
REALIZZAZIONE DI UN SISTEMA EMBEDDED CON ACCELERAZIONE HARDWARE 2D SU FPGA

POLITECNICO DI MILANO
FACOLTA DI INGEGNERIA
CORSO DI LAUREA IN INGEGNERIA INFORMATICA
STUDIO E REALIZZAZIONE DI UNAINFRASTRUTTURA DI COMUNICAZIONE PER
ARCHITETTURE DINAMICAMENTERICONFIGURABILI
Relatore: Prof. Fabrizio FERRANDI
Correlatore: Ing. Marco Domenico SANTAMBROGIO
Tesi di Laurea di:Daniele MarchettiMatricola n. 651270Valentina ValzelliMatricola n. 653373
ANNO ACCADEMICO 2005-2006


Indice
Introduzione 1
1 FPGA 31.1 Cos’e una FPGA . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Architettura di una FPGA . . . . . . . . . . . . . . . . . . . . . . 5
1.2.1 CLB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.2 I tri-state buffer . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.3 IOB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.4 Risorse di Interconnessione . . . . . . . . . . . . . . . . 8
1.2.5 Interconnessione diretta . . . . . . . . . . . . . . . . . . 8
1.2.6 Interconnessione segmentata . . . . . . . . . . . . . . . . 10
1.2.7 Blocchi di moltiplicatori . . . . . . . . . . . . . . . . . . 10
1.3 Le Spartan-3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.1 Architettura generale . . . . . . . . . . . . . . . . . . . . 12
1.3.2 CLB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.4 Virtex-II e Virtex-II Pro . . . . . . . . . . . . . . . . . . . . . . . 16
2 La riconfigurabilita dinamica parziale e il bus macro 232.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.2 Riconfigurabilita basata sui moduli . . . . . . . . . . . . . . . . . 24
2.2.1 Vincoli sui moduli . . . . . . . . . . . . . . . . . . . . . 25
2.3 Riconfigurabilita basata sulle differenze . . . . . . . . . . . . . . 28
2.3.1 Apportare piccole modifiche utilizzando FPGA Editor . . 29
3

2.3.2 Apportare piccole modifiche utilizzando Design Entry . . 32
2.4 Usare i bitstream e programmare le FPGA . . . . . . . . . . . . . 32
2.5 Il bus macro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.5.1 Cos’e il bus macro . . . . . . . . . . . . . . . . . . . . . 33
2.5.2 Il bus macro a livello fisico . . . . . . . . . . . . . . . . . 34
2.6 L’infrastruttura di comunicazione proposta . . . . . . . . . . . . . 36
3 Gli strumenti utilizzati 393.1 ISE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.2 FPGA Editor . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3 ModelSim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4 Metotologia 474.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.2 Il processo standard . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3 Il processo automatizzabile . . . . . . . . . . . . . . . . . . . . . 49
4.4 File XDL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.4.1 La struttura del file XDL . . . . . . . . . . . . . . . . . . 51
5 Implementazione 535.1 Step 1: il codice VHDL . . . . . . . . . . . . . . . . . . . . . . . 54
5.2 Step 2: FPGA Editor . . . . . . . . . . . . . . . . . . . . . . . . 56
5.3 Step 3: trasformazione in XDL . . . . . . . . . . . . . . . . . . . 57
5.4 Step 4: studio del file XDL . . . . . . . . . . . . . . . . . . . . . 57
5.5 Step 5: programma generatore di codice XDL . . . . . . . . . . . 58
6 Test e risultati 616.1 Tempo per la realizzazione del bus . . . . . . . . . . . . . . . . . 62
6.2 Il bus su Spartan-3 . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.2.1 Occupazione d’area . . . . . . . . . . . . . . . . . . . . . 62
6.2.2 Prestazioni temporali . . . . . . . . . . . . . . . . . . . . 63
6.3 Il bus su Virtex-II . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.3.1 Occupazione d’area . . . . . . . . . . . . . . . . . . . . . 65

6.3.2 Prestazioni temporali . . . . . . . . . . . . . . . . . . . . 65
6.4 Il bus su Virtex-II Pro . . . . . . . . . . . . . . . . . . . . . . . . 69
6.4.1 Occupazione d’area . . . . . . . . . . . . . . . . . . . . . 69
6.4.2 Prestazioni temporali . . . . . . . . . . . . . . . . . . . . 69
7 Conclusioni 73


Elenco delle figure
1.1 Significato della sigla identificatrice delle FPGA. . . . . . . . . . 5
1.2 Disposizione dei componenti in una FPGA. . . . . . . . . . . . . 6
1.3 CLB di una Spartan-3. . . . . . . . . . . . . . . . . . . . . . . . 6
1.4 Un tri-state in FPGA Editor . . . . . . . . . . . . . . . . . . . . . 7
1.5 Schema di uno IOB. . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.6 Interconnessione diretta. . . . . . . . . . . . . . . . . . . . . . . 10
1.7 Interconnessione segmentata. . . . . . . . . . . . . . . . . . . . . 11
1.8 Schema di un moltiplicatore semplice. . . . . . . . . . . . . . . . 11
1.9 Modelli di Spartan-3. . . . . . . . . . . . . . . . . . . . . . . . . 12
1.10 Una Spartan-3 montata su evaluation board. . . . . . . . . . . . . 13
1.11 Architettura della famiglia delle SPartan-3. . . . . . . . . . . . . 14
1.12 Numero di blocchi di RAM nelle Spartan-3. . . . . . . . . . . . . 14
1.13 Struttura di una slice. . . . . . . . . . . . . . . . . . . . . . . . . 15
1.14 CLB di una Virtex-II. . . . . . . . . . . . . . . . . . . . . . . . . 17
1.15 Connessione dei tri-state alle risorse di interconnessione orizzontali. 18
1.16 Tabella dei tri-state per le Virtex-II. . . . . . . . . . . . . . . . . . 18
1.17 IOB in una Virtex-II. . . . . . . . . . . . . . . . . . . . . . . . . 19
1.18 Collegamento Multiplexer-SelectRAM. . . . . . . . . . . . . . . 21
2.1 Comunicazione tra due moduli tramite bus macro . . . . . . . . . 25
2.2 Visualizzazione di un blocco . . . . . . . . . . . . . . . . . . . . 30
2.3 Cambiare i contenuti di un blocco RAM . . . . . . . . . . . . . . 31
2.4 Posizionamento del bus macro nell’area della FPGA . . . . . . . 34
2.5 Implementazione fisica del bus macro. . . . . . . . . . . . . . . . 35
7

2.6 Connessione dei tri-state alle linee orizzontali. . . . . . . . . . . . 36
2.7 Il bus in FPGA Editor. . . . . . . . . . . . . . . . . . . . . . . . 37
3.1 Interfaccia grafica di Project Navigator . . . . . . . . . . . . . . . 40
3.2 Editor testuale di Project Navigator . . . . . . . . . . . . . . . . . 40
3.3 Menu delle funzioni di Project Navigator . . . . . . . . . . . . . . 41
3.4 Interfaccia grafica di FPGA Editor. . . . . . . . . . . . . . . . . . 43
3.5 Interfaccia grafica di ModelSim SE 6.0 . . . . . . . . . . . . . . . 44
3.6 Finestra signals di ModelSim SE 6.0 . . . . . . . . . . . . . . . . 45
3.7 Finestra wave di ModelSim SE 6.0 . . . . . . . . . . . . . . . . . 46
4.1 Flusso di operazioni standard. . . . . . . . . . . . . . . . . . . . 48
4.2 Alternative per la creazione di un file .nmc. . . . . . . . . . . . . 49
4.3 Flusso di operazioni del programma generatore. . . . . . . . . . . 50
5.1 Flusso di operazioni del programma generatore. . . . . . . . . . . 54
6.1 Tempo per l’attraversamento del blocco d’ingresso (Tiopi). . . . . 67
6.2 Tempo per l’attraversamento del blocco d’uscita (Tioop). . . . . . 68

Elenco delle tabelle
1.1 Tabella delle verita di un tri-state. . . . . . . . . . . . . . . . . . 8
1.2 Tabella delle configurazioni a porta doppia e a porta singola della
SelectRAM. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.3 Tabella delle configurazioni a porta doppia e a porta singola della
SelectRAM+. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.4 Tabella riassuntiva delle famiglie di FPGA. . . . . . . . . . . . . 22
6.1 Tabella dell’occupazione d’area per una XC3S200-4ft256. . . . . 62
6.2 Suddivisione dei tempi per una XC3S200-4ft256. . . . . . . . . . 64
6.3 Tabella dei ritardi per una XC3S200-4ft256. . . . . . . . . . . . . 64
6.4 Ritardi per net in/out(0). . . . . . . . . . . . . . . . . . . . . . . 64
6.5 Ritardi per net in/out(1). . . . . . . . . . . . . . . . . . . . . . . 65
6.6 Ritardi per net in/out(2). . . . . . . . . . . . . . . . . . . . . . . 65
6.7 Ritardi per net in/out(3). . . . . . . . . . . . . . . . . . . . . . . 66
6.8 Tabella dell’occupazione d’area per la XC2V1000-5fg256. . . . . 66
6.9 Tabella del ritardo ingresso/uscita in una XC2V1000-5fg256. . . . 66
6.10 Suddivisione dei tempi per una XC2V1000-5fg256. . . . . . . . . 67
6.11 Tabella dei ritardi per una XC2V1000-5fg256. . . . . . . . . . . . 68
6.12 Ritardi per net in/out(0). . . . . . . . . . . . . . . . . . . . . . . 69
6.13 Ritardi per net in/out(1). . . . . . . . . . . . . . . . . . . . . . . 69
6.14 Ritardi per net in/out(2). . . . . . . . . . . . . . . . . . . . . . . 69
6.15 Ritardi per net in/out(3). . . . . . . . . . . . . . . . . . . . . . . 69
6.16 Tabella dell’occupazione d’area per la X2VP20-5fg676. . . . . . . 70
6.17 Tabella del ritardo ingresso/uscita in una X2VP20-5fg676. . . . . 70
9

6.18 Suddivisione dei tempi per una X2VP20-5fg676. . . . . . . . . . 71
6.19 Tabella dei ritardi per una X2VP20-5fg676. . . . . . . . . . . . . 71
6.20 Ritardi per net in/out(0). . . . . . . . . . . . . . . . . . . . . . . 71
6.21 Ritardi per net in/out(1). . . . . . . . . . . . . . . . . . . . . . . 72
6.22 Ritardi per net in/out(2). . . . . . . . . . . . . . . . . . . . . . . 72
6.23 Ritardi per net in/out(3). . . . . . . . . . . . . . . . . . . . . . . 72

Introduzione
Lo scopo di questo lavoro di tesi e quello di sviluppare un flusso di operazioni
che consenta la generazione, in maniera automatica, di una infrastruttura di comu-
nicazione per architetture dinamicamente riconfigurabili precedentemente creata.
L’infrastruttura cosı ottenuta verra successivamente testata su tre famiglie di FP-
GA: Spartan-3, Virtex-II e Virtex-II Pro.
I dispositivi logici riprogrammabili piu comuni sono le FPGA (Field Programmable
Gate Array); questi dispositivi danno la possibilita all’utilizzatore di riprogram-
mare anche solamente una parte delle risorse logiche disponibili, ed e possibile
farlo anche mentre le risorse rimanenti continuano a svolgere la loro funzione
senza venire influenzate dalle modifiche apportate; questo tipo di utilizzo viene
detto riconfigurabilita dinamica parziale e consiste nel partizionare l’area della
FPGA facendo in modo che in ogni partizione risiedano dei moduli (fissi o ri-
configurabili), garantendo cosı la possibilita che alcuni vengano riprogrammati
mentre altri stanno ancora operando; questo permette sia di rendere piu efficiente
l’utilizzo di tali dispositivi, poiche lo stesso dispositivo fisico puo essere utilizzato
piu volte per svolgere funzioni differenti, sia di svolgere funzioni piu complesse
che altrimenti avrebbero bisogno di una maggiore quantita di risorse logiche non
programmabili.
I vantaggi derivanti da questo tipo di utilizzo sono molteplici: prima di tutto e
possibile suddividere un algoritmo in blocchi e caricarlo in momenti diversi con-
sentendo cosı l’implementazione di algoritmi che non possono essere caricati in-
teramente sulla FPGA; inoltre si possono trarre dei benefici anche in termini di
prestazioni caricando ed eseguendo blocchi diversi in parallelo. Per comunicare
1

Introduzione
tra loro, i diversi moduli necessitano di una infrastruttura che consenta il passag-
gio dei dati da e verso il modulo stesso; questo viene garantito da uno speciale
tipo di bus, chiamato da Xilinx bus macro.
Nel Capitolo 1 verranno presentati l’architettura generale ed il principio di
funzionamento di una generica FPGA, per poi analizzare piu in dettaglio le tre
famiglie di FPGA (Spartan-3, Virtex-II e Virtex-II Pro) su cui verra testata l’in-
frastruttura generata.
Nel Capitolo 2 verranno introdotti i concetti base della riconfigurabilita di-
namica e verranno approfondite le due principali tecniche proposte da Xilinx.
Verra poi introdotto il ruolo ed il funzionamento del bus macro Xilinx e della
infrastruttura di comunicazione realizzata.
Nel Capitolo 3 verranno descritti i tre strumenti software principali, utilizzati
durante questo lavoro: ISe, FPGA Editor e Modelsim.
Nel Capitolo 4 si descrivera la metodologia per la generazione automatica
dell’infrastruttura di comunicazione.
Nel Capitolo 5 verranno illustrati i singoli passaggi per l’implementazione del
flusso di operazioni.
Nel Capitolo 6 l’infrastruttura realizzata verra testata sulle tre famiglie di
FPGA.
Nel Capitolo 7 verranno tratte le conclusioni di questo lavoro di tesi.
2

Capitolo 1
FPGA
In questo capitolo verranno analizzati i dispositivi su cui si e lavorato: le FP-
GA. Ne verra fatta un’introduzione generale esaminando i componenti fondamen-
tali, comuni a tutti i dispositivi, prescindendo dalla particolare famiglia di FPGA.
Successivamente si analizzeranno piu in dettaglio le tre specifiche famiglie di
FPGA.
1.1 Cos’e una FPGA
In questo paragrafo verranno presentate la FPGA e le loro componenti fondamen-
tali.
1.1.1 Introduzione
Le FPGA (Field Programmable Gate Array) sono circuiti integrati digitali che ap-
partengono alla famiglia dei dispositivi programmabili dall’utente via Software
[1]. Sono elementi che presentano caratteristiche intermedie rispetto ai dispositivi
ASIC (Application Specific Integrated Circuit) da un lato e a soluzioni implemen-
tate totalmente sofware dall’altro.
L’uso di tali componenti comporta alcuni vantaggi rispetto agli ASIC: si tratta
infatti di dispositivi standard la cui funzionalita non viene predeterminata dal pro-
duttore, che quindi puo produrre su larga scala a basso prezzo, ma viene imple-
3

Capitolo 1. FPGA
mentata successivamente dall’utilizzatore. La loro genericita e versatilita rende le
FPGA adatte ad un gran numero di applicazioni. Essi sono programmati diretta-
mente dall’utente finale, consentendo la diminuzione dei tempi di progettazione,
di verifica mediante simulazioni e di prova sul campo dell’applicazione. Il grande
vantaggio rispetto agli ASIC e che permettono di apportare eventuali modifiche
o correggere errori semplicemente riprogrammado il dispositivo in qualsiasi mo-
mento. L’ambiente di progettazione e anche piu semplice, intuitivo e di relati-
vamente facile acquisizione. Di contro per applicazioni su grandi numeri (piu
di qualche migliaio di pezzi) sono anti economici, perche il prezzo unitario del
dispositivo e superiore a quello degli ASIC (che invece hanno elevati costi di pro-
gettazione).
Il costo di tali dispositivi e oggi in rapida diminuzione: cio li rende sempre di
piu una valida alternativa alla tecnologia standard cell. Usualmente vengono pro-
grammati con linguaggi come il Verilog o il VHDL, ma non bisogna dimenticare
la modalita schematic-entry, che consente un approccio veloce e semplificato a
tale tecnologia, e peraltro, di pari potenzialita. Molte case costruttrici (ad esem-
pio Xilinx ed Altera) forniscono gratuitamente sistemi di sviluppo che supportano
quasi tutta la loro gamma di prodotti.
Una FPGA e fondamentalmente composta da un array di blocchi logici circondato
da una cornice di blocchi periferici che si interfacciano con l’esterno e un reticolo
di piste elettriche che, potenzialmente, collegano qualsiasi elemento dell’FPGA a
un altro. Il progettista puo configurare singolarmente un qualunque elemento di
queste tre categorie di oggetti. Programmare un blocco di logica significhera mod-
ificare la funzione logica da esso realizzata; programmare le piste elettriche vorra
dire realizzare la connessione fisica fra un blocco e un altro. La programmazione
degli elementi costitutivi dell’FPGA e affidata ad appositi strumenti software for-
niti dal produttore del componente. Questi programmi accettano al loro ingresso
una qualche descrizione del circuito che si vuole implementare sotto forma di
netlist. Una netlist in generale e generata da programmi che si trovano a monte
della fase di implementazione su FPGA.
Rispetto ad altri dispositivi dello stesso tipo offrono molteplici vantaggi che ne
4

Capitolo 1. FPGA
hanno favorito una grande diffusione; uno su tutti e la possibilita di svolgere con
un unico dispositivo un numero illimitato di funzioni diverse. L’unico vero punto
di debolezza delle FPGA sono le prestazioni temporali, che, rispetto alle ASIC,
risultano peggiori
Ogni dispositivo viene identificato da un codice univoco, il cui significato e illus-
trato in Figura 1.1.
Figura 1.1: Significato della sigla identificatrice delle FPGA.
1.2 Architettura di una FPGA
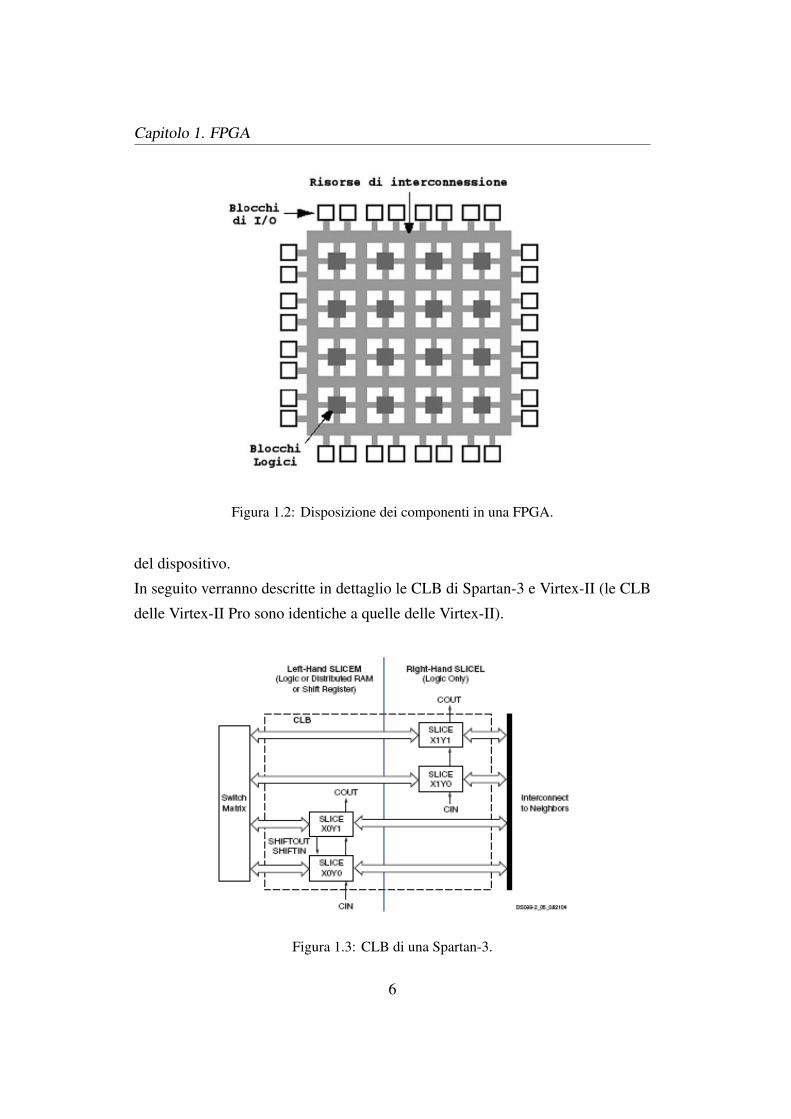
Gli elementi fondamentali che compongono una FPGA sono (Figura 1.2):
• risorse logiche riconfigurabili (CLB);
• un insieme di blocchi dedicati alle funzioni di I/O;
• le risorse di interconnessione dei blocchi.
1.2.1 CLB
Le CLB (Configurable Logic Block) costituiscono le componenti logiche fonda-
mentali di una FPGA, per l’implementazione dei circuiti logici sia sincroni che
sequenziali. Ogni CLB e formata da quattro slice, le quali sono raggruppate a
coppie e connesse fra di loro come mostrato in Figura 1.3. Le slice sono le unita
logiche che compongono le CLB; il loro contenuto varia a seconda della famiglia
5
Capitolo 1. FPGA
Figura 1.2: Disposizione dei componenti in una FPGA.
del dispositivo.
In seguito verranno descritte in dettaglio le CLB di Spartan-3 e Virtex-II (le CLB
delle Virtex-II Pro sono identiche a quelle delle Virtex-II).
Figura 1.3: CLB di una Spartan-3.
6

Capitolo 1. FPGA
Ad ogni slice sono associate delle coordinate, X e Y, per identificare la loro
posizione allinterno della FPGA. X indica il numero di colonna (crescente da sin-
istra verso destra), mentre Y il numero di riga (crescente dal basso verso l’alto).
Ogni CLB dispone di una connessione interna veloce, usata per connettersi ad una
matrice di switch, per accedere alle risorse generali di interconnessione.
1.2.2 I tri-state buffer
Il tri-state e un componente, come mostrato in Figura 1.4, con due linee di in-
gresso e una linea di uscita; in giallo e evidenziata la linea di ingresso dei bit di
informazione, in blu la linea di uscita, mentre in rosso e indicato il segnale di con-
trollo.
Il tri-state funziona come un interruttore: quando il segnale di controllo e a livel-
lo logico basso, l’ingresso e abilitato e il bit in entrata viene propagato in uscita;
quando il segnale di controllo e a livello logico alto, il tri-state si comporta come
un interruttore aperto e viene inibita la comunicazione tra ingresso e uscita.
Figura 1.4: Un tri-state in FPGA Editor
La Tabella 1.1 mostra tutte le possibili configurazione di ingresso/uscita che
puo assumere un tri-state.
7

Capitolo 1. FPGA
Si puo notare che, quando il segnale di controllo CTRL e alto, il segnale di uscita
OUT e indefinito (U=unknown).
IN CTRL OUT
0 0 0
1 0 1
0 1 U
1 1 U
Tabella 1.1: Tabella delle verita di un tri-state.
1.2.3 IOB
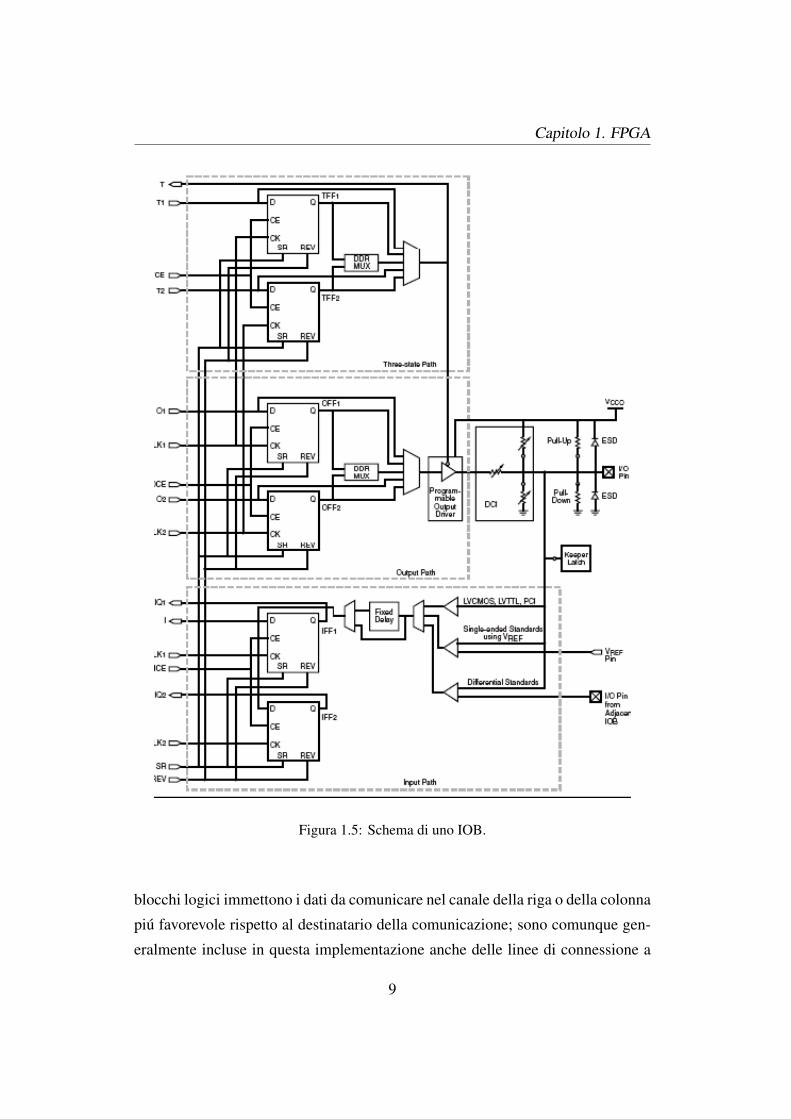
Gli IOB (Input Output Block) sono dei blocchi perimetrali della FPGA che svol-
gono le funzioni di ingresso e uscita; essi permettono di interfacciare i PIN es-
terni con i segnali generati dalla logica interna della FPGA. Uno IOB puo fornire
collegamenti di due tipi:
• unidirezionali: solo in ingrasso oppure solo in uscita;
• bidirezionali.
Ad uno IOB corrisponde un solo PIN. Lo schema interno di uno IOB e mostrato
in Figura 1.5
1.2.4 Risorse di Interconnessione
Le risorse di interconnessione permettono di colegare tra di loro tutti i vari com-
ponenti della FPGA come IOB, CLB, RAM, . . .
Esistono due principali modalita di interconnessione: interconnessione ‘diret-
ta’ e interconnessione ‘segmentata’.
1.2.5 Interconnessione diretta
L’interconnessione diretta e caratterizzata da gruppi di linee che attraversano il
dispositivo in tutta la sua dimensione (long line), come mostrato in Figura 1.6. I
8
Capitolo 1. FPGA
Figura 1.5: Schema di uno IOB.
blocchi logici immettono i dati da comunicare nel canale della riga o della colonna
piu favorevole rispetto al destinatario della comunicazione; sono comunque gen-
eralmente incluse in questa implementazione anche delle linee di connessione a
9

Capitolo 1. FPGA
corto raggio fra blocchi vicini (short line).
Figura 1.6: Interconnessione diretta.
1.2.6 Interconnessione segmentata
L’interconnessione segmentata e caratterizzata dall’utilizzo, non solamente di short
line e long line, ma anche di matrici di switch (switch matrix), cioe degli interrut-
tori programmabili che permettono di indirizzare il segnale sul canale corretto,
come si vede in Figura 1.7. Anche in questo caso puo essere previsto l’utilizzo
di interconnessioni globali per trasportare segnali lungo tutta la FPGA (segnali di
clock). Questa tecnica di interconnessione e quella adottata da Xilinx.
1.2.7 Blocchi di moltiplicatori
I moltiplicatori presenti sulle FPGA ricevono in ingresso parole di 18 bit x 18
bit e producono in uscita il prodotto di 36 bit. E comunque posssibile l’uti-
lizzo di moltiplicatori in cascata per effettuare calcoli di maggior complessita.
Fisicamente sono collocati, sulla superficie della FPGA, in fianco ai blocchi di
RAM; questo rende molto piu efficiente la gestione dei dati. Lo schema di un
moltiplicatore e mostrato in Figura 1.8
10

Capitolo 1. FPGA
Figura 1.7: Interconnessione segmentata.
Figura 1.8: Schema di un moltiplicatore semplice.
1.3 Le Spartan-3
La famiglia di FPGA Spartan-3 e stata progettata specificatamente per assecon-
dare sia le esigenze prestazionali, sia quelle di costo, riuscendo comunque a ge-
stire grosse quantita di informazioni.
Tutti i possibili modelli di Spartan-3 sono mostrati in Figura 1.9.
Le Spartan-3 costruiscono il loro successo sulle precedenti Spartan-2, rispetto
alle quali pero, e stato aumentato il numero di risorse logiche, la capacita della
RAM interna e il numero totale di I/O [5].
Inoltre, grazie all’esperienza maturata da Xilinx nel campo delle FPGA con la
famiglia delle Virtex-II, le Spartan-3 sono notevolmente piu economiche e perfor-
11

Capitolo 1. FPGA
Figura 1.9: Modelli di Spartan-3.
manti rispetto ai loro predecessori.
Grazie al loro eccezionale basso costo, le Spartan-3 sono ideali per una vasta gam-
ma di applicazioni nell’elettronica di consumo.
Per questo lavoro si prendera in esame il modello di Spartan3 XC3S200-4ft256.
Una FPGA della famiglia delle Spartan-3, montata su evaluation board, e mostrata
in Figura 1.10
1.3.1 Architettura generale
L’archittettura generale della famiglia delle Spartan-3 comprende cinque fonada-
mentali elementi programmabili:
• Configurable Logic Block (CLB);
• Input/Output Blocks (IOBs);
• blocchi di RAM;
• blocchi di moltiplicatori;
12

Capitolo 1. FPGA
Figura 1.10: Una Spartan-3 montata su evaluation board.
• Digital Clock Manager (DCM).
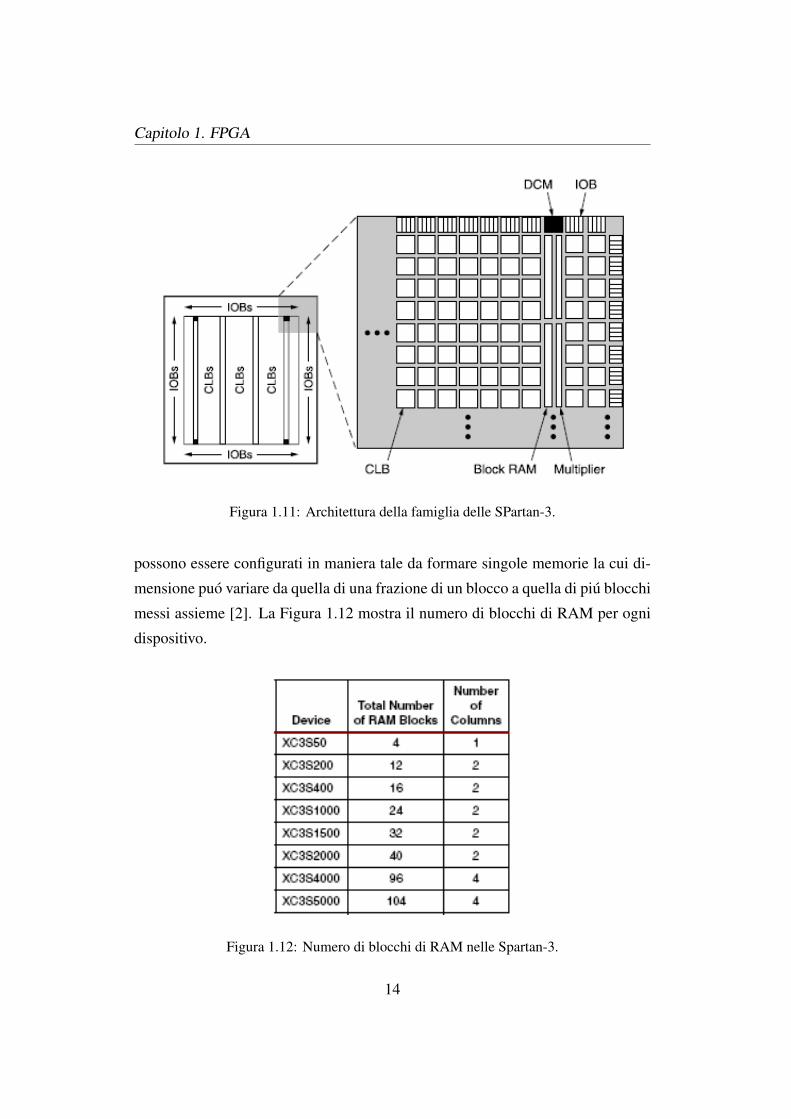
Tutti questi elementi sono disposti come mostrato in Figura 1.11: una serie di
IOB periferici circonda perimetralmente l’intera FPGA, il cui nucleo fondamen-
tale e invece costituito dagli array di CLB e da due colonne composte da un filare
di blocchi di RAM affiancato da uno di moltiplicatori.
I DCM sono posizionati al termine di ogni coppia di colonne RAM/Moltiplicatore,
come mostrato nel dettaglio in Figura 1.11.
Una fitta rete di interconnessioni basata su matrici di switch (in rapporto uno
ad uno con gli elementi funzionali) atta all’instradamento dei segnali permette la
comunicazione fra componenti della FPGA [2].
La Spartan3 XC3S200-4ft256 e dotata di due distinte colonne contenenti ciascu-
na 6 blocchi di RAM sincroni, ciascuno della capacita di 18 Kbit. Ovviamente la
quantita di dati memorizzabile in questi blocchi e in proporzione molto maggiore
di quella memorizzabile utilizzando le slice come Distributed RAM. I blocchi
13
Capitolo 1. FPGA
Figura 1.11: Architettura della famiglia delle SPartan-3.
possono essere configurati in maniera tale da formare singole memorie la cui di-
mensione puo variare da quella di una frazione di un blocco a quella di piu blocchi
messi assieme [2]. La Figura 1.12 mostra il numero di blocchi di RAM per ogni
dispositivo.
Figura 1.12: Numero di blocchi di RAM nelle Spartan-3.
14

Capitolo 1. FPGA
Dato che la Spartan-3 XC3S200-4ft256 ha due colonne di blocchi di RAM i
DCM sono in totale quattro, uno per ogni limite superiore o inferiore delle colonne
dei blocchi di RAM.
1.3.2 CLB
Le CLB di una Spartan-3 sono composte da quattro slice ciascuna, organizzate a
coppie come mostrato in Figura 1.3, ciascuna delle quali con una catena di riporto
indipendente.
Figura 1.13: Struttura di una slice.
Le singole slice, la cui struttura e mostrata in Figura 1.13 sono composte da
due LUT, Look-Up Table, da due registri ad esse dedicati e da una serie di risorse
aggiuntive che variano a seconda del dispositivo utilizzato.
La LUT di una Spartan-3 e un elemento combinatorio che implementa una fun-
zione booleana a N ingressi e una uscita: gli ingressi non fanno altro che se-
lezionare una fra 2N locazioni di memoria che conterranno 1 o 0 a seconda della
15

Capitolo 1. FPGA
funzione logica che si desidera realizzare [2].
L’infrastruttura di comunicazione progettata impernia tutto il suo funzion-
amento sull’utilizzo dei tri-state che pero non sono stati menzionati nella de-
scrizione dell’architettura della Spartan-3 XC3S200-4ft256; questo dispositivo
infatti, come tutte le altre Spartan-3 non e dotato di tri-state, come invece, ad
esempio, la Virtex-II e la Virtex-II Pro. La mancanza dei tri-state non compro-
mette pero il funzionamento del bus macro su questo dispositivo; il tri-state infatti,
come si puo vedere in Tabella 1.1 non fa altro che svolgere una funzione logica
f(net in,ctrl)=net out che e possibile simulare con l’utilizzo delle risorse logiche.
La simulazione della funzione logica dei tri-state ha pero delle ripercussioni in
termini di prestazioni, sia dal punto di vista delle risorse occupate, sia dal pun-
to di vista temporale, infatti le CLB impiegheranno del tempo aggiuntivo per la
simulazione, che altrimenti non verrebbe impegnato.
1.4 Virtex-II e Virtex-II Pro
In questo paragrafo verranno presentate le famiglie di FPGA Virtex-II e Virtex-II
Pro, facendo riferimento rispettivamente ai modelli XC2V1000-5fg256 e X2VP20-
5fg676. Le famiglie di FPGA Virtex-II e Virtex-II Pro sono state sviluppate per
alte prestazioni, sia per configurazioni a bassa densita, sia per configurazioni ad
alta densita, basate su IP-cores. Queste famiglie consentono soluzioni complete
per le telecomunicazioni, per i dispositivi wireless, per dispositivi di rete e video.
Anche l’architettura generale di queste FPGA include cinque elementi princi-
pali, organizzati, anche a livello fisico, in maniera regolare e simmetrica. Questi
componenti sono:
• i blocchi CLB;
• i blocchi di ingresso/uscita IOB;
• i blocchi SelectRAM (SelectRAM+ per la Virtex-II Pro);
16

Capitolo 1. FPGA
• i moltiplicatori;
• DCM (Digital Clock Manager).
.
Le CLB forniscono gli elementi funzionali per la logica combinatoria e sin-
crona. La differenza principale con una CLB di una Spartan-3 e la presenza dei
tri-state. I tri-state, associati a ciascun elemento della CLB, comandano le risorse
di routing orizzontali.
Ogni CLB e composta da quattro slice e due tri-state buffer, come mostrato in
Figura 1.14.
Figura 1.14: CLB di una Virtex-II.
Ogni CLB di una Virtex-II comprende due tri-state buffer (TBUFs), la cui
funzione fondamentale e quella di ‘guidare’ i segnali sui bus della FPGA. Ognuna
delle quattro slice ha accesso ai tri-state attraverso la matrice di switch, come
si vede in Figura 1.14, mentre i tri-state delle CLB circostanti possono accedere
all’uscita della slice tramite connessioni dirette. Le uscite dei tri-state sono con-
nesse alle risorse di interconnessione orizzontali, usate per implementare i tri-state
busses, come si vede in Figura 1.15.
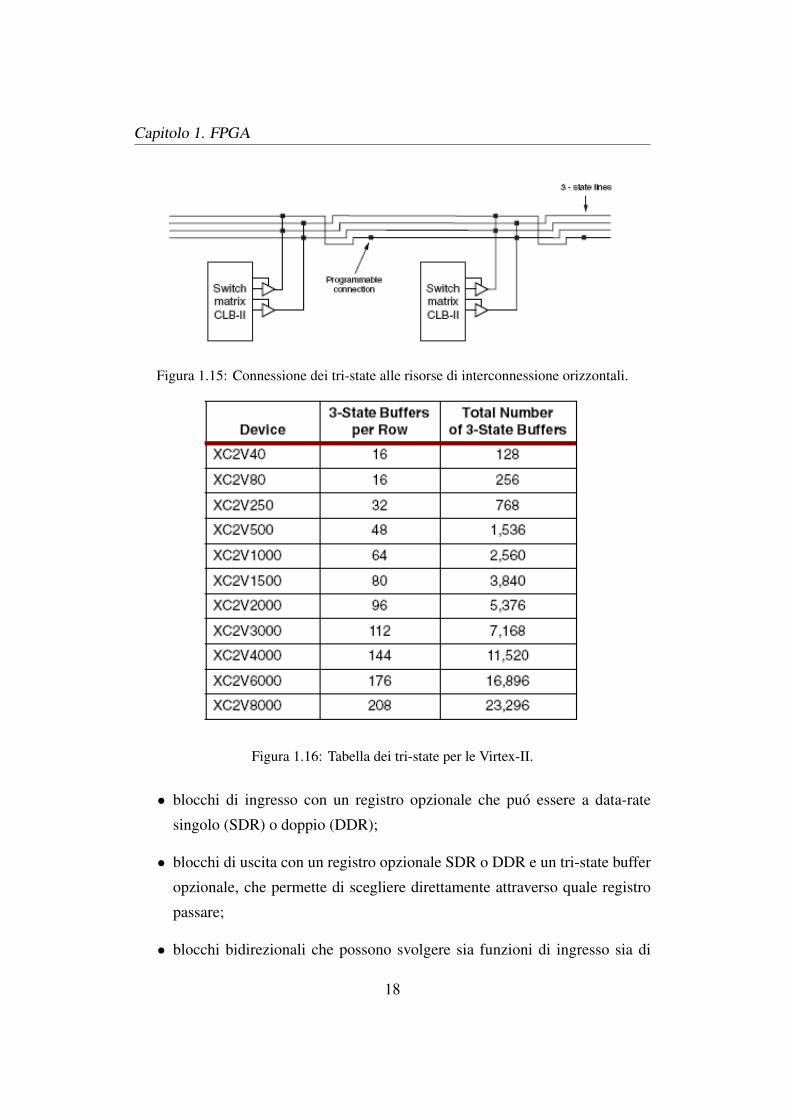
La Tabella 1.16 mostra il numero di tri-state per ogni dispositivo della famiglia
delle Virtex-II.
Tutti i blocchi IOB sono programmabili e appartengono a tre categorie:
17
Capitolo 1. FPGA
Figura 1.15: Connessione dei tri-state alle risorse di interconnessione orizzontali.
Figura 1.16: Tabella dei tri-state per le Virtex-II.
• blocchi di ingresso con un registro opzionale che puo essere a data-rate
singolo (SDR) o doppio (DDR);
• blocchi di uscita con un registro opzionale SDR o DDR e un tri-state buffer
opzionale, che permette di scegliere direttamente attraverso quale registro
passare;
• blocchi bidirezionali che possono svolgere sia funzioni di ingresso sia di
18

Capitolo 1. FPGA
uscita.
Questi registri opzionali possono essere, o Flip-Flop edge-triggered di tipo D
oppure dei latch level sensitive. Gli IOB supportano sia ingressi (e uscite) di tipo
single-ended sia di tipo differenziale. Lo schema di uno IOB e mostrata in Figura
1.17.
Figura 1.17: IOB in una Virtex-II.
I blocchi di memoria SelectRAM (SelectRAM+) sono delle RAM (True) Du-
al Port di 18 Kb, programmabili da 16K x 1 bit a 512 x 36 bit, variando cosı la
larghezza e l’altezza della RAM stessa. Ogni porta e totalmente sincrona e in-
dipendente e offre tre modalita di lettura e scrittura contemporanee. I blocchi di
memoria possono essere posizionati a cascata per implementare dei blocchi anco-
ra maggiori di memoria dedicata. La Tabella 1.2 mostra le possibili configurazioni
della SelectRAM.
La Tabella 1.3, invece, mostra le possibili configurazioni della SelectRAM+.
19

Capitolo 1. FPGA
16K x 1 bit 2K x 9 bit
8K x 2 bit 1K x 18 bit
4K x 4 bit 512 x 36 bit
Tabella 1.2: Tabella delle configurazioni a porta doppia e a porta singola della
SelectRAM.
16K x 1 bit 4K x 4bit 1K x 18 bit
8K x 2 bit 2K x 9 bit 512 x 36 bit
Tabella 1.3: Tabella delle configurazioni a porta doppia e a porta singola della
SelectRAM+.
Ad ogni blocco SelectRAM viene associato un blocco moltiplicatore dedicato
a 18 x 18 bit; questo moltiplicatore puo anche essere usato indipendentemente dal-
la SelectRAM ad esso associata. Sia la SelectRAM(+), sia il moltiplicatore, sono
collegati a quattro matrici di switch per l’accesso alle risorse di interconnessione.
I blocchi moltiplicatori delle Virtex-II e della Virtex-II Pro, come nelle Spartan-
3, sono dei moltiplicatori 18 bit x 18 bit con segno, in complemento a 2. Questi
blocchi possono essere associati ad un blocco di 18Kbit di SelectRAM(+) oppure
possono essere usati indipendentemente. Sono ottimizzati per operazioni ad al-
ta velocita e per avere dei bassi consumi di energia. Essi vengono connessi alle
SelectRam(+) tramite l’uso di quattro matrici di switch, come mostrato in Figura
1.18.
Il DCM (Digital Clocking Manager) e il clock globale forniscono una soluzione
completa per configurare schemi con un segnale di clock elevato. Sono disponi-
bili fino a 12 DCM, e ognuno di essi puo essere usato per eliminare il ritardo di
distribuzione del segnale. Il DCM permette inoltre lo sfasamento del segnale di
uscita di 90, 180 e 270 gradi. La Virtex-II ha sedici buffer MUX di clock globale,
e fino a otto reti per quadrante. Ogni MUX puo selezionare uno dei due segnali di
clock in ingresso e abilitarne uno o l’altro. Ogni blocco DCM puo gestire fino a
sedici MUX di clock globale.
I blocchi IOB, CLB, SelectRAM(+), moltiplicatori e i DCM utilizzano tutti lo
stesso schema di connessione e lo stesso accesso alla matrice globale di rout-
20

Capitolo 1. FPGA
Figura 1.18: Collegamento Multiplexer-SelectRAM.
ing. I timing models sono condivisi, cosı da incrementare la predicibilita delle
prestazioni. Vi sono un totale di sedici linee di clock globale, otto disponibili per
quadrante. Inoltre, vi sono ventiquattro long line verticali e orizzontali per riga
o colonna in modo che le risorse di routing secondarie e locali siano piu veloci.
Le connessioni della Virtex-II e della Virtex-II Pro sono relativamente indipen-
denti dal fanout di rete. Le risorse di routing verticali e orizzontali per ogni riga
o colonna includono ventiquattro long line, centoventi hex line, quaranta double
line e sedici direct connect line in tutte e quattro le direzioni.
Le istruzioni per la scansione di confine e i registri di dati associati supportano una
metodologia standard, in accordo con gli standard IEEE 1149.1, 1993 e 1532, per
accedere e configurare una scheda Virtex-II o Virtex-II Pro. La scansione di con-
fine consiste nellimplementazione di una modalita di sistema e di una modalita
di testing. Nella modalita di sistema, la Virtex-II o la Virtex-II Pro svolgono il
proprio lavoro durante lesecuzione delle istruzioni, non di testing, della scansione
di confine. Nella modalita test, le istruzioni della scansione di confine controllano
gli ingressi e le uscite con obiettivi di testing.
21

Capitolo 1. FPGA
Le Virtex-II e le Virtex-II Pro sono configurate caricando i dati nella memoria
di configurazione interna, usando le cinque modalita seguenti:
• Slave seriale;
• Master seriale;
• Slave SelectMAP;
• Master SelectMAP;
• scansione di confine (Boundary-Scan).
Nella Tabella 1.4 vengono confrontate le risorse logiche utilizzate nella pro-
gettazione della infrastruttura, disponibili nelle tre FPGA come descritto in [5],
[3] e [4]:
FAMIGLIA DISPOSITIVO CLB array (riga x colonna) tri-state per riga
Spartan-3 XC3S200 24 x 20 0
Virtex-II XC2V1000 40 x 32 64
Virtex-II Pro X2VP20 56 x 46 92
Tabella 1.4: Tabella riassuntiva delle famiglie di FPGA.
22

Capitolo 2
La riconfigurabilita dinamicaparziale e il bus macro
In questo capitolo verra introdotto il concetto di riconfigurabilita dinamica,
parziale e totale e le sue modalita implementative.
Successivamente verranno esaminate in modo dettagliato le due principali tec-
niche proposte da Xilinx per l’implementazione della riconfigurabilita dinamica,
la prima basata sui moduli, la seconda basata sulle differenze, considerandone
in particolar modo pregi e difetti di ognuna. Verra poi introdotto il ruolo ed
il funzionamento del bus macro Xilinx e della infrastruttura di comunicazione
realizzata.
2.1 Introduzione
Le FPGA, come gia indica il loro nome (Field Programmable Gate Array), non
vengono impostate dal costruttore per svolgere un’unica funzione, ma offrono la
possibilita all’utilizzatore di programmarle per svolgere una funzione desiderata.
Questo e stato uno dei principali fattori che hanno contribuito alla grande diffu-
sione sul mercato delle FPGA. Piu precisamente il termine riconfigurabilita indica
la possibilita di programmare piu volte lo stesso dispositivo. La riconfigurabilita
puo essere sia parziale, quando si riprogramma solamente una porzione di FPGA,
23

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
sia totale, quando e l’intero dispositivo ad essere riprogrammato.
L’idea fondamentale che sta alla base della riconfigurabilita dinamica e la suddivi-
sione dell’area della FPGA in sottoaree che chiameremo moduli, alcuni dei quali
saranno fissi, mentre altri saranno riconfigurabili.
La riconfigurabilita parziale e utile in applicazioni che richiedono il caricamento
di piu moduli sulla stessa area del dispositivo o quando ce la necessita di cambiare
una parte dellimplementazione senza dover obbligatoriamente resettare la FPGA
o riprogrammare lintero dispositivo. E possibile infatti caricare sul chip un nuovo
bitstream che agisce modificando solamente l’area della FPGA destinata a con-
tenere parti riconfigurabili, mentre il resto del dispositivo continua ad operare.
Per questo motivo la riconfigurabilita viene detta dinamica. Nonostante le aree
del dispositivo non riprogrammate continuino a svolgere la loro funzione, e bene
sottolineare che lungo tutta la durata di questo processo, non e possibile comuni-
care con la parte in cui sta avvenendo la riconfigurazione, ne e possibile utilizzare
i canali di comunicazione che attraversano tale area.
Di seguito verranno illustrate le due tecniche proposte da Xilinx per imple-
mentare la riconfigurabilita dinamica parziale: una basata sui moduli (module-
based) e una basata sulle differenze(difference-based). Nelle configurazioni in cui
devono essere riconfigurati grandi blocchi logici bisogna obbligatoriamente usare
la riconfigurabilita basata sui moduli [6].
2.2 Riconfigurabilita basata sui moduli
La tecnica basata sui moduli risulta essere molto semplice se i moduli stessi sono
indipendenti tra di loro, cioe non condividono alcun segnale di I/O eccetto il seg-
nale di clock. In questo caso infatti la riconfigurazione di un modulo non ha effetto
sugli altri moduli presenti sulla FPGA.
Se invece si verifica un’interazione tra moduli, per permettere ad un modulo di ri-
configurarsi, senza interrompere il funzionamento dei moduli circostanti, vengono
introdotti nell’architettura dei bus macro di cui parleremo piu approfonditamente
24

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
in seguito, il cui compito e di garantire la comunicazione tra due moduli, di cui
almeno uno e riconfigurabile come mostrato in figura 2.1
Figura 2.1: Comunicazione tra due moduli tramite bus macro
2.2.1 Vincoli sui moduli
Adottando la tecnica ”module-based” i vari moduli devono rispettare i seguenti
vincoli:
• il modulo deve avere una largezza (calcolata in numero di slice) che va da un
minimo di quattro slice all’ intera larghezza della FPGA, ed essere multipla
di quattro
• il modulo deve avere altezza pari all’altezza dell’intera FPGA
• il collocamente in orizzontale deve avvenire sempre sui confini di un blocco
di quattro slice; il collocamento piu a sinistra deve partire da una distanza x
= 0,4,8,... slice
• tutte le risorse logiche racchiuse dalla larghezza del modulo sono consider-
ate parte del bitstream del modulo riconfigurabile, chiamato frame. Il frame
include le slice, i TBUF, i blocchi RAM, i moltiplicatori, le celle IOB, e
soprattutto tutte le risorse di routing
• le risorse di clock (BUFGMUX, CLKIOB) sono sempre esterne al modulo
riconfigurabile. I clock hanno frame di bitstream diversi
25

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
• le celle IOB posizionate immediatamente sopra il margine superiore e im-
mediatamente sotto il margine inferiore di un modulo riconfigurabile sono
parte delle risorse dello stesso modulo
• se un modulo riconfigurabile occupa la parte piu a sinistra o la parte piu a
destra di una colonna di slice, tutte le IOB toccate dal bordo del modulo
sono parte delle risorse di quello specifico modulo
• per diminuire i problemi relativi alla complessita dell’ architettura, il nu-
mero di moduli riconfigurabili deve essere minore possibile (idealmente se
possibile ci dovrebbe essere un unico modulo riconfigurabile). Cio vuol dire
che la condizione che il numero di colonne di slice sia multiplo di quattro
e l’unico limite reale al numero di regioni dell’FPGA occupate dal modulo
riconfigurabile definito
• il confine di un modulo riconfigurabile non puo essere modificato. La po-
sizione e la regione di FPGA occupata da un singolo modulo riconfigurabile
devono essere fisse
• i moduli riconfigurabili, sia fissi sia riconfigurabili, comunicano con altri
moduli tramite a uno speciale bus macro
• l’implementazione deve essere progettata in modo che le porzioni statiche
dell’architettura non dipendano dallo stato del modulo sotto riconfigurazione
mentre questo si sta riconfigurando. L’implementazione deve raggiungere
il proprio scopo durante il processo di riconfigurazione. Sono richieste ma-
nipolazioni logiche esplicite (ad esempio modulo in stato ready/not ready)
• lo stato degli elementi di memoria nel modulo riconfigurabile viene con-
servato durante e dopo il processo di riconfigurazione. Lo sviluppo prende
vantaggio dal fatto di utilizzare l’informazione dello stato precedente dopo
che e stata caricata una nuova configurazione. D’altra parte non e pos-
sibile utilizzare i set/reset globali (GSR) dell’FPGA per inizializzare in-
dipendentemente lo stato dei moduli riconfigurabili. Se l’inizializzazione
26

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
(set/reset) e richiesta per un modulo riconfigurabile, i segnali di set/reset
definiti dall’utente devono essere definiti nel sorgente HDL.
Per essere conforme ai requisiti della riconfigurabilita parziale, il codice HDL
e i processi di sintesi devono seguire delle regole strutturali.
• la struttura generale deve essere un’architettura top-level in cui ogni modu-
lo funzionale e definito come una scatola nera. Al livello piu alto la strut-
tura e limitata ai soli segnali in ingresso e uscita, ai segnali di clock e al-
la creazione dei bus macro; non ci devono essere altre risorse nel disegno
generale
• per i nuovi utilizzatori della riconfigurabilita parziale e caldamente con-
sigliato di minimizzare il numero di moduli riconfigurabili nell’FPGA, ideal-
mente dovrebbe esserci un solo modulo riconfigurabile. Questa e unica-
mente una raccomandazione e non un vincolo di implementazione
• ogni modulo, fisso o riconfigurabile, deve essere anch’esso una scatola nera.
Per ognuno dei moduli bisogna definire i segnali di ingresso e uscita
• i bus macro sono usati come percorsi fissi di dati per i segnali tra un mod-
ulo riconfigurabile e un altro modulo. Il codice HDL deve garantire che
ogni segnale proveniente da un modulo riconfigurabile usato per comuni-
care con un altro modulo passi obbligatoriamente attraverso un busmacro.
Esistono versioni di busmacro specifiche per le FPGA serie Virtex, Virtex-
E, Virtex-II e Virtex-II Pro.Ogni bus macro ha quattro bit per permettere la
comunicazione tra moduli. Il numero di bus macro necessari dipende del
numero di bit che attraversano i confini dei moduli riconfigurabili. Ad es-
empio, se un modulo riconfigurabile A comunica con il modulo B tramite
32 bit, allora sono necessari (32/4 = ) 8 bus macro per definire i percorsi di
dati tra i moduli A e B
• se un segnale passa attraverso un modulo riconfigurabile B per connettere
due moduli A e C posizionati ai due lati di esso, devo essere utilizzati dei
27

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
bus macro per effettuare la connessione. Questo richiede la creazione di un
segnale intermedio definito nel modulo riconfigurabile B e questo segnale
non puo essere attivamente usato quando il modulo riconfigurabile B si sta
riconfigurando
• per semplicita, specialmente per i nuovi utilizzatori della configurabilita
parziale, Xilinx raccomanda di mantenere i segnali di clock i piu lineari
possibile
• tutti i segnali di clock definiti devono usare le risorse dedicate globali di
routing. I frame per i clock globali sono separati dai bitstream che definis-
cono le CLB. Bisogna sempre tenere indipendenti i segnali di clock durante
la riconfigurazione e non bisogna definire risorse di clock locali
• i moduli riconfigurabili non possono direttamente condividere i segnali con
gli altri moduli, eccetto i segnali di clock. Questo significa che i segnali
come i reset, le costanti ,etc. non possono essere condivisi
• il livello generale e sintetizzato abilitando l’aggiunta di I/O, producendo una
netlist generale
• ogni modulo e sintetizzato disabilitando l’aggiunta di I/O, producendo per
ogni modulo una netlist a livello di modulo
2.3 Riconfigurabilita basata sulle differenze
Ci sono due modi principali con cui una configurazione puo essere cambiata utiliz-
zando la riconfigurazione basata sulle differenze. La configurazione puo cambiare
o nel front-end (con l’HDL o lo Schematic) o nel back-end (file NCD). Per i cam-
biamenti front-end, la configurazione deve essere risintetizzata e riimplementata
per creare un nuovo NCD file place and route. Per i cambiamenti back-end al
file NCD, le sezioni di una configurazione possono essere modificate usando gli
strumenti di FPGA Editor. Il BitGen cambia e produce bitstream particolari che
modifucano solamente piccole sezioni dell’FPGA.
28

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
Modificare la configurazione di un modulo da un’implementazione ad un’altra
e molto veloce, tanto piu se le differenze di bitstream sono minori dei cambiamen-
ti al bitstrean dell’intera FPGA. Questi bitstream possono essere caricati veloce-
mente e facilmente, a seconda della loro dimenzione e del supporto software.
2.3.1 Apportare piccole modifiche utilizzando FPGA Editor
Vi sono tantissimi differenti tipi di cambiamenti che possono essere eseguiti per
creare una configurazione nell’FPGA, ma verranno menzionati tre di loro utiliz-
zati da FPGA Editor: cambiare gli standard I/O, i contenuti della BRAM e la
programmazione LUT. Anche se e possibile cambiare l’informazione di routing,
non e raccomandabile poiche causerebbe la possibilita di conflitti interni durante
la riconfigurazione, ma se bisogna cambiarla, una volta che il file NCD e aperto in
FPGA Editor, lo si puo salvare sotto un nome diverso, in modo che il file originale
non venga perso. Per esempio si puo fare File, Save As e modificare il nome del
file. Il secondo file rimarra aperto in FPGA Editor una volta che l’operazione e
stata completata. Una volta che la nuova configurazione e aperta, bisogna ren-
dere il file modificabile, cambiando le proprieta del file stesso, selezionando File,Main Properties cambiando l’Edit Mode in Read Write.
Si descrivono adesso i tipi di camnbiamenti che tramite FPGA Editor possono
essere apportati alle configurazioni dell’FPGA
• Cambiare le equazioni di LUT. L’elemento logico piu piccolo che puo es-
sere selezionato e la Slice. Prima di tutto, il blocco deve essere visualizzato.
Una slice puo essere trovata usando il pulsante Find nella parte destra del-
la finestra, oppure si possono vedere tutte le slice e selezionare a mano la
slice cercata. Una volta che la slice e selezionata (come mostrato in rosso in
Figura 2.2), bisogna premere il pulsante Editblock per aprire la barra degli
strumenti Block Editor.
Per prevenire cambiamenti non voluti, come impostazione le parti interne di
una slice non possono essere modificate. Ogni volta che un blocco e aperto,
per renderlo modificabile, bisogna selezionare il pulsante Begin Editing (il
29
Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
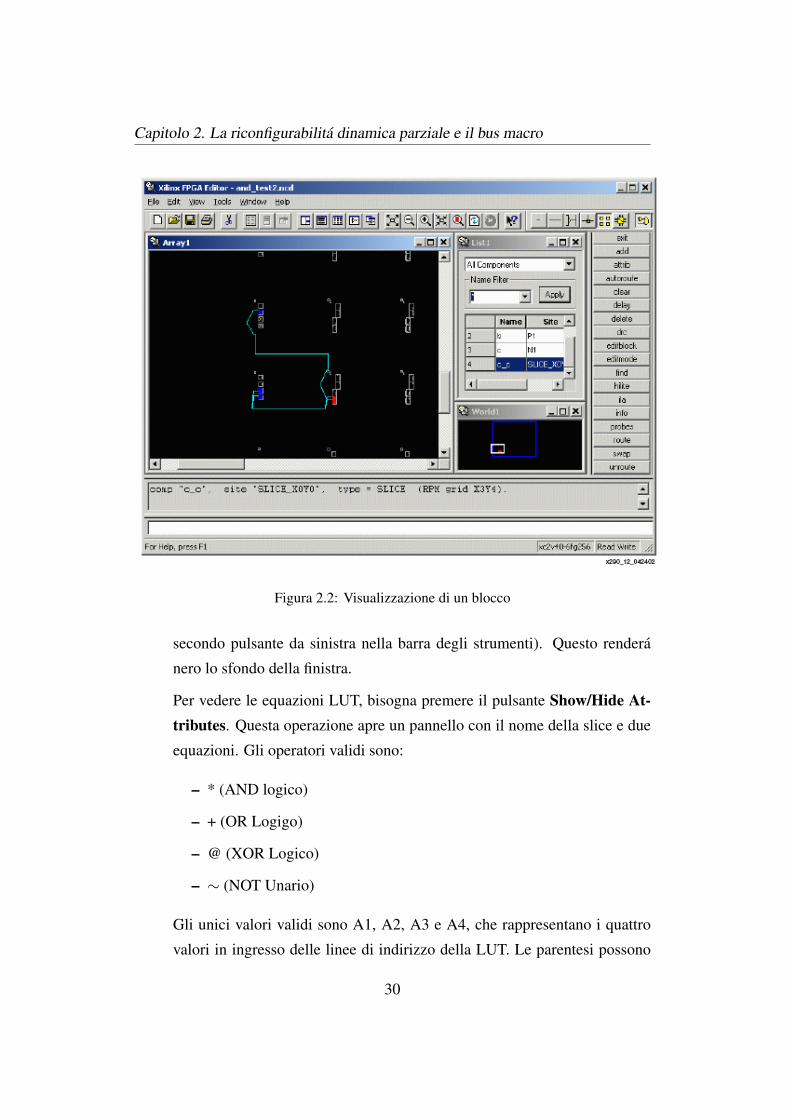
Figura 2.2: Visualizzazione di un blocco
secondo pulsante da sinistra nella barra degli strumenti). Questo rendera
nero lo sfondo della finistra.
Per vedere le equazioni LUT, bisogna premere il pulsante Show/Hide At-tributes. Questa operazione apre un pannello con il nome della slice e due
equazioni. Gli operatori validi sono:
– * (AND logico)
– + (OR Logigo)
– @ (XOR Logico)
– ∼ (NOT Unario)
Gli unici valori validi sono A1, A2, A3 e A4, che rappresentano i quattro
valori in ingresso delle linee di indirizzo della LUT. Le parentesi possono
30
Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
essere usate per raggruppare un gruppo, come ad esempio (A4 * A1) @ A3.
Una volta che gli attributi sono cambiati, salvare e chiudere la finestra.
• Cambiare i contenuti dei blocchi RAM.
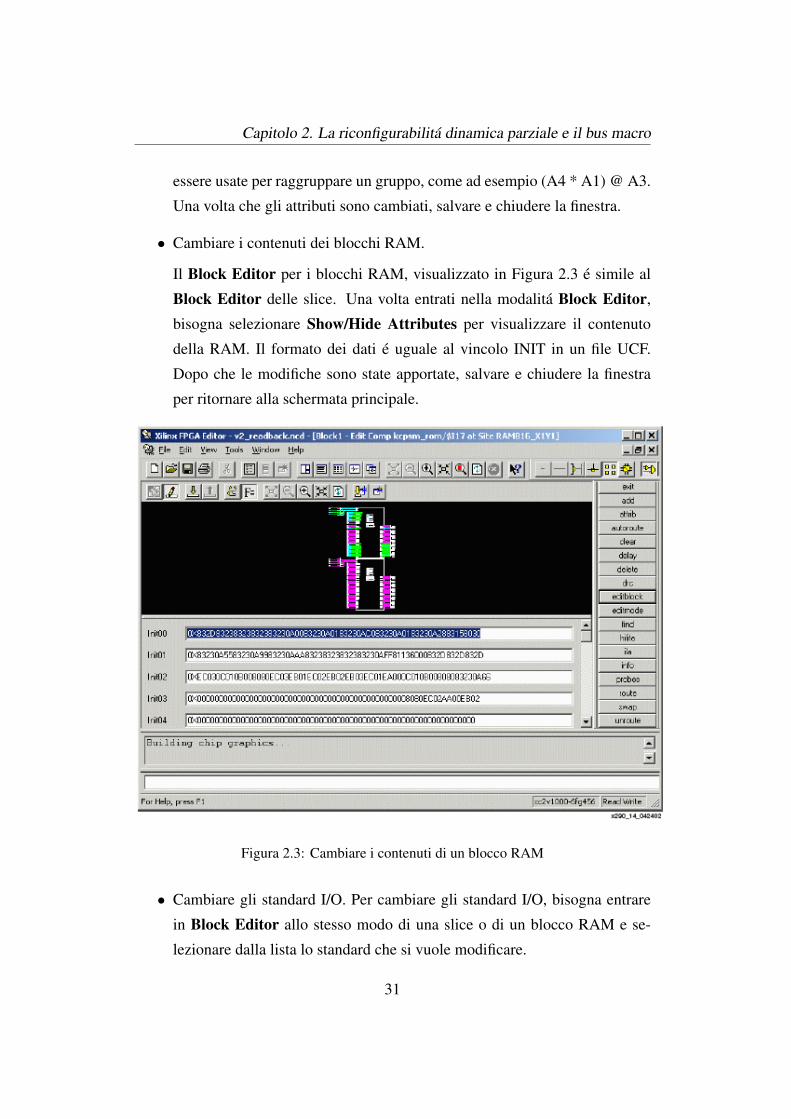
Il Block Editor per i blocchi RAM, visualizzato in Figura 2.3 e simile al
Block Editor delle slice. Una volta entrati nella modalita Block Editor,
bisogna selezionare Show/Hide Attributes per visualizzare il contenuto
della RAM. Il formato dei dati e uguale al vincolo INIT in un file UCF.
Dopo che le modifiche sono state apportate, salvare e chiudere la finestra
per ritornare alla schermata principale.
Figura 2.3: Cambiare i contenuti di un blocco RAM
• Cambiare gli standard I/O. Per cambiare gli standard I/O, bisogna entrare
in Block Editor allo stesso modo di una slice o di un blocco RAM e se-
lezionare dalla lista lo standard che si vuole modificare.
31

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
• Altri elementi modificabili. Sono numerose le modifiche che si possono
apportare alle slice, alle celle IOB e ai blocchi RAM, come ad esempio
l’inizializzazione e i valori di reset dei flip-flop, o le modalita di scrittura
dei blocci RAM. E comunque raccomandabile non modificare nessuna pro-
prieta o valore che influisca sul routing, per non correre il rischio di conflitti
interni.
2.3.2 Apportare piccole modifiche utilizzando Design Entry
La maggior parte delle modifiche descritte precedentemente possono essere ap-
portate operando a front-end. Questo metodo permette all’utente di trattare con
molti piu componenti dei blocchi RAM e degli standard I/O ma con lo svantaggio
di dover risintetizzare e riimplementare l’intera configurazione.
2.4 Usare i bitstream e programmare le FPGA
La riconfiguarazione parziale supporta le opzioni di programmazione parallela
SelectMAP o seriale JTAG. Poiche i bitstream parziali non sono distinguibili
da quelli totali gli utienti finali devono fare attenzione alla corretta sequenza di
applicazione di questi bitstream parziali nell’FPGA di riferimento. Il software
IMPACT, applicazione di configuazione di Xilinx, puo identificare un bitstream
parziale ma non puo determinare se questo e stato applicato nel corretto ordine.
Quando si scarica una FPGA usando un bitstream parziale, IMPACT visualizza
un messaggio indicando che si sta usando un bitstream parziale e di assicurarsi
di eseguire la corretta sequenza. A parte questo usare i bitstream parziali risulta
identico all’utilizzo di quelli totali.
Quando si seleziona un bitstream parziale nella configurazione Xilinx PROM
usando la capacita di formattazione del file IMPACT PROM, non e necessario ef-
fettuare alcuna operazione speciale o scegliere alcuna opzione. Gli utenti finali
devono essere consapevoli del fatto che quando si utilizza PROM le schede non
permettono di caricare dati di configurazione in modo selettivo, ma al contrario
tutti i dati vengono trasmessi all’FPGA collegata. Per caricare i dati selettiva-
32

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
mente, in caso di configurazione basata sui moduli, si puo considerare o System
ACE MPM per soluzioni a media densita o SYSTEM ACE CF per soluzioni ad
alta densita.
Quando si accende l’FPGA, un bistream totale deve essere caricato nella sche-
da. Solo in quel momento un bitstream parziale puo essere caricato per riconfig-
urare un modulo parzialmente riconfigurabile. Gli stati dei flip-flop e delle RAM
sono conservati durante il processo di riconfigurazione. Porzioni fisse possono
rimanere pienamente funzionanti durante il processo di riconfigurazione. Co-
munque, per un bitstream basato sui moduli, se i moduli che non riconfigurano
fanno affidamento allo stato dei segnali connessi al bus macro del modulo che si
sta riconfigurando, allora la configurazione deve tener conto del tempo di tran-
sizione durante la riconfigurazione parziale. Ad esempio, se un modulo fisso
che comunica con un modulo riconfigurabile tramite i bus macro non deve fare
affidamento ai segnali da e per il bus macro durante il tempo di riconfigurazione.
2.5 Il bus macro
In questo paragrafo verra descritto ed analizzato il bus macro proposto da Xilinx in
[6], le sue caratteristiche ed il suo principio di funzionamento. Verra poi presentata
l’infrastruttura di comunicazione proposta.
2.5.1 Cos’e il bus macro
Il bus macro e l’infrastruttura che permette la comunicazione intermodulare at-
traverso i confini dei moduli stessi e viene utilizzato per implementare la tecnica
di riconfigurabilita basata sui moduli.
I moduli non possono comunicare tra loro in modo diretto, ma devono servirsi del
bus macro. Come gia detto in precedenza, la comunicazione puo avvenire se e
solo se almeno uno dei due moduli e riconfigurabile.
Il bus macro deve essere una risorsa di interconnessione affidabile percio, a livello
fisico, il percorso attraverso il confine di due moduli deve essere fisso e statico.
33

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
Figura 2.4: Posizionamento del bus macro nell’area della FPGA
Come mostrato in Figura 2.4 il bus macro viene posizionato sul confine tra
il modulo A (a sinistra) e il modulo B (a destra); e importante sottolineare che,
durante la riconfigurazione, il percorso fisico di interconnessione non deve cam-
biare.
Un percorso fisso e richiesto perche, se una qualsiasi configurazione adottasse un
differente percorso per il bus macro, essa non sarebbe allineata correttamente con
le altre configurazioni e la comunicazione tra A e B si interromperebbe [6].
2.5.2 Il bus macro a livello fisico
Per l’implementazione a livello fisico del bus macro, il componente fondamentale
da utilizzare e il tri-state buffer, il cui funzionamento e gia stato descritto nel
34

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
Capitolo 1.
Come e gia stato detto, il bus macro viene posizionato sul confine di due mod-
uli, quindi si divide in due parti, destra e sinistra, ognuna dotata di un numero di
tri-state pari al numero di linee di bit.
Figura 2.5: Implementazione fisica del bus macro.
La Figura 2.5 mostra l’implementazione fisica del bus macro: come si puo
notare, il canale di uscita e bidirezionale, quindi risulta necessario utilizzare un
meccanismo che impedisca a entrambe le parti di trasmettere bit contemporanea-
mente sulla stessa linea di uscita.
Se, ad esempio, vogliamo trasmettere dei bit dal modulo a sinistra (B in figura)
al modulo a destra (C in figura) attraverso l’n-esima linea di uscita, dobbiamo
porre a ’0’ il segnale di controllo LT dell’n-esimo tri-state del modulo B e con-
temporaneamente, porre a ’1’ il segnale di controllo RT dell’n-esimo tri-state del
modulo C per impedire il conflitto sulla linea di uscita. In Figura 2.5 e mostrato
un bus macro a 4 bit; se si necessita di piu linee di bit bisogna posizionare nell’ar-
chitettura un numero maggiore di bus macro.
35

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
2.6 L’infrastruttura di comunicazione proposta
L’idea fondamentale che ha guidato la sviluppo di questa infrastruttura di comu-
nicazione, che d’ora in poi chiameremo bus, e stata quella di creare un canale di
comunicazione che fosse il piu flessibile possibile e quindi che si adattasse ad ogni
scenario d’uso.
Per fare cio si sono considerati distinti il piano del bus e quello delle risorse
logiche effettivamente utilizzate per implementare le funzioni logiche.
Il bus non e piu considerato come un’entita da posizionare sul confine di due mod-
uli, ma come un substrato sul quale le risorse logiche si appoggiano. Si e cercato
quindi di non vincolare il bus ad un particolare modello di FPGA o ad una parti-
colare funzione logica sintetizzata sulla FPGA.
Anche per questo bus, l’utilizzo dei tri-state e fondamentale: essi infatti vengono
interconnessi lungo la stessa linea orizzontale, formano quindi le singole linee di
bus. Come si puo notare dalla Figura 2.6, i tri-state sono connessi alle singole slice
tramite la switch matrix, e sono connessi direttamente alle linee orizzontali, che
sono quelle che poi verranno utilizzate come linee di bus, come si vede sempre in
Figura 2.6.
Figura 2.6: Connessione dei tri-state alle linee orizzontali.
36

Capitolo 2. La riconfigurabilita dinamica parziale e il bus macro
Il tri-state funziona come un’interruttore tra la CLB e le linee orizzontali: se
il suo segnale di controllo viene posto a ’0’, la linea e abilitata e i dati possono
transitarvi, altrimenti non lo e.
Le singole CLB, con i relativi tri-state, sono disposti a formare una specie di
reticolo, composto dalle linee orizzontali e dai segnali di controllo dei tri-state
che si trovano sulla stessa linea verticale come si vede in Figura 2.7.
Figura 2.7: Il bus in FPGA Editor.
37


Capitolo 3
Gli strumenti utilizzati
In questo capitolo si descriveranno i tre strumenti software principali utilizzati
durante lo sviluppo di questo lavoro.
3.1 ISE
ISE (Integrated Software Environment), prodotto dalla Xilinx, e un software che
permette lo sviluppo completo di un componente a partire dalla sua descrizione
in linguaggio Verilog o VHDL (VHSIC-HDL, Very high speed integrated circuit
Hardware Description Language)[2].
La funzione di interfaccia verso l’utente e svolta da Project Navigator, che gestisce
il processo di realizzazione del componente in tutte le fasi dello sviluppo. La
versione utilizzata per questo lavoro di tesi e la 8.3i, la cui interfaccia grafica e
mostrata in Figura 3.1.
Le componenti fondamentali di Project Navigator sono:
• Editor: esistono tre tipi di editor: testuale, di schemi logici e di vincoli fisici;
il piu utilizzato e l’editor di testo (in Figura 3.2), poiche permette di creare,
visualizzare e modificare i codici sorgente di un componente;
• Console: riporta dettagliatamente tutte le fasi dei processi a cui viene sotto-
posto il progetto. E fondamentale per effettuare debugging;
39
Capitolo 3. Gli strumenti utilizzati
Figura 3.1: Interfaccia grafica di Project Navigator
Figura 3.2: Editor testuale di Project Navigator
• Albero delle risorse: mostra tutti i file correlati con il progetto e il modello
di dispositivo utilizzato;
• Menu delle funzioni: e l’elemento principale di Project Navigator, poiche
grazie ad esso si accede a tutte le funzionalita messe a disposizione da ISE.
Il menu delle funzioni di ISE 8.1i.
40

Capitolo 3. Gli strumenti utilizzati
Figura 3.3: Menu delle funzioni di Project Navigator
Il menu delle funzioni di ISE 8.1i e mostrato in Figura 3.3.
Le funzioni sono suddivise in cinque gruppi:
• Design Entry Utilities;
• User Constraints;
• Synthesize-XST;
• Implement Design;
• Generate Programming File.
Il gruppo Design Entry Utilities permette di creare template dei moduli che
potranno successivamente essere istanziati in altre entita di livello superiore.
Inoltre, se e installata sul computer una versione di ModelSim, e possibile richia-
marla da questo menu premendo il tasto Launch ModelSim Simulator; in questo
modo verranno settati automaticamente tutti i parametri necessari per una corretta
41

Capitolo 3. Gli strumenti utilizzati
e completa simulazione.
Il gruppo User Constraints consente di impostare i vincoli relativi ai segnali,
nonche i vincoli spaziali e temporali che dovranno essere rispettati dai passi di
sintesi successivi.
Il gruppo Synthesize-XST e forse il gruppo fondamentale poiche mette a dis-
posizione dell’utente le funzionalita per il controllo della sintassi (Check Sintax)
del codice VHDL e per la sintesi del codice VHDL con XST (Xilinx Synthesize
Tool). Questa operazione comporta un notevole carico computazionale, dato che
il VHDL deve essere tradotto in una rete hardware composta da porte logiche e
interconnessioni. La riuscita di questa operazione e necessaria affinche si possa
passare alle fasi successive dello sviluppo.
Il gruppo Implement Design fornisce una serie di programmi (Translate, Map,
Place&Route) che, data la rete logica generata dalla sintesi, provvedono a map-
parla sulla FPGA che viene specificata al momento della creazione del progetto,
rispettando i vincoli di spazio imposti. Se questa operazione va a buon fine si pas-
sa poi a piazzare i blocchi e a creare una rete di instradamento tra i vari blocchi
logici della FPGA, cercando di rispettare le temporizzazioni imposte.
Il gruppo Generate Programming File permette di creare il bitstream neces-
sario per configurare la FPGA in maniera tale da svolgere la funzione progettata.
3.2 FPGA Editor
Fpga Editor e un tool-CAD grafico messo a disposizione da ISE, il quale, a sec-
onda del dispositivo utilizzato, permette di visualizzare e modificare le risorse
logiche e di interconnessione che saranno effettivamente occupate, quando il codice
42
Capitolo 3. Gli strumenti utilizzati
VHDL da cui si e partiti verra portato su dispositivo fisico.
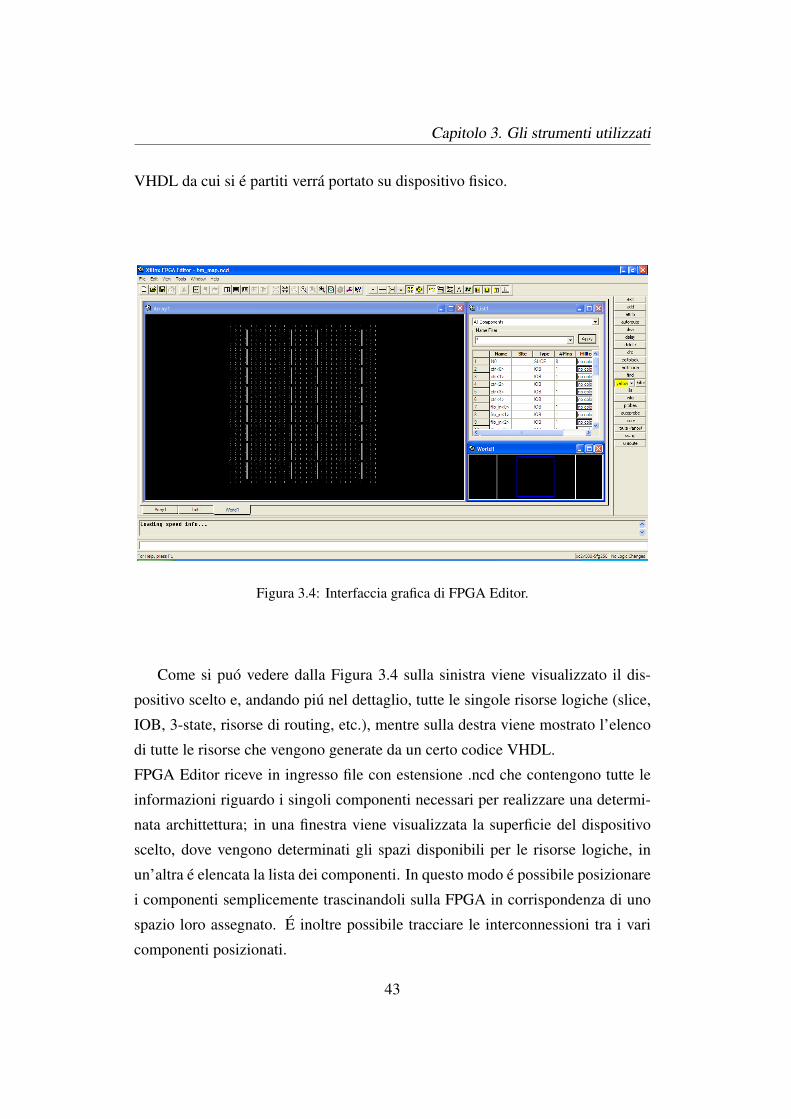
Figura 3.4: Interfaccia grafica di FPGA Editor.
Come si puo vedere dalla Figura 3.4 sulla sinistra viene visualizzato il dis-
positivo scelto e, andando piu nel dettaglio, tutte le singole risorse logiche (slice,
IOB, 3-state, risorse di routing, etc.), mentre sulla destra viene mostrato l’elenco
di tutte le risorse che vengono generate da un certo codice VHDL.
FPGA Editor riceve in ingresso file con estensione .ncd che contengono tutte le
informazioni riguardo i singoli componenti necessari per realizzare una determi-
nata archittettura; in una finestra viene visualizzata la superficie del dispositivo
scelto, dove vengono determinati gli spazi disponibili per le risorse logiche, in
un’altra e elencata la lista dei componenti. In questo modo e possibile posizionare
i componenti semplicemente trascinandoli sulla FPGA in corrispondenza di uno
spazio loro assegnato. E inoltre possibile tracciare le interconnessioni tra i vari
componenti posizionati.
43
Capitolo 3. Gli strumenti utilizzati
3.3 ModelSim
ModelSim SE (www.model.com) e uno strumento software prodotto dalla Men-
tor Graphics (www.mentor.com) e supportato dalla Xilinx. Scopo di ModelSim
e offrire agli utenti la possibilita di effettuare simulazioni del comportamento di
sistemi specificati tramite linguaggio VHDL, per verificarne il corretto funziona-
mento. Inoltre ModelSim offre un ambiente dove e possibile creare, sviluppare e
modificare moduli VHDL. La versione di ModelSim SE utilizzata per questo elab-
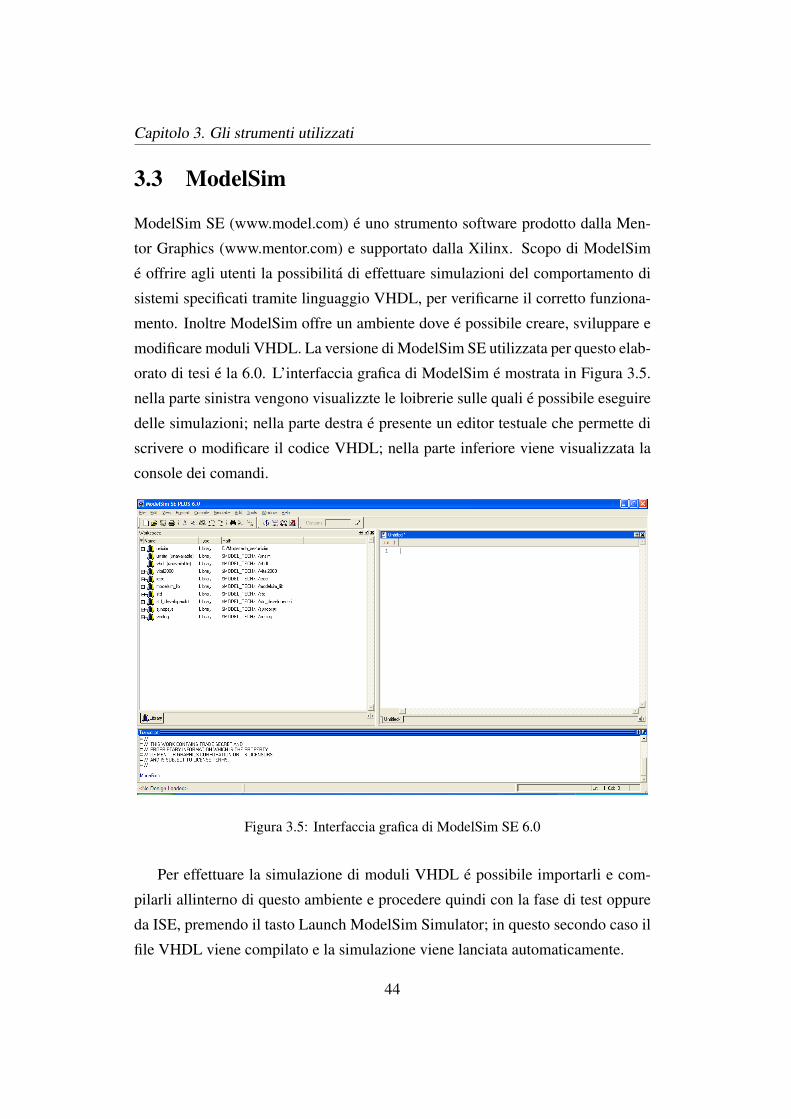
orato di tesi e la 6.0. L’interfaccia grafica di ModelSim e mostrata in Figura 3.5.
nella parte sinistra vengono visualizzte le loibrerie sulle quali e possibile eseguire
delle simulazioni; nella parte destra e presente un editor testuale che permette di
scrivere o modificare il codice VHDL; nella parte inferiore viene visualizzata la
console dei comandi.
Figura 3.5: Interfaccia grafica di ModelSim SE 6.0
Per effettuare la simulazione di moduli VHDL e possibile importarli e com-
pilarli allinterno di questo ambiente e procedere quindi con la fase di test oppure
da ISE, premendo il tasto Launch ModelSim Simulator; in questo secondo caso il
file VHDL viene compilato e la simulazione viene lanciata automaticamente.
44

Capitolo 3. Gli strumenti utilizzati
Figura 3.6: Finestra signals di ModelSim SE 6.0
Procedeno poi nella simulazione e necessario ‘forzare’ i valori dei segnali in
ingresso al componente che si sta testando, per poter vedere il suo comportamento
tramite i segnali in uscita al componente stesso. Questo e possibile tramite la fines-
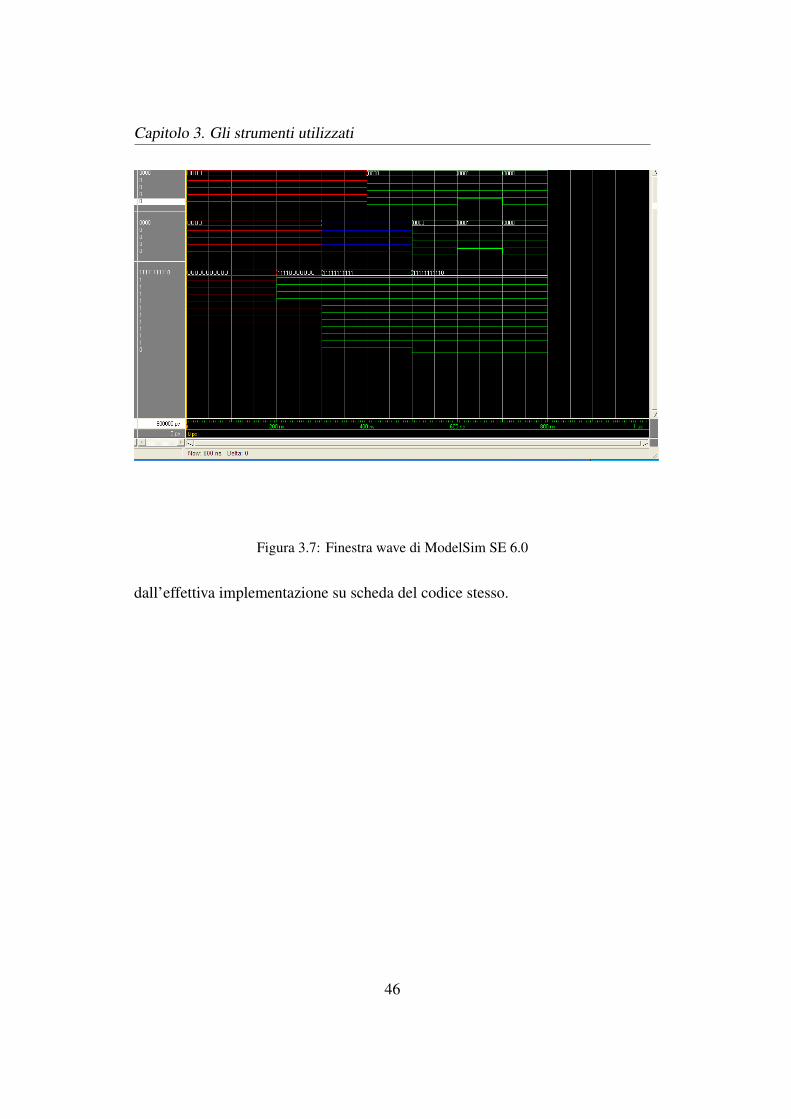
tra signals, mostrata in Figura 3.6. Infine e possibile monitorare l’evoluzione tem-
porale dei seganli attraverso al finestra wave, mostrata in Figura 3.7, che riporta
in modo garfico l’intero andamento dei segnali sui quali si sta agendo.
La grande utilita di ModelSim sta nel fatto che permette di testare un qualsiasi
codice VHDL senza portaro direttamente su scheda. Questo potrebbe anche es-
sere considerato un limite poiche la simulazione fatta da ModelSim e svincolata
45
Capitolo 3. Gli strumenti utilizzati
Figura 3.7: Finestra wave di ModelSim SE 6.0
dall’effettiva implementazione su scheda del codice stesso.
46

Capitolo 4
Metotologia
In questo capitolo verra illustrato il flusso di operazioni che, partendo dal
codice VHDL, permettano di generare in modo semi-automatico il canale di co-
municazione.
4.1 Introduzione
Per arrivare alla generazione automatica del canale di comunicazione si e comin-
ciato analizzando il processo standard per arrivare a creare una macro hardware,
cioe un componente hardware che e possibile istanziare e utilizzare (nel nostro
caso sotto forma di file .nmc); si e poi proceduto cercando di trovare un’alternati-
va al processo standard per arrivare agli stessi risultati, ma attraverso un processo
che potesse essere automatizzato.
4.2 Il processo standard
In questo paragrafo verranno descritte le operazioni che e necessario eseguire per
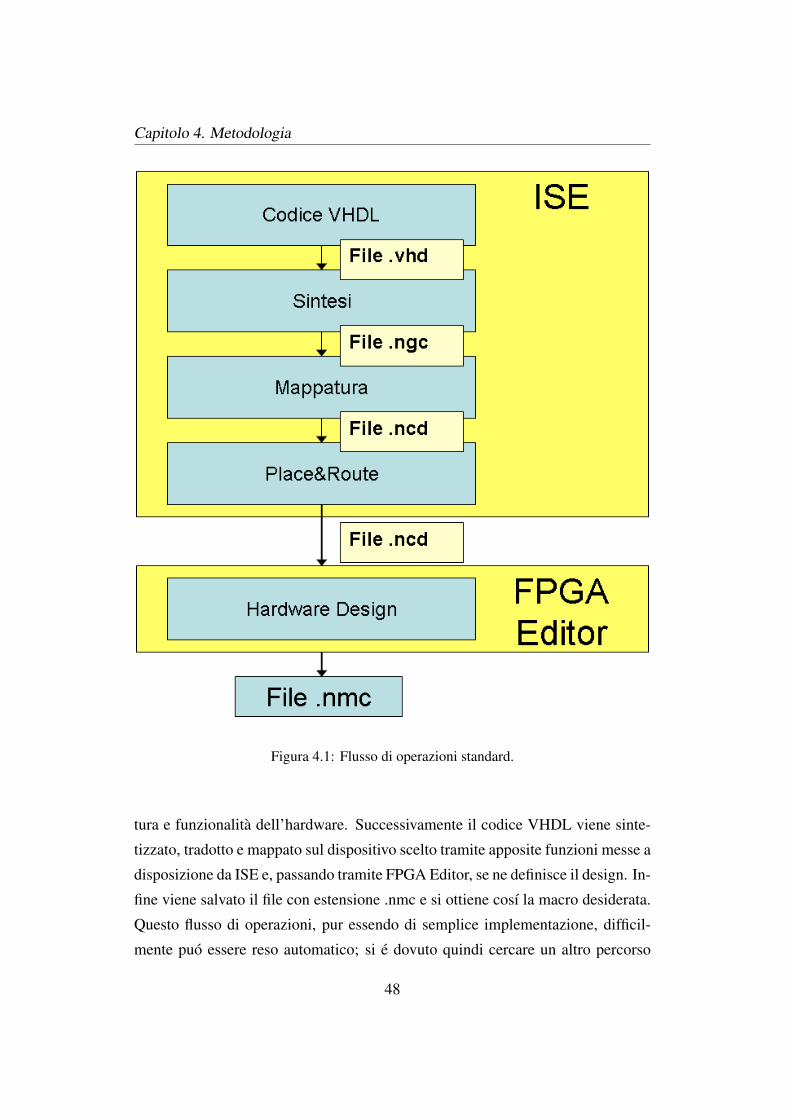
ottenere una macro hardware in modo non automatico, illustrate in Figura 4.1.
Per la generazione manuale di una macro hardware le operazioni sono le
seguenti: il punto di partenza e il codice VHDL, con cui vengono descritte strut-
47
Capitolo 4. Metodologia
Figura 4.1: Flusso di operazioni standard.
tura e funzionalita dell’hardware. Successivamente il codice VHDL viene sinte-
tizzato, tradotto e mappato sul dispositivo scelto tramite apposite funzioni messe a
disposizione da ISE e, passando tramite FPGA Editor, se ne definisce il design. In-
fine viene salvato il file con estensione .nmc e si ottiene cosı la macro desiderata.
Questo flusso di operazioni, pur essendo di semplice implementazione, difficil-
mente puo essere reso automatico; si e dovuto quindi cercare un altro percorso
48

Capitolo 4. Metodologia
per ottenere lo stesso risultato.
4.3 Il processo automatizzabile
Come mostrato in Figura 4.2 e possibile creare un file .nmc, sia passando attraver-
so FPGA Editor, sia creando un file di codice XDL, traducendolo in un file .ncd e
rinominandolo con estensione.nmc.
Figura 4.2: Alternative per la creazione di un file .nmc.
La seconda alternativa, quella che parte da un file di codice XDL, pur richieden-
do delle operazioni piu complesse, legate al formato del file XDL, e facilmente
automatizzabile.
Inizialmente e stato necessario creare alcuni file XDL, sempre partendo da codice
49

Capitolo 4. Metodologia
VHDL di moduli hardware di cui si conoscevano struttura e funzionalita, per
comprendere la sintassi e le regole del linguaggio XDL stesso, attraverso un’-
operazione di reverse engineering. Il flusso di operazioni completo parte quindi
comunque dal codice VHDL, che viene sintetizzato, tradotto e mappato, per poi
essere passato a FPGA Editor, in formato .ncd. A questo punto il file viene salvato
come file .nmc e trasformato in file XDL.
Successivamente e possibile studiare il formato del file cosı ottenuto e creare un
programma C che generi file XDL senza passare attraverso il codice VHDL.
Il flusso seguito dal programma C e invece mostrato in Figura 5.1: si parte
da alcuni parametri d’ingresso che danno informazioni sulle dimensioni e sul-
la posizione del bus (numero di moduli riconfigurabili, distanza tra i moduli),
il programma genera automaticamente un file XDL, lo trasforma in file .ncd e
successivamente lo trasforma ancora in file .nmc.
Figura 4.3: Flusso di operazioni del programma generatore.
50

Capitolo 4. Metodologia
4.4 File XDL
XDL, il cui acronimo sta per Xilinx Design Language, e un formato di file in-
termedio con cui viene descritta la rappresentazione di un circuito logico. Esso
da una visione semplicistica del circuito e delle connessioni tra componenti, ma
il suo vero punto di forza risiede nel fatto di essere codificato ASCII ed e quindi
possibile leggerlo, interpretarlo e modificarlo. Un file .ncd (o .nmc) viene quindi
trasformato in file XDL con un apposito comando; xdl -ncd2xdl nomefile.nmc;
in questo modo e stato possibile studiare il formato di file XDL gia generati ed e
stato possibile estrapolarne dei costrutti fondamentali per la costruzione del bus.
Si e notato anche che, modificando il file XDL e ritrasformandolo in file .ncd, le
modifiche avevano effetto sulla struttura del componente in esame. Questa fase di
studio ha permesso quindi di individuare le strutture fondamentali del linguaggio
XDL, descritte di seguito.
4.4.1 La struttura del file XDL
Ogni file XDL inizia con una parte di intestazione di questo tipo:
design XILINX NMC MACRO xc2vp7ff896-5;
module bus m0t0 , cfg SYSTEM MACRO::FALSE ;
dove vengono dichiarati il tipo do dispositivo usato (xc2vp7ff896-5), il nome
del modulo (bus) ed il componente di riferimento (m0t0); quest’ultimo e nec-
essario poiche XDL considera i componenti come se fossero disposti sopra un
reticolo, quindi per identificare il singolo componente vengono usate delle coor-
dinate , la cui origine e appunto il componente di riferimento. Successivamente
vengono dichiarati gli ingressi tramite cui accedere al bus dall’esterno; questo
avviene tramite il comando port, seguito dal nome, dalla locazione sul dispositivo
e dal tipo (ingresso, uscita o segnale di cntrollo di un 3-state):
port adrI0(0) m0t0 I ;
51

Capitolo 4. Metodologia
port adrT0(0) m0t0 T ;
port adr(0) m0t0 O ;
Dopo aver dichiarato le porte si passa ad istanziare i singoli 3-state; questo avviene
nel modo seguente:
inst m0t0 TBUF , placed R40C3 TBUF X4Y0 ,
cfg IINV::I TINV::T SUPERBEL::TRUE
;
Come per gli altri componenti si specifica la posizione, il tipo di componente
ed il nome del componente.
Per ultimo vengono specificate le reti (net), cioe si dichiara come devono essere
connessi tra di loro i singoli componenti:
net adr(0) O ,
cfg NET PROP::IS BUS MACRO: ,
outpin m0t0 O ,
outpin m1t0 O ,
outpin m2t0 O ,
;
La dichiarazione comprende il nome della rete, le connessioni dei singoli com-
ponenti e la loro funzione.
52

Capitolo 5
Implementazione
In questo capitolo verra descritta in modo dettagliato l’implemetazione dei
singoli passaggi che hanno portato alla realizzazione automatica dell’infrastrut-
tura di comunicazione.
L’intero processo e diviso in cinque fasi fondamentali (che chiameremo Step)
che sono descritte singolarmente nel seguito:
• la prima descrive la generazione del codice VHDL;
• la seconda illustra le operazioni per la creazione del file .nmc;
• la terza spiega la generazione del file XDL;
• la quarta descrive lo studio del formato del file XDL;
• la quinta descrive il funzionamento del programma generatore di codice
XDL.
Il flusso di operazioni che porta alla realizzazione dell’infrastruttura e mostrato
in Figura 5.1.
53

Capitolo 5. Implementazione
Figura 5.1: Flusso di operazioni del programma generatore.
5.1 Step 1: il codice VHDL
Il punto di partenza per lo sviluppo di una infrastruttura di comunicazione e certa-
mente la descrizione, mediante il linguaggio VHDL, delle funzionalita e dell’ar-
chitettura dello stesso.
Il VHDL e un linguaggio che viene usato per la descrizione dell’hardware, quindi
e necessario, per cominciare, scrivere del codice che descriva l’entita che si in-
tende realizzare in maniera rigorosa e formale, dichiarando in particolare le porte
di ingresso e di uscita, le risorse utilizzate e le interconnessioni tra porte e risorse.
L’output di questo step e quindi un file VHDL (.vhd) che descriva interamente la
struttura e le funzionalita del bus che si intende realizzare. Per scrivere codice
VHDL e stato utilizzato l’apposito editor messo a disposizione da ISE, ma questa
operazione puo essere svolta con un qualsiasi editor di testo. Il codice che e stato
realizzato e da cui si e partiti e mostrato di seguito:
54

Capitolo 5. Implementazione
01 library IEEE;
02 use IEEE.STD LOGIC 1164.ALL;
03 use IEEE.STD LOGIC ARITH.ALL;
04 use IEEE.STD LOGIC UNSIGNED.ALL;
05
06 library UNISIM;
07 use UNISIM.VComponents.all;
08
09 entity bus 4 is
10
11 Port ( net in : in std logic vector(0 to 3);
12 net out : out std logic vector(0 to 3);
13 ctrl : in std logic vector(0 to 4));
14
15 end bus 4;
16
17
18 architecture bus 4 of bus 4 is
19
20 begin
21
22 bus generatetor : for height in 0 to 3 generate
23
24 tbuf gen : for width in 0 to 4 generate
25 tbuf: BUFT port map (I=>net in(height),O=>net out(height),T=>ctrl(width));
26 end generate ;
27
28 end generate;
29
30 end architecture;
55

Capitolo 5. Implementazione
Nelle prime quattro righe vengono importate le librerie necessarie e viene
dichiarato in particolare quali verranno usate.
Dalla riga nove alla riga quindici il codice descrive l’entita bus 4 in termini di
porte, ovvero vengono dichiarato il numero ed il genere degli ingressi e delle us-
cite; ad esempio la riga undici dice che la porta ‘net in’ e un ingresso di tipo
standard logic vector di dimensione quattro.
Dalla riga diciotto fino alla fine si descrive il bus spiegandone la sua architettura;
in questo caso sono presenti due cicli annidati: il piu interno ha il compito di
istanziare il numero desiderato di tri-state sulla singola riga, mentre il ciclo piu
esterno ripetera la singola riga, quante volte necessario.
Tramite la funzione port map vengono poi mappati gli ingressi e le uscite dei
componenti appena istanziati.
5.2 Step 2: FPGA Editor
Questo step prende in ingresso il codice VHDL generato al punto precedente e,
tramite apposite funzionalita messe a disposizione da ISE viene tradotto e mappa-
to su uno specifico dispositivo che si intende utilizzare.
Dopo aver creato il codice VHDL, e necessario verificarne la correttezza sintatti-
ca, sintetizzarlo, tradurlo e mapparlo sul dispositivo scelto; tutto questo si realizza
tramite i menu Synthetize - XST e Implement Design di ISE.
Infine, sempre tramite funzionalita di ISE, bisogna effettuare il Placing & Routing
delle risorse che vengono utilizzate, sulla superficie della FPGA.
In questa fase i componenti istanziati con il codice vengono posizionati fisica-
mente sulla superficie del dispositivo in corrispondenza delle risorse logiche che
verranno occupate.
L’output finale di FPGA Editor e un file che puo avere estensione .ncd oppure
.nmc i quali descrivono il design dell’hardware, cioe la disposizione delle risorse
logiche occupate sulla FPGA. I file .ncd (oppure .nmc) sono dei file che vengono
generati dalla funzione Map di ISE e che possono essere visualizzati con FPGA
56

Capitolo 5. Implementazione
Editor.
Il file .ncd e quindi un file di design della FPGA, mente il file .nmc descrive una
macro hardware; le informazioni contenute da entrambi sono pero le medesime. Il
vero problema derivante dall’utilizzo di questo tipo di file e che non sono leggibili
ne tantomeno comprensibili a causa della loro codifica, ed e proprio per questo
motivo che si rende necessaria la conversione in un altro formato.
5.3 Step 3: trasformazione in XDL
Una volta salvato un file .nmc, tramite il comando ‘xdl -ncd2xdl nomefile.nmc’,
questo viene trasformato in un formato XDL.
XDL (Xilinx Design Language) e un formato intermedio di file, codificato in
ASCII e quindi leggibile con un qualsiasi editor di testo, che istanzia le risorse
logiche necessarie e ne individua le interconnessioni. Si vuole operare sul codice
XDL per due motivi:
• il codice XDL e leggibile infatti, grazie alla sua codifica (ASCII) pur non
essendo di immediata comprensione per quanto riguarda la sintassi, si puo
aprire e modificare con un qualsiasi editor testuale;
• il codice XDL e modificabile infatti modificano in modo opportuno il codice,
e possibile variare il numero, la disposizione e le interconnessioni dei com-
ponenti.
Inoltre la struttura del file XDL, come e gia stato detto, e ripetitiva; cio agevola
notevolmente l’automatizzazione del processo di creazione del file XDL. L’output
di questo step e quindi un file XDL.
5.4 Step 4: studio del file XDL
Questo step e necessario per lo studio e la comprensione della struttura, della sin-
tassi e delle regole che stanno alla base del formato di file XDL, e cio e stato
57

Capitolo 5. Implementazione
possibile utilizzando i file generati allo step precedente, aprendoli con un qual-
siasi editor testuale. I file generati, infatti, derivano da un codice VHDL noto,
quindi e possibile trovare delle corrispondenze tra quello che viene descritto nel
file VHDL e cio che invece troviamo nel codice XDL.
Il codice XDL inoltre e ripeitivo, cioe le strutture che si trovano al suo interno
sono sempre identiche; ad esempio l’istruzione per istanziare un tri-state e sem-
pre:
inst m0t0 TBUF , placed R40C3 TBUF X4Y0 ,
cfg IINV::I TINV::T SUPERBEL::TRUE
;
le uniche variazioni sono nel nome del componente e nei parametri per il suo
posizionamento sulla superficie della FPGA (riga R, colonna C, e coordinate del
componente X e Y).
5.5 Step 5: programma generatore di codice XDL
Dopo aver compreso il funzionamento del linguaggio XDL e soprattutto delle sue
istruzioni basilari, e stato creato un programma C che generasse in maniera semi
automatica il codice XDL stesso, prendendo in ingresso solo alcuni parametri
come il tipo di dispositivo utilizzato, il numero di istanze del singolo bus e la
spaziatura tra i diversi moduli.
I passaggi che deve eseguire il programma sono:
• creazione di un file .xdl e stampa al suo interno del codice necessario;
• conversione del file XDL in un file .ncd;
• rinominare il file.ncd appena ottenuto in un file .nmc (file di una macro
hardware).
Il programma infatti crea un file con estensione .xdl e, in base ai parametri
inseriti dall’utente, vi stampa all’interno le blocchi di codice corrispondenti alle
58

Capitolo 5. Implementazione
risorse che si intende utilizzare. Infine il file XDL viene chiuso, salvato e trasfor-
mato in file .nmc con il comando ‘xdl -xdl2ncd nomefile.nmc’, cosı puo essere
aperto con FPGA Editor.
Inoltre il programma e stato reso compatibile con piu dispositivi: e infatti possi-
bile scegliere, all’interno di tre famiglie di FPGA, che dispositivo utilizzre. Oltre
a questo e anche possibile decidere:
• il nome del file;
• il numero di istanze del singolo bus che si vogliono creare;
• il nome del file .nmc
• lo spazio da mantenere tra istanze diverse del bus (che deve essere per forza
multiplo di quattro).
59


Capitolo 6
Test e risultati
In questo capitolo verranno presentati i risultati in termini di occupazione
d’area e di ritardi introdotti dal bus sulle tre famiglie di FPGA, in particolare sul
modello XC3S200-4ft256 di Spartan-3, sul modello XC2V1000-5fg256 di Virtex-
II e sul modello X2VP20-5fg676 di Virtex-II Pro.
Inoltre verra mostrato l’incremento di prestazioni per la creazione della infrastrut-
tura proposta, rispetto al flusso standard. Tutti i test ed i risultati ottenuti sono
stati eseguiti tramite la simulazione del comportamento del bus e non caricando
l’infrastruttura direttamente su dispositivo e testandola. Questo e stato possibile
grazie a due funzioni di ISE: per l’occupazione d’area e stata utilizzata la funzione
‘View syinthesis report’ del menu Synthetize - XST, mentre per i ritardi introdotti
e stata utilizzato il tool ‘Xilinx Timing Analyzer’ dal menu Implement Design.
Parleremo in seguito di tempo per il calcolo logico riferendoci al tempo impiegato
da un segnale per attraversare i componenti della FPGA (tri-state, CLB, IOB....),
mentre parleremo di tempo per l’attraversamento, riferendoci al tempo che il seg-
nale impiega per attraversare le semplici risorse di interconnessione. Ad esempio,
se decidessimo di effettuare l’operazione Y=A+B con una porta OR, il tempo
richiesto sarebbe pari al tempo che il segnale piu lento tra A e B impiega, dall’in-
gresso, ad arrivare alla porta OR (tempo per l’attraversamento), piu il tempo di
calcolo della porta OR (tempo per il calcolo logico), piu il tempo che il segnale Y
impiega ad arrivare all’uscita (tempo per l’attraversamento).
61

Capitolo 6. Test e risultati
Nel seguito faremo riferimento all’infrastruttura di comunicazione con il ter-
mine bus. I test si riferiscono all’infrastruttura composta da quattro linee di bit e
da cinque segnali di controllo.
6.1 Tempo per la realizzazione del bus
Un primo dato significativo da sottolineare e la diminuzione del tempo neces-
sario per la realizzazione dell’infrastruttura di comunicazione; una misurazione
approssimativa del tempo di eseguzione del programma generatore ha dato un
risultato pari a 22 secondi (dal momento del lancio fino alla generazione del file
.nmc, eseguito su un P4) che si contrappone al tempo impiegato per la generazione
manuale, seguendo quindi il flusso standard, che e di alcuni minuti (in base alle
capacita e all’esperienza dell’utente).
Anche se la prima misura risulta influenzata dalla velocita del processore e dalle
dimensioni del bus, si puo comunque affermare che le due modalita di realiz-
zazione differiscono per un ordine di grandezza.
6.2 Il bus su Spartan-3
6.2.1 Occupazione d’area
Dato che il compito del bus e semplicemente quello di garantire il passaggio di
informazioni da un modulo ad un altro, e che esso quindi non svolge una vera e
propria funzione logica, l’occupazione di risorse e estremamente limitata. Per ver-
ificare nel dettaglio qualie e quante risorse sono state occupate, Project Navigator
mette a disposizione dell’utente il comando map report:
Numero di Slice occupate: 3 su 1920 (1%)
Numero di Lut a 4 ingressi occupate: 6 su 3840 (1%)
Numero di IOB occupati: 13 su 173 (7%)
Tabella 6.1: Tabella dell’occupazione d’area per una XC3S200-4ft256.
62

Capitolo 6. Test e risultati
6.2.2 Prestazioni temporali
Visto che il bus non svolge una funzione logica, le sue prestazioni temporali non
dovrebbero essere influenzate in alcun modo alcun tempo di calcolo, ma dovreb-
bero dipendere solamente dal tempo impiegato per attraversare un determinato
percorso e da eventuali ritardi introdotti dai componenti. Questo non e valido
pero per tutta la famiglia delle Spartan-3, che, come si e detto, deve spendere del
tempo per la simulazione del comportamento dei tri-state.
Post-Map Static Analysis
L’analisi post-map delle prestazioni viene effettuata tramite una funzione di
Project Navigator. Questo tipo di analisi tiene conto del tipo di dispositivo e del
codice VHDL, ma non di vincoli particolari di disposizione dei componenti e di
area.
Per quanto riguarda questo tipo di analisi non e importante verificare tutti i tempi
richiesti per l’attraversamnto di tutte le reti possibili; ad esempio non serve anal-
izzare la rete che dal segnale Ctrl(1) porta all’uscita net out(1). Si devono anal-
izzare invece le reti che dai quattro ingressi portano alle rispettive uscite, poiche
sono queste le reti che si utilizzano per la funzione di bus.
Il tempo richiesto per l’attraversamento di queste reti e pari a 7,05 ns, che e il
risultato della somma di altri due tempi: il semplice attraversamento della rete e il
tempo di calcolo della funzione tri-state.
Il percorso completo del segnale e il segnuente: dallo IOB di ingresso verso una
prima SLICE A e poi verso uno IOB di uscita. Nella SLICE A arriva anche il
segnale di controllo, dopo essere passato anch’esso attraverso una SLICE B.
I tempi per la logica e per l’attraversamento sono suddivisi come mostrato in
Tabella 6.2. Con questo tipo di analisi non vi sono distinzioni in base all’in-
gresso utilizzato: un segnale impiega il medesimo tempo ad attraversare la rete
per qualsiasi coppia ingresso/uscita.
Come si nota, la maggior parte del tempo e impiegato per il calcolo logico,
quindi si puo affermare che la mancanza dei tri-state incide molto negativamente-
63

Capitolo 6. Test e risultati
Tempo per il calcolo logico 6,850 ns 97,2%
Tempo per l’attraversamento 0,200 ns 2,8%
Tabella 6.2: Suddivisione dei tempi per una XC3S200-4ft256.
sulle prestazioni del bus.
Post-Place&Route Static Analysis
L’analisi post-place&route tiene conto, sia del dispositivo utilizzato, sia della
disposizione spaziale dei componenti all’interno dell’area della FPGA e dei vin-
coli imposti su di essi.
In questo modo si producono dei ritardi diversi a seconda della sottorete ingres-
so/uscita presa in considerazione, come mostrato in Tabella 6.3
INGRESSO USCITA RITARDO
net in(0) net out(0) 10,313 ns
net in(1) net out(1) 10,013 ns
net in(2) net out(2) 10,307 ns
net in(3) net out(3) 9,951 ns
Tabella 6.3: Tabella dei ritardi per una XC3S200-4ft256.
Analizzando le Tabelle 6.4, 6.5, 6.6, 6.7 si nota che il tempo per il calcolo
logico non varia al variare degli ingressi; quello che cambia e il tempo di attraver-
samento delle reti, proprio perche si sta tenendo conto del posizionamento dei
componenti.
Tempo per il calcolo logico 6,850 ns 66,4%
Tempo per l’attraversamento 3,463 ns 33,6%
Tabella 6.4: Ritardi per net in/out(0).
64

Capitolo 6. Test e risultati
Tempo per il calcolo logico 6,850 ns 68,4%
Tempo per l’attraversamento 3,163 ns 31,6%
Tabella 6.5: Ritardi per net in/out(1).
Tempo per il calcolo logico 6,850 ns 66,5%
Tempo per l’attraversamento 3,457 ns 33,5%
Tabella 6.6: Ritardi per net in/out(2).
6.3 Il bus su Virtex-II
6.3.1 Occupazione d’area
Per quanto riguarda le Virtex-II, le risorse logiche occupate in maggior percentuale
sono certamente i tri-state, elementi cardine del bus, insieme agli IOB di ingresso
e di uscita. Vengono anche impiegate due slice, ed in particolare il generatore
di funzione F, per la gestione della rete di controllo. I dati della Tabella 6.8 si
riferiscono all’occupazione di risorse logiche per la XC2V1000-5fg256.
6.3.2 Prestazioni temporali
Post-Map Static Analysis
Nelle Virtex-II i tempi impiegati per l’attraversamento del bus dipendono es-
clusivamente da due fattori: i ritardi introdotti dai componenti attravrsati e il tem-
po impiegato per attraversare le reti di collegamento. Il ritardo totale introdotto
dalle reti ingresso/uscita e pari a 5,290 ns. Questi ritardo si puo ripartire come
segue:
• Tiopi: tempo impiegato per andare dal Pad d’ingresso all’uscita I (vedi
Figura 6.1) pari a 0,718 ns;
• tempo per attraversare la rete che, dall’uscita I, porta all’ingresso del tri-
state pari a 0,100 ns;
65

Capitolo 6. Test e risultati
Tempo per il calcolo logico 6,850 ns 68,8%
Tempo per l’attraversamento 3,101 ns 31,2%
Tabella 6.7: Ritardi per net in/out(3).
Numero di Slice occupate: 2 su 5120 (1%)
Numero di Lut a 4 ingressi occupate: 2 su 10240 (1%);
Numero di IOB occupati: 13 su 172 (7%);
Numero di tri-state occupati: 20 su 2560 (1%);
Tabella 6.8: Tabella dell’occupazione d’area per la XC2V1000-5fg256.
• Tio: tempo per passare dall’ingresso del tri-state alla sua uscita pari a 0,476
ns;
• tempo per attraversare la rete che, dall’uscita del tri-state, porta all’ingresso
O1 dello IOB di uscita pari a 0,100 ns
• Tioop: tempo impiegato per andare dall’ingresso O1 al Pad d’uscita (vedi
Figura 6.2), pari a 3,896 ns.
La somma di questi tempi costitiuisce il ritardo finale introdotto dalla rete
ingresso/uscita del busmacro (net in/net out). Il risulato e mostrato in Tabella
6.11.
Tiopi: 0,718 ns +
Net: 0,100ns +
Tio: 0,476 ns +
Net: 0,100 ns +
Tioop: 3,896 ns +
Ritardo totale: = 5,290 ns
Tabella 6.9: Tabella del ritardo ingresso/uscita in una XC2V1000-5fg256.
La ripartizione dei tempi e mostrata in Tabella 6.10. Si nota che il ritardo
indotto dalla logica e diminuito sia in valore assoluto, sia in percentuale sul valore
66
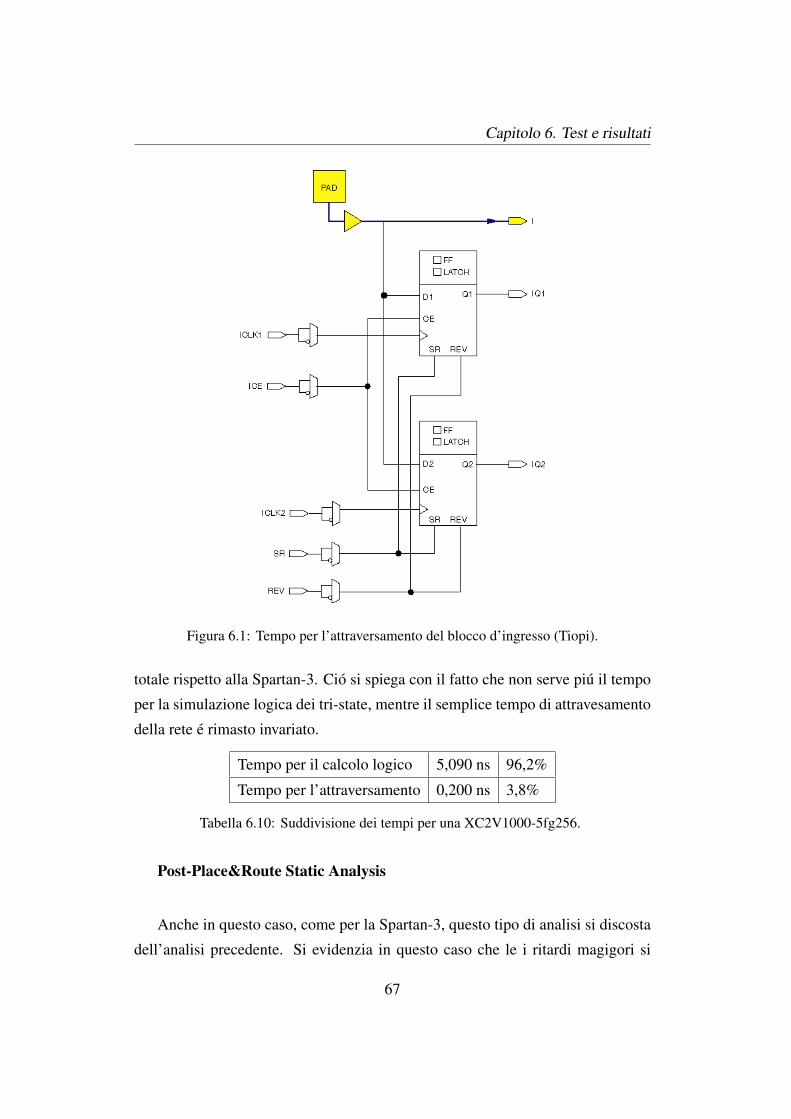
Capitolo 6. Test e risultati
Figura 6.1: Tempo per l’attraversamento del blocco d’ingresso (Tiopi).
totale rispetto alla Spartan-3. Cio si spiega con il fatto che non serve piu il tempo
per la simulazione logica dei tri-state, mentre il semplice tempo di attravesamento
della rete e rimasto invariato.
Tempo per il calcolo logico 5,090 ns 96,2%
Tempo per l’attraversamento 0,200 ns 3,8%
Tabella 6.10: Suddivisione dei tempi per una XC2V1000-5fg256.
Post-Place&Route Static Analysis
Anche in questo caso, come per la Spartan-3, questo tipo di analisi si discosta
dell’analisi precedente. Si evidenzia in questo caso che le i ritardi magigori si
67
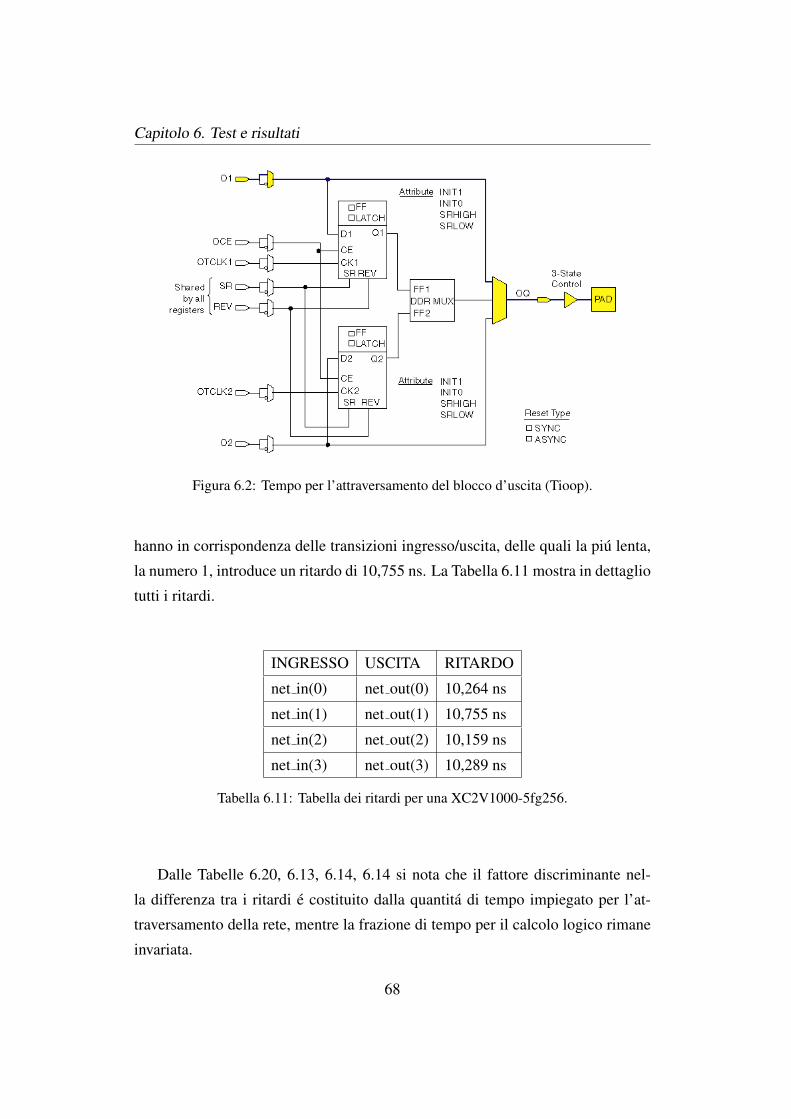
Capitolo 6. Test e risultati
Figura 6.2: Tempo per l’attraversamento del blocco d’uscita (Tioop).
hanno in corrispondenza delle transizioni ingresso/uscita, delle quali la piu lenta,
la numero 1, introduce un ritardo di 10,755 ns. La Tabella 6.11 mostra in dettaglio
tutti i ritardi.
INGRESSO USCITA RITARDO
net in(0) net out(0) 10,264 ns
net in(1) net out(1) 10,755 ns
net in(2) net out(2) 10,159 ns
net in(3) net out(3) 10,289 ns
Tabella 6.11: Tabella dei ritardi per una XC2V1000-5fg256.
Dalle Tabelle 6.20, 6.13, 6.14, 6.14 si nota che il fattore discriminante nel-
la differenza tra i ritardi e costituito dalla quantita di tempo impiegato per l’at-
traversamento della rete, mentre la frazione di tempo per il calcolo logico rimane
invariata.
68

Capitolo 6. Test e risultati
Tempo per il calcolo logico 5,090 ns 47,3%
Tempo per l’attraversamento 5,665 ns 52,7%
Tabella 6.12: Ritardi per net in/out(0).
Tempo per il calcolo logico 5,090 ns 48,1%
Tempo per l’attraversamento 5,489 ns 51,9%
Tabella 6.13: Ritardi per net in/out(1).
Tempo per il calcolo logico 5,090 ns 48,6%
Tempo per l’attraversamento 5,394 ns 51,4%
Tabella 6.14: Ritardi per net in/out(2).
Tempo per il calcolo logico 5,090 ns 49,5%
Tempo per l’attraversamento 5,199 ns 50,5%
Tabella 6.15: Ritardi per net in/out(3).
6.4 Il bus su Virtex-II Pro
6.4.1 Occupazione d’area
In questo caso, utilizzando una X2VP20-5fg676, ma come con ogni altra Virtex-
II Pro, la maggior parte delle risorse occupate sono tri-state e IOB, che sono le
risorse necessarie per espletare le funzioni prorie del bus; viene anche utilizzata
una slice, che gestisce la rete dei segnali di controllo.
6.4.2 Prestazioni temporali
Post-Map Static Analysis
Nelle Virtex-II Pro, come per le Virtex-II, i tempi impiegati per l’attraversa-
mento del bus dipendono esclusivamente da due fattori: i ritardi introdotti dai
componenti attravrsati e il tempo impiegato per attraversare le reti di collegamen-
to. Questi tempi sono cosı suddivisi:
69

Capitolo 6. Test e risultati
Numero di Slice occupate: 1 su 9280 (1%)
Numero di Lut a 4 ingressi occupate: 2 su 18560 (1%);
Numero di IOB occupati: 13 su 404 (3%);
Numero di tri-state occupati: 20 su 4640 (3%);
Numero di PPC405 utilizzati: 0 su 2 (0%)
Tabella 6.16: Tabella dell’occupazione d’area per la X2VP20-5fg676.
• Tiopi: tempo impiegato per andare dal Pad d’ingresso all’uscita I (vedi
Figura 6.1) pari a 0,909 ns;
• tempo per attraversare la rete che, dall’uscita I, porta all’ingresso del tri-
state pari a 0,100 ns;
• Tio: tempo per passare dall’ingresso del tri-state alla sua uscita pari a 0,603
ns;
• tempo per attraversare la rete che, dall’uscita del tri-state, porta all’ingresso
O1 dello IOB di uscita pari a 0,100 ns
• Tioop: tempo impiegato per andare dall’ingresso O1 al Pad d’uscita (vedi
Figura 6.2), pari a 2,798 ns.
La somma di questi tempi costitiuisce il ritardo finale introdotto dalla rete
ingresso/uscita del busmacro (net in/net out). Il risulato e mostrato in Tabella
6.19.
Tiopi: 0,909 ns +
Net: 0,100ns +
Tio: 0,603 ns +
Net: 0,100 ns +
Tioop: 2,798 ns +
Ritardo totale: = 4.510 ns
Tabella 6.17: Tabella del ritardo ingresso/uscita in una X2VP20-5fg676.
70

Capitolo 6. Test e risultati
La ripartizione dei tempi mostrata in Tabella 6.18. Il ritardo indotto dalla
logica ha subito una ulteriore riduzione rispetto alla Spartan-3 e alla Virtex-II.
Tempo per il calcolo logico 4,31 ns 95,6%
Tempo per l’attraversamento 0,200 ns 4,4%
Tabella 6.18: Suddivisione dei tempi per una X2VP20-5fg676.
Post-Place&Route Static Analysis
Anche per quanto riguarda la Virtex-II Pro, questo tipo di analisi si discosta
dell’analisi precedente. Si evidenzia in questo caso che le i ritardi magigori si
hanno in corrispondenza delle transizioni ingresso/uscita, delle quali la piu lenta,
la numero 1, introduce un ritardo di 10,543 ns. La Tabella 6.19 mostra in dettaglio
tutti i ritardi. Non si registra pero un senesibile miglioramento rispetto alla Virtex-
II.
INGRESSO USCITA RITARDO
net in(0) net out(0) 10,543 ns
net in(1) net out(1) 10,078 ns
net in(2) net out(2) 9,463 ns
net in(3) net out(3) 10,014 ns
Tabella 6.19: Tabella dei ritardi per una X2VP20-5fg676.
Dalle Tabelle 6.20, 6.21, 6.22, 6.22 si nota che, mentre il ritardo introdotto dal
calcolo logico risulta identico nei quattro casi, varia il tempo di attraversamento
della rete.
Tempo per il calcolo logico 4,31 ns 40,9%
Tempo per l’attraversamento 6,233 ns 59,1%
Tabella 6.20: Ritardi per net in/out(0).
Si nota come, rispetto alla Virtex-II il calcolo logico risulti piu veloce, mentre
il tempo di attraversamento non si discosta di molto dai valori precedenti.
71

Capitolo 6. Test e risultati
Tempo per il calcolo logico 4,310 ns 42,8%
Tempo per l’attraversamento 5,768 ns 57,2%
Tabella 6.21: Ritardi per net in/out(1).
Tempo per il calcolo logico 4,310 ns 45,5%
Tempo per l’attraversamento 5,153 ns 54,5%
Tabella 6.22: Ritardi per net in/out(2).
Tempo per il calcolo logico 4,310 ns 43,0%
Tempo per l’attraversamento 5,704 ns 57,0%
Tabella 6.23: Ritardi per net in/out(3).
72

Capitolo 7
Conclusioni
Lo scopo di questo lavoro di tesi e stato quello di studiare lo sviluppo di un’infras-
truttura di comunicazione, partendo dalla sua descrizione tramite codice VHDL e
arrivando a proporre una serie di operazioni che consentissero la creazione di un
processo automatizzabile per la generazione dell’infrastruttura stessa.
Successivamente si e passati all’implementazione vera e propria del processo, che,
in questo caso, e stato realizzato tramite un programma scritto in C.
Due sono i principali punti di interesse di questo lavoro:
• il mascheramento all’utente del funzionamento e della realizzazione del
bus;
• la potenziale estendibilita di processo a qualsiasi tipo di dispositivo;
• la diminuzione dei tempi per la generazione del bus.
Per prima cosa infatti il programma realizzato permette all’utente di creare ed
utilizzare il bus, senza doversi preoccupare di crearne uno ad hoc per ogni appli-
cazione e quindi senza dover passare attraverso il codice VHDL. L’utente infatti
fornisce dei parametri per la descrizione del tipo di dispositivo e per le dimensioni
del canale di comunicazione necessario, e il programma si occupa di realizzarlo.
Inoltre considerato che quello che cambia tra due dispositivi della stessa famiglia
(ma anche tra dispositivi di famiglie differenti), nella maggior parte dei casi e solo
73

Capitolo 7. Conclusioni
la quantita di risorse logiche e la loro disposizione, questo programma risulta es-
tendibile a qualsiasi tipo di dispositivo, a patto che vengano effettuati dei controlli
sul numero di risorse logiche effettivamente disponibili su ciascun dispositivo.
Infine, come e stato gia detto, il tempo necessario per la generazione del bus
in modo automatico, rispetto alla modalita manuale, e inferiore di un ordine di
grandezza.
74

Bibliografia
[1] W. Corti, A. Menesatti ”Metodologia Per La Riconfigurabilita Dinamica Di
Architetture FPGA”, tesi di laurea del Politecnico di Milano, 2003.
[2] F. Cancare, S. Guddemi ”Un’Architettura Per La Riconfigurabilita Di-
namica Basata Su Spartan-3”, tesi di laurea del Politecnico di Milano,
2004.
[3] Xilinx ”Virtex-II Platform FPGAs: Complete Data Sheet”, 2005.
[4] Xilinx ”Virtex-II Pro and Virtex-II Pro X Platform FPGAs: Complete Data
Sheet”, 2005.
[5] Xilinx ”Spartan-3 FPGA Family: Complete Data Sheet”, 2005.
[6] Xilinx ”Two Flows for Partial Reconfiguration: Module Based or Difference
Based”, 2004.
75


















