
Analisi dei dati - cpc-chiasso.ch nuova... · Gruppo di lavoro cantonale per un eserciziario di...
42
Analisi dei dati Dispense per la maturità professionale commerciale Gruppo di lavoro cantonale per un eserciziario di matematica. Anno scolastico 2015-16
Transcript of Analisi dei dati - cpc-chiasso.ch nuova... · Gruppo di lavoro cantonale per un eserciziario di...

Analisi dei dati
Dispense per la maturità professionale commerciale
Gruppo di lavoro cantonale per un eserciziario di matematica.
Anno scolastico 2015-16

Statistica descrittiva BRU 2015 2
Statistica descrittiva: sommario
1. Introduzione ................................................................................................................................................................ 3
2. La raccolta dei dati ...................................................................................................................................................... 3
2.1 Variabili statistiche ............................................................................................................................................ 3
2.2 Popolazione e campione .................................................................................................................................... 4
3. La statistica monovariata ............................................................................................................................................ 6
3.1 Distribuzioni di frequenze ................................................................................................................................. 6
3.1.1 Frequenze assolute ....................................................................................................................................... 6
3.1.2 Frequenze relative ........................................................................................................................................ 9
3.1.3 Frequenze cumulate ................................................................................................................................... 12
3.2 Indicatori di centralità ..................................................................................................................................... 14
3.2.1 La media aritmetica.................................................................................................................................... 14
3.2.2 La mediana ................................................................................................................................................. 16
3.2.3 La moda ..................................................................................................................................................... 18
3.2.4 Indicatori di centralità a confronto ............................................................................................................. 19
3.3 Indicatori di dispersione .................................................................................................................................. 20
3.3.1 Il campo di variazione ................................................................................................................................ 21
3.3.2 Lo scarto quadratico medio (o scarto tipo) ................................................................................................. 21
3.3.3 Lo scarto interquartile e il box-plot. ........................................................................................................... 22
4. Statistica bivariata ..................................................................................................................................................... 25
5 Soluzioni degli esercizi proposti ............................................................................................................................... 32

Statistica descrittiva BRU 2015 3
1. Introduzione
“La statistica è una disciplina che ha come fine lo studio quantitativo e qualitativo di un
particolare fenomeno in condizioni di non determinismo o incertezza ovvero di non
completa conoscenza di esso o parte di esso”. (Wikipedia 2015).
La statistica si occupa di:
a) raccogliere dati
b) analizzarli (rappresentandoli graficamente, estraendone indicatori,…)
c) trarre conclusioni o formulare previsioni sulla base delle informazioni ricavate.
Queste tre fasi sono strettamente correlate: al momento di raccogliere i dati è di vitale
importanza una riflessione attenta, perché il modo in cui si raccolgono i dati può influenzare
l’esito delle nostre conclusioni.
2. La raccolta dei dati
2.1 Variabili statistiche
Ogni volta che si raccolgono dei dati si ha a che fare con una variabile statistica (detta
anche carattere) che può assumere diversi valori (che vengono chiamati modalità).
La variabile indagata può esser di tipo qualitativo o quantitativo. Facciamo qualche
esempio:
Variabile (o carattere) tipo modalità possibili
Colore degli occhi qualitativo Azzurri, neri, castani, verdi…
Giorno della settimana qualitativo Lunedi, martedì,…
Numero di figli quantitativo 0,1,2,…
Altezza quantitativo 1.82, 1.78, 1.65,…
Da questi primi esempi vediamo che possiamo fare distinzione tra il colore degli occhi e il
giorno della settimana (che sono caratteri qualitativi), perché, mentre per i giorni della

Statistica descrittiva BRU 2015 4
settimana è possibile stabilire un ordine (in questo caso la sequenza), per i colori degli occhi
non vale lo stesso. Anche tra il numero di figli e l’altezza esiste una differenza importante:
mentre il primo può assumere solo valori interi e positivi (si tratta di una variabile discreta),
per la seconda esiste una varietà più alta di valori, che dipende soprattutto dalla precisione
con cui viene misurata (si parla qui di variabile continua). Per la variabile continua si pone
il problema dell’arrotondamento, che di solito viene fatto al momento della raccolta dei dati:
questa azione trasforma di fatto una variabile continua in una discreta (se arrotondiamo al
primo decimale, tutti i valori ottenuti saranno multipli interi di 0.1).
Da notare che il tipo di dati raccolti determina anche le operazioni possibili in fase di
analisi: non sarà possibile calcolare la media di dati qualitativi, mentre la media ottenuta per
il numero di figli andrà interpretata con prudenza, in quanto potrebbe assumere valori che la
nostra variabile non assume, al contrario di quanto può succedere con l’altezza (ad es. una
media di 1,3 figli non corrisponde alla situazione di nessuna famiglia esistente, mentre
un’altezza media di 1.79 m può benissimo essere l’altezza di persone realmente esistenti).
2.2 Popolazione e campione
Il “luogo di raccolta” dei dati preso nella sua totalità, viene indicato come popolazione. In
genere si tratta di una massa enorme di dati potenzialmente acquisibili. Il caso del
censimento o della dichiarazione d’imposta rappresentano esempi in cui la popolazione
viene analizzata interamente.
Nella maggior parte dei casi però si cerca di evitare questo tipo di sforzo.
Ci si limita pertanto a un campione, che dovrebbe essere un sottoinsieme rappresentativo
della popolazione. Con rappresentativo si intende che il campione, pur essendo una frazione
della popolazione, si comporta in modo se non identico, almeno molto simile alla
popolazione intera. Se questa premessa è realizzata, le conclusioni tratte per il campione si
potranno estendere alla popolazione.
Raccogliere dati senza tenere in considerazione questi fatti può portare a conclusioni
sbagliate (anche se la successiva analisi avviene in modo corretto).
Tra i metodi di campionamento troviamo la scelta casuale: in questo caso è importante

Statistica descrittiva BRU 2015 5
capire che il campione diventa tanto più rappresentativo quanto più grande è il sottoinsieme
scelto e bisognerà trovare un buon compromesso tra il risparmio nella raccolta e la loro
rappresentatività.
Sarebbe azzardato pensare di prevedere l’esito di una votazione in Ticino interrogando 3 o 4
persone incontrate per strada (anche se la varietà delle risposte è ristretta, in questo caso
sì/no), tuttavia è possibile formulare stime attendibili anche con piccole porzioni della
popolazione (ad es se si dispone di un campione accuratamente scelto in modo che rispecchi
le stesse quote della popolazione reale per età, sesso, formazione, appartenenza politica e
religiosa…).
Supponiamo di voler svolgere un’indagine che valuti le competenze e l’interesse dei giovani
per la politica in Ticino.
Quali dati vorreste raccogliere? (Dati anagrafici, tipo di formazione, affiliazione a un
partito o associazione, sport e hobby praticati…)
Con quale modalità? (Indagine telefonica, sondaggio via web, interviste personali…)
Solo con queste due semplici domande è facile accorgersi che ne nascono parecchie altre:
nel caso dei dati da raccogliere, ci rendiamo conto che non è semplice sapere in anticipo
quali informazioni relative ai soggetti interpellati abbiano (e in che misura) rilevanza per la
nostra indagine. Potremmo ad esempio scoprire che esiste una correlazione tra le attività
praticate nel tempo libero e le preferenze politiche (quindi sarebbe utile disporre di indagini
precedenti o affidarci all’esperienza di altri: ma le scoperte più interessanti sono quelle che
non ti aspetti, per cui ci dovremmo liberare dalle nostre proiezioni mentali e raccogliere
anche dati in apparenza non pertinenti, ma quali?).
Il modo con cui si intende procedere alla raccolta è importante per la rappresentatività del
campione scelto: chi raggiungiamo con la nostra indagine? O meglio ancora, chi non
raggiungiamo? Esiste ancora una fascia di popolazione che non usa o ha poca dimestichezza
con il web, e tra gli utilizzatori ce ne sono di restii a rispondere ai sondaggi. Le persone che
non appaiono sull’elenco del telefono inoltre sono in aumento, in seguito alla diffusione dei
cellulari e alle sempre più invadenti “chiamate commerciali” dove qualcuno cerca di
venderci qualcosa che non ci interessa. Il buon vecchio sistema di consumare le suole delle

Statistica descrittiva BRU 2015 6
scarpe non è immune da rischi: se fate il giro dei bar avreste risultati verosimilmente diversi
da quelli che otterreste all’uscita delle discoteche, in un centro commerciale, agli
allenamenti di società sportive, all’assemblea cantonale dei giovani o ai ritrovi scout. Se
credete che le scuole possano essere la soluzione, pensate alle differenze esistenti tra i
diversi percorsi scolastici e al fatto che una parte rilevante di “giovani” (dovremmo anche
metterci d’accordo sulla fascia d’età che ci interessa) potrebbe aver terminato gli studi.
Raggiungere tutti è quasi impossibile, ma trovare un campione rappresentativo non è certo
facile.
Ai giorni nostri per i sondaggi di opinione esistono strumenti molto potenti come i social
media, che permettono di raggiungere un’utenza enorme in tempi molto ristretti. Il fatto che
le loro banche dati non siano pubbliche, però, rappresenta un bell’ostacolo all’oggettività e
all’indipendenza dei risultati.
3. La statistica monovariata
3.1 Distribuzioni di frequenze
3.1.1 Frequenze assolute
Supponiamo di aver rilevato i pesi di 200 studenti maschi di una scuola:
allievo peso
1. 64.7 kg
2. 72.6 kg
……………………..
200. 67.9 kg
Un metodo per osservare e analizzare le caratteristiche di questo set di dati consiste nel
raggrupparlo in classi, allestendo una tabella come quella della pagina seguente (si procede
in pratica a un conteggio). I dati così tabellati costituiscono una sorta di sintesi dei dati
originali, con il vantaggio che se ne ha una migliore visione d’insieme e lo svantaggio che
una parte dell’informazione è andata perduta. Si tratta qui di trovare il giusto equilibrio tra
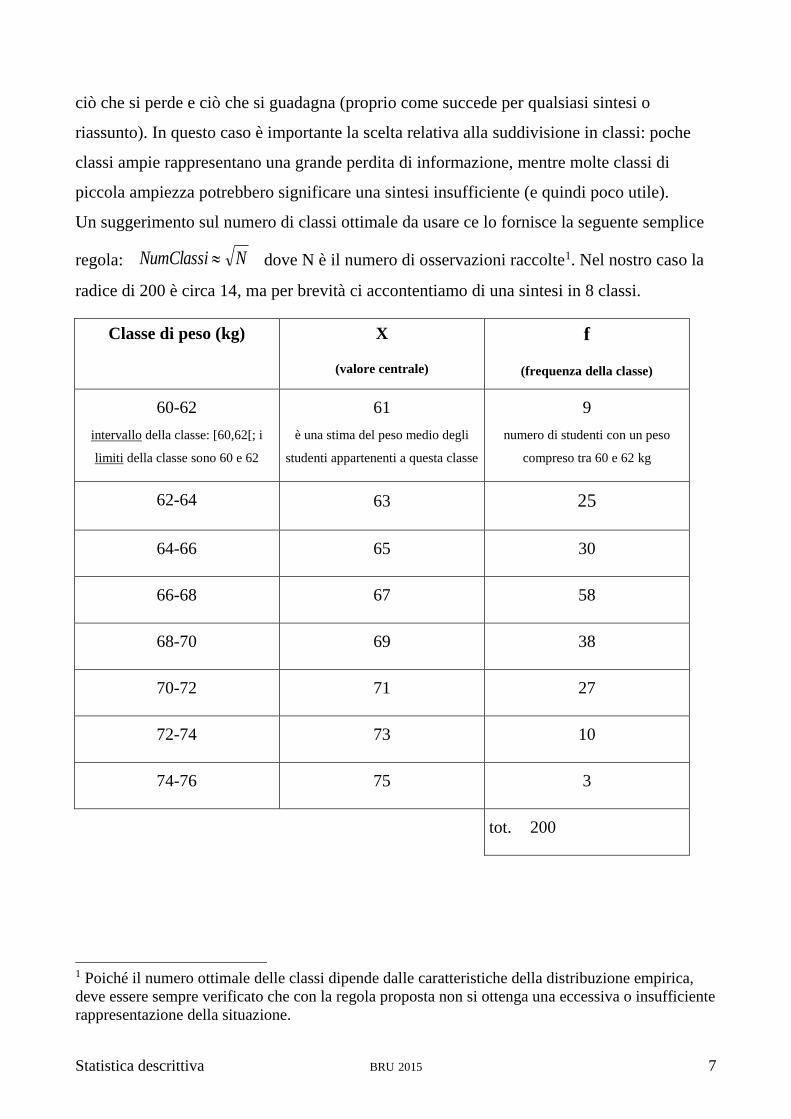
Statistica descrittiva BRU 2015 7
ciò che si perde e ciò che si guadagna (proprio come succede per qualsiasi sintesi o
riassunto). In questo caso è importante la scelta relativa alla suddivisione in classi: poche
classi ampie rappresentano una grande perdita di informazione, mentre molte classi di
piccola ampiezza potrebbero significare una sintesi insufficiente (e quindi poco utile).
Un suggerimento sul numero di classi ottimale da usare ce lo fornisce la seguente semplice
regola: NNumClassi dove N è il numero di osservazioni raccolte1. Nel nostro caso la
radice di 200 è circa 14, ma per brevità ci accontentiamo di una sintesi in 8 classi.
Classe di peso (kg) X
(valore centrale)
f
(frequenza della classe)
60-62
intervallo della classe: [60,62[; i
limiti della classe sono 60 e 62
61
è una stima del peso medio degli
studenti appartenenti a questa classe
9
numero di studenti con un peso
compreso tra 60 e 62 kg
62-64 63 25
64-66 65 30
66-68 67 58
68-70 69 38
70-72 71 27
72-74 73 10
74-76 75 3
tot. 200
1 Poiché il numero ottimale delle classi dipende dalle caratteristiche della distribuzione empirica,
deve essere sempre verificato che con la regola proposta non si ottenga una eccessiva o insufficiente
rappresentazione della situazione.
Statistica descrittiva BRU 2015 8
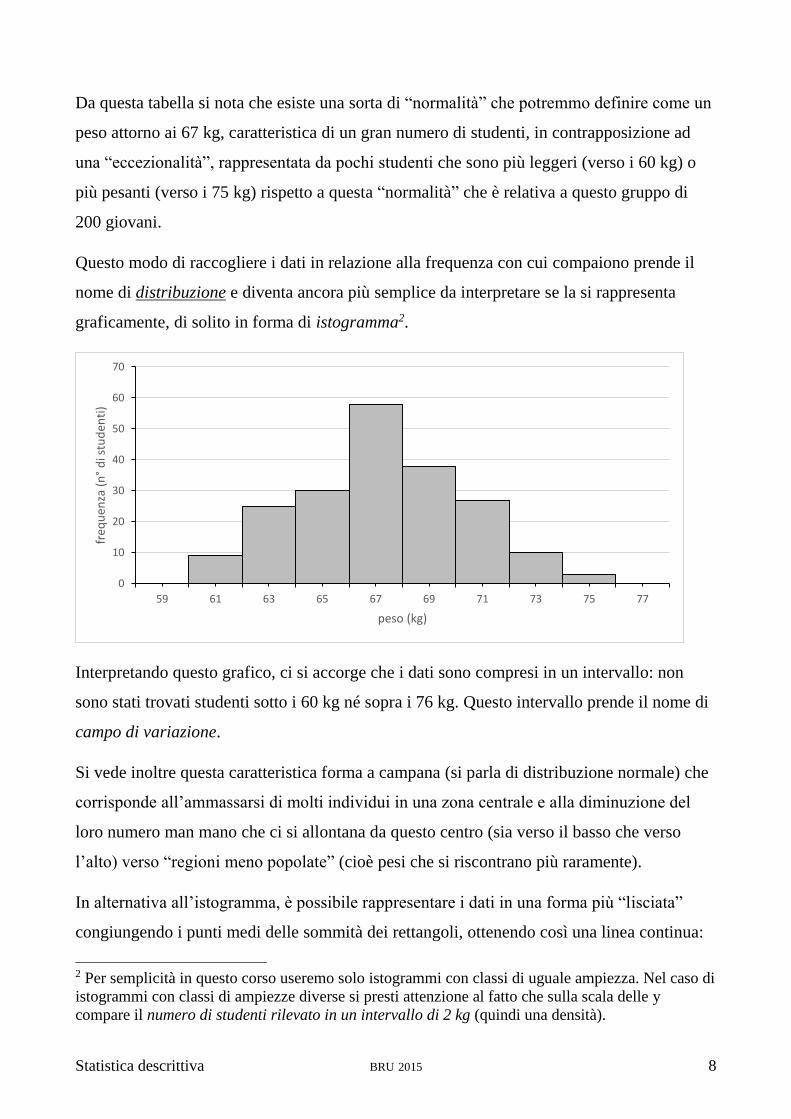
Da questa tabella si nota che esiste una sorta di “normalità” che potremmo definire come un
peso attorno ai 67 kg, caratteristica di un gran numero di studenti, in contrapposizione ad
una “eccezionalità”, rappresentata da pochi studenti che sono più leggeri (verso i 60 kg) o
più pesanti (verso i 75 kg) rispetto a questa “normalità” che è relativa a questo gruppo di
200 giovani.
Questo modo di raccogliere i dati in relazione alla frequenza con cui compaiono prende il
nome di distribuzione e diventa ancora più semplice da interpretare se la si rappresenta
graficamente, di solito in forma di istogramma2.
Interpretando questo grafico, ci si accorge che i dati sono compresi in un intervallo: non
sono stati trovati studenti sotto i 60 kg né sopra i 76 kg. Questo intervallo prende il nome di
campo di variazione.
Si vede inoltre questa caratteristica forma a campana (si parla di distribuzione normale) che
corrisponde all’ammassarsi di molti individui in una zona centrale e alla diminuzione del
loro numero man mano che ci si allontana da questo centro (sia verso il basso che verso
l’alto) verso “regioni meno popolate” (cioè pesi che si riscontrano più raramente).
In alternativa all’istogramma, è possibile rappresentare i dati in una forma più “lisciata”
congiungendo i punti medi delle sommità dei rettangoli, ottenendo così una linea continua:
2 Per semplicità in questo corso useremo solo istogrammi con classi di uguale ampiezza. Nel caso di
istogrammi con classi di ampiezze diverse si presti attenzione al fatto che sulla scala delle y
compare il numero di studenti rilevato in un intervallo di 2 kg (quindi una densità).
0
10
20
30
40
50
60
70
59 61 63 65 67 69 71 73 75 77
freq
uen
za (
n°
di s
tud
enti
)
peso (kg)
Statistica descrittiva BRU 2015 9
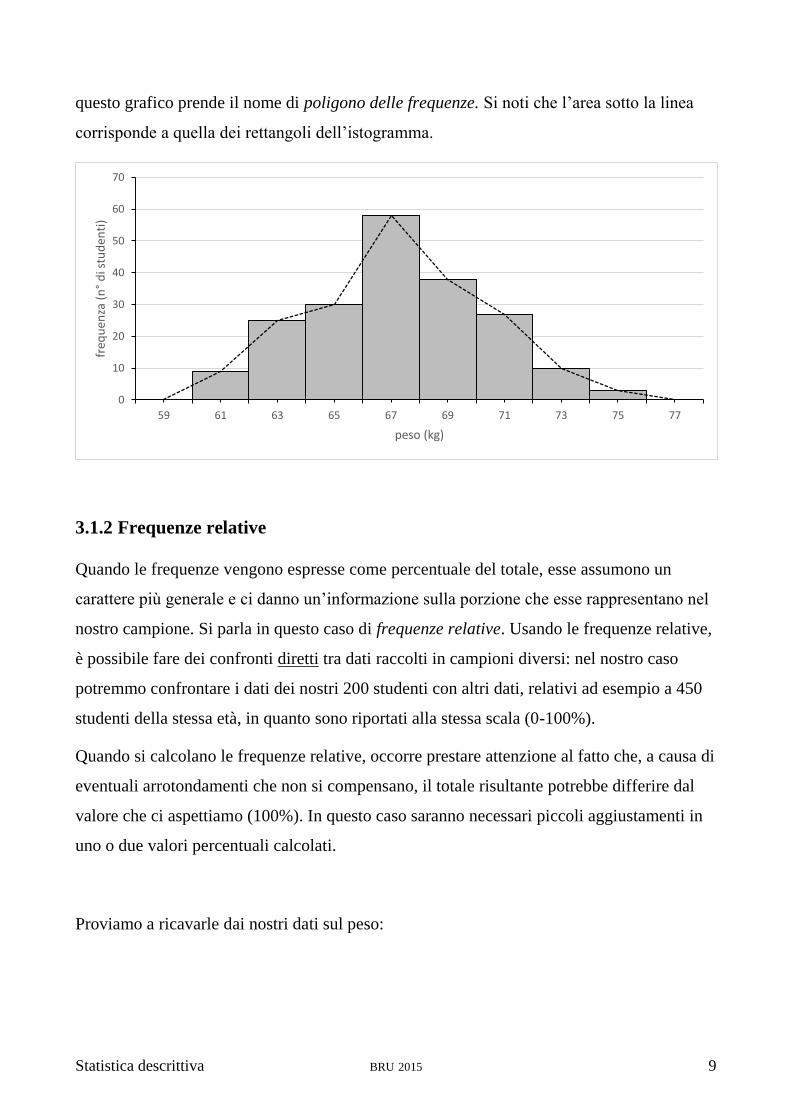
questo grafico prende il nome di poligono delle frequenze. Si noti che l’area sotto la linea
corrisponde a quella dei rettangoli dell’istogramma.
3.1.2 Frequenze relative
Quando le frequenze vengono espresse come percentuale del totale, esse assumono un
carattere più generale e ci danno un’informazione sulla porzione che esse rappresentano nel
nostro campione. Si parla in questo caso di frequenze relative. Usando le frequenze relative,
è possibile fare dei confronti diretti tra dati raccolti in campioni diversi: nel nostro caso
potremmo confrontare i dati dei nostri 200 studenti con altri dati, relativi ad esempio a 450
studenti della stessa età, in quanto sono riportati alla stessa scala (0-100%).
Quando si calcolano le frequenze relative, occorre prestare attenzione al fatto che, a causa di
eventuali arrotondamenti che non si compensano, il totale risultante potrebbe differire dal
valore che ci aspettiamo (100%). In questo caso saranno necessari piccoli aggiustamenti in
uno o due valori percentuali calcolati.
Proviamo a ricavarle dai nostri dati sul peso:
0
10
20
30
40
50
60
70
59 61 63 65 67 69 71 73 75 77
freq
uen
za (
n°
di s
tud
enti
)
peso (kg)
Statistica descrittiva BRU 2015 10
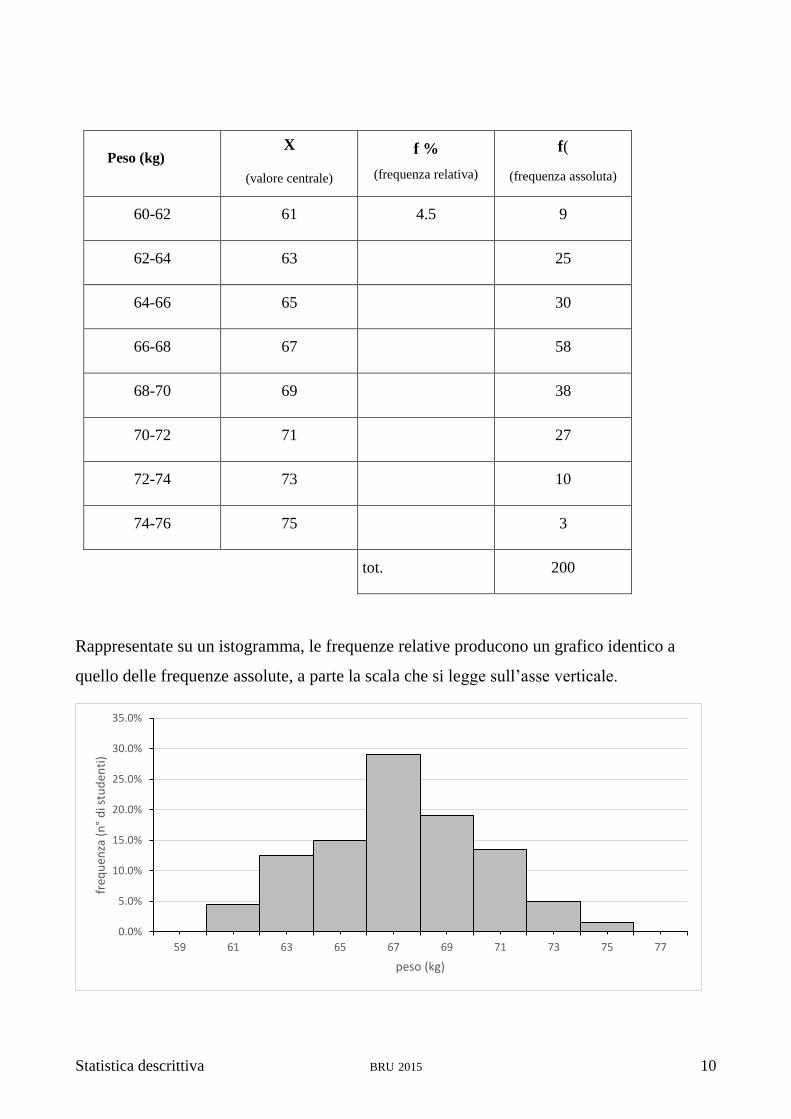
Peso (kg) X
(valore centrale)
f %
(frequenza relativa)
f(
(frequenza assoluta)
60-62 61 4.5 9
62-64 63 25
64-66 65 30
66-68 67 58
68-70 69 38
70-72 71 27
72-74 73 10
74-76 75 3
tot. 200
Rappresentate su un istogramma, le frequenze relative producono un grafico identico a
quello delle frequenze assolute, a parte la scala che si legge sull’asse verticale.
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
30.0%
35.0%
59 61 63 65 67 69 71 73 75 77
freq
uen
za (
n°
di s
tud
enti
)
peso (kg)

Statistica descrittiva BRU 2015 11
Da questo grafico però, è più facile tirare conclusioni del tipo “meno del 5% degli studenti
ha un peso inferiore a 62 kg” oppure “quasi un terzo degli studenti ha un peso compreso tra
66 e 68 kg”, che sono considerazioni che potrebbero essere confrontate con quelle fatte su
un qualsiasi altro campione di persone con caratteristiche simili al nostro.
Esercizio 1: dai seguenti dati raggruppati, relativi a 400 ragazze della stessa età dei nostri
studenti, ricavate le frequenze relative e rappresentatele su un istogramma da confrontare
con il grafico qui sopra. Quali differenze/analogie si osservano tra le due distribuzioni?
Commentate.
X (kg) 51 53 55 57 59 61 63 65 67 69
f 4 24 56 68 84 76 48 20 12 8
Esercizio 2: Supponete che i 200 studenti e le 400 ragazze facciano parte della stessa scuola
e che i loro pesi siano stati raccolti senza fare distinzioni di sesso. Allestite la tabella che ne
risulterebbe e rappresentate l’istogramma corrispondente. Cosa notate?
Statistica descrittiva BRU 2015 12
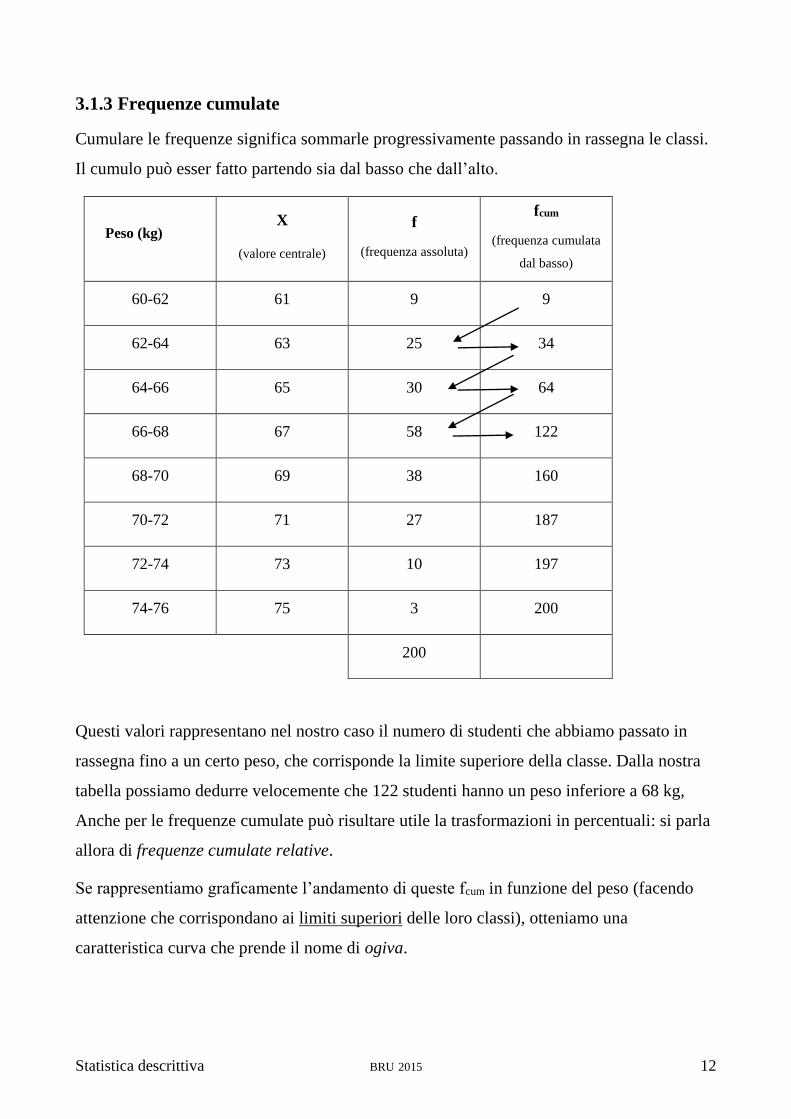
3.1.3 Frequenze cumulate
Cumulare le frequenze significa sommarle progressivamente passando in rassegna le classi.
Il cumulo può esser fatto partendo sia dal basso che dall’alto.
Peso (kg) X
(valore centrale)
f
(frequenza assoluta)
fcum
(frequenza cumulata
dal basso)
60-62 61 9 9
62-64 63 25 34
64-66 65 30 64
66-68 67 58 122
68-70 69 38 160
70-72 71 27 187
72-74 73 10 197
74-76 75 3 200
200
Questi valori rappresentano nel nostro caso il numero di studenti che abbiamo passato in
rassegna fino a un certo peso, che corrisponde la limite superiore della classe. Dalla nostra
tabella possiamo dedurre velocemente che 122 studenti hanno un peso inferiore a 68 kg,
Anche per le frequenze cumulate può risultare utile la trasformazioni in percentuali: si parla
allora di frequenze cumulate relative.
Se rappresentiamo graficamente l’andamento di queste fcum in funzione del peso (facendo
attenzione che corrispondano ai limiti superiori delle loro classi), otteniamo una
caratteristica curva che prende il nome di ogiva.
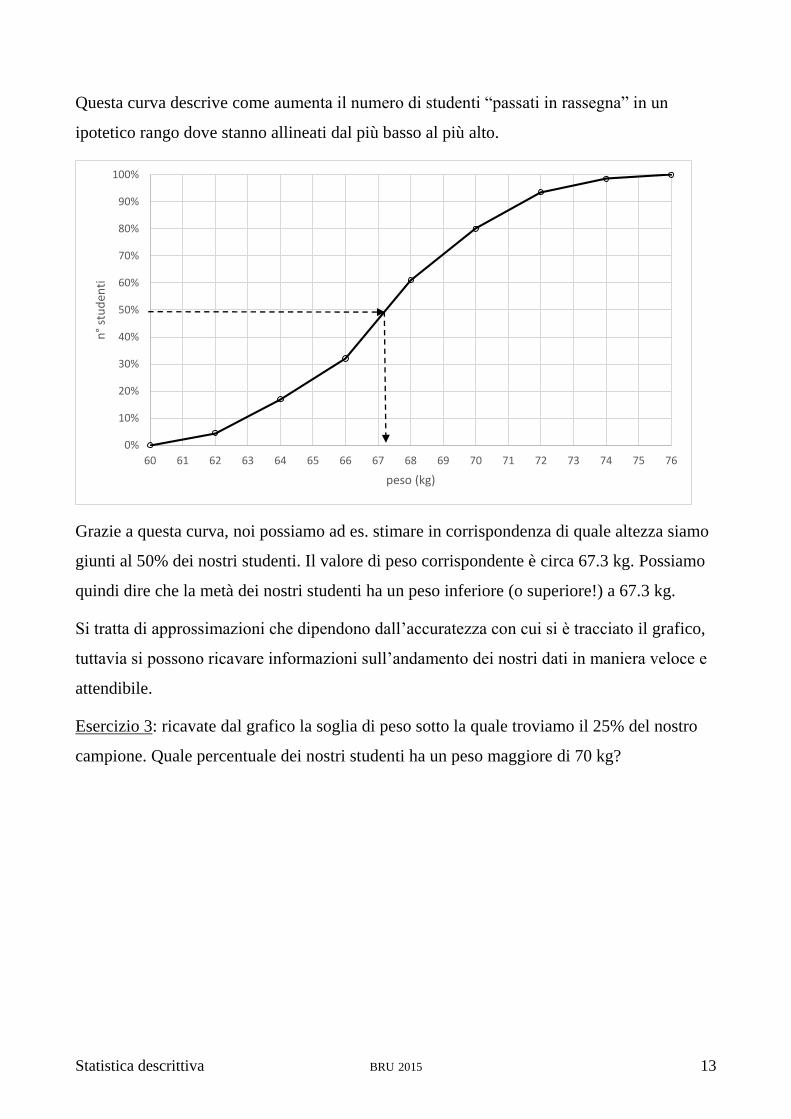
Statistica descrittiva BRU 2015 13
Questa curva descrive come aumenta il numero di studenti “passati in rassegna” in un
ipotetico rango dove stanno allineati dal più basso al più alto.
Grazie a questa curva, noi possiamo ad es. stimare in corrispondenza di quale altezza siamo
giunti al 50% dei nostri studenti. Il valore di peso corrispondente è circa 67.3 kg. Possiamo
quindi dire che la metà dei nostri studenti ha un peso inferiore (o superiore!) a 67.3 kg.
Si tratta di approssimazioni che dipendono dall’accuratezza con cui si è tracciato il grafico,
tuttavia si possono ricavare informazioni sull’andamento dei nostri dati in maniera veloce e
attendibile.
Esercizio 3: ricavate dal grafico la soglia di peso sotto la quale troviamo il 25% del nostro
campione. Quale percentuale dei nostri studenti ha un peso maggiore di 70 kg?
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76
n°
stu
den
ti
peso (kg)

Statistica descrittiva BRU 2015 14
3.2 Indicatori di centralità
Gli indicatori sono valori rappresentativi (un unico numero scaturito da tutti i dati).
Gli indicatori di centralità (o indici di posizione) dovrebbero fornirci l’indicazione della
posizione centrale attorno alla quale i dati si distribuiscono in maniera più o meno uniforme
3.2.1 La media aritmetica
È senz’altro il più famoso indicatore di centralità.
Lo si ricava sommando tra loro tutti i dati nxxx ,......,, 21 e dividendo il totale per il loro
numero:
n
xxxX n
......21 Media aritmetica semplice
Oppure, se i numeri kxxx ,......,, 21 compaiono con le frequenze kfff ,......,, 21
k
kk
fff
xfxfxfX
......
......
21
2211 Media aritmetica ponderata
Ad esempio per i 10 numeri 1423 4321
1,6,6,6,6,8,8,5,5,5
ffff
:
6.510
1666688555
X
che è lo stesso di 6.51423
1648253
X
Nel secondo caso si dice che il valore 5 ottiene ponderazione (o peso) pari a 3. Questa
ponderazione può essere anche interpretata come l’importanza che si dà a ognuno dei valori
utilizzati per il calcolo della media

Statistica descrittiva BRU 2015 15
Prendiamo il caso di una valutazione scolastica:
1°sem 2°sem Esame scritto Esame orale
4.5 5 4 5.5
Supponiamo che la nota dell’esame scritto conti doppio rispetto alle altre tre, la nota finale
sarebbe dunque:
6.45
23
1211
15.5241515.4
Abbiamo qui attribuito ponderazione 1 alle note di semestre e dell’esame orale,
ponderazione 2 alla nota dell’esame scritto. Si ottiene lo stesso risultato assegnando peso 4
alla nota dell’esame scritto e peso 2 alle altre tre (provare per credere: come mai?).
La media ponderata ci torna utile nel caso di dati raggruppati. Infatti, per restare sul nostro
esempio dei pesi, sappiamo che 9 di loro hanno un peso compreso tra 60 e 62 kg.
Stimiamo il loro peso medio come 61 (il valore centrale della classe) e facciamo i nostri
calcoli come se avessimo 9 studenti che pesano 61 kg.
Possiamo calcolare la media dei nostri 200 studenti come segue:
27.67200
375107327713869586730652563961
Ricordiamo che si tratta di una stima della vera media aritmetica calcolata sui dati grezzi, e
che dipende dal modo in cui si scelgono le classi.
Esercizio 4: calcolate la media del peso delle 400 ragazze del capitolo 3.1.2
X (kg) 51 53 55 57 59 61 63 65 67 69
f 4 24 56 68 84 76 48 20 12 8 400
fX
N
Xf
X
N
i
ii
1

Statistica descrittiva BRU 2015 16
Esercizio 5: 4 varietà di riso sono state mescolate ottenendo un miscuglio di 95 kg
Quantità (kg) 30 40 15 10
Prezzo al kg 2 2.10 2.50 2.80
Trovate il prezzo al kg del miscuglio (media ponderata dei prezzi).
Esercizio 6: Un gestore di fondi ha investito in modo differenziato 20 milioni ricavandone
diversi rendimenti
Capitale investito (Fr.) 8'500’000 5'800’000 3'600’000 2'100’000
Rendimento 1.5% 2% 1.75%0 2.5%
Trovate il tasso medio relativo ai 20 milioni (media ponderata dei tassi).
3.2.2 La mediana
La mediana di un insieme di valori ordinati per grandezza è il valore centrale (o la media
aritmetica dei due valori centrali).
es. 1. 3, 4, 4, 5, 6, 8, 8, 8, 10 mediana: 6
es. 2. 5, 5, 7, 9, 11, 12, 15, 18 mediana: (9+11)/2=10
Nel caso di dati raggruppati si procede di nuovo con una stima, visto che non si dispone più
dei dati grezzi.
Usiamo il solito esempio del peso degli studenti. Visto che N=200, dobbiamo stimare il
peso equivalente al 100° studente (abbiamo già fatto qualcosa di simile quando abbiamo
parlato di ogiva). Ci tornano utili anche le frequenze cumulate, infatti ci serve la classe in
cui fcum supera la soglia del 100 (classe mediana).

Statistica descrittiva BRU 2015 17
Il limite inferiore della classe mediana è 66, quindi il peso mediano sarà
66 + un certo valore.
Dobbiamo trovare il peso della 100a persona, che è la 36a della classe mediana:
100 - 64 (somma frequenze classi precedenti) = 36.
Questa persona peserà 66 + y
Supponendo che il peso delle persone all'interno della classe mediana sia
distribuito in modo uniforme (crescente), y può essere ricavata così:
y = (2 kg : 58) . 36 = 1,24
l’intervallo 66-68 (equivalente a 2 kg), viene suddiviso in 58 parti uguali,
ciascuna corrispondente a uno studente: poiché noi dobbiamo avanzare
all’interno della classe mediana di 36 studenti, moltiplichiamo per questo
numero il piccolo intervallo di peso occupato da ciascun studente.
Il peso mediano è dunque: 66 + 1.24 = 67.24
Peso (kg) X f fcum
60-62 61 9 9
62-64 63 25 34
64-66 65 30 64
66-68 67 58 122 Classe mediana
68-70 69 38 160
70-72 71 27 187
72-74 73 10 197
74-76 75 3 200
tot. 200

Statistica descrittiva BRU 2015 18
Oss. 1. Il risultato trovato significa quindi che 100 studenti pesano più di 67.24 kg e 100
pesano meno di 67.24 kg (è il dato centrale!)
3.2.3 La moda
La moda di un insieme di valori è il valore che si presenta con la più alta frequenza, cioè il
valore che compare più spesso.
es. 1. 2, 2, 5, 7, 9, 9, 9, 9, 10, 10, 11, 12, 18 moda: 9
es. 2. 3, 5, 8, 10, 12, 15, 16 in questo caso la moda non è definita
es. 3. 2, 3, 4, 4, 4, 5, 5, 7, 7, 7, 9 possono esistere 2 o più mode
es. 4. Abitazioni costruite in una città, suddivise per numero di locali:
N° locali N° abitazioni
1 120
2 350
3 730
4 1270
5 1090
6 700
7 280
Si può dire che gli appartamenti di quella città hanno tipicamente 4 stanze.
Per dati raggruppati si può stimare quale moda il valore centrale della classe con la più alta
frequenza, o più semplicemente, indicare l’intera classe modale.
Nel caso dei pesi degli studenti avremo quindi 67 kg oppure classe modale:66-68.
Statistica descrittiva BRU 2015 19
3.2.4 Indicatori di centralità a confronto
Sebbene siano tutte e tre indicatori di centralità, media mediana e moda ci danno questa
indicazione partendo da presupposti diversi, è quindi sempre necessario tener conto del
modo in cui sono ricavate prima di procedere con le interpretazioni.
Nel nostro esempio del peso degli studenti otteniamo tre valori molto vicini tra loro, poiché
la distribuzione è regolare e simmetrica. Nel caso di distribuzioni asimmetriche, (dove i
valori lontani dalla media non si comportano nello stesso modo verso il basso e verso
l’alto), ci si accorge che i tre indicatori reagiscono in modo diverso tra loro: la moda resta
inchiodata al punto culminante dell’istogramma, mentre media e mediana vengono attratte
(la media con maggior forza della mediana) dai valori estremi che si situano lontano dal
culmine.
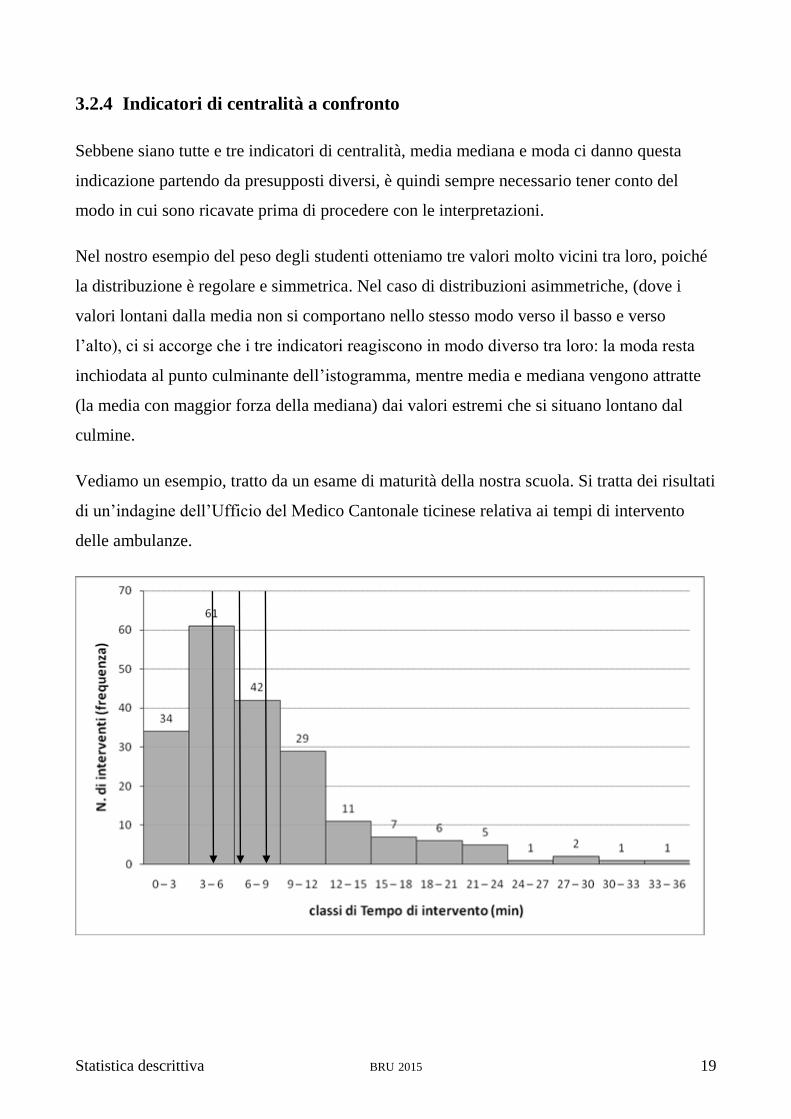
Vediamo un esempio, tratto da un esame di maturità della nostra scuola. Si tratta dei risultati
di un’indagine dell’Ufficio del Medico Cantonale ticinese relativa ai tempi di intervento
delle ambulanze.

Statistica descrittiva BRU 2015 20
Salta subito all’occhio che la distribuzione è asimmetrica poiché (per fortuna dei pazienti)
molti interventi hanno richiesto tempi brevi e pochissimi hanno richiesto attese oltre i 20
minuti. Le code della nostra curva sono diverse tra loro.
I tre indicatori Moda=4.50 Mediana=6.36 Media=7.94
sono rappresentati in quest’ordine dalle frecce sull’istogramma
Provate, come esercitazione, a ricavarli voi stessi.
Vediamo che in questo caso i tre indicatori si scostano tra loro: i valori molto alti (oltre i 20
minuti) seppur poco numerosi attraggono verso di sé la media e la mediana. La mediana
viene detta “robusta” perché resiste maggiormente a questo genere di attrazione di quanto
faccia la media.
Come abbiamo fatto noi stessi con questo esempio, l’interpretazione dei dati e dei loro
indicatori risulta più facile e sicura se fatta sulla base della loro rappresentazione grafica
(istogramma).
3.3 Indicatori di dispersione
Questi indicatori ci danno un’informazione relativa a come i dati si distribuiscono attorno a
un valore centrale (come ad es. la media).
Una critica che si è sentita più volte nei confronti della statistica, è che “se io mangio due
polli e tu nemmeno uno, la media dice che ne abbiamo mangiato uno a testa ma tu sei morto
di fame”, sebbene il tono sia quello di una battuta, dietro questa frase si nasconde una
grande verità: la media ci dà un’informazione relativa alla centralità, unicamente. Se
vogliamo ottenere altre informazioni sui nostri dati, dobbiamo calcolare altri indicatori.
Nel caso dei nostri polli, se oltre alla media fornissimo anche il campo di variazione, (si
veda il prossimo capitolo) che vale 2-0=2, potremmo facilmente distinguere il nostro
esempio da un altro caso ipotetico, in cui ognuna delle due persone mangia un pollo, perché
sebbene la media rimanga 1, il campo di variazione questa volta sarebbe 1-1=0.

Statistica descrittiva BRU 2015 21
3.3.1 Il campo di variazione
È la differenza fra il valore massimo ed il valore minimo dei dati:
Esempio a) 8, 9, 10, 15, 18 campo di variazione: 10
Esempio b) 3, 5, 6, 7, 10, 12, 15, 18 campo di variazione: 15
Esempio c) 3, 10, 10, 10, 11, 11, 11, 18 campo di variazione: 15
Il campo di variazione è 15 sia in b), sia in c), sebbene ci sia più dispersione in b) che in c),
dove la maggior parte dei dati si concentrano attorno ai valori centrali.
Ha il pregio di poter essere calcolato facilmente, ma proprio a causa di ciò, non è molto
significativo dal punto di vista del contenuto di informazione.
Nel caso di dati raggruppati, il campo di variazione può essere stimato come la differenza
tra il limite superiore della classe con i valori più alti e quello inferiore della classe con i
valori più bassi.
3.3.2 Lo scarto quadratico medio (o scarto tipo)
Quando si parla di scarto, si intende la distanza (differenza) di un dato dal valore centrale.
Es. 1: provate a calcolare gli scarti dalla media per uno degli esempi del capitolo 3.3.1.
Che cosa succede se calcoliamo il valore medio di questi scarti? Come lo spiegate?
Lo scarto quadratico medio è la media degli scarti (elevati al quadrato) rispetto alla media (è
quindi un indicatore che va accoppiato ad essa).
In sostanza si tratta di misurare tutte queste differenze, elevarle al quadrato per impedire che
le differenze negative compensino quelle positive, trovare la media di questi valori e
calcolarne la radice per compensare la distorsione introdotta con l’elevamento al quadrato.
La formula corrispondente è la seguente:
n
xxxxxxs n
22
2
2
1 .........

Statistica descrittiva BRU 2015 22
Nota: il metodo con cui viene calcolato s non distingue il modo in cui variano i dati sopra e
sotto la media. Ne consegue che esso si rivela particolarmente adatto a distribuzioni
simmetriche rispetto alla media.
Nel caso di dati raggruppati, le parentesi (gli scarti) al quadrato sono moltiplicate per le
frequenze e il numero n risulta dalla somma di tutte le frequenze (quindi calcoliamo una
media ponderata tra gli scarti dei valori centrali delle classi usando le frequenze come
ponderazione).
n
nn
fff
xxfxxfxxfs
.......
.........
21
22
22
2
11
Con l’uso del simbolo di sommatoria, questa formula può essere sintetizzata ulteriormente
n
i
i
n
i
ii
f
xxf
s
1
2
1
Esercizio 7: provate a calcolare s per gli esempi a), b) e c) del capitolo 3.3.1 e di
interpretarne il significato.
3.3.3 Lo scarto interquartile e il box-plot (diagramma a scatola).
Lo scarto interquartile si ricava utilizzando lo stesso metodo con cui viene calcolata la
mediana. Ricordiamo che la mediana è il valore in corrispondenza del quale il set di dati da
analizzare si spacca in due metà uguali. Ciò significa che metà dei dati è inferiore alla
mediana e l’altra metà è superiore. È però possibile, con lo stesso metodo di calcolo,
ricavare un valore che sia ad esempio maggiore del 30% dei dati (e quindi minore del
rimanente 70%). Questo particolare valore prende il nome di 30° percentile. In quest’ottica
il primo quartile corrisponde al 25° percentile (1/4 =25%), il secondo quartile è la mediana e

Statistica descrittiva BRU 2015 23
il terzo quartile è il 75° percentile. Se, oltre alla mediana, che ci dà un’indicazione di
centralità, calcoliamo anche il primo e il terzo quartile, abbiamo un’indicazione della
dispersione di metà dei nostri dati nelle vicinanze della mediana, se poi a queste
informazioni aggiungiamo i valori minimo e massimo, abbiamo una descrizione
dell’andamento dei nostri dati che si può leggere in modo simile alle curve di livello di una
cartina topografica.
Vediamo un esempio: nel caso degli interventi delle ambulanze del cap. 3.2.4, il totale degli
interventi considerati è 200. Il primo quartile si situa quindi in corrispondenza del 50°
intervento ( ¼ di 200) nei nostri dati ordinati. Visto che nella prima classe si trovano già 34
valori, per arrivare a 50 ne mancano 16. Nella seconda classe abbiamo 61 interventi:
dividiamo i tre minuti di ampiezza di questa classe per 61 e ne utilizziamo 16 da aggiungere
al limite inferiore (3 min): 1661
33 3.79 cioè ¼ degli interventi ha richiesto meno di
3.79 minuti (circa 3 minuti e 48 secondi).
Calcoliamo ora il terzo quartile. Dalle frequenze cumulate vediamo che in corrispondenza di
9 minuti abbiamo cumulato 137 interventi, mentre a 12 arriviamo a 166. Per trovare la
posizione del 150° intervento ( ¾ di 200) dividiamo l’ampiezza di 3 minuti della classe 9-12
per 29 e moltiplichiamo questo tempo che separa un intervento dal successivo per i 13
interventi che mancano (150-137=13), aggiungiamo poi questo valore al limite inferiore
della classe (9): 1329
39 10.34 cioè ¾ degli interventi ha richiesto meno di 10.34 minuti
(circa 10 minuti e 20 secondi).
Possiamo raccogliere tutte le informazioni in un grafico a scatola (box-plot) che ci dà
un’informazione sintetica ma al tempo stesso sufficientemente dettagliata dei nostri dati

Statistica descrittiva BRU 2015 24
La cosa che salta subito all’occhio in questo diagramma, è l’asimmetria: non solo la
mediana non si trova al centro del campo di variazione, ma il quarto che la precede è più
compresso (si trova in un intervallo più piccolo) del quarto che la segue. Infatti la mediana
non si trova al centro nemmeno del rettangolo formato da 1° e 3° quartile.
Questa asimmetria è del resto molto ben visibile nel rispettivo istogramma: la
rappresentazione grafica dei nostri dati è dunque senz’altro il miglior inizio e uno strumento
imprescindibile per la nostra analisi.
Anche per i dati grezzi è possibile ricavare un qualsiasi percentile. Allo scopo si può usare
la seguente regola: 𝑖 =𝛼
100∙ (𝑛 + 1) dove i rappresenta l’indice (la posizione all’interno
della sequenza ordinata) del dato che diventerà il nostro indicatore, α è la posizione
percentuale desiderata (nel caso della mediana α=50) e n è il numero dei dati di cui
disponiamo.
Nella maggior parte dei casi troveremo per i un valore non intero (al contrario di quanto ci
aspettiamo, trattandosi di un indice), per cui si arrotonderà all’intero più vicino, con una
sola eccezione: quando la parte decimale di i vale esattamente 0,5 l’indicatore è la media
aritmetica dei due dati con gli indici tra i quali è compreso i.
0 3 6 9 12 15 18 21 24 27 30 33 36
minuti
1° q
uartile
2° q
uartile
3° q
uartile
Valo
re min
imo
Valo
re massim
o

Statistica descrittiva BRU 2015 25
4. Statistica bivariata
Al contrario di quanto abbiamo visto finora, al momento di raccogliere dei dati, non ci si
accontenta di prendere nota unicamente del peso di una persona. Anzi, spesso per un’unica
persona vengono raccolte parecchie informazioni (si parla allora di statistica multivariata).
Noi qui ci accontentiamo del caso di due variabili.
Restando fedeli al nostro esempio sui dati fisici di una persona, potremmo interessarci ad
altezza e peso, che sono due variabili quantitative continue (si veda il cap 2.1), oppure al
colore degli occhi e dei capelli, che sono variabili qualitative.
Le tabelle seguenti potrebbero rappresentare il risultato delle nostre indagini:
Nome Altezza in cm Peso in kg
Aldo 175 70
Giovanni 165 56
Giacomo 158 54
… … …
Nome Colore dei capelli Colore degli occhi
Amelia nero nero
Brigitta biondo azzurro
Mariuccia rosso verde
… … …
Quando si ha a disposizione un elenco con decine di righe, in che modo è possibile
visualizzare questi dati per poterci ragionare sopra?
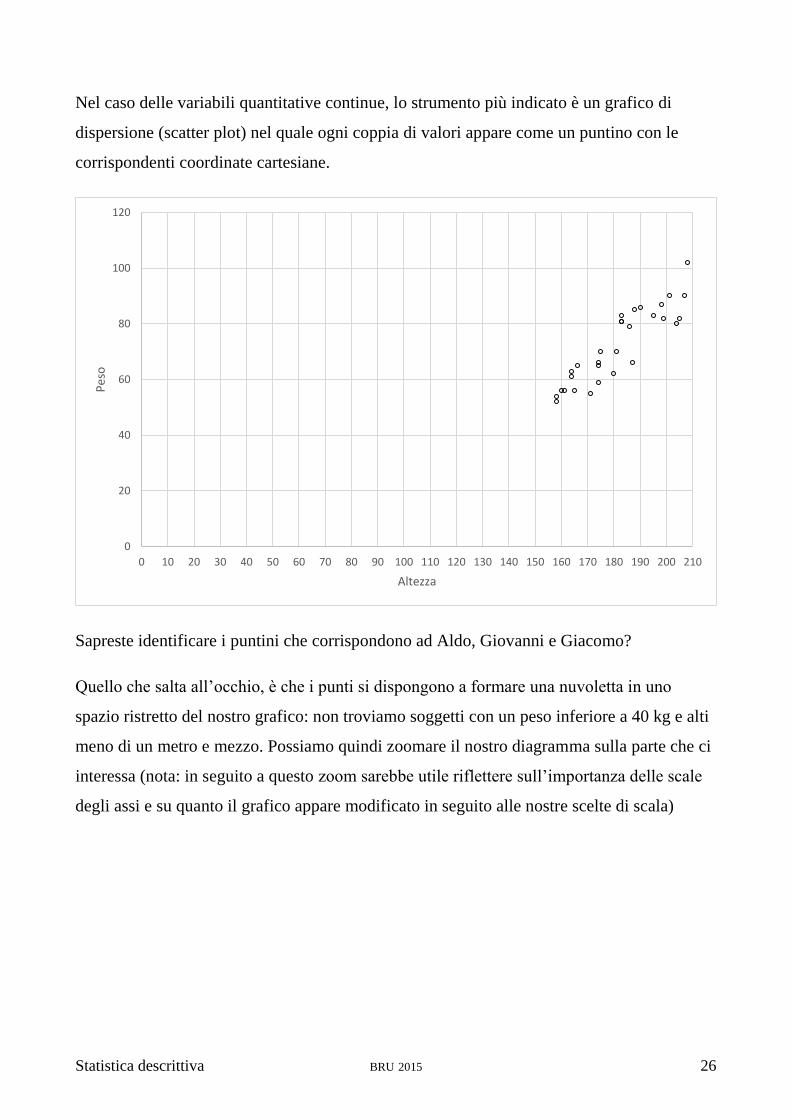
Statistica descrittiva BRU 2015 26
Nel caso delle variabili quantitative continue, lo strumento più indicato è un grafico di
dispersione (scatter plot) nel quale ogni coppia di valori appare come un puntino con le
corrispondenti coordinate cartesiane.
Sapreste identificare i puntini che corrispondono ad Aldo, Giovanni e Giacomo?
Quello che salta all’occhio, è che i punti si dispongono a formare una nuvoletta in uno
spazio ristretto del nostro grafico: non troviamo soggetti con un peso inferiore a 40 kg e alti
meno di un metro e mezzo. Possiamo quindi zoomare il nostro diagramma sulla parte che ci
interessa (nota: in seguito a questo zoom sarebbe utile riflettere sull’importanza delle scale
degli assi e su quanto il grafico appare modificato in seguito alle nostre scelte di scala)
0
20
40
60
80
100
120
0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210
Pes
o
Altezza
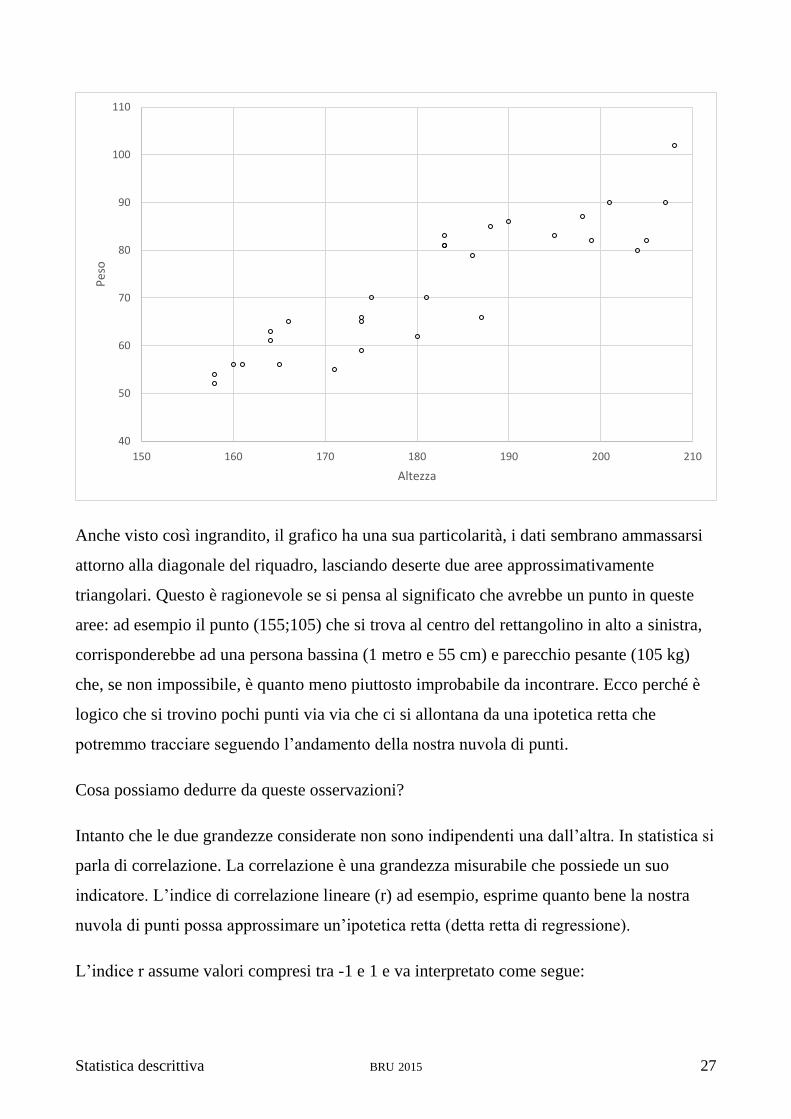
Statistica descrittiva BRU 2015 27
Anche visto così ingrandito, il grafico ha una sua particolarità, i dati sembrano ammassarsi
attorno alla diagonale del riquadro, lasciando deserte due aree approssimativamente
triangolari. Questo è ragionevole se si pensa al significato che avrebbe un punto in queste
aree: ad esempio il punto (155;105) che si trova al centro del rettangolino in alto a sinistra,
corrisponderebbe ad una persona bassina (1 metro e 55 cm) e parecchio pesante (105 kg)
che, se non impossibile, è quanto meno piuttosto improbabile da incontrare. Ecco perché è
logico che si trovino pochi punti via via che ci si allontana da una ipotetica retta che
potremmo tracciare seguendo l’andamento della nostra nuvola di punti.
Cosa possiamo dedurre da queste osservazioni?
Intanto che le due grandezze considerate non sono indipendenti una dall’altra. In statistica si
parla di correlazione. La correlazione è una grandezza misurabile che possiede un suo
indicatore. L’indice di correlazione lineare (r) ad esempio, esprime quanto bene la nostra
nuvola di punti possa approssimare un’ipotetica retta (detta retta di regressione).
L’indice r assume valori compresi tra -1 e 1 e va interpretato come segue:
40
50
60
70
80
90
100
110
150 160 170 180 190 200 210
Pes
o
Altezza

Statistica descrittiva BRU 2015 28
r=0 le due variabili sono totalmente incorrelate (questo significa che non c’è alcun
legame apparente tra loro), i punti riempiono il grafico in modo omogeneo.
r=+1 Le due variabili sono totalmente correlate e i punti sul grafico sono allineati su
una retta perfetta con pendenza positiva (quando una variabile aumenta, aumenta
anche l’altra)
r=-1 Le due variabili sono totalmente correlate e i punti sul grafico sono allineati su
una retta perfetta con pendenza negativa (quando una variabile aumenta, l’altra
diminuisce)
Tra questi valori limite (che nella realtà è improbabile ottenere) esistono valori intermedi
che rispecchiano nuvole di punti più o meno diffuse.
La regola per calcolare r è la seguente
yxN
i
N
i ii
N
i ii
N
i
N
i ii
N
i ii
ss
yxCov
yyN
xxN
yyxxN
yyxx
yyxxr
.
11
1
1 1
22
1
1 1
22
1
N
yyxxyxCov
N
i ii
1, è la covarianza tra x e y mentre i due termini al
denominatore sono gli scarti quadratici medi che abbiamo visto nel capitolo 3.3.2.
Il numero r scaturisce dunque da un confronto tra la “variabilità congiunta” di x e y con le
due “variabilità separate” di ciascuna di esse.
Naturalmente quando si raccolgono dei dati con un legame tra loro, non sempre essi si
allineano a formare una retta, ma può capitare di vedere tendenze con la forma di linee
curve (a dipendenza del tipo di funzione che lega le due variabili). In casi come questo il
nostro indicatore r non è più così significativo, in quanto “progettato” per riconoscere delle
rette. Illuminante a questo proposito è il fatto che i punti che si trovano su una parabola, se
si considera un intervallo simmetrico attorno al vertice, hanno un valore di r=0.
Per questo motivo, come già detto per la statistica univariata, la base di ogni riflessione deve
essere la rappresentazione grafica. Il nostro occhio è in grado di riconoscere delle regolarità

Statistica descrittiva BRU 2015 29
o delle tendenze in modo molto efficiente e comunque è buona regola non fidarsi mai di un
solo indicatore.
Torniamo ora al caso delle variabili qualitative (colore di occhi e capelli). Raggruppare e
visualizzare graficamente questo tipo di dati che non hanno valori numerici richiede uno
strumento diverso dallo scatter plot, si può ricorrere a quella che viene chiamata tabella di
contingenza (tabella delle frequenze congiunte), che si riempie procedendo a una conta delle
persone che hanno la stessa coppia di valori, nel nostro caso potremmo ottenere il risultato
seguente:
Occhi Totali
Azzurri Grigi Verdi Marroni Neri
Cap
elli
Biondi 26 5 2 2 1 36
Rossi 3 0 8 3 0 14
Castani 13 7 3 35 18 76
Neri 2 2 1 19 29 53
Totali 44 14 14 59 48 179
Quali informazioni riusciamo a estrarre da questa tabella?
Su un totale di 179 persone 76 hanno i capelli castani, quindi possiamo dire che circa il
42% delle persone prese in considerazione ( %4242.0179
76 ) ha i capelli castani.
D’altra parte possiamo osservare che, sempre in relazione al totale 179, sono 8 ad avere
contemporaneamente occhi verdi e capelli rossi, cioè circa il 4%.
Se però ci occupiamo solo della parte di popolazione che ha i capelli biondi, possiamo
calcolare che il 72% di essi ha gli occhi azzurri (26 su 36).
Esercizio 8: calcolate, per il nostro campione, le seguenti percentuali
a) persone con i capelli neri
b) persone che hanno sia occhi che capelli neri
Statistica descrittiva BRU 2015 30
c) tra le persone con i capelli castani, quante hanno gli occhi marroni?
d) tra le persone con gli occhi marroni, quante hanno i capelli castani?
e) supponendo che questo campione sia rappresentativo della popolazione ticinese, qual è la
probabilità, per una persona con i capelli castani, di avere gli occhi di colore nero?
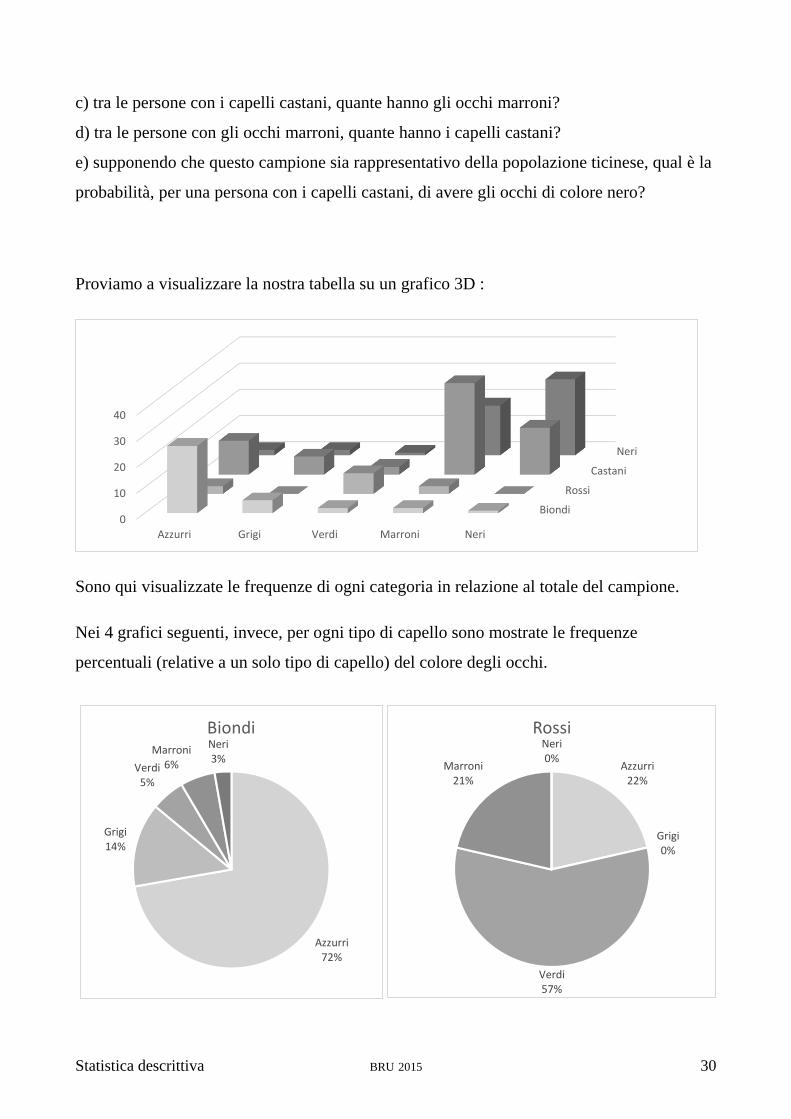
Proviamo a visualizzare la nostra tabella su un grafico 3D :
Sono qui visualizzate le frequenze di ogni categoria in relazione al totale del campione.
Nei 4 grafici seguenti, invece, per ogni tipo di capello sono mostrate le frequenze
percentuali (relative a un solo tipo di capello) del colore degli occhi.
Biondi
Rossi
Castani
Neri
0
10
20
30
40
Azzurri Grigi Verdi Marroni Neri
Azzurri72%
Grigi14%
Verdi5%
Marroni6%
Neri3%
Biondi
Azzurri22%
Grigi0%
Verdi57%
Marroni21%
Neri0%
Rossi
Statistica descrittiva BRU 2015 31
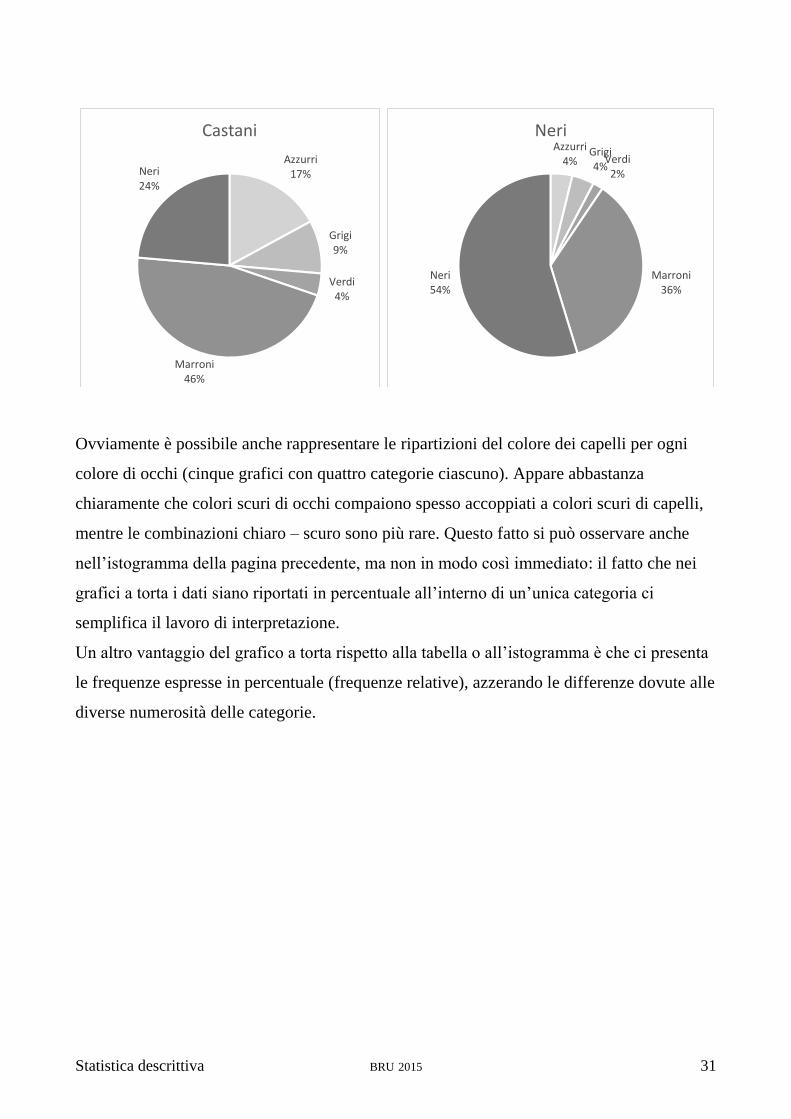
Ovviamente è possibile anche rappresentare le ripartizioni del colore dei capelli per ogni
colore di occhi (cinque grafici con quattro categorie ciascuno). Appare abbastanza
chiaramente che colori scuri di occhi compaiono spesso accoppiati a colori scuri di capelli,
mentre le combinazioni chiaro – scuro sono più rare. Questo fatto si può osservare anche
nell’istogramma della pagina precedente, ma non in modo così immediato: il fatto che nei
grafici a torta i dati siano riportati in percentuale all’interno di un’unica categoria ci
semplifica il lavoro di interpretazione.
Un altro vantaggio del grafico a torta rispetto alla tabella o all’istogramma è che ci presenta
le frequenze espresse in percentuale (frequenze relative), azzerando le differenze dovute alle
diverse numerosità delle categorie.
Azzurri17%
Grigi9%
Verdi4%
Marroni46%
Neri24%
CastaniAzzurri
4%Grigi4%
Verdi2%
Marroni36%
Neri54%
Neri
Statistica descrittiva BRU 2015 32
5 Soluzioni degli esercizi proposti
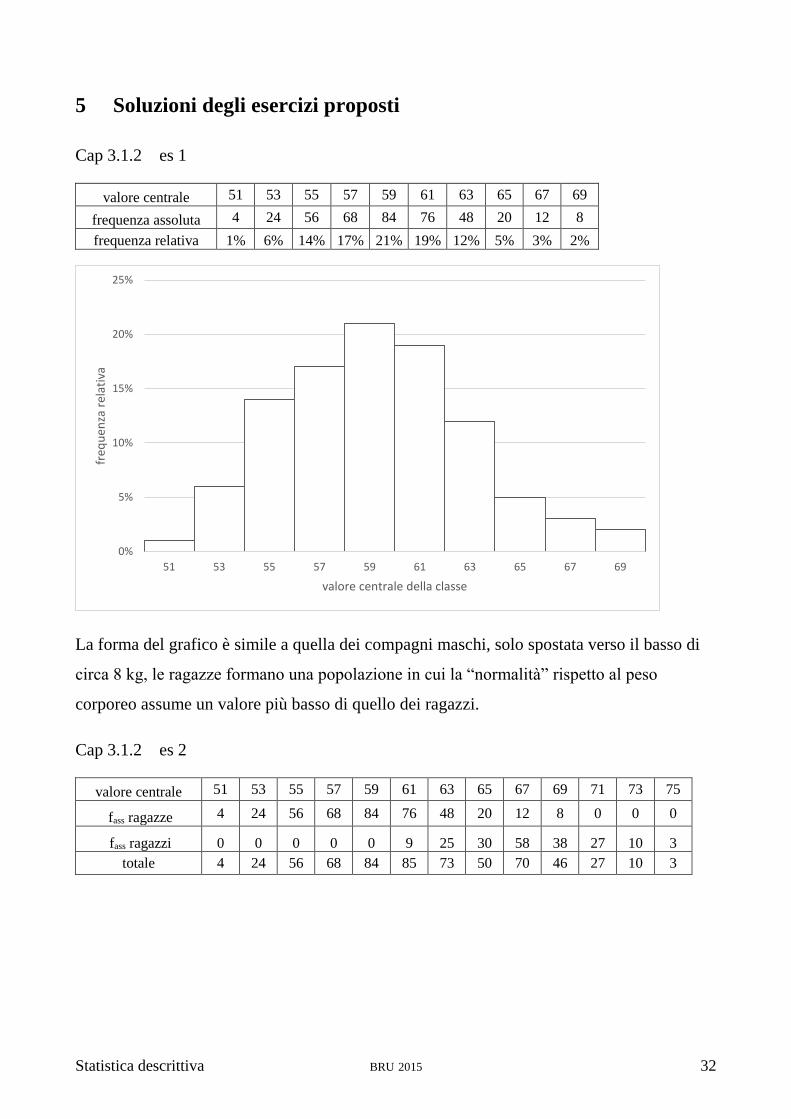
Cap 3.1.2 es 1
valore centrale 51 53 55 57 59 61 63 65 67 69
frequenza assoluta 4 24 56 68 84 76 48 20 12 8
frequenza relativa 1% 6% 14% 17% 21% 19% 12% 5% 3% 2%
La forma del grafico è simile a quella dei compagni maschi, solo spostata verso il basso di
circa 8 kg, le ragazze formano una popolazione in cui la “normalità” rispetto al peso
corporeo assume un valore più basso di quello dei ragazzi.
Cap 3.1.2 es 2
valore centrale 51 53 55 57 59 61 63 65 67 69 71 73 75
fass ragazze 4 24 56 68 84 76 48 20 12 8 0 0 0
fass ragazzi 0 0 0 0 0 9 25 30 58 38 27 10 3
totale 4 24 56 68 84 85 73 50 70 46 27 10 3
0%
5%
10%
15%
20%
25%
51 53 55 57 59 61 63 65 67 69
freq
uen
za r
elat
iva
valore centrale della classe
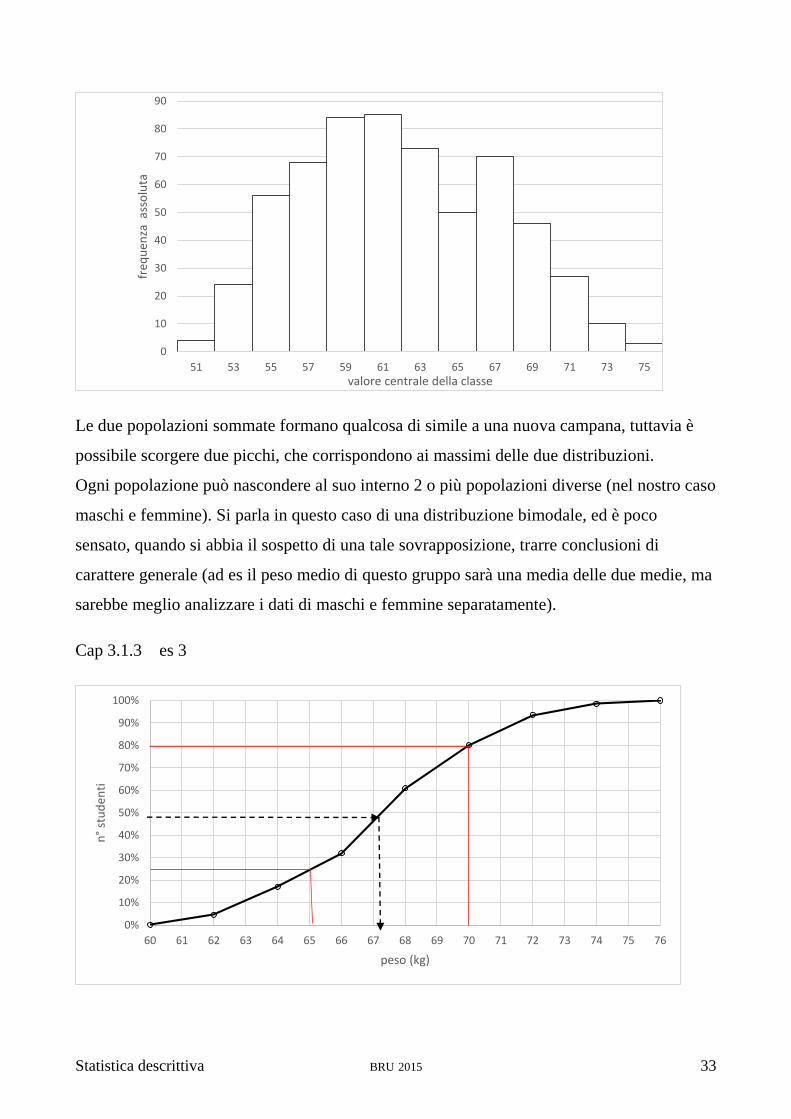
Statistica descrittiva BRU 2015 33
Le due popolazioni sommate formano qualcosa di simile a una nuova campana, tuttavia è
possibile scorgere due picchi, che corrispondono ai massimi delle due distribuzioni.
Ogni popolazione può nascondere al suo interno 2 o più popolazioni diverse (nel nostro caso
maschi e femmine). Si parla in questo caso di una distribuzione bimodale, ed è poco
sensato, quando si abbia il sospetto di una tale sovrapposizione, trarre conclusioni di
carattere generale (ad es il peso medio di questo gruppo sarà una media delle due medie, ma
sarebbe meglio analizzare i dati di maschi e femmine separatamente).
Cap 3.1.3 es 3
0
10
20
30
40
50
60
70
80
90
51 53 55 57 59 61 63 65 67 69 71 73 75
freq
uen
za a
sso
luta
valore centrale della classe
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76
n°
stu
den
ti
peso (kg)

Statistica descrittiva BRU 2015 34
Come si legge dal grafico, il 25% degli studenti ha un peso inferiore a 65 kg, mentre il 20%
di loro pesa più di 70 kg 8che è lo stesso che dire che l’80% pesa meno di 70 kg)
Cap 3.2.1 es 4
X (kg) 51 53 55 57 59 61 63 65 67 69
f 4 24 56 68 84 76 48 20 12 8 400
fX 204 1272 3080 3876 4956 4636 3024 1300 804 552 23704
26.59400
237041
N
Xf
X
N
i
ii
Cap 3.2.1 es 5
20.295
5.209
10154030
80.21050.21510.240230
medioprezzo
Cap 3.2.1 es 6
%8.101795.020000000
359000
2100000360000058000008500000
100
5.22100000
100
75.13600000
100
25800000
100
5.18500000
int
medio
Cap 3.3.2 es 7
Esempio a) 8, 9, 10, 15, 18
125
60
5
18151098
x
5
63234
5
1218121512101291282222222222
9.35
74

Statistica descrittiva BRU 2015 35
Esempio b) 3, 5, 6, 7, 10, 12, 15, 18
5.98
76
8
181512107653
x
8
5.9185.9155.9125.9105.975.965.955.9322222222
9.48
190
Esempio c) 3, 10, 10, 10, 11, 11, 11, 18
5.108
84
8
181111111010103
x
8
5.10185.10115.10115.10115.10105.10105.10105.10322222222
8.38
114
Cap 4 es 8
a) %3030.0179
53
b) %1616.0179
29
c) %4646.076
35
d) %5959.059
35
e) %2424.076
18

Statistica descrittiva BRU 2015 36
Cap 5.1
1 Il venditore fornisce un’indicazione che sembrerebbe di variabilità. Potrebbe trattarsi
del campo di variazione del consumo o forse, vedendo i dati reali della tabella, di
un’indicazione approssimativa del valore medio (corrisponde peraltro con la nostra
classe modale ). La sua indicazione non è statisticamente rigorosa ma probabilmente
dettata dall’esperienza.
Il costruttore fornisce dei dati statisticamente più rigorosi, infatti distingue tre diverse
popolazioni tra gli automobilisti, in base all’uso che faranno del veicolo. Si tratta di tre
indicatori di centralità (medie o mediane) calcolati in condizioni distinte di test
dell’automobile (in autostrada i consumi sono molto diversi che nel traffico di una
città, peraltro non è dato di sapere cosa significhi esattamente misto)
2 Dividendo il totale dei litri consumati per il totale dei chilometri percorsi si calcola di
fatto la media ponderata dei consumi istantanei.
Per capirlo possiamo immaginare che l’auto abbia un consumo di 8.0 litri/100km per
20 km e poi di 7.0 litri/100km per altri 30km.
La media ponderata dei due consumi sarebbe allora:
100
4.7
50
7.3
50
1.26.1
3020
30100
0.720
100
0.8
-dal secondo passaggio si vede già che al numeratore abbiamo il totale dei litri
consumati e al denominatore il totale dei chilometri percorsi (cioè il calcolo effettuato
da Barella).
3 Un’auto presenta un consumo di carburante differente a seconda del percorso abituale
(come indicato nella consegna 1) è poi abbastanza logico pensare che la cosa dipenda
anche dal carico (peso complessivo), dalla qualità e dal modo in cui sono gonfiati gli
pneumatici, da carichi sul tetto che presentino un’aumentata resistenza all’aria, perfino
dal tempo meteorologico (temperatura, umidità, vento…), dall’uso più o meno intenso
degli apparecchi elettrici e elettronici di bordo, dal tipo di carburante usato e dallo stile
di guida del conducente. Inoltre un errore di misura è possibile (sia prodotto dal
contachilometri che dal display della pompa di benzina che mostra i litri erogati e
Statistica descrittiva BRU 2015 37
dall’accuratezza con cui Barella riempie il serbatoio ogni volta allo stesso livello).
Questo elenco non è completo, è possibile che gli studenti trovino altre fonti di
variabilità.
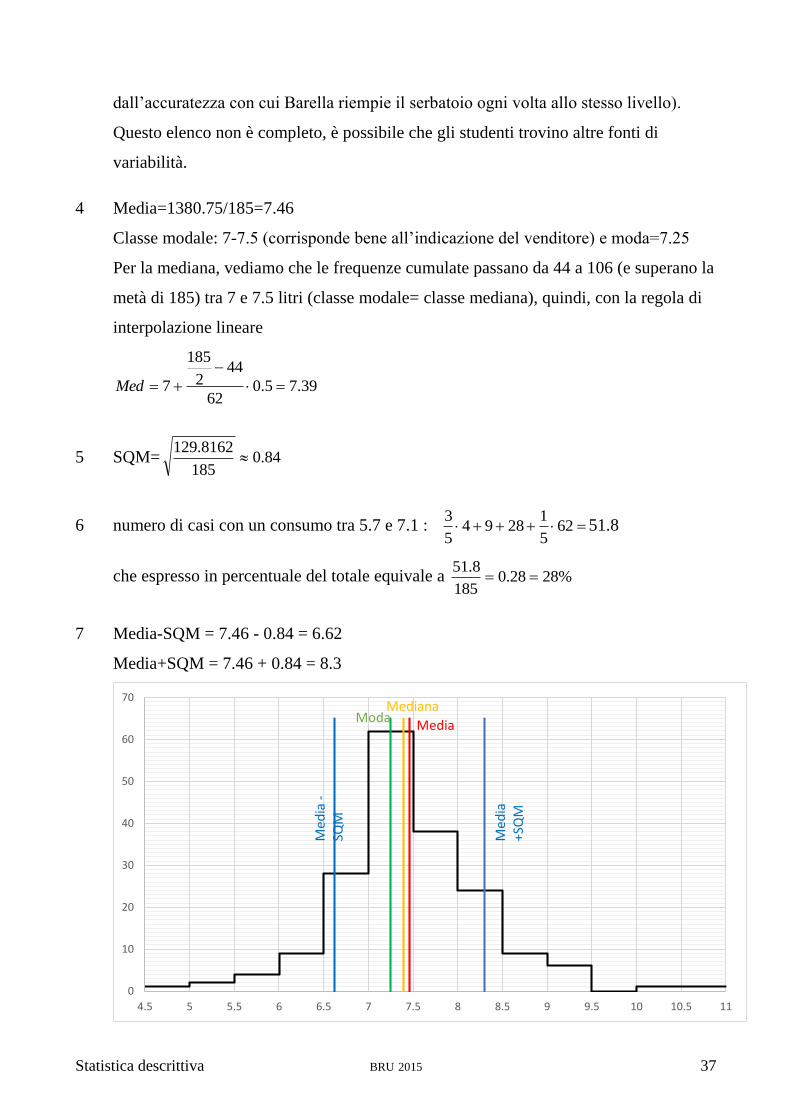
4 Media=1380.75/185=7.46
Classe modale: 7-7.5 (corrisponde bene all’indicazione del venditore) e moda=7.25
Per la mediana, vediamo che le frequenze cumulate passano da 44 a 106 (e superano la
metà di 185) tra 7 e 7.5 litri (classe modale= classe mediana), quindi, con la regola di
interpolazione lineare
39.75.062
442
185
7
Med
5 SQM= 84.0185
8162.129
6 numero di casi con un consumo tra 5.7 e 7.1 : 625
12894
5
351.8
che espresso in percentuale del totale equivale a %2828.0185
8.51
7 Media-SQM = 7.46 - 0.84 = 6.62
Media+SQM = 7.46 + 0.84 = 8.3
0
10
20
30
40
50
60
70
4.5 5 5.5 6 6.5 7 7.5 8 8.5 9 9.5 10 10.5 11
ModaMedia
Mediana
Med
ia -
SQM
Med
ia
+SQ
M

Statistica descrittiva BRU 2015 38
8 I tre indicatori di centralità ci danno un valore che potrebbe idealmente rappresentare il
consumo della nostra auto se dovesse sparire la variabilità. In altri termini potrebbe
essere il consumo che misureremmo se la nostra auto consumasse sempre allo stesso
modo. Questi valori collimano bene con l’indicazione del venditore che ha voluto
semplificare il più possibile l’informazione da dare al cliente e si è rivelato corretto,
anche se non statisticamente rigoroso. La casa produttrice ha fornito dei valori che
devono essere stati misurati su un banco di prova e a condizioni ottimali. Sebbene si
possa credere che questi dati siano stati raccolti ed esaminati in modo scientifico, è
probabile che nei test eseguiti alcune cause di variabilità che l’auto incontra sulla
strada siano state (intenzionalmente o meno si può discutere) tralasciate, ridotte o
eliminate. Difatti risultano sensibilmente inferiori al consumo reale di Barella (che
però potrebbe avere uno stile di guida particolarmente aggressivo o utilizzare l’auto in
un modo che ne aumenti il consumo).
L’indicatore di variabilità ci dà un’indicazione dell’intervallo entro il quale troviamo
una parte consistente dei valori misurati (i 2/3 circa). Abbiamo misurato un consumo
di 7.16 ±0.84 l ogni 100 km percorsi. Notiamo una lieve asimmetria nella curva
(evidenziata anche dalla discrepanza di media, mediana e moda), che comunque non
dovrebbe invalidare il valore di questo intervallo.
Cap 5.2
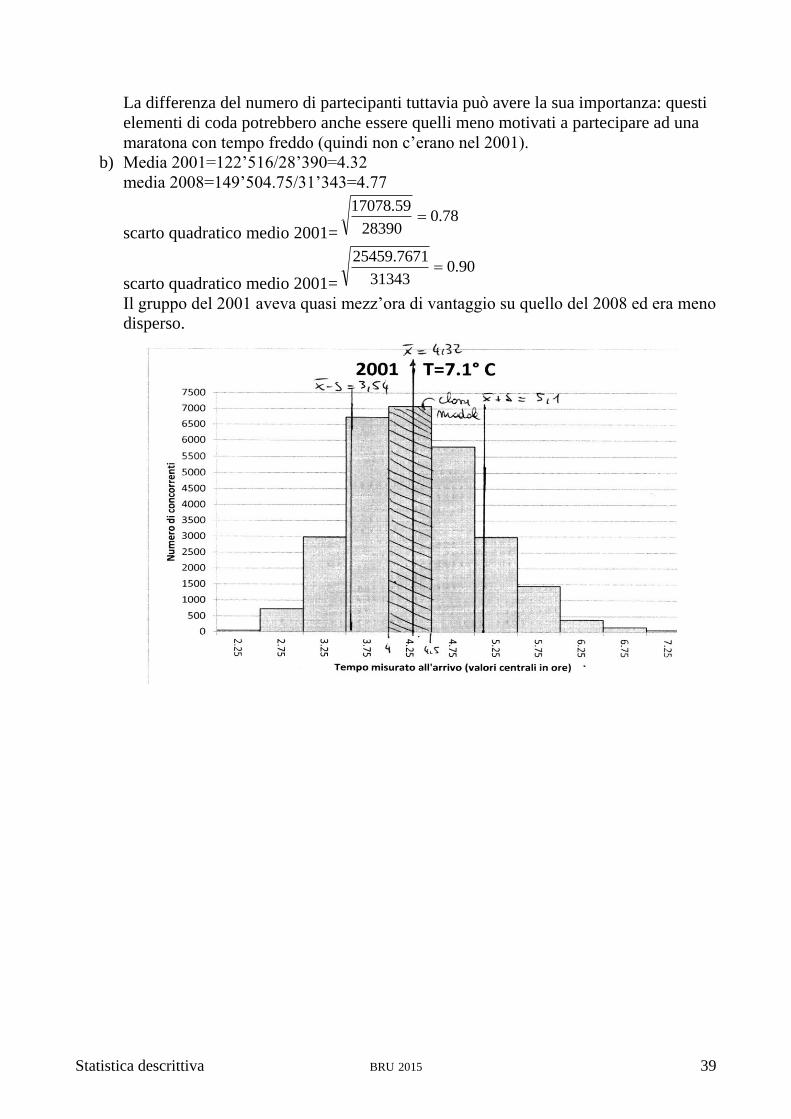
a) Dal confronto dei due istogrammi si vede uno spostamento di circa una classe: i dati
del 2001 sembrano essere spostati di circa mezz’ora verso sinistra rispetto a quelli del
2008. Questo starebbe a significare che i tempi realizzati nel 2001 siano mediamente
migliori di quelli registrati nel 2008. Alcuni forse noteranno nella distribuzione del
2001 una maggiore asimmetria, che si può ricondurre al fatto che la curva non può
spostarsi con la stessa facilità verso sinistra (sotto le 2 ore non è sceso ancora
nessuno e comunque correre in meno di tre ore è cosa per pochi) e verso destra
(correre tutti più lentamente è non solo possibile, ma anche facile…).
Il raffronto delle due ogive può esser fatto interpretando le curve come il numero di
atleti giunti all’arrivo col passar del tempo. Visto che la linea intera “decolla” prima e
si trova più in alto rispetto a quella tratteggiata fino circa alle 6 ore, ne deduciamo
che in qualsiasi momento compreso tra 2 e 6 ore dalla partenza, gli atleti che avevano
terminato la gara nel 2001 erano di più di quelli che lo avevano fatto nel 2008
realizzando lo stesso tempo. Dopo le 6 ore la situazione si inverte, ma questo è
dovuto al fatto che nel 2008 hanno corso circa 3000 atleti in più. Se avessimo
confrontato tra loro le due ogive delle frequenze relative, questo punto di incontro
sarebbe stato spostato al valore massimo del tempo.
Statistica descrittiva BRU 2015 39
La differenza del numero di partecipanti tuttavia può avere la sua importanza: questi
elementi di coda potrebbero anche essere quelli meno motivati a partecipare ad una
maratona con tempo freddo (quindi non c’erano nel 2001).
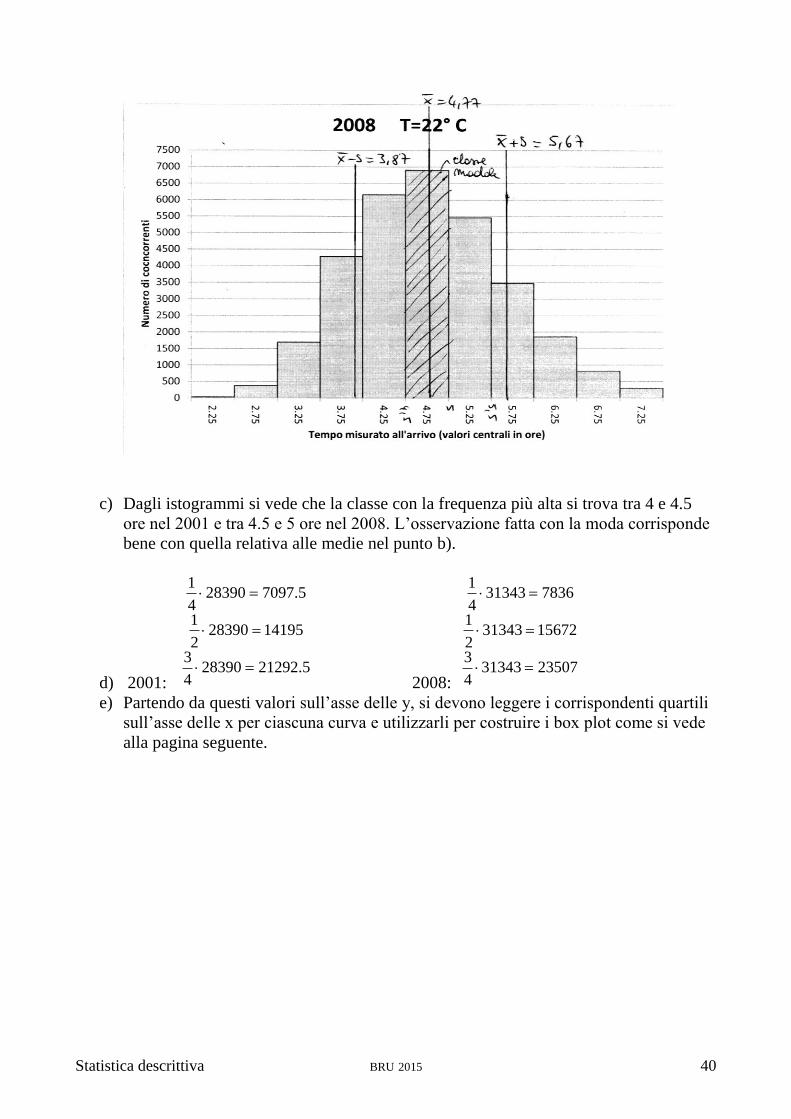
b) Media 2001=122’516/28’390=4.32
media 2008=149’504.75/31’343=4.77
scarto quadratico medio 2001=78.0
28390
59.17078
scarto quadratico medio 2001=90.0
31343
7671.25459
Il gruppo del 2001 aveva quasi mezz’ora di vantaggio su quello del 2008 ed era meno
disperso.
Statistica descrittiva BRU 2015 40
c) Dagli istogrammi si vede che la classe con la frequenza più alta si trova tra 4 e 4.5
ore nel 2001 e tra 4.5 e 5 ore nel 2008. L’osservazione fatta con la moda corrisponde
bene con quella relativa alle medie nel punto b).
d) 2001: 5.2129228390
4
3
14195283902
1
5.7097283904
1
2008: 2350731343
4
3
15672313432
1
7836313434
1
e) Partendo da questi valori sull’asse delle y, si devono leggere i corrispondenti quartili
sull’asse delle x per ciascuna curva e utilizzarli per costruire i box plot come si vede
alla pagina seguente.
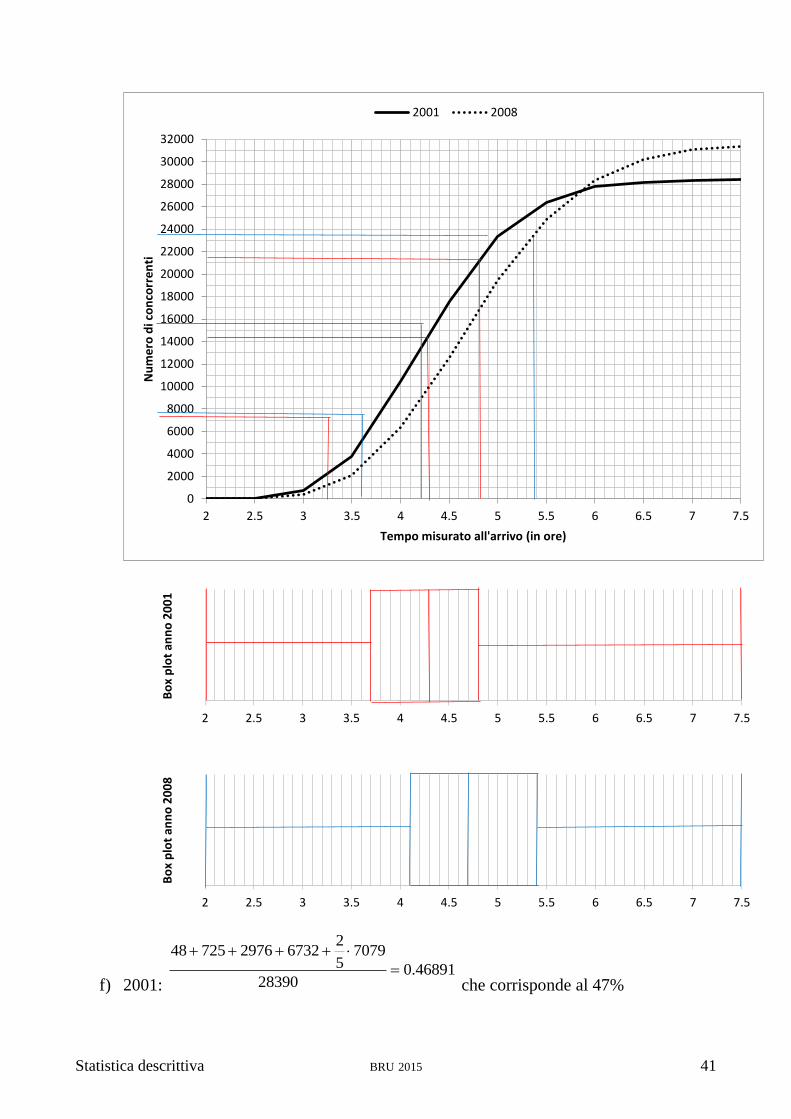
Statistica descrittiva BRU 2015 41
f) 2001: 46891.0
28390
70795
26732297672548
che corrisponde al 47%
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
22000
24000
26000
28000
30000
32000
2 2.5 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5
Nu
me
ro d
i co
nco
rre
nti
Tempo misurato all'arrivo (in ore)
2001 2008
2 2.5 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5
Bo
x p
lot
ann
o 2
00
1
2 2.5 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5
Bo
x p
lot
ann
o 2
00
8

Statistica descrittiva BRU 2015 42
2008: 28231.0
31343
61575
24282169737532
che corrisponde al 28%
qui la differenza è veramente notevole: mentre nel 2001 quasi la metà dei concorrenti
ha tenuto una media sopra i 10km/h, nel 2008 solo poco più di un quarto è riuscito a
fare altrettanto.
g) Che la maratona del 2001 sia andata complessivamente molto meglio di quella del
2008 appare chiaramente da tutte le osservazioni fatte nei punti precedenti. Ma se
questo fatto sia correlato direttamente alla temperatura andrebbe verificato con altre
indagini, ad esempio con una statistica bivariata su molte coppie di valori
temperatura - tempo medio (ciascuna relativa a una maratona diversa), oppure con
uno studio in cui si faccia correre la stessa tratta allo stesso atleta a temperature
diverse, ponendo attenzione a quali altri parametri possano influire sulle sue
prestazioni (è ipotizzabile ad es. che un atleta norvegese sia disturbato da temperature
sopra i 30° mentre uno etiope decisamente meno, e che a temperature sotto i 5° la
situazione si ribalti).


















