
DQQLH n i v e r s i t à d e g l i S t u d i d i P a l e r m o F a c o l t à d i I n g e g n e r i...
97
U n i v e r s i t à d e g l i S t u d i d i P a l e r m o F a c o l t à d i I n g e g n e r i a Corso di Laurea in Ingegneria Informatica progetto: $FWLYH1HWZRUNV1HZ,QWHOOLJHQW([SORUDWLRQ di progetto realizzato da /XSDUHOOR$OHVVDQGUR presentato come tesina per l’esame di I n t e l l i g e n z a A r t i f i c i a l e (corso tenuto dal prof. S.Gaglio nell’aa. 1998-1999) maggio 1999 DQQLH $OV:ROI
Transcript of DQQLH n i v e r s i t à d e g l i S t u d i d i P a l e r m o F a c o l t à d i I n g e g n e r i...

U n i v e r s i t à d e g l i S t u d i d i P a l e r m oF a c o l t à d i I n g e g n e r i a
Corso di Laurea in Ingegneria Informatica
progetto:
$FWLYH�1HWZRUNV��1HZ�,QWHOOLJHQW�([SORUDWLRQdi
progetto realizzato da
/XSDUHOOR�$OHVVDQGUR
presentatocome tesina per l’esame di
I n t e l l i g e n z a A r t i f i c i a l e(corso tenuto dal prof. S.Gaglio nell’aa. 1998-1999)
maggio 1999
D�Q�Q�L�H�$OV��:ROI�

D�Q�Q�L�H
progetto di studio ed applicazione software effettuata nel campo delle reti attive, PLANet in particolare.La parte software è stata realizzata in linguaggio PLAN (Packet Language for Active Networks) v.3.1(scritto in OCaml), sperimentata e testata su una rete PLANet comprendente alcuni computers deilaboratori 1 e 2 del CERE (Centro Studi sulle Reti di Computers, del CNR) ed altre macchine dislocate inaltre parti del mondo (si rimanda all’appendice A per una descrizione più accurata).
$OV��:ROI
Luparello Alessandro( Palermo, 11 Febbraio 1976)
matricola n. 0319099U n i v e r s i t à d e g l i S t u d i d i P a l e r m oIngegneria Informatica
v.le Regione Siciliana S.E. n.726 90129 Palermotel: 091-596177

Indice sinteticoContents
Prefazione ………………………………………………… Preface …………………………. 5
I Reti attive …….…………………………..……. Active Networks ………………. 6
1. Reti attive …………………………………………………………………………………….. 72. PLANet ………………………………………………………………………………………… 133. Linguaggio PLAN ………………………………………………………………………….. 28
II Analisi del progetto software ………. Analysis ………………………….. 48
4. Analisi del problema ……………………………………………………………………… 495. Analisi dell’algoritmo di risoluzione ideato ………………………………………. 52
III Osservazioni conclusive ………………… Observations……………………. 70
6. Osservazioni conclusive ……………………………………………………………………71
Appendici A. Prova sperimentale………………………………………….. 82B. Codice ………………….…….………………………………… 87
Riferimenti bibliografici ……………………….. Reference ……….………………..
Indice …………………………………………………………………………….………………..

PrefazionePreface
In questa brevissima introduzione voglio limitarmi a presentare il progetto D Q Q L H, frutto di
attenta analisi e meticolosa dedizione, come esperienza di ricerca. Esperienza che non posso
che reputare indubbiamente molto positiva, costruttiva ed importante.
Per lo studio delle reti attive in generale, e di PLANet in particolare, ci si è basati sui risultati di
ricerche effettuate prevalentemente da istituti quali il MIT, Massachussetts Institute of
Technology (Software Devices and Systems Group – Laboratory for Computer Science e
Telemedia, Networks and Systems Group) e la University of Pennsylvania (Department of
Computer and Information Science: Switchware project).
Per quel che riguarda la realizzazione pratica del progetto adesso presentato, è doveroso
sottolineare la collaborazione con l’ICSI (International Computer Science Institute) di Berkeley,
che ha anche permesso di utilizzare proprie macchine per la costruzione della nostra rete.
Ringraziamentiacknoledgments
Un cenno particolare va fatto in relazione al gentile interessamento (ed ai suggerimenti dati) del
prof. Michael Hicks, della University of Pennsylvania1. Ringrazio, ovviamente, il dott.
Giuseppe Di Fatta (all’ICSI di Berkeley), per i consigli ed il materiale fornitomi. Ringrazio
infine tutti quelli2 che hanno reso possibile, comodo e confortevole il mio lavoro all’interno
delle strutture universitarie3 (CERE, Centro di Studi sulle Reti di Elaboratori del CNR).
5 Uno dei principali ideatori del progetto PLANet, come si evince dalla ricorrenza del suo nometra gli autori del materiale utilizzato per il nostro studio (riferirsi alla bibliografia). Riguardo allo specificosupporto cui si è fatto cenno, si prega di fare riferimento alle note 7 ed 8 (ed al testo ad esse relativo) dellasezione 6 (osservazioni conclusive).2 Mi dispiace non essere in grado di elencare i nomi di queste persone: si tratta, comunque, di tuttii professori, assistenti e ricercatori (che si sono mostrati –tutti- affabili e cortesi (se non amichevoli) purdovendo sopportare a lungo la mia presenza, spero di non troppo disturbo) e di tutto il personale presente(sempre gentile…).3 Cosa che, mi dispiace enormemente dirlo, non può pensarsi scontata, ovvia e normale (comeinvece credo debba essere, in un contesto di sviluppo vero, attivo, concreto ed aggiornato degli studenti,dei progetti, dell’Università tutta e –conseguentemente- della nostra amata città e dell’intera società).Almeno nell’Università di Palermo cui pure sono fiero d’appartenere (più per campanilismo siciliano cheper razionali motivazioni) ed al cui miglioramento (o risanamento ?) vorrei, in minima parte (per quelloche mi compete), contribuire. Quanto detto, a titolo (ovviamente…) strettamente personale, è da ritenersiprivo di gratuite intenzioni polemiche (sterili lamentazioni, pur sempre molto in voga, vorrei nonappartenessero alla mia esperienza ed al mio bagaglio culturale) ma come (anche se piccolo…) sprononella direzione di una reale rinascita dell’ateneo palermitano.

3DUWH�3ULPD
R E T I A T T I V E$FWLYH�1HWZRUNV

Sezione 1
Reti attiveActive Networks
Introduzione
Abstract
Le reti attive permettono alle applicazioni di iniettare programmi in nodi di una rete locale o,
cosa più importante, su una rete geografica (wide area networks). Implicano veloci innovazioni
dei servizi forniti, essendo particolarmente facile sviluppare nuovi servizi di rete. Verranno
esplorati i concetti, ed in qualche modo l’architettura, delle reti attive, effettuando talora anche
confronti con la diffusa rete Internet.
Perché intodurre le reti attive?
Il ritmo delle innovazioni nelle applicazioni di rete è inesorabile. Nuove applicazioni continuano
ad emergere rapidamente e spesso riescono a trarre maggior beneficio (in termini di
performances) da servizi di rete che risultino particolarmente flessibili (adattandosi alla diversa
tipologia delle applicazioni, alle diverse necessità). Si è cominciato con l’osservare che, mentre
è comunque possibile sviluppare nuove routines di servizio in sistemi terminali, la loro
implementazione in nodi interni alla rete o perfino nello stesso strato di rete (network layer)1
spesso riusciva ad offrire migliori funzionalità e consentiva sensibili vantaggi nelle prestazioni.
Sfortunatamente l’attuale processo di modifica dei protocolli di gestione di rete è lento e
particolarmente difficoltoso, a causa della necessità di una standardizzazione che deve risultare
(ovviamente) compatibile con l’intera situazione presente.
1 Per dettagli in merito, ci si può riferire a qualunque testo relativo alla gestione delle reti dicomputers (testo di telematica, in generale). Ad es. citiamo [11]: Andrew Tanenbaum, Reti di computers.

Parte I, Sezione 1 Reti attive8
Le reti attive puntano a risolvere il problema della lentezza nell’evoluzione dei servizi di rete
mediante l’introduzione di un certo grado di programmabilità all’interno delle stesse
infrastrutture di rete, permettendo quindi un semplice e rapido inserimento di nuovi servizi.
Si crede fermamente nel fatto che l’abilità a costruire servizi di rete su misura per le
applicazioni riuscirà, in ultima analisi, a giustificare l’overhead necessario alla protezione
delle reti stesse. Conformemente a queste idee la ricerca sulle active networks sembra
focalizzarsi su due punti essenziali:
1. In che modo i nuovi servizi di rete possono essere utilizzati per potenziare le prestazioni
delle applicazioni.
2. Come è possibile costruire infrastrutture di rete programmabili senza compromettere le
prestazioni locali e le proprietà di sicurezza dell’intera rete.
Tradizionalmente le reti effettuano un passivo smistamento di pacchetti tra nodi terminali
(end-to-end): i dati utente (user data) sono trasferiti in modo “nascosto”, la rete è “insensibile”
ai bits che la attraversano e si limita ad instradarli senza effettuare alcuna modifica.
Le reti attive intendono rompere con questa tradizione permettendo alle reti di eseguire
elaborazioni “personalizzate” sui dati. Tali reti si possono dire attive in due sensi:
1. I routers eseguono calcoli sui dati utente che fluiscono su di essi.
2. Individui possono iniettare programmi nella rete, cosicché i processi sui nodi possano
diventare applicazioni specifiche per l’utente.
Sono stati individuati vari approcci architetturali alle reti attive. Uno di questi, ritenuto di
particolare interesse, rimpiazza i pacchetti passivi, dell’architettura dei giorni nostri, con
capsule attive: piccoli programmi che sono eseguiti in ogni router che attraversano. Questo
cambiamento nella prospettiva di visione delle architetture di rete, da pacchetti passivi a
capsule attive, verifica simultaneamente entrambe le proprietà di attività or ora descritte.
Le capsule, che contengono incapsulati (embedded) i dati utente, possono invocare metodi
predefiniti o impiantarne di nuovi all’interno dei nodi della rete.

Parte I, Sezione 1 Reti attive9
Vantaggi nell’utilizzo di reti attive
Ci sono tre principali vantaggi nel basare l’architettura di rete nel passaggio da pacchetti
passivi a programmi attivi:
1. Lo scambio di codice fornisce una base per i protocolli adattivi, rendendo le possibili
interazioni molto più cospicue che mediante il semplice scambio di dati a formato fisso.
2. Le capsule creano un mezzo per implementare specifiche funzioni a grana fine
(specifiche) nei punti strategici della rete.
3. L’astrazione di programmazione fornisce una potente piattaforma per una
personalizzazione, guidata dall’utente stesso, dell’infrastruttura, permettendo così a nuovi
servizi di essere sviluppati con un ritmo più veloce.
Diversi approcci alle reti attive
Si distinguono essenzialmente due diversi approcci alle reti attive:
A. Routers programmabili: approccio discreto
La gestione dei messaggi può essere architetturalmente separata dalle operazioni di
iniezione dei programmi nei nodi, per mezzo di un separato meccanismo per ognuna delle
funzioni.
Quando un pacchetto arriva, la sua intestazione (header) viene esaminata ed un
programma viene dedicato ad esaminare il suo contenuto; il programma analizza
attivamente il pacchetto, possibilmente modificandone il contenuto. Un grado di
personalizzazione dell’operazione è possibile perché l’intestazione del messaggio può
identificare quale programma dovrà essere eseguito; è perciò possibile, consentendo
l’utilizzo di diversi programmi, l’esecuzione di applicazioni che necessitano trattamenti
anche molto differenti.

Parte I, Sezione 1 Reti attive10
B. Capsule: approccio integrato
Altra estrema visione delle reti attive: ogni messaggio è un programma. Tutti i messaggi
(o capsule) che passano tra nodi contengono un piccolo programma che può inglobare dei
dati. Quando una capsula arriva su un nodo attivo, il suo contenuto viene valutato.
Si ipotizza che il programma sia costituito da istruzioni primitive (di un ridotto linguaggio
di programmazione), che eseguono operazioni elementari sul contenuto delle capsule
stesse e possono, inoltre, invocare metodi esterni, che potrebbero permettere l’accesso a
risorse esterne.
Considerazioni architetturali
La convenzionale architettura di rete separa lo strato superiore (end-to-end) da quello inferiore
(hop-by-hop). Le active networks sfidano questa tradizionale impostazione in diversi punti:
1. Le operazioni eseguite con le reti possono essere dinamicamente modificate.
2. Le reti possono essere rese specifiche per determinate applicazioni o in relazione agli
utenti che vi operano.
Stato attuale della ricerca mondiale sulle active networks
Elenco dei progetti attivi, ordinati per organizzazione:
Organization Research Title
BBN Systems and Technologies Smart Packets
Bellcore Protocol Boostersfor Distribuited Computing Systems
The Fox Project:Advanced Languages for Systems Software
Carnagie Mellon University
Active Networking for Storage
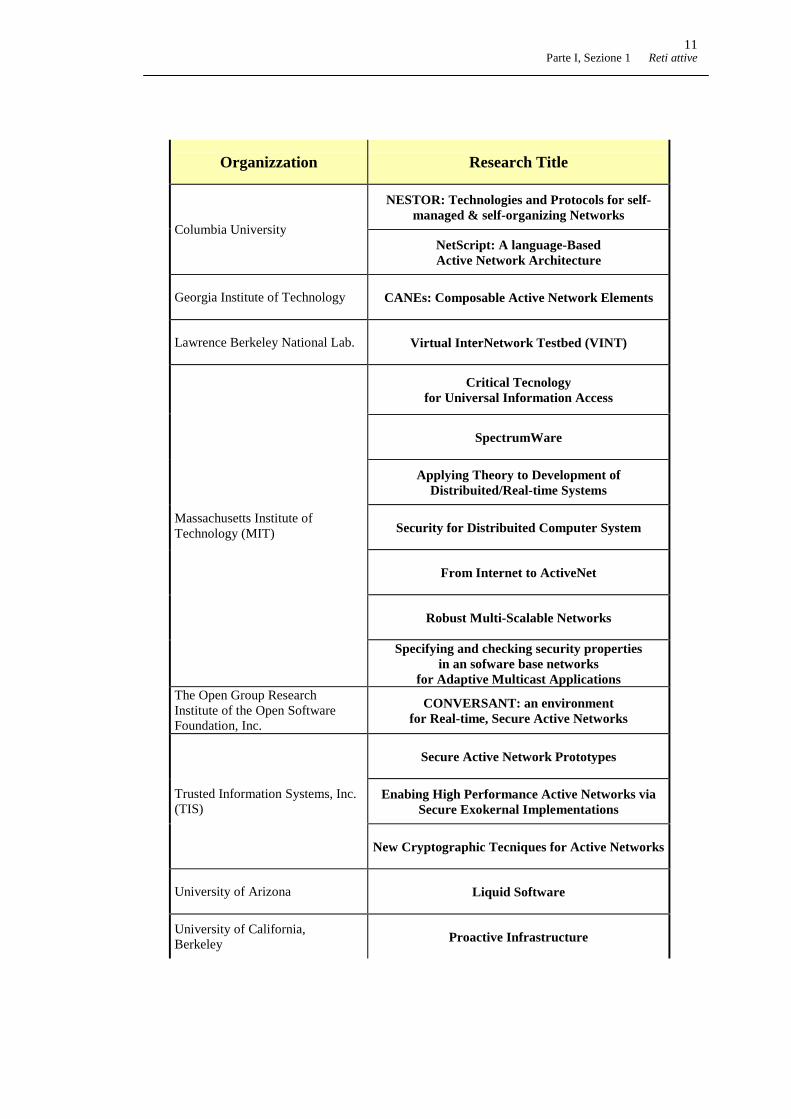
Parte I, Sezione 1 Reti attive11
Organizzation Research Title
NESTOR: Technologies and Protocols for self-managed & self-organizing Networks
Columbia UniversityNetScript: A language-BasedActive Network Architecture
Georgia Institute of Technology CANEs: Composable Active Network Elements
Lawrence Berkeley National Lab. Virtual InterNetwork Testbed (VINT)
Critical Tecnologyfor Universal Information Access
SpectrumWare
Applying Theory to Development ofDistribuited/Real-time Systems
Security for Distribuited Computer System
From Internet to ActiveNet
Robust Multi-Scalable Networks
Massachusetts Institute ofTechnology (MIT)
Specifying and checking security propertiesin an sofware base networks
for Adaptive Multicast ApplicationsThe Open Group ResearchInstitute of the Open SoftwareFoundation, Inc.
CONVERSANT: an environmentfor Real-time, Secure Active Networks
Secure Active Network Prototypes
Enabing High Performance Active Networks viaSecure Exokernal Implementations
Trusted Information Systems, Inc.(TIS)
New Cryptographic Tecniques for Active Networks
University of Arizona Liquid Software
University of California,Berkeley Proactive Infrastructure

Parte I, Sezione 1 Reti attive12
Organizzation Research Title
Adaptive Web CachingUniversity of California,Los Angeles (UCLA)
Middleware Framework
University of California,Santa Barbara
Thunder and Lightning:A communication Network
University of California,Santa Cruz Routing and Multicasting Services
University of Delaware Scalable, High Speed, Internet TimeSynchronization
University of Illinois Building dynamic interoperable securityarchitecture of active networks
University of Pennsylvania Accelerating Network Evolution with aSoftware Switch for Active Networks
Active Network Applications
University of WashingtonDesign and Demonstration of a scalable high
performance active network node
TNT: Reservation protocol(RSVP/RSVP2) Task
TNT: Scalable Personal
Rational ATM Internet Suite
Virtual InterNetwork Testbed (VINT)
USC Information Sciences Institute
Active Reservation Protocol (ARP)
Washington University in St.Louis High Performance Component-BasedDistribuited Applications
Multicast, Multimedia Infrastructure for theInternet
Xerox Palo Alto Research Center
Virtual InterNetwork Testbed (VINT)

Sezione 2
PLANetPLANet: An Active Internetwork
Introduzione
PLANet è sicuramente una rete attiva: essa implementa lo strato di servizio di rete direttamente
sopra le tecnologie dello strato di link, senza relazione con l’esistente infrastruttura IP1. PLANet
è inoltre “puramente attiva”: tutti i pacchetti contengono programmi scritti in un linguaggio
particolare dedicato (special-purpose packet language) chiamato PLAN (“Packet Language for
Active Networks”) e le potenzialità dei nodi possono essere estese mediante il caricamento
dinamico di codice addizionale (per modificare talune funzionalità o introdurne di nuove).
Andiamo adesso ad analizzare i due aspetti che rendono “attiva” la rete PLANet:
1. PLANet usa pacchetti attivi (active packets) che contengono programmi PLAN, come
menzionato prima. Per semplicità e per migliorare le prestazioni, un pacchetto PLAN può
scegliere di appoggiarsi ad un trasporto “passivo” e quindi necessita (in questo caso) di non
essere valutato in ogni nodo intermedio. I programmi PLAN sono tipicamente piccoli e
servono come “collante” tra routines di servizio (service routines) residenti nei routers, che
provvedono alle funzionalità generali (general-purpose functionalities) non esprimibili con
il solo linguaggio (le routines di servizio possono provvedere a semplici informazioni, come
potrebbe essere l’indirizzo dell’host attualmente raggiunto, oppure a funzionalità più
sostanziali, come segmentazione e riassemblamento di pacchetti).
1 IP: Internet Protocol. Per maggiori informazioni confrontare ad es. J.Postel “Internet Protocol”,Tech.Rep., IETF RFC 791, September 1981.

Parte I, Sezione 2 PLANet14
2. I nodi PLANet possono essere programmati tramite caricamento dinamico di estensioni
attive (active extensions) scritte in OCaml5, un “dialetto” del linguaggio di
programmazione ML6. Queste estensioni aggiungono nuove funzionalità, o migliorano
quelle esistenti, e possono generare servizi accessibili dai programmi PLAN. Vengono
utilizzate per programmare servizi essenziali necessari per operare nella rete, come
risoluzione si indirizzi (address resolution), routing, etc…, mentre i programmi PLAN
sono usati con lo scopo di breve comunicazione tra i nodi.
Tale architettura del nodo è visualizzata nello schema qui di seguito:
schizzo dell’architettura di un nodo PLANet
Prima, un pacchetto arriva direttamente attraverso l’interfaccia dello strato di link. Se il
programma ha raggiunto il suo nodo di destinazione (evaluation destination) viene “passato”
all’interprete PLAN per la valutazione, altrimenti è semplicemente instradato (routed) oltre.
Durante la valutazione, i programmi PLAN possono effettuare chiamate a servizi (tramite
service calls), incluso quello che trasmette il programma stesso in un altro nodo per essere
valutato.
PLAN
Molto del design di PLANet è sostanzialmente basato sul linguaggio dei suoi pacchetti (come
probabilmente si è già avuto modo di osservare in precedenza), il Packet Language for Active
5 Riferirsi, ad es., a [9]: OCaml home page: ZZZ�SDXLOODF�LQULD�IU�FDPO�LQGH[�HQJ�KWPO�6 Riferirsi, ad es., a [8]: Robert Harper, “ Introduction to Standard ML”, Carnage MellonUniversity, January 1993
PLAN program(s)
PLAN interpreter
Routing Extension
IP Ethernet
Active Packets
Active Extensions
Link layer

Parte I, Sezione 2 PLANet15
Networks (o PLAN)7. Questo è un “piccolo” linguaggio che ha molti elementi in comune con
altri linguaggi in qualche modo simili, come Haskell, Scheme ed ML8. La differenziazione di
maggiore importanza da questi ultimi è relativa al fatto che PLAN include primitive per valutare
espressioni in nodi “remoti”.
Un’altra speciale caratteristica del PLAN è una semantica impostata su risorse limitate
(resource-limited semantics), che assicura che i programmi abbiano sempre un termine e che i
pacchetti (ed i loro “discendenti”9) visitino al più un numero fissato di nodi.
PLAN è nato con l’obiettivo di essere flessibile a sufficienza per scrivere utili
programmi, ma limitato abbastanza da non permettere che i suoi programmi pongano rischi di
sicurezza. Per contrasto, le routines di servizio -a disposizione dei programmi stessi- sono di
carattere generale (general-purpose) e potrebbero necessitare d’essere protette mediante
crittografia (criptography) o altri mezzi10.
PLANet
PLANet è l’implementazione della rete attiva che andiamo a considerare, basata sull’ambiente
PLAN. Nasce e si sviluppa attingendo, quando possibile, all’esperienza pratica maturata
nell’utilizzo di Internet (e dell’IP); questa indica come sia opportuno seguire alcuni elementi
essenziali (core elements) :
• uniformità di indirizzamento allo strato di rete (network-layer addressing) e del formato dei
pacchetti.
7 Una descrizione sommaria del linguaggio PLAN sarà data anche nel seguito di questa stessasezione; per una trattazione minimamente più organica e più approfondita si può consultare la sezioneseguente (dedicata interamente ed esclusivamente proprio al PLAN).8 Se si vuole, ci si può riferire (ad es.) a:- “Haskell: A purely functional language”,ZZZ�KDVNHOO�RUJ, per l’Haskell- “Scheme home page”, ZZZ�VZLVV�DL�PLW�HGX�VFKHPH�KRPH�KWPO, per lo Scheme� R.Milner, M.Tofte, R.Harper, “The definition of Standard ML”, the MIT Press, 1990, oltre al già citato[8] (“ Introduction to Standard ML”), ovviamente per l’ML9 con questa dizione, si vogliono intendere tutti i pacchetti “generati” (ed iniettati nella rete) daquello in esame.10 In questa sezione, né nelle altre di questo lavoro, sarà preso in considerazione l’aspetto dellasicurezza (certamente importante ma molto complesso e forse eccessivamente distante dagli obiettivi checi siamo preposti). Qualora si fosse interessati, ci si potrebbe riferire (ad es.) a:- D:Scott, W.Arbaugh, A.Kerom, J.Smith, “A secure active network environment architecture:
Realization in SwitchWare”, IEEE Network Magazine, vol 12, no.3, pp. 37-45, 1998, Special issueon Active and Controllable Networks.
� M.Hicks, “PLAN sistem security”, Technical Report MS-CIS-98-25, Dep.of Comp.and InformationScience, Un.of Pennsylvania, April 1998.
A disposione, su Internet, all’indirizzo ZZZ�FLV�XSHQQ�HGX�aVZLWFKZDUH�SDSHUV�SURJSODQ�SV

Parte I, Sezione 2 PLANet16
• risoluzione di indirizzi (addess resolution) dello strato di link ad indirizzi dello strato di
rete.
• instradamento (routing) tra reti fisiche.
• “referto” degli errori incontrati (error reporting).
Questi elementi formano l’anima (core part) del PLAN stesso: ad eccezione della risoluzione
degli indirizzi, ognuno è potenzialmente considerabile come un’astrazione nel linguaggio. Da
Internet è inoltre stata adottata l’idea che la valutazione “remota” è la tecnica migliore; la
“consegna sicura” (reliable delivery) può essere ottenuta con l’aggiunta di servizi appropriati.
Oltre questi elementi centrali, sono stati implementati altri servizi, che pure -come i
primi- hanno controparti su Internet. Tali servizi non richiedono standardizzazione e non fanno
parte dei programmi PLAN ma sono elementi di routines di servizio caricabili (loadable service
routines)11 messe a disposizione dei programmi PLAN stessi.
A. Formato dei pacchetti PLAN (Packet Formats)
Per permettere interoperazionalità tra diverse reti fisiche, un’internetwork deve definire un
insieme di formati standard di pacchetti. In PLANet tutti i pacchetti consistono in programmi
PLAN, così che questa standardizzazione si riduce alla definizione di un ordinato schema
(standard) per i programmi PLAN (notiamo che ciò comporta una enorme semplificazione:
consideriamo, ad es., chi deve occuparsi dell’implementazione di nuovi servizi di rete, esso
necessiterà solamente di sapere quale informazione (what) deve essere elaborata, o
semplicemente trasmessa, e non come (how) questa è codificata).
Dall’esperienza con Internet si è ricavato che la maggior parte dei pacchetti richiede
solamente un semplice trasporto, ci si aspetta conformemente che una situazione analoga si
possa verificare (cosa statisticamente attendibile) anche in relazione alle reti attive, PLANet nel
nostro caso. Da qui la conseguente assunzione che un’alta percentuale dei pacchetti PLAN -
presenti nella rete- necessiterà di instradamento e non di valutazione e quindi la scelta di
disporre le informazioni necessarie all’instradamento in una posizione standard per migliorare
proprio l’efficienza di instradamento.
11 Delle routines di servizio a disposizione dei programmi PLAN si parlerà più lungamente (malimitando l’analisi dettagliata –necessariamente- solo a quelle concretamente utilizzate nel progettosoftware) nella sezione seguente (quella dedicata al PLAN).

Parte I, Sezione 2 PLANet17
Il formato dei pacchetti PLAN è illustrato nella figura qui di sotto e descritto di seguito.
Formato dei pacchetti PLAN
Analizziamone adesso, più o meno dettagliatamente, i vari campi (suddivisi in settori):
• Indirizzamento (Addressing)
I primi due campi del pacchetto indicano il nodo di destinazione dove il
programma dovrà essere valutato (evaluation destination, brevemente
evalDest) ed il nodo sorgente (source), che identifica il “nome” del
nodo che ha -per primo- generato il pacchetto (informazione utilizzata,
ad es., nella trasmissione dell’analisi degli errori riscontrati (error reporting)). Come per ogni
altra rete, importante è indubbiamente la risoluzione degli indirizzi dello strato di rete nello
strato di link (per il trasporto fisico).
evalDest
source
rb
session
flowId
routFun
handler
execFn
bindings
code
Address on which to evaluate
Integer global resource bound
Integer session identifier
Integer flow identifier
String name of routing function
String name of exception handler
chrunk
String name of fn to evaluate
List of PLAN value bindings
PLAN code
Address od Source

Parte I, Sezione 2 PLANet18
PLANet adotta un protocollo molto semplice quale l’ARP12 (Address Resolution Protocol).
• Programmi come dati13
Gli ultimi tre campi del pacchetto comprendono il chunk (forma breve di “code hunk”,
letteralmente “pezzetti di codice”), che è essenzialmente il suo (del pacchetto) programma:
- code ……… codice vero e proprio
- execFn …... punto di ingresso alla funzione (forse più chiaro nell’espressione: function entry
point)
- bindings … lista degli argomenti iniziali14
Quando un pacchetto PLAN raggiunge la sua destinazione
(evalDest), il suo codice viene “spacchettato” (si consenta,
senza eccessivi rimproveri, l’uso di questo –non felice (ne
siamo coscienti) ma comodo- termine) e l’appropriata
funzione viene “chiamata”, avendo come parametri gli
argomenti dati.
Osserviamo che, per quanto detto (e soprattutto per quanto non detto), il “chunk” di un
pacchetto potrebbe trasportare altri chunks come fossero dati, realizzando in tal modo un
elegante meccanismo di incapsulamento. Inoltre, con appropriate routines di servizio, i chunks
possono essere frammentati, trasportati, riassemblati e poi, infine, valutati15.
12 Come ci si può immaginare, non è negli obiettivi del presente lavoro (né, pur volendo, potrebbeessere) l’addentrarsi in particolari tecnici (fondamentali, magari interessanti, ma particolarmente ostici peri “non addetti” e per chi ha finalità diverse, precise ed improcrastinabili) quale, ad es., proprio larisoluzione degli indirizzi. Per quanto riguarda questo argomento si potrebbe rimandare ad una futurapubblicazione dello stesso autore oppure (per non costringere ad una lunga, estenuante, snervante e –probabilmente- inutile attesa chi fosse interessato) ad una delle pubblicazioni seguenti:- D.C.Plummer, “An Ethernet address resolution protocol”, Tech.Rep., IETF RFC 826, 1982- C.Hendrick, “Routing information protocol”, Tech.Rep., RFC 1058, June 1988- [11] Tanembaum, “Reti di Computer”.13 Un’esposizione più puntuale e meno astratta si può trovare nella sezione seguente.14 Gli argomenti sono valori PLAN che hanno un loro formato, come descritto nella sezione, aquesta, successiva.15 Questo permette di superare con semplicità l’ostacolo del limite –invalicabile come le zonemilitari- dato dall’MTU (maximum transferable unit). Tale limite consiste, molto brevemente, in unadimensione massima imposta ad ogni pacchetto che si muove sulla rete fisica. Per maggiori informazioni,si rimanda alla consultazione di articoli o testi specifici.

Parte I, Sezione 2 PLANet19
• Campi rimanenti
(Maggiori dettagli su alcuni di questi campi saranno dati nella sezione successiva, allorquando verranno prese in
considerazione le funzioni delle routines di servizio che, in un modo o nell’altro, interagiscono proprio con i suddetti
campi. Per gli altri si preferisce non andare oltre la succinta descrizione seguente)
Il terzo campo del pacchetto è un limite di risorse (resource bound): consiste nel massimo
numero di nodi che al pacchetto stesso è consentito attraversare (essenzialmente per porre un
freno alla moltiplicazione dei pacchetti, ed evitarne una permanenza “infinita” nella rete). Il
campo session funge da identificatore per i programmi applicativi sull’host, mentre il campo
flowId identifica il flusso di pacchetti attraverso un router.
B. Instradamento dei pacchetti (Routing)
Per determinare la direzione che un pacchetto PLAN dovrà prendere (next hop; ovvero il
prossimo nodo da attraversare, tra gli adiacenti a quello considerato e nella direzione di quello
di destinazione), ogni nodo intermedio valuta –in ogni pacchetto- la specificata routFun, che
“chiama” una routine di servizio residente nel nodo stesso.
Viene scelto tale approccio come alternativa a due punti estremi:
1. Si potrebbe richiedere che tutte le possibili destinazioni di valutazione (evaluation
destinations) siano dislocate esclusivamente all’interno della stessa rete del mittente; per
raggiungere destinazioni distanti, i pacchetti sarebbero valutati in ogni nodo intermedio per
determinare la prossima via di instradamento (next hop): la funzione di routing varierebbe
Sorgente
Destinazione

Parte I, Sezione 2 PLANet20
in relazione del nodo e del pacchetto. Un tale approccio risulterebbe senz’altro godere della
massima flessibilità, di contro –però- non potrebbe non dirsi molto costoso, sia in termini di
prestazioni (performance) che di convenienza (e comodità) per il programmatore.
2. Altro estremo è quello di implementare un unico protocollo di routing per tutti i nodi della
rete (o per una porzione autonoma di questa) e forzare tutti i pacchetti ad essere instradati
secondo tale determinazione.
Il considerare una funzione di routing relativa al pacchetto (e non più, quindi, ai nodi della rete)
serve come alternativa che non vuole favorire (e realmente non favorisce) nessuna strategia di
routing a discapito delle altre, risultando persino una scelta “leggera”: individua la direzione di
instradamento senza richiedere che il pacchetto venga valutato. L’unico costo aggiuntivo è
solamente quello relativo all’esecuzione della funzione di routing stessa.
La maggior parte dei pacchetti specifica una funzione di routing defaultRoute (che,
ovviamente, rappresenta la funzione di routing di default). Questa è implementata come un
semplice vettore di distanze di instradamento basato essenzialmente sul RIP16.
C. Analisi e gestione degli errori (Diagnostics and Error Handling)
Gli errori che possono presentarsi nell’ambito di una rete sono suddivisibili essenzialmente in
due categorie: errori di pacchetto (packet-level errors) ed errori relativi allo stato di rete
(network-level errors).
Gli errori di pacchetto si presentano quando un particolare
pacchetto fallisce il corretto raggiungimento della propria
destinazione, probabilmente perché tale destinazione è
troppo distante (il suo raggiungimento richiede una
quantità di risorse17 superiore a quelle disponibili che –
quindi- si esauriscono).
16 Alla strategia RIP viene dedicato una piccola annotazione nella sezione seguente: LinguaggioPLAN (relativamente alla presentazione del package di servizio RIP), qualora tali informazioni fosseroritenute insufficienti potrebbero consultarsi (ed es.) i testi già elencati nella precedente nota 12 (dellastessa sezione).17 Ricordiamo di aver già accennato al concetto di risorse proprio nella pagina precedente inrelazione allo schema del formato del pacchetto PLAN.

Parte I, Sezione 2 PLANet21
Errori di pacchetto sono inoltre (generalmente) sintomatici di anomalie a livello di rete: un ciclo
presente nella tabella di instradamento non può che provocare la terminazione del pacchetto
senza che questo possa raggiungere la sua destinazione.
Possiamo osservare che in una rete ben progettata, le applicazioni dovrebbero sempre
cercare di “catturare” (handle) gli errori a livello di pacchetto, così come gli amministratori
della rete stessa dovrebbero “diagnosticare” (diagnose) gli errori a livello di rete.
I mezzi mediante i quali gli errori a livello di pacchetto possono essere “catturati” sono molto
ricchi in PLAN, che da un livello di astrazione sono stati calati a livello di programma. Gli
errori che si presentano durante la valutazione del programma possono essere catturati
direttamente dal programma stesso, mentre errori che vengono alla luce nella fase di
instradamento possono essere catturati e manipolati dal nodo sorgente, mediante la routine di
servizio nominata nel campo handler del pacchetto18.
D. Dettagli implementativi
(tutte le informazioni qui presenti sono relative all’implementazione della rete PLANet, effettuata dal Department of
Computer and Information Science, University of Pennsylvania)
PLANet è implementato in OCaml v.2.0019 nello spazio utente del Kernel Linux ver. 2.0.30. La
scelta proprio di uno spazio utente sembra essere stata largamente motivata dalla convenienza
mentre non pochi sono stati gli sforzi per integrare PLANet nel kernel di vari sistemi operativi.
Perché OCaml ?
L’implementazione con questo linguaggio permette una completa indipendenza dalla macchina
ed un caricamento/scaricamento di codice (che risulta essere qualità indispensabile per il
caricamento dinamico delle estensioni attive). Inoltre, il codice sorgente OCaml è liberamente
disponibile, fatto oltremodo conveniente per le necessarie modifiche dirette alla specificazione
delle caratteristiche della rete.
18 Si riveda, a tal proposito, lo schema del formato del pacchetto PLAN.19 Come si è già avuto modo di dire in precedenza (e probabilmente si ripeterà nella sezionesuccessiva), per entrare in merito a questo linguaggio di programmazione potrebbe consultarsi il sito(citato nella nota 2) [9]: OCaml home page: ZZZ�SDXLOODF�LQULD�IU�FDPO�LQGH[�HQJ�KWPO�

Parte I, Sezione 2 PLANet22
Costruzione effettiva dei nodi attivi
Si è più volte detto (con anche troppa enfasi nella prefazione) che questo lavoro si inserisce (pur
come piccolissimo tassello) in un contesto ampio ed articolato20 di ricerca e studio attuale (vi si
lavora da non più di due anni, ben pochi punti possono ritenersi –di conseguenza-
definitivamente raggiunti e stabili), è quindi intuibile come diverse cose possano essere ancora
da definire, da “sistemare”, possano sembrare magari solamente abbozzate o drasticamente
semplificate21. E’ questo il caso (anche se si possono fare, e si faranno, esempi più evidenti e più
adatti) della costruzione materiale della rete.
Come si costruisce una rete PLAN?
E’ necessario pianificare la rete da costruire, e nel senso più restrittivo del termine:
Bisogna indicare (in un abbozzo di schema, per memorizzazione personale) il nome di tutti i
nodi (ossia il “nome” della macchina sulla quale si vuole lanciare il nodo attivo), tutti i
collegamenti tra loro (mediante specificazione delle interfacce nodo-nodo), il fatto se il nodo
debba essere un router o un host (ossia con possibilità di iniettare pacchetti dall’esterno),…
Tutte queste informazioni (che nel seguito saranno analizzate con più metodo, più chiaramente e
sicuramente più dettagliatamente) dovranno poi essere utilizzate per la costruzione effettiva,
nodo per nodo, della rete attiva.
Cominciamo con l’analizzare il comando che permette di “attivare” un nodo nella rete PLAN:
pland
Sintassi:
pland [-router] [-ip port] [-l log] [-rf rout_tab_file] [-hf host_table_file][-keypub public_key_file] [-keypriv private_key_file] [-policy policy_file]ifc_spec_file
comando necessario per costruire un nodo della rete attiva PLAN, secondo determinati parametri(si fa osservare che sono da intendersi come opzionali i parametri posti tra parentesi quadre)
20 Si confronti, a tal proposito, lo schema riassuntivo già evidenziato nella sezione precedente(quella relativa alle reti attive nel loro complesso).21 Intendo riferirmi alla problematica relativa a talune scelte drastiche e semplificative, forse anche“rozze” nella loro implemementazione, quali possono essere –ad es.- quelle sul package resident (comepuò leggersi nella sezione successiva, dedicata, appunto, all’analisi del linguaggio PLAN), che rivelano inmaniera molto esplicita la condizione di “work in progress” nella progettazione tutta.

Parte I, Sezione 2 PLANet23
Descrizione:
Pland è un demone (daemon program) che implementa un router attivo PLAN per la versione
3.1 del PLAN stesso. Attualmente pland può lavorare esclusivamente su sistemi UNIX ma sono
allo studio quei cambiamenti necessari per permettere l’esecuzione anche in sistemi Windows.
Esiste inoltre una versione di PLAN (la 2.2) scritta in Java, per questa la funzione che crea il
router attivo è nominata ARMain22.
Pland ed ARMain non sono compatibili l’uno con l’altro: ARMain trasmette e riceve
pacchetti incapsulati mediante ANEP, mentre pland “abbandona” l’incapsulazione ANEP per
utilizzare un formato di pacchetto più ottimizzato23.
Pland comunica con le applicazioni locali (definite applicazioni host, host applications)
mediante UNIX domain socket (ci si riferisca alla descrizione dell’opzione –ip). A seconda del
valore di alcuni flags usati durante l’attivazione del nodo, questo può utilizzare una
combinazione di due strati di link (link layers): Ethernet ed UDP/IP (come questi strati di link
sono scelti è deciso nel contenuto del ifc_spec_file; dettagli sul cui formato sono specificati di
seguito). Tali due link layers possono essere usati singolarmente o in combinazione;
essenzialmente questo permette di separare (isolare) reti PLANet basate su Ethernet salvo poi
connetterle (magari), tramite opportuni “tunnel”, ad Internet. Inoltre l’uso di UDP/IP consente a
più router attivi di essere presenti nello stesso host (ovviamente considerando numeri di porte
differenti).
indirizzi : gli indirizzi PLAN (strato di rete, network layer) sono costituiti da due
componenti: un indirizzo, di 32 bit, ed un numero di porta, di 16 bit.
Quando si lavora utilizzando Ethernet, la scelta di questi due campi è del tutto
arbitraria; mentre, se è UDP/IP ad essere utilizzato, la porzione dell’indirizzo
(primi 32 bit) deve corrispondere all’indirizzo IP della macchina sottostante e la
porzione di porta (ultimi 16 bit) deve essere una porta UDP non già utilizzata.
22 Può essere utile sapere (probabilmente non più che a titolo di curiosità) che l’implementazionedel progetto che si sta cercando (in modo -si spera- chiaro e lineare) di presentare, era stata iniziatautilizzando proprio la versione 2.2 di PLAN, scritta in Java. Si è passati poi (a lavoro già avviato ma consolo pochissimi inconvenienti, lo si ammette sinceramente) alla versione più avanzata per i vantaggi chequest’ultima portava come dote personale (specie in confronto con la versione più antica, troppodipendente dal suo linguaggio di costruzione), vantaggi –comunque- più volte accennati in precedenza.23 Non si vuole entrare nel dettaglio delle tecniche di incapsulazione (come già fatto più volte, sipreferisce non divagare in argomenti ritenuti troppo specifici e non strettamente utili alla comprensionedel progetto presentato). Per maggiori informazioni ci si può riferire, ad es., a:- D.S.Alexander, B.Branden, … “Active Network Encapsulation Protocol (ANEP)”, RFC, ANEP doc.- formato del pacchetto PLANet, in questa stessa sezione.

Parte I, Sezione 2 PLANet24
Per abilitare un servizio di sicurezza, un nodo PLAN può essere associato ad una coppia di
chiavi (pubblica e privata). Inoltre, è possibile specificare un file di supervisione (policy file) per
indicare il servizio di “polizia” da attivare automaticamente “all’accenzione” (start-up) del
nodo. Pland può utilizzare tecniche di instradamento statico o dinamico; il primo è in relazione
ad una tabella di startup, il secondo (considerato come default) è realizzato mediante un
protocollo di instradamento del tipo RIP24.
Opzioni del comando in linea (Command-line options)
- router specifica il modo router (router mode); questa opzione elimina la
possibilità del nodo di ricevere traffico locale dalla porta di riferimento
(implicit port).25 Questo potrebbe implicare (e generalmente implica) un
vantaggio nelle prestazioni del nodo (essenzialmente in termini di
tempo).
- ip incoming port Specifica il numero della porta di riferimento del nodo (implicit port),
che coinciderà con la porta di iniezione (injection port) qualora si
dovesse utilizzare il nodo in oggetto per iniettare un pacchetto nella
rete. Si considera, come default, in numero 3324.
- l logfile Specifica il nome del file dove scrivere i messaggi di logging (una sorta
di “diario di bordo” della valutazione dei pacchetti nel nodo).
- rf routfile Specifica che deve essere usata la tecnica di instradamento statica, la
cui tabella può essere trovata proprio nel routfile. Questo file ha la
forma di una lista di coppie di hosts: il primo elemento della coppia
indica un nodo della rete, il secondo indica il prossimo passo (hop)
verso questo (ossia il nodo, adiacente a quello in questione, nella
direzione di raggiungimento del primo).
24 Come si sarà certamente osservato, questa parte è quasi solamente accennata. La motivazionerisiede nel fatto che si tratta adesso di dettagli molto sofisticati che, sebbene sarebbe indubbiamente utileconsiderare ed approfondire, si preferisce non trattare nello specifico (come del resto si avrà modo diribadire nel seguito) perché non strettamente necessari allo sviluppo del progetto D Q Q L H e relativamentecomplessi.25 Ci si può riferire alla parte introduttiva della sezione successiva (PLAN), per un modelloschematico esemplificativo.

Parte I, Sezione 2 PLANet25
Qualora il primo elemento della coppia sia la parola default, allora la
direzione è quella da prendere nel caso si cerchi di raggiungere un nodo
non presente nella tabella (instradamento di default).
- hf hostfile Specifica il file che deve essere utilizzato per risolvere i nomi di host
(risoluzione imposta, ad esempio, già dalle funzioni di routine
getHostByName e thisHost).
Il formato che deve avere questo file è del tipo seguente (che riportiamo
con significato esemplificativo, utilizzando però solo connessioni di
tipo IP, non Ethernet):
176.123.6.23 archimede.cere.pa.cnr.it archimede arc176.123.6.12 galileo.cere.pa.cnr.it galileo128.32.201.59 panella.icsi.berkeley.edu panella
Osserviamo che ogni linea consiste in almeno due campi, separati da
spazi bianchi. Il primo è l’indirizzo del nodo, nel formato utilizzato
nell’IP (4 numeri compresi tra 0 e 255 (rappresentabili in 8 bit) separati
da un punto), il secondo campo rappresenta il domain name della
macchina. Eventuali altre parole (nella stessa riga) indicano nomi
(abbreviativi) equivalenti (nell’esempio fatto, archimede oppure arc
sono utilizzabili al posto del nome esteso archimede.cere.pa.cnr.it).
Il file di default è considerato con il nome di EXP_IP_ADDRS e
cercato nella directory attuale (quella dove si trova pland).
- keypub pubfile Specifica il file contenente un codificatore (a 64 bit) per la chiave
pubblica del nodo. Se questa opzione non è specificata, si ricerca il file
(nella directory locale) con il nome public.key.portnum, dove portnum
è il numero della porta di riferimento (implicit port) del nodo. Se questo
file non dovesse essere presente si utilizza una chiave di default.
- keypriv privfile Analogamente al precedente, specifica però una chiave privata. Il file
cercato (se non presente tale opzione) sarà quindi private.key.portnum,
con lo stesso significato visto in precedenza.
- policy policyfile Specifica il file contenete un programma che descrive la politica di
mantenimento della “sicurezza” nel nodo (node’s security policy).

Parte I, Sezione 2 PLANet26
Descrizione del file di interfaccia:
(denominato, nella synopsis, ifc_spec_file)
Il file di interfaccia descrive la struttura base dello strato di link (link layer), così come pland
dovrebbe utilizzarlo. In termini generali, questo file consiste in una lista di interfacce (devices)
che possono essere (nel caso di Ethernet) o rappresentare (nel caso di IP) le interfacce di rete
(network interfaces) che sono utilizzate da pland. Viene specificata, per ogni interfaccia, il suo
nome (identificativo), il tipo (ethernet o ip), l’indirizzo di rete ed un’opzionale lista di nodi
adiacenti. Tale lista di nodi adiacenti (neighbors) è usata per simulare il broadcast (diffusione di
pacchetti a tutti i “vicini” del nodo trasmittente). Piuttosto che addentrarci nella descrizione
delle specifiche lessicali e della grammatica26, si è ritenuto essere più utile fare un esempio
concreto della costruzione del file di interfaccia:
3ip0 ip archimede:3328 archimede:3332, leibniz:3328ip1 ip archimede:3329 fermat:3330eth0 ethernet archimede:3330
Questo file specifica che il nodo pland ha tre interfacce (indicato nel numero posto nella prima
riga), queste hanno i nomi: ip0, ip1, eth027 (indicati nella prima parola di ogni riga, oltre la
prima); le prime due interfacce sono di tipo IP, la terza è di tipo Ethernet (indicato nella seconda
parola di ogni riga: ip / ethernet). La parola posta come terzo “campo” della singola riga,
specifica il nome dell’interfaccia del nodo in questione (nome identificativo della macchina –
che deve essere conosciuto nel file hostfile- seguito da un numero –valido- di porta; come già
descritto quando si è parlato degli indirizzi, in questa stessa sezione).
Segue (nella riga) una lista di nomi identificativi di nodi della rete raggiungibili direttamente (o
meno) dal nodo in esame (del quale stiamo descrivendo il file di interfacciamento). Per
maggiore chiarezza e per avere comunque una visione complessiva, sintetica ed immediata di
quanto ci siamo sforzati di spiegare, segue adesso uno schema grafico rappresentante
l’interfacciamento prima descritto:
26 Qualora si rendesse necessario si può consultare l’articolo [5]: “pland: The PLAN ActiveRouter”. Per inciso, non posso che consigliarne una anche breve lettura, sia pur superficiale, per avere unavisione generale più completa e chiara.27 Per quel che riguarda il nome delle interfacce Ethernet, è bene osservare che questo –a differenzadi quanto avviene per il nome delle interfacce di tipo IP- non può essere scelto casualmente ma deverispecchiare il nome di un’interfaccia Ethernet conosciuta dal sistema (può usarsi il comando ifconfig (inLinux), per determinare nomi validi delle interfacce). Altra osservazione che bisogna fare in relazione alleinterfacce di tipo Ethernet è che, per poter accedere a queste, pland deve essere “lanciato” comesuperuser. Faccio notare qui che, nel progetto che ora viene presentato (la mia D Q Q L H), non vengonoutilizzate interfacce Ethernet ma solamente di tipo IP.

Parte I, Sezione 2 PLANet27
rappresentazione grafica dell’interfacciamento descritto dal file precedemente visto
Si è accennato (nella nota 26) al fatto che il nome di ogni interfaccia di tipo IP può essere scelto
a piacere, senza particolari attenzioni. Bisogna sottolineare però la presenza di un’eccezione,
dovuta al nome lo che è riservato e –quindi- non utilizzabile (esso identifica la speudo-
interfaccia locale; una sorta di “auto-anello” virtuale nella rappresentazione grafica di prima).
Qualora non si specifichi nessun valore come numero di porta, viene considerato
automaticamente quello della porta di riferimento (indicato nell’opzione –ip).
archimede
archimede leibnizfermat
3328
3329
3330
33283332
3330

Sezione 3
PLANPacket Language for Active Networks
Introduzione
La versione 3.1 del PLAN (quella utilizzata in questo progetto) è implementata in Ocaml,
versione 1.07. Le motivazioni di questa scelta sono già state accennate nella sezione precedente,
in relazione al paragrafetto D (“Dettagli implementativi”) ma possiamo riassumerle qui di
seguito in due soli punti:
1. L’implementazione con questo linguaggio permette una completa indipendenza dalla
macchina ed un semplice caricamento/scaricamento di codice (che risulta essere qualità
indispensabile per il caricamento dinamico delle estensioni attive).
2. Il codice sorgente OCaml è liberamente disponibile.
La versione precedente (PLAN 2.2) era scritta in Java (ed una sua estensione, Pizza), a questa si
è già fatto cenno (come pure dei motivi che hanno concorso a scegliere poi OCaml come
linguaggio per la versione successiva)1.
PLAN è un semplice linguaggio di programmazione funzionale, basato sulla natura
stessa del concetto di lambda calcolo2, con l’aggiunta di primitive per esprimere la valutazione
remota.
1 Si potrebbe rileggere (o leggere, a seconda della pazienza e della volontà del lettore) la nota 21nella sezione precedente (la 2).2 Si rimanda, non volendo essere eccessivamente pedandi nella spiegazione di ogni termineincontrato, a testi di supporto quali possono essere tutti quelli relativi a linguaggi funzionali, ad es: LISPo ML, per i quali citiamo rispettivamente:- D.Touretzky: “Common Lisp”, Zanichelli, Bologna, 1991- [8] R.Harper: “Introduction to Standard ML”, School of Computer Science, Carnegie Mellon
University, Pittsburgh, 1993

Parte I, Sezione 3 PLAN29
I programmi PLAN possono invocare alcuni servizi3, che sono elencati in librerie di funzioni
residenti sul nodo attivo.
Risorse limitate
Una caratteristica molto importante del linguaggio, che forse potrebbe essere considerata come
una forte limitazione alle sue potenzialità, è che ad esso sono fornite risorse limitate.
E le risorse sono limitate a proposito di due aspetti:
1. A tutti i programmi PLAN è assicurata la terminazione, limitando le risorse consumabili
in ogni singolo nodo attivo.
2. Le applicazioni PLAN sono limitate da una scorta massima iniziale (fornita al momento
dell’iniezione nella rete) di risorse (resource bound; possiamo fare riferimento al formato
del pacchetto PLAN, già analizzato nella sezione precedente) che limita la possibilità di
“girare” all’interno della rete (evitando, ad esempio, che un pacchetto -entrando in un
ciclo- vi possa rimanere indefinitamente, mantenendo in tal modo sempre occupati taluni
percorsi, con una conseguente degradazione delle prestazioni dell’intera rete).
Pacchetti PLAN
Per essere valutato, un programma PLAN è incapsulato in un pacchetto, iniettato all’interno
della rete attiva, e poi valutato. Come risultato della valutazione, il pacchetto potrebbe creare
altri pacchetti (“figli”) che hanno la possibilità d’essere valutati in altri nodi della rete.
A. Un programma PLAN4 può pensarsi suddiviso in due parti:
• Codice Consiste in una serie di definizioni che legano nomi ed astrazioni;
queste astrazioni hanno la forma di funzioni, valori ed eccezioni.
3 Riguardo ai servizi si parlerà con maggiore sistematicità nel seguito della stessa sezione.Anticipiamo comunque che non verranno analizzati, con lo stesso grado di dettaglio, tutti i packages diservizio a disposizione del linguaggio: maggiore precisione sarà dedicata a quelli contenenti funzioniche sono state effettivamente utilizzate nel nostro progetto, solamente accenni agli altri.4 Ci si riferisce, in realtà, non a programmi ma a chunks (code-hunks, letteralmente “pezzetti dicodice”) come già accennato nella sezione precedente. Una trattazione maggiormente organica eprecisa, ma non -comunque- esaustiva sul concetto di chunk può trovarsi più avanti in questa stessasezione…

Parte I, Sezione 3 PLAN30
• Invocazione Consiste in chiamate a funzioni (function calls) e relativi argomenti
(bindings). Queste saranno valutate (potenzialmente anche in nodi
diversi da quello della chiamata, qualora se ne richiedesse una
valutazione remota) solamente dopo che gli argomenti siano stati tutti a
loro volta valutati (passaggio che avviene all’atto della chiamata della
funzione e non alla sua valutazione)
Il PLAN adotta infatti una semantica che permette esclusivamente
passaggi per valore dei parametri (call-by-value semantics).
Per rendere più chiaro il concetto espresso ci si avvale subito5 della definizione di chunk,
concetto essenziale nella logica della programmazione PLAN:
chunks
I chunks sono costrutti di programmazione PLAN comprendenti6 un segmento di codice
(code segment) ed una chiamata a funzione (suspended function call). Provvedono a
supportare l’incapsulazione ed altre tecniche di programmazione di pacchetti.
Come già menzionato (nella sezione precedente), i chunks hanno tre componenti:
1. codice effettivo (in linguaggio PLAN).
2. funzione di “ingresso” (entry-point function) al codice.
3. collegamenti (bindings) con i parametri di tale funzione.
Un chunk può essere –per semplicità- visto come una tradizionale chiamata a funzione,
nella quale però gli argomenti sono stati assemblati ed il codice è parte integrante della
chiamata stessa. Quando un pacchetto PLAN giunge al suo nodo di destinazione, si
accede al codice mediante la sua funzione di ingresso (entry-point function), chiamata con
i parametri forniti. L’aspetto che riveste di maggiore potenzialità i chunks, è che essi sono
facilmente gestibili nell’ambito della programmazione stessa: infatti la sintassi
| f | (expr-1, … , expr-n)
è un’espressione di tipo chunk che crea un nuovo chunk (si perdoni il gioco di parole).
Intuitivamente, la barretta verticale ( | , pipe) individua la parte dell’espressione la cui
5 E non in seguito, facendone una trattazione più organica e completa, come in realtà era statoinizialmente ipotizzato e previsto.6 Come si sarà già intuito!

Parte I, Sezione 3 PLAN31
valutazione deve essere posticipata (la chiamata a funzione stessa, ovviamente).
Specificatamente, il chunk creato consiste nello stesso codice attualmente in esecuzione,
nella funzione di accesso f e nei collegamenti7 ai valori (value) ottenuti a seguito della
valutazione delle espressioni poste come argomenti (expr-1,…,expr-n).
Il chunk può essere adesso manipolato, copiato, passato come argomento oppure –da
notare con particolare attenzione- può apparire come bindings in altri chunks (in realtà
tale incapsulazione di un chunk in altri chunks rappresenta un meccanismo chiave in tutta
la programmazione PLAN). Oltre ad essere trattati come dati, il principale aspetto di un
chunk è ovviamente quello dell’esecuzione: il servizio eval effettua tale valutazione
mediante il caricamento (loading) del segmento di codice e l’invocazione della funzione
d’accesso (entry-point function) con i suoi argomenti.
Solamente a titolo di completezza8 accenniamo al fatto che è possibile “tradurre” il
chunk in una rappresentazione concreta (del tipo stringa di bit) mediante file di tipo blob.
Un esempio dell’incapsulamento dei chunks potrebbe essere il seguente (per quanto
stupido possa sembrare).
Si considerino le due funzioni così definite:
Supponiamo adesso la chiamata
viewIsZero (3,eval ( |isZero| (3) ))
ed osserviamo lo schema seguente.
7 Sicuramente renderebbe molto più il termine inglese binding, che –come per altri terminispecifici in lingua anglosassone- non sempre possiamo evitare di inserire nel testo (se non altro asupporto dei termini italiani, per una più immediata comprensione).
8 E non mediante una trattazione specifica. Si tratta infatti di un aspetto non semplice, inrelazione al quale si preferisce non entrare troppo in dettaglio (anzi non entrarvici proprio), anche invirtù del fatto che il progetto D Q Q L H non sfrutta le funzionalità fornite (non utili ai fini delraggiungimento degli obbiettivi preposti).
fun viewIsZero (numero :int, thisIsZero :bool) :unit=
(print (“il numero “^toString(numero));
if thisIsZero then print (“è zero”) else print (“non è zero”) )
fun isZero (numero:int):bool= if numero=0 then (true) else (false)

Parte I, Sezione 3 PLAN32
B. Un pacchetto PLAN consiste in un programma PLAN che è eseguito su un router attivo.
Oltre al codice, il pacchetto contiene diversi campi aggiuntivi9.
C. Un’applicazione PLAN è composta da una serie di pacchetti PLAN che, insieme,
formano un task. Questa è differente da una comune applicazione host10, che è un
programma che viene eseguito in un nodo terminale della rete e può essere scritto in
linguaggi differenti dal PLAN (linguaggi ad alto livello, non orientati ai pacchetti; come
Java o C, ad es.). Nel caso più semplice, un’applicazione PLAN è definita nell’iniezione
di un pacchetto nella rete e nella conseguente “progenie”11; è però possibile che tale
applicazione collabori con applicazioni host per completare un task.
9 Di questo si è già approfonditamente parlato nella sezione precedente, proprio nella partededicata ai pacchetti PLAN. Allora si è presentato l’argomento corredando la descrizione e l’analisi conuno schema grafico che, per quanto semplicistico, riassume bene tutti i concetti rendendoliimmediatamente concreti e visibili.10 Per avere più chiaro il concetto di applicazione host, si rimanda al prossimo paragrafetto.11 Con questo termine si vuole indicare l’insieme dei pacchetti generati (ed iniettati all’internodella rete) da quello in oggetto.
code
entry pnt
bindings
viewIsZero
fun viewIsZero (……
numero = 3
thisIsZero = fun isZero (……code
entry pnt. isZero
bindings numero = 3

Parte I, Sezione 3 PLAN33
Modello di valutazione (evaluation model)
Per comprendere come viene valutato un programma PLAN, è assolutamente necessario
conoscere dove viene valutato (ossia conoscere il suo ambiente di valutazione: evaluation
environment): la rete PLAN (PLANet), descritta –grosso modo- nella figura seguente.
PLANet: ambiente di valutazione dei pacchetti PLAN (PLAN evaluation environment)
Una rete PLAN consiste in hosts, che rappresentano i nodi terminali dell’ambiente, e routers,
che formano la struttura stessa della rete (active cloud: letteralmente “nuvola attiva”). Ci si
riferisce a routers ed hosts, insieme, come ai nodi della rete.
Tutti i nodi devono essere in grado di valutare programmi PLAN (inseriti in pacchetti), gli
hosts si distinguono dai routers anche per il fatto che in essi è possibile eseguire applicazioni
host, magari come parte di applicazioni PLAN.
PLANinterpreter
+ R V W
host application
implicit port
PLANinterpreter
5 R X W H U
PLANinterpreter
5 R X W H UPLAN
interpreter
5 R X W H U
$ F W L Y H & O R X G

Parte I, Sezione 3 PLAN34
Vita di un pacchetto PLAN
• Un pacchetto PLAN inizia la sua “vita” in un host, specificatamente per mezzo di
un’applicazione host. L’applicazione –infatti- “costruisce” un pacchetto PLAN e lo inietta
nella rete attiva “consegnandolo” all’interprete PLAN residente nell’host stesso. Ciò è
fatto mediante la creazione di una porta12 PLAN (che funge da interfaccia) tra
l’applicazione e l’interprete. Tale porta, che prende il nome di porta di iniezione (injection
port) o porta di riferimento (implicit port), permette all’interprete di mandare l’output
verso l’applicazione ed all’applicazione di sottoporre nuovi pacchetti PLAN.
• L’interprete locale allora procede con l’instradare il pacchetto verso la sua destinazione
(evalDest), mediante l’utilizzo della funzione di routing (routFun), definita nel pacchetto
stesso, che fornisce il nodo, adiacente a quello in esame- verso il quale il pacchetto dovrà
essere indirizzato (rappresenta il next-hop del quale si è già più volte accennato). Lungo la
strada verso il nodo di destinazione, ad ogni passaggio (hop) da un nodo ad un suo
adiacente, le risorse (resource bound) del pacchetto vengono decrementate di una unità;
qualora si raggiungesse il limite di risorse nulle, il pacchetto verrebbe terminato.
• Quando un pacchetto PLAN raggiunge la sua destinazione, il suo programma viene
valutato:
1. In prima istanza, il codice è analizzato (parsed) secondo uno schema top-down per
registrare tutti i collegamenti dell’implemetazione di variabili e funzioni (top-level
bindings).
2. Si procede con la valutazione vera e propria, mediante la chiamata a funzione (system
call) f (a1,..,an) definita nell’invocazione.
3. Tutte le eccezioni che non si è provveduto a catturare (e gestire) nel programma
stesso, saranno gestite dall’handler designato nelle specifiche del pacchetto13.
12 Come forse si sarà già detto, per port si intende una connessione biunivoce (duplex) tra unprogramma PLAN ed un’applicazione host.13 Per questo campo, come per altri precedentemente citati (es. evalDest, routFun,…), èconsigliabile (e difatti lo si sta consigliando esplicitamente) riferirsi allo schema grafico rappresentante(non solo nelle intenzioni, spero) la struttura di un pacchetto PLAN, schema già incontrato nella sezioneprecedente.

Parte I, Sezione 3 PLAN35
Eccezioni (exceptions)14
Il PLAN consente due costrutti sintattici relativi al trattamento delle eccezioni:(per ognuno dei costrutti presentati, viene considerata una porzione di codice a titolo esemplificativo…)
• try etry handle H => ehandle
Esegue l’espressione etry.
a) H indica un’eccezione (è un’exception literal).
Se tale eccezione (H) viene riscontrata nell’esecuzione di etry, allora si procede con la
valutazione dell’espressione ehandle.
b) H non indica un’eccezione, viene vista come il nome di una variabile alla quale,
ogni eccezione sollevata durante l’esecuzione di etry, viene collegata per la seguente
valutazione di ehandle. In tal modo (evidentemente) ogni eccezione viene catturata.
es.fun divisione (dividendo:int, divisore:int): int= try ( dividendo/divisore ) handle DivByZero => ( … )
• raise H
Solleva l’eccezione H. Qualora tale espressione sia contenuta all’interno di un blocco
try…handle (specifico per l’eccezione H evocata, caso a precedente, o generico per ogni
eccezione, caso b) allora implicherà la valutazione dell’espressione ehandle.
E’ opportuno evidenziare la grande importanza che questo costrutto può avere, all’interno
di una programmazione che vuole essere semplice e lineare, per via della possibilità data
al programmatore di definire esso stesso alcune eccezioni (tramite la parola chiave
exception, usata in un contesto di definizione (let-in-end15) ).
es.
fun prova (…) : unit = let exception <H>
fun prova ( ) : unit = ( … if (…) then (…) else raise (<H>) … )
in ( …
try prova( ) handle … ) end
14 Per un elenco delle eccezioni presenti a livello di programma PLAN, così come per quellerelative alle routines di servizio (cui si accennerà successivamente nella sezione) si può fare riferimentoall’articolo:[3] Jonathan T. Moore, Michael W. Hicks, Pankaj Kakkar “PLAN Programmer’s Guide”15 Si veda nel paragrafo dedicato ai costrutti del linguaggio, più avanti nella sezione.

Parte I, Sezione 3 PLAN36
Gestione degli errori (error handling)
Ogni eccezione “alzata” da un programma PLAN può essere catturata da un costrutto
try…handle di livello superiore. Tuttavia, nel caso che l’eccezione si presenti al di fuori
dell’esecuzione del programma (come accade, ad es., se il pacchetto eccede le risorse a
disposizione prima di poter essere valutato), oppure nel caso che non venga catturata,
l’ handler (esplicitato come campo del pacchetto) viene utilizzato per la gestione. Questo è –in
realtà- il nome di una funzione che viene invocata per essere eseguita nel nodo sorgente (del
pacchetto).
Il linguaggio fornisce un handler di default: defHandler. Inoltre esiste un servizio PLAN,
abort, che produce gli stessi effetti di un handler invocato.
Costrutti e primitive del linguaggio
Passiamo adesso ad analizzare e descrivere le primitive ed i costrutti forniti dal linguaggio
PLAN. E’ questa la parte più importante (insieme a quella che segue successivamente,
relativa ai servizi forniti) per coloro che intendano comprendere il linguaggio, non solo come
impostazione generica ed astratta, ma dettagliatamente nei suoi aspetti concreti e realizzativi.
Dalla grammatica16 del PLAN è possibile estrarre informazioni sui costrutti presenti, sui tipi di
valore possibili e sulle operazioni. Analizziamo adesso i costrutti17:
16 Non si tratta di esagerazione (magari dovuta a quel vago senso di onnipotenza che sembrainvadere gli studenti prossimi agli esami); un’attenta analisi della grammatica del PLAN (cui ci si puòriferire facilmente, [1]) risulta essere davvero oltremodo utile nella comprensione del linguaggio stesso.A volte (come nel caso –pur semplice- dei costrutti) quello della grammatica è addirittura l’unico puntocui poter fare riferimento. Ammettiamo –comunque- che il suo utilizzo non risulta essere affattodifficoltoso17 Tralasciamo la descrizione (peraltro banale) degli operatori e dei tipi base messi a disposizionedal linguaggio (per questi ci si può riferire agli già citati [1] (grammatica) e [2] (guida alprogrammatore) ).Non ci si aspettino costrutti complessi; come si nota immediatamente (ad occhio) il numero (…) diquesti è molto basso e si è a livelli di semplicità estrema. E’ buona cosa, comunque, non perdere di vistadue fatti, in questo contesto, importanti:a) Il PLAN è un linguaggio funzionale, aspettarsi la potenza espressiva di un linguaggio imperativo ad
alto livello (ad es. Java, C o –perché no- Pascal) implica ovviamente orientarsi decisamente versouna delusione (per inciso faccio notare d’essere stato il primo a cadere in questo tranello, ed arimanervi invischiato).
b) Il PLAN è stato costruito secondo alcune considerazioni (già tante volte ripetute) che riassumiamoin una sola parola: semplicità (considerando il punto di vista del pacchetto, non certo quello delprogrammatore).

Parte I, Sezione 3 PLAN37
• Costrutti del linguaggio:(Per ognuno dei costrutti presentati, viene considerata una parte di codice a titolo esemplificativo.Non vengonopresi ulteriormente in considerazione i costrutti relativi al trattamento delle eccezioni, già analizzati in precedenza)
1. let <defs-list> in <expr> end
Utilizzato per la definizione di variabili o funzioni locali (valide esclusivamente
all’interno del blocco in…end).
es. fun main ( ): unit= let val dividendo : int = leggiDividendo( )
val divisore : int = leggiDivisore ( ) (* non nullo *)fun divisione (dividendo:int, divisore:int) : int = dividendo/divisore
in ( … ) end
2. if <expr> then <expr> else <expr>
E’ il tipico costrutto if-then-else, non è prevista la possibilità di omettere l’else.
es. if (divisore=0) then ( … ) else ( … )
• Primitive del linguaggio:
Le primitive fornite dal linguaggio PLAN sono molto poche e suddivisibili in due categorie,
che andiamo adesso ad esaminare:
1. primitive di rete:
Le primitive di rete (network primitives) rappresentano forse l’aspetto di maggior interesse del
PLAN, permettendo una computazione “mobile” mediante creazione e trasmissione di nuovi
pacchetti attivi.
(a) OnRemote
La primitiva base OnRemote è pressochè generale. La sua sintassi è la seguente:
OnRemote ( E, H, Rb, Routing )
di tipo chunk(già analizzato in questa stessa sezione)
ricordiamo che eventuali parametrisaranno valutati subito (all’atto dellachiamata remota)
Host di destinazione
intero. Risorse del pacchettoattuale destinate al “figlio”
servizio (non funzionePLAN) di routing

Parte I, Sezione 3 PLAN38
Il suo significato è, banalmente: valuta E in H. Viene utilizzato il servizio Routing per
determinare il persorso necessario al raggiungimento della destinazione H. Infine, il
pacchetto in oggetto (“padre”, quello che chiama la OnRemote), dona Rb delle sue risorse
al pacchetto “figlio”.
- In caso di successo, la chiamata di OnRemote implica la creazione di un pacchetto
PLAN che è trasmesso ad un host adiacente (nella direzione della destinazione H,
come da risultato della routine di instradamento (Routing) ), decrementando la riserva
di risorse del pacchetto “padre” in esame della quantità destinata al “figlio” (Rb).
- In caso di insuccesso, verrà evocata un’eccezione.
(b) RetransOnRemote
Questa seconda primitiva, RetransOnRemote, è molto simile alla prima; eccetto che per il
fatto che tenta di assicurare una consegna affidabile dei pacchetti PLAN. La sintassi è:
RetransOnRemote ( Cs, K, n, H, Rb, Routing )
Tutti i chunks elencati nella lista Cs18, data come parametro, saranno trasmessi verso la
destinazione H mediante la routine di instradamento specificata e con un ammontare di
18 La lista di chunks potrebbe anche essere l’insieme di tutti i frammenti di un unico chunk(troppo “grosso”). Della frammentazione si accennerà in seguito (in questa stessa sezione), quandoverrà affrontato l’argomento dei pachage di servizio.
Lista di chunk(è infatti possibile trasmetterne più d’uno)
ricordiamo che eventuali parametrisaranno valutati subito (all’atto dellachiamata remota)
Host di destinazione
intero. Risorse del pacchetto attualedestinate ad ogni “figlio”, per ogniritrasmissione.
routine di servizio (nonfunzione PLAN) dirouting
tipo Key. Chiave utilizzata per la singolasessione di trasmissione, necessaria perdistinguere i segnali di acknoledgment (ack)che giungono sul nodo
numero massimo diritrasmissioni che possonovenire effettuate (fino allaricezione dell’ack)

Parte I, Sezione 3 PLAN39
risorse pari ad Rb, per ogni chunk trasmesso. Il pacchetto viene ritrasmesso ogni secondo
fino a che si riceva un acknoledgment19 di ricezione, per un massimo di n volte.
(c) OnNeighbor
Simile alla OnRemote, con la restrizione che il pacchetto “figlio” generato debba essere
eseguito in un nodo adiacente a quello attuale. La sintassi è:
OnNeighbor ( E, H, Rb, dev )
2. iteratori di liste
Gli iteratori di liste (che ne permettono, in pratica, la scansione sequenziale) sono basati sul
costrutto fold, con possibilità di associazione a destra o a sinistra. PLAN, per adesso almeno,
non supporta polimorfismi parametrici a livello di linguaggio o funzioni di alto livello, tali
iteratori di lista sono forniti come primitive di linguaggio piuttosto che come specifiche
funzioni.
1. foldl : ( D x E → D ) x D x E list → D
Per semplicità scriviamo che il significato dell’espressione seguente è quella riportata
a fianco:
foldl ( f, a, [b1,..,bn] ) f ( f … f ( a, b1), b2) …, bn )
19 Per maggiori dettagli, ci si può riferire alla trattazione del package reliable, di seguito nellasezione. Come piccola osservazione personale, mi permetto di sottolineare –senza alcuna volontàpolemica ed esclusivamente sulla base di (non pochi) riscontri sperimentali- che ben difficilmente(leggasi pure: mai) qualche frazione di secondo risulta essere sufficiente affinché possa riceversi ilsegnale di acknoledgement e quindi interrompere la ritrasmissione dei pacchetti. Sottolineo anchel’enorme spaventoso!, e non esagero) spreco di risorse legato a tale vana ritrasmissione. Si rimanda alcapitolo delle osservazioni conclusive (sezione 6) per un’analisi specifica dei problemi riscontrati edelle soluzioni proposte (nel mio piccolo).
di tipo chunk(già analizzato in questa stessa sezione)
ricordiamo che eventuali parametrisaranno valutati subito (all’atto dellachiamata remota)
intero. Risorse del pacchettoattuale destinate al “figlio”
dev. Interfaccia versola quale si raggiunge HHost di destinazione
(adiacente a quelloattuale)

Parte I, Sezione 3 PLAN40
2. foldr : ( D x E → E ) x D list x E → E
Analogamente a prima si può scrivere:
foldl ( f, [a1,..,an], b ) f ( a1, f ( a2,…f ( an, b ) … ) )
Servizi
Una parte importante20 delle funzionalità del linguaggio PLAN proviene dalle routines di
servizio. Mentre la prima21 release del PLAN offriva solamente pochissimi servizi, quella
attuale fornisce una ricca libreria nella quale scegliere. I servizi possono essere suddivisi in
due categorie:
1. Servizi essenziali (core services), presenti su tutti i routers della rete PLAN.
2. Servizi aggiuntivi (package services). Ogni package consiste in una o più routine di
servizio a disposizione dei programmi PLAN.
Come tutte le altre funzioni chiamate in PLAN, le funzioni di servizio possono ricevere più
argomenti22 e ritornano sempre un valore23.
1. Servizi essenziali.
Non vuole essere un gioco di parole ma tali servizi sono essenziali per davvero. Non
verrà fatto qui un sistematico elenco di tutte le funzioni fornite24 ma si provvederà
comunque (altrimenti sarebbe inutile l’intera sezione presente) ad analizzare quelle
funzioni che sono sembrate25 particolarmente interessanti ed utili.
20 Per quanto finora visto (e soprattutto per quello non visto) ci si può attendere che tale parte“importante” lo sia per davvero (vista la particolare “leggerezza” del linguaggio in sé). In effetti non èpraticamente possibile scrivere il codice di un’applicazione non banale (è sufficiente che sia non banaleappena un pò) senza utilizzare routines di servizio. Questo, per adesso solo un’aspettativa (ed unasperanza) diverrà evidente nel corso del presente paragrafo e –forse ancor di più- nell’ambito delleosservazioni conclusive sul linguaggio (sezione 6, parte III).21 Non ci si riferisce alla versione appena precedente; la già citata ver. 2.2 (quella scritta in Java)ha infatti circa le stesse routines di servizio presenti nella ver. 3.1 (adottata per il progetto D Q Q L H ).22 Nel senso stretto del termine: si tratta davvero di diversi argomenti; non di un unico argomento(eventualmente una tupla nella quale si facevano convogliare più dati) come accade per l’ML.23 Un servizio, così come una qualsiasi altra funzione PLAN, ritornerà una unità (unit) nel caso incui l’uscita (comunque presente) non abbia significato per il programma.24 Sarebbe troppo lungo, monotono e ben lontano dagli scopi che sono propri del nostro lavoro.Qualora lo si desideri (o qualora risulti necessario) si faccia riferimento alle guide [3] e [4].25 A detta di chi scrive, ovviamente. Non è stato effettuato un sondaggio d’opinione in merito nési è tentato di estrapolare commenti dagli articoli dei ricercatori statunitensi (sarebbe stato come cercaredi far uscire acqua dalle pietre).

Parte I, Sezione 3 PLAN41
• getRB: ( ) int
Non necessita di argomenti e ritorna un intero (come si evince dalla sintassi).
Fornisce l’ammontare delle risorse attualmente a disposizione del pacchetto. E’ un
servizio utilizzato moltissimo nel progetto, per quel che riguarda la non facile
gestione della trasmissione dei pacchetti attivi.
• getSource: ( ) host
Ritorna il nome (come host) del nodo specificato nel campo source del pacchetto.
Rappresenta il nodo che ha dato origine al più “anziano” pacchetto antenato
dell’attuale (potrebbe essere il pacchetto stesso, se non discendente da altri
pacchetti). Routine utilizzata in D Q Q L H per tutte quelle funzioni che
necessitavano d’essere poste in relazione direttamente con il nodo iniziale
(quartier generale, nel progetto).
• getSrcDev: ( ) dev
Ritorna l’interfaccia dalla quale il pacchetto è arrivato sul nodo in esame. Viene
utilizzata nel programma che presentiamo per individuare il nodo dal quale la
capsula (giunta su un router qualsiasi) proviene.
• getNeighbors: ( ) (host x dev) list
Utilizzando la tabella di routing di default, questa funzione determina i nodi
adiacenti (neighbors)26 di quello analizzato. Tale routine è stata estremamente
utilizzata nella stesura del codice che presentiamo (basato proprio
sull’esplorazione della rete attiva mediante propagazione delle capsule spia ai
“vicini” di ogni nodo)27.
• abort: chunk unit
Funzione molto particolare: comporta l’interruzione immediata dell’esecuzione
del programma di un pacchetto e la trasmissione di una routine (per trattare tale
situazione) al nodo sorgente (definito nel campo source del pacchetto stesso). Ad
una chiamata di abort –dunque- l’esecuzione del pacchetto viene terminata, ed
uno speciale pacchetto viene creato e trasmesso al sorgente. Quando vi arriva,
26 Per nodo adiacente si intende, come probabilmente risulta intuitivo, quel nodo che risulta –nella rete fisica- connesso a quello in esame mediante un link diretto27 Per ulteriori ragguagli, si rimanda (ovviamente) alla seconda e terza parte della presentedocumentazione.

Parte I, Sezione 3 PLAN42
setta a zero il suo resource bound e valuta il dato chunk (passato come
parametro)28.
• eval: chunk D
Sottrae una unità dall’ammontare attuale delle risorse del pacchetto, e valuta il
dato chunk. L’ambiente viene prima riinizializzato allo stato base (di default) del
nodo stesso; il risultato della valutazione del chunk è ritornato dalla eval. E’
importante sottolineare29 come tale funzione potrebbe essere utilizzata per
simulare la ricorsione.
2. Servizi aggiuntivi (package services)
Vi sono dieci package di servizio messi a disposione con l’attuale versione del PLAN.
Sono estremamente diversi tra loro e forniscono un vasto ventaglio di tipologie di
funzionalità, di queste verranno citate e commentate solo quelle ritenute
maggiormente utili alla comprensione del codice allegato.
I dieci package sono i seguenti:
- install Permette l’installazione di nuove routines di servizio ( eventualmente
scritte dall’utente stesso, in OCaml) mediante caricamento dinamico.
Si è forse dimenticato di dire in precedenza –cosa che pure ha
importanza non certo trascurabile- che è data possibilità ad un
qualunque programmatore di scrivere alcune proprie routines di
servizio (in OCaml, ribadiamo) che potranno successivamente essere
“caricate” sul singolo router (uno per volta) proprio mediante l’unica
funzione del package install: la installServices. Questo, come sembra
evidente, rende estremamente interessante la prospettiva di
costruzione di programmi, siano pure complessi, in PLAN; cosa
niente affatto scontata al solo esame del linguaggio30.
28 Se si dovesse essere interessati alla programmazione in linguaggio PLAN, o anche persemplice curiosità, si consiglia di fare riferimento al già citato (più volte) [3] (programmer’s guide)dove possono trovarsi (come è lecito attendersi) maggiori, e più dettagliate, informazioni.29 Lo si farà ancor meglio in seguito, nelle osservazioni conclusive (sezione 6), quando verrannoanalizzate le potenzialità ed i limiti del linguaggio PLAN in toto. Particolare attenzione sarà riservataanche alla ricorsione…30 Anche adesso non possiamo non ribadire che tutti questi concetti sul linguaggio PLANpotranno essere meglio valutati se inseriti in un contesto d’analisi più ampio (ci si riferisce nuovamentealla sezione 6, parte III, osservazioni conclusive)

Parte I, Sezione 3 PLAN43
- port Questo package provvede a rendere disponibili i mezzi perché un
programma PLAN possa interagire con delle applicazioni host.
Tutte le routines presenti, si basano sul concetto di port che si ha nella
rete PLANet: una port è una connessione bidirezionale (duplex) tra un
programma PLAN ed un’applicazione host. L’interfaccia verso il
router attivo può ricevere i pacchetti dalla rete, mentre l’interfaccia
verso l’applicazione può ricevere output in formato numerico,
relativamente al servizio utilizzato.
schizzo schematico di una porta (tra programma PLAN ed applicazione)
- resident Dati residenti sono quelli che permangono sul router anche dopo che il
programma PLAN che li ha creati è terminato (oppure ha abbandonato
il nodo per proseguire la propagazione all’interno della rete). Questa
caratteristica è stata aggiunta al PLAN per permettere ai programmi
una agevole strategia di attraversamento ed esplorazione della rete,
ossia proprio per rendere possibile la realizzazione di progetti come
quello che si sta presentando.
I dati residenti sono memorizzati in una tabella sul router, indicizzata
mediante un nome identificativo del dato ed una chiave di sessione. La
chiave serve essenzialmente a differenziare dati memorizzati da
differenti istanze della medesima applicazione PLAN.
esempio di una tabella di dati residenti in un determinato nodo
activerouter
hostapplication
port
keyidentifier data
“marking” <key> Observed
(“marking”, <key>) “ links” <key> [ 1; 3; 1; 2; 2 ]
“marking” <key2> Not Observed
(“marking”,<Key2>)
rappresenta evidentemente undato relativo ad una diversasessione di esplorazione (se diquesto si tratta)
timeout
300
300
300

Parte I, Sezione 3 PLAN44
Un potenziale pericolo, insito nel fatto stesso di permettere la
memorizzazione di dati residenti, è quello che programmi PLAN
potrebbero (anche se solo inavvertitamente) lasciare grandi quantità di
dati su un router, continuando così a consumare memoria anche dopo
la loro stessa terminazione. Per ovviare a questo problema, ogni
singolo dato residente ha associato un tempo di permanenza sul nodo
(timeout). Questo tempo è settato dall’utente all’atto stesso della
memorizzazione del dato, ma non può comunque superare i 300
secondi (5 minuti)31.
Sembra opportuno almeno citare qualche funzione di questo package
(cui si è fatto massicciamente ricorso nell’ambito della stesura del
codice di D Q Q L H), a titolo di esempio:
• get: (string, key) D
Riporta il valore memorizzato sul nodo che può essere individuato
mediante mediante la stringa (identifier) e la chiave della sessione.
Qualora non esistesse un valore in corrispondenza di questa
indicizzazione, verrebbe presentata un’eccezione di NotFound32.
• put: (string, key, D, int) unit
Inserisce una nuova riga nella tabella dei dati residenti sul nodo in
esame (del tipo di quella schematizzata prima), associando al dato
D (terzo argomento) la coppia per la identificazione (string e key).
Il quarto argomento specifica il numero di secondi che al dato è
permesso di “vivere” (come residente sul nodo, allo scadere di
questo timeout, il dato verrà automaticamente cancellato).
31 Tale soluzione appare forse eccessivamente grossolana: qualora fosse necessario conservaredati per un tempo più lungo, deve essere infatti l’utente stesso a prevedere (nel suo programma) unasorta di refreshing dei dati memorizzati sui vari nodi (mediante una nuova memorizzazione).I datiresidenti pongono anche altri problemi, oltre questo del tempo massimo di memorizzazione, qualequello –ad esempio- della necessità di una forma di “autorizzazione alla scrittura”; una analisi piùprecisa sarà condotta nella sezione 6 (osservazioni conclusive).32 Una delle eccezioni più ricorrenti durante la stesura del programma, il testing ed il debugging.

Parte I, Sezione 3 PLAN45
- RIP Implementa un protocollo di routing distribuito, basato sul protocollo
standard RIP33. Mette a disposizione del programmatore funzioni per
l’interazione diretta con la tabelle RIP stesse.
- arp Questo package, non utilizzato affatto nella stesura della tesina,
fornisce servizi necessari all’implementazione di strategie di
risoluzione di indirizzi (address resolution). E’ basato sullo standard
Address Resolution Protocol (ARP).
- flow In qualche applicazione, potrebbe essere utile (o intelligente)
instradare i pacchetti secondo una strategia particolare, comunque
diversa da quella di default, basata sul numero minimo di nodi da
attraversare (come già visto nella nota 33). La metrica basata sul
numero degli hop tende ad approssimare la latenza dei pacchetti nel
loro percorso; applicazioni che richiedono un’ampia larghezza di
banda dovrebbero però essere instradate secondo una metrica che
tenga in considerazione anche questo concetto (ben venga una strada
“più lunga” che consenta però una larghezza di banda superiore).
Questo package fornisce routines di servizio atte alla “creazione” di
nuove metriche e nuove strategie di instradamento.
33 Come si era promesso nella sezione precedente, diamo adesso un brevissimo cenno allastrategia di instradamento basata sul protocollo RIP (tale nota non vuole –ovviamente- essereconsiderata una trattazione sistematica dell’argomento, e neanche una semplice introduzione, masolamente quello che realmente rappresenta: un piccolissimo inciso finalizzato a dare appena ladefinizione del concetto di RIP, per poter avere –almeno lontanamente- idea del suo significato):Quella del RIP è una delle possibili stategie di “visione” della rete, necessaria per effettuarel’instradamento dei pacchetti. Si basa sulla trasmissione (da un nodo ai suoi vicini) delle tabelle dirouting del nodo stesso (inizialmente tale tabella è formata solamente dall’elenco dei vicini “fisici”),durante questa propagazione le tabelle vengono continuamente aggiornate (un nodo che riceve la tabellada un suo vicino, aggiorna la sua con i nuovi dati). In questo modo ben presto tutte le tabelle saranno“stabilizzate” (non sarà necessaria alcuna modifica) e la loro propagazione, che viene effettuatasolamente al presentarsi di modifiche, finisce col cessare (si ripresenta –appunto- in presenza dimodifiche nella rete, che possono essere –ad esempio- il crash di un router o il collegamento di unnuovo nodo).L’instradamento viene effettuato adesso consultando queste tabelle (che presentano l’elenco di tutti inodi della rete (o di una delimitata regione di questa), la distanza (in numero minimo di nodi daattraversare) da quello ove la tabella risiede ed il nodo adiacente a questo, nella direzione diraggiungimento della destinazione (secondo il cammino con il numero minimo di passi)).

Parte I, Sezione 3 PLAN46
- dns Questo package contiene una sola funzione (getHostByName), che
implementa la risoluzione dei nomi (nome del nodo – nome “fisico”).
Il mapping viene effettuato su una tabella statica, generata a partire da
un file specificato al momento dello startup del nodo34.
- frag Fornisce un’insieme di servizi usati per frammentare i programmi
PLAN in piccoli pezzi (di dimensione scelta) per poi riassemblarli alla
destinazione remota della trasmissione. Questo servizio, inizialmente
non considerato per la codifica del progetto D Q Q L H, si è reso
necessario assolutamente necessario per il fatto che la rete presenta un
limite massimo nella dimensione dei pacchetti trasmettibili (si tratta
del Maximum Transferable Unit, MTU, già citato in “programmi
come dati”, nella sezione precedente).
Schematizzazione del concetto di MTU, soluzione mediante frammentazione
- reliable Questo package fornisce al programmatore una serie di funzioni
utilizzabili congiuntamente alla primitiva RetransOnRemote (già
analizzata in precedenza), per assicurare una trasmissione quanto più
“sicura” ed attendibile dei dati/programmi PLAN.
Tra le funzioni presenti, analizziamo quella che è stata utilizzata
all’interno del progetto D Q Q L H:
source destination
+

Parte I, Sezione 3 PLAN47
• sendAck: (chunk, key, int) chunk
Costruisce un pacchetto incapsulandovi il chunk e la chiave
ricevuti come parametri. Il chunk viene “racchiuso” in un altro
chunk che consente la trasmissione, al nodo di provenienza (sent
back), di un segnale di ack (= trasmissione effettuata con
successo, pacchetto ricevuto). Tale segnale di ack è quello
necessario all’interruzione della sequenza di spedizione dei
pacchetti (della RetransOnRemote, se ne è già fatto cenno in
questa stessa sezione).
- csum Riguarda la strategia di incapsulazione.
- authproto Riguarda i meccanismi di sicurezza (security)35.
- security Anche questo package contiene routines inerenti ai meccanismi di
salvaguardia della sicurezza35.
34 Si tratta del file hostfile, già mensionato come opzione dell’istruzione di “lancio” del nodoattivo (costruzione effettiva di una rete PLAN, nella sezione precedente).35 Dei quali si è scelto, come più d’una volta già detto, di non parlare. V.nota 10, della sezioneprecedente, per i riferimenti bibliografici essenziali.

3DUWH�6HFRQGD
A N A L I S I D E LP R O G E T T O S O F T W A R E
$QDO\VLV

Sezione 4
Analisi del problemaAnalysis
Descrizione
Descrivere il problema che si è voluto affrontare non è affatto cosa difficile:
Avendo a disposizione una rete attiva sconosciuta è necessario stabilire quanti sono i routers
presenti nella stessa; si tratta quindi, semplicemente, di contare i nodi non terminali di una rete.
Per rendere immediatamente visualizzabile il problema, viene presentata questa piccolissimarete (nella quale i routers presenti –da contare- sono cinque)
Vincoli
I vincoli presenti in questo problema sono essenzialmente riconducibili all’unico concetto
riassunto nell’aggettivo “sconosciuta”, or ora attribuito alla rete in esame: della rete non si
conosce assolutamente nulla (questo fatto, vedremo meglio nella sezione seguente, ha limitato
fortemente il grado di efficienza potenzialmente associabile al programma di esplorazione

Parte II, Sezione 4 Analisi del problema50
sviluppato). Un vincolo realizzativo imposto è invece quello di non lasciare alcun dato sui nodi
attraversati1 (se si dovesse –considerando un esempio che si vedrà essere ben poco lontano dalla
realtà- scegliere di marcare in qualche modo i nodi stessi, tali machi dovranno essere
necessariamente cancellati prima della terminazione del programma) al fine di non introdurre
“impurità” sui nodi della rete in oggetto.
Sembra essere evidente che il programma debba funzionare in maniera del tutto
trasparente nei confronti di eventuali altri utenti della rete, nessun dato deve rimanere ad
occupare memoria dei nodi, nessuna riduzione delle prestazioni deve essere avvertita (ciò
implica che l’esplorazione avvenga con il minore sfruttamento possibile di risorse, quali tempo
di CPU, memoria nelle singole macchine, tempo di trasmissione e larghezza di banda nelle
connessioni tra i nodi).
Per rendere possibile tutto questo, l’algoritmo ideato deve risultare efficiente,
leggero, lineare (quanto possibile) ed affatto “incline” all’utilizzo di soluzioni laboriose,
impegnative (in termini di sfruttamento di risorse) e grossolane.
Difficoltà
Non sarà sfuggita la scelta del termine “semplicemente” (che si è pensato bene di sottolineare)
utilizzata nella definizione del problema affrontato, in relazione al grado di compessità dello
stesso. In effetti, contare non appare proprio come la più difficile delle operazioni che possono
essere effettuate su computers, e non si può certo pensare di contestare una così cristallina e
condivisibile posizione. Neanche sarebbe però corretto, non mensionare alcuni piccoli “scogli”
presenti nel problema stesso.
Tralasciando di affrontare2 questioni, pure affatto secondarie, quale potrebbero essere –ad
esempio- quella di dover scrivere il codice in un linguaggio funzionale interpretato3, oppure di
dover barcamenarsi tra sistemi operativi cui mai si ha avuto contatto4 e documentazioni spesso
particolarmente ostiche ed inaccessibili5, si può puntare direttamente su un punto.
1 Che (si suppone almeno…) sono tutti i nodi della rete.2 Ma non di citare…3 Dimenticando quindi quei begli ambienti visuali per la programmazione ad alto livello basata sulinguaggi imperativi, ben conosciuti nel loro approccio metodico alle più svariate situazioni, ricchi difunzioni e procedure di libreria che permettono di effettuare diversissime tipologie di operazioni,…4 Alludo a sistemi UNIX. Il fatto che questi fossero inizialmente estranei è imputabile, da un lato,allo stesso autore della presente tesina e, dall’altro (me lo si consenta), ai programmi universitari chesembrano non tenere in considerazione aspetti fondamentali del panorama informatico mondiale (presentee futuro).5 E non solo per il fatto (comunque per nulla trascurabile, purtroppo per me) d’essere scritte (comedel resto sembra essere decisamente ovvio !) in lingua inglese.

Parte II, Sezione 4 Analisi del problema51
Questo punto, di convergenza della grande maggioranza delle difficoltà incontrate, è
relativo all’ambiente di lavoro: le reti attive.
Cosa siano le reti attive e come funzionino, si è già avuto modo di osservare (ed
analizzare; anche con –si spera- sufficiente dettaglio) precedentemente6, ma la comprensione ed
assimilazione di tutti i dettagli concernenti le potenzialità delle reti stesse e del linguaggio di
programmazione delle capsule7, ha richiesto parecchio impegno, forse maggiore di quello che
potrebbe trasparire dalla presentazione che stiamo portando avanti.
6 L’intera prima parte (che consta di tre sezioni) della presente documentazione è stata dedicataall’introduzione alle reti attive, alla rete attiva PLANet (considerata nel progetto) ed al linguaggio diprogrammazione PLAN.7 Processo che, si può immaginare, non è certamente terminato né mai, credo, possa dirsi tale.

Sezione 5
Analisi dell’algoritmo di risoluzione ideatoAlgorithm
Introduzione
Bisogna ammettere che la stesura dell’algoritmo ha presentato notevoli difficoltà e la
sua versione ultima (quella che si andrà adesso a descrivere con particolare attenzione)
differisce, pur in modo non sostanziale, da quelle precedenti.
I motivi principali, sia delle difficoltà incontrate, che della necessità di effettuare
modifiche all’algoritmo stesso, sono riconducibili essenzialmente a due punti distinti:
a) Da un lato, all’iniziale mancata comprensione (nella sua globalità) delle potenzialità e dei
limiti del linguaggio di programmazione utilizzato (cosicché alcune delle funzionalità
inizialmente previste non sono state poi concretizzate, proprio perché di difficile –qualora
non addirittura impossibile- realizzazione pratica, mentre –di contro- altre scelte si sono
potute introdurre (e realizzare), anche con estrema semplicità)1.
b) Dall’altro (lato) alla condizione di pura sperimentazione in cui tale progetto si inserisce.
Questo aspetto, cui si è già fatto cenno nella prefazione, implica una mancanza di
conoscenza pressocchè assoluta dei meccanismi di funzionamento della rete attiva
considerata.
1 Per non fare discorsi privi di riscontri effettivi (che ricadrebbero quindi in elucubrazioni prive difondamento scientifico, per fortuna necessario nel campo in cui questo progretto vuole inserirsi), sembraopportuno considerare almeno un esempio, a supporto di quanto affermato (adesso e nel puntosuccessivo). Questo verrà fatto, con puntigliosa attenzione, lungo il corso di questa stessa sezione.

Parte II, Sezione 5 Analisi dell’algoritmo53
Diverse considerazioni, teoricamente esatte, “pulite” e lineari, si sono scontrate con
problemi pratici del tutto imprevisti (e comunque imprevedibili) relativi proprio al
funzionamento “concreto” della rete.
L’algoritmo risulta comunque completo ed il raggiungimento degli obiettivi preposti (già
brevemente descritti nella sezione precedente) può sicuramente dirsi avvenuto con successo (le
modifiche cui si accennava, lo si ripete, non hanno carattere sostanziale).
Come si è pensato di risolvere il problema?
Innanzi tutto si è voluto costruire un algoritmo di vera e propria “esplorazione”. La
finalità ultima (quella poi effettivamente realizzata e funzionante) permane pur sempre quella
del raggiungimento degli obiettivi posti nella definizione del problema1, ma la struttura
dell’algoritmo è tale da permettere, con modifiche mirate molto settoriali, una affatto complessa
(se non addirittura semplice) “riconversione” a scopi in qualche modo più completi2. In poche
parole si è effettuata una progettazione strutturalmente adatta a realizzare scopi esplorativi dalle
caratteristiche anche più ampie di un semplice conteggio.
Ci si è subito posti nell’ottica di dovere effettuare un’esplorazione il più possibile
flessibile ed esaustiva (quindi anche robusta). Perché questo potesse essere realizzato è stata
necessaria una fase di analisi del problema difficile e laboriosa, comprensiva di
approfondimenti, chiarimenti, modifiche (cui si è accennato) e continui adattamenti.
Sono state effettuate diverse scelte atte a privilegiare un aspetto (robustezza e
flessibilità) piuttosto che un altro:
• Una scelta fatta è stata quella di basarsi esclusivamente sui link che, da ogni nodo della rete,
si dipartono verso i suoi “vicini” (nodi ad esso adiacenti: “fisicamente” collegati in modo
diretto); questa scelta è stata motivata dall’intenzione di rendere l’esplorazione
assolutamente svincolata dalla natura, e dalle proprietà specifiche, della rete su cui si opera.
Inizialmente, in realtà, si era pensato di effettuare un’esplorazione di diversa concezione,
forse più “elegante” di quella attualmente presentata, ma che doveva basarsi su assunti
1 Si può fare riferimento alla sezione precedente.2 Di questo argomento, come –in genere- dell’intero ambito delle prospettive future di sviluppo, sidiscuterà con maggiore approfondimento nella sezione dedicata alle conclusioni finali sul progetto portatoavanti ed ora presentato.

Parte II, Sezione 5 Analisi dell’algoritmo54
molto specifici su strutturazioni gerarchiche ordinate presenti nella rete3. Una tale forma di
assunzione, è sembrata però eccessivamente restrittiva (e poco realistica, in considerazione
del meccanismo di “costruzione continua” cui le reti sono generalmente sottoposte;
prestandosi a qualunque genere di modifica, risulta impensabile mantenervi una sorta di
ordine gerarchico inviolabile)4 ed è stata abbandonata a favore dell’ottica di massima
flessibilità già descritta.
• Un’altra scelta effettuata, in conformità con quelle che abbiamo voluto fossero le linee
guida del progetto (presentate nella sezione precedente), è stata quella di minimizzare, per
quanto possibile, il numero delle capsule presenti nella rete. Questo al fine di rendere il più
possibile “trasparente” l’intera operazione di esplorazione, e di ridurre le probabilità di
errore relativi a disfunzionamenti eventualmente presentabili proprio a livello di rete.
La realizzazione, per seguire tale direttiva, si è indirizzata quindi verso la restrizione di un
solo attraversamento possibile per ogni singolo nodo: Ogni nodo della rete può essere
analizzato da una sola capsula e, una volta raggiunto, nessuna altra capsula può accedervi
(neanche come nodo intermedio per tentare di raggiungerne altri).
Scenario
L’ambiente a cui il progetto si apre consta di tre “attori” principali (ed unici), divisi in due
categorie in relazione alla loro tipologia:
a) Struttura fisica sulla quale si va ad operare:
In questo gruppo è presente il nodo della rete (o, meglio, le strutture ivi presenti).
b) Oggetti software:
- Capsula esploratrice (“spia”), che è quella sulla quale ricade l’intero compito
dell’esplorazione (e cui viene dedicata la quasi totalità del codice).
- “Quartier generale”, che effettua (come risulterà chiaro nell’analisi dell’algoritmo) una
sorta di supervisione dell’avanzamento dell’esplorazione stessa.
3 Si voleva cercare una suddivisione “fisica”, oltre che concettuale ed ideale, della retecompessiva, in piccole reti locali connesse via via verso livelli sempre più alti, fino a giungere ad unasorta di top-level.4 Per avere un’idea del livello di disordine potenzialmente presente su una rete (e dellaimpossibilità di garantire una strutturazione ordinata stabile) si consideri –a titolo esemplificativo-Internet.

Parte II, Sezione 5 Analisi dell’algoritmo55
Informazioni presenti
Si fornirà adesso, in una brevissima panoramica, una descrizione delle informazioni principali
(necessarie all’algoritmo, come descritto di seguito) che sono inserite negli “oggetti” che
compongono lo scenario in cui ci muove, della loro strutturazione astratta (e cenni sulla
realizzazione concreta) e del loro significato (e funzione) all’interno del progetto5.
1. Nodo della rete
Alcune informazioni associate ad ogni nodo della rete risultano essere assolutamente
necessarie per il corretto funzionamento dell’esplorazione.
rappresentazione schematizzata di un nodo della retesi può osservare sia la zona protetta da mutua esclusione che le connessioni fisiche con nodi adiacenti
5 Anche se questo, come ovvio, può essere maggiormente chiarito solamente con uncontemporaneo confronto (passo-passo) con l’analisi dell’algoritmo.
semaforo
TTLresiduo
Counter
Status
status deilinks
router
area dei datiprotetti in mutua
esclusione
W
W
P
W
K
K
parent
89 14
Observed
free

Parte II, Sezione 5 Analisi dell’algoritmo56
Tali informazioni, schematizzate nella rappresentazione grafica precedente, vengono
adesso definite:
a) Semaforo
E’ una varibile intera (funge comunque da flag: 0/1) introdotta per gestire la mutua
esclusione nell’accesso ai dati condivisi.
Tutti i campi informativi introdotti nel nodo (visualizzati in figura all’interno della
zona verde) risultano essere, infatti, del tutto generali e “globali”: ogni capsula che,
in qualsiasi modo, debba interagire con nodo in esame, deve poter aver accesso ai
suoi dati residenti (fosse pure solo per sapere se il nodo è già stato osservato da
qualche altra capsula “spia” esploratrice o meno). Ovvia, quindi, la necessità di
introdurre meccanismi atti a garantire l’effettiva mutua esclusione nell’accesso ai
dati, quale salvaguardia della integrità e consistenza degli stessi6.
b) Status
Consiste in un campo intero (utilizzato come flag: 0/1) indicante lo stato del nodo
(non osservato / osservato).
La sua introduzione è motivata, quasi esclusivamente, dalla volontà di mantenere
una sorta di “pulizia logica” (e linearità) nell’algoritmo stesso. Il suo utilizzo pratico
è, infatti, molto circoscritto (e, comunque, non strettamente necessario) proprio per
via della condizione di non lasciare alcun dato residente sul nodo (lo stato <non
osservato> non è quindi mai presente come dato fisicamente residente sul nodo
stesso)7.
c) TTL residuo
Time To Live (tempo di vita): indica la quantità di risorse teoricamente ancora
disponibili per la capsula che dovrà dipartire dal nodo per “risalire” verso
l’avamposto. Tale quantità è, come si sarà potuto certamente intuire, strettamente
legata all’algoritmo di esplorazione della rete; la sua funzione (lo scopo per il quale
è stata considerata ed introdotta) è però risultata inapplicabile per limitazioni
strettamente legate alla gestione interna della rete attiva PLAN.
6 Altri cenni sulla mutua esclusione si dovranno presentare anche più avanti nella sezione (quandoverrà affrontato il problema delle caratteristiche “avanzate” del progetto sviluppato)7 Ovviamente, se la capsula giunge su un nodo in cui non è presente il dato status (così come tuttigli altri), potrà “dedurre” di trovarsi su un nodo non già raggiunto da altre capsule.

Parte II, Sezione 5 Analisi dell’algoritmo57
Un solo cenno sull’algoritmo, per chiarire il concetto:
La capsula spia che giunge su un nodo inesplorato (fase di esplorazione), dopo aver
effettuato talune operazioni (poi meglio specificate), si propaga a tutti gli adiacenti
(cui è consentito accedere)8 suddividendo equamente le risorse (o TTL) a
disposizione. Quando (fase di rientro) le capsule lanciate ritornano al nodo in
esame, vi “scaricano” le risorse ancora a disposizione (non utilizzate), oltre ad altre
informazioni.
Schematizzazione della gestione delle risorse nell’attraversamento di un router(a): fase di esplorazione: divisione equa delle risorse tra tutte le capsule “figlie”
(b): fase di rientro, nell’ipotesi che l’ultima capsula figlia a rientrare sia quella con risorse pari a 3(cosa del tutto plausibile: rientra con meno risorse = ha raggiunto maggiori profondità = torna ultima)
osserviamo (in corsivo) come ben più efficiente sia la gestione delle risorse qualora fosse possibilerealizzare un “riutilizzo” di quelle rimanenti.
L’idea di base, tuttora pienamente valida e potenzialmente applicabile, era quella di
poter riutilizzare queste risorse (altrimenti del tutto sprecate) assegnandole alla
capsula che, ritornata per ultima, avrebbe dovuto abbandonare il nodo facendo
“rotta” verso il predecessore. Purtroppo però, l’implementazione dell’architettura
della rete PLANet non consente, a tutt’oggi, di effettuare “passaggi” di risorse da
una capsula ad un’altra (né tantomeno –ma questo appare ben giustificabile-
aggiunte arbitrarie di risorse ad una specifica capsula).
8 Si potrà meglio osservare in seguito (nella parte strettamente dedicata all’algoritmo) a qualegenere di “consenso” si fa adesso riferimento. Non bisogna spedire una capsula spia al nodo (puradiacente) dal quale essa è appena giunta, ad esempio.
100
33
33
33
3
31
3
12
31+3+12=46

Parte II, Sezione 5 Analisi dell’algoritmo58
Il dato TTL residuo, quindi, non può servire a svolgere il compito che si era, in
prima istanza, immaginato. Si è comunque voluto scegliere di non eliminare del
tutto questa informazione, per poterla eventualmente sfruttare nel caso (si spera non
eccessivamente irrealistico) di una revisione, in tal senso, della disciplina di
gestione delle risorse intrapresa in PLANet.
d) Counter
E’ un campo contenente una variabile intera. Il nome del campo, data la finalità
ultima del progetto, lascia intuire la sua importanza: è il campo cui convogliano i
risultati parziali, via via raggiunti, sul numero di routers attualmente contati in
un’area che può essere vista come facente capo al nodo in esame.
e) Links
Implementato mediante una lista, vuole rappresentare il vettore degli stati di
avanzamento dell’esplorazione nelle direzioni dei vicini. Ogni elemento di tale
vettore9 contiene informazioni relative al link cui corrisponde (la corrispondenza
viene costruita, e mantenuta, sulla base della posizione all’interno del vettore: ad
es., lo stato dell’esplorazione nella direzione del terzo vicino10 sarà individuata dal
terzo elemento del vettore considerato).
Gli stati di avanzamento dell’esplorazione possibili sono i seguenti:
0. stato di esplorazione non ancora effettuata;
1. stato di attesa: una spia è stata lanciata nella corrispondente direzione e se ne
attende il rientro con le informazioni;
2. stato di terminazione dell’esplorazione: la capsula spia lanciata ha fatto ritorno,
oppure la direzione di esplorazione non deve essere intrapresa11 (in questo caso
il link si dirà “barricato”).
9 Lo si indicherà come tale anche se, come detto, la sua implementazione effettiva è realizzatamediante una lista di interi (il PLAN non ammette array, né consente la definizione di tipi). Si avrà ancoramodo di affrontare l’argomento, persino da due differenti punti di vista:- Uno, più pratico, della costruzione di funzioni (ad-hoc) finalizzate ad adattare la struttura
realmente a disposizione (lista) con quella ideale, e più logica nel nostro contesto, (array);- L’altro, più teorico, dell’analisi complessiva e conclusiva sui vari aspetti del linguaggio PLAN
(potenzialità e limitazioni).Ci si può riferire, rispettivamente, alla sezione seguente ed alla sezione relativa alle osservazioniconclusive.10 Terzo nella lista di vicini fornita dalla routine di servizio getNeighbors.11 Come già più volte accennato, molti concetti adesso espressi potranno trovare una chiaracollocazione (ed essere compresi in modo più sistematico ed organizzato) all’interno dell’analisidell’algoritmo.

Parte II, Sezione 5 Analisi dell’algoritmo59
3. indica il link verso il nodo “padre”, dal quale si è giunti nel nodo in esame, ed al
quale ritornare le informazioni raccolte, quando la fase esplorativa termina.
Osservazione:
Si vuole fare notare che, in linea con quanto chiarito precedentemente (al momento
della definizione del problema e durante l’introduzione alla presente sezione), tutte le
strutture informative sul nodo (siano esse dati strutturati o semplici flag) cui ci si avvale
nell’esplorazione, e che –proprio per questo motivo- non possono non essere mantenute
residenti sulla memoria dei singoli nodi, saranno poi completamente eliminate: sui nodi
della rete, al termine dell’esplorazione, non resterà nessuna traccia , nessuna “impurità”
relativa alla sessione esplorativa effettuatavi.
2. Capsula spia (esploratrice)
Che la capsula esploratrice abbia necessità di poter disporre di qualche dato, magari
aggiornabile, sembra essere abbastanza intuitivo (si prenda, come esempio, il contatore
dei routers: è un dato necessario che la capsula deve mantenere). I dati questa volta non
sono però residenti su supporto fisico, ma semplici variabili interne al pacchetto.
schema riassuntivo dei dati memorizzati sulla singola spia
Key
Counter
Outpost
direction
level prec
level MAX
numero routerscontati
dir. propagazione:Esplorazione-Rientroultimo livello di
profondità raggiunto
profondità massimaraggiungibile
avamposto diriferimento
chiave della sessionedi esplorazione

Parte II, Sezione 5 Analisi dell’algoritmo60
Tali informazioni, schematizzate nella rappresentazione grafica precedente, vengono
adesso definite:
a) Key
E’ la chiave della sessione di esplorazione, necessaria per poter aver accesso a tutti i
dati residenti sui nodi, riconoscendoli relativi appunto alla propria sessione di
lavoro.
b) Counter
E’, banalmente, il numero di routers contati, che fanno capo alla spia in oggetto.
Visualizzazione della strategie di propagazione all’indietro delleinformazioni ricavate (somma del numero dei routers contati)
Dall’analisi dell’algoritmo, si può evincere chiaramente come tale variabile (e
quindi l’effettivo conteggio dei routers) entri in gioco solamente nella fase di
“rientro” delle capsule (e non nella fase, precedente, di esplorazione).
c) Outpost
Variabile di tipo host, rappresenta il nome del nodo che ha la funzione di avamposto
(base intermedia di esplorazione). E’ a questo nodo che la spia deve fare
riferimento: tutti i dati (nella fase di rientro) dovranno essere definitivamente
depositati in quel nodo (su cui viene operata un’azione di coordinamento12 da parte
del quartier generale13).
12 Si rimanda, nuovamente, all’analisi dell’algoritmo.13 Rappresenta il nodo di iniezione della prima spia (ossia il punto da dove avviene la richiestadell’esplorazione), il punto dove far confluire i dati finali, nonché il nodo che coordina, come detto,l’avanzamento dell’intera sessione esplorativa.
7(5+0+2)
52
0

Parte II, Sezione 5 Analisi dell’algoritmo61
d) Direction
Individua la direzione di propagazione della capsula, distinguendo nettamente
quindi (distinzione necessaria per la strategia scelta) tra fase di esplorazione
(ricognizione) e fase di rientro (con raccolta dei dati).
e) Level prec.
Valore intero. Memorizza il livello (inteso come distanza14 dal quartier generale)
dell’ultimo router osservato (si ponga attenzione al fatto che si parla proprio di
routing osservato, escludendo quindi sia i nodi terminali che quei routers che, pur
acceduti dalla spia, non vengono da essa “osservati”15). Il motivo dell’introduzione
di tale dato è dettato dalla necessità di non permettere ad una capsula esploratrice di
esaminare nodi (nella sola fase di esplorazione, ovviamente) che si trovino ad un
livello inferiore di quello appena precedentemente raggiunto (tale strategia, si
comprenderà meglio nell’analisi dell’algoritmo, è indispensabile per garantire il
corretto funzionamento della gestione delle basi intermedie (avamposti)).
f) Level MAX
Anche questo è un valore intero. Indica il massimo grado di profondità al quale la
spia può spingersi durante la fase di esplorazione. Oltre questo livello sarà richiesta
(al quartier generale) la costruzione di un nuovo avamposto.
14 La distanza tra due nodi, come si sarà probabilmente già accennato in precedenza, è misuratacome il minimo numero di nodi da attraversare (quindi il minimo numero di hop da effettuare) perraggiungere un nodo dall’altro. Premettiamo adesso (si consiglia di fare adesso riferimento al codicestesso) che ottenere tale quantità non risulta affatto complesso: basta semplicemente scorrere la tabella dirouting del nodo in esame (si vuole ricordare, infatti, che PLANet adotta, di default, la strategia RIP, chebasa l’instadamento dei pacchetti appunto su tale minima distanza; si può confrontare la nota 33 dellasezione precedente per un cenno sulla politica di tale tecnica di routing).15 Perché, ad es., quel dato router era già stato oggetto dell’esplorazione di un’altra capsula spia.

Parte II, Sezione 5 Analisi dell’algoritmo62
3. Quartier generale
Il quartier generale indica, secondo la nominazione che si è voluta dare ad ogni
elemento del progetto, il nodo che sta alla base dell’intera fase esplorativa. La sua
funzione, già accennata poco prima, verrà ulteriormente descritta (con maggiore
dettaglio) durante l’analisi dell’algoritmo; si può comunque intuire, dato il compito di
coordinamento cui è chiamato, la necessità di avere a disposizione alcuni dati.
Questa entità è, tra quelle esaminate, l’unica a servirsi sia di dati residenti sul nodo
(appunto quello di iniezione), sia di dati non residenti. Ciò anche a sottolineare il
duplice aspetto cui il termine quartier generale fa riferimento: uno relativo
concretamente al nodo stesso (che, si ribadisce, è quello di iniezione) e l’altro associato
alla funzione che, sul nodo, resta attiva.
schematizzazione grafica del quartier generale.nella parte azzurra sono rappresentate le risorse residenti, accedibili in mutua esclusione,
mentre le frecce rosa indicano i legami tra i vari dati
Semaforo(message)
tipo dirichiesta
livellodell’avamposto
nome (host)dell’avamposto
informazionidall’avamposto(TTLr e Count)
Key
resource bound perogni livello diesplorazione
numero routersattualmente contati
TTL residuo attualmenteaccantonato
elenco degliavamposti aperti
step di livello(per area di
esplorazione)
numero avamposti aperti

Parte II, Sezione 5 Analisi dell’algoritmo63
Sulla base della rappresentazione schematica appena fornita, passiamo adesso ad
analizzare i singoli campi di informazione:
Dati non residenti sul nodo:
a) Key
E’ la chiave identificativa della sessione di esplorazione attualmente attiva. Viene
creata proprio sul quartier generale al momento dell’iniezione della prima capsula
spia ed è la stessa chiave che ogni capsula utilizza per memorizzare (ed averne poi
accesso) i dati temporanei sui vari routers esaminati.
b) lista outpost aperti
E’ una lista di host contenente l’elenco di tutti gli avamposti che, al momento,
risultano “aperti” (ne è stata richiesta la costruzione16 ma non ancora l’eliminazione,
l’esplorazione dell’area consentita non è, evidentemente, terminata).
c) numero outpost aperti
Indica, banalmente, il numero delle basi intermedie ancora in attività. Viene
incrementato ad ogni richiesta di costruzione di un nuovo avamposto e
decrementato al momento dell’eliminazione dell’avamposto stesso. Può essere visto
anche come dato ridondante (per garantire una maggiore sicurezza) dato che
coincide sempre con la lunghezza della lista degli avamposti aperti.
d) RB per livello
E’ un dato di tipo intero. Rappresenta la quantità di risorse (resource bound, o
anche TTL) da assegnare ad ogni nuovo avamposto (o, meglio, alla prima spia
lanciata verso l’avamposto, che poi si propagherà a partire proprio da quella base).
Tale valore dovrà essere sufficiente (sarà quindi necessariamente sovrastimato) a
garantire l’esplorazione dell’intera area lecitamente analizzabile dalla spia (in
relazione al livello di profondità, cui si è già accennato).
16 E’ proprio in questo istante che il nome del nodo (richiedente la costruzione dell’avamposto)viene inserito nella lista.

Parte II, Sezione 5 Analisi dell’algoritmo64
e) level step
Indica la profondità che dovrà avere l’area esplorativa facente capo ad ogni base
intermedia. Coincide quindi con il passo di incremento del limite estremo
raggiungibile, nel passaggio da un avamposto al successivo (ad es. se tale step fosse
pari a 10, la massima profondità raggiungibile sarebbe 10, per il primo avamposto,
10+10=20, per gli avamposti seguenti, e così via…).
f) act. Count
Indica il numero dei routers attualmente contati. Inizializzato a zero, viene
successivamente aggiornato sommandovi il contenuto dei contatori parziali,
trasmessi da ogni avamposto al termine della ricognizione ad esso associata (quindi
contestualmente alla richiesta di “eliminazione” dell’avamposto stesso). Quando la
sessione esplorativa è conclusa (non vi sono più basi intermedie aperte), conterrà il
numero definitivo dei routers presenti nella rete esaminata.
g) act. TTLr
Indica il numero delle risorse (cumulate) non utilizzate (e, per quanto già detto in
precedenza, non utilizzabili)17 che fanno riferimento ai vari avamposti. Questo dato
viene raccolto, trasmesso ed aggiornato con le stesse modalità descritte per il
counter.
Dati residenti sul nodo:
h) semaforo (message)
Come quello presente in ogni router della rete, è necessario per garantire la
consistenza dei dati residenti, cui più capsule possono accedere (in questo specifico
caso –quartier generale- solo in scrittura)18.
17 Si può rileggere (qualora non se ne ricordasse il contenuto) il tratto relativo alla descrizione delcampo TTL residuo sul router, in questa stessa sezione.18 Non si può fare a meno di rinviare ancora una volta, per un approccio forse più esauriente esicuramente più completo, alla descrizione ed analisi dell’algoritmo.

Parte II, Sezione 5 Analisi dell’algoritmo65
i) tipo richiesta (flag)
Si sarà già intuito (ma diverrà probabilmente più chiaro successivamente) che
possono giungere due tipi di richieste a questo particolare nodo:
1. richiesta di creazione di una nuova base intermedia;
2. richiesta di eliminazione di un avamposto (ad esplorazione terminata).
Il flag che stiamo descrivendo serve appunto a discriminare tra le due possibilità.
j) nome outpost
Questo campo, come i due successivamente descritti, entra in gioco solo all’arrivo,
sul quartier generale, di una qualche richiesta (tra le due esaminate nel punto
precedente). Qui, la spia richiedente, memorizzerà (temporaneamente) il nome
dell’host per cui effettua la segnalazione (indipendentemente dal tipo di questa).
k) level outpost
Similmente al precedente, vi si memorizza il livello di profondità della base in
esame. Viene utilizzato quasi esclusivamente nella fase di creazione
(dell’avamposto), per poter considerare l’overhead di risorse necessario alla
trasmissione della nuova capsula spia (in modo che, iniziando la sua fase
esplorativa, questa disponga interamente delle risorse assegnate per ogni livello
(come già descritto), senza che debba, da queste, prelevarsi quella quantità
necessaria al raggiungimento dell’avamposto stesso).
l) outpost information
Su questo campo (coppia di interi) si potrà scrivere solamente al momento della
richiesta di cancellazione di un avamposto attualmente attivo. Contestualmente a
tale richiesta, infatti, su questo campo verranno memorizzate le informazioni
(numero di routers contati e TTL residuo) raccolte durante la missione svolta (e
conclusa) nell’area di pertinanenza della base richiedente.

Parte II, Sezione 5 Analisi dell’algoritmo66
Algoritmo
Dell’algoritmo studiato si sono avute già parecchie anticipazioni nel corso di questa
stessa sezione (erano, a dire il vero, necessarie per rendere minimamente comprensibile quanto
descritto). Ciò non limita però l’importanza di questo paragrafo19 né, tantomeno, l’attenzione e
la meticolosa cura che si è posta nella sua stesura.
L’algoritmo di risoluzione del problema che ci si è posti, può pensarsi suddiviso in due
parti complementari: da un lato si ha quello che può essere definito (a ragione) il cuore
dell’intero progetto, ossia la strategia di ricognizione della spia; dall’altro c’è l’algoritmo
relativo alla gestione del quartier generale che, in qualche modo, coordina l’intera missione.
A. Strategia di esplorazione
Si tratta dell’algoritmo implementato nel codice della capsula spia. Si ricordi (dall’analisi
delle reti attive)20 che questo programma viene eseguito su ogni nodo raggiunto dalla
capsula.
Operazioni di inizializzazione:
- lettura dello status del nodo raggiunto (status)- calcolo del livello di profondità a cui il nodo si trova (level)- individuazione del nodo dal quale si proviene (parent)- tentativo di settare ad “occupato” il semaforo
if semaforo settato then
if nodo è router non marcato then
if in area di esplorabilità then
{ marking dello status del nodo: Observed; inizializza lo status dei links (inserisce il parent); inizializzazione del contatore e del TTL residuo (=0); lancio capsule a tutti i vicini consentiti }
else
19 Verso il quale si sono fatti moltissimi richiami da diverse parti dell’intera documentazionepresente.
la spia si trova su un router nonprecedentemente analizzato
il semaforo è stato settato correttamente, se nededuce che fosse libero
il cui link si trovanello stato free
Parte II, Sezione 5 Analisi dell’algoritmo67
if livello inferiore del precedente then
{ barrica link verso il nodo precedente; torna indietro senza effettuare altre operazioni }else
{ marking dello stato del nodo: Observed; torna indietro; effettua richiesta di costruzione di un nuovo avamposto }
else
if il router è il predecessore (parent) ed attende il rientro della spia then
{ aggiorna i campi TTL e Count con le informazioni raccolte; aggiorna lo status dei link, barricando quello dal quale si proviene; if tutti i links sono chiusi then abbandoniamo il nodo }
else
if si è su un nodo terminale o su un router marcato da altra spia then
{ if nodo marcato da altra spia thenbarrica il link verso il nodo dal quale si è giunti;
torna al nodo precedente }
else if tutti i links sono chiusi then abbandoniamo il nodo
else ritenta l’accesso al nodo
20 Esaminate nella prima parte (sezioni 1,2 e 3) del progetto.
il livello raggiunto è oltre illimite massimo consentito
la spia è giunta su un nodo terminaleoppure su un nodo già marcato
il link nella relativa direzione sitrova ancora nello stato di wait
la spia è sul nodo padre del precedente (sta risalendoverso l’avamposto), ma non è più attesa (il link
relativo è stato già barricato)
il semaforo è stato trovato alzato (accesso nonconsentito: altra spia presente al suo interno

Parte II, Sezione 5 Analisi dell’algoritmo68
Sembra opportuno adesso focalizzare l’attenzione su un paio di punti ritenuti
particolarmente importanti (o che, comunque, necessitano di un ulteriore livello di
dettaglio):
1. procedura di barricamento
consiste nel porre a “K”21 il link in questione (quello relativo al nodo dal quale la spia
proviene), per impedire che una qualche altra capsula esploratrice possa ripercorrere (in
senso inverso, quindi verso un nodo già esaminato) la connessione stessa.
2. procedura di abbandono del nodo
Questa operazione viene effettuata dalla spia che, tornando (fase di rientro) su un nodo,
barricando il link dal quale proviene, verifica che non vi sono altri link aperti (nessuna
capsula è ancora attesa dal router in questione).
{
if il nodo da abbandonare non è un avamposto then
propagazione della spia all’indietro (verso il nodo predecessore: parent)
else trasmissione della richiesta di cancellazione dell’avamposto al quartier generale(fornendo le informazioni raccolte: TTL res. e routers contati);
cancellazione di tutti i dati residenti sul nodo stesso
}
21 Si rimanda alla parte (in questa stessa sezione) che analizza i dati residenti su ogni singolorouter.
osserviamo come, in linea con quantodetto, nessuna informazione permane
sui nodi della rete al termine dellasessione di esplorazione

Parte II, Sezione 5 Analisi dell’algoritmo69
B. Gestione del quartier generale
Si tratta della strategia eseguita sul nodo di iniezione, che resta poi quello verso il quale
convoglieranno via via tutti i dati parziali, le richieste di creazione e cancellazione di
avamposti.Ne viene fornita, è sembrato più opportuno così, una schematizzazione mediante
diagramma a blocchi:
Semaforo(per le richieste)
libero occupato
tipo dirichiesta
creazionenuovo
avamposto
cancellazioneavamposto
(area esplorata)
nessuna
ancoraavamposti aperti ?
no
silettura nomeavamposto
lettura nomeavamposto
lancio spia verso ilnuovo avamposto(definita l’area di
esplorazione) lettura informazionifornite dall’avamposto
(TTLr e Count)
aggiornamento dati(cumulativi):TTLr e Count
aggiornamentodell’elenco (e del
numero) degli avampostiancora aperti
aggiornamento elenco (enumero) degli avamposti
ancora aperti
aggiornamentodell’elenco (e del
numero) degli avampostiancora aperti
missione terminata

3DUWH�7HU]D
O S S E R V A Z I O N IC O N C L U S I V E
&RQFOXVLRQV

Sezione 6
Osservazioni conclusiveConclusions
Questa sezione è interamente dedicata ad una dettagliata analisi di talune particolarità del
progetto, o del linguaggio adoperato, sulle quali si vuole poter indirizzare fortemente
l’attenzione.
Si è pensato fosse opportuno suddividere la presente in tre parti, sulla base all’argomento
principale cui le osservazioni stesse si riferiscono; ciò non esclude, però, una marcata ed
esplicita coesione tra i paragrafi (ben presente).
A. Osservazioni sulla rete attiva PLANet
La rete PLANet sembra essere davvero una soluzione efficace ed efficiente ai problemi di
realizzazione di una rete attiva. Non sono certamente in grado di esprimere giudizi di
carattere tecnico sull’architettura di rete considerata, molte parti della sua natura (e non
certamente di trascurabile importanza) mi sono attualmente del tutto oscure1 ma , per la
lunga fase di sperimentazione pratica cui la realizzazione del progetto D Q Q L H mi ha
costretto, la mia esperienza non può che definirsi soddisfacente.
Credo comunque di poter evidenziare due punti che ritengo essere, pur per opposti motivi,
degni di nota in questo contesto.
1 Solo per fare qualche esempio, si possono considerare i problemi della sicurezza, dellaaffidabilità, delle prestazioni,…

Parte III, Sezione 6 Osservazioni conclusive72
1. possibilità di scrivere (e caricare sui routers) routines di servizio
Credo che questa sia una delle più interessanti caratteristiche (tra quelle da me
conosciute) dell’implementazione dell’architettura PLANet, se non altro per i suoi
molteplici risvolti pratici. In realtà però tale possibilità non è stata sfruttata nel
progetto realizzato, da un lato perché il dover scrivere codice in OCaml ha
funzionato un po’ da deterrente, dall’altro –e principalmente- perché il contesto
ove ci si muoveva non sembrava affatto richiedere interventi simili.
Perché si è voluto citare, come esempio di caratteristica positiva della rete,
proprio questo?
Probabilmente per via della enorme flessibilità che una tale possibilità introduce
all’interno della rete stessa (si pensi a quante e quali funzionalità sarebbe possibile
far diventare bagaglio interno di uno o più nodi non terminali)3.
2. impossibilità di scambiare risorse tra due capsule
E’ quasi certamente il più grosso inconveniente che mi è possibile attribuire alla
politica di gestione della rete. E’ fin troppo ovvia la forzata impossibilità di
aggiungere, in modo del tutto arbitrario, risorse ad una capsula già iniettata
all’interno della rete (si violerebbe uno dei pilastri principali che, come
specificatamente spiegato4, vuole limitare la proliferazione incontrollata, ed
incontrollabile, di pacchetti); di contro non si riesce però ad immaginare (o non si
riesce a condividerle) motivazioni tali da impedire lo spostamento di risorse da
una capsula ad un’altra.
Ciò non risulterebbe neanche eccessivamente distante dall’attuale gestione
delle risorse: si ricorda, infatti, come sia tuttora possibile che una capsula, durante
la sua esecuzione, crei altre capsule (“figlie”), e trasmetta ad esse parte delle
proprie risorse.
Comunque sia, una simile possibilità non è stata implementata (per lo meno
allo stato attuale delle cose) e questo ha provocato molti problemi, contribuendo
3 Non riesco a non fare un esempio che (come si avrà comunque modo di riaffermare anche piùavanti nella stessa sezione) mi sta particolarmente a cuore: alcune funzioni di supporto alla gestionedelle liste; non esistenti né come routines di servizio né come funzioni del linguaggio. Quando, pocooltre, verranno elencate ed esaminate (con una ancora indomata dose di orgoglio) le funzioni PLAN cheè stato necessario scrivere, quale indispensabile aiuto alla realizzazione delle strategie che si è volutoscegliere, si immagini quanto sarebbe opportuno inserirle –come package- all’interno di ogni nodo (epoterle conseguentemente utilizzare da ogni differente capsula).4 Nella sezione dedicata alla rete attiva PLANet ma anche (secondariamente) in quella relativa allinguaggio PLAN.

Parte III, Sezione 6 Osservazioni conclusive73
in maniera pressoché determinate5 alla creazione di una mal controllata
“emorragia”6 di risorse nell’esecuzione del programma che stiamo presentando.
3. poco flessibile gestione della trasmissione “sicura” dei pacchetti
Come già descritto precedentemente (nella sezione dedicata al linguaggio di
programmazione PLAN), esiste una funzione di trasmissione remota, la
RetransOnRemote, che permette l’invio di un pacchetto con eventuale
ritrasmissione fino alla ricezione di un ack che ne confermi la ricezione. Ebbene,
la gestione di questo meccanismo funziona7 mediante l’utilizzo di una tabella di
ritrasmissione (retransmit table):
Ogni volta che la RetransOnRemote viene chiamata con una lista di chunks,
viene aggiunta una nuova riga (entry) nella tabella di ritrasmissione, indicizzata
tramite la chiave della sessione (utilizzata come sequenza numerica). Solo quando
viene ricevuto l’ack, questa riga viene cancellata.
La tabella è inizializzata per permettere la memorizzazione di 10 linee, è quindi
una tabella statica, a dimensione fissa. Sarebbe stato certamente molto più
flessibile, adattivo ed efficiente considerare una tabella che possa crescere
dinamicamente (growable), come ammesso dagli stessi progettisti7.
La limitazione della dimensione della tabella ha creato, durante la fase di
sperimentazione prima e di testing poi, alcune difficoltà al corretto funzionamento
del programma8: frequente (specie su routers con molti nodi adiacenti) era la
saturazione della tabella di ritrasmissione, espicitata dal messaggio d’errore (tra i
più gettonati) di Retransmit table is full.
5 Un’altra importante motivazione è questa volta imputabile a limitazioni nella flessibilità dellinguaggio adoperato.6 Mi si perdoni il termine, forse non proprio puramente scientifico (se non in campi dal nostroben distanti); dello speco (veramente eccessivo) di risorse si tornerà comunque a parlare presto. Solo unultimo cenno, per chetare eventuali eccessi di curiosità: come si è ovviato al problema? Nel modopeggiore possibile (ma l’unico da noi realizzabile, a meno di non iniziare a modificare il codice sorgentedelle funzioni PLAN) aumentando cioè il budget di risorse inizialmente fornito (al momento dellainiezione)7 Queste informazioni sono state fornite dal prof. Michael Hicks (ZZZ�FLV�XSHQQ�HGX�aPZK,PZK#GVO�FLV�XSHQQ�HGX), della University of Pennsylvania, a seguito di una nostra interrogazione inmerito. Ringrazio qui nuovamente (già fatto nella premessa all’intero lavoro) il professore per l’aiuto(indispensabile) fornito e per l’interesse mostrato verso il progetto D Q Q L H, questo mi riempepersonalmente di fiducia ed orgoglio.8 E’ stato proprio questo motivo (cui non si è riusciti a rimediare) a spingerci verso la richiesta diulteriori informazioni in merito, richiesta cui si è fatto riferimento già nella nota precedente.

Parte III, Sezione 6 Osservazioni conclusive74
Si è rimediato a questo problema (non avendo intenzione di riscrivere il codice
(ML) della gestione della ritrasmissione in un’ottica maggiormente dinamica)
solamente modificando il codice del file reliable/reliable.ml, nel punto dove
veniva stabilita la dimensione massima della tabella; che abbiamo pensato di
portare da 10 a 100 (let retransmit_store_size=10).
B. Osservazioni sul linguaggio di programmazione PLAN
Sul linguaggio PLAN si è già abbondantemente parlato nella sezione dedicata, e proprio in
quel contesto sono state non poche le parentesi di commento (che pure hanno finito col
rimandare a questa parte conclusiva). Il paragrafetto che vi si presenta viene quindi
organizzato come una sorta di schematizzazione (con un tentativo di analisi) dei vari punti
“dubbi” incontrati finora:
• dati residenti
Si è già accennato al fatto che è possibile scrivere dati su un nodo della rete e si è
anche sottolineato il fatto che a tali dati è associato un tempo di permanenza sulla
memoria del nodo (timeout), assegnato dall’utente ma limitato da un tetto superiore di
300 secondi (5 minuti). Và da sé che un tale sistema di gestione dei dati residenti non
può pensarsi definitivo (sicuramente appare grossolano ed inelegante) e difatti gli
stessi autori9 esplicitano la speranza di poter, in futuro, implementare un mezzo più
“piacevole” di mantenimento della “pulizia” dei nodi (magari mediante una sorta di
garbage collection, dei dati inutilizzati).
Un altro punto (forse neanche ancora accennato) non propriamente “inattaccabile”
nella gestione dei dati residenti è quello che riguarda la, forse eccessiva, libertà
consentita nell’accesso alle risorse sui nodi (si allude principalmente alla memoria).
Anche qui sembrano allo studio eventuali procedure di autentificazione che possano
abilitare o meno la scrittura sul nodo (magari effettuando un filtraggio, permettendo
quindi tale operazione a seconda del possesso di determinati privilegi che potrebbero
essere richiesti alle capsule).
9 In un commento al package resident, nella guida al programmatore (riferirsi a [3])

Parte III, Sezione 6 Osservazioni conclusive75
• dichiarazione di tipi complessi
Non è affatto possibile, in PLAN, effettuare dichiarazioni di tipi di dati. E’ però
consentito, come unica (comunque non poco importante) forma di
“personalizzazione”, costruire tuple (date dal prodotto cartesiano di uno o più tipi
base).
La volontà di parlare ora di questo argomento (non certo fondamentale se paragonato
agli altri) è dovuta principalmente al desiderio di esprimere le difficoltà incontrate nel
non poter usare un tipo vettore (ma anche all’ambizione di poter elencare adesso
talune delle funzioni appositamente realizzate). Si ricorderà10 come si sia imposta la
necessità di ideare funzioni ad-hoc, tali da consentire l’applicazione alle liste (unica
struttura dati, ad eccezione della già citata tupla, consentita) di tecniche caratterizzanti
le strutture statiche.
Verranno adesso (solamente) elencate alcune delle più importanti tra le funzioni cui si
è fatto (ormai fin troppo ampiamente) riferimento:
- reverse che effettua l’inversione dell’ordine degli elementi del vettore in
esame.
- seek che restituisce l'elemento alla posizione indicata dal parametro
(simulazione dell’accesso diretto in lettura); qualora non vi fossero elementi nella
posizione richiesta (minore di 1 o maggiore del numero di valori presenti nel
vettore) si fornisce un false come risultato (accanto ad un valore numerico privo
comunque di significato)
- modL che permette di modificare l'elemento di una data posizione nel vettore
(simulando l’accesso diretto in scrittura)
- trouve che individua la posizione della prima occorrenza di un elemento
passato come parametro. Restituisce 0 se l’elemento non dovesse essere presente.
10 E’ comunque permesso riprendere in considerazione la sezione dedicata all’analisidell’algoritmo (nel paragrafo che esaminava i dati residenti sul nodo, in particolare i links)

Parte III, Sezione 6 Osservazioni conclusive76
• costrutti di loop
La completa assenza di possibilità di effettuare cicli condizionati, che –invece-
risultano essere spesso indispensabili nel nostro progetto11, ci ha posti in una
situazione complessa: riuscire a sfruttare ogni mezzo disponibile per simularne, in
qualche modo12, l’effetto.
Proviamo ad analizzare le tecniche adoperate a tale scopo:
1. ciclo di scorrimento condizionato di una lista13
Si è reso necessario nella ricerca di un dato elemento all’interno della lista14.
Serviva, quindi, una scansione della stessa lista fino all’individuazione del
simbolo cercato.
soluzione implementata:
Si è utilizzata la fornita funzione di scansione (incondizionata) della lista stessa
(foldl), con l’aggiunta di una memorizzazione temporanea (come dato residente)
delle informazioni richieste (ad esempio la posizione dell’elemento cercato),
quando ottenute. Alla fine del ciclo (terminata la scansione dell’intera lista) si è
provveduto a riportare il dato memorizzato e quindi a cancellarlo.
11 E non poteva essere certo diversamente, stando alla celebre legge di Murphy (non ancoradimostrata con rigore matematico ma neppure una volta smentita da prove empiriche).12 Si lascia immaginare (ma tutto verrà chiarito poco oltre) come questo in qualche modoimplichi metodi non proprio da manuale. Ancora adesso non riusciamo a non rabbrividirne, data lapalese violazione di ogni minimo concetto di pulizia logica (sia essa d’analisi o di programmazione).
Premetto che non si va certamente fieri delle soluzioni trovate (che spesso brillano perineleganza) ma che queste stesse si sono rivelate provvidenziali per la prosecuzione realizzativadell’intero progetto (altrimenti costretto ad una “fine” prematura, particolarmente dolorosa). Con ciònon si vuole certo affermare, con il più alto grado di sicurezza, che non sia effettivamente possibileindividuare (con una straordinaria fantasia e mediante una celeste illuminazione) soluzioni menogrossolane e più efficienti (noi, comunque, non siamo riusciti ad andare oltre le scelte fatte; e non vedosinceramente quale ulteriore tempo avremmo potuto investirvi).13 Vettore, secondo la nostra concezione (esplicitamente dichiarata già in questa stessa sezione).14 Ad esempio, la direzione verso il parent del nodo in esame (individuato come quello aventesimboloP(=3) nello lo status del link corrispondente).

Parte III, Sezione 6 Osservazioni conclusive77
2. ciclo di attesa di un evento (repeat…until)
a) primo caso(Attesa dello “spegnimento” di un semaforo)
Quando una capsula tenta l’accesso ad un nodo e trova, in questo, il semaforo
acceso (è quindi presente un’altra capsula che –al momento- esegue istruzioni
interne al blocco critico), dovrebbe attenderne lo spegnimento (effettuato, da
buona norma, dalla stessa capsula interna al blocco).
soluzione implementata:
Si è scelto di rimandare indietro (al nodo dal quale proveniva, che –
comunque- è un nodo adiacente) la capsula che ha fallito il tentativo d’accesso
per farla poi subito rispedire nuovamente verso la destinazione (nuovo
tentativo)15.
b) secondo caso(Ciclo di “coordinamento” effettuato dal quartier generale)
Il quartier generale, come si può benissimo evidenziare dal diagramma a
blocchi16, necessita di attendere il verificarsi di un evento (che può essere,
ricordiamo: la richiesta di insediamento di una nuova base d’avamposto, la
richiesta di eliminazione di una base che ha terminato l’esplorazione dell’area
assegnata o il verificarsi della condizione di fine lavoro).
soluzione implementata:
Si è pensato (senza avere però troppi gradi di libertà) di servirci della
ricorsione. Al termine del test sul verificarsi di un evento (così come al
termine della trattazione di uno dei primi due eventi elencati) si procede col
richiamare la stessa funzione, ripetendo quindi nuovamente i test…
15 Si fa notare comunque notare che, sperimentalmente, si è osservata una bassa probabilità difallimento del tentativo d’accesso (inferiore al 10%) e, nella quasi totalità dei casi, non è statanecessaria una seconda rispedizione (non si è quindi giunti ad un terzo tentativo d’accesso, sufficiente ilsecondo).16 Ci si riferisca alla sezione precedente (analisi dell’algoritmo).

Parte III, Sezione 6 Osservazioni conclusive78
Sarebbe bastato il costrutto di un qualunque ciclo o, al limite richiamare la
stessa funzione senza dover necessariamente far uso della ricorsione, ma né
l’una né l’altra possibilità viene messa a disposizione del programmatore17.
C. Osservazioni sul progetto software realizzatoSviluppi futuri
Sarebbe bello, in questa ultima parte, fare solamente un lungo, ricco e coinvolgente elogio
delle notevoli potenzialità che il progetto sembra possedere (secondo il mio modesto,
asettico, obiettivo e disinteressato parere).
Pur volendo rimarcare la vastità dell’ambiente cui ci si è addentrati, l’aspetto di solidità,
flessibilità e robustezza che credo possa essere disinvoltamente accordato alla struttura
dell’algoritmo e il grado di competenza ed efficienza complessivamente (nello studio
teorico e nella realizzazione pratica) raggiunto non sembra corretto non citare (ed
esaminare) quelle che sono considerabili come imperfezioni, modificabili magari in
successive versioni ma attualmente presenti.
17 Che, in certi casi, raggiunge livelli di stess e confuzione tali da spingerlo (a rischio discomunica da parte di tutta la comunità civile) a rimpiangere i vecchio, “sporco”, disordinato,pericoloso, incondizionato, destabilizzante, impresentabile ed inutilizzabile go to.

Parte III, Sezione 6 Osservazioni conclusive79
• mutua esclusione
In un ambiente distribuito come quello considerato, il problema di garantire la mutua
esclusione nell’accesso a dati condivisi e quello –forse ancora più pressante- di
mantenere l’atomicità di alcune sequenze di operazioni (che non devono essere
interrotte), è di grande (fondamentale) importanza.
La difficoltà realizzativa e, soprattutto, la inadeguata soluzione trovata18, spinge però a
proporre un cospiquo sforzo nella direzione di limitare il più possibile (ma meglio
eliminare) la dimensione dei blocchi critici considerati.
• spreco di risorse
Si è più volte (e non solo in questa sezione) fatto riferimento al problema della
gestione, non proprio efficientissima, delle risorse. In realtà si tratta di una vera e
propria enorme voragine che implica uno spreco spesso inaccettabile (e, da un punto
di vista di linearità e “purezza”, assolutamente insopportabile) di resource bound in
una sessione esplorativa (tanto che, come già detto, si è costretti a sovradimensionarne
tantissimo la quantità inizialmente fornita).
A cosa sia dovuto questo spreco si sarà, probabilmente, compreso; riassumiamo
comunque (in una sintetica schematizzazione) tali motivazioni:
1. La necessità di garantire una trasmissione affidabile delle capsule ha spinto
all’utilizzo della RetransOnRemote che, ripetiamo, suddivide le risorse
equamente a tutte le possibili ritrasmissioni, anche quando queste non
risultino necessarie:
nella semplice trasmissione da un nodo al suo adiacente, considerando un limite massimo di treritrasmissioni, si ha una perdita di 667 (su 1000) unità di risorsa (contro l’unica (1) necessaria)
18 Si faccia riferimento alla trattazione del problema dell’inesistenza di cicli nel linguaggio PLAN
1000
x 3 ritr.
333

Parte III, Sezione 6 Osservazioni conclusive80
2. L’impossibilità di trasferire risorse da una capsula all’altra19 è stata ulteriore
vincolo ad una politica di recupero delle risorse stesse. Ricordiamo come si
sia progettato, e sia stato mantenuto tuttora presente, un meccanismo che –
potendo effettuare la citata operazione di trasferimento- riuscirebbe a ridurre
(sensibilmente) lo spreco cui ci si riferisce.
riportiamo la schematizzazione già considerata nella sezione 5 (nella parte dedicata ai dati residenti)riguardo la gestione delle risorse nell’attraversamento di un router
(a): fase di esplorazione: divisione equa delle risorse tra tutte le capsule “figlie”(b): fase di rientro, nell’ipotesi che l’ultima capsula figlia a rientrare sia quella con risorse pari a 3osserviamo (in verde) come ben più efficiente sia la gestione delle risorse qualora fosse possibile
realizzare un “riutilizzo” di quelle rimanenti.
19 Tale argomento è stato affrontato nella parte iniziale di questa stessa sezione.
100
33
33
33
3
31
3
12
31+3+12=46
(a) (b)

A P P E N D I C E

Appendice A
Prova sperimentale
In questa brevissima appendice viene sinteticamente descritta la rete che si è ideata come
scenario ove poter effettuare un (significativo) testing del programma realizzato.
Si vuole qui mettere in evidenza lo sforzo proteso al mantenimento del più alto grado di
genericità possibile nella costruzione della rete. Si è infatti cercato di non rimare invischiati in
nessun genere di “ordine”, né esplicitamente prestabilito, né involontariamente realizzato.
A tale scopo di genericità (che fornisce uno strumento ideale di testing), si vuole giungere
attraverso la realizzazione di alcune condizioni:
• non tutti i nodi della rete devono avere un eguale numero di adiacenti.
• devono (ovviamente) essere presenti sia routers che nodi terminali.
• non dovrebbe esistere alcun grado di gerarchizzazione esplicita tra i nodi della rete.
Nella costruzione della rete attiva si è voluto utilizzare un certo numero di macchine differenti
(cfr. tabella seguente), per fornire alla rete stessa le condizioni di aleatorietà implicate sia da
performances (computazionali) non più necessariamente coincidenti, che dalla presenza di
connessioni effettive (con il loro grado di efficienza e velocità) tra macchine diverse.

Appendice B Prova Sperimentale83
Viene adesso presentato il tracciamento schematico della rete attiva PLANet che è stata
costruita:
Schematizzazione della rete attiva utilizzata come rete di testing del programma presentato
12
3
4
5
13
15
16
14
6
789
11
1012

Appendice B Prova Sperimentale84
Viene presentata adesso una tabella riassuntiva dello schema prima tracciato; quasi una
legenda, necessaria a comprendere -nel suo insieme- l’effettiva dimensione della rete in esame
e la sua concreta dislocazione pratica nelle macchine disponibili.
id. nodonum.vicini
nome macchina(dove si trova il nodo)
elenco dei numeri diporta utilizzati
1 1 3348
2 1 3329
3 4 3330-31-32-33
4 4
archimedearchimede.cere.pa.cnr.it
3334-35-36-37
5 1 3328
6 3 3329-30-31
7 1 3332
8 2
galileogalileo.cere.pa.cnr.it
3333-3334
9 4 3328-29-30-31
10 1 3332
11 3 3333-34-35
12 1
fermatfermat.cere.pa.cnr.it
3336
13 4 leibnizleibniz.cere.pa.cnr.it
3328-29-30-31
14 1 panellapanella.icsi.berkeley.edu
3332
15 4 3339-40-41-42
16 1
archimedearchimede.cere.pa.cnr.it
3343
Tabella riassuntiva dei principali attributi dei nodi della retein relazione alla sua reale dislocazione

Appendice B Prova Sperimentale85
Si ponga attenzione alla scelta di inserire nella rete, per rendere ancor più concrete le
intenzioni inizialmente espresse, un nodo attivo posto su una macchina dislocata negli Stati
Uniti (precisamente a Berkeley, in California).
Il fatto che tale nodo (il 14) sia stato configurato come nodo terminale sembra abbastanza
intuitivo, specie nella considerazione che il suo effettivo posizionamento “fisico” lo potrebbe
far classificare come nodo (decisamente) remoto, rappresentante magari una porta d’accesso
ad un’altra rete attiva PLANet, in qualche modo locale:
scenario prospettato, in cui più reti attive locali sono connesse tra loro medianteopportuni (e robusti) canali di trasmissione
Si vuole prospettare questo scenario per indirizzare, verso simili situazioni (affatto lontane da
una realistica configurazione), un eventuale sviluppo futuro del progetto che si è appena
terminato di descrivere.

(* progetto: A N N I E
Active Network, New Intelligent Exploration *)
(* Alessandro Luparello
v.le Regione Siciliana S.E., 726
90129 Palermo *)
(* Universita' degli Studi di Palermo
Facolta' di Ingegneria Informatica *)
(* Il progetto effettua l'esplorazione di una qualsiasi rete attiva PLANet, col fine di restituire il numero di routers ivi pre senti
Per una migliore comprensione dell'algoritmo e, di conseguenza, del codice, si consiglia di esaminare anche la documentazion e
allegata *)(* Linguaggio PLAN 3.1 *)
(* Il codice nel seguito e' quello contenuto in ogni singola capsula che si muove nella rete *)(* Puo' essere pensato come suddiviso in sezioni tematiche:
1. parte generale sulla gestione delle strutture dati (liste come fossero array)
Comprende funzioni di carattere generale (facilmente trasportabili e riutilizzabili in altri programmi PLAN)
per simulare l'utilizzo di un array dinamico, avando a disposizione solamente il tipo lista.Sono presenti quindi funzioni come:
- reverse che effettua l'inversione dell'ordine degli elementi
- seek che restituisce l'elemento alla posizione indicata (accesso diretto!)
- modL che permette di modificare l'elemento di una data posizione (accesso diretto!)- trouve che individua la posizione della prima occorrenza di un elemento
Tali funzioni (come altre) sono presenti spesso in due versioni: una relativa a liste di interi (necessaria per la
gestione dell'array degli status dei links (verso i vicini) di ogni router), l'altra relativa a liste di host*dev
(risultante dalla funzione PLAN di lettura dell'elenco dei vicini di un nodo: necessaria appunto per la gestione
della lista degli adiacenti di un nodo.
2. parte relativa alle funzioni di test
Comprende le funzioni:
- isOutpost che restituisce un boolean in conformita' al fatto che la capsula si trovi o meno in un avamposto- isFather che restituisce true se il nodo in esame e' quello di provenienza della capsula (a seconda della
direzione di esplorazione: forward (->false), rewind (->true)
- isTerminal che indica se il nodo in esame e' un terminale (->true) o un router
- isClosed che riferisce se tutti i links della capsula sono stati "chiusi" (tutte le strade esplorabili sonostate esplorate)
3. parte relativa alle funzioni di lettura di dati sul nodo (non necessariamente dati resident)
Comprende le funzioni:
- previousNode che fornisce il nome del nodo (tipo host) dal quale la capsula proviene (l'ultimo analizzatoprima di quello in esame). Necessario per settare lo status del relativo link a "P".
- controlloStatus che ritorna lo status del nodo in oggetto (osservato/non osservato)
- controlloLevel che ritorna il livello di profondita' attualmente raggiunto (come distanza minima del nodo
in esame con il quartier generale)- FoundPrecNode che ritorna il nome (fornito come tipo host) del nodo precedente (secondo il cammino della
particolare strada di esplorazione effettuata). Individuato come quello marcato con "P"
nell'array dello status dei links del nodo
4. parte relativa alle funzioni di scrittura sul nodoComprende le funzioni:
- markNode che effettua il marking dello status del nodo in esame: non osservato -> osservato
- markLinks che effettua il marking iniziale e l'aggiornamento dell'array degli status dei links agli adiacenti
- mark TTLr che effettua il marking iniziale e l'aggiornamento (solamente mediante somma) dell'indicatore dellaquantita' di TTL (risorse vitali) residuo (relativo a tutte le capsule spia facenti capo al nodo)
- markCount che effettua la modifica principale (dato lo scopo del programma): quella relativa all'inizializzazione
ed aggiornamento del contatore di tutti i routers contati dalle spie facenti capo al nodo in esame
5. parte relativa alle funzioni di trasmissione delle capsule:Comprende le funzioni:
- ReliableDeliver che consente di effettuare una trasmissione "sicura".
Permette: - la frammentazione/riassemblamento del pacchetto (la sua dimensione supera
l'MTU dei links)- la ripetizione della trasmissione, nel caso di perdita del pacchetto nella
rete (e' presente infatti un segnale di ack)
- launchCaps che effettua la trasmissione delle capsule spia a tutti i vicini del nodo in esame, purche'
cio' sia consentito (ad esempio non si ritrasmette una spia al vicino dal quale si proviene)- goPrec che consente alla capsula spia di tornare indietro senza compiere alcuna operazione
(necessario, ad esempio, quando si raggiunge un nodo terminale)
- leaveNode che permette di "abbandonare" il nodo, una volta raccolte tutte le informazioni (sono
ritornate tutte le spie mandate in missione ai nodi vicini). Effettua la cancellazione
dei dati residenti ----> Nessun dato (o mark) resta residente sul nodo quando questo viene abbandonato, in fase di risalita delle informazioni raccolte.
6. parte relativa alla gestione degli avamposti:
Per quanto riguarda la creazione di un nuovo avamposto si hanno le funzioni:- messageNewO che effettua la richiesta "formale" al quartier generale
- newOutpostHQ che effettua la trasmissione della richiesta di formazione di un nuovo avamposto
Per quanto riguarda la cancellazione di un avamposto (missione terminata->zona esplorata interamente) si ha la funzione:
- messageDelO che effettua la richiesta "formale" al quartier generale (passando come parametri anche i
dati raccolti (uno fra tutti: numero di router contati))
7. parte relativa alle funzioni prinpali:
a) spy e' la funzione "scheletro" dell'algoritmo considerato alla base del processo di esplorazione(una sorta di main function, richiamata dalla capsula che raggiunge un nodo)
b) loop e' la funzione stabilmente eseguita sul quartier generale, gestisce le richieste di creazione e
cancellazione di avamposti, in attesa della terminazione del processo di esplorazione
c) go e' la funzione di iniezione (quella che viene lanciata dal terminale), gestisce il lancio
della prima spia e l'insediamento del loop sul quartier generale)*)

(* Parte contenente tutte le funzioni relative all'utilizzo delle liste *)
(* In particolare sono presenti funzioni di supporto che consentono di utilizzare la lista come fosse un array *)
(* Possiamo osservare come talune di queste funzioni siano del tutto generiche ed esportabili ad altri programmi (come e' stato fatto) *)
(* restituisce la lista (di interi) in ingresso ivertendo l'ordine degli elementi*)
fun reverse (Lista:int list):int list=
let val NewLista:int list=[]
fun appR (l:int list, i: int):int list=i::l (* appende un elemento intero in testa ad una lista di interi *) in foldl (appR,NewLista,Lista) end
(* restituisce la lista (di hosts) in ingresso ivertendo l'ordine degli elementi*)
fun reverseH (ListaH:host list):host list=
let val NewListaH:host list=[] fun appRH (l:host list, i: host):host list=i::l (* appende un elemento di tipo host in testa ad una lista di hosts *)
in
foldl (appRH,NewListaH,ListaH)
end
(* appende in coda di una lista di host *)
fun appendH (ListaH:host list, CodaH: host):host list = reverseH (CodaH::reverseH(ListaH))
(* restituisce l'elemento presente nella posizione i-ma (true) oppure false se la lista [di interi] non ha posizione i-ma *)fun seek (i:int, Lista:int list):bool*int=
let val K:key=generateKey() (* chiave interna alla funzione *)
fun Eseek (K:key, i:int, Lista:int list):int= (* Effective-SEEK *)
let val cont:int=1 (* contatore della posizione attualmente analizzata*)
fun contr_seek (other: (key*int*int), elemLista:int):key*int*int=
(* controllo se siamo giunti alla posizione i-ma e riporto elemento *)
if snd other=#3 other then (* giunti all'i-mo elemento *)
( put ("pippo",fst other,elemLista,300);
(fst other,snd other+1,#3 other)
)
else (* non i-mo elemento *)(fst other,snd other+1,#3 other)
in
(
foldl (contr_seek,(K,cont,i),Lista); (* scansione lista degli elementi *) get ("pippo",K) (* riporto valore trovato *)
)
end
val present:bool=(i>0)and(i<=length(Lista)) (* la posizione i-ma e' presente nella lista ? *)
val elem:int=if present then Eseek (K,i,Lista) else 0 (* elemento posto nell'i-ma posizione *) in
(
delete ("pippo",K); (* cancellazione dei dati temporaneamente scritti sul nodo *)
(present,elem) (* valori di ritorno *) )
end
(* restituisce l'host presente nella posizione i-ma (true) oppure false se la lista [di host*dev (neighbors)] non ha posizione i-ma *)
fun seekHNb (i:int, Lista:(host*dev) list):bool*host= let val K:key=generateKey() (* chiave interna alla funzione *)
fun Eseek (K:key, i:int, Lista:(host*dev) list):host= (* Effective-SEEK *)
let val cont:int=1 (* contatore della posizione attualmente analizzata
*) fun contr_seek (other: (key*int*int), elemLista:host*dev):key*int*int= (* controllo se siamo giunti alla posizione i-ma,riporto elemento *)
if snd other=#3 other then (* giunti all'i-mo elemento *)
(
put ("pippo",fst other,fst elemLista,300);
(fst other,snd other+1,#3 other) )
else (fst other,snd other+1,#3 other) (* non i-mo elemento *)
in
( foldl (contr_seek,(K,cont,i),Lista); (* scansione lista degli elementi *)
get ("pippo",K) (* riporto valore trovato *)
)
end val present:bool=(i>0)and(i<=length(Lista)) (* la posizione i-ma e' presente nella lista ? *)
val elem:host=if present then Eseek (K,i,Lista) else hd thisHost() (* in else un valore (host) che comunque non verra' mai gua rdato *)
in
(
delete ("pippo",K); (* cancellazione dei dati temporaneamente scritti sul nodo *) (present,elem) (* valori di ritorno *)
)
end
(* copia gli elementi della lista (di interi) dalla pos. 'a' alla 'z' nella nuova *)
fun duplicaL (Lista:int list, NewLista: int list, a:int, z:int):int list=
let val pos:int=1 (* indice scorrimento lista *)
fun copy (other: (int list)*int*int*int,elemLista:int ) : int list*int*int*int= (* copia elemento *)
if ((#4 other>=snd other) and (#4 other<=#3 other)) then (elemLista::fst other,snd other,#3 other,#4 other+1) else (fst other,snd other,#3 other,#4 other+1)
in
reverse (fst foldl (copy,(NewLista,a,z,pos),Lista))
end
(* restituisce la lista con il settaggio previsto (NEW al posto dell'i-mo elemento) *)
fun modLista (Lista :int list, (* lista *)
i :int, (* posizione cui cambiare l'elemento *)
NEW :int (* nuovo elemento *) ) :int list= let val NewLista: int list = [] (* lista di supporto *)
in
(
(* copia i primi i-1 elementi nella nuova lista appende il nuovo elemento
copia i restanti elementi della lista *)
duplicaL (Lista,NEW::reverse (duplicaL (Lista,NewLista,1,i-1)),i+1,length(Lista))

)
end
fun trouveEff (elem:int,Lista:int list,iterazione:int):int=
(
if member (elem,Lista) then (* se l'elemento cercato fa parte della lista... *)
if hd Lista=elem then iterazione else eval (|trouveEff|(elem,tl Lista,iterazione+1)) (* ritorna valore o continua la scansione *)
else 0
)
(* restituisce la posizione del valore elem nella lista [di interi] (prima occorrenza), 0 se non presente *)
fun trouve (elem:int,Lista:int list):int=trouveEff (elem,Lista,1)
fun trouveEffH (Host :host ,neigh:(host*dev) list, iterazione:int):int= let val NewLista:host list=[] (* lista vuota, di supporto *)
fun hostOnly (neigh:(host*dev)list) : host list= (* ricopia la lista dei neighbors in una lista di soli hosts *)
let fun copyH (NewLista:host list, elemLista:host*dev): host list = (fst elemLista)::NewLista
in reverseH (foldl (copyH,NewLista,neigh))
end
val hostneigh:host list= hostOnly (neigh) (* lista di tutti gli host vicini (senza devices) *)
in
( if member (Host,hostneigh) then (* se l'elemento cercato fa parte della lista... *)
if fst hd neigh=Host then iterazione
else eval (|trouveEffH|(Host,tl neigh,iterazione+1)) (* ritorna valora o continua la scansione *)
else 0 )
end
(* restituisce la posizione del valore elem nella lista [di host*dev(neighbors)] (prima occorrenza), 0 se non presente *)
fun trouveH (Host :host ,neigh:(host*dev) list): int= trouveEffH (Host,neigh,1)
(* ---------------------------------------------------------------------------------------------------------------------------- ------------------- *)
(* Terminata la parte relativa alle funzioni generali di gestione delle liste, segue quella relativa al progetto in se: *)(* procedure di supporto all'esplorazione *)
(* funzione utilizzata come chunk della abort -> nessuna operazione da fare *)
(* presa in considerazione quando si tenta di effettuare operazioni non consentite, secondo l'algoritmo *)
fun null():unit=()
(* ----------------- funzioni di test: *)
(* La capsula e' su un avamposto ? *)
(* ritorna true se l'host thisH appartiene ad uno degli host dell'unica macchina outpost *)
fun isOutpost (outpost:host):bool=thisHostIs(outpost)
(* ritorna true se il nodo in cui ci si trova e' "padre" di quello precedente *)
fun isFather (direction:int) : bool= (direction=1)
(* ritorna true se il nodo in cui ci si trova e' un terminale *)fun isTerminal (neighbors: (host*dev)list ) : bool=
if length (neighbors)=1 then true (* il nodo ha un solo adiacente -> terminale *)
else false
(* ritorna vero se tutti i links sono chiusi (-> tutte le strade sono gia' state esplorate) *)fun isClosed (Key:key):bool=
let fun allLinksClosed (Key:key):bool=
let val links:int list=try get ("links",Key) handle NotFound => abort (|null|()) (* lettura della lista degli status dei
links *)fun isKP (Key:key,link:int):key= (* test sul singolo link *)
if (link=2)or(link=3) then (Key) (* se il link e' marcato K (oppure P), continua la scansione *)
else (put ("closed",Key,false,300);Key) (* altrimenti (link in Wait) viene modificato il valore del flag *)
in (put ("closed",Key,true,300);
foldl (isKP,Key,links);
get ("closed",Key)
)
end val allLinksAreClosed:bool=allLinksClosed(Key) (* variabile da riportare in uscita *)
in
(
delete ("closed",Key); (* cancella il dato temporaneamente memorizzato sul nodo *) allLinksAreClosed (* ritorna il valore risultante del test effettuato *)
)
end
(* ----------------- funzioni di lettura dati: *)
(* ritorna il nome(host) del nodo (adiacente) dal quale la capsula proviene *)
(* ritornando l'host che, tra i neighbors, ha un device uguale al parametro *)
fun previousNode (Key:key, Neigh:(host*dev)list, deviceIN:dev):host= let
fun returnH (Key:key) : host=
let val retH : host = get("prov",Key)
in
( delete ("prov",Key); (* cancella dato momentaneamente residente *)
retH (* ritorna dato *)
)
end fun controlladev (unvicino: host*dev, other:key*dev) : key*dev=
if (snd unvicino=#2 other) then ( put ("prov",fst other,fst unvicino,300); (other) )
else ( (other) )

in
(
(* scandisce la lista dei vicini sino a trovare quello con la cui interfaccia coincida con quella *) (* che si ha come parametro (che coincide con quella che indica l'ingresso della caspula nel nodo stesso) *)
foldr (controlladev, Neigh, (Key,deviceIN) );
returnH (Key) (* ritorna il valore cancellando i dati temporanei *)
) end
(* ritorna l'host contrassegnato dal mark-link:P *)
fun FoundPrecNode (K:key, neigh: (host*dev)list) : host= try snd seekHNb(trouve(3,get("links",K)),neigh) handle NotFound => abort (|null|())
(* ritorna lo status del nodo sul quale ci si trova *)
fun controlloStatus (Key:key): int =
( try
get("status",Key)
handle NotFound => (0)
)
(* ritorna il livello del nodo sul quale ci troviamo *)
(* non vi sono funzioni che lo permettono --> sfruttiamo la tabella di RIP *)
fun controlloLevel (Key: key , HQ: host) : int = let val RIPtable: (host*host*dev*int)list = RIPGetRoutes() (* tabella di RIP del nodo *)
(* controlla se il record della RIP table e' quello dell'head-quartier e memorizza la distanza *)
fun distanza (lineaRIP: host*host*dev*int , other: key*host) : key*host =
if (fst lineaRIP=snd other) then ( put("distanza",fst other,#4 lineaRIP,300); other )else ( other )
in
(
foldr (distanza,RIPtable,(Key,HQ)); (* individua distanza (salva il dato temporaneamente sul nodo) *)
let val dist:int=get ("distanza",Key) (* legge il risultato della ricerca *) in ( delete ("distanza",Key); (* cancella il dato temporaneo *)
dist ) (* ritorna in uscita il risultato richiesto *)
end
) end
(* ----------------- funzioni di scrittura dati (marking): *)
(* marca il nodo attuale *)
fun markNode (Key:key,mark:int):unit = put ("status",Key,mark,300)
(* inizializza la lista dei links *)
fun initLinks (n:(host*dev) list):int list= let fun incoda (n:host*dev,l:int list):int list=0::l (* 0 indica link libero (da esplorare) *)
val lista:int list=foldr (incoda,n,[])
in
lista end
(* setta e marca i links *)
(* se direzione e' di avanzamento in esplorazione (forward) marca a P il link dal quale la capsula proviene *)
(* altrimenti lo marca a K *)fun markLinks (Key:key, dir:int, Host:host, neigh:(host*dev)list, ThisIsOutpost:bool) : unit=
let val links:int list=( (* ritorna la situazione dei links salvata. Se non ancora presente, la inizializza *)
try
get("links",Key) handle NotFound=> ( initLinks (neigh) )
)
val markIs:int= if (dir=0 and not ThisIsOutpost) then 3 else 2 (* valore del marchio al link: 3->P, 2->K *)
val pos :int= trouveH (Host,neigh) (* trova posizione del link nella lista (=posizione dell'host in questione nella list a dei vicini) *)
in put ("links",Key,modLista (links,pos,markIs),300) (* aggiorna la lista dello stato dei links *)
end
(* aggiorna il contenuto informativo del nodo attuale: TTL residuo *)fun markTTLr (Key:key, dir:int, TTLr:int):unit=
(
if (dir=0) then put ("TTLr",Key,0,300)
else let val TTLr_prec:int=get("TTLr",Key)
in
put ("TTLr",Key,TTLr_prec + TTLr,300)
end
)
(* aggiorna il contenuto del contatore sul nodo in esame *)
fun markCount (Key:key, dir:int, count:int):unit=
( if (dir=0) then put ("Count",Key,0,300) (* direzione di esplorazione -> inizializzazione del valore a 0 *)
else (* direzione di rientro ... *)
let val count_prec:int=get("Count",Key)
in
put ("Count",Key,count + count_prec,300) (* somma nuovo valore al precedente *) end
)
(* ----------------- funzioni relative alla trasmissione delle capsule: *)
(* Permette la trasmissione "sicura" dei pacchetti da un nodo all'altro *)
fun ReliableDeliver (dest:host, totalRB:int, type:int, c:chunk):unit= let val trasmissionKey : key = generateKey() (* chiave della sessione di trasmissione *)
val Nrip : int = 2 (* massimo 2 ritrasmissoni / si suppone siano sufficienti *)
val RB_Ack : int = 10 (* risorse da assegnare al messaggio di ACK *)
val RB : int = totalRB/Nrip-RB_Ack-1 (* risorse per ogni tentativo di trasmissione *) val codeData : chunk = sendAck (c,trasmissionKey,RB_Ack) (* capsula con "ricevuta di ritorno" (acknoledgment) *)
val codeDataFrag : chunk list = fragment (codeData,getMTU(snd defaultRoute(dest))-fragment_overhead) (* capsula framme ntata *)
val RBperFrag : int = (RB/length(codeDataFrag)) (* risorse per ogni ogni frammento *)

in
RetransOnRemote (codeDataFrag, trasmissionKey, Nrip, dest, RBperFrag, defaultRoute)
end
(* lancia le capsule a tutti i vicini con link liberi (marcati con F) *)
fun launchCaps (Key:key, thisH:host, neigh:(host*dev)list, outpost:host,dir:int,newlevel: int,levelMAX:int,level_step:int):unit =
let
(* effettua il lancio della capsula spia al vicino in esame (se cio' e' consentito) *)
fun launchSPY (other: key*int list*host*int*int *host*int*int*int*int, vicino:host*dev): key*int list*host*int*int*host*int *int*int*int=
let val Key : key = fst other (* chiave della sessione di esplorazione *) val links : int list = snd other (* lista dello status dei links *)
val parent : host = #3 other (* l'host attuale (#3 other e' thisHost) diviene "padre" *)
val pos : int = #4 other (* posizione del link da esaminare *)
val RB : int = #5 other (* risorse a disposizione per la capsula *)
val outpost : host = #6 other (* nome dell'avamposto: resta immutato *) val direct : int = #7 other (* direzione di avanzamento della spia: resta immutato *)
val level_prec : int = #8 other (* il livello attualmente raggiunto diviene livello precedente per la nuova capsula *)
val levelMAX : int = #9 other (* livello massimo di esplorabilita' per la spia: resta immutato *)
val level_step : int = #10 other (* passo di modifica del livello massimo di avanzamento: resta immutato *) in
(
if (snd seek(pos,links)=0) then (* link F (da visionare) *)
( print ("--spia lanciata a "^toString(fst vicino));
ReliableDeliver (fst vicino,RB,0,|spy|(Key,0,outpost,direct,level_prec,levelMAX,level_step)); (Key, modLista (links,pos,1 (*W*)) ,parent ,pos+1, RB, outpost, direct, level_prec, levelMAX, level_step)
)
else (* link P,K,W (da non visionare) *)
(Key, links ,parent, pos+1, RB, outpost, direct, level_prec, levelMAX, level_step) )
end
val i:int=0 (* posizione (nell'elenco dei neighbors) della destinazione della nuova spia *)
val links:int list=get ("links",Key) (* status dei links *) fun getNumFreeLinks (links:int list):int= (* ritorna il numero dei link ancora aperti (da esplorare) *)
let val num:int=0
fun inc (link:int,count:int):int= if link=0 (*-F-*) then (count+1) else (count)
in foldr (inc,links,num)
end
val numFreeLinks :int = getNumFreeLinks (links) (* numero links da esplorare *)
val RBperSPY :int = getRB()/numFreeLinks-1 (* risorse da assegnare ad ogni spia *) in
(* aggiornamento dello status dei links *)
put ("links",Key,snd foldl (launchSPY,(Key,links,thisH,i+1,RBperSPY, outpost,dir,newlevel,levelMAX,level_step),neigh),300)
end
(* la capsula torna al nodo precedente senza compiere alcuna operazione *)
(* necessario, ad esempio, quando si e' raggiunto un nodo terminale *)
fun goPrec (Key:key, parent:host, thisH:host, outpost:host, levelP:int,levelMAX:int,levelStep:int,counter:int, daOutpost:bool) : unit = let val RB:int=if not daOutpost then getRB() (* se non proveniamo da un avamposto -> tutte le risorse *)
else getRB()/2-1 (* altrimenti meta' risorse: *)
(* l'altra meta' viene utilizzata per le procedure di costruzione dell'avamposto stesso *)
in
ReliableDeliver (parent,RB,0,|spy|(Key,counter,outpost,1,levelP,levelMAX,levelStep)) (* trasmissione della capsula *) end
(* abbandona il nodo, verso il suo precedente *)fun leaveNode ( Key:key, thisH:host, neigh: (host*dev) list,
outpost: host, ThisIsOutpost: bool,
level_prec:int, levelMAX:int, level_step:int ):unit =
let
val Count : int = get ("Count",Key)+1 (* conteggio memorizzato +1 (router attuale) *) val TTLr : int = get ("TTLr",Key) (* TTL residuo memorizzto *)
val Nneigh : int = length (neigh) (* numero di vicini: destinatari dei barricatori *)
val RBforB : int = 100 (* risorsa attribuita ad ogni barricatore (eccediamo per un'eventuale ritrasmissione) = 100 *)
val RBforBs: int = RBforB *Nneigh (* risorse accantonate per lanciare poi tutti i barricatori *)
(* manda un massaggio al quartie generale: cancella avamposto *)
fun delOutpostHQ (Key:key,thisH:host,level:int):unit=
let val OCount: int= get ("Count",Key)+1 (* Routers contati dalla spia: +1 e' relativo all'avamposto stesso *) val OTTLr : int= get ("TTLr",Key)
in (
print ("messaggio all'HQ con i dati seguenti:\n avamposto da chiudere: "^toString(thisH)^"\n routers contati: "^to String(OCount));
ReliableDeliver (getSource(),getRB(),1,|messageDelO| (Key,thisH,level,OCount,OTTLr)) (* trasmissione messaggio *)
) end
in
( if not ThisIsOutpost then (* Non siamo su un avamposto --> torniamo al P *) let val P : host = FoundPrecNode(Key,neigh)
in
(
print ("Abbandono il nodo --> spia al P: "^toString(P));
ReliableDeliver (P,getRB(),0,|spy|(Key,Count,outpost,1,level_prec,levelMAX,level_step)); (* trasmissione della spia al n odo prec.*)print("Routers contati dalla spia: "^toString(Count));
(* cancellazioni informazioni poste sul nodo (compito svolto prec. dai DESTROYERs *)
try delete("status",Key) handle NotFound =>(); try delete("links",Key) handle NotFound =>();
try delete("Count",Key) handle NotFound =>();
try delete("TTLr",Key) handle NotFound =>();
print ("tutti i dati residenti sono stati cancellati (nodo liberato!)");
delete ("marking",Key) )
end
else (* Siamo su un avamposto --> trasmettiamo dati al quartie generale *)
( print ("lascio outpost");
delOutpostHQ (Key,thisH,level_prec)
)

)
end
(* Rilancia la capsula spia nel caso in cui il nodo di destinazione era momentaneamente occupato (semaforo in ALT) *)
fun RilanciaSpy (D : host, (* nodo ove rilanciare la capsula spia *)
Key : key, (* chiave della sessione di esplorazione *)
counter : int, (* numero di router contati finora (in fase di ritorno) dalla capsula *) outpost : host, (* identificatore dell'avamposto al quale si fa riferimento *)
direction : int, (* indicatore della direzione di avanzamento: 0=forward, 1=rewind *)
level_prec : int, (* livello di profondita' finora raggiunto *)
levelMAX : int, (* massimo livello di profondita' che la spia puo' raggiungere (fino al prossimo avamposto) *) level_step : int (* passo di incremento del limite di profondita' alla creazione di un avamposto *)
): unit=
(
print ("<<** "^toString(D)^" occupato ("^toString(getRB())^")");
print ("Riprovo..."); ReliableDeliver (D,getRB(),0,|spy|(Key,counter,outpost,direction,level_prec,levelMAX,level_step)) )
(* ----------------- funzioni relative alla gestione degli avamposti: *)
(* creazione avamposto ... *)
(* riprova a lanciare la richiesta di creazione di un nuovo avamposto *)fun RiprovaMessaggeNO (Key:key, thisH:host, level:int):unit=
(
print("ritento lancio richiesta new outpost");
ReliableDeliver (getSource(),level+1,1,|messageNewO| (Key,thisH,level)) )
(* messaggio al quartier generale -> creazione nuovo avamposto *)
fun messageNewO (Key:key, thisH:host, level:int):unit=
let val CANwrite : bool = try setGT ("message",Key,1,300) handle NotFound => ( put("message",Key,1,300); true) in
(
if CANwrite then
( put ("outpostName",Key,thisH,300);
put ("outpostLevel",Key,level,300);
put ("flag",Key,1,300);
setLT ("message",Key,0,300) (* abbasso il flag sui messaggi (semaforo) *) )
else ReliableDeliver (thisH,getRB(),1,|RiprovaMessageNO|(Key,thisH,level))
)
end
(* manda un messaggio al quartier generale, crea avamposto *)
fun newOutpostHQ (Key:key,thisH:host,level:int,dir:int) :unit =
ReliableDeliver (getSources(),level+1,1,|messageNewO| (Key,thisH,level)) (* manda messaggio all'HQ: nuovo avamposto *)
(* cancellazione avamposto ... *)
(* ritrasmissione messaggio di richiesta cancellazione dell'avamposto *)fun RiprovaMessageDO (Key:key, thisH:host, level:int, OCount:int, OTTLr:int):unit=
(
print("ritento lancio: cancellazione");
ReliableDeliver (getSource(),getRB(),1,|messageDelO| (Key,thisH,level,OCount,OTTLr)) )
(* messaggio di richiesta di cancellazione di un avamposto *)
fun messageDelO (Key:key, thisH:host, level:int, OCount:int, OTTLr:int):unit=
let val CANwrite : bool = try setGT ("message",Key,1,300) handle NotFound => ( put("message",Key,1,300); true) in
(
if CANwrite then
( put ("outpostName",Key,thisH,300);
put ("outpostInfo",Key,(OCount,OTTLr),300);
put ("outpostLevel",Key,level,300);
put ("flag",Key,2,300);setLT ("message",Key,0,300) (* abbasso il flag sui messaggi *)
)
else ReliableDeliver (thisH,getRB(),1,|RiprovaMessageDO|(Key,thisH,level,OCount,OTTLr))
)
end
(* ---------------------------------------------------------------------------------------------------------------------------- ---*)
(* Opzione di VERBOSE *)
(* Visualizzazione dati all'arrivo della capsula spia nel nodo (modalita' -VERBOSE) *)fun printDATA (Key:key,parent:host, outpost:host, direction:int, status:int, level:int, thisH:host, thisD:dev, endHost:bool,cou nter:int):unit =
let val dir :string= if direction=0 then "FORWARD" else "BACK" (* direzione di esplorazione *)
val stat:string= if status=1 then "OBSERVED" else "NOT OBSERVED" (* stato del nodo *)
val term:string= if endHost then "TERMINAL" else "ROUTER" (* tipologia del nodo: terminale/router *) in
(
print ("\n\n*****************************************\n"^toString(Key));
if isOutpost(outpost) then print ("\nNodo: "^toString(thisH)^" [ AVAMPOSTO ]")
else print ("\nNodo: "^toString(thisH)^" ("^term^") "); print ("raggiunto dal: "^toString(parent)^" by interfaccia: "^toString(thisD));
print ("RB: "^toString(getRB())^"\nOutpost e': "^toString(outpost)^"\nquartier generale: "^toString(getSource()));
print ("Status: "^stat^", profondita': "^toString(level));
print ("direzione: "^dir^""); if direction=0 then print ("finora ho contato: "^toString(counter)^" routers\n") else () )
end

(* ---------------------------------------------------------------------------------------------------------------------------- ---*)(* Funzione principale di gestione della capsula spia *)
(* funzione riportante l'algoritmo di utilizzo della spia *)
fun spy (Key : key, (* chiave della sessione di esplorazione *) counter : int, (* numero di router contati finora (in fase di ritorno) dalla capsula *)
outpost : host, (* identificatore dell'avamposto al quale si fa riferimento *)
direction : int, (* indicatore della direzione di avanzamento: 0=forward, 1=rewind *)
level_prec : int, (* livello di profondita' finora raggiunto *) levelMAX : int, (* massimo livello di profondita' che la spia puo' raggiungere (fino al prossimo avamposto) *)
level_step : int (* passo di incremento del limite di profondita' alla creazione di un avamposto *)
): unit=
let val status : int = controlloStatus(Key) (* status del nodo in esame *)
val level : int = controlloLevel (Key,getSource()) (* livello del nodo in esame *) val neighbors : (host*dev)list= getNeighbors() (* nodi adiacenti a quello in esame (links) *)
val thisD : dev = getSrcDev() (* interfaccia del nodo in esame (quella dalla quale vi siamo arrivati) *)
val thisH : host = thisHost(thisD) (* Host in esame *)
val endHost : bool = isTerminal(neighbors) (* siamo su un nodo terminale ? *) val parent : host = previousNode (Key,neighbors,thisD) (* nodo dal quale proveniamo *)
val ThisIsOutpost : bool = isOutpost(outpost) (* siamo arrivati all'outpost ? *)
val MUTEX : bool = try setGT ("marking",Key,1,300) handle NotFound => (put("marking",Key,1,300); true) (* chiudo il
semaforo se aperto *)
in (
if MUTEX then (* la mutua esclusione e' salvaguardata, il semaforo (libero) e' stato posizionato ad ALT *)
(
printDATA (Key,parent,outpost,direction,status,level,thisH,thisD,endHost,counter); (* visualizzazione dati significativi ( -VERBOSE) *) print ("SEM alzo il flag"); (* indicatore di semaforo occupato *)
if ( ((status=0) and not endHost) or (ThisIsOutpost and direction=0)) then (* router non marcato *)
(
if ((level>=level_prec) and (level<levelMAX)) then (* libero/ entro l'area di esplorabilita' *) (
markNode (Key,1); (* status nodo: Observed *)
print ("Mark: OBSERVED");
markLinks (Key,direction,parent,neighbors,ThisIsOutpost); (* inizializzazione dei links *)print ("Mark links "^toString(get("links",Key))^"\nvicini: "^toString(neighbors));
launchCaps (Key,thisH,neighbors,outpost,direction,level,levelMAX,level_step); (* lancio delle capsule spia ai vicini *)
print ("Lancio capsule effettuato...");
markTTLr (Key,0,0); (* inizializzazione del TTL residuo *)print ("set TTL: 0");
markCount (Key,0,0); (* inizializzazione del COUNTER *)
print ("set count: 0")
)
else (* libero/ fuori area di esplorabilita' *) (
if (level<level_prec) then (* libero/ fuori area/ livello inferiore *)
(
print ("livello inferiore, barrico (->"^toString(parent)^") e torno indietro (RB: ^toString(getRB())^")");markLinks (Key,1,parent,neighbors,ThisIsOutpost);
goPrec (Key,parent,thisH,outpost,level,levelMAX,level_step,counter,false)
)
else (* libero/ fuori area/ oltre limite MAX *)
(print ("Nuovo avamposto");
markNode(Key,1); (* Observed *)
goPrec(Key,parent,thisH,outpost,level,levelMAX,level_step,counter,true); (* la capsula ritorna indietro *)
newOutpostHQ (Key,thisH,level,direction) (* richiesta nuovo avamposto *))
)
)
else (* router gia' marcato o terminale *) let val prec_Wait : bool = if (not endHost) then (snd seek (trouveH(parent,neighbors),get("links",Key))=1 ) (* spia ancora attesa *)
else false
(* spia non piu attesa *)
in (
if (isFather(direction) and prec_Wait) then (* terminale o marcato/ padre in attesa *)
(* nodo di provenienza e link dal quale proveniamo a W (non a K: risultato inutile) *)
(print ("\nNodo di provenienza...(di "^toString(parent)^")");
markTTLr (Key,1,getRB()); (* aggiornamento del TTL residuo *)
print ("TTL (+ "^toString(getRB())^")");
markCount (Key,1,counter); (* aggiornamento del COUNTER *)
print ("Count (+ "^toString(counter)^")");markLinks (Key,direction,parent,neighbors,ThisIsOutpost); (* aggiornamento dello status dei links *)
print ("Mark -K- link verso "^toString(parent)^"\nora: "^toString(get("links",Key)));
if isClosed(Key) then (* tutti i links sono stati esplorati *)
( print ("* Tutti i links sono stati esplorati");
leaveNode(Key,thisH,neighbors,outpost,ThisIsOutpost,level_prec,levelMAX,level_step); (* la capsula abban dona il nodo *)
print ("Nodo lasciato")
)
else () )
else (* terminale o marcato/ non padre in attesa *)
(
if (not isFather(direction)) then (* terminale o marcato/ terminale o marcato da altri *)(
if (not endHost) then (* terminale o mercato/ marcato da altri *)
(
markLinks (Key,1,parent,neighbors,ThisIsOutpost); (* barrichiamo il link verso il nodo di prov.*)
print ("barrico verso "^toString(parent));print ("I links sono adesso... "^toString (get("links",Key)))
)
else ();
print ("(nodo gia' raggiunto o terminale) torno indietro (RB: "^toString(getRB())^")"); goPrec(Key,parent,thisH,outpost,level,levelMAX,level_step,counter,false) (* la spia torna indietro *)
)
else (* terminale o marcato/ padre non in attesa *)

(
print ("il link e' gia' stato barricato, le mie informazioni non sono utili!");
if isClosed(Key) then (* controllo sullo stato dei links: tutti chiusi ? *) (
print ("* Tutti i links sono stati esplorati");
leaveNode(Key,thisH,neighbors,outpost,ThisIsOutpost,level_prec,levelMAX,level_step); (* la capsula ab bandona il nodo *)
print ("Nodo lasciato") )
else ()
)
)
)
end;
print ("SEM abbasso il flag"); (* indichiamo d'aver "liberato" la risorsa *) try setLT ("marking",Key,0,300) handle NotFound => put ("marking",Key,0,300) (* abbassamento del flag semaforo (-> libero) *)
)
else (* nodo momentaneamente inaccessibile (un'altra spia sta modificando i dati) *)
( print ("**>> ["^toString(parent)^"] tentato accesso ("^toString(getRB())^")");
ReliableDeliver (parent,getRB(),0,|RilanciaSpy|(thisH,Key,counter,outpost,direction,level_prec,levelMAX,level_step))
)
)
end
(* ---------------------------------------------------------------------------------------------------------------------------- ---*)
(* Ciclo di attesa sul quartier generale... *)
(* Ciclo di attesa sul quartier-generale, gestisce interazione con avamposti (creazione, cancellazione, trasporto dati) *)(* Termina con la fine dell'esplorazione *)
fun Loop (Key:key,OOList:host list,OONum:int, layerRB:int, levelStep:int, actCOUNT:int,actTTLr:int): int*int =
let val CANreadMess : bool= try setGT ("message",Key,1,300) handle NotFound=> (put("message",Key,1,300); true) (* alziamo i l semaforo *)
val flag : int = try get("flag",Key) handle NotFound=> 0 (* stato del flag /se non presente(300s. dall'ultima modifica) e'0 *) in
(
if CANreadMess then (* nessuno sta,al momento, scrivendo messaggi *)
( if flag=1 then (* 1 = richiesta creazione di un nuovo outpost *)
let val newOutpostName : host =get ("outpostName",Key) (* nome del nuovo avamposto da creare *)
val newOutpostLevel : int =get ("outpostLevel",Key) (* profondita' a cui si trova *)
val newLayerRB : int =layerRB+newOutpostLevel (* risorse da fornire: devono essere uguali per tutti gli stra ti, *)
(* quindi indipendenti dalla profondita' *) val OpenOutposts : host list =appendH(OOList,newOutpostName) (* nuovo outpost "aperto" si aggiunge alla lista *)
in
(
print ("\nArriva richiesta nuovo avamposto da "^toString(newOutpostName)^"\n");
(* lanciamo una spia verso il nuovo avamposto *)
ReliableDeliver (newOutpostName,newLayerRB,0,|spy| (Key,0,newOutpostName,0,newOutpostLevel,newOutpostLevel+levelStep, levelStep));
print ("spia lanciata...\n");
(* resettiamo il flag a 0 (nessuna novita')/ cancelliamo gli altri campi *)
put ("flag",Key,0,300);
delete ("outpostName",Key);
delete ("outpostLevel",Key); print ("cancellati dati...\n");
(* modifica: aggiungiamo il nuovo avamposto nell'elenco degli avamposti ancora attivi/ incrementiamo il loro numero *)
setLT("message",Key,0,300);
(* ripetiamo il ciclo *)
eval (|Loop| (Key,OpenOutposts,OONum+1,layerRB,levelStep,actCOUNT,actTTLr))
)
end else
if flag=2 then (* 2 = in un avamposto si e' terminata la missione esplorativa *)
let val OutpostName : host = get ("outpostName",Key) (* nome dell'avamposto da "smontare" *)
val OutpostLevel : int = get ("outpostLevel",Key) (* profondita' a cui si trova *) val OutpostInfo : int*int = get ("outpostInfo",Key) (* informazioni raccolte nell'avamposto: count+TTLr
*)
val OpenOutposts : host list = remove(OutpostName,OOList) (* outpost "chiuso" si toglie dalla lista *)
in
( print ("\n-> Close outpost: "^toString(OutpostName)^" Dati: "^toString(fst OutpostInfo)^", "^toString(snd OutpostInfo));
(* resettiamo il flag a 0 (nessuna novita')/ cancelliamo gli altri campi *)
put ("flag",Key,0,300); delete ("outpostName",Key);
delete ("outpostLevel",Key);
delete ("outpostInfo",Key);
(* modifica: cancelliamo l'avamposto dalla lista di quelli ancora "attivi"/ decrementiamo il loro numero *) setLT("message",Key,0,300);
eval (|Loop| (Key,OpenOutposts,OONum-1,layerRB,levelStep,actCOUNT+fst OutpostInfo,actTTLr+snd OutpostInfo) )
)
end else (* 0 = nessuna nuova richiesta dal campo *)
if OONum=0 then (actCOUNT,actTTLr) (* chiusi tutti gli avamposti--> missione terminata *)
else (* non chiusi tutti gli avamposti *)
(
setLT("message",Key,0,300); (* abbassiamo il semaforo *) eval (|Loop| (Key,OOList,OONum,layerRB,levelStep,actCOUNT,actTTLr)) (* ripetiamo il ciclo *)
)
)
else (* qualche spia sta' mandando un messaggio... attendere prima di leggere *) (
print ("\noccupato...");
eval (|Loop| (Key,OOList,OONum,layerRB,levelStep,actCOUNT,actTTLr)) (* ripetiamo il ciclo *)

)
)
end
(* ---------------------------------------------------------------------------------------------------------------------------- ---*)
(* Funzione relativa all'inizio dell'esplorazione (funzione di iniezione) *)
(* funzione di lancio del programma *)
fun go ():unit= let val Key : key = generateKey() (* secret Key !!!!! *)
val OONum : int = 1 (* numero degli outpost di cui si attende la "chiusura" *)
val layerRB : int = 999999999 (* resource bound da assegnare ad ogni avamposto (per esaminare il suo strato) *)
val levelStep : int = 10 (* profondita' stabilita per ogni strato *)
val actualCOUNT : int = 0 (* inizializzazione: routers attualmente contati *) val actualTTLr : int = 0 (* inizializzazione: TTL attualmente residuo *)
in
(
if (length(getNeighbors())=1) then (* siamo su un nodo terminale *) let val firstOutpost : host = fst hd getNeighbors() (* primo outpost *)
val OOList : host list = [firstOutpost] (* elenco degli outpost ancora "aperti" ........... consideriamo anche il primo *)
in
(
print ("Siamo su un terminale, lancio il primo avamposto nel router prossimo\nPARTITO...."); ReliableDeliver (fst hd getNeighbors(),layerRB,0,|spy| (Key,actualCOUNT,firstOutpost,0,0,levelStep,levelStep));
print ("LOOP:....");
print ("\nI routers nella rete sono : "^ toString (fst Loop (Key,OOList,OONum,layerRB,levelStep,actualCOUNT,actualTTLr)))
) end
else (* siamo su un nodo non terminale *)
let val firstOutpost : host = hd thisHost() (* primo outpost: questo stesso di iniezione *)
val OOList : host list = [firstOutpost] (* elenco degli outpost ancora "aperti" ........... consideriamo anche il primo *) in
(
print ("Siamo su un router, questo e' il primo avamposto\nPARTITO....");
spy (Key,actualCOUNT,firstOutpost,0,0,levelStep,levelStep);
print ("\nI routers nella rete sono : "^ toString (fst Loop (Key,OOList,OONum,layerRB,levelStep,actualCOUNT,actualTTLr))) )
end
)
end

Riferimenti bibliograficireferences
[1] Jonathan T. Moore, Pankaj KakkarPLAN Grammar (for PLAN ver.3.1) November, 1998ZZZ�FLV�XSHQQ�HGX�aVZLWFKZDUH�3/$1�GRHVaRFDPO�JUDPPDU�JUDPPDU�KWPOwork supported by DARPA under Contract N66001-96-C-852
[2] Pankaj Hakkar, Michael W. HicksPLAN Tutorial (for PLAN ver.3.1) November, 1998ZZZ�FLV�XSHQQ�HGX�aVZLWFKZDUH�3/$1�GRHVaRFDPO�WXWRULDO�WXWRULDO�KWPOwork supported by DARPA under Contract N66001-96-C-852
[3] Jonathan T. Moore, Michael W. Hicks, Pankaj KakkarPLAN Programmer’s Guide (for PLAN ver.3.1) November, 1998ZZZ�FLV�XSHQQ�HGX�aVZLWFKZDUH�3/$1�GRHVaRFDPO�JXLGH�JXLGH�KWPOwork supported by DARPA under Contract N66001-96-C-852
[4] Michael W. HicksPLAN Service Programmer’s Guide (for PLAN ver.3.1) November, 1998ZZZ�FLV�XSHQQ�HGX�aVZLWFKZDUH�3/$1�GRHVaRFDPO�VHUYBJXLGHO�VHUYBJXLGH�KWPOwork supported by DARPA under Contract N66001-96-C-852
[5] Michael W. Hickspland: The PLAN Active Router (for PLAN ver.3.1) November, 1998ZZZ�FLV�XSHQQ�HGX�aVZLWFKZDUH�3/$1�GRHVaRFDPO�SDSHUV�SODQHW�SVwork supported by DARPA under Contract N66001-96-C-852
[6] Michael W.Hicks, Jonathan T.Moore, D.Scott Alexander, Carl A.Gunter, Scott M.NettlesDepartment of Computer and Information Science. University of Pennsylvania
PLANet: An Active Internetwork March, 1999ZZZ�FLV�XSHQQ�HGX�aMRQP�SDSHUV�LQIRFRP���DEV�KWPOsubmitted to 1999 IEEE Conference on Computer Communication (INFOCOM’99)work supported by DARPA under Contract N66001-96-C-852
[7] Jonathan T.Moore, Michael W. Hicks, Scott M.NettlesDepartment of Computer and Information Science. University of PennsylvaniaChunks in PLAN: Language Support for programs as Packets March, 1999^MRQP�PZK�QHWWOV`#GVO�FLV�XSHQQ�HGXsubmitted to 1999 IEEE Conference on Computer Communication (INFOCOM’99)
[8] Robert HarperSchool of Computer Science. Carnage Mellon University. Pittsburgh, PA 15213-3891
(with exercices by Kevin Mitchell, Edinburgh University, Edinburgh, UK)
Introduction to Standard ML January, 1993
[9] OCaml home page: ZZZ�SDXLOODF�LQULD�IU� FDPO�LQGH[�HQJ�KWPO

[10] Stuart J. Russel, Peter Norvig edizione italiana a cura di Luigia Carlucci AielloIntelligenza Artificiale (Artificial Intelligence. A modern approach) Febbraio, 1998Prentice Hall International, UTET
[11] Andrew S. TanenbaumReti di computer (Computer Network) Novembre, 1991Prentice Hall International, Jackson libri
[12] David L.Tennenhouse, David J.Wetherall Telemedia, Networks and System Group, MITTowards an Active Network Architecture^GOW�GMZ`# OFV�PLW�HGX ZZZ�WQV�OFV�PLW�HGX��An earlier version of this paper was delivered during the keynote session of Multimedia Computing andNetworking, San Jose, CA January, 1996
[13] David Wetherall, Ulana Legedza, John GuttagSoftware Devices and Systems Group, Laboratory for Computer Science, MITIntroducing New Internet Services: Why and How July, 1998^GMZ�XODQD�JXWWDJ`# OFV�PLW�HGX ZZZ�VGV�OFV�PLW�HGX��To appear in IEEE NETWORK Magazine Special Issue on Active and Programmable Networks
[14] J.M.Smith, D.J.Farabert, C.A.Gunter, S.M. Nettles, Mark E.Segal, W.D.Sincoskie,D.C.Feldmeier, D.Scott AlexanderCIS Department, University of Pennsylvannia; Bellcore; MUSIC Semiconductors, Inc.SwitchWare: Towards an Active Network ArchitectureResearch supported by DARPA under Contract DABT 63-95-C-0079 and N66001-96-C-852.Additional support by Intel, Hewlett-Packard and AT&T.

IndiceIndex
Prefazione …………………………………………………………………………………………….. 5
I Reti attive ……..…………………………………………………………………………… 6
1. Reti attive ………………………………………..…………………………………………… 7
- Introduzione 7
- Perché introdurre le reti attive? 7
- Vantaggi nell’utilizzo delle reti attive 9
- Diversi approcci alle reti attive: 9
A. Routers programmabili (approccio discreto) 9
B. Capsule (approccio integrato) 10
- Considerazioni architetturali 10
- Stato attuale della ricerca: Progetti 10
2. PLANet ……………………………………………………………………………………… 13
- Introduzione 13
- PLAN 14
- PLANet 15
A. Formato pacchetti PLAN 16
- indirizzamento 17
- programmi come dati 18
- campi rimanenti 19
B. Instradamento dei pacchetti 19
C. Analisi e gestione degli errori 20
D. Dettagli implementativi 21
- perché Ocaml 21
- Costruzione effettiva dei nodi attivi 22
3. Linguaggio PLAN …………………..……………………………………………………. 28
- Introduzione 28
- Risorse limitate 29
- Pacchetti: a) programma PLAN 29
chunks 30
b) pacchetto PLAN 32
c) applicazione PLAN 32
- Modello di valutazione 33
- Vita di un pacchetto 34
- Eccezioni 35
- Gestione degli errori 36
- Costrutti e primitive del linguaggio: 36
a) costrutti 37
b) primitive: 37
b.1) primitive di rete 37
b.2) iteratori di liste 39

- Servizi 40
1. servizi essenziali (core services) 40
2. servizi aggiuntivi (package services) 42
II Analisi del progetto software ………………………………………………….. 48
4. Analisi del problema …………………………………………………………………… 49
- descrizione 49
- vincoli imposti 49
- difficoltà intrinseche 50
5. Analisi dell’algoritmo di risoluzione ideato …………………………………… 52
- introduzione 52
- come si è pensato di risolvere il problema 53
- scenario su cui ci si muove 54
- informazioni presenti 55
1. nel singolo nodo della rete 55
2. nella capsula spia (esploratrice) 59
3. nel quartier generale 62
- Algoritmo 66
A. strategie di esplorazione 66
B. gestione del quartier generale 69
III Osservazioni conclusive ……………………………………….………………….. 70
6. Osservazioni conclusive ………………………………………………………………… 71
A. Osservazioni sulla rete attiva PLANet 71
1. possibilità di scrivere routines di servizio 72
2. impossibilità di scambiare risorse tra capsule 72
3. poco flessibile gestione della trasmissione sicura dei pacchetti73
B. Osservazioni sul linguaggio di programmazione PLAN 74
- dati residenti 74
- dichiarazione di tipi complessi 75
- costrutti di loop 76
1. scorrimento condizionato di una lista 77
2. ciclo di attesa di un evento 77
C. Osservazioni sul progetto software realizzato – Sviluppi futuri 78
- mutua esclusione 79
- spreco di risorse 79
Appendici A. Prova sperimentale ………………………………………….. 82
B. Codice ………………..………………………..………………… 87
Riferimenti bibliografici ……………………………..………………………………………………


















