
1.5: Gestione dei Processi e della CPU - Vito Asta - Home Page · – Informazioni per la gestione...
44
1.5.1 1.5: Gestione dei Processi e della CPU ● Concetto di Processo ● Multitasking ● Operazioni sui processi ● Stati di un processo ● Eventi e risorse ● Context switch ● Scheduling dei processi – A breve termine – A medio/lungo termine ● Scheduling della CPU ● Algoritmi di scheduling della CPU
Transcript of 1.5: Gestione dei Processi e della CPU - Vito Asta - Home Page · – Informazioni per la gestione...

1.5.1
1.5: Gestione dei Processi e della CPU● Concetto di Processo
● Multitasking
● Operazioni sui processi
● Stati di un processo
● Eventi e risorse
● Context switch
● Scheduling dei processi
– A breve termine
– A medio/lungo termine
● Scheduling della CPU
● Algoritmi di scheduling della CPU
● Latenza di dispatch

1.5.2
Concetto di Processo● Terminologia usuale:
– Sistemi batch: job
– Sistemi timesharing: processo, o task
● Processo = un programma in esecuzione, nel suo proprio ambiente operativo.
● Un processo include:
– Program Counter
– Sezione testo (codice del programma readonly, shared)
– Stack (nella fase utente)
– Sezione dati
– Unix only: sezione dati non inizializzati (bss).
● Avanzamento di un processo = avanzamento nell'esecuzione delle sue istruzioni.
1.5.3
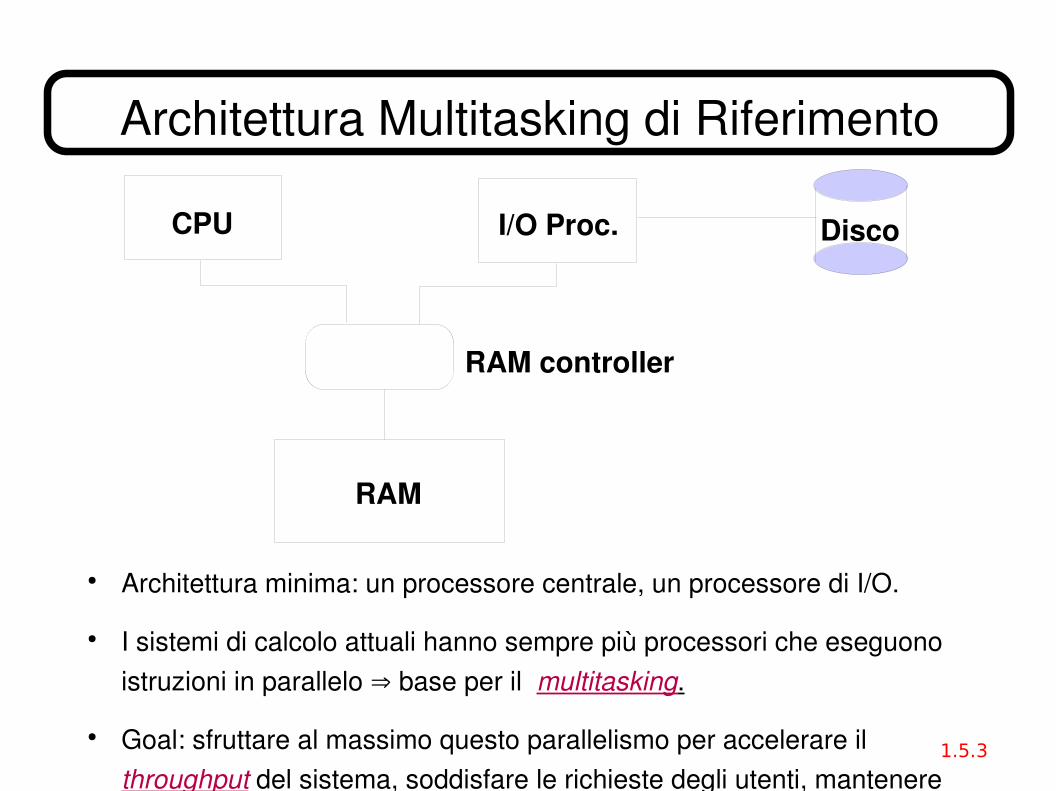
Architettura Multitasking di Riferimento
● Architettura minima: un processore centrale, un processore di I/O.
● I sistemi di calcolo attuali hanno sempre più processori che eseguono istruzioni in parallelo ⇒ base per il multitasking.
● Goal: sfruttare al massimo questo parallelismo per accelerare il throughput del sistema, soddisfare le richieste degli utenti, mantenere impegnati tutti i processori.
CPU I/O Proc. Disco
RAM controller
RAM
1.5.4
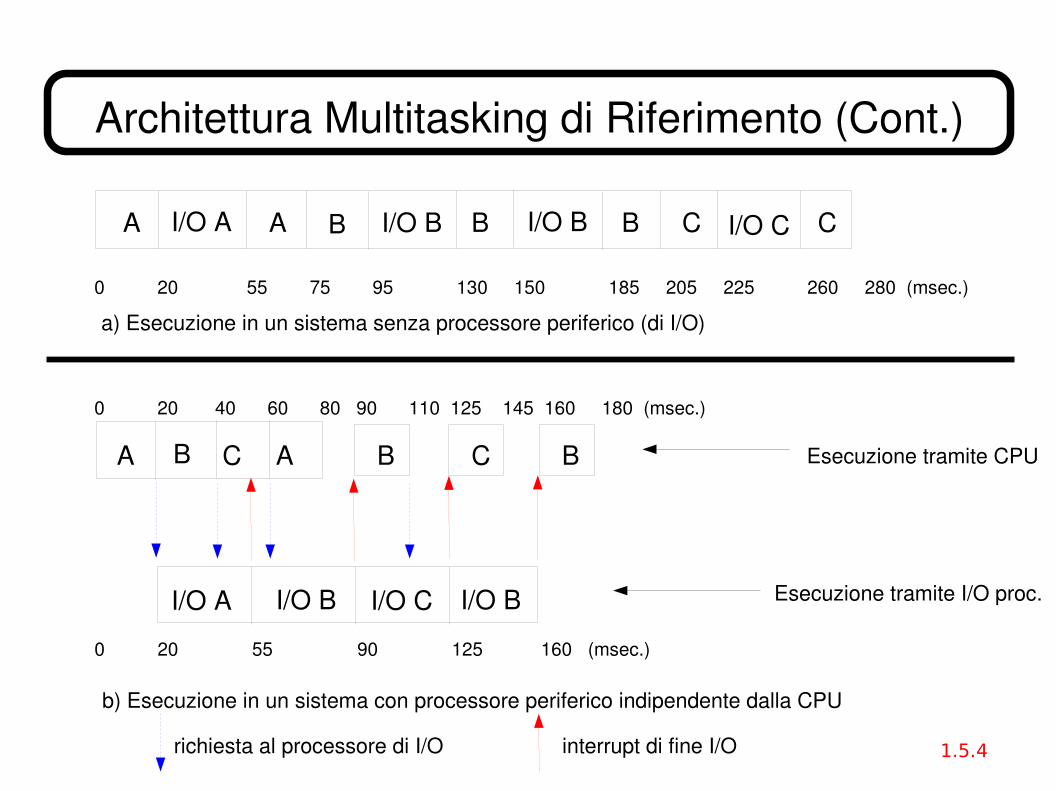
Architettura Multitasking di Riferimento (Cont.)
A I/O A A B I/O B B BI/O B I/O C
a) Esecuzione in un sistema senza processore periferico (di I/O)
A AB C
I/O A I/O B I/O C
B
b) Esecuzione in un sistema con processore periferico indipendente dalla CPU
Esecuzione tramite CPU
Esecuzione tramite I/O proc.
C C
0 20 55 75 95 130 150 185 205 225 260 280 (msec.)
0 20 40 60 80 90 110 125 145 160 180 (msec.)
0 20 55 90 125 160 (msec.)
I/O B
C B
richiesta al processore di I/O interrupt di fine I/O

1.5.5
Operazioni su Processi● N.B. argomenti ripresi in maggior dettaglio in questa e nella prossima
dispensa.
● Creazione
– Processi padri creano processi figli e così via (albero di processi).
– Risorse: condivise o no, in tutto o in parte, tra padre e figlio● es.: file aperti, memoria condivisa, socket (networking), etc.
– Esecuzione:● padre e figlio si eseguono concorrentemente o no; padre sincronizzato
sulla terminazione del figlio● Figlio esegue un programma specificato dal padre, oppure lo stesso
programma del padre● Terminazione
– Con chiamata di sistema esplicita (es. exit()) o implicita (esecuzione ultima istruzione del programma)
– Con codice di uscita (OK/ERR), recuperato dal Kernel o dal processo padre
– Forzata dal Kernel in caso di errore programma (abort).

1.5.6
Operazioni su Processi (Cont.)● Sincronizzazione
– Tra processi, su base cooperativa
– Sincronizzazione sulla terminazione di un processo
● Comunicazione
– Richiede la sincronizzazione
– Comunicazione di dati tra processi● Onetoone, one.tomany, many.tomany, manytoone● Internamente alla macchina o attraverso rete di calcolatori
● Segnalazione
– Comunicazione non di dati, ma di eventi asincroni
– Implementata di norma con interrupt software
– Utilizzabile per provocare la terminazione di altri processi (es. padre che termina un figlio, o altre situazioni).

1.5.7
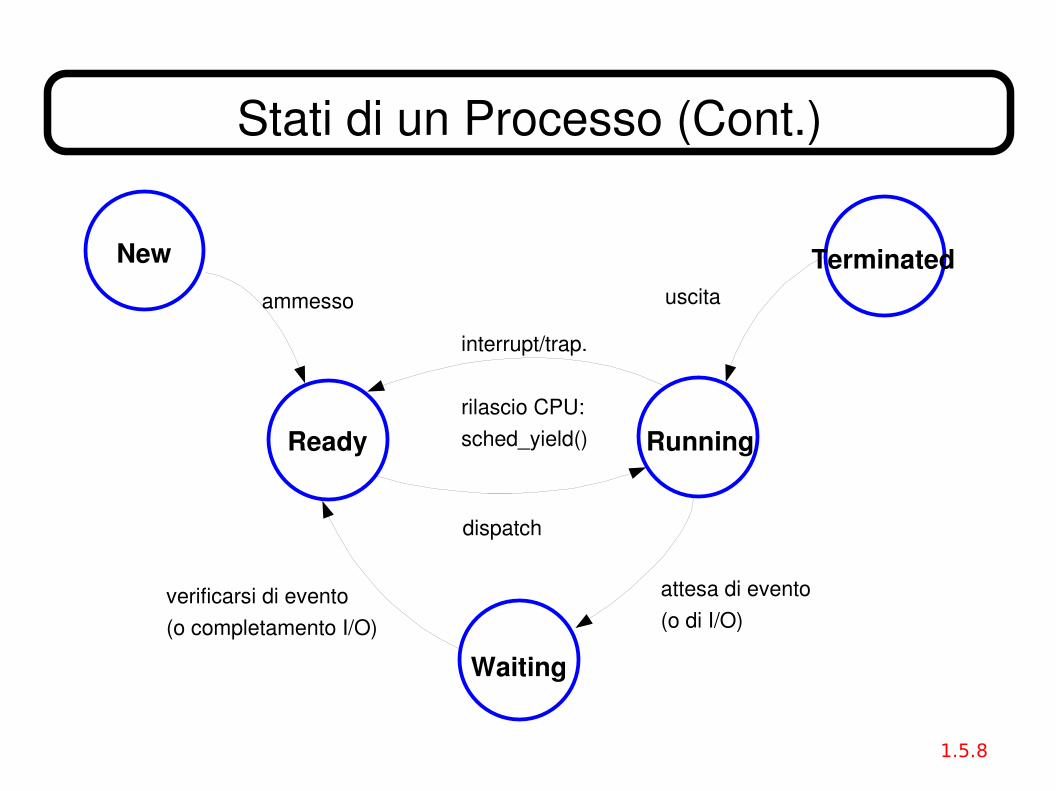
Stati di un Processo● Durante la sua esecuzione, un processo cambia stato
– New: il processo è in fase di creazione
– Running: il processo ha il controllo della CPU, e sta eseguendo istruzioni del programma (è in fase di avanzamento)
– Waiting, o Asleep: il processo sta aspettando il verificarsi di qualche evento (o l'acquisizione di qualche risorsa)
– Ready: il processo è in attesa di avere il controllo della CPU
– Terminated: il processo ha terminato l'esecuzione del programma, ed è in fase di terminazione.
● Perchè "Asleep":
– Un processo "va a dormire" in attesa di un evento; quando l'evento si verifica, il processo "viene svegliato" e ricomincia a eseguire istruzioni.
1.5.8
Stati di un Processo (Cont.)
New
Ready
Terminated
Running
Waiting
ammesso uscita
interrupt/trap. rilascio CPU:sched_yield()
dispatch
attesa di evento(o di I/O)
verificarsi di evento(o completamento I/O)

1.5.9
Descrittore di Risorsa● Descrittori di risorse: strutture di dati, usate dal Kernel, utilizzate per
gestire le varie risorse presenti nel sistema.
– Qualunque risorsa hardware o software; reale o astratta
– Contengono informazioni sulla risorsa, sul suo stato, etc.; spesso anche puntatori a funzione (operazioni sulla risorsa)
– Utilizzati dagli algoritmi che gestiscono le varie risorse
– Strutt. dati diverse per ciascuna risorsa
– In un S.O. (ad es. Linux), ci sono centinaia di tipi diversi
– Esempi di risorse:● Aree di memoria● Blocchi di disco● Pacchetti dati per interfacce di rete● ...● Processi (risorsa astratta).

1.5.10
Descrittore di Processo● Descrittore di processo (Process Descriptor, PD): descrittore di risorsa
per la risorsa "processo" informazioni associate a ciascun processo, usate dal Kernel; contenute in una struttura dati.
● Contiene:– Identificatore del processo (PID)
– Stato del processo
– Program Counter e registri CPU (compresi i condition code del PSW)
– Stack
– Informazioni per lo scheduling della CPU (priorità, etc.)
– Informazioni per la gestione di memoria RAM
● Registri MMU, limiti di memoria, etc.– Informazioni di contabilizzazione risorse
● Tempo CPU, user/system time, etc.– Informazioni sui canali di I/O
● File aperti, dispositivi allocati in uso, etc.
● Gestito da tutti gli algoritmi di scheduling applicati ai processi.

1.5.11
Eventi e Risorse● Risorsa = qualunque oggetto (reale o astratto) che i processi usano e
che può condizionarne l'avanzamento.
● Avanzamento di un processo: condizionato dalla disponibilità di risorse di vario tipo.
● Compito tipico di un S.O. multitasking: controllare l'uso di risorse da parte dei processi in modo da risolvere eventuali conflitti.
● Risorsa = formalizzazione di Evento:
– Processo in attesa di evento E: in attesa di acquisire la risorsa R(E).
– Il processo è bloccato su E, ovvero in attesa di acquisire R(E).
– Evento = la risorsa R(E) diventa disponibile.

1.5.12
Eventi e Risorse (Cont.)● Risorse: due tipi
– Risorse permanenti (o riusabili)● Utilizzate più volte da più processi; il loro stato non cambia.● Seriali (utilizzabili da un processo alla volta) o condivise (shared) (caso
opposto).● Prodotte dal Kernel per processi; recuperate sistematicamente dal
Kernel (al più tardi, alla terminazione del processo).● Associate normalmente a entità fisiche (o ad esse riconducibili).● Es.: area di memoria (per dati; per libreria condivisa).● Numero finito Np, determinato a priori, di tipi di risorse permanenti; per
ogni tipo Ti di risorsa (1 <= i <= Np) il Kernel dispone di un numero finito ni, determinato a priori, di unità di risorsa disponibili.

1.5.13
Eventi e Risorse (Cont.)– Risorse consumabili
● Oggetti transienti; tempo di vita = dalla produzione alla consumazione.● Prodotte
– da processi (produttori) per altri processi (consumatori)– dal Kernel per processi.
● Associate normalmente a entità astratte (o ad esse riconducibili).● Es.: buffer con dati, trasferiti da un processo ad un altro.● La produzione (da processo Pp) e la consumazione (da Pc) di una
risorsa consumabile sincronizza Pc rispetto a Pp.
● Numero finito Nc, determinato a priori, di tipi di risorse consumabili; per ogni tipo Tj di risorsa (1 <= j <= Nc) il Kernel dispone di un numero infinito (non noto a priori) di unità nj di risorse, che possono essere prodotte continuamente da processi produttori, in quantità e ad istanti di tempo non predicibili (dipende dal comportamento di tali processi).

1.5.14
Eventi e Risorse (Cont.)● Schema interazione risorse permanenti:
– P richiede risorsa R (P va a dormire)
– Kernel assegna risorsa R a P (Kernel risveglia P)
– P acquisisce R e la utilizza
– P rilascia R (Kernel risveglia altri processi in attesa)
● Schema interazione risorse consumabili:
– loop:
● Pc (processo consumatore) richiede risorsa R (Pc va a dormire)
● Pp (processo produttore) produce risorsa R (Pp risveglia Pc)
● Pc acquisisce R e la consuma
Pp e Pc sono sincronizzati.
Esempio tipico: una pipe tra processi
ls | wc

1.5.15
Eventi e Risorse (Cont.)● Descrittore di risorsa:
– Utilizzato dal Kernel (Resource Manager) per gestire tutte le risorse
– Contiene:● Nome o tipo di risorsa● Numero totale di unità (configurato nel sistema solo ris. permanenti)● Numero di unità disponibili (a un dato istante)● Puntatore a lista dei processi in attesa di acquisizione della risorsa.

1.5.16
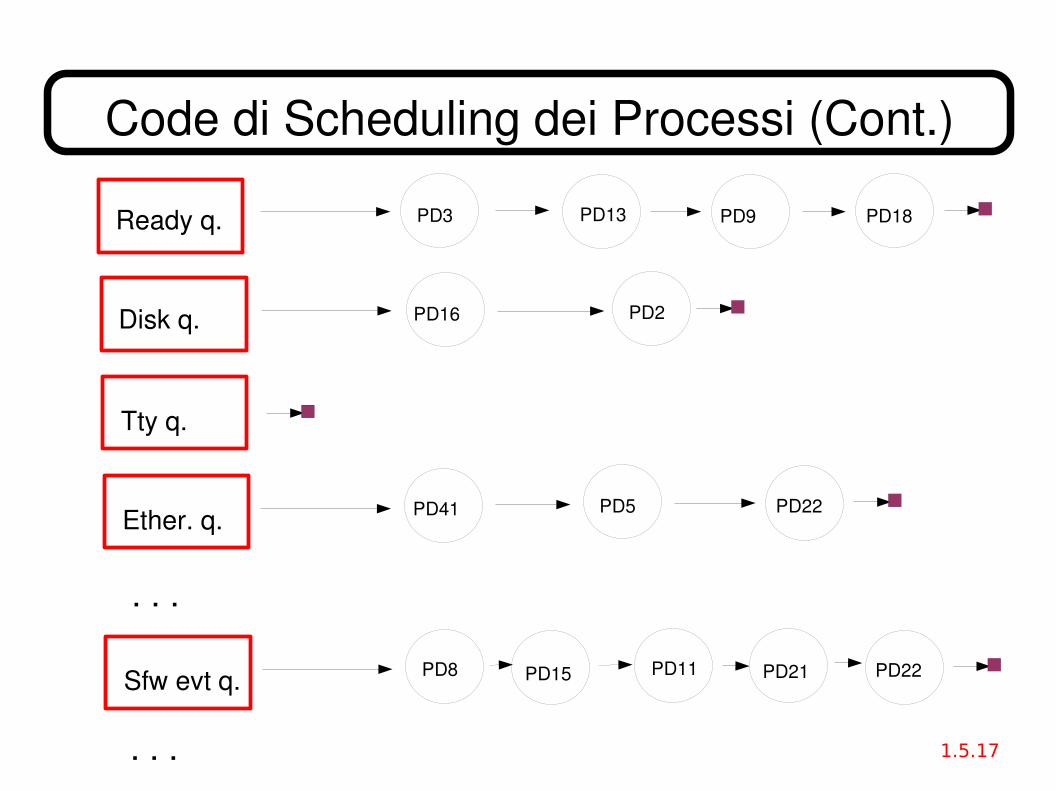
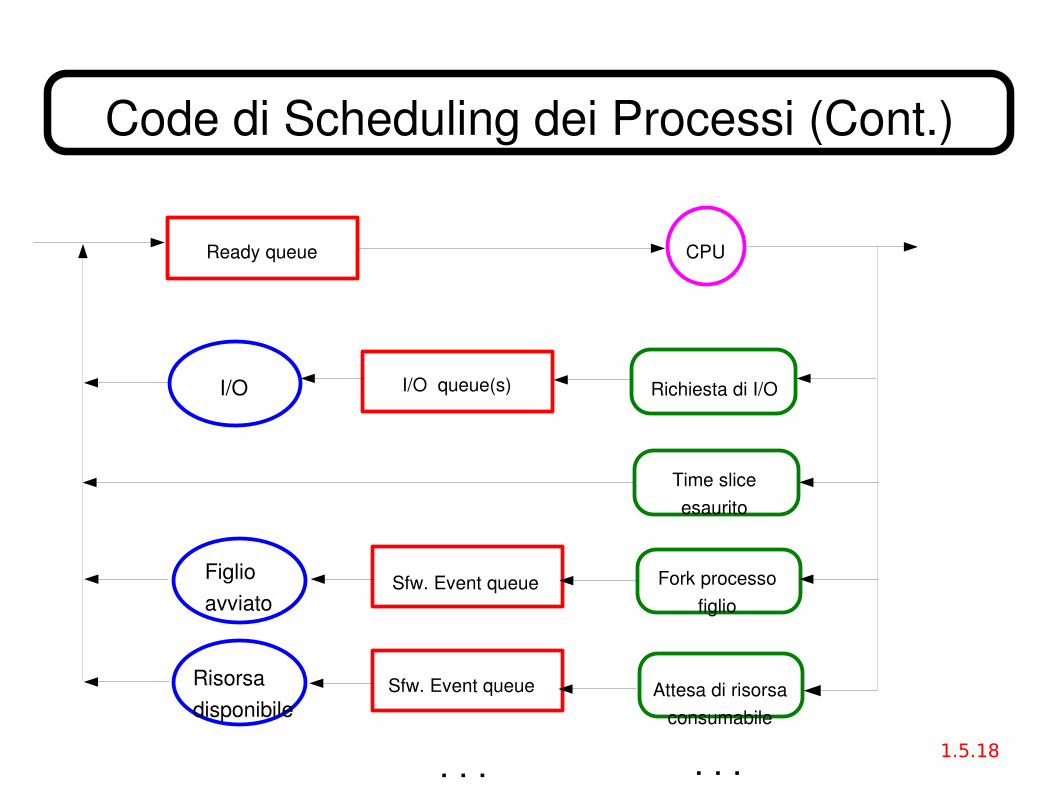
Code di Scheduling dei Processi● Job queue insieme di tutti i processi nel sistema.● Ready queue insieme di tutti i processi in stato Ready, pronti ad
eseguirsi e in attesa della CPU.● Device queues insieme di tutti i processi in attesa del completamento
di un'operazione di I/O da parte di una data periferica.● Più in generale, Event queues insieme di tutti i processi in attesa di
qualche evento o risorsa (di tipo hardware o software)– es.: in attesa della terminazione di un processo figlio.
● I processi migrano tra le varie code durante l'esecuzione.● Le code sono normalmente implementate con liste collegate di strutture
di dati PD, nel Kernel (collegamento semplice o doppio).
1.5.17
Code di Scheduling dei Processi (Cont.)
Ready q.
Disk q.
Tty q.
Ether. q.
PD16
PD3 PD13 PD9 PD18
PD2
PD5PD41 PD22
Sfw evt q. PD15PD8 PD22
. . .
. . .
PD11 PD21
1.5.18
Code di Scheduling dei Processi (Cont.)
Richiesta di I/O
Time slice esaurito
Fork processo figlio
Attesa di risorsa consumabile
Ready queue
I/O queue(s)
Sfw. Event queue
Sfw. Event queue
. . . . . .
CPU
I/O
Figlioavviato
Risorsadisponibile

1.5.19
Context Switch● Context switch: parte del lavoro di uno scheduler di processi. Quando la
CPU commuta ad un altro processo della Ready queue, il Kernel deve salvare lo stato (il PD) del processo precedente e caricare lo stato del nuovo processo (salvato in precedenza nel suo PD).
● Il tempo di context switch è tutto overhead; non c'è nessun lavoro utile durante la commutazione (dal punto di vista dell'avanzamento dei processi), quindi va minimizzato.
● Il tempo di overhead può dipendere dal supporto hardware della CPU.

1.5.20
Context Switch (Cont.)
(overhead)
(overhead)
(N.B. PCB = PD)

1.5.21
Thread● Un thread (o processo leggero, lightweight process, LWP) è un'unità di
esecuzione del programma associato a un processo; comprende almeno– Program Counter e registri CPU (non tutti)– uno stack (e uno Stack Pointer)
● Un thread condivide con i thread suoi pari (peer thread)– sezione testo– sezione dati– risorse del S.O.
(N.B. peer = "di pari livello").● Un processo tradizionale (processo pesante, heavyweight process)
equivale a un task con soltanto un thread.● I thread sono una soluzione elegante al problema di minimizzare
l'overhead dello scheduler (context switch).

1.5.22
Thread (Cont.)● Esempi d'uso:
– In un server a più thread, un thread principale è bloccato in attesa di connessioni da client, mentre altri thread possono eseguirsi.
– In applicazioni che richiedono un buffer comune (es. produttore consumatore), l'uso di più thread velocizza il programma.
– In un sistema WYSIWIG di trattamento di testo, dopo l'inserzione di un paragrafo, un thread può provvedere a riformattare tutto il testo, mentre un altro thread è pronto immediatamente ad accettare nuovi comandi dall'utente.
● Thread a livello Kernel: supportate direttamente nel kernel, con chiamate di sistema specifiche (Mach, OS/2, Linux).
● Thread a livello utente: implementate con un set di chiamate a routine di libreria che lavorano a livello utente (libreria Pthread, POSIX.1c).
● Pro e contro:– Uno ULT (Userlevel thread) è più veloce da commutare, e più leggero
– Tutti i peer ULT sono visti come un processo unico dal kernel, quindi lo scheduler potrebbe penalizzarli
– Una chiamata bloccante blocca tutto un processo, quindi tutti i suoi ULT.

1.5.23
Scheduling di Processi● Promemoria: scheduling = trovare un ordinamento ottimale di certe
operazioni di un dato tipo, secondo alcune metriche prestazionali.
– Operazione fondamentale in molte parti di un S.O.
– Quasi tutte le risorse hardware di un calcolatore sono sottoposte a scheduling prima dell'uso (CPU, dischi, etc.).
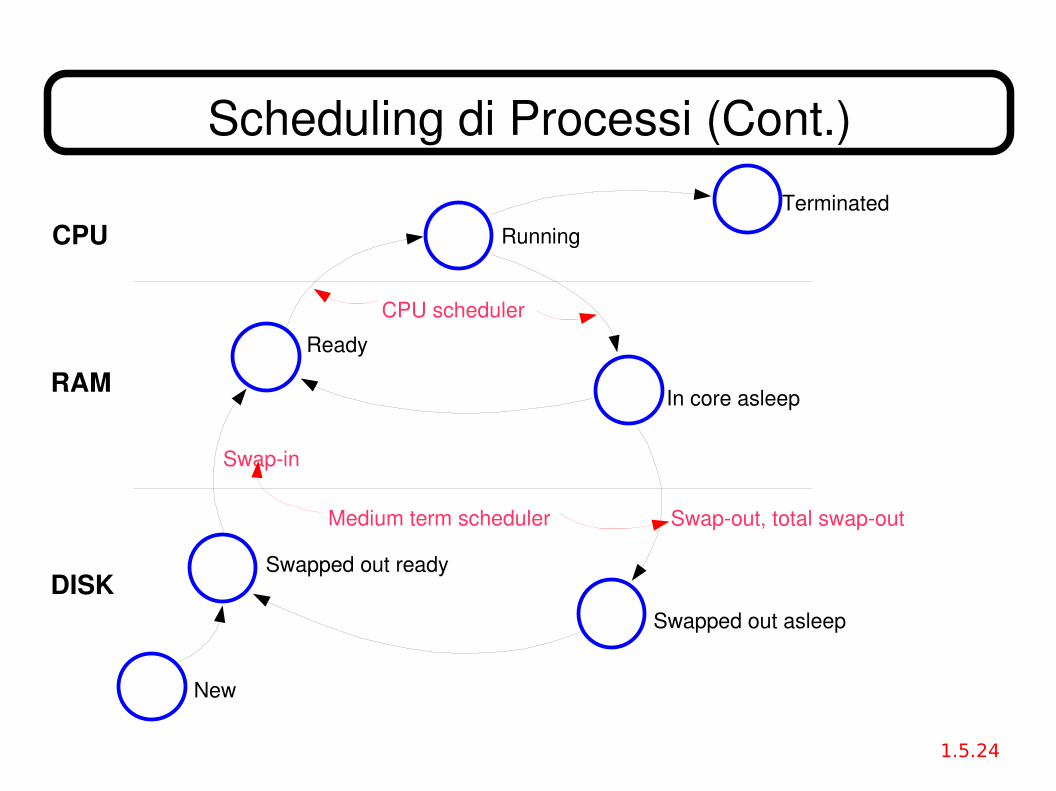
● Scheduler a lungo termine (o job scheduler) tipico dei sistemi batch. Seleziona quali processi inserire nella ready queue e li carica in RAM.
● Scheduler a breve termine (o scheduler della CPU) seleziona qual'è il prossimo processo da eseguire, e gli alloca la CPU.
● Sistemi timesharing: lo scheduling a lungo termine è assente; sostituito da uno job scheduler a medio termine, che si occupa dello swapping dei task tra la RAM e il disco (zona di swap).
– Verrà esaminato in seguito.
– Swapping parziale, pagina per pagina (paginazione)
– Swapping totale di tutto il processo (total swapout), se ci sono troppi processi in esecuzione e la RAM è insufficiente.
1.5.24
Scheduling di Processi (Cont.)
Running
Ready
In core asleep
Swapped out ready
Swapped out asleep
New
TerminatedCPU
RAM
DISK
CPU scheduler
Swapin
Swapout, total swapoutMedium term scheduler

1.5.25
Scheduling di Processi (Cont.)● Scheduler a breve termine: chiamato molto di frequente
(millisecondi) ⇒ deve essere veloce.
● Scheduler a mediolungo termine: chiamato di rado (secondi; minuti) ⇒ può essere lento.
● Lo scheduler a medio/lungo termine controlla il grado di multiprogrammazione, cioè il numero di processi concorrentemente in memoria.

1.5.26
Cicli di Uso della CPU● I processi possono essere caratterizzati come:
– Processi I/Obound passano più tempo in attesa di operazioni di I/O che in fasi di calcolo; molti burst di CPU, brevi.
– Processi CPUbound passano la maggior parte del tempo in fasi di calcolo; pochi burst di CPU, lunghi.
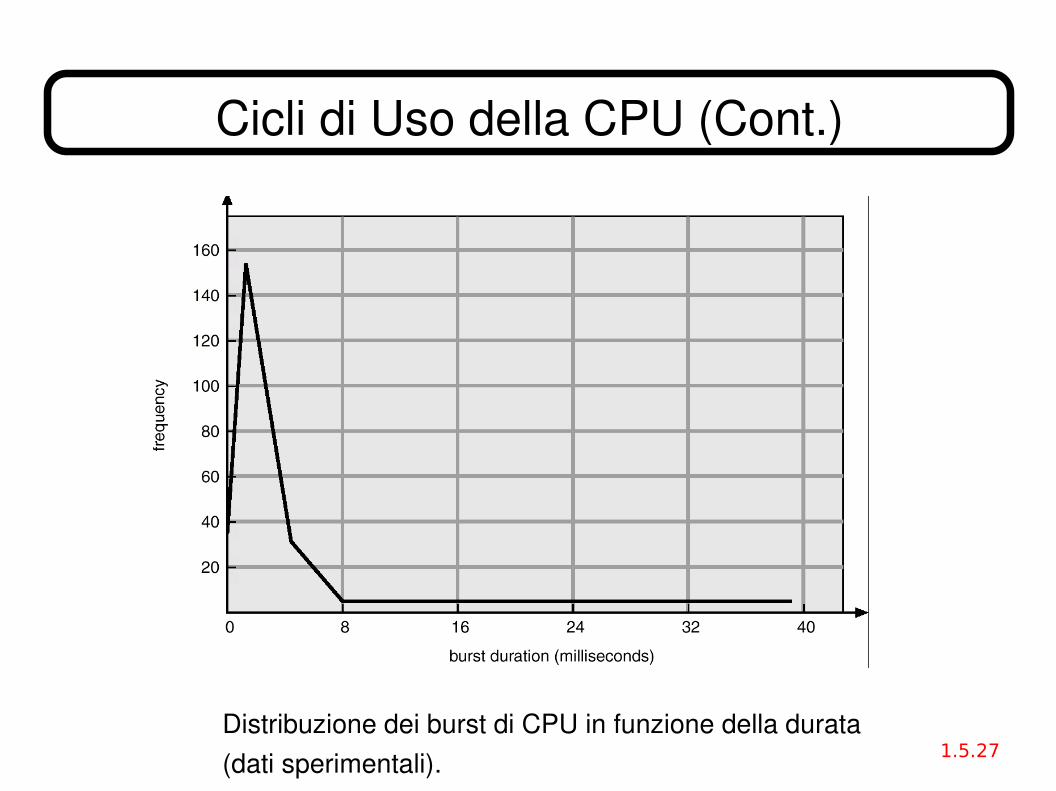
● Tutti i processi (senza eccezione) alternano continuamente l'esecuzione di cicli di CPU con cicli di attesa di I/O (istruzioni eseguite, per conto del processo, da un processore periferico) ⇒ CPUI/O burst cycle.
● I burst di CPU tendono ad avere una distribuzione statistica ben delineata, con decadimento esponenziale o iperesponenziale.
1.5.27
Cicli di Uso della CPU (Cont.)
Distribuzione dei burst di CPU in funzione della durata(dati sperimentali).

1.5.28
Scheduling della CPU● Scheduler della CPU (scheduler a breve termine): seleziona qual'è il
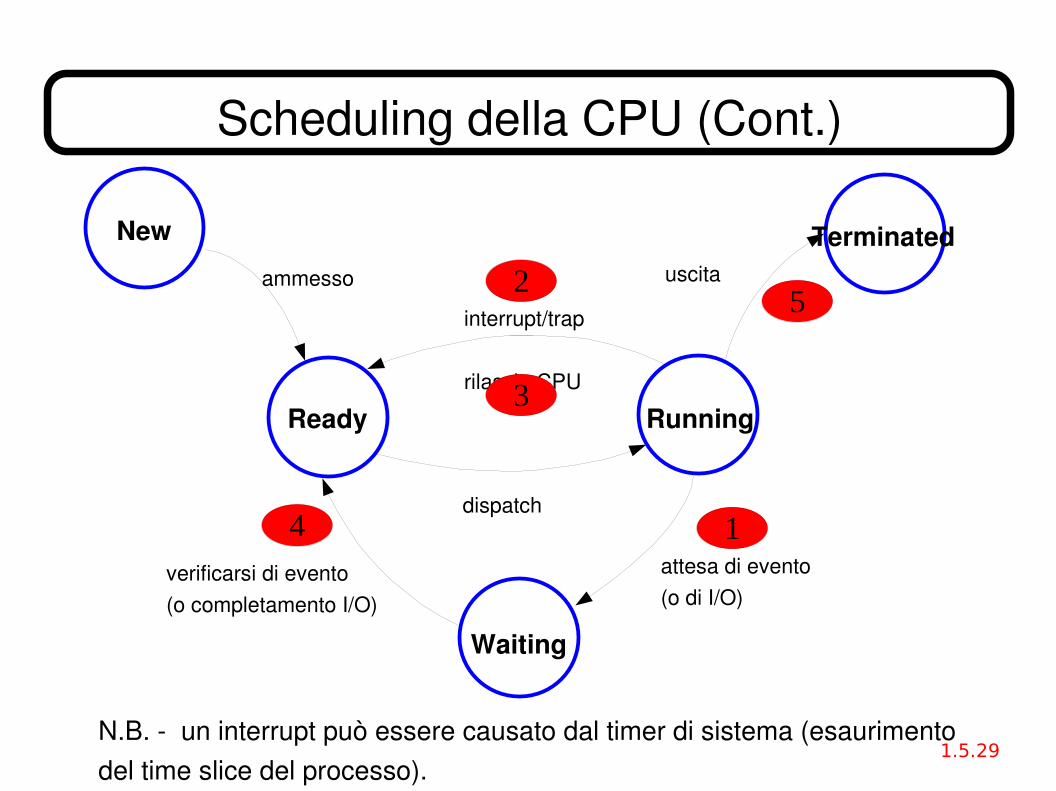
prossimo processo da eseguire, e gli alloca la CPU.● Le decisioni di scheduling possono aver luogo quando un processo:
1. Passa da stato Running a Waiting
2. Passa da Running a Ready per un interrupt o un trap
3. Passa da Running a Ready perchè rilascia volontariamente la CPU
4. Passa da Waiting a Ready
5. Termina.● Uno scheduler che prende decisioni solo nei casi 1, 3 e 5 è senza
prelazione (nonpreemptive) (una decisione deve comunque essere presa).
● Ogni altro tipo di scheduler è con prelazione (preemptive).
1.5.29
Scheduling della CPU (Cont.)
New
Ready
Terminated
Running
Waiting
ammesso uscita
interrupt/trap rilascio CPU
dispatch
attesa di evento(o di I/O)
verificarsi di evento(o completamento I/O)
N.B. un interrupt può essere causato dal timer di sistema (esaurimentodel time slice del processo).
14
5
3
2

1.5.30
Scheduling della CPU (Cont.)● Lo scheduling senza prelazione è molto più semplice, e non necessita
di particolare supporto hardware, ma è meno efficiente.● Lo scheduling con prelazione è in grado di intervenire "d'autorità" in
qualunque circostanza, e pertanto di proteggere la risorsa "CPU" dall'uso indiscriminato di un singolo processo.
● Lo scheduling senza prelazione deve far affidamento sulla "cooperatività" di tutti i processi per funzionare correttamente; per questo può essere adatto a sistemi di tipo personale (PC), ma è inadeguato per un sistema multiutente timesharing.

1.5.31
Criteri di Scheduling● Influenzano la scelta dello specifico algoritmo di scheduling che si vuole
adottare.
● Dipendono ovviamente dalle specifiche metriche prestazionali di interesse:
– Utilizzo CPU mantenere la CPU più occupata possibile (MAX)
– Throughput del sistema numero di processi che completano l'esecuzione nell'unità di tempo (MAX)
– Tempo di turnaround tempo necessario per eseguire un particolare processo (dall'avvio del processo alla sua terminazione) (MIN)
– Tempo d'attesa tempo che un processo ha speso nella ready queue (MIN)● L'algoritmo di scheduling non influenza il tempo impiegato per eseguire il
programma, ma il tempo perso in attesa della CPU.– Tempo di risposta intervallo di tempo tra l'invio di una richiesta al programma
e l'inizio della risposta (per ambienti interattivi); definibile anche come il tempo speso nella ready queue fino alla prima transizione in stato Running (MIN).
● Di solito si considerano valori medi; talvolta, valori minimi o massimi, o ancora la varianza: puntare sulla prevedibilità delle prestazioni.

1.5.32
Scheduling FCFS● Scheduling FCFS = First Come, First Served esempio per valutazione
prestazioni:
Processo Burst Time (msec)
P1 24
P2 3
P3 3
● Ordine di arrivo: P1, P2, P3
● Tempo d'attesa: P1 = 0; P2 = 24; P3 = 27
● Tempo medio d'attesa: (0 + 24 + 27)/3 = 51/3 = 17 msec
P1 P2 P3
24 27 300

1.5.33
Scheduling FCFS (Cont.)● Ordine di arrivo: P2, P3, P1
● Tempo d'attesa: P1 = 6; P2 = 0; P3 = 3● Tempo medio d'attesa: (6 + 0 + 3)/3 = 9/3 = 3 msec● Molto meglio del primo caso.● Effetto convoglio (convoy effect): molti processi brevi che aspettano
dietro a un processo lungo.● FCFS è senza prelazione, quindi inadeguato per il timesharing.
P1
0 3 6 30
P1P2 P3

1.5.34
Scheduling SJF● Scheduling SJF = Shortest Job First; detto anche SJN (Shortest Job
Next). Si associa ad ogni processo la lunghezza del suo prossimo burst di CPU; si seleziona il processo con la minima lunghezza.
● Due varianti:– SJF senza prelazione una volta data la CPU a un processo, questo non
può essere prelazionato fino al completamento del suo burst di CPU.– SJF con prelazione se si presenta un nuovo processo con burst di CPU
inferiore al tempo rimanente per il processo in esecuzione, questo viene prelazionato. Schema detto ShortestRemainingTimeFirst (SRTF).
● SJF è ottimale: fornisce il minimo tempo medio di attesa possibile per un dato insieme di processi.
● Unico problema: occorre predire il futuro...– Inadeguato (a meno di approssimazioni) per scheduling a breve termine– Usato spesso per scheduling a lungo termine in sistemi batch, basandolo
sul limite di tempo del processo, che viene specificato alla sottomissione dei job.
– Usato per confronto altri algoritmi (limite teorico ottimale).– Approssimazione: stimare la lunghezza del prossimo burst (media
esponenziale).

1.5.35
Scheduling SJF senza prelazione● Esempio per valutazione prestazioni:
Processo Tempo di arrivo Burst Time
P1 0 7
P2 2 4
P3 4 1
P4 5 4● SJF (senza prelazione):
● Tempo medio di attesa: [0 + (82) + (74) + (125)] / 4 = P1 P2 P3 P4
= (0 + 6 + 3 + 7) / 4 = 16/4 = 4 msec
0 7 8 12 16
P1 P2 P3 P4
P4P1 P3P2
Tempi di arrivo

1.5.36
Scheduling SJF con prelazione● Stesso esempio:
Processo Tempo di arrivo Burst Time
P1 0 7
P2 2 4
P3 4 1
P4 5 4● SJF (con prelazione):
● Tempo medio di attesa: [(0 + 112) + (0 + 54) + 0 + (75)] / 4 = (9 + 1 + 0 +2)/4 = 12/4 = 3 msec
Prestazioni migliori dello SJF senza prelazione.
0 2 4 5 7 11 16
P1 P2 P3 P4
P1P4
Tempi di arrivo
P1 P2 P3 P2

1.5.37
Scheduling con Priorità● Scheduling con priorità (priority scheduling): si associa ad ogni processo una
priorità (un intero), che dovrà variare dinamicamente– Di solito, intero più piccolo = priorità massima.
● La CPU è data ogni volta al processo più prioritario– Senza prelazione– Con prelazione.
● SJF è uno scheduling con priorità: la priorità è la lunghezza (stimata) del prossimo burst di CPU.
● Problema (generale): starvation (blocco indefinito) processi a bassa priorità potrebbero non essere mai eseguiti.– To starve = morire di fame
● Soluzione: tecnica dell' invecchiamento (aging) al passare del tempo, aumentare la priorità dei processi in attesa.– Soluzione pratica molto diffusa negli scheduler timesharing: priorità = f( TCPU / Teff )
TCPU = tempo CPU usato Teff = tempo effettivo trascorso● Effetto collaterale benefico: privilegiare i processi che richiedono poco tempo di
CPU (processi interatttivi) (basso tempo di risposta), pur garantendo l'avanzamento dei processi CPUbound.

1.5.38
Scheduling RR● Scheduling RR = Round Robin adatto in particolare per sistemi real
time (hard o soft), o anche per sistemi timesharing.
● Viene data ad ogni processo una piccola quantità di tempo CPU (quanto di tempo time quantum, o timeslice). Dopo questo tempo, il processo è prelazionato e aggiunto in coda alla ready queue (che lavora come una coda circolare).
● Se ci sono n processi nella ready queue, e il timeslice è q, ogni processo ottiene 1/n del tempo CPU, in frazioni lunghe al massimo q unità di tempo alla volta. Nessun processo aspetta più di (n1)q unità di tempo.
● Prestazioni:– q grande ⇒ FIFO (FCFS)– q piccolo ⇒ noto come processor sharing (condivisione di processore).– N.B. q deve essere grande rispetto al context switch, altrimenti l'overhead
è troppo alto (se il c.s. = 10% di q, ~10% del tempo CPU è sprecato)● Regola pratica: l'80% dei burst di CPU devono essere minori del time
quantum.

1.5.39
Scheduling RR (Cont.)● Esempio per valutazione prestazioni:
Processo Burst Time
P1 180
P2 60
P3 240
P4 130
P5 40
● SJF:
● Tempo medio di attesa: (230 + 40 + 410 + 100 + 0)/5 = 156 msec.
● Tempo medio di risposta: 156 msec.
P5 P2 P4 P1 P3
0 40 100 230 410 650
Si assume che tutti i processi siano arrivati contemporaneamente nellaready queue, nell'ordine indicato, e chenessun altro processo arrivi nel frattempo.

1.5.40
Scheduling RR (Cont.)● RR, con timeslice = 70 msec.:
● Tempo medio di attesa: (370 + 70 + 410 + 380 + 270)/5 = 300 msec.
● Tempo medio di risposta: (0 + 70 + 130 + 200 + 270)/5 = 134 msec.
● Tipicamente con RR si ottengono tempi di attesa (e quindi, a parità di programmi, tempi di turnaround) più alti di SJF, ma tempi di risposta molto migliori
– N.B. al diminuire del timeslice, il tempo medio di attesa cambia ma rimane pressochè invariato, mentre diminuisce sensibilmente il tempo di risposta; nell'esempio visto, con timeslice = 40 msec. si ha un tempo medio di risposta pari a 80 msec.
0 70 130 200 270 310 380 450 510 550 620 650
P1 P2 P3 P4 P5 P1 P3 P4 P1 P3 P3
Durata del timeslice 70 60 70 70 40 70 70 60 40 70 30

1.5.41
Contesti particolari● Sistemi multiCPU:
– Algoritmi più complessi
– Due categorie:● Multiprocessing simmetrico (un'unica ready queue; load sharing)● Multiprocessing asimmetrico (una sola CPU accede alle strutture dati
del kernel; condivisione di dati più semplice non ci sono conflitti).● Sistemi realtime:
– Hard realtime: task critici hanno limiti massimi di tempo di risposta● Non si può usare paginazione di memoria né dischi (tempi di
esecuzione hanno variazioni imprevedibili)● Quindi, solo software special purpose su hardware dedicato.
– Soft realtime: task critici hanno stabilmente maggior priorità degli altri● Possono essere compatibili con sistemi timesharing classici (es.
sistema generalpurpose con supporto multimedia)● Requisiti:
– Scheduling con priorità Bassa latenza di dispatch.

1.5.42
Latenza di Dispatch● Latenza di dispatch: tempo tra il verificarsi di un evento e il suo
trattamento.
– Parametro fondamentale per i sistemi interattivi e (soprattutto) realtime
– Influenza direttamente il tempo di risposta.
● Problema: per assicurare la consistenza di strutture dati, i Kernel (incluso molte implementazioni di Unix) permettono un context switch solo:
– Al completamento di una chiamata di sistema (cioè: le chiamate di sistema non sono prelazionabili)
– Quando c'è un blocco per attesa di I/O
In questi casi, la latenza di dispatch è inevitabilmente lunga.● Soluzioni:
– Inserire punti di prelazionabilità nel codice di chiamate di sistema complesse o lente (in punti "sicuri" per le strutture dati)
– Rendere tutto il kernel prelazionabile, aggiungendo meccanismi di sincronizzazione (mutex).

1.5.43
Latenza di Dispatch (Cont.)● Solaris2 ha un fullypreemptible kernel (kernel totalmente
prelazionabile); effetti sulla latenza di dispatch:
– Oltre 100 msec. con la prelazionabilità disabilitata
– 2 msec. con la prelazionabilità abilitata.
● Linux ha iniziato ad introdurre meccanismi per la prelazionabilità del kernel a partire dalla versione 2.0; la versione 2.4 ha un kernel quasi totalmente prelazionabile.
– Meccanismi:● Semafori di kernel● Spinlock (per SMP).
– Non sono disponibili misure esatte sulle prestazioni.

1.5.44
Latenza di Dispatch (Cont.)
Fase dei conflitti nel dispatching:● Prelazione dei processi eventualmente attivi nel kernel● Rilascio di risorse da parte di processi a bassa priorità, richieste da un processo a priorità maggiore.


















