
O-Triangle approach Roma (Forum P.A.), 14 maggio 2004 Luigi Quitadamo [email protected]

APPLICAZIONE DI TECNICHE DI TTTEEEXXXTTT MMMIIINNNIIINNNGGG ALLA RACCOLTA DI DOCUMENTI
SSSAAAEEE NNNEEEWWWSSS DEL 1999 E 2000 Sono stati analizzati i testi di 3262 documenti relativi al settore “Technology” con lo scopo di individuare le aree tecnologiche emergenti. L’identificazione delle macro aree tecnologiche, necessario punto di partenza, fornisce inoltre gli strumenti per classificare i documenti e quindi organizzare e rendere più fruibile l’informazione disponibile. L’analisi che segue è volta quindi a rispondere sia ad una esigenza conoscitiva (quali sono le trasformazioni tecnologiche in atto, chi ne è protagonista, …) che organizzativa (come catalogare l’informazione in modo da poterla in seguito reperire velocemente). Si tratta di un’analisi di tipo esplorativo, che viene per la prima volta effettuata su questo tipo di documenti, una successiva focalizzazione guidata da obiettivi di business più specifici consentirà di ottenere approfondimenti su particolari aree tecnologiche. Il presente documento si compone di una parte metodologica, che descrive il processo di analisi nelle diverse fasi, e di una parte di commento dei risultati ottenuti. Occorre precisare che l’applicazione di strumenti automatici all’analisi testuale mentre da una parte consente di mettere in evidenza le relazioni effettivamente presenti tra i diversi documenti senza distorsione alcuna dovuta a preconcetti, dall’altra manca dell’”intelligenza” necessaria per capire quali tra le associazioni individuate sono “spurie”, non hanno cioè, in questo contesto, contenuto semantico significativo per il ricercatore. Durante il processo di analisi si è cercato di eliminare alcune di queste associazioni. IL PROCESSO DI ANALISI La prima fase del processo di analisi consiste nel separare le varie parti del documento: titolo e testo, che costituiscono la parte testuale, “Subjects”, ”Source”, “State”, “Language” e “Date”, che costituiscono la metainformazione. La parte testuale viene successivamente sottoposta ad analisi linguistica con l’obiettivo di 1) individuare la funzione grammaticale di ogni singola parola e 2) ottenere una lemmatizzazione, ricondurre cioè ogni termine alla sua radice (i verbi alla forma infinita, i sostantivi al singolare, ecc…). A questo scopo sono stati utilizzati due diversi software, il primo è in grado di riconoscere anche i nomi delle organizzazioni, o società, e i nomi propri di persona e di luogo presenti nel testo, nonché le parole composte (es: joint_venture), ma non distingue tra verbi, aggettivi e sostantivi, il secondo opera quest’ultima distinzione. Abbiamo così ottenuto una caratterizzazione di ogni documento in base a:
UWORD Sostantivi, verbi e aggettivi UTERM Termini composti UNAME Nomi propri ORG Nomi propri di società PERSON Nomi propri di persona PLACE Nomi propri di luogo UABBR Abbreviazioni
analisi linguistica IM
OTHER Altro NN Sostantivi JJ Aggettivi
analisi linguistica ID
VV Verbi

2
NPRO Nomi propri SOURCE Fonte DATE Data MONTHYEAR Mese di pubblicazione PERIOD Periodo di pubblicazione SUBJECTS Argomento ORG2 Società o organizzazione (dal titolo) STATE Nazione
METAINFORMAZIONE
LANGUAGE Lingua La metainformazione è stata arricchita dell’elemento ORG2 che contiene il nome dell’organizzazione che compare nel titolo del documento, a differenza di ORG, che è una lista delle organizzazioni individuate automaticamente all’interno del testo e che potrebbero non essere le principali protagoniste della notizia. Le date di pubblicazione sono inoltre state raggruppate per mese e per periodo (ultimi tre mesi, estate 2000, primo semestre 2000 e anno 1999) a fini statistici. I documenti che hanno subito questo processo sono a questo punto analizzabili con tecniche di data mining. Un esempio di documento originale e di sua trasformazione per l’analisi è fornito negli allegati. Scopo dell’analisi di data mining è di individuare similitudini tra documenti sulla base delle quali ottenere automaticamente dei raggruppamenti omogenei per argomento. Queste tecniche consentono infatti di identificare dei pattern, o sequenze, di parole che si ripetono con una certa costanza e di raggruppare i documenti che condividono la stessa sequenza. Sono state effettuate due analisi, la prima valuta la somiglianza dei documenti solo in base ai sostantivi (NN), la seconda anche in base a verbi, aggettivi e parole composte (UWORD e UTERM). Per la prima analisi, sostantivi che compaiono meno di 6 volte nell’intero insieme di documenti non sono stati considerati, abbiamo quindi lavorato su un totale di 1428 sostantivi, dai quali sono stati ulteriormente eliminati 45 parole che, pur comparendo con una frequenza maggiore, sono state considerate di scarso interesse. Per la seconda analisi sono stati considerati tutti i sostantivi, verbi, aggettivi e parole composte che compaiono in almeno 4 documenti, per un totale di 3097 termini da cui sono stati eliminati 54 termini che tendevano a formare raggruppamenti di scarso interesse (la lista è disponibile in allegato). Per esempio le parole future e product tendevano a formare un gruppo i cui documenti avevano come caratteristica comune quella di essere annunci estivi di nuovi modelli, indipendentemente dalle loro caratteristiche tecniche. Queste parole non sono state eliminate fisicamente (e quindi compaiono nei risultati), ma è loro stato assegnato peso nullo nella valutazione della somiglianza tra documenti. La prima analisi ha consentito di individuare 25 raggruppamenti principali, che contengono l’85% dei documenti. Questi gruppi sono molto omogenei e forniscono una panoramica dei principali argomenti. La seconda individua 100 gruppi, essendo 100 il limite imposto al numero di gruppi, e l’85% dei documenti si trova nei primi 67. Si tratta di argomenti più specifici, che richiedono maggiore sforzo interpretativo.

3
COMMENTO DEI RISULTATI
Analisi 1
Interpretazione dei cluster L’obiettivo principale di questo studio è di fornire una panoramica sui principali argomenti presenti nella collezione di documenti non tralasciando, però, di individuare insiemi di documenti più ridotti con specificità particolari. I documenti sono stati raggruppati scegliendo i parametri della classificazione automatica in modo tale da ottenere un numero relativamente limitato di clusters (circa una trentina) contenenti il 90% dei documenti. Una scelta dei parametri della classificazione più restrittiva permette invece di evidenziare meglio tecnologie particolari. Ad esempio in questo studio i documenti relativi alle tecnologie dei sensori tendono a raggrupparsi (cluster 13): una scelta più restrittiva avrebbe diviso questo cluster in più cluster secondo il tipo di applicazione dei sensori. Nella mappa sono rappresentati i primi 25 cluster (84.76% dei documenti). I legami, rappresentati da una linea che unisce due cluster, consentono di individuare delle macro aree ovvero dei cluster collegati tra loro poiché condividono alcuni aspetti comuni. Graf. 1: Mappa dei 25 cluster principali

4
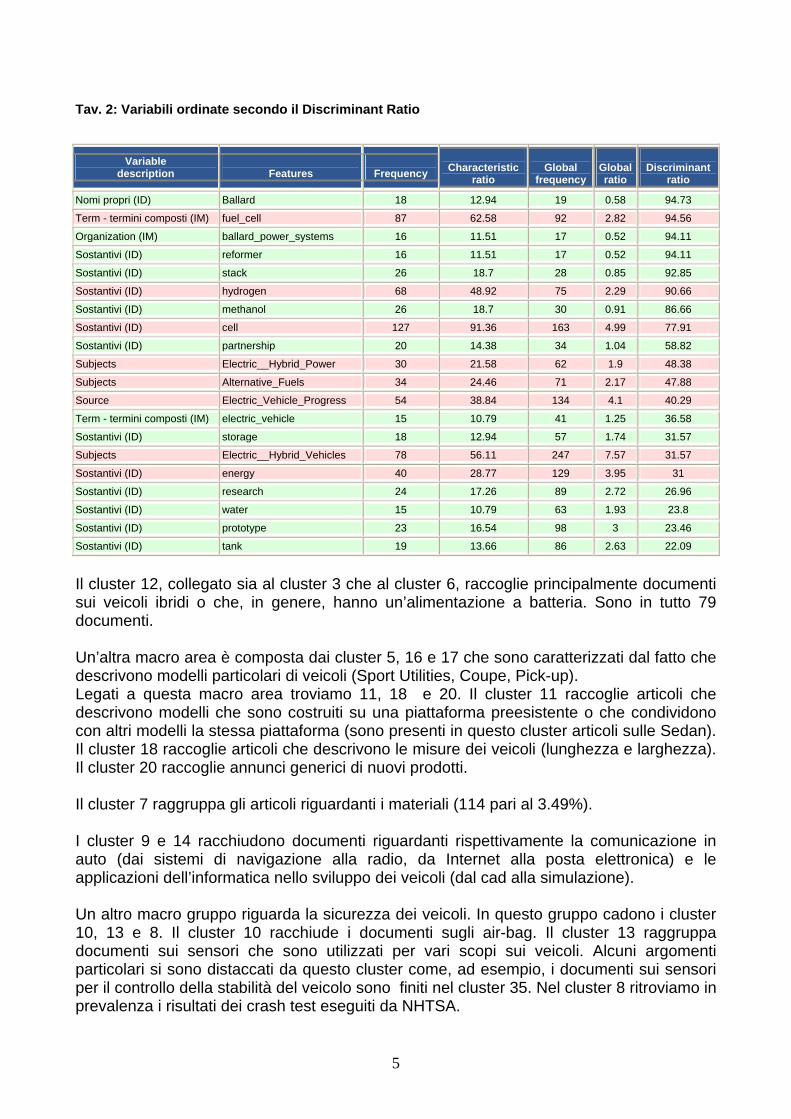
I primi due cluster, che insieme raccolgono il 30% dei documenti, contengono, in generale, documenti con descrizioni dei nuovi modelli usciti. Il primo cluster è caratterizzato da documenti abbastanza lunghi che descrivono le caratteristiche tecniche dei nuovi veicoli. Il secondo cluster contiene documenti più brevi rispetto al primo ed, in genere, si tratta di annunci di versioni speciali piccoli mutamenti o di caratteristiche estetiche. Nel terzo cluster gli annunci contengono una descrizione più dettagliata dei veicoli per quanto concerne l’emissione dei gas, e la riduzione del consumo del carburante. Il processo di classificazione automatica ha, dunque, raggruppato tutte le notizie specifiche in questo settore indipendentemente se esse siano state precedentemente classificate sotto il subject “Emission” o “Fuel economy” ma in base al contenuto del testo (ad esempio si può vedere il terzo od il quinto documento del cluster 3). Legati al cluster 3 troviamo i cluster 6 (celle a combustibile), 12 (batteria, veicoli ibridi) e 24 (cilindro). Questi cluster formano una macro area relativa ai problemi della riduzione del consumo e dell’inquinamento e alle nuove fonti energetiche. I documenti appartenenti al cluster 6 trattano, dunque, di veicoli che utilizzano le celle a combustibile e del funzionamento delle stesse. Sono in tutto 139 pari al 4.26% di tutti i documenti. Il report automatico ci permette per questo cluster (scelto a titolo di esempio) di conoscere le modalità più frequenti per ciascuna delle variabili analizzate (Tav.1) o le modalità che appaiono prevalentemente in questo cluster rispetto alla loro frequenza nell’intera collezione di documenti (Tav. 2). Tav. 1: Variabili ordinate secondo il Characteristic Ratio
Variable description
Features
Frequency
Characteristic
ratio
Global
frequency
Global ratio
Discriminant
ratio
Sostantivi (ID) cell 127 91.36 163 4.99 77.91
Sostantivi (ID) fuel 126 90.64 641 19.65 19.65
Language English 112 80.57 2261 69.31 4.95
State USA 96 69.06 1735 53.18 5.53
Sostantivi (ID) vehicle 94 67.62 1620 49.66 5.8
Term - termini composti (IM) fuel_cell 87 62.58 92 2.82 94.56
Subjects USA 85 61.15 1100 33.72 7.72
Subjects Electric__Hybrid_Vehicles 78 56.11 247 7.57 31.57
Sostantivi (ID) hydrogen 68 48.92 75 2.29 90.66
Period 1999 63 45.32 1535 47.05 4.1
Sostantivi (ID) system 63 45.32 1056 32.37 5.96
Sostantivi (ID) motor 54 38.84 1339 41.04 4.03
5
Tav. 2: Variabili ordinate secondo il Discriminant Ratio
Variable
description
Features
Frequency
Characteristicratio
Global
frequency
Global ratio
Discriminant
ratio
Nomi propri (ID) Ballard 18 12.94 19 0.58 94.73
Term - termini composti (IM) fuel_cell 87 62.58 92 2.82 94.56
Organization (IM) ballard_power_systems 16 11.51 17 0.52 94.11
Sostantivi (ID) reformer 16 11.51 17 0.52 94.11
Sostantivi (ID) stack 26 18.7 28 0.85 92.85
Sostantivi (ID) hydrogen 68 48.92 75 2.29 90.66
Sostantivi (ID) methanol 26 18.7 30 0.91 86.66
Sostantivi (ID) cell 127 91.36 163 4.99 77.91
Sostantivi (ID) partnership 20 14.38 34 1.04 58.82
Subjects Electric__Hybrid_Power 30 21.58 62 1.9 48.38
Subjects Alternative_Fuels 34 24.46 71 2.17 47.88
Source Electric_Vehicle_Progress 54 38.84 134 4.1 40.29
Term - termini composti (IM) electric_vehicle 15 10.79 41 1.25 36.58
Sostantivi (ID) storage 18 12.94 57 1.74 31.57
Subjects Electric__Hybrid_Vehicles 78 56.11 247 7.57 31.57
Sostantivi (ID) energy 40 28.77 129 3.95 31
Sostantivi (ID) research 24 17.26 89 2.72 26.96
Sostantivi (ID) water 15 10.79 63 1.93 23.8
Sostantivi (ID) prototype 23 16.54 98 3 23.46
Sostantivi (ID) tank 19 13.66 86 2.63 22.09
Il cluster 12, collegato sia al cluster 3 che al cluster 6, raccoglie principalmente documenti sui veicoli ibridi o che, in genere, hanno un’alimentazione a batteria. Sono in tutto 79 documenti. Un’altra macro area è composta dai cluster 5, 16 e 17 che sono caratterizzati dal fatto che descrivono modelli particolari di veicoli (Sport Utilities, Coupe, Pick-up). Legati a questa macro area troviamo 11, 18 e 20. Il cluster 11 raccoglie articoli che descrivono modelli che sono costruiti su una piattaforma preesistente o che condividono con altri modelli la stessa piattaforma (sono presenti in questo cluster articoli sulle Sedan). Il cluster 18 raccoglie articoli che descrivono le misure dei veicoli (lunghezza e larghezza). Il cluster 20 raccoglie annunci generici di nuovi prodotti. Il cluster 7 raggruppa gli articoli riguardanti i materiali (114 pari al 3.49%). I cluster 9 e 14 racchiudono documenti riguardanti rispettivamente la comunicazione in auto (dai sistemi di navigazione alla radio, da Internet alla posta elettronica) e le applicazioni dell’informatica nello sviluppo dei veicoli (dal cad alla simulazione). Un altro macro gruppo riguarda la sicurezza dei veicoli. In questo gruppo cadono i cluster 10, 13 e 8. Il cluster 10 racchiude i documenti sugli air-bag. Il cluster 13 raggruppa documenti sui sensori che sono utilizzati per vari scopi sui veicoli. Alcuni argomenti particolari si sono distaccati da questo cluster come, ad esempio, i documenti sui sensori per il controllo della stabilità del veicolo sono finiti nel cluster 35. Nel cluster 8 ritroviamo in prevalenza i risultati dei crash test eseguiti da NHTSA.
6
Rimane un’altra macro area relativa agli annunci di nuove fabbriche e di raggiunte certificazioni di qualità (cluster 4) ed altre notizie riguardo ai produttori (cluster 22). Il cluster 21 riguarda, invece, i richiami delle auto. Alcuni dei rimanenti cluster individuano aree molto specifiche come, ad esempio, i sistemi antifurto (cluster 52) o l’utilizzo della fibra di carbonio (cluster 61).
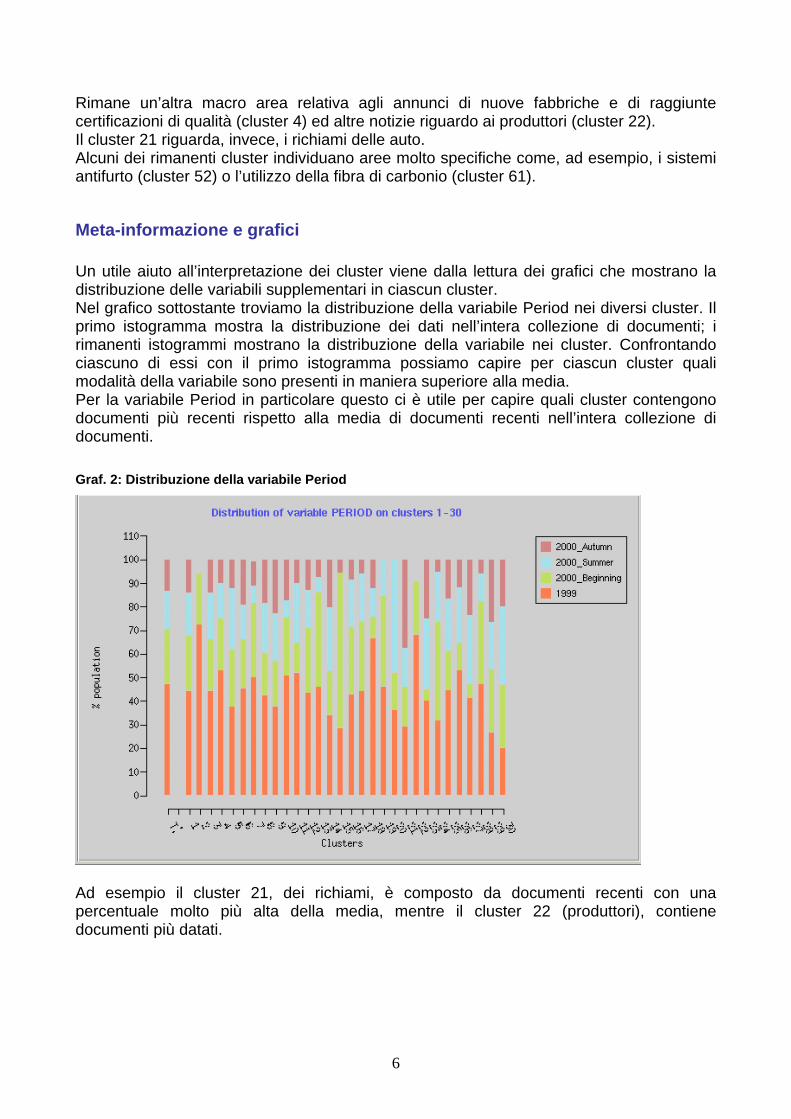
Meta-informazione e grafici Un utile aiuto all’interpretazione dei cluster viene dalla lettura dei grafici che mostrano la distribuzione delle variabili supplementari in ciascun cluster. Nel grafico sottostante troviamo la distribuzione della variabile Period nei diversi cluster. Il primo istogramma mostra la distribuzione dei dati nell’intera collezione di documenti; i rimanenti istogrammi mostrano la distribuzione della variabile nei cluster. Confrontando ciascuno di essi con il primo istogramma possiamo capire per ciascun cluster quali modalità della variabile sono presenti in maniera superiore alla media. Per la variabile Period in particolare questo ci è utile per capire quali cluster contengono documenti più recenti rispetto alla media di documenti recenti nell’intera collezione di documenti. Graf. 2: Distribuzione della variabile Period
Ad esempio il cluster 21, dei richiami, è composto da documenti recenti con una percentuale molto più alta della media, mentre il cluster 22 (produttori), contiene documenti più datati.

7
Ai documenti, che abbiamo analizzato, era stato precedentemente assegnato un subject. Nel grafico seguente vediamo la distribuzione dei subject nei diversi cluster. Per fare emergere meglio le caratteristiche dei cluster abbiamo eliminato il subject “cars” ed i subject relativi agli stati ed alla zone geografiche. Possiamo notare che i subject contenuti nei primi due cluster sono effettivamente pochi (ovvero gli articoli erano stati classificati con il subject generico cars o con il paese di appartenenza). A titolo di esempio possiamo osservare che nel cluster 6 (celle a combustibile) sono presenti i subject “Electric & Hybrid Vehicles”, “Alternative fuels” e “Government Policy & Legislation”. La presenza di quest’ultimo subject evidenzia l’interesse delle agenzie governative per questa tecnologia. Graf. 3: Distribuzione della variabile Subjects
La variabile UTERM contiene i termini composti automaticamente riconosciuti dal programma. In questo caso il grafico ci aiuta a comprendere se nei documenti di un determinato cluster viene usata una terminologia particolare. Ad esempio, nel cluster 3, troviamo i termini composti “Fuel Economy”, “Diesel Engine”, “Gasoline Engine”, “Passenger Car” , “Fuel consumption” e “Electric motor”.

8
Graf. 4: Distribuzione della variabile Uterm
Il grafico della variabile ORG2 relativa alle organizzazioni ci permette di vedere se in un cluster si concentrano documenti di una o più case produttrici. Graf. 5: Distribuzione della variabile ORG2
La variabile Stateb contiene i dati sugli stati estratti dai Subjects (la variabile State invece contiene informazioni sullo stato di pubblicazione). Dal grafico 6 emerge, ad esempio, che nel cluster 13 (relativo ai sensori) e nel cluster 24 (cilindro) non ci sono articoli riferibili al Giappone. Nei cluster 2, 3, 4 e 14 troviamo, invece, una frequenza superiore alla media di documenti concernenti il Giappone. Analoghe considerazioni possono essere fatte per le altre nazioni. Nel cluster 10 (air-bag) troviamo una presenza consistente di documenti

9
francesi (circa il 15%). A conferma di questo vediamo emergere il nome Renault nel grafico 5. Graf. 6: Distribuzione della variabile Stateb
L’ultimo grafico riguarda la rivista sul quale il documento è pubblicato. Graf. 7: Distribuzione della variabile Source

10
Analisi 2 La seconda analisi tende a raggruppare i documenti in un numero molto maggiore di clusters (superiore a 200). Questo sia per la maggiore ricchezza di vocaboli tenuta in considerazione (oltre ai sostantivi, sono analizzati verbi, aggettivi e termini composti), sia per il criterio più restrittivo di somiglianza utilizzato. Poiché sopra al centesimo cluster, si ottengono gruppi molto piccoli, in gran parte di un documento solo, si è limitato a 100 il numero dei cluster. La mappa mostra i primi 50.
Ogni cluster è descritto dalle parole chiave che maggiormente lo caratterizzano, queste parole sono state arbitrariamente colorate per agevolare la lettura della mappa. In nero compaiono i gruppi che contengono notizie più generiche, oppure gruppi poco significativi (ad esempio il cluster 27 contiene documenti caratterizzati dalla parola first, ma che in realtà trattano degli argomenti più disparati). In blu sono evidenziati cluster che, pur non trattando di una specifica tecnologia, individuano un argomento ben definito (si tratta di crash test, certificazioni internazionali, richiami di auto, riconoscimenti). Gli argomenti in qualche modo collegati alle emissioni di gas sono rappresentati in verde, mentre quelli sui materiali sono in marrone. Infine il rosa indica i sistemi di adattamento e strumenti di controllo e il rosso i sensori. Volendo analizzare più in dettaglio il contenuto di questi ultimi gruppi, è possibile selezionarli dalla mappa ed evidenziare nuovi legami che, perché più deboli o perché coinvolgono altri cluster più piccoli, non erano presenti nella mappa generale. Si fornisce, di questi cluster selezionati, un breve commento, rimandando alla lettura dei documenti per un’analisi più approfondita.

11
CLUSTER 37 Riduzione dell’errore umano come causa di incidenti Parole chiave (comuni a quasi tutti i documenti): system, driver, vehicle, warning, camera, data, cruise_control, traffic, radar, distance, computer, lane, speed, adaptive, object, alert, vision, ahead, image, safe, sensor, infrared, analysis, pedestrian, obstacle, visual, intelligent, digital, environment, sound, mimic, mirror, glare, eye, hazard Piloti automatici. Sistemi di monitoraggio della velocità e della distanza dagli altri veicoli sulla strada e/o dei segnalatori di carreggiata, e di adeguamento della velocità e posizione. Riconoscimento degli ostacoli, dei pedoni, dei segnali stradali, del ghiaccio, … dello stato di veglia del guidatore. Sistemi per migliorare il campo visivo e la visione notturna. Sistemi di segnalazione di potenziali pericoli. Utilizzano videocamere, radar, sensori, segnali acustici. CLUSTER 28 Sitemi integrati di comunicazione, intrattenimento e comfort. Parole chiave (comuni a quasi tutti i documenti): vehicle, system, driver, include, seat, instrument, climate, mirror, entertainment, communication, radio, screen, integrate, feature, function, panel, device Strumenti integrati di controllo della climatizzazione, dei sistemi hi-fi, del telefono cellulare, del sistema di navigazione, della posizione dei sedili e degli specchi, delle luci. Riconoscimento vocale e delle impronte digitali.

12
CLUSTER 74 Sitemi integrati di comunicazione, intrattenimento e comfort con uso di display. Parole chiave: display, screen, console, control, feature, function, safety, mobile, phone Strumenti di controllo che utilizzano display, o schermi, o console. Schermi per la visualizzazione di mappe e per il sistema di navigazione. CLUSTER 21 Estensioni telematiche dei sistemi di navigazione Parole chiave: navigation_system, information, access, service, e-mail, phone, voice, screen, computer, telematics, navigation, wireless, internet, web Servizi telematici per l’accesso ad informazioni sui ristoranti, il tempo, il traffico, le stazioni di rifornimento, le località turistiche; per notizie sul mercato azionario e sportive, e per l’e-mail. Servizi telematici personalizzati, servizi per la diagnostica da remoto e il soccorso stradale. Attivazione vocale. Tecnologie wireless. CLUSTER 31 Sensori per la regolazione del sistema di sospensioni Parole chiave: sensor, brake, suspension, system, shock, absorber, wheel, hydraulic, force, roll, millisecond, pressure, spring Strumenti meccanici, idraulici ed elettronici per controllo delle oscillazioni dovute a curve, accelerazioni, frenate e cattive condizioni della strada. Uso di sensori per il monitoraggio del peso sulle sospensioni, della posizione delle ruote, ecc… CLUSTER 49 Sistemi per la stabilità Parole chiave: wheel, torque, transfer, axle, steer, system, pump, differential, clutch, actuator Sistemi di controllo della distribuzione di potenza tra gli assi per la guida a 4 ruote motrici, per aumentare la stabilità in curva e ridurre il raggio di curva e per l’anti-slittamento (mediante sensori che controllano la differenza di velocità tra ruote anteriori e posteriori). CLUSTER 59 Sensori Parole chiave: sensor, position, signal, output, linear, pedal, hall_effect, temperature_range Sensori di posizione/rotazione dell’acceleratore, del pedale, delle sospensioni, dell’albero, del volante, del telaio. Danno segnali di output lineari. Specifiche su intervallo di temperatura, modalità di installazione, … Inoltre sensori di velocità, luminosità, di umidità, di peso/posizione degli occupanti.

13
CLUSTER 84 Sensori per misurazione angolare Parole chiave: sensor, measure, external, field, angle, thermal, surface, signal, resistance Notizie tecniche su sensori per la misurazione angolare. Espansione termica, campi magnetici esterni. CLUSTER 20 Air bags intelligenti Parole chiave: air_bag, system, sensor, occupant, seat, position, passenger, deploy, impact, force, crash, side, safety, detect, sense Sistemi per il controllo della forza di spiegamento dell’air bag. Utilizzano sensori per misurare la forza d’urto, la posizione dei sedili, l’allacciamento delle cinture di sicurezza. Appositi sensori, inoltre, rilevano la presenza dei passeggeri, la loro posizione e il loro peso. CLUSTER 66 Controlli di sicurezza Parole chiave: crash, safety, impact, dummy, simulate, force, test, measure, side, frontal Centri di simulazione di incidenti, standard di sicurezza, test di funzionamento dispositivi di sicurezza, in particolare air bags. CLUSTER 32 Risultati di crash tests Parole chiave: crash_test, rating, score, impact, injury, star, conduct, dummy, side, frontal Punteggi ottenuti a seguito di crash test frontali e laterali.

14
ALLEGATO 1 DOCUMENTO ORIGINALE >>> 35:TOYOTA: Avalon Receives Top Score in Frontal Offset Crash Tests Toyota Motor Corp.'s Avalon received the top score -- a "good" rating earning a "best pick" -- in the 40 mile per hour frontal offset crash tests on new or updated vehicles. The tests were conducted by the Insurance Institute for Highway Safety, a nonprofit group funded by automobile insurers. Nissan Motor Co. Ltd.'s Maxima midsize sedan and Infiniti I30 luxury sedan, the Nissan Sentra small car and Mazda Motor Corp.'s Mazda MPV minivan all scored "average" marks. Isuzu Motors Ltd..'s Rodeo sport utility, also sold by Honda Motor Co. Ltd. as the Honda Passport, earned a "poor" rating due to high crash forces recorded on the crash dummy's head, indicating an increased likelihood of injury. In the crash tests, the vehicles were driven into a deformable barrier at 40 mph, with the driver's side of the vehicle taking the impact. The tests measured the potential for injury to the head, neck, chest and foot areas, and the risk of intrusion into the passenger compartment. SUBJECTS: Japan; Safety; Passenger Vehicles; SOURCE: Reuters, June 21, 2000;Japan;English

15
ALLEGATO 2 DOCUMENTO TRASFORMATO PER L’ANALISI tn.5.26.35 ORG2 TOYOTA tn.5.26.35 DATE 6/21/2000 tn.5.26.35 JJ deformable tn.5.26.35 JJ frontal tn.5.26.35 JJ good tn.5.26.35 JJ high tn.5.26.35 JJ increased tn.5.26.35 JJ new tn.5.26.35 JJ nonprofit tn.5.26.35 JJ poor tn.5.26.35 JJ small tn.5.26.35 JJ top tn.5.26.35 JJ updated tn.5.26.35 LANGUAGE English tn.5.26.35 MONTHYEAR 2000_06 tn.5.26.35 NN area tn.5.26.35 NN automobile tn.5.26.35 NN average tn.5.26.35 NN barrier tn.5.26.35 NN car tn.5.26.35 NN chest tn.5.26.35 NN compartment tn.5.26.35 NN crash tn.5.26.35 NN driver tn.5.26.35 NN due tn.5.26.35 NN dummy tn.5.26.35 NN foot tn.5.26.35 NN force tn.5.26.35 NN frontal tn.5.26.35 NN group tn.5.26.35 NN head tn.5.26.35 NN highway tn.5.26.35 NN hour tn.5.26.35 NN impact tn.5.26.35 NN injury tn.5.26.35 NN institute tn.5.26.35 NN insurance tn.5.26.35 NN insurer tn.5.26.35 NN intrusion tn.5.26.35 NN likelihood tn.5.26.35 NN luxury tn.5.26.35 NN mark tn.5.26.35 NN maxima tn.5.26.35 NN mile tn.5.26.35 NN motor tn.5.26.35 NN neck tn.5.26.35 NN offset

16
tn.5.26.35 NN passenger tn.5.26.35 NN passport tn.5.26.35 NN potential tn.5.26.35 NN rating tn.5.26.35 NN risk tn.5.26.35 NN rodeo tn.5.26.35 NN safety tn.5.26.35 NN score tn.5.26.35 NN sedan tn.5.26.35 NN side tn.5.26.35 NN sport tn.5.26.35 NN test tn.5.26.35 NN utility tn.5.26.35 NN vehicle tn.5.26.35 NPRO .. tn.5.26.35 NPRO Co tn.5.26.35 NPRO Corp. tn.5.26.35 NPRO Honda tn.5.26.35 NPRO I30 tn.5.26.35 NPRO Infiniti tn.5.26.35 NPRO Isuzu tn.5.26.35 NPRO Ltd tn.5.26.35 NPRO Ltd. tn.5.26.35 NPRO MPV tn.5.26.35 NPRO Mazda tn.5.26.35 NPRO Nissan tn.5.26.35 NPRO Sentra tn.5.26.35 NPRO TOYOTA tn.5.26.35 NPRO Toyota tn.5.26.35 NPRO midsize tn.5.26.35 NPRO minivan tn.5.26.35 NPRO mph tn.5.26.35 ORG honda_motor_co tn.5.26.35 ORG insurance_institute_for_highway_safety tn.5.26.35 ORG isuzu_motors tn.5.26.35 ORG mazda_motor tn.5.26.35 ORG nissan_motor tn.5.26.35 ORG toyota_motor tn.5.26.35 SOURCE Reuters tn.5.26.35 STATE Japan tn.5.26.35 SUBJECTS Japan tn.5.26.35 SUBJECTS Passenger_Vehicles tn.5.26.35 SUBJECTS Safety tn.5.26.35 UNAME avalon tn.5.26.35 UNAME honda_passport tn.5.26.35 UNAME infiniti_i30 tn.5.26.35 UNAME maxima tn.5.26.35 UNAME mazda_mpv tn.5.26.35 UNAME rodeo tn.5.26.35 UTERM crash_test tn.5.26.35 UTERM frontal_offset_crash_test

17
tn.5.26.35 UTERM luxury_sedan tn.5.26.35 UTERM top_score tn.5.26.35 UWORD area tn.5.26.35 UWORD automobile tn.5.26.35 UWORD average tn.5.26.35 UWORD barrier tn.5.26.35 UWORD car tn.5.26.35 UWORD chest tn.5.26.35 UWORD compartment tn.5.26.35 UWORD conduct tn.5.26.35 UWORD crash tn.5.26.35 UWORD deformable tn.5.26.35 UWORD drive tn.5.26.35 UWORD driver tn.5.26.35 UWORD due tn.5.26.35 UWORD dummy tn.5.26.35 UWORD earn tn.5.26.35 UWORD earning tn.5.26.35 UWORD foot tn.5.26.35 UWORD force tn.5.26.35 UWORD fund tn.5.26.35 UWORD group tn.5.26.35 UWORD head tn.5.26.35 UWORD high tn.5.26.35 UWORD hour tn.5.26.35 UWORD impact tn.5.26.35 UWORD increase tn.5.26.35 UWORD indicate tn.5.26.35 UWORD injury tn.5.26.35 UWORD insurer tn.5.26.35 UWORD intrusion tn.5.26.35 UWORD likelihood tn.5.26.35 UWORD mark tn.5.26.35 UWORD measure tn.5.26.35 UWORD midsize tn.5.26.35 UWORD mile tn.5.26.35 UWORD minivan tn.5.26.35 UWORD mph tn.5.26.35 UWORD neck tn.5.26.35 UWORD nonprofit tn.5.26.35 UWORD passenger tn.5.26.35 UWORD pick tn.5.26.35 UWORD poor tn.5.26.35 UWORD potential tn.5.26.35 UWORD rating tn.5.26.35 UWORD receive tn.5.26.35 UWORD record tn.5.26.35 UWORD risk tn.5.26.35 UWORD score tn.5.26.35 UWORD sedan tn.5.26.35 UWORD sell

18
tn.5.26.35 UWORD side tn.5.26.35 UWORD small tn.5.26.35 UWORD sport tn.5.26.35 UWORD taking tn.5.26.35 UWORD test tn.5.26.35 UWORD update tn.5.26.35 UWORD utility tn.5.26.35 UWORD vehicle tn.5.26.35 VV conduct tn.5.26.35 VV drive tn.5.26.35 VV earn tn.5.26.35 VV fund tn.5.26.35 VV indicate tn.5.26.35 VV measure tn.5.26.35 VV motor tn.5.26.35 VV pick tn.5.26.35 VV receive tn.5.26.35 VV record tn.5.26.35 VV score tn.5.26.35 VV sell tn.5.26.35 VV take


















