
Progettazione e Realizzazione di un Sistema per Analisi ... · Flusso Ottico e stima del movimento...
97
1 UNIVERSITA’ DEGLI STUDI DI PARMA Facoltà di Ingegneria Corso di laurea in Ingegneria elettronica Anno accademico 2000 / 2001 Progettazione e Realizzazione di un Sistema per Analisi del Moto di Oggetti in Scene Stradali Relatore: Correlatore: Chiarissimo Prof. Ing. Giovanni Adorni Chiarissimo Prof. Ing. Stefano Cagnoni Tesi di laurea di: Pier Paolo Ampollini
-
Upload
nguyenmien -
Category
Documents
-
view
214 -
download
0
Transcript of Progettazione e Realizzazione di un Sistema per Analisi ... · Flusso Ottico e stima del movimento...

1
UNIVERSITA’ DEGLI STUDI DI PARMAFacoltà di Ingegneria
Corso di laurea in Ingegneria elettronicaAnno accademico 2000 / 2001
Progettazione e Realizzazione di un
Sistema per Analisi del Moto di
Oggetti in Scene Stradali
Relatore: Correlatore:Chiarissimo Prof. Ing. Giovanni Adorni Chiarissimo Prof. Ing. Stefano Cagnoni
Tesi di laurea di: Pier Paolo Ampollini

2
Indice
1 INTRODUZIONE 4
2 FLUSSO OTTICO E STIMA DEL MOVIMENTO 7
2.1. Stime basate sul Flusso Ottico 82.1.1. Pro e contro 14
2.2. Stime basate su corrispondenze discrete 152.2.1. Pro e contro 19
2.3. L’algoritmo di Gabriele Maris e lo sviluppo successivo 202.3.1. La prima stesura 212.3.2. Primi risultati ed alcuni esempi 282.3.3. Time to Impact 302.3.4. L’algoritmo sviluppato 332.3.5. Test e risultati 392.3.6. Preparazione alla tesi 402.3.7. Ultimi test e conclusioni 42
3 IL SISTEMA APACHE 44
3.1. Come funziona 45
3.2. Problemi e possibili sviluppi 47
4 FLUSSO FOR LINUX 49
4.1. Uno sguardo d’insieme 504.1.1. Gli elementi del sistema 51
4.2. L’algoritmo sviluppato 514.2.1. La thread ScriviOnline 534.2.2. La procedura videoplay 554.2.3. La procedura Flusso ed i suoi moduli 56

3
4.2.3.1. grabba_scaled 574.2.3.2. acquisisci_sfondo 584.2.3.3. elaborazione_immagine_ppmgs 604.2.3.4. reset_of 614.2.3.5. operatore_ppmgs 614.2.3.6. combinaflussiottici e visualizzaflussoottico 62
4.3. L’elaborazione delle immagini 654.3.1. gradient 664.3.2. estrai_auto 684.3.3. binary 704.3.4. CodSoft_ppmgs 73
4.4. L’estrazione del flusso ottico 75
4.5. Prove effettuate e risultati ottenuti 80
4.6. Conclusioni 84
APPENDICE A - MANUALE UTENTE 86
A.1 Pulsantiera 86
A.2 Le finestre 88
APPENDICE B - LISTATI 90
B.1 graphics.h 90
B.2 flusso_d.h 91
B.3 flusso4l.h 92
B.4 opt_flow.h 95
BIBLIOGRAFIA 96

4
Capitolo 1
Introduzione
Trovandosi di fronte ad un amico incapace di vedere qualcosa di apparentemente ovvio e banale,
chiunque esclamerebbe “Ma apri gli occhi!”, e solo il più paziente ed imperturbabile dei lettori
riuscirebbe a trattenersi. Bisogna riconoscere, comunque che, vedere un’ovvietà è cosa ben più
complessa di quanto comunemente si creda, e in casi di cecità “inspiegabile” si farebbe meglio a
consigliare di usare il cervello, cioè di pensare, piuttosto che di guardare. Il guaio di tale consiglio è
che sarebbe spesso considerato paradossale o incomprensibile. Vi è infatti l’opinione diffusa
secondo cui sussiste una rigida dicotomia tra il vedere ed il pensare, che implicitamente nega che sia
possibile qualsiasi influenza del secondo sul primo. Non è inoltre chiaro che cosa precisamente
sarebbe necessario pensare in ogni singola circostanza dal momento che si è di solito tanto
interiormente inconsapevoli degli essenziali processi sottostanti alla visione, quanto incapaci di far
loro appello coscientemente.
D’altra parte , gli addetti alla computer vision, sono costretti ad affrontare tali problemi
direttamente, poiché i programmi vedono nella misura in cui i programmatori sono in grado di
rendere quella connessione funzionalmente esplicita. La presente questione è enormemente
complessa, e anche il solo compito di rendere una macchina capace di riconoscere in un’ampia
gamma di casi semplici oggetti è un problema complicato.
L’inseguimento di oggetti non rigidi e la classificazione del loro moto è un problema che presenta
numerose sfide. L’importanza che questi problemi rivestono nel modo moderno è sottolineata dal
crescente interesse, che negli ultimi anni, li ha investiti. Soluzioni efficaci a queste tipologie di problemi
potrebbero condurre all’apertura di “nuovi mercati” in settori quali la sorveglianza video, l’analisi del
moto, le interfacce della realtà virtuale, processi di riconoscimento e navigazione per robot. Vediamo
alcuni esempi in dettaglio.
Immagini come quelle acquisite da telecamere a circuito chiuso, sono normalmente utilizzate, anche
se di bassa qualità e difficili da interpretare, in sistemi di sicurezza. Le procedure di visione artificiale

5
forniscono metodi per migliorare la qualità delle immagini, interpretare degli eventi e monitorare delle
scene complesse.
§ Monitoraggio anti-intrusione - Telecamere che sorvegliano delle zone ampie, quali ad
esempio i perimetri delle prigioni, sono normalmente collegate al sistema d’allarme. Se
l’allarme viene fatto scattare delle immagini sono subito immagazzinate per permettere
l’identificazione della causa. Molti falsi allarmi sono prodotti da animali selvatici ed il
processo di ricostruzione degli eventi si rileva una perdita di tempo. Un sistema per
localizzare e identificare la causa degli allarmi può essere utilizzato per minimizzare il
numero di falsi allarmi.
§ Identificazione dei numeri di targa – Le tecniche di visione artificiale hanno reso
possibile la lettura dei numeri di registrazione dei veicoli attraverso immagini video.
Questa tecnologia, che può essere utilizzata in innumerevoli applicazioni, risulta molto
meno invasiva rispetto a quelle tecniche impieganti dispositivi quali ad esempio i
transponders o i sistemi GPS.
§ Inseguimento di persone – In alcune situazioni i movimenti delle persone possono
essere interessanti, ad esempio il monitoraggio di centri commerciali. Questi sistemi sono
sviluppati per sorvegliare una zona imparando i percorsi abituali utilizzati dagli individui
che la attraversano, qualunque deviazione rispetto ai percorsi abituali viene segnalata
come anomalia e può far scattare un allarme.
Le tecniche di visione artificiale trovano impiego in molti altri campi, quali il monitoraggio del traffico
sia terrestre che aereo, sistemi automatici di ispezione industriale, eccetera e non basterebbe un
singolo capitolo di questa tesi per descriverli tutti in modo accurato.
In questo lavoro affronterò le problematiche legate alla progettazione di un dispositivo per l’analisi
del moto in scene stradali. Cercherò di vedere se è possibile utilizzare il flusso ottico, risultato
prodotto dall’analisi del moto, come dispositivo di segnalazione dell’avvenuto passaggio di un
oggetto in movimento entro una determinata zona.
Nel capitolo 2 affronterò le tematiche legate alla determinazione del flusso ottico, soffermandomi
sull’algoritmo sviluppato da G. Maris e sulle modifiche da me introdotte.
Nel capitolo 3 darò una breve descrizione del sistema APACHE evidenziando i problemi che hanno
dato vita a questo lavoro.

6
Nel capitolo 4 affronterò il nucleo di questo lavoro, darò una descrizione del codice sviluppato,
parlerò dei risultati ottenuti e delle conclusioni alle quali sono giunto.

7
Capitolo 2
Flusso Ottico e stima del movimento
“Ogni organismo vivente sfrutta la rilevazione del moto come metodo fondamentale per la
percezione del proprio movimento, della struttura dell’ambiente in cui si trova come pure del
movimento di altri organismi presenti nell’ambiente che lo circonda.”
Partendo da questa assunzione si può affermare che l’evoluzione temporale dell’ambiente e della
scena osservata, porta una grande quantità di informazione necessaria alla percezione naturale ed
artificiale, degli “eventi” che hanno luogo nel campo visivo.
Anche quando la scena è stazionaria, gli oggetti presenti in essa possono apparire in movimento a
causa del moto dell’osservatore o degli occhi o comunque dei sensori che analizzano la scena stessa:
anzi il moto relativo tra oggetti e sensori è proprio un metodo fondamentale d’indagine per la
comprensione della struttura spaziale dell’ambiente in esame.
Sebbene i sistemi di visione biologici siano discreti, la quantizzazione da loro prodotta è talmente fine
da essere in grado di produrre un uscita essenzialmente di tipo continua. Questa uscita così ottenuta
è in grado di riprodurre il flusso persistente che il mondo osservato imprime sulla retina. La sequenza
di informazioni così ottenute viene chiamata Flusso Ottico o in inglese Optical Flow.
Il Flusso Ottico, detto anche campo di velocità istantanea, assegna ad ogni punto in movimento
all’interno del campo visivo una “velocità retinica” bidimensionale, tramite l’analisi di questa struttura
dati è possibile ricostruire l’ambiente osservato.
I sensori di tipo non-biologico funzionano, essenzialmente, nello stesso modo quantizzando più o
meno finemente la variabile temporale che caratterizza l’evoluzione dell’ambiente. Agendo secondo
questa modalità generano una sequenza di immagini che riprodotte possono dare la sensazione di un
flusso continuo di avvenimenti in funzione dell’intervallo di tempo tra un’immagine e quella seguente.
Da un punto di vista informatico il problema del calcolo del flusso ottico si riduce all’acquisizione di
immagini dell’ambiente in esame ed alla loro elaborazione in tempi sufficientemente rapidi per poter

8
apprezzare le variazioni “ambientali” in esse contenute.
L’analisi dei cambiamenti nel tempo della struttura e della distribuzione dei livelli di grigio (o di
colore) registrati dai sensori e immagazzinati in una sequenza di immagini, implica l’elaborazione di
segnali a tre ed eventualmente a quattro dimensioni, producendo quindi una quantità di dati non
trascurabile. Questo è uno dei problemi principali della visione a basso livello : la necessità di gestire
enormi volumi di dati in tempi relativamente brevi per consentire l’impiego dei risultati ottenuti in
situazioni reali. Situazioni che possono comprendere l’inseguimento di bersagli, la guida di robot e la
navigazione di veicoli autonomi ed altre problematiche in cui il tempo riveste un’importanza
determinante.
In generale, la stima del movimento 3D a partire dalle sue proiezioni 2D in una sequenza di immagini
comprende tecniche di diverso livello raggruppabili a seconda della “filosofia” che ne sta alla base.
Come prima distinzione possiamo evidenziare due categorie fondamentali: la stima basata sul flusso
ottico e la stima basata sulle corrispondenze discrete. All’interno di queste due metodologie è
possibile effettuare un’ulteriore separazione delle tecniche in esse contenute a seconda che siano o
non siano dipendenti dal dominio, cioè che si basino o meno su conoscenze a priori dell’ambiente in
esame.
Quello che mi preme fare notare, però, è l’appartenenza di questi quesiti alla categoria dei problemi
inversi o mal condizionati, per i quali non è garantita l’esistenza e l’unicità della soluzione, la quale
risulta comunque molto se non troppo “sensibile” ad errori e approssimazioni nei dati di partenza.
Passiamo ora ad analizzare più in dettaglio queste tecniche, in modo da poterne evidenziare le
caratteristiche principali, sia in positivo che in negativo, per essere poi in grado di spiegare le scelte
effettuate nell’ambito di questa tesi.
2.1. Stime basate sul Flusso Ottico
Una tra le due classi di metodi di stima del moto 3D è basato sul calcolo del cosiddetto flusso ottico
(“optical flow”), ovvero sulle variazioni nel tempo di valori risultanti dall’applicazione di operatori
locali all’immagine. Il risultato di questo metodo viene rappresentato tramite un insieme, se non più
propriamente una matrice, di vettori rappresentanti i movimenti dei punti appartenenti agli oggetti
presenti nell’immagine. In poche parole il flusso ottico rappresenta la traiettoria seguita dai punti
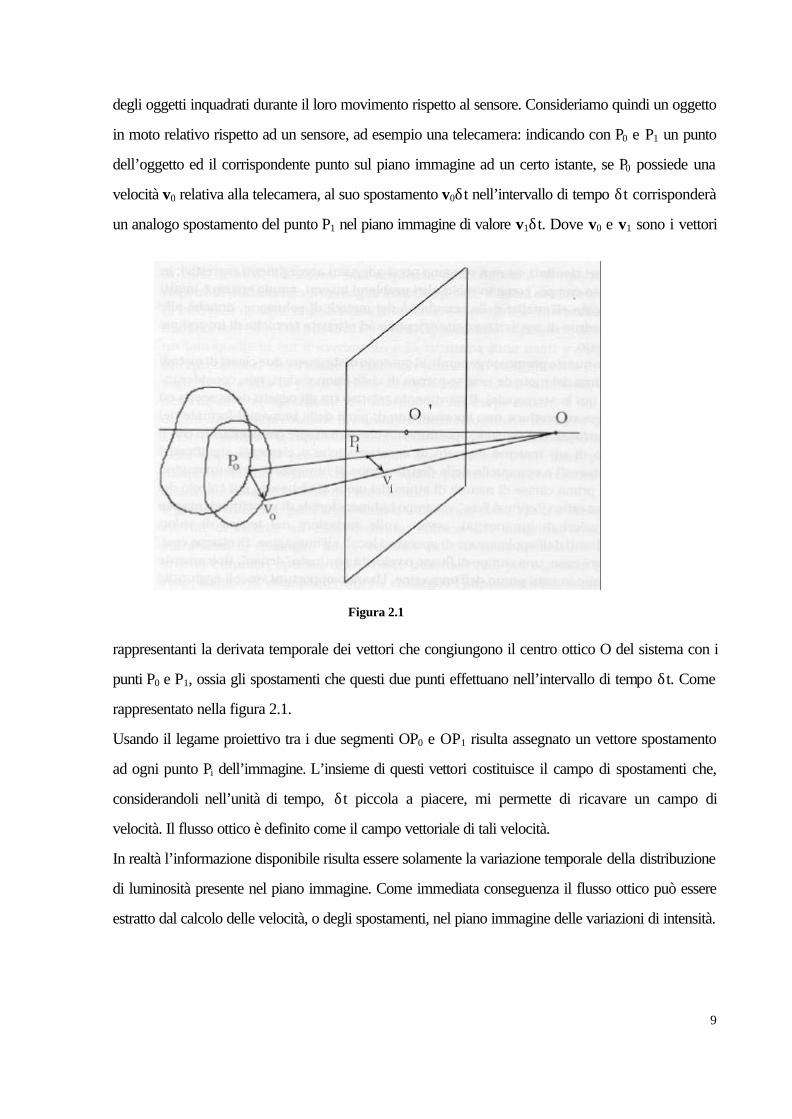
9
degli oggetti inquadrati durante il loro movimento rispetto al sensore. Consideriamo quindi un oggetto
in moto relativo rispetto ad un sensore, ad esempio una telecamera: indicando con P0 e P1 un punto
dell’oggetto ed il corrispondente punto sul piano immagine ad un certo istante, se P0 possiede una
velocità v0 relativa alla telecamera, al suo spostamento v0δt nell’intervallo di tempo δt corrisponderà
un analogo spostamento del punto P1 nel piano immagine di valore v1δt. Dove v0 e v1 sono i vettori
rappresentanti la derivata temporale dei vettori che congiungono il centro ottico O del sistema con i
punti P0 e P1, ossia gli spostamenti che questi due punti effettuano nell’intervallo di tempo δt. Come
rappresentato nella figura 2.1.
Usando il legame proiettivo tra i due segmenti OP0 e OP1 risulta assegnato un vettore spostamento
ad ogni punto Pi dell’immagine. L’insieme di questi vettori costituisce il campo di spostamenti che,
considerandoli nell’unità di tempo, δt piccola a piacere, mi permette di ricavare un campo di
velocità. Il flusso ottico è definito come il campo vettoriale di tali velocità.
In realtà l’informazione disponibile risulta essere solamente la variazione temporale della distribuzione
di luminosità presente nel piano immagine. Come immediata conseguenza il flusso ottico può essere
estratto dal calcolo delle velocità, o degli spostamenti, nel piano immagine delle variazioni di intensità.
Figura 2.1

10
Sia f(x, y, t) la funzione rappresentante l’intensità luminosa nell’immagine nel punto di coordinate (x,
y) all’istante di tempo t. Assumendo che tale intensità vari solamente a causa del moto 3D1 che si
proietta sul piano immagine, e che quindi sia la medesima al tempo t + δt nel punto (x + δx, y +
δy), si può scrivere:
1 L’assunzione appena effettuata ricade nei “vincoli aggiuntivi” di cui parlerò verso la fine del paragrafo.

11
f(x + δx, y + δy, t + δt) = f(x, y, t) (1.1.1)
dove δx = uδt e δy = vδt, essendo u e v le componenti della velocità, cioè del
vettore del flusso ottico applicato in questo punto, nelle direzioni x e y:
u = dx/dt e v = dy/dt (1.1.2)
Considerando le variazioni temporali e spaziali piccole a “piacere” si può espandere
il primo membro della (1.1.1) in serie di Taylor ottenendo la seguente relazione:
f(x, y, t) + fxδx + fyδy +ftδt + ε = f(x, y, t) (1.1.3)
dove fx, fy e ft indicano le derivate parziali dell’intensità rispetto alle variabili spaziali e
temporale, ed ε contiene i termini di ordine superiore (trascurabili). Dividendo per dt
tendente anche a zero si ricava la cosiddetta “equazione di vincolo del flusso ottico”:
fxu + fyv + f t = 0 (1.1.4)
La (1.1.4) non permette di calcolare le due incognite u e v:
v . grad(f) = - f t (1.1.5)
prodotto scalare tra il vettore gradiente della luminosità e il vettore velocità.
Quest’ultima relazione implica che sono soluzioni della (1.1.4) tutti i vettori v che la
soddisfano e quindi fornisce l’informazione relativa alla componente del flusso ottico

12
nella direzione del gradiente (che vale ft / (fx2 + fy
2)½), ma non in quella
perpendicolare, cioè lungo le linee a intensità luminosa costante. Inoltre v non può
essere calcolato nei punti in cui il gradiente è nullo. Queste ultime affermazioni si
rifanno a quanto accennato in precedenza sui problemi inversi o mal condizionati.
Per ricavare il flusso ottico è quindi necessario introdurre delle ipotesi aggiuntive
derivate da conoscenze a priori, in questo modo ci si sposta verso un approccio al
problema di tipo “dipendente dal dominio”, oppure tramite l’imposizione di vincoli
aggiuntivi quali possono essere la continuità della funzione luminosità o,
analogamente, del colore all’interno dell’immagine, sempre in funzione del tempo.
Una possibile soluzione è ottenuta minimizzando contemporaneamente lo
scostamento da zero del primo membro della (1.1.4) e le variazioni del flusso ottico
misurate dal suo gradiente. In poche parole si arriva alla soluzione minimizzando,
rispetto a u e v la seguente relazione:
??{(fxu + fyv + f t)2 + λ [(ux2 + uy
2) + (vx2 + vy
2)]}dx dy (1.1.6)
La minimizzazione viene effettuata tramite un processo iterativo dopo aver posto in
forma discreta gli operatori richiesti. Vengono utilizzati degli stimatori discreti delle
derivate spaziali e di quella temporale, limitandoli, tipicamente, alle differenze finite
del primo ordine, e il doppio integrale viene sostituito da una doppia sommatoria. Per
questa possibile soluzione è stata assunta la regolarità del flusso ottico e la continuità
della luminosità dell’immagine. Se il flusso presenta delle discontinuità, come accade
in corrispondenza dei bordi degli oggetti, occorre evitare che il metodo tenti di
estendere con regolarità la soluzione da una regione all’altra. Ciò non è semplice
poiché queste discontinuità permetterebbero la segmentazione dell’immagine e lo

13
sfruttamento di queste informazioni fornirebbe una stima migliore del flusso ottico.
Una soluzione possibile prevede l’introduzione della segmentazione nell’algoritmo
iterativo di stima, individuando le zone dove il flusso varia bruscamente ed
impedendo all’iterazione successiva di collegare con continuità la soluzione attraverso
la discontinuità.
Proseguendo nell’analisi si potrebbero portare alla luce altre limitazioni, sempre
risolvibili mediante l’introduzione di vincoli aggiuntivi o di operazioni di elaborazione
di altre caratteristiche delle immagini in esame. Questo però ci farebbe perdere molto
tempo, considerando il fatto che sarebbe necessario proporre con i dovuti dettagli
anche i numerosi metodi alternativi di calcolo del flusso ottico. Quello che mi preme
sottolineare è come ogni metodo utilizzato propone un problema che necessita
dell’introduzione di vincoli per l’ottenimento della soluzione, vincoli che si possono
raggruppare nelle due categorie elencate in precedenza: indipendenza dal dominio e
dipendenza dal dominio.
Nella prima possiamo evidenziare i due principi di continuità della luminosità e del
colore (non subiscono variazioni brusche passando da un’immagine a quella
successiva), come pure possiamo introdurre gli operatori che ci permettono di
estrarre informazioni caratterizzanti le componenti dell’immagine. Vedi ad esempio la
segmentazione come pure la cosiddetta features extraction (estrazione delle
caratteristiche) nelle loro molteplici versioni: estrazioni dei contorni, delle regioni,
delle textures, dei punti dominanti nelle curve, ecc.
Nella seconda categoria possiamo raggruppare quei vincoli che dipendono dal
dominio da un punto di vista della “comprensione logica” di quanto può avvenire
nell’ambiente che si sta analizzando. Tra questi possiamo includere: la struttura degli
oggetti presenti, la velocità massima alla quale si possono muovere i soggetti

14
dell’analisi, la direzione preferenziale del movimento (moto comune, moto conosciuto
o piccoli cambiamenti nella direzione della velocità), il cosiddetto consistent match
(due punti appartenenti ad una stessa immagine, normalmente, non si associano con il
medesimo punto di un’altra immagine), ecc.
2.1.1. Pro e contro
Proseguiamo ora con una breve analisi dei pro e dei contro della stima basata sul
flusso ottico. La disponibilità del campo vettoriale di velocità o di spostamento in due
dimensioni permette di stimare il movimento e la struttura spaziale degli oggetti in
moto, quindi dare una rappresentazione dell’ambiente osservato, mediante
un’opportuna formulazione delle relazioni tra i punti delle superfici componenti gli
oggetti nello spazio e quelli nel piano immagine, e tra le associate velocità. Tali
relazioni sono indotte dalla proiezione prospettica e richiedono alcune assunzioni,
tipicamente la variazione “dolce” del flusso ottico e la regolarità della superficie 3D,
per poterne troncare ai primi termini lo sviluppo in serie di Taylor. Le equazioni finali
sono, nella forma generale, piuttosto complesse, permettono però, dopo aver
introdotto ulteriori vincoli, di ottenere un flusso ottico abbastanza preciso. Questa
precisione viene pagata in termini computazionali, infatti la maggior parte se non la
totalità degli algoritmi che si basano su queste tecniche sono di tipo iterativo e
richiedono la soluzione di equazioni simili alla (1.1.6) per ogni pixel appartenente
all’immagine o alla regione dell’immagine interessata. Quindi massimizzazione o
minimizzazione di funzioni errore che possono richiedere numerosi cicli di calcolo
prima di fornire il risultato cercato. Se a tutto questo aggiungiamo che le funzioni
errore richiedono l’utilizzo di operatori opportuni per il calcolo dei loro termini, che
normalmente gestiscono strutture dati di tipo float (virgola mobile), si comprende

15
come queste tecniche tendono a non essere utilizzate o comunque poco sfruttate in
situazioni reali. Nei casi in cui esse vengono adottate è possibile osservare l’impiego
di una serie di drastiche limitazioni per quanto riguarda l’ambiente percepibile oppure
l’utilizzo di macchine di calcolo molto potenti se non addirittura costruite ad hoc per il
problema specifico.
2.2. Stime basate su corrispondenze discrete
Il movimento relativo tra gli oggetti della scena ed il sensore produce uno
spostamento di parti delle immagini formatesi nel piano focale del sensore stesso.
Spostamento che può essere caratterizzato con il moto di un insieme discreto di
attributi o elementi significativi (“features”). Questo moto può essere ricavato
dall’estrazione delle componenti osservabili in un’immagine della sequenza e dalla
successiva determinazione della corrispondenza nelle immagini successive.
La situazione può essere schematizzata come in figura 2.2, dove le “qualità
specifiche” sono i punti Pi individuati sul piano immagine (X, Y) ad un certo istante
come la proiezione dei punti pi dell’oggetto (in coordinate x, y, z): all’istante
successivo i punti si sono spostati rispettivamente in P’i e p’i. Queste variazioni di
posizione dei punti corrispondenti in (X, Y) sono i dati disponibili per tentare di
ricavare il movimento di punti pi in (x, y, z) tra i due istanti, sempre che il problema
ammetta soluzione.

16
Il problema oltre ad essere mal condizionato è anche intrinsecamente ambiguo: la
soluzione, quando esiste, può essere ottenuta solo a meno di una costante,
tipicamente un fattore di scala sulla traslazione. Ad esempio, se consideriamo due
oggetti, uno di date dimensioni e l’altro di dimensioni doppie, non è possibile
distinguere i seguenti due moti: il primo oggetto che subisce una certa rototraslazione
alla distanza d dal sensore ed il secondo che si muove con velocità di traslazione
doppia e di rotazione identica al precedente ma ad una distanza 2d dal sensore.
La differenza sostanziale rispetto al paragrafo precedente risiede nel numero elevato
e nella densità del flusso ottico, qui assunto disponibile in pochi punti dell’immagine.
Nell’esempio citato in figura si fa riferimento ai punti che compongono l’oggetto,
nell’insieme dei metodi di calcolo affrontabili in questo paragrafo, è possibile
utilizzare come elementi significativi altre caratteristiche rappresentative, quali ad
esempio vertici, linee di separazione tra superfici, regioni ecc. Per questo motivo
risulta difficile descrivere in modo sistematico e sintetico i possibili metodi di
soluzione, che andrebbero classificati secondo una varietà di parametri tra i quali
possiamo citare:
Figura 2.2

17
ü il tipo di osservabili considerato (punti, linee, angoli, …)
ü eventuali vincoli spaziali tra gli osservabili (la complanarità per esempio)
ü il tipo di proiezione impiegata
ü i parametri del moto ricercati
ü la linearità o meno del sistema di equazioni
ü la rigidità o meno del moto
ü la limitazione o meno a piccoli spostamenti, e analogamente l’uso di un
numero limitato di viste o di una lunga sequenza
L’ipotesi su cui si basano i metodi di stima del movimento da osservabili estratti in
un’immagine e poi “inseguiti” nella sequenza è che siano innanzitutto individuati
elementi caratteristici in una vista, e che sia stata stabilita la corrispondenza tra di essi
nella sequenza. Stabilire e mantenere le corrispondenze interframe può essere
tutt’altro che semplice, sia perché gli elementi da inseguire non permangono
necessariamente in tutte le immagini costituenti la sequenza (possibili occlusioni), sia
perché è proprio il movimento una delle proprietà che permettono di individuare le
corrispondenze.
“Nel sistema visivo umano i processi di corrispondenza e quelli di struttura e
movimento sono strettamente connessi.”
In ogni caso, le tecniche più comuni adottate per individuare gli osservabili sono
basate sull’analisi delle caratteristiche locali della distribuzione di luminosità, ad
esempio: la tessitura (texture), gli angoli, tratti di contorno rettilineo, intersezioni di
linee. Per trovare la soluzione al problema delle corrispondenze vengono utilizzate

18
delle misure di somiglianza opportunamente formulate: la correlazione locale, le
misure di somiglianza strutturale. Anche nell’applicazione di queste metodologie è
importante far notare come vengano impiegati dei vincoli aggiuntivi simili a quelli
affrontati nel paragrafo precedente, si parla anche in questo caso di indipendenza o
dipendenza dal dominio. Andiamo a vedere alcune di queste procedure nel dettaglio.
Consideriamo inizialmente la situazione descritta dalla figura 2.2, gli osservabili sono
dei punti, dove (x, y, z) sono le coordinate di un punto generico p appartenente alla
superficie di un oggetto in moto rigido relativo al sensore, e (X, Y) quelle della
proiezione P sul piano immagine. Le relazioni che descrivono la proiezione di tipo
prospettica sono:
X = F · x/z Y = F · y/z
(1.2.1)
X’ = F · x’/z’ Y’ = F · y’/z’
Dove F = OO’ è la lunghezza focale, che per semplicità viene assunta unitaria. La
relazione che regola il moto di un corpo rigido, che possiede sei gradi di libertà, è
data dalla:
p’ = R · p + T (1.2.2)
dove p’ e p sono vettori di componenti (x’, y’, z’) e (x, y, z), R è una matrice di
rotazione ortonormale di dimensioni 3x3 e con elementi funzione di tre parametri
indipendenti (quali due coseni direttori di un asse e l’angolo di rotazione attorno a
questo) e T vettore traslazione di componenti Tx, Ty e Tz. A partire dalla situazione di

19
base descritta dalle (1.2.1) e (1.2.2) si ramificano una varietà di tecniche possibili,
che conducono a equazioni lineari o non lineari, in incognite che sono o le posizioni
successive dei punti p o i parametri del moto come R e T.
Introducendo nelle (1.2.1) anche le variazioni di posizione e di orientamento del
sensore si ottiene un sistema composto da almeno 18 equazioni non lineari in 18
incognite, senza garanzia teorica sull’unicità della soluzione. Siamo in presenza di una
notevole mole di calcoli, soprattutto se pensata per applicazioni real time,
considerando anche il fatto che la soluzione per questo tipo di sistemi viene ricercata
con algoritmi iterativi ai minimi quadrati.
2.2.1. Pro e contro
Esistono vincoli aggiuntivi e metodi per affrontare il problema che permettono di
ridurre il numero di equazioni e di incognite semplificando notevolmente il problema.
Non è mia intenzione affrontarne la descrizione in questa sede per non appesantire
troppo il lavoro. Mi preme sottolineare il fatto che questo tipo di soluzione presenta
dei vantaggi, in termini di costi di elaborazione, nei confronti della stima del
movimento mediante il flusso ottico. Infatti tramite l’applicazione di maschere
opportunamente studiate, alla sequenza di immagini in esame e precedentemente
elaborata, è possibile ottenere una valutazione del movimento ed in particolare del
flusso ottico qualitativamente accurata in tempi di calcolo sufficientemente brevi.
Soprattutto se si pensa che la maggior parte, se non la totalità, di queste operazioni
utilizzano dei dati di tipo intero. Sarà questa la strada che seguirò nel proseguimento
di questo lavoro. Un altro vantaggio non trascurabile, che si può rivelare anche
svantaggioso in taluni casi, è il fatto che utilizzando le tecniche descritte in questo
paragrafo il calcolo del movimento si può facilmente concentrare su alcuni oggetti

20
della scena trascurando il resto, situazione importante nei casi di inseguimento e/o di
catalogazione degli enti presenti o che ci si aspetta siano presenti nella scena.
L’obbiezione più importante che può essere sollevata nei riguardi delle procedure
evidenziate è la loro “inesattezza” formale, dovuta alle semplificazioni richieste per
poter essere in grado di ottenere una soluzione senza dover affrontare una quantità di
calcoli “mostruosa”.
2.3. L’algoritmo di Gabriele Maris e lo svilupposuccessivo
Un metodo di calcolo del flusso ottico degno di attenzione è stato presentato, nel suo
lavoro di tesi presso l’università di Parma, dall’ingegnere Gabriele Maris. Questo
algoritmo si basa sulle metodiche viste nel paragrafo 1.2, cioè stima il flusso ottico e
conseguentemente il movimento tramite le corrispondenze discrete, ossia dopo aver
effettuato una prima elaborazione sulle immagini costituenti la sequenza per estrarne i
cosiddetti osservabili, ne ricerca le affinità nelle varie immagini. Nato per architetture
di tipo parallelo, per la precisione fu sviluppato su una macchina CAM 8, a causa
della quantità di calcoli necessari per l’ottenimento della soluzione al problema posto
e della velocità di calcolo elevata di queste tipologie di calcolatori. In seconda battuta
fu convertito e modificato, dal sottoscritto, nell’ambito dell’esame per il corso di
Intelligenza Artificiale, per adattarsi a processori sequenziali in ambiente Unix/Linux.
Analizziamo ora le varie parti nelle quali può essere suddiviso evidenziando le scelte
effettuate a livello di stesura del codice. Nei sottoparagrafi 1.3.1 e 1.3.2 parlerò della
prima conversione effettuata fornendo alcuni risultati di esempio, nel 1.3.3 e nel 1.3.5

21
ragionerò sul time to impact e sulla sua introduzione nell’algoritmo, nel 1.3.6 e nel
1.3.7 descriverò infine le modifiche apportate in preparazione della mia tesi.
2.3.1. La prima stesura
Evitando un’analisi dettagliata delle scelte effettuate da Maris per l’ottenimento
dell’algoritmo suddetto, peraltro ampiamente trattate nella sua tesi, passiamo
immediatamente allo studio delle quattro parti fondamentali nelle quali può essere
suddiviso:
a) il Filtro Quantizzatore
b) l’Estrattore di Roberts
c) il Codificatore Soft 3 x 3 a 4 bit/pixel
d) l’Operatore di Matching
a) Dalle osservazioni svolte durante il suo lavoro Maris afferma che il rumore
aleatorio presente in una immagine, dovuto alle più svariate cause quali difetti
nelle lenti, rumori termici nella matrice CCD, piccole oscillazioni della telecamera,
ecc., può essere eliminato, in parte se non del tutto, tramite la soppressione di un
certo numero dei bit meno significativi di ogni pixel. Il Filtro Quantizzatore si
occupa di operare questa soppressione mediante la traslazione a destra di un
certo numero di posizioni del contenuto informativo di ogni pixel. Il numero di
posizioni è stato impostato a 3 tenendo presente che ad ogni pixel sono associati
8 bit di informazione (immagini con 256 toni di grigio). La realizzazione di questa
funzione fu immediata.
A B
C D
Figura 2.3

22
b) In seguito all’operazione di riduzione del rumore, il calcolo del flusso ottico
richiede l’estrazione delle features delle quali analizzare le corrispondenze. In
questo algoritmo si è scelto di rilevare i contorni degli oggetti presenti
nell’immagine. Questa operazione viene eseguita mediante il calcolo del
gradiente dei livelli di grigio di un certo intorno del punto in questione. Se il
valore ottenuto supera una soglia prefissata il punto viene marcato come
contorno. La scelta di Maris è caduta sull’estrattore di Roberts, semplice da
implementare e veloce nell’esecuzione dato che necessita di un numero
esiguo di operazioni. È composto da due fasi distinte: calcolo del gradiente e
confronto con la soglia. L’intorno utilizzato per il calcolo del gradiente non è
simmetrico rispetto al punto in esame, infatti siano A, B, C e D quattro pixel
appartenenti all’immagine disposti secondo la figura 2.3. Il pixel A è quello
per il quale si vuole verificare se si tratta di un punto di contorno oppure no.
Si ha quindi il seguente algoritmo
GradRob = max {abs(A – D) ; abs(B – C)}
Se (GradRob > Soglia) allora {A è un punto di contorno}
Il codice per questo operatore risulta abbastanza semplice, si è pensato di
utilizzare una matrice immagine locale per la memorizzazione del valore logico
(abs(A – D) > Soglia)

23
Come conseguenza l’elaborazione dei contorni avviene mediante due
“passate” dell’immagine, nella prima si verifica se abs(A – D) è maggiore
della soglia, nella seconda si effettua il medesimo controllo per abs(B – C), in
questo modo se una delle due condizioni si verifica il pixel in esame viene
marcato come contorno. Infine sono utilizzati due cicli for per annullare il
contenuto dell’ultima colonna e dell’ultima riga che, non venendo elaborate
dall’estrattore di Roberts, contengono valori “non corretti” per la codifica
soft successiva.
c) A questo punto l’immagine risulta essere binarizzata e contenente le linee di
contorno degli oggetti presenti più eventuali distorsioni e/o disturbi, i
cosiddetti artefatti. La presenza di artefatti rende problematica l’operazione
di matching tra due immagini consecutive appartenenti alla sequenza in
esame. Per questo motivo, G. Maris ha pensato di effettuare una codifica
dell’immagine binarizzata tramite l’applicazione di una maschera 3x3 in modo
da semplificare quest’azione e tentare di correggere gli errori che si possono
avere a causa della presenza di disturbi. L’idea di questa soluzione nasce da
una serie di osservazioni ambientali discusse con la dovuta ricchezza di
particolari nel paragrafo della tesi di Maris attinente alla codifica geometrica
degli oggetti. Passando alla conversione della funzione in linguaggio C mi
sono accorto che il codice utilizzato per la codifica, il cui intento principale
era quello di poter correggere un errore (distanza di Hamming uguale a 3),
presentava delle ambiguità, cioè era dotato di una distanza di Hamming
minima uguale a 2. Ho contattato Maris, il quale mi ha spiegato che il
problema era stato risolto analizzando i risultati di uno studio di tipo statistico,

24
sulla distribuzione dei costrutti 3x3 all’interno dell’immagine. Come
conseguenza risulta sufficiente e necessario definire, una volta per tutte,
l’insieme di regole di assegnazione delle parole di codice. In questo modo le
ambiguità vengono eliminate in modo brusco (senza rispettare la teoria di
Hamming), dividendo le parole di codice in ingresso in insiemi separati a cui
corrispondono regole di associazione distinte. A livello di linguaggio C, ciò
viene fatto tramite una sequenza di istruzioni di confronto che si escludono a
vicenda, ossia se una fornisce un risultato positivo quelle seguenti non
vengono neppure analizzate. Ciò è stato ottenuto mediante una serie di
istruzioni if contenenti un’operazione logica su di una variabile di controllo
(flag) in grado di inibire l’esecuzione del codice associato a quel particolare
if, per quanto riguarda la ricerca di una codifica a distanza uno. La codifica a
distanza zero, ovviamente, non presenta questo tipo di problematiche. Ultimi
due punti da evidenziare nel sorgente dell’operatore sono:
§ l’utilizzo di una matrice locale nella quale memorizzare gli offset
rispetto al pixel in esame, per eseguire la codifica della struttura
3x3 in esame. Scelta operata in base a criteri di velocità,
comodità e modificabilità eventuale del codice.
§ l’utilizzo di una matrice immagine temporanea nella quale
immagazzinare la codifica dell’immagine per poi trasferirla nella
matrice immagine fornita in ingresso.

25
d) Dopo aver applicato i punti a), b) e c) a due immagini consecutive
appartenenti alla medesima sequenza si è pronti ad utilizzare un operatore di
matching in grado di rilevare le corrispondenze tra gli osservabili che si sono
“mossi” calcolando gli spostamenti relativi dei punti costituenti. All’interno
della propria tesi, G. Maris, ha sviluppato un certo numero di operatori, per
la precisione 9, caratterizzati dalle differenti dimensioni della griglia da
sovrapporre all’immagine, e da come ci si “muove” all’interno di questa
griglia. È importante notare che esistono due modi fondamentali di spostarsi,
per indice crescente o per indice decrescente. Assumendo come indice zero
il punto del quale si vuole verificare il movimento relativo, all’atto della
conversione in linguaggio C ho preferito considerare unicamente il modo per
indice crescente, poiché, trovato un match valido, la scansione della griglia
Figura 2.4

26
viene interrotta, mentre quella per indice decrescente continua fino all’indice
zero, e quindi, in linea di massima, la scelta effettuata risulta più veloce. Altra
caratteristica da evidenziare, prima di passare ad un’analisi più in profondità
dei singoli operatori, è la capacità, da parte di questi operatori, di rilevare
spostamenti minimi di un numero di pixel per frame variabile e definibile
dall’utente. Maris ha considerato come rumore e quindi assimilati a
spostamento nullo quelli di 1 pixel per frame, di conseguenza non mi sono
sentito di cambiare questa impostazione. Sempre pensando alle
problematiche di compatibilità, nel caso specifico con maschere di tipo
differente, e tenendo conto delle diverse velocità di esecuzione, tutti gli
operatori sono stati costruiti per essere contenuti completamente nella
regione significativa dell’immagine, vedi figura 2.4 nella quale viene
evidenziata in grigio quell’area dell’immagine non considerata per la ricerca
delle corrispondenze nei casi specifici di operatori laterali destri come ad
esempio il 3x21R. Si ha quindi una perdita di informazione rispetto ad una
cornice di pixel vicino ai bordi dell’immagine di dimensioni dipendenti
dall’operatore utilizzato. Anche in questo caso, come per il codificatore soft,
ho deciso di utilizzare una matrice locale nella quale ho memorizzato gli
spostamenti relativi al punto in analisi (indice “zero”). Ciò mi ha permesso di
scrivere un codice più compatto e riutilizzabile, tramite piccole variazioni, per
un sottoinsieme di operatori. Negli operatori 3x21L e 3x21R il codice è lo
stesso cambia unicamente il file header a cui fanno riferimento, analogamente
per il sottoinsieme formato dal 5x12L e dal 5x12R. L’operatore 3x21B è di
tipo bilaterale simmetrico, ricerca il match in due colonne, una a destra e una
a sinistra del punto in esame, contemporaneamente. Ciò ha reso necessario

27
l’utilizzo di un flag (RFF) per mantenere memoria del ritrovamento di un
match e in quale colonna (destra o sinistra), inibire ulteriori ricerche, inibire
ulteriori ricerche in quella colonna, annullare il flusso ottico nel caso si abbia
una ambiguità (match valido in tutte e due le colonne) oppure nel caso in cui
non si abbia alcun match. Per gli operatori 5x11B e Extended Cocle la
situazione cambia radicalmente. Non cambia per quanto riguarda l’utilizzo
della matrice “op” (contenente gli offset), tramite la quale è stato possibile
“riutilizzare” il codice, basta osservare le analogie tra i due operatori normali
e i due a settori per rendersene conto. Osservando la struttura delle griglie
utilizzate si nota la presenza di due regioni distinte al loro interno, ecco dove
si ha il cambiamento. La regione più esterna, le ultime 6 colonne per il 5x11B
e le ultime 2 per l’Extended Cocle, viene scandita normalmente in modalità
bilaterale simmetrica, come per il 3x21B. La regione più interna, le prime 5
colonne per il 5x11B e le prime 7 per l’Extended Cocle, viene scandita
secondo un andamento a chiocciola di tipo normale o a settori. La presenza
di queste due zone viene trasferita all’interno del codice mediante l’utilizzo di
due cicli, uno while e uno for, ben distinti. La scansione della chiocciola
viene effettuata tramite il ciclo while, in esso il flag RFF serve sempre a
marcare l’avvenuta individuazione di un match valido, la variabile ia serve per
contare gli anelli della chiocciola mentre z per conteggiare gli elementi
presenti in ogni anello. Per quanto riguarda la ricerca a settori risulta
necessario mantenere memoria del settore di lavoro e/o di riscontro del
match, per fare questo ho semplicemente modificato la matrice “op”
introducendovi un valore rappresentante il settore e ho deciso di evidenziare
l’ottenimento di un match positivo tramite la memorizzazione del settore di

28
ritrovamento in RFF. L’ultima istruzione di tipo if serve per annullare il flusso
ottico nel caso non venga ritrovato alcun match. Nella figura 2.5 sono
riportati gli operatori utilizzati.
2.3.2. Primi risultati ed alcuni esempi
Questa prima stesura del programma fu provata su alcune sequenze di immagini, tra
le varie prove effettuate una fra le più significative fu quella riportante una pianta in
movimento relativo verso destra rispetto alla telecamera. Questa sequenza, come si
può vedere dalla figura 2.6 nella quale sono riportate la prima e l’ultima immagine
componenti la sequenza stessa, contiene una quantità enorme di strutture estraibili
secondo l’algoritmo sviluppato.
Figura 2.5

29
Per questo motivo è stata considerata un test importante per verificare il
funzionamento del programma. Nella figura 2.7 viene riportato il flusso ottico di una
coppia consecutiva di immagini di questa sequenza, si nota immediatamente l’alta
densità di vettori concordanti nella direzione del movimento rilevato, ed anche se
l’immagine non è facilmente interpretabile ad occhio nudo si può affermare che il
flusso ottico viene calcolato correttamente, almeno da un punto di vista qualitativo.
Come conclusione il programma, nella sua prima stesura, funziona.
Figura 2.6
Figura 2.7

30
2.3.3. Time to Impact
Con il nome di time to impact (time to collision, time to contact …) si identifica una
caratteristica, per non dire capacità, comune ad ogni essere vivente dotato di sensori
“visivi” di tipo passivo. Avvalendosi unicamente di misure di tipo ottico, il flusso
ottico in particolare, e non conoscendo la propria velocità o la distanza da una
superficie, o comunque da un oggetto, è possibile determinare il momento in cui si
verificherà il contatto con questa superficie. L’importanza di questa capacità si
intuisce osservando il ruolo che riveste nel regolare il movimento degli appartenenti al
regno animale. Di conseguenza risulta un argomento fondamentale della branca
scientifica denominata Intelligenza Artificiale per quanto riguarda le problematiche
legate a quelle operazioni automatiche che possono essere raccolte sotto il nome di
navigazione e manipolazione di oggetti.
In questo sottoparagrafo parlerò della teoria alla base del time to impact, per poi
concentrarmi, nei sottoparagrafi successivi, sullo sviluppo di un algoritmo in grado di
ricavarlo partendo dal flusso ottico. In figura 2.8 si può osservare la geometria ottica
rappresentante il problema del calcolo del time to impact.

31
Un punto di interesse P alle coordinate (X, Y, Z) viene riprodotto attraverso il fuoco
di proiezione centrato nell’origine del sistema di coordinate (0, 0, 0). P è fisso nello
spazio fisico e non si muove. L’origine o fuoco di proiezione si muove con una
velocità dZ/dt. Se il sensore, nel nostro caso una telecamera, è rivolto nella
medesima direzione del moto, allora questa direzione è comunemente conosciuta con
il nome di “fuoco di espansione” (FOE, Focus Of Expansion), dato che si tratta del
punto dal quale i vettori del flusso ottico divergono. Considerando il caso di un robot
mobile si può ragionevolmente assumere che la direzione della telecamera sia la
medesima del moto, non è quindi necessario risolvere il caso generale di
“egomotion”2 per poter ottenere dei risultati utili. Il piano immagine è posto ad una
distanza z davanti all’origine; per convenienza si pone z = 1. Il valore attuale di z
dipende da più fattori tra i quali la distanza focale della telecamera, per comodità si
2 Situazione in cui il sensore possiede, contemporaneamente, una velocità di traslazione e una dirotazione, quest’ultima descrive l’egomotion.
Figura 2.8

32
2ZZYZ
Yy &&& ⋅−=
cerca di modificare questi fattori per portarsi nella situazione desiderata. Il piano
immagine si muove assieme all’origine. P viene proiettato, su questo piano, nel punto
p. Al movimento di avvicinamento del piano immagine a P corrisponde una
variazione della posizione di p sempre sul piano immagine.
Usando una relazione tra triangoli equilateri possiamo scrivere:
(1.3.1)
derivando rispetto al tempo si ottiene:
(1.3.2)
Dato che il punto P è, per ipotesi, immobile nello spazio possiamo affermare che:
(1.3.3)
Introducendo la (1.3.3) nella (1.3.2) e sostituendo a Y il valore y · Z, sempre nella
(1.3.2), possiamo ottenere la seguente espressione:
(1.3.4)
Riscrivendola otteniamo la relazione finale sulla quale si baserà il lavoro svolto
successivamente:
(1.3.5)
0=Y&
ZZyy && ⋅−=
τ=−=Z
Zy
y&&
ZYy
zy == 1

33
Quantità conosciuta con il nome di tempo di impatto. Si nota immediatamente che la
parte a primo membro (all’estrema sinistra) è interamente composta da grandezze di
tipo ottico e che quindi ci fornisce un metodo per il calcolo del time to contact basato
sulle immagini registrate dal sensore. Considerando una telecamera indirizzata nella
stessa direzione del FOE è sufficiente prendere un punto nell’immagine e dividerne la
distanza dal FOE per la propria divergenza dal FOE stesso; divergenza che risulta
essere il modulo del flusso ottico di quel punto. Come si ricava dalla (1.3.5)
considerata insieme alla figura 2.8.
2.3.4. L’algoritmo sviluppato
La scelta dell’algoritmo da utilizzare e le modifiche da apportare per calcolare il time
to contact, sempre sfruttando gli operatori di G. Maris per ottenere il flusso ottico, è
stato il passo successivo. Questa operazione si è rivelata più difficile del previsto a
causa della carenza di materiale a disposizione. Purtroppo questo argomento risulta
poco trattato anche a livello mondiale. La mia scelta è quindi caduta sul primo
metodo di calcolo reperito che fosse accompagnato da una accurata descrizione, per
la precisione il lavoro svolto da Ted Camus [1]. Innanzi tutto sottolineerei il fatto che
il lavoro di Camus è stato effettuato su porzioni di immagini 256 x 256 estratte da
immagini 512 x 512 e successivamente sottocampionate in un formato 64 x 64. Ciò
presenta una evidente differenza con il mio compito teso ad una verifica del ttc in
condizioni reali, senza l’impiego di preelaborazioni esasperate delle immagini. Inoltre
la velocità di movimento della telecamera è stata fissata in modo da ottenere un
frame per cm di spostamento, determinando, così, delle velocità relative in pixel per
frame molto basse, un’ulteriore vincolo che ho cercato di eliminare sempre per

34
tendere all’obbiettivo di applicazioni in campo reale. Il risultato è stato una sequenza
composta da approssimativamente 140 immagini.
La prima operazione da compiere è il calcolo delle coordinate del FOE all’interno
delle immagini della sequenza. Per determinare questi due valori si può sfruttare il
fatto che i vettori del flusso ottico possono essere rappresentati utilizzando le
componenti X e Y che li caratterizzano. Nel caso di un movimento in avanti e di un
solo oggetto occupante l’intero campo visivo, si può calcolare il FOE mediando i
fattori X e Y di tutti i vettori del flusso ottico, assegnando ad ogni componente il peso
equivalente ad un pixel trascurandone il valore effettivo, mantenendone il segno, e
trattando la media ottenuta come un offset rispetto alla linea di vista, la cui direzione è
stata assunta come perpendicolare al piano immagine e quindi coincidente con la
direzione del movimento (si proietta sul piano immagine nel punto centrale).
Le restrizioni imposte per quanto riguarda il moto ed il numero di oggetti inseguibili
all’interno del campo visivo, riducono le possibili applicazioni ma permettono di
semplificare la geometria del sistema. Considerando il fatto che lo scopo principale di
questo lavoro sarebbe un’eventuale realizzazione nell’ambito della robotica per
quanto concerne la navigazione, si può affermare che queste ultime restrizioni non
sono critiche.
Dalla (1.3.5) ricavata in precedenza per il ttc e dalla figura 2.8, che ne descrive la
geometria si osserva che la divergenza prevista di ogni punto appartenente ad una
circonferenza di un dato raggio centrata nel FOE dovrebbe essere sempre uguale
(per esempio quella del punto A è uguale a quella del punto P). È quindi giustificato
mediare le misure del flusso ottico lungo circonferenze di dato raggio per ottenere il
valore della divergenza da introdurre nell’equazione suddetta, cercando in questo

35
modo di limitare gli eventuali errori introdotti dal rumore o comunque da fenomeni di
tipo aleatorio.
Il numero di misure singole, sulle quali effettuare la media, associate ad ogni
circonferenza, è uguale a quattro volte il raggio in pixel della circonferenza stessa, ed
ogni misura singola è la media pesata tra i quattro pixel più vicini al punto, espresso in
coordinate reali, appartenente alla circonferenza. Infine la variabile y della (1.3.5)
viene assimilata al raggio, espresso in pixel, della particolare circonferenza usata.
Per ottenere un valore più preciso e meno sensibile ai fenomeni aleatori sempre
presenti in natura, è possibile eseguire il calcolo di t su più circonferenze
contemporaneamente ed effettuare la media sui risultati ottenuti.
Per una misura ancora più accurata, e sempre più stabile, è possibile mantenere in
memoria i valori istantanei calcolati nei t istanti di tempo precedenti, in modo da
calcolare una media tra t + 1 valori istantanei di t .
Da quanto appena detto si evince l’enorme importanza della parte dell’algoritmo
riguardante il calcolo delle coordinate del Fuoco di Espansione. Ho effettuato un
primo tentativo determinando le coordinate secondo l’algoritmo di Camus senza
utilizzare alcun accorgimento.
Utilizzando come test una sequenza composta da 20 immagini prelevate dal robot
Nomad in movimento di avvicinamento verso una parete, si è osservato uno
sbilanciamento del flusso ottico.
Questo sbilanciamento ha dato origine
a delle oscillazioni troppo accentuate e
non regolari del FOE rispetto al LOS
(Line of Sight, linea di vista). Nella
tabella qui di seguito sono riportati i
Figura 2.9

36
valori calcolati dalla procedura precedente per il caso appena descritto. Nella figura
2.9 viene riportata una delle immagini appartenente alla sequenza utilizzata con lo
scopo di far comprendere l’ambiente di lavoro nel quale sono stati sviluppati gli
algoritmi.
X Y
1-2 167.0 -128.0
2-3 54.0 -17.0
3-4 -74.0 16.0
4-5 70.0 20.0
5-6 138.0 -12.0
6-7 148.0 -123.0
7-8 160.0 14.0
8-9 171.0 36.0
9-10 238.0 -8.0
10-11 120.0 -13.0
11-12 -146.0 -37.0
12-13 -341.0 6.0
13-14 -1.0 15.0
14-15 -279.0 -22.0
15-16 -105.0 -70.0
16-17 -66.0 2.0
17-18 -96.0 17.0
18-19 -231.0 -16.0
19-20 -36.0 -65.0
Si può facilmente osservare come in alcuni casi le coordinate del FOE escono
addirittura dall’immagine, ciò, ovviamente, non va bene. Successivamente ho operato
un secondo tentativo limitando la superficie sulla quale effettuare il calcolo del FOE
ad una sottoimmagine 64 x 64 centrata nel
LOS. Mi sono basato sul fatto che a noi
interessa il calcolo del ttc rispetto al muro
davanti al Nomad e quindi i dati di
movimento generati dalle pareti che
passano a fianco del robot possono essere
Figura 2.10

37
considerati come rumore e quindi eliminati. La tabella seguente riporta i risultati degli
offset tenendo conto di questa limitazione sempre per la medesima sequenza utilizzata
in precedenza.
X Y
1-2 1.0 -15.0
2-3 17.0 -10.0
3-4 8.0 2.0
4-5 2.0 4.0
5-6 12.0 -5.0
6-7 12.0 -20.0
7-8 7.0 2.0
8-9 26.0 -1.0
9-10 68.0 -17.0
10-11 44.0 -7.0
11-12 -40.0 0.0
12-13 -47.0 11.0
13-14 38.0 21.0
14-15 -144.0 13.0
15-16 12.0 -5.0
16-17 40.0 27.0
17-18 50.0 43.0
18-19 -119.0 -16.0
19-20 47.0 -51.0

38
Nella figura 2.10 è riportato uno dei flussi ottici risultanti dalla sequenza in questione. In esso si
possono facilmente vedere i vettori risultanti dal movimento relativo delle pareti laterali del corridoio
evidenziati dai due ellissoidi. Purtroppo anche questa soluzione ha prodotto, come si osserva dalla
tabella, delle oscillazioni troppo ampie del FOE rispetto al LOS per poter essere considerata buona.
Tutti questi risultati sono comprensibili alla luce dei forti vincoli imposti da Camus nel suo lavoro.
Come conseguenza ho pensato di considerare le coordinate del FOE e quelle del LOS coincidenti,
approssimazione valida nel mio caso di lavoro. Ho quindi eliminato dal mio algoritmo il calcolo degli
offset del FOE.
Dopo aver affrontato il problema del FOE mi sono concentrato sul cuore dell’algoritmo ossia il
modo di calcolare il ttc. Tutto il lavoro svolto fino ad ora, incluso quello riguardante il flusso ottico, è
stato raggruppato in un programma completo (ttcextn e ttcexts) in grado di elaborare sequenze di
immagini almeno di 64 x 64 e di estrarne il time to impact.
Il programma funziona nel seguente modo. Innanzi tutto viene allocato lo spazio per la matrice
tridimensionale contenente le coordinate dei punti appartenenti alle circonferenze, scelta effettuata
per contenere in un’unica struttura tutti i dati necessari alle operazioni sulle circonferenze utilizzate. In
questo modo non sono stato vincolato a scegliere le circonferenze una volta per tutte ma queste
possono essere impostate al momento dell’esecuzione del programma, ciò equivale ad
un’allocazione di tipo dinamico. Insieme all’inizializzazione delle variabili usate vengono caricate in
memoria le circonferenze. Successivamente viene prelevata la prima immagine della sequenza per
elaborarla applicando nell’ordine il filtro quantizzatore, l’estrattore di Roberts e il codificatore soft,
questa diviene l’immagine old. A questo punto si entra nel ciclo principale del programma. In esso
viene caricata l’immagine successiva, definita come new, elaborandola come sopra , poi la si
confronta con la precedente per ottenere il flusso ottico. Dai vettori del flusso ottico si ricava il valore
istantaneo del time to impact riguardante queste due immagini, che poi verrà mediato con i valori
calcolati per le 7 coppie di immagini precedenti. Questa situazione richiede che l’algoritmo arrivi a
regime, cioè prima di avere dei risultati attendibili è necessario che abbia elaborato almeno 7 coppie
di immagini.
Arrivati in questa fase si “butta via” la vecchia immagine (old) si trasforma la nuova in vecchia, si
carica il prossimo frame della sequenza e si ripetono le operazioni appartenenti al ciclo principale fino
ad esaurimento della sequenza.

39
Dalla tipologia del nostro problema, ossia la ricerca del ttc in un movimento ortogonale diretto verso
una superficie, si comprende la necessità di utilizzare degli operatori bilaterali per poter ricavare un
flusso ottico il più “realistico” possibile. Eliminando il 3x21B (perdita di informazioni, operatore
troppo “basso”, ha il lato corto di soli 3 pixel), ho preferito concentrare la mia attenzione
all’Extended Cocle rispetto al 5x11B a causa della più spiccata simmetria puntuale del primo rispetto
al secondo. Come primo programma ho utilizzato l’operatore con la scansione della chiocciola
secondo la modalità normale, ecco il perché del nomi ttcextn e ttcexts (Extended Cocle a settori)
per l’eseguibile. Oltre a quanto detto in precedenza mi preme sottolineare il fatto che il programma
visualizza sullo schermo i valori del time to contact e li salva contemporaneamente nel file di testo
risultatinofoe.txt.
2.3.5. Test e risultati
Il primo passo fu quello di effettuare una serie di test utilizzando una sequenza di immagini artificiale,
costruita ad hoc, rappresentante un quadrato in espansione. Lo scopo di questa prova era quello di
permettere il debugging del programma, sia da un punto di vista sintattico che dal punto di vista della
coerenza dei risultati prodotti. Terminata la fase di debugging mi sono rivolto ad una sequenza reale,
prelevata sul campo tramite la telecamera del robot Nomad. La sequenza rappresenta il robot in
movimento lungo un corridoio diretto verso il muro terminale del corridoio stesso. Il muro è stato
“marcato” tramite l’apposizione, ad altezza telecamera, di un poster contenente segni di riferimento.
La prima prova, effettuata con il programma completo con il calcolo del FOE secondo la teoria di
Camus, ha dato origine a risultati disastrosi. Infatti ritornando alle tabelle presentate nel paragrafo
1.3.4 si vede che già nella prima coppia di immagini le coordinate del FOE escono dal piano
immagine. Oltre a quanto detto in precedenza mi preme far notare il fatto che aver scelto una
sequenza con pochi frame, 1 ogni 20 cm circa di movimento, ha prodotto un campo di vettori di
flusso ottico molto numeroso con velocità maggiori, anche di molto, di 1 pixel per frame. Come si
può osservare dalla figura 2.10, più ci si allontana dal punto centrale dell’immagine (LOS e FOE,
nella nostra assunzione), e più i vettori del flusso ottico aumentano d’ampiezza. È stato per questo
motivo che ho pensato di considerare un area limitata per il calcolo del time to contact (circonferenze
di raggio massimo uguale a 31 pixel) e del FOE per cercare di limitare le forti oscillazioni rilevate.
Questa scelta si rivelò profondamente errata, non solo in relazione ai risultati ottenuti, più coerenti

40
rispetto ai precedenti ma comunque inesatti, ma soprattutto nei riguardi della teoria del flusso ottico e
nelle assunzioni fatte per giungere a questo risultato.
Approfondendo le conoscenze sull’argomento in questione, e di questo devo ringraziare l’ing.
Tistarelli dell’università di Genova [2] e [3], sono riuscito a comprendere l’errore fatto. Nei due
lavori citati vengono analizzati i metodi principali di calcolo del flusso ottico evidenziando gli errori
che possono nascere durante le operazioni sia da un punto di vista qualitativo che quantitativo.
Fattore di grande interesse risulta essere la direzione scelta per il sensore in rapporto a come si
svolge il moto all’interno del campo visivo di quest’ultimo. Impostare il punto rappresentante la linea
di vista della telecamera come coincidente con il fuoco di espansione del campo vettoriale del flusso
ottico e considerarne un intorno per il calcolo del tempo di impatto è errato. Infatti i vettori che si
generano in prossimità di queste coordinate sono “piccoli” in modulo, di conseguenza gli errori che
possono insorgere nel loro calcolo a causa del rumore presente nel dispositivo di acquisizione hanno
un peso maggiore rispetto a vettori lontani che presentano un modulo “grande”. Questo problema
viene maggiormente esaltato se la “velocità” media in pixel per frame, presente all’interno della
sequenza, eccede di molto i valori di 2, 3 pixel per frame. Concludendo il metodo proposto da
Camus [1] presenta dei vincoli troppo restrittivi per il suo utilizzo, senza operare delle modifiche
importanti, in situazioni reali. O comunque può essere applicato in condizioni particolari di
sorveglianza nelle quali la LOS ed il FOE non coincidono.
2.3.6. Preparazione alla tesi
Alla luce di queste “nuove” conoscenze ed in preparazione del lavoro da svolgere per l’esame di tesi
mi sono dedicato al consolidamento del programma basato sugli algoritmi di Maris e Camus. Come
primo passo ho definito una libreria per la gestione della struttura dati contenente le coordinate dei
punti costituenti i cerchi di cui sopra. Questo modulo fa riferimento ad un’altra libreria che si occupa
della creazione, distruzione, visualizzazione e inizializzazione di strutture dati di tipo matriciale, per la
precisione:
• matrici 2D di char (immagini e flusso ottico)
• matrici 3D frastagliate nelle righe (seconda dimensione) di float (circonferenze)
• matrici 2D di float pensate per una possibile applicazione a colori con metodi di
calcolo del flusso ottico appartenenti alla prima macrocategoria descritta

41
(paragrafo 2.1, è stata abbandonata per motivi di calcolo, se ne parlerà nel
prossimo capitolo)
A questa libreria si lega anche quella per la gestione della struttura dati contenente il flusso ottico
calcolato creata per facilitarne l’utilizzo e rendere più comprensibile il codice che lo riguarda,
soprattutto il modulo destinato al calcolo del time to impact.
Per semplificare la visualizzazione del flusso ottico ho definito una libreria che permette di effettuarne
il salvataggio secondo un formato utilizzabile dal programma MatLab (le immagini 2.7 e 2.12 sono un
esempio di applicazione). Purtroppo questo programma, che permette di riprodurre facilmente il
campo di vettori del flusso ottico non funziona in ambiente Unix/Linux, quindi per poter verificare in
tempi brevi i risultati prodotti ho definito una libreria includente una funzione per il disegno di questi
vettori in maniera semplice veloce, e spero comprensibile (un esempio è la figura 2.10). Sfruttando
queste librerie ho definito un modulo contenente alcune procedure che si occupano della gestione
delle uscite prodotte dal programma, ossia il loro salvataggio su hard disk:
• immagini in formato PGM per il risultato del filtro quantizzatore, dell’estrattore di
Roberts e del codificatore soft
• flusso ottico ricavato esportabile secondo tre formati: immagine di tipo PGM,
matrice delle componenti (x, y) dei vettori, matrice per MatLab.
La prima stesura presentava un grosso difetto, il programma poteva utilizzare un solo operatore, la
scelta del quale veniva effettuata durante la fase di compilazione. Questo difetto è stato eliminato
ridefinendo i moduli contenenti i vari operatori, nella parte di codice contenete la definizione della
struttura della matrice di matching, in modo tale da poter essere inglobati nel programma tutti
insieme.
Ho introdotto un nuovo algoritmo di calcolo delle coordinate del fuoco di espansione, adesso si
hanno due possibili metodi:
• metodo sviluppato da Camus
• calcolo delle coordinate del punto di intersezione dei vettori del flusso ottico
Per quanto riguarda il secondo punto non è stata implementata, per motivi di tempo, la possibilità di
definire una soglia per il modulo del vettore sotto la quale non considerare il vettore in esame nel
computo totale. Logica conseguenza di quanto detto in precedenza riguardo all’errore presente nei
vettori di modulo piccolo [2] e [3].

42
Un altro difetto della prima stesura riguarda il passaggio al programma dei parametri necessari al suo
funzionamento, ad esempio la sequenza di immagini da utilizzare, mediante riga di comando. Avendo
introdotto le seguenti possibilità di scelta:
• l’operatore di matching
• il tipo di algoritmo per il calcolo del FOE
• quali e quante circonferenze
• quanti valori istantanei di TTI per il calcolo del valore medio
• le uscite disponibili dal programma
• la sequenza di immagini
per semplificare questo procedimento ho definito un modulo contenete il codice riguardante la fase di
inizializzazione del programma facente riferimento ad un file di configurazione contenente tutti i
parametri necessari e definibili per il corretto funzionamento del programma. Da questo momento in
poi l’eseguibile ha cambiato nome in timetocontact_new.
Tutte queste modifiche sono servite successivamente per permettere un facile trasferimento delle
componenti di codice necessarie allo sviluppo del programma principale di questa tesi, come si vedrà
nel prossimo capitolo.
2.3.7. Ultimi test e conclusioni
Il codice ottenuto alla fine delle modifiche descritte nel paragrafo 2.3.6 è stato testato su di una serie
di sequenze gentilmente fornite dall’ing. Tistarelli. I risultati sono stati confortanti soprattutto per
quanto riguarda il tti, migliorato di molto rispetto alla prima stesura. In queste prove si è osservato un
comportamento qualitativamente corretto a fronte di una serie di valori quantitativamente non
accurati. Quest’ultimo problema è da imputare al fatto che l’algoritmo di calcolo del flusso ottico non
è molto sofisticato e che funziona abbastanza bene in situazioni che presentano un unico oggetto in
moto all’interno del campo visivo. Inoltre è necessario per poter calcolare il time to impact che le
coordinate del fuoco di espansione siano contenute all’interno dell’immagine in misura tale da
permettere l’utilizzo corretto delle circonferenze scelte. Di seguito riporto i dati estratti dalla sequenza
caratterizzata dalle immagini di figura 2.11 rappresentanti la prima e l’ultima rispettivamente, mentre
in figura 2.12 viene presentato il flusso ottico ricavato per una coppia di immagini consecutive della
medesima sequenza.Figura 2.11

43
FOE - X FOE - Y TTI mediato
1-2 157.338196 140.395584 1.673028
2-3 150.354599 126.923409 3.998635
3-4 146.991806 140.691589 6.734520
4-5 145.765656 144.553696 8.294420
5-6 144.484070 122.739380 10.116780
6-7 151.914444 130.757111 11.982764
7-8 145.707367 129.678604 17.415642
8-9 142.179886 141.869949 23.548075
9-10 145.736267 152.909378 26.456690
10-11 133.802216 132.794006 25.369814
11-12 150.218384 157.254730 23.460073
12-13 141.765076 153.773041 20.929058
13-14 149.690948 157.523331 19.361246
N.B. le coordinate del FOE sono calcolate come intersezione dei vettori di flusso ottico.
Si osserva facilmente che dopo il periodo necessario per arrivare a regime, 7 valori istantanei in
questo caso, il tempo di impatto si stabilizza e comincia a diminuire definendo un avvicinamento agli
oggetti presenti nell’immagine.
Figura 2.12

44
Capitolo 3
Il sistema APACHE
In questo capitolo darò una breve descrizione del sistema APACHE evidenziandone le relazioni con
il presente lavoro di tesi.
In ambito scientifico è ormai assoldato che lo sviluppo di supporti intelligenti per i veicoli e per il
controllo del traffico abbia assunto una dimensione ed un’importanza di livello mondiale (Shibata and
French 1997). È possibile identificare due campi principali di sviluppo: la produzione di infrastrutture
intelligenti e la produzione di veicoli intelligenti. Una recente ricerca di tipo comparativo ha
evidenziato che l’interesse per problematiche di questo tipo si è spostato al di fuori dell’Unione
Europea, gli Stati Uniti d’America ed il Giappone, ed altre nazioni minori, sono ora interessate allo
sviluppo ed all’acquisizione di tecnologie di questo tipo. La visione artificiale mediante supporto
computerizzato gioca un ruolo fondamentale nel creare sistemi intelligenti mirati al miglioramento della
gestione, della sicurezza e del controllo del traffico. Questo tipo di sistemi può essere facilmente
raggruppato in due categorie: “dispositivi on board”, che implementano i veicoli intelligenti, e
“dispositivi on the road”, che implementano le infrastrutture intelligenti.
Il sistema nato dal progetto chiamato APACHE – Automatic PArking CHEck – è stato pensato per
essere un dispositivo di tipo “on the road” fornendo allo stesso tempo una soluzione a basso costo
per il problema del controllo degli accessi ad aree circoscritte. Implementa una architettura di
sorveglianza in grado di leggere le targhe dei veicoli che accedono all’area controllata in modo
automatico. Il processo di riconoscimento è completamente automatizzato e solamente nel caso in
cui il livello di affidabilità delle targhe riconosciute scenda al di sotto di una certa soglia, un segnale
d’allarme può essere inviato ad un operatore umano insieme all’immagine che ha causato il problema
per permettere una lettura di tipo manuale. Molti sistemi funzionalmente simili ad APACHE sono stati
sviluppati utilizzando varie tecniche per stabilire l’istante in cui avviare la procedura di
riconoscimento, per segmentare l’immagine catturata e per effettuare il riconoscimento dei caratteri

45
costituenti la targa. Alcuni di questi sistemi si trovano ancora in uno stato di prototipo mentre altri
sono prodotti completi ed immessi sul mercato. Oltre alla telecamera, molti di questi impianti
richiedono dei dispositivi addizionali per poter operare correttamente, come ad esempio sensori
all’infrarosso o di movimento. Nella fase di pianificazione del sistema APACHE è stato scelto di
adottare un’architettura basata esclusivamente sulla visione. Per questa ragione il sistema non
necessita di hardware particolare per funzionare, ma utilizzando dispositivi facilmente reperibili “negli
scaffali” dei negozi di elettronica si dimostra molto competitivo dal punto di vista del rapporto
prezzo/prestazioni.
La presenza di un sensore ottico, quale può essere una telecamera, risulta essere la richiesta minima
per un sistema di sorveglianza il cui compito sia quello di registrare quanto accade nell’area sotto il
suo controllo.
L’utilizzo, per il controllo ambientale, di un’architettura basata unicamente su procedure di visione
presenta alcuni vantaggi rispetto ad altre soluzioni come ad esempio il sistema Telepass adottato
dalla Società Autostrade Italiana. L’impatto di tipo architettonico e di “inquinamento visivo” sono
parametri di vitale importanza. Un sistema del tipo utilizzato per APACHE è paragonabile ad una
comunissima installazione di tipo semaforica piuttosto che ad un portale speciale come quello
richiesto dal sistema Telepass, inoltre la flessibilità e la gestione a livello economico rappresentano
altri due parametri molto importanti da tenere in considerazione. La presenza della sola telecamera
elimina la necessità di carte speciali o di equipaggiamenti basati su microprocessori da installare sul
veicolo per fornirgli l’accesso alle aree controllate, in questo modo si riduco i costi per l’utente,
eliminando il problema della ricarica periodica della carta e/o della manutenzione dei dispositivi
installati sul mezzo di trasporto. Inoltre utilizzando unicamente dei sensori di tipo passivo che si
basano sulle radiazioni luminose presenti nell’ambiente, si riduce drasticamente l’inquinamento
elettromagnetico, che, come sappiamo, è diventato molto importante in quest’ultimo periodo. Infine è
molto più semplice gestire l’accesso temporaneo alle zone controllate, basta infatti aggiornare un
database centrale che contiene le targhe dei veicoli abilitati.
3.1. Come funziona

46
Il sistema si appoggia unicamente su procedure di “computer vision” ed è disegnato come un set di
moduli in cascata, ognuno dei quali è responsabile di un singolo passo nella sequenza di operazioni
che compongono il processo di riconoscimento delle targhe. APACHE è suddivisibile in tre moduli: il
modulo di segmentazione delle targhe, che si occupa del rilevamento della posizione della targa del
veicolo all’interno dell’immagine in ingresso e della seguente estrazione; il modulo di segmentazione
dei simboli, che estrae i simboli presenti nella targa uno ad uno; ed il modulo di riconoscimento dei
simboli, che classifica i simboli estratti caratterizzando così la targa. I primi due moduli combinano
tecniche di elaborazione d’immagini e conoscenze a priori sulla topologia delle targhe, mentre il terzo
modulo impiega un approccio a rete neurale.
APACHE è un sistema basato su un software interamente sviluppato in C e C++, codificato
inizialmente in ambiente DOS è stato poi riscritto e compilato per funzionare anche in ambiente
Linux. Le immagini, riprese da posizione fissa (vedi figura 3.1), vengono elaborate da un PC dotato
di una scheda di acquisizione video specifica e, in uscita sul video, viene fornita una visualizzazione
della targa letta. L'uso principale per il quale fu dato il via allo sviluppo del software riguardava,
come accennato in precedenza, i caselli autostradali. Questo tipo di applicazione, già oggi utilizzata,
funge da supporto ai tradizionali sistemi Telepass e Viacard. In un casello in cui non funzioni
correttamente uno dei sistemi previsti, entra in gioco la telecamera che aiuta un operatore ad
identificare l'auto ''non riconosciuta''. Da questa applicazione deriva l'idea per un'altra, del tutto
sperimentale al momento, che possa regolamentare l'accesso ai centri storici: il sistema deve
riconoscere le auto che accedono a zone riservate per verificarne i permessi. Fattore fondamentale,
in questo caso, è che la strada non può più essere ''strutturata'', cioè non è più possibile sistemare
Figura 3.1

47
dispositivi che rilevino la presenza dell'auto o che ne regolino il flusso (sbarre, guardrail, spire
annegate nell’asfalto, ecc.) e che comunque prevedano la posa di sensori nelle immediate vicinanze
del passaggio. L'unico sensore di APACHE è una ''semplice'' telecamera posta ad una certa altezza
(circa 4 m), perché non sia facilmente raggiungibile, e ad una distanza di circa 10 m perché possa
inquadrare la targa posteriore dell'auto in modo agevole. Tutto il sistema non deve richiedere la
presenza sul posto di un operatore che, invece, può controllare il corretto funzionamento di più
installazioni da una postazione remota. Un'altra possibile espansione dovrà riguardare la capacità di
leggere le targhe dei ciclomotori in quanto mezzi fondamentali, non tanto nelle autostrade dalle quali
sono esclusi, quanto nei centri storici.
3.2. Problemi e possibili sviluppi
Da quanto visto nel paragrafo precedente, il tipo di sensore utilizzabile per fornire ad APACHE
l’informazione temporale di quando scattare il fermo immagine sul quale effettuare le elaborazioni di
ricerca della targa, riveste una importanza critica, soprattutto se si vuole installare questo dispositivo
in determinati ambienti. Riflettendo sulla conformazione tipica dei centri storici delle città presenti in
Italia risulta molto complesso se non impossibile predisporre l’utilizzo di sbarre, spire annegate nel
manto stradale, ecc. Bisogna quindi trovare una strada alternativa poiché, l’estrazione corretta della
targa è molto sensibile alla “qualità” dell’immagine fornita al sistema. Qualità che dipende non solo
dalla risoluzione con cui la telecamera può osservare l’ambiente controllato, ma soprattutto da due
fattori estranei al concetto standard di qualità dell’immagine stessa. Il primo è che il veicolo da
“analizzare” deve essere presente all’interno dell’immagine, se non fosse presente APACHE
perderebbe del tempo a ricercarne la targa con la possibilità di mancare il passaggio di uno o più
veicoli successivi, quest’ultimo problema dipende dai tempi di elaborazione. Il secondo punto
dipende da una situazione che si è verificata durante gli ultimi test effettuati presso la palazzina 1 del
dipartimento di Ingegneria. Acquisendo le immagini direttamente dalla telecamera, è stato osservato
che la probabilità di riuscita della ricerca della targa, e della conseguente estrazione dei simboli, viene
influenzata dalla posizione della targa all’interno dell’immagine stessa. A questo aggiungiamo che in
taluni casi, dipendenti dal colore e dalla forma dell’automobile, la telecamera presenta un notevole

48
problema di saturazione quando l’oggetto dell’indagine tende ad occupare almeno il 90% del campo
visivo, livello di zoom necessario per poter riconoscere i caratteri della targa. Inoltre questa
situazione tende a presentarsi in istanti molto vicini a quello di fermo immagine “ideale”. Possiamo
concludere affermando che il tempo riveste una importanza fondamentale e le possibili soluzioni per
eliminare la spira ne dovranno tenere conto.

49
Capitolo 4
Flusso for Linux
Compreso che cos’è APACHE e quali sono le sue limitazioni viene spontaneo porsi la seguente
domanda:
“È possibile determinare l’istante migliore nel quale scattare il fermo immagine, dal quale
estrarre la targa del veicolo, che sia a due o a quattro ruote, senza utilizzare un sensore di
tipo invasivo come ad esempio una spira annegata nell’asfalto?”
Ragionando su questo interrogativo e riconsiderando quanto detto nel capitolo 2 sulle informazioni
che sarebbe possibile estrarre da un’analisi dell’ambiente soggetto ad indagine, una prima risposta
sarebbe sì. Lo scopo di APACHE, come detto nel capitolo 3, è quello di sorvegliare una porzione di
strada per identificare le targhe dei veicoli che la percorrono. Per poter scegliere il momento in cui
acquisire l’immagine da elaborare è necessario poter caratterizzare in qualche modo il moto dei
veicoli che attraversano il campo visivo della telecamera. Viene quindi effettuata una elaborazione di
tipo “cognitiva” ricadendo in quella branca dell’ingegneria chiamata Intelligenza Artificiale. Uno degli
strumenti resi disponibili da quest’ultima per caratterizzare il movimento di oggetti acquisiti tramite
una telecamera è l’estrazione del loro flusso ottico. Quindi, come conseguenza immediata, si
potrebbe pensare di sostituire la spira utilizzata fino ad ora, o qualunque altro tipo di sensore
invasivo, con un sistema informatico in grado di calcolarlo e valutarlo per stabilire quando ottenere
l’immagine da passare ad APACHE per le elaborazioni del caso. Da un punto di vista puramente
teorico tutto ciò è possibile, da un punto di vista pratico cosa si può dire?
Nel presente lavoro di tesi cercherò di fornire una risposta a questo interrogativo la più esauriente
possibile.

50
4.1. Uno sguardo d’insieme
Partendo da questi presupposti ho cercato di ottenere un programma in grado di ricavare il flusso
ottico da una sequenza di immagini prelevata dalla telecamera. Ho scelto per il programma il nome
flusso4l ovvia storpiatura di flusso for linux, ed è con questo nome che lo indicherò nel proseguo di
questo lavoro.
Flusso4l è basato su di un software sviluppato interamente in C e C++ ovviamente in ambiente
Linux. La GUI (Graphics User Interface) è stata implementata utilizzando le librerie grafiche QT,
scelta imposta dalla necessità di far girare il programma sullo stesso computer predisposto per
APACHE. Su questa macchina erano state installate solo queste librerie.
Il sistema sviluppato funziona nel seguente modo. Una telecamera situata in posizione fissa, installata
su di un palo “semaforico” al di fuori della palazzina 1 del dipartimento di Ingegneria ad un’altezza
approssimativa di 4 m, sorveglia un tratto di strada del parcheggio antistante. Le immagini riprese
vengono elaborate da un PC dotato di scheda di acquisizione video. Confrontando il risultato di
queste elaborazioni per coppie di immagini temporalmente consecutive, il sistema è in grado di
estrarre il flusso ottico degli oggetti in movimento (autovetture, biciclette, motocicli e pedoni) presenti
all’interno del campo visivo della telecamera.
Il dispositivo funziona correttamente in tutte le condizioni meteo nelle quali è stato possibile testarlo,
tra queste sono escluse la presenza di nebbia e di neve poiché non erano “disponibili” nelle giornate
dedicate alle prove “su strada”. Al momento il flusso ottico rilevato è di tipo monolaterale, viene cioè
privilegiata una direzione di ricerca specifica impostandola al momento di avviare il sistema. Ciò si
realizza tramite l’utilizzo di una serie di maschere, dette di matching, che vedremo in dettaglio più
avanti, che vengono sovrapposte alle immagini elaborate determinando così la direzione di ricerca del
flusso ottico. Questo è un discorso che può sembrare limitativo ma se si pensa che lungo una strada i
veicoli la percorrono lungo due sensi ben precisi appartenenti alla medesima direzione, la
semplificazione effettuata non solo ha un senso logico ma ricade in quei vincoli di conoscenza a
priori, di cui ho discusso nel secondo capitolo, che permettono di alleggerire il problema che si sta
tentando di risolvere. Comunque sono in fase di sviluppo una serie di maschere di tipo bilaterale che
permetterebbero l’estrazione del flusso ottico lungo i due sensi appartenenti alla medesima direzione.
Queste maschere presentano alcuni problemi di cui parlerò più avanti.

51
4.1.1. Gli elementi del sistema
Il sistema che oggi rappresenta flusso4l è costituito da un PC basato su un processore Pentium Intel
II a 600 MHz, con 128 MB di RAM, da una scheda di acquisizione video Matrox Comet a 16 MB
di RAM PCI con ingresso video composito e da una telecamera a CCD.
In fase di test la telecamera è stata sostituita con un videoregistratore in modo da poter effettuare le
stime dei tempi di elaborazione sulla stessa sequenza di immagini, ottenendo così dei risultati coerenti.
Il VCR è stato utilizzato anche nella fase di estrazione dei risultati da salvare su hard disk. Si è
rilevato un ottimo strumento di supporto.
Il monitor del PC permette, tramite l’interfaccia utente, il controllo di tutte le funzioni del sistema e
risulta utile come dispositivo di verifica del corretto funzionamento del programma.
Per quanto riguarda il PC, al momento della stesura di questo testo, il modello rappresentante l’entry
level è basato su di un processore con frequenza di clock intorno agli 800 MHz se non addirittura
1000 MHz. È chiaro come la capacità computazione del PC utilizzato in sede di sviluppo di questa
tesi risulti inferiore rispetto a queste macchine, soprattutto se consideriamo che passando ad un 1000
MHz le operazioni su numeri interi, che rappresentano le fondamenta di questo lavoro, come
vedremo più avanti, vengono eseguite, approssimativamente, in metà tempo.
La scheda di acquisizione sulla quale si basa l’intero sistema è in grado di importare immagini PAL e
NTSC a piena risoluzione (768 x 576 pixel per lo standard PAL) attraverso un ingresso Y/C in cui li
segnale di luminanza (Y) e quello di crominanza (C) sono separati. Le limitazioni maggiori di questo
hardware risiedono nella memoria a disposizione, in quantità e velocità, nel BUS di comunicazione
utilizzato, PCI invece che il più veloce AGP, e nella velocità del processore che la governa.
4.2. L’algoritmo sviluppato
Il programma che gestisce l’estrazione del flusso ottico è fondamentalmente basato su di un ciclo
infinito nel quale viene catturata una coppia di immagini consecutive, queste vengono elaborate

52
singolarmente per estrarne le caratteristiche salienti, nel nostro caso gli oggetti in movimento, e poi
confrontate tramite opportuni operatori di matching per estrarne il campo di vettori del flusso ottico.
Al di fuori del ciclo rimangono unicamente le parti di inizializzazione e terminazione delle varie funzioni
nonché le procedure di gestione delle variazioni dei parametri utilizzati nelle operazioni svolte. Nella
figura 4.1 è raffigurato il diagramma di flusso del main o nucleo centrale del programma. In esso si
possono riconoscere tre blocchi principali:
§ il primo effettua l’inizializzazione dell’oggetto grafico di tipo QT che rappresenta
l’interfaccia utente e delle strutture dati delle due thread utilizzate; dopo l’inizializzazione
le thread vengono attivate e si esce da questo primo blocco.
§ il secondo ed i terzo gestiscono le due thread create; uno si occupa del calcolo del flusso
ottico “off line” (thread ScriviOffline), cioè lo estrae da sequenze di immagini statiche
salvate su hard disk; l’altro controlla l’estrazione del flusso ottico “on line” (thread
ScriviOnline), utilizzando le immagini prelevate direttamente dalla telecamera.
L’utilizzo delle thread, peraltro non necessario in questo contesto specifico, è stato pensato come
esercizio di programmazione finalizzato all’integrazione delle procedure sviluppate in questo lavoro
con il sistema APACHE. Quando queste due realizzazioni saranno integrate il modulo di APACHE
rimarrà in attesa di un segnale che il dispositivo di calcolo del flusso ottico dovrà inviargli quando un
oggetto rilevabile si presenterà nella posizione migliore per analizzarlo. Una struttura di questo tipo
può essere facilmente “riprodotta” mediante l’utilizzo di due processi concomitanti, uno che funziona
continuativamente e l’altro che “dorme” fino a quando non si verifica una situazione particolare. A
Figura 4.1

53
livello software si ottiene tutto ciò mediante l’impiego delle thread. Le due procedure si devono
escludere a vicenda, non potendo essere attive contemporaneamente, verificando e modificando
delle opportune variabili ambientali. Ambedue contengono un ciclo infinito dal quale usciranno
solamente quando il programma verrà terminato tramite la pressione del pulsante di uscita. Tra le due
la più importante è sicuramente quella che si occupa dell’acquisizione diretta dalla telecamera e sarà
quella descritta nel proseguo di questo lavoro. La seconda è stata sviluppata con il solo intento di
poter avere a disposizione uno strumento per il debugging e per l’estrazione di risultati senza
influenzare il funzionamento normale del programma, questi concetti verranno espansi nel paragrafo
dedicato alle prove effettuate.
4.2.1. La thread ScriviOnline
Dedichiamoci ora a dare una breve spiegazione di questo blocco del programma. In figura 4.2 sono
riportati il diagramma di flusso ed il codice della thread.
void *ScriviOnline(Flusso4L *data){ data->videoOFF = true; data->flowOFF = true; for ( ; ; ) { while (!data->videoOFF) { //start_time(); data->videoplay(); if ((!data->flowOFF) && (data->op_loaded)) {
//preprocedure();data->Flusso();//afterprocedure(0);
} //printresult(); } }
Figura 4.2

54
La fase di inizializzazione, che lega la thread all’oggetto grafico QT chiamato Flusso4L, è definita
dall’assegnamento del valore true a due variabili globali che regolano l’attività della scheda di
acquisizione video (videoOFF) e l’attivazione della parte di codice per il calcolo del flusso ottico
(flowOFF). Il ciclo “infinito” è suddiviso in due parti, l’accesso ad ognuna delle due viene regolato
tramite l’impiego di due relazioni booleane basate sulle variabili di cui sopra, più una terza che viene
definita e modificata in un’altra parte del programma (op_loaded) e di cui parlerò più avanti. In
poche parole quando il sistema viene attivato tramite la pressione del pulsante “PLAY”, presente
nell’interfaccia utente, videoOFF viene posta a false e la scheda video comincia ad acquisire
immagini e a visualizzarle sul monitor del PC. Una volta impostati i parametri che influenzano il
calcolo del flusso ottico, è in questa fase che la variabile op_loaded può essere modificata, e
regolata la posizione dell’obbiettivo della telecamera, premendo il pulsante “Flusso ON”, sempre
presente nell’interfaccia utente, anche la variabile flowOFF viene posta a false ed il sistema
comincia a calcolare il flusso ottico.

55
4.2.2. La procedura videoplay
Questa procedura si occupa dell’acquisizione delle immagini tramite la scheda Matrox, della
conseguente visualizzazione sullo schermo nell’interfaccia utente e di rendere disponibile l’immagine
acquisita al resto del programma. Non c’è molto altro da dire se non che il metodo di acquisizione è
del tipo un’immagine alla volta. Questa scelta è stata condizionata da due fattori, il più importante è
sicuramente quello legato al metodo di calcolo del flusso ottico, per cui la situazione ideale sarebbe
quella di elaborare l’immagine acquisita e confrontarla con quella mantenuta in memoria,
appartenente all’istante di acquisizione precedente, già elaborata, nell’intervallo di tempo richiesto
void Flusso4L::videoplay(){ int c; unsigned char *src; unsigned int colore;
QPainter p(video_group); QImage *qimmvideo = new QImage();
c = METEOR_CAP_SINGLE; ioctl(fd, METEORCAPTUR, &c); src = mmbuf + off.frame_offset[0]; temp = src;
qimmvideo->create(IMGX/2, IMGY/2, 32, 0, QImage::IgnoreEndian); for(int a = 0; a < IMGY/2; a++) { for(int b = 0; b < IMGX/2; b++) { colore = ((unsigned int) (((*(src++)) & 0xff)) |
(unsigned int) (((*(++src)) & 0xff) << 8) |(unsigned int) (((*(++src)) & 0xff) << 16));
src += 5; qimmvideo->setPixel(b, a, colore); } src += DIMX * 4; } if (sartoON) for (int a = mini[0]; a < maxi[0] + 1; a++) if ((a == mini[0]) || (a == maxi[0]))
for (int b = areaim[a - mini[0]][0]; b < (areaim[a - mini[0]][1] + 1); b++) { qimmvideo->setPixel(b, a, VALBLACK);}
else {qimmvideo->setPixel(areaim[a - mini[0]][0], a, VALBLACK);qimmvideo->setPixel(areaim[a - mini[0]][1], a, VALBLACK);
} p.drawImage(4, 4, *qimmvideo, 0, 0, -1, -1); qimmvideo->~QImage();
Figura 4.3

56
dalla scheda per acquisire la prossima immagine. In questo modo la scheda ed il software di
elaborazione lavorerebbero in modo indipendente. Purtroppo le librerie sviluppate per l’impiego
della scheda in ambiente Linux contengono degli errori per quanto concerne l’acquisizione in
modalità continua3. Questi errori possono portare alla elaborazione di immagini non completamente
acquisite, ad esempio un’immagine composta per metà da quella acquisita nell’istante t-1 e per l’altra
metà da quella dell’istante t. Il flusso ottico che ne consegue risulta errato e questo è il secondo
fattore. Ciò richiede che le due procedure di acquisizione ed elaborazione siano sincronizzate. Se a
questo aggiungiamo che la documentazione riguardo l’utilizzo delle funzionalità della scheda di
acquisizione non esaurisce in maniera sufficiente tutte le possibili applicazioni, si può affermare che
questo problema non presenta una facile soluzione. Considerando tutto questo ed il fatto che
l’operazione di acquisizione è di tipo non atomico, si comprende come la tecnica implementata sia la
più semplice ed affidabile a disposizione. Unico neo di questa scelta risulta essere l’enorme
dipendenza dai tempi di calcolo per quanto riguarda la visualizzazione sul monitor di quanto
osservato dalla telecamera. In figura 4.3 viene riportato il codice di questa procedura. Ultimo punto
degno di nota è la presenza del ciclo for condizionato dall’essere true la variabile sartoON. Questa
parte di codice serve a visualizzare a schermo la cosiddetta area di taglio che serve per simulare, a
livello software, l’impiego di una spira o comunque a ridurre la zona di ricerca del flusso ottico. Ne
parlerò in maniera più approfondita nel prossimo paragrafo.
4.2.3. La procedura Flusso ed i suoi moduli
Cominciamo ad analizzare il cuore pulsante del programma. Questa procedura può essere divisa in
due blocchi principali, il primo si occupa di gestire la prima immagine che viene elaborata, mentre il
secondo, che rappresenta il processo a regime, gestisce l’acquisizione delle immagini successive, la
loro elaborazione ed il confronto per l’estrazione del flusso ottico. In figura 4.4 (a) ne riporto il
diagramma di flusso ed il relativo codice in figura 4.4 (b), la variabile first_time serve per
discriminare quando si tratta della prima immagine o di una delle seguenti. Riassumendo l’algoritmo
funziona nel seguente modo: acquisisce la prima immagine e la elabora estraendone gli osservabili e
classificandola come immagine old; poi acquisisce l’immagine successiva, classificata new, la elabora
e la confronta con la old per estrarne il flusso ottico; a questo punto la new viene “trasformata” in
old ed il ciclo ricomincia con una nuova immagine new. Questa procedura è composta da una serie
3 Questo problema è stato evidenziato già dalle prime stesure del sistema APACHE.
Figura 4.4 (a)
void Flusso4L::Flusso(){ if (first_time) { img_old.grabba_scaled(temp, LARGHEZZA, SCALAX, SCALAY, caricafile); acquisisci_sfondo(); elaborazione_immagine_ppmgs(&img_old); first_time = false; } else { img_new.grabba_scaled(temp, LARGHEZZA, SCALAX, SCALAY, caricafile); elaborazione_immagine_ppmgs(&img_new); reset_of(); operatore_ppmgs(sartoON); combinaflussiottici(COMBFLOW); visualizzaflussoottico(); if (outfoON) salvafo(); img_old = img_new; }}
Figura 4.4 (b)

57
di moduli che vengo eseguiti ripetutamente per ogni immagine e per ogni coppia di immagini
consecutive. Andiamo ad analizzarli nel dettaglio.
4.2.3.1. grabba_scaledLe immagini acquisite dalla scheda Matrox vengono memorizzate, all’interno del programma, in una
struttura dati appropriata definita tramite la classe ‘image’. Questa struttura dati permette la loro
successiva elaborazione senza intaccare quella parte di memoria destinata alla scrittura dei dati video
prelevati dalla telecamera. Otteniamo così una separazione netta tra i dati che verranno elaborati dal
programma e quelli acquisiti dalla scheda video. Separazione che viene ottenuta tramite una
mappatura diretta della porzione di memoria nella quale la scheda andrà a scrivere mediante
l’istruzione C mmap. grabba_scaled è una delle funzioni membro di questa classe, situata all’interno
del file graphics.cpp si occupa del caricamento delle immagini acquisite nella struttura dati
appropriata operando anche un cambio di dimensioni. L’acquisizione delle immagini viene effettuata
alla risoluzione massima di 768 x 576 pixel. Questo valore, necessario ad APACHE per poter
estrarre correttamente le targhe, non risulta indispensabile per il calcolo del flusso ottico, anzi, è
preferibile ridurre la quantità di dati da elaborare per ridurre i tempi di calcolo il più possibile. Per
fare un semplice esempio consideriamo l’immagine a risoluzione piena per uno dei tre toni di colore,
essa sarà formata da 768 x 576 x 8 = 3'538'944 bit, se ora prendiamo una immagine i cui lati sono
la metà otteniamo 384 x 288 x 8 = 884'736 bit, esattamente un quarto del valore precedente. Per
questi motivi, è stata scelta una scalatura ad 1/3 delle dimensioni originali, valore che si è poi rivelato,
in sede di sperimentazione, come un buon compromesso tra i tempi di elaborazione e la risoluzione
del flusso ottico ricavato. Poiché la procedura in questione occupa, all’incirca, il 10 – 12%4 del
tempo complessivo di esecuzione, ho optato per una azione di scalatura molto brutale priva di
operazioni di mediazione.
Vengono trasferiti nell’immagine ridotta 1 pixel ogni n, dove n è il fattore di scalatura, quindi nel caso
del valore scelto in precedenza uno ogni tre. In figura 4.5 riporto il codice per questa procedura con
l’intento di far notare la presenza di una macro da me chiamata INDICE_X, con X uguale a 3 o 4,
che verrà ampiamente utilizzata all’interno della classe ‘image’.
4 I tempi di esecuzione saranno trattati più approfonditamente nel paragrafo 4.5.

58
Dato che la struttura dati ove vengono immagazzinate le immagini acquisite è definita come un vettore
di char unsigned (privo di segno) ho pensato di utilizzare una macro apposita per indirizzarne gli
elementi come se si trattasse di una matrice di pixel, con ad ogni pixel associate le tre componenti
colore5. In questo modo il codice risulta molto più semplice da comprendere ed è stata molto più
semplice la sua stesura.
4.2.3.2. acquisisci_sfondoUno dei problemi fondamentali nei processi di elaborazione di immagini riguarda la gestione del
rumore presente nelle immagini stesse introdotto dai dispositivi di acquisizione quali la telecamera.
Come precedentemente accennato nel capitolo 2, il rumore termico intrinseco alla matrice CCD, le
variazioni di posizione dell’obbiettivo prodotte da vibrazioni o folate di vento, nel caso in cui la
telecamera sia fissata in una posizione esposta agli agenti atmosferici, possono generare delle
variazioni di luminosità tra una acquisizione e quella successiva. Queste variazioni sono estremamente
dannose per le operazioni di ricerca delle corrispondenze soprattutto nella fase di estrazione dei
5 La scelta di utilizzare immagini a colori verrà spiegata poco più avanti.
void image::grabba_scaled(unsigned char *vi, int dim, int sX, int sY, bool sel)
{ int i, j;
switch (sel) { case 0: //grabba dalla scheda for (i = 0; i < H; i++) for (j = 0; j < L; j++) {
RgbPtr[INDICE_3(i, j, 2, L)] = vi[INDICE_4(i * sY, j * sX, 0, dim)]; //bRgbPtr[INDICE_3(i, j, 1, L)] = vi[INDICE_4(i * sY, j * sX, 1, dim)]; //gRgbPtr[INDICE_3(i, j, 0, L)] = vi[INDICE_4(i * sY, j * sX, 2, dim)]; //r
} break; case 1: //grabba dalla sequenza file for (i = 0; i < H; i++) for (j = 0; j < L; j++) {
RgbPtr[INDICE_3(i, j, 0, L)] = vi[INDICE_3(i * sY, j * sX, 0, dim)]; //rRgbPtr[INDICE_3(i, j, 1, L)] = vi[INDICE_3(i * sY, j * sX, 1, dim)]; //gRgbPtr[INDICE_3(i, j, 2, L)] = vi[INDICE_3(i * sY, j * sX, 2, dim)]; //b
} }}
Figura 4.5

59
contorni e della successiva codifica. Nell’algoritmo sviluppato da G. Maris trattato sempre nel
capitolo 2 si cerca di ridurre il peso di questi errori filtrando preventivamente le immagini da
elaborare. Questo è un comportamento di tipo general pourpose, si adatta abbastanza bene a molte
delle possibili situazioni ambientali che ci si può trovare ad osservare, però, non possedendo
conoscenze specifiche, non è in grado di sfruttare le proprie potenzialità al meglio. Al contrario il
dispositivo APACHE e il flusso4l possiedono alcune informazioni a priori che sarebbe bene sfruttare.
Una delle più importanti è sicuramente quella che ci permette di considerare come “immutabile”,
entro periodi di tempo medio-brevi, lo sfondo della scena osservata. Una volta che il dispositivo sarà
installato la strada che si appresterà a sorvegliare non potrà certamente mutare, almeno nella struttura
di base, da un’immagine all’altra. Considerando che il compito di flusso4l è quello di estrarre gli
oggetti in movimento ho pensato di sfruttare una delle idee di APACHE a mio favore. Sfruttare lo
sfondo come una specie di filtro con il quale pre-elaborare le immagini in modo da eliminare tutti gli
oggetti fissi il cui flusso ottico non deve essere elaborato, che potrebbero causare i problemi di cui
sopra. Questo modulo si occupa della memorizzazione dello sfondo in una variabile dedicata. Come
si può vedere nella figura 4.6, che ne riporta il codice, esso sfrutta la procedura descritta nel
paragrafo 4.2.3.1 più un’altra di cui darò spiegazione poco più avanti. In poche parole questo
modulo memorizza l’immagine di sfondo scalandola e poi ne calcola l’immagine gradiente,
quest’ultima e quella che viene restituita in uscita. È possibile richiamare questa procedura mediante
la pressione del pulsante, presente nell’interfaccia utente, chiamato “Acquisisci Sfondo”. Questa
funzionalità è stata inserita per permettere al sistema di adattarsi ad eventuali cambiamenti che
potrebbero insorgere, quali ad esempio un veicolo che parcheggia all’interno del campo visivo come
pure le variazioni di intensità luminosa nel passaggio tra il giorno e la notte e viceversa. Anche il
procedimento utilizzato per l’impiego dello sfondo memorizzato verrà affrontato più avanti, in una
sede più opportuna.
void Flusso4L::acquisisci_sfondo(){ img_sfondo.grabba_scaled(temp, LARGHEZZA, SCALAX, SCALAY, caricafile); img_sfondo.gradient(TYPE_GRAD);}
Figura 4.6

60
4.2.3.3. elaborazione_immagine_ppmgsQuesto è il modulo che si occupa di effettuare quella serie di elaborazioni sulle immagini, necessarie
per estrarre le features o osservabili indispensabili per il calcolo del flusso ottico tramite il metodo
delle corrispondenze discrete (vedi paragrafo 2.2). Le operazioni che vengono eseguite si basano su
alcune soglie, vedremo tutto ciò più in dettaglio nel paragrafo 4.3, è per questo che, nel codice,
rappresentato in figura 4.7, è presente una variabile booleana, per la precisione soglieON, che viene
impiegata come semaforo. Essa inibisce la modifica dei valori delle soglie quando il programma si
trova all’interno di questo modulo. In questo modo tutta l’immagine viene processata con i valori
delle soglie uguale per ogni pixel. La sequenza di operazioni che vengono effettuate è la seguente:
§ viene estratto il gradiente dell’immagine
§ il gradiente viene confrontato con lo sfondo per evidenziare gli oggetti in movimento
§ l’immagine ottenuta dal punto precedente viene binarizzata
§ l’immagine binarizzata viene codificata per estrarne gli osservabili
Le istruzioni di tipo if presenti all’interno di questo modulo servono unicamente per controllare la
visualizzazione delle uscite prodotte dalla varie procedure. Visualizzazione che avviene, se attivata,
void Flusso4L::elaborazione_immagine_ppmgs(image *img){ soglieON = false; img->gradient(TYPE_GRAD);
if ((multi1ON) && (multi11_sel == 0)) visualizza(img, 1, 0); if ((multi2ON) && (multi22_sel == 0)) visualizza(img, 2, 0); if (outgrad1ON) salva_grad(img, 1);
estrai_auto(img, TYPE_ESTR);
if ((multi1ON) && (multi11_sel == 1)) visualizza(img, 1, 1); if ((multi2ON) && (multi22_sel == 1)) visualizza(img, 2, 1); if (outgrad2ON) salva_grad(img, 2);
img->binary(TYPE_BIN, RANGEBIN, outistoON, DIROUT);
if ((multi1ON) && (multi11_sel == 2)) visualizza(img, 1, 2); if ((multi2ON) && (multi22_sel == 2)) visualizza(img, 2, 2);
img->CodSoft_ppmgs(); soglieON = true;}
Figura 4.7

61
nelle due porzioni dell’interfaccia utente classificate come display multifunzione (vedi Appendice A).
Si può scegliere se osservare il risultato prodotto dal gradiente, dall’estrazione dell’auto o dalla
binarizzazione.
4.2.3.4. reset_ofDel presente modulo c’è poco da dire. La sua funzione è quella di “resettare”, ossia portare a zero i
tre flussi ottici corrispondenti ai tre toni colore. Questa operazione è necessaria per evitare che, il
risultato del ciclo precedente influisca su quello attuale determinando un flusso ottico errato. Le
funzioni che utilizza appartengono alla classe ‘opt_flow’. Definita nel file opt_flow.cpp essa si occupa
della gestione della struttura dati nella quale vengono memorizzati i quattro flussi ottici, i tre per i toni
colore e quello cumulativo, elaborati dal programma durante ogni ciclo di confronto tra coppie di
immagini. Come la classe ‘image’ anch’essa utilizza, come struttura dati, un vettore di char dotati di
segno nel quale vengono registrate le componenti X e Y dei vettori ricavati per ogni pixel
dell’immagine. Lo stesso indirizzamento di questo vettore viene effettuato tramite una macro identica
nel concetto a quella descritta nel paragrafo 4.2.3.1.
4.2.3.5. operatore_ppmgsIl modulo descritto in questo paragrafo è il nucleo centrale del calcolo del flusso ottico. Si basa sul
discorso fatto nel capitolo 2 a proposito dell’estrazione del flusso ottico mediante corrispondenze
discrete. Il ciclo di base deriva in maniera totale dall’algoritmo di G. Maris. Come si può facilmente
vedere in figura 4.8 per ogni punto dell’immagine old la cui codifica risulta non nulla viene effettuata
la ricerca di un punto con codifica analoga nell’immagine new partendo dalle medesime coordinate
estratte dalla old6. La ricerca avviene mediante la sovrapposizione di opportune maschere di
matching all’immagine new. L’operazione viene ripetuta per tutti e tre i toni di colore producendo in
uscita i corrispondenti flussi ottici, chiamati OpFl_r, OpFl_g e OpFl_b. Ultimo punto da evidenziare
la ripetizione del codice all’interno dell’istruzione if … else. L’istruzione di controllo del flusso del
programma è stata introdotta per utilizzare l’opzione che si riconduce alla procedura di taglio di una
regione dell’immagine. Mediante la pressione del pulsante “Sarto ON” è possibile attivarla,
disattivarla o cambiarne i parametri. La ridondanza del codice è necessaria per verificare, nel caso in
void operatore_ppmgs(bool sartoON){ int i, j, h, l, starti, endi;
h = img_old.getH(); l = img_old.getL(); if (sartoON) { if (mini[1] >= limri + 1) starti = mini[1]; else starti = limri + 1; if ((maxi[1] + 1) <= h - limrf - 1) endi = maxi[1] + 1; else endi = h - limrf - 1; for (i = starti; i < endi; i++) for (j = areaop[i - mini[1]][0]; j < (areaop[i - mini[1]][1] + 1); j++) {
if (img_old.getR(i, j) != 0) matching_ppmgs(img_old.getR(i, j), &OpFl_r, i, j, 'r');if (img_old.getG(i, j) != 0) matching_ppmgs(img_old.getG(i, j), &OpFl_g, i, j, 'g');if (img_old.getB(i, j) != 0) matching_ppmgs(img_old.getB(i, j), &OpFl_b, i, j, 'b');
} } else { for (i = limri + 1 ; i < h - limrf - 1; ++i) // l'1 tiene conto della cornice nulla for (j = limci + 1; j < l - limcf - 1; ++j) {
if (img_old.getR(i, j) != 0) matching_ppmgs(img_old.getR(i, j), &OpFl_r, i, j, 'r');if (img_old.getG(i, j) != 0) matching_ppmgs(img_old.getG(i, j), &OpFl_g, i, j, 'g');if (img_old.getB(i, j) != 0) matching_ppmgs(img_old.getB(i, j), &OpFl_b, i, j, 'b');
} }
Figura 4.8 – versione senza parallelismo

62
cui il “sarto” sia attivo, che l’area di ricerca contenga la maschera di matching utilizzata, per una più
accurata descrizione di questa problematica si rimanda al paragrafo 4.4.
4.2.3.6. combinaflussiottici e visualizzaflussootticoGli ultimi due moduli della procedura Flusso servono, il primo, a combinare i tre flussi ottici ricavati
dalle componenti colore in un unico campo vettoriale, il secondo, alla visualizzazione di quest’ultimo
all’interno dell’interfaccia utente per poter avere un riscontro immediato dei calcoli effettuati. In figura
4.9 (a) e (b) riporto il codice per queste due funzioni.
La combinazione può avvenire secondo due modalità differenti di sommatoria vettoriale pesata. La
prima considera il peso delle tre componenti secondo l’equazione che determina, dati i valori dei tre
colori, la funzione di luminanza, quindi il rosso pesato con un fattore 0.299, il verde con 0.587 ed il
blu con 0.114. La seconda utilizza dei pesi uguali, quindi una combinazione a peso uniforme con
valore 0.333. La scelta tra quale delle due eseguire viene effettuata in fase di compilazione
impostando a 0 o a 1, rispettivamente, il parametro COMBFLOW. L’idea alla base della
combinazione vettoriale dei tre flussi ottici risiede nella possibilità di ridurre l’effetto degli errori
avvenuti nel calcolo di questi ultimi imputabili come sempre alla presenza di un rumore di tipo
aleatorio.

63
Per quanto riguarda la procedura di visualizzazione mi preme far notare come i vettori di flusso ottico
vengono rappresentati in una immagine negativa. Ho adottato questa soluzione per favorire la
velocità con la quale disegnare i pixel dei vettori e per non complicare troppo il codice. Situazione
che si era venuta a creare nella prima stesura dove, per evitare di inizializzare, rendendola
completamente bianca, l’immagine da presentare sullo schermo del monitor, ero stato costretto a
tenere conto dell’orientamento dei vettori stessi. In quest’ultima versione i vettori vengono
rappresentati con il colore bianco ed i loro punti di origine in verde, lo sfondo rimane nero. Un
esempio è riportato nella figura 4.10.
void combinaflussiottici(int sel){ int i, j, h, l;
h = OpFl.getH(); l = OpFl.getL(); switch (sel) { case 0: //combinazione peso luminanza for (i = 0; i < h; ++i) for (j = 0; j < l; ++j) OpFl.putXY(i, j,
(char) (0.299 * OpFl_r.getX(i, j) + 0.587 * OpFl_g.getX(i, j) + 0.114 *OpFl_b.getX(i, j)),
(char) (0.299 * OpFl_r.getY(i, j) + 0.587 * OpFl_g.getY(i, j) + 0.114 *OpFl_b.getY(i, j))); break; case 1: //combinazione peso uniforme for (i = 0; i < h; ++i) for (j = 0; j < l; ++j) OpFl.putXY(i, j,
(char) (0.333 * OpFl_r.getX(i, j) + 0.333 * OpFl_g.getX(i, j) + 0.333 *OpFl_b.getX(i, j)),
(char) (0.333 * OpFl_r.getY(i, j) + 0.333 * OpFl_g.getY(i, j) + 0.333 *OpFl_b.getY(i, j))); }}
Figura 4.9 (a)

64
void Flusso4L::visualizzaflussoottico(void){ int max_delta; float x, inc_x, y, inc_y;
QImage *qimm0 = new QImage(); QPainter p0(video_group);
qimm0->create(IMGX/SCALAXI, IMGY/SCALAYI, 32, 0, QImage::IgnoreEndian); for (int i = 0; i < IMGY/SCALAYI; i++) for (int j = 0; j < IMGX/SCALAXI; j++) if ((OpFl.getX(i, j) != 0) || (OpFl.getY(i, j) != 0)) {
//puntoqimm0->setPixel(j + 1, i, VALGREEN);qimm0->setPixel(j + 1, i + 1, VALGREEN);qimm0->setPixel(j, i + 1, VALGREEN);qimm0->setPixel(j - 1, i + 1, VALGREEN);qimm0->setPixel(j - 1, i, VALGREEN);qimm0->setPixel(j - 1, i - 1, VALGREEN);qimm0->setPixel(j, i - 1, VALGREEN);qimm0->setPixel(j + 1, i - 1, VALGREEN);//rettaif (abs(OpFl.getX(i, j)) > abs(OpFl.getY(i, j))) max_delta = abs(OpFl.getX(i, j));else max_delta = abs(OpFl.getY(i, j));inc_x = (float) OpFl.getX(i, j) / max_delta;inc_y = (float) OpFl.getY(i, j) / max_delta;for (int k = 0; k <= max_delta; ++k) { x = j + (k * inc_x); y = i - (k * inc_y); qimm0->setPixel((int) ceil(x), (int) ceil(y), VALWHITE);}
} p0.drawImage(8 + LARGHEZZA/2, 4, *qimm0, 0, 0, -1, -1); qimm0->~QImage();
Figura 4.9 (b)

65
4.3. L’elaborazione delle immaginiNel paragrafo 4.2.3.3 ho descritto a grandi linee il funzionamento della procedura che si occupa
dell’elaborazione delle immagini, con lo scopo di estrarne gli osservabili. In questo paragrafo
desidero riprendere il discorso per evidenziare le scelte effettuate in sede di “compilazione” degli
algoritmi e fornire una spiegazione più approfondita delle procedure che compongono la funzione
elaborazione_immagine_ppmgs.
Cominciamo con il dire che le operazione svolte in questa parte del programma, anche per quanto
riguarda la sequenza di esecuzione, derivano dall’algoritmo di G. Maris da me “rimaneggiato” per
questo scopo, come visto nel capitolo 2. La prima evoluzione che salta agli occhi è quella riguardante
il tipo dei dati da elaborare, non più immagini a toni di grigio ma immagini a colori. Come evidenziato
da P. Golland in [4] e [6], G. Buchsbaum in [5] e N. Otha in [7], la stima del flusso ottico è una fase
di basso livello del problema di ricostruzione del moto. L’uscita prodotta da questa fase è una
proiezione bidimensionale del campo delle velocità nel piano immagine, che viene analizzata
successivamente per ottenere descrizioni ad alto livello del moto. È assoldato che il problema di
determinazione del flusso ottico non può essere risolto completamente partendo da una sequenza di
immagini in Bianco e Nero senza introdurre delle informazioni aggiuntive sulla natura del moto
osservato.
Un’immagine a colori può essere considerata come una combinazione di un numero, normalmente
tre, di immagini indipendenti ottenute simultaneamente dallo stesso punto di vista da sensori visivi
differenti. Conseguentemente, da un punto di vista teorico, fornisce una quantità di informazione
equivalente a quella di un set di immagini in Bianco e Nero acquisite da differenti telecamere.
Figura 4.10

66
Comunque, un’immagine a colori, possiede un vantaggio significativo rispetto ad un’insieme di
immagini in Bianco e Nero: si ha piena corrispondenza tra le componenti colore dell’immagine.
Questo elimina la necessità di risolvere il problema della corrispondenza, che è conosciuto come
molto complesso da risolvere in generale. Quindi, le immagini a colori, sono candidate naturali per
l’ottimizzazione della soluzione al problema della stima del flusso ottico. Partendo da questo
osservazioni ho cercato di sviluppare un algoritmo basato sul lavoro svolto da P. Golland [4].
Purtroppo, già dalla prima stesura, ho compreso che i calcoli necessari per il conseguimento del
flusso ottico erano, da un punto di vista temporale, troppo onerosi, pregiudicando così un possibile
impiego in applicazioni real-time. Richiedevano l’utilizzo di strutture dati in virgola mobile. Sono
quindi tornato sui miei passi e, riprendendo l’algoritmo di Maris ho cercato il modo di integrare in
esso la capacità di gestire le immagini a colori.
4.3.1. gradient
La scelta più semplice e coerente mi è sembrata quella di considerare le tre componenti colore
dell’immagine come tre immagini a toni di grigio distinte. Quindi ho “moltiplicato” per tre la fase di
elaborazione dell’immagine per l’estrazione degli osservabili, rimandando ad una fase successiva a
quella di ricerca delle corrispondenze (vedi paragrafo 4.2.3.6), e la combinazione dei tre flussi ottici
ricavati.
Le prime due fasi dell’algoritmo visto nel capitolo 2 consistono nell’applicazione di un filtro
quantizzatore, con lo scopo di ridurre il rumore, e nella successiva estrazione e binarizzazione dei
contorni mediante l’operatore di Roberts. In una prima fase di sperimentazione sulle immagini a
colori ho osservato che queste due operazioni tendevano a fornire una quantità di dati eccessiva,
ossia si otteneva in uscita un’immagine a colori contenente dei contorni “rumorosi”. Con contorni
rumorosi intendo evidenziare la presenza di sagome, appartenenti ad osservabili di tipo fisso (lo
sfondo) e non, che risultavano instabili, modificandosi da un’immagine a quella consecutiva, anche di
un numero rilevante di pixel. Ho cercato di eliminare questo problema introducendo la conoscenza a
priori dello sfondo dell’area osservata sottraendolo all’immagine. Purtroppo, sempre a causa
dell’instabilità di prima, dovuta essenzialmente alla binarizzazione ricavata con l’estrattore di Roberts,
i risultati ottenuti non mi hanno soddisfatto. Le immagini risultanti contenevano, ancora, troppe
features non “interessanti” la cui presenza andava ad intaccare il calcolo del flusso ottico, dando

67
luogo a campi vettoriali “sporcati” dalla presenza di vettori relativi a spostamenti di osservabili
appartenenti allo sfondo. Ho quindi cercato una strada alternativa per l’estrazione dei contorni e la
loro binarizzazione.
Andando a rileggere la documentazione di APACHE mi sono accorto che in esso era presente
un’operazione di estrazione parziale dei contorni mediante il gradiente orizzontale. Questa procedura
sfrutta il cosiddetto operatore della differenza del massimo. Avendo la necessità di ottenere i
contorni sia orizzontali che verticali ho considerato la versione completa. Il funzionamento di
quest’operatore è il seguente: dato il pixel di coordinate (i, j) si considerano anche gli otto pixel
adiacenti; si analizzano i nove pixel per trovare quello con il valore massimo; l’entità del gradiente del
pixel preso in esame è uguale alla differenza tra il valore del pixel dato e quello del pixel ottenuto
dalla ricerca del massimo, il risultato ottenuto va poi memorizzato nell’immagine nella locazione del
pixel considerato, in figura 4.11 è riportata la maschera utilizzata. Dai primi test effettuati ho visto
che, oltre a fornire un’immagine dei contorni di buona qualità, il nuovo metodo di calcolo risultava più
veloce. Per ridurre ulteriormente i tempi di elaborazione ho pensato di effettuare immediatamente la
modifica del contenuto del pixel valutato, senza attendere che l’operazione di estrazione del gradiente
sia stata applicata a tutta l’immagine. In questo modo si ha sicuramente una perdita di informazione
che però, in fase di sperimentazione, è risultata accettabile, come si può vedere dalle due immagini
riportate in figura 4.12, la prima rappresenta il gradiente ottenuto dall’elaborazione “canonica”
(modifica alla fine delle operazioni), la seconda quello ottenuto dalla modifica immediata, viene
riportata anche l’immagine dalla quale sono state ricavate. La funzione che si occupa di questa
elaborazione, chiamata gradient, è una delle funzioni membro della classe ‘image’, a causa della
Figura 4.11
Figura 4.12

68
lunghezza il codice relativo non viene riportato. Ho comunque lasciato la possibilità di scegliere, in
fase di compilazione, modificando il parametro TYPE_GRAD definito in flusso_d.h, quale dei due
metodi utilizzare. Come ultima considerazione sottolineo il fatto che, data la forma della maschera da
applicare all’immagine, come riportata in figura 4.11, alla fine delle operazioni, una cornice di
spessore un pixel, costituita per la dalla prima e dall’ultima colonna e dalla prima e dall’ultima riga,
non essendo stata elaborata contiene informazioni non coerenti, per questo motivo il suo contenuto
viene posto a zero.
4.3.2. estrai_auto
In uscita dalla procedura di calcolo del gradiente abbiamo un’immagine nella quale sono stati
evidenziati i contorni degli oggetti presenti nel campo visivo della telecamera, che siano in movimento
oppure no. Bisogna quindi riuscire a discriminare tra gli osservabili appartenenti allo sfondo, e quindi
statici, e quelli in movimento. Per fare ciò ho pensato di introdurre nuovamente la conoscenza a priori
dello sfondo, confortato dal fatto che questo tipo di operazione è già presente nel sistema APACHE.
La funzione che se ne occupa è stata chiamata estrai_auto. Il funzionamento, in linea di massima è il
seguente. Nell’istante in cui viene avviato il sistema di calcolo del flusso ottico, il programma
memorizza la prima immagine acquisita, dopo l’estrazione del gradiente, considerandola come
sfondo. Alternativamente si può premere il pulsante di acquisizione dello sfondo nell’interfaccia
utente che funziona nello stesso modo, immagazzinando l’immagine “gradientizzata” appena acquisita
come sfondo. Come riportato in figura 4.7, la seconda operazione eseguita è l’estrazione dell’auto.
Sfruttando lo sfondo registrato lo si sottrae all’immagine che si sta elaborando, il modulo del valore
risultante dalla sottrazione viene confrontato con una soglia e se questo risulta minore il pixel
corrispondente viene azzerato. In poche parole si effettua un confronto fra pixel corrispondenti come
posizione delle due immagini, se la differenza è al di sotto di un certo valore si assume che questi
siano gli stessi e che quindi appartengano allo sfondo. Il valore della soglia, dopo ripetute prove, è
stato fissato a 25, comunque è stata introdotta la possibilità di modificarlo, interagendo con
l’interfaccia utente, per poterlo adattare alle varie situazioni ambientali in cui il sistema si potrà trovare
ad operare. Questo valore è risultato ottimale per condizioni classificabili come standard, ossia
funzionamento diurno in assenza di fenomeni atmosferici quali neve e nebbia, è stato verificato anche
in condizioni di pioggia e si è dimostrato funzionale. Un possibile sviluppo futuro potrebbe prevedere

69
l’eventualità di rendere automatico l’adattamento della soglia alle condizioni ambientali tramite il
feedback da un sensore di luminosità, sensore che potrebbe essere anche di tipo software. In figura
4.13 sono riportati alcuni risultati ottenuti per tre valori di soglia, con l’immagine di partenza
corrispondente. Anche per questa parte dell’algoritmo ho cercato soluzioni alternative per ridurre il
più possibile i tempi di elaborazione. Andando ad osservare il codice, non riportato sempre a causa
delle dimensioni, si può notare come esistano tre varianti della procedura. Nelle prime due il
confronto fra l’immagine di sfondo e quella appena acquisita viene effettuato in un intorno del pixel
dello sfondo, per la precisione gli otto pixel adiacenti. L’unica differenza fra questi due metodi risiede
nel tentativo di ottenere tempi di elaborazione differenti agendo sul metodo di indirizzamento di
questo intorno. Il terzo non considera più l’intorno ma il singolo pixel, in questo modo si ha
sicuramente una diminuzione dei tempi pagandola in termini di perdita di informazione. Anche in
questo caso la modifica dell’immagine può avvenire o alla fine delle operazioni sull’intera immagine
oppure subito dopo aver ottenuto il risultato per il singolo pixel. La scelta che ha sembrato
Soglia = 4 Soglia = 21
Soglia = 38
Figura 4.13

70
determinare, durante i test finali, il compromesso migliore fra tempi di esecuzione e perdita di
informazione è risultata quella di modificare l’immagine immediatamente utilizzando il secondo
metodo. Comunque si ha sempre la possibilità di agire in fase di compilazione scegliendo uno dei tre
metodi a disposizione con la modifica immediata o alla fine delle operazioni.
Le differenze grafiche tra un metodo e l’altro sono simili a quelle riportate nella figura 4.12 per
quanto riguarda l’operazione di estrazione del gradiente.
4.3.3. binary
A questo punto non rimane che binarizzare l’immagine in modo da poterla codificare
successivamente ed ottenere gli osservabili sui quali effettuare la ricerca delle corrispondenze. La
risoluzione di questa fase non è stata banale.
Considerando quanto visto finora avrei potuto utilizzare il metodo sviluppato in APACHE anche per
la procedura di binarizzazione. Purtroppo, le prime prove hanno dato un esito negativo. Andando ad
analizzare più in dettaglio questo procedimento si capisce immediatamente il perché. La funzione
presentata in APACHE utilizza un’unica soglia per decidere se un pixel deve essere acceso oppure
no, soglia che viene impostata sfruttando l’andamento di tipo bimodale dell’istogramma della
distribuzione dei toni di grigio dell’immagine. Viene scelto il minimo locale presente tra i due massimi.
Osservando i tre istogrammi prodotti dall’estrazione del gradiente si vede subito che questi non sono
di tipo bimodale, addirittura non ci si avvicinano nemmeno un poco. La funzione che meglio li
approssima è il ramo del primo quadrante dell’iperbole equilatera con coefficiente positivo. Come
conseguenza immediata la scelta della soglia risulta estremamente complessa.

71
Ho riconsiderato il sistema APACHE è ho notato un particolare che mi era sfuggito in precedenza,
l’estrazione dello sfondo veniva eseguita dopo la binarizzazione.
Ho quindi
pensato di
verificare
l’andamen
to degli
istogramm
i dopo la
sottrazion
e dello
sfondo
“gradientizzato”7. Come si vede nelle figure 4.14 (a) e (b) gli istogrammi assumono una forma
monomodale più o meno accentuata. Ciò mi ha portato ha pensare che la maggior parte dei pixel
Figura 4.14 (a)
Figura 4.14 (b)

72
rimanenti appartengano agli oggetti in movimento. Considerata la struttura di questi diagrammi ho
ideato un sistema di binarizzazione che potremmo definire a filtro passa banda. Non potendo
binarizzare tutti i pixel rimanenti, è sempre presente del rumore, ho pensato di concentrare la mia
attenzione su quei toni di colore che presentano il maggior numero di occorrenze. Ho quindi
predisposto due metodi di binarizzazione che definiscono una finestra da applicare agli istogrammi
suddetti per individuare quali pixel devono essere “accesi” e quali “spenti”.
Uno si comporta in tutto e per tutto come un filtro passa banda e per questo motivo l’ho definito di
tipo orizzontale. Ricerca il tono che presenta il maggior numero di occorrenze per poi porlo al centro
della finestra di passaggio. La larghezza di questa finestra viene impostata agendo sulla parte
dell’interfaccia utente che include le due barre a scorrimento per il gradiente e per la binarizzazione.
Dopo ripetute prove ho fissato il valore iniziale a 30, ed ho preferito dare una forma sbilanciata verso
destra alla finestra, con rapporti di ¼ e ¾, rispetto al tono che presenta il maggior numero di
occorrenze.
Il secondo metodo, definito di tipo verticale, agisce in una maniera leggermente diversa. Una volta
identificato il tono con il maggior numero di occorrenze vengono accesi quei pixel che appartengono
a quei toni il cui numero di occorrenze è entro una certa distanza dal valore del tono massimo.
Mentre prima si determinavano due soglie laterali che indicavano dei toni ben precisi, adesso viene
fissata un’unica soglia che indica non il tono ma un numero di occorrenze. Quindi un dato pixel viene
acceso se appartiene ad un tono il cui numero di occorrenze supera o al limite uguaglia la soglia.
A prima vista questi due metodi non sembrano essere molto differenti, in realtà la binarizzazione di
tipo verticale presenta una particolarità che, osservata in sede di studio teorico si è confermata a
pieno in fase di test. Essa permette a parità di soglia scelta, soprattutto nei casi di valori bassi, di
recuperare delle informazioni perse quando vengono utilizzate le immagini a colori. L’utilizzo di una
soglia minima sul numero di occorrenze fa si che anche i pixel appartenenti al tono zero vengano
accesi dato che questo tono contiene almeno il 50% dei pixel presenti nell’immagine. In questo modo
si ha un effetto di sagomatura dei contorni delle zone andate perse in negativo, si evidenziano i
contorni ma non i punti interni a queste regioni.

73
Per questi motivi ho preferito utilizzare questo metodo nel proseguo della tesi, fissando la soglia ad
un valore di 20, anch’esso sperimentalmente. In figura 4.15 riporto alcuni esempi di binarizzazione di
tipo verticale.
4.3.4. CodSoft_ppmgs
Giunti a questo punto non rimane che codificare le strutture presenti nell’immagine estraendo così gli
osservabili da ricercare nell’evolversi della scena. Per questa operazione mi sono ricondotto al
lavoro fatto sull’algoritmo di Maris. Come descritto nel capitolo 2 le strutture che si vanno a definire
rappresentano degli osservabili di dimensioni minime, infatti ogni singolo pixel viene etichettato in
funzione della disposizione, nel dominio acceso/spento, degli otto pixel adiacenti. Come conseguenza
l’informazione trasportata da queste features risulta minima, in compenso il tempo necessario alla
loro definizione è ridotto a minimi termini.
Soglia = 4 Soglia = 24
Soglia = 44
Figura 4.15

74
Avendo deciso di seguire il metodo Maris il grosso del lavoro è coinciso con il trovare delle soluzioni
per ridurre all’osso i tempi di elaborazione8. Come primo passo ho sfruttato il fatto che i dati trattati
sono di tipo on/off (i pixel possono essere accesi o spenti) ed ho quindi parallelizzato la ricerca
dell’etichetta corrispondente. Definendo l’intorno del pixel sotto indagine, corrispondente alla
maschera 3x3 di cui sopra, come una sequenza di bit posti a 1 o a 0 a seconda che il pixel sia
acceso o spento, è possibile sfruttare l’operazione “ex-or” bit a bit per velocizzare il confronto con le
etichette prestabilite. In questo modo, una volta definita la stringa di bit, il confronto avviene in un
unico ciclo di clock, si sfrutta così quel poco di capacità di calcolo parallelo presente anche nei
processori di tipo sequenziale. Considerando che i registri dei processori di ultima generazione sono
a 32 bit e che la codifica della maschera ne richiede 9, ho pensato di vedere se l’etichettatura
contemporanea di due pixel poteva presentare dei vantaggi, e questo è stato il secondo passo
intrapreso nell’ottimizzazione della procedura di codifica. In figura 4.16 sono riportati due stringhe di
esempio con la relativa maschera di partenza. In conclusione il passaggio dall’assenza di parallelismo
ad un parallelismo su di una sola etichetta ha migliorato i tempi di elaborazione riducendoli quasi a
metà (~ 46%). Il passaggio al parallelismo su due etichette, al contrario, non ha portato dei
miglioramenti significativi (~ 1 – 2%) rispetto alla situazione con l’etichetta singola. L’impossibilità di
scendere ulteriormente nei tempi considerando due o tre (massimo possibile con 32 bit) etichette
contemporaneamente risiede nei tempi aggiuntivi richiesti per la preparazione della stringa contenete
le tre maschere. Inoltre la ricerca dell’etichetta giusta da attribuire al pixel viene notevolmente
complicata, e questo sforzo computazionale aggiuntivo introduce, senz’altro, dell’ulteriore ritardo.

75
All’interno del codice elaborato, disponibile nella versione elettronica della presente tesi, si può
notare la presenza dei due metodi sviluppati con in aggiunta quello da cui sono partito. La scelta di
quale utilizzare viene effettuata in fase di compilazione impostando ad 1, 2 o 3 il parametro ALGOG
presente nel file flusso_d.h.
4.4. L’estrazione del flusso otticoUna volta effettuata la codifica di una coppia di immagini consecutive binarizzate si può passare alla
fase di estrazione del flusso ottico. Il metodo scelto è quello della ricerca delle corrispondenze
discrete fra i “micro-osservabili” estratti evidenziati nel passaggio precedente. Questa ricerca sfrutta
completamente le idee sviluppate nell’algoritmo di Maris, che, come descritto nel capitolo 2, significa
Figura 4.16
Figura 4.17

76
applicare a queste immagini una maschera di estrazione specifica. Nella figura 4.17 viene presentato
il diagramma di flusso della procedura operatore_ppmgs. In esso è presente la possibilità di
scegliere tra due funzioni di matching, una di tipo normale, l’altra di tipo parallelizzata, ne darò una
descrizione più approfondita qualche riga più avanti. La funzione può essere descritta nel seguente
modo: date le due immagini elaborate, si ricercano nella prima, discriminandole secondo gli istanti
temporali nei quali sono state acquisite, i pixel che presentano una codifica non nulla, una volta
trovato uno di questi pixel si applica alla seconda immagine, alle tre componenti colore
separatamente, la procedura matching_ppmgs (matching_ppmgs_par nella versione con il
massimo parallelismo possibile) nelle coordinate corrispondenti al pixel trovato per estrarre, se
possibile, il flusso ottico corrispondente.
La procedura di matching è quindi il cuore della fase di estrazione del flusso ottico. In figura 4.18 è
rappresentato il diagramma di flusso corrispondente sia per la versione normale (a) che per quella
parallelizzata (b).
La maschera di matching che viene sovrapposta alla seconda immagine serve per definire un
percorso di ricerca, in essa sono memorizzati gli offset rispetto al punto di applicazione (le
coordinate del pixel etichettato rilevato nella prima immagine) secondo i quali ci si deve muovere per
ritrovare l’etichetta di partenza. La forma di questa maschera risulta quindi fondamentale, sia per il
tipo di flusso ottico che si vuole rilevare, che per il tempo necessario alla ricerca. Considerando la
situazione ambientale nella quale la telecamera si trova ad operare ho sviluppato una serie di
maschere che potessero adattarvisi il più possibile. In figura 4.19 sono rappresentate le principali con
una immagine tipo prelevata dalla telecamera. Come si può facilmente intuire la sede stradale
osservata ci permette di definire una conoscenza a priori che influenza la forma di queste maschere,
una volta stabilita la direzione in cui le macchine possono muoversi non ha senso utilizzare una
maschera che rileva il flusso ottico prediligendo una direzione ortogonale a quella evidenziata. Per
questo motivo ho preferito concentrarmi su strutture rettangolari di tipo monolaterale, più adatte a
rilevare il flusso ottico di oggetti in movimento lungo una precisa direzione. Questi “oggetti” sono
utilizzati nel seguente modo: la maschera viene suddivisa in una serie di colonne (evidenziate in figura
4.20), si ricerca il match all’interno della prima colonna muovendosi dal centro verso l’esterno, se
viene trovato un match i valori degli offset, corrispondenti alla casella della maschera, sono
memorizzati come coordinate del flusso ottico e si esce dalla procedura di matching per quel pixel
particolare, altrimenti si prosegue considerando la colonna successiva e così via fino ad esaurimentoFigura 4.18 (a)

77
delle caselle dalla maschera. Cercando di fornire una valenza di generalità all’algoritmo ho costruito
le otto famiglie, nelle quali possono essere raggruppate le maschere (la stella di figura 4.19),
caratterizzandole mediante l'angolo con il quale sono orientate rispetto all’asse X del piano immagine.
All’interno di ognuna di queste famiglie le maschere possono assumere dimensioni differenti sia come
lato minore che come lato maggiore. Per semplificare la costruzione di questi oggetti ho sviluppato un
programma
molto
semplice
(chiamato
XxYYZZZ),
per la sua
descrizione
rimando
sempre alla
versione
elettronica.
In un primo momento era stata inclusa la possibilità di sfruttare completamente la dimensione della
maschera per ricercare le corrispondenze discrete. Purtroppo il codice necessario per il controllo
dell’uscita di parte dalla maschera dall’immagine si è rivelato complesso e dispendioso in termini di
Figura 4.18 (b)
Figura 4.19

78
tempo. Per questo motivo ho deciso di abbandonare la prima stesura delle maschere che
includevano un blocco iniziale percorso a spirale per tenere in considerazione l’aleatorietà del
rumore. Inoltre la struttura di questo blocco crea dei problemi di incompatibilità di codice nel
passaggio alle maschere di tipo bilaterali9. In figura 4.21 è riportato una maschera d’esempio. Ho
comunque lasciato la possibilità di utilizzare questo tipo di maschere nel programma, è necessario
impostare a 1 il parametro ALGOP presente nel file flusso_d.h10.
Le etichette utilizzate nell’operazione di codifica, come specificato nella tesi di Maris, sono 16,
questo vuol dire che per codificarle bastano 4 bit. Considerando nuovamente che i processori
impiegati nella maggior parte delle macchine disponibili sul mercato utilizzano parole di 32 bit,
sarebbe ipotizzabile effettuare la verifica di un possibile match su 8 pixel in parallelo. Ho quindi
analizzato i gradi di parallelismo implementabili nel codice. Prima di procedere rendiamo noto che i
test effettuati hanno permesso di fissare a 5 o a 7 le dimensioni ottimali del lato corto delle maschere.
Considerando il modo di procedere per colonne nella ricerca dei match si evidenzia immediatamente
l’impossibilità di sfruttare a pieno la quota di parallelismo disponibile. Infatti, procedendo secondo
quanto descritto poche righe sopra, la situazione ideale, quella di effettuare la ricerca all’interno di
una colonna alla volta, ci impone una soglia massima di pixel da verificare nel loro contenuto in
codifica, per l’appunto 5 o 7. In aggiunta a ciò le maschere diagonali presentano un ulteriore
problema, come si può vedere nella figura 4.22. Nella rotazione che da operatore orizzontale o
verticale determina la struttura diagonale, le colonne subiscono una “deformazione”, in linea di
massima ogni colonna contiene un numero maggiore di elementi.
Figura 4.20

79
Più precisamente questo valore risulta uguale a (2 · X) – 1 dove X rappresenta la dimensione del lato
corto della maschera. Dividendo la colonna in due parti, la prima contenete X elementi e la seconda
X – 1, è quindi possibile sfruttare lo stesso codice sviluppato per le maschere non-diagonali. A
questo punto non mi rimane che fornire una breve descrizione del funzionamento della procedura
matching_ppmgs_par per terminare questo paragrafo. Come si vede dal diagramma di flusso,
figura 4.18, la prima operazione consiste nel definire la stringa contenente l’etichetta da ricercare,
identificata nell’immagine old. La stringa viene costruita ripetendo 7 volte l’etichetta suddetta
traslandola, in ogni ripetizione, di 4 bit. Questa soluzione permette di risparmiare in complessità non
dovendo discriminare il tipo di maschera a seconda delle dimensioni del lato corto. Il passo
successivo è rappresentato da un ciclo che scorre l’intera maschera conteggiando il numero di
colonne che la compongono. Il suddetto ciclo viene suddiviso in due parti, la prima valida per tutte le
maschere, la seconda serve unicamente per quelle diagonali dato che considera il secondo blocco
della colonna. In tutte e due le parti la colonna in esame viene codificata in una stringa simile a quella
ottenuta per l’etichetta da ricercare, prelevando le etichette dei pixel corrispondenti nell’immagine
chiamata new. Questa operazione viene effettuata dalla funzione codifica, è importante sottolineare
come la stringa venga definita in modo tale da rispettare la sequenza di scansione, definita in
precedenza, delle celle della colonna. Se la codifica ottenuta è diversa da zero questa viene
confrontata bit a bit, sempre utilizzando l’operazione ex-or, con la stringa di partenza. Il risultato di
Figura 4.21
Figura 4.22

80
questo confronto viene elaborato dalla funzione estrai_match che verifica la presenza o meno di una
corrispondenza, restituendo, in caso di match positivo, le coordinate in cui si è verificato all’interno
della maschera permettendo così alla funzione chiamante di calcolare le componenti del vettore del
flusso ottico. Nel caso in cui la maschera sia di tipo diagonale e non sia stato identificato alcun match
da questa prima operazione, l’elaborazione viene ripetuta per la seconda parte della colonna. Questi
calcoli vengono ripetuti fino a quando non si riscontra una corrispondenza positiva o si esauriscono le
colonne della maschera. A questo punto vengono memorizzate le componenti del vettore del flusso
ottico, nulle nel caso non sia stato identificato alcun match.
4.5. Prove effettuate e risultati ottenuti
Avendo osservato il corretto funzionamento degli algoritmi sviluppati11. Il sistema completo è stato
sottoposto ad una serie di test con l’intento di misurarne i tempi di elaborazione e di verificarne i
limiti. A questo scopo sono state registrate su supporto magnetico (videocassetta S-VHS) un certo
numero di sequenze dell’area sorvegliata dalla telecamera installata presso la palazzina 1 del
dipartimento di Ingegneria. Si è cercato di riprendere il maggior numero di automezzi per poter
disporre di una vasta campionatura di forme e colori. Inoltre sono state registrate delle sequenze
“pilotate”, per poter conoscere a priori le velocità con le quali i veicoli si presentavano nel campo
visivo della telecamera, in modo da poter stimare i limiti di elaborazione conseguenti. Infine è stato
svolto un lavoro di ricerca sulla qualità del flusso ottico estratto a seconda del livello di zoom
utilizzato.
Nelle figure 4.23 e 4.24 sono riportati i flussi ottici ricavati con un’immagine appartenente alle
sequenze utilizzate. Le maschere con lato corto uguale a 7 si sono dimostrate più efficaci dal punto di
vista dei tempi di esecuzione. Situazione prevedibile a livello teorico a causa dello sfruttamento
migliore del parallelismo disponibile. Parlando sempre di tempi di elaborazione il sistema si è
assestato su valori dell’ordine di 3 – 4 elaborazioni di coppie di immagini al secondo. Ciò ha
permesso di definire, in condizioni di zoom “massimo”12, la velocità di soglia intorno a 20 – 25 km/h,
sorpassato questo valore il flusso rilevato è talmente scarno che non si può pensare di utilizzarlo per
attivare l’acquisizione del fermo immagine.

81
Per quanto riguarda la stabilità del sistema, in funzione del colore delle vetture, considerando sempre
le condizioni di zoom “massimo” (situazione critica in generale), si può affermare che qualche
problema viene sollevato dai colori chiari, quali il bianco ed il grigio metallizzato. Il flusso ottico
rilevato in questi casi si presenta poco denso rischiando di compromettere il suo impiego in una
possibile funzione di catalogazione degli oggetti in movimento13 (macchine, pedoni, motocicli, ecc.).
La forma degli oggetti in movimento non sembra influenzare in alcun modo la qualità del flusso ottico.
Passando ad esaminare i risultati ottenuti con lo zoom impostato ad un livello minimo non ho
osservato limitazioni degna di nota. Gli oggetti in movimento vengono individuati e risolti senza
evidenziare una velocità limite, bisogna tenere presente che nel tratto di strada osservato risulta
difficile se non impossibile superare i 40 km/h, o problemi legati a forme e colori. Inoltre, dato che il
campo visivo è molto più ampio, gli osservabili tendono ad occuparlo per un tempo maggiore
fornendo in questo modo un numero di immagini sulle quali lavorare superiore al caso precedente.
Situazione ideale per applicazioni di sorveglianza o simili.

82
0 50 100 150 200 2500
20
40
60
80
100
120
140
160
180
Flusso Ottico
0 50 100 150 200 2500
20
40
60
80
100
120
140
160
180
Flusso Ottico
0 50 100 150 200 2500
20
40
60
80
100
120
140
160
180
Flusso Ottico
Figura 4.23

83
0 50 100 150 200 2500
20
40
60
80
100
120
140
160
180
Flusso Ottico
0 50 100 150 200 2500
20
40
60
80
100
120
140
160
180
Flusso Ottico
Figura 4.24
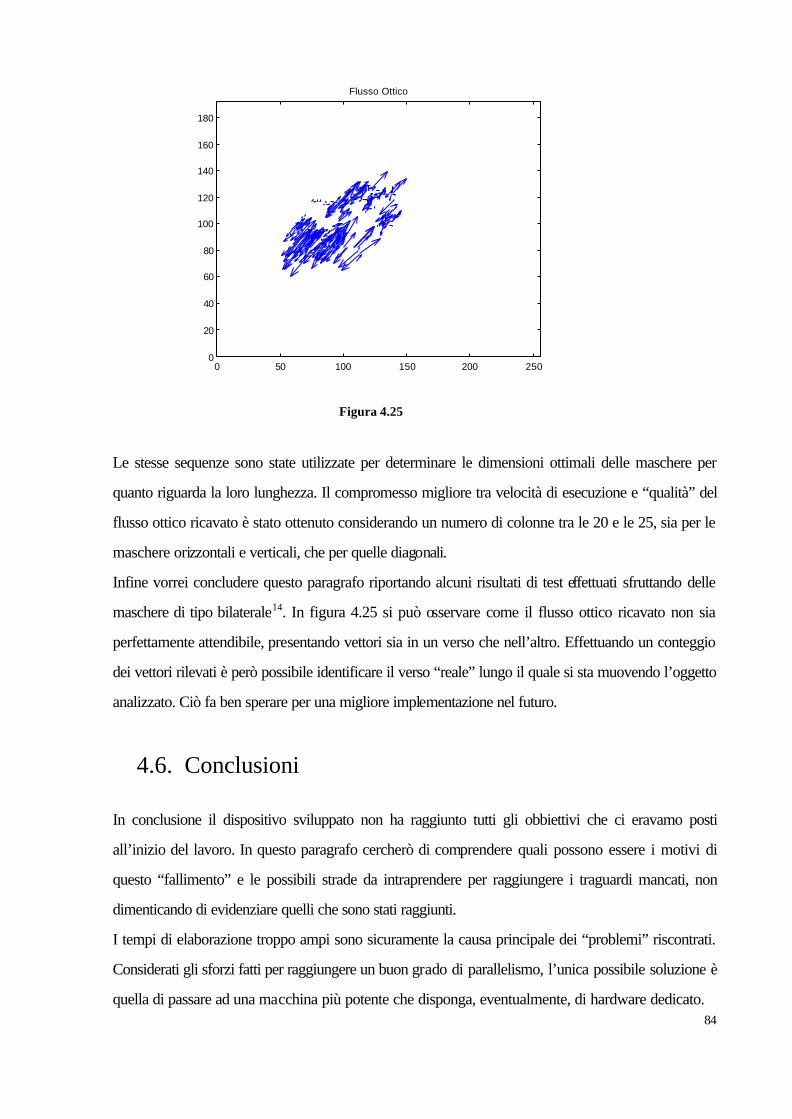
84
Le stesse sequenze sono state utilizzate per determinare le dimensioni ottimali delle maschere per
quanto riguarda la loro lunghezza. Il compromesso migliore tra velocità di esecuzione e “qualità” del
flusso ottico ricavato è stato ottenuto considerando un numero di colonne tra le 20 e le 25, sia per le
maschere orizzontali e verticali, che per quelle diagonali.
Infine vorrei concludere questo paragrafo riportando alcuni risultati di test effettuati sfruttando delle
maschere di tipo bilaterale14. In figura 4.25 si può osservare come il flusso ottico ricavato non sia
perfettamente attendibile, presentando vettori sia in un verso che nell’altro. Effettuando un conteggio
dei vettori rilevati è però possibile identificare il verso “reale” lungo il quale si sta muovendo l’oggetto
analizzato. Ciò fa ben sperare per una migliore implementazione nel futuro.
4.6. Conclusioni
In conclusione il dispositivo sviluppato non ha raggiunto tutti gli obbiettivi che ci eravamo posti
all’inizio del lavoro. In questo paragrafo cercherò di comprendere quali possono essere i motivi di
questo “fallimento” e le possibili strade da intraprendere per raggiungere i traguardi mancati, non
dimenticando di evidenziare quelli che sono stati raggiunti.
I tempi di elaborazione troppo ampi sono sicuramente la causa principale dei “problemi” riscontrati.
Considerati gli sforzi fatti per raggiungere un buon grado di parallelismo, l’unica possibile soluzione è
quella di passare ad una macchina più potente che disponga, eventualmente, di hardware dedicato.
0 50 100 150 200 2500
20
40
60
80
100
120
140
160
180
Flusso Ottico
Figura 4.25

85
Il passaggio da un Pentium 600 MHz a uno a 1000 MHz permette di ridurre del 50% i tempi di
elaborazione delle operazioni sugli interi. La stessa scheda di acquisizione video può essere
migliorata, passando da una PCI ad una utilizzante il bus AGP il miglioramento è notevole. Si
potrebbe pensare di utilizzare un sistema bi-processore in modo da ottenere un grado superiore di
parallelismo e quindi effettuare le elaborazioni sulle immagini in tempi nettamente inferiori. In
definitiva, il passaggio ad un sistema con più potenza di calcolo, non porterebbe che miglioramenti
significativi al sistema permettendo di aumentare la velocità di esecuzione15.
L’impiego di una macchina dedicata dal punto di vista del sistema operativo porterebbe degli ulteriori
vantaggi in termini di tempi di esecuzione. Le prove sono state effettuate su di un calcolatore che
presentava dei processi attivi in grado di occupare il 5 – 10% delle risorse di calcolo del processore.
La qualità del flusso ottico rilevato è influenzata sensibilmente dalla maschera di matching utilizzata.
Quelle costruite approssimano solamente le situazioni ambientali che il sistema si può trovare ad
affrontare, non sono in grado di adattarsi per fornire il risultato migliore. Utilizzando una telecamera
dotata di feedback sulla sua posizione, azimut e tilt, è possibile, utilizzando delle formule di
deformazione prospettica, adattare la struttura della maschera all’ambiente osservato migliorando di
conseguenza il flusso ottico ottenuto.
Le micro-strutture utilizzate come osservabili nell’operazione di codifica dell’immagine sono un altro
parametro in grado di influenzare le proprietà del flusso ottico rilevato. È importante far notare che
queste sono le medesime utilizzate nell’algoritmo di Maris e che sono state rilevate, mediante un
lungo lavoro di ricerca statistica, in ambiente indoor. Per scene outdoor di tipo stradale potrebbero
essere differenti. Inoltre una dimensione maggiore del 3x3 utilizzato potrebbe essere migliore. Non
ho potuto compiere questo genere di valutazioni a causa del troppo tempo che richiedono, però
sarebbe utile che qualcuno affrontasse queste problematiche.
Concludendo posso dire che il sistema è ben lungi dall’essere finito, però penso di aver aperto una
strada percorribile della quale non si sapeva nulla, soprattutto se fosse transitabile e in quale
direzione si potesse sviluppare. Auguro quindi un sentito in bocca al lupo a chi proseguirà questo
lavoro.

86
Appendice A
Manuale utente
La trattazione di come si debba utilizzare Flusso for Linux è stata lasciata in un'appendice in quanto
non rappresenta ancora un argomento fondamentale. Il sistema è in fase di sviluppo e sarebbe
prematuro indicare ad un ipotetico
utente l'uso di funzionalità non ancora stabilizzate. Di contro è però necessario indicare, anche in
modo sommario, l'uso dei “tasti” e delle indicazioni
mostrati sullo schermo.
Una precisazione: questa guida all'uso non può prescindere dal resto della
presente trattazione. Non vengono qui spiegati di nuovo gli scopi di tutte le altre caratteristiche già
ampiamente descritte nel resto del testo.
A.1 PulsantieraDunque all'avvio del programma si trova sullo schermo una finestra suddivisa in più zone (figura A.1).
All’estrema destra si ha la pulsantiera dei comandi (dettaglio, figura A.2). Questa è stata suddivisa in
tre zone distinte facilmente identificabili. Muovendosi dall’alto verso il basso abbiamo le “Video
Options” mediante le quali è possibile regolare i parametri di visualizzazione delle immagini acquisite
quali: la luminosità, il contrasto, ecc. Il secondo gruppo, chiamato “Optical Flow Options”, consente
le regolazioni più importanti del sistema. Il primo bottone, “Flusso ON”, abilita o disabilita il calcolo
del flusso ottico quando le immagini vengono ottenute mediante la scheda di acquisizione video. Il
pulsante successivo permette di effettuare le elaborazioni prelevando una sequenza di immagini
statiche memorizzate su di un supporto fisico, quale ad esempio un hard disk. Il terzo pulsante
permette di cambiare l’operatore di matching (maschera) andandolo a prelevare nella directory
opportuna e visualizzandone il nome poche righe più sotto, vedi figura A.3. Il quarto pulsante serve
per acquisire una nuova immagine e memorizzarla come sfondo, viene abilitato una volta che è stato
attivato il processo di calcolo del flusso ottico.

87
La zona successiva contiene i pulsanti per scegliere quale tipo di binarizzazione utilizzare (figura A.4),
e le due barre a scorrimento per impostare le soglie dell’operazione di binarizzazione e di estrazione
del gradiente.
Immediatamente dopo si può individuare un’area chiamata “Output”, in essa sono presenti i pulsanti
per attivare il salvataggio dei prodotti intermedi dell’elaborazione (N.B. la funzione di salvataggio del
risultato della binarizzazione non è stata ancora implementata).
Figura A.1

88
Infine, sempre nell’area centrale abbiamo un pulsante chiamato “Sarto ON”, esso permette di
attivare e disattivare la funzione di spira virtuale caricando la struttura opportuna, in questo momento
ne sono disponibili due, e di cambiare la struttura utilizzata.
Nella terza zona sono presenti due pulsanti, il primo, etichettato “PLAY”, attiva o disattiva
l’acquisizione dalla scheda Matrox, l’altro permette di uscire dal programma.
A.2 Le finestreLa parte rimanente della finestra principale è adibita alla visualizzazione dei risultati ottenuti. In alto a
sinistra vengono riprodotte le immagini acquisite dalla scheda o prelevate dall’hard disk. Nel caso in
cui la spira virtuale sia attiva essa viene disegnata sovrapponendola all’immagine in elaborazione, un
esempio è riportato in figura A.4.
Figura A.2
Figura A.3

89
In alto a destra viene disegnato il flusso ottico ricavato secondo le modalità descritte
precedentemente nel capitolo 4. La rappresentazione del flusso ottico avviene automaticamente nel
caso in cui si stia operando in modalità “off line” (immagini statiche da hard disk).
La metà inferiore dello schermo è stata suddivisa in due display multifunzione, vedi dettaglio in figura
A.5, dove, tramite le corrispondenti pulsantiere, è possibile visualizzare i risultati delle fasi intermedie
dell’estrazione del flusso ottico. In particolare le immagini risultanti dalla binarizzazione,
dall’estrazione del gradiente e dall’estrazione dell’auto. Queste ultime funzionalità sono comode in
fase di analisi del flusso ottico “off line”, cioè quando si utilizzano sequenze di immagini statiche
memorizzate su hard disk, poiché appesantiscono notevolmente l’elaborazione.
Figura A.4
Figura A.5

90
Appendice B
Listati
Nella seguente appendice riporto i file header ai quali il sistema sviluppato fa riferimento. Non riporto
i sorgenti a causa dell’enorme quantità di righe che li compongono, né fornirò alcuna descrizione
degli header, visto che le parti più importanti sono già state affrontate nei capitoli precedenti. Mi
preme comunque sottolineare la modalità di compilazione. Ricordando che il sistema utilizza le
librerie grafiche QT, ci viene in aiuto un comodo generatore di Makefile. Il programma tmake
sembra fatto apposta per compilare programmi che richiedono questo tipo di librerie, si rimanda al
manuale relativo per i dovuti chiarimenti.
B.1 graphics.h/*************************************************************************** graphics.h - description ------------------- begin : Wed Dec 27 2000 copyright : (C) 2000 by email : ***************************************************************************/
/*************************************************************************** * * * This program is free software; you can redistribute it and/or modify * * it under the terms of the GNU General Public License as published by * * the Free Software Foundation; either version 2 of the License, or * * (at your option) any later version. * * * ***************************************************************************/
#ifndef __GRAPHICS_H__#define __GRAPHICS_H__
#include <stdio.h>
void salva_istogrammi(int istr[], int istg[], int istb[], char* dir);
#define ALGOG 3#define INDICE_3(i, j, k, Larg) ((i) * 3 * (Larg) + (j) * 3 + (k))#define INDICE_4(i, j, k, Larg) ((i) * 4 * (Larg) + (j) * 4 + (k))
#if (ALGOG == 1)int match_uno(unsigned char Pixel[9], unsigned char *codifica);int match_zero(unsigned char Pixel[9], unsigned char *codifica);#endif

91
#if (ALGOG == 2)int match_uno(short pixelcod, unsigned char *codifica);int match_zero(short pixelcod, unsigned char *codifica);int contacod(short pixelcod, short val);#endif
#if (ALGOG == 3)int match_uno(unsigned int pixelcod, unsigned short *codifica, int flag);int match_zero(unsigned int pixelcod, unsigned short *codifica);int contacod(short pixelcod, short val);#endif
//dichiarazione della classe 'image'class image { private: int H, L; public: unsigned char *RgbPtr; image(int h, int l); image& operator=( const image&); void saveImageppm(FILE *file); void grabba_scaled(unsigned char *vi, int dim, int sX, int sY,
bool sel); int getH(void) {return H; }; int getL(void) {return L; }; unsigned char getR(int i, int j) {return RgbPtr[INDICE_3(i, j, 0, L)];}; unsigned char getG(int i, int j) {return RgbPtr[INDICE_3(i, j, 1, L)];}; unsigned char getB(int i, int j) {return RgbPtr[INDICE_3(i, j, 2, L)];}; void putRGB(int i, int j, unsigned char r, unsigned char g,
unsigned char b); void putR(int i, int j, unsigned char r); void putG(int i, int j, unsigned char g); void putB(int i, int j, unsigned char b); void gradient(int sel); void binary(int sel, int range, bool out, char *dir); void CodSoft_ppmgs(void); ~image();};
#endif
B.2 flusso_d.h/*************************************************************************** flusso_d.h - description ------------------- begin : Sat Mar 31 2001 copyright : (C) 2001 by email : ***************************************************************************/
/*************************************************************************** * * * This program is free software; you can redistribute it and/or modify * * it under the terms of the GNU General Public License as published by * * the Free Software Foundation; either version 2 of the License, or * * (at your option) any later version. * * * ***************************************************************************/
#ifndef __FLUSSO_D_H__

92
#define __FLUSSO_D_H__
#include "graphics.h"#include "optflow.h"
#define DEV_VIDEO "/dev/mmetfgrab0"#define IDS_STATUS_DEFAULT "Ready."#define DIRIMM "/home/ampollini/Tesi/IMMAGINI/"#define DIROP "/home/ampollini/Tesi/OPERATORI/"#define DIROUT "/home/ampollini/Tesi/OUTPUT/"#define DIRSAR "/home/ampollini/Tesi/TAGLIO/"#define OPDEF "op_5x_36_45nb.op"#define COMBFLOW 0#define TYPE_ESTR 0#define TYPE_GRAD 1#define TYPE_BIN 0#define DIMX 768#define DIMY 576#define SCALAX 3.0#define SCALAY 3.0#define SCALAXI 3#define SCALAYI 3#define VALWHITE ((unsigned int) (255 & 0xff)) | ((unsigned int) (255 & 0xff) << 8) |((unsigned int) (255 & 0xff) << 16)#define VALGRAY ((unsigned int) (127 & 0xff)) | ((unsigned int) (127 & 0xff) << 8) |((unsigned int) (127 & 0xff) << 16)#define VALBLACK ((unsigned int) (0 & 0xff)) | ((unsigned int) (0 & 0xff) << 8) |((unsigned int) (0 & 0xff) << 16)#define VALGREEN ((unsigned int) (0 & 0xff)) | ((unsigned int) (255 & 0xff) << 8) |((unsigned int) (0 & 0xff) << 16)
#define ALGOF 2#define ALGOOP 2
//dichiarazioni delle variabili globali
extern int IMGX, IMGY, RANGE, op_type, no_blocco, colmax, ang_op, lato_op;
//dichiarazione delle funzioni visibili da tutti i moduli
void acquisisci_sfondo(void);void estrai_auto(image *img, int sel);void operatore_ppmgs(bool sartoON);#if (ALGOOP == 1)void matching_ppmgs(unsigned char b, opt_flow *OF1, int y, int x, char sel);#endif#if (ALGOOP == 2)void matching_ppmgs_par(unsigned char b, opt_flow *OF1, int y, int x, char sel);unsigned int codifica(int k, int ooc, char sel, int x, int y);bool estrai_match(unsigned int cod, int k, int ooc, int *indice);#endifvoid carica_operatore(FILE *file);void reset_of(void);void combinaflussiottici(int sel);void salvafo(void);void salva_grad(image *img, int sel);void freepattern(int **a, int n);
#endif
B.3 flusso4l.h/*************************************************************************** flusso4l.h - description

93
------------------- begin : gio feb 28 17:40:53 CET 2001 copyright : (C) 2001 by email : ***************************************************************************/
/*************************************************************************** * * * This program is free software; you can redistribute it and/or modify * * it under the terms of the GNU General Public License as published by * * the Free Software Foundation; either version 2 of the License, or * * (at your option) any later version. * * * ***************************************************************************/
#ifndef FLUSSO4L_H#define FLUSSO4L_H
#define DEV_VIDEO "/dev/mmetfgrab0"
// include files for QT#include <qdialog.h>#include <qfiledialog.h>#include <qapplication.h>#include <qstring.h>#include <qmainwindow.h>#include <qpixmap.h>#include <qapp.h>#include <qstatusbar.h>#include <qmessagebox.h>#include <qpainter.h>#include <qpushbutton.h>#include <qlayout.h>#include <qlineedit.h>#include <qgroupbox.h>#include <qcheckbox.h>#include <qslider.h>#include <qlabel.h>#include <qbuttongroup.h>#include <qradiobutton.h>#include <qimage.h>#include <qcolor.h>#include <math.h>
// application specific includes#include "graphics.h"
/******************************************************//* This Class is the base class for your application. *//******************************************************/
class Flusso4L : public QMainWindow{ Q_OBJECT
public: int fd; //dev/video int LARGHEZZA ; int ALTEZZA; /* construtor */ Flusso4L(); /* destructor */ ~Flusso4L(); /* elaboration cicle */ void Flusso(); void Flussofromfile();

94
void initStatusBar(); /* overloaded for Message box on last window exit */ bool queryExit(); void carica_operatore(FILE *); void videoplay(); void videoplayClicked(); void dafileClicked(); void operatoreClicked(); bool videoOFF; bool caricafile; bool seq_loaded; bool op_loaded; bool seq_ended; bool flowOFF; bool first_time;
public slots: void slotB_Button1Clicked(); void slotB_videoplayClicked(); void slotB_caricadafile(); void slotB_inseriscioperatore(); void slotB_sarto(); void slotB_acquisiscisfondo(); void slotB_flussoON(); void slotCB_multi1ON(); void slotCB_multi2ON(); void slotCB_output(); void slotRB_multi11(int); void slotRB_multi22(int); void slotRB_binary(int); void slotS_ValueChanged(int);
private: QPushButton *button1, *b_videoplay, *b_sfondo, *loadFile, *OpEdit, *flussoon, *b_sarto; QGroupBox *video_group,*videooption_group,*flusso_group,*multi1_group, *multi2_group; QCheckBox *outfo, *outgrad1, *outgrad2, *outbin,*outisto, *multi1on, *multi2on; QSlider *ChromaSlider, *HueSlider, *ContrastSlider, *BrightSlider, *GradientSlider, *BinarySlider; QButtonGroup *out_group, *binary_group, *multi11_group, *multi22_group; QRadioButton *binary_v, *binary_h, *binary_multi1, *grad_multi1, *auto_multi1, *binary_multi2, *grad_multi2, *auto_multi2; QLabel *bright, *bright_value, *hue, *hue_value,*contrast,*contrast_value, *chroma, *chroma_value, *gradient, *gradient_value,*binary, *binary_value, *operatore, *OpInUse, *sartoInUse; bool outfoON, outgrad1ON, outgrad2ON, outbinON, outistoON; bool multi1ON, multi2ON, soglieON; bool sartoON; int multi11_sel, multi22_sel, binary_sel; void elaborazione_immagine_ppmgs(image *img); void init_frame_grabber(); void init_operatore(); int **carica_pattern_taglio(const char *s, int sel); void inserisci_nome_file(const char *s); void inserisci_operatore(const char *s); void acquisisci_sfondo(); int acquisisci_immagine(); void visualizza(image *img, int sel, int multi_sel); void visualizzaflussoottico(void);};
#endif // FLUSSO4L_H

95
B.4 opt_flow.h/*************************************************************************** optflow.h - description ------------------- begin : Tue Mar 28 2001 copyright : (C) 2001 by email : ***************************************************************************/
/*************************************************************************** * * * This program is free software; you can redistribute it and/or modify * * it under the terms of the GNU General Public License as published by * * the Free Software Foundation; either version 2 of the License, or * * (at your option) any later version. * * * ***************************************************************************/
#ifndef __OPTFLOW_H__#define __OPTFLOW_H__
#define INDICE_2(i, j, k, Larg) ((i) * 2 * Larg + (j) * 2 + (k))
//dichiarazione della classe 'opt_flow'class opt_flow { private: int H, L; public: char *OFPtr; opt_flow(int h, int l); void reset(); void saveMatlabformat(FILE *file); int getH(void) {return H; }; int getL(void) {return L; }; char getX(int i, int j) {return OFPtr[INDICE_2(i, j, 0, L)];}; char getY(int i, int j) {return OFPtr[INDICE_2(i, j, 1, L)];}; void putXY(int i, int j, char valx, char valy); void putX(int i, int j, char valx); void putY(int i, int j, char valy); ~opt_flow();};
#endif

96
Bibliografia
[_] V. Cantoni e S. Levialdi. La visione delle macchine. TecnicheNuove. 1989.
[_] S. Russel e P. Norvig. Artificial Intelligence – a modern approach. Prentice Hall International
Editions. 1995.
[1] T. Camus. Calculating Time-to-Contact Using Real-Time Quantized Optical Flow. Technical
report n° 14 presso il Max-Planck-Institut für biologische kybernetik.
[2] M. Tistarelli. Multiple Constraints to Compute Optical Flow. Reprint from “IEEE
Transactions on Pattern Analysis and Machine Intelligence”. Vol. 18, No. 12, December
1996.
[3] M. Tistarelli e G. Sandini. On the Advantages of Polar and Log-Polar Mapping for Direct
Estimation of Time-to-impact from Optical Flow. Reprint from “IEEE Transactions on
Pattern Analysis and Machine Intelligence”. Vol. 15, No. 4, April 1993.
[4] P. Golland. Use of Color for Optical Flow Estimation. Master of Science in Computer
Science. Israel Institute of Technology, 1995.
[5] G. Buchsbaum. A spatial processor model for object color perception. Journal of Franklin
Inst., 1980.
[6] P. Golland e A.M. Bruckstein. Why R.G.B. ? or How to design color displays for Martians.
Technical Report 9401, IS Lab, CS Department, Technion, Haifa, Israel, 1994.
[7] N. Otha. Optical flow detection by color images. In Proceeding of IEEE International
Conference on Image Processing, Pan Pacific, Singapore, 1989.

97
[_] J.L. Barron, D.J. Fleet, S.S. Beauchemin, e T.A. Burkitt. Performance of Optical Flow
Techniques. In Computer Vision and Pattern Recognition, 1992.
[_] M.J. Black e P. Anandan. A Framework for the Robust Estimation of Optical Flow. In
International Conference on Computer Vision, 1993.
[_] M.C. Cooper. The Tractability of Segmentation and Scene Analysis. International Journal of
computer Vision, 30(1), 1998.
[_] D.J. Heeger. Optical Flow using Spatiotemporal Filters. International Journal of Computer
Vision, 1998.
[_] B.K.P. Horn e B.G. Schunk. Determining Optical Flow. Artificial Intelligence, August, 1981.
[_] B.G. Schunk e B.K.P. Horn. Constraints on Optical Flow Computation. In Pattern
Recognition and Image Processing, August, 1981.


















