
VARIABILI CASUALI DI USO COMUNE VARIABILE CASUALE … Lezione 3.pdf · Lezione 3 4 LA UNIFORME...
56
VARIABILI CASUALI DI USO COMUNE VARIABILE CASUALE UNIFORME UNIFORME DISCRETA x i p i 1 1/N 2 1/N ... ..... N 1/N 1 X~ U(N); X~ R(N) M e = = μ 21+ N
Transcript of VARIABILI CASUALI DI USO COMUNE VARIABILE CASUALE … Lezione 3.pdf · Lezione 3 4 LA UNIFORME...

VARIABILI CASUALI DI USO COMUNE VARIABILE CASUALE UNIFORME UNIFORME DISCRETA
xi pi 1 1/N 2 1/N ... ..... N 1/N 1
X~ U(N); X~ R(N)
Me = =μ 21+N

Lezione 3
2
∑=
=μN
i 12 x2
i pi = ∑=
N
i 1i2
N1 = =
6
︶12︶ ︵1︵ ++ NN
=μ−μ=σ 22
2 12
1N2 −
=γ1 0
2γ = - )1N(5)1N(6
2
2
−
+
è sempre platicurtica; per N grande è 2γ ≈ -6/5. Da X è possibile sempre derivare:
Y = a + bX
yi pi a+b1 1/N a+b2 1/N ..... ... a+bN 1/N 1

Variabili casuali di uso comune
3
Per
a = - σμ = -
1N)1N(3
−+ ; b =
σ1 =
1N122 −
è la v.c. uniforme standardizzata. Esempio La v.c.
xi 1 2 3 4 5 6
pi 16 1
6 16 1
6 16 1
6 connessa al lancio di una dado regolare. Si ottiene:
Me = 3.5; 691
2 =μ ; 3μ = 73.5 ; 4μ = 350
da cui si ottiene
12352 =σ ; CV =
215 ; 1γ = 0;
175222
2 −=γ .
Lezione 3
4
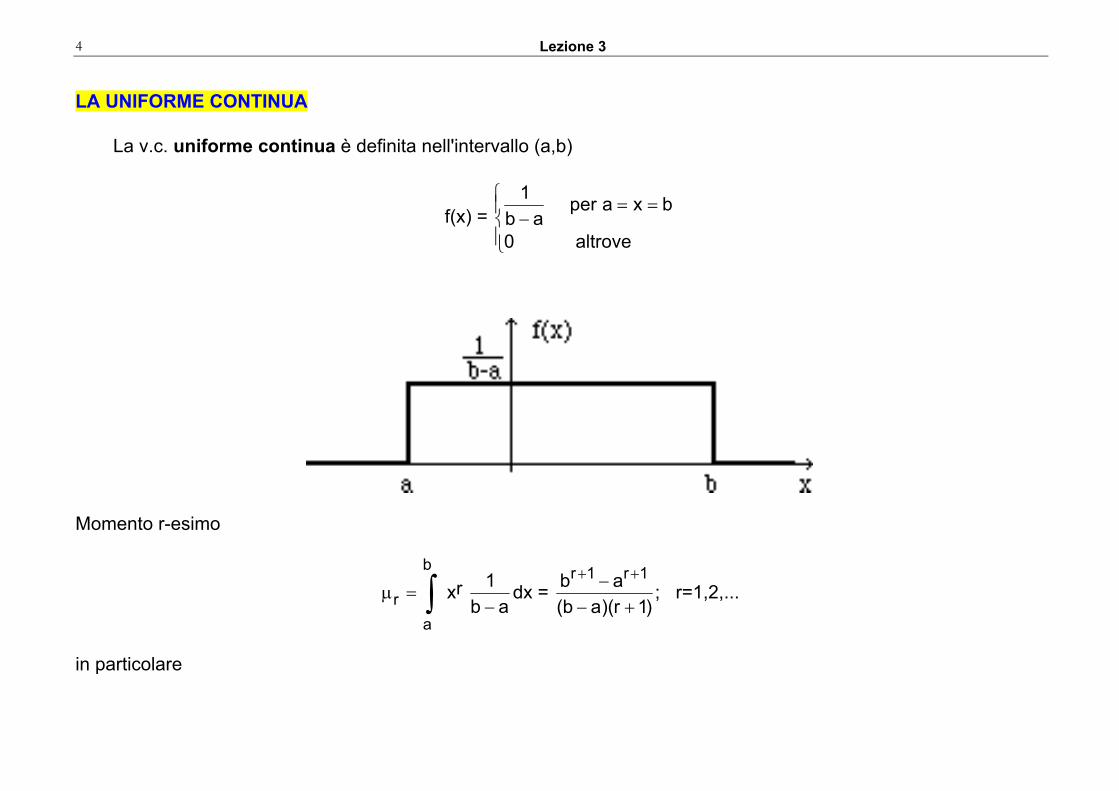
LA UNIFORME CONTINUA La v.c. uniforme continua è definita nell'intervallo (a,b)
f(x) = ⎪⎩
⎪⎨⎧ ==
−altrove0
bxaperab
1
Momento r-esimo
∫=μ
b
ar xr
ab1−
dx = )1r)(ab(
ab 1r1r
+−− ++
; r=1,2,...
in particolare

Variabili casuali di uso comune
5
)ab(2
ab 221 −
−=μ = b+a
2 ; )ab(3
ab 332 −
−=μ ;
)ab(4ab 44
3 −−
=μ ; )ab(5
ab 554 −
−=μ
da cui
2σ = 12
)ab( 2− ; 1γ = 0; 2γ = - 56
è simmetrica e platicurtica. L funzione di ripartizione F(x):

Lezione 3
6
Esempio X con funzione di densità
f(x) = ⎪⎩
⎪⎨⎧ π∈
πaltrove0
]2,0[xper21
rμ = (2π)r+12π(r+1)
Me =μ = π; 2σ = π2
3
LA VARIABILE CASUALE BINOMIALE La v.c. di Bernoulli:
xi pi 0 1-p=q 1 p 1

Variabili casuali di uso comune
7
Può essere generata estraendo una unità di rilevazione da una popolazione le cui unità assumono solo due caratteri: bianche (in proporzione pari a p) e rosse (in proporzione pari a q=1-p) Esempio La prova consiste nel lancio di una moneta ben equilibrata:
xi pi 0 1/2 1 1/2 1
è una particolare Bernoulli con p=1/ 2. Momento di ordine r
∑=
=μk
1ir xr
i pi = 0r (1-p)+ 1r p = p
μ= p; 2σ = pq; )p1(p
p211 −
−=γ ;
)p1(p1
2 −=γ - 6
La Binomiale come una generalizzazione della v.c. di Bernoulli ottenuta estrendo, con reimmissione, N palline.
X ~B(N;p) = ∑=
N
1i
Bi(1;p)

Lezione 3
8
Binomiale come somma di N v.c. di Bernoulli indipendenti.
Bi = esce pallina bianca alla i-esima estrazione Ri = esce pallina rossa alla i-esima estrazione si ha P(Bi) = p, P(Ri) = q per i=1,2,...,N: Ax = in N estrazioni (effettuate con rimessa) la pallina bianca si presenta x volte:
B1∩B2∩ ... ∩Bx∩Rx+1∩Rx+2∩ ... ∩RN
P(B1∩B2∩ ... ∩Bx∩Rx+1∩Rx+2∩ ... ∩RN) = px qN-x
Ma perché Ax sia verificata, le x palline bianche possono presentarsi non necessariamente ai primi x posti: i modi incompatibili, in cui le x palline bianche possono presentarsi, sono tanti quante sono le combinazioni di N oggetti ad
x ad x cioè ⎟⎟⎠
⎞⎜⎜⎝
⎛
x
N:
P(Ax) = ⎟⎟⎠
⎞⎜⎜⎝
⎛
x
Npx qN-x

Variabili casuali di uso comune
9
x px
0 ⎟⎟⎠
⎞⎜⎜⎝
⎛
0
Np0 qN-0
1 ⎟⎟⎠
⎞⎜⎜⎝
⎛
1
Np1 qN-1
2 ⎟⎟⎠
⎞⎜⎜⎝
⎛
2
Np2 qN-2
... ......
N ⎟⎟⎠
⎞⎜⎜⎝
⎛
N
NpN qN-N
1

Lezione 3
10
Le probabilità px di B(N; p) possono essere calcolate ricursivamente: po = (1-p)
N
px = px-1 p1p
n1xN
−+− per x=1,2, ..., N
La binomiale è simmetrica se p=q=1/2, è asimmetrica positiva per p < 1/2, è asimmetrica negativa per p>1/2.

Variabili casuali di uso comune
11
μ = E[B(N;p)] = ∑=
N
1i
p = Np
μ2 = Np + N(N-1)p2 μ3 = N(N-1)(N-2)p3 + 3N(N-1)p2 + Np μ4 = N(N-1)(N-2)(N-3)p4 + 6N(N-1)(N-2)p3 + 7N(N-1)p2 + Np σ
2 = Npq
Se Xi~B(Ni;p), i=1,2,...,k, sono k v.c. Binomiali indipendenti allora
X = ∑=
k
1i
Xi
è ancora una Binomiale X~B(N1+N2+...+Nk; p).

Lezione 3
12
Esempio
Il 10% delle piante immesse in un nuovo impianto muore. Al livello di almeno il 99% determinare il numero delle piante da immettere nel vivaio in modo che almeno 6 di queste sopravvivano. Posto: p = 0.9 (successo di sopravvivenza di una pianta)
1-p = 0.1 (insuccesso di sopravvivenza di una pianta)
X = N° piante che sopravvive
P{X ≥ 6} = ︶9.0︵
6⎟⎟⎠
⎞⎜⎜⎝
⎛∑=
xNN
x
x(0.1)
N-x ≥ 0.99
(a) per N = 9 si ha:
P(X ≥ 6) = x)9.0(x
99
6x∑
=⎟⎟⎠
⎞⎜⎜⎝
⎛ (0.1)
9-x = 0.99167
(b) per N = 8 si ha:
P(X ≥ 6) = x)9.0(x
88
6x∑
=⎟⎟⎠
⎞⎜⎜⎝
⎛(0.1)
8-x = 0.96191
Deve essere almeno N = 9 perché, con probabilità maggiore o eguale a 0.99, almeno 6 piante sopravvivano.

Variabili casuali di uso comune
13
Se X è una v.c. Binomiale B(N;p), la v. c. Binomiale frequenza è F = NX = ∑
=
N
1iN1 Bi(1;p)
x px
0 ⎟⎟⎠
⎞⎜⎜⎝
⎛
0
Np0 qN-0
1/N ⎟⎟⎠
⎞⎜⎜⎝
⎛
1
Np1 qN-1
2/N ⎟⎟⎠
⎞⎜⎜⎝
⎛
2
Np2 qN-2
... ......
1 ⎟⎟⎠
⎞⎜⎜⎝
⎛
N
NpN qN-N
1
μ = E(F) = E ⎟⎠⎞
⎜⎝⎛NX =
N1 Np = p
var(F) = var ⎟⎠⎞
⎜⎝⎛NX = 1
N2 Npq = Npq
la media di F è proprio pari a p, mentre la variabilità di F decresce al crescere di N.

Lezione 3
14
La variabile casuale di Poisson La v.c. di Poisson è una variabile casuale discreta e viene, di solito, utilizzata per analizzare fenomeni connessi a conteggi, viene anche detta degli eventi rari.
⎟⎟⎠
⎞⎜⎜⎝
⎛
=→
∞→ x
Nlim
λNp0p
Npx qN-x =
!x1
λx e-λ
, x = 0,1, 2, ...

Variabili casuali di uso comune
15
x px
0 e-λ 1 λ e-λ
2 λ2 e-λ/2 3 λ3 e-λ/6 ... ... x λx e-λ/x! ... ... 1
Le probablità di una P(λ) soddisfanno le seguenti relazioni po = e-λ
px = px-1 xλ per x=1,2,.....
Lv.c. di Poisson può essere espressa come somma di infinite Bernoulli indipendenti:
P(λ) =
λ=→
∞→
Np0p
Nlim B(N;p) = ∑
=λ=
→∞→
N
1iNp
0pNlim Bi(1;p)
X = ∑=
k
1i
Xi = P(λ1+λ2+...+λk),

Lezione 3
16
μ = E[P(λ)] = λ
μ2 = E[P2(λ)]= λ + λ2
In particolare
σ
2 = μ2 - μ2 = λ + λ2 - λ2 = λ;
γ1 = λ1
γ2 = λ1
Esempio
La probabilità di avere un parto trigemino è p = 1/8000. Calcolare la probabilità che osservando 10.000 parti a caso: (a) se ne abbiamo non più di 4 trigemini; (b) almeno 4 trigemini.
(a) P{X ≤ 4} = ∑=
4
0j
P(x=j) = 0.99088
(b) P{X ≥ 4} = 1 - P{X < 4} = 1 -∑=
3
0j
P(x=j) = 0.03826
N = 10.000 è "grande" e p = 1/8.000 è "piccolo" si può usare l'approssimazione di Poisson con λ = 10.000 8.000 = 1.25

Variabili casuali di uso comune
17
(a) P{X ≤ 4} = ∑=
4
0j
P(X=j) = 0.99006
(b) P{X ≥ 4} = 1 - P{X < 4} = 1 -∑=
3
0j
P(x=j) = 0.03891
Esempio Il numero di vendite per settimana si comporta come una di Poisson. Inoltre, è noto che in media vende 2 manufatti al giorno. Determinare lo stock di magazzino in modo che quel venditore abbia probabilità di almeno il 99% di avere merce per soddisfare la domanda di una settimana. λ = 2 × 7 = 14
beni venduti in media al giorno
giorni della settimana
Bisogna trovare n per cui
P{X ≤ N} ≥ 0.99 cioè
!je jN
0j
λλ−
=∑ = e-λ
!j
jN
0j
λ
=∑ ≥ 0.99
Per N= 23 si ha:

Lezione 3
18
P{X ≤ 23} = 0.99067
Il venditore deve tenere in magazzino almeno 23 manufatti per essere sicuro al 99% di soddisfare le richieste di una settimana. La variabile casuale Normale La v.c. Normale è nota anche come v.c. degli errori accidentali. E’ funzione di soli due parametri: la media μ e la varianza σ
2; si scrive
X~N(μ, σ
2)
La f.d. di una v.c. Normale con media μ e varianza σ
2 è
f(x) = 22
1
πσexp
⎭⎬⎫
⎩⎨⎧
μ−σ
− 22 )x(
21
risulta
f(μ - x) = f(μ + x). e quindi
μ = Me

Variabili casuali di uso comune
19
max f(x) = f(μ) = c = 22
1
πσ
Supponiamo di avere due fenomeni aleatori X ed Y che si distribuiscono entrambi come normali con uguale varianza e medie diverse:
X~N(μ1; σ2); Y~N(μ2; σ
2)
con μ1 ≤ μ2

Lezione 3
20
Le v.c. Normali abbiano uguale media ma varianza diversa:

Variabili casuali di uso comune
21
Le Normali posseggono una proprietà riproduttiva: se è X~N(μ, σ2), allora
Z = a + b X ~N(a + bμ, b
2σ
2)
In particolare, come già visto in altra occasione, se è
a = - σμ
, b = σ1
si ottiene
Z = - σμ
+ σ1
X = σ
μ−X~N(0, 1)
la v.c. Normale standardizzata:
Calcolare la probabilità che X cada nell'intervallo [a, b]:

Lezione 3
22
P{a ≤ X ≤b} = 2
b
a 2
1
πσ∫ exp⎭⎬⎫
⎩⎨⎧ μ−
σ− 2
2 )x(2
1dx
il problema si ricorre alla seguente procedura: (a) si sono tabulate le probabilità relative alla Normale standardizzata; (b) si standardizza la v.c. X ed i relativi estremi dell'intervallo [a, b]; (c) si usa la tavola delle probabilità della standardizzata per calcolare le probabilità cercate.
P{a ≤ X ≤b}= P⎭⎬⎫
⎩⎨⎧
σμ−
=σ
μ−=
σμ− bXa
= P⎭⎬⎫
⎩⎨⎧
σμ−
==σ
μ− bZa
la probabilità che X cada nell'intervallo [a, b] risulta uguale alla probabilità che Z cada nell'intervallo
⎥⎦⎤
⎢⎣⎡
σμ−
σμ− b,a
.
Da un punto di vista grafico si ha una situazione come quella qui appresso riportata

Variabili casuali di uso comune
23
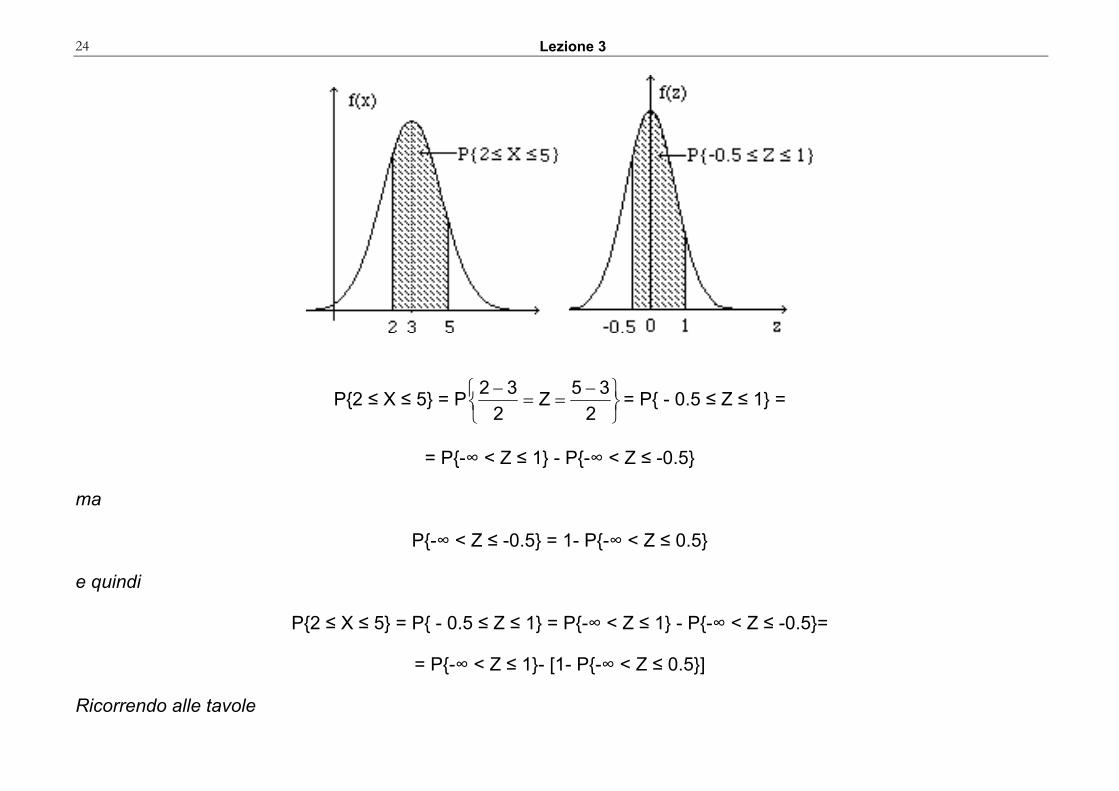
Esempio Supponiamo che sia X~N(3, 4), calcolare
P{2 ≤ X ≤ 5}
Lezione 3
24
P{2 ≤ X ≤ 5} = P⎭⎬⎫
⎩⎨⎧ −
==−
235Z
232 = P{ - 0.5 ≤ Z ≤ 1} =
= P{-∞ < Z ≤ 1} - P{-∞ < Z ≤ -0.5}
ma
P{-∞ < Z ≤ -0.5} = 1- P{-∞ < Z ≤ 0.5}
e quindi
P{2 ≤ X ≤ 5} = P{ - 0.5 ≤ Z ≤ 1} = P{-∞ < Z ≤ 1} - P{-∞ < Z ≤ -0.5}=
= P{-∞ < Z ≤ 1}- [1- P{-∞ < Z ≤ 0.5}]
Ricorrendo alle tavole

Variabili casuali di uso comune
25
P{2 ≤ X ≤ 5}= P{-∞ < Z ≤ 1}- [1- P{-∞ < Z ≤ 0.5}] =
= 0.8413 - (1 - 0.6915) = 0.5328.
I momenti della generica v.c. X~N(μ, σ2)
E(Xr) = ⎟
⎟⎠
⎞⎜⎜⎝
⎛∑= j
rr
0j
μr- j
σj E(Z
j)
da cui:
E(X2) = ⎟⎟
⎠
⎞⎜⎜⎝
⎛∑= 0
22
0j
μ2-j
σjE(Z
j) = μ2
+ σ2
E(X3) = ⎟⎟
⎠
⎞⎜⎜⎝
⎛∑= j
33
0j
μ3-j
σjE(Z
j) = μ
3 + 3μσ2
E(X4) = ⎟⎟
⎠
⎞⎜⎜⎝
⎛∑= j
44
0j
μ4-j
σjE(Z
j) = μ
4 + μ2σ
2 + 3σ4
Esempio

Lezione 3
26
Un fenomeno si distribuisce normalmente con μ=3 e σ2 = 4, calcolare: (a) P{1.5 ≤ X ≤ 4.3} (b) P{4.21 ≤ X ≤ 6.35} (a)
si ottiene
P{1.5 ≤ X ≤ 4.3}= P⎭⎬⎫
⎩⎨⎧ −
==−
233.4Z
235.1 = P{-0.75 ≤ Z ≤ 0.65} =
= P{-∞ < Z ≤ 0.65} - P{-∞ < Z ≤ -0.75} =
= P{-∞ < Z ≤ 0.65} - [1 - P{-∞ < Z ≤ 0.75}] =
= 0.7422 - (1- 0.7734) = 0.5156 (b)

Variabili casuali di uso comune
27
si ottiene
P{4.21 ≤ X ≤ 6.35} = P⎭⎬⎫
⎩⎨⎧ −
==−
2335.6Z
2321.4 = P{0.605 ≤ Z ≤ 1.675}≈
≈ P{0.60 ≤ Z ≤ 1.67} = P{-∞ < Z ≤ 1.67} - P{-∞ < Z ≤ 0.60} =
= 0.95254 - 0.7257 = 0.2268

Lezione 3
28
Richiamiamo le identità |X - b | ≤ c = -c ≤ X-b ≤ c = b-c ≤ X ≤ b+c
|X - b | ≥ c = (X-b ≥ c)∪(X-b ≤ -c) = (X ≥ b+c)∪ (X ≤ b-c)
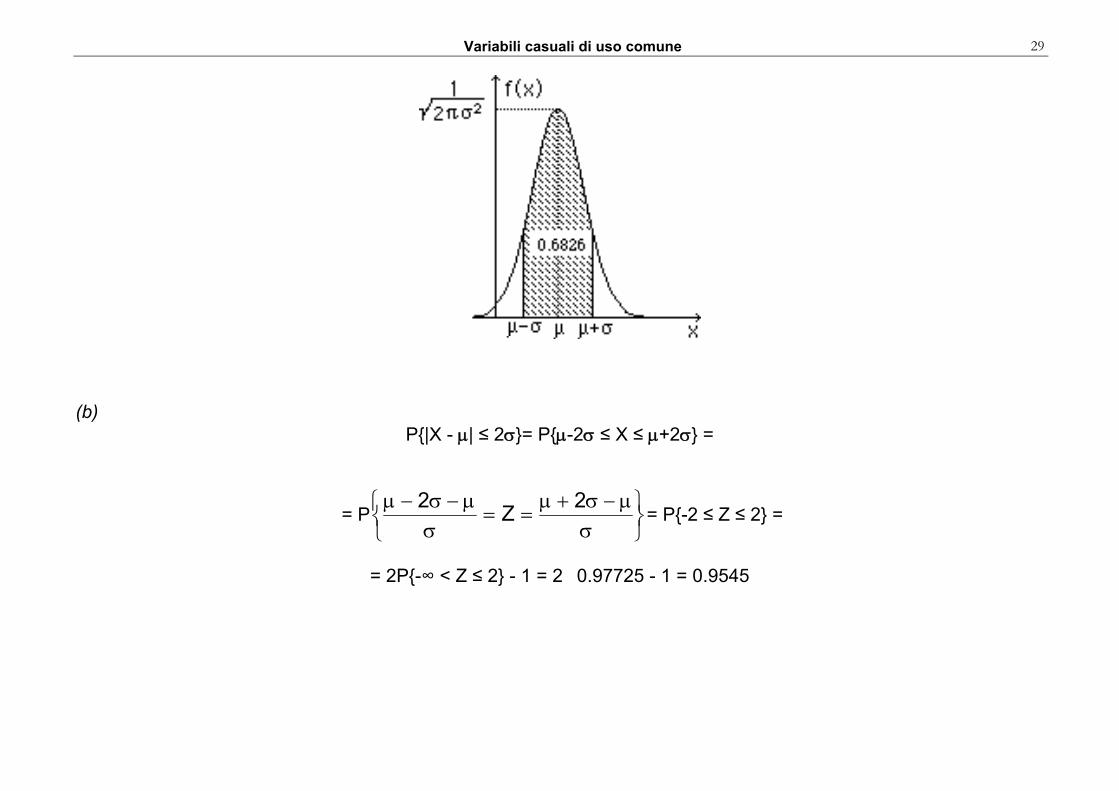
Esempio Supposto che il fenomeno X si distribuisca come una v.c. Normale con media � e varianza �2 qualsiasi, calcolare (a) P{|X - μ | ≤ σ } (b) P{|X - μ | ≤ 2σ } (c) P{|X - μ | ≤ 3σ } (a)
P{|X - μ| ≤ σ}= P{μ−σ ≤ X ≤ μ+σ} =
= P⎭⎬⎫
⎩⎨⎧
σμ−σ+μ
==σ
μ−σ−μ Z = P{-1 ≤ Z ≤ 1} =
= 2P{-∞ < Z ≤ 1} - 1 = 2×0.8413 - 1 = 0.6826
Variabili casuali di uso comune
29
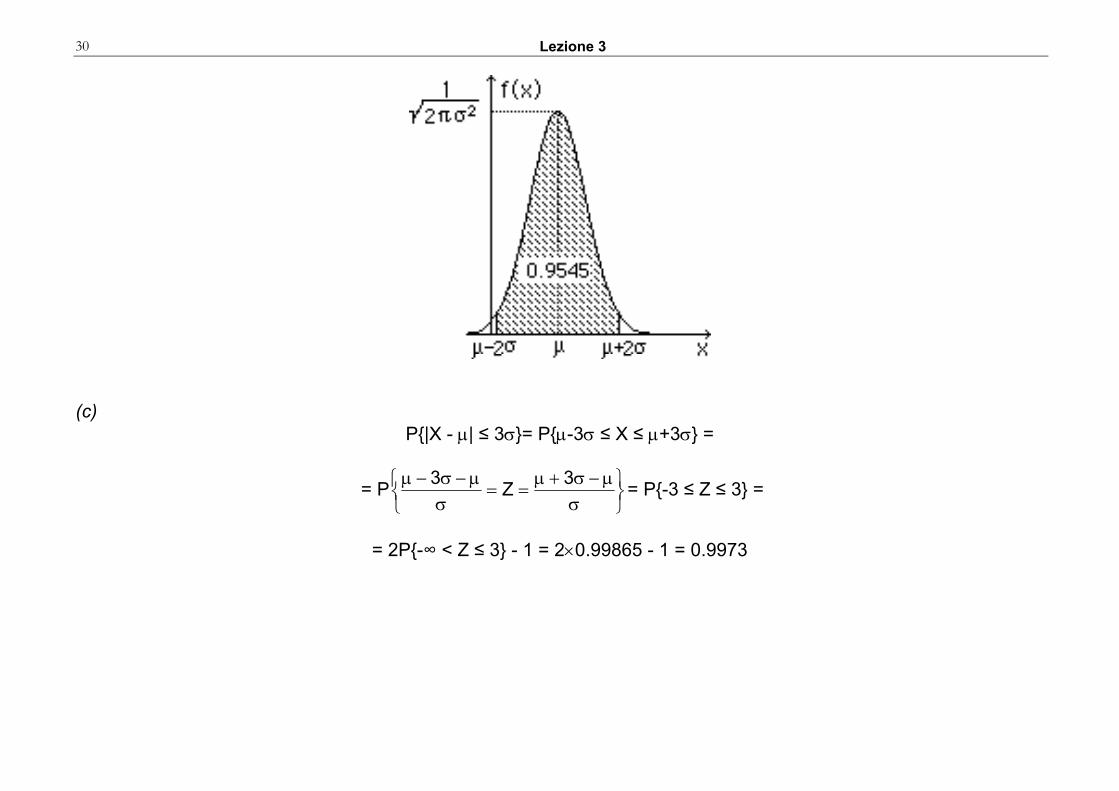
(b)
P{|X - μ| ≤ 2σ}= P{μ-2σ ≤ X ≤ μ+2σ} =
= P⎭⎬⎫
⎩⎨⎧
σμ−σ+μ
==σ
μ−σ−μ 2Z2= P{-2 ≤ Z ≤ 2} =
= 2P{-∞ < Z ≤ 2} - 1 = 2�0.97725 - 1 = 0.9545
Lezione 3
30
(c) P{|X - μ| ≤ 3σ}= P{μ-3σ ≤ X ≤ μ+3σ} =
= P⎭⎬⎫
⎩⎨⎧
σμ−σ+μ
==σ
μ−σ−μ 3Z3 = P{-3 ≤ Z ≤ 3} =
= 2P{-∞ < Z ≤ 3} - 1 = 2×0.99865 - 1 = 0.9973

Variabili casuali di uso comune
31
Vogliamo individuare la costante a di modo che, fissato, α sia
P{|X - μ| ≤ a} = α
P{|X - μ| ≤ a}= P{μ-a ≤ X ≤ μ+a} = ∫+μ
−μ
a
a
f(x)dx = α
α = P{|X - μ| ≤ a}= P{μ-a ≤ X ≤ μ+a} =
= P⎭⎬⎫
⎩⎨⎧
σμ−+μ
==σ
μ−−μ aZa= P
⎭⎬⎫
⎩⎨⎧
σ==
σ− aZa
= 2P⎭⎬⎫
⎩⎨⎧
σ==
aZ0
da cui

Lezione 3
32
P⎭⎬⎫
⎩⎨⎧
σ≤≤
aZ0 = 2α
che è equivalente a
P⎭⎬⎫
⎩⎨⎧
σ≤≤∞−
aZ = 2α
+ 0.5
Dalla tavola della standardizzata, in corrispondenza di α* = 2α
+ 0.5, si ricava il valore zα ≈ σa
e quindi a ≈ zασ.
Esempio Supponiamo che sia X~N(μ, 4) e si voglia individuare la costante a per cui risulti
P{|X - μ| ≤ a}= 0.65
In questo caso si ha α* = 0.652 + 0.5 = 0.825. Il valore più vicino ad α* riportato nella tavola della Normale
standardizzata è 0.8238 in corrispondenza del quale si ha zα= 0.93 e quindi risulta
a ≈ 2 (0.93) = 1.86.

Variabili casuali di uso comune
33
una qualsiasi combinazione lineare di Normali indipendenti si distribuisce ancora come una v.c. Normale Xi~N(μi, σ2
i ), i=1,2,...,k, indipendenti, la nuova v.c.
Y = co + c1X1 + c2X2 + ... + ckXk
è Normale con μy = co + c1μ1 + c2μ2 + ... + ckμk σ2
y = c21 σ2
1 + c22 σ2
2+ ... + c2k σ2
k cioè
Y ~N(co + c1μ1 + c2μ2 + ... + ckμk; c21 σ2
1 + c22 σ2
2+ ... + c2k σ2
k )

Lezione 3
34
LA V.C. CHI-QUADRATO
Siano date k v.c. normali standardizzate indipendenti:
Z1~N(0, 1), Z2~N(0, 1), ..., Zk~N(0, 1) Allora la nuova v.c.
Y = ∑=
k
1i
Z2i
è la v.c. Chi-quadrato con k gradi di libertà.
gradi di libertà = numero delle variabili - numero dei vincoli
La v.c. χ2k è continua in (0; +∞), la f.d. è
f(y) = )2/k(2
ye2/k
1)2/k(2/y
Γ
−−per y > 0
ove Γ(p) è detta funzione gamma

Variabili casuali di uso comune
35
Γ(p) = ∫∞
0
xp-1e-x dx , per p > 0; Γ(p+1) = p Γ(p),
se p è un numero intero si ha
Γ(p) = (p-1)!; Γ ⎟⎠⎞
⎜⎝⎛ +
21p = p
.....
2)1p2(531 −
π ;
Γ ⎟⎠⎞
⎜⎝⎛21
= π .

Lezione 3
36
Per quel che riguarda la media e la varianza della v.c. Chi-quadrato, ricordando che E(Z) =0, E(Z2) = 1, E(Z3) = 0, E(Z4) = 3, risulta
E(χ2r ) = E
⎥⎥⎦
⎤
⎢⎢⎣
⎡∑
=
2i
k
1i
Z = ∑=
k
1i
E[Z2i ] = k
var(χ2r ) = var
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
∑=
2i
k
1i
Z = ∑=
k
1i
var[Z2i ] = 2k
possiamo così calcolare il momento secondo della v.c. χ2k ottenendo
μ2 = σ2 + μ2 = 2k + k2
γ1 = k8
> 0; γ2 = k
12> 0
X~χ2
k ; Y~χ2h allora V = X + Y ~χ2
hk+

Variabili casuali di uso comune
37
T DI STUDENT Date le due v.c. Z~N(0, 1) ed Y ~χ2
k indipendenti
v.c. T di Student con k gradi di libertà è
T(k) = k/Y
Z=
k/
)1,0(N2kχ
La v.c. T di Student è funzione del solo parametro k e la sua f.d., si dimostra, è data da
f(t) = )k/t1()k
21(
)]1k(21[
k1 2+
Γ
+Γ
π-(k+1)/2 , - ∞ < t < ∞

Lezione 3
38
Quando è k=1 questa variabile casuale prende il nome di v.c. di Cauchy.
μr = E(T r) =
)21()k
21(
2/r )]rk(21[)]1r(
21[k
ΓΓ
−Γ+Γ se r è pari ed r<k.
σ2 =
2kk−
se k > 2; γ1 = 0 se k >3; γ2 = 4k
6−
>0 se k >4.
Questo vuole dire che la v.c. T di Student, oltre ad essere simmetrica, è sempre leptocurtica. Tenendo conto che
E ⎟⎠⎞
⎜⎝⎛ χ2
kk1
= 1k k =1; var ⎟⎠⎞
⎜⎝⎛ χ2
kk1
= 2k1
2k = k2
1k χ2k , al divergere di k all'infinito, assume il suo valore medio 1 con certezza. Ma allora per
T(k) = k/
)1,0(N2kχ
si ha
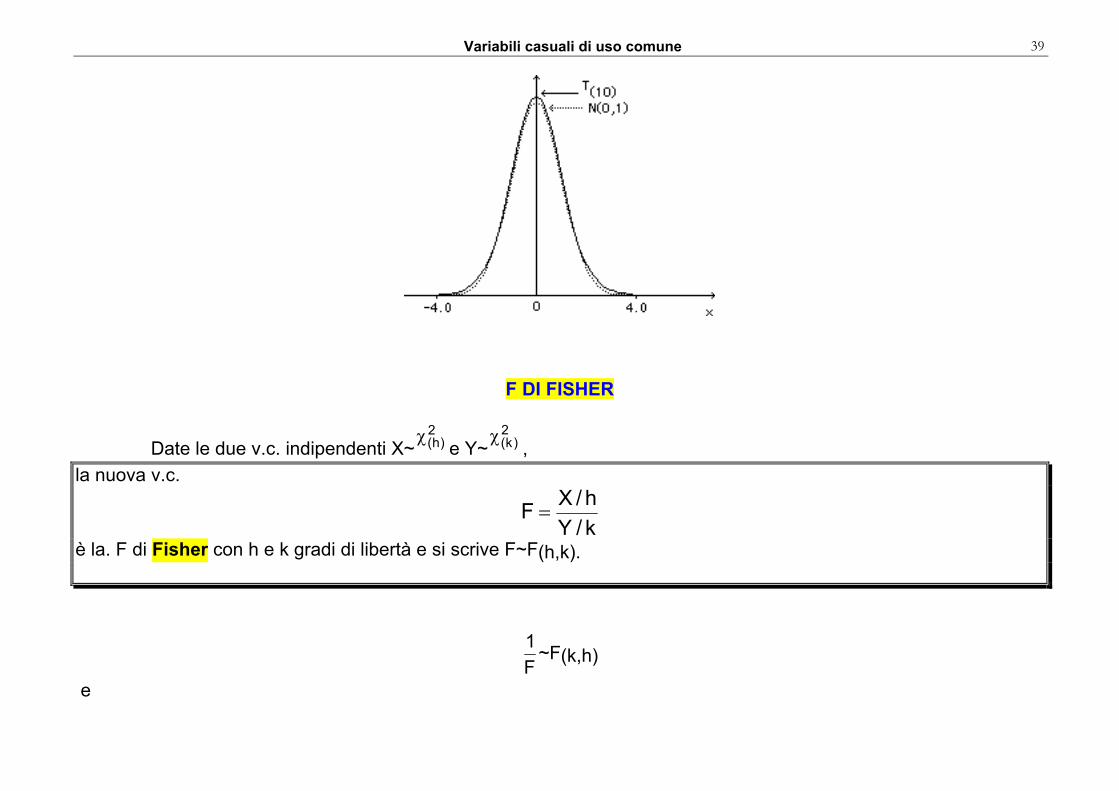
T(k) → N(0, 1), per ∞→k .
Variabili casuali di uso comune
39
F DI FISHER
Date le due v.c. indipendenti X~2
)h(χe Y~
2)k(χ,
la nuova v.c.
k/Yh/XF =
è la. F di Fisher con h e k gradi di libertà e si scrive F~F(h,k).
F1 ~F(k,h)
e

Lezione 3
40
P{0 ≤ F(h,k) ≤ 1/Fo} = P{Fo ≤ F(k,h) ≤ +∞} per Fo > 0 Inoltre, la v.c. F di Fisher può essere considerata una generalizzazione della v.c. T di Student dato che si verifica facilmente, dalle definizioni delle due v.c., che se è X~T(k) risulta immediatamente
2
2k
2)k(
k/
)1,0(NT⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
χ= =
k/1/
2k
21
χ
χ~F(1,k)
f(F) = 2/)kh(
12/h2/h
)k/Fh1(
Fkh
k21h
21
)kh(21
+
−
+⎟⎠⎞
⎜⎝⎛
⎟⎠⎞
⎜⎝⎛Γ⎟
⎠⎞
⎜⎝⎛Γ
⎥⎦⎤
⎢⎣⎡ +Γ
per 0<F<∞

Variabili casuali di uso comune
41
μr = E(Fr) = ⎟⎠⎞
⎜⎝⎛Γ⎟
⎠⎞
⎜⎝⎛Γ
⎟⎠⎞
⎜⎝⎛ −Γ⎟
⎠⎞
⎜⎝⎛ +Γ
k21h
21h
rk21rh
21k
r
r
per - 12 h < r < 12 k
da cui si ottiene:
μ = 2k
k−
per k > 2
var(F) =)4k()2k(h
)2kh(k22
2
−−
−+ per k>4
γ1 = 6k
)2kh2()2kh(h
)4k(8−
−+−+
−> 0 per k > 6
γ2 = 12[(k-2)2(k-4)+h(h+k-2)(5k-22)]h(k-6)(k-8)(h+k-2) > 0 per k > 8
F(h,k) → 2)h(h
1χ .

Lezione 3
42
V.C. LOGNORMALE La v.c. Y si distribuisce come una Lognormale con parametri (λ, δ) Più precisamente, data la v.c. X~LN(λ, δ) la nuova v.c.
Y = eX prende il nome di v.c. Lognormale con parametri (λ, δ)
f(x) = πδ 2x
1exp
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎟⎠⎞
⎜⎝⎛
δλ−
−2)xlog(
21
, -∞<λ<∞, δ>0

Variabili casuali di uso comune
43
μ = eλ e
δ2/2 ; σ2 = e2λ eδ2
(eδ2 - 1); γ1 = (e
δ2 + 2) 1e −2δ > 0; γ2 = e
4δ2+ 2e
3δ2 + 3e
2δ2 - 6 > 0.
La v.c. Lognormale è una v.c. sempre asimmetrica positiva e leptocurtica, si osservi che la distribuzione Lognormale è tanto più vicina alla simmetria ed alla mesocurtosi quanto più δ è piccolo.

Lezione 3
44
NORMALE DOPPIA La v.c. Normale doppia (X, Y) è definita sull'intero piano (x, y) ed è funzione dei cinque parametri:
μx, μy, σ2x , σ2
y , σxy
Di solito, per indicare che la v.c. (X, Y) si distribuisce come una Normale doppia si usa la notazione seguente:
(X, Y) ~N2(μx, μy, σ2x , σ2
y , σxy)
(X, Y) ~N2(μ; Σ ); ⎟⎟⎠
⎞⎜⎜⎝
⎛
μ
μ=μ
y
x, ⎟
⎟⎠
⎞⎜⎜⎝
⎛
σσ
σσ=Σ
yxy
xyx
f(x,y) = 2
yx 12
1
ρ−πσ σexp
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
σ
μ−+
σ
μ−
σμ−
−σ
μ−
ρ−− 2
y
2y
y
y
x
x2x
2x
2
)y(yxr2
)x(
)1(21
• Ogni combinazione lineare di una Normale doppia è ancora una normale; • Ciascuna marginale di una normale doppia è una normale semplice: X~N(μx, σ
2x ) Y~N(μy, σ
2y ).

Variabili casuali di uso comune
45
μx = μy =0, σ2x =1, σ2
y =2, ρ =0.5 μx = μy =0, σ2x =1, σ2
y =2, ρ = 0
μx = μy =0, σ2x = σ2
y =2, ρ =0.5

Lezione 3
46
Data la v.c. (X, Y) Normale doppia, condizione necessaria e sufficiente perché X ed Y siano indipendenti è che sia ρ = 0.
l'indipendenza è equivalente all'incorrelazione
(X|Y=y)~N⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
σ
σ−σμ−
σ+
σμ 2
y
2xy2
xy2y
xyx ),y(
(Y|X=x)~N⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
σ
σ−σμ−
σ+
σμ 2
x
2xy2
yx2x
xyy ),x(
La media della v.c. condizionata (Y|X=x) è una retta:
μy|x = μy + )x( x2x
xy μ−σ
σ= ⎟
⎟⎠
⎞⎜⎜⎝
⎛μ
σ
σ−μ x2
x
xyy + 2
x
xy
σ
σx = βo + β1x
μx|y = μx + )y( y2y
xy μ−σ
σ= αo + α1y
La densità della normale doppia ha un unico massimo per (x, y) = (μx, μy) ed è costante sull'ellisse con centro in

Variabili casuali di uso comune
47
(μx, μy)
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
σ
μ−+
σ
μ−
σμ−
ρ−σ
μ−2y
2y
y
y
x
x2x
2x )y(yx
2)x(
= c
ove si è supposto che fosse σxy > 0.
• X-Y ~ N(μx - μy; σ2x + σ2
y +2σxy)
• X+Y ~ N(μx + μy; σ2x + σ2
y +2σxy)
• se è μx=μy=0 si ha 2xy
2y
2x
1σ−σσ
[X2σ2
y - 2 XYσxy + Y2σ2
x ] ~ χ22

Lezione 3
48
ALCUNE LEGGI DI CONVERGENZA Data la successione di variabili casuali indipendenti
X1, X2, …, Xn,…≡ {Xn} con
μ1, μ2, ..., μn, ....
σ21 , σ2
2 , ...., σ2n , ....
e consideriamo la v.c. media
n_X = ∑
=
n
1jn1
Xj
Visto che le Xi sono indipendenti, segue
E(_Xn) = ∑
=
μ
n
1jjn
1≡ μ
(n)
Var(_Xn) = ∑
=
σn
1j
2j2n
1
Nel caso particolare in cui è

Variabili casuali di uso comune
49
μ1 = μ2 = … = μn = … = μ
σ21 = σ2
2 = … = σ2n = … = σ2
si ha
E(_Xn) = μ; Var(
_Xn) =
n
2σ
Definizione La successione di v.c. {Xn} converge in probabilità o debolmente a X
∞→nlim P{|Xn - X| < ε} = 1; per ogni ε > 0
si scrive
∞→nlim Xn = X; Xn
P→X

Lezione 3
50
Definizione La successione di v.c. {Xn} converge in media quadratica a X
∞→nlim E[(Xn - X)2] = 0
Xn .m.q
→ X La convergenza in media quadratica implica quella in probabilità. Se
∑=
∞→
n
1j2n n1lim σ
2j = 0
allora _Xn - μ(n)
P→0
Data la successione di v.c. {Xn}, nel caso particolare in cui risulti E(Xi) = μ, allora
_Xn - μ
P→0
Se g(. ) è una funzione continua e se Xn P→X allora
g(Xn) P→g(X)

Variabili casuali di uso comune
51
Definizione Convergenza in distribuzione o in legge ad X se
∞→nlim Fn(x) = F(x)
Xn L→X
in ogni punto di continuità di F(x). (a) F(x) viene detta la distribuzione asintotica della successione. (b) La convergenza in probabilità implica quella in distribuzione. In generale, non è vero il viceversa. (c) I due tipi di convergenza si equivalgono se X è una v.c. degenere:
Xn P→c ⇔ Xn
L→c
(d) Se g(. ) è una funzione continua e se Xn L→X allora
E[g(Xn)] ⎯→ E[g(X)]
Definizione La successione di v.c. {Xn} converge uniformemente in distribuzione alla v.c. X se
xnsuplim
∞→|Fn(x) - F(x)| = 0
Se {Xn} converge in distribuzione a X e se la funzione di ripartizione di X è continua allora la convergenza è uniforme.

Lezione 3
52
Altri risultati: (a) date le due successione di v.c. {Xn} ed {Yn}, se
|Xn-Yn| P→0; Yn
L→Y
allora
Xn L→Y
(b) Date le due successioni di v.c. {Xn} ed {Yn}, se
Xn L→X; Yn
P→0
allora
Xn Yn P→0
(c) Date le due successioni di v.c. {Xn} ed {Yn}, se
Xn L→X; Yn
P→c
allora
Xn + Yn L→X + c; Xn Yn
L→Xc
IL TEOREMA DEL LIMITE CENTRALE

Variabili casuali di uso comune
53
Data la successione di v.c. indipendenti:
X1, X2, ..., Xn, ...
con medie finite e varianze finite e strettamente positive. Consideriamo la standardizzata
Zn = )X...XXvar(
)X...XX(E)X...XX(
n21
n21n21+++
+++−+++=
= 2n
22
21
n21n21
...
)...()X...XX(
σ++σ+σ
μ++μ+μ−+++
si dimostra che Zn converge in distribuzione alla v.c. Normale standardizzata per n→∞:
Zn L→N(0, 1).
Per n finito ma grande si avrà
Zn ≈ Z ~N(0, 1)

Lezione 3
54
che equivale a
2n
22
21
n21n21
...
)...()X...XX(
σ++σ+σ
μ++μ+μ−+++≈ Z
da cui si ricava
(X1 + X2 + ...+ Xn) ≈ (μ1+ μ2+ ...+ μn) + 2n
22
21 ... σ++σ+σ Z
Ma al secondo membro dell'ultima espressione vi è una trasformazione lineare di una Normale standardizzata che, come sappiamo, è ancora una v.c. Normale e precisamente:
(X1 + X2 + ...+ Xn) ≈ N[(μ1+ μ2+ ...+ μn); (σ21 + σ2
2 + ...+ σ2n )]

Variabili casuali di uso comune
55
Esempio
χ2k ≈ N(k, 2k)

Lezione 3
56
Per Np > 20 ( oppure p ≈ 0.5) possiamo utilizzare il teorema limite centrale ed ottenere l'approssimazione
B(N, p) ≈ N(Np, Np(1-p))
![DISTRIBUZIONE UNIFORME CONTINUA e de nita su un a;b ......4)P[X 15] = 3 4 DISTRIBUZIONE NORMALE O GAUSSIANA E la distribuzione di probabilit a continua piu impor- tante. Descrive molti](https://static.fdocumenti.com/doc/165x107/60f4e1eeab795814f05513e8/distribuzione-uniforme-continua-e-de-nita-su-un-ab-4px-15-3-4-distribuzione.jpg)










![...Regione Emilia-Romagna A / Generatore numenxasuali Risultato generazione Generazione di 5 numeri distinti nell'intervallo [ 1, 43 ] Parametri del generatore: seme= 1041345, m =](https://static.fdocumenti.com/doc/165x107/5e8c2b82e0cc1047cd082064/-regione-emilia-romagna-a-generatore-numenxasuali-risultato-generazione-generazione.jpg)






