
3) ANALISI DEI RESIDUI -...
13
3) ANALISI DEI RESIDUI Dopo l’analisi di regressione si eseguono alcuni test sui residui per avere una ulteriore conferma della validità del modello e delle assunzioni (distribuzione normale degli errori, ovvero dei residui, omogeneità delle varianze d’errore, indipendenza degli errori dai valori delle variabile indipendente). Per fare questo occorre fare alcune trasformazioni e calcolare appropriati parametri. n umidità X peso Y Y pred Y predetto Standardizzato Residuo Residuo standardizzato Leverage h Residuo studentizzato t 9 0 8,98 8,704 1,564 0,276 0,930 0,306 1,218 0,263 12 8,14 8,065 1,192 0,075 0,252 0,178 0,298 0,774 29,5 6,67 7,134 0,648 -0,464 -1,564 0,053 -1,710 0,131 43 6,08 6,415 0,229 -0,335 -1,131 0,007 -1,204 0,268 53 5,9 5,883 -0,081 0,017 0,056 0,001 0,060 0,954 62,5 5,83 5,378 -0,376 0,452 1,525 0,018 1,634 0,146 75,5 4,68 4,686 -0,780 -0,006 -0,019 0,076 -0,022 0,983 85 4,2 4,180 -1,074 0,020 0,067 0,144 0,078 0,940 93 3,72 3,754 -1,323 -0,034 -0,116 0,219 -0,142 0,891 media 50,39 6,02 6,02 0 0,000 h outlier >2*n.var. / n = 0,444 t ( 0,05; df = n-2) dev(SQ) 8301,39 24,13 23,51 8 0,616 media = 0,111 v. crit= 2,365 var(MQ) 1037,67 3,02 2,94 1 0,077 ds 32,21 1,74 1,71 1 0,278 Durbin- Watson = 1,42 MQ da anova (si ottiene dividendo la SQ per n-2 df) 0,088 D (upper) = 1,36 da cui ds = 0,297 1) La standardizzazione si ottiene sottraendo al valore osservato la media e dividendo per la deviazione standard (Per i residui la deviazione standard è ottenuta a partire da una varianza (MQ) che a sua volta è stato ricavata dividendo per n-2 la devianza (SQ). In excel, invece, si divide sempre per n-1!) 2) Il coefficiente di leverage (leva, influenza), che varia tra 0 ed 1, è una misura di quanto un dato valore della variabile indipendente si discosta dalla sua media. I valori di Y relativi ad X con elevati valori di leva (h's outliers) hanno maggior peso nel determinare l'andamento della linea di regressione. Leverage 1 , h = (x - x ) 2 / devianza x Il valore critico di leva, oltre al quale abbiamo degli outlier (h outlier ) è calcolato moltiplicando per 2 il numero delle variabili (sia dipendenti che indipendenti) e dividendo per n, numero totale di osservazioni. 3) Studentizzazione (proposta da Student) è una sorta di standardizzazione in cui si tiene conto anche dei valori di leva. Si preferisce usare i residui studentizzati in quanto, incorporando i valori di leva, hanno varianze costanti, inoltre seguono la distribuzione di t con n -1-p gl ( p = numero di regressori, ovvero variabili indipendenti) se le assunzioni di base sono soddisfatte. Studentizzati = residuo/ds (residuo) *radq(1-h -1/n) In alcuni software si possono considerare i residui, standardizati e studentizzati, "deleted" ovvero il calcolo dei residui viene fatto a partire da una linea di regressione ottenuta escludendo di volta in volta il valore corrispondente. Nell'esaminare questi residui ed il valore di leverage abbiamo che: 1) elevati valori di h ma con valori osservati con quelli attesi e quindi non sono un problema; 2) valori elevati di residui (ovvero discordanza tra valori osservati ed attesi) ma con bassi valori di leverage sono ininfluenti nel determinare l'andamento della curva, e quindi non sono ugualmente un problema. Si può x 1 Secondo Sokal : h j = 1/n + [(x j - ) 2 / devianza x]; (per più valori di Y per ogni X si usa 1/n). In questo caso il calcolo dei valori studentizzati si fa senza 1/n (residuo/ds (residuo) *radq(1-h), per cui risultano uguali.
Transcript of 3) ANALISI DEI RESIDUI -...

3) ANALISI DEI RESIDUI Dopo l’analisi di regressione si eseguono alcuni test sui residui per avere una ulteriore conferma della validità del modello e delle assunzioni (distribuzione normale degli errori, ovvero dei residui, omogeneità delle varianze d’errore, indipendenza degli errori dai valori delle variabile indipendente). Per fare questo occorre fare alcune trasformazioni e calcolare appropriati parametri.
n umidità X
peso Y Y pred
Y predetto Standardizzato Residuo
Residuo standardizzato
Leverage h
Residuo studentizzato t
9 0 8,98 8,704 1,564 0,276 0,930 0,306 1,218 0,263 12 8,14 8,065 1,192 0,075 0,252 0,178 0,298 0,774 29,5 6,67 7,134 0,648 -0,464 -1,564 0,053 -1,710 0,131 43 6,08 6,415 0,229 -0,335 -1,131 0,007 -1,204 0,268 53 5,9 5,883 -0,081 0,017 0,056 0,001 0,060 0,954 62,5 5,83 5,378 -0,376 0,452 1,525 0,018 1,634 0,146 75,5 4,68 4,686 -0,780 -0,006 -0,019 0,076 -0,022 0,983 85 4,2 4,180 -1,074 0,020 0,067 0,144 0,078 0,940 93 3,72 3,754 -1,323 -0,034 -0,116 0,219 -0,142 0,891
media 50,39 6,02 6,02 0 0,000 houtlier >2*n.var. / n = 0,444 t( 0,05; df = n-2) dev(SQ) 8301,39 24,13 23,51 8 0,616 media = 0,111 v. crit= 2,365 var(MQ) 1037,67 3,02 2,94 1 0,077
ds 32,21 1,74 1,71 1 0,278 Durbin- Watson = 1,42
MQ da anova (si ottiene dividendo la SQ per n-2 df) 0,088 D(upper) = 1,36 da cui ds = 0,297
1) La standardizzazione si ottiene sottraendo al valore osservato la media e dividendo per la deviazione standard (Per i residui la deviazione standard è ottenuta a partire da una varianza (MQ) che a sua volta è stato ricavata dividendo per n-2 la devianza (SQ). In excel, invece, si divide sempre per n-1!) 2) Il coefficiente di leverage (leva, influenza), che varia tra 0 ed 1, è una misura di quanto un dato valore della variabile indipendente si discosta dalla sua media. I valori di Y relativi ad X con elevati valori di leva (h's outliers) hanno maggior peso nel determinare l'andamento della linea di regressione.
Leverage1, h = (x - x )2/ devianza x
Il valore critico di leva, oltre al quale abbiamo degli outlier (houtlier) è calcolato moltiplicando per 2 il numero delle variabili (sia dipendenti che indipendenti) e dividendo per n, numero totale di osservazioni. 3) Studentizzazione (proposta da Student) è una sorta di standardizzazione in cui si tiene conto anche dei valori di leva. Si preferisce usare i residui studentizzati in quanto, incorporando i valori di leva, hanno varianze costanti, inoltre seguono la distribuzione di t con n -1-p gl ( p = numero di regressori, ovvero variabili indipendenti) se le assunzioni di base sono soddisfatte. Studentizzati = residuo/ds(residuo)*radq(1-h -1/n) In alcuni software si possono considerare i residui, standardizati e studentizzati, "deleted" ovvero il calcolo dei residui viene fatto a partire da una linea di regressione ottenuta escludendo di volta in volta il valore corrispondente. Nell'esaminare questi residui ed il valore di leverage abbiamo che: 1) elevati valori di h ma con valori osservati con quelli attesi e quindi non sono un problema; 2) valori elevati di residui (ovvero discordanza tra valori osservati ed attesi) ma con bassi valori di leverage sono ininfluenti nel determinare l'andamento della curva, e quindi non sono ugualmente un problema. Si può
x1 Secondo Sokal : hj = 1/n + [(xj- )2/ devianza x]; (per più valori di Y per ogni X si usa 1/n). In questo caso il calcolo dei valori studentizzati si fa senza 1/n (residuo/ds(residuo)*radq(1-h), per cui risultano uguali.
sintetizzare, quindi, dicendo:che grandi errori con piccoli valori di leva, al pari di piccoli errori con grandi valori di leva, sono accettabili. Diversamente,3) valori elevati di entrambi possono influire pesantemente nel determinare l'andamento della retta di regresione, pertanto vanno considerarti con cautela. E’ pertanto necessario analizzare questi valori di leva contestualmente a quelli dei valori dei residui standardizzati o studentizzati. Quando si individuano dei valori outlier per entrambi (h outlier e residuo stundentizzato > t critico) potrebbe essere utile rifare l'analisi di regressione eliminando tali valori. 4) Il coefficiente di Durbin –Watson testa l’assunzione dell’indipendenza degli errori2. il valore di Durbin-Watson si calcola dal rapporto tra la somma delle differenze tra due residui adiacenti elevate al quadrato3 e la somma dei quadrati dei residui4. Il valore ottenuto viene confrontato con quello tabulato: se è inferiore al valore critico più basso (D-Lower) c'è una correlazione seriale, se è compreso tra il valore critico superiore (D-Upper) e quello inferiore c'è la probabilità di un correlazione, se è maggiore del valore critico superiore, non c'è autocorrelazione. Il valore di D-Upper, per 15 osservazioni (la tavola parte da 15), con una variabile indipendente, alla probabilità di 0,05, sarebbe 1,36, per cui per i dati analizzati non ci sarebbe autocorrelazione (DW = 1,42).
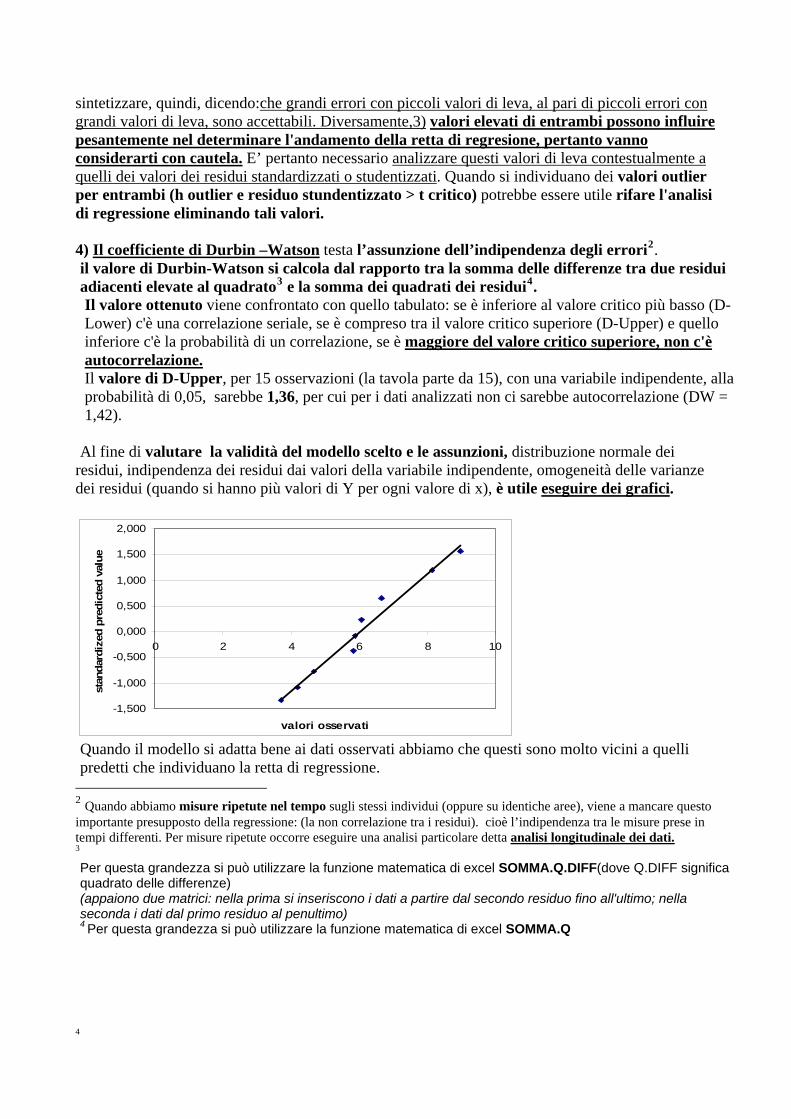
Al fine di valutare la validità del modello scelto e le assunzioni, distribuzione normale dei residui, indipendenza dei residui dai valori della variabile indipendente, omogeneità delle varianze dei residui (quando si hanno più valori di Y per ogni valore di x), è utile eseguire dei grafici.
-1,500
-1,000
-0,500
0,000
0,500
1,000
1,500
2,000
0 2 4 6 8
valori osservati
stan
dar
diz
ed p
redic
ted v
alue
10
Quando il modello si adatta bene ai dati osservati abbiamo che questi sono molto vicini a quelli predetti che individuano la retta di regressione.
2 Quando abbiamo misure ripetute nel tempo sugli stessi individui (oppure su identiche aree), viene a mancare questo importante presupposto della regressione: (la non correlazione tra i residui). cioè l’indipendenza tra le misure prese in tempi differenti. Per misure ripetute occorre eseguire una analisi particolare detta analisi longitudinale dei dati. 3 Per questa grandezza si può utilizzare la funzione matematica di excel SOMMA.Q.DIFF(dove Q.DIFF significa quadrato delle differenze) (appaiono due matrici: nella prima si inseriscono i dati a partire dal secondo residuo fino all'ultimo; nella seconda i dati dal primo residuo al penultimo) 4 Per questa grandezza si può utilizzare la funzione matematica di excel SOMMA.Q
4

Inoltre se gli errori sono indipendenti dai valori della X questi si devono posizionare in modo del tutto casuale rispetto alla retta di regressione
-2
-1,5
-1
-0,5
0
0,5
1
1,5
2
0 20 40 60 80 100
Umidità
Stu
den
tize
d r
esid
ual
s
Ascissa: Valori predetti (osservati o standardizzati) Con questo grafico si visualizza se è soddisfatta l'ipotesi che gli errori (residui) sono normalmente distribuiti. In una distribuzione normale standardizzata (media 0 e sd 1) il 95% dei dati è compreso tra -1,96 e + 1,96. Per questa assunzione si può usare anche le opzioni dell'analisi descrittiva sui residui standardizzati. Se si utilizzano valori studentizzati dei residui allora è anche possibile evidenziare eventuali outlier con la distribuzione di t, per n -1-p gradi di libertà. Grafici analoghi sono anche quelli che hanno sull'ascissa i valori predetti (standardizzati o meno) e/o sull’ordinata i residui standardizzati. E' da evitare un grafico che abbia sulle ascisse i valori osservati di Y perché questi possono essere correlati con gli errori, cosa che non avviene con quelli predetti. Nel caso di più valori di Y per ogni X, questo grafico visualizza anche la dispersione (varianza) dei valori di Y per ogni valore di X, la quale deve essere omogenea. Se questa assunzione è soddisfatta, anche i valori degli errori sono distribuiti a caso ed indipendentemente dai valori della X. Quando le varianze non siano omogenee si può ricorrere a delle trasformazioni.
0,000
0,250
0,500
0,750
1,000
0 20 40 60 80 100umidità
levera
ge
media = 0,111
Con questo grafico si illustrano i valori di leva, che in questo caso non devono superare il valore critico di 0,44.
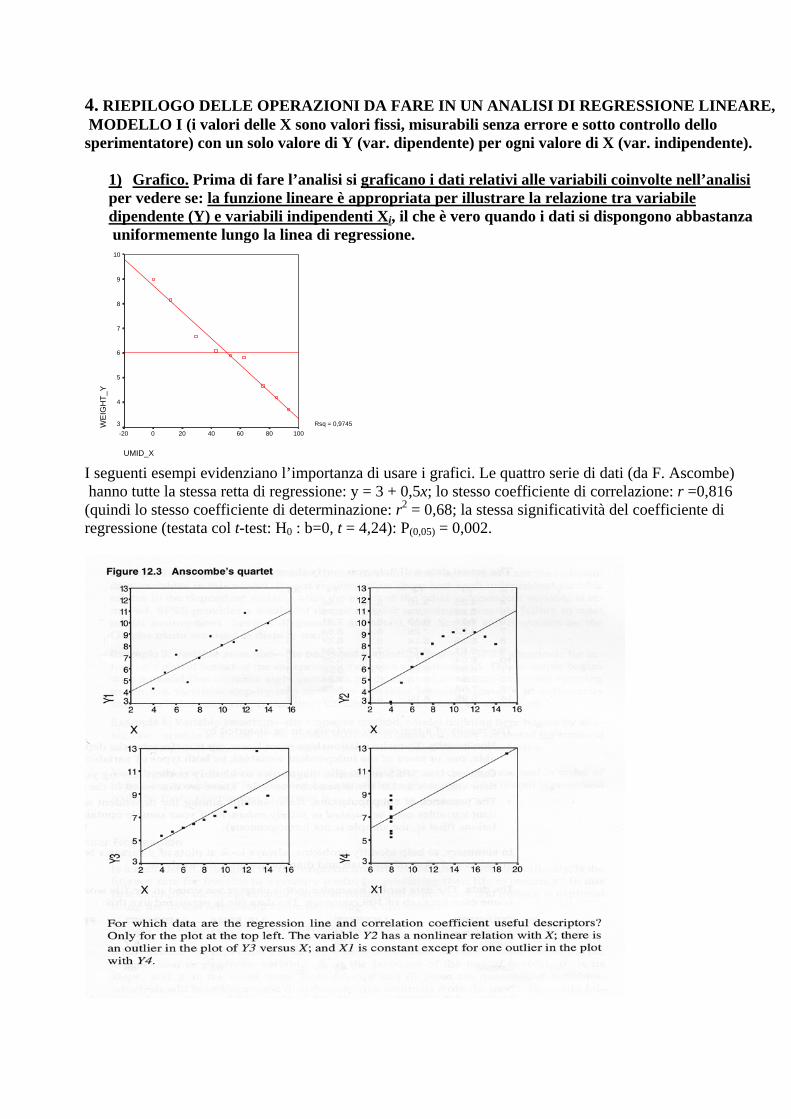
4. RIEPILOGO DELLE OPERAZIONI DA FARE IN UN ANALISI DI REGRESSIONE LINEARE, MODELLO I (i valori delle X sono valori fissi, misurabili senza errore e sotto controllo dello sperimentatore) con un solo valore di Y (var. dipendente) per ogni valore di X (var. indipendente).
1) Grafico. Prima di fare l’analisi si graficano i dati relativi alle variabili coinvolte nell’analisi per vedere se: la funzione lineare è appropriata per illustrare la relazione tra variabile dipendente (Y) e variabili indipendenti Xi, il che è vero quando i dati si dispongono abbastanza uniformemente lungo la linea di regressione.
UMID_X
100806040200-20
WE
IGH
T_Y
10
9
8
7
6
5
4
3 Rsq = 0,9745
I seguenti esempi evidenziano l’importanza di usare i grafici. Le quattro serie di dati (da F. Ascombe) hanno tutte la stessa retta di regressione: y = 3 + 0,5x; lo stesso coefficiente di correlazione: r =0,816 (quindi lo stesso coefficiente di determinazione: r2 = 0,68; la stessa significatività del coefficiente di regressione (testata col t-test: H0 : b=0, t = 4,24): P(0,05) = 0,002.

Nel caso avessimo più valori di Y per ciascun valore di X:
Da notare che gli outlier di una distribuzione univariata sono valori particolarmente distanti dalla loro media, mentre nella distribuzione bivariata (regressione) sono valori particolarmente differenti da quelli predetti (ovvero dalla retta di regressione). Nel grafico “a” il punto in basso a destra è un outlier nella regressione (mentre non è un outlier rispetto alle due variabili considerate singolarmente). Se la retta non è la funzione ottimale per spiegare la relazione tra le due variabili, come pure se le varianze non sono omogenee, si può tentare di risolvere il problema in vario modo:
1) trasformando le variabili in modo da rendere lineare la relazione tra variabili; 2) utilizzare test non parametrici al posto dell’analisi di regressione (il test più utilizzato è quello di Kendall, vedi Sokal pag, 539); 3) utilizzare regressioni curvilinee.
2) Determinazione dei parametri della retta di regressione. Si determinano i valori della funzione Lineare, “b” (coefficiente di regressione) ed “a” (intercetta), poi si testa la:
i. significatività della regressione, attraverso l’analisi della varianza di regressione (F test tra la varianza di regressione e la varianza dei residui). E’ anche possibile testare la significatività di b (t test ottenuto dal rapporto del valore di b sul suo errore standard) anche se questo test risulta ridondante in quanto strettamente correlato al precedente test (t2 = F);
ii. significatività del modello, attraverso il valore di r2, coefficiente di determinazione, che si ottiene dal rapporto tra la varianza di regressione e quella totale. Un’altro parametro è l’errore standard della regressione, ovvero la deviazione standard del residuo. Se questo valore non risulta inferiore a quello della deviazione standard dei valori osservati per la variabili dipendente, allora la regressione lineare non è un miglior predittore della relativa media;
3) Analisi dei residui. E’ necessaria per avere una ulteriore conferma della validità del modello e per testare se sono soddisfatte le assunzioni richieste da questo tipo di analisi: distribuzione normale degli errori, ovvero dei residui, l’indipendenza degli errori dai valori della variabile indipendente, l’omogeneità delle varianze d’errore (quando si abbia più valori

di Y per un dato valore di X), e l’assenza di valori di leva che possano pilotare la regressione.
Oltre ai test sui residui è possibile fare queste verifiche graficando i dati ottenuti.
a) La validità del modello può essere confermata graficando i valori predetti standardizzati (ordinate) verso i valori osservati (ascisse). Se il modello è valido i valori osservati non devono discostarsi molto dalla retta di regressione (valori predetti);
Scatterplot
Dependent Variable: WEIGHT_Y
Reg
ress
ion
Sta
ndar
dize
d P
redi
cted
Val
ue
2,0
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
WEIGHT_Y
109876543
b) La distribuzione normale degli errori può essere visualizzata graficando i valori residui studentizzati, o standardizzati(ordinate) verso i valori della variabile indipendente (ordinate) oppure verso i valori predetti (standardizzati o meno)
UMID_X
100806040200-20
Sta
nd
ard
ize
d R
esi
du
al
2,0
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
-2,0
Se la distribuzione dei residui standardizzati (o studentizzata ) è normale, il 95% dei valori deve essere compreso tra -1,96 e +1,96. Se si utilizzano valori studentizzati dei residui allora è anche possibile evidenziare eventuali outlier con la distribuzione di t, per n -1-p gradi di libertà.

c) L’indipendenza degli errori (residui) dai valori della variabile indipendente può essere messa in evidenza dal grafico precedente o da grafici simili
-2,0
-1,5
-1,0
-0,5
0,0
0,5
1,0
1,5
2,0
-1,5 -1 -0,5 0 0,5 1 1,5 2
predetti standardizzati
resi
dui st
uden
tizz
ati
Se gli errori sono indipendenti questi si devono posizionare casualmente rispetto ai valori predetti. L’assunzione dell’indipendenza degli errori può essere testata calcolando il coefficiente di Durbin –Watson
d) L’omogeneità delle varianze d’errore, importante quando si abbiano più di un valore di Y per
ogni valore di X, può essere anch’essa visualizzata con i grafici sopra illustrati.
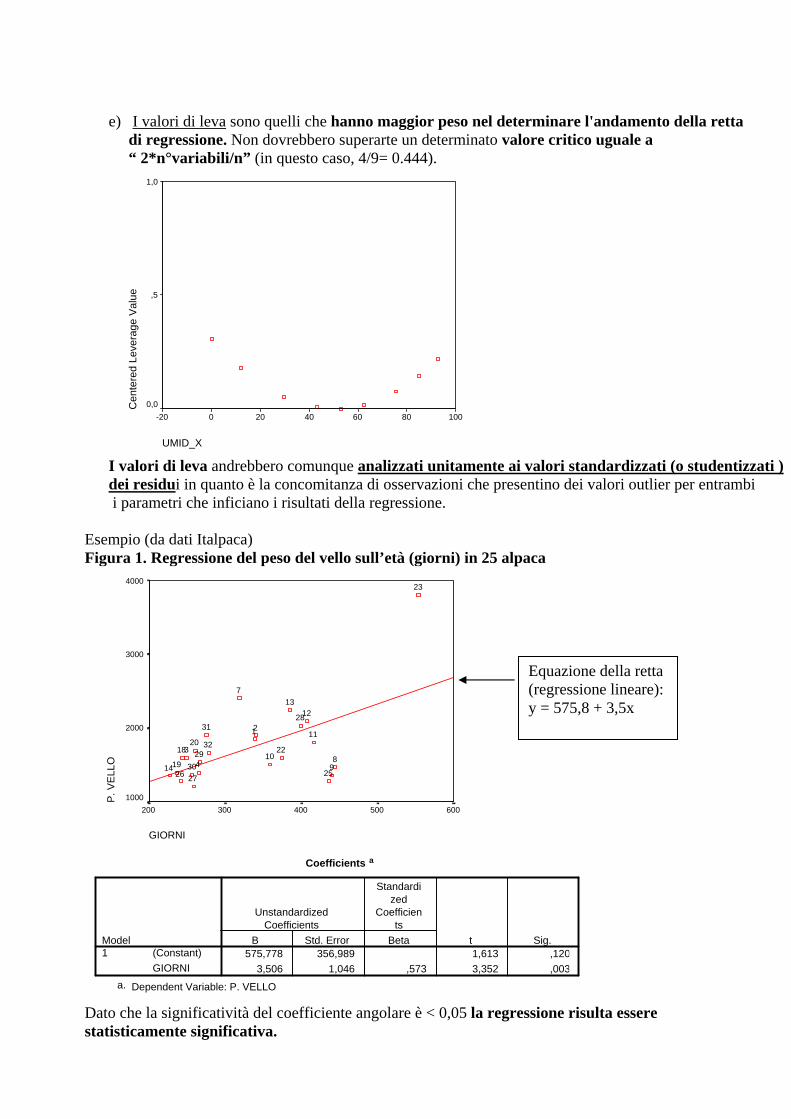
e) I valori di leva sono quelli che hanno maggior peso nel determinare l'andamento della retta di regressione. Non dovrebbero superarte un determinato valore critico uguale a “ 2*n°variabili/n” (in questo caso, 4/9= 0.444).
UMID_X
100806040200-20
Ce
nte
red
Le
vera
ge
Va
lue
1,0
,5
0,0
I valori di leva andrebbero comunque analizzati unitamente ai valori standardizzati (o studentizzati ) dei residui in quanto è la concomitanza di osservazioni che presentino dei valori outlier per entrambi i parametri che inficiano i risultati della regressione.
Esempio (da dati Italpaca) Figura 1. Regressione del peso del vello sull’età (giorni) in 25 alpaca
GIORNI
600500400300200
P.
VE
LL
O
1000
4000
3000
2000
32
31
30
29
28
2726 25
23
2220
19
18
14
1312
11
1098
7
4
3
21
Equazione della retta (regressione lineare): y = 575,8 + 3,5x
Coefficients a
575,778 356,989 1,613 ,120
3,506 1,046 ,573 3,352 ,003
(Constant)
GIORNI
Model1
B Std. Error
UnstandardizedCoefficients
Standardized
Coefficients
Beta t Sig.
Dependent Variable: P. VELLOa.
Dato che la significatività del coefficiente angolare è < 0,05 la regressione risulta essere statisticamente significativa.

Dall’analisi dei residui risultava: Fig. 2. Analisi dei residui relativi alla regressione del peso del vello sull’età (giorni)
GIORNI
600500400300200
-2Sta
ndar
dize
d R
esid
ual
3
2
1
0
-1
ID 23
ID 23, residuo studentizzato = 3,46; distribuzione di t(0,05; 23) = 0,00212 Fig. 3. Analisi dei valori di leva (leverage) relativi alla regressione del peso del vello sull’età (giorni)
GIORNI
600500400300200
-,1Cen
tere
d Le
vera
ge V
alue
,3
,2
,1
0,0
ID 23 valore di leva = 0,277 valore critico di leva pari a “2*n°var / n, che nel nostro caso è 2*2/25 = 0,16
ID 23
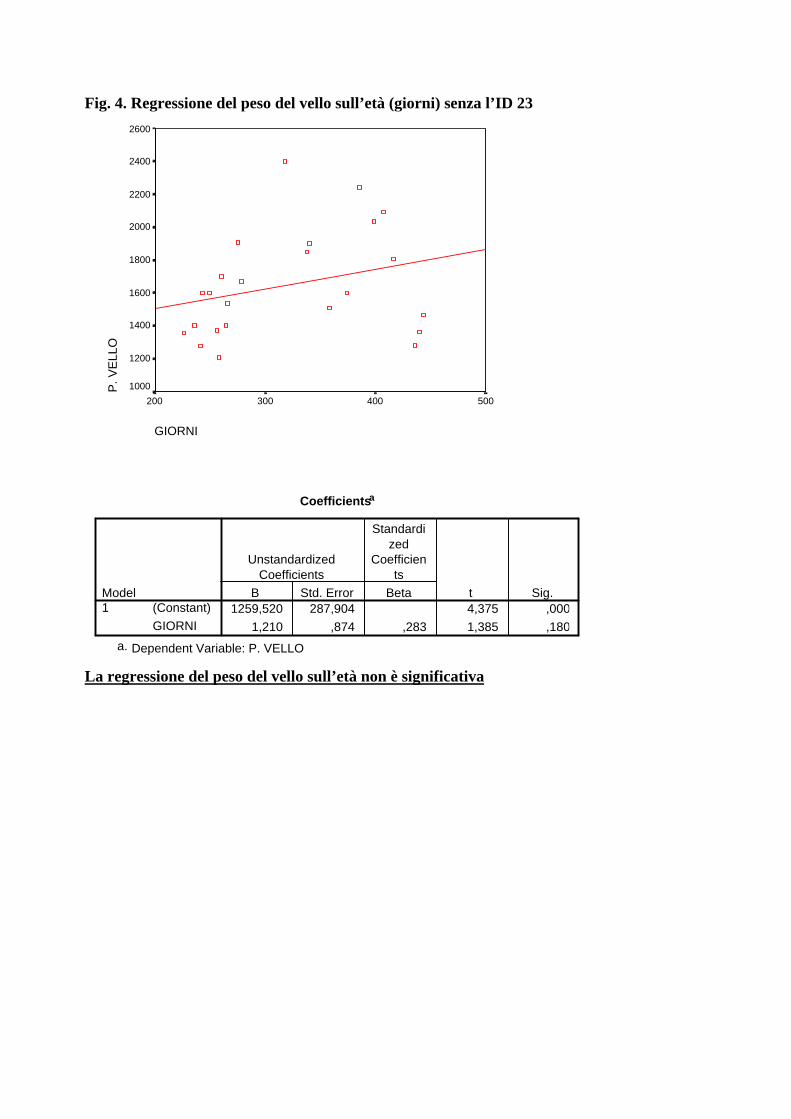
Fig. 4. Regressione del peso del vello sull’età (giorni) senza l’ID 23
GIORNI
500400300200
1000P.
VE
LLO
2600
2400
2200
2000
1800
1600
1400
1200
Coefficientsa
1259,520 287,904 4,375 ,000
1,210 ,874 ,283 1,385 ,180
(Constant)
GIORNI
Model1
B Std. Error
UnstandardizedCoefficients
Standardized
Coefficients
Beta t Sig.
Dependent Variable: P. VELLOa.
La regressione del peso del vello sull’età non è significativa
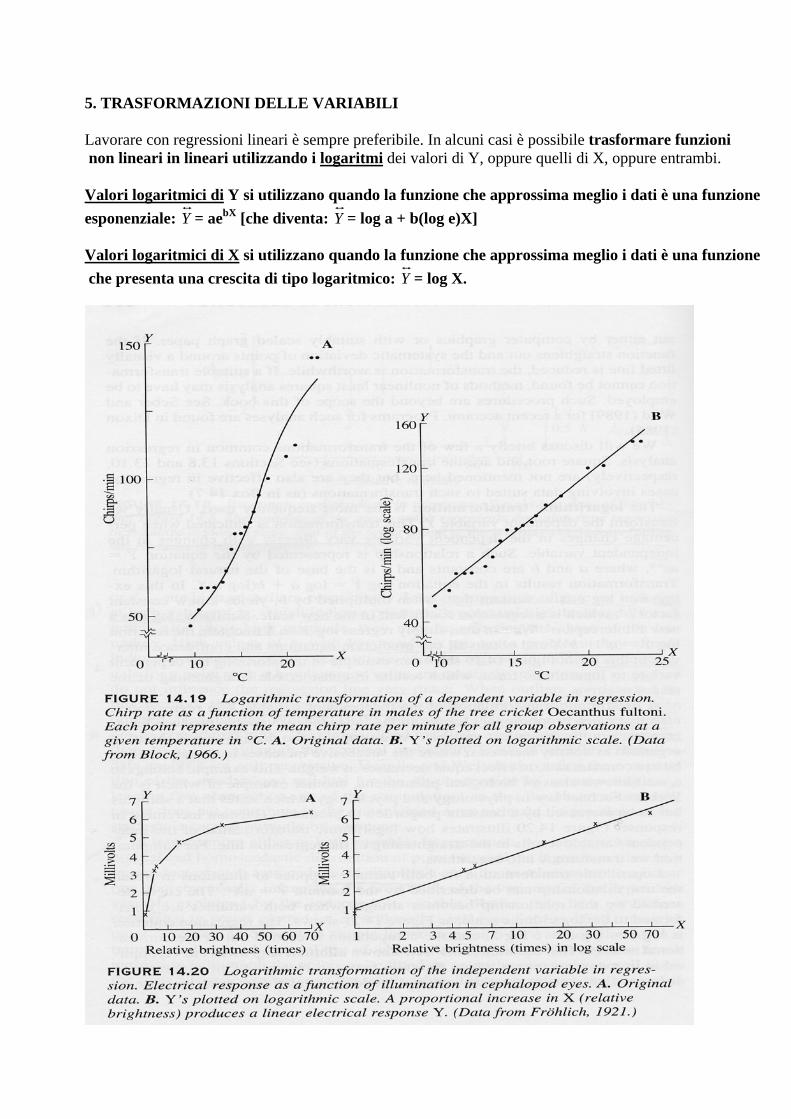
5. TRASFORMAZIONI DELLE VARIABILI Lavorare con regressioni lineari è sempre preferibile. In alcuni casi è possibile trasformare funzioni non lineari in lineari utilizzando i logaritmi dei valori di Y, oppure quelli di X, oppure entrambi. Valori logaritmici di Y si utilizzano quando la funzione che approssima meglio i dati è una funzione
esponenziale: Y = aebX [che diventa: Y = log a + b(log e)X] Valori logaritmici di X si utilizzano quando la funzione che approssima meglio i dati è una funzione
che presenta una crescita di tipo logaritmico: Y = log X.
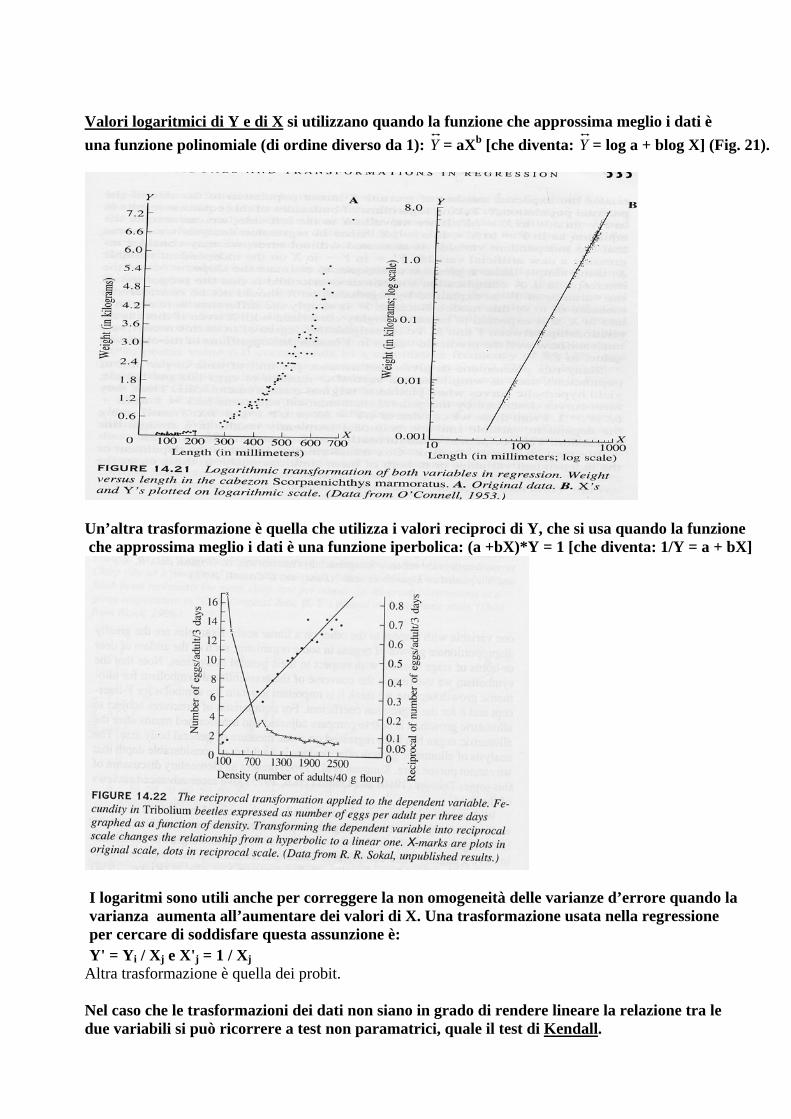
Valori logaritmici di Y e di X si utilizzano quando la funzione che approssima meglio i dati è
una funzione polinomiale (di ordine diverso da 1): Y = aXb [che diventa: Y = log a + blog X] (Fig. 21).
n’altra trasformazione è quella che utilizza i valori reciproci di Y, che si usa quando la funzione
U che approssima meglio i dati è una funzione iperbolica: (a +bX)*Y = 1 [che diventa: 1/Y = a + bX]
nche per correggere la non omogeneità delle varianze d’errore quando la
A la dei probit.
el caso che le trasformazioni dei dati non siano in grado di rendere lineare la relazione tra le
I logaritmi sono utili avarianza aumenta all’aumentare dei valori di X. Una trasformazione usata nella regressione per cercare di soddisfare questa assunzione è: Y' = Yi / Xj e X'j = 1 / Xj ltra trasformazione è quel
Ndue variabili si può ricorrere a test non paramatrici, quale il test di Kendall.



















