Analisi in silico per la ricerca di domini conservati di NRPSs batteriche in genomi eucariotici
11
Analisi in Analisi in silico silico per la per la ricerca di domini conservati ricerca di domini conservati di NRPSs batteriche in di NRPSs batteriche in genomi eucariotici genomi eucariotici Università degli Studi “La Sapienza” ROMA Anno 2002/2003 Pietro Buffa MASTER in BIOinforma tica Applicazioni BioMediche e Farmaceutiche. Direttore Master: Prof.ssa Anna Tramontano Relatore: Prof. Stefano Pascarella
description
BIO informatica. MASTER in. Applicazioni BioMediche e Farmaceutiche. Università degli Studi “La Sapienza” ROMA Anno 2002/2003. Analisi in silico per la ricerca di domini conservati di NRPSs batteriche in genomi eucariotici. Direttore Master : Prof.ssa Anna Tramontano - PowerPoint PPT Presentation
Transcript of Analisi in silico per la ricerca di domini conservati di NRPSs batteriche in genomi eucariotici

Analisi in Analisi in silicosilico per la ricerca di domini per la ricerca di domini conservati di NRPSs batteriche in conservati di NRPSs batteriche in
genomi eucarioticigenomi eucariotici
Analisi in Analisi in silicosilico per la ricerca di domini per la ricerca di domini conservati di NRPSs batteriche in conservati di NRPSs batteriche in
genomi eucarioticigenomi eucariotici
Università degli Studi “La Sapienza” ROMA
Anno 2002/2003
Pietro Buffa
MASTER inBIOinformatica
Applicazioni BioMediche e Farmaceutiche.
Direttore Master: Prof.ssa Anna Tramontano
Relatore: Prof. Stefano Pascarella
Generalità sulle Non Ribosomal Peptide Syntetases, NRPSs
Le NRPSs provvedono ad una sintesi peptidica differente da quella svolta dai ribosomi, essi si presentano generalmente come grossi enzimi multifunzionali con un’organizzazione molecolare
di tipo modulare.
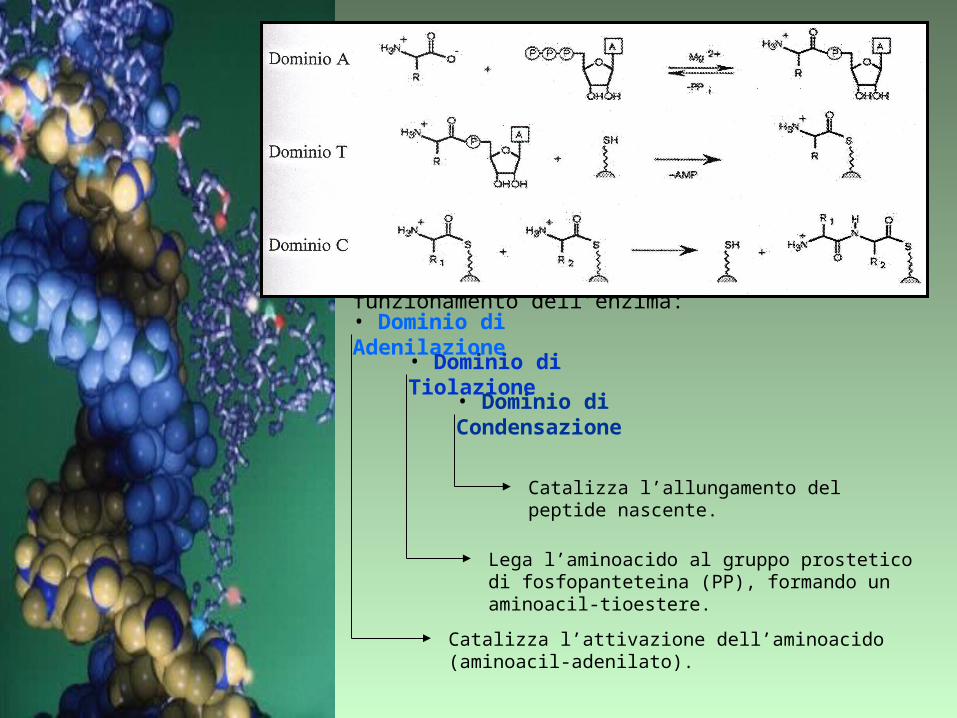
Il modulo più semplice è composto da tre domini indispensabili per il corretto funzionamento dell’enzima:
• Dominio di Adenilazione
• Dominio di Tiolazione
• Dominio di Condensazione
Catalizza l’attivazione dell’aminoacido (aminoacil-adenilato).
Lega l’aminoacido al gruppo prostetico di fosfopanteteina (PP), formando un aminoacil-tioestere.
Catalizza l’allungamento del peptide nascente.
Diversi studi condotti sul dominio di Adenilazione di questa famiglia di enzimi hanno dimostrato che:
• La natura del substrato che sarà inserito nel peptide La natura del substrato che sarà inserito nel peptide sintetizzato dalle NRPSs è controllata principalmente da questo sintetizzato dalle NRPSs è controllata principalmente da questo
dominio.dominio.
• La presenza di un aminoacil-adenilato è la necessaria La presenza di un aminoacil-adenilato è la necessaria premessa alla formazione dell’aminoacil-tioestere nel dominio premessa alla formazione dell’aminoacil-tioestere nel dominio
di Tiolazione e quindi alla sintesi del peptide.di Tiolazione e quindi alla sintesi del peptide.
• Studi condotti su oltre 150 domini di Adenilazione provenienti Studi condotti su oltre 150 domini di Adenilazione provenienti da organismi diversi, hanno rivelato la presenza di importanti da organismi diversi, hanno rivelato la presenza di importanti residui conservati coinvolti nel legame e nell’idrolisi dell’ATP. residui conservati coinvolti nel legame e nell’idrolisi dell’ATP. Sulla base di queste osservazioni è oggi possibile prevedere la Sulla base di queste osservazioni è oggi possibile prevedere la
specificità di un dominio di adenilazione a partire dalla specificità di un dominio di adenilazione a partire dalla struttura primaria con una accuratezza di circa l’86% struttura primaria con una accuratezza di circa l’86%
(Stachelhaus et al, 1999).(Stachelhaus et al, 1999).
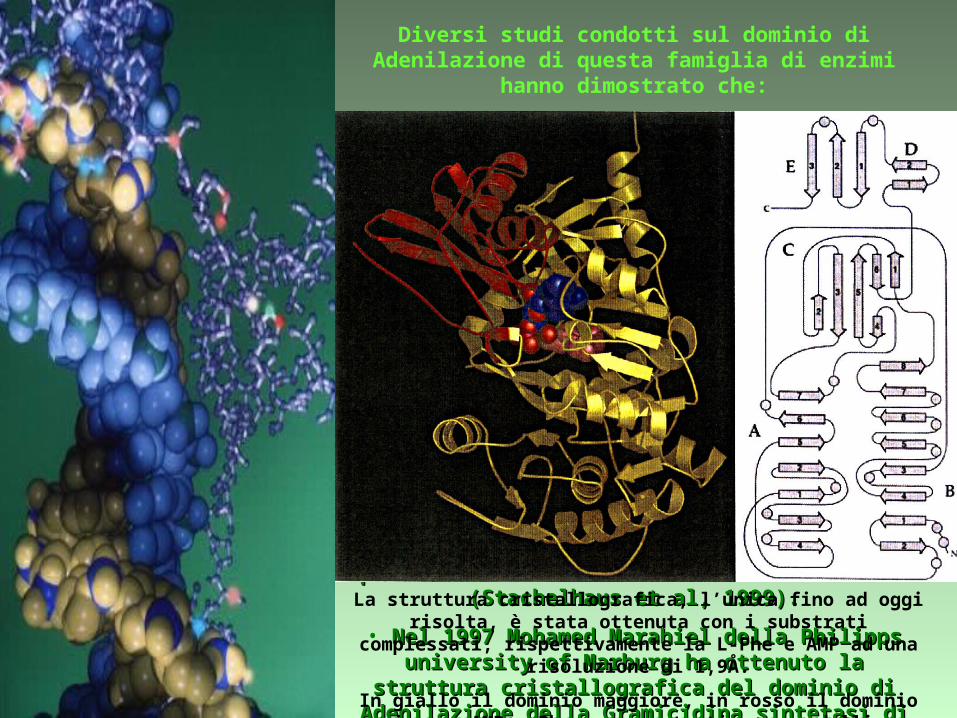
• Nel 1997 Mohamed Marahiel della Philipps university of Nel 1997 Mohamed Marahiel della Philipps university of Marburg ha ottenuto la struttura cristallografica del dominio di Marburg ha ottenuto la struttura cristallografica del dominio di
Adenilazione della Gramicidina sintetasi di Adenilazione della Gramicidina sintetasi di Bacillus brevis.Bacillus brevis.
La struttura cristallografica, l’unica fino ad oggi risolta, è stata ottenuta con i substrati complessati, rispettivamente la L-Phe e AMP
ad una risoluzione di 1,9Å.
In giallo il dominio maggiore, in rosso il dominio minore. AMP e Phe sono mostrati come modelli a spazio pieno.
SCOPO DEL LAVORO
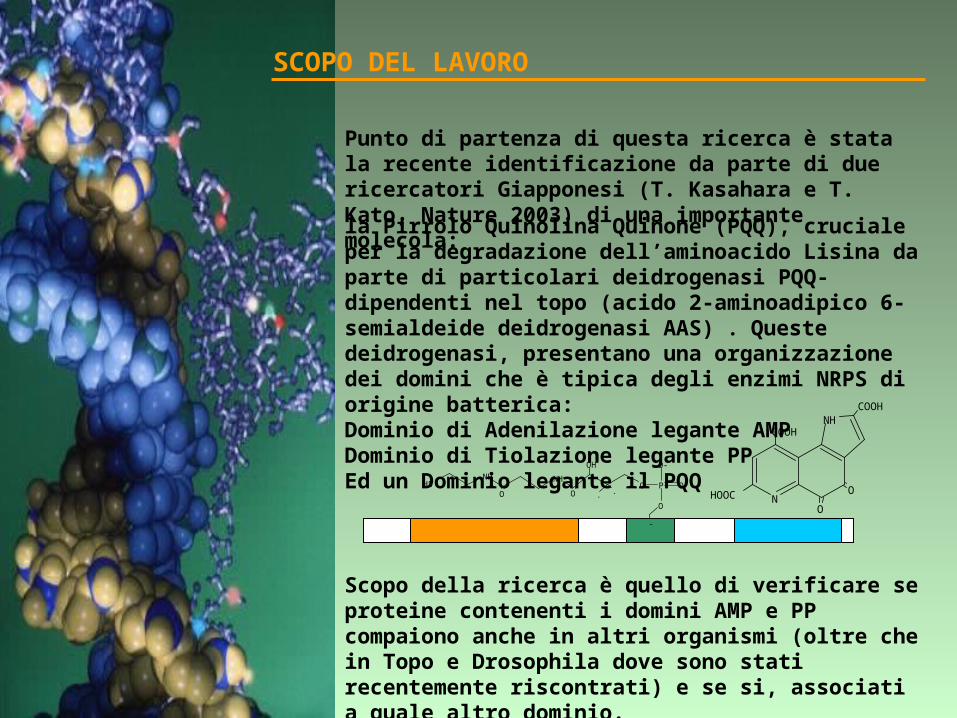
Punto di partenza di questa ricerca è stata la recente identificazione da parte di due ricercatori Giapponesi (T. Kasahara e T. Kato, Nature 2003) di una importante molecola:
la Pirrolo Quinolina Quinone (PQQ), cruciale per la degradazione dell’aminoacido Lisina da parte di particolari deidrogenasi PQQ-dipendenti nel topo (acido 2-aminoadipico 6-semialdeide deidrogenasi AAS) . Queste deidrogenasi, presentano una organizzazione dei domini che è tipica degli enzimi NRPS di origine batterica:Dominio di Adenilazione legante AMPDominio di Tiolazione legante PPEd un Dominio legante il PQQ
P O
O-
O
-
ONHNH
HSO O
OH
. .NHOOC
COOH
O
O
NHCOOH
Scopo della ricerca è quello di verificare se proteine contenenti i domini AMP e PP compaiono anche in altri organismi (oltre che in Topo e Drosophila dove sono stati recentemente riscontrati) e se si, associati a quale altro dominio.

RISULTATI DELLA RICERCA
Ricerca di nuove sequenze proteiche correlate alle Ricerca di nuove sequenze proteiche correlate alle NRPSs batteriche in diversi genomi eucarioticiNRPSs batteriche in diversi genomi eucariotici
Una preliminare ricerca sulle banche dati proteiche, ha permesso di individuare 15 proteine correlate alle NRPSs batteriche (contenenti cioè i domini fondamentali), non ancora annotate nella loro funzione in banca dati.
Sono state utilizzate come sonda le proteine:
AAS (Acido 2-aminoadipico 6-semialdeide deidrogenasi) di topo
[Accession number, 30348962]
U26 di Drosophila [Accession number, AAF52679]
EBONY di Drosophila [Accession number, CAA11962]
CODICE Seq. ORGANISMO DOMINI LUNGProt.
In SILICO
Nr:GI_8885525 A. thaliana AMP-PP-WD40(PQQ) 1175 NO
Nr:GI_22327387 A. thaliana AMP-PP-WD40(PQQ) 1040 NO
Nr:GI_20466612 A. thaliana AMP-PP-WD40(PQQ) 1040 NO
Nr:GI_17556356 C. elegans C-AMP-PP-C-PP-C-AMP-P 2870 NO
Trembl :q95q02 C. elegans AMP-PP-PP-C-AMP-PP 2870 NO
Nr:GI_24817561 C. elegans AMP-PP-WD40(PQQ) 707 NO
Nr:GI_24817562 C. elegans AMP-PP-WD40(PQQ) 714 NO
Nr:GI_20151443 D. melanogaster AMP-PP- ? 703 NO
Nr:GI_24648676 D. melanogaster AMP-PP- ? 879 NO
Nr:GI_32867661 D. melanogaster AMP-PP- ? 879 NO
Nr:GI_22945960 D. melanogaster AMP-PP-PQQ 1012 NO
Nr :GI_3286766 D. melanogaster AMP-PP- ? 879 NO
Nr:GI_5777799 D. melanogaster AMP-PP-PQQ 824 NO
Nr:GI_21291643 A. gambiae AMP-PP-? 881 NO
Nr:GI_31235353 A. gambiae AMP-PP-PQQ 824 NO

Le sequenze precedentemente elencate sono state utilizzate come sonda per ricerche di similarità sulle Banche Dati Genomiche utilizzando il modulo “tblastn” del programma BLAST implementato sia su NCBI che su ENSEMBL.
R. Norvegicus (Rat)
M. Musculus
H. Sapiens
D. Melanogaster
C. Elegans
C. Briggsae
A.Thaliana
D. Rerio (Zebrafish)
A.Gambiae
S. Scrofa
G. Gallus
B. Taurus
C. Intestinalis
F. Rubripes
O. sativa
Per alcuni genomi non si sono avuti risultati positivi.
Per altri si è trovata una notevole similarità e la presenza di residui chiave veniva mantenuta. Per queste sequenze si è proceduto all’esportazione delle rispettive sequenze genomiche in formato FASTA.

Costruzione di geni in silico per le sequenze ritrovate Costruzione di geni in silico per le sequenze ritrovate in seguito alle ricerche genomichein seguito alle ricerche genomiche
ORGANISMO CODICE SEQUENZA SONDA
LOCALIZZAZIONE GENOMICA
LUNGHEZZA PROTEINA
30348962 Crom.14 Contig: RNOR01037209
1152 AA
30348962 Crom. 4 Contig:AC06820.5.1.147534
556 AA
Danio Rerio (zebrafish)
30348962 Contig: CTG11952.6 1003 AA
Fugu Rubripes 30348962 Scaffold: 632 1088 AA
Ciona Intestinalis
30348962 AABS01000029_1 1074 AA
Oryza sativa 8885525 Nr:GI_19925098 1285 AA
Oryza sativa 8885525 Nr:GI_19961040 1551 AA
Oryza sativa 8885525 Nr:GI_19963553 1461 AA
Homo Sapiens
Rattus norvegicus
Le sequenze genomiche precedentemente esportate e salvate vengono utilizzate in questa seconda fase del lavoro, per cercare di ottenere, attraverso l’uso di programmi quali GenScan e genomeScan, una corretta costruzione del gene specifico per ogni sequenza ed arrivare alla fine, alla predizione della relativa sequenza proteica completa.

Realizzazione di un allineamento multiplo completoRealizzazione di un allineamento multiplo completo
– Parte dell’allineamento multiplo di 35 sequenze proteiche appartenenti alla famiglia della NRPSs,. L’allineamento è stato formattato utilizzando il programma ESPRIT 2.1.
• Abbiamo utilizzato 35 sequenze
• Da tutte le 35 seq. È stata manualmente eliminata la regione contenente il dominio C-terminale
• E’ stato utilizzato il programma HMMERalign
• Sono state eliminate dall’allineamento multiplo le regioni iniziali e terminali poichè non avendo corrispondenze ben definite, potevano creare un fastidioso rumore di fondo che andrebbe a disturbare la successiva fase di generazione dell’albero evolutivo
DFFxxLGG(HD)S(LI)Residui fondamentali del dominio
di tiolazione. La serina lega il gruppo prostetico di
fosfopanteteina.
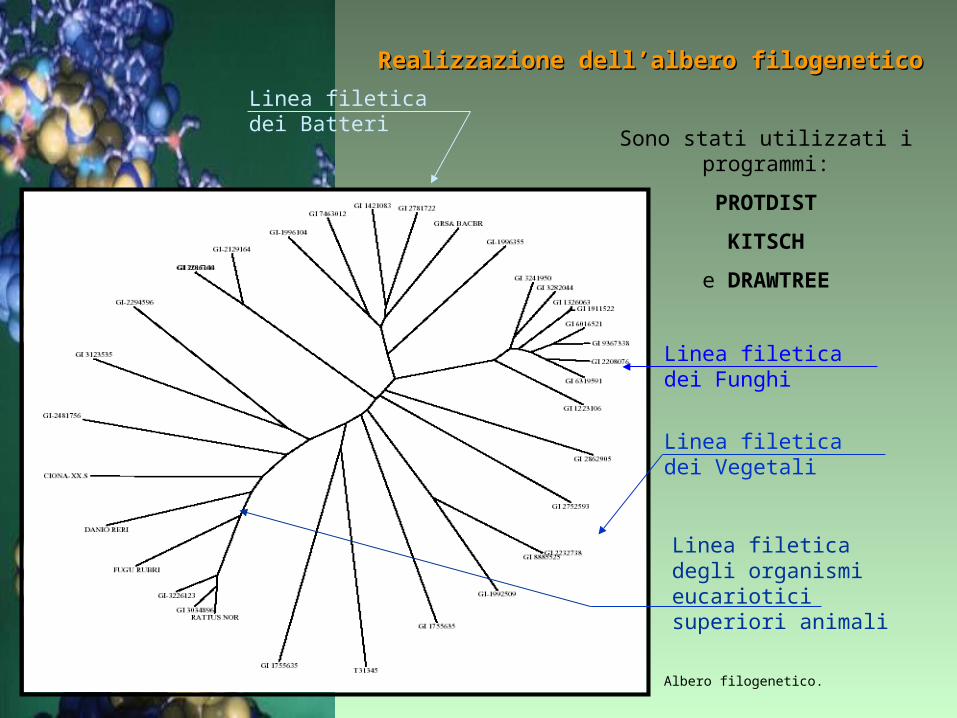
Realizzazione dell’albero filogeneticoRealizzazione dell’albero filogenetico
Albero filogenetico.
Sono stati utilizzati i programmi:
PROTDIST
KITSCH
e DRAWTREE
Linea filetica dei Batteri
Linea filetica dei Funghi
Linea filetica dei Vegetali
Linea filetica degli organismi eucariotici superiori animali

Il completamento in corso di vari progetti gnomici ha permesso di individuare numerose proteine correlate
alle NRPSs batteriche in organismi eucariotici superiori non ancora annotate in banca dati.
La conoscenza del sistema sintetico delle NRPSs e la comprensione più approfondita dell’evoluzione che queste proteine enzimatiche , conosciute fino a poco
tempo fa soltanto a livello batterico, potrebbero avere avuto, potrebbe risultare utile per cercare di far luce
su determinate vie metaboliche non ancora molto chiare in diversi organismi superiori.
DISCUSSIONE

RINGRAZIAMENTI