
Programmazione Non Lineare
29
Programmazione non lineare Davide Torlo 24/07/2014 1
-
Upload
davide-torlo -
Category
Documents
-
view
60 -
download
2
description
Parziale tesi di laurea su programmazione non lineare con vincoli di disuguaglianze
Transcript of Programmazione Non Lineare

Programmazione non lineare
Davide Torlo
24/07/2014
1

Indice
1 Introduzione 3
2 Prerequisiti 4
2.1 Il Teorema di Danskin . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Teorema di Lyusternik . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1 Esempio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.2 Formulazione alternativa del teorema di Lyusternik . . . . . . . . 9
2.3 Principio ε-variazionale di Ekeland . . . . . . . . . . . . . . . . . . . . . 11
2.4 Funzioni di penalizzazione . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 Programmazione non lineare 18
3.1 Problema di programmazione non lineare . . . . . . . . . . . . . . . . . . 18
3.2 Condizioni necessarie del primo ordine (Fritz John) . . . . . . . . . . . . 19
3.2.1 Lagrangiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2.2 Dimostrazione con le funzioni di penalizzazione . . . . . . . . . . 22
3.2.3 Dimostrazione con il principio ε-variazionale di Ekeland . . . . . . 24
3.3 Altre condizioni del primo ordine . . . . . . . . . . . . . . . . . . . . . . 25
3.4 Condizioni del secondo ordine . . . . . . . . . . . . . . . . . . . . . . . . 27
4 Exempla 29
2

1 Introduzione
qua devo ancora riscrivere tutta l’intro, non corregga
Perche voglio parlare di programmazione non lineare?
Qua vorrei presentare due problemi concreti di cui voglio trovare un minimo di una fun-
zione vincolato con disuguaglianze da Rn a R.
Quindi vorrei spiegare cosa e un programma non lineare. Un problema di programmazione
non lineare e un problema di ottimizzazione vincolata del tipoott f(x)
gi(x) ≤ 0, i = 1, ..., r
hj(x) = 0, j = 1, ...,m
(1)
Con ottimizzazione si intende la ricerca di minimi o massimi assoluti e locali. In ogni
situazione possiamo scrivere la ricerca di un ottimo come la ricerca di un minimo, sem-
plicemente cambiando il segno di f(x). Da ora in poi, scriveremo il problema comemin f(x)
gi(x) ≤ 0, i = 1, ..., r
hj(x) = 0, j = 1, ...,m
(2)
Prima di studiare i metodi che portano alla ricerca delle soluzioni di questi problemi,
abbiamo bisogno di alcuni prerequisiti che studio nel seguente paragrafo.
3

2 Prerequisiti
In questa sezione presenteremo alcuni risultati che ci saranno utili per trattare la pro-
grammazione non lineare. In particolare, passeremo in rassegna il Teorema di Dan-
skin, il Teorema di Lyusternik, il Principio ε-Variazionale di Ekeland e le Funzioni di
Penalizzazione.
2.1 Il Teorema di Danskin
Il teorema di Danskin e un teorema fondamentale per il calcolo delle derivate delle con-
dizioni di ottimo. Infatti, permette di calcolare la derivata della funzione marginale data
dal massimo su una curva di livello.
Nella nostra trattazione verra usato nella dimostrazione del teorema di Fritz John, nella
versione con il principio ε-variazionale di Ekeland, quando, appunto, servira calcolare la
derivata di una funzione di tal tipo.
Teorema (Danskin)
Siano X ⊆ Rn aperto, Y sottoinsieme compatto di uno spazio topologico T e f : X×Y →R una funzione continua. Supponiamo che ∇xf(x, y) esista e sia continua. Allora la
funzione marginale
ϕ(x) := maxy∈Y
f(x, y)
e continua in X, ha derivata ϕ′(x,h) in ogni direzione h data da
ϕ′(x,h) = maxy∈Y (x)
〈∇xf(x, y),h〉,
dove Y (x) = {y ∈ Y : ϕ(x) = f(x, y)}.
Dimostrazione
Iniziamo provando la continuita.
Siano x0 ∈ X, {xk}∞1 ⊆ X tali che xk −−−→k→∞
x0. Per ogni k, per la compattezza di
Y, ∃yk ∈ Y : ϕ(xk) = f(xk, yk); inoltre, si ha che {yk} o una sua sottosuccessione
converge ad un punto y0 ∈ Y e, per ipotesi, f(xk, yk) ≥ f(xk, y) ∀y ∈ Y .
limk→+∞
ϕ(xk) = limk→+∞
f(xk, yk) = f(x0, y0) ≥ limk→+∞
f(xk, y) = f(x0, y), ∀y ∈ Y.
Quindi f(x0, y0) = ϕ(x0) = limk→+∞
ϕ(xk), pertanto ϕ e continua in x0.
Passiamo ora alla dimostrazione della seconda tesi.
4

Sia h 6= 0 ∈ Rn, e sia {xk}∞1 con xk = x0 + tkh, tk ≥ 0, una successione convergente a x0
(tk → 0). Sia y ∈ Y (x0); se ϕ(xk) = f(xk, yk), k ≥ 1, allora
ϕ(xk)− ϕ(x0)
tk=f(xk, yk)− f(x0, y)
tk=
=f(xk, yk)− f(xk, y)
tk+f(xk, y)− f(x0, y)
tk≥
≥ 0 +f(xk, y)− f(x0, y)
tk= 〈∇xf(x0 + t′kh, y),h〉,
dove l’ultima uguaglianza e dovuta al teorema del valor medio.
Per le ipotesi, per ogni y ∈ Y (x0) si ha:
lim infk→∞
ϕ(xk)− ϕ(x0)
tk≥ 〈∇xf(x0, y),h〉,
da cui
lim infk→∞
ϕ(xk)− ϕ(x0)
tk≥ max
y∈Y (x0)〈∇xf(x0, y),h〉.
Poiche ϕ(xk) = f(xk, yk), ho che
ϕ(xk)− ϕ(x0)
tk=f(xk, yk)− f(x0, yk)
tk+f(x0, yk)− f(x0, y0)
tk≤
f(xk, yk)− f(x0, yk)
tk+ 0 = 〈∇xf(x0 + t′′kh, yk),h〉,
quindi
lim supk→∞
ϕ(xk)− ϕ(x0)
tk≤ lim sup
k→∞〈∇xf(x0 + t′′kh, yk),h〉 =
= 〈∇xf(x0, y0),h〉 ≤ maxy∈Y (x0)
〈∇xf(x0, y0),h〉,
da cui segue la tesi. �
Questo teorema verra largamente usato nella teoria che sara sviluppata in seguito.
5

2.2 Teorema di Lyusternik
Il teorema di Lyusternik mette in relazione l’insieme delle direzioni tangenti in un punto
a un insieme di livello di una funzione con il nucleo dell’applicazione lineare associata al
differenziale della funzione nel punto. Questo teorema verra usato nella dimostrazione
delle condizioni di Fritz John. Puo anche essere dimostrato attraverso le funzioni di
penalizzazione che introdurremo piu avanti. Prima di enunciare il teorema introduciamo
le seguenti definizioni:
Definizione
Siano M un sottoinsieme non vuoto di Rn e x ∈M . Un vettore d ∈ Rn si dice direzione
tangente a M in x se esiste una successione {xn} ⊂M convergente a x e una successione
{αn} ⊂ R tali che
limn→∞
αn(xn − x) = d.
Definizione
Si dice cono tangente a M in x l’insieme di tutte le direzioni tangenti a M in x e si
indica con TM(x).
Figura 1: Cono tangente a S1 in (1, 0, 0)
Teorema (Lyusternik)
Siano U ⊆ Rn aperto, f : U → Rm una funzione di classe C1. Per ogni x0 ∈ U , si consideri
M := f−1(f(x0)). Allora TM(x0) = kerDf(x0).
Dimostrazione
Senza perdita di generalita supponiamo x0 = 0 e f(x0) = 0 (altrimenti si consideri la
funzione x 7→ f(x+ x0)− f(x0)). Sia A := Df(0).
6

Dimostriamo inizialmente l’inclusione di TM(0) in kerDf(0).
Se d ∈ TM(0) allora ∃t : x(t) = td + o(t). Applicando f abbiamo che
0 = f(td + o(t)) = f(0) + tDf(0)d + o(t),
il che implica Df(0)d = 0 e d ∈ kerDf.
Ho dimostrato che TM(0) ⊆ kerDf(0).
Dimostriamo ora l’inclusione inversa.
Sia K := kerDf(0). Siccome Df(0) e un’applicazione lineare su Rn, possiamo porre
L := K⊥, K ' Rn−m, L ' Rm
e si puo vedere x ∈ Rn ' Rn−m × Rm, cioe possiamo scrivere x = (y, z) ∈ K × L e
A = [Dyf(0), Dzf(0)].
Per definizione, kerDf(0) viene mappato da A in 0, cioe
0 = A(K) = {A(d1, 0) : d1 ∈ Rn−m} = Dyf(0)(Rn−m),
ma il rango di A e m, quindi Dzf(0) e non singolare.
Usando il teorema della funzione implicita abbiamo che ∃ U1 ∈ Rm e U2 ∈ Rn−m e una
mappa α : U1 → U2, di classe C1, tale che α(0) = 0 e f(x) = 0 ↔ z = α(y), ma
(x = (y, z)), quindi f(y, α(y)) = 0.
Derivando ho che
0 = Dyf(y, α(y)) +Dzf(y, α(y)) ·Dα(y);
nell’origine x = 0, ma Dyf(0) = 0 e Dzf(0) e non singolare, percio Dα(y) = 0.
Se |y| → 0 ho che, usando la formula di Taylor,
α(y) = α(0) +Dα(0) · y + o(y) = o(y).
Se prendiamo d = (d1, 0) ∈ K e una successione di punti x(t) := (td1, α(td1)) = (td, o(t)),
possiamo dimostrare che appartengono a M e quindi che d ∈ TM(0). Infatti f(x(t)) = 0,
quindi x(t) ∈ M , e per t → 0 abbiamo che x(t)−tdt
= (0, o(t)t
) → 0, dunque il vettore d
appartiene al cono tangente.
Quindi ho che d ∈ TM(0)⇒ K ⊆ TM(0). Segue la tesi. �
7

2.2.1 Esempio
Proviamo ora a vedere in un esempio concreto in che modo coincidano il kerDf(x0) e il
TM(x0).
Figura 2: Tangente alla circonferenza nel punto x0
Prendiamo una funzione f da R3 a R2:
f(x) =
(x2 + y2 + z2 − 1
z
).
E sia x0 = (1, 0, 0) ∈ f−1(0, 0). Abbiamo che
M = f−1(0, 0) = {(x, y, z) ∈ R3 : x2 + y2 + z2 − 1 = 0, z = 0}.
8

Il suo tangente nel punto x0 possiamo vedere facilmente che e lo spazio vettoriale generato
la retta tangente alla circonferenza M in x0:
TM(x0) = {z = 0, x = 0, y ∈ R}.
Se proviamo a calcolare il differenziale nel nostro punto otteniamo lo stesso risultato,
infatti
Df(x, y, z) =
(2x 2y 2z
0 0 1
),
Df(1, 0, 0) =
(2 0 0
0 0 1
),
kerDf(1, 0, 0) = {2x = 0, z = 0, y ∈ R} = TM(x0).
Come possiamo notare in figura, il livello zero e l’intersezione tra la sfera e il piano, ovvero
la circonferenza arancione di centro l’origine e raggio 1 sul piano xOy. Il tangente nel
punto x0 e la retta rossa.
2.2.2 Formulazione alternativa del teorema di Lyusternik
L’enunciato del teorema di Lyusternik, come presentato ora, e quello che lui stesso aveva
dimostrato nel 1934. Ma le tecniche dimostrative che aveva usato, possono portare a
risultati piu ampi di quelli da lui dimostrati. Spesso, infatti, con il teorema di Lyusternik
si indicano anche altri enunciati, in particolare i due seguenti.
Ricoprimenti
Siano X, Y spazi di Banach, g : X → Y di classe C1 e sia un punto x0 ∈ g−1(0), tale che
g ivi soddisfa la condizione di Lyusternik, ovvero g′(x0)X = Y . Sia x ∈ x0 + ker g′(x0),
allora d(x, g−1(0)) = o(||x− x0||), ovvero ∀Bρ(x) ∃a > 0 tale che g(Bρ(x)) ⊃ Baρ(g(x)).
Da qui discende facilmente l’enunciato originale di Lyusternik.
Distanza
Sotto le stesse ipotesi abbiamo che d(x, g−1(y)) ≤ 1a||g(x)−y||, ∀x ∈ U(x0), ∀y ∈ U(0) ⊂
Y.
Le due formulazioni sono equivalenti, mentre quella di Lyusternik e una conseguenza
di queste. Questo teorema viene molto usato nella ricerca di massimi e minimi vincolati.
Consideriamo il problema di minimo (P )
min f(x), g(x) = 0.
9

Due modalita sono possibili a questo punto. La prima e di considerare individualmen-
te un’approssimazione della funzione obiettivo e dei vincoli. Usiamo in questo caso la
formulazione della distanza per il teorema di Lyusternik e del cono tangente. Sappia-
mo che f, g ∈ C1, di conseguenza Tg−1(0)(x0) = x0 + ker g′(x0). Allora abbiamo che
f ′(x0) si annulla sul ker g′(x0), per la condizione di Lyusternik, esiste y∗ ∈ Y ∗ tale che
f ′(x0) + y∗g′(x0) = 0. Questa, come vedremo piu avanti, e la regola dei moltiplicatori di
Lagrange.
La seconda possibilita e quella di considerare un unico funzionale che mappi sia la fun-
zione obiettivo che i vincoli. Ricordiamo, ora, il teorema di Grave, che dice:
Sia g un operatore C1 in x0, che soddisfa la condizione di Lyusternik. Allora per ogni
intorno di g(x0) esiste un intorno di x0 tale che g(U(x0)) ⊇ U(g(x0)).
Riconsiderando il problema (P ) e prendendo Φ(x) = (f(x), g(x)) : X → R × Y , abbia-
mo che se x0 e un punto di minimo, allora Φ lı non puo verificare il teorema di Grave,
perche non esiste un intorno di Φ(x0) contenuto nell’immagine di un intorno di x0. Allora
non puo valere la condizione di Lyusternik in x0 per Φ. Ovvero Φ′(x0)X 6= R × Y , ma
g′(x0)X = Y , dunque ∃y∗ ∈ Y ∗ tale che f ′(x0) + y∗g′(x0) = 0.
Ancora una volta otteniamo la regola dei moltiplicatori di Lagrange.
Questo ci dice di come il teorema di Lyusternik, sia la base della ricerca dei minimi
di funzioni vincolate, in quanto da questo teorema possiamo raggiungere le condizioni
necessarie che sono alla base di questa materia.
10
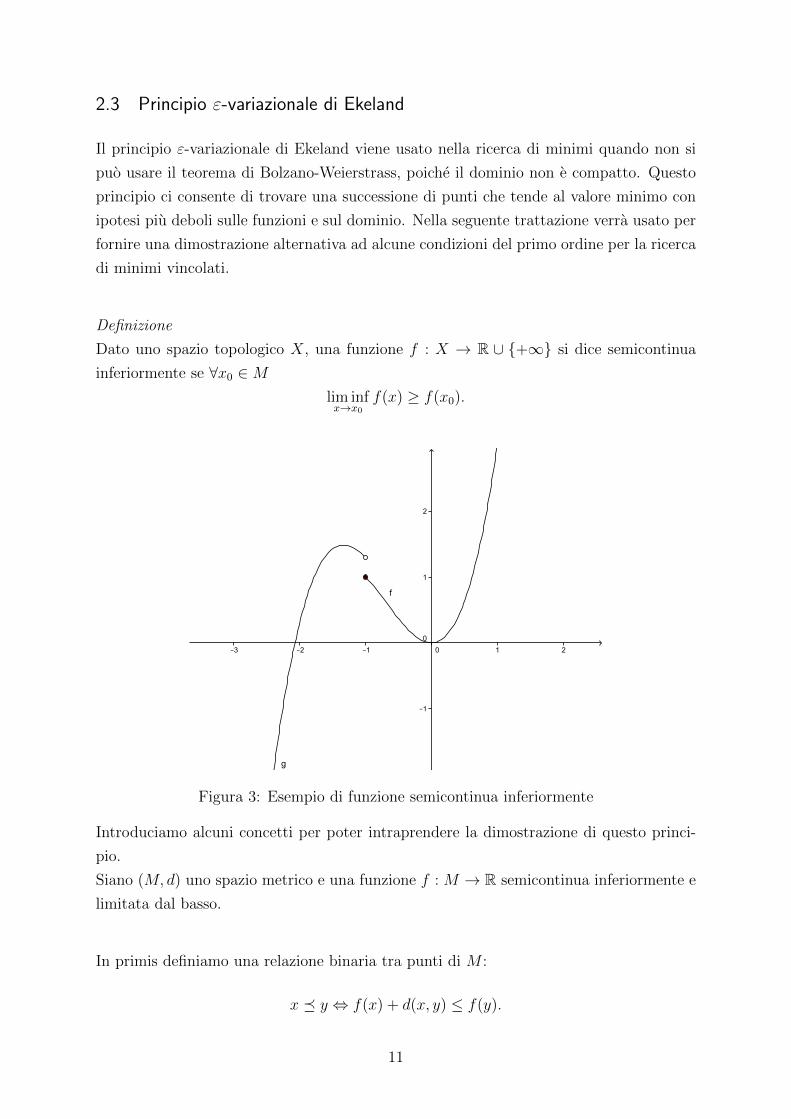
2.3 Principio ε-variazionale di Ekeland
Il principio ε-variazionale di Ekeland viene usato nella ricerca di minimi quando non si
puo usare il teorema di Bolzano-Weierstrass, poiche il dominio non e compatto. Questo
principio ci consente di trovare una successione di punti che tende al valore minimo con
ipotesi piu deboli sulle funzioni e sul dominio. Nella seguente trattazione verra usato per
fornire una dimostrazione alternativa ad alcune condizioni del primo ordine per la ricerca
di minimi vincolati.
Definizione
Dato uno spazio topologico X, una funzione f : X → R ∪ {+∞} si dice semicontinua
inferiormente se ∀x0 ∈Mlim infx→x0
f(x) ≥ f(x0).
Figura 3: Esempio di funzione semicontinua inferiormente
Introduciamo alcuni concetti per poter intraprendere la dimostrazione di questo princi-
pio.
Siano (M,d) uno spazio metrico e una funzione f : M → R semicontinua inferiormente e
limitata dal basso.
In primis definiamo una relazione binaria tra punti di M :
x � y ⇔ f(x) + d(x, y) ≤ f(y).
11

Abbiamo che (M,�) e un poset. Infatti si prova facilmente che:
i) x � x;
ii) x � y e y � x implica x = y;
iii) x � y e y � z implica x � z.
Definiamo ora ∀x ∈M
S(x) := {y ∈M : y � x} = {y ∈M : f(y) + d(x, y) ≤ f(x)}.
Figura 4: In blu S(x)
Definizione
Diremo che x e un d-point se S(x) = {x}.
Il seguente teorema, non e solo un lemma utile ai fini di dimostrare il principio ε-
variaizionale di Ekeland, ma e una vera e propria caratterizzazione di ogni spazio metrico
completo. Questa caratterizzazione e molto utile allo studio di ottimi, dell’analisi con-
vessa, e viene anche usato per dedurre il teorema del punto fisso di Kirk-Caristi per
multi-funzioni.
12

Teorema
Sia (M,d) uno spazio metrico. Allore le seguenti affermazioni sono equivalenti:
a) (M,d) e uno spazio metrico completo.
b) Per ogni funzione f : M → R ∪ {∞} semicontinua inferiormente e limitata dal basso,
per ogni punto x0 ∈M , esiste un d-point x tale che x � x0.
Dimostrazione
Dimostriamo che a) implica b).
Se f(x0) = +∞ allora ∀x ∈M : f(x) < +∞ x � x0. Quindi procediamo usando questo
x al posto di x0. Trovato il d-point x avro che x � x � x0. Seguira la tesi.
Se f(x0) < +∞ costruisco una successione {xn}∞0 ⊂ M ricorsivamente, scegliendo arbi-
trariamente xn+1 ∈ S(xn).
{xn}∞0 e di Cauchy: infatti, se n ≥ m, ho che xn � xn−1 � ... � xm, quindi f(xn) +
d(xn, xm) ≤ f(xm). In particolare, {(f(xn)}∞0 e una successione decrescente e limitata dal
basso, quindi converge ad un certo α ∈ R. Dal momento che d(xn, xm) ≤ f(xm)−f(xn)→0 con m,n→ 0, {xn}∞0 e di Cauchy. Per la completezza di M , ∃x ∈M : xn → x. Inoltre
xk ∈ S(xn) ∀k ≥ n, ma S(xn) sono chiusi, quindi contengono anche x per ogni n.
Di conseguenza x ∈⋂∞k=1 S(xk).
Per garantire che x sia un d-point, devo aggiungere delle condizioni nella scelta degli
xn.
xn : f(xn) ≤ infx∈S(xn−1)
f(x) +1
n
Cosı se z ∈ S(x), allora abbiamo che z � x � xn−1 � xn
f(z) + d(z, xn) ≤ f(xn) ≤ infS(xn−1)
f +1
n≤ f(z) +
1
n
d(z, xn) ≤ 1
n→ 0 ⇒ xn → z ⇒ x = z
Segue quindi che S(x) = {x}, cioe x e un d-point.
Dimostriamo ora che b) implica a).
Prendiamo una successione di Cauchy {xn}∞1 ⊆M . Voglio mostrare che ha limite in M .
Sia f(x) := 2 limn→∞ d(x, xn). f(x) e ben definita; infatti si verifica facilmente che
{d(x, xn)}∞1 e di Cauchy in R, e, per la completezza di R, la successione converge e ha
limite.
f e continua, infatti |(d(x, xn) − d(y, xn))| ≤ d(x, y), per ogni n e le successioni delle
distanze convergono. Ora
1
2|f(x)− f(y)| = | lim
n→∞(d(x, xn)− lim
m→∞d(y, xm))|.
13

Essendo le successioni di Cauchy, ∀ε > 0 ∃N : ∀n,m > N, |d(y, xm) − d(y, xn)| ≤ ε.
Quindi posso scrivere
1
2|f(x)− f(y)| ≤ | lim
n→∞((d(x, xn)− d(y, xn))) + ε|
Con ε che tende a 0 abbiamo che, per monotonia, il tutto e ≤ d(x, y). Abbiamo ora la
continuita.
Si noti che f(xn)→ 0. Sia x ∈M un d-point di f . Allora
f(x) ≤ f(xn) + d(x, xn) ∀n ≥ 1.
Per n→∞ abbiamo che f(x) ≤ f(x)2
, ma, siccome f e positiva, f(x) = 0.
Cio implica che d(x, xn)→ 0, quindi la successione converge.
Quindi (M,d) e completo. �
A questo punto si puo dedurre con facilita il principio ε-variazionale di Ekeland.
Teorema (Principio ε-variazionale di Ekeland)
Sia (M,d) uno spazio metrico completo e sia f : M → R ∪ {+∞} semicontinua inferior-
mente, limitata dal basso.
Allora ∀ε ≥ 0, ∀λ ≥ 0, ∀x ∈M tali che f(x) ≤ infx∈M f(x) + ε, ∃xε ∈M :f(xε) ≤ f(x)
d(xε, x) ≤ λ
f(xε) < f(z) + ελd(z, xε) ∀z ∈M z 6= xε
(3)
Dimostrazione
E sufficiente dimostrare il teorema per λ = 1 e ε = 1; il caso generale segue sostituendo
alla funzione distanza d la funzione dλ
e sostituendo alla funzione f la funzione fε.
A questo punto basta applicare il teorema precedente. Infatti ∀x ∈ M ∃x � x, con x
d-point. La terza condizione e verificata dalla definizione di d-point, mentre le prime due
derivano dalla seguente disuguaglianza
f(x) + d(x, x) ≤ f(x) ≤ infMf + 1 ≤ f(x) + 1,
dove la prima disuguaglianza e conseguenza del fatto che x � x. �
La conclusione a cui giunge il teorema e che prendendo una funzione semicontinua in-
feriormente, in uno spazio metrico, fissato un coefficiente angolare, possiamo trovare un
14

punto, tale per cui, tracciando un cono che ha vertice nel punto e che scende con coeffi-
ciente angolare dato, questo sia completamente al di sotto della funzione data.
Se, come in figura, lo spazio metrico e R, possiamo tracciare una coppia di semirette con
coefficiente angolare ± ελ, che dal d-point generano un cono verso il basso sotto al quale
la funzione non scende mai.
Figura 5: Principio ε-variazionale di Ekeland
Corollario 1
Sia (M,d) uno spazio metrico completo e sia f : M → R ∪ {+∞} semicontinua inferior-
mente, limitata dal basso.
Allora ∀ε ≥ 0 e x ∈M tali che f(x) ≤ infx∈M f(x) + ε, ∃xε ∈M :f(xε) ≤ f(x)
d(xε, x) ≤√ε
f(xε) ≤ f(z) +√ε d(z, xε), ∀z ∈M : z 6= xε
(4)
Dimostrazione
Basta sostituire√ε a λ nel Principio di Ekeland. �
Corollario 2
Sia X uno spazio di Banach e sia f : X → R Gateaux differenziabile, semicontinua
inferiormente e limitata dal basso. Sia ε > 0, e sia x ∈ X un punto tale che
f(x) ≤ infXf + ε.
15

Allora esiste un punto xε ∈ X tale che
f(xε) ≤ f(x),
||x− xε|| ≤ 1,
||∇f(xε)|| ≤ ε.
E di conseguenza esiste una successione {xn} ⊂ X che soddisfa la condizione
f(xn)→ infXf e ∇f(xn)→ 0.
Dimostrazione
Il principio ε-variazionale di Ekeland fornisce un punto che soddisfa le prime due condi-
zioni. Per provare la terza notiamo che per ogni direzione d ∈ X, ||d|| = 1, abbiamo
che
t〈∇f(xε),d〉+ o(t) = f(xε + td)− f(xe) ≥ −tε
per t → 0, dove l’uguaglianza e verificata perche Gateaux differenziabile e la disugua-
glianza arriva dalla terza disuguaglianza del principio di Ekeland. Abbiamo dunque che
〈∇f(xε),d〉 ≥ −ε, ovvero 〈∇f(xε),d〉 ≤ ε ∀d ∈ X, ||d|| = 1. Dunque ||∇f(xε)|| ≤ ε.
Sia yn un punto in X che soddisfi f(yn) ≤ infX f + 1/n. Abbiamo gia mostrato che
esiste un punto xn che soddisfa le seguenti condizioni: f(xn) ≤ f(yn) ≤ infX f + 1/n e
||∇f(xn)|| ≤ 1/n. La successione {xn}∞1 soddisfa le proprieta richieste. �
2.4 Funzioni di penalizzazione
I metodi di penalizzazione sono degli algoritmi usati per risolvere un problema di ottimo
vincolato, attraverso una serie di problemi di ottimo libero, che convergano alla medesima
soluzione. Il metodo prevede l’aggiunta di una funzione di penalizzazione alla funzione
obiettivo. La funzione di penalizzazione e definita come un multiplo della misura di
allontanamento dal vincolo. Per esempio se il nostro problema consiste inmin f(x)
ci(x) ≥ 0 ∀i ∈ I,
questo viene trasformato in una serie di problemi, al variare di k, del tipomin Φk(x) = f(x) + σk∑
i∈I g(ci(x))
g(ci(x)) =min(0, ci(x))2.
16

Useremo questa tecnica per dare una dimostrazione alternativa per le condizioni di Fritz
John, in quell’occasione sara chiaro che le funzioni di penalizzazioni φk condurranno
alla ricerca di minimi liberi, utilizzando tecniche tipiche di quell’ambito. In particolare
verra posto uguale a 0 il differenziale delle funzioni di penalizzazioni, trovando cosı una
successione di minimi liberi che tendera al minimo del problema vincolato.
17

3 Programmazione non lineare
3.1 Problema di programmazione non lineare
Un problema di programmazione non lineare consiste in un problema di ottimizzazione
(P ), con vincoli di uguaglianza e di disuguaglianza, avente questa forma:
min f(x)
gi(x) ≤ 0, i = 1, ..., r (P )
hj(x) = 0, j = 1, ...,m
dove f, {gi}r1 e {hj}m1 sono funzioni a valori reali definite su un sottoinsieme U ⊆ Rn. La
funzione f si chiama funzione obiettivo di (P ), mentre le disuguaglianze e le uguaglianze
con le gi e le hj si chiamano vincoli del problema.
La regione ammissibile di (P ) e il sottoinsieme di punti che soddisfano tutti i vincoli:
F(P ) = {x ∈ U : gi(x) ≤ 0, i = 1, ..., r, hj(x) = 0, j = 1, ...,m}.
Definizione
Un punto ammissibile x∗ si chiama punto di minimo locale di (P ) se e un minimo di f
in un intorno amissibile di x∗, ovvero se ∃ε tale che
f(x∗) ≤ f(x) ∀x ∈ F(P ) ∩Bε(x∗).
Il punto si dice di minimo globale se f(x∗) ≤ f(x) ∀x ∈ F(P ).
Definizione
Dato un punto x ∈ F(P ), un vincolo gi si dice attivo se gi(x) = 0, si dice inattivo se
gi(x) < 0.
Notiamo infatti che, nella ricerca di un minimo, se x∗ e un minimo e gi(x∗) < 0, per
qualche i, allora il vincolo gi non gioca un ruolo attivo nella ricerca del minimo.
Quindi definiamo per ogni punto x ∈M I(x) := {i : gi(x) = 0} l’insieme dei vincoli attivi
in x.
Definizione
Sia x∗ ∈ F(P ). Una direzione tangente d a F(P ) in x∗ si dice direzione ammissibile.
L’insieme delle direzioni ammissibili di (P ) in un punto x∗ verra denotato con FD(x∗).
Un vettore d ∈ Rn si chiama direzione discendente per f in x∗ se esiste una sequenza
di punti xn → x∗ ⊂ Rn, non necessariamente ammissibili, con direzione tangente d e
18

tali che f(xn) ≤ f(x∗) per ogni n. Se f(xn) < f(x∗) ∀n, allora verra detta d direzione
strettamente discendente. L’insieme di tutte le direzioni strettamente discendenti a F(P )
in un punto x∗ sara denotato con SD(f ;x∗).
Osservazione Se x∗ e un punto di minimo locale di (P ), allora
FD(x∗) ∩ SD(f ;x∗) = ∅.
3.2 Condizioni necessarie del primo ordine (Fritz John)
In questo paragrafo ci concentreremo sulle condizioni necessarie per un punto di minimo
locale di un problema (P ). Le condizioni che vogliamo presentare sono le condizioni di
Fritz John (FJ) e sono utilizzabili quando tutte le funzioni coinvolte, f, gi, hj sono di
classe C1 su un aperto contenente la regione ammissibile F(P ). In questa situazione,
possiamo ridefinire una versione linearizzata delle direzioni ammissibili e delle direzioni
discendenti:
LFD(x∗) := {d : 〈∇gi(x∗),d〉 < 0, i = 1, ..., r, 〈∇hj(x∗),d〉 = 0, j = 1, ...,m},
LSD(f ;x∗) := {d : 〈∇f(x),d〉 < 0}.
Per motivare questa scelta basta usare la formula di Taylor del primo ordine. Per esempio,
se f e la funzione differenziabile su un aperto di Rn e d ∈ LSD(f ;x), allora
f(x+ dt) = f(x) + t
[〈∇f(x),d〉+
o(t)
t
]< f(x),
in un intorno di x. Cosı, per un vincolo attivo, abbiamo che, se d ∈ LFD(x∗) ∩LSD(f ;x∗), allora f(x∗ + td) < f(x∗) e gi(x
∗ + td) < gi(x∗) = 0. Quindi per vincoli e
funzioni sufficientemente regolari le direzioni ammissibili e discendenti sono equivalenti
nelle due versioni, linearizzata e non.
Lemma (Teorema di Motzkin)
Siano {ai}l1, {bj}m1 , e {ck}p1 vettori in Rn. Allora il sistema lineare:〈ai, x〉 < 0, i = 1, ..., l,
〈bj, x〉 ≤ 0, j = 1, ...,m,
〈ck, x〉 = 0, k = 1, ..., p,
e inconsistente se e solo se esistono dei vettori moltiplicatori
19

λ := (λ1, ..., λl) ≥ 0, λ 6= 0
µ := (µ1, ..., µm) ≥ 0,
δ := (δ1, ..., δp),
tali chel∑1
λiai +m∑1
µjbj +
p∑1
δkck = 0.
La dimostrazione di questo teorema e molto lunga e con conti complicati, ma intuitiva-
mente elementare. Quindi non presenteremo la dimostrazione.
Teorema (Fritz John)
Se un punto x∗ e di minimo locale per (P ), allora esistono dei moltiplicatori (λ, µ) :=
(λ0, λ1, ..., λr, µ1, ..., µm), non tutti nulli, tali che
λ0∇f(x∗) +r∑i=1
λi∇gi(x∗) +m∑j=1
µj∇hj(x∗) = 0,
λi ≥ 0, gi(x∗) ≤ 0, λigi(x
∗) = 0, i = 1, ..., r.
La seconda condizione si chiama anche condizione di complementarieta, infatti fa sı che
per ogni vincolo inattivo (con gi < 0) il suo moltiplicatore relativo λi = 0, cosı che non
influisca nella prima uguaglianza.
Dimostrazione
Per la condizione di complementarita, possiamo riscrivere la tesi nella forma
λ0∇f(x∗) +∑
i∈I(x∗)
λi∇gi(x∗) +m∑j=1
µj∇hj(x∗) = 0.
Se i vettori {∇hj}m1 sono linearmente dipendenti, allora esistono dei moltiplicatori µ :=
(µ1, ..., µm) 6= 0 tali che∑m
j=1 µj∇hj(x∗) = 0. Ponendo quindi tutti i λi = 0, la tesi e
verificata. Se sono linearmente indipendenti vogliamo provare che
A := {d : 〈∇f(x∗),d〉 < 0, 〈∇gi(x∗),d〉 < 0, i ∈ I(x∗),
〈∇hj(x∗),d〉 = 0, j = 1, ...,m} = ∅.
Per assurdo, supponiamo che esista d nell’insieme A, tale che ||d|| = 1. Siccome {∇hj}m1sono linearmente indipendenti, segue dal teorema di Lyusternik che esiste una successione
xn → x∗, con direzione tangente d, e che soddisfa l’equazione hj(xn) = 0, j = 1, ...,m.
20

Inoltre abbiamo che
f(xn) = f(x∗) +
[〈∇f(x∗),
xn − x∗
||xn − x∗||〉+
o(xn − x∗)||xn − x∗||
]· ||xn − x∗||,
dove (xn − x∗)/||xn − x∗|| → d e o(xn − x∗)/||xn − x∗|| → 0 per n→∞.
Poiche il termine all’interno delle quadre e negativo per n sufficientemente grande, ab-
biamo che f(xn) < f(x∗). Applicando lo stesso ragionamento per ogni vincolo gi attivo
in x∗, abbiamo che gi(xn) < gi(x∗) = 0. Possiamo quindi concludere che {xn}∞1 e una
successione ammissibile per (P ), tale che f(xn) < f(x∗) per n grande. Cio contraddice
l’ipotesi che x∗ sia un minimo locale. Arriviamo quindi all’assurdo.
Non esistono d tali che i prodotti scalari con i gradienti della funzione obiettivo e dei
vincoli gi siano tutti negativi.
Per il teorema di trasposizione di Motzkin, segue che
∃(λ, µ) := (λ0, λ1, ..., λr, µ1, ..., µm) 6= 0
che soddisfano la tesi. �
3.2.1 Lagrangiana
La funzione lagrangiana e uno strumento molto utile nel calcolo dei minimi vincolati di
molti problemi. Infatti, in questi punti, il differenziale della lagrangiana si annulla sotto
opportune condizioni.
Definizione
Data f : U ⊆ Rn → R funzione obiettivo, {gi}r1, {hj}m1 funzioni da U → R vincoli
rispettivamente di disuguaglianza e di uguaglianza per il problema (P ). La funzione
lagrangiana debole per (P ) e L : U × Rr+1 × Rm → R come segue
L(x;λ, µ) := λ0f(x) +r∑i=1
λigi(x) +m∑j=1
µjhj(x) (λi ≥ 0, i = 0, ..., r).
Se λ0 > 0 possiamo definire la funzione lagrangiana
L(x;λ, µ) := f(x) +r∑i=1
λigi(x) +m∑j=1
µjhj(x) (λi ≥ 0, i = 1, ..., r).
(λi, µj) si chiamano moltiplicatori di lagrange. Il teorema di Fritz John dimostra che se
x∗ e un minimo per la funzione f , vincolata dalle gi e le hj, tutte funzioni di classe C1,allora ∃(λ∗i , µ∗j) 6= 0 tale che ∇xL(x∗;λ∗i ;µ
∗j) = 0.
Una nota particolare va al significato dei moltiplicatori di Lagrange. In campo economico,
21

infatti, considerando il problema a due variabilimin f(x, y)
g(x, y) = b
con funzione lagrangiana L(x, y, λ) = f(x, y)− λ(g(x, y)− b).Sia z il valore di minimo del problema vincolato. Variando b nel vincolo abbiamo una
variazione del minimo z = z(b), che corrispondera ad un punto (x(b), y(b)) e ad un
moltiplicatore λ(b). Avremo allora che L(x(b), y(b), λ(b)) = z(b).
Ora possiamo calcolare il tasso di variazione di z rispetto a b, cioe la variazione di z in
conseguenza a una variazione unitaria di b.
z′(b) =dL
db= fxx
′ + fyy′ − λ′(g − b)− λ(gxx
′ + gyy′ − 1) =
= fxx′ + fyy
′ − λ(gxx′ + gyy
′ − 1) = (fx − λgx)x′ + (fy − λgy)y′ + λ = λ.
Questo ci dice che il moltiplicatore di Lagrange e la misura della variazione del valore
minimo z in corrispondenza di una variazione unitaria di b. Se b rappresenta una risorsa e
−f(x, y) fornisce il profitto di un processo produttivo dove l’utilizzo della risorsa e legato
dal vincolo g(x, y) = b, allora il valore del moltiplicatore e un prezzo. Per questo motivo
solitamente gli economisti danno al moltiplicatore di Lagrange il nome di prezzo ombra.
In particolare se b = b + h avremo che, usando la formula di Taylor al primo ordine
z(b) − z(b) = λh + o(h). Il moltiplicatore ci dice di quanto si discostera il minimo
variando il vincolo.
3.2.2 Dimostrazione con le funzioni di penalizzazione
Ora ridimostriamo le condizioni di Fritz John usando un altro approccio con le funzioni
di penalizzazione. Le basi della dimostrazione non variano molto, in quanto il teorema
di Lyusternik puo essere dimostrato basandosi sulle funzioni di penalizzazione. Ma e
interessante poterla vedere da un altro punto di vista.
Dimostrazione
Consideriamo la funzione di penalizzazione
Fk(x) = f(x) +k
2
r∑i=1
g+i (x)2 +k
2
m∑j=1
hj(x)2 +k
2||x− x∗||2,
dove g+i (x) =max{0, gi(x)} e k > 0 e un parametro. Sia ε > 0 abbastanza piccolo da far
sı che f(x∗) ≤ f(x) ∀x ∈ F(P ) ∩Bε(x∗).
22

Sia xk un minimo globale di Fk su Bε(x∗), che esiste per il teorema di Weierstrass.
Notando che Fk(x∗) = f(x∗), abbiamo che
f(xk) ≤ f(xk) +k
2
r∑i=1
g+i (xk)2 +
k
2
m∑j=1
hj(xk)2 +
k
2||xk − x∗||2 (∗)
= F (xk) ≤ F (x∗) = f(x∗).
Le funzioni g+i , hj e f sono limitate su Bε(x∗). L’ultima disuguaglianza mostra che anche
le successioni {kg+i (xk)2/2}∞k=0 e {kh2j(xk)/2}∞k=0 sono limitate. Quindi abbiamo che, per
k → ∞, g+i (xk) → 0 e hj(xk) → 0. Sia x ∈ Bε(x∗) un punto limite della successione
{xk}∞0 . Abbiamo che g+i (x) = 0 (ovvero, gi(x) ≤ 0) e hj(x) = 0. Quindi x e un punto
ammissibile di (P ).
Passando al limite in (∗), abbiamo che
f(x) ≤ f(x) +1
2||x− x∗||2 ≤ f(x∗).
Dato che f(x∗) ≤ f(x) ∀x ∈ F(P )∩Bε(x∗), abbiamo anche che f(x∗) ≤ f(x). Cio implica
che ||x− x∗||2 = 0, ovvero, x = x∗.
Di conseguenza, il problema di ottimo
min{Fk(x) : x ∈ Bε(x∗)}
diventa un problema di ottimo libero per k abbastanza grande: ∇Fk(xk) = 0, cioe
∇f(xk) +r∑i=1
(kg+i (xk))∇gi(xk) +m∑j=1
(khj(xk))∇hj(xk) + (xk − x∗) = 0.
Definiamo αi,k = kg+i (xk) e βj,k = khj(xk), riscaliamo il vettore
(1, α1,k, ..., αr,k, β1,k, ..., βm,k, 1)
in modo che la sua norma 1 (somma dei valori assoluti delle componenti) sia uguale a
1, ovvero dividiamo tutto per γk := 2 +∑r
i=1 αi,k +∑m
j=1 |βj,k| e chiamiamo il nuovo
vettore:
αk := (λ0,k, λ1,k, ..., λr,k, µ1,k, ..., µm,k, λ0,k).
Dividendo l’equazione precedendo per γk da entrambi i lati otteniamo:
λ0,k∇f(xk) +r∑i=1
λi,k∇gi(xk) +m∑j=1
µj,k∇hj(xk) + λ0,k(xk − x∗) = 0.
23

Dal momento che le componenti di αk sono limitate, possiamo assumere che convergano
per k →∞ (altrimenti scegliamo una sottosuccessione convergente). Definiamo i limiti di
λi,k → λi (i = 0, ..., r) e µj,k → µj (j = 1, ...,m). Facendo tendere k →∞ nell’equazione
precedente, abbiamo che
λ0∇f(x∗) +r∑i=1
λi∇gi(x∗) +m∑j=1
µj∇hj(x∗) = 0.
Notando che λi = 0 per i vincoli inattivi, infatti, se xk → x∗, kg+i (xk) = 0 per k
abbastanza grandi.
Segue la tesi. �
3.2.3 Dimostrazione con il principio ε-variazionale di Ekeland
Vogliamo ora dare una terza dimostrazione del Teorema di Fritz John, questa volta, sfrut-
tando il principio ε-variazionale di Ekeland. Il vantaggio di questa dimostrazione e che
si puo applicare a qualunque problema con funzione e vincoli definiti su uno spazio di
Banach.
Dimostrazione
Sia x∗ un punto di minimo locale del problema (P ), dove f(x∗) ≤ f(x) per ogni x
ammissibile nella bolla chiusa C = Br(x∗) = {x : ||x−x∗|| ≤ r}. Definiamo l’insieme
T := {(λ0, λ, µ) ∈ R× Rr × Rm : (λ0, λ) ≥ 0, ||(λ0, λ, µ)|| = 1},
e per un ε > 0 dato, dove√ε < r, definiamo la funzione
F (x) := maxT{λ0(f(x)− f(x∗) + ε) +
r∑i=1
λigi(x) +m∑j=1
µjhj(x)}.
Chiaramente F (x∗) = ε. In piu, la funzione F e positiva su C, perche se x ∈ C e
F (x) ≤ 0, allora scegliendo λ0 = 1, λi = 1, e |µj| = 1, rispettivamente, otteniamo
f(x) ≤ f(x∗)−ε, gi(x) ≤ 0, e hj(x) = 0, che significa che x e ammissibile per il problema
(P ). Ma questo e un assurdo, dal momento che x∗ e un minimo globale del problema (P )
su C. Dunque abbiamo che
F (x∗) ≤ infCF (x) + ε.
Segue dal principio ε-variazionale di Ekeland che esiste un punto xε tale che ||xε−x∗|| ≤√ε e
F (xε) ≤ F (x) +√ε||x− xε|| ∀x ∈ C.
24

Quindi, il punto xε minimizza la funzione G(x) := F (x) +√ε||x − xε|| sulla bolla C =
Br(x∗). Ma ||xε − x∗|| ≤
√ε < r, quindi xε appartiene all’interno di C e dal momento
che F (xε) > 0, il massimo della definizione di F e raggiunto in un unico punto non mi
ricordo pi‘u perche
(λ0(ε), λ(ε), µ(ε)) ∈ T . Segue dal teorema di Danskin che se d e un vettore unitario in
Rn, allora
G′(xε;d) = 〈λ0(ε)∇f(xε) +r∑i=1
λi(ε)∇gi(xε) +m∑j=1
µj(ε)∇hj(xε),d〉+√ε = 0,
dove abbiamo usato il fatto che la funzione N(x) = ||x − xε|| ha derivata direzionale
N ′(xε;d) = ||d|| = 1. Segue che ||∇F (xε)|| ≤√ε, cioe,
||λ0(ε)∇f(xε) +r∑i=1
λi(ε)∇gi(xε) +m∑j=1
µj(ε)∇hj(xε)|| ≤√ε.
Per la compattezza di T , con ε→ 0, esiste una successione convergente (λ0(ε), λ(ε), µ(ε))→(λ0, λ, µ) ∈ T. Visto che xε → x∗, otteniamo
λ0∇f(x∗) +r∑i=1
λi∇gi(x∗) +m∑j=1
µj∇hj(x∗) = 0.
E chiaro dalla definizione di F che se gi(x∗) < 0, allora λi(ε) = 0 per ε abbastanza piccolo;
dunque anche la condizione di complementarieta λigi(x∗) = 0 rimane valida. �
3.3 Altre condizioni del primo ordine
Corollario 1 (Condizioni di Karush-Kuhn-Tucker)
Se i vettori
{∇gi(x∗), i ∈ I(x∗), ∇hj(x∗), j = 1, ...,m}
sono linearmente indipendenti, allora λ0 > 0 e abbiamo che (KKT)
∇f(x∗) +r∑i=1
λi∇gi(x∗) +m∑j=1
µj∇hj(x∗) = 0,
λi ≥ 0, gi(x∗) ≤ 0, λigi(x
∗) = 0, i = 1, ..., r,
hj(x∗) = 0, j = 1, ...,m.
25

Dimostrazione
Sia, per assurdo, λ0 = 0; allora, per il teorema di Fritz John, abbiamo
∑i∈I(x∗)
λi∇gi(x∗) +m∑j=1
µj∇hj(x∗) = 0.
Ma i vettori sono tutti linearmente indipendenti, quindi tutti i moltiplicatori sono uguali
a 0, il che e assurdo.
Le altre discendono direttamente dal teorema precendente. �
Le condizioni che si impongono in questo teorema si chiamano condizioni di Karush-
Kuhn-Tucker (KKT) per il problema (P ). Esse sono verificate anche con ipotesi meno
forti dell’indipendenza lineare dei gradienti dei vincoli.
Corollario 2
Una condizione necessaria e sufficiente delle condizioni di KKT in x∗, ovvero
∇f(x∗) +r∑
i∈I(x∗)
λi∇gi(x∗) +m∑j=1
µj∇hj(x∗) = 0,
e che l’intersezione dei seguenti insiemi sia vuota:
{d : 〈∇f(x∗) < 0} ∩ {d : 〈∇gi(x∗) ≤ 0, i ∈ I(x∗)}
∩{d : 〈∇hj(x∗),d〉 = 0, j = 1, ...,m} = ∅.
Dimostrazione La dimostrazione segue immediatamente dalla versione omogenea del teo-
rema di trasposizione di Motzkin.
Lemma
Sia C un insieme convesso in Rn, T uno spazio topologico e sia f : C → T una funzione
differenziabile su un aperto contente C. Allora f e convessa se e solo se il piano tangente
in ogni punto x ∈ C giace sotto il grafico di f , ovvero
f(y) ≥ f(x) + 〈∇f(x), y − x〉 per ogni x, y ∈ C.
Corollario 3 (Condizioni di Karush-Kuhn-Tucker, vincoli concavi e lineari)
Sia x∗ un punto di minimo locale del problema (P ). Le condizioni KKT valgono in x∗ se
i vincoli attivi {gi}i∈I(x∗) sono funzioni concave in un intorno convesso di x∗ e i vincoli di
uguaglianza {hj} sono funzioni affini su Rn.
In particolare, le condizioni KKT valgono se tutti i vincoli attivi in x∗ sono funzioni affini.
26

Dimostrazione
Sia d tale che
〈∇gi(x∗),d〉 ≤ 0, i ∈ I(x∗), 〈∇hj(x∗),d〉 = 0, j = 1, ...,m.
I punti x(t) = x∗+ td sono punti ammissibili per t > 0 piccolo a sufficienza, dal momento
che
gi(x∗ + td) ≤ gi(x
∗) + t〈∇gi(x∗),d〉 ≤ 0,
per il lemma precedente. Similmente
hj(x∗ + td) = hj(x
∗) + t〈∇hj(x∗),d〉 = 0,
poiche le hj sono funzioni affini. Dal momento che x∗ e un punto di minimo locale
del problema (P ), abbiamo che f ′(x;d) = 〈∇f(x∗),d〉 ≥ 0 e valgono le condizioni del
Corollario 2. Per il suddetto corollario, valgono le condizioni KKT. �
3.4 Condizioni del secondo ordine
A questo punto della trattazione, consideriamo il problema (P ) con funzione obiettivo f
e vincoli gi e hj di classe C2. Le condizioni del primo ordine (KKT e FJ) devono ancora
valere nei punti di minimo locale, ma non vale il viceversa: una funzione che soddisfa
KKT o FJ in un punto x non e detto che abbia un minimo in tal punto.
Le condizioni del secondo ordine forniscono un’ulteriore restrizione nella ricerca degli zeri.
Si puo notare che le condizioni di minimo sono formulate sulla funzione lagrangiana e non
sulla funzione obiettivo, anche questo passaggio richiede alcune condizioni per formulare
correttamente il problema.
Denotiamo con ∇2xL(x, λ, µ) la matrice Hessiana della funzione lagrangiana L rispetto
alla variabile x, cioe
∇2xL(x, λ, µ) = ∇2f(x) +
r∑i=1
λi∇2gi(x) +m∑j=1
µj∇2hj(x).
Lemma
Sia x∗ un punto di minimo locale per (P ) che soddisfa le condizioni KKT con i mol-
tiplicatori λ∗, µ∗. Se d ∈ Rn e una direzione ammissibile in x∗ con la proprieta che
esiste una successione di punti ammissibili {xk} che converge a x∗ e che soddisfa la
condizione (xk − x∗)/||xk − x∗|| → d, gi(xk) = 0, i ∈ I(x∗), e hj(xk) = 0, allora
〈∇2xL(x∗, λ∗, µ∗)d,d〉 ≥ 0.
27

Dimostrazione
Siano d e {xk} come nelle ipotesi. Definiamo dk = xk − x∗, abbiamo che
0 ≤ f(xk)− f(x∗) = L(xk, λ∗, µ∗)− L(x∗, λ∗, µ∗)
= 〈∇xL(x∗, λ∗, µ∗),dk〉+1
2〈∇2
xL(x∗, λ∗, µ∗)dk,dk〉+ o(||dk||2)
=1
2〈∇2
xL(x∗, λ∗, µ∗)dk,dk〉+ o(||dk||2),
dove la prima disuguaglianza vale perche x∗ e minimo locale di (P ), la seconda uguaglian-
za segue dalla formula di Taylor al secondo ordine, e l’ultima dalle condizioni di KKT
in x∗. Dividendo entrambi i membri per ||dk||2 e mandando k → ∞, concludiamo che
〈∇2xL(x∗, λ∗, µ∗)d,d〉 ≥ 0. �
Teorema
Sia x∗ un punto di minimo locale per (P ) soddisfacente le condizioni KKT con i molti-
plicatori λ∗, µ∗. Se i gradienti attivi
∇gi(x∗), i ∈ I(x∗), ∇hj(x∗), j = 1, ...,m
sono linearmente indipendenti, allora ∇2xL(x∗, λ∗, µ∗) e semidefinita positiva sul sottospa-
zio lineare
M = (span{∇gi(x∗), i ∈ I(x∗), ∇hj(x∗), j = 1, ...,m})⊥.
Ovvero, se una direzione d soddisfa
〈d,∇gi(x∗)〉 = 0, i ∈ I(x∗), 〈d,∇hj(x∗)〉 = 0, j = 1, ...,m,
allora 〈∇2xL(x∗, λ∗, µ∗)d,d〉 ≥ 0.
Dimostrazione
Dal momento che i gradienti attivi sono linearmente indipendenti, segue dal teorema di
Lyusternik che M coincide con l’insieme delle direzioni tangenti all’insieme
{x : gi(x) = 0, i ∈ I(x∗), hj(x) = 0, j = 1, ...,m}
nel punto x∗. Se x ‘e un punto vicino a x∗ appartenente a questo insieme, allora x e
chiaramente un punto ammissibile per (P ). Il teorema segue direttamente dal lemma
precedente.
28

4 Exempla
Ho cercato un po’ di esempi: nel campo economico, su un libro di ricerca operativa, in
allegato un paio di pagine, in particolare es 13.8-5 e 13.8-8, ho trovato alcuni problemi
carini che trattano di situazioni concrete, di produzione e massimizzazione di profitti,
ma sono tutti con funzioni lineari a tratti e discontinue in qualche punto, quindi tutta
la trattazione fatta fino ad ora non serve a molto... Si potrebbero riadattare cambiando
qualche formula? Secondo me il contesto era quello giusto.
Nel Guler ci sono anche lı esempi interessanti, ma se sono interessanti o sono banali o
molto difficili, ma qualcosa si potrebbe prendere anche lı.
Es18 p 245 Trovare il cerchio di raggio minimo che contiene il triangolo di vertici (0,0)
(1,0) (0,1), facilotto ma concreto.
Esercizi che mi ispirano ma non so come affrontare (non c’ho pensato molto): 21 p245.
Esercizio 25 p246 massimizzare la somma dei quadrati dei lati di un triangolo iscritto
nella circonferenza unitaria, carino, come fare boh.
29


















