
GiovanniM.Marchetti 30maggio20181 preliminari 1.1 Introduzione...
140
Note a “All of Statistics” Giovanni M. Marchetti 30 maggio 2018
Transcript of GiovanniM.Marchetti 30maggio20181 preliminari 1.1 Introduzione...

Note a “All of Statistics”
Giovanni M. Marchetti
30 maggio 2018

ii

Indice
1 Preliminari 11.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Calcolo scientifico in R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
6 Modelli e inferenza 36.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36.2 Modelli parametrici e non . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36.3 Concetti fondamentali di inferenza . . . . . . . . . . . . . . . . . . . . . . . . 6
6.3.1 Stima puntuale frequentista . . . . . . . . . . . . . . . . . . . . . . . 66.3.2 Intervalli di confidenza . . . . . . . . . . . . . . . . . . . . . . . . . . 86.3.3 Test delle ipotesi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
7 Stima della funzione di ripartizione 137.1 Funzione di ripartizione empirica . . . . . . . . . . . . . . . . . . . . . . . . . 137.2 Funzionali statistici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
8 Il bootstrap 178.1 Simulazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178.2 Intervalli di confidenza col bootstrap . . . . . . . . . . . . . . . . . . . . . . . 208.3 Note bibliografiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238.4 Appendice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
9 Inferenza parametrica 259.1 Parametri di interesse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259.2 Metodo dei momenti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259.3 Massima verosimiglianza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279.4 Proprietà dello stimatore di Massima Verosimiglianza . . . . . . . . . . . . 309.5 Consistenza della stima di MV . . . . . . . . . . . . . . . . . . . . . . . . . . 319.6 Equivarianza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 329.7 Normalità asintotica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 339.8 Ottimalità . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399.9 Il Metodo Delta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399.10 Modelli multiparametrici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 409.11 Bootstrap parametrico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 409.12 Verifica delle assunzioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
iii

iv INDICE
9.13 Appendice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 429.13.1 Proofs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
10 Verifica di ipotesi e valori p 4310.1 Riassunto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4310.2 Il test di Wald . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4410.3 Valore p . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4710.4 La distribuzione χ2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4910.5 Test chi quadro di Pearson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4910.6 Test di permutazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5110.7 Test del rapporto di verosimiglianza . . . . . . . . . . . . . . . . . . . . . . . 5210.8 Test multipli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5210.9 Test di bontà di adattamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5210.10Note bibliografiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5310.11Appendice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
11 Inferenza Bayesiana 5511.1 La filosofia bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5511.2 Il metodo bayesiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5711.3 Trasformazioni del parametro . . . . . . . . . . . . . . . . . . . . . . . . . . . 6411.4 Simulazione della distribuzione a posteriori . . . . . . . . . . . . . . . . . . . 6411.5 Proprietà per grandi campioni delle procedure bayesiane . . . . . . . . . . . 6711.6 A priori piatte, improprie e non informative . . . . . . . . . . . . . . . . . . 6811.7 Problemi multiparametrici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6811.8 Test bayesiani . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6911.9 Pro e contro l’inferenza bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . 69
12 Teoria statistica delle decisioni 71
13 Regressione Lineare e Logistica 7313.1 Regressione lineare semplice . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7313.2 Minimi quadrati e massima verosimiglianza . . . . . . . . . . . . . . . . . . 7613.3 Proprietà degli stimatori dei MQ . . . . . . . . . . . . . . . . . . . . . . . . . 7713.4 Intervalli di previsione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7913.5 Regressione lineare multipla . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8313.6 Scelta del modello . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8613.7 Regressione logistica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
A Terminologia inglese e italiana 103
B Analisi dei dati 107B.1 Inserire dati in R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107B.2 Statistica descrittiva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109B.3 Indagini statistiche, esperimenti, osservazioni . . . . . . . . . . . . . . . . . 110B.4 Tabulazione e distribuzioni di frequenza . . . . . . . . . . . . . . . . . . . . . 112

INDICE v
B.5 Diagrammi a barre e istogrammi . . . . . . . . . . . . . . . . . . . . . . . . . 113B.6 Quantili . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116B.7 Box-plot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
C Tavole utili 119C.1 Normale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119

vi INDICE

1
preliminari
1.1 Introduzione
Queste dispense contengono delle note al libro di Larry Wasserman (2004), limitate ai ca-pitoli previsti dal corso di Statistica B000365 al corso di Laurea triennale di Matematica.Prima occorre leggere il libro cercando di apprendere i concetti e la terminologia facendole opportune traduzioni in italiano (in fondo alle note trovate un’appendice con le tradu-zioni dei termini tecnici). Molte cose alla prima lettura non saranno del tutto chiare. Aquesto punto queste possono essere utili. Seguitele e cercate di fare gli esercizi del libro e glieventuali esercizi supplementari. Le soluzioni sono in appendice. Queste note contengonoanche i dati e gli esempi fatti a lezione.
Il corso si articola su 12 settimane con i seguenti argomenti (tra parentesi i capitoli deilibri).
1. Analisi dei dati con R
2. Modelli e inferenza statistica (Wasserman, cap. 6)
3. Stima della funzione di ripartizione (Wasserman, cap. 7)
4. Bootstrap (Wasserman, cap. 8)
5. Inferenza Parametrica, metodo di massima verosimiglianza (Wasserman, cap. 9)
6. Test delle ipotesi e valore-p (Wasserman, cap. 10)
7. Inferenza Bayesiana (Wasserman, cap. 11)
8. Regressione lineare e logistica (Wasserman, cap.13)
Avvertenza. Il corso di Statistica richiede le nozioni fondamentali di Calcolo delle Proba-bilità. Il Corso di Calcolo delle Probabilità è quindi un prerequisito importante per seguireil corso. Se non avete ancora dato l’esame troverete molte difficoltà a seguire il Corso diStatistica! Il libro di Probabilità che si presuppone abbiate studiato è quello di Baldi (2011).Anche i primi 5 capitoli di Wasserman (2004) sono dedicati al Calcolo delle Probabilità.
1

2 1. PRELIMINARI
Sito del corso. Il corso di Statistica ha un sito web dedicato al link
http://local.disia.unifi.it/gmm/statmat.html
dove potete trovare il syllabus, i libri di testo, queste dispense, dati aggiuntivi ecc.
1.2 Calcolo scientifico in R
Useremo spesso per le illustrazioni il linguaggio R. Questo linguaggio è simile a Matlab erichiede qualche tempo per essere imparato a fondo, ma è abbastanza semplice usarlo pereseguire gli esempi trattati nel corso e ripaga molto lo sforzo perché permette di acqui-sire rapidamente le basi dell’analisi dei dati e didatticamente è molto efficace. Le note diEmmanuel Paradis (2005) R for Beginners che si possono scaricare dal link
https://cran.r-project.org/doc/contrib/Paradis-rdebuts_en.pdf
sono estremamente utili.R è il linguaggio di programmazione più usato dagli statistici. È di pubblico domi-
nio, e si scarica dal sito del http://cran.r-project.org). È utile abbinarlo al sistema disviluppo RStudio che si scarica da
http://www.rstudio.com/products/RStudio/
Avvertenza. La conoscenza approfondita del linguaggio R non è parte dell’esame, ma ènecessario aver praticato le applicazioni illustrate nel testo e saper interpretare i risultati!C’è una domanda specifica all’orale!

6
modelli e inferenza
6.1 Introduzione
Normalmente ci immaginiamo una popolazione come un insieme di individui o unità distudio, ossia come un entità unica senza struttura. Quando prendiamo in esame una va-riabile misurata su ogni unità, la popolazione assume la struttura di variabile aleatoria.Per questo nel libro la popolazione oggetto di studio è modellata come una funzione diripartizione F che descrive completamente la variabile.
Le osservazioni disponibili sulla popolazione sono ottenute con un meccanismo diestrazione probabilistico chiamato modello di campionamento che nel caso più sempliceè il campione casuale (vedi attentamente la definizione 2.41 a p. 39 del libro). Un campio-ne casuale è un n-pla di osservazioni generate da variabili indipendenti e identicamentedistribuite con funzione di ripartizione F(x) (o funzione di densità f(x)).
Notazione per un campione casuale: X1, . . . ,Xn ∼ F , dove F è la funzione di riparti-zione. Si dà per scontato che le osservazioni siano i.i.d.
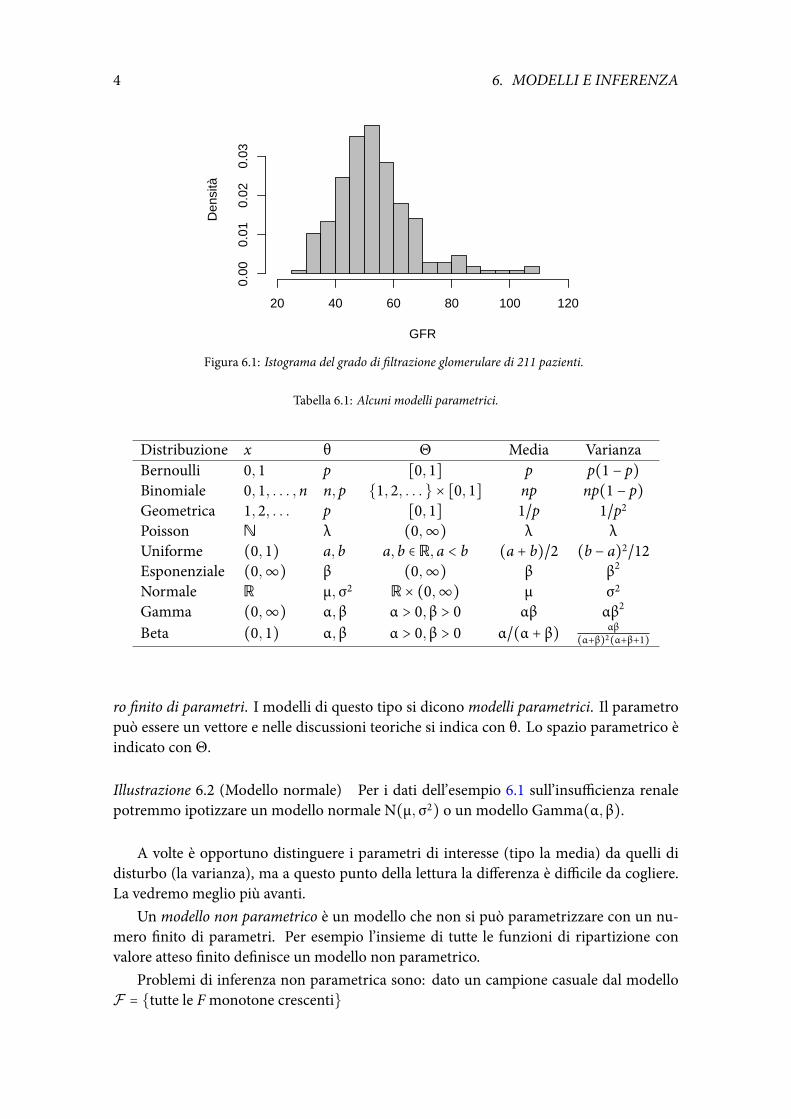
Illustrazione 6.1 (Studio dell’insufficienza renale) Il gradodi filtrazione glomerulare (gfr)è un indicatore importante per la diagnosi di insufficienza renale. Valori bassi del gfr indi-cano problemi ai reni. Nella Fig. 6.1 è riportato l’istogramma di questo indicatore per 211pazienti. La popolazione oggetto di studio è quella dei pazienti con una potenziale insuf-ficienza renale. I dati sono un campione casuale da questa popolazione se le osservazionisono indipendenti (pazienti distinti) e ottenute da una popolazione omogenea.
6.2 Modelli parametrici e non
Poiché la popolazione non è nota dobbiamo cercare di delimitare almeno una famiglia didistribuzioni che contiene la vera popolazione. Questa operazione si chiama specificazionedi un modello statistico. Un modello statistico è dunque un’opportuna famiglia di distribu-zioni di probabilità che si suppone contenga la descrizione della popolazione reale oggettodi studio.
Spesso il modello si sceglie utilizzando una classe nota di distribuzioni di probabilitàunivariate e cercando di rispettare la natura del fenomeno studiato (continuo, discreto,binario, positivo). La Tabella 6.1 riporta alcune classi di variabili aleatorie di uso comune,con i relativi parametri. Come si vede queste classi di distribuzioni dipendono da un nume-
3
4 6. MODELLI E INFERENZA
GFR
Den
sità
20 40 60 80 100 120
0.00
0.01
0.02
0.03
Figura 6.1: Istograma del grado di filtrazione glomerulare di 211 pazienti.
Tabella 6.1: Alcuni modelli parametrici.
Distribuzione x θ Θ Media VarianzaBernoulli 0, 1 p [0, 1] p p(1 − p)Binomiale 0, 1, . . . ,n n,p {1, 2, . . .} × [0, 1] np np(1 − p)Geometrica 1, 2, . . . p [0, 1] 1/p 1/p2
Poisson N λ (0,∞) λ λUniforme (0, 1) a,b a,b ∈ R,a < b (a + b)/2 (b − a)2/12Esponenziale (0,∞) β (0,∞) β β2
Normale R μ,σ2 R × (0,∞) μ σ2
Gamma (0,∞) α,β α > 0,β > 0 αβ αβ2
Beta (0, 1) α,β α > 0,β > 0 α/(α + β) αβ(α+β)2(α+β+1)
ro finito di parametri. I modelli di questo tipo si dicono modelli parametrici. Il parametropuò essere un vettore e nelle discussioni teoriche si indica con θ. Lo spazio parametrico èindicato con Θ.
Illustrazione 6.2 (Modello normale) Per i dati dell’esempio 6.1 sull’insufficienza renalepotremmo ipotizzare un modello normale N(μ,σ2) o un modello Gamma(α,β).
A volte è opportuno distinguere i parametri di interesse (tipo la media) da quelli didisturbo (la varianza), ma a questo punto della lettura la differenza è difficile da cogliere.La vedremo meglio più avanti.
Un modello non parametrico è un modello che non si può parametrizzare con un nu-mero finito di parametri. Per esempio l’insieme di tutte le funzioni di ripartizione convalore atteso finito definisce un modello non parametrico.
Problemi di inferenza non parametrica sono: dato un campione casuale dal modelloF = {tutte le F monotone crescenti}
6.2. MODELLI PARAMETRICI E NON 5
Età gestazionale
Circ
onfe
renz
a ad
dom
e
●●
●●
●
●
●
●●●●●
●
●
●
●
●
●●●●●
●
●●
●●●
●●
●
●
●
●●●●
●●
●
●
●●●●
●
●●
●●
●
●
●●
●
●●
●
●
●
●●
●
●●●●●●●
●
●
●
●●
●
●
●
●
●●
●●●●
●
●
●●●●●●
●
●
●●●
●
●
●
●
●●●●
●●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●●●●
●●●●●●●
●●●●
●
●●●
●
●●●●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●●●
●
●●●
●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●●
●●
●●
●
●
●●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●●●
●
●●●
●
●
●
●●
●
●
●●
●●
●
●
●
●●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●●
●
●
●
●●●
●
●●●
●●
●●●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●●●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●
●●
●
●
●
●
●
10 15 20 25 30 35 40 45
0
100
200
300
400
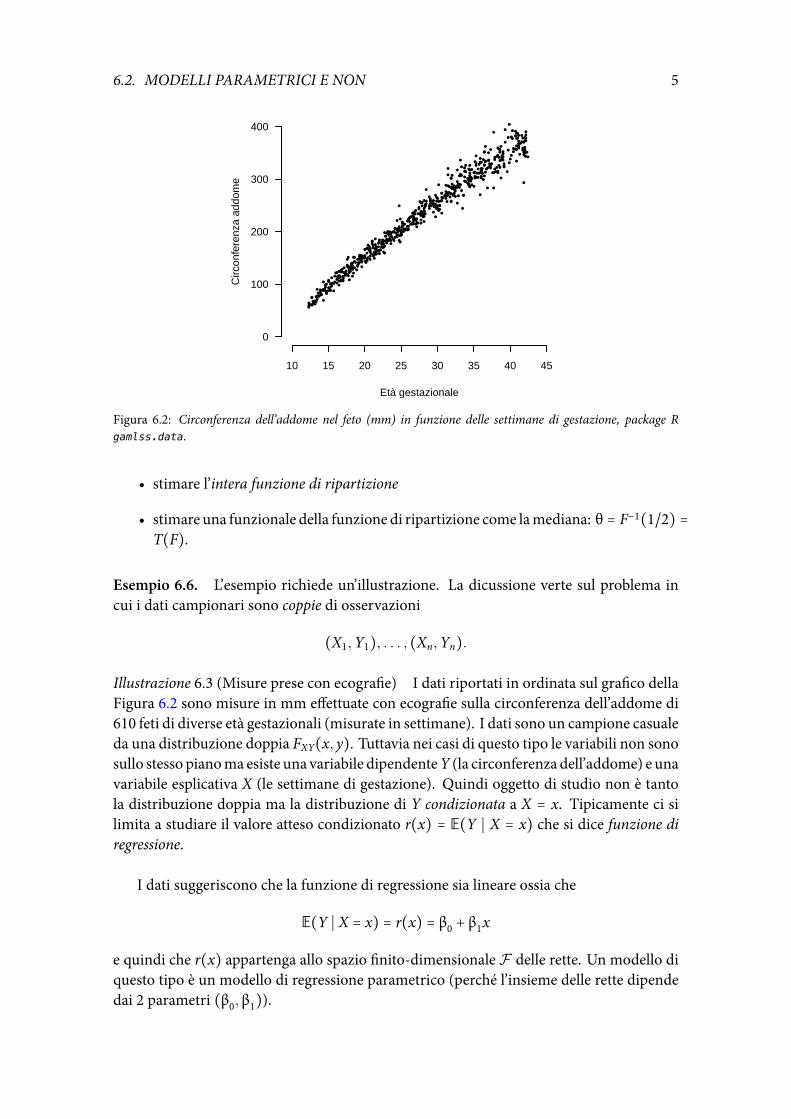
Figura 6.2: Circonferenza dell’addome nel feto (mm) in funzione delle settimane di gestazione, package Rgamlss.data.
• stimare l’intera funzione di ripartizione
• stimare una funzionale della funzione di ripartizione come lamediana: θ = F−1(1/2) =T(F).
Esempio 6.6. L’esempio richiede un’illustrazione. La dicussione verte sul problema incui i dati campionari sono coppie di osservazioni
(X1,Y1), . . . , (Xn,Yn).
Illustrazione 6.3 (Misure prese con ecografie) I dati riportati in ordinata sul grafico dellaFigura 6.2 sono misure in mm effettuate con ecografie sulla circonferenza dell’addome di610 feti di diverse età gestazionali (misurate in settimane). I dati sono un campione casualeda una distribuzione doppia FXY(x, y). Tuttavia nei casi di questo tipo le variabili non sonosullo stesso pianoma esiste una variabile dipendenteY (la circonferenza dell’addome) e unavariabile esplicativa X (le settimane di gestazione). Quindi oggetto di studio non è tantola distribuzione doppia ma la distribuzione di Y condizionata a X = x. Tipicamente ci silimita a studiare il valore atteso condizionato r(x) = E(Y ∣ X = x) che si dice funzione diregressione.
I dati suggeriscono che la funzione di regressione sia lineare ossia che
E(Y ∣ X = x) = r(x) = β0 + β1x
e quindi che r(x) appartenga allo spazio finito-dimensionale F delle rette. Un modello diquesto tipo è un modello di regressione parametrico (perché l’insieme delle rette dipendedai 2 parametri (β0,β1)).

6 6. MODELLI E INFERENZA
Se la funzione di regressione appartiene a una famiglia F infinito-dimensionale si haun modello di regressione non parametrico.
L’esempio 6.6 introduce altre definizioni che saranno chiarite più avanti.Studiate con attenzione la dimostrazione che un modello di regressione si può sempre
scrivere come Y = r(X) + ε.
6.3 Concetti fondamentali di inferenza
6.3.1 Stima puntuale frequentista
Stima e stimatore. La stima della quantità incognita θ di interesse nella popolazione sibasa su un algoritmo (un procedimento basato su una formula in forma chiusa, o anche suun processo iterativo).
Per esempio, per stimare lamedia della popolazione μ = EF(X) si usa lamedia del cam-pione xn = (x1+⋯+xn)/n. Per stimare la mediana F−1(1/2) si usa la mediana campionariam calcolata con l’algoritmo seguente.
1. Ordina il vettore x = (x1, . . . , xn) ottenendo (x(1), . . . , x(n)).
2. d = ⌊(n + 1)/2⌋
3. if n disparim = x(d)elsem = {x(d) + x(d+1)}/2end
In entrambi i casi, abbiamo usato per la stima il metodo di analogia cioè abbiamo presocome stima del parametro, il parametro calcolato sulla distribuzione empirica dei dati.
La stima di un parametro θ si indica formalmente come una funzione
θ = T(x) = T(x1, . . . , xn)
dei soli dati campionari.
Illustrazione 6.4 (Stimadellamedia e dellamediana) La stimadellamedia e dellamedianaper i dati sull’insufficienza renale sono
x = 54.26, m = 52.
Questi valori forniscono alcune statistiche descrittive del campione. Per dei complementidi statistica descrittiva si veda l’Appendice B.

6.3. CONCETTI FONDAMENTALI DI INFERENZA 7
Inferenza frequentista. L’inferenza frequentista è basata su una misura della bontà dellastima T(x) nel campionamento ripetuto. Immaginiamo una ipotetica successione infinitadi insiemi di dati x(1), x(2), x(3), . . . generati dallo stessomeccanismo che ha generato x cheproduce una successione di stime θ
(1), θ(2), θ(2), . . . . Allora la bontà della stima si giudica
dalle proprietà di questa successione infinita.Formalmente l’insieme delle stime nel campionamento ripetuto è descritto dalla stima
interpretata come una variabile aleatoria T(X) = T(X1, . . . ,Xn) dove X è un campionecasuale. Quindi occorre distinguere attentamente
• la stima nel campione osservato x che è un numero θ = T(x)
• lo stimatorenel campionamento ripetuto che è una variabile aleatoriaT(X) = T(X1, . . . ,Xn).
Per valutare in senso inferenziale una stima θ si valuta la sua distribuzione di probabilitàindividuandone i vantaggi e gli svantaggi.
Stimatore della media. Consideriamo lo stimatore media campionaria Xn = 1n ∑
ni=1Xi
di μ = EF(X).Per questo stimatore conosciamo vari risultati importanti tra cui 2 risultatifondamentali del calcolo delle probabilità: la legge dei grandi numeri e il teorema centraledel limite. Li riassumo di seguito.
(A) Se (X1, . . . ,Xn) ∼ F allora EF(Xn) = μ
(B) Se (X1, . . . ,Xn) ∼ N(μ,σ2) allora Xn ∼ N(μ,σ2/n)
(C) La media campionaria Xn converge in probabilità alla media della popolazione μ =EF(X) qualunque sia la distribuzione F (legge dei grandi numeri).
(D)√n(Xn − μ) converge in legge a una Normale, qualunque sia F (Teorema centrale del
limite).
La convergenza in probabilità →p e in legge ↝ sono spiegate nella definizione 5.1 dellibro e sul Baldi (2011).
Quindi sappiamo che lo stimatore Xn è vicino a μ con elevata probabilità. Inoltre lasua distribuzione campionaria (opportunamente standardizzata) è approssimativamentenormale se n è grande.
Da quanto visto per la media estrapoliamo le proprietà principali degli stimatori θn ingenere che sono
(A) la non distorsione o correttezza
(B) la conoscenza della distribuzione campionaria a partire dalla conoscenza di F e ladeterminazione della varianza dello stimatore var[T(X)]
(C) la consistenza
(D) la normalità asintotica

8 6. MODELLI E INFERENZA
Errore quadratico medio. La deviazione standard dello stimatore è particolarmente im-portante: fornisce una misura dell’errore di campionamento. Questo indice si chiamaerrore standard (anche se è semplicemente la deviazione standard): se(θn) =
√var(θn).
L’errore standard dipende dalla distribuzione incognita della popolazione, per esempio
se(Xn) = σ/√n.
Quindi l’errore standard è un parametro che va stimato a sua volta.
Illustrazione 6.5 (Come stimare l’errore standard) Riprendiamo i dati sui malati ai reni.La stima della media μ è xn = 54.26. Qual’è l’errore standard? Sappiamo che è σ/
√n,
ma ovviamente σ2 è incognito e dobbiamo stimarlo. Uno stimatore intuitivo di σ2 è lostimatore per analogia
σ2 = 1n
n
∑i=1(xi − xn)2 = 187.37
che ci permette di ottenere l’errore standard stimato
se = σ/√n = 0.94.
In conclusione, abbiamo una stima della media di gfr di 54.26 ml con s.e. = 0.94 ml.
Un esempio simile è il 6.8 del libro per il caso dello stimatore della probabilità disuccesso p.
L’errore dovuto al campionamento non dipende solo dalla variabilità dello stimatoreattorno alla sua media. È rilevante anche la distorsione indicata con bias = E(θn) − θ.Per questo si introduce un indice più generale, l’errore quadratico medio (MSE), definitoall’equazione (6.6) del libro.
Il Teorema 6.9 mostra che il MSE è la somma della varianza più il quadrato della di-storsione. Notate che l’errore quadratico medio di uno stimatore di θ è una funzione diθ!
6.3.2 Intervalli di confidenza
Questo paragrafo è un’introduzione agli intervalli di confidenza. È utile avere in mentequesto esempio.
Illustrazione 6.6 Supponete che il campione delle 211 misure sulla capacita di filtrazio-ne dei reni gfr provenga da una popolazione normale N(θ,σ2 = 142), Per il momen-to supponete di conoscere esattamente la varianza della popolazione. Allora l’intervalloaleatorio
(Xn − 1.96 ⋅ se, Xn − 1.96 ⋅ se), se = σ/√n = 14/
√211 = 0.964 (6.1)
comprende la media incognita θ con probabilità 0.95. Perché? Perché essendo Xn ∼N(θ, se2) risulta
P(Xn − 1.96 ⋅ 0.964 ≤ μ ≤ Xn + 1.96 ⋅ 0.964) = P(−1.96 ≤ Z ≤ 1.96) = 0.95.
6.3. CONCETTI FONDAMENTALI DI INFERENZA 9
dove Z ∼ N(0, 1). Fate per esercizio tutti i passaggi.Quindi il 95% degli intervalli (6.1) nel lungo andare comprendono θ e quindi forni-
scono un intervallo di confidenza di livello 0.95 per θ. Nel particolare campione osservatol’intervallo di confidenza risulta
xn ± 1.96 ⋅ 0.964, ossia 54.26 ± 1.89.
Notare che NON SI PUÒ dire che θ cade in questo intervallo con probabilità 0.95!Leggete bene la nota su libro sull’interpretazione degli intervallo di confidenza e l’Esempio6.13. L’esempio 6.14 è più difficile.
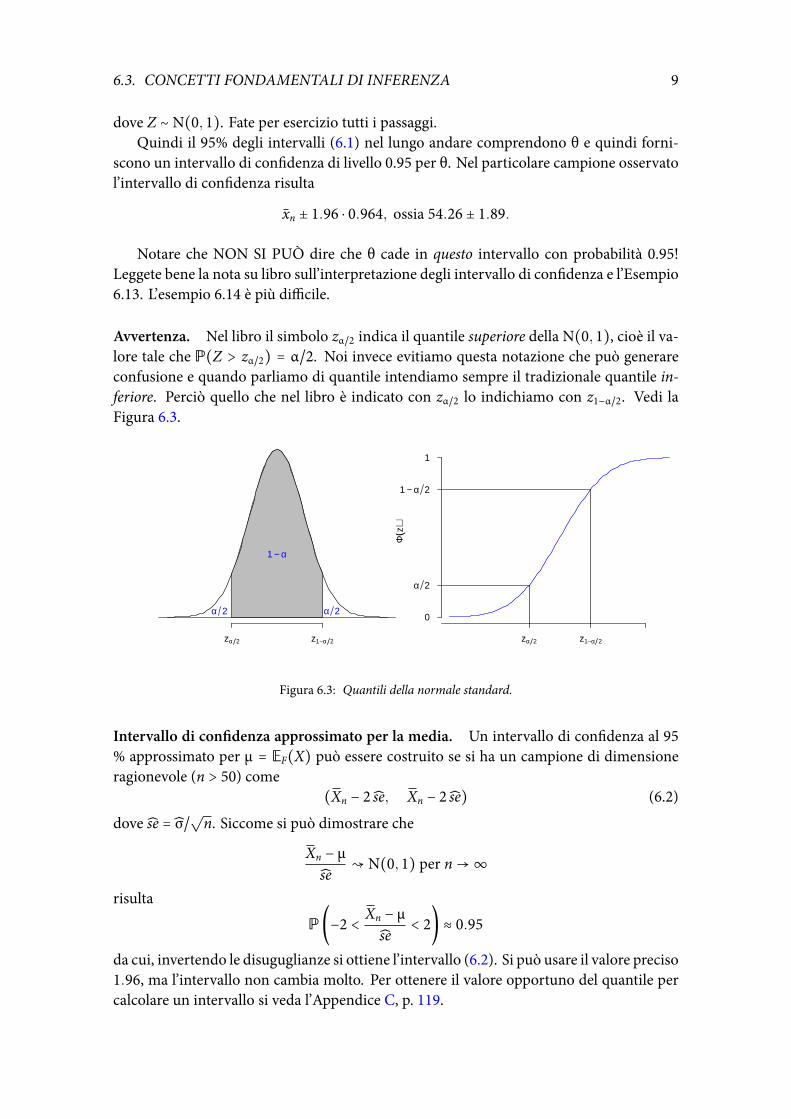
Avvertenza. Nel libro il simbolo zα/2 indica il quantile superiore della N(0, 1), cioè il va-lore tale che P(Z > zα/2) = α/2. Noi invece evitiamo questa notazione che può generareconfusione e quando parliamo di quantile intendiamo sempre il tradizionale quantile in-feriore. Perciò quello che nel libro è indicato con zα/2 lo indichiamo con z1−α/2. Vedi laFigura 6.3.
zα 2 z1−α 2
1 − α
α 2α 2
Φ(z
)
zα 2 z1−α 2
0
α 2
1 − α 2
1
Figura 6.3: Quantili della normale standard.
Intervallo di confidenza approssimato per la media. Un intervallo di confidenza al 95% approssimato per μ = EF(X) può essere costruito se si ha un campione di dimensioneragionevole (n > 50) come
(Xn − 2 se, Xn − 2 se) (6.2)
dove se = σ/√n. Siccome si può dimostrare che
Xn − μse↝ N(0, 1) per n→∞
risulta
P(−2 < Xn − μse< 2) ≈ 0.95
da cui, invertendo le disuguglianze si ottiene l’intervallo (6.2). Si può usare il valore preciso1.96, ma l’intervallo non cambia molto. Per ottenere il valore opportuno del quantile percalcolare un intervallo si veda l’Appendice C, p. 119.

10 6. MODELLI E INFERENZA
Disuguaglianza di Hoeffding. L’esempio 6.15 è basato sulla disuguaglianza di Hoeff-ding spiegata a p. 64 del libro. Il libro non la dimostra e la applica principalmente alcaso di un campione casuale da una Bernoulli di parametro p. È utile confrontarla con ladisuguaglianza di Chebyshev (vedi p. 64 del libro): Per un dato ε > 0
Chebyshev P(∣Xn − p∣ > σ) ≤ p(1 − p)nε2 ≤ 1
4nε2 (6.3)
Hoeffding P(∣Xn − p∣ > σ) ≤ 2e−2nε2 (6.4)
Quindi se X1, . . . ,Xn ∼ Binom(1,p) e il campione ha dimensione n = 100 e ε = 0.2 allorala disuguaglianza di Chebyshev implica che
P(∣Xn − p∣ > 0.2) ≤ 0.0625
ovvero la probabilità che la proporzione campionariaXn stia nell’intervallo p±0.2 è almeno1 − 0.0625 = 0.9375.
Per la disuguaglianza di Hoeffding
P(∣Xn − p∣ > 0.2) ≤ 0.00067
e quindi afferma che la stessa probabilità è almeno 1 − 0.00067 = 0.99933.
Intervallo di confidenza per una proporzione di successi. La disuguaglianza di Hoeff-ding suggerisce un modo semplice per costruire un intervallo di confidenza per la proba-bilità p di successo dato un campione casuale.
Volendo un livello di confidenza 1 − α di almeno 0.95 basta risolvere l’equazione
α = 2e−2nε2
ottenendo il margine di errore
εn =√
log(n/α)/(2n)
e un intervallo di confidenza Xn ± εn tale che
P(Xn − εn ≤ p ≤ Xn + εn) ≥ 1 − α.
L’esempio 6.17 invece introduce un intervallo di confidenza asintotico Xn ± z1−α/2se conse =√Xn(1 − Xn)/n, basato sull’approssimazione normale
Xn − pse↝ N(0, 1) per n→∞.
Il simbolo z1−α/2 indica il quantile della normale standard di ordine 1 − α/2.Il teorema 6.16 è un estensione ad ogni stimatore che è asintoticamente normale. Verrà
studiato più approfonditamente in seguito.

6.3. CONCETTI FONDAMENTALI DI INFERENZA 11
6.3.3 Test delle ipotesi
Questo è un paragrafo brevissimo introduttivo. L’importante è capire l’idea dei test che èqualcosa di molto diverso dalla stima. Un test si usa per verificare una teoria. Il libro fal’esempio della verifica cha la probabilità di testa sia uguale alla probabilità di croce. Cisono moltissimi esempi importanti che generalizzano questa situazione.
• Due variabili hanno la stessa media?
• Due variabili sono indipendenti?
• C’è differenza tra due farmaci rispetto all’efficacia nel guarire una malattia?
• L’uso del telefonino provoca danni al cervello?

12 6. MODELLI E INFERENZA

7
stima della funzione di ripartizione
7.1 Funzione di ripartizione empirica
La definizione è abbastanza intuitiva. È interessante osservare che è definita come unasomma di variabili aleatorie binarie indipendenti e identicamente distribuite.
I dati di Cox e Lewis dell’esempio 7.2 si importano col comando
source('http://local.disia.unifi.it/gmm/data/nerve.R')
Il grafico si può ottenere con i comandi
hist(nerve, main = "", freq = FALSE)plot(ecdf(nerve), main = "")
Il teorema 7.3 descrive le proprietà della funzione di ripartizione empirica Fn(x) comestimatore di F(x). Il risultato mostra che per grandi campioni la funzione di ripartizioneempirica non si discosta molto dalla vera funzione di ripartizione. La dimostrazione sullibro non è riportata, ma va fatta perché è semplice e istruttiva.
Dimostrazione del Teorema 7.3. Poiché le variabili Zi = I(Xi ≤ x) ∼ Binom(1,F(x)) sonoBernoulli indipendenti con probabilità di successo F(x) costante, la funzione di ripartizio-ne empirica è una media aritmetica Zn = ∑i Zi/n di queste variabili i.i.d. Quindi sappiamoche
E(Zn) = E(Fn(x)) = E(Zi) = F(x),var(Zn) = var(Fn(x)) = var(Zi)/n = F(x)[1 − F(x)]/n.
Quindi il MSE è uguale alla varianza ed è infinitesimo per n che tende a∞. Questa è unacondizione sufficiente che implica la convergenza in probabilità per ogni x,
Fn(x)→p F(x).
Infine valgono le condizioni del teorema centrale del limite per cui√n(Fn(x) − F(x))↝ N(0,F(x)[1 − F(x)])
13

14 7. STIMA DELLA FUNZIONE DI RIPARTIZIONE
Il teorema 7.4 di Glivenko-Cantelli (non dimostrato qui) è ancora più stringente estabilisce che non solo ∣Fn(x) − F(x)∣→p 0 ma anche supx ∣Fn(x) − F(x)∣→p 0.
La disuguaglianza di DKWdel teorema 7.5 quantifica il tasso di convergenza del teore-ma di Glivenko-Cantelli quando n tende all’infinito. La disuguaglianza non è dimostratanel nostro corso. Usando questa disuguaglianza si può costruire una banda di confidenzaper la funzione di ripartizione F della popolazione.
7.2 Funzionali statistici
Un funzionale statistico è una funzione T(F) della funzione di ripartizione. Ad esempio lamediana e il valore atteso sono funzionali statistici. La mediana è q1/2 = F−1(1/2), mentreil valore atteso di una v.a. X con funzione di ripartizione F(x) e funzione di densità omassadi probabilità f(x) è
E(X) = ∫ xdF(x) =⎧⎪⎪⎨⎪⎪⎩
∫∞−∞ xf(x)dx nel caso continuo∑i xif(xi) nel caso discreto
Spesso si usa come stimatore di un funzionale statistico T(F) lo stimatore per analogiao stimatore per sostituzione T(Fn) (metodo plug-in). Se il funzionale è lineare, cioè se ha laforma
T(F) = ∫∞
−∞r(x)dF(x)
dove r(x) è una funzione lineare di x, lo stimatore col metodo di sostituzione risulta sem-plicemente
T(Fn) =1n∑i
r(Xi)
perché Fn è discreta e assegna massa di probabilità 1/n ad ogni punto.Il libro mostra vari esempi di stimatori ottenuti col metodo di sostituzione:
1. La media campionaria Xn = 1n ∑iXi è uno stimatore di μ
2. La varianza campionaria σ2 = 1n ∑iX2
i − X2n = 1
n ∑i(Xi − Xn)2 è uno stimatore di σ2
3.1n ∑i(Xi−Xn)3
σ3 è uno stimatore della asimmetria.
4. Dato un campione casuale i.i.d. (X1,Y1), . . . , (Xn,Yn) da una distribuzione F(x, y),il coefficiente di correlazione campionario
ρ = ∑i(Xi − Xn)(Yi − Yn)√∑i(Xi − Xn)2∑i(Yi − Yn)2
è lo stimatore per sostituzione del coefficiente di correlazione nella popolazione.
7.2. FUNZIONALI STATISTICI 15
Grafico quantile contro quantile. Sappiamo che la funzione quantile è un’inversa x =F−1(p) della funzione di ripartizione p = F(x). L’inversa è unica se la funzione di ripar-tizione è strettamente crescente, altrimenti occorre definire un’inversa generalizzata; vedisul libro l’esempio 7.14. La funzione quantile empirica è definita in modo tale che
F−1n (i/n) = x(i). (7.1)
dove x(i) è l’i-esima osservazione nella successione ordinata dei dati xi.In un modello parametrico, come sappiamo, si ipotizza che la popolazione segua una
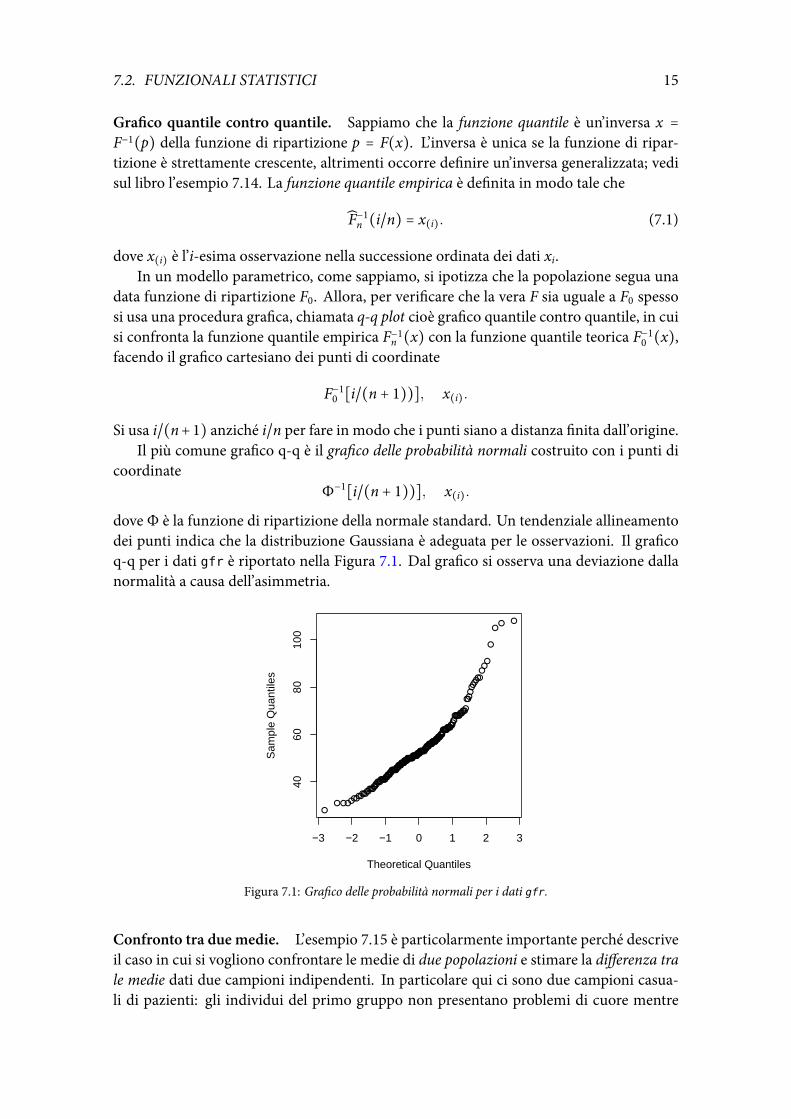
data funzione di ripartizione F0. Allora, per verificare che la vera F sia uguale a F0 spessosi usa una procedura grafica, chiamata q-q plot cioè grafico quantile contro quantile, in cuisi confronta la funzione quantile empirica F−1n (x) con la funzione quantile teorica F−10 (x),facendo il grafico cartesiano dei punti di coordinate
F−10 [i/(n + 1))], x(i).
Si usa i/(n+1) anziché i/n per fare in modo che i punti siano a distanza finita dall’origine.Il più comune grafico q-q è il grafico delle probabilità normali costruito con i punti di
coordinateΦ−1[i/(n + 1))], x(i).
dove Φ è la funzione di ripartizione della normale standard. Un tendenziale allineamentodei punti indica che la distribuzione Gaussiana è adeguata per le osservazioni. Il graficoq-q per i dati gfr è riportato nella Figura 7.1. Dal grafico si osserva una deviazione dallanormalità a causa dell’asimmetria.
●
●
●●
●
●
●
●
●●●●
●
●●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●●
●●
●●
●
●
−3 −2 −1 0 1 2 3
4060
8010
0
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Figura 7.1: Grafico delle probabilità normali per i dati gfr.
Confronto tra due medie. L’esempio 7.15 è particolarmente importante perché descriveil caso in cui si vogliono confrontare le medie di due popolazioni e stimare la differenza trale medie dati due campioni indipendenti. In particolare qui ci sono due campioni casua-li di pazienti: gli individui del primo gruppo non presentano problemi di cuore mentre
16 7. STIMA DELLA FUNZIONE DI RIPARTIZIONE
gli individui del secondo gruppo hanno problemi di arteriosclerosi. Su tutti i pazienti simisura il tasso di colesterolo.
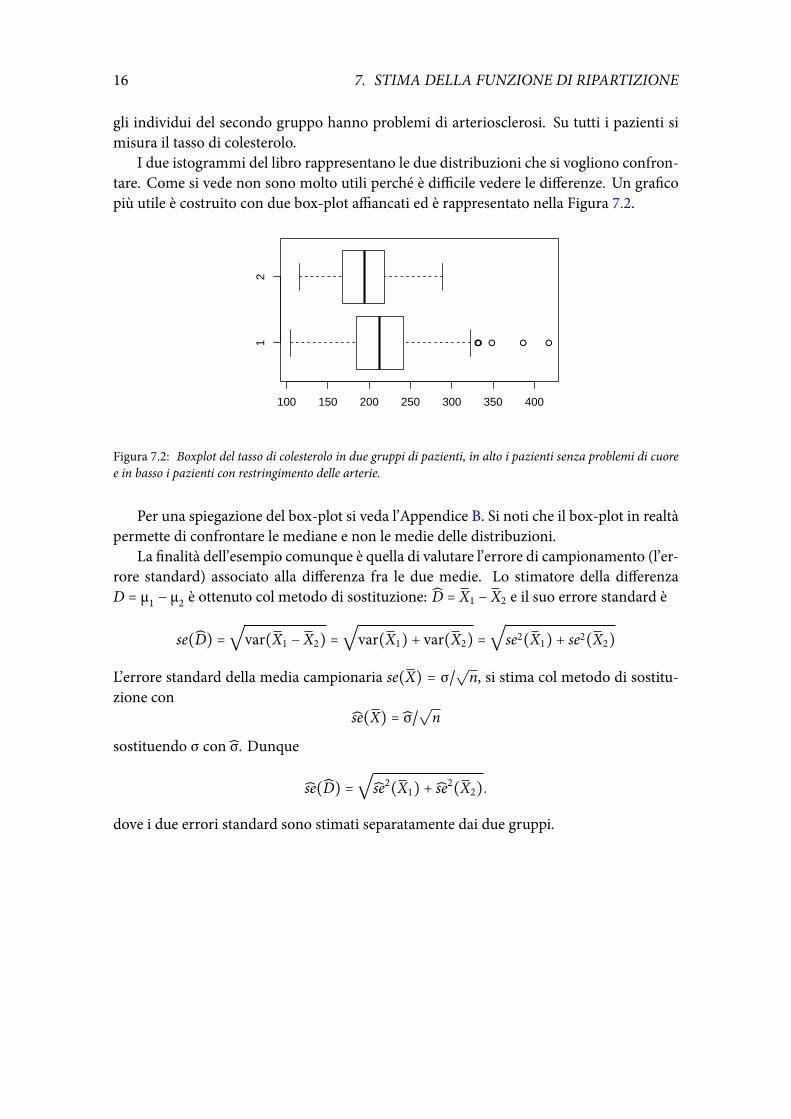
I due istogrammi del libro rappresentano le due distribuzioni che si vogliono confron-tare. Come si vede non sono molto utili perché è difficile vedere le differenze. Un graficopiù utile è costruito con due box-plot affiancati ed è rappresentato nella Figura 7.2.
● ●●● ●12
100 150 200 250 300 350 400
Figura 7.2: Boxplot del tasso di colesterolo in due gruppi di pazienti, in alto i pazienti senza problemi di cuoree in basso i pazienti con restringimento delle arterie.
Per una spiegazione del box-plot si veda l’Appendice B. Si noti che il box-plot in realtàpermette di confrontare le mediane e non le medie delle distribuzioni.
La finalità dell’esempio comunque è quella di valutare l’errore di campionamento (l’er-rore standard) associato alla differenza fra le due medie. Lo stimatore della differenzaD = μ1 − μ2 è ottenuto col metodo di sostituzione: D = X1 − X2 e il suo errore standard è
se(D) =√
var(X1 − X2) =√
var(X1) + var(X2) =√se2(X1) + se2(X2)
L’errore standard della media campionaria se(X) = σ/√n, si stima col metodo di sostitu-
zione conse(X) = σ/
√n
sostituendo σ con σ. Dunque
se(D) =√se2(X1) + se2(X2).
dove i due errori standard sono stimati separatamente dai due gruppi.

8
il bootstrap
Il bootstrap è una tecnica per valutare le proprietà degli stimatori (varianza, bias) attraversoil ricampionamento dal campione osservato. L’idea sembra abbastanza pazzesca ed è dovutaa Bradley Efron alla fine anni ’70.
Se potessimo ottenere tutti i campioni possibili di numerosità n dalla popolazione F,potremmo calcolare la distribuzione campionaria di uno stimatore Tn e la sua varianzavarF(Tn). Siccome è impossibile, l’idea di Efron è stimare varF(Tn) con varFn(Tn).
Poiché varFn(Tn) può essere difficile da calcolare l’approssimiamo usando la simula-zione e l’algoritmo seguente:
1. Si estrae un campione X∗1 , . . . ,X∗n di numerosità n da Fn: questo è equivalente aestrarre un campione con reimmissione da X1, . . . ,Xn
2. Si calcola la stima Tn(X∗1 , . . . ,X∗n)
3. Si ripetono i passi 1 e 2 B volte ottenendo T∗n,1, . . . ,T∗n,B
4. Si stima la vera varianza bootstrap con la varianza campionaria
vboot =1B
B
∑b=1(T∗n,b −
1B
B
∑r=1
T∗n,r)2
(8.1)
Di solito B = 200 campioni sono sufficienti per la stima della varianza.La tecnica è semplice e i conti li facciamo con un computer. Il difficile è capire perché
questa tecnica funziona.
8.1 Simulazione
Avvertenza: nel libro alle righe 3,5,6 della p. 108, Yn deve essere corretto con YB.Il punto di partenza è capire che si può usare la simulazione e la legge dei grandi nu-
meri per approssimare qualsiasi media. Se siamo in grado di simulare osservazioni i.i.dY1, . . . ,YB da una legge Y ∼ G, poiché YB →p EG(Y) basta estrarre un campione casualeabbastanza grande da G per approssimare la media.
In generale il metodo funziona anche per approssimare E[h(Y)] perché
1B
B
∑j=1
h(Yi)→p E[h(Y)], per B→∞.
17

18 8. IL BOOTSTRAP
In particolare se si calcola la varianza campionaria di Yj, j = 1, . . . ,B questa converge inprobabilità alla varianza della legge G per B che tende a infinito.
Illustrazione 8.1 (Stima dellamedia di una lognormale) Una v.a. Y ha densità lognormalese Y = exp(X) e X ∼ N(μ,σ2). Siccome sappiamo simulare osservazioni da una normalein R possiamo ottenere un campione da una lognormale con le istruzioni seguenti (dovesuppongo che μ = 2 e σ = 1/2):
X = rnorm(B, mean = 2, sd = 1/2)Y = exp(X)EY = mean(Y)
Con B = 100000 otteniamo Y = 8.375619 che approssima il vero valore che è E(Y) =exp(μ + σ2/2) = 8.372897.
Pertanto siccome siamo in grado di simulare un campione casuale dalla funzione diripartizione empirica Fn possiamo approssimare quanto vogliamo la varianza varFn(Tn)dove Tn = T(X1, . . . ,Xn) è una statistica campionaria. Campionare dalla funzione di ri-partizione empirica equivale a estrarre un campione casuale con ripetizione di dimensionen dal campione stesso!
Illustrazione 8.2 Se il campione fosse (1, 6, 5) l’estrazione di B = 4 campioni bootstrap sieffettua con il codice R
> set.seed(100)> x = c(1, 6, 5)> sample(x, size = 3, replace = TRUE)[1] 1 6 5> sample(x, size = 3, replace = TRUE)[1] 5 1 6> sample(x, size = 3, replace = TRUE)[1] 6 5 6> sample(x, size = 3, replace = TRUE)[1] 5 6 5
Nota: set.seed(100) serve a indicare un punto di inizio nella simulazione di numeripseudo-aleatori, in modo che i risultati siano replicabili.
Notate che anche se siamo in gradodi approssimare quanto vogliamo la varianza varFn(Tn)tutto tipende dalla dipende da quanto bene Fn approssima F in modo che siamo in gradodi stimare bene varF(Tn). Per questo il libro sottolinea che col bootstrap stiamo facendo 2approssimazioni della varianza della distribuzione campionaria dello stimatore:
• quella di varF(Tn) con varFn(Tn) (non piccola)
• quella di varFn(Tn) con vboot (piccola).

8.1. SIMULAZIONE 19
La seconda approssimazione è ottenuta calcolando su ogni campione bootstrap le sti-me T∗n,1, . . . ,T∗n,B e quindi calcolando la varianza (e la deviazione standard) delle stimebootstrap con la formula della varianza (8.1).
Illustrazione 8.3 (Stima bootstrap dell’errore standard della media) Abbiamo visto cheper i dati gfr la stima dellamedia è 54.26 con un errore standard stimato se = σ/
√n = 0.94.
Proviamo ora a stimare l’errore standard con il bootstrap. Ecco il codice:
> B = 1000> x = gfr> n = length(x)> boo = rep(0, B)> for(i in 1:B){+ j = sample(1:n, size = n, replace = TRUE)+ boo[i] = mean(x[j])+ }> se = sqrt(var(boo))> se[1] 0.9604089
Esistono anche vari package R per il bootstrap che facilitano le operazioni. Per esempiopossiamo usare quello originale di Efron & Tibshirani (1993):
> library(bootstrap)> boo = bootstrap(gfr, nboot = 1000, mean)$thetastarsqrt(var(boo))[1] 0.9401793
La stima dell’errore standard è leggermente diversa dalla precedente perché dipen-de dalla simulazione. La funzione R bootstrap produce la successione boo delle stimebootstrap, che può essere visualizzata con un istogramma nella Figura 8.1.
boo
Den
sity
51 52 53 54 55 56 57
0.0
0.1
0.2
0.3
0.4
Figura 8.1: Distribuzione delle stime boostrap della media dei dati gfr.
L’esempio 8.2. del libromostra come stimare l’errore standard dell’indice di asimmetria(skewness). Concretamente, si procede come sopra dopo aver definito una funzione R peril calcolo dell’indice di simmetria.

20 8. IL BOOTSTRAP
skewness = function(x){m = mean(x)n = length(x)num = sum((x-m)^3)/nsh = sqrt(sum((x-m)^2)/n)num/sh^3
}boo = bootstrap(nerve, nboot = 1000, skewness)$thetastarsqrt(var(boo))[1] 0.1617007
Riassunto
• Lo stimatore è un algoritmo che applicato ai dati originali fornisce la stima θ, mentreapplicato ai dati bootstrap fornisce T∗n
• L’algoritmo può essere anche complesso con la conseguenza che i calcoli teorici perdeterminarne la distribuzione campionaria sono troppo difficili
• Il campione casuale viene usati per stimare F con Fn: questa approssimazione intaluni casi può essere scarsa!
• la simulazione da Fn permette di sostituire i calcoli teorici.
8.2 Intervalli di confidenza col bootstrap
Il libro discute tremetodi per costruire gli intervalli di confidenza colmetododel bootstrap.Noi ci limitiamo a considerare i primi due.
Metodo 1. L’intervallo più facile da fare è
Tn ± z1−α/2seboot
dove seboot è la stima bootstrap dell’errore standard e l’intervallo (zα/2, z1−α/2) ha probabilità1 − α di contenere un valore Z normale standard.
È chiaro che questo metodo funziona solo se Tn ≈ N(θ, se(Tn)). Ma spesso la distri-buzione non è normale o lo stimatore ha una certa distorsione.
Il paragrafo seguente si può omettere.
Metodo della quantità pivot. Un pivot è una funzione dei dati e del parametro la cuidistribuzione non dipende dal parametro e si conosce esattamente. Per esempio se la leggedella popolazione è normale e X1, . . . ,Xn ∼ N(μ,σ2) con una varianza σ2 nota allora
R = Xn − μ ∼ N(0,σ2/n) fissa qualunque sia μ.

8.2. INTERVALLI DI CONFIDENZA COL BOOTSTRAP 21
e quindi R è un pivot. Allora questo consente di costruire un intervallo di confidenzafacendo perno sul pivot. Infatti posto v = σ/
√n
P (−z1−α/2v < Xn − μ < z1−α/2v) = 1 − α = P (Xn − z1−α/2v < μ < Xn + z1−α/2v) .
Questa è esattamente la tecnica usata nell’Illustrazione 6.6 per costruite un intervallo diconfidenza per la media.
Gli intervalli bootstrap basati sulla quantità pivot hanno buone proprietà senza fareassunzioni di normalità. Si ragiona in questo modo: supponiamo che Rn = Tn − θ sia unpivot. Se ne conoscessimo la distribuzione potremmo trovare invertendo la sua funzionedi ripartizione H(r) un intervallo di confidenza esatto (a,b)
a = Tn −H−1(1 − α/2), b = Tn −H−1(α/2)
(guardate la Figura 6.3; la giustificazione formale è sul libro). Tutto questo sarebbe bello,ma disgraziatamente non conosciamo la sua distribuzione…Allora la stimiamo usando ilbootstrap! Ecco come:
1. partiamo dai campioni bootstrap denotati con: x∗1 , . . . , x∗B
2. per ciascun campione calcoliamo le stime T∗n,1, . . . ,T∗n,B e ne calcoliamo i β-quantiliT∗β per ogni β che ci interessa
3. stimiamo la funzione di ripartizione H del pivot con il bootstrap
R∗1 = T∗n,1 − Tn, . . . ,R∗B = T∗n,B − Tn
ottenendo H e i suoi β-quantili che sono collegati ai β-quantili T∗β , perché
H−1(β) = r∗β = T∗β − Tn
per ogni valore desiderato di β.
4. Infine stimiamo a e b con
a = Tn − H−1(1 − α2) = Tn − r∗1−α/2 = 2Tn − T∗1−α/2
b = Tn − H−1( α2) = Tn − r∗α/2 = 2Tn − T∗α/2
Illustrazione 8.4 (Intervallo bootstrap per l’indice di asimmetria dei dati nerve) La si-mulazione bootstrap in R viene ottenuta coi comandi seguenti. La funzione R skewness èstata definita in precedenza.
source("http://local.disia.unifi.it/gmm/data/nerve.R")library(bootstrap)tboot = bootstrap(nerve, nboot = 1000, skewness)['thetastar']t1 = quantile(tboot, 0.025); t2 = quantile(tboot, 0.975);tn = skewness(nerve)ci = unname(c(2*tn - t2, 2*tn - t1))ci1.464492 2.100048

22 8. IL BOOTSTRAP
Metodo 3: intervallo basato sui percentili. L’intervallo di confidenza di livello 1 − αbasato sui percentili bootstrap ha estremi
T∗α/2, T∗1−α/2
dove gli estremi sono i percentili della distribuzione empirica degli stimatori
T∗1 = Tn(x∗1), . . . ,T∗B = Tn(x∗B)
Qual è la giustificazione di questo intervallo? La distribuzione degli stimatori bootstrapin generale non è normale. Pertanto gli intervalli di confidenza asintotici normali (metodo1) spesso non sono appropriati. Lo sarebbero se avessimo un modo di trasformare glistimatori T∗ in modo da renderli distribuiti normalmente.
Infatti, se conoscessimo una trasformazione monotona crescente m(⋅) tale che U =m(T∗) sia normale, cioè
U ∼ N(φ, c2), φ = m(θ)per qualche c noto potremmo usare il fatto che
P(U − z1−α/2c ≤ φ ≤ U + z1−α/2c) = 1 − α (8.2)
per costruire un intervallo di confidenza per φ = m(θ). Quindi possiamo trasformareall’indietro l’intervallo usando la trasformazione inversa m−1(⋅).
Illustrazione 8.5 Supponiamo di voler stimare il parametro θ = eμ di una popolazioneX ∼ N(μ,σ2) in cui in realtà μ = 0 e σ2 = 1 usando un campione di dimensione 10.Col bootstrap possiamo calcolare intervalli di confidenza standard (metodo 1) e basati suipercentili.
> set.seed(200)> x = rnorm(10)> emean = function(x) exp(mean(x))> boo = bootstrap(x, nboot = 1000, theta = emean)> tstar = boo$thetastar> hist(tstar, 30)> plot(density(tstar))> quantile(tstar, c(0.025, 0.975))
2.5% 97.5%0.7983212 1.6617608> c(mean(x) - 1.96 * sd(tstar), mean(x) + 1.96 * sd(tstar))[1] -0.2874089 0.5908780> ltstar = log(tstar)> exp(c(mean(x) - 1.96 * sd(ltstar), mean(x) + 1.96 * sd(ltstar)))[1] 0.8047719 1.6831473
Tuttavia, se non conosciamo m(⋅)ma sappiamo che esiste, possiamo comunque usarem(⋅) per trasformare gli stimatori bootstrap. Procediamo così:
U∗1 = m(θ∗1), . . . ,U∗B = m(θ
∗B)

8.3. NOTE BIBLIOGRAFICHE 23
e quindi calcoliamo i percentili empirici di ordine α/2 e 1 − α/2, cioè U∗α/2 e U∗1−α/2.Poiché m(⋅) è monotona crescente tali percentili sono le trasformazioni dei percentili
di T∗ cioèU∗α/2 = m(T∗α/2), U∗1−α/2 = m(T∗1−α/2)
D’altra parte poiché U ∼ N(φ, c2)
U∗α/2 = φ + zα/2c = φ − z1−α/2c, U∗1−α/2 = φ + z1−α/2c.
e inoltreU∗α/2 ≈ U − z1−α/2c, U∗1−α/2 ≈ U + z1−α/2c.
Perciò dalla (8.2)
1 − α = P(U − z1−α/2c ≤ φ ≤ U + z1−α/2c) ≈ P(U∗α/2 ≤ φ ≤ U∗1−α/2)
a infine
1 − α ≈ P(U∗α/2 ≤ φ ≤ U∗1−α/2) = P[m(T∗α/2) ≤ m(θ) ≤ m(T∗1−α/2)]= P(T∗α/2 ≤ θ ≤ T∗1−α/2).
Il che ci porta alla definizione degli intervalli di confidenza basati sui percentili. La co-sa strabiliante è che il risultato non dipende da m(⋅) cioè dal fatto di conoscere la tra-sformazione, ma il metodo sostanzialmente trova da solo la trasformazione. Purtroppola trasformazione esatta n(⋅) non sempre esiste, ma è possibile dimostrare l’esistenza ditrasformazioni approssimate.
A questo punto gli esempi del libro 8.5, 8.6 e 8.7 sono abbastanza facili da seguire.
8.3 Note bibliografiche
Un libro raccomandato è Efron & Tibshirani (1993). Per vedere che aspetto ha Brad Efronguardate il video https://youtu.be/H2tOhMaXWvI.
8.4 Appendice
Il metodo jackknife lo saltiamo. La giustificazione dell’intervallo basato sui percentili l’horiportata in queste note.

24 8. IL BOOTSTRAP

9
inferenza parametrica
Come avete visto, nei capitoli precedentiWasserman si occupa esclusivamente di inferenzanon parametrica perché il modello assunto non è mai specificato in modo parametrico.Non fare assunzioni parametriche è un grande vantaggio e il bootstrap è un metodo moltoutile e generale.
Tuttavia a volte il modello può essere specificato in modo parametrico e le assunzionipiù specifiche permettono di usare dei metodi di stima e delle procedure più semplici eaccurate con meno dispendio di tempo macchina usando la teoria asintotica.
Mentre il boostrap è una tecnica nata dopo l’era dei computer i metodi di inferenzaparametrica sono nati molto prima e hanno permesso di effettuare analisi anche complessecon metodi ingegnosi e con calcoli relativamente semplici.
Questo capitolo è molto denso e contiene una quantità di risultati notevole. Quindiva affrontato con calma, con esempi e aspettando che i risultati vengano digeriti e bencompresi.
9.1 Parametri di interesse
Nel modello normale (X1, . . . ,Xn) ∼ N(μ,σ2) il parametro di interesse primario è la mediaμ. σ2 è un parametro di interesse secondario che serve a determinare la precisione dellastima di μ. Non solo, ma la presenza di σ2 impedisce di trovare facilmente un pivot percostruire intervalli di confidenza. Infatti Xn − μ ∼ N(0,σ2/n) non è un pivot se non siconosce σ2. Per questo σ2 si chiama parametro di disturbo.
L’Esempio 9.1 del libro mostra che talvolta il parametro di interesse è una funzione deiparametri (μ,σ), come τ = P(X > 1) = 1 −Φ[(1 − μ)/σ].
L’Esempio 9.2 mostra che se se si vuole stimare la media di una popolazione che ha lalegge X ∼ Gamma(α,β), risulta E(X) = αβ.
9.2 Metodo dei momenti
Dunque da qui in avanti assumiamo che la distribuzione della popolazione sia specificatada un modello parametrico (tipo Normale o Gamma, etc.) (X1, . . . ,Xn) ∼ f(x; θ).
Per stimare i parametri finora abbiamo fatto ricorso al metodo di sostituzione. In Sta-tistica esistono vari altri metodi di stima che prendono le mosse da un principio generale.
25

26 9. INFERENZA PARAMETRICA
Questi principi sono sensati, ma in un certo senso arbitrari. Tuttavia rendono la vita piùfacile perché permettono di automatizzare le procedure di inferenza.
La definizione del metodo dei momenti che risale a Chebyshev nel 1887 è la seguente.Se θ = (θ1, . . . , θk) è un vettore di d parametri si determinano i momenti teorici di ordine1, . . . , k
α1 = E(X),α2 = E(X2), . . . ,αk = E(Xk)
e si osserva che sono tutti funzione di θ poiché
E(Xj) = αj(θ) = ∫ XjdFθ(x)
Quindi si stimano i parametri imponendo che i momenti teorici siano uguali ai momentiempirici
αj = 1n ∑
ni=1X
ji, j = 1, . . . , k.
Questo implica k vincoli espressi da altrettante equazioni che se ammettono un’unica so-luzione forniscono lo stimatore θ del metodo dei momenti.
Illustrazione 9.1 (Stimadei parametri di unaGamma) I primi duemomenti dellaGamma(α,β)sono
α1(α,β) = αβα2(α,β) = var(X) + E(X)2 = αβ2 + α2β2
Quindi le equazioni sono
X = αβ1n ∑
ni=1X2
i = αβ2 + α2β2
da cui si ottengono le stime
α = X2
σ2 , β = σ2
XAbbiamo usato notazione σ2 per indicare lo stimatore per sostituzione della varianza
σ2 = 1n(Xi − X)2 = 1
n ∑ni=1X2
i − X2.
Ad esempio supponendo che i dati gfr siano un campiona casuale da una Gamma deter-miniamo i parametri
α = 15.72, β = 3.45
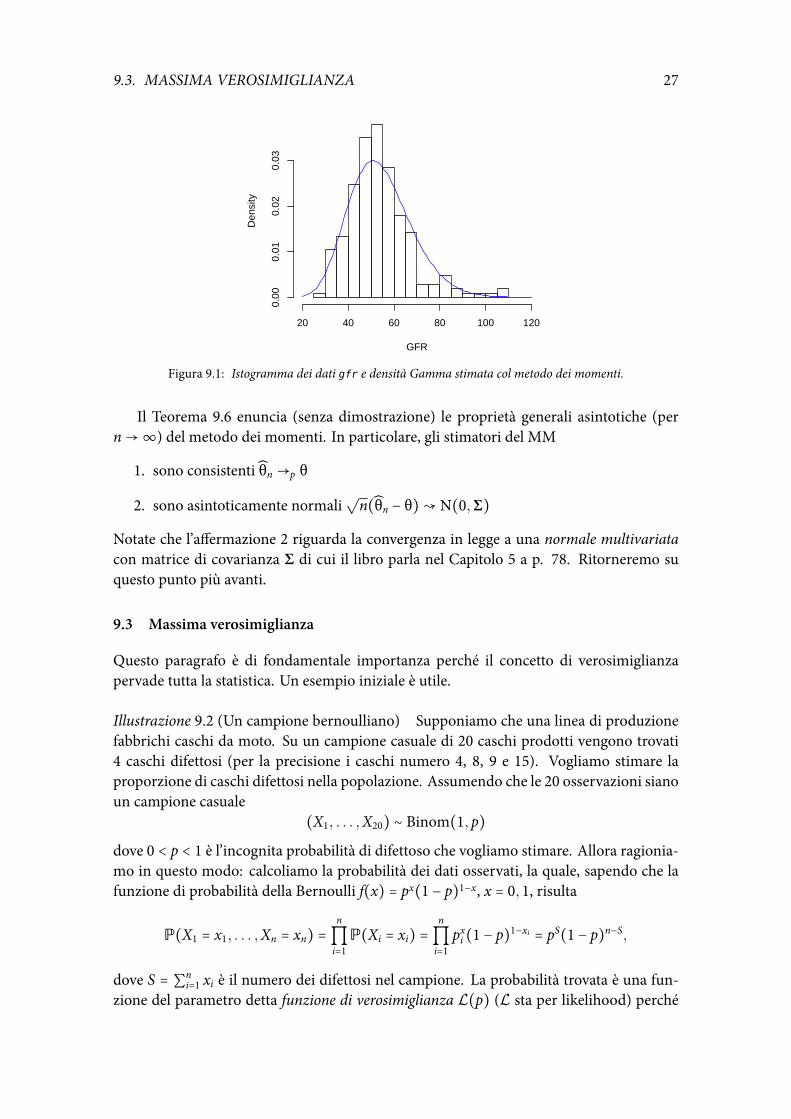
dedotti da x = 54.26 e σ2 = 187.37. La densità stimata è rappresentata nella Figura 9.1. Ilcodice R è il seguente.
xbar = mean(gfr); s2 = sum((gfr - xbar)^2)/length(gfr)hist(gfr, 20, main = "", xlab = 'GFR', freq = FALSE)a = xbar^2/s2; b = s2/xbarcurve(dgamma(x, shape = a, scale = b), add= TRUE, col = "blue")
9.3. MASSIMA VEROSIMIGLIANZA 27
GFR
Den
sity
20 40 60 80 100 120
0.00
0.01
0.02
0.03
Figura 9.1: Istogramma dei dati gfr e densità Gamma stimata col metodo dei momenti.
Il Teorema 9.6 enuncia (senza dimostrazione) le proprietà generali asintotiche (pern→∞) del metodo dei momenti. In particolare, gli stimatori del MM
1. sono consistenti θn →p θ
2. sono asintoticamente normali√n(θn − θ)↝ N(0,Σ)
Notate che l’affermazione 2 riguarda la convergenza in legge a una normale multivariatacon matrice di covarianza Σ di cui il libro parla nel Capitolo 5 a p. 78. Ritorneremo suquesto punto più avanti.
9.3 Massima verosimiglianza
Questo paragrafo è di fondamentale importanza perché il concetto di verosimiglianzapervade tutta la statistica. Un esempio iniziale è utile.
Illustrazione 9.2 (Un campione bernoulliano) Supponiamo che una linea di produzionefabbrichi caschi da moto. Su un campione casuale di 20 caschi prodotti vengono trovati4 caschi difettosi (per la precisione i caschi numero 4, 8, 9 e 15). Vogliamo stimare laproporzione di caschi difettosi nella popolazione. Assumendo che le 20 osservazioni sianoun campione casuale
(X1, . . . ,X20) ∼ Binom(1,p)
dove 0 < p < 1 è l’incognita probabilità di difettoso che vogliamo stimare. Allora ragionia-mo in questo modo: calcoliamo la probabilità dei dati osservati, la quale, sapendo che lafunzione di probabilità della Bernoulli f(x) = px(1 − p)1−x, x = 0, 1, risulta
P(X1 = x1, . . . ,Xn = xn) =n
∏i=1
P(Xi = xi) =n
∏i=1
pxi (1 − p)1−xi = pS(1 − p)n−S,
dove S = ∑ni=1 xi è il numero dei difettosi nel campione. La probabilità trovata è una fun-
zione del parametro detta funzione di verosimiglianza L(p) (L sta per likelihood) perché
28 9. INFERENZA PARAMETRICA
indica quanto è verosimile che il campione sia stato generato da un modello Bernoullicon parametro p. Il logaritmo della funzione di verosimiglianza viene detto funzione dilog-verosimiglianza e si indica con ℓ(p) = logL(p).
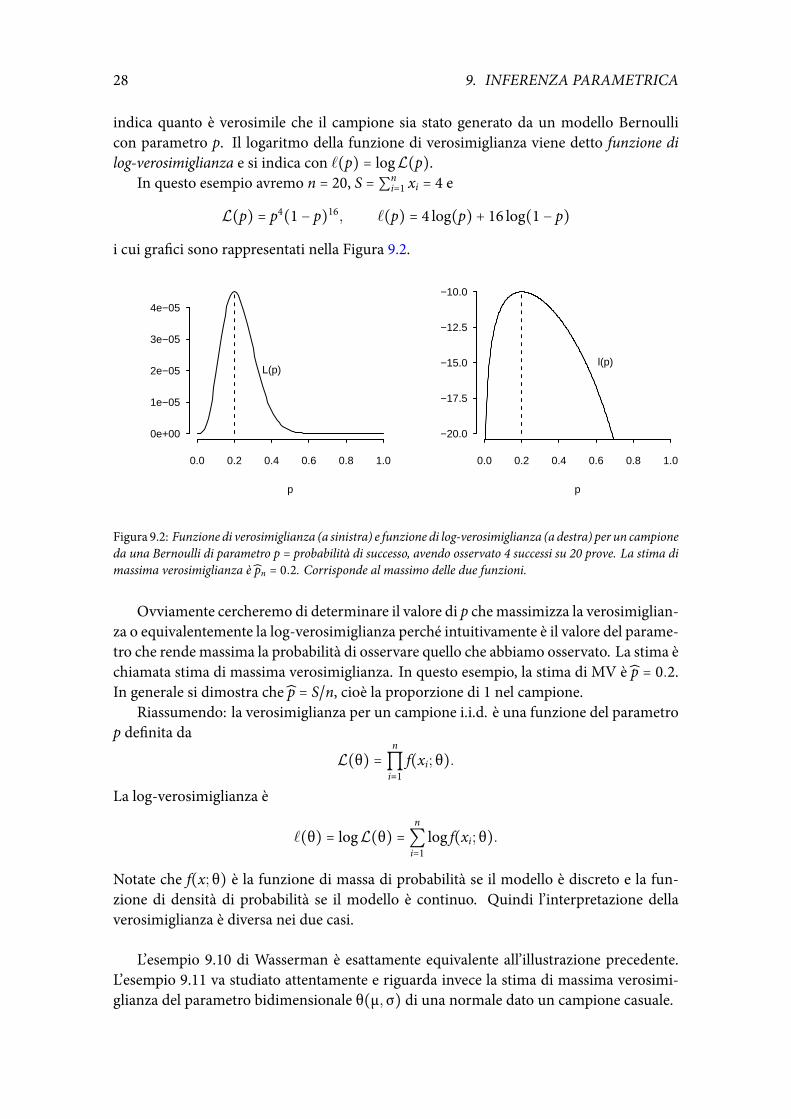
In questo esempio avremo n = 20, S = ∑ni=1 xi = 4 e
L(p) = p4(1 − p)16, ℓ(p) = 4 log(p) + 16 log(1 − p)
i cui grafici sono rappresentati nella Figura 9.2.
p
0.0 0.2 0.4 0.6 0.8 1.0
0e+00
1e−05
2e−05
3e−05
4e−05
L(p)
p
0.0 0.2 0.4 0.6 0.8 1.0
−20.0
−17.5
−15.0
−12.5
−10.0
l(p)
Figura 9.2: Funzione di verosimiglianza (a sinistra) e funzione di log-verosimiglianza (a destra) per un campioneda una Bernoulli di parametro p = probabilità di successo, avendo osservato 4 successi su 20 prove. La stima dimassima verosimiglianza è pn = 0.2. Corrisponde al massimo delle due funzioni.
Ovviamente cercheremo di determinare il valore di p chemassimizza la verosimiglian-za o equivalentemente la log-verosimiglianza perché intuitivamente è il valore del parame-tro che rende massima la probabilità di osservare quello che abbiamo osservato. La stima èchiamata stima di massima verosimiglianza. In questo esempio, la stima di MV è p = 0.2.In generale si dimostra che p = S/n, cioè la proporzione di 1 nel campione.
Riassumendo: la verosimiglianza per un campione i.i.d. è una funzione del parametrop definita da
L(θ) =n
∏i=1
f(xi; θ).
La log-verosimiglianza è
ℓ(θ) = logL(θ) =n
∑i=1
log f(xi; θ).
Notate che f(x; θ) è la funzione di massa di probabilità se il modello è discreto e la fun-zione di densità di probabilità se il modello è continuo. Quindi l’interpretazione dellaverosimiglianza è diversa nei due casi.
L’esempio 9.10 di Wasserman è esattamente equivalente all’illustrazione precedente.L’esempio 9.11 va studiato attentamente e riguarda invece la stima di massima verosimi-glianza del parametro bidimensionale θ(μ,σ) di una normale dato un campione casuale.

9.3. MASSIMA VEROSIMIGLIANZA 29
Avvertenza. Nell’esempio 9.11 il libro usa la notazione S2 per indicare la varianza cam-pionaria che in precedenza era stata indicata con σ2. Naturalmente non ha niente a chefare con il numero di successi S.
Illustrazione 9.3 (Stima di MV dei parametri di una Gamma) Dato un campione casuale(X1, . . . ,Xn) ∼ Gamma(α,β) la verosimiglianza è
L(α,β) =n
∏i=1
1Γ(α)βα xα−1
i e−xi/β
La log-verosimiglianza semplificando è
ℓ(α,β) = − log Γ(α)n − nα logβ + (α − 1) log [n
∏i=1
xi] −∑i xiβ
Le equazioni di verosimiglianza sono
−nΨ(α) − n log β +∑i log xi = 0
−nαβ+ ∑i xi
β2 = 0
dove Ψ(α) = ddα log Γ(α) è la cosiddetta funzione digamma. Risolvendo la seconda rispetto
a β risulta β = x/α e sostituendo nella prima equazione si ottiene l’equazione
−nΨ(α) − n logxα+∑
ilog yi = 0
che deve essere risolta numericamente rispetto ad α. In R la massimizzazione è ottenutacon le istruzioni seguenti applicate ai dati gfr:
library(MASS)fitdistr(gfr, 'gamma')
da cui otteniamo le stime di MV di α = 17.256 e di β = 1/0.318 = 3.14:
Fitting of the distribution ' gamma ' by maximum likelihoodParameters:
estimate Std. Errorshape 17.256381 1.66369895rate 0.318011 0.03110879
Notare che le stime sono diverse da quelle del metodo dei momenti. Come vedremo leproprietà del metodo dei momenti sono inferiori a quelle del metodo di MV.
Illustrazione 9.4 (A hard example: un modello non regolare) Supponete che il tempo diattesaX di un autobus sia distribuito uniformemente tra 0 e unmassimo θ > 0: X ∼ U(0, θ)e che abbiate un campione casuale di osservazioni (x1, . . . , xn) sui tempi di attesa. Qual èla stima di massima verosimiglianza di θ? La verosimiglianza è
L(θ) = f(x1, . . . , xn; θ) =⎧⎪⎪⎨⎪⎪⎩
1θn se θ ≥max{xi}0 se θ <max{xi}.
Per trovare il massimo non si può usare la derivata perché il massimo è in corrispondenzadi un punto di discontinuità della funzione, ma si vede che il massimo è x(n) =max{xi}.

30 9. INFERENZA PARAMETRICA
9.4 Proprietà dello stimatore di Massima Verosimiglianza
La stima di massima verosimiglianza è assai diffusa nell’inferenza classica ed è il metodoprincipale usato in ogni situazione.
• Perché è un metodo automatico. In ogni situazione, disponendo di un modello pa-rametrico, la stima θ di ottiene scrivendo la verosimiglianza e massimizzandola conun metodo numerico o addirittura con una forma chiusa.
• Perché ha ottime proprietà frequentiste asintotiche. Per grandi campioni gli stima-tori di MV sono asintoticamente non distorti, consistenti e con una varianza che èla minima possibile.
• Perché gli stimatori sono asintoticamente normali e la loro varianza si calcola auto-maticamente dalla verosimiglianza.
L’inferenza basata sul metodo di massima verosimiglianza è chiamata inferenza Fisherianain onore di Ronald Fisher (1890–1962) il principale scopritore del metodo.
Nota. Le proprietà frequentiste degli stimatori di MV riguardano il comportamento nelcampionamento ripetuto delle stime θn. Notate che la log-verosimiglianza è una funzionedi θ e dei dati campionari X = (X1, . . . ,Xn)
ℓn(θ,X) =n
∑i=1
log f(X; θ)
quindi il massimo θ(X) della log-verosimiglianza rispetto a θ (ammesso che esista e siaunico e finito) è una funzione dei dati campionari e quindi è una variabile aleatoria.
Notate che quando si parla di proprietà degli stimatori ci riferiamo a proprietà chevalgono per una classe molto ampia di modelli con verosimiglianza regolare¹.
Nelle dimostrazioni seguenti è essenziale capire bene la definizione di convergenza ilprobabilità e il legge e tenere presente i risultati importanti che seguono (cfr. a p. 75 dellibro).
Proposizione 9.1 (Relazioni tra tipi di convergenza)
Xn →p X Ô⇒ Xn ↝ XXn ↝ c per qualche reale c, Ô⇒ Xn →p c.
¹Si dice che il modello ha verosimiglianza regolare se
• Lo spazio parametrico Θ è un aperto di Rd
• ℓ(θ) è derivabile almeno tre volte
• con derivate (parziali) continue in Θ.
• θn esiste ed è unica ed è un punto interno di Θ
• Il supporto della funzione di densità f(x; θ) non dipende dal parametro
• È possibile derivare ∫Y f(y; θ)dy due volte sotto il segno di integrale.

9.5. CONSISTENZA DELLA STIMA DI MV 31
Proposizione 9.2 (Lemma della funzione continua) Se g è una funzione continua
Xn →p X Ô⇒ g(Xn)→p g(X)Xn ↝ X Ô⇒ g(Xn)↝ g(X).
Proposizione 9.3 (Lemma di Slutsky) Se Xn ↝ X e Yn ↝ c dove c è una costante allora
Xn + Yn ↝ X + c, XnYn ↝ cX
9.5 Consistenza della stima di MV
Il libro introduce la divergenza di Kullback-Leibler tra due densità
D(f, g) = ∫ f(x) log f(x)g(x)
dx = Ef [logf(x)g(x)]
È unmodo per misurare l’informazione aggiuntiva necessaria per ottenere f partendo da g.
Proposizione 9.4 (Disuguaglianza di Shannon.) Risulta sempre che D(f, g) ≥ 0. Si haD(f, g) = 0 se e solo se f = g.
Dimostrazione. Poiché
D(f, g) = Ef [logf(x)g(x)] = Ef [− log
g(x)f(x)]
e poiché − log è una funzione strettamente convessa, per la disuguaglianza di Jensen²
D(f, g) > − logEf [g(x)f(x)] = − log∫
x∶f(x)>0
g(x)f(x)
f(x)dx = 0
se {x ∶ f(x) > 0} ha probabilità 1 sotto g(x) e con uguaglianza se e solo se f(x)/g(x) ècostante con probabilità 1.
Una condizione necessaria per dimostrare la consistenza dello stimatore diMVè l’iden-tificabilità del modello: dati due parametri θ,ψ ∈ Θdifferenti, cioè tale che θ ≠ ψ, le densitàcorrispondenti sono differenti e D(fθ, fψ) = D(θ,ψ) > 0.
Ecco il risultato di consistenza e la sua dimostrazione in un caso particolare (che nellibro è riportata in appendice).
Proposizione 9.5 (Consistenza dello stimatore di MV) Se lo spazio parametrico è finito eil modello è identificabile allora θn →p θ⋆.
Dimostrazione. Sia X1, . . . ,Xn ∼ X ∼ f(x; θ), e sia θ⋆ il vero valore del parametro che hagenerato i dati. Allora la stima di MV si ottiene equivalentemente massimizzando
Mn(θ) = 1n{ℓn(θ) − ℓn(θ⋆)} =
1n ∑
ni=1 log
f(Xi;θ)f(Xi;θ⋆) .
²È spiegata nel Teorema 4.9 a p. 66 del libro. In sintesi se T(⋅) è strettamente convessa E[T(X)] >T[E(X)].

32 9. INFERENZA PARAMETRICA
Per la legge dei grandi numeri al crescere di n,Mn(θ) converge con probabilità 1 (e quindiin probabilità) a −D(θ, θ⋆):
Mn(θ)→p Ef (f(X; θ)f(X; θ⋆)
) = −D(θ⋆, θ)
che è sempre negativa a meno che θ = θ⋆.Quindi poiché θ = θn è il valore che massimizza Mn(θ)
P(θn ≠ θ⋆) = P(maxθ≠θ⋆
1n
n
∑i=1
logf(Xi; θ)f(Xi; θ⋆)
> 0)
≤ ∑θ≠θ⋆
P(1n
n
∑i=1
logf(Xi; θ)f(Xi; θ⋆)
> 0)
→ 0 per n→∞.
Questo implica che θn →p θ⋆.
Notare che la disuguaglianza deriva dalla disuguaglianza di Boole³.
9.6 Equivarianza
L’equivarianza è una proprietà molto utile degli stimatori di MV. Non è una proprietàasintotica, ma esatta che permette di ottenere subito la stima di massima verosimiglianzadopo una riparametrizzazione.
Proposizione 9.6 (Equivarianza della stima diMV) Se θ è lo stimatore diMV di θ e g ∶ Θ →T è una funzione biunivoca allora lo stimatore di MV di τ = g(θ) è g(θ).
Dimostrazione. Sia h = g−1 l’inversa di g e sia θ = h(τ). Le verosimiglianza nella parame-trizzazione τ e nella parametrizzazione θ sono identiche perché
L(τ)(τ) =∏if(Xi;h(τ)) = L(θ)(h(τ))
e τ e h(τ) identificano lo stesso modello probabilistico. Di conseguenza, se esiste la stimadi MV θ di θ, essa è legata alla stima di MV di τ dalla relazione τ = g(θ).
Ecco alcuni esempi.
Illustrazione 9.5 (Stima del tasso di guasto) Sia dato un campione casuale di durate Xi ∼Exp(β) esponenziali con parametro β = E(X). La stima di MV di β si ottiene facilmente:
L(β) =∏i
1βe−xi/β, ℓ(β) = −n log β −∑
ixi/β
³Infatti,
P(max{X,Y} > 0) = 1 −P(X ≤ 0 ∩ Y ≤ 0) = P(X > 0 ∪ Y > 0) ≤ P(X) +P(Y)
per la disuguaglianza di Boole.

9.7. NORMALITÀ ASINTOTICA 33
Derivando si ottiene l’equazione di verosimiglianza
ℓ′(β) = −nβ+ nx
β2 = 0, (β > 0)
da cui si ottiene β = x.Il parametro λ = 1/β è il tasso istantaneo di guasto dell’esponenziale. Qual è la sua
stima di MV? Il modo diretto è quello di riparametrizzare la verosimiglianza:
L∗(λ) =∏i λe−λxi , ℓ∗(λ) = n log λ − λ∑i xi.
Derivando ℓ∗ e uguagliando a zero abbiamo ℓ′∗(λ) = n/λ − nx = 0 da cui
λ = 1/x = 1/β.
Per ottenere questo risultato bastava invocare l’equivarianza degli stimatori di verosimi-glianza.
Notate che β ↦ λ = 1/β è una biiezione g ∶ (0,∞) → (0,∞). Osservate anche che lostimatore λ non è corretto per λ perché
E(1/X) ≠ 1/E(X) = 1/E(X) = 1/β = λ.
Illustrazione 9.6 (Stima dimassima verosimiglianza del logit) Dato un campione i.i.d. dalmodello di Bernoulli con parametro p, la stima diMVdi p è p = S/n dove S è la proporzionedi 1.
Talvolta invece della probabilità di successo p conviene usare un parametro diverso,detto logit definito da
φ = logit(p) = log[p/(1 − p)] = log(p) − log(1 − p).
Il vantaggio del logit è quello di non essere compreso in un intervallo limitato, ma di poterassumere qualsiasi valore reale. Infatti il logit è una funzione biunivoca che trasforma unaproporzione compresa tra 0 e 1, in un numero reale. Le probabilità comprese tra 0.2 e 0.8sono trasformate in modo quasi lineare tra −1.4 e 1.4.
Il rapporto p/(1 − p) è usato frequentemente nel mondo delle scommesse e si chiamaquota (in inglese odds). Spiegazione: se alla roulette si scommette un euro sul rosso si hadiritto ad avere oltre alla posta un altro euro. La scommessa è data 1 a 1 e la quota e 1. Se siscommette un euro su un evento che ha probabilità 1/4, si ha diritto ad avere 3 euro oltrealla posta perché la scommessa è data 1 a 3 e la quota è infatti p/(1−p) = (0.25/0.75) = 1/3.
La stima di massima verosimiglianza del logit φ = log[p/(1 − p)] per l’equivarianza èsemplicemente
φ = logp
1 − p= log
Sn − S
.
9.7 Normalità asintotica
Nei modelli con verosimiglianza regolare le informazioni fondamentali per fare inferenzasono contenute nelle derivate parziali della log-verosimiglianza rispetto a θ.
Sia dato il campione casuale X = (X1, . . . ,Xn) ∼ f(x; θ), con θ unidimensionale. Allorain un modello regolare dove è possibile derivare due volte la log-verosimiglianza:

34 9. INFERENZA PARAMETRICA
• La derivata prima della log-verosimiglianza per una osservazione x si dice score cioèpunteggio
s(X, θ) = ℓ′(θ;X)Lo score per il campione X = (Xi, i = 1, . . .n) è la somma dei punteggi
s(X, θ) =n
∑i=1
s(Xi, θ) =n
∑i=1
ℓ′(Xi, θ).
Lo score s(X, θ), per θ, fissato è una statistica campionaria. Nel campionamentoripetuto è una variabile aleatoria.
• La varianza dello score si dice informazione di Fisher
In(θ) = varθ{s(X, θ)}.
Per capire il significato dell’informazione di Fisher è utile la proposizione seguente.
Proposizione 9.7 (Informazione attesa e osservata) Risulta che
In(θ) = Eθ[−ℓ′′(θ;X)].
La proposizione introduce la derivata seconda della log-verosimiglianza cambiata disegno. Questa quantità è una misura della curvatura della log-verosimiglianza in un pun-to. L’informazione di Fisher è la curvatura media della log-verosimiglianza, nel campio-namento ripetuto. Per questo si chiama anche informazione attesa.
Ecco la dimostrazione.
Dimostrazione. a) Per prima cosa dimostriamo che lo score per una osservazione ha valoreatteso nullo:
Eθ[s(X; θ)] = 0. (9.1)
Caso continuo. Si parte dall’identità
1 = ∫ f(x; θ)dx (9.2)
e si considerano le derivate rispetto a θ di ambo i membri, ottenendo:
0 = ddθ ∫
f(x; θ)dx
Se le condizioni di regolarità sono soddisfatte, allora possiamo scambiare le operazioni diintegrazione e derivazione:
0 = ∫ddθ
f(x; θ)dx
= ∫ { ddθ log f(x; θ)}f(x; θ)dx
= ∫ ℓ′(θ; x)f(x; θ)dx
= Eθ[s(θ;X)].

9.7. NORMALITÀ ASINTOTICA 35
Quindi anche la statistica score per il campione s(X, θ) = ∑i s(Xi, θ) ha valore atteso zero.Notiamo poi che
In(θ) = varθ[∑ni=1 s(Xi, θ)] = ∑n
i=1 varθ[s(Xi, θ)]
data l’indipendenza delle osservazioni Xi. Poi, denotando con I(θ) = varθ[s(Xi, θ)] l’in-formazione di Fisher per l’osservazione Xi (identica per ogni osservazione), abbiamo
In(θ) = nI(θ) = n{Eθ(s(X, θ)2) − Eθ[s(X, θ)]2} = nEθ[s(X, θ)2].
Derivando per la seconda volta l’identità (9.2) abbiamo
0 = ddθ ∫
ℓ′(θ; x)f(x; θ)dx
= ∫ddθ{ℓ′(θ; x)f(x; θ)}dx
= ∫ ℓ′′(θ; x)f(x; θ) + ℓ′(θ; x) ddθ
f(x; θ)dx
= ∫ ℓ′′(θ; x)f(x; θ) + ℓ′(θ; x)ℓ′(θ; x)f(x; θ)dx
= ∫ ℓ′′(θ; x)f(x; θ)dx + ∫ ℓ′(θ; x)2f(x; θ)dx
= −Eθ[−ℓ′′(θ;X)] + Eθ[s2(X, θ)].
Quindi I(θ) = E[−ℓ′′(θ;X)] e In(θ) = E[−ℓ′′(θ;X)].
Illustrazione 9.7 (Modello di Bernoulli) Nelmodello di Bernoulli, (X1, . . . ,Xn) ∼ Binom(1, θ)(dove θ = p) la log-verosimiglianza è
ℓ(θ) = S log(θ) + (n − S) log(1 − θ),
e la stima di MV è la proporzione di successi θ = Xn = S/n dove S = ∑iXi.La derivata seconda cambiata di segno è
−ℓ′′(θ;X) = Sθ2 −
n − S(1 − θ)2
e quindi nel punto di massimo θ = S/n (assumendo S ≠ 0, S ≠ n) risulta
−ℓ′′(θ,X) = nθ(1 − θ)
.
L’informazione di Fisher è
In(θ) = Eθ (Sθ2 −
n − S(1 − θ)2
) = nθ(1 − θ)
.
Per altri esempi vedete (e fate) gli esercizi a fine capitolo.
36 9. INFERENZA PARAMETRICA
Approssimazione della log-verosimiglianza relativa Sviluppando in serie di Taylor alsecondo ordine la log-verosimiglianza si ottiene
ℓ(θ) ≃ ℓ(θ) + ℓ′(θ)(θ − θ) + 12ℓ′′(θ)(θ − θ)2
Se abbiamo un solo massimo, risultano ℓ′(θ) = 0 e ℓ′′(θ) < 0. Quindi posto v2 =−1/ℓ′′(θ) > 0 abbiamo
ℓ(θ) − ℓ(θ) ≃ − 12v2 (θ − θ)2.
La funzione a primo membro è il log della verosimiglianza relativa
ℓ(θ) − ℓ(θ) = logL(θ)L(θ)
e la sua approssimazione quadratica è una parabola con vertice in θ e concavità verso il bas-so, con una curvatura tanto maggiore quanto più piccola è v2. La curvatura è direttamenteproporzionale a n come si vede dall’esempio seguente.
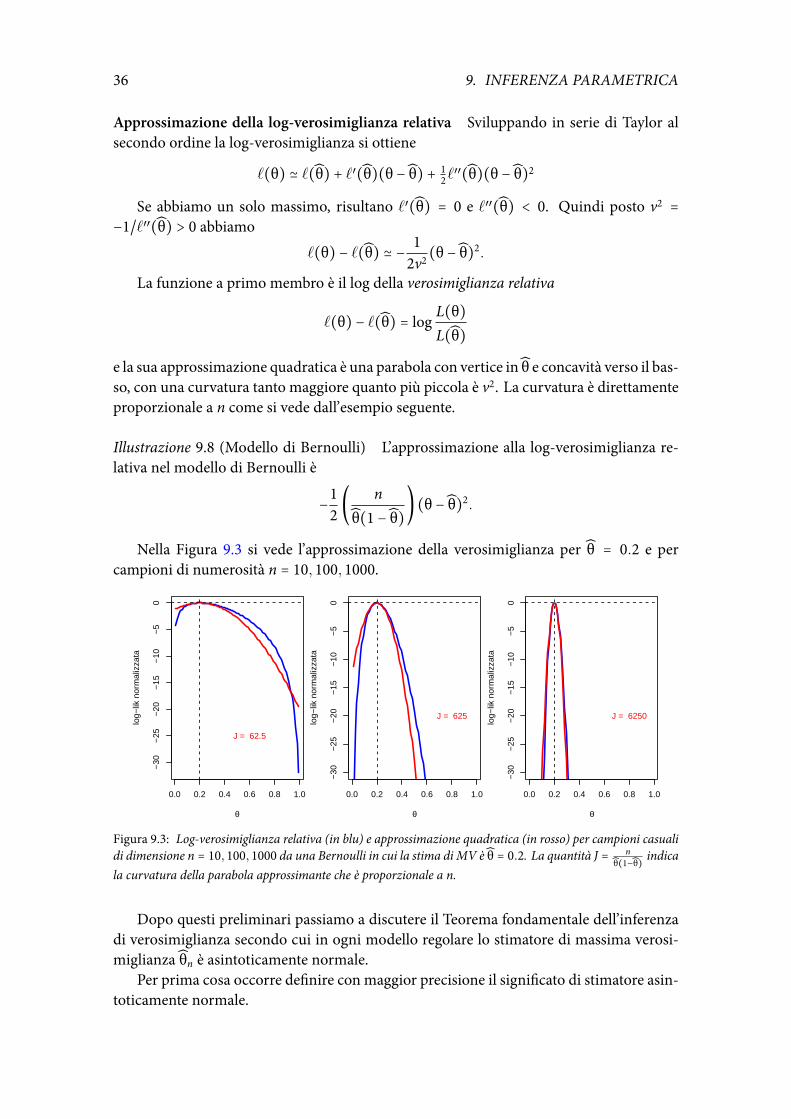
Illustrazione 9.8 (Modello di Bernoulli) L’approssimazione alla log-verosimiglianza re-lativa nel modello di Bernoulli è
−12( nθ(1 − θ)
) (θ − θ)2.
Nella Figura 9.3 si vede l’approssimazione della verosimiglianza per θ = 0.2 e percampioni di numerosità n = 10, 100, 1000.
0.0 0.2 0.4 0.6 0.8 1.0
−30
−25
−20
−15
−10
−5
0
θ
log−
lik n
orm
aliz
zata
J = 62.5
0.0 0.2 0.4 0.6 0.8 1.0
−30
−25
−20
−15
−10
−5
0
θ
log−
lik n
orm
aliz
zata
J = 625
0.0 0.2 0.4 0.6 0.8 1.0
−30
−25
−20
−15
−10
−5
0
θ
log−
lik n
orm
aliz
zata
J = 6250
Figura 9.3: Log-verosimiglianza relativa (in blu) e approssimazione quadratica (in rosso) per campioni casualidi dimensione n = 10, 100, 1000 da una Bernoulli in cui la stima di MV è θ = 0.2. La quantità J = n
θ(1−θ)indica
la curvatura della parabola approssimante che è proporzionale a n.
Dopo questi preliminari passiamo a discutere il Teorema fondamentale dell’inferenzadi verosimiglianza secondo cui in ogni modello regolare lo stimatore di massima verosi-miglianza θn è asintoticamente normale.
Per prima cosa occorre definire con maggior precisione il significato di stimatore asin-toticamente normale.

9.7. NORMALITÀ ASINTOTICA 37
Definizione 9.1 Si dice che uno stimatore Tn(X) = Tn(X1, . . . ,Xn) è asintoticamentenormale se esiste una successione numerica θn tale che
√n(Tn − θn)↝ N(0,ω2) per n→∞.
In tal caso si può approssimare la distribuzione di Tn per un n grande ma finito conTn ≈ N(θn,ω2/n).
• La quantità ω2/n si dice varianza asintotica dello stimatore Tn.
• L’errore standard asintotico dello stimatore è
se(Tn) = ω/√n
Il risultato fondamentale è il Teorema 9.18 del libro. I dati (X1, . . . ,Xn) siano un campionecasuale da un modello regolare con un parametro unidimensionale θ.
Teorema 9.1 (Cramér) Se il modello è regolare, la successione di stimatori di massimaverosimiglianza θn è asintoticamente normale, con varianza asintotica
I(θ)−1 = n/In(θ).
Inoltre,θn − θ√1/In(θ)
↝ N(0, 1), θn − θ√
1/In(θn)↝ N(0, 1)
dove il denominatore è l’errore standard. La normalità asintotica si ha anche se si sostituiscea θ, la stima di MV θn.
Il fatto di conoscere automaticamente che per un gran numero di modelli si conosceesattamente la distribuzione asintotica di Z = (θn − θ)/se permette di usare Z come pivot ecostruire un intervallo di confidenza senza difficoltà. Tipicamente si calcola un intervalloθn ± 2se con livello di confidenza approssimato 95% (vedi Wasserman (2004), p. 129).
Illustrazione 9.9 (Campione casuale dall’esponenziale) Sia (X1, . . . ,Xn) ∼ Exp(λ) il mo-dello esponenziale parametrizzato con il tasso di guasto λ = 1/β > 0. La funzione punteg-gio è
s(X; λ) = ddλ ∑i(log λ − λXi) =
nλ−∑iXi =
nλ−∑
iXi,
dove∑iXi ∼ Gamma(n, 1/λ). Quindi l’informazione attesa risulta
In(λ) = varλ (nλ −∑iXi) = varλ(∑iXi) =nλ2 .
Lo stimatore di massima verosimiglianza del tasso di guasto λ = 1/Xn ha distribuzioneasintotica normale. Il suo errore standard asintotico è se(λ) = λ/
√n = 1/(Xn
√n).
Ecco la dimostrazione che nel libro è riportata in Appendice.

38 9. INFERENZA PARAMETRICA
Dimostrazione. Consideriamo l’approssimazione di Taylor della funzione score s(θ,X) =ℓ′(θ;X) nel punto θn.
ℓ′(θn) = 0 = ℓ′(θ) + (θn − θ)ℓ′′(θ) + 12(θn − θ)2ℓ′′′(θ∗n)
dove θ∗n è compresa tra θ e θn. Quindi⁴,
0 ≈ ℓ′(θ) + (θn − θ)ℓ′′(θ).
Dopo qualche semplificazione si può scrivere√n(θn − θ) = ℓ′(θ)/
√n
−ℓ′′(θ)/n≡ numn
dennAllora, posto Yi = S(θ,Xi) = d
dθ log f(Xi; θ) e Y = ∑i Yi/n risulta
numn = n−1/2∑iYi =√nY
poiché E(Yi) = 0 e var(Yi) = I(θ), per il TCL, per n→∞,
numn =√n(Y − 0)↝W ∼ N(0, I(θ)).
Quindi guardiamo il denominatore e per la Proposizione 9.7 sappiamo che
denn =1n∑i−ℓ′′(θ;Xi)→p I(θ)
per la LGN. Pertanto, per il lemma di Slutsky 9.3, p. 31 (ricordate che se U →p c alloraU↝ c),
numn
denn↝ W
I(θ)∼ N(0, I(θ)−1).
L’ultima parte della dimostrazione sul libro spiega che se si usa I(θn) invece di I(θ) siottiene lo stesso la convergenza in legge alla normale. Infatti, si nota che I(θn)→p I(θ) e ilrisultato segue dal lemma di Slutsky.
Non invarianza dell’informazione Fisher. L’informazione non è invariante rispetto ariparametrizzazioni del modello.
Illustrazione 9.10 (Campione casuale dall’esponenziale (segue)) Sia (X1, . . . ,Xn) ∼ Exp(β)il modello esponenziale parametrizzato con la media β > 0. Lo score è
s(X;β) = ddβ∑i(− log β − Xi/β) = −
nβ+ S
β2 ,
e quindiIn(β) = varβ(s(X;β)) =
1β4nβ
2 = nβ2
ricordando che varβ(S) = nβ2. Quindi l’errore standard asintotico dello stimatore di MVβ = Xn è se(β) = β/
√n.
⁴Qui il libro, semplifica, omettendo perché per n → ∞ si può omettere il resto di Lagrange. Questorichiede una condizione supplementare sulla derivata terza della log-verosimiglianza.

9.8. OTTIMALITÀ 39
9.8 Ottimalità
Nel libro si confronta l’efficienza relativa della media θn rispetto alla mediana campio-naria θn in un modello normale (X1, . . . ,Xn) ∼ N(θ,σ2). Verifichiamo con una simula-zione che la varianza asintotica della mediana è π
2σ2/n. La simulazione estrae campionidi numerosità 100 da una N(θ = 50,σ2 = 200). Ci aspettiamo di trovare la varianza èvar(θn) = (σ2/n)(π/2) = π. Ecco il codice.
B = 10000; med = rep(0,B); n = 500; th = 10; sigma2 = 1000for(i in 1:B){
x = rnorm(n, mean = th, sd = sqrt(sigma2))med[i] = median(x)
}MSE = mean((med - th)^2)bias = mean((med - th))variance = var(med)c(MSE, bias, variance)
hist(med, 100, main = "", freq = FALSE, ylim = c(0, 0.4))curve(dnorm(x, mean = 10, sd = sqrt(2)), add = TRUE)
9.9 Il Metodo Delta
Se Tn è uno stimatore asintoticamente normale il metodo delta permette di trovare ladistribuzione limite di una trasformazione g(Tn) dove g(⋅) è una funzione liscia.
Proposizione 9.8 (Metodo Delta) Sia Tn una successione di v.a. tale che√n(Tn − θ)↝ N(0,ω2), (ω > 0)
Se g(⋅) è una funzione derivabile tale che g′(θ) ≠ 0 allora√n [g(Tn) − g(θ)]↝ N(0, g′(θ)2ω2).
Dimostrazione del Metodo Delta. Schema di dimostrazione. Siccome g è continua g(Tn)sarà vicina a g(θ) con elevata probabilità. Usiamo lo sviluppo di Taylor di g(Tn) al se-cond’ordine rispetto a θ:
g(Tn) ≃ g(θ) + g′(θ)(Tn − θ)
Il resto converge a zero in probabilità. Quindi possiamo scrivere, dopo aver moltiplicatoambo i membri per
√n,
√ng(Tn) − g(θ)
g′(θ)≃√n(Tn − θ)
Quindi la distribuzione a primo membro avrà approssimativamente la stessa distribu-zione di quella a secondo membro che converge in legge a una normale N(0,ω2).

40 9. INFERENZA PARAMETRICA
L’applicazione tipica del metodo delta avviene per gli stimatori di MV che sono asin-toticamente normali. In tal caso conoscendo l’errore standard asintotico di θn possiamotrovare l’errore standard asintotico di g(θn) con la regola
se(g(θn)) = se(θn)∣g′(θn)∣ (9.3)
9.10 Modelli multiparametrici
Supponiamo che (X1, . . . ,Xn) ∼ f(x; θ) con θ = (θ1, . . . , θk) ∈ Θ ⊆ Rk. Le quantità diverosimiglianza sono legate al gradiente e all’Hessiano della log-verosimiglianza ℓn(θ;X).L’informazione di Fisher è una matrice k × k ottenuta come valore atteso dell’Hessianocambiato di segno.
In(θ) = −[Iij(θ)], Iij(θ) = −E(∂2ℓn∂θi∂θj
) .
Il teorema di Cramér si generalizza introducendo la matrice inversa dell’informazioneI−1n (θ) = [Iij(θ)]. Si dimostra sotto opportune assunzioni di regolarità che lo stimato-re congiunto di MV θn converge in legge a una normale multivariata (una generalizza-zione della normale che studieremo più avanti). In particolare ogni componente θi èasintoticamente normale
√n(θi − θi)↝ N(0, Iii(θ))
dove Iii(θ) è la varianza asintotica di θi.
9.11 Bootstrap parametrico
Per esemplificare il bootstrap parametrico che è veramente semplice da applicare vediamoquesto esempio relativo a un campione da un’esponenziale.
Illustrazione 9.11 (Tasso di guasto di condizionatori) La durata di un impianto di condi-zionamento su un aereo è un tipico problema di affidabilità. Il tempo che intercorre finoal guasto è chiaramente una variabile aleatoria continua. I dati seguenti sono stati raccoltiin 171 casi relativi ad impianti di condizionamento di aerei Boeing 720. I dati sono tempiarrotondati in ore e quindi benché il tempo sia una grandezza continua si presentano comenumeri interi. Il file si trova sul sito web del corso col nome proschan.txt.
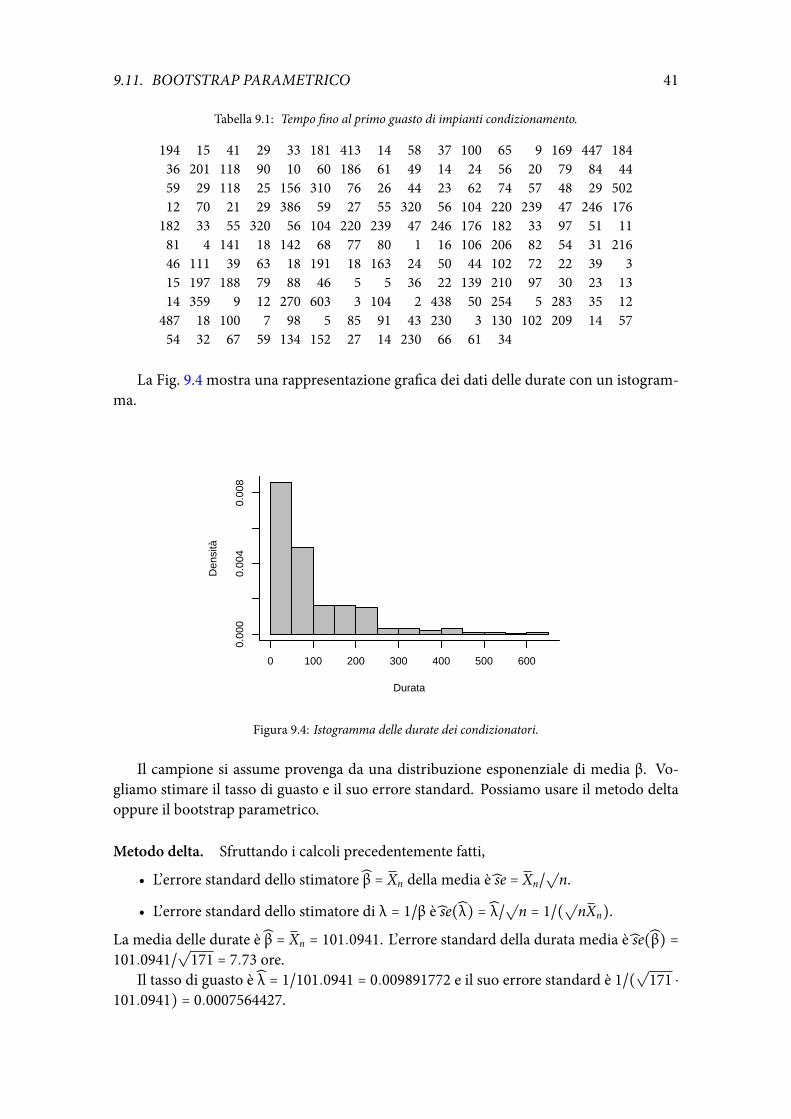
9.11. BOOTSTRAP PARAMETRICO 41
Tabella 9.1: Tempo fino al primo guasto di impianti condizionamento.
194 15 41 29 33 181 413 14 58 37 100 65 9 169 447 18436 201 118 90 10 60 186 61 49 14 24 56 20 79 84 4459 29 118 25 156 310 76 26 44 23 62 74 57 48 29 50212 70 21 29 386 59 27 55 320 56 104 220 239 47 246 176
182 33 55 320 56 104 220 239 47 246 176 182 33 97 51 1181 4 141 18 142 68 77 80 1 16 106 206 82 54 31 21646 111 39 63 18 191 18 163 24 50 44 102 72 22 39 315 197 188 79 88 46 5 5 36 22 139 210 97 30 23 1314 359 9 12 270 603 3 104 2 438 50 254 5 283 35 12
487 18 100 7 98 5 85 91 43 230 3 130 102 209 14 5754 32 67 59 134 152 27 14 230 66 61 34
La Fig. 9.4 mostra una rappresentazione grafica dei dati delle durate con un istogram-ma.
Durata
Den
sità
0 100 200 300 400 500 600
0.00
00.
004
0.00
8
Figura 9.4: Istogramma delle durate dei condizionatori.
Il campione si assume provenga da una distribuzione esponenziale di media β. Vo-gliamo stimare il tasso di guasto e il suo errore standard. Possiamo usare il metodo deltaoppure il bootstrap parametrico.
Metodo delta. Sfruttando i calcoli precedentemente fatti,
• L’errore standard dello stimatore β = Xn della media è se = Xn/√n.
• L’errore standard dello stimatore di λ = 1/β è se(λ) = λ/√n = 1/(
√nXn).
La media delle durate è β = Xn = 101.0941. L’errore standard della durata media è se(β) =101.0941/
√171 = 7.73 ore.
Il tasso di guasto è λ = 1/101.0941 = 0.009891772 e il suo errore standard è 1/(√
171 ⋅101.0941) = 0.0007564427.

42 9. INFERENZA PARAMETRICA
Bootstrap parametrico. Si tratta di estrarre B campioni i.i.d. di dimensione n = 171 daExp(λ) ottenendo da ciascuno i tassi di guasto
λ∗1 , . . . , λ
∗B
e quindi calcolareseboot =
√1B ∑
Bb=1(λ
∗b − λ)2.
Ecco il codice R:
b = 2000lam = rep(0, B)lamh = 1/101.0941for(b in 1:B){
x = rexp(171, rate = lamh)lam[b] = 1/mean(x)
}seboot = sqrt(sum((lam - lamh)^2)/B)seboot[1] 0.0007987644
9.12 Verifica delle assunzioni
Leggere.
9.13 Appendice
9.13.1 Proofs
Le dimostrazioni sono riportate prima in queste note.
Avvertenza. Le sezioni dalla 9.13.2 in poi le saltiamo.

10
verifica di ipotesi e valori p
10.1 Riassunto
I test delle ipotesi sono una particolare forma di inferenza frequentista in cui si usano i datiper confutare omantenere un’ipotesi di baseH0 su un parametro θ. Vogliamo scegliere unaregola di decisione che nel lungo andare permetta di fare meno errori.
Terminologia
• Ipotesi H0: θ ∈ Θ0 ⊂ Θ. Nel caso unidimensionale Θ0 può essere di tipo
puntuale Θ0 = {θ ∈ Θ ∶ θ = θ0}unilaterale Θ0 = {θ ∈ Θ ∶ θ ≥ θ0}.
• Ipotesi semplice: se Θ0 è un singleton e quindi identifica una singola distribuzionedella popolazione
• Ipotesi composita: se Θ0 non è un singleton
• Ipotesi alternativa H1 ∶ θ ∈ Θ ∖Θ0
• Statistica test: una statisticaT(X1, . . . ,Xn) chemisuri l’allontanamento dei dati dall’ipo-tesi H0
• Regione critica: un sottoinsieme R ⊂ X dello spazio campionario che definisce laregola di decisione. Se (X1, . . . ,Xn) ∈ R si rifiuta H0. Altrimenti si mantiene.
• Errore di tipo I: rifiutare H0 quando è vera (condannare un innocente)
• Errore di tipo II: accettare H0 quando è falsa (liberare un colpevole)
• Potenza del test: la probabilità di rifiutare H0 al variare del valore di θ
β(θ) = Pθ{(X1, . . . ,Xn) ∈ R}
• Ampiezza del test: il sup della probabilità di errore del primo tipo
• Livello del test: una probabilità α tale che l’ampiezza del test sia sempre ≤ α
43

44 10. VERIFICA DI IPOTESI E VALORI P
Illustrazione 10.1 (Controllo di qualità) Come manager responsabile del controllo dellaqualità di un fast food vuoi essere sicuro che gli hamburger surgelati consegnati dal tuofornitore pesino in media 100 g. Sai già che la deviazione standard del peso degli hambur-ger è 3g. Per rifiutare una consegna di hamburger, usi questa regola di decisione: rifiutila consegna se il peso medio di un campione casuale di 20 hamburger è inferiore a 98 g.Qual è il sup della probabilità di errore del primo tipo?
L’ipotesi nulla è H0 ∶ μ ≥ 100 dove μ = E(X) e X è il peso di un hamburger. Se suppo-niamo che X ∼ N(μ,σ = 3) e abbiamo un campione (X1, . . . ,X20) la probabilità di erroredel primo tipo è
P(X < 98;μ ≥ 100) = P(Z < 98 − μ3/√
20) = Φ( 98 − μ
3/√
20)
che si verifica essere una funzione strettamente decrescente. Quindi il sup si ottiene perμ = 100. Pertanto l’ampiezza del test è
Φ(98 − 1003/√
20) = Φ(−2.981) = 0.0014.
Viceversa, supponiamo di volere un test di livello α = 0.01. Qual’è la regione critica dausare per X? Basta procedere in questo modo
supμ≥100
P(X < k) = P(Z < k − 1003/√
20) = Φ ((k − 100)/0.67) = 0.01
Quindi, invertendo,
(k − 100)/0.67 = Φ−1(0.01) = −2.33 ⇐⇒ k = 100 − (2.33)(0.67) = 98.439.
e la regione di rifiuto è X < 98.439.
10.2 Il test di Wald
Di solito il test di Wald si adopera avendo lo stimatore di MV di θ e il suo errore standardstimato. Si usa per il test di un’ipotesi θ = θ0 contro l’alternativa bilaterale θ ≠ θ0. Lastatistica test è
W = θn − θ0
se0=√I(θ0)(θn − θ0)↝ N(0, 1)
la cui distribuzione asintotica sotto H0 è N(0, 1). Asintoticamente l’ampiezza del test haampiezza α.
La regione critica usata è R = {(X1, . . . ,Xn) ∶ ∣W∣ > z1−α/2}. Si può usare equivalente-
mente la statistica test W =√I(θn)(θn − θ0).
La probabilità di corretto rifiuto si calcola usando il teorema 10.6. Verificate per eser-cizio.

10.2. IL TEST DI WALD 45
Test su una differenza di proporzioni, campioni indipendenti. Il modello è più com-plicato del solito. Qui supponiamo di avere due campioni casuali indipendenti. Le osser-vazioni sono
(X1, . . . ,Xm) ∼ Binom(1,p1), (Y1, . . . ,Yn) ∼ Binom(1,p2)
e sono i.i.d. separatamente leX e leY. Complessivamente sono solo indipendenti. Volendoverificare se p1 = p2 possiamo introdurre il parametro δ = p1 − p2 e sottoporre a test H0 ∶δ = 0 contro H1 ∶ δ ≠ 0 usando la statistica test di Wald. Poiché δ = p1 − p2 e δ0 = 0,
W = p1 − p2
se(δ)
e si dimostra subito che
se(δ) =√
p1(1 − p1)m
+ p2(1 − p2)n
.
Illustrazione 10.2 (Sconsigliati al test di ingresso) Al test di ingresso a Economia sonosconsigliati gli studenti che hanno preso un punteggio inferiore a 8. I risultati di una provarecente sono i seguenti:
Punteggio Liceo Tecnico≥ 8 576 373< 8 38 42
Totale 614 415
La probabilità di fallire il test è uguale fra gli studenti provenienti dai Licei e quelli prove-nienti da gli Istituti Tecnici? Il sistema di ipotesi è H0 ∶ δ = 0 contro H1 ∶ δ ≠ 0. I calcoli dafare sono
p1 = 38/614 = 0.061, p2 = 42/415 = 0.10
Come si vede δ = −0.039. Quindi la differenza tra le proporzioni è leggermente a favore deiLicei. Tuttavia la domanda è piuttosto: questa differenza potrebbe semplicemente esseredovuta al caso? Per valutarla calcoliamo l’errore standard se =
√v21 + v2
2 dove
v21 = p1(1 − p1)/614, v2
2 = p2(1 − p2)/415
da cui se = 0.0177. Il test di Wald è dunque
W = −0.0390.0177
= −2.2
Questo valore porta a rifiutare l’ipotesi H0? La regione di rifiuto R dipende dall’ampiezzadel test. Se vogliamo α = 0.01 la regione critica approssimata per W è
R = {W < −z1−α/2} ∪ {W > z1−α/2} = {W < −2.58} ∪ {W > 2.58}.
Quindi non rifiutiamo H0. Verificate se per un ampiezza α = 0.05 si prenderebbe la stessadecisione.

46 10. VERIFICA DI IPOTESI E VALORI P
FM
0 5 10 15 20 25
Figura 10.1: Due box-plot appaiati relativi al punteggio al test di ammissione alla Facoltà di Economia diFirenze, nel 2013, distinti per sesso (M = maschi, F = femmine).
Test su una differenza di proporzioni: campioni dipendenti. Una situazione diversa siha se i dati sono appaiati (X1,Y1), . . . , (Xn,Yn). L’esempio del libro è utile quando si vo-gliono confrontare sugli stessi dati due metodi di previsione. Xi vale 0 o 1 se la previsionedel primo metodo è sbagliata o corretta su dataset i. Analogamente per Yi. In questo casoabbiamo Xi ∼ Binom(1,p1) e Yi ∼ Binom(1,p2) come prima ma Xi e Yi non sono indipen-denti. Volendo verificare l’ipotesi δ = p1 − p2 = 0 si procede come indicato nell’Esempio10.7 calcolando prima le differenze Di = Xi − Yi in modo che E(Di) = δ con stima δ = D.La statistica di Wald è
W = Dse
dove
se = 1√n
¿ÁÁÀ1
n
n
∑i=1(Di −D)2.
Test sulla differenza di due medie: campioni indipendenti.
Illustrazione 10.3 (Punteggio al test di accesso all’università) Nella Figura 10.1 è ripor-tato un confronto di box-plot per due gruppi di studenti di ambo i sessi (615 maschi e513 femmine) presentatisi al test di ammissione a una Facoltà, relativamente al punteggioottenuto. C’è una differenza significativa tra i punteggi dei due gruppi? Anche in questocaso sembra appropriato supporre che i dati siano due campioni casuali indipendenti dadue popolazioni con la stessa varianza.
Diciamo che il primo è il gruppo delle femmine e il secondo è il gruppo dei maschi equindi numerosità, medie e varianze campionarie risultano
nF = 513 xF = 12.43, s2F = 14.77nM = 615 xM = 14.06 s2M = 15.07.
e la differenza delle medie e il relativo errore standard risultano
δ = 14.06 − 12.43 = 1.63, se =√
15.07/615 + 14.77/513 = 0.231
La statistica di Wald risultaW = 1.63/0.231 = 7.05.
L’ipotesi di uguaglianza delle medie dei punteggi tra maschi e femmine è rifiutata al livelloα = 0.01.

10.3. VALORE P 47
Test col bootstrap. Nel libro sono omessi molti dettagli.
Relazione tra intervalli di confidenza e test. Il Teorema 10.10 è importante.
Proposizione 10.1 Il test di Wald di ampiezza α rifiuta H0 ∶ θ = θ0 contro H1 ∶ θ ≠ θ0 se esolo se, calcolato l’intervallo di confidenza di livello 1 − α
C = (θ − z1−α/2se, θ + z1−α/2se)
questo non contiene θ0.
Dimostrazione. Vedi Esercizio 3 del capitolo. Un test di livello α è definito dalla sua regionedi rifiuto R(θ0) che dipende dal valore del parametro sottoposto a test. Quindi se i dati(X1, . . . ,Xn) non appartengono a R(θ0) si accetta H0 e
P[(X1, . . . ,Xn) ∉ R(θ0)] = 1 − α.
Viceversa, se i dati (x1, . . . , xn) sono fissi, consideriamo l’insieme A(x1, . . . , xn) dei valoridi θ0 che vengono accettati se si applica il test ai dati. Siccome vale l’equivalenza
θ0 ∈ A(x1, . . . , xn) ⇐⇒ (x1, . . . , xn) ∉ R(θ0),
abbiamoP[θ0 ∈ A(X1, . . . ,Xn)] = P[(X1, . . . ,Xn) ∉ R(θ0)] = 1 − α
e quindi A(x1, . . . , xn) è un intervallo di confidenza con livello 1 − α.
Notate che Wasserman (e con lui molti statistici) preferisce gli intervalli di confidenzaai test perché sono più informativi. Leggete bene la differenza tra significatività statistica esignificatività pratica.
10.3 Valore p
La teoria del valore p o livello di significatività dei dati viene presentata definendo questoconcetto come il minimo livello α al quale si rifiuta H0. Per precisare questo concettoconviene dare una definizione equivalente.
Definizione 10.1 (Livello di significatività dei dati.) Data la statistica test T(X) con va-lore osservato toss, e la regione di rifiuto definita per valori grandi di T, si dice livello disignificatività dei dati la probabilità
p = supθ∈Θ0
Pθ{T(X) ≥ toss}
Quindi il valore p è la probabilità di osservare nel campionamento ripetuto un valoredella statistica test T uguale al valore osservato toss o più estremo, se fosse vera l’ipotesinulla.
In altre parole p è il livello del test se si prendesse come valore critico k = toss.

48 10. VERIFICA DI IPOTESI E VALORI P
In questa impostazione, il risultato di un test è un valore p piuttosto che una decisionedi rifiuto o non rifiuto di H0 a un livello α prefissato. Il valore p si può considerare comeuna misura standardizzata dell’evidenza empirica contro l’ipotesi nulla. Tradizionalmentesi riporta il valore p su una scala grossolana, come quella della Tabella 10.1.
Tabella 10.1: Interpretazione del p-value.
p-value Prove contro H0 Risultato< 0.01 molto forti altamente significativo
[0.01, 0.05) forti significativo[0.05, 0.10) deboli non significativo> 0.10 scarse non significativo
Diremo pertanto che l’evidenza contraria è significativa se p < 0.05 e in tal caso l’ipotesiè rifiutata. Se p > 0.05 di solito le prove controH0 non sono considerate decisive, e l’ipotesiH0 viene mantenuta. Notare che questo implica che i dati non contraddicono l’ipotesi H0,non che i dati confermano H0. Si noti che anche se la scelta del limite 0.05 è del tuttoarbitraria, è universalmente impiegata nelle pubblicazioni scientifiche.
Abbiamo il risultato seguente che collega il livello di significatività alle regioni critiche.
Proposizione 10.2 (Relazione tra livello del test e p-value.) Si rifiuta H0 al livello α se e solose il p-value è p ≤ α.
L’interpretazione dei p-value è oggetto di un dibattito particolarmente acceso. Moltistatistici criticano specialmente l’interpretazione errata o acritica dei p-value. Altri so-no contrari ai p-value in linea di principio perché preferiscono l’impostazione Bayesianadell’Inferenza Statistica. Qui ci limitiamo a fare alcune precisazioni importanti.
• L’evidenza contraria all’ipotesi aumenta al diminuire del p-value. Un piccolo p-valuesignifica che sotto ipotesi nulla è improbabile osservare un valore della funzione te-st come quello che è stata osservata o più ampia. Quindi siamo portati a dubitaredell’ipotesi nulla.
• Quindi il p-value NON è la probabilità che l’ipotesi nulla sia vera. Questa è chiara-mente una confusione perché l’ipotesi nulla non è un evento aleatorio.
• Tuttavia, un p-value grande NON significa un forte supporto a favore dell’ipotesinulla. Un p-value elevato può capitare sia perché l’ipotesi H0 è vera sia perché il testha scarsa potenza e quindi i dati non sono sufficienti per confutare H0.
• È fuorviante riportare i risultati solo se questi sono statisticamente significativi. In-fatti alcuni test possono essere significativi solo per effetto del caso.
Illustrazione 10.4 (Valore p del test sulla differenza dei punteggi.) Riconsideriamo il testsulla differenza dei punteggi medi tra studenti maschi e femmine. La statistica di Waldosservata è woss = 7.05 e quindi il valore p è
P{W > 7.05 oppure W < −7.05} < 0.001

10.4. LA DISTRIBUZIONE Χ2 49
quindi indica una differenza altamente significativa. Notate che per avere una statistica testche porta al rifiuto solo per valori grandi occorre considerare ∣W∣ e quindi il valore p vacalcolato sommando le probabilità nelle due code.
10.4 La distribuzione χ2
La distribuzione chi quadro è un caso particolare della distribuzione Gamma. La genesi èla seguente.
• Se Z ∼ N(0, 1) allora Z2 ∼ χ21 ≡ Gamma(1/2, 2)
• Se Z1, . . . ,Zk ∼ N(0, 1) i.i.d allora∑ki=1 ∼ χ2
k ≡ Gamma(k/2, 2)
Il valore atteso e la varianza di U ∼ χ2k sono
E(U) = k, var(U) = 2k.
10.5 Test chi quadro di Pearson
Multinomiale. Il modello considerato consiste in un campione casuale da una distribu-zione Multinomiale. Questa distribuzione è una generalizzazione della Binomiale. Unabreve spiegazione si trova su Wasserman (2004) a p. 39. Qui fornisco qualche dettaglio inpiù.
Supponiamo di avere un’urna con 4 tipi di palline: A, B, C, D. Le proporzioni di pallinedi ogni tipo nell’urna siano pA,pB,pC e pD. Se ora estraiamo n palline indipendentemente,con ripetizione e definiamo il vettore aleatorio X = (XA,XB,XC,XD) dove le componentisono il numero di volte che è uscita la pallina A,B,C,D la sua distribuzione di probabilitàè detta Multinomiale
X ∼Mult(n,p = (pA,pB,pC,pD))
e ha distribuzione di probabilità
P(x) = n!xA!xB!xC!xD!
pxAA pxBB pxCC pxDD
dove la costante iniziale è il coefficiente multinomiale (il numero di modi in cui è pos-sibile partizionare un insieme di numerosità n in classi di numerosità xA, xB, xC, xD). Ledistribuzioni marginali delle componenti sono binomiali. Notate che le componenti sonodipendenti fra loro perché se cresce il numero di palline di tipo A per esempio deve dimi-nuire il numero delle palline di tipo diverso. Infatti c’è il vincolo che il totale delle pallinedeve sempre essere uguale ad n.
Se n = 1, cioè facciamo una sola estrazione, x è un vettore binario in cui vi sono tuttizero tranne la componente che è stata estratta. In tal caso diremo che X ha la distribuzioneMultinomiale elementare. Quando si estrae un campione casuale di dimensione n da unadistribuzione discreta del tipo
x ∶ A B C D Totp(x) ∶ pA pB pC pD 1

50 10. VERIFICA DI IPOTESI E VALORI P
le osservazioni individuali possono essere interpretate come estrazioni da una multino-miale elementare. Le frequenze dopo la classificazione dei dati campionari in una tabella
x ∶ A B C D Totfrequenze ∶ xA xB xC xD n
possono essere interpretate come un vettore x ∼ Mult(n,p) con distribuzione multino-miale:
(X1, . . . ,Xn) ∼Mult(1,p)⇒n
∑i=1
Xi ∼Mult(n,p).
Illustrazione 10.5 (Esperimento di Mendel) L’esempio 10.18 del libro è utile per capirel’uso della multinomiale. Mendel prese in considerazione la trasmissione di due coppie dicaratteri: il colore (giallo o verde) e la forma (liscia o rugosa) del seme di pisello. Nota; inquest’ultimo caso la forma poteva essere liscia (B) o rugosa (b), con liscia dominante surugosa. Riuscì ad isolare linee di piante omozigote per il colore e per la forma e consideròi 4 incroci possibili alla prima generazione e i 16 incroci possibili alla seconda. In 556prove si accorse che al termine si ottenevano le 4 situazioni diverse A = gialli-lisci, B =gialli-rugosi, B = verdi-lisci, D = verdi-rugosi con frequenze
x ∶ A B C D Totfrequenze ∶ 315 101 108 32 556
Secondo la sua teoria le 4 combinazioni avevano le probabilità teoriche
x ∶ A B C D Totp(x) ∶ 9/16 3/16 3/16 1/16 1
Test chi quadro Esistono un’infinità di test basati sulla distribuzione χ2. Il test di Pearsonè un test per confutare che le frequenze osservate si conformino a quelle di una distribuzio-ne discreta teorica fissata. Per esempio nel nostro caso, posto p0 = (9/16, 3/16, 3/16, 1/6)verifichiamo l’ipotesi
H0 ∶ (pA,pB,pC,pD) = p0
controH1 ∶ (pA,pB,pC,pD) ≠ p0.
La statistica test usata èT = ∑
i∈{A,B,C,D}
(Xi − np0i )2
np0i
In altre parole la statistica è basata sugli scarti tra frequenze osservate e teoriche
osservate ∶ 315 101 108 32 556teoriche ∶ 312.75 104.25 104.25 34.75 556
Il Teorema 10.17 afferma che se è vera l’ipotesi, T ↝ χ2k−1 per n → ∞, dove k = 4. La
statistica test in questo case è T = 0.47. Il valore p è
p = P(χ2r > 0.47) = 0.93

10.6. TEST DI PERMUTAZIONE 51
non significativo. La teoria di Mendel non viene confutata dai dati. Tuttavia si può arguireche il test di ipotesi non sia lo strumento migliore per avvalorare la teoria.
Il teorema 10.17 non è dimostrato nel libro.
10.6 Test di permutazione
I test di permutazione si usano per verificare se due trattamenti sono diversi fra loro senzafare alcuna assunzione. Per esempio se misuriamo una risposta su
un campione di trattati (X1, . . . ,Xm) ∼ FXun campione di controlli (Y1, . . . ,Yn) ∼ FY
vogliamo verificareH0 ∶ FX = FY contro H1 ∶ FX ≠ FY.
Il punto essenziale è che calcolando la statistica test T = ∣Xm − Ym∣ su ognuna delle (n +m)! = N! permutazioni X1, . . . ,Xm,Y1, . . . ,Yn) dei dati, se fosse veraH0 ognuno i valori Tj
ottenuti hanno tutti la stessa probabilità. Come misura dell’evidenza contraria a H0 allorasi considera il valore osservato toss di T e il valore p
p = P0(T > toss) =1N!
N!
∑j=1
I[Tj > toss].
Invece della differenza delle medie si possono usare altri indici, ad esempio la differenzadelle mediane.
Siccome non è fattibile calcolare tutte le permutazioni si campiona casualmente dall’in-sieme di tutte le permutazioni. L’algoritmo è riportato sul libro. In R le permutazionicasuali si ottengono usando la funzione sample:
sample(1:10)[1] 9 2 7 1 5 10 8 3 6 4
Illustrazione 10.6 (Dati sul DNA) Ecco il codice R per l’esempio 10.20:
x = c(230, -1350, -1580, -400, -760)y = c(970, 110, -50, -190, -200)B = 10000d = rep(0,B)xy = c(x,y)for(i in 1:B){
dati = sample(xy)d[i] = abs(median(dati[1:5]) - median(dati[6:10]))
}toss = abs(median(xy[1:5]) - median(xy[6:10]))p = sum(d>toss)/Bp[1] 0.0473
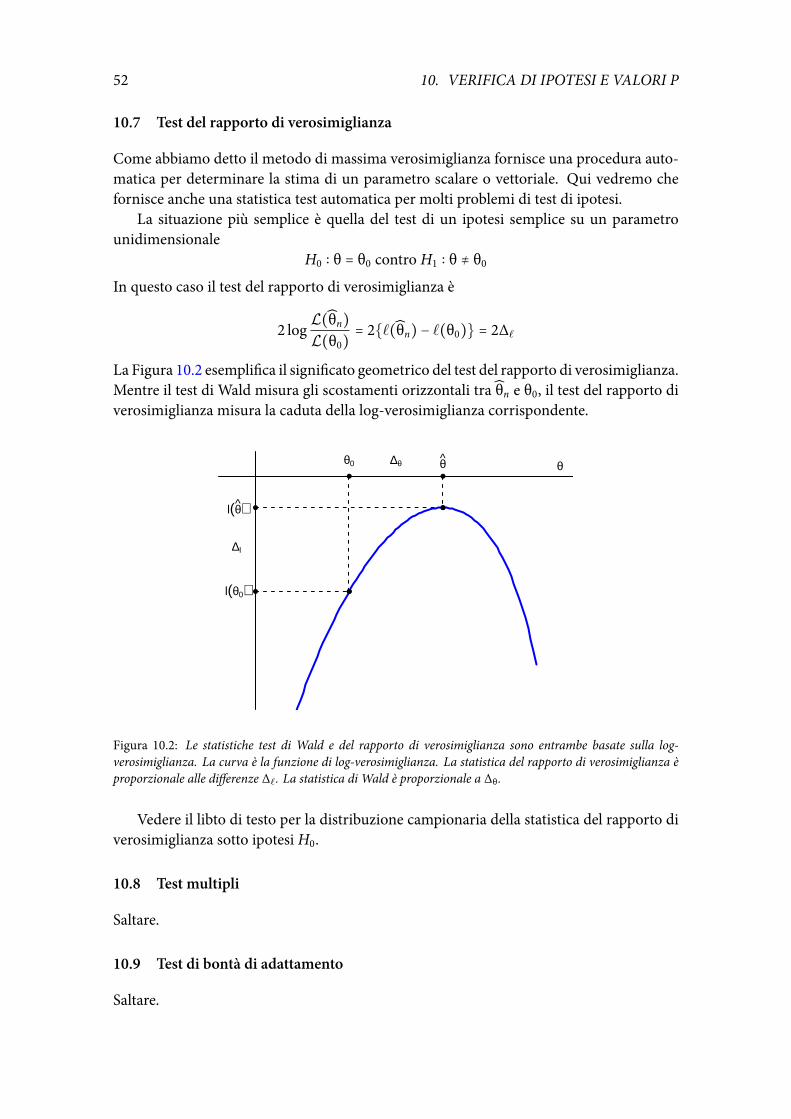
52 10. VERIFICA DI IPOTESI E VALORI P
10.7 Test del rapporto di verosimiglianza
Come abbiamo detto il metodo di massima verosimiglianza fornisce una procedura auto-matica per determinare la stima di un parametro scalare o vettoriale. Qui vedremo chefornisce anche una statistica test automatica per molti problemi di test di ipotesi.
La situazione più semplice è quella del test di un ipotesi semplice su un parametrounidimensionale
H0 ∶ θ = θ0 contro H1 ∶ θ ≠ θ0
In questo caso il test del rapporto di verosimiglianza è
2 logL(θn)L(θ0)
= 2{ℓ(θn) − ℓ(θ0)} = 2Δℓ
La Figura 10.2 esemplifica il significato geometrico del test del rapporto di verosimiglianza.Mentre il test di Wald misura gli scostamenti orizzontali tra θn e θ0, il test del rapporto diverosimiglianza misura la caduta della log-verosimiglianza corrispondente.
θ●
●
●
●● ●
● ●
θ0 θ
l(θ0)
l(θ)
∆l
∆θ
Figura 10.2: Le statistiche test di Wald e del rapporto di verosimiglianza sono entrambe basate sulla log-verosimiglianza. La curva è la funzione di log-verosimiglianza. La statistica del rapporto di verosimiglianza èproporzionale alle differenze Δℓ. La statistica di Wald è proporzionale a Δθ.
Vedere il libto di testo per la distribuzione campionaria della statistica del rapporto diverosimiglianza sotto ipotesi H0.
10.8 Test multipli
Saltare.
10.9 Test di bontà di adattamento
Saltare.

10.10. NOTE BIBLIOGRAFICHE 53
10.10 Note bibliografiche
Casella e Berger (2002) è un libro di inferenza utile per approfondire.
10.11 Appendice
Lemma di Neyman e Pearson Saltare.
Test t di Student È un classico test esatto sulla media di una popolazione normale.

54 10. VERIFICA DI IPOTESI E VALORI P

11
inferenza bayesiana
11.1 La filosofia bayesiana
Formula di Bayes. I tre esempi seguenti sono tratti da McElreath (2016).
Illustrazione 11.1 (Test sul vampirismo) Supponiamo che un test diagnostico possa sco-prire da un prelievo di sangue se uno/a è un vampiro nel 95% dei casi. È un test che quindifunziona molto bene. Il test però può anche sbagliare perché ci sono dei falsi positivi. In-fatti, nell’1% dei casi il test risulta positivo per una persona normale. Sappiamo inoltre chei vampiri sono rari: solo lo 0.1% di persone sono vampiri.
Una persona va a fare il test e il test risulta positivo! Qual è la probabilità che la personasia davvero un vampiro?
Una soluzione semplice consiste nel ragionare con i numeri interi. Supponiamo che lapopolazione sia di 100.000 persone. Allora, di questi 100 sono vampiri.
Di questi 100 vampiri 95 sono positivi al test. Dei restanti 99.900 mortali 999 risultanopositivi al test.
Ora se testiamo tutti i 100.000 e prendiamo i
positivi = 95 + 999 = 1094
quanti di loro sono veramente vampiri? Ovviamente solo 95 e quindi (V = vampiro, V =mortale, + = positivo)
P(V ∣ +) = 951094
≃ 0.087.
La soluzione formale consiste nell’usare la formula di Bayes
P(vampiro∣+) = P(+ ∣ V)P(V)P(+ ∣ V)P(V) +P(+ ∣ V)P(V)
= 9595 + 999
≃ 0.087.
Quindi, nonostante i timori la probabilità di essere un vampiro è piuttosto piccola.
Perché la formula di Bayes serve all’inferenza?
Illustrazione 11.2 (Stima della proporzione di successi.) Supponiamo di avere un urnacontenente 4 palline di colori bianco o nero. Le palline bianche sono i successi, le nere
55

56 11. INFERENZA BAYESIANA
sono gli insuccessi. Quindi, estraiamo un campione casuale con ripetizione di 3 pallinedall’urna e osserviamo il campione (●, ●, ○) cioè x = (0, 0, 1).
L’urna potrebbe essere di 5 tipi diversi, cioè
U0 ∶ ● ● ● ●U1 ∶ ○ ● ● ●U2 ∶ ○ ○ ● ●U3 ∶ ○ ○ ○ ●U4 ∶ ○ ○ ○ ○
La probabilità di successo nell’unaUj è θj = j/4. Possiamo usare dunque la verosimiglianzacioè calcolare la probabilità del risultato x data l’urna:
P(x ∣ U0) = 0P(x ∣ U1) = 1
4 (34)
2 = 964
P(x ∣ U2) = 24 (
24)
2 = 864
P(x ∣ U3) = 34 (
14)
2 = 364
P(x ∣ U4) = 0
e l’urna U1 è la più plausibile. Quindi, θ = 1/4 è la stima di massima verosimiglianza dellaproporzione di successi.
Dire “urna più plausibile” è sinonimo di “urna più probabile”, ma in realtà P(x ∣ Uj)non è una probabilità dell’urna. Precisamente dovremmo invece calcolare qual è l’urna piùprobabile condizionatamente all’aver osservato il campione x. L’unico modo per farlo èusare la formula di Bayes:
P(Uj ∣ x) =P(x ∣ Uj)P(Uj)∑4
i=0P(x ∣ Ui)P(Ui).
Il risultato dipende dalle probabilità P(Uj) che misurano la nostra incertezza sulle urneprima di aver estratto il campione, dette probabilità a priori. Le probabilità a priori delleurne sono le probabilità assegnate alle 5 congetture sulla struttura dell’urna e possono es-sere determinate sia se si dispone di informazioni sul meccanismo di creazione dell’urna,sia se consideriamo ogni congettura ugualmente probabile. In questo caso possiamo fareriferimento al principio di indifferenza e assegnare probabilità uniformi¹:
P(Uj) =15.
La formula di Bayes fornisce le probabilità a posteriori attraverso il prodotto delle verosi-miglianze per le a priori, sommando e infine normalizzando rispetto a
P(x) =4
∑i=0
P(x ∣ Ui)P(Ui) =116
.
¹Lo so, avete visto che il risultato rende impossibili le congetture U0 e U4. Però prima di aver visto ilrisultato x se tutte le congetture sono indifferenti, assegnamo probabilità 1/5 anche alle urne U0 e U4. Comevedremo le probabilità a posteriori di U0 e U4 invece diventano zero.

11.2. IL METODO BAYESIANO 57
Pertanto, otterremo le probabilità a posteriori delle congetture:
P(U0 ∣ x) = 0P(U1 ∣ x) = ( 9
64)(15)/
116 =
920
P(U2 ∣ x) = ( 864)(
15)/
116 =
820
P(U3 ∣ x) = ( 364)(
15)/
116 =
320
P(U4 ∣ x) = 0
La formula di Bayes con le a priori uniformi ci fornisce lo stesso risultato del metodo dimassima verosimiglianza: l’urna 1 è quella che ha la massima probabilità a posteriori.Tuttavia, se avessimo utilizzato delle informazioni a priori con probabilità non uniformiavremmo ottenuto risultati diversi e anche contrastanti col metodo di massima verosimi-glianza.
Illustrazione 11.3 (Aggiornamento delle probabilità a posteriori.) Supponiamo ora diestrarre un’ulteriore pallina dall’urna, indipendentemente, e di osservare (●), un insuc-cesso. Come si modificano le probabilità a posteriori? Potremmo rifare i conti dall’inizioprendendo x = (0, 0, 1, 0) oppure possiamo equivalentemente aggiornare le probabilità aposteriori ottenute alla luce della nuova estrazione. In questo secondo caso denotiamo conx′ = (0) il nuovo dato e calcoliamo
P(Uj ∣ x, x′)∝ P(x′ ∣ Uj)P(Uj ∣ x),
con la costante di proporzionalità∑4i=0P(x′ ∣ Ui)P(Ui ∣ x). Otteniamo la tabella aggiornata
Urna Verosimiglianza Vecchia a posteriori Nuova a posterioriU0 0 0 0U1
34
920
2746
U224
820
1646
U314
320
346
U4 0 0 0
11.2 Il metodo bayesiano
Dagli esempi precedenti è evidente che il nodo centrale del paradigma bayesiano è co-stituito dalla a priori. Questa è una distribuzione di probabilità del parametro prima diaver visto i dati. Abbiamo visto che le probabilità a priori delle 5 congetture sulla strutturadell’urna definiscono una distribuzione a priori uniforme sul parametro θ, la proporzionedi successi nell’urna, risulta:
θ ∶ 0 1/4 2/4 3/4 1f(θ) ∶ 1/5 1/5 1/5 1/5 1/5
Queste probabilità non hanno natura frequentista in generale, ma esprimono la nostra in-certezza sul parametro. La distribuzione a priori uniforme esprime in questo caso un’in-differenza, ma in generale può essere una distribuzione qualsiasi. Inoltre la distribuzio-ne a priori sulla probabilità di successo non deve essere necessariamente discreta comenell’esempio, può essere una densità di probabilità f(θ) per θ ∈ (0, 1).

58 11. INFERENZA BAYESIANA
Il modello statistico usato negli esempi è il modello Bernoulliano
f(x ∣ θ) = θx(1 − θ)1−x, x = 0, 1
Notate che la funzione del modello è scritta come f(x ∣ p) invece di f(x;p) perché p è unavariabile casuale.
Dopo aver osservato un campione x = (x1, . . . , xn) la formula di Bayes ci permette diaggiornare la nostra incertezza sul parametro p combinando le probabilità a priori con laverosimiglianza. La formula di Bayes nel caso di una a priori continua f(θ) prevede che lacostante di proporzionalità sia calcolata con un integrale e non con una sommatoria:
f(θ ∣ x) = f(x ∣ θ) f(θ)∫ f(x ∣ θ) f(θ)dθ
∝ Ln(θ) f(θ).
La distribuzione a posteriori (o finale) è l’aggiornamento della a priori (o finale) tramitela verosimiglianza, verosimiglianza che di norma ha un peso rilevante in tale aggiorna-mento. L’inferenza bayesiana è basata essenzialmente sull’analisi dell’intera distribuzionea posteriori.
• La stima puntuale di θ si ottiene usando un’indice di posizione calcolato su f(θ ∣ x).La stima di Bayes è basata sulla media
θn = ∫ θf(θ ∣ x)dθ
La stima MAP (massimo della a posteriori) è basata sulla moda (cfr. con la stima diMV).
• La stima per intervallo si ottiene cercando un intervallo (a,b) tale che gli estremisiano determinati dai quantili di ordine α/2 e 1 − α/2 della a posteriori f(θ ∣ x),cosicché
P(θ ∈ (a,b) ∣ x) = ∫b
af(θ ∣ x)dθ = 1 − α
Tali intervalli si chiamano intervalli di credibilità.
Illustrazione 11.4 (Stima bayesiana di una proporzione.) Consideriamo un nuovo caso incui il modello è basato su un campione casuale da una Bernoulli di parametro θ. A prioripensiamo che θ sia intorno a 1
2 e specifichiamo la densità iniziale (vedi Fig. 11.1)
f(θ) = 6θ(1 − θ), 0 ≤ θ ≤ 1
Estraiamo il campione e i dati x sono composti da s = 4 successi e n− s = 16 insuccessi. Laverosimiglianza è L(θ)∝ θ4(1 − θ)16. Perciò la distribuzione a posteriori è
f(θ ∣ x)∝ [θ4(1 − θ)16] ⋅ [6θ(1 − θ)] = 6 ⋅ θ5(1 − θ)17.
La figura 11.1 mostra il confronto tra le tre distribuzioni coinvolte nella formula di Bayes.
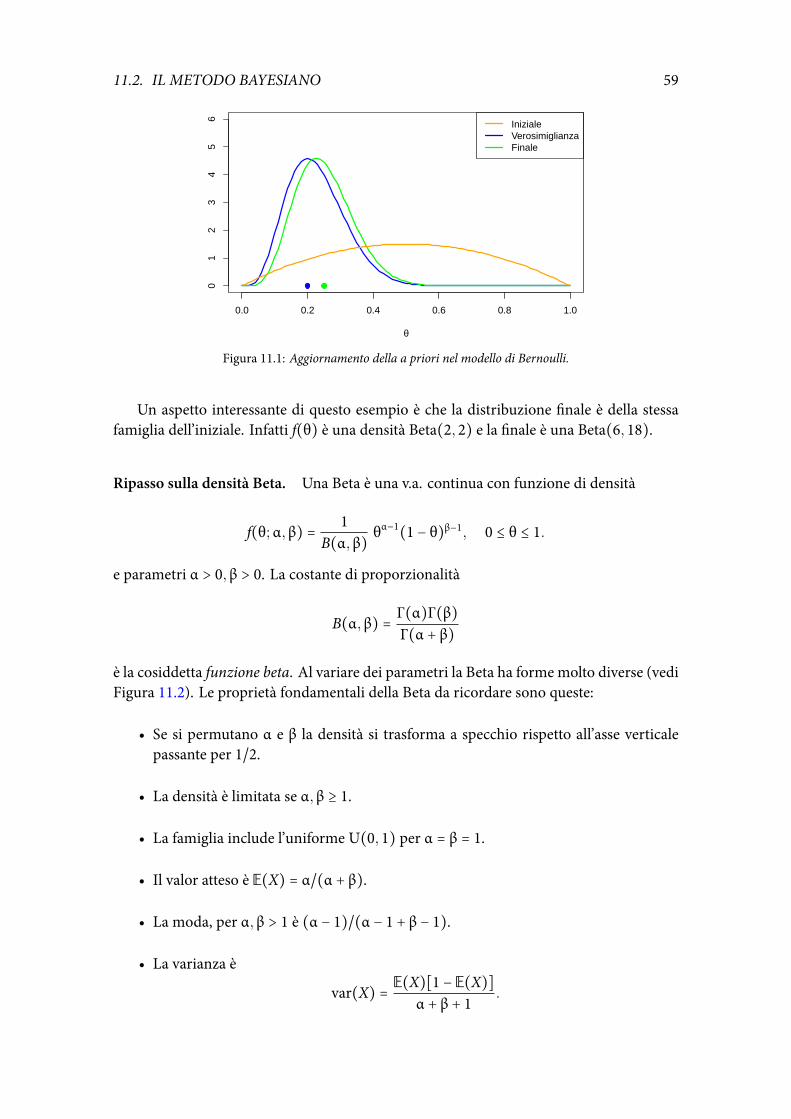
11.2. IL METODO BAYESIANO 59
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
6
θ
InizialeVerosimiglianzaFinale
Figura 11.1: Aggiornamento della a priori nel modello di Bernoulli.
Un aspetto interessante di questo esempio è che la distribuzione finale è della stessafamiglia dell’iniziale. Infatti f(θ) è una densità Beta(2, 2) e la finale è una Beta(6, 18).
Ripasso sulla densità Beta. Una Beta è una v.a. continua con funzione di densità
f(θ;α,β) = 1B(α,β)
θα−1(1 − θ)β−1, 0 ≤ θ ≤ 1.
e parametri α > 0,β > 0. La costante di proporzionalità
B(α,β) = Γ(α)Γ(β)Γ(α + β)
è la cosiddetta funzione beta. Al variare dei parametri la Beta ha forme molto diverse (vediFigura 11.2). Le proprietà fondamentali della Beta da ricordare sono queste:
• Se si permutano α e β la densità si trasforma a specchio rispetto all’asse verticalepassante per 1/2.
• La densità è limitata se α,β ≥ 1.
• La famiglia include l’uniforme U(0, 1) per α = β = 1.
• Il valor atteso è E(X) = α/(α + β).
• La moda, per α,β > 1 è (α − 1)/(α − 1 + β − 1).
• La varianza è
var(X) = E(X)[1 − E(X)]α + β + 1
.

60 11. INFERENZA BAYESIANA
0.0 0.2 0.4 0.6 0.8 1.0
1.0
2.0
3.0
Beta( 0.5 , 0.5 )
0.0 0.2 0.4 0.6 0.8 1.0
12
34
5
Beta( 0.5 , 1 )
0.0 0.2 0.4 0.6 0.8 1.0
12
34
5
Beta( 1 , 0.5 )
0.0 0.2 0.4 0.6 0.8 1.0
0.6
0.8
1.0
1.2
1.4
Beta( 1 , 1 )
0.0 0.2 0.4 0.6 0.8 1.00.
00.
51.
01.
52.
0
Beta( 1 , 2 )
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
2.0
Beta( 2 , 1 )
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
Beta( 2 , 2 )
0.0 0.2 0.4 0.6 0.8 1.0
0.0
1.0
2.0
Beta( 2 , 6 )
0.0 0.2 0.4 0.6 0.8 1.0
0.0
1.0
2.0
Beta( 6 , 2 )
Figura 11.2: Densità Beta al variare dei parametri α e β.
Famiglie coniugate. In statistica bayesiana se succede che combinandouna distribuzioneiniziale appartenente a una certa famiglia con la verosimiglianza del modello si ottiene unafinale che appartiene ancora alla stessa famiglia dell’iniziale si dice che tale famiglia è laconiugata del modello.
Proposizione 11.1 La famiglia Beta è una famiglia coniugata del modello di Bernoulli.
Dimostrazione. Supponiamo che la distribuzione iniziale sia θ ∼ Beta(α,β) dove α e βsono due valori fissati. Supponiamo che i dati contengano s successi e n − s insuccessi.Allora
f(θ)∝ θα−1(1 − θ)β−1
L(θ)∝ θs(1 − θ)n−s
f(θ ∣ y)∝ θs+α−1(1 − θ)n−s+β−1
Quindi il nucleo della densità finale è di tipo Beta e la densità propria si ottiene dividendoper
B(s + α,n − s + β)
Quindi la distribuzione a posteriori è ancora di tipo Beta
θ ∣ x ∼ Beta(s + α,n − s + β).

11.2. IL METODO BAYESIANO 61
Stimabayesianadi unaproporzione Nelmodello di Bernoulli con iniziale θ ∼ Beta(α,β)la stima di Bayes è
θ = s + αn + α + β
La stima MAP è inveceθMAP =
s + α − 1n + α + β − 2
.
L’effetto della distribuzione iniziale si riflette nella correzione al numeratore e denomina-tore del rapporto tra il numero di successi e numero di prove. Un confronto diretto con lastima di MV si deduce dalla tabella seguente
Metodo StimaMLE s
nBayes s+α
n+α+βMAP s+α−1
n+α+β−2
È interessante notare che seguendo il principio di indifferenza e scegliendo pertanto unainiziale uniforme, θ ∼ Beta(1, 1), la stima di MV e la stima MAP coincidono. La stima diBayes
θ = s + 1n + 2
invece corrisponde ad aggiungere ai dati un successo e un insuccesso (vedi Capitolo suglistimatori).
Per esercizio verificate che la stima di Bayes θ si può scrivere come una combinazionelineare convessa della stima dimassima verosimiglianza θ e della media della distribuzioneiniziale θ0 = α/(α + β)
θ = λnθ + (1 − λn)θ0
doveλn =
nα + β + n
.
Nella Figura 11.3 si analizza l’effetto della distribuzione a priori e della dimensione cam-pionaria sulla stima di Bayes.
Nota a proposito della a priori Beta. Confrontando la a priori f(θ) ∝ θα−1(1 − θ)β−1 ela verosimiglianza L(θ) ∝ θs(1 − θ)n−s si nota che la densità a priori è equivalente a α − 1successi a priori e β − 1 insuccessi a priori per un totale di α + β − 2 osservazioni virtualitotali. I parametri della densità a priori si chiamano di solito iperparametri.
Stima bayesiana della media di una normale. Il modello normale è un altro esempioimportante nelle applicazioni. La famiglia normale è coniugata del modello normale equindi è la scelta più semplice per la distribuzione a priori. I parametri della normale apriori vanno scelti dal ricercatore e si chiamano, come si diceva sopra, iperparametri. Ilrisultato seguente spiega come si ottiene la distribuzione a posteriori.
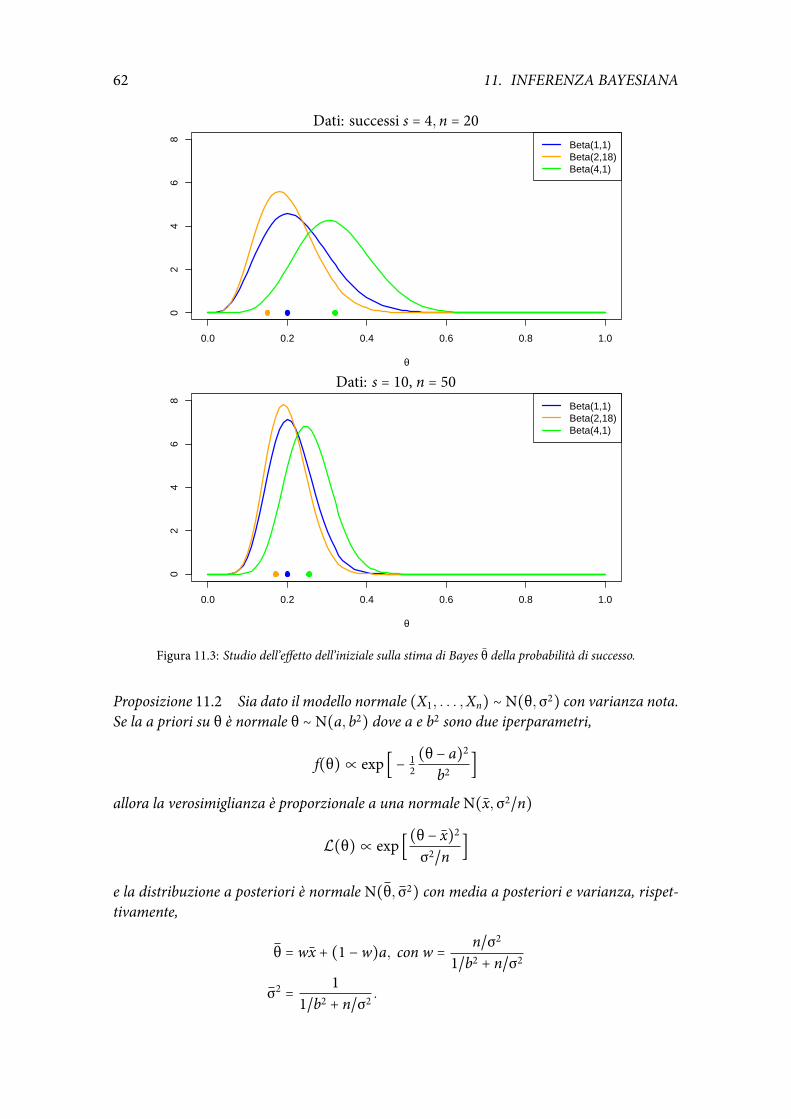
62 11. INFERENZA BAYESIANA
Dati: successi s = 4,n = 20
0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
θ
Beta(1,1)Beta(2,18)Beta(4,1)
Dati: s = 10, n = 50
0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
θ
Beta(1,1)Beta(2,18)Beta(4,1)
Figura 11.3: Studio dell’effetto dell’iniziale sulla stima di Bayes θ della probabilità di successo.
Proposizione 11.2 Sia dato il modello normale (X1, . . . ,Xn) ∼ N(θ,σ2) con varianza nota.Se la a priori su θ è normale θ ∼ N(a,b2) dove a e b2 sono due iperparametri,
f(θ)∝ exp [ − 12(θ − a)2
b2 ]
allora la verosimiglianza è proporzionale a una normale N(x,σ2/n)
L(θ)∝ exp [(θ − x)2
σ2/n]
e la distribuzione a posteriori è normale N(θ,σ2) con media a posteriori e varianza, rispet-tivamente,
θ = wx + (1 −w)a, con w = n/σ2
1/b2 + n/σ2
σ2 = 11/b2 + n/σ2 .

11.2. IL METODO BAYESIANO 63
La dimostrazione è lasciata per esercizio.
Illustrazione 11.5 (Stima di una costante fisica, (Box e Tiao, 1973)) Due fisici desideranostimare una costante θ. Il fisico A ha una buona conoscenza dell’area di studio e descrive lasua incertezza con una distribuzione iniziale normale N(900, 202). Il fisico B ha scarsa co-noscenza a priori di θ e descrive la sua incertezza con una iniziale normale molto variabilecon una media 800 e una deviazione standard b = 80: θ ∼ N(a = 800,b2 = 802).
Quindi entrambi decidono di misurare la costante ed ottengono una misura x = 850sapendo che X è una realizzazione di una normale X ∼ N(θ, 402).
A e B derivano le distribuzioni a posteriori, moltiplicando la verosimiglianza per la loroa priori secondo la Prop. 11.2 e ottengono
n = 1 A priori Verosimiglianza A posterioriA ∶ θ ∼ N(900, 202) θ ∣ x ∼ N(890, 7.92)
↘ ↗N(850, 402)
↗ ↘B ∶ θ ∼ N(800, 802) θ ∣ x ∼ N(840, 35.72)
Ad esempio per Bθ = wx + (1 −w)a = w ⋅ 850 + (1 −w) ⋅ 800
con pesi
w = 1/402
1/402 + 1/802 = 0.8 e (1 −w) = 0.2
Quindi la media a posteriori è
θ = 0.8 ⋅ 850 + 0.2 ⋅ 800 = 840.
Dunque in termini relativi A ha imparato poco dall’esperimento, mentre B ha imparatoparecchio.
A e B decidono di raccogliere altre 99 misurazioni indipendenti cioè in totale un cam-pione di dimensione n = 100. La media campionaria risulta x = 870. La verosimiglianzadi θ dato il campione x risulta proporzionale a una densità normale N(x,σ/
√n) cioè una
normale con media 870 e deviazione standard 40/√
100 = 4. Le distribuzioni a posterioririsultano perciò quelle della tabella seguente.
n = 100 A priori Verosimiglianza A posterioriA ∶ θ ∼ N(900, 202) θ ∣ x ∼ N(871.2, 3.92)
↘ ↗N(850, 42)
↗ ↘B ∶ θ ∼ N(800, 802) θ ∣ x ∼ N(869.8, 3.9952)
Dopo 100 osservazioni A e B hanno aggiornato le loro a priori e si trovano praticamentein totale accordo l’una con l’altra e con la verosimiglianza.

64 11. INFERENZA BAYESIANA
Formule con le precisioni. Denotiamo
• ω2 = 1/σ2: la precisione di campionamento
• ω20 = 1/b2: la precisione a priori
La media e la precisione della a posteriori sono
θ = x ⋅ nω2
nω2 + ω20+ a ⋅ ω2
0
nω2 + ω20
ω2 = ω20 + nω2.
11.3 Trasformazioni del parametro
Ci occupiamo di trovare la distribuzione a posteriori di un parametro ψ = g(θ)? Consi-deriamo la densità di θ ∣ x e calcoliamo la funzione di ripartizione della variabile aleatoriatrasformata g(θ) ∣ x
H(ψ ∣ x) = P[g(θ) ≤ ψ ∣ x] = ∫Af(θ ∣ x)dθ
dove A = {θ ∶ g(θ) ≤ ψ}. Quindi la distribuzione a posteriori h(ψ ∣ x) si ottiene derivandoH rispetto a ψ. In pratica se la trasformazione è strettamente monotona allora
h(ψ ∣ x) = f(g−1(ψ) ∣ x) ∣dg−1(ψ)dψ
∣ .
Illustrazione 11.6 (Inferenza sul logit.) Sia (X1, . . . ,Xn) ∼ Bernoulli(θ). Il logit è unafunzione strettamente monotona crescente: ψ = log[θ/(1 − θ)] e l’inversa è θ = eψ
1+eψ . Sescegliamo una iniziale uniforme θ ∼ Beta(1, 1) otteniamo una finale Beta(s + 1,n − s + 1).Quindi, la distribuzione a posteriori per il logit è
h(ψ ∣ x) = 1B(s + 1,n − s + 1)
θs(1 − θ)n−s ddψ
eψ
1 + eψ
= 1B(s + 1,n − s + 1)
( eψ
1 + eψ)s( 11 + eψ
)n−s eψ
(1 + eψ)2
correggendo quello che è scritto sul libro.
11.4 Simulazione della distribuzione a posteriori
Illustrazione 11.7 Supponiamodi avere un campione da unaBernoulli(θ) con θ ∼ U(0, 1).Sia s = 10 e n = 40. La verosimiglianza è L(θ) = (ns)θ
s(1 − θ)n−s. La distribuzione aposteriori si può simulare con il codice R seguente

11.4. SIMULAZIONE DELLA DISTRIBUZIONE A POSTERIORI 65
set.seed(145) # si può cambiares = 10; n = 40theta = seq( 0, 1 , len = 1000 )prior = dbeta( theta , 1 , 1 )lik = dbinom(s , prob = theta , size = n )prod = lik * priorbayes = prod / sum(prod)post = sample( theta , prob = bayes , size = 10000 , replace = TRUE )plot(density( post ), lwd = 2 , col = 'red' , xlab = expression(theta), main = "")
Per simulare la distribuzione a posteriori del logit non c’è bisogno di fare i calcolidell’Esempio 11.3 del libro, ma basta sostituire le ultime due righe di codice con
logit = function(x) log(x) - log(1-x)post = sample( logit(theta) , prob = bayes , size = 10000 , replace = TRUE )plot(density( post ), lwd = 2 , col = 'red' , xlab = expression(theta), main = "")
Nella Figura 11.4 si vedono le distribuzioni a posteriori simulate di f(θ ∣ x) e h(ψ ∣ x).
0.1 0.2 0.3 0.4 0.5
01
23
45
6
θ
Density
−2.5 −2.0 −1.5 −1.0 −0.5 0.0
0.0
0.4
0.8
ψ
Density
Figura 11.4: Distribuzioni a posteriori simulate per θ (a sinistra) e ψ (a destra). La distribuzione esatta di ψ èriportata in blu.
Intervalli basati sulla densità a posteriori. Un intervallo basato sulla a posteriori centra-to, di livello 1 − α è l’intervallo di estremi (a,b) dove a è il quantile di ordine α/2 e b è ilquantile 1 − α/2 della distribuzione a posteriori (vedi Figure 11.5).
0 5 10 15 20
0.00
0.05
0.10
0.15
θ
a b
α 2 α 2
Figura 11.5: Intervalli di credibilità
Illustrazione 11.8 (Gelman et al. (2014)) Che cos’è la placenta previa?

66 11. INFERENZA BAYESIANA
(Wikipedia) La placenta previa è considerata una delle emergenze ostetriche delterzo trimestre di gravidanza, soprattutto durante il parto. Anatomicamente laplacenta si viene a trovare davanti alla parte di presentazione fetale. Può esserecausa di emorragie gravi.
Ci interessa stimare la proporzione θ di femmine sul totale delle nascite da madri con laplacenta previa. In uno studio svolto in Germania si è trovato che su 980 nati da madri conplacenta previa 437 erano femmine.
La proporzione di femmine nella popolazione nel complesso è 0.485 e siamo ancheinteressati a verificare se θ < 0.485.
Se la distribuzione a priori viene specificata uniforme, avremo
• Verosimiglianza L(θ) = θ437(1 − θ)543
• Iniziale θ ∼ Beta(1, 1)
• Finale θ ∣ s ∼ Beta(437 + 1, 543 + 1)
• Media della finale 438/982 = 0.446.
L’intervallo di credibilità al 95% si puòottenere simulandodalla a posteriori Beta(438, 544).
set.seed(100)B = 10000theta = rbeta(B, 438, 544)quantile(theta, c(0.025, 0.975))
2.5% 97.5%0.4156825 0.4766452
Un tipico parametro usato in questi problemi è il rapporto fra i sessi φ = (1 − θ)/θ tra laproporzione maschi e la proporzione di femmine alla nascita. Un intervallo bayesiano al95% per questo parametro si trova ancora per simulazione:
phi = (1-theta)/thetaquantile(phi, c(0.025, 0.975))
2.5% 97.5%1.097997 1.405682
Quindi l’intervallo a posteriori al 95% è [1.10, 1.41]. Il valore del rapporto φ per la po-polazione europea nel complesso è (1 − 0.485)/0.485 = 1.06, mentre la distribuzione aposteriori è concentrata su valori più alti di 1.06. D’altra parte
P(θ ≤ 0.485) = 0.993
calcolato con sum(theta < 0.485)/B.
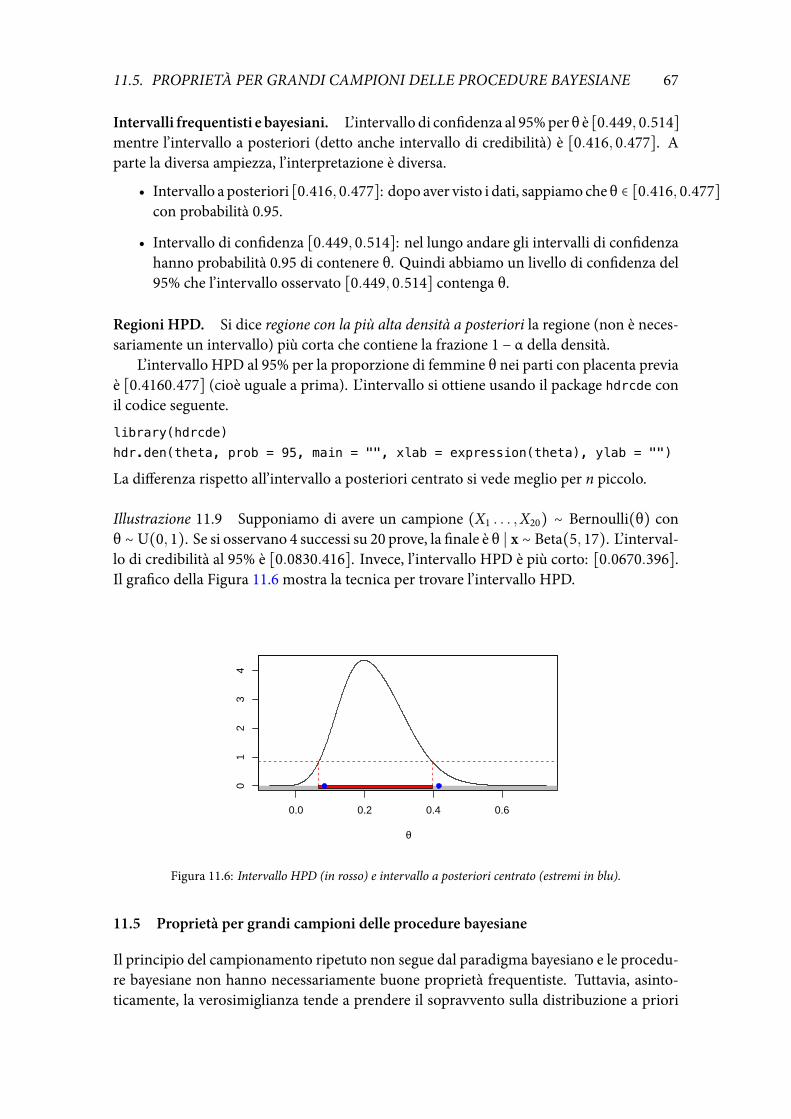
11.5. PROPRIETÀ PER GRANDI CAMPIONI DELLE PROCEDURE BAYESIANE 67
Intervalli frequentisti e bayesiani. L’intervallo di confidenza al 95%per θ è [0.449, 0.514]mentre l’intervallo a posteriori (detto anche intervallo di credibilità) è [0.416, 0.477]. Aparte la diversa ampiezza, l’interpretazione è diversa.
• Intervallo a posteriori [0.416, 0.477]: dopo aver visto i dati, sappiamo che θ ∈ [0.416, 0.477]con probabilità 0.95.
• Intervallo di confidenza [0.449, 0.514]: nel lungo andare gli intervalli di confidenzahanno probabilità 0.95 di contenere θ. Quindi abbiamo un livello di confidenza del95% che l’intervallo osservato [0.449, 0.514] contenga θ.
Regioni HPD. Si dice regione con la più alta densità a posteriori la regione (non è neces-sariamente un intervallo) più corta che contiene la frazione 1 − α della densità.
L’intervallo HPD al 95% per la proporzione di femmine θ nei parti con placenta previaè [0.4160.477] (cioè uguale a prima). L’intervallo si ottiene usando il package hdrcde conil codice seguente.
library(hdrcde)hdr.den(theta, prob = 95, main = "", xlab = expression(theta), ylab = "")
La differenza rispetto all’intervallo a posteriori centrato si vede meglio per n piccolo.
Illustrazione 11.9 Supponiamo di avere un campione (X1 . . . ,X20) ∼ Bernoulli(θ) conθ ∼ U(0, 1). Se si osservano 4 successi su 20 prove, la finale è θ ∣ x ∼ Beta(5, 17). L’interval-lo di credibilità al 95% è [0.0830.416]. Invece, l’intervallo HPD è più corto: [0.0670.396].Il grafico della Figura 11.6 mostra la tecnica per trovare l’intervallo HPD.
θ
0.0 0.2 0.4 0.6
01
23
4
Figura 11.6: Intervallo HPD (in rosso) e intervallo a posteriori centrato (estremi in blu).
11.5 Proprietà per grandi campioni delle procedure bayesiane
Il principio del campionamento ripetuto non segue dal paradigma bayesiano e le procedu-re bayesiane non hanno necessariamente buone proprietà frequentiste. Tuttavia, asinto-ticamente, la verosimiglianza tende a prendere il sopravvento sulla distribuzione a priori

68 11. INFERENZA BAYESIANA
e la distribuzione a posteriori converge in legge a una normale N(θn, I(θn)−1). Pertan-to considerando la distribuzione campionaria frequentista dello stimatore MAP questa èasintoticamente equivalente alla distribuzione dello stimatore di MV θn. La dimostrazioneè in appendice.
11.6 A priori piatte, improprie e non informative
Il paragrafo sul libro è molto chiaro. Faccio solo una annotazione. Una a priori uniformesu un parametro θ diventa una a priori non uniforme se si riparametrizza il modello conτ = g(θ). Le a priori piatte non sono invarianti quando si riparametrizza.
Questomostra che usare una a priori piatta per rappresentare l’assenza di informazionisu unparametro cozza contro il fatto che essa comporta la presenza di informazioni per unatrasformazione 1-1 del parametro. Tuttavia spesso l’uniforme è una proprietà desiderabileper ragioni soggettive piuttosto che per la necessità di esprimere l’ignoranza sul parametro.Inoltre, all’aumentare della dimensione campionaria ogni effetto di una a priori uniformetende a svanire.
Nonostante quanto si è detto sopra, la densità a priori di Jeffreys (che non è piattain generale) è tuttavia invariante rispetto a trasformazioni. Questo succede perché tale apriori dipende dalla informazione attesa I(τ) che si trasforma conformemente a g(θ).
11.7 Problemi multiparametrici
Un aspetto molto interessante dell’approccio bayesiano è la soluzione brillante del proble-ma dei parametri di disturbo. Se il parametro è ad esempio θ = (θ1, θ2), la formula diBayes permette di aggiornare una densità a priori bivariata f(θ) nella densità a posterioribivariata
f(θ ∣ x)∝ L(θ)f(θ)La distribuzione a posteriori del parametro di interesse θ1 si ottiene integrando via il pa-rametro di disturbo θ1
f(θ1 ∣ x)∝ ∫ f(θ ∣ x)dθ2.
Se non si riesce a fare l’integrale precedente ma si conosce la densità a posteriori si puòottenere il risultato per simulazione.
Illustrazione 11.10 (Confronto di Binomiali) Supponiamo di avere due campioni casualidi pazienti entrambi di dimensione 200 con un numero di successi x1 = 160 e x2 = 148. Sivuole stimare la differenza tra le probabilità τ = p2 − p1. Assumiamo il modello
X1 ∼ Binom(200,p1), X2 ∼ Binom(200,p2)
con una a priori f(p1,p2) = 1. Allora la densità a posteriori è
f(p1,p2 ∣ x1, x2)∝ p1601 (1 − p1)40p148
2 (1 − p2)52 ∝ Beta(161, 41)Beta(149, 53)
Quindi beta simulare
P(1)1 , . . . ,P(1)B ∼ Beta(161, 41), P(2)1 , . . . ,P(2)B ∼ Beta(149, 53),
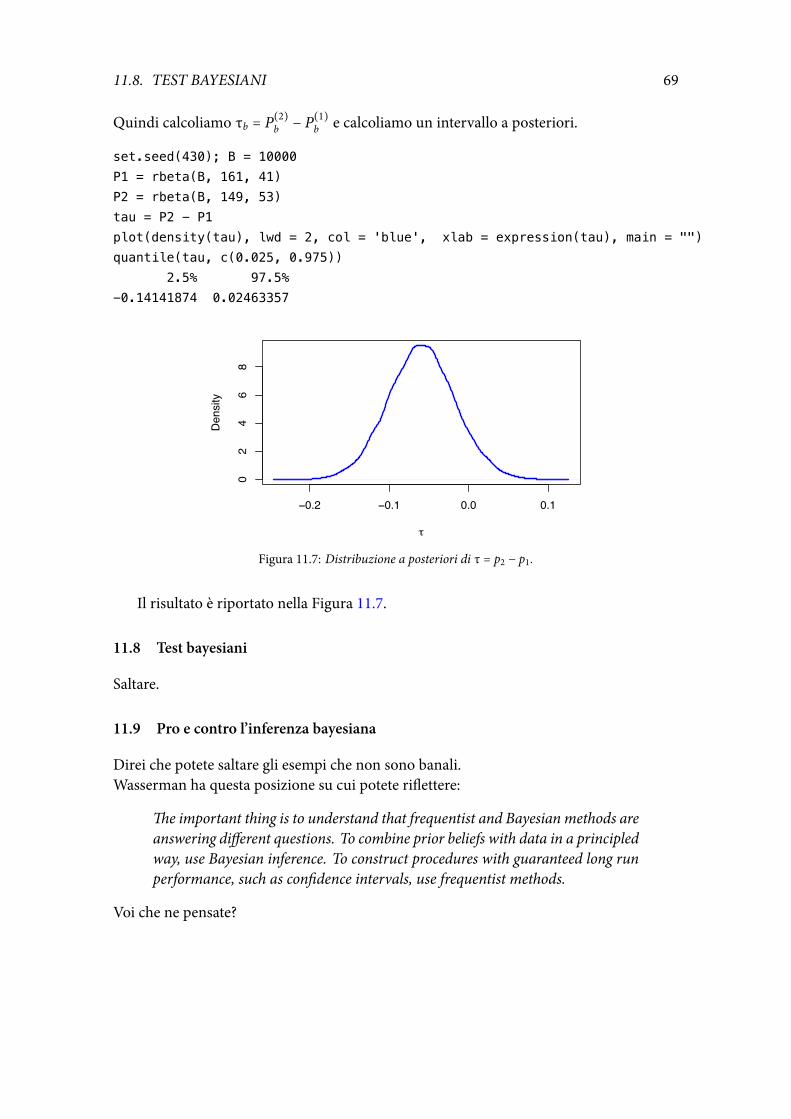
11.8. TEST BAYESIANI 69
Quindi calcoliamo τb = P(2)b − P(1)b e calcoliamo un intervallo a posteriori.
set.seed(430); B = 10000P1 = rbeta(B, 161, 41)P2 = rbeta(B, 149, 53)tau = P2 - P1plot(density(tau), lwd = 2, col = 'blue', xlab = expression(tau), main = "")quantile(tau, c(0.025, 0.975))
2.5% 97.5%-0.14141874 0.02463357
−0.2 −0.1 0.0 0.1
02
46
8
τ
Density
Figura 11.7: Distribuzione a posteriori di τ = p2 − p1.
Il risultato è riportato nella Figura 11.7.
11.8 Test bayesiani
Saltare.
11.9 Pro e contro l’inferenza bayesiana
Direi che potete saltare gli esempi che non sono banali.Wasserman ha questa posizione su cui potete riflettere:
The important thing is to understand that frequentist and Bayesian methods areanswering different questions. To combine prior beliefs with data in a principledway, use Bayesian inference. To construct procedures with guaranteed long runperformance, such as confidence intervals, use frequentist methods.
Voi che ne pensate?

70 11. INFERENZA BAYESIANA

12
teoria statistica delle decisioni
Questo capitolo non è previsto nel corso.
71

72 12. TEORIA STATISTICA DELLE DECISIONI

13
regressione lineare e logistica
Questo è un capitolo molto denso e con vari risultati fondamentali nelle applicazioni. Ag-giungerò qualche appendice e spiegazione al testo che è molto scarno. Pertanto dedicate aquesto capitolo un tempo adeguato.
13.1 Regressione lineare semplice
Per regressione si intende lo studio del valor medio di una variabile dipendente Y condi-zionata al valore x di una variabile X. La variabile Y si dice anche risposta e la variabile Xsi dice esplicativa. Le due variabili non sono perciò sullo stesso piano.
Si dice funzione di regressione il valore atteso condizionato r(x) = E(Y ∣ X = x).Vogliamo stimare la funzione di regressione da un campione casuale
(X1,Y1), . . . , (Xn,Yn) ∼ FXY.
La funzione di regressione può essere molto complicata, ma localmente essa è beneapprossimata da unmodello lineare. Pertanto si introduce il modello di regressione linearesemplice
E(Yi ∣ Xi) = β0 + β1Xi (13.1)var(Yi ∣ Xi) = σ2. (13.2)
La prima assunzione è la linearità, la seconda è l’omoschedasticità, ossia l’assunzione chevariabilità di Yi ∣ Xi non dipenda da Xi.
Nota. Le assunzioni sono sempre condizionate ai valori osservati di Xi. Tutta l’inferenzache facciamo è condizionata.
Assunzioni. Se si definisce lo scarto εi = Yi − β0 − β1Xi detto termine di errore, si puòscrivere
Yi = β0 + β1Xi + εi
73

74 13. REGRESSIONE LINEARE E LOGISTICA
con¹
E(εi ∣ Xi) = E(Yi ∣ Xi) − E(β0 + β1Xi ∣ Xi) = β0 + β1Xi − (β0 + β1Xi) = 0var(εi ∣ Xi) = var(Yi − β0 − β1Xi ∣ Xi) = var(Yi ∣ Xi) = σ2
Minimi quadrati. La stima dei minimi quadrati di β0,β1) nel modello di regressionelineare semplice si ottiene minimizzando
minβ0,β1
n
∑i=1(Yi − β0 − β1Xi)2.
Nel caso della regressione lineare semplice le stime dei minimi quadrati sono le statistiche
β0 = Y − β1X
β1 =∑n
i=1(Xi − X)(Yi − Y)∑n
i=1(Xi − X)2.
Le stime sono uniche se n > 1 e le osservazioni xi non sono tutte uguali.
• I valori stimati (o previsti o adattati) sono Yi = β0 + β1Xi
• i residui sono le differenze tra valori osservati e previsti
εi = Yi − (β0 + β1Xi) = Yi − Yi.
• Il valore del minimo si dice devianza residua e si indica con
RSS =n
∑i=1[yi − (β0 + β1Xi)]2
Illustrazione 13.1 (Dati sulle circonferenze dell’addome.) Le stime dei MQ si ottengonoin R con i comandi seguenti:
data(abdom, package = "gamlss.data")mq = lm(y ~ x, data = abdom)summary(mq)
Estimate Std. Error t value Pr(>|t|)(Intercept) -55.1795 2.0010 -27.58 <2e-16 ***x 10.3382 0.0701 147.49 <2e-16 ***---Residual standard error: 14.63 on 608 degrees of freedomMultiple R-squared: 0.9728, Adjusted R-squared: 0.9728F-statistic: 2.175e+04 on 1 and 608 DF, p-value: < 2.2e-16
¹Nota che cov(k,Y) = kE(Y) − kE(Y) = 0.
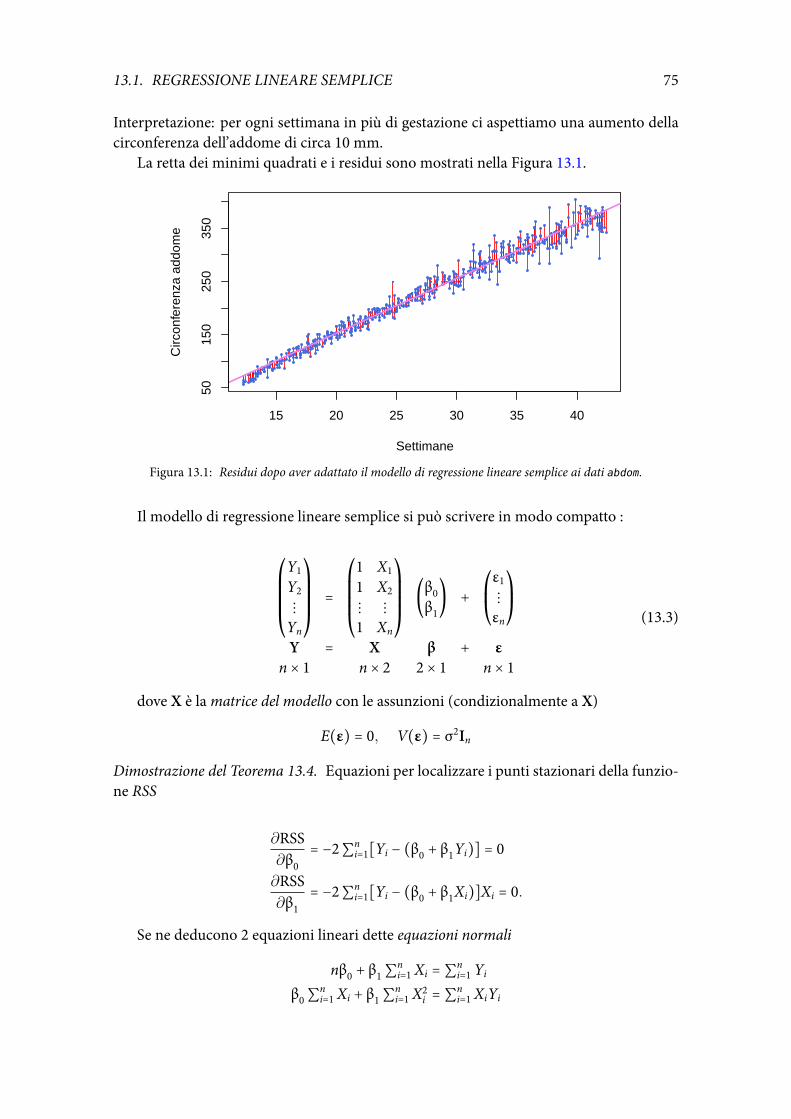
13.1. REGRESSIONE LINEARE SEMPLICE 75
Interpretazione: per ogni settimana in più di gestazione ci aspettiamo una aumento dellacirconferenza dell’addome di circa 10 mm.
La retta dei minimi quadrati e i residui sono mostrati nella Figura 13.1.
15 20 25 30 35 40
5015
025
035
0
Settimane
Circ
onfe
renz
a ad
dom
e
Figura 13.1: Residui dopo aver adattato il modello di regressione lineare semplice ai dati abdom.
Il modello di regressione lineare semplice si può scrivere in modo compatto :
⎛⎜⎜⎜⎜⎝
Y1
Y2
⋮Yn
⎞⎟⎟⎟⎟⎠
=
⎛⎜⎜⎜⎜⎝
1 X1
1 X2
⋮ ⋮1 Xn
⎞⎟⎟⎟⎟⎠
(β0β1) +
⎛⎜⎝
ε1
⋮εn
⎞⎟⎠
Y = X β + εn × 1 n × 2 2 × 1 n × 1
(13.3)
dove X è la matrice del modello con le assunzioni (condizionalmente a X)
E(ε) = 0, V(ε) = σ2In
Dimostrazione del Teorema 13.4. Equazioni per localizzare i punti stazionari della funzio-ne RSS
∂RSS∂β0
= −2∑ni=1[Yi − (β0 + β1Yi)] = 0
∂RSS∂β1
= −2∑ni=1[Yi − (β0 + β1Xi)]Xi = 0.
Se ne deducono 2 equazioni lineari dette equazioni normali
nβ0 + β1∑ni=1Xi = ∑n
i=1 Yi
β0∑ni=1Xi + β1∑
ni=1X2
i = ∑ni=1XiYi

76 13. REGRESSIONE LINEARE E LOGISTICA
Risolvendo rispetto a β0,β1 si ottengono dopo qualche manipolazione le equazioni (13.5)e (13.6) del libro. Il sistema si può scrivere in forma matriciale come
(XTX)β = XTY. (13.4)
Quindi se X è di rango pieno il sistema ha una e una sola soluzione
β = (XTX)−1XTY.
Per la dimostrazione della equazione (13.7) vedi gli esercizi.
Proprietà dei residui. Il sistema di equazioni normali ha come implicazione il fatto chei residui dei MQ soddisfano i due vincoli seguenti
∑i(Yi − Yi) = 0
∑i(Yi − Yi)Xi = 0.
I due vincoli si riassumono dicendo che i residui hanno somma nulla (somma adattati =somma osservati) e sono incorrelati con la variabile esplicativa.
Una conseguenza è che
∑i
ε2i =∑
i[(Yi − Y) + β1(Xi − X)]2
=∑i(Yi − Y)2 + β
21∑
i(Xi − X)2 − 2β1(Yi − Y)(Xi − X)
=∑i(Yi − Y)2 − β
21∑
i(Xi − X)2. (13.5)
VariabileX centrata. Se si usa come variabile esplicativa Xi = Xi−X e si assume ilmodello
Yi = γ0 + γ1(Xi − X) + εi
si verifica che gli stimatori dei MQ di γ0 e γ1 sono
γ0 = Y, γ1 = β1.
13.2 Minimi quadrati e massima verosimiglianza
Il modello di regressione lineare semplice spesso è usato con l’aggiunta dell’assunzione dinormalità degli errori:
(Yi ∣ Xi) ∼ N(β0 + β1Xi,σ2), ossia εi∣Xi ∼ N(0,σ2) indipendenti. (13.6)
Questo permette di utilizzare il metodo di MV. Il libro dimostra che lo stimatore di MV diβ0 e β1 sono gli stessi del metodo dei minimi quadrati.
Lo stimatore di MV di σ2 non coincide con lo stimatore corretto di σ2:
σ2MV =
RSSn
, σ2 = RSSn − 2

13.3. PROPRIETÀ DEGLI STIMATORI DEI MQ 77
13.3 Proprietà degli stimatori dei MQ
Due proprietà fondamentali degli stimatori β0, β1 sono
• Gli stimatori sono corretti per β0 e β1 e sono una combinazione lineare di Y1, . . . ,Yn
• La matrice di covarianza degli stimatori è
cov((β0, β1)) = (var(β0) cov(β0, β1)⋅ var(β1)
) = σ2
ns2X(∑i X2
in −X⋅ 1
)
dove s2X = ∑i(Xi − X)2/n.
Dimostrazione. Scriviamo β = (β0, β1)T. Allora β = LY con L = (XTX)−1XT. Perciò
E(β) = E[LY] = LE[Y]= LE(Xβ + ε) = L[Xβ + E(ε)]= LXβ = (XTX)−1XTXβ = β.
Quindi notiamo che
cov(Y) = cov(Xβ + ε) = cov(ε) = σ2In.
Perciò
cov(β) = cov(LY) = Lcov(Y)LT
= σ2(XTX)−1XTX(XTX)−1 = σ2(XTX)−1
L’errore standard stimato èse2(βj) = σ2cjj
doveσ2 = RSS/(n − 2), C = (XTX)−1 = (cij).
Proprietà asintotiche. Sotto opportune condizioni (vedi esercizi) gli stimatori dei mini-mi quadrati sono
• consistenti βj →p βj, j = 0, 1
• asintoticamente normaliβj − βj
se(βj)↝ N(0, 1)

78 13. REGRESSIONE LINEARE E LOGISTICA
Intervalli di confidenza e test.
• Quindi è possibile costruire degli intervalli di confidenza approssimati di livello 1−αcon
βj ± z1−α/2se(βj)
• Il test di Wald per l’ipotesi H0 ∶ βj = 0 contro H1 ∶ βj ≠ 0 rifiuta H0 a livelloapprossimato α se
RRRRRRRRRRRR
βj
se(βj)
RRRRRRRRRRRR> z1−α/2
Il valore p è
p = P⎧⎪⎪⎨⎪⎪⎩∣Z∣ >
βj
se(βj)
⎫⎪⎪⎬⎪⎪⎭, dove Z ≈ N(0, 1).
Illustrazione 13.2 (Intervallo di confidenza per il coefficiente di regressione) Nella regres-sione semplice il parametro β1 si dice coefficiente di regressione. Misura la variazione attesadi Y corrispondente a una variazione unitaria di X. Per i dati abdom la stima è β1 = 10.338.Come si ottiene un intervallo di confidenza di livello 95%? Ecco le istruzioni R.
confint(mq, level = 0.95)2.5 % 97.5 %
(Intercept) -59.10923 -51.24980x 10.20057 10.47589
Da cui otteniamo l’intervallo (10.2, 10.48).
Illustrazione 13.3 (Test sul coefficiente di regressione.) Ancora per i dati abdom doman-diamoci se la pendenza della retta di regressione è significativamente diversa da zero:β1 = 0 contro β1 ≠ 0. Le quantità rilevanti sono già contenute nell’output della funzione Rsummary. Lo replichiamo qui sotto.
summary(Scode)Estimate Std. Error t value Pr(>|t|)
(Intercept) -55.1795 2.0010 -27.58 <2e-16 ***x 10.3382 0.0701 147.49 <2e-16 ***---Residual standard error: 14.63 on 608 degrees of freedom
La statistica di Wald è RRRRRRRRRRRR
βj
se(βj)
RRRRRRRRRRRR= ∣10.3382
0.0701∣ = 147.49
Nell’output è indicata con t per un motivo che sarà spiegato nell’appendice. Ovviamenteè un valore estremamente improbabile se fosse vera l’ipotesi nulla. Il valore di 147.49 èsicuramente incluso in qualsiasi regione critica con livello α < 0.001. Il valore p è
p = P(∣Z∣ > 147.49) < 10−16.

13.4. INTERVALLI DI PREVISIONE 79
13.4 Intervalli di previsione
Notate la differenza:
• Un intervallo di confidenza è un intervallo con estremi (L,U), con L e U variabilialeatorie, che comprende un parametro con una probabilità fissata 1 − α.
• Un intervallo di previsione è un intervallo con estremi (L,U), con L e U variabilialeatorie, che comprende una variabile aleatoria futura con una probabilità fissata1 − α.
Analizziamo i due problemi separatamente.
Varianza dello stimatore di un valore adattato. Ricordate che E(Y ∣ Xi) = μi è il valoreatteso della risposta che corrisponde a un dato valore Xi. Un valore adattato Yi = β0 + β1Xi
è lo stimatore dei minimi quadrati di μi.Come potete verificare per esercizio
var(Yi) = var(β0 + β1x) = var(β0) + x2var(β1) + 2x cov(β0, β1)
= σ2 (1n+ (x − x)
2
Σi(xi − x)2) .
Quindi
se(Yi) = σ
¿ÁÁÀ1
n+ (x − x)
2
Σi(xi − x)2. (13.7)
Intervalli di confidenza per una media. Yi è corretto per μi ed è una combinazionelineare di stimatori asintoticamente normali. Quindi
Yi − μi
se(Yi)↝ N(0, 1)
PertantoYi ± z1−α/2se(Yi)
è un intervallo di confidenza di livello approssimato 1 − α per μi.
Nota. La formula (13.7) è un diversa da quella di Wasserman (2004) ma è equivalente.
Illustrazione 13.4 (Stima della circonferenza addominale) Vogliamo stimare media dellacirconferenza addominale di un feto di 30 settimane.
predict(m, newdata = data.frame (x = 30), interval = "confidence", se.fit = TRUE)$fit
fit lwr upr1 254.9673 253.7447 256.19
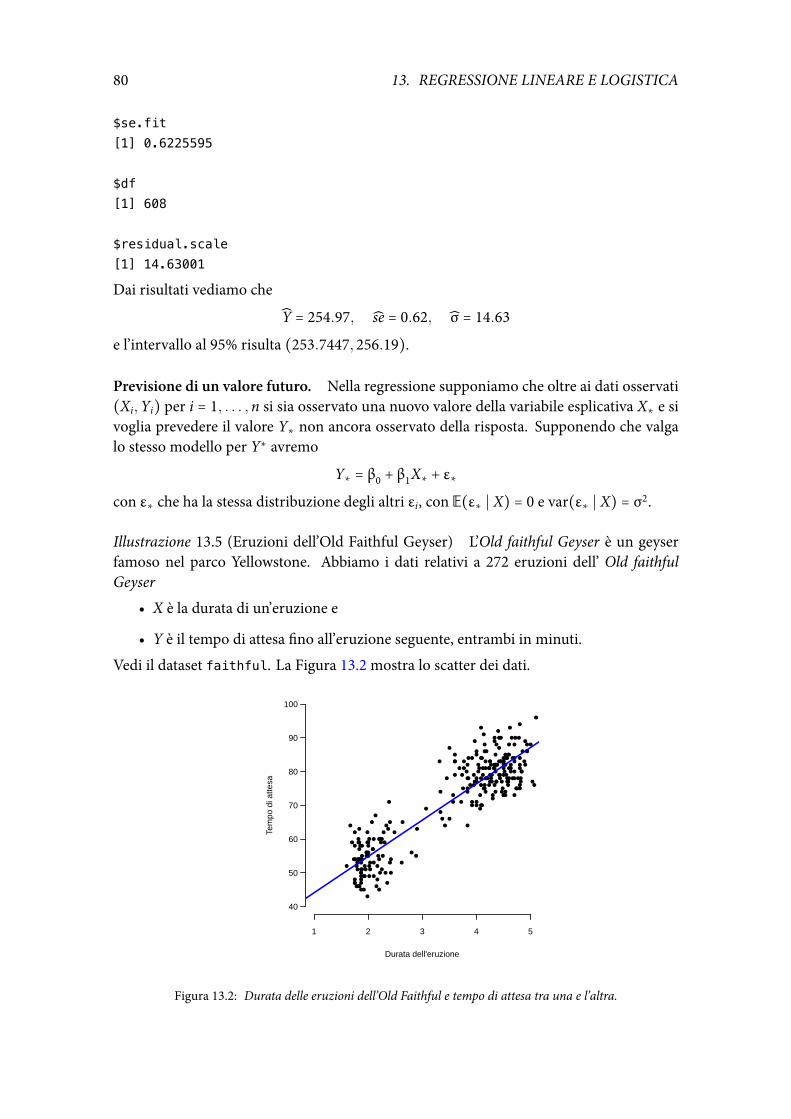
80 13. REGRESSIONE LINEARE E LOGISTICA
$se.fit[1] 0.6225595
$df[1] 608
$residual.scale[1] 14.63001
Dai risultati vediamo che
Y = 254.97, se = 0.62, σ = 14.63
e l’intervallo al 95% risulta (253.7447, 256.19).
Previsione di un valore futuro. Nella regressione supponiamo che oltre ai dati osservati(Xi,Yi) per i = 1, . . . ,n si sia osservato una nuovo valore della variabile esplicativa X∗ e sivoglia prevedere il valore Y∗ non ancora osservato della risposta. Supponendo che valgalo stesso modello per Y∗ avremo
Y∗ = β0 + β1X∗ + ε∗con ε∗ che ha la stessa distribuzione degli altri εi, con E(ε∗ ∣ X) = 0 e var(ε∗ ∣ X) = σ2.
Illustrazione 13.5 (Eruzioni dell’Old Faithful Geyser) L’Old faithful Geyser è un geyserfamoso nel parco Yellowstone. Abbiamo i dati relativi a 272 eruzioni dell’ Old faithfulGeyser
• X è la durata di un’eruzione e
• Y è il tempo di attesa fino all’eruzione seguente, entrambi in minuti.
Vedi il dataset faithful. La Figura 13.2 mostra lo scatter dei dati.
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
Durata dell'eruzione
Tem
po d
i atte
sa
1 2 3 4 5
40
50
60
70
80
90
100
Figura 13.2: Durata delle eruzioni dell’Old Faithful e tempo di attesa tra una e l’altra.

13.4. INTERVALLI DI PREVISIONE 81
Le stime dei minimi quadrati della regressione del tempo di attesa rispetto alla duratadell’eruzione sono le seguenti.
Y: Tempo di attesa Stima se 2.5% 97.5%(costante) 33.47 1.15 31.20 35.75Durata 10.73 0.31 10.10 11.35σ = 5.914 (270 gl)
Pertanto, per ogniminuto in più di durata dobbiamo aspettare l’eruzione seguente circa11 minuti in più. La variabilità residua non è bassa perché è di circa 6 minuti.
Supponiamo che un turista arrivi alla fine di un’eruzione durata x∗ = 3.5 minuti. Fraquanto tempo si prevede che si verifichi la prossima eruzione?
La stima del tempo di attesa medio dopo una eruzione di 3.5 minuti è
μ∗ = 33.47 + (10.73)(3.5) = 71.03 minuti
con un errore standard stimato (poiché n = 272, x = 3.487 e Σi(xi − x)2 = 353.04)
se(μ∗) = σ
¿ÁÁÀ1
n+ (x∗ − x)
2
Σi(xi − x)2
= 5.914√
1272+ 3.5 − 3.487
353.04= 0.36.
Dunque il tempo di attesa MEDIO è stimato con molta precisione.Ma il nostro problema è prevedere invece il tempo di attesa della prossima eruzione.
In questo caso si deve prevedere la variabile aleatoria
Y∗ = μ∗ + ε∗
La previsione Y∗ si ottiene come somma
• della stima del valor medio μ∗ e
• del miglior predittore lineare dell’errore ε∗.
Quest’ultimo è semplicemente il valore atteso E(ε∗) = 0 e dunque il predittore di Y∗risulta
Y∗ = μ∗ + 0 = β0 + β1X∗
coincidente con lo stimatore della media μ∗.
Per valutare l’errore della previsione abbiamo bisogno di un risultato.
Proposizione 13.1 Nel modello di regressione lineare semplice l’errore quadratico medio diprevisione di Y∗ è
E[(Y∗ − Y∗)2] = σ2 (1 + 1n+ (x∗ − x)
2
Σi(xi − x)2) .

82 13. REGRESSIONE LINEARE E LOGISTICA
Dimostrazione. . Poiché Y∗ = β0+ β1X∗ e Y∗ sono indipendenti, E(Y∗Y∗) = E(Y∗)E(Y∗) =μ2∗ e quindi
E[(Y∗ − Y∗)2] = E(Y2∗) + E(Y2
∗) − 2μ2∗
= var(β0 + β1X∗) + var(ε∗).
Pertanto il risultato segue dalla proposizione precedente e da var(ε∗) = σ2.
Notate che l’errore quadratico medio di previsione è la somma
• dell’incertezza sulla stima del valor medio μ∗
• dell’incertezza sulla previsione dell’errore individuale irriducibile legato alla nuovaosservazione x∗.
L’errore standard stimato di previsione è la radice quadrata dell’errore quadratico mediostimato sostituendo a σ2 la stima di regressione σ2 = RSS/(n − 2):
sep(x∗) = σ
¿ÁÁÀ1 + 1
n+ (x∗ − x)
2
Σi(xi − x)2.
Per costruire un intervallo di previsione usiamo una procedura simile a quella vista perl’intervallo di confidenza.
Proposizione 13.2 L’intervallo di estremi
Y∗ ± z1−α/2sep(x∗)
è un intervallo di previsione approssimato del valore futuro Y∗.
Dimostrazione. Risulta che
Y∗ − Y∗sep(x∗)
=Y∗ − (β0 + β1x∗)
σ√
1 + 1/n + (x∗ − x)2/Σi(xi − x)2↝ N(0, 1)
Illustrazione 13.6 (Intervallo di previsione per i tempi di attesa) La previsione puntuale èY∗ = 33.47 + (10.73)(3.5) = 71.03 minuti. L’errore standard di previsione risulta
sep(x∗) = 5.914√
1 + 1/272 + (3.5 − 3.487)2/353.04 = 5.9 min.
L’intervallo di previsione approssimato al 95% risulta
71.03 − (1.96)(5.914) = 59.4; 71.03 + (1.96)(5.914) = 82.6.
Quindi si prevede di attendere tra 60 e 83 minuti. Il codice usato è il seguente.
mq = lm(waiting ~ eruptions, data = faithful)predict (mq, data.frame (eruptions = 3.5), interval= "prediction",
level= 0.95, se.fit = TRUE)$fit
fit lwr upr
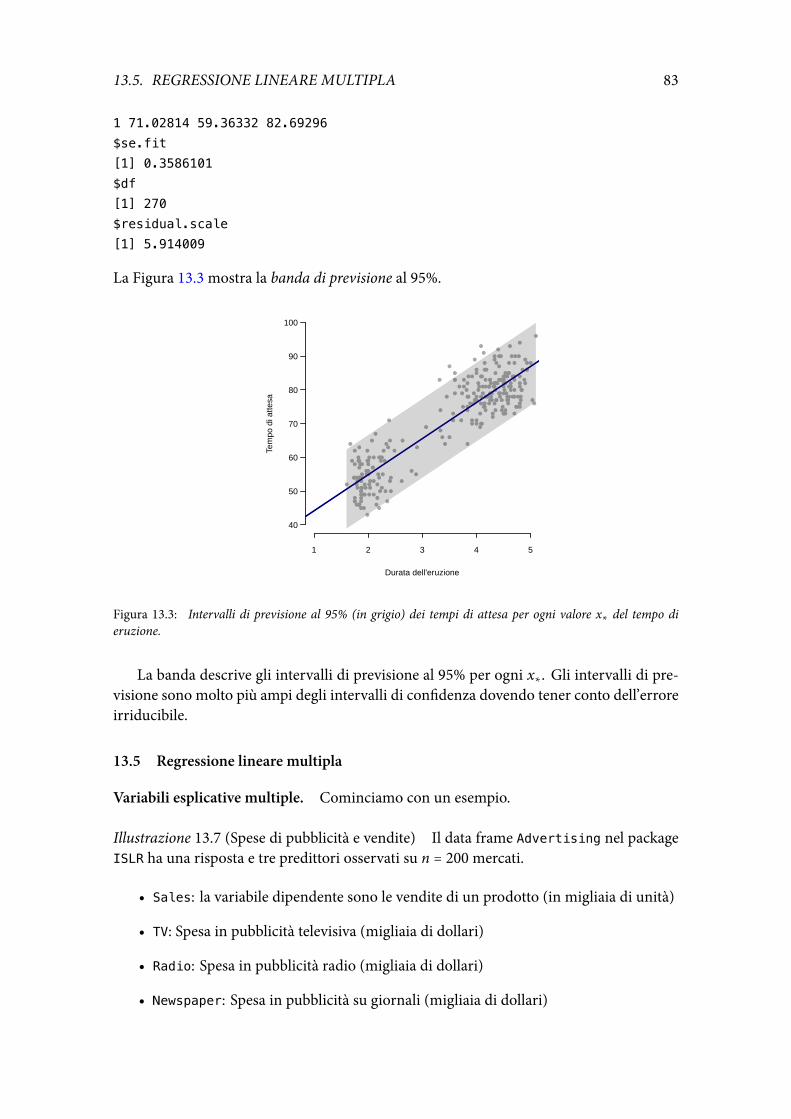
13.5. REGRESSIONE LINEARE MULTIPLA 83
1 71.02814 59.36332 82.69296$se.fit[1] 0.3586101$df[1] 270$residual.scale[1] 5.914009
La Figura 13.3 mostra la banda di previsione al 95%.
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
Durata dell'eruzione
Tem
po d
i atte
sa
1 2 3 4 5
40
50
60
70
80
90
100
Figura 13.3: Intervalli di previsione al 95% (in grigio) dei tempi di attesa per ogni valore x∗ del tempo dieruzione.
La banda descrive gli intervalli di previsione al 95% per ogni x∗. Gli intervalli di pre-visione sono molto più ampi degli intervalli di confidenza dovendo tener conto dell’erroreirriducibile.
13.5 Regressione lineare multipla
Variabili esplicative multiple. Cominciamo con un esempio.
Illustrazione 13.7 (Spese di pubblicità e vendite) Il data frame Advertising nel packageISLR ha una risposta e tre predittori osservati su n = 200 mercati.
• Sales: la variabile dipendente sono le vendite di un prodotto (in migliaia di unità)
• TV: Spesa in pubblicità televisiva (migliaia di dollari)
• Radio: Spesa in pubblicità radio (migliaia di dollari)
• Newspaper: Spesa in pubblicità su giornali (migliaia di dollari)
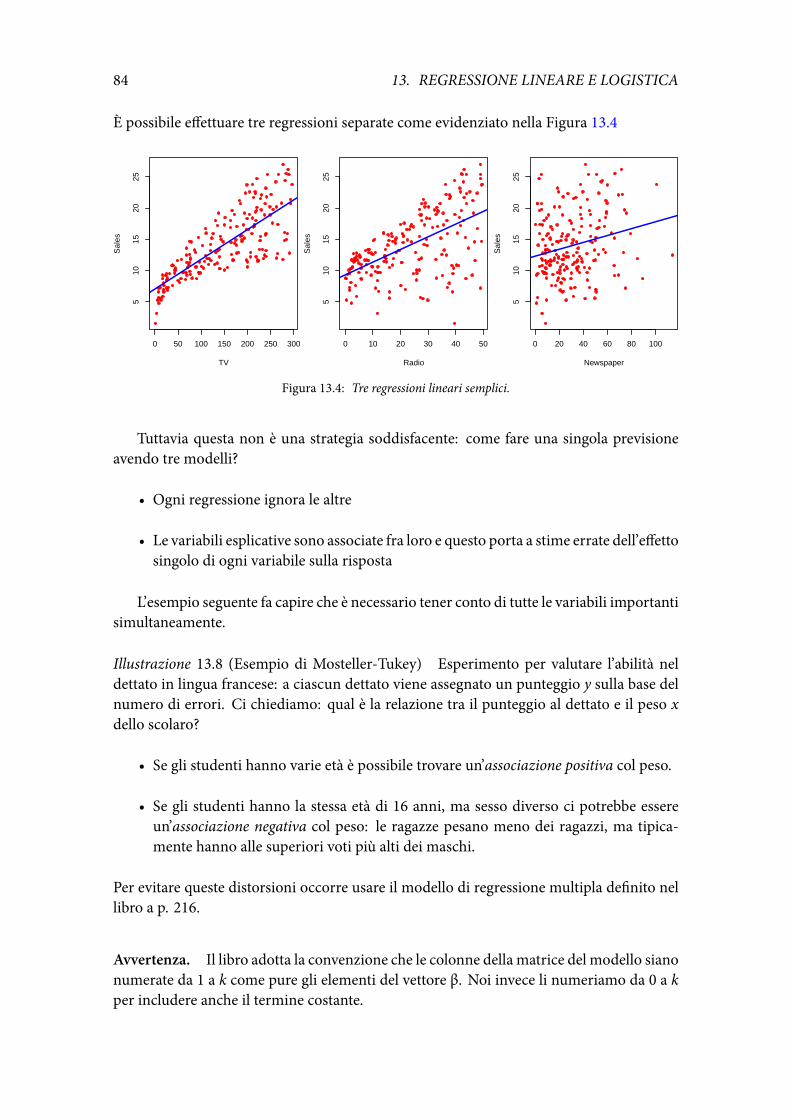
84 13. REGRESSIONE LINEARE E LOGISTICA
È possibile effettuare tre regressioni separate come evidenziato nella Figura 13.4
0 50 100 150 200 250 300
510
1520
25
TV
Sal
es
0 10 20 30 40 50
510
1520
25
Radio
Sal
es
0 20 40 60 80 100
510
1520
25
Newspaper
Sal
es
Figura 13.4: Tre regressioni lineari semplici.
Tuttavia questa non è una strategia soddisfacente: come fare una singola previsioneavendo tre modelli?
• Ogni regressione ignora le altre
• Le variabili esplicative sono associate fra loro e questo porta a stime errate dell’effettosingolo di ogni variabile sulla risposta
L’esempio seguente fa capire che è necessario tener conto di tutte le variabili importantisimultaneamente.
Illustrazione 13.8 (Esempio di Mosteller-Tukey) Esperimento per valutare l’abilità neldettato in lingua francese: a ciascun dettato viene assegnato un punteggio y sulla base delnumero di errori. Ci chiediamo: qual è la relazione tra il punteggio al dettato e il peso xdello scolaro?
• Se gli studenti hanno varie età è possibile trovare un’associazione positiva col peso.
• Se gli studenti hanno la stessa età di 16 anni, ma sesso diverso ci potrebbe essereun’associazione negativa col peso: le ragazze pesano meno dei ragazzi, ma tipica-mente hanno alle superiori voti più alti dei maschi.
Per evitare queste distorsioni occorre usare il modello di regressione multipla definito nellibro a p. 216.
Avvertenza. Il libro adotta la convenzione che le colonne della matrice del modello sianonumerate da 1 a k come pure gli elementi del vettore β. Noi invece li numeriamo da 0 a kper includere anche il termine costante.

13.5. REGRESSIONE LINEARE MULTIPLA 85
Modello di regressione multipla
⎛⎜⎜⎜⎜⎝
Y1
Y2
⋮Yn
⎞⎟⎟⎟⎟⎠
=
⎛⎜⎜⎜⎜⎝
1 X11 ⋯ X1k
1 X21 X2k
⋮ ⋮ ⋮1 Xn1 ⋯ Xnk
⎞⎟⎟⎟⎟⎠
⎛⎜⎜⎜⎜⎝
β0β1⋮βk
⎞⎟⎟⎟⎟⎠
+⎛⎜⎝
ε1
⋮εn
⎞⎟⎠
Y = X β + εn × 1 n × (k + 1) (k + 1) × 1 n × 1
dove X è la matrice del modello con le assunzioni² (condizionalmente a X)
E(ε ∣ X) = 0, cov(ε ∣ X) = σ2In
Un modo alternativo di scrivere il modello è il seguente che generalizza la scrittura delmodello di regressione lineare semplice.
Yi = β0 + β1Xi1 +⋯ + βkXik + εi = β0 + βTxi + εi
Caratteristiche delle variabili esplicative. I termini Xj, j = 1, . . . , k possono avere naturadiversa. Possono essere:
• variabili quantitative
• trasformazioni di variabili come X2, log(X),√X
• variabili qualitative trasformate in gruppi di variabili dicotomiche dette dummy
• variabili di interazione come X3 = X1 ⋅ X2.
Il Teorema 13.13 del libro generalizza quanto visto per il modello lineare semplice.
Illustrazione 13.9 (Codice per analizzare i dati dell’Esempio 13.14 del libro) Le stimedell’esempio del libro si trovano con le istruzioni seguenti in R.
crime = read.table('http://local.disia.unifi.it/gmm/data/crime.txt', header = TRUE)out = lm(Crime ~ Age + Southern + Education +
Expenditure + Labor + Males +pop + U1 + U2 + Wealth, data=crime)
summary(out)Estimate Std. Error t value Pr(>|t|)
(Intercept) -589.39985 167.59057 -3.517 0.001201 **Age 1.04058 0.44639 2.331 0.025465 *Southern 11.29464 13.24510 0.853 0.399441Education 1.17794 0.68181 1.728 0.092620 .Expenditure 0.96364 0.24955 3.862 0.000451 ***Labor 0.10604 0.15327 0.692 0.493467
²Ricordate che L’operatore cov(⋅) denota la matrice di covarianza di un vettore aleatorio.

86 13. REGRESSIONE LINEARE E LOGISTICA
Males 0.30353 0.22269 1.363 0.181344pop 0.09042 0.13866 0.652 0.518494U1 -0.68179 0.48079 -1.418 0.164774U2 2.15028 0.95078 2.262 0.029859 *Wealth -0.08309 0.09099 -0.913 0.367229---Residual standard error: 24.56 on 36 degrees of freedom
Il termine residual standard error indica la stima σ =√RSS/(n − k − 1).
13.6 Scelta del modello
Il problema della scelta del modello è IL problema fondamentale della regressione e ci sonovari modi di affrontarlo a seconda dell’obiettivo che ci si pone nell’analisi. Si può usare laregressione con due scopi:
(a) a fini esplicativi
(b) a fini predittivi
Nel primo caso l’analisi è volta a capire la struttura delle associazioni tra le variabili e ilmeccanismo generatore della risposta. Nel secondo caso l’obiettivo è meno ambiziosoperché si vuole solo prevedere Y nel modo ottimale partendo dalle variabili esplicative X.In questo caso non interessa capire il meccanismo generatore, ma solo costruire unmodel-lo empirico che permetta di fornire buone previsioni. Tipicamente l’obiettivo (a) si cercadi perseguire con un numero ridotto di variabili ben scelte e con un indagine di buonaqualità mentre l’obiettivo (b) è più usato quando si ha un gran numero di variabili e pocheconoscenze teoriche sul problema oggetto di studio.
Prima di discutere la scelta delmodello seguendo il libro diWasserman vediamo alcunicasi di studio in cui il fine della regressione è esplicativo.
Illustrazione 13.10 (Previsioni meteo) Minneapolis-St. Paul nel Minnesota è una zonadove cade parecchia neve. Nel 1974 in un programma televisivo un meteorologo affer-mò che esisteva una associazione crescente tra la quantità di neve caduta a Novembre e laquantità di neve caduta il resto dell’anno. Nella Figura 13.5 abbiamo riportato un graficodi dispersione della quantità di neve (in pollici) caduta a Minneapolis-St. Paul dal 1884 al2010, nel mese di Novembre e nel resto dell’anno. La figura non evidenzia una relazioneforte tra le due variabili e il coefficiente di correlazione è solo 0.095. Tuttavia la retta diregressione ha pendenza positiva come previsto dal meteorologo. Il test di β1 = 0 tuttavianon è significativo come mostra la tabella delle stime seguente:
Risposta: Neve nel resto dell’annoTermini Stima se W p(cost.) 38.41 2.01 19.13 —Novembre 0.23 0.22 1.06 0.29 (n.s.)

13.6. SCELTA DEL MODELLO 87
0 10 20 30 40
20
40
60
80
Novembre
Resto dell'anno
Figura 13.5: Quantità di neve in pollici caduta a Minneapolis-St Paul, Minnesota dal 1884 al 2010. In ascissela quantità caduta a Novembre, in ordinate la quantità caduta nel resto dell’anno. Sul grafico è riportata anchela retta dei minimi quadrati y = 38.41 + 0.23x. Nonostante la pendenza sia positiva, il coefficiente non èsignificativo.
Illustrazione 13.11 (Rendimento di un processo chimico) Un processo chimico ha unrendimento Y he dipende dalla temperatura X. I dati sono i seguenti
X ∶ 15 16 17 18 19 20 21 22 23Y ∶ 90.0 90.9 90.7 87.9 86.4 82.5 80.0 76.0 70.0
Il modello di regressione semplice appare appropriato a giudicare dall’andamento non li-neare dei punto sullo scatter. Il modello Yi = β0 + β1Xi + β2X2
i + εi appare migliore perchéinclude il modello lineare semplice e può catturare il tipo di non linearità presente nei dati.In R diamo i comandi
> x = 15:23> y = c(90.0, 90.9, 90.7, 87.9, 86.4, 82.5, 80.0, 76.0, 70.0)> x2 = x*x> m2 = lm(y ~ x + x2)
Estimate Std. Error t value Pr(>|t|)(Intercept) 0.60952 13.59104 0.045 0.965684x 11.54405 1.44929 7.965 0.000208 ***x2 -0.37024 0.03807 -9.725 0.0000679 ***---Residual standard error: 0.6682 on 6 degrees of freedom
La parabola adattata è mostrata nella Figura 13.6.

88 13. REGRESSIONE LINEARE E LOGISTICA
16 18 20 2270
7580
8590
x
y
Figura 13.6: Adattamento di una parabola.
Una volta adattato il modello quadratico si può effettuare un test di Wald dell’ipotesi
H0 ∶ β2 = 0 contro H1 ∶ β2 ≠ 0
che in questo caso svolge il ruolo di un test di linearità. La statistica test è W = −9.725(p < 0.001). Dunque il termine quadratico è altamente significativo. Il modello inoltreappare adeguato guardando i residui.
Qual è la temperatura a cui si ha il massimo rendimento? Sotto il modello, il massi-mo si ottiene nel vertice della parabola θ = −β1/(2β2) che viene stimato col metodo disostituzione:
θ = −β1/(2β2) = 15.59.
Illustrazione 13.12 (Effetto dell’isolamento sul consumo di gasolio) In un esperimento, èstato misurato il consumo settimanale di gasolio per riscaldamento di casa in due inverniprima e dopo un intervento di isolamento dei muri. Ci sono in totale n = 56 settimanedivise in due gruppi di dimensione 26 (prima) e 30 (dopo). Il consumo di gasolio Y èmisurato in litri. I due gruppi sono definiti da una variabile binaria x che vale 0 prima deltrattamento di isolamento e 1 dopo.
La differenza tra il consumo medio prima e dopo l’isolamento è di circa 36 litri con unerrore standard se = 7.5 e quindi la differenza tra le medie è significativa.
Tuttavia, l’effetto dell’isolamento può essere messo in dubbio dal fatto che i due gruppidi osservazioni sono stati ottenuti in due stagioni in condizioni di temperatura diverse.Per esempio, l’analisi precedente potrebbe essere distorta se la temperatura della secondastagione fosse stata sensibilmente più elevata della prima.
Il modo migliore per tener fare in modo che la temperatura non disturbi il confronto èsvolgere l’esperimento tenendo fissa la temperatura. Ma se questo non è stato fatto come inquesto caso, un modo per aggiustare la misura dell’effetto³ del trattamento tenendo contodella temperatura consiste nell’adattare un modello di regressione che tenga anche contodella temperatura.
³Quando si usa il termine effetto nella regressione non si intende l’effetto causale della variabile esplicativasulla risposta, ma il grado di associazione lineare.
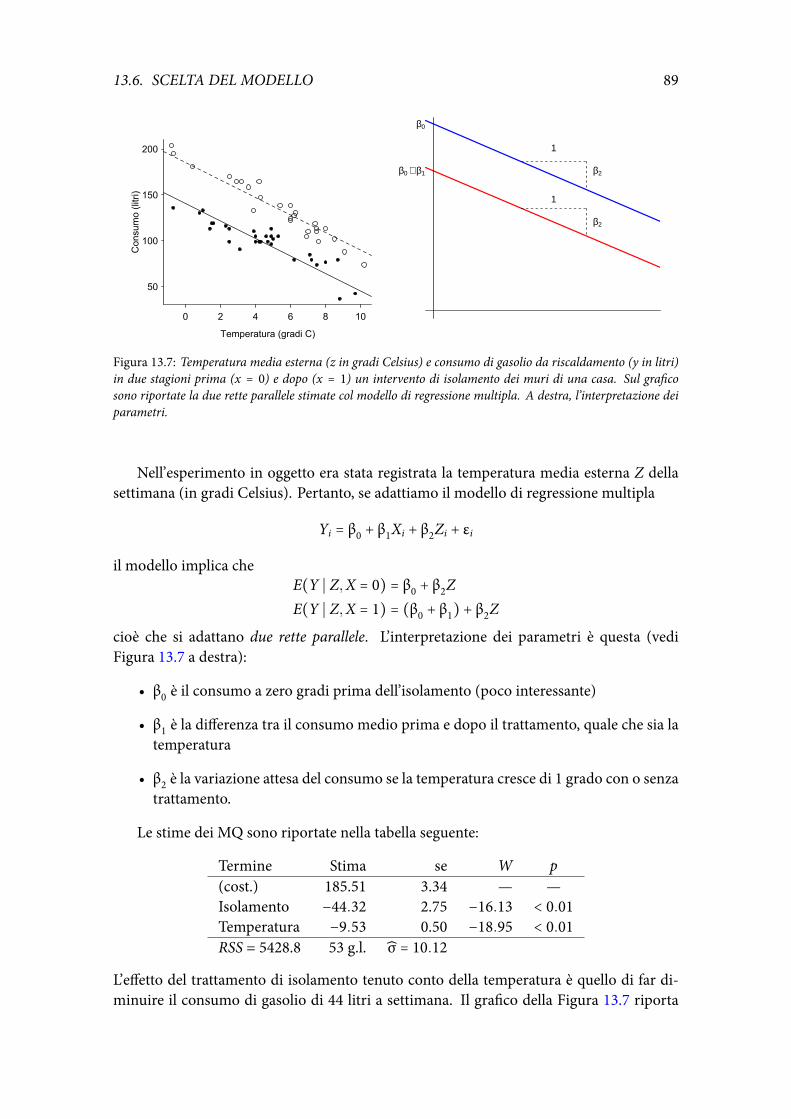
13.6. SCELTA DEL MODELLO 89
Temperatura (gradi C)
Con
sum
o (li
tri)
0 2 4 6 8 10
50
100
150
200
β0
β0 + β1
β2
β2
1
1
Figura 13.7: Temperatura media esterna (z in gradi Celsius) e consumo di gasolio da riscaldamento (y in litri)in due stagioni prima (x = 0) e dopo (x = 1) un intervento di isolamento dei muri di una casa. Sul graficosono riportate la due rette parallele stimate col modello di regressione multipla. A destra, l’interpretazione deiparametri.
Nell’esperimento in oggetto era stata registrata la temperatura media esterna Z dellasettimana (in gradi Celsius). Pertanto, se adattiamo il modello di regressione multipla
Yi = β0 + β1Xi + β2Zi + εi
il modello implica cheE(Y ∣ Z,X = 0) = β0 + β2ZE(Y ∣ Z,X = 1) = (β0 + β1) + β2Z
cioè che si adattano due rette parallele. L’interpretazione dei parametri è questa (vediFigura 13.7 a destra):
• β0 è il consumo a zero gradi prima dell’isolamento (poco interessante)
• β1 è la differenza tra il consumo medio prima e dopo il trattamento, quale che sia latemperatura
• β2 è la variazione attesa del consumo se la temperatura cresce di 1 grado con o senzatrattamento.
Le stime dei MQ sono riportate nella tabella seguente:
Termine Stima se W p(cost.) 185.51 3.34 — —Isolamento −44.32 2.75 −16.13 < 0.01Temperatura −9.53 0.50 −18.95 < 0.01RSS = 5428.8 53 g.l. σ = 10.12
L’effetto del trattamento di isolamento tenuto conto della temperatura è quello di far di-minuire il consumo di gasolio di 44 litri a settimana. Il grafico della Figura 13.7 riporta

90 13. REGRESSIONE LINEARE E LOGISTICA
lo scatter del consumo rispetto alla temperatura. I due gruppi sono rappresentati da duepunti di diverso colore. Le rette adattate risultano
Y = 185.51 − 9.53Z (senza isolamento), Y = 141.19 − 9.53Z (con isolamento)
e sono riportate sullo stesso grafico. L’effetto dell’isolamento è la differenza β1 = 141.19 −185.51 = −44.32 tra le intercette delle due rette parallele stimate. Notare che questo effettoe’ maggiore di quello ottenuto prima ignorando la temperatura che risultava di −35.87.
L’effetto della temperatura tenuto conto dell’isolamento infatti è altamente significativoe comporta una diminuzione del gasolio consumato di circa 10 litri a settimana (W = 18.9).
Una conseguenza del modello adattato è che l’effetto dell’isolamento è lo stesso qua-le che sia la temperatura esterna, e l’effetto della temperatura è lo stesso quale che sia iltrattamento. Questo fenomeno si chiama assenza di interazione.
Interazione. Quando l’effetto di una variabile X su Y è sempre β1 qualunque valore as-suma la variabile concomitante Z si dice che c’è assenza di interazione.
C’è interazione invece se l’effetto di X su Y dipende da Z.
(a) modello senza interazione (o modello additivo)
E(Y ∣ X,Z) = β0 + β1X + β2Z
(b) Modello con interazione
E(Y ∣ X,Z) = β0 + β1X + β2Z + β3X ⋅ Z.
Nel modello (b) si definisce un termine di interazione come prodotto X ⋅ Z. In questo casoc’è interazione tra X e Z perché l’effetto lineare di Z su Y, misurato con la derivata parzialerispetto a Z, è
∂E(Y∣X,Z)∂Z
= β2 + β3X
e quindi dipende da X.
Formula del modello. Nella formula del modello l’interazione è definita dall’operatore :(due punti)
consumo ~ temperatura + isolamento + temperatura:isolamento
che si può abbreviare in
consumo ~ temperatura * isolamento
mint = lm(consumo ~ temperatura*isolamento)Estimate Std. Error t value Pr(>|t|)
(Intercept) 194.0788 3.8501 50.409 < 2e-16 ***temperatura -11.1353 0.6368 -17.487 < 2e-16 ***isolamento -60.3143 5.0996 -11.827 2.32e-16 ***temperatura:isolamento 3.2650 0.9093 3.591 0.000731 ***---Residual standard error: 9.15 on 52 degrees of freedom
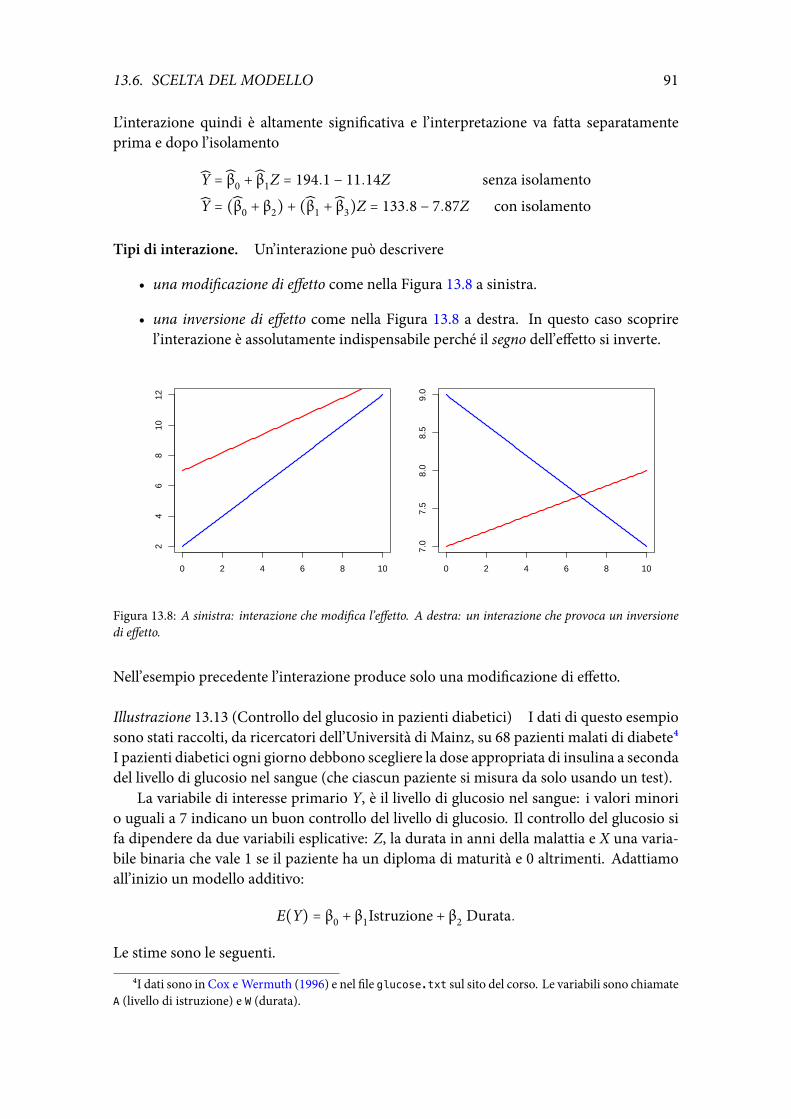
13.6. SCELTA DEL MODELLO 91
L’interazione quindi è altamente significativa e l’interpretazione va fatta separatamenteprima e dopo l’isolamento
Y = β0 + β1Z = 194.1 − 11.14Z senza isolamento
Y = (β0 + β2) + (β1 + β3)Z = 133.8 − 7.87Z con isolamento
Tipi di interazione. Un’interazione può descrivere
• una modificazione di effetto come nella Figura 13.8 a sinistra.
• una inversione di effetto come nella Figura 13.8 a destra. In questo caso scoprirel’interazione è assolutamente indispensabile perché il segno dell’effetto si inverte.
0 2 4 6 8 10
24
68
1012
0 2 4 6 8 10
7.0
7.5
8.0
8.5
9.0
Figura 13.8: A sinistra: interazione che modifica l’effetto. A destra: un interazione che provoca un inversionedi effetto.
Nell’esempio precedente l’interazione produce solo una modificazione di effetto.
Illustrazione 13.13 (Controllo del glucosio in pazienti diabetici) I dati di questo esempiosono stati raccolti, da ricercatori dell’Università di Mainz, su 68 pazienti malati di diabete⁴I pazienti diabetici ogni giorno debbono scegliere la dose appropriata di insulina a secondadel livello di glucosio nel sangue (che ciascun paziente si misura da solo usando un test).
La variabile di interesse primario Y, è il livello di glucosio nel sangue: i valori minorio uguali a 7 indicano un buon controllo del livello di glucosio. Il controllo del glucosio sifa dipendere da due variabili esplicative: Z, la durata in anni della malattia e X una varia-bile binaria che vale 1 se il paziente ha un diploma di maturità e 0 altrimenti. Adattiamoall’inizio un modello additivo:
E(Y) = β0 + β1Istruzione + β2 Durata.
Le stime sono le seguenti.
⁴I dati sono in Cox e Wermuth (1996) e nel file glucose.txt sul sito del corso. Le variabili sono chiamateA (livello di istruzione) e W (durata).
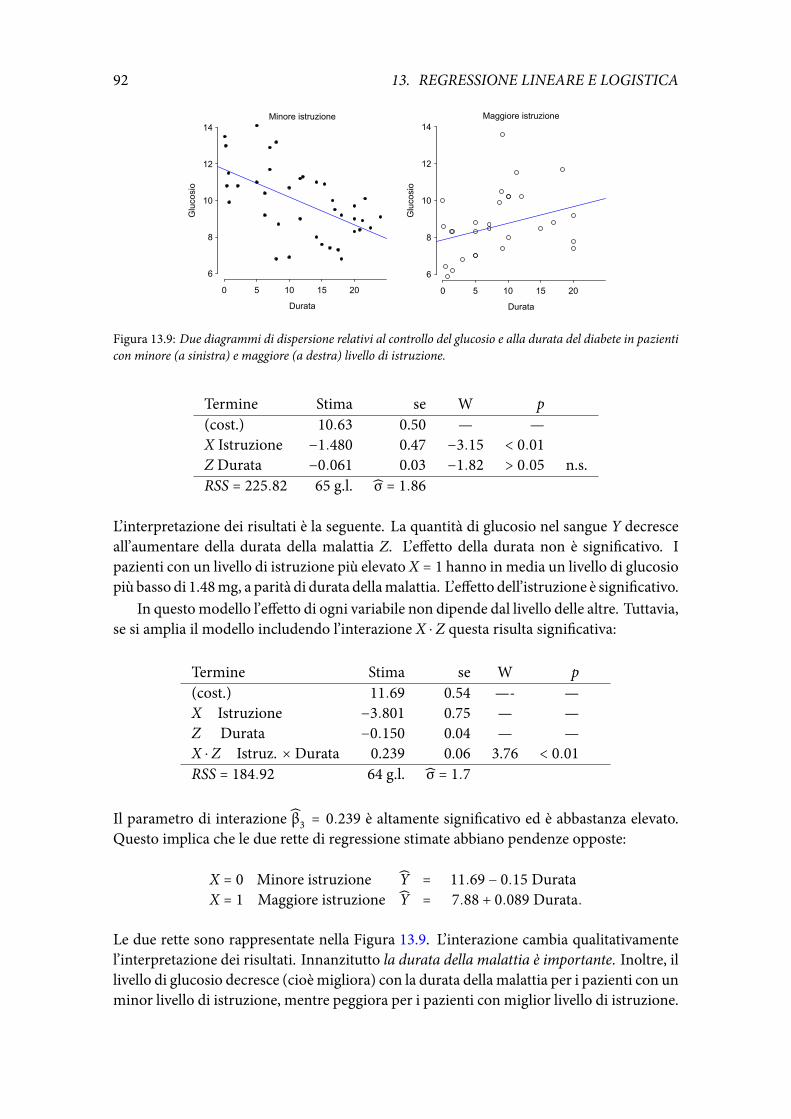
92 13. REGRESSIONE LINEARE E LOGISTICA
Durata
Glucosio
0 5 10 15 20
6
8
10
12
14Minore istruzione
Durata
Glucosio
0 5 10 15 20
6
8
10
12
14Maggiore istruzione
Figura 13.9: Due diagrammi di dispersione relativi al controllo del glucosio e alla durata del diabete in pazienticon minore (a sinistra) e maggiore (a destra) livello di istruzione.
Termine Stima se W p(cost.) 10.63 0.50 — —X Istruzione −1.480 0.47 −3.15 < 0.01Z Durata −0.061 0.03 −1.82 > 0.05 n.s.RSS = 225.82 65 g.l. σ = 1.86
L’interpretazione dei risultati è la seguente. La quantità di glucosio nel sangue Y decresceall’aumentare della durata della malattia Z. L’effetto della durata non è significativo. Ipazienti con un livello di istruzione più elevato X = 1 hanno in media un livello di glucosiopiù basso di 1.48mg, a parità di durata dellamalattia. L’effetto dell’istruzione è significativo.
In questomodello l’effetto di ogni variabile non dipende dal livello delle altre. Tuttavia,se si amplia il modello includendo l’interazione X ⋅ Z questa risulta significativa:
Termine Stima se W p(cost.) 11.69 0.54 —- —X Istruzione −3.801 0.75 — —Z Durata −0.150 0.04 — —X ⋅ Z Istruz. × Durata 0.239 0.06 3.76 < 0.01RSS = 184.92 64 g.l. σ = 1.7
Il parametro di interazione β3 = 0.239 è altamente significativo ed è abbastanza elevato.Questo implica che le due rette di regressione stimate abbiano pendenze opposte:
X = 0 Minore istruzione Y = 11.69 − 0.15 DurataX = 1 Maggiore istruzione Y = 7.88 + 0.089 Durata.
Le due rette sono rappresentate nella Figura 13.9. L’interazione cambia qualitativamentel’interpretazione dei risultati. Innanzitutto la durata della malattia è importante. Inoltre, illivello di glucosio decresce (cioèmigliora) con la durata della malattia per i pazienti con unminor livello di istruzione, mentre peggiora per i pazienti con miglior livello di istruzione.

13.6. SCELTA DEL MODELLO 93
Indice di determinazione lineare Un modo per valutare quanto il modello adattato siavicino ai dati è quello di calcolare l’indice di determinazione lineare R2 definito da
R2 = ESSTSS= ∑i(yi − y)2
∑i(yi − y)2
L’indice TSS misura la variabilità delle risposta detta devianza totale, mentre ESS, det-ta varianza spiegata dal modello, misura la variabilità ricostruita dai valori adattati. Conqualche manipolazione si dimostra che
TSS = ESS + RSS =∑i(yi − y)2 +∑
i(yi − yi)2 (13.8)
ossia la devianza totale si scompone in due parti: la devianza spiegata più la devianza re-sidua. Questa identità richiede che il modello assunto da cui sono stati ottenuti i valoriadattati contenga l’intercetta.
Perciò risulta che 0 ≤ R2 ≤ 1. L’interpretazione dell’indice è semplice: indica la frazionedella variabilità osservata che si ricostruisce col modello. Più R2 è vicino a 1 e minore è ladevianza residua.
• R2 = 1 se RSS = 0 cioè se l’adattamento è perfetto.
• R2 = 0 se ESS = 0 cioè se yi = y cioè se i valori adattati sono costanti e quindi se nonc’è una relazione tra y e x.
Dimostrazione della (13.8). Per semplicità considero solo il caso della regressione linearesemplice.
∑i(yi − y)2 =∑
i[(yi − yi) + (yi − y)]2
=∑i(yi − yi)2 +∑
i(yi − y)2 + 2∑
i(yi − yi)(yi − y)
Il doppio prodotto si annulla perché per il sistema di equazioni normali, se c’è l’intercetta
∑i(yi − yi) = 0∑i(yi − yi)xi = 0
e quindi 2∑i(yi − yi)(β0 + β1xi − y) = 2(β0 − y)∑i(yi − yi) + 2β1∑i(yi − yi)xi = 0.
Illustrazione 13.14 (Scomposizione della devianza per i dati sulla circonferenza dell’addo-me) Le devianze risultano
RSS ESS TSS R2
130135 4655764 4785899 0.9728
Quindi la variabilità della circonferenza dell’addome è spiegata dal modello per il 97% esolo per il 3% è non spiegata.
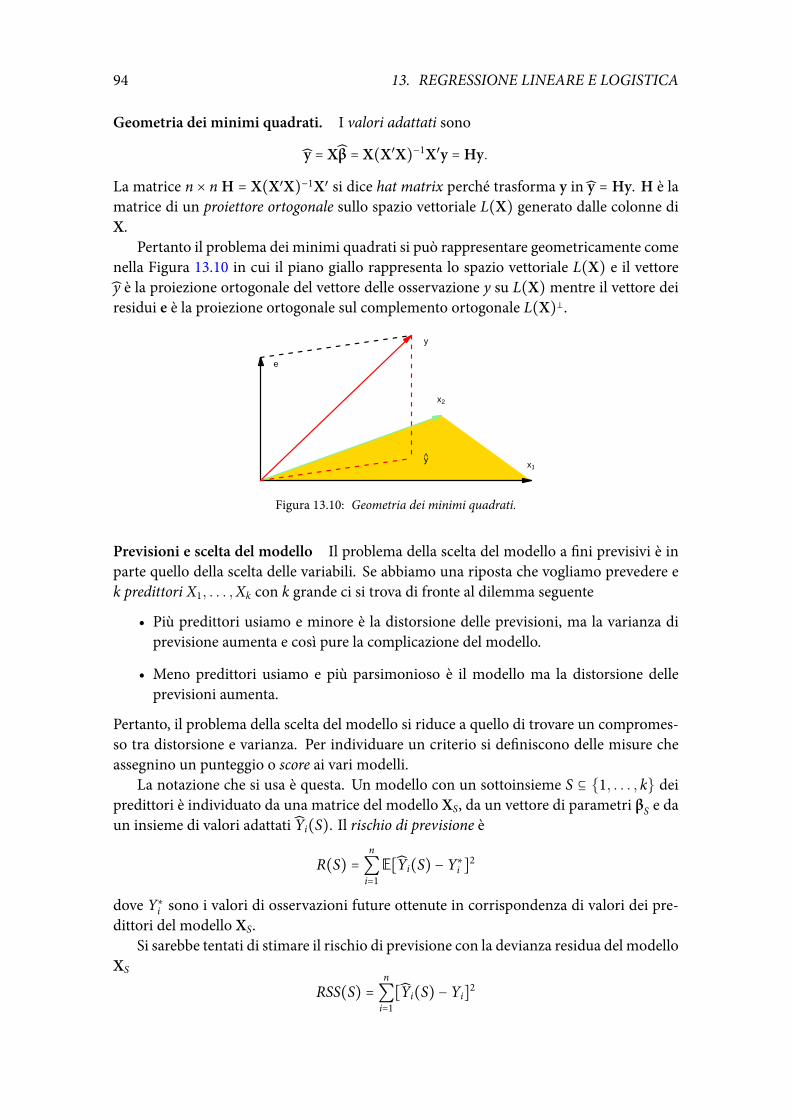
94 13. REGRESSIONE LINEARE E LOGISTICA
Geometria dei minimi quadrati. I valori adattati sono
y = Xβ = X(X′X)−1X′y = Hy.
La matrice n × n H = X(X′X)−1X′ si dice hat matrix perché trasforma y in y = Hy. H è lamatrice di un proiettore ortogonale sullo spazio vettoriale L(X) generato dalle colonne diX.
Pertanto il problema dei minimi quadrati si può rappresentare geometricamente comenella Figura 13.10 in cui il piano giallo rappresenta lo spazio vettoriale L(X) e il vettorey è la proiezione ortogonale del vettore delle osservazione y su L(X) mentre il vettore deiresidui e è la proiezione ortogonale sul complemento ortogonale L(X)⊥.
x1
x2
y
y
e
Figura 13.10: Geometria dei minimi quadrati.
Previsioni e scelta del modello Il problema della scelta del modello a fini previsivi è inparte quello della scelta delle variabili. Se abbiamo una riposta che vogliamo prevedere ek predittori X1, . . . ,Xk con k grande ci si trova di fronte al dilemma seguente
• Più predittori usiamo e minore è la distorsione delle previsioni, ma la varianza diprevisione aumenta e così pure la complicazione del modello.
• Meno predittori usiamo e più parsimonioso è il modello ma la distorsione delleprevisioni aumenta.
Pertanto, il problema della scelta del modello si riduce a quello di trovare un compromes-so tra distorsione e varianza. Per individuare un criterio si definiscono delle misure cheassegnino un punteggio o score ai vari modelli.
La notazione che si usa è questa. Un modello con un sottoinsieme S ⊆ {1, . . . , k} deipredittori è individuato da una matrice del modello XS, da un vettore di parametri βS e daun insieme di valori adattati Yi(S). Il rischio di previsione è
R(S) =n
∑i=1
E[Yi(S) − Y∗i ]2
dove Y∗i sono i valori di osservazioni future ottenute in corrispondenza di valori dei pre-dittori del modello XS.
Si sarebbe tentati di stimare il rischio di previsione con la devianza residua del modelloXS
RSS(S) =n
∑i=1[Yi(S) − Yi]2

13.6. SCELTA DEL MODELLO 95
ma sfortunatamente questa stima è fortemente distorta perché la devianza residua di unmodello con S predittori è sempre minore della devianza residua di un modello con S′predittori se S′ ⊂ S. In modo simile ma inverso si comporta l’indice R2 = 1−RSS/TSS, cioèR2(S) ≥ R2(S′). Questo si vede dal Teorema 13.15 del libro secondo cui
R(S) = E[RSS(S)] + 2n
∑i=1
cov(Yi,Yi)
e quindiE[RSS(S)] ≤ R(S)
perché le covarianze sono sempre positive e crescono all’aumentare del numero di predit-tori. La dimostrazione è lasciata per esercizio.
Nota. Non confondete S con la deviazione standard. Ho usato la notazione RSS(S) perindicare quello che il libro chiama training error.
Una misura accurata del rischio di previsione comunemente usata per i modelli diregressione multipla con errori normali è l’indice di Mallows
R(S) = RSS(S) + 2∣S∣σ2
dove ∣S∣ è il numero di predittori nel modello e σ2 = RSS/(n−k−1) è la stima corretta dellavarianza nel modello completo con ∣S∣ = k + 1.
L’idea pertanto è quella di scegliere, nell’ambito di tutti i possibili 2∣S∣modelli, ilmodelloo i modelli che hanno l’indice di Mallows (che spesso è indicato con Cp) più piccolo.
Illustrazione 13.15 (Previsione del tasso di criminalità) Riprendiamo i dati sul tasso dicriminalità e cerchiamo i migliori modelli con un numero di variabili ∣S∣ = 1, 2, . . . , 10dove k = 10 è il numero di variabili considerate in Wasserman (2004), p. 221. Il numero disottoinsiemi predittori è 210 = 1024. Per valutare l’indice Cp su tutti i sottoinsiemi usiamola funzione regsubsets nel package R leaps.
crime = read.table('http://local.disia.unifi.it/gmm/data/crime.txt',header = TRUE)
library(leaps)modelli = regsubsets(Crime ~ Age + Southern + Education +
Expenditure + Labor + Males + pop + U1 + U2 + Wealth,nvmax= 10, data=crime)
out = summary(modelli)
e otteniamo
Selection Algorithm: exhaustiveAge Southern Education Expenditure Labor Males pop U1 U2 Wealth
1 ( 1 ) " " " " " " "*" " " " " " " " " " " " "2 ( 1 ) "*" " " " " "*" " " " " " " " " " " " "3 ( 1 ) "*" " " " " "*" " " "*" " " " " " " " "
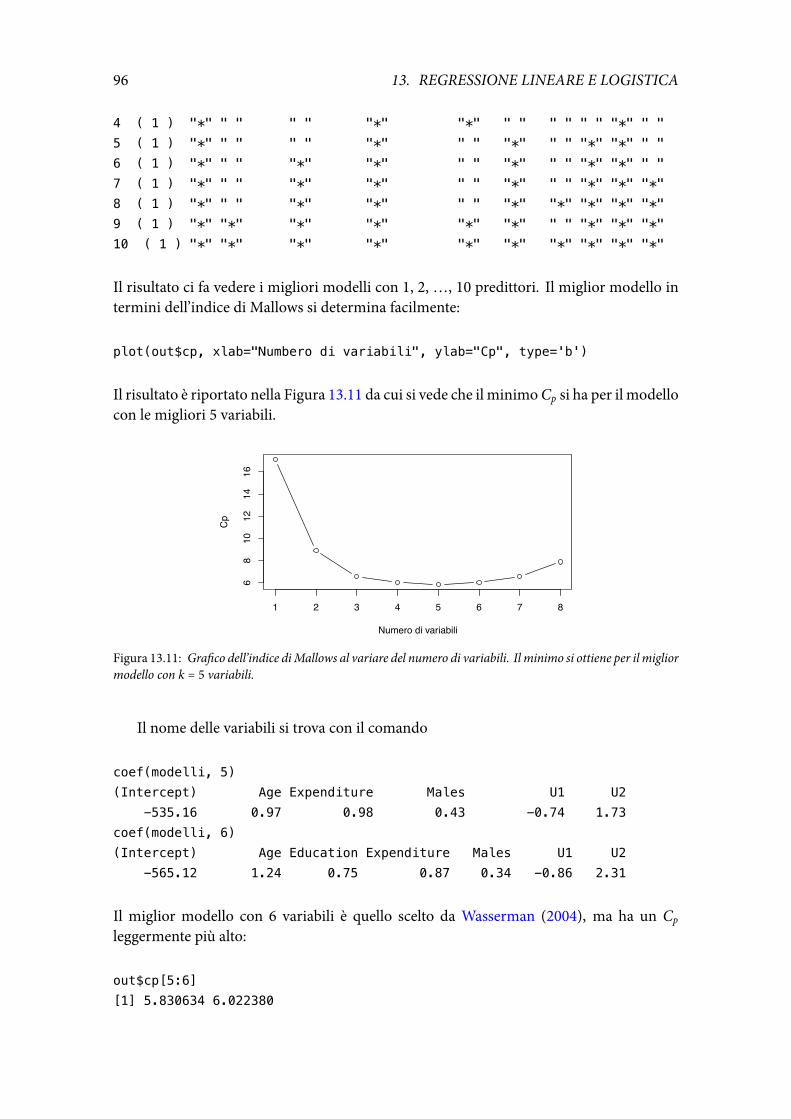
96 13. REGRESSIONE LINEARE E LOGISTICA
4 ( 1 ) "*" " " " " "*" "*" " " " " " " "*" " "5 ( 1 ) "*" " " " " "*" " " "*" " " "*" "*" " "6 ( 1 ) "*" " " "*" "*" " " "*" " " "*" "*" " "7 ( 1 ) "*" " " "*" "*" " " "*" " " "*" "*" "*"8 ( 1 ) "*" " " "*" "*" " " "*" "*" "*" "*" "*"9 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*" "*"10 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*" "*"
Il risultato ci fa vedere i migliori modelli con 1, 2, …, 10 predittori. Il miglior modello intermini dell’indice di Mallows si determina facilmente:
plot(out$cp, xlab="Numbero di variabili", ylab="Cp", type='b')
Il risultato è riportato nella Figura 13.11 da cui si vede che il minimoCp si ha per il modellocon le migliori 5 variabili.
1 2 3 4 5 6 7 8
68
1012
1416
Numero di variabili
Cp
Figura 13.11: Grafico dell’indice diMallows al variare del numero di variabili. Il minimo si ottiene per il migliormodello con k = 5 variabili.
Il nome delle variabili si trova con il comando
coef(modelli, 5)(Intercept) Age Expenditure Males U1 U2
-535.16 0.97 0.98 0.43 -0.74 1.73coef(modelli, 6)(Intercept) Age Education Expenditure Males U1 U2
-565.12 1.24 0.75 0.87 0.34 -0.86 2.31
Il miglior modello con 6 variabili è quello scelto da Wasserman (2004), ma ha un Cp
leggermente più alto:
out$cp[5:6][1] 5.830634 6.022380

13.7. REGRESSIONE LOGISTICA 97
13.7 Regressione logistica
La regressione logistica si usa quando la risposta Yi è binaria invece che continua. Peresempio, una banca raccoglie dati sulle caratteristiche dei clienti possessori di carte di cre-dito e vuole prevedere se il cliente va in default. Oppure un in un processo industriale sivuole studiare a cosa sono imputabili i difetti di produzione.
Illustrazione 13.16 (Difetti di produzione) Tipicamente la presenza di difetti dipende dal-la qualità dellamateria prima usata. I dati seguenti sono stati ottenuti prendendo 22 partitedi materiale grezzo ciascuna con un indice di purezza xi, i = 1, . . . , 22, quindi lavorandociascuna con un processo produttivo standard e rilevando alla fine la variabile binaria yiche misura la presenza o assenza di difetti nel prodotto finito.
xi 7.2 6.3 8.5 7.1 8.2 4.6 8.5 6.9 8.0 8.0 9.1yi 0 1 1 0 1 1 0 1 0 1 0xi 6.5 4.9 5.3 7.1 8.4 8.5 6.6 9.1 7.1 7.5 8.3yi 0 1 1 0 1 0 1 0 1 0 0
La variabile dipendente è binaria e il consueto diagramma di dispersione, con la retta deiminimi quadrati, riportato nella Figura 13.12, appare poco informativo.
Purezza
Difetti
4 5 6 7 8 9 10
0.0
0.2
0.4
0.6
0.8
1.0
Figura 13.12: Presenza di difetti e indice di purezza del materiale. Sul grafico è riportata la retta di regressione(tratteggiata) e la funzione adattata col modello logistico.
La presenza di difetti decresce all’aumentare dell’indice di purezza, ma il fatto singolareè che tutti i punti stanno obbligatoriamente su due rette orizzontali in corrispondenza di y =0 e y = 1. La retta dei minimi quadrati sembra poco utile perché passando in mezzo ai datifinisce per uscire dalla fascia delle due rette e quindi non può rappresentare correttamentei dati. La funzione di regressione invece dovrebbe essere una funzione compresa tra 0 e 1perché essa è uguale alla probabilità di successo: E(Y ∣ X = x) = P(Y = 1 ∣ X = x).
Caratteristiche del modello logistico:
• Risposta Yi ∼ Bernoulli(pi), dove pi è la probabilità di successo dell’unità i-esima.

98 13. REGRESSIONE LINEARE E LOGISTICA
• Variabili esplicative Xi = (Xi1 . . . ,Xik)
• Si ipotizza che le probabilità di successo siano funzione delle variabili esplicativeosservate secondo una funzione non lineare
pi = p(xi;β0,β) =exp[β0 + βTxi]
1 + exp[β0 + βTxi]= g(β0 + βTxi)
dove g(z) = ez1+ez , (z ∈ R) è la funzione logistica mostrata nella Figura 13.3 del libro.
• L’inversa della funzione logistica è la funzione logit, cioè
g−1(p) = logit(p) = log [p/(1 − p)] = z.
Quindi il modello si può scrivere come
logit(pi) = β0 + βTxi = β0 +k
∑j=1
βjxij.
I parametri β0 e β1 sono incogniti e devono essere stimati dai dati. Per la stima non si usanoi minimi quadrati (che dovrebbero essere applicati a una funzione non lineare), ma si usail metodo di stima della massima verosimiglianza che ha migliori proprietà statistiche o siusa una stima Bayesiana (che qui omettiamo).
Stimadimassimaverosimiglianza. Consideriamo il caso della regressione logistica sem-plice (con una sola esplicativa).
La log-verosimiglianza per una osservazione è
logP(Yi = yi) = log[pyii (1 − pi)1−yi]= yi logpi + (1 − yi) log(1 − pi)
= yi log(pi
1 − pi) + log(1 − pi)
= yi(β0 + β1xi) − log (1 + eβ0+β1xi)
La log-verosimiglianza per tutti i dati è
ℓ(β) =n
∑i=1[yi(β0 + β1xi) − log (1 + eβ0+β1xi)]
Le equazioni di stima risultano
∂ℓ
∂β0=
n
∑i=1(yi − p(xi;β)) = 0
∂ℓ
∂β1=
n
∑i=1
xi(yi − p(xi;β)) = 0
dovep(xi;β) = logit−1(β0 + β1xi);

13.7. REGRESSIONE LOGISTICA 99
e quindi sono due equazioni non lineari in β0,β1.La prima implica che ∑i yi = ∑i pi = ∑i E(Yi): Il numero atteso di dati nella classe 1
coincide con il numero osservato di dati nella classe 1.Per risolvere le equazioni si usa un metodo numerico di tipo Newton-Raphson che
è spiegato sul libro a p. 224. In R la stima di MV si ottiene con la funzione glm e laspecificazione di un modello binomiale.
Illustrazione 13.17 (Difetti di produzione (segue)) Adattiamo il modello logistico con laMV usando come variabile esplicativa la variabile purezza.
y = c(0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0)x = c(7.2, 6.3, 8.5, 7.1, 8.2, 4.6, 8.5, 6.9, 8.0, 8.0, 9.1,
6.5, 4.9, 5.3, 7.1, 8.4, 8.5, 6.6, 9.1, 7.1, 7.5, 8.3)m = glm(y ~ x, family = binomial)summary(m)
Otteniamo
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) 6.4329 3.5104 1.833 0.0669 .x -0.8684 0.4643 -1.870 0.0614 .---
Null deviance: 30.498 on 21 degrees of freedomResidual deviance: 25.783 on 20 degrees of freedomAIC: 29.783Number of Fisher Scoring iterations: 4
Quindi le stime delle probabilità di difetto sono
pi = logit−1(6.43 − 0.87xi).
Il segno negativo del coefficiente di regressione logistica implica che all’aumentare del-la purezza la probabilità stimata di difetti decresce. L’effetto massimo della purezza sullaprobabilità di difetti (che si ottiene quando p = 0.5) è β1/4 = −0.22. Cioè se la purezzaaumenta di 1 la probabilità di difetti al massimo decresce di 0.22. La funzione logisticastimata è riportata sulla Figura 13.12.
Vediamo ora alcuni esempi di regressione logistica multipla.
Illustrazione 13.18 (Difetti di produzione (segue)) Abbiamo studiato la presenza di di-fetti Y in un prodotto ottenuto da 22 partite di materiale grezzo con un indice di purezzavariabile. Supponiamo di avere altre 22 partite di materiale con gli stessi indici purezza eche da esse si ottenga il prodotto con un nuovo processo a bassa temperatura che si vuoleconfrontare con quello standard precedente. I dati completi, riguardanti sia il processostandard che quello modificato sono riportati nella Tabella 13.1 Se indichiamo con X il

100 13. REGRESSIONE LINEARE E LOGISTICA
Tabella 13.1: Presenza di difetti nella produzione ottenuta con un processo standard e un processo modificatocon materia prima caratterizzata da un diverso indice di purezza.
Indice Processo Processo Indice Processo Processodi purezza standard modificato di purezza standard modificato
7.2 0 0 6.5 0 16.3 1 0 4.9 1 18.5 1 0 5.3 1 07.1 0 1 7.1 0 18.2 1 0 8.4 1 04.6 1 0 8.5 0 18.5 0 0 6.6 1 06.9 1 1 9.1 0 08.0 0 0 7.1 1 08.0 1 0 7.5 0 19.1 0 0 8.3 0 0
1, difetti presenti 0, difetti assenti
tipo di processo usato X = 0 per il processo standard e X = 1 per il processo modificato,siamo interessati al modello
logitP(Difetti) = β0 + β1 Processo + β2 Purezza.
Il parametro β1 misura l’effetto del tipo di processo a parità di indice di purezza.Ci sono in totale n = 44 unità sperimentali cioè le partite di materiale grezzo, che
vengono successivamente lavorate. Su ogni partita si osserva l’indice di purezza zi e il tipodi processo xi (0 = standard e 1 = modificato). Il modello logistico per dati binari
logit(pi) = β0 + β1xi + β2zi)
definisce due modelli a seconda che xi = 0 o xi = 1, ossia
P(Difetti∣Processo standard) = logit−1(β0 + β2zi)P(Difetti∣Processo modificato) = logit−1(β0 + β1 + β2zi).
Quindi il modello specifica due curve logistiche traslate con diversa intercetta. Le stime dimassima verosimiglianza sono:
Termine Stima s.e. z p-value(cost.) 4.461 2.159 — —X −0.864 0.672 −1.287 > 0.05 n.s.Z −0.604 0.284 −2.129 0.03−2ℓ(M) = 52.81 41 g.l.
Le curve logistiche interpolate sono disegnate nel grafico della Figura 13.13. La probabilitàdi difetto decresce con l’aumentare della purezza del materiale e decresce passando dalprocesso standard al processo modificato. L’effetto del processo infatti fa spostare tutta lacurva verso sinistra. Tuttavia, a giudicare dal test di Wald, l’effetto del tipo di processo nonè significativo, mentre l’effetto della purezza del materiale è significativo al livello del 5%.
Il codice R per creare i dati e adattare il modello è il seguente:
13.7. REGRESSIONE LOGISTICA 101
0 2 4 6 8 10
0.0
0.4
0.8
Purezza
Pr(difetti)
Figura 13.13: Probabilità stimata di difetti in funzione dell’indice di purezza del materiale. La linea continuariguarda il processo standard e la linea tratteggiata il processo modificato. I dati non segnalano una differenzasignificativa tra le due curve logistiche.
z = scan()7.2 6.3 8.5 7.1 8.2 4.6 8.5 6.9 8.0 8.0 9.16.5 4.9 5.3 7.1 8.4 8.5 6.6 9.1 7.1 7.5 8.37.2 6.3 8.5 7.1 8.2 4.6 8.5 6.9 8.0 8.0 9.16.5 4.9 5.3 7.1 8.4 8.5 6.6 9.1 7.1 7.5 8.3
x = scan()0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 01 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1
y = scan()0 1 1 0 1 1 0 1 0 1 00 1 1 0 1 0 1 0 1 0 00 0 0 1 0 0 0 1 0 0 01 1 0 1 0 1 0 0 0 1 0
ml = glm(y ~ x + z, binomial)summary(ml)
Ecco infine l’esempio riportato sul libro sui dati CORIS.
Illustrazione 13.19 (Analisi dei dati CORIS) Le istruzioni R sono le seguenti.
d = read.csv('http://local.disia.unifi.it/gmm/data/coris.csv')m.coris = glm(chd ~ . , binomial, data = d)summary(m.coris)
Coefficients:

102 13. REGRESSIONE LINEARE E LOGISTICA
Estimate Std. Error z value Pr(>|z|)(Intercept) -6.1507209 1.3082600 -4.701 2.58e-06 ***sbp 0.0065040 0.0057304 1.135 0.256374tobacco 0.0793764 0.0266028 2.984 0.002847 **ldl 0.1739239 0.0596617 2.915 0.003555 **adiposity 0.0185866 0.0292894 0.635 0.525700famhist 0.9253704 0.2278940 4.061 4.90e-05 ***typea 0.0395950 0.0123202 3.214 0.001310 **obesity -0.0629099 0.0442477 -1.422 0.155095alcohol 0.0001217 0.0044832 0.027 0.978350age 0.0452253 0.0121298 3.728 0.000193 ***--
Null deviance: 596.11 on 461 degrees of freedomResidual deviance: 472.14 on 452 degrees of freedomAIC: 492.14
Number of Fisher Scoring iterations: 5

Appendice A
terminologia inglese e italiana
Nota: molte traduzioni di termini inglesi sono errate perché basate su “falsi amici”, masono ormai entrate nell’uso comune. Per esempio consistent significa coerente, ma vienetradotto impropriamente con consistente.
Termine inglese Traduzione italianaasymptotically normal asintoticamente normalebar plot diagramma a barrebias distorsione, sovrastima, sottostimabins classi di un istogrammabootstrap bootstrapbound limitebox-plot grafico a scatolacategorical variable variabile qualitativa¹central limit theorem teorema centrale del limiteconditional independence indipendenza condizionataconditional expectation valor medio condizionatoconfidence level livello di confidenzaconfidence interval intervallo di confidenzaconsistency consistenzaconsistent consistentecovariance covarianzacovariate variabile esplicativaconvergence in distribution convergenza in leggeconvergence in probability convergenza in probabilitàcorrelation correlazionecovariance covarianzaderivative derivatadistribution function funzione di ripartizione, leggeexpectation valore atteso, valor medio, speranzaexpected value valore atteso, valor medio, speranzaexplanatory variable variabile esplicativa
¹Alcuni dicono variabile categorica, che è un falso amico.
103

104 APPENDICE A. TERMINOLOGIA INGLESE E ITALIANA
Termine inglese Traduzione italianafactor fattore, variabile esplicativa qualitativafit adattamento di un modellofitted values valori adattatihistogram istogrammainequality disuguaglianzainteraction interazioneinterquartile range scarto interquartileiteration iterazioneleast-squares minimi quadratilikelihood verosimiglianzalikelihood ratio rapporto di verosimiglianzalocation parameter parametro di posizionelogit logitlog-likelihood log-verosimiglianzamean square error errore quadratico mediomethod of moments metodo dei momentimoment momentonormal probability plot grafico di probabilità normalinull hypothesis ipotesi H0, ipotesi nullaodds quota di scommessaodds-ratio rapporto delle quoteoutlier valore atipico, anomaloparameter parametroparameter space spazio parametricoplug-in estimator stimatore per analogia o per sostituzioneposterior distribution distribuzione a posteriori, finaleprediction previsionepredictor predittore (funzione o variabile)prior distribution distribuzione a priori, inizialeqq-plot grafico quantile contro quantilerandom sample campione casualerandom variable variabile aleatoria, variabile casualerange campo di variazioneregression function funzione di regressioneresidual residuoresidual sum of squares devianza residuaresponse variabile dipendente, rispostarisk rischiosample campione, (a volte dato campionario)sample size dimensione campionariasampling distribution distribuzione campionariascale parameter parametro di scalascatterplot grafico di dispersione

105
Termine inglese Traduzione italianascore punteggioshape parameter parametro di formaskewness asimmetriastandard deviation deviazione standard, scarto quadratico mediostatistic statistica campionariaStatistics² Statisticatest of hypotheses verifica d’ipotesi, test di ipotesiunbiased non distorto, correttouncorrelated non correlate, incorrelate³variance varianza
²Notate, con la s finale.³Non si dice scorrelate.

106 APPENDICE A. TERMINOLOGIA INGLESE E ITALIANA

Appendice B
analisi dei dati
B.1 Inserire dati in R
In questo corso usiamo il linguaggio R per l’analisi dei dati. Ci sono 4 modi fondamentaliper caricare dati in R.
• Dati interni al sistema
• Dati interni inseriti manualmente
• Dati esterni in formato testo
• File sorgente
• Immagini di workspace
Poi ce ne sono altri che qui omettiamo.
Dati interni ad R. I dati inclusi nel sistema R si possono visualizzare con
data()
Per caricare in memoria il database¹ trees si usa:
data(trees)
Se il database sta in un package, prima bisogna caricare la libreria relativa. Ad esempio, sesi vuole leggere il dataset whiteside che sta nel package MASS:
library(MASS)data(whiteside)
oppure
data(whiteside, package = 'MASS')
¹Il termine usato in R è dataframe, ma spesso noi usiamo database come sinonimo.
107

108 APPENDICE B. ANALISI DEI DATI
Dati inseriti manualmente. Spesso i dati si inseriscono manualmente. Per esempio sevogliamo inserire il peso, l’altezza e il sesso per 4 individui:
peso = c(60,65, 75, 78)altezza = c(165, 170, 175, 180)sesso = c('f', 'f', 'm', 'm'); sesso = factor(sesso)
Dati in formato testo. I dati possono essere inseriti in un file di testo dati.txt con uneditore col formato seguente
peso altezza sesso60 165 f65 170 f75 175 m78 180 m
I dati si importano in un dataset col comando
mieidati = read.table("dati.txt", header=TRUE)
Nota: Occorre specificare correttamente i percorsi dei file. I caratteri “backslash” \usaticome separatori delle cartelle nel sistema operativoMS DOS vanno sostituiti con i caratteri/. Per esempio: read.table('/stat/dati.txt') legge il file che in DOS si scriverebbecome \stat3\dati.txt.
Se i dati in formato testo stanno su un sito web occorre specificarli col loro indirizzoweb. Per esempio
gfr = read.table('http://local.disia.unifi.it/gmm/data/gfr.txt', header = FALSE)
File sorgente. I file sorgente sono quelli che contengono istruzioni in linguaggio R equindi hanno estensione .R. Si leggono con il comando source. Ad esempio, per leggereil file nerve.R dal mio sito web, il codice è
source('http://local.disia.unifi.it/gmm/data/nerve.R')
Il comando esegue le istruzioni interne al file e crea una variabile nerve.A volte i file con estensione .R possono contenere vari oggetti R incluse delle funzioni.
Immagini di workspace Al termine di ogni sessione il sistema chiede se deve salvarelo spazio di lavoro o workspace. In caso affermativo salva un immagine della memoriacontenente tutti gli oggetti creati in un file .RData. Si possono salvare in questo modoanche singoli oggetti o gruppi di oggetti. Questi file hanno l’estensione .RData.
Per caricare in memoria queste immagini si usa il comando load. Ad esempio suppo-nendo di avere un file di nome lezione.RData, esso si carica con l’istruzione
load('lezione.RData')
x

B.2. STATISTICA DESCRITTIVA 109
Tabella B.1: Un campione casuale di 10 studenti partecipanti a un test d’ingresso a Economia a Firenze, conosservazioni su 4 variabili.
Unità Voto maturità Punteggio Sesso Scuola1 88 13.50 F T2 66 11.50 F T3 76 12.50 F L4 80 7.75 F P5 68 11.75 F L6 74 10.00 M L7 91 21.75 M L8 80 14.75 M T9 74 18.75 M L
10 74 12.50 M T
B.2 Statistica descrittiva
La Statistica studia i fenomeni collettivi ossia cerca di cogliere gli aspetti che si riferisconoall’intero sistema oggetto di studio ignorando per definizione le particolarità dei singoliindividui. La descrizione del fenomeno studiato è basata su caratteri misurabili.
Ogni carattere studiato, come per esempio l’età o il sesso di un individuo, può assumereun certo insieme di modalità diverse: per l’età le modalità sono un sottoinsieme dei realipositivi, per il sesso le modalità sono maschio o femmina.
Il paragone con i concetti del calcolo delle probabilità è immediato: gli individui, ov-vero le unità di osservazione, corrispondono agli eventi elementari ω e il processo di os-servazione di un carattere sull’unità corrisponde alla definizione di una variabile aleatoriaX. Quando osserviamo un carattere su un’unità ω il risultato è quello di ottenere unadeterminazione o realizzazione x = X(ω) di una variabile X.
Nell’analisi dei dati è importante capire che una variabile è una misurazione di unacarattere concreto che interessa studiare, non semplicemente un oggetto matematico.
Illustrazione B.1 (Test d’accesso a Economia) Supponiamo di voler studiare i risultati deltest di accesso alla facoltà di Economia di Firenze in un certo anno accademico. Gli studentisono le unità statistiche. Su di essi si vogliono studiare i 4 caratteri
• Voto alla maturità (intero da 60 a 100)
• Punteggio al test
• Sesso (F = femmina, M = maschio)
• Tipo di scuola (L = liceo, T = tecnico, P = professionale, A = altro)
La rilevazione su un campione casuale di studenti produce le determinazioni delle varia-bili riportate nella Tab. B.1. Se la variabile X misura il punteggio al test, essa associa allostudente 1 il punteggio x1 = 13.5.
Si distinguono due categorie fondamentali di dati

110 APPENDICE B. ANALISI DEI DATI
Tabella B.2: Tipi di dati
Dato EsempiQualitativo binario Presenza/assenza, buono/difettoso, sano/malatoQualitativo nominale Gruppo sanguigno, religione, lingua, trattamentoQualitativo ordinale Gravità di sintomi, livello di istruzioneDiscreto Numero di richieste di rimborso, numero di figliContinuo Durata di una chiamata telefonica, peso, temperatura
• i dati qualitativi (il tipo di scuola)
• i dati quantitativi (il punteggio al test).
Anche la distinzione operata per le variabili aleatorie è rilevante e si distinguono
• le variabili discrete le cui modalità appartengono a un sottoinsieme degli interi
• le variabili continue le cui modalità appartengono a un sottoinsieme dei reali.
La Tabella B.2 fornisce alcuni esempi.Le variabili possono essere classificate anche a seconda del ruolo che svolgono nell’in-
dagine in
• variabili dipendenti o risposte
• variabili esplicative.
Una variabile dipendente viene logicamente dopo una variabile esplicativa e le duevariabili sono su due piani diversi.
È possibile fare un’ulteriore distinzione tra le variabili esplicative in
• trattamenti
• variabili intrinseche
Un trattamento è una variabile che può essere concettualmente manipolata per ogni unitàstatistica. Una variabile intrinseca invece esprime una proprietà immutabile dell’unità sta-tistica. Per esempio la terapia post menopausa è un trattamento con duemodalità (placeboe somministrazione ormonale) che possono essere assegnate a ogni donna sotto il control-lo del medico. Invece l’età della donna una variabile intrinseca perché è una caratteristicadella persona che non può essere manipolata.
B.3 Indagini statistiche, esperimenti, osservazioni
Il problema della pianificazione e della raccolta dei dati costituisce un parte importante deimetodi della Statistica. Il tipo fondamentale di indagine è quello in cui le osservazioni sonoun campione casuale da una singola popolazione. Per campione si intende un sottoinsiemedi unità della popolazione. L’inferenza statistica si occupa del problema di estrapolare leconclusioni ottenute da un campione casuale alla popolazione di riferimento.

B.3. INDAGINI STATISTICHE, ESPERIMENTI, OSSERVAZIONI 111
QI
xx x xxx x xxx x x x x x
x x xx x x xx x xx x x x
90 100 110 120 130 140
C
T
Figura B.1: Effetto della preparazione (T = trattati, C = controlli) sulla misura del quoziente di intelligenza.
Definire la popolazione oggetto di studio non è semplice e tipicamente i modelli dipopolazione che formuliamo in questo corso riguardano una popolazione ipotetica infinitache viene pensata come una superpopolazione mentre la popolazione osservabile è finita ecomposta diN unità, da cui viene estratto un campione casuale di n < N unità. Si ha quindilo schema:
Superpopolazione infinita→ Popolazione finita→ Campione casuale
In molti esempi che facciamo useremo i dati campionari per stimare delle caratteristichedella superpopolazione assunta e non della popolazione finita.
I dati che raccogliamo possono derivare da un esperimento programmato o da osser-vazioni passive. In un esperimento programmato l’obiettivo è quello di verificare se untrattamento X ha influenza su una risposta Y e il ricercatore ha il controllo su alcuni aspet-ti della raccolta dei dati. In particolare, le unità di studio sono assegnate casualmente allemodalità di trattamento per garantire che i sottogruppi prodotti abbiano approssimativa-mente la stessa distribuzione rispetto a tutte le variabili anche non osservate e quindi sianocomparabili. L’operazione di assegnazione casuale si chiama randomizzazione.
Illustrazione B.2 (Test di intelligenza) Nei test di intelligenza si sottopone ad ogni sog-getto un questionario e si costruisce in base alle risposte un punteggio chiamato quozientedi intelligenza. Volendo indagare se una preparazione specifica al test influenza la misuradel quoziente di intelligenza si può effettuare un esperimento randomizzato. In uno stu-dio descritto da Hodges e Lehmann (1970) si sono usati n = 29 soggetti e si sono formaticasualmente un gruppo di trattamento di 14 persone e un gruppo di controllo formato dal-le rimanenti 15. I soggetti del primo gruppo sono stati preparati con domande simili espiegando le relative soluzioni. I soggetti del secondo gruppo invece non hanno ricevutoalcuna preparazione. La risposta è il punteggio finale al test per ciascun soggetto:
Gruppo di controllo94 95 98 100 101 102 105 107 108 109 113 117 119 122 127Gruppo di trattamento97 108 111 112 114 118 120 121 123 125 126 128 131 139
La rappresentazione cartesiana dei dati è mostrata nella Fig. B.1. La questione è: la prepa-razione al test influenza sistematicamente la misura del quoziente di intelligenza?

112 APPENDICE B. ANALISI DEI DATI
Tabella B.3: Distribuzione di frequenza degli studenti secondo il tipo di scuola e il punteggio al test.
Scuola Frequenza Frequenza relativaL 614 0.54T 415 0.37P 63 0.06A 36 0.03Totale 1128 1.00
Punteggio Frequenza Frequenza relativa(-5,0] 1 0.00(0,5] 17 0.02(5,10] 234 0.21(10,15] 500 0.44(15,20] 319 0.28(20,25] 57 0.05Totale 1128 1.00
Speso non si riesce ad effettuare un esperimento programmato in cui il trattamentosia assegnato sotto il controllo del ricercatore. Si osserva invece passivamente il sistemaoggetto di studio, e le unità di studio risultano assegnate ai trattamenti dal sistema stessosenza alcun intervento del ricercatore.
Illustrazione B.3 (Peso alla nascita) In un’indagine è stato considerato un campione (vedicasuale di 1009 bambini di ambo i sessi (non gemelli) nati in North Carolina (USA) nel2004 si sono classificati in due gruppi: madri fumatrici o non fumatrici. La variabile og-getto di studio è il peso alla nascita. La questione è: il fumo della madre influenza il pesodel nascituro? Se è chiaro che il fumo è un fattore di rischio è impossibile effettuare unesperimento randomizzato con soggetti umani e quindi l’unica cosa possibile è effettuareuno studio osservativo raccogliendo i dati così come si presentano.
B.4 Tabulazione e distribuzioni di frequenza
Quando un carattere è discreto con un numero ridotto di modalità la prima cosa che si puòfare per riassumere i dati è classificare le unità secondo le modalità del carattere e contan-do quante unità hanno ciascuna modalità. Questo conteggio viene chiamato frequenzaassoluta associata a una modalità del carattere.
Se le variabili sono continue o ad esse assimilabili la tabulazione va invece fatta perclassi di modalità.
Illustrazione B.4 (Studenti secondo il tipo di scuola e il punteggio) Al primo test di accessoalla facoltà di Economia di Firenze nel 2013 si sono presentati 1128 studenti. Classifichia-mo pertanto questi studenti secondo il tipo di scuola, con modalità L = liceo, T = istitutotecnico, P = istituto professionale, A = altra scuola. Le frequenze risultanti sono elencatein alto nella Tab. B.3. Nella Tab. B.3 sono state calcolate anche le frequenze relative cioè ilrapporto tra il numero di studenti di ogni tipo di scuola e il numero totale di studenti.
Volendo invece effettuare la tabulazione secondo il punteggio degli studenti convieneprima definire delle classi di punteggio, come ad esempio
(−5, 0] (0, 5] (5, 10] (10, 15] (15, 20] (20, 25].

B.5. DIAGRAMMI A BARRE E ISTOGRAMMI 113
Queste classi trasformano il punteggio che è una variabile con molte modalità in una va-riabile ordinale “classi di punteggio” producendo la distribuzione di frequenza riportatain basso nella Tab. B.3.
La frequenza relativa è una stima della probabilità di un evento e quindi è interpretabilecome la stima della probabilità che la variabile X assuma un certo valore x o appartenga auna certa classe.
La scelta delle classi per una variabile continua deve definire una successione di in-tervalli contigui che copra il range della variabile realizzando un compromesso tra i dueestremi: troppe classi rischiano di essere vuote e poche classi rischiano di essere pocoinformative.
B.5 Diagrammi a barre e istogrammi
Se il carattere studiato è discreto la tipica rappresentazione grafica è il diagramma a bar-re che rappresenta la distribuzione di frequenza relativa (xj, fj) in coordinate cartesianecon dei segmenti che collegano (xj, 0) e (xj, fj), per ogni j = 1, . . . , J e che quindi hannolunghezza pari alla frequenza relativa. La lunghezza totale dei segmenti è 1.
Invece se il carattere è continuo la corretta rappresentazione grafica è l’istogramma.L’istogramma è costruito definendo prima delle classi di ampiezza costante b e estremoiniziale x0
(x0 + (j − 1)b, x0 + jb], j = 1, . . . , J
calcolando la distribuzione delle frequenze relative fj e quindi disegnando dei rettangoliaffiancati con base b e con altezza uguale ad dj = fj/h, di modo che l’area dei rettangoli siapari alla frequenza relativa. L’area totale sotto l’istogramma è quindi uguale a 1. Le quantitàdj sono dette densità di frequenza.
Gli istogrammi sono spesso confusi con i diagrammi a barre. Questo è dovuto special-mente all’uso di Excel. In Excel infatti è complicato costruire dei veri istogrammi in cui lafrequenza relativa è uguale all’area e il programma stesso non fa distinzione terminologica.
Illustrazione B.5 (Distribuzione dei tipi di scuola e dei punteggi) Confrontiamo nellaFig. B.2 il diagramma a barre per il tipo di scuola e l’istogramma per il punteggio.
Scuola
Fre
quen
za r
elat
iva
L T P A
0.1
0.2
0.3
0.4
0.5
Punteggio
Den
sità
−5 0 5 10 15 20 25
0.00
0.02
0.04
0.06
0.08
0.10
Figura B.2: Diagramma a barre e istogramma.

114 APPENDICE B. ANALISI DEI DATI
La forma di un istogramma dipende dall’ampiezza di classe scelta. Se b è troppo grandel’istogramma non ha risoluzione ed è troppo piatto, se b è troppo piccolo l’istogramma ètroppo irregolare. Si veda la Fig.B.3. Da notare che anche la scelta del solo estremo inferiorex0 della prima classe influenza anche sensibilmente la forma dell’istogramma²
Punteggio
Den
sità
0 5 10 15 20 25
0.00
0.02
0.04
0.06
0.08
0.10
0.12
PunteggioD
ensi
tà
0 5 10 15 20 25
0.00
0.02
0.04
0.06
0.08
0.10
0.12
Figura B.3: . Istogramma dei punteggi con 20 e 50 classi.
L’istogramma permette di stimare la densità f(x) della variabile continua che ha ge-nerato i dati osservati xi. Uno svantaggio dell’istogramma è rappresentato dal fatto chementre la densità f(x) si suppone liscia, la stima f(x) non è liscia, ma è costante a tratti.Per questo sono stati proposti vari stimatori alternativi della densità detti stimatori kernel.
Si possono costruire istogrammi con classi di ampiezza diversa usando lamedesima re-gola: ogni rettangolo deve avere un area uguale alla frequenza relativa di unità appartenentialla classe.
Illustrazione B.6 (Istogramma con classi di diversa ampiezza) Nel censimento del 2000il Bureau of Census ha stabilito che esistevano circa 124 milioni di americani che lavo-ravano fuori casa. Il tempo impiegato per andare a lavorare è stato rilevato ottenendo ladistribuzione di frequenza dei tempi, con classi di ampiezza diversa riportata nella Fig. B.4.
L’istogramma si può disegnare in R con i comandi seguenti.
counts = c(4180407,13687604,18618305,19634328,17981756,7190540,16369097,3212387,4122419,9200414,6461905,3435843)
breaks = c(0,5,10,15,20,25,30,35,40,45,60,90,150)mids = diff(breaks)/2 + breaks[-length(breaks)]den = 100 * counts /(sum(counts) * diff(breaks))work = list(breaks= breaks, counts = counts, density = den,
mids = mids, xname = NULL, equidist = FALSE)class(work) = "histogram"plot(work, main = NULL, xlab = "Tempo di viaggio (min)",
ylab = "Densità", axes = FALSE, col = "gray")axis(1, at = c(0, 30, 60, 90, 120, 150))axis(2, las = 1)
²La funzione R hist in mancanza del numero di classi usa la cosiddetta regola di Sturges b = ⌈log2 n+ 1⌉.
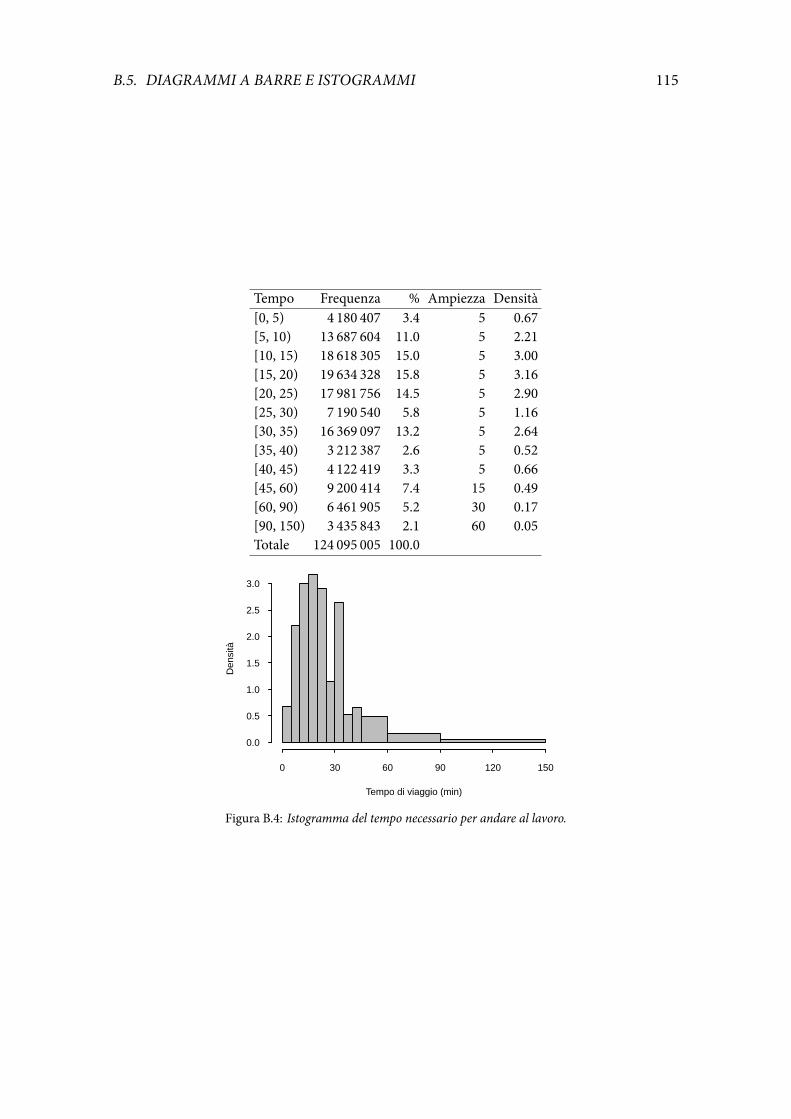
B.5. DIAGRAMMI A BARRE E ISTOGRAMMI 115
Tempo Frequenza % Ampiezza Densità[0, 5) 4 180 407 3.4 5 0.67[5, 10) 13 687 604 11.0 5 2.21[10, 15) 18 618 305 15.0 5 3.00[15, 20) 19 634 328 15.8 5 3.16[20, 25) 17 981 756 14.5 5 2.90[25, 30) 7 190 540 5.8 5 1.16[30, 35) 16 369 097 13.2 5 2.64[35, 40) 3 212 387 2.6 5 0.52[40, 45) 4 122 419 3.3 5 0.66[45, 60) 9 200 414 7.4 15 0.49[60, 90) 6 461 905 5.2 30 0.17[90, 150) 3 435 843 2.1 60 0.05Totale 124 095 005 100.0
Tempo di viaggio (min)
Den
sità
0 30 60 90 120 150
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Figura B.4: Istogramma del tempo necessario per andare al lavoro.
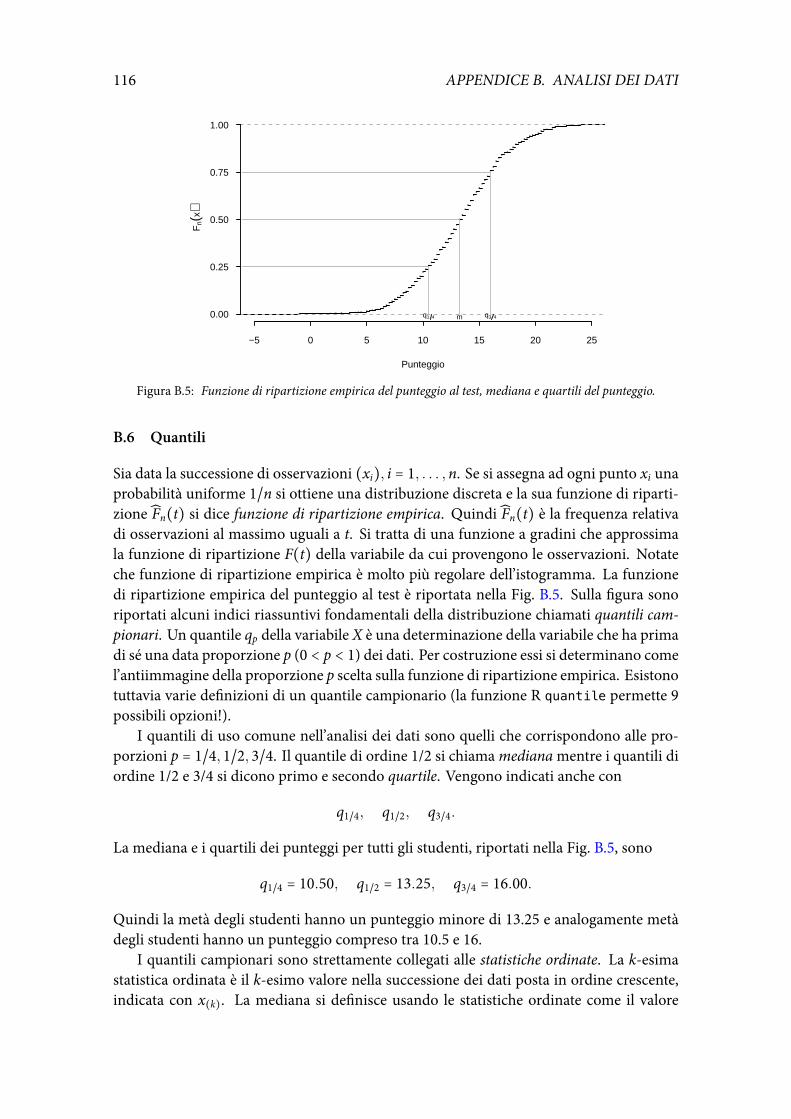
116 APPENDICE B. ANALISI DEI DATI
Punteggio
Fn(x
)
−5 0 5 10 15 20 25
0.00
0.25
0.50
0.75
1.00
mq1 4 q3 4
Figura B.5: Funzione di ripartizione empirica del punteggio al test, mediana e quartili del punteggio.
B.6 Quantili
Sia data la successione di osservazioni (xi), i = 1, . . . ,n. Se si assegna ad ogni punto xi unaprobabilità uniforme 1/n si ottiene una distribuzione discreta e la sua funzione di riparti-zione Fn(t) si dice funzione di ripartizione empirica. Quindi Fn(t) è la frequenza relativadi osservazioni al massimo uguali a t. Si tratta di una funzione a gradini che approssimala funzione di ripartizione F(t) della variabile da cui provengono le osservazioni. Notateche funzione di ripartizione empirica è molto più regolare dell’istogramma. La funzionedi ripartizione empirica del punteggio al test è riportata nella Fig. B.5. Sulla figura sonoriportati alcuni indici riassuntivi fondamentali della distribuzione chiamati quantili cam-pionari. Un quantile qp della variabile X è una determinazione della variabile che ha primadi sé una data proporzione p (0 < p < 1) dei dati. Per costruzione essi si determinano comel’antiimmagine della proporzione p scelta sulla funzione di ripartizione empirica. Esistonotuttavia varie definizioni di un quantile campionario (la funzione R quantile permette 9possibili opzioni!).
I quantili di uso comune nell’analisi dei dati sono quelli che corrispondono alle pro-porzioni p = 1/4, 1/2, 3/4. Il quantile di ordine 1/2 si chiama mediana mentre i quantili diordine 1/2 e 3/4 si dicono primo e secondo quartile. Vengono indicati anche con
q1/4, q1/2, q3/4.
La mediana e i quartili dei punteggi per tutti gli studenti, riportati nella Fig. B.5, sono
q1/4 = 10.50, q1/2 = 13.25, q3/4 = 16.00.
Quindi la metà degli studenti hanno un punteggio minore di 13.25 e analogamente metàdegli studenti hanno un punteggio compreso tra 10.5 e 16.
I quantili campionari sono strettamente collegati alle statistiche ordinate. La k-esimastatistica ordinata è il k-esimo valore nella successione dei dati posta in ordine crescente,indicata con x(k). La mediana si definisce usando le statistiche ordinate come il valore

B.7. BOX-PLOT 117
centrale nella successione ordinata se n è dispari e come la semisomma dei 2 valori centralise n è pari. Formalmente, posto d = (n + 1)/2:
q1/2 =⎧⎪⎪⎨⎪⎪⎩
x(d), se n è dispari{x(⌈d⌉) + x(⌊d⌋)}/2 se n è pari.
(B.1)
Illustrazione B.7 (Mediana del punteggio per il campione di 10 studenti) Le statisticheordinate del punteggio per il campione di 10 studenti sono
x(1) = 7.75, x(2) = 10.00, x(3) = 11.50, x(4) = 11.75, x(5) = 12.50x(6) = 12.50, x(7) = 13.50, x(8) = 14.75, x(9) = 18.75, x(10) = 21.75.
La mediana del punteggio quindi è (n = 10 è pari)
q1/2 = {x(5) + x(6)}/2 = (12.5 + 12.5)/2 = 12.5.
Unmodo semplice per calcolare i quartili q1/4 e q3/4 è basato sulla divisione in duemetàdei dati in base alla mediana calcolata, e dall’applicazione ricorsiva della mediana delle duemetà.
Algoritmo per calcolare i quartili. Posto d = (n + 1)/2, definire la prima e la secondametà della successione ordinata nel modo seguente
1. Se n è pari, A = [x(1), . . . , x(⌊d⌋)], B = [x(⌈d⌉), . . . , x(n)]
2. Se n è dispari A = [x(1), . . . , x(d)], B = [x(d), . . . , x(n)]
3. Calcolare q1/4 come la mediana di A e q3/4 come la mediana di B.
B.7 Box-plot
Il box-plot è una rappresentazione grafica sintetica di una variabile quantitativa suggeritada Tukey, basata su 5 quantili
xmin, q1/4, q1/2, q3/4, xmax.
L’idea base è quella di rappresentare la parte centrale della distribuzione con un rettangolo(la scatola) con base [q1/4,q3/4] con due code attaccate all’estremità che vanno da q1/4 a xmin
e da q3/4 a xmax. Inmezzo alla scatola si riporta in scala la mediana. Nella forma completa ilbox-plot include anche una rappresentazione delle unità cosiddette anomale o outlier. Unoutlier è un dato che sta lontano dal centro della distribuzione. Per un box-plot si scegliedi definire un’osservazione x un outlier se x /∈ [L,U] dove gli estremi sono
L = q1/4 − 1.5 IQR, U = q3/4 + 1.5 IQR. (B.2)
dove IQR = q3/4 − q1/4 è la differenza interquartile.

118 APPENDICE B. ANALISI DEI DATI
Procedura per disegnare un box-plot
1. Disegnare una scatola con estremi in q1/4 e q3/4. Il 50% centrale dei dati è compresotra q1/4 e q3/4.
2. Disegnare la mediana con una linea verticale.
3. Disegnare le code da ogni estremo della scatola fino al punto più lontano che non siaun outlier.
4. Rappresentare gli outlier come punti isolati.
Il box-plot riassume una variabile quantitativa evidenziando vari aspetti: la medianaindica la posizione della distribuzione. L’ampiezza della scatola è uguale allo scarto inter-quartile e indica la variabilità. La posizione dellamediana rispetto ai quartili e la lunghezzadelle code segnala un tipo di asimmetria. Gli outlier sono indicati come punti isolati.
I box-plot danno per scontato che il grosso della distribuzione sia nel mezzo. Pervisualizzare eventuali picchi della distribuzione è necessario un istogramma.
Illustrazione B.8 (Box-plot affiancati) Un esempio tipico di applicazione è quello in cui sivogliono confrontare graficamente due o più distribuzioni. Si veda l’esempio 7.15 del libroe la Figura 7.2, p. 16.
Per ottenere i box-plot della Figura 7.2, p. 16 si usano le istruzioni
bloodfat = read.table('http://local.disia.unifi.it/gmm/data/bloodfat.txt')boxplot(chol ~ group, data = bloodfat, horizontal = TRUE)
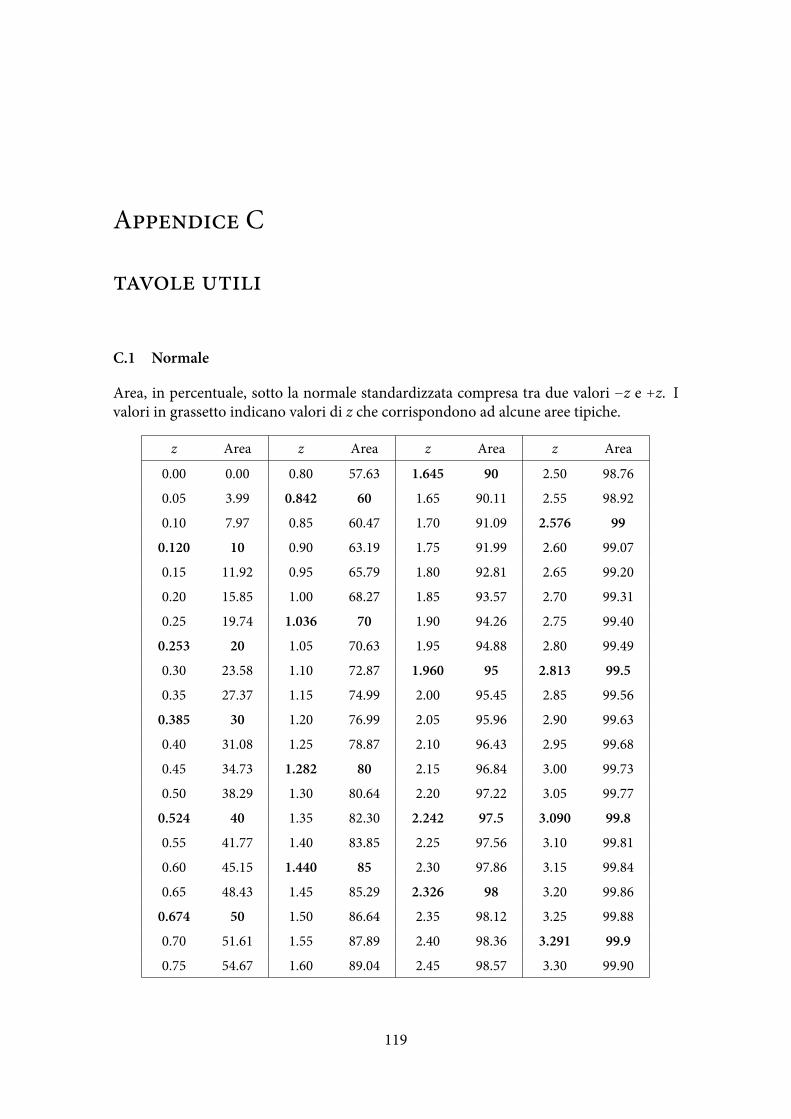
Appendice C
tavole utili
C.1 Normale
Area, in percentuale, sotto la normale standardizzata compresa tra due valori −z e +z. Ivalori in grassetto indicano valori di z che corrispondono ad alcune aree tipiche.
z Area z Area z Area z Area
0.00 0.00 0.80 57.63 1.645 90 2.50 98.76
0.05 3.99 0.842 60 1.65 90.11 2.55 98.92
0.10 7.97 0.85 60.47 1.70 91.09 2.576 99
0.120 10 0.90 63.19 1.75 91.99 2.60 99.07
0.15 11.92 0.95 65.79 1.80 92.81 2.65 99.20
0.20 15.85 1.00 68.27 1.85 93.57 2.70 99.31
0.25 19.74 1.036 70 1.90 94.26 2.75 99.40
0.253 20 1.05 70.63 1.95 94.88 2.80 99.49
0.30 23.58 1.10 72.87 1.960 95 2.813 99.5
0.35 27.37 1.15 74.99 2.00 95.45 2.85 99.56
0.385 30 1.20 76.99 2.05 95.96 2.90 99.63
0.40 31.08 1.25 78.87 2.10 96.43 2.95 99.68
0.45 34.73 1.282 80 2.15 96.84 3.00 99.73
0.50 38.29 1.30 80.64 2.20 97.22 3.05 99.77
0.524 40 1.35 82.30 2.242 97.5 3.090 99.8
0.55 41.77 1.40 83.85 2.25 97.56 3.10 99.81
0.60 45.15 1.440 85 2.30 97.86 3.15 99.84
0.65 48.43 1.45 85.29 2.326 98 3.20 99.86
0.674 50 1.50 86.64 2.35 98.12 3.25 99.88
0.70 51.61 1.55 87.89 2.40 98.36 3.291 99.9
0.75 54.67 1.60 89.04 2.45 98.57 3.30 99.90
119

120 APPENDICE C. TAVOLE UTILI

Bibliografia
Baldi, P. (2011). Calcolo delle Probabilità. McGraw-Hill Education.
Casella, G., Berger, R. L. (2002). Statistical inference, 2a ed., Duxbury, Pacific Grove, CA,USA.
Box, G. E. P., Tiao, G. C. (1973). Bayesian inference in statistical analysis. Addison-Wesley,Reading, MA, USA.
Cox, D. R., Wermuth, N. (1996). Multivariate dependencies. Chapman and Hall, London.
Efron, B., Tibshirani, R. (1993).An Introduction to the Bootstrap. New York: Chapman andHall.
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D.B., Vehtari, A., Rubin, D. B. (2014).Bayesian data analysis. CRC Press: Boca Raton, FL, USA.
Hodges, J. L. jr. e Lehmann, E. R. (1970). Basic concepts of probability and statistics, 2a ed.Society for Industrial and Applied Mathematics, Philadelphia.
McElreath, R. (2016). Statistical Rethinking. Chapman & Hall, CRC, New York.
Wasserman, L. (2004). All of Statistics. Springer, New York.
121

122

soluzioni agli esercizi
Il simbolo † indica che l’esercizio è difficile.
Esercizi Capitolo 6
1. Ovviamente il bias è zero perché la media aritmetica è uno stimatore non distortodel valor medio E(X) = λ. L’errore quadratico medio è var(X) = n−1var(X) = λ/n.
2. † La distribuzione dello stimatore θ = max{X1, . . . ,Xn} si trova partendo dalla suafunzione di ripartizione
G(t) = P(θ ≤ t) = P(X1 ≤ t, . . . ,Xn ≤ t) =n
∏i=1
F(t)
dove F(t) è la funzione di ripartizione della uniforme U(0, θ)
F(t) =
⎧⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎩
0 t < 0t/θ 0 ≤ t ≤ θ1 t > θ
Quindi G(t) = F(t)n e la densità è
g(t) = G′(t) = nF(t)n−1f(t) = (n/θ)(t/θ)n−1.
Il valore atteso èE(θ) = ∫
θ
0tg(t)dt = n
n + 1θ.
Dunque il bias è
bias = nn + 1
θ − θ = − θn + 1
(sottostima)
per trovare la varianza si calcola prima il momento secondo
E(θ2) = ∫
θ
0t2g(t)dt = nθ2
n + 2e quindi
var(θ) = E(θ2) − [E(θ)]2 = nθ2
n + 2− ( nθ
n + 1)
2
= nθ2
(n + 2)(n + 1)2
e l’errore quadratico medio risulta
bias2 + var(θ) = 2θ2
(n + 1)(n + 2)
123

3. Lo stimatore θ = 2X è non distorto perché
E(θ) = 2E(X) = 2E(X) = 2 ⋅ θ/2 = θ.
Quindi l’EQM è uguale alla varianza
var(θ) = var(2X) = 4var(X) = 4var(X)/n = 4θ2
12n= θ2
3n.
Esercizi aggiuntivi
1. Date la definizione di indipendenza di 2 variabili aleatorie X, Y con funzione diripartizione congiunta FXY(x, y) e funzioni di ripartizioni marginali FX(x), FY(y).
2. Quando due variabili aleatorie X e Y si dicono identiche?
3. Una popolazione ha distribuzione normale X ∼ N(μ = 10,σ2 = 4). Estrarre con Run campione casuale di dimensione 100 dalla popolazione.
4. Come si costruisce un istogramma? Che cosa misura l’altezza di ogni rettangolodella figura? Calcolare l’area complessiva sotto l’istogramma della Figura 6.1.
5. Scrivete a memoria la densità di una Poisson.
6. Scrivete a memoria la densità di una Gamma con parametro α = 1 e di una Gammacon parametro β = 1
7. Se E(Y ∣ X) = 5 + 2X e X ∼ N(10, 1) qual è E(Y)? Che risultato avete usato?Soluzione: Si usa la legge del valore atteso iterato E(Y) = EX[E(Y ∣ X)]. Per cuiE(Y) = EX(5 + 2X) = 5 + 2μ = 25. La dimostrazione della legge del valore attesoiterato è semplice:
E(Y) = ∫ ∫ yf(x, y)dydx
= ∫ ∫ yf(y ∣ x)f(x)dydx
= ∫ [∫ yf(y ∣ x)dy] f(x)dx
= ∫ E(Y ∣ x)f(x)dx = EX[E(Y ∣ X)].
8. Supponiamo che un costruttore di auto verifichi la capacità di assorbimento di unnuovo tipo di paraurti con 25 prove in cui l’auto viene fatta sbattere su un ostacoloa una velocità fissata e rilevando ogni volta se si osservano danni visibili (Xi = 1), omeno (Xi = 0). Supponiamo che nelle 25 prove si osservino danni 10 volte. Stimarela probabilità p di danneggiamento e fornire l’errore standard della stima.
9. Rappresentare graficamente il MSE dello stimatore p = ∑iXi/n = S/n della probabi-lità di successo p in un campione di n = 10 prove. Quindi considerate lo stimatorealternativo p = S+2
n+4 ottenuto aggiungendo 2 successi e 2 insuccessi ai dati. Calcolateil bias, la varianza e il MSE di p.
124

10. Confrontate graficamente il MSE di p e di p per n = 10 e per n = 100.
11. Considera una popolazione normale di cui si conosce la varianza. Qual è il livellodi confidenza dell’intervallo Xn ± 2.8σ/
√n?
12. Gli intervalli(52.40332, 56.12749); (52.70482, 55.82599)
sono intervalli di confidenza per la media μ della capacità di filtrazione del rene inuna popolazione di pazienti.
a. Qual è la media campionaria osservata?
b. Entrambi gli intervalli sono stati calcolati sugli stessi dati. Il livello di confidenzadi uno dei due è 0.9 e l’altro è di 0.95. Quale dei due è l’intervallo che ha il livello 0.9e perché?
13. Calcolare l’intervallo di confidenza asintotico al livello del 95% per la media μ deidati gfr (Illustrazione 6.1, p. 3).
Esercizi Capitolo 7
1. Vedi la dimostrazione in queste note.
2. Stimatori p = Xn, q = Ym. Poiché var(Xn) = p(1 − p)/n l’errore standard stimato èse =√Xn(1 − Xn)/n. Inoltre
P(−1.64 ≤ Xn − pse≤ 1.64) ≈ 0.90
un intervallo approssimato al 90% è Xn ± 1.64 se.
Lo stimatore della differenza p − q è Xn − Ym con varianza
var(Xn − Yn) =p(1 − p)
n+ q(1 − q)
m
ed errore standard stimato
se(Xn − Yn) =
√Xn(1 − Xn)
n+ Ym(1 − Xm)
m
L’intervallo di confidenza è Xn − Ym ± 1.64 se(Xn − Yn).
3. Ecco una funzione per questo esperimento al computer.
`ecdfCI` = function(x, level = 0.95){n = length(x)Fn = ecdf(x)alpha = 1 - leveleps = sqrt(log(2/alpha)/(2 * n))
125

y = seq(min(x), max(x) , len = 500)lu = cbind(pmax(Fn(y) - eps, 0), pmin(Fn(y) + eps, 1))
# plot(Fn, main = "")lines(y, lu[,1], col = "red")lines(y, lu[,2], col = "red")
}x = rnorm(100); curve(pnorm(x), -4,4); ecdfCI(x)x = rcauchy(100); curve(pcauchy(x), -10,10); ecdCI(x)
4. La distribuzione limite di Fn(x) è√n(Fn(x) − F(x))↝ N(0,F(x)[1 − F(x)]).
5. † Poniamo Zi = I[Xi < x] e Uj = I[Xj < y]. Quindi Fn(x) = Zn e Fn(y) = Un eE(Zn) = F(x), E(Un) = F(y).Perciò la covarianza è per x < y
cov(Fn(x), Fn(y)) = cov(Zn,Un) = E(ZnUn) − E(Zn)E(Un)
= 1n2∑
i,jE(Zi,Uj) − F(x)F(y)
= 1n2
n
∑i=1
E(Zi,Ui) +1n2∑
i≠jE(Zi,Uj) − F(x)F(y)
Quindi si nota che se x < y risulta ZiUi = Zi, mentre per l’indipendenza di Xi e Xj,E(ZiUj) = E(Zi)E(Uj). Quindi,
cov(Fn(x), Fn(y)) =1n2
n
∑i=1
E(Zi) +1n2∑
i≠jE(Zi)E(Uj) − F(x)F(y)
= 1n2
n
∑i=1
E(Zi) +1n2∑
i≠jE(Zi)E(Uj) − F(x)F(y)
= nF(X)n2 + n(n − 1)
n2 F(x)F(y) − F(x)F(y)
= 1n(F(x) + (n − 1)F(x)F(y) − nF(x)F(y))
= 1n(F(x) − F(x)F(y)).
Si conclude che Fn(x) e Fn(y) sono v.a. correlate positivamente: se Fn(x) sovrastimaF(x) allora Fn(y) tende a sovrastimare F(y).
6. Sia θ = Fn(b) − Fn(a), la varianza è
var(θ) = 1nF(b)(1 − F(b)) +
1nF(a)(1 − F(a)) −
2nF(a)(1 − F(b))
= 1nθ(1 − θ), dove θ = F(b) − F(a).
126
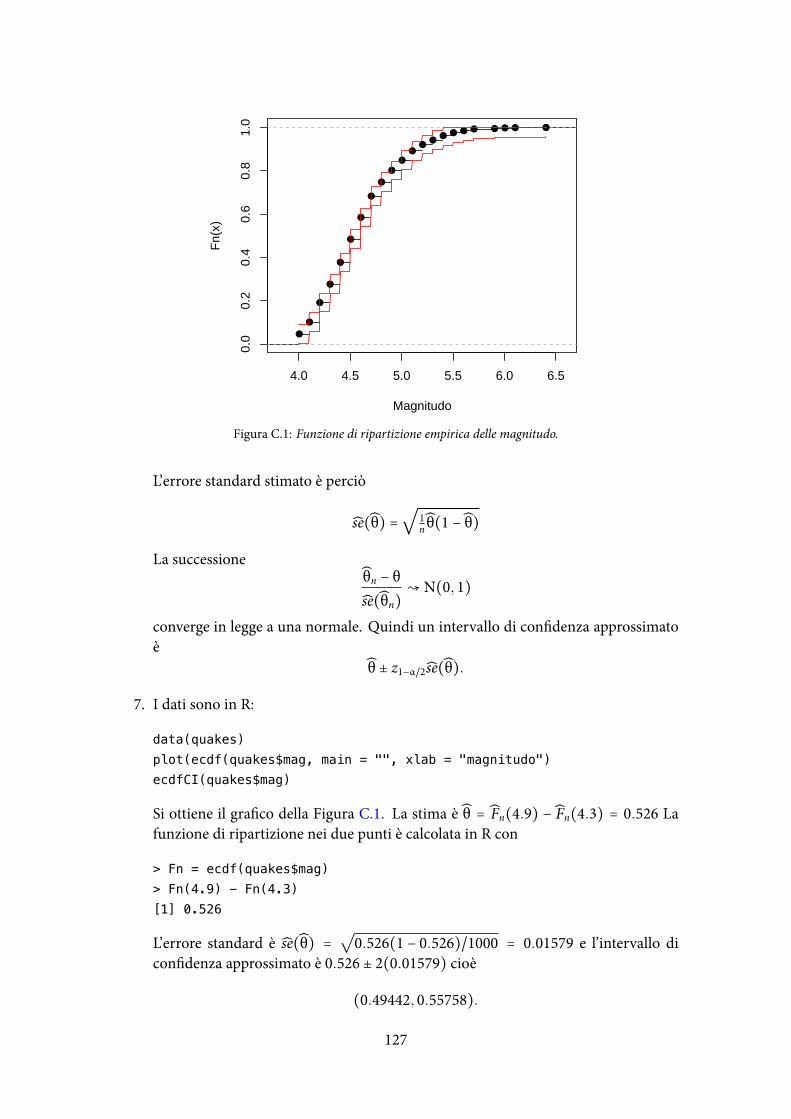
4.0 4.5 5.0 5.5 6.0 6.5
0.0
0.2
0.4
0.6
0.8
1.0
Magnitudo
Fn(
x)
●
●
●
●
●
●
●
●
●
●
●●
●●
● ● ● ● ● ● ● ●
Figura C.1: Funzione di ripartizione empirica delle magnitudo.
L’errore standard stimato è perciò
se(θ) =√
1n θ(1 − θ)
La successioneθn − θse(θn)
↝ N(0, 1)
converge in legge a una normale. Quindi un intervallo di confidenza approssimatoè
θ ± z1−α/2se(θ).
7. I dati sono in R:
data(quakes)plot(ecdf(quakes$mag, main = "", xlab = "magnitudo")ecdfCI(quakes$mag)
Si ottiene il grafico della Figura C.1. La stima è θ = Fn(4.9) − Fn(4.3) = 0.526 Lafunzione di ripartizione nei due punti è calcolata in R con
> Fn = ecdf(quakes$mag)> Fn(4.9) - Fn(4.3)[1] 0.526
L’errore standard è se(θ) =√
0.526(1 − 0.526)/1000 = 0.01579 e l’intervallo diconfidenza approssimato è 0.526 ± 2(0.01579) cioè
(0.49442, 0.55758).
127

8. I dati sono inclusi in R. Quindi
> x = faithful$waiting> mean(x)[1] 70.89706> sd(x)/sqrt(length(x))[1] 0.8243164> median(x)[1] 76
Il tempo medio di attesa è 70.89 minuti con e.s. = 0.82 minuti. L’intervallo diconfidenza approssimato al 90% è 70.89 ± 1.645(0.82). Il tempo mediano è 76minuti.
9. I dati si possono riassumere con una tabella 2 × 2
GuarigioneTrattamento Sì No TotaleStandard 90 10 100Nuovo 85 15 100Totale 175 25 200
Abbiamo θ = p1 − p2 = 0.9 − 0.85 = 0.05. L’errore standard stimato è
se(θ) =√(0.9)(0.1)/100 + (0.85)(0.15)/100 = 0.0466369.
Gli intervalli di confidenza sono
0.05 ± (1.28)(0.0466)0.05 ± (1.96)(0.0466).
10. I dati sono sul mio sito.
> source("http://local.disia.unifi.it/gmm/data/clouds.R")> summary(clouds)Unseeded_Clouds Seeded_CloudsMin. : 1.00 Min. : 4.101st Qu.: 24.82 1st Qu.: 98.12Median : 44.20 Median : 221.60Mean : 164.59 Mean : 441.983rd Qu.: 159.20 3rd Qu.: 406.02Max. :1202.60 Max. :2745.60
La stima della differenza tra le medie è θ = 441.98 − 164.59 = 277.39 e l’errorestandard è
se(θ) =
√σ2
1
26+ σ2
2
26=√
77521.26/26 + 423523.94/26 ≃ 138.82.
128

L’intervallo di confidenza approssimato al 95%è 277.39±(2)(138.82) cioè (−0.2437, 555.036).L’intervallo non dimostra che il trattamento sia utile, ma la numerosità campionarianon è molto elevata e l’approssimazione normale è dubbiosa.
Esercizi aggiuntivi
1. Fate il grafico della funzione di ripartizione dei dati gfr dell’Illustrazione 6.1, p. 3. Idati si importano in R dal mio sito con il comando
gfr = read.table('http://local.disia.unifi.it/gmm/data/gfr.txt')
2. Dimostrare che la covarianza tra X e Y è σXY = E(XY) − μXμY.
Esercizi Capitolo 8
1. Input dei dati
LSAT = c(576, 635, 558, 578, 666, 580, 555, 661,651, 605, 653, 575, 545, 572, 594)
GPA = c(3.39, 3.30, 2.81, 3.03, 3.44, 3.07, 3.00, 3.43,3.36, 3.13, 3.12, 2.74, 2.76, 2.88, 2.96)
Notate che l’ultimo dato è 2.96 anziché 3.96 come indicato nel libro. Lo stimatoreper sostituzione del coefficiente di correlazione è a p. 102 e a p. 113. L’errore standardbootstrap si trova come segue:
> library(bootstrap)> xdata = cbind(LSAT, GPA)> theta = function(x,xdata){ cor(xdata[x,1],xdata[x,2]) }> out = bootstrap(1:nrow(xdata), 1000, theta, xdata)> tstar = out$thetastar> sd(star)[1] 0.1389392
Quindi se = 0.139.
Metodo 1: 0.776 ± (2)(0.139) cioè (0.498, 1.054)Metodo 2: (0.589, 1.093) usando le istruzioni
t1 = quantile(tboot, 0.025); t2 = quantile(tboot, 0.975)tn = 0.776 # lo dà il libroci = c(2*tn - t2, 2*tn - t1) # nota l'inversione
Metodo 3: (0.459, 0.963) usando il codice
c(t2, t1)
Notare che nei primi 2 casi il metodo produce un intervallo che contiene valoriimpossibili > 1.
129

2. Il vero valore di θ = skewness(X) è θ = (eσ2+ 2)√eσ2− 1 = (e + 2)
√e − 1 = 6.18.
Usiamo la funzione skewness già definita.
> method1 = function(x) c(mean(x) - 2 * sd(x), mean(x) + 2 * sd(x))> method2 = function(x, tn){
t1 = quantile(x, 0.025); t2 = quantile(x, 0.975)unname(c(2*tn - t2, 2*tn - t1))}
> method3 = function(x) unname(c(quantile(x, 0.025), quantile(x, 0.975)))> set.seed(123)conta = 0for(i in 1:200){x = exp(rnorm(50))tstar = bootstrap(x, nboot = 1000, skewness)$thetastarci = method1(tstar)if(ci[1] < 6.18 & 6.18 < ci[2]) conta = conta + 1}copertura = conta/200
L’intervallo ottenuto col metodo del pivot in questo caso non contiene il vero valore.
3. Simulazione. La popolazione è una t di Student con 3 gradi di libertà. Guardate laforma della distribuzione con il codice
curve(dt(x, 3), -6, 6)curve(dnorm(x), add = TRUE, lty = 2)
La curva tratteggiata è la normale standard. La simulazione è qui sotto. La facciosolo per (i) e (ii).
> set.seed(100)> x = rt(25, df = 3)> theta = function(x) (quantile(x, 0.75) - quantile(x, 0.25))/1.34> require(bootstrap)> tstar = bootstrap(x, nboot = 1000, theta = theta)$thetastar> seboot = sd(tstar)> ci.norm = unname(c(theta(x) - 2*seboot, theta(x) + 2 * seboot)); ci.norm[1] 0.5664602 1.4906888> ci.perc = unname(quantile(tstar, c(0.025, 0.975))); ci.perc[1] 0.5134424 1.4063859> len.norm = ci.norm[2] - ci.norm[1]; len.norm[1] 0.9242286> len.perc = ci.perc[2] - ci.perc[1]; len.perc[1] 0.8929435
Il livello di copertura si simula estraendo più campioni e calcolando la proporzionedegli intervalli che contengono il vero valore di θ, che si calcola in R con
130

> (qt(0.75, 3) - qt(0.25, 3))/1.34[1] 1.14163
4. † I campioni bootstrap distinti si possono sintetizzare con len-uple a = (a1,a2, . . . ,an)con ∑i ai = n dove ai = 0, . . . ,n sono le ripetizioni delle osservazioni campiona-rie (x1, . . . , xn). Queste n-uple corrispondono alle possibili modalità di una mul-tinomiale di indice n. Queste sono tante quanto i punti di un simplesso discreton1-dimensionale e risultano
(2n − 1n).
5. † La distribuzione bootstrap è
x X1 X2 ⋯ Xn
P(X∗ = x) 1/n 1/n ⋯ 1/n
Quindi il valor atteso e la varianza condizionati sono
E(X∗i ∣ X1, . . . ,Xn) =n
∑xx P(X∗ = x) = 1
n∑iXi = X
var(X∗i ∣ X1, . . . ,Xn) =∑x(x − X)2P(X∗ = x) = 1
n∑i(Xi − X)2
Poiché X∗ = 1n ∑iX∗i
E(X∗ ∣ X1, . . . ,Xn) =1n∑i
E(X∗i ∣ X1, . . .Xn) = X
var(X∗ ∣ X1, . . . ,Xn) =1n2∑
ivar(X∗i ∣ X1, . . . ,Xn) =
1n2∑
i(Xi − X)2
Quindi il valore atteso e la varianza marginali sono
E(X∗) = E{E(X∗ ∣ X1, . . . ,Xn)} = E(X) = μvar(X∗) = var{E(X∗ ∣ X1, . . . ,Xn)} + E{var(X∗ ∣ X1, . . . ,Xn)}
= var(X) + 1n2E{∑
i(Xi − X)2}
= σ2
n+ 1nE{∑
i(Xi − X)2/n}
= σ2
n+ 1nn − 1n
σ2 = σ2
n(2 − 1
n) .
6. Esperimento al computer discusso già in questi appunti.
7. † La distribuzione del massimo θ sappiamo che è
g(θ) = (nθ)( θ
θ)n−1
131

Il bootstrap parametrico riesce ad approssimare bene questa distribuzione. Inveceil bootstrap non parametrico non riesce ad approssimare bene questa distribuzione.Infatti
P(θ∗= θ) = P(max{X∗1 , . . . ,X∗n} =max{X1, . . . ,Xn}= P(X(n) sta nel campione bootstrap)= 1 −P{X(n) non sta nel campione bootstrap}
= 1 − (1 − 1n)n
→ 1 − e−1 = 0.632
Quindi P(θ = θ) = 0 mentre P(θ∗= θ) ≃ 0.632.
Soluzioni Capitolo 9
1. Vedi questi appunti.
2. Sia (X1, . . . ,Xn) ∼ U(a,b). E(X) = (a + b)/2
E(X2) = (b − a)2/12 + {(a + b)/2}2 = (a2 + ab + b2)/3.
Quindi si scrivono le due equazioni
(a + b)/2 =∑iXi/n
(a2 + ab + b2)/3 =∑iX2i /n
La verosimiglianza è
L(a,b) =⎧⎪⎪⎨⎪⎪⎩
( 1b−a)
n se a < X(1),X(n) < b0 altrimenti
che è massimizzata per a = X(1) e b = X(n). La stima di MV di τ = E(X) = (a + b)/2è τ = (X(1) + X(n))/2.
Lo stima ore non parametrico è τ = ∑iXi/n il cui MSE è
MSE(τ) = bias2 + var(τ) = 0 + σ2/n = (b − a)2/(12n).
Per a = 1,b = 3,n = 10, risulta 0.0333. Per simulazione la stima di MV ha un MSEdi 0.015, che è abbastanza più piccolo.
3. (a) Il parametro τ = x0.95 è il quantile 0.95 di X ∼ N(μ,σ2). Poiché il quantile ècollegato al quantile della normale standard dalla relazione lineare
x0.95 = μ + σ z0.95 = μ + 1.645 σ
132

lo stimatore di MV di τ èτ = x + 1.645 σ.
(b) Un intervallo di confidenza per τ richiede la stima dell’errore standard che si puòottenere col metodo delta (multivariato). La matrice di informazione di μ e σ e lasua inversa sono
In(μ.σ) = (n/σ2 00 2n/σ2) , I−1n (μ,σ) =
1n(σ
2 00 σ2/2)
(vedi la soluzione dell’esercizio 8).Abbiamo quindi τ = g(μ,σ) = μ + 1.645 σ e il gradiente risulta
∇g = (∂g∂μ∂g∂σ
) = (∂∂μ(μ + 1.645 σ)∂∂σ(μ + 1.645 σ)
) = ( 11.645)
Per il metodo delta risulta
se(τ)2 = (∇g)TI−1n (∇g)
= (1, 1.645)(σ2/n 00 σ2/(2n))(
11.645) =
σ2
n(1 + 1.6452/2) = σ2
n2.353013
Quindi l’errore standard stimato è
se(τ) = σ√n√
2.353013 = σ√n1.534
L’intervallo approssimato normale si calcola quindi come al solito. (c) In R:
x = c(3.23, -2.50, 1.88, -0.68, 4.43, 0.17,1.03, -0.07, -0.01, 0.76, 1.76, 3.18,0.33, -0.31, 0.30, -0.61, 1.52, 5.43,1.54, 2.28, 0.42, 2.33, -1.03, 4.00, 0.39)
m = mean(x)sig = sd(x)n = length(x)tauh = m + qnorm(0.05) * sigseh = sig/sqrt(n) * 1.534> seh[1] 0.5691243
Con il bootstrap parametrico si calcola l’errore standard così.
tstar = rep(0, 1000)for (i in 1:1000){
y = rnorm(n, mean = m, sd = sig)tstar[i] = quantile(y, 0.95)
}sd(tstar)[1] 0.663066
4.
133

Soluzioni Capitolo 10
1. † Dimostrazione del teorema 10.14. Il valore p è una statistica 0 ≤ α(X) ≤ 1 tale chei valori piccoli segnalano l’evidenza contraria all’ipotesi H0.
Proposizione 10.14. Sia H0 ∶ θ = θ0 contro H1 ∶ θ ≠ θ0 e sia Rα una regione critica dilivello α cioè tale che
Pθ0[X ∈ Rα] = α.
Allora,Pθ0[α(X) ≤ u] = u per ogni 0 ≤ u ≤ 1.
Quindi α(X) è uniformemente distribuito su (0, 1).
Dimostrazione. Se il valore p è minore di un reale 0 ≤ u ≤ 1 allora rifiuteremmoanche ai livelli v > u. Quindi l’evento α(X) ≤ u implica che {X ∈ Rv} per ogni v > u.Inoltre, l’evento {X ∈ Ru} implica che α(X) ≤ u. Quindi
Pθ0[α(X) ≤ u] = Pθ0[X ∈ Ru] = u.
Soluzioni Capitolo 11
1. Dimostrazione. Ecco la dimostrazione nel caso in cui il campione abbia dimensione1. Indico con k0 = 1/b2 la precisione della distribuzione a priori e con k1 = 1/σ2 laprecisione della verosimiglianza. La distribuzione a posteriori risulta
f(θ ∣ x)∝ L(θ)f(θ) = exp [−k1(x − θ)22
] exp [−k0(θ − a)22
]
= exp{− 12[k1(x − θ)2 + k0(θ − a)2]} .
Possiamo usare l’identità
k1(θ − x)2 + k0(θ − a)2 = (k0 + k1)(θ − c)2 +k0k1
k0 + k1(x − a)2
dove c è un punto intermedio fra θ e a
c = k1
k0 + k1x + k0
k0 + k1a = wx + (1 −w)a. (C.1)
Poiché il secondo addendo non dipende da θ, esso può essere incorporato nellacostante di proporzionalità e la a posteriori risulta
f(θ ∣ x)∝ exp [ − 12(k0 + k1)(θ − c)2]
cioè una densità di tipo normale N(c,d2) dove c è la media della a posteriori e
d2 = 1k0 + k1
= 11b2 + 1
σ2
.
134


















