
Metodi Quanti – Qualitativi per le scienze sociali seminari... · Nvivo QDA miner Annotape...
33
1 Metodi Quanti – Qualitativi per le scienze sociali Analisi matematica di dati testuali. (3 Incontro) Alessandro Pepe. Ph.D. [email protected] Metodi di ricerca: programma per Ph.D.
Transcript of Metodi Quanti – Qualitativi per le scienze sociali seminari... · Nvivo QDA miner Annotape...

1
Metodi Quanti – Qualitativi per
le scienze sociali
Analisi matematica di dati testuali. (3 Incontro)
Alessandro Pepe. Ph.D.
Metodi di ricerca: programma per Ph.D.

2
Termini diversi
� Analisi matematica di dati testuali� Analisi statistica di dati testuali� Applicazione di mixed-method� Analisi quanti-qualitativa� Computer assisted textual analysis (CATA)� Quantitative textual analysis (QTA)� Computer Aided Qualitative Data Software
Analysis (CAQDAS).
Verso una integrazione tra metodi quantitativi e qualitativi di analisi testuale
Parole al posto dei NumeriParole come Numeri
Parole e Numeri
Insieme di metodologie per combinare i risultati quantitativi e qualitativi all’interno di un singolo disegno di ricerca, in modo da valutare le stesse, sovrapposte o complementari domande di ricerca.

3
Esempi
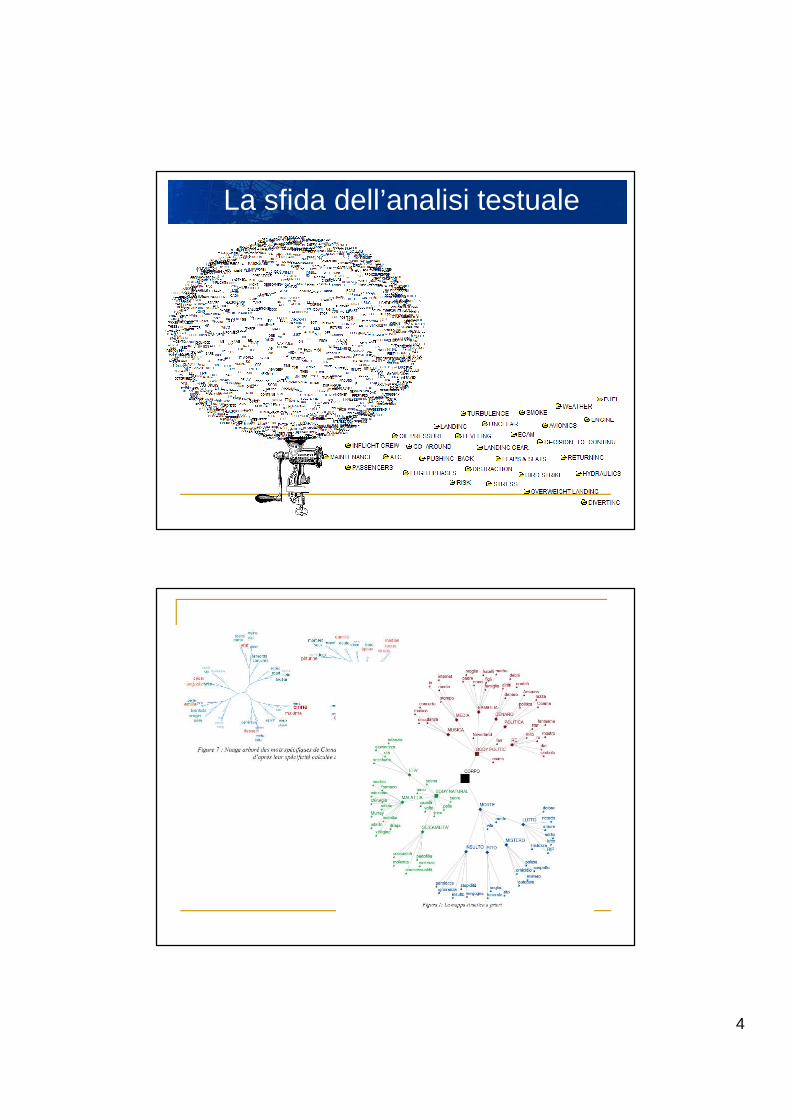
4
La sfida dell’analisi testuale
5
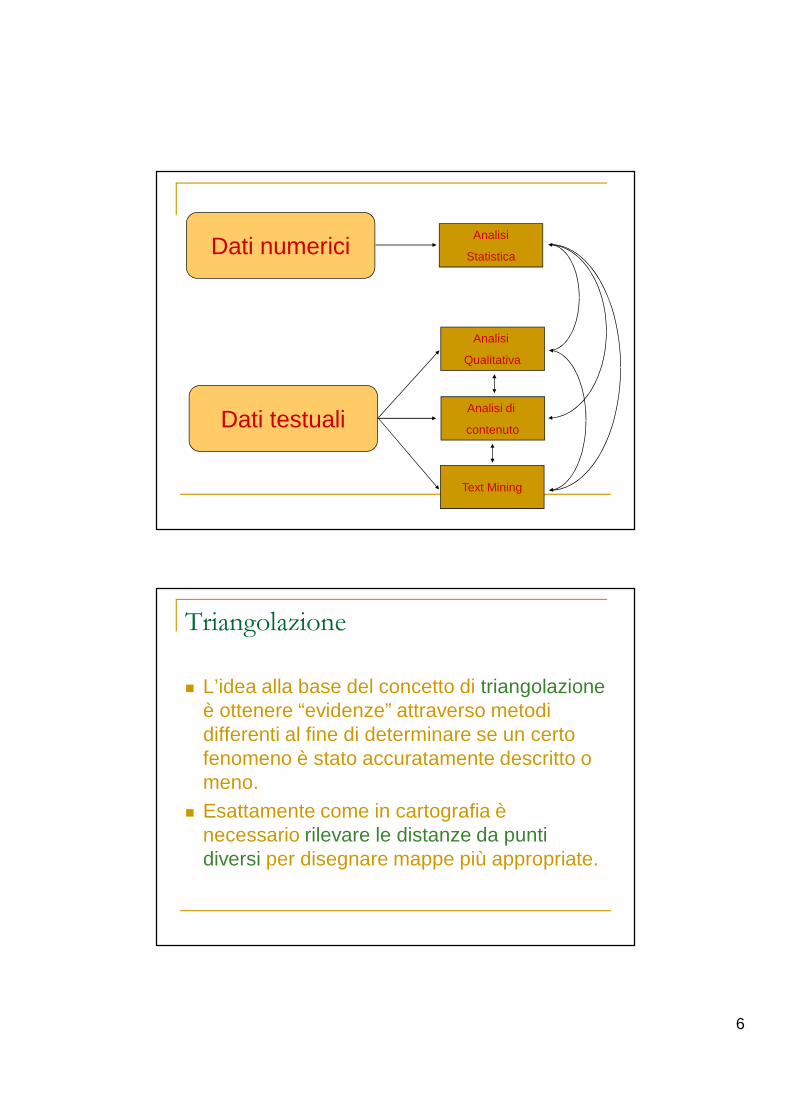
6
Dati numericiAnalisi
Statistica
Dati testuali
Analisi
Qualitativa
Analisi di
contenuto
Text Mining
Triangolazione
� L’idea alla base del concetto di triangolazioneè ottenere “evidenze” attraverso metodi differenti al fine di determinare se un certo fenomeno è stato accuratamente descritto o meno.� Esattamente come in cartografia è
necessario rilevare le distanze da punti diversi per disegnare mappe più appropriate.

7
Triangolazione cartografica (1600)
Attenzione alla triangolazione
� E’ importante che i metodi coinvolti tendano a risolvere e non ad amplificare i reciproci bias metodologici (Moran-Ellis et al., 2006; Webb, Campbell, Schwartz & Secherst, 1966) � Al cuore dell’idea di triangolazione vi è il
tentativo di aumentare la fiducia (confidence) nei risultati delle misurazioni che implica la convergenza dei risultati finali . Può essere chiamata validità incrementale del modello di triangolazione (p.47).

8
Software per CATA
� T-lab (global tool e comparative tool)� Simstat+wordstat (simile a spss, mappe di calore)� Lexico (descrizioni lessicometriche)� Nvivo� QDA miner� Annotape (trascrizioni audio)� Atlas-ti (codifica e raggruppamento pdf, audio e video)� Automap (individual model representation)� Kwalitan (analisi di contenuto in grounded theory)� The ethograph
Altri software
VBPro M. Mark Miller Newspaper articles
Yoshikoder Will Lowe Political documents
General Inquirer Philip Stone General mainframe computer application (1960s)
Profiler Plus Michael Young Communications of world leaders
LIWC 2007 Pennebaker, Booth, & Francis Linguistic characteristics & psychometrics
Diction 5.0 Rod Hart Political speech
PCAD 2000 Gottschalk & Bechtel Psychiatric diagnoses
WORDLINK James Danowski Network analysis/communication
CATPAC Joseph Woelfel Consumer behavior/marketing
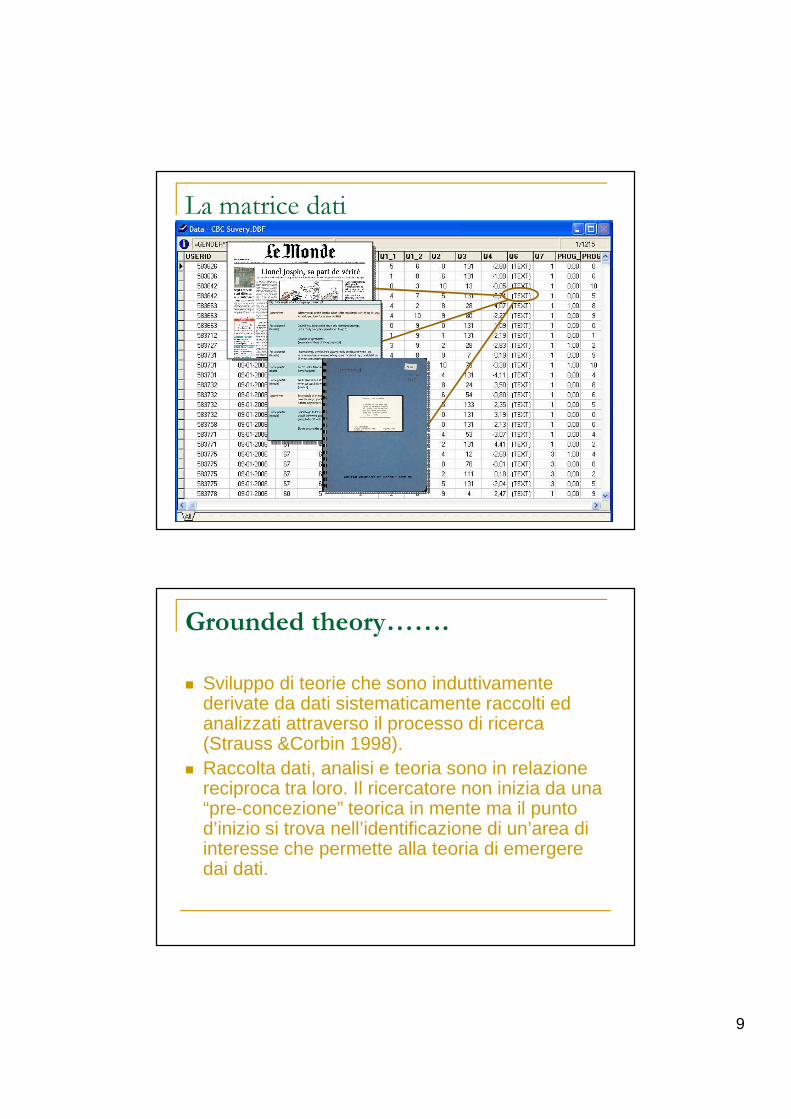
9
La matrice dati
Grounded theory…….
� Sviluppo di teorie che sono induttivamente derivate da dati sistematicamente raccolti ed analizzati attraverso il processo di ricerca (Strauss &Corbin 1998). � Raccolta dati, analisi e teoria sono in relazione
reciproca tra loro. Il ricercatore non inizia da una “pre-concezione” teorica in mente ma il punto d’inizio si trova nell’identificazione di un’area di interesse che permette alla teoria di emergere dai dati.

10
Grounded theory coinvolge….
1. Un iniziale tentativo di sviluppare categorie che illuminano i dati.2. Saturazione semantica delle teorie con evidenze appropriate e rilevanti.3. Sviluppo delle categorie in un framework maggiormente rilevante e significativo al di fuori del setting di indagine (Glaser &Strauss, 1967).
Glaser/Strauss si separano...
� Glaser’s (1978, 1998) assume una realtà esterna oggettiva e concreta che può essere raccontata da un osservatore neutrale che raccoglie dati in modo sistematico � posizione molto vicina al positivismo tradizionale (Charmaz, 2000 ).
� Strauss e Corbin pongono l’accento sulla raccolta dati esente da bias metodologici e sul fatto che ciò che si raccolgie sono i punti di vista dei rispondenti sulla realtà (Strauss & Corbin 1998).
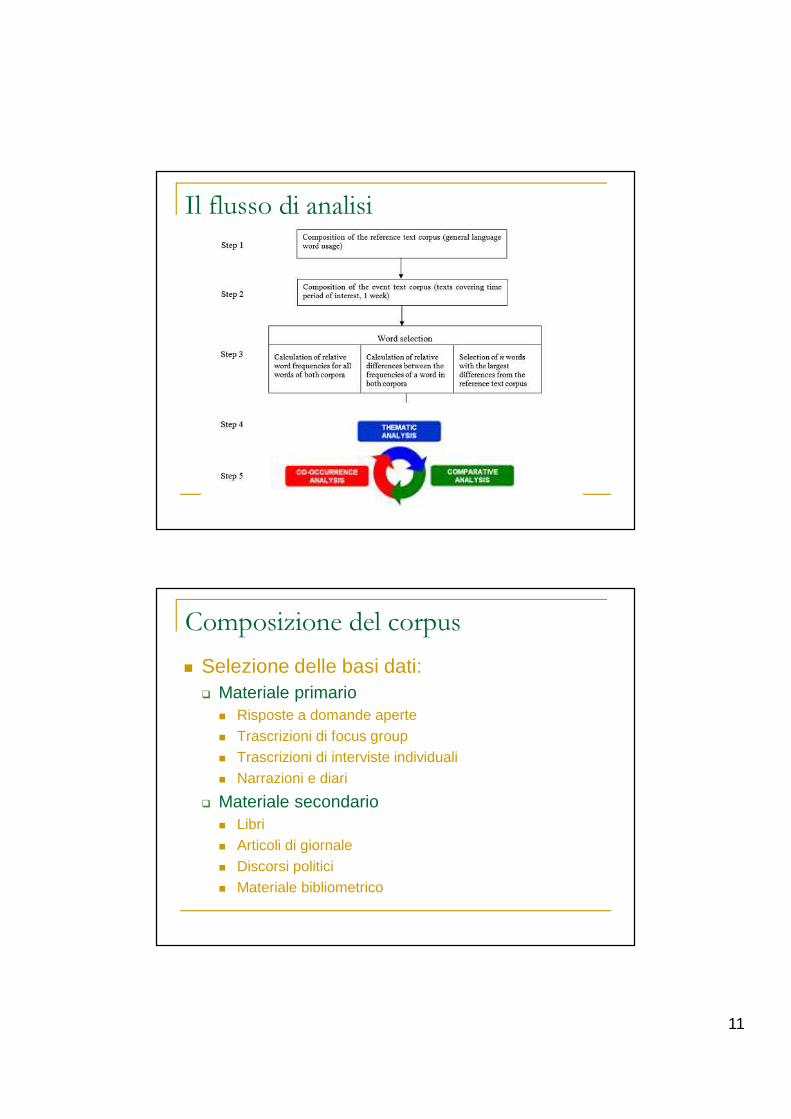
11
Il flusso di analisi
Composizione del corpus
� Selezione delle basi dati:� Materiale primario� Risposte a domande aperte� Trascrizioni di focus group� Trascrizioni di interviste individuali� Narrazioni e diari
� Materiale secondario� Libri� Articoli di giornale� Discorsi politici� Materiale bibliometrico

12
Unità di contesto e Unità lessicali.
Pre-editing dei dati
� Tre ostacoli principali:� Polisemia del linguaggio: una idea � forme multiple
� Polimorfia del linguaggio: una parola � molte idee
� Connotazioni del linguaggio: emozionalità associata ad una idea
� Fondamentale stabilità delle decisioni prese

13
Denotazione vs. connotazione
� La denotazione è il significato che la parola ha nel dizionario.
� Le connotazioni di una parola sono i suoi aspetti emozionali associati alle idee.
� Le connotazioni possono essere positive o negative (effetto Pollyanna � Positive words are used far more often that negative words among languages and cultures as diverse as Chinese, Finnish and Turkish; (Boucher & Osgood, 1968).
� Il lusso....
Operazioni manuali di pre-ediding
� Normalizzazione � pulizia del testo da un punto di vista ortografico, errori di digitazione, grammaticale (correzione ‘ragionata’ di word) e messa a ‘norma’ da un pdv del software.
� Sinonimizzazione � Raggruppare i sinonimi di una parola in un unico lemma,evita di lavorare con frequenze di occorrenza basse ma “artificiali solo lessicalmente e non semanticamente differenti .
� I codici della linguistica naturale non sono mai isomorfici e quindi, tecnicamente, in linguistica contemporanea il concetto di sinonimo non esiste (Delabastita, 1993), è noto che questa sia una pratica comunemente accettata negli studi psicologici.
� Esempio: insegnante, docente, maestro, professore, prof. nell'unico lemma insegnante

14
Operazioni manuali di pre-editing
� Disambiguazione� trasformazione di lemmi polimorfici e ambigui. Ad esempio piano (�trasformato in pianoforte oppure lasciato come piano; pesca; ancora; regola)� Connotazione� identificazione della
connotazione positiva/negativa + identificazione degli antecedenti significativi (poco felice, non felice, mai felice, molto felice, � il software separa…meglio unire con underscore)
Operazioni automatiche editing: lessicalizzazione

15
Operazioni automatiche editing
� Lemmatizzazione � riportare le singole forme grafiche al loro lemma originale (ad esempio ricondurre al singolare tutte le forme plurali).
� Questo passaggio fonde tutte le forme flesse di uno stesso lemma riportate nella forma grafica (occorrenza), alla sua forma non declinata.
� Nell'analisi testuale l'unità statistica di analisi è la forma grafica, ossia una sequenza di caratteri dell'alfabeto delimitata da due separatori. Si tratta di parole singole o gruppi di parole inscindibili (cioè che hanno senso solo se prese insieme).
� Quando le forme grafiche sono intese come unità statistiche vengono chiamate word token e rappresentano le occorrenze cioè tutte le parole che compaiono in un testo anche se ripetute.
Terminologia� Occorrenza� è la forma grafica� Lemma (Token)� è la forma grafica ricondotta� Hapax� parole che compaiono una sola volta� Stop word � parole vuote escluse dall’analisi
(connettori)
� Faccio girare il software � due esiti (tabelle di frequenza e matrici di occorrenza)
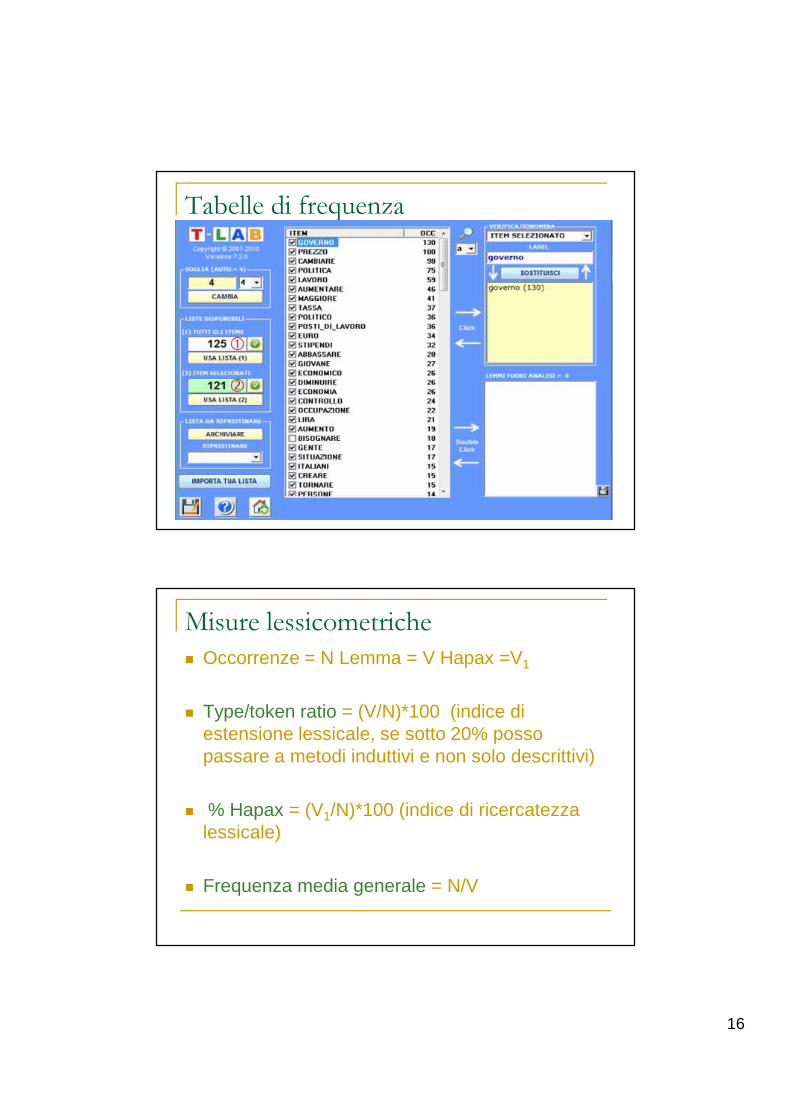
16
Tabelle di frequenza
Misure lessicometriche
� Occorrenze = N Lemma = V Hapax =V1
� Type/token ratio = (V/N)*100 (indice di estensione lessicale, se sotto 20% posso passare a metodi induttivi e non solo descrittivi)
� % Hapax = (V1/N)*100 (indice di ricercatezza lessicale)
� Frequenza media generale = N/V

17
Legge di Zipf
Indici ricchezza lessicale

18
Tasso di copertura del testo
Generazione matrici di occorrenza (1)
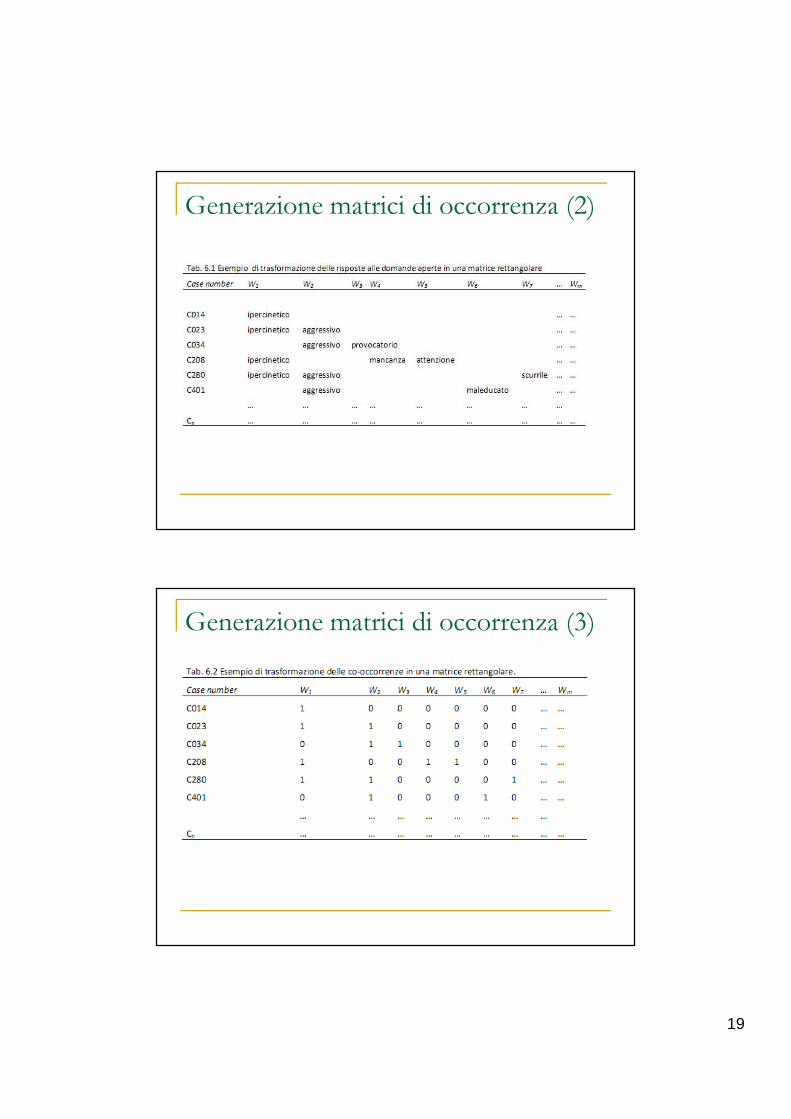
19
Generazione matrici di occorrenza (2)
Generazione matrici di occorrenza (3)
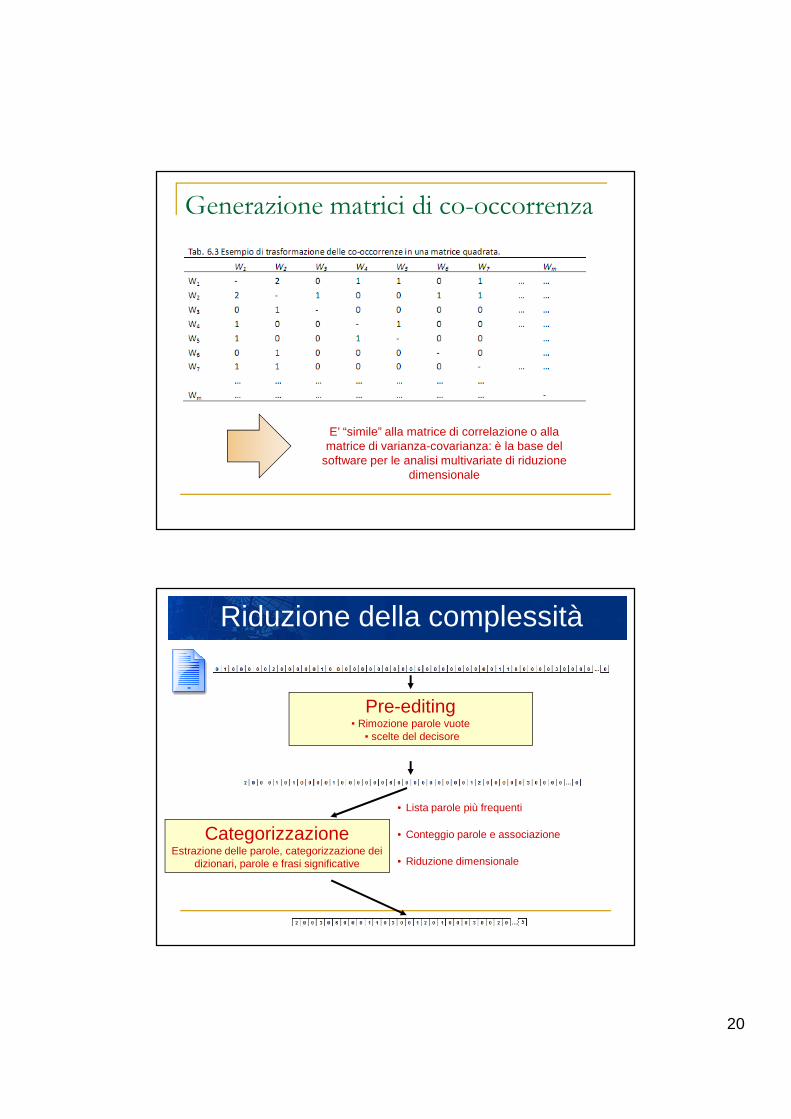
20
Generazione matrici di co-occorrenza
E’ “simile” alla matrice di correlazione o alla matrice di varianza-covarianza: è la base del
software per le analisi multivariate di riduzione dimensionale
Riduzione della complessità
Pre-editing▪ Rimozione parole vuote
▪ scelte del decisore
CategorizzazioneEstrazione delle parole, categorizzazione dei
dizionari, parole e frasi significative
• Lista parole più frequenti
• Conteggio parole e associazione
• Riduzione dimensionale

21
Strumenti per l’analisi: Global mapping vs. comparative tool
Analisi delle co-occorrenze:1) Conteggio piano delle frequenze2) Analisi di distribuzione lessicale3) Analisi di associazione di parole4) Analisi delle sequenze (catene markoviane)
Analisi tematiche:5) Analisi tematica dei contesti elementari6) Classificazione tematica dei documenti7) Analisi valenza tematica
Analisi comparative:9) Analisi specificità lessicali10) Analisi tipicità lessicali11) Analisi corrispondenze12) Analisi corrispondenze multiple13) Analisi di Cluster
Conteggio piano delle frequenze
� Estrazione dalle liste di frequenza di parole target:� Aggettivi� Verbi� Nomi
� Strategia puramente descrittiva �output visuali� Nessuna applicazione statistica
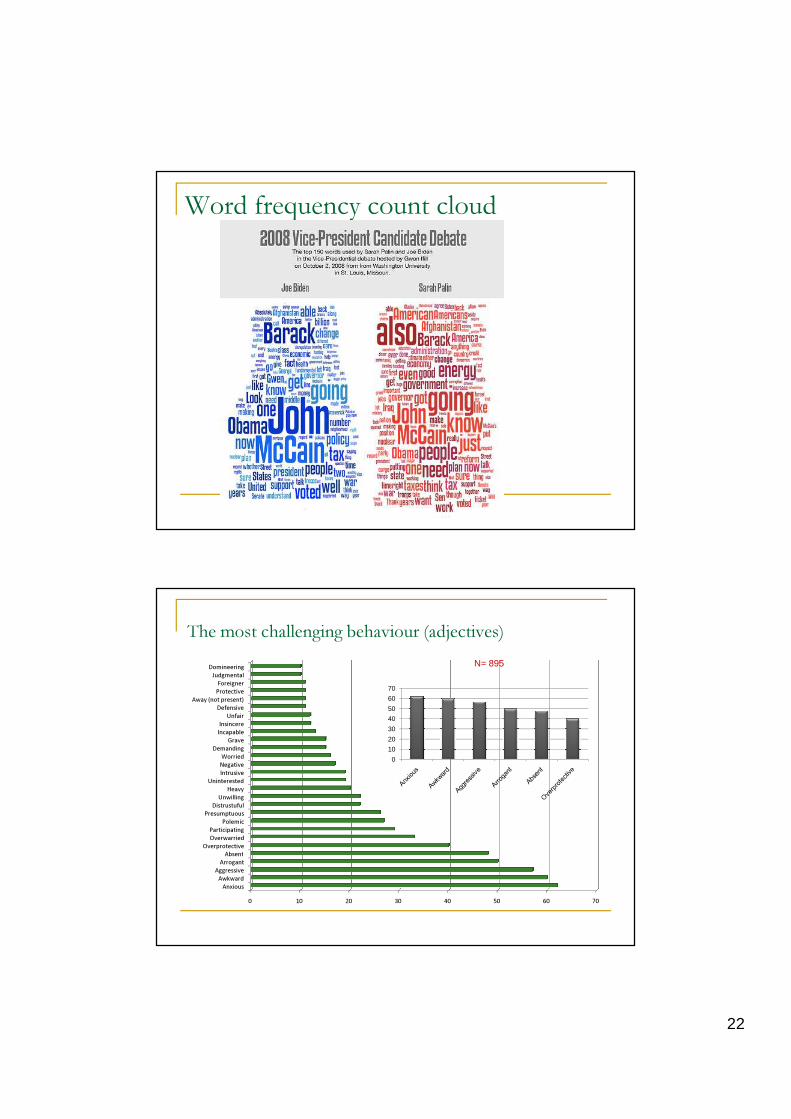
22
Word frequency count cloud
The most challenging behaviour (adjectives)
0 10 20 30 40 50 60 70
Anxious
Awkward
Aggressive
Arrogant
Absent
Overprotective
Overwarried
Participating
Polemic
Presumptuous
Distrustuful
Unwilling
Heavy
Uninterested
Intrusive
Negative
Worried
Demanding
Grave
Incapable
Insincere
Unfair
Defensive
Away (not present)
Protective
Foreigner
Judgmental
Domineering
0
10
20
30
40
50
60
70
N= 895

23
Associazione di parole
� Analisi dedicata allo studio dei sistemi di co-occorrenza (parola-parola)� Indica quanto coppie di parole tendono ad
essere associate tra loro.� Due indicatori statistici: indice di associazione
e chi-quadro.� Indici di associazione: Jaccard, Dice, Salton� Indici di dipendenza della distribuzione: chi-
quadro.
Misure di associazione
C= Cosine Coefficient (Salton 1989)
( , )x y
C x yx y
∩=×
χ² =Chi Square
22 ( )O E
Eχ −=∑
C(x,y): unità lessicale
x∩y: numero di co-occorrenze
nell’unità lessicale
x,y: numero occorrenze nell’unità
lessicale
O: observed frequency of
lexical unit
E: expected frequency of
lexical unit

24
Coseno di Salton + Chi quadro
Verificare sulla tabelle di distribuzione chi-quadro i livelli di significativita
χ² = 3.84 (p < .05); 6.63 ( p < .01); 10.83 ( p < .001)
Coseno di Salton� da 0 a 1 � si comporta come la correlazione
Riportare i risultati.
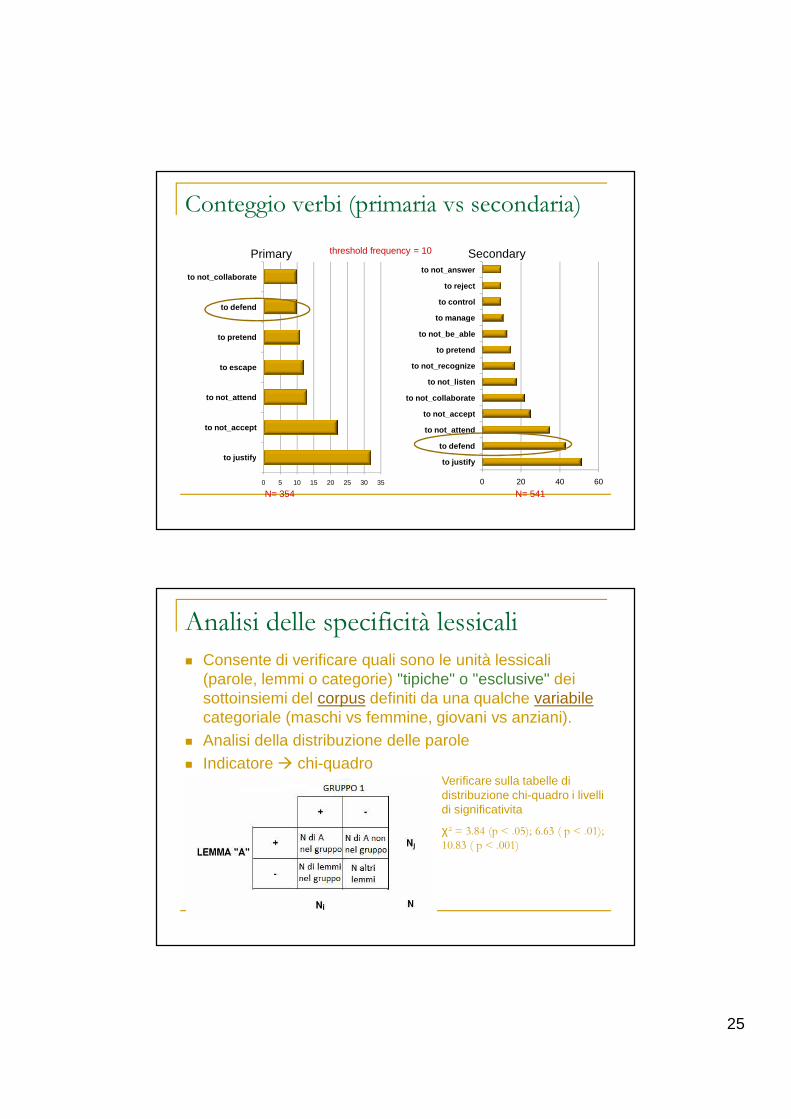
25
Conteggio verbi (primaria vs secondaria)
to justify
to not_accept
to not_attend
to escape
to pretend
to defend
to not_collaborate
0 5 10 15 20 25 30 35
Primary
to justify
to defend
to not_attend
to not_accept
to not_collaborate
to not_listen
to not_recognize
to pretend
to not_be_able
to manage
to control
to reject
to not_answer
0 20 40 60
Secondarythreshold frequency = 10
N= 354 N= 541
Analisi delle specificità lessicali
� Consente di verificare quali sono le unità lessicali (parole, lemmi o categorie) "tipiche" o "esclusive" dei sottoinsiemi del corpus definiti da una qualche variabilecategoriale (maschi vs femmine, giovani vs anziani).
� Analisi della distribuzione delle parole� Indicatore � chi-quadro
Verificare sulla tabelle di distribuzione chi-quadro i livelli di significativita
χ² = 3.84 (p < .05); 6.63 ( p < .01);
10.83 ( p < .001)

26
Esempio praticoSPECIFICITY - Hong Kong
----------- ----
LEMMA CHI2 SUB TOT
disturb 18,58 15 17classmate 17,72 19 24instruction 16,98 14 16teacher 15,35 20 27lesson 14,14 26 39unable 13,29 10 11not_listen 12,22 11 13classroom 11,85 32 53
SPECIFICITY - USA
----------- ----
LEMMA CHI2 SUB TOT
task 10,92 51 62
defiant 10,14 24 26
time 9,99 27 30
direction 8,37 21 23
blurt 6,22 14 15
constant 6,17 31 38
aggressive 6,06 17 19
refuse 5,11 21 25
SPECIFICITY - Sud Africa----------- ----
LEMMA CHI2 SUB TOT
talkative 20,43 41 43aggressive 19,82 40 42not_complete 18,41 34 35distract 16,71 51 58disobedient 14,08 27 28fight 13,69 30 32bully 11,59 36 41leave 11,47 47 56disruptive 8,43 33 39noisy 7,99 17 18task 5,79 40 51
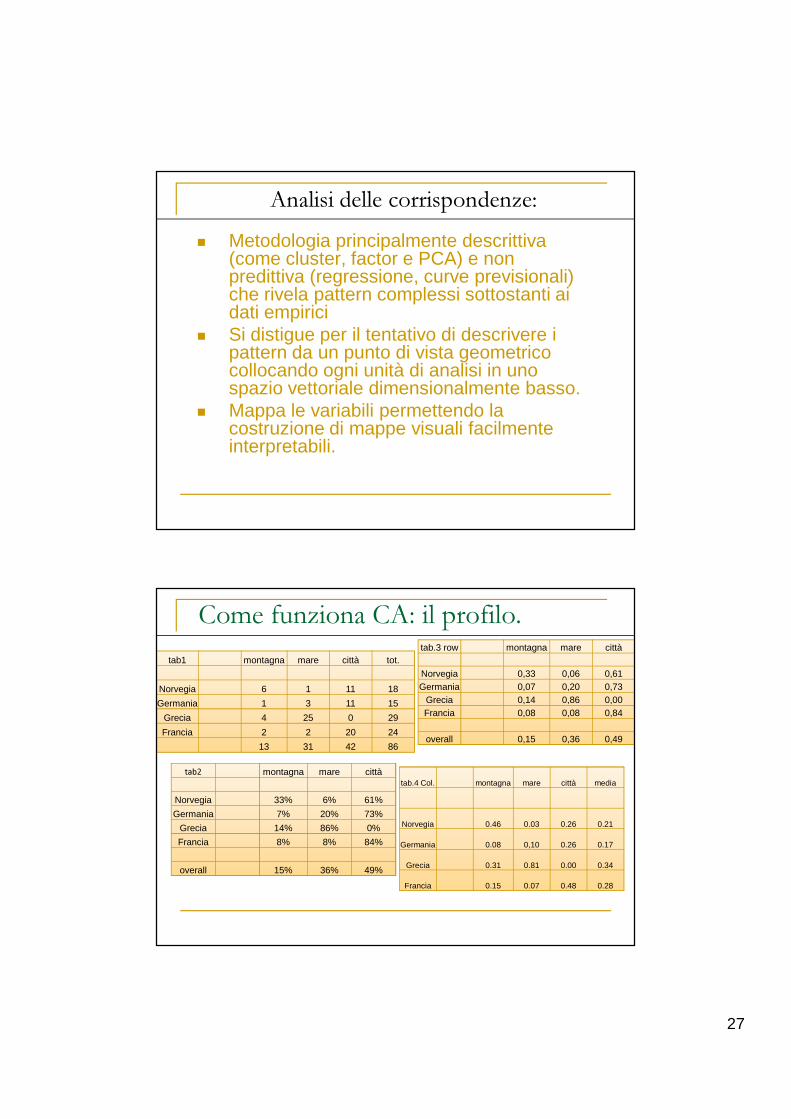
27
� Metodologia principalmente descrittiva (come cluster, factor e PCA) e non predittiva (regressione, curve previsionali) che rivela pattern complessi sottostanti ai dati empirici
� Si distigue per il tentativo di descrivere i pattern da un punto di vista geometrico collocando ogni unità di analisi in uno spazio vettoriale dimensionalmente basso.
� Mappa le variabili permettendo la costruzione di mappe visuali facilmente interpretabili.
Analisi delle corrispondenze:
Come funziona CA: il profilo.
tab1 montagna mare città tot.
Norvegia 6 1 11 18
Germania 1 3 11 15
Grecia 4 25 0 29
Francia 2 2 20 24
13 31 42 86
tab2 montagna mare città
Norvegia 33% 6% 61%
Germania 7% 20% 73%
Grecia 14% 86% 0%
Francia 8% 8% 84%
overall 15% 36% 49%
tab.3 row montagna mare città
Norvegia 0,33 0,06 0,61Germania 0,07 0,20 0,73
Grecia 0,14 0,86 0,00Francia 0,08 0,08 0,84
overall 0,15 0,36 0,49
tab.4 Col. montagna mare città media
Norvegia 0.46 0.03 0.26 0.21
Germania 0.08 0,10 0.26 0.17
Grecia 0.31 0.81 0.00 0.34
Francia 0.15 0.07 0.48 0.28
28
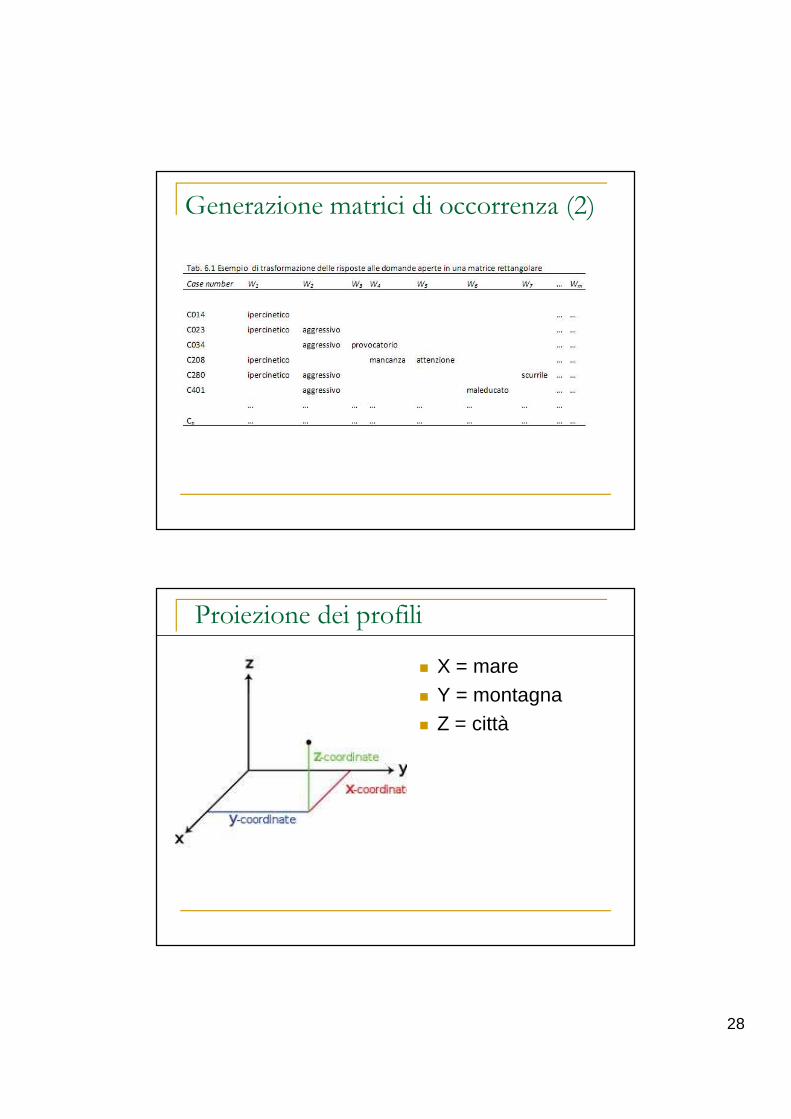
Generazione matrici di occorrenza (2)
Proiezione dei profili
� X = mare� Y = montagna� Z = città
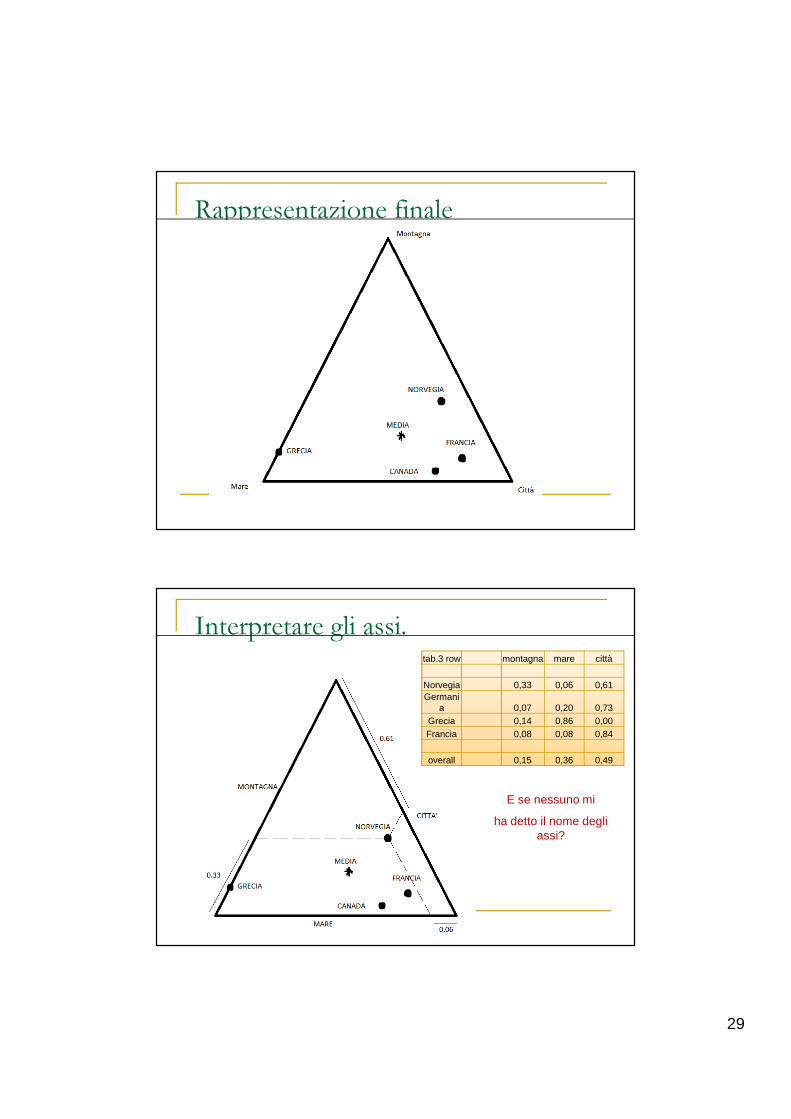
29
Rappresentazione finale
Interpretare gli assi.tab.3 row montagna mare città
Norvegia 0,33 0,06 0,61Germani
a 0,07 0,20 0,73Grecia 0,14 0,86 0,00Francia 0,08 0,08 0,84
overall 0,15 0,36 0,49
E se nessuno mi
ha detto il nome degli assi?
30
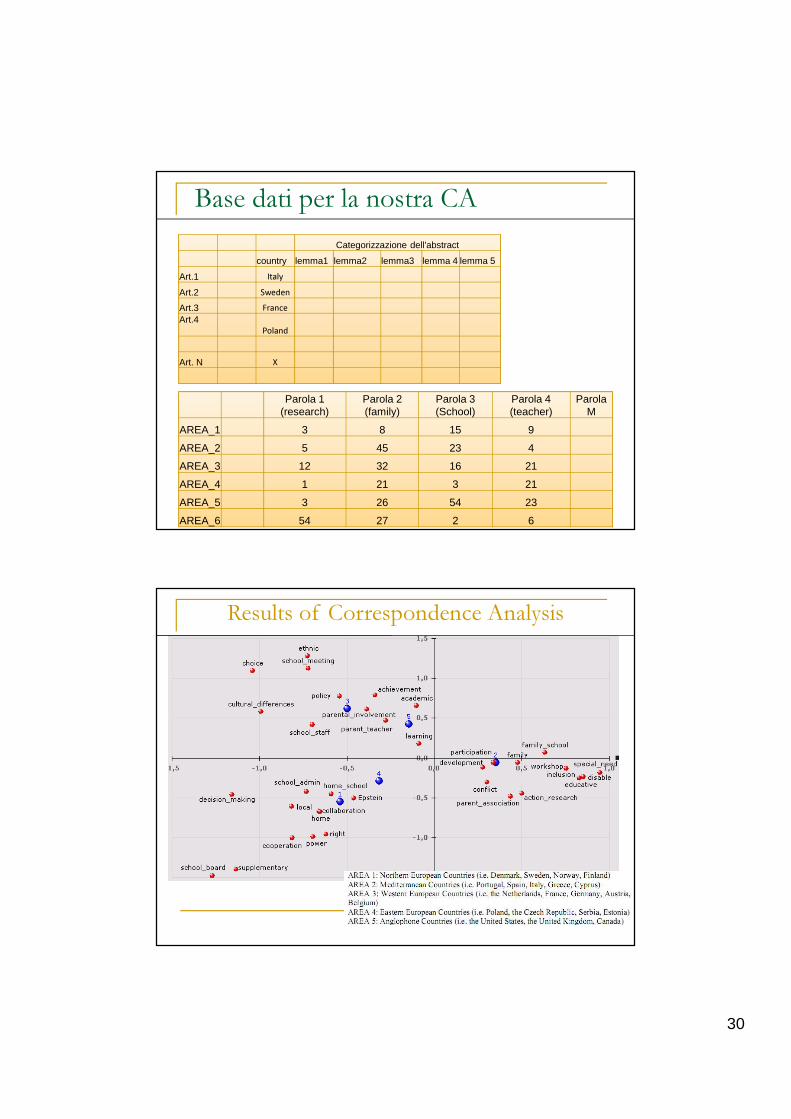
Base dati per la nostra CA
Categorizzazione dell'abstract
country lemma1 lemma2 lemma3 lemma 4 lemma 5
Art.1 Italy
Art.2 Sweden
Art.3 France
Art.4Poland
Art. N X
Parola 1 (research)
Parola 2 (family)
Parola 3 (School)
Parola 4 (teacher)
Parola M
AREA_1 3 8 15 9
AREA_2 5 45 23 4
AREA_3 12 32 16 21
AREA_4 1 21 3 21
AREA_5 3 26 54 23
AREA_6 54 27 2 6
Results of Correspondence Analysis

31
Numero di dimensioni
� Inerzia� è il corrispettivo lessicale della varianza nelll’analisi delle corrispondenze.
� Al pari dell’analisi delle componenti principali (ACP) e dell’analisi fattoriale (AF) anche nell’analisi delle corrispondenze vanno predilette soluzioni dimensionali in grado di spiegare il 60-70% della varianza complessiva.
Decomporre l’inerzia
� Massa� è la percentuale di dati che si riferiscono alla variabile bersaglio, è il peso assoluto della modalità della variabile nel database..
� Contributo all’inerzia (CRT) � ci dice quale percentuale della varianza del fattore viene spiegata dalle diverse modalità della variabile
� Qualità� ci dice quanto la modalità della variabile contribuisce al significato dell’asse

32
Interpretare gli assi
Risultati

33
Risultati
� Asse X � la diversificazione del fronte di ricerca ERNAPE può essere spiegato a partire dall’opposizione tra gli studi che si focalizzano sul contributo della famiglia (AREA 2) da studi in cui la parola famiglia non appare (AREA 1 e 3) come conseguenza di uno spostamento nell’attenzione dei ricercatori.
� Asse Y � le distanze geometriche di A3, A1 e A2 sono equivalenti (proiezione dei punti su Y). La dimensione segrega quindi paesi nordici e continentali dalle ricerche effettuare nell’area mediterranea. Interpretazione che ricalca la cornice teorica di Ravn (2003, 2005)
Cosa ci portiamo a casa.
� Logiche e contesti dell’analisi matematica di dati testuali� Basi dati primarie e secondarie di dati� Strumenti di analisi� Analisi testuale delle corrispondenze.


















