
ADDENDUM - Università degli Studi di Roma "Tor … · Web viewLe operazioni all’interno...
121
UNIVERSITÀ DEGLI STUDI DI ROMA TOR VERGATA CORSO DI LAUREA IN INGEGNERIA DELLE TELECOMUNICAZIONI GESTIONE di SISTEMI & SERVIZI di TELECOMUNICAZIONE (ADDENDUM) Pietro de Santis 1 BUSINESS LEG - REG
-
Upload
nguyenkhue -
Category
Documents
-
view
220 -
download
0
Transcript of ADDENDUM - Università degli Studi di Roma "Tor … · Web viewLe operazioni all’interno...

UNIVERSITÀ DEGLI STUDI DI ROMA TOR VERGATA
CORSO DI LAUREA IN INGEGNERIA DELLE TELECOMUNICAZIONI
GESTIONE di SISTEMI & SERVIZI
di TELECOMUNICAZIONE
(ADDENDUM)
Pietro de Santis
1
BUSINESS
ST&E
LEG - REG
SOCIAL

Lezioni tenute dal 22/09/2008 al 15/11/2008 (Anno Accademico 2008-2009)
2

3

ADDENDUM (“for further reading”)
I CONTENUTI DI QUESTO ADDENDUM NON COSTIUISCONO
ARGOMENTI DI ESAME PER L’ A.A. 2008-2009
4

ADDENDUM
INDICEA.1 La gestione distribuita: definizione, motivazioni e implementazione con tecnologie DOC (Distributed Object Computing)
A.2 L’Architettura CORBA Common Object Request Broker Architecture) della OMG (Object Management Group)
A.3 Integrazione delle gestioni di reti e servizi
A.4 Elementi di programmazione a oggetti
A.5 Il Technology Actor
A.6 Il modello di riferimento ODP-RM dell’ITU-T
5

ADDENDUM No.1
A.1 La gestione distribuita: definizione, motivazioni e implementazione con tecnologie DOC (Distributed Object Computing)
A.1.1 Definizione e motivazioni della gestione decentralizzata. La risoluzione efficace/efficiente dei problemi insorti in una architettura gestionale centralizzata.
A fine anni novanta nuovi sistemi di gestione si sono resi necessari per far fronte ai cambiamenti subiti dai mercati TLC e dalle imprese fornitrici di servizi TLC. Nelle TelCo questi cambiamenti si sono verificati su cinque fronti:
1) aumento del numero e tipologie di utenti,
2) aumento dei tipi e qualità dei servizi TLC,
3) aumento della complessità dei sistemi TLC,
4) utilizzazione da parte di uno stesso sistema TLC (TelCo) di una molteplicità di dominii amministrativi (e.g. imprese multinazionali) e tecnologici diversi (sviluppo tecnologico)
5) decentralizzazione delle TelCo in risposta ad una domanda globalmente estesa (progresso economico e diffusione delle TLC) e localmente diversificata (classi di utenti diverse)
Questi cambiamenti hanno causato nei sistemi di gestione un aumento di carico computazionale e di complessità delle funzionalità gestionali. Inoltre queste funzionalità dovevano svolgersi utilizzando tecnologie gestionali diverse e/o situate in dominii amministrativi diversi.
A fronte di tutto ciò ci si pone allora la seguente domanda: Quali modifiche si sono dovute apportare ai vecchi sistemi di gestione per far fronte a queste nuove esigenze?
Inizilmente, la gestione delle reti TLC veniva effettuata da sistemi gestionali dotati di architetture centralizzate nelle quali l’ “intelligenza» gestionale” (cioè la capacità di processing e di immagazzinamento della informazione gestionale) era concentrata in un mainframe localizzato in una singola stazione di gestione collegata con una molteplicità di «agenti» poco intelligenti (che quindi non hanno responsabilità di
6

gestione e giocano un ruolo subordinato) collocati in prossimità delle risorse gestite. Un esempio tipico di gestione centralizzata è la gestione SNMP v.1
A.1.2 La gestione “debolmente” distribuita per risolvere i problemi di scalabilita’ della gestione centralizzata.
Col passare del tempo la gestione reti è divenuta sempre più gestione congiunta di reti/servizi e all’ aumentare del numero di reti/servizi da gestire, le architetture gestionali centralizzate hanno cominciato a presentare problemi di scalabilità cioé a livello gestore si sono verificati fenomeni di congestione di traffico gestionale che non potevano più essere risolti in modo economico semplicemente adottando elaboratori più potenti e.g. supercomputers. Al contrario la soluzione del problema richiedeva un cambiamento della architettura del sistema attraverso un processo di decentralizzazione del ruolo gestore secondo il quale il ruolo di un singolo gestore viene suddiviso fra una molteplicità di componenti gestori cooperanti, interconnessi in forma gerarchica da una rete di comunicazione dati (Architettura Manager-of-Managers, MoM). Questo tipo di gestione, caratterizzata da una struttura gerarchica di gestori che controllano agenti poco intelligenti è stata denominata «Gestione a distribuzione debole» o «Gestione debolmente distribuita o interconnessa in rete». Modelli gestionali tipici di questo questo tipo di gestione sono i modelli OSI-SM, TMN, SNMPv.2.
Ma esaminiamo più dettagliatamente quest’ultimo punto. I sistemi di gestione, come sistemi informatici specializzati al processing di informazione gestionale, recentemente hanno potuto profittare dello sviluppo impetuoso sia delle tecnologie informatiche che delle tecnologie TLC e della riduzione progressiva dei relativi costi. La riduzione dei costi e il progresso delle tecnologie necessarie a fronteggiare le nuove problematiche hanno portato a concludere che, superato un certo limite di carico computazionale, una risoluzione economicamante vantaggiosa dei problemi di congestione a livello gestore deve effettuarsi con un cambiamento drastico dell’ architettura del sistema, passando da una architettura centralizzata a una architettura gestionale decentralizzata o interconnessa in rete (networked architecture)
Una architettura gestionale a distribuzione debole ha due caratteristiche principali
1) più gestori interconnessi da una rete di comunicazione di tipo gerarchico (MoM) cooperano per il raggiungimento di uno scopo prefissato (nel nostro caso, la gestione di un sistema TLC) e gestiscono una moltitudine di agenti poco intelligenti.
2) il carico computazionale è opportunamente suddiviso fra i vari gestori in base a criteri funzionali, geografici, amministrativi etc.Ad esempio in un modello TMN stratificato esiste un gestore servizi, un gestore di rete ed un gestore elementi di rete.
7

A.1.3 Caratteristiche di un sistema gestionale “fortemente” distribuito
Una «gestione debolmente distribuita» (e.g. OSI-SM, SNMPv.2) è un primo passo verso quello che in questo corso chiameremo una «gestione distribuita» nel quale anche gli agenti hanno responsabilità gestionali e possono svolgere compiti gestionali complessi e quindi l’ «intelligenza» gestionale viene effettivamente distribuita su tutta la rete gestionale la quale si fa carico dei problemi della distribuzione (e.g. localizzazione, sincronismo, interoperabilità di componenti con etereogeneità di ambiente locale etc). In letteratura questa gestione viene chiamata «gestione fortemente distribuita» o «a distribuzione forte» (per distinguerla dalla «gestione debolmente distribuita»)
Il passaggio da “distribuzione debole” a “distribuzione forte” è stato motivato dalla necessità di dare una risposte a due problemi legati alla poca intelligenza degli agenti: affidabilità e flessibilità del sistema gestionale. Un sistema debolmente distribuito è poco affidabile perchè se salta una connessione gestore-agente quest’ultimo non è in grado di prendere autonomamente alcuna decisione gestionale e.g. per riparare il guasto. Inoltre un sistema gestionale debolmente distribuito è poco flessibile perchè tutte le attività a livello agente sono prefissate e non possono essere dinamicamente cambiate.
Ma l’ «intelligenza» della rete può essere aumentata fino al punto che l’esistenza della rete può essere completamente nascosta agli occhi degli utenti/programmatori di applicazioni. In tal caso l’utente del sistema gestionale cioè il gestore del sistema TLC o il programmatore del sistema gestionale operano esattamente come se la rete non ci fosse e.g. non devono specificare dove si devono effettuare le operazioni desiderate ma solo quali operazioni si vogliono effettuare, al resto pensa il sistema stesso. Quando ciò avviene il sistema interconnesso in rete diviene un vero sistema distribuito (distributed). D’ora innanzi quando parliamo di sistema distribuito parliamo di sistema fortemente distribuito..
Allora in questo corso un sistema gestionale distribuito è così definito:
DEFINIZIONE di SISTEMA GESTIONALE «DISTRIBUITO». Un sistema gestionale distribuito é un sistema costituito da componenti applicativi autonomi, residenti in nodi elaborativi remoti interconnessi da una rete di comunicazione dati, che cooperano in un contesto di elaborazione virtualmente unitario.
Quindi la differenza fra “sistema interconnesso in rete” e “sistema distribuito” è proprio il «Contesto di elaborazione virtualmente unitario». «Contesto di elaborazione virtualmente unitario» significa che un utilizzatore o un programmatore di una applicazione distribuita non si accorge (e quindi non si deve occupare) delle problematiche legate alla distribuzione poichè di esse se ne fa carico il sistema stesso tramite una infrastruttura software (piattaforma) chiamata «middleware». Ad esempio in un sistema distribuito un utilizzatore/programmatore di una applicazione non si deve preoccupare di conoscere gli indirizzi in rete dei componenti che devono effettuare le operazioni nè tantomeno deve preoccuparsi dei loro linguaggi di programmazione: il sistema si occupa di tutto ciò. Una bella discussione sui sistemi distribuiti e interconnessi
8

in rete si trova a pagg.14-15 dell’ ottimo testo di H.G. Hegering et al. «Integrated Management of Networked Systems», Morgan Kaufman Publishers Inc.,1999.
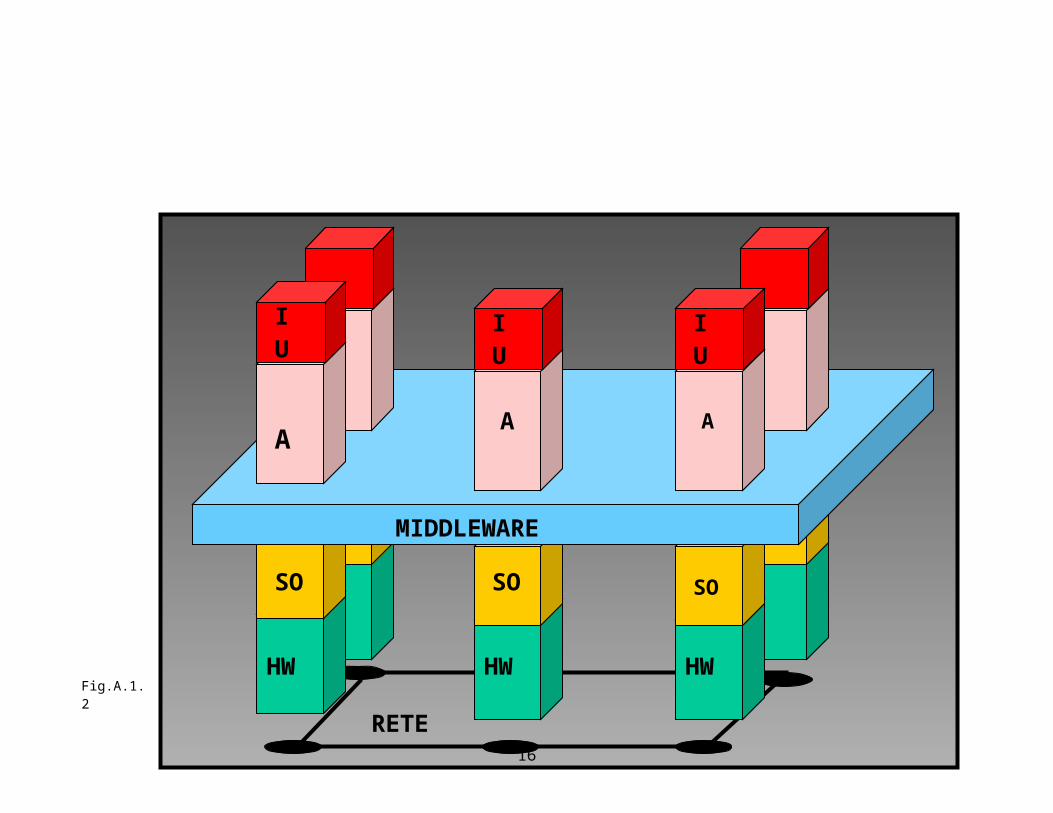
La Fig.A.1.2 illustra in modo schematico il fatto che il middleware è un software di intermediazione fra il software applicativo (A) e il software del sistema operativo (SO) che crea un “ambiente computazionale virtualmente unitario”. In figura si nota una rete di distribuzione con cinque nodi nei quali risiedono gli elaboratori (HW, Hard-Ware) e ai quali si può accedere tramite una interfaccia di utente (IU). Ripetiamo: tramite il middleware, un sistema distribuito è così sofisticato da offrire esso stesso una serie di servizi che rendono invisibili all’utilizzatore o al programmatore le problematiche della distribuzione.
Ma vediamo in dettaglio di cosa si tratta. Presentiamo qui di seguito le caratteristiche e le problematiche di un sistema distribuito. Nel paragrafo seguente presenteremo le tecnologie DOC (Distributed Object Computing) che forniscono una piattaforma middleware per la risoluzione delle problematiche legate alla distribuzione, utilizzando i principii dell’orientamento agli oggetti.
A.1.4 Caratteristiche di un “sistema gestionale distribuito”
Un sistema gestionale distribuito è un sistema informatico distribuito che processa informazione gestionale. Esso presenta una serie di caratteristiche, specifiche della sua natura distribuita e, al tempo stesso, presenta una serie di problemi da risolvere prima o nel corso dello sviluppo di una applicazione. Qui di seguito riportiamo le caratteristiche principali tipiche di un sistema distribuito generico. In un sistema distribuito generico i componenti godono delle seguenti proprietà
1. SEPARAZIONE SPAZIALE. I componenti risiedono in nodi elaborativi remoti e le comunicazioni fra componenti avviene con scambio di messaggi e.g. secondo un paradigma cliente-server. L’interscambio di dati fra componenti implica un ritardo non trascurabile dovuto al tempo di transito lungo le linee di interconnessione (comprensivo di processing e buffering).
2. INDIPENDENZA o AUTONOMIA. Ogni componente opera in modo autonomo senza una conoscenza precisa dello stato degli altri componenti o del sistema nel suo complesso (tempi di propagazione anche molto brevi implicano decine di migliaia di operazioni a livello del singolo componente). Un componente e’ tanto piu’ autonomo quanto maggiore è la velocità di processing dei dati all’interno del compente rispetto alla velocita’ di trasmissione dei dati in rete.
3. ETEROGENEITA’ . Componenti diversi possono operare in ambienti (linguaggi di programmazione, sistemi operativi, interfacce, hardware) diversi. L’eterogeneita’ offre il vantaggio di poter scegliere per la tecnologia implementativa di ogni componente quanto di meglio offra il mercato (ottimizzazione della tecnologia a livello componente) ma introduce problemi di interconnessione/integrazione fra componenti realizzati con tecnologie differenti.
9

SISTEMA SOFTWARE DISTRIBUITO
Nodo elaborativo Archivi centralizzati
Terminali Utente
Applicazioni
Archivi locali No.1
Stazioni Utente
Nodo elaborativo No.1
Nodo elaborativo No.2
Archivi locali No.2
Archivi locali No.3
Nodo elaborativo No.3
Stazioni Utente
ARCHITETTURA CENTRALIZZATA
Fig. A.1.1 Architettura centralizzata e distribuita
ARCHITET- TURA INTERCONNESSA
IN RETE
11

MIDDLEWARE
HW
SO
RETE
A
IU
A A
IU
SO SO
HW HW
IU
Fig.A.1.2
12

A.1.5 Problematiche di un sistema gestionale distribuito: le domande!
A.1.5.1 Problematiche di un sistema distribuito causate dalla sua natura distribuita.
Un sistema gestionale distribuito presenta una serie di problematiche causate dalla sua natura distribuita. Qui di seguito elenchiamo alcune problematiche legate alla natura distribuita del sistema, sottoforma di domande a cui uno sviluppatore di applicazioni distribuite deve rispondere. Si assume che il sistema distribuito sia costituito da elementi chiamati genericamente «componenti», residenti nei nodi di una rete di comunicazione dati. In un sistema distribuito basato su tecnologie orientate agli oggetti un «componente» è un «oggetto». In questo caso più oggetti possono risiedere nello stesso nodo.
1. ACCESSO
i) Come fanno componenti operanti in ambienti diversi, (e.g. con linguaggi di programmazione o sistemi operativi diversi) a interagire e cooperare?
ii) Come fa una nuova applicazione ad essere compatibile con componenti pre-esistenti di prima generazione (componenti legacy) che operano in ambienti diversi?
iii) Come fa un applicazione a non diventare obsoleta cioé come potrà un applicazione essere compatibile con componenti di seconda generazione realizzati con le nuove tecnologie che emergeranno sul mercato?
2. MALFUNZIONAMENTI/GUASTI
i) Come si fa a costruire una grossa applicazione nella quale i guasti/malfunzionamenti rimangono localizzati dove sono avvenuti mentre altri componenti, ubicati altrove nel sistema, continuano a funzionare correttamente come se nulla fosse accaduto?
ii) Come si fa ad evitare che il guasto di un componente si propaghi nel sistema e causi un guasto di grosse dimensioni?
iii) Come può un componente continuare a funzionare mentre il sistema, individuato il guasto/malfunzionamento, ne sta effettuando la riparazione?
3. LOCAZIONE In un sistema orientato agli oggetti, un oggetto cliente chiede servizi ad un altro oggetto
servente cioé chiede ad un altro oggetto di effettuare certe operazioni e di riinviare i risultati delle operazioni stesse. Per far ciò si deve collegare con l’ interfaccia di un altro oggetto che supporta le operazioni desiderate. Ma come fa un oggetto a collegarsi con l’interfaccia di un altro oggetto senza conoscerne la locazione cioè l’indirizzo in rete dell’interfaccia stessa?
13

4. MIGRAZIONE
i) Come può un componente essere trasferito in un’altra locazione in rete senza che il componente stesso o altri componenti si accorgano di nulla cioe’ senza che gli altri componenti debbano modificare le loro invocazioni?
ii) Come si fa a ridistribuire il carico computazionale in modo ottimale e/o a minimizzare le latenze attraverso il sistema?
5. PERSISTENZA
Come può il sistema deattivare o riattivare un componente senza che il componente o gli altri componenti si accorgano di nulla?
6. RILOCAZIONE
Come può un componente già collegato con un altro componente ignorare il riposizionamento di quest’ultimo? (Vedi anche “Trasparenza di rilocazione” qui di seguito)
1. REPLICA
Come può un gruppo di componenti residenti in locazioni diverse fornire lo stesso servizio (componenti “repliche”) cioè come può un componente ottenere il servizio desiderato ignorando se il servizio è fornito da un componente o da una sua replica?
8. TRANSAZIONE
Come può il sistema ottenere consistenza di dati fra un certo numero di componenti tramite coordinamento delle loro attività senza che essi se ne accorgano?
Tutte queste domande identificano problemi che possono essere risolti in due modi:
1) Il problema è risolto di volta in volta in proprio dallo sviluppatore di sistema nell’ambito della progettazione/programmazione di ogni singola applicazione,
2) Il problema è risolto una volta per tutte da una infrastruttura standardizzata (e.g. definita da organizzazioni/consorzi internazinali denominati “enti di standardizzazione” sulla base dello stato dell’arte industriale), infrastruttura chiamata middleware che supporta le applicazioni specifiche sviluppate dal progettista e, al tempo stesso, si fa carico di fornire la soluzione ai summenzionati problemi tramite la fornitura di servizi forniti al programmatore.
Se sceglie di utilizzare parte o tutto il middleware messo a sua disposizione dal sistema (talvolta in forma standardizzata), il programmatore di applicazioni non dovrà risolvere le problematiche causate dalla natura distribuita del sistema e potrà concentrarsi sui problemi specifici della sua applicazione. In questo caso si dice che il sistema distribuito offre (o possiede) trasparenze di distribuzione, cioé il progettista dei
14

componenti del sistema “non vede” (da cui il nome “trasparenza”) i dettagli relativi alla distribuzione. Egli deve semplicemente scegliere le trasparenze pre-confezionate che vuole utilizzare, messe a sua disposizione dal middleware sotto forma di servizi che egli può invocare.
A.1.6 Le «trasparenze di distribuzione» offerte da un sistema distribuito: le risposte!
Qui di seguito descriveremo otto trasparenze di distribuzione che vengono messe a disposizione del programmatore da parte del sistema per risolvere in modo trasparente (cioè a lui invisibile) le problematiche precedentemente elencate. La numerazione delle trasparenze corrisponde alla numerazione delle domande precedentemente formulate. Ad esempio la trasparenza numero 1 (trasparenza di accesso) offre la risposta a tutte le domande formulate sotto il numero 1.
Notare che la realizzazione delle trasparenze richiede che il sistema svolga una molteplicità di funzioni di supporto. Ad esempio, se un oggetto cliente é collegato con l’ interfaccia di un altro oggetto server e questa interfaccia viene riposizionata in una nuova località senza che l’oggetto cliente se ne accorga é necessario che il sistema offra una trasparenza di rilocazione e perchè ciò avvenga è necessario che esso svolga una una funzione di riposizionamento.
ELENCO DELLE TRASPARENZE DI DISTRIBUZIONE
1. TRASPARENZA di ACCESSO (ACCESS TRANSPARENCY): Questa trasparenza nasconde le differenze relative alla eterogeneità fra componenti e.g. permettendo a componenti diversi di interagire e cooperare. “Componenti diversi “ significa componenti che operano in ambienti computazionali diversi e.g. linguaggi di programmazione, struttura dati, sistemi operativi diversi. La trasparenza si realizza includendo nel collegamento fra un componente A e un componente B opportuni componenti intermedi di supporto che effettuano le opportune conversioni dettate dalla natura della eterogeneità dei componenti A e B.
2. TRASPARENZA ai GUASTI (FAILURE TRANSPARENCY): Questa trasparenza nasconde il guasto di un componente agli altri componenti e, viceversa, scherma un componente dai guasti degli altri componenti. Inoltre questa trasparenza garantisce che un utilizzatore possa continuare a essere servito con il servizio richiesto mentre il sistema ripara il guasto sul componente invocato e successivamente guastatosi. Più funzioni di supporto intervengono per realizzare questa trasparenza: funzione di individuazione guasti e riparazione guasti (checkpoint and recovery function), funzione di rilocazione (relocation function), funzione di replica (replication function). In questo modo si realizza un sistema “tollerante ai guasti” (fault tolerant).
3. TRASPARENZA di LOCAZIONE (LOCATION TRANSPARENCY): Questa trasparenza maschera la locazione in rete di un componente. Usando una terminologia propria dei sistemi telefonici, ciò significa che all’interno del sistema esiste
15
un elenco “pagine bianche” che lega i nomi dei componenti agli indirizzi dei componenti e che questo libro viene automaticamente utilizzato dal sistema quando un componente A vuole collegarsi con un componente B specificandone solo il nome e ignorandone la locazione (indirizzo) in rete.
4. TRASPARENZA di MIGRAZIONE (MIGRATION TRANSPARENCY): Mentre la trasparenza di locazione maschera la locazione in rete di un oggetto, la trasparenza di migrazione maschera la variazione di locazione. Questo significa che il sistema può cambiare l’indirizzo di un componente nel libro “pagine bianche” senza notificare questo cambiamento ai componenti.
5. TRASPARENZA di PERSISTENZA (PERSISTENCE TRANSPARENCY): Questa trasparenza nasconde la deattivazione/riattivazione dei componenti. Supponiamo che un componente A invochi un servizio su un componente B. Il componente A ignora se il componente B invocato era precedentemente deattivato ed è stato riattivato in occasione della sua invocazione, cioè il componente A non sa se il componente B è stato sempre attivo o è attivo solo quandi egli lo invoca. La deattivazione/riattivazione é usata quando il sistema non può offrire in modo continuo ad un componente le risorse necessarie. Queste risorse possono essere risorse di memorizzazione e/o processing e/o comunicazione. Agli occhi del componente A il componente B è sempre attivo e quindi il componente A non deve preoccuparsi della sua attivazione prima di invocarlo. Per fornire questa trasparenza il sistema deve svolgere una “funzione di deattivazione e riattivazione” (deactivation and reactivation function)
6. TRASPARENZA di RILOCAZIONE (RELOCATION TRANSPARENCY): Abbiamo visto che la trasparenza di locazione maschera la locazione in rete dei componenti mentre la trasparenza di migrazione maschera il cambiamento di locazione. Ora introduciamo la trasparenza di rilocazione che maschera la riconfigurazione di un canale fra due componenti che hanno già stabilito un collegamento. Se un componente A è collegato con un altro componente B in locazione L e questo componente B è rilocato in una locazione L’ diversa da L (dopo invocazione di un servizio da parte del componente A), il componente A non si accorge di questo cambiamento. Questo equivale a dire che se fra gli oggetti A e B è stato stabilito un canale di collegamento, il canale è automaticamente riconfigurato e collegato dal sistema con la nuova locazione L’ senza che il componente A venga a saperlo. Per fare ciò il sistema svolge una “funzione di riposizionamento” (relocation function).
7. TRASPARENZA di REPLICA (REPLICATION TRANSPARENCY):
Questa trasparenza nasconde l’uso da parte del sistema di componenti residenti in locazioni diverse ma equivalenti per la fornitura di un servizio (repliche) cioe’ nasconde l’esistenza di un gruppo di componenti capaci di rimpiazzarsi mutuamente per fornire lo stesso servizio. Quindi un componente che ottiene l’esecuzione di un servizio non sa se il servizio e’ stato effettuato dal componente invocato o da un suo equivalente residente in una locazione diversa . Si tratta quindi di una forma di ridondanza di componenti utile per creare un sistema tollerante ai guasti (fault tolerant). Richiede l’uso di una funzione di replica (replication function).
16

8. TRASPARENZA di TRANSAZIONE (TRANSACTION TRANSPARENCY): nasconde il coordinamento di attività in una configurazione di componenti che partecipano ad un processo al fine di mantenere la consistenza di dati all’interno della configurazione stessa. Per questa trasparenza il sistema svolge un funzione di transazione (transaction function)
A.1.7 Le funzioni di supporto svolte dal sistema
L’implementazione delle trasparenze che offrono all’utente o al programmatore di una applicazione distribuita una visione virtualmente unitaria del sistema, e’ bene che sia effettuata da funzioni di supporto pre-confezionate (talvolta standardizzate) svolte dal sistema stesso. Le funzioni di supporto rappresentano i mattoni con cui costruire la base del sistema distribuito, che possono essere invocate dalle applicazioni, senza che debbano essere programmate di volta in volta nell’ambito di ogni singola applicazione. Alcune di queste funzioni sono state già identificate nel paragrafo precedente.
A.1.8 Tecnologie software per sistemi gestionali distribuiti: Distributed Object Computing (DOC)
Una architettura gestionale distribuita si implementa in modo economicamente vantaggioso utilizzando le tecnologie software DOC, Distributed Object Computing atte ad effettuare l’eleborazione distribuita utilizzando l’ “orientamento agli oggetti”. Il DOC nasce dalla combinazione di tecnologie di elaborazione distribuita (Distributed Computing) e tecnologie orientate agli oggetti (Object Orientation).
Distributed Object Computing = Distributed Computing + Object Orientation
L’Orientamento agli Oggetti è non solo un paradigma di analisi di sistema (system analysis) ma anche una tecnica di modellazione di sistema (sistem design) nella quale il sistema viene “visto” e modellato come una molteplicità di ”oggetti” interagenti. Un “oggetto” è la rappresentazione di una entità reale esistente nel sistema reale da modellare. “An object is an entity that exhibits some well defined behaviour: objects do things and we ask them to perform what they do by sending them messages” [G.Booch, “Object Oriented Analysis and Design” Addison-Wesley, 1994]
Adottiamo la seguente definizione :
DEFINIZIONE di ELABORAZIONE DISTRIBUITA a OGGETTI (Distributed Object Computing, DOC): L’elaborazione distribuita a oggetti é un tipo di elaborazione distribuita che adotta la filosofia dell’orientamento agli oggetti e fornisce un contesto virtualmente unitario di elaborazione in cui i processi eleborativi cooperano come se risiedessero su un unica macchina. Il passaggio dall’Orientamento agli Oggetti al Distributed Object Computing introduce la possibilità di creare ambienti computazionali nei quali gli oggetti possono risidere in
17

processi o macchine eterogenee residenti anche in sedi remote interconnesse da una rete di distribuzione.
A.1.9 Il «middleware»
Il DOC offre una infrastruttura software di intermediazione (middleware) che si fa carico di tutte le problematiche relative alla distribuzione e quindi permette di sviluppare/utilizzare applicazioni gestionali con gli stessi criteri adottati per la programmazione a oggetti non distribuita.
Si dice anche che il middleware realizza tutta una serie di «Trasparenze di distribuzione» ovvero rende le problematiche di distribuzione invisibili allo sviluppatore di applicazioni. Un elenco delle problematiche relative alla distribuzione e delle relative trasparenze fornite dal middleware è stato già presentato nei paragrafi precedenti.
A.1.10 Il « middleware » come bus di integrazione di componenti eterogenei
Ma c’è un altro aspetto del middleware che va tenuto presente. Abbiamo visto che una caratteristica delle architetture distribuite e’ la eterogeneità dei componenti (cioèi vari componenti operano in « ambienti » diversi). Abbiamo anche visto che componenti applicativi eterogenei non comunicano fra di loro a meno che non vengano prese opportune precauzioni e.g. l’uso di una piattaforma di intermediazione «middleware». Attraverso il middleware componenti eterogenei non solo coesistono ma possono anche comunicare e cooperare facilmente. Questa possibilità è estremamente importante perché permette la scelta di una tecnologia ottimale per ogni componente
Quindi il middleware funziona anche come un poderoso bus di integrazione di componenti applicativi eterogenei che apre la strada a tutta una serie di integrazioni fra componenti, ognuno ottimizzato per una funzionalita’ specifica. Nel nostro corso di GST le integrazioni possibili sono classificabili in tre categorie (Vedi Appendice 3 alla prima parte del corso)
1. integrazione « cross-domain » fra applicazioni gestionali di rete relative a dominii tecnologici diversi (e.g. gestione reti ATM, SDH, Frame Relay etc.)
2. integrazione delle gestioni reti, servizi e assistenza clienti (Customer Relation Management, CRM).
3. integrazione fra applicazioni gestionali appartenenti a fornitori partner operanti in domini amministrativi diversi (in inglese «application interworking», cioè cooperazione fra applicazioni di TelCo diverse).
18

A.1.11 Riepilogo: le motivazioni per una gestione distribuita
In conclusione, il passaggio da sistemi gestionali centralizzati a sistemi gestionali distribuiti e’ stato motivato e facilitato da:
1. Cambiamenti nei mercati/sistemi TLC (espansione, decentralizzazione)
2. Necessità di avere sistemi gestionali scalabili, capaci di supportare la crescita progressiva di carichi computazionali/numero di funzioni gestionali, conseguente all’ espansione dei mercati TLC, senza cambiamento di architettura.
3. Disponobilità a livello commerciale di tecnologie informatiche DOC a prezzi convenienti (cioè prezzi che rendono il sistema distribuito economicamente competitivo con il sistema centralizzato)
19

ADDENDUM No.2
A.2 L’Architettura CORBA Common Object Request Broker Architecture) della OMG (Object Management Group)
PREMESSA: La tecnologia computazionale a oggetti distribuiti CORBA fa parte degli argomenti trattati in un corso di informatica. Qui di seguito, per completezza ma senza entrare nei dettagli, riportiamo alcuni concetti fondamentali che si ritiene sia opportuno conoscere nell’ambito di un corso di Gestione dei Sistemi TLC. Per maggiori dettagli vedere: S.Russo et al., ”Introduzione a CORBA”, McGraw hill, 2002.
Abbiamo in precedenza evidenziato l’importanza del “middleware” nella realizzazione dei sistemi fortemente distribuiti cioè quei sistemi dove il sistema stesso si fa carico delle problematiche generate dalla distribuzione in rete delle applicazioni e abbiamo detto che il middleware permette la realizzazione di un ambiente computazionale virtualmente unitario. Poi abbiamo detto che l’ambiente computazionale può adottare la filosofia dell’ “orientamento agli oggetti” e così realizzare un sistema DOC, Distributed Object Computing. Ora vogliamo descrivere una piattaforma middleware per un sistema DOC chiamata Object Request Brocker, ORB. A2.1 Definizione di CORBA
CORBA (Common Request Broker Architecture) é una architettura che descrive i dettagli di una infrastruttura computazionale a oggetti distribuiti (middleware) chiamata ORB (Object Request Broker). Il middleware ORB permette interazioni fra oggetti distribuiti secondo il paradigma cliente-servente indipendentemente dall’ambiente locale degli oggetti e dalle caratteristiche della rete.
Ricordiamo che il termine «ambiente locale» significa l’insieme di linguaggio di programmazione, sistema operativo e piattaforma hardware utilizzati dal cliente o dal servente. Ad esempio, utilizzando CORBA, un servizio di gestione può implementarsi con applicazioni cliente e applicazioni servente scritte in qualsiasi linguaggio (C, C++, Java, ADA o anche FORTRAN), che girano su qualsiasi macchina (SUN SPARC, Silicon Graphics, PC) con qualsiasi sistema operativo (Windows NT, UNIX)
Ricordiamo inoltre che il termine “ broker” in inglese significa «intermediario». Più specificatamente il termine broker individua la persona che funge da intermediario nell’acquisto di titoli (e.g. azioni o obbligazioni) nello stock market. La infrastruttura Object Request Brocker (ORB) usa il termine “broker” perchè essa opera come intermediario nelle interazioni fra gli oggetti remoti in rete (cioè formulare richieste e
20

ricevere risposte) garantendo la trasparenza delle problematiche della distribuzione (cioè rendendo le problematiche della distribuzione invisibili agli occhi dello sviluppatore delle applicazioni cliente e/o servente). Ad esempio un oggetto cliente richiede ad un oggetto server di effettuare certe operazioni (fra quelle pubblicate in lingua IDL all’interfaccia dell’oggetto server, IDL = Inteface Definition Language), l’oggetto server effettua le operazioni richieste ed invia i risultati all’oggetto cliente che li aveva richiesti. Le operazioni all’interno dell’oggetto server possono adottare un linguaggio di programmazione locale e.g. C++.
Inoltre l’architettura CORBA descrive un insieme di servizi comuni di vario tipo offerti dalla piattaforma ORB agli oggetti in rete e.g. creazione e distruzione degli oggetti (life-cycle service), identificazione degli oggetti tramite un «riferimento all’oggetto» (naming service), memorizzazione degli oggetti in una varietà di storage servers (persistence service), instaurazione di relazioni fra oggetti anche del tipo n:m (relationship service) e così via. La OMG introdotto quindici servizi.CORBA (vedi dopo)
La tecnologia Common Object Request Broker Architecture (CORBA) fu sviluppata dal Object Management Group, OMG (sito internet www.omg.org) nel 1992.
Ricordiamo che OMG é un consorzio con sede negli USA costituito da piu’ di 700 industrie attive nel campo dell’informatica con la partecipazione delle più importanti industrie di computers. Il mandato del gruppo OMG é la promozione delle tecniche a oggetti (cioè“orientate agli oggetti”) nello sviluppo del software. Notare che OMG produce specifiche e.g. documenti che descrivono cosa deve fare il software CORBA ma non produce le implementazioni pratiche di queste specifiche. Ciò per ovvie ragioni: non vuole competere con i suoi stessi membri che operano nel campo della progettazione, realizzazione e vendita delle tecnologie software.
A.2.2 L’essenza di CORBA: l’incapsulamento dell’implementazione degli oggetti server
CORBA si basa su sette concetti fondamentali:
1) La separazione fra interfaccia e implementazione dell’oggetto server (oggetto CORBA). La “implementazione dell’oggetto” significa “le modalità e i linguaggio locale adottato dal server per eseguire le operazioni ed ottenere i risultati richiesti dal Cliente”
2) Il linguaggio IDL (Interface Description Language) per descrivere l’interfaccia dell’oggetto servente
3) La piattaforma “middleware” ORB (Object Request Broker)
21

4) La creazione delle procedure di interfaccia “stubs” per le interfacce client-ORB e ORB-server
5) La localizzazione in rete dell’oggetto servente tramite il riferimento all’oggetto IOR (Interoperable Object Reference)
6) Il protocollo comunicativo IIOP (per il trasferimento delle richieste da Cliente a Server)
7) La fornitura di servizi da parte della piattaforma ORB.
A.2.3 La separazione tra interfaccia e implementazione dell’oggetto servente.
Nella metodologia a oggetti l’ «incapsulamento» è un concetto complementare al concetto di «astrazione»
La separazine fra interfaccia e implementazione dell’oggetto Server si basa su una proprietà della metodologia dell’ “orientamento agli oggetti”: l’ incapsulamento. Ricordiamo che astrazione e incapsulamento sono concetti complementari. L’astrazione mette a fuoco il comportamento dell’oggetto osservabile all’esterno mentre l’incapsulamento mette a fuoco l’implementazione delle operazioni interne all’oggetto che determinano questo comportamento. L’incapsulamento viene anche definito «occultamento di informazione, in inglese, «information hiding », nel senso che l’incapsulamento effettua l’occultamento di tutti quei dettagli (e.g. la struttura interna dell’oggetto e l’implementazione delle operazioni) che non appaiono nella specifica di interfaccia relativa al comportamento dell’oggetto. Alcuni autori si spingono fino al punto di dire che affinché l’astrazione funzioni, l’implementazione deve essere incapsulata.
Esempio di incapsulamento nella programmazione a oggertti con linguaggio di programmazione C++.
Ricordiamo che nel caso della programmazione a oggetti (e.g. programmazione con linguaggio C++), ogni classe é caratterizzata da 1) proprietà (quelle che chiameremo “attributi” nella descrizione degli oggetti OSI) e 2) moduli di programma per eseguire le operazioni assegnate alla classe. Un utilizzatore della classe e.g. il programma principale, richiede ad una istanza della classe di invocare il modulo di programma adatto a “effettuare una certa operazione” ( cioè, con linguaggio tipico del paradigma “Client-Server”, a “fornire un certo servizio”). Quello che l’utilizzatore vede della classe é la sua interfaccia, cioé la descrizione dei servizi forniti e le modalità per richiederli mentre i dettagli del codice di implementazione della classe sono visibili solo alla classe ma non all’utilizzatore. Ad esempio, consideriamo un programma per il calcolo degli interessi mensili dei conti correnti in una banca. In questo caso i dettagli dell’algoritmo usato per calcolare gli interessi accumulati in un mese nel conto corrente di Pietro De Santis sono noti solo alla classe «conti correnti» e non all’utilizzatore del programma. Cioé i dettagli del calcolo degli interessi vengono incapsulati nell’oggetto
22

istanza della classe. Il vantaggio di questa separazione fra implementazione e interfaccia della classe é che i moduli di programma di una classe (cioè i dettagli del calcolo degli interessi) possono essere modificati come si vuole senza modificare il programma (purché l’operazione «calcolare interessi» specificata nell’ interfaccia della classe resti immutata).
Il cliente conosce solo l’operazione da effettuare e ignora tutto il resto
In una architettura CORBA, un oggetto Client che richiede un servizio a un oggetto Server non si deve affatto preoccupare di conoscerne i dettagli e.g. la sua locazione in rete e il suo ambiente locale oppure i dettagli del protocollo di comunicazione adottato in rete. Il Client deve solo 1) conoscere il nome simbolico dell’operazione da invocare e 2) ottenere dall’ORB il «riferimento all’oggetto» o IOR (Interoperable Object Reference) cioè l’indirizzo in rete dell’oggetto su cui deve essere eseguita l’operazione.
INTERFACCIA(Linguaggio IDL)
IMPLEMENTAZIONE(e.g. linguaggio JAVA)
OGGETTO SERVENTE
OGGETTO CLIENTE
e.g. linguaggio C++
Fig. A.2.1 La separazione fra interfaccia e implementazione dell’oggetto server
23

Da parte sua il Server non conosce affatto i dettagli implementativi del Client. Quello che il Server deve fare é effettuare l’operazione invocata cioè fornire il servizio pubblicato sulla sua interfaccia e rinviare al Client il risultato dell’operazione. Quindi, dal punto di vista del Client un oggetto Server é caratterizzato da : 1) IOR che identifica l’ indirizzo in rete del server in modo univoco, 2) operazioni pubblicate nell’ interfaccia dell’oggetto stesso. In altre parole, il Client “vede” solo l’interfaccia del Server e il suo IOR mentre l’implementazione dell’oggetto, cioè i dati e il metodo necessari all’esecuzione dell’operazione invocata espressi in linguaggio di programmazione locale, non é a lui visibile. É la separazione fra interfaccia e implementazione dell’oggetto cioé l’incapsulamento della implementazione dell’ oggetto Server, reso possibile dalla metodologia orientata agli oggetti, l’essenza di CORBA. Fintantoché l’interfaccia del Server non cambia, il Client può sempre ottenere i servizi stipulati dal contratto Cliente-Server anche se il Server cambia il suo ambiente locale e.g. linguaggio di programmazione. Del cambio di linguaggio di programmazione se ne occupa la piattaforma CORBA non il cliente.
A.2.4 Il linguaggio di interfaccia IDL
Le operazioni effettuate dall’oggetto Server, cioè l’ oggetto destinatario delle richieste di servizio da parte dell’oggetto Client, sono pubblicate nell’interfaccia dell’oggetto Server stesso e sono definite usando il linguaggio IDL (Interface Definition Language, IDL, Linguaggio di Definizione di Interfaccia) standardizzato dalla ITU-T nella raccomandazione X.920. Il linguaggio IDL é indipendente sia dagli ambienti locali in cui operano cliente e servente sia dai protolli comunicativi nella rete che li interconnette. Quindi gli oggetti servente usano il linguaggio “dichiarativo” IDL per definire le loro interfacce. “Dichiarativo” significa che IDL é un linguaggio usato solo per la specifica delle interfacce degli oggetti e non é un linguaggio di programmazione per le applicazioni cliente e server che sono invece espresse in linguaggio locale.
Il linguaggio IDL è simile al sottoinsieme del linguaggio C++ (header file) per la dichiarazione delle classi. La piattaforma CORBA fornisce tramite compilatore la mappatura fra IDL e i linguaggi locali (e.g. C++) usati negli stubs (Application Programming Interface) Client e Server rispettivamente linkati alle applicazioni Client e Server
L’interfaccia di un oggetto Server descritta con linguaggio IDL (interfaccia IDL) é costituita dai seguenti elementi:
1. Nome dell’interfaccia
2. Nome delle interfaccie da cui si ereditano proprietà (corrisponde alle superclassi elencate dopo la parola chiave “DERIVED FROM” nelle maschere di classe in una MIB del modello OSI-SM)
24

3. Attributi. Proprità degli oggetti. A queste proprieta’ si puo’ accedere tramite le operazioni di lettura (get) o di scrittura (set) del valore associato all’attributo stesso.(corrisponde agli “attributi” degli oggetti gestiti in una MIB del modello OSI-SM)
4. Operazioni. Sono azioni che l’oggetto compie. Collettivamente l’insieme di operazioni definite in una interfaccia costituiscono il comportamento dell’oggetto.
5. Eccezioni. Una eccezione é l’indicazione che l’esecuzione di una operazione porta ad un fallimento. L’inclusione di una operazione nella lista delle eccezioni significa che la richiesta di quella operazione viene riggettata.
In Fig. A.2.2 é mostrato un grafo orientato esempio di definizione di interfaccia usando il linguaggio IDL.
La definizione comincia con la parola chiave interface.
Il nome dell’interfaccia é chiamata BigBox (GrossaScatola). Questa interfaccia é la specializzazione di una interfaccia piu’ generica appartenente all’oggetto Box (Scatola), di cui eredita le tutte le proprietà.(Gerarchia di ereditarietà: BigBox “is-a” Box. La BigBox è una specializzazione di Box)
L’ interfaccia é caratterizzata da due attributi: HeightofBox (AltezzadellaScatola) e WidthofBox (LarghezzadellaScatola) e supporta due operazioni: GetContents (LeggiContenuti della scatola) e GetNumberofItems (LeggiNumeroOggetti contenuti nella scatola).
Entrambe le operazioni hanno come parametro di ingresso (in) BoxNumber (NumeroScatola).
I Data Types usati per i nomi e i valori degli attributi appartengono alle seguenti categorie:
1) “float”, appartenente alla categoria primitive/floating point,
2) “string”, appartenente alla categoria template e
3) “long” appartenente ad una delle sei categorie primitive/integer. [Per dettagli sui tipi di dati del linguaggio IDL vedere: J. Schettino, L.O’Hara: “CORBA for Dummies”, IDG Books Worldwide, 1998, pp.64-74].
La Fig. A.2.3 e’ un altro esempio di interfaccia IDL con nomi e data types. Notare come le specifiche d’interfaccia in linguaggio IDL non forniscono alcun dettaglio
25

Fig. A.2.2 Esempio di interfacia in lingaggio IDL con due attributi, due operazioni e l’eredità da una interfaccia di base
Interface Big Box : Box { attribute float HeightofBox; attribute float WidthofBox; string GetContents (in BoxNumber) long GetNumberof Items ( in BoxNumber)};
Interfaccia “di base” da cui l’interfaccia BigBox eredita proprietà
Nome dell’interfaccia
Data Types dei valori di ritorno (risultati delle operazioni)
Nome attributiNome operazioni Parametri di ingresso (dal cliente al server)
Data Types dei nomi degli attributi
26

INTERFACCIA IDL dell’ OGGETTO “STOCK” nel SISTEMA SOFTWARE “PORTFOLIO MANAGEMENT SYSTEM”
STOCK
Attributi1. Symbol
Investment Amount Units Current Price
Operazioni
1. Buy Sell
Calculate Current Value
Calculate Investment Change
Interface Stock {readonly attribute string Symbol ;readonly attribute double InvestmentAmountreadonly attribute float Units ;attribute double CurrentPrice ;
void Buy ( in double AmountinDollars) ;double Sell ( in float SellUnits) ;double CalculateCurrentValue ( out double InvestmentChange) ; } ;
Elementi di interfaccia
Rappresentazione dell’interfaccia in linguaggio IDL
Fig A.2.3 Esempio di interfaccia IDL27

sulla implementazione dell’ oggetto server (e.g. il linguaggio di programmazione utilizzato localmente all’interno dell’oggetto).
A.2.5 La piattaforma ORB
La piattaforma ORB (Object Request Broker) rappresenta il bus di comunicazione che permette l’interazione fra oggetti distribuiti, anche se eterogenei, secondo il paradigma cliente-servente. In particolare la piattaforma ORB e’ responsabile di trovare l’oggetto server (sulla base del suo “riferimento all’oggetto”), prepararlo a ricevere l’invocazione, comunicargli i parametri di invocazione, raccogliere i risultati delle operazioni effettuate e ritornarli all’oggetto cliente invocante. I messaggi di richiesta-rispostra vengono mediati (ricordaste i “blocchi di mediazione” nell’architettura funzionale del modello TMN?) da opportune procedure di interfaccia client-ORB e ORB-server chiamati ripettivamente “client stub” (o semplicemente “stub”) e “server stub” (o semplicemente “skeleton”)
A.2.6 I servizi CORBA
L’OMG ha specificato una serie di servizi molti dei quali sono stata implementati da venditori commerciali. I servizi sono specificati come oggetti CORBA. Quindi come tutti gli oggetti CORBA essi sono specifcati come interfacce IDL che indicano la semantica delle funzionalità offerte astraendosi da qualsiasi aspetto implemetativo. I servizi sono :
1. Life Cycle2. Persistence3. Naming1. Event2. Concurrency3. Transaction4. Relationship5. Externalization6. Query7. Licensing8. Properties9. Time10. Security11. Trader12. Collection
Qui ci limitiamo a menzionare i più importanti da un punto di vista TMN. I tre
servizi sono :
i) Servizi di Life Cycle. Questi servizi offrono la gestione del ciclo di vita degli oggetti CORBA dalla loro nascita alla loro morte. In particolare questi servizi permettono di creare, copiare, spostare e
28

cancellare oggetti. Le versioni più recenti di questi servizi tengono anche conto delle relazioni fra oggetti. Ad esempio se cancello un oggetto, cancello anche tutti chi oggetti in esso contenuti cioé gli oggetti che con esso hanno una relazione di contenimento. In queste versioni i servizi life cycle sono strettamente collegati con i Servizi di Riferimento. Una delle operazioni più interessanti rese possibili da questi servizi é la creazione degli oggetti da parte di un cliente. In CORBA un cliente può interagire con un oggetto servente solo se ne conosce un riferimento, cioé l’oggetto deve già esistere ed essere localizzato in un nodo della rete. Quindi un cliente da solo non può creare un oggetto direttamente. Il servizio Life Cycle mette a disposizione del cliente un «oggetto fabbrica» (factory object) di cui esso conosce il riferimento (e.g. attraverso invocazione di metodo su un altro oggetto chiamato «localizzatore di fabbrica») capace di 1) istanziare l’oggetto specificato di una classe specificata., 2) registrarlo con l’Object Adapter e 3) restituire al cliente il riferimento all’oggetto (indirizzo). In definitiva l’oggetto fabbrica crea oggetti su richiesta del cliente. Ad esempio, in una azienda TLC, un oggetto fabbrica puo essere utile per creare dinamicamente istanze di ordini nell’ambito di un processo gestione ordinazioni di servizi TLC (service provisioning)
ii) Relationship Service. Fornisce un meccanismo per creare, cancellare e «percorrere» relazioni fra oggetti senza che gli oggetti relazionati conoscano alcunché gli uni degli altri. Sono possibili relazioni 1-1, 1-n, n-m. Due tipi di relazioni sono disponibili: relazioni di “containment” e relazioni di “reference”
iii) Naming Service. Si tratta di un servizio elenchi “pagine bianche” che fornisce le associazioni fra i nomi simbolici degli oggetti CORBA e i corrispondenti indirizzi (“riferimenti all’oggetto”) i.e. servizi che identificano univocamente la locazione di un oggetto all’interno della rete CORBA.
A.2.7 Differenze fra OSI e CORBA
1. Comunicazioni gestionali. In OSI le comunicazioni gestionali avvengono fra entità applicative gestionali che giocano il ruolo di gestori o agenti. Il gestore invoca su un agente una operazione da effettuarsi su un oggetto gestito, modello di una risorsa gestita. In CORBA il concetto di entità gestionale non esiste. L’invocazione di una operazione su un oggetto server (relativamente ad una operazione contenuta nella specifica di interfaccia dell’oggetto stesso) é effettuata da un altro oggetto (cliente).
2. Oggetto come istanza di una classe. In OSI gli oggetti (istanze di classi di oggetti) sono memorizzati in una struttura ad albero (albero di contenimento) contenuta nella MIB. La rappresentazione degli oggetti si effettua tramite maschere GDMO con tipi di
29

dato definiti dalla sintassi ASN.1. In CORBA un oggetto come istanza di una classe é semplicemente l’implementazione (algoritmo + dati) di un oggetto server. L’oggetto server é definito da una interfaccia vista dall’oggetto cliente descritta in linguaggio IDL.
3 Relazioni fra oggetti. Ricordiamo che G.Booch nel suo classico libro, « Object–oriented analysis and design, second edition, Addison-Wesley, 2000 » a pag.97 distingue due tipi di relazioni fra oggetti : i collegamenti (links), nei quali gli oggetti relazionati si scambiano messaggi, e le aggregazioni (aggregations), le quali stabiliscono una relazione tipo padre-figlio o contenitore-contenuto fra gli oggetti relazionati senza scambio di messaggi.
In OSI, se si prende in considerazione la struttura dell’albero di contenimento si vede che gli oggetti sono mutuamente relazionati da relazioni di aggregazione (secondo la definizione di G.Booch). Si puo’ anche riconoscere che in un albero di contenimento OSI, un oggetto supporta solo un numero limitato di relazioni con gli altri oggetti e la topologia dell’albero é tipicamente statica cioé non cambia di frequente. Nella rappresentazione GDMO dell’oggetto queste relazioni fanno parte della definizione dell’oggetto stesso tramite le maschere di name-binding (Vedi par.4.7). Le relazioni fra oggetti mostrate in un albero di contenimento servono a stabilire un nome globalmente univoco (DN, Distinguished Name) per l’oggetto e, al tempo stesso, identificare l’ubicazione dell’oggetto stesso all’interno della MIB (navigando nell’albero di contenimento partendo dalla radice e muovendosi lungo una traiettoria che conduce all’ oggetto desiderato).
In CORBA le relazioni che legano un oggetto con gli altri oggetti sono del tipo “collegamento” (terminologia di G.Brooch). Infatti gli oggetti CORBA si scambiano messaggi secondo un paradigma client-server. Si tratta quindi di una relazione diversa da quella posseduta dalle relazioni fra oggetti OSI. Inoltre in CORBA le relazioni non fanno parte della definizione dell’oggetto cioé le descrizione di una interfaccia non contiene alcuna informazione relativa agli oggetti collegati. La situazione é molto più flessibile che in OSI. Infatti, le relazioni fra oggetti CORBA sono definite e memorizzate da un servizio CORBA chiamato Servizio di Relazione (vedi par. 12.2.2.7). In CORBA un oggetto non conosce le sue relazioni con gli altri oggetti. Esse sono definite per lui dalla piattaforma CORBA tramite i servizi di relazione. Quindi può accadere che uno stesso oggetto cambi le sue relazioni con gli altri oggetti senza cambiare la sua identità (i.e. senza cambiare le caratteristiche di comportamento specificate nelle sua interfaccia) e questo è molto importante nel caso in cui un oggetto rappresenti un servizio “supportato” di volta in volta da oggetti rete diversi (uno stesso servizio telefonico Roma-New York una volta è via cavo un’altra volta è via satellite) . La topologia delle relazioni fra oggetti si può costruire tramite i Servizi di Relazione. Quindi l’ “albero di contenimento” che stabilisce le relazioni fra oggetti in una MIB OSI non ha significato in CORBA. Le conseguenze di questo fatto sono che:
1) le mutue relazioni fra oggetti non sono utilizzabili al fine di conoscere la locazione di un oggetto in rete né tantomeno la sua identità identificata dalla sua interfaccia.
30

2) l’effettuazione di operazioni di scoping e filtraggio, sebbene effettuabili
tramite i servizi di relazione, sono più difficili in un ambiente CORBA proprio perché manca un albero di contenimento.
A.2.8 L’utilizzazione di OSI per la gestione rete e di CORBA per la gestione servizi
Vediamo ora quale é la migliore utilizzazione delle tecnologie OSI e CORBA in un contesto TMN. Cominciamo con l’analisi comparata delle caratteristiche della gestione di rete e dei servizi.
a) La gestione di rete e dei suoi elementi é caratterizzata da un gran numero di oggetti relativamente semplici, nel senso che essi non hanno comportamenti e/o relazioni complicate. Infatti, questi comportamenti e/o relazioni si definiscono abbastanza facilmente sulla base delle caratteristiche fisiche della rete TLC e dei parametri che si vogliono gestire. Poiché una rete TLC una volta realizzata é relativamente statica , cioé ogni elemento di rete ha una ubicazione fisica ben precisa che non subisce rapide variazioni nel tempo, una gran parte degli oggetti che modellizzano una rete sono oggetti statici. Tuttavia il numero di risorse da gestire e, quindi di oggetti gestiti, può aumentare nel tempo e ciò puo causare una saturazione del sistema di gestione con relativi problemi di scalabilità.
Ricordiamo che tradizionalmente le componenti di un sistema per la gestione di rete e dei suoi elementi sono: 1) entità applicative gestionali con ruolo di gestore che hanno una visione globale delle risorse loro affidate e sono utilizzate da personale specializzato e/o da programmi gestionali per emettere richieste di operazioni gestionali. Un gestore controlla un certo numero di agenti e normalmente risiede in un centro gestionale (architettura centralizzata). 2) entità applicative gestionali con ruolo di agente che hanno una visione specifica degli oggetti loro affidati e.g. lo stato dei vari elementi di rete, i loro dati di utilizzazione/funzionamento etc. Un agente normalmente risiede vicino o addirittura all’interno delle risorse gestite. 3) una piattaforma di comunicazione (e.g. il protocollo CMIP) per il trasferimento di informazione gestionale gestore-agente.
Sappiamo che esiste una tecnologia sviluppata specificamente per l’implementazione della gestione reti e elementi di rete: la tecnologia OSI-SM. Tuttavia molto spesso la rete che supporta un servizio end-to-end fra due terminali d’utente é costituita da sotto-reti che utilizzano tecnologie diverse cioé, come si dice in gergo, esistono sotto-reti rappresentative di dominii tecnologici diversi e.g. ATM, SDH, Frame Relay etc. Ogni sotto-rete deve avere un sistema di gestione OSI-SM che soddisfa le specifiche dettate dalla particolare tecnologia adottata. Ad esempio una sotto-rete ATM può presentare una interfaccia standardizzata per reti pubbliche del tipo ATM-M4 (Vedi Fig. 9.1) mentre una sotto-rete di accesso ADSL può presentare una interfaccia non standard. In queso caso la gestione di una connessione end-to-end implica una molteplicità di sistemi di gestione, un sistema di gestione per dominio tecnologico. In queste circostanze l’uso di CORBA come piattaforma di integrazione per diverse
31

tecnologie di rete appare molto interessante. La Fig.12.4.1 mostra lo schema di principio per un sistema di gestione di una rete costituita da diversi domini tecnologici. (Gestione integrata di una rete eterogenea, « cross-domain integration »).
b) La gestione dei servizi é modellizzata con oggetti molto più complicati degli oggetti rete. Questi oggetti rappresentano funzioni di gestione relative ai servizi supportate da funzioni di gestione a livello rete. Cosa significa «supportate» ? Facciamo un esempio. Un servizio di videoconferencing stabilisce delle «sessioni» durante le quali gli utenti si scambiano informazioni di natura multimediale. Ogni sessione di videoconferencing richiede, a livello di rete fisica, l’esistenza di connessioni circuitali a larga banda che trasportano l’informazione scambiata fra gli utenti attraverso dominii tecnologici diversi con certe caratteristiche prestazionali e.g. bit error rate, tempo di ritardo, qualità di servizio, livello di sicurezza etc. Il tutto in modo estremamente dinamico, cioé variabile nel tempo in dipendenza delle esigenze dei partecipanti alla videiconferenza. Quindi, in generale gli oggetti che modellizzano i servizi (oggetti servizio) sono molto più complicati e più dinamici degli oggetti che modellizzano le reti e gli elementi di rete (oggetti rete). Il fatto che una sessione di videoconferencing a livello servizi sia implementata tramite connessioni end-to-end a livello rete si esprime nel linguaggio dei modelli dicendo che gli oggetti servizi sono supportati da oggetti rete.
Abbiamo capito che le risorse di rete supportano i servizi e che, quindi, a livello di modelli, gli oggetti rete supportano gli oggetti servizio ma dobbiamo ora riconoscere che la relazione servizi-risorse rete é una relazione piuttosto complessa. Ad esempio, un servizio può nascere nel laptop di un impiegato nell’ ufficio vendite di una compagnia di servizi TLC a New York ed essere poi realizzato tramite una rete internazionale gestita da un fornitore di servizi a Pechino o un operatore di rete a Parigi cioé un oggetto servizio deve mantenere la sua identità indipendentemente dalla ubicazione delle risorse fisiche e può essere supportato da risorse diverse in tempi diversi. Inoltre poiché ogni fornitore di servizi tende a fornire un numero crescente di servizi (“fare più soldi”!!) con lo stesso numero di risorse di rete, si può verificare che la rete gestionale dei servizi divenga insufficiente (saturazione nella gestione a livello servizi) mentre la rete gestionale della rete rimanga perfettamente adeguata. Tutto ciò si può anche esprimere dicendo che si possono verificare problemi di scalabilità a livello servizi e non a livello reti Quindi gli oggetti servizio possono trovarsi in situazioni completamente diverse da quelle degli oggetti rete.
Data la complessità e la dinamicità degli oggetti servizio, la tecnologia distribuita CORBA sembra più adatta a implementare la gestione dei servizi che non la tecnologia OSI, progettata e realizzata per oggetti di rete di natura molto più statica. Infatti, il linguaggio CORBA IDL permette di specificare operazioni gestionali complicate con interfacce generiche relativamente semplici (l’oggetto CORBA nel suo interno si fa carico delle specificità della implementazione del servizio da fornire). Tutto ciò rende la tecnologia CORBA il candidato ideale sia per implementare la gestione servizi sia per integrare la gestione servizi con la gestione reti. Ovviamente le due gestioni implicano modelli informativi diversi poiché gli oggetti sono diversi e questo va tenuto conto nei processo di integrazione.
32

In conclusione la tecnologia CORBA appare come complementare alla tecnologia OSI. Inoltre la tecnologia CORBA può essere utilizzata per
1) integrare diverse tecnologie di gestione rete, e.g. con protocolli CMIP, SNMP (Vedi Fig. A.2.8.1)
2) realizzare la gestione servizi e integrarla con le gestione rete. Vedremo nel prossimo capitolo i vari metodi per integrare queste due tecnologie.
33

ADATTATORECORBA-XYZ
AGENTESISTEMALEGACY
GATEWAYCORBA-CMIP
AGENTE CMIP
AGENTE SNMP
GATEWAY CORBA-SNMP
GESTORE di RETE “CROSS-DOMAIN”
(CORBA)
34

Fig. A.2.8.1. Gestione integrata di una rete eterogenea che usa CORBA come piattaforma di integrazione. Integrazione uno-a-uno CORBA-“Tecnologia gestionale specifica” per ottenere una “gestione cross-domain” i.e. gestione di rete attraverso diversi domini tecnologici (qualsiasi, CMIP, SNMP)
35

ADDENDUM No.3
A.3 Integrazione delle gestioni di reti, servizi e relazioni clienti (modelli & tecnologie)
A.3.1 Generalità
Abbiamo visto che in una impresa TelCo, proprietario-gestore di reti e fornitore di servizi TLC, quando si parla di “oggetti” (materiali o immateriali) da gestire in effetti si fa riferimento ad almeno cinque tipi diversi di gestioni settoriali: gestione elementi di rete, gestione reti, gestione servizi, gestione relazioni clienti e gestione d’impresa (quest’ultima solo in parte). A queste si aggiunge la gestione delle relazioni commerciali con imprese “partner” fornitrici di servizi TLC e con imprese “supplier” fornitrici di tecnologie ICT (i.e. partners & suppliers). Oggi la filosofia prevalente é di adottare modelli gestionali e tecnologie software ottimizzati per ogni tipo di gestione settoriale e poi integrare i vari modelli/tecnologie utilizzando computazione distribuita, e.g. Distributed Object Computing (DOC), con opportune infrastrutture di integrazione, e.g. middleware tipo CORBA.
A.3.1.1 Modelli e tecnologie per le gestioni settoriali
Riconosciamo innanzi tutto che i vari tipi di gestione settoriale elementi di rete, rete, servizi e relazioni clienti hanno esigenze diverse, devono soddisfare requisiti diversi e quindi richiedono modelli e tecnologie implementative diverse. Infatti
1. La gestione degli elementi di rete (Network Element, NE) richiede modelli gestionali molto dettagliati capaci di gestire le caratteristiche dei singoli componenti (e.g. autocommutatori, istradatori, linee di trasmissione etc.). In genere si tratta di modelli gestionali proprietari del costruttore, implementati con sistemi OS (Operations Systems = Sistemi di Esercizio) attestati direttamente sull’elemento di rete.
2. La gestione delle reti richiede un modello più astratto, meno dettagliato. Infatti, informazione dettagliata è necessaria per operare uno switch ma solo una parte di essa è necessaria per operare una rete. Per creare un modello gestionale di rete basta modellare le caratteristiche complessive di un insieme di apparati e.g. le caratteristiche delle connessioni end-to-end da una terminazione di rete all’altre.
3. La gestione dei servizi deve gestire una molteplicità di processi gestionali con variazioni temporali su base day-by-day e geograficamente distribuiti e.g. accettazione/processing delle richieste di installazione servizi presentate dai clienti, monitoraggio e controllo della qualità dei servizi, preparazione di tariffe e sconti, fatturazione/raccolta pagamenti etc, su base globale. In queste circostanze è opportuno sviluppare modelli di gestione servizi estremamente flessibili e facili da adottare alle
36

esigenze di una varietà di mercati , ma soprattutto, indipendenti da domini tecnologici e amministrativi i.e. i modelli gestionali devono ignorare la eterogeneità delle tecnologie implementative di apparati e reti provenienti da costruttori diversi (domini tecnologici diversi) assieme alla etereogeneità delle procedure gestionali dovuta a gestori locali residenti in sedi remote spesso distribuiti su base multinazionale (domini amministarativi diversi). Infatti, dal punto di vista della fornitura/acquisizione di un servizio TLC non fa alcuna differenza se il servizio è abilitato da una rete terrestre wireline o wireless, con tecnologia ATM o tecnologia SONET o via satellite. Quello che conta è che le risorse allocate in rete siano capaci di soddisfare i requisiti del servizio stesso e.g. larghezza di banda, qualità della trasmissione, tempi di ritardo etc.
4. Nella gestione delle relazioni clienti (effettuata separatamente ma non indipendentemente dalla gestione servizi) si devono gestire in modo efficiente una molteplicità di transazioni con coinvolgimento diretto del cliente e con tempi caratteritici dell’ordine dei minuti (eventi CRM, Customer Relation Management) e.g. invio al Cliente di informazioni sui servizi erogati e sulle loro caratteristiche, accesso dettagliato da parte dei clienti ai records delle fatturazioni/pagamenti, notifica proattiva di malfunzionamenti e conseguenti degradazioni della QoS, soddisfacimento dei reclami in modo rapido con riparazioni accurate etc. utilizzando tecnologie periferiche facilmente disponibili ai Clienti possibilmente attraverso terminali di gestione facilmente accessibili e.g. telefono, internet, fax .
Si tratta quindi di soddisfare per i quattro tipi di gestione requisiti diversi nel modo migliore possibile, utilizzando per ciascun tipo modelli/ tecnologie gestionali ottimali e aggregando poi le soluzioni parziali in un' unica soluzione integrata (possibilmente “loosely coupled”)
Ad esempio, si possono adottare le seguenti tecnologie gestionali,
1) tecnologia OSI (con linguaggio GDMO/ASN.1) per la gestione delle reti e degli elementi di rete utilizzando un paradigma Manager-Agent che opera su oggetti gestiti contenuti nelle MIB (studiato nella seconda parte del corso),
2) tecnologia CORBA (con linguaggio IDL) per la gestione dei servizi usando un paradigma Client-Server
3) tecnologie Java/Web per gestire l’interfaccia cliente utilizzando la rete internet.
Queste tecnologie devono poi cooperare in un sistema gestionale organico i.e. vanno poi integrate in un unico sistema gestionale integrato. Il livello di integrazione fra modelli gestionali diversi può essere più o meno spinto: da una semplice conversione di linguaggio e di protocollo comunicativo fra modelli gestionali diversi (e.g. conversione di linguaggio IDL – GDMO e viceversa) fino ad effettuare una mappatura fra modelli informativi (object models) diversi e.g. modello informativo servizi e modello informativo reti. Vedremo i dettagli dei vari livelli di integrazione fra poco.
37

A.3.2.2 Esempio di “Gestione TLC” con la G maiuscola
La figura A.3.1 è un esempio di sistema di Gestione TLC i.e. gestione integrata a tre livelli: clienti-servizi-reti. Il sistema adotta una architettura simile a quella del modello TMF (Tele-Management Forum) che, ricordiamo, era un modello processuale inserito in un modello statico del tipo “TMN stratificato” ma con la separazione fra gestione servizi (processi operativi) e gestione relezioni clienti (processi transazionali).
Il sistema di figura A.3.1 contiene tre ambienti integrati ma diversi per tecnologia e funzionalità gestionale.
GESTIONE CUSTOMER CARE (JAVA/WEB)
GESTIONE SERVIZI (CORBA)
GESTIONE RETE (OSI)
Applicazioni
Gestione Servizi
Appl. Gestione
Reti
Interfaccia Accesso Clienti
Strato Accesso Servizi
Strato Integrazione Gestione Servizi – Gestione Reti
SP/SP
Funzioni GR Supporto GR Dati GR
Funzioni GS Supporto GS Dati GS
Fig. A.3.1 Esempio di architettura per gestione integrata relazioni clienti-servizi-reti
Risorse Rete
Clienti
38

Il sistema di figura A.3.1 contiene tre ambienti integrati ma diversi per tecnologia e funzionalità gestionale. La descrizione degli ambienti è ripresa da G.Chen & Q.Kong “Integrated Telecommunications Management Solutions”, IEEE Press, 2000, Capitolo 10.
1) Ambiente Gestione Relazioni Clienti (CRM, Customer Relations Management) con tecnologia Java/Web. In questo ambiente si eseguono i processi necessari al Cliente per accedere all’ ambiente “Gestione Servizi” sottostante. É costituito da due comparti dove avvengono: 1) processi di Interfaccia Accesso Clienti (Customer Access Interface, CAI) e 2) processi di Gestione Relezioni Clienti (Customer Relation Management, CRM). Lo scopo dell’interfaccia CAI è quello di permettere ai Clienti l’accesso all’ambiente CRM indipendentemente dalle tecnologie/protocolli di accesso e.g. telefono. Computer (Pagine Web, e-mail), fax etc. Lo scopo dell’ambiente CRM è quello di indirizzare le singole richieste dei Clienti agli opportuni processi di Service Management.
L’ambiente CAI è popolato dai terminali posseduti dai clienti e da una “logica di presentazione” (Presentation Logic) che ha il duplice scopo di verificare la natura/validità di ciascuna richiesta formulata dai Clienti e indirizzarla all’adattatore appropriato (PLA, Presentation Logic Adapter). L’aggiunta di una nuova tecnologia di accesso richiede solo l’aggiunta di un nuovo PLA senza cambiare null’altro. Il PLA adatta una particolare richiesta al Controllore di Workflow (Work Flow Controller, WFC) che controlla il flusso dei processi CRM associati alla richiesta ricevuta. Infatti ogni richiesta del cliente a sua volta innesca una serie di processi applicativi CRM (vedi qui sotto). Il controllore WFC decide quali e quando certi processi applicativi devono essere eseguiti seguendo un ordine logico prestabilito. Il controllore WFC è anche seguito da un adattatore ai particolari processi applicativi CRM ai quali di volta in volta si deve accedere (Application Logic Adapter, ALA). Quindi l’interfaccia di accesso alla gestione customer care è costituita dai seguenti elementi:
1. Terminale gestionale,
2. Logica di presentazione PL,
3. Adattatore di logica PLA,
4. Controllore WFC,
5. Adattatore di applicazione ALA.
39

La gestione relazione cliente (CRM, Customer Relation Management) è costituita da un insieme di processi CRM e da un insieme di “oggetti” (business objects) che vengono creati nel corso di questi processi. Fra gli oggetti creati a livello CRM dobbiamo menzionare: contratto SLA iniziale, ordine di servizio, servizio, billing records etc Esempi di processi applicativi CRM utilizzabili dal singolo Cliente sono:
1. Visionare “catalogo prodotti e servizi” (messo a disposizione dei clienti per la scelta dei servizi adatti alle proprie esigenze),
2. Ordinare un servizio TLC,
3. Revisionare il proprio conto/fatture,
4. Revisionare il proprio contratto SLA,
5. Effettuare richieste di informazione circa le statistiche di funzionamento dei serrvizi,
6. Presentare reclami relativi a malfunzionamenti, etc.
Molte di queste attività sono di inoltro delle richieste dei Clienti verso i processi svolti a livello Service Management, SM (Gestione Servizi). In pratica i processi CAI e CRM effettuano un primo livello di controllo di ciascuna richiesta proveniente dai Clienti e poi la inoltrano agli opportuni processi SM sottostanti i.e. rivolgono ai processi SM sottostanti specifiche invocazioni di servizio per conto dei Clienti. La mappatura fra i processi CRM e i processi SM sottostanti viene effettuata nello strato accesso servizi (Fig.A3.1) che integra le due gestioni.
2) Ambiente gestione servizi con tecnologia CORBA . Questo ambiente
fornisce le funzionalità necessarie a trasformare le funzionalità offerte dalle risorse di rete in funzionalità disponibili ai clienti (i.e. capacità/abilità di effettuare richieste di informazione, segnalazioni, piazzamento ordini etc.) e in senso inverso, a trasformare le richieste dei clienti in operazioni gestionali sulle reti. Questo ambiente é costituito da quattro componenti:
1) un insieme di funzionalità di gestione e.g. modello FCAPS dell’ITU-T più funzionalità di supporto,
2) uno “strato accesso servizi” di integrazione con la gestione relazioni clienti,
40

3) una interfaccia SP/SP (SP, Service Provider) con fornitori di servizi partner,
4) uno strato di integrazione con la gestione reti.
3) Ambiente gestione reti con tecnologia OSI . Offre una gestione reti di tipo tradizionale in supporto alla fornitura di servizi ai clienti.
A.3.2 Metodi di integrazione (Fig. A.3.2 e Fig. A.3.3)
Esistono metodi differenti per effettuare l’integrazione delle tecnologie gestionali e ogni metodo ha uno scopo differente. Qui vogliamo esaminare tre metodi. Si faccia riferimento alla Fig.A.3.3 dove sono mostrati due fornitori di servizio (SP1 e SP2) con le relative gestione reti (NM) e gestione servizi (SM):
1) Il metodo “gateway di integrazione” o semplicemente metodo “gateway” è usato per integrare tecnologie di gestione di reti diverse. (Vedere la freccia orizzontale a tratteggiatura fine nella Fig. A.3.3). Ad esempio nel caso di sottoreti realizzate con tecnologie gestionali eterogenee (e.g. OSI, SNMP, proprietarie) il metodo “gateway” può fornire una gestione di rete unificata tecnologicamente neutra. utilizzando una tecnologia CORBA. Per l’ integrazione CORBA/OSI, questo metodo prevede una mappatura uno-a-uno fra oggetti OSI (rappresentati in linguaggio GDMO/ASN.1) e oggetti CORBA (rappresentati con linguaggio IDL). La mappatura è realizzata tramite conversione di linguaggi e adattamento fra i due modelli informativi senza cambiare la granularità degli oggetti (mappatura uno-a-uno, vedi Fig.A.3.2).
2) Il metodo “mappatura astratta” è particolarmente usato per integrare tecnolgie per la gestione reti con tecnologie per la gestione servizi. (Vedere le frecce oblique a tratteggiatura grossa nella Fig. A.3.3). In questo caso ci sono due tipi di oggetti rete: oggetti rete specifici secondo un modello OSI a livello di gestione rete e oggetti rete generici secondo un modello CORBA, utilizzati per supportare oggetti servizi a livello gestione servizi. Gli oggetti rete generici sono ottenuti attraverso un processo di generalizzazione applicato agli oggetti rete specifici. Le regole di astrazione da oggetti rete specifici a oggetti rete astratti sono implementate da “integratori tecnologici OSI-CORBA”.
3) Il metodo “interworking applicativo” usato per integrare gli OSS di SP partner operanti in dominii amministrativi federati (Vedere la freccia orizzontale continua in Fig.A.3.3). In generale non è necessario nè possibile per fornitori partner implementare i loro OSS con gli stessi modelli informativi o gli stessi modelli di processo. Tuttavia è cruciale fornire ai clienti servizi tipo “one-stop-shopping” cioè servizi nei quali il cliente contatta un unico fornitore di servizio (il fornitore principale) il quale poi si occupa delle relazioni con gli altri fornitori (fornitori federati o partner) partecipanti
41

alla fornitura del servizio. Per far ciò è necessaria la interoperabilità degli OSS dei fornitori federati e il mutuo scambio di informazione fra le relative applicazioni gestionali.
La condizione necessaria per la interoperabilità delle applicazioni (interworking applicativo) di due fornitori partner è la creazione da parte di entrambi di una interfaccia comune generica, semplice e tecnologicamente neutra ( i.e. indipendente dalle particolari tecnologie implementative adottate dai fornitori partner).che garantisca e.g. l’interscambio di ordinativi di servizi, notifiche di guasti e/o malfunzionamenti, richieste di informazione sui servizi, tariffe e fatturazione etc.
NOTA BENE. Questi erano proprio i criteri iniziali adottati anche nello sviluppo degli standards OSI per l’interconnessione fra apparati eterogenei. Tuttavia, nel tempo, questi standards hanno perso la loro caratteristica di neutralità tecnologica. Essi sono divenuti sempre più specializzati a particolari tecnologie, sempre più complicati e quidi sono tornati a creare una situazione in cui c’è di nuovo bisogno di ……standards per interconnettere tecnologie standardizzate & eterogenee!
42

IDL Object
Attributes
Invocation Methods
Get, set, create, delete, action
MIB GDMOObjects
IDL Interface Objects
Manager sideAgent side
CMIP-IIOPConversion
ORB
ManagerAgent
Fig. A.3.2 Mappatura degli oggetti e conversione dei protocolli con l’approccio “gateway”.
GDMO Object
Attributes
Operations
Get, set, create, delete, action, filter, scope,
sinchronozation, linked reply
Notification
Behavours
OBJECT1-to-1
MAPPING
GDMO IDL I.F.
ASN.1 IDL Def.
IIOPCMIP
43

La figura A.3.2 illustra l’utilizzazione dei tre metodi di integrazione “gateway di integrazione”, “mappatura astratta” e “interworking applicativo”. In questa figura sono usati i seguenti acronimi: FS = Fornitore di Servizio, SM = Service Management e NM = Network Management.
Esiste un testo sull’integrazione delle tecnologie gestionali per sistemi TLC purtroppo scritto in un inglese pessimo: “Integrated Telecommunications Management Solutions”, G.Chen, Q. Kong, IEEE Press, 2000. Tuttavia non contiene il modello ODP/ODMA dell’ITU-T. Per quest’ultimo si deve far riferimento alle raccomadazioni originali (scaricabili dal sito ITU-T, a pagamento tramite carta di credito. Costano circa 20-30 euro a raccomandazione).
SP1 SP2
1. GATEWAY D’INTEGRAZIONE
SM SM
NM NM
2. MAPPATURA ASTRATTA
NM NM
3. INTERWORKING APPLICATIVO
Fig.A.3.3 Tre diversi metodi di integrazione di tecnologie gestionali.
44

ADDENDUM No.4
A.4 Elementi di programmazione a oggetti
PREMESSA. Riportiamo in questo Addendum alcune nozioni elementari di informatica relative alla programmazione a oggetti e all’elaborazione distribuita a oggetti, necessarie alla comprensione di parte del materiale presentato nel corso di GST. Questa parte può essere ignorata da studenti che già abbiano preso un corso introduttivo di informatica e/o già abbiano una familiarità con questi concetti.
A.4.1 Gli oggetti come esecutori di compiti di programmazione.
Nell’ingegneria del software si possono utilizzare diversi paradigmi/stili di programmazione ognuno dei quali comprende diversi linguaggi. Esempi di paradigmi/stili di progammazione sono: « Procedure Oriented » (algoritmi), « Object Oriented » (oggetti e classi di oggetti), « Logic Oriented », « Rule Oriented » etc. Esempi di linguaggi di programmazione a oggetti sono C++ e SmallTalk.
La programmazione a oggetti é un metodo di programmazione in cui i programmi sono organizzati come collezioni di oggetti cooperanti e dove ogni oggetto rappresenta l’istanza di una classe facente parte di una gerarchia di classi relazionate per ereditarietà.
Nella programmazione a oggetti, un programma é suddiviso in un programma principale (main program) e una molteplicità di sottoprogrammi ognuno dei quali esegue uno o più sottocompiti (sub-tasks). Ogni sottoprogramma che esegue un sottocompito é riguardato come una classe (di oggetti) con attributi e operazioni. Ad esempio, consideriamo un programma di gestione di un sistema bancario. In questo caso le classi sono «conti correnti », « conti di risparmio » e « prestiti ». Un esempio di operazione associata con i conti correnti o con i conti di risparmio é: « calcolare gli interessi compositi dovuti al saldo». Un esempio di oggetto, come istanza della classe «conti correnti», é il conto corrente di Pietro de Santis (dove sono specificati i valori degli attributi: codice fiscale, tipo di conto, saldo etc.).
Nella programmazione a oggetti, una operazione effettuabile da una classe é vista anche come la fornitura di un servizio. Infatti nella programmazione a oggetti, quando il programma va in esecuzione invia richieste di servizio agli oggetti. Gli oggetti rispondono eseguendo il servizio richiesto cioé eseguendo il sottocompito e restituendo i risultati dell’operazione. Il programma principale coordina le risposte dei vari oggetti.
La programmazione a oggetti ha una infrastruttura concettuale (Object Model) caratterizzata da cinque elementi principali :
45

1. Astrazione
2. Incapsulamento (Occultamento di informazione)
3. Modularità
4. Ereditarietà
5. Polimorfismo
Astrazione. L’astrazione é uno dei modi usati dall’uomo per gestire la complessità. Scegliere l’insieme ottimale di astrazioni costituisce il problema principale nelle tre fasi di sviluppo del software: analisi (OOA, Object Oriented Analysis) progettazione (OOD, Object Oriented Design) e programmazione (OOP, Object Oriented Programming).
Booch [1994] ha definito astrazione come segue:
« L’ astrazione denota le caratteristiche essenziali di un oggetto che lo distinguono da tutti gli altri oggetti e quindi, fornisce confini concettuali ben definiti, relativamente alla prospettiva dell’osservatore ».
Quindi una astrazione mette a fuoco la vista esterna di un oggetto (interfaccia) e serve a separare il comportamento essenziale di un oggetto dalla sua implementazione. Il comportamento di un oggetto può caratterizzarsi facendo riferimento alle interazioni con altri oggetti cioé considerando le operazioni che possono essere effettuate su di esso (a richiesta di altri oggetti) e le operazioni che esso può effettuare su altri oggetti cioé osservando come un oggetto agisce (sugli altri oggetti) e reagisce (a stimoli provenientu da altri oggetti).
Le interazioni fra oggetti possono anche riguardarsi come esecuzione di «contratti» fra oggetti: la vista esterna di un oggetto definisce un contratto su cui altri oggetti possono contare, contratto che deve essere implementato dalla vista interna (i cui dettagli sono invisibili all’esterno). Questo contratto stabilisce tutte le operazioni che un oggetto cliente può aspettarsi da un oggetto server cioé stabilisce il comportamento di cui é responsabile un oggetto server nei confronti di un oggetto cliente. Per questo talvolta l’interfaccia di on oggetto server é anche chiamata una interfaccia contrattuale.
Incapsulamento. Astrazione e incapsulamento sono concetti complementari.
L’astrazione mette a fuoco il comportamento dell’oggetto osservabile all’esterno mentre l’incapsulamento mette a fuoco l’implementazione delle operazioni che avvengono all’interno e che determinano questo comportamento. L’incapsulamento viene anche definito «occultamento di informazione, information hiding » nel senso che l’incapsulamento effettua l’occultamento di tutti quei dettagli (e.g. la struttura interna dell’oggetto e l’implementazione delle operazioni) che non appaiono nella specifica di interfaccia che definisce il comportamento essenziale dell’oggetto. Alcuni autori si
46

spingono fino al punto di dire che affinché l’astrazione funzioni, l’implementazione deve essere incapsulata.
Nel caso della programmazione a oggetti, ogni classe é caratterizzata da 1) proprietà (quelle che avevamo chiamato « attributi » nella descrizione degli oggetti OSI) e 2) moduli di programma per eseguire le operazioni assegnate alla classe. Un utilizzatore della classe e.g. il programma principale, richiede ad una istanza della classe di invocare il modulo di programma adatto a fornire un certo servizio. Quello che l’utilizzatore vede della classe é la sua interfaccia, cioé la descrizione dei servizi forniti e le modalità per richiederli. I dettagli del codice di implementazione della classe sono visibili solo alla classe ma non all’utilizzatore. Ad esempio, nel caso di un programma di conto corrente facente parte di un pacco software che modellizza attività bancarie, i dettagli dell’algoritmo usato per calcolare l’interesse sono noti solo alla classe «conti correnti» e non all’utilizzatore. Cioé questi dettagli vengono incapsulati nell’oggetto. Il vantaggio di questa separazione fra implementazione e interfaccia della classe é che i metodi di una classe possono essere modificati come si vuole purché la interfaccia della classe resti immutata.
Ereditarietà. Il concetto di ereditarietà fra classi di oggetti é stato già illustrato nell’ambito del modello OSI. In pratica, la eredità fra classi permette ad una classe (sotto-classe) di ereditare le caratteristiche di una o piu’ classi (super-classi). Nel caso della programmazione a oggetti, il vantaggio di utilizzare il concetto di eredità é dovuto alla possibilità di ri-usare il programma di una superclasse. Ad esempio una classe « conti correnti per ICTtadini adulti » puo’ utilizzare il programma relativo alla superclasse generica «conti correnti» e specializzarla opportunamente al caso di ICTtadini adulti.
Polimorfismo. Il concetto di polimorfismo é illustrato per gli oggetti del modello OSI nella seconda Parte del corso. Un servizio ha diverse implementazioni a seconda della classe a cui é associato. Ad esempio, nel caso della banca, sia la classe di oggetti A « conti correnti » che la classe di oggetti B « conti di risparmio » forniscono il servizio «calcolo interessi». Le due classi eseguono la stessa operazione ma ogni classe la esegue con una modalità specifica della classe stessa.
A.4.2 Un esempio di linguaggio di programmazione a oggetti: il linguaggio C++
Consideriamo un esempio di linguaggio di programmazione a oggetti : il linguaggio C++. Senza entrare nei dettagli della sintassi del linguaggio C++ vediamo quale é l’architettura del programma. Il programma é suddiviso in tre sezioni:
1) la descrizione delle interfacce (classi),
2) la funzione main (main function),
3) l’implementazione degli oggetti.
47

Nella sezione relativa alla descrizione delle interfacce sono descritte le classi di oggetti che costituiscono il programma. Ogni classe é costituita da due parti: una parte « pubblica » e una parte « privata ». La parte pubblica si riferisce alle operazioni associate alla classe, mentre la parte privata si riferisce agli attributi (proprietà). Ad esempio consideriamo un programma che calcola la superficie di tre forme geometriche diverse : un cerchio, un rettangolo e un quadrato. Cerchio, rettangolo e quadrato rappresentano le tre classi di oggetti che costituiscono il programma. Per prima cosa si devono rappresentare le loro interfacce. La descrizione dell’ interfaccia della classe « cerchio » ha una parte privata (attributo), « raggio » ed una parte publica (operazione) « calcola e stampa l’area del cerchio ». La classe « rettangolo » ha due attributi, la « larghezza » e la « lunghezza » ed una operazione : « calcola e stampa l’area del rettangolo ».
La funzione main (main function) crea oggetti dalle varie classi, cioé istanzizza le classi. Ad esempio specifica il nome della classe « cerchio » (e.g. « Pietro ») e il valore del raggio (e.g. 27.3). Specifica la classe rettangolo con il nome « Paolo », una larghezza 13.56 e una altezza 43.2.
La sezione di implementazione specifica il codice per le varie operazioni publicizzate nelle interfacce. Cosi’ specificherà che il calcolo dell’area del cerchio Pietro é : 3.14*Raggio*Raggio. Analogamente l’area del rettangolo Paolo é: altezza*lunghezza.
Le tre sezioni possono realizzarsi in tre file separati. Un file di intestazione (class header file) per la descrizione delle classi (interfacce), un file per la main function ed infine un file per l’implementazione delle classi (class implementation file). Quest’ultimo puo’essere compilato in codice oggetto, memorizzato in libreria e linkato con la funzione main quando il programma va in esecuzione. Da tutto cio’ si vede l’incapsulamento dell’implementazione, che puo’ cambiare codice senza che si debbia cambiare il programma.
A.4.3 Elaborazione distribuita a oggetti (Distributed Object Computing, DOC)
Le nozioni seguenti sono prese da C. Batini, B.Pernici, G. Santucci : « Sistemi informativi », Vol.5, pp.9-79, Franco Angeli Editore, 2001.
Un sistema di elaborazione si chiama centralizzato quando i dati e le applicazioni risiedono in un unico nodo elaborativo.
Un sistema di elaborazione si chiama distribuito quando le applicazioni fra loro cooperanti risiedono su più nodi elaborativi interconnessi da una rete di comunicazionee la rete di comunicazione offre una serie di trasparenze..
Un analisi critica delle architetture centralizzate e distribuite ha portato alla definizione di un nuovo modello: il Distributed Object Computing, DOC, che fornisce un contesto virtualmente unitario di elaborazione in cui i processi eleborativi (Oggetti) cooperano come se risiedessero su un unica macchina. Il contesto unitario di eleborazione
48

é realizzato mediante una infrastruttura tecnologica a oggetti distribuiti (middleware) che ne permette la distribuzione fisica su piu’ nodi elaborativi connessi fra di loro da una rete in modo che :
1) la progettazione, realizzazione e gestione delle applicazioni basate sulla infrastruttura puo’ avvenire con tecniche e complessità simili a quelle che si incontrano nei sistemi centralizzati.
2) si demanda ai fornitori e agli specialisti di infrastrutture ad oggetti distribuiti la risoluzione di tutte le problematiche architetturali, tecnologiche e gestionali proprie delle infrastrutture stesse.
A.4.4 Transazioni: infrastrutture DOC ad accoppiamento forte o debole
Nella seconda metà degli anni novanta, si é verificato un ulteriore raffinamento delle metodologie e tecnologie DOC che si sono distinte in infrastrutture computazionali appartenenti a due gruppi rispettivamente caratterizzati da 1) accoppiamento forte, per sistemi operanti in uno stesso dominio amministarativo e 2) accoppiamento debole, per sistemi di cooperazione fra domini amministrativi diversi (federazione di organizzazioni partner).
Una infrastruttura DOC con accoppiamento forte é caratterizzato dall’ integrazione in schemi unitari delle risorse informative (dati) ed elaborative (programmi) cioè integrazione di contributi informativi ed elaborativi eterogenei fornendone una visione unitaria ad un unica autorità amministrativa. In questo scenario i servizi erogati all’utenza sono concepiti come transazioni.
1) Transazioni
DEFINIZIONE A.4.4.1 Una transazione é definita come un processo per il quale si deve verificare il perfetto completamento o il rigetto totale, senza possibilità di risultati intermedi. ESEMPI A.4.4.1. Se un Cliente chiede a una TelCo l’installazione di un servizio TLC, il relativo processo di “service provisioning” deve risultare nell’effettuazione dell’istallazione o nel rigetto della richiesta: non si può rispondere al Cliente che il servizio è stato installato “in parte”. Analogamente se il Cliente segnala un guasto non si può rispondergli che il guasto è stato “parzialmente” riparato.
Allora, una transazione é una unità indivisibile di lavoro costituita da un insieme di operazioni la cui esecuzione fa passare il sistema target da uno stato consistente con la realtà ad un altro stato anch’esso consistente con la realtà.
Una transazione gode dell’ insieme di proprietà ACID (discusse a lezione) :
Atomicity (Atomicità),
Consistency (Consistenza),
49

Isolation (Isolamento),
Durability (Persistenza)
Per una discussione di queste proprietà vedi: G.Chen & Q.Kong, “Integrated Telecommunications Management Solutions”, IEEE Press, 2000, padg. 69. Tutto questo richiede, nel caso di transazioni distribuite, la aggiunta di un insieme di componenti infrastrutturali specifici e.g. Transaction Processing Monitor. Il risultato che si ottiene é quello di ottenere processi transazionali con una elevata qualità di servizio. Il prezzo che si paga è un aumento dei vincoli tecnologici e organizzativi fra gli “agenti” che cooperano nell’esecuzione dei processi stessi. In un sistema distribuito le interazioni fra “oggetti” partecipanti ad una transazione avvengono con logiche di tipo sincrono e con scambi diretti di messaggi.
2) Infrastruttura DOC per federazioni di partners (accoppiamento debole)
Nel secondo caso (accoppiamento debole) l’infrastruttura distribuita a oggetti é chiamata non tanto ad integrare contributi informativi ed elaborativi eterogenei fornendone una visione unitaria ad un unica autorità amministrativa quanto a permettere ai varii contributi forniti dalle organizzazioni partner di essere messi a fattore comune per fornire nuovi servizi a valore aggiunto. In questo caso l’enfasi é posta sulla identificazione di interfacce scambio dati e/o richiesta servizi costruite con protocolli comuni nonché sull’attivazione e esecuzione progressiva dei servizi messi a fattor comune rispettando tuttavia l’autonomia organizzativa e tecnologica dei partners. Cio’ é possibile utilizzando concetti astratti comuni lasciando le implementazioni specifiche dei servizi ai partners. A tal fine é importante sviluppare dizionari dati (repositories) che contengono le definizioni dei concetti comuni condivisi dai partners e le regole di corrispondenza di questi con le implementazioni specifiche effettuate dai singoli partners. In questo caso i servizi erogati all’utenza sono concepiti come procedure per le quali sono da assicurare il tracciamento e l’avanzamento affidabile lungo una catena concordata di passi ognuno dei quali gode delle caratteristiche di transazionalità. Il passaggio da un passo a quello successivo é ottenuto con logiche di tipo asincrono con scambio di messaggi tramite code d’attesa. (Vedi prossimo paragrafo)
A.4.5 Modalità di comunicazione fra oggetti in un ambiente DOC: sincrona o asincrona.
La modalità sincrona é analoga alla chiamata di procedura nei linguaggi di programmazione tradizionali, con il relativo passaggio di parametri. Secondo questa modalità l’oggetto cliente usa l’interfaccia dell’oggetto servente identificando il servizio per nome e passando i valore dei parametri d’ingresso previsti. Ricevuta la richiestal’oggetto servente esegue l’insieme di operazioni necessarie per l’erogazione del servizio restituendo al cliente l’insieme dei valori calcolati per i parametri di ritorno previsti. Gli oggetti cliente e servente devono essere contemporaneamente attivi nel momento in cui
50

Attesa
Processo cliente Processo servente
AttesaAttività
(Esecuzione Servizio)
Attività
Attività Attesa
Richiesta di servizio
Restituzione della risposta
Tempo
Fig. A.4.1 Relazione di servizio sincrona cliente e servente
51

il servizio viene richiesto e il cliente rimane in attesa (attivo ma bloccato) finché il servente non completa il compito richiesto e restituisce la risposta.
Nella modalità asincrona gli oggetti interagenti possono essere attivi in momenti diversi. Infatti la comunicazione avviene tramite scambio di messaggi unidirezionali: il cliente invia un messaggio ad una coda d‘attesa e il servente preleva i messaggi dalla coda, la quale, quindi, costitruisce un elemento di disaccoppiamento fra i due oggetti. Notare che il servente puo’ prelevare i messaggi dalle code in base alla loro priorità e non necessariamente in base al loro ordine di arrivo. Esistono quattro schemi di interazione : Publish & Subscribe, Multicasting, Instance based Routing e Store & Forward.
A.4.6 Caratteristiche del middleware in ambiente DOC
i) Formalismi di definizione degli oggetti
Nel DOC gli oggetti sono definiti tramite un linguaggio dichiarativo di interfaccia (IDL, Interface Definition Language) che si usa per descrivere i servizi che un oggetto mette a disposizione degli altri oggetti nel sistema. Il linguaggio IDL permette di descrivere una sorta di contratto fra cliente e servente: il servente si impegna a fornire servizi coerenti con la sua interfaccia mentre il cliente si impegna a invocare i servizi disponibili in stretta conformità con quanto stabilito dall’interfaccia. Una volta definita l’interfaccia di un oggetto, il DOC fa sì che i servizi da esso offerti possono essere invocati da un qualsiasi altro oggetto anche se realizzato in un differente linguaggio di programmazione.
ii) Protocolli di interoperabilità
Con il linguaggio IDL il progettista definisce le interfacce esposte dagli oggetti al resto del sistema ma non definisce il protocollo di interoperabilità (tipi di messaggi e sequenze ammissibili) con cui le richieste e le risposte sono trasportate sulla rete dati. É questa una funzione espletata dal middleware. Esistono dei processi di trasformazione (marshaling e demarshaling) dalla strutture dati IDL ai messaggi trasmessi in rete (lato cliente) e viceversa (lato servente)
iii) Meccanismi di intermadiazione fra oggetti (object broker)
Quale é il meccanismo che permette al cliente che richiede servizi di individuare i serventi che li forniscono ? Un primo meccanismo (direct mail) é anche il più semplice : il cliente conosce l’indirizzo esatto del servente che gli può fornire il servizio desiderato e.g. indirizzo IP se il protocollo di rete fosse TCP/IP. Tuttavia se il servente viene riallocato si deve notificare ciò a tutti i clienti che usufruiscono di quel particolare servente. Il problema si risolve con un oggetto intermediario: l’Object Request Broker, ORB. L’ORB mantiene un registro dei servizi e degli indirizzi dei serventi che li forniscono (e.g. servizio “pagine gialle”). In fase di progettazione del software l’ORB permette di separare il problema della suddivisione dell’applicazione fra vari oggetti (i.e.
52
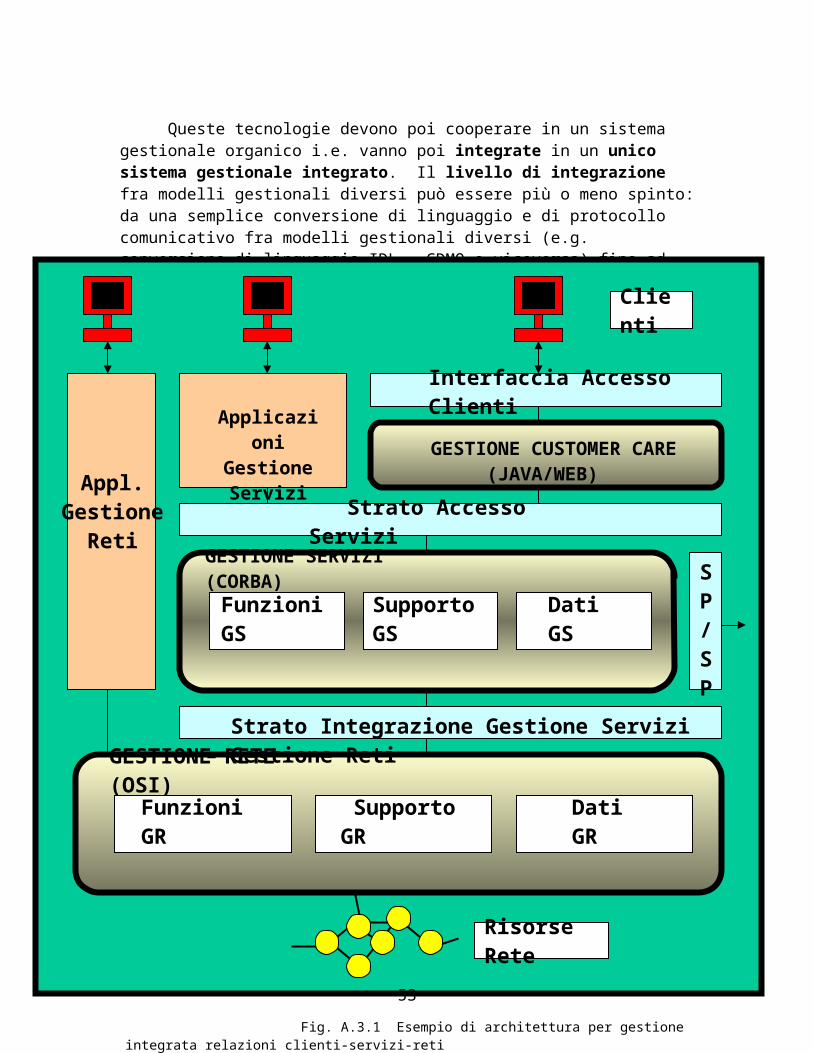
distribuzione dell’applicazione) dal problema di individuare la locazione degli oggetti in rete.iv) Meccanismi di intermediazione nel caso di comunicazioni asincrone: il message broker,
Abbiamo visto in precedenza che nel caso di comunicazione asincrona esistono delle code d’attesa fra oggetti cliente e servente. I message brokers sono oggetti gestori di code di messaggi che assicurano l’instradamento e la consegna di messaggi che ricevono da parte di oggetti mittenti verso gli oggetti destinatari. Abbiamo anche visto che la comunicazione asincrona fra oggetrti é tipica di sistemi di distribuzione ad accoppiamento debole dove i servizi erogati all’utenza sono procedure costituite da una catena di passi eseguiti da oggetti diversi. Il message broker é l’oggetto che governa le code di messaggi per uno svolgimento corretto delle catene di passi. Le corrispondenti tecnologie si chiamano Message Oriented Middleware (MOM).
v) Gestione delle transazioni
Abbiamo definito transazione un processo gestito «tutto o niente» che soddisfa le proprietà di transizionalità abbreviate nella sigla ACID. Quando si é in presenza di logiche applicative piuttosto complesse si richiedono componenti infrastrutturali specifici chiamati Transaction Processing Monitors (TPC). A livello teorico si dimostra che non é possibile definire un protocollo di coordinamento non bloccante fra nodi partecipanti ad una transazione distribuita che assicuri, in un numero finito di passi, l’atomicità della transazione. Un buon compromesso pratico fra le esigenze di integrità del sistema e i carichi di comunicazione fra i partecipanti a una transazione distribuita é costituita dal Protocollo di Commit a 2 fasi (2PC) secondo il quale un componente svolge il ruolo di coordinatore (Transaction Manager, TM) mentre gli altri componenti svolgono il ruolo di gestori di risorse (Resource Manager, RM). Le modalità di attivazione e uso del protocollo 2PC sono standardizzate nell’ambito del modello Distributed Transaction Processing, DTP definito dal consorzio X/Open.
Oggi le tematiche della gestione delle transazini distribuite sono affrontate da una nuova classe di prodotti di base chiamati Object Transaction Monitors, OTM che integrano le logiche di gestione di oggetti proprie degli object brokers con i meccanismi di gestione di transazioni proprie dei TPC.
53

ADDENDUM No.5
A.5 Il “Technology Actor”
A.5.1 Tecnologia & innovazione tecnologica
Un Technology Actor è un TLC Stakeholder che opera in un Ambiente “Engineering”. Esso rappresenta l’aspetto “Engineering” di
1) persona fisica o giuridica che non produce tecnologie ma ha una grande expertise nello stato dell’arte di Tecnologie ICT (ICT Technologist),
2) impresa telecom che produce Tecnologie ICT innovative per uso proprio (“end-user innovation”) o per venderle sul mercato (se necessario, dopo averle brevettate),
3) impresa telecom che non sviluppa in proprio nuove tecnologie ma assembla tecnologie innovative in un prodotto TLC finito. In questo caso il contenuto “engineering” si riduce a laboratori di assemblaggio e a studi di analisi comparata e forecasting delle varie tecnologie disponibili sul mercato (“Technology scanning and forecasting ).
Ricordiamo che in questo corso per Tecnologia ICT si intendono i componenti ICT di un sistema TLC osservati dal Punto di Vista Engineering.. Una nuova tecnologia viene realizzata tramite una attività di engineering (engineering “per” tecnologia) oppure viene utilizzata in un processo di engineering per realizzare nuovi prodotti (engineering “con” tecnologia).
L’ innovazione tecnologica nel campo delle telecomunicazioni si riferisce alla produzione di tecnologie che cambiano le prestazioni delle tecnologie ICT già esistenti. Come già detto, l’innovazione, a differenza della “creatività” che può essere individuale, è in generale il risultato di attività aziendale. Una impresa TelCo innova i suoi servizi TLC. Una impresa ManTec innova i suoi prodotti TLC.
Le sorgenti di una tecnologia innovativa sono in genere di natura aziendale o imprenditoriale (technology incubators) e una tecnologia, a differenza di un prodotto R & D, è un prodotto finale pronto per essere utilizzato in una varietà di possibili impieghi nell’ambito di un certo settore applicativo (industrializzazione e, se necessario, commercializzazione) con buone prospettive di successo economico-finanziario senza peraltro eliminare completamente rischi di insuccesso particolarmente per l’innovazione tecnologica di tipo “disruptive” dove, come mostreremo fra poco, almeno inizialmente non esiste un mercato. Quindi, a differenza di un prototipo R&D, una tecnologia innovativa ha una forte connotazione “business”. Per questo i politici e i sindacati
54

parlano sempre di “innovazione tecnologica” e molto meno di ricerca ………infatti la tecnologia, a differenza della ricerca, profuma di pecunia!! Purtroppo si dimentica che la tecnologia innovativa è il risultato prodotto da un sistema paese come culmine della filiera ER&S - R&D - nuova tecnologia!
Quello che viene chiamato “trasferimento tecnologico” spesso è la selezione di prodotti R & D più promettenti da un punto di vista economico-commerciale e loro trasformazione da prototipo a prodotto finale pronto per il mercato (i.e. con una “ricaduta industriale” con tempi tipicamente di 1-2 anni). Una impresa “tecnologicamente innovativa” ha una grossa percentuale di ricavi (e.g. 70-80 %) generati da tecnologie immesse sul mercato da meno di cinque anni oppure, beneficiando di risultati di in-house R&D e attraverso un trasferimento di diritti di proprietà intellettuale, ha “spun off” un numero di piccole imprese start up che producono e commercializzano (con successo? vedi dopo) tecnologie cutting edge. Ad esempio, France Telecom negli ultimi cinque anni ha investito somme significative di “corporate venture capital” (capitale di rischio) ed ha creato quindici imprese start up che immettono sul mercato (emergente) prodotti TLC innovativi sia HW che SW.
.A.5.2 Politica dell’innovazione
Spesso le attività di innovazione tecnologica perseguite dalle singole industrie sono “dirette” dai governi nazionali (“approccio dirigistico” all’ innovazione) che, tramite opportune agenzie create ad hoc (e.g. Consigli per l’Innovazione e la Crescita), definiscono priorità di sviluppo a livello nazionale. E’ nell’ambito di questo indirizzamento governativo che le varie industrie, fra tutti i progetti dettati dal mercato, scelgono poi opportuni progetti. Nel 2006 tutto questo è già avvenuto in Germania e Francia. Tuttavia è importante riconoscere che molti economisti attestati su posizioni liberiste ritengono che l’approccio dirigistico all’innovazione sia sostanzialmente inefficace e meglio sarebbe se le singole industrie, anche nel campo dell’innovazione, fossero lasciate completamente libere di scegliere e di competere senza alcun intervento governativo.
A.5.3 Utilizzazione di una tecnologia
Everett Rogers ha pubblicato nel testo ormai classico “Diffusion of Innovations” una teoria sulla diffusione dell’innovazione (dall’innovatore ai consumatori di tecnologie innovative) la quale mostra che ogni tecnologia ha un ciclo di vita caratterizzato da una “curva di diffusione” (curva a S) mappata nei piani coordinati “growth of revenues vs. time” oppure “prestazione del prodotto innovato” vs. tempo o “engineering effort” (“piano delle prestazioni”). La prestazione di un prodotto è misurata dai valori di una serie di attributi e.g. per un mainframe computer gli attributi sono capacità, velocità di operazione, fidatezza, mentre per un notebook computer sono peso, robustezza, consumo di potenza, amichevolezza di utilizzo.
55

A.5.4 Innovazione tecnologica “incrementale” o “radicale”
Nel tempo, per prosperare e soddisfare le aspettative dei suoi clienti (rapporto prezzo-qualità attraente) e dei suoi investitori (fare profitti sugli investimenti) e per mantenere un vantaggio competitivo rispetto alla concorrenza, una grossa impresa fornitrice di un prodotto TLC ben affermato in un certo mercato (impresa cosiddetta “incumbent enterprise” o “mainstream enterprise”) introdurrà miglioramenti di prestazione graduali o evolutivi (incremental) fino ad un certo livello di prestazione e poi per migliorare ulteriormente passa a nuove successive generazioni di tecnologia (cambiamento “radicale” di tecnologia o cambiamento effettuato con tecnologia radicale, radical technology). Così facendo le prestazioni dei suoi prodotti descrivono sul piano coordinato prestazioni vs. tempo una traiettoria denominata “product performance improvement trajectory” (brevemente “traiettoria di prestazione”) che è l’inviluppo di successive curve a S interallacciate (e.g. una curva a S parte dal punto di flesso della precedente curva a S). Ad esempio nel mercato dei disk drives l’impresa cercherà un prodotto la cui capacità di memoria aumenta mediamente di un tot % ogni cinque anni a parità di peso e prezzo.
Una tecnologia “innovativa incrementale” può nascere in maniera del tutto informale come risultato di scambio di idee fra addetti ai lavori all’interno di una impresa telecom. Per una tecnologia “innovativa radicale” (breakthrough innovation) in generale è invece necessario capitalizzare sui risultati ottenuti da attività formali di Ricerca & Sviluppo (R & D)
Definizione OCSE (1995) di innovazione tecnologica di prodotto e processo: “Technological Product & Process (TPP) innovations comprise tchnologically implemented new products and processes and significant technological improvements in products and processes. A TPP innovation has been implemented if it has been introduced on the market (product innovation) or used within a production process (process innovation). TPP innovations involve scientific, technological, organizational, financial and commercial activities”.
A.5.5 Innovazione tecnologica tramite “sustaining” o “disruptive” technologies (aspetto business)
Un prodotto TLC (sia HW o SW, sia componente o sistema ottenuto assemblando componenti), risultato di attività di innovazione, le cui prestazioni supportano o rinforzano le “traiettorie di prestazione” previste/richieste da un certo mercato costituisce una sustaining innovation o sustaining technology che può poi implicare cambiamenti di natura incrementale o radicale. Se le prestazioni del nuovo prodotto sono peggiori dei valori stabiliti dalle traiettorie di prestazione (almeno nel breve termine)
56

esso può essere scartato o salvato e riconosciuto come una “disruptive innovation” o “disruptive technology”. (“Disruptive technologies underperform established technologies in mainstream markets”).
Si potrebbe osservare che una disruptive technology dovrebbe essere sempre scartata dal management dell’impresa incumbent come palesemente non adatta ai propri clienti (inseriti in un mercato “mainstream”). E questo in effetti è ciò che accade nella maggioranza dei casi proprio perché questa tecnologia non risponde alle esigenze dei clienti importanti. Tuttavia per disruptive technology qui si intende una nuova tecnologia e.g. un prodotto più leggero o più piccolo o meno performante ma anche meno costoso di quelli esistenti, che non solo non è da scartare ma al contrario suscita interesse in quanto offre notevoli vantaggi per prestazioni diverse da quelle tenute in alta considerazione sul mercato mainstream (infatti offre una diversa “value proposition”). Questi vantaggi di prestazione possono rendere appetibile una disruptive technology non nel mercato mainstream ma in mercati paralleli o “mercati emergenti” i quali , technology driven almeno nel breve termine, sorgono in parallelo al mercato mainstream e possono essere vantaggiosamente sfruttati da imprese nuovi entranti (“new entrants”). Ovviamente la scelta di entrare in un mercato emergente potrebbe esser fatta anche dall’incumbent ma, in tutta onestà si deve riconoscere che per il management della grossa impresa incumbent non è facile scegliere fra 1) investimento di capitale in una sustaining technology con buoni margini di profitto nell’ambito di un mercato stabile che risponde pienamente alla domanda dei clienti più importanti e, invece, 2) investimento di capitale in una disruptive technology con bassi margini di profitto in un mercato emergente (quindi che ancora non esiste) dove si devono ancora creare clienti importanti! E’ proprio questa situazione che è stata definita dal guru C.M. Christensen (Harvard University) come l’”innovator’s dilemma” (il dilemma dell’innovatore)! cioè il “dilemma dell’innovatore”. Come si risolve il dilemma?
Tenendo sempre presente che solo i maghi sono in possesso di sfere di cristallo per prevedere il futuro e che spesso i pionieri sono individui stesi per terra con la faccia nel fango e una freccia nella schiena, C.M Christensen ha suggerito diverse possibili soluzioni al “dilemma dell’innovatore”. Ad esempio possibili soluzioni prese in considerazione da grosse compagnie incumbent sono 1) creare una “spin-off company” ad hoc la cui cultura e le cui dimensioni (piccole) si attaglino meglio a un mercato emergente ad alto rischio oppure 2) entrare nel mercato emergente in un secondo tempo cercando poi di “catch up” (letteralmente “riacchiappare”) i “nuovi entranti” partiti prima e superarli poi in velocità. (non facile! ma vedi qui sotto).
Tuttavia è un fatto che la storia delle applicazioni di nuove tecnologie è piena di casi in cui le disruptive technologies sono state causa di morte per grosse imprese di successo gestite secondo i migliori canoni della prassi manageriale mentre sono state la fortuna di piccoli imprenditori aggressivi e lungimiranti (“start-up” enterprises) che nel breve termine hanno accettato minori margini di profitto in mercati di nicchia ma che nel lungo termine hanno rimpiazzato gli incumbents ormai defunti e sepolti proprio in quelli che erano i loro mercati. Il termine “disruptive” deriva proprio dal fatto che le disruptive technologies, dopo una fase prototipale, possono poi avere un tasso di crescita di
57

prestazione così accelerato da superare la richiesta del loro mercato target (product performance overshoots market demand) e divenire pienamente competitive anche nel mercato mainstream che inizialmente le aveva snobbate: a quel punto, se accolte con favore dai clienti mainstream, le disruptive technologies possono essere letali per gli incumbents! E’ il caso dei transistors che inizialmente erano una disruptive technology rispetto ai tubi o del mercato dei minicomputers rispetto ai mainframe computers, o dei desktop computers rispetto ai minicomputers o dei laptop computers rispetto ai desktop computers. Stesso discorso vale per la fotografia digitale rispetto alla fotografia tradizionale a pellicola o i telefonini cellulari rispetto ai telefoni fissi. Tutte queste erano inizialmente disruptive technologies partite su mercati emergenti che migliorando rapidamente nel tempo le proprie prestazioni hanno poi in parte eroso mercati mainstream per anni regno incontrastato degli incumbents e delle loro sustaining technologies. Notare che tutto questo à vero in generale e non solo nel campo ICT (e.g. “on-line retailing” rispetto a “brick and mortar retailing”).
A.5.6 Innovazione di processo e di prodotto
Notare come il cambiamento di prestazione di una tecnologia possa ottenersi
1) lasciando inalterato il processo di produzione e cambiando le caratteristiche fisiche del prodotto (e.g. migliorando la qualità o la natura delle materie prime o cambiando i componenti da assemblare nel prodotto finale)
2) cambiando il processo di produzione (e.g. miglior controllo delle fasi del processo o utilizzo di personale meglio addestrato o raffinamento delle attività di processo e.g. progettazione di sistema più rapida e accurata) e lasciando inalterate le caratteristiche fisiche del prodotto ma migliorandone le prestazioni
3) cambiando entrambi, processo e prodotto. Ad esempio un apparato del tipo “disruptive technology” (prestazioni inferiori nel mercato mainstream ma attraenti per mercati emergenti) si può ottenere cambiando processo e prodotto adottando un processo di produzione semplificato e utilizzando componenti mass-produced disponibili off-the-shelf più economici.
A.5.7 Innovazione con prodotti Hardware (HW) o Software (SW)
Specialmente dopo l’avvento di internet la innovazione tecnologica ha portato a sviluppare tecnologie “disruptive” di natura software che hanno rappresentato una minaccia diretta per tecnologie tradizionali ( “established technologies”) di natura hardware. Esempi classici sono il commercio on-line (on line retailing) verso il commercio tradizionale svolto nei negozi (brick & mortar retailing) come pure le attività bancarie on line (on line banking) verso le attività bancarie svolte nelle banche. Ovviamente qui si parla di servizi di “contenuto” e non di “carriage”.
A.5.8 Uso di tecnologie innovative
58

Infine le tecnologie innovative possono essere usate almeno in due maniere diverse in corrispondenza di due tipi di innovatori. Esistono innovatori che le producono e vendono cioè le immettano sul mercato dopo aver risolto problemi legati alla certificazione dei prodotti e la protezione della proprietà intellettuale (brevetti), oppure esistono innovatori che utilizzano le nuove tecnologie in-house poiché i prodotti esistenti non soddisfano le loro esigenze (end-user innovation). Eric von Hippel in “Sources of Innovation” identifica questo secondo tipo di innovazione come la più frequente.
.
THE “INNOVATION” TREE
Persona decomp. 14/08/06.PdS
EA.71Commercially
Available /Market tested
EA.72Proprietary
EA34.41.51.66.72Innovator of TLC HW Product with a sustaining Incrementalproprietary product(in-house testing)
EA34.42.52.64.71Innovator of TLC SW Production Process witha disruptive cpmmerciallyavailable technology
An “Innovator of TLC technology” is a telecomenterprise which producesnew TLC technologies(Processes or Products)
Object Type names are obtained by adding/replacing the “differentiae” met navigating to the right
EA.64 /EA.65
TLC SW / HW Production
Process
EA.66 / EA.67
TLC SW / HW Product
IRM-T location identifier
IRM-T location name(“differentia”)
EA.33TLC Technologist
EA.35TLC Technology
Scanning & Forecasting
Center
EA.41Sustaining
EA.42Disruptive
3. Actor Type. 4. Change (1) 7. Commercialization6. Innovation
Domain5.Change (2)
EA.51Incremental
EA.52Radical
EA.34TLC Technology
Innovator
Fig. A.5.1 L’albero dell’innovazione tecnologica nel campo delle telecomunicazioni
59

ADDENDUM No.6
Il Modello di Riferimento ODP-RM (ITU-T Recommendation X.902)
Il Modello di Riferimento ODP (ODP-RM) permette la creazione di applicazioni distribuite con componenti eterogenei tipo “plug & play” e fornisce una infrastruttura generale per lo sviluppo di standards. Gli standards che soddisfano le raccomandazioni del Modello di Riferimento ODP sono chiamati standards ODP.
Il Modello ODP-RM si basa su quattro elementi
Modellazione a oggetti. La formulazione delle specifiche del sistema si basa sull’ “orientamento agli oggetti”. Ricordiamo che si tratta di un sistema software e quindi gli oggetti vanno intesi nel senso della programmazione a oggetti.(Vedi Appendice)
Cinque punti di vista. Il sistema è specificato come aggregazione di cinque gruppi di specifiche relativi all’osservazione del sistema da cinque punti di vista (enterprise, information, computation, engineering, technology)
Infrastruttura per le trasparenze di distribuzione (e.g. CORBA),
Criteri di conformità. Il modello offre una infrastruttura per la verifica dei criteri di conformità.
L’ODP-RM é stato definito in tre documenti ITU-T della serie X:
1. Fondamenti. Pubblicati nella raccomandazione ITU-T X.902 (Nov.1995)
2. Architettura. Pubblicata nella raccomandazione ITU-T X.903 (Nov.1995)
3. Complementi. Pubblicati nella raccomandazione ITU-T X.90
60

A.6.1 Fondamenti del Modello di Riferimento ODP (ODP-RM)
I fondamenti dell’ODP-RM definiscono un insieme di concetti di base come:
1) oggetti, loro interfacce e punti di interazione, comportamento e stato di un oggetto,
2) Composizione e decomposizione di oggetti, tipo e classe di oggetti, maschere di rappresentazione, ruoli,
3) Gruppi e dominii, denominazione, contratto, liason e collegamento.
Non ci spingeremo nello studio di questi dettagli. Molti di questi concetti sono stati definiti in precedenza per sistemi non distribuiti ma, ahimé, talvolta con definizioni leggermente diverse. Quindi bisogna fare attenzione e se necessario le differenze saranno opportunamente messe in evidenza. Lo studente interessato é invitato a leggersi il documento ITU-T X.902.
A.6.2 Architettura del Modello di Riferimento ODP (ITU-T Recom. X.902)
L’Architettura del modello di riferimento ODP-RM fornisce la descrizione di una infrastruttura per gli standards ODP. La descrizione si articola in quattro parti:
1. Punti di Vista per strutturare le specifiche di un sistema ODP in gruppi.
2. Linguaggi per descrivere le “viste” di un sistema ODP, osservate dai Punti di Vista.
3. Funzioni di supporto richieste per supportare i sistemi ODP e realizzare le trasparenze.
4. Trasparenze di Distribuzione per far si’ che i problemi dovuti alla distribuzione vengono occultati agli “occhi” dei programmatori o utilizzatori di una applicazione distribuita, semplificando la programmazione o utilizzazione dell’ applicazione stessa.
61

A.6.3 I “Punti di Vista” e le “Viste” nel Modello di Riferimento ODP-RM (Open Distributed Processing – Reference Model) dell’ ITU-T
“Un qualsiasi sistema reale si può specificare/rappresentare con cinque gruppi di specifiche/caratteristiche (“Viste”) ottenute “osservando” il sistema da cinque
“Punti di Vista”.
Per semplificare e categorizzare le specifiche di un futuro sistema distribuito o per ottenere una rappresentazione di un sistema distribuito già esistente, il modello di riferimento (standard) ODP-RM dell’ITU-T identifica cinque “Viste” che rappresentano il sistema “osservato” da cinque “Punti di Vista”.
NOTA A.6.1 Il modello ODP-RM è stato sviluppato per sistemi distribuiti ma molti concetti in esso contenuti (e.g. “Punti di Vista”) sono ugualmente validi anche per sistemi non distribuiti. (Vedi: G. Blair, J:B. Stefani, “Open Distributed Processing and Multimedia”, Addison Wesley, 1998, pag. 28)
Un “Punto di Vista” è un punto di osservazione che un osservatore adotta per osservare un sistema target reale e che gli permette di mettere a fuoco solo quelle caratteristiche del sistema che sono rilevanti ai suoi interessi/conoscenze (“concerns”). L’informazione ottenuta con una osservazione effettuata da un certo Punto di Vista può poi essere raccolta in un modello astratto del sistema target (“Vista” del sistema ottenuta da un certo “Punto di Vista”). In tal caso l’ “Osservatore” diventa anche un “Modellatore” del sistema target e nella creazione del modello adotta un “linguaggio di rappresentazione” e un “livello di astrazione” che sposano i requisiti formulati a priori dagli “Utilizzatori” del modello (e committenti della operazione di modellazione)
Secondo il modello di riferimento ODP-RM un sistema distribuito può essere specificato osservandolo dai cinque Punti di Vista:
1. Impresa,
2. Informazione,
3. Computazione,
4. Engineering
5. Tecnologia.
I risultati di queste osservazioni sono utilizzati per creare cinque sottomodelli (o “Viste”) che nel loro insieme costituiscono la rappresentazione/specifica di un sistema
62

reale. Quindi, secondo il modello ODP-RM, la specifica complessiva di un sistema e’ strutturata in cinque gruppi di specifiche corrispondenti alle cinque viste.
Consistenza/compatibilità fra viste
La ITU-T, nel modello di riferimento ODP-RM non offre alcun dettaglio sulle relazioni fra le cinque viste. Ad esempio non esiste un «criterio di layering» come nell’architettura OSI-SM dove uno strato inferiore offriva servizi allo strato superiore e a sua volta riceveva servizi dallo strato inferiore.
Un sistema ODP viene quindi specificato tramite cinque gruppi di «specifiche di sistema» indipendenti ma mutuamente consistenti o compatibili. La consistenza/ compatibilità fra le cinque rappresentazioni deriva dal fatto che tutte descrivono lo stesso sistema reale. Ovviamente un sistema reale non ammette che i risultati di osservazioni effettuate allo stesso momento ma da punti di vista diversi siano reciprocamente incompatibili.
Linguaggio e oggetti di una vista
Per ogni punto di vista si introduce un insieme strutturato di concetti di base, insieme chiamato linguaggio, che viene utilizzato per rappresentare una vista del sistema ODP come osservata da quel particolare punto di vista. Tuttavia si tratta di un linguaggio generico (meta-linguaggio) senza specifiche di natura sintattica o semantica. Se si utilizza una rappresentazione a oggetti del sistema , per ogni punto di vista ci sono oggetti che modellizzano la realtà secondo quel particolare punto di vista. Nei cinque gruppi di specifiche per un sistema ODP ci saranno quindi cinque tipi di linguaggi e cinque tipi di oggetti relativi ai cinque punti di vista.
Dettaglio delle specifiche
I cinque gruppi di specifiche di sistema del modello ODP impongono diversi livelli di condizionamento (cioé numero di regole da rispettare) sui sistemi a norma ODP. Ad esempio le specifiche relative alla distribuzione in rete del carico computazionale (vista computazionale) e le corrispondenti soluzioni di engineering che le supportano (vista engineering) richiedono che un gran numero di condizioni vengano soddisfatte per garantire interoperabilità e portabilità dei componenti del sistema. Al contrario, poiche’ ODP-RM é un modello generico che offre linee guida piuttosto che regole specifiche, ci sono poche regole da rispettare relative ai due punti di vista «impresa» e «informazione». Ma vediamo in dettaglio i vari punti di vista.
Punti di Vista
i) Punto di vista «Impresa» (Enterprise)
Il punto di vista « impresa » concentra l’attenzione dell’osservatore sugli obbiettivi strategici, gli scopi specifici da raggiungere e le politiche da implementere
63

da parte di un sistema ODP. Una «impresa» può essere quel che si vuole e.g. un sistema e-mail, una base dati, un sistema operativo, una compagnia telefonica o un sistema per i servizi di video-conferenza.
Comunita’ di oggetti
Nella vista «impresa» di un sistema ODP gli oggetti che condividono un comune obiettivo sono raggruppati in gruppi chiamati comunità. Una comunità é specificata da tre quantità: 1) obiettivo della comunità, 2) ruoli degli oggetti parte della comunità 3) politiche che governano il comportamento degli oggetti.
Ruoli Un ruolo é definito in termini di permessi, obbligazioni, proibizioni per
l’oggetto impresa che gioca quel ruolo. Ad esempio, ci saranno oggetti impresa che giocano il ruolo di clienti, utilizzatori di servizi, fornitori di servizio, proprietari, azionisti, presidenti, managers etc. e ognuno di questi avrà l’obbligo, il permesso o la proibizione di compiere certe azioni.
Politiche
Esempi di politiche che governano il comportameto (le azioni) degli oggetti impresa sono le interazioni fra oggetti stessi, la attivazione/deattivazione degli oggetti, la configurazione degli oggetti, l’ assegnazione di ruoli agli oggetti etc.
Una politica ha un carattere di regolamentazione, cioe’ e’ un insieme di regole per il raggiungimento di uno scopo comune formulate come obblighi, permessi, proibizioni etc. Essa viene specificata con un «policy statement». Ad esempio un «policy statement» puo’essere del tipo seguente:
« gli oggetti impresa [che giocano il ruolo di] manager dell’ufficio commerciale hanno l’obbligo di effettuare la fatturazione relativa ai servizi resi e la proibizione di progettare un apparato ».
Fanno parte della specifica delle politiche di impresa l’individuazione degli aspetti economico-finanziari del business, l’organizzazione della struttura aziendale in relazione agli obbiettivi di business, l’evoluzione del business per soddisfare future domande di mercato, etc. Federazioni
Una federazione é un caso particolare di comunità costituita da un insieme di
gruppi di oggetti impresa dove ogni gruppo (dominio) risponde ad una autorità differente, ma tutti i gruppi insieme collaborano per uno scopo comune. Una federazione puo’ essere costituita da dominii amministrativi (e,g, gruppi di oggetti impresa soggetti a diversi criteri di gestione da parte di diversi gestori) o da dominii tecnologici (e.g. gruppi di oggetti impresa utilizzanti diverse tecnologie hardware e/o software). Un
64

esempio di federazione di dominii amministrativi é la collaborazione di PTT nazionali per la fornitura di un servizio internazionale. Un esempio di federazione di dominii tecnologici é l’integrazione di tecnologie che utilizzano risorse diverse con prestazioni diverse.
ESEMPIO: IL SOTTOMODELLO «IMPRESA» DI UN SISTEMA DI TELECONFERENZA (MULTIMEDIALE.)
La Fig. A.6.1 mostra come ODP-RM specificherebbe un sistema di teleconferenza multimediale (Multi-Media Conferencing System, MMCS), osservandolo da un punto di vista « impresa ». Un servizio di conferenza multimediale permette a un gruppo di persone residenti in localita’ diverse (fisicamente distribuite) di cooperare su uno stesso documento multimediale (costituito da testo, video e audio) e di scambiarsi informazione anch’essa multimediale. I fornitori di servizio, i clienti o abbonati, gli utenti, il sistema MMCS e il contratto sono oggetti impresa rappresentati in figura con maschere rettangolari suddivise in tre zone dedicate rispettivamente al nome della classe, attributi e operazioni. Queste si chiamano notazioni grafiche OMT (Object Modeling Technique) e sono state sviluppate da Rumbaugh.
Notare come gli oggetti in una comunità di utenti (User Community) giochino i ruoli di clienti (che acquisiscono i servizi dai fornitori di servizio) e utilizzatori (e.g. impiegati di una compagnia di servizi TLC che sono autorizzati a utilizzare terminali collegati ad un LAN). Ulteriori suddivisioni dei ruoli sono possibili. Ad esempio gli utilizzatori possono suddividersi ulteriormente in « partecipanti alla sessione » e «leaders di sessione». I fornitori di servizi fanno parte di una federazione cioe’ un partnership di fornitori appartenenti a dominii amministrativi diversi.
La Fig. A.6.1 presenta quindi una rappresentazione «impresa» di un sistema MMCS come una associazione ternaria fra tre gruppi di oggetti impresa: una comunità di utenti, una federazione di PTT (fornitrice di servizi) e il sistema MMCS. É una versione ODP di un business model! Notare come l’accordo fra cliente e fornitore di servizio é formalizzato da un contratto, anch’esso rappresentato da un oggetto impresa.
ii) Punto di vista « Informazione » (Information)
Il sottomodello visto dal punto di vista Informazione mette a fuoco l’informazione all’interno del sistema quando il sistema fornisce servizi. In particolare, questo punto di vista descrive i dettagli relativi alla natura dell’informazione e al processing/immagazzinamento/comunicazione di informazione all’interno del sistema. La rappresentazione viene effettuata tramite schemi che mostrano le relazioni fra gli oggetti informativi (elementi della vista «informazione»). Gli schemi possono includere (o non includere) informazioni relative alla evoluzione temporale delle relazioni inter-oggetto e, conseguentemente, possono avere un carattere dinamico (rapidamente variabile nel tempo), statico (cioé congelato ad un certo istante) o invarante (cioé completamente indipendente dal tempo).
ESEMPIO: IL SOTTOMODELLO «INFORMAZIONE» DI UN SISTEMA MMCS.
65

La Fig. A.6.2 mostra un sottomodello statico relativo alla vista «informazione» del sistema MMCS già esaminato nella Fig. A.6.1. Lo schema statico si riferisce allo stato degli oggetti congelato ad un certo istante nel corso di una sessione di videoconferenza. Per questo non appaiono oggetti come il fornitore di servizi o il contratto, i quali hanno già giocato un ruolo prima dell’inizio di una sessione ma non durante una sessione. Anche in questo caso sono usate le notazioni OMT di Rumbaugh per la rappresentazione degli oggetti. Quindi, anche qui, gli oggetti informativi sono rappresentati da rettangoli con tre zone dedicate al nome della classe, agli attributi e alle operazioni. É interessante fare un paragone fra le rappresentazioni dei sottomodelli «impresa» di Fig. A.6.1 e «informazione» di Fig.A.6.2. Questo paragone evidenzia i seguenti fatti :
1. Ai fini dei flussi di informazione nel corso di una sessione di videoconferenza, l’oggetto fornitore di servizio, mostrato sul lato sinistro della rappresentazione «impresa», é inessenziale cioé non gioca più nessun ruolo e quindi non é «visto» dal punto di vista informazione cioé non esiste nella rappresentazione «informazione» del sistema MMCS. D’altra parte il punto di vista «informazione» vede oggetti come sessione e connessione non visti dal punto di vista « impresa ».
2. Lo scambio di informazione fra utilizzatori avviene tramite oggetti
informazione rappresentativi di sessioni che, a loro volta usano connessioni (livello rete). Le connessioni supportano flussi di informazione la cui natura può essere, separatamente, di tipo audio, video o testo oppure di tutti i tre tipi messi insieme (connessione multimediale).
Infine notare gli attributi dell’oggetto «cliente»: parametri della configurazione del sistema scelta dal cliente, larghezza di banda allocata, lista degli utilizzatori registrati e autorizzati a usufruire del servizio etc.
iii) Punto di vista «Computazione» (Computation)
Il sottomodello osservato dal punto di vista «Computazione» (o punto di vista computazionale) specifica la distribuzione attraverso il sistema ODP delle funzionalità e del carico computazionale. Il punto di vista computazionale decompone una applicazione in oggetti computazionali, ognuno dei quali svolge una funzione specifica e interagisce con gli altri oggetti attraverso interfacce ben definite. Il punto di vista computazionale specifica le interfacce degli oggetti, indipendentemente dal punto di vista engineering che invece specifica i meccanismi di interazione fra oggetti, realizzati dal sistema in modo trasparente (cioè invisibile) per gli utilizzatori o programmatori grazie a un software di intermediazione (middleware).
Il modello computazionale è rappresentato con un linguaggio computazionale che specifica la forma delle interfacce, come le interfacce si possono collegare (binding
66

establishment) e quale tipo di interazione può verificarsi con un certa interfaccia. Si tratta quindi di un linguaggio descrittivo di interfaccia (Interface Definition Language).
Le interazioni fra oggetti (attraverso le relative interfacce) possono essere di tre tipi: 1) operazioni e.g. client-server, 2) stream e.g. flussi continui di informazione audio, video o multimediale e 3) segnali e.g. notifica di eventi. Ad esempio una interfaccia operazionale è la specifica dell’insieme di operazioni tipo client-server (quindi con invocazioni di procedure e risposte) che possono essere supportate da quell’interfaccia assieme alla specifica della natura dell’interfaccia e.g. se è l’interfaccia di un oggetto «cliente» o «servente». Invece una interfaccia « stream » rappresenta la abilità di un oggetto computazionale a scambiare flussi continui di dati (e.g. audio o video o multimediali) con un altro oggetto anch’esso dotato di interfaccia « stream » senza invio di invocazioni di procedure e risposte con i relativi risultati (Vedi Appendice B).
Notare come gli oggetti computazionali siano specificati in termini di interfacce (i.e. specifiche delle operazioni, streams o segnali supportati) tramite un linguaggio descrittivo di interfaccia mentre gli oggetti informativi non lo siano.
ESEMPIO: IL SOTTOMODELLO COMPUTAZIONALE
La Fig.A.6.3 mostra gli oggetti computazionali derivati dagli oggetti informazione di Fig.A.6.2. Notare come il mapping dagli oggetti informativi agli ogetti computazionali non è necessariamente uno-a-uno. Infatti, più oggetti informativi con legami funzionali possono essere raggruppati in un oggetto computazionale, secondo criteri stabiliti dal progettista. I raggruppamenti degli oggetti informativi di Fig.A.6.2 in oggetti computazionali di Fig. A.6.3 sono i seguenti:Oggetti User e Leading User → Oggetto User
Oggetti relativi alla Conferenza (e.g. MMCS, Session, Subsession etc.) → Oggetto Conference
Oggetti relativi alla Connessione (e.g. Connection Manager) → Oggetto Binding
In Fig.A.6.3 i trattini verticali rappresentano le interfacce fra oggetti computazionali attraverso le quali transitano messaggi relativi a operazioni e.g. cliente-servente o flussi continui di informazione e.g. informazione multimediale. Sono queste interfacce che devono essere specificate e che caratterizzano gli oggetti computazionali. iv)
iv) Il punto di vista «Engineering»
Il punto di vista « Engineering » definisce i meccanismi necessari a supportare le interazioni fra oggetti nel sistema distribuito inclusa l’infrastruttura middleware di supporto alle applicazioni. Esso adotta i concetti generali di Distributed Object Computing (DOC) sviluppati dall’industria informatica e precedentemente illustrati. Quindi mentre il sottomodello computazionale descrive la natura degli oggetti costitutivi
67

del sistema ODP, il sottomodello engineering descrive la creazione, attivazione, deattivazione degli oggetti, la loro localizzazione nel sistema e.g. in quale nodo, capsula, agglomerato sono residenti e le loro interazioni via canali di collegamento (Vedi dopo).
Il punto di vista engineering vede gli oggetti computazionali contenuti nella vista computazionale come «Basic Engineering Objects» cioé come oggetti engineering di base. In aggiunta a questi oggetti di base la vista engineering comprende una varietà di oggetti di supporto e di controllo organizzati in gruppi che fanno parte di una struttura a compartimenti come mostrato in Fig.A.6.5.
In Fig.A.6.5 si riconosce un insieme di oggetti contenuti in un nodo (e.g. rappresentativo di host computer) che é sotto il controllo di un nucleo (e.g. rappresentativo di un sistema operativo) responsabile di tutta una serie di servizi di supporto che vanno dalla creazione del gruppo di oggetti contenuti nel nodo, alla inizializzazione degli oggetti. Quando un oggetto é creato, tramite la specifica della sua interfaccia (e.g. la specifica delle operazioni che l’oggetto e’ capace di implementare e che possono essere richieste dagli altri oggetti), il nucleo genera un riferimento di interfaccia. Quindi, il riferimento di interfaccia é la chiave che permette l’accesso alle informazioni specificate nell’interfaccia di un oggetto.
68

MMConferencing
System
CUSTOMER
SERVICE PROVIDER
CONTRACT
Agreement
User Community
[Agreement between different TLC Operators]
Telecom Federation
(PTT Telecom)
Information about:AccountingMaintenanceSecurityQoSProvisionig
USER(Employees)(Company)
Class
Attributes
Operations
Fig. A.6.1 Rappresentazione di un sistema di videoconferencing dal Punto di Vista “Impresa”
Ternary association is authorized by
69

Simple Connection
Multimedia Connection
Built from
Built from one of
Voice Data Video
Leading UserLeader
connected to
User SubsessionCustomer
Consists of
Participates in
Connection Manager
Uses
Connection Group
Uses
MMCS
Session
QoS infoBilling info
ConfigureCreate sess.
Conn. Users Status info
Connected to
BWRegist. UsersConf. Param.
Change Conf.
Part. usersSess. status
Fig. A.6.2 Rappresentazione statica di un sistema MMCS visto dal punto di vista “Informazione” durante una sessione.
Aggregation
Generalization
Compression Type, Quality
ColourCompr. Type
Quality
70

User Leading User
Connection Manager
MMCS Subsession
Session
Computation Object A
Computation Object B
User Object
Conference Object
Fig. A.6.3 Rappresentazione di un sistema MMCS dal punto di vista “Computazione”
A
B
Binding Object
71

Gli oggetti engineering in un nodo sono suddivisi in gruppi chiamati capsule e ogni capsula é controllata da un manager di capsula, (CapM in Fig.A.6.5). Ogni capsula é a sua volta suddivisa in agglomerati (« clusters ») di oggetti ognuno dei quali é controllato da un manager di agglomerato (CluM in Fig.A.6.5). L’agglomerato è il piu’ puccolo insieme di oggetti su cui operano le funzioni ODP
Gli oggetti engineering di base possono essere interconnessi direttamente cioé senza l’intermediazione di altri oggetti engineering di supporto (e.g. collegamento locale, fra oggetti residenti nello stesso nodo, che non è oggetto di standardizzazione ODP) oppure tramite oggetti di supporto attraverso un canale (collegamento di distribuzione fra oggetti residenti in nodi diversi, che è oggetto di standardizzazione ODP). La Fig.A.6.5 mostra un esempio di collegamento di distribuzione tramite un canale che si estende fra due oggetti engineering residenti in due nodi diversi. La Fig.A.6.6 mostra la struttura di un canale costituita da un collegamento di quattro tipi diversi di oggetti engineering di supporto: stubs, binders, protocol objects e interceptors. Tutti questi oggetti sono necessari per garantire che il sistema ODP offra le trasparenze tipiche di un sistema distribuito, quindi fanno parte di quello che viene usualmente definito «middleware»
Il punto di vista di engineering introduce una terminologia specializzata. Ecco i termini piùusati.
Canale, un collegamento logico di comunicazione fra due oggetti engineering di base (e.g. componenti di un programma applicativo) che si trovano in località remote (e.g. due nodi diversi). Un canale fra due oggetti engineering di base, ad esempio un cliente e un server, é costituito da un insieme di oggetti engineering di supporto mutuamente collegati tramite collegamenti locali (che non sono oggetto di standardizzazione), come mostrato in Fig.A.6.6
Stub, un oggetto che si occupa dell’informazione contenuta nel canale. Esso esegue le seguenti operazioni: 1) trasforma i dati nel canale da/in una forma comprensibile localmente (linguaggio locale), 2) esercita il controllo e conserva i records dei dati trasmessi per scopi di sicurezza e accounting. Gli oggetti stub sono responsabili della trasparenza di accesso
Binder, oggetto responsabile della creazione e mantenimento dell’associazione fra oggetti collegati dal canale (garantendo l’integrità del collegamento). Gli oggetti binder sono responsabili delle trasparenze di rilocazione
Oggetto Protocollo, oggetto responsabile della fornitura di funzioni di comunicazione agli oggetti applicazione.
72

Intercettore, oggetto che risiede al confine fra due dominii (e.g. amministrativi) e effettua controlli e trasformazioni dei dati che attraversano il confine.
Oggetto Cliente, un oggetto che riceve servizi da altri oggetti.Oggetto Server, un oggetto che fornisce servizi ad altri oggetti.
Notare che la vista engineering deve conformarsi alle politiche specificate nella vista “impresa”. Essa descrive i mezzi con cui implementare gli artifatti descritti nelle viste “impresa, informazione e computazione”. Gli oggetti computazionali sono implementati nella vista engineering come oggetti engineering di base che possono essere generati automaticamente e.g. da un compilatore. I bindings computazionali sono realizzati con bindins locali o canali nella vista “engineering”. La vista engineering non dice nulla a proposito delle tecnologie implementative da adottare. Cio’ sara’ fatto nella vista “tecnologia”.
73

N
Capsule
Capsule
Cluster
Nucleus
CluM
CapM
CapM
BEO
BEO
BEO
BEO BEO
BEO
BEO
CluM
CluM
NODE
Fig. A.6.4 La rappresentazione engineering di un sistema ODP é costituita da gruppi di oggetti di base (BEO, Basic Engineerin Objects) e da oggetti di supporto.
74

Capsule
Capsule
N
Nucleus
CluM
CapM
BEO
BEO
BEO
BEO BEO
CluM
CapM BEO
BEO
CluM
NODE 1
Fig. A.6.5 Gli oggetti engineering di base possono interagire attraverso collegamenti locali o di distribuzione. La figura mostra un collegamento di distribuzione (canale) fra due oggetti engineering di base residenti in due nodi diversi.
N
Nucleus
NODE 2
75

Server Basic Engineering Object
Server Stub
Server Binder
Server Protocol Object
Interceptor
Client Basic Engineering Object
Clint Stub
Client Binder
Client Protocol Object
Fig. A.6.6 Modello di Riferimento ODP. Esempio di canale.
Interfacce di controllo
76

v) Il punto di vista « Tecnologia »
Il punto di vista « Tecnologia » descrive l’implementazione del sistema ODP in termini di oggetti tecnologici (sia hardware che software). Poichè la tecnologia è in continua evoluzione, la separazione di questa vista dalle altre, permette di aggiornare la vista tecnologica (cioè cambiare la tecnologia implementativa) senza modificare le altre viste
A.6.4 Le funzioni ODP
Le funzioni ODP sono funzioni necessarie per l’ ODP. Esse appartengono a quattro gruppi :
1. Funzioni di gestione
Gestione di nodoGestione di oggettoGestione di clusterGestione di capsula
2. Funzioni di coordinamento
Notifica di eventiCheckpoint e recoveryDeattivazione e riattivazioneGruppoReplica (Trasparenza)Migrazione (Trasparenza)Transazione (Trasparenza)Tracking del riferimento di interfaccia engineering
3. Funzioni di ripositorio
StorageOrganizzazione dell’informazioneRilocazioneRipositorio di tipi (Type repository)Trading
4. Funzioni di sicurezza.
Controllo di accessoSecurity auditAutenticazioneIntegritàConfidenzialità
77

Non-repudiationKey management
A.6.5 Conformità delle realizzazioni di sistema con le specifiche ODP.
La realizzazione di un sistema ODP inizia con la fomulazione dei requisiti di sistema che riflettono i bisogni di potenziali utenti, continua con la preparazione delle specifiche di sistema (secondo i cinque punti di vista) e finisce con l’implementazione delle specifiche ai vari livelli (sistema reale). Ogni specifica identifica una serie di requisiti.
Si chiama conformità (conformance) la relazione fra una specifica e la sua implementazione. La conformità é completamente o parzialmente verificata attraverso opportuni tests quando rispettivamente tutti o alcuni requisiti contenuti nella specifica sono soddisfatti nell’implementazione.
Un test di conformità é il processo attraverso il quale si misura il livello di conformità. I tests vengono effettuati in specifici punti di conformità (conformance points) individuati nella specifiche.
Si chiama «compliance» la relazione fra due specifiche A e B che condividono una molteplicità di requisiti. Essa è totalmente o parzialmente verificata quando B verifica tutti o alcuni requisiti dettati da A.
Si chiama raffinamento (refinement) la relazione fra due specifiche A e B in cui B aggiunge dettagli a A. Una serie di specifiche relazionate da raffinamento inizia con una specifica generica e finisce con una specifica molto dettagliata. É il caso delle specifiche relative ai punti di vista computazionale, engineering e tecnologico.
Si chiama consistenza (consistency) la relazione fra due specifiche A e B quando esiste almeno un prodotto reale che implementa sia A che B.
Una specifica ha validità interna (internal validity) quando non esiste alcun conflitto fra le sue proprietà interne, cioéle proprietà non sono mutuamente contraddittorie, e quindi esiste almeno un prodotto reale che soddisfa completamente la specifica.
78

A.6.6 L’architettura ODMA per la gestione distribuita
Generalità
Il modello di riferimento ODP-RM é stato definito da ITU-T/ISO con lo scopo di fornire una infrastruttura generica di riferimento utilizzabile per creare applicazioni distribuite e/o la creazione di standards per grossi sistemi distribuiti eterogenei. Questa infrastruttura generica puo’essere specializzata a casi particolari.
In questo paragrafo vogliamo illustrare come il modello ODP-RM possa essere specializzato alla gestione di sistema. Come risultato di questa specializzazione la ITU-T/ISO ha definito una architettura standard chiamata ODMA (Open Distributed Management Architecture) per la specifica/sviluppo di applicazioni distribuite aperte per la gestione di sistema. Ovviamente una applicazione gestionale distribuita é adatta a gestire risorse anch’esse distribuite. L’architettura ODMA, come specializzazione dell’ODP-RM, é descritta nella raccomandazione ITU-T X.703 (Ottobre 1997).
A.6.7 I concetti di base dell’ODMA.
L’infrastruttura ODMA é basata su una serie di concetti fondamentali che sono presentati qui di seguito. In molti casi si tratta di una specializzazione dei concetti ODP-RM. Tenere presente che d’ora in poi l’aggetivo «gestionale» é usato nel senso di « relativo alla gestione di sistema ». Useremo l’abbreviazione OCG per Oggetto Computazionale Gestionale.
1. Oggetto computazionale gestionale (OCG). Nome specifico di oggetto computazionale conforme al modello di riferimento ODP-RM che supporta almeno una interfaccia gestore o gestita. (Una interfaccia gestore o gestita é definita qui di seguito nel No. 5,6).
2. Oggetto engineering gestionale: Nome specifico di oggetto engineering conforme al modello di riferimento ODP-RM che supporta almeno una interfaccia gestore o gestita.
3. Ruolo gestore: Comportamento di un OCG nel processare notifiche e nell’iniziare operazioni, in una interazione con un altro OCG (Vedi Fig. 10.7.2.1).
4. Ruolo gestito: Comportamento di un OCG che nell’emettere notifiche e effettuare operazioni, in una interazione con un altro OCG (Vedi Fig. 10.7.2.1).
5. Interfaccia gestore: Interfaccia supportata da un OCG nel ruolo gestore.
6. Interfaccia gestita: Interfaccia supportata da un OCG nel ruolo gestito.
79

7. Interfaccia operativa server (mos interface): Interfaccia operativa di un OCG che puo’ solo accettare messaggi di operazioni gestionali.
8. Interfaccia operativa cliente (moc interface): Interfaccia operativa di un OCG che puo’ solo emettere massaggi di operazioni gestionali.
9. Notifica: Una interazione per la quale il contratto fra l’oggetto invocante (cliente) e l’oggetto ricevente (server) é limitato a specificare l’abilità del server a ricevere l’informazione inviata dal cliente. 10. Interfaccia server di notifica (ns interface): Interfaccia operazionale di un OCG che puo’ solo accettare messaggi di notifiche gestionali.
11. Interfaccia cliente di notifica (nc interface): Interfaccia operazionale di un OCG che puo’ solo emettere messaggi di notifiche gestionali.
12. Risposta linkata: Una sequenza di operazioni fra OCG nei ruoli gestore e gestito. La prima operazione é effettuata dall’oggetto nel ruolo gestore. Le operazioni seguenti sono iniziate dagli OCG nel ruolo gestito e trasportano risposte all’OCG gestore.
13. Interfaccia cliente di risposta linkata (lrc interface): Una interfaccia operazionale di un OCG che puo’ emettere risposte multiple.
14. Interfaccia server di risposta linkata (lrs interface): Una interfaccia d’operazione di un OCG che puo’ accettare risposte multiple da una molteplicità di messaggi gestionali.
moc mos
ncns
Oggetto computazionale gestionale in ruolo GESTORE
Oggetto computazionale gestionale in ruolo GESTITO
operazione
notifica
Interfacce gestore Interfacce gestite
Fig.A.6.7 Il caso più semplice di interazione fra due oggetti computazionali. gestionali.
G g
80

Nelle precedenti definizioni sono state definite sei tipi di interfacce, relative alle tre interazioni: operazione (mo), notifica (n) e risposta linkata (lr). In ogni interazione ci sono poi interfacce cliente (c) e server (s). Le corrispondenti sei notazioni sono: moc, mos, nc, ns, lrc, lrs (Vedi Tavola A.6.7e Fig.A.6.7per il caso più semplice di interazione fra due oggetti computazionali gestionali). Nella Fig.A.6.7 i trattini verticali rappresentano le interfacce mentre le frecce rappresentano il verso del flusso di informazione. Le notazioni usate sono «G» per gestore e «g» per gestito. Nella Tavola A.6.7 abbiamo anche riportato il ruolo delle interfacce ODMA. Ci sono quattro ruoli relativi alle combinazioini di G, g, c, e s.
La Fig. A.6.8 mostra il caso di un oggetto computazionale gestore che interagisce con due oggetti computazionali gestiti tramite due oggetti computazionali di collegamento (binding) rappresentativi delle funzioni di supporto operation dispatching e notation dispatching necessarie per controllare i collegamenti. La Fig. A.6.9 rappresenta il corrispondente punto di vista engineering.
INTERFACCIA
RUOLO
Gc Gs
gc
gs
TIPO
moc
ns / lrs
nc / lrc
mos
Tavola A.6.7 Ruoli e tipi di interfacce ODMA
81

moc nsnc
mosnc
g1 g2
Not. dispatcherOp. dispatcher
G
mos
moc nsnc
ns
mos
moc
Fig. A.6.8 Oggetti computazionali gestionali con oggetti binding (Operation dispatcher, Notification dispatcher). G = Gestore, g = Gestito.
82

mos moc
OD
moc ns
G
nc ns
ND
mos nc
g
mos nc
g
Node at the managing side Node at the managed side
Node at the managed side
= stub + binder + protocol object = channel
Fig. A.6.9 Punto di vista engineering corrispondente a Fig. A.6.8 83

A.6.8 Bibliografia
1.5.1 G.Blair, J.B.Stefani, Open Distributed Processing & Multimedia, Addison Wesley Pub. Co., Novembre 1997
2. Janis R. Putman, Architecting with RM-ODP, Prentice Hall PTR, Ottobre 2000
84

FINE
85

Finito di preparare il 22 Febbraio 2009
86


















