casi concreti che ci capiteranno questa ipotesi sara sempre verificata, e bene non dimenticare questo aspetto. Dalpunto di vista operativo del calcolo di un limite, se si presenta la possibilita di applicare il teorema di De l’Hopital,il procedimento corretto sarebbe quello di calcolare a parte il limite del quoziente delle derivate e solo quando si etrovato quest’ultimo, concludere tornando al limite originario. E consuetudine invece continuare il calcolo del limiteoriginario uguagliandolo al limite del quoziente delle derivate, senza ancora sapere se quest’ultimo esiste. Per indicareche si sta applicando il teorema di De l’Hopital, e che quindi ci si muove nell’ambito delle sue ipotesi, si usa scrivere
una H sul simbolo di uguaglianza tra i due limiti, cioe si scriveH=.
Osservazione Abbiamo detto che il teorema e applicabile alle forme indeterminate 0/0 o ∞/∞. Puo succedere cheil limite non sia inizialmente di questa forma, ma che lo diventi dopo una semplice trasformazione. Negli esempi cheseguono ci sono alcune situazioni di questo tipo.
Esempi
• I limiti notevoli nella forma 0/0, visti in precedenza, si possono calcolare agevolmente con il teorema di Del’Hopital. Consideriamone ad esempio uno e lo studente provi anche con gli altri:
limx→0
(1 + x)b − 1
x
H= lim
x→0
b (1 + x)b−1
1= b
(si noti che le ipotesi del Teorema sono soddisfatte).
• Calcoliamo il limx→0
ln(1 + x)
ex − 1. Osserviamo che anche qui le ipotesi del Teorema sono soddisfatte. Possiamo scrivere
limx→0
ln(1 + x)
ex − 1
H= lim
x→0
1/(1 + x)
ex= 1. 199
• Consideriamo il limite limx→0+
x ln x, che abbiamo peraltro gia calcolato con un cambio di variabile. Non e una f.i.
prevista dal Teorema di De l’Hopital, ma lo diventa se riscriviamo (come fatto anche con il cambio di variabile)
limx→0+
x ln x = limx→0+
lnx
1/x
(ora f.i. (−∞)/(+∞)
).
Siamo ora quindi nella seconda situazione prevista dal Teorema.
Le ipotesi sono soddisfatte e possiamo scrivere
limx→0+
lnx
1/x
H= lim
x→0+
1/x
−1/x2 = limx→0+
(−x) = 0.
199Il limite si poteva anche calcolare riconducendolo ai limiti notevoli:
limx→0
ln(1 + x)
ex − 1= lim
x→0
(ln(1 + x)
x· x
ex − 1
)
= 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 IL TEOREMA DI DE L’HOPITAL
DERIVATE
205
• Il teorema di De l’Hopital puo essere applicato ripetutamente. Si consideri il seguente esempio:
limx→0+
x3 ln2 x.
Anzitutto lo si scrive nella forma (+∞)/(+∞) con limx→0+
ln2 x
1/x3. Ora si applica il teorema una prima volta.
limx→0+
ln2 x
1/x3H= lim
x→0+
2 lnx · 1/x−3/x4 = lim
x→0+
2 lnx
−3/x3 .
e ancora una f.i. (−∞)/(−∞). Si applica nuovamente il teorema.
. . .H= lim
x→0+
2/x
9/x4= lim
x→0+
2x3
9= 0.
• Anche i limiti sul confronto tra potenze/logaritmi/esponenziali si risolvono immediatamente con il Teorema diDe l’Hopital. Si ha infatti
limx→+∞
x
exH= lim
x→+∞1
ex= 0
e
limx→+∞
lnx
x
H= lim
x→+∞1/x
1= 0.
• Si potrebbe a questo punto anche provare abbastanza facilmente che xn e trascurabile rispetto ad ex, perx→ +∞, qualunque sia n ∈ N. Con n applicazioni successive del Teorema si arriva infatti a dire che il limite
limx→+∞
xn
ex= 0. Si provi ad esempio con lim
x→+∞x4
ex.
• Analogamente si puo provare che lnx e trascurabile rispetto a x1/n per x→ +∞, per ogni n ∈ N, considerando
il limx→+∞
lnx
x1/n. Si ha
limx→+∞
ln x
x1/nH= lim
x→+∞
1x
1nx
1/n−1= lim
x→+∞n
x1/n= 0, ∀n ∈ N.
Osservazione Ci si puo chiedere perche abbiamo considerato il limite di ln xx1/n e non piu semplicemente di
ln xxn . In realta non si voleva complicare inutilmente la vita allo studente, c’e un motivo piu profondo. Sappiamoche lnxe trascurabile rispetto ad x, per x→ +∞ (lo abbiamo dimostrato poco fa applicando il Teorema di Del’Hopital). Quindi a maggior ragione il lnx e trascurabile rispetto alle potenze xn, con n > 1 (x e trascurabilerispetto ad xn). Pertanto un confronto del tipo ln x
xn non e piu di tanto significativo. Invece e piu interessantechiedersi se il logaritmo e trascurabile anche rispetto a potenze di x di esponente piu basso, come ad esempio lepotenze x1/n.200 Si noti che cosı, al crescere di n, possiamo far diventare l’esponente piccolo quanto vogliamoe ottenere quindi potenze sempre piu deboli. Il risultato del limite e appunto che il logaritmo e trascurabilerispetto ad x1/n, qualunque sia n.
• Non sempre l’applicazione ripetuta del teorema porta al risultato voluto. Si consideri il seguente esempio, moltoistruttivo.
limx→0−
xe−1/x. 201
Il limite e nella f.i. 0 · (+∞). Lo riscriviamo come
limx→0−
xe−1/x = limx→0−
x
e1/x(ora f.i. 0/0)
e applichiamo il teorema di De l’Hopital. Otteniamo
limx→0−
x
e1/xH= lim
x→0−
1
e1/x · (−1/x2) = limx→0−
−x2e1/x
(ancora f.i. 0/0).
200Sappiamo gia che questo e vero ma, se vi ricordate, non lo abbiamo mai dimostrato.201Lo studente sa gia calcolare questo limite con un cambio di variabile. Si provi per esercizio.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 DERIVATE SUCCESSIVE
DERIVATE
206
Non serve continuare ad applicare il teorema: la forma si complica sempre di piu. Basta invece riscrivere il limiteiniziale come
limx→0−
xe−1/x = limx→0−
e−1/x
1/x(f.i. (+∞)/(−∞))
e applicare il teorema. Si ottiene
limx→0−
e−1/x
1/x
H= lim
x→0−
e−1/x · 1/x2−1/x2 = lim
x→0−(−e−1/x) = −∞.
Quindi forme equivalenti da un punto di vista algebrico possono non essere ugualmente indicate per l’applicazionedel teorema di De l’Hopital. Ovviamente a priori puo non essere facile intuire quale sia la forma piu opportuna,ma non c’e nulla di male nel provare una strada e poi eventualmente lasciarla se ci si accorge che da quella partenon si va lontani.
Esercizio 5.1 Calcolare i seguenti limiti con il teorema di De l’Hopital, dopo aver osservato che il teorema e
applicabile.
(a) limx→+∞
ln2 x
x2(b) lim
x→+∞x3
ex2 (c) limx→+∞
x
e√x
(d) limx→−∞
√1 + x2
x(e) lim
x→−∞(xex) (f) lim
x→0
(1 + x)α − 1
x
(g) limx→+∞
(
x ln
(
1 +1
x
))
(h) limx→0+
(xe1/x) (i) limx→0
e−1/x2
x
(j) limx→0+
x−√x3√x
(k) limx→0
1− ln(e+ x)
x(l) lim
x→0
ex − 1− xln2(1 + x)
6 Derivate successive
Sia f : I → R una funzione derivabile nell’intervallo I e sia f ′ : I → R la sua derivata. Se f ′ e a sua volta derivabilein I, possiamo indicare con f ′′ (o con D2f) la D(f ′) e chiamarla derivata seconda di f in I.Il discorso puo continuare con la derivata terza, e cosı via. Quindi in generale possiamo dare la seguente
Definizione Siano I un intervallo e f : I → R. Poniamo D0f = f e, se Dnf e derivabile, Dn+1f = D(Dnf).Quindi, con formula ricorsiva, la derivata (n+ 1)-esima viene definita come la derivata della derivata n-esima.
Esempio Abbiamo gia ovviamente tutto quello che ci serve per calcolare, in un punto o in tutto un intervallo, laderivata seconda (e le successive) di una funzione. Consideriamo ad esempio la funzione f(x) = lnx in (0,+∞). Datoche f ′(x) = 1
x , avremo f ′′(x) = − 1x2 , f
′′′(x) = 2x3 , e cosı via.
Siano I un intervallo e n un intero positivo. Abbiamo gia visto che solitamente si indica con C (I) la classe di tutte lefunzioni continue in I.
Definizione Si indica con C n(I) la classe di tutte le funzioni f : I → R che hanno derivata n-esima continua in I.202
Si indica infine con C∞(I) la classe delle funzioni che sono infinitamente derivabili in I, cioe le funzioni che hannoderivata di qualunque ordine.
Osservazione Dato che l’esistenza della derivata prima implica la continuita, per lo stesso motivo l’esistenza delladerivata seconda implica la continuita della derivata prima, l’esistenza della derivata terza implica la continuita delladerivata seconda, e cosı via. Quindi, definendo la classe C∞(I) non occorre dire derivata di qualunque ordine continua,dato che la derivata di ordine n+ 1 garantisce la continuita della derivata di ordine n, qualunque sia n.E facile rendersi conto che le funzioni elementari, nei rispettivi domini, sono infinitamente derivabili, con l’unicaeccezione della funzione potenza che, quando e definita in zero, puo in qualche caso non essere derivabile in talepunto.203
202Attenzione che in C n(I) ci sono le funzioni che hanno derivata n-esima continua, non le funzioni che hanno derivata n-esima, cioe chesono derivabili n volte. Una funzione puo avere derivata n-esima, ma puo succedere che la derivata n-esima non sia continua: tale funzionenon sta in Cn(I).203Si pensi ad esempio a f(x) =
√x, che non e derivabile in 0 da destra, o a 3
√x, che non e derivabile in 0. E chiaro che non tutte le
potenze presentano problemi di derivabilita in zero: f(x) = x3 e derivabile in 0 con derivata nulla.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

7 FUNZIONI CONVESSE
DERIVATE
207
La proposizione seguente illustra alcune proprieta di una funzione legate al segno della derivata seconda di questa inun punto.
Proposizione Sia I un intervallo aperto, f : I → R e x0 ∈ I. Valgono le proprieta seguenti:
(i) se f e derivabile due volte in x0 e f ′′(x0) > 0, allora esiste un intorno (x0 − δ, x0 + δ) tale che
f(x) ≥ f(x0) + f ′(x0)(x− x0) ∀x ∈ (x0 − δ, x0 + δ)
(il verso della disuguaglianza si inverte se f ′′(x0) < 0);
(ii) se f e derivabile due volte in x0, se f′(x0) = 0 e f ′′(x0) > 0, allora x0 e un punto di minimo locale. Se invece
f ′(x0) = 0 e f ′′(x0) < 0, allora x0 e un punto di massimo locale.
Osservazioni Il significato geometrico della (i) e che, se la derivata seconda di una funzione in un punto e positiva,allora la funzione, almeno in un intorno di tale punto, sta al di sopra della sua retta tangente in quel punto.La (ii) fornisce un secondo metodo operativo per stabilire se un punto e di massimo o di minimo per una funzione(derivabile almeno due volte). E alternativo a quello gia visto che permette di stabilire la natura di un punto stazionarioattraverso lo studio del segno della derivata prima. Questo comporta il calcolo della derivata seconda, ma in compensorichiede soltanto il valore di questa nel punto e non in tutto un intorno.L’annullarsi della derivata prima e anche della derivata seconda nel punto che si sta studiando in genere non consentedi giungere ad una conclusione sulla natura del punto. C’e una versione piu generale della (ii), che richiede il calcolodelle derivate successive alla seconda, ma non la vediamo.
Esempio Consideriamo la funzione f(x) = x lnx e studiamo la natura del punto x0 = 1/e. Si ha
f ′(x) = lnx+ 1 e f ′(1/e) = 0.
Il punto 1/e e quindi un punto stazionario di f . Calcoliamo la derivata seconda:
f ′′(x) = 1/x e f ′′(1/e) = e > 0.
Quindi, in base alla (ii), il punto 1/e e punto di minimo locale di f .
7 Funzioni convesse
Talvolta puo essere interessante una proprieta geometrica di alcuni insiemi di R2 (o di R3 e in generale di Rn) o dialcune funzioni: la convessita. Vediamo intanto le definizioni di tale proprieta.Premetto che, dati due punti x e y nel piano, indico con [x,y] il segmento (estremi inclusi) che li congiunge.
Definizione Sia E un sottoinsieme di R2. Diciamo che E e convesso se per ogni x e y in E, il segmento [x,y] econtenuto in E.
Esempi Un cerchio in R2 e un insieme convesso. Anche un rettangolo e convesso.204
Anche un qualunque poligono regolare (triangolo equilatero, quadrato, pentagono,esagono, . . . ) e convesso. Si osservi che non e significativo che il triangolo siaequilatero: qualunque triangolo e convesso.L’insieme dei punti di una retta nel piano e convesso. L’insieme dei punti di unaparabola invece no. Non e convesso l’insieme dei punti di una circonferenza (attenzionea non confondere circonferenza e cerchio). Non e convesso l’insieme dei punti esterniad un cerchio (o ad un triangolo, quadrato, . . . ). Non e convesso l’insieme raffiguratoqui a fianco.
x
y
Ora vediamo quando una funzione e convessa. Definiamo prima un particolare insieme associato ad una funzione.
204Attenzione a non credere che cerchio o rettangolo vogliano dire solo il bordo. Anche con i triangoli o i poligoni in genere e lo stesso.Essi comprendono anche la parte interna al contorno che disegniamo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
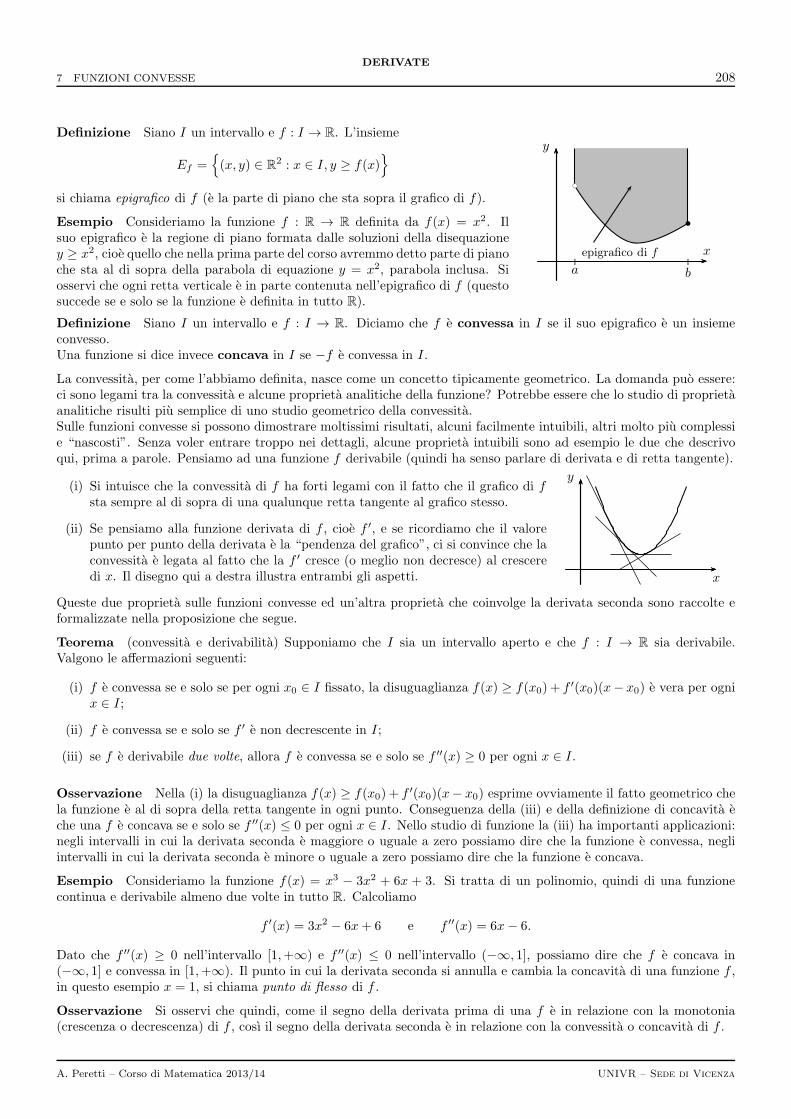
7 FUNZIONI CONVESSE
DERIVATE
208
Definizione Siano I un intervallo e f : I → R. L’insieme
Ef ={
(x, y) ∈ R2 : x ∈ I, y ≥ f(x)}
si chiama epigrafico di f (e la parte di piano che sta sopra il grafico di f).
Esempio Consideriamo la funzione f : R → R definita da f(x) = x2. Ilsuo epigrafico e la regione di piano formata dalle soluzioni della disequazioney ≥ x2, cioe quello che nella prima parte del corso avremmo detto parte di pianoche sta al di sopra della parabola di equazione y = x2, parabola inclusa. Siosservi che ogni retta verticale e in parte contenuta nell’epigrafico di f (questosuccede se e solo se la funzione e definita in tutto R).
epigrafico di f|
a|
b
bc
b
x
y
Definizione Siano I un intervallo e f : I → R. Diciamo che f e convessa in I se il suo epigrafico e un insiemeconvesso.Una funzione si dice invece concava in I se −f e convessa in I.
La convessita, per come l’abbiamo definita, nasce come un concetto tipicamente geometrico. La domanda puo essere:ci sono legami tra la convessita e alcune proprieta analitiche della funzione? Potrebbe essere che lo studio di proprietaanalitiche risulti piu semplice di uno studio geometrico della convessita.Sulle funzioni convesse si possono dimostrare moltissimi risultati, alcuni facilmente intuibili, altri molto piu complessie “nascosti”. Senza voler entrare troppo nei dettagli, alcune proprieta intuibili sono ad esempio le due che descrivoqui, prima a parole. Pensiamo ad una funzione f derivabile (quindi ha senso parlare di derivata e di retta tangente).
(i) Si intuisce che la convessita di f ha forti legami con il fatto che il grafico di fsta sempre al di sopra di una qualunque retta tangente al grafico stesso.
(ii) Se pensiamo alla funzione derivata di f , cioe f ′, e se ricordiamo che il valorepunto per punto della derivata e la “pendenza del grafico”, ci si convince che laconvessita e legata al fatto che la f ′ cresce (o meglio non decresce) al cresceredi x. Il disegno qui a destra illustra entrambi gli aspetti. x
y
Queste due proprieta sulle funzioni convesse ed un’altra proprieta che coinvolge la derivata seconda sono raccolte eformalizzate nella proposizione che segue.
Teorema (convessita e derivabilita) Supponiamo che I sia un intervallo aperto e che f : I → R sia derivabile.Valgono le affermazioni seguenti:
(i) f e convessa se e solo se per ogni x0 ∈ I fissato, la disuguaglianza f(x) ≥ f(x0) + f ′(x0)(x− x0) e vera per ognix ∈ I;
(ii) f e convessa se e solo se f ′ e non decrescente in I;
(iii) se f e derivabile due volte, allora f e convessa se e solo se f ′′(x) ≥ 0 per ogni x ∈ I.
Osservazione Nella (i) la disuguaglianza f(x) ≥ f(x0) + f ′(x0)(x− x0) esprime ovviamente il fatto geometrico chela funzione e al di sopra della retta tangente in ogni punto. Conseguenza della (iii) e della definizione di concavita eche una f e concava se e solo se f ′′(x) ≤ 0 per ogni x ∈ I. Nello studio di funzione la (iii) ha importanti applicazioni:negli intervalli in cui la derivata seconda e maggiore o uguale a zero possiamo dire che la funzione e convessa, negliintervalli in cui la derivata seconda e minore o uguale a zero possiamo dire che la funzione e concava.
Esempio Consideriamo la funzione f(x) = x3 − 3x2 + 6x + 3. Si tratta di un polinomio, quindi di una funzionecontinua e derivabile almeno due volte in tutto R. Calcoliamo
f ′(x) = 3x2 − 6x+ 6 e f ′′(x) = 6x− 6.
Dato che f ′′(x) ≥ 0 nell’intervallo [1,+∞) e f ′′(x) ≤ 0 nell’intervallo (−∞, 1], possiamo dire che f e concava in(−∞, 1] e convessa in [1,+∞). Il punto in cui la derivata seconda si annulla e cambia la concavita di una funzione f ,in questo esempio x = 1, si chiama punto di flesso di f .
Osservazione Si osservi che quindi, come il segno della derivata prima di una f e in relazione con la monotonia(crescenza o decrescenza) di f , cosı il segno della derivata seconda e in relazione con la convessita o concavita di f .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 FORMULA DI TAYLOR
DERIVATE
209
Vediamo, per finire, un esempio di studio di funzione completo, in cui utilizziamo tutti gli strumenti analitici visti.
Studiamo la funzione f(x) =√x · lnx.
Essa e definita nell’intervallo aperto (0,+∞). Possiamo affermare che essa e continua e derivabile (e C∞) in tutto ilsuo dominio, essendo prodotto di funzioni derivabili in tale intervallo. Si noti che la funzione x 7→ √x non e derivabilein 0 da destra, pur essendo definita in 0. Ma la nostra funzione x 7→ √x lnx non e definita in 0.La funzione f assume valori positivi nell’intervallo (1,+∞) e valori negativi in (0, 1); assume il valore zero in x = 1.Calcoliamo ora i limiti agli estremi del dominio. Trattandosi dell’intervallo (0,+∞), i limiti da studiare sono perx→ 0+ e all’infinito.
limx→0+
f(x) = 0 205 e limx→+∞
f(x) = +∞.
Calcoliamo e studiamo la derivata prima:
f ′(x) = D(x1/2 lnx) =1
2x−1/2 lnx+ x1/2 · 1
x=
1
2x−1/2(lnx+ 2) =
lnx+ 2
2√x
.
La derivata si annulla per lnx + 2 = 0, cioe per x = e−2. La derivata e positiva in (e−2,+∞) e negativa in (0, e−2):quindi la funzione e decrescente in (0, e−2) e crescente in (e−2,+∞).Il punto x = e−2 e quindi punto di minimo locale; inoltre f(e−2) = −2e−1.Per poter tracciare un grafico piu accurato possiamo ancora calcolare il limite della derivata per x→ 0+ (ci consentedi capire con che pendenza la funzione tende a zero):206
limx→0+
f ′(x) = limx→0+
lnx+ 2
2√x
= −∞.
Il grafico della funzione e quindi tangente all’asse negativo delle ordinate.Ora possiamo calcolare e studiare la derivata seconda per avere informazioni sulla convessita/concavita della funzione.Si ha
f ′′(x) = D
[1
2x−1/2(lnx+ 2)
]
=1
2
(
−1
2
)
x−3/2(ln x+ 2) +1
2x−1/2 · 1
x
= −1
4x−3/2(lnx+ 2) +
1
2x−3/2
= −1
4x−3/2(lnx+ 2− 2)
= −1
4x−3/2 lnx = − lnx
4√x3.
e−2
−2e−1
1
x
y
La derivata seconda di f e positiva nell’intervallo (0, 1), negativa in (1,+∞) e si annulla in 1: quindi f e convessa in(0, 1) e concava in (1,+∞). Il punto 1 e punto di flesso. Il grafico e disegnato qui sopra.
8 Formula di Taylor
Il teorema di Taylor, spesso citato in modo riduttivo come Formula di Taylor, e, a dire il vero, uno dei risultatipiu importanti dell’analisi matematica. All’interno di questo corso non dedico pero a questo argomento uno spazioproporzionato alla sua importanza. Mi limito sostanzialmente a dare un’idea di che cosa dice questo teorema e forniscoalcuni casi particolari, quelli relativi alle funzioni elementari. Particolarmente importante e lo sviluppo della funzioneesponenziale, che verra utilizzato nell’insegnamento di Statistica.Il teorema dice sostanzialmente che una funzione derivabile un certo numero di volte in un punto puo essere approssi-mata, nelle vicinanze di tale punto, da un polinomio, cioe da una funzione particolarmente semplice. Il senso preciso di
205Possiamo arrivare al risultato ad esempio con il cambio di variabile 1/√x = t (da cui x = 1
t2):
limx→0+
(√x lnx) = lim
x→0+
lnx
1/√x
= limt→+∞
ln(1/t2)
t= lim
t→+∞
− ln t2
t= lim
t→+∞
−2 ln t
t= 0 (confronto standard).
206Se una funzione e derivabile in x0 da destra, la sua derivata destra ci dice con che pendenza la funzione “esce dal punto” (x0, f(x0)).Se non e derivabile in x0, il limite della derivata (da destra e da sinistra) ci puo dare la stessa informazione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

8 FORMULA DI TAYLOR
DERIVATE
210
che cosa si debba intendere con “puo essere approssimata” viene precisato in modo rigoroso nell’enunciato del teorema,che pero non fornisco nel dettaglio. Le uniche cose che mi sento di dire, affinche chi legge ne abbia un’idea in qualchemodo piu approfondita, sono le seguenti:
• il teorema non si limita a dimostrare l’esistenza di un qualche polinomio con la caratteristica detta, ma dimostrache c’e un solo polinomio di questo tipo e ne da una completa descrizione (da qui il nome di Formula di Taylor);
• i coefficienti del polinomio (che si chiama naturalmente Polinomio di Taylor) dipendono, attraverso una sempliceespressione, dalle derivate (successive) della funzione;
• la formula puo essere di vari ordini e cioe, data una funzione e un punto in cui essa e derivabile, si puo scrivere,per tale funzione e in quel punto, la relativa formula di ordine uno, due, e cosı via. La formula di un certo ordinen dipende dalle derivate fino alla n-esima e fornisce un polinomio di grado n;
• grosso modo una parte rilevante del risultato generale si puo esprimere a parole in questi termini: piu e elevatol’ordine della formula e migliore e l’approssimazione che il polinomio fornisce della funzione.
8.1 Alcuni sviluppi notevoli
Fornisco qui gli sviluppi di Taylor delle funzioni elementari.
8.1.1 Funzione esponenziale
Per la funzione esponenziale f(x) = ex, nelle vicinanze del punto x0 = 0 il polinomio di Taylor di grado n e
1 + x+x2
2!+x3
3!+ . . .+
xn
n!, che si puo scrivere sinteticamente con
n∑
k=0
xk
k!.
La formula di Taylor dice che questo polinomio, in prossimita del punto x0 = 0 fornisce una “buona approssimazione”della funzione esponenziale, cioe afferma che
ex ∼= 1 + x+x2
2!+x3
3!+ . . .+
xn
n!.
Come gia detto la formula, essendo valida per ogni n, puo essere utilizzata di volta in volta con l’ordine n piuopportuno.207
8.1.2 Funzione logaritmica
Vediamo un altro esempio importante, relativo alla funzione logaritmica. Con f(x) = lnx, non possiamo calcolareil polinomio a partire dal punto x0 = 0, dato che in 0 la funzione non esiste. Allora sono possibili due alternative:mantenere la funzione f(x) = lnx con punto iniziale diverso da zero (ad esempio prendere x0 = 1), oppure cambiarela funzione per poterla approssimare nelle vicinanze di x0 = 0. Solitamente si preferisce la seconda alternativa e siconsidera la funzione f(x) = ln(1 + x). I polinomi di Taylor di questa funzione in prossimita di x0 = 0 sono
x , x− 1
2x2 , x− 1
2x2 +
1
3x3 , x− 1
2x2 +
1
3x3 − 1
4x4 , . . .
Si capisce facilmente che l’espressione generale del polinomio di grado n si puo scrivere con
x− x2
2+x3
3− x4
4+ . . .+
(−1)n−1
nxn.208
207Significa che ad esempio possiamo scrivere ex ∼= 1 + x, oppure ex ∼= 1 + x + x2
2!, e cosı via, a seconda delle necessita. Piu si sale col
grado del polinomio “piu l’approssimazione e buona”.208Si puo quindi scrivere in forma compatta, con il simbolo di sommatoria,
ln(1 + x) ∼=n∑
k=1
(−1)k−1
kxk.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 SOLUZIONI DEGLI ESERCIZI
DERIVATE
211
8.1.3 Funzione potenza
L’ultima funzione elementare e la funzione potenza f(x) = xα. Qui si presenta lo stesso problema della funzionelogaritmica: per alcuni valori di α la funzione puo non essere definita in zero (ad esempio α negativo) e per altripuo non essere derivabile in zero (ad esempio α = 1/3). Allora come prima manteniamo il punto iniziale x0 = 0 macambiamo la funzione considerando la f(x) = (1 + x)α.I polinomi di Taylor di questa funzione in prossimita di x0 = 0 sono
1 + αx , 1 + αx +α(α− 1)
2!x2 , 1 + αx+
α(α− 1)
2!x2 +
α(α − 1)(α− 2)
3!x3 , . . .
Quindi si puo scrivere in generale
(1 + x)α ∼= 1 + αx +α(α− 1)
2x2 + . . .+
α(α − 1) · · · (α− n+ 1)
n!xn 209
Riassumo qui di seguito gli sviluppi di Taylor trovati:
• ex ∼= 1 + x+x2
2!+x3
3!+ . . .+
xn
n!, in prossimita di x0 = 0.
• ln(1 + x) ∼= x− x2
2+x3
3− . . .+ (−1)n−1
nxn, in prossimita di x0 = 0.
• (1 + x)α ∼= 1 + αx+α(α − 1)
2x2 + . . .+
α(α − 1) · · · (α− n+ 1)
n!xn, in prossimita di x0 = 0.
Osservazione Un aspetto importante, che sarebbe chiaro dall’enunciato rigoroso del teorema di Taylor, e che la bontadell’approssimazione del polinomio nei confronti della funzione vale nelle vicinanze del punto iniziale considerato. Laqualita dell’approssimazione puo peggiorare drasticamente a mano a mano che ci si allontana dal punto iniziale.
9 Soluzioni degli esercizi
Esercizio 1.1
(a) f(x) = ln2 x, con x0 = e. Il rapporto incrementale, nella “forma in x” e nella “forma in h” e
ln2 x− 1
x− e oppureln2(e+ h)− 1
h.
(b) f(x) =1
1 + x, con x0 = 1. Il rapporto incrementale, nelle due forme, e
11+x − 1
2
x− 1oppure
12+h − 1
2
h.
(c) f(x) =
{x ln(1/x) x 6= 0
0 x = 0, con x0 = 0. Il rapporto incrementale e
x ln( 1x )− 0
x= ln
(1
x
)
oppureh ln( 1h )− 0
h= ln
(1
h
)
. 210
209Un caso notevole e la funzione f(x) =√1 + x, per la quale possiamo scrivere, al primo ordine,
√1 + x ∼= x+ 1
2x e, al secondo ordine,√
1 + x ∼= x+ 12x− 1
8x2 + o(x2).
210Si noti che quando il punto iniziale e x0 = 0 la forma in x e la forma in h sono ovviamente identiche, a meno di un banale cambio nelnome della variabile.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 SOLUZIONI DEGLI ESERCIZI
DERIVATE
212
(d) f(x) =
{x2 x ≤ 1
ex x > 1, con x0 = 1. Qui abbiamo due diversi rapporti incrementali, uno a destra e uno a
sinistra. A sinistra si hax2 − 1
x− 1oppure
(1 + h)2 − 1
h.
A destra si ha inveceex − 1
x− 1oppure
e1+h − 1
h.
Attenzione nel secondo a non cadere nell’errore di scrivere (ex − e)/(x − 1). Il valore della funzione nel puntoiniziale, cioe f(x0), non cambia passando da destra a sinistra.
Esercizio 2.1
(a) D(x2 lnx) = 2x lnx+ x2 · 1x= 2x lnx+ x.
(b) D
(1− x1 + x2
)
=(−1)(1 + x2)− (1− x) · 2x
(1 + x2)2.
(c) D(x√
1 + x2)=√
1 + x2 + x · 2x
2√1 + x2
=√
1 + x2 +x2√1 + x2
.
(d) D(ln(x+ ex)
)=
1 + ex
x+ ex.
(e) D((x2 + ex)2
)= 2(x2 + ex)(2x+ ex).
(f) D(√x2 lnx
)=
1
2√x2 lnx
(
2x lnx+ x2 · 1x
)
.
(g) Questa e piu lunga:
D
(x+ e2x
x+ ln(2x)
)
=(1 + 2e2x)(x+ ln(2x))− (x+ e2x)(1 + 1/x)
(x+ ln(2x))2.
(h) D(ln2(x+ lnx)
)= 2 ln(x + lnx) · 1
x+ lnx· (1 + 1/x).
(i) D
(1
x+ e−x
)
= − 1
(x+ e−x)2(1 − e−x).
(j) D(ln(x ln x)
)=
1
x lnx(lnx+ 1).
Esercizio 2.2
Ricordo che l’equazione della retta tangente nel punto (x0, f(x0)) e y = f(x0) + f ′(x0)(x − x0).(a) f(x) = x+ lnx, con x0 = 1. La derivata e f ′(x) = 1 + 1/x e quindi f ′(x0) = 2. Pertanto l’equazione della retta
tangente ey = 1 + 2(x− 1).
(b) f(x) = xex, con x0 = 1. La derivata e f ′(x) = ex + xex e quindi f ′(x0) = 2e. Pertanto l’equazione della rettatangente e
y = e+ 2e(x− 1).
(c) f(x) = x+√x, con x0 = 4. La derivata e f ′(x) = 1+1/(2
√x) e quindi f ′(x0) = 5/4. Pertanto l’equazione della
retta tangente ey = 6 + 5(x− 4)/4.
(d) f(x) =√1− x2, con x0 = 1/2. La derivata e f ′(x) = −2x
2√1−x2
= − x√1−x2
e quindi f ′(x0) = −1/√3. Pertanto
l’equazione della retta tangente e
y =
√3
2− 1√
3(x− 1/2).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 SOLUZIONI DEGLI ESERCIZI
DERIVATE
213
Esercizio 4.1
(a) f(x) = x3 − 6x2 + 9x+ 1.
La funzione e definita in tutto R ed e derivabile (e un polinomio). La derivata e
f ′(x) = 3x2 − 12x+ 9 = 3(x2 − 4x+ 3) = 3(x− 1)(x− 3).
Studiando la positivita della derivata si trova che la funzione f e crescente in (−∞, 1]∪ [3,+∞) e decrescente in[1, 3]. Quindi ha in 1 un punto di massimo e in 3 un punto di minimo (in 1 e in 3 la derivata si annulla).
(b) f(x) = x+ ln(1 + x2).
La funzione e definita in tutto R ed e derivabile perche somma di funzioni derivabili. La derivata e
f ′(x) = 1 +2x
1 + x2=
1+ x2 + 2x
1 + x2=
(x+ 1)2
1 + x2.
La derivata si annulla in −1 ed e positiva per tutti gli altri valori reali. Quindi la funzione f e crescente in tuttoR e ha in −1 un punto stazionario (che non e ovviamente ne di massimo ne di minimo).
(c) f(x) = x− ex+1.
La funzione e definita in tutto R ed e derivabile perche somma di funzioni derivabili. La derivata e
f ′(x) = 1− ex+1.
La derivata si annulla in −1 ed e positiva per tutti i valori minori di −1. Quindi la funzione f e crescente in(−∞,−1], decrescente in [−1,+∞) e ha in −1 un punto di massimo.
(d) f(x) = x+ 1/x
La funzione e definita in tutto R ad esclusione di 0; e derivabile nel suo dominio. La derivata e
f ′(x) = 1− 1/x2.
La derivata si annulla in x = ±1 ed e positiva per x < −1 oppure per x > 1. Quindi la funzione f e crescente in(−∞,−1]∪ [1,+∞) e decrescente in [−1, 0)∪ (0, 1]. Ha quindi un punto di massimo in −1 e un punto di minimoin 1.
Esercizio 5.1
In tutti lascio allo studente il compito di verificare anzitutto che il teorema di De l’Hopital e applicabile (si ricordi chelo e con le forme indeterminate del tipo ∞/∞ o 0/0).
(a) Si ha
limx→+∞
ln2 x
x2H= lim
x→+∞2 lnx · 1/x
2x= lim
x→+∞lnx
x2.
Ora si possono utilizzare i noti risultati sul confronto tra un logaritmo e una potenza, oppure procedere ancoracon De l’Hopital:
limx→+∞
lnx
x2H= lim
x→+∞1/x
2x= lim
x→+∞1
2x2= 0.
(b) Si ha
limx→+∞
x3
ex2
H= lim
x→+∞3x2
2xex2 = limx→+∞
3x
2ex2
H= lim
x→+∞3
4xex2 = 0.
(c) Si ha
limx→+∞
x
e√x
H= lim
x→+∞1
e√x · 1/(2√x) = lim
x→+∞2√x
e√x
H= lim
x→+∞1/√x
e√x · 1/(2√x) = lim
x→+∞2
e√x= 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 SOLUZIONI DEGLI ESERCIZI
DERIVATE
214
(d) Questo e un curioso esempio in cui il comodo metodo di De l’Hopital non funziona, cioe non permette di arrivaread una risposta. Infatti
limx→−∞
√1 + x2
x
H= lim
x→−∞2x/(2
√1 + x2)
1= lim
x→−∞x√
1 + x2
e si intuisce che derivando un’altra volta si torna al punto di partenza. Non funziona nemmeno l’espediente (cheavete visto in un esempio della lezione) di scrivere
limx→−∞
√1 + x2
x= lim
x→−∞1/x
1/√1 + x2
e provare a derivare (cosı si complica sempre di piu, provate). Il limite occorre calcolarlo in un altro modo, cheperaltro gia conoscete. Portando sotto radice la x a denominatore (attenzione al segno!) si ha semplicemente
limx→−∞
√1 + x2
x= lim
x→−∞
(
−√
1 + x2
x2
)
= −1.
(e) Il limite proposto e nella f.i. −∞ · 0. Per applicare De l’Hopital occorre prima trasformarlo.
limx→−∞
(xex) = limx→−∞
x
e−x= lim
x→−∞1
−e−x= 0.
(f) Lo studente attento avra riconosciuto uno dei limiti notevoli (il limite vale α). Anche se non precisato nel testo,osserviamo che α puo essere un qualunque numero reale e che e ragionevole sia α 6= 1, altrimenti il limite ebanalmente 1.
limx→0
(1 + x)α − 1
x
H= lim
x→0
α(1 + x)α−1
1= α.
(g) Il limite e nella f.i. +∞ · 0. Per applicare De l’Hopital occorre prima trasformarlo.
limx→+∞
(x ln(1 + 1/x)) = limx→+∞
ln(1 + 1/x)
1/x.
Qui sarebbe piu invitante un cambio di variabile (1/x = t). Procediamo comunque con De l’Hopital.
limx→+∞
ln(1 + 1/x)
1/x
H= lim
x→+∞1/(1 + 1/x) · (−1/x2)
−1/x2 = limx→+∞
1
1 + 1/x= 1.
(h) La forma e 0 · ∞ e occorre trasformarlo.
limx→0+
(xe1/x) = limx→0+
e1/x
1/x
H= lim
x→0+
e1/x(−1/x2)−1/x2 = lim
x→0+e1/x = +∞.
Da notare che se avessimo scrittolim
x→0+(xe1/x) = lim
x→0+
x
e−1/x
con De l’Hopital il limite si sarebbe complicato (provare).
Da notare anche che per x→ 0− non e invece una forma indeterminata e il limite e 0.
(i) Forma 0/0. Con De l’Hopital
limx→0
e−1/x2
x
H= lim
x→0
e−1/x2 · 2/x31
= limx→0
2e−1/x2
x3,
ma il limite cosı si complica. Proviamo allora prima a trasformarlo con
limx→0
e−1/x2
x= lim
x→0
1/x
e1/x2
H= lim
x→0
−1/x2e1/x2 · (−2/x3) = lim
x→0
x
2e1/x2 =0
+∞ = 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

9 SOLUZIONI DEGLI ESERCIZI
DERIVATE
215
(j) Si ha
limx→0+
x−√x3√x
= limx→0+
x− x1/2x1/3
H= lim
x→0+
1− 12x
−1/2
13x
−2/3.
Ora, dato che le potenze sono degli infiniti, possiamo trascurare la costante 1 a numeratore e considerare il
limx→0+
− 12x
−1/2
13x
−2/3= −3
2lim
x→0+
x2/3
x1/2= −3
2lim
x→0+x1/6 = 0.
(k) Si ha
limx→0
1− ln(e+ x)
x
H= lim
x→0
− 1e+x
1= −1
e.
(l) Si ha
limx→0
ex − 1− xln2(1 + x)
H= lim
x→0
ex − 1
2 ln(1 + x) · 11+x
.
Il fattore 11+x tende a 1 e possiamo considerare
1
2limx→0
ex − 1
ln(1 + x)
H=
1
2limx→0
ex
1/(1 + x)=
1
2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
216
10 Appendice – Studio di funzione
In questa appendice presento alcuni esempi di studio di funzione. Studiamo le seguenti funzioni:
1. f(x) = x2(x+ 1)(x− 2) 2. f(x) =x
x3 + 1
3. f(x) = x lnx 4. f(x) = x3 lnx2
5. f(x) = x3ex 6. f(x) = x2e−x2
7. f(x) =lnx
x8. f(x) =
√x2 + 1
x
9. f(x) = x−√x2 + 1 10. f(x) = x2 − lnx
◮ 1. Studiamo la funzione f(x) = x2(x+ 1)(x− 2) = x4 − x3 − 2x2.La funzione e definita in tutto R, essendo un polinomio. Possiamo anche affermare subito che essa e continua ederivabile in tutto il suo dominio, essendo somma di funzioni continue e derivabili.La funzione si annulla per x = 0, x = −1, x = 2. Possiamo ora studiare il segno della funzione. Si ha
x2(x + 1)(x− 2) > 0 se e solo se (x+ 1)(x− 2) > 0 cioe per x < −1 oppure x > 2.
Ovviamente la funzione e invece negativa per −1 < x < 2.Calcoliamo ora i limiti agli estremi del dominio. Trattandosi di tutto R, dobbiamo calcolare i limiti agli infiniti.
limx→+∞
f(x) = +∞ e limx→−∞
f(x) = +∞.211
Studiamo ora l’andamento della funzione, cioe troviamo dove la funzione cresce e dove decresce, e cerchiamo se ci sonopunti di massimo o di minimo locale. Calcoliamo quindi la derivata:
f ′(x) = 4x3 − 3x2 − 4x = x(4x2 − 3x− 4).
Ci sono punti stazionari, punti cioe in cui la derivata si annulla. Sono 0 e 3±√73
8 .212 Per capire qual e la natura diquesti punti, studiamo il segno della derivata. Studiando il segno dei due fattori, si trova che
f ′(x) > 0 nell’insieme (3−√73
8 , 0) ∪ (3+√73
8 ,+∞)
e invecef ′(x) < 0 nell’insieme (−∞, 3−
√73
8 ) ∪ (0, 3+√73
8 ).
Pertanto possiamo concludere che la funzione e decrescente in (−∞, 3−√73
8 ), crescente in (3−√73
8 , 0), decrescente in
(0, 3+√73
8 ) e ancora crescente in (3+√73
8 ,+∞). Inoltre possiamo affermare che il punto 3−√73
8 e punto di minimo
locale, il punto 0 e di massimo locale e il punto 3+√73
8 e di minimo locale. Per ottenere un grafico abbastanza precisoin questo caso conviene calcolare il valore della funzione nei punti di massimo e di minimo (in quelli di minimo e
meglio accontentarsi di un valore approssimato): si ha f(3−√73
8 ) ≈ −0.39 e f(3+√73
8 ) ≈ −2.83. In 0 la funzionevale ovviamente 0. Possiamo allora disegnare un grafico sommario (non riporto sul grafico l’indicazione dei punti dimassimo e minimo per non pasticciare inutilmente la figura).
−1 2 x
y
211I risultati si ottengono considerando che le potenze terza e seconda sono trascurabili rispetto alla potenza quarta, per x → +∞.212Valori approssimati di questi ultimi due sono 3−
√73
8≈ −0.69 e 3+
√73
8≈ 1.44.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
217
Dal grafico appare evidente che il punto 3+√73
8 e in realta punto di minimo globale per la funzione. La funzione none invece limitata superiormente.Per completare lo studio possiamo calcolare e studiare la derivata seconda (il grafico dice che devono esserci dei puntidi flesso). Si ha
f ′′(x) = 12x2 − 6x− 4.
La derivata seconda si annulla in 3±√57
12 . Lo studio del segno di f ′′ porta a dire che
f ′′(x) > 0 per x < 3−√57
12 e per x > 3+√57
12
e invecef ′′(x) < 0 per 3−
√57
12 < x < 3+√57
12 .
Quindi la funzione f e convessa per x < 3−√57
12 , concava per 3−√57
12 < x < 3+√57
12 e ancora convessa per x > 3+√57
12 .
Possiamo concludere anche che 3−√57
12 e 3+√57
12 sono punti di flesso.213
◮ 2. Studiamo la funzione f(x) = xx3+1 .
La funzione e definita in tutti i punti diversi da −1, dove si annulla il denominatore. Dove e definita e continua ederivabile.La funzione si annulla in x = 0. Possiamo studiare il segno della funzione, studiando il segno di numeratore edenominatore. Risulta
x
x3 + 1> 0 se x < −1 oppure x > 0.
Ovviamente la funzione e invece negativa per −1 < x < 0.Calcoliamo ora i limiti agli estremi del dominio, cioe in −1 e agli infiniti. Si ha facilmente
limx→±∞
x
x3 + 1= 0 214
elim
x→(−1)+
x
x3 + 1= −∞ e lim
x→(−1)−
x
x3 + 1= +∞.
Studiamo ora la derivata. Si ha
f ′(x) =x3 + 1− x · 3x2
(x3 + 1)2=
1− 2x3
(x3 + 1)2.
La derivata si annulla in 13√2, che e quindi un punto stazionario.
Studiamo il segno della derivata. Si ha
f ′(x) > 0 nell’insieme (−∞,−1) ∪ (−1, 13√2)
e invecef ′(x) < 0 nell’intervallo ( 1
3√2,+∞).
Pertanto possiamo dire che la funzione e crescente in (−∞,−1), crescente in (−1, 13√2) e decrescente in ( 1
3√2,+∞).
Inoltre il punto 13√2e punto di massimo locale. Possiamo disegnare un grafico sommario.
−11/ 3
√2 x
y
La funzione non e limitata, ne inferiormente ne superiormente. Non facciamo lo studio della derivata seconda.215
213Valori approssimati dei due punti di flesso sono 3−√
5712
≈ −0.37 e 3+√
5712
≈ 0.88, che sono coerenti con la posizione dei punti dimassimo e di minimo.214Il risultato segue osservando che il numeratore e trascurabile rispetto al denominatore.215Lo studio porterebbe a concludere che la derivata seconda si annulla in x = 0 e in x = 3
√2. Solo il secondo e punto di flesso.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
218
◮ 3. Studiamo la funzione f(x) = x lnx.La funzione e definita sulle x positive, cioe sull’intervallo (0,+∞). Dove e definita e continua e derivabile.La funzione si annulla in x = 1. Studiamo il segno della funzione. Risulta
x lnx > 0 se x > 1.
Ovviamente la funzione e invece negativa per 0 < x < 1.Calcoliamo ora i limiti agli estremi del dominio, cioe in 0 da destra e a +∞. Si ha
limx→0+
x lnx = 0 216
elim
x→+∞x lnx = +∞.
Studiamo ora la derivata. Si haf ′(x) = lnx+ 1.
La derivata si annulla in 1e , che e quindi un punto stazionario.
Studiamo il segno della derivata. Si ha
f ′(x) > 0 nell’intervallo (1e ,+∞)
e invecef ′(x) < 0 nell’intervallo (0, 1e ).
Pertanto possiamo dire che la funzione e decrescente in (0, 1e ) e crescente in (1e ,+∞). Inoltre il punto 1e e punto di
minimo locale.Possiamo disegnare un grafico sommario. Per ottenere un grafico piu accurato in prossimita dell’origine, possiamocalcolare la pendenza da destra (cioe la derivata destra in 0). Dato pero che la funzione non e definita in 0, anzichela derivata destra con la definizione, possiamo fare il limite da destra della derivata. Calcoliamo quindi
limx→0+
f ′(x) = limx→0+
(lnx+ 1) = −∞.
Questo significa che il grafico, nell’origine, da destra, e tangente all’asse verticale.Non e difficile studiare la derivata seconda. Si ha
f ′′(x) =1
x,
che e ovviamente sempre positiva in (0,+∞). Quindi la funzione e convessa. Ecco un grafico sommario.
1
1/ebc
x
y
1/ebc
x
y
La figura a destra evidenzia quello che accade in prossimita dell’origine. Si puo percepire che il grafico si avvicinaall’origine tangente all’asse verticale, quindi “con pendenza infinita”.A conclusione possiamo osservare che 1
e e punto di minimo globale e che la funzione non e limitata superiormente.
216Il limite e gia stato calcolato in altre occasioni. Un modo e il seguente:
limx→0+
x lnx = limx→0+
lnx1x
= limy→+∞
ln 1y
y= lim
y→+∞
− ln y
y= 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
219
◮ 4. Studiamo la funzione f(x) = x3 lnx2.La funzione e definita sulle x diverse da zero, cioe sull’insieme (−∞, 0) ∪ (0,+∞). Dove e definita e continua ederivabile.Qui possiamo osservare una cosa importante: il dominio e simmetrico rispetto all’origine e la funzione e dispari, cioesimmetrica rispetto all’origine.217 La possiamo allora studiare intanto sull’intervallo (0,+∞).218
La funzione si annulla in x = 1. Studiamo il segno della funzione. Risulta
x3 lnx2 > 0 se x > 1.
Ovviamente la funzione e invece negativa per 0 < x < 1.Calcoliamo ora i limiti agli estremi dell’intervallo (0,+∞), cioe in 0 da destra e a +∞. Si ha
limx→0+
x3 lnx2 = limx→0+
lnx2
1/x3.
Con il cambio di variabile 1x = y (da cui x = 1/y) si ottiene
limx→0+
lnx2
1/x3= lim
y→+∞ln(1/y2)
y3= lim
y→+∞−2 ln yy3
= 0.
Poilim
x→+∞x3 lnx2 = +∞.
Studiamo ora la derivata. Si ha
f ′(x) = 3x2 lnx2 + x3 · 1
x2· 2x = 3x2 lnx2 + 2x2 = x2(3 lnx2 + 2).
La derivata si annulla se 3 lnx2 + 2 = 0, cioe se lnx2 = − 23 , cioe se x2 = e−2/3, cioe se x = e−1/3, che e quindi un
punto stazionario.Studiamo il segno della derivata. Si ha
f ′(x) > 0 nell’intervallo (e−1/3,+∞)
e invecef ′(x) < 0 nell’intervallo (0, e−1/3).
Pertanto possiamo dire che la funzione e decrescente in (0, e−1/3) e crescente in (e−1/3,+∞). Inoltre il punto e−1/3 epunto di minimo locale.Come fatto nell’esercizio precedente, per ottenere un grafico piu accurato in prossimita dell’origine, possiamo calcolarela pendenza da destra. Facciamo anche qui il limite da destra della derivata, cioe
limx→0+
f ′(x) = limx→0+
x2(3 lnx2 + 2) = 0.219
Questo significa che questa volta la funzione, nell’origine, da destra, e tangente all’asse orizzontale.Non e difficile studiare la derivata seconda. Si trova che
f ′′(x) = 2x(3 lnx2 + 5),
da cui segue che c’e un punto di flesso in e−5/6 (cioe prima del punto di minimo, come deve necessariamente essere).Ecco un grafico sommario (a sinistra quello su (0,+∞) e a destra quello su tutto il dominio, ottenuto ricordando chela funzione e dispari).
1
e−1/3
bc
x
y
−1
1−e−1/3
e−1/3
bc
x
y
217Si ha infatti che f(−x) = (−x)3 ln(−x)2 = −x3 lnx2 = −f(x).218Si potrebbe osservare anche che la funzione coincide con 2x3 lnx, ma mettiamo di non accorgerci di questo.219E chiaro che basta fare il limite di x2 lnx2, che pero con il cambio di variabile x2 = y diventa il limy→0+ y ln y, che abbiamo giacalcolato prima e che risulta uguale a 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
220
◮ 5. Studiamo la funzione f(x) = x3ex.Il dominio e tutto R. La funzione non ha simmetrie,220 pur essendo il dominio simmetrico rispetto all’origine. Lafunzione e continua e derivabile.La funzione si annulla in x = 0. Il segno della funzione e immediato. Risulta
x3ex > 0 se x > 0.
Ovviamente la funzione e invece negativa per x < 0.Calcoliamo ora i limiti agli estremi del dominio, cioe agli infiniti. Si ha
limx→+∞
x3ex = +∞
e
limx→−∞
x3ex = limx→−∞
x3
e−x= lim
y→+∞(−y)3ey
= limy→+∞
−y3ey
= 0.
Studiamo ora la derivata. Si haf ′(x) = 3x2ex + x3ex = x2ex(3 + x).
La derivata si annulla in x = −3 e in x = 0, che sono quindi punti stazionari.Studiamo il segno della derivata. Si ha
f ′(x) > 0 nell’insieme (−3, 0) ∪ (0,+∞)
e invecef ′(x) < 0 nell’intervallo (−∞,−3).
Pertanto possiamo dire che la funzione e decrescente in (−∞,−3) e crescente in (−3,+∞). Inoltre il punto −3 e puntodi minimo locale. Da osservare anche che 0, pur essendo un punto stazionario, non e ne di massimo ne di minimo.221
Anche qui non e difficile studiare la derivata seconda. Si trova che
f ′′(x) = xex(x2 + 6x+ 6),
da cui segue che ci sono due punti di flesso: in −3−√3 e in −3 +
√3 (entrambi negativi) e che la funzione e concava
in (−∞,−3−√3), convessa in (−3−
√3,−3 +
√3), concava in (−3 +
√3, 0) e infine ancora convessa in (0,+∞).
Ecco un grafico sommario.
−3−3−√3 −3+
√3
x
y
A conclusione possiamo dire che −3 e punto di minimo globale e che la funzione non e limitata superiormente.
220Infatti f(−x) = (−x)3e−x = −x3e−x non e uguale ne a f(x) ne a −f(x), a causa della non simmetria della funzione esponenziale.221Non e ne di massimo ne di minimo poiche la funzione e crescente sia a sinistra sia a destra di 0. Si puo dire che 0 e un punto di flessoa tangente orizzontale.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
221
◮ 6. Studiamo la funzione f(x) = x2e−x2
.Il dominio e tutto R. La funzione ha questa volta simmetria ed e in particolare una funzione pari.222 La possiamostudiare nell’intervallo [0,+∞). La funzione e continua e derivabile.La funzione si annulla in x = 0. Il segno della funzione e immediato. Risulta
x2e−x2
> 0 se x > 0.
Calcoliamo ora i limiti agli estremi del dominio, cioe all’infinito. Si ha
limx→+∞
x2e−x2
= limx→+∞
x2
ex2= lim
y→+∞y
ey= 0.
Studiamo ora la derivata. Si ha
f ′(x) = 2xe−x2
+ x2 · e−x2 · (−2x) = 2xe−x2
(1− x2).
La derivata si annulla in x = 0 e in x = 1, che sono quindi punti stazionari. Studiamo il segno della derivata. Si ha
f ′(x) > 0 nell’intervallo (0, 1)
e invecef ′(x) < 0 nell’intervallo (1,+∞).
Pertanto possiamo dire che la funzione e crescente in (0, 1) e decrescente in (1,+∞). Inoltre il punto 1 e punto dimassimo locale. La natura del punto 0 sara chiara quando faremo il grafico su tutto R.Qui ci sono un po’ di calcoli per studiare la derivata seconda, ma non e difficile. Si trova che
f ′′(x) = 2e−x2
(2x4 − 5x2 + 1),
da cui segue che ci sono due punti di flesso, e sono le soluzioni positive dell’equazione x2 = 5±√17
4 .223
Ecco un grafico sommario (a sinistra quello su [0,+∞) e a destra quello su tutto il dominio, ottenuto ricordando chela funzione e pari).
1 x
y
1−1 x
y
Dal grafico risulta che la funzione ha in −1 e 1 punti di massimo globali e in 0 il punto di minimo globale.
222Infatti f(−x) = (−x)2e−(−x)2 = x2e−x2= f(x).
223Valori approssimati di questi sono(
5−√
174
)1/2≈ 0.47 e
(5+
√17
4
)1/2≈ 1.51. Stanno naturalmente uno a sinistra e uno a destra del
punto di massimo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
222
◮ 7. Studiamo la funzione f(x) =lnx
x.
La funzione e definita sulle x positive, cioe sull’intervallo (0,+∞). Dove e definita e continua e derivabile.La funzione si annulla in x = 1. Studiamo il segno della funzione. Risulta
lnx
x> 0 se x > 1.
Ovviamente la funzione e invece negativa per 0 < x < 1.Calcoliamo ora i limiti agli estremi del dominio, cioe in 0 da destra e a +∞. Si ha
limx→0+
lnx
x= −∞
e
limx→+∞
lnx
x= 0.
Studiamo ora la derivata. Si ha
f ′(x) =1x · x− lnx
x2=
1− lnx
x2.
La derivata si annulla in e, che e quindi un punto stazionario.Studiamo il segno della derivata. Si ha
f ′(x) > 0 nell’intervallo (0, e)
e invecef ′(x) < 0 nell’intervallo (e,+∞).
Pertanto possiamo dire che la funzione e crescente in (0, e) e decrescente in (e,+∞). Inoltre il punto e e punto dimassimo locale.Non e difficile studiare la derivata seconda. Si ha
f ′′(x) =− 1
x · x2 − (1− lnx) · 2xx4
=2 lnx− 3
x3.
La derivata seconda si annulla in e3/2. La funzione e concava in (0, e3/2) e convessa in (e3/2,+∞). Il punto e3/2 e unpunto di flesso.Ecco un grafico sommario.
e e3/21 x
y
Il grafico e stato ottenuto, come tutti gli altri, con un software che consente di riportare esattamente i valori assuntidalla funzione (qui ad esempio ho disegnato la funzione per valori di x compresi tra 0 e 10). A volte puo succedereche il grafico “reale”, cioe quello che si ottiene senza cambiamenti di scala sugli assi, non dica in modo cosı esplicitoquello che si e trovato con lo studio analitico. In questo caso non ho utilizzato cambiamenti di scala sugli assi, quindiil grafico e esattamente cosı. Possiamo notare che i punti di massimo e di flesso sono poco evidenti e che soprattuttola funzione decresce molto lentamente, per x→ +∞, cosa che non era cosı facilmente intuibile.Il grafico qui sotto e invece lo stesso con x ∈ (0, 20) e ho usato un cambiamento di scala sulle x.
ee3/2
1 x
y
Il punto di massimo e un po’ piu evidente, e forse anche il punto di flesso.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
223
◮ 8. Studiamo la funzione f(x) =
√x2 + 1
x.
La funzione e definita sulle x diverse da zero, cioe sull’insieme (−∞, 0) ∪ (0,+∞). Dove e definita e continua ederivabile.Qui possiamo osservare che il dominio e simmetrico rispetto all’origine e la funzione e dispari, cioe simmetrica rispettoall’origine. La possiamo allora studiare intanto sull’intervallo (0,+∞).La funzione non si annulla per nessun valore di x. Il segno della funzione e immediato. Risulta
√x2 + 1
x> 0 se x > 0.
Calcoliamo ora i limiti agli estremi dell’intervallo (0,+∞), cioe in 0 da destra e a +∞. Si ha
limx→0+
√x2 + 1
x= +∞
e
limx→+∞
√x2 + 1
x= lim
x→+∞x
x= 1.224
Studiamo ora la derivata. Si ha
f ′(x) =
2x2√x2+1
· x−√x2 + 1
x2=x2 − x2 − 1
x2√x2 + 1
=−1
x2√x2 + 1
.
La derivata non si annulla mai, e quindi non vi sono punti stazionari e nemmeno punti di massimo o di minimo locale.Ovviamente il segno della derivata e negativo in tutto l’intervallo (0,+∞), e cioe la funzione e decrescente in taleintervallo.Ecco un grafico sommario (a sinistra quello su (0,+∞) e a destra quello su tutto il dominio, ottenuto ricordando chela funzione e dispari).
1
x
y
1
−1x
y
La funzione non e limitata ne inferiormente ne superiormente. Non studiamo la derivata seconda.
224A numeratore 1 e trascurabile e il tutto e equivalente a√x2, cioe x. In questi casi (limite finito all’infinito) si dice che la funzione ha
un asintoto orizzontale, qui dato dalla retta di equazione y = 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
224
◮ 9. Studiamo la funzione f(x) = x−√x2 + 1.
La funzione e definita in tutto R. E continua e derivabile.Questa volta, anche se il dominio e simmetrico rispetto all’origine, la funzione non ha simmetrie.La funzione non si annulla per nessun valore di x: infatti l’equazione
x =√
x2 + 1
non ha soluzioni.225 Risulta inoltre sempre vero che
x <√
x2 + 1 226
e quindi la funzione assume valori negativi in tutto R.Calcoliamo ora i limiti agli estremi del dominio, cioe agli infiniti. Si ha
limx→−∞
(x−√
x2 + 1) = −∞
e
limx→+∞
(x−√
x2 + 1) = limx→+∞
(x−√x2 + 1)(x +
√x2 + 1)
x+√x2 + 1
= limx→+∞
x2 − (x2 + 1)
x+√x2 + 1
= 0. 227
Studiamo ora la derivata. Si ha
f ′(x) = 1− 2x
2√x2 + 1
=
√x2 + 1− x√x2 + 1
.
Si puo osservare che la derivata ha a denominatore una quantita positiva e a numeratore l’opposto della funzione stessa(cioe −f(x)). Quindi possiamo concludere immediatamente che la derivata e positiva in tutto R. La funzione e quindicrescente nel suo dominio e non vi sono punti di massimo o di minimo locale. Ecco un grafico sommario (nell’originela funzione vale f(0) = −1).
−1
x
y
La funzione e limitata superiormente, ma non ha massimo. Non e limitata inferiormente. Non studiamo la derivataseconda.
225Ovviamente impossibile se x < 0 e, per x ≥ 0, elevando al quadrato si ottiene x2 = x2 + 1, che non e mai vera.226Se x e negativo la cosa e evidente. Se x e positivo, elevando al quadrato, si ottiene x2 < x2 + 1, che e certamente vera.227Da notare che questo limite si deve necessariamente risolvere con la razionalizzazione. Non sono applicabili ne i confronti ne i principidi eliminazione/sostituzione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

10 APPENDICE – STUDIO DI FUNZIONE
DERIVATE
225
◮ 10. Studiamo la funzione f(x) = x2 − lnx.La funzione e definita sulle x positive, cioe sull’intervallo (0,+∞). Dove e definita e continua e derivabile.Lo studio del segno risulterebbe difficile in questo caso e per il momento lo saltiamo.228
Calcoliamo direttamente i limiti agli estremi del dominio, cioe in 0 da destra e a +∞. Si ha
limx→0+
(x2 − lnx) = +∞
elim
x→+∞(x2 − lnx) = +∞.229
Studiamo ora la derivata. Si ha
f ′(x) = 2x− 1
x=
2x2 − 1
x.
Questo quoziente si annulla in 1√2e in − 1√
2, ma soltanto il primo dei due e accettabile quale punto stazionario di f .
Studiamo il segno della derivata. Si ha
f ′(x) > 0 nell’intervallo ( 1√2,+∞)
e invecef ′(x) < 0 nell’intervallo (0, 1√
2).
Pertanto possiamo dire che la funzione e decrescente in (0, 1√2) e crescente in ( 1√
2,+∞). Inoltre il punto 1√
2e punto
di minimo locale.Qui non e difficile studiare la derivata seconda. Si trova che la funzione e convessa in quanto
f ′′(x) =4x · x− (2x2 − 1)
x2=
2x2 + 1
x2.
Ecco un grafico sommario.
1/√2
x
y
In realta e doverosa una precisazione. Non abbiamo studiato il segno della funzione, quindi per quanto ne sappiamonon e detto che la funzione sia sempre positiva nel suo dominio. Questo problema si puo pero risolvere facilmente,dato che se risulta che nel punto di minimo ( 1√
2) la funzione e positiva, allora possiamo concludere che lo e sempre.
Risulta infattif( 1√
2) = 1
2 − ln 1√2= 1
2 + ln√2 = 1
2 + 12 ln 2 > 0.
A conclusione possiamo osservare che 1√2e punto di minimo globale e che la funzione non e limitata superiormente.
228L’equazione x2 − lnx = 0 (o la disequazione x2 − lnx > 0) non appartiene a nessuna delle classi di equazioni che siamo in grado dirisolvere in modo esatto.229Il risultato segue dal principio di eliminazione: il logaritmo e trascurabile rispetto a x2 per x → +∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 PRIMITIVE
INTEGRALE INDEFINITO
226
II-7 Integrale indefinito
1 Primitive
Definizione Siano I un intervallo e f : I → R. Una funzione F : I → R si chiama primitiva di f in I se F ederivabile in I e F ′(x) = f(x) per ogni x ∈ I.Esempi
• Consideriamo la funzione f : R → R definita da f(x) = ex. Ovviamente la funzione F (x) = ex e primitiva di fin tutto R, dato che quest’ultima e derivabile e D(ex) = ex in tutto R.
• Consideriamo la funzione f : R → R definita da f(x) = x2. La funzione F (x) = x3/3 e primitiva di f in tuttoR, dato che e derivabile e D(x3/3) = x2 in tutto R.
• Consideriamo la funzione f : (0,+∞) → R definita da f(x) = 1x . La funzione F (x) = lnx e primitiva di f in
(0,+∞), dato che e derivabile e D(lnx) = 1x in (0,+∞).
• Consideriamo la funzione f : (0,+∞)→ R definita da f(x) = lnx+ 1. La funzione F (x) = x lnx e primitiva dif , dato che e derivabile e D(x ln x) = lnx+ 1 in (0,+∞).
• Anche se non fornisco qui esempi espliciti, lo studente sappia che ci sono funzioni che non hanno una primitiva.
Proposizione Siano I un intervallo e sia f : I → R. Valgono le proprieta seguenti:
(i) se F e una primitiva di f in I, per ogni c ∈ R anche F + c e una primitiva di f in I;
(ii) se F e G sono due primitive di f in I, allora F −G e costante.
Osservazione La dimostrazione della (i) e immediata, dato che la derivata di una costante e nulla. La (ii) e invecemeno banale e deriva da una conseguenza del teorema del valor medio per cui, se la derivata di una funzione e semprenulla, allora questa funzione e necessariamente costante. Nel nostro caso la derivata di F − G e nulla, dato cheD(F −G) = DF −DG = f − f = 0; quindi F −G e costante, come detto.
Osservazione I due punti della proposizione precedente dicono sostanzialmente che, se c’e una primitiva di unafunzione f , allora ce ne sono infinite altre, e sono tutte e sole le funzioni che si ottengono sommando una costantearbitraria alla primitiva originaria.
Definizione Siano I un intervallo e f : I → R. L’insieme delle primitive di f in I si chiama integrale indefinitodi f in I e viene indicato con uno dei simboli
∫
f oppure
∫
f(x) dx.
Per i punti (i) e (ii) dell’ultima Proposizione, se F e una primitiva di f , allora
∫
f ={F + c : c ∈ R
}.
Per non appesantire la notazione, si scrive anche
∫
f = F + c oppure
∫
f(x) dx = F (x) + c. 230
E chiaro dunque che per conoscere l’integrale indefinito di una funzione e sufficiente trovare una primitiva di talefunzione. Tutte le altre si ottengono aggiungendo a questa una costante arbitraria.
230Solitamente si usa la prima forma quando si fa riferimento ad una generica funzione f , mentre si usa la seconda quando si considerauna ben precisa funzione, in cui e naturale l’indicazione della variabile.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 TECNICHE DI INTEGRAZIONE I
INTEGRALE INDEFINITO
227
Esempi Per gli esempi introduttivi della pagina precedente possiamo allora dire che
• si ha ∫
ex dx = ex + c, in tutto R.
• Si ha ∫
x2 dx =x3
3+ c, in tutto R.
• Si ha ∫1
xdx = lnx+ c, in (0,+∞).231
Osservazione Dato che in (−∞, 0) si ha ugualmente D ln(−x) = 1/x, solitamente si scrive∫
1
xdx = ln |x|+ c,
ottenendo cosı una scrittura valida sia in (0,+∞) sia in (−∞, 0).• Dalla tabella delle derivate delle funzioni elementari e dalla definizione di integrale indefinito, si ricava il seguenteelenco di integrali indefiniti immediati:
∫
xα dx =xα+1
α+ 1+ c, ∀α 6= −1
∫1
xdx = ln |x|+ c
∫
ex dx = ex + c
∫
ax dx =ax
ln a+ c
2 Tecniche di integrazione I
Per il momento, oltre alla definizione di primitiva, abbiamo visto sostanzialmente alcuni esempi in cui si trova unaprimitiva ricordando alcune formule di derivazione. Ma si pone ora il quesito di come procedere in generale per trovareuna primitiva di una funzione qualunque. Diciamo subito che non esiste un metodo generale: a differenza quindi diquanto avviene per il calcolo della derivata, per il calcolo di una primitiva un metodo del tutto generale non c’e. Cisono alcuni metodi possibili, ciascuno dei quali funziona in alcuni casi. Vediamo ora alcuni di questi metodi, corredatida qualche esempio che aiuta a capire in quali casi un metodo puo funzionare.
2.1 Linearita dell’integrale
La proposizione seguente fornisce una proprieta del tutto generale dell’integrale indefinito.
Proposizione Siano I un intervallo, f, g : I → R e F,G loro primitive in I. Allora una primitiva di c1f + c2g ec1F + c2G, qualunque siano c1, c2 ∈ R.
Osservazione La proposizione dice quindi che se conosco una primitiva di f e di g allora ho una primitiva di c1f+c2g(c1, c2 sono costanti, cioe numeri reali fissati). La dimostrazione e immediata, osservando che c1F + c2G e derivabilee che
(c1F + c2G)′ = c1F
′ + c2G′
= c1f + c2g.
La proposizione consente quindi, nel calcolo di un integrale indefinito, di applicare questa proprieta di linearita:∫(c1f(x) + c2g(x)
)dx = c1
∫
f(x) dx + c2
∫
g(x) dx.
Come caso particolare rilevante, se dobbiamo calcolare l’integrale indefinito di una somma di due funzioni possiamoquindi cercare separatamente le primitive delle due funzioni e, una volta trovate, ne possiamo fare la somma.
231Sarebbe bene precisare sempre in quale intervallo considero un certo integrale indefinito, come ho indicato nei tre esempi. Devo direpero che questo di solito non viene fatto, e che si sottintende che il risultato vale nel piu grande insieme in cui le funzioni sono definite (ederivabili).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 TECNICHE DI INTEGRAZIONE I
INTEGRALE INDEFINITO
228
Esempi Esempi di utilizzo della proprieta di linearita.
• Dovendo calcolare∫(3x + 2) dx e osservando che x2/2 e una primitiva di x e che x e una primitiva di 1, si ha
allora:∫(3 · x+ 2 · 1) dx = 3x2/2 + 2x+ c.
• E chiaro allora come si procede in generale per integrare un qualunque polinomio. Se
P (x) = anxn + an−1x
n−1 + . . .+ a1x+ a0,
allora si ha ∫
P (x) dx = anxn+1
n+ 1+ an−1
xn
n+ . . . a1
x2
2+ a0x+ c.
Quindi, ad esempio,∫
(3x3 − 2x2 − 3x+ 5) dx = 3x4
4− 2
x3
3− 3
x2
2+ 5x+ c.
• Nel caso abbia
∫P (x)
xkdx bastera dividere ogni monomio del polinomio P per xk e poi applicare la linearita.
Ad esempio∫x3 − 2x2 + 3x+ 1
x2dx =
∫ (
x− 2 +3
x+
1
x2
)
dx =x2
2− 2x+ 3 ln |x| − 1
x+ c.
• Abbiamo visto poco fa che la linearita consente di integrare tutti i polinomi. Piu in generale consente di integrarela somma di piu potenze. Se gli αi sono numeri reali diversi da −1, abbiamo che
∫ m∑
i=1
cixαi dx 232 =
∫
(c1xα1 + c2x
α2 + . . .+ cmxαm) dx
= c1xα1+1
α1 + 1+ c2
xα2+1
α2 + 1+ . . .+ cm
xαm+1
αm + 1+ c
=
m∑
i=1
cixαi+1
αi + 1+ c.
Quindi, ad esempio, avremo∫ (
3√x− 1√
x
)
dx =
∫(x1/3 − x−1/2
)dx =
x4/3
4/3− x1/2
1/2+ c =
3
4
3√x4 − 2
√x+ c.
• Volendo calcolare l’integrale indefinito della funzione f(x) = 3x2 − 2
x− 3ex utilizzando la linearita dell’integrale
avremo ∫ (
3x2 − 2
x− 3ex
)
dx = 3
∫
x2 dx− 2
∫1
xdx− 3
∫
ex dx = x3 − 2 ln |x| − 3ex + c.
2.2 Integrali quasi immediati
Un primo insieme di formule di integrazione “quasi immediata” si puo ricavare ancora dalle regole di derivazione dellafunzione composta. Si hanno i seguenti casi rilevanti (ai quali per comodita do il nome di integrale quasi immediatodi tipologia (i), (ii) e (iii)):
(i)
∫
fαDf =fα+1
α+ 1+ c, per ogni α 6= −1
(
infatti D fα+1
α+1 = fαDf)
(ii)
∫Df
f= ln |f |+ c
(
infatti D ln |f | = Dff
)
(iii)
∫
ef Df = ef + c 233(
infatti Def = ef Df)
232Si noti che∑m
i=1 cixαi puo non essere un polinomio, dato che gli esponenti possono non essere interi.
233Con la scrittura esplicita della variabile le tre formule si scrivono ovviamente∫
fα(x) f ′(x) dx =fα+1(x)
α+ 1+ c ,
∫f ′(x)
f(x)dx = ln |f(x)|+ c ,
∫
ef(x) f ′(x) dx = ef(x) + c.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 TECNICHE DI INTEGRAZIONE I
INTEGRALE INDEFINITO
229
Esempi
• Nel tipologia (i) rientra:
∫ln2 x
xdx =
∫
ln2 x · 1xdx =
ln3 x
3+ c.
• Nel tipologia (ii) rientra:
∫1
x lnxdx =
∫1/x
lnxdx = ln | lnx|+ c.
• Nel tipologia (iii) rientra:
∫
2xex2
dx = ex2
+ c.
Importante osservare che molte forme, anche se non inizialmente di questo tipo, si possono ricondurre facilmente aqueste tipologie. Lo vediamo su alcuni esempi istruttivi.
• Consideriamo
∫ √x+ 1dx. Questo integrale e gia della tipologia (i), con f(x) = 1 + x e α = 1/2. Si ha quindi
∫ √x+ 1dx =
∫
(x+ 1)1/2 dx =(1 + x)3/2
3/2+ c =
2
3
√
(x+ 1)3 + c.
•
∫ √3x− 2 dx. E come prima, con f(x) = 3x − 2. Questa volta pero c’e una costante da “aggiustare” per
rientrare nella tipologia (i). Infatti occorre che dentro all’integrale ci sia anche la derivata di f , che in questocaso e 3. Sfruttando la linearita dell’integrale possiamo semplicemente moltiplicare e dividere per 3 e scrivere
∫ √3x− 2 dx =
1
3
∫
3(3x− 2)1/2 dx =1
3
(3x− 2)3/2
3/2+ c = 2/9
√
(3x− 2)3 + c. 234
Riassumendo possiamo vedere la cosa in questi termini: per essere nella tipologia (i) devo avere dentro all’inte-grale una potenza di f per la derivata di f . Dato che chiaramente deve essere f(x) = 3x− 2 e risulta f ′(x) = 3,mi serve un 3 dentro all’integrale. Moltiplico quindi per 3 dentro all’integrale e contemporaneamente divido per3 fuori dall’integrale.
• Consideriamo
∫1
2x+ 1dx. Qui siamo molto vicini alla tipologia (ii). Infatti, se poniamo f(x) = 2x+1, che ha
per derivata 2, possiamo scrivere∫
1
2x+ 1dx =
1
2
∫2
2x+ 1dx =
1
2ln |2x+ 1|+ c.
•
∫
e1−2x dx. Qui e ovviamente la tipologia (iii) che possiamo intravedere. Possiamo porre f(x) = 1− 2x, che ha
derivata −2, e quindi possiamo scrivere∫
e1−2x dx = −1
2
∫
(−2)e1−2x dx = −1
2e1−2x + c.
• Talvolta puo essere utile un piccolo “trucco”. Ad esempio, con
∫x
x+ 1dx, si puo aggiungere e togliere 1 a
numeratore per ottenere il denominatore e poter scrivere la frazione come somma di due frazioni:∫
x
x+ 1dx =
∫x+ 1− 1
x+ 1dx =
∫ (
1− 1
x+ 1
)
dx = x− ln |x+ 1|+ c.
• Qualche volta i due trucchi del moltiplicare/dividere e dell’aggiungere/togliere possono essere applicati congiun-tamente. Ad esempio
∫x
2x+ 1dx =
1
2
∫2x
2x+ 1dx =
1
2
∫2x+ 1− 1
2x+ 1dx =
1
2
∫ (
1− 1
2x+ 1
)
dx =1
2x− 1
4ln |2x+ 1|+ c.
234Si ricordi sempre che, per controllare la correttezza del risultato, per vedere cioe se la primitiva trovata e effettivamente una primitiva,basta controllare che la derivata di quest’ultima sia la funzione da integrare. Questo e un utile esercizio che gli studenti che vedono questecose per la prima volta dovrebbero sempre fare, anzitutto perche rafforzano le tecniche di derivazione e in secondo luogo perche chiarisconomolti aspetti legati anche all’integrazione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 TECNICHE DI INTEGRAZIONE II
INTEGRALE INDEFINITO
230
Osservazione E chiaro che il metodo di “aggiustamento delle costanti” funziona solo in casi particolari. Mi spiego:se avessimo
∫ex
2+1 dx, osservando che D(ex2+1) = 2xex
2+1, non possiamo certo moltiplicare dentro all’integrale per2x e dividere fuori per 2x (con le costanti funziona (linearita dell’integrale) ma con la variabile no!).Pero potremmo avere situazioni come le seguenti:
•
∫
x√
x2 + 1dx. Possiamo vedere in questo l’integrale della potenza, con esponente 1/2, della funzione f(x) =
x2 + 1. La tipologia (i) chiede che dentro all’integrale ci sia anche la derivata di f , che e f ′(x) = 2x: c’e x,manca il 2. Quindi, come prima, moltiplicando e dividendo per 2,
∫
x√
x2 + 1dx =1
2
∫
2x√
x2 + 1dx =1
2
∫
2x(x2 + 1)1/2 dx =1
2
(x2 + 1)3/2
3/2+ c =
1
3
√
(x2 + 1)3 + c.
• Consideriamo
∫x
1 + x2dx. Si osserva che a numeratore compare la derivata del denominatore, a meno di una
costante moltiplicativa (un 2). Allora possiamo rientrare nella tipologia (ii) moltiplicando e dividendo per 2:
∫x
1 + x2dx =
1
2
∫2x
1 + x2dx =
1
2ln(1 + x2) + c. 235
•
∫
xe2x2
dx. Siamo nella tipologia (iii), con f(x) = 2x2, la cui derivata e f ′(x) = 4x. Allora
∫
xe2x2
dx =1
4
∫
4xe2x2
dx =1
4e2x
2
+ c.
• Consideriamo ancora
∫x2
x3 + 1dx. Siamo nella tipologia (ii), con f(x) = x3 + 1, la cui derivata e f ′(x) = 3x2.
Allora ∫x2
x3 + 1dx =
1
3
∫3x2
x3 + 1dx =
1
3ln∣∣x3 + 1
∣∣+ c. 236
• Ancora:
∫
(x + 2) 3√
(x2 + 4x+ 1)2 dx. Osserviamo che dentro all’integrale c’e f(x) = x2 + 4x + 1 elevata alla
2/3 e che f ′(x) = 2x+ 4. Dentro all’integrale c’e anche x+ 2. Quindi possiamo scrivere
∫
(x+ 2) 3√
(x2 + 4x+ 1)2 dx =1
2
∫
(2x+ 4) 3√
(x2 + 4x+ 1)2 dx =1
2
(x2 + 4x+ 1)5/3
5/3+ c.
3 Tecniche di integrazione II
3.1 Formula di integrazione per parti
Un’importante modalita di calcolo degli integrali e data dalla seguente
Proposizione Sia I un intervallo e siano f, g : I → R. Supponiamo poi che f sia derivabile e che G sia una primitivadi g in I. Vale la formula, detta formula di integrazione per parti,
∫
f g = f G−∫
Gf ′ oppure
∫
f(x) g(x) dx = f(x)G(x) −∫
G(x) f ′(x) dx.
Osservazioni La formula dice sostanzialmente che l’integrale del prodotto di due funzioni puo essere trasformatoin: “la prima funzione per una primitiva della seconda meno l’integrale di questa primitiva della seconda funzione perla derivata della prima”. Solitamente f viene detta la parte finita e g viene detta la parte differenziale. La formula diintegrazione per parti puo quindi essere cosı ricordata: “l’integrale della parte finita per la parte differenziale e uguale
235Si noti che in questo caso si puo anche non mettere il valore assoluto, dato che l’argomento del logaritmo e certamente positivo.236Qui no che non possiamo togliere il valore assoluto: l’argomento del logaritmo x3 + 1 puo anche essere negativo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 TECNICHE DI INTEGRAZIONE II
INTEGRALE INDEFINITO
231
alla parte finita per una primitiva della parte differenziale meno l’integrale di questa primitiva per la derivata dellaparte finita”.Per provare la formula dobbiamo dimostrare che la derivata di quello che sta a destra, cioe f G−
∫Gf ′, e la funzione
che sta sotto l’integrale di sinistra, cioe fg. Infatti
D
(
fG−∫
Gf ′)
= f ′G+ fg −Gf ′ = fg. 237
Esempi Ecco alcuni esempi d’uso della formula di integrazione per parti.
•
∫
xex dx. Scegliendo come parte finita x e come parte differenziale ex abbiamo:238
∫
xex dx = xex −∫
1 ex dx
= xex − ex + c.
•
∫
lnxdx. Scegliendo come parte finita lnx e come parte differenziale 1 abbiamo:239
∫
lnxdx =
∫
1 · lnxdx
= lnx · x−∫
x · 1xdx
= x lnx− x+ c.
•
∫
x lnxdx. Scegliendo come parte finita lnx e come parte differenziale x abbiamo
∫
x ln xdx = lnx · x2
2−∫x2
2· 1xdx
=x2
2ln x− 1
2
∫
xdx
=x2
2ln x− x2
4+ c.
• La formula di integrazione per parti puo essere applicata ripetutamente. Si consideri
∫
x ln2 xdx. Scegliendo
come parte finita ln2 x e come parte differenziale x abbiamo con una prima integrazione per parti∫
x ln2 xdx = ln2 x · x2
2−∫x2
2· 2 lnx · 1
xdx
=x2
2ln2 x−
∫
x lnxdx.
237Nella speranza che questo modo, non del tutto rigoroso ma efficace, di presentare la dimostrazione semplifichi la comprensione dellastessa, faccio notare che se nel simbolo
∫Gf ′ vediamo una qualunque primitiva di Gf ′, la derivata D(
∫Gf ′) e appunto Gf ′, mentre la
derivata di fg si ottiene con la solita regola di derivazione del prodotto.238Non esistono regole su quale sia la scelta “giusta”, cioe la scelta che permette di calcolare l’integrale. L’integrazione per parti nonrisolve in un solo passo l’integrale. Lo risolve a patto che siamo in grado di calcolare il nuovo integrale che compare dopo l’applicazionedella formula. E un po’ come nell’applicazione del teorema di De l’Hopital: non si sa a priori se il metodo funziona, si prova e si vedesubito se puo funzionare. Magari non si risolve al primo tentativo ma, se la forma si semplifica, c’e la speranza che applicando nuovamenteil teorema si arrivi alla conclusione.
Ad esempio (istruttivo), nell’∫xex dx, se prendiamo come parte finita ex e come parte differenziale x, al primo passo si ha
∫
xex dx = ex · x2
2−∫
x2
2· ex dx
e si vede subito che l’integrale si complica. Quindi non si continua su questa strada.239Anche questo esempio e istruttivo: si noti che l’integrazione per parti puo essere applicata anche quando non c’e un prodotto evidente.Un prodotto si puo sempre creare anche se non c’e, basta moltiplicare per 1. Sembra una cosa inutile (e il piu delle volte lo e), ma non nelcalcolo degli integrali. Non e detto pero che funzioni sempre.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 TECNICHE DI INTEGRAZIONE II
INTEGRALE INDEFINITO
232
Ora possiamo integrare nuovamente per parti (ma qui conviene utilizzare direttamente il risultato che e statotrovato sopra, integrando appunto per parti). Si ottiene
∫
x ln2 xdx =x2
2ln2 x− x2
2lnx+
x2
4+ c.
• Lo studente provi a risolvere l’integrale
∫
x2ex dx, integrando due volte per parti e cerchi di intuire che nello
stesso modo e possibile risolvere un integrale del tipo
∫
P (x)ex dx, dove P e un qualunque polinomio.
3.2 Integrazione per sostituzione
Un’altra importante modalita di calcolo degli integrali si ricava dalla seguente
Proposizione Siano I, J intervalli, f : I → R, g : J → I (per cui si puo definire la funzione composta f(g)). Inoltreg sia derivabile e F sia una primitiva di f in I. Allora F (g) e una primitiva di f(g) g′.
Osservazione Per provare la Proposizione basta ricordare la formula di derivazione della funzione composta:
(F (g))′ = (F ′(g)) g′ = (f(g)) g′.
La Proposizione e nota come formula di integrazione per sostituzione (o cambio di variabile).Se la scriviamo nella forma integrale e con l’indicazione esplicita della variabile, essa dice che
∫
f(g(x)
)g′(x) dx = F
(g(x)
)+ c.
La formula potrebbe essere ricordata e applicata direttamente come e scritta,240 quindi senza fare ricorso ad un vero eproprio cambio di variabile. Per cercare di capire invece come intervenga un possibile cambio di variabile consideriamonell’integrale la sostituzione (o cambio di variabile) g(x) = t. Ora accordiamoci di accettare questa “regola pratica delcalcolo”: dt = g′(x) dx. Allora otteniamo formalmente
∫
f(
t︷︸︸︷
g(x) )
dt︷ ︸︸ ︷
g′(x) dx =
∫
f(t) dt.
Se F e una primitiva di f (come detto nella formulazione della Proposizione), allora sappiamo integrare
∫
f(t) dt = F (t) + c = (tornando alla variabile x) = F (g(x)) + c,
che e appunto il risultato voluto.
Esempi Vediamo alcuni esempi di integrazione per sostituzione. Essi indicano il procedimento operativo chesolitamente occorre seguire.
• Consideriamo
∫1
x ln2 xdx. Qui in realta non e necessario un cambio di variabile, dato che siamo nella tipologia
di integrazione della potenza di una funzione per la sua derivata. Si puo fare quindi
∫1
x ln2 xdx =
∫
(lnx)−2 · 1xdx =
(lnx)−1
−1 + c = − 1
lnx+ c.
Pero possiamo anche procedere con il cambio di variabile. Ponendo lnx = t, ricaviamo da questa x e successi-vamente calcoliamo il dx: si ha x = et e quindi dx = et dt. Pertanto l’integrale diventa
∫1
x ln2 xdx =
∫1
ett2· et dt =
∫1
t2dt = −1
t+ c = − 1
lnx+ c.
240Cioe senza un effettivo cambio di variabile. La formula dice sostanzialmente che possiamo calcolare una primitiva di una funzionecomposta (cioe f(g)) a patto che nell’integrale ci sia anche la derivata di g (moltiplicata per il resto) e che io conosca una primitiva di f .
Un esempio potrebbe essere∫2xex
2dx, e lo studente si accorgera che in questo caso siamo in una delle tipologie viste in precedenza.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 TECNICHE DI INTEGRAZIONE II
INTEGRALE INDEFINITO
233
• Consideriamo
∫e−x
1 + e−xdx. Poniamo e−x = t, da cui −x = ln t, cioe x = − ln t e dx = − 1
t dt. Pertanto
l’integrale diventa
∫e−x
1 + e−xdx =
∫t
1 + t·(
−1
t
)
dt = −∫
1
1 + tdt = − ln |1 + t|+ c = − ln(1 + e−x) + c.
• Consideriamo
∫1
1 +√xdx. Poniamo
√x = t, da cui x = t2 e dx = 2t dt. Pertanto l’integrale diventa
∫1
1 +√xdx =
∫1
1 + t·2t dt = 2
∫t
1 + tdt = 2
∫t+ 1− 1
1 + tdt = 2
(
t− ln |1+t|)
+c = 2√x−2 ln(1+
√x))
+c.
• Un integrale importante in Statistica (Probabilita):
∫
e−(x−µσ )2 dx (µ e σ sono numeri fissati, che avranno
un significato molto importante quando userete questo integrale l’anno prossimo). Limitiamoci ad operare uncambio di variabile, ponendo x−µ
σ = t. Si ricava x − µ = σt e quindi x = µ + σt, da cui dx = σ dt. Pertantol’integrale diventa ∫
e−(x−µσ )
2
dx =
∫
e−t2 · σ dt = σ
∫
e−t2 dt.
Non cerchiamo una primitiva della funzione e−t2 .241
Osservazione A conclusione di queste sezioni sui vari metodi di integrazione fin qui presentati e forse opportunofare il punto. Come si vede, per il calcolo di un integrale indefinito, cioe sostanzialmente il calcolo di una primitiva diuna funzione, esistono varie tecniche possibili. La difficolta in genere e data dal fatto che a priori non si sa quale delletecniche possa avere successo (e l’esperienza che puo aiutare).Se lo studente riflette su quali tipi di funzioni siamo riusciti ad integrare, si accorgera che non e nemmeno cosı semplicerispondere in modo sintetico alla domanda stessa.Volendo a tutti costi cercare qualche “regola”, si puo osservare che:
• se ho l’integrale di una somma (o differenza) di funzioni, posso fare la somma (o differenza) degli integrali, apatto di saper calcolare questi ultimi. Se ci sono costanti moltiplicative, queste possono essere “portate fuoridall’integrale”);
• se ho l’integrale di un prodotto di funzioni, puo funzionare l’integrazione per parti; ma l’integrale potrebbe ancheessere piu semplice (quasi immediato) a patto che rientri in una delle tipologie considerate;
• abbiamo visto anche esempi di integrazione per parti quando non si aveva un prodotto (almeno non cosı evidente);
• se abbiamo composizioni di funzioni potremmo essere in una delle tipologie, e questo succede quando nell’integralec’e anche la derivata di una delle funzioni componenti;
• se tutto il resto fallisce si puo provare con la sostituzione.
In conclusione: una regola generale non c’e. Faccio osservare anche che ci sono classi di funzioni che non abbiamoancora incontrato per l’integrazione: ad esempio, sappiamo integrare un polinomio, ma in presenza di un quoziente dipolinomi, a parte qualche caso semplice, non abbiamo un metodo generale. Qualche studente potrebbe farsi questadomanda: tutte le funzioni hanno una primitiva? Attenzione, la domanda e piu sottile di quanto possa sembrare. Hoappena detto che ci sono casi in cui non abbiamo un metodo generale. La vera domanda e quindi: ogni funzione hauna primitiva, a prescindere dal fatto che ci sia un metodo per calcolarla? La risposta nella prossima dispensa.
241Dal punto di vista del calcolo della primitiva questa e una funzione particolare. Diro qualcosa di piu nella prossima dispensa.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
INTEGRALE INDEFINITO
234
Esercizio 3.1 Calcolare i seguenti integrali indefiniti.
(a)
∫
3√1 + 5xdx (b)
∫ √2x+ 1dx
(c)
∫1
1 + 10xdx (d)
∫1√1− x dx
(e)
∫x+ 1
2x+ 1dx (f)
∫1− x3x− 1
dx
(g)
∫1
xln2 xdx (h)
∫x2
1 + x3dx
(i)
∫e1/x
x2dx (j)
∫1√
x(1 +√x)
dx
(k)
∫
x√
1 + x2 dx (l)
∫ √
1 + 1/x2
x3dx
(m)
∫
x2e−x dx (n)
∫
x ln xdx
4 Soluzioni degli esercizi
Esercizio 3.1
(a)
∫
3√1 + 5xdx. E un integrale quasi immediato. Occorre pero “aggiustare una costante”.242 Si ha
∫
3√1 + 5xdx =
1
5
∫
5(1 + 5x)1/3 dx =1
5
(1 + 5x)4/3
4/3+ c =
3
203√
(1 + 5x)4 + c.
(b)
∫ √2x+ 1dx. Integrale quasi immediato. Basta solo aggiustare la costante:
∫ √2x+ 1dx =
1
2
∫
2(2x+ 1)1/2 =1
2
(2x+ 1)3/2
3/2+ c =
1
3
√
(2x+ 1)3 + c.
(c)
∫1
1 + 10xdx. Integrale quasi immediato. Anche qui basta aggiustare la costante:
∫1
1 + 10xdx =
1
10
∫10
1 + 10xdx =
1
10ln |1 + 10x|+ c.
(d)
∫1√1− x dx. Integrale quasi immediato. Aggiustando la costante:
∫1√1− x dx = −
∫
−(1− x)−1/2 dx = − (1− x)1/21/2
+ c = −2√1− x+ c.
(e)
∫x+ 1
2x+ 1dx. Qui possiamo cercare di ottenere a numeratore il denominatore, con un’opportuna operazione di
dividi/moltiplica:∫
x+ 1
2x+ 1dx =
1
2
∫2x+ 2
2x+ 1dx =
1
2
∫2x+ 1 + 1
2x+ 1dx =
1
2
∫
1 dx+1
2
∫1
2x+ 1dx =
1
2x+
1
4ln |2x+ 1|+ c.
Ricordo che una procedura del tutto analoga e quella di dividere il polinomio x+1 per il polinomio 2x+1 (con ladivisione tra polinomi vista all’inizio del corso). Lo studente provi a ricalcolare l’integrale usando questa tecnica.
242Ricordo che con “aggiustare una costante” intendo moltiplicare e dividere per una costante in modo da far rientrare l’integrale in unintegrale immediato di una qualche tipologia.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
INTEGRALE INDEFINITO
235
(f)
∫1− x3x− 1
dx. Come sopra, dopo aver cambiato di segno:
∫1− x3x− 1
dx = −∫
x− 1
3x− 1dx = −1
3
∫3x− 3
3x− 1dx = −1
3x+
2
9ln |3x− 1|+ c.
(g)
∫1
xln2 xdx. E un integrale quasi immediato del tipo
∫fαDf , con f data dalla funzione logaritmica. Quindi
∫1
xln2 xdx =
ln3 x
3+ c.
(h)
∫x2
1 + x3dx. E un integrale del tipo
∫Dff , con f data dalla funzione 1 + x3. Bisogna pero anche aggiustare
una costante. ∫x2
1 + x3dx =
1
3
∫3x2
1 + x3dx =
1
3ln |1 + x3|+ c.
Lo si poteva anche risolvere con un cambio di variabile. Ponendo x3 = t si ricava x = t1/3 e quindi dx = 13 t
−2/3 dt.Pertanto sostituendo si ottiene
∫x2
1 + x3dx =
∫t2/3
1 + t· 13t−2/3 dt =
1
3
∫1
1 + tdt =
1
3ln |1 + t|+ c =
1
3ln |1 + x3|+ c.
(i)
∫e1/x
x2dx. E del tipo
∫efDf , con f data dalla funzione 1/x. Bisogna pero anche aggiustare il segno.
∫e1/x
x2dx = −
∫
e1/x ·(
− 1/x2)
dx = −e1/x + c.
Anche questo si puo risolvere con un cambio di variabile: ponendo 1x = t si ricava x = 1
t e quindi dx = − 1t2 dt.
Pertanto sostituendo si ottiene
∫e1/x
x2dx =
∫et
1/t2·(
− 1
t2
)
dt = −∫
et dt = −et + c = −e1/x + c.
(j)
∫1√
x(1 +√x)
dx. La derivata di 1 +√x e 1/(2
√x). Quindi si puo aggiustare una costante e ricondurlo ad
un integrale del tipo∫
Dff , con f data appunto da 1 +
√x. Allora
∫1√
x(1 +√x)
dx = 2
∫1
2√x(1 +
√x)
dx = 2 ln(1 +√x) + c.
Alternativamente, con un cambio di variabile: ponendo√x = t si ricava x = t2 e quindi dx = 2t dt. Pertanto
sostituendo si ottiene∫
1√x(1 +
√x)
dx =
∫1
t(1 + t)· 2t dt = 2
∫1
1 + tdt = 2 ln |1 + t|+ c = 2 ln(1 +
√x) + c.
(k)
∫
x√
1 + x2 dx. Con la sostituzione x2 = t, da cui x =√t e quindi dx = 1
2√tdt, si ha
∫
x√
1 + x2 dx =
∫ √t√1 + t · 1
2√tdt =
1
2
∫ √1 + t dt =
1
2
(1 + t)3/2
3/2+ c =
1
3
√
(1 + x2)3 + c.
Lascio allo studente provare la risoluzione con un cambio di variabile: si puo porre x2 = t, oppure 1 + x2 = t,oppure
√1 + x2 = t. E un utile esercizio provare le tre possibilita.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
INTEGRALE INDEFINITO
236
(l)
∫ √
1 + 1/x2
x3dx. La derivata di 1 + 1/x2 e −2/x3. Quindi si puo aggiustare una costante e ricondurlo ad un
integrale del tipo∫fαDf , con f data da 1 + 1/x2. Si ha
∫ √
1 + 1/x2
x3dx = −1
2
∫ −2x3
√
1 + 1/x2 dx = −1
2
(1 + 1/x2)3/2
3/2+ c = −1
3
√
(1 + 1/x2)3 + c.
Anche qui lascio per esercizio la risoluzione con un cambio di variabile.
(m)
∫
x2e−x dx. Per parti, con parte finita x2:
∫
x2e−x dx = x2(−e−x)−∫
(−e−x) · 2xdx
= −x2e−x + 2
∫
xe−x dx
= −x2e−x + 2(
x(−e−x)−∫
(−e−x) dx)
= −x2e−x − 2xe−x + 2
∫
e−x dx
= −x2e−x − 2xe−x − 2e−x + c.
(n)
∫
x lnxdx. Per parti, con parte finita lnx:
∫
x ln xdx = lnx · x2
2−∫x2
2· 1xdx
=1
2x2 lnx− 1
2
∫
xdx
=1
2x2 lnx− 1
4x2 + c.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
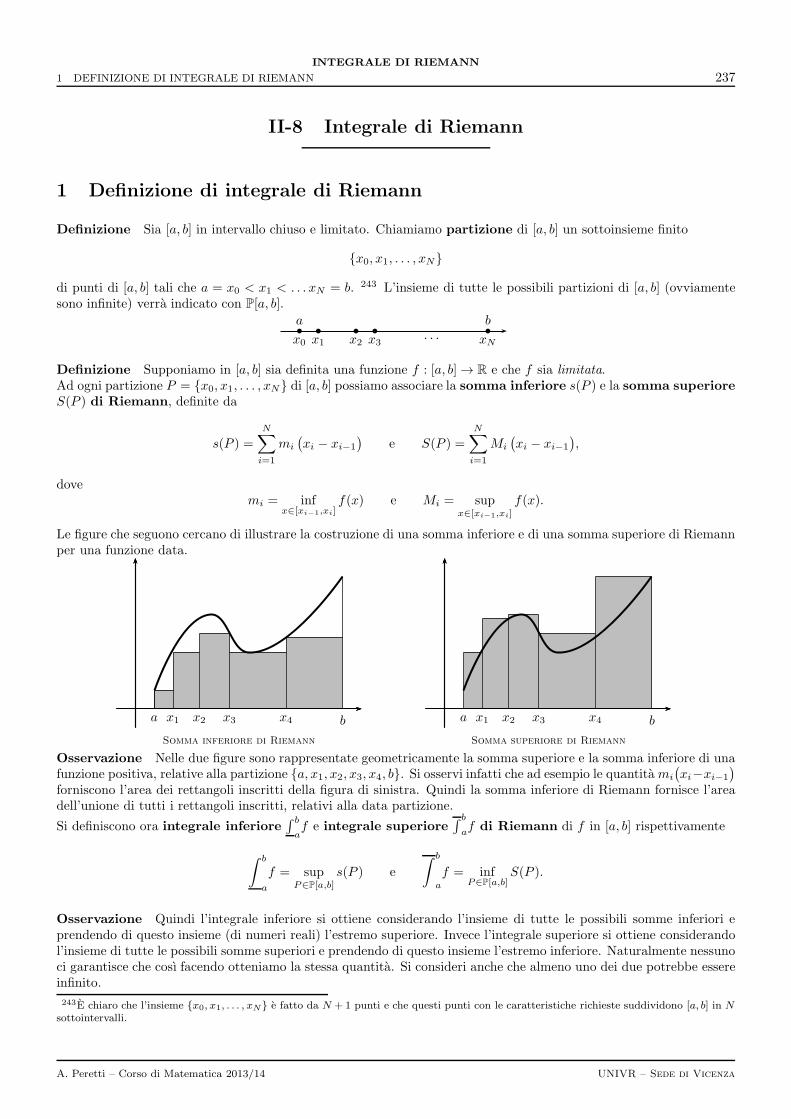
1 DEFINIZIONE DI INTEGRALE DI RIEMANN
INTEGRALE DI RIEMANN
237
II-8 Integrale di Riemann
1 Definizione di integrale di Riemann
Definizione Sia [a, b] in intervallo chiuso e limitato. Chiamiamo partizione di [a, b] un sottoinsieme finito
{x0, x1, . . . , xN}
di punti di [a, b] tali che a = x0 < x1 < . . . xN = b. 243 L’insieme di tutte le possibili partizioni di [a, b] (ovviamentesono infinite) verra indicato con P[a, b].
ba
x0bb
xNb
x1b
x2b
x3 . . .
Definizione Supponiamo in [a, b] sia definita una funzione f : [a, b]→ R e che f sia limitata.Ad ogni partizione P = {x0, x1, . . . , xN} di [a, b] possiamo associare la somma inferiore s(P ) e la somma superioreS(P ) di Riemann, definite da
s(P ) =N∑
i=1
mi
(xi − xi−1
)e S(P ) =
N∑
i=1
Mi
(xi − xi−1
),
dovemi = inf
x∈[xi−1,xi]f(x) e Mi = sup
x∈[xi−1,xi]
f(x).
Le figure che seguono cercano di illustrare la costruzione di una somma inferiore e di una somma superiore di Riemannper una funzione data.
a bx1 x2 x3 x4
Somma inferiore di Riemann
a bx1 x2 x3 x4
Somma superiore di Riemann
Osservazione Nelle due figure sono rappresentate geometricamente la somma superiore e la somma inferiore di unafunzione positiva, relative alla partizione {a, x1, x2, x3, x4, b}. Si osservi infatti che ad esempio le quantitami
(xi−xi−1
)
forniscono l’area dei rettangoli inscritti della figura di sinistra. Quindi la somma inferiore di Riemann fornisce l’areadell’unione di tutti i rettangoli inscritti, relativi alla data partizione.
Si definiscono ora integrale inferiore∫ b
af e integrale superiore
∫ b
af di Riemann di f in [a, b] rispettivamente
∫ b
a
f = supP∈P[a,b]
s(P ) e
∫ b
a
f = infP∈P[a,b]
S(P ).
Osservazione Quindi l’integrale inferiore si ottiene considerando l’insieme di tutte le possibili somme inferiori eprendendo di questo insieme (di numeri reali) l’estremo superiore. Invece l’integrale superiore si ottiene considerandol’insieme di tutte le possibili somme superiori e prendendo di questo insieme l’estremo inferiore. Naturalmente nessunoci garantisce che cosı facendo otteniamo la stessa quantita. Si consideri anche che almeno uno dei due potrebbe essereinfinito.
243E chiaro che l’insieme {x0, x1, . . . , xN} e fatto da N +1 punti e che questi punti con le caratteristiche richieste suddividono [a, b] in Nsottointervalli.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
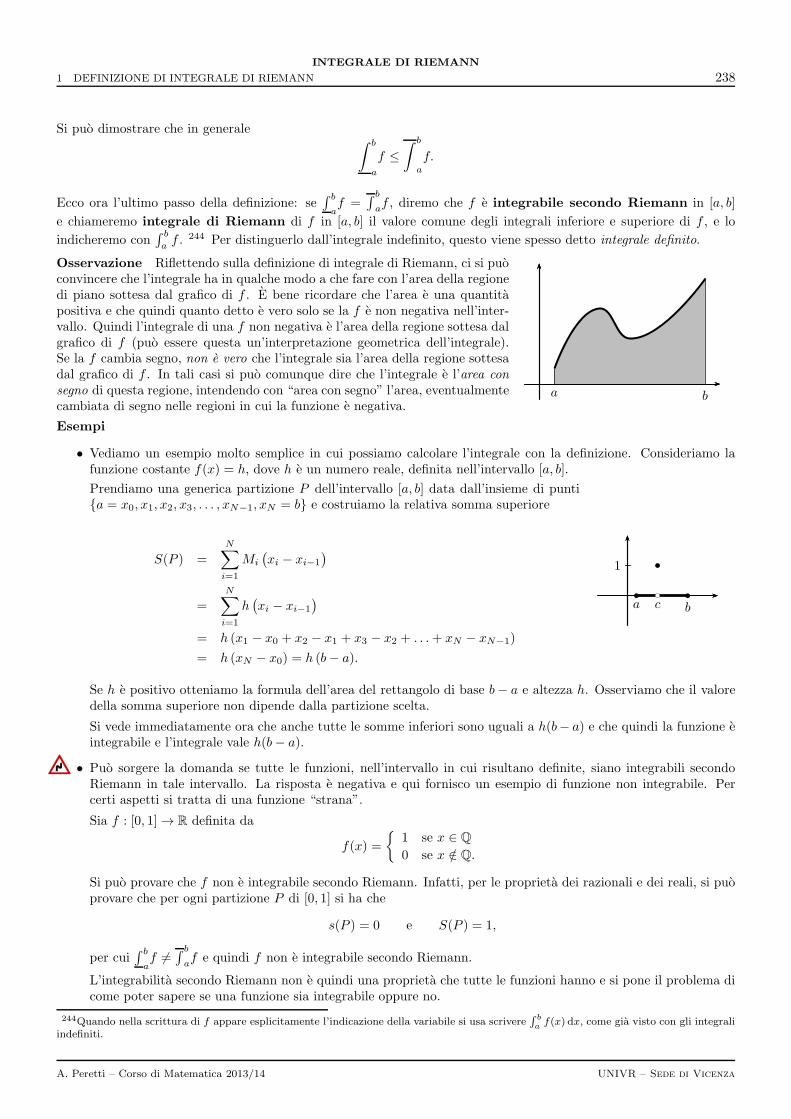
1 DEFINIZIONE DI INTEGRALE DI RIEMANN
INTEGRALE DI RIEMANN
238
Si puo dimostrare che in generale∫ b
a
f ≤∫ b
a
f.
Ecco ora l’ultimo passo della definizione: se∫ b
af =
∫ b
af , diremo che f e integrabile secondo Riemann in [a, b]
e chiameremo integrale di Riemann di f in [a, b] il valore comune degli integrali inferiore e superiore di f , e lo
indicheremo con∫ b
af . 244 Per distinguerlo dall’integrale indefinito, questo viene spesso detto integrale definito.
Osservazione Riflettendo sulla definizione di integrale di Riemann, ci si puoconvincere che l’integrale ha in qualche modo a che fare con l’area della regionedi piano sottesa dal grafico di f . E bene ricordare che l’area e una quantitapositiva e che quindi quanto detto e vero solo se la f e non negativa nell’inter-vallo. Quindi l’integrale di una f non negativa e l’area della regione sottesa dalgrafico di f (puo essere questa un’interpretazione geometrica dell’integrale).Se la f cambia segno, non e vero che l’integrale sia l’area della regione sottesadal grafico di f . In tali casi si puo comunque dire che l’integrale e l’area consegno di questa regione, intendendo con “area con segno” l’area, eventualmentecambiata di segno nelle regioni in cui la funzione e negativa.
a b
Esempi
• Vediamo un esempio molto semplice in cui possiamo calcolare l’integrale con la definizione. Consideriamo lafunzione costante f(x) = h, dove h e un numero reale, definita nell’intervallo [a, b].
Prendiamo una generica partizione P dell’intervallo [a, b] data dall’insieme di punti{a = x0, x1, x2, x3, . . . , xN−1, xN = b} e costruiamo la relativa somma superiore
S(P ) =
N∑
i=1
Mi
(xi − xi−1
)
=N∑
i=1
h(xi − xi−1
)
= h (x1 − x0 + x2 − x1 + x3 − x2 + . . .+ xN − xN−1)
= h (xN − x0) = h (b− a).
bc
b
b b
a c b
|1
Se h e positivo otteniamo la formula dell’area del rettangolo di base b− a e altezza h. Osserviamo che il valoredella somma superiore non dipende dalla partizione scelta.
Si vede immediatamente ora che anche tutte le somme inferiori sono uguali a h(b− a) e che quindi la funzione eintegrabile e l’integrale vale h(b− a).
• Puo sorgere la domanda se tutte le funzioni, nell’intervallo in cui risultano definite, siano integrabili secondoRiemann in tale intervallo. La risposta e negativa e qui fornisco un esempio di funzione non integrabile. Percerti aspetti si tratta di una funzione “strana”.
Sia f : [0, 1]→ R definita da
f(x) =
{1 se x ∈ Q
0 se x /∈ Q.
Si puo provare che f non e integrabile secondo Riemann. Infatti, per le proprieta dei razionali e dei reali, si puoprovare che per ogni partizione P di [0, 1] si ha che
s(P ) = 0 e S(P ) = 1,
per cui∫ b
af 6=
∫ b
af e quindi f non e integrabile secondo Riemann.
L’integrabilita secondo Riemann non e quindi una proprieta che tutte le funzioni hanno e si pone il problema dicome poter sapere se una funzione sia integrabile oppure no.
244Quando nella scrittura di f appare esplicitamente l’indicazione della variabile si usa scrivere∫ ba f(x) dx, come gia visto con gli integrali
indefiniti.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 PROPRIETA DELL’INTEGRALE DI RIEMANN
INTEGRALE DI RIEMANN
239
2 Condizioni di esistenza dell’integrale di Riemann
Data la complessita della definizione, non e facile capire se una funzione e integrabile secondo Riemann. Si pone allorala seguente questione: ci sono proprieta di una funzione che assicurano la sua integrabilita? La risposta e affermativa.
Teorema Supponiamo che sia f : [a, b]→ R. Se vale una delle condizioni seguenti:
(i) f e continua in [a, b];
(ii) f e monotona in [a, b];
(iii) f e limitata e ha un numero finito di punti di discontinuita in [a, b],
allora f e integrabile secondo Riemann.
Osservazione Ribadisco che queste condizioni sono singolarmente sufficienti per l’integrabilita. Ciascuna quindi,indipendentemente dalle altre, garantisce l’integrabilita secondo Riemann della funzione.
Osservazione Il teorema permette di affermare che una grandissima parte delle funzioni, definite in un intervallo,che solitamente incontriamo sono integrabili secondo Riemann. Ad esempio un qualunque polinomio, considerato inun qualunque intervallo [a, b], lo e. Tutte le funzioni elementari, considerate in un intervallo [a, b] in cui risultanodefinite, lo sono (sono funzioni continue).245 Anche la funzione f(x) = |x|, pur non essendo una funzione elementare, econtinua in qualunque intervallo chiuso e limitato e quindi integrabile secondo Riemann in tale intervallo. La funzione
f(x) =
{x x ∈ [0, 1)
x− 1 x ∈ [1, 2]
e integrabile secondo Riemann in [0, 2], dato che, pur non essendo continua nemonotona, e limitata e ha un solo punto di discontinuita.
b b
bbc
|
|
1 2
1
3 Proprieta dell’integrale di Riemann
Teorema Supponiamo che [a, b] sia un intervallo chiuso e limitato e che f, g siano integrabili secondo Riemann in[a, b]. Allora valgono le proprieta seguenti:
(i) (linearita) se c1, c2 sono due costanti, allora c1f + c2g sono integrabili secondo Riemann in [a, b] e si ha
∫ b
a
(c1f + c2g) = c1
∫ b
a
f + c2
∫ b
a
g;
(ii) (monotonia) se f ≤ g, allora∫ b
a
f ≤∫ b
a
g; 246
(iii) se a < c < b, allora∫ b
a
f =
∫ c
a
f +
∫ b
c
f ;
(iv) se |f(x)| ≤M , allora∣∣∣∣∣
∫ b
a
f
∣∣∣∣∣≤M (b − a);
(v) fg e integrabile secondo Riemann in [a, b];
(vi) |f | e integrabile secondo Riemann in [a, b] e
∣∣∣∣∣
∫ b
a
f
∣∣∣∣∣≤∫ b
a
|f |.
245Si faccia attenzione: l’intervallo deve essere chiuso e limitato, almeno per ora. Quindi non possiamo dire ad esempio che lnx in (0, 1)sia integrabile.246Non si confonda la monotonia di una funzione con la monotonia dell’integrale. Qui si parla di monotonia dell’integrale.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO DELL’INTEGRALE
INTEGRALE DI RIEMANN
240
Osservazione Il punto (vi) ribadisce quindi che se f e integrabile allora anche |f | lo e e aggiunge una disuguaglianzatra gli integrali.
Osservazioni Supponiamo che a > 0 e che f sia integrabile secondo Riemann in [−a, a]. Si intuisce, e non sarebbedifficile dimostrarlo, che
• se f e dispari, allora∫ a
−a f = 0;
• se f e pari, allora∫ a
−af = 2
∫ a
0f .
Quindi, anche se non sappiamo ancora come calcolare gli integrali, possiamo dire che∫ 1
−1x3 dx = 0, dato che la funzione
x 7→ x3 e integrabile (in quanto monotona, o continua) e dispari, cioe simmetrica rispetto all’origine. Possiamo anche
dire che∫ 1
−1x2 dx = 2
∫ 1
0x2 dx, ma quest’ultimo non lo sappiamo ancora calcolare.
E importante il seguente
Teorema (della media integrale). Supponiamo che f sia continua in [a, b]. Allora esiste c ∈ [a, b] tale che
f(c) =1
b − a
∫ b
a
f oppure, analogamente,
∫ b
a
f = (b − a)f(c).
Il numero1
b− a
∫ b
a
f si chiama media integrale di f in [a, b].
Osservazione Il teorema ha una semplice interpretazione geometrica:scrivendo la tesi nella forma
∫ b
a
f = (b− a)f(c)
vi si legge che l’integrale e uguale all’area del rettangolo di base l’intervallo[a, b] e altezza f(c). Attenzione che questa interpretazione geometrica vale sepossiamo identificare l’integrale con l’area, cioe se la f e positiva.
a bc
f(c)
Osservazione La tesi puo essere falsa in assenza dell’ipotesi di continuita di f .
Consideriamo la funzione f : [0, 2]→ R definita da
f(x) =
{1 se 0 ≤ x ≤ 1
2 se 1 < x ≤ 2.
La media integrale di f in [0, 2] e
1
2
∫ 2
0
f =3
2,
ma non esiste nessun punto c dell’intervallo [0, 2] in cui f(c) = 32 .
b b
bbc
|
1 2
1
2
3/2
Osservazione Un’interessante questione e se l’annullarsi dell’integrale comporta necessariamente che la funzione siasempre nulla. Qualche studente forse dira subito che questo e falso, ricordando uno degli esempi iniziali di calcolodell’integrale con la definizione (lo si cerchi). E notera che in quell’esempio la funzione non era continua. Infatti lacontinuita e importante in questo aspetto. Si potrebbe dimostrare che, se f e continua e non negativa in [a, b] e se∫ b
af = 0, allora f e identicamente nulla in [a, b]. Per esercizio lo studente verifichi che la conclusione puo essere falsa
se si omette l’ipotesi di non negativita di f o quella di continuita.
4 Calcolo dell’integrale
La definizione di integrale non e comoda per il calcolo operativo degli integrali. Occorre un metodo di calcolo piuefficace, e tra poco lo otteniamo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
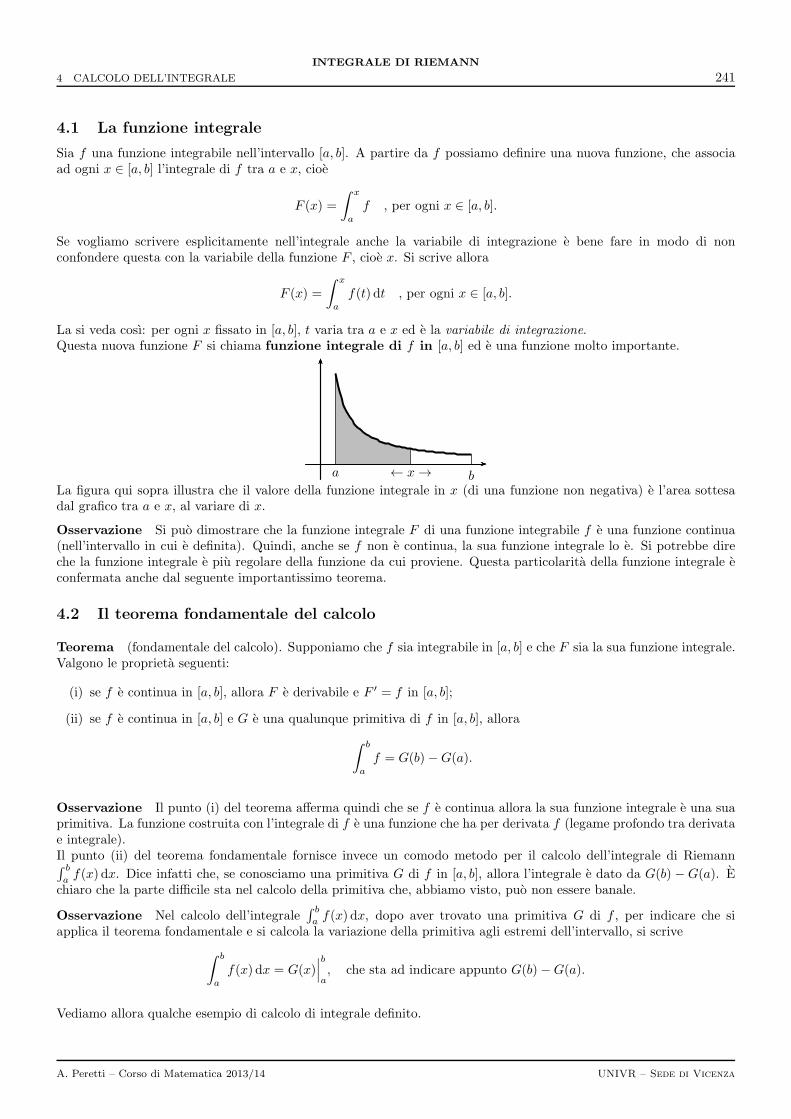
4 CALCOLO DELL’INTEGRALE
INTEGRALE DI RIEMANN
241
4.1 La funzione integrale
Sia f una funzione integrabile nell’intervallo [a, b]. A partire da f possiamo definire una nuova funzione, che associaad ogni x ∈ [a, b] l’integrale di f tra a e x, cioe
F (x) =
∫ x
a
f , per ogni x ∈ [a, b].
Se vogliamo scrivere esplicitamente nell’integrale anche la variabile di integrazione e bene fare in modo di nonconfondere questa con la variabile della funzione F , cioe x. Si scrive allora
F (x) =
∫ x
a
f(t) dt , per ogni x ∈ [a, b].
La si veda cosı: per ogni x fissato in [a, b], t varia tra a e x ed e la variabile di integrazione.Questa nuova funzione F si chiama funzione integrale di f in [a, b] ed e una funzione molto importante.
a b← x→La figura qui sopra illustra che il valore della funzione integrale in x (di una funzione non negativa) e l’area sottesadal grafico tra a e x, al variare di x.
Osservazione Si puo dimostrare che la funzione integrale F di una funzione integrabile f e una funzione continua(nell’intervallo in cui e definita). Quindi, anche se f non e continua, la sua funzione integrale lo e. Si potrebbe direche la funzione integrale e piu regolare della funzione da cui proviene. Questa particolarita della funzione integrale econfermata anche dal seguente importantissimo teorema.
4.2 Il teorema fondamentale del calcolo
Teorema (fondamentale del calcolo). Supponiamo che f sia integrabile in [a, b] e che F sia la sua funzione integrale.Valgono le proprieta seguenti:
(i) se f e continua in [a, b], allora F e derivabile e F ′ = f in [a, b];
(ii) se f e continua in [a, b] e G e una qualunque primitiva di f in [a, b], allora
∫ b
a
f = G(b)−G(a).
Osservazione Il punto (i) del teorema afferma quindi che se f e continua allora la sua funzione integrale e una suaprimitiva. La funzione costruita con l’integrale di f e una funzione che ha per derivata f (legame profondo tra derivatae integrale).Il punto (ii) del teorema fondamentale fornisce invece un comodo metodo per il calcolo dell’integrale di Riemann∫ b
af(x) dx. Dice infatti che, se conosciamo una primitiva G di f in [a, b], allora l’integrale e dato da G(b) −G(a). E
chiaro che la parte difficile sta nel calcolo della primitiva che, abbiamo visto, puo non essere banale.
Osservazione Nel calcolo dell’integrale∫ b
a f(x) dx, dopo aver trovato una primitiva G di f , per indicare che siapplica il teorema fondamentale e si calcola la variazione della primitiva agli estremi dell’intervallo, si scrive
∫ b
a
f(x) dx = G(x)∣∣∣
b
a, che sta ad indicare appunto G(b)−G(a).
Vediamo allora qualche esempio di calcolo di integrale definito.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO DELL’INTEGRALE
INTEGRALE DI RIEMANN
242
Esempi
• Calcoliamo∫ 1
−1x2 dx. Si ha
∫ 1
−1
x2 dx =x3
3
∣∣∣∣
1
−1
=1
3−(
−1
3
)
=2
3. 247
• Calcoliamo∫ 1
03√xdx. Si ha
∫ 1
0
3√xdx =
∫ 1
0
x1/3 dx =x4/3
4/3
∣∣∣∣
1
0
=3
4.
• Calcoliamo∫ e
1lnxdx. Si ha (ricordo che l’integrazione di lnx si fa per parti)
∫ e
1
lnxdx = (x ln x− x)∣∣∣
e
1= 1.
• Calcoliamo∫ 1
−1 xe−x2
dx. Ricordando che
∫
xe−x2
dx = −1
2
∫
(−2)xe−x2
dx = −1
2e−x2
+ c,
si ha ∫ 1
−1
xe−x2
dx = −1
2e−x2
∣∣∣
1
−1= 0.
Il risultato era prevedibile, dato che la funzione e dispari e l’intervallo e simmetrico rispetto all’origine.
Esempio Per concludere questa sezione vediamo come si puo ottenere l’espressione di una funzione integrale.248
Consideriamo ancora la funzione f(x) = xe−x2
nell’intervallo [−1, 1]. Troviamo l’espressione della funzione integraledi f in tale intervallo. Dalla definizione di funzione integrale abbiamo
F (x) =
∫ x
−1
te−t2 dt = −1
2
∫ x
−1
(−2)te−t2 dt = −1
2e−t2
∣∣∣
x
−1= −1
2
(e−x2 − e−1
).
A verifica del teorema fondamentale, possiamo osservare che calcolando la derivata di F otteniamo
F ′(x) = −1
2e−x2 · (−2x) = xe−x2
= f(x).
Non approfondisco questo aspetto, ma per evitare che qualche studente perda inutilmente del tempo nel calcolo diqualche integrale (talvolta per fare qualche esercizio in piu ci si inventa una funzione e si prova ad integrarla) avvertoche ci sono funzioni che non si possono integrare. Chiarisco il significato: ci sono funzioni che non hanno primitiveelementari. Ogni funzione continua ha primitive, in conseguenza del teorema fondamentale del calcolo: se f e continuain [a, b] allora F (x) =
∫ x
af e una primitiva di f . Non e detto pero che se f e una composizione di funzioni elementari
tale primitiva sia ancora una funzione esprimibile attraverso funzioni elementari. Ci sono funzioni “elementari” per cuisi puo dimostrare che la primitiva non e “elementare”. Tra queste la piu “famosa” e f(x) = e−x2
.249 Quindi possiamo
certamente dire che F (x) =∫ x
0 e−t2 dt e una primitiva di e−x2
in tutto R, ma non possiamo esprimere F mediantefunzioni elementari (per esprimerla non possiamo fare a meno di usare l’integrale o altre forme ancora piu complicatee comunque non elementari).
247Per quanto detto in precedenza sugli integrali di funzioni pari o dispari, si poteva anche fare
∫ 1
−1x2 dx = 2
∫ 1
0x2 dx = 2 · x3
3
∣∣∣∣
1
0
=2
3.
248Per chiarire il significato di questo faccio osservare che con “espressione della funzione integrale” si potrebbe senz’altro intenderel’espressione fornita dalla definizione stessa di funzione integrale, cioe
∫ xa f(t) dt. Pero questa e un’espressione che coinvolge l’integrale e
quindi esprime la F (x) in un modo che non e la composizione di funzioni elementari. Allora la dicitura corretta potrebbe essere: vediamocome ottenere l’espressione di una funzione integrale in termini di funzioni elementari.249Nemmeno ex
2ha primitive elementari, ma “quella col meno” e piu famosa, essendo una funzione fondamentale nella teoria della
probabilita.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO DELL’INTEGRALE
INTEGRALE DI RIEMANN
243
Esercizio 4.1 Calcolare i seguenti integrali di Riemann.
(a)
∫ 1
0
√xdx (b)
∫ 7/2
0
13√1 + 2x
dx
(c)
∫ 2
1
e1−x dx (d)
∫ 1/10
0
1
1 + 10xdx
(e)
∫ 1
0
x3
1 + x4dx (f)
∫ 4
1
e√x
√xdx
(g)
∫ 1
0
x2√
1 + x3 dx (h)
∫ e
1
√lnx
xdx
(i)
∫ e
1
x2 lnxdx (j)
∫ 2
1
x
1 + x2dx
(k)
∫ −2
−3
1
x(x + 1)dx (l)
∫ 3
2
1
x(x − 1)2dx
4.3 Integrale di una f definita a tratti
Se dobbiamo calcolare l’integrale di una funzione definita a tratti basta utilizzare la proprieta (iii) dell’integrale diRiemann, quella che afferma che se ho una partizione dell’intervallo di integrazione, il calcolo dell’integrale puo esserescomposto nella somma di piu integrali, ciascuno dei quali su di un sottointervallo della partizione.Vediamo allora come si procede in un paio di semplici esempi.
• Se dobbiamo calcolare
∫ 2
0
|x2 − x| dx, dobbiamo anzitutto osservare che la funzione x 7→ x2 − x cambia segno
nell’intervallo di integrazione e quindi (dalla definizione di valore assoluto) si ha
f(x) =
{x2 − x se x ∈ (−∞, 0] ∪ [1,+∞)
x− x2 se x ∈ (0, 1).
Pertanto, usando la proprieta (iii) dell’integrale, possiamo scrivere
∫ 2
0
|x2 − x| dx =
∫ 1
0
(x− x2) dx+
∫ 2
1
(x2 − x) dx
=
(x2
2− x3
3
)∣∣∣∣
1
0
+
(x3
3− x2
2
)∣∣∣∣
2
1
=1
2− 1
3+
(8
3− 4
2
)
−(1
3− 1
2
)
= 1.
1 2
2
x
y
• Se dobbiamo calcolare l’integrale in [−1, 2] della funzione
f(x) =
x+ 1 −1 ≤ x ≤ 0
−x 0 < x ≤ 1
x 1 < x ≤ 2,
(lo studente dica perche questa funzione e integrabile) possiamo scrivere
b
b
bc
b
bc
b
−1 1 2
1
−1
2
x
y
∫ 2
−1
f(x) dx =
∫ 0
−1
(x+ 1) dx+
∫ 1
0
(−x) dx+
∫ 2
1
xdx
=
(x2
2+ x
)∣∣∣∣
0
−1
− x2
2
∣∣∣∣
1
0
+x2
2
∣∣∣∣
2
1
=3
2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CALCOLO DELL’INTEGRALE
INTEGRALE DI RIEMANN
244
Un utile esercizio e verificare il risultato utilizzando il grafico di f e calcolando con la geometria elementare learee dei triangoli/quadrati individuati nella figura.
Osservazione Si potrebbe dimostrare rigorosamente, ma mi limito ad enunciare questa semplice ed intuitiva que-stione: il valore dell’integrale non dipende dai singoli valori che la funzione assume in qualche punto (diciamo in unnumero finito di punti). Ad esempio, nel caso appena visto della funzione definita a tratti, noi potremmo cambiare ilvalore di f in 0 e in 1, cioe agli estremi degli intervalli, senza modificare con questo il valore dell’integrale. E forse siintuisce anche che farlo in due punti o in mille non fa differenza, il valore dell’integrale resterebbe sempre lo stesso.Diversa e la questione se cambiamo il valore di f in un numero infinito di punti, ma qui non vado oltre.
4.4 Funzione integrale di una f definita a tratti
Nel corso di Statistica gli studenti incontreranno anche questo problema: scrivere l’espressione di una funzione integraledi una funzione definita a tratti.
Il problema e per molti aspetti simile a quello appena incontrato, con la piccoladifficolta aggiuntiva dovuta alla presenza della variabile x. Consideriamo ad esempiola funzione
f(x) =
0 −2 ≤ x ≤ −1−x −1 < x ≤ 0
1 0 < x ≤ 1.b b
bc
b
bc b
−2 −1 1
1
x
y
Questa funzione e integrabile nell’intervallo [−2, 1] (lo studente dica perche) e quindi possiamo scrivere la funzioneintegrale di f in tale intervallo, che per definizione e
F (x) =
∫ x
−2
f(t) dt.
Evidentemente e un problema analogo a quello gia incontrato poco fa quando abbiamo trovato l’espressione di unafunzione integrale. L’unica differenza e che ora la f e definita a tratti e quindi non abbiamo un’unica espressione di f ,ma in questo caso tre espressioni distinte, ciascuna valida in un certo intervallo. Allora dobbiamo distinguere tutti icasi possibili circa la posizione della x, che puo stare nel primo ([−2,−1]), nel secondo ((−1, 0]) o nel terzo intervallo((0, 1]). Quindi abbiamo:
• se x ∈ [−2,−1]F (x) =
∫ x
−2
f(t) dt =
∫ x
−2
0 dt = 0;
• se x ∈ (−1, 0]F (x) =
∫ x
−2
f(t) dt =
∫ −1
−2
0 dt+
∫ x
−1
(−t) dt = − t2
2
∣∣∣∣
x
−1
= −x2
2+
1
2;
• se infine x ∈ (0, 1]
F (x) =
∫ x
−2
f(t) dt =
∫ −1
−2
0 dt+
∫ 0
−1
(−t) dt+∫ x
0
1 dt = − t2
2
∣∣∣∣
0
−1
+ t∣∣∣
x
0=
1
2+ x.
Quindi riassumendo possiamo scrivere
F (x) =
0 se − 2 ≤ x ≤ −1−x2
2 + 12 se − 1 < x ≤ 0
12 + x se 0 < x ≤ 1.
Nelle due figure qui sotto ho riportato nuovamente a sinistra il grafico di f e a destra quello di F .
b b
bc
b
bc b
−2 −1 1
1
x
y
b
b
−2 −1 1
1/2
3/2
x
y
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
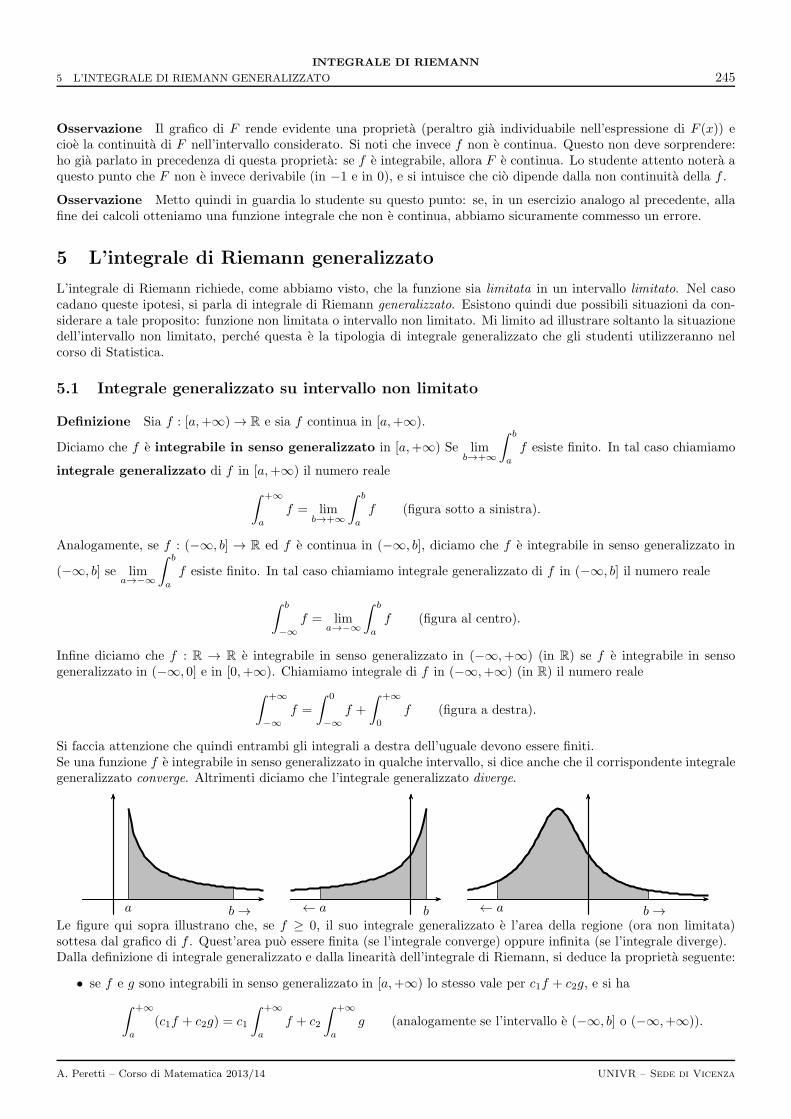
5 L’INTEGRALE DI RIEMANN GENERALIZZATO
INTEGRALE DI RIEMANN
245
Osservazione Il grafico di F rende evidente una proprieta (peraltro gia individuabile nell’espressione di F (x)) ecioe la continuita di F nell’intervallo considerato. Si noti che invece f non e continua. Questo non deve sorprendere:ho gia parlato in precedenza di questa proprieta: se f e integrabile, allora F e continua. Lo studente attento notera aquesto punto che F non e invece derivabile (in −1 e in 0), e si intuisce che cio dipende dalla non continuita della f .
Osservazione Metto quindi in guardia lo studente su questo punto: se, in un esercizio analogo al precedente, allafine dei calcoli otteniamo una funzione integrale che non e continua, abbiamo sicuramente commesso un errore.
5 L’integrale di Riemann generalizzato
L’integrale di Riemann richiede, come abbiamo visto, che la funzione sia limitata in un intervallo limitato. Nel casocadano queste ipotesi, si parla di integrale di Riemann generalizzato. Esistono quindi due possibili situazioni da con-siderare a tale proposito: funzione non limitata o intervallo non limitato. Mi limito ad illustrare soltanto la situazionedell’intervallo non limitato, perche questa e la tipologia di integrale generalizzato che gli studenti utilizzeranno nelcorso di Statistica.
5.1 Integrale generalizzato su intervallo non limitato
Definizione Sia f : [a,+∞)→ R e sia f continua in [a,+∞).
Diciamo che f e integrabile in senso generalizzato in [a,+∞) Se limb→+∞
∫ b
a
f esiste finito. In tal caso chiamiamo
integrale generalizzato di f in [a,+∞) il numero reale
∫ +∞
a
f = limb→+∞
∫ b
a
f (figura sotto a sinistra).
Analogamente, se f : (−∞, b] → R ed f e continua in (−∞, b], diciamo che f e integrabile in senso generalizzato in
(−∞, b] se lima→−∞
∫ b
a
f esiste finito. In tal caso chiamiamo integrale generalizzato di f in (−∞, b] il numero reale
∫ b
−∞f = lim
a→−∞
∫ b
a
f (figura al centro).
Infine diciamo che f : R → R e integrabile in senso generalizzato in (−∞,+∞) (in R) se f e integrabile in sensogeneralizzato in (−∞, 0] e in [0,+∞). Chiamiamo integrale di f in (−∞,+∞) (in R) il numero reale
∫ +∞
−∞f =
∫ 0
−∞f +
∫ +∞
0
f (figura a destra).
Si faccia attenzione che quindi entrambi gli integrali a destra dell’uguale devono essere finiti.Se una funzione f e integrabile in senso generalizzato in qualche intervallo, si dice anche che il corrispondente integralegeneralizzato converge. Altrimenti diciamo che l’integrale generalizzato diverge.
a b→ b← a ← a b→Le figure qui sopra illustrano che, se f ≥ 0, il suo integrale generalizzato e l’area della regione (ora non limitata)sottesa dal grafico di f . Quest’area puo essere finita (se l’integrale converge) oppure infinita (se l’integrale diverge).Dalla definizione di integrale generalizzato e dalla linearita dell’integrale di Riemann, si deduce la proprieta seguente:
• se f e g sono integrabili in senso generalizzato in [a,+∞) lo stesso vale per c1f + c2g, e si ha
∫ +∞
a
(c1f + c2g) = c1
∫ +∞
a
f + c2
∫ +∞
a
g (analogamente se l’intervallo e (−∞, b] o (−∞,+∞)).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 L’INTEGRALE DI RIEMANN GENERALIZZATO
INTEGRALE DI RIEMANN
246
Vale inoltre la seguente importante proprieta:
• se f e continua in [a,+∞) e se |f | e integrabile in senso generalizzato in [a,+∞),250 allora anche f lo e e
∣∣∣∣
∫ +∞
a
f
∣∣∣∣≤∫ +∞
a
|f |.
Esempio La funzione x 7→ e−x e integrabile in senso generalizzato in [0,+∞) e
∫ +∞
0
e−x dx = 1.
Infatti,
∫ +∞
0
e−x dx = limb→+∞
∫ b
0
e−x dx
(teorema fond. calcolo) = limb→+∞
(−e−x
)∣∣∣
b
0
= limb→+∞
(1− e−b
)
= 1.
Si verifichi che invece non e finito∫ +∞−∞ e−x dx.
Esempio Consideriamo l’integrale di una funzione potenza, in particolare consideriamo
∫ +∞
1
1
xαdx con α > 0, 251
distinguendo i vari casi.Se α = 1, si ha
∫ +∞
1
1
xdx = lim
b→+∞
∫ b
1
1
xdx
(teorema fond. calcolo) = limb→+∞
lnx∣∣∣
b
1
= limb→+∞
ln b
= +∞.
Se α 6= 1, abbiamo
∫ +∞
1
1
xαdx = lim
b→+∞
∫ b
1
x−α dx
(teorema fond. calcolo) = limb→+∞
x−α+1
−α+ 1
∣∣∣∣
b
1
=1
1− α limb→+∞
(b1−α − 1
).
Il limite e infinito se 0 < α < 1 ed e invece finito se α > 1.Quindi, riassumendo, l’integrale converge se α > 1 e diverge se 0 < α ≤ 1. 252
Ad esempio,∫ +∞1
1x2 dx converge, dato che α = 2 > 1. Invece
∫ +∞1
1x dx e
∫ +∞1
1√xdx non convergono, dato che in
entrambi α ≤ 1.
5.2 Criteri di convergenza
Lo studio dell’integrabilita in senso generalizzato di una funzione attraverso la definizione, cioe attraverso il calcolodel limite dell’integrale, risulta talvolta impraticabile, perche richiede il calcolo di una primitiva della funzione, cosanon sempre possibile. Sono utili allora criteri che permettano di stabilire la convergenza dell’integrale generalizzatosenza dover calcolare una primitiva.
250Enunciati analoghi si hanno naturalmente per funzioni definite in intervalli del tipo (−∞, b] o (−∞,+∞).251Si noti che il caso piu significativo e quello di una funzione potenza che tenda a zero quando x → +∞, e quindi il modello piu ragionevolee appunto 1
xα con α > 0. Se la potenza tende all’infinito l’integrale non puo convergere.252Per ricordare piu facilmente il risultato: l’integrale converge se la potenza per x → +∞ tende a zero rapidamente, quindi con α > 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 L’INTEGRALE DI RIEMANN GENERALIZZATO
INTEGRALE DI RIEMANN
247
In questa sezione presento alcuni criteri di convergenza per integrali generalizzati. Per brevita enuncio i criteri relativi
agli integrali generalizzati del tipo∫ +∞a
f ; criteri analoghi valgono per integrali del tipo∫ b
−∞ f .
Criteri del confronto. Siano f, g funzioni continue in [a,+∞), a valori non negativi.Valgono le affermazioni seguenti:
(i) se f ≤ g, e g e integrabile in senso generalizzato in [a,+∞), allora anche f e integrabile in senso generalizzatoin [a,+∞);
(ii) se f ≥ g, e g non e integrabile in senso generalizzato in [a,+∞), allora nemmeno f e integrabile in sensogeneralizzato in [a,+∞);
(iii) se f(x) e trascurabile rispetto a g(x), per x→ +∞,253 e g e integrabile in senso generalizzato in [a,+∞), alloraanche f e integrabile in senso generalizzato in [a,+∞);
(iv) se f(x) ha lo stesso ordine di grandezza di g(x), per x→ +∞,254 allora f e g hanno lo stesso carattere, cioe unae integrabile se e solo se e integrabile l’altra.
Osservazione Si faccia attenzione che i criteri si applicano, come detto, a funzioni a valori non negativi.
Osservazione Si noti che, se avessimo il caso di f(x) equivalente a g(x), per x → +∞, e ricordo che significa che
limx→+∞
f(x)
g(x)= 1, allora si ricade nel caso (iv).
Osservazione In realta (iii) e (iv) sono conseguenze di (i). Questo perche (punto (iii)), se f(x) e trascurabile rispettoa g(x) per x→ +∞, allora f e definitivamente minore o uguale a g,255
I criteri presentati hanno utili conseguenze (confronti con le potenze).Supponiamo che f sia continua e positiva in [a,+∞).
Corollario Se
f(x) e trascurabile rispetto a1
xα, per x→ +∞ e α > 1,
allora f e integrabile in senso generalizzato in [a,+∞). E conseguenza della (iii) e del fatto che, essendo α > 1, 1/xα
e integrabile.
Corollario Se1
xαe trascurabile rispetto a f(x) , per x→ +∞ e α ≤ 1,
allora f non e integrabile in senso generalizzato in [a,+∞). E conseguenza della (ii) e del fatto che, essendo α ≤ 1,1/xα non e integrabile.
Corollario Se
f(x) e dello stesso ordine di grandezza di1
xα, per x→ +∞, e α > 1,
allora f e integrabile in senso generalizzato in [a,+∞); e conseguenza della (iv) e del fatto che, essendo α > 1, 1/xα
e integrabile. Quando invece la relazione vale con α ≤ 1, allora f non e integrabile in senso generalizzato in [a,+∞).
Osservazione Si faccia attenzione. Se per una certa funzione f abbiamo che f(x) e dello stesso ordine di grandezzadi 1/xα per x→ +∞, possiamo sempre stabilire se la funzione f e integrabile in senso generalizzato oppure no.Se abbiamo invece che f(x) e trascurabile rispetto a 1/xα per x → +∞, possiamo concludere solo se α > 1. Quindi,ad esempio, se trovo che f(x) e trascurabile rispetto a 1/x per x→ +∞, non posso concludere nulla sull’integrabilitadi f .256
253Ricordo che significa che limx→+∞f(x)g(x)
= 0.
254Ricordo che la scrittura significa che limx→+∞f(x)g(x)
esiste finito e diverso da zero.255Ricordo che definitivamente significa “da un certo punto in poi”. Quindi dire che una proprieta vale definitivamente vuol dire che nonvale dappertutto ma vale da un certo punto (valore reale) in poi.256Si considerino ad esempio le due funzioni f1(x) = 1/x2 e f2(x) = 1/(x lnx) nell’intervallo [2,+∞). Entrambe sono o(1/x), perx → +∞. La prima e integrabile in senso generalizzato in [2,+∞), la seconda no.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 L’INTEGRALE DI RIEMANN GENERALIZZATO
INTEGRALE DI RIEMANN
248
Esempi
• Consideriamo
∫ +∞
1
lnx
x3dx.257
Dopo aver osservato che la funzione integranda e continua e non negativa nell’intervallo di integrazione, ricor-dando che lnx ≤ x per ogni x > 0, possiamo dire che ln x
x3 ≤ xx3 = 1
x2 . Quindi, essendo 1/x2 integrabile in sensogeneralizzato in [1,+∞), per la (i) dei Criteri del confronto il nostro integrale converge.
• Consideriamo l’integrale
∫ +∞
2
1
lnxdx. Questo non si puo calcolare con la definizione in quanto 1
ln x e una delle
funzioni che non hanno primitiva elementare.
L’integrale non converge. Infatti in [2,+∞) la funzione e continua e positiva, si ha x ≥ lnx, e quindi 1lnx ≥ 1
x .Dato che 1/x non e integrabile in senso generalizzato in [2,+∞), dalla (ii) dei Criteri del confronto segue allorache nemmeno f(x) = 1
ln x e integrabile in senso generalizzato in [2,+∞).
• Consideriamo
∫ +∞
0
x e−x dx.258
La funzione f(x) = x e−x e continua e non negativa nell’intervallo considerato. Confrontando f(x) con 1/x2
possiamo osservare che
limx→+∞
f(x)
1/x2= lim
x→+∞x3
ex
= 0 (confronto standard).
Pertanto f(x) e trascurabile rispetto a 1/x2, per x→ +∞. Dall’integrabilita di x 7→ 1/x2 in [1,+∞), per la (iii)dei Criteri del confronto, allora anche f e integrabile in senso generalizzato in [1,+∞), e quindi in [0,+∞).
• L’integrale
∫ +∞
1
x+ lnx
x3 + ln3 xdx converge. Infatti, f(x) = x+ln x
x3+ln3 xe continua e non negativa in [1,+∞) e, trascu-
rando i logaritmi, f(x) risulta equivalente a xx3 , cioe equivalente a 1
x2 , per x → +∞. Quindi, dato che 1/x2 eintegrabile in senso generalizzato in [1,+∞), anche f lo e (per la (iv)).
• Consideriamo
∫ +∞
−∞e−x2
dx e si tratta di un esempio importante (fondamentale nella teoria della probabilita).
La funzione f(x) = e−x2
non ha primitive elementari, cioe le sue primitive non si possono esprimere attraversofunzioni elementari o loro composizioni. Quindi non siamo in grado di calcolare l’integrale con la definizione.Possiamo pero provare che l’integrale in questione e finito, cioe che f e integrabile in senso generalizzato in(−∞,+∞). Vediamo perche. Si tratta di una funzione continua in tutto R, positiva e pari (simmetrica rispettoall’asse y). Possiamo considerarla nell’intervallo [0,+∞). Possiamo ora osservare che
limx→+∞
e−x2
1/x2= lim
x→+∞x2
ex2
= limt→+∞
t
et
= 0 (confronto standard).
Pertanto e−x2
e trascurabile rispetto a 1/x2, per x→ +∞. Dato che la funzione x 7→ 1/x2 e integrabile in sensogeneralizzato in [1,+∞), per i Criteri del confronto anche f e integrabile in senso generalizzato in [1,+∞), equindi e integrabile in senso generalizzato in [0,+∞), dato che tra 0 e 1 l’integrale e certamente finito. Dallasimmetria segue che anche l’integrale generalizzato in (−∞, 0] esiste (ed e uguale a quello in [0,+∞)). Quindi
f(x) = e−x2
e integrabile in senso generalizzato in (−∞,+∞).
257Per la verita questo integrale si potrebbe calcolare anche con la definizione, dato che di questa funzione siamo in grado di trovare unaprimitiva (lo studente provi per esercizio: il risultato e 1
4).
258Anche questo integrale si potrebbe calcolare con la definizione, dato che siamo in grado di trovare una primitiva della funzione (lostudente provi per esercizio: il risultato e 1).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
INTEGRALE DI RIEMANN
249
E una funzione (e un integrale) assolutamente fondamentale nel calcolo delle probabilita (li incontrerete nuova-
mente nel corso di Statistica). Si puo dimostrare che∫ +∞−∞ e−x2
dx =√π.
Osservazione Faccio nuovamente osservare che con i Criteri del confronto possiamo studiare l’integrabilita in sensogeneralizzato di funzioni di cui non siamo in grado di trovare una primitiva.259
Osservazione Se f e una funzione integrabile in senso generalizzato a −∞, e possibile scrivere la sua funzioneintegrale con primo estremo −∞, cioe la funzione
F (x) =
∫ x
−∞f(t) dt.
Ad essa e applicabile il teorema fondamentale del calcolo integrale, che garantisce, nel caso f sia continua, la derivabilitadi F e l’uguaglianza F ′(x) = f(x). Ritroverete anche questa particolare situazione nel corso di Statistica. Per gli scopidel calcolo delle probabilita e ad esempio importante la funzione
x 7→∫ x
−∞e−t2 dt.
Qui l’applicazione del teorema fondamentale porta a dire facilmente che questa funzione e monotona crescente. Inoltreessa e positiva e limitata. Le due figure qui sotto illustrano f(x) = e−x2
e la sua funzione integrale F (x) =∫ x
−∞ e−t2 dt.
f√π
√π2
F
Esercizio 5.1 Calcolare i seguenti integrali generalizzati, utilizzando la definizione.
(a)
∫ 0
−∞ex dx (b)
∫ +∞
4
1√xdx
(c)
∫ +∞
−∞xe−x2
dx (d)
∫ +∞
2
1
x ln xdx
Esercizio 5.2 Stabilire se i seguenti integrali generalizzati convergono, utilizzando i criteri di convergenza.
(a)
∫ +∞
0
1
x3 + x+ 1dx (b)
∫ +∞
0
x2 + x+ 1
x3 + x2 + x+ 1dx
(c)
∫ +∞
1
1
x2 +√xdx (d)
∫ +∞
1
13√x2 + x+ 1
dx
(e)
∫ +∞
1
1 + e−x
xdx (f)
∫ +∞
1
1 + e−2x
x2dx
(g)
∫ +∞
1
1
x2 + 2−xdx (h)
∫ +∞
−∞x2e−x2
dx
6 Soluzioni degli esercizi
Esercizio 4.1
(a)
∫ 1
0
√xdx. Si ha
∫ 1
0
√xdx =
x3/2
3/2
∣∣∣
1
0=
2
3.
259E chiaro che, in questi casi, con i criteri di confronto si puo dire solo se l’integrale e finito o infinito. Per calcolarlo, quando converge,occorrono altre tecniche.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
INTEGRALE DI RIEMANN
250
(b)
∫ 7/2
0
13√1 + 2x
dx. Si ha
∫ 7/2
0
13√1 + 2x
dx =1
2
(1 + 2x)2/3
2/3
∣∣∣∣
7/2
0
=3
4(82/3 − 1) =
9
4.
(c)
∫ 2
1
e1−x dx. Si ha∫ 2
1
e1−x dx = −e1−x∣∣∣
2
1= 1− 1/e.
(d)
∫ 1/10
0
1
1 + 10xdx. Si ha
∫ 1/10
0
1
1 + 10xdx =
1
10ln(1 + 10x)
∣∣∣
1/10
0=
1
10ln 2. 260
(e)
∫ 1
0
x3
1 + x4dx. Si ha
∫ 1
0
x3
1 + x4dx =
1
4
∫ 1
0
4x3
1 + x4dx =
1
4ln(1 + x4)
∣∣∣
1
0=
1
4ln 2.
(f)
∫ 4
1
e√x
√xdx. Si ha
∫ 4
1
e√x
√xdx = 2
∫ 4
1
e√x
2√xdx = 2e
√x∣∣∣
4
1= 2e(e− 1).
L’integrale e stato risolto riconducendolo ad un integrale immediato del tipo∫efDf . Si poteva anche risolverlo
con un cambio di variabile. A tale proposito, ricordo che una buona procedura e la seguente: risolvere anzituttol’integrale indefinito, operando il cambio di variabile. Una volta trovata la primitiva, calcolare l’integrale definito.Alternativamente si puo anche operare il cambio di variabile sull’integrale definito, ma in questo caso occorrericordarsi di cambiare anche gli estremi di integrazione. Ad esempio, nell’integrale in questione, questo secondomodo di procedere porterebbe a scrivere (con la sostituzione
√x = t, da cui x = t2 e quindi dx = 2t dt)
∫ 4
1
e√x
√xdx =
∫ 2
1
et
t· 2t dt = 2
∫ 2
1
et dt = 2et∣∣∣
2
1= 2(e2 − e).
Cosı facendo non c’e ovviamente la necessita di tornare alla variabile x.
(g)
∫ 1
0
x2√
1 + x3 dx. Si ha
∫ 1
0
x2√
1 + x3 dx =1
3
∫ 1
0
3x2√
1 + x3 dx =1
3
(1 + x3)3/2
3/2
∣∣∣∣
1
0
=2
9(2√2− 1).
(h)
∫ e
1
√lnx
xdx. Si ha
∫ e
1
√lnx
xdx =
∫ e
1
(ln x)1/2 · 1xdx =
(lnx)3/2
3/2
∣∣∣∣
e
1
=2
3.
(i)
∫ e
1
x2 lnxdx. Qui serve prima un’integrazione per parti per risolvere l’integrale indefinito.
∫
x2 lnxdx = lnx · x3
3−∫x3
3· 1x=x3
3lnx− x3
9+ c =
1
9x3(3 lnx− 1) + c.
Quindi∫ e
1
x2 lnxdx =
(1
9x3(3 lnx− 1)
∣∣∣∣
e
1
=1
9(2e3 + 1).
260Il valore assoluto qui si puo omettere dato che l’argomento e positivo nell’intervallo di integrazione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
INTEGRALE DI RIEMANN
251
(j)
∫ 2
1
x
1 + x2dx. L’integrale si riconduce facilmente ad un integrale immediato:
∫ 2
1
x
1 + x2dx =
1
2
∫2x
1 + x2dx =
1
2ln(1 + x2)
∣∣∣
2
1=
1
2ln
5
2.
(k)
∫ −2
−3
1
x(x+ 1)dx. Si ha
∫ −2
−3
1
x(x + 1)dx =
∫ −2
−3
1 + x− xx(x + 1)
dx =
∫ −2
−3
(1
x− 1
x+ 1
)
dx =(
ln |x| − ln |x+ 1|∣∣∣
−2
−3= 2 ln 2− ln 3. 261
(l)
∫ 3
2
1
x(x − 1)2dx. Anche qui si puo arrivare alla soluzione con il solito trucco di aggiungere e togliere:
1
x(x − 1)2=
1− x+ x
x(x − 1)2= − 1
x(x− 1)+
1
(x− 1)2.
Ora si puo scomporre il primo termine nuovamente con l’aggiungere e togliere e si ottiene
1
x(x− 1)2= −1− x+ x
x(x − 1)+
1
(x − 1)2=
1
x− 1
x− 1+
1
(x− 1)2.
Pertanto∫ 3
2
1
x(x − 1)2dx =
∫ 3
2
(1
x− 1
x− 1+
1
(x− 1)2
)
dx =
(
ln |x| − ln |x− 1| − 1
x− 1
∣∣∣∣
3
2
= ln 3− 2 ln 2 + 1/2.
Esercizio 5.1
(a)
∫ 0
−∞ex dx. Si ha
∫ 0
−∞ex dx = lim
a→−∞
∫ 0
a
ex dx = lima→−∞
ex∣∣∣
0
a= lim
a→−∞(1− ea) = 1.
(b)
∫ +∞
4
1√xdx. Si ha
∫ +∞
4
1√xdx = lim
b→+∞
∫ b
4
1√xdx = lim
b→+∞2√x∣∣∣
b
4= lim
b→+∞(2√b− 4) = +∞.
(c)
∫ +∞
−∞xe−x2
dx. Si ha
∫ +∞
−∞xe−x2
dx =
∫ 0
−∞xe−x2
dx+
∫ +∞
0
xe−x2
dx
= lima→−∞
∫ 0
a
xe−x2
dx + limb→+∞
∫ b
0
xe−x2
dx
= lima→−∞
(
−1/2e−x2∣∣∣
0
a+ lim
b→+∞
(
−1/2e−x2∣∣∣
b
0
= −1/2 lima→−∞
(1 − e−a2
)− 1/2 limb→+∞
(e−b2 − 1)
= 0. 262
261Si noti che in questo caso non si puo omettere il valore assoluto nelle primitive, poiche la funzione e negativa nell’intervallo diintegrazione.262Si noti che la funzione e dispari. Attenzione! Non e vero in generale che l’integrale generalizzato di una funzione dispari e sempre 0, inquanto l’integrale potrebbe non essere finito. E vero pero che, se una funzione dispari e integrabile in senso generalizzato, allora l’integralee zero.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
INTEGRALE DI RIEMANN
252
(d)
∫ +∞
2
1
x lnxdx. Si noti che la funzione e continua in tutto l’intervallo di integrazione.
∫ +∞
2
1
x lnxdx = lim
b→+∞
∫ b
2
1
x lnxdx = lim
b→+∞ln lnx
∣∣∣
b
2= lim
b→+∞
(ln ln b− ln ln 2
)= +∞.
Quindi l’integrale diverge.
Esercizio 5.2
(a)
∫ +∞
0
1
x3 + x+ 1dx.
La funzione e continua e positiva in [0,+∞). Trascurando a denominatore x + 1 rispetto ad x3 possiamo direche
1
x3 + x+ 1e equivalente a
1
x3, per x→ +∞.
Quindi per il criterio del confronto, dato che la funzione 1/x3 e integrabile all’infinito, l’integrale dato converge.
(b)
∫ +∞
0
x2 + x+ 1
x3 + x2 + x+ 1dx.
La funzione e continua e positiva in [0,+∞). Trascurando tutte le quantita trascurabili possiamo dire che
x2 + x+ 1
x3 + x2 + x+ 1e equivalente a
x2
x3=
1
x, per x→ +∞.
Quindi per il criterio del confronto, dato che la funzione 1/x non e integrabile all’infinito, l’integrale dato nonconverge.
(c)
∫ +∞
1
1
x2 +√xdx.
Funzione continua e positiva nell’intervallo di integrazione. Trascurando la radice abbiamo che
1
x2 +√x
e equivalente a1
x2, per x→ +∞.
Quindi l’integrale converge.
(d)
∫ +∞
1
13√x2 + x+ 1
dx.
Funzione continua e positiva nell’intervallo di integrazione. Trascurando, sotto radice, x + 1 rispetto ad x2,possiamo dire che
13√x2 + x+ 1
e equivalente a1
x2/3, per x→ +∞.
Dato che 23 < 1 l’integrale diverge.
(e)
∫ +∞
1
1 + e−x
xdx.
La funzione e positiva nell’intervallo di integrazione e, trascurando l’esponenziale (che tende a zero per x→ +∞),possiamo dire che
1 + e−x
xe equivalente a
1
x, per x→ +∞.
Quindi l’integrale dato diverge.
(f)
∫ +∞
1
1 + e−2x
x2dx.
Trascurando l’esponenziale abbiamo che
1 + e−2x
x2e equivalente a
1
x2, per x→ +∞.
Quindi l’integrale dato converge.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
INTEGRALE DI RIEMANN
253
(g)
∫ +∞
1
1
x2 + 2−xdx.
La funzione e positiva nell’intervallo di integrazione e, trascurando l’esponenziale, abbiamo che
1
x2 + 2−xe equivalente a
1
x2, per x→ +∞.
Quindi l’integrale dato converge.
(h)
∫ +∞
−∞x2e−x2
dx.
Possiamo osservare che la funzione e pari. Allora consideriamo
∫ +∞
0
x2e−x2
dx. Facciamo un confronto con la
funzione 1/x2. Si ha
limx→+∞
x2e−x2
1/x2= lim
x→+∞x4
ex2 = limt→+∞
t2
et= 0.
Quindi abbiamo che x2e−x2
e trascurabile rispetto a 1/x2, per x → +∞. Allora per il criterio del confrontol’integrale dato converge.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 SUCCESSIONI
SUCCESSIONI E SERIE
254
II-9 Successioni e serie
1 Successioni
Una successione reale e una funzione definita in N (insieme dei numeri naturali) a valori in R. Indichero quasi sempreuna successione scrivendo n 7→ an, dove n ∈ N e an appartiene ad R. Qualche volta usero la notazione classica f(n).Puo succedere che una successione non sia definita su tutti i numeri naturali, bensı in un sottoinsieme di N, come adesempio sui numeri naturali maggiori o uguali di un certo n0 ∈ N. Ad esempio la successione n 7→ 1
ln(n−1) e definita
∀n ∈ N, n ≥ 3. Chiamero allora in generale successione una funzione definita in N, ad eccezione al piu di un numerofinito di punti.
Osservazione Data una funzione di variabile reale f : (a,+∞) → R, con a ≥ 0, si puo ottenere da questa unasuccessione considerando la restrizione di f all’insieme N, o ad un suo sottoinsieme. Cosı ad esempio la successioneprecedente n 7→ 1
ln(n−1) si puo vedere come la restrizione ad N \ {1, 2} della funzione f : (2,+∞) → R definita da
f(x) = 1ln(x−1) .
Una proprieta importante delle successioni puo essere la monotonia. Una successione n 7→ an e crescente se
∀n si ha an+1 > an (equivale a dire che ∀n,m : n < m =⇒ an < am)
(non decrescente se ∀n si ha an+1 ≥ an).La successione e invece decrescente se
∀n si ha an+1 < an (equivale a dire che ∀n,m : n < m =⇒ an > am)
(non crescente se ∀n si ha an+1 ≤ an). 263
Osservazione Una successione puo non essere crescente, ma esserlo da un certo punto in poi. In questo caso diremoche la successione e definitivamente crescente (modo di dire gia usato tra l’altro con gli integrali generalizzati). Lostesso dicasi per gli altri casi di monotonia.
1.1 Limite di una successione
Particolarmente importante e il concetto di limite di una successione. L’unico caso significativo di limite di unasuccessione e il limite per n → +∞. La definizione, che comunque non vediamo, e ovviamente simile a quella dellimite di una funzione reale per x che tende a +∞. Il concetto e quello di capire, quando n tende all’infinito, a chevalore (se esiste) si avvicina la quantita an. Se tale valore e ℓ scriveremo
limn→+∞
an = ℓ (ℓ ∈ R)
Invece si scrive rispettivamentelim
n→+∞an = +∞ oppure lim
n→+∞an = −∞
se il valore di an tende a diventare infinitamente grande, positivo o negativo.Ovviamente, come per le altre funzioni, il limn→+∞ an in qualche caso puo non esistere.Anche per le successioni vale il risultato, gia visto per le funzioni di variabile reale, per cui se la funzione e monotonaallora il limite esiste. Vale infatti il seguente
Teorema (di esistenza del limite per successioni monotone) Se la successione n 7→ an e monotona crescente (o nondecrescente), allora il lim
n→+∞an esiste ed e uguale al sup
n∈N
{an}. Tale limite risulta finito se la successione e limitata
superiormente,264 risulta +∞ in caso contrario.Analogamente, se la successione n 7→ an e monotona decrescente (o non crescente), allora il lim
n→+∞an esiste ed e uguale
all’ infn∈N
{an}. Il limite e finito se la successione e limitata inferiormente, e −∞ in caso contrario.
Si puo dimostrare il seguente risultato, facilmente intuibile.
263Se la successione e definita in un sottoinsieme di N, al scrittura “∀n” va intesa nel senso “per ogni n in cui e definita la successione”.264Ricordo che una successione, come una qualunque funzione, e limitata superiormente se lo e la sua immagine. Nel nostro caso quindila successione n 7→ an e limitata superiormente se e e limitato superiormente l’insieme {an : n ∈ N}.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 SUCCESSIONI
SUCCESSIONI E SERIE
255
Proposizione Data una funzione f : (0,+∞) → R, se questa ha limite per x → +∞, allora anche la successionen 7→ an = f(n) ha limite per n→ +∞ e i due limiti coincidono.
Esempio Consideriamo la successione an =n− 1
n+ 1e il limite
limn→+∞
n− 1
n+ 1.
Dato che
limx→+∞
x− 1
x+ 1= 1,
possiamo concludere che anche limn→+∞
n− 1
n+ 1= 1.
Esempio Possiamo dire che limn→+∞
lnn
nvale zero, dato che lim
x→+∞lnx
x= 0. Quindi possiamo dire che lnn e
trascurabile rispetto ad n, per n→ +∞.
Esempio Ricordando il limite fondamentale, si puo concludere che la successione definita da an =(1 + 1
n
)nha
limite per n→ +∞ e
limn→+∞
(
1 +1
n
)n
= e.
Osservazione Si noti che non vale il viceversa dell’ultima proposizione: non e vero cioe che, se la successionen 7→ an = f(n) ha limite, allora anche la funzione di variabile reale definita da x 7→ f(x) ha limite. Si consideri adesempio la successione n 7→ n − ⌊n⌋. 265 Essa ovviamente vale 0 per ogni n, quindi ha limite 0 per n → +∞. Lafunzione x 7→ x− ⌊x⌋ non ha invece limite per x→ +∞. 266
Quanto detto nella proposizione ha importanza nel calcolo del limite di una successione. Puo essere comodo cioe,nel calcolo del limite di una successione, considerare il limite della funzione “corrispondente”. Questo perche ci sonometodi molto potenti di calcolo del limite di una funzione di variabile reale che non sono applicabili al calcolo dellimite di una successione.267
Definizione Se n 7→ an e una successione, chiamiamo sottosuccessione di questa una qualunque sua restrizione, conl’unica richiesta che quest’ultima sia definita su infiniti naturali.Data cioe una successione n 7→ an definita in N, se A e un sottoinsieme infinito di N, si chiama sottosuccessione lasuccessione m 7→ am definita per m ∈ A.Esempio Se consideriamo la successione n 7→ (−1)n (che assume, alternativamente i valori 1 e −1), possiamocostruire la sua sottosuccessione definita sui numeri naturali pari. Si tratta ovviamente di una successione che assumesempre il valore 1. La sottosuccessione definita invece sui numeri naturali dispari assume sempre il valore −1.Abbiamo visto poco fa che, se una funzione ha limite all’infinito, allora ha lo stesso limite la successione ad essaassociata. E facile allora intuire che anche una sottosuccessione ha lo stesso limite della successione da cui proviene.Meglio: se una successione ha limite, allora ogni sua sottosuccessione ha lo stesso limite.Puo succedere, come nel caso della sottosuccessione di n 7→ (−1)n definita sugli n pari, che la sottosuccessione abbialimite, mentre la successione non lo ha.268
Attenzione. Per provare che una successione ha limite non basta quindi calcolare il limite di una sottosuccessione.Per provare invece che una successione non ha limite si puo cercare di dimostrare che ci sono due sue diverse sotto-successioni che hanno limiti diversi. Cosı, nel caso di n 7→ (−1)n, possiamo dire che essa non ha limite dato che lasottosuccessione sugli n pari vale sempre 1, e quindi ha limite 1, mentre la sottosuccessione sugli n dispari vale sempre−1, e quindi ha limite −1.Esercizio 1.1 Si calcolino i limiti indicati.
(a) limn→+∞
2n+ 1
3n+ 2(b) lim
n→+∞ln2 n
n√n
(c) limn→+∞
2n+ 3 lnn
4n2 + 5 ln2 n(d) lim
n→+∞
(√n+ 1−√n
)
265Ricordo che il simbolo ⌊. . .⌋ sta ad indicare la parte intera di . . ..266Si vada a rivedere il grafico della funzione, nella dispensa sulle Funzioni reali.267A titolo di esempio, il teorema di De l’Hopital per il calcolo dei limiti, che abbiamo visto in precedenza. Come lo studente ricordera,per l’applicazione del teorema e necessario che le funzioni siano derivabili: le successioni non sono invece funzioni derivabili (perche?).268Rinunciando al formalismo di una dimostrazione rigorosa, si capisce pero facilmente che la successione n 7→ (−1)n non puo avere limite,dato che passa “perennemente” dal valore 1 al valore −1 e viceversa.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SERIE
SUCCESSIONI E SERIE
256
2 Serie
Il concetto di serie cerca di rispondere alla domanda: come ci comportiamo se dobbiamo “sommare infiniti termini”?269
Possiamo ragionare intanto cosı: supponiamo che gli infiniti termini da sommare siano i valori di una certa successione.
Definizione Data una successione n 7→ an, si dice somma parziale n-esima di an la nuova successione definitada
sn = a1 + a2 + . . .+ an , ∀n 270
Osservazione I primi termini della successione sn sono quindi
s1 = a1 , s2 = a1 + a2 , s3 = a1 + a2 + a3 , . . .
Osservazione Data una successione n 7→ an, resta allora ad essa associata una nuova successione, la successionedelle somme parziali di questa, cioe n 7→ sn.
Definizione Si dice serie associata alla successione n 7→ an la successione n 7→ sn delle sue somme parziali.La successione n 7→ an viene detta il termine generale della serie.
Definizione Si dice che la serie (di termine generale an) converge se la successione n 7→ sn delle somme parziali dian ha limite finito. Si dice che la serie diverge se n 7→ sn ha limite infinito. Si dice infine che la serie e indeterminatase non esiste il limite di n 7→ sn.Con la dicitura studiare il carattere di una serie si intende stabilire se la serie converge, diverge o e indeterminata.
Osservazione Se la serie converge, il limn→+∞ sn si dice la somma della serie (anziche il limite della serie, comesarebbe piu appropriato). Se la serie converge possiamo dire, in modo poco rigoroso ma efficace, che la somma dellaserie e la somma degli infiniti termini da cui siamo partiti.
La serie associata alla successione n 7→ an viene usualmente indicata con la scrittura
+∞∑
n=1
an271 oppure con a1 + a2 + . . .+ an + . . . .
Nel seguito, quando non c’e il rischio di fare confusione, anziche
+∞∑
n=1
an scrivero piu semplicemente∑an. Spesso,
quando possibile, anziche far “partire” n da 1 lo si fa partire da 0 e si scrive quindi
+∞∑
n=0
an. A volte n puo anche partire
da un n0 > 1.
Esempi
• Consideriamo la serie+∞∑
n=1
n,
cioe la serie di termine generale an = n. La sua somma parziale n-esima e
sn = 1 + 2 + . . .+ n =n(n+ 1)
2(ricordare il piccolo Gauss).
Questa serie quindi diverge, dato che limn→+∞ sn = limn→+∞n(n+1)
2 = +∞.
• Si chiama serie di Mengoli la serie
+∞∑
n=1
1
n(n+ 1)=
1
1 · 2 +1
2 · 3 +1
3 · 4 + . . . ,
269Se state pensando che la somma di infiniti termini debba necessariamente essere infinita tra breve vedremo che questo non e vero.270Chiaramente, se la successione n 7→ an e definita per n ≥ n0, anche sn e definita per n ≥ n0.271Si legge “sommatoria per n che va da 1 a +∞ di an”.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SERIE
SUCCESSIONI E SERIE
257
cioe la serie di termine generale an = 1n(n+1) . La sua somma parziale n-esima e
sn =1
1 · 2 +1
2 · 3 +1
3 · 4 + . . .+1
n(n+ 1)
=
(
1− 1
2
)
+
(1
2− 1
3
)
+
(1
3− 1
4
)
+ . . .+
(1
n− 1
n+ 1
)
= 1− 1
n+ 1(si noti che quasi tutti i termini si semplificano).
Pertanto
limn→+∞
sn = limn→+∞
(
1− 1
n+ 1
)
= 1,
e quindi la serie di Mengoli converge e la sua somma e 1. Questo e il primo esempio che prova che la somma diinfiniti termini puo essere un numero finito.
• Consideriamo la serie∑+∞
n=0
(√n+ 1−√n
). Risulta
sn = 1+ (√2− 1) + (
√3−√2) + (
√4−√3) + . . .+ (
√n+ 1−√n)
=√n+ 1 (anche qui quasi tutti i termini si semplificano).
La serie diverge in quanto limn→+∞ sn = limn→+∞√n+ 1 = +∞.
Osservazione Nei tre esempi abbiamo potuto stabilire il carattere della serie (e la sua somma quando essa e con-vergente) utilizzando soltanto la definizione, che al momento e l’unico strumento a nostra disposizione. Faccio notareche questo e per certi versi analogo al calcolo di un integrale generalizzato a +∞ attraverso la definizione, cioe conil calcolo di una primitiva: trovare una primitiva e paragonabile a trovare l’espressione generale della somma parzialesn. Forse si intuisce che questo non e sempre cosı facile come negli esempi proposti. Tra breve impareremo a studiareil carattere di una serie anche quando non si puo ottenere la generica somma parziale (e questo e paragonabile allostudio della convergenza dell’integrale anche senza il calcolo della primitiva).
Esercizio 2.1 Si scriva l’espressione del termine generale delle seguenti serie:
(a) 1 +1
3+
1
5+
1
7+ . . . (b) 1 +
1
4+
1
9+
1
16+ . . .
(c)3
2+ 1 +
5
8+
6
16+ . . . (d)
1
2+
1
6+
1
12+
1
20+
1
30+ . . .
Uno dei pochi risultati del tutto generali sulle serie e il seguente importante
Teorema (condizione necessaria di convergenza)Sia n 7→ an una successione. Se la serie
∑an converge, allora lim
n→+∞an = 0.
Osservazione La dimostrazione di questo risultato e immediata. Se s e la somma della serie, per ipotesi un numeroreale, si ha
limn→+∞
an = limn→+∞
(sn − sn−1)272
= limn→+∞
sn − limn→+∞
sn−1
= s− s= 0.
272Segue dal fatto chesn = a1 + . . .+ an−1
︸ ︷︷ ︸
sn−1
+an = sn−1 + an e quindi an = sn − sn−1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SERIE
SUCCESSIONI E SERIE
258
Osservazioni Questo risultato fornisce una condizione necessaria per la convergenza di una serie. Puo essere utilequindi non tanto per stabilire che una serie converge, quanto per stabilire che una serie non converge.273 Ad esempio,
si consideri la serie
+∞∑
n=1
n
n+ 1. Dato che il limite del termine generale e 1, la serie non converge.
Attenzione che la condizione del teorema non e sufficiente, cioe non basta provare che il termine generale tende a zeroper provare che una serie converge.
Esempio Un esempio che prova che il tendere a zero del termine generale non e sufficiente per la convergenza della
serie e il seguente: si consideri la serie
+∞∑
n=0
(√n+ 1−√n
)(gia incontrata poco fa). Per il termine generale si ha
√n+ 1−√n =
(√n+ 1−√n)(
√n+ 1 +
√n)√
n+ 1 +√n
=1√
n+ 1+√n
e questo tende a zero per n→ +∞ ma, come visto prima, la serie diverge.
Esempio Un altro esempio di serie non convergente con termine generale che tende a zero e la serie+∞∑
n=1
ln
(
1 +1
n
)
.
Possiamo scrivere
ln
(
1 +1
n
)
= lnn+ 1
n= ln(n+ 1)− lnn.
Quindi la successione delle somme parziali e
sn = ln 2 + ln
(
1 +1
2
)
+ ln
(
1 +1
3
)
+ . . .+ ln
(
1 +1
n
)
= ln 2 + ln
(3
2
)
+ ln
(4
3
)
+ . . .+ ln
(n+ 1
n
)
= ln 2 + ln 3− ln 2 + ln 4− ln 3 + . . .+ ln(n+ 1)− lnn
= ln(n+ 1).
Pertanto limn→+∞
sn = limn→+∞
ln(n+1) = +∞, e quindi la serie diverge. Il termine generale della serie pero tende a zero.
2.1 La serie armonica
Una serie molto importante e la serie+∞∑
n=1
1
n= 1 +
1
2+
1
3+
1
4+ . . .
detta serie armonica. Si puo dimostrare (non sarebbe facile farlo con la sola definizione) che la serie armonicadiverge.Si chiama inoltre serie armonica generalizzata la serie
+∞∑
n=1
1
nα, con α > 0.
La convergenza della serie armonica generalizzata dipende, come e facile intuire, dal valore di α. Si puo dimostrareche la serie armonica generalizzata converge se α > 1 e diverge se 0 < α < 1. Si noti che gli altri casi (cioe α ≤ 0) nonsono significativi dato il termine generale non tende a zero. E si noti inoltre l’analogia dei risultati sulla convergenzadella serie armonica con quelli riguardanti la convergenza dell’integrale generalizzato
∫ +∞1
1xα dx.
273La convergenza e nell’ipotesi del teorema e quindi esso non mi puo consentire di provare che una serie converge. Invece mi puo servireper provare che non converge, dato che, se non sono vere le necessarie conseguenze della convergenza della serie, la serie non puo convergere.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SERIE
SUCCESSIONI E SERIE
259
Esempi Sono esempi di serie armoniche generalizzate convergenti le seguenti:
+∞∑
n=1
1
n2,
+∞∑
n=1
14√n5
,
+∞∑
n=1
1
n√n
in cui abbiamo rispettivamente α = 2, α = 5/4 e α = 3/2 (tutti maggiori di 1). Sono invece esempi di serie armonichegeneralizzate divergenti le seguenti:
+∞∑
n=1
1√n
,
+∞∑
n=1
13√n2
,
+∞∑
n=1
1√n · 3√n
in cui abbiamo rispettivamente α = 1/2, α = 2/3 e α = 5/6 (tutti minori di 1).
2.2 La serie geometrica
Altra serie estremamente importante e la serie
+∞∑
n=0
rn , con r ∈ R.
Essa viene detta serie geometrica di ragione r.Possiamo studiare in dettaglio la convergenza della serie geometrica. Anzitutto due casi semplici:
• se r = 0 ovviamente la serie converge e ha per somma 0; 274
• se r = 1 la serie diverge in quanto la somma parziale n-esima e sn = n+ 1 e pertanto limn→+∞ sn = +∞.
Possiamo poi ottenere la somma parziale n-esima in generale (con r 6= 0 e r 6= 1), in quanto si ha
sn = 1 + r + r2 + r3 + . . .+ rn
e, moltiplicando ambo i membri per r (r 6= 0), si ottiene
r · sn = r(1 + r + r2 + . . .+ rn)
= r + r2 + r3 + . . .+ rn + rn+1
(aggiungo e tolgo 1) = 1 + r + r2 + . . .+ rn︸ ︷︷ ︸
sn
+rn+1 − 1
= sn + rn+1 − 1.
Pertanto
(1− r)sn = 1− rn+1 e quindi (r 6= 1) sn =1− rn+1
1− r .
Disponendo ora dell’espressione della somma parziale, possiamo concludere in tutti i casi non ancora risolti.
• Se |r| < 1, abbiamo che rn+1 → 0 per n→ +∞, e quindi limn→+∞
sn =1
1− r .
• Se r > 1, limn→+∞
sn = +∞.275
• Se r ≤ −1, si puo vedere con qualche conto che il limite di sn non esiste e quindi che la serie e indeterminata.
Riassumendo, per la serie geometrica
+∞∑
n=0
rn si hanno i seguenti risultati:
⊲ la serie converge se |r| < 1 e ha per somma 11−r ;
⊲ la serie diverge (a +∞) se r ≥ 1;
⊲ la serie e indeterminata se r ≤ −1.274Si potrebbe obiettare (rigorosamente) che, se r = 0, n non puo partire da 0 ma deve partire da 1.275Il numeratore tende a −∞ e il denominatore e un numero negativo dato che r > 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CRITERI PER SERIE A TERMINI NON NEGATIVI
SUCCESSIONI E SERIE
260
Esempio Determiniamo la somma della serie
+∞∑
n=0
2−n. Possiamo riscriverla come
+∞∑
n=0
1
2no anche come
+∞∑
n=0
(1
2
)n
.
Si tratta quindi di una serie geometrica di ragione r = 12 . Essa e convergente, dato che la ragione e in valore assoluto
minore di 1. Con quanto trovato poco fa, possiamo concludere che la somma della serie e
1
1− 12
= 2.
Osservazione La serie geometrica “inizia con n = 0”. Se invece abbiamo una serie geometrica convergente che,anziche iniziare con n = 0 inizia con n = 1, basta fare cosı (aggiungo e tolgo il termine “mancante” r0):
+∞∑
n=1
rn =
+∞∑
n=0
rn − r0 =1
1− r − 1 =r
1− r .
Quindi, ad esempio, la serie
+∞∑
n=1
1
2nha per somma
12
1− 12
= 1.
Piu in generale la somma di una serie geometrica convergente che inizia con n = p e
+∞∑
n=p
rn =+∞∑
n=0
rn −p−1∑
n=0
rn =1
1− r −1− rp1− r =
rp
1− r .
Osservazione Riflettendo sulla serie armonica generalizzata e sulla serie geometrica, e chiaro a questo punto unfatto del tutto generale: la convergenza di una serie dipende da quanto rapidamente il suo termine generale tende azero. In altre parole una serie converge se il suo termine generale tende a zero “abbastanza rapidamente”. Nel casoad esempio della serie armonica generalizzata
∑+∞1=n
1nα , abbastanza rapidamente vuol dire con α > 1. Vedremo piu
avanti che la serie armonica e in certo qual modo uno spartiacque tra le serie convergenti e quelle divergenti.
Esercizio 2.2 Si dica se la serie
+∞∑
n=0
5−n converge e, in caso affermativo, se ne calcoli la somma.
Esercizio 2.3 Si dica se la serie
+∞∑
n=1
2−n/2 converge e, in caso affermativo, se ne calcoli la somma.
Esercizio 2.4 Si dica se la serie
+∞∑
n=2
(−1)nen
converge e, in caso affermativo, se ne calcoli la somma.
3 Criteri per serie a termini non negativi
Le serie con termine generale non negativo, cioe le serie del tipo∑+∞
n=0 an, con an ≥ 0 per ogni n, non possono essereindeterminate (quindi o convergono o divergono). Infatti in questo caso la successione delle somme parziali e nondecrescente e quindi ha limite,276 che potra essere finito (e non negativo) o infinito. Se il termine generale non tendea zero, sicuramente la serie diverge.277
Vediamo qui alcuni criteri di convergenza per serie a termini non negativi.
276Per il teorema di esistenza del limite per successioni monotone.277Infatti, se il termine generale non tende a zero, la serie non puo convergere e, non potendo essere indeterminata, necessariamentediverge.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CRITERI PER SERIE A TERMINI NON NEGATIVI
SUCCESSIONI E SERIE
261
3.1 Criteri del confronto
Proposizione (Criterio del confronto) Siano an e bn due successioni tali che 0 ≤ an ≤ bn per ogni n.Se∑
n bn converge, allora∑
n an converge; se∑
n an diverge, allora∑
n bn diverge.278
Osservazione Quando valgono le ipotesi del criterio del confronto si dice che la serie∑
n an e minorante della serie∑
n bn (o che la seconda e maggiorante della prima).Il criterio e applicabile anche se
∑
n an e definitivamente minorante di∑
n bn, e cioe se an ≤ bn vale da un certo n0
in poi.
Esempi
• Consideriamo la serie
+∞∑
n=1
1
n2. Si tratta di un caso particolare di serie armonica generalizzata. Sappiamo gia, con
quanto detto in precedenza, che essa converge. Ora lo dimostriamo di nuovo, utilizzando il criterio del confronto.Si ha
1
n2≤ 1
n(n− 1), ∀n ≥ 2. 279
La serie∑+∞
n=21
n(n−1) =∑+∞
n=11
n(n+1) converge (e la serie di Mengoli) e quindi, per il criterio del confronto,
converge anche la serie data.
Chiaramente a questo punto possiamo dire, sempre per il criterio del confronto, che converge anche una qualunque
serie del tipo
+∞∑
n=1
1
nα, con α > 2: infatti, se α > 2, allora 1
nα < 1n2 .
• Dal fatto che la serie armonica
+∞∑
n=1
1
ndiverge possiamo dedurre che divergono tutte le serie del tipo
+∞∑
n=1
1
nαcon
0 < α < 1: infatti da nα ≤ n, vera per ogni n, si ha che∑+∞
n=11nα e maggiorante della serie armonica e quindi,
per il criterio del confronto, diverge.
Osservazione Come conseguenza del criterio del confronto abbiamo il risultato che segue. Siano an e bn due
successioni a termini positivi e sia limn→+∞
anbn
= 0 (quindi possiamo anche dire che an e trascurabile rispetto a bn per
n→ +∞).
(i) Se∑
n bn converge, allora anche∑
n an converge;
(ii) Se∑
n an diverge, allora anche∑
n bn diverge.
Possiamo stabilire ora due utili criteri di confronto con successioni infinitesime campione: se n 7→ an e una successionepositiva, allora
• se, per n→ +∞, an e trascurabile rispetto a 1nα con α > 1, allora la serie
∑
n an converge;
• se, per n→ +∞, 1n e trascurabile rispetto ad an, allora la serie
∑
n an diverge.
Esempio La serie+∞∑
n=2
1
n2 lnnconverge perche 1
n2 lnn e trascurabile rispetto a 1n2 per n→ +∞.
Esempio La serie
+∞∑
n=2
1
lnndiverge perche 1
n e trascurabile rispetto a 1lnn per n→ +∞.
Altra sostanziale conseguenza del criterio del confronto e la seguente utilissima
Proposizione (Criterio del confronto asintotico) Siano an e bn due successioni a termini positivi. Se an e bn sono
equivalenti per n→ +∞, cioe se limn→+∞
anbn
= 1, allora le due serie∑
n an e∑
n bn hanno lo stesso carattere.
278Si noti ancora la somiglianza di questo criterio con quelli di confronto per gli integrali generalizzati.279Infatti n(n− 1) = n2 − n ≤ n2, da cui, passando ai reciproci, si ricava la disuguaglianza scritta.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CRITERI PER SERIE A TERMINI NON NEGATIVI
SUCCESSIONI E SERIE
262
Osservazione In realta per garantire la tesi e sufficiente che il limite di an/bn sia finito e diverso da zero,280 datoche la convergenza non dipende da una costante moltiplicativa.
Esempio Consideriamo la serie
+∞∑
n=1
n+ 1
n2 + n.
Trascurando, nel termine generale della serie, le quantita trascurabili, e cioe 1 a numeratore ed n a denominatore,possiamo dire che n+1
n2+n e equivalente a nn2 = 1
n , per n → +∞. Quindi la serie data e come la serie armonica e cioediverge.
Esempio Consideriamo la serie
+∞∑
n=1
2n + n3
3n + n2.
Ricordando che n3 e trascurabile rispetto a 2n e n2 e trascurabile rispetto a 3n, per n→ +∞, allora 2n+n3
3n+n2 e equivalente
a 2n
3n =(23
)n. Quindi la serie data ha lo stesso carattere della serie geometrica di ragione 2
3 < 1, che e convergente, equindi converge.
Osservazione I vari criteri di confronto per le serie a termini non negativi sono in tutto e per tutto analoghi a quellivisti per gli integrali generalizzati a +∞.
Esercizio 3.1 Si studi carattere delle seguenti serie, usando i criteri del confronto:
(a)
+∞∑
n=1
n+ 1
2n+ 1(b)
+∞∑
n=1
1
1 + n2
(c)
+∞∑
n=1
1√
n(n+ 1)(d)
+∞∑
n=2
1
nen
3.2 Criterio del rapporto
Proposizione (Criterio del rapporto) Sia an una successione a termini positivi tale che
ℓ = limn→+∞
an+1
anesista, finito o infinito.
Valgono le affermazioni seguenti:
(i) se ℓ < 1, allora la serie∑
n an converge;
(ii) se ℓ > 1, allora la serie∑
n an diverge.
Osservazione Il criterio del rapporto non e applicabile, e quindi nulla si puo dire, quando risulta
ℓ = limn→+∞
an+1
an= 1.
Si pensi ad esempio alle due successioni 1n e 1
n2 . Per entrambe ℓ = 1, ma la serie∑ 1
n diverge mentre la∑ 1
n2 converge.
Esempi
• Si consideri la serie
+∞∑
n=0
1
n!. Si ha281
limn→+∞
an+1
an= lim
n→+∞1/(n+ 1)!
1/n!= lim
n→+∞n!
(n+ 1)!= lim
n→+∞1
n+ 1= 0.
Quindi ℓ = 0 e pertanto la serie converge per il criterio del rapporto. Si poteva anche utilizzare un confrontocon la serie di Mengoli.
280Si ricordi che “limite del quoziente an/bn finito e diverso da zero” si puo esprimere dicendo che an e bn hanno lo stesso ordine digrandezza.281Ricordo che n! = 1 · 2 · . . . · n per ogni n ∈ N.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CRITERI PER SERIE A TERMINI NON NEGATIVI
SUCCESSIONI E SERIE
263
• Si consideri la serie
+∞∑
n=0
n
2n. Si ha
limn→+∞
an+1
an= lim
n→+∞(n+ 1)/2n+1
n/2n= lim
n→+∞
(n+ 1
2n+1· 2
n
n
)
= limn→+∞
n+ 1
2n=
1
2.
Quindi ℓ = 12 e pertanto la serie converge per il criterio del rapporto.
3.2.1 Lo sviluppo in serie di ex
Sia x un numero reale e consideriamo la serie
+∞∑
n=0
xn
n!. Si ha
limn→+∞
an+1
an= lim
n→+∞xn+1/(n+ 1)!
xn/n!= lim
n→+∞
(xn+1
(n+ 1)!· n!xn
)
= limn→+∞
x
n+ 1= 0. 282
Quindi, per il criterio del rapporto, la serie converge qualunque sia x.Si puo dimostrare che
+∞∑
n=0
xn
n!= ex. 283
Osservazione Dalla convergenza della serie+∞∑
n=0
xn
n!segue che la successione n 7→ xn
n! tende a zero per n→ +∞ per
ogni x, e che quindi xn e trascurabile rispetto a n! per n→ +∞, qualunque sia x.Come caso particolare abbiamo quindi che en e trascurabile rispetto a n!, per n → +∞. Dato che gli studenti sonosoliti ricordare la classica gerarchia degli infiniti “logaritmi < potenze < esponenziali”, e da questa forse ricavarel’impressione che gli esponenziali siano infiniti “imbattibili”, la relazione trovata poco fa, cioe che en e trascurabilerispetto a n!, fa quindi, per cosı dire, crollare il mito, dato che individua un infinito piu forte di un esponenziale.284
Chi vuole puo provare a dimostrare che d’altro canto n! e trascurabile rispetto a en2
, sempre per n→ +∞.
Esercizio 3.2 Si studi il carattere delle seguenti serie, usando il criterio del rapporto:
(a)
+∞∑
n=1
1
(2n+ 1)!(b)
+∞∑
n=1
n2
2n
(c)+∞∑
n=1
n
(n+ 1)!(d)
+∞∑
n=1
1
n3n
3.3 Criterio della radice
Proposizione (Criterio della radice) Sia an una successione a termini positivi tale che
ℓ = limn→+∞
n√an esista, finito o infinito.
Valgono le affermazioni seguenti:
(i) se ℓ < 1, allora la serie∑
n an converge;
(ii) se ℓ > 1, allora la serie∑
n an diverge.
Osservazione Come il criterio del rapporto, anche il criterio della radice non e applicabile quando risulta
ℓ = limn→+∞
n√an = 1.
282Non si faccia confusione qui: la variabile del limite e n, che tende all’infinito, mentre x e costante.283Si osservi che i primi termini della serie (detta serie esponenziale) sono i termini del polinomio di Taylor di ex. In uno dei capitoli
precedenti scrivevamo ex ∼= 1+x+ x2
2!+ x3
3!. La serie esponenziale “estende all’infinito” la validita della formula di Taylor e da la possibilita
di scrivere ex come una somma di infiniti termini di tipo polinomiale. Si chiama lo sviluppo in serie di Taylor di ex. Si noti anche che conl’approssimazione polinomiale siamo costretti ad usare il simbolo “∼=” mentre con la serie di Taylor possiamo senz’altro scrivere “=”, datoche le due espressioni danno effettivamente la stessa quantita.284E peraltro facile capire che ex non sia l’infinito piu forte, dato che basta un xex per averne uno piu forte. Non esiste un infinito piuforte di tutti gli altri.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CRITERI PER SERIE A TERMINI DI SEGNO NON COSTANTE
SUCCESSIONI E SERIE
264
Esempi
• Si consideri la serie+∞∑
n=1
1
nn. Si ha
limn→+∞
n
√
1
nn= lim
n→+∞1
n= 0,
e quindi, per il criterio della radice, la serie converge (si poteva anche utilizzare il criterio del rapporto o il criteriodel confronto).
• Si consideri la serie
+∞∑
n=1
e−n lnn. Si ha
limn→+∞
n√e−n lnn = lim
n→+∞e− lnn = lim
n→+∞1
n= 0,
e quindi, per il criterio della radice, la serie converge.
• Si consideri la serie
+∞∑
n=1
en lnn−n2
. Si ha
limn→+∞
n√en lnn−n2 = lim
n→+∞elnn−n = lim
n→+∞n
en= 0 (confronto standard)
e quindi, per il criterio della radice, la serie converge.
• Si consideri la serie
+∞∑
n=1
(
1 +1
n
)−n2
. Si ha
limn→+∞
n
√
(1 + 1/n)−n2 = limn→+∞
(1 + 1/n)−n = limn→+∞
1
(1 + 1/n)n= 1/e, 285
e quindi, per il criterio della radice, la serie converge. Si noti che invece la serie
+∞∑
n=1
(
1 +1
n
)−n
diverge in quanto
il suo termine generale non tende a zero (tende a 1/e). Alla stessa serie non e applicabile il criterio della radice,dato che limn→+∞ n
√
(1 + 1/n)−n = limn→+∞(1 + 1/n)−1 = 1.
Esercizio 3.3 Si studi il carattere delle seguenti serie:
(a)
+∞∑
n=1
n2
2n2 + 1(b)
+∞∑
n=1
1
(2n)!
(c)
+∞∑
n=1
n
1 + n2(d)
+∞∑
n=1
1 +√n
n+ n2
(e)
+∞∑
n=1
2n+1
nn(f)
+∞∑
n=0
2n + 3n
4n + 5n
(g)+∞∑
n=1
(
1 +1
n
)−2n
(h)+∞∑
n=0
2−n2
4 Criteri per serie a termini di segno non costante
Definizione Si dice che una serie∑+∞
n=0 an e assolutamente convergente (o che converge assolutamente) se
converge la serie∑+∞
n=0 |an|.285Si ricordi il limite fondamentale limn→+∞(1 + 1/n)n = e.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CRITERI PER SERIE A TERMINI DI SEGNO NON COSTANTE
SUCCESSIONI E SERIE
265
Osservazione Per evitare a questo punto confusione, la convergenza vista finora viene detta semplice (si dice ancheche la serie converge semplicemente).Tra i due tipi di convergenza sussiste una relazione, espressa dalla seguente
Proposizione Se una serie converge assolutamente allora converge semplicemente e si ha inoltre |∑ an| ≤∑ |an|.
Esempio La serie
+∞∑
n=1
(−1)nn2
ha termini di segno non costante (alternativamente uno positivo e l’altro negativo).
Essa converge in quanto converge assolutamente. Infatti
∣∣∣∣
(−1)nn2
∣∣∣∣=
1
n2, ∀n ≥ 1
e, come noto,∑+∞
n=11n2 converge.
Osservazione La proposizione appena vista puo fornire un utile criterio di convergenza semplice per serie a termininon tutti positivi. L’assoluta convergenza e una condizione sufficiente per la convergenza semplice. Nulla si puo dire senon c’e assoluta convergenza. Vedremo tra breve un esempio di serie convergente ma non assolutamente convergente.
Tra le serie a termini di segno non costante una classe importante e costituita dalle serie a termini di segno alternato.Una serie e a termini di segno alternato se puo essere scritta come
+∞∑
n=0
(−1)nbn, con bn > 0 per ogni n.
Proposizione (Criterio di Leibnitz le serie a termini di segno alternato) Sia bn una successione decrescente einfinitesima (cioe che tende a zero) per n→ +∞. Allora la serie
∑+∞n=0(−1)nbn converge.
Esempio Un caso interessante e la cosiddetta serie armonica a segni alternati, cioe
+∞∑
n=1
(−1)n 1n= −1 + 1
2− 1
3+
1
4− 1
5+ . . . .
Ovviamente essa non converge assolutamente. Pero converge semplicemente: infatti la successione n 7→ 1/n edecrescente e infinitesima per n→ +∞ e quindi per il criterio di Leibnitz la serie converge.
Esempio Anche la serie+∞∑
n=2
(−1)n 1
lnnconverge, in base al criterio di Leibnitz. Infatti la successione n 7→ 1/ lnn e
decrescente e infinitesima.
Esempio Si faccia attenzione a non credere che la presenza nel termine generale di una serie dell’espressione (−1)n
faccia automaticamente della serie una serie a termini di segno alternato. Si consideri ad esempio la serie
+∞∑
n=1
1 + (−1)nn
.
I termini dispari sono nulli, mentre quelli pari valgono 2n . Quindi si tratta di una serie a termini positivi e si ha
+∞∑
n=1
1 + (−1)nn
=+∞∑
n=1
2
2n=
+∞∑
n=1
1
n.
La serie coincide con la serie armonica e pertanto diverge.
Osservazione Puo succedere che in una serie a termini di segno alternato∑+∞
n=0(−1)nbn la successione n 7→ bn nonsia in realta decrescente, ma lo sia da un certo punto in poi (cioe sia definitivamente decrescente). Come gia osservatoin altre occasioni, il carattere di una serie non dipende da quello che succede in un numero finito di primi termini.Anche l’applicazione del criterio di Leibnitz risente di questo aspetto. Il criterio si potrebbe enunciare dicendo che sela successione n 7→ bn e infinitesima e definitivamente decrescente, allora la serie converge.
Esercizio 4.1 Si studi il carattere delle seguenti serie:
(a)
+∞∑
n=1
(−1)n√n
(b)
+∞∑
n=2
(−1)nln2 n
(c)
+∞∑
n=0
(−1)n 2
3n
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
SUCCESSIONI E SERIE
266
5 Soluzioni degli esercizi
Esercizio 1.1
(a) Il limite si presenta nella forma indeterminata (+∞)/(+∞). Dividendo numeratore e denominatore per n il
limite e uguale al limn→+∞2+1/n3+2/n = 2
3 .
(b) Il limite si presenta nella forma indeterminata (+∞)/(+∞). Possiamo scrivere ln2 nn√n= ln2 n
n3/2 . Se consideriamo la
corrispondente funzione di variabile reale f(x) = ln2 xx3/2 , per x → +∞ si ha un noto confronto tra un logaritmo
ed una potenza. Come visto in molte occasioni, si ha limx→+∞ln2 xx3/2 = 0 e pertanto anche limn→+∞
ln2 nn3/2 = 0.
(c) Il limite si presenta nella forma indeterminata (+∞)/(+∞). Pensando alla funzione di variabile reale f(x) =2x+3 ln x
4x2+5 ln2 xe ricordando i soliti confronti logaritmi/potenze, per x → +∞ a numeratore e a denominatore sono
trascurabili i logaritmi e quindi il limite e uguale al limx→+∞2x4x2 = limx→+∞
12x che vale zero. Pertanto anche
il limite limn→+∞2n+3 lnn
4n2+5 ln2 n= 0.
(d) Il limite si presenta nella forma indeterminata +∞−∞. Possiamo scrivere (razionalizzando)
limn→+∞
(√n+ 1−√n
)
= limn→+∞
(√n+1−√
n)(√n+1+
√n)√
n+1+√n
= limn→+∞
n+1−n√n+1+
√n= lim
n→+∞1√
n+1+√n= 0.
In qualche caso si puo stabilire il limite di una successione n 7→ an considerando la serie di termine generalean. Se la serie converge allora la successione tende a zero (la nota condizione necessaria di convergenza di una
serie). Si noti che nel nostro caso questo espediente non si puo utilizzare, dato che la serie∑+∞
n=0
(√n+ 1−√n
)
diverge (e uno dei primi esempi incontrati sulle serie).
Esercizio 2.1
(a) I denominatori sono i numeri naturali dispari e quindi si puo scrivere
1 +1
3+
1
5+
1
7+ . . . =
+∞∑
n=0
1
2n+ 1. 286 Il termine generale e quindi an =
1
2n+ 1.
(b) I denominatori sono i quadrati dei numeri naturali. Quindi possiamo scrivere
1 +1
4+
1
9+
1
16+ . . . =
+∞∑
n=1
1
n2. Il termine generale e quindi an =
1
n2.
(c) Notando che 1 = 4/4, a numeratore ci sono i numeri naturali a partire da 3 e a denominatore ci sono le potenzedi 2 (a partire da 21). Quindi possiamo scrivere
3
2+ 1 +
5
8+
6
16+ . . . =
+∞∑
n=1
n+ 2
2n. Il termine generale e quindi an =
n+ 2
2n.
(d) Possiamo scrivere
1
2+
1
6+
1
12+
1
20+
1
30+ . . . =
+∞∑
n=1
1
n(n+ 1). Il termine generale e quindi an =
1
n(n+ 1).
286Come gia osservato altre volte, la scrittura non e unica. Si puo anche scrivere ad esempio
1 +1
3+
1
5+
1
7+ . . . =
+∞∑
n=1
1
2n− 1o ancora
+∞∑
n=10
1
2n− 19o in infiniti altri modi.
Si noti che cio che fa passare da una espressione all’altra non e che un cambio di variabile, analogo a quelli che abbiamo visti con gliintegrali.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
SUCCESSIONI E SERIE
267
Esercizio 2.2
Si tratta di una serie geometrica di ragione r = 1/5. La serie converge in quanto la ragione sta nell’intervallo(−1, 1) (condizione necessaria e sufficiente di convergenza di una serie geometrica). In generale la somma di una seriegeometrica (convergente) di ragione r e 1/(1− r), quindi nel nostro caso la somma della serie e 1/(1− 1/5) = 5/4 (laserie parte da n = 0 e quindi non occorre togliere nessuno dei primi termini).
Esercizio 2.3
Possiamo scrivere 2−n/2 = ( 1√2)n, e quindi si tratta di una serie geometrica di ragione r = 1√
2. La serie converge
in quanto la ragione sta nell’intervallo (−1, 1). Qui la serie inizia da n = 1 e quindi la somma e 1/(1 − r) − r0 =
1/(1− r)− 1 = r/(1 − r). Nel nostro caso quindi la somma della serie e 1/√2
1−1/√2= 1√
2−1.
Esercizio 2.4
Si ha∑+∞
n=2(−1)n
en =∑+∞
n=2
(− 1
e
)ne quindi si tratta di una serie geometrica di ragione r = −1/e. La serie converge in
quanto la ragione sta nell’intervallo (−1, 1). Qui occorre fare attenzione al fatto che la serie parte da n = 2 e quindi
la somma e 1/(1− r) − r0 − r1 = r2/(1− r) = 1/e2
1+1/e = 1/(e2 + e).
Esercizio 3.1
(a)
+∞∑
n=1
n+ 1
2n+ 1. Il termine generale non tende a zero, quindi la serie, essendo a termini positivi, diverge. Volendo
applicare il confronto possiamo dire che (n+1)/(2n+1) e equivalente a 1/2, per n→ +∞ (nel senso che abbiamosempre dato a questa locuzione, cioe nel senso che il limite del rapporto tra (n+ 1)/(2n+ 1) e 1/2 e 1).
(b)+∞∑
n=1
1
1 + n2. Serie a termini positivi. Possiamo dire che 1/(1 + n2) e equivalente a 1/n2, per n → +∞. La serie
data e quindi come la serie armonica generalizzata∑+∞
n=1 1/nα con α = 2, e quindi converge.
(c)
+∞∑
n=1
1√
n(n+ 1). Serie a termini positivi. Sul termine generale possiamo dire che
1√
n(n+ 1)=
1√n2 + n
e equivalente a1
n, per n→ +∞ (lo si verifichi).
Quindi la serie e come la serie armonica, che diverge.
(d)
+∞∑
n=2
1
nen. La serie e a termini positivi. Qui possiamo usare un confronto con una serie geometrica, dato che
1
nene trascurabile rispetto a
1
en, per n→ +∞ (lo studente verifichi questa scrittura).
La serie geometrica∑+∞
n=21en =
∑+∞n=2(
1e )
n converge perche la ragione e tra −1 e 1. Quindi anche la serie dataconverge.
Esercizio 3.2
(a)
+∞∑
n=1
1
(2n+ 1)!. Serie a termini positivi. Ponendo an = 1/(2n + 1)!, il criterio del rapporto dice di calcolare il
limn→+∞(an+1/an): se tale limite e minore di 1 allora la serie converge, se invece e maggiore di 1, allora la seriediverge. Quindi nel nostro caso si ha
limn→+∞
an+1
an= lim
n→+∞1/(2n+ 3)!
1/(2n+ 1)!= lim
n→+∞(2n+ 1)!
(2n+ 3)!= lim
n→+∞1
(2n+ 3)(2n+ 2)= 0. 287
Quindi la serie converge in base al criterio del rapporto.
287Si ha infatti (2n + 3)! = (2n+ 3)(2n + 2)(2n + 1)!.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
SUCCESSIONI E SERIE
268
(b)
+∞∑
n=1
n2
2n. Serie a termini positivi. Ponendo an = n2
2n , calcoliamo il limite
limn→+∞
an+1
an= lim
n→+∞(n+ 1)2/2n+1
n2/2n= lim
n→+∞(n+ 1)22n
n22n+1= lim
n→+∞(n+ 1)2
2n2= 1/2.
Quindi la serie converge in base al criterio del rapporto.
(c)
+∞∑
n=1
n
(n+ 1)!. Serie a termini positivi. Calcoliamo il limite
limn→+∞
(n+ 1)/(n+ 2)!
n/(n+ 1)!= lim
n→+∞(n+ 1)(n+ 1)!
n/(n+ 2)!= lim
n→+∞n+ 1
n(n+ 2)= 0.
Quindi la serie converge in base al criterio del rapporto.
(d)
+∞∑
n=1
1
n3n. Serie a termini positivi. Calcoliamo il limite
limn→+∞
1/((n+ 1)3n+1)
1/(n3n)= lim
n→+∞n3n
(n+ 1)3n+1= lim
n→+∞n
3(n+ 1)= 1/3.
Quindi la serie converge in base al criterio del rapporto.
Esercizio 3.3
(a)
+∞∑
n=1
n2
2n2 + 1. Serie a termini positivi. Osserviamo che
limn→+∞
n2
2n2 + 1= 1/2.
Quindi il termine generale non tende a zero. La serie diverge.
(b)+∞∑
n=1
1
(2n)!. Serie a termini positivi con termine generale che tende a zero. Si puo usare il criterio del rapporto
(provare) oppure un confronto. Osservando che
(2n)! = 2n(2n− 1)(2n− 2) · · · 1 > 2n(2n− 1) se n > 2,
allora possiamo dire che la serie data e minorante della serie∑+∞
n=1 1/(2n(2n − 1)). Quest’ultima e come∑+∞
n=1 1/n2, che converge. Quindi la serie data converge per il criterio del confronto.
(c)
+∞∑
n=1
n
1 + n2. Serie a termini positivi. Semplicemente con un confronto: la serie e come
∑+∞n=1 1/n, che diverge.
(d)+∞∑
n=1
1 +√n
n+ n2. Serie a termini positivi. Trascurando le quantita trascurabili, la serie e come
∑+∞n=1
√n
n2 , cioe
∑+∞n=1
1n3/2 , che converge.
(e)+∞∑
n=1
2n+1
nn. Termini positivi e termine generale che tende a zero (lo si verifichi). Si puo fare col criterio del
rapporto (provare), ma forse qui conviene il criterio della radice. Ricordo che, detto an il termine generale dellaserie, il criterio della radice dice di calcolare il limn→+∞ n
√an: se tale limite e minore di 1 allora la serie converge,
se invece e maggiore di 1, allora la serie diverge. Quindi nel nostro caso calcoliamo il
limn→+∞
n√
2n+1/nn = limn→+∞
n√
2 · 2n/nn = limn→+∞
(n√2 · n√
2n/nn)
= limn→+∞
(
n√2 · 2
n
)
.
Ora il fattore 2/n tende a zero, mentre il fattore n√2 = 21/n tende a 1, per n → +∞. Quindi il limite vale 0 e,
per il criterio della radice, la serie data converge.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
SUCCESSIONI E SERIE
269
(f)
+∞∑
n=0
2n + 3n
4n + 5n. Termini positivi e termine generale che tende a zero (lo si verifichi). Possiamo prima semplifi-
care l’espressione del termine generale trascurando le quantita trascurabili, che sono 2n a numeratore e 4n adenominatore (lo studente verifichi che in effetti e cosı). Quindi possiamo scrivere che
2n + 3n
4n + 5ne equivalente a
3n
5n=
(3
5
)n
, per n→ +∞.
Allora la nostra serie e asintotica alla serie geometrica∑+∞
n=0(35 )
n, che converge perche la ragione e tra −1 e 1.Quindi anche la serie data converge per il criterio del confronto asintotico.
(g)
+∞∑
n=1
(
1 +1
n
)−2n
. Vediamo intanto se il termine generale tende a zero.
limn→+∞
(
1 +1
n
)−2n
= limn→+∞
1
(1 + 1n )
2n= lim
n→+∞1
(
(1 + 1n )
n)2 =
1
e2,
ricordando il limite fondamentale. Pertanto il termine generale della serie data non tende a zero e quindi la seriediverge.
(h)
+∞∑
n=0
2−n2
. Il termine generale tende ovviamente a zero. Cerchiamo di applicare il criterio della radice con il
limn→+∞
n√2−n2 = lim
n→+∞2−n = 0.
Quindi in base al criterio della radice la serie data converge.
Esercizio 4.1
(a)
+∞∑
n=1
(−1)n√n
. Serie a termini di segno alternato. Vediamo col criterio di Leibnitz.
Consideriamo la successione n 7→ 1/√n. Essa tende a zero per n → +∞ ed e decrescente, dato che la funzione
radice e crescente (e una potenza di esponente positivo). Quindi la serie data converge (semplicemente) in baseal criterio di Leibnitz. Si noti che la serie non converge assolutamente, dato che
∑+∞n=1 1/
√n =
∑+∞n=1 1/n
1/2 euna serie armonica generalizzata divergente.
(b)
+∞∑
n=2
(−1)nln2 n
. Serie a termini di segno alternato. Vediamo col criterio di Leibnitz.
Consideriamo la successione n 7→ 1/ ln2 n. Essa tende a zero per n→ +∞ ed e decrescente, dato che la funzionelogaritmica e crescente. Quindi la serie data converge (semplicemente) in base al criterio di Leibnitz.
Si noti che la serie non converge assolutamente, dato che∑+∞
n=2 1/ ln2 n diverge: infatti, come in un esercizio
molto simile in precedenza, ricordando che ln2 n e trascurabile rispetto ad n, possiamo affermare che 1/n etrascurabile rispetto a 1/ ln2 n. Pertanto, dato che la serie armonica diverge, allora diverge anche la serie data.
(c)
+∞∑
n=0
(−1)n 2
3n. Serie a termini di segno alternato. Vediamo col criterio di Leibnitz.
La successione n 7→ 23n tende a zero per n → +∞ ed e decrescente dato che la funzione esponenziale a
denominatore e crescente. Quindi la serie data converge in base al criterio di Leibnitz.
Questa volta c’e anche convergenza assoluta, dato che la serie∑+∞
n=023n e uguale a 2
∑+∞n=0
13n e quest’ultima
converge essendo una serie geometrica di ragione 13 .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
SUCCESSIONI E SERIE
270
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

Parte III
Nella terza parte del corso di Matematica affrontiamo alcuni degli argomenti che fanno parte di quello che va sotto ilnome di Algebra lineare.Alcuni di voi probabilmente hanno gia incontrato alcuni di questi argomenti e sanno gia ad esempio che cosa e unamatrice o come si risolve in generale un sistema di equazioni lineari. Sono generalmente argomenti piu semplici rispettoa quelli dell’Analisi, anche se presentano un livello di astrazione notevole.
Ecco un sintetico elenco di quanto vedremo in questa parte del corso.
• La struttura di spazio vettoriale, che e l’ambiente ideale per trattare tutti questi concetti
• I concetti essenziali sulle trasformazioni lineari e sulle matrici
• La definizione di determinante e rango e alcuni risultati generali che mettono in relazione questi con altri aspettirilevanti delle trasformazioni
• I sistemi lineari e un metodo generale per la loro risoluzione


1 LA STRUTTURA DI SPAZIO VETTORIALE
SPAZI VETTORIALI RN
273
III-1 Spazi vettoriali Rn
1 La struttura di spazio vettoriale
In questa dispensa definiamo un “ambiente” in cui si possono trattare problemi in piu variabili. Nella II parte delcorso abbiamo visto molti aspetti legati ad R e alle funzioni definite in R. Volendo vedere la cosa da un punto di vistaapplicativo, tutto questo puo servire se abbiamo un problema in una sola variabile. Molto spesso invece (quasi sempre)nelle applicazioni si affrontano questioni che devono necessariamente prevedere la presenza di piu di una variabile. Perquesto, oltre che per i soliti aspetti teorici generali che comunque la matematica studia, quanto vediamo ora assumeun’importanza molto rilevante.Iniziamo prendendo in considerazione l’insieme i cui elementi sono le n-uple ordinate di numeri reali, dove n e unnumero naturale, con n ≥ 2. Si tratta dell’insieme, che indichero con Rn, definito da
Rn ={
(x1, x2, . . . , xn) : xi ∈ R, 1 ≤ i ≤ n}
.288
Se (x1, x2, . . . , xn) e un elemento di Rn, lo si chiama anche vettore. I numeri reali xi (i = 1, 2, . . . , n) si dicono lecomponenti del vettore.Gli elementi di Rn, qualora non sia indispensabile fare riferimento alle loro singole componenti, saranno indicati conlettere minuscole in grassetto: cosı, scrivendo x ∈ Rn, intendero che x = (x1, x2, . . . , xn). Metto in guardia glistudenti: i vettori sono fatti di numeri reali e le operazioni che tra breve vedremo coinvolgono vettori e numeri realiinsieme. Una difficolta che spesso si incontra e capire che cosa e vettore e che cosa e numero reale. La notazione ingrassetto viene usata per aiutare a non fare confusione.Talvolta nel seguito mi sara utile considerare un certo numero, diciamo k, di vettori, tutti appartenenti ad Rn. Liindichero allora ad esempio con v1,v2, . . . ,vk, e metto in guardia lo studente a non confondere le due scritture
(x1, x2, . . . , xn) : xi ∈ R e v1,v2, . . . ,vk : vj ∈ Rn .
La prima si riferisce ad un vettore di n componenti (quindi un elemento di Rn), la cui generica componente e xi,mentre la seconda sta ad indicare k vettori di Rn, dei quali il generico viene indicato con vj .Ovviamente, se ho la necessita di riferirmi alla i–esima componente del j–esimo vettore, usero la scrittura vji .Ora che abbiamo definito l’ambiente, occorre precisare quali operazioni posso fare nell’ambiente stesso.
Nell’insieme Rn possiamo definire le seguenti due operazioni, che chiamiamo rispettivamente addizione e moltipli-cazione per gli scalari o piu semplicemente moltiplicazione scalare.L’addizione viene definita in questo modo: se x = (x1, x2, . . . , xn) e y = (y1, y2, . . . , yn) sono due elementi di Rn,poniamo
x+ y = (x1 + y1, x2 + y2, . . . , xn + yn).
E chiaro che in questo modo la somma dei due vettori e ancora un vettore di Rn.La moltiplicazione per uno scalare, cioe per un numero reale, e definita cosı: se x = (x1, x2, . . . , xn) e un elemento diRn e α e un numero reale, allora
αx = (αx1, αx2, . . . , αxn) ,
dove ovviamente αxi e il prodotto (in R) dei due numeri reali α e xi, per ogni i = 1, 2, . . . , n.Si puo facilmente verificare che le operazioni appena definite hanno le seguenti proprieta.
1a. ∀x,y ∈ Rn si ha x+ y = y + x, (proprieta commutativa dell’addizione);
1b. ∀x,y, z ∈ Rn si ha (x+ y) + z = x+ (y + z), (proprieta associativa dell’addizione);
1c. esiste un vettore (e il vettore nullo e si indica con 0) tale che x+ 0 = x, ∀x ∈ Rn; 289
1d. ogni vettore x ∈ Rn ha un opposto (si indica con −x) tale che x+ (−x) = 0;
2a. ∀x ∈ Rn e ∀α, β ∈ R si ha α(βx) = (αβ)x (proprieta associativa della moltiplicazione per gli scalari);
2b. ∀x ∈ Rn e ∀α, β ∈ R si ha (α+ β)x = αx+ βx (proprieta distributiva della moltiplicazione scalare
288La scrittura (x1, x2, . . . , xn) e della massima generalita, dato che non viene esplicitamente indicato il numero di componenti, se nonattraverso il numero n. Se devo riferirmi alla generica componente, senza indicare esattamente quale, posso indicarla con xi, e ovviamentei e un numero intero che sta tra 1 ed n. La scrittura formale dice proprio questo.289Si tratta ovviamente del vettore con tutte le componenti nulle, cioe 0 = (0, 0, . . . , 0).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
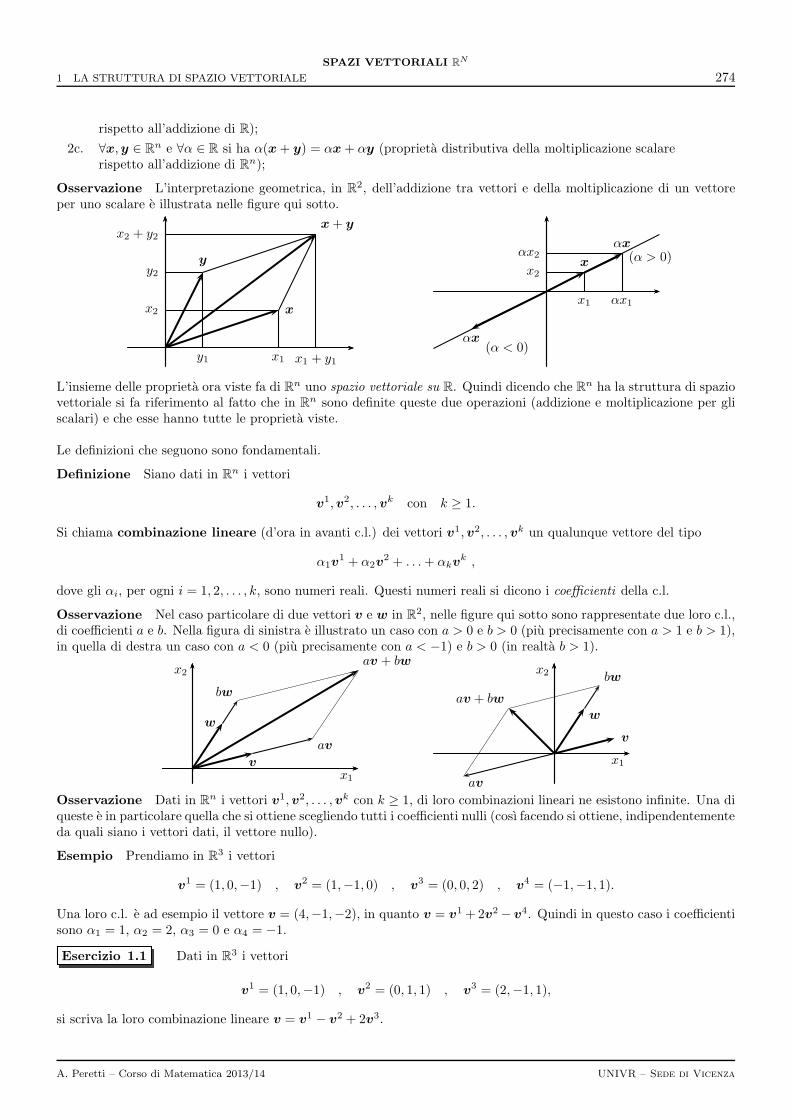
1 LA STRUTTURA DI SPAZIO VETTORIALE
SPAZI VETTORIALI RN
274
rispetto all’addizione di R);
2c. ∀x,y ∈ Rn e ∀α ∈ R si ha α(x+ y) = αx+ αy (proprieta distributiva della moltiplicazione scalarerispetto all’addizione di Rn);
Osservazione L’interpretazione geometrica, in R2, dell’addizione tra vettori e della moltiplicazione di un vettoreper uno scalare e illustrata nelle figure qui sotto.
x
y
x+ y
x1
x2
y1
y2
x1 + y1
x2 + y2
x
αx
αx
(α > 0)
(α < 0)
x1
x2
αx1
αx2
L’insieme delle proprieta ora viste fa di Rn uno spazio vettoriale su R. Quindi dicendo che Rn ha la struttura di spaziovettoriale si fa riferimento al fatto che in Rn sono definite queste due operazioni (addizione e moltiplicazione per gliscalari) e che esse hanno tutte le proprieta viste.
Le definizioni che seguono sono fondamentali.
Definizione Siano dati in Rn i vettori
v1,v2, . . . ,vk con k ≥ 1.
Si chiama combinazione lineare (d’ora in avanti c.l.) dei vettori v1,v2, . . . ,vk un qualunque vettore del tipo
α1v1 + α2v
2 + . . .+ αkvk ,
dove gli αi, per ogni i = 1, 2, . . . , k, sono numeri reali. Questi numeri reali si dicono i coefficienti della c.l.
Osservazione Nel caso particolare di due vettori v e w in R2, nelle figure qui sotto sono rappresentate due loro c.l.,di coefficienti a e b. Nella figura di sinistra e illustrato un caso con a > 0 e b > 0 (piu precisamente con a > 1 e b > 1),in quella di destra un caso con a < 0 (piu precisamente con a < −1) e b > 0 (in realta b > 1).
v
w
av
bw
av + bw
x1
x2
v
w
av
bw
av + bw
x1
x2
Osservazione Dati in Rn i vettori v1,v2, . . . ,vk con k ≥ 1, di loro combinazioni lineari ne esistono infinite. Una diqueste e in particolare quella che si ottiene scegliendo tutti i coefficienti nulli (cosı facendo si ottiene, indipendentementeda quali siano i vettori dati, il vettore nullo).
Esempio Prendiamo in R3 i vettori
v1 = (1, 0,−1) , v2 = (1,−1, 0) , v3 = (0, 0, 2) , v4 = (−1,−1, 1).
Una loro c.l. e ad esempio il vettore v = (4,−1,−2), in quanto v = v1 +2v2− v4. Quindi in questo caso i coefficientisono α1 = 1, α2 = 2, α3 = 0 e α4 = −1.
Esercizio 1.1 Dati in R3 i vettori
v1 = (1, 0,−1) , v2 = (0, 1, 1) , v3 = (2,−1, 1),
si scriva la loro combinazione lineare v = v1 − v2 + 2v3.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 DIPENDENZA E INDIPENDENZA LINEARE
SPAZI VETTORIALI RN
275
2 Dipendenza e indipendenza lineare
Definizione Nello spazio vettoriale Rn, i vettori v1,v2, . . . ,vk si dicono linearmente dipendenti (d’ora in avantil.d.) se esiste una loro c.l. uguale al vettore nullo con coefficienti non tutti nulli (cioe con almeno un coefficiente nonnullo).290
Definizione I vettori v1,v2, . . . ,vk si dicono linearmente indipendenti (d’ora in avanti l.i.) se non sono l.d. ecioe se l’unica loro c.l. uguale al vettore nullo e quella in cui tutti i coefficienti sono nulli.291
Osservazione Se concordiamo di chiamare banale una combinazione lineare con coefficienti tutti uguali a zero,possiamo dire che dei vettori sono l.d. se c’e una loro c.l. non banale uguale al vettore nullo. Invece i vettori sono l.i.se l’unica loro c.l. uguale al vettore nullo e quella banale.
Esempio In R2 i vettoriv1 = (1,−2) , v2 = (−2, 4)
sono l.d. in quanto 2v1 + v2 = 0.In R3 i vettori
v1 = (1, 0, 1) , v2 = (0, 1, 0) , v3 = (0, 0, 1)
sono l.i. Infatti, supponiamo che ci sia una c.l. dei tre vettori uguale al vettore nullo. Allora sara
α1(1, 0, 1) + α2(0, 1, 0) + α3(0, 0, 1) = (0, 0, 0) , che significa (α1, α2, α1 + α3) = (0, 0, 0).
Ma da quest’ultima si ricava che deve necessariamente essere α1 = α2 = α3 = 0.
Osservazione Le due definizioni sono tradizionalmente ostiche per molti studenti.Ribadisco che esse dicono in pratica che i vettori sono l.d. se il vettore nullo si puo scrivere in modo non banale,cioe con coefficienti non tutti nulli, come c.l. dei vettori dati e invece i vettori sono l.i. se il vettore nullo si puoscrivere come loro c.l. soltanto in modo banale, cioe con coefficienti tutti nulli. Si tratta ovviamente di due proprietamutuamente esclusive (o e l’una o e l’altra).Per verificare attraverso la definizione se dei vettori dati sono dipendenti o indipendenti basta porre una generica loroc.l. uguale al vettore nullo e trovare se i coefficienti devono necessariamente essere tutti nulli oppure no (come fattonell’esempio dei tre vettori).
Esercizi
⊲ Se abbiamo un solo vettore, esso e l.i. se e solo se non e il vettore nullo.
⊲ Se tra i vettori v1,v2, . . . ,vk c’e il vettore nullo, i vettori sono sicuramente l.d. Attenzione pero che dei vettoripossono essere l.d. anche se nessuno di essi e il vettore nullo (come visto in uno degli esempi).
⊲ Se V ={v1,v2, . . . ,vk
}e i vettori di V sono l.i., allora ogni sottoinsieme di V e costituito da vettori l.i.
⊲ Invece, se V ={v1,v2, . . . ,vk
}e i vettori di V sono l.d., allora ogni insieme di vettori che contenga V e costituito
da vettori l.d.
Se abbiamo un insieme di almeno due vettori vale il seguente risultato:
Teorema
i) Nello spazio vettoriale Rn, i vettori v1,v2, . . . ,vk, con k ≥ 2, sono l.d. se e solo se almeno uno di essi si puoscrivere come c.l. dei rimanenti.
ii) I vettori v1,v2, . . . ,vk, con k ≥ 2, sono l.i. se e solo se nessuno di essi si puo scrivere come c.l. degli altri.
290Scritta formalmente, questa definizione dice che i vettori v1, v2, . . . ,vk sono l.d. se
∃α1, α2, . . . , αk , con αi 6= 0 per qualche i, tali che α1v1 + α2v
2 + . . .+ αkvk = 0.
291Scritta formalmente, questa definizione dice che i vettori v1, v2, . . . ,vk sono l.i. se e solo se
α1v1 + α2v
2 + . . .+ αkvk = 0 =⇒ α1 = α2 = . . . = αk = 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 DIPENDENZA E INDIPENDENZA LINEARE
SPAZI VETTORIALI RN
276
Osservazione La dimostrazione non e difficile. Per comprendere meglio le definizioni vediamo ad esempio ladimostrazione della i). Se i vettori v1,v2, . . . ,vk sono l.d. significa per definizione che si ha
α1v1 + α2v
2 + . . .+ αkvk = 0 con almeno un αi 6= 0.
Mettiamo che sia il primo, cioe sia α1 6= 0 (se non fosse il primo potrei comunque usare un ragionamento del tuttoanalogo). Allora possiamo scrivere
α1v1 = −α2v2 − . . .− αkv
k e quindi v1 = −α2
α1v2 − . . .−
αk
α1vk.
Quindi ho dimostrato che possiamo scrivere v1 come c.l. degli altri.Viceversa, se uno dei vettori si puo scrivere come c.l. dei rimanenti (mettiamo sia il primo), significa che avremov1 = β2v2 + . . .+ βkv
k, da cui potremo scrivere v1 − β2v2 − . . .− βkvk = 0 e quindi ho scritto il vettore nullo comec.l. dei vettori dati e almeno un coefficiente e diverso da zero (infatti il primo coefficiente e 1).E chiaro che tutto funziona se i vettori da cui si parte sono almeno due, da cui l’ipotesi che sia k ≥ 2.
Esercizio 2.1 Si dica, usando la definizione, se i vettori
v1 = (1,−1) , v2 = (−1, 1) , v3 = (0, 1)
sono linearmente dipendenti o indipendenti.
Esercizio 2.2 Si dica, usando la definizione, se i vettori
v1 = (1, 2) , v2 = (1,−1)
sono linearmente dipendenti o indipendenti.
Esercizio 2.3 Si dica, usando la definizione, se i vettori
v1 = (−1, 0, 1) , v2 = (1, 1, 0)
sono linearmente dipendenti o indipendenti.
Esercizio 2.4 Si dica, usando la definizione, se i vettori
v1 = (0, 1, 1) , v2 = (1, 0,−1) , v3 = (1, 1, 0)
sono linearmente dipendenti o indipendenti.
Esaminiamo ora un particolare ed importantissimo insieme di vettori di Rn. Consideriamo (in Rn) i vettori
u1,u2, . . . ,un ,
dove il generico vettore uj ha nulle tutte le sue componenti tranne la j–esima, che e uguale ad 1. Quindi u1 ha laprima componente 1 e le altre 0, u2 ha la seconda componente 1 e le altre 0, e cosı via fino ad un, che ha l’ultimacomponente 1 e le altre 0. Possiamo formalizzare la definizione dicendo che
uji =
{1 se i = j0 se i 6= j.
Faccio notare esplicitamente che in Rn l’insieme in questione e costituito da n elementi.Ad esempio, in R3, questo insieme e costituito dai vettori
u1 = (1, 0, 0) , u2 = (0, 1, 0) , u3 = (0, 0, 1) .
I vettori u1,u2, . . . ,un si dicono i vettori fondamentali di Rn. Vediamo perche questo insieme di vettori e importante.
Osservazione Ogni vettore di Rn si puo scrivere (in modo unico) come combinazione lineare dei vettori fondamentali(di Rn). Basta osservare infatti che, considerato un qualunque vettore x = (x1, x2, . . . , xn) ∈ Rn, si puo scrivere
x = x1u1 + x2u
2 + . . .+ xnun ,
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 BASE E DIMENSIONE DI UNO SPAZIO VETTORIALE
SPAZI VETTORIALI RN
277
che e una combinazione lineare dei vettori fondamentali. Inoltre si osserva che i coefficienti di tale combinazione linearesono le componenti del vettore x. Quando scriviamo un vettore come n-upla di componenti, queste componenti sonoquindi i coefficienti della combinazione lineare di vettori fondamentali attraverso la quale si puo esprimere il vettorestesso.
Osservazione I vettori fondamentali quindi, attraverso loro opportune combinazioni lineari, permettono di otteneretutti i vettori di Rn. Per questo si dice che i vettori fondamentali sono generatori (o un insieme di generatori) dellospazio Rn.
Viene data infatti in generale la seguente
Definizione I vettori v1,v2, . . . ,vk si dicono generatori dello spazio vettoriale Rn se ogni vettore x ∈ Rn si puoscrivere come c.l. di v1,v2, . . . ,vk, se cioe per ogni v ∈ Rn esistono dei coefficienti α1, α2, . . . , αk tali che
x = α1v1 + α2v
2 + . . .+ αkvk.
Esempio I vettori v1 = (1, 1) e v2 = (1,−1) sono generatori di R2. Infatti, preso un qualunque vettore (x, y) ∈ R2,si puo scrivere
(x, y) = α1v1 + α2v
2 (basta prendere α1 = x+y2 e α2 = x−y
2 ).
3 Base e dimensione di uno spazio vettoriale
Segue una definizione fondamentale.
Definizione Una base di uno spazio vettoriale Rn e un insieme di vettori che siano contemporaneamente generatoridi Rn e linearmente indipendenti.
Osservazione I vettori fondamentali di Rn sono una base di Rn. Infatti, oltre ad essere, come gia visto, generatoridi Rn, e facile dimostrare che sono anche l.i. Lo studente e invitato a dimostrarlo.
Osservazione In Rn non vi e un’unica base: ad esempio, in R2, abbiamo visto che i vettori fondamentali u1 = (1, 0)e u2 = (0, 1) formano una base. Ma anche ad esempio l’insieme dei due vettori v = (12 ,
12 ) e w = (12 ,− 1
2 ) forma unabase. Infatti, osservando che v + w = u1 e v − w = u2, si ha subito che ogni vettore x di R2, potendosi scriverecome c.l. di u1 e u2, si puo anche scrivere come c.l. di v e w, e quindi v e w sono generatori di R2. Inoltre non edifficile verificare che una c.l. di v e w e nulla solo se sono nulli i due coefficienti, e quindi v e w sono l.i. Pertantoessi formano una base di R2.
Definizione In Rn la base formata dai vettori fondamentali si chiama la base fondamentale (o base canonica).Ad esempio, in R2 la base fondamentale e
{(1, 0), (0, 1)
}e in R3 e
{(1, 0, 0), (0, 1, 0), (0, 0, 1)
}.
Si puo dimostrare che vale la
Proposizione Se {v1,v2, . . . ,vk} e una base di Rn, allora ogni x ∈ Rn si puo scrivere in modo unico come c.l. deivettori della base.
Osservazione Si intuisce forse che il fatto che i vettori siano generatori garantisce che x si possa scrivere come loroc.l. e il fatto che siano l.i. garantisce l’unicita della scrittura.
Quello che segue e un risultato fondamentale, che giustifica la definizione successiva.
Teorema Tutte le basi di Rn sono formate da n vettori.Pertanto ha senso porre la seguente importante definizione:
Definizione La dimensione di uno spazio vettoriale Rn e il numero di elementi delle basi dello spazio. Essa siindica con dimRn.
Osservazione Quindi si ha che dimRn = n. La dimensione di R2 e 2, la dimensione di R3 e 3, e cosı via.
Sono importanti anche i seguenti risultati:
Proposizione
1. Ogni insieme di piu di n vettori nello spazio vettoriale Rn e formato da vettori l.d.
2. Un insieme di n vettori di Rn e una base se e solo se i vettori sono l.i.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOTTOSPAZI
SPAZI VETTORIALI RN
278
3. Un insieme di n vettori di Rn e una base se e solo se i vettori sono generatori di Rn.
Osservazione La Proposizione quindi stabilisce questo fatto importante: in uno spazio di dimensione n, se abbiamopiu di n vettori, essi sono certamente dipendenti; inoltre n vettori, se linearmente indipendenti, sono anche generatori(e quindi una base) e viceversa, se generatori, allora sono anche indipendenti (e quindi una base). Si faccia attenzione:questi risultati valgono quando si hanno vettori in numero uguale alla dimensione dello spazio.
4 Sottospazi
Definizione Un sottoinsieme non vuoto S di Rn si dice sottospazio di Rn se per ogni scelta di x e y in S tutte leloro c.l. αx+ βy appartengono a S.
Osservazioni Non e difficile provare che:
• se S e sottospazio di Rn, allora S contiene l’origine di Rn. Infatti, se x,y ∈ S, allora anche 0 · x+ 0 · y = 0 ∈ S;
• sottospazi molto particolari di uno spazio Rn sono {0} e tutto Rn, e sono detti sottospazi banali.292
Esempi Verifichiamo, a titolo di esercizio, che:
• In R2, l’insieme S ={
(s, 0) : s ∈ R
}
e sottospazio di R2.
In S stanno i punti (vettori) con la seconda componente nulla. Se prendiamo due qualunque di questi puntiallora certamente ogni loro c.l. ha la seconda componente nulla. Quindi S e per definizione un sottospazio di R2.
• In R2, l’insieme S ={
(s1, s2) : s21 + s22 ≤ 1
}
non e sottospazio di R2.
Si tratta del cerchio di centro l’origine e raggio 1. Pur contenendo il vettore nullo, l’insieme S non soddisfa laproprieta dei sottospazi: infatti, se consideriamo ad esempio i due punti (1, 0) e (0, 1), che stanno in S, e nefacciamo la somma, otteniamo il vettore (1, 1), che non sta in S.
• In R3, l’insieme S ={
(s1, s2, s3) : s1 + s2 + s3 = 0}
e sottospazio di R3.
Detto a parole, si tratta dei vettori (di tre componenti) la cui somma delle componenti e nulla. Siano x =(x1, x2, x3) e y = (y1, y2, y3) in S: allora x1 + x2 + x3 = 0 e y1 + y2 + y3 = 0. Se costruiamo una generica c.l. deidue vettori x e y (indichiamola con ax+ by) allora si ha
ax+ by = a(x1, x2, x3) + b(y1, y2, y3)
= (ax1, ax2, ax3) + (by1, by2, by3)
= (ax1 + by1, ax2 + by2, ax3 + by3).
Ora, se sommiamo le componenti di quest’ultimo, otteniamo
ax1 + by1 + ax2 + by2 + ax3 + by3 = a(x1 + x2 + x3) + b(y1 + y2 + y3) = a · 0 + b · 0 = 0,
e quindi la generica c.l di x e y sta in S, cioe S e un sottospazio di R3.
Dovrebbe essere naturale pensare che in generale l’insieme S ={
(s1, . . . , sn) : s1 + . . . + sn = 0}
e sottospazio
di Rn.
Possiamo ripetere per un sottospazio la definizione di vettori generatori e di base.
Definizione Se S e sottospazio di Rn, si dice che i vettori v1,v2, . . . ,vk generano (o sono generatori di S) se ognivettore di S si puo scrivere come c.l. dei vettori v1,v2, . . . ,vk.
Definizione I vettori v1,v2, . . . ,vk sono una base di S se sono generatori di S e nello stesso tempo sono linearmenteindipendenti.
292Non si faccia confusione tra ∅ e {0}: il primo e l’insieme che non ha elementi, il secondo e l’insieme che contiene il solo vettore nullo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOTTOSPAZI
SPAZI VETTORIALI RN
279
Osservazione Sono le stesse definizioni gia incontrate prima, solo che allora erano riferite a tutto lo spazio Rn, orainvece riguardano un suo sottospazio. Come fatto per lo spazio Rn, si puo definire in modo analogo la dimensionedi un suo sottospazio, riferendosi al numero di elementi che costituiscono le basi del sottospazio.Si puo dimostrare, come si intuisce facilmente, che se S e sottospazio di Rn, allora 0 ≤ dim S ≤ n. L’unico sottospaziocon dimensione 0 e il sottospazio banale formato dal solo vettore nullo e l’unico sottospazio di dimensione n e tutto lospazio Rn, cioe l’altro sottospazio che abbiamo chiamato banale.
Per capire un po’ piu a fondo come si possano ottenere sottospazi di Rn, partiamo da un semplice esercizio: dimostriamoche, se consideriamo ad esempio in R3 due vettori qualunque v1 e v2, l’insieme di tutte le c.l. di questi due vettoriformano un sottospazio di R3. Per fissare le idee indichiamo con S l’insieme di tutte le c.l. di v1 e v2. Formalmente
S ={
α1v1 + α2v
2 : α1, α2 ∈ R
}
.
Per dimostrare che S e sottospazio di R3 come sempre dobbiamo far vedere che, presi due elementi generici di S, ogniloro c.l. e ancora un elemento di S. Siano allora x e y elementi di S; questo significa che
x = x1v1 + x2v
2 e y = y1v1 + y2v
2.
Ora prendiamo una generica c.l. di x e y e sia ax+ by. Allora
ax+ by = a(x1v1 + x2v
2) + b(y1v1 + y2v
2) = ax1v1 + ax2v
2 + by1v1 + by2v
2 = (ax1 + by1)v1 + (ax2 + by2)v
2.
Si tratta allora di una c.l. di v1 e v2 (a, b, x1, y1, x2, y2 sono numeri) e quindi di un elemento di S ed e quello chevolevamo provare.Quanto appena trovato e un risultato che si generalizza facilmente: se in Rn prendiamo certi vettori v1,v2, . . . ,vk,l’insieme di tutte le loro c.l. forma un sottospazio di Rn. Vale anche se considero un solo vettore v: le c.l. di v sonoovviamente i vettori del tipo αv, dove α e un qualunque numero reale.
Definizione In Rn si chiama sottospazio generato da v1,v2, . . . ,vk il sottospazio formato da tutte le c.l. div1,v2, . . . ,vk.
Osservazione Quanto trovato ci fornisce un modo per costruire sottospazi di Rn. Resta poi aperta la questione seogni sottospazio di Rn sia ottenibile in questo modo, cioe come sottospazio generato da alcuni vettori. Di questo cioccupiamo tra un po’. Ora costruiamo qualche sottospazio con qualche esempio.
Esempio Prendiamo, in R2, il vettore v = (1, 2). Cerchiamo di capire comee fatto geometricamente il sottospazio generato da v. Si tratta come dettodell’insieme di tutte le c.l. di v e cioe dell’insieme
S ={
αv : α ∈ R
}
.
Sono tutti i multipli del vettore v e quindi, ricordando il significato geometricodella moltiplicazione scalare, sono tutti (e soli) i vettori che stanno sulla retta(passante per l’origine) che contiene v.
v
1
2
x1
x2 S
Possiamo dire molte cose di S (possiamo dire tutto):
• v e un generatore di S, in quanto ogni elemento di S si puo scrivere come c.l. di v
• v forma una base di S, 293 in quanto v, non essendo nullo, e linearmente indipendente
• come conseguenza del punto precedente la dimensione di S e 1.
Esempio Consideriamo ora, sempre in R2, due vettori e siano v e w. Come e fatto geometricamente il sottospaziogenerato da v e w? Si tratta ancora dell’insieme di tutte le c.l. di v e w e cioe di
S ={
av + bw : a, b ∈ R
}
.
Possiamo ancora aiutarci con la geometria e con l’interpretazione geometrica della c.l. av + bw. Si dovrebbe intuireche possiamo avere due casi ben distinti: se i due vettori v e w stanno sulla stessa retta (sono linearmente dipendenti)allora prendendo tutte le c.l dei due vettori otteniamo quello che si otteneva prima con un solo vettore, cioe la retta
293Per l’esattezza dovremmo scrivere che {v} e una base di S.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOTTOSPAZI
SPAZI VETTORIALI RN
280
che contiene entrambi; se invece i due vettori non sono sulla stessa retta (cioe sono linearmente indipendenti) alloracon le c.l. di v e w possiamo ottenere tutti i vettori del piano.294
Allora possiamo concludere l’esempio dicendo:
• se v e w sono l.d. il sottospazio S da essi generato e rappresentato da una retta per l’origine. In questo casodim S = 1;
• se v e w sono l.i. il sottospazio S da essi generato e tutto R2. In questo caso ovviamente dim S = 2.
Osservazione Non e difficile capire che non ci sono situazioni “intermedie”, cioe sottospazi che siano “un po’ piudi una retta e un po’ meno di tutto R2”. In altre parole in R2 i sottospazi non banali sono soltanto le rette perl’origine.295
Osservazione Qualcuno potrebbe porsi questa domanda: possono esserci in R2 sottospazi di dimensione 1 che nonsono rette? Per arrivare a convincersi che la risposta e no, si rifletta su queste due considerazioni: per prima cosa unsottospazio deve essere necessariamente un insieme non limitato (quindi un segmento, un triangolo, un quadrato, uncerchio, . . . non possono essere sottospazi); secondo, se in un sottospazio c’e un punto, allora deve esserci necessaria-mente anche tutta la retta che passa per quel punto e per l’origine (segue dalla definizione di sottospazio). E si tengaanche conto infine del fatto che, se ci sono nell’insieme due vettori l.i., allora c’e tutto R2.
Esempio Che cosa succede in R3? Possiamo anche qui procedere per esempi, come prima. Se consideriamo ilsottospazio generato da un solo vettore v, si tratta di una retta per l’origine (sottospazio di dimensione 1). Seconsideriamo il sottospazio generato da v e w, per analogia con quanto succede in R2 si intuisce che si possono averedue casi: o una retta per l’origine, se v e w sono l.d. (stanno sulla stessa retta) oppure l’insieme delle c.l. di duevettori l.i. Non e difficile intuire che sono i punti del piano che contiene i due vettori. Con due soli vettori non si puoottenere nulla che non stia nel loro stesso piano. In questo caso si tratta di un sottospazio di dimensione 2.Ora ci si chiede: e con 3 vettori v,w, z che cosa possiamo ottenere? Semplice, ci si arriva anche qui per analogia conquanto accade in R2:
• se i tre vettori stanno sulla stessa retta, otteniamo la retta che li contiene (sottospazio di dimensione 1);
• se i tre vettori non stanno sulla stessa retta ma stanno sullo stesso piano otteniamo il piano che li contiene(sottospazio di dimensione 2);
• se i tre vettori non stanno sullo stesso piano otteniamo tutto R3, che l’unico sottospazio di dimensione 3.
E ora l’osservazione che permette poi di capire l’aspetto cruciale in generale: quello che determina la dimensione delsottospazio generato da alcuni vettori non e il numero di questi, ma e il numero di vettori linearmente indipendentiche ci sono tra questi, o meglio ancora il massimo numero di vettori l.i. tra questi.
Poniamoci ora due importanti domande relative al sottospazio S generato dai vettori v1,v2, . . . ,vk in Rn.
1. Qual e la dimensione di S?
2. Come si puo trovare una base di S?
Osservazione Si noti che non mi chiedo di trovare dei generatori di S dato che, per definizione, v1,v2, . . . ,vk sonogeneratori dello spazio da essi generato.Gli esempi appena visti in R2 ed R3 e la considerazione fatta alla fine di questi esempi ci permette di risponderesubito alla prima domanda: la dimensione di S dipende da quanti vettori l.i. ci sono tra i vettori v1,v2, . . . ,vk ed eesattamente il massimo numero di vettori l.i. che possiamo trovare tra i generatori (ovviamente sara dim S ≤ k).Per arrivare a rispondere alla seconda domanda basta fare queste considerazioni: se i vettori v1,v2, . . . ,vk sono l.i.allora essi formano una base di S. 296
294Questo forse puo non essere di immediata comprensione, ma a tale scopo e utile il seguente esercizio: disegnate due vettori l.i., poiprendete un qualunque altro vettore del piano e cercate di ottenerlo come c.l. dei due vettori fissati, ricordando la costruzione geometricadella diagonale del parallelogramma. Se i due vettori iniziali li avete presi nello stesso quadrante, ad esempio il primo, provate a scegliereil terzo nel secondo o terzo quadrante e constatate che e sempre possibile ottenerlo come c.l. degli altri due.295Che i sottospazi siano solo le rette per l’origine segue ovviamente dal fatto, trovato all’inizio, che ogni sottospazio deve contenere ilvettore nullo.296Segue direttamente dalla definizione di base di un sottospazio: una base e un insieme di generatori l.i. del sottospazio. I vettoriv1,v2, . . . ,vk sono come detto generatori del sottospazio da essi generato (e solo un giro di parole) e, essendo l.i., sono allora una base.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 PRODOTTO INTERNO
SPAZI VETTORIALI RN
281
Se i vettori sono l.d. allora posso trovarne uno che dipende dagli altri (definizione di vettori l.d.), lo tolgo dal gruppoe mi rifaccio la stessa domanda di prima: quelli che restano sono l.i.? Se sı sono una base, se no ne posso trovare unaltro che dipende dagli altri e toglierlo, e cosı via.Senza scendere nei particolari di un procedimento che dovrebbe apparire abbastanza convincente, si puo dimostrareche questo metodo funziona: permette, o prima o dopo, di trovare finalmente un insieme di vettori l.i. e di concludereche esso e una base di S.
Osservazione Le risposte alle due domande (come trovare la dimensione e una base del sottospazio generato dav1,v2, . . . ,vk) le abbiamo, ma lo studente lungimirante potrebbe osservare che le cose non e detto siano semplici daun punto di vista operativo, cioe nei casi concreti. E avrebbe senz’altro visto giusto. Come stabilire qual e, con 10o 50 vettori, il massimo numero di quelli indipendenti? Come trovare, tra 10 o 50 vettori, se ce n’e uno che dipendedagli altri e poi ripetere questa operazione fino ad averli indipendenti?297
A titolo di esempio (ma con solo quattro vettori in R2), consideriamo il sottospazio di R2 generato dai vettori
v1 = (1, 1) , v2 = (1,−1) , v3 = (0, 2) , v4 = (2, 0).
Possiamo osservare che i vettori sono dipendenti (sono 4 in uno spazio di dimensione 2) e che, ad esempio, v4 = v1+v2.Eliminiamo v4 (perche il sottospazio generato da v1,v2,v3 coincide con quello generato da v1,v2,v3,v4).I vettori rimasti sono ancora dipendenti in quanto, ad esempio, v3 = v1 − v2. Eliminiamo anche v3, per lo stessomotivo di prima. Restano v1 e v2, che sono indipendenti. Essi sono una base per il sottospazio in questione (che tral’altro in questo caso e tutto R2).
Osservazione Lo studente molto lungimirante, riflettendo bene sull’esempio proposto, potrebbe ora osservare cheall’inizio abbiamo eliminato v4, trovandolo dipendente dagli altri. Ma anche v1 dipende dagli altri, perche dalla stessarelazione usata prima possiamo ricavare v1 = v4 − v2. E se avessimo eliminato v1 al posto di v4? Avremmo avutoalla fine una base diversa e magari una dimensione diversa? Ebbene, sı e no: sı alla prima domanda e no alla seconda.Possiamo certamente trovare basi diverse (la base di uno spazio, o di un sottospazio, non e unica, lo abbiamo gia visto)ma la dimensione e unica. Alla fine del nostro processo di eliminazione dei vettori dipendenti potremmo trovare avolte una base diversa ma fatta dallo stesso numero di vettori dell’altra.Torneremo piu avanti sulla questione di come si possa operare nel concreto per risolvere le due questioni.
Esercizio 4.1 Si stabilisca se i seguenti insiemi sono sottospazi. In caso affermativo se ne indichi una base.
(a) S1 ⊆ R2, con S1 ={
(s,−s) : s ∈ R
}
(b) S2 ⊆ R2, con S2 ={
(s, s2) : s ∈ R
}
(c) S3 ⊆ R2, con S3 ={
(s, s− 1) : s ∈ R
}
(d) S4 ⊆ R2, con S4 ={
(s1, s2) : |s1| ≤ 1, |s2| ≤ 1}
(e) S5 ⊆ R3, con S5 ={
(s1, s2, s3) : s1 = s3
}
(f) S6 ⊆ R3, con S6 ={
(s1, s2, s3) : s1 − s3 = 1}
5 Prodotto interno
Definisco ora una nuova operazione tra vettori di Rn.
Definizione Siano x,y ∈ Rn, con x = (x1, x2, . . . , xn) e y = (y1, y2, . . . , yn).Si definisce prodotto interno (o prodotto scalare) di x e y il numero reale
〈x,y〉 = x1y1 + x2y2 + . . .+ xnyn =n∑
i=1
xiyi .
297Si noti che non e rilevante soltanto il numero di vettori ma anche lo spazio in cui si trovano questi vettori: se con 10 vettori in R2 forsele cose non sono poi tanto complicate, ben diverso e il caso di 10 vettori in R10.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 PRODOTTO INTERNO
SPAZI VETTORIALI RN
282
Osservazione Il nome prodotto scalare fa riferimento al fatto che il risultato di questa operazione tra vettori e unoscalare, cioe un numero reale.298
Ad esempio, il prodotto interno di x = (1, 2, 3) e y = (−3, 2, 1) e 〈x,y〉 = 4, il prodotto interno di x = (0,−1, 1) ey = (1, 1, 0) e 〈x,y〉 = −1, il prodotto interno di x = (0,−1, 1) e y = (1, 1, 1) e 〈x,y〉 = 0.
Osservazione Si verifica facilmente che il prodotto interno tra vettori di Rn ha queste proprieta:
1. 〈x,x〉 ≥ 0, ∀x ∈ Rn, e 〈x,x〉 = 0 se e solo se x = 0;
2. 〈x,y〉 = 〈y,x〉, ∀x,y ∈ Rn ;
3. 〈αx+ βy, z〉 = α〈x, z〉+ β〈y, z〉, ∀α, β ∈ R, ∀x,y, z ∈ Rn.
Utilizzando la definizione di prodotto interno si puo dare l’ulteriore importante
Definizione Si definisce norma (euclidea) del vettore x ∈ Rn (e si scrive ‖x‖) il numero reale
‖x‖ =√
〈x,x〉 =
√√√√
n∑
i=1
x2i .
Esempio In R3 il vettore x = (1,−2, 3) ha norma euclidea ‖(1,−2, 3)‖ =√1 + 4 + 9 =
√14.
Osservazione Il concetto di norma e un concetto molto generale. Una norma in Rn e in generale una qualunquefunzione definita in Rn a valori in R che abbia le seguenti proprieta:
1. ‖x‖ ≥ 0, ∀x ∈ Rn e ‖x‖ = 0 se e solo se x = 0;
2. ‖αx‖ = |α|‖x‖, ∀x ∈ Rn, ∀α ∈ R;
3. ‖x+ y‖ ≤ ‖x‖+ ‖y‖, ∀x,y ∈ Rn.
Osservazione La prima proprieta dice che la norma non e mai negativa ed e nulla solo se il vettore e nullo; la secondae una proprieta di omogeneita e dice che se moltiplico il vettore per una costante, la norma subisce la stessa sorte(tenendo conto che, se la costante e negativa, la norma non puo diventare negativa); la terza si chiama disuguaglianzatriangolare e si legge dicendo che la norma della somma di due vettori e non maggiore della somma delle due norme.
Esercizio Lo studente verifichi tali proprieta sulla norma euclidea in Rn.
La norma euclidea non e l’unica norma possibile in Rn.Altri esempi di norme (non euclidee) in Rn sono le seguenti, dette rispettivamente norma uno, norma p (o p-norma)e norma infinito:
‖x‖1 =
n∑
i=1
|xi| , ‖x‖p =
(n∑
i=1
|xi|p)1/p
(p > 0) 299 , ‖x‖∞ = max1≤i≤n
|xi|.
Osservazione Si noti che ci sono infinite p-norme, dato che possiamo fissare un qualunque p > 0. Si noti anche chela norma 2 (quella con p = 2) e la norma euclidea.
Esempio In R4 prendiamo il vettore x = (−2, 0, 1,−3). Si ha
‖x‖1 = 2 + 1 + 3 = 6 , ‖x‖2 =√
22 + 1 + 32 =√14 , ‖x‖3 =
3√
23 + 1 + 33 =3√36 , ‖x‖∞ = 3.
Osservazione La norma e in qualche modo legata alla lunghezza del vettore. La norma euclidea e quella che appuntousiamo abitualmente per misurare le lunghezze: e una delle possibili norme. Anche le altre norme danno un certo tipodi informazione sulla lunghezza del vettore.
298Non si faccia confusione tra prodotto scalare e moltiplicazione scalare. Il primo moltiplica due vettori e ha per risultato un numero, laseconda moltiplica un vettore per un numero e ha per risultato un vettore.299Il parametro p puo essere un qualunque numero reale positivo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 PRODOTTO INTERNO
SPAZI VETTORIALI RN
283
Osservazione Se dividiamo un qualunque vettore v 6= 0 per la sua norma, cioemoltiplichiamo v per il numero reale 1
‖v‖ , otteniamo un vettore di norma 1 che, ad
esempio in R2 o in R3, possiamo dire avere la stessa direzione e lo stesso verso di v(lo si dice talvolta vettore normalizzato, cioe vettore che ha le stesse caratteristichedell’altro, ma ha norma 1). Se poniamo u = v
‖v‖ , allora possiamo scrivere v = ‖v‖·u.
v
1
u = v/‖v‖
Utilizzando il concetto di norma, e possibile definire la distanza tra gli elementi di Rn:
Definizione Dati x,y ∈ Rn, si chiama distanza (euclidea) tra x e y la norma (euclidea) della differenza dei duevettori, cioe il numero reale
d(x,y) = ‖x− y‖.
Esempio In R2 la distanza euclidea tra x = (2, 1) e y = (1,−3) e d(x,y) = ‖(1, 4)‖ =√17. In R3 la distanza tra
due vettori fondamentali e√2 (anche in R2 e anche in generale in Rn).
Osservazione Anche il concetto di distanza, come quello di norma, e piu generale di quanto la definizione precedentepossa far pensare. In generale, in un insieme X 300 si definisce distanza una qualunque funzione δ definita in X ×Xa valori reali che abbia le seguenti proprieta:
1. δ(x,y) ≥ 0, ∀x,y ∈ X e δ(x,y) = 0 se e solo se x = y;
2. δ(x,y) = δ(y,x), ∀x,y ∈ X ;
3. δ(x,y) ≤ δ(x, z) + δ(z,y), ∀x,y, z ∈ X .b
b
b
x
y
z
Osservazione In pratica questo e quello che chiediamo ad una funzione per chiamarla distanza: di non essere mainegativa e di ridursi a zero solo quando i due punti coincidono, di essere simmetrica e infine, la meno banale delle tre,di soddisfare una sorta di disuguaglianza triangolare.
Esercizio Si determini, prima in R2 e in R3 e poi in generale in Rn, la distanza euclidea, la distanza in norma uno,in norma p e in norma infinito dei vettori fondamentali.
Esercizio Si verifichi che in Rn (ma anche in un qualsiasi insieme X) la funzione
δ(x,y) =
{0 se x = y
1 se x 6= y
e una distanza (distanza 0− 1).
Osservazione Questo risultato puo sorprendere, dato che difficilmente useremmo questa funzione per misurare ladistanza tra due punti (l’informazione che tale distanza fornisce e veramente poca). Pero anche questa funzione ha leproprieta richieste per essere una distanza.
Esercizio Si dimostri che, se x 7→ ‖x‖ e una norma in uno spazio vettoriale, allora δ(x,y) = ‖x − y‖ e unadistanza.301
Osservazione Non tutte le distanze si ricavano da una norma nel modo suggerito nell’esercizio precedente. Adesempio la distanza 0− 1 definita sopra non si puo ricavare da una norma. Lo studente cerchi di capire perche.
Osservazione Data in uno spazio vettoriale una distanza δ, il definire ‖x‖ = δ(x, 0) non porta in generale ad unanorma (anche se cosı accade in Rn con la distanza euclidea). Lo studente verifichi che ad esempio con la distanza 0−1la funzione x 7→ δ(x,0) non e una norma.
Si puo dimostrare che vale la seguente importante disuguaglianza di Cauchy–Schwarz :
|〈x,y〉| ≤ ‖x‖‖y‖, ∀x,y ∈ Rn.
300Si noti che viene richiesto solo che X sia un insieme, quindi non uno spazio vettoriale. Questo perche le proprieta (che seguono) delladistanza non richiedono nessuna struttura particolare in X. Lo studente e invitato a riconsiderare le proprieta della norma e a constatareche queste ultime richiedono invece una struttura, quella di spazio vettoriale.301Cioe se una funzione x 7→ ‖x‖ ha le tre proprieta di una norma allora la funzione (x,y) 7→ ‖x−y‖ ha le tre proprieta di una distanza.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 PRODOTTO INTERNO
SPAZI VETTORIALI RN
284
Osservazione A parole: il prodotto interno di due vettori e, in modulo, minore o uguale del prodotto delle normedei vettori.Riporto anche la dimostrazione della disuguaglianza di Cauchy–Schwarz, che non e difficile.
Dimostrazione La dimostrazione e “ingegnosa”. Consideriamo i vettori del tipo x+ ty con t ∈ R: si ha
0 ≤ 〈x+ ty,x+ ty〉= 〈x,x〉+ 〈x, ty〉+ 〈ty,x〉+ 〈ty, ty〉= 〈x,x〉+ 2t〈x,y〉+ t2〈y,y〉= ‖x‖2 + 2t〈x,y〉+ t2‖y‖2.
Quest’ultimo e un polinomio di secondo grado in t, che risulta quindi non negativo per ogni valore di t. Il discriminantedell’equazione deve allora essere ≤ 0, e pertanto
∆ = 〈x,y〉2 − ‖x‖2‖y‖2 ≤ 0,
da cui〈x,y〉2 ≤ ‖x‖2‖y‖2, e quindi |〈x,y〉| ≤ ‖x‖‖y‖.
Veniamo ora all’importante concetto di ortogonalita.
Definizione Due vettori x e y di Rn si dicono ortogonali se il loro prodotto interno e nullo, cioe se 〈x,y〉 = 0.
Esempio In R3 i vettori x = (2,−1, 1) e y = (1, 1,−1) sono ortogonali.
Osservazione Se v ∈ Rn, allora l’insieme di tutti i vettori di Rn ortogonali a v e un sottospazio di Rn. Dimostria-molo. Sia S l’insieme dei vettori di Rn ortogonali a v, cioe sia
S ={x ∈ Rn : 〈x,v〉 = 0
}.
Siano x,y ∈ S. Dimostriamo che allora anche una qualunque c.l. di x e y appartiene ad S. Indichiamo con ax+ byla c.l.. Si ha
〈ax+ by,v〉 = a〈x,v〉+ b〈y,v〉 = 0
e quindi e dimostrato che S e un sottospazio.Lo stesso risultato si generalizza facilmente ad un qualunque sottoinsieme di Rn, cioe: se T ⊂ Rn, allora l’insieme deivettori di Rn ortogonali a tutti gli elementi di T e un sottospazio di Rn (che si chiama complemento ortogonale di T ).La dimostrazione e analoga alla precedente, ma vediamola: ora si ha
S ={x ∈ Rn : 〈x, t〉 = 0, ∀t ∈ T
}.
Se x,y ∈ S, allora per una qualunque c.l. di x e y (e sia ax + by), se t e un qualunque elemento dell’insieme T ,avremo
〈ax+ by, t〉 = a〈x, t〉+ b〈y, t〉 = 0
e quindi S e un sottospazio.
Esempio In R2, il complemento ortogonale del sottospazio (di dimensione 1) costituito da una retta per l’origine ela retta (per l’origine) perpendicolare alla retta data (ha anch’esso dimensione 1).In R3, il complemento ortogonale del sottospazio (di dimensione 1) costituito da una retta per l’origine e il piano (perl’origine) perpendicolare alla retta (il piano ha dimensione 2). Invece il complemento ortogonale al sottospazio (didimensione 2) costituito da un piano per l’origine e la retta (per l’origine) perpendicolare al piano. Si intuisce che c’eun legame tra le dimensioni di sottospazi che sono complementi ortogonali l’uno dell’altro. Quale?
Definizione I vettori di un insieme X ⊂ Rn si dicono ortonormali (o X e un insieme ortonormale) se, presi x e y,con x 6= y, si ha che 〈x,y〉 = 0 e inoltre 〈x,x〉 = 1 per ogni x in X .
Esempio In R2 i due vettori(
1√2, 1√
2
)
e(
− 1√2, 1√
2
)
sono ortonormali.
In R3 i due vettori(
2√6, 1√
6,− 1√
6
)
e(
1√3,− 1√
3, 1√
3
)
.
Ovviamente, in generale, in Rn i vettori fondamentali u1,u2, . . . ,un sono ortonormali.Sui vettori ortonormali sussistono importanti risultati. Uno dei piu immediati e il seguente:
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
SPAZI VETTORIALI RN
285
Teorema In Rn, se i vettori x1,x2, . . . ,xk sono ortonormali, allora sono anche l.i.
Particolarmente importanti sono gli insiemi di vettori che sono contemporaneamente ortonormali e basi dello spazio acui appartengono (o di un suo sottospazio).
Definizione I vettori x1,x2, . . . ,xn sono una base ortonormale di Rn se sono una base di Rn e sono ortonormali.
Esempio I vettori fondamentali di Rn sono quindi una base ortonormale di Rn. Non si tratta dell’unica base
ortonormale di Rn. Ad esempio, in R2, una base ortonormale e data dai vettori(
1√2, 1√
2
)
e(
− 1√2, 1√
2
)
.
In R3, ad esempio, i tre vettori(
2√6, 1√
6,− 1√
6
)
,(
1√3,− 1√
3, 1√
3
)
,(
0, 1√2, 1√
2
)
formano una base ortonormale.
Esercizio 5.1 Dati i vettori
v1 = (1, 0,−1) , v2 = (1,−1, 1),si calcoli 〈v1,v2〉. Si calcoli poi la norma euclidea di v1 e v2 e infine si calcolino
‖v1‖1 , ‖v2‖1 , ‖v1‖3 , ‖v2‖3 , ‖v1‖∞ , ‖v2‖∞.
Esercizio 5.2 Dato v = (2, 1) ∈ R2, si trovi un vettore di norma unitaria che genera lo stesso sottospazio di v.
Esercizio 5.3 Dati i vettori di R3
v1 = (0, 1, 1) , v2 = (−1, 1, 1),
si trovino due vettori di norma unitaria che generano lo stesso sottospazio generato da v1 e v2.
Esercizio 5.4 Si verifichi che i vettori
x1 =
(
1
2,
√3
2
)
, x2 =
(√3
2,−1
2
)
sono ortonormali.
Esercizio 5.5 Si verifichi che i vettori
x1 =
(
− 1√2,1√6,− 1√
3
)
, x2 =
(1√2,1√6,− 1√
3
)
, x3 =
(
0,
√2√3,1√3
)
sono ortonormali.
6 Soluzioni degli esercizi
Esercizio 1.1
Si hav = v1 − v2 + 2v3 = (1, 0,−1)− (0, 1, 1) + 2(2,−1, 1) = (5,−3, 0).
Esercizio 2.1
Procediamo con la definizione.Dato che v1+v2 = 0, i vettori sono linearmente dipendenti, in quanto abbiamo trovato una combinazione lineare nonbanale (cioe con coefficienti non tutti nulli) uguale al vettore nullo (la c.l. e 1 · v1 + 1 · v2 + 0 · v3 = 0). Possiamoanche osservare che c’e almeno uno dei tre vettori che si puo scrivere come combinazione lineare degli altri (infattiv2 = −v1).Si poteva arrivare alla conclusione anche osservando che i vettori dati sono tre e che appartengono ad uno spazio didimensione 2. Quindi, dai risultati visti nella lezione, essi sono certamente dipendenti.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
SPAZI VETTORIALI RN
286
Esercizio 2.2
Sono due vettori in R2 e quindi dal semplice confronto tra il numero dei vettori e la dimensione dello spazio non sipuo dire nulla. Questa volta non e evidente se ci sia una c.l. non banale che dia il vettore nullo. Affrontiamo quindiil problema nella sua generalita: prendiamo una c.l. dei due vettori, poniamola uguale al vettore nullo e vediamo sela cosa puo sussistere in modo non banale oppure no.
α1(1, 2) + α2(1,−1) = (0, 0) equivale a (α1 + α2, 2α1 − α2) = (0, 0) e cioe
{α1 + α2 = 0
2α1 − α2 = 0.
Anche se non abbiamo ancora trattato i sistemi lineari in generale, dalle conoscenze che gli studenti hanno dalle scuolesecondarie (si ricava α2 dalla seconda equazione e lo si sostituisce nella prima) si trova facilmente che deve essereα1 = α2 = 0, cioe l’unica soluzione e quella banale. I due vettori sono quindi linearmente indipendenti.
Esercizio 2.3
Anche qui il semplice confronto tra il numero dei vettori e la dimensione dello spazio non ci consente di concludere(sono due vettori in uno spazio di dimensione 3 e quindi nulla si puo dire).Costruiamo la generica combinazione lineare dei due vettori:
α1(−1, 0, 1) + α2(1, 1, 0) = (−α1 + α2, α2, α1).
Questo vettore e il vettore nullo se (e solo se) si ha contemporaneamente −α1 + α2 = 0, α2 = 0 e α1 = 0. E chiaroche l’unica possibilita e con α1 = α2 = 0. Pertanto i vettori sono linearmente indipendenti.Si puo anche osservare che nessuno dei due vettori e c.l. dell’altro.302
Esercizio 2.4
Se ci si accorge subito che la somma dei primi due vettori e il terzo vettore l’esercizio e finito, dato che v1+v2−v3 = 0e la c.l. non banale che mi da il vettore nullo, e quindi i vettori sono linearmente dipendenti.Se non ci si accorge di questo si puo affrontare il problema costruendo la generica c.l dei tre vettori. Si ha
α1(0, 1, 1) + α2(1, 0,−1) + α3(1, 1, 0) , che e uguale a (α2 + α3, α1 + α3, α1 − α2).
Questo vettore e il vettore nullo se e solo se
α2 + α3 = 0
α1 + α3 = 0
α1 − α2 = 0.
Ricavando α3 dalla prima e sostituendo nelle altre si trova il sistema
α3 = −α2
α1 − α2 = 0
α1 − α2 = 0.
Chiaramente il sistema non ha come unica soluzione quella banale (cioe α1 = α2 = α3 = 0) dato che ad esempioα1 = 1, α2 = 1, α3 = −1 e una soluzione non banale. Pertanto i vettori sono linearmente dipendenti, dato che risultav1 + v2 − v3 = 0.Si puo anche osservare che l’ultima uguaglianza scritta permette di esprimere uno dei tre vettori come c.l. degli altri(ad esempio v3 = +v1 + v2).
Esercizio 4.1
(a) L’insieme S1 e formato dai vettori di R2 in cui la seconda componente e l’opposto della prima. Dimostriamo conla definizione che e un sottospazio di R2. Facciamo vedere cioe che, presi due generici elementi di S1, ogni loroc.l. e ancora un elemento di S1. Siano
(x,−x) e (y,−y) due generici elementi di S1.
302Dire che un vettore v e c.l. di un altro vettore u significa che v si ottiene come moltiplicazione scalare di u per una qualche costante.Si puo anche dire che i due sono proporzionali.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
SPAZI VETTORIALI RN
287
Per ogni α, β ∈ R si ha
α(x,−x) + β(y,−y) = (αx+ βy,−αx− βy) = (αx + βy,−(αx+ βy)).
Quindi la c.l. sta in S1, dato che la seconda componente e l’opposto della prima. Quindi S1 e un sottospazio.
Per determinare una base di S1 basta osservare che gli elementi di S1, cioe i vettori del tipo (s,−s) (con s ∈ R) sipossono scrivere come s(1,−1), e cioe sono i multipli del vettore (1,−1). Allora il vettore (1,−1) e un generatoredi S1. Ma (1,−1) e anche linearmente indipendente, essendo non nullo. Quindi una base di S1 e {(1,−1)}.
(b) S2 non e un sottospazio. Infatti non e vero che, presi due generici elementi di S2, ogni loro c.l. e ancora unelemento di S2. Possiamo vederlo ad esempio considerando che
(1, 1) ∈ S2 e (−1, 1) ∈ S2.
La somma dei due pero e (0, 2), che non sta in S2. Questo e sufficiente per concludere che S2 non e un sottospazio.Si poteva anche osservare che
(1, 1) ∈ S2 ma 2(1, 1) = (2, 2) /∈ S2.
(c) S3 non e un sottospazio. Lo si puo affermare poiche S3 non contiene il vettore nullo. Oppure, con la definizione,si puo osservare che ad esempio
(0,−1) ∈ S3 e (1, 0) ∈ S3,
ma la loro somma (1,−1) non sta in S3. Oppure anche osservando che
(1, 0) ∈ S3 ma 2(1, 0) = (2, 0) /∈ S3.
(d) S4 e (in R2) il quadrato di vertici (1, 1), (−1, 1), (−1,−1), (1,−1). Pur contenendo l’origine, S4 non soddisfa laproprieta richiesta ai sottospazi: infatti, ad esempio,
(1, 1) ∈ S4 e (−1, 1) ∈ S4,
ma la loro somma (0, 2) non sta in S4. Si puo anche osservare che
(1, 1) ∈ S4 ma 2(1, 1) = (2, 2) /∈ S4.
(e) S5 e (in R3) l’insieme dei vettori che hanno uguali la prima e la terza componente. S5 contiene il vettore nullo equindi puo essere un sottospazio. Vediamo con la definizione: prendiamo due generici elementi di S5, indichiamolicon x = (x1, x2, x3) e y = (y1, y2, y3) (quindi x1 = x3 e y1 = y3), e facciamo una loro generica combinazionelineare con coefficienti α e β:
αx + βy = α(x1, x2, x3) + β(y1, y2, y3) = (αx1 + βy1, αx2 + βy2, αx3 + βy3).
Ora, dato che x1 = x3 e y1 = y3, evidentemente la prima e la terza componente sono uguali. Quindi αx + βysta in S5 e allora S5 e un sottospazio di R3.
Per trovare una base di S5 si fa cosı: gli elementi di S5 sono del tipo (t, z, t), con t, z ∈ R (questi sono tutti ivettori che hanno prima e terza componente uguali). Possiamo scrivere tali vettori nella forma
(t, z, t) = t(1, 0, 1) + z(0, 1, 0).
Questo prova che (1, 0, 1) e (0, 1, 0) sono generatori di S5. E immediato capire che i due vettori sono l.i. Quindiessi formano una base di S5. La scrittura corretta e: una base di S5 e {(1, 0, 1), (0, 1, 0)}.
(f) S6 non e invece un sottospazio. Non contiene l’origine.
Oppure, con la definizione,(1, 0, 0) ∈ S6 e (0, 0,−1) ∈ S6,
ma la loro somma (1, 0,−1) non sta in S6. O anche osservando che
(1, 0, 0) ∈ S6 ma 2(1, 0, 0) = (2, 0, 0) /∈ S6.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
SPAZI VETTORIALI RN
288
Esercizio 5.1
Si ha〈v1,v2〉 = 〈(1, 0,−1), (1,−1, 1)〉 = 1− 1 = 0.
La norma euclidea (che coincide con la norma 2) di un vettore x = (x1, x2, . . . , xn) e data da ‖x‖2 =(∑n
i=1 x2i
)1/2.
Quindi si ha‖v1‖2 =
√2 e ‖v2‖2 =
√3.
La norma 1 e invece data da ‖x‖1 =∑n
i=1 |xi|, e quindi
‖v1‖1 = 2 e ‖v2‖1 = 3.
La norma 3 e data da ‖x‖3 =(∑n
i=1 |xi|3)1/3
, e quindi
‖v1‖3 =3√2 e ‖v2‖3 =
3√3.
Infine la norma ∞ e data da ‖x‖∞ = max1≤i≤n |xi|, e quindi
‖v1‖∞ = 1 e ‖v2‖∞ = 1.
Esercizio 5.2
Basta normalizzare il vettore v, cioe dividere v per la sua norma (usiamo quella euclidea). Si ha ‖v‖ =√5 e quindi
un vettore di norma 1 che genera lo stesso sottospazio di v e ad esempio u = 1√5v = 1√
5(2, 1) = ( 2√
5, 1√
5).
Esercizio 5.3
Anche qui basta normalizzare i due vettori: si ha
u1 =1
‖v1‖v1 =
(
0,1√2,1√2
)
e
u2 =1
‖v2‖v2 =
(
− 1√3,1√3,1√3
)
.
Esercizio 5.4
Dobbiamo verificare che x1 e x2 sono ortogonali e di norma 1. Si ha
‖x1‖ =√
1/4 + 3/4 = 1 , ‖x2‖ =√
3/4 + 1/4 = 1.
Inoltre il prodotto interno 〈x1,x2〉 = 12 ·
√32 −
√32 · 12 = 0.
Possiamo quindi affermare che i due vettori sono ortonormali.
Esercizio 5.5
Verifichiamo che x1,x2,x3 sono ortonormali, cioe sono di norma 1 e a due a due ortogonali. Si ha
‖x1‖ =√
1/2 + 1/6 + 1/3 = 1 , ‖x2‖ =√
1/2 + 1/6 + 1/3 = 1 , ‖x2‖ =√
2/3 + 1/3 = 1.
Calcoliamo ora i prodotti interni a due a due:
〈x1,x2〉 = −1/2 + 1/6 + 1/3 = 0 , 〈x1,x3〉 = 1/3− 1/3 = 0 , 〈x2,x3〉 = 1/3− 1/3 = 0.
Possiamo quindi affermare che i tre vettori sono ortonormali.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 TRASFORMAZIONI LINEARI
TRASFORMAZIONI LINEARI E MATRICI
289
III-2 Trasformazioni lineari e matrici
In questa sezione vediamo alcune nozioni fondamentali sulle trasformazioni lineari tra due spazi vettoriali Rn e Rm esulle matrici.I vettori generalmente sono da intendere come vettori colonna (il motivo apparira chiaro tra un po’). Talvolta pero,quando la cosa non sara del tutto indispensabile, per “esigenze tipografiche” saranno scritti in riga.
1 Trasformazioni lineari
Da un punto di vista generale teorico e nello stesso tempo da un punto di vista delle applicazioni e fondamentale ilconcetto di trasformazione (di uno spazio in un altro). Qui ci occuperemo di un particolare tipo di trasformazioni (letrasformazioni lineari) tra due spazi vettoriali (nel caso da noi considerato spazi Rn). Successivamente parleremo dimatrici, che non sono altro che strumenti per rappresentare le trasformazioni lineari.Consideriamo una funzione f , definita nello spazio vettoriale Rn, a valori nello spazio vettoriale Rm. 303 Scriviamonaturalmente
f : Rn → Rm.
Qualora se ne presenti l’opportunita, per distinguere una tale funzione dalle usuali funzioni reali di variabile reale, cioedalle funzioni definite in R a valori in R, che lo studente ha visto in precedenza, si puo dire che, se n > 1, la funzionee di variabile vettoriale e, se m > 1, la funzione e a valori vettoriali.Possiamo ovviamente pensare anche a funzioni reali di variabile vettoriale (f : Rn → R, con n > 1) e a funzionivettoriali di variabile reale (f : R→ Rm, con m > 1).Particolare importanza per i nostri scopi hanno le seguenti funzioni:
Definizione Se f : Rn → Rm, diciamo che f e una trasformazione lineare di Rn in Rm se f ha queste dueproprieta:
1. ∀x,y ∈ Rn, f(x+ y) = f(x) + f(y) (proprieta di additivita);
2. ∀x ∈ Rn e ∀α ∈ R, f(αx) = αf(x) (proprieta di omogeneita).
Osservazione Si noti che nella definizione di trasformazione lineare si utilizza la struttura (le operazioni) di spaziovettoriale, sia nel dominio sia nel codominio di f .
Osservazione Immediata conseguenza della definizione data e che, se f e una trasformazione lineare di Rn in Rm
e se v1,v2, . . . ,vk sono vettori di Rn, allora per ogni c.l. α1v1 + α2v
2 + . . .+ αkvk dei k vettori si ha
f(α1v1 + α2v
2 + . . .+ αkvk) = α1f(v
1) + α2f(v2) + . . .+ αkf(v
k).
Si puo dire quindi che il trasformato di una c.l. e la c.l. dei trasformati.
Esempi
• Al solo scopo di mostrare come si deve procedere per provare che una trasformazione e lineare, in base alladefinizione, fornisco il seguente esempio che, pur essendo contrassegnato dalla “doppia curva”, piu che difficile elungo. Consideriamo la funzione f : R2 → R2 definita da
f
(x1x2
)
=
(2x1 − x2x1 + x2
)
.
Verifichiamo che e una trasformazione lineare. Si tratta di verificare che f ha le due proprieta previste nelladefinizione.
303Si faccia attenzione quindi che in generale gli spazi tra cui la funzione e definita possono essere diversi: sono entrambi spazi tipo Rn,ma con dimensioni che possono essere diverse. Naturalmente, come caso particolare, potremo avere funzioni definite nello stesso spazio.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 TRASFORMAZIONI LINEARI
TRASFORMAZIONI LINEARI E MATRICI
290
Per quanto riguarda la proprieta 1, presi due generici elementi x = (x1, x2) e y = (y1, y2) in R2, abbiamo
f(x+ y) = f
((x1x2
)
+
(y1y2
))
(per definizione di vettore somma) = f
(x1 + y1x2 + y2
)
(per la definizione di f) =
(2(x1 + y1)− (x2 + y2)(x1 + y1) + (x2 + y2)
)
(per le proprieta di R) =
(2x1 − x2 + 2y1 − y2x1 + x2 + y1 + y2
)
(per definizione di vettore somma) =
(2x1 − x2x1 + x2
)
+
(2y1 − y2y1 + y2
)
(per la definizione di f) = f
(x1x2
)
+ f
(y1y2
)
= f(x) + f(y).
L’additivita e dunque dimostrata.
Vediamo l’omogeneita (proprieta 2). Preso un x ∈ R2 e un numero reale α, abbiamo
f(αx) = f
(
α
(x1x2
))
(per definizione di moltiplicazione scalare) = f
(αx1αx2
)
(per la definizione di f) =
(2αx1 − αx2αx1 + αx2
)
(per definizione di moltiplicazione scalare) = α
(2x1 − x2x1 + x2
)
(per la definizione di f) = αf
(x1x2
)
= αf(x).
Quindi f e una trasformazione lineare, essendo additiva ed omogenea.
• Consideriamo ora la funzione f : R2 → R2 definita da
f
(x1x2
)
=
(x1x22
)
.
Questa non e una trasformazione lineare. Infatti non e additiva.304 Siano, ad esempio,
x =
(11
)
e y =
(12
)
.
Risulta allora
f(x+ y) = f
(23
)
=
(29
)
mentre f(x) + f(y) = f
(11
)
+ f
(12
)
=
(11
)
+
(14
)
=
(25
)
.
Si vede facilmente che f non e nemmeno omogenea. Si potrebbe dire che f e lineare nella sua prima componente,ma non nella seconda.
304Un commento e d’obbligo. Per provare che f non e additiva e sufficiente quello che si chiama un controesempio (ne basta uno solo):un controesempio e un caso particolare in cui la proprieta in questione non vale. Se possiamo trovare un controesempio significa che laproprieta in generale non vale. Si noti che invece, nell’esempio precedente, per provare che la trasformazione era lineare, abbiamo dovutoprovarlo in generale, cioe con riferimento a vettori del tutto generici. Nel presente esempio la prova della non linearita puo finire con laverifica della non additivita (la definizione di linearita richiede l’additivita e l’omogeneita, quindi se una trasformazione non e additiva none nemmeno lineare).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 TRASFORMAZIONI LINEARI
TRASFORMAZIONI LINEARI E MATRICI
291
Osservazione (importante, vedi anche la nota) Lo studente noti come, nel primo esempio, per dimostrare che fe lineare sia necessario farlo in generale, cioe con riferimento a generici vettori x e y per l’addizione e un genericovettore x e un generico numero reale α per la moltiplicazione scalare. In questo secondo esempio invece, per provareche f non e lineare, basta far vedere che anche una sola delle due proprieta non vale anche solo in un caso particolare.
• La funzione
f
(x1x2
)
= x1 − x2
e una trasformazione lineare di R2 in R (lo si verifichi).
• La funzione
f
(x1x2
)
= x1x2
non e una trasformazione lineare di R2 in R (lo si verifichi).
• La funzione
f
(x1x2
)
=
(x1 + 1x2
)
non e una trasformazione lineare di R2 in R2 (lo si verifichi).
Osservazione Se f e lineare, allora f(0) = 0. Infatti
f(0 · x) = 0 · f(x) (omogeneita) e quindi f(0) = 0.
Questo risultato fornisce un semplice metodo per dimostrare, in certi casi, che una trasformazione non e lineare. Seinfatti una trasformazione f non trasforma 0 in 0, allora non puo essere lineare. Ad esempio, nell’ultimo dei casiproposti qui sopra, si ha f
(00
)=(10
), e quindi f non e lineare. Si osservi anche che invece, nel secondo dei casi proposti,
f non e lineare pur verificando la proprieta f(0) = 0. Anche nel primo caso proposto si ha f(0) = 0, ma questonon basta per dire che la trasformazione e lineare, trattandosi di una condizione necessaria ma non sufficiente per lalinearita.
Sia f una trasformazione lineare di Rn in Rm. Si puo pensare che sia
f(x) =
f1(x)...
fm(x)
,
dove ciascuna fj e una trasformazione lineare di Rn in R. In pratica fj(x) e la j-esima componente del vettore f(x).Si puo dimostrare facilmente che f e lineare se e solo se tutte le componenti fj sono lineari.Quindi, ad esempio per dimostrare che
f
(x1x2
)
=
(2x1 − x2x1 + x2
)
e lineare si potrebbe dimostrare che le sue singole componenti lo sono, e cioe che sono lineari le funzioni (a valori reali)
f1
(x1x2
)
= 2x1 − x2 e f2
(x1x2
)
= x1 + x2.
Parliamo ora dell’importante questione della rappresentazione di una trasformazione lineare.Cominciamo con il caso particolare di una trasformazione lineare f : Rn → R (cioe a valori in R). Se, dato x ∈ Rn,scriviamo x = x1u
1+x2u2 + . . .+xnu
n, dove u1,u2, . . . ,un sono i vettori della base fondamentale di Rn, la linearitadi f permette di scrivere
f(x) = f(x1u1 + x2u
2 + . . .+ xnun) = x1f(u
1) + x2f(u2) + . . .+ xnf(u
n)
(si noti che gli xj e gli f(uj) qui sono tutti numeri reali, dato che f ha valori in R).Se poniamo a =
(f(u1), f(u2), . . . , f(un)
), allora possiamo scrivere f(x) = 〈a,x〉. 305
305Si tratta del prodotto interno tra i due vettori a e x.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 TRASFORMAZIONI LINEARI
TRASFORMAZIONI LINEARI E MATRICI
292
Il vettore a e sufficiente per rappresentare la trasformazione f . A titolo di esempio, se
f(x) = f(x1, x2
)= 3x1 − 2x2 = 〈(3,−2), (x1, x2)〉 = 〈a,x〉,
e chiaro che per rappresentare f basta il vettore a = (3,−2).A questo punto non e difficile capire che e possibile rappresentare una qualunque trasformazione lineare f attraversouna sorta di “tabella”: bastera rappresentare ogni componente di f con un vettore (riga) come appena visto edaccostare tali vettori riga uno sull’altro.
Esempio Consideriamo ad esempio la trasformazione lineare f : R3 → R2 definita da
f(x) = f
x1x2x3
=
(2x1 − x2x2 + x3
)
.
Se rappresentiamo le due componenti del vettore f(x) rispettivamente con i vettori riga
(2 − 1 0) e (0 1 1),
e accostiamo poi verticalmente questi due otteniamo
(2 −1 00 1 1
)
.
Questa si chiama matrice. Possiamo scrivere il vettore f(x) come prodotto tra la matrice suddetta e il vettore x,cioe scrivere
f
x1x2x3
=
(2x1 − x2x2 + x3
)
=
(2 −1 00 1 1
)
x1x2x3
,
se pensiamo che tale prodotto matrice×vettore avvenga calcolando i prodotti interni delle righe della matrice per ilvettore colonna x.Saremmo pervenuti allo stesso risultato ragionando anche cosı: la linearita di f , come prima, porta a dire che
f(x) = f
x1x2x3
= f(x1u1 + x2u
2 + x3u3) = x1f(u
1) + x2f(u2) + x3f(u
3) = x1
(20
)
+ x2
(−11
)
+ x3
(01
)
. 306
Quello che abbiamo ottenuto e una c.l. dei vettori f(u1), f(u2), f(u3), che sono le immagini dei vettori fondamentalidi R3 attraverso la trasformazione f .Pertanto la f puo essere rappresentata da questi soli vettori, questa volta disposti in colonna. Se li affianchiamo inuna tabella, otteniamo la stessa matrice di prima.Riassumendo, la matrice
(2 −1 00 1 1
)
rappresenta la trasformazione f e la scrittura
(2 −1 00 1 1
)
x1x2x3
e un modo di scrivere il vettore f(x) come prodotto tra la matrice ed il vettore x. Tale vettore f(x) puo essereottenuto in due modi:
• facendo i prodotti interni delle righe della matrice per la colonna x
• facendo la c.l. delle colonne della matrice con coefficienti dati dalle componenti del vettore x.
In generale allora, se f e una trasformazione lineare di Rn in Rm, dalla linearita segue che
f(x) = f(x1u1 + x2u
2 + . . .+ xnun)
= x1f(u1) + x2f(u
2) + . . .+ xnf(un)
= Ax,
306Dato che f(u1) = f(
100
)
=(20
); f(u2) = f
(010
)
=(−11
); f(u3) = f
(001
)
=(01
).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 TRASFORMAZIONI LINEARI
TRASFORMAZIONI LINEARI E MATRICI
293
intendendo che A e la matrice ottenuta disponendo in colonna le immagini dei vettori fondamentali del dominio di f(cioe Rn) e che Ax rappresenta una c.l. delle colone di A con coefficienti dati dalle componenti di x.La matrice A si chiama matrice di rappresentazione della trasformazione lineare f .
Osservazione Si noti anche che, viceversa, data una generica matrice A di m righe ed n colonne, se diamo allascrittura Ax il significato appena detto, e cioe
Ax = x1a1 + x2a
2 + . . .+ xnan,
dove gli aj sono le colonne della matrice A, allora la scrittura f(x) = Ax, per ogni x ∈ Rn definisce una funzione di Rn
in Rm. Tale funzione e una trasformazione lineare.307 Pertanto possiamo dire che c’e una corrispondenza biunivocatra l’insieme delle trasformazioni lineari di Rn in Rm e le matrici di m righe ed n colonne. Questo risultato vienetalvolta indicato come teorema di rappresentazione delle trasformazioni lineari.
Osservazione Si noti che se f e una trasformazione lineare di Rn in Rm, allora la sua matrice di rappresentazioneha m righe (come la dimensione di Rm) ed n colonne (come la dimensione di Rn).
Osservazione Un aspetto importante, sul quale d’altro canto dico subito che non mi soffermero, e il seguente: nonappena c’e l’esigenza di dare ad una trasformazione lineare una qualche rappresentazione, occorre scrivere i vettoririspetto ad una qualche base dei rispettivi spazi vettoriali. In quanto fatto finora si e implicitamente inteso che talerappresentazione sia rispetto alle basi fondamentali (di Rn e di Rm). La trasformazione non dipende dal sistemadi riferimento, in quanto stabilisce una corrispondenza tra vettori di due spazi, ma la matrice che rappresenta latrasformazione dipende invece dalla base che viene utilizzata.308 Possiamo dire che ogni trasformazione lineare puoessere rappresentata da molte matrici, a seconda della base, e che una matrice puo rappresentare molte trasformazionilineari, sempre a seconda della base scelta. Non studieremo le questioni legate al cambio di base. Per noi si tratterasempre di rappresentare rispetto alle basi fondamentali.
Esercizio 1.1 Scrivere la matrice di rappresentazione delle seguenti trasformazioni lineari, indicando poi tra
quali spazi e definita la trasformazione stessa.
(a) f
x1x2x3
=
(2x1 − 3x2 + 5x3
x2 − x3
)
(b) f
(x1x2
)
=
x1 − x23x1 + 2x2
x1
(c) f
x1x2x3
=
x3x1x2
Esercizio 1.2 Si scriva l’espressione analitica della trasformazione lineare rappresentata dalle seguenti matrici
A, precisando poi tra quali spazi e definita la trasformazione stessa.
(a) A =
(1 23 4
)
(b) A =
1 0 −10 1 1−1 1 0
(c) A =
123
Esercizio 1.3 Verificare che le seguenti trasformazioni non sono lineari.
(a) f
(x1x2
)
=
(x1 + 1x2 − 1
)
(b) f
(x1x2
)
=
(x1x2x1 + x2
)
(c) f
(x1x2
)
=x1x2
x21 + x22 + 1
307Infatti
(per definizione di f) f(x + y) = A(x + y)
(per definizione di Ax) = (x1 + y1)a1 + . . .+ (xn + yn)a
n
(prop. distributiva della molt. scalare in Rm) = x1a1 + y1a
1 + . . .+ xnan + yna
n
(per definizione di Ax) = Ax+ Ay
(per definizione di f) = f(x) + f(y).
Cosı e dimostrata l’additivita di f .Analogamente (lo studente rifletta su quali proprieta vengono utilizzate per ottenere i passaggi indicati)
f(αx) = A(αx) = (αx1)a1 + . . .+ (αxn)a
n = α(x1a1) + . . .+ α(xna
n) = αAx = αf(x),
e questo prova l’omogeneita.308Una qualche analogia con questo aspetto la possiamo rilevare ad esempio nella seguente osservazione: la distanza che separa due localitanon dipende da come la esprimiamo, ma la sua misura sı, cambia cioe se la esprimiamo in metri o in millimetri.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MATRICI
TRASFORMAZIONI LINEARI E MATRICI
294
2 Matrici
Una matrice quindi non e che un modo per rappresentare una trasformazione lineare.Solitamente le matrici si indicano con lettere maiuscole. Come gia osservato, la matrice che rappresenta una trasfor-mazione di Rn in Rm ha m righe ed n colonne: diremo che e una matrice m× n.Possiamo vedere un vettore riga come una matrice 1 × n, cioe come larappresentazione di una f : Rn → R, e un vettore colonna come una matricem× 1, e quindi come la rappresentazione di una f : R→ Rm.In alcuni casi potra essere utile vedere in una matrice solo l’aspetto generaledi rappresentazione di una trasformazione lineare, in altri sara utile vedereaspetti piu particolari, come ad esempio i singoli elementi della matrice.Chiameremo elemento di posto (i, j) il numero che si trova nella riga i ecolonna j della matrice. Se la matrice viene indicata con A, e consuetudineindicare con aij il suo elemento di posto (i, j).
riga i→
colonna j↓
a11 . . . a1j . . . a1n...
......
ai1 . . . aij . . . ain...
......
am1 . . . amj . . . amn
Osservazioni
• Gli elementi della 1a riga sono caratterizzati dal fatto che il primo indice e per tutti 1. Quindi sono gli elementidel tipo a1j , con j = 1, 2, . . . , n.
• Gli elementi della 1a colonna sono caratterizzati dal fatto che il secondo indice e per tutti 1. Quindi sono glielementi del tipo ai1, con i = 1, 2, . . . ,m.
• Gli elementi della i-esima riga sono quelli del tipo aij , con j = 1, 2, . . . , n.
• Gli elementi della j-esima colonna sono quelli del tipo aij , con i = 1, 2, . . . ,m.
La matrice di rappresentazione della trasformazione nulla309 e la matrice nulla e tutti i suoi elementi sono nulli.Se A e la matrice di rappresentazione della trasformazione f , allora la matrice che rappresenta −f si indica con −A esi chiama l’opposta di A: il suo elemento di posto (i, j) e l’opposto del corrispondente elemento di A.Una matrice si dice quadrata di ordine n se rappresenta una trasformazione f : Rn → Rn. In una matrice quadratail numero delle righe e uguale al numero delle colonne. Tale numero e detto appunto l’ordine della matrice quadrata.Quindi, dicendo ad esempio che A e una matrice quadrata di ordine 3, si intende che A e una matrice 3 × 3, erappresenta cioe una trasformazione lineare f : R3 → R3.In una matrice quadrata gli elementi di posto (i, j) con i = j formano la diagonale principale della matrice. Adesempio, nella matrice quadrata 3× 3
1 2 34 5 67 8 9
, la diagonale principale e data dagli elementi a11 = 1, a22 = 5, a33 = 9.
Definizione Se A e una matrice m× n, si chiama matrice trasposta di A, e si indica con AT , la matrice di n righeed m colonne il cui elemento di posto (i, j) e aji.
Osservazione Quindi l’elemento di posto (i, j) della trasposta si ottiene prendendo l’elemento di indici scambiatidella matrice A. Si puo anche dire che AT e la matrice che si ottiene da A scambiando le righe con le colonne.
Esempio La matrice
(1 2 34 5 6
)
ha come matrice trasposta la matrice
1 42 53 6
.
Non si tratta, come forse si potrebbe pensare, della matrice che rappresenta la trasformazione inversa.310
Definizione Una matrice quadrata A si dice simmetrica se AT = A, e quindi se aij = aji, per ogni i, j.
Esempio E’ simmetrica la matrice
A =
1 0 20 0 32 3 −1
.
309La trasformazione nulla e quella che trasforma ogni vettore nel vettore nullo, cioe quella tale che f(x) = 0 per ogni x ∈ Rn.310Di trasformazione inversa parleremo alla fine di questa dispensa.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MATRICI
TRASFORMAZIONI LINEARI E MATRICI
295
Osservazione Per essere simmetrica una matrice deve essere quadrata. Si tratta poi di una simmetrica rispetto alladiagonale principale.
Definizione Una matrice quadrata A e diagonale se risulta aij = 0 per ogni i, j, con i 6= j.Quindi una matrice e diagonale se sono nulli gli elementi che non stanno sulla diagonale principale. Faccio osservareche nella definizione non si fa riferimento agli elementi che stanno sulla diagonale principale, i quali possono esserenulli oppure no.
Esempi Sono ad esempio matrici diagonali
A =
(1 00 −1
)
, B =
−1 0 00 0 00 0 1
, C =
0 0 0 00 1 0 00 0 1 00 0 0 0
.
Risulta chiaro dalle definizioni che una matrice diagonale e anche simmetrica.Un particolare ed importante esempio di matrice diagonale e la matrice di rappresentazione della trasformazione lineareidentita da Rn ad Rn. Si chiama identita da Rn ad Rn la trasformazione che associa ad ogni x lo stesso x, cioe lafunzione In(x) = x, per ogni x ∈ Rn. E un semplice esercizio provare che tale trasformazione e lineare. Cerchiamo dicapire com’e fatta la matrice che rappresenta tale trasformazione. Dato che
In(x) = x = x1u1 + x2u
2 + . . .+ xnun,
la matrice di rappresentazione e la matrice che ha come colonne i vettori fondamentali. Quindi questa matrice ha1 sulla diagonale principale e 0 fuori di questa. Tale matrice si chiama ovviamente matrice identita e si indica disolito con I (oppure In se si vuole precisare che si tratta dell’identita in Rn). Alcuni esempi sono
I2 =
(1 00 1
)
, I3 =
1 0 00 1 00 0 1
, I4 =
1 0 0 00 1 0 00 0 1 00 0 0 1
.
E naturale a questo punto definire nell’insieme delle matrici alcune operazioni.Le prime due sono immediate, perche derivano direttamente dalle operazioni definite sulle trasformazioni lineari, dicui le matrici sono rappresentazioni.Nell’insieme delle matrici m×n, se A,B rappresentano rispettivamente due trasformazioni f, g di Rn in Rm, la matriceche rappresenta la trasformazione somma f + g deve necessariamente essere quella che si ottiene da A e B sommandogli elementi di posto corrispondente. Tale matrice verra indicata con A+B.Analogamente, se A rappresenta la trasformazione f e α ∈ R, la matrice che rappresenta la trasformazione αf devenecessariamente essere quella che si ottiene da A moltiplicando tutti i suoi elementi per α. Si indica naturalmente conαA.Abbiamo quindi definito nell’insieme delle matrici m×n un’addizione tra matrici e una moltiplicazione di una matriceper uno scalare. Lo 0 (elemento neutro dell’addizione) per le matrici m× n e chiaramente la matrice nulla m× n.Esercizio Dimostrare che la somma di matrici diagonali e una matrice diagonale.
A questo punto ci si aspetta un prodotto tra matrici e la prima cosa che viene in mente e la matrice che rappresenta ilprodotto delle due trasformazioni. Potremmo vedere che questa strada non si rivela la piu interessante, semplicementeperche non disponiamo di un “interessante” prodotto di trasformazioni. Il problema e che se f e g sono due trasfor-mazioni, f(x) e g(x) non sono in genere numeri reali ma vettori. La via da seguire e quella di pensare al prodotto didue trasformazioni in termini di composizione delle due.311 Ricordo intanto che, se f, g : Rn → Rm, allora non si puoin generale parlare di funzione composta f ◦ g (oppure g ◦ f) a meno che non sia m = n. 312
Il caso piu generale in cui esiste la trasformazione composta e quello in cui g : Rn → Rm e f : Rm → Rp. Infatti alloraesiste la trasformazione composta f ◦ g : Rn → Rp, dato che il codominio di g coincide con il dominio di f . Parlandodi composizione delle trasformazioni lineari vale il seguente risultato:
Teorema Se g : Rn → Rm e f : Rm → Rp sono due trasformazioni lineari, allora f ◦ g e una trasformazione lineareda Rn ad Rp.
311Qui sarebbe forse opportuno che lo studente, prima di continuare, andasse a rivedere le questioni legate alla composizione delle funzioni,cioe alla definizione di funzione composta, vista nella seconda parte del corso.312Si ricordi che (f ◦ g)(x) significa f(g(x)) e che quindi occorre che g(x) appartenga al dominio di f . Pertanto se le due trasformazionisono definite tra gli stessi spazi deve essere m = n.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MATRICI
TRASFORMAZIONI LINEARI E MATRICI
296
Osservazione La tesi importante del teorema non e che f ◦ g e una trasformazione da Rn a Rp (questo e implicitonella definizione di trasformazione composta), ma e piuttosto che tale trasformazione composta e lineare, cosa che none scontata e che va quindi dimostrata. E la dimostrazione non e difficile.
Dimostrazione Occorre dimostrare l’additivita e l’omogeneita della funzione composta. Si ha
(f ◦ g)(x+ y) = f(g(x+ y)) = f(g(x) + g(y)) = f(g(x)) + f(g(y)) = (f ◦ g)(x) + (f ◦ g)(y)
e(f ◦ g)(αx) = f(g(αx)) = f(αg(x)) = αf(g(x)) = α(f ◦ g)(x).
Quindi la linearita e dimostrata.
La cosa interessante e ora capire come si ottiene la matrice di rappresentazione della trasformazione composta. Nonvediamo i dettagli formali, do semplicemente il risultato: se la matrice A rappresenta la trasformazione f e la matriceB rappresenta la trasformazione g, allora la trasformazione composta f ◦ g e rappresentata dalla matrice AB, che sidice matrice prodotto righe per colonne di A per B e che e la matrice che ha come elemento di posto (i, j) ilprodotto interno della i-esima riga della prima (cioe A) per la j-esima colonna della seconda (cioe B).
Esempio Siano
A =
(0 1 −11 2 0
)
e B =
1 01 11 −1
.
La matrice A rappresenta una trasformazione lineare f da R3 a R2; la matrice B rappresenta una trasformazionelineare g da R2 a R3.E quindi possibile costruire la trasformazione composta f ◦ g che, attenzione, va da R2 a R2. Il prodotto righe percolonne AB e quindi una matrice 2× 2. Risulta
AB =
(0 1 −11 2 0
)
1 01 11 −1
=
(0 23 2
)
.313
In questo caso e possibile costruire anche la trasformazione composta g ◦ f , che sara una trasformazione da R3 a R3.Il prodotto righe per colonne BA e una matrice 3× 3. Risulta
BA =
1 01 11 −1
(0 1 −11 2 0
)
=
0 1 −11 3 −1−1 −1 −1
.
Seguono ora alcune osservazioni.
Osservazioni
• Si intuisce che, nel prodotto di due matrici, come nella composizione di due trasformazioni, l’ordine e importante.
• Date due matrici A e B, per poter effettuare il prodotto righe per colonne AB e necessario e sufficiente che ilnumero di colonne di A sia uguale al numero di righe di B.
• Il prodotto righe per colonne AB (quando si puo fare) e una matrice che ha tante righe quante ne ha A e tantecolonne quante ne ha B (si dia una motivazione a questa regola pensando al significato delle due matrici).
• Il prodotto tra matrici ha come caso particolare il prodotto di una matrice per un vettore, o di un vettore peruna matrice, o anche di un vettore per un vettore.
Ad esempio, se
A =
(0 1 −11 2 0
)
e x =
123
,
possiamo scrivere
Ax =
(0 1 −11 2 0
)
123
=
(−15
)
. 314
313L’elemento di posto (1, 1) (lo 0) e il prodotto interno della 1a riga di A per la 1a colonna di B, l’elemento di posto (1, 2) (il 2) e ilprodotto interno della 1a riga di A per la 2a colonna di B, e cosı via.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MATRICI
TRASFORMAZIONI LINEARI E MATRICI
297
Si considerino anche questi altri esempi:
(1 − 1)
(1 0 −11 2 0
)
= (0 − 2 − 1) , (1 2 3)
456
= 32 ,
(12
)
(3 4) =
(3 46 8
)
.
• Un caso particolare in cui il prodotto tra due matrici si puo fare e quando le matrici sono quadrate (ovviamentedevono essere anche dello stesso ordine). Questo perche la composizione di due trasformazioni lineari di unospazio in se ovviamente e sempre possibile. Si verifica facilmente su qualche esempio che in questo caso il prodottonon e commutativo. Quindi, se A e B sono matrici quadrate, puo succedere che AB sia diversa da BA.
Consideriamo il seguente esempio:
A =
(1 20 1
)
e B =
(0 11 0
)
.
Risulta
AB =
(1 20 1
)(0 11 0
)
=
(2 11 0
)
mentre
BA =
(0 11 0
)(1 20 1
)
=
(0 11 2
)
.
Nel prodotto tra matrici occorre dunque fare attenzione all’ordine in cui si effettua l’operazione: quindi molti-plicare A a destra per B non equivale in genere a moltiplicare A a sinistra per B. 315
• Non vale, nel prodotto tra matrici, la legge di annullamento del prodotto, alla quale siamo abituati in R. 316
Puo cioe succedere che il prodotto di due matrici non nulle sia la matrice nulla.
Ad esempio, questo succede con
A =
(1 −1−1 1
)
e B =
(1 11 1
)
.
• Nell’insieme delle matrici quadrate n×n la matrice identita In e elemento neutro del prodotto. E facile dimostrareinfatti che si ha AIn = InA = A, qualunque sia la matrice A n× n.
Osservazione Si puo dimostrare in generale che, dovendo fare la matrice trasposta di un prodotto di due matrici Ae B, si puo fare il prodotto delle trasposte, ma occorre scambiare l’ordine. Vale cioe la formula generale
(AB)T = BTAT .
Non e cosı difficile da dimostrare: l’elemento di posto (i, j) di (AB)T e l’elemento di posto (j, i) di AB (la traspostascambia le righe con le colonne); quindi si tratta del prodotto interno
⟨j-esima riga di A , i-esima colonna di B
⟩.
L’elemento di posto (i, j) di BTAT e il prodotto interno
⟨i-esima riga di BT , j-esima colonna di AT
⟩,
314Quindi la scrittura Ax, utilizzata gia da un po’ per indicare una c.l. delle colonne di A con coefficienti in x, non e altro che un prodottorighe per colonne di due matrici, delle quali la seconda e un vettore colonna. Si ricordi che prima avevamo scritto
Ax =
(0 1 −11 2 0
)
123
=
(01
)
· 1 +
(12
)
· 2 +
(−10
)
· 3 =
(01
)
+
(24
)
+
(−30
)
=
(−15
)
.
315Naturalmente, come gia detto prima, se le matrici non sono quadrate, puo succedere che sia possibile moltiplicare A a destra per Bma non a sinistra.316La legge di annullamento del prodotto dice che il prodotto di due numeri reali e nullo se e solo se almeno uno dei due numeri e nullo.Con le matrici non vale.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MATRICI
TRASFORMAZIONI LINEARI E MATRICI
298
cioe il⟨i-esima colonna di B , j-esima riga di A
⟩.
Per la proprieta commutativa del prodotto interno si tratta dello stesso valore. Quindi le due matrici sono uguali.
Esempio Verifichiamo questo risultato su di un semplice esempio: siano
A =
(1 0−1 1
)
e B =
(0 −11 1
)
.
Abbiamo
AB =
(0 −11 2
)
e quindi (AB)T =
(0 1−1 2
)
.
Ora calcoliamo BTAT :
BTAT =
(0 1−1 1
)(1 −10 1
)
=
(0 1−1 2
)
. Si ha invece ATBT =
(1 −10 1
)(0 1−1 1
)
=
(1 0−1 1
)
.
Chiudiamo il paragrafo con un paio di esempi importanti. In precedenza abbiamo visto come dalla definizione analiticadi una trasformazione lineare (cie dall’espressione di f(x)) si possa facilmente trovare la sua matrice di rappresen-tazione. Ora vediamo come si possa ottenere la matrice di rappresentazione di una trasformazione definita inveceattraverso alcuni suoi aspetti geometrici.
Esempio Consideriamo la trasformazione del piano in se (quindi di R2 in R2)individuata dalla rotazione del piano di un angolo di π/2 radianti.317
Le questioni aperte sono due: constatare che si tratta di una trasformazione linearee trovare poi la matrice di rappresentazione.Lasciando da parte gli aspetti formali, non e difficile capire che la trasformazionee in effetti lineare: per quanto riguarda l’additivita, se abbiamo due vettori x,y ela loro somma x + y (si pensi al parallelogramma), allora sottoponendo x + y allarotazione si ottiene lo stesso vettore che si ottiene sottoponendo x e y alla rotazionee poi calcolandone la somma. Ancora piu evidente e l’omogeneita: la rotazione di unvettore αx porta allo stesso vettore che si ottiene ruotando prima x e moltiplicandopoi quest’ultimo per α.
u1
u2
−u1
Troviamo ora la matrice di rappresentazione di questa rotazione del piano in se. Qui occorre ricordare che la matriceha per colonne i trasformati dei vettori fondamentali. Quindi, se indichiamo con r la trasformazione in questione(r : R2 → R2), e con R la sua matrice di rappresentazione, allora le due colonne di R sono
r(u1) = r
(10
)
=
(01
)
= u2 e r(u2) = r
(01
)
=
(−10
)
= −u1.
La matrice di rappresentazione della rotazione e quindi la matrice
R =
(0 −11 0
)
.
Moltiplicando per questa matrice un qualunque vettore di R2 si ottiene il vettore trasformato, cioe quello ottenutodalla sua rotazione di 90 gradi.318
Esempio La non commutativita del prodotto tra matrici non e che la conseguenza della non commutativita dellacomposizione di trasformazioni lineari. Questo significa ad esempio che se noi operiamo due rotazioni dello spazioR3 in se, la trasformazione risultante dipende dall’ordine con cui operiamo le due trasformazioni. Verifichiamo peresercizio il tutto su di un esempio particolare.Consideriamo la trasformazione lineare f nello spazio tridimensionale (vedi figura sotto a sinistra) che mantiene fissol’asse x1 e fa ruotare in senso antiorario gli assi x2 e x3 di un angolo di π/2. 319 Consideriamo poi la trasformazioneg che mantiene fisso l’asse x2 e fa ruotare in senso antiorario gli assi x1 e x3 di un angolo di π/2 (a destra).
317Si tratta quindi di una rotazione di 90 gradi. Si faccia anche attenzione, per fissare le idee, al fatto che la rotazione e di un angolopositivo e quindi e una rotazione in senso antiorario.
318Ad esempio, il trasformato del vettore
(21
)
e il vettore
(0 −11 0
)(21
)
=
(−12
)
, come si verifica facilmente sul grafico.
319Si rifletta sul fatto che tale trasformazione lineare e univocamente individuata da queste condizioni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IMMAGINE DI UNA TRASFORMAZIONE LINEARE
TRASFORMAZIONI LINEARI E MATRICI
299
x2
x3
x1
u2
u3
u1
−u2
f
x2
x3
x1
u2
u3
−u3u1
−u2
g
Indicando come sempre con u1,u2,u3 i vettori fondamentali di R3, possiamo dire che le due trasformazioni sonounivocamente individuate dalle seguenti condizioni (si verifichi sulle figure qui sopra):
f(u1) = u1
f(u2) = u3
f(u3) = −u2da cui la matrice di rappresentazione di f e A =
1 0 00 0 −10 1 0
;
g(u1) = −u3
g(u2) = u2
g(u3) = u1da cui la matrice di rappresentazione di g e B =
0 0 10 1 0−1 0 0
.
Costruiamo ora le trasformazioni composte: con f ◦ g si ha
(f ◦ g)(u1) = f(g(u1)) = f(−u3) = u2
(f ◦ g)(u2) = f(g(u2)) = f(u2) = u3
(f ◦ g)(u3) = f(g(u3)) = f(u1) = u1con matrice AB =
0 0 11 0 00 1 0
.
Con g ◦ f invece si ha
(g ◦ f)(u1) = g(f(u1)) = g(u1) = −u3
(g ◦ f)(u2) = g(f(u2)) = g(u3) = u1
(g ◦ f)(u3) = g(f(u3)) = g(−u2) = −u2con matrice BA =
0 1 00 0 −1−1 0 0
.
Lo studente verifichi che le matrici prodotto sono quelle che si ottengono eseguendo il prodotto righe per colonne.
Esercizio 2.1 Date le seguenti matrici, si scriva per ciascuna la matrice trasposta e poi si calcolino i prodotti a
due a due, nei casi in cui e possibile.
A =
(3 −11 2
)
B =
(0 1 −2−1 1 0
)
C =
2 11 00 −1
D =
1 0 −10 2 01 −1 1
Esercizio 2.2 Date le due trasformazioni lineari
f : R2 → R3 con f
(x1x2
)
=
x1 + x2x1 − x2x1 − 2x2
e g : R3 → R2 con g
y1y2y3
=
(y2 + y3y1 − y2
)
,
si scriva l’espressione analitica delle trasformazioni composte g ◦ f e f ◦ g.
3 Immagine di una trasformazione lineare
Sia f una trasformazione lineare di Rn in Rm.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IMMAGINE DI UNA TRASFORMAZIONE LINEARE
TRASFORMAZIONI LINEARI E MATRICI
300
Definizione Definiamo immagine di f l’insieme
Im f ={f(x) : x ∈ Rn
}. 320
Osservazione Ovviamente Im f ⊆ Rm. Inoltre, dal fatto che f(0) = 0 segue che l’immagine di f non puo esserevuota.
Teorema Im f e un sottospazio di Rm.
Osservazione Allo studente non sfugga che la definizione di immagine di f definisce un particolare sottoinsieme diRm. Il teorema prova che questo sottoinsieme ha una struttura ben precisa, quella di sottospazio. Dire sottospazio eben diverso dal dire sottoinsieme.
Dimostrazione Se y1,y2 ∈ Im f , significa che esistono x1,x2 ∈ Rn tali che y1 = f(x1) e y2 = f(x2). Allora, per lalinearita di f , se α1, α2 ∈ R, si ottiene
α1y1 + α2y
2 = α1f(x1) + α2f(x
2) = f(α1x1 + α2x
2),
e questo significa che α1y1 + α2y
2 e immagine di un vettore di Rn e cioe appartiene a Im f . Abbiamo quindi provatoche facendo una c.l. di due elementi di Im f si ottiene ancora un elemento di Im f , e quindi che Im f e un sottospazio.
Osservazione Dato che ogni y ∈ Im f e c.l. dei vettori f(uj), cioe i trasformati dei vettori fondamentali di Rn,321
allora il sottospazio Im f e generato dai vettori f(uj). E, dato che tali vettori sono le colonne della matrice dirappresentazione di f , possiamo anche dire che Im f e generato dalle colonne di tale matrice.
Esempio Si consideri la matrice
A =
(1 −1 2−1 1 −2
)
.
Essa rappresenta una trasformazione lineare f : R3 → R2. Sappiamo gia come ottenere l’espressione di questa f . 322
Ora possiamo dire che l’immagine di f e un sottospazio di R2 e che questo sottospazio e generato dai vettori(
1−1
),
(−11
),(
2−2
), cioe che tutti gli elementi dell’immagine di f si possono scrivere come un’opportuna c.l. di questi tre. La
domanda che puo nascere e: l’immagine di f e in realta tutto lo spazio R2 (cioe si ha dim Im f = 2) oppure e unsottospazio non banale (cioe si ha dim Im f < 2)? In realta sappiamo gia dare una risposta: l’immagine di f e tuttoR2 se e soltanto se tra i vettori colonna della matrice A ce ne sono almeno due che risultano linearmente indipendenti,cosa che in questo caso e falsa (provare a dimostrarlo). In questo caso si ha dim Im f = 1.
Definizione Se f e una trasformazione lineare di Rn in Rm, si definisce rango di f e si indica con r(f) la dimensionedel sottospazio Im f .
Esempio Data la trasformazione lineare f : R4 → R3 definita da
f
xyzt
=
x− y + t0
y + z − t
,
determiniamo la dimensione di Im f . Troviamo poi una base di Im f .Dall’identita
x− y + t0
y + z − t
= x
100
+ y
−101
+ z
001
+ t
10−1
320Non e una novita: si tratta di quello che abbiamo sempre chiamato immagine di una funzione. Si noti che si puo scrivere in modoequivalente
Im f ={y ∈ Rm : ∃x ∈ Rn tale che y = f(x)
}.
Si ha anche, con altra notazione, Im f = f(Rn).321Ogni y che sta in Im f e un f(x), per qualche x in Rn, e si puo sempre scrivere f(x) = x1f(u1) + . . . xnf(un).322Ricordo che l’espressione di f e l’espressione analitica di f(x). In questo caso e
f(x) = Ax =
(1 −1 2−1 1 −2
)
x1
x2
x3
=
(x1 − x2 + 2x3
−x1 + x2 − 2x3
)
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 INVERSIONE DI UNA TRASFORMAZIONE LINEARE
TRASFORMAZIONI LINEARI E MATRICI
301
si ricava che i vettori
v1 =
100
, v2 =
−101
, v3 =
001
, v4 =
10−1
sono generatori di Im f (sono le colonne della matrice che rappresenta f). Tali vettori sono certamente linearmentedipendenti, dato che sono 4 vettori in uno spazio di dimensione 3. Possiamo osservare poi che v4 = −v2, quindi v4
dipende linearmente dagli altri 3 e lo possiamo eliminare. Ma si ha anche v3 = v1 + v2, e quindi anche v3 dipendelinearmente dagli altri 2 e puo essere eliminato. Restano v1 e v2, che sono indipendenti. Quindi r(f) = dim Im f = 2e una base di Im f e formata appunto da v1 e v2.
La nozione di rango si estende alle matrici con la seguente naturale
Definizione Data una matrice m× n A, che rappresenta una trasformazione f : Rn → Rm, si definisce rango di Ae si indica con rA il rango della trasformazione f .
Osservazione Dato che il rango della matrice A e la dimensione di Im f e che questo spazio e generato dalle colonnedi A, allora rA coincide con il massimo numero di colonne l.i. di A. Il rango e un concetto fondamentale, sia da unpunto di vista teorico sia nelle applicazioni.
Concludiamo il paragrafo con un altro risultato importante, di cui non do dimostrazione.
Teorema Data una qualunque matrice A, risulta
rA = rAT .
Osservazione Mettendo insieme i risultati e le osservazioni precedenti, possiamo allora dire che in una qualunquematrice il massimo numero di colonne indipendenti coincide con il massimo numero di righe indipendenti. Si notiancora una volta che le righe e le colonne sono vettori appartenenti in genere a spazi diversi.Non disponiamo ancora di un metodo “comodo” per il calcolo del rango di una matrice. Arriveremo a questo traun po’. Rinvio anche ulteriori esercizi sulla determinazione dell’immagine di una trasformazione lineare a quandodisporremo di ulteriori strumenti.
4 Inversione di una trasformazione lineare
In questo paragrafo ci poniamo il problema di studiare l’invertibilita di una trasformazione lineare. Dato che, permotivi che via via risulteranno chiari, l’unico caso significativo a questo proposito e quello delle trasformazioni linearidi uno spazio in se (di Rn in Rn), per la definizione seguente consideriamo una trasformazione di questo tipo.
Definizione La trasformazione f : Rn → Rn si dice invertibile se esiste g : Rn → Rn tale che
f ◦ g = g ◦ f = In,
avendo indicato con In la trasformazione identita su Rn. 323
Se f e invertibile la trasformazione g si chiama inversa di f e si indica con f−1. Si puo dimostrare che vale il seguente
Teorema Se f e una trasformazione lineare invertibile, allora anche f−1 e lineare.324
Parlando di funzioni in generale, nella seconda parte del corso, avevamo visto che una funzione e invertibile se esoltanto se e contemporaneamente iniettiva e suriettiva (si vada eventualmente a rivedere questi concetti). Il risultatonaturalmente vale ancora parlando di funzioni che sono in particolare trasformazioni lineari. Per queste ultime le dueproprieta si possono esprimere nel modo che ora vediamo.Torniamo a considerare una generica trasformazione lineare f : Rn → Rm. La trasformazione f puo avere queste dueproprieta:
(i) Per ogni x ∈ Rn, se f(x) = 0, allora x = 0 (equivale a dire che l’unico vettore che viene trasformato nel vettorenullo e il vettore nullo);
(ii) Per ogni y ∈ Rm esiste un x ∈ Rn tale che f(x) = y (cioe ogni vettore y di Rm e il trasformato di qualche x).
323Lo studente noti che il concetto di invertibilita e lo stesso che abbiamo gia incontrato per una funzione reale.324Si noti che senza questo risultato non si poteva dare per scontato che l’inversa di una trasformazione lineare fosse anch’essa lineare.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 INVERSIONE DI UNA TRASFORMAZIONE LINEARE
TRASFORMAZIONI LINEARI E MATRICI
302
Esercizio Si dimostri che la proprieta (i) equivale a dire che per ogni x,y ∈ Rn, se f(x) = f(y), allora x = y e chequesta a sua volta equivale a dire che per ogni x,y ∈ Rn, se x 6= y, allora f(x) 6= f(y).
Osservazione La proprieta (i) esprime quindi il fatto che f e iniettiva. La proprieta (ii) invece esprime il fatto chef e suriettiva. Possiamo dire che f e suriettiva se e solo se Im f = Rm (mentre in generale si ha Im f = f(Rn) ⊂ Rm),e cioe se e solo se il rango di f e m.Sull’invertibilita di una trasformazione lineare sussiste sempre lo stesso risultato (valido per le funzioni in generale):
Teorema Una trasformazione lineare f : Rn → Rn e invertibile se e solo se valgono le proprieta (i) e (ii) (contem-poraneamente), cioe f e invertibile se e solo se e iniettiva e suriettiva.
Esempi Una trasformazione lineare f : Rn → Rm puo essere iniettiva ma non suriettiva, oppure suriettiva ma noniniettiva.
• Si consideri ad esempio la trasformazione lineare f : R→ R2, definita da
f(x) =
(x2x
)
, ∀x ∈ R.
Essa e iniettiva, dato che(
x2x
)
=(00
)
puo aversi solo con x = 0. Essa non e suriettiva, dato che ad esempio il
vettore(13
)
non e immagine di nessun x.
• Si consideri ora la trasformazione lineare f : R2 → R, definita da
f
(xy
)
= x, ∀(xy
)
∈ R2.
Essa non e iniettiva, dato che ad esempio i vettori(11
)
e(12
)
hanno la stessa immagine. Essa e invece suriettiva,
dato che ogni x ∈ R e immagine, ad esempio, del vettore(x0
)
.
Ci sono anche esempi di trasformazioni che non sono ne iniettive ne suriettive:
• consideriamo la f : R2 → R2, definita da
f
(xy
)
=
(x0
)
, ∀(xy
)
∈ R2.
Essa non e iniettiva, dato che ad esempio i vettori(11
)
e(12
)
hanno la stessa immagine. Essa non e nemmeno
suriettiva, dato che ad esempio il vettore(11
)
non e immagine di nessun vettore.
Per capire meglio come opera una trasformazione invertibile, enuncio questo risultato generale:
Proposizione Una trasformazione f e invertibile se e solo se trasforma basi in basi, cioe se e solo se, data unaqualunque base di Rn {v1,v2, . . . ,vn}, allora {f(v1), f(v2), . . . , f(vn)} e anch’essa una base di Rn.
Osservazione Come caso particolare di quanto appena detto abbiamo che f e invertibile se e solo se i vettorif(u1), f(u2), . . . , f(un) sono una base di Rn.
Visti i risultati sulle trasformazioni invertibili, possiamo dare la seguente
Definizione Se A e la matrice di rappresentazione della trasformazione lineare f : Rn → Rn e se f e invertibile,allora si chiama matrice inversa di A la matrice di rappresentazione di f−1.Questo equivale a chiamare invertibile una matrice n× n A se esiste un’altra matrice n× n B tale che valga
AB = BA = In,
dove In e la matrice identita delle matrici n× n.Osservazione Per quanto visto in precedenza, possiamo dire che una matrice A e invertibile se e solo se le suecolonne sono linearmente indipendenti.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
TRASFORMAZIONI LINEARI E MATRICI
303
Esempio La matrice
A =
(0 11 0
)
e invertibile, dato che le sue colonne sono i vettori fondamentali di R2. Si trova facilmente che la matrice inversa e lamatrice stessa.Si intuisce pero che con matrici di ordine 3 o piu non e cosı facile trovare la matrice inversa (e nemmeno capirese la matrice e invertibile). Serve allora un procedimento di calcolo che, data una qualunque matrice quadrata, midica intanto se essa e invertibile e, in caso affermativo, mi permetta di trovare la matrice inversa. Arriveremo a taleprocedimento nella prossima dispensa.
5 Soluzioni degli esercizi
Esercizio 1.1
(a) La matrice di rappresentazione di f e
(2 −3 50 1 −1
)
, dato che f
x1x2x3
=
(2 −3 50 1 −1
)
x1x2x3
.
La trasformazione f e definita in R3 a valori in R2, cioe possiamo scrivere f : R3 → R2.(b) La matrice di rappresentazione di f e
1 −13 21 0
, dato che f
(x1x2
)
=
1 −13 21 0
(x1x2
)
.
La trasformazione f e definita in R2 a valori in R3, cioe possiamo scrivere f : R2 → R3.(c) La matrice di rappresentazione di f e
0 0 11 0 00 1 0
, dato che f
x1x2x3
=
0 0 11 0 00 1 0
x1x2x3
.
La trasformazione f e definita in R3 a valori in R3, cioe possiamo scrivere f : R3 → R3.
Esercizio 1.2
(a) La trasformazione rappresentata da A e una funzione f : R2 → R2 la cui espressione analitica e
f
(x1x2
)
=
(1 23 4
)(x1x2
)
=
(x1 + 2x23x1 + 4x2
)
.
(b) La trasformazione rappresentata da A e una funzione f : R3 → R3 la cui espressione analitica e
f
x1x2x3
=
1 0 −10 1 1−1 1 0
x1x2x3
=
x1 − x3x2 + x3−x1 + x2
.
(c) La trasformazione rappresentata da A e una funzione f : R→ R3 la cui espressione analitica e
f(x) =
123
x =
x2x3x
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
TRASFORMAZIONI LINEARI E MATRICI
304
Esercizio 1.3
(a) La trasformazione e da R2 a R2. Si puo osservare che, banalmente, il trasformato del vettore nullo non e il vettore
nullo. Infatti f(00
)
=(
1−1
)
. Lo studente provi a trovare un controesempio all’additivita e all’omogeneita.
(b) La trasformazione e da R2 a R2. Si puo osservare che questa volta il trasformato del vettore nullo e il vettore
nullo. Pero la trasformazione non e additiva. Infatti con x =(10
)
e y =(01
)
si ha che f(x+y) = f(11
)
=(12
)
, mentre
f(x) + f(y) =(01
)
+(01
)
=(02
)
.
Lo studente provi a trovare un controesempio all’omogeneita.(c) Anche in questo caso il trasformato del vettore nullo e lo zero (qui il numero reale zero). Pero la trasformazione
non e omogenea. Infatti con x =(11
)
si ha che f(2x) = f(22
)
= 49 , mentre 2f(x) = 2 · 13 = 2
3 .
Lo studente provi a trovare un controesempio all’additivita.
Esercizio 2.1
Le matrici trasposte sono
AT =
(3 1−1 2
)
BT =
0 −11 1−2 0
CT =
(2 1 01 0 −1
)
DT =
1 0 10 2 −1−1 0 1
.
I prodotti che si possono fare sono i seguenti:
AB =
(1 2 −6−2 3 −2
)
BC =
(1 2−1 −1
)
BD =
(−2 4 −2−1 2 1
)
.
Sono anche possibili, scambiando l’ordine, i prodotti DC, CB e CA. Lo studente provi a calcolarli.
Esercizio 2.2
Si potrebbe rispondere alla domanda operando soltanto sulle espressioni analitiche delle due trasformazioni, ma forseconviene utilizzare le rispettive matrici di rappresentazione. Troviamo intanto allora queste matrici, che indichiamocon Af e con Ag. Si ha
Af =
1 11 −11 −2
e Ag =
(0 1 11 −1 0
)
.
Per quanto visto nella lezione, la trasformazione composta g ◦ f e rappresentata dalla matrice prodotto (righe percolonne) di Ag per Af , cioe da
AgAf =
(0 1 11 −1 0
)
1 11 −11 −2
=
(2 −30 2
)
.
Pertanto l’espressione analitica di g ◦ f : R2 → R2 e
g ◦ f(x1x2
)
=
(2 −30 2
)(x1x2
)
=
(2x1 − 3x2
2x2
)
.
La trasformazione composta f ◦ g e invece rappresentata dalla matrice prodotto di Af per Ag, cioe da
AfAg =
1 11 −11 −2
(0 1 11 −1 0
)
=
1 0 1−1 2 1−2 3 1
.
Quindi l’espressione analitica di f ◦ g : R3 → R3 e
f ◦ g
x1x2x3
=
1 0 1−1 2 1−2 3 1
x1x2x3
=
x1 + x3−x1 + 2x2 + x3−2x1 + 3x2 + x3
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DETERMINANTE DI UNA MATRICE
DETERMINANTE E RANGO
305
III-3 Determinante e rango
1 Determinante di una matrice
Veniamo ora alla definizione di determinante di una matrice quadrata.Quella che presento e una definizione ricorsiva. Per avere un esempio (piu semplice) di definizione ricorsiva, lo studenteconsideri quanto segue.Il fattoriale di un numero naturale n ≥ 1 si puo definire in modo diretto come
n! = 1 · 2 · 3 · . . . · n.
Allo stesso risultato si perviene pero anche definendo
0! = 1
e n! = n(n− 1)! , per n ≥ 1.
Questa e una definizione ricorsiva, in quanto nel definire il fattoriale di n si utilizza il fattoriale di n− 1, che ancoranon e stato definito. La definizione non avrebbe senso se non ci fosse quella che si chiama la base della definizionericorsiva, e cioe in questo caso la definizione di 0!.La definizione ricorsiva di determinante di una matrice quadrata, che ora presento, procede in modo analogo, definendoil determinante di una matrice di ordine n in funzione del determinante di una matrice di ordine n− 1.Sono necessarie alcune definizioni preliminari.
Definizione Se A e una matrice qualunque (anche non quadrata), si chiama sottomatrice di A una qualunquematrice che si ottiene da A eliminando alcune righe e alcune colonne.
Esempio Se
A =
1 2 0 −10 −1 1 01 0 1 0
,
una sottomatrice di A e la matrice
1 −10 01 0
, ottenuta eliminando la seconda e la terza colonna.
Un’altra sottomatrice di A e la matrice(
2 −1−1 0
)
, ottenuta eliminando la terza riga e la prima e terza colonna.
Osservazione Si noti che le sottomatrici possono essere formate quindi da elementi non adiacenti nella matriceoriginaria. Inoltre le sottomatrici di una matrice data possono essere quadrate oppure no. E evidente che, per ottenereuna sottomatrice quadrata da una matrice che non lo e, dovro eliminare un numero di righe diverso dal numero dicolonne, mentre le sottomatrici quadrate di una matrice quadrata si ottengono eliminando un numero di righe ugualeal numero di colonne. Una sottomatrice quadrata k × k si dice una sottomatrice quadrata di ordine k.
Sono necessarie ora altre due definizioni preliminari, nelle quali procediamo come se sapessimo gia che cosa e ildeterminante di una matrice quadrata.
Definizione Se A e una matrice quadrata e se aij e il suo elemento di posto (i, j), si definisce minore comple-mentare di aij il numero
Mij = determinante della sottomatrice di A ottenuta eliminando la i-esima riga e la j-esima colonna.
E ovvio che, se la matrice A e di ordine n, allora la sottomatrice di cui si parla nella definizione di minore complementaree una sottomatrice quadrata di ordine n − 1. Faccio esplicitamente notare che il minore complementare di aij nondipende dal valore di aij .
325
325Il motivo dovrebbe essere chiaro: per trovare il minore complementare di aij si eliminano la i-esima riga e la j-esima colonna e quindisi elimina l’elemento aij .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DETERMINANTE DI UNA MATRICE
DETERMINANTE E RANGO
306
Definizione Sempre se A e una matrice quadrata e se aij e il suo elemento di posto (i, j), si definisce complementoalgebrico di aij il numero
Aij = (−1)i+jMij .
Dato che la quantita (−1)i+j vale o +1 oppure −1, a seconda che l’esponente sia pari o dispari, in pratica ilcomplemento algebrico di aij coincide col suo minore complementare se la somma degli indici di riga e di colonna epari, ed e invece l’opposto del minore complementare se tale somma e dispari.
Inizia ora la definizione ricorsiva di determinante. Parliamo sempre di matrici quadrate.Sia dunque A una matrice quadrata di ordine n.
⊲ Se n = 1, allora il determinante di A e per definizione l’unico elemento che la costituisce (un numero reale).326
⊲ Se invece n > 1,
Definizione Si definisce determinante di A il numero reale
detA = a11A11 + a12A12 + . . .+ a1nA1n =
n∑
i=1
a1iA1i.
Il determinante di una matrice di ordine n viene quindi definito attraverso i determinanti di matrici di ordine n−1(quelli che figurano nei complementi algebrici). La definizione, a parole, potrebbe quindi essere: il determinantedi A e la somma dei prodotti degli elementi della prima riga per i rispettivi complementi algebrici.
Esempi Vediamo qualche esempio. Per le matrici di ordine 1 il calcolo del determinante non crea problemi.Consideriamo una generica matrice quadrata di ordine 2:
A =
(a11 a12a21 a22
)
.
Risulta
detA = a11 · A11 + a12 · A12
= a11 · (−1)1+1M11 + a12 · (−1)1+2M12
= a11a22 − a12a21.
Abbiamo allora una comoda regola per il calcolo del determinante di tutte le matrici quadrate di ordine 2. Ad esempio,il determinante della matrice (
1 23 4
)
e 1 · 4− 2 · 3 = −2.
Consideriamo ora una generica matrice quadrata di ordine 3:
A =
a11 a12 a13a21 a22 a23a31 a32 a33
.
Procedendo con la definizione abbiamo
detA = a11 ·A11 + a12 · A12 + a13 · A13
= a11 · (−1)1+1M11 + a12 · (−1)1+2M12 + a13 · (−1)1+3M13
= a11(a22a33 − a23a32)− a12(a21a33 − a23a31) + a13(a21a32 − a22a31)= a11a22a33 − a11a23a32 − a12a21a33 + a12a23a31 + a13a21a32 − a13a22a31.
326Questa e la base della definizione ricorsiva di determinante.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DETERMINANTE DI UNA MATRICE
DETERMINANTE E RANGO
307
La formula che risulta non e evidentemente cosı semplice da ricordare.327 Esiste anche un metodo pratico che aiutaa ricostruire la formula, e che si chiama regola di Sarrus : si affiancano alla matrice data nuovamente la prima e laseconda colonna, ottenendo cosı la seguente matrice 3× 5:
a11 a12 a13 a11 a12a21 a22 a23 a21 a22a31 a32 a33 a31 a32
.
Ora basta sommare i prodotti degli elementi che figurano nelle diagonali indicatedalle frecce che puntano a SE (ց) e sottrarre i prodotti degli elementi delle diago-nali indicate dalle frecce che puntano a SO (ւ). Si vede facilmente che il risultatoe esattamente la sequenza di fattori trovati poco fa con la definizione, con i segnicorretti.
ց ց ց ւ ւ ւ
a11 a12 a13 a11 a12a21 a22 a23 a21 a22a31 a32 a33 a31 a32
Consideriamo ad esempio la matrice
A =
1 1 21 −1 00 2 1
.
Con la definizione di determinante otteniamo
detA = 1 · A11 + 1 ·A12 + 2 · A13
= 1 · (−1)1+1M11 + 1 · (−1)1+2M12 + 2 · (−1)1+3M13
= M11 −M12 + 2M13
= −1− 1 + 4 = 2.
Con la regola di Sarrus, dalla matrice
1 1 2 1 11 −1 0 1 −10 2 1 0 2
otteniamodetA = (−1 + 0 + 4)− (0 + 0 + 1) = 2.
Attenzione: la regola di Sarrus vale solo per le matrici di ordine 3. Non c’e una regola analoga per matrici di ordinemaggiore di 3.Consideriamo, a titolo di esempio conclusivo, una matrice quadrata di ordine 4:
A =
1 0 −1 11 1 0 −10 0 1 11 1 0 1
.
Risulta, con la definizione,
detA = 1 · A11 + 0 ·A12 + (−1) ·A13 + 1 · A14
= M11 −M13 −M14.
Procedendo ora sulle sottomatrici di ordine 3 abbiamo
M11 = 1 · 1 + (−1) · (−1) = 2 ;
M13 = 1 · (−1)− 1 · (−1)− 1 · 0 = 0 ;
M14 = 1 · (−1)− 1 · (−1) = 0
e quindi detA = 2− 0− 0 = 2.
327In questo caso e certamente piu semplice ricordare il metodo che porta a questa formula, piu che la formula stessa.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DETERMINANTE DI UNA MATRICE
DETERMINANTE E RANGO
308
Osservazione Nella definizione di determinante, cioe nella formula
detA = a11A11 + a12A12 + . . .+ a1nA1n,
i calcoli sono svolti con riferimento alla prima riga: abbiamo detto infatti che si tratta della somma dei prodotti deglielementi della prima riga di A per i rispettivi complementi algebrici.Si puo dimostrare pero un risultato interessante e per nulla prevedibile secondo il quale, se noi effettuiamo lo stessotipo di calcolo con riferimento ad una qualunque riga o qualunque colonna, il risultato e sempre lo stesso.In altre parole, se fissiamo una qualunque riga (o colonna) e facciamo la somma dei prodotti degli elementi di quellariga (o colonna) per i rispettivi complementi algebrici, otteniamo sempre detA. Quindi possiamo dire che
detA = ai1Ai1 + ai2Ai2 + . . .+ ainAin (per qualunque i = 1, . . . , n)
= a1jA1j + a2jA2j + . . .+ anjAnj (per qualunque j = 1, . . . , n).
Questo risultato va sotto il nome di primo teorema di Laplace.Rispetto a quale riga o colonna calcolare il determinante di una matrice e quindi a questo punto una scelta diconvenienza. Ovviamente conviene operare rispetto alla riga o colonna che contiene il maggior numero di zeri.
Osservazione Si puo dimostrare facilmente che il determinante di una matrice diagonale e il prodotto degli elementiche stanno sulla diagonale principale. Si consideri una generica matrice diagonale
a11 0 . . . 00 a22 . . . 0...
.... . .
...0 0 . . . ann
.
Sviluppando rispetto alla prima riga si ottiene
detA = a11 ·A11 (gli altri sono nulli)
= a11 · a22 ·A′22 (gli altri sono nulli) 328
= . . . = a11 · a22 · . . . · ann.
Elenco qui di seguito alcune tra le principali proprieta del determinante.
Siano a1,a2, . . . ,an vettori colonna di Rn. 329 Indico con A la matrice che si ottiene affiancando tali vettori. Valgonole proprieta:
1. det(αA) = αn detA (si ricordi che moltiplicare per α la matrice vuol dire moltiplicare per α tutti i suoi elementi).
2. Il determinante e nullo se la matrice ha una riga (o una colonna) nulla: la cosa e ovvia se si pensa di calcolareil determinante rispetto a quella riga (o colonna).
3. Scambiando tra loro due righe (o due colonne) il determinante cambia segno.
4. Il determinante e nullo se vi sono due righe (o due colonne) uguali: immediata conseguenza della precedente.
5. Il determinante non cambia se si aggiunge ad una riga un’altra riga moltiplicata per una costante (lo stesso conle colonne).
6. Il determinante e nullo se le righe (o le colonne) sono vettori linearmente dipendenti.
Osservazione Faccio notare che i punti 2,4 e 6 forniscono condizioni sufficienti per l’annullarsi del determinante.Si puo dimostrare che solo la condizione espressa al punto 6 e anche necessaria, e ovviamente raccoglie in se le altrecome casi particolari.330
328Indico con A′22 il complemento algebrico dell’elemento di posto (2, 2) della matrice che si e ottenuta da A dopo aver eliminato la prima
riga e la prima colonna.329Lo stesso se si trattasse di vettori riga.330Questo significa che: se la matrice ha una riga o una colonna nulla, allora ha determinante nullo, ma non e detto che se il determinantee nullo ci sia necessariamente una riga o colonna nulla. Lo stesso con la 4: se la matrice ha due righe uguali, allora ha determinante nullo,ma se il determinante e nullo non e detto che ci siano due righe uguali.
Invece per la 6 il discorso e diverso: se le righe (o colonne) sono l.d., allora il determinante e nullo e se il determinante e nullo, allora lerighe (e le colonne) sono linearmente dipendenti.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DETERMINANTE DI UNA MATRICE
DETERMINANTE E RANGO
309
Osservazione La proprieta 5 puo risultare molto utile nel calcolo del determinante. Le operazioni di cui si parla inquesta proprieta (ad esempio aggiungere ad una riga un’altra riga moltiplicata per una costante) si chiamano operazionielementari. Nel calcolo del determinante di una matrice di ordine elevato (pensiamo ad esempio ad una matrice delquarto ordine) puo essere utile l’applicazione di un certo numero di operazioni elementari: queste, lasciando inalteratoil determinante, possono annullare alcuni elementi della matrice. Una volta che un po’ di elementi sono diventati zero,si puo procedere al calcolo del determinante con la definizione. Vediamo il tutto in un paio di esempi.Prendiamo la matrice
A =
1 0 −1 11 1 0 −10 0 1 11 1 0 1
,
gia considerata prima. La definizione di determinante porta a sviluppare i calcoli rispetto alla prima riga, ma giail farlo rispetto alla terza riga (o anche seconda o terza colonna) porta dei vantaggi. Ma possiamo anche effettuareprima un’operazione elementare per introdurre nuovi zeri: ad esempio possiamo annullare l’elemento di posto (3, 4),togliendo alla quarta colonna la terza (o sommando alla quarta colonna la terza moltiplicata per −1, che e lo stesso).331
Si ottiene la matrice
A =
1 0 −1 21 1 0 −10 0 1 01 1 0 1
,
che ha lo stesso determinante di A. Possiamo ora calcolare il determinante rispetto alla terza riga, e dobbiamo calcolaresolo un determinante del terzo ordine. Si ottiene
detA = 1 · det
1 0 21 1 −11 1 1
.
Ora per esercizio possiamo utilizzare ancora operazioni elementari. Possiamo annullare l’elemento di posto (1, 3).Attenzione pero: nell’annullare un elemento dobbiamo fare in modo che gli elementi gia nulli restino tali; quindi perannullare il 2 in alto a destra non aggiungeremo alla prima riga il doppio della seconda, ma ad esempio toglieremoalla terza colonna il doppio della prima. Otteniamo quindi
detA = det
1 0 01 1 −31 1 −1
= 2.
Vediamo un altro esempio. Consideriamo la matrice simmetrica
A =
0 1 1 11 0 1 11 1 0 11 1 1 0
.
Vogliamo annullare gli elementi della prima colonna a partire dal secondo. L’elemento di posto (1, 1) e nullo econviene allora procedere cosı: scambiare la prima con la seconda riga (il determinante cambia segno per la proprieta3) e annullare gli elementi non nulli della prima colonna con operazioni elementari. Si ha
detA = − det
1 0 1 10 1 1 11 1 0 11 1 1 0
= − det
1 0 1 10 1 1 10 1 −1 00 1 0 −1
. 332
Ora sviluppando rispetto alla prima colonna otteniamo
detA = − det
1 1 11 −1 01 0 −1
.
331Attenzione. Colonne con colonne e righe con righe. Se sommiamo ad una colonna una riga moltiplicata per una costante, il determinantepuo cambiare.332Per annullare a31 ho tolto la prima riga alla terza; per annullare a41 ho tolto la prima riga alla quarta.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 CALCOLO DELLA MATRICE INVERSA
DETERMINANTE E RANGO
310
Posso annullare l’elemento di posto (1, 3), sommando alla prima riga la terza e ottengo
detA = − det
2 1 01 −1 01 0 −1
= (−1)(−1)(−3) = −3. 333
Da ricordare il seguente importante risultato:
Teorema (di Binet) Se A e B sono matrici quadrate dello stesso ordine, vale l’uguaglianza
det(AB) = detA · detB.
Osservazione Si noti che, come visto, le matrici AB e BA possono essere diverse ma, per il teorema di Binet, essehanno lo stesso determinante.
Esercizio 1.1 Data la matrice
1 2 34 5 67 8 9
, si calcolino i complementi algebrici di a11, a12, a22, a32.
Esercizio 1.2 Si calcolino, con la definizione, i determinanti delle matrici
A1 =
(1 2−3 5
)
, A2 =
1 2 34 5 67 8 9
, A3 =
0 1 −1 22 −1 0 11 0 2 −1−1 2 1 0
.
Esercizio 1.3 Si verifichi il teorema di Binet con le matrici
A =
(1 23 4
)
e B =
(2 34 1
)
.
Esercizio 1.4 Si calcoli nuovamente il determinante di A3 con operazioni elementari: si annullino gli elementi
della prima colonna a partire dal secondo.
2 Calcolo della matrice inversa
Torniamo a parlare ora di matrice inversa. Abbiamo gia visto in precedenza che cosa significa che una matrice einvertibile. Non abbiamo ancora pero a disposizione un procedimento di calcolo che consenta di dire se una matrice einvertibile e di calcolare la matrice inversa.Un metodo generale, ma di non facile applicazione se l’ordine della matrice e maggiore di 2, e quello che vediamo orasu questo esempio.
Esempio Consideriamo la matrice
A =
(1 02 1
)
.
Cerchiamo una matrice B =
(x yz t
)
tale che AB =
(1 00 1
)
. Si ottiene
AB =
(1 02 1
)(x yz t
)
=
(x y
2x+ z 2y + t
)
,
333Per il calcolo del determinante ho sviluppato rispetto alla terza colonna, quindi il primo −1 e quello davanti al determinante. il secondo−1 e l’elemento di posto (3, 3) della matrice e infine il −3 e il determinante della sottomatrice 2× 2 che si ottiene eliminando la terza rigae la terza colonna.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 CALCOLO DELLA MATRICE INVERSA
DETERMINANTE E RANGO
311
pertanto deve essere334 B =(
1 0−2 1
)
e si vede subito che anche BA =(1 00 1
)
. Pertanto A e invertibile e B e la
sua matrice inversa. Si intuisce facilmente che questo metodo per trovare la matrice inversa diventa molto pesante alcrescere dell’ordine della matrice. Gia con una matrice 3 × 3 richiede la soluzione di un sistema di 9 equazioni in 9incognite.Consideriamo ora la matrice
A =
(1 −1−1 1
)
.
Procedendo come prima, calcoliamo
(1 −1−1 1
)(x yz t
)
=
(x− z y − t−x+ z −y + t
)
.
E evidente che la matrice a secondo membro non puo essere la matrice identita per nessun valore delle incognite.335
In questo caso la matrice A non e invertibile. Si osservi che la matrice che risultava prima invertibile ha determinante1 e quest’ultima invece ha determinante 0.
Ecco ora il risultato fondamentale.
Teorema Una matrice A e invertibile se e solo se il suo determinante non e zero.
Osservazione La dimostrazione di questo teorema consentirebbe di dare giustificazione al metodo, che ora vieneindicato, per il calcolo della matrice inversa, quando questa esiste. Detta A la matrice di cui vogliamo trovare l’inversa,consiglio allo studente di seguire questi passi successivi: dopo aver verificato che il determinante di A non si annulla,
1. Costruire la matrice dei complementi algebrici di A, cioe la matrice che ha per elemento di posto (i, j) ilcomplemento algebrico di aij (che abbiamo indicato con Aij nella definizione di determinante).336
2. Scrivere la trasposta della matrice dei complementi algebrici (viene detta matrice aggiunta di A e indicata disolito con A⋆).
3. Dividere la matrice aggiunta per il determinante di A.
Pertanto, se A e invertibile, si ha
A−1 =1
detA·A⋆.
EsempiVediamo un paio di esempi di calcolo della matrice inversa.La matrice
A =
(1 23 4
)
e invertibile in quanto detA = −2. La matrice dei complementi algebrici e
(4 −3−2 1
)
. La matrice aggiunta e A⋆ =
(4 −2−3 1
)
e la matrice inversa e quindi
A−1 = −1
2
(4 −2−3 1
)
=
(−2 132 − 1
2
)
.
Per verificare la correttezza del risultato si puo moltiplicare questa matrice per la matrice iniziale e constatare che ilprodotto e la matrice identita I2.Consideriamo ora la matrice
A =
0 1 01 0 00 0 1
.
334Uguagliando la matrice AB con la matrice identita, x deve essere 1, y deve essere 0 e sostituendo nelle altre si ricava che deve esserez = −2 e t = 1.335Si noti che nella matrice prodotto che abbiamo ottenuto gli elementi della prima colonna sono opposti e questo non e vero nella matriceidentita.336Ricordo che Aij = (−1)i+jMij , dove Mij e il minore complementare di aij .
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CALCOLO DEL RANGO
DETERMINANTE E RANGO
312
Essa e invertibile dato che detA = −1. La matrice dei complementi algebrici e
0 −1 0−1 0 00 0 −1
che, essendo simmetrica, coincide con A⋆ =
0 −1 0−1 0 00 0 −1
.
Pertanto la matrice inversa e
A−1 =
0 1 01 0 00 0 1
= A.
Lo studente e invitato a verificare che i prodotti A ·A−1 e A−1 ·A sono entrambi uguali alla matrice identita I3.
Definizione Si dicono singolari le matrici con determinante nullo (e quindi non invertibili). Quelle invertibili sidicono anche non singolari.
Esercizio 2.1 Si stabilisca se le seguenti matrici sono invertibili e, in caso affermativo, se ne calcoli la matrice
inversa:
A1 =
(1 23 4
)
, A2 =
1 0 02 4 53 0 6
, A3 =
1 0 1 00 1 1 01 1 0 10 0 1 0
.
3 Calcolo del rango
Abbiamo visto in precedenza che il rango rA di una matrice m × n A e il rango della trasformazione lineare che Arappresenta (cioe la dimensione dell’immagine di questa) e che questo coincide con il massimo numero di colonne (orighe) l.i. di A. Ricordando che in uno spazio non ci possono essere piu vettori l.i. di quella che e la dimensione dellospazio, si ha subito che risulta sempre
0 ≤ rA ≤ min{m,n}. 337
Osservazione La definizione di rango non ha carattere “operativo”, cioe non suggerisce come si possa determinareil rango nei casi concreti, a meno che non si trovi un modo “operativo” per decidere se dei vettori assegnati sono onon sono linearmente indipendenti.
Esiste un tale metodo operativo e mi limito ad enunciare il risultato teorico sul quale tale metodo si fonda.Anzitutto diamo la seguente
Definizione Sia A una matrice m × n. Si chiamano minori di A di ordine k i determinanti delle sottomatriciquadrate di A di ordine k.
Esempio Consideriamo ad esempio la matrice
A =
1 1 2 00 1 1 −1−1 1 0 −2
.
Trattandosi di una matrice 3 × 4, essa ha minori di ordine 1, 2 e 3. I suoi minori di ordine 1 sono: 0, 1, −1, 2 e −2(ci sono 12 sottomatrici quadrate di ordine 1, ma i determinanti sono soltanto questi).Ci sono 18 sottomatrici quadrate di ordine 2; un minore di ordine 2 e ad esempio 1, dato che e il determinante dellasottomatrice (
1 10 1
)
che si ottiene eliminando la terza riga e la terza e quarta colonna. Un altro minore di ordine 2 e −2, dato che e ildeterminante della sottomatrice (
1 01 −2
)
337L’unico caso in cui puo risultare rA = 0 e quando si tratta della matrice nulla, quindi tipicamente sara 1 ≤ rA ≤ min{m, n}.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CALCOLO DEL RANGO
DETERMINANTE E RANGO
313
che si ottiene eliminando la seconda riga e la prima e terza colonna.Infine ci sono 4 sottomatrici quadrate di ordine 3; un minore di ordine 3 e ad esempio 0, dato che e il determinantedella sottomatrice
A =
1 2 00 1 −1−1 0 −2
che si ottiene eliminando la seconda colonna. Si verifichi che nella matrice A tutti i minori di ordine 3 sono nulli.
Osservazione Non si confonda il minore con la sottomatrice. Il minore e un numero e non una sottomatrice.L’ordine di ogni minore di una matrice A di m righe ed n colonne (con m,n ≥ 1) e sicuramente (un numero naturale)compreso tra 1 e il minimo tra m ed n.
Vale ora il seguente risultato:
Teorema Sia A una matrice m× n. La matrice A ha rango k se e solo se esiste almeno un minore di A di ordine kdiverso da zero e tutti i minori di A di ordine k + 1, se ci sono, hanno valore zero.
Esempio Con una matrice 3× 4 avremo che il rango e 2 se e solo se la matrice ha un minore di ordine 2 diverso dazero e tutti i minori di ordine 3 sono invece nulli.
Per quanto riguarda l’indipendenza dei vettori fornisco quest’altro risultato generale:
Teorema Dati i vettori v1,v2, . . . ,vk ∈ Rn, sia V la matrice che si ottiene disponendo tali vettori in colonna (o inriga, e lo stesso). I vettori sono indipendenti se e solo se la matrice V ha rango k.
Osservazione Quindi i k vettori sono l.i. se e solo se il rango di questa matrice e uguale al numero dei vettori cheabbiamo considerato. Questo teorema fornisce un metodo operativo per stabilire se dei vettori dati sono l.i. oppureno: tutto e ricondotto al calcolo del rango della matrice costruita con i vettori dati.
Osservazione Dal teorema segue immediatamente un fatto gia noto, che cioe, dati i vettori v1,v2, . . . ,vk ∈ Rn, sek > n, allora i vettori sono sicuramente linearmente dipendenti. Infatti la matrice V ha certamente rango minore ouguale a n e quindi il rango non puo essere k. Analogamente possiamo dire che nella matrice V non puo esserci unminore di ordine k in quanto, come gia osservato, l’ordine dei minori di V non puo superare il minimo tra n e k, chein questo caso e certamente n.
Valendo il risultato del teorema che stabilisce il legame tra il rango e i minori della matrice, si puo dire allora che ilrango di una matrice coincide col massimo ordine dei suoi minori non nulli oppure, equivalentemente, col massimoordine delle sue sottomatrici quadrate non singolari.In molti testi lo studente puo trovare quest’ultima quale definizione di rango di una matrice.
Vediamo ora un paio di esempi. Consideriamo la matrice
A =
(2 −2 0−1 1 1
)
.
E evidente che A ha sottomatrici quadrate di ordine 1 e 2. Le sottomatrici di ordine 1 sono 6 e i minori di ordine 1sono: 2,−2, 0,−1, 1.Le sottomatrici di ordine 2 sono 3 e i minori di ordine 2 sono: 0, 2,−2. Il rango di A e quindi 2.La matrice
A =
(1 −1 1−1 1 −1
)
ha invece rango 1, dato che tutti i suoi minori di ordine 2 sono nulli.
Osservazione E chiaro che in generale non serve trovare tutti i minori della matrice per stabilire qual e il rango.Se ne trovo uno di ordine k diverso da zero, non serve trovare gli altri minori di ordine k o quelli di ordine minore dik, dato che il rango e sicuramente almeno k. Occorrera invece considerare quelli di ordine maggiore di k, sempre chece ne siano.La matrice
A =
0 1 0 00 0 0 −11 0 0 1
puo avere al piu rango 3. Dato che la terza colonna e nulla, ogni sottomatrice di ordine 3 che contiene la terza colonnaha sicuramente determinante nullo. L’unica sottomatrice di ordine 3 non singolare puo essere quella che non contienela terza colonna. Tale sottomatrice ha determinante uguale a −1. Quindi il rango di A e 3.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CALCOLO DEL RANGO
DETERMINANTE E RANGO
314
Ancora, la matrice
A =
1 1 2 00 1 1 −1−1 1 0 −2
,
presa come esempio poco fa per il calcolo di alcuni minori, ha almeno rango 2 (ad esempio, il primo minore di ordine2 in alto a sinistra vale 1). Ora si puo osservare che la terza colonna e la somma delle prime due e che la quartacolonna e la differenza delle prime due. Questo ci permette di dire che certamente tutti i minori di ordine 3 sono nulli(lo studente lo verifichi con il calcolo diretto). Pertanto il rango, non potendo essere 3, e 2.
Osservazione Si dice che una matrice m×n A ha rango massimo (o rango pieno) se risulta rA = min{m,n}. Se lamatrice e quadrata di ordine n, essa ha un solo minore di ordine n, che coincide col detA. Allora una matrice quadrataha rango massimo se e solo se il suo determinante non e zero, il che equivale al fatto che le righe (e le colonne) sonoindipendenti, oppure al fatto che la matrice e invertibile.Lo studente presti attenzione al fatto che e falso affermare in generale che in una matrice a rango pieno sono linearmenteindipendenti sia le righe sia le colonne, a meno che la matrice non sia quadrata.
Osservazione Sia A una matrice m × n. Per riassumere, possiamo affermare che, affinche il rango di A sia k, enecessario e sufficiente che valgano le seguenti due proprieta:
1. esiste un minore non nullo di A di ordine k;2. non esistono minori di A di ordine k + 1 oppure, se ne esistono, sono tutti nulli.338
Relativamente al punto 2, e evidente che esistono minori di ordine k + 1 se e solo se k < min{m,n}.Esempio Talvolta la matrice puo dipendere da uno (o piu) parametri reali. In questi casi e ovvio che il rango dellamatrice dipende anch’esso dai valori che si attribuiscono ai parametri.
Consideriamo ad esempio la matrice
Ax =
x 0 1 1−1 x 0 −11 2 x 1
.
A priori (cioe per il solo fatto che la matrice e 3× 4) possiamo dire che i valori possibili del rango della matrice sono1, 2 o 3.Da un esame un po’ piu dettagliato risulta che rA e almeno 2, qualunque sia il valore di x. Esiste infatti, qualunquesia x, almeno un minore non nullo di ordine 2 (ad esempio quale?).Ora vediamo se ci sono valori di x per cui il rango e 3, oppure no. Consideriamo un minore di ordine 3. In questi casioccorre un po’ di scaltrezza. Un minore di una matrice che dipende da un parametro x e un polinomio nella variabilex. Anche se in generale non e vero che “il numero di x” presenti nella sottomatrice coincida con il grado del polinomio,e comunque bene fare in modo che non ci siano troppe x nella sottomatrice che vado a scegliere.Quindi la scaltrezza consiste nello scegliere, possibilmente, una sottomatrice che contenga “tanti zeri e poche x”.La cosa e particolarmente apprezzabile nell’esempio che stiamo considerando. Se scegliamo la sottomatrice di ordine3 costituita dalle prime 3 colonne di A, il minore corrispondente e
x · x2 + 1 · (−2− x) = x3 − x− 2.
Possiamo dire che esiste certamente almeno uno zero reale di questo polinomio339, ma non siamo in grado di trovarloin quanto il polinomio non si fattorizza in polinomi di grado inferiore a coefficienti razionali.Se scegliamo invece la sottomatrice costituita dalle ultime 3 colonne, il minore corrispondente e
−1 · (x + 2) + 1 · x2 = x2 − x− 2 = (x+ 1)(x− 2).
Possiamo ora affermare che, se x 6= −1 e x 6= 2, il rango e 3, poiche per tali valori di x questo minore di ordine 3 enon nullo.Ci restano da studiare due casi: x = −1 e x = 2.Lo studente stia attento a non cadere nella tentazione di affermare che per tali valori di x il rango e sicuramente 2:prima di arrivare a questa conclusione occorre esaminare i minori di ordine 3 non ancora considerati. Di solito convienesostituire i valori del parametro x nella matrice (cioe scrivere le matrici A−1 e A2 nel nostro caso) e poi calcolare altri
338Si noti che, se i minori di ordine k + 1 sono tutti nulli ed esistono minori di ordine > k + 1, allora questi sono certamente tutti nulli.339Lo possiamo affermare in base al teorema degli zeri, applicato ad esempio nell’intervallo [0, 2], dato che in esso il polinomio assumevalori opposti agli estremi.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 CALCOLO DEL RANGO
DETERMINANTE E RANGO
315
minori non ancora esaminati (nel nostro caso ce ne sono tre oltre a quello gia considerato): se ne troviamo uno nonnullo, possiamo concludere che il rango e 3; il rango e invece 2 se tutti e tre i minori di ordine 3 sono nulli.Nel nostro caso, dato che il minore relativo alla sottomatrice formata dalle prime tre colonne risulta essere il polinomioP (x) = x3 − x − 2, possiamo intanto calcolare tale polinomio per i valori x = −1 e x = 2. Risulta P (−1) = −2 eP (2) = 4. Entrambi i valori sono non nulli e quindi il rango e 3 anche per x = −1 e x = 2. Pertanto concludiamo cheil rango di Ax e 3 qualunque sia x ∈ R.
Consideriamo ora la matrice
Ax =
x 0 1 1−1 x −1 −11 2 x 1
.
Possiamo subito affermare che il rango di A e almeno 2 in quanto il determinante della sottomatrice di ordine 2 formatada 2a e 3a riga e 2a e 3a colonna e non nullo qualunque sia x (il minore e x2 + 2).Poi, con procedimento analogo a quello usato nell’esempio precedente, il minore relativo alla sottomatrice formatadalle ultime 3 colonne e
−1 · (x+ 2) + 1 · (x2 + 2) = x2 − x = x(x − 1).
Possiamo dire allora che, se x 6= 0 e x 6= 1, il rango e 3.Se x = 0 oppure se x = 1 si ottengono rispettivamente le due matrici
A0 =
0 0 1 1−1 0 −1 −11 2 0 1
e A1 =
1 0 1 1−1 1 −1 −11 2 1 1
.
Il rango di A0 e 3 in quanto la sottomatrice formata dalle prime tre colonne e non singolare.Il rango di A1 e invece 2. Si puo infatti osservare che ci sono tre colonne uguali. Pertanto ogni sottomatrice quadratadi ordine 3 e singolare, avendo sicuramente almeno due colonne uguali. In conclusione quindi rAx = 2 per x = 1 erAx = 3 per ogni x 6= 1.
Esercizio 3.1 Si calcoli il rango delle seguenti matrici:
A1 =
(−1 22 −4
)
, A2 =
1 2 34 5 67 8 9
, A3 =
1 −1 22 −2 4−1 1 −2
A4 =
(1 −1 2−1 1 3
)
, A5 =
(−1 2 12 −4 −2
)
A6 =
1 −1 2 10 1 −1 01 0 1 1
, A7 =
0 1 −1 01 0 1 01 1 0 1
.
Esercizio 3.2 Dati i vettori
v1 = (2,−1) , v2 = (1, 1),
si dica se essi sono linearmente dipendenti o indipendenti (non si utilizzi la definizione ma i risultati legati al rangodi un’opportuna matrice). Si stabilisca poi la dimensione del sottospazio da essi generato in R2. Si indichi infine unabase di tale sottospazio.
Esercizio 3.3 Dati i vettori
v1 = (−1, 2) , v2 = (1,−2) , v3 = (−2, 4),
si dica se essi sono linearmente dipendenti o indipendenti (come prima non si utilizzi la definizione ma i risultati legatial rango). Si stabilisca poi la dimensione del sottospazio da essi generato in R2. Si indichi infine una base di talesottospazio.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
DETERMINANTE E RANGO
316
Esercizio 3.4 Dati i vettori
v1 = (1, 0,−1) , v2 = (1, 1, 0) , v3 = (−1, 0, 1),
si dica se essi sono linearmente dipendenti o indipendenti (non si utilizzi la definizione ma i risultati legati al rangodi un’opportuna matrice). Si stabilisca poi la dimensione del sottospazio da essi generato in R3. Si indichi infine unabase di tale sottospazio.
Esercizio 3.5 Dati i vettori
v1 = (1, 2,−1) , v2 = (3,−1, 2) , v3 = (−2, 3,−3) , v4 = (4, 1, 1),
si dica se essi sono linearmente dipendenti o indipendenti (come prima, non si utilizzi la definizione ma i risultati legatial rango). Si stabilisca poi la dimensione del sottospazio da essi generato in R3. Si indichi infine una base di talesottospazio.
Esercizio 3.6 Si studi, al variare del relativo parametro in R, il rango delle matrici
Ax =
(1 −1 x−2 x −4
)
, Ay =
y −1 00 1 11 1 2y
, Az =
−1 z −1z −1 1−1 1 −1
At =
0 1 2 t1 −1 1 −1t 0 1 2
, Au =
1 u 2 0u 2 3 −u−1 1 0 −2
.
4 Soluzioni degli esercizi
Esercizio 1.1
Indicando come sempre con Aij il complemento algebrico di aij e con Mij il relativo minore complementare, si ha
A11 =M11 = det
(5 68 9
)
= 45− 48 = −3.
Poi
A12 = −M12 = − det
(4 67 9
)
= −(36− 42) = 6
A22 = M22 = det
(1 37 9
)
= 9− 21 = −12
A32 = −M32 = − det
(1 34 6
)
= −(6− 12) = 6.
Esercizio 1.2
La definizione prevede di calcolare il determinante sviluppando i calcoli rispetto alla prima riga. Quindi abbiamo
detA1 = 1 · 5− 2 · (−3) = 5 + 6 = 11.
Poi
detA2 = 1 · det(5 68 9
)
− 2 · det(4 67 9
)
+ 3det
(4 57 8
)
= −3− 2(−6) + 3(−3) = 0.
Infine
detA3 = − det
2 0 11 2 −1−1 1 0
− det
2 −1 11 0 −1−1 2 0
− 2 det
2 −1 01 0 2−1 2 1
= −5− 5 + 10 = 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
DETERMINANTE E RANGO
317
Esercizio 1.3
Si tratta di verificare che si ha det(AB) = detA · detB.
detA = −2 , detB = −10 , AB =
(1 23 4
)(2 34 1
)
=
(10 522 13
)
QuindidetA · detB = 20 e det(AB) = 130− 110 = 20.
Esercizio 1.4
L’elemento di posto (1, 1) e nullo e quindi dobbiamo intanto scambiare le prime due righe, ricordando che cosı facendoil determinate cambia segno. Quindi
detA3 = − det
2 −1 0 10 1 −1 21 0 2 −1−1 2 1 0
.
Ora possiamo annullare gli elementi di posto (3, 1) e (4, 1) con operazioni elementari sulle righe. In particolare perannullare il primo possiamo togliere alla terza riga la prima moltiplicata per 1/2; per annullare il secondo possiamoaggiungere alla quarta riga la prima moltiplicata per 1/2. Si ottiene quindi
detA3 = − det
2 −1 0 10 1 −1 20 1/2 2 −3/20 3/2 1 1/2
.
Ora, sviluppando rispetto alla prima colonna, si ha
detA3 = −2 det
1 −1 21/2 2 −3/23/2 1 1/2
.
Ancora con operazioni elementari possiamo annullare il secondo e il terzo elemento della prima riga (rispettivamenteaggiungendo alla seconda colonna la prima e togliendo alla terza colonna la prima moltiplicata per 2). Si ottiene
detA3 = −2 det
1 0 01/2 5/2 −5/23/2 5/2 −5/2
= 0 (sviluppando rispetto alla prima riga).
Esercizio 2.1
Consideriamo
A1 =
(1 23 4
)
.
La matrice e invertibile, dato che il suo determinante non si annulla (detA1 = −2). Allora possiamo calcolare lamatrice inversa A−1
1 . La matrice dei complementi algebrici e
(4 −3−2 1
)
. La matrice aggiunta e A⋆1 =
(4 −2−3 1
)
.
La matrice inversa e allora
A−11 =
1
detA1A⋆
1 = −1
2
(4 −2−3 1
)
=
(−2 13/2 −1/2
)
.
Si ha infatti, a verifica di questo,
A1A−11 =
(1 23 4
)(−2 13/2 −1/2
)
=
(1 00 1
)
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
DETERMINANTE E RANGO
318
Consideriamo
A2 =
1 0 02 4 53 0 6
.
Risulta detA2 = 24 e quindi A2 e invertibile. La matrice dei complementi algebrici e
24 3 −120 6 00 −5 4
. La matrice aggiunta e A⋆2 =
24 0 03 6 −5−12 0 4
.
La matrice inversa e allora
A−12 =
1
detA2A⋆
2 =1
24
24 0 03 6 −5−12 0 4
=
1 0 01/8 1/4 −5/24−1/2 0 1/6
.
Consideriamo infine
A3 =
1 0 1 00 1 1 01 1 0 10 0 1 0
.
Si noti che A3 e una matrice simmetrica. Risulta detA3 = −1 e quindi A3 e invertibile. La matrice dei complementialgebrici e340
−1 0 0 10 −1 0 10 0 0 −11 1 −1 −2
. La matrice aggiunta e la stessa, dato che anche questa e simmetrica.
La matrice inversa e allora
A−13 =
1
detA3A⋆
3 = −
−1 0 0 10 −1 0 10 0 0 −11 1 −1 −2
=
1 0 0 −10 1 0 −10 0 0 1−1 −1 1 2
.
Esercizio 3.1
(a) detA1 = 0, quindi il rango e 1.
(b) detA2 = 0 (lo abbiamo calcolato in un esercizio precedente). Pertanto il rango di A2 non e 3. Dato che esistealmeno un minore del secondo ordine diverso da zero (ad esempio quello che si ottiene con le prime due righe ele prime due colonne) risulta rA2 = 2.
(c) Si potrebbe osservare che la seconda riga e il doppio della prima e che la terza e l’opposto della prima. Questoporta subito a dire che il rango e 1. Se uno non si accorge delle dipendenze, arriva comunque alla stessaconclusione calcolando prima il determinante, che e nullo. Quindi il rango non e massimo. Ora si passa ai minoridel secondo ordine e si vede facilmente che sono tutti nulli. Pertanto si ha rA3 = 1.
(d) La matrice A4 puo avere al piu rango 2 (e ha evidentemente almeno rango 1). Il minore che si ottiene con leprime due colonne e nullo, ma quello che si ottiene con le ultime due colonne non lo e, e quindi si ha rA4 = 2.
(e) Anche A5 puo avere al piu rango 2 (e ha evidentemente almeno rango 1). Questa volta tutti e tre i minori delsecondo ordine sono nulli e quindi rA5 = 1. Si noti anche che le due righe sono proporzionali, cioe linearmentedipendenti.
340Occorre un po’ di pazienza nei calcoli dei complementi algebrici. Si sfruttino le proprieta del determinante: accade spesso che ci sianodue righe o due colonne uguali o che ci sia una riga o colonna nulla.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
DETERMINANTE E RANGO
319
(f) La matrice A6 puo avere al piu rango 3 (e ha evidentemente almeno rango 1). Il minore del secondo ordine chesi ottiene con le prime due righe e le prime due colonne e diverso da zero: questo dice che il rango e almeno 2(quindi o e 2 o e 3). Se non si scoprono evidenti dipendenze tra le righe o colonne341 occorre passare a considerarei minori del terzo ordine (e ce ne sono 4 al piu da esaminare). Si trova che sono tutti nulli. Quindi rA6 = 2.
(g) La matrice A7 puo avere al piu rango 3 (e ha evidentemente almeno rango 1). Osservando che il minore delsecondo ordine che si ottiene con le prime due righe e le prime due colonne e diverso da zero, si ha che il rangoe almeno 2. Il minore del terzo ordine che si ottiene con le prime tre colonne e nullo. Questo non consente diconcludere che il rango e 2: infatti il minore del terzo ordine che si ottiene con le ultime tre colonne e diverso dazero e quindi rA7 = 3.
Esercizio 3.2
Si tratta di due vettori in R2. Essi sono l.i. se e soltanto se il rango della matrice342
V =
(2 1−1 1
)
e uguale a 2, cioe se e solo se il determinante di V e diverso da zero. Si ha detV = 3 e quindi i due vettori sonolinearmente indipendenti.La dimensione del sottospazio da essi generato e uguale al rango di V e cioe 2.Essi generano tutto R2 e ne costituiscono una base.
Esercizio 3.3
Si tratta di tre vettori in R2. Possiamo dire a priori che essi sono dipendenti, poiche sono in numero maggiore delladimensione dello spazio cui appartengono. Si puo anche affermare che sono dipendenti in quanto il rango della matrice
V =
(−1 1 −22 −2 4
)
non puo essere 3.La dimensione del sottospazio da essi generato e uguale al rango di V . Possiamo osservare che le due righe sonodipendenti (sono multiple una dell’altra). Quindi il rango di V non puo essere 2, ma e certamente 1. Pertanto ladimensione del sottospazio generato da v1,v2,v3 e 1.Una base di tale sottospazio e formata da uno qualunque dei tre vettori: ad esempio una base e {v1} (anche {v2} e{v3} sono basi dello stesso sottospazio).
Esercizio 3.4
Per sapere se i tre vettori sono dipendenti o indipendenti possiamo calcolare il rango della matrice che si ottienedisponendo i vettori ad esempio in colonna: sia
V =
1 1 −10 1 0−1 0 1
.
Il determinante di V e zero. Pertanto i tre vettori sono dipendenti (si puo osservare che v3 e l’opposto di v1).La dimensione del sottospazio da essi generato coincide con il rango della matrice V . Il rango di V e chiaramente 2(non puo essere 3 in quanto il determinante si annulla), dato che ad esempio il primo minore di ordine 2 in alto asinistra e diverso da zero. Quindi la dimensione del sottospazio generato da v1,v2,v3 e 2.Una base di tale sottospazio e una qualunque coppia di vettori indipendenti scelti tra v1,v2,v3. Qui e importantericordare che per sapere se dei vettori sono l.i. basta controllare che il rango della matrice formata con questi vettorisia uguale al numero dei vettori stessi. Ad esempio, se voglio sapere se v1,v2 sono l.i. basta che il rango della matriceformata con v1,v2 sia 2. Nel nostro caso il rango della sottomatrice di V formata dalle prime due colonne e appunto2. Quindi v1,v2 sono l.i. e quindi sono una base per quel sottospazio. Possiamo osservare che anche v2,v3 sono unabase del sottospazio, dato che anche il rango della sottomatrice formata dalla seconda e terza colonna e 2. Invecev1,v3 non sono una base del sottospazio, dato che sono l.d. Infatti il rango della sottomatrice di V formata dallaprima e terza colonna non e 2, ma 1 (tutti e tre i minori del secondo ordine di questa sottomatrice sono nulli).
341Qui in realta e semplice accorgersi che la terza riga e somma delle prime due. Questo permette di concludere che il rango e 2.342Dispongo i vettori in colonna ma sarebbe lo stesso disporli in riga.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
DETERMINANTE E RANGO
320
Esercizio 3.5
Costruiamo una matrice disponendo i vettori ad esempio in colonna (e lo stesso anche se li disponiamo in riga):
V =
1 3 −2 42 −1 3 1−1 2 −3 1
.
Ora affrontiamo la prima questione, se cioe i vettori siano dipendenti o indipendenti. Qui non serve molto: i vettori sonocertamente dipendenti in quanto sono quattro vettori in uno spazio (R3) di dimensione 3. Possiamo quindi affermarequesto anche senza scoprire qualche particolare dipendenza tra le colonne di V (dipendenza che c’e sicuramente).Chiamiamo ora per comodita S il sottospazio generato dai quattro vettori. Possiamo dire che la dimensione di Scoincide con il rango della matrice V . E chiaro che tale dimensione non puo essere piu di 3. Potremmo calcolare ilrango attraverso il calcolo dei minori di V . Oppure possiamo cercare di scoprire qualche particolare dipendenza nellecolonne di V . Ad esempio possiamo osservare che la terza colonna e la differenza delle prime due (cioe v3 = v1− v2).Ma si ha anche che la quarta colonna e la somma delle prime due (v4 = v1 + v2). Allora il sottospazio generatoda v1,v2,v3,v4 e lo stesso generato da soltanto v1,v2. Dato che questi ultimi due sono l.i. (e qui lo possiamo diresemplicemente perche la sottomatrice formata da v1 e v2 ha evidentemente rango 2) allora la dimensione di S e 2.343
Dato che v1 e v2 sono l.i. e sono generatori di S, essi formano una base di S.
Esercizio 3.6
(a) Sia dunque Ax =
(1 −1 x−2 x −4
)
. Evidentemente il rango di Ax e almeno 1 e al piu 2, a seconda del valore del
parametro x. Possiamo procedere cosı: consideriamo uno dei minori del secondo ordine, ad esempio il primo,cioe il
det
(1 −1−2 x
)
= x− 2.
Possiamo allora dire che, se x 6= 2, allora il rango e certamente 2, dato che c’e un minore del secondo ordinediverso da zero.
Per x = 2 non possiamo dire che il rango non e 2, ma dobbiamo considerare prima gli altri minori. Convieneallora sostituire x = 2 nella matrice:
A2 =
(1 −1 2−2 2 −4
)
.
Dopo aver osservato che le righe sono chiaramente dipendenti, possiamo concludere che per x = 2 il rango e 1.
(b) Sia Ay =
y −1 00 1 11 1 2y
. Il rango di Ay e almeno 1 e al piu 3, a seconda del valore del parametro y. Conviene
iniziare dal calcolo del determinante. Si ha
detAy = det
y −1 00 1 11 1 2y
= 2y2 − y − 1 = (y − 1)(2y + 1).
Possiamo ora affermare che, se y 6= 1 e y 6= −1/2, il rango e 3. Restano poi da studiare i casi y = 1 e y = −1/2.Con y = 1 abbiamo
A1 =
1 −1 00 1 11 1 2
.
Inutile calcolare il determinante, dato che e certamente nullo. C’e almeno un minore del secondo ordine diversoda zero (ad esempio quello che si ottiene con la sottomatrice in alto a sinistra) e quindi si ha rA1 = 2.
Con y = −1/2 abbiamo
A−1/2 =
−1/2 −1 00 1 11 1 −1
.
Anche in questo caso il rango e 2, dato che c’e almeno un minore del secondo ordine diverso da zero.
343Se avessimo calcolato il rango attraverso i minori di V avremmo trovato che tutti i minori del terzo ordine sono nulli e invece c’e almenoun minore del secondo ordine diverso da zero.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
DETERMINANTE E RANGO
321
(c) Sia Az =
−1 z −1z −1 1−1 1 −1
. Il rango di Az e almeno 1 e al piu 3, a seconda del valore del parametro z. Conviene
iniziare dal calcolo del determinante. Si ha
detAz = det
−1 z −1z −1 1−1 1 −1
= (z − 1)2.
Possiamo affermare che, se z 6= 1, il rango e 3. Resta poi da studiare il caso z = 1.
Con z = 1 abbiamo
A1 =
−1 1 −11 −1 1−1 1 −1
.
Le righe sono a due a due dipendenti344 e quindi rA1 = 1.
(d) Sia At =
0 1 2 t1 −1 1 −1t 0 1 2
. Il rango di At e almeno 1 e al piu 3, a seconda del valore del parametro t. Si
vede facilmente che il rango e almeno 2, per ogni valore di t. Consideriamo il minore del terzo ordine dato dallasottomatrice delle prime tre colonne:
det
0 1 21 −1 1t 0 1
= 3t− 1.
Allora, se t 6= 1/3, il rango e 3.
Con t = 1/3 abbiamo
A1/3 =
0 1 2 1/31 −1 1 −1
1/3 0 1 2
.
Il minore del terzo ordine dato dalla sottomatrice delle ultime tre colonne vale 20/3 e quindi il rango di A1/3 e3. Pertanto il rango e 3 per ogni valore di z.
(e) Sia Au =
1 u 2 0u 2 3 −u−1 1 0 −2
. Il rango di Au e almeno 1 e al piu 3, a seconda del valore del parametro u. Si vede
facilmente che il rango e almeno 2, per ogni valore di u (minore del secondo ordine ottenuto dalla sottomatriceformata da seconda e terza riga e seconda e terza colonna, ad esempio).
Consideriamo il minore del terzo ordine dato dalla sottomatrice delle prime tre colonne:
det
1 u 2u 2 3−1 1 0
= 1− u.
Allora, se u 6= 1, il rango e 3.
Con u = 1 abbiamo
A1 =
1 1 2 01 2 3 −1−1 1 0 −2
.
C’e una dipendenza tra le righe, ma non e cosı evidente. Procediamo con gli altri minori del terzo ordine: si ha
det
1 1 01 2 −1−1 1 −2
= 0 , det
1 2 01 3 −1−1 0 −2
= 0 , det
1 2 02 3 −11 0 −2
= 0.
Quindi concludiamo che rA1 = 2.
344Si faccia attenzione che e diverso affermare che tre vettori sono dipendenti dall’affermare che sono a due a due dipendenti: la primaaffermazione non esclude che tra i tre vettori ce ne siano due di indipendenti, mentre la seconda esclude questo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 SISTEMI DI EQUAZIONI LINEARI
SISTEMI DI EQUAZIONI LINEARI
322
III-4 Sistemi di equazioni lineari
1 Sistemi di equazioni lineari
Con il termine equazione lineare in n incognite si intende un’equazione del tipo
a1x1 + a2x2 + . . .+ anxn = b,
dove a1, a2, . . . , an e b sono numeri reali fissati e x1, x2, . . . , xn sono le incognite.Con sistema di m equazioni lineari in n incognite si intende la scrittura
a11x1 + a12x2 + . . .+ a1nxn = b1a21x1 + a22x2 + . . .+ a2nxn = b2...
am1x1 + am2x2 + . . .+ amnxn = bm.
Ciascuna riga del sistema e ovviamente un’equazione lineare nelle incognite x1, x2, . . . , xn.Solitamente i numeri aij , con 1 ≤ i ≤ m e 1 ≤ j ≤ n, si dicono i coefficienti del sistema, i numeri bi, con 1 ≤ i ≤ m, sonoi termini noti e le xj , con 1 ≤ j ≤ n, sono appunto le incognite del sistema. Talvolta, anziche dire piu correttamentesistema di equazioni lineari, diremo piu sinteticamente sistema lineare o semplicemente sistema.E immediato osservare che il sistema (di m equazioni ed n incognite) si puo scrivere, in forma matriciale, con Ax = b,avendo posto
A =
a11 a12 . . . a1na21 a22 . . . a2n...
.... . .
...
am1 am2 . . . amn
, x =
x1x2...
xn
e b =
b1b2...
bm
(A si dice la matrice del sistema, x il vettore delle incognite e b il vettore dei termini noti).Ribadisco che A e b si presumono fissati, cioe sono rispettivamente una matrice ed un vettore di numeri reali assegnati.Con il termine soluzione del sistema intendiamo ogni vettore x tale che Ax = b.
Risolvere il sistema significa trovare tutte le sue soluzioni. Un sistema si dice possibile se ha almeno una soluzione. Sidice impossibile se non ha soluzioni. Si e soliti anche chiamare determinato un sistema possibile che abbia un’unicasoluzione, indeterminato un sistema possibile che abbia piu di una soluzione. Un sistema si dice quadrato se la matriceA e quadrata.
Osservazione Dato il sistema Ax = b, e chiaro che risolvere il sistema significa trovare la controimmagine di battraverso la trasformazione lineare f rappresentata dalla matrice A (f : Rn → Rm, con f(x) = Ax),345 cioe l’insiemedei vettori di Rn che la f trasforma nel vettore b. E evidente che il sistema e possibile se e solo se b ∈ Im f o, se sipreferisce, se e solo se b si puo scrivere, in Rm, come combinazione lineare delle colonne di A.346
Definizione Un sistema si dice omogeneo se b = 0.
Osservazione Un sistema omogeneo Ax = 0 e sempre possibile, avendo sicuramente almeno la soluzione nullax = 0. Quindi la domanda interessante nel caso di sistema omogeneo e se esso ha altre soluzioni oltre a quella nulla,oppure no.
Vale il seguente importante risultato:
Teorema Dato un sistema omogeneo Ax = 0, in n variabili, le sue soluzioni formano un sottospazio di Rn. Ladimensione di tale sottospazio e n− rA.345Ricordo che in generale, data una funzione g : X → Y , se B ⊂ Y , allora la controimmagine di B attraverso la funzione g e l’insieme
g−1(B) = {x ∈ X : g(x) ∈ B}.
Quindi la controimmagine di b attraverso f ef−1({b}) = {x ∈ Rn : f(x) = b}.
346Si ricordi che l’immagine di una trasformazione lineare e generata dalle colonne della sua matrice di rappresentazione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 ALCUNI RISULTATI GENERALI
SISTEMI DI EQUAZIONI LINEARI
323
Osservazione Il rango della matrice A ha dunque un’importanza rilevante non solo come dimensione dell’immaginedella trasformazione associata alla matrice A o nella dipendenza/indipendenza lineare dei vettori, ma anche nelladimensione delle soluzioni di un sistema lineare.
Esercizio 1.1 Si scrivano in forma matriciale i seguenti sistemi lineari:
(a)
{x− y = 1
x+ 2y = −2 (b)
{x+ z = 3
y − z = 2(c)
{y + t = 1
x− z = 0
2 Alcuni risultati generali
Il seguente teorema fornisce in un certo senso la struttura dell’insieme delle soluzioni di un sistema lineare, quandoqueste esistono.
Teorema Se x e una soluzione (soluzione particolare) del sistema Ax = b, allora l’insieme delle sue soluzioni e datoda
S ={x+ y : Ay = 0
}.
Osservazione Dato un sistema Ax = b, si usa chiamare sistema omogeneo associato il sistema Ax = 0. Il teoremadice quindi che (tutte) le soluzioni di un sistema si ottengono sommando ad una soluzione particolare del sistemastesso (indicata nell’enunciato da x) le soluzioni del sistema omogeneo associato. Questo risultato e importante emolto generale. Presento anche la dimostrazione, che e semplice.
Dimostrazione Dobbiamo dimostrare due cose: che ogni soluzione del sistema puo essere scritta come somma di x edi una soluzione dell’omogeneo associato e che, viceversa, ogni vettore di questo tipo e soluzione.Per ipotesi Ax = b. Sia v una generica soluzione del sistema. Possiamo scrivere v = x+(v−x). Ora il vettore v−x
e soluzione del sistema omogeneo associato, infatti A(v − x) = Av − Ax = b − b = 0 e la prima parte e dimostrata(il vettore v − x e il vettore y dell’enunciato).Viceversa, dato un vettore del tipo x+ y, con Ay = 0, chiaramente si ha A(x+ y) = Ax+Ay = b+ 0 = b e quindiun tale vettore e soluzione.
Osservazione Abbiamo visto poco fa che le soluzioni di un sistema omogeneo formano un sottospazio di Rn. L’in-sieme delle soluzioni di un sistema non omogeneo invece no (basta ricordare che tale insieme, non contenendo il vettorenullo, non puo essere un sottospazio). Tale insieme pero, pur non essendo un sottospazio di Rn, tuttavia gli assomigliamolto, essendo sostanzialmente una traslazione di un sottospazio propriamente detto: viene detto sottospazio affine.Si puo parlare di dimensione del sottospazio affine delle soluzioni di Ax = b, riferendosi alla dimensione delle soluzionidi Ax = 0.
Osservazione Il teorema appena visto ha un’importante conseguenza. Se un sistema e possibile, cioe ha soluzioni,allora o ne ha una o ne ha infinite. Infatti se non ne ha soltanto una, lo spazio delle soluzioni del sistema omogeneoassociato non e banale (cioe costituito dal solo vettore nullo) e quindi ha almeno dimensione 1, ma sappiamo bene cheun sottospazio di dimensione 1 ha pur sempre infiniti elementi.
2.1 Il teorema di Rouche – Capelli
Il seguente e un risultato fondamentale e fornisce una condizione necessaria e sufficiente affinche un sistema abbiasoluzioni. Conviene prima dare questa
Definizione Dato un sistema Ax = b, la matrice, che si indica con A|b, ottenuta affiancando ad A il vettore b qualeulteriore colonna, si chiama matrice completa del sistema. Solitamente A viene detta allora matrice incompleta.
Teorema (di Rouche – Capelli) Un sistema Ax = b ha almeno una soluzione se e solo se rA = r(A|b).Osservazione Il teorema di Rouche – Capelli fornisce quindi una condizione del tutto generale (necessaria esufficiente) per l’esistenza di soluzioni di un sistema.
Osservazione Ricordando quanto detto poco fa, quando un sistema Ax = b e possibile, con A matrice m × n, ladimensione dello spazio delle sue soluzioni e n− rA.Grazie al teorema di Rouche – Capelli e relativamente semplice sapere se un sistema ha soluzioni oppure no. Cometrovare le soluzioni (quando esistono) lo vediamo tra breve. Vediamo intanto un altro importante risultato.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL CALCOLO DELLE SOLUZIONI NEL CASO GENERALE
SISTEMI DI EQUAZIONI LINEARI
324
2.2 Il teorema e la regola di Cramer
Il teorema di Cramer parla di sistemi quadrati.
Teorema (di Cramer) Un sistema quadrato Ax = b ha una sola soluzione se e solo se detA 6= 0.
Osservazione Si noti che quindi, nel caso sia detA = 0, ci si puo attendere che il sistema o sia impossibile oppureabbia piu di una soluzione.
Osservazione Relativamente al calcolo della soluzione di un sistema quadrato Ax = b, con detA 6= 0, il modo piunaturale per trovare la soluzione e sicuramente x = A−1b. 347 Esiste un metodo equivalente che consente di trovare lasoluzione componente per componente, evitando cosı il calcolo della matrice inversa. Si tratta della cosiddetta regoladi Cramer : dato il sistema Ax = b, con A quadrata di ordine n non singolare, l’unica soluzione del sistema e il vettorex ∈ Rn la cui i-esima componente e
xi =1
detA· detAi,
dove Ai e la matrice che si ottiene da A, sostituendo alla i-esima colonna il vettore b.Non fornisco una dimostrazione della regola di Cramer. Vediamo invece un paio di esempi.
Esempio Risolvere il sistema{x1 − x2 = 1
2x1 + x2 = 1.
Dopo aver osservato che detA = 3, possiamo dire che c’e una sola soluzione e utilizzando la regola di Cramer otteniamo
x1 =1
3det
(1 −11 1
)
=2
3,
x2 =1
3det
(1 12 1
)
= −1
3.
L’unica soluzione e quindi il vettore (23 ,− 13 ).
Esempio Risolvere il sistema
x1 + x2 − x3 = 0
x1 + x3 = 1
x1 − x2 = 2.
Risulta detA = 3 e pertanto anche in questo caso il sistema ha una sola soluzione. Applicando la regola di Cramer siottiene
x1 =1
3det
0 1 −11 0 12 −1 0
= 1;
x2 =1
3det
1 0 −11 1 11 2 0
= −1;
x3 =1
3det
1 1 01 0 11 −1 2
= 0.
L’unica soluzione e quindi il vettore (1,−1, 0).
3 Il calcolo delle soluzioni nel caso generale
Al momento abbiamo imparato a risolvere un caso particolare di sistemi, quelli quadrati con determinante di A diversoda zero. Ora vediamo come affrontare il caso generale.Prima pero facciamo qualche ulteriore considerazione sui sistemi omogenei. Come gia osservato in precedenza, essihanno sempre almeno la soluzione nulla. Sull’esistenza di altre soluzioni, distinguiamo i due casi:
347Dall’equazione matriciale Ax = b, moltiplicando ambo i membri a sinistra per A−1, che esiste in quanto detA 6= 0, si ottiene appuntox = A−1b.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL CALCOLO DELLE SOLUZIONI NEL CASO GENERALE
SISTEMI DI EQUAZIONI LINEARI
325
• se il sistema Ax = 0 e quadrato, con A matrice n× n, in base al teorema di Cramer possiamo dire che esso hasoluzioni non nulle se e solo se A e singolare, cioe detA = 0;348
• se il sistema Ax = 0 non e quadrato, con A matrice m× n e m 6= n, il sistema ha soluzioni non nulle se e solose rA < n. A tale proposito si osservi che la condizione e sicuramente verificata se m < n, cioe se il sistema hapiu incognite che equazioni.
Vediamo ora come si possono calcolare le soluzioni di un sistema in tutti i casi diversi da quello di sistema quadratocon detA 6= 0.349 Esiste un metodo generale che porta ad esprimere le soluzioni in funzione di un certo numero diparametri arbitrari. Vediamo questo metodo e poi lo applicheremo ad alcuni esempi conclusivi.Dato il sistema Ax = b, supponiamo di aver trovato che rA = r(A|b) = r e indichiamo con A una sottomatricequadrata di A non singolare di ordine r (potrebbero ovviamente esserci piu sottomatrici con queste caratteristiche).Riscriviamo il sistema eliminando le eventuali equazioni corrispondenti a righe di A che non figurano in A e “portandoa secondo membro” le eventuali incognite relative a colonne di A che non figurano in A.350
Si puo dimostrare che in questo modo otteniamo un sistema ridotto equivalente a quello dato (cioe con lo stesso insiemedi soluzioni).351
In tale sistema ridotto le r incognite relative alle colonne di A che figurano in A vengono espresse in funzione dellealtre n− r, che a questo punto diventano parametri arbitrari. Infatti e chiaro che, fissati in modo arbitrario i valoridi questi n− r parametri, e cioe per ogni scelta di questi, il sistema ha una ed una sola soluzione poiche e un sistemaquadrato e il determinante della matrice di questo sistema (cioe A) e non nullo.352
Osservazione Il fatto che tutte le soluzioni si possano esprimere al variare di n− r parametri arbitrari e una sortadi modo “operativo” di affermare che la dimensione dello spazio delle soluzioni e n− r.Come anticipato nella nota, e evidente che, nel caso sia r = n, avremo necessariamente m > n (altrimenti il sistema equadrato con matrice non singolare e si ricade nel teorema di Cramer) e il procedimento descritto sopra consiste nellasola eliminazione delle equazioni “superflue”: una volta eliminate queste equazioni, il sistema e quadrato ed ha unasola soluzione per il teorema di Cramer.
Per il calcolo esplicito delle soluzioni basta risolvere il sistema ridotto con la regola di Cramer, considerando parametriarbitrari, come gia detto, le incognite che figurano a destra. Questo e un metodo del tutto generale. Concludiamoallora con un certo numero di esempi di risoluzione di un sistema in cui usiamo questo metodo, nei vari casi possibili.
Esempio Risolvere il sistema{x− y + z = 2
−x+ y + z = 1.
Poniamo
A|b =
(1 −1 1
−1 1 1
∣∣∣∣
2
1
)
. Risulta rA = r(A|b) = 2.
Il sistema e quindi possibile e lo spazio delle sue soluzioni ha dimensione n− rA = 3− 2 = 1.Quale sottomatrice di ordine massimo non singolare possiamo prendere quella formata dalla 1a e dalla 3a colonna di
A, e cioe A =
(1 1−1 1
)
. Si noti che invece, ad esempio, la sottomatrice formata dalle prime due colonne e singolare.
Riscriviamo allora il sistema dato nel sistema equivalente (non ci sono equazioni da eliminare){x+ z = 2 + y
−x+ z = 1− y.
Osservando che detA = 2, con la regola di Cramer si ottiene
x =1
2det
(2 + y 11− y 1
)
=1
2(2 + y − 1 + y) =
1
2+ y,
z =1
2det
(1 2 + y−1 1− y
)
=1
2(1− y + 2 + y) =
3
2.
348Infatti il sistema e certamente possibile e quindi la condizione detA = 0 equivale alla non unicita della soluzione.349Quindi qui si considerano sistemi o con m 6= n o con m = n ma detA = 0.350Si ottiene cosı un sistema di r equazioni, con r incognite “a sinistra” e n− r incognite “a destra”. Le incognite a destra assumono orail significato di parametri, come vediamo subito.351Il portare a destra alcune incognite e chiaro che non fa cambiare le soluzioni. L’eliminazione delle equazioni e un’azione piu pericolosaovviamente, ma in questo caso non modifica l’insieme delle soluzioni poiche si tratta di equazioni dipendenti dalle altre.352Aggiungo solo che, se fosse r = n (e quindi n − r = 0), quello che resta dopo aver eliminato le equazioni in piu e semplicemente unsistema quadrato di Cramer, senza parametri.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL CALCOLO DELLE SOLUZIONI NEL CASO GENERALE
SISTEMI DI EQUAZIONI LINEARI
326
Pertanto le soluzioni si possono scrivere come i vettori
(12 + y, y, 32
),
dove y e un numero reale arbitrario.Volendo, possiamo esprimere le soluzioni trovate nella forma x+y, con Ay = 0, ossia “soluzione particolare + soluzionidel sistema omogeneo associato”: basta scrivere
(12 + y, y, 32
)=
(12 , 0,
32
)+(y, y, 0
)
=(12 , 0,
32
)
︸ ︷︷ ︸
x
+ y(1, 1, 0
)
︸ ︷︷ ︸
S0
,
dove ho indicato per comodita con S0 lo spazio delle soluzioni del sistema omogeneo associato. Si tratta, al variare diy ∈ R, del sottospazio generato dal vettore (1, 1, 0), traslato del vettore (12 , 0,
32 ). Il vettore (1, 1, 0) e chiaramente una
base dello spazio delle soluzioni del sistema omogeneo associato al sistema dato.
Osservazione Quello seguito non era l’unico modo di procedere. Si poteva anche porre
A =
(−1 11 1
)
(2a e 3a colonna di A),
riscrivere il sistema come { −y + z = 2− xy + z = 1 + x,
trovare, con la regola di Cramer (ora detA = −2),
y = −1
2det
(2− x 11 + x 1
)
= −1
2(2− x− 1− x) = −1
2+ x,
z = −1
2det
(−1 2− x1 1 + x
)
= −1
2(−1− x− 2 + x) =
3
2,
ed esprimere quindi le soluzioni con i vettori
(x,− 1
2 + x, 32)
=(0,− 1
2 ,32
)+(x, x, 0
)
=(0,− 1
2 ,32
)+ x(1, 1, 0), con x ∈ R.
E chiaro che questo e un modo solo formalmente diverso di scrivere le soluzioni trovate prima: al variare dei parametri(y nel primo modo, x nel secondo) in tutto l’insieme R si ottiene lo stesso insieme di vettori in R3.Si osservi che non era invece possibile esprimere le soluzioni in funzione di z, in quanto la sottomatrice di A formatadalla 1a e 2a colonna e singolare.
Esempio Risolvere il sistema{x− y + t = 0
−x+ y + z = 1.
Poniamo
A|b =
(1 −1 0 1
−1 1 1 0
∣∣∣∣
0
1
)
. Risulta rA = r(A|b) = 2.
Il sistema e possibile e lo spazio delle soluzioni ha dimensione n− rA = 4− 2 = 2.Quale sottomatrice di ordine massimo non singolare possiamo prendere quella formata dalla 1a e dalla 3a colonna di
A, e cioe A =
(1 0−1 1
)
.
Riscriviamo allora il sistema dato nel sistema equivalente
{x = y − t−x+ z = 1− y.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL CALCOLO DELLE SOLUZIONI NEL CASO GENERALE
SISTEMI DI EQUAZIONI LINEARI
327
Con la regola di Cramer (ma e sicuramente piu semplice in questo caso sostituire ad x nella seconda equazione y − t)si ottiene353 {
x = y − tz = 1− t.
Pertanto le soluzioni si possono scrivere come i vettori
(y − t, y, 1− t, t
), con y, t ∈ R.
Anche qui possiamo esprimere le soluzioni nella forma x+ S0, con lo stesso significato di prima per S0:
(y − t, y, 1− t, t
)=
(0, 0, 1, 0
)+(y, y, 0, 0
)+(−t, 0,−t, t
)
=(0, 0, 1, 0
)
︸ ︷︷ ︸
x
+ y(1, 1, 0, 0
)+ t(−1, 0,−1, 1
)
︸ ︷︷ ︸
S0
,
dove y e t sono numeri reali arbitrari. I vettori (1, 1, 0, 0) e (−1, 0,−1, 1) sono generatori dello spazio S0 e, essendol.i., sono anche una base di tale spazio delle soluzioni del sistema omogeneo associato.
Osservazione Anche in questo caso non era l’unico modo di procedere. Si poteva anche porre
A =
(1 1−1 0
)
(1a e 4a colonna di A),
riscrivere il sistema come {x+ t = y
−x = 1− y − zed esprimere le soluzioni come i vettori
(−1 + y + z, y, z, 1− z
)=(−1, 0, 0, 1
)+ y
(1, 1, 0, 0
)+ z
(1, 0, 1,−1
), con y, z ∈ R.
Non era invece possibile esprimere le soluzioni in funzione di x e y, in quanto la sottomatrice di A formata dalla 1a e2a colonna e singolare.
Osservazione Lo studente, prendendo in esame i due esempi visti, puo osservare che in entrambi abbiamo risolto ilsistema in due modi alternativi. Per chiarire bene le osservazioni che seguono, riporto qui le soluzioni trovate utiliandola forma x+ S0. Nel primo esempio abbiamo trovato
(12 , 0,
32
)+ y
(1, 1, 0
)oppure
(0,− 1
2 ,32
)+ x
(1, 1, 0
),
mentre nel secondo abbiamo trovato
(0, 0, 1, 0
)+ y
(1, 1, 0, 0
)+ t(−1, 0,−1, 1
)oppure
(−1, 0, 0, 1
)+ y
(1, 1, 0, 0
)+ z
(1, 0, 1,−1
).
Ora il commento e: nel primo esempio i vettori x sono diversi, ma il generatore dello spazio S0 e lo stesso vettore, cioe(1, 1, 0). Nel secondo esempio sono diversi sia x sia i generatori (meglio: uno dei due generatori e diverso, l’altro e lostesso).Non ci si deve assolutamente aspettare che in generale i vettori siano gli stessi, ne gli x, ne i generatori di S0. Nel primoesempio S0 ha dimensione 1 e quindi i possibili generatori sono tutti proporzionali tra loro. Abbiamo trovato lo stesso,ma potevamo trovare l’opposto o anche ad esempio (2, 2, 0). Nel secondo esempio S0 ha dimensione 2 e qui potevamotrovare due vettori “completamente diversi” o meglio diversi, ma pur sempre generatori dello stesso sottospazio.
Esempio Risolvere il sistema{x+ y − z − t = 1
x+ y + z − t = 1.
Poniamo
A|b =
(1 1 −1 −11 1 1 −1
∣∣∣∣
1
1
)
. Risulta rA = r(A|b) = 2.
353Attenzione quando, per risolvere il sistema, si usa una sostituzione anziche la regola di Cramer: e facile fare confusione tra vereincognite e parametri. Basta pero tenere presente questo: se ho portato a destra y e t vuol dire che ho deciso di usare y e t come parametri,e quindi le incognite (qui x e z) devono essere espresse in funzione di y e t.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL CALCOLO DELLE SOLUZIONI NEL CASO GENERALE
SISTEMI DI EQUAZIONI LINEARI
328
Il sistema e possibile e lo spazio delle soluzioni ha dimensione n− rA = 4− 2 = 2.Quale sottomatrice di ordine massimo non singolare possiamo prendere quella formata dalla 2a e dalla 3a colonna di
A, e cioe A =
(1 −11 1
)
.
Riscriviamo allora il sistema dato nel sistema equivalente
{y − z = 1− x+ t
y + z = 1− x+ t.
Con la regola di Cramer si ottiene (si ha detA = 2)
y =1
2det
(1− x+ t −11− x+ t 1
)
= 1− x+ t e z =1
2det
(1 1− x+ t1 1− x+ t
)
= 0.
Pertanto le soluzioni si possono scrivere come i vettori
(x, 1− x+ t, 0, t
)=(0, 1, 0, 0
)
︸ ︷︷ ︸
x
+ x(1,−1, 0, 0
)+ t(0, 1, 0, 1
)
︸ ︷︷ ︸
S0
,
dove x e t sono numeri reali arbitrari.
Esempio Risolvere il sistema
x− 2y = 1
−x+ 3y = 1
x− y = 3.
Poniamo
A|b =
1 −2−1 3
1 −1
∣∣∣∣∣∣
1
1
3
. Risulta rA = r(A|b) = 2. 354
Il sistema e possibile e lo spazio delle soluzioni ha dimensione n− rA = 2− 2 = 0, cioe la soluzione e unica.Quale sottomatrice di ordine massimo non singolare possiamo ad esempio prendere quella formata dalle prime due
righe e dalle prime due colonne di A, e cioe A =
(1 −2−1 3
)
.
Possiamo quindi eliminare la terza equazione, perche dipendente dalle altre due. Il sistema si riduce allora al sistemaequivalente
{x− 2y = 1
−x+ 3y = 1,
che e un sistema quadrato con determinante della matrice diverso da zero. L’unica soluzione e il vettore di componenti
x = det
(1 −21 3
)
= 5 e y = det
(1 1−1 1
)
= 2.
Pertanto la soluzione e (5, 2).
Esempio Risolvere il sistema
x− 2y + z = 1
−x+ 3y + z = 2
y + 2z = 3.
Poniamo
A|b =
1 −2 1
−1 3 1
0 1 2
∣∣∣∣∣∣
1
2
3
.
Il sistema e quadrato, ma il determinante di A e nullo. Il rango di A e 2 e anche il rango di A|b e 2. Quindi il sistemae possibile e lo spazio delle soluzioni ha dimensione n− rA = 3− 2 = 1.
354Si noti che l’annullarsi del determinante della matrice A|b e in questo caso condizione necessaria (ma non sufficiente) affinche esistaalmeno una soluzione. Infatti, se cosı non fosse, cioe se il determinante fosse diverso da zero, il rango della matrice completa sarebbe 3,mentre quello della matrice incompleta e certamente al piu 2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL CALCOLO DELLE SOLUZIONI NEL CASO GENERALE
SISTEMI DI EQUAZIONI LINEARI
329
Quale sottomatrice di ordine massimo non singolare possiamo ad esempio prendere quella formata dalle prime due
righe e dalle prime due colonne di A, e cioe A =
(1 −2−1 3
)
.
Possiamo eliminare la terza equazione, perche dipendente dalle altre due. Il sistema si riduce allora al sistemaequivalente
{x− 2y + z = 1
−x+ 3y + z = 2.
Si puo far diventare parametro la z e, con il metodo gia visto prima, si trovano le soluzioni
(7− 5z, 3− 2z, z
)=(7, 3, 0
)
︸ ︷︷ ︸
x
+ z(−5,−2, 1
)
︸ ︷︷ ︸
S0
, con z ∈ R.
Esempio Risolvere il sistema
x1 − x2 + x3 = 1
2x1 − x3 = 0
−x1 + x2 − x3 = −1−x1 − x2 + 2x3 = 1.
Poniamo
A|b =
1 −1 1
2 0 −1−1 1 −1−1 −1 2
∣∣∣∣∣∣∣∣
1
0
−11
.
La matrice completa A|b e quadrata e risulta detA|b = 0 (la prima e la terza riga sono opposte). Si noti, come giaosservato in precedenza in un caso analogo, che l’annullarsi del determinante di A|b e una condizione necessaria perl’esistenza di soluzioni: infatti se fosse det(A|b) 6= 0, avremmo che r(A|b) = 4, mentre sicuramente rA < 4. 355
Risulta (lo studente faccia la verifica) rA = r(A|b) = 2. Per il teorema di Rouche – Capelli lo spazio delle soluzioni hadimensione 1. Possiamo scegliere quale sottomatrice di ordine massimo non singolare quella formata da 1a e 2a riga,
2a e 3acolonna, e cioe A =
(−1 10 −1
)
. Il sistema equivalente e
{ −x2 + x3 = 1− x1−x3 = −2x1.
Con la regola di Cramer (ma qui e piu veloce una semplice sostituzione) si trova
{x3 = 2x1x2 = 3x1 − 1.
Le soluzioni sono i vettori(x1, 3x1 − 1, 2x1
)= (0,−1, 0) + x1(1, 3, 2), al variare di x1 in R.
Osservazione Anche in questo caso si potevano considerare altre sottomatrici non singolari, ad esempio
A =
(2 0−1 1
)
(2a e 3a riga, 1a e 2acolonna).
Avremmo ottenuto il sistema equivalente
{2x1 = x3−x1 + x2 = x3 − 1
e quindi
{x1 = 1
2x3x2 = 3
2x3 − 1,
da cui le soluzioni(12x3,
32x3 − 1, x3
)= (0,−1, 0) + x3(
12 ,
32 , 1) con x3 ∈ R arbitrario.
E ovviamente lo stesso insieme di prima: infatti la soluzione particolare e la stessa e lo spazio S0 e generato da unvettore proporzionale al precedente, dato che e il generatore di prima diviso per 2.
355L’annullarsi del determinante di A|b non e ovviamente una condizione sufficiente per l’esistenza di soluzioni dato che, con detA = 0,si potrebbe comunque avere ad esempio r(A|b) = 3 e rA = 2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 IL CALCOLO DELLE SOLUZIONI NEL CASO GENERALE
SISTEMI DI EQUAZIONI LINEARI
330
Esercizio 3.1 Si risolvano i seguenti sistemi lineari (l’insieme delle soluzioni deve essere espresso con la notazione
insiemistica; nel caso il sistema sia indeterminato, e richiesta l’indicazione di una soluzione particolare e di un insiemedi generatori dello spazio delle soluzioni del sistema omogeneo associato).
(a)
{x− y = 1
x+ 2y = −2 (b)
{x− y = 1
−x+ y = 2
(c)
{x+ y − z = 0
x+ z = 1(d)
{x+ y + z = 1
x− y − z = 2(e)
{x− y − z + t = 1
−x+ y − z − t = 2
(f)
y − z = 2
x+ y = 1
x− z = 0
(g)
x− y + 2z = 3
x+ y − z = 2
2x+ z = 1
(h)
2x− y + z = 1
x+ 2z = 1
x− y − z = 0
(i)
2x− y = 1
x+ y = 2
x− 2y = −1(j)
x− y + t = 1
y + z − t = 1
x− 2y − z + 2t = 0
Esercizio 3.2 Si determini una base dell’immagine delle trasformazioni lineari rappresentate dalle seguenti
matrici. Si determini poi una base dello spazio S0 delle soluzioni del sistema omogeneo associato alle stesse matrici.
(a) A1 =
(3 41 2
)
(b) A2 =
(1 −2−1 2
)
(c) A3 =
(1 0 −10 1 1
)
(d) A4 =
0 11 01 −1
(e) A5 =
0 −1 11 1 11 0 2
(f) A6 =
1 −1 0 20 1 −1 1−1 3 −2 0
Esercizio 3.3 Per ciascuno dei seguenti sistemi lineari (dipendenti da un parametro k) si dica per quali valori
reali del parametro il sistema ha soluzioni e in questi casi si dica qual e la dimensione dello spazio delle soluzioni. Sitrovi infine l’insieme delle soluzioni.
(a)
{x+ ky = 1
x− y = 2(b)
{x+ 2y = 1
3x+ ky = 3
(c)
{kx− y + 2z = 0
x+ y − 2z = 1(d)
x− y + kz = 0
x+ z = 1
x+ 2y = 3
(e)
x+ y = 0
x+ 2y = k
−x+ y = 1
(f)
k2x− y + z = 2
2x+ y + z = k
x− 4y + 2z = 5
(g)
x+ ky = 1
x− y = 1
kx+ y = 1
(h)
kx+ 2y − z = 1
−x+ y − 2z = 0
y − z = 0
x− y + 2z = k
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
331
4 Soluzioni degli esercizi
Esercizio 1.1
(a) La scrittura matriciale e(1 −11 2
)(xy
)
=
(1−2
)
.
(b) La scrittura matriciale e(1 0 10 1 −1
)
xyz
=
(32
)
.
(c) La scrittura matriciale e356
(0 1 0 11 0 −1 0
)
xyzt
=
(10
)
.
Esercizio 3.1
Indichero sempre con A la matrice del sistema (incompleta), con A|b la matrice completa e con S l’insieme dellesoluzioni dei sistemi.
(a) Si tratta di un sistema quadrato. Si ha detA = 3 e quindi il sistema ha un’unica soluzione. Con la regola diCramer si ottiene
x =1
3det
(1 −1−2 2
)
= 0
e
y =1
3det
(1 11 −2
)
= −1.
Quindi S ={(0,−1)
}.
(b) Si tratta ancora di un sistema quadrato. Questa volta pero si ha detA = 0. La matrice incompleta ha rango 1,mente la matrice completa ha rango 2. Quindi il sistema e impossibile e risulta S = ∅.
(c) Si ha
A|b =(1 1 −11 0 1
∣∣∣∣
0
1
)
.
Risulta rA = 2 = rA|b, e quindi il sistema e possibile. Possiamo anche affermare che lo spazio delle soluzioni hadimensione 1, dato che vi sono 3 incognite e il rango di A e 2.
Osservando che il minore che si ottiene con le prime due colonne e diverso da zero, possiamo far diventareparametro z (e quindi esprimere poi le soluzioni in funzione di z) e riscrivere il sistema nel sistema equivalente
{x+ y = z
x = 1− z cioe
{x = 1− zy = 2z − 1.
Pertanto le soluzioni sono
S ={
(1− z, 2z − 1, z) : z ∈ R
}
={
(1,−1, 0) + z(−1, 2, 1) : z ∈ R
}
.
A commento dell’ultima scrittura, possiamo dire che il vettore (1,−1, 0) e una soluzione particolare del sistemae il vettore (−1, 2, 1) e un generatore dello spazio S0 delle soluzioni del sistema omogeneo associato Ax = 0.
356Scelgo il seguente ordine nelle incognite del sistema: x, y, z, t. Non e evidentemente l’unica scelta possibile. Uno potrebbe seguire adesempio l’ordine alfabetico t, x, y, z. Questo comporterebbe soltanto un riordinamento delle colonne della matrice e un riordinamento dellecomponenti del vettore delle incognite. Nulla cambia nelle soluzioni del sistema, a parte l’ovvio riordinamento.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
332
(d) Si ha
A|b =(1 1 1
1 −1 −1
∣∣∣∣
1
2
)
.
Anche qui rA = 2 = rA|b e lo spazio delle soluzioni ha dimensione 1, dato che vi sono 3 incognite e il rango diA e 2.
Possiamo riscrivere il sistema nel sistema equivalente (facendo diventare parametro z)
{x+ y = 1− zx− y = 2 + z.
Con la regola di Cramer si ottiene
x = −1
2det
(1− z 12 + z −1
)
= −1
2(−1 + z − 2− z) = 3
2,
y = −1
2det
(1 1− z1 2 + z
)
= −1
2(2 + z − 1 + z) = −z − 1
2.
PertantoS =
{
(32 ,−z − 12 , z) : z ∈ R
}
={
(32 ,− 12 , 0) + z(0,−1, 1) : z ∈ R
}
.
(e) Si ha
A|b =(
1 −1 −1 1
−1 1 −1 −1
∣∣∣∣
1
2
)
.
Risulta rA = 2 = rA|b. Lo spazio delle soluzioni ha dimensione 2, dato che vi sono 4 incognite e il rango di A e2.
Si tratta ora di scegliere quali incognite far diventare parametri (sono 2). Qui attenzione: non si puo “portarea destra a parametro” z e t, dato che il minore che si ottiene con le prime due colonne e nullo. Osservandoinvece che il minore ottenuto con la seconda e terza colonna di A e diverso da zero (vale 2), possiamo riscrivereil sistema nel sistema equivalente
{ −y − z = 1− x− ty − z = 2 + x+ t.
Con la regola di Cramer si ottiene
y =1
2det
(1− x− t −12 + x+ t −1
)
=1
2(−1 + x+ t+ 2 + x+ t) = x+ t+
1
2,
z =1
2det
(−1 1− x− t1 2 + x+ t
)
=1
2(−2− x− t− 1 + x+ t) = −3
2.
Pertanto
S ={
(x, x + t+ 12 ,− 3
2 , t) : x, t ∈ R
}
={
(0, 12 ,− 32 , 0) + x(1, 1, 0, 0) + t(0, 1, 0, 1) : x, t ∈ R
}
.
A conclusione possiamo dire che il vettore (0, 12 ,− 32 , 0) e una soluzione particolare del sistema e che i vettori
(1, 1, 0, 0) e (0, 1, 0, 1) sono generatori dello spazio S0 delle soluzioni del sistema omogeneo associato (sono ancheuna base di tale spazio).
(f) Questo e un sistema quadrato. Si ha
A|b =
0 1 −11 1 0
1 0 −1
∣∣∣∣∣∣
2
1
0
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
333
Risulta detA = 2. Quindi il sistema ha un’unica soluzione e con la regola di Cramer si ottiene
x =1
2det
2 1 −11 1 00 0 −1
= −1
2,
y =1
2det
0 2 −11 1 01 0 −1
=3
2,
z =1
2det
0 1 21 1 11 0 0
= −1
2.
PertantoS =
{
(− 12 ,
32 ,− 1
2 )}
.
(g) E un sistema quadrato e si ha
A|b =
1 −1 2
1 1 −12 0 1
∣∣∣∣∣∣
3
2
1
.
Qui si puo intuire che il sistema e impossibile osservando che nella matrice A la terza riga e la somma delle primedue, mentre questo non e vero nella matrice A|b. Comunque procediamo con il confronto dei ranghi. RisultadetA = 0 e rA = 2. Invece rA|b = 3, dato che ad esempio il determinante della sottomatrice di A|b formatadalle ultime tre colonne vale 4. Il sistema e quindi impossibile.
(h) Si ha
A|b =
2 −1 1
1 0 2
1 −1 −1
∣∣∣∣∣∣
1
1
0
.
Questa volta rA = 2, ma anche rA|b = 2, dato che la terza riga e la differenza delle prime due, che sonoindipendenti. Il sistema e possibile e lo spazio delle soluzioni ha dimensione 1.
Possiamo eliminare la terza equazione e quindi il sistema si puo ridurre al sistema equivalente{
2x− y + z = 1
x+ 2z = 1e quindi al
{2x− y = 1− zx = 1− 2z
cioe
{x = 1− 2z
y = 1− 3z.
Pertanto le soluzioni sono
S ={
(1− 2z, 1− 3z, z) : z ∈ R
}
={
(1, 1, 0) + z(−2,−3, 1) : z ∈ R
}
.
A conclusione possiamo affermare allora che il vettore (1, 1, 0) e una soluzione particolare del sistema e che ilvettore (−2,−3, 1) e un generatore (e base) dello spazio S0 delle soluzioni del sistema omogeneo associato.
(i) Si ha
A|b =
2 −11 1
1 −2
∣∣∣∣∣∣
1
2
−1
.
In questo caso abbiamo la matrice completa quadrata e la matrice incompleta non quadrata. Il sistema e possibilesolo se detA|b = 0.357 Risulta detA|b = 0. Si ha rA = rA|b = 2 e quindi il sistema e possibile. Lo spazio dellesoluzioni ha dimensione 0, il che significa che c’e un’unica soluzione.
Possiamo eliminare un’equazione, ad esempio la terza. Il sistema equivale allora a{
2x− y = 1
x+ y = 2.
Con la regola di Cramer si trova
S ={
(1, 1)}
.
357Infatti, se fosse detA 6= 0, avremmo che il rango di A|b sarebbe 3, mentre il rango di A non puo essere piu di 2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
334
(j) Si ha
A|b =
1 −1 0 1
0 1 1 −11 −2 −1 2
∣∣∣∣∣∣
1
1
0
.
Lo studente calcoli i ranghi delle due matrici (sono entrambi uguali a 2): possiamo concludere che rA = rA|b = 2anche osservando che la terza riga e la differenza delle prime due, che sono indipendenti. Possiamo eliminare laterza equazione e il sistema equivale allora al sistema
{x− y + t = 1
y + z − t = 1.
Osservando che e diverso da zero il minore ottenuto con le colonne relative a x e y, possiamo far diventareparametri z e t e riscrivere
{x− y = 1− ty = 1− z + t
cioe
{x = 2− zy = 1− z + t.
Le soluzioni sono allora358
S ={
(2 − z, 1− z + t, z, t) : z, t ∈ R
}
={
(2, 1, 0, 0) + z(−1,−1, 1, 0)+ t(0, 1, 0, 1) : z, t ∈ R
}
.
A conclusione come sempre possiamo dire che il vettore (2, 1, 0, 0) e una soluzione particolare del sistema eche i vettori (−1,−1, 1, 0) e (0, 1, 0, 1) sono generatori (e anche base) dello spazio S0 delle soluzioni del sistemaomogeneo associato.
Esercizio 3.2
(a) Indichiamo con f1 la trasformazione lineare rappresentata da A1: f1 e una trasformazione da R2 a R2. L’im-magine di f1, che e un sottospazio di R2, e generata dalle colonne della matrice A1. Si tratta di due vettorilinearmente indipendenti, dato che detA1 6= 0. Pertanto una base di Im f1 e costituita dall’insieme dei duevettori. Possiamo scrivere quindi
base di Im f1 =
{(31
)
,(42
)}
. 359
Im f1 coincide con tutto lo spazio R2.
Ora passiamo allo spazio delle soluzioni del sistema omogeneo associato alla matrice A1. Si tratta di un sotto-spazio di R2 di dimensione 2 − rA1 = 2 − 2, e cioe il sottospazio banale fatto dal solo vettore nullo. Possiamoquindi scrivere S0 = {(0, 0)}.
(b) Indichiamo con f2 la trasformazione lineare rappresentata da A2: f2 e una trasformazione da R2 a R2. L’im-magine di f2, che e un sottospazio di R2, e generata dalle colonne della matrice A2, che pero sono due vettori
linearmente dipendenti, dato che(−22
)
= −2(
1−1
)
. Pertanto una base di Im f2 e costituita da uno solo dei due
vettori (indifferentemente). Quindi, ad esempio, possiamo scrivere
base di Im f2 =
{(
1−1
)}
.
Im f2 e un sottospazio di R2 di dimensione 1.
Ora passiamo allo spazio S0 delle soluzioni del sistema omogeneo associato alla matrice A2. Si tratta di unsottospazio di R2 di dimensione 2− rA2 = 2− 1 = 1. Tale spazio e dato dalle soluzioni del sistema
{x1 − 2x2 = 0
−x1 + 2x2 = 0.
358Si noti che talvolta per il calcolo delle soluzioni ho usato la regola di Cramer, altre volte, quando la presenza di zeri rende il calcoloquasi immediato, ho ricavato direttamente i valori delle incognite in funzione dei parametri.359Le basi sono insiemi di vettori. Vanno quindi indicate utilizzando le parentesi graffe.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
335
Le due equazioni sono evidentemente dipendenti (la seconda si ottiene dalla prima cambiando il segno). Quindiil sistema equivale alla sola equazione
x1 − 2x2 = 0 che equivale alla x1 = 2x2.
Quindi possiamo dire che S0 e dato dai vettori (x1, x2) ∈ R2 del tipo (2α, α), con α ∈ R.360 Pertanto
S0 ={
(2α, α) : α ∈ R
}
={
α(2, 1) : α ∈ R
}
.
Quindi
base di S0 =
{(21
)}
.
(c) Indichiamo con f3 la trasformazione lineare rappresentata da A3: f3 e una trasformazione da R3 a R2. L’im-magine di f3, che e un sottospazio di R2, e generata dalle colonne della matrice A3, che pero sono certamentedipendenti, essendo tre vettori in uno spazio di dimensione 2. Per trovare una base di Im f3 occorre trovare deigeneratori indipendenti. Possiamo osservare che le prime due colonne sono i vettori fondamentali di R2 e quindila terza colonna e certamente c.l. delle prime due. Possiamo scrivere pertanto361
base di Im f3 =
{(10
)
,(01
)}
.
Im f3 e un sottospazio di R2 di dimensione 2, e quindi e tutto R2.
Ora passiamo allo spazio S0 delle soluzioni del sistema omogeneo associato alla matrice A3. Si tratta di unsottospazio di R3 di dimensione 3− rA3 = 3− 2 = 1. Tale spazio e dato dalle soluzioni del sistema
{x1 − x3 = 0
x2 + x3 = 0, cioe
{x1 = x3x2 = −x3.
Possiamo quindi scrivere
S0 ={
(α,−α, α) : α ∈ R
}
={
α(1,−1, 1) : α ∈ R
}
.
Quindi
base di S0 =
{
1−11
}
.
(d) Indichiamo con f4 la trasformazione lineare rappresentata da A4: f4 e una trasformazione da R2 a R3. L’imma-gine di f4 e un sottospazio di R3 ed e generata dalle colonne della matrice A4. Sono due vettori l.i (e immediatovedere che il rango della matrice e 2). I due vettori sono quindi una base dell’immagine di f4. Pertanto
base di Im f4 =
{
011
,
10−1
}
.
Im f4 e un sottospazio di R3 di dimensione 2.
Ora passiamo allo spazio S0 delle soluzioni del sistema omogeneo associato alla matrice A4. Si tratta di unsottospazio di R2 di dimensione 2 − rA4 = 2− 2 = 0, che si riduce quindi al solo vettore nullo. Verifichiamolo:esso e dato dalle soluzioni del sistema
x2 = 0
x1 = 0
x1 − x2 = 0
, che equivale a
{x1 = 0
x2 = 0.
Possiamo quindi scrivereS0 =
{(0, 0)
}.
360Ho in pratica chiamato α quello che era x2 (il parametro): quindi x1 diventa 2α. Ovviamente la notazione e irrilevante: si potevabenissimo scrivere (2x2, x2), con x2 ∈ R.361Qui ho chiamato α quello che era x3: quindi x1 diventa α e x2 diventa −α.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
336
(e) Indichiamo con f5 la trasformazione lineare rappresentata da A5: f5 e una trasformazione da R3 a R3. L’im-magine di f5 e un sottospazio di R3 ed e generata dalle colonne della matrice A5. Possiamo osservare che ildeterminante di A5 e nullo: lo si vede o dal calcolo diretto, o notando che la terza riga e la somma delle primedue. Questo dice che le colonne sono dipendenti. Si vede facilmente che il rango di A5 e 2 e ad esempio leprime due colonne sono indipendenti, dato che il minore che si ottiene dalla sottomatrice formata con la primae seconda colonna e prima e seconda riga e diverso da zero. Quindi possiamo dire che dim(Im f5) = 2 e che
base di Im f5 =
{
011
,
−110
}
.362
Ora passiamo allo spazio S0 delle soluzioni del sistema omogeneo associato alla matrice A5. Si tratta di unsottospazio di R3 di dimensione 3− rA5 = 3− 2 = 1. Tale spazio e dato dalle soluzioni del sistema
−x2 + x3 = 0
x1 + x2 + x3 = 0
x1 + 2x3 = 0.
Il sistema equivale a{x3 = x2x1 + 2x2 = 0
e cioe
{x3 = x2x1 = −2x2.
Possiamo quindi scrivere
S0 ={
(−2α, α, α) : α ∈ R
}
={
α(−2, 1, 1) : α ∈ R
}
.
Si ha
base di S0 =
{
−211
}
.
(f) Indichiamo con f6 la trasformazione lineare rappresentata da A6: f6 e una trasformazione da R4 a R3. L’imma-gine di f6 e un sottospazio di R3 ed e generata dalle colonne della matrice A6. Come sempre la dimensione diIm f6 coincide con il rango della matrice A6, che puo essere al piu 3 (e anche evidentemente almeno 2). Proce-dendo al calcolo dei minori del terzo ordine, si puo verificare che essi sono tutti nulli (lo si faccia). Si arriva piurapidamente al risultato se ci si accorge che c’e una dipendenza tra le righe, in quanto la prima e due volte laseconda meno la terza. Quindi il rango non e 3, ma 2. Si vede facilmente che ad esempio le prime due colonnesono indipendenti (il minore che si ottiene dalla sottomatrice formata con la prima e seconda colonna e prima eseconda riga e diverso da zero). Quindi possiamo dire che dim(Im f6) = 2 e che
base di Im f6 =
{
10−1
,
−113
}
.363
Ora passiamo allo spazio S0 delle soluzioni del sistema omogeneo associato alla matrice A6. Si tratta di unsottospazio di R4 di dimensione 4− rA6 = 4− 2 = 2. Tale spazio e dato dalle soluzioni del sistema
x1 − x2 + 2x4 = 0
x2 − x3 + x4 = 0
−x1 + 3x2 − 2x3 = 0.
Ricordando che il rango di A6 e 2, possiamo ridurre il sistema ad esempio alle prime due equazioni:
{x1 − x2 + 2x4 = 0
x2 − x3 + x4 = 0cioe
{x1 − x2 = −2x4x2 = x3 − x4
cioe ancora
{x2 = x3 − x4x1 = x3 − 3x4.
362Indicando con c1, c2, c3 le tre colonne di A5, possiamo dire che sono basi di Im f5
{c1, c2} , {c1, c3} , {c2, c3}.
363Si verifichi che scegliendo in tutti i modi possibili due delle quattro colonne si ottiene sempre una base di Im f6.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
337
Possiamo quindi scrivere
S0 ={
(α− 3β, α− β, α, β) : α, β ∈ R
}
={
α(1, 1, 1, 0) + β(−3,−1, 0, 1) : α, β ∈ R
}
.
Questo significa che i due vettori (1, 1, 1, 0) e (−3,−1, 0, 1) sono generatori di S0, ma e immediato capire chesono linearmente indipendenti (la matrice da essi formata ha rango 2) e che quindi essi costituiscono una basedi S0. Pertanto
base di S0 =
1110
,
−3−101
.
Esercizio 3.3
(a) Scriviamo le matrici del sistema:
A|b =(1 k
1 −1
∣∣∣∣
1
2
)
.
Si tratta di un sistema quadrato. Calcoliamo il determinante di A. Risulta detA = −1 − k. Allora possiamodire che, se k 6= −1, per il teorema di Cramer il sistema ha una sola soluzione, che poi troveremo. Se invecek = −1 allora il rango di A e 1. Il rango di A|b invece e 2. Quindi per il teorema di Rouche–Capelli, se k = −1,il sistema non ha soluzioni.
Per tutti i valori di k 6= −1 la soluzione e (con la regola di Cramer):
x = − 1
1 + kdet
(1 k2 −1
)
=1 + 2k
1 + k
e
y = − 1
1 + kdet
(1 11 2
)
= − 1
1 + k.
L’insieme delle soluzioni e quindi S = {(1+2k1+k ,− 1
1+k )}, per ogni k 6= −1.
(b) Scriviamo le matrici del sistema:
A|b =(1 2
3 k
∣∣∣∣
1
3
)
.
Calcoliamo il determinante di A: risulta detA = k − 6. Allora possiamo dire che, se k 6= 6, per il teorema diCramer il sistema ha una sola soluzione, che poi troveremo. Se invece k = 6 allora il rango di A e 1. Anche ilrango di A|b e 1. Quindi per il teorema di Rouche–Capelli, se k = 6, il sistema ha soluzioni. Possiamo dire chela dimensione dello spazio delle soluzioni e 1 (dato dalla differenza tra n = 2 e rA = 1).
Il sistema quindi ha soluzioni per ogni valore del parametro k. Risolviamo ora il sistema. Se k 6= 6 la soluzionee (regola di Cramer):
x =1
k − 6det
(1 32 k
)
= 1
e
y =1
k − 6det
(1 31 3
)
= 0.
L’insieme delle soluzioni e quindi S = {(1, 0)}, per ogni k 6= 6.
Se k = 6 il sistema si puo ridurre ad una sola equazione, ad esempio x + 2y = 1, cioe x = 1 − 2y. Pertantol’insieme delle soluzioni si puo scrivere come S = {(1− 2y, y) : y ∈ R} = {(1, 0) + y(−2, 1) : y ∈ R}.
(c) Scriviamo le matrici del sistema:
A|b =(k −1 2
1 1 −2
∣∣∣∣
0
1
)
.
Qui il sistema non e quadrato. Dobbiamo studiare il rango delle due matrici. Possiamo dire subito che il rangodi A|b e 2, dato che la sottomatrice di A|b formata dalle ultime due colonne e non singolare. Ora si tratta divedere se il rango di A e 2 oppure 1. Si noti che il minore di A che si ottiene dalla seconda e terza colonna e
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
338
nullo e che quindi dobbiamo considerare un altro minore. Consideriamo quello che si ottiene con le prime duecolonne: esso risulta uguale a k+1. Possiamo quindi dire che se k 6= −1 il rango di A e 2 e quindi per tali valoridel parametro il sistema ha soluzioni. Invece per k = −1 le due righe di A sono opposte e quindi risulta rA = 1e il sistema e impossibile.
Troviamo allora le soluzioni per k 6= −1. La dimensione dello spazio delle soluzioni e 1 (n = 3 e rA = 2). Ilsistema si puo riscrivere come
{kx− y = −2zx+ y = 1 + 2z.
Risolto con la regola di Cramer esso fornisce
x =1
k + 1det
(−2z −11 + 2z 1
)
=1
k + 1
e
y =1
k + 1det
(k −2z1 1 + 2z
)
=2(k + 1)z + k
k + 1.
L’insieme delle soluzioni e quindi S = {( 1k+1 ,
2(k+1)z+kk+1 , z) : z ∈ R}, per ogni k 6= −1.364
(d) Scriviamo le matrici del sistema:
A|b =
1 −1 k
1 0 1
1 2 0
∣∣∣∣∣∣
0
1
3
.
Si tratta di un sistema quadrato. Calcoliamo il determinante di A. Risulta detA = 2k− 3. Allora possiamo direche, se k 6= 3
2 , per il teorema di Cramer il sistema ha una sola soluzione, che poi troveremo. Se invece k = 32
allora il rango di A e 2 (il minore che si ottiene con le prime due righe e le prime due colonne e diverso da zero).Il rango di A|b e pure 2, dato che la colonna dei termini noti (b) e la somma delle prime due. Quindi per ilteorema di Rouche–Capelli, se k = 3
2 , il sistema ha soluzioni.
Troviamo ora le soluzioni. Se k 6= 32 la soluzione e (regola di Cramer):
x =1
2k − 3det
0 −1 k1 0 13 2 0
= 1,
y =1
2k − 3det
1 0 k1 1 11 3 0
= 1
e
z =1
2k − 3det
1 −1 01 0 11 2 3
= 0.
L’insieme delle soluzioni e quindi S = {(1, 1, 0)}, per ogni k 6= 32 .
Se k = 32 lo spazio delle soluzioni ha dimensione n− rA = 3− 2 = 1. Il sistema si puo ridurre al sistema (prime
due equazioni):{x− y = − 3
2z
x = 1− z cioe
{x = 1− zy = 1 + 1
2z.
Pertanto l’insieme delle soluzioni e S = {(1− z, 1 + 12z, z) : z ∈ R} = {(1, 1, 0) + z(−1, 12 , 1) : z ∈ R}.
(e) Scriviamo le matrici del sistema:
A|b =
1 1
1 2
−1 1
∣∣∣∣∣∣
0
k
1
.
Il sistema non e quadrato ma la matrice A|b e quadrata. Possiamo allora iniziare calcolando il determinante diA|b: risulta detA|b = 1− 2k. Allora possiamo dire che, se k 6= 1
2 , il sistema non puo avere soluzioni, dato che ilrango di A|b e 3, mentre il rango di A non puo essere piu di 2, visto che A ha solo due colonne.
364Quindi per ogni valore di k 6= −1 abbiamo infinite soluzioni, espresse in funzione del parametro z.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
339
Il sistema puo avere soluzioni solo per k = 12 , ma occorre controllare che sia effettivamente cosı.365 Si vede
facilmente che, con k = 12 , si ha rA = rA|b = 2. Il sistema ha quindi soluzioni. La dimensione dello spazio delle
soluzioni e data da n− rA = 2− 2 = 0, quindi c’e una sola soluzione. La possiamo trovare riducendo il sistemaad esempio alla prima e terza equazione:
{x+ y = 0
−x+ y = 1
che ha l’unica soluzione (− 12 ,
12 ).
(f) Scriviamo le matrici del sistema:
A|b =
k2 −1 1
2 1 1
1 −4 2
∣∣∣∣∣∣
2
k
5
.
Visto cheA e quadrata cominciamo dal determinante di A: risulta (1a riga) detA = k2·6+1·3+1·(−9) = 6(k2−1).Allora possiamo dire che, per k 6= 1 e k 6= −1 il sistema ha una sola soluzione, che ora calcoliamo con la regoladi Cramer:
x =1
6(k2 − 1)det
2 −1 1k 1 15 −4 2
= . . . = − 1
3(k + 1),
y =1
6(k2 − 1)det
k2 2 12 k 11 5 2
= . . . =2k2 − 3k − 4
6(k + 1),
z =1
6(k2 − 1)det
k2 −1 22 1 k1 −4 5
= . . . =4k2 + 9k + 8
6(k + 1).
Studiamo ora i casi che restano.
Per k = 1 sostituiamo e otteniamo
A|b =
1 −1 1
2 1 1
1 −4 2
∣∣∣∣∣∣
2
1
5
.
Risulta che il rango di A e 2, dato che ad esempio la sottomatrice formata dalle prime due righe e dalle primedue colonne e non singolare. Per calcolare il rango di A|b si potrebbe cercare di scoprire una dipendenza tra lerighe (o colonne), ma non e cosı evidente. Calcoliamo allora i minori del terzo ordine. Si ha
det
1 −1 22 1 11 −4 5
= 0 , det
1 1 22 1 11 2 5
= 0 , det
−1 1 21 1 1−4 2 5
= 0.
Quindi il rango non e 3 ed e sicuramente 2 per quanto gia osservato su A. Pertanto il sistema ha soluzioni conk = 1 e lo spazio delle soluzioni ha dimensione 3 − 2 = 1. Le soluzioni si trovano riducendo prima il sistema a(prime due equazioni e parametro z):
{x− y = 2− z2x+ y = 1− z.
Ora con la regola di Cramer:
x =1
3det
(2− z −11− z 1
)
=1
3(3− 2z)
e
y =1
3det
(1 2− z2 1− z
)
=1
3(z − 3).
Le soluzioni per k = 1 sono quindi date dall’insieme S = {(13 (3− 2z), 13 (z − 3), z)}, con z ∈ R.
Per k = −1 sostituiamo e otteniamo
A|b =
1 −1 1
2 1 1
1 −4 2
∣∣∣∣∣∣
2
−15
.
365Non siamo infatti sicuri che i due ranghi siano uguali: potrebbe essere che il rango di A|b e 2 mentre il rango di A e 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
340
Risulta che il rango di A e ancora 2 (A e la stessa di prima). Questa volta pero il rango di A|b e 3, dato che lasottomatrice di A|b formata da 1a, 2a e 4a colonna e non singolare (il minore corrispondente vale −6). Quindiper k = −1 il sistema non ha soluzioni.
(g) Scriviamo le matrici del sistema:
A|b =
1 k
1 −1k 1
∣∣∣∣∣∣
1
1
1
.
La matrice A|b e quadrata e conviene iniziare calcolando il determinante di A|b: risulta detA|b = k2− 1. Allorapossiamo dire che, se k 6= ±1, il sistema non puo avere soluzioni, dato che il rango di A|b e 3, mentre il rango diA non puo essere piu di 2, visto che A ha solo due colonne.
Il sistema quindi puo avere soluzioni solo per k = 1 oppure k = −1 e occorre controllare che sia effettivamentecosı.
Con k = 1 si ha
A|b =
1 1
1 −11 1
∣∣∣∣∣∣
1
1
1
.
Si vede facilmente che rA = rA|b = 2. Il sistema ha quindi soluzioni e la dimensione dello spazio delle soluzionie data da 2− 2 = 0, quindi c’e una sola soluzione. La possiamo trovare riducendo il sistema a:
{x+ y = 1
x− y = 1
che ha l’unica soluzione (1, 0).
Con k = −1 si ha
A|b =
1 −11 −1−1 1
∣∣∣∣∣∣
1
1
1
.
Ora il rango di A e 1, dato che le due colonne sono dipendenti. Il rango di A|b invece e 2, dato che ad esempiola seconda e terza colonna sono indipendenti. Quindi il sistema non ha soluzioni per k = −1.
(h) Scriviamo le matrici del sistema:
A|b =
k 2 −1−1 1 −20 1 −11 −1 2
∣∣∣∣∣∣∣∣
1
0
0
k
.
La matrice A|b e quadrata e conviene iniziare calcolando il determinante di A|b. Sviluppando il calcolo rispettoalla quarta colonna si ottiene
detA|b = − det
−1 1 −20 1 −11 −1 2
+ k det
k 2 −1−1 1 −20 1 −1
= k(k − 1).
Allora possiamo dire che, se k 6= 0 e k 6= 1, il sistema non puo avere soluzioni, dato che il rango di A|b e 4,mentre il rango di A non puo essere piu di 3, visto che A ha solo tre colonne.
Il sistema quindi puo avere soluzioni solo per k = 0 oppure k = 1 e occorre controllare che sia effettivamentecosı.
Con k = 0 si ha
A|b =
0 2 −1−1 1 −20 1 −11 −1 2
∣∣∣∣∣∣∣∣
1
0
0
0
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
341
Il rango di A e 3, dato che la sua sottomatrice formata dalle prime tre righe e non singolare. Il rango di A|b equindi anch’esso 3. Il sistema ha dunque soluzioni per k = 0. Troviamole. Riduciamo il sistema eliminando laquarta equazione: il sistema diventa
2y − z = 1
−x+ y − 2z = 0
y − z = 0.
La soluzione (unica) si trova facilmente con la regola di Cramer ed e (−1, 1, 1).Con k = 1 si ha
A|b =
1 2 −1−1 1 −20 1 −11 −1 2
∣∣∣∣∣∣∣∣
1
0
0
1
.
Per il calcolo del rango di A possiamo osservare che in A la quarta riga e l’opposto della seconda e quindi puoessere trascurata. Resta allora da esaminare il minore che deriva dalle prime tre righe, che risulta essere 0. Allorail rango di A e 2. Il rango di A|b invece e 3, dato che ad esempio il minore di ordine 3 che deriva dalle prime trerighe e dalle ultime tre colonne e diverso da zero. Pertanto con k = 1 il sistema non ha soluzioni.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 SOLUZIONI DEGLI ESERCIZI
SISTEMI DI EQUAZIONI LINEARI
342
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

Parte IV
Nella quarta parte del corso di Matematica torniamo ad affrontare argomenti di Analisi. Si tratta di alcuni aspetti,visti nella parte II sulle funzioni di una variabile, rivisitati ora in piu variabili (essenzialmente due). Mentre non c’ealcuna differenza sostanziale nel passare da due a tre o piu varibili, a volte ci possono essere importanti novita nelpassare da una a due variabili, e vedremo perche. Tenendo conto del fatto che quasi sempre nelle applicazioni una solavariabile non basta, ecco che questi ultimi argomenti acquistano particolare importanza proprio per le appplicazionidella matematica che solitamente vengono fatte nel seguito del corso di studi.
Ecco il solito sintetico elenco di quanto vedremo in questa parte del corso.
• Alcuni aspetti generali sulle funzioni di piu variabili
• Le forme quadratiche
• Le derivate delle funzioni di piu variabili
• La ricerca e lo studio dei massimi e dei minimi delle funzioni di piu variabili


1 INSIEMI IN RN
FUNZIONI REALI DI PIU VARIABILI
345
IV-1 Funzioni reali di piu variabili
In questa parte del corso studieremo alcuni concetti analitici sulle funzioni di piu variabili reali.366 Come le funzioni diuna variabile reale sono definite in genere in particolari sottoinsiemi di R, cosı le funzioni di due variabili sono definitein sottoinsiemi di R2, quelle di tre variabili in sottoinsiemi di R3, e cosı via. Nella terza parte del corso abbiamo giaparlato estesamente di R2, R3, . . . , ma l’approccio qui e un po’ diverso, diciamo che e piu analitico e meno algebrico(per farmi capire: e piu simile a quello della parte II piuttosto che a quello della parte III).Inizio richiamando alcuni concetti generali gia visti (nella parte I) sulla rappresentazione di R2 nel piano cartesiano esu alcuni sottoinsiemi di R2, R3, e in generale di Rn.
1 Insiemi in Rn
L’obiettivo di questa sezione e quello, come detto, di famigliarizzare lo studente con alcuni sottoinsiemi di R2 (e ingenerale di Rn). Richiamiamo pero anzitutto alcuni concetti e simbologie, gia incontrati in R, che ci saranno utili nelseguito.Attraverso la corrispondenza biunivoca tra i punti di un asse cartesiano e i numeri reali, abbiamo visto come associaread ogni punto la sua ascissa e, viceversa, ad ogni numero reale il punto che puo essere considerato la sua immaginegeometrica. Nella parte II di questo corso abbiamo spesso utilizzato alcuni importanti sottoinsiemi di R, gli intervalli.Dati a, b ∈ R, con a ≤ b, sappiamo che e un intervallo di R ad esempio l’insieme
[a, b] = {x ∈ R : a ≤ x ≤ b}.
Altri esempi di intervalli sono, come noto,
(a, b) = {x ∈ R : a < x < b},[a, b) = {x ∈ R : a ≤ x < b},(a, b] = {x ∈ R : a < x ≤ b}.
I numeri a e b sono gli estremi dell’intervallo. Se gli estremi sono entrambi compresi nell’intervallo di cui si vuolparlare si dice che l’intervallo e chiuso; se invece sono entrambi esclusi si parla di intervallo aperto.Abbiamo incontrato molto spesso anche intervalli illimitati, precisamente gli insiemi del tipo
[a,+∞) = {x ∈ R : x ≥ a},(a,+∞) = {x ∈ R : x > a},(−∞, b] = {x ∈ R : x ≤ b},(−∞, b) = {x ∈ R : x < b}, dove a, b ∈ R.
Dato un punto x0 ∈ R, abbiamo poi definito intorni di x0 di raggio δ gli intervalli del tipo
(x0 − δ, x0 + δ),
dove δ puo essere un qualunque numero reale positivo, che viene detto il raggio dell’intorno.Abbiamo anche definito, dati due punti x e y in R, la distanza di x e y come il numero reale non negativo
d(x, y) = |x− y|,
dopodiche abbiamo potuto scrivere
(x0 − δ, x0 + δ) ={z ∈ R : d(z, x0) < δ
}={z ∈ R : |z − x0| < δ
},
dove si esprime in una identita insiemistica il fatto che l’intorno di x0 di raggio δ e costituito dai punti che distano dax0 meno di δ.
366Sono gli stessi concetti visti per le funzioni di una variabile (limiti, continuita, derivabilita, integrabilita) adattati alla presenza di piuvariabili. Vedremo che per alcuni di questi non e necessario aggiungere molto, essendo l’estensione del tutto immediata, per altri invece lecose non sono altrettanto dirette.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
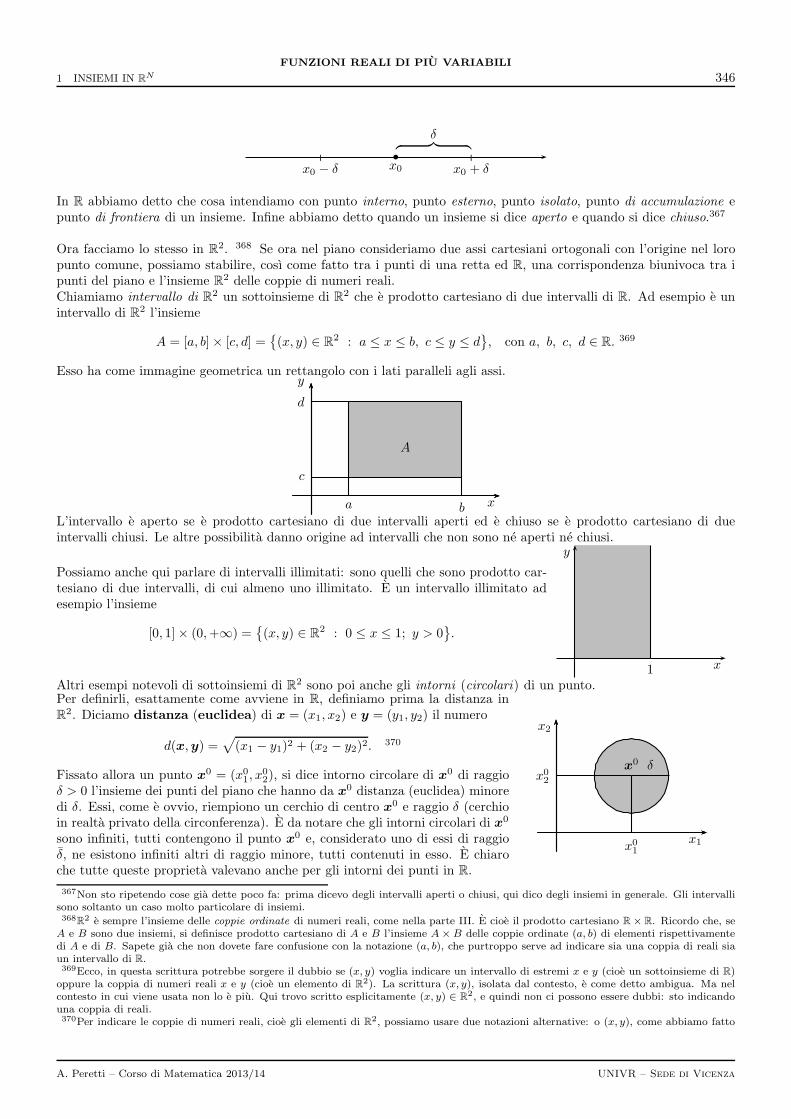
1 INSIEMI IN RN
FUNZIONI REALI DI PIU VARIABILI
346
|
x0 − δb
x0|
x0 + δ
δ︷ ︸︸ ︷
In R abbiamo detto che cosa intendiamo con punto interno, punto esterno, punto isolato, punto di accumulazione epunto di frontiera di un insieme. Infine abbiamo detto quando un insieme si dice aperto e quando si dice chiuso.367
Ora facciamo lo stesso in R2. 368 Se ora nel piano consideriamo due assi cartesiani ortogonali con l’origine nel loropunto comune, possiamo stabilire, cosı come fatto tra i punti di una retta ed R, una corrispondenza biunivoca tra ipunti del piano e l’insieme R2 delle coppie di numeri reali.Chiamiamo intervallo di R2 un sottoinsieme di R2 che e prodotto cartesiano di due intervalli di R. Ad esempio e unintervallo di R2 l’insieme
A = [a, b]× [c, d] ={(x, y) ∈ R2 : a ≤ x ≤ b, c ≤ y ≤ d
}, con a, b, c, d ∈ R. 369
Esso ha come immagine geometrica un rettangolo con i lati paralleli agli assi.
a b
c
d
x
y
A
L’intervallo e aperto se e prodotto cartesiano di due intervalli aperti ed e chiuso se e prodotto cartesiano di dueintervalli chiusi. Le altre possibilita danno origine ad intervalli che non sono ne aperti ne chiusi.
Possiamo anche qui parlare di intervalli illimitati: sono quelli che sono prodotto car-tesiano di due intervalli, di cui almeno uno illimitato. E un intervallo illimitato adesempio l’insieme
[0, 1]× (0,+∞) ={(x, y) ∈ R2 : 0 ≤ x ≤ 1; y > 0
}.
1 x
y
Altri esempi notevoli di sottoinsiemi di R2 sono poi anche gli intorni (circolari) di un punto.Per definirli, esattamente come avviene in R, definiamo prima la distanza inR2. Diciamo distanza (euclidea) di x = (x1, x2) e y = (y1, y2) il numero
d(x,y) =√
(x1 − y1)2 + (x2 − y2)2. 370
Fissato allora un punto x0 = (x01, x02), si dice intorno circolare di x0 di raggio
δ > 0 l’insieme dei punti del piano che hanno da x0 distanza (euclidea) minoredi δ. Essi, come e ovvio, riempiono un cerchio di centro x0 e raggio δ (cerchioin realta privato della circonferenza). E da notare che gli intorni circolari di x0
sono infiniti, tutti contengono il punto x0 e, considerato uno di essi di raggioδ, ne esistono infiniti altri di raggio minore, tutti contenuti in esso. E chiaroche tutte queste proprieta valevano anche per gli intorni dei punti in R.
x0 δ
x01
x02
x1
x2
367Non sto ripetendo cose gia dette poco fa: prima dicevo degli intervalli aperti o chiusi, qui dico degli insiemi in generale. Gli intervallisono soltanto un caso molto particolare di insiemi.368R2 e sempre l’insieme delle coppie ordinate di numeri reali, come nella parte III. E cioe il prodotto cartesiano R× R. Ricordo che, seA e B sono due insiemi, si definisce prodotto cartesiano di A e B l’insieme A× B delle coppie ordinate (a, b) di elementi rispettivamentedi A e di B. Sapete gia che non dovete fare confusione con la notazione (a, b), che purtroppo serve ad indicare sia una coppia di reali siaun intervallo di R.369Ecco, in questa scrittura potrebbe sorgere il dubbio se (x, y) voglia indicare un intervallo di estremi x e y (cioe un sottoinsieme di R)oppure la coppia di numeri reali x e y (cioe un elemento di R2). La scrittura (x, y), isolata dal contesto, e come detto ambigua. Ma nelcontesto in cui viene usata non lo e piu. Qui trovo scritto esplicitamente (x, y) ∈ R2, e quindi non ci possono essere dubbi: sto indicandouna coppia di reali.370Per indicare le coppie di numeri reali, cioe gli elementi di R2, possiamo usare due notazioni alternative: o (x, y), come abbiamo fatto
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 INSIEMI IN RN
FUNZIONI REALI DI PIU VARIABILI
347
Richiamiamo brevemente in R2 le nozioni topologiche, gia note in R, di punti interni, esterni, isolati, di frontiera e diaccumulazione di un insieme.
Definizione Dato un insieme A ⊂ R2, un punto x0 si dice
• interno di A se esiste almeno un intorno circolare di x0 tutto contenuto in A;
• esterno di A se esiste almeno un intorno circolare di x0 tutto costituito da punti non appartenenti ad A;
• di frontiera di A se x0 non e ne interno ne esterno ad A. Significa allora che in qualunque intorno circolare dix0 cadono almeno un punto di A e almeno un punto non appartenente ad A;
• isolato se x0 ∈ A ed esiste almeno un intorno circolare di x0 che non contiene alcun punto di A eccetto x0;
• di accumulazione di A se in qualunque intorno circolare di x0 cadono infiniti punti di A.
E importante inoltre l’ulteriore
Definizione Un insieme A ⊂ R2 si dice
• aperto se ogni punto di A e interno ad A;
• chiuso se il suo insieme complementare371 e aperto.
Osservazioni ed esempi.
⊲ Si puo osservare che un punto isolato e certamente di frontiera, un punto interno e certamente di accumulazione,punti esterni e punti isolati non possono essere di accumulazione. Inoltre si noti che i punti isolati di un insiemeappartengono certamente all’insieme, quelli esterni certamente non appartengono e infine quelli di frontiera, odi accumulazione, possono appartenere oppure no all’insieme.
⊲ R2 e aperto e chiuso nello stesso tempo, da cui ∅ e anch’esso aperto e chiuso. Lo stesso accadeva in R.
⊲ Abbiamo gia visto che un intervallo in R2 e aperto se e solo se e prodotto cartesiano di due intervalli (di R)entrambi aperti ed e chiuso se e solo se e prodotto cartesiano di due intervalli entrambi chiusi.
⊲ In generale i punti esterni sono quelli che risultano interni al complementare dell’insieme in questione.
⊲ I punti di frontiera di un intervallo sono i punti che stanno sui lati del rettangolo, a prescindere dal fatto chequesti facciano parte oppure no del rettangolo stesso.
⊲ I punti di accumulazione di un intervallo sono tutti i punti che sono interni oppure di frontiera per l’intervallo.Il loro insieme coincide quindi con l’intervallo chiuso.
Vediamo ora alcuni esempi sugli intervalli.
Consideriamo in R2 l’insieme I = [0, 1)× (−1, 1]. Si tratta sostanzialmente di un rettangolo,in cui alcune parti del bordo sono comprese ed altre escluse. E un insieme che non e neaperto ne chiuso. L’insieme dei suoi punti interni e l’insieme (0, 1)×(−1, 1), cioe il rettangoloaperto. L’insieme dei suoi punti di frontiera e costituito dai lati del rettangolo.372 L’insiemedei punti di accumulazione di I e l’intervallo [0, 1]× [−1, 1], cioe il rettangolo chiuso.
1
−1
1
bc
bc
x
y
Altro esempio. Consideriamo l’insiemeA = (−1, 1)× {0}.
fino ad ora, oppure (x1, x2). E bene che lo studente si abitui ad utilizzare l’una o l’altra indifferentemente, anche perche nei corsi successivipotra vederle utilizzate entrambe. La prima e forse piu semplice, ma la seconda ha il vantaggio di poter essere estesa ad un qualunquenumero di variabili. Tornando al significato della definizione di distanza, non dovrebbe essere difficile capire che sotto questa definizione sinasconde uno dei piu famosi teoremi della geometria, il teorema di Pitagora, e dovreste avere tutti una qualche conoscenza in merito.371Ricordo che, dato in generale un insieme X ed A ⊂ X, l’insieme degli elementi di X che non appartengono ad A si dice complementaredi A (rispetto ad X). Nel nostro caso abbiamo A ⊂ R2 e sottintendo che il complementare sia rispetto a tutto R2.372Si puo darne una scrittura formale, ma non preoccupatevi piu di tanto di questo. Si puo scrivere che l’insieme dei punti di frontiera diI e l’insieme
({0} × [−1, 1]
)∪({1} × [−1, 1]
)∪([0, 1]× {−1}
)∪([0, 1]× {1}
).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 INSIEMI IN RN
FUNZIONI REALI DI PIU VARIABILI
348
L’insieme A e il prodotto cartesiano dell’intervallo (−1, 1) (sulle ascisse) e del punto0 sulle ordinate, cioe e l’insieme delle coppie che hanno come prima componente unnumero scelto tra −1 e 1 e come seconda sempre 0. Ovviamente si tratta di unsegmento orizzontale sull’asse x.
bc bc
−1 1
x
y
L’insieme A non ha punti interni. Questa e una situazione in qualche modo interessante, dato che l’intervallo (−1, 1)ha punti interni in R. Poi possiamo affermare che tutti i punti di A sono di frontiera e sono di frontiera anche gliestremi del segmento, cioe i punti (−1, 0) e (1, 0), che pure non fanno parte del segmento. I punti di accumulazione diA sono dati dal segmento con i suoi estremi, cioe dall’insieme [−1, 1]× {0}.Gli studenti si costruiscano altri esempi in proposito.
Tutto quanto detto per R2 puo essere esteso in modo del tutto naturale ad Rn,l’insieme delle n-uple ordinate di numeri reali. Da notare che, in tal caso, solo pern = 3 si puo dare ancora un’immagine geometrica, che sara ambientata in quello chesi puo chiamare lo spazio a tre dimensioni nel senso elementare e intuitivo del termine,attrezzato con una terna di assi cartesiani ortogonali.Si possono chiamare intervalli in Rn i prodotti cartesiani di n intervalli di R. Adesempio e un intervallo di R3 l’insieme
A = [0, 1]× (−1, 0)× [−1, 1]
la cui immagine geometrica e un parallelepipedo con le facce parallele ai pianicoordinati. Si osservi che non tutte le facce appartengono al parallelepipedo.
x1
x2
x3
1
−11
−1
Si dira intorno circolare di un punto x0 ∈ Rn di raggio δ l’insieme dei punti di Rn che hanno distanza euclidea da x0
minore di δ, definendo distanza euclidea di x e y, dove x = (x1, . . . , xn) e y = (y1, . . . , yn), il numero
d(x,y) =
√√√√
n∑
i=1
(xi − yi)2. 373
L’intorno circolare di un punto x0 ∈ R3 di raggio δ e rappresentato dalla sfera di centro x0 e raggio δ.
Si estendono ai sottoinsiemi di Rn, in modo del tutto analogo a quanto fatto in R2, tutte le nozioni topologiche.Come gia in R e in R2, anche in Rn si dice aperto ogni insieme i cui punti siano tutti punti interni. Abbiamo giavisto che, ad esempio, in R2 un rettangolo privato dei lati e un insieme aperto, e cosı pure un cerchio privato dellacirconferenza. In R3 sono aperti ad esempio un parallelepipedo privato delle facce oppure una sfera privata dellasuperficie sferica.Si dira poi chiuso un insieme che sia complementare (rispetto a Rn) di un insieme aperto.
1.1 Simmetrie degli insiemi
Puo essere utile in molti casi sfruttare un qualche tipo di simmetria degli insiemi di R2 (il discorso vale anche in R3 ein Rn ma noi vedremo solo esempi in R2). Anzitutto vediamo quali tipi di simmetrie considerare. Qui indico con x ey (anziche con x1 e x2) le coordinate cartesiane.
Definizioni Sia A ⊂ R2. Diciamo che A e simmetrico rispetto alle x se vale la seguente proprieta:
se (x, y) ∈ A allora (−x, y) ∈ A.
Diciamo invece che A e simmetrico rispetto alle y se vale la proprieta:
se (x, y) ∈ A allora (x,−y) ∈ A.
Quindi in pratica un insieme e simmetrico rispetto alle x se e simmetrico rispetto all’asse delle ordinate e, viceversa,e simmetrico rispetto alle y se e simmetrico rispetto all’asse delle ascisse.Nelle figure qui sotto sono rappresentati un insieme simmetrico rispetto alle x (a sinistra) ed un insieme simmetricorispetto alle y.
373Ricordo che, se x = (x1, . . . , xn) ∈ Rn, si definisce norma euclidea di x il numero reale non negativo ‖x‖ =(∑n
i=1 x2i
)1/2. Dati allora
x,y ∈ Rn, si puo allora ridefinire d(x,y) = ‖x − y‖.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 INSIEMI IN RN
FUNZIONI REALI DI PIU VARIABILI
349
A
x
y A
x
y
Esempi L’insieme A ={(x, y) ∈ R2 : y ≤ 1 − x2
}e simmetrico rispetto alle x. Se disegniamo l’insieme A la cosa
e evidente, ma lo stesso si puo dimostrare anche con la definizione: se (x, y) ∈ A significa che y ≤ 1 − x2. Ma alloraanche (−x, y) ∈ A dato che y ≤ 1 − (−x)2, essendo questa equivalente alla precedente. Non c’e invece simmetriarispetto alle y.374
L’insieme A ={(x, y) ∈ R2 : (x− 1)2 + y2 ≤ 1
}e simmetrico rispetto alle y. Anche qui la rappresentazione grafica di
A porta subito ad accorgersi della simmetria. Con la definizione: se (x, y) ∈ A significa che (x− 1)2 + y2 ≤ 1. Alloraanche (x,−y) ∈ A dato che (x− 1)2 + (−y)2 ≤ 1 equivale alla precedente. Non c’e simmetria rispetto alle x.
Osservazione Ci sono insiemi che risultano simmetrici sia rispetto alle x sia rispetto alle y. Ad esempio il cerchiounitario A =
{(x, y) ∈ R2 : x2 + y2 ≤ 1
}lo e.375
Conviene considerare anche un altro tipo di simmetria.
Definizione Sia A ⊂ R2. Diciamo che A e simmetrico rispetto all’origine se vale laseguente proprieta
se (x, y) ∈ A allora (−x,−y) ∈ A.La figura a fianco presenta un esempio di insieme in cui vale questa proprieta.
Ax
y
Esempio L’insieme A ={(x, y) ∈ R2 : x = y
}e simmetrico rispetto all’origine. Si tratta ovviamente della retta
bisettrice del primo e terzo quadrante. Con la definizione: se (x, y) ∈ A allora x = y, ma quindi −x = −y, e pertanto(−x,−y) ∈ A. Si osservi che A non e simmetrico ne rispetto alle x ne rispetto alle y. Si osservi che anche l’insiemeraffigurato qui sopra, pur essendo simmetrico rispetto all’origine, non e simmetrico ne rispetto alle x ne rispetto alley.
Osservazione Come osservato un attimo fa un insieme puo non essere simmetrico ne rispetto alle x ne rispetto alley ma esserlo rispetto all’origine. Invece vale senz’altro che un insieme simmetrico rispetto alle x e rispetto alle y esimmetrico rispetto all’origine.Lo si intuisce da considerazioni grafiche o lo si dimostra facilmente con le definizioni: se A e simmetrico sia rispettoalle x sia rispetto alle y, dal fatto che (x, y) ∈ A possiamo dedurre che (−x, y) ∈ A (per la simmetria rispetto alle x)e da quest’ultima dedurre che (−x,−y) ∈ A (per la simmetria rispetto alle y). Quindi e provata la simmetria rispettoall’origine.
374Dovrebbe essere (x,−y) ∈ A, cioe −y ≤ 1− x2, cosa che non possiamo dedurre dalla y ≤ 1− x2.375Non e rilevante che sia quello unitario, cioe di raggio 1: qualunque cerchio con centro nell’origine e simmetrico sia rispetto alle x siarispetto alle y. Esercizio: qual e la condizione necessaria e sufficiente affinche un cerchio sia simmetrico rispetto alle sole x?
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI DA RN A R
FUNZIONI REALI DI PIU VARIABILI
350
2 Funzioni da Rn a R
Nella seconda parte del corso abbiamo studiato le funzioni reali di variabile reale, cioe le funzioni da R a R.Qui consideriamo le funzioni da Rn a R, dette anche funzioni reali di n variabili.376 Piu in generale ci occuperemo difunzioni definite in un sottoinsieme A di Rn, a valori reali. Scriveremo
f : A ⊂ Rn → R.
Come sempre, se vogliamo riferirci alla funzione nel suo complesso, scriviamo semplicemente f ; se invece, postox = (x1, . . . , xn), vogliamo indicare il numero reale che e immagine di x attraverso la funzione f , scriveremo f(x)oppure f(x1, . . . , xn).Si dice come sempre dominio (o campo di esistenza o insieme di definizione) della funzione f l’insieme dei punti percui esiste il corrispondente secondo la legge f , cioe l’insieme degli x per cui esiste f(x).L’insieme di definizione puo essere fornito esplicitamente, unitamente alla legge che definisce la funzione. Oppure, nelcaso sia fornita soltanto la legge, puo essere chiesto di determinare l’insieme di definizione: in tal caso questo e il piugrande sottoinsieme di Rn in cui e definita l’espressione che fornisce la legge di corrispondenza.Se f : A ⊂ Rn → R, il simbolo f(A) indica come sempre l’immagine della funzione f , cioe l’insieme dei valori che lafunzione assume in corrispondenza degli elementi di A. Chiaramente f(A) ⊂ R.
Come per le funzioni di una variabile, chiamiamo grafico di una funzione f : A ⊂ Rn → R l’insieme
Gf ={(x, f(x)
): x ∈ A
}
={(x1, . . . , xn, f(x1, . . . , xn)
): (x1, . . . , xn) ∈ A
}
.
Si tratta di un sottoinsieme dello spazio Rn+1. Quindi le funzioni di una variabile hanno grafico in R2 (e nella II partedi questo corso abbiamo imparato a trovare il grafico di tali funzioni), le funzioni di due variabili hanno grafico in R3.Non e possibile disegnare il grafico di funzioni di piu di due variabili, dato che e un sottoinsieme almeno di R4.Il grafico di una f : A ⊂ R2 → R e generalmente una superficie in R3. Ad esempio, il grafico della funzione f : R2 → R
definita da f(x1, x2) = x1 + x2 e un piano nello spazio R3.
EsempiSono esempi di funzioni definite in opportuni sottoinsiemi di R2 le seguenti funzioni:
⊲ f1(x1, x2) = x31 + x22 + x1x2 + 1
⊲ f2(x1, x2) =√
x21 + x22
⊲ f3(x1, x2) =x1 + x2x21 + x22
⊲ f4(x1, x2) =ln(x1 + x22 − 1)
3x2
⊲ f5(x1, x2) = max(x1, x2).377
In questi casi non e esplicitamente indicato l’insieme di definizione e, come detto, si sottintende quindi che esso sia ilpiu ampio sottoinsieme di R2 in cui ha senso l’espressione analitica che definisce la funzione.Negli esempi proposti il campo di esistenza di f1, f2, f5 e tutto R2.Per la f3 occorre che il denominatore non si annulli, quindi deve essere x21+x
22 6= 0. Il
campo di esistenza e quindi R2 \ {(0, 0)}, cioe il complementare dell’insieme {(0, 0)}(tutto il piano ad eccezione dell’origine).Per la f4 l’unica condizione e che l’argomento del logaritmo sia positivo, dato che ildenominatore e sempre diverso da zero. Quindi deve essere x1 + x22 − 1 > 0, cioex1 > 1 − x22. Ricordando la geometria analitica della parte I del corso si ha che ilcampo di esistenza, cioe l’insieme
{(x1, x2) ∈ R2 : x1 > 1− x22},
e la parte di piano evidenziata in grigio qui a fianco. E un insieme aperto.
1
−1
x1 = 1− x22
x1
x2
Vediamo altri esempi di funzioni da Rn a R.
376Nella III parte abbiamo studiato, tra le altre cose, particolari funzioni da Rn a Rm, quelle che abbiamo chiamato trasformazioni lineari.377Si tratta della funzione che associa al punto (x1, x2) il massimo tra x1 e x2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI DA RN A R
FUNZIONI REALI DI PIU VARIABILI
351
• Funzioni lineari. Sia v ∈ Rn e sia v = (v1, v2, . . . , vn). La funzione f : Rn → R definita da
f(x) = 〈v,x〉 378 = v1x1 + v2x2 + . . .+ vnxn
e lineare, come abbiamo gia visto nelle lezioni della parte III. Abbiamo anche visto che ogni funzione lineare daRn a R e di questa forma, cioe si puo scrivere come prodotto interno di un vettore fissato v per il vettore x.
Se n = 2 si ha
f(x1, x2) = v1x1 + v2x2 (quindi ad esempio f(x1, x2) = 3x1 +12x2).
Il grafico di questa funzione, qualunque siano i coefficienti, e un piano perl’origine in R3. 379 Osserviamo che l’insieme
{
(x1, x2) ∈ R2 : f(x1, x2) = 0}
,
cioe l’insieme delle soluzioni dell’equazione v1x1 + v2x2 = 0, e in R2 la rettaortogonale (perpendicolare) al vettore v = (v1, v2).
v1
v2v
v1x1 + v2x2 = 0
x1
x2
Con n = 3 le funzioni lineari sono quelle del tipo
f(x1, x2, x3) = v1x1 + v2x2 + v3x3
e l’insieme delle soluzioni dell’equazione v1x1 + v2x2 + v3x3 = 0 e questa volta il piano (in R3) ortogonale(perpendicolare) al vettore v = (v1, v2, v3).
• Forme quadratiche. Sia A una matrice n× n. La funzione f : Rn → R definita da
f(x) = 〈Ax,x〉 380
si chiama forma quadratica associata ad A. Ad esempio, se n = 2 e
A =
(a11 a12a21 a22
)
, si ha f(x1, x2) = a11x21 + a12x1x2 + a21x2x1 + a22x
22.
Nel caso particolare in cui A sia una matrice diagonale di elementi λ1, λ2, con λ1 6= 0, λ2 6= 0, si ha
f(x1, x2) = λ1x21 + λ2x
22.
Il grafico di f dipende in modo cruciale dal segno di λ1 e λ2. Lasciando allo studente il compito di convincersidi quanto segue, mi limito ad elencare i tre casi possibili, accompagnandoli con un grafico.
Se λ1 > 0 e λ2 > 0, come ad esempio in f(x1, x2) = 3x21 + 2x22, il grafico di f e un paraboloide. I valori dellafunzione sono evidentemente sempre non negativi e quindi il paraboloide sta nel semispazio delle x3 ≥ 0 (figurasotto a sinistra). Si puo anche scrivere che f(R2) = [0,+∞).
Se λ1 < 0 e λ2 < 0 il grafico di f e ancora un paraboloide. I valori della funzione sono evidentemente semprenon positivi e quindi il paraboloide sta nel semispazio delle x3 ≤ 0 (figura al centro). Si puo anche scrivere chef(R2) = (−∞, 0].Se λ1 > 0 e λ2 < 0 il grafico di f e un iperboloide (a una falda). La funzione puo assumere sia valori positivi siavalori negativi (figura a destra). In questo caso f(R2) = R.
x
x
x
1
2
3
x
x
x
1
2
3
x
xx
1
23
378Ricordo che la scrittura 〈x,y〉, dove x e y sono due vettori di Rn, indica il prodotto interno dei due: 〈x,y〉 =∑ni=1 xiyi.
379Le funzioni lineari in una variabile sono le funzioni del tipo f(x) = vx, con v ∈ R. Sono quindi quelle che hanno per grafico una rettaper l’origine.380Si tratta del prodotto interno di Ax, che e un vettore di Rn dato dal prodotto di A per x, per il vettore x.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI DA RN A R
FUNZIONI REALI DI PIU VARIABILI
352
Alle forme quadratiche e in particolare allo studio del segno di queste e dedicata la prossima dispensa.
Osservazione Il caso in cui uno dei due coefficienti λ1, λ2 e nullo e meno significativo. Vale comunque la penaosservare che (mettiamo sia λ1 > 0 e λ2 = 0) in tal caso si ha f(x1, x2) = λ1x
21 e il valore di f dipende dalla
sola x1. Si tratta di un paraboloide degenere e si intuisce facilmente che il grafico si ottiene facendo muovere laparabola x3 = λ1x
21 lungo l’asse x2.
Qui sotto riporto i grafici di alcune forme quadratiche, ottenuti con un software scientifico. Il grafico a destra equello di una forma quadratica del tipo f(x1, x2) = λ1x
21 con λ1 > 0.
1 -10,5 -0,5
xy
000
0,5
1
1,5
0,5
2
-0,51 -1
-1-1-0,5
-1
-0,5
y -0,5x
00
0
0,5
0,5
1
0,51 1-1
-0,5-1
y-0,5
x
000
0,1
0,5
0,2
0,3
0,51
0,4
0,5
1
• Polinomi. Un monomio in Rn e una funzione della forma
(x1, . . . , xn) 7→ xr11 · · ·xrnn ,
dove r1, . . . , rn sono interi non negativi. Si chiama grado del monomio il numero intero non negativo r1+. . .+rn.
Un polinomio e una combinazione lineare di monomi. Il grado di un polinomio e il massimo dei gradi dei monomidi cui e combinazione lineare.
Ad esempio, e un monomio in tre variabili la funzione f(x1, x2, x3) = x1x22x
33; si tratta di un monomio di sesto
grado. Un esempio di polinomio e la funzione g(x1, x2, x3) = 2x1x22x
33 − 3x4x32x
23; e un polinomio di nono grado.
Il piu generale polinomio di secondo grado in R2 e
P (x1, x2) = ax21 + bx22 + cx1x2 + dx1 + ex2 + f,
con a, b, c, d, e, f ∈ R e almeno uno dei coefficienti a, b, c diverso da zero (altrimenti e ancora un polinomio manon e piu di secondo grado).
Il piu generale polinomio di secondo grado in R3 e
P (x1, x2, x3) = ax21 + bx22 + cx23 + dx1x2 + ex1x3 + fx2x3 + gx1 + hx2 + ix3 + j,
con a, b, . . . , j ∈ R e almeno uno dei coefficienti a, b, . . . , f diverso da zero. In generale non si tratta ovviamentedi una forma quadratica (lo e se e solo se g = h = i = j = 0). Volendo lo si puo vedere come la somma di unaforma quadratica, di una funzione lineare e di una costante.
• Funzioni radiali.
Una funzione f : Rn → R si dice radiale se esiste una funzione f0 : [0,+∞)→ R tale che
f(x) = f0(‖x‖), per ogni x ∈ Rn. 381
La funzione f0 si dice il profilo di f . Piu in generale la funzione profilo puo essere definita in un intervallo deltipo [0, r) e la funzione radiale f in un intorno dell’origine di raggio r.
Ad esempio, la funzione f(x1, x2) = x21 + x22 e radiale, in quanto
x21 + x22 = ‖(x1, x2)‖2.
Il profilo e la funzione f0 : [0,+∞)→ R con f0(t) = t2.
Osservazione Il grafico di una funzione radiale definita in R2 si ottiene “facendo ruotare il suo profilo” attornoall’asse x3. Ecco alcuni esempi di funzioni radiali, con i relativi grafici.
381La definizione puo risultare di difficile comprensione. Si noti che f e funzione di n variabili, mentre f0 e funzione di una variabile, cioedi un numero reale. Infatti l’argomento di f0 e la norma del vettore x, che e appunto un numero reale. In sostanza la definizione dice cheil valore che la funzione associa ad x dipende soltanto dalla norma di x o, in altre parole, che a punti alla stessa distanza dall’origine lafunzione associa lo stesso valore.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI DA RN A R
FUNZIONI REALI DI PIU VARIABILI
353
⊲ f(x1, x2) = x21 + x22, definita in tutto R2; come detto ha profilo f0 : [0,+∞)→ R con f0(t) = t2.
⊲ g(x1, x2) =√
x21 + x22, definita in tutto R2; ha profilo f0 : [0,+∞)→ R con f0(t) = t.
⊲ h(x1, x2) =√
1− x21 − x22, definita nel cerchio unitario
B(0, 1) ={
x ∈ R2 : ‖x‖ ≤ 1}
;
ha profilo f0 : [0, 1]→ R con f0(t) =√1− t2.
21 1( ,0, )x x
x
x
fG
x
1
2
3
1 1( ,0, )x x
gG
x
x
x
1
2
32( ,0, 1- )x xÖ
hG1 1
x
x
x
1
2
3
Il grafico di f e il paraboloide gia incontrato prima; il grafico di g e una superficie conica con vertice nell’origine; Ilgrafico di h e una calotta sferica con centro nell’origine.
Esercizio 2.1 Si descriva il campo di esistenza delle seguenti funzioni, specificando se si tratta di insiemi aperti,
chiusi o ne aperti ne chiusi:
(a) f(x, y) = ln(x − y + 1) (b) f(x, y) =1 + x+ y
1− 2x+ 3y
(c) f(x, y) =√
x+ y2 + 1 (d) f(x, y) =√
1− x2 − y2
(e) f(x, y) = ln(1− 2x2 − y2) (f) f(x, y) =√xy
(g) f(x, y) = ln(1 − xy) (h) f(x, y) =√
1− y2
Esercizio 2.2 Si determini il campo di esistenza delle seguenti funzioni e lo si rappresenti graficamente.
(a) f(x, y) =√
x(y + 1) (b) f(x, y) =√x+ 1−√1− x− y
(c) f(x, y) = log
(1− x1− y
)
(d) f(x, y) = ln y + ln(x+ y)
(e) f(x, y) =
√
x2 + y2 − 4
y − 1(f) f(x, y) = log
(x
x− y2 + 1
)
(g) f(x, y) =
√xy + 1
x+ y + 1(h) f(x, y) = log
((x− 1)2 + y2 − 4
4− x2 − (y − 1)2
)
Esercizio 2.3 Si scriva l’espressione analitica del profilo delle seguenti funzioni radiali:
(a) f(x, y) = e−x2−y2
(b) f(x, y) =√
x2 + y2 + 1
(c) f(x, y) =1
1 + x2 + y2(d) f(x, y) = ln(2− x2 − y2)
(e) f(x, y) =√
x2 + y2 − x2 − y2 (f) f(x, y) = 1 + x4 + 2x2y2 + y4
2.1 Simmetrie di una funzione
Talvolta puo essere utile sfruttare alcune caratteristiche di simmetria di una funzione di piu variabili. Qui consideriamosolo le funzioni di due variabili e torno ad indicare gli elementi di R2 con la notazione (x, y).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI DA RN A R
FUNZIONI REALI DI PIU VARIABILI
354
Definizioni Sia A ⊂ R2 un insieme simmetrico rispetto alle x.
(i) Diciamo che una funzione f definita in A e pari rispetto alle x se vale la seguente proprieta:
se (x, y) ∈ A allora f(−x, y) = f(x, y).
(ii) Diciamo che una funzione f definita in A e dispari rispetto alle x se vale la seguente proprieta:
se (x, y) ∈ A allora f(−x, y) = −f(x, y).
Sia A ⊂ R2 un insieme simmetrico rispetto alle y.
(iii) Diciamo che una funzione f definita in A e pari rispetto alle y se vale la proprieta:
se (x, y) ∈ A allora f(x,−y) = f(x, y).
(iv) Diciamo che una funzione f definita in A e dispari rispetto alle y se vale la proprieta:
se (x, y) ∈ A allora f(x,−y) = −f(x, y).
Sia A ⊂ R2 un insieme simmetrico rispetto all’origine.
(v) Diciamo che una funzione f definita in A e pari rispetto all’origine se vale la seguente proprieta:
se (x, y) ∈ A allora f(−x,−y) = f(x, y).
(vi) Infine diciamo che una funzione f definita in A e dispari rispetto all’origine se vale la seguente proprieta:
se (x, y) ∈ A allora f(−x,−y) = −f(x, y).
Osservazione Lo studente avra notato le evidenti analogie con le simmetrie delle funzioni di una variabile (funzionipari o dispari).
Esempi
⊲ La funzione f(x, y) = x2 + y3 e pari rispetto alle x. Si noti anche che non e dispari rispetto alle y.
⊲ La funzione f(x, y) = x2y3 e pari rispetto alle x e dispari rispetto alle y.
⊲ La funzione f(x, y) = x2y2 e pari, sia rispetto alle x sia rispetto alle y. Si tratta di una funzione pari rispettoall’origine.
⊲ La funzione f(x, y) = x2y3 e dispari rispetto all’origine, pari rispetto alle x e dispari rispetto alle y.
⊲ La funzione f(x, y) = xy3 e pari rispetto all’origine, dispari rispetto alle x e dispari rispetto alle y.
2.2 Insiemi di livello e curve di livello
Farsi un’idea del grafico di una funzione di piu variabili e piuttosto difficile. Come gia detto, anzi, non e nemmenopossibile rappresentare il grafico se il numero di variabili e maggiore di 2. Nel caso di due variabili il grafico e unasuperficie in R3 e non ci sono tecniche generali come quelle che abbiamo studiato nella Parte II.Una valida alternativa al grafico e data dagli insiemi di livello, che nel caso di due variabili sono le curve di livello. Ingenerale si ha
Definizione Data una funzione f : A ⊂ Rn → R, si definisce insieme di livello k di f l’insieme dei punti di A incui la funzione ha valore k, cioe formalmente
Lk ={x ∈ A : f(x) = k
}.
Si tratta quindi di un sottoinsieme del dominio della funzione.Nel caso n = 2 tali insiemi sono solitamente curve nel piano e prendono quindi il nome di curve di livello k.Ovviamente l’insieme (la curva) cambia al variare del valore k. Studiare le curve di livello significa appunto capirecome variano le curve al variare del livello.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI DA RN A R
FUNZIONI REALI DI PIU VARIABILI
355
Esempio Consideriamo la funzione f(x, y) = x2+ y2. Naturalmente, se pensiamo ad un livello negativo, ad esempio−1, dobbiamo dire che la curva di livello −1 non c’e poiche la funzione non puo avere valore negativo. Pertanto lacurva di livello −1 e l’insieme vuoto. La curva di livello 0 invece non e vuota, ma si riduce al solo punto origine(0, 0).382
Se ora fissiamo un livello positivo, ad esempio 1, la curva corrispondente questa volta c’e ed e proprio una curva insenso letterale: si tratta dell’insieme delle soluzioni dell’equazione x2 + y2 = 1 e quindi, come noto, della circonferenzadi centro l’origine e raggio 1. Al variare del livello k (positivo) abbiamo circonferenze con centro sempre nell’origine eraggio
√k. Quindi al crescere di k le curve di livello sono circonferenze di raggio crescente.
Esempio Consideriamo la funzione f(x, y) = xy. La curva di livello 0 e l’insieme delle soluzioni dell’equazionexy = 0 e cioe i due assi cartesiani.383 La curva di livello k positivo e l’insieme delle soluzioni dell’equazione xy = k ecioe i punti di un’iperbole centrata nell’origine e rami nel primo e terzo quadrante. Anche con k negativo si hanno ipunti di un’iperbole centrata nell’origine, ma con rami nel secondo e quarto quadrante.
Osservazione Le curve di livello possono essere una valida alternativa al grafico della funzione in quanto, anche senon ci mostrano i valori della funzione, ci dicono pero in quali punti la funzione ha valore costante, al variare di questovalore. E la tecnica usata nelle mappe geografiche per indicare la morfologia del terreno (il livello indica la quota sullivello del mare) oppure nelle mappe meteo (il livello indica la pressione al suolo o in quota). Nelle mappe geografichela presenza di curve di livello molto ravvicinate indica una variazione molto rapida della quota, e quindi una zona dipendenza molto forte, mentre curve di livello molto lontane indicano regioni sostanzialmente piatte.Vediamo qualche altro esempio.
Esempi
• Le curve di livello k della funzione f(x, y) = x+ y2 +1 si ottengono a partire dall’equazione x+ y2 +1 = k, cioex = −y2 + k − 1. Si tratta di parabole con asse dato dall’asse x e concave verso sinistra. Al crescere del valorek la parabola si “sposta verso destra”.
• Le curve di livello k della funzione f(x, y) = ln(x + y) si ottengono a partire dall’equazione ln(x + y) = k, cioex + y = ek, cioe y = ek − x. Si tratta ovviamente di rette di pendenza −1 e ordinata all’origine ek, quindicertamente positiva.384 Al crescere di k la retta si “sposta verso l’alto”.
• Le curve di livello k della funzione f(x, y) =√
1− x2 − y2 si ottengono a partire dall’equazione√
1− x2 − y2 =k, cioe 1−x2−y2 = k2, cioe ancora x2+y2 = 1−k2. Se k e negativo non c’e curva di livello, dato che l’equazioneiniziale
√
1− x2 − y2 = k non ha certamente soluzioni. Se k = 0 abbiamo la circonferenze di centro l’originee raggio 1. Se k > 0 abbiamo circonferenze di centro l’origine e raggio
√1− k2: la quantita sotto radice deve
pero essere positiva, e quindi deve anche essere k < 1. Infine per k = 1 la curva si riduce alla sola origine. Siriconoscera la morfologia della calotta sferica rappresentata un paio di pagine fa.
Esercizio 2.4 Si descrivano le curve di livello 1 delle seguenti funzioni.
(a) f(x, y) = ln(x − y + 1) (b) f(x, y) =1 + x+ y
1− 2x+ 3y
(c) f(x, y) =√
x+ y2 + 1 (d) f(x, y) =√
1− x2 − y2
(e) f(x, y) = ln(1− 2x2 − y2) (f) f(x, y) =√xy
(g) f(x, y) = ln(1 − xy) (h) f(x, y) =√
1− y2
2.3 Restrizione di una funzione ad una curva
Esaminiamo ora un concetto che, pur essendo presente anche nella trattazione delle funzioni di una variabile, trovapero il suo significato piu pieno con le funzioni di piu variabili. Tale concetto ci sara utile in seguito, soprattuttoquando parleremo di limiti, continuita e derivabilita. Si tratta del concetto di restrizione di una funzione.Prima pero serve il concetto di curva in Rn. Per non appesantire l’esposizione, considero solo curve in R2.Chiamiamo curva in R2 una funzione continua γ definita in un intervallo I di R a valori in R2. Pertanto abbiamo
γ : I → R2, con γ(t) =(γ1(t), γ2(t)
),
382Quindi si noti che la curva puo non esserci oppure puo essere qualcosa che solitamente non chiameremmo “curva”.383La curva di livello 0 e quindi l’insieme dei punti che stanno in almeno uno dei due assi.384Questo fa sı che la retta stia nell’insieme di esistenza della funzione, che non e tutto R2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 FUNZIONI DA RN A R
FUNZIONI REALI DI PIU VARIABILI
356
dove γ1, γ2 sono funzioni continue definite nell’intervallo I.385
L’immagine della curva γ, cioe il sottoinsieme di R2
{(γ1(t), γ2(t)
): t ∈ I
}
,
si chiama sostegno della curva γ. Purtroppo talvolta si identifica la curva con il suo sostegno. Nel linguaggio comuneinfatti dicendo curva nel piano intendiamo l’insieme dei punti che formano la figura geometrica. Nella nostra definizionesarebbe meglio chiamare quest’ultima il sostegno (o l’immagine) della curva e chiamare curva soltanto la funzione cheha per immagine la figura geometrica.
Esempi
• La funzione γ(t) = (0, t), con t ∈ R e una curva in R2. La sua immagine (sostegno) e l’asse delle ordinate.
• La funzione γ(t) = (1+ t, 1− t), con t ∈ [−1, 1] e una curva in R2. La sua immagine e un segmento nel piano.386
• La funzione γ(t) = (t, t2), con t ∈ [0, 1] e una curva in R2. La sua immagine e un arco di parabola.387
Data una funzione f : A ⊂ R2 → R e data una curva γ : I → R2, con immagine contenuta in A, chiamiamo restrizionedi f alla curva γ la funzione f ◦ γ, cioe la funzione (composta) che a t associa f(γ(t)).388
Esempi
• Data la funzione f(x1, x2) = x1 − x2, la sua restrizione alla curva γ(t) = (t, 0), con t ∈ R, e una restrizione di fall’asse x1.
389 Si tratta della funzione g(t) = f(t, 0) = t.
La restrizione della stessa funzione alla curva γ(t) = (t, t), con t ∈ R, e una restrizione di f alla retta di equazionex1 = x2. Si tratta della funzione g(t) = f(t, t) = 0, con t ∈ R.
• La restrizione della funzione f(x1, x2) = x1x2
x21+x2
2
alla curva γ(t) = (t, t), con t ∈ (0,+∞) e la funzione g(t) =
f(t, t) = 12 , con t ∈ (0,+∞).
Una restrizione della stessa funzione alla parte di parabola di equazione x2 = x21 che sta nel primo quadrante sipuo ottenere con la funzione g(t) = f(t, t2) = t
1+t2 , con t ∈ (0,+∞).
Anche se ho presentato i concetti di curva e di restrizione nel caso bidimensionale, tutto si potrebbe estendere in modoimmediato al caso n-dimensionale.A titolo di esempio, una restrizione della funzione
f : R3 → R, con f(x1, x2, x3) = e−x21−x2
2−x23
alla retta passante per il punto (1, 1, 0) e parallela all’asse x3 si ottiene390 considerando la restrizione di f alla curvaγ : R→ R3, con
γ(t) = (1, 1, t);
si tratta pertanto della funzione
g(t) = f(γ(t)) = f(1, 1, t) = e−2−t2 .
Esercizio 2.5 Si determini una curva che parametrizza la retta di equazione x+ y + 1 = 0.
385In pratica quindi una curva e una funzione che alla variabile reale t associa due componenti, γ1(t) e γ2(t), e queste sono funzionicontinue di t.386Si puo vedere cosı: nello stesso modo in cui facevamo nella parte III, possiamo scrivere (1+ t, 1− t) = (1, 1)+ t(1,−1), quindi al variaredi t in tutto R si otterrebbe la retta che contiene il vettore (1,−1) traslata del vettore (1, 1). Con t ∈ [−1, 1] si ottiene solo una parte diquesta retta e cioe un segmento. Possiamo anche precisare che gli estremi del segmento, che si ottengono con i valori estremi di t (−1 e 1),sono i punti (0, 2) e (2, 0).387Qui si puo ragionare cosı: se poniamo x = t e y = t2, allora tra x e y sussiste la relazione y = x2, che come sappiamo individua nelpiano una parabola. Con t ∈ [0, 1] si ottiene una parte della parabola, quella compresa tra i punti (0, 0) e (1, 1).388Il nome restrizione deriva da fatto che in pratica non considero la f su tutto il suo dominio, ma soltanto sui punti della curva γ. Sinoti pero che la restrizione, essendo la funzione composta, non e definita sul sostegno della curva, cioe in R2, ma sull’intervallo I in cui edefinita la curva. I valori della restrizione sono pero i valori di f sul sostegno della curva.389Non e unica la restrizione di f all’asse x1: ad esempio la funzione g(t) = f(t3, 0) = t3 e un’altra restrizione di f all’asse x1.390I punti di questa retta si ottengono traslando l’asse x3 del vettore (1, 1, 0): dato che l’asse x3 e individuato dal vettore (0, 0, 1), allorai punti della retta si possono esprimere con t(0, 0, 1) + (1, 1, 0), cioe con (1, 1, t).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 LIMITE
FUNZIONI REALI DI PIU VARIABILI
357
Esercizio 2.6 Si determini una curva che parametrizza la parabola di equazione x+ y2 + 1 = 0.
Esercizio 2.7 Si determini una curva che parametrizza il ramo destro dell’iperbole di equazione x2−y2−1 = 0.
Esercizio 2.8 Si scriva la restrizione della funzione f(x, y) = x+exy2
alla curva γ(t) = (t, ln t), con t ∈ (0,+∞).
Esercizio 2.9 Si scriva la restrizione della funzione f(x, y) = x/y alla curva γ(t) = (t, 1/t), con t ∈ (0,+∞).
Esercizio 2.10 Si scriva la restrizione della funzione f(x, y) = x + ln(x + y) alla curva γ(t) = (1/t, t), con
t ∈ (0,+∞).
3 Limite
Si potrebbe formulare una definizione rigorosa del concetto di limite per funzioni di piu variabili, ricalcando sostan-zialmente la definizione valida in precedenza. Non abbiamo pero visto nel dettaglio quella definizione e non la vedremonemmeno nella sua generalizzazione a piu variabili.Verremmo cosı a definire rigorosamente il significato di scritture come
lim(x1,x2)→(x0
1,x0
2)f(x1, x2) = ℓ , lim
(x1,x2)→(x01,x0
2)f(x1, x2) = +∞ , lim
(x1,x2)→(x01,x0
2)f(x1, x2) = −∞.
e anche come
lim(x1,x2)→∞
f(x1, x2) = ℓ 391 , lim(x1,x2)→∞
f(x1, x2) = +∞ , lim(x1,x2)→∞
f(x1, x2) = −∞.
Mi limito soltanto a presentare la possibilita di indagare sul limite di una funzione di due variabili operando dellerestrizioni sulla funzione stessa.
Osservazione Detto in modo molto impreciso ma che rende bene l’idea, il limite di una funzione di piu variabili e“piu difficile che esista” rispetto al limite di una funzione di una sola variabile.A titolo di esempio, si consideri la funzione
f(x1, x2) =x1x2x21 + x22
, con (x1, x2) 6= (0, 0). (17)
Si puo verificare facilmente chelim
(x1,x2)→(0,0)f(x1, x2) (18)
non esiste, sulla base di un risultato, che enuncio soltanto, ma che appare tuttavia molto plausibile. Lo dico primaa parole, poi formalizzo. Se il limite di una funzione, per (x1, x2) che tende ad un certo punto (x01, x
02), esiste, allora
se tendiamo a questo punto lungo alcune particolari curve, allora dobbiamo trovare sempre lo stesso risultato, cioe lostesso limite, indipendentemente da quale curva consideriamo.Se cioe
lim(x1,x2)→(x0
1,x0
2)f(x1, x2) esiste, finito o infinito, chiamiamolo λ
e se γ e una curva in R2 con γ(t0) = (x01, x02), allora
limt→t0
(f ◦ γ)(t) 392
esiste ed e uguale a λ.Quindi, se il limite esiste, deve essere lo stesso lungo una qualunque restrizione. Ma allora, se troviamo che ci sonodue diverse restrizioni lungo le quali i limiti sono diversi, possiamo dire che il limite non esiste.Tornando alla nostra funzione (17), consideriamo la curva
γ(t) = (t, 0), con t ∈ R.
391Si osservi che ho scritto (x1, x2) → ∞ e non ±∞. Per le funzioni di due variabili la variabile tende ad un “infinito senza segno”(potrebbe essere che la x1 tenda a +∞ e la x1 tenda invece a −∞). Quindi si dice che la variabile tende ad ∞, intendendo che (x1, x2) siallontana infinitamente dall’origine, in tutte le direzioni possibili.392Si noti che la funzione f potrebbe non essere definita in (x0
1, x02) e quindi f ◦ γ potrebbe non essere definita in t0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 CONTINUITA
FUNZIONI REALI DI PIU VARIABILI
358
Si tratta di una curva che ha per sostegno l’asse x1 (le ascisse). Se calcoliamo ora il limite lungo questa restrizioneotteniamo
limt→0
(f ◦ γ)(t) = limt→0
f(t, 0) = limt→0
0
t2= 0.
Anche lungo la restrizione dell’asse x2 il limite e zero (lo si verifichi).Ma se consideriamo la curva
γ(t) = (t, t), con t ∈ R,
cioe quella che ha per sostegno la bisettrice del primo e terzo quadrante, otteniamo
limt→0
(f ◦ γ)(t) = limt→0
f(t, t) = limt→0
t2
2t2=
1
2.
Il limite (18) quindi non esiste.Un altro esempio:
lim(x1,x2)→∞
ex1+x2 non esiste.
Infatti, se consideriamo la restrizione di f(x1, x2) = ex1+x2 alla curva γ(t) = (t, 0), con t ∈ (0,+∞), otteniamola funzione (f ◦ γ)(t) = et, che, per t → +∞, tende a +∞. Se invece consideriamo la restrizione di f alla curvaγ(t) = (−t, 0), con t ∈ (0,+∞), otteniamo la funzione (f ◦ γ)(t) = e−t, che, per t→ +∞, tende a zero. Notiamo cheentrambi i sostegni delle due curve “tendono all’infinito” per t→ +∞.393 Quindi il limite non esiste, essendo diversosu due restrizioni che “tendono entrambe all’infinito”.
Esercizio 3.1 Data la funzione f(x, y) =x− yx+ y
, si calcolino i limiti di f nell’origine lungo le seguenti restrizioni:
(a) la retta di equazione y = x
(b) la parabola di equazione y = x2
(c) la parabola di equazione x = y2
Esercizio 3.2 Data la funzione f(x, y) =x3 + y3
x2 + y2, si calcolino i limiti nell’origine di f lungo le seguenti restrizioni:
(a) la retta di equazione y = x
(b) la parabola di equazione y = x2
(c) la parabola di equazione x = y2
(d) la curva di equazione y = ex − 1
4 Continuita
Veniamo ora al concetto di continuita, gia trattato nella II parte per le funzioni di una variabile. La definizione eformalmente la stessa che abbiamo gia incontrato.
Definizione Se f : A ⊂ Rn → R e se x0 e un punto del dominio A, si dice che f e continua in x0 se si ha che
limx→x
0f(x) = f(x0).
Se f e continua in tutti i punti di A si dice che f e continua in A.
Per le funzioni continue valgono in Rn tutti i teoremi gia visti in R. A tale proposito ricordo che sono di fondamentaleimportanza tutti i teoremi che affermano che somme e prodotti di funzioni continue sono funzioni continue. Anchequozienti di funzioni continue, dove il quoziente esiste, sono funzioni continue. Infine funzioni composte di funzionicontinue sono funzioni continue.Ad esempio sono continue, nei rispettivi campi di esistenza, le funzioni
• f(x1, x2) = 2x21x2 + 3x1x32
393Possiamo dire che i punti di una curva γ : (a,+∞) → R2 tendono all’infinito per t → +∞ se ‖γ(t)‖ → +∞ per t → +∞.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI PIU VARIABILI
359
• g(x1, x2, x3) = ln(x1 − x2 + x3)
• h(x1, x2, . . . , xn) = e−∥∥(x1,x2,...,xn)
∥∥
2
.
• Anche la funzione
f(x1, x2, . . . , xn) =1
∑ni=1 xi
,
dove esiste,394 e continua.
Vale in Rn un teorema che generalizza il fondamentale Teorema di Weierstrass, che lo studente ha visto per funzionidi una variabile.
Teorema (di Weierstrass) Se f e definita e continua in un sottoinsieme chiuso e limitato di Rn, allora valgono leseguenti proprieta:
(i) f e limitata e la sua immagine e un insieme chiuso e limitato;395
(ii) f assume quindi un valore massimo e un valore minimo.
Se in particolare f e definita e continua in un intervallo chiuso e limitato di Rn, allora
(iii) l’immagine di f e un intervallo chiuso e limitato.
E una conseguenza del teorema di Weierstrass il
Teorema (degli zeri) Se f e continua in un intervallo chiuso e limitato di Rn ed assume in esso valori di segnoopposto, essa in qualche punto necessariamente si annulla.
Osservazione Come gia in una sola variabile, per la validita della tesi e cruciale che la funzione sia definita in unintervallo.396
5 Soluzioni degli esercizi
Esercizio 2.1
(a) f(x, y) = ln(x− y+1). L’unica condizione di esistenza e data dalla disequazione x− y+1 > 0, cioe y < x+1. Ilcampo di esistenza di f e quindi il semipiano che si trova al di sotto delle retta di equazione y = x+1. La rettanon fa parte dell’insieme. Si tratta di un insieme aperto, dato che tutti i suoi punti sono interni all’insieme.
(b) f(x, y) =1 + x+ y
1− 2x+ 3y. La condizione di esistenza e data dal non annullarsi del denominatore, cioe dalla condi-
zione 1− 2x+3y 6= 0, che si puo anche scrivere y 6= 23x− 1
3 . Si tratta quindi dei punti del piano che non stannosulla retta di equazione y = 2
3x− 13 . L’insieme e aperto, dato che tutti i punti sono interni.
(c) f(x, y) =√
x+ y2 + 1. La condizione di esistenza e data da x+ y2+1 ≥ 0, soddisfatta da tutti i punti del pianoche stanno alla destra della parabola di equazione x = −y2 − 1. Si tratta di una parabola con asse coincidentecon l’asse x, con la concavita rivolta verso sinistra. Il campo di esistenza di f e un insieme chiuso, dato che ipunti sulla parabola fanno parte dell’insieme.
(d) f(x, y) =√
1− x2 − y2. La condizione di esistenza e data da 1 − x2 − y2 ≥ 0, cioe x2 + y2 ≤ 1, soddisfattada tutti i punti del piano appartenenti al cerchio di centro l’origine e raggio 1 (bordo compreso). Il campo diesistenza di f e un insieme chiuso, dato che i punti sulla circonferenza fanno parte dell’insieme.
(e) f(x, y) = ln(1− 2x2 − y2). La condizione di esistenza e data da 1− 2x2 − y2 > 0, cioe 2x2 + y2 < 1, soddisfattada tutti i punti del piano interni all’ellisse di centro l’origine e semiassi a = 1√
2e b = 1 (bordo escluso). Il campo
di esistenza di f e un insieme aperto, dato che i punti sull’ellisse non fanno parte dell’insieme.
394Chiaramente la funzione esiste nei punti (x1, x2, . . . , xn) ∈ Rn in cui si ha∑n
i=1 xi 6= 0.395In generale non e detto che l’immagine sia un intervallo; vedi il successivo punto (iii).396Per la verita basta che la funzione sia definita in un insieme che non sia “fatto da due parti separate”.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
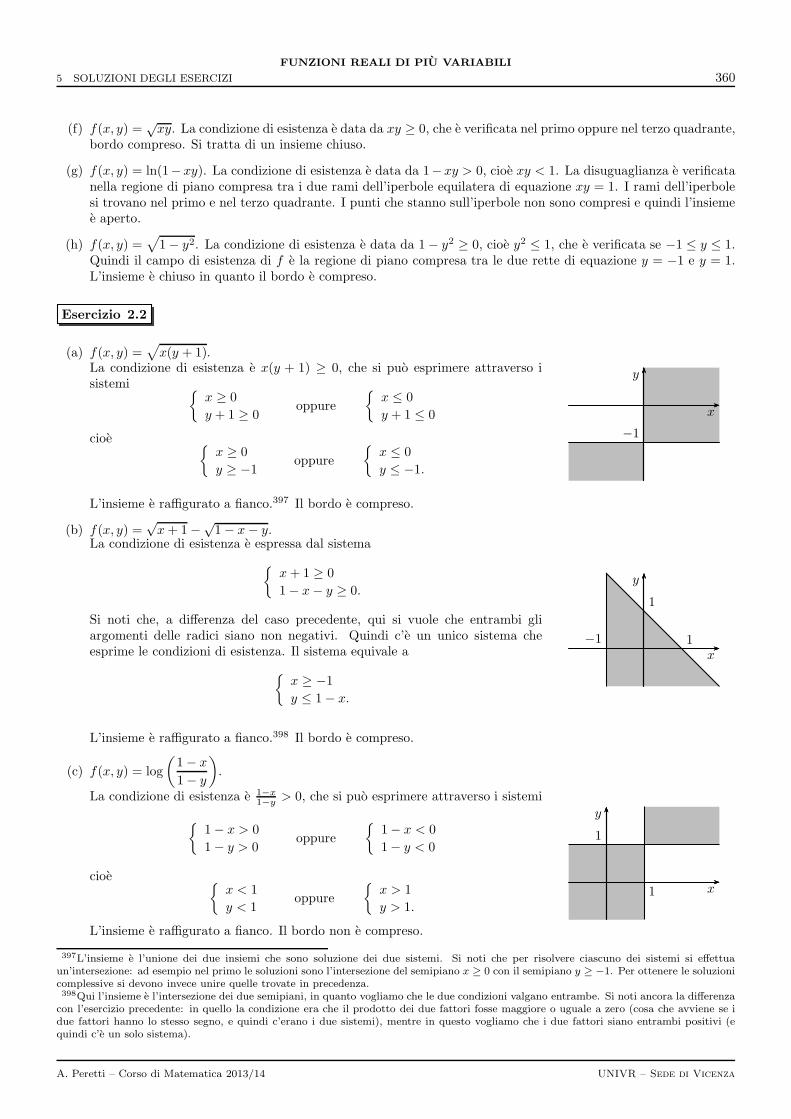
5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI PIU VARIABILI
360
(f) f(x, y) =√xy. La condizione di esistenza e data da xy ≥ 0, che e verificata nel primo oppure nel terzo quadrante,
bordo compreso. Si tratta di un insieme chiuso.
(g) f(x, y) = ln(1−xy). La condizione di esistenza e data da 1−xy > 0, cioe xy < 1. La disuguaglianza e verificatanella regione di piano compresa tra i due rami dell’iperbole equilatera di equazione xy = 1. I rami dell’iperbolesi trovano nel primo e nel terzo quadrante. I punti che stanno sull’iperbole non sono compresi e quindi l’insiemee aperto.
(h) f(x, y) =√
1− y2. La condizione di esistenza e data da 1− y2 ≥ 0, cioe y2 ≤ 1, che e verificata se −1 ≤ y ≤ 1.Quindi il campo di esistenza di f e la regione di piano compresa tra le due rette di equazione y = −1 e y = 1.L’insieme e chiuso in quanto il bordo e compreso.
Esercizio 2.2
(a) f(x, y) =√
x(y + 1).La condizione di esistenza e x(y + 1) ≥ 0, che si puo esprimere attraverso isistemi {
x ≥ 0
y + 1 ≥ 0oppure
{x ≤ 0
y + 1 ≤ 0
cioe {x ≥ 0
y ≥ −1 oppure
{x ≤ 0
y ≤ −1.
−1x
y
L’insieme e raffigurato a fianco.397 Il bordo e compreso.
(b) f(x, y) =√x+ 1−√1− x− y.
La condizione di esistenza e espressa dal sistema
{x+ 1 ≥ 0
1− x− y ≥ 0.
Si noti che, a differenza del caso precedente, qui si vuole che entrambi gliargomenti delle radici siano non negativi. Quindi c’e un unico sistema cheesprime le condizioni di esistenza. Il sistema equivale a
{x ≥ −1y ≤ 1− x.
−1 1
1
x
y
L’insieme e raffigurato a fianco.398 Il bordo e compreso.
(c) f(x, y) = log
(1− x1− y
)
.
La condizione di esistenza e 1−x1−y > 0, che si puo esprimere attraverso i sistemi
{1− x > 0
1− y > 0oppure
{1− x < 0
1− y < 0
cioe {x < 1
y < 1oppure
{x > 1
y > 1.
L’insieme e raffigurato a fianco. Il bordo non e compreso.
1
1
x
y
397L’insieme e l’unione dei due insiemi che sono soluzione dei due sistemi. Si noti che per risolvere ciascuno dei sistemi si effettuaun’intersezione: ad esempio nel primo le soluzioni sono l’intersezione del semipiano x ≥ 0 con il semipiano y ≥ −1. Per ottenere le soluzionicomplessive si devono invece unire quelle trovate in precedenza.398Qui l’insieme e l’intersezione dei due semipiani, in quanto vogliamo che le due condizioni valgano entrambe. Si noti ancora la differenzacon l’esercizio precedente: in quello la condizione era che il prodotto dei due fattori fosse maggiore o uguale a zero (cosa che avviene se idue fattori hanno lo stesso segno, e quindi c’erano i due sistemi), mentre in questo vogliamo che i due fattori siano entrambi positivi (equindi c’e un solo sistema).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
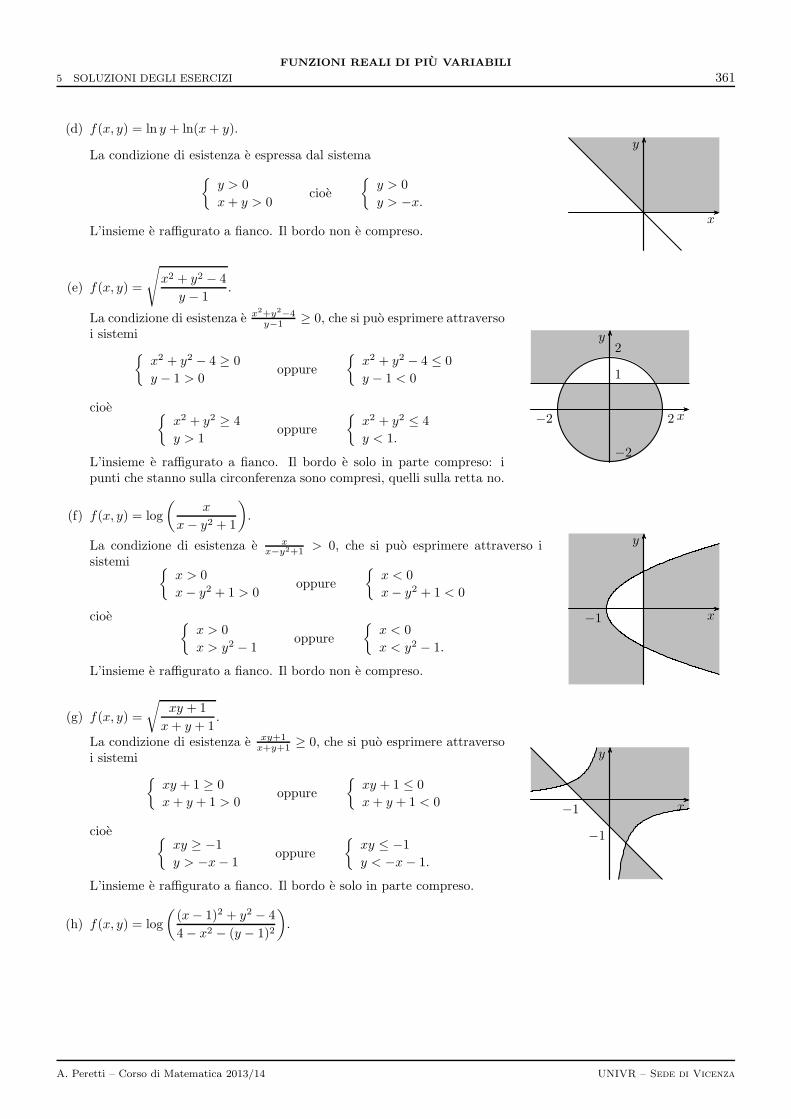
5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI PIU VARIABILI
361
(d) f(x, y) = ln y + ln(x+ y).
La condizione di esistenza e espressa dal sistema
{y > 0
x+ y > 0cioe
{y > 0
y > −x.
L’insieme e raffigurato a fianco. Il bordo non e compreso.x
y
(e) f(x, y) =
√
x2 + y2 − 4
y − 1.
La condizione di esistenza e x2+y2−4y−1 ≥ 0, che si puo esprimere attraverso
i sistemi
{x2 + y2 − 4 ≥ 0
y − 1 > 0oppure
{x2 + y2 − 4 ≤ 0
y − 1 < 0
cioe {x2 + y2 ≥ 4
y > 1oppure
{x2 + y2 ≤ 4
y < 1.
L’insieme e raffigurato a fianco. Il bordo e solo in parte compreso: ipunti che stanno sulla circonferenza sono compresi, quelli sulla retta no.
2−2
1
2
−2
x
y
(f) f(x, y) = log
(x
x− y2 + 1
)
.
La condizione di esistenza e xx−y2+1 > 0, che si puo esprimere attraverso i
sistemi {x > 0
x− y2 + 1 > 0oppure
{x < 0
x− y2 + 1 < 0
cioe {x > 0
x > y2 − 1oppure
{x < 0
x < y2 − 1.
L’insieme e raffigurato a fianco. Il bordo non e compreso.
−1 x
y
(g) f(x, y) =
√xy + 1
x+ y + 1.
La condizione di esistenza e xy+1x+y+1 ≥ 0, che si puo esprimere attraverso
i sistemi
{xy + 1 ≥ 0
x+ y + 1 > 0oppure
{xy + 1 ≤ 0
x+ y + 1 < 0
cioe {xy ≥ −1y > −x− 1
oppure
{xy ≤ −1y < −x− 1.
L’insieme e raffigurato a fianco. Il bordo e solo in parte compreso.
−1
−1
x
y
(h) f(x, y) = log
((x− 1)2 + y2 − 4
4− x2 − (y − 1)2
)
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI PIU VARIABILI
362
La condizione di esistenza e (x−1)2+y2−44−x2−(y−1)2 > 0, che si puo esprimere
attraverso i sistemi
{(x− 1)2 + y2 > 4
x2 + (y − 1)2 < 4oppure
{(x− 1)2 + y2 < 4
x2 + (y − 1)2 > 4.
Le corrispondenti equazioni individuano due circonferenze, rispettiva-mente di centro (1, 0) e (0, 1), entrambe di raggio 2. L’insieme eraffigurato a fianco. Il bordo non e compreso.
b
b
11
3
3
−1 −1 x
y
Esercizio 2.3
(a) Il profilo di f e la funzione f0 : [0,+∞)→ R definita da f0(t) = e−t2 .
Infatti risulta: f(x, y) = f0(√
x2 + y2) = e−(√
x2+y2)2 = e−x2−y2
.
(b) Il profilo di f e la funzione f0 : [0,+∞)→ R definita da f0(t) =√t2 + 1.
Infatti risulta: f(x, y) = f0(√
x2 + y2) =√
(√
x2 + y2)2 + 1 =√
x2 + y2 + 1.
(c) Il profilo di f e la funzione f0 : [0,+∞)→ R definita da f0(t) =1
1+t2 .
Infatti risulta: f(x, y) = f0(√
x2 + y2) = 1
1+(√
x2+y2)2= 1
1+x2+y2 .
(d) Il profilo di f e la funzione f0 : [0,√2)→ R definita da f0(t) = ln(2− t2).
Infatti risulta: f(x, y) = f0(√
x2 + y2) = ln(2− (√
x2 + y2)2) = ln(2− x2 − y2).
(e) Il profilo di f e la funzione f0 : [0,+∞)→ R definita da f0(t) = t− t2.Infatti risulta: f(x, y) = f0(
√
x2 + y2) =√
x2 + y2 − x2 − y2.
(f) Il profilo di f e la funzione f0 : [0,+∞)→ R definita da f0(t) = 1 + t4.
Infatti risulta: f(x, y) = 1 + (x2 + y2)2 = f0(√
x2 + y2) = 1 + (√
x2 + y2)4.
Esercizio 2.4
(a) La curva di livello 1 ha equazione ln(x− y + 1) = 1, cioe x− y + 1 = e. Si tratta di una retta.
(b) La curva di livello 1 ha equazione 1+x+y1−2x+3y = 1, cioe 3x− 2y = 0. Si tratta di una retta per l’origine.
(c) La curva di livello 1 ha equazione√
x+ y2 + 1 = 1, cioe x+ y2 = 0. Si tratta di una parabola con asse paralleloall’asse x.
(d) La curva di livello 1 ha equazione√
1− x2 − y2 = 1, cioe x2 + y2 = 0. La curva si riduce ad un punto, l’origine.
(e) La curva di livello 1 ha equazione ln(1− 2x2− y2) = 1, cioe 1− 2x2− y2 = e, cioe 2x2 + y2 = 1− e. L’equazionenon ha soluzioni e quindi la curva e l’insieme vuoto.
(f) La curva di livello 1 ha equazione√xy = 1, cioe xy = 1. La curva e un’iperbole che sta nel primo e terzo
quadrante.
(g) La curva di livello 1 ha equazione ln(1 − xy) = 1, cioe 1 − xy = e, cioe xy = 1 − e. La curva e un’iperbole chesta nel secondo e quarto quadrante.
(h) La curva di livello 1 ha equazione√
1− y2 = 1, cioe y2 = 0. L’equazione definisce l’asse x.
Esercizio 2.5
Possiamo scrivere l’equazione nella forma y = −x − 1, da cui una curva che parametrizza la retta e la curva γ(t) =(t,−t− 1), con t ∈ R.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 SOLUZIONI DEGLI ESERCIZI
FUNZIONI REALI DI PIU VARIABILI
363
Esercizio 2.6
Possiamo scrivere l’equazione nella forma x = −y2 − 1, da cui una curva che parametrizza la parabola e la curvaγ(t) = (−t2 − 1, t), con t ∈ R.
Esercizio 2.7
Possiamo scrivere l’equazione nella forma x2 = 1 + y2. Osservando che e richiesto il ramo di destra, quello cioe con xpositivo, possiamo scrivere l’equazione equivalente x =
√
1 + y2. Una curva che parametrizza il ramo dell’iperbole ela curva γ(t) = (
√1 + t2, t), con t ∈ R.
Esercizio 2.8
La restrizione e la funzione f(γ(t)) = t+ et ln2 t, definita per t ∈ (0,+∞).
Esercizio 2.9
La restrizione e la funzione f(γ(t)) = t1/t = t2, definita per t ∈ (0,+∞).
Esercizio 2.10
La restrizione e la funzione f(γ(t)) = 1t + ln(1t + t), definita per t ∈ (0,+∞).
Esercizio 3.1
(a) Lungo la retta di equazione y = x, ad eccezione dell’origine, la funzione f vale zero. Il limite e quindi zero.
(b) Lungo la parabola di equazione y = x2, e quindi lungo la curva γ(t) = (t, t2), ad eccezione dei punti (0, 0) e
(−1, 1), la restrizione di f e la funzione g(t) = t−t2
t+t2 = 1−t1+t . Per t→ 0 il limite vale 1.
(c) Lungo la parabola di equazione x = y2, e quindi lungo la curva γ(t) = (t2, t), ad eccezione dei punti (0, 0) e
(1,−1), la restrizione di f e la funzione g(t) = t2−tt2+t =
t−1t+1 . Per t→ 0 il limite vale −1.
Esercizio 3.2
(a) Lungo la retta di equazione y = x, e quindi lungo la curva γ(t) = (t, t), la restrizione di f e la funzione
g(t) = 2t3
2t2 = t, e quindi il limite e zero.
(b) Lungo la parabola di equazione y = x2, e quindi lungo la curva γ(t) = (t, t2), la restrizione di f e la funzione
g(t) = t3+t6
t2+t4 = t+t4
1+t2 . Per t→ 0 il limite vale 0.
(c) Lungo la parabola di equazione x = y2, e quindi lungo la curva γ(t) = (t2, t), la restrizione di f e ancora la
funzione g(t) = t+t4
1+t2 , per cui il limite per t→ 0 vale ancora 0.
(d) Lungo la curva di equazione y = ex− 1, e quindi lungo la curva γ(t) = (t, et− 1), la restrizione di f e la funzione
g(t) = t3+(et−1)3
t2+(et−1)2 , per cui il limite e
limt→0
t3 + (et − 1)3
t2 + (et − 1)2= lim
t→0
t3(1 + ( et−1t )3)
t2(1 + ( et−1t )2)
= limt→0
t = 0.399
399Si ricordi il limite notevole limt→0et−1
t= 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 FORME QUADRATICHE
FORME QUADRATICHE
364
IV-2 Forme quadratiche
1 Forme quadratiche
Si dice forma quadratica (scrivero per comodita f.q.) nelle variabili x1, x2, . . . , xn un qualunque polinomio omogeneodi secondo grado nelle variabili x1, x2, . . . , xn.
400
Posto x = (x1, x2, . . . , xn), una f.q. si puo scrivere come
Q(x) =
n∑
i,j=1
aijxixj =
n∑
i=1
n∑
j=1
aijxixj .
Ad esempio, nel caso n = 2 (due variabili), una f.q. e un polinomio del tipo
Q(x1, x2) = a11x21 + a12x1x2 + a21x2x1 + a22x
22,
401
e, con n = 3, del tipo
Q(x1, x2, x3) = a11x21 + a12x1x2 + a13x1x3 + a21x2x1 + a22x
22 + a23x2x3 + a31x3x1 + a32x3x2 + a33x
23.
Si puo verificare facilmente che, usando una scrittura vettoriale/matriciale, possiamo scrivere una f.q. piu sintetica-mente come
Q(x) = 〈Ax,x〉 = xTAx,
dove A e una matrice n× n e il simbolo 〈 , 〉 indica come sempre il prodotto interno in Rn. Quindi l’espressione chedefinisce la f.q. si ottiene o come prodotto interno del vettore Ax per il vettore x, oppure come prodotto matricialedel vettore riga x per la matrice A per il vettore colonna x.Ad esempio, se prendiamo la f.q. in due variabili Q(x1, x2) = 2x21 − 3x1x2 + 4x22, abbiamo
⟨(2 −30 4
)(x1x2
)
,
(x1x2
)⟩
=
⟨(2x1 − 3x2
4x2
)
,
(x1x2
)⟩
= 2x21 − 3x1x2 + 4x22
e analogamente
(x1 , x2)T
(2 −30 4
)(x1x2
)
= (2x1 , −3x1 + 4x2)
(x1x2
)
= 2x21 − 3x1x2 + 4x22.
Una f.q. e quindi una particolare funzione Q : Rn → R di n variabili a valori reali.Si verifica facilmente che si puo sempre scrivere una f.q. usando una matrice simmetrica, come illustra il seguenteesempio.
Esempio Si consideri la f.q. Q(x1, x2) = 2x21 − 5x1x2 + 3x22. Chiaramente si puo scrivere
Q(x1, x2) = (x1, x2)
(2 −50 3
)(x1x2
)
,
ma si puo anche scrivere
Q(x1, x2) = (x1, x2)
(2 −5/2−5/2 3
)(x1x2
)
,
e cosı la matrice che rappresenta la f.q. e simmetrica. Apparentemente e piu complicato, ma ci sono invece enormivantaggi. Analogamente, con la f.q. Q(x1, x2, x3) = x1x2 − 3x1x3 + x22 − 2x2x3, si puo scrivere Q(x) = 〈Ax,x〉, con
A =
0 1/2 −3/21/2 1 −1−3/2 −1 0
.402
400Un polinomio P , di variabili x1, x2, . . . , xn, e omogeneo di secondo grado se risulta P (αx1, αx2, . . . , αxn) = α2P (x1, x2, . . . , xn). Inpratica in un tale polinomio compaiono soltanto i termini del tipo aijxixj , con i, j ∈ {1, 2, . . . , n}. Detto a parole, e un polinomio disecondo grado e tutti i monomi in esso presenti sono di secondo grado (non ci sono monomi di primo grado o costanti).401Si noti che i termini “misti”, cioe in x1x2, sono termini simili, per la proprieta commutativa, e che quindi, sommandoli, si possonoscrivere come un unico termine.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SEGNO DI UNA FORMA QUADRATICA
FORME QUADRATICHE
365
Attenzione! D’ora in avanti sottintendero che la matrice di rappresentazione della f.q. sia simmetrica.
Osservazione Qualunque f.q. assume il valore 0 in corrispondenza del vettore nullo (in questo le f.q. assomiglianoalle trasformazioni lineari).
2 Segno di una forma quadratica
E importante il segno di una forma quadratica Q(x), cioe il segno che la funzione assume al variare del vettore x.Appunto con riguardo al segno di tali valori, si possono classificare le f.q. come segue:
Definizione (classificazione delle forme quadratiche in base al segno)
(i) Una f.q. si dice definita positiva seQ(x) > 0 per ogni x 6= 0;
(ii) una f.q. si dice definita negativa seQ(x) < 0 per ogni x 6= 0;
(iii) una f.q. si dice semidefinita positiva se
Q(x) ≥ 0 per ogni x ed esiste x 6= 0 tale che Q(x) = 0;
(iv) una f.q. si dice semidefinita negativa se
Q(x) ≤ 0 per ogni x ed esiste x 6= 0 tale che Q(x) = 0;
(v) una f.q. si dice indefinita se
esistono x,y 6= 0 tali che Q(x) > 0 e Q(y) < 0.
Osservazione Occorre qualche commento. Per quanto riguarda le f.q. definite (casi (i) e (ii)), dobbiamo escludere ilvettore nullo poiche come detto in 0 la forma vale 0; nelle forme semidefinite (casi (iii) e (iv)) si richiede esplicitamenteche mantengano sempre lo stesso segno e che si annullino in modo non banale, cioe in qualche vettore diverso da 0. Leforme indefinite (caso (v)) sono quelle che possono cambiare segno, cioe assumere sia segno positivo sia segno negativo.
Esempi Vediamo qualche semplice esempio in cui si puo stabilire il segno di una forma quadratica senza troppafatica.
• Consideriamo la f.q. Q(x1, x2) = x21 + x22.
Non e difficile capire che e un esempio di forma definita positiva. Infatti assume valori sempre non negativi e siannulla solo nell’origine, quindi e positiva in qualunque punto diverso dall’origine.
• Consideriamo la f.q. Q(x1, x2) = x21 + 2x1x2 + x22.
Si tratta questa volta di una forma semidefinita positiva. Infatti la possiamo riscrivere comeQ(x1, x2) = (x1+x2)2
e ora si capisce che assume valori sempre non negativi ma non si annulla soltanto nell’origine, dato che ad esempiosi annulla nel punto (1,−1).403
402In generale, per ogni i, j possiamo scrivere
aijxixj + ajixjxi =aij + aji
2xixj +
aij + aji
2xjxi,
e da questa formula deriva la possibilita di rappresentare la forma quadratica con una matrice simmetrica.403La forma si annulla evidentemente in tutti i punti in cui si ha x1 + x2 = 0, cioe sulla bisettrice del secondo e quarto quadrante.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SEGNO DI UNA FORMA QUADRATICA
FORME QUADRATICHE
366
• Consideriamo la f.q. Q(x1, x2) = x21 − x22.Si tratta di una forma indefinita. Infatti possiamo osservare facilmente che puo assumere sia valori positivi siavalori negativi: ad esempio risulta Q(1, 0) = 1 e Q(0, 1) = −1.
Non e difficile costruire esempi di forme definite negative o semidefinite negative, modificando in modo ovvio gli esempiappena visti.
In generale non e cosı semplice stabilire il segno di una forma quadratica (per quelle definite in R2 le cose sonoabbastanza facili, ma quando abbiamo piu di due variabili le cose possono diventare complicate). Per il riconoscimentodi una f.q. esistono alcuni metodi operativi. Ne studiamo uno generale, che fa uso del segno di alcuni minori dellamatrice stessa.404 Successivamente applichiamo il metodo ai casi particolari di forme quadratiche definite in R2 e inR3.
2.1 Il metodo dei minori principali
I criteri che presento per classificare una f.q. prendono in esame il segno di alcuni particolari minori della matricedella forma quadratica. Per la validita di questi criteri ricordo ancora una volta che la matrice deve essere simmetrica.Occorrono intanto un paio di definizioni.
Definizione Sia A una matrice simmetrica di ordine n.
• Si chiamanominori principali di A di ordine k (k ≤ n) i minori405 che si ottengono considerando sottomatriciformate da k righe e dalle corrispondenti colonne.406
• Si chiamano minori principali di Nord–Ovest (NO) di A di ordine k i minori principali che si ottengonoconsiderando le prime k righe (e quindi di conseguenza le prime k colonne).
Esempio Consideriamo la matrice
A =
1 2 32 4 53 5 6
.
I minori principali di ordine 1 sono gli elementi sulla diagonale (dati dalla 1a riga e 1a colonna, oppure 2a riga e 2a
colonna, oppure 3a riga e 3a colonna):1 , 4 , 6.
I minori principali di ordine 2 sono (1a e 2a, oppure 1a e 3a, oppure 2a e 3a riga, e corrispondenti colonne):
det
(1 22 4
)
= 0 , det
(1 33 6
)
= −3 , det
(4 55 6
)
= −1.
Il minore principale di ordine 3 (tutte e tre le righe) e detA = −1.I minori principali di NO sono invece soltanto:
1 (di ordine 1), det
(1 22 4
)
= 0 (di ordine 2), detA = −1 (di ordine 3).
Osservazione I minori principali sono alcuni tra i minori della matrice, i minori principali di NO sono a loro voltaalcuni dei minori principali. I minori principali (e quindi anche i minori principali di NO) si ottengono a partire dasottomatrici simmetriche rispetto alla diagonale principale.
Osservazione A titolo di esempio, in una matrice di ordine 4, vi sono:
⊲ 4 minori principali di ordine 1,407
⊲ 6 minori principali di ordine 2,408
404Ricordo che si chiama minore di una matrice il determinante di una sua qualunque sottomatrice quadrata.405Ho gia richiamato che cosa vuol dire minore di una matrice. Ricordo inoltre che un minore e di ordine k se la sottomatrice da cuiproviene e di ordine k, cioe e una sottomatrice k × k, cioe quadrata con k righe e k colonne.406Per intendersi, se scelgo 1a, 3a e 5a riga devo scegliere 1a, 3a e 5a colonna.407Sono gli elementi della diagonale principale della matrice.408Sono i determinanti delle sottomatrici che si ottengono scegliendo in tutti i modi possibili 2 righe su 4 nella matrice: quindi 1a e 2a,1a e 3a, 1a e 4a, 2a e 3a, 2a e 4a, 3a e 4a. Non c’e liberta di scelta sulle colonne, dato che devono essere quelle corrispondenti alle righe.Come noto il numero di scelte possibili di 2 elementi in un insieme di 4 elementi e
(42
)= 6.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SEGNO DI UNA FORMA QUADRATICA
FORME QUADRATICHE
367
⊲ 4 minori principali di ordine 3,409
⊲ 1 minore principale di ordine 4.410
Vi sono invece soltanto 4 minori principali di NO, uno per ogni ordine.
Esercizio Quanti sono i minori principali di NO di una matrice di ordine n? Quanti sono i minori principali? Einfine quanti sono i minori?
Qui di seguito fornisco, senza dimostrazione, i criteri per decidere il segno di una forma quadratica in base al segnodei minori principali della sua matrice.
(i) La f.q. 〈Ax,x〉 e definita positiva se e solo se tutti i minori principali di NO di A sono positivi.
(ii) La f.q. 〈Ax,x〉 e definita negativa se e solo se tutti i minori principali di NO di A di ordine pari sono positivi etutti i minori principali di NO di A di ordine dispari sono negativi.
(iii) La f.q. 〈Ax,x〉 e semidefinita positiva se e solo se tutti i minori principali di A sono non negativi (≥ 0) edetA = 0.
(iv) La f.q. 〈Ax,x〉 e semidefinita negativa se e solo se tutti i minori principali di A di ordine pari sono non negativi(≥ 0), tutti i minori principali di A di ordine dispari sono non positivi (≤ 0) e detA = 0.
(v) la f.q. e indefinita se e solo se non si verifica nessuna delle situazioni precedenti.
Osservazione Prestate attenzione al fatto che per caratterizzare le forme definite si considerano i minori principalidi NO, mentre per caratterizzare le forme semidefinite si devono considerare i minori principali, che sono in numeromaggiore.
Riporto qui per comodita dello studente le regole per il caso particolare con n = 2, cioe le regole valide per le f.q. indue variabili, quelle del tipo
Q(x, y) = ax2 + bxy + cy2 con matrice associata A =
(a b
2b2 c
)
.
(i) La f.q. Q e definita positiva se e solo se a > 0 e ac− b2
4 > 0
(ii) La f.q. Q e definita negativa se e solo se a < 0 e ac− b2
4 > 0
(iii) La f.q. Q e semidefinita positiva se e solo se a ≥ 0, c ≥ 0 e ac− b2
4 = 0
(iv) La f.q. Q e semidefinita negativa se e solo se a ≤ 0, c ≤ 0 e ac− b2
4 = 0
(v) La f.q. Q e indefinita se e solo se ac− b2
4 < 0.
Osservazione Tutto si giustifica anche osservando che il discriminante dell’equazione ax2 + bxy + cy2 = 0, cioe
∆ = b2 − 4ac e uguale a −4(ac− b2
4 ) = −4 detA. Quindi se detA > 0 allora ∆ < 0 e pertanto il polinomio non si puoscomporre (f.q. definita); se invece detA < 0 allora ∆ > 0 e pertanto il polinomio si puo scomporre e la f. q. risultaindefinita; se infine detA = 0 allora il polinomio e il quadrato di un binomio e si hanno i casi di f.q. semidefinita.
Vediamo alcuni esempi di studio del segno di una f.q.
Esempio Consideriamo la f.q.Q(x, y) = 9x2 + 12xy + 4y2.
La matrice e
A =
(9 66 4
)
.
Il determinante di A e nullo e i minori principali di ordine 1 sono positivi: quindi la f.q. e semidefinita positiva.
409Sono i determinanti delle sottomatrici che si ottengono scegliendo in tutti i modi possibili 3 righe su 4 nella matrice e quindi 1a, 2a e3a, oppure 1a, 2a e 4a, oppure 1a, 3a e 4a oppure 2a, 3a e 4a.410E evidentemente il determinante della matrice.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SEGNO DI UNA FORMA QUADRATICA
FORME QUADRATICHE
368
Lo si puo verificare anche in base alla definizione: possiamo scrivere
9x2 + 12xy + 4y2 = (3x+ 2y)2,
e quindi si ha chiaramente Q(x, y) ≥ 0 in tutto R2 e Q(x, y) = 0 sui punti della retta 3x+2y = 0 (y = − 32x), ossia sul
sottospazio{α(2,−3) : α ∈ R
}.
Esempio Consideriamo la f.q.Q(x, y) = x2 + 4xy + 2y2.
La matrice e
A =
(1 22 2
)
.
Il determinante di A e −2, negativo. Quindi la f.q. e indefinita. Si noti che ad esempio si ha Q(1, 0) = 1 eQ(1,−1) = −1.Esempio Consideriamo la f.q.
Q(x, y, z) = x2 − 2xy + 2y2 + 2yz + 2z2.
La matrice e
A =
1 −1 0−1 2 10 1 2
.
I tre minori principali di NO sono tutti uguali ad 1, quindi la f.q. e definita positiva.Lo si puo verificare anche in base alla definizione: possiamo scrivere
x2 − 2xy + 2y2 + 2yz + 2z2 = (x− y)2 + (y + z)2 + z2,
e si tratta intanto di una quantita sicuramente non negativa.411 Puo essere nulla solo se i tre termini quadratici sonocontemporaneamente nulli, cioe se
x− y = 0
y + z = 0
z = 0,
sistema omogeneo che ha come unica soluzione la soluzione nulla (per teorema di Cramer oppure con una semplicesostituzione). Pertanto per definizione la f.q. e definita positiva.
Esempio Consideriamo la f.q.
Q(x1, x2, x3) = −2x21 + 4x1x2 − 4x22 + 5x2x3 − 2x23.
La matrice e
A =
−2 2 02 −4 5/20 5/2 −2
.
Il minore principale di NO di ordine 1 e negativo: la f.q. non puo essere quindi definita o semidefinita positiva. Ilminore principale di NO di ordine 2 e 4, positivo: questo non aggiunge alcuna informazione. Il determinante di A e92 , positivo: pertanto la f.q. non puo essere definita o semidefinita negativa. Allora e necessariamente indefinita.Possiamo verificare il risultato anche attraverso la definizione, osservando che ad esempio si ha Q(1, 0, 0) = −2 < 0 einvece Q(1, 1, 1) = 1 > 0. La f.q. quindi cambia segno.
Esempio Consideriamo la f.q.
Q(x1, x2, x3) = x21 + 4x1x2 + 5x22 − 4x2x3 + 4x23.
La matrice e
A =
1 2 02 5 −20 −2 4
.
Il minore principale di NO di ordine 1 e positivo: la f.q. non puo essere quindi definita o semidefinita negativa. Ilminore principale di NO di ordine 2 e positivo: questo non aggiunge alcuna informazione. Il determinante di A e nullo:
411Possiamo dire che e non negativa ma ancora non possiamo dire se e definita o semidefinita, senza studiare dove si annulla.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 SEGNO DI UNA FORMA QUADRATICA
FORME QUADRATICHE
369
pertanto la f.q. non puo essere definita positiva. Controllando tutti i restanti minori principali (di ordine 1 e 2), chesono positivi, si conclude che la f.q. e semidefinita positiva.Possiamo verificare anche qui il risultato attraverso la definizione: possiamo scrivere
x21 + 4x1x2 + 5x22 − 4x2x3 + 4x23 = x21 + 4x1x2 + 4x22 + x22 − 4x2x3 + 4x23 = (x1 + 2x2)2 + (x2 − 2x3)
2.
Quindi la forma e certamente non negativa. Vediamo se si annulla in modo non banale. Risulta Q(x1, x2, x3) = 0 se esolo se {
x1 + 2x2 = 0
x2 − 2x3 = 0,
che ha per soluzioni i vettori multipli di (−4, 2, 1). Quindi la forma si annulla in modo non banale, e questo confermache e semidefinita positiva.
Esempio Consideriamo la f.q.Q(x1, x2, x3, x4) = (x1 − x2)2 + (x3 + x4)
2.
La matrice e
A =
1 −1 0 0−1 1 0 00 0 1 10 0 1 1
.
Il determinante e nullo (due righe uguali) e gli altri minori principali sono tutti uguali a 0 oppure a 1. La f.q. equindi semidefinita positiva. Verifichiamolo anche con la definizione. Dall’espressione iniziale si vede che la forma ecertamente non negativa. Si annulla inoltre sul sottospazio412
{
α(1, 1, 0, 0) + β(0, 0, 1,−1) : α, β ∈ R
}
.
Esempio Consideriamo la f.q.
Q(x1, x2, x3, x4) = 2x1x2 + 2x22 + 2x2x3 + x23 + 2x3x4 + 2x24.
La matrice e
A =
0 1 0 01 2 1 00 1 1 10 0 1 2
.
La f.q. non e definita, dato che il primo minore principale di NO e nullo. Il secondo minore principale di NO e negativoe, essendo di ordine pari, rende la f.q. indefinita.Con qualche tentativo si puo anche provare il risultato attraverso la definizione: ad esempio si ha che
Q(−2, 1, 0, 0) = −2 < 0 e Q(0, 0, 1, 0) = 1 > 0,
quindi la forma assume valori di segno opposto.
Esercizio 2.1 Per ciascuna delle seguenti forme quadratiche, espresse attraverso la forma analitica, si scriva la
matrice simmetrica che le rappresenta:
(a) q(x, y) = 3x2 − 3xy + y2
(b) q(x, y, z) = −x2 + 6xy + 5xz − 2y2 − 2yz + 3z2
(c) q(x, y, z, t) = xz − 2xt− y2 + z2 + 4zt.
Esercizio 2.2 Per ciascuna delle seguenti matrici si scriva la forma analitica della corrispondente forma quadra-
tica; si classifichi quindi la f.q. col metodo dei minori principali.
A1 =
(3 22 2
)
, A2 =
(5 55 5
)
, A3 =
(−2 44 −8
)
, A4 =
(−1 11 −3
)
, A5 =
(−2 33 −1
)
412Per trovarlo bisogna naturalmente risolvere il sistema omogeneo Ax = 0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
FORME QUADRATICHE
370
Esercizio 2.3 Date le seguenti forme quadratiche, si scriva la matrice (simmetrica) che le rappresenta e se ne
studi il segno, sia attraverso la definizione sia attraverso il segno dei minori principali.
(a) q1(x, y, z) = (2x− y)2 + z2
(b) q2(x, y, z) = x2 + (x+ y)2 + (y − z)2
(c) q3(x, y, z) = −(x+ y + z)2 − (x− y − z)2
(d) q4(x, y, z) = (x− y)2 − (y − z)2
Esercizio 2.4 Date le seguenti forme quadratiche, si scriva la matrice (simmetrica) che le rappresenta e se ne
studi il segno col metodo dei minori principali. Si confermi poi il risultato ottenuto attraverso la definizione.
(a) q1(x, y, z, t) = (x− t)2 + y2 + z2
(b) q2(x, y, z, t) = −(x+ y − t)2 − (x − y + z)2
(c) q3(x, y, z, t) = (x+ z)2 + 2y2 + (y + t)2 + z2
(d) q4(x, y, z, t) = x2 + 2y2 + (2z − t)2 − z2
Esercizio 2.5 Si determini il segno della forma quadratica
q(x, y, z) = (x− y)2 + y2 − z2
e il segno della sua restrizione al sottospazio di R3 generato dai vettori u1 = (1, 0, 0) e u2 = (0, 1, 0).
Esercizio 2.6 Si determini il segno della forma quadratica
q(x, y, z, t) = (x− z)2 − (y + t)2
e il segno della sua restrizione al sottospazio di R4 generato dai vettori (1, 0, 0, 0), (0, 0, 1, 0) e (0,−1, 0, 1).
3 Soluzioni degli esercizi
Esercizio 2.1
(a) La matrice simmetrica e(
3 −3/2−3/2 1
)
.
(b) La matrice simmetrica e
−1 3 5/23 −2 −1
5/2 −1 3
.
(c) La matrice simmetrica e
0 0 1/2 −10 −1 0 0
1/2 0 1 2−1 0 2 0
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
FORME QUADRATICHE
371
Esercizio 2.2
• La f.q. rappresentata da A1 eq1(x, y) = 3x2 + 4xy + 2y2.
I minori principali di NO sono 3 e 2. Quindi la forma e definita positiva.
• La f.q. rappresentata da A2 eq2(x, y) = 5x2 + 10xy + 5y2.
I minori principali del primo ordine sono uguali a 5; il minore principale del secondo ordine (il determinante) enullo. Quindi la forma e semidefinita positiva.
• La f.q. rappresentata da A3 eq3(x, y) = −2x2 + 8xy − 8y2.
I minori principali del primo ordine sono negativi (−2 e −8); il determinante e nullo. Pertanto la forma esemidefinita negativa.
• La f.q. rappresentata da A4 eq4(x, y) = −x2 + 2xy − 3y2.
I minori principali del primo ordine sono negativi (−1 e −3) e il determinante e positivo. Pertanto la forma edefinita negativa.
• La f.q. rappresentata da A5 eq5(x, y) = −2x2 + 6xy − y2.
I minori principali del primo ordine sono negativi (−2 e −1), ma il determinante e pure negativo. Pertanto laforma e indefinita.
Esercizio 2.3
(a) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q1(x, y, z) = 4x2 − 4xy + y2 + z2.
La matrice simmetrica che rappresenta q1 e quindi
A1 =
4 −2 0−2 1 00 0 1
.
Osservando l’espressione analitica iniziale di q1 e immediato capire che la forma e semidefinita positiva: infattichiaramente non e mai negativa e si annulla se e solo se
{2x− y = 0
z = 0cioe
{y = 2x
z = 0,cioe nel sottospazio di R3 generato dal vettore (1, 2, 0).
Pertanto la f.q. non e mai negativa e si annulla in modo non banale: quindi e semidefinita positiva. Alla stessaconclusione si perviene anche con il calcolo dei minori principali: quelli del primo ordine sono positivi, quelli delsecondo ordine sono o positivi o nulli e il determinante e nullo.
(b) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q2(x, y, z) = 2x2 + 2xy + 2y2 − 2yz + z2.
La matrice simmetrica che rappresenta q2 e quindi
A2 =
2 1 01 2 −10 −1 1
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
FORME QUADRATICHE
372
I minori principali di NO sono 2, 3 e 1, quindi la f.q. e definita positiva. Stessa conclusione osservandol’espressione originaria di q2: e somma di quadrati e quindi mai negativa e si annulla se e solo se
x = 0
x+ y = 0
y − z = 0
cioe
x = 0
y = 0
z = 0.
Annullandosi solo nell’origine, la f.q. e appunto definita positiva.
(c) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q3(x, y, z) = −2x2 − 2y2 − 4yz − 2z2.
La matrice simmetrica che rappresenta q3 e quindi
A3 =
−2 0 00 −2 −20 −2 −2
.
Minori principali del primo ordine negativi; minori principali del secondo ordine positivi o nulli; determinantenullo. Quindi la f.q. e semidefinita negativa.
Dall’espressione analitica si ha che la f.q. e certamente non positiva e si annulla se e solo se
{x+ y + z = 0
x− y − z = 0.
Attraverso la soluzione del sistema si trova che la f.q. si annulla nel sottospazio di R3 generato dal vettore(0,−1, 1), quindi si annulla in modo non banale. Pertanto, anche in base alla definizione, e semidefinita negativa.
(d) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q4(x, y, z) = x2 − 2xy + 2yz − z2.
La matrice simmetrica che rappresenta q4 e quindi
A4 =
1 −1 0−1 0 10 1 −1
.
Dall’espressione analitica si ha che la f.q. e certamente indefinita, poiche ad esempio q4(1, 0, 0) > 0 e q4(0, 0, 1) <0. Attraverso l’esame dei minori principali e chiaro che i minori principali del primo ordine cambiano segno equindi la forma e certamente indefinita.
Esercizio 2.4
(a) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q1(x, y, z, t) = x2 − 2xt+ t2 + y2 + z2.
La matrice simmetrica che rappresenta q1 e quindi (l’ordine che considero e: x, y, z, t)
A1 =
1 0 0 −10 1 0 00 0 1 0−1 0 0 1
.
Il determinante e chiaramente nullo e quindi la forma non puo essere definita. Dobbiamo esaminare i minoriprincipali. Quelli del primo ordine sono tutti positivi; quelli del secondo ordine (sono 6) positivi o nulli; quellidel terzo ordine (sono 4) positivi o nulli e il determinante e nullo (si osservi, anche per il calcolo dei minori delterzo ordine, che la prima e quarta riga sono opposte). Pertanto la f.q. e semidefinita positiva.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
FORME QUADRATICHE
373
Stessa conclusione osservando che la forma e non negativa e si annulla se e solo se
x− t = 0
y = 0
z = 0,
e quindi si annulla, in modo non banale, sul sottospazio di R4 generato dal vettore (1, 0, 0, 1).
(b) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q2(x, y, z, t) = −2x2 − 2xz + 2xt− 2y2 + 2yz + 2yt− z2 − t2.La matrice simmetrica che rappresenta q2 e quindi
A2 =
−2 0 −1 10 −2 1 1−1 1 −1 01 1 0 −1
.
Il determinante e nullo (la terza riga e la somma di prima e quarta) e quindi la forma non puo essere definita.C’e la possibilita che sia semidefinita negativa, e dobbiamo esaminare i minori principali. Quelli del primo ordinesono tutti negativi; quelli del secondo ordine sono positivi o nulli; quelli del terzo ordine sono negativi o nulli eil determinante come detto e nullo. Quindi in effetti la f.q. e semidefinita negativa.
Stessa conclusione osservando che la forma e non positiva e si annulla se e solo se{x+ y − t = 0
x− y + z = 0,
e quindi si annulla, in modo non banale, sul sottospazio di R4 generato dai vettori (1, 0,−1, 1) e (0, 1, 1, 1).
(c) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q3(x, y, z, t) = x2 + 2xz + 3y2 + 2yt+ 2z2 + t2.
La matrice simmetrica che rappresenta q3 e quindi
A3 =
1 0 1 00 3 0 11 0 2 00 1 0 1
.
Qui si arriva alla conclusione con l’esame dei soli minori principali di NO: infatti sono tutti e quattro positivi(valgono 1, 3, 3 e 2). La f.q e definita positiva. Stessa conclusione osservando che la forma e non negativa e siannulla se e solo se
x+ z = 0
y = 0
y + t = 0
z = 0.
Si vede facilmente che l’unica soluzione e il vettore nullo e quindi la f.q. si annulla soltanto nell’origine.
(d) Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q4(x, y, z, t) = x2 + 2y2 + 3z2 − 4zt+ t2.
La matrice simmetrica che rappresenta q4 e quindi
A4 =
1 0 0 00 2 0 00 0 3 −20 0 −2 1
.
I primi 3 minori principali di NO sono positivi, ma il determinante e negativo, e quindi la f.q. e indefinita.
Dalla forma analitica si puo osservare che ad esempio si ha q4(1, 0, 0, 0) > 0 e q4(0, 0, 1, 2) < 0, che conferma ilrisultato trovato.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
FORME QUADRATICHE
374
Esercizio 2.5
Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q(x, y, z) = x2 − 2xy + 2y2 − z2.
La matrice simmetrica che rappresenta q e quindi
A =
1 −1 0−1 2 00 0 −1
.
La forma e certamente indefinita (i minori principali del primo ordine cambiano di segno).413
I vettori del sottospazio (chiamiamolo S) di R3 generato da u1 e u2 sono le combinazioni lineari di u1 e u2, e quindisono i vettori del tipo
a(1, 0, 0) + b(0, 1, 0) = (a, b, 0), con a, b ∈ R.
Pertanto la restrizione di q al sottospazio S coincide con la f.q.
a2 − 2ab+ 2b2, definita in R2.
Tale f.q. e chiaramente definita positiva.414 Per concludere: la forma quadratica q e indefinita in R3, ma la suarestrizione ad S e definita positiva.
Esercizio 2.6
Sviluppando i quadrati dei binomi nell’espressione analitica si ottiene
q(x, y, z, t) = x2 − 2xz − y2 − 2yt+ z2 − t2.
La matrice simmetrica che rappresenta q e quindi
A =
1 0 −1 00 −1 0 −1−1 0 1 00 −1 0 −1
.
La forma e indefinita (i minori principali del primo ordine cambiano di segno).415
I vettori del sottospazio S di R4 generato da u1, u3 e u4 − u2, sono le combinazioni lineari di questi vettori, e quindisono i vettori del tipo
au1 + bu3 + c(u4 − u2) = au1 − cu2 + bu3 + cu4, con a, b, c ∈ R.
Per ottenere l’espressione analitica della restrizione si puo utilizzare la matrice416 oppure piu semplicemente l’espres-sione analitica di q, calcolandola nel vettore (a,−c, b, c). Si ottiene
(a− b)2 − (−c+ c)2 = (a− b)2, definita in R3. 417
Quindi la restrizione ad S e semidefinita positiva.Per concludere: la forma quadratica q e indefinita in R4, e la sua restrizione ad S e semidefinita positiva.
413Si noti anche che, ad esempio, q(1, 0, 0) > 0 e q(0, 0, 1) < 0.414Il risultato si puo certamente ottenere ad esempio scrivendo la matrice della forma quadratica (matrice 2 × 2) e calcolando i minoriprincipali di NO. Si noti ancora che q(u3) < 0 e che u3 /∈ S.415Si noti che, ad esempio, q(u1) > 0 e q(u4) < 0 (sono il primo e il quarto vettore fondamentale di R4).416Basta calcolare il prodotto vettore-matrice-vettore sTAs, dove s = (a,−c, b, c).417Attenzione. La forma e definita in R3, anche se poi dipende esplicitamente da due sole variabili. Questo permette di dire subito che siannulla in modo non banale, in (0, 0, 1) ad esempio. Ma si annulla comunque in modo non banale anche in (1, 1, 0).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DERIVATE PARZIALI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
375
IV-3 Derivate delle funzioni di piu variabili
Come abbiamo visto nella II parte del corso, la derivata di una funzione non e altro che un rapporto tra due variazioni,quello del valore della funzione in corrispondenza a quello della variabile. Si ricordera (spero) che piu precisamentecon derivata di f in un punto intendiamo il limite del rapporto incrementale di f .418
Volendo costruire anche per funzioni di n > 1 variabili un rapporto incrementale, cioe un quoziente di variazioni, ci siimbatte in una difficolta. Vediamolo per semplicita con due variabili: consideriamo il punto (x0, y0) e il punto (x, y),in prossimita di (x0, y0). Volendo fare quello che si fa in una variabile, la variazione di f e
f(x, y)− f(x0, y0)
e per ora non cambia molto; la variazione della variabile e invece
(x, y)− (x0, y0) , che adesso e un vettore.
Ora pero non possiamo costruire il rapporto incrementale, dato che il denominatore non e un numero.419
Possiamo ancora cercare di definire una derivata nel modo tradizionale, cioe come limite di un rapporto incrementale,ma dobbiamo fare in modo che quel denominatore torni ad essere un numero reale.
1 Derivate parziali
Sempre considerando il caso di due sole variabili, se in prossimita di (x0, y0) prendiamo un punto facendo variare solola prima componente, cioe consideriamo un punto (x, y0), possiamo costruire il rapporto incrementale
f(x, y0)− f(x0, y0)x− x0
.
Si noti che, dato che solo la x varia, la variazione che sta a denominatore e data dalla variazione della sola x, e quindiil denominatore torna ad essere un numero.Allora possiamo definire una derivata, che sara ovviamente una derivata rispetto alla x.
Definizione Se (x0, y0) e un punto interno al dominio di f , chiamiamo derivata parziale di f rispetto ad x nelpunto (x0, y0) il
limx→x0
f(x, y0)− f(x0, y0)x− x0
, se questo e finito.
Analogamente, possiamo costruire un altro rapporto incrementale se in prossimita di (x0, y0) prendiamo un puntofacendo variare solo la seconda componente, cioe consideriamo un punto (x0, y). Avremo allora la derivata rispettoalla y.
Definizione Chiamiamo derivata parziale di f rispetto ad y nel punto (x0, y0) il
limy→y0
f(x0, y)− f(x0, y0)y − y0
, se questo e finito.
La derivata parziale di f rispetto ad x nel punto (x0, y0) si indica con i simboli∂f
∂x(x0, y0) oppure f
′x(x0, y0). Se questa
esiste, diciamo anche che f e derivabile parzialmente rispetto ad x nel punto (x0, y0).
Analogamente la derivata parziale di f rispetto ad y nel punto (x0, y0) si indica con i simboli∂f
∂y(x0, y0) oppure
f ′y(x0, y0) e, se questa esiste, diciamo che f e derivabile parzialmente rispetto ad y nel punto (x0, y0).Dicendo semplicemente che una funzione f di due variabili e derivabile in (x0, y0) si intende che essa e derivabileparzialmente in (x0, y0) sia rispetto ad x sia rispetto ad y.
418Ricordo la definizione formale: la derivata di una funzione f : A ⊂ R → R in un punto x0 interno ad A e il
limx→x0
f(x)− f(x0)
x− x0= lim
h→0
f(x0 + h)− f(x0)
h(quando questo e un numero).
419Si noti che, tra le tante operazioni che abbiamo definito in questo corso, molte delle quali definite tra vettori (vedi parte III), non cen’e nessuna che preveda il quoziente tra un numero e un vettore.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DERIVATE PARZIALI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
376
In tal caso si chiama gradiente di f in (x0, y0) il vettore delle sue derivate parziali. Si scrive
∇f(x0, y0) =(∂f
∂x(x0, y0),
∂f
∂y(x0, y0)
)
=(
f ′x(x0, y0), f
′y(x0, y0)
)
.
In generale, per una funzione di n variabili, avremo n possibili derivate parziali.A partire dal punto x0 = (x01, . . . , x
0n) possiamo dare una variazione ad una sola delle n variabili, diciamo la xi,
passando per questa dal valore x0i al valore xi. Consideriamo poi il
limxi→x0
i
f(x01, . . . , x0i−1, xi, x
0i+1, . . . , x
0n)− f(x01, . . . , x0i−1, x
0i , x
0i+1, . . . , x
0n)
xi − x0i.
Se esso esiste finito, lo chiamiamo derivata parziale di f rispetto a xi nel punto x0, e diciamo che f e derivabile
parzialmente rispetto a xi nel punto x0. Per indicare tale derivata si usano i simboli∂f
∂xi(x0) oppure f ′
xi(x0).
Se nel punto x0 la funzione f e derivabile parzialmente rispetto a tutte le sue n variabili, si dira brevemente che ederivabile nel punto x0.Se f e una funzione derivabile nel punto x0, il gradiente di f in x0 e il vettore
∇f(x0) =
(∂f
∂x1(x0), . . . ,
∂f
∂xn(x0)
)
=(
f ′x1(x0), . . . , f ′
xn(x0)
)
.
Esempi
• Consideriamo la funzionef(x, y) = x+ ey,
definita in tutto R2. Consideriamo poi il punto (x0, y0) = (1, 0), in cui la funzione vale 2.
Si ha∂f
∂x(1, 0) = lim
x→1
f(x, 0)− f(1, 0)x− 1
= limx→1
x+ 1− 2
x− 1= 1.
Si ha poi∂f
∂y(1, 0) = lim
y→0
f(1, y)− f(1, 0)y
= limy→0
1 + ey − 2
y= lim
y→0
ey − 1
y= 1. 420
Quindi f e derivabile nel punto (1, 0) e ∇f(1, 0) = (1, 1).
• Consideriamo la funzionef(x, y) = x ln y,
definita sul semipiano y > 0. Consideriamo poi il punto (x0, y0) = (2, 1), in cui la funzione vale 0.
La funzione vale 0 lungo la retta y = 1 e quindi la derivata parziale rispetto ad x e nulla. Si ha poi
∂f
∂y(2, 1) = lim
y→1
f(2, y)− f(2, 1)y − 1
= limy→1
2 ln y
y − 1= 2. 421
Quindi f e derivabile nel punto (2, 1) e ∇f(2, 1) = (0, 2).
• Consideriamo la funzionef(x, y) = x2
√y,
definita nel semipiano y ≥ 0. Consideriamo il punto (x0, y0) = (1, 4), interno al dominio, in cui la funzione vale2. Si ha
∂f
∂x(1, 4) = lim
x→1
f(x, 4)− f(1, 4)x− 1
= limx→1
2x2 − 2
x− 1= lim
x→1
2(x− 1)(x+ 1)
x− 1= 4.
Si ha poi∂f
∂y(1, 4) = lim
y→4
f(1, y)− f(1, 4)y − 4
= limy→4
√y − 2
y − 4= lim
y→4
√y − 2
(√y − 2)(
√y + 2)
=1
4.
Quindi f e derivabile nel punto (1, 4) e ∇f(1, 4) = (4, 14 ).
420E uno dei limiti notevoli.421Cambio di variabile y − 1 = t e poi si trova ancora uno dei limiti notevoli.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DERIVATE PARZIALI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
377
• Si consideri infine funzionef(x, y) = |x|+ y,
definita in tutto R2.Per facilitare la comprensione dei calcoli che seguono, possiamo riscriverela f come
f(x, y) =
{x+ y se x ≥ 0, y ∈ R
−x+ y se x <, y ∈ R
e rappresentiamo quanto scritto nella figura a fianco (nel primo e quartoquadrante la funzione e x + y, mentre nel secondo e terzo quadrante lafunzione e −x+ y).
x
y
f(x,y)=x+y
f(x,y)=−x+y
Consideriamo ora il punto (x0, y0) = (0, 1), in cui si ha f(x0, y0) = 1. Dare una variazione solo ad x vuol diremuoversi lungo una retta passante per (0, 1) e parallela all’asse x (tale retta ha equazione y = 1). Su di essa, adestra di (0, 1), la funzione vale x+ y, mentre a sinistra vale −x+ y.
Si ha percio
limx→0+
f(x, 1)− f(0, 1)x
= limx→0+
x+ 1− 1
x= 1,
limx→0−
f(x, 1)− f(0, 1)x
= limx→0−
−x+ 1− 1
x= −1,
e pertanto questa funzione non ammette derivata parziale rispetto adx nel punto (0, 1). Cio e sufficiente per dire che in quel punto non ederivabile.
y = 1
1
f(x,y)=x+yf(x,y)=−x+y
x
y
C’e invece in (0, 1) derivabilita parziale rispetto ad y, dato che
limy→0
f(0, y)− f(0, 1)y − 1
= limy→0
y − 1
y − 1= 1.
Si noti che il calcolo della derivata parziale rispetto a x richiede di distinguere i due casi x > 0 e x < 0, mentreil calcolo della derivata parziale rispetto a y non lo richiede.
Si consideri ora il punto (x0, y0) = (1, 0). Facendo variare solo la x e per-correndo quindi l’asse x (con y = 0) si trova che sia a destra sia a sinistra,in un intorno sufficientemente piccolo di (1, 0), la funzione vale x+ y. Si haquindi
limx→1
x− 1
x− 1= 1,
e quindi la funzione e derivabile parzialmente rispetto a x in (1, 0).
x = 1
1
f(x,y)=x+y
x
y
Percorrendo invece una parallela all’asse y (con x = 1) si trova ancora che sia al di sopra sia al di sotto di (1, 0)la funzione vale x+ y. Si ha quindi
limy→0
1 + y − 1
y= 1,
e quindi la funzione in (1, 0) e derivabile parzialmente anche rispetto ad y ed e pertanto derivabile. Si ha∇f(1, 0) = (1, 1).
Osservazione Non e difficile intuire e capire che studiare la derivabilita parziale rispetto ad x di una funzione f inun punto (x0, y0) equivale a studiare la derivabilita in t = 0 della restrizione di f alla curva γx(t) = (x0 + t, y0).Analogamente, studiare la derivabilita parziale rispetto ad y in (x0, y0) equivale a studiare la derivabilita in t = 0 dellarestrizione di f alla curva γy(t) = (x0, y0 + t).
La figura a fianco illustra che il sostegno della curva γx e la retta di equazioney = y0 e il sostegno della curva γy e la retta di equazione x = x0. Anzi,possiamo dimostrare facilmente che, se c’e derivabilita parziale, allora risulta
∂f
∂x(x0, y0) = (f ◦ γx)′(0) e
∂f
∂y(x0, y0) = (f ◦ γy)′(0).
by = y0
x = x0
x0
y0
x
y
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 DERIVATE PARZIALI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
378
Infatti, con il cambio di variabile x− x0 = t (quindi x = x0 + t), si ha
limx→x0
f(x, y0)− f(x0, y0)x− x0
= limt→0
f(x0 + t, y0)− f(x0, y0)t
= limt→0
f(γx(t))− f(γx(0))t
,
e quest’ultimo e proprio la derivata della funzione f(γx(t)) = (f ◦ γx)(t) in t = 0.E chiaro che analogamente si ha, per la derivata rispetto ad y,
limy→y0
f(x0, y)− f(x0, y0)y − y0
= limt→0
f(x0, y0 + t)− f(x0, y0)t
= limt→0
f(γy(t))− f(γy(0))t
,
e cioe la derivata della funzione f(γy(t)) = (f ◦ γy) in t = 0.
Possiamo verificare il tutto su qualche esempio.
• Riprendendo la prima funzione degli esempi precedenti, cioe la
f(x, y) = x+ ey, nel punto (1, 0),
per la derivata parziale rispetto ad x consideriamo la curva γx(t) = (1 + t, 0) e la restrizione
f(1 + t, 0) = 2 + t.
Tale funzione e derivabile in t = 0 con derivata uguale ad 1.
Per la derivata parziale rispetto ad y consideriamo invece la curva γy(t) = (1, t) e la restrizione
f(1, t) = 1 + et,
che e derivabile in t = 0 con derivata uguale ad 1.
• Per la seconda funzione, cioef(x, y) = x ln y, nel punto (2, 1),
per la derivata parziale rispetto ad x consideriamo la restrizione di f alla curva γx(t) = (2 + t, 1), che e
f(2 + t, 1) = (2 + t) · 0 = 0,
da cui ∂f∂x (2, 1) = 0. Per la derivata parziale rispetto ad y consideriamo la restrizione di f alla curva γy(t) =
(2, 1 + t), che ef(2, 1 + t) = 2 ln(1 + t),
da cui ∂f∂y (2, 1) = 2.
• Infine, per la terza funzione, cioef(x, y) = |x|+ y, nel punto (0, 1),
si ha invece
f(0 + t, 1) = |t|+ 1 =
{t+ 1 se t ≥ 0
−t+ 1 se t < 0
e tale funzione non e derivabile in t = 0. Quindi f non e derivabile parzialmente rispetto ad x.
Rispetto ad y invece c’e derivata parziale, dato che la restrizione alla curva (0, 1 + t) coincide con la funzionet 7→ 1 + t, che e certamente derivabile.
• Ancora un esempio. Per la funzione
f(x, y) = |x+ y2|, nel punto (0, 0),
l’esame della derivabilita parziale rispetto ad x porta a considerare la restrizione
f(t, 0) = |t|,
che non e derivabile in t = 0. L’esame della derivabilita parziale rispetto ad y porta invece a considerare larestrizione
f(0, t) = |t2| = t2,
che e derivabile in t = 0, con derivata nulla. Pertanto si ha ∂f∂y (0, 0) = 0, mentre la ∂f
∂x (0, 0) non esiste.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 REGOLE DI DERIVAZIONE
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
379
Spendiamo ora due parole sull’interpretazione geometrica delle derivate parziali. Tenendo conto di quanto espostonell’ultima osservazione, che cioe le derivate parziali coincidono con le derivate (monodimensionali) lungo opportunerestrizioni, si intuisce facilmente che, se la f e derivabile rispetto ad x nel punto (x0, y0), allora nel piano di equazioney = y0
422 vi e una (ed una sola) retta tangente al grafico di f (vedi figura sotto a sinistra). La derivata parziale di frispetto ad x e la pendenza (coefficiente angolare) di tale retta, indicata con r1 in figura.Analogamente, se f e derivabile rispetto ad y in (x0, y0), allora nel piano di equazione x = x0 vi e una (ed una sola)retta tangente al grafico di f (figura sotto a destra). La derivata parziale di f rispetto ad y e la pendenza di questaretta, indicata con r2 in figura.
z
x
x
r
y
y
00
1
x
y y
0
0
z
x
r2
Esercizio 1.1 Si calcolino le derivate parziali delle seguenti funzioni attraverso la definizione, cioe con il limite
del rapporto incrementale parziale.
(a) f(x1, x2) = x1ex2 nel punto (1, 1)
(b) f(x, y) = (x+ y)ex−y nel punto (2, 1)
(c) f(x1, x2) =lnx2x1
nel punto (e, 1)
(d) f(x, y) = x√x+ y nel punto (−1, 2)
2 Regole di derivazione
Per quanto riguarda il calcolo delle derivate, come avviene per le funzioni di una sola variabile, la definizione (cioeil limite del rapporto incrementale) si utilizza solamente in casi particolari, come ad esempio le funzioni definite atratti, o perche espressamente richiesta.423 Per il calcolo ci sono metodi piu comodi per procedere, quelli che vengonocomunemente detti regole di derivazione. Si ottengono comode regole di derivazione parziale semplicemente tenendoconto del fatto che nella derivazione rispetto alla variabile xi tutte le altre variabili sono da mantenersi costanti: quindile regole di calcolo sono le consuete regole di derivazione delle funzioni di una sola variabile.424
Esempi
• Calcoliamo le derivate parziali della funzione f(x, y) = x2y3. Derivando rispetto ad x, quindi con y costante, siha
∂f
∂x(x, y) = 2xy3.
Derivando rispetto ad y, quindi con x costante, si ha
∂f
∂y(x, y) = 3x2y2.
422Si tratta di un piano “verticale” parallelo al piano x, z e che contiene il punto (x0, y0).423Solitamente per capire se lo studente ha studiato bene anche la teoria.424Sarebbe come derivare una funzione di una variabile che dipende anche da alcuni parametri, i quali pero sono da ritenersi costantial momento della derivazione. Ad esempio, se consideriamo la funzione f(x) = ax2 + bx + c e intendiamo che a, b, c sono costanti, si haf ′(x) = 2ax+ b.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 REGOLE DI DERIVAZIONE
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
380
• Con la funzione f(x, y) = xy , derivando rispetto ad x si ha
∂f
∂x(x, y) =
1
y.
Derivando rispetto ad y si ha invece∂f
∂y(x, y) = − x
y2.
• Le derivate parziali della funzione f(x, y) = x2yexy2
sono:
∂f
∂x(x, y) = 2xyexy
2
+ x2yexy2 · y2 = 2xyexy
2
+ x2y3exy2
e∂f
∂y(x, y) = x2exy
2
+ x2yexy2 · 2xy = x2exy
2
+ 2x3y2exy2
.
• Con la funzione f(x, y) = ln
(x
ln y
)
abbiamo
∂f
∂x(x, y) =
ln y
x· 1
ln y=
1
x.
e∂f
∂y(x, y) =
ln y
x·(
− x
ln2 y
)
· 1y= − 1
y ln y.
• Con la funzione f(x1, x2, x3) =√
x1 +√x2 +
√x3, si ha
∂f
∂x1(x1, x2, x3) =
1
2√
x1 +√x2 +
√x3
,
∂f
∂x2(x1, x2, x3) =
1
2√
x1 +√x2 +
√x3
· 1
2√x2 +
√x3
e infine∂f
∂x3(x1, x2, x3) =
1
2√
x1 +√x2 +
√x3
· 1
2√x2 +
√x3· 1
2√x3.
Osservazione Faccio esplicitamente notare una cosa, che risulta peraltro evidente dagli esempi appena visti. Se fe una funzione di due variabili, allora in genere le sue derivate parziali sono anch’esse funzioni di due variabili e, ingenerale, funzioni di n variabili hanno derivate parziali che sono anch’esse funzioni di n variabili.
Esercizio 2.1 Si calcolino le derivate parziali delle seguenti funzioni con le regole di derivazione.
(a) f(x, y) = (x+ 2y)e3x−4y (b) f(x1, x2) = x2 ln(x21 + x2)
(c) f(x, y) =y2
x(d) f(x, y) = x+
√
x2 + y3
(e) f(x1, x2) =x1 + x2x1 − x2
(f) f(x, y) =x
yey/x
(g) f(x, y) =y
x+ y2(h) f(x1, x2) =
x1 + lnx2x2 + lnx1
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 DIFFERENZIABILITA
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
381
3 Derivabilita e continuita
E da mettere in evidenza il seguente fatto: lo studente ricordera che con le funzioni di una variabile la derivabilitain un punto implica la continuita nello stesso punto. Questo risultato non vale piu con funzioni di piu variabili: orala derivabilita di una funzione nel punto x0 non garantisce la continuita della funzione in x0. In altre parole ci sonoesempi di funzioni derivabili in un punto ma non continue in quel punto.Un esempio in merito e fornito dalla funzione di due variabili
f(x, y) =
{1 se xy = 0
0 se xy 6= 0.
La funzione vale 1 sugli assi cartesiani e vale 0 in tutti gli altri punti del piano. Le restrizioni agli assi x e y dellafunzione f sono funzioni costanti, con valore 1, quindi la funzione f e derivabile parzialmente in (x0, y0) = (0, 0) conderivate parziali entrambe nulle. Non c’e pero continuita in (0, 0), dato che il limite nell’origine non esiste: infatti lerestrizioni lungo gli assi cartesiani hanno limite 1, mentre la restrizione ad una qualunque altra retta per l’origine halimite 0.Il motivo del fatto che in piu variabili la derivabilita parziale in un punto x0 non implica la continuita in x0 efacilmente intuibile: l’esistenza delle derivate parziali dipende dal comportamento della funzione soltanto lungo ledirezioni parallele agli assi cartesiani, mentre la continuita coinvolge i valori in tutto un intorno del punto x0. Quindila derivabilita lungo le direzioni fondamentali non da sufficienti garanzie sul comportamento della funzione lungo altrepossibili direzioni.
Osservazione Sorge spontanea a questo punto una domanda: se la derivabilita parziale non e sufficiente a garantirela continuita, quali proprieta possono esserlo? Qui mi limito a citare soltanto questo risultato: se una funzione f haderivate parziali in un insieme A e queste derivate parziali sono funzioni continue in A, allora f e continua in A. Lefunzioni che hanno derivate parziali continue sono le cosiddette funzioni di classe C 1, come in R erano di classe C 1 lefunzioni con derivata (prima) continua.
4 Differenziabilita
Nell’osservazione che chiude la sezione precedente ho citato una proprieta che garantisce la continuita. Un’altraproprieta di questo tipo, molto importante anche nelle applicazioni, e la differenziabilita. Non ne abbiamo parlatoin precedenza, cioe per le funzioni di una sola variabile, in quanto il concetto, in una sola variabile appunto, non sidiscosta molto da quello di derivabilita. In piu variabili invece la differenziabilita acquista un significato diverso daquello di derivabilita (parziale) e sicuramente importante, sia da un punto di vista teorico, sia applicativo.Presento prima la definizione con riferimento a funzioni di due variabili e successivamente ne do la generalizzazionead n variabili.Per introdurre il concetto, in modo che la definizione formale non risulti di non immediata comprensione, si puo direche una funzione e differenziabile in un punto se la variazione dei suoi valori, in prossimita di questo punto, e in buonaapprossimazione una funzione lineare della variazione delle variabili indipendenti.
Definizione Sia f : A ⊂ R2 → R e sia (x01, x02) un punto interno ad A. Diciamo che f e differenziabile in (x01, x
02)
se c’e una funzione lineare del tipo c1(x1 − x01) + c2(x2 − x02) tale che la differenza
f(x1, x2)− f(x01, x02)−[
c1(x1 − x01) + c2(x2 − x02)]
sia trascurabile.425
Osservazione Si noti che dire che la variazione di f e sostanzialmente lineare equivale a dire che la differenza tra talevariazione e una funzione lineare e trascurabile. Quindi differenziabile in un punto vuol dire che in prossimita di questopunto la variazione della funzione e praticamente lineare rispetto alle variazioni delle variabili (cioe proporzionale aqueste). Si dovrebbe intuire che la novita rispetto alla derivazione parziale e che ora non opero nessuna restrizione dellafunzione ma considero tutti i punti in prossimita di (x01, x
02). E forse si intuisce anche che quindi la differenziabilita mi
puo garantire un maggior numero di proprieta della funzione f rispetto a quanto possono fare le derivate parziali.La funzione lineare (x1−x01, x2−x02) 7→ c1(x1−x01)+ c2(x2−x02) si chiama il differenziale di f in (x01, x
02) e si indica
con df(x01, x02). Si tratta della funzione lineare delle variazioni di x1 e x2. A volte si scrive anche df = c1 dx1+c2 dx2.
425In realta dovrei direi, piu rigorosamente, trascurabile rispetto a che cosa. La differenza deve essere trascurabile rispetto alla distanzadi (x1, x2) da (x0
1, x02). E ricordo che il significato di cio e che, al tendere di (x1, x2) a (x0
1, x02), cioe al tendere a zero della loro distanza, il
rapporto tra la differenza f(x1, x2)− f(x01, x
02)−
[
c1(x1 − x01) + c2(x2 − x0
2)]
e tale distanza tende a zero.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 DERIVATE SECONDE E TEOREMA DI SCHWARZ
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
382
Il differenziale, quando la funzione e differenziabile, fornisce una buona approssimazione della variazione di f inprossimita di un punto che stiamo considerando.
Osservazione Si puo dimostrare che, se una funzione f e differenziabile nel punto (x01, x02), allora le due costanti
c1 e c2 del differenziale non sono altro che le due derivate parziali di f in (x01, x02), e che quindi possiamo scrivere
df = ∂f∂x1
dx1 +∂f∂x2
dx2 (le derivate parziali sono calcolate nel punto (x01, x02)).
Esempio Scriviamo il differenziale della funzione f(x, y) = x2 + y2 nel punto (x0, y0) = (1, 2).Ci servono intanto le due derivate parziali. Si ha
∂f
∂x(x0, y0) =
∂f
∂x(1, 2) = 2 e
∂f
∂y(x0, y0) =
∂f
∂y(1, 2) = 4.
Pertanto il differenziale di f in (1, 2) e df(1, 2) = 2(x− x0) + 4(y − y0) = 2(x− 1) + 4(y − 2) = 2 dx+ 4dy.
Osservazione Si potrebbe provare che l’interpretazione geometrica della differenziabilita per le funzioni di duevariabili e l’esistenza del piano tangente al grafico della funzione nel punto che viene considerato. Ricordando chel’interpretazione geometrica della derivata in una variabile era l’esistenza della retta tangente, si potrebbe dire che ilconcetto che generalizza la derivata in due variabili e la differenziabilita e non la derivabilita parziale.
Per fornire ora la definizione di differenziabilita in n variabili conviene forse formalizzare in modo leggermente diversola scrittura della funzione lineare (cioe del differenziale). Possiamo dire che una funzione lineare in n variabili e ilrisultato del prodotto interno di un vettore costante per il vettore delle variabili.426
Detto questo, possiamo quindi dare la seguente
Definizione Sia f : A ⊂ Rn → R e sia x0 un punto interno ad A. Diciamo che f e differenziabile in x0 se c’e unvettore c per cui la differenza
f(x)− f(x0)− 〈c,x− x0〉 sia trascurabile.427
La funzione lineare 〈c,x− x0〉 si chiama il differenziale di f in x0 e si indica con df(x0).
Vale in generale il risultato che, se una funzione e differenziabile in un punto x0, le costanti ci che compaiono nel suodifferenziale sono le derivate parziali di f nel punto x0. Possiamo anche sintetizzare questo scrivendo che
c = ∇f(x0),
ossia che
df(x0) = 〈∇f(x0),x− x0〉 = 〈∇f(x0), dx〉 =n∑
i=1
∂f
∂xi(x0) dxi.
Osservazione Ricordo, a conclusione della sezione, che se una funzione e differenziabile in un punto, allora essa inquesto punto e continua e derivabile parzialmente rispetto a tutte le sue variabili.
Esercizio 4.1 Si scriva il differenziale delle seguenti funzioni, nel punto indicato.
(a) f(x, y) = x2y3 in (−1, 2) (b) f(x, y) = x ln(x+ y) in (1, 0)
5 Derivate seconde e teorema di Schwarz
Come avviene per le funzioni di una variabile, per le quali, dopo la derivata prima, possono essere definite la derivataseconda e tutte le altre, cosı analogamente puo avvenire per le funzioni di piu variabili.Se f : A ⊂ Rn → R e se f e derivabile parzialmente in A, come gia osservato ogni derivata parziale ∂f
∂xie una funzione
definita in A a valori in R, che associa ad ogni x appartenente ad A il numero reale ∂f∂xi
(x). Tali funzioni possono
quindi a loro volta essere derivabili parzialmente rispetto alle variabili x1, . . . , xn.428
426In due variabili possiamo scrivere cioec1(x1 − x0
1) + c2(x2 − x02) = 〈c,x− x0〉,
se poniamo c = (c1, c2), x = (x1, x2) e x0 = (x01, x
02).
427Una scrittura “estesa” di f(x)− f(x0)− 〈c,x− x0〉 potrebbe essere
f(x1, . . . , xn)− f(x01, . . . , x
0n) −
n∑
i=1
ci(xi − x0i ).
428Se f e di due variabili, la derivata parziale di f rispetto ad x puo essere a sua volta derivata rispetto ad x o rispetto ad y, e lo stessoper la derivata parziale di f rispetto ad y.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

5 DERIVATE SECONDE E TEOREMA DI SCHWARZ
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
383
Ciascuna ∂f∂xi
puo avere dunque n derivate parziali ; la derivata parziale di ∂f∂xi
rispetto ad xj viene indicata con ilsimbolo
∂2f
∂xi∂xj,
e viene detta derivata parziale seconda di f rispetto ad xi e rispetto a xj . Per una funzione di n variabilivi sono dunque nel complesso n2 derivate parziali seconde. Vi sono quelle ottenute derivando due volte rispetto allastessa variabile, che si indicano con
∂2f
∂x21, . . . ,
∂2f
∂x2n
e quelle ottenute invece derivando rispetto a variabili diverse, e cioe
∂2f
∂xi∂xj, con i, j = 1, . . . , n e i 6= j.
Queste ultime si chiamano derivate seconde miste.
Esempi
• La funzione f(x, y) = x2 + y3 ha derivate parziali prime
∂f
∂x(x, y) = 2x e
∂f
∂y(x, y) = 3y2
e derivate parziali seconde
∂2f
∂x2(x, y) = 2 ,
∂2f
∂x∂y(x, y) = 0 ,
∂2f
∂y∂x(x, y) = 0 ,
∂2f
∂y2(x, y) = 6y.
• La funzione f(x, y) =x
yha derivate parziali prime
∂f
∂x(x, y) =
1
ye
∂f
∂y(x, y) = − x
y2
e derivate parziali seconde
∂2f
∂x2(x, y) = 0 ,
∂2f
∂x∂y(x, y) = − 1
y2,
∂2f
∂y∂x(x, y) = − 1
y2,
∂2f
∂y2(x, y) =
2x
y3.
• La funzione f(x1, x2) = ln(x1 + lnx2) ha derivate parziali prime
∂f
∂x1(x1, x2) =
1
x1 + lnx2e
∂f
∂x2(x1, x2) =
1
x1 + lnx2· 1
x2
e derivate parziali seconde
∂2f
∂x21(x1, x2) = − 1
(x1 + lnx2)2,
∂2f
∂x1∂x2(x1, x2) = − 1
(x1 + lnx2)2· 1
x2,
∂2f
∂x2∂x1(x1, x2) = − 1
(x1 + lnx2)2· 1
x2,
∂2f
∂x22(x1, x2) = − 1
(x1 + lnx2)2· 1
x22+
1
x1 + lnx2·(
− 1
x22
)
.
Lo studente forse avra notato che in tutte le funzioni degli esempi proposti le derivate seconde miste sono uguali. Valeinfatti in proposito il seguente importante risultato.
Teorema (di Schwarz) Data la funzione f , definita nell’aperto A ⊂ Rn e qui derivabile parzialmente due volte, se
le derivate seconde miste ∂2f∂xi∂xj
e ∂2f∂xj∂xi
sono continue in A, allora esse sono uguali.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
384
Osservazione Le funzioni di uso comune, cioe in pratica le funzioni che si ottengono dalle funzioni elementari conoperazioni elementari, hanno derivate (di ogni ordine) continue. Vale quindi per queste il teorema di Schwarz. Abbiamogia detto che le funzioni con derivate prime continue si dicono di classe C 1. Analogamente, quelle con derivate secondecontinue si dicono di classe C 2, e cosı via. Quelle che hanno derivate di ogni ordine continue si dicono di classe C∞. Lefunzioni elementari e quelle che si ottengono da queste con operazioni di somma, prodotto, quoziente e composizionesono quindi, nei punti interni dei rispettivi domini, funzioni di classe C∞.
Osservazione Le derivate seconde di una funzione definita in Rn solitamente si scrivono in una matrice n×n, dettamatrice Hessiana o gradiente secondo. Si scrive
∇2f =
∂2f∂x2
1
. . . ∂2f∂x1∂xn
.... . .
...∂2f
∂xn∂x1. . . ∂2f
∂x2n
.
Nel caso di una funzione f(x, y) di due variabili il gradiente secondo e la matrice 2× 2
∇2f =
∂2f∂x2
∂2f∂x∂y
∂2f∂y∂x
∂2f∂y2
.
Osservazione Se la funzione soddisfa le ipotesi del teorema di Schwarz, e quindi ∂2f∂x∂y = ∂2f
∂y∂x , la sua matriceHessiana e una matrice simmetrica.
Vedremo nella prossima dispensa del corso come le derivate parziali prime di una funzione (cioe il gradiente) possanoessere utili nella ricerca dei punti stazionari e come invece le derivate parziali seconde (cioe la matrice Hessiana) sianoimportanti per studiare la natura dei punti stazionari, cioe per capire se essi sono punti di massimo o di minimo.Il gradiente secondo e utile anche nello studio della convessita e della concavita della funzione (esattamente come laderivata seconda per le funzioni di una variabile).
Esercizio 5.1 Calcolare il gradiente secondo (ossia la matrice Hessiana) delle seguenti funzioni.
(a) f(x, y) = x2y3 + xy2 (b) f(x1, x2) =x2x1
(c) f(x, y) = xyex+y (d) f(x, y) = xe1/y
(e) f(x, y, z) = xyz (f) f(x1, x2, x3) =x1x2x3
6 Soluzioni degli esercizi
Esercizio 1.1
(a) Si ha f(1, 1) = e. La derivata parziale rispetto ad x1 e
limt→0
(1 + t)e − et
= limt→0
e+ et− et
= e.
La derivata parziale rispetto ad x2 e
limt→0
e1+t − et
= limt→0
e · et − et
= e limt→0
et − 1
t= e.429
(b) Si ha f(2, 1) = 3e. La derivata parziale rispetto ad x e
limt→0
(2 + t+ 1)e2+t−1 − 3e
t= lim
t→0
(3 + t)e1+t − 3e
t= lim
t→0
3e(et − 1) + etet
t= 4e.
429Si ricordi il limite notevole limt→0et−1
t= 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
385
La derivata parziale rispetto ad y e
limt→0
(2 + 1 + t)e2−1−t − 3e
t= lim
t→0
(3 + t)e1−t − 3e
t= lim
t→0
3e(e−t − 1) + ete−t
t= −2e.
(c) Si ha f(e, 1) = 0. La derivata parziale rispetto ad x1 e
limt→0
0
t= 0.
La derivata parziale rispetto ad x2 e
limt→0
ln(1+t)e
t=
1
elimt→0
ln(1 + t)
t=
1
e.430
(d) Si ha f(−1, 2) = −1. La derivata parziale rispetto ad x e
limt→0
(−1 + t)√−1 + t+ 2 + 1
t= lim
t→0
(t− 1)√t+ 1 + 1
t
= limt→0
t√t+ 1−
√t+ 1 + 1
t
= limt→0
(1−√t+ 1
t+√t+ 1
)
=1
2.431
La derivata parziale rispetto ad y e
limt→0
−√−1 + 2 + t+ 1
t= lim
t→0
1−√t+ 1
t= −1
2.
Esercizio 2.1
(a) Si ha∂f
∂x= e3x−4y + (x+ 2y)e3x−4y · 3
e∂f
∂y= 2e3x−4y + (x+ 2y)e3x−4y · (−4).
(b) Si ha∂f
∂x1= x2 ·
1
x21 + x2· 2x1
e∂f
∂x2= ln(x21 + x2) + x2 ·
1
x21 + x2.
(c) Si ha∂f
∂x= − y
2
x2e
∂f
∂y=
2y
x.
(d) Si ha∂f
∂x= 1 +
1
2√
x2 + y3· 2x
e∂f
∂y=
1
2√
x2 + y3· 3y2.
430Si ricordi il limite notevole limt→0ln(1+t)
t= 1.
431Si ricordi il limite notevole limt→0(1+t)b−1
t= b. Quindi limt→0
1−√
t+1t
= − limt→0(1+t)1/2−1
t= −1/2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
386
(e) Si ha∂f
∂x1=x1 − x2 − (x1 + x2)
(x1 − x2)2= − 2x2
(x1 − x2)2e
∂f
∂x2=x1 − x2 + x1 + x2
(x1 − x2)2=
2x1(x1 − x2)2
.
(f) Si ha∂f
∂x=
1
yey/x +
x
yey/x ·
(
− y
x2
)
=1
xyey/x(x− y)
e∂f
∂y= − x
y2ey/x +
x
yey/x · 1
x=
1
y2ey/x(y − x).
(g) Si ha∂f
∂x= − y
(x+ y2)2
e∂f
∂y=x+ y2 − y · 2y
(x+ y2)2=
x− y2(x+ y2)2
.
(h) Si ha
∂f
∂x1=x2 + lnx1 − (x1 + lnx2) · 1
x1
(x2 + lnx1)2
e∂f
∂x2=
1x2(x2 + lnx1)− (x1 + lnx2)
(x2 + lnx1)2.
Esercizio 4.1
(a) Le due derivate parziali sono ∂f∂x (x, y) = 2xy3 e ∂f
∂y (x, y) = 3x2y2 e quindi
∂f
∂x(−1, 2) = −16 e
∂f
∂y(−1, 2) = 12.
Quindi il differenziale e df(−1, 2) = −16(x+ 1) + 12(y − 2) = −16 dx+ 12 dy.
(b) Le due derivate parziali sono ∂f∂x (x, y) = ln(x+ y) + x
x+y e ∂f∂y (x, y) =
xx+y e quindi
∂f
∂x(1, 0) = 1 e
∂f
∂y(1, 0) = 1.
Quindi il differenziale e df(1, 0) = x− 1 + y = dx+ dy.
Esercizio 5.1
(a) f(x, y) = x2y3 + xy2. Il gradiente di f e
∇f =(
2xy3 + y2, 3x2y2 + 2xy)
.
Il gradiente secondo e
∇2f =
(2y3 6xy2 + 2y
6xy2 + 2y 6x2y + 2x
)
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

6 SOLUZIONI DEGLI ESERCIZI
DERIVATE DELLE FUNZIONI DI PIU VARIABILI
387
(b) f(x1, x2) =x2x1
. Il gradiente di f e
∇f =(
− x2x21,1
x1
)
.
Il gradiente secondo e
∇2f =
(2x2
x31
− 1x21
− 1x21
0
)
.
(c) f(x, y) = xyex+y. Il gradiente di f e
∇f = ex+y(
(1 + x)y, x(1 + y))
.
Il gradiente secondo e
∇2f = ex+y
((2 + x)y 1 + x+ y + xy
1 + x+ y + xy x(2 + y)
)
.
(d) f(x, y) = xe1/y. Il gradiente di f e
∇f = e1/y(
1,− x
y2
)
.
Il gradiente secondo e
∇2f = e1/y(
0 − 1y2
− 1y2 (2− y) x
y3
)
.
(e) f(x, y, z) = xyz. Il gradiente di f e
∇f =(
yz, xz, xy)
.
Il gradiente secondo e
∇2f =
0 z yz 0 xy x 0
.
(f) f(x1, x2, x3) =x1x2x3
. Il gradiente di f e
∇f =(x2x3,x1x3,−x1x2
x23
)
.
Il gradiente secondo e
∇2f =
0 1x3
−x2
x23
1x3
0 −x1
x23
−x2
x23
−x1
x23
2x1x2
x33
.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MASSIMI E MINIMI LIBERI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
388
IV-4 Massimi e minimi delle funzioni di piu variabili
In questa dispensa vediamo alcuni risultati teorici riguardanti i punti di massimo e di minimo delle funzioni derivabili(di piu variabili). Vediamo anche come, in conseguenza di tali risultati, si procede nella ricerca dei punti di massimoe di minimo. Considereremo due situazioni generali ben distinte: la ricerca dei massimi e minimi cosiddetti liberi e laricerca dei massimi e minimi vincolati. Anche se i risultati teorici sono enunciati in generale per funzioni definite inRn o in sottoinsiemi di Rn, gli esempi riguarderanno, sia per i massimi e minimi liberi sia per quelli vincolati, soltantofunzioni definite in R2 o suoi sottoinsiemi.
1 Massimi e minimi liberi
Iniziamo con un paio di definizioni fondamentali, gia incontrate nella seconda parte del corso per le funzioni di unavariabile.
Definizione Sia f : A ⊂ Rn → R una funzione. Diciamo che il punto x0 ∈ A e un punto di massimo globale dif se vale
f(x0) ≥ f(x), per ogni x ∈ A.Analogamente diciamo che il punto x0 ∈ A e un punto di minimo globale di f se vale
f(x0) ≤ f(x), per ogni x ∈ A.
Osservazione Un punto di massimo (minimo) globale e un punto in cui la funzione assume il suo valore massimo(minimo). L’aggettivo globale sta a significare che prendo in considerazione tutto il dominio in cui e definita lafunzione. Come sempre non si deve fare confusione tra il massimo della funzione e il punto di massimo: il punto dimassimo e un punto del dominio di f , mentre il massimo e il massimo dei valori che la funzione assume, quindi nelcodominio di f . Pertanto, se ad esempio f : R2 → R, il punto di massimo appartiene ad R2, mentre il massimo e unnumero reale.
Osservazione Non e detto ovviamente che tutte le funzioni abbiano punti di massimo o di minimo globale. Lostudente sa gia fornire controesempi con funzioni di una sola variabile.
Definizione Sia f : A ⊂ Rn → R una funzione definita in un insieme A aperto. Diciamo che il punto x0 ∈ A e unpunto di massimo locale di f se esiste un intorno U di x0 tale che
f(x0) ≥ f(x), per ogni x ∈ U .
Analogamente diciamo che il punto x0 ∈ A e un punto di minimo locale di f se esiste un intorno U di x0 tale che
f(x0) ≤ f(x), per ogni x ∈ U .
Quello che fa la differenza con le definizioni precedenti (massimi globali) e che ora ci si accontenta che la disequazionevalga in un intorno del punto x0 e non in tutto il dominio di f .Possiamo dare la definizione di punto di massimo (minimo) locale di una funzione definita in un generico sottoinsiemedi Rn (anche non aperto), con una piccola avvertenza in piu. Possiamo cioe dire che x0 ∈ A e un punto di massimolocale di f se esiste un intorno U di x0 tale che
f(x0) ≥ f(x), per ogni x ∈ U ∩ A (e analogamente per il minimo).
Osservazione Lo studente rifletta sull’importanza dell’ipotesi sull’insieme A. Consideri in particolare che, se adesempio l’insieme A fosse chiuso e se x0 fosse un punto di frontiera per A, la prima definizione data non avrebbe senso:nessun punto di frontiera potrebbe essere punto di massimo o di minimo locale.
Osservazione Un punto di massimo (minimo) globale e anche di massimo (minimo) locale. Non vale il viceversa.Non e comunque una novita: questo si ha anche con le funzioni di una sola variabile. Si pensi ad esempio alla funzionex 7→ 2x3 − 3x2 + 1, definita in tutto R. Essa ha in 0 un punto di massimo locale e in 1 un punto di minimo locale,ma non ha punti ne di massimo ne di minimo globali. Puo essere un utile esercizio di ripasso verificare il tutto con unsemplice studio della funzione in questione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MASSIMI E MINIMI LIBERI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
389
Esempi La funzione f : R2 → R, definita da f(x, y) = x2 + y2, ha in x0 = (0, 0) un punto di minimo globale.432
La funzione f : R2 → R, definita da f(x, y) = e−x2−y2
, ha in x0 = (0, 0) un punto di massimo globale (si consideri che
f e una funzione radiale, con profilo la funzione f0 : [0,+∞)→ R definita da f0(t) = e−t2).Diamo ora un’altra importante definizione, che non dovrebbe sorprendere lo studente che ricorda le cose viste con lefunzioni di una sola variabile.
Definizione Sia f : A ⊂ Rn → R una funzione di classe C 1 nell’insieme A.433 Se x0 e un punto interno ad A,diciamo che x0 e un punto stazionario di f se ∇f(x0) = 0.
Osservazione Lo studente non confonda i concetti di punto di massimo (minimo) e di punto stazionario. Si noti chenelle definizioni di punto di massimo (minimo) non si fa nessuna ipotesi sulla derivabilita, e che invece nella definizionedi punto stazionario la derivabilita e ovviamente necessaria. Si ricordi a tale proposito che ad esempio la funzione (diuna variabile) f(x) = |x| ha in 0 un punto di minimo (locale e globale) ma non e in tale punto derivabile.
Per comprendere e ricordare meglio i risultati che ora enuncero, lo studente potrebbe rivedere rapidamente gli analoghirisultati visti nella seconda parte del corso per le funzioni definite in R.
Proposizione Se f e una funzione di classe C 1 nell’insieme A e x0 e un punto di massimo (o minimo) locale per finterno ad A, allora x0 e un punto stazionario di f .
Osservazione Tale risultato viene talvolta indicato come la condizione necessaria del primo ordine per l’esistenzadi un punto di massimo o di minimo locali (per funzioni derivabili).434
Osservazione Si noti che, come avveniva per le funzioni di una sola variabile, la condizione necessaria vale nei puntiinterni. Lo studente vada a rivedere l’analoga proposizione incontrata nella seconda parte del corso e le osservazioniche la seguono.
Osservazione Ricordo che non vale il viceversa della proposizione appena vista. Non e vero cioe che, se x0 estazionario, allora esso sia necessariamente o di massimo o di minimo. Si ricordi il classico controesempio (in unavariabile) dato da x 7→ x3, che in x0 = 0 ha un punto stazionario, che pero non e ne di massimo ne di minimo.
Esempio Come esempio in R2 della stessa situazione possiamo considerare la funzione f(x, y) = x2 − y2. Si vedefacilmente che l’origine x0 = (0, 0) e un punto stazionario di f . Infatti f e certamente di classe C 1 e si ha ∇f(x, y) =(2x,−2y). Pertanto risulta ∇f(x0) = ∇f(0, 0) = (0, 0). Possiamo vedere altrettanto facilmente che l’origine non epunto ne di massimo ne di minimo di f . 435 A tale proposito ci possono tornare utili le restrizioni di f . Se consideriamola restrizione di f alla retta (t, 0), con t ∈ R, otteniamo la funzione
f1(t) = t2,
per cui x0 = (0, 0) non puo essere punto di massimo. Se invece consideriamo la restrizione di f alla retta (0, t), cont ∈ R, otteniamo la funzione
f2(t) = −t2,per cui x0 = (0, 0) non puo essere nemmeno punto di minimo.
Osservazione Possiamo in generale fare uso di un fatto abbastanza intuitivo: se f ha in x0 un punto di massimo(minimo) locale, allora ogni restrizione “passante per x0” deve avere anch’essa un punto di massimo (minimo) locale.436
Osservazione Per la ricerca dei punti di massimo o di minimo, valendo la condizione del primo ordine, convienecercare intanto gli eventuali punti stazionari (si parla sempre di funzioni derivabili). La condizione pero non consentedi decidere se i punti stazionari trovati siano di massimo o di minimo (o nessuna delle due cose). Si osservi che non euna novita: anche con le funzioni di una variabile si procede nello stesso modo. Anche con quelle, inoltre, sapere chef ′(x0) = 0 non ci consente di dire nulla sul punto x0. Con una variabile occorre studiare o il segno della derivata primain prossimita di x0 oppure la derivata seconda in x0. Anche per le funzioni di piu variabili un aiuto per poter direqualcosa sulla natura del punto stazionario viene dalle derivate seconde: i risultati generali che dicono come stanno le
432Il risultato si trova immediatamente pensando che la funzione assume sempre valori non negativi e si annulla nell’origine.Alternativamente si puo osservare che f e una funzione radiale, con profilo la funzione f0 : [0,+∞) → R definita da f0(t) = t2.433Ricordo che dicendo che f e di classe C 1 in A si intende che f ha derivate continue in A. Piu avanti, dicendo che f e di classe C 2 inA si intende che f ha derivate seconde continue in A.434Il risultato esprime infatti che la stazionarieta, cioe l’annullarsi della derivata, e condizione necessaria per avere un punto di massimoo di minimo. Dicendo primo ordine ci si riferisce all’ordine di derivazione: qui si usa infatti la derivata prima.435Basterebbe ricordare il grafico di questa funzione (e una forma quadratica), che abbiamo incontrato parlando appunto di formequadratiche.436Piu precisamente, se f ha in x0 un punto di massimo (minimo) locale e se γ e una curva tale che γ(t0) = x0, allora la restrizione f ◦ γha in t0 un punto di massimo (minimo) locale.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MASSIMI E MINIMI LIBERI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
390
cose sono le condizioni del secondo ordine. Ecco una prima condizione, anche questa necessaria per la presenza di unpunto di massimo o di minimo.
Proposizione Sia f una funzione di classe C 2 nell’insieme A e sia x0 un punto stazionario di f interno ad A. Sipuo dimostrare che
• se x0 e punto di massimo locale, allora ∇2f(x0) e definito negativo o semidefinito negativo;
• se x0 e punto di minimo locale, allora ∇2f(x0) e definito positivo o semidefinito positivo.
Osservazione Ovviamente ∇2f(x0) e il gradiente secondo (matrice hessiana) calcolato nel punto x0. Qui occorrericordare le definizioni viste un paio di lezioni fa: lo studente, se necessario, vada a rivedere le definizioni di formaquadratica (o matrice simmetrica) semidefinita, definita e indefinita.
Ecco ora le condizioni sufficienti per poter dire che un punto e di massimo o di minimo locale.
Proposizione Sia f una funzione di classe C 2 nell’insieme A e sia x0 un punto stazionario di f interno ad A. Sipuo dimostrare che
• se ∇2f(x0) e definita negativa, allora x0 e punto di massimo locale;
• se ∇2f(x0) e definita positiva, allora x0 e punto di minimo locale;
• se ∇2f(x0) e indefinita, allora x0 non e ne di massimo ne di minimo locale.
Osservazione Per lo studio dei massimi e dei minimi locali di una funzione di piu variabili (di classe C 2) si iniziaquindi con la ricerca dei punti stazionari. Poi occorre studiare la natura degli (eventuali) punti stazionari trovati. Sicalcola il gradiente secondo e si studia il segno della forma quadratica associata al gradiente secondo. Se si e fortunatiil gradiente secondo risulta o definito o indefinito, e quindi si puo concludere. Se non si e fortunati, il gradiente secondorisulta semidefinito e non si puo concludere nulla. Si noti quindi che non sempre si riesce a stabilire la natura delpunto stazionario con le derivate seconde. Ma nemmeno questa e una novita: anche con funzioni di una variabile, setroviamo un punto x0 tale che f ′(x0) = f ′′(x0) = 0, da questa sola informazione non possiamo concludere nulla sulfatto che x0 sia di massimo o di minimo.
Osservazione Il comportamento locale di una funzione in prossimita di un suo punto stazionario dipende quindidal segno del suo gradiente secondo. In pratica succede che se il gradiente secondo e indefinito (si ricordi qual e ilsignificato originale di questo termine) ci sono direzioni lungo le quali i valori della funzione aumentano e ci sono altredirezioni lungo le quali i valori di f diminuiscono. A questa situazione, in cui non c’e ne massimo ne minimo, si dail nome di punto di sella. Se invece il gradiente secondo e definito, ad esempio positivo, (e anche qui si riveda ladefinizione del termine) in tutte le direzioni i valori della funzione aumentano e pertanto si ha la presenza di un puntodi minimo.
Osservazione Un’importante applicazione dell’uso delle derivate parziali per la ricerca dei punti di massimo e diminimo in piu variabili e il metodo dei minimi quadrati, che userete l’anno prossimo in Statistica. Si veda l’appendiceA alla fine di questa dispensa.E ora il momento di vedere qualche esempio di studio dei massimi e minimi di una funzione di due variabili.
Esempi
• Cerchiamo i punti di massimo e di minimo locale della funzione
f(x, y) = 2x3 − 6xy + 3y2.
I punti stazionari si trovano calcolando anzitutto il gradiente di f :
∇f(x, y) = (6x2 − 6y,−6x+ 6y),
ponendolo poi uguale al vettore nullo e risolvendo cioe il sistema
{6x2 − 6y = 0
−6x+ 6y = 0, che ha le due soluzioni (0, 0) e (1, 1).437
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MASSIMI E MINIMI LIBERI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
391
Questo significa che, in tutto R2, la funzione f ha soltanto questi due punti stazionari. Ora dobbiamo studiarela natura di questi punti. Ci serve intanto il gradiente secondo, che risulta
∇2f(x, y) =
(12x −6−6 6
)
.
Studiamo la natura del punto (0, 0) calcolando
∇2f(0, 0) =
(0 −6−6 6
)
. Si tratta di una matrice indefinita.438
Pertanto l’origine non e ne di massimo ne di minimo.
Studiamo la natura del punto (1, 1) calcolando
∇2f(1, 1) =
(12 −6−6 6
)
. Si tratta di una matrice definita positiva.439
Pertanto (1, 1) e punto di minimo locale.
• Consideriamo i semplici casi delle funzioni
f(x, y) = x2 + y2 e g(x, y) = x2 − y2.
Abbiamo∇f(x, y) = (2x, 2y) e ∇g(x, y) = (2x,−2y).
Entrambe hanno, come unico punto stazionario, l’origine (0, 0).
I gradienti secondi sono
∇2f(x, y) =
(2 00 2
)
e ∇2g(x, y) =
(2 00 −2
)
.
Il primo e definito positivo, il secondo e indefinito. Pertanto f ha in (0, 0) un punto di minimo locale (in realtae di minimo globale) e g ha in (0, 0) un punto che non e ne di massimo ne di minimo (classico punto di sella,come avevamo gia concluso prima, utilizzando le restrizioni).
• Ora un caso in cui non si riesce a concludere. Consideriamo la funzione f(x, y) = x2 + y4. Il gradiente e
∇f(x, y) = (2x, 4y3), da cui l’unico punto stazionario e l’origine.
Il gradiente secondo e
∇2f(x, y) =
(2 00 12y2
)
e quindi ∇2f(0, 0) =
(2 00 0
)
,
che pero e semidefinito. Quindi le condizioni del secondo ordine non ci consentono di concludere. In realta none un caso particolarmente complicato dato che, osservando che la funzione e non negativa in tutto R2 e chenell’origine si annulla, possiamo dire facilmente che l’origine e punto di minimo globale.
Osservazione Generalmente la ricerca dei punti di massimo o minimo globali e piu complicata. Una funzionepotrebbe avere ad esempio due punti di massimo locale e un punto di minimo locale, ma per sapere chi sono i punti dimassimo e di minimo globali (se ci sono) non possiamo concludere con il semplice confronto dei valori. Se la funzionee definita in tutto R2, non possiamo trascurare quello che succede ad esempio all’infinito.Si consideri ancora l’esempio (gia visto) di f(x, y) = 2x3 − 6xy + 3y2, che ha un minimo locale in (1, 1), oltre ad unpunto stazionario ne di massimo ne di minimo in (0, 0). Non possiamo certo dire che (1, 1) e punto di minimo globalese la motivazione e che si tratta dell’unico punto di minimo trovato.
437Attenzione in generale qui. I sistemi che si ottengono annullando un gradiente non sono in genere dei sistemi lineari, e quindi qui nonvalgono i risultati visti nella parte III, come i teoremi di Cramer o di Rouche-Capelli. Per risolvere un sistema come quello dell’esempiosi puo pero semplicemente ricavare una delle incognite da una delle due equazioni e sostituire quanto trovato nell’altra. Qui ad esempiodalla seconda equazione si ricava y = x; sostituendo nella prima equazione si ha x2 − x = 0, che da per soluzioni x = 0 oppure x = 1. Dax = 0 si trova quindi y = 0 (da cui il punto (0, 0)) e da x = 1 si trova y = 1 (da cui il punto (1, 1)).438Abbiamo imparato che lo studio del segno della f.q. puo essere condotto attraverso il calcolo dei minori principali. In questo casodet∇2f(0, 0) < 0, e quindi, trattandosi di un minore principale di ordine pari, la f.q. e indefinita.439I minori principali di NO sono entrambi positivi e quindi la f.q. e definita positiva.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MASSIMI E MINIMI LIBERI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
392
Possiamo pero dire che f non ha punti di massimo globale, dato che se ne avesse, questi sarebbero anche punti dimassimo locale, mentre di questi non ne abbiamo trovati.In realta f non ha nemmeno punti di minimo globale, in quanto e illimitata. Infatti, se consideriamo la restrizioneche si ottiene con la curva γ(t) = (t, 0), otteniamo (f ◦ γ)(t) = 2t3 che, variando t in tutto R, non e limitata, neinferiormente, ne superiormente. Quindi non lo e nemmeno f .
Esempi
• Cerchiamo i punti di massimo e di minimo della funzione f(x, y) = x(ey − 1), in tutto R2. Il gradiente e
∇f(x, y) = (ey − 1, xey).
Per trovare i punti stazionari dobbiamo annullare il gradiente e considerare quindi il sistema
{ey − 1 = 0
xey = 0cioe
{ey = 1
x = 0.
Quindi c’e un solo punto stazionario: (0, 0). Il gradiente secondo e
∇2f(x, y) =
(0 ey
ey xey
)
e quindi ∇2f(0, 0) =
(0 11 0
)
.
La matrice e indefinita e pertanto (0, 0) non e ne di massimo ne di minimo. Quindi con le condizioni del secondoordine in questo caso possiamo concludere. Proviamo a convincerci del risultato con le restrizioni.
Possiamo osservare che ad esempio le restrizioni lungo gli assi non dicono molto. Infatti
f1(t) = f(t, 0) = 0 e f2(t) = f(0, t) = 0.
Proviamo con la restrizione lungo la retta di equazione y = x:
f3(t) = f(t, t) = t(et − 1).
Lungo questa retta l’origine sembrerebbe un punto di minimo, dato che per ogni t 6= 0 risulta f3(t) > 0. Malungo la retta di equazione y = −x si ha:
f4(t) = f(t,−t) = t(e−t − 1),
e qui l’origine assomiglia invece ad un punto di massimo locale, dato che risulta f4(t) < 0 per ogni t 6= 0.Abbiamo quindi il tipico comportamento di un punto di sella.
Si vede facilmente che f non e limitata: lo provano le due restrizioni f3 ed f4: f3 non e limitata superiormentee f4 non lo e inferiormente.440
• Cerchiamo i punti di massimo e minimo della funzione f(x, y) = e−x2−y2
, in tutto R2. Il gradiente e
∇f(x, y) =(
−2xe−x2−y2
,−2ye−x2−y2)
, da cui l’unico punto stazionario e (0, 0).
Il gradiente secondo e
∇2f(x, y) =
(
−2(1 + 2x2)e−x2−y2
4xye−x2−y2
4xye−x2−y2 −2(1 + 2y2)e−x2−y2
)
e quindi ∇2f(0, 0) =
(−2 00 −2
)
.
Si tratta di una matrice definita negativa e quindi l’origine e un punto di massimo locale. E in realta un puntodi massimo globale: lo si capisce o pensando al grafico (funzione radiale con f0(t) = e−t2) o considerando chef(0, 0) = 1 e
e−x2−y2 ≤ 1 per ogni (x, y) ∈ R2.
Gli esempi visti riguardano funzioni definite in tutto R2. Le condizioni enunciate pero valgono in generale in insiemiaperti. Possono quindi essere utilizzate ad esempio nell’insieme dei punti interni al dominio di una funzione.
440Due restrizioni particolarmente “convenienti” per studiare la natura dell’origine e la limitatezza di f sono quelle di equazione y =ln(x+ 1) e y = ln(1− x): infatti lungo la prima la funzione diventa x 7→ x2 e lungo la seconda x 7→ −x2.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

1 MASSIMI E MINIMI LIBERI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
393
Esempi
• Consideriamo la funzione f(x, y) = x ln y.
La funzione f e definita nel semipiano delle y > 0, che e un insieme aperto. Cerchiamo i punti stazionaricalcolando intanto
∇f(x, y) =(
ln y,x
y
)
, che si annulla nel punto (0, 1).
Il gradiente secondo e
∇2f(x, y) =
(0 1
y1y − x
y2
)
e quindi ∇2f(0, 1) =
(0 11 0
)
.
La matrice e indefinita e quindi il punto non e ne di massimo ne di minimo. Si puo confermare questa conclusioneutilizzando ad esempio le restrizioni date dalle curve α(t) = (t, 1 + t) e β(t) = (t, 1− t).
• Consideriamo la funzione f : C → R, con f(x, y) = x+ y e C ={
(x, y) ∈ R2 : x2 + y2 ≤ 1}
.
Qui l’insieme in cui viene considerata la funzione e un insieme chiuso.441
Le condizioni studiate valgono nei punti interni a C, cioe nell’insieme{
(x, y) ∈ R2 : x2 + y2 < 1}
.442
Osservando che ∇f = (1, 1), possiamo dire che non ci sono punti stazionari interni a C, e quindi non ci sonopunti di massimo o di minimo interni a C. Attenzione a non pensare a questo punto che non ci siano punti dimassimo o di minimo in C: certamente ce ne sono, dato che, essendo C un insieme chiuso e limitato ed essendof continua, il teorema di Weierstrass dice che f ha almeno un punto di massimo e almeno un punto di minimo inC. Evidentemente tali punti non sono interni a C (se lo fossero sarebbero punti stazionari), e devono stare quindisulla frontiera di C, cioe sulla circonferenza di equazione x2 + y2 = 1. Impareremo piu avanti come trovarli.
• Consideriamo la funzione f(x, y) = x2 − y2 nel quadrato Q = [−1, 1]× [−1, 1].Q e un insieme chiuso e limitato di R2, e quindi anche qui il teorema di Weierstrass garantisce che esistono unpunto di massimo e un punto di minimo di f in Q. Annullando il gradiente di f , come gia visto, si trova l’originecome unico punto stazionario, che pero non e ne di massimo ne di minimo. Anche in questo caso allora i puntidi massimo e minimo globali stanno sul bordo. Per trovarli si potrebbero utilizzare le restrizioni di f al bordodel quadrato. Lo studente provi a farlo:443 trovera che ci sono due punti di massimo globale in (1, 0) e (−1, 0)(dove la funzione vale 1), e due punti di minimo globale in (0, 1) e (0,−1) (dove la funzione vale −1). Si notianche che la funzione si annulla nei punti di Q che stanno lungo le rette di equazioni y = x e y = −x.
Esercizio 1.1 Si determinino i punti stazionari delle seguenti funzioni e si stabilisca la loro natura con le
condizioni del secondo ordine. Nei casi in cui tali condizioni non sono sufficienti, si stabilisca la natura dei puntistazionari con lo studio del segno.
(a) f(x, y) = x2 − xy + y2 − x+ y, in tutto R2
(b) f(x, y) = x2 − 3xy + y2 + x+ y + 1, in tutto R2
(c) f(x, y) = x3 − xy + y3, in tutto R2
(d) f(x, y) = x2(ey − 1), in tutto R2
(e) f(x, y) = x2 ln2 y, nel dominio di f , cioe R× (0,+∞)
(f) f(x, y) = x4 + y4 − 4xy, in tutto R2
(g) f(x, y) = x+ y − 13 (x
3 + y3), in tutto R2
(h) f(x, y) = (1− x2)y + x2, in tutto R2
441La funzione esiste anche all’esterno del cerchio C, ma la consideriamo solo nel cerchio.442Si rifletta su questo particolare: le condizioni, mettiamo quelle del primo ordine, non sono necessarie sul bordo del cerchio, cioe inaltre parole non e detto che in un punto di massimo che sta sul bordo il gradiente debba essere nullo, dato che il fatto che il punto sia dimassimo potrebbe dipendere non tanto dalle caratteristiche della funzione quanto da quelle del bordo e la condizione del primo ordine nontiene in nessun conto come e fatto il bordo.443Ad esempio, per trovare la restrizione di f sul lato superiore del quadrato, basta pensare alla curva γ(t) = (t, 1), con t ∈ [−1, 1], cheha per sostegno appunto questo lato del quadrato. La restrizione di f e allora la funzione t 7→ t2 − 1.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MASSIMI E MINIMI VINCOLATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
394
2 Massimi e minimi vincolati
Abbiamo incontrato in precedenza il concetto di curva in R2.
Definizione Diciamo che una curva γ : I → R2 e regolare se e di classe C 1 e se γ′(t) 6= 0 per ogni t ∈ I.444
Esempi La curva γ(t) = (t, 1−t), con t ∈ R, il cui sostegno445 e la retta di equazioney = 1− x, e regolare, dato che si ha γ′(t) = (1,−1) per ogni t ∈ R.La curva γ(t) = (t2−1, t), con t ∈ R, il cui sostegno e la parabola raffigurata a fianco,e regolare. Infatti γ′(t) = (2t, 1) e questo vettore non e mai nullo.Tra breve ci porremo il problema di determinare i punti di massimo e di minimodi una funzione di due variabili lungo una curva del piano. Per arrivare ad unaformulazione piu rigorosa del problema e per vedere i metodi per la sua risoluzioneoccorre introdurre qualche concetto generale.
x1
x2
bγ(0)
bγ(1)
bγ(−1)
In R2 una curva regolare e un caso particolare di un concetto piu generale, quello di varieta, proposto nella seguentedefinizione.
Definizione Un sottoinsieme V di R2 si dice una varieta unidimensionale se V e localmente il grafico di una funzionedi classe C 1.
Osservazione Occorre chiarire il significato di questa definizione. “Localmente”significa in un opportuno intorno. La definizione vuol dire che per ogni punto P ∈ Vnelle vicinanze di P l’insieme V e il grafico di una qualche funzione. Ovviamente nonsi richiede che, qualunque sia il punto P , la funzione sia sempre la stessa: la funzionedipende, in generale, dal punto P che scegliamo. Vediamo qualche esempio. x1
x2
b P
V
Esempi
• Consideriamo la parabola di equazione y = x2.
Preso un qualunque punto P = (x0, y0) della parabola, e ovvio che nelle vi-cinanze di P la parabola e il grafico della funzione x 7→ x2, definita per xappartenente ad un intervallo (x0 − δ, x0 + δ).446
Quindi la parabola e una varieta unidimensionale in R2. x
y
bP
x0
y0
x0−δ x0+δ
• Consideriamo la parabola di equazione x = y2.
x
y
bP
y0
y0+δ
y0−δ
x0
Se prendiamo un qualunque punto P = (x0, y0) della parabola, anche qui ov-viamente nelle vicinanze di P la parabola e il grafico della funzione y 7→ y2,definita per y appartenente ad un intervallo (y0 − δ, y0 + δ). Quindi anchequesta parabola e una varieta unidimensionale in R2.Possiamo anche osservare che, con y0 > 0, nelle vicinanze di P la parabolae anche il grafico della funzione x 7→ √x, con x appartenente ad un intornodel tipo (x0 − δ, x0 + δ), a patto che tale intorno non contenga l’origine. E seprendiamo un punto P = (x0, y0) della parabola con y0 < 0, nelle vicinanze diP la parabola e il grafico della funzione x 7→ −√x, con x in (x0 − δ, x0 + δ), eanche qui l’intorno non deve contenere l’origine.
Se prendiamo infine il punto P = (0, 0), nelle vicinanze di P la parabola non e il grafico di nessuna funzione dellavariabile x. La parabola e invece il grafico della funzione y 7→ y2, definita per y in un intorno (−δ, δ). Si notiche nella definizione di varieta unidimensionale non si fa riferimento a quale tipo di funzione, se della variabilex o y, ma si chiede soltanto che ci sia una funzione di cui la varieta e il grafico.
• Consideriamo la circonferenza di equazione x2 + y2 = 1.
444Non vado troppo in profondita su questo aspetto. Mi limito a dire che, se γ(t) = (γ1(t), γ2(t)), allora diciamo che la curva e di classeC 1 se le sue due componenti γ1(t) e γ2(t) sono di classe C 1 e chiamiamo derivata di γ semplicemente la funzione γ′(t) = (γ′
1(t), γ′2(t)).
Quindi, dicendo γ′(t) 6= 0 per ogni t ∈ I, si intende che il vettore γ′(t) non e mai nullo.445Ricordo che il sostegno della curva e la sua immagine, cioe l’insieme dei punti γ(t), al variare di t nell’intervallo I.446Questo e un caso in cui la funzione e sempre la stessa, qualunque sia il punto, ma abbiamo gia detto che in altri casi puo non esserecosı.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MASSIMI E MINIMI VINCOLATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
395
Preso un punto P = (x0, y0) sulla circonferenza, con y0 > 0, la circonferenza elocalmente il grafico della funzione x 7→
√1− x2. Se prendiamo un punto P = (x0, y0)
con y0 < 0, la circonferenza e localmente il grafico della funzione x 7→ −√1− x2.
Se prendiamo il punto P = (1, 0), nelle vicinanze di P la circonferenza e il grafico
della funzione y 7→√
1− y2, con y in un opportuno intervallo del tipo (−δ, δ).Se infine prendiamo P = (−1, 0), nelle vicinanze di P la circonferenza e il grafico della
funzione y 7→ −√
1− y2, con y in un opportuno intervallo del tipo (−δ, δ).x
y
bP
x0
y0y0+δ
y0−δ
Abbiamo esaminato tutti i punti della circonferenza. La circonferenza di equazione x2 + y2 = 1 e dunque unavarieta unidimensionale in R2.
Si noti che con y0 > 0 e x0 > 0 la circonferenza e localmente il grafico anche della funzione y 7→√
1− y2. Nelpunto (0, 1) la circonferenza e localmente il grafico di una funzione della variabile x ma non della variabile y.
• Consideriamo l’insieme delle soluzioni dell’equazione x2 − y2 = 0, cioe
(x + y)(x− y) = 0,
che e dato dall’unione delle rette di equazione y = x e y = −x. Tale insiemenon e una varieta unidimensionale in R2. Infatti, se prendiamo l’origine, chefa parte di questo insieme, nelle vicinanze di questo punto l’insieme non e ilgrafico di nessuna funzione, ne della variabile x, ne della variabile y, come sipuo capire facilmente.
x
y y = x
y = −x
Osservazione Possiamo notare dagli esempi che, nei casi in cui abbiamo una varieta unidimensionale, la funzionedi cui la varieta e il grafico e stata ottenuta “ricavando” y in funzione di x (oppure x in funzione di y) nell’equazioneche definisce la varieta. Si dice che abbiamo esplicitato la variabile x (o la y) in funzione dell’altra variabile. None difficile intuire che questo non sempre si puo fare: l’equazione che definisce la varieta potrebbe essere molto piucomplicata di quelle che abbiamo incontrato negli esempi. Si pensi ad esempio all’insieme delle soluzioni dell’equazionex3 +xy+ y3 = 0. Oltre al problema di capire se e una varieta, e evidente che esplicitare una variabile rispetto all’altranon e cosı facile come in precedenza.
In generale esempi di varieta unidimensionali in R2 sono:
• i sostegni delle curve regolari iniettive;447
• l’insieme delle soluzioni di un’equazione del tipo g(x, y) = 0 con g di classe C 1 e gradiente non nullo.448
Sia ora f una funzione di classe C 1 sull’aperto A ⊂ R2 e sia V ⊂ A una varieta unidimensionale. Vogliamo studiarecome si determinano i punti di massimo/minimo locale della restrizione di f a V . V si chiama anche il vincolo, dacui il nome di ricerca dei massimi/minimi vincolati.Anzitutto osserviamo che un punto puo essere di massimo/minimo vincolato senza essere di massimo/minimo per f .Ad esempio, la funzione f(x, y) = x2− y2 ha nell’origine un punto di minimo lungo il vincolo dato dall’asse x, ma nonha nell’origine un punto di minimo (l’origine e, come abbiamo visto, un punto di sella).
Vincolo in forma parametrica
Vediamo ora il caso di un vincolo dato come sostegno di una curva regolare (si dice anche che il vincolo e dato informa parametrica). Sia V il sostegno di una curva regolare γ e sia P = γ(t0). Si puo provare facilmente che in questocaso P e un punto stazionario vincolato di f su V se e solo se
Df(γ(t0)) = 0.449
447Non approfondisco la questione delle curve iniettive, dette anche semplici. Una curva e iniettiva se non passa mai due volte per lostesso punto. L’ultimo esempio visto sopra mostra che se una curva passa due volte per lo stesso punto non da origine ad una varieta.448Anche qui non approfondiamo la questione: dico solo che l’annullarsi del gradiente e un fatto sgradevole per le proprieta che stiamoconsiderando. Si osservi che questo risultato fornisce un modo operativo per capire se un insieme nel piano e una varieta: studiandol’annullarsi del gradiente abbiamo cioe modo di sapere ad esempio se l’insieme delle soluzioni dell’equazione x3 +xy+y3 = 0 e una varieta.
Si osservi anche che nell’ultimo esempio (l’insieme delle soluzioni dell’equazione x2 − y2 = 0), che non e una varieta, la funzione eg(x, y) = x2−y2 e il gradiente di questa nell’origine si annulla. L’annullarsi del gradiente e quindi un evento che puo impedire di esprimerel’insieme come grafico di una funzione.449Attenzione a non fraintendere in qualche modo la notazione: si tratta della derivata, calcolata in t0, della funzione t 7→ f(γ(t)) =f(γ1(t), γ2(t)).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MASSIMI E MINIMI VINCOLATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
396
Esempio Troviamo i punti stazionari vincolati della funzione f(x, y) = x+ y sul sostegno della curva γ(t) = (t3, t2),con t ∈ R. Si ha
Df(γ(t)) = Df(t3, t2) = D(t3 + t2) = 3t2 + 2t = 0, che ha per soluzioni 0 e − 23 .
Ci sono due punti stazionari vincolati: l’origine e il punto (− 827 ,
49 ).
Esempio Troviamo i punti stazionari vincolati della funzione f(x, y) = ex−y2 sul sostegno della curva γ(t) = (t, et),con t ∈ R. Si ha
Df(γ(t)) = Df(t, et) = D(et − e2t) = et − 2e2t = et(1− 2et) = 0, che ha per soluzione t0 = − ln 2.
C’e un unico punto stazionario vincolato, il punto P = γ(t0) = (− ln 2, 12 ).
Osservazione Per stabilire se i punti stazionari trovati sono punti di massimo/minimo si possono usare le tecnichestudiate per le funzioni di una variabile. Infatti e chiaro che, una volta sostituita l’espressione della curva nella funzione,si tratta di studiare una funzione di una sola variabile, data dal parametro t.
Esercizio 2.1 Si determinino i punti stazionari vincolati delle seguenti funzioni, sul sostegno delle curve indicate:
(a) f(x, y) = x2 + y2, con γ(t) = (t2, t) e t ∈ R
(b) f(x, y) = x+ y, con γ(t) = (t3 − 1,−t) e t ∈ R
(c) f(x, y) = 2x2 − y2, con γ(t) = (t2, t3) e t ∈ (−1, 1)
(d) f(x, y) = x+ ln(1 + y2), con γ(t) = (1 + t2, t) e t ∈ R
Vincolo “esplicitabile”
Passiamo ora al caso in cui la varieta V (il vincolo) sia dato come soluzioni di una certa equazione. Per quanto dettoin precedenza, supponiamo che nelle vicinanze del punto P = (x0, y0) ∈ V la varieta V sia il grafico della funzioney = g(x) di classe C 1, con x ∈ (x0 − δ, x0 + δ).450
Definizione Diciamo che P e punto stazionario vincolato di f sulla varieta V se
Df(x0, g(x0)
)= 0.451
Osservazione Naturalmente, se x0 e punto di massimo o di minimo per la funzione x 7→ f(x, g(x)), allora (x0, y0) =(x0, g(x0)) e punto stazionario vincolato di f su V .
Osservazione Se avessimo che V e il grafico della funzione x = h(y), di classe C 1, con y ∈ (y0−δ, y0+δ), potremmodire che P e punto stazionario vincolato di f su V se
Df(h(y0), y0
)= 0.
Esempio Cerchiamo i punti stazionari vincolati della funzione f(x, y) = x2 + y2 sulla varieta definita dall’equazionex+ y − 1 = 0.Si tratta di una retta: possiamo “esplicitare il vincolo” (cioe esplicitare la y nel vincolo) scrivendo y = 1 − x, conx ∈ R. Quindi consideriamo la funzione x 7→ f(x, 1 − x), con x ∈ R. Si ha
Df(x, 1− x) = D(2x2 − 2x+ 1) = 4x− 2 = 0, che ha per soluzione x = 12 (da cui y = 1
2 ).
Pertanto c’e il solo punto stazionario vincolato P = (12 ,12 ).
Esempio Cerchiamo i punti stazionari vincolati della funzione f(x, y) = x2− y2 sulla varieta V data dalla paraboladi equazione y − x2 = 0. Dopo aver esplicitato il vincolo nella forma y = x2, consideriamo la funzione x 7→ f(x, x2),con x ∈ R. Si ha
Df(x, x2) = D(x2 − x4) = 2x− 4x3 = 2x(1− 2x2) = 0, che ha per soluzioni x = 0, x = ± 1√2.
450Stiamo in pratica ipotizzando di conoscere, almeno in un intorno del punto che ci interessa, l’espressione della funzione di cui la varietae il grafico.451A scanso di possibili fraintendimenti, Df(x0, g(x0)) e la derivata della funzione x 7→ f(x, g(x)), calcolata nel punto x0.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MASSIMI E MINIMI VINCOLATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
397
Pertanto i punti stazionari vincolati sono i punti (0, 0), ( 1√2, 12 ) e (− 1√
2, 12 ).
Esempio Cerchiamo i punti stazionari vincolati della funzione f(x, y) = x + y sulla varieta definita dall’equazionex− y2 = 0.Si tratta di una parabola: possiamo esplicitare il vincolo scrivendo x = y2, con y ∈ R. Quindi consideriamo la funzioney 7→ f(y2, y), sempre con y ∈ R. Si ha
Df(y2, y) = D(y2 + y) = 2y + 1 = 0, che ha per soluzione y = − 12 .
Pertanto c’e il solo punto stazionario vincolato P = (14 ,− 12 ).
Esempio Cerchiamo i punti stazionari vincolati della funzione f(x, y) = x2−xy+y2 sulla varieta data dalla paraboladi equazione x− y2 + 1 = 0. Dopo aver esplicitato il vincolo nella forma x = y2 − 1, possiamo scrivere
f(y2 − 1, y) = (y2 − 1)2 − y(y2 − 1) + y2 = y4 − y3 − y2 + y + 1.
Annullando la derivata si ottiene
Df(y2 − 1, y) = 4y3 − 3y2 − 2y + 1 = 0, cioe (y − 1)(4y2 + y − 1) = 0.
Abbiamo tre possibili soluzioni, che sono y = 1, oppure y = −1±√17
8 . Dall’equazione x = y2 − 1 otteniamo i tre punti
della parabola che sono i punti stazionari vincolati. Il primo e (0, 1) e gli altri due sono((−1−
√17
8 )2 − 1, −1−√17
8
)e
((−1+
√17
8 )2 − 1, −1+√17
8
).
Osservazione Puo sembrare che il determinare i punti stazionari vincolati non sia piu difficile che trovare i puntistazionari di una funzione di una variabile, dato che, negli esempi visti, in effetti abbiamo sempre dovuto annullare laderivata di una funzione di una sola variabile. Ovviamente questo e vero, a patto pero di essere in grado di esplicitareil vincolo. Una varieta e localmente, per definizione, il grafico di una funzione, ma trovare nei casi concreti questafunzione, come gia detto, puo non essere per nulla agevole.
Osservazione Analogamente al caso del vincolo in forma parametrica, nei casi in cui si puo esplicitare la relazionetra x e y che definisce il vincolo non e difficile stabilire se i punti stazionari vincolati trovati sono punti di massimo odi minimo vincolati: basta infatti usare le tecniche studiate in precedenza per le funzioni di una variabile.Cosı ad esempio non e difficile capire che il punto (14 ,− 1
2 ) e un punto di minimo locale vincolato per la funzionef(x, y) = x+ y sulla parabola di equazione x− y2 = 0. La restrizione di f al vincolo, cioe la funzione y 7→ y2 + y, hain y = − 1
2 un punto di minimo.Analogamente il punto (12 ,
12 ) e un punto di minimo locale vincolato per la funzione f(x, y) = x2 + y2 sulla retta di
equazione x + y − 1 = 0. Anche qui la restrizione di f al vincolo, cioe la funzione x 7→ 2x2 − 2x+ 1, ha in x = 12 un
punto di minimo.
Esercizio 2.2 Si determinino i punti stazionari vincolati delle seguenti funzioni, sul vincolo indicato, espresso
in forma di equazione:
(a) f(x, y) = x+ y2, sul vincolo dato da y − x2 = 0
(b) f(x, y) = x2 + 2xy + 2y2, sul vincolo dato da 2x− y + 1 = 0
(c) f(x, y) = x3 − xy + y3, sul vincolo dato da x+ y + 1 = 0
(d) f(x, y) = (x2 + 1) ln y, sul vincolo dato da x2 − y + 1 = 0
Caso generale – Funzione Lagrangiana
Per finire, vediamo un fondamentale risultato generale. Supponiamo che il vincolo sia dato in forma implicita comeinsieme delle soluzioni di un’equazione del tipo g(x, y) = 0, con g funzione di classe C 1 e ∇g 6= 0.452
Si puo dimostrare che P e un punto stazionario vincolato di f su V se e solo se ∇f(P ) e un multiplo di ∇g(P ).453452Ribadisco che, se siamo in grado di esplicitare il vincolo, allora abbiamo gia un modo per procedere. Quanto segue assume quindiparticolare valore nei casi in cui risulta complicato o non siamo in grado di esplicitare il vincolo.453Significa quindi che i due vettori ∇f(P ) e ∇g(P ) sono proporzionali, cioe in altre parole che esiste uno scalare λ tale che ∇f(P ) =λ∇g(P ). Questo risultato e dovuto a Lagrange.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MASSIMI E MINIMI VINCOLATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
398
La ricerca dei punti stazionari vincolati in questi casi si puo effettuare quindi scrivendo il sistema
∂f∂x = λ ∂g
∂x
∂f∂y = λ∂g
∂y
g(x, y) = 0
(19)
in cui le prime due equazioni richiedono che il punto cercato renda proporzionali i gradienti e la terza chiede inveceche tale punto appartenga al vincolo. Anche il coefficiente di proporzionalita λ, detto moltiplicatore di Lagrange eun’incognita nel sistema. Questo metodo si chiama appunto metodo dei moltiplicatori di Lagrange. Si tratta diun metodo importantissimo, tanto nella teoria quanto nelle applicazioni. Esso ha una validita che va ben oltre l’ambitoche stiamo qui considerando. Si tratta di uno dei metodi piu generali della matematica e delle sue applicazioni.Alla scrittura del sistema (19) si puo arrivare anche definendo la cosiddetta funzione Lagrangiana (o semplicementeLagrangiana) del problema:
L(x, y, λ) = f(x, y)− λg(x, y).
Al sistema (19), che raccoglie le condizioni di Lagrange, si arriva annullando il gradiente della Lagrangiana, e cioe
∇L(x, y, λ) =(∂f
∂x− λ∂g
∂x,∂f
∂y− λ∂g
∂y,−g(x, y)
)
.
E importante osservare che, dopo aver definito la Lagrangiana, la condizione di stazionarieta vincolata si traducenella stazionarieta (senza vincoli) della funzione Lagrangiana. Quindi possiamo dire che i punti di massimo/minimovincolati vanno cercati tra i punti stazionari della funzione Lagrangiana.
Vediamo ora qualche esempio.
Esempio Consideriamo la funzione f(x, y) = xy sul vincolo dato dall’equazione x+ y − 1 = 0.La funzione Lagrangiana del problema e
L(x, y, λ) = xy − λ(x+ y − 1).
Il gradiente della Lagrangiana e∇L(x, y, λ) =
(y − λ, x− λ,−x− y + 1
)
e quindi le condizioni di Lagrange sono
y − λ = 0
x− λ = 0
x+ y = 1
cioe
y = λ
x = λ
x+ y = 1
cioe
y = λ
x = λ
2λ = 1
dal quale si ottiene λ = x = y = 12 .
Pertanto si ha l’unico punto stazionario vincolato (12 ,12 ). Si noti che il punto trovato sta sul vincolo e in questo punto
i gradienti di f(x, y) = xy e di g(x, y) = x + y − 1 sono rispettivamente ∇f(12 , 12 ) = (12 ,12 ) e ∇g(12 , 12 ) = (1, 1),
chiaramente proporzionali.
Esempio Consideriamo l’esempio gia incontrato della funzione f(x, y) = x2 − y2 sul vincolo dato dall’equazionex2 − y = 0.La funzione Lagrangiana del problema e
L(x, y, λ) = x2 − y2 − λ(x2 − y).
Il gradiente della Lagrangiana e∇L(x, y, λ) =
(2x− 2λx,−2y + λ,−x2 + y
)
e quindi le condizioni di Lagrange sono
2x− 2λx = 0
−2y + λ = 0
x2 = y
cioe
2x(1− λ) = 0
2y = λ
x2 = y.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

2 MASSIMI E MINIMI VINCOLATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
399
Ragionando sulla prima equazione si ha che deve essere o x = 0 oppure λ = 1. Con x = 0 si ottiene y = 0 dalla terzae λ = 0 dalla seconda. Altrimenti con λ = 1 si ha y = 1
2 dalla seconda e x = ± 1√2dalla terza.
Pertanto si trovano tre punti stazionari vincolati: (0, 0), ( 1√2, 12 ) e (− 1√
2, 12 ), gia trovati prima per altra via.
Esempio Altro caso gia visto: troviamo i punti stazionari vincolati della funzione f(x, y) = x + y sul vincolo datodall’equazione x− y2 = 0.La funzione Lagrangiana del problema e
L(x, y, λ) = x+ y − λ(x − y2).
Le condizioni di Lagrange sono
1− λ = 0
1 + 2λy = 0
x− y2 = 0 454
cioe
λ = 1
1 + 2y = 0
x = y2cioe
λ = 1
y = − 12
x = 14 .
Unico punto stazionario vincolato e quindi (14 ,− 12 ).
Esempio Riprendiamo la funzione f(x, y) = x2 + y2 sul vincolo dato dall’equazione x+ y − 1 = 0.La funzione Lagrangiana del problema e
L(x, y, λ) = x2 + y2 − λ(x+ y − 1).
Le condizioni di Lagrange sono
2x− λ = 0
2y − λ = 0
x+ y − 1 = 0
cioe
x = λ/2
y = λ/2
λ/2 + λ/2− 1 = 0
cioe
λ = 1
x = 1/2
y = 1/2.
Unico punto stazionario vincolato e quindi (12 ,12 ).
Esempio Consideriamo la funzione f(x, y) = x+ y sul vincolo dato dall’equazione x2 + y2 − 1 = 0, notando che quiesplicitare la x o la y non e cosı banale.455
La funzione Lagrangiana del problema e
L(x, y, λ) = x+ y − λ(x2 + y2 − 1).
Le condizioni di Lagrange sono
1− 2λx = 0
1− 2λy = 0
x2 + y2 − 1 = 0
cioe
1 = 2λx
1 = 2λy
x2 + y2 − 1 = 0.
Osserviamo che λ = 0 non porta a soluzioni.456 Quindi, dato che deve essere λ 6= 0, possiamo dividere per λ eotteniamo
x = 1/(2λ)
y = 1/(2λ)
1/(4λ2) + 1/(4λ2)− 1 = 0
cioe
λ = ±1/√2
x = 1/(2λ)
y = 1/(2λ).
Soluzioni sono pertanto i due punti ( 1√2, 1√
2) e (− 1√
2,− 1√
2).
Si notera che in questi esempi abbiamo parlato solo di punti stazionari (vincolati), e non di punti di massimo o diminimo. Lo studente lungimirante avra capito che le condizioni di Lagrange che abbiamo visto sono a tutti gli effetticondizioni del primo ordine. Ci si aspetta allora anche condizioni del secondo ordine, che usano cioe le derivate seconde.Ci sono infatti, ma presumibilmente il tempo a mia disposizione per questo corso sta per finire. Non vediamo questecondizioni.
454Si ricordi che l’ultima condizione di Lagrange e semplicemente l’appartenenza al vincolo, che quindi puo essere riscritta direttamente,senza fare il calcolo della derivata parziale rispetto al moltiplicatore.455Non e difficile ma occorre considerare due casi possibili. Infatti, se vogliamo ad esempio esplicitare y in funzione di x possiamo riscrivereil vincolo nella forma y2 = 1 − x2 ma ora dobbiamo tenere in conto che non c’e un solo modo di scrivere y in funzione di x, dato che puoessere y =
√1− x2 oppure y = −
√1− x2. Quindi per questa strada dovremmo considerare le due possibilita separatamente. Col metodo
dei moltiplicatori di Lagrange questo non serve.456Con λ = 0 le prime due equazioni non sono certamente soddisfatte.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
400
Esercizio 2.3 Si determinino i punti stazionari vincolati delle seguenti funzioni, sul vincolo indicato, espresso
in forma di equazione: si utilizzi il metodo dei moltiplicatori di Lagrange.
(a) f(x, y) = xy, sul vincolo dato da 2x− y + 1 = 0
(b) f(x, y) = x2 + y2, sul vincolo dato da x− y + 1 = 0
(c) f(x, y) = x, sul vincolo dato da x2 + y2 − 1 = 0
(d) f(x, y) = x2 − y2, sul vincolo dato da x+ y − 1 = 0
3 Soluzioni degli esercizi
Esercizio 1.1
(a) Il gradiente della funzione f(x, y) = x2 − xy + y2 − x+ y e
∇f(x, y) = (2x− y − 1,−x+ 2y + 1) .
Quindi scriviamo il sistema
{2x− y − 1 = 0
−x+ 2y + 1 = 0cioe
{2x− y = 1
x− 2y = 1.
Si tratta di un sistema di equazioni lineari. Con le tecniche imparate nella parte III di questo corso si trovafacilmente l’unica soluzione (13 ,− 1
3 ), che e quindi l’unico punto stazionario della funzione.
Per stabilire la natura di tale punto calcoliamo il gradiente secondo
∇2f(x, y) =
(2 −1−1 2
)
che risulta definita positiva. Il punto (13 ,− 13 ) e pertanto un punto di minimo locale.
(b) Il gradiente della funzione f(x, y) = x2 − 3xy + y2 + x+ y + 1 e
∇f(x, y) = (2x− 3y + 1,−3x+ 2y + 1) .
Quindi scriviamo il sistema
{2x− 3y + 1 = 0
−3x+ 2y + 1 = 0cioe
{2x− 3y = −1−3x+ 2y = −1.
Si trova l’unica soluzione (1, 1), che e l’unico punto stazionario della funzione.
Per stabilire la natura del punto calcoliamo il gradiente secondo
∇2f(x, y) =
(2 −3−3 2
)
che risulta indefinita. Il punto (1, 1) non e pertanto ne di massimo ne di minimo locale (e un punto di sella).
(c) Il gradiente della funzione f(x, y) = x3 − xy + y3 e
∇f(x, y) =(3x2 − y,−x+ 3y2
).
Quindi scriviamo il sistema
{3x2 − y = 0
−x+ 3y2 = 0cioe
{y = 3x2
−x+ 27x4 = 0cioe
{x(27x3 − 1) = 0
y = 3x2.
Con x = 0 si trova y = 0 e quindi la soluzione (0, 0). Con x = 1/3 si trova y = 1/3 e quindi la soluzione (13 ,13 ).
Vi sono dunque due punti stazionari: l’origine e (13 ,13 ).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
401
Per stabilire la natura dei punti stazionari calcoliamo il gradiente secondo
∇2f(x, y) =
(6x −1−1 6y
)
.
Calcolando questa matrice nei due punti si ha allora
∇2f(0, 0) =
(0 −1−1 0
)
, che e indefinita e
∇2f(13 ,13 ) =
(2 −1−1 2
)
, che e definita positiva.
Il punto (0, 0) non e ne di massimo ne di minimo locale, mentre il punto (13 ,13 ) e di minimo locale.
(d) Il gradiente della funzione f(x, y) = x2(ey − 1) e
∇f(x, y) =(2x(ey − 1), x2ey
).
Quindi scriviamo il sistema{
2x(ey − 1) = 0
x2ey = 0.
Dalla seconda equazione, dato che non puo essere ey = 0, deve necessariamente essere x = 0. La prima equazionee allora necessariamente soddisfatta. Pertanto le soluzioni sono tutti i punti con x = 0, e cioe tutti i punti dell’assey. Questi sono i punti stazionari.
Per stabilirne la natura calcoliamo il gradiente secondo
∇2f(x, y) =
(2(ey − 1) 2xey
2xey x2ey
)
.
Nei punti del tipo (0, y) il gradiente secondo vale
∇2f(0, y) =
(2(ey − 1) 0
0 0
)
, che e semidefinita (positiva o negativa a seconda di y).
Le condizioni del secondo ordine non consentono di concludere. Possiamo allora studiare il segno della funzione f :la funzione e nulla sugli assi, positiva sul primo e sul secondo quadrante e negativa sul terzo e quarto quadrante.Quindi i punti del tipo (0, y) con y > 0 sono di minimo locale, quelli del tipo (0, y) con y < 0 sono di massimolocale, mentre l’origine non e ne di massimo ne di minimo.
(e) La funzione f(x, y) = x2 ln2 y e ovviamente definita sulle y > 0. Il gradiente della funzione e
∇f(x, y) =(
2x ln2 y,2x2 ln y
y
)
.
Quindi scriviamo il sistema {
2x ln2 y = 02x2 ln y
y = 0.
Dalla prima, se x = 0 anche la seconda e soddisfatta, e quindi sono soluzioni tutti i punti del tipo (0, y), cony > 0. Poi, sempre dalla prima, se y = 1 anche la seconda e soddisfatta e pertanto sono soluzioni anche tutti ipunti del tipo (x, 1), con x qualunque. Allora i punti stazionari sono quelli del semiasse positivo delle y e quellidella retta di equazione y = 1.
Per stabilirne la natura calcoliamo il gradiente secondo
∇2f(x, y) =
(
2 ln2 y 4x ln y · 1y4x ln y · 1y 2x2 · 1−ln y
y2
)
.
Nei punti del tipo (0, y) il gradiente secondo vale
∇2f(0, y) =
(2 ln2 y 0
0 0
)
, che e semidefinita positiva.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
402
Nei punti del tipo (x, 1) il gradiente secondo vale
∇2f(x, 1) =
(0 00 2x2
)
, che e ancora semidefinita positiva.
Le condizioni del secondo ordine non consentono di concludere in nessun caso. Lo studio del segno della funzione,che e nulla sui punti stazionari e per il resto positiva, porta a dire che tutti i punti stazionari sono di minimo(globale).
(f) Il gradiente della funzione f(x, y) = x4 + y4 − 4xy e
∇f(x, y) =(4x3 − 4y, 4y3 − 4x
).
Quindi scriviamo il sistema
{4x3 − 4y = 0
4y3 − 4x = 0cioe
{4x3 = 4y
4y3 = 4xcioe
{x3 = y
x9 = x
e quest’ultimo fornisce le soluzioni (0, 0), (1, 1) e (−1,−1), che sono i punti stazionari.
Il gradiente secondo e
∇2f(x, y) =
(12x2 −4−4 12y2
)
.
Pertanto si ha
∇2f(0, 0) =
(0 −4−4 0
)
, che e indefinita.
Si ha poi
∇2f(1, 1) = ∇2f(−1,−1) =(12 −4−4 12
)
, che e definita positiva.
Pertanto possiamo concludere che (1, 1) e (−1,−1) sono punti di minimo locale, mentre (0, 0) non e ne di massimone di minimo.
(g) Il gradiente della funzione f(x, y) = x+ y − 13 (x
3 + y3) e
∇f(x, y) =(1− x2, 1− y2
).
Quindi scriviamo il sistema{
1− x2 = 0
1− y2 = 0cioe
{x2 = 1
y2 = 1
e quest’ultimo fornisce le soluzioni (1, 1), (1,−1), (−1, 1) e (−1,−1).Il gradiente secondo e
∇2f(x, y) =
(−2x 00 −2y
)
.
Pertanto si ha
∇2f(1, 1) =
(−2 00 −2
)
, che e definita negativa;
poi
∇2f(1,−1) =(−2 00 2
)
, che e indefinita;
poi
∇2f(−1, 1) =(2 00 −2
)
, che e indefinita;
e infine
∇2f(−1,−1) =(2 00 2
)
, che e definita positiva.
Pertanto possiamo concludere che (1, 1) e un punto di massimo locale, (−1,−1) e punto di minimo locale, (1,−1)e (−1, 1) non sono ne di massimo ne di minimo.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
403
(h) Il gradiente della funzione f(x, y) = (1− x2)y + x2 e
∇f(x, y) =(−2xy + 2x, 1− x2
).
Quindi scriviamo il sistema{ −2xy + 2x = 0
1− x2 = 0cioe
{2x(1− y) = 0
x2 = 1
e quest’ultimo fornisce le soluzioni (1, 1) e (−1, 1). Il gradiente secondo e
∇2f(x, y) =
(−2y + 2 −2x−2x 0
)
.
Pertanto si ha
∇2f(1, 1) =
(0 −2−2 0
)
, che e indefinita
e
∇2f(−1, 1) =(0 22 0
)
, che e indefinita.
Pertanto possiamo concludere che i due punti stazionari non sono ne di massimo ne di minimo.
Esercizio 2.1
(a) La restrizione della funzione f alla curva γ e la funzione
g(t) = f(γ(t)) = f(t2, t) = t4 + t2.
Calcolando la derivata di questa si ottiene
g′(t) = 4t3 + 2t = 2t(2t2 + 1).
Questa funzione si annulla soltanto per t = 0, pertanto c’e l’unico punto stazionario (0, 0).
(b) La restrizione della funzione f alla curva γ e la funzione
g(t) = f(γ(t)) = f(t3 − 1,−t) = t3 − 1− t.
Calcolando la derivata di questa si ottieneg′(t) = 3t2 − 1.
Questa funzione si annulla per t = ± 1√3, pertanto ci sono due punti stazionari, i punti
(3−3/2 − 1,−3−1/2
)e
(−3−3/2 − 1, 3−1/2
).
(c) La restrizione della funzione f alla curva γ e la funzione
g(t) = f(γ(t)) = f(t2, t3) = 2t4 − t6 = t4(2 − t2).
Calcolando la derivata di questa si ottiene
g′(t) = 8t3 − 6t5 = 2t3(4− 3t2).
Questa funzione si annulla per t = 0 oppure per t = ± 2√3, valori questi ultimi che pero non appartengono
all’intervallo (−1, 1). Pertanto c’e il solo punto stazionario dato dall’origine.
(d) La restrizione della funzione f alla curva γ e la funzione
g(t) = f(γ(t)) = f(1 + t2, t) = 1 + t2 + ln(1 + t2).
Calcolando la derivata di questa si ottiene
g′(t) = 2t+2t
1 + t2= 2t
(
1 +1
1 + t2
)
.
Questa funzione si annulla soltanto per t = 0. Pertanto c’e il solo punto stazionario (1, 0).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
404
Esercizio 2.2
(a) Possiamo esplicitare il vincolo nella forma y = x2. Allora consideriamo la funzione
f(x, x2) = x+ x4.
La derivata si annulla in x = − 13√4= −4−1/3. Il punto stazionario vincolato e quindi (−4−1/3, 4−2/3).
(b) Possiamo esplicitare il vincolo nella forma y = 2x+ 1. Allora consideriamo la funzione
f(x, 2x+ 1) = x2 + 2x(2x+ 1) + 2(2x+ 1)2 = 13x2 + 10x+ 2.
La derivata si annulla in x = − 513 . Il punto stazionario vincolato e quindi (− 5
13 ,313 ).
(c) Possiamo esplicitare il vincolo nella forma y = −x− 1. Allora consideriamo la funzione
f(x,−x− 1) = x3 − x(−x− 1) + (−x− 1)3 = −2x2 − 2x− 1.
La derivata si annulla in x = − 12 . Il punto stazionario vincolato e quindi (− 1
2 ,− 12 ).
(d) Possiamo esplicitare il vincolo nella forma y = x2 + 1. Allora consideriamo la funzione
f(x, x2 + 1) = (x2 + 1) ln(x2 + 1).
La derivata e x 7→ 2x ln(x2 +1)+ (x2 +1) 2xx2+1 = 2x
(ln(x2 + 1) + 1
)e si annulla soltanto per x = 0. Quindi c’e
il solo punto stazionario vincolato (0, 1).
Esercizio 2.3
(a) Abbiamo f(x, y) = xy e poniamo g(x, y) = 2x− y + 1.
La funzione Lagrangiana del problema e
L(x, y, λ) = xy − λ(2x− y + 1).
Le condizioni di Lagrange sono
y − 2λ = 0
x+ λ = 0
2x− y + 1 = 0
cioe
y = 2λ
x = −λ−2λ− 2λ+ 1 = 0
cioe
λ = 14
x = − 14
y = 12 .
Pertanto si ha l’unico punto stazionario vincolato (− 14 ,
12 ).
(b) Abbiamo f(x, y) = x2 + y2 e poniamo g(x, y) = x− y + 1.
La funzione Lagrangiana del problema e
L(x, y, λ) = x2 + y2 − λ(x − y + 1).
Le condizioni di Lagrange sono
2x− λ = 0
2y + λ = 0
x− y + 1 = 0
cioe
x = λ/2
y = −λ/2λ/2 + λ/2 + 1 = 0
cioe
λ = −1x = − 1
2
y = 12 .
Pertanto si ha l’unico punto stazionario vincolato (− 12 ,
12 ).
(c) Abbiamo f(x, y) = x e poniamo g(x, y) = x2 + y2 − 1.
La funzione Lagrangiana del problema e
L(x, y, λ) = x− λ(x2 + y2 − 1).
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

3 SOLUZIONI DEGLI ESERCIZI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
405
Le condizioni di Lagrange sono
1− 2λx = 0
−2λy = 0
x2 + y2 − 1 = 0.
Fissiamo l’attenzione sulla seconda equazione, che e soddisfatta o con λ = 0 o con y = 0. Il valore λ = 0non e accettabile, in quanto per tale valore la prima equazione non e soddisfatta. Allora proviamo con y = 0.Sostituendo nella terza equazione, otteniamo x2 = 1, che e verificata con x = ±1. Pertanto, con x = 1 otteniamola soluzione (1, 0) (e λ = 1
2 ) e con x = −1 otteniamo la soluzione (−1, 0) (e λ = − 12 ).
Abbiamo dunque due punti stazionari vincolati: (1, 0) e (−1, 0).
(d) Abbiamo f(x, y) = x2 − y2 e poniamo g(x, y) = x+ y − 1.
La funzione Lagrangiana del problema e
L(x, y, λ) = x2 − y2 − λ(x + y − 1).
Le condizioni di Lagrange sono
2x− λ = 0
−2y − λ = 0
x+ y − 1 = 0
cioe
x = λ/2
y = −λ/2λ/2− λ/2 = 1
che e evidentemente impossibile. Pertanto non ci sono punti stazionari vincolati.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 APPENDICE – INTERPOLAZIONE CON IL METODO DEI MINIMI QUADRATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
406
4 Appendice – Interpolazione con il metodo dei Minimi quadrati
Concludo questa dispensa con un’applicazione di quanto fin qui visto, relativamente alla ricerca dei massimi e minimidelle funzioni di piu variabili. Si tratta di un argomento molto importante nella Statistica, che quindi ritroveretel’anno prossimo. Presento la questione da un punto di vista prettamente matematico. Nel corso di Statistica vedretetutte le relative considerazioni, legate a quella disciplina.
Supponiamo di avere un certo numero di punti nel piano, diciamo N punti, quindi N coppie del tipo (xi, yi), coni = 1, 2, . . . , N . Una raffigurazione di tali punti potrebbe essere qualcosa che assomiglia alla figura qui sotto a sinistra.
x
y
x
y
Consideriamo ora una retta nel piano, di equazione y = b0+ b1x. Per misurare “quanto la retta si adatta ai punti”possiamo considerare la quantita
N∑
i=1
(b0 + b1xi − yi)2. (20)
Serve qualche commento. Quello che abbiamo fatto e considerare, per ogni punto (xi, yi), la differenza tra lasua ordinata yi e quella del corrispondente punto sulla retta, cioe del punto sulla retta con la stessa ascissa. Talepunto e ovviamente (xi, b0 + b1xi). Questa differenza puo essere positiva o negativa, a seconda che il punto si trovirispettivamente al di sotto o al di sopra della retta. Il motivo dell’elevamento al quadrato e che vogliamo valutare gliscostamenti dalla retta indipendentemente dal segno.457 Nella figura sopra a destra ho evidenziato, con pochi punti,le differenze di cui parlavo.
Si intuisce che la quantita indicata in (20) sara grande se la retta si adatta male ai punti e piccola se invece siadatta bene. Si intuisce forse anche che solo in casi estremamente particolari questa quantita puo essere zero.458
Ora veniamo al dunque. Se cerchiamo la retta che meglio si adatta ai punti siamo interessati a minimizzare laquantita (20). Formalizzando quindi il problema possiamo definire la funzione
f(b0, b1) =
N∑
i=1
(b0 + b1xi − yi)2, (21)
funzione ovviamente delle due variabili b0, b1. Dobbiamo trovare quali sono i valori di b0, b1 che rendono minima lafunzione f , cioe dobbiamo risolvere un problema di minimo (non vincolato) per una funzione di due variabili. Abbiamovisto che la tecnica analitica e anzitutto annullare il gradiente di f , cioe le sue derivate parziali, che ora calcoliamo.Faccio notare che per calcolare le derivate in presenza di una sommatoria basta ricordare che la derivata di una sommae la somma delle derivate e quindi bastera fare la sommatoria delle derivate dei singoli termini. Quindi abbiamo (persemplicita evito d’ora in poi di scrivere l’indice delle sommatorie, ricordando pero quando servira che si tratta di Ntermini)
f ′b0(b0, b1) =
∑
2(b0 + b1xi − yi) e f ′b1(b0, b1) =
∑
2(b0 + b1xi − yi) · xi.
Nel punto cercato queste due derivate devono annullarsi. In particolare dovra essere nulla la derivata parziale di frispetto a b0, cioe dovra essere
∑
(b0 + b1xi − yi) = 0 e cioe Nb0 + b1∑
xi −∑
yi = 0.
457Qualcuno potrebbe osservare che si poteva anche considerare il valore assoluto di quella differenza, cioe considerare la quantita∑N
i=1 |b0 + b1xi − yi|, e sarebbe un’osservazione giustissima. Pero il valore assoluto ha lo spiacevole difetto di rendere non derivabilile funzioni, come dovreste ricordare. E la non derivabilita, per quello che stiamo per fare nel seguito, e assolutamente deleteria.458L’unico caso e quando tutti i punti sono allineati, cioe in altre parole quando c’e una retta che passa per tutti i punti. Questoperche l’unico modo per annullare l’intera sommatoria e annullare tutti i suoi termini, essendo questi non negativi. Quindi si deve avereb0 + b1xi = yi per ogni i.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

4 APPENDICE – INTERPOLAZIONE CON IL METODO DEI MINIMI QUADRATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
407
Dividendo questa equazione per N otteniamo
b0 + b1
∑xiN−∑yi
N= 0.
Se indichiamo con
x =1
N
∑
xi e y =1
N
∑
yi
(x e y non sono altro che le medie aritmetiche delle xi e delle yi e il punto (x, y) si dice il baricentro dell’insieme dipunti), l’ultima equazione puo essere scritta come b0 + b1x− y, e cioe y = b0 + b1x. Questo dice una cosa importantee cioe che la retta cercata deve passare per il baricentro dell’insieme dei punti.
Tenendo conto allora che deve essere b0 = y − b1x, la nostra funzione diventa
f(b0, b1) =∑(
y − b1x+ b1xi − yi)2
=∑[
b1(xi − x)− (yi − y)]2.
Ponendo per comodita ∆xi = xi − x e ∆yi = yi − y si puo scrivere
f(b0, b1) =∑[
b1∆xi −∆yi]2.
La derivata parziale rispetto a b1 di f e allora
f ′b1(b0, b1) =
∑
2(b1∆xi −∆yi) ·∆xi
per cui, annullandola, avremo
∑
(b1∆xi −∆yi) ·∆xi = 0 cioe b1∑
(∆xi)2 −
∑
∆xi∆yi = 0,
da cui infine si ricava
b1 =
∑∆xi∆yi
∑(∆xi)2
.
Quindi la retta che meglio si adatta ai punti dati (retta che minimizza gli scarti quadratici, quindi metodo deiminimi quadrati) e la retta di equazione
y = b0 + b1x con b0 = y −mx e b1 =
∑∆xi∆yi
∑(∆xi)2
, 459 (22)
detta dalla Statistica retta dei minimi quadrati o retta di regressione.E doverosa una precisazione finale. Abbiamo trovato un punto stazionario della funzione f : occorrerebbe accertarsi
che si tratta in effetti di un punto di minimo per la funzione stessa. Questo si puo fare, o considerando le derivateparziali seconde oppure scrivendo la matrice di rappresentazione della parte quadratica della funzione stessa.460 Devodire onestamente pero che, a volerlo fare questo controllo, non e proprio facilissimo. Nell’esempio numerico che presentotra breve cerchero di convincervi che si tratta effettivamente di un minimo disegnando il grafico della funzione f .
Puo essere forse il caso di accennare ad una generalizzazione di tutto questo. Il modello scelto per operarel’interpolazione e chiaramente un modello lineare, cioe abbiamo determinato quale sia la retta che meglio si accostaai dati. A priori o nel caso in cui la retta non ci soddisfi, possiamo decidere di utilizzare un altro tipo di modello.Potremmo pensare ad una relazione di tipo quadratico tra x e y (quindi una parabola di interpolazione) o in generalead una funzione y = ϕ(x). Tenendosi nella massima generalita il nostro problema diventa la minimizzazione dellaquantita
N∑
i=1
(ϕ(xi)− yi)2.
E chiaro che per poter operare la minimizzazione, scrivendo le condizioni di ottimalita come abbiamo fatto nel casolineare, occorre avere a disposizione un modello preciso, cioe una certa forma funzionale con dei parametri incogniti.
459La Statistica scrivera piu semplicemente b1 =σxy
σ2x, indicando con σxy la covarianza di x e y e con σ2
x la varianza di x.460Attenzione che f non e una forma quadratica, in quanto contiene anche una parte lineare e una parte costante. Possiamo dire infattiche f e un polinomio di secondo grado in due variabili, con termini di grado uno e di grado zero (basta sviluppare i conti relativi alquadrato). Per quanto riguarda la verifica delle condizioni del secondo ordine quello che conta pero e la sola parte quadratica, dato che lealtre, derivando due volte, vengono eliminate.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza
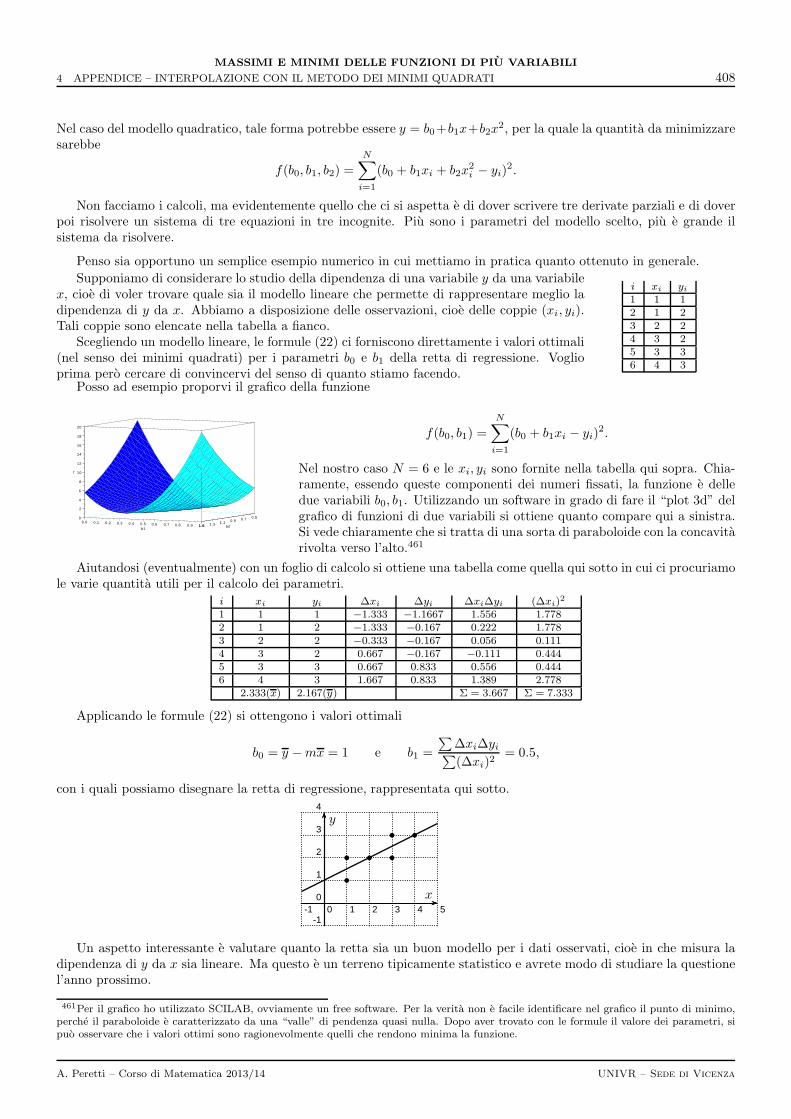
4 APPENDICE – INTERPOLAZIONE CON IL METODO DEI MINIMI QUADRATI
MASSIMI E MINIMI DELLE FUNZIONI DI PIU VARIABILI
408
Nel caso del modello quadratico, tale forma potrebbe essere y = b0+b1x+b2x2, per la quale la quantita da minimizzare
sarebbe
f(b0, b1, b2) =
N∑
i=1
(b0 + b1xi + b2x2i − yi)2.
Non facciamo i calcoli, ma evidentemente quello che ci si aspetta e di dover scrivere tre derivate parziali e di doverpoi risolvere un sistema di tre equazioni in tre incognite. Piu sono i parametri del modello scelto, piu e grande ilsistema da risolvere.
Penso sia opportuno un semplice esempio numerico in cui mettiamo in pratica quanto ottenuto in generale.
Supponiamo di considerare lo studio della dipendenza di una variabile y da una variabilex, cioe di voler trovare quale sia il modello lineare che permette di rappresentare meglio ladipendenza di y da x. Abbiamo a disposizione delle osservazioni, cioe delle coppie (xi, yi).Tali coppie sono elencate nella tabella a fianco.
Scegliendo un modello lineare, le formule (22) ci forniscono direttamente i valori ottimali(nel senso dei minimi quadrati) per i parametri b0 e b1 della retta di regressione. Voglioprima pero cercare di convincervi del senso di quanto stiamo facendo.
i xi yi1 1 12 1 23 2 24 3 25 3 36 4 3
Posso ad esempio proporvi il grafico della funzione
b0b1
0.50.70.90.0 0.1 1.10.2 0.3 0.4 0.5 1.30.6 0.7 0.8 0.9 1.01.5
0
2
4
6
8
f 10
12
14
16
18
20
f(b0, b1) =
N∑
i=1
(b0 + b1xi − yi)2.
Nel nostro caso N = 6 e le xi, yi sono fornite nella tabella qui sopra. Chia-ramente, essendo queste componenti dei numeri fissati, la funzione e delledue variabili b0, b1. Utilizzando un software in grado di fare il “plot 3d” delgrafico di funzioni di due variabili si ottiene quanto compare qui a sinistra.Si vede chiaramente che si tratta di una sorta di paraboloide con la concavitarivolta verso l’alto.461
Aiutandosi (eventualmente) con un foglio di calcolo si ottiene una tabella come quella qui sotto in cui ci procuriamole varie quantita utili per il calcolo dei parametri.
i xi yi ∆xi ∆yi ∆xi∆yi (∆xi)2
1 1 1 −1.333 −1.1667 1.556 1.7782 1 2 −1.333 −0.167 0.222 1.7783 2 2 −0.333 −0.167 0.056 0.1114 3 2 0.667 −0.167 −0.111 0.4445 3 3 0.667 0.833 0.556 0.4446 4 3 1.667 0.833 1.389 2.778
2.333(x) 2.167(y) Σ = 3.667 Σ = 7.333
Applicando le formule (22) si ottengono i valori ottimali
b0 = y −mx = 1 e b1 =
∑∆xi∆yi
∑(∆xi)2
= 0.5,
con i quali possiamo disegnare la retta di regressione, rappresentata qui sotto.
-1 0 1 2 3 4 5-1
0
1
2
3
4
x
y
b
b b b
b b
Un aspetto interessante e valutare quanto la retta sia un buon modello per i dati osservati, cioe in che misura ladipendenza di y da x sia lineare. Ma questo e un terreno tipicamente statistico e avrete modo di studiare la questionel’anno prossimo.
461Per il grafico ho utilizzato SCILAB, ovviamente un free software. Per la verita non e facile identificare nel grafico il punto di minimo,perche il paraboloide e caratterizzato da una “valle” di pendenza quasi nulla. Dopo aver trovato con le formule il valore dei parametri, sipuo osservare che i valori ottimi sono ragionevolmente quelli che rendono minima la funzione.
A. Peretti – Corso di Matematica 2013/14 UNIVR – Sede di Vicenza

Indice analitico
algebra dei limiti, II-4, 162
base di Rn, III-1, 277base di un sottospazio, III-1, 278base fondamentale di Rn, III-1, 277binomio di Newton, Introduzione, 26
circonferenza, I-5, 96combinazione lineare di vettori, III-1, 274combinazioni di un insieme, Introduzione, 25complemento algebrico, III-3, 306completamento del quadrato, I-1, 38confronti standard, II-4, 168controimmagine
di una funzione reale, II-3, 135di una funzione, II-1, 112
criteri del confronto (serie), II-9, 261criterio del rapporto (serie), II-9, 262criterio della radice (serie), II-9, 263criterio di Leibnitz (serie), II-9, 265
derivatadestra, II-6, 194sinistra, II-6, 194
derivata, II-6, 195derivata parziale, IV-3, 375derivate successive, II-6, 206determinante di una matrice, III-3, 306differenziale, IV-3, 382dimensione di Rn, III-1, 277disequazioni
con valore assoluto, I-3, 75di primo e secondo grado, I-3, 63esponenziali, I-3, 71intere, I-3, 66irrazionali, I-3, 69logaritmiche, I-3, 73razionali (fratte), I-3, 68sistemi di disequazioni di 1o e 2o grado, I-3, 65
disposizioni di un insieme, Introduzione, 24distanza tra vettori, III-1, 283disuguaglianza di Cauchy–Schwarz, III-1, 283divisione tra polinomi, I-1, 32
ellisse, I-5, 99equazione della retta tangente, II-6, 197equazioni
con valore assoluto, I-3, 75di primo grado, I-3, 58di secondo grado, I-3, 58esponenziali, I-3, 71intere, I-3, 60irrazionali, I-3, 69logaritmiche, I-3, 73razionali (fratte), I-3, 61
equazioni, I-3, 56estremi di un insieme, II-2, 123estremi di una funzione reale, II-3, 134
forma quadraticadefinita negativa, IV-2, 365definita positiva, IV-2, 365indefinita, IV-2, 365semidefinita negativa, IV-2, 365semidefinita positiva, IV-2, 365
forma quadratica, IV-2, 364forme indeterminate nei limiti, II-4, 163funzione
biiettiva, II-1, 112composta, II-1, 115continua, II-5, 179convessa, II-6, 208crescente, II-3, 136decrescente, II-3, 136definita a tratti, II-3, 139dello stesso ordine di grandezza, II-4, 168differenziabile, IV-3, 381discontinua, II-5, 179dispari, II-3, 137equivalente, II-4, 168iniettiva, II-1, 112inversa, II-1, 117monotona, II-3, 136non crescente, II-3, 136non decrescente, II-3, 136pari, II-3, 136suriettiva, II-1, 112trascurabile, II-4, 168valore assoluto, II-3, 139
funzione, II-1, 111funzione elementare
funzione esponenziale, II-3, 133funzione logaritmica, II-3, 133funzione potenza, II-3, 132
funzione integrale, II-8, 241funzione Lagrangiana, IV-4, 398
gradiente, IV-3, 376gradiente secondo, IV-3, 384grado di un monomio, I-1, 31grado di un polinomio, I-1, 31grafico di una funzione reale, II-3, 131
immaginedi una funzione reale, II-3, 134di una funzione, II-1, 111di una trasformazione lineare, III-2, 299
insiemeaperto, II-2, 128chiuso, II-2, 128
409

convesso, II-6, 207inferiormente limitato, II-2, 123limitato, II-2, 123superiormente limitato, II-2, 123
insieme delle parti (insieme potenza), Introduzione, 14integrale
di Riemann generalizzato, II-8, 245di Riemann, II-8, 237indefinito, II-7, 226
integrazioneper parti, II-7, 230per sostituzione, II-7, 232
interpolazione, IV-4, 406intorno di un numero reale, II-2, 127iperbole, I-5, 101
limitazioni di un insieme, II-2, 123limite, II-4, 156limite di una successione, II-9, 254limite fondamentale, II-4, 172limiti
di funzioni composte, II-5, 184di funzioni elementari, II-4, 161
limiti notevoli, II-5, 187logaritmo (definizione), I-2, 50
massimo/minimo di una funzione reale, II-3, 134matrice
diagonale, III-2, 295identita, III-2, 295inversa, III-2, 302quadrata, III-2, 294simmetrica, III-2, 294trasposta, III-2, 294
matrice, III-2, 294matrice Hessiana, IV-3, 384media integrale, II-8, 240metodo dei minimi quadrati, IV-4, 406metodo dei moltiplicatori di Lagrange, IV-4, 398minore
complementare, III-3, 305di una matrice, III-3, 312principale di Nord–Ovest, IV-2, 366principale, IV-2, 366
moltiplicazione scalare, III-1, 273monomio, I-1, 31
norma di un vettore, III-1, 282
parabola, I-5, 92permutazioni di un insieme, Introduzione, 23polinomio, I-1, 31potenza
con esponente intero, I-2, 44con esponente irrazionale, I-2, 49con esponente naturale, I-2, 44con esponente razionale, I-2, 48
potenza, I-2, 44
primitiva di una funzione, II-7, 226principi di eliminazione/sostituzione, II-4, 169prodotti/potenze notevoli, I-1, 31prodotto cartesiano di insiemi, I-4, 82prodotto interno (o scalare) di vettori, III-1, 281prodotto righe per colonne, III-2, 296proprieta dell’integrale di Riemann, II-8, 239punto
di accumulazione di un insieme, II-2, 127a tangente verticale, II-6, 197angoloso, II-6, 197di cuspide, II-6, 197di frontiera di un insieme, II-2, 127di massimo/minimo globale, II-3, 138di massimo/minimo locale, II-3, 138esterno ad un insieme, II-2, 127interno di un insieme, II-2, 127isolato di un insieme, II-2, 127stazionario vincolato, IV-4, 396stazionario, II-6, 202
radice n-esima, I-2, 45rango
di una matrice, III-2, 301di una trasformazione lineare, III-2, 300
rapporto incrementale, II-6, 194rappresentazione sul piano cartesiano, I-4, 82rappresentazione sullo spazio cartesiano, I-4, 86razionalizzazione di una frazione, I-2, 48regola
di Cramer, III-4, 324di Ruffini, I-1, 34di Sarrus, III-3, 307
restrizione di una funzione, II-1, 119retta
dei minimi quadrati, IV-4, 407di regressione, IV-4, 407per due punti, I-5, 90tangente, II-6, 196
retteparallele e perpendicolari, I-5, 90passanti per un punto, I-5, 89
rette nel piano, I-5, 88
segno di una forma quadratica, IV-2, 365serie
armonica generalizzata, II-9, 258armonica, II-9, 258assolutamente convergente, II-9, 264geometrica, II-9, 259semplicemente convergente, II-9, 265
serie, II-9, 256sistema di equazioni lineari, III-4, 322sistema lineare
omogeneo, III-4, 322quadrato, III-4, 322
somma parziale di una successione, II-9, 256sottomatrice, III-3, 305
410

sottospazio di Rn, III-1, 278sottospazio generato, III-1, 279struttura
algebrica dei reali, II-2, 122di ordine dei reali, II-2, 122
successione, II-9, 254
teoremadegli zeri, II-5, 182dei valori intermedi, II-5, 182del confronto dei limiti, II-4, 160del valor medio (di Lagrange), II-6, 201della media integrale, II-8, 240di Cramer, III-4, 324di De l’Hopital, II-6, 203di esistenza del limite, II-4, 160di Rolle, II-6, 201di Rouche–Capelli, III-4, 323di Ruffini, I-1, 38di Schwarz, IV-3, 383di Weierstrass, II-5, 182fondamentale del calcolo, II-8, 241fondamentale delle funzioni continue, II-5, 181
trasformazione lineare, III-2, 289trasformazioni grafiche elementari, II-3, 147
valore assoluto di un numero reale, II-2, 125varieta unidimensionale, IV-4, 394vettori
generatori di un sottospazio, III-1, 278linearmente dipendenti, III-1, 275linearmente indipendenti, III-1, 275ortogonali, III-1, 284ortonormali, III-1, 284
vettori fondamentali di Rn, III-1, 276
411


















