
Note di Data Warehouse e Business Intelligence - La gestione delle descrizioni
27
Metodi per il trattamento del significato dei campi codice presenti nelle tabelle dimensionali
-
Upload
massimo-cenci -
Category
Software
-
view
117 -
download
2
Transcript of Note di Data Warehouse e Business Intelligence - La gestione delle descrizioni

Metodi per il trattamento del significato dei campi codice
presenti nelle tabelle dimensionali
La gestione delle descrizioni, è un argomento poco discusso in ambito Data Warehouse e Business Intelligence. Se ne parla poco nei libri e negli articoli, nonostante sia un argomento cruciale perché riguarda il modo con cui vediamo le informazioni.
Parleremo quindi di descrizioni. In particolare delle descrizioni dei codici che sono presenti nelle tabelle dimensionali di un Data Warehouse.
E’ sempre affascinante scoprire la complessità che si nasconde dietro quelle che sembrano delle banalità. E’ necessario che tutti, utenti finali, capiprogetto, architetti dati e le altre figure coinvolte sappiano che la gestione delle descrizioni è unargomento particolarmente complesso. Il modo migliore per introdurre questo argomento è partire con semplice esempio reale.
Supponiamo di osservare un utente finale che ha di fronte un’interfaccia grafica di Business Intelligence. L’utente ha bisogno di estrarre dei dati numerici, per esempio dei movimenti di Conto Corrente, e vuole filtrare solo i clienti che hanno una particolare professione, per esempio, solo gli impiegati.
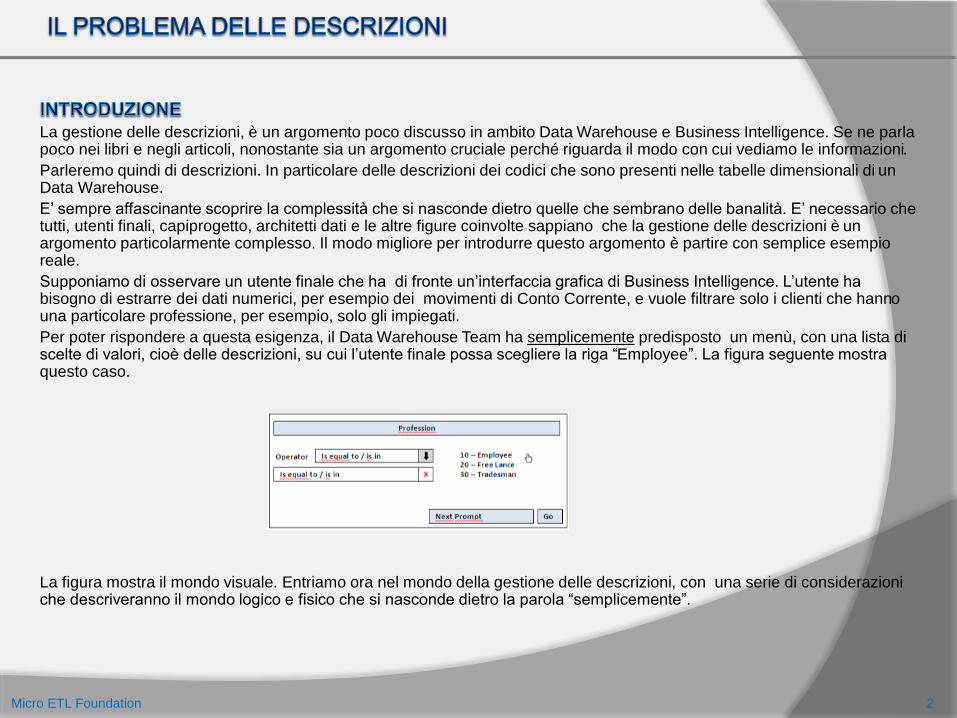
Per poter rispondere a questa esigenza, il Data Warehouse Team ha semplicemente predisposto un menù, con una lista di scelte di valori, cioè delle descrizioni, su cui l’utente finale possa scegliere la riga “Employee”. La figura seguente mostra questo caso.
La figura mostra il mondo visuale. Entriamo ora nel mondo della gestione delle descrizioni, con una serie di considerazioni che descriveranno il mondo logico e fisico che si nasconde dietro la parola “semplicemente”.
2Micro ETL Foundation

La descrizione “Employee” associata al codice “10” è una descrizione voluta dall’utente finale. E’ molto importante mostrare una descrizione che sia in sintonia con la nomenclatura abituale dell’utente finale. Questa necessità ha una conseguenza molto importante. La descrizione del codice che giunge dai sistemi alimentanti (chiamiamola esterna), non è assolutamente detto che sia la stessa dell’utente finale, anzi il più delle volte può essere diversa. Questo perché è la descrizione presente nei sistemi operazionali, non in quelli di sintesi. Quindi è necessario avere sempre all’interno del Data Warehouse due descrizioni. Quella dei sistemi esterni, chiamiamola “external description” e quella finale, chiamiamola “business description”. Averle entrambe è importante perché è l’unico anello di congiunzione fra due sistemi che hanno finalità diverse.
Come si vede nell’esempio, nella lista delle scelte, non deve comparire solo la descrizione, ma anche il codice. Spesso questo non succede, e viene mostrata solo la descrizione. Il suggerimento di mostrare entrambe le descrizioni, (una delle regole che fanno parte della metodologia che ho chiamato MEF ,Micro ETL Foundation), è importante. Definiamo questa nuova descrizione come “descrizione estesa”, e deve essere ottenuta concatenando il valore del codice con un “-“ (meno) e con la descrizione del valore. E’ utile fare questo, perché gli utenti finali non sono tutti uguali. Alcuni ragionano per descrizioni, ma altri ragionano per codici. Spesso, sono così tanti anni che lavorano in un certo ambiente, che per loro è più facile trovare i clienti con professione “10” piuttosto che quelli con professione “Employee”. Inoltre le descrizioni, nel tempo, potrebbero variare, per cui la presenza del codice è senza dubbio più sicura. La cosa migliore è mostrarli entrambi, codice edescrizione, per soddisfare tutte le tipologie di utenti. Quindi mostriamo: “10 – Employee”
Poiché abbiamo una descrizione esterna e una descrizione di business, dobbiamo decidere con quale delle due costruire la descrizione estesa. In genere è opportuno usare un’unica descrizione, cioè la descrizione di business, ma può essere una scelta accettabile anche avere due descrizioni estese.
Diamo ora un’occhiata al mondo fisico che sta dietro alla lista di valori mostrata all’utente finale. Perché ,come sappiamo, le considerazioni logiche, hanno sempre delle conseguenze fisiche.
Quando un utente richiede una scelta di valori sull’interfaccia di Business Intelligence, il display della lista è quasi sempre il risultato della generazione di una query sul database del Data Warehouse. In genere, è molto probabile che parta una “select distinct” dei valori della descrizione estesa, sulla tabella dimensionale. La descrizione estesa può essere implementata senza occupare spazio, con la caratteristica delle colonne virtuali. Le colonne virtuali sono definibili su Oracle,ma è sempre possibile creare delle viste che creano quelle colonne. Mostreremo in seguito come definirla
3Micro ETL Foundation

Ecco un esempio, molto semplificato delle colonne di una possibile tabella dimensionale dei clienti, su cui si baserà la lista di valori:
CUST_KEY – Chiave artificiale associate al cliente
CUST_COD – Chiave naturale del codice cliente
PROF_COD – Codice della professione
PROF_HDS – Descrizione esterna (host description).
PROF_BDS – Descrizione di Business (business description)
PROF_XDS – Descrizione estesa. Ottenuta concatenando il codice con la business description
Adottiamo, come sempre, una naming convention. Su questo tema ho già scritto molto sul mio blog, in questo caso assumiamo che tutti i campi di codici descrittivi, cioè di codici per cui abbia un senso avere una descrizione, si chiamino *_COD, le descrizioni esterne con *_HDS, le descrizioni di business con *_BDS, le descrizioni estese con *_XDS.
Quindi, quello che è un semplice “click” su una lista di scelte, nasconde in realtà varie considerazioni. Ma la cosa più sorprendente, è che quanto descritto è solo la punta dell’iceberg. La punta è ciò che vede l’utente finale. Ma cosa succede sotto la superficie dell’acqua ? E’ così banale prendere le descrizioni che arrivano (forse) dai sistemi alimentanti e inserirlinelle tabelle dimensionali ? Come sempre succede, in un Data Warehouse niente è banale e tutto è più complicato di quello che sembra. Infatti le descrizioni dei codici possono situarsi, secondo la mia esperienza, in 7 luoghi diversi.
1. La descrizione del codice è già presente nella tabella anagrafica (che diverrà la tabella dimensionale)
2. La descrizione del codice è presente in una tabella di descrizioni, esclusivamente per quel codice.
3. La descrizione del codice è presente in una tabella di descrizioni globale per tutti i codici. (o quasi tutti)
4. La descrizione del codice è presente in un foglio excel/csv
5. La descrizione del codice è presente in un documento Word o pdf o xml
6. La descrizione del codice è dentro una email.
7. La descrizione del codice è hard-coded nel codice delle forms dei sistemi alimentanti, per cui, dopo una telefonata a qualche referente dei sistemi alimentanti, torniamo ad uno dei punti 4 o 5 o 6.
4Micro ETL Foundation

Al di là di dove sono le descrizioni e del modo con cui le acquisiremo, come possiamo gestire le descrizioni nel nostro Data
Warehouse? Il mio consiglio è quello di avere sempre una tabella di metadati simile a quella del caso 3 e ricondurre tutti gli
altri casi ad essa. Ma per poterlo fare, dobbiamo introdurre il concetto di dominio di valori. Il concetto è molto semplice. Basta
dare un nome all’insieme dei valori associati a un certo codice. Per esempio, se sappiamo che l’insieme di valori possibili del
codice professione è
10 = Employee
20 = Free Lance
30 = Tradesman
Associamo a questo dominio di valori un nome, per esempio “PROF”, e inseriamo questi dati in una tabella di metadati che
chiamiamo MEF_DOM_CFT (MEF Domains Configuration). La tabella può avere una struttura molto semplice con le
seguenti informazioni:
DOM_COD Codice di dominio
COD_TXT Valore del codice
HDS_TXT Descrizione esterna
BDS_TXT Descrizione di business
Le descrizioni sono un dato che varia raramente. Anche supponendo di poterle reperire in modo semplice, sarebbe uno
spreco di tempo impostare un caricamento/aggiornamento giornaliero della tabella dei domini. Conviene effettuare un
caricamento iniziale massivo e gestire in seguito le eventuali modifiche e aggiunte.
Vediamo ora una serie di considerazioni relative alla gestione dei domini.
5Micro ETL Foundation

Spesso capita di ricevere nei flussi di input delle descrizioni brevi e delle descrizioni lunghe. Ovviamente, se sono presenti
nel flusso è opportuno caricarle, ma conviene utilizzare sempre la descrizione breve come “descrizione esterna”. Ormai la
tendenza è di abbreviare le informazioni (vedi il linguaggio degli sms) per cui descrizioni lunghe che possono creare problemi
di dimensionamento sulle interfacce grafiche (PC e Tablet e smartphone) a mio avviso si possono ignorare.
La descrizione di Business è necessariamente manuale. Sarà l’utente finale che deciderà quale descrizione preferisce
vedere. Il caricamento iniziale deve però inizializzare la descrizione di business uguale a quella esterna, se e solo se la
descrizione di business è vuota (per non sovrascrivere quanto inserito manualmente). Poi, di volta in volta, si procederà alle
modifiche sulla base delle interviste agli utenti finali.
Un altro punto che non deve essere trascurato è il seguente: quanto sono attendibili codici e descrizioni che troviamo nei
punti dal 2 al 6 ? Come spesso succede, la documentazione non sempre è aggiornata, per cui rischiamo di non avere il
dominio completo del codice. Su questo punto, dobbiamo essere proattivi, nel senso che non possiamo chiedere in modo
generico un aggiornamento della documentazione ai sistemi alimentanti. Dobbiamo essere noi a chiedere in modo preciso le
descrizioni dei codici che non troviamo nella documentazione.
Chi ha esperienza di Data Warehouse sa che, purtroppo, se aspettiamo che termini l’analisi dei domini, perdiamo molto
tempo, per cui dobbiamo agire in modo preventivo. Il mio consiglio è quello di riempire in automatico la tabella dei domini con
i valori dei codici presenti nei campi delle tabelle di Staging Area, dando ad essi un nome UNIVOCO, di default e una
descrizione standard del tipo “nd” (not defined). In un secondo tempo possiamo intervenire sui domini generici modificando il
loro nome di default. Il nome dominio di default che adotteremo sarà <codice flusso>.<nome colonna>.
Infine il motivo principale della esistenza della tabella dei domini. Il riutilizzo della descrizione. Nelle tabelle di un Data
Warehouse lo stesso dominio si può applicare a tante colonne che, nonostante abbiano nomi diversi, fanno riferimento allo
stesso dominio di valori. Per esempio, un codice valuta, può essere presente in una tabella con nome VALTRAT (valuta di
trattazione) e VALNEG (valuta di negoziazione), ma entrambi devono avere lo stesso dominio, che possiamo chiamare
“VAL”.
6Micro ETL Foundation

A questo punto, approfondiamo la gestione delle descrizioni con una simulazione reale, ovviamente molto semplificata, dopo
avere creato l’ambiente di simulazione. Il piano di lavoro è il seguente.
Creare l’ambiente
Caricare la tabella dei domini
Caricare la tabella anagrafica in Staging Area.
Aggiornare la tabella dei domini sulla base dei codici che troviamo nella tabella di Staging Area
Caricare la tabella dimensionale
Aggiornare la tabella dimensionale con le descrizioni
(tutti gli script SQL degli oggetti che verranno mostrati in seguito, sono scaricabili da Google drive:
https://drive.google.com/open?id=0B2dQ0EtjqAOTTlpjNFlRdzZzbTQ&authuser=0
)
Prepariamo un ambiente di simulazione, creando le tabelle necessarie con le sole informazioni che servono, cioè la tabella di
staging area, la tabella dimensionale e quella dei domini. Come possiamo vedere, la tabella dimensionale contiene sia la
descrizione esterna che quella di business. La descrizione estesa è costruita utilizzando la caratteristica delle colonne
virtuali.
7Micro ETL Foundation

Il caricamento di questa tabella sarà necessariamente un mix di caricamento automatico e di caricamento manuale.
Facciamo riferimento ai 7 casi visti in precedenza.
Se i domini sono già presenti in una tabella specifica o una generalizzata, basterà uno statement SQL per caricarla.
Se sono presenti in un foglio excel, convertirlo in file CSV, puntarli con una external table e quindi caricarli con uno statement
SQL.
Diversamente, bisogna caricarli a mano uno ad uno.
Supponiamo di essere in quest’ultimo caso e carichiamo il dominio del codice professione con un semplice script SQL.
Notiamo la differenza fra descrizione esterna e descrizione di business. Se, come spesso accade, il sistema alimentante è un
mainframe, le descrizioni arriveranno tutte in caratteri maiuscoli e non saranno molto user-friendly per una reportistica
direzionale. Dopo l’inserimento, il contenuto della tabella dei domini sarà quindi:
8Micro ETL Foundation
Ovviamente, se non abbiamo ancora preso in considerazione l’analisi dei domini o siamo ancora in attesa di
documentazione, questo step può essere ignorato. La tabella rimane vuota e vedremo come caricarla in automatico in uno
step successivo.
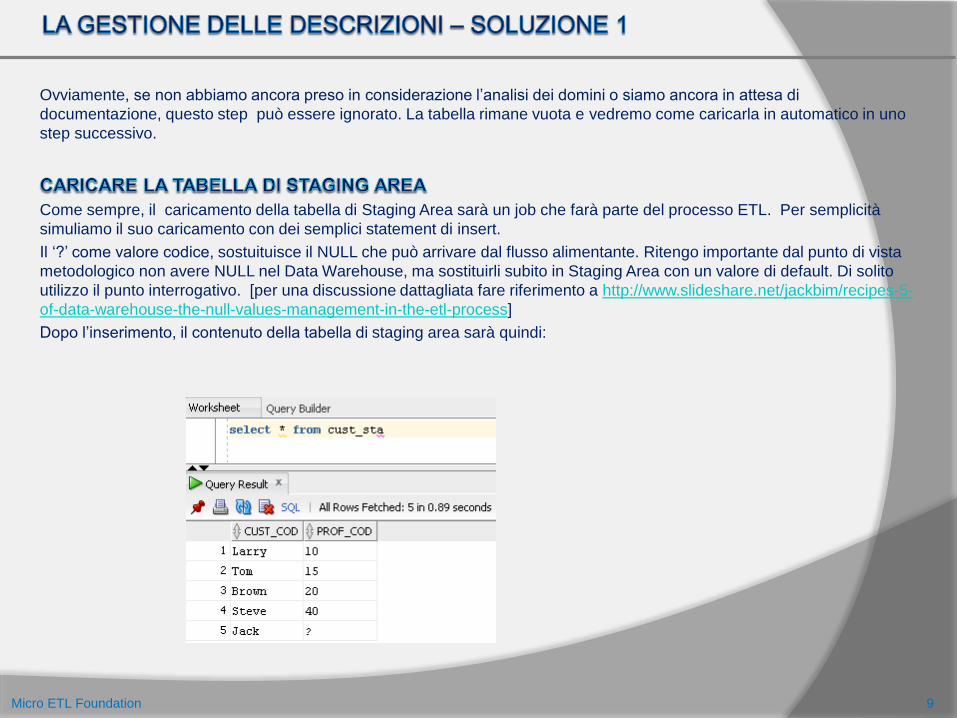
Come sempre, il caricamento della tabella di Staging Area sarà un job che farà parte del processo ETL. Per semplicità
simuliamo il suo caricamento con dei semplici statement di insert.
Il ‘?’ come valore codice, sostuituisce il NULL che può arrivare dal flusso alimentante. Ritengo importante dal punto di vista
metodologico non avere NULL nel Data Warehouse, ma sostituirli subito in Staging Area con un valore di default. Di solito
utilizzo il punto interrogativo. [per una discussione dattagliata fare riferimento a http://www.slideshare.net/jackbim/recipes-5-
of-data-warehouse-the-null-values-management-in-the-etl-process]
Dopo l’inserimento, il contenuto della tabella di staging area sarà quindi:
9Micro ETL Foundation
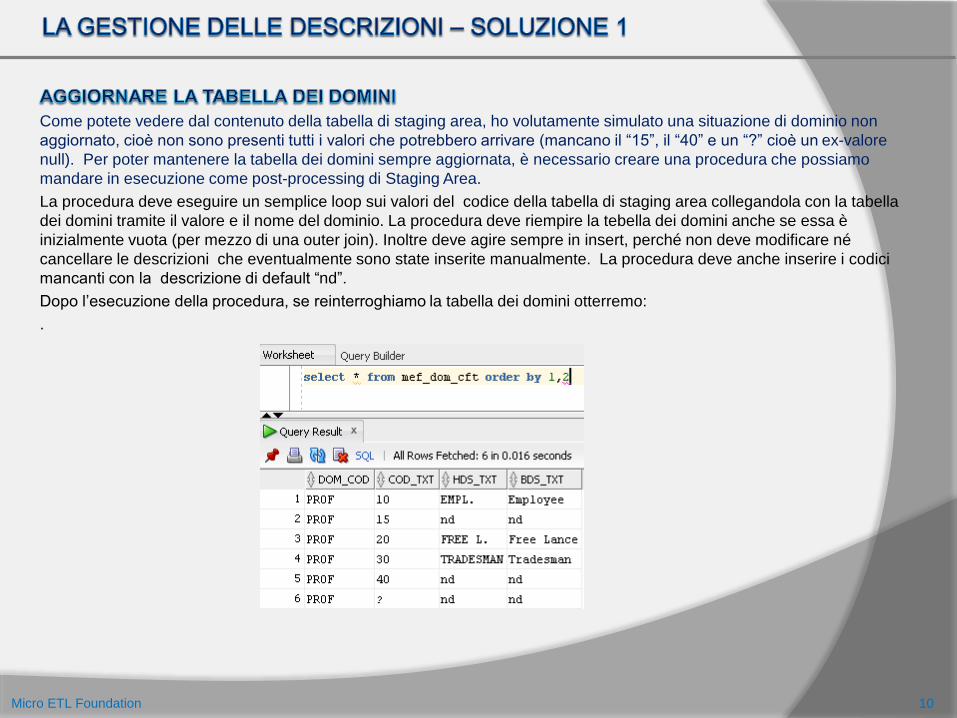
Come potete vedere dal contenuto della tabella di staging area, ho volutamente simulato una situazione di dominio non
aggiornato, cioè non sono presenti tutti i valori che potrebbero arrivare (mancano il “15”, il “40” e un “?” cioè un ex-valore
null). Per poter mantenere la tabella dei domini sempre aggiornata, è necessario creare una procedura che possiamo
mandare in esecuzione come post-processing di Staging Area.
La procedura deve eseguire un semplice loop sui valori del codice della tabella di staging area collegandola con la tabella
dei domini tramite il valore e il nome del dominio. La procedura deve riempire la tebella dei domini anche se essa è
inizialmente vuota (per mezzo di una outer join). Inoltre deve agire sempre in insert, perché non deve modificare né
cancellare le descrizioni che eventualmente sono state inserite manualmente. La procedura deve anche inserire i codici
mancanti con la descrizione di default “nd”.
Dopo l’esecuzione della procedura, se reinterroghiamo la tabella dei domini otterremo:
.
10Micro ETL Foundation
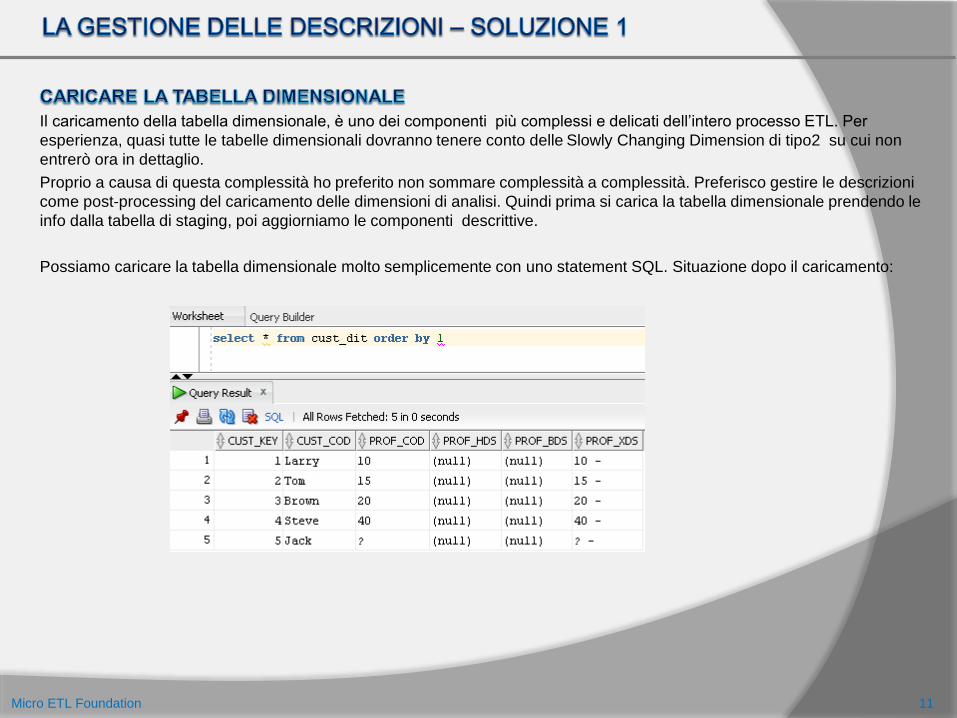
Il caricamento della tabella dimensionale, è uno dei componenti più complessi e delicati dell’intero processo ETL. Per
esperienza, quasi tutte le tabelle dimensionali dovranno tenere conto delle Slowly Changing Dimension di tipo2 su cui non
entrerò ora in dettaglio.
Proprio a causa di questa complessità ho preferito non sommare complessità a complessità. Preferisco gestire le descrizioni
come post-processing del caricamento delle dimensioni di analisi. Quindi prima si carica la tabella dimensionale prendendo le
info dalla tabella di staging, poi aggiorniamo le componenti descrittive.
Possiamo caricare la tabella dimensionale molto semplicemente con uno statement SQL. Situazione dopo il caricamento:
11Micro ETL Foundation
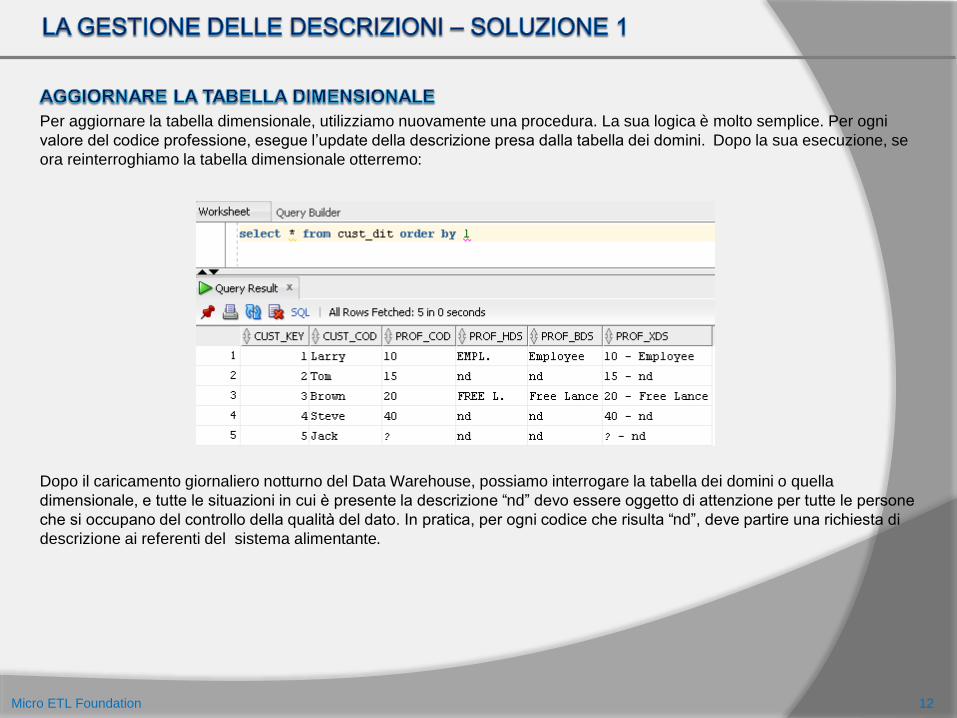
Per aggiornare la tabella dimensionale, utilizziamo nuovamente una procedura. La sua logica è molto semplice. Per ogni
valore del codice professione, esegue l’update della descrizione presa dalla tabella dei domini. Dopo la sua esecuzione, se
ora reinterroghiamo la tabella dimensionale otterremo:
Dopo il caricamento giornaliero notturno del Data Warehouse, possiamo interrogare la tabella dei domini o quella
dimensionale, e tutte le situazioni in cui è presente la descrizione “nd” devo essere oggetto di attenzione per tutte le persone
che si occupano del controllo della qualità del dato. In pratica, per ogni codice che risulta “nd”, deve partire una richiesta di
descrizione ai referenti del sistema alimentante.
12Micro ETL Foundation

La soluzione 1 è servita per prendere coscienza delle problematiche e delle difficoltà associate alla gestione delle descrizioni.
La soluzione mostrata, sebbene funzionante, è quasi impraticabile in un Data Warehouse reale. Le procedure che
aggiornano la tabella dei domini e la tabella dimensionale sono specifiche per il codice professione e dovrebbero essere
ripetute, con le opportune modifiche, per tutti gli altri codici che necessitano di descrizione. In un Data Warehouse, possiamo
avere decine di dimensioni di analisi, ognuna con decine di codici descrittivi. E’ impensabile scrivere centinaia di procedure
per la gestione delle descrizioni.
Vediamo quindi come modificare le procedure per gestire tutti i codici in modo automatico. Per ottenere il risultato indicato,
dobbiamo necessariamente farci aiutare da alcune tabelle di configurazione. In particolare una tabella di configurazione del
flusso di input, che mi indichi il nome della tabella di staging area e di quella dimensionale. E abbiamo bisogno di una tabella
di configurazione di tutte le colonne che necessitano di una descrizione.
Arricchiamo la tabella di staging area supponendo la presenza di tre codici. Il primo, già visto nella fase precedente è il
codice della professione. Il secondo è il codice dello stato del cliente. Il terzo è il codice del tipo cliente. Adeguiamo anche la
tabella dimensionale con i nuovi codici.
13Micro ETL Foundation

Introduciamo ora le due nuove tabelle di configurazione. Una tabella di configurazione dei flussi di input (MEF_IO_CFT ) e
una tabella di configurazione delle colonne dei flussi (MEF_STA_CFT), che diverranno colonne dimensionali.
La tabella MEF_IO_CFT contiene, per ogni identificatore di un flusso (IO_COD) , il nome della tabella di staging
(STA_TABLE_COD ) e il nome della tabella dimensionale (DIM_TABLE_COD ) alimentata dalla tabella di staging.
La tabella MEF_STA_CFT contiene, per ogni identificatore di un flusso (IO_COD), il nome della colonna codice
(COLUMN_COD) e il nome del dominio associato (DOM_COD). Questa tabella di confgurazione è molto importante, perché
è l’unico luogo in cui definiamo per ogni codice, il nome del suo dominio. Questo nome ci permetterà di accedere alla tabella
di configurazione dei domini per trovare le descrizioni.
Per il nostro esempio, Inseriamo una riga di configurazione nella MEF_IO_CFT e inseriamo tre righe nella MEF_STA_CFT ,
una per ogni codice, supponendo che il tipo cliente non sia ancora stato preso in considerazione nell’analisi del suo dominio.
Per cui il codice dominio rimane NULL.
.
14Micro ETL Foundation
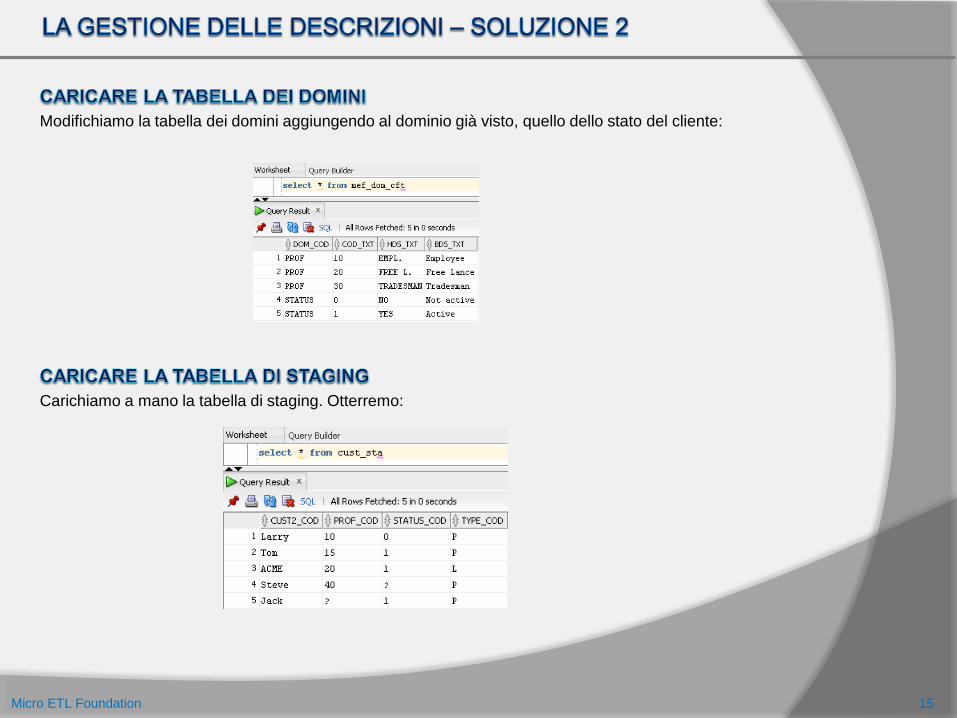
Modifichiamo la tabella dei domini aggiungendo al dominio già visto, quello dello stato del cliente:
Carichiamo a mano la tabella di staging. Otterremo:
15Micro ETL Foundation

Utilizzeremo una unica procedura simile a quella vista nella soluzione 1. Essa, utilizzando le informazioni delle tabelle di
configurazione, deve creare in modo dinamico lo statement SQL di aggiornamento. Inoltre, nel caso in cui non siano definiti i
domini, deve associare in automatico il codice di dominio di default secondo quanto già descritto. Anche se nell’esempio non
è presente, è opportuno sottolineare la seguente nota di configurazione.
Poiché a volte può essere utile chiamare un campo “*_COD” anche se non è sensato associare ad esso una descrizione di
dominio, assumiamo che, se impostiamo il codice dominio uguale alla parola “NULL”, tale campo non verrà preso in
considerazione nel trattamento dei domini.
Un esempio di questo caso può essere il codice cliente o, conosciuto soprattutto in ambito bancario, il codice NDG (Numero
Direzione Generale). Questo campo, lo chiameremo per comodità NDG_COD, ma non ha senso associare ad esso un
dominio di valori, perché la sua descrizione naturale sarà l’intestazione (o la concatenazione di più intestazioni) sempre già
presente nella tabella anagrafica degli NDG. Quindi, per esempio, dovremmo configurare questo codice con:
INSERT INTO MEF_STA_CFT VALUES (NDG,'NDG_COD',’NULL’);
La procedura presenta delle istruzioni
“set serveroutput on” che ci permettono
di vedere un esempio dello statement
SQL che viene generato in automatico
per ogni source/column.
16Micro ETL Foundation
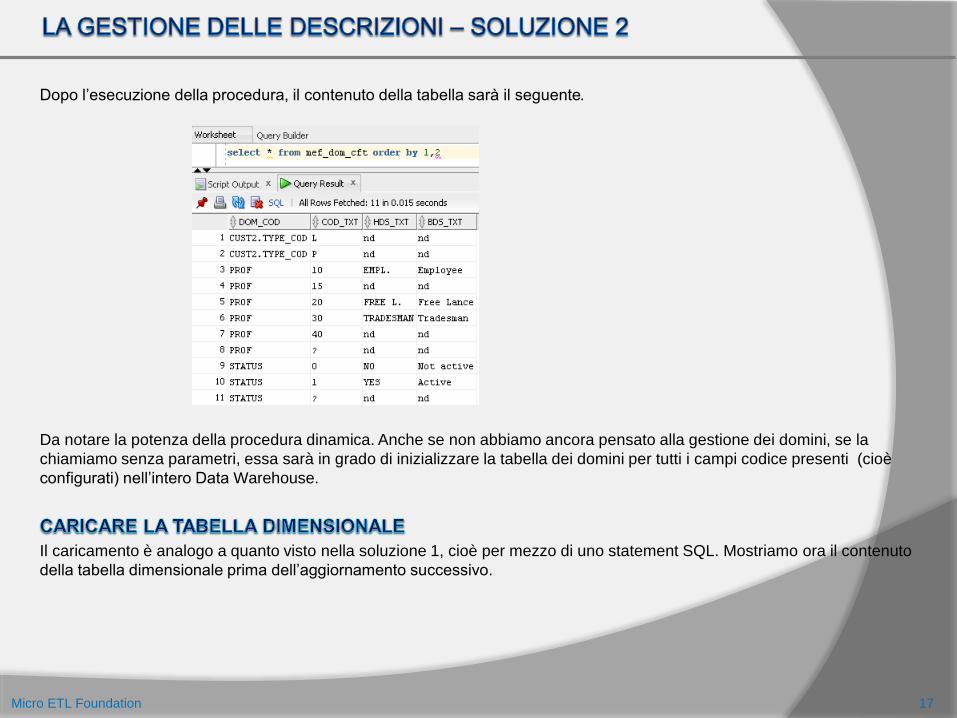
Dopo l’esecuzione della procedura, il contenuto della tabella sarà il seguente.
Da notare la potenza della procedura dinamica. Anche se non abbiamo ancora pensato alla gestione dei domini, se la
chiamiamo senza parametri, essa sarà in grado di inizializzare la tabella dei domini per tutti i campi codice presenti (cioè
configurati) nell’intero Data Warehouse.
Il caricamento è analogo a quanto visto nella soluzione 1, cioè per mezzo di uno statement SQL. Mostriamo ora il contenuto
della tabella dimensionale prima dell’aggiornamento successivo.
17Micro ETL Foundation
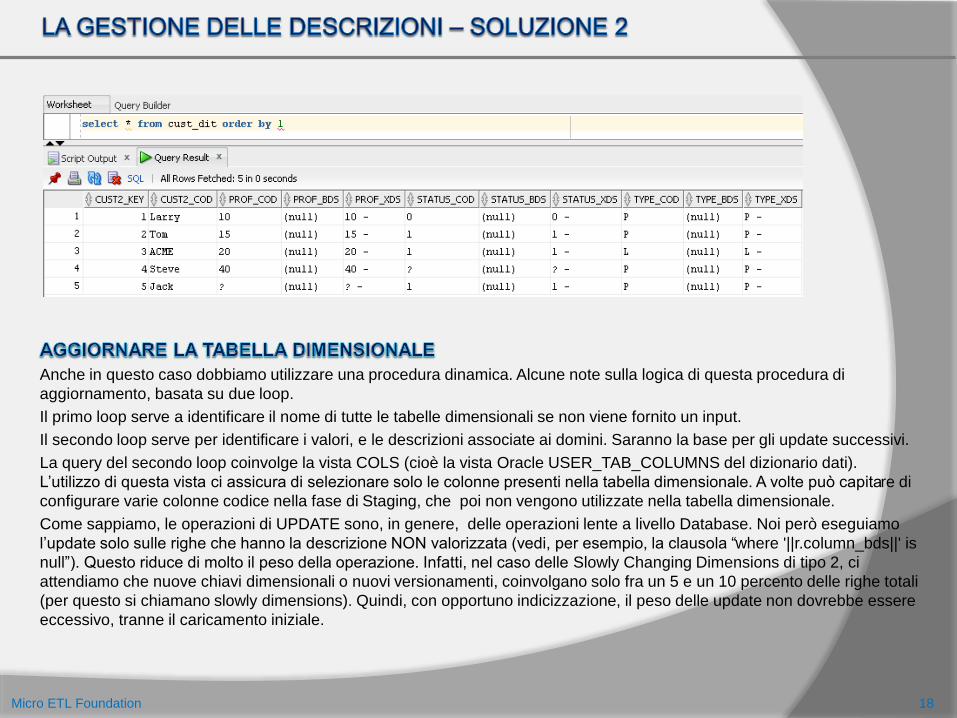
Anche in questo caso dobbiamo utilizzare una procedura dinamica. Alcune note sulla logica di questa procedura di
aggiornamento, basata su due loop.
Il primo loop serve a identificare il nome di tutte le tabelle dimensionali se non viene fornito un input.
Il secondo loop serve per identificare i valori, e le descrizioni associate ai domini. Saranno la base per gli update successivi.
La query del secondo loop coinvolge la vista COLS (cioè la vista Oracle USER_TAB_COLUMNS del dizionario dati).
L’utilizzo di questa vista ci assicura di selezionare solo le colonne presenti nella tabella dimensionale. A volte può capitare di
configurare varie colonne codice nella fase di Staging, che poi non vengono utilizzate nella tabella dimensionale.
Come sappiamo, le operazioni di UPDATE sono, in genere, delle operazioni lente a livello Database. Noi però eseguiamo
l’update solo sulle righe che hanno la descrizione NON valorizzata (vedi, per esempio, la clausola “where '||r.column_bds||' is
null”). Questo riduce di molto il peso della operazione. Infatti, nel caso delle Slowly Changing Dimensions di tipo 2, ci
attendiamo che nuove chiavi dimensionali o nuovi versionamenti, coinvolgano solo fra un 5 e un 10 percento delle righe totali
(per questo si chiamano slowly dimensions). Quindi, con opportuno indicizzazione, il peso delle update non dovrebbe essere
eccessivo, tranne il caricamento iniziale.
18Micro ETL Foundation
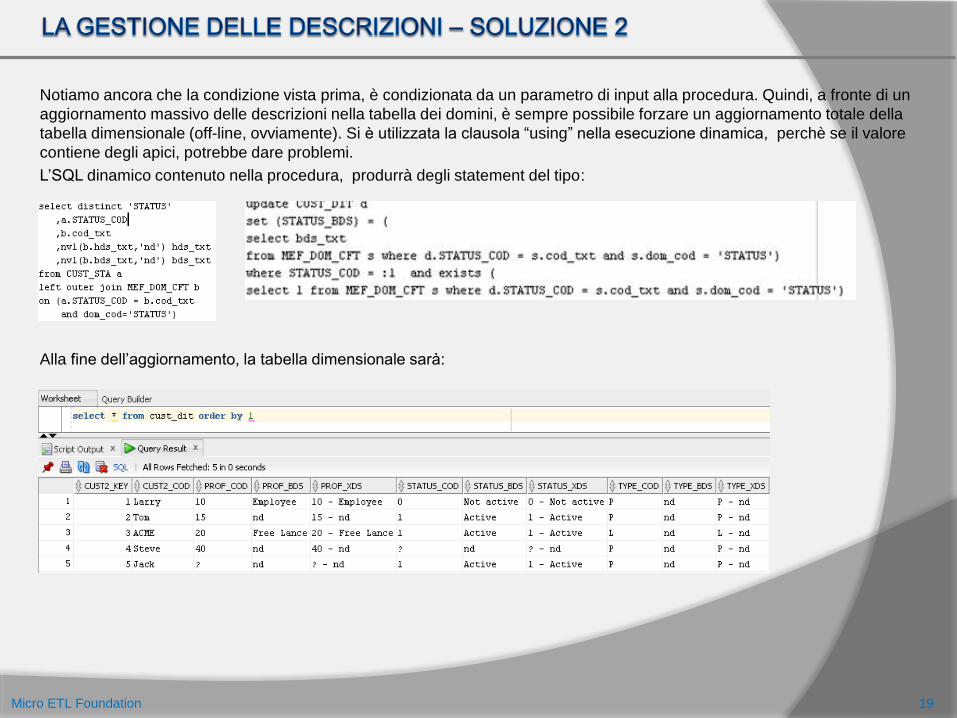
Notiamo ancora che la condizione vista prima, è condizionata da un parametro di input alla procedura. Quindi, a fronte di un
aggiornamento massivo delle descrizioni nella tabella dei domini, è sempre possibile forzare un aggiornamento totale della
tabella dimensionale (off-line, ovviamente). Si è utilizzata la clausola “using” nella esecuzione dinamica, perchè se il valore
contiene degli apici, potrebbe dare problemi.
L’SQL dinamico contenuto nella procedura, produrrà degli statement del tipo:
Alla fine dell’aggiornamento, la tabella dimensionale sarà:
19Micro ETL Foundation

Le soluzioni precedenti hanno prodotto una gestione abbastanza precisa delle descrizioni. La fase due lo ha resa dinamica e
riutilizzabile per tutte le tabelle dimensionali di un Data Warehouse. Purtroppo, siamo ancora molto lontano dalla realtà. Non
abbiamo preso in considerazione un fattore molto importante: la dipendenza tra i codici.
In un Data Warehouse di medie / grandi dimensioni e soprattutto in un Enterprise Data Warehouse, dove la dipendenza tra
codici esiste, la fase 2 non funziona più perché abbiamo a che fare con le seguenti situazioni.
Supponiamo di essere una banca che ha acquisito altre banche. Il Data Warehouse dovrà contenere i dati di tutto il gruppo,
per cui anche la tabella dei clienti dovrà essere unica, con un codice istituto che differenzia la clientela. Applichiamo ora
concettualmente questo fatto al nostro esempio della CUST_DIT.
Siamo proprio sicuri che il codice professione “10” che significa (ha come descrizione) “Emplyee” per la banca B1, ha lo
stesso significato per la banca B2 ?
La domanda è ovviamente retorica. La risposta è NO. Non possiamo avere questa garanzia, né possiamo sperare che la
fase di migrazione dei dati dalla banca acquisita alla banca acquirente abbia normalizzato tutte le tabelle e i significati.
Questo è il problema della interdipendenza fra codici. Un codice non ha più una descrizione univoca, ma ha una descrizione
diversa a seconda del valore di un altro codice.
Deve essere chiaro che questo problema non si presenta solo in caso di fusioni societarie, ma anche su tabelle di un unico
istituto. Un altro esempio può essere la causale di un movimento bancario.
Un codice causale “01” può avere un significato “Descr XXX” se il movimento avviene dallo sportello bancario, ma può avere
una descrizione diversa “Descr YYY” con lo stesso codice “01” se la transazione avviene via Web. In questo caso il codice
causale è dipendente dal codice canale di trasmissione.
Quando parlo di interdipendenza fra codici, non significa fra 2 codici, ma anche fra più codici. Un esempio può essere la
tabella degli strumenti finanziari. Poiché gli strumenti finanziari sono molto numerosi, in essa compare quasi sempre una
gerarchia che classifica gli strumenti finanziari associandoli a categorie , gruppi e sottogruppi.
Come possiamo vedere dall’esempio seguente, il sottogruppo con codice “1” ha 3 descrizioni diverse a seconda del gruppo
a cui appartiene. A sua volta il gruppo con codice “2” ha due descrizioni diverse a seconda della categoria a cui appartiene.
20Micro ETL Foundation
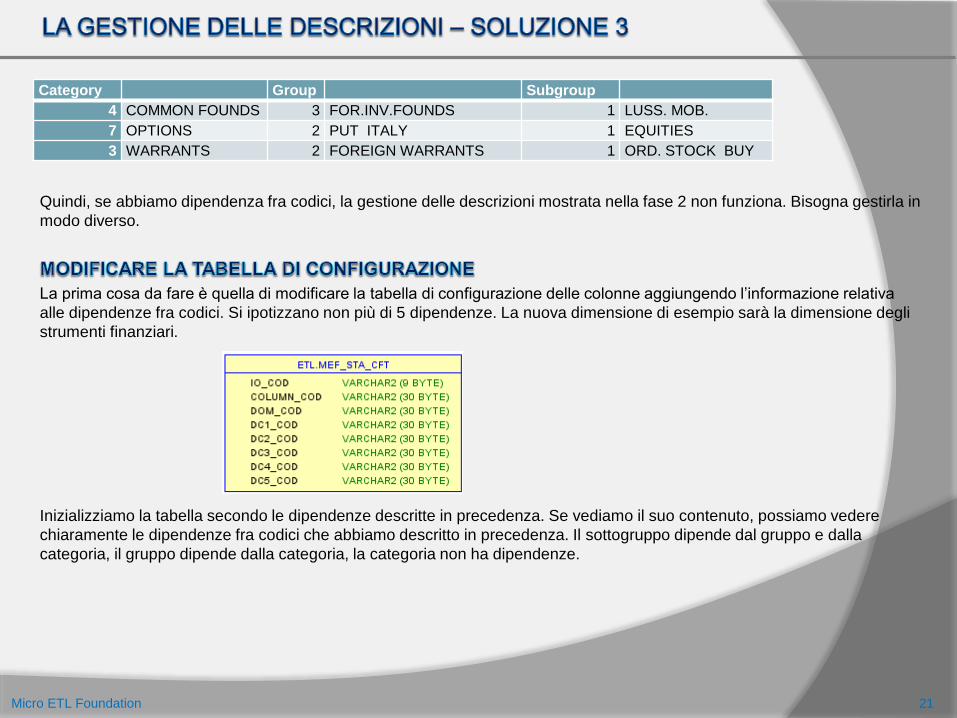
Quindi, se abbiamo dipendenza fra codici, la gestione delle descrizioni mostrata nella fase 2 non funziona. Bisogna gestirla in
modo diverso.
La prima cosa da fare è quella di modificare la tabella di configurazione delle colonne aggiungendo l’informazione relativa
alle dipendenze fra codici. Si ipotizzano non più di 5 dipendenze. La nuova dimensione di esempio sarà la dimensione degli
strumenti finanziari.
Inizializziamo la tabella secondo le dipendenze descritte in precedenza. Se vediamo il suo contenuto, possiamo vedere
chiaramente le dipendenze fra codici che abbiamo descritto in precedenza. Il sottogruppo dipende dal gruppo e dalla
categoria, il gruppo dipende dalla categoria, la categoria non ha dipendenze.
21Micro ETL Foundation
Category Group Subgroup
4 COMMON FOUNDS 3 FOR.INV.FOUNDS 1 LUSS. MOB.
7 OPTIONS 2 PUT ITALY 1 EQUITIES
3 WARRANTS 2 FOREIGN WARRANTS 1 ORD. STOCK BUY

Inizializziamo anche la tabella di configurazione dei flussi con un semplice statement SQL.
La tabella dei domini deve contenere il valore dei codici di dipendenza. Queste relazioni devono essere oggetto di analisi.
Come nella fase precedente, anche se non sono conosciute, tutte le combinazioni di dipendenze verranno inizializzate
automaticamente dopo il caricamento della staging area. Il campo DCLIST_TXT è solo informativo ed è utile per sapere quali
sono i nomi delle colonne dipendenti a cui i codici DV* fanno riferimento.
22Micro ETL Foundation
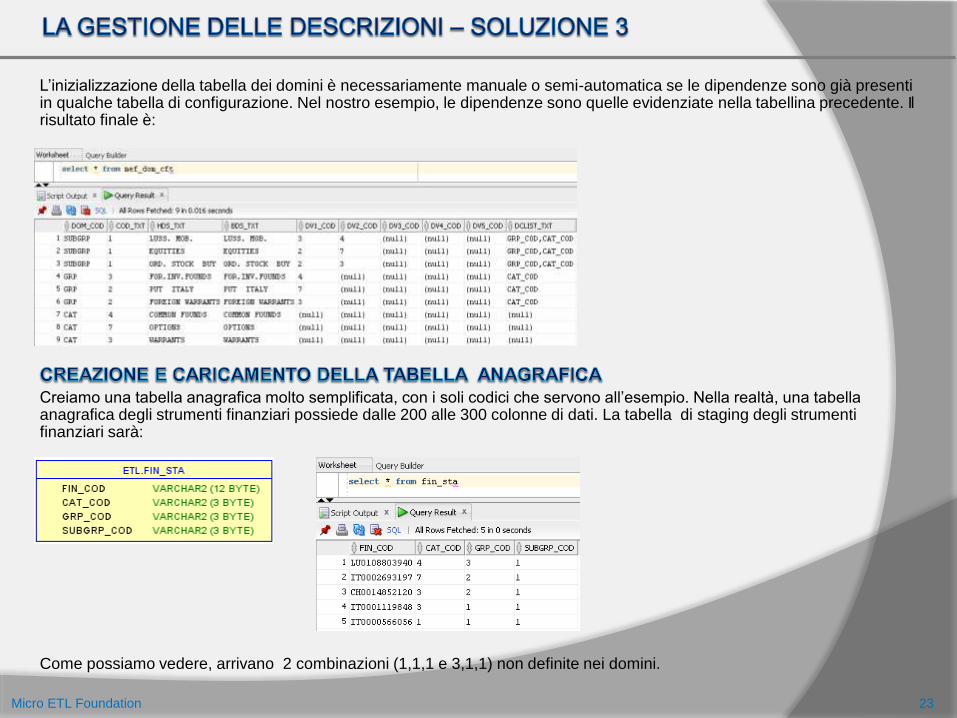
L’inizializzazione della tabella dei domini è necessariamente manuale o semi-automatica se le dipendenze sono già presenti in qualche tabella di configurazione. Nel nostro esempio, le dipendenze sono quelle evidenziate nella tabellina precedente. Il risultato finale è:
Creiamo una tabella anagrafica molto semplificata, con i soli codici che servono all’esempio. Nella realtà, una tabella anagrafica degli strumenti finanziari possiede dalle 200 alle 300 colonne di dati. La tabella di staging degli strumenti finanziari sarà:
Come possiamo vedere, arrivano 2 combinazioni (1,1,1 e 3,1,1) non definite nei domini.
23Micro ETL Foundation
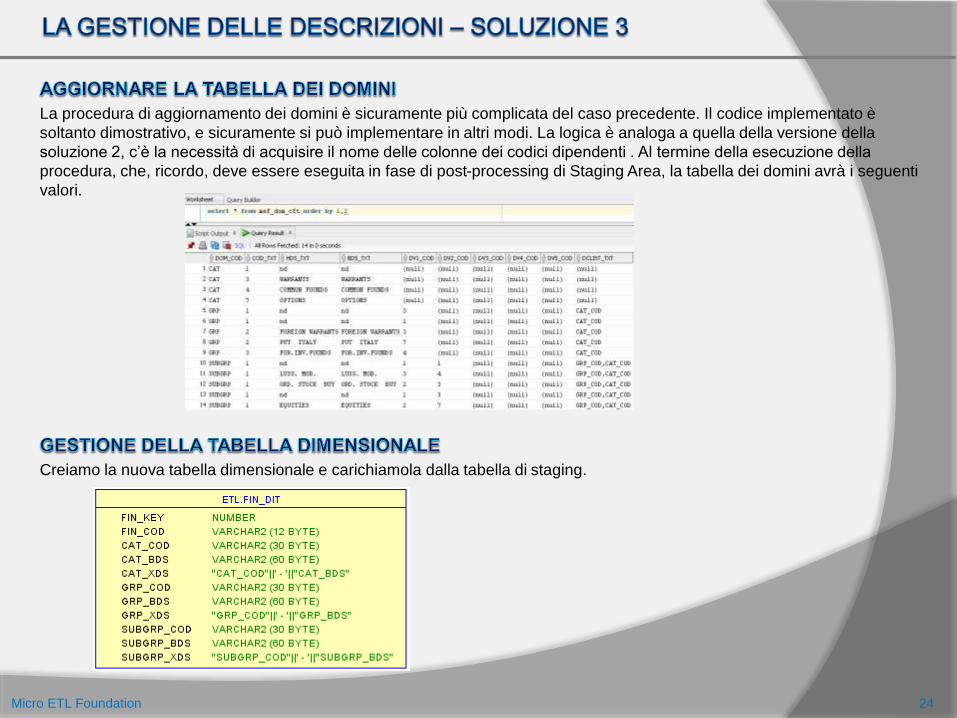
La procedura di aggiornamento dei domini è sicuramente più complicata del caso precedente. Il codice implementato è
soltanto dimostrativo, e sicuramente si può implementare in altri modi. La logica è analoga a quella della versione della
soluzione 2, c’è la necessità di acquisire il nome delle colonne dei codici dipendenti . Al termine della esecuzione della
procedura, che, ricordo, deve essere eseguita in fase di post-processing di Staging Area, la tabella dei domini avrà i seguenti
valori.
Creiamo la nuova tabella dimensionale e carichiamola dalla tabella di staging.
24Micro ETL Foundation
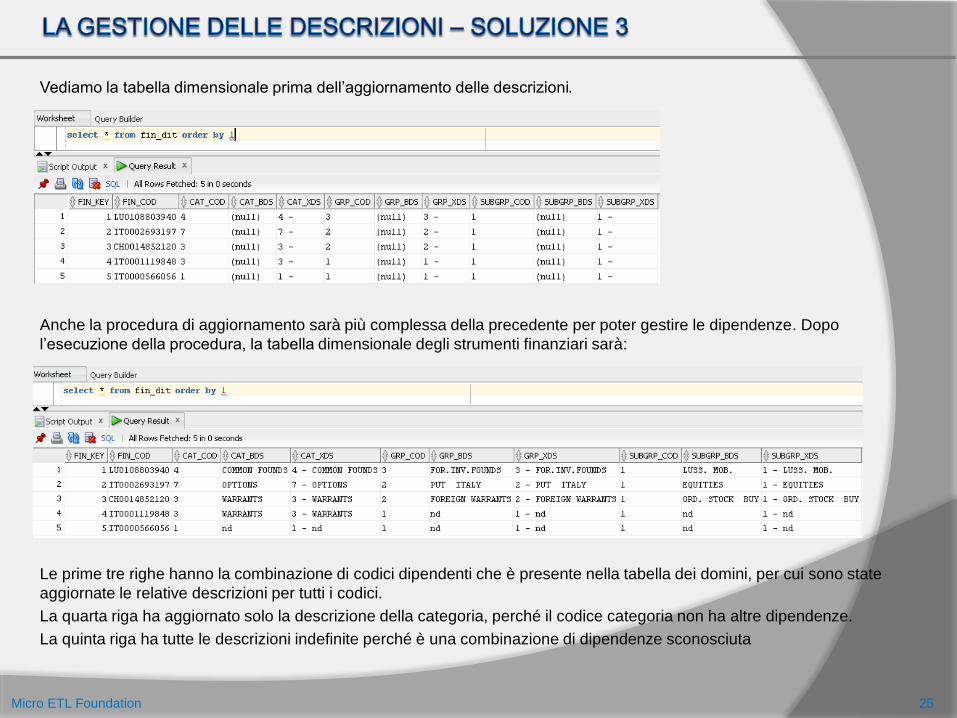
Vediamo la tabella dimensionale prima dell’aggiornamento delle descrizioni.
Anche la procedura di aggiornamento sarà più complessa della precedente per poter gestire le dipendenze. Dopo
l’esecuzione della procedura, la tabella dimensionale degli strumenti finanziari sarà:
Le prime tre righe hanno la combinazione di codici dipendenti che è presente nella tabella dei domini, per cui sono state
aggiornate le relative descrizioni per tutti i codici.
La quarta riga ha aggiornato solo la descrizione della categoria, perché il codice categoria non ha altre dipendenze.
La quinta riga ha tutte le descrizioni indefinite perché è una combinazione di dipendenze sconosciuta
25Micro ETL Foundation

Molti rimarranno stupiti nel vedere rappresentata una ulteriore soluzione 4. Sembra incredibile, ma non abbiamo ancora detto
tutto sulla gestione delle descrizioni. Riassumiamo l’analisi che abbiamo fatto finora.
Nella soluzione 1 abbiamo evidenziato il problema, abbiamo introdotto alcune tabelle di configurazione necessarie alla
gestione, abbiamo definito una naming convention. Nella soluzione 2 abbiamo automatizzato il processo, abbiamo introdotto
altre tabelle di configurazione a supporto di una gestione dinamica delle descrizioni. Abbiamo mostrato come pre-caricare la
tabella dei domini prima ancora di farci dare tali informazioni dai sistemi alimentanti. Nella soluzione 3 abbiamo gestito la
interdipendenza fra codici.
Cosa manca ancora ?
La risposta dipende dalle caratteristiche internazionali del vostro Data Warehouse. Se siete sicuri che il Data Warehouse è
interno e usato solo da utenti della vostra lingua madre, potete fermarvi alla soluzione 3, Altrimenti dovete prendere in
considerazione la gestione multilingua.
Non farò un esempio completo come le altre fasi. L’intervento che bisogna fare è una modifica alla tabella dei domini,
aggiungendo il campo di codice lingua. (e alcune colonne tecniche che è sempre utile avere). Quindi bisogna aggiungere
codice lingua come campo chiave nelle procedure che sono state implementate. Con la gestione della lingua, la tabella dei
domini aumenterà di volume tante volte quante sono le lingue presenti.
26Micro ETL Foundation
La tabella dei domini che vediamo qui a fianco, la
possiamo considerare completa, e consiglio comunque di
crearla subito con il codice lingua anche se al momento
non verrà utilizzato.
Come abbiamo visto, la gestione delle descrizioni non è un argomento semplice, ha molte implicazioni, coinvolge molte
persone ed è estremamente importante perché non è un dettaglio tecnico, ma coinvolge il modo con cui l’utente finale vede il
dato. Aspetto determinante per il successo del Data Warehouse.
Spero che questo ho scritto serva per tutte le persone coinvolte nella progettazione di un Data Warehouse, a prendere
coscienza del problema. L’attività “Gestione delle descrizioni” deve diventare un punto fisso nei Gantt di progetto.
- ricordo che tutti gli script si trovano su Google drive:
https://drive.google.com/open?id=0B2dQ0EtjqAOTTlpjNFlRdzZzbTQ&authuser=0
27Micro ETL Foundation


















