
Tecnologie innovative nell’organizzazione uno sguardo al ...
17
Tecnologie innovative nell’organizzazione: uno sguardo al futuro Congreso Nazionale AcEMC 2018 – Pisa, November 9, 2018 Franca Dipaola, Mauro Gatti, Anna Giulia Bottaccioli, Dana Shiffer, Maura Minonzio, Roberto Menè, Marco Anastasio, Enrico Brunett a Disclosures: none Raffaello Furlan Humanitas Research Hospital and Humanitas University, Rozzano, Italy
Transcript of Tecnologie innovative nell’organizzazione uno sguardo al ...

Tecnologie innovative nell’organizzazione:
uno sguardo al futuro
Congreso Nazionale AcEMC 2018 – Pisa, November 9, 2018
Franca Dipaola, Mauro Gatti, Anna Giulia Bottaccioli, Dana Shiffer, Maura Minonzio, Roberto Menè,
Marco Anastasio, Enrico Brunetta
Disclosures: none
Raffaello Furlan
Humanitas Research Hospital and Humanitas University, Rozzano, Italy
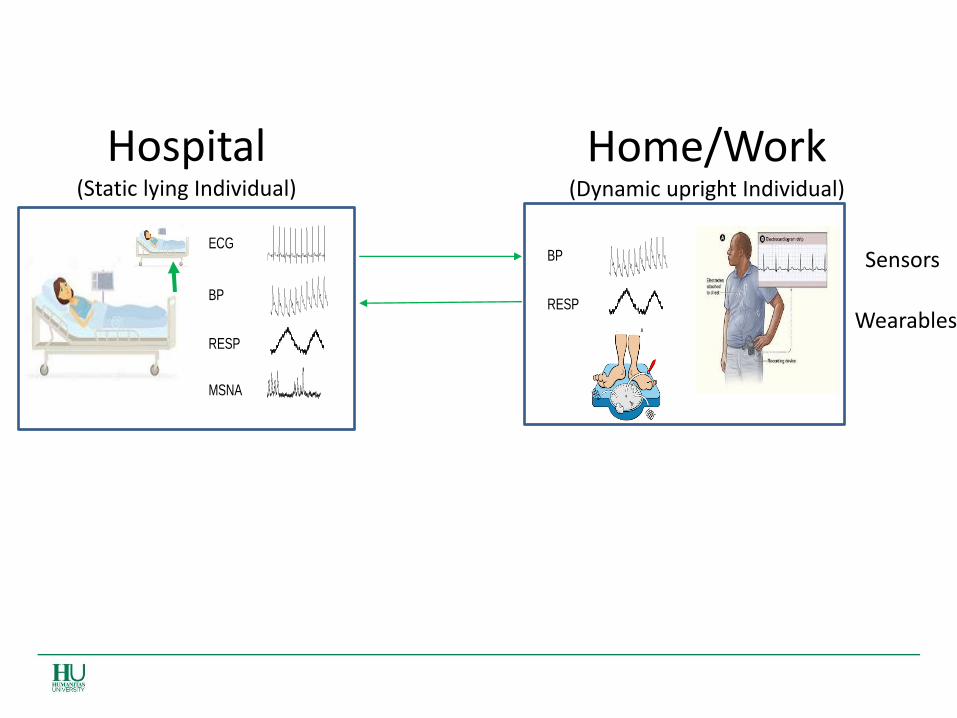
Hospital (Static lying Individual)
Home/Work (Dynamic upright Individual)
Sensors
Wearables RESP
ECG
BP
MSNA
RESP
ECG
BP
MSNA
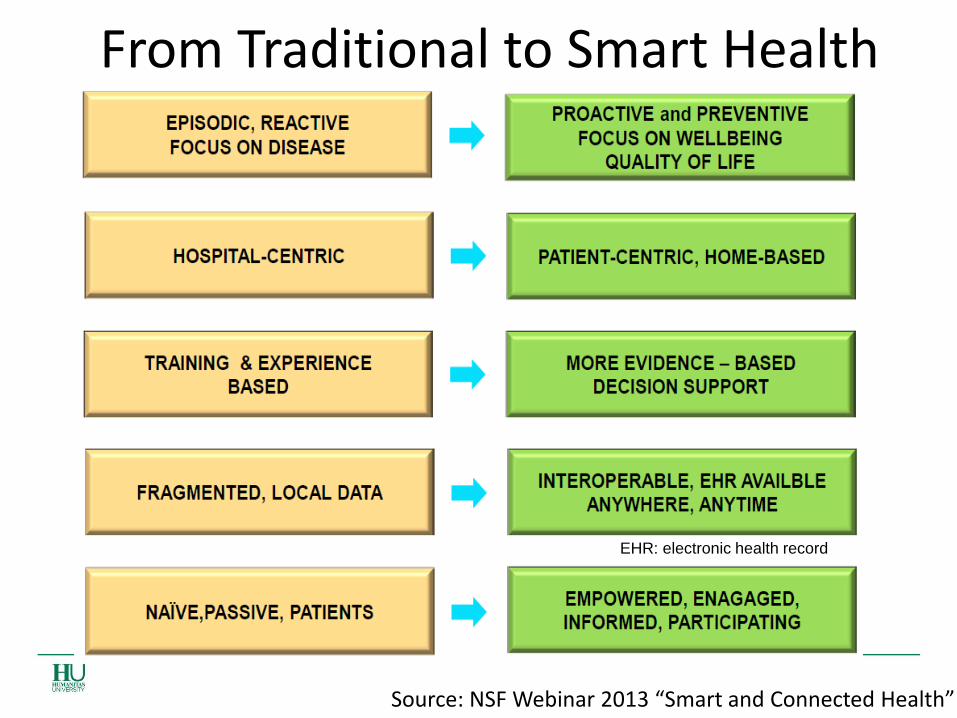
From Traditional to Smart Health Care
Source: NSF Webinar 2013 “Smart and Connected Health”
EHR: electronic health record

• Artificial Intelligence: is a Computer Science area aimed
at creating systems (algorhythms) able to address tasks
• Artificial Neural Networks: their framework is non-linear,
may forcast events, more effective than logistic models
(multivariable logistic regression) in clasifying elements
• Machine learning: modelling a system, intelligent
algorhythms may learn and perform better the more you
feed them by data (big data…)
• Deep learning: machine learning algorhythms based on
a neural structure (non-linear)
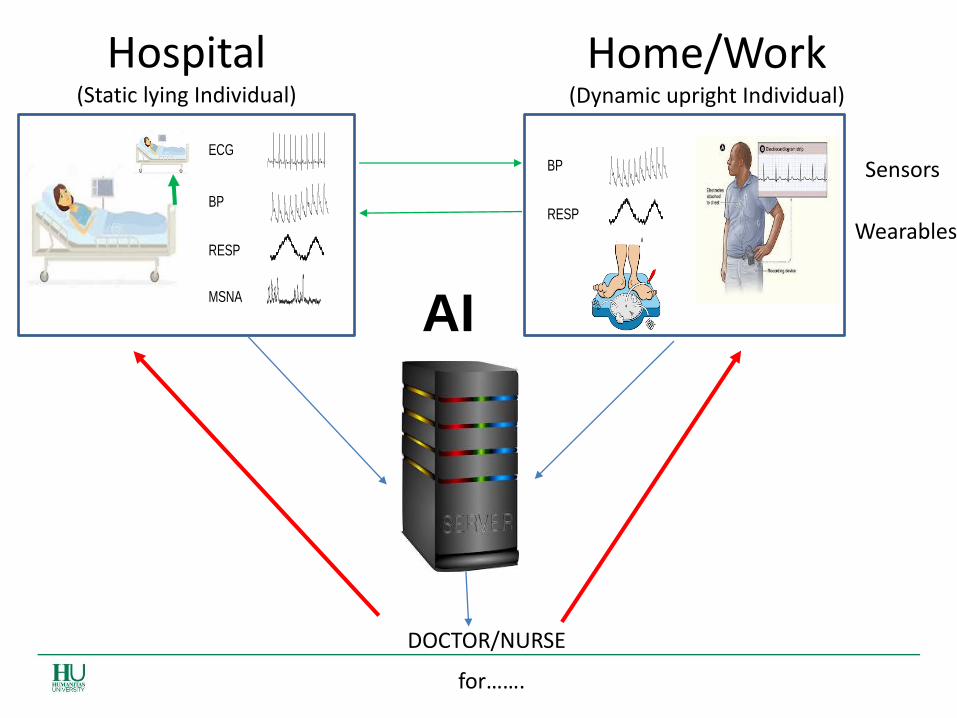
Hospital (Static lying Individual)
Home/Work (Dynamic upright Individual)
Sensors
Wearables
AI
RESP
ECG
BP
MSNA
RESP
ECG
BP
MSNA
DOCTOR/NURSE
for…….

- Text classification from natural language
analysis
- Correct automatic identification (and
classification) of patients suffering from a
certain disease
- Prediction i.e. group/individual risk
stratification for prognostic purposes

AIM To recognize patients suffering from
syncope using natural language processing on
ED medical records
Example 1

Background
• Hospital discharge diagnoses are frequently used to identify study populations. The International Classification of Disease, 9th revision, Clinical Modified (ICD-9-CM), is one of the most widespread coding system available currently.
• By means of language uniformity, ICD-9-CM enables data extraction from both administrative and clinical database thus permitting, among others, to perform large sample size studies quickly and inexpensively.
• However, robustness of results depends on the accuracy of ICD-9-CM code association with the disease.
• Syncope diagnosis is often an exclusion process, not supported by any biomarker or imaging test. Such sources of imprecision may reduce the diagnostic accuracy of ICD-9-CM 780.2 coding for syncope (“syncope and collapse”), particularly whenever this approach is based on the use of secondary data.
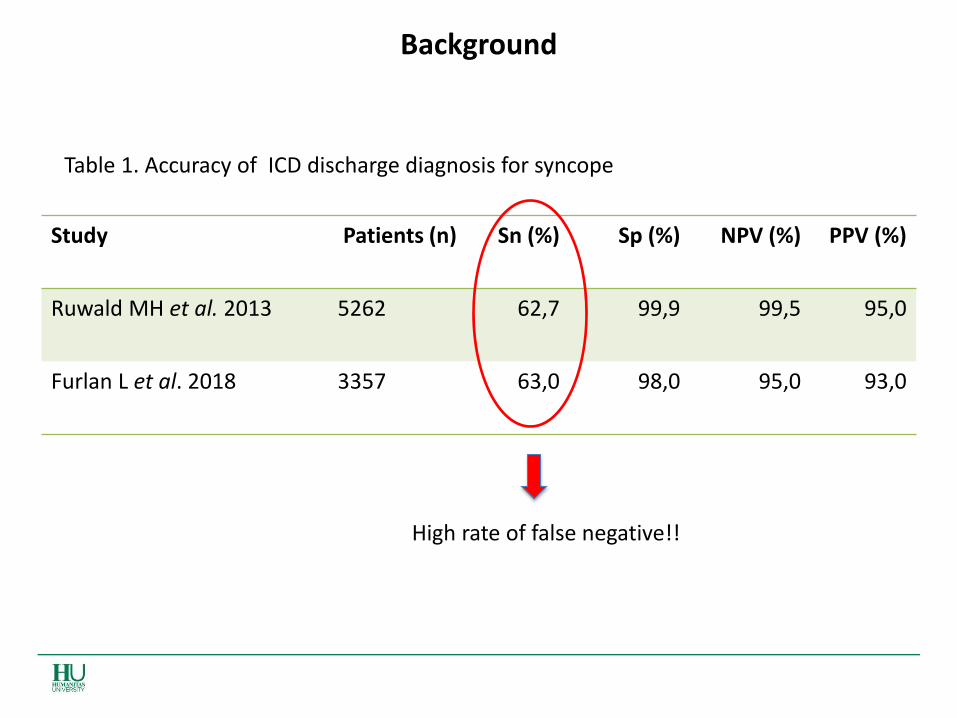
Background
Study Patients (n) Sn (%) Sp (%) NPV (%) PPV (%)
Ruwald MH et al. 2013 5262 62,7 99,9 99,5 95,0
Furlan L et al. 2018 3357 63,0 98,0 95,0 93,0
Table 1. Accuracy of ICD discharge diagnosis for syncope
High rate of false negative!!

Hypothesis
• A cognitive (intelligent) algorithm based approach
could be (more) suitable in automatically identifying true
syncope patients from administrative data set.

What does a Cognitive Algorhythm do
when analyzing natural language texts?
Two statements may be characterized by different words, different syntax but may be semantically alike
Es. my belly is soring (soffro per un mal di pancia ) vs
I have got an abdominal pain (ho un dolore all’addome)
Natural language processing can identify similarities in the meaning between phrases/statements made by different words and classifies/categorizes

Aim
• To develop machine learning algorithms based on natural language processing which may enable the identification of patients affected by syncope in Emergency Department (ED), by using administrative data.
Methods
• Study design: Retrospective, observational.
• Study population: medical records of all patients evaluated at Humanitas Research Hospital ED between 1st December 2013 and 31st March 2014 (2013 dataset) and 1st December 2015 and 31st March 2016 (2015 dataset) were analyzed.
Each dataset was extracted from the Humanitas Hospital electronic repository by IT department experts, corresponds to 4 months ED visits, and was made available in the format of a Microsoft Excel spreadsheet.
The following fields were considered: a. patient’s age; b. ICD-9-CM coding at ED discharge; c. patient’s clinical features as described by triage operators; d. patient’s clinical features - ED physician description of patient’s medical history and ED discharge diagnosis.

Methods-2
Step 1: by manual evaluation of medical records, syncope was identified if either the term “syncope” was clearly reported in the ED discharge diagnosis description or if the description of the episode agreed with the ESC definition of syncope.
Clinical judgment of Emergency physicians was considered the “gold standard” for syncope diagnosis.
Step 2: The 2013 and 2015 datasets were combined in a single dataset which was used to feed machine learning algorithms.
The concept of a three-way partition: Data were split in training, validation and test data to prevent overfitting and ensure reliability. The methodology used is Nested Cross Validation
which provides results distribution accuracy rather than single point estimate
Classification of records was performed by developing multiple feature extractor algorithms (both manual and automatic) and testing their performance in combination with multiple classifiers. For each combination of feature extractor and classifier we measured algorithm accuracy on the validation set using multiple accuracy measures.
To get a single measure that could encompass the need to give more relevance to sensitivity (need low false negative) without glossing over precision (need low false positives), the F_3 was selected for giving triple importance to sensitivity over precision.
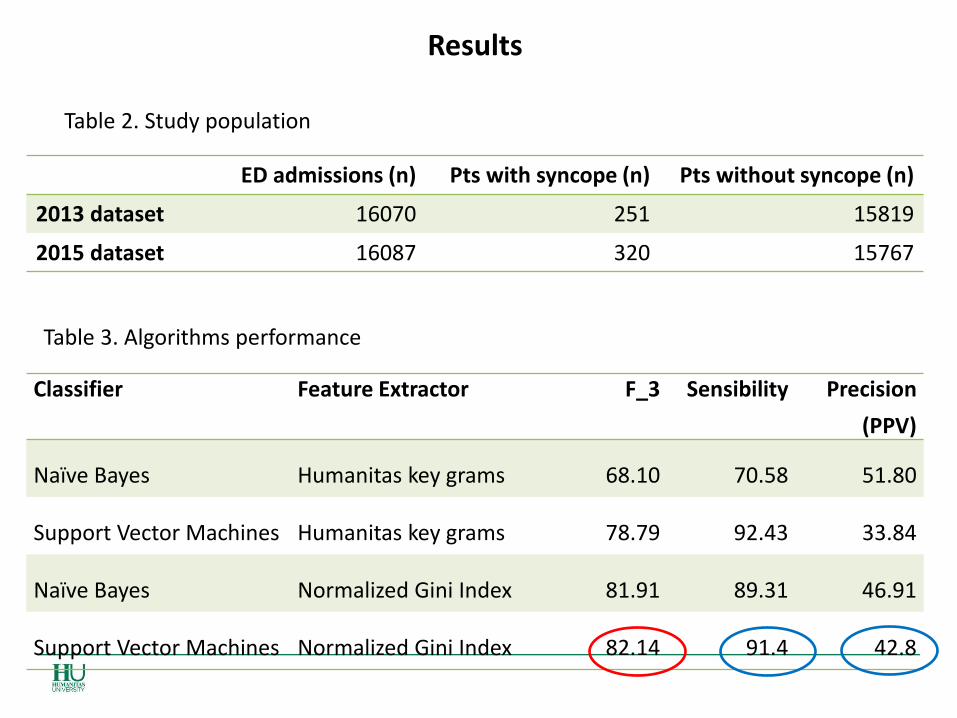
Results
ED admissions (n) Pts with syncope (n) Pts without syncope (n)
2013 dataset 16070 251 15819
2015 dataset 16087 320 15767
Table 2. Study population
Table 3. Algorithms performance
Classifier Feature Extractor F_3 Sensibility Precision
(PPV)
Naïve Bayes Humanitas key grams 68.10 70.58 51.80
Support Vector Machines Humanitas key grams 78.79 92.43 33.84
Naïve Bayes Normalized Gini Index 81.91 89.31 46.91
Support Vector Machines Normalized Gini Index 82.14 91.4 42.8

Study strengths
Significant reduction in the required time to analyze large databases (from 7.4 months /person down to few minutes!)
Low usage costs
High reproducibility (in Italian language)
Non-external validation in a different patient cohort
Study limitations
Future perspectives
Applications of algorithms in individual risk prediction



















