
Nessun titolo diapositiva - ge.infn.itsquarcia/DIDATTICA/SRS/02_Campionamento.pdf · al numero...
31
SMID a.a. 2005/2006 17/1/2006 Campionamento Corso di Statistica per la Ricerca Sperimentale
Transcript of Nessun titolo diapositiva - ge.infn.itsquarcia/DIDATTICA/SRS/02_Campionamento.pdf · al numero...

SMIDa.a. 2005/2006
17/1/2006
Campionamento
Corso di Statistica per la Ricerca Sperimentale

Probabilità e frequenza
Dolore molto forte alla regione addominale destra?
Probabilità definita come quante volte (frequenza) ci aspettiamo che avvenga un certo evento rispetto al numero teorico di volte che possa avvenire
Nella pratica quotidiana (“media”) questi concetti vengono utilizzati in modo diffuso (e, a volte, scorretto)
30% di probabilità di avere un calcolo renale!Eventi mutuamente escludentisi
Calcolo renale sì: p = 0.3Calcolo renale no: q = 1 - p = 1 - 0.3 = 0.7

Mortalità probabilisticaEvento certo p = 1, evento impossibile p = 0Eventi mutuamente escludentisip(evento) = probabilità che l’evento avvengap(non_evento) = probabilità che l’evento non avvenga
In una regione abitano 600000 abitanti con etàcompresa tra 45 e 55 anni
3000 muoiono per problemi cardiopaticip(evento) = 3000/600000 = 0.005 (5 ‰)p(non_evento) = 0.995 ma non è la sopravvivenza!

Preparazione dei dati
Saper raccogliere correttamente i dati
Saper leggere ed interpretare dati statisticiRiuscire a compiere elaborazioni statistiche
La statistica è una scienza logica, quindi facilel’elaborazione statistica è ormai facilitata dall’utilizzo di pacchetti informatici avanzati
L’interpretazione statistica è invece complessa
Mutua esclusione delle cause di morte!non si può morire per cardiopatia o per cancro

Importanza del campionamentoPermette di trarre conclusioni o fare previsioni limitando l'osservazione solo a un gruppo dei soggetti
le conclusioni deducibili da questo sottoinsieme sono generalizzabili all'insieme maggiore
Si definisce "popolazione" l'insieme maggiore
che compongono l'insieme maggiore nel quale una certa conclusione o previsione può essere utilizzata
se i soggetti rappresentativi sono ben scelti
e "campione" della popolazione il gruppo scelto come rappresentativo della popolazione stessa

PopolazioneIdentifica un gruppo di persone appartenenti a una certa comunità geopolitica
tutte le possibili misure (o dati) che possono essere usati per studiare un certo problema
In statistica popolazione ha un significato più largo:
La popolazione può essere:
• infinita con elementi identificabili ma ignoti
• effettuato sull’intera popolazioneLo studio dovrebbe essere:
• legato ad un periodo di tempo determinato
• finita (iscritti ad un corso in un determinato anno)

CaratteristichePOPOLAZIONE
Tecniche campionarieCAMPIONE “rappresentativo” (n)Rilevamento ed elaborazione dei dati
Stime campionarie(media m e deviazione standard s)
INFERENZA STATISTICAParametri della popolazione (N)
(media μ e deviazione standard σ)Valorevero = μ ± σ ≈ Valoreatteso = m ± (s / √n)

Tipi di popolazioneCriteri di identificazione della popolazione
Studenti italianiStudenti universitari
Studenti Facoltà scientifiche
Studenti SMIDDel III anno
Di sesso maschile
Popolazione infinita Popolazione finita

Scelta del campioneIl campione deve essere somigliante alla popolazione da cui il campione è stato estrattoTra campione e popolazione esiste pur sempre una differenza (ignota) dell’errore di campionamento• selezione non corretta (vizio di campionamento)• casualità della scelta del campione (valutabile)
campionamento casuale (randomizzazione)campionamento stratificato (classi proporzionali)campionamento sistematico a cadenza prefissatacampionamento a presentazione

Scopo campionamentoOttenere stime e/o inferenze (cioè testare ipotesi) sulla natura della popolazione
non è necessario misurare massa corporea e pressione arteriosa in tutti gli italiani
senza dover ricorrere alla “collezione” completa delle misure possibili nella popolazione stessa
Rapporto tra massa corporea e pressione arteriosa
Stime sufficientemente accurate si possono ottenerelimitando l'osservazione a poche migliaia di
individui

Campione rappresentativoRiflettere la distribuzione geografica del paese,
(soggetti campionati da ogni regione in rapporto alla popolazione relativa)
il sesso,le caratteristiche socio-economiche,
(campionamento in rapporto al reddito)lo stile di vita/abitudini
(consumo alcool, fumo, uso farmaci, …)
E’ fondamentale che la scelta sia fatta casualmente

BiasSe la scelta del campione non viene fatta con criteri casuali è pressoché inevitabile che il campione sia viziato e che si introduca un errore pregiudiziale
che distorce l'interpretazione dei dati in maniera sistematica
Esempio: il rapporto tra massa corporea e pressione arteriosa è influenzato dall'età
se il campione è stato ricavato in una comunitàcon età media inferiore alla media nazionale
le conclusioni tratte da questo campione non possono essere applicate alla comunità nazionale

Tipi di parametri
• caratterizzati dal fatto che tra due valori ci può essere solo un numero limitato di valori (–, 0, +)
caratterizzati dall'avere un numero infinito di valori possibili tra due valori (peso, età, …)
Dati continui
Dati ordinali
• che non implicano alcun ordine (sesso, razza)Dati nominali (o categorici)
Dati discreti
La distinzione tra dati continui e dati ordinali sotto certi aspetti e in certi contesti è più teorica che reale

Distribuzione dei datiAbbiamo definito il campione come un sottoinsieme di soggetti nel quale noi effettuiamo una serie di misurazioni per stimare alcune caratteristiche della popolazione che lo stesso campione rappresenta Analogamente analizzando la distribuzione dei dati nel campione possiamo stimare la distribuzione dei dati nella popolazione corrispondente La distribuzione è la frequenza (assoluta o relativa) con la quale si verificano certi valori di una certa misura nella popolazione in esame
rappresentazioni grafiche o equazioni matematiche

Ricerca statistica
i dati sono una collezione di misure sperimentali o di rilevazioni epidemiologiche
Il ricercatore altro non è che un collezionista di dati
per lo statistico, i dati sono variabiliI dati non sono sottoposti all'analisi necessariamente nella stessa forma nella quale sono stati raccolti
Le variabili sono quindi i dati scritti in una forma che permetta la loro analisi statistica
I dati nominali che includono N categorie di una certa caratteristica (ad esempio la razza) possono essere rappresentati da N – 1 variabili (B/N/G/altro)
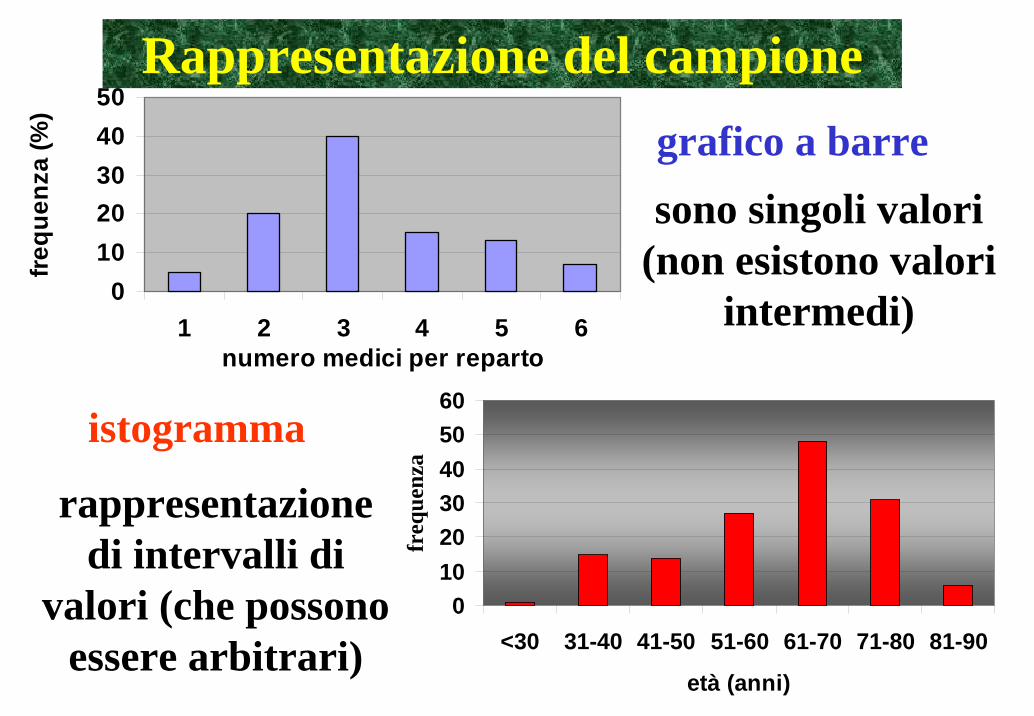
01020304050
1 2 3 4 5 6numero medici per reparto
frequ
enza
(%)
Rappresentazione del campione
0102030405060
<30 31-40 41-50 51-60 61-70 71-80 81-90
età (anni)
freq
uenz
aistogramma
sono singoli valori (non esistono valori
intermedi)
rappresentazione di intervalli di
valori (che possono essere arbitrari)
grafico a barre

Valore medioTabelle e grafici costituiscono sono strumenti di illustrazione e di divulgazione ma non di sintesi dell’informazione dei datiUna sintesi è invece la media aritmetica semplice
m = ∑ xi / n i = 1, n
che risulta la miglior rappresentazione del valore vero della popolazione che ha media μ
μ = ∑ x’i / N i = 1, N
dove x’i sono i valori degli N dati della popolazione

Media e medianaLa media può essere immaginata come il centro di gravità di una distribuzione
misura di localizzazione più frequentemente impiegata in statistica biomedica
Tuttavia la media (specialmente nei campioni di piccole dimensioni) tende ad essere influenzata dai valori estremiQuando questa influenza è evidente si può utilizzare la mediana (punto di mezzo della distribuzione) che non risente dei valori estremi
la mediana è il centro fisico della distribuzione

Indici di dispersione
Il più elementare indice è l’intervallo di variazione, differenza tra il valore massimo e quello minimo, ossia il range
Due distribuzioni possono avere stessa media, moda e mediana ma essere del tutto differenti a causa della dispersione dei dati
Scarti di ogni osservazione rispetto a tutte le altre?Scarto di ogni misura rispetto alla media
εi = xi – m ∑ εi = 0 poco utile!

Varianza
Per inserire questa dipendenza (numero N di osservazioni) si introduce la varianza
non tiene conto del numero di osservazioni
s2 = ∑ (xi – m)2 / novvero la varianza corretta
ove n – 1 sono le osservazioni indipendentis2 = ∑ (xi – m)2 / (n – 1)
devianza δ = ∑ (xi – m)2 ≥ 0
(gradi di libertà)

Deviazione standardUna distribuzione può essere espressa da un indice di tendenza centrale e da un indice di dispersione
due informazioni sono espresse nelle stesse unitàDeviazione standard (o scarto quadratico medio)
Si definisce l’errore standard ossia la deviazione standard di una media
s = √s2 = √ [ ∑ (xi – m)2 / (n – 1) ]
sm = s / √n
Errore non sui singoli dati ma sulla loro media!

Misure fisiche ed erroriOgni risultato di una misura è affetto da un errore che dipende dalla sensibilità dello strumentoutilizzato per misurarlaSe l’indeterminazione è più grande della sensibilitàoccorre operare N misure: il valore v è dato dalla media delle misure e l’errore sx della misura è dato dalla deviazione standard
v = m ± sx ERRORE STATISTICO
v = m ± sm = m ± (s / √n)
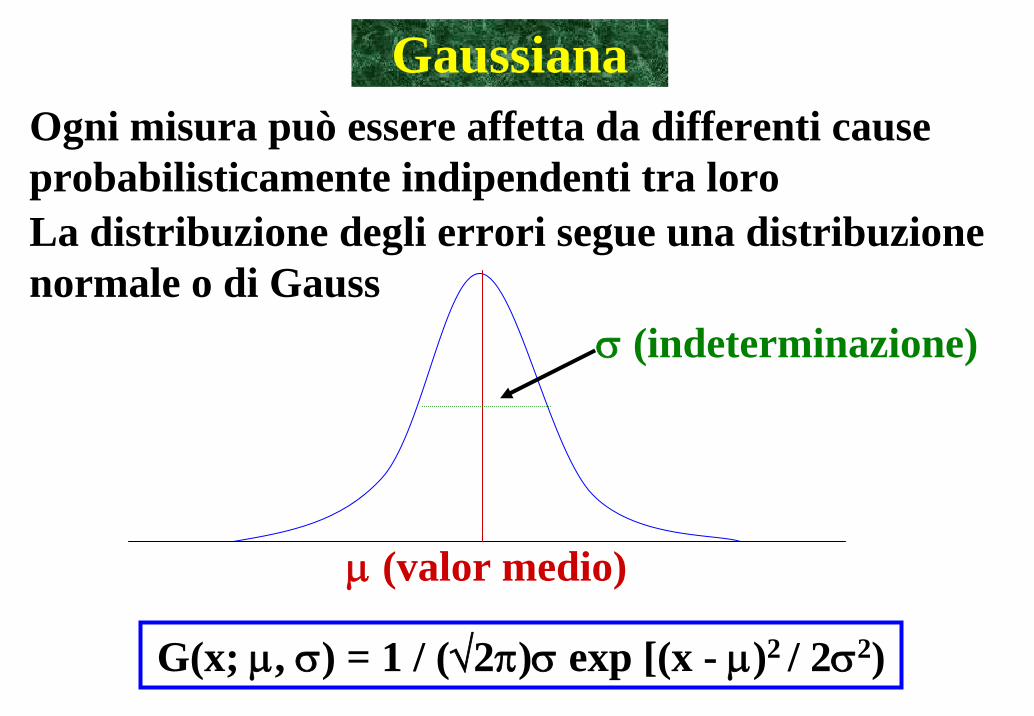
Gaussiana
G(x; μ, σ) = 1 / (√2π)σ exp [(x - μ)2 / 2σ2)
μ (valor medio)
σ (indeterminazione)
Ogni misura può essere affetta da differenti cause probabilisticamente indipendenti tra loroLa distribuzione degli errori segue una distribuzione normale o di Gauss
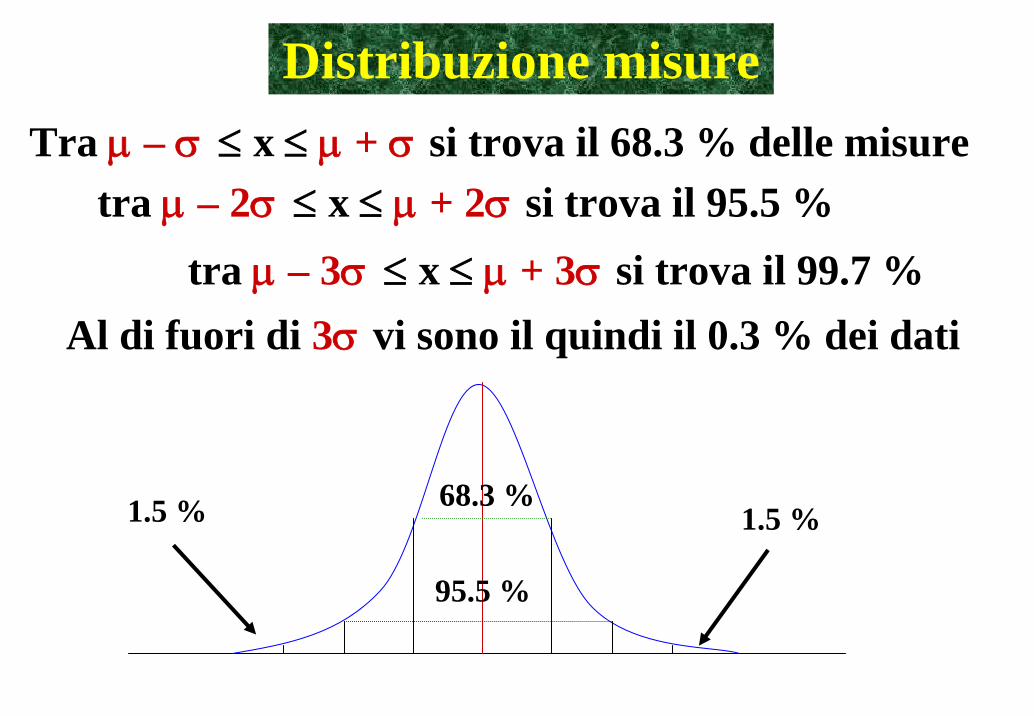
Distribuzione misureTra μ – σ ≤ x ≤ μ + σ si trova il 68.3 % delle misure
Al di fuori di 3σ vi sono il quindi il 0.3 % dei dati
tra μ – 2σ ≤ x ≤ μ + 2σ si trova il 95.5 %tra μ – 3σ ≤ x ≤ μ + 3σ si trova il 99.7 %
68.3 %
95.5 %
1.5 % 1.5 %
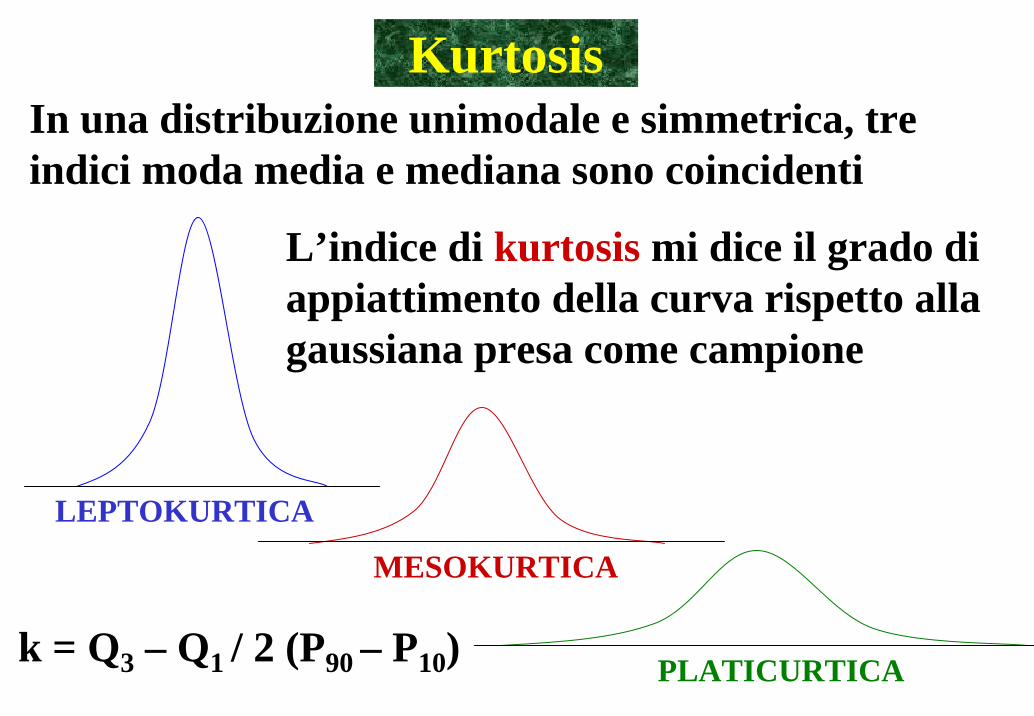
Kurtosis
L’indice di kurtosis mi dice il grado di appiattimento della curva rispetto alla gaussiana presa come campione
In una distribuzione unimodale e simmetrica, tre indici moda media e mediana sono coincidenti
k = Q3 – Q1 / 2 (P90 – P10)
LEPTOKURTICA
MESOKURTICA
PLATICURTICA

Skewness
Quanto più i tre indici si scostano tanto più la distribuzione diventa asimmetrica
In una distribuzione unimodale e simmetrica, i tre indici moda media e mediana sono coincidenti
mediamoda
mediana
SKEWNESS POSITIVA
SKEWNESS NEGATIVA
sk = (media – moda) / s

ProprietàLa distribuzione normale permette di calcolare la probabilità di un certo intervallo di valori utilizzando l'integrale della distribuzione compreso tra i valori
Per risalire alla probabilità di un certo intervallo dobbiamo effettuare il calcolo nella specifica distribuzione di quella particolare variabile
I valori di pressione sistolica compresi tra 120 e 140 mmHg costituiscono circa il 30% della distribuzione di valori della pressione sistolica nella popolazione
Se ci riferiamo alla pressione diastolica (se quindi cambiamo variabile) cambia anche la probabilità dell'intervallo che sarà del 5%
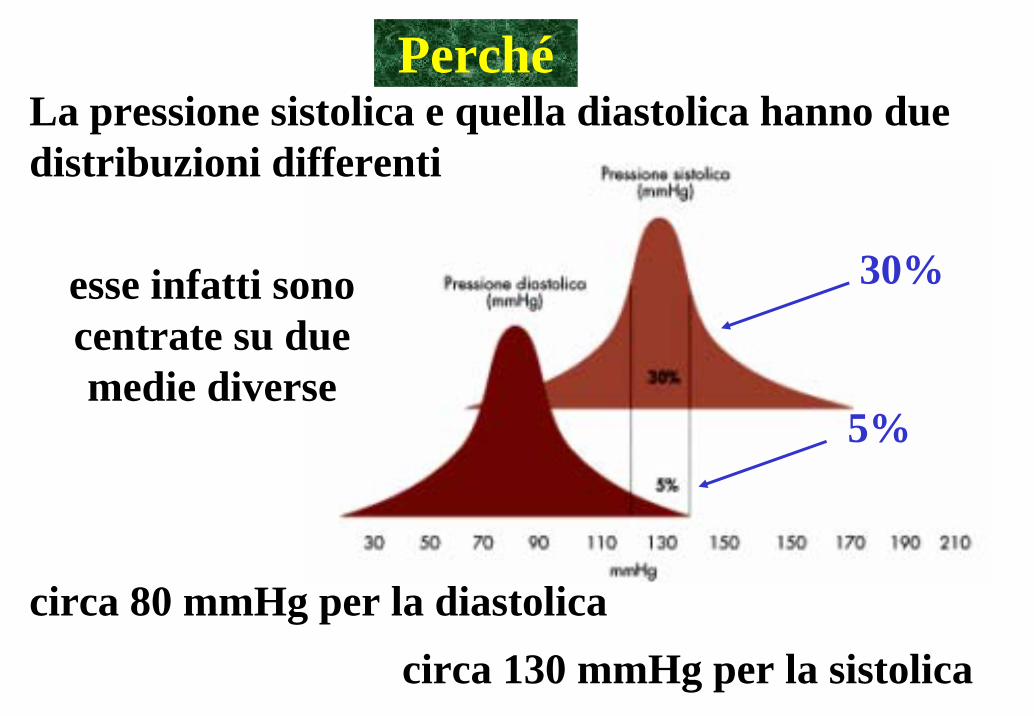
PerchéLa pressione sistolica e quella diastolica hanno due distribuzioni differenti
circa 80 mmHg per la diastolica
esse infatti sono centrate su due medie diverse
circa 130 mmHg per la sistolica
30%
5%

NormalizzazioneSi crea una distribuzione ideale nella quale i valori sono trasformati in deviazioni normali standardizzate
z = (x - μ) / σ
differenza tra un certo valore della variabile e la media della distribuzione divisa per la deviazione standard della stessa distribuzione
z è un numero puro dato che la "standardizzazione" elimina il problema delle unità di misura
dove z è la deviata media standardizzata, μ la media della popolazione e σ la deviazione standard

EsempioSe abbiamo una serie di valori di glicemia con media 100 mg/dl e deviazione standard 25 mg/dl
quindi la probabilità di avere dei valori di glicemia con valori maggiori o uguali a 1 è del 0.1587 (16%)
distribuzione simmetrica, la probabilità associata a 75 mg/dl è identica, cioè 1 (25/25 = 1)
Valori compresi tra 75 e 125 mg/dl
la deviazione media standardizzata corrispondente a una glicemia di 125 mg/dl è 25/25 = 1
La probabilità dell'intervallo è quindi= 1.000 – 0.3174 = 0.6826 (68%)1.000 – 2 • 0.1587
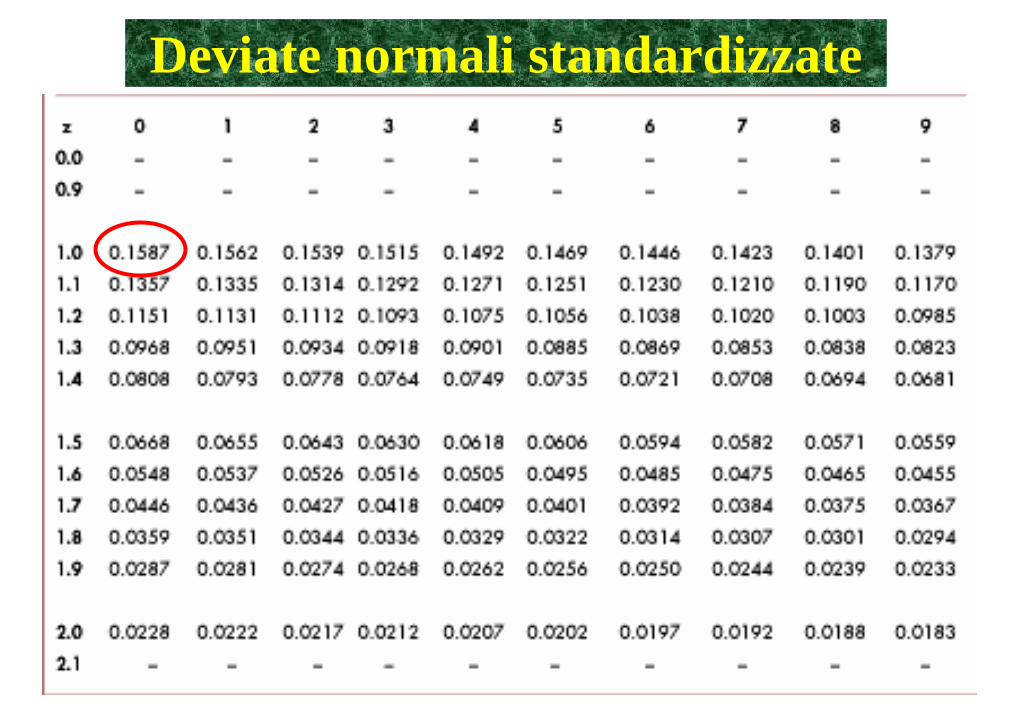
Deviate normali standardizzate


















