
UNIVERSITÀ DEGLI STUDI DI ROMA “LA...
136
UNIVERSITÀ DEGLI STUDI DI ROMA “LA SAPIENZA” FACOLTÀ DI SCIENZE STATISTICHE DIPARTIMENTO DI SCIENZE ATTUARIALI E FINANZIARIE DOTTORATO DI RICERCA IN SCIENZE ATTUARIALI XVIII CICLO TESI DI DOTTORATO “METODO SIMULATIVO, FAST FOURIER TRANSFORM ED EXTREME VALUE THEORY PER L’ANALISI DEL COSTO SINISTRI AGGREGATO NELLE ASSICURAZIONI DANNI” Coordinatore Prof. Fabio Grasso Rocco Roberto Cerchiara Roma, 20 marzo 2006
Transcript of UNIVERSITÀ DEGLI STUDI DI ROMA “LA...

UNIVERSITÀ DEGLI STUDI DI ROMA “LA SAPIENZA”
FACOLTÀ DI SCIENZE STATISTICHE
DIPARTIMENTO DI SCIENZE ATTUARIALI E FINANZIARIE
DOTTORATO DI RICERCA IN SCIENZE ATTUARIALI XVIII CICLO
TESI DI DOTTORATO
“METODO SIMULATIVO, FAST FOURIER TRANSFORM ED EXTREME VALUE THEORY PER L’ANALISI DEL COSTO SINISTRI AGGREGATO
NELLE ASSICURAZIONI DANNI”
Coordinatore Prof. Fabio Grasso Rocco Roberto Cerchiara
Roma, 20 marzo 2006

2
Introduzione Pag. 4 Capitolo 1 L’analisi del risk profile di una Compagnia Danni nell’ottica del progetto Solvency II
“ 6
1.1 I rischi connessi all’attività assicurativa danni 1.2 Alcuni dei più recenti sistemi di analisi della rischiosità di una
Compagnia danni
1.2.1 Il sistema Risk Based Capital utilizzato negli USA 1.2.2 Il modello proposto dalla FSA nel Regno Unito
1.2.3 L’approccio dell’IAA Insurer Solvency Assessment Working
Party
1.2.4 Lo Swiss Solvency Test 1.2.5 Il progetto Solvency II
1.2.5.1 Il contributo del CEIOPS
1.3 Cenni al caso dell’operational risk 1.4 Commenti in merito ai diversi approcci
“
“
“
“
“
“
“
“
“
“
6
11
12
20
27
34
38
44
46
52
Capitolo 2 I metodi per la valutazione della funzione di ripartizione del costo sinistri aggregato
“ 54 2.1 Il modello “compound” per il costo sinistri aggregato 2.2 La Teoria dei Valori Estremi e la logica POT 2.3 Il calcolo numerico della distribuzione del costo sinistri aggregato
2.3.1 Cenni ai metodi Ricorsivi
2.3.2 I Metodi di Inversione
2.3.2.1 Il metodo della Fast Fourier Transform
2.3.3 L’approccio simulativo
“
“
“
“
“
“
“
54
61
71
74
76
77
84

3
2.4 L’utilizzo della FFT nell’ambito della modellizzazione delle
dipendenze e dell’aggregazione tra rami
2.4.1 Caso 1: Indipendenza tra rami 2.4.2 Caso 2: Dipendenza tra rami
2.4.3 L’utilizzo della FFT per variabili bivariate
2.5 Alcuni confronti
2.5.1 Una breve comparazione tra il metodo di simulazione e la FFT
2.5.2 La modellizzazione della dipendenza tra sinistri di entità ordinaria ed i c.d. “Large Claims” nell’ambito di un modello di solvency assessment
Pag.
“
“
“
“
“
“
87
89
90
91
93
95
98
Capitolo 3 Alcuni esempi di applicazione della FFT, EVT e Simulazione
“ 103
3.1 La determinazione della distribuzione del costo sinistri aggregato nel ramo RCA del mercato italiano. Simulazione o FFT? 3.2 L’applicazione dell’EVT ai fini della modellizzazione del danno aggregato
“
“
103
117
Conclusioni “ 123 Appendice A Il metodo di Inversione diretta
“ 127
Appendice B Un procedimento nel caso di singoli sinistri considerati come variabili aleatorie indipendenti, ma non necessariamente con la stessa distribuzione
“ 128 Bibliografia “ 132 Ringraziamenti “ 136

4
Introduzione
La corretta determinazione della funzione di ripartizione della variabile
aleatoria costo sinistri aggregato ha un ruolo fondamentale nell’ambito dell’analisi
della rischiosità e della solvibilità di una compagnia di assicurazione contro i danni.
Tale esigenza sta divenendo sempre più pressante anche nell’ottica del progetto
comunitario denominato Solvency II, destinato alla revisione dell’intero complesso di
regole applicabili al settore assicurativo e riassicurativo, sulla base di una struttura
c.d. a tre pilastri che consenta una convergenza con la logica dell’approccio
prospettato in ambito bancario (Basilea II). E’ possibile osservare lo sviluppo di un
numero elevato di studi basati sulla definizione di modellistiche complesse che
consentano un’analisi integrata dei rischi insiti nell’attività assicurativa, volte anche
all’individuazione di eventuali dipendenze o correlazioni tra gli elementi
caratterizzanti il risk profile delle compagnie di assicurazione.
A tal fine nella parte iniziale della tesi sono descritti alcuni dei più recenti
sistemi di analisi del profilo di rischio e della solvibilità delle compagnie di
assicurazioni danni, tra cui il sistema Risk Based Capital (RBC) utilizzato negli USA,
quello proposto dalla Financial Services Authority (FSA), l’approccio
dell’International Actuarial Association Insurer Solvency Assessment Working Party
(IIA ISA-WP) e lo Swiss Solvency Test (SST), evidenziandone le peculiarità in
relazione alla modellizzazione del costo sinistri aggregato.
Le tecniche principali concernenti la modellizzazione del costo sinistri
aggregato sono oggetto del successivo capitolo 2, con particolare riferimento alla Fast
Fourier Transform (FFT), al metodo simulativo di Monte Carlo ed all’Extreme Value
Theory (EVT). Le diverse tecniche vengono analizzate anche ricorrendo a diversi

5
esempi basati su dati reali, come il Database dei dati incendio danesi del periodo
1980-2002.
Nella parte conclusiva del capitolo 2 viene esposto anche il caso semplificato di un
modello complesso di solvency assessment, dove è necessario analizzare la
dipendenza tra sinistri di entità ordinaria ed i c.d. “Large Claims”. In tale ambito é
utilizzato il metodo della FFT a due dimensioni ai fini della modellizzazione di
eventuali dipendenze sulle singole componenti del danno aggregato.
Successivamente nel capitolo 3 vengono fornite alcune applicazioni e confronti
tra i risultati ottenuti dai Metodi di Simulazione e FFT, utilizzando le statistiche
ANIA sul ramo R.C.Auto.
Infine, sulla base del set di dati “1991-1992 SOA Group of Medical Insurance
Large Claims” e sfruttando l’EVT, vengono evidenziate sia le problematiche
connesse alla valutazione del danno aggregato attraverso la logica Peaks Over
Threshold (POT) che la significatività della scelta della soglia in termini di valore
atteso di tale variabile aleatoria.
I risultati finali non mirano a fornire la preferibilità di un metodo rispetto agli
altri, ma evidenziano, con particolare riferimento alla complessità dei modelli
necessari all’applicazione del nuovo sistema di solvibilità, l’importanza e la
possibilità dell’utilizzo integrato di differenti tecniche ai fini dell’analisi della
distribuzione del costo sinistri aggregato di una Compagnia di assicurazioni contro i
danni e quindi la possibile interazione tra le tecniche EVT, FFT Simulazione1.
1 Nota dell’ autore: le variabili aleatorie saranno indicate con il simbolo ∼ in testa alla lettera con cui verranno indicate. Inoltre in luogo della parole “variabile aleatoria” si utilizzerà l’abbreviazione “v.a.”.

6
Capitolo 1
L’analisi del risk profile di una Compagnia Danni nell’ottica del
progetto Solvency II
Nelle pagine seguenti vengono presentati alcuni modelli di analisi del profilo di
rischiosità delle Compagnie di Assicurazione contro i danni, nati in relazione al
futuro progetto di solvibilità, c.d. Solvency II, evidenziandone le caratteristiche
peculiari con particolare riferimento all’underwriting risk e alla modellizzazione del
costo sinistri aggregato delle assicurazioni contro i danni.
1.1 I rischi connessi all’attività assicurativa danni
Innanzitutto è necessario specificare il concetto di rischio: “Risk is the chance
of something happening that will have an impact upon objectives. It is measured in
terms of consequences and likelihood” (si veda Australian and New Zealand Standard
on Risk Management, 1995). Tale definizione quindi non ha una connotazione
esclusivamente negativa, ma anche positiva, infatti: “Risk management is as much
about identifying opportunities as avoiding or mitigating losses”.
In base a quanto mostrato in IAA-WP [2004] si riporta una possibile
classificazione dei rischi in campo assicurativo (danni e vita):
o Underwriting risk: riserve insufficienti, crescita rapida, ecc.;
o Market risk: rischio di tasso di interesse, Asset/Liability Mismatching, ecc.;
o Credit risk: rischio di default, rischio di concentrazione;
o Operational risk: the risk of loss resulting from inadequate or failed internal
processes, people, systems or from external events (si veda Basilea II).

7
o Liquidity Risk;
o Event Risk: rischio reputazionale, legale, ecc.
all’interno dei quali esistono dei rischi specifici che possono a volte essere
caratterizzati da reciproche dipendenze. Di seguito si farà riferimento esclusivamente
all’underwriting risk e un breve cenno all’operational risk che può essere
modellizzato con le tecniche attuariali trattate in questa tesi di dottorato.
Ai fini dell’underwriting risk si richiama la definizione proposta dal IIA WP
[2004]: “is the specific insurance risk arising from the underwriting of insurance
contracts. The risks within the underwriting risk category are associated with both
the perils covered by the specific line of insurance and with the specific processes
associated with the conduct of the insurance business.” In tal caso viene proposto al
suo interno una serie di rischi che possono essere comuni a tutti, o quasi, i rami:
o Underwriting Process Risk: derivante dall’esposizione a perdite
finanziarie relative alla selezione ed approvazione dei rischi da
assicurare;
o Pricing Risk (premi insufficienti);
o Product Design Risk;
o Claims Risk (for each peril): il caso di un sinistro che produca ulteriori
sinistri o delle c.d. Cat Losses;
o Economic Environment Risk: si pensi agli effetti della crescita dei tassi
di inflazione (in particolare per le polizze vita);
o Net Retention Risk: livelli di ritenzione eccessivamente elevate che
compromettono i profitti;
o Policyholder Behaviour Risk: si pensi ad esempio al caso dei riscatti
delle polizze vita in situazioni in cui i mercati finanziari sono poco
appetibili;
o Reserving Risk: riserve tecniche insufficienti o run-off risk.

8
Per comprendere la significatività della corretta quantificazione di tale rischio,
ma non solo di questo, si richiama un interessante studio di A.M. Best sulle principali
cause delle insolvenze avvenute nel mercato USA tra il 1969 ed il 1998 (n. 683),
sintetizzato in Savelli [2005]:
- Riserve/Premi insufficienti: 22%
- Crescita rapida: 13%
- CAT losses: 6%
- Sovrastima assets: 6%
- Insolvenza riassicuratori: 3%
- Andamento società controllate: 4%
- Variazioni significative “core business” 4%
- Frodi 7%
- Miscellanea 7%
- Cause non identificabili 28% TOTALE 100%
Tabella 1.1.1: Cause di insolvenze nel mercato USA (1969-1998) – numero 683 imprese Fonte A.M. Best – Sigma [2000]
dove le prime tre cause indicate nella tabella sono riclassificabili nell’ambito
dell’underwriting risk e forniscono un totale del 41%. Sulla base del precedente
Rapporto Müller [1997], lo “Sharma” report [2002], commissionato dalla EU
Insurance Supervisors, presenta i casi di fallimento o di crisi (near misses) delle
Compagnie di Assicurazione europee tra il 1996 e il 2001. La conclusione è stata che
tali situazioni di sofferenza sono state causate in molti casi da una c.d. “causal chain”
di eventi legati al fallimento, le cui interrelazioni sono risultate molto difficili da
stimare.
Infatti é necessario osservare che non tutti i rischi sono “facilmente” quantificabili
(ad es. l’Operational risk e ovviamente le relative interdipendenze). A titolo di
esempio viene riportato una rappresentazione grafica sulle differenti collocazioni dei

9
rischi in termini di complessità e difficoltà nella relativa quantificazione (fonte
Federal Office of Private Insurance [2004]).
Figura 1.1.1: Relazione tra rischio assicurativo e
complessità nella quantificazione/misurazione
In tale ambito si sottolinea l’importanza di modelli che consentano una
misurazione e aggregazione delle diverse componenti di rischio nell’ambito
dell’attività assicurativa. Esistono in letteratura diversi approcci che consentono la
valutazione della rischiosità di una Compagnia di Assicurazione, tra cui quelli basati
sull’analisi multivariata dei ratios di bilancio (si veda ad esempio De Angelis P., De
Felice M., Ottaviani R. [1988]), di tipo stocastico a “valori di mercato” (De Felice M.
e Moriconi F. [2002]) e modelli di Teoria del Rischio (tra i più recenti Daykin et al.
[1994], Savelli N. [2003]). Nella presente tesi di dottorato si farà riferimento a
quest’ultimo approccio, anche nell’ottica del futuro progetto di solvibilità nella UE
(Solvency II), che in parte sarà basato su Risk Theory Models.
Nella Figura 1.2 viene riportato lo schema generale delle possibili interazioni e
interdipendenze con la teoria del rischio. L’obiettivo generale è esaminare come una
Compagnia di assicurazione possa reagire a diversi eventi potenziali, quali la
variazione del tasso di inflazione e di rendimento degli investimenti, causati da
recessioni o boom nell’economia nazionale, dalla pressione della concorrenza, ecc., e
trovare risposte che offrano una protezione adeguata.

10
Figura 1.1.2: La teoria del rischio e le interazioni possibili (fonte Pentikainen e Rantala [1999])
Nella teoria classica del rischio elementi come l’interesse e le spese erano
ignorati ed assumevano come unica variabile aleatoria il costo sinistri. La moderna
teoria del rischio ha introdotto e sviluppato modelli di simulazione della gestione di
una compagnia di assicurazioni, i cosiddetti management simulation models, in grado
di rappresentare, sfruttando la teoria del rischio, le molteplici interdipendenze
esistenti e valutare, a seguito di reiterate simulazioni, non solo il valore atteso, ma
anche la variabilità, e quindi la rischiosità, del processo economico e patrimoniale
legato all’impresa.
Infine nella figura seguente è possibile individuare un esempio grafico di
aggregazione dei rischi a cui si dovrebbe tendere con il futuro sistema di solvibilità,
TEORIA CLASSICA DEL RISCHIO
(Numero e costo sinistri) Cicli Inflazione Attivi (ROE) Run-off Spese Catastrofi Rischi diversi (frode) Controllo dinamico
SOLVIBILITÀ E SOLIDITÀ FINANZIARIA -Legislazione -Aspetti manageriali -Costo per la solvibilità -Normative nazionali
I N T E R A Z I O N I
DECISIONI DEL MANAGEMENT -Premi -Riserve -Riassicurazione (pieno) -Selezione dei rischi -Investimenti -Politica di vendita -Livello di sicurezza
MERCATO -Modello ad una unità -Strategie di competizione -Modelli a unità multiple -Teoria dei giochi
DISCIPLINE COLLEGATE -Matematica statistica -Analisi matematica -Teoria del controllo -Teorie di mercato dei capitali -Econometria -Sistemi dinamici -Ricerca operativa -Teoria dei giochi -EDP
Organizzazione per la pianificazione e statistiche

11
dove é possibile sintetizzare questo processo: identificare tutte le fonti di rischio,
individuare e combinare le distribuzioni, misurare la necessità di capitale e calcolare
il contributo di ciascuna business line e dei singoli rischi.
Figura 1.1.2: IRM e Aggregazione dei rischi
1.2 Alcuni dei più recenti sistemi di analisi della rischiosità di una Compagnia
danni
Attualmente si stanno sviluppando a livello internazionale i nuovi framework di
vigilanza (tra cui Solvency II), che tendono verso la definizione di ratios patrimoniali
calibrati sul risk profile delle Compagnie (risk-based capital requirements) e i nuovi
principi contabili internazionali che contribuiscono a modificare concetti consolidati
con l’introduzione ad esempio delle riserve sinistri stocastiche, il fair value, ecc.
In tale contesto in continuo mutamento, il progetto Solvency II ha come
obiettivo la riforma delle attuali regole di solvibilità nell’Unione Europea. Lo scopo è
l’introduzione di un regime di solvibilità che non si limiti all’analisi dei soli “rischi

12
tecnici”, ma che consideri l’intero risk profile, che sia flessibile, non eccessivamente
complesso e compatibile con i metodi di controllo delle autorità di vigilanza.
Il progetto "Solvency II" è diviso in due fasi distinte: la prima, avviata all'inizio
del 2001 e conclusasi due anni dopo, è stata sostanzialmente una fase di studio delle
principali problematiche. La seconda fase, avviata nel 2003 e tuttora in corso, è
dedicata all'elaborazione di soluzioni dettagliate ed ha come obiettivo la redazione di
una bozza della nuova direttiva entro il 2005.
Nella prima fase si è ritenuto fondamentale ricercare nei sistemi di vigilanza
esteri, in primis il RBC americano, principi che potessero essere trasferiti alla realtà
europea. A tale scopo nelle pagine successive si riporta la descrizione dei principali
sistemi di solvency assessment per le compagnie danni, con particolare riferimento
alla modellizzazione della v.a. costo sinistri aggregato X~ delle Compagnie Danni.
Ai fini di un elenco esaustivo delle diverse metodologie di analisi della solvibilità in
campo assicurativo si rimanda ad esempio a KPMG Report [2002] e a CEA and
Mercer Oliver Wyman [2005] ed al contributo ad esempio di Meyers [2004], “An
Analysis of the Underwriting Risk for DFA Insurance Company”, in merito all’analisi
dell’Underwriting Risk nell’ambito di modelli di tipo Dinamic Financial Analysis.
1.2.1 Il sistema Risk Based Capital utilizzato negli USA
Un possibile approccio metodologico fornito dalla letteratura attuariale per la
valutazione della solvibilità di una compagnia di assicurazioni é rappresentato dalla
definizione di metodologie di controllo mediante raffinate tecniche di selezione degli
indicatori di bilancio, sulla base dei quali poter valutare lo stato di benessere della
compagnia (oltre alla vasta letteratura statunitense, ricordiamo i contributi forniti da
studiosi italiani, tra cui, Buoro [1980], De Angelis, De Felice e Ottaviani [1988], De

13
Angelis, Gismondi e Ottaviani [1993]). Esso ha conosciuto particolare sviluppo negli
Stati Uniti, paese in cui per molti anni la stessa autorità federale di controllo sulle
imprese di assicurazione NAIC (National Association of Insurance Commissioners)
ha adottato criteri di vigilanza preventivi basati su indicatori di bilancio (c.d. Early
Warning System), laddove l’incisività degli interventi é calibrata a seconda della
vicinanza dei valori registrati per l’impresa a ‘soglie di attenzione” prefissate.
Il sistema Risk Based Capital (RBC) è stato introdotto nel 1993 dal NAIC dopo
che negli anni ’80 l’azione combinata della riduzione dei tassi di interessi e
dell’aumento della frequenza e della gravità dei sinistri mise in crisi un numero
rilevante di compagnie (cfr Quaderno ISVAP [1998]). Difatti il numero di insolvenze
fu più che triplo nel periodo 1984-1992 rispetto agli 8 anni precedenti.
Il principio fondamentale è quello di tenere conto del risk profile della
compagnia, con standard minimi di patrimonialità, cioé il c.d. Risk Based Capital
requirements). Il calcolo è effettuato applicando ai c.d. “valori di base”, coincidenti
con (o ad essi correlati) determinate voci di bilancio, un fattore percentuale
moltiplicativo fissato dalla NAIC. Il capitale minimo così stabilito viene raffrontato
con il capitale proprio dell’impresa. Sono previsti quattro stadi di intervento
dell’autorità di vigilanza, calibrati in funzione della gravità della situazione di rischio
dell’impresa, determinata in base al valore assunto dal rapporto tra il capitale proprio
dell’impresa e il capitale minimo risultante dalla formula.
La formula RBC è basata sulle seguenti categorie di rischio:
o Asset Risk (R0, R1, R2): rischio che il valore degli attivi sia insufficiente a far
fronte agli impegni contrattuali. Tale rischio è quantificato applicando alle voci
di bilancio diversi coefficienti di rischio che variano in funzione delle varie
tipologie di rischio (da 0% al 15%). Si ricavano quindi due requisiti

14
patrimoniali R1 e R2 rispettivamente per obbligazioni ed altri investimenti a
breve e per azioni, beni immobili e partecipazioni. Ad entrambi i requisiti
vengono attuate eventuali maggiorazioni o riduzioni a fronte di concentrazione
o diversificazione degli investimenti (c.d. Bond Size Adjustment Factor).
Inoltre si considera anche un requisito R0 in relazione ad imprese controllate
(funzione quindi del relativo RBC).
o Credit Risk (R3): il requisito è ricavato in funzione del tipo di credito assunto;
per la riassicurazione è prevista una percentuale del 10% e percentuali inferiori
per altri tipi di credito. Nella formula finale R3 viene posto uguale al 50% del
RBC derivante dal Credit risk.
o Off-balance risk: i cosiddetti rischi fuori bilancio, includono quei rischi
potenziali non rilevabili dai valori iscritti a bilancio. Alcuni di essi devono
essere indicati nelle note al bilancio; il requisito di capitale per la loro copertura
è pari all’1% dei relativi importi indicati nelle note. Gli off-balance-sheet risk
sono ripartiti nei vari gruppi prima elencati.
La quarta categoria di rischi, l’Underwriting Risk, é la componente più
significativa della formula e rappresentava negli USA circa i due terzi del requisito
complessivo RBC per il mercato danni (si veda Quaderno ISVAP [1998]).
L’underwriting risk è distinto in due sottocategorie: il rischio derivante da una
inadeguata riservazione (reserving risk) e quello derivante da una inadeguata politica
di tariffazione (pricing risk).
Tali requisiti vengono calcolati utilizzando un coefficiente di ponderazione
differenziato per ramo di attività. I fattori determinati dal Naic per tutte le compagnie
si basano sul peggiore risultato del mercato degli ultimi 10 anni in termini di run-off
ratio per quanto riguarda il rischio di riservazione e di loss-ratio per il rischio di
tariffazione. Questi coefficienti saranno poi modificati per tenere conto delle

15
specifiche caratteristiche in termini di run-off ratio e loss-ratio di ogni impresa
rispetto al mercato.
E’ da evidenziare che l’underwriting risk si calcola in relazione agli affari al netto
della riassicurazione e dipende pertanto in maniera considerevole dall’adeguatezza
(cfr. Quaderno ISVAP [1998]), dall’estensione e dalla tipologia delle cessioni in
riassicurazione (riassicurazione proporzionale, non proporzionale, riassicurazione c.d.
finanziaria).
A) Il rischio di riservazione
I fattori da moltiplicare per le riserve tecniche variano da un minimo di 17,5% (“low
risk profile”) a un massimo di 83,8% (assicurazioni ad alto profilo di rischio) in
funzione della rischiosità del ramo. La formula semplificata per la determinazione del
fattore di ponderazione α può essere espressa nel modo seguente (si veda il Rapporto
Müller [1997]):
α = max {0, [(Fqx (0,5 CDx /IDx + 0,5) + 1) PVqx -1]} (1.2.1.1)
dove
Fqx = fattore determinato dal NAIC in base al peggiore tasso di run-off del mercato
degli ultimi dieci anni per il ramo generico x;
CDx = run-off ratio medio della compagnia negli ultimi 10 anni (massimo = 400%);
IDx= run-off ratio medio del mercato negli ultimi 10 anni;
PVqx= tasso di sconto stabilito dal NAIC per attualizzare le riserve.
Si noti che è possibile, a differenza dell’attuale mercato RCA italiano,
l’attualizzazione delle riserve, con tasso = 5% nel 1998. Si osservi come tale fattore
sia legato al 50% all’andamento della Compagnia e al 50% a quello del mercato,
essendo

16
x
xx
IDIDCD ⋅+⋅ 5,05,0
Inoltre si osservi che se xx CDID = , cioè se la Compagnia è perfettamente allineata con
l’andamento di mercato, dovrebbe accantonare un capitale di sicurezza in grado di
proteggerla dall’ipotesi che la peggiore performance registrata dal mercato in passato
si ripeta nel futuro.
L’aggiustamento, operato per tenere conto dei futuri redditi da investimento, si
rende necessario in quanto in bilancio le riserve sinistri sono generalmente riportate
al lordo di sconti, fatta eccezione per il ramo “workers’ compensation” (infortuni sul
lavoro). In tal modo, considerato che la differenza tra riserve non scontate e riserve
attualizzate rappresenta già un “cuscinetto” implicito contro l’insolvenza, si evita di
aggravare ingiustificatamente il requisito patrimoniale di copertura.
Sono previste delle deduzioni per i contratti in cui l’impresa può richiedere una
integrazione al premio nel caso di aumento della frequenza dei sinistri, per le polizze
di responsabilità civile dei medici che coprono solo i rischi avvenuti e denunciati
prima della scadenza contrattuale, per le imprese con una buona diversificazione del
proprio business su vari rami.
Per le compagnie i cui premi negli ultimi anni sono cresciuti più del 10% il
requisito RBC per il rischio di riservazione dovrà essere incrementato di una
percentuale pari a 50 % * (Tasso di Crescita – 10%) * 90%.
B) Il rischio di tariffazione
Anche in questo caso il requisito di capitale atto a proteggersi dal rischio di
tariffazione si otterrà moltiplicando i fattori di ponderazione per i premi netti di ogni
ramo. I fattori di ponderazione andranno da un minimo del 15,8% a un massimo del
74,2% a seconda della rischiosità del ramo.

17
La formula di calcolo dei fattori di ponderazione è del tutto analoga a quella utilizzata
per il rischio di riservazione.
β = max {0, [f p x (0,5 CLx /ILx + 0,5) PV p x + CEx - 1]} (1.2.1.2)
fpx = un fattore fornito dalla NAIC per coprire il peggiore loss ratio del mercato negli
ultimi 10 anni nel ramo x;
CLx = il loss ratio medio della compagnia registrato nel ramo x negli ultimi 10 anni;
ILx = il loss ratio medio del mercato nel ramo x relativo agli ultimi 10 anni (dato
comunicato dalla NAIC);
PVpx = fattore espresso al valore attuale (al 5% di interesse) fornito dalla NAIC che
rappresenta il valore dei premi al netto dei caricamenti;
CEx= il tasso di caricamento della compagnia per il ramo x.
Vengono inoltre operati gli aggiustamenti già illustrati per il reserving risk, per
tenere conto della stipulazione di contratti che prevedono meccanismi di riduzione
del rischio tecnico e dell’aggravamento del rischio derivante dalla crescita eccessiva.
In relazione a tale ultimo correttivo, il sistema prevede che il RBC per il pricing risk
sia incrementato in base al risultato della seguente formula: 25%*(crescita -10%)*
90%.
Si noti infine che la formula generale non include l’interest rate risk (oggetto
di diverse critiche)2.
Una riduzione generale è contenuta nella formula al fine di prevedere la
parziale compensazione tra i diversi rischi considerati, ma nessun tentativo viene
effettuato per quantificare l’effettiva correlazione esistente tra i vari gruppi di rischio:
2 Infatti, sebbene la American Academy of Actuaries Task Force on Risk Based, che ha coadiuvato la NAIC durante i lavori, abbia raccomandato più volte di includere l’interest rate risk nella formula danni, la NAIC ha rinviato la decisione in attesa di valutare più a fondo la rilevanza del rischio di tasso per le compagnie danni (Quaderno ISVAP 1998).

18
(1.2.1.3)
dove
R4 = R3 + requisito patrimoniale previsto per il rischio di riservazione;
R5 = requisito patrimoniale previsto per il rischio di tariffazione.
Da tale formula si ottiene il c.d. Authorized Control Level (RBC totale). Si noti che i
termini sotto radice sono ipotizzati reciprocamente indipendenti, mentre la loro
somma è correlata con il termine R0 (in cui è anche presente il rischio tecnico).
Dai dati che compaiono nel Quaderno ISVAP [1998] il peso dei rischi tecnici
sull’ACL è pari a circa al 60% (mercato USA 1995).
I tipi di intervento dell’autorità di vigilanza dipendono dal rapporto tra il TAC
(Total Adjusted Capital) che rappresenta grossomodo il patrimonio netto dell’impresa
e il ACL. Se il TAC risulta inferiore a determinate soglie, calcolate in termini di
percentuali dell’Authorized Control Level RBC, sono previsti quattro livelli di
intervento di gravità crescente in funzione dell’aumentare del deficit:
1) Company Action Level RBC = 2 * ACL;
2) Regulatory Action Level RBC = 1,5 * ACL;
3) Authorized Control Level RBC = ACL;
4) Mandatory Control Level RBC = 0,7 ACL.
Se il TAC è inferiore al Company Action Level l’impresa deve presentare
all’autorità di vigilanza, entro 45 giorni, un piano che identifichi le cause del deficit e
le iniziative che intende adottare per risanare la situazione. Il piano deve inoltre
contenere previsioni sull’evoluzione della situazione finanziaria senza e con i
correttivi proposti.
25
24
23
22
210 RRRRRRACL +++++=

19
Se il TAC è inferiore al Regulatory Action Level l’autorità è legittimata a dettare
misure vincolanti per il management dell’impresa.
Se il TAC scende al di sotto dell’Authorized Company Level l’autorità di vigilanza
può disporre l’amministrazione straordinaria dell’impresa o la liquidazione.
Infine se il TAC è inferiore al Mandatory Control Level l’organo di controllo deve
assumere la gestione dell’impresa ed avviare la procedura liquidativa.
Se le misure di vigilanza richieste da un certo livello non vengono rispettate
dalla compagnia si procede con le misure previste dal livello successivo.
Dall’introduzione del nuovo sistema (1994) al 1998, il solvency ratio (capital
funds/premi netti) è salito dal 72% al 103%. Negli stessi anni la media di mercato del
RBC ratio è passato dal 432% del 1994 al 415% del 1998. L’incidenza delle
compagnie al di sotto del CAL è stata compresa tra 1.3% e 2.2%, mentre quella delle
compagnie al di sotto del ACL ha variato tra lo 0.8% e l’1.2% (fonte Savelli [2005]).
Si segnala che negli ultimi tempi si sta auspicando un cambiamento nei livelli
di intervento. Si vuole cioè integrare prevedendo possibilità d’intervento anche al di
sopra del 200% qualora il Combined ratio sia particolarmente sfavorevole (si veda
The Naic RBC formula revisited, CAS Spring Meeting Maggio 2004).
Figura 1.2.1.1: Fonte The Naic RBC formula revisited, CAS Spring Meeting Maggio 2004

20
1.2.2 Il modello proposto dalla FSA nel Regno Unito
In base al Consultation Paper 190 Financial Services Authority, [Luglio 2003],
“Enhanced Capital Requirements and Individual Capital Assessments for non-life
insurers”, il nuovo regime per le assicurazioni danni si basa su due elementi
fondamentali:
o un nuovo risk-based Enhanced Capital Requirement (ECR), basato su un
capitale aggiuntivo in relazione ai tre rischi: asset, underwriting e reserving,
calcolato in base ad una standardized formula, basata su coefficienti
moltiplicativi da applicare rispettivamente a attivi, premi e passività, a loro
connessi alla volatilità dei mercati e dei risultati tecnici e allo sviluppo della
riserva sinistri nel tempo;
o Individual Capital Guidance (ICG): un calcolo aggiuntivo basato su Internal
Models o Stress Scenario Testing da parte degli assicuratori (own view), al fine
di rendere sensibile le Compagnie stesse sui propri requisiti di capitale
(orizzonte temporale). In tale ambito sarà utilizzato un time horizon di un anno
al livello di confidenza del 99,5%. L’ICG non potrà mai essere inferiore al
Margine Minimo di Solvibilità della UE (MMS).
L’obiettivo è giungere a un sistema più trasparente, aderente ai rischi e che permetta
un intervento tempestivo della vigilanza, ma anche rendere risk sensitive le
Compagnie di Assicurazione.
La proposta della FSA è che le Compagnie assicurative devono possedere un
capitale pari al massimo valore tra il MMS UE e l’ ECR (calcolo prescritto dalla FSA
con una maggiore accuratezza al profilo di rischio). Si precisa che il modello si
riferisce a 24 classi di business così individuate: 8 rami o LOBs (Accident&Health,

21
Motor, Aviation, Marine, Transport, Property, Liability, Miscellaneous&Pecuniary
Loss), in cui per ognuno si considerano 3 differenti coperture riassicurative
(Direct&Facoltative, Proportional Treaty e Non-Proportional Treaty).
L’ECR sarà quindi dato dalla seguente formula:
UCRCACECR ++= (1.2.2.1)
dove
AC = Asset Charge, requisito di capitale relativo al rischio delle attività, ottenuto
applicando delle percentuali diverse a seconda della rischiosità delle varie
attività;
RC = Riserve Charge, che rappresenta il requisito di capitale ottenuto applicando i
risk factors di ogni classe di rischio alle riserve (Riserva Sinistri comprensiva
degli IBNR e Riserva Premi) al netto della riassicurazione;
UC = Underwriting Charge, che viene ricavato applicando i coefficienti ai premi di
ogni classe. La FSA nella scelta dei fattori di rischio utilizza diversi elementi:
o il livello di capitale proprio delle imprese;
o il risultato di analisi attuariali in relazione ai dati disponibili relativi ai bilanci
1985-2001 di tutti gli assicuratori più grandi del Regno Unito e la gran parte
delle Compagnie più piccole (Lloyd’s of London non inclusi);
o l’ approccio utilizzato da alcune società di rating (non potendo conoscere, però
tutte le informazioni a disposizione di quest’ultime);
o i requisiti richiesti da altri sistemi di solvibilità;
o la calibrazione dei requisiti di capitale minimo per il settore bancario.

22
In particolare l’approccio si basa su quattro punti principali (si veda anche la figura
1.2.2.1):
PASSO 1
Ricavare le distribuzioni per ciascun fattore di rischio (stimando anche le dipendenze
tra i fattori di rischio). In particolare si è proceduto all’analisi dei dati storici per
ottenere una distribuzione dei possibili risultati per ciascuna delle categorie di attivi e
per ognuna delle classi di riserve e underwriting.
Per il Reserving Risk la variabilità dei risultati delle riserve é stata esaminata
ricorrendo al bootstrapping applicato ai triangoli dei sinistri pagati e riservati
(ricorrendo anche al metodo Chain Ladder) e considerando il run-off attuale in ogni
bilancio per ciascun assicuratore.
I risultati hanno suggerito la selezione di una deviazione standard del run-off delle
riserve dipendenti dalla dimensione attraverso la formula aR-β (dove R è la
dimensione della riserva e a, β sono parametri dipendenti dalla classe di business).
Per l’Underwriting Risk sono stati costruiti modelli separati per ciascuna delle 24
classi. In particolare l’Underwriting Profit al netto della riassicurazione UPNet è dato
da:
UPNet = Premi – Costo sinistri (avvenuti nell’anno) – Spese (avv. anno)
Il ciclo di mercato dell’underwriting per tutte le classi combinate é stato
modellizzato come un processo AR2, che produce un cammino ciclico simile a
quello presente nel settore assicurativo reale:
UWn = UWn-1 + α (UWn-1 - µ) + β (UWn-1 – UWn-2) + errore (1.2.2.1)
dove
23
UWn = underwriting result espresso come una percentuale dei premi di competenza
dell’anno n
µ = é il valore atteso di UW;
α, β sono parametri;
α (UWn-1 - µ) é il c.d. mean reversion term. Se la profittabilità diverge dalla sua
media a lungo termine, ha l’effetto di invertire la tendenza riportando tale indice alla
normalità. Infatti se il mercato non va bene, le Compagnie tagliano alcuni rami o
riducono il loro volume di business;
β (UWn-1 – UWn-2) é un termine che ha l’effetto inverso rispetto alla mean reversion e
che produce il cammino ciclico su indicato. Si tiene conto del fatto che quando i tassi
crescono, spesso tendono a crescere e quando cominciano a diminuire continueranno
secondo tale trend;
Il termine di errore produce le oscillazioni rispetto al valore atteso.
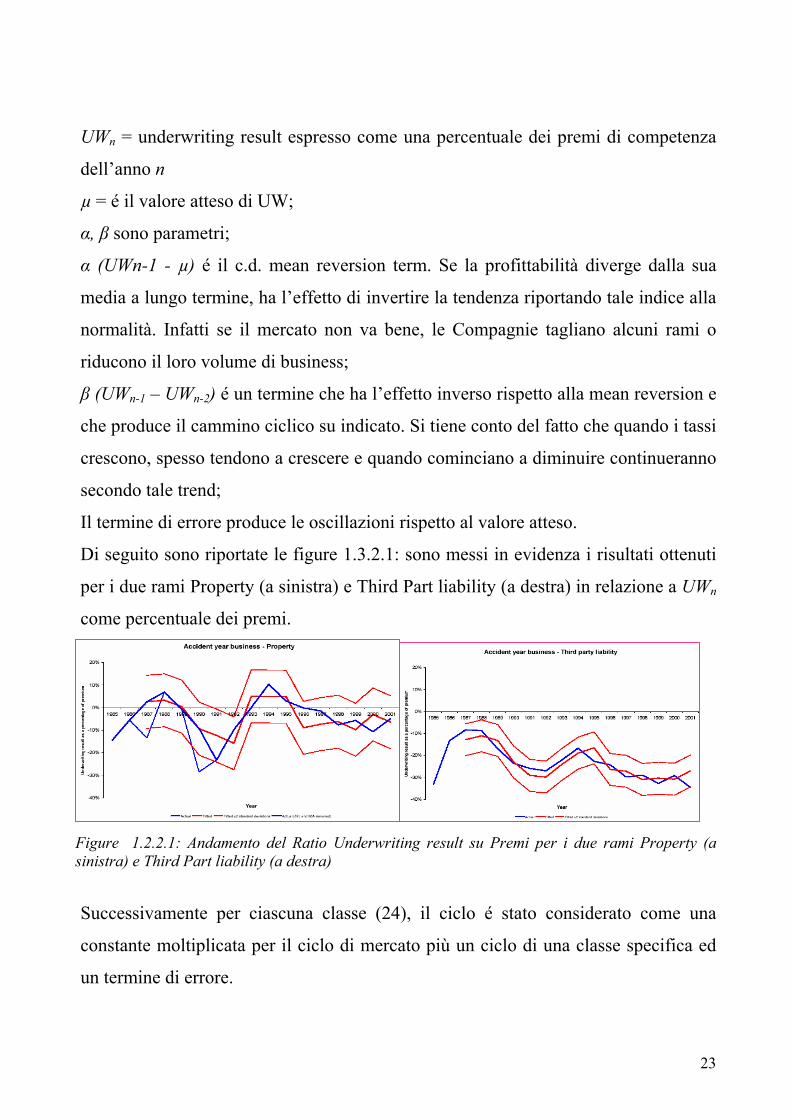
Di seguito sono riportate le figure 1.3.2.1: sono messi in evidenza i risultati ottenuti
per i due rami Property (a sinistra) e Third Part liability (a destra) in relazione a UWn
come percentuale dei premi.
Figure 1.2.2.1: Andamento del Ratio Underwriting result su Premi per i due rami Property (a sinistra) e Third Part liability (a destra)
Successivamente per ciascuna classe (24), il ciclo é stato considerato come una
constante moltiplicata per il ciclo di mercato più un ciclo di una classe specifica ed
un termine di errore.

24
Infine il risultato dell’underwriting per un dato assicuratore e una data classe è stato
calcolato come un multiplo del risultato per quella classe per l’intero mercato più un
ciclo specifico dell’assicuratore ed un termine di errore.
Si noti che si è proceduto dal mercato verso il singolo assicuratore per tenere
conto delle correlazioni che a volte condizionano tutte le Compagnie di un mercato.
PASSO 2
Combinare le distribuzioni per ciascun assicuratore al fine di ottenere una
distribuzione di rischio generale; a questo riguardo é stato prodotto un modello
semplificato DFA per ciascun assicuratore nel mercato (10.000 simulazioni per
assicuratore).
PASSO 3
Sulla base della distribuzione generale i requisiti di capitale sono calcolati per
ciascuna Compagnia secondo il prescelto orizzonte temporale e il livello di
confidenza.
PASSO 4
Selezione dei fattori finali (da applicare per qualsiasi assicuratore) utilizzando un
metodo di ottimizzazione allo scopo di ricavare i ECR il più possibile prossimi ai
requisiti teorici calcolati per ciascuna Compagnia al punto 3. Sono stati sfruttati i
requisiti di capitale teorici per le Compagnie reali e tutti i fattori sono stati
riproporzionati attraverso lo stesso moltiplicatore al fine di mantenere la appropriata
relatività tra le classi (in modo da consentire la diversificazione tra i rischi).
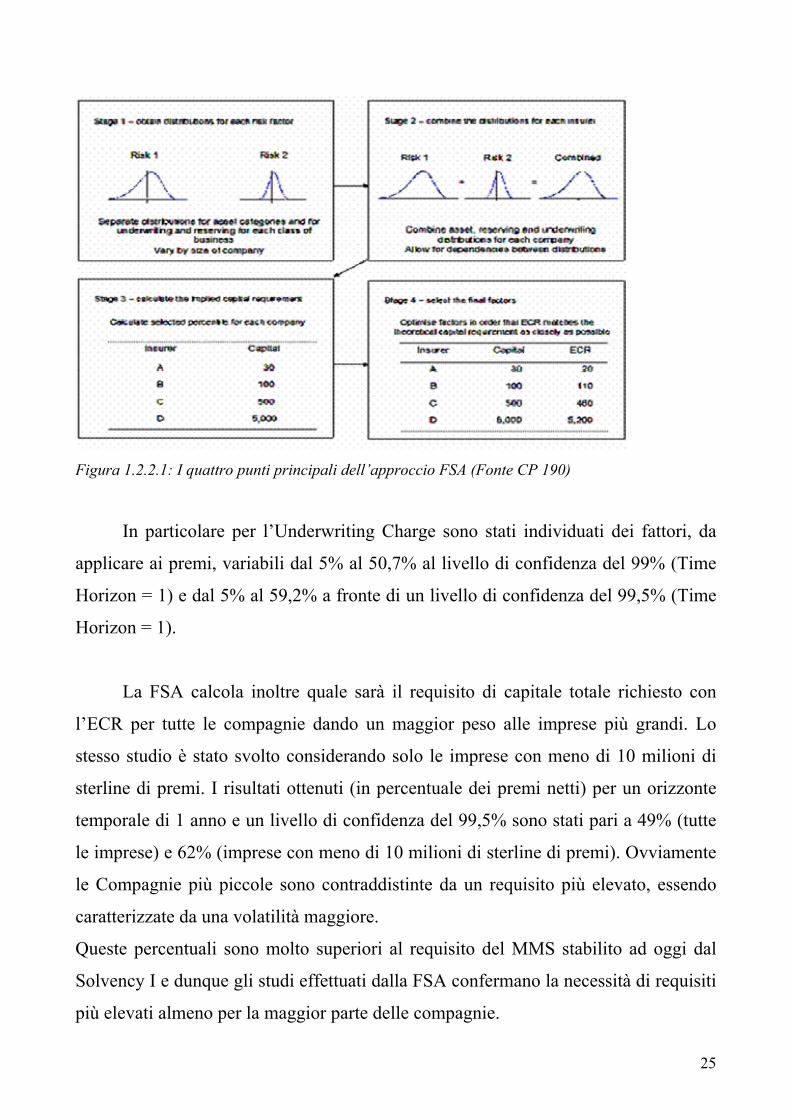
25
Figura 1.2.2.1: I quattro punti principali dell’approccio FSA (Fonte CP 190)
In particolare per l’Underwriting Charge sono stati individuati dei fattori, da
applicare ai premi, variabili dal 5% al 50,7% al livello di confidenza del 99% (Time
Horizon = 1) e dal 5% al 59,2% a fronte di un livello di confidenza del 99,5% (Time
Horizon = 1).
La FSA calcola inoltre quale sarà il requisito di capitale totale richiesto con
l’ECR per tutte le compagnie dando un maggior peso alle imprese più grandi. Lo
stesso studio è stato svolto considerando solo le imprese con meno di 10 milioni di
sterline di premi. I risultati ottenuti (in percentuale dei premi netti) per un orizzonte
temporale di 1 anno e un livello di confidenza del 99,5% sono stati pari a 49% (tutte
le imprese) e 62% (imprese con meno di 10 milioni di sterline di premi). Ovviamente
le Compagnie più piccole sono contraddistinte da un requisito più elevato, essendo
caratterizzate da una volatilità maggiore.
Queste percentuali sono molto superiori al requisito del MMS stabilito ad oggi dal
Solvency I e dunque gli studi effettuati dalla FSA confermano la necessità di requisiti
più elevati almeno per la maggior parte delle compagnie.

26
Si sottolinea un cambiamento chiave nel policy statement (in risposta ai commenti
che l’ FSA ha ricevuto nella consultazione): conferma che l’ECR sarà, per il
momento, privatamente riportato all’FSA e non sarà uno “stringente” requisito di
capitale. L’ECR sarà usato sia come benchmark sia come base per definire un ICA
degli assicuratori non-vita.
Per gli assicuratori non-vita e vita, l’FSA ha chiesto che l’ICA mostri i risultati
basati su un livello di confidenza equivalente al 99,5% sul periodo di un anno (ciò
assicurerà consistenza tra le Compagnie, anche se gli assicuratori auspicano di
adottare un più elevato standard ai fini dei loro scopi manageriali).

27
1.2.3 L’approccio dell’IAA Insurer Solvency Assessment Working Party
L’ International Actuarial Association ha istituito l’Insurer Solvency Assessment
Working Party che ha predisposto un apposito rapporto su un nuovo framework di
vigilanza. Il Case Study sviluppato dal WP per il Non-Life riguarda principalmente
l’Underwriting Risk. Ad avviso del WP per individuare la misura dell’Underwriting
Risk nell’ambito dello Standardised Factor-Based Approach sono necessari i seguenti
dati per ciascuna Linea di Business (LoB):
o Size Factor (SF): per incrementare il livello relativo di capitale per portafogli di
minori dimensioni;
o Coefficiente di Variabilità (CoV)
o Confidence Factor (CF)
o Coefficienti di Correlazione (CC) – per ogni coppia di LoB.
Nel rapporto viene proposto la costituzione di un requisito di capitale più
aderente alle caratteristiche di ciascuna impresa (Target Capital), desumibile da due
possibili approcci: uno standard e uno più avanzato tramite l’utilizzo di modelli
interni (IRM).
Lo IAA sottolinea come possano essere scelti molti approcci standard di differente
complessità. Il metodo più semplice consiste nel considerare un unico fattore o una
sola scala di fattori di rischio per ogni prodotto e per ogni impresa (standard model).
Un approccio più complesso richiederebbe l’identificazione delle molteplici
componenti di rischio delle imprese e la creazione di un requisito di capitale per
ognuna di esse (IRM), che può risultare molto difficile da realizzare.
Il primo metodo consiste nell’individuare la distribuzione di probabilità della
c.d. riserva di rischio (risk margin, surplus, risk riserve, etc.). Scegliendo una
probabilità di non fallimento del 99%, si dovrà determinare il 99° percentile.

28
Indicando con µ la media e σ lo scarto quadratico medio del costi sinistri
aggregato e con p99 il 99° percentile, si avrà:
p99 = µ + K * σ (1.2.3.1)
K è un fattore che varia al variare della distribuzione scelta e del percentile
considerato (ovviamente funzione crescente del percentile e della pesantezza della
coda).
Dato che µ rappresenta il valore medio delle passività, ai fini della sua copertura si
utilizzeranno le riserve tecniche (che forniscono infatti una stima puntuale degli
impegni futuri), mentre K * σ rappresenta il capitale da possedere.
In generale per il ramo j-esimo (o Line of Business – LoB) il requisito minimo di
capitale sarà:
Cj = Kj * σj (1.2.3.2)
Ponendo:
jj
jj vCov ==
µσ
(1.2.3.3)
allora si avrà Cj = Kj * µj * vj. Si noti che µj, essendo legato alla sinistrosità del ramo
j, sarà calcolato dalla compagnia; ad esso sarà legato anche vj (dipendente dalla
dimensione dell’Impresa), mentre Kj sarà indicato dal supervisor.
I requisiti di capitale per ogni ramo saranno quindi combinati in un requisito totale:
jiji
jij
j CCCC **,2 ∑∑
≠
+= ρ (1.2.3.4)

29
dove ji,ρ rappresenta la correlazione tra i rami i e j. Se la correlazione fosse uguale a
1, il requisito totale C sarebbe semplicemente la somma dei requisiti parziali Cj. Se
invece tutti i rami fossero a due a due indipendenti, il coefficiente di correlazione
sarebbe pari a 0 e quindi il secondo termine all’interno della radice si annullerebbe.
E’ quindi necessario stimare la correlazione fra i differenti LoB e questo dovrà essere
un compito dell’autorità di vigilanza.
Lo IIA WP sottolinea che per poter valutare le dipendenze, il concetto classico
di correlazione lineare è insufficiente e propone, per poter indagare adeguatamente le
dipendenze delle code delle distribuzioni, di utilizzare le funzioni Copula (si veda
Wang [1998], IIA WP [2004]).
Il secondo approccio, ai fini della determinazione del requisito minimo da
possedere, consiste nell’approssimare la distribuzione dell’ammontare di capitale
dell’impresa con una specifica distribuzione simulata e calcolare il VaR o il TVaR
per un livello di confidenza scelto (ad esempio il 99% ). Le µj e σj possono essere
utilizzate per calcolare la media e lo scarto quadratico medio del risk capital della
compagnia con la seguenti formule:
jiji
ijj
j
jj
σσρσσ
µµ
*2 ∑∑
∑
≠
+=
=
µ e σ possono essere usati come parametri di una particolare distribuzione (ad
esempio la lognormale). Il requisito totale sarà dunque pari alla misura di rischio
utilizzata (VaR o TVaR) diminuita di µ.
Lo IAA fornisce un esempio (appendice B) di modello Risk Based sensibile al
volume di premi, alla volatilità di ogni linea di business, ai trattamenti riassicurativi e

30
alle dipendenze eventualmente esistenti fra le varie linee di business. La formula
richiede che ogni compagnia inserisca nel modello le proprie uscite attese divise per
ramo di assicurazione. Gli altri parametri saranno invece determinati in modo
univoco dalla vigilanza.
Il modello calcolerà i primi due momenti della distribuzione totale delle uscite e poi
stimerà il TVaR99% assumendo la distribuzione del costo sinistri aggregato come
Lognormale.
Dal punto di vista tecnico si tratta di un modello di simulazione dove è necessario
seguire i seguenti passi (tale metodologia sarà ripresa nei successivi capitoli 2 e 3):
1. Si ricava un numero pseudo casuale qi da una distribuzione Gamma con media
1 e varianza c (si veda Daykin et al. [1994], Savelli [2002] e il successivo
capitolo 2).
2. Si ricava un numero pseudo casuale Ki da una distribuzione con media λi qi
dove λi è il numero di sinistri atteso per la linea di assicurazione i-esima.
3. Per ogni i e per ogni k=1,2, …, Ki si sceglie un importo casuale del costo del
singolo sinistro, Zik da una distribuzione lognormale con media µi e scarto
quadratico medio σi.
4. Si ricava quindi il danno aggregato per la linea di assicurazione i: ∑=
=iK
kiki ZX
1
5. Si sceglie poi un numero casuale p, da una distribuzione uniforme (0,1). Per
ogni linea i si sceglie βt come il p-esimo percentile di una distribuzione con
media E[βt]=1 e Var[βt]=bi. Questo fornisce una distribuzione dei βt in cui
ogni coefficiente di correlazione ρij è uguale a 1.
6. E’ possibile quindi scrivere che il danno aggregato per la compagnia é:
∑=i
ii XX β
31
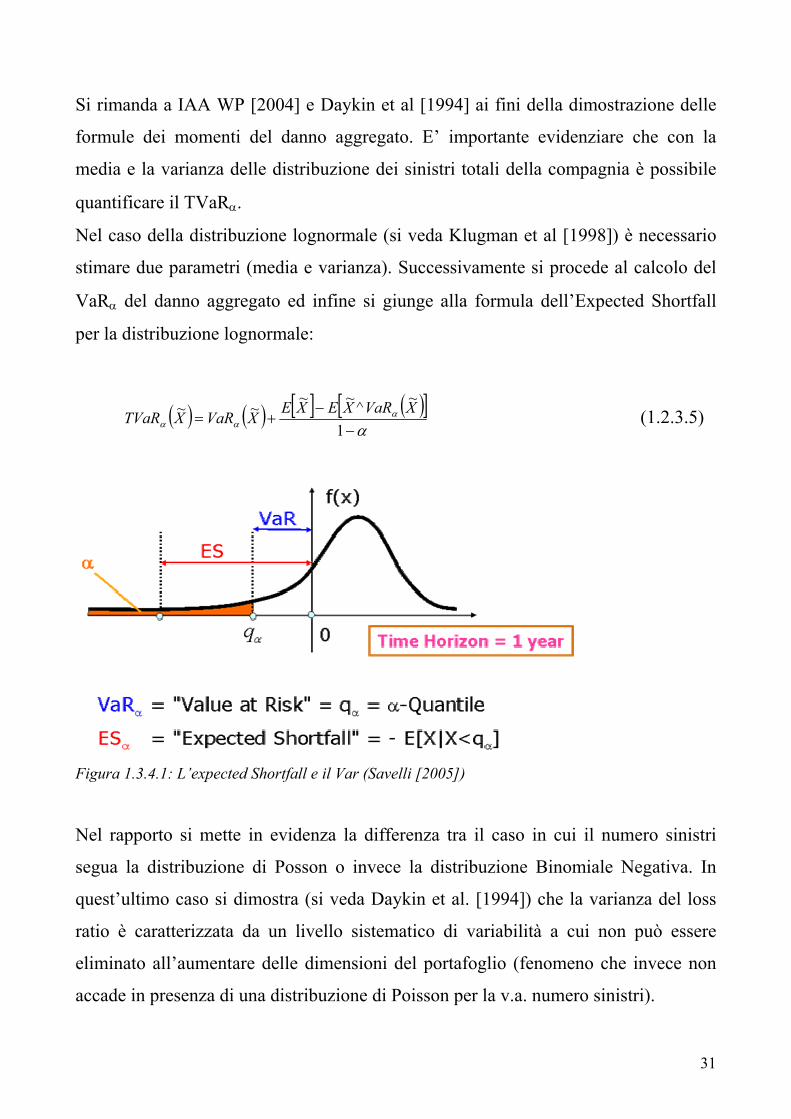
Si rimanda a IAA WP [2004] e Daykin et al [1994] ai fini della dimostrazione delle
formule dei momenti del danno aggregato. E’ importante evidenziare che con la
media e la varianza delle distribuzione dei sinistri totali della compagnia è possibile
quantificare il TVaRα.
Nel caso della distribuzione lognormale (si veda Klugman et al [1998]) è necessario
stimare due parametri (media e varianza). Successivamente si procede al calcolo del
VaRα del danno aggregato ed infine si giunge alla formula dell’Expected Shortfall
per la distribuzione lognormale:
( ) ( ) [ ] ( )[ ]α
ααα −
−+=
1
~^~~~~ XVaRXEXEXVaRXTVaR (1.2.3.5)
Figura 1.3.4.1: L’expected Shortfall e il Var (Savelli [2005])
Nel rapporto si mette in evidenza la differenza tra il caso in cui il numero sinistri
segua la distribuzione di Posson o invece la distribuzione Binomiale Negativa. In
quest’ultimo caso si dimostra (si veda Daykin et al. [1994]) che la varianza del loss
ratio è caratterizzata da un livello sistematico di variabilità a cui non può essere
eliminato all’aumentare delle dimensioni del portafoglio (fenomeno che invece non
accade in presenza di una distribuzione di Poisson per la v.a. numero sinistri).

32
Nel caso di dipendenza strutturale quindi si dimostra che (si veda anche Heckman e
Meyers [1983]):
iiiikEi
ii cbcbXEX
VAR ++ →
+∞→]
~[]~[
~β (1.2.3.6)
dove bi dipende dalla correlazione tra linee di business diverse, mentre ci dalla
correlazione delle polizze di una stessa linea di business. bi sarà quindi influenzato da
quegli eventi che incidono sul loss ratio di tutti i rami. L’obiettivo è quindi quello di
stabilire dei bi e ci per ogni linea che possano essere utilizzati da tutte le imprese.
L’analisi dei loss ratio riscontrati nelle varie linee di business permette di stimare lo
scarto quadratico medio e ricavare dei possibili bi e ci.
Quindi per utilizzare il modello descritto precedentemente è necessario disporre di:
o Media e Coefficiente di Variazione della distribuzione lognormale dell’importo
del singolo sinistro per ogni ramo (proprio di ogni impresa).
o I parametri bi e ci per ogni ramo forniti dall’autorità di vigilanza e uguali per
tutte le imprese.
Sarà quindi possibile calcolare la media e lo scarto quadratico medio della
distribuzione lognormale dell’importo del sinistro dopo l’applicazione della
riassicurazione. Si potrà poi stimare il numero di sinistri attesi i per ogni ramo
semplicemente dividendo il totale dei sinistri attesi per un ramo con l’intensità di
sinistro attesa µi.
A questo punto sono disponibili tutte le informazioni necessarie per calcolare
media e varianza della distribuzione lognormale aggregata dei sinistri di una
compagnia considerando anche l’eventuale uso di riassicurazione, e quindi il TVaR

33
per ogni impresa. Secondo questo modello standard il risk based capital che le
imprese dovranno possedere sarà pari a:
TC = TVaR99% - Perdite medie sul Business corrente Netto Riass - Perdite medie al
netto sul business corrente sulle riserve Netto Riass + PML per Catastrofi
dove PML per Catastrofi è la c.d. Massima Perdita Probabile in evento ad un sinistro
di natura catastrofale.
Nel case study dello IAA WP viene considerato il RBC di 2 diverse compagnie
aventi entrambe un portafoglio assicurativo composto ciascuno da 6 rami assicurativi
di tipo Property&Liability (diversi solo per il volume complessivo, dove la
compagnia ABC è dieci volte più grande dell’altra XYZ), secondo 3 differenti
strategie di riassicurazione. Il RBC ottenuto per la Compagnia ABC (medio-grande)
corrisponde al 49% del Volume dei Premi Diretti (al lordo della riassicurazione) e al
41,3% (al netto della riassicurazione). Per la società XYZ le percentuali,
rispettivamente, al lordo e al netto riassicurazione sono pari a 63% e 43%
(ovviamente più elevate rispetto alla ABC assicurazioni, data la minore numerosità
del portafoglio).
Lo stesso WP ha ricalcolato il RBC sulla base dell’IRM, che si differenzia
dall’approccio Factor-Based Formula per l’adozione di ipotesi meno conservative in
termini di correlazioni e di CoV della claim severità e lo sviluppo diretto del calcolo
mediante modelli di simulazione senza utilizzare l’ipotesi che la distribuzione di X
possa essere approssimata dalla LogNormale.
In tal caso i risultati del RBC mediante IRM Model:

34
o per l’Insurer ABC – medio/grande si ha una riduzione del RBC tra il 36% (riass.
XL tutti rami) ed il 41% (caso no riass.);
o per l’Insurer XYZ – piccolo si ha una riduzione del RBC tra il 35% (riass. XL
tutti rami) ed il 15% (caso no riass.).
1.2.4 Lo Swiss Solvency Test
In Svizzera il Federal Office for Private Insurers (FOPI) ha prodotto nel 2004 il
c.d. Swiss Solvency Test (SST) in cui i rischi considerati sono sia assicurativi che
finanziari (non sono considerati quindi i rischi operativi o di strategia), ma può anche
essere considerata la Riassicurazione, ivi compreso quindi il rischio di credito
derivante dal default del riassicuratore.
Lo SST si basa su una struttura a moduli, consistente di differenti modelli
standard. Gli output dei modelli standard rappresentano funzioni di distribuzione, che
consentono significative integrazioni dei modelli interni (come si può vedere nella
figura seguente).
Figura 1.2.4.1: Fonte FOPI 2004: Schema di funzionamento del modello non-life

35
Limitando la descrizione ai rami danni, i modelli standard sono rappresentati da:
o Rischio di Mercato: Modelli del tipo Riskmetrics con appross. 25 fattori di
rischio (tassi di interesse, FX, azioni, spreads,…);
o Property & Casualty: Modelli Interni (non una formula ma processi prefissati).
Il risultato tecnico è dato dalla seguente equazione:
Premi Netto Costi – Costo sinistri Attualizzato – Run off Result attualizzato =
P = Premi di competenza;
K = Costi;
P – K = ipotizzato costante;
d(0)CY = fattore di attualizzazione per l’anno corrente (current year);
SCY = sinistri di competenza, che per ogni Line of Business (LoB) sono splittati tra
normali e large claims; si tiene conto anche di eventi catastrofali con effetto
simultaneo su diverse LoB;
d(0)PY = fattore di attualizzazione dell’anno precedente (previous year);
(CPY – 1) R(0)PY = Run off result risk, dove CPY R(0)
PY é la riserva stocastica rivalutata
(distribuita per ipotesi secondo la Lognormale), con valore atteso R(0)PY , cioé la c.d.
Best Estimate. Sul run-off risk agiscono due cause: aleatorietà dei sinistri (stochastic
risk) e l’incertezza nella stima dei parametri (parameter risk).
Per i sinistri ordinari vengono stimati le distribuzioni (Lognormale) e vengono
aggregati utilizzando una matrice di correlazione. Gli elementi della matrice sono
stimati in base ai dati storici (standard values).
(0) (0) (0)( 1)CY CY PY PY PYP K d S d C R= − − ⋅ − ⋅ − ⋅

36
Per i large claims viene utilizzata la distribuzione Compound Poisson-Pareto.
Emerge comunque la Necessità di formulare linee guida per il cut-off della
Distribuzione di Pareto delle LoB con un α (tail index) < 2, caso in cui i momenti
della Pareto non sono finiti. Attualmente vengono utilizzate regole diverse a fronte di
differenti LoB (possibili sviluppi futuri: utilizzare l’Extreme Value Theory o
distribuzioni troncate).
Nel caso di accumulo di sinistri in seguito ad un singolo evento (che coinvolge
differenti LoB) è modellizzato sempre con una distribuzione Compound Poisson. E’
auspicabile l’introduzione di dipendenza strutturale attraverso la distribuzione
Binomiale Negativa per il processo della variabile aleatoria Numero Sinistri.
Attualmente è postulata l’indipendenza tra i diversi sinistri e tra numero e costo.
I sinistri ordinari e large vengono aggregati attraverso la convoluzione che viene
calcolata numericamente in base alla formula ricorsiva di Panjer (si veda il capitolo
2).
L’aggregazione successiva con i sinistri catastrofali viene realizzata in base ad un
metodo per scenari.
Il SST é basato sulla valutazione a valori di mercato delle passività in cui viene
incluso un margine di rischio. L’obiettivo finale é misurare il Target Capital in base
alla formula:
Target Capital = Expected Shortfall + Risk Margin
= Capitale Richiesto + Margine di Rischio
dove il primo addendo copre il rischio lungo un anno di orizzonte temporale, mentre
il secondo fa riferimento al rischio relativo al run-off del portafoglio (figura 1.2.4.2).

37
Figura 1.2.4.2: Target Capital nel SST (fonte CEA [2005])
Il Field Test del 2004 é stato basato esclusivamente sul portafoglio svizzero
(senza filiali in paesi stranieri) per alcune Compagnie mono e multi ramo, dal quale è
emerso che:
o Rischio di Credito: L’approccio standard di Basilea II é difficilmente
implementabile;
o L’Aggregazione di risultati dei modelli standard e valutazioni per scenari non
hanno funzionato in maniera appropriata. Per il field test del 2005, le
aggregazioni saranno modificate;
o Alcuni scenari non sono risultati significativi (non descrivevano alcuni rischi
significativi o contraddistinti da una probabilità più elevata)
o Alcune problematiche necessitano di un margine di rischio oltre la best-estimate:
tra l’1% e il 4% della best estimate delle passività. Tra l’8% e il 40%
dell’Expected Shortfall ad 1 anno (piccolo per Property&Casualty, grande per
portafogli vita);
o Il Capitale Obiettivo (Target Capital) é significativamente superiore a quello
risultante dai requisiti previsti da Solvency I;
o La variabilità del ratio Capitale Obiettivo/Best-Estimate é abbastanza piccola;
o Il Rischio di Mercato é significativo anche per i portafogli Property &Casualty
(si pensi invece al modello RBC USA);

38
o In caso di insolvenza, l’autorità di vigilanza richiede che capitale disponibile sia
tale da consentire ad un secondo assicuratore di acquisire il portafoglio di attivi
e passivi.
1.2.5 Il progetto Solvency II
La formula attuale del Margine Minimo di Solvibilità (MMS) fa riferimento
quasi esclusivamente all’underwriting risk (senza comunque considerare gli effetti di
eventuali livelli significativi di correlazione e/o tail-dependencies tra i vari rami).
Secondo il Müller Working Party (1997) il Margine di Solvibilità deve coprire
solo i rischi che non sono coperti da altre misure di prevenzione e propone in
particolare l’introduzione di un terzo indice “alternativo” (basato sulla riserva
sinistri): proposto al fine di affrontare il rischio di run-off delle riserve sinistri per i
rami (come quelli di R.C.) aventi tempi di liquidazione di vari anni - long term risk e
long tail risk (rischio particolarmente rilevante in alcuni mercati, come quello
italiano).
A tal fine è stata introdotta la nuova disciplina UE, c.d. Solvency I, con la Dir.
2002/13/CE del 5 marzo 2002 (recepita in Italia con D. Lgs. n. 307 del 3 novembre
2003). La nuova normativa (Solvency I) recentemente introdotta in ambito
assicurativo non è ancora soddisfacente per la definizione del margine di solvibilità
delle compagnie. L’unica modifica rilevante rispetto al passato è stato l’inserimento
nel calcolo del margine minimo di un aumento del 50% dei premi e dei sinistri medi
del ramo RCGenerale. Restano dunque irrisolti i numerosi problemi, già evidenziati
dal Report del Müller Working Party nel 1997, primo fra tutti la non sensibilità del
margine minimo rispetto all’effettiva rischiosità dell’impresa di assicurazione.

39
I requisiti di capitale conosceranno quindi con il Solvency I un aumento molto
inferiore a quello ritenuto necessario dalla maggior parte delle analisi svolte: ad
esempio gli studi effettuati dalla FSA per l’introduzione dell’ECR (Enhanced Capital
Requirement) mostrano come, scelta una probabilità di fallimento non superiore allo
0,5%, saranno necessari dei requisiti di capitale pari mediamente al 49% dei premi
netti, percentuale destinata a salire al 62% per le imprese con meno di 10 milioni di
sterline di premi. Il Solvency I va dunque considerato come una misura provvisoria,
non atta al superamento dei limiti della vecchia direttiva, ma ad un semplice
aggiustamento in vista della riforma dei prossimi anni.
Il progetto destinato a cambiare profondamente le compagnie di assicurazione,
interessando tutti i soggetti legati al business assicurativo, dall’azionista
all’assicurato, dal management all’autorità di vigilanza, sarà invece il Solvency II.
La sua importanza è accentuata dal fatto che i nuovi standard contabili IAS
diminuiranno il livello di prudenza in molte nazioni. La prima fase del progetto
solvibilità II è terminata, la seconda è tuttora in corso e si stima che si potrà
concludere, con una prima bozza della nuova direttiva, entro il 2005, mentre la sua
entrata in vigore è prevista per il 2008-2009.
Gli elementi essenziali all’attuazione di Solvency II:
o Ruolo fondamentale assunto nel futuro dai Modelli Interni (IRM).
o Strumenti di analisi quantitativa sono necessari per l’analisi del risk profile
(con particolare riferimento eventi estremi e alle dipendenze).
o Attualmente l’indice minimo di solvibilità nella UE per le Compagnie Danni é
circa pari al 16-20% dei premi netti, mentre i risultati dei recenti studi mettono
in evidenza come il ratio del capitale minimo debba essere significativamente
incrementato (almeno fino al 35-40% dei premi).

40
o Occorre fare attenzione a regole che impongano un eccessivo requisito di
capitale con indesiderabili effetti su un più elevato costo del capitale per il
mercato assicurativo.
Il solvency framework proposto è analogo al Three-Pillars approach di Basel II
(e ripreso anche dalla Commiss. Europea e CEIOPS):
Figura 1.2.5.1: L’approccio a tre pilastri (Seminario IIA 2002)
Il primo pilastro è rappresentato da Minimum Financial Requirements, che comporta
il mantenimento di:
o appropriate riserve tecniche;
o idonee attività a copertura degli impegni tecnici;
o un ammontare minimo di capitale per ogni assicuratore.
Nell’ambito del Pillar I capital requirements, è generalmente condiviso che debbano
essere ricompresi le seguenti tipologie di rischio:
o underwriting risk
o credit risk
o market risk
o operational risk

41
Il secondo pilastro è il Supervisory Review Process, che risulta necessario in aggiunta
al Pillar I, in quanto non tutte le tipologie di rischio possono essere adeguatamente
stimate mediante misure puramente quantitative. Tale fase richiede una Independent
Review (dalla Vigilanza o da una entità qualificata appositamente designata), in
special modo quando sono utilizzati Internal Models.
Tale Review comporterà l’intervento della Vigilanza se il capitale della
compagnia non risulterà sufficiente a far fronte ai rischi assunti. Il Pillar II, come
detto, intende non solo assicurare che le compagnie abbiano un appropriato capitale
di rischio a fronte dei vari rischi d’impresa, ma anche incoraggiare gli assicuratori “to
develop and use better risk management techniques” in modo da monitorare e gestire
il profilo di rischio dell’azienda.
Come in Basilea II, sarà fissato uno Standardized Approach (di seguito SA)
che comporti misure di capitale alquanto prudenziali (ad es. mediante sovrastima dei
coefficienti di correlazione), comportando quindi un maggiore interesse da parte delle
compagnie a stimare il Target Capital tramite Internal Models che colgano con
maggiore precisione la connessione dei vari rischi, determinando in tal modo una
misura di capitale molto verosimilmente più contenuta di quella fissata mediante lo
SA. Gli IRM permetteranno alle Compagnie di personalizzare e correggere i risultati
degli Standard Models: “build risk-based formulas as approximations to internal
model” (Panjer H. [2003]).
Gli IRM potranno essere utilizzati non solo per la stima del capitale da
possedere dalla compagnia, ma soprattutto come valido supporto delle decisioni del
management dell’impresa, per questo dovrà essere sempre considerato il trade-off
rischio-rendimento.

42
Infine il terzo pilastro, Measures to Foster Market Discipline, serve a
rafforzare la market discipline introducendo dei requisiti di disclosure. Secondo vari
esperti il Pillar III dovrebbe giocare un ruolo particolarmente importante in futuro
nello screening degli operatori da parte della clientela, potendo far risaltare con
maggiore evidenza di quanto non sia possibile oggi con il Solvency I l’effettivo grado
di sicurezza della compagnia (es. ass. Vita ed RCA), laddove la clientela ed il
mercato nel suo insieme potranno individuare il trade-off tra pricing e solvency
dell’operatore assicurativo.
I requisiti minimi di capitale si distingueranno in “target capital requirement” e
“minimum capital requirement” e dovranno essere calcolati in modo che risultino
sufficienti dati una certa probabilità di rovina.
Il Target Capital costituirà il capitale auspicabile che ogni impresa dovrà
possedere, il suo calcolo potrà avvenire sia attraverso un metodo standard (tipo RBC
americano) che tramite modelli interni di gestione del rischio.
Nel metodo standard si potrebbero stabilire dei parametri uguali per tutte le
imprese europee oppure permettere una certa diversificazione tramite l’utilizzo di
parametri flessibili per meglio cogliere le differenze di ogni realtà nazionale (ad
esempio la tassazione).
Sarà indispensabile stabilire un requisito di capitale per la copertura
dell’underwriting risk (il più rilevante per una compagnia), del rischio di credito e del
rischio di mercato.
Come visto in precedenza per le analisi del Target Capital è sovente
considerato un orizzonte temporale di 1 anno. Inoltre sono raccomandate dall’IAA
WP due misure di rischio raccomandate dall’IAA-SWP:

43
1) SHORT-TERM: l’ammontare del capitale necessario deve risultare sufficiente per
un livello di confidenza molto alto (99%) che comprende al termine di 1 ANNO il
valore attuale delle future obbligazioni residue (e.g. best estimate value con un
moderato livello di confidenza, come ad es. il 75%);
2) LONG-TERM: per far fronte alla complessa natura di alcuni rischi, può essere
imposta anche una seconda condizione. Qualora il valore attuale delle passività
(riferito ad un orizzonte di 2-3 anni per le ass.ni non-life e considerato ad un livello di
confidenza abbastanza elevato - es. 90/95%) sia più grande, allora dovrebbe essere
mantenuta quest’ultima misura di capitale. Questa seconda misura considera i vari
rischi per gli anni considerati, includendo sia rischi sistematici che rischi non-
sistematici.
I requisiti di capitali saranno così influenzati non solo dalla dimensione
dell’impresa, ma anche dalla differente volatilità dei vari rami assicurativi, dalle
caratteristiche dei trattati riassicurativi, dai caricamenti applicati, dall’inflazione, dal
tasso di crescita e dal tasso di interesse.
Per quanto riguarda il calcolo dei requisiti di capitale per la coperture dei rischi
di credito e di mercato probabilmente si utilizzeranno metodi simili a quelli utilizzati
nei modelli Risk Management che si stanno sviluppando in ambito bancario (ivi
compresi metodi di scorino e di rating, strumenti di analisi statistica multivariata,
ecc.).
Il calcolo del minimum capital requirement (MCR), ovvero del livello sotto il
quale la compagnia non dovrà mai scendere, sarà molto semplice. La scelta consisterà
se calcolarlo come una frazione del target capital o, come sembra più probabile, in
modo simile al margine minimo di solvibilità odierno.

44
In conclusione il progetto Solvency II costituisce una grande opportunità a
disposizione del mercato europeo e dovrà portare al miglioramento
dell’armonizzazione degli standard europei e delle riserve tecniche, ad una più
profonda conoscenza dei rischi, ad una maggiore trasparenza, ad un uso più efficiente
del capitale ed infine ad una migliore protezione degli assicurati.
1.2.5.1 Il contributo del CEIOPS
Il CEIOPS (Committee of European Insurance and Occupational Pensions
Supervisors) é stato costituito alla fine del 2003, su richiesta della Commissione
Europea (call for advice) ed in relazione alla c.d. Procedura Lamfalussy (destinata ad
incentivare il processo di convergenza verso il mercato unico), con compiti consultivi
all’emanazione e all’applicazione della normativa legata al nuovo sistema di
solvibilità per le compagnie di assicurazione vita, danni e di riassicurazione dell’UE.
Tale commissione ha dato e continua a dare luogo ad un a serie di report progressivi
sullo stato dell’arte e risponde ai c.d. call for advice, su diverse tematiche quali la
riassicurazione, la valutazione delle riserve tecniche danni e vita, i Solvency Capital
Requirement e l’utilizzo degli Internal Risk Models, ecc.
Data l’elevata complessità delle tematiche che progressivamente stavano
emergendo il CEIOPS ha continuato a lavorare su Solvency II (a livello globale)
assistendo la UE nell’articolazione delle diverse fasi di realizzazione. In tale ottica la
commissione mira ad occuparsi dell’intero sviluppo del progetto e non solo
contribuire all’emanazione della bozza della prima direttiva (2006).
Attualmente sta contribuendo a colmare alcuni gap sulle tematiche ancora
irrisolte o che hanno bisogno di una maggiore analisi tecnica in relazione ai c.d.

45
Quantitative Impact Studies. In particolare il CEIOPS pubblicherà ulteriori
consultation paper, concentrati su argomenti non completati come le riserve tecniche,
il Pillar 2, ecc.. Gli studi di impatto quantitativo consentono di simulare gli effetti
sulle risorse finanziarie delle imprese di assicurazione dei nuovi requisiti proposti dal
progetto Solvency II. Essi rappresentano un processo iterativo, con simulazioni
successive, man mano più affinate ed estese che serviranno per fornire input alla
Commissione Europea per l’Impact Assessment che dovrà accompagnare la
presentazione della Direttiva Quadro prevista entro luglio 2007. Gli studi di impatto
quantitativo vengono effettuati dalle singole imprese su base volontaria e dovranno
essere completati entro il 31 dicembre 2005.
In ottobre 2005 il CEIOPS ha avviato un Quantitative Impact Study diretto alle
riserve tecniche vita e Danni, con particolare riferimento alla scelta del livello di
prudenza che deve essere adottato nella quantificazione. L’obiettivo è che le riserve
tecniche dovranno essere calcolate secondo criteri più armonizzati di quelli in essere:
central estimate + margin for risk and uncertainty. L’ipotesi di lavoro della
Commissione è il 75% della distribuzione delle probabilità come benchmark per il
livello di confidenza delle riserve.
Un più ampio ed approfondito studio (QIS2), sarà avviato a maggio 2006, in
relazione ai requisiti di capitale. Il Minimum Capital Requirement dovrebbe essere
calcolato in maniera semplificata e avere una ulteriore soglia minima espressa in
valore assoluto (euro). Le opzioni all’esame della Commissione e del CEIOPS per il
Mininum Capital Requirement:
o adottare l’attuale margine di solvibilità (“SOLVENCY I”);
o adottare il margine attuale con l’aggiunta dell’asset risk;
o prendere a riferimento il Solvency Capital Requirement o come base per una
formula semplificata o in termini percentuali;

46
o applicare un semplice “risk margin” alle riserve tecniche.
Stime dei nuovi requisiti minimi, sia pur approssimative, dovrebbero essere
disponibili prima che la direttiva quadro sia formalmente proposta.
1.3 Cenni all’Operational Risk
In base all’Intervento del Comitato di Basilea, è possibile fornire la seguente
definizione di Operational Risk: “Rischio associato a possibili perdite derivanti da
inefficienti procedure interne di monitoraggio e controllo nella gestione del
portafoglio”. Rappresenta tutti i rischi che non possono essere inclusi nei rischi
finanziari e di credito, esclusi i rischi strategici e reputazionali.
Ad esempio: a causa della negligenza di un operatore (fattore di rischio
persone) si verifica un errore di data entry (evento rischio) in una determinata attività
di un processo di back office (punto di rischio); il verificarsi dell’errore sarà
caratterizzato da una certa probabilità di accadimento (frequenza) e comporterà una
perdita che può essere caratterizzata da livelli differenti di gravità (impatto-severity).
Nel sistema bancario internazionale è stato stimato che i rischi possono essere così
ripartiti (fonte Deloitte [2003]):
- rischio di credito 50%
- rischio di mercato 15%
- rischio operativo e altri rischi 35%.
In analogia con il progetto Solvency II è interessante evidenziare i tre approcci
definiti da Basilea II per la misurazione del Rischio Operativo (si veda Basilea II,
Savelli [2005], Embrechts [2005]):

47
Figura 1.3.1: I tre approcci per la misurazione dell’Operational Risk – Fonte: Embrechts [2005] e Savelli N. [2005]
Le banche che utilizzano approcci di tipo Basic Indicator Approach (BIA) o
Standardised Approach (SA) non possono ridurre il Capital Charge (CC) in relazione
all’eventuale impatto della assicurazione (risk mitigation). Tale riduzione può essere
applicata solo nel caso di approcci Advanced Measurement Approach (AMA), nel
limite del 20% del requisito totale per l’OpRisk e sotto certe condizioni.
Inoltre si vuole evitare il c.d. “Cherry-picking Risk”: una volta che le banca ha
adottato un approccio più evoluto, non è più consentito tornare al calcolo del CC
mediante approcci più semplificati.
Per quanto concerne le correlazioni sia per lo SA che per l’AMA il totale del
CC è ottenuto semplicemente mediante la somma dei singoli valori ottenuti per ogni
combinazione (non viene prevista alcuna correzione per tener conto della
correlazione, a causa della mancanza di experience al riguardo).

48
E’ previsto l’utilizzo dell’ Individual Measurement Approach (IMA) o del Loss
Distribution Approach (LDA) a seconda degli eventi connessi all’Operational Risk.
Nel primo caso si ha:
(1.3.1)
dove ei,k = Expected Loss per la business line i e la tipologia di rischio k
Per l’approccio LDA il CC è basato sulla semplice somma dei singoli VaR per
l’OpRisk per ogni classe i,k (Business line/Risk type). Nel LDA va studiata la
variabile aleatoria delle Op.Losses XLDA relative ad un generico anno:
(1.3.2)
dove
L è il numero delle Business Lines (8);
T è il numero delle tipologie degli eventi (7);
N~ i,k rappresenta la v.a. numero degli eventi di perdita della combinazione i,k
che si verificheranno nell’anno considerato;
Z~ i,k,j denota invece la v.a. della j-esima perdita (severity) verificatasi nell’anno,
sempre relativa alla combinazione i,k.
L’approccio è del tutto analogo a quello utilizzato in ambito attuariale classico
nelle assicurazioni danni per lo studio della v.a. del costo sinistri aggregato dei vari
rami danni.
Le ipotesi principali sono che per ogni singola combinazione i,k viene ipotizzato che
le v.a. Z~ i,k,j delle severity siano indipendenti ed identicamente distribuite (i.i.d.),
∑∑∑= = =
=L
i
T
k
N
jjkiLDA
ki
ZX1 1
~
1,,
, ~~

49
nonché il numero delle losses e le severity delle stesse siano reciprocamente
indipendenti.
I passi di calcolo sono simili a quelli visti nel caso dell’approccio dell’IAA WP
[2004]:
o in primo luogo, per ogni combinazione viene individuata la distrib. di
probabilità della v.a. numero delle losses N~ i,k – es. Poisson, Poisson Misturata,
Binomiale Negativa, Binomiale, ecc., con parametri (possibilmente) ricavati dai
dati empirici;
o successivamente, sempre per ogni combinazione i,k viene associata la
distribuzione di probabilità della v.a. Z~ i,k,j (tra cui Weibull, di tipo light-tail,
Gamma, Exponential, Gumbel, LogNormal, di tipo medium-tail o Pareto, di tipo
heavy-tail distrib). In genere nelle ass. danni le distrib. di riferimento sono la
LogNormale e la Pareto.
o Solitamente la distribuzione composta delle losses non è agevole da ottenere in
forma analitica, ed a tal fine si ricorre a Modelli di simulazione Monte Carlo per
ottenere la distrib. simulata di X~ (tra le alternative vi sono la FFT e la Recursion
formula di Panjer come si vedrà in dettaglio nel capitolo 2).
o Le Unexpected Losses (Time Horizon = 1 anno) vengono individuate sulla base
del livello di confidenza fissato (es. 99%, 99.5%, 99.9%) e della misura di
rischio prescelta (VaR o TVaR).
o Nel caso delle Operational Losses è particolarmente difficile individuare
(mediante gli approcci attuariali classici) la coda estrema della distribuzione con
sufficiente affidabilità (e quindi stimare le UL), soprattutto per livello di
confidenza molto elevati (maggiori del 99.9%). In tali casi, spesso si ricorre alla
Extreme Value Theory (EVT) per la stima delle large losses (per l’esattezza
delle losses in eccesso di una elevata soglia u, come si vedrà nel capitolo 2),
mentre per le losses piccole/medie si mantiene l’approccio attuariale
tradizionale.

50
Figura 1.3.2: Rappresentazione delle Operational losses (Fonte Savelli [2005])
In merito alle differenze tra LDA e IMA, è necessario precisare che la prima
metodologia ha l’obiettivo di stimare direttamente le UL e non é basata sull’ipotesi
sottostante l’IMA che le UL possano esprimersi in funzione delle EL mediante i
fattori moltiplicativi γi,k.(es. ULi,k= γi,k x ELi,k). Il LDA ha il vantaggio di accrescere
la sensibilità del CC al risk–profile effettivo della banca per l’OpRisk. Ovviamente
per l’applicazione di tale approccio sono necessari:
o requisiti sulla “qualità” dei dati;
o “robuste” tecniche di stima;
o metodi di validazione “appropriati”.
Il Comitato di Basilea incoraggia il settore bancario a continuare nello sviluppo
di tali approcci, dato che sono emerse difficoltà nella modellizzazione
dell’operational risk secondo l’approccio attuariale tradizionale, con particolare
riferimento alla irregolarità dei rischi estremi (ricorso alla Estreme Value Theory).

51
Nel prossimo futuro sarà opportuno stimare anche le correlazioni interne tra le
differenti LoB dell’Operational Risk e quelle esterne con i diversi fattori di rischio
complessivo (Credit Risk e Market Risk).
Sarà necessario introdurre una classificazione delle cause che generano il
rischio operativo, che sia il più generale possibile. Oltre ai cosiddetti “problemi di
sistema”, controlli “poor”, “errore umano o di processo”, è necessario considerare
altri eventi, che comunque hanno un effetto sul conto economico (spese legali, spese
per interessi, etc.), adottando una classificazione delle perdite per area di impatto sui
risultati, con l’obiettivo di spiegare la volatilità dei guadagni, derivante, appunto,
dall’effetto diretto di tali costi sui risultati.
E’ auspicabile concentrarsi, non sul sistema complessivo, ma su alcuni processi
più “sensibili”. Infatti alcuni processi possono essere esposti al rischio di “failure”,
ma con effetti monetari che possono essere alquanto trascurabili e quindi non oggetto
di un’immediata analisi.
La stima dell’Operational Risk per le compagnie di assicurazione rivestirà un
ruolo altrettanto strategico alla luce del Solvency II. L’esperienza del settore bancario
risulterà senz’altro utile, dato che sta avviando modelli di scoring, di rating e di
analisi statistica multivariata per la quantificazione di tale rischio.

52
1.4 Commenti in merito ai diversi approcci
Da quanto esposto un aspetto di indubbio interesse è rappresentato dai livelli di
intervento dell’autorità di vigilanza nel RBC americano ai fini della futura
applicazione del progetto Solvency II, che però andranno calibrati sulla realtà delle
Compagnie europee di assicurazioni.
In chiusura al capitolo, sulla base di quanto esposto in CEA and Mercer Oliver
Wyman [2005], nella Figura 1.4.1 viene riportato un interessante confronto in termini
di valutazione di attivi e passivi tra il sistema FSA e quello Svizzero. Nel caso del
SST il Target Capital é dato dalla somma del capitale richiesto eccedente dal valore
di mercato delle passività, ma include anche il risk margin (a differenza del modello
FSA).
Figura 1.4.1: Target Capital nei sistemi FSA e SST
Di seguito viene riportata una tabella dove vengono indicati i sistemi che
utilizzano come misura di rischio il VaR e quelli che usano il TVaR. Come si vede
l’unico sistema è il SST ad usare il Tail VaR (si noti che vi sono inclusi anche altri
sistemi non considerati in questa tesi, tra cui il sistema proposto dalla FTK
dell’Olanda, o dalla GDV in Germania, ecc.).

53
Figura 1.4.2: Misure di rischio nei diversi sistemi di assessment della solvibilità
Infine viene riportata la tabella di confronto in termini di livello di confidenza
adottato. Emerge come nel RBC USA sia incluso nel calcolo dei fattori di rischio
(seppur non specificato direttamente), mentre l’FSA ricorre al 99,5% e il SST si rifà
invece al concetto legato al TVaR. Si noti che a differenza di Solvency I, in Basilea II
sono implicitamente utilizzati diversi livelli di confidenza a fronte dei diversi rischi.
Figura 1.4.3: Livelli di confidenza adottati nei diversi sistemi di solvency test

54
Capitolo 2
I metodi per la valutazione della funzione di ripartizione del costo sinistri aggregato
In questo capitolo sono descritti i differenti approcci utilizzabili ai fini della
valutazione della funzione di ripartizione del costo sinistri aggregato, con particolare
riferimento alle tecniche:
• Extreme Value Theory
• Fast Fourier Transform
• di Simulazione
2.1 Il modello “compound” per il costo sinistri aggregato
L’approccio considerato è quello della teoria del rischio secondo
l’impostazione collettiva, il cui modello base fu presentato da Ph. Lundberg al VI
Congresso Internazionale degli Attuari in Vienna nel 1909 e rielaborato
successivamente dall’autore stesso e soprattutto da H. Cramer (1930) e da Laurin
(1930).
Viene determinata, in funzione della variabile aleatoria numero di sinistri e
della variabile aleatoria ammontare del costo del singolo sinistro, la distribuzione
della variabile aleatoria danno aggregato X~ .
La variabile aleatoria danno aggregato è data dalla:
∑=
=k
iiZX
~
1
~~ (2.1.1)

55
dove k~ è la variabile aleatoria numero sinistri mentre iZ~ indica il costo dell’i-esimo
sinistro.
Nella letteratura attuariale la variabile aleatoria numero di sinistri è tipicamente
descritta dalle distribuzioni di probabilità di Poisson o Binomiale Negativa.
Nel primo caso avremo che la probabilità che si verifichino esattamente k
sinistri è data da:
,...2,1,0,!
==−
kk
epk
kλλ (2.1.2)
dove λ>0 è l’unico parametro (che corrisponde alla media e alla varianza di tale
distribuzione).
La funzione generatrice delle probabilità (FGP) è data dalla:
[ ] ( )1~~ )( −== tkk etEtP λ (2.1.3)
Adottando tale distribuzione implicitamente si suppone che i rischi siano omogenei,
che non sussistano fluttuazioni a breve termine o cicli di lungo periodo (si veda Beard
et al. [1984] e Daykin et al. [1994]).
Nel secondo caso avremo che la probabilità che si verifichino esattamente k
sinistri è data da:
( )( ) ,...2,1,0
111
!=
+
+⋅Γ
+Γ= k
kp
k
k ββ
βαβα
α
(2.1.4)

56
o secondo Beard et al. [1994] e Savelli [2003], introducendo la v.a. continua 0~ >q fattore di disturbo o misurante: ( ) ( ) ( ) ( ) ( ) qdqf
kqeqdqfqkPqp q
kq
Qk ∫∫∞ −∞
==0
~0 !
|~ λλ
, con ( ) 1~ =qE .
La distribuzione Binomiale Negativa ha la funzione generatrice delle
probabilità pari a:
[ ] ( )[ ] αβ −−−== 11)(~
~ ttEtP kk . (2.1.5)
Per tale distribuzione si ha [ ] αβ=kE ~ < [ ] ( )βαβ += 1~kVar , mentre il rapporto Varianza
su Media (si veda Heckman e Meyers [1983] e Beard et al. [1984]) è pari a
β+= 1]~[]~[
kEkVar (2.1.6)
Diversi autori utilizzano tale ratio per descrivere la distribuzione Binomiale Negativa.
In particolare Heckman e Meyers [1983] usano il cosiddetto “contagion parameter” c
per definire la relazione tra varianza e media di tale distribuzione:
( )]~[1]~[]~[ kcEkEkVar +⋅= (2.1.7)
Per quanto concerne la variabile aleatoria costo del singolo sinistro Z~ in molti
casi è possibile applicare distribuzioni teoriche, tra cui Pareto, Gamma, Weibull,
Lognormale, ecc., che possono essere ordinate secondo il seguente ranking in base
alla pesantezza delle code (si veda Wang [1998]):

57
Distribuzione Ranking
Pareto 1
Lognormale 2
Gaussiana Inversa Esponenziale 3
Gaussiana Inversa 4
Weibull 5
Gamma 6
Ai fini delle applicazioni realizzate in questa tesi di dottorato è stata sfruttata
anche la Teoria dei Valori Estremi. La metodologia basata sull’Extreme Value
Theory (EVT) consente di ottenere una rappresentazione parametrica della coda della
distribuzione del costo del singolo sinistro, senza la necessità di avanzare ipotesi sulla
forma funzionale dell’intera “distribuzione originaria” delle suddette perdite (si veda
il paragrafo 2.2 e la Figura 2.1.1).
Figura 2.1.1: Esempio di stima parametrica mediante l’EVT
Una volta individuate le distribuzioni utili alla rappresentazione delle variabili
aleatorie k~ e Z~ (si veda Klugman et al. [1998]), si può procedere all’individuazione
della funzione di ripartizione della )(~ xFX , nell’ipotesi che il numero sinistri e il costo
del singolo sinistro siano stocasticamente indipendenti e che le iZ~ siano i.i.d.:

58
{ } { } ( )xSpkkxXpxXxF kZ
kk
kkX
*~
00
~~~Pr~Pr)( ⋅==≤=≤= ∑∑
∞
=
∞
=
(2.1.8)
dove ( )xS k
Z*~ è la k-esima convoluzione della funzione di ripartizione del costo del
singolo sinistro Z~ , che a sua volta può essere ottenuta come:
( )
≥<
=0,10,00*
~xx
xSZ
e, nel caso di variabili aleatorie continue,
( ) ( ) ( )∫+∞
∞−
− −= ydSyxSxS Zk
Zk
Z ~)1(*
~*~ .
Nel caso di variabili discrete si avrà
( ) ( ) ( )∑=
− ⋅−=x
yZ
kZ
kZ ysyxSxS
0
~)1(*
~*~ . (2.1.9)
dove )(~ ysZ è la funzione di densità del costo del singolo sinistro. E’ importante distinguere tra tre casi: • se k
~~Poisson Pura allora X~ definisce un processo di Poisson composto;
• se k
~~Poisson mista allora X~ definisce un processo di Poisson composto misto;
• se k
~~Polya allora X~ definisce un processo di Polya composto.
La formula (2.1.8) è chiamata distribuzione composta, a cui corrisponde una
funzione di densità:
∑∞
=
=0
*~~ )()(
k
kXkX xspxf (2.1.10)
La corrispondente Funzione Generatrice delle Probabilità (di seguito FGP) è
data dalla seguente formula (si veda ad es. Klugman et al. [1998]):

59
( ) [ ] [ ] [ ])()( ~~~
~~
~ tPPtPEtEtP Zkk
ZX
X === (2.1.11) dato che le iZ~ sono i.i.d.
Esistono simili relazioni per le altre funzioni generatrici:
Funzione Caratteristica (FC) In base al teorema di Eulero )sin()cos( titeit += con i2 = -1 si ha
( ) [ ] ( )[ ]tPeEt ZkXit
X ~~~
~ φφ == (2.1.12) Panjer e Willmot [1992] utilizzano la Trasformata di Laplace, la cui esistenza è
sempre assicurata per variabili aleatorie non negative:
( ) [ ] ( )[ ]tLPeEtL ZkXt
X ~~~
~ == − (2.1.13) Funzione Generatrice dei momenti (FGM) ( ) ( )[ ]tMPtM ZkX ~~~ = (2.1.14) Infine i momenti di X~ possono essere ottenuti in termini dei momenti di k~ e Z~ :
[ ] [ ] [ ]ZEkEXE ~~~ ⋅= [ ] [ ] [ ] [ ] [ ]22 ~~~~~ ZEkVarZEkEXVar ⋅+⋅= (2.1.15) [ ]( )[ ] [ ] [ ] [ ] [ ] [ ]3~,3~,3
3 ~~~~3~~~ ZEZVarZEkVarkEXEXE kZ ⋅+⋅⋅⋅+⋅=− µµ

60
Nel caso della distribuzione di Poisson Composta Semplice i momenti della X~ sono
(si veda Bear et al. [1994]):
( )( )( ) 33
22
1
~
~
~
anXk
anX
anXE
⋅=
⋅=
⋅=
σ
( )23
2
3~
na
nax =γ
avendo indicato con aj il momento semplice di ordine j del costo del singolo sinistro,
mentre nel caso della distribuzione di Poisson Composta Misto i momenti della X~
sono dati dalle:
( )( )( ) 33
2~21
22
21
~
~
~
anXk
ananX
anXE
q
⋅=
⋅⋅+⋅=
⋅=
σσ
( )23
2~
21
22
3~~
31
32~2
23
~3
q
qqqx
anna
anmanna
σ
σγσγ
+
+⋅+=
In pochi casi è possibile ottenere risultati analitici che consentono di ridurre i
problemi computazionali relativi alla convoluzione (Klugman et al. [1998]). Ad
esempio nel caso in cui le jZ~ siano i.i.d. e di tipo esponenziale con media θ e
( ) ( ) 1~ 1 −⋅−= xtM Z θ , e k~ segue la distribuzione geometrica con parametro β
( ) ( )[ ] 1~ 11 −−−= ttPk β , allora la distribuzione della X~ è di tipo Compound Geometric-
Exponential (si veda Klugman et al.). In tal caso la funzione di ripartizione del danno
aggregato è data dalla
( ) .0,1
exp1
1)(~ ≥
+
−+
−= xxxFX βθββ
(2.1.16)
Un altro caso che semplifica i problemi computazionali connessi alla convoluzione,
sempre in relazione alla scelta della Z~ , è quello relativo alle distribuzioni “chiuse
sotto convoluzione” (closed under convolution): la condizione essenziale è che

61
aggiungendo “membri” i.i.d. di una famiglia si ottiene un altro membro di quella
famiglia.
Ad esempio la distribuzione Gamma soddisfa tale condizione e gode dell’ulteriore
proprietà che nel caso vengano aggiunti k membri di una famiglia si ottiene un
membro con tutti, ad eccezione di uno, i parametri modificati ed il rimanente
parametro moltiplicato per k.
Indicando con ( )azfZ ;~ la funzione di densità del costo del singolo sinistro, allora la
funzione di densità di kZZ ~...~1 ++ è data dalla ( )akzfZ ⋅;~ . In questo caso si ricava che
∑∑∞
=
∞
=
⋅==1
~
1
*~~ );();()(
kZk
k
kZkX akzspazspxf , (2.1.17)
cioè si elimina la necessità di eseguire la convoluzione.
Per la maggior parte delle distribuzioni delle variabili aleatorie k~ e Z~ , i valori
della distribuzione composta possono essere ottenuti solo numericamente (si veda
Klugman et al [1998]).
2.2 La Teoria dei Valori Estremi e la logica POT
La Teoria dei Valori Estremi (di seguito EVT) é una delle possibili tecniche di
modellizzazione della coda della distribuzione della v.a. Z~ e quindi utile nello studio
del comportamento della variabile X~ .
Il numero di contributi scientifici, basati su questa teoria, in ambito finanziario,
ingegneristico, climatologico, idrologico sta crescendo esponenzialmente e le più
recenti applicazioni stanno volgendo verso l’analisi delle dipendenze e la
modellizzazione delle variabili multivariate (Embrechts et al. [2005]). Nell’ambito

62
assicurativo è sicuramente importante menzionare, tra i numerosi autori, Embrechts
P. et al. [1997], McNeil [1997] and Berlaint J. [2001].
In queste pagine viene richiamata brevemente la parte teorica utile alle
applicazioni realizzate nel lavoro di Cerchiara e Esposito [2004] e successivamente in
questa tesi.
Dato un insieme di dati del costo del singolo sinistro nZZZ ,..., 21 , assunti per
ipotesi independenti e i.i.d., con
{ }zZPF iZi≤= (2.2.1)
si pone l’attenzione sulla distribuzione del massimo ),....,(max 1 nn ZZM = .
In particolare viene analizzata la distribuzione limite allo scopo di studiare il
comportamento dei sinistri estremi.
In base al Teorema di Fisher–Tippet le sequenze di numeri reali 0>nc e Rdn ∈
sono tali che
( ) HdMc dnnn →−−1 se ∞→n
per una distribuzione non degenere H.
Qualsiasi distribuzione dei valori estremi può essere ricondotta alla famiglia delle
funzioni di distribuzione della seguente forma:
{ }[ ]{ }
=−−≠+−
=−
,0expexp,0)1(exp)(
/1
ξξξ ξ
ξ sezsezzH (2.2.2)
con z tale che 1+ξ z >0.
Questa generalizzazione é nota come Generalised Extreme Value (GEV) distribution.
E’ caratterizzata dal parametro ξ , detto “tail index”, che fornisce indicazione della

63
pesantezza della coda. Più è grande il tail index, maggiore è il peso della coda della
distribuzione. Inoltre la (2.2.2) raggruppa 3 distribuzioni dei valori estremi che
differiscono tra loro in base al valore assunto da ξ . In particolare:
1. Distribuzione di Frèchet se ξ > 0
2. Distribuzione di Weibull se ξ < 0
3. Distribuzione di Gumbel se ξ = 0.
In queste pagine viene richiamata la logica Peaks Over Threshold (POT), uno
dei possibili approcci per stimare la funzione di ripartizione dei valori oltre una certa
soglia.
Definita una soglia u, gli eventi estremi vengono definiti come “Peaks (Excesses)
Over Threshold”. Si è interessati a determinare la distribuzione limite (per la soglia u
che tende all’infinito) di tali eccessi.
In particolare è possibile definire la excess distribution function
( ) ( )( ) 0,
1
~)~|~()( ≥
−−+
=>≤−= yuF
uFuZFuZyuZPyFu (2.2.3)

64
dove u é una data soglia, mentre )~|~()( uZuZEue >−= é nota come mean excess
function della variabile aleatoria Z~ , che rappresenta il valore atteso delle eccedenze
oltre la soglia u.
Il teorema Pickands-Balkema-de Haan dimostra che la distribuzione degli eccessi
tende alla Distribuzione Generalizzata di Pareto (GPD):
( )
=−−
≠+−=≈>≤−=
−
0 se )/exp(1
0 se )/1(1)~|~()(
1
,
ξβ
ξβξξ
βξ
z
zzGuZzuZPzFu (2.2.4)
Il parametro ξ é già stato descritto in precedenza, mentre β é il parametro di scala.
Alcuni risultati notevoli (Embrechts et al. [1997]) della EVT consentono di
individuare le stime per il Quantile px̂ al livello di confidenza p (e quindi per la coda
destra 1-F(x)):
( )
−
−+=
−
11ˆˆ
ˆξ̂
ξβ p
Nnux
up (2.2.5)
dove
n = num. osservaz. totali
Nu = num. osservaz. in eccesso della soglia u.
L’applicazione di tale metodo necessita di un’attenta analisi dal punto di vista
grafico della distribuzione che si sta analizzando, che va condotta sulla base di diversi
passi che si ritiene, ai fini di una migliore comprensione della metodologia, di
riportare sulla base di un esempio relativo a dati reali.
L’obiettivo è quindi capire se è possibile utilizzare la GPD e cercare di determinare la
soglia sulla base dell’EVT (logica POT), in riferimento al Database aggiornato
(rispetto alla versione presentata in Embrechts et al. [1997]) dei dati Incendio Danesi
relativo ai periodi 1980-2002, che riporta gli importi rivalutati in base all’indice del

65
costo della vita (CPI) danese al 31.12.20023. Le analisi sono state condotte
utilizzando congiuntamente i software R e Matlab. Di seguito si riporta una breve
descrizione dei dati (1980-2002):
Numero di sinistri 6.870 Media 4.572.984 Somma 31.416.397.376
Minimo 206.837 Standard Deviation 10.539.402 25% Quantile 1.787.635
Massimo 412.032.891 Coefficiente di Variazione 2,30 50% Quantile 2.439.245
Range di variazione 411.826.054 Skewness 17,64 75% Quantile 3.974.104
Tabella 2.2.1. Alcuni dati di sintesi dati incendio danesi (1980-2002) – valori in DK
Si noti l’elevata asimmetria, pari a 17,64 e l’elevato range di variazione.
Successivamente si riportano i grafici su scala logaritmica separando i dati relativi a
1980-1990, 1991-2002 e 1980-2002 (in milioni DK), dato che la prima parte del
Database è stato oggetto di studio di numerosi lavori (Embrechts et al. [1997],
McNeil [1997], Corradin [2002]) e si cercherà di capire se l’intero set di informazioni
può essere modellizzato con l’EVT:
Istogramma dei Data Danesi - 1980-1990
dati in milioni su scala logaritmica
Freq
uenz
e
1 2 3 4 5 6
010
2030
Istogramma dei Data Danesi - 1991-2002
dati in milioni su scala logaritmica
Freq
uenz
e
-1 0 1 2 3 4 5
010
2030
4050
60
Istogramma dei Data Danesi - 1980-2002
dati in milioni su scala logaritmica
Freq
uenz
e
0 2 4
020
4060
8010
0
Figura 2.2.1. Grafici su scala logaritmica dati relativi ai periodi 1980-1990, 1991-2002 e 1980-2002 (dati in milioni DK)
3 Tali informazioni sono state messe gentilmente a disposizione da Mette Rytgaard.
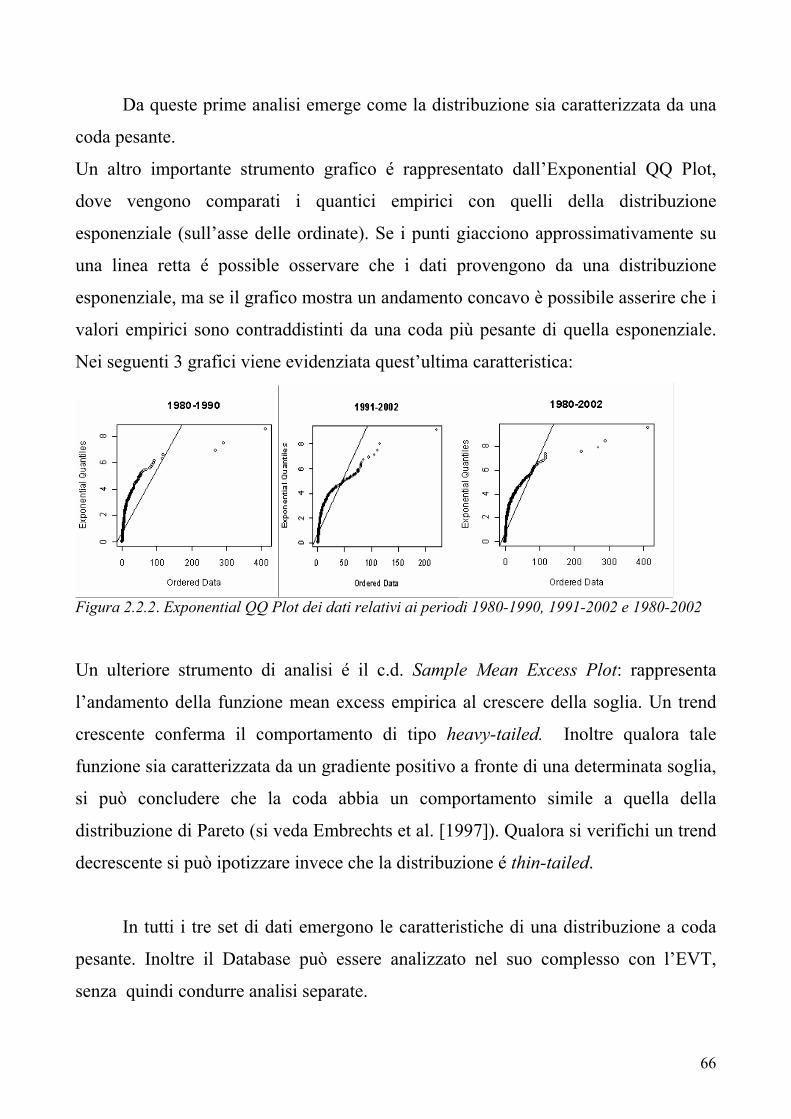
66
Da queste prime analisi emerge come la distribuzione sia caratterizzata da una
coda pesante.
Un altro importante strumento grafico é rappresentato dall’Exponential QQ Plot,
dove vengono comparati i quantici empirici con quelli della distribuzione
esponenziale (sull’asse delle ordinate). Se i punti giacciono approssimativamente su
una linea retta é possible osservare che i dati provengono da una distribuzione
esponenziale, ma se il grafico mostra un andamento concavo è possibile asserire che i
valori empirici sono contraddistinti da una coda più pesante di quella esponenziale.
Nei seguenti 3 grafici viene evidenziata quest’ultima caratteristica:
Figura 2.2.2. Exponential QQ Plot dei dati relativi ai periodi 1980-1990, 1991-2002 e 1980-2002 Un ulteriore strumento di analisi é il c.d. Sample Mean Excess Plot: rappresenta
l’andamento della funzione mean excess empirica al crescere della soglia. Un trend
crescente conferma il comportamento di tipo heavy-tailed. Inoltre qualora tale
funzione sia caratterizzata da un gradiente positivo a fronte di una determinata soglia,
si può concludere che la coda abbia un comportamento simile a quella della
distribuzione di Pareto (si veda Embrechts et al. [1997]). Qualora si verifichi un trend
decrescente si può ipotizzare invece che la distribuzione é thin-tailed.
In tutti i tre set di dati emergono le caratteristiche di una distribuzione a coda
pesante. Inoltre il Database può essere analizzato nel suo complesso con l’EVT,
senza quindi condurre analisi separate.

67
Figura 2.2.3. Empirical Mean Excess Function dei dati relativi ai periodi 1980-1990, 1991-2002 e 1980-2002 (dati in milioni DK)
Si può notare che il trend lineare e variazioni di pendenza si verificano in particolare
in due punti (si vedano le parti cerchiate). In tal caso si ha una prima indicazione ai
fini della scelta della soglia in relazione ai valori 10 e tra 20 e 30.
La scelta della soglia è tipicamente un compromesso fra (si veda McNeil [1997]):
o selezionarne una sufficientemente alta da poter considerare verificate in modo
essenzialmente esatto le tesi del teorema asintotico;
o individuarne una sufficientemente bassa da poter disporre di un sufficiente
numero di valori estremi tale da ottenere stime significative dei parametri.
Si tratta dunque di un trade-off fra varianza e distorsione della stima. Incrementando
il numero di osservazioni per la serie di valori estremi (cioè con una soglia più bassa),
alcune osservazioni dal centro della distribuzione empirica vengono introdotte nella
serie dei valori estremi, e la stima ottenuta per il tail index sarà più precisa (a varianza
più bassa), ma distorta. D’altra parte scegliendo una soglia più elevata la stima
risulterà meno distorta ma al tempo stesso più volatile, a causa delle minori
osservazioni a disposizione.
Nella figura seguente dove viene riportato l’andamento dello shape parameter al
variare della soglia. Nelle zone dove la spezzata è approssimativamente parallela
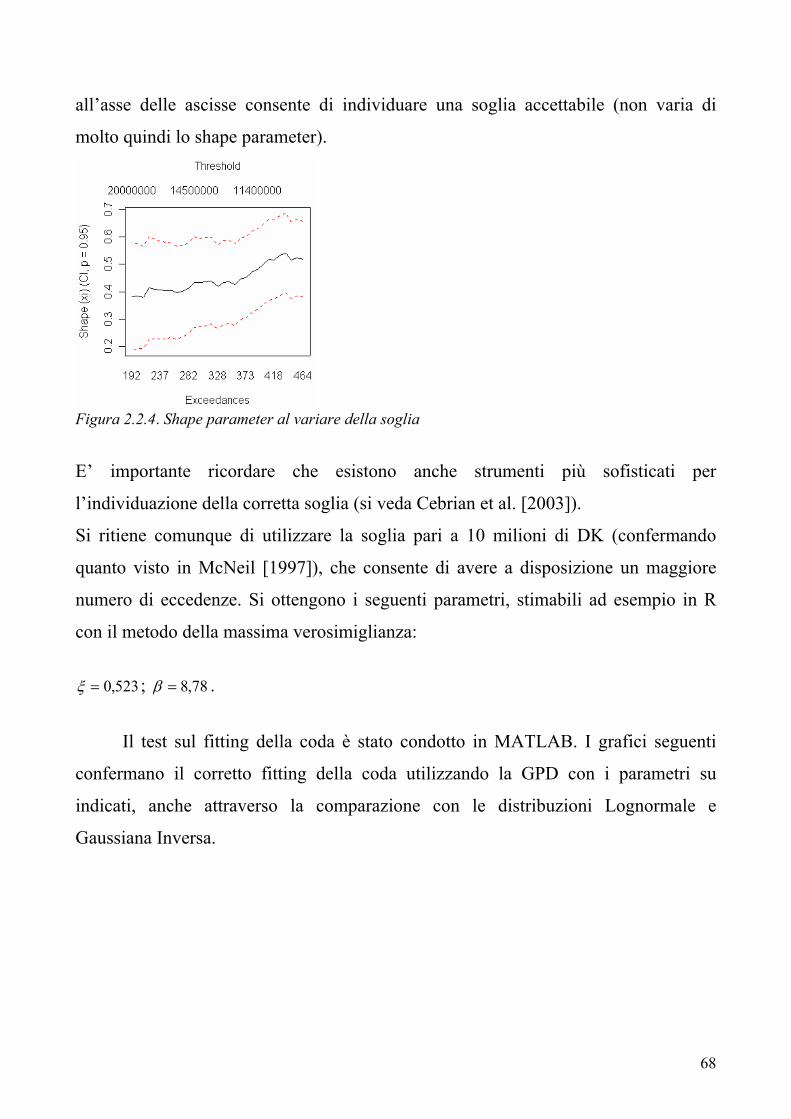
68
all’asse delle ascisse consente di individuare una soglia accettabile (non varia di
molto quindi lo shape parameter).
Figura 2.2.4. Shape parameter al variare della soglia
E’ importante ricordare che esistono anche strumenti più sofisticati per
l’individuazione della corretta soglia (si veda Cebrian et al. [2003]).
Si ritiene comunque di utilizzare la soglia pari a 10 milioni di DK (confermando
quanto visto in McNeil [1997]), che consente di avere a disposizione un maggiore
numero di eccedenze. Si ottengono i seguenti parametri, stimabili ad esempio in R
con il metodo della massima verosimiglianza:
523,0=ξ ; 78,8=β .
Il test sul fitting della coda è stato condotto in MATLAB. I grafici seguenti
confermano il corretto fitting della coda utilizzando la GPD con i parametri su
indicati, anche attraverso la comparazione con le distribuzioni Lognormale e
Gaussiana Inversa.
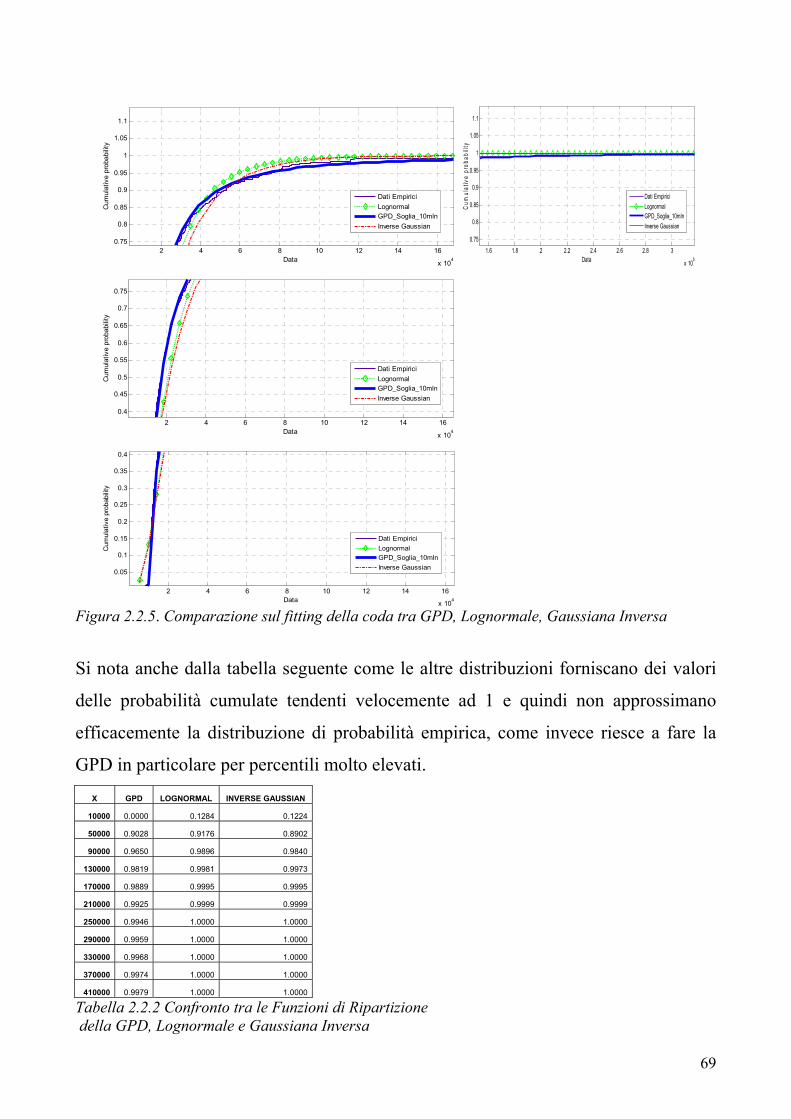
69
2 4 6 8 10 12 14 16
x 104
0.75
0.8
0.85
0.9
0.95
1
1.05
1.1
Data
Cum
ulat
ive
prob
abili
ty
Dati EmpiriciLognormalGPD_Soglia_10mlnInverse Gaussian
1.6 1.8 2 2.2 2.4 2.6 2.8 3
x 105
0.75
0.8
0.85
0.9
0.95
1
1.05
1.1
Data
Cum
ulat
ive
prob
abili
ty
Dati EmpiriciLognormalGPD_Soglia_10mlnInverse Gaussian
2 4 6 8 10 12 14 16
x 104
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
Data
Cum
ulat
ive
prob
abili
ty
Dati EmpiriciLognormalGPD_Soglia_10mlnInverse Gaussian
2 4 6 8 10 12 14 16
x 104
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Data
Cum
ulat
ive
prob
abili
ty
Dati EmpiriciLognormalGPD_Soglia_10mlnInverse Gaussian
Figura 2.2.5. Comparazione sul fitting della coda tra GPD, Lognormale, Gaussiana Inversa
Si nota anche dalla tabella seguente come le altre distribuzioni forniscano dei valori
delle probabilità cumulate tendenti velocemente ad 1 e quindi non approssimano
efficacemente la distribuzione di probabilità empirica, come invece riesce a fare la
GPD in particolare per percentili molto elevati.
X GPD LOGNORMAL INVERSE GAUSSIAN
10000 0.0000 0.1284 0.1224
50000 0.9028 0.9176 0.8902
90000 0.9650 0.9896 0.9840
130000 0.9819 0.9981 0.9973
170000 0.9889 0.9995 0.9995
210000 0.9925 0.9999 0.9999
250000 0.9946 1.0000 1.0000
290000 0.9959 1.0000 1.0000
330000 0.9968 1.0000 1.0000
370000 0.9974 1.0000 1.0000
410000 0.9979 1.0000 1.0000
Tabella 2.2.2 Confronto tra le Funzioni di Ripartizione della GPD, Lognormale e Gaussiana Inversa

70
Si rimanda a Rytgaard [2005] per un’interessante analisi di tale database dove
la coda é modellizzata con una distribuzione di Pareto considerando il parametro ξ
come v.a..
L’EVT è stato oggetto di numerosi studi in campo non solo assicurativo, ma
finanziario, geologico, ecc. Meritevole di menzione è il contributo della Banca di
Italia in ambito bancario, con particolare riferimento a Moscadelli [2004]. In tale
lavoro emerge un’attenta analisi di comparazione tra i tradizionali modelli attuariali
di analisi del costo sinistri e l’EVT secondo la logica POT, dove emerge una
significativa efficacia di quest’ultima metodologia “non tradizionale”.
Si sottolinea che, come emergerà nelle pagine successive, la preferibilità di un
metodo è fortemente condizionato dai dati e dal fenomeno che si stanno analizzando
e modellizzando, e difficilmente un metodo è più efficace di un altro in qualsiasi
situazione. A tale riguardo sono meritevoli di menzione, ad esempio i contributi di
Clemente e Parrini [2005] e Cooray K. e Ananda M. [2005]. In particolare in
quest’ultimo contributo viene dimostrato come i dati del Danish Fire Database
(periodo 1980-1990) presi a riferimento da diversi autori, tra cui ad esempio
Embrechts et al. [1997], McNeil [1997], possano essere modellizzati con un buon
livello di fitting attraverso una distribuzione composta Lognormale a due parametri
per i sinistri al di sotto di una certa soglia (sinistri ordinari) e Pareto a due parametri
per i large claims.
Di seguito si riporta un esempio di tale distribuzione composta (θ>0 e α>0).
(2.2.5)

71
Figura 2.2.6 – Distribuzione Lognormale-Pareto con parametri θ =50 e α=0.5
Per un maggiore dettaglio sulle diverse tipologie di distribuzione per la severity
si rimanda a Hogg e Klugman [1984] e a Klugman et al. [1998].
2.3 Il calcolo numerico della distribuzione del costo sinistri aggregato
In letteratura esistono diversi approcci ai fini della valutazione numerica della
distribuzione del costo sinistri aggregato.
L’utilizzo di distribuzioni approssimate (si veda Beard et al [1984]) consente di
evitare il calcolo diretto della (2.1.8). Ad esempio si supponga che i dati empirici
relativi ad un portafoglio assicurativo forniscano i seguenti valori:
[ ][ ] 141.52;247.179~
3,2;7,6~
~
~
==
==
Z
k
ZE
kE
σ
σ
In base alle (2.1.15) si ottiene [ ] 955.200.1~ =XE e [ ] 1110*88180,1~ =XVar .
Ipotizzando che la X~ si distribuisce secondo la Lognormale, i parametri possono
essere stimati attraverso il metodo dei momenti ed in base ai dati empirici:
[ ] ( )[ ] ( )22
2
22exp~2/exp~
σµ
σµ
+=
+=
XE
XE (2.3.1)
Con semplici passaggi quindi si ricava 93731.13=µ e 122636.2 =σ . In tal modo è
possibile conoscere, ad esempio la
…. = Lognormale ___ = Pareto ---- = Distribuzione Composta
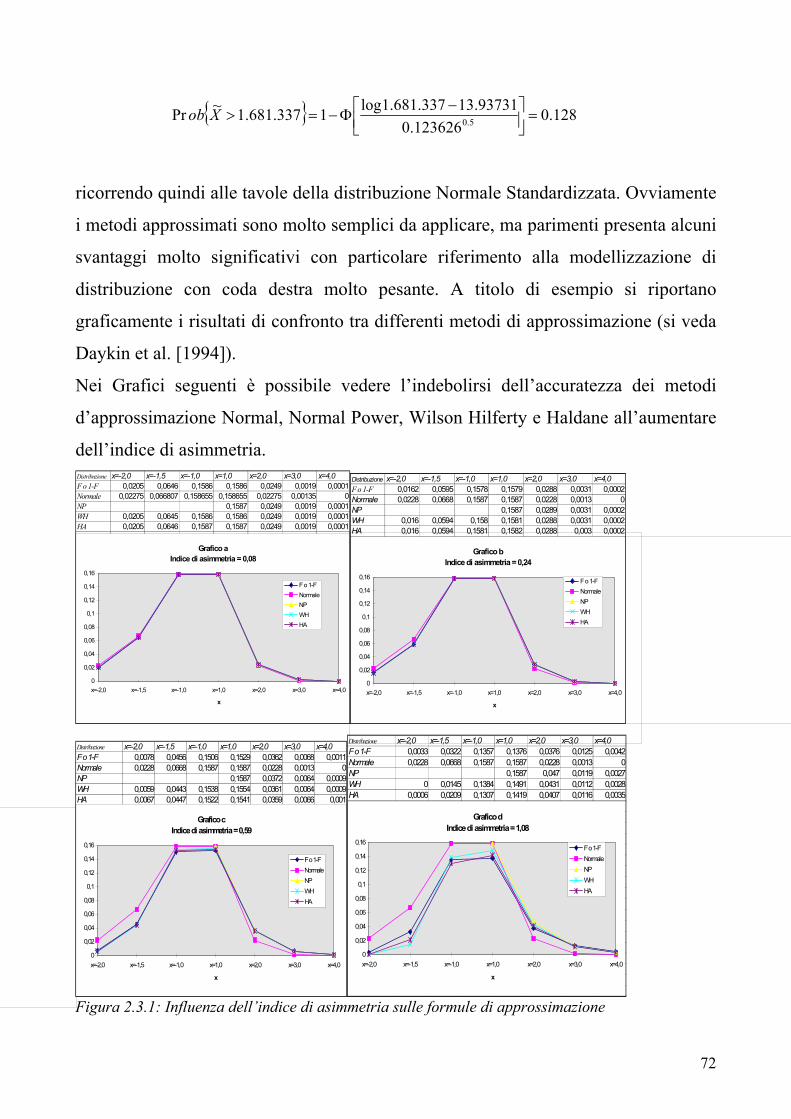
72
{ } 128.0123626.0
93731.13337.681.1log1337.681.1~Pr 5.0 =
−
Φ−=>Xob
ricorrendo quindi alle tavole della distribuzione Normale Standardizzata. Ovviamente
i metodi approssimati sono molto semplici da applicare, ma parimenti presenta alcuni
svantaggi molto significativi con particolare riferimento alla modellizzazione di
distribuzione con coda destra molto pesante. A titolo di esempio si riportano
graficamente i risultati di confronto tra differenti metodi di approssimazione (si veda
Daykin et al. [1994]).
Nei Grafici seguenti è possibile vedere l’indebolirsi dell’accuratezza dei metodi
d’approssimazione Normal, Normal Power, Wilson Hilferty e Haldane all’aumentare
dell’indice di asimmetria. Distribuzione x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0F o 1-F 0,0205 0,0646 0,1586 0,1586 0,0249 0,0019 0,0001Normale 0,02275 0,066807 0,158655 0,158655 0,02275 0,00135 0NP 0,1587 0,0249 0,0019 0,0001WH 0,0205 0,0645 0,1586 0,1586 0,0249 0,0019 0,0001HA 0,0205 0,0646 0,1587 0,1587 0,0249 0,0019 0,0001
Grafico aIndice di asimmetria = 0,08
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0
x
F o 1-FNormaleNPWHHA
Distribuzione x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0F o 1-F 0,0162 0,0595 0,1578 0,1579 0,0288 0,0031 0,0002Normale 0,0228 0,0668 0,1587 0,1587 0,0228 0,0013 0NP 0,1587 0,0289 0,0031 0,0002WH 0,016 0,0594 0,158 0,1581 0,0288 0,0031 0,0002HA 0,016 0,0594 0,1581 0,1582 0,0288 0,003 0,0002
Grafico bIndice di asimmetria = 0,24
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0
x
F o 1-FNormaleNPWHHA
Distribuzione x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0F o 1-F 0,0078 0,0456 0,1506 0,1529 0,0362 0,0068 0,0011Normale 0,0228 0,0668 0,1587 0,1587 0,0228 0,0013 0NP 0,1587 0,0372 0,0064 0,0009WH 0,0059 0,0443 0,1538 0,1554 0,0361 0,0064 0,0009HA 0,0067 0,0447 0,1522 0,1541 0,0359 0,0066 0,001
Grafico cIndice di asimmetria = 0,59
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0
x
F o 1-FNormaleNPWHHA
Distribuzione x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0F o 1-F 0,0033 0,0322 0,1357 0,1376 0,0376 0,0125 0,0042Normale 0,0228 0,0668 0,1587 0,1587 0,0228 0,0013 0NP 0,1587 0,047 0,0119 0,0027WH 0 0,0145 0,1384 0,1491 0,0431 0,0112 0,0028HA 0,0006 0,0209 0,1307 0,1419 0,0407 0,0116 0,0035
Grafico dIndice di asimmetria = 1,08
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
x=-2,0 x=-1,5 x=-1,0 x=1,0 x=2,0 x=3,0 x=4,0
x
F o 1-FNormaleNPWHHA
Figura 2.3.1: Influenza dell’indice di asimmetria sulle formule di approssimazione

73
In linea generale non vi sono grandi differenze di accuratezza tra gli approcci
NP, WH e di Haldane. Grande rilevanza ai fini di una scelta è la convenienza pratica,
che in tale ottica fa propendere per la formula di WH. Per quanto riguarda la
Normale, essa fornisce un’approssimazione alquanto deficitaria, eccetto il caso in cui
l’asimmetria è molto limitata.
E’ possibile trovare una notevole raccolta di confronto tra metodi esatti,
approssimati in Pentikainen [1987], dove sono considerate 54 distribuzioni di tipo
diverso. Dai test applicati è emerso che l’accuratezza dei metodi approssimativi è di
regola buona, o quantomeno soddisfacente, nel caso di scarsa asimmetria, quando il
numero di sinistri non è troppo piccolo e se la distribuzione dell’importo del singolo
sinistro non è molto eterogenea, cioè non ha una lunga coda (in genere quest’ultima
condizione è soddisfatta quando i rischi di punta vengono riassicurati).
Meritevole di menzione è anche l’utilizzo dell’approssimazione in base alla
distribuzione Beta per il claim ratio seguito da Campagne negli studi preparatori del
margine di solvibilità danni CEE (si veda De Wit e Kastelijn [1980]).
Una seconda alternativa è rappresentata dal c.d. calcolo diretto, cioè dalla
valutazione numerica degli integrali
∫−
− −=x
kk ydSyxSxSZZZ
0
)1(* )()()( ~~~ (2.3.2)
Tali integrali sono in forma Lebesgue-Stieltjes, valutabili attraverso metodi di
integrazione numerica che conducono ad una elevata, a volte eccessiva, complessità
computazionale (si veda Loss Models [1998] in merito ai metodi pratici per ovviare a
tali problemi tecnici), in genere di ordine n3, per ottenere distribuzioni per valori di x
da 0 a n.

74
Esistono metodi che consentono di calcolare più rapidamente la distribuzione
del danno aggregato riconducibili a tre grandi categorie:
o Metodi Ricorsivi: riducono il numero di computazioni ad un ordine di n2, ma si
possono applicare solo in presenza di alcune distribuzioni della k~ (si veda in
particolare Panjer [1981])
o Metodi di Inversione
o Simulazione.
2.3.1 Cenni ai metodi Ricorsivi
Tale approccio sarà trattato brevemente, non essendo oggetto della presente
tesi (si noti che tale metodo viene utilizzato anche dal FOPI nello SST).
Il problema è stato studiato da vari autori, tra cui ricordiamo Panjer [1981] che
ha proposto una formula ricorrente che permette di calcolare la funzione di
ripartizione in questione, nell’ipotesi che le variabili aleatorie, rappresentanti il danno
di ciascun sinistro, siano mutuamente indipendenti ed identicamente distribuite. Dal
1981 ad oggi sono stati scritti numerosi articoli per generalizzare la formula di
Panjer, ma occorre sottolineare che l’estensione della formula iniziale comporta
condizioni via via meno comode per le applicazioni.
E’ possibile valutare tale funzione attraverso la formula ricorrente di Panjer, che nel
caso di distribuzione discreta del costo di ogni singolo sinistro, definita per valori
positivi, allora si risolve in una semplice relazione di ricorrenza, mentre se il costo
del singolo sinistro é una variabile aleatoria continua, essa si trasforma in una
relazione di ricorrenza nella forma di equazione integrale di Volterra. Nel caso di una

75
distribuzione mista si ricorre a procedure di discretizzazione4 al fine di ottenere limiti
superiori ed inferiori ed approssimazioni per la distribuzione del danno cumulato.
Indicando con:
∑∞
=
∗⋅=0
)( )()(n
nn ifpig (2.3.1.1)
la probabilità che la determinazione del danno aggregato é pari ad i, allora la formula
di Panjer é la seguente:
( ) ( ) ( )∑=
−
+=
i
jjigjf
ijbaig
1 (2.3.1.2)
Un’ulteriore ipotesi emersa nei primi lavori per l’applicabilità é che la probabilità pn
sia rappresentata dalla distribuzione di Poisson, o dalla distribuzione binomiale o
dalla binomiale negativa, od anche dalla distribuzione geometrica. Successivamente è
stata estesa a numerose altre distribuzioni (distribuzione di Waring, Ipergeometrica,
Negativa Ipergeometrica, Waring generalizzata, ecc.).
Infatti per le distribuzioni su elencate vale la seguente relazione ricorrente:
+= − n
bapp kk 1 k= 1,2,3,... (2.3.1.3)
dove a e b sono dei numeri reali da determinare e dipendenti dalle distribuzioni scelte
per rappresentare il numero di sinistri, come è possibile vedere nella Tabella 2.3.1.1
(si veda Panjer H. e Willmot G. [1992]).
Distribuzione
numero sinistri
Valore di
a
Valore di
b
Poisson (λ) 0 λ
Binomiale(q,m) -q/(1+q) (m+1)[q/(1-q)]
Geometrica(β) β/(1+β) 0
Binomiale Neg.(β,r) β/(1+β) (r-1)[β/(1+β)]
Tabella 2.3.1.1: Parametri per differenti distribuzioni del numero sinistri, soddisfacenti la (2.3.1.3) 4 Sussistono essenzialmente due metodi per rendere discreta la distribuzione del costo globale sinistri: il metodo del punto medio ed il metodo del valore atteso non distorto. Per chi fosse interessato all’argomento si veda Daykin et al.[1994].
a
Bino. Neg. r >1
0<r<1
Geom. r=1
Poisson Binomiale m=1 2 3 ecc.
b
rette b=-(m+1)a

76
2.3.2 I Metodi di Inversione
I metodi di inversione sono utilizzati ai fini della valutazione numerica della
distribuzione di probabilità (tra i primi Bohman [1964] e Seal [1971]) o di alcune
funzioni ad essa correlate, come ad esempio l’aggregate excess of loss premium (si
veda Heckman e Meyers [1983]), ricorrendo ad una trasformata di una tra la FGP,
FGM o FC della variabile aleatoria considerata.
Le distribuzioni composte sono facilmente trattabili con tale approccio, dato
che le loro trasformate sono ancora funzioni composte e immediatamente valutabili
una volta note le distribuzioni delle variabili aleatorie k~ e Z~ . Richiamando le
espressioni della FC si ha:
( ) [ ] ( )[ ]tPeEt ZkXit
X ~~~
~ φφ == (2.3.2.1)
La FC esiste sempre ed è unica ed a fronte di una data FC, esiste sempre un’unica
distribuzione.
L’obiettivo dei metodi di inversione è ottenere numericamente la distribuzione dalla
FC. Inoltre possono essere ricondotti a tre grandi categorie:
• Fast Fourier Transform (Brigham [1974], Bertram [1981], Robertson [1983],
Wang [1998]), su cui saranno basate parte delle applicazioni di questa tesi di
dottorato.
• Inversione numerica diretta (Heckman e Meyers [1983]), che verrà esposta
brevemente nell’Appendice A.

77
• Il procedimento di inversione della Trasformata di Fourier nel caso dei singoli
costi sinistri considerati come v. a. indipendenti, ma non necessariamente con
la stessa distribuzione proposto da Ferrara et al. [1996] (Appendice B).
2.3.2.1 Il metodo della Fast Fourier Transform
I metodi che sfruttano la trasformata di Fourier (Fast Fourier Transformation),
a cui sono ricorsi, tra i primi, Bohman e Esscher [1964], Bertram [1981], Heckman e
Meyers [1983] e Robertson [1983], sono procedimenti che consentono di ottenere la
funzione di ripartizione del danno globale, ma possono essere sfruttati anche come
controllo esterno del calcolo diretto adottato6.
La Fast Fourier Transform (FFT) è un algoritmo che può essere usato per
invertire la Funzione Caratteristica al fine di ottenere la distribuzione di probabilità di
variabili aleatorie discrete. La prima applicazione al costo sinistri aggregato è dovuta
a Robertson [1983], il quale nel suo lavoro fornisce una dettagliata descrizione sia a
livello teorico che implementativo che risulta molto utile in particolare per chi
affronta per la prima volta tale argomento.
Ai fini della esposizione di tale approccio si prenderà come riferimento Robertson
[1983], Klugman et al. [1998] e Wang [1998].
Per una funzione continua f(x), la Trasformata di Fourier è la mappa (o
applicazione dallo spazio dei numeri complessi Cn allo spazio Cn):
( ) ∫+∞
∞−
⋅= dxexfzf izx)(&& (2.3.2.1)
6 Si veda C. Ferrara et al. [1996].

78
La funzione di partenza può essere riottenuta dalla sua Trasformata di Fourier:
( ) ∫+∞
∞−
−⋅= dzezfxf izx)(21 &&π
(2.3.2.2)
Si noti che se f(x) è una funzione di densità, allora )(zf&& è la sua FC (come visto in
precedenza).
Nel caso di variabili aleatorie discrete (o di tipo misto) la definizione può essere
generalizzata.
Sia fx una funzione definita per tutti i valori interi di x, periodica con periodo di
lunghezza n (in modo che fx+n = fx per ogni x). Allora a fronte del generico vettore
(f0,f1, …, fn-1), la Trasformata discreta di Fourier è la c.d. one-to-one mapping xf&& di n
punti in n punti (dove x = …., -1,0,1,….), definita dalla
∑−
=
−=
=
1
0,...1,0,1.....,,2exp
n
jjk kjk
niff π&& (2.3.2.3)
Tale mappa è biettiva ed inoltre kf&& è periodica con lunghezza n.
L’inversa di questa applicazione rappresenta la funzione di partenza:
∑−
=
−=
−=
1
0
,...1,0,1....,,2exp1 n
kkj jkj
nif
nf π&& (2.3.2.4)
E’ ovvio che, in base alla trasformata discreta di Fourier, per ottenere n valori di kf&& , è
necessario valutare un numero di termini di ordine n2.

79
E’ possibile ricorrere, quindi, alla c.d. Fast Fourier Transform (di seguito FFT),
cioè ad un algoritmo che consente di calcolare la trasformata discreta di Fourier, ma
che riduce il numero di iterazioni ad un ordine di n log2 n (si veda Robertson per una
esauriente spiegazione tecnica). Tale effetto è sicuramente significativo, in particolar
modo quando il numero di punti è molto elevato (si noti quanto indicato nella tabella
successiva):
Caso I Caso II Caso III n (punti) 100 1.000 10.000 Trasformata Discreta di Fourier (n2) 10.000 1.000.000 100.000.000 FFT (n log2 n) 664 9.966 132.877 Riduzione - 9.336 - 990.034 - 99.867.123 Riduzione % -93,36% -99,00% -99,87%
Tabella (2.3.2.1)
Il concetto su cui si basa la FFT è che la trasformata discreta di Fourier di lunghezza
n = 2r può essere riscritta come la somma di due trasformate discrete, ciascuna di
lunghezza n / 2 = 2r-1, riferite rispettivamente alla prima metà e alla seconda metà dei
punti:
∑∑
∑∑
∑
−
=+
−
=
−
=+
−
=
−
=
+
=
=
++
=
=
=
1
012
1
02
12/
012
12/
02
1
0
2exp2exp22exp
)12(2exp22exp
2exp
m
jj
m
jj
n
jj
n
jj
n
jjk
jkm
ifkn
ijkn
if
kjn
ifjkn
if
jkn
iff
πππ
ππ
π&&
dove m = n/2. Quindi
bk
akk fk
niff &&&&&&
+=π2exp (2.3.2.5)

80
A loro volta akf&& e b
kf&& possono essere scritte come la somma di due trasformate di
lunghezza m / 2 = 2r-1. Tale procedimento può essere continuato successivamente fino
ad arrivare ad un numero r di volte dove le trasformate hanno lunghezza 1.
Una volta note le trasformate di lunghezza 1, è possibile ricomporre le trasformate di
lunghezza 2, 22, 23, …, 2r attraverso la (2.3.2.5).
E’ importante notare che:
o La FC mappa una funzione di densità continua in una funzione continua a
valori complessi.
o La FFT invece mappa un vettore di n valori in un vettore di n valori complessi.
Tale analogia con la FC è fondamentale ai fini della comprensione delle
applicazioni della FFT (si veda Wang [1998]).
o La FFT della somma di due v.a. stocasticamente indipendenti è pari al prodotto
delle FFT delle due v.a.
o Esistono diversi software che prevedono una routine di calcolo in base alla FFT
e non impongono quindi la necessità di scrivere un apposito programma: R,
Matlab, Excel con differenti capacità in termini di numero massimo di punti
elaborabili (di seguito sarà utilizzato Matlab).
o Per utilizzare in modo ottimale la FFT è necessario che il vettore iniziale sia di
lunghezza 2r. In caso negativo è sufficiente aggiungere in coda (a destra) un
numero di zeri tali da raggiungere la dimensione ottimale.
Ai fini delle applicazioni in campo attuariale e probabilistico, le fj possono
rappresentare delle probabilità, ad esempio ponendo ( ) { }jkobfjf jk ===~Pr~ . Se una
v.a. k~ ha le seguenti probabilità:
p0 = 0.5 p2 = 0.4 p5 = 0.1

81
è possibile rappresentarle con il vettore
kf ~ = [0.5,0,0.4,0,0,0.1].
Applicando la FFT a tale vettore si ottiene il seguente vettore f&& :
[1.0; 0.35-0.2598i; 0.25+0.433i; 0.8; 0.25-0.433i; 0.35+0.2598i]. Si noti che se si aggiunge uno zero in coda al vettore delle probabilità il risultato
cambia nettamente. Infatti applicando la FFT a
kf ~ =[0.5;0;0.4;0;0;0.1;0]
si ottiene
[1.0; 0.389-0.293i; 0.0495+0.130i; 0.812+0.235i; 0.812-0.2345i; 0.0495-0.1302i;
0.3887+0.2925i].
Tale elemento è essenziale nella corretta applicazione della FFT (come si vedrà di
seguito).
Nell’ambito dell’approccio collettivo della Teoria del Rischio la FFT riveste un
ruolo fondamentale nella determinazione della distribuzione del danno aggregato.
Prima di descrivere l’applicazione della FFT è importante premettere che la FC può
essere riscritta nel modo seguente (si veda Wang [1998]):
[ ] ( )[ ][ ] [ ] ( ))()(~)( ~~~
~~~...~~
~~
~ 21 tPtEkkeEEeEt Zkk
ZkZZZti
kXti
Xk φφφ ===== +++⋅⋅ (2.3.2.6)
Quindi la FC del danno aggregato è pari alla FGP della variabile aleatoria numero
sinistri calcolata nella variabile )(~ tZφ (FC della v.a. costo del singolo sinistro). Tale
relazione consente di comprendere meglio i passi necessari ai fini dell’applicazione
della FFT:

82
1. Scegliere il valore n = 2r del numero di punti desiderati per la distribuzione
del costo sinistri aggregato (che indicherà quindi la dimensione del vettore
delle probabilità da ricercare) a fronte di un determinato valore intero r. Si noti
che la conoscenza a priori del valore medio e della standard deviation della v.a.
X~ facilita l’individuazione del corretto valore di n.
2. Discretizzare5 la distribuzione di probabilità della Z~ (qualora sia continua).
Esistono diverse metodologie che consentono la discretizzazione (si veda
Klugman et al . [1998], Wang [1998]), tutte comunque basate sul c.d. span h
(passo o fattore di scala), la cui scelta è funzione della precisione desiderata e
della pesantezza della coda della distribuzione della Z~ (che sarà quindi uguale
a 0*h, 1*h, 2*h, …, (m-1)*h). In tal modo si ottiene il vettore
[ ])1(),....,1(),0( ~~~~ −= mffff ZZZZ.
Come detto in precedenza è necessario aggiungere al vettore di probabilità così
ottenuto, un numero di zeri tale che il numero di elementi sia pari a n (c.d.
padding zeros). In tal modo si otterrà il seguente vettore discreto:
[ ])1(),....,1(),0( ~~~~ −= nffff ZZZZ
3. Applicare la FFT al Z
f ~ : )( ~~ ZZfFFTf =&& ottenendo la FC della distribuzione
discretizzata della v.a. Z~ , cioè la )(~ tZφ . Il risultato è ancora un vettore di n = 2r
elementi.
4. Applicare la FGP della v.a. k~ , elemento per elemento, alla FFT del vettore
delle probabilità della v.a. Z~ :
( )ZkX
fPf ~~~&&&& = .
5 Si noti che Robertson [1983] utilizza distribuzioni piecewise di tipo uniforme per la v.a. Z~ .

83
Si ottiene quindi la FC della v.a. danno aggregato: ( ))()( ~~~ tPt ZkX φφ = ,
rappresentato da un vettore di n = 2r elementi.
5. Applicare la Inverse FFT (IFFT), anch’essa disponibile nei software
menzionati in precedenza, che, in base alla (2.3.2.4), risulta essere differente
dalla FFT solamente per una variazione di segno e una divisione per n. In tal
modo si ottiene la distribuzione esatta del danno aggregato:
( )XX
fIFFTf ~~&&=
Si noti che la scelta del numero di punti n è cruciale ai fini dell’accuratezza
della valutazione della distribuzione della X~ . In particolare nel caso di distribuzioni
della Z~ in cui si hanno probabilità non nulle oltre il valore n, può verificarsi un errore
nella stima nella coda destra della distribuzione della X~ , dato che viene violata
l’ipotesi iniziale che la funzione e la sua trasformata siano entrambe periodiche con
periodo n. In questo caso Klugman et al. [1998] suggeriscono di inserire tutte le
rimanenti probabilità nel punto n, in modo che la somma di tutte le probabilità sia
pari a 1 e quindi sia garantita la periodicità e che anche la somma delle probabilità
Xp ~ stimate sia 1.
Comunque è importante che n sia abbastanza grande. La scelta è dettata ovviamente
sia dal tipo di software che si utilizza (in Excel il numero massimo di punti è 4.096 =
2r, con r = 12, mentre in Matlab si riesce anche ad utilizzare r = 20 e quindi
1.048.576 punti), ma anche la conoscenza della distribuzione, o comunque i relativi
momenti, della v.a. oggetto di studio. Tale elemento, a parere di scrive, può, a volte,
creare una sorta di loop tra metodo di stima e obiettivo della stima stessa.
Un altro elemento, come si vedrà nelle applicazioni del capitolo 3, è la scelta
dello span. Infatti un valore troppo elevato può influenzare l’accuratezza della
distribuzione discretizzata. Un valore troppo piccolo però può produrre il c.d.
wrapping nella distribuzione del danno aggregato, cioè la presenza di probabilità
diverse da zero in prossimità del numero massimo di punti n.

84
2.3.3 L’approccio simulativo
I precedenti metodi numerici conducono alla determinazione di una
distribuzione da ritenersi “esatta”, a meno di un livello di errore che comunque può
essere ridotto in modo significativo all’aumentare dei punti considerati.
Il secondo elemento da sottolineare è che la reale distribuzione del costo del
singolo sinistro viene sostituita da una distribuzione alternativa: “aritmetizzata” nel
caso della FFT e della formula ricorsiva, una piecewise linear function nel modello di
Heckman e Meyers [1983]. A volte tale elemento può comportare una distorsione
nell’accuratezza della stima.
Un approccio alternativo è rappresentato dall’approccio simulativo basato sul
Metodo di Monte Carlo, fondato sul seguente Lemma:
“A fronte di qualsiasi variabile aleatoria X~ e di una determinazione u di una
variabile aleatoria U~ distribuita uniformemente in (0,1), X~ e ( )uFX1~ − hanno la stessa
Funzione di Ripartizione”:
( ){ } { } )()(PrPr ~~1~ xFxFuxuF
XXX =≤=≤−
Quindi una simulazione con il metodo di Monte Carlo di una variabile X~ può essere
ottenuta attraverso la generazione di un numero pseudo casuale u secondo la
distribuzione uniforme U~ ∼ Uniforme(0,1) e successivamente invertendo )(1~
* uFx X−= .
Graficamente (si veda ad esempio Daykin et al. [1994]) la procedura è
rappresentabile nella figura seguente:
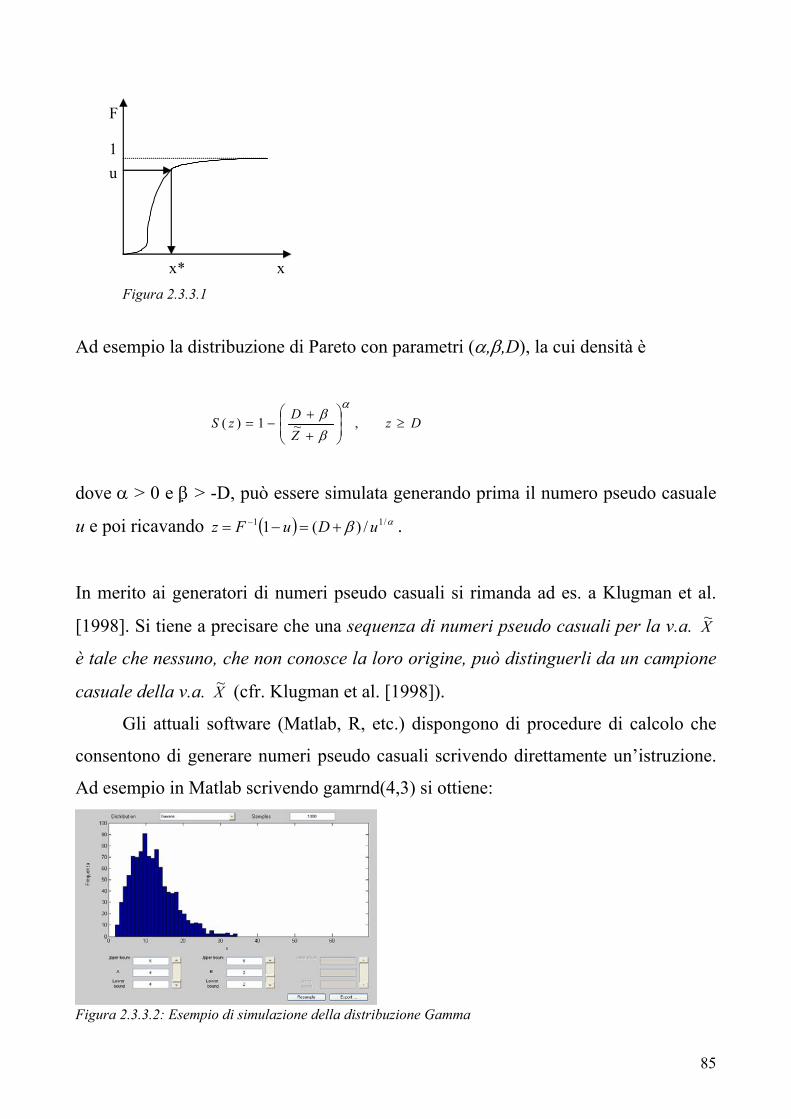
85
x
u
x*
1
F
Figura 2.3.3.1
Ad esempio la distribuzione di Pareto con parametri (α,β,D), la cui densità è
dove α > 0 e β > -D, può essere simulata generando prima il numero pseudo casuale
u e poi ricavando ( ) αβ /11 /)(1 uDuFz +=−= − .
In merito ai generatori di numeri pseudo casuali si rimanda ad es. a Klugman et al.
[1998]. Si tiene a precisare che una sequenza di numeri pseudo casuali per la v.a. X~
è tale che nessuno, che non conosce la loro origine, può distinguerli da un campione
casuale della v.a. X~ (cfr. Klugman et al. [1998]).
Gli attuali software (Matlab, R, etc.) dispongono di procedure di calcolo che
consentono di generare numeri pseudo casuali scrivendo direttamente un’istruzione.
Ad esempio in Matlab scrivendo gamrnd(4,3) si ottiene:
Figura 2.3.3.2: Esempio di simulazione della distribuzione Gamma
DzZDzS ≥
+
+−= ,~1)(
α
ββ

86
Ai fini della simulazione del processo composto della v.a. X~ è sufficiente
seguire i seguenti passi (si veda Daykin et al. [1994]):
1. Generare il numero di sinistri k in base ad una determinata distribuzione di
probabilità (poisson semplice, binomiale negativa, etc.).
2. Generare esattamente k numeri Z1, Z2, …, Zk secondo una determinata
distribuzione di probabilità (lognormale, pareto, etc.).
3. La somma Z1 + Z2 + … + Zk = X fornisce un numero pseudo casuale della v.a.
danno aggregato.
4. Ripetere i tre precedenti step per ottenere il numero n desiderato di valori di X~ .
Si noti che nel caso k~ segua la distribuzione negativa in genere si procede ad un
doppio stadio di simulazione:
o generare un numero pseudo casuale q secondo l’apposita
distribuzione (Gamma(h,h) nel caso del Processo di Polya);
o generare un numero pseudo casuale in base alla distribuzione di
Poisson Semplice con parametro n q in luogo di n (si veda Daykin et
al [1994] e Savelli [2003] per i dettagli).
Il passo numero 4 ovviamente pone la questione dell’accuratezza della stima e
quindi della scelta del numero di simulazioni da effettuare. In questo senso si può
ricorrere al Teorema del Limite Centrale. Sulla base dell’esempio riportato in
Klugman et al. [1998] si può individuare un numero minimo di simulazioni affinché
il valore atteso della v.a. da simulare sia compreso in un intervallo ± 1% del valore
reale ad un livello di confidenza del 95%:

87
( )
+≤≤−=
=
+≤
−≤−=≤≤=
µσ
µσ
µσσ
µµ
σµµ
nY
n
nnX
nX n
n
01.0~01.0Pr
01.001.0Pr01.199.0Pr95.0
dove Y~ è la v.a. Normale Standardizzata. Quindi il livello minimo potrà essere
desunto da 96.101.0=µ
σ n, da cui ( )2/38416 µσ=n , dove σ e µ possono essere ricavati
dai valori campionari della deviazione standard s e media x nelle simulazioni.
La regola che consente di terminare le iterazioni sarà data dalla:
( )2/38416 xsn ⋅=
Si noti che oltre all’accuratezza della stima, occorrerebbe stimare anche eventuali
errori di modello e di parametro (si veda ad es. Daykin [1994]).
Si rimanda ad esempio a Wang[1998], Embrechts [2005] ai fini dell’utilizzo
della simulazione nella modellizzazione delle dipendenze in connessione con le c.d.
Copule.
Si veda Rytgaard e Savelli [2004] in merito all’applicazione del metodo
simulativo per la modellizzazione di sistemi di tipo RBC, in presenza di diversi
trattati riassicurativi.
2.4 L’utilizzo della FFT nell’ambito della modellizzazione delle dipendenze e
dell’aggregazione tra rami
Il metodo utilizzato da Wang [1998] é contraddistinto da un’elevata velocità di
elaborazione e gode anche di un’importante peculiarità rappresentata dalla

88
possibilità di estendere il metodo della FFT alla modellizzazione di variabili
multivariate o la combinazione di diverse linee di business (rami). Tale elemento
ovviamente riveste particolare importanza per quanto menzionato in merito al
progetto Solvency II.
Si supponga che una Compagnia di assicurazioni danni sia caratterizzata da
solo due rami:
o Ramo 1 dove la v.a. numero sinistri è k~ , mentre la severity è descritta
dalla v.a. Z~
o Ramo 2 dove la v.a. numero sinistri è h~ , mentre la severity è descritta
dalla v.a. Y~ .
Si ipotizzi inoltre che k~ , Z~ , h~ e Y~ siano tutte mutuamente indipendenti. L’obiettivo
è calcolare la distribuzione del danno aggregato derivante dalla combinazione dei due
rami:
)~...~~()~...~~(~~21~21 hk YYYZZZX +++++++=
In base a quanto ipotizzato si ha che
( ) ( ))()()( ~~~~~ tPtPt YhZkX φφφ ⋅= (2.4.1)
In base alla proprietà precedente allora la FFT della distribuzione della v.a. X~
derivante dall’aggregazione dei due rami si può ricavare secondo i seguenti passi:
o si ricavi per i due rami:
)()( ~~~~YhZk fPmefPg &&&&&&&& ==
o invece di applicare la Inverse FFT (IFFT) a ciascuno dei due vettori di cui al
punto precedente, si effettua il prodotto elemento per elemento di g&& e m&& .

89
o Infine si applica la IFFT:
( )mgIFFTfX
&&&& ⋅=~ .
Sotto tale approccio quindi la v.a. numero sinistri “aggregata” deriva dalla
convoluzione delle singole distribuzioni delle v.a. numero sinistri dei due rami.
Generalizzando per n linee di business è necessario distinguere tra il caso in cui
sussista indipendenza tra i diversi rami o meno per quanto concerne la v.a. numero
sinistri.
2.4.1 Caso 1: Indipendenza tra rami
Qualora le n linee di business siano indipendenti e ciascun ramo sia
caratterizzato da una v.a. numero sinistri distribuita secondo la Poisson Semplice con
media λj e distribuzione del costo del singolo sinistro Sj, con j = 1, …, n, in termini di
FC si otterrà il seguente risultato:
( ) ( )( ) ( ) ( )( )1
1
1
1
~~~~ −
=
−
=
=== ∏∏ tn
j
tn
jZkX
ZjZj
jjeetPt φλφλ
φφ (2.4.1.1)
dove nλλλλ +++= ...21 rappresenta il numero atteso di sinistri del portafoglio
aggregato e )(...)()( ~~1
~1
tttnZ
nZZ φ
λλ
φλλφ ++= la relativa FC risultante come media pesata
delle singole FC con pesi dati dai rapporti tra numero sinistri di ramo e numero atteso
sinistri totale. Di conseguenza la Funzione di Ripartizione del costo del singolo
sinistro del portafoglio aggregato sarà data da
( ) ( ) ( )zSzSzS nn
λλ
λλ
++= ...11 (2.4.1.2)

90
2.4.2 Caso 2: Dipendenza tra rami
Nel caso di correlazione tra rami (o in presenza dei fattori di disturbo), è
possibile ricorrere alla distribuzione Binomiale Negativa per modellizzare le v.a.
numero sinistri dei singoli rami. In tal caso [ ]jkE ~ rappresenta il numero atteso di
sinistri di ciascuna linea di business j e jβ+1 rappresenta il c.d. ratio Varianza/Media.
Seguendo ad esempio Wang [1998] si dimostra banalmente che il numero
atteso sinistri del portafoglio aggregato sarà dato da:
[ ] [ ] [ ]nagg kEkEkE ~...~~1 ++= (2.4.2.1)
mentre la varianza totale sarà pari a:
[ ] [ ] [ ]∑∑∑<==
+=
=
ijij
n
jj
n
jjagg kkCovkVarkVarkVar ~,~2~~~
11 (2.4.2.2)
In tal caso si ipotizza che il numero sinistri del portafoglio aggregato si distribuisca
secondo la Binomiale Negativa con parametri stimabili dalle due relazioni precedenti.
Quindi la distribuzione del costo del singolo sinistro per tutte linee è:
( ) ( ) ( )zSkEkEzS
kEkEzS n
agg
n
agg ]~[]~[...
]~[]~[
11 ++= (2.4.2.3)
Si noti che in questo caso la differenza tra l’approccio individuale (dove
ciascuna linea di business è caratterizzata da una specifica Binomiale Negativa) e
quello aggregato è l’ipotesi che il numero sinistri aggregato per tutte linee si
distribuisca secondo la Binomiale Negativa e quindi i diversi fattori di disturbo
vengono sintetizzati in unica variabile, con il rischio di perdere l’effetto di ciascun

91
ramo. Wang [1998] evidenzia come poter facilmente tenere conto di tale elemento. A
fronte di una matrice di correlazione tra le n v.a. numero sinistri:
nnnn
n
n
ρρρ
ρρρρρρ
...............
...
...
21
22221
11211
,
è possibile calcolare il ratio totale Varianza/Media ricorrendo alla (2.4.2.2) e alla
formula
[ ] ( ) ( )ijjiij kVarkVarkkCov ~~~,~ ρ= .
Ovviamente tale metodo non è esatto se la v.a. numero sinistri di ciascuna linea
si distribuisce seconda una specifica Binomiale Negativa. Si rimanda ad esempio a
Wang [1998], dove viene fornita una vasta gamma di metodi che evitano tale
approssimazione (copule, distortion method, component method, ecc.) ed un’analisi
di confronto tra copule-simulazione da una parte e FC-FFT dall’altra.
2.4.3 L’utilizzo della FFT per variabili bivariate
Di seguito si farà un breve accenno al caso di distribuzione bivariate la cui
distribuzione può essere costruita secondo la metodologia precedentemente vista,
utilizzando però la FFT a due dimensioni (in Matlab è disponibile ad esempio
l’istruzione fft2).
L’applicazione è facilmente comprensibile attraverso l’esempio ripreso da Homer e
Clark [2004]. Nell’ambito di un trattato di riassicurazione si vuole costruire la
distribuzione bivariata della v.a costo sinistri aggregato trattenuto INSX~ e dell’eccesso
di perdita aggregato REX~ (per ipotesi discretizzate).

92
Per modellizzare la variabile bivariata connessa alla riassicurazione è necessario
utilizzare la matrice di probabilità Mf , dove il generico elemento m(j,k) rappresenta la
probabilità che INSX~ = h1 * j e REX~ = h2 * k, dove h1 e h2 sono gli span relativi alle
due v.a..
Nel caso di un solo sinistro la matrice è facilmente costruibile. Si indichi con
( ) ( )3.0;3.0;4.0,, 321~ == ffffZ
il vettore delle probabilità del costo del singolo sinistro
(che in questo caso coincide con il danno aggregato), nel caso quindi possa assumere
le determinazioni h * k, dove h è il fattore di scala (ad esempio pari a euro 1.000) e k
= 0,1,2. Allora a fronte di una priorità di un trattato excess of loss pari a euro 1.000 e
posto h1 = h2 = h = 1.000, si avrà (j indica le righe e k indica le colonne):
=
00003,03,0004,0
fM
Tale matrice esprime pienamente le probabilità e le dipendenze delle due v.a. INSX~ e REX~ . La somma degli elementi di ciascuna riga (0,4;0,6;0) fornisce la distribuzione di INSX~ , mentre la somma degli elementi di ciascuna colonna (0,7;0,3;0) rappresenta la
distribuzione di REX~ .
Il vantaggio di tale rappresentazione è che la tecnica FFT può essere applicata anche
al caso bivariato per calcolare la distribuzione del danno aggregato, la procedura
precedentemente esposta e che viene riportata sinteticamente (ovviamente va
effettuato il padding per garantire un numero di punti sufficienti per la X~ ):
M = IFFT(FGP(FFT(Mf))) (2.4.3.1)
dove ovviamente FFT e IFFT sono riferite al caso a due dimensioni.

93
2.5 Alcuni confronti
Negli ultimi tre decenni diversi metodi sono stati proposti per la valutazione
della distribuzione del danno aggregato:
o Panjer [1981] introduce la formula ricorsiva, caratterizzata da una notevole
semplicità nella comprensione ed applicabilità. L’unico livello di errore può
intervenire nella discretizzazione della distribuzione della v.a. Z~ .
o Heckman e Meyers [1983] utilizzano invece un metodo di inversione diretto
della FC.
o Robertson [1983] sfrutta il metodo della FFT, basato però su una distribuzione
piecewise di tipo uniforme per la v.a. Z~ . Tale metodo viene ripreso con alcuni
accorgimenti da Wang [1998].
o Ferrara et al. [1996] utilizzando un metodo alternativo basato comunque sulla
trasformata di Fourier.
Il metodo proposto da Wang [1998] ovviamente è contraddistinto da un’elevata
velocità di elaborazione, ma è anche estendibile alla modellizzazione di variabili
multivariate (così come l’approccio simulativo).
Il metodo ricorsivo può incorrere in alcuni problemi di overflow/underflow a
fronte di un elevato valore del numero atteso di sinistri e quindi per portafogli con
dimensioni elevate, a cui Panjer e Wilmott [1986] hanno fornito una soluzione.
L’approccio proposto da Heckman e Meyers [1983] invece funziona efficientemente
nel caso su indicato (così come i metodi approssimati nel caso di asimmetria
limitata).
Nel caso della FFT la soluzione invece è quella di ridurre lo span h in modo da
cogliere bene le caratteristiche della distribuzione del costo del singolo sinistro. Nel

94
caso di distribuzioni divisibili della v.a. k~ come la Poisson Semplice o la Binomiale
Negativa, il problema può essere aggirato costruendo la distribuzione del danno
aggregato per “pezzi”, cioè sulla base di un piccolo numero di sinistri alla volta e
combinando i risultati attraverso la convoluzione.
Inoltre risulta essere più veloce rispetto al metodo ricorsivo riducendo il numero di
iterazioni da n2 a n log2 n.
Per quanto concerne il metodo simulativo, esso differisce significativamente
dai precedenti per quanto già indicato nel paragrafo 2.3.3.
Un indubbio vantaggio è rappresentato dalla flessibilità, cioè dal poter articolare e
complicare il modello (tipico caso degli Internal Risk Models), sulla base però di una
buona esperienza di programmazione.
Un’ulteriore problematica è rappresentata dal fatto che, fornendo solo valori numerici
campionari, è molto difficile riuscire a comprendere le interrelazioni tra variabili
aleatorie utilizzate nel modello implementato.
In base a quanto evidenziato nessun modello risulta essere migliore di un altro
in qualsiasi casistica, ma l’analista dovrebbe utilizzarli come strumenti
complementari per avere una garanzia maggiore sull’attendibilità dei risultati.
Nel paragrafo 2.5.1 si riportano alcuni esempi di confronto tra i metodi di
simulazione e la FFT ai fini della determinazione della distribuzione della v.a. X~ . I
risultati ed i grafici sono ripresi dal sito della CAS:
http://www.casact.org/library/aggregate.htm, dove è possibile scaricare il software D-
Builder implementato da Hou-wen Jeng.
Nel paragrafo 2.5.2 si riporta un interessante caso, basato sul lavoro di Homer e
Clark [2004]. E’ un esempio di modello semplificato di solvency assessment nel cui

95
ambito è necessario modellizzare della dipendenza tra sinistri di entità ordinaria ed i
c.d. “Large Claims” (si ricordi anche quanto visto per il SST).
2.5.1 Una breve comparazione tra il metodo di simulazione e la FFT
A fronte di una distribuzione della v.a. k~ con parametro pari a 100 e una
distribuzione di Pareto con α = 3 e β = 100 (valori ipotizzati), nella figura successiva
è possibile osservare i primi due valori caratteristici del danno aggregato.
Figura 2.5.1.1 – FFT - λ = 100
Di seguito invece vengono riportati i risultati ottenuti con il metodo della FFT (h = 50 – Figura 2.5.1.2)
Figura 2.5.1.2 – FFT - λ = 100 e nella Figura 2.5.1.3 quanto ottenuto con il metodo simulativo (Monte Carlo –
10.000 simulazioni - λ = 100).

96
Figura 2.5.1.3 – 10.000 simulazioni - λ = 100
E’ evidente come il metodo FFT risulti un metodo esatto confrontando la funzione di
densità ottenuta con il metodo simulativo. Si noti inoltre come vengano riportati nella
Figura 2.5.1.3 i limiti inferiori e superiori per ciascun livello di probabilità e non il
singolo quantile come nella Figura 2.5.1.2 relativo alla FFT.
Si osservi anche che al livello di probabilità al 99.97%-99.98% le stime dei percentili
risultano sostanzialmente diverse tra la FFT e la simulazione: tale elemento sottolinea
l’importanza e l’attenzione che deve essere adottata in sede di stima dei percentili
nelle code delle distribuzioni del danno aggregato.
A titolo di esempio si riporta il caso in cui, a parità di distribuzione del costo
del singolo sinistro, il parametro della v.a. numero sinistri sia pari a 1.000 (e non
100).
Nelle Figure 2.5.1.4 e 2.5.1.5 si nota come la differenza delle stime nelle code tende
ad ampliarsi nella coda destra della distribuzione a seguito nell’incremento del
numero di atteso di sinistri (che contribuisce ad una riduzione della variabilità
relativa e dell’indice di asimmetria).

97
Figura 2.5.1.4 – FFT - λ = 1.000
Figura 2.5.1.5 – 10.000 simulazioni - λ = 1.000
Aumentando il numero di simulazione ovviamente si tende ad avere una maggiore
stabilità nelle stime del metodo simulativo (Figura 2.5.1.6 - 100.000 simulazioni).
Figura 2.5.1.6 - 100.000 simulazioni - λ = 1.000

98
2.5.2 La modellizzazione della dipendenza tra sinistri di entità ordinaria ed i c.d.
“Large Claims” nell’ambito di un modello di solvency assessment
Sulla base di quanto evidenziato nel lavoro di Homer e Clark [2004] una
ipotetica Compagnia di Assicurazioni Danni ha sviluppato un modello, basato su un
approccio simulativo, con l’obiettivo di individuare la distribuzione di probabilità dei
risultati, includendo la modellizzazione dei tassi di interesse e di diverse complesse
strutture riassicurative.
Tale modello però è basato su una ipotesi semplificatrice, in quanto “piccoli” e
“grandi” sinistri vengono simulati separatamente e quindi i relativi costi sinistri
aggregati sono ipotizzati reciprocamente indipendenti (si veda anche il paragrafo
3.2). In particolare la procedura simula un valore “aggregato” per tutti i sinistri
ordinari e simula individualmente i grandi sinistri (come nello SST presentato nel
capitolo 1).
Riprendendo tale esempio ed utilizzando l’EVT si riesce ad individuare la
soglia pari a DK 10.000.000 come discriminante tra piccoli e grandi sinistri
(truncation point). L’obiettivo è quello di dimostrare la possibilità di un utilizzo
congiunto tra EVT, FFT e simulazione. Si immagini di avere individuato delle
dipendenze tra small e large claims. Al fine di modellizzare il costo sinistri aggregato
si ipotizzi ora di avere discretizzato la distribuzione (nel senso della FFT) in solo 5
(ipotetici ) punti, ottenendo la seguente distribuzione discreta: Probabilità Severity
0,00% 0
43,80% 2.000.000
24,60% 4.000.000
13,80% 6.000.000
7,80% 8.000.000
10,00% 10.000.000
Media 4.312.000
Tabella 2.5.2.1: Distribuzione di probabilità ipotizzata per la Z~

99
Di seguito viene riportata la matrice che consente di individuare le dipendenze
tra sinistri ordinari e grandi sinistri (secondo la procedura vista nel paragrafo 2.4.3).
Nella prima colonna viene riportata la distribuzione di probabilità della Z~ fino al
valore della soglia (di seguito indicati come sinistri small) e nella cella (0,1) viene
riportata la probabilità di avere un sinistro di entità maggiore della soglia (10%).
Numero sinistri Large Importo Sinistri small 0 1 2 3 4 5
- 0,000 0,100 0,000 0,000 0,000 0,000 2.000.000 0,438 0,000 0,000 0,000 0,000 0,000 4.000.000 0,246 0,000 0,000 0,000 0,000 0,000 6.000.000 0,138 0,000 0,000 0,000 0,000 0,000 8.000.000 0,078 0,000 0,000 0,000 0,000 0,000 10.000.000 0,000 0,000 0,000 0,000 0,000 0,000 12.000.000 0,000 0,000 0,000 0,000 0,000 0,000 14.000.000 0,000 0,000 0,000 0,000 0,000 0,000 16.000.000 0,000 0,000 0,000 0,000 0,000 0,000 18.000.000 0,000 0,000 0,000 0,000 0,000 0,000 20.000.000 0,000 0,000 0,000 0,000 0,000 0,000 Tabella 2.5.2.1: Matrice congiunta del numero sinistri small e large
Tale rappresentazione fornisce anche un esempio della flessibilità del metodo
che può operare su grandezze con unità di misura diverse (numeri ed importi).
In presenza di dipendenze tra piccoli e grandi sinistri e se viene utilizzata una
singola frequenza per generare il numero complessivo di sinistri K, allora la
covarianza tra il costo sinistri aggregato relativo ai due gruppi, rispettivamente, SmallX~
e eLX arg~ (si veda Homer e Clark [2004]) può essere scritta:
[ ] [ ] [ ]( )kEZEpZEpXXCov keLSmalleLSmall ~~)1(*~)~,~( 2
~argarg −⋅⋅−⋅= σ (2.5.2.1)
dove p è la probabilità che un sinistro sia “piccolo”. Nel caso in cui k~ si distribuisca
secondo la Binomiale Negativa il segno della (2.5.2.1) è positivo; qualora segua la
distribuzione Poisson Semplice la covarianza è nulla e si può ricorrere al caso di
indipendenza su indicato.

100
In virtù delle dipendenze ipotizzate, per la v.a. numero sinistri viene quindi utilizzata
una distribuzione Binomiale Negativa con media = 10 e varianza = 20 (per ipotesi).
La distribuzione aggregata sarà data dall’espressione:
10
~~
)2(
)))(((−−=
=
tFGP
MFFTPGFIFFTM Zx
Una volta eseguita la procedura si ottiene la seguente matrice ( XM ~ ):
Numero sinistri large
SmallX~ 0 1 2 3 4 5 6
Totale Riga = ( )xXpr Small =~
- 0,37% 0,15% 0,03% 0,01% 0,00% 0,00% 0,00% 0,6% 2.000.000 0,57% 0,25% 0,07% 0,02% 0,00% 0,00% 0,00% 0,9% 4.000.000 0,74% 0,36% 0,09% 0,03% 0,00% 0,00% 0,00% 1,2% 6.000.000 0,91% 0,50% 0,14% 0,04% 0,00% 0,00% 0,00% 1,6% 8.000.000 1,19% 0,65% 0,20% 0,06% 0,01% 0,00% 0,00% 2,1% 10.000.000 1,44% 0,83% 0,28% 0,08% 0,01% 0,00% 0,00% 2,6% 12.000.000 1,71% 1,03% 0,36% 0,10% 0,02% 0,00% 0,00% 3,2% 14.000.000 1,87% 1,23% 0,45% 0,13% 0,03% 0,00% 0,00% 3,7% 16.000.000 2,10% 1,42% 0,54% 0,16% 0,03% 0,01% 0,00% 4,3% 18.000.000 2,23% 1,78% 0,62% 0,19% 0,04% 0,01% 0,00% 4,9% 20.000.000 2,41% 1,82% 0,70% 0,21% 0,05% 0,01% 0,00% 5,2% 22.000.000 2,46% 1,83% 0,77% 0,24% 0,06% 0,01% 0,00% 5,4% 24.000.000 2,55% 1,90% 0,82% 0,26% 0,06% 0,01% 0,00% 5,6% 26.000.000 2,44% 1,94% 0,86% 0,28% 0,07% 0,02% 0,00% 5,6% 28.000.000 2,39% 1,95% 0,88% 0,30% 0,08% 0,02% 0,00% 5,6% 30.000.000 2,31% 1,93% 0,89% 0,31% 0,08% 0,02% 0,00% 5,5% 32.000.000 2,21% 1,87% 0,89% 0,31% 0,08% 0,02% 0,00% 5,4% 34.000.000 2,09% 1,80% 0,87% 0,31% 0,09% 0,02% 0,00% 5,2% 36.000.000 1,95% 1,71% 0,84% 0,31% 0,09% 0,02% 0,00% 4,9% 38.000.000 1,81% 1,61% 0,81% 0,30% 0,09% 0,02% 0,01% 4,6% 40.000.000 1,70% 1,57% 0,76% 0,29% 0,08% 0,02% 0,01% 4,4% 42.000.000 1,66% 1,55% 0,72% 0,28% 0,08% 0,02% 0,01% 4,3% 44.000.000 1,40% 1,26% 0,66% 0,26% 0,08% 0,02% 0,00% 3,7% 46.000.000 1,32% 1,20% 0,61% 0,25% 0,08% 0,02% 0,00% 3,5% 48.000.000 1,16% 1,04% 0,56% 0,23% 0,07% 0,02% 0,00% 3,1% 50.000.000 1,03% 0,93% 0,50% 0,21% 0,07% 0,02% 0,00% 2,8% Totale 100,0% Tabella 2.5.2.2: Distribuzione bivariata del numero dei grandi sinistri e dell’importo dei sinistri ordinari (in dollari) La distribuzione marginale della v.a. SmallX~ si ottiene sommando le probabilità in
ciascuna riga. In tal caso [ ]SmallXE ~ = 28.010.459 DK.

101
Di seguito viene riportata la corrispondente funzione di ripartizione.
Funzione di Ripartizione Marginale dell'importo dei piccoli sinistri
-0.10.20.30.40.50.60.70.80.91.0
-
4,00
0,000
8,00
0,000
12,000
,000
16,000
,000
20,000
,000
24,000
,000
28,000
,000
32,000
,000
36,000
,000
40,000
,000
44,000
,000
48,000
,000
52,000
,000
56,000
,000
Figura 2.5.2.2: Funzione di Ripartizione di SmallX~
Successivamente viene ricavata la distribuzione di frequenza condizionata per i
grandi sinistri, attraverso il “rescaling” della XM ~ , rapportando ogni elemento al totale
della rispettiva riga:
Numero "grandi" sinistri
SmallX~ 0 1 2 3 4 5 6 Totale - 64,7% 26,2% 5,2% 1,6% 0,8% 0,8% 0,8% 100.0% 2.000.000 62,4% 27,4% 7,2% 1,6% 0,4% 0,4% 0,4% 100.0% 4.000.000 60,3% 29,3% 7,3% 2,0% 0,3% 0,3% 0,3% 100.0% 6.000.000 57,0% 31,3% 8,8% 2,2% 0,2% 0,2% 0,2% 100.0% 8.000.000 56,3% 30,8% 9,5% 2,6% 0,5% 0,2% 0,2% 100.0% 10.000.000 54,5% 31,4% 10,6% 2,8% 0,4% 0,1% 0,1% 100.0% 12.000.000 53,1% 32,0% 11,2% 2,9% 0,6% 0,1% 0,1% 100.0% 14.000.000 50,4% 33,1% 12,1% 3,4% 0,8% 0,1% 0,1% 100.0% 16.000.000 49,3% 33,3% 12,7% 3,6% 0,7% 0,3% 0,1% 100.0% 18.000.000 45,8% 36,5% 12,7% 3,8% 0,8% 0,3% 0,1% 100.0% 20.000.000 46,3% 35,0% 13,5% 3,9% 1,0% 0,3% 0,1% 100.0% 22.000.000 45,8% 34,1% 14,3% 4,4% 1,1% 0,3% 0,1% 100.0% 24.000.000 45,5% 33,9% 14,6% 4,6% 1,1% 0,3% 0,1% 100.0% 26.000.000 43,5% 34,6% 15,3% 4,9% 1,2% 0,3% 0,1% 100.0% 28.000.000 42,5% 34,7% 15,7% 5,2% 1,4% 0,4% 0,1% 100.0% 30.000.000 41,7% 34,8% 16,1% 5,5% 1,4% 0,4% 0,1% 100.0% 32.000.000 41,1% 34,7% 16,5% 5,7% 1,5% 0,4% 0,1% 100.0% 34.000.000 40,3% 34,7% 16,8% 5,9% 1,8% 0,4% 0,1% 100.0% 36.000.000 39,6% 34,7% 17,1% 6,2% 1,9% 0,5% 0,1% 100.0% 38.000.000 39,0% 34,7% 17,4% 6,4% 1,9% 0,5% 0,1% 100.0% 40.000.000 38,4% 35,5% 17,2% 6,4% 1,8% 0,5% 0,1% 100.0% 42.000.000 38,5% 35,9% 16,7% 6,4% 1,9% 0,5% 0,1% 100.0% 44.000.000 38,0% 34,2% 17,9% 6,9% 2,2% 0,6% 0,1% 100.0% 46.000.000 37,9% 34,5% 17,5% 7,1% 2,2% 0,6% 0,1% 100.0% 48.000.000 37,5% 33,7% 18,2% 7,4% 2,4% 0,6% 0,2% 100.0%
50.000.000 37,3% 33,8% 18,1% 7,4% 2,5% 0,7% 0,2% 100.0%
Tabella 2.5.2.3: Rescaling della Tabella 3.2.1.2

102
Quest’ultima tabella consente di evidenziare ancora meglio le dipendenze tra i
sinistri ordinari e large claims. A questo punto è possibile ricavare il valore atteso
della v.a. discreta numero di grandi sinistri (v.a. condizionata): ]~
[ arg eLkE = 0.8713566.
Effettuando 200.000 simulazioni per la eLZ arg~ (numero in genere sufficiente a
garantire un buon grado di approssimazione) in base alla distribuzione GPD con
parametri 523,0=ξ ; 78,8=β (si veda il paragrafo 2.2) si ottiene un valore medio
]~[ arg eLZE = 27,6299 * 107.
Infine il danno aggregato è dato da:
]~[]~
[]~[]~[ argarg eLeLSmall ZEkEXEXE ⋅+= = 28.010.459 + 240.754.946 = 268.765.405
La procedura del modello di solvency assessment è stata quindi ottimizzata e occorre
eseguire i seguenti passi:
1. Si ricava il valore atteso di SmallX~ dalla distribuzione marginale;
2. Determinare il numero di grandi sinistri in base alla distribuzione marginale di
frequenza (condizionata a quella dei piccoli sinistri);
3. Simulare il valore della severity per ciascun grande sinistro.
In tal modo quindi si procede efficientemente senza simulare singolarmente i piccoli
sinistri, ma si riesce comunque a preservare la struttura di dipendenza individuata.
Tale esempio quindi fornisce un caso di applicazione congiunta tra EVT, FFT e
simulazione6 anche nel caso di variabili multivariate.
6 Si rimanda inoltre a Embrechts [2005] in riferimento ad esempio all’applicazione dell’EVT al caso di variabili multivariate e al concetto di Extreme Value Copula.

103
Capitolo 3
Alcuni esempi di applicazioni della FFT, EVT e Simulazione
In questo capitolo vengono fornite alcune applicazioni e confronti tra i risultati
ottenuti dai Metodi di Simulazione e FFT, utilizzando le statistiche ANIA sul ramo
R.C.Auto.
Inoltre, sulla base del set di dati “1991-1992 SOA Group of Medical Insurance
Large Claims” e sfruttando l’EVT, vengono evidenziate sia le problematiche
connesse alla valutazione del danno aggregato attraverso la logica Peaks Over
Threshold (POT), che la significatività della scelta della soglia in termini di valore
atteso di tale variabile aleatoria.
3.1 La determinazione della distribuzione del costo sinistri aggregato nel ramo
RCA del mercato italiano. Simulazione o FFT?
L’obiettivo è stimare la distribuzione del Danno Aggregato attraverso
l’approccio simulativo e l’approccio seguito con la FFT (Wang [1998]), in presenza
di una frequenza sinistri variabile per classi di Bonus Malus.
Di seguito vengono richiamati, ai fini di una più chiara comprensione, i risultati
ottenuti in Cerchiara [2003], [2005]. In tali lavori, sulla base principalmente dei
contributi di Lemaire [1995], Grasso [1996], Verico [2000], Picech et al. [2003],
Savelli [2002], sono stati analizzati gli effetti della tariffazione a posteriori (in
presenza di differenti sistemi Bonus Malus e No Claim Discount) sulla Riserva di
Rischio ed in termini di probabilità di rovina su un orizzonte temporale di 30 anni e
portafoglio chiuso (Cerchiara [2003]) e su un time horizon di 60 anni a portafoglio
aperto (Cerchiara [2005]). Il modello è stato costruito sulla base dell’approccio
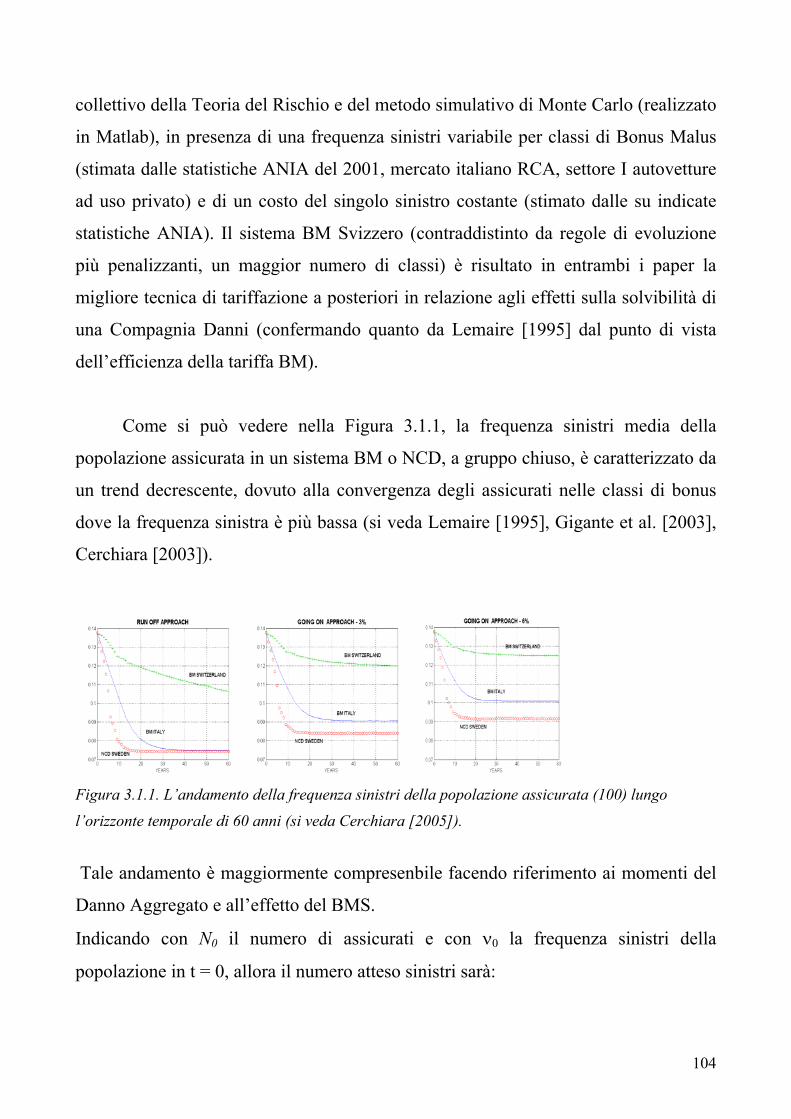
104
collettivo della Teoria del Rischio e del metodo simulativo di Monte Carlo (realizzato
in Matlab), in presenza di una frequenza sinistri variabile per classi di Bonus Malus
(stimata dalle statistiche ANIA del 2001, mercato italiano RCA, settore I autovetture
ad uso privato) e di un costo del singolo sinistro costante (stimato dalle su indicate
statistiche ANIA). Il sistema BM Svizzero (contraddistinto da regole di evoluzione
più penalizzanti, un maggior numero di classi) è risultato in entrambi i paper la
migliore tecnica di tariffazione a posteriori in relazione agli effetti sulla solvibilità di
una Compagnia Danni (confermando quanto da Lemaire [1995] dal punto di vista
dell’efficienza della tariffa BM).
Come si può vedere nella Figura 3.1.1, la frequenza sinistri media della
popolazione assicurata in un sistema BM o NCD, a gruppo chiuso, è caratterizzato da
un trend decrescente, dovuto alla convergenza degli assicurati nelle classi di bonus
dove la frequenza sinistra è più bassa (si veda Lemaire [1995], Gigante et al. [2003],
Cerchiara [2003]).
Figura 3.1.1. L’andamento della frequenza sinistri della popolazione assicurata (100) lungo
l’orizzonte temporale di 60 anni (si veda Cerchiara [2005]).
Tale andamento è maggiormente compresenbile facendo riferimento ai momenti del
Danno Aggregato e all’effetto del BMS.
Indicando con N0 il numero di assicurati e con ν0 la frequenza sinistri della
popolazione in t = 0, allora il numero atteso sinistri sarà:

105
( ) ∑=
⋅=⋅=M
iii NvNkE
1,0,0000
~ ν (3.1.1)
dove ν0,i e N0,i sono, rispettivamente, la frequenza sinistri e il numero di assicurati
nella classe i. Nel generico anno t>0 allora il numero atteso di sinistri è dato da:
( ) ( )[ ] ( )[ ] ( ) ( ) ( )tBMtttBMot gkEgNkE ααν −⋅+⋅=+⋅⋅−⋅= 11~11~
00 (3.1.2)
dove g é il tasso di crescita della popolazione assicurata, tale che ( )tt gNN +⋅= 10 ; (1-
αBM) é il fattore di riduzione annuo della frequenza sinistri della popolazione,
dipendente, come si vede in Figura 3.1.1, dal tipo di BMS o NCDS utilizzato, e αBM è
quindi una successione di valori crescenti fino ad un certo valore temporale t
(dipendente a sua volta dal sistema usato) e successivamente costante.
Il valore atteso di tX~ sarà:
( ) ( ) ( ) ( ) ( ) ( ) ( )tBMttttt igXEZEkEXE α−⋅+⋅+⋅=⋅= 111~~~~
0 (3.1.3)
dove i è un tasso costante di inflazione annua del costo del singolo sinistro, mentre
varianza e skewness sono dati da (si veda Savelli [2002]):
( ) ( ) ( ) ( ) ( )tBMttt igXX ασσ −⋅+⋅+⋅= 111~~ 2
022 (3.1.4)
( ) ( )( ) ( )tBMt
t
gXX
αγγ
−⋅+⋅=
11
1~~0 (3.1.5)
Nell’ambito delle applicazioni realizzate nella presente tesi di dottorato si è
considerato il solo sistema Bonus Malus italiano. Dato un portafoglio di polizze
RCA omogeneo a priori, per calcolare, in ogni istante t, l’ammontare dei premi,

106
quello dell’i-esimo sinistro e la distribuzione degli assicurati nelle M classi di merito,
è sufficiente:
1. conoscere la struttura del sistema BM;
2. particolarizzare le distribuzioni del numero di sinistri annui e dell’ammontare
degli stessi tk~ e tiZ ,~ .
In merito al punto 1, indicando con M il numero massimo di classi e con s la classe di
ingresso, si riportano le regole evolutive del sistema BM italiano7 (M = 18 e s = 14):
( )
=−+
=−=+
,.....3,2,1~)1~3~,18min(
0~1,1~max~
1
ttt
tt
t
kkY
kYY (3.1.6)
Per quanto concerne la v.a. numero sinistri è stata scelta la distribuzione di
Poisson, nonostante non sempre si adatti bene al modellizzare tale v.a., ai fini degli
obiettivi di tale applicazione non è essenziale utilizzare una distribuzione che
consenta un perfetto fitting dei dati osservati (si veda ad esempio Lemaire [1995] per
le possibili distribuzione del numero sinistri del ramo RCA).
Il parametro λ, come già premesso, è costituito da un vettore di frequenze
relative, i cui elementi sono variabili per classe di appartenza, stimato dalla reale
curva nel mercato italiano nel 2003 (dati Ania, settore I autovetture ad uso privato).
Si vedano le figure 3.1.2 (si noti la concentrazione di assicurati nella classe 1) e 3.1.3
dove viene riportata la su indicata curva perequata della frequenza sinistri.
7 Per il Sistema Bonus Malus italiano è stata considerata, per tutti gli assicurati, la classe di ingresso 14, ipotizzando quindi rischi assicurati per la prima volta.

107
Ripartizione percentuale Veicoli Anno nelle classi di BM - ANNO 2003
-
5.0
10.0
15.0
20.0
25.0
30.0
35.0
40.0
45.0
50.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18Classi di BM
Figura 3.1.2. Ripartizione percentuale dei veicoli anno nelle classi di BM (Ania 2003).
Frequenza Sinistri variabile per classe di BM
0%
5%
10%
15%
20%
25%
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
CLASSI DI BM
Freq Sinistri OSSERVATA
Freq Sinistri PEREQUATA
Figura 3.1.3. Frequenze sinistri osservata e perequata (Ania 2003).
Per quanto concerne la distribuzione del costo del singolo sinistro è stata scelta la
Lognormale (utilizzando le stesse distribuzioni presentate nel contributo del IIA WP
[2004]) caratterizzata dalla seguente densità:
[ ]
2
2)ln(
2)(1)( σ
µ
πσ
−−−
⋅⋅−=
dz
edz
zs
dove z > d = 0. I valori caratteristici fino al terzo ordine sono dati da:
[ ]
+
== 21
2
~σµ
eaZE e [ ] ( )2222
2~ σµ+== eaZE
[ ] ( ) ( )1~ 222 −⋅= + σσµ eeZVar
[ ] ( )
−⋅+= 12~ 22 σσγ eeZ
y = 6.18 * exp(0.05 * x)
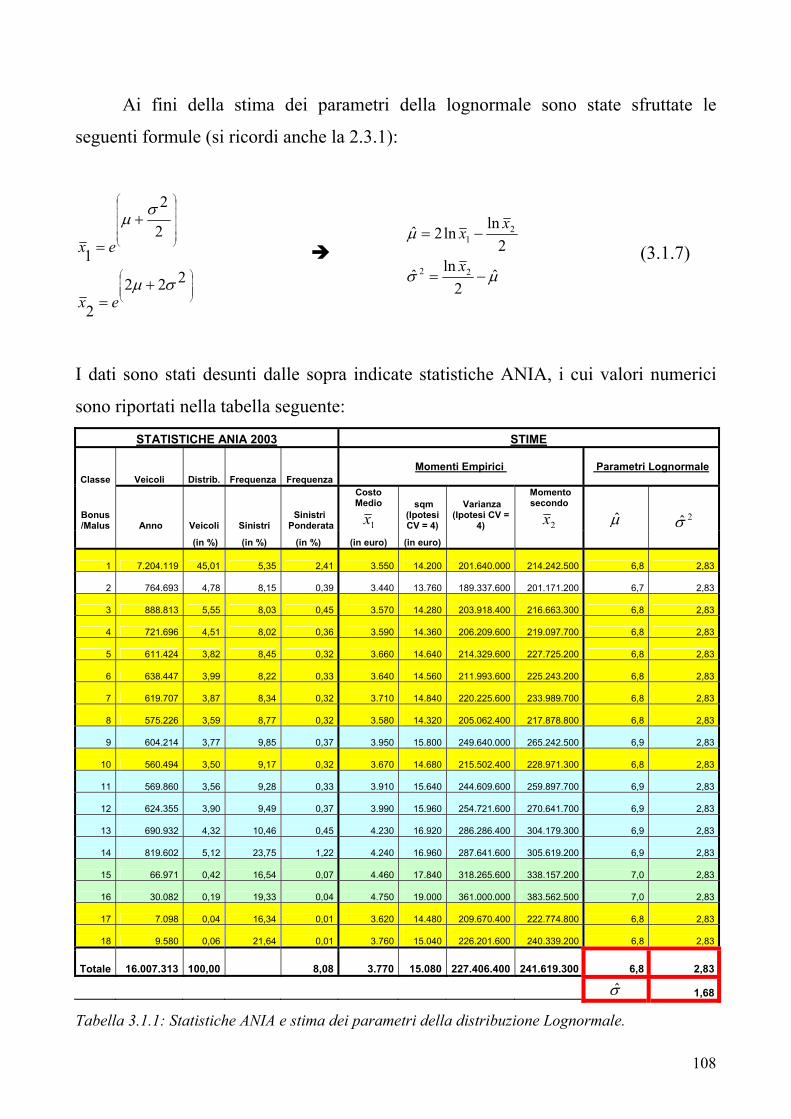
108
Ai fini della stima dei parametri della lognormale sono state sfruttate le
seguenti formule (si ricordi anche la 2.3.1):
+=
+
=
222
2
2
2
1
σµ
σµ
ex
ex µσ
µ
ˆ2
lnˆ
2lnln2ˆ
22
21
−=
−=
x
xx (3.1.7)
I dati sono stati desunti dalle sopra indicate statistiche ANIA, i cui valori numerici
sono riportati nella tabella seguente:
STATISTICHE ANIA 2003 STIME
Classe Veicoli Distrib. Frequenza Frequenza
Momenti Empirici
Parametri Lognormale
Bonus /Malus Anno
Veicoli Sinistri
Sinistri Ponderata
Costo Medio
1x
sqm (Ipotesi CV = 4)
Varianza (Ipotesi CV =
4)
Momento secondo
2x
µ̂
2σ̂
(in %) (in %) (in %) (in euro) (in euro)
1 7.204.119 45,01 5,35 2,41
3.550
14.200
201.640.000
214.242.500 6,8 2,83
2 764.693 4,78 8,15 0,39
3.440
13.760
189.337.600
201.171.200 6,7 2,83
3 888.813 5,55 8,03 0,45
3.570
14.280
203.918.400
216.663.300 6,8 2,83
4 721.696 4,51 8,02 0,36
3.590
14.360
206.209.600
219.097.700 6,8 2,83
5 611.424 3,82 8,45 0,32
3.660
14.640
214.329.600
227.725.200 6,8 2,83
6 638.447 3,99 8,22 0,33
3.640
14.560
211.993.600
225.243.200 6,8 2,83
7 619.707 3,87 8,34 0,32
3.710
14.840
220.225.600
233.989.700 6,8 2,83
8 575.226 3,59 8,77 0,32
3.580
14.320
205.062.400
217.878.800 6,8 2,83
9 604.214 3,77 9,85 0,37
3.950
15.800
249.640.000
265.242.500 6,9 2,83
10 560.494 3,50 9,17 0,32
3.670
14.680
215.502.400
228.971.300 6,8 2,83
11 569.860 3,56 9,28 0,33
3.910
15.640
244.609.600
259.897.700 6,9 2,83
12 624.355 3,90 9,49 0,37
3.990
15.960
254.721.600
270.641.700 6,9 2,83
13 690.932 4,32 10,46 0,45
4.230
16.920
286.286.400
304.179.300 6,9 2,83
14 819.602 5,12 23,75 1,22
4.240
16.960
287.641.600
305.619.200 6,9 2,83
15 66.971 0,42 16,54 0,07
4.460
17.840
318.265.600
338.157.200 7,0 2,83
16 30.082 0,19 19,33 0,04
4.750
19.000
361.000.000
383.562.500 7,0 2,83
17 7.098 0,04 16,34 0,01
3.620
14.480
209.670.400
222.774.800 6,8 2,83
18 9.580 0,06 21,64 0,01
3.760
15.040
226.201.600
240.339.200 6,8 2,83
Totale
16.007.313 100,00 8,08
3.770
15.080
227.406.400
241.619.300 6,8 2,83
σ̂ 1,68
Tabella 3.1.1: Statistiche ANIA e stima dei parametri della distribuzione Lognormale.
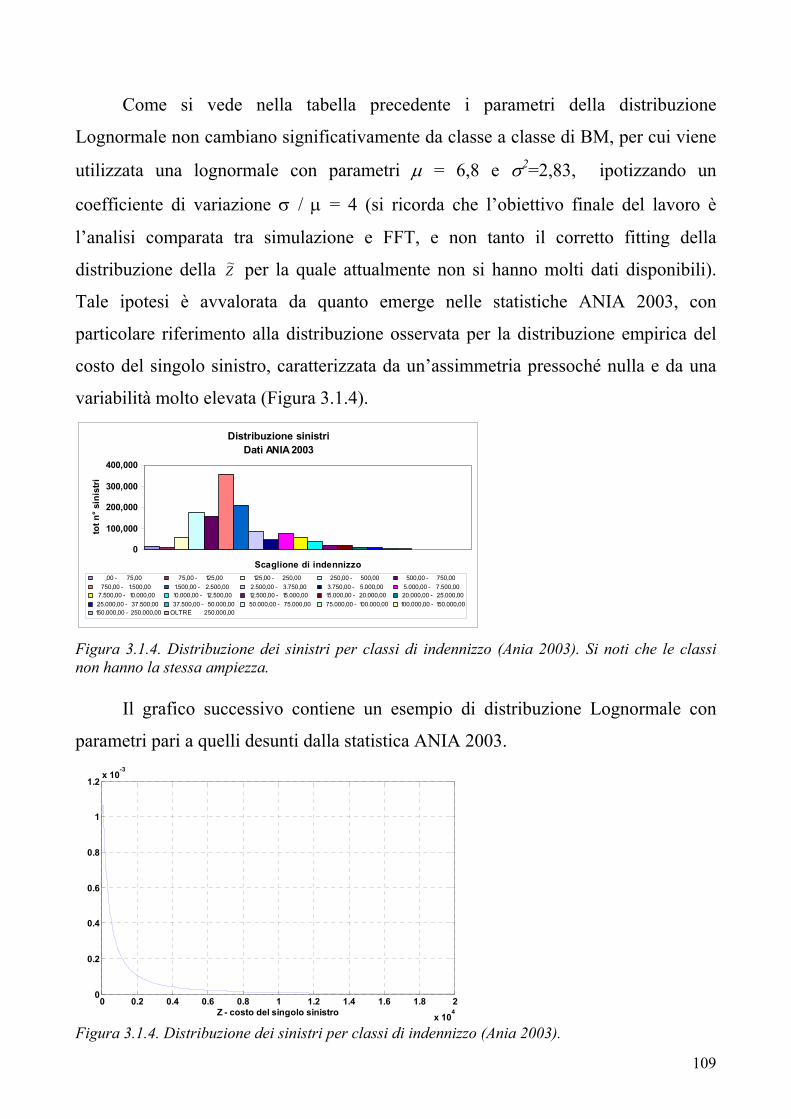
109
Come si vede nella tabella precedente i parametri della distribuzione
Lognormale non cambiano significativamente da classe a classe di BM, per cui viene
utilizzata una lognormale con parametri µ = 6,8 e σ2=2,83, ipotizzando un
coefficiente di variazione σ / µ = 4 (si ricorda che l’obiettivo finale del lavoro è
l’analisi comparata tra simulazione e FFT, e non tanto il corretto fitting della
distribuzione della Z~ per la quale attualmente non si hanno molti dati disponibili).
Tale ipotesi è avvalorata da quanto emerge nelle statistiche ANIA 2003, con
particolare riferimento alla distribuzione osservata per la distribuzione empirica del
costo del singolo sinistro, caratterizzata da un’assimmetria pressoché nulla e da una
variabilità molto elevata (Figura 3.1.4).
Distribuzione sinistriDati ANIA 2003
0
100,000
200,000
300,000
400,000
Scaglione di indennizzo
tot n
° sin
istri
,00 - 75,00 75,00 - 125,00 125,00 - 250,00 250,00 - 500,00 500,00 - 750,00 750,00 - 1.500,00 1.500,00 - 2.500,00 2.500,00 - 3.750,00 3.750,00 - 5.000,00 5.000,00 - 7.500,00 7.500,00 - 10.000,00 10.000,00 - 12.500,00 12.500,00 - 15.000,00 15.000,00 - 20.000,00 20.000,00 - 25.000,00 25.000,00 - 37.500,00 37.500,00 - 50.000,00 50.000,00 - 75.000,00 75.000,00 - 100.000,00 100.000,00 - 150.000,00 150.000,00 - 250.000,00 OLTRE 250.000,00
Figura 3.1.4. Distribuzione dei sinistri per classi di indennizzo (Ania 2003). Si noti che le classi non hanno la stessa ampiezza.
Il grafico successivo contiene un esempio di distribuzione Lognormale con
parametri pari a quelli desunti dalla statistica ANIA 2003.
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
0.2
0.4
0.6
0.8
1
1.2x 10
-3
Z - costo del singolo sinistro Figura 3.1.4. Distribuzione dei sinistri per classi di indennizzo (Ania 2003).

110
In base alle seguenti ipotesi, di seguito vengono riportati i risultati ottenuti
attraverso il modello di simulazione basato sui seguenti parametri:
o ik~ ∼ Poisson(λiBM);
o Z~ ∼ Lognormale(6,8;2,83);
o Numero assicurati = 10.000;
o Numero Simulazioni (Matlab) = 10.000;
o Time horizon = 3 anni;
o Portafoglio chiuso.
E’ importante notare che in questo caso il numero massimo di simulazioni è
fortemente condizionato dal tipo di modello che si è cercato di sviluppare. Dato che
viene utilizzata una frequenza sinistri variabile per ogni classe di BM è necessario
controllare per ogni testa assicurata la classe di appartenenza ed in funzione di
quest’ultima selezionare la corretta frequenza sinistri da inserire nel generatore di
numeri pseudo casuali utilizzato per la v.a. numero sinistri in base alla distribuzione
di Poisson (in Matlab poissrnd).
Quindi è necessario simulare il numero di sinistri per ciascuna testa assicurata e
non si può procedere ad unica simulazione per l’intero collettivo (si veda ad esempio
Savelli [2002]). Tale elemento spiega il notevole tempo computazionale necessario
per effettuare le 10.000 simulazioni per le 10.000 teste distribuite in modo diverso
nelle 18 classi nei 3 anni di sviluppo (circa 12 ore). Al problema del time consuming
contribuiscono anche le simulazioni del costo del singolo sinistro (si ricordi quanto
evidenziato nel paragrafo 2.3.3).
Si sottolinea inoltre che nei precedenti lavori del [2003] e [2005] si era cercato
un diverso compromesso, dato che le finalità erano diverse, considerando un numero
minore di assicurati (100), un numero maggiore di anni di sviluppo (rispettivamente
30 e 60 anni) e utilizzando un costo medio del singolo sinistro costante.
Di seguito sono riportati i risultati ottenuti con tale modello :

111
0 1 2 3 4 5 6 7 8 9
x 106
0
0.2
0.4
0.6
0.8
1
x - Valori Simulati
F(x)
Funzione di Ripartizione SIMULATA T=1
Figura 3.1.5. Distribuzione simulata del danno aggregato.
T=1 Valori "Esatti" Valori Simulati Errore Percentuale
Media Numero Sinistri 1.243 1.244 0,07%
Costo medio del singolo sinistro 3.770 3.765 -0,12%
Media Danno Aggregato = n*a1 4.686.587 4.683.853 -0,06%
Deviazione Standard Danno Agg 548.054 543.888 -0,76%
Coefficiente di variazione 11,7% 11,6% -0,70%
Indice di Asimmetria 1,99 1,76 -11,35%
T=2 Valori "Esatti" Valori Simulati Errore Percentuale
Media Numero Sinistri 1.206 1.205 -0,04%
Costo medio del singolo sinistro 3.770 3.773 0,07%
Media Danno Aggregato = n*a1 4.546.468 4.547.688 0,03%
Deviazione Standard Danno Agg 539.799 547.693 1,46%
Coefficiente di variazione 11,9% 12,0% 1,44%
Indice di Asimmetria 2,02 2,77 -11,35%
T=3 Valori "Esatti" Valori Simulati Errore Percentuale
Media Numero Sinistri 1.169 1.169 0,01%
Costo medio del singolo sinistro 3.770 3.778 0,20%
Media Danno Aggregato = n*a1 4.408.659 4.417.820 0,21%
Deviazione Standard Danno Agg 531.555 582.804 9,64%
Coefficiente di variazione 12,1% 13,2% 9,41%
Indice di Asimmetria 2,05 4,95 141,53%
Tabella 3.1.2: Risultati delle 10.000 simulazioni
I valori esatti sono stati ricavati applicando i dati osservati nelle formule dei momenti
del Processo Composto di Poisson semplice di cui al capitolo 2.

112
Si noti come all’aumentare del tempo il numero atteso di sinistri diminuisca per
effetto di concentrazione degli assicurati verso le classi di bonus dove la frequenza
sinistri è più bassa (risultato che si riflette anche in termini di variabilità della v.a. k~ ).
Per quanto concerne i momenti del danno aggregato non emergono significative
differenze per [ ]XE ~ tra i valori esatti e quelli simulati in tutti i tre anni considerati.
E’ importante invece commentare quanto accade per la varianza del danno
aggregato dove, all’aumentare del tempo, la differenza tra valore esatto e valore
simulato tende ad ampliarsi. Tale fenomeno è dovuto all’aumento di variabilità nel
processo del costo del singolo sinistro, imputabile sia alla procedura di simulazione
(dato che a fronte di un maggiore numero di assicurati la variabilità dei risultati
diminuirebbe) sia alla diminuzione del numero atteso di sinistri che influisce anche
sul numero di simulazioni che vengono effettuate per la v.a. Z~ (si ricordi i passi di
simulazione evidenziati nel paragrafo 2.3.3 e le formule dei momenti del danno
aggregato). Analogo ragionamento può essere fatto per l’indice di asimmetria.
I risultati ottenuti nel precedente approccio sono stati quindi confrontati con
quelli ottenuti utilizzando la FFT in riferimento, per semplicità, ad un anno come
orizzonte temporale di sviluppo.
In questo caso l’obiettivo è individuare la distribuzione del costo sinistri aggregato
per tutte le 18 classi del sistema Bonus Malus (BMS) e successivamente aggregare
tali risultati secondo la metodologia evidenziata nel paragrafo 2.4.1. In tal caso si
suppone che non vi siano correlazioni fra le v.a. numero sinistri nelle diverse classi di
BM (Wang [1998] considera il caso dell’aggregazione tra rami).
Indicando con [ ] jjkE λ=~ il numero atteso di sinistri per j-esima classe (j=1,
…,18) ricavato come visto nella (3.1.1) ed utilizzando la stessa distribuzione del costo
del singolo sinistro per ciascuna classe di merito (Sj = S), in base alla (2.4.1.1):

113
( ) ( )( ) ( ) ( )( )118
1
118
1
~~~~ −
=
−
=
=== ∏∏ t
j
t
jZkX
ZjZj
jjeetPt φλφλ
φφ
si dimostra che in questo caso, dato che 1821 ... λλλλ +++= ,
)()(...)(...)( ~~1~~11
tttt ZZn
Zn
Z nφφ
λλ
λλφ
λλφ
λλ
=
++=++ .
L’ipotesi di utilizzare un’unica distribuzione per le jZ~ semplifica quindi
l’applicazione della FFT. Ai fini dell’individuazione della distribuzione del costo
sinistri aggregato per le 18 classi si applica quindi la procedura vista nel paragrafo
2.3.2.1:
o Discretizzare la distribuzione Lognormale della Z~ , ottenendo
[ ])1(),....,1(),0( ~~~~ −= mffff ZZZZ (in tal caso si è proceduto utilizzando
un’apposita procedura in Matlab basata sull’istruzione histc applicata
alla distribuzione della Z~ ricavata da 2 milioni di simulazioni);
o Scegliere il numero di punti, n=2r , necessari per la distribuzione della
X~ ;
o Aggiungere zeri al vettore precedente in modo tale che il numero di
probabilità sia pari a n: [ ])1(),....,1(),0( ~~~~ −= nffff ZZZZ
o Applicare la FFT ottenendo )( ~~ ZZfFFTf =&& , ottendendo la FC della Z~ ;
o Applicare la FGP della k~ , elemento per elemento, alla FFT:
)( ~~~ ZkXfPf &&&& = , ottenendo quindi la FC del danno aggregato;
o Applicare la IFFT per ottenere il vettore delle probabilità ricercato:
)( ~~ XXfIFFTf &&= .
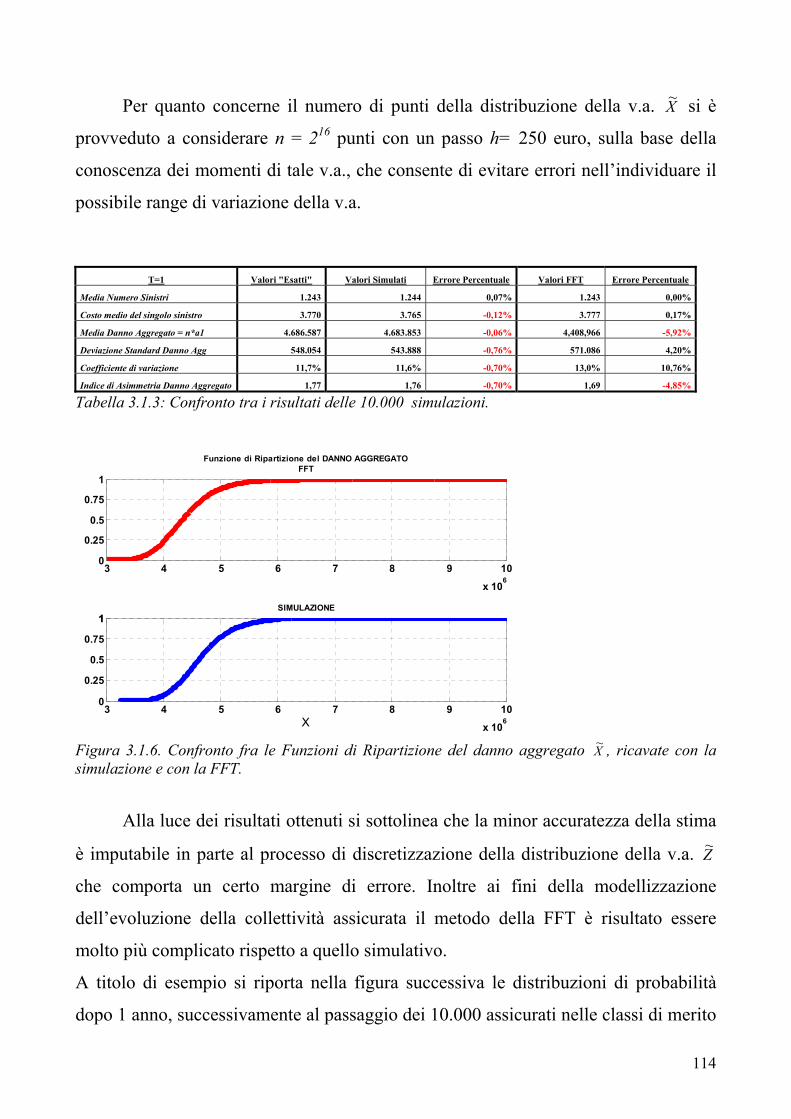
114
Per quanto concerne il numero di punti della distribuzione della v.a. X~ si è
provveduto a considerare n = 216 punti con un passo h= 250 euro, sulla base della
conoscenza dei momenti di tale v.a., che consente di evitare errori nell’individuare il
possibile range di variazione della v.a.
T=1 Valori "Esatti" Valori Simulati Errore Percentuale Valori FFT Errore Percentuale
Media Numero Sinistri 1.243 1.244 0,07% 1.243 0,00%
Costo medio del singolo sinistro 3.770 3.765 -0,12% 3.777 0,17%
Media Danno Aggregato = n*a1 4.686.587 4.683.853 -0,06% 4,408,966 -5,92%
Deviazione Standard Danno Agg 548.054 543.888 -0,76% 571.086 4,20%
Coefficiente di variazione 11,7% 11,6% -0,70% 13,0% 10,76%
Indice di Asimmetria Danno Aggregato 1,77 1,76 -0,70% 1,69 -4,85%
Tabella 3.1.3: Confronto tra i risultati delle 10.000 simulazioni.
3 4 5 6 7 8 9 10
x 106
0
0.25
0.5
0.75
11
X
SIMULAZIONE
3 4 5 6 7 8 9 10
x 106
0
0.25
0.5
0.75
1
Funzione di Ripartizione del DANNO AGGREGATOFFT
Figura 3.1.6. Confronto fra le Funzioni di Ripartizione del danno aggregato X~ , ricavate con la simulazione e con la FFT.
Alla luce dei risultati ottenuti si sottolinea che la minor accuratezza della stima
è imputabile in parte al processo di discretizzazione della distribuzione della v.a. Z~
che comporta un certo margine di errore. Inoltre ai fini della modellizzazione
dell’evoluzione della collettività assicurata il metodo della FFT è risultato essere
molto più complicato rispetto a quello simulativo.
A titolo di esempio si riporta nella figura successiva le distribuzioni di probabilità
dopo 1 anno, successivamente al passaggio dei 10.000 assicurati nelle classi di merito
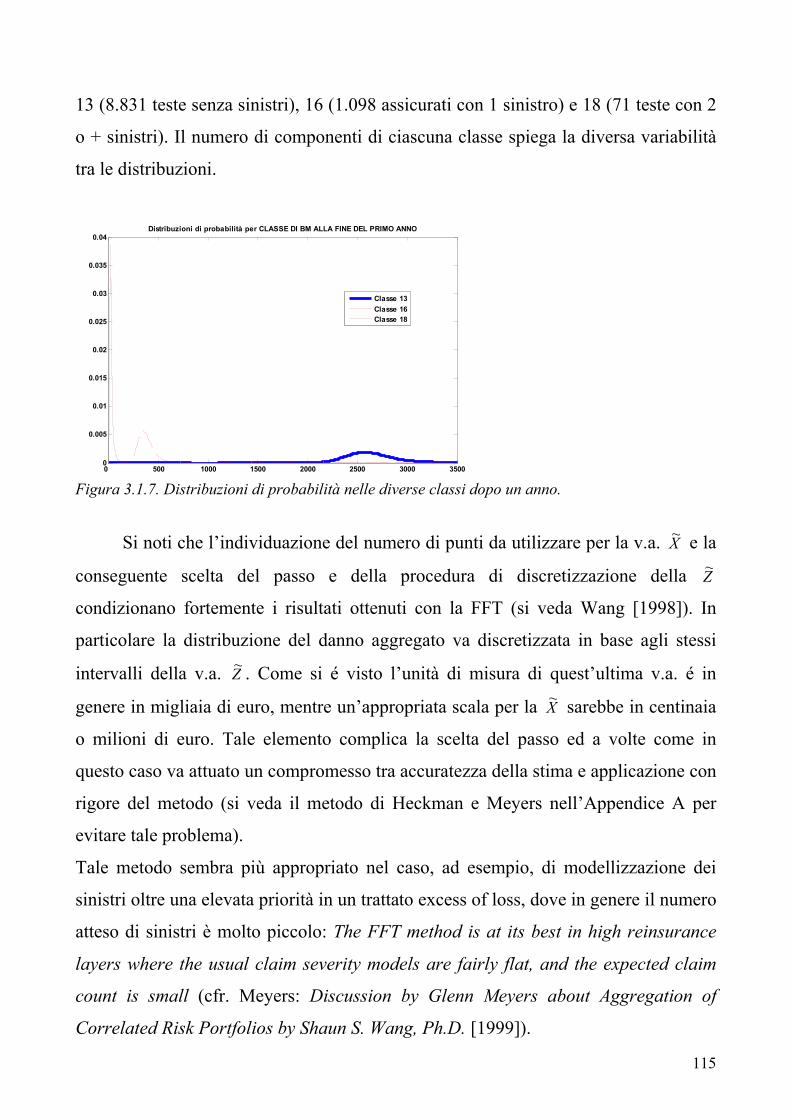
115
13 (8.831 teste senza sinistri), 16 (1.098 assicurati con 1 sinistro) e 18 (71 teste con 2
o + sinistri). Il numero di componenti di ciascuna classe spiega la diversa variabilità
tra le distribuzioni.
0 500 1000 1500 2000 2500 3000 35000
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04Distribuzioni di probabilità per CLASSE DI BM ALLA FINE DEL PRIMO ANNO
Classe 13Classe 16Classe 18
Figura 3.1.7. Distribuzioni di probabilità nelle diverse classi dopo un anno.
Si noti che l’individuazione del numero di punti da utilizzare per la v.a. X~ e la
conseguente scelta del passo e della procedura di discretizzazione della Z~
condizionano fortemente i risultati ottenuti con la FFT (si veda Wang [1998]). In
particolare la distribuzione del danno aggregato va discretizzata in base agli stessi
intervalli della v.a. Z~ . Come si é visto l’unità di misura di quest’ultima v.a. é in
genere in migliaia di euro, mentre un’appropriata scala per la X~ sarebbe in centinaia
o milioni di euro. Tale elemento complica la scelta del passo ed a volte come in
questo caso va attuato un compromesso tra accuratezza della stima e applicazione con
rigore del metodo (si veda il metodo di Heckman e Meyers nell’Appendice A per
evitare tale problema).
Tale metodo sembra più appropriato nel caso, ad esempio, di modellizzazione dei
sinistri oltre una elevata priorità in un trattato excess of loss, dove in genere il numero
atteso di sinistri è molto piccolo: The FFT method is at its best in high reinsurance
layers where the usual claim severity models are fairly flat, and the expected claim
count is small (cfr. Meyers: Discussion by Glenn Meyers about Aggregation of
Correlated Risk Portfolios by Shaun S. Wang, Ph.D. [1999]).

116
I risultati sono condizionati anche dalla scelta di una distribuzione (ipotizzata)
della Z~ con numerosi piccoli sinistri, ma con una coda molto lunga: tale elemento
condiziona sia i risultati che i tempi di elaborazioni richiedendo una notevole
frammentazione della distribuzione di partenza: The FFT method is at its worse when
the claim severity distributions have a high proportion of small claims, but also a
long tail, and the expected claim count is large (cfr. Meyers: Discussion by Glenn
Meyers about Aggregation of Correlated Risk Portfolios by Shaun S. Wang, Ph.D.
[1999]).
A giudizio dell’autore nell’ambito di modelli con elevata complessità del tipo
Risk Based Capital, dove sono presenti diverse componenti aleatorie, rimane la
preferibilità del metodo simulativo, dove oltre all’accuratezza anche i tempi di
elaborazione sono essenziali ai fini dell’applicabilità di un approccio o meno.

117
3.2 L’applicazione dell’EVT ai fini della modellizzazione del danno aggregato
Nel paragrafo 2.1 è stato fornito un esempio di come capire se l’EVT secondo la
logica POT sia adatta o meno a descrivere la coda della distribuzione della v.a. Z~ che
nell’ambito di questa tesi di dottorato rappresenta il costo del singolo sinistro.
Nelle pagine seguenti viene evidenziato come modellizzare il danno aggregato
secondo l’EVT utilizzando la logica POT (si veda Gigante et al. [2002], Cebrian et al.
[2003], Cerchiara e Esposito [2005]).
Sono stati considerati i dati messi in rete dalla Society of Actuaries (SOA),
relativi a “1991-1992 SOA Group of Medical Insurance Large Claims”. Sono
costituiti da 75.789 osservazioni di sinistri eccedenti $25.000 nel periodo 1991.
Il costo medio del singolo sinistro é pari a $58.410; il database é caratterizzato da un
significativo numero di sinistri di importo elevato, con un massimo pari a $ 4.518.420
(Tabella 3.2.1).
Numero di sinistri 75.789
Minimo 25.000 Range 4.493.420
Massimo 4.518.420 Media 58.413
25% Quantile 30.543 Deviazione Standard 66.005
50% Quantile 40.224 Coefficiente di Variazione 1,13
75% Quantile 61.322 Skewness 13,21
Tabella 3.2.1: Alcuni dati statistici per il Database SOA (ammontari in $)
Sulla base di quanto evidenziato nel paragrafo 2.1 si pone l’attenzione sulla coda
della distribuzione empirica. Emerge una notevole asimmetria positiva (13,21) ed un
ampio intervallo di variazione ($ 4.493.420).
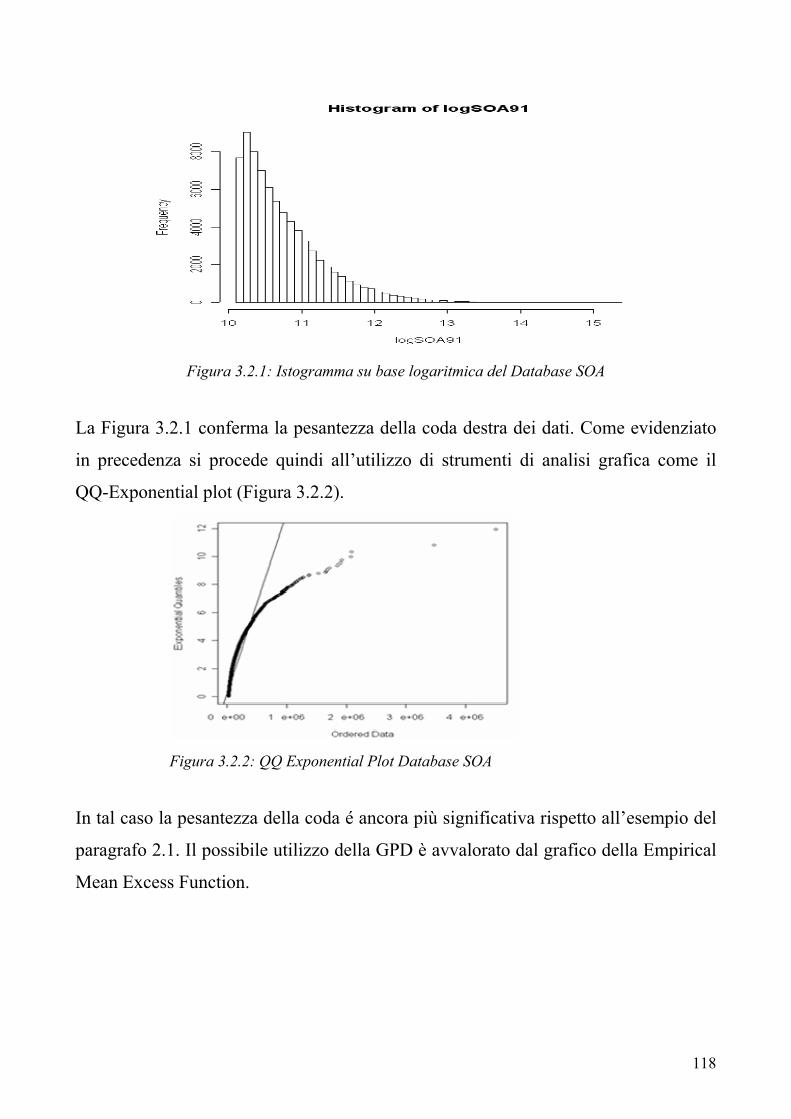
118
Figura 3.2.1: Istogramma su base logaritmica del Database SOA
La Figura 3.2.1 conferma la pesantezza della coda destra dei dati. Come evidenziato
in precedenza si procede quindi all’utilizzo di strumenti di analisi grafica come il
QQ-Exponential plot (Figura 3.2.2).
Figura 3.2.2: QQ Exponential Plot Database SOA
In tal caso la pesantezza della coda é ancora più significativa rispetto all’esempio del
paragrafo 2.1. Il possibile utilizzo della GPD è avvalorato dal grafico della Empirical
Mean Excess Function.
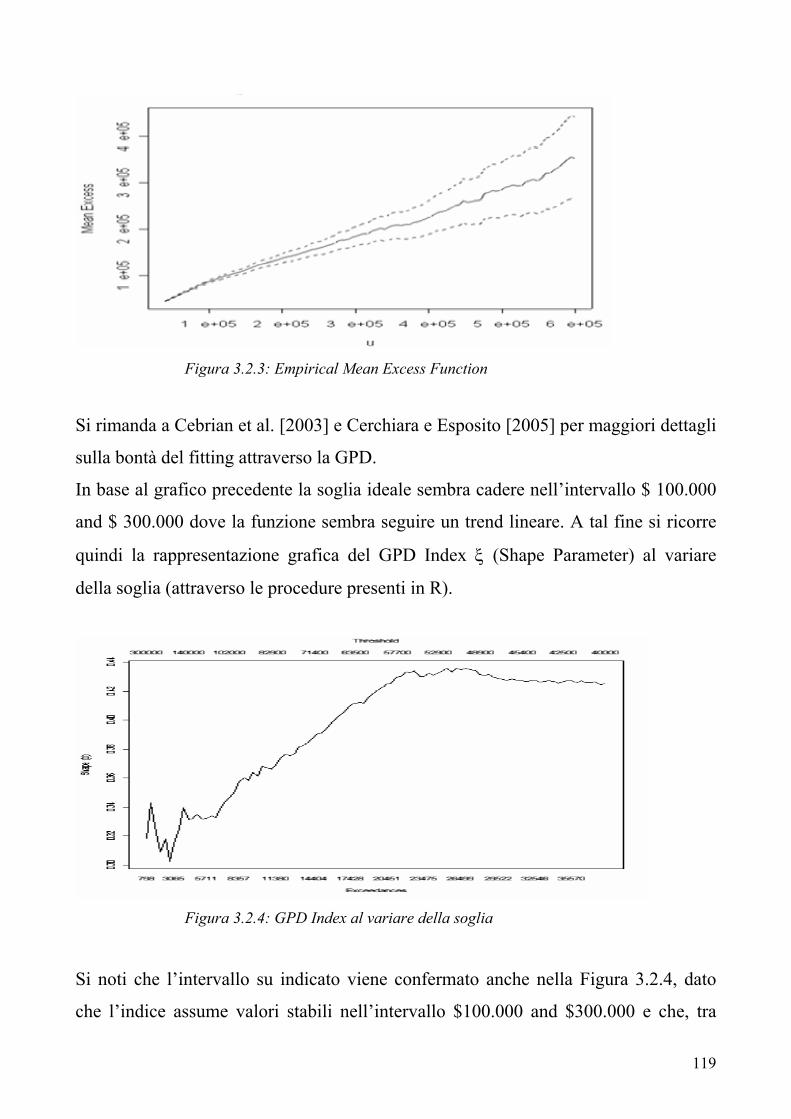
119
Figura 3.2.3: Empirical Mean Excess Function
Si rimanda a Cebrian et al. [2003] e Cerchiara e Esposito [2005] per maggiori dettagli
sulla bontà del fitting attraverso la GPD.
In base al grafico precedente la soglia ideale sembra cadere nell’intervallo $ 100.000
and $ 300.000 dove la funzione sembra seguire un trend lineare. A tal fine si ricorre
quindi la rappresentazione grafica del GPD Index ξ (Shape Parameter) al variare
della soglia (attraverso le procedure presenti in R).
Figura 3.2.4: GPD Index al variare della soglia
Si noti che l’intervallo su indicato viene confermato anche nella Figura 3.2.4, dato
che l’indice assume valori stabili nell’intervallo $100.000 and $300.000 e che, tra

120
l’altro assicura un buon numero di eccedenze. Cebrian et al. [2003], sulla base del
Gertensgarbe plot, individuano la soglia ideale in circa u= $ 200.000.
A fronte di tale soglia si ottiene un fitting efficace della distribuzione di partenza
(Figura 3.2.5).
Figure 3.2.5: Coda Empirica versus GPD (u =200.000)
L’obiettivo é evidenziare l’utilità dell’EVT nella modellizzazione del danno
aggregato e la significatività della corretta scelta della soglia. A tal fine l’analisi è
condotta considerando non un’unica soglia, ma un intervallo di threshold compreso
tra $ 100.000 and $ 300.000.
Nella tabella 3.2.2 si riportano innanzitutto i quantili al livello 99.0%, 99.5% e
99.99% empirici a confronto con le stime dei quantici ricavabili con la GPD in base
alla formula (2.1.4), dove in tal caso n è il numero di sinistri pari a 75.789.
u 99,00% 99,50% 99,99%
300.000 306.510 405.236 1.640.367
225.000 306.926 405.200 1.651.005
200.000 307.337 406.129 1.625.770
175.000 307.578 406.333 1.608.526
150.000 305.472 404.673 1.701.722
100.000 304.519 405.049 1.775.419
Empirical Quantiles 1991 305.983 406.516 1.716.546
Tabella 3.2.2: Quantili empirici versus Quantili della GPD al variare della soglia

121
Si noti come in tale intervallo le stime dei quantili non differiscono molto al variare
della soglia e approssimano bene i valori empirici.
A questo punto si procede alla stima del valore atteso del danno aggregato, che
nell’ipotesi di indipendenza stocastica tra le v.a. k~ e Z~ e che le iZ~ siano i.i.d., è dato
da
[ ] [ ] [ ]ZEkEXE ~~~ ⋅=
In tale ambito si può sfruttare un modello mistura (si veda Bühlman et al. [1982],
Gigante et al. [2002]):
[ ] [ ] [ ] [ ] ( ) [ ] ( ) [ ]{ }uZZEuZuZZEuZkEXEXEXE >⋅>+≤⋅≤⋅=+= ~~~Pr~~~Pr~~~~21 (3.2.1)
In questo modo vengono combinate, nell’ipotesi di indipendenza, una distribuzione di
sinistri “ordinari”, cioé al di sotto della soglia u, con una distribuzione a coda pesante
di sinistri “estremi”, cioè oltre la soglia.
Nel modello proposto viene utilizzata la distribuzione empirica per la variabile
aleatoria k~ per i sinistri sia al di sotto che oltre la soglia u (con 789.75]~[ =kE ). Per il
costo del singolo sinistro Z~ viene utilizzata la distribuzione empirica per i sinistri
ordinary, mentre i large claims sono modellizzati con la GPD.
In tale contesto la soglia u gioca un ruolo cruciale nella definizione del danno
atteso. Nella tabella 3.2.3 vengono riportate il numero di eccedenze, il valore atteso
del danno aggregato, rispettivamente, per i sinistri ordinari, ]~[ 1XE , ed estremi, ]~[ 2XE ,
il valore di ]~[XE .
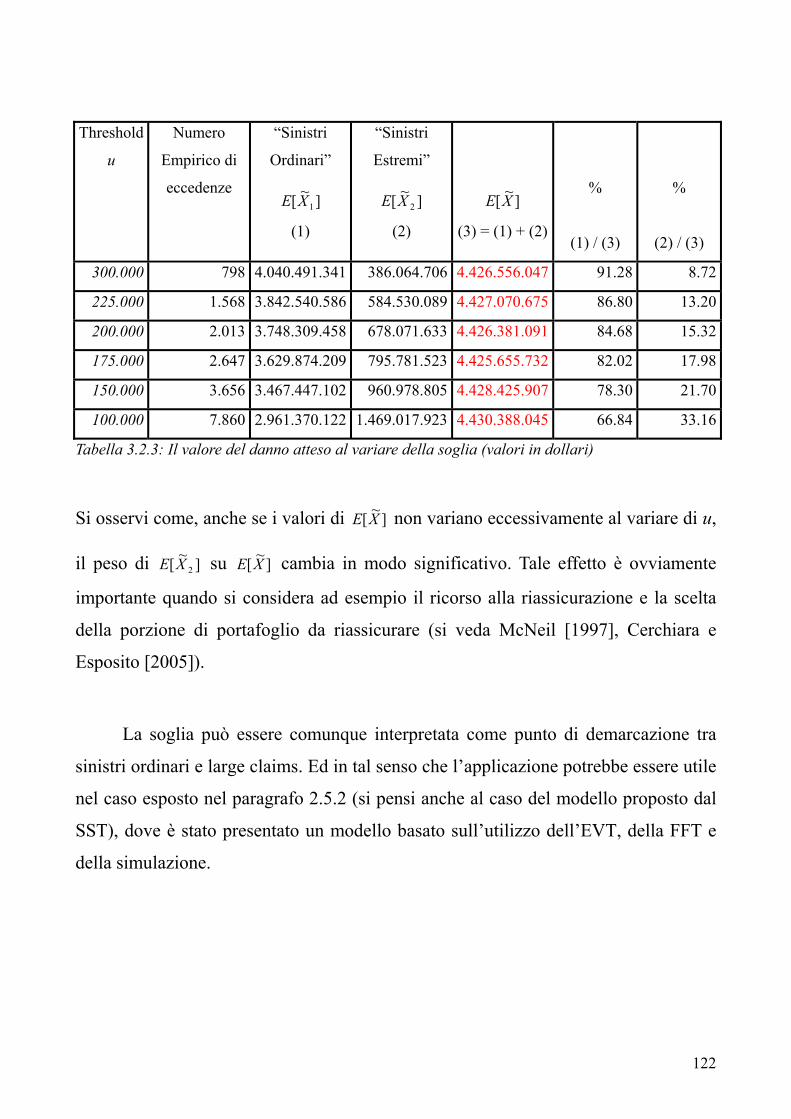
122
Threshold
u
Numero
Empirico di
eccedenze
“Sinistri
Ordinari”
]~[ 1XE
(1)
“Sinistri
Estremi”
]~[ 2XE
(2)
]~[XE
(3) = (1) + (2)
%
(1) / (3)
%
(2) / (3)
300.000 798 4.040.491.341 386.064.706 4.426.556.047 91.28 8.72
225.000 1.568 3.842.540.586 584.530.089 4.427.070.675 86.80 13.20
200.000 2.013 3.748.309.458 678.071.633 4.426.381.091 84.68 15.32
175.000 2.647 3.629.874.209 795.781.523 4.425.655.732 82.02 17.98
150.000 3.656 3.467.447.102 960.978.805 4.428.425.907 78.30 21.70
100.000 7.860 2.961.370.122 1.469.017.923 4.430.388.045 66.84 33.16
Tabella 3.2.3: Il valore del danno atteso al variare della soglia (valori in dollari)
Si osservi come, anche se i valori di ]~[XE non variano eccessivamente al variare di u,
il peso di ]~[ 2XE su ]~[XE cambia in modo significativo. Tale effetto è ovviamente
importante quando si considera ad esempio il ricorso alla riassicurazione e la scelta
della porzione di portafoglio da riassicurare (si veda McNeil [1997], Cerchiara e
Esposito [2005]).
La soglia può essere comunque interpretata come punto di demarcazione tra
sinistri ordinari e large claims. Ed in tal senso che l’applicazione potrebbe essere utile
nel caso esposto nel paragrafo 2.5.2 (si pensi anche al caso del modello proposto dal
SST), dove è stato presentato un modello basato sull’utilizzo dell’EVT, della FFT e
della simulazione.

123
Conclusioni
Il progetto Solvency II è destinato a cambiare profondamente il processo
aziendale delle compagnie di assicurazione della UE, interessando tutti i soggetti
legati al business assicurativo, dall’azionista all’assicurato, dal management
all’autorità di vigilanza. In relazione al futuro sistema di solvibilità, si stanno
sviluppando a livello internazionale i nuovi framework di vigilanza, che tendono
verso la definizione di ratios patrimoniali calibrati sul risk profile delle Compagnie
(risk-based capital requirements).
Si sottolinea inoltre che i nuovi principi contabili internazionali (IAS)
contribuiranno a modificare ulteriormente concetti consolidati in ambito assicurativo,
con l’introduzione, ad esempio, delle riserve sinistri stocastiche, il fair value, ecc.. In
tale contesto emerge quindi la necessità di modelli che consentano di cogliere
efficacemente il risk profile delle compagnie assicurative, in relazione anche a
elementi molto particolari quali l’operational risk.
Tra i più recenti sistemi di analisi del profilo di rischio delle compagnie danni,
oggetto della presente tesi di dottorato, e del sottostante Underwriting Risk si segnala
la particolarità dello Swiss Solvency Test, che si diversifica dagli altri modelli
analizzati, in relazione all’adozione di una misura di rischio come il TVaR e
considera un Capitale Obiettivo (Target Capital) comprensivo del c.d. Risk Margin.
Un aspetto di indubbio interesse ai fini della futura applicazione del progetto
Solvency II è rappresentato dai livelli di intervento utilizzati dall’autorità di vigilanza
americana nel sistema RBC, che però andranno calibrati sulla realtà delle compagnie
assicurative Europee.

124
Successivamente sono stati analizzati alcuni dei differenti approcci utili alla
valutazione della funzione di ripartizione del costo sinistri aggregato di una
compagnia danni, con particolare riferimento all’Extreme Value Theory (EVT), Fast
Fourier Transform (FFT) e ai processi di Simulazione.
In merito alla FFT è stato analizzato il metodo proposto da Wang [1998]
contraddistinto da una velocità di elaborazione superiore rispetto ai metodi simulativi
e a quelli ricorsivi (Panjer [1981]), ma è anche estendibile alla modellizzazione di
variabili multivariate (così come l’approccio simulativo). Come dimostrato in
letteratura tale modellistica presenta alcuni problemi nel caso di un elevato valore del
numero atteso di sinistri e quindi per portafogli con dimensioni elevate. Si segnala
che l’approccio proposto da Heckman e Meyers [1983] di inversione diretta invece
funziona efficientemente nel caso sopra indicato (così come i c.d. metodi
“approssimati” nel caso di asimmetria limitata).
Per quanto concerne il metodo simulativo, esso differisce significativamente
dai precedenti approcci. Un indubbio vantaggio è rappresentato dalla flessibilità, cioè
dal poter articolare e complicare il modello utilizzato (tipica esigenza nel caso degli
Internal Risk Models).
E’ sicuramente meno indicato nel caso di piccoli portafogli dove i metodi esatti
ovviamente rappresentano la metodologia ideale e meno complicata da utilizzare.
L’approccio simulativo é stato applicato ai fini della modellizzazione del costo
sinistri aggregato del ramo RCA italiano su un orizzonte temporale di tre anni,
evidenziando una buona approssimazione dei momenti esatti di tale distribuzione
(stimati dai dati ANIA del 2003).
Successivamente tali risultati sono stati confrontati con quelli ottenuti applicando la
FFT (un anno di sviluppo). Tale metodo sembra più appropriato nel caso, ad esempio,
di modellizzazione dei sinistri oltre una elevata priorità in un trattato excess of loss e

125
quindi con un numero limitato di punti. Si sottolinea infatti che i risultati sono
condizionati anche dalla scelta di una distribuzione del danno aggregato con molti
sinistri di lieve entità, ma con una coda molto lunga: tale elemento condiziona sia i
risultati che i tempi di elaborazioni richiedendo una notevole frammentazione della
distribuzione di partenza del costo del singolo sinistro, in quanto un requisito
essenziale all’applicazione della FFT è la discretizzazione di quest’ultima variabile
aleatoria.
A giudizio dell’autore nell’ambito di modelli con elevata complessità rimane la
preferibilità del metodo simulativo.
L’EVT è stato oggetto di numerosi studi in campo non solo assicurativo, ma
finanziario, geologico, ecc.. Risulta essere una metodologia che si adatta bene a
modellizzare le code delle distribuzioni e anche l’operational risk. Ovviamente la sua
preferibilità rispetto alla metodologie attuariali tradizionali dipende (come per
qualsiasi altro metodo) dal tipo di dati che sono oggetto di analisi.
Nella presente tesi l’EVT è stata applicata su due differenti set di dati: “1998-
2002 Danish Fire Losses”, sulla base del quale è stata dimostrata la teoria e la tecnica
di applicazione, e “1991-1992 SOA Group of Medical Insurance Large Claims”.
Quest’ultimo Database è stato utilizzato per valutare il valore atteso del danno
aggregato attraverso un modello di tipo mistura, evidenziando la significatività della
scelta della soglia ai fini di una corretta valutazione del momento semplice del primo
ordine di tale variabile aleatoria.
Sono state evidenziate anche le problematiche connesse alla valutazione delle
dipendenze nel caso di un modello di solvency assessment, dove è necessario
analizzare la dipendenza tra sinistri di entità ordinaria ed i c.d. “Large Claims”, sulla
base dell’esempio fornito da Homer e Clark [2004] che fornisce un modello basato
sull’utilizzo integrato dell’EVT, della FFT e della simulazione. Infatti la soglia

126
individuata con l’EVT può essere comunque interpretata come punto di
demarcazione tra sinistri ordinari e large claims (come nel caso dello Swiss Solvency
Test). In tale ambito viene utilizzato il metodo della FFT a due dimensioni,
evidenziandone la capacità di modellizzare non solo la distribuzione del costo sinistri
aggregato, ma anche eventuali dipendenze sulle sue singole componenti. Si evidenzia
quindi l’utilità della FFT nel caso di variabili aleatorie bivariate e la possibile
combinazione con la simulazione dei large claims.
I risultati finali non mirano quindi a fornire la preferibilità di un metodo
rispetto agli altri, ma evidenziano, con particolare riferimento alla complessità dei
modelli necessari all’applicazione del nuovo sistema di solvibilità, l’importanza e la
possibilità dell’utilizzo integrato di differenti tecniche ai fini dell’analisi della
distribuzione del costo sinistri aggregato.

127
Appendice A
Il Metodo di inversione Diretta
Heckman e Meyers [1983] hanno applicato l’inversione della FC per la
valutazione della distribuzione del costo sinistri aggregato:
o utilizzando la c.d. piecewise linear function in luogo della effettiva
distribuzione del costo del singolo sinistro, cioè dividendo il range di
variazione della v.a. Z~ in intervalli non necessariamente di uguale ampiezza;
o applicando metodi approssimati di integrazione numerica;
o i rimanenti passi sono simili a quelli previsti per la FFT.
Dal punto di vista implementativo presenta diverse difficoltà comunque superiori
rispetto alla FFT, dato che utilizza metodi di integrazione numerica.
Può comportare errori di stima anche in funzione dell’ampiezza degli intervalli
prescelti per la v.a. Z~ .
Si veda anche Heckman e Meyers [1983] e Klugman et al. [1998] per maggiori
dettagli ed il sito http://www.casact.org/cotor/fftcalc.htm dove viene evidenziato un
interessante confronto tra i metodi diretti di inversione e la FFT.

128
Appendice B
Un procedimento nel caso dei singoli costi sinistri considerati come variabili
aleatorie indipendenti, ma non necessariamente con la stessa distribuzione
Sul piano formale il calcolo della distribuzione del danno aggregato non
presenta alcun problema, mentre le difficoltà nascono sul piano applicativo, data
l’onerosità del calcolo stesso. Infatti tutta la letteratura innanzi citata, si occupa di
ricercare delle metodologie per il rapido calcolo della formula in questione. In questa
appendice viene evidenziata, nell’ambito di un approccio collettivo, un’altra tecnica
per definire la distribuzione del danno aggregato (Ferrara et al. [1996]).
Si ipotizzi di conoscere le distribuzioni delle variabili aleatorie che definiscono
l’ammontare del danno del primo sinistro, del secondo sinistro, ..., del k-esimo
sinistro, supposte mutuamente indipendenti, ma non necessariamente con la stessa
distribuzione, ed inoltre si assuma di poter calcolare facilmente le probabilità che si
verifichino un determinato numero di sinistri.
Si indichi con ~Z 1,~Z 2,...,
~Z i,...,~Z k le variabili aleatorie mutuamente indipendenti
(ed in numero finito), rappresentanti l’ammontare del danno conseguente al primo
sinistro, al secondo sinistro, ecc., fra i possibili sinistri che possono verificarsi in un
periodo di tempo. Sotto determinate ipotesi5, una volta noti i primi due momenti di
ciascuna variabile aleatoria ~Z i, è possibile calcolare i primi due momenti della
variabile aleatoria somma nk ZZZY ~...~~~
21)( +++= , e quindi della distribuzione del
danno cumulato.
Sfruttando ulteriori ipotesi per la variabile aleatoria numero sinistri (Poisson o
Binomiale), vengono calcolate anche i primi due momenti della generica variabile
5 Si veda C. Ferrara et al. [1996] per maggiore dettaglio.

129
aleatoria danno aggregato, ~X , che risulta da una mistura delle variabili )(~ kY con
coefficienti pk. In tal modo, senza dover ricorrere alla convoluzione, si ottengono i
momenti primo e secondo:
[ ] [ ][ ] ( )[ ]∑
∑
=
=
=
=
K
k
kk
K
k
kk
YEpXE
YEpXE
0
2)(2
0
)(
~
~
(B.1)
con K infinito nel caso della Poisson, K finito per la Binomiale.
Tale procedimento si basa sulla ricerca di insiemi ridotti (trascurando gli
elementi meno significativi dal punto di vista attuariale), sia per il numero di sinistri,
che per l’ammontare del danno, che consentono di determinare la funzione di
ripartizione ed i relativi valori caratteristici (momenti primi e secondi) del danno
aggregato, in modo analiticamente approssimato. L’aver considerato tale
impostazione come calcolo “esatto” non costituisce un controsenso, poiché questo
procedimento è, infatti, di tipo approssimato, ma con prefissati limiti superiori degli
errori di approssimazione; gli errori massimi sulla funzione di ripartizione convoluta,
sul momento primo e secondo risultano essere inferiori a 10-6, ottenendo risultati,
quindi, che possono essere considerati “esatti”. Infatti le probabilità che in genere
vengono utilizzate in ambito attuariale per le concrete valutazioni, sono generalmente
espresse, al più, con sei cifre decimali; pertanto il calcolo delle effettive distribuzioni
di probabilità della somma di variabili aleatorie, con valutazioni precise fino alla
sesta cifra decimale è da considerarsi esatto (cfr Ferrara et al. [1996]).
Occorre evidenziare, innanzitutto, la validità del procedimento (B.1) per
qualsiasi distribuzione del numero di sinistri. Ciò deriva dal fatto che, in tale ambito
viene considerato prima lo sviluppo di pk, al fine di individuare i punti in cui le
130
probabilità sono significative. Diversa è la logica delle formule ricorrenti riferite allo
sviluppo di Panjer.
In termini di applicazioni, possono essere valutate sia distribuzioni del numero
sinistri già eseguite in letteratura con altri procedimenti (Poisson, ipergeometrica,
ecc.), sia distribuzioni composte (Poisson e Gamma, Pareto e Poisson, ecc.). In ogni
caso i valori di pk che risultano in genere significativi, sono limitati a poche decine di
unità, confermando, così, l’idea di trascurare i valori non influenti praticamente sulla
misura della probabilità dell’ammontare globale del danno, cioè l’ipotesi che è alla
base del metodo seguito. In queste applicazioni vengono sfruttate, come “controllo
esterno” della convoluzione degli ammontari di un sinistro, delle formule fondate
sulle trasformate nel discreto.
Ferrara et al. [1996] forniscono un’interessante applicazione in questo ambito.
Ammontari Poisson Bin.Neg. Ammontari Poisson Bin.Neg.
minore o uguale minore o uguale 0 0,00789 0,01226 400 0,95725 0,94408
20 0,01522 0,02169 420 0,95952 0,957940 0,02977 0,03857 440 0,97834 0,9683960 0,06744 0,08484 460 0,98473 0,9767280 0,09966 0,11941 480 0,9895 0,98267
100 0,14549 0,16762 500 0,99283 0,98735120 0,21992 0,24441 520 0,99514 0,99081140 0,28118 0,30365 540 0,99677 0,99339160 0,35175 0,37123 560 0,99787 0,99529180 0,44134 0,45614 580 0,99861 0,99666200 0,51302 0,52219 600 0,9991 0,99764220 0,58426 0,58781 620 0,99943 0,99836240 0,66095 0,65841 640 0,99964 0,99886260 0,72071 0,71348 660 0,99977 0,99921280 0,77394 0,76307 680 0,99986 0,99946300 0,82462 0,81074 700 0,99991 0,99953320 0,86308 0,84778 720 0,99995 0,99975340 0,89457 0,87884 740 0,99997 0,99983360 0,92177 0,90623 760 0,99998 0,99989380 0,94187 0,92731 780 0,99999 0,99992
Tabella B.1 Funzione di ripartizione del danno aggregato Grafico 1 con due diversi modelli del numero sinistri
Se si considera la distribuzione dell’ammontare di un sinistro, con opportune
modifiche, presentata da Panjer e Willmot [1992], pag.178, e se si assume come
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
0
140
280
420
560
700
Pois s on
Bin.Neg.

131
parametri per le distribuzioni del numero sinistri λ=4,841423259 (Poisson) e
r=23,43937917, α=0.2065508316 (Binomiale Negativa), per un collettivo di 1.440
unità, applicando il procedimento degli insiemi ridotti, viene ottenuta la distribuzione
del danno cumulato (identica a quella presentata in Panjer e Willmot [1992], pag.208)
nella Tabella 1 (ammontari in unità convenzionali). Si noti che applicando il
procedimento proposto si ricavano ulteriori valori corrispondenti ad ammontari del
danno non previsti nel detto sviluppo presentato Panjer e Willmot [1992].
La media é 207,25 per entrambi le distribuzioni del numero dei sinistri, mentre
lo s.q.m. é 102,602 per la Poisson e 111,156 per la Binomiale negativa.

132
Bibliografia
Balkema A., De Haan L. [1974], Residual Life Time at Great Age, Annals of Probability 2, 792-804 Basel Committee (2001): The New Basel Capital Accord - 2nd Consultative Paper (www.bis.org/bcbs) Beard R.E., Pentikäinen T., Pesonen E. [1984], Risk Theory, 3rd edition, Chapman & Hall, London and New York Berlaint J., Matthys G. , Dierckx G. [2001], Heavy tailed distributions and rating, Astin Bulletin 2001 CEA and Mercer Oliver Wyman [2005], Essential groundwork for the Solvency II Project, www.cea.assur.org Cebrian A., Denuit M., Lambert P. [2003], Generalized Pareto fit to the society of actuaries large claims database, North American Actuarial Journal, vol. 7, n°3, Luglio. CEIPOS [2003-2005]: Documenti Vari, in www.ceiops.org Cerchiara R. R. [2003], Un primo approccio verso la definizione della relazione tra pricing e solvibilità del ramo RCA, Rapporto Scientifico AMASES, n° 22 Cerchiara R. R. [2005], Bonus Malus Systems and Risk Reserve In Automobile Insurance, Atti del XII Convegno di Teoria del Rischio, Università del Molise, Campobasso Cerchiara R. R., Esposito G. [2005], Extreme value theory: the choice of threshold for rating and reinsurance, Quaderni del Dipartimento di Scienze Statistiche Attuariali, Università La Sapienza, Roma Cerchiara R. R., Esposito G. [2005], The Extreme Value Theory and the Risk Reserve in non life insurance companies, presentato al VIII Italian-Spanish Meeting On Financial Mathematics, Verbania, 2005 ed in corso di pubblicazione in Annali n° 11, Università del Sannio, Benevento Clemente G., Parrini C. [2005], An analysis of the claim distribution for fire risk with regard to industrial sector, in corso di pubblicazione

133
Cooray K. e Ananda M. [2005], Modelling actuarial data with composite lognormal-Pareto model, Scandinavian Actuarial Journal, 5, 321-334 Conigliani C., Tancredi A. [2004], Semi-parametric modelling for costs of health care technologies, Statistics in Medicine. Corradin S. [2002], Economic Risk Capital and Reinsurance: an Extreme Value Theory’s Application to Fire Claims of an Insurance Company, Astin Bullettin. Cruz M. G. [2002], Modeling, measuring and hedging operational risk Daboni L. [1993], Lezioni di tecnica attuariale delle assicurazioni contro i danni, Ed. Lint, Trieste Daykin C. D., Pentikainen T., Pesonen M. [1994], Practical risk theory for actuaries, Chapman and Hall, London Embrechts P., Kluppelbrg C., Mikosch T. [1997], Modelling extremal events, Springer Verlag, Berlin Embrechts P. [2005], Quantifying Regulatory Capital for Operational Risk: Utopia or Not, 75° Anniversario dell’Istituto Italiano degli Attuari, Giornata di studio ”Il sistema di Solvibilità II”, Roma Embrechts P., Frey R., McNeil J. A. [2005], Quantitative Risk Management, Princeton Series in Finance, Princeton Federal Office of Private Insurance [2004], White Paper of the Swiss Solvency Test, Novembre 2004, www.bpv.admin.ch . Ferrara C., Manna A., Tomassetti A. [1996], Teoria del rischio per un collettivo: un procedimento per il calcolo “esatto” della distribuzione globale del danno, Giornale dell’Istituto Italiano degli Attuari, Vol. LIX FSA & Watson Wyatt [2003], Calibration of the general insurance risk based capital model FSA [2003], Enhanced capital requirements and individual capital assessments for non-life insurers, Consultation Paper 190 FU L., Mutual G., Moncher R., West B. [2004], Severity distribution’s for GLM’s: Gamma or Lognormal?, CAS Spring Meeting, Colorado

134
Gigante P., Picech L., Sigalotti L. [2002], Rate making and large claims, ICA September 2002 Gigante P., Picech L., Sigalotti L. [2003], A model to evaluate bonus-malus systems by recursive procedures, Giornale dell’Istituto Italiano degli Attuari, LXIV (1-2), 85-107 Heckman P.E. & Meyers G. [1983], The calculation of aggregate loss distributions from claim severity and claim count distributions, Casualty Actuarial Society, PCAS LXX Hogg R.V., Klugman S. [1984], Loss distributions, Ed. John Wiley & Sons, New York Homer D. L., Clark D. R. [2004], Insurance Applications of Bivariate Distributions, CAS Forum, IAA Insurer Solvency Assessment Working Party [2004], A Global Framework for Insurer Solvency Assessment, Giugno 2004 ISVAP [1999], Il margine di solvibilità delle imprese di assicurazione: confronto tra i sistemi europeo ed americano, Quaderno ISVAP n. 6 Klugman S., Panjer H., Willmot G. [1998], Loss Models - From Data to Decisions, John Wiley & Sons, New York, First Edition Klugman S., Panjer H., Willmot G. [1998], Loss Models - From Data to Decisions, John Wiley & Sons, New York, Second Edition KPMG Report [2002], Study into the methodologies to assess the overall financial position of an insurance undertaking from the perspective of prudential supervision, European Commission Lemaire J. [1995], Bonus-Malus Systems in Automobile Insurance, Kluwer Academic Publishers McNeil A. [1997], Estimating the tails of the loss severity distributions using extreme value theory, ASTIN Bulletin, 27, 117-137 Meyers G. [1999], Discussion Paper about “Aggregation of correlated risk portfolios: models and algorithms” by Wang S.S. [1998], PCAS LXXXVI Meyers G. [2005], On predictive Modelling for Claim Severity, CARe Seminar

135
Moscadelli M. [2004]: The modelling of operational risk: experience with the analysis of the data collected by the Basel Committee, Temi di discussione Banca d’Italia, n. 517 Műller Working Party [1997], Solvency of insurance undertakings, Report of the EU Insurance Supervisory Authorities Panjer H. e Willmot G. [1992], Insurance Risk Models, Society of Actuaries Pentikainen T. [1987], Approximative Evaluation of the Distribuction Function of Aggregate Claims, Astin Bullettin, Vol.17, N. 1 Pentikainen T., Rantala [1999], “Risk Theory”, Seminario Istituto Italiano degli Attuari, 20/04/1999 Pickands J. [1975], Statistical Inference Using Extreme Order Statistics, Annals of Statistics 3, 119-131 Rytgaard M. [2005], A Mixed Poisson Process from Real Life, Reykjavik, 18-21 Giugno 2005 Robertson J. P. [1983], The Computation Of Aggregate Loss Distributions, PCAS LXXIX Savelli N. [2002], Solvency and Traditional Reinsurance for non-life insurance, Atti del IX Convegno di Teoria del Rischio, Università del Molise, Campobasso. Savelli N. [2003], A Risk Theoretical Model For Assessing The Solvency Profile of a General Insurer, Proceedings of XXXIV ASTIN Colloquium, Berlin. Rytgaard M. e Savelli N. [2004], Risk-Based Capital Requirements For Property And Liability Insurers According To Different Reinsurance Strategies And The Effect On Profitability, Proceedings of XXXV Astin Colloquium, Bergen. Savelli N. [2005], Il Rischio Operativo nelle Banche: Metodologie di valutazione e strumenti di copertura assicurativa, Università Cattolica, Milano Savelli N. [2005], Solvency II e Internal risk models, Seminario SIFA, Milano. Sigma [2000], Solvency of non-life insurers:Balancing security and profitability expectations, Swiss Re, n. 1, 2000 Wang S.S. [1998], Aggregation of correlated risk portfolios: models and algorithms, PCAS LXXXV

136
Ringraziamenti
Ringrazio mia moglie per il suo continuo, costante e instancabile sostegno durante
questo mio percorso così articolato.
Ringrazio il Prof. Savelli N. per avermi costantemente supportato nella preparazione
della presente tesi e lungo tutto il mio percorso universitario.
Infine un sentito grazie, oltre che all’attuale coordinatore Prof. Grasso F., alla
Prof.ssa Vitali L. che ha accompagnato i miei “esordi” nell’ambito del dottorato,
stimolandomi nella mia attività di ricerca e fornendomi sempre utili consigli.















![)DVFLFROR LQIRUPDWLYR 3ROL]]D GL $VVLFXUD]LRQH … · decorrenza; il tentato suicidio; la mutilazione volontaria; i sinistri provocati volontariamente dall'Assicurato; i sinistri](https://static.fdocumenti.com/doc/165x107/5c6f47d009d3f2154d8be99b/dvflfror-lqirupdwlyr-3rold-gl-vvlfxudlrqh-decorrenza-il-tentato-suicidio.jpg)


