
Propagazione delle varianze, conosciuta come propagazione...
23
Propagazione delle varianze, conosciuta come propagazione degli errori. Siano x 1 , x 2 , … x n n variabili casuali e poniamo , , … ) = y ( ) Supponiamo inoltre nota la matrice delle covarianze delle x e vogliamo determinare la varianza di y. Se facciamo uno sviluppo in serie di Taylor, bloccata al primo ordine, intorno al valore = ( , , … ) di (x 1 , x 2 , … x n ), abbiamo y ( ) = y( ) + ∑ - ) più termini di ordine superiore e dove la derivata è calcolata in = . Il valore atteso di questa espressione vale {( )} )
-
Upload
nguyenngoc -
Category
Documents
-
view
218 -
download
0
Transcript of Propagazione delle varianze, conosciuta come propagazione...

Propagazione delle varianze,
conosciuta come propagazione
degli errori.
Siano x1, x2, … x n n variabili casuali e
poniamo
, , … ) = y ( )
Supponiamo inoltre nota la matrice delle
covarianze delle x e vogliamo determinare la
varianza di y.
Se facciamo uno sviluppo in serie di Taylor,
bloccata al primo ordine, intorno al valore
= ( , , … )
di (x1, x2, … x n ), abbiamo
y ( ) = y( ) + ∑ - )
più termini di ordine superiore e dove la
derivata è calcolata in = .
Il valore atteso di questa espressione vale
{ ( )} )

più termini di ordine superiore, poiché ogni
termine del primo ordine vale zero.
Solo nel caso in cui le quantità ( xi – μi )
siano piccole, i termini di ordine superiore
possono essere trascurati.
A questo punto si può ottenere la varianza di
y.
V{ ( )}=E{ ( ) [ ( )]}2 { ( ) ( )}
Per quanto detto prima, sempre trascurando i
termini di ordine superiore, si ha che
V{ ( )} ∑ ∑
( )
dove le derivate sono calcolate in = .
Per n variabili indipendenti tutti i termini di
covarianza sono zero e la varianza di y vale
V{ ( )} ∑ (
)² ( )

Un esempio.
Consideriamo la media aritmetica di n
variabili indipendenti x1, x2, … x n aventi tutti
la stessa varianza σ²:
=
∑
Le derivate parziali di y rispetto ad ogni xi
valgono 1/n e le derivate di ordine più alto
sono nulle.
Ne consegue, senza nessuna approssimazione
che la varianza della media aritmetica vale
) = ∑ (
)² σ²
²

Campione e popolazione
Una funzione di densità di probabilità f(x) per
una variabile continua o, equivalentemente,
un insieme di probabilità nel caso discreto
descrivono le proprietà di una popolazione. In
fisica si associa una variabile casuale all’esito
di una osservazione e la p.d.f. f(x)
descriverebbe l’esito di tutte le possibili
misure su un sistema se le misure fossero
ripetute infinite volte nelle stesse condizioni
sperimentali. Poiché ciò è impossibile, il
concetto di popolazione per un fisico
rappresenta un'idealizzazione che non può
essere ottenuta nella pratica.
Un reale esperimento consiste di un numero
finito di osservazioni e una successione x1, x2,
… xn di una certa quantità costituisce un
campione di dimensione n. Per questo
campione possiamo definire la media
aritmetica o media del campione
=
∑

e la varianza del campione
=
∑
- )²
la cui distribuzione dipenderà dalla
distribuzione parente e dalla dimensione del
campione Le due quantità sono funzioni di
variabili casuali e sono anche esse variabili
casuali. Infatti se prendiamo un nuovo
campione di dimensione n otterremo in
generale una nuova media aritmetica e una
nuova varianza : ossia queste grandezze
avranno una loro distribuzione, che dipenderà
dalle proprietà della distribuzione “parente” e
dalla dimensione n del campione.
Il nostro obiettivo è adesso come ricavare, a
partire dalle informazioni che ricaviamo da
un campione, informazioni che riguardano
l’intera popolazione. Naturalmente il
campione deve essere rappresentativo della
popolazione, altrimenti, come accade spesso
nei sondaggi, si ottengono risultati sbagliati.

Per la legge dei grandi numeri la media del
campione tende alla media della popolazione
al tendere di n all’infinito.
Infatti questa legge ( nella forma debole )
prevede che, dato un intero positivo ε, la
probabilità che la media del campione
differisca da μ di una quantità maggiore di ε
tende a zero nel limite di n infinito :
Si può anche dimostrare che il valore atteso
della media del campione coincide con la
media della popolazione e che il valore atteso
di s2 coincide con σ
2 .

Distribuzioni di probabilità
Si possono diverse distribuzioni di
probabilità: quelle di cui parleremo per il
momento è la distribuzione binomiale, quella
di Poisson, quella uniforme, quella normale e
quella del χ².
Distribuzione binomiale. Supponiamo di avere due esiti esclusivi A e Ā
di un certo esperimento: A è chiamato un
“successo” e Ā un “insuccesso”. Per ogni
esperimento sia p ( 0 ≤ p ≤ 1 ) la probabilità
che si verifichi un successo e q=1-p la
probabilità di un insuccesso. Allora per una
successione di n prove indipendenti, la
probabilità di avere r successi e n-r insuccessi
è data :
) ( ) pr
( 1-p)n-r
dove il coefficiente binomiale
( ) =
)

tiene conto che non è importante l’ordine con
cui si verificano gli r successi. Questa
distribuzione si dice anche di Bernoulli, dal
nome dello scienziato svizzero Jakob
Bernoulli.
Si può dimostrare ( vedi “Severi”) che μ=
E(r) = np e che la varianza V(r) =np(1-p).
Il grafico che segue mostra l’andamento di
una binomiale per diversi valori di p e di n:
all’aumentare di n tende ad una distribuzione
normale.

Distribuzione di Poisson
In una distribuzione binomiale può capitare
che p sia molto piccola ed n molto grande,
sicché il valore atteso μ = np può essere
considerevole.
Nel caso limite che p tenda a zero ed n tenda
all’infinito con μ finito, si dimostra che la
binomiale può essere scritta come
)
con r=1,2,….
che costituisce la distribuzione scoperta da
Siméon_Denis Poisson.
Un tipico caso in cui si applica questa
distribuzione è quella degli eventi rari.
Si può dimostrare che E(r) = μ e che la
varianza vale ancora μ.
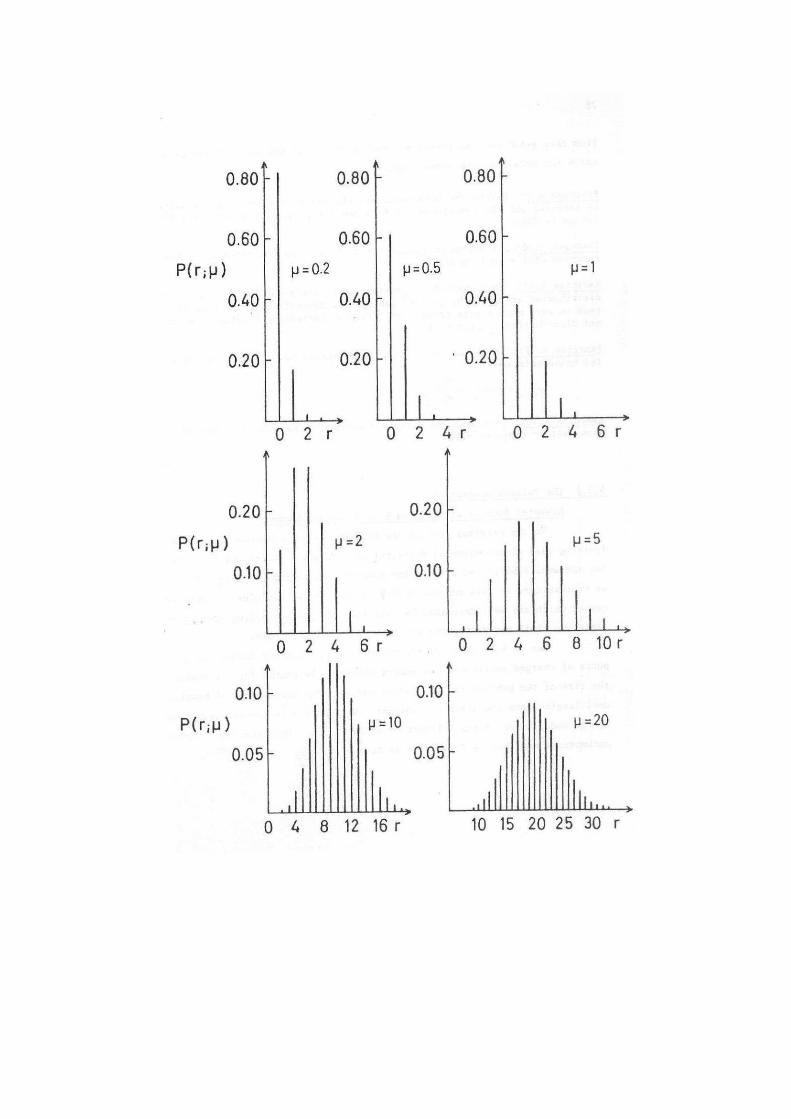
La prossima figura illustra la distribuzione di
Poisson per diversi valori di p: anche essa
tende ad una distribuzione normale al
crescere di μ.

Distribuzione uniforme
Immaginiamo di avere una variabile continua
x che abbia p.d.f. costante sull’intero
intervallo in cui essa sia definita. Allora
) =
con a ≤x ≤ b fornisce una p.d.f. costante.
Si può vedere che
)
)
)
)²
)
dove F(x) è la funzione di distribuzione
cumulativa.
La prossima figura illustra f(x) e F(x).

Distribuzione normale ( o di Gauss )
Questa distribuzione deriva da una
binomiale quando n tende all’infinito. Fu
trovata inizialmente da Abraham de
Moivre e da Pierre-Simon de Laplace;
deve il suo nome anche a Gauss in quanto
egli l’ha applicata agli errori di misura. La
p.d.f. normale ad una dimensione ha la
forma generale :
)
√ )
con - ∞ ≤ x ≤ ∞
Si può dimostrare che E(x) = μ e che V(x) =
σ2. Quindi i parametri μ e σ
2 che compaiono
nella distribuzione hanno il solito significato
di valore medio e varianza della distribuzione.
La distribuzione normale è simmetrica
intorno a μ e quindi la mediana coincide con
μ. Inoltre ha la sua moda ( ossia il suo
massimo) per x = μ. Si può vedere inoltre che
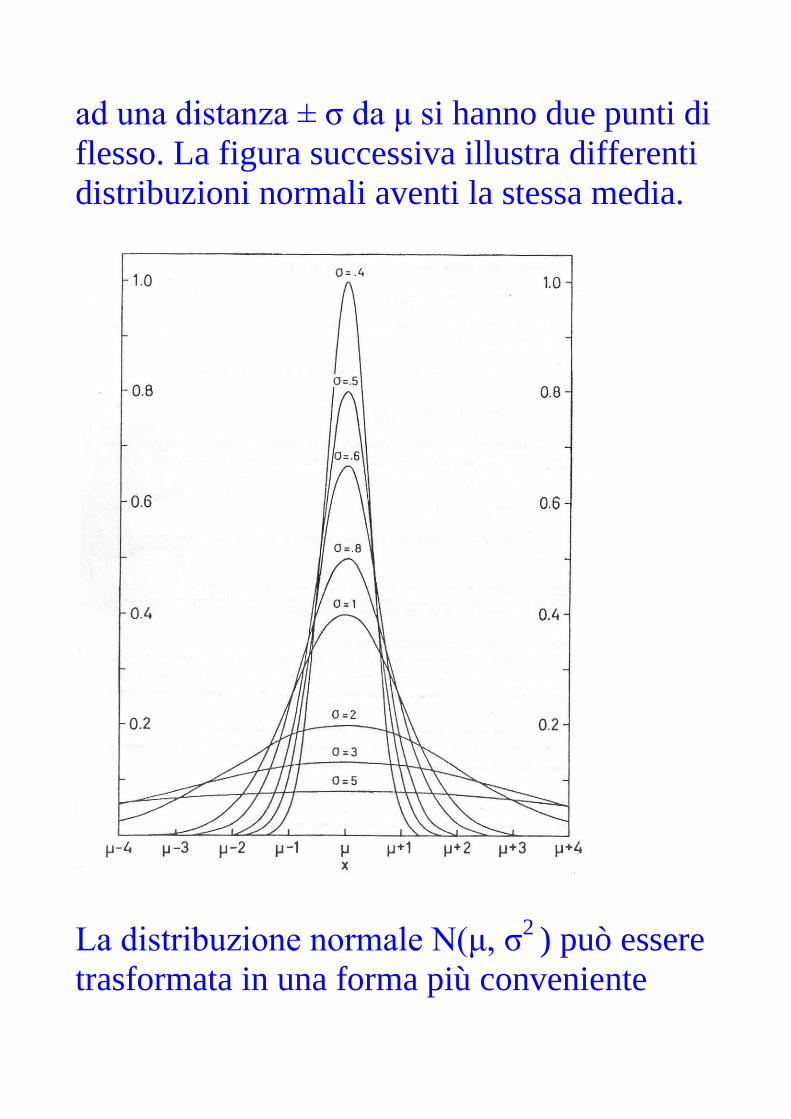
ad una distanza ± σ da μ si hanno due punti di
flesso. La figura successiva illustra differenti
distribuzioni normali aventi la stessa media.
La distribuzione normale N(μ, σ2 ) può essere
trasformata in una forma più conveniente
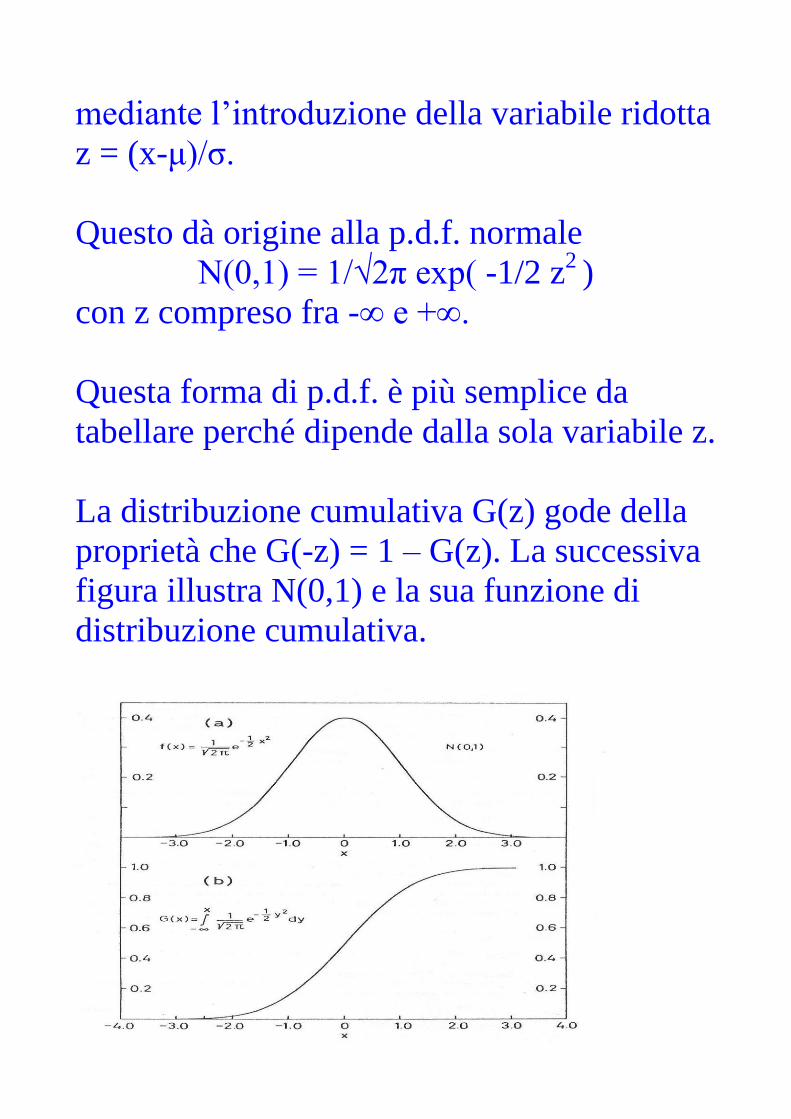
mediante l’introduzione della variabile ridotta
z = (x-μ)/σ.
Questo dà origine alla p.d.f. normale
N(0,1) = 1/√2π exp( -1/2 z2 )
con z compreso fra -∞ e +∞.
Questa forma di p.d.f. è più semplice da
tabellare perché dipende dalla sola variabile z.
La distribuzione cumulativa G(z) gode della
proprietà che G(-z) = 1 – G(z). La successiva
figura illustra N(0,1) e la sua funzione di
distribuzione cumulativa.

La funzione di distribuzione cumulativa
standard G(z) è usata per determinare il
contenuto di probabilità di un dato intervallo
per un valore distribuito normalmente e
viceversa per determinare un intervallo
corrispondente ad una certa probabilità.
Sia x una variabile casuale distribuita secondo
N(μ, σ2 ). Vogliamo determinare la probabilità
che x cada entro un certo intervallo [a,b].
Ora P( a ≤ x ≤ b) = P( x ≤ b) – P( x ≤ a), che è
equivalente a scrivere che
P( a ≤ x ≤ b) = G[(b-μ)/σ] - G[(a-μ)/σ].
Usando le opportune tavole si trova che :
P( - ) 2 G(1) -1 = 0,6827
P( - ) 2 G(2) -1 = 0,9545
P( - ) 2 G(3) -1 = 0,9973
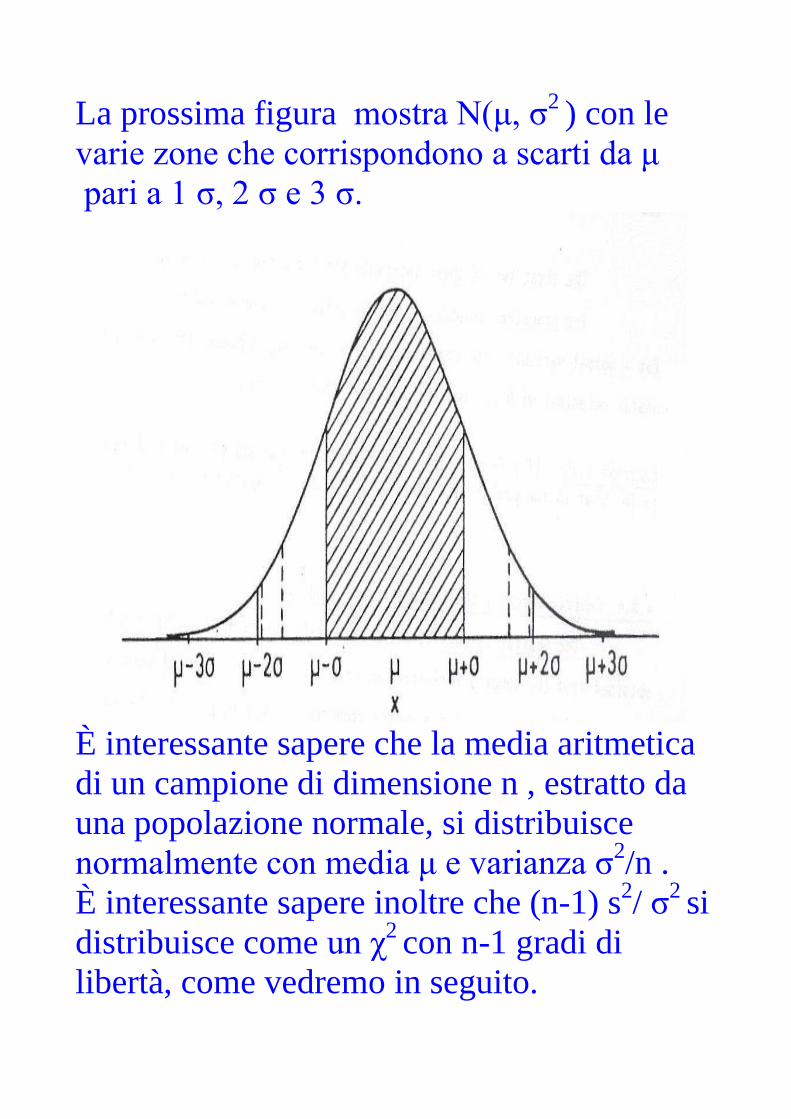
La prossima figura mostra N(μ, σ2 ) con le
varie zone che corrispondono a scarti da μ
pari a 1 σ, 2 σ e 3 σ.
È interessante sapere che la media aritmetica
di un campione di dimensione n , estratto da
una popolazione normale, si distribuisce
normalmente con media μ e varianza σ2/n .
È interessante sapere inoltre che (n-1) s2/ σ
2 si
distribuisce come un χ2 con n-1 gradi di
libertà, come vedremo in seguito.

Concludiamo con l’enunciare il teorema del
Limite Centrale dovuto sempre a Laplace.
Se x1, x2, … x N sono un insieme di N variabili
casuali indipendenti, ognuno aventi media
della popolazione μi e varianza finita ,
allora la variabile
∑ ∑
√∑
ha, come distribuzione limite, una
distribuzione normale, centrata su zero e
varianza pari ad 1.
In particolare la media aritmetica di n misure
xi della stessa grandezza fisica x nelle stesse
condizioni tende ad una distribuzione normale
con media µ e varianza σ² per n anche
se la distribuzione di x non è normale: la
cosa importante è che la varianza sia finita.Il
motivo per cui in laboratorio è consigliabile
effettuare misure ripetute è proprio legato al
Teorema del Limite Centrale.

La distribuzione del χ2
Consideriamo una grandezza x, che si
distribuisca secondo una distribuzione
normale, centrata intorno a X con varianza
σ². Introduciamo il concetto di variabile
standard z definendola come z = (x-X)/σ.
Si può dimostrare che z si distribuisce
secondo una distribuzione normale, centrata
sullo zero e con varianza pari ad 1.
Consideriamo ora ν variabili standard zi.
Possiamo definire allora la grandezza χ2
come la somma dei quadrati di ν variabili
standard:
Il parametro ν viene chiamato numero di
gradi di libertà.
Si può ricavare la funzione di distribuzione
fν(χ2), tale che fν(χ
2) d χ
2 dia la probabilità di

trovare un valore del chi quadro compreso fra
χ2 e χ
2+d χ
2:
dove C è un fattore di normalizzazione. Si
può vedere che
C= 2½ν
Γ(½ν)
dove Γ è la funzione Gamma di Eulero, che le
seguenti proprietà :
Γ(x+1) = x Γ(x)
Γ(½) = √π
Γ(1) = 1
A questo punto è possibile ricavare la
probabilità P(χ2
> χ2
0 ), ossia la probabilità di
trovare un valore di χ2
maggiore di uno
fissato χ2
0 .
e quindi ottenere il valore atteso e la varianza
del chi quadro :

In alcune situazioni è più opportuno usare il
cosiddetto chi quadro ridotto, definito come
rapporto fra il chi quadro e il numero di gradi
di libertà. Si ha in tal caso
La tabella A.16 del Severi mostra i valori del
χ2
ridotto ordinati per righe, individuate dai
valori di ν e per colonne individuate dai
valori di P(χ2/
χ20/ν ). La tabella D del
Taylor illustra i valori di P(χ2/
χ20/ν ) in
funzione di ν e di χ20/ν.
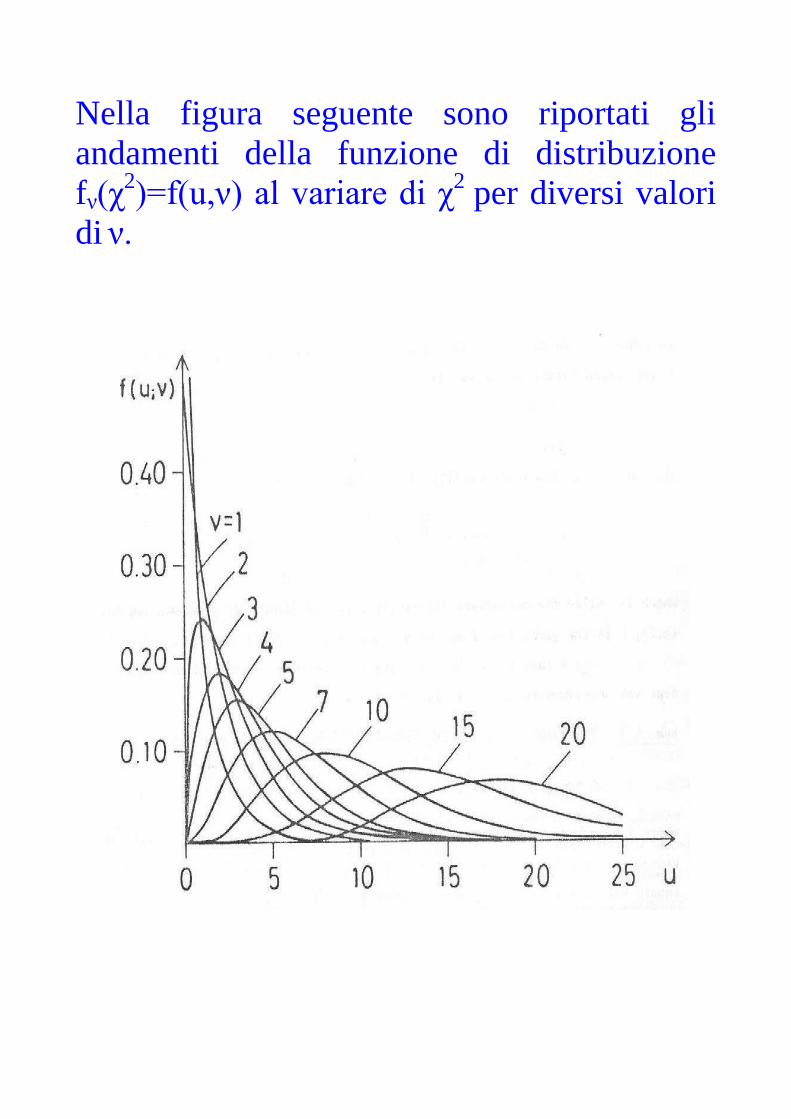
Nella figura seguente sono riportati gli
andamenti della funzione di distribuzione
fν(χ2)=f(u,ν) al variare di χ
2 per diversi valori
di ν.

In particolare si nota che f1 (χ2) , essendo
proporzionale a exp(-χ2/2)/√ χ
2, diverge per χ
2
tendente a zero.
Inoltre si nota che f2(χ2), essendo
proporzionale a exp(- χ2/2 ) , ha l'andamento
di un esponenziale decrescente.
Per ν maggiore di due, la funzione vale zero
per χ2
uguale a zero, manifesta un massimo
per un valore del χ2
pari a ν-2 e poi decresce
con una coda, più o meno lunga, verso lo
zero al divergere di χ2.
Come si vede, la funzione non è simmetrica,
ma tende, al crescere di ν ad una distribuzione
normale di pari valore atteso e varianza.
Nella pratica questo limite si ritiene raggiunto
per ν pari a circa 30.
È opportuno rimarcare infine che , quando
viene usato ai fini di test di ipotesi, il χ2
sperimentale χ2
0 deve essere tale che
P(χ2 > χ
20 ) ≥ 0.05

( ossia l'area sottesa dalla funzione di
distribuzione fra χ2
0 e ∞ deve essere
maggiore od uguale al 5 per cento ), affinché
l'ipotesi non sia rigettata. Talora questo taglio
del 5 per cento viene portato al 10 per cento.
Il motivo di questo taglio è dovuto al
desiderio di ridurre la possibilità di accettare
per buona un'ipotesi falsa a costo di perdere
un'ipotesi buona ma avente bassa probabilità
di verificarsi.


















