
VIII Convegno Internazionale sui Metodi Quantitativi per ... · precedente panel europeo sulle...
26
VIII Convegno Internazionale sui Metodi Quantitativi per le Scienze Applicate Dipartimento di Metodi Quantitativi Università degli Studi di Siena Nuove metodologie di stima nell’indagine Istat su reddito e condizioni di vita: problemi aperti e prospettive Claudio Ceccarelli e Andrea Cutillo Istituto Nazionale di Statistica Versione preliminare Da non citare Certosa di Pontignano 11 –13 Settembre 2006
Transcript of VIII Convegno Internazionale sui Metodi Quantitativi per ... · precedente panel europeo sulle...

VIII Convegno Internazionale sui Metodi Quantitativi per le Scienze Applicate
Dipartimento di Metodi Quantitativi Università degli Studi di Siena
Nuove metodologie di stima nell’indagine Istat su reddito e condizioni di vita: problemi aperti e prospettive
Claudio Ceccarelli e Andrea Cutillo Istituto Nazionale di Statistica
Versione preliminare Da non citare
Certosa di Pontignano 11 –13 Settembre 2006

1 Premessa Il regolamento dell’Unione Europea n° 1177/2003 definisce gli elementi fondamentali del progetto EU-SILC (European Statistics on Income and Living Conditions) che, sostituendo il precedente panel europeo sulle famiglie (ECHP), è nato per rispondere alla sempre più crescente domanda di indicatori su povertà, esclusione sociale, distribuzione del reddito e, più in generale, sulla qualità della vita delle famiglie dell’ Unione Europea. La nuova indagine su redditi e condizioni di vita delle famiglie è la fonte informativa che l’Istat utilizza, a partire dal 2004, per produrre gli indicatori necessari per la partecipazione al progetto EU-SILC. L’indagine, grazie a definizioni e metodi armonizzati, produce dati comparabili con quelli raccolti dagli altri paesi dell’Unione Europea. Per soddisfare le esigenze informative a livello comunitario, è stato progettato un disegno di indagine tale da consentire la produzione di due tipologie di stime annuali: cross-section in grado fornire annualmente, per ogni paese membro, indicatori di povertà, distribuzione del reddito e altri aspetti delle condizioni di vita delle famiglie; longitudinali al fine di individuare le dinamiche delle condizioni di vita degli individui che vengono seguiti per quattro anni. La componente longitudinale di EU-SILC, quindi, consente l’analisi dei cambiamenti nel tempo a livello individuale, come ad esempio le transizioni dall’istruzione al lavoro o dal lavoro alla pensione, oppure i flussi di entrata e di uscita nelle diverse attività economiche e, principalmente, i cambiamenti nei livelli di reddito e l’entrata o l’uscita dalla condizione di povertà. Le norme e le direttive principali che regolano, oltre al campionamento, l’inseguimento degli individui e le definizioni da applicare alle statistiche EU-SILC vengono stabilite nei Regolamenti Comunitari (CE) n. 1177/2003 e n. 1982/2003 della Commissione Europea. 2 Definizioni 2.1 La popolazione di riferimento e l’unità di rilevazione La popolazione di riferimento è costituita da tutti i componenti delle famiglie residenti in Italia, anche se temporaneamente all'estero. Sono escluse le famiglie residenti in Italia che vivono abitualmente all’estero e i membri permanenti delle convivenze istituzionali (ospizi, brefotrofi, istituti religiosi, caserme, ecc.). L'unità di rilevazione è la famiglia di fatto. Questa va intesa come un insieme di persone legate da vincoli di matrimonio, parentela, affinità, adozione, tutela o da vincoli affettivi, coabitanti ed aventi dimora abituale nello stesso comune (anche se non residenti secondo l’anagrafe nello stesso domicilio)1. Tutti gli individui appartenenti alle famiglie campione debbono essere intervistati a patto che abbiano compiuto 15 anni nell’anno di riferimento del reddito, ovvero l’anno solare precedente a quello dell’intervista2. Ogni individuo che appartiene alla famiglia campione intervistato nella prima wave diviene individuo campione e va intervistato anche nelle wave successive a meno che, nel frattempo, sia deceduto o si sia trasferito all’estero. La definizione di famiglia longitudinale deriva direttamente da quella di individuo campione. Da un punto di vista formale, l’unità di rilevazione appena definita si riferisce alla famiglia al tempo t1, cioè alla prima wave dell’indagine longitudinale. Dalla seconda wave in poi (da t2 a t4), le famiglie
1 Nel caso dell’indagine EU-SILC, il personale di servizio o alla pari e le persone che abitualmente non vivono più nella famiglia ma ne hanno fatto parte per almeno 3 mesi nell’anno di riferimento del reddito vanno incluse nella rilevazione (fornendo soltanto le informazioni richieste nel registro familiare) ma non divengono individui campione e quindi non dovranno poi essere seguiti per gli altri anni del processo longitudinale. Gli ospiti sono comunque esclusi dalla rilevazione. 2 In realtà Eurostat chiede di intervistare tutti gli individui che nell’anno di riferimento del reddito abbiano compiuto 16 anni. L’Italia ha scelto di intervistare anche i quindicenni per uniformare le definizioni a quelle di altre indagini, come la Rilevazione sulle Forze di Lavoro, in modo da poter confrontare e integrare il patrimonio informativo di tutte le fonti disponibili.
1

campione sono quelle composte da almeno un individuo campione. Dalla seconda wave in poi, tutti i componenti, a qualsiasi titolo, che si aggiungono alla famiglia campione sono considerati individui coabitanti. Tali individui continuano ad essere intervistati nelle wave successive solo se restano “agganciati” ad un individuo campione. 2.2 Periodicità e riferimento temporale L'indagine viene svolta annualmente, in un periodo successivo alle dichiarazioni dei redditi in modo da dare la possibilità alle famiglie e agli individui di poter utilizzare le informazioni derivanti dalle proprie dichiarazioni fiscali. Le notizie acquisite fanno riferimento a due periodi distinti: alcune alla data di indagine (anno t) e altre, principalmente quelle sul reddito, all’anno precedente (t-1). I riferimenti temporali delle notizie raccolte sono: il periodo dell’intervista (anno t). A questo vanno ricondotte le informazioni familiari e individuali che caratterizzano la condizione di vita attuali (come ad esempio, le caratteristiche dell’ abitazione, il possesso dei beni durevoli, le condizioni di salute degli individui, l’istruzione, l’attuale condizione lavorativa, ecc.). Gli ultimi dodici mesi. A questi vanno ricondotte, ad esempio, le principali spese per l’abitazione. Nell’anno t-1. A questo vanno ricondotte tutte le informazioni familiari ed individuali che caratterizzano la situazione economica della famiglia e degli individui (come ad esempio i mutui e i prestiti, i redditi, ecc.). 2.3 Gli elementi caratteristici del disegno di campionamento La progettazione del disegno di campionamento passa per l’analisi dei principali obiettivi conoscitivi dell’indagine. L’indagine fornisce sia dati trasversali su reddito, povertà e esclusione sociale e condizioni di vita, sia dati longitudinali su reddito, lavoro e su alcuni indicatori non-monetari di esclusione sociale. In particolare, per rispondere ai requisiti di EU-SILC i principali parametri da stimare sono: la percentuale di individui poveri e il reddito medio annuo familiare netto, per la componente cross-section; la variazione della percentuale di famiglie povere e del reddito familiare medio e la percentuale di famiglie che permangono nello stato di povertà per due o più occasioni di indagine, per la componente longitudinale. I domini di studio pianificati, ossia gli ambiti rispetto ai quali sono calcolati i parametri relativi alla popolazione di riferimento, sono: l’intero territorio nazionale, le cinque ripartizioni territoriali, le regioni (eccezion fatta per il Trentino-Alto Adige per il quale le province di Trento e Bolzano sono trattate separatamente). L’indagine è basata su 4 campioni longitudinali. Tali campioni sono sfasati nel tempo in modo che in ogni wave ci sia la chiusura del panel che arriva alla quarta wave e l’inizio di un nuovo panel. Ogni campione longitudinale è a due stadi con stratificazione delle unità di primo stadio, i comuni, mentre le unità di secondo stadio sono le famiglie estratte dalle anagrafi dei comuni campione. La stratificazione delle unità di primo stadio, effettuata a livello regionale, è basata sulla dimensione demografica dei comuni e determina la suddivisione del territorio nazionale in 288 strati. All’interno di ciascuna regione sono presenti tre tipologie di strato:
- gli strati AR (autorappresentativi), dove è presente un solo comune che entra quindi automaticamente in tutte e quattro i campioni longitudinali;
- gli strati NAR (non autorappresentativi) del primo tipo, che raggruppano pochi comuni di grandi dimensioni; da ognuno di questi strati sono estratti due comuni campione, ognuno dei quali è presente in due dei quattro campioni longitudinali3;
3 All’interno di ogni strato NAR del primo tipo, ognuno dei due comuni estratti ha due campioni longitudinali. Ad esempio, nel 2004, il primo comune ha avuto i campioni C1 e C3 mentre l’altro i campioni C2 e C4; nel 2005, il primo comune ha avuto i campioni C3 e C5 mentre il secondo sempre i campioni C2 e C4.
2
- gli strati NAR del secondo tipo, che raggruppano i comuni di minore dimensione demografica; da ogni strato di questo tipo sono estratti quattro comuni campione, ognuno dei quali è presente in un solo campione longitudinale.
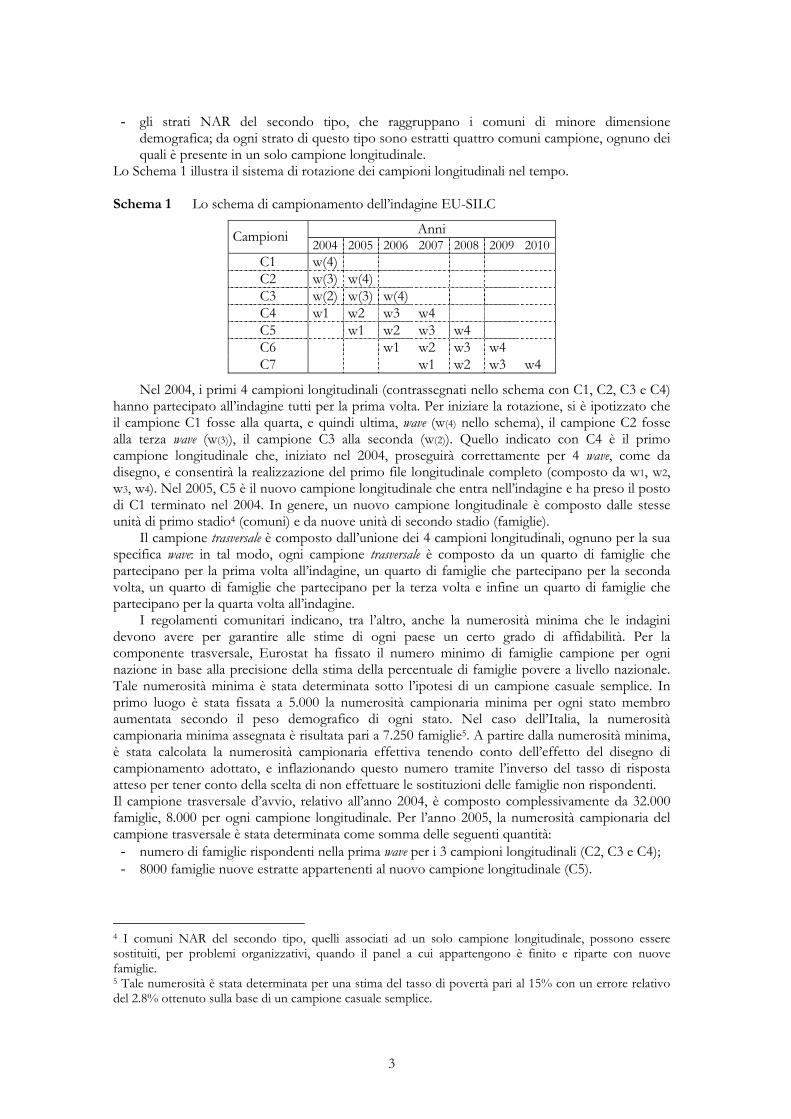
Lo Schema 1 illustra il sistema di rotazione dei campioni longitudinali nel tempo. Schema 1 Lo schema di campionamento dell’indagine EU-SILC
Anni Campioni 2004 2005 2006 2007 2008 2009 2010C1 w(4) C2 w(3) w(4) C3 w(2) w(3) w(4) C4 w1 w2 w3 w4 C5 w1 w2 w3 w4 C6 w1 w2 w3 w4 C7 w1 w2 w3 w4
Nel 2004, i primi 4 campioni longitudinali (contrassegnati nello schema con C1, C2, C3 e C4) hanno partecipato all’indagine tutti per la prima volta. Per iniziare la rotazione, si è ipotizzato che il campione C1 fosse alla quarta, e quindi ultima, wave (w(4) nello schema), il campione C2 fosse alla terza wave (w(3)), il campione C3 alla seconda (w(2)). Quello indicato con C4 è il primo campione longitudinale che, iniziato nel 2004, proseguirà correttamente per 4 wave, come da disegno, e consentirà la realizzazione del primo file longitudinale completo (composto da w1, w2, w3, w4). Nel 2005, C5 è il nuovo campione longitudinale che entra nell’indagine e ha preso il posto di C1 terminato nel 2004. In genere, un nuovo campione longitudinale è composto dalle stesse unità di primo stadio4 (comuni) e da nuove unità di secondo stadio (famiglie).
Il campione trasversale è composto dall’unione dei 4 campioni longitudinali, ognuno per la sua specifica wave: in tal modo, ogni campione trasversale è composto da un quarto di famiglie che partecipano per la prima volta all’indagine, un quarto di famiglie che partecipano per la seconda volta, un quarto di famiglie che partecipano per la terza volta e infine un quarto di famiglie che partecipano per la quarta volta all’indagine. I regolamenti comunitari indicano, tra l’altro, anche la numerosità minima che le indagini devono avere per garantire alle stime di ogni paese un certo grado di affidabilità. Per la componente trasversale, Eurostat ha fissato il numero minimo di famiglie campione per ogni nazione in base alla precisione della stima della percentuale di famiglie povere a livello nazionale. Tale numerosità minima è stata determinata sotto l’ipotesi di un campione casuale semplice. In primo luogo è stata fissata a 5.000 la numerosità campionaria minima per ogni stato membro aumentata secondo il peso demografico di ogni stato. Nel caso dell’Italia, la numerosità campionaria minima assegnata è risultata pari a 7.250 famiglie5. A partire dalla numerosità minima, è stata calcolata la numerosità campionaria effettiva tenendo conto dell’effetto del disegno di campionamento adottato, e inflazionando questo numero tramite l’inverso del tasso di risposta atteso per tener conto della scelta di non effettuare le sostituzioni delle famiglie non rispondenti. Il campione trasversale d’avvio, relativo all’anno 2004, è composto complessivamente da 32.000 famiglie, 8.000 per ogni campione longitudinale. Per l’anno 2005, la numerosità campionaria del campione trasversale è stata determinata come somma delle seguenti quantità:
- numero di famiglie rispondenti nella prima wave per i 3 campioni longitudinali (C2, C3 e C4); - 8000 famiglie nuove estratte appartenenti al nuovo campione longitudinale (C5).
4 I comuni NAR del secondo tipo, quelli associati ad un solo campione longitudinale, possono essere sostituiti, per problemi organizzativi, quando il panel a cui appartengono è finito e riparte con nuove famiglie. 5 Tale numerosità è stata determinata per una stima del tasso di povertà pari al 15% con un errore relativo del 2.8% ottenuto sulla base di un campione casuale semplice.
3

3 La gestione del campione longitudinale e le regole di inseguimento L’indagine su reddito e condizioni di vita si avvale di un sistema informatizzato per la
gestione delle indagini sulle famiglie dell’Istat. Questo sistema, denominato SIGIF (SIstema per la Gestione delle Indagini sulle Famiglie), consente la gestione automatizzata delle fasi organizzative del processo: dall’invio delle circolari ai comuni per l’estrazione delle famiglie campione, alla determinazione del campione per la wave t+1 a partire dagli esiti delle interviste realizzate nella wave t.
L’utilizzo di un sistema informatizzato favorisce la riduzione degli effetti dovuti alla errata identificazione degli individui campione che vanno inseguiti ed intervistati per tutte le wave dell’indagine. Il problema delle chiavi identificative nasce quando le operazioni di rilevazione sul campo e la successiva digitazione su supporto magnetico possono alterare la chiave identificativa degli individui campione. In tal senso, oltre a un’accurata verifica della coincidenza delle chiavi tra i questionari e la lista degli individui campione, la procedura di acquisizione, realizzata in BLAISE, è tale da controllare le notizie contenute in SIGIF riferite agli individui campione già intervistati sin dalla fase di registrazione.
Sempre in SIGIF, grazie all’implementazione delle regole di inseguimento definite da Eurostat, è stato sviluppato un modulo ad hoc per la gestione delle interviste degli individui campione che si spostano dall’indirizzo in cui si trovavano in occasione della precedente intervista. In particolare, sono state acquisite dalle anagrafi dei comuni le informazione su eventuali trasferimenti degli individui campione tra una wave e l’altra, e tali informazioni sono state utilizzate per comunicare al rilevatore i cambiamenti di indirizzo non appena abbia verificato l’effettivo trasferimento degli individui campione. Si è scelto infatti di far tornare comunque il rilevatore all’indirizzo della wave precedente in modo da verificare l’effettivo trasferimento dell’individuo campione al nuovo indirizzo6 e da poter seguire spostamenti degli individui campione di fatto. L’individuo di fatto, che non risulta in anagrafe come appartenente alla famiglia campione, può essere seguito nei suoi spostamenti solo se si fa riferimento all’indirizzo di partenza. Nel caso di famiglie composte da due o più componenti, sono di fondamentale importanza le informazioni raccolte presso l’indirizzo originario, soprattutto nel caso in cui non tutti gli individui campione si sono spostati all’interno del territorio nazionale. Nel caso in cui già risulta uno spostamento in anagrafe di una intera famiglia campione, casi comunque sufficientemente rari, tornare all’indirizzo originario consente di verificare se al trasferimento anagrafico coincide anche il trasferimento effettivo della famiglia7. La metodologia adottata e il processo informatico che la gestisce garantiscono il controllo puntuale e in tempo reale della situazione degli spostamenti sul territorio degli individui e delle famiglie campione in modo da ridurre la componente di attrition dovuta alla difficoltà di inseguimento delle famiglie sul territorio.
Per quanto riguarda la riduzione dell’attrition dovuto alla volontà delle famiglie a collaborare, in fase di istruzione ai rilevatori è stata sottolineata con forza la differenza esistente tra nuove e vecchie famiglie campione e l’importanza di favorire un nuovo contatto con famiglie che già “hanno aperto la porta” ai rilevatori. In tal senso, i comuni sono stati invitati a utilizzare gli stessi rilevatori della wave precedente. Anche per quanto riguarda le famiglie alla prima intervista, è stato ribadito e sottolineato quanto sia importante, in indagini di tipo longitudinale, instaurare sin da subito un rapporto di fiducia tra rilevatore e famiglia campione.
6 Ogni rilevatore ha a disposizione tutte le informazioni della famiglia campione nel modello RIL: nel caso di nuove famiglie, le informazioni presenti sono di provenienza anagrafica; per le famiglie già intervistate sono presenti le notizie raccolte nella wave precedente e quindi anche quelle riferite ai componenti di fatto. 7 In molti casi al cambio di residenza non coincide il trasferimento effettivo della famiglia, ad esempio per motivi fiscali, o per la non immediata disponibilità della nuova abitazione, ecc.
4

4 Le stime trasversali L’indagine, nella sua componente trasversale, deve produrre sia le stime riferite al numero di
individui (o famiglie) che nella popolazione di riferimento possiedono una certa caratteristica, sia il livello di una quantità misurata sugli individui (o famiglie), come ad esempio il reddito. Per il calcolo dei coefficienti di riporto all’universo si utilizza una procedura generalizzata di stima, denominata Genesees, così come accade in tutte le indagini campionarie condotte dall’Istat. La procedura si basa sull’uso di una famiglia di stimatori, noti in letteratura come calibration estimator (stimatori di ponderazione vincolata). La metodologia alla base di tali stimatori consente la determinazione di un unico coefficiente di riporto all’universo in grado di produrre stime coerenti a totali noti, desunti da fonti esterne, sia per individui sia per famiglia assegnando, cioè, lo stesso coefficiente di riporto all’universo a tutti gli individui della stessa famiglia. La famiglia di stimatori di ponderazione vincolata coincide asintoticamente con lo stimatore di regressione generalizzato: per campioni sufficientemente grandi, quindi, tali stimatori hanno approssimativamente le stesse proprietà, ovvero sono corretti, consistenti e con la stessa varianza campionaria 8. La strategia adottata per la costruzione dei coefficienti di riporto all’universo si sviluppa attraverso le fasi tipiche utilizzate per la costruzione degli stimatori nelle varie indagini campionarie dell’Istituto. In particolare possiamo distinguere:
- la determinazione della probabilità di inclusione di ogni unità statistica e del relativo peso base;
- calcolo dei coefficienti di correzione per mancata risposta totale; - determinazione dei coefficienti di riporto all’universo finali vincolati ai totali noti desunti da
fonti esterne all’indagine. 4.1 La probabilità di inclusione e il peso base Il principio su cui è basato ogni metodo di stima campionaria è che le unità appartenenti al campione rappresentino anche le unità della popolazione di riferimento che non sono incluse nel campione stesso. A tale scopo, ad ogni unità campionaria viene attribuito un peso, o coefficiente di riporto all’universo, che indica quante unità della popolazione sono rappresentate, rispettivamente, da ogni unità presente nel campione. Senza perdere di generalità e per chiarire gli argomenti trattati, definiamo la seguente simbologia:
U popolazione di riferimento oggetto di indagine; yk valore della variabile Y assunto dalla k-esima osservazione della popolazione; πk probabilità, assegnata da un generico disegno di campionamento, che l’unità k-esima ha di essere inclusa nel campione s;
Il totale di una generica variabile Y, calcolato sull’intera popolazione, assume la seguente forma: ∑
∈=
UkkyY (1)
In linea teorica il disegno di campionamento assegna le probabilità di inclusione ad ogni unità del campione in modo tale che
∑∈
=sj jjyYπ1ˆ (2)
8 Il software, denominato Genesees, richiama la metodologia illustrata da Deville, J.C. e Särndal, C.E. in Calibration Estimation in Survey Sampling, Journal of the American Statistical Association, Vol. 87, n.418, 1992.
5

sia uno stimatore corretto della (1). Nel caso del campione di EU-SILC, come nel caso dei disegni di campionamento tradizionalmente utilizzati dall’Istat per le principali indagini su famiglie e individui, la probabilità di inclusione assume la seguente forma:
hi
hi
hi
hh
hi mM
PPn=
π1
(3)
dove :
h denota l’indice di strato; i è l’indice di comune; nh indica il numero di comuni campione dello strato h; Ph indica il totale della popolazione residente nello strato h; Phi il totale della popolazione residente nel comune i dello strato h; Mhi indica il totale di famiglie residenti nel comune i dello strato h; mhi indica il numero di famiglie campione nel comune i dello strato h.
In tal senso, ogni famiglia estratta da un certo comune campione si vede assegnata dal disegno di campionamento la medesima probabilità di inclusione9.
Pertanto la (2) può essere scritta come:
∑∑= =
=H
h
m
i hihi
hyY
1 1
1ˆπ
(4)
4.2 La correzione per mancata risposta Nel corso della fase di raccolta delle informazioni presso le famiglie che formano il campione, come accade per tutte le indagini statistiche, alcune di queste si trovano nell’impossibilità di partecipare all’indagini. Quando il meccanismo che genera la mancata partecipazione, e quindi la mancata risposta, è ignorabile si assume l’ipotesi che il comportamento dei rispondenti sia del tutto simile a quello dei non rispondenti con conseguente riduzione casuale della numerosità del campione teorico di partenza e riduzione della precisione delle stime prodotte. In tale circostanza, il correttore per mancata risposta assume la forma dell’inverso della probabilità di risposta (δhi):
rhi
hi
hi mm
=δ1
(5)
in cui m rappresenta il numero di famiglie rispondenti nel comune i dello strato h mentre il coefficiente di riporto all’universo corretto per mancata risposta risulta essere:
rhi
rhi
hi
hi
hhr
hi
hi
hi
hi
hi
hh
hihihi m
MPPn
mm
mM
PPnk ===
δπ11
(6)
9 Nel caso di EU-SILC, in ogni campione longitudinale, il numero di comuni campione in ogni strato è pari a 1. Inoltre, l’espressione (3) diventa 1/πhi= Mhi/mhi nel caso dei comuni AR che costituiscono uno strato a se.
6

Quando il meccanismo che genera la mancata risposta è non ignorabile, come nella maggior parte delle situazioni reali, l’ipotesi di uguaglianza di comportamento tra chi partecipa e chi non partecipa all’indagine viene meno ed è quindi necessario ricorrere ad altre ipotesi e strumenti in modo da poter ricondurre la problematica in un contesto di ignorabilità del meccanismo di mancata risposta. Per l’indagine EU-SILC si è pensato di adottare una strategia che ripercorre i criteri delle celle di ponderazione al fine di individuare delle sottopopolazioni dove è ipotizzabile una uguaglianza di comportamento di risposta tra coloro che hanno partecipato all’indagine e coloro che non hanno partecipato. La metodologia sottesa alle celle di ponderazione rientra nel novero della modellizzazione esplicita per la riduzione della distorsione della mancata risposta totale. In particolare, si determina la probabilità di risposta in funzione delle variabili che determinano le celle. In EU-SILC, utilizzando le informazioni da fonte anagrafica disponibili già in fase di estrazione del campione, è stata operata una suddivisione in celle omogenee secondo le variabili per le quali si è avuto un tasso di risposta differenziato. In particolare, per ognuno dei quattro campioni che compongono il campione complessivo trasversale, sono state utilizzate le seguenti informazioni:
- dimensione demografica del comune in classi (D, 5 modalità); - cittadinanza della persona di riferimento (T, 2 modalità); - regione di residenza (L, 21 modalità); - distribuzione delle famiglie per numero di componenti (C, 4 modalità) 10.
Sia Z la partizione delle famiglie campione composta dagli elementi (celle) generati dal prodotto cartesiano (D×T×L×C) delle modalità delle variabili considerate. Per ogni cella z della partizione Z è stata calcolata la probabilità di risposta (η) come rapporto tra il numero di famiglie rispondenti e il numero di famiglie desunto dal campione teorico. In simboli:
z
rz
z mm
=η (7)
L’inverso di η è il correttore per mancata risposta e ad ogni famiglia del comune i dello strato h, appartenente alla cella z viene moltiplicato il proprio peso base per tale correttore, pertanto il coefficiente di riporto all’universo corretto per mancata risposta totale diviene:
rz
z
hi
hi
hi
hh
zhizhi m
mmM
PPnk ==
ηπ11* (8)
Nel caso in cui in una cella z* si presenta una scarsa numerosità (≤13) di famiglie rispondenti e/o un elevato valore del correttore (1/η >2,4)11 allora si procede al collassamento delle celle nel modo seguente:
- si determina una nuova partizione Q generata dal prodotto cartesiano (D×T×L) delle modalità delle variabili considerate escluse quelle relative alla distribuzione delle famiglie per numero componenti;
- si individua la cella q (elemento della partizione Q) che contiene la cella z* (elemento di Z) e si calcola il rapporto ηq;
10 La difficoltà ad ottenere l’intervista è crescente al crescere dell’ampiezza demografica del comune di residenza e al diminuire del numero di componenti della famiglia perché spesso non si riesce proprio ad effettuare il contatto; le famiglie con persona di riferimento straniera hanno minori probabilità di partecipare all’indagine, in parte per l’alta mobilità degli stranieri sul territorio, in parte per le difficoltà o la diffidenza che possono avere persone di lingua e cultura differenti rispetto agli intervistatori. Si riscontrano inoltre notevoli differenze nella partecipazione all’indagine a seconda della regione di residenza. 11 L’evidenza empirica e le varie prove effettuate hanno contribuito a determinare tali limiti.
7

- si attribuisce il valore ηq a tutte le famiglie della cella z* (sempre che per la cella q siano soddisfatti i vincoli sopra descritti)12.
Nel caso del collassamento delle celle, il numero teorico delle famiglie campione non coincide con il numero dato come somma dei coefficienti per mancata risposta (1/ηz)13. Per tale motivo, per ognuno dei quattro campioni longitudinali, si procede a un riproporzionamento, di un fattore λ, dei coefficienti appena calcolati in modo che sia soddisfatta la seguente ugualianza:
∑∈
=Zz z
mη
λ 1 (9)
Il peso base corretto per mancata risposta assume, quindi, la seguente forma:
(10) λψ ⋅= *zhizhi k
mentre la stima del totale espressa dalla (4) diviene:
(11) ∑=
=rm
jjjyY
1
ˆ ψ
dove mr è il numero complessivo di famiglie rispondenti. Dal processo di validazione sono emerse, anche per EU-SILC, discrepanze, in alcuni casi accentuate, tra la stima di aggregati di interesse e i dati provenienti da altre fonti usati come riferimento nel processo di validazione. Tali differenze sono dovute verosimilmente al diverso comportamento di risposta in funzione del livello e della tipologia di reddito. Tale fenomeno, già riscontrato in altre indagini sui redditi come quella condotta dalla Banca d’Italia14, porta a possibili distorsioni nella stima degli aggregati e delle distribuzioni di interesse.
La soluzione adottata per la prima wave di EU-SILC, soluzione che possiamo definire transitoria, è stata quella di inserire un coefficiente di correzione ν calcolato utilizzando la metodologia degli stimatori di ponderazione vincolata e le informazioni desunte dalla Rilevazione Continua sulle Forze di Lavoro. L’utilizzo di tali stimatori per limitare gli effetti dovuti alla mancata risposta totale rappresenta un esempio di modellizzazione implicita del processo di mancata risposta. Nello specifico, l’informazione utilizzata è la condizione professionale della popolazione opportunamente riclassificata15 desunta dalla RCFL del IV trimestre 200416. I totali noti applicati, distinti per ognuno dei 4 campioni longitudinali che compongono il campione trasversale, sono:
12 Qualora il collassamento produca celle non utilizzabili, si procede ad una nuova operazione di collassamento togliendo prima la cittadinanza, poi le informazioni sulla dimensione demografica del comune. 13 La somma dei correttori per mancata risposta fornisce come risultato il numero teorico di unità campionarie; nel caso di E-USILC tale numero è pari a m per ognuno dei 4 campioni longitudinali. 14 Il Supplemento al Bollettino statistico della Banca d’Italia del Gennaio 2006, a pagina 35 recita: "…La difficoltà a ottenere l'intervista è crescente al crescere del reddito e del titolo di studio del capofamiglia; minori difficoltà si incontrano con le famiglie con un ridotto numero di componenti, con capofamiglia pensionato o residenti in comuni di piccole dimensioni…". 15 Le modalità della condizione professionale utilizzata in questo contesto sono: 1) dirigente, quadro e impiegato; 2) operaio e assimilati; 3) imprenditore e libero professionista; 4) lavoratori in proprio, soci di cooperative e coadiuvante nell’azienda di un familiare; 5) persone con contratto di collaborazione coordinata e continuativa e prestatori d’opera occasionali; 6) persone in cerca di occupazione, 7) inattivi.
8

- distribuzione delle famiglie per numero di componenti; - popolazione per sesso e classi d’età17; - popolazione per condizione professionale.
L’introduzione dei totali noti riferiti alla popolazione per sesso e classi d’età e alla distribuzione delle famiglie per numero componenti sono serviti per dare “stabilità” ai correttori in funzione sia della costruzione delle celle di ponderazione sia della “calibrazione” successiva che porta ai coefficienti di riporto all’universo finali18. Con riferimento alla (10), per ogni famiglia campione del comune i appartenente allo strato h e per ogni cella di ponderazione z elemento della partizione Z, il correttore completo per mancata risposta assume la seguente forma: (12) gzhizghi νψψ ×=*
dove l’indice g esprime la generica combinazione dei totali noti inseriti nel passo di calibrazione.
Merita un cenno di approfondimento il vincolo imposto sulle famiglie per numero componenti. Attualmente l’Istat non dispone di statistiche annuali provenienti da fonte anagrafica che riguardano la distribuzione delle famiglie per numero componenti. Eurostat, dal canto suo, ne suggerisce l’introduzione nel pacchetto dei di vincoli per la costruzione degli stimatori. Non avendo dati da fonte anagrafica, si è optato per l’inserimento della distribuzione delle famiglie per numero componenti, desunta sempre dalla RCFL (in conformità di quanto fatto per i dati sull’occupazione), in questo passo piuttosto che nel passo finale di calibrazione proprio per la natura del dato considerato e per la transitorietà della soluzione adottata. E’ infatti previsto un progetto, infatti, per il rilascio annuale dei dati da fonte anagrafica sulla distribuzione delle famiglie per numero componenti. 4.3 I totali noti e i coefficienti di riporto all’universo finali Per il calcolo dei coefficienti di riporto all’universo finali, come già evidenziato nel corso del lavoro, si adottano gli stimatori di ponderazione vincolata (calibration estimator) metodologia implementata in un software, denominato Genesees, utilizzato in numerose altre indagini dell’istituto. La metodologia si basa sull’utilizzo di opportune informazioni ausiliarie, sintetizzate in totali noti, che, correlate con le variabili principali oggetto di indagine, hanno la funzione di aumentare l’accuratezza delle stime. La scelta delle informazioni ausiliarie, inoltre, è anche legata alla disponibilità periodica di tali fonti: proprio per questo Eurostat suggerisce ma non impone l’utilizzo delle informazioni da utilizzare per la costruzione delle stime finali. In EU-SILC, come in ogni indagine armonizzata a livello di Unione Europea, la strategia di ponderazione è “guidata” al fine di garantire la comparabilità delle stime di ogni paese membro, oltre che per l’aumento dell’accuratezza delle stime. In particolare, il documento EU-SILC 134-rev/04 - Cross-sectional weighting: first year each sub-sample - suggerisce, tra l’altro, i totali noti da utilizzare per la costruzione dello stimatore di ponderazione vincolata.
Ognuno dei quattro campioni longitudinali è vincolato a: 16 Il riferimento al IV trimestre 2004 della RCFL, che coincide con il periodo di rilevazione dei dati di EU-SILC, è perché in EU-SILC la rilevazione dettagliata delle caratteristiche della condizione è riferita a tale periodo. 17 Le classi d’età utilizzate sono: 0-14, 15-24, 25-44, 45-64, 65 e più al netto delle convivenze istituzionali.. 18 In genere, quando si operano calibrazioni successive è necessario inserire in ogni passo dei vincoli altamente correlati con i vincoli dell’ultimo passo. Trattandosi di procedure indipendenti, infatti, c’è il rischio che ciò che si intende imporre in un generico passo di calibrazione venga sostanzialmente annullato nel passo successivo. Nel nostro caso si è preferito inserire la distribuzione per sesso e classe d’età (più ampie di quelle finali) in modo da “indirizzare” la calibrazione utilizzata per correggere la mancata risposta nella direzione dei vincoli finali che, nel caso di EU-SILC, hanno il solo obiettivo di aumentare l’accuratezza delle stime.
9

- popolazione residente19 per ripartizione territoriale, sesso e classi d’età (0-15, 16-19, 20-24, 25-29, 30-34, 35-39, 40-44, 45-49, 50-54, 55-59, 60-64, 65-69, 70-74, 75 e più) al 31 dicembre dell’anno di riferimento del reddito (anno t-1);
- il numero di famiglie residenti per regione riferite alla data di rilevazione (31 dicembre dell’anno t).
Per esigenze informative nazionali, le stime prodotte con il campione trasversale (la somma dei
4 campioni longitudinali) sono vincolate anche a: - popolazione residente per regione, sesso e classi d’età (0-14, 15-24, 25-44, 45-64, 65 e più) al
31 dicembre dell’anno di riferimento del reddito (anno t-1); - popolazione residente per ripartizione, sesso e classi d’età al 31 dicembre dell’anno di
rilevazione (anno t); - popolazione straniera maggiorenne residente per ripartizione e sesso al 31 dicembre dell’anno
di riferimento del reddito (anno t-1) ; - popolazione straniera maggiorenne residente per ripartizione e provenienza (UE e non UE)
31 dicembre dell’anno di riferimento del reddito (anno t-1). Il sistema di vincoli così congeniato offre la possibilità di fornire stime accurate anche a
livello regionale che sono di notevole interesse e soddisfano anche importanti esigenze informative interne.
In secondo luogo, il vincolo sulla popolazione all’anno t-1 (suggerito da Eurostat) non è sufficiente a controllare la stima del numero di nati tra l’anno di riferimento del reddito (t-1) e il momento dell’effettuazione dell’indagine (anno t). Infatti, calcolando l’età rispetto alla data di riferimento del reddito, questa può assumere valore pari a “-1” in corrispondenza di tutti coloro che sono nati dopo il 31 dicembre dell’anno t-1. L’inserimento del vincolo aggiuntivo della popolazione per sesso e classe d’età riferita al momento di rilevazione (anno t), garantisce anche una certo livello di accuratezza delle stime del numero di nati desumibili da EU-SILC. Anche se questa non è certamente la fonte ufficiale del numero di nati in un certo anno, l’informazione può essere utile per calcolare indicatori sulle condizioni socio-economiche di particolari sottoinsiemi di famiglie. 5 La valutazione della strategia di stima
Nell’indagine EU-SILC italiana, la strategia di ponderazione si basa sulla possibilità di essere variata in funzione del tipo di mancata risposta che ogni anno può verificarsi, senza per questo stravolgere la natura e la struttura della calibrazione finale. Quest’ultima deve infatti restare quanto più possibile invariata per consentire la comparabilità delle stime prodotte sia nel tempo che nei confronti degli altri paesi europei20. Nella wave del 2004 è stata utilizzata una correzione per mancata risposta tramite la metodologia delle celle di ponderazione. Questa, come vedremo in seguito, non ha apportato migliorie rispetto alla “tradizionale” correzione per strato tali da giustificarne l’utilizzo, probabilmente a causa della limitata disponibilità di informazioni sul campione estratto, tanto da rendere necessario un passo di calibrazione intermedio che tenesse conto di informazioni campionarie provenienti dall’indagine RCFL. Tuttavia, si sono comunque utilizzate le celle di ponderazione perché questa sarà la metodologia utilizzata dalla wave 2005, a partire dalla quale si potranno usare le informazioni collezionate nella wave precedente (per tre quarti del campione) e le informazioni da fonte fiscale21 (per tutti e quattro i campioni
19 Si intende al netto delle convivenze istituzionali. 20 A meno di possibili miglioramenti, quale ad esempio la disponibilità annuale da fonte anagrafica della distribuzione delle famiglie per numero di componenti. 21 E’ in avanzato stato lo studio dei dati fiscali, cosa che permetterà il linkage con il campione estratto con conseguente revisione della parte della strategia relativa ai correttori per mancata risposta. La disponibilità di
10
longitudinali) al fine di formare delle celle più caratterizzate rispetto al processo che determina la mancata risposta22. L’obiettivo è quello determinare una partizione “ottimale” del campione tale che in ogni cella si possa assumere la casualità del meccanismo che ha generato la mancata risposta. In questo senso, si può dire che la strategia adottata nella wave 2004 rappresenta una soluzione temporanea al problema della distorsione dovuta a differenti comportamenti di risposta.
E’ il caso di evidenziare che l’intero processo di correzione per mancata risposta ha riguardato separatamente i quattro campioni longitudinali (C1, C2, C3 e C4): anzitutto questi sono formalmente campioni indipendenti tra di loro; inoltre, si pone la questione della coerenza tra le stime cross-section relative ad un certo anno e le stime ottenute dai quattro campioni longitudinali, ognuno dei quali rappresenta lo stesso determinato anno del campione cross-section ma in quattro panel differenti: le stime ottenute dai quattro campioni devono essere quindi ragionevolmente coerenti tra di loro per essere una base di partenza per la determinazione dei coefficienti di riporto all’universo longitudinali. La sperimentazione per il calcolo di questi ultimi prevede infatti un passo di calibrazione che consente di ottenere la coerenza tra le stime prodotte con la prima wave del campione longitudinale e le stesse prodotte dall’intero campione cross-section riferito all’anno di ingresso nell’indagine del campione longitudinale in questione. Ad esempio, il campione C4 dell’indagine 2004, nella seconda wave del suo panel, al netto della mancata risposta totale, deve essere rappresentativo della popolazione iniziale al netto delle uscite da tale popolazione: nel calcolo dei coefficienti di riporto longitudinali, il primo passo di calibrazione serve a far convergere le stime ottenute dal campione C4 con le stime dei principali aggregati realizzate con campione cross-section del 2004 (che contiene C1, C2, C3 e C4). Il coefficiente di riporto all’universo finale del campione longitudinale si ottiene poi a partire dal peso precedentemente calcolato vincolando ai totali noti da fonte esterna secondo le indicazioni che suggerisce Eurostat23.
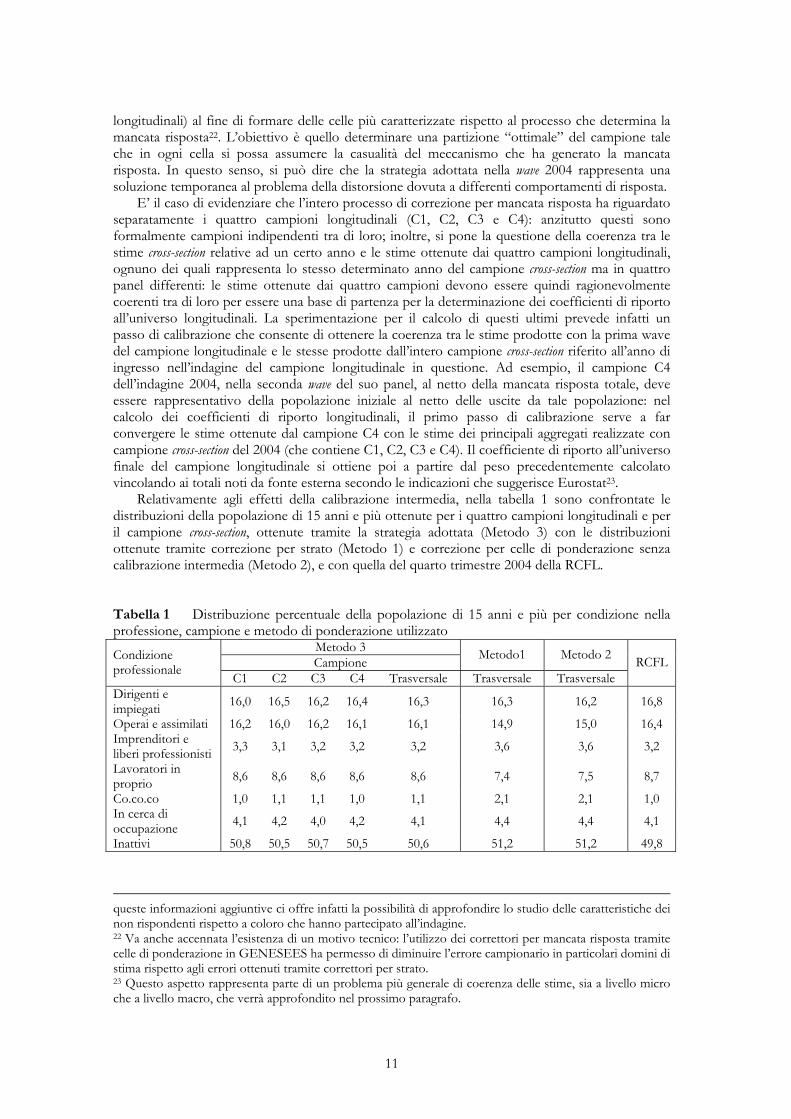
Relativamente agli effetti della calibrazione intermedia, nella tabella 1 sono confrontate le distribuzioni della popolazione di 15 anni e più ottenute per i quattro campioni longitudinali e per il campione cross-section, ottenute tramite la strategia adottata (Metodo 3) con le distribuzioni ottenute tramite correzione per strato (Metodo 1) e correzione per celle di ponderazione senza calibrazione intermedia (Metodo 2), e con quella del quarto trimestre 2004 della RCFL. Tabella 1 Distribuzione percentuale della popolazione di 15 anni e più per condizione nella professione, campione e metodo di ponderazione utilizzato
Metodo 3 Campione Metodo1 Metodo 2 Condizione
professionale C1 C2 C3 C4 Trasversale Trasversale Trasversale RCFL
Dirigenti e impiegati 16,0 16,5 16,2 16,4 16,3 16,3 16,2 16,8
Operai e assimilati 16,2 16,0 16,2 16,1 16,1 14,9 15,0 16,4 Imprenditori e liberi professionisti 3,3 3,1 3,2 3,2 3,2 3,6 3,6 3,2
Lavoratori in proprio 8,6 8,6 8,6 8,6 8,6 7,4 7,5 8,7
Co.co.co 1,0 1,1 1,1 1,0 1,1 2,1 2,1 1,0 In cerca di occupazione 4,1 4,2 4,0 4,2 4,1 4,4 4,4 4,1
Inattivi 50,8 50,5 50,7 50,5 50,6 51,2 51,2 49,8
queste informazioni aggiuntive ci offre infatti la possibilità di approfondire lo studio delle caratteristiche dei non rispondenti rispetto a coloro che hanno partecipato all’indagine. 22 Va anche accennata l’esistenza di un motivo tecnico: l’utilizzo dei correttori per mancata risposta tramite celle di ponderazione in GENESEES ha permesso di diminuire l’errore campionario in particolari domini di stima rispetto agli errori ottenuti tramite correttori per strato. 23 Questo aspetto rappresenta parte di un problema più generale di coerenza delle stime, sia a livello micro che a livello macro, che verrà approfondito nel prossimo paragrafo.
11

L’introduzione del passo di calibrazione intermedio permette di rispettare sostanzialmente in tutti e quattro i campioni longitudinali la distribuzione della popolazione di 15 anni e più per condizione professionale riclassificata. In realtà, anche le stime trasversali ottenute tramite i due diversi metodi di correzione della mancata risposta avrebbero permesso di rispettare, anche se non in maniera così forte, la distribuzione delle Forze Lavoro: in questi due casi, tuttavia, differenze più marcate si sono verificate considerando separatamente i quattro campioni longitudinali24. E’ in effetti questa la ragione che rende opportuno l’utilizzo della calibrazione intermedia, che consente di rispettare sempre la distribuzione della popolazione per condizione professionale, distribuzione non di primario interesse per EU-SILC ma sicuramente legata alle variabili oggetto di indagine, migliorando verosimilmente l’accuratezza delle stime.
Il coefficiente così ottenuto per la wave 2004 può quindi essere considerato come un coefficiente che considera la non ignorabilità del meccanismo che determina la mancata risposta, ed è il risultato congiunto di una modellizzazione esplicita (le celle di ponderazione) e di una modellizzazione implicita (la calibrazione intermedia) del processo che determina la mancata risposta.
E’ opportuno dare una valutazione sui diversi metodi di correzione della mancata risposta proposti: questo viene fatto sulla base del cambiamento che si ottiene tra il set dei pesi diretti e il set dei pesi finali, scomponendo questa misura nel contributo introdotto nei diversi passi. Per fare questo si è seguita l’impostazione di Dufour et al. (2001), secondo i quali la misura globale del cambiamento D si divide in quattro termini:
GRRRD +++= int1201 (13)
dove R01 misura i cambiamenti nei pesi individuali che risultano tra il set dei pesi diretti e i pesi intermedi corretti per mancata risposta; R12 misura i cambiamenti nei pesi individuali che si verificano passando dai pesi intermedi ai pesi finali; Rint rappresenta una misura di interazione tra i due passi di cambiamento dei pesi. Il segno di questo valore indica se i due processi si stanno muovendo nella stessa direzione, quando positivo, o in direzioni opposte, quando negativo. Infine, il temine G rappresenta il cambiamento medio dovuto dalla mancata risposta totale; G può anche essere visto come la distorsione dovuta alla mancata risposta totale. Il valore assoluto di G, dovuto al livello della mancata risposta, sarà quindi uguale per ognuno dei metodi proposti25.
La tabella 2 presenta il valore di D diviso per le sue componenti per ognuno dei tre metodi proposti, insieme al contributo percentuale di ciascuna componente sul totale del cambiamento. Come già detto, il Metodo 1 rappresenta la correzione per mancata risposta per strato senza passo di calibrazione intermedio; il Metodo 2 rappresenta la correzione tramite celle di ponderazione ma senza passo di calibrazione intermedio; il Metodo 3 rappresenta l’utilizzo delle celle di ponderazione e del passo di calibrazione intermedio, ed è quindi il metodo effettivamente utilizzato per la wave 2004. Secondo gli autori precedentemente citati sono da preferire i metodi che migliorano la comprensione del meccanismo che determina la mancata risposta, e che aumentano quindi il contributo dovuto al primo passo (R01), diminuendo al contempo il contributo percentuale della distorsione dovuta al fattore G.
24 Queste distribuzioni non sono presentate per motivi di spazio e di comprensibilità della tabella. Si consideri inoltre che i quattro campioni devono essere rappresentativi a livello di ripartizione territoriale (NUTS II level). Differenze ancora più marcate rispetto alle Forze di Lavoro si sono verificate tra le distribuzioni ripartizionali nei quattro sottocampioni. 25 La metodologia adottata è presentata in Appendice.
12

Tabella 2 Valore medio di D per metodo utilizzato, per componente e contributo percentuale alla misura del cambiamento Metodo D R01
R01/D (%) R12
R12/D (%) Rint
Rint/D (%) G G/D
(%) Metodo1 0,415 0,090 21,74 0,232 55,98 -0,002 -0,50 0,094 22,79 Metodo2 0,386 0,070 18,21 0,217 56,20 0,004 1,08 0,094 24,50 Metodo3 0,470 0,169 35,99 0,219 46,73 -0,013 -2,85 0,094 20,13
Passando dalla correzione per strato a quella tramite celle di ponderazione le cose rimangono
sostanzialmente invariate: diminuisce leggermente la distanza complessiva tra pesi base e pesi finali D. Il contributo dovuto alla correzione per mancata risposta passa invece dal 21,7% al 18,2% mentre quello dovuto alla distorsione, misurata dal termine G, aumenta dal 22,8% al 24,5%. Questo significa che le informazioni disponibili per creare le celle di ponderazione non sono allo stato sufficienti a creare una partizione ottimale del campione26. Si è scelto comunque di utilizzare questa procedura per i motivi precedentemente esposti, integrandola però con l’introduzione del primo passo di calibrazione. Introducendo questa calibrazione intermedia che tiene conto della distribuzione della popolazione per condizione professionale riclassificata e delle famiglie per numero di componenti, la misura globale del cambiamento aumenta in valore assoluto. Contrariamente a quanto si potrebbe pensare, questo non è necessariamente un aspetto negativo. Bisogna infatti considerare che il disegno di campionamento non solo è fatto in un momento in cui non sono disponibili le popolazioni aggiornate utilizzate nella calibrazione finale, ma è anche realizzato utilizzando una stratificazione che considera solamente la dimensione demografica del comune e non anche altre informazioni sulle famiglie legate sia alle variabili oggetto di indagine che al meccanismo che genera la mancata risposta. Il contributo dovuto alla correzione della mancata risposta diventa più importante, arrivando a spiegare il 36% del totale del cambiamento, indicando come questa procedura sembra modellare meglio la mancata risposta. All’aumentare del contributo percentuale di R01 diminuisce il contributo di R12, mostrando come le modifiche introdotte tramite poststratificazione divengono via via meno importanti all’aumentare della variazione introdotta dal trattamento della mancata risposta. Infine, la misura di G vede diminuire il proprio contributo relativo, facendo così diminuire l’importanza della distorsione dovuta alla mancata risposta globale. Complessivamente, poiché G è costante, Rint è molto vicino allo 0 e R12 rimane all’incirca costante, la variazione complessiva di D è influenzata principalmente dal metodo per la correzione della mancata risposta utilizzato.
Resta da stabilire quanto il metodo adottato per ottenere una presumibile maggiore accuratezza della stima abbia influito sull’errore campionario. Tramite l’errore di campionamento è possibile dare una valutazione del grado di precisione delle stime ottenute da un’indagine campionaria. Con riferimento alla stima nel dominio d, possono essere calcolati l'errore di campionamento assoluto espresso come:
dY
)Yr(aV)Y(ˆ dd =σ (14) e l'errore di campionamento relativo espresso come:
d
dd Y
)Y(σ)Y(ˆ =ε (15)
26 Si consideri che delle informazioni utilizzate per la creazione delle celle, la dimensione demografica del comune è già inserita in fase di determinazione degli strati, la cittadinanza è inserita nel set di vincoli finali, così come il numero di famiglie per regione. La nuova informazione introdotta si riduce quindi alla distribuzione delle famiglie estratte per numero componenti.
13
Nella (14) denota la stima della varianza campionaria di . )Yr(aV d dYNelle tabelle 3 e 4 sono riportati i valori medi, con relativi errori di campionamento
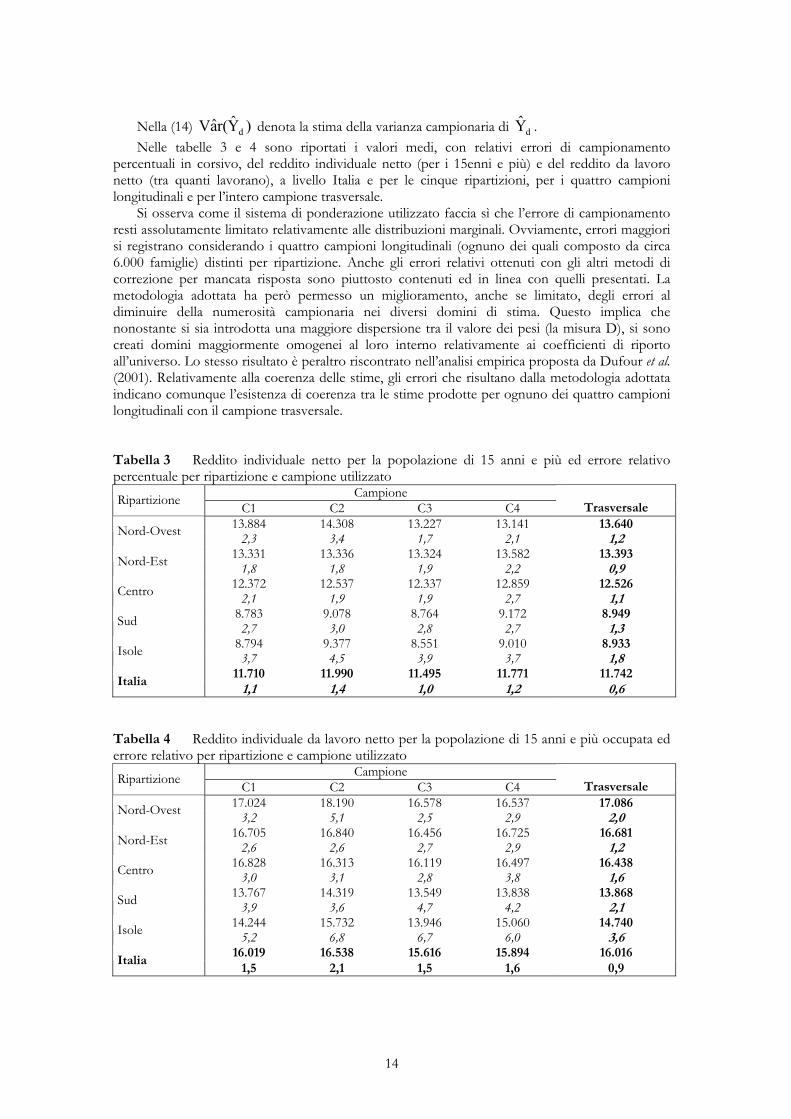
percentuali in corsivo, del reddito individuale netto (per i 15enni e più) e del reddito da lavoro netto (tra quanti lavorano), a livello Italia e per le cinque ripartizioni, per i quattro campioni longitudinali e per l’intero campione trasversale.
Si osserva come il sistema di ponderazione utilizzato faccia sì che l’errore di campionamento resti assolutamente limitato relativamente alle distribuzioni marginali. Ovviamente, errori maggiori si registrano considerando i quattro campioni longitudinali (ognuno dei quali composto da circa 6.000 famiglie) distinti per ripartizione. Anche gli errori relativi ottenuti con gli altri metodi di correzione per mancata risposta sono piuttosto contenuti ed in linea con quelli presentati. La metodologia adottata ha però permesso un miglioramento, anche se limitato, degli errori al diminuire della numerosità campionaria nei diversi domini di stima. Questo implica che nonostante si sia introdotta una maggiore dispersione tra il valore dei pesi (la misura D), si sono creati domini maggiormente omogenei al loro interno relativamente ai coefficienti di riporto all’universo. Lo stesso risultato è peraltro riscontrato nell’analisi empirica proposta da Dufour et al. (2001). Relativamente alla coerenza delle stime, gli errori che risultano dalla metodologia adottata indicano comunque l’esistenza di coerenza tra le stime prodotte per ognuno dei quattro campioni longitudinali con il campione trasversale.
Tabella 3 Reddito individuale netto per la popolazione di 15 anni e più ed errore relativo percentuale per ripartizione e campione utilizzato
Campione Ripartizione C1 C2 C3 C4
Trasversale 13.884 14.308 13.227 13.141 13.640 Nord-Ovest 2,3 3,4 1,7 2,1 1,2 13.331 13.336 13.324 13.582 13.393 Nord-Est 1,8 1,8 1,9 2,2 0,9 12.372 12.537 12.337 12.859 12.526 Centro 2,1 1,9 1,9 2,7 1,1 8.783 9.078 8.764 9.172 8.949 Sud 2,7 3,0 2,8 2,7 1,3 8.794 9.377 8.551 9.010 8.933 Isole 3,7 4,5 3,9 3,7 1,8 11.710 11.990 11.495 11.771 11.742
Italia 1,1 1,4 1,0 1,2 0,6
Tabella 4 Reddito individuale da lavoro netto per la popolazione di 15 anni e più occupata ed errore relativo per ripartizione e campione utilizzato
Campione Ripartizione C1 C2 C3 C4
Trasversale 17.024 18.190 16.578 16.537 17.086 Nord-Ovest 3,2 5,1 2,5 2,9 2,0 16.705 16.840 16.456 16.725 16.681 Nord-Est 2,6 2,6 2,7 2,9 1,2 16.828 16.313 16.119 16.497 16.438 Centro 3,0 3,1 2,8 3,8 1,6 13.767 14.319 13.549 13.838 13.868 Sud 3,9 3,6 4,7 4,2 2,1 14.244 15.732 13.946 15.060 14.740 Isole 5,2 6,8 6,7 6,0 3,6 16.019 16.538 15.616 15.894 16.016
Italia 1,5 2,1 1,5 1,6 0,9
14
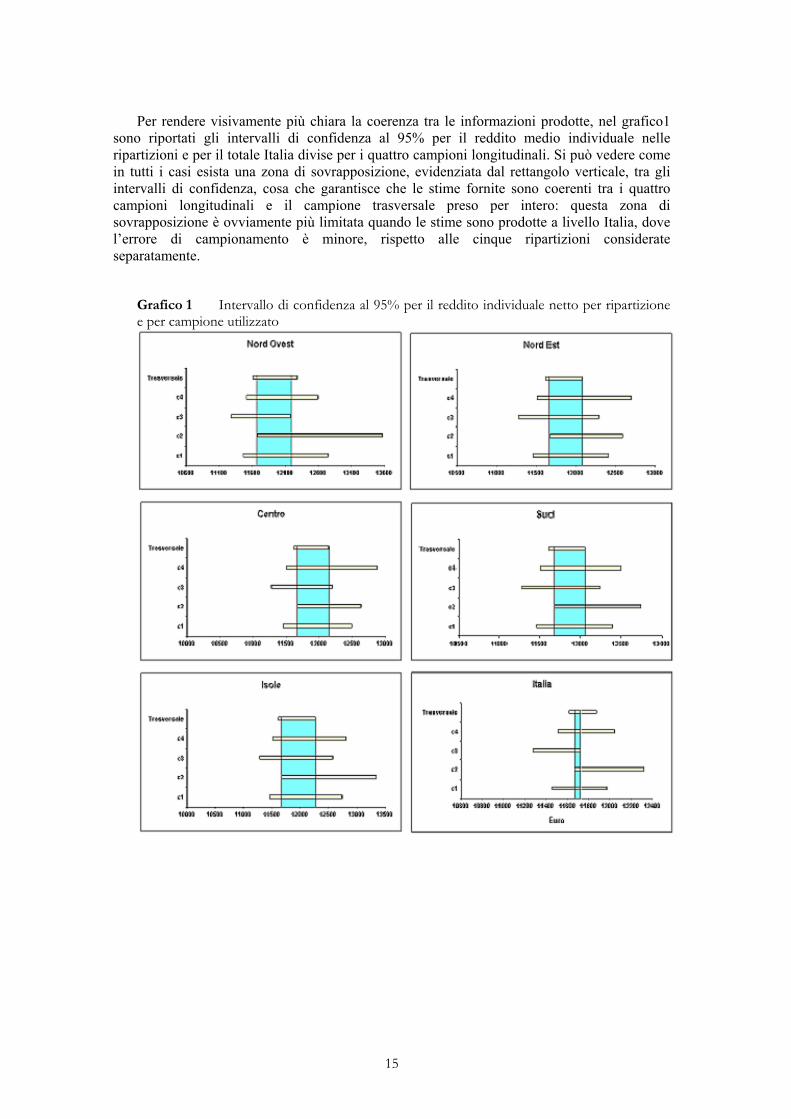
Per rendere visivamente più chiara la coerenza tra le informazioni prodotte, nel grafico1 sono riportati gli intervalli di confidenza al 95% per il reddito medio individuale nelle ripartizioni e per il totale Italia divise per i quattro campioni longitudinali. Si può vedere come in tutti i casi esista una zona di sovrapposizione, evidenziata dal rettangolo verticale, tra gli intervalli di confidenza, cosa che garantisce che le stime fornite sono coerenti tra i quattro campioni longitudinali e il campione trasversale preso per intero: questa zona di sovrapposizione è ovviamente più limitata quando le stime sono prodotte a livello Italia, dove l’errore di campionamento è minore, rispetto alle cinque ripartizioni considerate separatamente.
Grafico 1 Intervallo di confidenza al 95% per il reddito individuale netto per ripartizione e per campione utilizzato
15

6 Problemi aperti e prospettive
6.1 Le stime trasversali Nella wave condotta nel 2004, la strategia di ponderazione si basa sull’assunto di fondo che è
quello di offrire la possibilità di essere variata in funzione del tipo di mancata risposta che ogni anno può verificarsi senza stravolgere la natura e la struttura della calibrazione finale. In tal senso, la scelta di inserire un primo passo di calibrazione soddisfa un duplice obiettivo: affinare la correzione per mancata risposta con informazioni più correlate con il reddito; rendere la procedura flessibile in funzione delle informazioni disponibili e del tipo di mancata risposta che si presenta. Come più volte accennato, la strategia adottata rappresenta una soluzione temporanea al problema della distorsione dovuta a differenti comportamenti di risposta rispetto al reddito.
Con la realizzazione della seconda wave e con i consistenti avanzamenti nel linkage e nello studio dei dati fiscali, si è aperta una nuova fase di sperimentazione che, inevitabilmente, porterà a rivedere la parte della strategia relativa ai correttori per mancata risposta. La disponibilità di altre e importanti informazioni ci offre la possibilità di approfondire lo studio delle caratteristiche dei non rispondenti rispetto a coloro che hanno partecipato all’indagine. La strategia adottata per la riduzione dell’effetto delle mancate risposte sulle stime finali, strategia che nel luglio scorso è stata proposta anche da Eurostat (cfr. Verma et al., 2006) può essere sensibilmente migliorata con l’uso dei dati da fonte fiscale. Per quanto riguarda i coefficienti di riporto all’universo della seconda wave, la procedura di ponderazione dovrà tener conto del fatto che il campione trasversale è composto da un campione longitudinale (C5) di famiglie che hanno effettuato la prima intervista e di tre campioni (C2, C3, C4) che sono alla seconda intervista. Da un punto di vista metodologico, cambia la determinazione della probabilità di inclusione delle famiglie (famiglie split) generate da quegli individui campione (intervistati nella wave precedente) che escono dalla famiglia di origine per crearne una nuova. La costruzione del coefficiente di correzione per la mancata risposta totale passa attraverso la sperimentazione che dovrà favorire l’impiego delle informazioni fiscali per la determinazione delle “celle di ponderazione”. L’obiettivo è quello determinare una partizione “ottimale” del campione dove in ogni cella si possa assumere la casualità del meccanismo che ha generato la mancata risposta. Le variabili utilizzate per costruire le celle di ponderazione in occasione della prima wave, infatti, non hanno consentito di determinare una partizione ottimale allo scopo tanto da rendere necessario un primo passo di calibrazione. In tale ambito, l’uso dei dati fiscali favorirà la realizzazione di “celle” composte da famiglie con comportamenti analoghi, condizionatamente alle caratteristiche delle proprie condizioni di vita. Per determinare la partizione ottimale sono in corso di sperimentazione tecniche di analisi fattoriale per la sintesi delle informazioni disponibili e di cluster analysis per la creazione delle “celle”. Altro elemento di discussione riguarda gli stranieri. E’ fuori di dubbio che il comportamento, sia in termini di condizioni di vita sia in termini di collaborazione alle indagini, sia differenziato tra cittadini italiani e stranieri ma anche tra stranieri di nazionalità diversa. Inoltre, il numero di stranieri residenti in Italia ha raggiunto negli ultimi anni livelli tali da rendere il fenomeno non trascurabile anche nell’ambito delle indagini campionarie con una sempre più crescente richiesta di informazione statistica riferita ai cittadini stranieri. L’Istituto, in generale, e la Direzione sulle condizioni di vita, in particolare, hanno iniziato da tempo a lavorare sia per ottenere una maggiore attenzione nella rilevazione dei dati forniti da persone straniere, sia sul fronte della costruzioni delle stime, più attendibili e accurate rispetto al passato quando il fenomeno non raggiungeva tali proporzioni.
Anche nell’indagine sulle condizioni di vita, infatti, oltre a tutto il lavoro in fase di rilevazione, sono state utilizzate informazioni ausiliarie sui cittadini stranieri sia per la costruzione dei coefficienti per mancata risposta sia per la realizzazione delle stime finali. Il punto focale in merito alle statistiche sui cittadini stranieri è la valutazione, già dalla seconda wave, dell’attendibilità delle stime. Anche se argomento non strettamente connesso al contesto del presente articolo, un tassello importante al fine di produrre indicatori attendibili, sarà il consolidamento delle procedure
16

di rilevazione delle informazioni. In tal senso, un’attenta valutazione della qualità del lavoro svolto dai rilevatori nell’intervistare cittadini stranieri favorirà la soluzione dei punti critici in vista delle interviste successive. 6.2 Le stime longitudinali
La metodologia di riporto all’universo dei dati longitudinali è simile a quella correntemente utilizzata dall’Istat per il riporto all’universo dei dati cross-section, si basa, come detto, sull’uso degli stimatori di ponderazione vincolata.
Il campione longitudinale può produrre stime di flusso tra due periodi ma anche stime di stock riferite ad ogni singola wave dei campioni longitudinali. Nel caso di EU-SILC, la popolazione di riferimento dei campioni longitudinali è quella di inizio periodo di ogni campione.
Come già evidenziato, il campione cross-section è composto dalla somma dei 4 campioni longitudinali; ognuno di questi può essere considerato come un campione casuale dell’intero campione cross-section che lo contiene. L’attrition e la non casualità della mancata risposta introducono una distorsione nelle stime degli aggregati (sia di stock sia di flusso). Per ridurre tale distorsione e, quindi, garantire un certo grado di attendibilità delle stime, si sta sperimentando una procedura per il calcolo dei coefficienti di riporto all’universo basata su passi di calibrazione successivi supportata da opportuni totali noti.
Il particolare schema di campionamento che caratterizza EU-SILC impone una serie di riflessioni riguardo le informazioni che di volta in volta l’indagine produce. In primo luogo è necessario tener conto di cosa accade a partire dalla seconda wave in poi. Con riferimento al 2005, sarà prodotto un file con i risultati relativi all’indagine cross-section, come unione dei quattro campioni longitudinali e tre file longitudinali relativi ai tre campioni che, non rinnovandosi, sono stati già intervistati nel 2004. Con riferimento allo Schema 2, il file cross-section è composto dalle sezioni C1(w4), C2(w3), C3(w2) e C4w1 mentre i file longitudinali sono: C2(w4)-C2(w3), C3(w3)-C3(w2) e C4w2- C4w1. Schema 2 I file prodotti dall’indagine EU-SILC
File prodotti Anni Cross-section Longitudinali 2004 C1(w4) C2(w3) C3(w2) C4w1 2005 C2(w4) C3(w3) C4w2 C5w1 C2(w4) C2(w3) C3(w3) C3(w2) C4w2 C4w1 2006 C3(w4) C4w3 C5w2 C6w1 C3(w4) C3(w3) C3(w2) C4w3 C4w2 C4w1 C5w2 C5w1 2007 C4w4 C5w3 C6w2 C7w1 C4w4 C4w3 C4w2 C4w1 C5w3 C5w2 C5w1 C6w2 C6w1 2008 C5w4 C6w3 C7w2 C8w1 C5w4 C5w3 C5w2 C5w1 C6w3 C6w2 C6w1 C7w2 C7w1
Il problema che deriva dalla realizzazione e diffusione di file longitudinali intermedi, e di diffonderne i risultati successivamente alla diffusione delle stime ottenute con l’indagine cross-section pone l’accento su vari aspetti relativi alla coerenza delle informazioni a disposizione per ogni wave. In particolare:
- coerenza delle informazioni riferite allo stesso individuo in tempi diversi (micro-coerenza); - coerenza delle stime degli aggregati nel tempo (macro-coerenza); - coerenza tra le stime prodotte con l’indagine cross-section e quelle prodotte con i vari file
longitudinali riferiti allo stesso anno (macro-coerenza).
17

6.2.1 Coerenza a livello micro Il controllo e la correzione dei dati in senso longitudinale agiscono a livello di singola unità
statistica (singolo record) identificando e imputando le mancate risposte parziali e/o gli errori logico-formali che derivano dalle incompatibilità esistenti a livello individuale in tempi diversi27. Le informazioni raccolte a livello individuale in due anni successivi necessitano di coerenza tra variabili che descrivono le condizioni di vita della famiglia in senso non monetario (nella fattispecie tutte le variabili qualitative), di quella tra le variabili in senso monetario (le variabili quantitative) e delle combinazioni tra loro. Il legame tra variabili monetarie e non, riferite ad uno stesso individuo in tempi successivi impone un controllo che tenga conto di tutte le informazioni in questione. Ad esempio, la condizione professionale al tempo 1 (lav1) deve essere coerente con il reddito da lavoro al tempo 1 (red1) così come deve essere coerente con la condizione professionale al tempo 2 (lav2). La condizione professionale al tempo 2 (lav2) dovrà essere coerente con il reddito red2 che a sua volta dovrà essere coerente con red1.
La soluzione del problema micro, da un punto di vista strettamente metodologico, non pone problemi insormontabili anche in considerazione del fatto che sia l’approccio deterministico sia quello probabilistico offrono la possibilità di realizzare le correzioni necessarie per garantire la coerenza intra record in tempi diversi. Inoltre, il ricorso a dati da fonte amministrativa (anagrafico e fiscale) consentono di risolvere in modo adeguato le incongruenze che possono verificarsi. In tal senso, sarà valutata anche l’opportunità di iniziare le correzioni dai dati grezzi o sfruttare già le correzioni effettuate al momento della creazione del file cross-section. Stabilita la validità delle informazioni raccolte, in presenza di valori mancanti o di incongruenze28, le imputazioni/correzioni saranno basate sul criterio del minimo cambiamento e della prevalenza nella risoluzione delle incongruenze intra record sia in senso cross-section sia in senso longitudinale.
L’applicazione del criterio del minimo cambiamento consente di mantenere il più possibile le stesse informazioni rilevate riferite agli stessi individui presenti nei vari campioni longitudinali. Le principali metodologie adottate dall’Istat si basano essenzialmente su tale criterio. 6.2.2 Coerenza a livello macro Altro aspetto da affrontare è quello relativo alla coerenza delle informazioni diffuse in forma aggregata nel tempo. Con riferimento allo Schema 3, in ogni campione longitudinale, due wave successive contengono le stesse unità campionarie, al netto dell’attrition. Ad esempio, nel 2007 verrà realizzata l’ultima wave del campione C4 con la creazione del file (C4W4-C4W3-C4W2-C4W1) mentre il file C4W3-C4W2-C4W1 è già stato diffuso nel 2006. Questi due file contengo le stesse unità statistiche, al netto dell’attrition, quindi devono fornire le stesse stime dei flussi in comune (ad esempio le transizioni da C4W2 a C4W3), e devono fornire le stime di stock per le stesse wave presenti nei due file, nell’esempio C4W3, C4W2 e C4W1.
27 Le incoerenze logiche tra valori singolarmente ammissibili di variabili differenti, i valori mancanti e i valori fuori dominio possono essere assimilati alle mancate risposte parziali. La metodologia che guida i processi di correzione adottati dipende essenzialmente dalle relazioni esistenti tra le variabili e non dai valori che queste assumono. 28 L’imputazione di un record longitudinale, in cui figurano i valori delle variabili relativi a differenti occasioni d’indagine su una stessa unità, può essere effettuata imputando tutte le variabili che lo richiedono oppure limitare l’imputazione soltanto alle variabili di una data occasione, mantenendo inalterate quelle delle occasioni precedenti. Quest’ultima, si rivela più praticabile laddove ogni occasione d’indagine produce risultati definitivi. Seguendo la prima strategia, invece, i dati rilevati sarebbero considerati sempre provvisori sino all’ultima occasione d’indagine.
18

Schema 3 Le coerenze tra componenti longitudinali nei diversi anni d’indagine
2004 2005 2006 2007 C1(w4) C2(w3) C2(w4) C3(w2) C3(w3) C3(w4) C4w1 C4w2 C4w3 C4w4 C5w1 C5w2 C5w3 C6w1 C6w2 C7w1
Non meno importante, è l’aspetto legato alla coerenza tra stime cross-section relative ad un
certo anno e le stime ottenute dalle varie componenti dei campioni longitudinali. Ad esempio, dallo Schema 3 l’indagine cross-section riferita nell’anno 2007 (composta dai campioni C4w4- C5w3- C6w2- C7w1) e le stime di un certo aggregato devono essere coerenti con:
- le stime prodotte dalla quarta wave del campione longitudinale C4; - le stime prodotte dalla terza wave del campione longitudinale C5; - le stime prodotte dalla seconda wave del campione longitudinale C6.
I problemi maggiori sorgono nella messa a punto di metodologie per la soluzione dei problemi di macro-coerenza, in riferimento sia alle stime di flusso e di stock prodotte dai vari campioni longitudinali sia a quelle provenienti dall’indagine cross-section. Risolvere il problema della coerenza, significa tener conto complessivamente di tutte le informazioni a disposizione al momento della creazione dei file. Rispettare simultaneamente tutti gli aspetti sopra menzionati risulta praticamente impossibile visto il tipo di diffusione e la tempistica che Eurostat richiede.
La soluzione del problema, quindi, richiede un approccio che si allontana dalla simultaneità e punta a mantenere integra, il più possibile, l’informazione di partenza “spendendo” più risorse nella validazione del singolo record.
La sperimentazione in corso per la determinazione dei coefficienti di riporto all’universo longitudinali prevede un passo di calibrazione che consente di ottenere la coerenza tra le stime prodotte con la prima wave del campione longitudinale e le stesse prodotte dall’intero campione cross-section riferito all’anno di ingresso nell’indagine del campione longitudinale in questione. Ad esempio, il campione C4 alla prima wave è, per costruzione, rappresentativo a livello di ripartizione geografica. Nella seconda wave, al netto della mancata risposta totale, il campione è rappresentativo della popolazione iniziale al netto delle uscite da tale popolazione. Nel calcolo dei coefficienti di riporto longitudinali, un primo livello di calibrazione è tale da far convergere le stime ottenute dal campione C4w1 con le stime dei principali aggregati (o delle variabili ad essi maggiormente correlate) realizzate con campione cross-section del 2004 (che contiene C1(w4), C2(w3), C3(w2) e C4w1). Il coefficiente di riporto all’universo finale del campione longitudinale, si ottiene a partire dal peso precedentemente calcolato vincolando ai totali noti da fonte esterna secondo le indicazioni che suggerisce Eurostat (popolazione per sesso e classi d’età).
Per quanto riguarda i flussi tra wave diverse presenti in diversi file prodotti29, sarà garantita un certo livello di coerenza, grazie alla validazione approfondita a livello di micro-record e supportata dallo studio delle cause dell’attrition, con l’introduzione di opportuni coefficienti di correzione per mancata risposta che di volta in volta riportano il campione osservato al campione teorico mediante l’utilizzo del maggior numero di informazioni possibili a disposizione sui non rispondenti e correlate alle variabili fondamentali dell’indagine.
Altro elemento da valutare, nel trattamento delle informazioni longitudinali, è l’impatto delle osservazioni outlier sulle stime dei flussi. Queste, ovviamente, hanno un loro impatto sulle stime cross-section e sulla distribuzione del reddito, soprattutto quando si esamina la situazioni per
29 Ad esempio, i flussi riferiti alle wave C4W 2- C4W 1 presente nei file C4W3- C4W 2- C4W 1 che sarà prodotto in occasione dell’indagine del 2006 e il file C4W 4- C4W 3- C4W 2- C4W 1 prodotto nell’indagine del 2007.
19

sottoclassi di individui, e assume un aspetto rilevante anche nella trattazione longitudinale delle transizioni. L’approccio che verrà sperimentato, oltre a una validazione più efficace, grazie alle informazioni riferite a più istanti di tempo, si basa sul trattamento di tali casi come riferiti ad una sottopopolazione differente e quindi da “rappresentare” in modo diverso rispetto alle altre sottopopolazioni che caratterizzano l’universo di riferimento. In sostanza, le unità outlier si vedranno assegnato un differente coefficiente di riporto all’universo in base alla dimensione della sottopopolazione che rappresentano.
20

Riferimenti bibliografici Ballin, M., Falorsi P.D., Falorsi S., Pallara S., 2000, Il trattamento delle mancate risposte totali
nelle indagini Istat sulle famiglie e sulle imprese: soluzioni attuali e linee di ricerca, Giornate di studio su “La qualità dell’informazione statistica” SIEDS-ISTAT, Roma 6-7 aprile 2000.
Banca d’Italia, (2006), I bilanci delle famiglie italiane nell’anno 2004, Supplemento al bollettino statistico, Gennaio 2006
Brewer, K.R.V., Hanif, M., 1983, Sampling with Unequal Probabilities, Springer-Verlag. New-York.
Cochran, W. G., (1977), Sampling Techniques, Wiley, New York. Deville J. C., Särndal C. E., (1992), Calibration Estimator, in Survey Sampling, Journal of the
American Statistical Association, vol. 87, pp.376-382. Deville, J. C., (2000), Simultaneous calibration of several survey, Proceedings of statistics Canada
symposium 99, pp. 207-212. Dufour J., Gagnon F., Morin Y., Renaud M., and Sarndal C.E., (2001), A Better Understanding of
Weight Transformation Through a Measure of Change, Survey Methodology, June 2001, vol.27, N.1.
EU-SILC 065/04 – Description of Target variables: Cross-sectional and Longitudinal EU-SILC 090/02 – Commission Regulation on Sampling and tracing rules EU-SILC 132/04 – Technical document on intermediate and final quality report EU-SILC 134-rev/04 – Cross-sectional weighting: first year each sub-sample EU-SILC 157/05 – Cross-sectional weighting: from second year of the survey onwards Falorsi, P. D., Falorsi S., (1998), The Italian generalized estimation package: some experimental
results for estimation on households suveys with different non response mechanism, Quaderni di Ricerca, ISTAT, n.4, pp.63-94.
Falorsi, S., Pagliuca, D., Scepi, G., (2000), Generalised Software for Sampling Errors – GSSE”, Research in Official Statistics - ROS, vol. 3, n. 2, pp. 89-108.
Fellegi I.P. e Holt D. (1976), A Systematic Approach to Automatic Edit and Imputation. Journal of the American Statistical Association, 71, 17-35.
Giommi A. (1987), Nonparametric Methods for Estimating Individual Response Probabilities, Survey Methodology, December 1987, vol.13, N.2.
Hidiroglou M., and Srinath K.P. (1981), Some Estimators for a Population Total from Simple Random Samples Containing Large Units, Journal of the American Statistical Association, vol. 76.
Horvitz, D.G., Thompson, D. J, (1952), A Generalization of Sampling without Replacement from Finite Universe, Journal of the American Statistical Association, vol. 47, pp. 663-685.
Kasprzyk D., Duncan G.J., Kalton G., Singh M.P., (1989), Panel Survey, John Wiley and Sons, United States.
Kish, L., 1965, Survey Sampling, Wiley, New York. Little R. J. A., (1982), Models for Nonresponse in Sample Surveys, Journal of the American
Statistical Association, vol. 77, N. 387. Masselli M. (1989). Manuale di tecniche di indagine – il sistema di controllo della qualità dei dati.
Vol. 6, Note e Relazioni, Istat. Raghunathan T. E., Lepkowski J.M., Van Hoewyk J., and Solemberger P., (2001), A Multivariate
Technique for Multiply Imputing Missing Values Using a Sequence of Regression Models, Survey Methodology, June 2001, vol.27, N.1.
Regolamento (CE) N. 1177/2003 del Parlamento Europeo e del Consiglio Regolamento (CE) N. 1982/2003 del Parlamento Europeo e del Consiglio Renssen R.H., Nieuwenbroek N.J (1977), Aligning Estimates for Common Variables in Two or
More Sample Survey, Journal of the American Statistical Association, vol. 92, N. 437.
21

Riccini Margarucci E. e Floris P. (2000), Controllo e correzione dati - Manuale utente. ISTAT – Dipartimento d’Informatica Gruppo Software Generalizzato.
Rosati S. (2000), La correzione di dati longitudinali nell’indagine Forze di lavoro. Rivista di Statistica Ufficiale – Quaderni di Ricerca, n. 3, ISTAT.
Särndal, C.E., Swensson , B. and Wretman, J., (1989), The weighted residual technique for estimating the variance of the general regression estimator of the finite population total, Biometrika, vol. 76, n. 3, pp. 527-537
Särndal, C.E., Swensson, B. and Wretman, J., (1992), Model Assisted Survey Sampling, Springer-Verlag. New-York.
Singh A.C, Kennedy B., and Wu S. (2001), Regression Composite Estimation for the Canadian Labour Force Survey with a Rotating Panel Design, Survey Methodology, June 2001, vol.27, N.1.
Singh, A. C., Mohl, C. A., (1996), Understanding Calibration Estimators in Survey Sampling, Survey Methodology, vol. 22, n. 2, pp. 107-115.
Verma V., (1995), Weighting for Wave 1. Documento EUROSTAT, doc. PAN 36/95. Verma V., Ghellini G., Bartoletti S., Ballini F., Pierozzi F (2006), EU-SILC weighting procedures:
an outline, Output II.1(b) – Advanced Estimation Methods – International Social Research. Woodruff, R.S., (1971), A Simple Method for Approximating the Variance of a Complicated
Estimate, Journal of the American Statistical Association, vol.66, n. 334, pp. 411-414.
22

Appendice - La misura del cambiamento tra pesi diretti e pesi finali
Sia i0ψ il peso diretto proveniente dal disegno per la famiglia i, i1ψ il coefficiente ottenuto
dopo la correzione per mancata risposta, i2ψ il coefficiente di riporto all’universo e sia sr ⊂ il campione di rispondenti sottoinsieme del campione estratto s. Poiché si vuole valutare il cambiamento introdotto con i diversi sistemi, la prima operazione da fare consiste nella “sterilizzazione” della distorsione introdotta dalla differenza tra le popolazioni al momento della ponderazione finale (N1) e quella disponibile al momento del disegno di campionamento (N0) tramite normalizzazione dei coefficienti i0ψ di modo che 1N=0
si∑ψ . In questa maniera è
possibile isolare l’effetto dovuto alla mancata risposta da quello derivante dalla differenza tra N1 e N0. Risulterà quindi:
∑ ∑ ∑ ==<r r r
iii NNN 121110 ;; ψψψ .
Si definiscano le seguenti quantità:
∑∑
=
ri
ri
0
1
01 ψ
ψψ (A1)
e
∑∑
=
ri
ri
0
2
02 ψ
ψψ (A2)
Il rapporto 01ψ misura il cambiamento medio che si verifica tra i pesi intermedi e i pesi
diretti (normalizzati) risultanti dal disegno, e si discosta tanto più dal valore di 1 quanto maggiore è la mancata partecipazione all’indagine. Il rapporto 02ψ rappresenta invece il cambiamento medio tra il set di pesi finali e il set di pesi iniziali. Per quantificare invece il cambiamento che si verifica a livello di singola unità si definiscono, per ogni unità i appartenente al sottocampione r di rispondenti, le quantità
)( 010
101 ψψ
ψ
i
iir = (A3)
e
)( 020
202 ψψ
ψ
i
iir = (A4)
che rappresentano l’impatto individuale della correzione rispetto alla media nell’intero campione. Queste quantità variano intorno ad 1 e sono tali che le loro medie pesate sono pari ad 1.
23

10
020
0
010
==∑
∑∑
∑
ri
ir
i
ri
ir
i rr
ψ
ψ
ψ
ψ (A5)
La misura del cambiamento complessivo tra l’insieme dei pesi diretti e l’insieme dei pesi finali,
passando attraverso il set dei pesi intermedi, può essere calcolato attraverso la misura di distanza D:
∑
∑
−
=
ri
r i
ii
D0
2
0
20 1
ψψψ
ψ (A6)
che rappresenta una media ponderata tramite il set dei pesi diretti della seguente misura del cambiamento individuale:
2
0
1
1
2 1
−
i
i
i
i
ψψ
ψψ
. (A7)
La misura del cambiamento D si divide in quattro termini (Dufour et al., 2001):
GRRRD +++= int1201 (A8)
dove
∑∑ −
=
ri
ir
i
i
rR
0
2010
2
001
)1(
ψ
ψψ (A9)
misura i cambiamenti nei pesi individuali che risultano tra il set dei pesi diretti e i pesi intermedi corretti per mancata risposta;
∑∑ −
=
ri
iir
i
i
rrR
0
201020
2
012
)(
ψ
ψψ (A10)
misura i cambiamenti nei pesi individuali che si verificano passando dai pesi intermedi ai pesi finali;
∑∑ −−
=
ri
iiir
i
i
rrrR
0
01010202
0int
)1)((2
ψ
ψψ (A11)
rappresenta una misura di interazione tra i due passi di cambiamento dei pesi. Il segno di questo valore indica se i due processi si stanno muovendo nella stessa direzione, quando positivo, o in direzioni opposte, quando negativo; infine, il temine
24

202 )1( −= ψG (A12)
rappresenta il cambiamento medio dovuto dalla mancata risposta totale; G può anche essere visto come la distorsione al quadrato30 dovuta alla mancata risposta totale. Infatti, interpretando D
come l’errore quadratico medio della misura i
i
0
2
ψψ
rispetto ad 1, D risulta pari alla somma tra la
distorsione introdotta introdotta e la varianza, data dalla somma delle altre tre componenti. Il valore di G, dovuto al livello della mancata risposta totale, è quindi in valore assoluto uguale qualunque sia il metodo di ponderazione utilizzato.
30 O il quadrato della differenza tra 02ψ , media di i
i
0
2
ψψ
, ed 1
25


















