
MESSAGGI E COMUNICAZIONE - istanze.unibo.it · 7.1.1 La funzione di appartenenza ad insiemi sfumati...
250
1 MESSAGGI E COMUNICAZIONE Trasformazione delle simiglianze in programmazione logica 1. RAPPRESENTAZIONE DELLA CONOSCENZA 1.1 Messaggi e comunicazione 1.2 Rappresentazione simbolica 2. IL CONCETTO DI SIMIGLIANZA 2.1 Induzione di una metrica su insiemi 2.2 Definizione di una metrica associativa 2.3 Il processo di inferenza 2.4 Il trattamento dell'incertezza 3. IL PROCESSO DI ASTRAZIONE 3.1 Principali meccanismi di astrazione 3.2 Il processo di categorizzazione 3.3 Algoritmi genetici 4. I CRITERI DI CLASSIFICAZIONE 4.1 Sistemi di classificazione 4.2 Teoria matematica della classificazione 5. LOGICA MATEMATICA 5.1 La logica proposizionale 5.1.1 Semantiche della logica proposizionale 5.1.2 Teorie proposizionali 5.1.3 Logica proposizionale come sistema deduttivo 5.2 Logica classica del primo ordine 5.2.1 Linguaggi della logica del primo ordine 5.2.2 Semantica della logica del primo ordine 5.2.3 Teorie del primo ordine 5.2.4 Logica del primo ordine come sistema deduttivo 5.3 Logica del primo ordine multi-ordinata 5.4 Il metodo di risoluzione 5.4.1 La forma in clausole 5.4.2 Le regole di risoluzione 5.4.3 Soluzione lineare 5.5 Logica classica del secondo ordine 5.5.1 Linguaggi logici del secondo ordine 5.5.2 Semantica della logica del secondo ordine 5.5.3 Teorie del secondo ordine 5.5.4 Logica del secondo ordine come sistema deduttivo 5.5.5 Espressioni con predicati e funzioni 5.6 Logica modale 5.6.1 Logica proposizionale modale 5.6.2 Logica modale del primo ordine 6. PROGRAMMAZIONE LOGICA 6.1 Ragionamento non monotonico 6.2 Clausole di Horn 6.3 Metodo di risoluzione SLD 6.4 Semantica di un linguaggio di programmazione 6.5 Base di conoscenza basata sulla logica dei predicati 6.6 Un filtro prolog
Transcript of MESSAGGI E COMUNICAZIONE - istanze.unibo.it · 7.1.1 La funzione di appartenenza ad insiemi sfumati...

1
MESSAGGI E COMUNICAZIONE Trasformazione delle simiglianze in programmazione logica 1. RAPPRESENTAZIONE DELLA CONOSCENZA 1.1 Messaggi e comunicazione 1.2 Rappresentazione simbolica 2. IL CONCETTO DI SIMIGLIANZA 2.1 Induzione di una metrica su insiemi 2.2 Definizione di una metrica associativa 2.3 Il processo di inferenza 2.4 Il trattamento dell'incertezza 3. IL PROCESSO DI ASTRAZIONE 3.1 Principali meccanismi di astrazione 3.2 Il processo di categorizzazione 3.3 Algoritmi genetici 4. I CRITERI DI CLASSIFICAZIONE 4.1 Sistemi di classificazione 4.2 Teoria matematica della classificazione 5. LOGICA MATEMATICA 5.1 La logica proposizionale 5.1.1 Semantiche della logica proposizionale 5.1.2 Teorie proposizionali 5.1.3 Logica proposizionale come sistema deduttivo 5.2 Logica classica del primo ordine 5.2.1 Linguaggi della logica del primo ordine 5.2.2 Semantica della logica del primo ordine 5.2.3 Teorie del primo ordine 5.2.4 Logica del primo ordine come sistema deduttivo 5.3 Logica del primo ordine multi-ordinata 5.4 Il metodo di risoluzione 5.4.1 La forma in clausole 5.4.2 Le regole di risoluzione 5.4.3 Soluzione lineare 5.5 Logica classica del secondo ordine 5.5.1 Linguaggi logici del secondo ordine 5.5.2 Semantica della logica del secondo ordine 5.5.3 Teorie del secondo ordine 5.5.4 Logica del secondo ordine come sistema deduttivo 5.5.5 Espressioni con predicati e funzioni 5.6 Logica modale 5.6.1 Logica proposizionale modale 5.6.2 Logica modale del primo ordine 6. PROGRAMMAZIONE LOGICA 6.1 Ragionamento non monotonico 6.2 Clausole di Horn 6.3 Metodo di risoluzione SLD 6.4 Semantica di un linguaggio di programmazione 6.5 Base di conoscenza basata sulla logica dei predicati 6.6 Un filtro prolog

2
7. TRASFORMAZIONE DELLE SIMIGLIANZE 7.1 Descrizione di oggetti come insieme di attributi 7.1.1 La funzione di appartenenza ad insiemi sfumati 7.1.2 Rappresentazione tramite proprietà 7.1.3 Implicazione semantica 7.1.4 Definizione di un'algebra sulle proprietà 7.2 Ruolo delle irrilevanze nella formazione di concetti 7.3 Simiglianze nel caso di corrispondenza biunivoca 7.3.1 Corrispondenze, trasformazioni, simiglianze 7.3.2 Costruzione di una metrica sull'insieme dei naturali 7.4 Sistemi di deduzione basati su regole 7.5 Logiche a più di due valori 7.5.1 Logica modale non monotonica intuizionista 7.5.2 Logica modale non monotonica a tre valori 7.5.3 Logica modale non monotonica a quattro valori 7.6 Rappresentazione in uno spazio vettoriale binario 7.7 Sistemi ipotetici in comunicazione reciproca 7.8 Trasformazioni T da |P(X) a |P(X) 7.9 Rappresentazioni di regole tramite corrispondenze 7.10 Sistemi di regole ricavabili da corrispondenze 7.11 Leggi di riduzione dei sistemi di regole 7.12 Equivalenza di sistemi di regole 7.13 Definizione di trasformazioni particolari 7.14 Misura dell'affidabilità delle deduzioni 7.15 Interpretazione statistica dell'affidabilità 7.16 Generalizzazione operazioni OR AND XOR 7.17 Implicazione semantica di raggruppamento 7.18 Conclusioni

3
Introduzione La comunicazione, i messaggi, la capacità di comunicare scam- biando messaggi sono aspetti fondamentali della natura umana e forse della vita stessa. Intorno alla metà di questo secolo l'ingegneria dei sistemi di comunicazione ha subito un notevole impulso; se la prima metà del novecento ha assistito allo sviluppo dei sistemi analogici, la seconda metà ha assistito allo sviluppo dei sistemi di comu- nicazione numerici o digitali. Una delle ragioni risiede nel fatto che le apparecchiature in grado di elaborare i segnali numerici sono in genere più sempli- ci di quelle che elaborano dati analogici, in particolare si é visto che le informazioni poste in una forma discreta sono più facilmente trasmesse, con grande affidabilità anche in un canale disturbato. Nella teoria dell'informazione é possibile identificare eventi fisici di cui essa fornisce un modello; come ogni modello anche la teoria dell'informazione é riduttiva, trascura certi eventi e di certi altri ignora alcuni aspetti. Nella teoria dell'informazione i messaggi sono più importanti del loro supporto materiale, la forma é più importante della materia; accanto al mondo della fisica, dove imperano le forze e le quantità di moto, e dove le azioni e le reazioni sono rette da equazioni specifiche, esiste un mondo in cui l'energia, magari piccolissima, associata ad un messaggio può scatenarne una gran- dissima. Nel mondo dell'informazione ciò che conta non sono gli oggetti ma le differenze tra gli oggetti, e l'informazione risie- de nelle differenze che generano altre differenze e che si propa- gano lungo un canale di comunicazione dalla sorgente all'utiliz- zatore. Comunque quando si parla di differenze queste debbono essere ri- ferite ad un osservatore che sia in grado di percepirle e quindi, eventualmente di riprodurle: questo carattere relativo dell'in- formazione é così fondamentale che spesso é sottaciuto. In realtà non ha neppur senso parlare di sorgente d'informazione se non si specifica anche quale sia l'utente di questa sorgente: una sorgente appare diversa a utenti diversi, perciò si dovrebbe sempre far riferimento a coppie sorgente-utente. É importante osservare che la produzione d'informazione da parte di una sorgente può essere un atto spontaneo oppure provocato. In particolare é l'interesse dell'utente che sollecita la sor- gente a fornire messaggi che corrispondono ad informazione utile in vista dei fini dell'utente stesso. Riassumendo, l'utente sarà in grado di impiegare l'informazione solo se potrà: 1) rilevare l'informazione pertinente ai propri fini; 2) ricondurre tale informazione ad una propria esperienza prece- dente che consenta la comprensione del significato dei messaggi ricevuti. É importante sottolineare che il processo di comunicazione fra una sorgente ed un utente é multiforme e si svolge su diversi livelli: A) livello del rilevamento delle differenze che costituiscono l'informazione; B) livello della comprensione del significato delle differenze rilevate;

4
C) livello dell'impiego delle differenze rilevate e comprese. Questi tre livelli non sempre sono separabili con precisione e, se lo sono, non sempre si possono ordinare gerarchicamente; occorre ricordare che la teoria di Shannon si situa nettamente al livello A), livello sintattico o tecnico, mentre non tocca né il livello B), livello semantico, né quello C), livello pragmatico. Nel presente lavoro si propone un approccio sinergico a tutti e tre questi livelli A), B) e C) integrando il livello sintattico con il livello semantico e il livello pragmatico, utilizzando le tecniche della programmazione logica. Ovviamente, il risultato presenta un marcato riduzionismo e note- voli semplificazioni concettuali, d'altra parte l'idea di due si- stemi a stati finiti in comunicazione reciproca governati da un motore inferenziale che utilizza regole, produce inferenze e tra- smette messaggi tramite un canale di comunicazione, si presenta come un affascinante modello per lo studio dei processi fondamen- tali alla base della comprensione e trasmissione di informazione tra sistemi in comunicazione reciproca.

5
1. LA RAPPRESENTAZIONE DELLA CONOSCENZA 1.1 Messaggi e comunicazione La capacità di comunicare é una caratteristica notevole dei sistemi intelligenti. Acquisizione, immagazzinamento, recupero, ed infine uso dell'informazione sono processi di estrema importanza, che si verificano con facilità nel corso dell'esperienza umana. La diffusione nella nostra realtà sociale di continui scambi di messaggi ci rende familiari alcuni concetti che necessitano, per una loro reale comprensione, di una pausa di riflessione. Tramite la comunicazione e l'elaborazione di strutture di messaggi si compiono atti che vengono riconosciuti come manifestazione di intelligenza. L'uomo ha costruito diverse macchine in grado di manipolare messaggi tra cui, la più recente, l'elaboratore elettronico. Claude E. Shannon pubblicò, nel 1948, una memoria dal titolo: "A mathematical theory of communication". Il nome di Shannon é legato alla ricerca di una codificazione dei messaggi, scelti da un insieme noto, che permettesse di trasmetterli con precisione e uniformità in presenza di rumore. Il problema di una codificazione efficiente e le sue conseguenze costituiscono il centro della teoria dell'informazione. In effetti, ogni comunicazione comporta una qualche specie di codificazione. In teoria qualsiasi messaggio può essere codificato nel sistema binario ed essere trasmesso elettricamente come una sequenza di impulsi o di assenza di impulsi. Si é dimostrato che campionando periodicamente un segnale continuo, come per esempio un'onda sonora, e rappresentando le ampiezze di ogni campione con valori ad esse più approssimati di un insieme discreto di valori, si può rappresentare e codificare perfino tale onda continua come una sequenza di cifre binarie con una precisione grande a piacere. Gli elaboratori elettronici funzionano utilizzando la rappresentazione binaria di numeri e cifre, i numeri e le cifre poi vengono utilizzati per manipolare i messaggi. Come si rappresentano numeri e cifre in un linguaggio binario? Nella codifica ASCII si considerano otto bit a formare un carattere: carattere 8 bit 0 = 00110000 1 = 00110001 2 = 00110010 3 = 00110011 ... A = 01000001 B = 01000010 C = 01000011 D = 01000100 ... Prendiamo due persone che, da due stanze separate, si scambino dei messaggi conversando. Ogni messaggio viene codificato in parole appartenenti a frasi di una determinata lingua, viene trasformato in onde sonore che attraversano le stanze e la parete, viene raccolto dall'orecchio

6
e trasformato in impulsi elettrochimici, riconosciuto come essere un messaggio e non rumore, suddiviso in frasi e parole e finalmente viene interpretato come significativo da parte dell'ascoltatore. Utilizzando delle tecnologie telematiche la comunicazione potrebbe avvenire anche nel seguente modo: Il soggetto A scrive un messaggio codificandolo in parole e frasi di una certa lingua, il sistema lo codifica in una forma binaria e lo trasmette a notevole distanza, un sistema ricevente ritrasforma il messaggio in frasi e parole che possono essere lette dal soggetto B che riceve il messaggio per lui significativo. Supponiamo che un soggetto C intercetti il segnale trasmesso lungo la linea nel momento in cui esso si presenta come una successione di impulsi. Se il messaggio trasmesso fosse : "Le mele sono mature", il soggetto C rivelerebbe la seguente successione di impulsi: "0100110001000101001000000100110101000101010011000100010100100000 0101001101001111100111001001111001000000100110010100000101010100 010101010101001001000101" che si presenta come una successione di impulsi all'apparenza governata dal caso in cui compare una maggior frequenza di zeri rispetto agli uni (93 zeri su 152 contro 59). Se ricevessimo dallo spazio una successione di impulsi del tipo di quella sopra descritta probabilmente la attribuiremmo al puro caso e ben difficilmente ad intelligenze che desiderano mettersi in contatto con la nostra cultura inviando messaggi. Pur essendoci delle regolarità nella successione di impulsi, tali regolarità sono difficilmente individuabili e senza la chiave interpretativa il segnale appare casuale, anche se ogni impulso é in realtà strettamente determinato dal messaggio e nessun bit può essere alterato senza alterare il messaggio stesso. La probabilità di ottenere per puro caso il segnale binario di cui sopra é 0.5 elevato alla 152 cioé circa due volte ogni dieci miliardi di miliardi di miliardi di miliardi di miliardi di di tentativi (1.75 E-46). Un altra possibilità consiste nell'utilizzare un unico impulso: l'interruttore di una lampadina. In tal caso i due soggetti A e B potrebbero essersi accordati sul fatto che qualora una lampadina ben in vista si accende allora si desume che: "le mele sono mature". In tali circostanze un unico impulso é sufficiente e la sua probabilità é di un mezzo (0.5). Il messaggio trasmesso é lo stesso, ma il canale di trasmissione ha potenzialità molto diverse. Dal punto di vista del soggetto C il messaggio é costituito da un singolo impulso che si presenta oppure no. Sarebbe per lui molto più facile mettere in relazione il verificarsi di un tale evento con il fatto che "le mele sono mature", sempre che tutto ciò possa avere un senso per il soggetto C. Per trasmettere messaggi diversi sarebbero necessari altri canali predisposti appositamente allo scopo. Aumentare il numero di messaggi trasmessi sullo stesso canale significa aumentare la complessità della codifica dei messaggi stessi. É possibile ridurre la complessità della codifica dei messaggi aumentando il numero dei canali, anche se in realtà la complessità del messaggio globale non viene ridotta, infatti colui che riceve i messaggi dovrà fare una sintesi riconoscendo ogni canale che potenzialmente trasporta un certo tipo di

7
messaggio. Un modo per farsi un'idea di che cosa significa "rappresentazione della conoscenza" consiste nel considerare la seguente ipotetica situazione: due sistemi che comunicano tramite un canale informa- tivo.
(fig 1.1) Due sistemi S1, S2 in comunicazione tramite un canale si scambia- no messaggi relativamente a qualcosa che di solito si referenzia come la "realtà" esterna, ovvero oggettiva, nel senso di cono- scibile o riconoscibile da entrambi i sistemi S1, S2. Se denotiamo con R la realtà oggettiva, nel senso di "insieme di informazioni" condivisibili dai due sistemi allora il messaggio che S1 può trasmettere a S2, facente riferimento a qualche in- formazione di R, dovrà essere rappresentabile sia in R1, rappre- sentazione di R per S1, sia in R2 rappresentazione di R per S2. Ora, lasciando in sospeso il problema della generazione delle rappresentazioni R1 ed R2 a partire da una interazione di S1 e S2 con R, ci si può concentrare nell'analisi del flusso di messaggi nel canale di comunicazione tra S1 e S2. Infatti due sistemi co- municano attraverso un canale di comunicazione che possiede una determinata struttura sia fisica che logica. Consideriamo un caso semplice, due sistemi che comunicano scam- biandosi messaggi selezionati da un determinato repertorio finito attraverso un canale binario. Ogni messaggio si presenta nella forma di successione di bit per es. <010010111...>. Ad ogni mes- saggio é associato un insieme ordinato di bit, tale associazione é condivisa da entrambi i sistemi. Consideriamo un caso banale: il canale di comunicazione può es- sere solo in ON oppure in OFF. In altri termini il canale consi- ste di un interruttore che può essere o acceso o spento.

8
La realtà condivisibile R tra S1 e S2 consiste semplicemente in un bit. Ipotizziamo che una bella ragazza e il suo spasimante si accordi- no di scambiarsi un messaggio di tipo binario: se la ragazza si trova in casa tiene aperta la finestra, quando esce chiude la fi- nestra. Per lo spasimante la finestra aperta o chiusa rappresenta un ca- nale di comunicazione binario: <1> La ragazza si trova in casa :- Finestra aperta. <0> La ragazza é uscita :- Finestra chiusa. Se i due amanti non possiedono altri canali di comunicazione, al- lora, per lo spasimante la ragazza risulta inconoscibile ed é rappresentabile da qualcosa, su cui si può fantasticare, ma che sostanzialmente c'é quando la finestra é aperta e che non c'é quando la finestra é chiusa. L'idea che lo spasimante si crea ( la rappresentazione della ra- gazza nella testa dello spasimante ) riguardo alla ragazza e alla situazione potrebbe essere varia e articolata ma certamente fon- data solamente su rappresentazioni generate da situazioni del tutto diverse da quelle relative allo stato della finestra, da altri canali di comunicazione, da altre situazioni; in altri ter- mini da una realtà diversa da quella condivisa con la ragazza nella realtà. Dall'esempio emerge che la realtà R condivisa da due sistemi che comunicano sia una mera convenzione tra S1 e S2; tale convenzione si esplica in una relazione tra una rappresentazione arbitraria in S1 e una rappresentazione corrispondente in S2 altrettanto ar- bitraria e sostanzialmente inconoscibile nella reale forma. Allora il processo di comunicazione consiste in un processo di corrispondenza tra stati arbitrari di S1 e S2. Vediamo un altro esempio: supponiamo che il messaggio tra S1 ed S2 sia: ho visto un cavallo alato. S2 che riceve il messaggio da S1 cerca di far corrispondere la rappresentazione che S1 gli evoca tramite il messaggio con la propria esperienza passata; cerca pertanto di ricordare se tra i propri ricordi vi sia l'esperienza di aver visto un cavallo ala- to. La parola cavallo recupera dalla memoria un animale quadrupe- de correlato di un certo numero di caratteristiche, immagini, e- sperienze, ecc... in altri termini rappresentazioni. La caratte- ristica di essere un animale con le ali non trova riscontro nelle rappresentazioni di S2, per cui S2 risponde ad S1 che non "crede" al messaggio che S1 gli ha inviato; S1 di rimando dice: era in una raffigurazione di un famoso pittore. S1 allora riconosce il messaggio iniziale come vero, infatti egli stesso aveva in prece- denza avuto occasione di vedere il quadro a cui fa riferimento S2; semplicemente non aveva collegato tale rappresentazione al messaggio si S1, d'altra parte la parola cavallo denota, nel con- testo considerato, sia un animale che un disegno: oggetti estre- mamente diversi. Eppure chiunque riconosce facilmente che una raffigurazione di un cavallo e l'animale cavallo in carne ed ossa possiedono, indubbiamente, in comune qualcosa di essenziale. Consideriamo due sistemi S1, S2 identici, con rappresentazioni i- dentiche e che si evolvono nel tempo in maniera identica. Supponiamo che S1 decida di informare S2 sul proprio stato, per far ciò invierà ad S2 un messaggio. Il messaggio rappresenterà lo stato di S1. La comunicazione tra S1 ed S2 consiste, come abbiamo visto, nel mettere in relazione uno stato (una rappresentazione) di S1 con uno stato di S2 e avviene in due passi: 1) S1 seleziona un messaggio corrispondente ad un certo stato

9
m1 tra tutti i messaggi possibili e lo invia a S2. 2) S2 riceve un messaggio corrispondente ad m1 e lo collega allo stato identico nella propria rappresentazione. Tutto ciò non modifica la situazione di S2. In questo caso l'informazione trasmessa é nulla. Da notare che l'informazione, misurata secondo la teoria di Shan- non, presente nel messaggio non é nulla, anzi tanto più vasto é l'insieme dei messaggi possibili tanto più il contenuto in- formativo del messaggio é elevato, il problema consiste nel fat- to che S2 conosce a priori il contenuto del messaggio, pertanto il messaggio diviene inutile. Emerge, da quanto esposto, l'importanza di condensare l'informa- zione trasmessa in un messaggio alle sole parti non prevedibili dal ricevente. Ad esempio la frase: il cavallo ha quattro gambe; non apporta al- cuna informazione a chi già lo sa, poiché é un messaggio cor- rispondente ad una rappresentazione già esistente, pertanto tale messaggio diviene inutile e privo di contenuto informativo. La sinteticità osservabile nell'uso comune del linguaggio mette in evidenza, in maniera a volte sorprendente, l'importanza di questo principio di economia nei messaggi trasmessi. La comunicazione tra S1 ed S2 coinvolge un ulteriore processo di comprensione del messaggio: il processo di induzione che S2 com- pie rispetto a ciò che S1 comunica, in altri termini la comuni- cazione dipende dalle aspettative di S2 nei confronti di S1: da ciò che S1 sa o crede di sapere sugli stati di S1. In questo contesto diviene interessante il concetto di sincroni- cità: la coincidenza del messaggio o parti del messaggio con le aspettative di S2, rende S2 più sicuro rispetto alle proprie credenze riguardo ad S1; il messaggio che non contraddice le ipo- tesi di S2 rafforza S2 nelle proprie credenze; un messaggio con- tradittorio costringe S2 a rivedere le proprie ipotesi su S1. Di più se un particolare messaggio, estremamente improbabile si allinea, anche per caso, a determinati schemi interpretativi al- lora tali schemi raggiungono un livello di verosimiglianza diffi- cilmente ritrattabile da parte di S2. Supponiamo che S1 ed S2 siano sistemi a stati finiti (n stati). In particolare che S1 disponga di n messaggi M1 tra cui poter se- lezionare il messaggio da inviare ad S2, e che S2 sia in grado di ricevere m messaggi M2 e riconoscerli. Se denotiamo con M3 l'in-
sieme dei k messaggi in comune tra M1 ed M2, M1 ∩ M2 = M3, allora solo k degli n messaggi di S1 risulta comprensibile ad S2, nel senso di messaggi riconoscibili. Affinché un nuovo messaggio msg1(k+1) possa essere riconosciuto da S2 occorre che si stabili-
sca una relazione tra msg1(k+1) ∈ M1 e un messaggio msg2(k+1) ∈ M2 di S2. Tale relazione si può stabilire solo se msg1(k+1) deriva da una combinazione di messaggi di M3 oppure da altri canali di comunicazione. Nel caso non esistano altri canali di comunicazione allora msg1(k+1) é una funzione di un sottoinsieme di M3, il nuovo mes- saggio risulta essere una combinazione di un sottoinsieme parti- colare di vecchi messaggi. Infatti se S1, S2 sono due sistemi che comunicano tramite k pos- sibili messaggi attraverso un unico canale, in altri termini nel caso non esistano altri canali di comunicazione, l'unico modo per comprendere un nuovo messaggio a disposizione di S2 é interpre- tarlo attraverso la trasmissione di un insieme di messaggi rico- noscibili. In sostanza nessun nuovo messaggio può essere appreso, ma sono possibili solo raggruppamenti di messaggi in un nuovo codice. In pratica l'unica possibilità di creare nuovi messaggi consiste

10
in una operazione di codifica. Supponiamo, ora, che i sitemi S1, S2 siano macchine a stati fini- ti, come ad esempio lo sono i calcolatori elettronici. In particolare consideriamo la memoria M1 di S1: M1 può essere visto come il risultato prodotto dal sistema di memorizzazione a disposizione del sistema S1; in M1 sono rappresentati tutti i messaggi selezionabili da S1. In M1 vi saranno un certo numero di stati possibili n, ed un certo numero di stati significativi k, corrispondenti a messaggi memorizzati. Per come sono costruiti i computer gli stati elementari di base sono stati binari 0,1. La memoria M1 diviene rappresentabile da un vettore di n stati binari: n bit. I bit della memoria possono essere raggruppati in maniera da as- sumere un significato simbolico comprensibile da un utilizzatore umano. La comunicazione tra un elaboratore elettronico ed un essere uma- no viene infatti mediata dal linguaggio. Da quanto tratteggiato risulta evidente come la rappresentazione della conoscenza in generale sia un processo estrememente fumoso ed arbitrario: l'uomo opera con una conoscenza limitata e incer- ta. Criteri di valutazione come la completezza e la consistenza relativamente ad una concreta rappresentazione della conoscenza sono applicabili solo in domini ristretti e ben definiti. A questo proposito vorrei riportare alcune considerazioni filoso- fiche che alcuni pensatori hanno espresso in relazione ai proces- si cognitivi. Ogni sapere nel mondo si riferisce ad oggetti particolari e viene conquistato, con determinati metodi, da punti di vista determina- ti. (Karl Jaspers) É perciò errato assolutizzare in un sapere totale un qualsiasi sapere. Volontà di potenza e volontà di verità nella scienza sono spesso in contraddizione, solo chi si pone umilmente in ascolto può interpretare correttamente i messaggi particolarmente con- trastanti le credenze che si sono affermate nella storia e nella scienza in un particolare periodo storico. Cosa sono ragione ed intelletto? La ragione é un moto senza un punto fisso! É stimolo a criticare ogni posizione acquisita. Si contrappone alla tendenza ad adagiarsi su dogmi fissati. Esige ponderazione - si contrappone all'arbitrio. Sviluppa la conoscenza di sé rendendo consapevoli i limiti. Esige un incessante ascolto e sa attendere. É il contrario dell'ebbrezza affettiva immediata. La ragione é volontà di unità. Essa non può tralasciare nulla di ciò che esiste, nulla trascu- rare, nulla escludere. Essa é in sé stessa apertura illimitata. La ragione é attratta da ciò che le é più estraneo. La ragione non vuole ingannare sé stessa mistificando la real- tà. La ragione é indissolubilmente legata alla volontà di comunica- zione. La verità senza comunicazione appare ad essa identica alla non- verità. Non é la ragione che porta la verità, ma la cerca insieme a co- lui che incontra, ascoltando, interrogando, sperimentando. La verità non può essere esaurita nel tempo.

11
Per l'uomo nel tempo la verità esiste solo nella forma della ve- rità che diviene tale nella comunicazione. Noi non sappiamo gli uni degli altri nulla di essenziale fuorché quando entriamo in reciproca comunicazione. La ragione ha un potente avversario che si annida dentro di noi, c'é qualcosa che fa parte della vita, una pulsione all'afferma- zione della trascendenza. C'é qualcosa in noi che desidera non la ragione ma il mistero. Tutto ciò che la ragione non afferra spinge potentemente contro di essa e allora siamo allettati irresistibilmente da questa e- splosione e non ci basta più l'efficacia razionalmente fondata ma la magia assurge a dogma, non la fidata fedeltà ma l'avventu- ra. Ma anche in questo caso la potenzialità della comunicazione si esprime nella varietà espressiva, per esempio nel parlare per immagini, nell'interminabile spiegare la spiegazione. Nonostante tutto un messaggio, sia pur nella sua incertezza, vie- ne trasmesso e comunicato e può essere parzialmente interpretato dalla ragione. La perversione della non-ragione consiste nell'impulso diretto a disfarsi della propria realtà, verso cui si é responsabili, ed a spostarla su qualcos'altro, su un arcano, un essente autentico, lasciandosi prendere dal fascino del mormorio di ciò che manca di ragione. Come presunta verità dell'essenza non resta che una fantasia non vincolante, risolventesi in sentimenti di commozione privi di af- fetto. É facile cadere in un invasamento: questa tendenza a rendere as- soluto il proprio pensiero, a farne l'unico vero, a identificare se stesso con la cosa coinvolgendosi in essa con interessamento egocentrico, ed allontanare quanto non favorisce la propria cau- sa. Affinché nel mondo del pensiero si instauri un pieno disinteres- se, é necessario che coloro che pensano siano interiormente in- dipendenti. E tale l'uomo diviene solo quando é spenta in lui la volontà di potenza, e forse anche solo quando si trova di fatto in condizioni di impotenza. L'impotenza sembra la condizione per operare effettivamente in modo libero e destare la libertà. Nell'accontentarsi senza voler imporre a tutti i costi la propria volontà, il singolo uomo ha la probabilità di contribuire per la sua piccolissima parte a far sì che si crei uno spazio in cui la verità possa prosperare.

12
1.2 Rappresentazione simbolica Consideriamo il compito di rappresentare un problema. Se utilizziamo un qualsiasi supporto di memorizzazione dei dati del problema, allora la struttura del supporto influenzerà la forma della nostra rappresentazione. Una prima possibilità per rappresentare un problema é utilizza- re dei simboli; caso della logica simbolica. In altri termini si tratta di rappresentare le relazioni e le ca- ratteristiche di un problema come espressioni simboliche logiche. Notevoli sforzi sono stati profusi nel tentativo di aumentare il campo di possibilità di questo tipo di espressione. Il comportamento del cervello é troppo complicato per poter es- sere rappresentato con la logica simbolica. Si possono utilizzare frames: combinazione di strumenti e metodi che descrivono le attività del cervello umano senza confinarla nella logica simbolica. Il metodo della logica simbolica é in letteratura conosciuto co- me l'approccio dichiarativo, mentre il metodo alternativo, dei frames, é chiamato approccio procedurale. Questi due approcci si sono contrapposti e completati l'uno con l'altro nel corso dello sviluppo dell'intelligenza artificiale. Esiste un terzo approccio, che considera la conoscenza e l'infor- mazione stessa così come sono rispettandone la struttura e la forma. Nello studio dell'intelligenza artificiale, é naturale avere un certo interesse riguardo al comportamento del cervello umano e a come esso lavora, in particolare rivolgere particolare attenzione a come sia possibile rappresentare il suo funzionamento con un computer. Una proprietà fondamentale della conoscenza é che essa deve es- sere affidabile e vera. É possibile a volte rendere, una conoscenza inaffidabile, affi- dabile chiarendo le condizioni sotto cui essa é vera. Specificando cioé il contesto interpretativo e le condizioni per le quali un'affermazione generale, inaffidabile, diviene verifi- cabile e vera. Le informazioni che utilizziamo nella vita di tutti i giorni sono per lo più inaffidabili, ed é difficile rendere tutta questa conoscenza affidabile semplicemente specificando sotto quali con- dizioni essa risulta vera. Nella nostra vita quotidiana la maggior parte dell'informazione é basata sulla nostra specifica esperienza ma, questa, non é universalmente vera. Noi possiamo fidarci di un fatto quando le nostre osservazioni lo confermano. Possiamo dire che tali fatti sono conoscenza quando più persone ritengono tali fatti conoscenza condivisa. Le leggi sono un altro aspetto che deve essere tenuto presente. Le leggi hanno, di solito, la forma: SE si verifica il tal fatto ALLORA il tal altro fatto é vero. Occorre avere particolare cura per generalizzare un fatto o una legge come universale; infatti le leggi hanno spesso solo una va- lidità particolare, contestuale, non universale. Perciò, é sempre importante accertarsi che la legge sia usata nel modo appropriato e nel dominio di competenza per poter deci- dere se la conclusione che traiamo corrisponde a un fatto affida- bile oppure no.

13
A causa del fatto che non ci possiamo garantire sulla verità delle nostre affermazioni, la conoscenza nella vita di tutti i giorni é frammentaria e non organizzata. Essa é anche contrad- ditoria. La conoscenza, in ambito accademico, non può essere contradditoria. Comunque, nella vita di tutti i giorni, noi pos- siamo convivere con una conoscenza contradditoria fintanto che tale conoscenza non diviene contradditoria in un qualche senso immediato. Quando la conoscenza diviene contradditoria, tentiamo di espanderla e di aggiungere alcune condizioni extra per render- la non contradditoria. La conoscenza richiede spiegazione. La conoscenza senza spiegazione é semplicemente un assioma. Generalmente la spiegazione é fornita utilizzando la ricostru- zione a partire dagli elementi principali. In altre parole, spieghiamo un concetto combinando i concetti parziali che lo compongono e i concetti elementari. La conoscenza aumenta con lo studio ed é ulteriormente espansa dall'inferenza. Comunque non si può considerare affidabile il risultato di un'inferenza se non vengono confermati i fatti a cui tale inferenza porta. Consideriamo due sistemi S1 ed S2 che comunicano tramite un cana- le di comunicazione binario. Proponiamoci di analizzare il processo di riconoscimento di un messaggi inviato da S1 ad S2. Il processo consiste sostanzialmente nel collegare un messaggio msg1 inviato nel canale binario, arbitraria successione di bit, con una rappresentazione x1 interna al sistema S2. Allora x1 = f(msg1), la rappresentazione x1 di S2 é esprimibile in funzione del messaggio msg1. In altri termini tutto funziona come se fosse x1 = msg1 ; la rappresentazione x1 può essere i- dentificata con il messaggio ad essa collegata. Essendo msg1 una stringa di bit, anche x1, la rappresentazione interna di S2 cor- rispondente a msg1 messaggio inviato da S1, può essere conside- rata come una stringa di bit. Infatti ogni rappresentazione interna presente nella memoria di un calcolatore corrisponde ad una stringa di bit. Eppure noi parliamo di oggetti, di attributi, di dati, ecc... Oggetti, attributi, dati, ecc... non sono altro che interpreta- zioni, in particolare ogni raggruppamento arbitrario di bit po- trebbe essere associato ad una specifica interpretazione. É chiaro comunque che solo alcuni tra tutti i raggruppamenti di bit possibili sono significativi; a tali raggruppamenti corri- spondono infatti i simboli che utilizziamo nel colloquio con l'e- laboratore. Il problema diviene, dunque, quale é la relazione tra i simboli che utilizziamo e le stringhe di bit; essenzialmente é un pro- blema di codifica. Se V = <b1,b2,b3,...,bn> é il vettore binario con cui rappre- sentiamo la memoria di S2, allora ogni sottoinsieme di V puo es- sere connesso ad un simbolo per noi significativo. Il messaggio msg1 inviato da S1 può allora essere considerato come un sottoinsieme x1 di V.

14
2. LE SIMIGLIANZE 2.1 Induzione di una metrica su insiemi In una struttura di memorizzazione di dati le informazioni sono memorizzate in termini di rappresentazioni e tali rappresentazio- ni si avvalgono di un supporto fisico che é specifico del siste- ma utilizzato. Supponiamo di poter parlare in termini di proprietà o attributi che identificano le rappresentazioni e che da tali rappresenta- zioni si possa risalire alle informazioni originarie. Ogni proprietà raggruppa tutte le entità che posseggono la pro- prietà medesima; ogni proprietà crea pertanto una partizione dello spazio di rappresentazione. É possibile considerare due rappresentazioni più o meno simili (o dissimili) sulla base di considerazioni concernenti le pro- prietà che esse mostrano. In particolare considerazioni su quali e quante proprietà esse hanno in comune o si presentano nell'una e non nell'altra. Il concetto di dissimiglianza é un criterio metrico che ci con- sente di associare le ricorrenze di dati in maniera dinamica sen- za la necessità di creare rigide classi di equivalenza. É possibile far dipendere il processo di associazione tra la ri- correnza A e la ricorrenza B (oppure l'insieme di ricorrenze B1,B2,...,Bm) da un parametro di soglia che misura il grado di dissimiglianza oltre il quale le ricorrenze non sono più asso- ciabili. Descrivendo gli oggetti della nostra rappresentazione, le enti- tà, in termini di proprietà possiamo creare dei processi asso- ciativi e generare degli schemi classificatori basati su conside- razioni intrinseche agli oggetti stessi e in cui tutto il conte- nuto informativo rappresentato é presente nel dato. Le classi ottenute in tal modo sono dinamiche e si autogenerano nel modello sulla base delle ricorrenze specifiche presenti in memoria. Uno spazio di memorizzazione contiene dati, i dati sono sostan- zialmente rappresentabili ( almeno per un elaboratore ciò é ve- ro) tramite un vettore binario finito. Possedere un criterio associativo basato sulle proprietà delle rappresentazioni in memoria produce una semplificazione in molti problemi di memorizzazione e ricerca delle informazioni. É possibile considerare simili due rappresentazioni in memoria quando il peso degli attributi comuni alle due rappresentazioni supera il peso degli attributi diversi. Per fissare le idee consideriamo l'insieme degli stati possibili di un generico sistema di memorizzazione e rappresentiamolo con un insieme di vettori V = <v1,v2,...,vn>. Costruiamo un criterio di dissimiglianza che consenta di associa- re oppure no uno stato possibile vk nello spazio dei vettori V da un arbitrario stato vl o da un insieme di stati vl1,vl2,...,vlm. Generiamo perciò una funzione distanza definita tra i vettori dello spazio V. La funzione costruita sul rapporto tra la misura dell'insieme differenza simmetrica e la misura dell'insieme unione tra due vettori di V, vk e vl ci fornisce una metrica particolarmente in- teressante per trattare la differenza tra rappresentazioni. L'insieme differenza simmetrica contiene le proprietà che appar- tengono ad una rappresentazione ma non all'altra e viceversa. L'insieme unione contiene le proprietà che appartengono o ad una rappresentazione o all'altra. In altre parole il rapporto tra il numero di attributi che sono

15
in comune e il numero di attributi complessivamente coinvolti nella descrizione degli oggetti confrontati é una funzione me- trica e ad essa attribuiamo un ruolo determinante nel processo di associazione e di valutazione delle simiglianze tra rappresenta- zioni. La funzione sopra descritta induce effettivamente una metrica ed é notevole notare come essa non dipenda da tutte le proprietà definite su V ma dipenda solamente da quelle appartenenti ad uno o all'altro tra gli insiemi confrontati; di più essa ha una va- lidità del tutto generale. La caratteristica di cui appena detto risulta particolarmente va- lida in quanto non richiede una definizione preliminare di tutto lo spazio metrico generato (tutti gli attributi gestiti dal si- stema, tutti i domini, ecc...) si presenta invece in maniera di- namica: ogni attributo viene aggiunto solo nel momento in cui viene utilizzato; tipicamente quando un oggetto che possiede tale attributo entra in relazione col sistema di memorizzazione. In altri termini, la dissimiglianza tra due entità rappresentate nel sistema viene misurata sulla base delle proprietà effettiva- mente manifestate dalle entità confrontate e non sulla base di proprietà ipotetiche o possibili: il riferimento é circostan- ziale e determinato e non assoluto e trascendente.

16
2.2 Definizione di una metrica associativa Descriviamo la notazione che utilizzeremo nel seguito. Il simbolismo di cui faremo uso si considera come una particolare forma di linguaggio scientifico. Quest'ultimo si distingue dal linguaggio ordinario per la sua precisione, in quanto un segno o un insieme di segni di un linguaggio scientifico deve soddisfare l'esigenza di avere, per coloro che l'impiegano, un unico signi- ficato, e questo non sempre avviene nel linguaggio ordinario. A meno che non venga specificato diversamente, in un certo conte- sto, ai fini di una maggiore chiarezza espositiva, utilizzeremo la seguente notazione: a) Simboli del calcolo delle proposizioni: P - proposizione
¬P - negazione P & Q - congiunzione P v Q - disgiunzione P -> Q - implicazione P <-> Q - doppia implicazione b) Simboli del calcolo delle classi
x ∈ α - appartenenza α ⊂ β - inclusione α = β - identità α' - complementazione α ∩ β - intersezione α ∪ β - unione c) Quantificatori (x) - universale (per ogni)
(∃x) - esistenziale (esiste un) Definiamo ora una metrica associativa su un arbitrario insieme di oggetti, consideriamo alcune definizioni.
Definizione 2.2.1 (Definizione di σ-anello) Sia X un insieme non vuoto e S un sottoinsieme non vuoto di |P(X), potenza di X, S é un anello se:
(i) xi, xj ∈ S => xi \ xj ∈ S
∞ (ii) xn ∈ S (n) ∈ |N => ∪ xn ∈ S n=1
Se, di più, X ∈ S, allora S é una σ-algebra.

17
Definizione 2.2.2 (Definizione di Spazio Topologico) Sia T una topologia per X; (x,T) spazio topologico:
1) ∅ ∈ T e X ∈ T
2) (xi),(xj) xi,xj ∈ T ∪ xk ∈ T k=i,j
3) (x1),(x2),...,(xn) con n finito x1,x2,...,xn ∈ T n
∩ xk ∈ T k=1
allora T é una σ-algebra. TEOREMA 2.2.3
Se ƒ: X --> Y e T é un σ-anello di sottoinsiemi di Y, -1
allora ƒ (y): y ∈ T é un σ-anello di sottoinsiemi di X.
Se S é un σ-anello di sottoinsiemi di X, allora -1
y : y ⊂ Y, ƒ (y) ∈ S é un σ-anello di sottoinsiemi di Y.

18
(fig 2.1) TEOREMA 2.2.4 INDUZIONE DI SPAZI METRICI ISOMETRICI SU INSIEMI
Sia µ1 : T1 --> |R+ \ ∞ una misura finita sulla topologia T1 (X,T1) , vale :
(i) µ1 é non negativa
(ii) µ1(∅) = 0
(iii) µ1 é numerabilmente additiva
(iv) µ1 é finita
di più valga (v) µ1(xi) ≠ 0 (xi) ∈ T1 , xi ≠ ∅ Siano (X,T1) , (Y,T2) due spazi topologici. -1
Sia ƒ : T1 ---> T2 tale che ƒ (∅) = ∅ .
Consideriamo la seguente funzione µ2 : T2 ---> |R+ \ ∞

19
-1
così definita: µ2(y) = µ(ƒ (y)) , y ∈ T2
allora µ2 é una misura finita infatti :
(i) µ2 é non negativa -1
(ii) µ2(∅) = µ1(ƒ (∅)) = µ1(∅) = 0
(iii) µ2 é numerabilmente additiva essendolo µ1
(iv) µ2 é finita -1
e allora vale µ2(yi) = µ1(ƒ (yi)) = µ1(xi)
dove xi ∈ T1 e yi ∈ T2 . Poniamo
µ1(xi ∆ xj) a) dx (xi,xj) = kx --------------- (xi),(xj) ∈ T1 µ1(xi ∪ xj)
µ2(yi ∆ yj) b) dy (yi,yj) = ky --------------- (yi),(yj) ∈ T2 µ2(yi ∪ yj) dx e dy sono distanze e inducono spazi metrici su T1 e T2 Mx = (T1,dx) , My(T2,dy)
allora (xi),(xj),(yi),(yj) xi,xj ∈ T1 yi,yj ∈ T2
2.2.5) dx (xi,xj) = β dy (yi,yj) vale a dire Mx é isometrico a My. Dimostrazione della 2.2.5). -1 -1 -1
poiché ƒ (yi) \ ƒ (yj) = ƒ (yi \ yj) ,
-1 ∞ ∞ -1 ƒ ( ∪ yn ) = ∪ ƒ ( yn ) e n=1 n=1 -1
µ2 ( y ) = µ1 (ƒ ( y )) si ha

20
-1
µ2 ( yi ∆ yj) = µ1 (ƒ ( yi ∆ yj ) = -1 -1
= µ1 (ƒ ( yi ) ∆ ƒ ( yj )) = µ1 ( xi ∆ xj ) e -1
µ2 ( yi ∪ yj) = µ1 (ƒ ( yi ∪ yj ) = -1 -1
= µ1 (ƒ ( yi ) ∪ ƒ ( yj )) = µ1 ( xi ∪ xj ) . allora
µ2(yi ∆ yj) µ1(xi ∆ xj) dy (yi,yj) = ky ------------- = ky ------------- =
µ2(yi ∪ yj) µ1(xi ∪ xj)
ky µ1(xi ∆ xj) 1 = ---- kx ------------- = --- dx (xi,xj)
kx µ1(xi ∪ xj) β kx
dove β = ---- ky Esempio:
consideriamo una ƒ : X ---> Y dove X = [1,4] Y = [1,2[ , [3,4[ , [5,6]
ƒ(x) = x x ∈ [1,2[
ƒ(x) = x + 1 x ∈ [2,3[
ƒ(x) = x + 2 x ∈ [3,4]
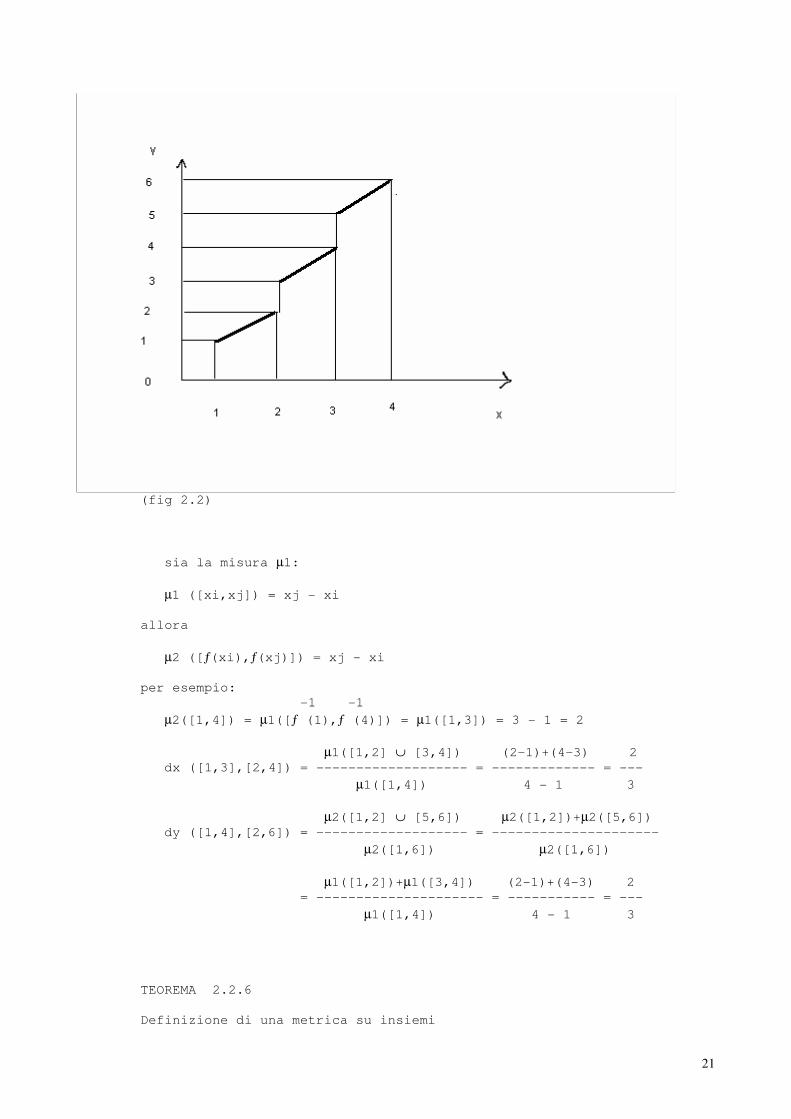
21
(fig 2.2)
sia la misura µ1:
µ1 ([xi,xj]) = xj - xi allora
µ2 ([ƒ(xi),ƒ(xj)]) = xj - xi per esempio: -1 -1
µ2([1,4]) = µ1([ƒ (1),ƒ (4)]) = µ1([1,3]) = 3 - 1 = 2
µ1([1,2] ∪ [3,4]) (2-1)+(4-3) 2 dx ([1,3],[2,4]) = ------------------- = ------------- = ---
µ1([1,4]) 4 - 1 3
µ2([1,2] ∪ [5,6]) µ2([1,2])+µ2([5,6]) dy ([1,4],[2,6]) = ------------------- = ---------------------
µ2([1,6]) µ2([1,6])
µ1([1,2])+µ1([3,4]) (2-1)+(4-3) 2 = --------------------- = ----------- = ---
µ1([1,4]) 4 - 1 3 TEOREMA 2.2.6 Definizione di una metrica su insiemi

22
Sia X un insieme non vuoto e S un sottoinsieme ≠ ∅ di |P(X), la potenza di X.
Sia µ : S ---> |R+ \ ∞ una misura su S.
Allora la funzione d : S x S ---> |R+ , k ∈ |R+ definita come:
a) d(∅,∅) = 0 per xi=xj=∅
b) d(xi,xj) = k se µ(xi ∪ xj) = 0
µ(xi ∆ xj) c) d(xi,xj) = k ------------ (xi), (xj), xi,xj ∈ S µ(xi ∪ xj) xi,xj ≠ ∅
µ(xi ∪ xj) ≠ 0 dove
(xi ∆ xj) = (xi ∪ xj) \ (xi ∩ xj) é la differenza asimmetrica; soddisfa a:
1) 0 ≤ d(xi,xj) < +∞ 2) d(xi,xj) = 0 sse xi=xj 3) d(xi,xj) = d(xj,xi)
4) d(xi,xj) + d(xi,xk) ≥ d(xj,xk) (xi),(xj),(xk) ∈ S e pertanto (S,d) é uno spazio metrico e d é una distanza. Dimostrazione : La dimostrazione dei punti 1) 2) e 3) segue immediatamente dalle definizioni. Per dimostrare il punto 4) procediamo come segue:
4) d(x1,x2) + d(x1,x3) - d(x2,x3) ≥ 0 (x1),(x2),(x3) ∈ S LEMMA 2.2.7
A.1) µ(x1 ∩ x2) ≥ µ(x1 ∩ x3) - [ µ(x3) - µ(x3 ∩ x2) ]

23
Dimostrazione della A.1: poiché la misura dell'unione di due insiemi disgiunti é sempre uguale alla somma della misura dei due insiemi vale:
per ogni xm,xn ∈ S
B.1 µ(xm) = µ(xm ∩ xn) + µ(xm \ xn)
B.2 µ(xm \ xn) = µ(xm) - µ(xm ∩ xn) in particolare
B.3 µ(x1 ∩ x3) = µ(x1 ∩ x3 ∩ x2) + µ((x1 ∩ x3) \ x2)
B.4 µ(x3) - µ(x3 ∩ x2) = µ(x3 \ x2)
ora poiché per ogni xm, xn, xk ∈ S vale: (con xm' si indica il complementare di xm)
C.1 xm \ xn = xm ∩ xn'
C.2 (xm \ xn) \ [xm \ (xn ∪ xk)] = = (xm ∩ xn') ∩ [xm ∩ (xn ∪ xk)']' = = (xm ∩ xn') ∩ [xm' ∪ (xn ∪ xk)] applicando le regole di De Morgan
(A ∪ B)' = A' ∩ B' e
(A ∩ B)' = A' ∪ B' la C.2 diviene
C.2 [(xm ∩ xn') ∩ xm'] ∪ [(xm ∩ xn') ∩ (xn ∪ xk)] =
[(xm ∩ xn' ∩ xn) ∪ (xm ∩ xn' ∩ xk)] = xm ∩ xn' ∩ xk

24
(fig. 2.3) perciò
C.3 (xk ∩ xm) \ xn = (xk ∩ xm) ∩ xn' = xk ∩ xm ∩ xn'
C.4 (xm \ xn) \ [xm \ (xn ∪ xk)] = (xk ∩ xm) \ xn da cui
D.1 µ(xm \ xn) = µ((xk ∩ xm) \ xn) + µ(xm \ (xn ∪ xk)) quindi applicata nel nostro caso:
D.2 µ(x3 \ x2) = µ((x1 ∩ x3) \ x2) + µ(x3 \ (x2 ∪ x1))

25
(fig. 2.4) Allora la A.1, per la B.3 e per la B.4, diviene
A.1 µ(x1 ∩ x2) ≥ µ(x1 ∩ x3) - [µ(x3) - µ(x3 ∩ x2)]
µ(x1 ∩ x2) ≥ µ(x1 ∩ x3 ∩ x2) + µ((x1 ∩ x3) \ x2) -
- [µ(x3) - µ(x3 ∩ x2)]
µ(x1 ∩ x2) ≥ µ(x1 ∩ x3 ∩ x2) + µ((x1 ∩ x3) \ x2) - µ(x3 \ x2) per la D.2 si ottiene
µ(x1 ∩ x2) ≥ µ(x1 ∩ x3 ∩ x2) + µ((x1 ∩ x3) \ x2) -
- µ((x1 ∩ x3) \ x2) - µ(x3 \ (x2 ∪ x1)) pertanto
µ(x1 ∩ x2) ≥ µ(x1 ∩ x3 ∩ x2) - µ(x3 \ (x2 ∪ x1)) che dimostra l'asserto (Lemma 2.2.7) LEMMA 2.2.8
A.2 µ(x1 ∪ x2) = µ(x1) + µ(x2) - µ(x1 ∩ x2) la dimostrazione é immediata. Consideriamo la 4)

26
4) d(x1,x2) + d(x1,x3) - d(x2,x3) ≥ 0
µ(x1 ∆ x2) µ(x1 ∆ x3) µ(x2 ∆ x3) ------------ + ------------ - ------------ ≥ 0 µ(x1 ∪ x2) µ(x1 ∪ x3) µ(x2 ∪ x3)
µ(x1 ∪ x2) - µ(x1 ∩ x2) µ(x1 ∪ x3) - µ(x1 ∩ x3) ------------------------- + ------------------------- -
µ(x1 ∪ x2) µ(x1 ∪ x3)
µ(x2 ∪ x3) - µ(x2 ∩ x3) - ------------------------- ≥ 0 µ(x2 ∪ x3) Consideriamo il termine:
µ(x2 ∪ x3) - µ(x1 ∩ x3) µ(x2) + µ(x3) - 2 µ(x2 ∩ x3) T.1 ------------------------- = ------------------------------
µ(x2 ∪ x3) µ(x2) + µ(x3) - µ(x2 ∩ x3)
dal lemma A.1 µ(x2 ∩ x3) ≥ µ(x2 ∩ x1) - [µ(x1) - µ(x1 ∩ x3)] otteniamo
µ(x2 ∪ x3) - µ(x1 ∩ x3) ------------------------- ≤ µ(x2 ∪ x3)
µ(x2) + µ(x3) - 2 µ(x2 ∩ x1) -[µ(x1) - µ(x1 ∩ x3)] ≤ ------------------------------------------------------ µ(x2) + µ(x3) - µ(x2 ∩ x1) + [µ(x1) - µ(x1 ∩ x3)]
µ(x2) + µ(x3) + 2µ(x1) - 2µ(x2 ∩ x1) - 2µ(x1 ∩ x3) = ----------------------------------------------------
µ(x1) + µ(x2) + µ(x3) - µ(x2 ∩ x1) - µ(x1 ∩ x3)
µ(x1) + µ(x2) - µ(x2 ∩ x1) - µ(x2 ∩ x1) = --------------------------------------------------- +
µ(x1) + µ(x2) - µ(x2 ∩ x1) + [µ(x3) - µ(x1 ∩ x3)]
µ(x1) + µ(x3) - µ(x1 ∩ x3) - µ(x1 ∩ x3) + --------------------------------------------------- =
µ(x1) + µ(x3) - µ(x1 ∩ x3) + [µ(x2) - µ(x2 ∩ x1)]
µ(x1 ∪ x2) - µ(x1 ∩ x2) = ----------------------------------- +
µ(x1 ∪ x2) + [µ(x3) - µ(x1 ∩ x3)]
µ(x1 ∪ x3) - µ(x1 ∩ x3) + -----------------------------------
µ(x1 ∪ x3) + [µ(x2) - µ(x2 ∩ x1)]

27
poiché [µ(xm) - µ(xm ∩ xn)] ≥ 0 vale:
µ(x1 ∪ x2) - µ(x1 ∩ x2) ----------------------------------- +
µ(x1 ∪ x2) + [µ(x3) - µ(x1 ∩ x3)]
µ(x1 ∪ x3) - µ(x1 ∩ x3) + ----------------------------------- ≤ µ(x1 ∪ x3) + [µ(x2) - µ(x2 ∩ x1)]
µ(x1 ∪ x2) - µ(x1 ∩ x2) µ(x1 ∪ x3) - µ(x1 ∩ x3) ≤ ------------------------- + ------------------------- µ(x1 ∪ x2) µ(x1 ∪ x3) che dimostra la tesi. (punto 4) Esempio:
d(xi,xk) + d(xk,xj) ≥ d(xi,xj) Consideriamo come elementi dell'insieme S tre intervalli in |R. x1 = [1,4] x2 = [3,5] x3 = [2,6]
µ([1,4] ∆ [2,6]) (2-1)+(6-4) 3 d(x1,x3) = ------------------ = ------------- = ---
µ([1,4] ∪ [2,6]) (6-1) 5
µ([2,6] ∆ [3,5]) (3-2)+(6-5) 2 d(x3,x2) = ------------------ = ------------- = ---
µ([2,6] ∪ [3,5]) (6-2) 4
µ([1,4] ∆ [3,5]) (3-1)+(5-4) 3 d(x1,x2) = ------------------ = ------------- = ---
µ([1,4] ∪ [3,5]) (5-1) 4 3 2 22 15 3 --- + --- = ---- > ---- = --- 5 4 20 20 4 1 2 3 4 5 6
x1 []
x1 []
x1 [] (fig 2.5)

28
2.3 Il processo di inferenza Il processo di inferenza é essenzialmente un processo di prova ed errore. Quando un programma analizza un certo stato, deve essere in grado di decidere se sta andando nella direzione giusta o se deve cam- biare direzione. Questa decisione é un compito estremamente dif- ficile, in essa si riassume tutta la potenzialità dell'algoritmo di soluzione. Metodi euristici cercano di produrre inferenze generate dal com- puter procedendo nello stesso modo in cui noi procederemmo sulla base della nostra esperienza. Affinché un programma possa produrre inferenze corrette é ne- cessario che utilizzi quei principi euristici che sono più effi- caci per uno scopo particolare: più lo scopo é particolare e definito più i principi euristici possono essere efficaci. É importante a questo scopo scoprire come sia possibile utiliz- zare la conoscenza euristica umana nei programmi a computer. I metodi di inferenza possono essere classificati in : 1) inferenza probabilistica; 2) inferenza induttiva; 3) inferenza basata sul ragionamento del senso comune 4) inferenza basata sul ragionamento qualitativo 5) inferenza basata sul ragionamento analogico Il processo di scoprire le similarità e di usarle in una infe- renza é esso stesso un'inferenza nota come principio di inferen- za, e tale inferenza esiste ovunque e ovunque viene utilizzata. Infatti ovunque nel ragionamento umano troviamo questo principio di inferenza: il riconoscimento delle similarità. Non si potrebbe vivere senza operare con tale inferenza. Nel giudizio che diamo, costantemente, su di un fatto presente, teniamo in considerazione tutti i fatti precedenti che presentano delle relazioni con il fatto attuale e il nostro giudizio si basa sulla quantità di similarità che riusciamo a scoprire. Inferire una conclusione da un'inferenza - regola di inferenza - trovando le similarità dalle sue ipotesi é un importante tecni- ca. Le similarità si manifestano grazie ad un accordo o concomi- tanza delle rappresentazioni dei fatti considerati. Anche nel ca- so di accordo perfetto, ci sono molte forme in cui si manifesta questo accordo, per esempio, l'accordo di due simboli, l'accordo di due liste di simboli, l'accordo di due strutture o l'accordo di due strutture grafiche. Nel caso di accordo non perfetto, vi sono ancora parecchie possibilità. Basta pensare a cosa inten- diamo quando diciamo che due stringhe di caratteri sono simili, o che due strutture grafiche sono simili, o due frasi, oppure quan- do riconosciamo similarità fra due figure bidimensionali, dise- gni, melodie, storie e così via. Anche se il riconoscimento di similarità, che sta alla base dell'inferenza, non é stato studiato a sufficienza, rimane co- munque un problema veramente cruciale. Per eseguire con successo un tale riconoscimento, dobbiamo trova- re similarità tra un determinato oggetto e il nostro modello in- terno oppure, se vogliamo, la rappresentazione dell'oggetto nella nostra base di conoscenza. Questo processo di riconoscimento é anche un processo di infe- renza. Quindi, riconoscimento, inferenza, e conoscenza sono con- cetti tutti strettamente correlati. É particolarmente difficile rappresentare il nostro complesso

29
mondo utilizzando soltanto regole. Comunque nel caso di due sistemi S1, S2 collegati tramite un ca- nale di comunicazione binario esiste la possibilità di definire le similarità esistenti tra i messaggi che possono viaggiare nel canale di comunicazione: poiché i messaggi non sono altro che vettori binari se trasformiamo tali vettori in uno spazio di rap- presentazione opportuno nel quale ad ogni bit viene associata una proprietà dotata di significato allora la presenza di proprietà comuni a due messaggi ci fornisce un criterio di similarità uti- lizzabile per valutare la similarità dei messaggi. Normalmente la comunicazione avviene tramite lo scambio di parole organizzate in frasi di senso compiuto. Una idea che si é sviluppata nel tempo tra gli informatici é stata quella di classificare le parole: questo tentativo ha dato origine ai thesaurus. Vediamo un esempio di thesaurus per parole in generale. Partiamo dal presupposto che il mondo in cui viviamo contiene una vasta collezione di conoscenze che può essere considerata anche come una collezione di concetti. Poiché i concetti possono essere espressi da parole, una colle- zione di parole può supportare l'intera collezione della nostra conoscenza. L'unità base del linguaggio é la parola. Molta conoscenza può essere espressa come frasi che sono costi- tuite da combinazioni di parole. Allora, le parole, considerate come unità base delle frasi, costituiscono la base per esprimere la conoscenza, ed é veramente importante organizzarle in maniera sistematica. La maniera in cui noi classifichiamo le parole dipende da come le riconosciamo, comprendiamo, e da come rappresentano il mondo. Tutto ciò si presenta come un compito molto difficile e non si é ancora in grado di creare una classificazione soddisfacente. É interessante a questo proposito il tentativo di P. Roget. Un punto degno di nota nella sua classificazione é l'enfasi ri- posta sui concetti astratti, fisici e meccanici; intelletto, vo- lontà, emozione, ... É inoltre interessante notare come l'intelletto sia suddiviso in due grandi gruppi: la formazione delle idee e la comunicazione delle idee. Il tesaurus di Roget sembra sottolineare i sinonimi piuttosto che l'organizzazione di parole per concetti generali e parole per concetti specifici. TABELLA Tesaurus di Roget ----------------------------------------------------------------- classe sezione codice ----------------------------------------------------------------- 1. relazioni astratte esistenza 1-8 relazioni 9-24 quantità 25-57 ordine 58-83 numero 84-105 tempo 106-139 cambiamento 140-152 causalità 153-179 2. spazio spazio in generale 180-191 dimensioni 192-239 forma 240-263 movimento 264-315 3. materia materia in generale 316-320 materia inorganica 321-356

30
materia organica 357-449 4. intelletto (uso della mente) (1) formazione di idee in generale 450-454 condizioni a priori e operazioni 455-466 materiale per il ragionamento 467-475 processi per il ragionamento 476-479 risultati del ragionamento 480-504 estensioni del pensiero 505-513 pensiero creativo 514-515 (2) comunicazione delle idee natura delle idee comunicate 516-524 modelli di comunicazione 525-549 significato delle idee comunicate 550-599 5. volontà (esercizio della volontà) (1) volontà individuale volontà in generale 600-619 volontà prospettica 620-679 azione volontaria 680-703 antagonismo 704-728 esito dell'azione 729-736 (2) volontà sociale volontà sociale in generale 737-759 volontà sociale particolare 760-767 volontà sociale condizionata 768-774 relazioni possessive 775-819 6. emozione,religione e moralità generale 820-826 emozione personale 837-887 emozione interpersonale 888-921 moralità 922-975 religione 976-1000 ----------------------------------------------------------------- (fig 2.6) A differenza del thesaurus di Roget che presenta un carattere ge- nerale, la maggior parte dei thesaurus costruiti si occupano di termini tecnici propri di settori particolari. I concetti propri di aree tecniche come per esempio l'ingegneria elettronica, la scienza del computer o l'economia sono espressi in termini tecnici. É necessario raggruppare tutti i termini tecnici di una partico- lare materia e chiarire le relazioni tra tali termini per rendere il significato dei termini e delle strutture il più chiaro pos- sibile. A differenza di un thesaurus di termini generali, un the- saurus di termini tecnici é di solito creato con un preciso pro- posito; come per esempio creare un sistema di ricerca delle in- formazioni con una determinata organizzazione e utilizzare tale organizzazione come strumento per processare il linguaggio natu- rale. É possibile individuare le seguenti relazioni dalle connessioni tra termini tecnici:

31
1) relazioni tra nomi a) sinonimi - antinomie b) termini generali - termini specifici c) parole simili d) relazioni d1) relazione parte_di, relazione composto_da d2) relazione d'ordine, di causa-effetto, successione d3) relazione logica d4) relazione di simiglianza (determinata dall'avere le stesse caratteristiche) e) parole composte - parole derivate 2) relazioni tra verbi e nomi esempio a) soggetto del verbo il cane abbaia b) oggetto comprare un libro c) beneficiario dare qualcosa al cane d) strumento, metodo mangia col cucchiaio e) locazione va a Roma f) tempo arriva alle cinque f) causa arriverò tardi a causa di un terremoto g) ruolo la sua funzione é dirigente I sistemi di Information - Retrieval usano spesso relazioni che valgono tra le parole, come nel caso 1). Le relazioni del tipo 2) tra verbi e nomi vengono utilizzate per analizzare frasi oppure per analizzare il contesto di un'azione nell'ambito della rappresentazione della conoscenza. Nell'ambito di un'area tecnica una parola conserva un preciso si- gnificato tecnico a cui é fortemente legata. Considerando il mondo accademico come un'area tecnica specifica, notiamo che oltre alle parole che sono considerate standard nel mondo accademico, varie altre parole possono essere usate per in- dicare lo stesso oggetto. Una parola che sia ufficialmente riconosciuta come indice é chiamata descrittore; altre parole sono considerate non- descrittori. Accenniamo brevemente ad un ulteriore tentativo di classificazio- ne delle relazioni possibili tra i nomi: relazione simbolo descrizione ---------------------------------------------------------------- 1) gerarchica BT termine generale (broader term) NT termine particolare (narrower term) 2) generica BTG termine generale generico NTG termine particolare generico 3) partitiva BTP termine generale partitivo NTP termine particolare partitivo 4) associativo RT termine in relazione 5) antinomia A 6) equivalenza USE utilizza per UF usato per USE+ usa in combinazione

32
Appare evidente dagli esempi riportati quanto risulti complesso e difficoltoso il compito di classificare in uno schema complessivo le parole del linguaggio. Effettivamente la complessità del linguaggio é notevole e di fronte al problema di trovare dei criteri che ci consentano di afferrare le similarità tra messaggi espressi nel linguaggio na- turale chiunque si scoraggerebbe ancor prima di cominciare. D'altra parte possiamo ragionare su messaggi più semplici di quelli espressi nel linguaggio naturale e concentrarci su cosa succede nel canale di comunicazione tra due sistemi che si scam- biano messaggi. L'informazione generalmente contiene alcune caratteristiche chia- mate attributi. Ogni pezzo di informazione si distingue da un'altro sulla base del valore che assume ciascun attributo. Supponiamo di chiamare ciascun attributo fi (i=1,2,...,n) e il valore di ogni attributo fij (j=1,2,...,ji). Allora ogni pezzo di informazione esiste in ciascuno dei punti del reticolo j1 x j2 x ... x jn dello spazio n-dimensionale i cui assi sono le fi. In altre parole, ogni pezzo di informazione a può esse- re rappresentato utilizzando il seguente vettore: a: (f1a, f2a, ... ,fna) tale vettore é chiamato vettore degli attributi e il suo raggio é detto spazio delle caratteristiche (feature space). Dove fia é il valore dell'attributo fi per la parte di in- formazione a.

33
(fig 2.7) 2.4 Il trattamento dell'incertezza Consideriamo, ora brevemente, il tema della conoscenza inferen- ziale e della risoluzione di problemi. (Inferential Knowledge and Problem Solving). Il primo compito che ci si prefigge quando si affronta un proble- ma, cercandone una soluzione automatica, consiste nel rappresen- tare lo spazio degli stati del problema stesso. Vi sono principalmente due tipi di informazione che descrivono gli stati accessibili di un problema: a) primo tipo di conoscenza: certi fatti sono veri; b) secondo tipo di conoscenza: regole del tipo "IF fatto1 THEN fatto2". Per esempio consideriamo il seguente semplice problema: depositiamo tre monete sul tavolo a caso, alcune saranno rivolte dalla parte testa altre dalla parte croce. Il gioco consiste nell'ottenere tutte le monete girate nello stesso verso, tutte testa o tutte croci, a partire dalla configu- razione casuale iniziale; l'unica mossa consentita consiste nel girare due monete contemporaneamente. Allora, riassumendo, si hanno i seguenti punti: 1) La soluzione é la configurazione con tutte e tre le monete dalla stessa faccia: T T T oppure C C C. 2) Ad ogni istante il problema é espresso da uno stato partico- lare. 3) Le regole del gioco consistono nella transizione da uno stato ad un'altro. 4) Sono permesse parecchie transizioni che creano una struttura ad albero. Tale struttura é chiamata: albero di ricerca (search tree). Poiché il numero degli stati é finito abbiamo uno spazio degli stati finito (state-space search). Ad ogni transizione ogni transizione successiva é ammessa: gli stati successivi sono in relazione OR (Or tree). Avremo un grafo degli stati (state graph). La verifica delle regole della forma A --> B é detta pattern- matching. Questo primo semplice esempio contiene gli elementi principali da definire nella formalizzazione della soluzione automatica di pro- blemi. Nell'esempio le configurazioni possono essere elencate una per una e rappresentate per esempio come (T,C,T). Vediamo un caso leggermente più complesso, consideriamo n mone- te. In tal caso il numero delle configurazioni diviene eccessivo. Rappresentiamo allora gli stati raggruppandoli (grouping state) con la coppia di valori numerici (n1,n2) che rappresentano: 1) n1 = numero di T teste nella configurazione; 2) n2 = numero di C croci nella configurazione; 3) n1 + n2 = n ; 4) n1 ed n2 positivi. Le regole diventano:

34
stato corrente stato successivo a) (n1,n2) (n1-2,n2+2) b) (n1,n2) (n1+2,n2-2) Il Goal : (0,n) oppure (n,0). Dagli esempi risulta evidente come l'algoritmo di soluzione sia legato al tipo di rappresentazione del problema. Per affrontare problemi di una certa complessità occorre raffi- nare gli algoritmi di risoluzione e implementare con metodo la base di conoscenza. Alcune tipologie di risoluzione e di rappresentazione della base di conoscenza sono divenute di uso corrente grazie alla diffusio- ne e standardizzazione dei sistemi esperti, anche se la ricerca in tale settore non li rende definitivi, oggigiorno possiamo tro- vare sistemi esperti efficienti ed affidabili. I sistemi esperti si compongono di: a) una base di conoscenza; b) un motore inferenziale. I principali problemi non ancora completamente risolti ed oggetto di ricerca nel settore dei sistemi esperti possono essere rias- sunti nei seguenti punti: 1) La complessità del problema: problemi troppo complessi pre- sentano notevoli difficoltà di implementazione anche per i si- stemi esperti più sofisticati; 2) Incompletezza o incertezza delle informazioni disponibili; 3) difficoltà di razionalizzare in modo preciso molti procedi- menti mentali utilizzati, invece, dall'esperto umano; Quando ci si trova di fronte ai problemi sopra esposti, nello sviluppo di un sistema esperto, le possibili alternative per su- perare l'ostacolo sono: a) procedere per tentativi; b) sviluppare metodi di implementazione che utilizzino processi mentali deduttivi in ambito di incertezza. Un sistema esperto possiede di solito un modulo chiamato modulo di spiegazione che consente all'utilizzatore di analizzare i pas- si logici che il sistema ha seguito per fornire la risposta. Il colloquio avviene tramite un modulo di interfaccia. Un sistema esperto utilizza la descrizione del problema per de- terminarne la soluzione, mentre i sistemi tradizionali utilizzano una procedura di risoluzione. La descrizione dettagliata del problema costituisce per il siste- ma esperto la propria base di conoscenza. I sistemi esperti sono di supporto per la soluzione di problemi complessi. Alcuni sistemi trattano efficacemente le informazioni della base di conoscenza utilizzando il concetto di stato. Il processo di risoluzione é visto come il passaggio da uno sta- to appartenente ad una classe (stati iniziali) ad uno appartenen- te ad un'altra (stati finali) ; il passaggio é scomposto in una catena di passaggi a successivi stati intermedi. Il primo passo per la soluzione di un problema é la sua defini- zione precisa: per far questo generalmente occorre puntare l'at-

35
tenzione su alcuni aspetti: a) il campo di definizione del problema (l'insieme di tutti gli stati possibili); b) lo stato iniziale del problema; c) lo stato finale del problema; d) le regole che definiscono le possibili transizioni tra uno stato e l'altro; e) i fatti e le regole che aiutano a decidere la via migliore da seguire per passare da uno stato ad un altro (conoscenza euristica). É utilizzando la conoscenza euristica che si stabiliscono le "priorità" tra gli stati. La conoscenza, per poter essere interpretata dal motore inferen- ziale, deve essere "racchiusa" in strutture formali adeguate. Il metodo principale consiste nella rappresentazione della cono- scenza tramite regole. L'insieme delle regole e delle proposizioni della base di cono- scenza forma un grafo (e non un albero) in quanto regole diverse possono avere in comune delle proposizioni antecedenti e possono avere la stessa proposizione come conseguente. Proposizioni che sono fra gli antecedenti di una regola possono essere conseguenti di altre. Un importante problema che ci si pone durante la progettazione degli algoritmi risolutivi é come trasformare il grafo del pro- blema in un albero. Le regole si possono suddividere in tre classi: 1) question - affermazioni iniziali ; 2) proposizioni intermedie ; 3) goal - deduzioni finali. Esiste un nodo spinoso noto a coloro che si occupano di risolu- zione di problemi tramite l'utilizzo di grafi e consiste nel pro- blema dei grafi viziosi: grafi che presentano dei cicli inelimi- nabili (loop). Il problema dei grafi viziosi può essere formulato nel modo se- guente:
Esiste un ai ∈ a1,a2,...,an tale che se: a1,a2,...,an--> bj ; ...,bj,...-->... ...--> vk ; ...,vk,...--> z tale che z = ai Le principali tecniche per descrivere la conoscenza necessaria a imitare l'euristica sono: a) l'uso di metaregole, regole che parlano di regole, che consi- gliano la scelta di regole al posto di altre ( es. probabilità e livello di astrazione ) ; b) l'uso di funzioni di valutazione, in altri termini indicatori con cui valutare il percorso più probabile.

36
Nella soluzione di un problema la ricerca euristica e la ricerca sistematica possono essere utilizzate in maniera sinergica. La ricerca euristica non garantisce la soluzione ottima, in par- ticolare si osserva: a) adeguatezza statistica dell'euristica in contrasto con la b) particolarità individuale dell'evento. Consideriamo, ora, il funzionamento di un sistema esperto dal punto di vista algoritmico. Un sistema esperto funziona sulla base del motore inferenziale. Il funzionamento del motore inferenziale é costituito essenzial- mente da una iterazione di cicli di riconoscimento/attivazione di regole, tipicamente suddivise in: a) ricerca nella base di conoscenza delle regole pertinenti, os- sia quelle collegate con lo stato attuale nel processo di solu- zione del problema considerato; b) selezione della prima regola incontrata oppure della regola più appropriata (strategia prefissata); c) esecuzione della regola e registrazione nella base di dati dei cambiamenti conseguenti all'applicazione della regola. Ad ogni ciclo si producono nuove informazioni che si aggiungono alla base di dati e che vengono utilizzate nei cicli successivi. Il processo si arresta quando viene trovata la soluzione. É importante ricordare che si hanno due diversi livelli di sod- disfacimento per una proposizione: 1) il livello di valutazione parziale che si ha quando é stata applicata una regola che ha come conseguente una certa proposi- zione; 2) il livello di valutazione globale che si ha quando sono state applicate tutte le regole che hanno quelle proposizioni come con- seguente. Quando il motore inferenziale tratta l'incertezza é necessario che per la valutazione globale si tenga conto dei contributi ap- portati da tutte le singole regole che hanno quella proposizione come conseguente cioé tutte le valutazioni parziali. Esistono due modalità di procedere nella ricerca di una soluzio- ne, goal, date certe premesse: modalità forward e modalità bac- kward: a) forward - si procede dal basso verso l'alto (bottom-up) (questions) dai dati del problema ---> goal; b) backward - si procede dall'alto verso il basso (top-down) dal goal ---> ai dati del problema (questions). Esistono alcuni modi di percorrere l'albero di ricerca, in parti- colare: 1) da sinistra verso destra (breadth first) un livello dopo l'altro; 2) in profondità, dall'alto al basso nell'albero (depth first); 3) con funzione di valutazione, il percorso più promettente

37
(best first). Soffermiamoci, in particolare, sul metodo best first. Data la lista dei nodi iniziali si esplora il primo nodo, e si genera la lista dei nodi figli. Con l'aiuto di una funzione euristica si riordina la lista tota- le, ovvero quella iniziale unita a quella dei nodi figli generati nella prima esplorazione. Alcuni nodi possono essere scartati. Si prende il primo nodo e si genera la lista dei nodi figli. Il processo si ripete. Il risultato é una visita in alcuni tratti in profondità e in altri per livelli. Quando si gestisce l'incertezza bisogna tener conto di tutte le componenti che contribuiscono alla valutazione di una proposizio- ne. Col metodo best first non si tiene conto del contributo di quelle componenti che si suppongono ininfluenti al fine della va- lutazione globale di una proposizione; si effettuano cioé delle potature sui rami che vengono valutati portare contributo nullo. Vediamo, nel seguito succintamente, una struttura teorica per il trattamento dell'incertezza. I sistemi esperti che trattano l'incertezza lavorano con regole e proposizioni a cui sono associati dei pesi che, in generale, con- sistono di numeri reali. Il motore inferenziale non deve solo in- dividuare una soluzione (goal) vera, piuttosto deve essere in grado di gestire e "diffondere" l'incertezza espressa nei pesi delle question e delle regole attraverso tutta la rete di dedu- zioni, per fornire il peso di ogni goal. La propagazione dell'incertezza prevede passi di quattro tipi: 1) il peso delle proposizioni negate deve essere derivato dal pe- so delle proposizioni affermative; 2) il peso di una proposizione conseguente deve essere calcolato dai pesi delle proposizioni antecedenti; 3) il peso di una proposizione conseguente di una regola riceve da tale regola un contributo dipendente dal peso della regola; 4) una proposizione conseguente varie regole riceve un peso glo- bale ottenuto componendo i contributi di ciascuna regola. Si denota come "combining function" la funzione che combina i pe- si nella maniera richiesta dai punti sopra esposti. Esistono due tipi di approccio al problema dei pesi: a) approccio "estensionale" - in questo approccio non si parla di pesi come probabilità classiche, ma ci si pone al di fuori di qualsiasi struttura probabilistica; b) approccio "intensionale" - in questo approccio si cerca di in- terpretare i pesi come delle probabilità. Analizziamo alcune caratteristiche tipiche di una "combining function". Assumiamo che l'insieme dei pesi sia contenuto nell'intervallo [-1,1] dove si intende: peso 1 - certamente vero peso -1 - certamente falso peso 0 - completamente indeterminato - sconosciuto.

38
definiamo allora: 1) w(P) - peso globale della proposizione p ;
2) w(¬P) - peso della negazione della proposizione p ; 3) wr(A) - peso antecedente della regola r ; 4) w(r) - peso della regola r ; 5) wr(P) - peso parziale della proposizione P dovuto alla regola r. gli operatori della combining function diventano:
a) neg(w(P)) = w(¬P) peso di una proposizione negata; b) conj(w(a1),...,w(an)) = wr(A) peso di un antecedente; c) ctr(wr(A),w(r)) = wr(P) peso parziale; d) glob(w1(P),...,wn(P)) = w(P) peso globale. Descriviamo per sommi capi il sistema di deduzione di Hajek. Poiché per la propagazione della conoscenza incerta ci avvaliamo di un certo numero di funzioni operanti su un insieme di pesi, é ragionevole pensare di poterla inquadrare in una struttura alge- brica, in particolare in un gruppo. Una struttura algebrica é composta da: 1. un insieme S detto sostegno; 2. un certo numero di operazioni defiite su S; 3. un certo numero di assiomi: proprietà che le operazioni deb- bono soddisfare. Esaminiamo le esigenze di propagazione dell'incertezza. Oltre al livello di fiducia attribuito ad una proposizione o re- gola dobbiamo essere in grado di esprimere anche un grado di fi- ducia "indifferente" o "sconosciuto"; lo indicheremo con e ele- mento neutro :
e: S° ---> S La funzione glob deve calcolare il peso globale di una proposi- zione in funzione dei contributi che le derivano dalle regole di cui é conseguente. Si può dedurre da un'operazione binaria di composizione: + : S x S ---> S tale che glob(w1,w2,...,wn) = w1 + w2 + ... + wn Poiché vogliamo che l'ordine delle regole convergenti ad una proposizione sia ininfluente sul peso globale delle proposizioni la composizione + deve godere delle seguenti proprietà: 1) associativa: (w + v) + u = w + (v + u) = w + v + u 2) commutativa: w + v = v + w 3) elemento neutro: w + e = w La funzione neg calcola, noto il peso di una proposizione, il peso della sua negazione. Si può esprimere tale funzione median- te l'operazione unaria: _ ( ) : S ---> S di simmetria: _ _ neg(w) = w inoltre w + w = e vogliamo infine essere sempre in grado di dire quale é il minore fra due pesi dati: introduciamo una relazione d'ordine tale che per ogni w, v, u :

39
1. w ≤ v oppure w > v per cui l'ordine é totale su S 2. W ≤ v , v ≤ u ---> w ≤ u 3. w ≤ v ---> w + u ≤ v + u Abbiamo così identificato un gruppo abeliano ordinato G compo- sto di: a) un sostegno S b) operatori - 1. zeraria: elemento neutro e _ 2. unaria: elemento simmetrico ( ) 3. binaria: composizione + c) assiomi: 1. associatività (w+v)+w = w+(v+u) = w+v+u 2. commutatività w+v = v+w 3. w+e = w _ 4. w+w = e
5. w≤v oppure w>v 6. w≤v , v≤u --> w≤u 7. w≤v --> w+u ≤ v+u Vediamo allora come si presenta il sistema di deduzione di Hajek. 1. Un sistema di regole R esente da loop. 2. Un opportuno dominio D nell'intervallo [-1,1] di pesi _
3. Una struttura < D,+,( ),e,≤ > che sia la chiusura di un grup- po abeliano ordinato 4. Le funzioni neg, conj, ctr definite come segue: _ a) neg(a) = a b) conj(a,b) = min(a,b) c) ctr(a,b) = min(a,b) se a > e , b > e oppure ___ _
min(a,b) se a > e , b ≤ e oppure
e se a ≤ e d) la funzione glob definita come
w1,w2,...,wn ∈ D : glob(w1,w2,...,wn) = w1+w2+...+wn Con queste assunzioni siamo pertanto in grado di determinare: 1. il peso di una regola 2. il peso globale di una proposizione Per quanto riguarda l'approccio probabilistico al trattamento dell'incertezza é possibile riportare le seguenti considerazio- ni. Si può interpretare il peso di una proposizione come una "misu- ra" (essenzialmente una misura di probabilità) della collezione di tutti i possibili mondi in cui la proposizione é vera. Il tentativo é indirizzato a trovare la migliore distribuzione che soddisfi le condizioni marginali e usarle per trovare le pro-

40
babilità delle proposizioni. Esistono due approcci: a) teoria della probabilità diretta; b) teoria della probabilità condizionata. La teoria della probabilità condizionata osserva che le probabi- lità associate ai possibili risultati cambiano ad ogni passo in dipendenza dello svolgersi degli eventi. Queste osservazioni suggeriscono che l'accumularsi di evidenze può cambiare le probabilità degli eventi. In generale non ci sono ragioni "a priori". Vediamo un approccio, dovuto ad Hajek, al trattamento dell'incer- tezza con utilizzo dei concetti della probabilità. Consideriamo le regole espresse nella forma: A ---> H(w) dove A = antecedente, H = conseguente, w = peso. Per semplificare supponiamo siano vere le seguenti affermazioni: 1. La base di conoscenza non deve avere proposizioni intermedie, vi saranno solo question e goal; 2. I pesi appartengono all'intervallo [0,1] anziché a [-1,1]; 3. L'utente ha la possibilità di rispondere utilizzando solo i pesi 0,0.5,1 che corrispondono rispettivamente a no, non so, si.
Se Ω é un certo campo di conoscenza e K é un sistema di pesi allora possiamo scrivere Γ = (Ω,K). Per ogni goal H e ogni congiunzione elementare E di question possiamo definire peso globale di H dato E come:
1) W(Γ) = Σ(+) K(En --> E) per ogni En appartenente ad E
Una distribuzione congiunta su Quest ∪ Goal é una funzione D as- sociata ad ogni congiunzione elementare di elementi di
Quest ∪ Goal tale che:
2) Σ(+) D(K) = 1 per ogni K appartenente al dominio di D La probabilità
3) P(K) = Σ(+) D(Kn) per ogni K appartenente al D dominio di D e per tutti i Kn che contengono K
la probabilità condizionata E ∈ Ques, H ∈ Goal é data da: P(H,E) D 4) P(H/E) = ------------- D P(E) D L'approccio probabilistico al trattamento dell'incertezza presen- ta notevoli difficoltà sia tecniche che concettuali e la ricerca é ancora lontana da una soluzione definitiva o anche semplice- mente dalla costruzione di un modello probabilistico soddisfacen-

41
te. A questo riguardo, trovo utile riportare alcune considerazioni ed alcuni teoremi significativi nello studio della problematica con- nessa all'approccio probabilistico del trattamento dell'incertez- za in un sistema di deduzioni. Facendo riferimento al modello di Gaines vi sono alcuni punti da tenere in considerazione. La conoscenza che deve essere acquisita consiste in: a) conoscenza fattuale ovvero descrizione del mondo e metodi di risoluzione; b) valutazioni euristiche ed empiriche. La nozione centrale di tale modello é il concetto di distinzio- ne. Le distinzioni sono le strutture più elementari dell'informazio- ne, ciò che é distinguibile da tutto il resto; le distinzioni possono riguardare elementi statici o elementi dinamici. In particolare una semplice classificazione delle distinzioni po- trebbe essere la seguente: a) costruzioni - le distinzioni fatte sugli eventi del mondo; b) esperienze - eventi che capitano o che facciamo accadere; c) ipotesi - razionalizzazioni dell'esperienza; d) analogie - corrispondenza rilevante tra ipotesi diverse; e) astrazioni - raffinamenti delle analogie; f) trascendenze - ciò che va al di là dell'astrazione. L'acquisizione delle valutazioni segue la fase di rappresentazio- ne della conoscenza questo processo riguarda: 1) lo schema di percezione dell'incertezza; 2) il metodo di propagazione dell'incertezza; 3) le valutazioni sugli elementi del mondo e sui mezzi di solu- zione dei problemi. In relazione alla possibilità di costruire un gruppo abeliano idoneo all'implementazione di un sistema di deduzione con carat- teristiche analoghe ai sistemi prospettati divengono utili i se- guenti teoremi e le seguenti proposizioni. TEOREMA 2.4.1 (di Levi). In base al teorema di Levi un gruppo può essere ordinato se e solo se per ogni x diverso da e elemento neutro, per ogni n numero naturale positivo si ha: 1. n * x = x + x + ... + x diverso da e PROPOSIZIONE 2.4.2 _
Dato il gruppo abeliano ordinato G = < S1, + , ( ) , ≤ >, se S ha almeno un elemento oltre ad e, allora non esiste in G un ele- mento che sia massimo né uno che sia minimo, per cui G é infi- nito. La dimostrazione segue dalle seguenti osservazioni:
1. per ogni x ∈ G se x < e --> x + x < x (x + x) ∈ G, 2. per ogni x ∈ G se e < x --> x < x + x (x + x) ∈ G.

42
PROPOSIZIONE 2.4.3
Sia ƒ una funzione crescente di [-1,1] su [-∞,+∞], sostegno del gruppo additivo di reali |R = <[-∞,+∞], + , - , 0 , ≤ >. Su [-1,1] esiste un gruppo abeliano ordinato archimedeo
G = <[-1,1], + , - , ≤ > tale per cui ƒ é un isomorfismo da G ad |R se e solo se ƒ é dispari, ossia se per ogni x vale:
1. ƒ(-x) = - ƒ(x) . PROPOSIZIONE 2.4.4
Ogni gruppo ordinato G = <[-1,1], + , - , ≤ > é isomorfo al gruppo additivo dei reali |R = <[-∞,+∞], + , - , 0 , ≤ > . Per ogni x ∈ [0,1] vi é un unico isomorfismo di G su |R che ad x assegna immagine 1 ∈ [-∞,+∞]. PROPOSIZIONE 2.4.5
Siano ƒ1 ed ƒ2 funzioni crescenti dispari di [-1,1] su [-∞,+∞]. Esiste un gruppo ordinato G su [-1,1] tale che sia ƒ1 che ƒ2 trasformano isomorficamente G in |R, se e solo se esiste un c>0
tale che ƒ1(x) = c ƒ2(x). PROPOSIZIONE 2.4.6
per ogni gruppo abeliano ordinato archimedeo G = <[-1,1],+,-,≤ > esiste un'unica minima estensione non-archimedea G1 contenuta o uguale a G determinata a meno di un isomorfismo. TEOREMA 2.4.7 (Belief network decomposition) Data una rete di affidabilità arbitraria (belief network) che possa essere suddivisa in due insiemi di nodi, A e B, connessi con un singolo arco da un nodo x in A ad un nodo y in B. Se l'evidenza negli insiemi é e(A) ed e(B), allora la probabili- tà a posteriori: PA/e(A),e(B) e PB/e(A),e(B) può essere calcolata trasmettendo un singolo messaggio con un numero per ciascun valore possibile di x da un insieme all'al- tro. In più, i due messaggi sono indipendenti.

43
(fig 2.8) I messaggi mandati tra A e B contengono tutte le informazioni rilevanti su ciascun insieme. Il vantaggio di utilizzare messaggi per aggiornare la situazione sui nodi, anziché ricalcolare tutte le probabilità utilizzando le formule di Bayes, consiste nel fatto che é possibile comuni- care solo le variazioni conservando integra la conoscenza sul si- stema. Questo teorema rappresenta una fondamentale indicazione sulla di- namica di sistemi in comunicazione reciproca e ci fornisce un im- portante analogia in relazione a quanto si verrà sostenendo nel seguito.

44
3. IL PROCESSO DI ASTRAZIONE 3.1 Principali meccanismi di astrazione La conoscenza é generalizzata attraverso il processo di astra- zione. La classificazione di fatti simili selezionati in una lar- ga collezione di fatti é un particolare tipo di astrazione. L'astrazione é un procedimento mentale che si adotta quando si evidenziano alcune proprietà e caratteristiche di un insieme di oggetti, escludendone altre giudicate non rilevanti e giungendo alla definizione di un nuovo oggetto come concetto unificante ri- spetto alle proprietà considerate. Il processo di astrazione non é ancora ben compreso, né é chiaro in che modo esso si presenti nel ragionamento umano, é possibile comunque elencare alcune tipologie di astrazione: la classificazione, l'aggregazione, la generalizzazione, l'asso- ciazione. a) La classificazione é il processo di astrazione fondamentale che conduce alla definizione di una classe di oggetti basandosi sulla osservazione che tali oggetti hanno alcune proprietà in comune. b) L'aggregazione é un processo di astrazione mediante il quale si giunge ad un "oggetto" nuovo aggregando oggetti. Il fatto di costituire un nuovo oggetto diviene una proprietà che si aggiunge a ciascun oggetto costituente l'aggregato. c) La generalizzazione consiste in una aggregazione di classi di oggetti basandosi sulle proprietà comuni. d) L'associazione consiste nel suddividere un determinato insieme di oggetti in gruppi separati. La proprietà di appartenere ad un determinato gruppo si aggiunge a tutti gli oggetti costituenti il gruppo medesimo. Nel lavoro di analisi di problemi per la loro rappresentazione simbolica esistono alcuni termini particolarmente significativi che vengono solitamente utilizzati: 1) Entità Le entità sono degli elementi base di ogni rappresentazione, l'ossatura, la parte costituente. Un'entità descrive un concetto, un oggetto, un fatto,... Un'entità possiede un nome e in relazione a tale nome si aggre- gano gli attributi che descrivono l'entità. Il nome dell'entità é il suo primo attributo, anche se non sem- pre esso risulta essere univoco. 2) Gli attributi Gli attributi sono anch'essi elementi fondamentali nella rappre- sentazione, esprimono le caratteristiche delle entità, la con- formazione, le parti costituenti, ma anche la sintesi, il concet- to unitario, la forma. Gli attributi possiedono un nome, una descrizione con cui sono identificati. 3) Le proprietà Anche le proprietà descrivono le entità e svolgono un ruolo analogo agli attributi; anche se vi sono differenze concettuali, al fine di descrivere entità, le proprietà vengono considerate equivalenti agli attributi.

45
4) Gli oggetti Gli oggetti rappresentano entità con un certo spessore ed una particolare individualità. Un oggetto richiama direttamente alla mente qualcosa di concreto e tangibile, a differenza dell'entità che appare un concetto più astratto. Comunque esistono fraintendimenti ed ambiguità che avvicinano il concetto di oggetto al concetto di entità mol- to più di quanto possa sembrare ad un'analisi superficiale: per esempio un albero é un oggetto o un'entità? L'albero che ho in giardino potrebbe essere un oggetto in un senso più forte rispetto all'abete che rappresenta una famiglia di alberi illustrato sul libro di botanica. Il primo possiede un'esistenza propria, il secondo é una rappre- sentazione di una classe astratta, ma, occorre ricordare, che a livello di costruzione di sistemi automatici, per esempio i com- puter, ogni componente é una rappresentazione astratta rispetto ad una "realtà di interesse" ad esso estranea. 5) I termini In ogni caso qualsiasi tipo di rappresentazione simbolica utiliz- za simboli, e tali simboli costituiscono l'abecedario con cui en- tità, oggetti, attributi, proprietà possono esprimersi nella rappresentazione: il simbolo, il nome, il termine rappresentano il mattone fondamentale su cui tutta la rappresentazione viene costruita. 6) Le classi I raggruppamenti di oggetti, o di entità rappresentano delle classi: per esempio gli abeti. Ora, i raggruppamenti di attributi rappresentano oggetti, rag- gruppamenti di oggetti rappresentano entità, raggruppamenti di entità rappresentano classi; ma appartenere ad una determinata classe é un attributo o una proprietà di un oggetto, pertanto un raggruppamento di entità rappresenta un attributo. 7) I domini Una classe di entità che gode di una certa proprietà viene chiamata dominio della proprietà stessa. I domini sono classi che possiedono una determinata caratteristi- ca idonea all'espletazione di un certo compito; uno specifico do- minio viene di solito definito in relazione ad una specifica fun- zione. 8) Le regole Una trasformazione da un oggetto ad un'altro oggetto, da una pro- prietà ad un'altra proprietà, é descrivibile con una regola. Una regola consiste in una relazione tra insiemi di oggetti o in- siemi di attributi e di solito si esprime nella forma: Se fatto-1 allora fatto-2. 9) I legami I legami tra oggetti o tra attributi descrivono una prima rela- zione fondamentale in cui gli oggetti o gli attributi stessi en- trano in reciproco rapporto. Per cui se esiste una regola del ti- po "Se fatto-1 allora fatto-2" esiste anche un legame tra il fat- to-1 e il fatto-2, una connessione logica esprimibile in concomi- tanza di eventi spazio temporali oppure semplicemente di coinci- denza fra termini nella rappresentazione; I termini e i legami, in particolare i legami binari, costituiscono l'ossatura di qual- siasi sistema di rappresentazione a stati finiti. 10) I processi I processi attuano le regole. I processi realizzano ciò che le

46
regole descrivono. Un processo possiede una dimensione temporale attraverso cui esso stesso si svolge; partendo da certe premesse produce determinati risultati. I processi sono trasformazioni nella rappresentazione; le tra- sformazioni descritte da regole determinano l'evoluzione del si- stema di memorizzazione. 11) Frames o strutture I termini non sempre assolvono con efficacia al loro compito di rappresentare oggetti o attributi; la ragione principale di que- sta inadeguatezza risiede nella non univocità dei termini uti- lizzati rispetto alla complessità della "realtà di interesse". Ragioni di efficenza costringono alla sintesi e pertanto diviene necessario ricondurre ad ambiti ristretti di validità, frames o strutture appunto, il significato che il termine esprime. 12) Il contesto Il contesto é un particolare tipo di struttura, con un signifi- cato intuitivo specifico, relativamente alla restrizione ad un particolare ambito degli elementi della rappresentazione. 13) I fatti I processi fanno riferimento ad un divenire, a trasformazioni nel tempo; i fatti o gli eventi, rappresentano gli oggetti nella loro dimensione temporale, in sostanza gli oggetti possono essere pen- sati come a raggruppamenti di eventi che presentano una partico- lare costanza e continuità rispetto a determinati attributi. 14) La relazione parte_di Un oggetto può essere parte di un altro oggetto. Gli oggetti possono essere scomposti in parti, in particolare ogni attributo di un oggetto può essere discriminante e consen- tire l'individuazione di un oggetto che é parte dell'oggetto o- riginario: nella rappresentazione, oltre al nome, le sole infor- mazioni che possediamo sugli oggetti sono costituite dall'insieme di attributi che tali oggetti possiedono, per cui la possibilità di individuare le parti costituenti un oggetto risiedono esclusi- vamente nella possibilità di distinguere gli attributi da esso posseduti. Esiste una analogia tra l'appartenere ad un insieme ed essere parte di un altro oggetto. 15) La relazione composto_da Un oggetto può essere composto da altri oggetti. Esiste una analogia tra essere un insieme di elementi ed essere composto da un insieme di altri oggetti. 16) I verbi I verbi sono gli operatori del linguaggio naturale, e nello stes- so tempo descrivono i processi, le trasformazioni, le azioni che si svolgono nella realtà. In una rappresentazione utilizzabile da una procedura automatica i verbi possono essere descritti da regole e da relazioni. 17) Gli operatori Gli operatori sono processi definiti che operano trasformazioni sugli oggetti nella rappresentazione. Gli operatori possono essere descritti da insieme di regole che definiscono, a partire da certi stati in ingresso, quali debbono essere gli stati in uscita, dopo l'esecuzione dell'operatore me- desimo. 18) I dati

47
Tutte le informazioni che il sistema di rappresentazione é in grado di manipolare debbono essere trasformate in dati, ovvero, configurazioni statiche e definite di componenti del supporto di memorizzazione; una tale trasformazione implica un processo fon- damentale a cui l'informazione é sottoposta per poter essere me- morizzata: la codifica. 19) Gli aggregati Il processo di aggregazione é il processo fondamentale che con- sente la costruzione di classi e di raggruppamenti caratterizzan- ti gli oggetti e gli attributi che sono descritti nella rappre- sentazione. L'aggregazione tra elementi costituenti il sistema di rappresentazione non avviene in maniera statica una volta per tutte, é piuttosto un processo dinamico in continua evoluzione; non esistono aggregati definitivi, ogni raggruppamento é possi- bile al fine di ottenere un determinato risultato. Non si riparte, comunque, sempre da capo, ogni raggruppamento che ha prodotto risultati significativi lascia una traccia di sé che può essere utilizzata dal sistema di rappresentazione: in parti- colare una volta attribuito un nome ad una determinata classe, questa risulta presente nella rappresentazione. 20) Le registrazioni Il processo di memorizzazione delle informazioni avviene effet- tuando delle registrazioni; le registrazioni consistono nella ef- fettiva modificazione degli stati interni alla rappresentazione che conserveranno traccia degli eventi associati alle registra- zioni medesime: una tale variazione di stati può coinvolgere, nel contempo, la costruzione o identificazione di aggregati con funzione classificatoria delle informazioni memorizzate. 21) Le inferenze Le inferenze rappresentano ciò che il sistema di rappresentazio- ne si aspetta succeda in realtà nel mondo. Le inferenze dovrebbero avere una base statistica, anche se, af- finché la statistica sia valida occorre che i parametri di valu- tazione delle previsioni siano conformi, non solo nella forma ma anche nella sostanza, con i fenomeni reali, per definizione inco- noscibili, che avvengono nella "realtà di interesse". Le inferenze si esprimono attraverso regole, ovvero attraverso la relazione di causa ed effetto tra eventi rappresentati nel sistema; una tale relazione viene espressa solitamente nella forma: Dal fatto-1 ne consegue, salvo evidenza del contrario, il fatto-2. Vedremo in seguito come, in una particolare rappresentazione de- gli oggetti e delle classi, si possa ricondurre i suddetti pro- cessi di astrazione in un unico schema. Introdurremo nel seguito un esempio di rappresentazione formale che ci consentirà ulteriori considerazioni su tali processi fon- damentali di astrazione, per far ciò ci serviremo del formalismo della programmazione logica. Partiremo con l'indroduzione alla logica matematica, ma prima tratteremo del concetto di simiglianza in un senso molto genera- le.

48
3.2 Il processo di categorizzazione Il mondo di cui ognuno ha esperienza é composto da una quantità enorme di oggetti, se rispondessimo in modo unico registrando tutte le differenze tra le cose ben presto saremmo sopraffatti dalla complessità dell'ambiente. La creazione di categorie rende "equivalenti" cose discernibil- mente diverse, consente di raggruppare gli oggetti e gli eventi in classi, e di rispondere ad essi in funzione della loro appar- tenenza ad una data classe piuttosto che della loro unicità (J.S.Bruner, 1956). Vi sono principalmente almeno cinque vantaggi nella formazione di categorie (Stephen K. Reed, Psicologia cognitiva): 1) riduzione della complessità ambientale; 2) strumento di identificazione (riconoscimento); 3) minore necessità di apprendimento costante; 4) possibilità di decidere sull'appropriatezza delle azioni; 5) possibilità di ordinare e porre in relazione classi di ogget- ti o eventi; In particolare ,occorre sottolineare un aspetto fondamentale, ri- conducibile al fatto di possedere uno schema di classi: le cate- gorie consentono di riconoscere oggetti nuovi sulla base del con- fronto con oggetti simili. Consideriamo il processo di identificazione dei concetti. Tale processo riguarda la capacità di riconoscere fatti, eventi, idee, oggetti come appartenenti ad uno schema più generale; in altri termini riconoscerli appartenenti ad una classe sulla base delle caratteristiche che tali oggetti presentano. É possibile isolare quattro regole principali di combinazione logica di caratteristiche che consentono di individuare concetti: a) regola congiuntiva; AND - identificazione di una o più caratteristiche per un certo scopo; b) regola disgiuntiva: OR - equivalenza tra due o più caratteristiche per un certo sco- po; c) regola condizionale: IF fact-1 THEN fact-2 - se si verifica una determinata condizione fact-1 allora é possibile una certa azione fact-2; d) regola bicondizionale: IF fact-k THEN SELECT fact-1 fact-2 ... fact-n - se si verifica una determinata condizione allora si applica una determinata re- gola di selezione; esempio: caratteristica condizionata da altre caratteristiche IF maschio THEN entra SOLO SE ha la cravatta. Nel processo di identificazione dei concetti sulla base delle ca- ratteristiche riscontrate nell'esperienza si rileva statistica-

49
mente che, oltre all'uso sistematico delle regole sopra riporta- te, esiste una dominanza legata alla frequenza dei casi positivi, sembrerebbe che vi sia uno squilibrio di base nella valutazione dei fatti tra eventi che accadono ed eventi che potrebbero acca- dere o che sono negati. É esperienza comune che esistano delle categorie a cui tutti fanno riferimento, categorie fortemente condivise dalla comuni- tà; le categorie naturali. Le categorie naturali si sono formate evolutivamente e hanno rag- giunto per l'uomo una notevole stabilità, eppure le categorie naturali non raccolgono esemplari ugualmente buoni, consideriamo per esempio i colori, essi sono distinti in intervalli di lun- ghezza d'onda e si presentano alla percezione con caratteristiche estremamente diverse l'uno dall'altro; dal punto di vista dei fe- nomeni fisici la differenza tra il colore viola e il colore rosso é piccola mentre percettivamente sono colori nettamente distin- ti. Se analizzate in dettaglio le categorie naturali mostrano una struttura gerarchica e dimensioni continue piuttosto che discre- te. Nelle categorie naturali alcuni esemplari sembrano essere più centrali di altri. Una affermazione di particolare interesse é la seguente: La differenziazione delle categorie é misurabile determinando in quale misura i membri di una categoria condividono alcuni attri- buti e posseggono attributi diversi da quelli di altre categorie. (Rosch, Gray, Johnsen e Boyes-Braem, 1976). É possibile pensare ad un buon esemplare per ciascuna categoria, ma si tratta di un oggetto ben diverso dalla media di tutti gli esemplari. Il concetto di esemplare medio assume significato quando si pensa agli oggetti di una medesima categoria base. Mentre é assurdo tentare di definire la forma media di una clas- se: per es. la forma media dei mobili ? Si utilizza il termine tipicità per designare il grado in cui ciascun membro rappresenta una data categoria. Per dimostrare che un esemplare buono é quello che condivide molti attributi con altri membri della medesima categoria é ne- cessario fornire una misura delle somiglianze come "aria di fami- glia" (family resemblance), prendendo in considerazione quanti membri condividono lo stesso attributo. Il criterio di somiglianza é utile per predire la tipicità dei membri delle comuni categorie tassonomiche, tuttavia non si rive- la utile nel predire le tipicità nel caso di categorie riferite a scopi. La ragione di ciò sta nel fatto che i membri delle ca- tegorie riferite ad uno scopo sono selezionati sulla base di un principio sottostante, piuttosto che sulla base di attributi con- divisi. Esiste, in tal caso, un diverso livello semantico. Consideriamo, ora, il problema di categorizzare pattern nuovi. Esistono due principali approcci al problema: 1) modello del prototipo; 2) modello della frequenza delle caratteristiche. In particolare é possibile utilizzare quattro principali regole di classificazione per costruire la funzione di somiglianza tra

50
pattern: a) regola della massima vicinanza (nearest-neighbor rule); b) regola della distanza media (average distance rule); c) regola del prototipo; d) regola della frequenza delle caratteristiche. Non tutti utilizzano la strategia del prototipo, ma essa appare prevalente. La regola che ci sembra più interessante e che svilupperemo nel seguito é invece la regola della massima vicinanza. Vedremo come tale regola possa essere generalizzata in maniera tale da comprendere le altre. Benché il modello del prototipo sia il migliore nel predire il modo in cui i soggetti umani classificano facce schematiche (Reed, 1972) in altri casi il modello delle frequenze delle ca- ratteristiche si dimostra più appropriato. L'unico problema, per i vari modelli basati sulla frequenza delle caratteristiche, risiede nella necessità di operare un gran nu- mero di confronti, per valutare sia le combinazioni di caratteri- stiche sia le caratteristiche isolate. (Reitman e Bower 1973). Medin e Schaffer(1978) proposero un modello in cui gli esemplari di una categoria vengono depositati in memoria e le configurazio- ni nuove vengono confrontate con gli esemplari recuperati sulla base delle somiglianze. Maggiore é la somiglianza tra le confi- gurazioni nuove e un esemplare in memoria, maggiore é la proba- bilità che questo venga recuperato. Il modello di Medin e Schaffer misura la somiglianza di combina- zioni di caratteristiche. Consideriamo il problema dell'organizzazione semantica della struttura di memorizzazione. Uno scienziato deve organizzare la propria base di conoscenza. La costruzione dell'edificio scientifico ha bisogno dei fatti al- lo stesso modo in cui la costruzione di una casa ha bisogno delle pietre; ma un'accumulazione di fatti non costituisce una scienza più di quanto un mucchio di pietre non costituisce una casa. (Henri Poincaré). Allo scopo di recuperare le informazioni rilevanti dalla memoria a lungo termine MLT, dobbiamo essere in grado di organizzare la nostra memoria. Molta dell'organizzazione é semantica, cioé si basa sul significato dell'informazione. Un modo particolarmente efficiente di organizzare l'informazione consiste nella formazione di gerarchie. Fondamentalmente esistono due modelli di memoria semantica: 1) uno si basa sull'assunzione che le persone confrontano le ca- ratteristiche delle due categorie allo scopo di determinare la loro relazione. 2) l'altro modello si basa sull'assunzione che la relazione tra due categorie viene immagazzinata direttamente nella rete seman- tica, una struttura consistente in concetti collegati ad altri concetti mediante nessi che specificano la natura delle relazio- ni. Il primo modello é abbastanza simile ai modelli di categorizza- zione.

51
Una idea chiave relativamente al funzionamento di un sistema di riconoscimento é quella di propagazione dell'attivazione (sprea- ding activation). Quando viene attivato un concetto vengono attivati in parte anche concetti collegati, in quanto l'attivazione si diffonde lungo i nessi della rete. Gli effetti dell'organizzazione della base di conoscenza non si limitano creare una struttura gerarchica, tipicamente ad albero rovesciato; é necessario che le parole siano "associate" in col- legamento tra loro. Quando le parole associate sono collegate tra loro, i soggetti ricordano molte più parole di quando le stesse parole sono collegate a caso. L'organizzazione semantica del materiale migliora la rievocazio- ne, anche quando l'organizzazione non é del tipo gerarchico. Esistono due modelli, implementati a calcolatore, particolarmente interessanti che eseguono il riconoscimento di un oggetto in una categoria: 1) modello della rete gerarchica (Collins e Quillian, 1969); 2) modello del confronto di caratteristiche (Smith, Shoben e Rips, 1974). Secondo il modello del confronto della rete gerarchica, l'infor- mazione categoriale viene immagazzinata direttamente mediante as- sociazioni. Sono stati fatti degli esperimenti che mostrano come il tempo di risposta sia influenzato dal livello in cui gli attributi sono immagazzinati. Ciò conferma la previsione che il passaggio da un livello all'altro della gerarchia richiede tempo, in particolare l'ipotesi secondo la quale il tempo di risposta aumenta quando si devono recuperare le caratteristiche immagazzinate in un dato li- vello della gerarchia. Un'altra previsione interessante riguarda la facilitazione del recupero dalla memoria quando l'informazione critica é preceduta dal recupero di un'informazione simile. Esistono comunque alcune anomalie nel modello: a) vi sono casi in cui il tempo di verifica non é funzione del livello nella gerarchia. b) effetto tipicità: membri più tipici di una categoria vengono classificati con maggiore facilità dei membri meno tipici. Vediamo in maggior dettaglio il modello del confronto di caratte- ristiche. Il significato delle parole viene rappresentato in memoria da una lista di caratteristiche. Le caratteristiche sono utilizzate per definire le categorie, ma il loro grado di associazione con una data categoria é variabi- le. Esistono tue tipi di caratteristiche: a) caratteristiche "definienti" proprietà essenziali; b) caratteristiche "tipiche". Le caratteristiche definienti sono quelle che un oggetto deve possedere per poter essere membro di una categoria, mentre le ca- ratteristiche tipiche sono quelle possedute normalmente, pur non essendo necessarie. I confronti tra le caratteristiche per valutare la simiglianza possono essere di due tipi: a) o su tutte le caratteristiche indistintamente; b) oppure solo sulle caratteristiche definienti. Il modello del confronto di caratteristiche spiega le eccezioni

52
dovute all'effetto "ampiezza" delle categorie in quanto si basa sulle simiglianze e non sull'ampiezza delle categorie, spiega i- noltre l'effetto tipicità. Vi sono, da segnalare, alcune difficoltà presenti nel modello: 1) il giudizio di somiglianza é arbitrario; 2) necessità di calcoli nelle classificazioni; se abbiamo appreso che un pettirosso é un uccello sembrerebbe più facile utilizzare questa informazione direttamente piuttosto che calcolare la somiglianza tra pettirosso ed uccello; 3) scarse evidenze che le persone possano identificare caratteri- stiche definienti. Sono stati costruiti e implementati su calcolatore anche sistemi di categorizzazione basati sul modello a reti semantiche: a) Modello a propagazione dell'attivazione (Collins e Loftus, 1975); b) Modello ACT (John Anderson, Language, memory and thought, 1976); Prendiamo, ora, in considerazione il linguaggio umano nel suo complesso. Il linguaggio si compone di parole. Nella memoria semantica si stabiliscono associazioni fra parole. Le parole possono venire combinate a loro volta in frasi compiu- te. Una possibile spiegazione di questa capacità di combinazione é basata, di nuovo, sul concetto di associazione: associazione tra parole. Una prima difficoltà consiste nel fatto che nel linguaggio vi sono così tante parole combinabili che sembra che per poter for- mare frasi corrette debba essere necessario imparare un numero pressoché infinito di associazioni. Per questa ragione, principalmente, é necessario lo studio della grammatica. Lo studio dell'ambiguità linguistica, fenomeno particolarmente interessante, consente di fare luce sulle strategie utilizzate per la risoluzione delle ambiguità ai fini della comprensione del testo. Chomsky (1957) ha dimostrato che l'ipotesi associazionistica dell'apprendimento linguistico pone dei problemi che sembrano in- sormontabili: 1) una prima difficoltà é il numero di associazioni necessarie; 2) una seconda difficoltà risiede nel trattamento delle relazio- ni fra parole non adiacenti. Una divisione fondamentale e quella che solitamente si stabilisce fra sintagma nominale e sintagma verbale, all'interno dell'anali- si grammaticale delle strutture di frasi. a) sintagma nominale: aggettivi, nomi. b) sintagma verbale: avverbi, verbi e sintagmi nominali. Esiste un'intera disciplina che si occupa dello studio della struttura delle frasi: la grammatica strutturale. La rappresentazione del linguaggio come sistema di regole costi- tuisce un'attraente alternativa alla rappresentazione in termini
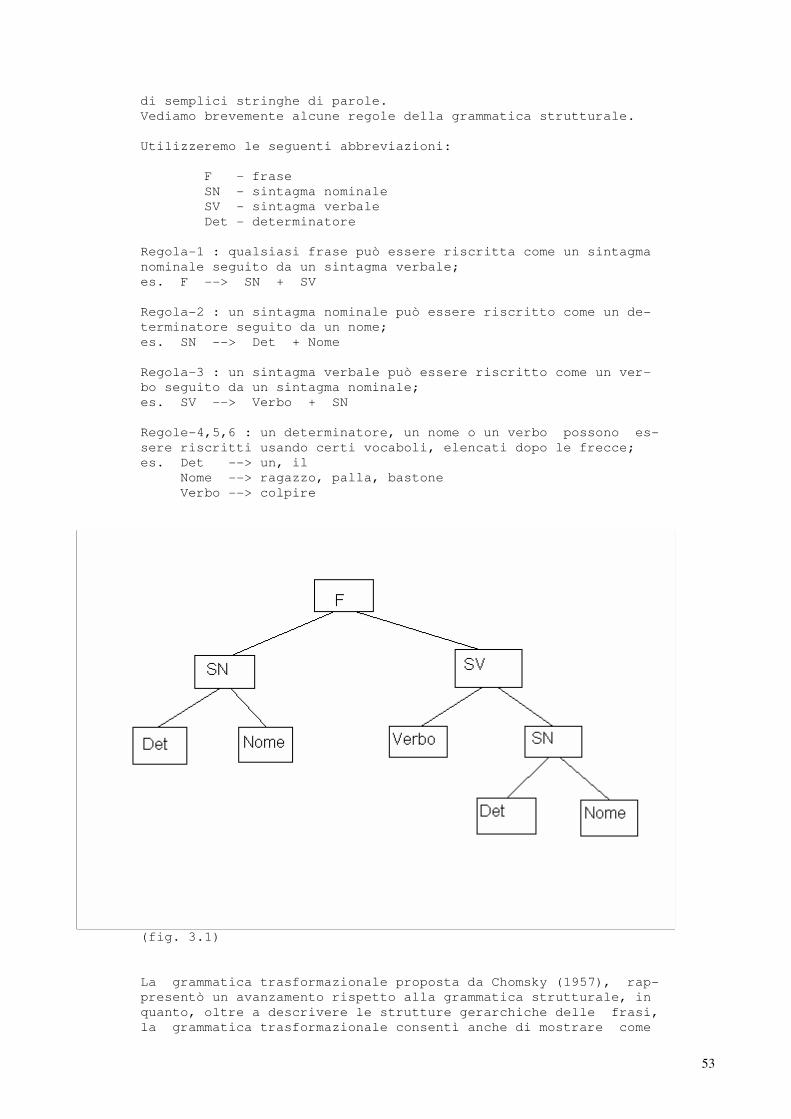
53
di semplici stringhe di parole. Vediamo brevemente alcune regole della grammatica strutturale. Utilizzeremo le seguenti abbreviazioni: F - frase SN - sintagma nominale SV - sintagma verbale Det - determinatore Regola-1 : qualsiasi frase può essere riscritta come un sintagma nominale seguito da un sintagma verbale; es. F --> SN + SV Regola-2 : un sintagma nominale può essere riscritto come un de- terminatore seguito da un nome; es. SN --> Det + Nome Regola-3 : un sintagma verbale può essere riscritto come un ver- bo seguito da un sintagma nominale; es. SV --> Verbo + SN Regole-4,5,6 : un determinatore, un nome o un verbo possono es- sere riscritti usando certi vocaboli, elencati dopo le frecce; es. Det --> un, il Nome --> ragazzo, palla, bastone Verbo --> colpire
(fig. 3.1) La grammatica trasformazionale proposta da Chomsky (1957), rap- presentò un avanzamento rispetto alla grammatica strutturale, in quanto, oltre a descrivere le strutture gerarchiche delle frasi, la grammatica trasformazionale consentì anche di mostrare come

54
le frasi possono essere trasformate in altre frasi. Tuttavia Chomsky non rimase completamente soddisfatto della gram- matica trasformazionale, e continuò a lavorare sulla sua teoria. I risultati del suo lavoro furono pubblicati in un secondo libro (Chomsky, 1965) dove egli introdusse un nuovo aspetto della gram- matica: il ruolo del significato. Esistono infatti alcune difficoltà che si incontrano analizzando il linguaggio e che la grammatica trasformazionale non risolve in maniera soddisfacente, in particolare: riconoscere i diversi si- gnificati delle frasi ambigue. Per esempio: un tipo di ambiguità abbastanza frequente nella lingua inglese é la seguente: a) they are flying planes - sono aerei volanti - stanno facendo volare degli aerei b) flying planes can be dangerous - gli aerei volanti possono essere pericolosi - far volare gli aerei può essere pericoloso secondo Chomsky (1965) questo tipo di ambiguità é risolvibile solo postulando un livello di analisi in grado di rappresentare direttamente il significato della frase. Si rende quindi necessario considerare la grammatica trasforma- zionale come costituita da due livelli: 1) il livello superficiale, collegato direttamente alla frase sentita; 2) il livello profondo, che ne rappresenta invece il significato. Per raggiungere il livello profondo, relativo al significato sia- mo costretti a considerare il contesto. Vi sono alcuni effetti tipici del contesto sulla comprensione di una frase. Nella vita di ogni giorno, le molte ambiguità potenziali del linguaggio vengono corrette dal contesto, che nella maggior parte dei casi rende chiaro il significato della frase. Sembra che il ruolo del contesto non sia quello di attivare l'uno o l'altro dei possibili significati, ma quello di consentire al sistema di selezionare, fra i significati attivati, quello appro- priato. Tale selezione avviene velocemente, abbastanza da scon- giurare possibili interferenze da parte del significato inappro- priato. In conclusione il contesto può influire in maniera determinante sulla comprensione di parole o frasi; il contesto può avere ef- fetti sia negativi che positivi in relazione al compito svolto nella comprensione di frasi. Oltre al contesto esistono anche altri elementi che influenzano la corretta comprensione di frasi, probabilmente riconducibili al contesto, ma non in maniera direttamente evidente. Il linguaggio coinvolge anche significati impliciti, non rappre- sentati direttamente dalle parole nel discorso. Spesso é suffi- ciente che un messaggio implichi una certa azione perché chi a- scolta resti convinto che l'azione ha avuto effettivamente luogo: es: il pitone catturò il topo --> il pitone si é mangiato il topo. Vi sono esempi che dimostrano che spesso la gente non distingue fra affermazioni esplicite e implicazioni, cosicché i messaggi impliciti vengono ad assumere, nel vissuto dell'ascoltatore, lo stesso peso di quello che é stato detto esplicitamente.

55
Nel ragionamento logico spesso compare il problema opposto: la gente non vede le implicazioni logiche di certe affermazioni, o ne vede di scorrette; es: ogni carta che ha una D su una faccia ha un 3 sull'altra (fig. 3.2)
3 7 D K cosa si trova dietro il 3? La gente compie questo tipo di errori a causa di una tendenza a verificare, invece che a falsificare, la regola data; mentre in- vece l'informazione potenzialmente falsificante é l'unica neces- saria. Un fatto curioso é il seguente: la gente risolve con più faci- lità problemi logici se applicati a situazioni concrete - il contenuto semantico di un'affermazione é una determinante importante della comprensione linguistica. Che cosa possiamo trarre da quanto delineato in relazione al pro- cesso di memorizzazione, in particolare riguardo alla comprensio- ne e al ricordo? L'importanza della conoscenza di un soggetto diventa evidente quando bisogna capire idee molto astratte. Un contesto significante migliora la rievocazione se viene forni- to prima della lettura del materiale. É necessario migliorare la comprensione se si vuol migliorare il ricordo. Le conoscenze dei soggetti riguardo le attività di ogni giorno possono essere rappresentate per mezzo di SCRIPTS (copioni), con- tenenti un elenco degli eventi più comunemente associati ad una determinata attività. Il concetto di script é stato utilizzato per studiare come la conoscenza intorno ad una certa attività abituale consenta di capire e ricordare l'informazione complessiva in essa contenuta. (Black e Turner, 1979) (Schank e Abelson, 1977). La facilità con cui vengono ricordati gli eventi che ostacolano il raggiungimento di uno scopo suggerisce che gli scripts sono orientati a scopi. In che modo le strutture di memorizzazione possono aiutarci nel compito relativo alla risoluzione di problemi? Un metodo di classificazione dei problemi li raggruppa in tre ca- tegorie: a) problemi di organizzazione; b) problemi di scoperta della struttura; c) problemi che coinvolgono trasformazioni. La soluzione é influenzata dalle proprietà della memoria a bre- ve termine e dalla memoria a lungo termine, in particolare i fat- tori coinvolti sono: 1) la capacità; 2) il tempo di immagazzinamento; 3) il tempo di recupero. Un punto fondamentale é il seguente:

56
- Le prestazioni sono influenzate dalle dimensioni dello spazio di ricerca, che riguarda il numero di mosse legali corrispondenti a ciascun punto del problema. Ora, esperimenti di psicologia cognitiva hanno dimostrato che le principali strategie di tipo generale utilizzate nella risoluzio- ne dei problemi si possono classificare nelle seguenti: a) analisi mezzi / fini b) formulazione di sottoscopi c) uso di analogie d) costruzione di diagrammi La strategia di maggior interesse, per la presente trattazione, riguarda l'uso di analogie. Talvolta l'uso di soluzioni analoghe si dimostra utile anche se spesso le persone non notano l'esistenza dell'analogia. Cercheremo, nel seguito di delineare in che senso sia possibile introdurre le analogie all'interno di una rappresentazione forma- le di regole e dati.

57
3.3 Algoritmi genetici Gli algoritmi genetici nascono dalla ricerca di procedure basate sui meccanismi di selezione naturale e di genetica naturale. Il processo di astrazione ci porta a immaginare funzioni di ri- cerca, ottimizzazione e apprendimento automatico delle informa- zioni. Tramite lo studio di algoritmi di tipo genetico possiamo ipotiz- zare meccanismi che consentano la costruzione di categorie a- stratte generali a partire dai dati elementari. Per introdurre gli algoritmi genetici occorre fare riferimento a processi analoghi ai processi biologici. Gli algoritmi genetici sono sostanzialmente algoritmi di ricerca che sfruttano le caratteristiche dei meccanismi di selezione e genetica naturale. Le informazioni sono organizzate in stringhe di dati corredati da algoritmi che ne consentono la riproduzione di generazione in ge- nerazione. Tali algoritmi combinano la sopravvivenza delle stringhe, valuta- te come migliori, con l'interscambio di informazioni strutturate e casuali e con alcune tipologie di ricerca tipiche del ragiona- mento umano. Vengono generate strutture di stringhe che si riproducono di ge- nerazione in generazione. Alcuni obiettivi di tale ricerca sono (Holland) : 1) ottenere una spiegazione astratta e rigorosa dei processi a- dattativi; 2) disegnare sistemi artificiali che presentino tali caratteri- stiche. Il tema centrale della ricerca sugli algoritmi genetici é stata la ROBUSTEZZA, l'equilibrio tra EFFICIENZA, EFFICACIA e FLESSIBI- LITÀ dei sistemi biologici. Autoriparazione, autoguida, riproduzione sono presenti anche in alcuni sofisticati sistemi artificiali ma gli algoritmi genetici presentano queste caratteristiche in una maniera particolarmente interessante: tali caratteristiche scaturiscono direttamente dall'impostazione generale propria degli algoritmi genetici. Nei metodi tradizionali di ottimizzazione e ricerca la robustezza viene ricavata essenzialmente dall'euristica; in particolare esi- tono tipicamente quattro metodi di ottimizzazione e ricerca: 1) metodi basati sul calcolo suddivisi in 1.1) metodi diretti 1.2) metodi indiretti - di ricerca con utilizzo del gradiente 1.3) metodi basati sull'esistenza di funzioni derivabili che descrivono i fenomeni 2) metodi enumerativi ricerca su tutto lo spazio (finito) di possibilità utilizzabili, ovviamente, quando il numero di possibilità é relativamente basso 3) metodi casuali gli algoritmi genetici sono un esempio di ricerca che utilizza scelte random come strumento per guidare una ricerca esplorativa di alto livello nello spazio codificato 4) metodi associativi

58
ricerca basata sui raggruppamenti associativi che organizzano lo spazio delle soluzioni É facile rendersi conto che i metodi di ricerca convenzionale non presentano quelle caratteristiche di robustezza proprie degli algoritmi genetici. Il filo conduttore degli algoritmi genetici si basa principalmen- te su tre idee: 1) l'astrazione di operatori e strutture da esempi naturali 2) l'analisi di tali strutture e meccanismi utilizzando la tecni- ca della matematica formale 3) applicazioni di queste astrazioni a problemi pratici All'inizio della ricerca sugli algoritmi genetici si trova una importante domanda: d) data una popolazione di struttura finita e dei relativi finiti valori di profitto, quale informazione é disponibile per guidare la ricerca delle strutture migliori? La risposta a questa domanda é sempre la stessa: r) similarità di alto profitto (highly fit similarities) Senza conoscenza specifica del problema le uniche informazioni che possiamo esplorare con una certa confidenza é ciò che é contenuto nelle similarità ad alto profitto tra le strutture di una popolazione. Se non abbiamo la possibilità di sperimentare delle combinazioni di tali similarità ad alto valore, allora siamo fortemente limitati in ciò che produce la massima poten- zialità del metodo. Questo punto é semplice ma essenziale: per tale ragione non é conveniente utilizzare conoscenze specifiche del problema che non siano rappresentabili nello schema generale. Vi sono principalmente quattro motivi per cui gli algoritmi gene- tici si differenziano dai metodi tradizionali: 1) gli algoritmi genetici lavorano con i codici dell'insieme dei parametri e non con i parametri stessi; 2) gli algoritmi genetici ricercano una popolazione di punti e non un singolo punto; 3) gli algoritmi genetici utilizzano una funzione di valutazione (funzione obiettivo) e non derivate o altre conoscenze ausilia- rie; ( payoff information) 4) gli algoritmi genetici utilizzano regole di transizione proba- bilistiche e non regole deterministiche. Molte tecniche di ricerca richiedono molte informazioni ausilia- rie per poter lavorare correttamente. Per esempio la tecnica del gradiente necessita delle derivate, per trovare il picco, e altre procedure di ricerca locali come la tecnica dell'ottimizzazione combinatoriale richiede l'accesso ai parametri tabellari. Viceversa, gli algoritmi genetici non necessitano di tali infor- mazioni ausiliarie: essi richiedono solo il valore di valutazione (payoff value) associato ad ogni singola stringa.

59
Vediamo ora lo schema generale di un algoritmo genetico. Il meccanismo di un semplice algoritmo genetico é sorprendente- mente semplice, e coinvolge solamente operazioni di duplicazione di stringhe. La semplicità delle operazioni e la potenzialità degli effetti sono due delle caratteristiche più accattivanti dell'approccio algoritmi genetici. Un semplice algoritmo genetico che fornisce buoni risultati in molti problemi pratici é composto da tre operatori: 1) riproduzione; 2) interazione (crossover) 3) mutazione consideriamo una popolazione di n stringhe definite su un oppor- tuno alfabeto, in tal modo si codifica una "idea" completa o le prescrizioni per eseguire un particolare compito, in tal caso o- gni stringa é un' "idea" completa. Le sottostringhe di ogni stringa contengono "nozioni" che sono rilevanti per il lavoro. Visto in questi termini, la popolazione non contiene semplicemen- te n idee, ma piuttosto contiene una moltitudine di nozioni e riarrangiamenti di nozioni relativamente a quel particolare com- pito. Gli algoritmi genetici esplodono tale insieme di informa- zioni con: 1) riproducendo nozioni di alta qualità in accordo con le pre- stazioni o il compito da svolgere; 2) mescolando queste nozioni con molte altre nozioni di alto li- vello proprie di altre stringhe, grazie alll'azione di interazio- ne (crossover) con le precedenti riproduzioni, tali nozioni si rispecchiano nelle nuove idee costruite dalle parti di alto li- vello nei tentativi passati: scambiando nozioni per formare nuove idee si innesca un processo di innovazione. Osserviamo, ora, in maggior dettaglio il concetto di simiglianza tra stringhe così come viene utilizzato dagli algoritmi geneti- ci. Un punto fondamentale é il seguente: in un processo di ricerca guidato esclusivamente da una funzione di costo (payoff) quale informazione é contenuta in una popolazione di stringhe e nelle rispettive funzioni obiettivo per ottenere un risultato positivo? Un importante criterio consiste nel considerare le similarità esistenti tra le stringhe sulla base della funzione di costo. Analizzando tali similarità in maggior dettaglio notiamo che certi pattern di stringhe appaiono più fortemente associati a buone prestazioni. In particolare sembra perfettamente ragionevo- le mescolare e confrontare quelle sottostringhe che sono maggior- mente correlate a risultati positivi ottenuti. In pratica: prima cerchiamo similarità tra le stringhe di una determinata popolazione, quindi cerchiamo le relazioni casuali tra tali similarità relativamente alla funzione di costo (obiec- tive function). In un certo senso, non siamo interessati alle stringhe e alle stringhe solamente, poiché importanti similari- tà tra stringhe ci possono aiutare nella ricerca, ci chiediamo in che modo e in quale senso una stringa può essere simile a stringhe successive. In specifico, ci chiediamo in che modo una stringa sia rappresentativa di altre stringhe (string classes) tramite la coincidenza in certe posizioni nella stringa (binary strings). Per far ciò si può utilizzare il concetto di schema. Uno schema (Holland, 1968, 1975) é un corpo di similarità che

60
descrive un sottoinsieme di stringhe che presentano coincidenze in certe posizioni. Limitiamoci al seguente alfabeto 0,1,* dove * significa non de- terminato o non considerato (metasymbol). Allora lo schema *111* rappresenta l'insieme di stringhe: 01110,01111,11110,11111. Vediamo ora alcuni fondamenti matematici con cui costruire algo- ritmi genetici. Consideriamo stringhe binarie V=0,1 e schemi H nella forma V+=0,1,*. Denotiamo con o(H) il numero di posizioni fisse nello schema H. Definiamo una distanza d(H) definita sugli schemi. Gli schemi e le loro proprietà sono attrezzi notazionali inte- ressanti per una discussione rigorosa e una classificazione delle similarità tra stringhe. L'effetto dovuto alla riproduzione delle stringhe sul numero di individui corrispondenti ad un determinato schema é facile da determinare. Supponiamo che ad un certo tempo t vi siano m esempi corrispondenti ad un particolare schema H in una popolazione A(t) m = m(H,t) nella riproduzione, una stringa é copiata in accordo con una funzione di costo o più precisamente una stringa Ai viene sele- zionata con una probabilità: fi Pi = --------
Σ fj ci aspettiamo perciò che la generazione successiva: f(H) m(H,t+1) = m(H,t) * n * ------------
Σ fj dove f(H) é la media su tutte le stringhe rappresentate da H al tempo t. Poiché la media su l'intera popolazione può essere scritta:
_ Σ fj f = ------- n otteniamo: f(H) m(H,t+1) = m(H,t) ---_----- f In altri termini, uno schema si evolve come il rapporto tra la media della funzione di costo dello schema e la media della fun- zione di costo su tutta la popolazione. Supponiamo che un particolare schema H rimanga sopra la media di
una quantità c⋅f con c costante: possiamo scrivere

61
_ _ (f + cf) m(H,t+1) = m(H,t) ----_-------- = (1+c) * M(H,t) f partendo con t=0 e mantenendo c costante (e inferiore a 1) otte- niamo l'equazione dell'interesse composto. (progressione geome- trica) t m(H,t) = m(H,0) * (1 + c) per l'effetto di miscuglio si può ricavare che la probabilità di sopravvivenza vale: d(H)
Ps ≥ 1 - Pc --------- l - 1 dove Pc é la probabilità di scelta ed l la lunghezza, da cui: f(H) d(H)
m(H,t+1) ≥ m(H,t) * ---_---- [ 1 - Pc --------- ] f l - 1 considerando anche le mutazioni esse interessano solo le posizio- ni fisse o(H), se Pm é la probabilità della mutazione si ottie- ne: f(H) d(H)
m(H,t+1) ≥ m(H,t) ---_------ [ 1 - Pc -------- - o(H) Pm ] f l - 1 Concludendo: Corti schemi, di basso ordine, che si trovano sopra la media ricevono un incremento esponenziale nei tentativi delle generazioni successive. (Schema Theorem - Teorema fondamentale degli algoritmi genetici) Un esempio di applicazione degli algoritmi genetici é l'applica- zione alla soluzione del problema dei due (k) banditi armati. Il problema dei due banditi armati coinvolge un importante quesi- to di teoria statistica delle decisioni. Supponiamo di avere una slot-machine con due leve: leva destra e leva sinistra. Supponiamo che le probabilità di vincita siano n1
con varianza σ1 e n2 con varianza σ2 ; n1 > n2 ... con quale leva dobbiamo giocare? Naturalmente con quella legata alla probabilità maggiore ma poi- ché non sappiamo prima della fine quale leva é associata al più alto grado di vincita ci troviamo in un dilemma. Non solo dobbiamo prendere una sequenza di decisioni ma dobbiamo annotare ciò che succede per poter decidere quale leva é mi- gliore ad un determinato istante. Sfortunatamente una strategia ottimale non sembra realizzabile poiché richiederebbe la conoscenza di ciò che succederà prima che si avveri.

62
Lo "Schema Theorem" garantisce un andamento di tipo almeno espo- nenziale sul numero di tentativi giusti osservati. In tal modo l'algoritmo genetico é un buon algoritmo per approssimare la procedura ottimale nella ricerca tra soluzioni alternative. Accenniamo,ora, alla tecnica dei blocchi di costruzione. L'utilizzo degli schemi fornisce agli algoritmi genetici una no- tevole potenzialità. Semplicemente ricombinando schemi di basso ordine e corti ma con un alto potenziale rispetto alla funzione obiettivo é possibile ottenere stringhe di alto potenziale rispetto alla funzione o- biettivo stessa. In un certo senso, lavorando con questi particolari schemi (bloc- chi di costruzione), si ottiene una riduzione della complessità del problema infatti piuttosto che ottenere alte prestazioni cer- cando tutte le combinazioni di stringhe é possibile costruire stringhe sempre migliori a partire dalle soluzioni parziali mi- gliori presenti nelle generazioni passate. Tali schemi con alti valori della funzione obiettivo li denotiamo come blocchi di costruzione (building blocks) e li utilizziamo per accelerare la ricerca della soluzione. Comunque é importante tenere ben presente che semplici algoritmi genetici dipendono dalla ricombinazione dei blocchi di costruzio- ne per accedere alla soluzione ottimale. Se i blocchi di costru- zione non sono corretti a causa della errata codifica utilizzata o a causa della forma della funzione di costo stessa, il problema può richiedere molto tempo prima di fornire la soluzione o anche solo per giungere in prossimità della soluzione ottimale. Le condizioni di similarità sulle stringhe possono essere viste come punti di un iperpiano. Consideriamo stringhe e schemi di tre posizioni l=3. É facile disegnare lo spazio della ricerca:

63
(fig 3.3) Generalizzando allo spazio a n-dimensioni punti, linee e piani divengono degli iperpiani di varie dimensioni < n. Allora possiamo pensare agli algoritmi genetici come operatori che ricercano soluzioni migliori attraversando differenti iper- piani. Esiste, comunque, un problema fondamentale: la codifica. Il problema della codifica é un problema centrale ma in un certo senso la codifica di un problema per una ricerca genetica non sussiste come problema poiché il limite del programmatore di al- goritmi genetici risiede principalmente nel limite della propria fantasia o immaginazione. Gli algoritmi genetici trovano le simi- larità in qualsiasi codice arbitrario vengano espresse e tramite queste costruiscono i blocchi ottimali. Come é possibile scegliere una buona codifica? Gli algoritmi genetici ci aiutano essendo robusti, ma esistono due principi base che possono essere utili nella costruzione del codice con cui rappresentare le informazioni con stringhe: 1) il principio della costruzione di blocchi sensati: l'utente deve scegliere un codice corto, di basso ordine che sia rilevante per il problema in esame e relativamente non correlato agli schemi sulle altre posizioni fisse; 2) il principio del minimo alfabeto: l'utente deve scegliere l'alfabeto più ridotto che permette una naturale espressione del problema. Esiste un altro aspetto importante da tenere in considerazione: la discretizzazione del problema. In molti problemi di ottimizzazione, (optimal control problems) non si presenta un singolo parametro di controllo ma piuttosto una funzione di controllo che deve essere specificata in ogni punto nel continuo - (functional) - per applicare algoritmi gene- tici a questi problemi, essi devono essere ricondotti a parametri finiti prima di codificare i parametri stessi. Con un'algoritmo genetico, poiché dobbiamo lavorare con struttu- re di lunghezza finita, prima riduciamo il problema del continuo ad un numero finito di parametri e quindi riduciamo questi para- metri (finiti) in stringhe tramite qualche processo di codifica. Vi sono poi i vincoli che si possono introdurre nel contesto dell'algoritmo di risoluzione. Molti problemi pratici contengono uno o più vincoli che devono essere soddisfatti. I vincoli sono di solito o uguaglianze o disuguaglianze. Poiche le relazioni di ugualianza possono essere trattate come scatole nere in realtà ci interessano principalmente le disugua- lianze. Un algoritmo genetico genera delle sequenze di parametri che possono essere testati utilizzando i vincoli, un modello, e la funzione di profitto (objective function). Eseguiamo il modello, valutiamo la funzione obiettivo, e control- liamo se i vincoli sono violati o meno. Di più, possiamo diminuire il rango della funzione obiettivo in relazione al "grado" di violazione dei vincoli (penalty method). In un modello a penalizzazione, un problema con vincoli viene

64
trasformato in un problema con costo o penalità legata ad ogni violazione dei vincoli. Tale costo é incluso nella valutazione della funzione obiettivo. É possibile infine ottenere una ottimizzazione multiobiettivo. L'approccio di utilizzare una funzione obiettivo che rappresenta un singolo criterio di selezione funziona bene in molti problemi, ma ci sono volte in cui sono presenti simultaneamente parecchi criteri e non é possibile (od opportuno) combinare questi para- metri in un singolo numero. Quando ciò succede il problema di- viene un problema "multiobiettivo" o "multicriterio". In una ottimizzazione multiobiettivo (o vettoriale) la nozione di ottimale non é del tutto ovvia: occorre rispettare l'integrità di ciascun criterio separatamente. Allora, in tali problemi invece di ottenere una singola risposta otteniamo un insieme di risposte che sono non dominate da altre (p-optimal). Per rendere la definizione pareto-ottimalità (P- optimal) consideriamo il vettore X come parzialmente minore di Y X < pY dove valga:
(X < pY) <==> (i) (Xi ≤ Yi) (∃i) ( Xi < Yi ). Sotto tali condizioni diremo che X domina Y. Vi sono alcune osservazioni da evidenziare su come gli algoritmi genetici utilizzano la base di conoscenza. In particolare le tecniche basate sulla conoscenza euristica ti- pica del ragionamento umano. Senza alcun dubbio, l'uomo combina nozioni di alto livello per speculare su nuove idee. Perciò considerare la sovrapposizione casuale come "il" procedimento per eccellenza dell'inventiva uma- na sembra veramente troppo restrittivo e semplicistico. Quando cerchiamo di pensare a cose nuove, siamo deliberati nelle scelte delle nozioni che formeranno le nuove idee. Occorre una elevata dose di conoscenza per decidere quali nozioni possono essere plausibili e ancor prima che le combinazioni ri- sultantanti abbiano un senso nel contesto corrente. In altre parole per l'uomo il pensiero innovativo é "diretto" da conoscenza. In contrasto con tutto ciò, nella sua forma pura, gli algoritmi genetici appaiono come limitate procedure di ricer- ca: essi esplorano solo i codici e le funzioni obiettivo per de- terminare tentativi plausibili di stringhe delle future genera- zioni. D'altra parte, l'indifferenza verso informazioni specifi- che del problema danno in larga parte agli algoritmi genetici la capacità di lavorare bene senza conoscenze peculiari e con al- trettanta facilità li rende in grado di trasferire tale cono- scenza ad altri domini. D'altro canto, non utilizzare tutta la conoscenza disponibile in un particolare problema mette gli algo- ritmi genetici in svantaggio rispetto a metodi che di ciò fanno uso. La semplicità concettuale e di funzionamento rendono gli algo- ritmi genetici estremamente interessanti. Immaginiamo che la ricerca sull'Intelligenza Artificiale sia tracciabile in un grafico a due dimensioni:
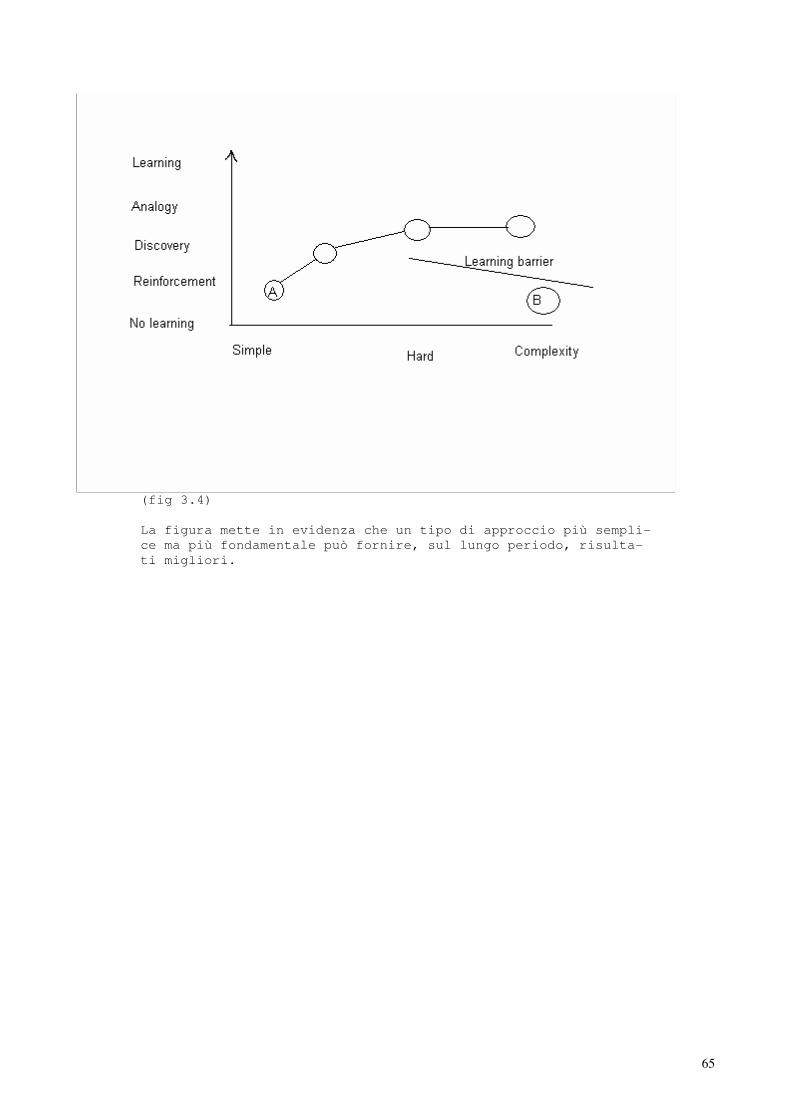
65
(fig 3.4) La figura mette in evidenza che un tipo di approccio più sempli- ce ma più fondamentale può fornire, sul lungo periodo, risulta- ti migliori.

66
4. I CRITERI DI CLASSIFICAZIONE 4.1 Sistemi di classificazione Un sistema di classificazione solitamente consiste di: 1) regole e messaggi di sistema 2) apporto di credibilità al sistema 3) algoritmo di classificazione vero e proprio. Esiste un prodotto CL-ONE che consente la costruzione di reti pa- rallele semantiche in un ambiente classificatore facente uso di algoritmi genetici. Per molto tempo i membri della comunità di Intelligenza Artifi- ciale hanno criticato le macchine che apprendono basate su algo- ritmi genetici come troppo semplici per spiegare la formazione e l'uso di concetti di alto livello. Forrest (1982,1985) nella sua dissertazione dimostrò la possibi- lità di implementazione di reti semantiche di alto llivello in un ambiente di classificazione basato su algoritmi genetici. Dal successo di mappare il lavoro simbolico di ricercatori di In- telligenza Artificiale in un formato "classificatorio", Forrest ha offerto, in un certo senso, una dimostrazione di esistenza re- lativamente al fatto che sistemi di classificazione possono emu- lare i modelli complessi della Intelligenza Artificiale simboli- ca. I componenti principali nel lavoro di Forrest sono: 1) generatore di classi e parser 2) tavola di conversione dei simboli 3) comandi di processore esterni 4) sistema di classificazione. Anche altri autori hanno sviluppato sistemi di classificazione che utilizzano algoritmi genetici (L.B.Booker, D.E.Goldberg, J.H.Holland). I sistemi di classificazione sono sistemi fortemente paralleli, selettori di messaggi e basati su regole che imparano grazie all'assegnamento di credito (bucket brigade algorithm) e regole per scoprire nuovi dati (algoritmi genetici). Essi operano in am- bienti che mostrano una o più delle seguenti caratteristiche: 1) eventi perpetuamente nuovi accompagnati da grande rumore o da- ti irrilevanti; 2) richieste di azioni continue e spesso in tempo reale; 3) obiettivi impliciti o definiti in maniera non esatta 4) funzione di rinforzo o di merito (payoff) ottenibile solo at- traverso una lunga sequenza di azioni. I sistemi di classificazione sono disegnati per assorbire nuove informazioni continuamente dal proprio ambiente, analizzando in-

67
siemi di ipotesi in competizione (espresse da regole) senza di- sturbare in maniera significativa le capacità già acquisite. Nel seguito si accennerà alle definizioni, alla teoria, e alle estensioni di applicazioni dei sistemi di classificazione, con- frontandoli con altre tecniche di costruzione di macchine che ap- prendono, e concludendo con una discussione sui vantaggi, proble- mi, e le estensioni possibili dei sistemi di classificazione. Quali sono i meccanismi di apprendimento di nuove classi? In che modo é possibile per un sistema modificarsi per incremen- tare le proprie capacità di riconoscimento di nuovi input? Esistono due tipi di cure: a) un agente esterno può intervenire per fornire nuove modalità di funzionamento b) il sistema può autonomamente revisionare il proprio comporta- mento sulla base della propria esperienza. Per i sistemi di maggiore interesse come: sistemi cognitivi, eco- nomici, ecc ... la prima ipotesi é raramente applicabile. Tali sistemi sono immersi in ambienti continuamente mutevoli in cui tempestivi interventi dall'esterno sono difficili se non im- possibili. L'unica possibilità é l'apprendimento o per usare un termine più comprensivo é l'adattamento. In altri termini, l'oggetto del sistema che apprende, naturale o artificiale, é l'aumento di conoscenza in una situazione di in- certezza. Più direttamente un sistema che apprende migliora le proprie prestazioni tramite generalizzazioni basate sulle proprie esperienze. Chiaramente, in una situazione di continua novità, l'esperienza può guidare le azioni future solo se esistono rile- vanti regolarità nell'ambiente. Nell'ambito dell' Intelligenza Artificiale il problema di estrar- re delle regolarità é il problema di scoprire utili rappresen- tazioni o categorie. Per una macchina che apprende il problema consiste nel costruire categorie rilevanti dalle primitive del sistema. Scoprire categorie rilevanti é solo metà del lavoro; il sistema deve anche scoprire quale tipo di azione é appropriata per cia- scuna categoria. Esiste un altro problema nel costruire le rap- presentazioni: in ambienti complessi, i tentativi di soddisfare una richiesta comportano poche informazioni in relazione al pro- cesso di livello superiore che porta alla risoluzione della ri- chiesta. Come fa il sistema di apprendimento a riconoscere il valore im- plicito di certe azioni ad un certo stadio ancora incompleto? Le informazioni coinvolte ad un certo stadio intermedio possono essere usate per costruire un modello dell'ambiente, e tale mo- dello può essere usato per estrapolare previsioni. La verifica o falsificazione della previsione in eventi successivi può essere usata per avvalorare il modello. Il modello, naturalmente, include anche una funzione di merito, così che le previsioni sul valore di certe azioni possono essere controllate e riviste. Riassumendo, i sistemi di apprendimento di maggior interesse pre- sentano le seguenti problematiche: 1) dati sempre nuovi concernenti l'ambiente, spesso rumorosi o irrilevanti 2) richieste continue di azioni, spesso in tempo reale 3) richieste non ben definite o implicite 4) funzione di merito o di rinforzo dispersa che richiede lunghe sequenze di azioni.

68
Per affrontare questi problemi il sistema di apprendimento deve: 1) inventare categorie che scoprano regolarità, rilevanti per il problema, nel proprio ambiente; 2) utilizzare il flusso di informazioni incontrate sul percorso per ridefinire il proprio modello di ambiente; 3) assegnare azioni appropriate alle categorie man mano create. Richieste sempre nuove e dati sempre nuovi in continuo cambiamen- to forniscono poche opportunità di ottimizzazione, conviene piuttosto utilizzare il concetto di competizione. Tipicamente relazioni complesse tra le primitive del linguaggio e le frasi (regole) che specificano le azioni rendono difficile trovare combinazioni semplici di primitive che forniscono genera- lizzazioni plausibili dall'esperienza.
fig. (4.1) Vediamo lo schema di un sistema di classificazione generico co- struito secondo i criteri abbozzati. Esso si compone genericamente di: a) messaggi provenienti dall'interfaccia di ingresso (input in- terface); b) messaggi in uscita sull'interfaccia di output (output interfa- ce); c) messaggi dal monitor interno (GOALS messages); d) funzione di valutazione (payoff);

69
e) un nucleo interno - algoritmo di classificazione che consente di creare i raggruppamenti e migliorare le performances f) algoritmo di assegnamento del credito tramite la funzione di valutazione (bucket brigade - credit assignment); g) algoritmo genetico vero e proprio (Discovery); Il punto di partenza di questo approccio verso le macchine che imparano consiste in un insieme di sistemi basati su regole indi- rizzati al compito di scoprire algoritmi. Le regole devono con- sentire l'estrazione e la ricombinazione di blocchi di costruzio- ne (building blocks) dalle regole correntemente usate per formare nuove regole e tali regole devono poter interagire sia in modo semplice che in una modalità fortemente parallela. I sistemi di classificazione sono paralleli, elaborano messaggi, sono basati su regole in cui le regole hanno una forma semplice. Le regole sono solitamente in una forma condizione/azione. La condizione specifica quale messaggio soddisfa la regola e l'a- zione specifica quali messaggi occorre attivare in tal caso.
(fig. 4.2) Un sistema di classificazione base si compone delle seguenti par- ti principali: a) interfaccia messaggi in ingresso (input interface); b) interfaccia messaggi in uscita verso l'ambiente (output inter- face); c) lista complessiva dei messaggi (messages list); d) lista corrente messaggi condizione (IF list); e) lista corrente messaggi attivi (THEN list - active messages); In particolare: 1. Tutti i messaggi vengono testati e forniscono altri messaggi se verificati.

70
2. Le classificazioni vincenti generano nuovi messaggi. Un sistema di classificazione base esegue i seguenti passi: 1. tutti i messaggi in input vengono aggiunti alla lista messag- gi; 2. tutti i messaggi vengono valutati e tutte le condizioni con- trollate; 3. per quei messaggi che soddisfano le condizioni richieste ven- gono generati i messaggi corrispondenti alla parte azione (ac- tion); 4. tutti i messaggi nella lista vengono sostituiti con i nuovi; 5. I messaggi vengono riportati nella lista di output in funzione delle richieste; 6. ritorna al punto 1.

71
4.2 Teoria matematica della classificazione Principalmente la classificazione di oggetti avviene in base all'analisi degli attributi posseduti dagli oggetti stessi. Gli oggetti possono essere organizzati in classi e raggruppati in concetti. I principi di classificazione si dividono in artificiali e natu- rali. Ad esempio come uso del principio naturale si potrebbe prendere la classificazione degli animali e delle piante in ac- cordo con i dettagli delle loro caratteristiche e strutture. La moderna biologia si focalizza sulla spiegazione della funzione informativa dei geni e delle molecole, anche se per un lungo pe- riodo le classificazioni degli organismi é stata il principale argomento della biologia. É possibile generare una classificazione senza nessun principio naturale. In tal caso, é più semplice trattare la classifica- zione in maniera globale considerando una base di conoscenza lo- cale; poiché é più facile determinare similarità locali, sul- la base di tali similarità locali possiamo determinare quali og- getti sono più vicini o simili ad altri. Per misurare la vicinanza locale, possiamo usare l'idea di dimen- sione o cordinata. Supponiamo di avere w1, w2, ... ,wn come parole chiave che de- scrivono il contenuto di un libro. Queste parole per ciascun li- bro sono diverse e all'interno di ciascun libro l'importanza re- lativa di una parola chiave é differente. Per rappresentare gli attributi di tutti i libri possiamo prende- re tutte le possibili chiavi e scriverle come un vettore <w1,w2,...,wn>. Se un libro ha una chiave associata, il valore dell'importanza di questa chiave é 1. Altrimenti, il valore del- la sua importanza é 0. Alternativamente, possiamo avere le altre chiavi ad un valore tra 0 e 1 in relazione alla loro importanza. Supponiamo sia v(ai), il valore di importanza della parola chia- ve wi ed assumiamo che le parole chiave siano ordinate da w1 a wn. Possiamo allora rappresentare il vettore di parole chiave a con l'espressione: a : < v(a1), v(a2), ... , v(an) > In tal modo il libro a é espresso come un punto nello spazio n-dimensionale le cui coordinate stanno tra 0 e 1, tale spazio é detto spazio degli attributi. Per determinare se due oggetti sono simili, si può introdurre l'idea di distanza nello spazio n-dimensionale. Una semplice misura di distanza é la distanza Euclidea: /------------------- / n 2
d( v1, v2 ) = || v1 - v2 || = \/ Σ (v1i - v2i) i=1 Consideriamo, ora, il problema della classificazione. Quando facciamo riconoscimento di forme (pattern recognition), per esempio nel caso di riconoscimento di caratteri, assumiamo che ciascun carattere abbia una forma standard ideale. In tal ca- so il nostro compito risulta difficoltoso poiché dobbiamo essere

72
in grado di interpretare sia i caratteri stampati sia quelli scritti a mano che di solito non corrispondono perfettamente a tali forme ideali. Un sistema di riconoscimento di forme prima studia le caratteri- stiche delle forme dei caratteri ideali, quindi determina la po- sizione della forma ideali nello spazio degli attributi, e rico- nosce i caratteri non perfettamente corrispondenti misurando la loro distanza da tale posizione. Supponiamo di avere un vettore di caratteristiche di una forma ideale v1 e la forma di un carat- tere corrispondente al vettore x, allora; d (v1,x) < l possiamo dire che x é riconosciuto essere il carattere v1 dove l é qualche distanza fissata. Supponiamo di avere due vettori di attributi corrispondenti a due caratteri ideali v1, v2 allora dovremmo avere: d (v1,v2) > l o se possibile d (v1,v2) > 2l Se abbiamo n forme standard e ciascuno di esse soddisfa la con- dizione di cui sopra, allora dato un carattere sconosciuto x , il sistema confronterà il relativo vettore con ciascun vettore ideale vi e determinerà il carattere più simile tramite: min(i) ( d(vi,x) ) oppure
se d(vi,x) ≤ l allora x appartiene a vi se d(vi,x) > l per ogni i allora x non viene riconosciuto Consideriamo il caso in cui la forma standard vi non sia deter- minabile e non possa essere perciò utilizzata. In tal caso dobbiamo ottenere qualcosa che sostituisce vi , per esempio prendendo la media di molte forme che appartengono alla stessa classe. In altre parole il sistema non si riferisce diret- tamente a vi ma usa molte forme che riconosce appartenere a vi:
x ∈ S(vi) dove S(vi) é la collezione delle forme osservate che appartengo- no al pattern vi. Se in numero di tali forme é k, allora il valore medio é: 1
vi = ----- Σ x k x ∈ S(vi) Tale valore medio verrà designato come forma standard. Consideriamo ora il problema del clustering. Abbiamo visto che é possibile classificare figure utilizzando la vicinanza tra una forma sconosciuta e un insieme di forme stan- dard nel caso in cui queste ci siano date. Sfortunatamente non sempre é possibile averle. Nel caso in cui non sia possibile avere un insieme di forme stan- dard di confronto possiamo usare il metodo del raggruppamento (clustering). Il clustering consiste in una collezione di metodi quantitativi per determinare se un insieme di punti in uno spazio n- dimensionale possono essere raggruppati, e quindi scoprire quanti gruppi esistono.

73
Se possiamo identificare alcuni gruppi di dati in questo modo, possiamo immaginare che ciascun gruppo rappresenti un'entità nella classificazione e che il numero dei raggruppamenti cori- sponde al numero di entità nella classificazione. Ciò fornisce un modo naturale di dividere i punti in gruppi di oggetti. Il tipo più semplice di clustering é il ragruppamento semplice (simple clustering). Supponiamo di denotare N oggetti con x = x1,x2, ... ,xn. Ciascun xi rappresenta un vettore che ha n valori di attribu- to xi = <xi1, xi2, ... , xin>. La distanza tra un oggetto xi e xj é d(xi,xj) ; xi e xj
appartengono alla stessa classe se d(xi,xj) ≤ T per un valore specificato di T. Vediamo ora alcuni algoritmi di creazione delle classi. (1) Algoritmo - Simple clustering 1. prendi il primo oggetto, x1 e rendilo il centro del cluster z1. (z1 = x1) 2. per ogni oggetto arbitrario xi ;
se d(xi,z1) ≤ T allora xi appartiene a z1 ; se d(xi,z1) > T allora costruiamo un nuovo cluster z2 = xi; 3. supponiamo di aver processato (i) oggetti e di aver costruito k cluster centrati in (z1, z2, ... ,zk) ; consideriamo l'oggetto xi+1, IF d(xi+1,z1) > T, d(xi+1,z2) > T, ... , d(xi+1,zk) > T THEN creiamo un altro cluster zk+1 = xi+1;
IF d(xi+1,zl) ≤ T ( l ≤ k ) é vera per qualche zl THEN si conclude che xi+1 appartiene a zl; 4. quando si arriva a xn, si ferma il processo. l'ultimo zl diviene zk. Questo algoritmo genera k gruppi dipendenti da T e dipende an- che dall'ordine in cui si presentano gli oggetti. (2) Algoritmo - K-average algorithm Un altro metodo conosciuto di raggruppamento é chiamato algorit- mo k-medio. Questo metodo presume che ci siano k gruppi e cerca di dividere il tutto in k gruppi: 1. vengono creati k centri z1(1), z2(1), ... , zk(1) si potrebbe prendere anche k oggetti a caso da X; 2. Al k-esimo passo, il sistema classifica gli elementi di X in k gruppi utilizzando il seguente metodo se per un certo oggetto: || x - zj(k) || < || x - zi(k) || é vera per tutti i = 1,2,...,k (i diverso da j) allora x appartiene a zj(k) in altre parole cerchiamoo il cluster che é più vicino a x;

74
3. supponiamo sia Sj(k) l'insieme di vettori assegnati a zj(k) calcoliamo un nuovo centro zj(k+1) per Sj(k) come: 1 zj(k+1) = ---------------------
Nj Σ x x ∈ Sj(k) dove Nj é il numero di oggetti di Sj(k) zj(k+1) é il centro di gravità dei punti che appartengono a Sj(k); 4. Assumiamo che l'algoritmo sia completato e ci fermiamo quando zj(k+1) = Zj(k) é vero per tutti j = 1,2,...,k e i centri di gravità non si spostano più. Nel metodo sopra descritto si inizia con k gruppi. Si può utilizzare differenti valori di k, k é arbitrario. Esiste un'altro metodo che cerca di creare raggruppamenti miglio- ri combinando automaticamente k. Con questo metodo, misuriamo l'efficienza della classificazione determinando quanto compatto é ciascun gruppo. La compattezza può essere calcolata come segue: 1. La media della distanza tra due oggetti in un gruppo é data da: _ 1
Dj = ----- Σ || x - zj || i = 1,2,...,k. Nj x ∈ Sj _ 2. La media dei Dj per tutti i gruppi vale: 1 k _
D = ----- Σ Nj ⋅ Dj dove N é il numero di gruppi. N j=i

75
5. LOGICA MATEMATICA 5.1 La logica proposizionale La moderna logica classica consiste in un sistema formale svilup- pato originariamente per trattare con argomenti logici in matema- tica. La parte proposizionale di questo sistema riguarda argomen- ti costruibili utilizzando proposizioni costanti e connettivi per costruire le frasi. Le proposizioni costanti sono nomi che deno- tano frasi dichiarative. I connettivi sono operatori che consen- tono la costruzione di frasi composte a partire da quelle atomi- che o elementari. Un alfabeto della logica proposizionale classica consiste di sim- boli primitivi appartenenti alle classi seguenti: (i) Un insieme numerabile di proposizioni costanti; (ii) Una costante-vera: "Vero";
(iii) Connettivi: "->" implicazione e "¬" negazione; (iv) parentesi : "(" e ")". Le classi (ii)-(iv) sono fisse, mentre la classe (i) varia da al- fabeto ad alfabeto, in particolare, può essere vuoto. Assumiamo che l'insieme di proposizioni costanti sia numerabile e denotiamole con lettere minuscole, p, q e r. Esse possono rappre- sentare frasi comuni del linguaggio corrente. Definizione 5.1.1 L'insieme di formule sopra ad un alfabeto AL é costituito dal più piccolo insieme che soddisfa le seguenti condizioni: (i) Vero e ogni proposizione costante di AL é una formula.
(ii) Se A e B sono formule, allora lo sono anche (¬A) e (A->B). L'insieme di tutte le formule sopra un alfabeto AL é detto lin- guaggio proposizionale su AL, e lo denoteremo con L(AL). Si può assumere che l'alfabeto sia fissato e che si possa scri- vere L al posto di L(AL). É facile vedere che la restrizione a- gli alfabeti con un insieme numerabili di proposizioni costanti ci assicura la calcolabilità di ogni proposizione del linguag- gio: per ogni alfabeto AL (con un insieme numerabile di proposi- zioni costanti), é possibile costruire una procedura effettiva per decidere se una determinata espressione (cioé una sequenza di simboli) é una formula su Al. Utilizzeremo le lettere maiuscole A,B,C, e D, con o senza sub- scritti e primitive, come variabili sintattiche definite sulle
formule. Le formule della forma (¬A) e (A->B) si leggono come "non A" e "Se A allora B", rispettivamente. (¬A) é detta nega- zione di A; (A->B) é detta implicazione con antecedente A e con- seguente B. Introduciamo, ora, ulteriori connettivi tra le frasi: "v" disgiunzine "&" congiunzione
"≡" equivalenza tramite le seguenti definizioni:

76
(A v B) = ((¬A) -> B) (A & B) = (¬((¬A) v (¬B))) (A ≡ B) = ((A -> B) & (B -> A)) Le formule sopra definite si possono leggere anche rispettivamen-
te: (A v B) come "A o B", (A & B) come "A e B", e (A ≡ B) come "A sse B" (A se e solo se B) o anche equivalenza tra A e B. La costante Falso la possiamo utilizzare come abbreviazione di
¬Vero. Per rendere le formule più facilmente comprensibili si possono adottare alcune convenzioni: utilizzare anche le parentesi "" "" "[" "]" con lo stesso significato delle "(" ")"; omettere le parentesi quando tale omissione non causa confusione; per rendere minimo il numero di parentesi, é possibile introdurre una gerar-
chia dei connettivi, con precedenza nell'ordine: ¬,&,v,->,≡ ; as- sumiamo anche che connettivi binari siano associati a destra, ciò permette di omettere le parentesi esterne. Per esempio la formula: (((p & q) v r)->(p v r)) può essere scritta come: p & q v r -> p v r
e la formula (((p v q) v Falso) & (¬q)) si riduce a (p v q v Falso) & ¬q. Scriviamo anche che A = B per indicare che A e B sono esattamente la stessa formula. Diremo che A é una sottoformula di B se e solo se A é una for- mula che compare in B. In particolare, per ogni formula A, A é una sottoformula di A.

77
5.1.1 Semantiche della logica proposizionale Le semantiche per la logica proposizionale sono basate sulle se- guenti notazioni: Definizione 5.1.2 Un interpretazione per un linguaggio proposizionale L(AL) é una funzione che assegna a ciascuna proposizione costante di AL un elemento dell'insieme 0,1. Dove con 1 si indica che la proposizione é vera e con 0 che é falsa. L'interpretazione allora fornisce i valori di verità per le pro- posizioni costanti. Definizione 5.1.3
Sia m un interpretazione per L e supponiamo che A ∈ L. Il valore di verità di A in m, denotato con V(A), é un elemento di 0,1 definito dalle: (i) V(Vero) = 1; (ii) V(p) = m(p);
(iii) V(¬B) = 1 - V(B); (iv) V(B -> C) = 1 sse V(B) = 0 o V(C) = 1. Dalla definizione precedente possiamo ricavare le seguenti condi-
zioni per i simboli v,&,≡ e Falso: (v) V(B v C) = max(V(B),V(C)); (vi) V(B & C) = min(V(B),V(C));
(vii) V(B ≡ C) = 1 sse V(B) = V(C); (viii) V(Falso) = 0. Osserviamo che i valori di verità di formule composte sono determinati univocamente dai valori di verità dei componenti. Questo principio é detto principio estensionale e vale tipica- mente per tutti i sistemi di logica classica. Diremo che A é vera (o rispettivamente falsa) in m sse V(A) = 1, (rispettivamente V(A) = 0). A é soddifacibile sse V(A) = 1, per qualche interpretazione m. A é una tautologia sse V(A) = 1, per ogni interpretazione m. Se V(A) = 1, allora m é detto modello per A. Esempio:
Sia A nella forma p v ¬q -> p (nella notazione A = p v ¬q -> p) e consideriamo due interpretazioni, m1 ed m2 tali che: m1(p) = m1(q) = 1; m2(p) = m2(q) = 0; A é vera in m1 ma é falsa in m2. Allora A é soddisfacibile ma non é una tautologia. L'interpretazione m1 é un modello per A. Esistono varie tecniche per determinare se una formula é una tautologia. La più utilizzata é quella basata sul concetto di tavola della verità. Illustriamo il metodo con un esempio.
La tabella di verità della formula (p -> ¬q) v q ha la forma:

78
p q ¬q p->¬q (p->¬q) v q --------------------------------------- 0 0 1 1 1 0 1 0 1 1 1 0 1 1 1 1 1 0 0 1 La tabella può essere considerata una abbreviazione delle se- guenti argomentazioni. Sia m una interpretazione arbitraria. Se m
assegna 0 sia a p che a q allora il valore di ¬q in m é 1, il valore di p->¬q in m é 1 e il valore di (p -> ¬q) v q in m é 1. (per la prima riga). Ogni riga possiede un significato analogo e le quattro righe e- sauriscono tutti i casi possibili. Poiché in tutti i casi il valore della formula é 1 essa é una tautologia. Questa tecnica può essere applicata ad ogni formula. Se una formula contiene n proposizioni costanti differenti allora la tavola di verità si comporrà di 2 elevato alla n righe. Il problema di validità per la logica proposizionale consiste nella possibilità di determinare se una determinata proposizione é una tautologia oppure no. Teorema 5.1.4 Il problema di validità per la logica proposizionale é decidi- bile. O brevemente, la logica proposizionale é decidibile. Elenchiamo alcune importanti tautologie:
(T1) (A -> B) ≡ (¬A v B) (T2) (A ≡ B) ≡ ((¬A v B) & (A v ¬B)) (T3) (¬(A & B)) ≡ (¬A v ¬B) (T4) (¬(A v B)) ≡ (¬A & ¬B) Regole di De Morgan (T5) (¬¬A) ≡ A Legge della doppia negazione (T6) (A v (B & C)) ≡ ((A v B) & (A v C)) (T7) (A & (B v C)) ≡ ((A & B) v (A & C)) leggi distributive (T8) (A & B) ≡ (B & A) (T9) (A v B) ≡ (B v A) Leggi commutative (T10) A v ¬A Legge del terzo escuso (T11) A -> A Riflessività dell'implicazione
(T12) ((A ≡ B) & (B ≡ C)) -> (A ≡ C) Transitività dell'equivalenza
(T13) (A -> B) ≡ (¬B -> ¬A) legge della contrapposizione (T14) ¬(A & ¬A) Legge della contraddizione (T15) Falso -> A
(T16) (A -> Falso) ≡ ¬A (T17) A -> Vero
(T18) (Vero -> A) ≡ A Due formule A e B si dicono logicamente equivalenti, A <=> B, se e solo se entrambe forniscono gli stessi valori di verità in o- gni interpretazione, o alternativamente se essi hanno gli stessi modelli. Vi sono tre importanti proprietà delle formule equivalenti: Teorema 5.1.5
(i) A <=> B sse A ≡ B é una tautologia; (ii) A <=> B e B <=> C implica A <=> C

79
(Transitività della relazione di equivalenza); (iii) Se B é una sottoformula di A, e À é il risultato del- la sostituzione in una o più occorrenze di B in A con C, e B <=> C, allora A <=> À. (Teorema della sostituzione). Il teorema della sostituzione assieme al principio di transitivi- tà della relazione di equivalenza, sono spesso utilizzati per mostrare che formule di una data classe possono essere trasforma- te in formule equivalenti che mostrino certe desiderate proprie- tà sintattiche. Illustreremo questo fatto in relazione ad un importante teorema. n
Scriviamo ∩ Ai come abbreviazione di A1 & A2 & ... & An i=1 n
e ∪ Ai come abbreviazione di A1 v A2 v ... v An i=1 Una formula atomica consiste o in una proposizione costante o nella costante Vero. Una formula B si dice essere nella forma congiuntiva normale sse n m(i)
B = ∩ [ ∪ Bij ], i=1 j=1 dove Bij può essere o una formula atomica o la negazione di una formula atomica. Una formula B si dice che é la forma congiunti- va normale di una formula A se é in forma normale congiuntiva e vale A <=> B. Teorema 5.1.6 Ogni formula A può essere effettivamente trasformata in una sua forma normale congiuntiva. Dimostrazione: si procede in tre passi 1) eliminare l'implicazione -> e l'equivalenza ð sostituendo in A
(B -> C) con (¬B v C) (B ≡ C) con ((¬B v C) & (B v(B v ¬C))
fintanto che la formula risultante contiene solo v,& e ¬ come connettivi.
2) Spostare la negazione ¬ in avanti sostituendo
¬(B v C) con ¬B & ¬C ¬(B & C) con ¬B v ¬C ¬¬B con B
fintanto che tutte le ricorrenze della negazione ¬ non compaiono immediatamente prima delle formule atomiche. 3) Distribuire & (e) sopra v (o) sostituendo (B & C) v D con (B v D) & (C v D) B v (C & D) con (B v C) & (B v D) e denotando con A’ la formula risultante.

80
Eseguendo l'algoritmo sopra descritto viene costruita una sequen- za di formule A0, A1, ... ,An, tale che A0 = A, An = A’, A’ é in
forma normale congiuntiva, e per ciascun i (0≤i<n), Ai+1 é il risultato di una sostituzione di una sottoformula di Ai con una sottoformula equivalente. Allora, dal teorema di sostituzione, Ai <=> Ai+1 per ciascun i e quindi dalla transitività della re- lazione di equivalenza A0 <=> An, Quindi, A’ é una forma normale congiuntiva di A. Esempio:
Consideriamo la formula A = r v ¬(p -> q). 1) eliminando -> si ottiene r v ¬(¬p v q). 2) spostando la negazione si ottiene r v (p & ¬q) 3) distribuendo & sopra v si ottiene (r v p) & (r v ¬q) che é la desiderata forma normale congiuntiva per A.

81
5.3 Teorie proposizionali Uno dei concetti centrali della logica proposizionale è quello di teoria proposizionale. Tale teoria consiste in una collezione di formule su un linguaggio di proposizioni, che si ripropone di fornire una descrizione di un determinato mondo. (Un particolare dominio, una realtà, un campo di interesse,...). Definizione 5.1.7 Una teoria proposizionale consiste in una coppia T = <L,S>, dove L é un linguaggio proposizionale ed S é un insieme di formule di L calcolabili. Gli elementi di S rappresentano gli assiomi (o le premesse) di T. Se S é vuoto, allora T é detto calcolo pro- posizionale. Abbreviando la frase teoria proposizionale in teoria, denoteremo le teorie con la lettera T. Di solito, le teorie vengono identificate con l'insieme degli as- siomi che le determinano. In tal caso si assume che il linguaggio della teoria T consista di tutte le formule costruibili utiliz- zando le proposizioni costanti che compaiono negli assiomi di T. Per esempio, quando affermiamo che T consiste di p & q -> r e r -> q allora stiamo facendo l'implicita assunzione che T = <L,p & q -> r, r -> q>, dove L é il linguaggio corrispon- dente all'alfabeto con p, q e r come uniche proposizioni costan- ti. Una teoria si dice finita (rispettivamente infinita) se e solo se l'insieme degli assiomi é finito (rispettivamente infinito). Se T é una teoria finita con assiomi A1,...,An allora T viene spesso denotata con A1,...,An o semplicemente A1,...,An. T' é una sottoteoria di T, sse gli assiomi di T' sono un sot- toinsieme degli assiomi di T. Osserviamo che per ciascuna formula A é possibile associare una teoria < L,A>, dove L é il lin- guaggio consistente di tutte le formule costruibili utilizzando le proposizioni costanti presenti in A. In questo senso ogni for- mula può essere interpretata come una teoria. Una interpretazione m é un modello per una teoria T se tutti gli assiomi di T sono veri in m. Una teoria può avere molti modelli oppure non averne nessuno; una teoria che possiede un modello é detta soddisfacibile, viceversa é detta insoddisfacibile. Teorema 5.1.8 (Teorema di compattezza) Una teoria T ha un modello sse ciascuna sottoteoria di T ha un modello. Una formula si dice essere una conseguenza semantica di una teo-
ria T, denotata come T ⇒ A, sse A é vera in ogni modello di T. In particolare, A é una conseguenza semantica del calcolo propo-
sizionale, ⇒ A, sse A é vera in ogni interpretazione per L.
Se T ⇒ A, allora possiamo anche dire che A é una conseguenza lo- gica di T, A é implicata da T, o T implica A.

82
Esempio: Consideriamo la teoria T consistente di: Domenica Domenica -> Vado a pescare
Sono stanco -> ¬Vado a pescare Si può facilmente verificare che T possiede un modello m dato da m(Domenica)=1 ; m(Vado a pescare)=1 ; m(Sono stanco)=0
perciò la teoria implica T ⇒ ¬Sono stanco
Si può osservare che il simbolo ⇒ denota una relazione binaria, di solito chiamata relazione di implicazione per la logica propo- sizionale, che vale tra una teoria T e una formula A sse T impli- ca A. Teorema 5.1.9 La relazione di implicazione della logica proposizionale gode delle seguenti proprietà:
(i) T ⇒ B sse T ∪ ¬B é insoddisfacibile; (ii) T, A ⇒ B sse T ⇒ A -> B;
(iii) A1,...,An ⇒ B sse ⇒ A1 & ... & An -> B (iv) Se T é un sottoinsieme di T'
allora A : T ⇒ A é sottoinsieme di A : T' ⇒ A (Monotonicità nell'espansione delle teorie) Le asserzioni (iii) e (iv) necessitano di una particolare atten- zione. Riguardo alla (iii), il problema di determinare se una formula B segue da una teoria A1,...,An si riduce al problema di determinare se la formula A1 & A2 ... & An -> B é una tauto- logia. Per quanto riguarda la (iv), tale proposizione esprime il fatto che se A segue da una teoria T, allora, se aggiungiamo nuo- vi assiomi a T, A é ancora derivabile dalla teoria estesa. Questa proprietà, conosciuta come principio di monotonicità, é sottintesa in tutti i sistemi logici classici. Due teorie T e T' si dicono logicamente equivalenti, T <=> T' sse sono soddisfacibili dagli stessi modelli. Un'importante proprietà delle teorie equivalenti é data dal se- guente teorema. Teorema 5.1.10
Per ogni teoria T e T', T <=> T' sse A: T ⇒ A = A: T' ⇒ A. In altri termini da teorie equivalenti si deducono esattamente le stesse formule, pertanto due teorie equivalenti sono indistingui- bile dal punto di vista delle applicazioni pratiche. Teorema 5.1.11 Se T = A1,...,An, allora T <=> A1 & ... & An. Allora ogni teoria finita si può identificare con la congiunzio- ne di tutti i suoi assiomi. Due formule A e B si dicono equivalenti in una teoria T sse pos-

83
seggono gli stessi valori di verità in ogni modello per T, o,
alternativamente, sse T implica la formula A ≡ B.

84
5.4 La logica proposizionale come sistema deduttivo Allo stesso modo in cui si può considerare le formule in rela- zione al loro significato e valore di verità (vero-falso), cioé il modo in cui si può considerare la logica proposizionale da una prospettiva semantica, così é possibile focalizzare gli a- spetti puramente sintattici del formalismo, considerandolo un si- stema deduttivo. Definizione 5.1.12 Un sistema deduttivo, o sistema inferenziale, o teoria formale, o teoria assiomatica, o assiomatizzazione, ... per la logica proposizionale consiste in DS = <L,S,R>, dove: (i) L é un linguaggio proposizionale (ii) S é un sottoinsieme numerabile di L gli elementi di S sono detti assiomi (iii) R = R1,...,Rn é un insieme finito di regole di infe- renza. Ciascuna regola Ri é una funzione parziale da Lk a L
Ri : Lk ---> L (k ≥ 1). Se A1,...,Ak appartengono al dominio di Ri, allora possiamo dire che Ri é applicabile a A1,...,Ak e che Ri(A1,...,Ak) consiste nelle dirette conseguenze di A1,...,An in virtù della Ri. Assumiamo che ciascuna Ri sia calcolabile, cioé esista una procedura effettiva che prende la tupla A1,...,Ak di formule da L, determini se Ri é applicabile ad essa, e, se lo é fornisca Ri(A1,...,Ak). Per un sistema deduttivo nella logica proposizionale, brevemente "sistema deduttivo", la regola di inferenza più conosciuta é probabilmente (MP) modus ponens, che afferma che B é una diretta conseguenza di A e A -> B; dove A e B indicano formule del lin- guaggio considerato. MP é solitamente scritta nel formalismo: A, A -> B ------------- B che può essere formalmente considerato come una funzione parzia- le (una corrispondenza) da LxL a L tale che:
(i) il dominio di MP é <A,A -> B>: A,B ∈ L; (ii) MP(<A,A -> B>) = B. É facile vedere che MP modus ponens é una regola calcolabile. Una regola di inferenza R si dice solida (o anche che conserva la funzione di verità) sse per qualsiasi interpretazione m e ogni A1,...,Ak nel dominio di Ri, Ri(A1,...,Ak) é vera in m, quando A1,...,Ak sono vere in m. Chiaramente, MP é una regola che con- serva la funzione di verità poiché, per ogni formula A e B, B é vera in ogni interpretazione in cui A e A -> B sono vere. Una formula A é dimostrabile in DS = <L,S,R> (o anche A é un teorema in DS) sse esiste una sequenza A1,...,Am di formule di L
tali che A coincide con Am e, per ciascun i, 1 ≤ i ≤ m, ogni Ai ∈ S oppure Ai é una diretta conseguenza di qualche formula precedente in virtù di qualche regola di R. Una tale sequenza é chiamata dimostrazione di A in DS. Nella definizione di sistema deduttivo DS = <L,S,R>, sono state fatte due importanti assunzioni. Primo, l'insieme S di assiomi deve essere un sottoinsieme calco-

85
labile di L, cioé deve esistere una procedura effettiva per de- cidere quando una determinata formula di L é logicamente un as- sioma oppure no.
Secondo, ogni regola di inferenza Ri ∈ R deve essere calcolabile, nel senso che deve esistere una procedura effettiva che prende una tupla A1,...,Ak di formule da L, determina se la tupla appar- tiene al dominio di Ri, e, se vi appartiene, calcola Ri(A1,...,Ak). Queste assunzioni assicurano, considerando il caso in cui ci re- stringiamo a linguaggi calcolabili, che la nozione di dimostra- zione é calcolabile nel senso seguente: esiste una procedura effettiva che prende una sequenza finita E1,...,En di espressioni linguistiche arbitrarie e determina se la sequenza é una dimostrazione di En oppure no, in DS. L'esistenza di una tale procedura é fondamentale, poiché la no- zione di dimostrazione, come sopra specificato, é stata origina- riamente formulata allo scopo di formalizzare le argomentazioni matematiche. Ovviamente, se un matematico prova una dimostrazio- ne, dovrebbe esistere un metodo effettivo per verificarla. La nozione di dimostrazione può essere generalizzata nel modo seguente: sia DS = <L,S,R> un sistema di deduzioni e supponiamo che T sia una teoria su L. Possiamo dire che una formula A é una formula
dimostrabile da T in DS, T(DS) → A, sse esiste una sequenza A1,...,Am di formule di L tali che A coincide con Am e, per ogni
i 1 ≤ i ≤ m, ogni Ai ∈ (S ∪ T) oppure Ai é una conseguenza di- retta di qualche formula precedente in virtù di qualche regola di R. Una tale sequenza si dice dimostrazione di A da T in DS.
Se T(DS) → A, allora possiamo anche dire che A é una conseguenza sintattica di T in DS, o anche che A é un teorema di T in DS.
Scriviamo (DS) → A come abbreviazione per (DS) → A.
In altri termini (DS) → A é una notazione simbolica per l'affer- mazione: A é un teorema in DS. Nella definizione della nozione di teoria, abbiamo assunto che l'insieme degli assiomi di qualsiasi teoria sia un sottoinsieme calcolabile del suo linguaggio. Questo assicura, nel caso in cui tutte le altre richieste di calcolabilità siano soddisfatte, che la nozione generalizzata di dimostrazione é effettivamente cal- colabile. In altre parole, per qualsiasi teoria T e qualsiasi si- stema di deduzioni DS, esiste una procedura effettiva per decide- re se una determinata sequenza di espressioni linguistiche arbi- trarie formano una dimostrazione su T e DS.
Un sistema di deduzioni DS si dice solido sse (DS) → A implica che A é una tautologia. Per garantire questa solidità, che é chiaramente una proprietà desiderabile, é sufficiente aggiunge- re due proprietà al sistema di deduzioni DS: primo, tutti gli assiomi logici devono essere delle tautologie; secondo, tutte le regole di inferenza debbono essere solide. Sono particolarmente interessanti quei sistemi di deduzione soli- di che sono anche completi, cioé consentono di provare qualsiasi tautologia. Parecchi di tali sistemi di deduzione sono stati pro- posti in letteratura; il più comune é forse il seguente: Definizione 5.1.13 Sia L un linguaggio proposizionale. Denotiamo con PL(L) il sistema di deduzioni <L,S,R> dato da: (i) S consiste nei seguenti assiomi (A1) Vero (A2) A -> (B -> A)

86
(A3) (A -> (B -> C)) -> ((A -> B) -> (A -> C))
(A4) (¬B -> ¬A) -> ((¬B -> A) -> B) (ii) R contiene solo il modus ponens come unica regola. Notiamo che (A2)-(A4) sono uno schema di assiomi ciascuno dei quali rappresenta un numero infinito di assiomi. É facile vedere che S é un sottoinsieme calcolabile di L. Possiamo assumere che il linguaggio L sia fissato e che il simbo-
lo PL(L) → possa essere scritto semplicemente →.
Se T → A, allora diremo che A é dimostrabile da T nella logica
proposizionale. In maniera analoga, se → A, allora diremo che A é dimostrabile nella logica proposizionale o alternativamente, che A é un teorema della logica proposizionale.
Scriviamo T ¬→ A e ¬→ A come le negazioni per T → A e → A.
La relazione binaria denotata col simbolo →, cioe, la relazione
che vale fra una teoria T e una formula A sse T → A, é detta re- lazione di dimostrabilità della logica proposizionale classica.
La relazione binaria corrispondente al simbolo ¬→ si riferisce alla relazione di indimostrabilità della logica proposizionale classica. Denotiamo con Th l'operatore della logica proposizionale classica di dimostrabilità, in altri termini, l'operatore che assegna a ciascuna teoria T l'insieme Th(T) di tutte le formule dimostrabi-
li da T nella logica proposizionale: Th(T) = A: T → A. Teorema 5.1.14 L'operatore Th soddisfa le seguenti proprietà: (i) T é sottoinsieme di Th(T); (ii) Th(T) = Th(Th(T)); idempotenza (iii) Se T é sottoinsieme di T' allora Th(T) é sottoinsieme di Th(T'); monotonicità Si può osservare che (iii) rappresenta la controparte sintattica del principio di monotonicità espresso dal teorema 5.1.9 (iv). La sintassi e la semantica della logica proposizionale sono con- nesse dal seguente risultato fondamentale: Teorema 5.1.15
(i) Se T → A , allora T ⇒ A; (teorema di solidità)
(ii) Se T ⇒ A , allora T → A; (teorema di completezza)
Corollario 5.1.16 → A sse ⇒ A. Una teoria T sopra L si dice consistente sse esiste una formula
A ∈ L tale che T ¬→ A. La nozione di consistenza rappresenta la controparte sintattica della nozione di soddisfacibilità: Teorema 5.1.17 T é consistente sse é soddisfacibile. Il risultato seguente corrisponde dal teorema 5.1.9 (ii)-(iii):

87
Teorema 5.1.18 (Teorema di deduzione)
(i) T,A → B sse T → A -> B;
(ii) A1,A2,...,An → B sse → A1 & A2 & ... & An -> B. Abbiamo anche la seguente controparte del teorema di compattezza: Teorema 5.1.19 T é consistente sse ogni sottoteoria finita di T é consistente.

88
5.2 Logica classica del primo ordine La logica classica del primo ordine, conosciuta anche come logica dei predicati di ordine minimo o logica dei predicati del primo ordine, é la logica fondamentale per tutti i sistemi logici. Il suo linguaggio é sufficientemente ricco da esprimere le argo- mentazioni principali utilizzate nella matematica e in applica- zioni diverse dalla matematica che utilizzano il ragionamento de- duttivo. 5.2.1 Il linguaggio della logica del primo ordine. Un alfabeto nella logica classica del primo ordine consiste di simboli primitivi appartenenti alle seguenti classi: (i) Un insieme V numerabile di variabili individuali: x1,x2,...; (ii) Una costante vera: "Vero";
(iii) Connettivi per le frasi: "¬" e "->"; (iv) Un quantificatore universale: "(_)" per ogni _ ; (v) parentesi: "(",")"; (vi) Un insieme numerabile di predicati costanti |P,
a ciascun P ∈ |P, é assegnato un intero non negativo chiamato arità di P; (vii) Un distinto predicato costante di arità 2: "=" 2-ary predicato - ugualianza; (viii) Un insieme numerabile |F di funzioni costanti
a ciascuna ƒ ∈ |F é assegnato un intero non negativo chiamato arità dell ƒ. Le classi (i)-(v) sono fisse e i loro membri debbono essere pre- senti in tutti gli alfabeti. Le altre classi possono variare e, in particolare, l'insieme delle funzioni costanti può essere vuoto. Assumiamo, comunque, che ogni alfabeto includa almeno un predica- to costante di arità positiva. Gli insiemi |P e |F debbono esse- re calcolabili nel senso che é richiesta l'esistenza di una pro-
cedura effettiva π(|P) e π(|F) che dato un arbitrario simbolo s, determina se s ∈ |P o se s ∈ |F e ne fornisce l'arità. I predicati costanti 0-ary sono le proposizioni costanti. Le funzioni costanti 0_ary sono gli individui o anche gli oggetti costanti. Intruduciamo alcuni simboli speciali: x,y,u,z per le variabili individuali; P,Q,R per i predicati costanti di arità positiva; p,q,r per le proposizioni costanti; f,g,h per le funzioni costan- ti di arità positiva; a,b,c per individui costanti. I predicati e le funzioni costanti possono consistere in frasi del linguaggio comune. Ogni alfabeto della logica del primo ordine determina in maniera univoca tre classi di espressioni: termini, formule atomiche e formule.

89
Definizione 5.2.1 Sia AL un alfabeto della logica del primo ordine. L'insieme TM(AL) dei termini su AL consiste nel più piccolo in- sieme tale che: (i) Tutte le variabili individuali e tutte le costanti indivi- duali di AL sono membri di TM(AL);
(ii) Se α1,...,αn ∈ TM(AL) (n ≥ 1) e f é una funzione n-ary co- stante di AL, allora f(α1,...,αn) ∈ TM(AL). L'insieme AFORM(AL) di tutte le formule atomiche su AL consiste nel più piccolo insieme tale che: (i) Vero e tutte le proposizioni costanti di AL appartengono a AFORM(AL);
(ii) Se α1,...,αn ∈ TM(AL) (n ≥ 1) e P é un predicato costante n-ary di AL, allora P(α1,...,αn) ∈ AFORM(AL);
(iii) Se α1,α2 ∈ TM(AL), allora (α1 = α2) ∈ AFORM(AL), nel caso in cui AL contenga il simbolo "=". L'insieme L(AL) delle formule sopra AL consiste nel più piccolo insieme tale che:
(i) Se A ∈ AFORM(AL), allora A ∈ L(AL);
(ii) Se A,B ∈ L(AL) e x é una variabile, allora (¬A) ∈ L(AL) (A -> B) ∈ L(AL) e ((x)(A)) ∈ L(AL). [(per ogni x(A)) ∈ L(AL)] L'insieme L(AL) é detto linguaggio del primo ordine su AL, e o- gni linguaggio del primo ordine include come sottoinsieme proprio una classe di formule della logica proposizionale. Abbreviamo la notazione L(AL), essendo AL fisso, con L. É facile vedere che la restrizione ad alfabeti composti da in- siemi di funzioni e predicati calcolabili garantisce la calcola- bilità di ogni linguaggio del primo ordine. L é detto essere un linguaggio del primo ordine con ugualianza
sse "=" ∈ AL, oppure linguaggio del primo ordine senza ugualianza in caso contrario.
Formule nella forma (¬A) e (A -> B) hanno lo stesso significato di quelle della logica proposizionale. Una formula della forma ((x)(A)) si legge per ogni elemento x A é vera. Diciamo che la ricorrenza di x in (x) é universalmente quantificata. Di piu, aggiungiamo un simbolo E (quantificatore esistenziale):
(∃x(A)) = (¬((x)(¬(A)))) non é vero che per ogni x A non é vera.
Una formula della forma (∃x(A)) si legge "per qualche elemento x, A é vera". La ricorrenza di x in ∃x si chiama quantificazione esistenziale. Introduciamo una importante convenzione nella notazione:
scriviamo "Q1x1...Qnxn.", dove Q1...Qn ∈ (_),E, per indicare che tutte le ricorrenze di x1,...xn che seguono il punto "." sono vincolate dalla condizione Q1x1,...,Qnxn.

90
Per esempio (x)Ey.P(x) & Q(y) sta per (x)Ey[P(x) & Q(y)]. Una ricorrenza di una variabile si dice libera in una formula A sse non é quantificata. Per esempio, nella formula P(x) v Q(x), entrambe le ricorrenze di x sono libere; in P(x) -> (x).Q(x), la prima ricorrenza di x é libera, mentre la seconda e la terza non lo sono. Una variabile x si dice libera in A sse x ha ricorrenze libere in A. Scriviamo A(x1,...,xn) per indicare che alcune va- riabili in A sono libere, non che tutte le variabili x1,...,xn siano libere e nemmeno che siano le uniche variabili libere in A.
Per ogni formula A(x1,...,xn) abbiamo A(α1,...,αn) per denotare il risultato della simultanea sostituzione in A dei termini
α1,...,αn per tutte le ricorrenze libere di x1,...,xn. Una formula che non contenga variabili libere si dice chiusa, al- trimenti si dice aperta. Le formule chiuse sono anche chiamate sentenze o affermazioni. Una formula (un termine) si dice base (ground) sse non contiene alcuna variabile.
Sia A una formula con variabili x1,...,xn (n ≥ 1). La chiusura universale di A, (A) per ogni A, é la formula (x1),...,(xn).A.
La chiusura esistenziale di A, (∃A) esiste A, é la formula (∃x1),...,(∃xn).A. A si dice sottoformula di B se A ricorre in B. Definizione 5.2.2 Sia L(AL) un linguaggio del primo ordine con uguaglianza. L'insieme di assiomi per l'uguaglianza per L(AL) consiste in: (E1) (x).x = x riflessività (E2) (x)(y).x = y -> y = x simmetria (E3) (x)(y)(z).x = y & y = z -> x = z transitività (E4) (x1)...(xn)(y1)...(yn)[x1=y1 & ... & xn=yn &
& P(x1,...xn) -> P(y1,...,yn)], per ogni n-ary (n≥1) predicato costante P ∈ AL (E5) (x1)...(xn)(y1)...(yn)[x1=y1 & ... & xn=yn ->
-> f(x1,...,xn) = f(y1,...,yn)], per ogni n-ary (n≥1) funzione costante f ∈ AL. Gli assiomi (E4)-(E5) sono gli assiomi di sostitutività dell'u- guaglianza.

91
5.2.2 Semantica della logica del primo ordine La semantica della logica del primo ordine é basata sui seguenti concetti: Definizione 5.2.3 Una struttura per un linguaggio L(AL) del primo ordine consiste in M = <D,m> dove: (i) D é un insieme non vuoto, chiamato dominio (universo) di M (ii) m é una funzione che assegna a ciascun predicato costante
n-ary (n≥0) di AL, diverso da "=", una relazione n-ary su D; alla costante "=", se presente il AL, la relazione identica su D, e a
ciascuna funzione costante n-ary (n≥0) di AL una funzione da D elevato alla n in D. Tenendo presente che relazioni 0-ary su D e funzioni 0-ary da D0 in D sono identificate dai valori di verità e dagli elementi di D, rispettivamente, per ogni struttura M = <D,m> per L(AL), m as- segna a ciascuna proposizione costante in AL, un elemento di 0,1, e a ciascuna costante individuale in AL un elemento di D. Data una struttura M =<D,m> per L(AL), possiamo scrivere |M| per denotare il dominio di M. Se K é un predicato o una funzione co- stante in AL, allora M|K| sta per m(K). Utilizziamo la frase "M é una struttura del primo ordine" (M é una struttura per la logica del primo ordine) per indicare che M é una struttura per qualche linguaggio L del primo ordine. Per una struttura del primo ordine M, denotiamo con As(M) l'in- sieme degli assegnamenti su M, cioé l'insieme di tutte le fun-
zioni dall'insieme delle variabili in |M|. Se a ∈ As(M) e x é una variabile, allora scriviamo [a]x per denotare l'insieme di quegli assegnamenti su M che differiscono da "a" al massimo su x. Formalmente,
[a] = a’:a’ ∈ As(M) e a’(y) = a(y), per ogni y diverso da x Definizione 5.2.4 Sia M una struttura del primo ordine per L(AL)
Il valore Va(α) di un termine α ∈ TM(AL) in M rispetto ad a ∈ As(M) é un elemento di |M| definito dalle seguenti ricor- renze su α: (i) Va(x) = a(x) (ii) Va(a) = M|a|
(iii) Va(f(α1,...,αn)) = M|f|(Va(α1),...,Va(αn)).
Il valore di verità Va(A) di una formula A ∈ L(AL) in M corri- spondente ad a ∈ As(M) é un elemento di 0,1 definito da: (i) Va(Vero) = 1 (ii) Va(p) = M|p|
(iii) Va(P(α1,...,αn)) = M|P|(Va(α1),...,Va(αn)) (iv) Va(α = β) = 1 sse Va(α) = Va(β) (v) Va(B -> C) = 1 sse Va(B) = 0 oppure Va(C) = 1
(vi) Va(¬B) = 1 - Va(B)

92
(vii) Va((x)B) = 1 sse Va(B) = 1, per ogni a’ ∈ [a]x Le condizioni per il valore di verità seguenti si derivano dalle
definizioni di &, v, ≡, Falso e (∃x) : (viii) Va(B & C) = min(Va(B),Va(C)) (ix) Va(B v C) = max(Va(B),Va(C))
(x) Va(B ≡ C) = 1 sse Va(B) = Va(C) (xi) Va(Falso) = 0
(xii) Va((∃x)B) = 1 sse Va(B) = 1, per qualche a’ ∈ [a]x. Una formula si dice soddisfatta in una struttura M da una asse-
gnazione a ∈ As(M) sse Va(A) = 1. A é soddisfacibile sse Va(A) = 1, per qualche struttura M e
qualche a ∈ As(M); in caso contrario si dice insoddisfacibile. A é vera in M sse Va(A) = 1, per ogni a ∈ As(M). Se A é vera in M, allora M si dice modello per A. A é (logicamente) valida sse A é vera in ogni struttura M. Esempio: Sia A= P(x,f(x)) -> (y)P(x,y) e consideriamo la struttura M tale che |M| sia l'insieme degli interi positivi, M|P| é la
relazione ≤, e M|f| é la funzione di successione. A é soddisfatta in M da a ∈ As(M) sse a(x) = 1. Allora, A é soddisfacibile ma non valida. Il teorema seguente elenca i risultati base che riguardano le no- zioni di verità, soddisfacibilità e validità: Teorema 5.2.5 (i) A é vera in M sse (A) é vera in M (ii) A é valida sse (A) é valida
(iii) A é soddisfacibile sse (∃A) é soddisfacibile (iv) A é valida sse ¬A non é soddisfacibile Il problema della validità nella logica del primo ordine consi- ste nel determinare se una formula arbitraria del primo ordine é valida oppure no. Teorema 5.2.6 (Church 1936) Il problema di validità nella logica del primo ordine é indeci- dibile. Il risultato sopra riportato può essere espresso anche dicendo che, in generale, un insieme di formule valide (su di un linguag- gio del primo ordine L) non é un sottoinsieme calcolabile di L. Comunque, un tale insieme é ricorsivamente numerabile e quindi abbiamo: Teorema 5.2.7 Un insieme di formule valide su un linguaggio L del primo ordine é un sottoinsieme di L parzialmente calcolabile.
Pertanto esiste una procedura π che prende una formula arbitraria A ∈ L e determina che A é valida, nel caso in cui lo sia; altri-

93
menti, se A non é valida, π può terminare e determinare che A non é valida oppure continuare indefinitivamente nella ricerca della validità della formula. In altri termini si può dire che la logica del primo ordine é parzialmente decidibile o semi-decidibile. Una istanza di una formula proposizionale A é qualsiasi formula ottenibile da A con la sostituzione uniforme con formule delle proposizioni costanti che compaiono in A. É facile vedere che ogni istanza di una tautologia é valida. Elenchiamo alcune formule valide importanti a fini pratici:
(V1) (x)A -> (∃x)A (V2) (x)A(x) -> A(α), se α é libera per x in A(x) (V3) A(α) -> (∃x)A(x) se α é libera per x in A(x) (V4) (∃x)(y)A -> (y)(∃x)A (V5) (x)(y)A ≡ (y)(x)A (V6) (∃x)(∃y)A ≡ (∃y)(∃x)A (V7) (x)A ≡ ¬(∃x)¬A (V8) (∃x)A ≡ ¬(x)¬A (V9) (x)(A -> B) -> ((x)A -> (x)B)
(V10) (x)A & (x)B ≡ (x)(A & B) (V11) (x)A v (x)B -> (x)(A v B)
(V12) (∃x)A v (∃x)B ≡ (∃x)(A v B) (V13) (∃x)(A & B) -> (∃x)A & (∃x)B Le formule seguenti sono valide nel caso in cui A non contenga ricorrenze libere di x.
(V14) (x)A ≡ A (V15) (∃x)A ≡ A (V16) (∃x)B v A ≡ (∃x)(B v A) (V17) A v (∃x)B ≡ (∃x)(A v B) (V18) (x)B v A ≡ (x)(B v A) (V19) A v (x)B ≡ (x)(A v B) (V20) (∃x)B & A ≡ (∃x)(B & A) (V21) A & (∃x)B ≡ (∃x)(A & B) (V22) (x)B & A ≡ (x)(B & A) (V23) A & (x)B ≡ (x)(A & B) Due formule A e B si dicono logicamente equivalenti, A <=> B, sse per esse vale la stessa funzione di verità per ogni struttura M
ed ogni assegnamento a ∈ AS(M). Il teorema seguente corrisponde strettamente al teorema 5.1.5 ed elenca le proprietà basilari delle formule equivalenti: Teorema 5.2.8
(i) A <=> B sse A ≡ B é valida; (ii) A <=> B e B <=> C implica A <=> C; (transitività) (iii) Se B é una sottoformula di A, e A’ é il risultato della sostituzione di una o più ricorrenze di B in A con C, e B <=> C, allora A <=> A’. (teorema di sostituzione). Si dice che B é una variante immediata di A sse A = Qxi.C(xi) e
B = Qxj.C(xj), dove Q ∈ (_),(∃_), e C(xi) non ha ricorrenze li- bere di xj. Diremo che B é un invariante di A sse B é il risul- tato della sostituzione di una o più sottoformule di A con le

94
loro varianti immediate. Per esempio: (x).P(x) & Q(x) é una va- riante immediata di (z).P(z) & Q(z).
Allora (∃y)[R(y) -> (z).P(z) & Q(z)] é una variante di (∃y)[R(y) -> (x).P(x) & Q(x)]. Teorema 5.2.9 (teorema delle varianti) Se B é una variante di A, allora A <=> B. Una formula A si dice in forma normale congiuntiva prefissa sse é nella forma: m k(i)
Q1x1 ... Qnxn.[ ∩ ∪ Aij ] dove i=1 j=1
(i) per ciascun i, 1 ≤ i ≤ n, Qi ∈ (_),(∃_); m k(i)
(ii) x1,...,xn sono variabili distinte ricorrenti in ∩ ∪ Aij i=1 j=1 (iii) ogni Aij é una formula atomica oppure la negazione di una formula atomica. La parte Q1x1...Qnxn, che può essere vuota, si chiama prefisso di A; m k(i)
la parte ∩ ∪ Aij é detta matrice di A. i=1 j=1 Diremo che B é la forma normale prefissa congiuntiva di A sse B é in forma prefissa congiuntiva e A <=> B. Teorema 5.2.10 Ogni formula A può essere trasformata effettivamente nella sua forma prefissa congiuntiva normale. Dimostrazione: Costruiremo una formula A’ in forma prefissa nor- male congiuntiva con sostituzioni successive nelle sottoformule di A con delle formule di volta in volta equivalenti. Allora dal teorema 5.2.8 (ii)-(iii) A’ <=> A. La costruzione si esegue in sei passi. passo 1. Eliminazione dei quantificatori ridondanti. Vengono eliminati da
A tutti i quantificatori (x), (∃x) applicati a sottoformule che non contengono x. Denotiamo il risultato con A1. passo 2. Rinominazione delle variabili. Si prende la sottoformula di A1
più a sinistra che compare nella forma (x)B(x) o (∃x)B(x) tale che x appare in qualche altra parte di A1, e si cambia con
(y)B(y) o (∃y)B(y), rispettivamente, dove y é una nuova variabi- le. Si ripete il processo fino a quando tutte le variabili quantifi- cate sono distinte e nessuna variabile risulta essere sia vinco- lata che libera. Denotiamo il risultato con A2, A1 <=> A2. passo 3.

95
Eliminazione di -> e ≡ sostituendo in A2
(B -> C) con (¬B v C) (B ≡ C) con ((¬B v C) & (B v ¬C)) fino a che la formula risultante A3 contiene solo i connettivi
v , & e ¬. passo 4.
Spostamento in avanti della negazione ¬ sostituendo in A3
¬(x)B con (∃x)¬B ¬(∃x)B con (x)¬B ¬(B v C) con ¬B & ¬C ¬(B & C) con ¬B v ¬C ¬¬B con B
fino a che ciascuna ricorrenza di ¬ precede immediatamente una formula atomica, denotiamo il risultato con A4. passo 5. Spostamento dei quantificatori a sinistra sostituendo in A4
(∃x)B v C con (∃x)(B v C) C v (∃x)B con (∃x)(C v B) (x)B v C con (x)(B v C) C v (x)B con (x)(C v B)
(∃x)B & C con (∃x)(B & C) C & (∃x)B con (∃x)(C & B) (x)B & C con (x)(B & C) C & (x)B con (x)(C & B) fintanto che tutti i quantificatori sono sulla sinistra. Denotiamo il risultato con la formula A5, osserviamo che a causa del passo 2, rinominazione delle variabili, C non contiene ricor- renze di x e quindi A5 <=> A4. passo 6. Distribuzione di & su v sostituendo nella A5 fintanto che é pos- sibile (B & C) v D con (B v D) & (C v D) B v (C & D) con (B v C) & (B v D) denotiamo la formula risultante con A’; questa é la desiderata forma normale congiuntiva prefissa di A. Vediamo un esempio che illustra il procedimento:
A = P(x,y) -> [(∃x).Q(x) & (∃z)(x = y)] applicando i passi 1-6 otteniamo:
A1 = P(x,y) -> [(∃x).Q(x) & x = y] A2 = P(x,y) -> [(∃z).Q(z) & z = y] A3 = ¬P(x,y) v [(∃z).Q(z) & z = y] A4 = A3

96
A5 = (∃z)[¬P(x,y) v (Q(z) & z = y)] A’ = (∃z)[(¬P(x,y) v Q(z)) & (¬P(x,y) v z = y)] A’ é la forma prefissa congiuntiva normale di A. Una formula A si dice in forma prefissa normale sse é nella for-
ma Q1x1...Qnxn.B (n ≥ 0), dove (i) per ogni i (1 ≤ i ≤ n) Qi ∈ (_),(∃_); (ii) x1,...,xn sono variabili distinte ricorrenti in B; (iii) B non contiene quantificatori. Come prima "Q1x1,...,Qnxn" é chiamato prefisso di A e B é chia- mata matrice di A. Da notare che la forma prefissa congiuntiva normale é un caso particolare della forma prefissa. Segue per- ciò che ogni formula può essere effettivamente trasformata nel- la equivalente formula in forma prefissa normale.

97
5.2.3 Teorie del primo ordine Una teoria del primo ordine T = <L,S>, si compone di un linguag- gio L del primo ordine e un insieme S calcolabile di sentenze, cioé formule chiuse di L. Gli elementi di S sono gli assiomi o premesse di T. Se S = , allora T si chiama calcolo dei predicati su L. Una teoria del primo ordine, o brevemente una teoria, viene deno- tata con la lettera T. Possono esistere teorie con uguaglianza oppure senza uguaglianza. Le teorie si possono identificare con l'insieme dei loro assiomi, in tal caso si adotta la convenzione che il linguaggio di una teoria T consista in tutte le formule costruibili utilizzando predicati e funzioni costanti presenti negli assiomi di T. Una teoria si dice finita se l'insieme degli assiomi é finito altrimenti si dice infinita. Se T é una teoria su L(AL) e
A1,...,An sono sentenze in L(AL), allora T ∪ A1,...,An é una teoria; T si dice sottoteoria di T' se ogni assioma di T é anche assioma di T'. Notiamo che ogni sentenza A può essere associata univocamente ad una teoria <L(A),A>, dove L(A) é il linguaggio costituito da tutte le formule costruibili dalle funzioni e pre- dicati costanti ricorrenti in A. Allora, le sentenze possono essere considerate come teorie del primo ordine. Una struttura M é un modello per una teoria T sse tutti gli as- siomi di T sono veri in M. Una teoria si dice soddifacibile sse possiede un modello; altrimenti é insoddisfacibile. Teorema 5.2.11 (Teorema di compattezza) Una teoria T ha un modello sse ogni sottoteoria finita di T ha un modello. Una formula A si dice conseguenza semantica di una teoria T,
T ⇒ A, sse A é vera in ogni modello per T. In particolare, A é una conseguenza semantica del calcolo dei
predicati su L, ⇒ A, sse A é vera in ogni struttura per L.
Se T ⇒ A, allora possiamo dire che A segue logicamente da T, A é deducibile da T, o che T implica A. Esempio: Consideriamo i seguenti assiomi per T: Uccello(Titti) (x).Uccello(x) -> Vola(x) (x).Vola(x) -> Ha-le-ali(x) Si può vedere facilmente che la formula Vola(Titti) e Ha-le-ali(Titti) sono vere in ogni modello di T;
allora T ⇒ Vola(Titti) e T ⇒ Ha-le-ali(Titti).
Il simbolo ⇒ denota una relazione binaria, chiamata relazione di implicazione della logica classica del primo ordine; e vale tra
una teoria e una formula A sse T ⇒ A. Il teorema seguente é la controparte del teorema 5.1.9 Teorema 5.2.12

98
La relazione di implicazione della logica del primo ordine gode delle seguenti proprietà:
(i) T ⇒ B sse la teoria T ∪ ¬(B) é non soddisfacibile; (ii) T, A ⇒ B sse T ⇒ A -> B;
(iii) A1,...,An ⇒ B sse ⇒ A1 & ... & An -> B; (iv) Se T é una sottoteoria di T', allora
A: T ⇒ A é sottoinsieme di A: T' ⇒ A monotonicità. Riguardo alla (iii) il problema di determinare se una formula B segue da una teoria A1,...,An si riduce a determinare se la formula A1 & ... & An -> B é valida. L'asserzione (iv) esprime il principio di monotonicità della lo- gica del primo ordine. Le teorie T e T' sono logicamente equivalenti, T <=> T', sse pos- siedono gli stessi modelli. La proprietà più importante delle teorie equivalenti é che esse deducono esattamente le stesse formule: Teorema 5.2.13
T <=> T' sse A: T ⇒ A = A: T' ⇒ A. Esiste anche la controparte del teorema 5.1.11 Teorema 5.2.14 Se T = A1,...,An, allora T <=> A1 & ... & An. Due formule A e B si dicono equivalenti per una teoria T sse go- dono della stessa funzione di verità in ogni modello M di T e
per ogni a ∈ As(M). Sia T una teoria su un linguaggio del primo ordine L con ugua- glianza. L'insieme degli assiomi di uguaglianza per T sono gli stessi assiomi validi per L. (def. 5.2.2). esempio: Sia T consistente nelle seguenti affermazioni Elefante(Luca) (x).Elefante(x) -> Elefante(padre(x)) Luca = Marco L'insieme degli assiomi di uguaglianza consistono in (E1)-(E3) def. 5.2.2 a cui si aggiungono: (x)(y)[x = y & Elefante(x) -> Elefante(y)] (x)(y)[x = y -> padre(x) = padre(y)] Definizione 5.2.15 (sentenza universale) Una sentenza si dice universale sse la sua forma normale prefissa non contiene quantificatori esistenziali. Una teoria si dice universale sse tutti i suoi assiomi sono uni- versali. Il seguente teorema afferma uno dei principali risultati della logica del primo ordine: Teorema 5.2.16 (Teorema di Skolem - Löwenheim)

99
(i) Ogni teoria del primo ordine senza uguaglianza soddisfaci- bile ha un modello con un dominio numerabile. (ii) Ogni teoria del primo ordine con uguaglianza ha un modello con un dominio contabile (cioé finito o numerabile).

100
5.2.4 Logica del primo ordine come sistema di deduzione Un sistema di deduzione per la logica del primo ordine é difini- to in maniera analoga a quello della logica proposizionale, ad eccezione del fatto che L é ora un linguaggio del primo ordine. Se <L,S,R> é un sistema dedutivo per la logica del primo ordine
e Ri ∈ R, allora Ri si dice solido, o alternativamente Ri é un sistema di regole che conservano le funzione di verità, sse per ogni struttura M ed ogni formule A1,...,Ak nel dominio di Ri, Ri(A1,...,Ak) é vera in M, nel caso in cui tutte le A1,...,Ak sono vere in M. La nozione di dimostrazione é analoga a quella specificata per
la logica proposizionale. Scriviamo T(DS) → A per indicare che A
é dimostrabile da T in DS; (DS) → A é una abbreviazione per
(DS) → A. Le richieste di calcolabilità imposte sui sistemi di deduzione garantisce, nel caso in cui ci restringiamo a linguaggi calcola- bili del primo ordine e a teorie calcolabili, che le dimostrazio- ni sono calcolabili.
Un sistema di deduzione DS = <L,S,R> si dice solido sse (DS) → A implica che A é valida. DS si dice completo sse ogni formula va- lida di L é dimostrabile in DS. Il seguente sistema di deduzione per la logica del primo ordine é sia solido che completo. Definizione 5.2.17 Sia L un linguaggio del primo ordine. Denotiamo con FOL(L) il sistema di deduzione <L,S,R> dato da: (i) S consiste negli assiomi seguenti: (A1) Vero (A2) A -> (B -> A) (A3) (A -> (B -> C)) -> ((A -> B) -> (A -> C))
(A4) (¬B -> ¬A) -> ((¬B -> A) -> B) (A5) (x)A(x) -> A(α), dove α é qualsiasi termine libero per x in A(x) (A6) (x)(A -> B) -> (A -> (x)B), dove A non contiene ricorrenze libere di x Se L é un linguaggio con l'uguaglianza, allora S in più contiene l'assioma dell'uguaglianza per L. (ii) R consiste nelle seguenti regole di inferenza: (MP) B é una diretta conseguenza di A e A -> B (GEN) (x)A é una diretta conseguenza di A. É facile vedere che FOL(L) soddisfa le richieste di calcolabili- tà imposte sui sistemi di deduzione. (GEN) e detta regola di ge- neralizzazione.
Possiamo assumere che L sia fissato, e FOL(L) → sia abbreviato
in →. Se T → A, allora diremo che A é dimostrabile da T nella
logica del primo ordine. Se → A, allora diremo che A é dimostra- bile nella logica del primo ordine, o anche che A é un teorema
nella logica del primo ordine. Scriviamo T ¬→ A e ¬→ A come nega-

101
zione di T → A e → A rispettivamente.
La relazione binaria denotata col simbolo → é chiamata relazione di dimostrabilità della logica classica del primo ordine. Denotiamo con Th l'operatore di dimostrabilità per la logica classica del primo ordine, cioé l'operatore che assegna a cia- scuna teoria T del primo ordine l'insieme Th(T) di tutte le sen- tenze dimostrabili da T nella logica del primo ordine. L'operatore Th gode delle proprietà base dell'operatore di dimo- strabilità della logica proposizionale, in particolare per ogni teoria T contenuta nella teoria T' implica Th(T) contenuto in Th(T'). La sintattica e la semantica della logica del primo ordine sono connesse dal seguente teorema: Teorema 5.2.18
(i) Se T → A, allora T ⇒ A; (teorema di solidità)
(ii) Se T ⇒ A, allora T → A; (teorema di completezza) Crollario 5.2.19
→ A sse ⇒ A. Una teoria T su L si dice consistente sse esiste una formula
A ∈ L tale che T ¬→ A. Come nel caso della logica proposizionale; la nozione di consi- stenza é una controparte sintattica di quella di soddisfacibili- tà: Teorema 5.2.20 T é consistente sse T é soddisfacibile. Teorema 5.2.21 (teorema di deduzione)
(i) T,A → B sse T → A -> B
(ii) A1,...,An → B sse → A1 & ... & An -> B Teorema 5.2.22 T é consistente sse ogni sottoteoria di T é consistente.

102
5.3 Logica del primo ordine multi-ordinata La logica del primo ordine multi-ordinata differisce dalla logica del primo ordine ordinaria nel fatto che contempla parecchi tipi (ordinati) di variabili - ciascuna tipo associato ad un partico- lare sottodominio di oggetti. Anche le funzioni e i predicati co- stanti sono ordinati nel senso che i loro argomenti sono limitati ai termini di tipo appropriato. Per esempio, utilizzando la logi- ca del primo ordine multi-ordinata, dovendo introdurre un predi- cato costante binario Insegnanti dovremo fare attenzione nella definizione del suo primo argomento che sia ristretto al tipo In- segnante e che il suo secondo argomento sia un oggetto del tipo Studente. Da un punto di vista strettamente tecnico, la logica multi- ordinata si presenta come un espediente superfluo, poiché é ri- conducibile alla logica ordinaria. Comunque, essa si presta ad una naturalezza di rappresentazione che le ha consentito di esse- re implementata in parecchie applicazioni pratiche. Sia k un intero positivo e supponiamo che t1,...,tk siano oggetti distinti a cui ci riferiremo come a tipi base. Definiamo l'insie- me dei tipi basati su t1,...,tk, TP(t1,...,tk) come l'insieme più piccolo che soddifa a:
(i) ti ∈ TP(t1,...,tk), per ogni i (1 ≤ i ≤ k); (ii) per ogni tupla t=<ti1,...,tin>, dove n ≥ 0 e ti1,...,tik so- no elementi di t1,...,tk (non necessariamente distinti),
t ∈ TP(t1,...,tk). I tipi adempiono al compito della classificazione: i tipi base vengono utilizzati per classificare le variabili e più general- mente i termini, mentre quelli nella forma <ti1,...,tin> forni- scono una classificazione delle funzioni e dei predicati costan- ti. Specificatamente, un predicato costante di un tipo
<ti1,...,tin> (n≥0) rappresenta un predicato costante n-ary con il primo argomento del tipo ti1, e n-esimo del tipo tin. Predica- ti costanti del tipo < > sono appunto proposizioni costanti.
Una funzione costante di tipo <ti,ti1,...,tin> (n≥0) rappresenta una funzione costante n-ary che prende termini del tipo ti1,...,tin come propri argomenti e il valore della funzione é un termine del tipo ti. Funzioni costanti di tipo <ti> si chiama- no costanti individuali di tipo ti. Un alfabeto della logica k-ordinata con t1,...,tk come tipi base consiste di simboli primitivi appartenenti alle seguenti catego- rie: (i) k insiemi numerabili V1,...Vk.
Gli elementi di Vi (1≤i≤k) rappresentano le variabili individuali del tipo ti, e le denotiamo con xi1,xi2,... (ii) Una costante vera: Vero
(iii) Connettivi per le frasi: "¬" e "->" (iv) Un quantificatore: "(_)" per ogni (v) Parentesi: "(",")" (vi) Un insieme numerabile |P di predicati costanti

103
a ciascun P ∈ |P é assegnato univocamente un tipo <ti1,ti2,...,tin> ∈ TP(t1,...,tk), detto tipo di P (vii) Un predicato binario costante: "=" si assume che gli argomenti di "=" possano essere di tipo qualsiasi (viii) Un insieme numerabile |F di funzioni costanti
a ciascuna f ∈ |F é assegnato univocamente un tipo non vuoto <ti,ti1,...,tin>, detto tipo della f. Le classi (i)-(v) sono fisse, mentre le altre possono essere di- verse da un alfabeto ad un'altro. L'insieme delle funzioni co- stanti può essere vuoto. Assumiamo che ogni alfabeto contenga almeno un predicato costante di arità positiva, cioé o un ele- mento di |P con tipo diverso da < >, oppure la costante "=". Gli insiemi |P e |F debbono essere calcolabili nel senso che deve
esistere una procedura effettiva πP e πF che, dato un simbolo ar- bitrario s, determini se s ∈ |P o se s ∈ |F, e ne fornisca il tipo. definizione 5.3.1 sia AL un alfabeto della logica k-ordinata con tipi base t1,...,tk; l'insieme TM(i,AL) di termini del tipo ti su AL consi- ste nell'insieme più piccolo tale che: (i) tutte le variabili individuali del tipo ti e tutte le co- stanti individuali del tipo ti sono membri di TM(i,AL) (ii) se f é una funzione costante di tipo <ti,ti1,...,tin> e
α1,...,αn sono termini di tipo ti1,...,tin rispettivamente allora f(α1,...,αn) ∈ TM(i,AL). L'insieme AFORM(AL) delle formule atomiche su AL é l'insieme più piccolo tale che: (i) "Vero" e tutte le proposizioni costanti di AL sono elemen- ti di AFORM(AL) (ii) Se P é un predicato costante del tipo <ti1,...,tin> (n>0)
e α1,...,αn sono termini di tipo ti1,...,tin, rispettivamente, allora P(α1,...,αn) ∈ AFORM(AL) (iii) Se α e β sono termini di tipo arbitrario, allora (α=β) ∈ AFORM(AL), nel caso in cui "=" ∈ AL. L'insieme L(AL) di formule su AL consiste nell'insieme più pic- colo tale che:
(i) Se A ∈ AFORM(AL), allora A ∈ AL (ii) Se A, B ∈ L(AL) e x é una variabile individuale di tipo qualunque, allora (¬A) ∈ L(AL), (A -> B) ∈ L(AL) e ((x)A) ∈ L(AL) L'insieme L(AL), brevemente L, si chiama anche linguaggio k- ordinato su AL. La restrizione agli alfabeti con un insieme cal- colabile di predicati e funzioni costanti assicura la calcolabil- tà di ogni linguaggio k-ordinato. Un linguaggio k-ordinato L(AL) può essere con uguaglianza oppure
senza, "=" ∈ AL oppure no. I restanti connettivi logici vengono definiti come nei casi pre- cedenti così come le convenzioni di terminologia e di notazione già viste valgono anche per la logica multi-ordinata.

104
Esempio: Assumiamo che i seguenti fatti siano veri: (F1) Giovanni, Maria e Giorgio sono studenti (F2) Marco e Anna sono i soli insegnanti (F3) Tutti gli insegnanti sono insegnanti di Maria (F4) Alcuni studenti hanno come insegnante Anna Intruduciamo due tipi base: Insegnanti e Studenti (abbreviato in i, s rispettivamente); un predicato costante binario di tipo <i,s>: Insegna; tre costanti individuali di tipo s: Giovanni, Ma- ria e Giorgio; due costanti individuali di tipo i: Marco e Anna. allora (F1)-(F4) possono essere rappresentati con:
(A1) (∃xs)(∃ys)(∃zs).(xs=Giovanni) & (ys=Maria) & (zs=Giorgio) (A2) (xt).(xt=Marco) v (xt=Anna) (A3) (xt).Insegna(xt,Maria)
(A4) (∃xs).Insegna(Anna,xs) Vediamo ora la semantica della logica multi-ordinata. Definizione 5.3.2 Sia AL un alfabeto per una logica k-ordinata con tipo base t1,...,tk; una struttura per L(AL): M=<D1,...,Dk,m> dove: (i) D1,...,Dk sono insiemi non vuoti chiamati sottodomini di M k
∪ Di é detto dominio di M i=1 (ii) m consiste in una funzione che assegna a ciascun predicato
costante di tipo <ti1,...,tin> (n≥0) di AL diverso da "=" una relazione su Di1 x ... x Din (prodotto dei domini) assegna alla costante "=", se presente in AL, la relazione identità sul dominio di M, e a ciascuna funzione costante
di tipo <ti,ti1,...,tin> (n≥1), una funzione da Di1 x ... x Din a Di. Sia M = <D1,...,Dk,m> una struttura per un linguaggio L(AL) nella logica k-ordinata del primo ordine, dove AL é un alfabeto con tipi base t1,...,tk. Denotiamo con |M|i l'insieme Di. Se K é un predicato o una funzione costante di AL, allora M|K| sta per m(K). Con As(M) denotiamo l'insieme degli assegnamenti su M, cioé l'insieme di tutte le funzioni k k
a: ∪ Vi ---> ∪ |M|i i=1 i=1
tale che a(xi) ∈ |M|i per ogni variabile xi di tipo ti. Se a ∈ As(M) e xi é una variabile di tipo ti, allora [a]xi de- nota l'insieme di quegli assegnamenti su M che differiscono da "a" al massimo su xi. Definizione 5.3.3 Sia M una struttura per L(AL), dove AL é un alfabeto per la lo-
gica k-ordinata con tipi base t1,...,tk. Il valore Va(α) di un termine α di tipo t1 in M dove a ∈ As(M) é un elemento di |M|i viene definito come segue:

105
(i) Va(xi) = a(xi) (ii) Va(b) = M|b| dove b é un individuo costante
(iii) Va(f(α1,...,αn)) = M|f|(Va(α1),...,Va(αn)).
Il valore di verità Va(A) di una formula A ∈ L(AL) in M con a ∈ AS(M), é un elemento di 0,1 specificato da: (i) Va(Vero) = 1 (ii) Va(p) = M|p| dove p é una proposizione costante
(iii) Va(P(α1,...,αn)) = M|P|(Va(α1),...,V(αn)) (iv) Va(α = β) = 1 sse Va(α) = Va(β) (v) Va(B -> C) = 1 sse Va(B) = 0 oppure Va(C) = 1
(vi) Va(¬B) = 1 - Va(B) (vii) Va((xi)B) = 1 sse Va’(B) = 1 per ogni a’ ∈ [a]xi.
Le nozioni: "A é soddisfacibile in M da a ∈ As(M)", "A é soddi- facibile","A é vera in M","A é valida" e "A e B sono equivalen- ti" sono definite come nei casi visti in precedenza. Il teorema 5.2.8 vale anche per le logiche multi-ordinate. Anche la definizione di teoria per la logica k-ordinata é analo- ga a quanto visto in precedenza,T = <L,S> dove L é un linguaggio k-ordinato ed S é un insieme di affermazioni calcolabili. Di so- lito, M é un modello per una teoria T sse tutte le affermazioni di S sono vere in M. Una teoria con un modello si dice soddisfa- cibile, due teorie che hanno esattamente gli stessi modelli si
dicono equivalenti. Scriviamo T ⇒ A per indicare che A é vero in ogni modello di T. I risultati dei teoremi 5.2.11, 5.2.12, 5.2.13, 5.2.14 e 5.2.16 si possono generalizzare alla logica multi-ordinata. É possibile costruire un sistema di deduzioni solido e completo per la logica multi-ordinata.

106
5.4 Il metodo di risoluzione Come abbiamo visto il problema della validità per la logica del primo ordine é indecidibile. In altri termini non esiste un al- goritmo per decidere se data una formula arbitraria del primo or- dine questa sia valida oppure no. Il problema é comunque semi- decidibile nel senso che esiste una procedura che conferma la va- lidità di ogni formula valida, ma che cicla indefinitamente per alcune formule che pure sono valide. Una di queste procedure, chiamata metodo di risoluzione, é particolarmente significativa. La sua efficienza la rende particolarmente adatta ad essere im- plementata a calcolatore. Prima di addentrarci nella descrizione del metodo di risoluzione, facciamo due importanti osservazioni:
primo, poiché A1,...,An ⇒ A sse A1 & ... & An -> A é valida, ogni procedura in grado di confermare la validità di una formula del primo ordine può essere utilizzata per dimostrare che una data formula é deducibile da una data teoria finita del primo ordine; secondo, poiché una formula é valida sse la sua negazione é non soddisfacibile, un modo di mostrare la validità di una for-
mula A consiste nel mostrare che la formula ¬A non é soddisfaci- bile. Questo é appunto il tipo di approccio adottato dal metodo di risoluzione, che di fatto trova formule non soddisfacibili. Allora per dimostrare la validità di una formula A, applicheremo
il metodo di risoluzione a ¬A. Se ¬A é non soddisfacibile allora A é valida e il processo si arresta, in caso contrario il pro- cesso può continuare indefinitamente.

107
5.4.1 La forma in clausole Il metodo di risoluzione si applica solo a formule che siano in una forma particolare, detta "in forma di clausole". Per introdurre questa nozione, ci necessitano alcune definizioni preliminari. I letterali sono formule atomiche (letterali positivi) o negazio- ni di formule atomiche (letterali negativi), li denoteremo con la lettera l, e con il simbolo |l| indicheremo la formula atomica
corrispondente; per esempio |P(x,b)|=P(x,b), |¬Q(f(x))|=Q(f(x)). Denotiamo con ¬l il complemento di l. Una clausola é una formula C nella forma l1 v ... v ln (n≥0) do- ve l1,...,ln sono letterali. Se n=0, allora C e detta clausola
vuota e la indicheremo con Θ. Una formula si dice in forma di clausola sse é nella forma
(C1) & ... & (Cn) (n≥1) dove C1,...,Cn sono clausole. Una teoria si dice in forma di clausole se tutti gli assiomi sono in forma di clausole. Ricordando che un'affermazione si dice essere universale sse la sua forma prefissa congiuntiva normale non contiene quantificato- ri esistenziali, é facile vedere che trasformando una tale for- mula nella sua forma prefissa congiuntiva normale si ottiene una affermazione della forma: (_)[C1 & ... & Cn] dove C1,...,Cn sono clausole. Abbiamo pertanto il seguente risultato: Teorema 5.4.1 (i) Ogni affermazione universale può essere effettivamente tra- sformata in una affermazione equivalente in forma di clausola; (ii) Per ogni teoria universale T, esiste una teoria T' in forma di clausole tale che T <=> T'. Il teorema 5.4.1 non vale necessariamente per affermazioni non universali o teorie non universali; comunque, si può dimostrare che ogni formula A può essere effettivamente trasformata in una affermazione A’ in forma di clausola tale che A e soddisfacibile sse A’ é soddisfacibile. Anche per una teoria T esiste una teo- ria T' in forma di clausole tale che T é soddisfacibile sse T' é soddisfacibile. Definizione 5.4.2 Sia A una formula. una forma in clausole di A é ogni formula ot- tenuta da A tramite la seguente costruzione: Passo 0.
Si prende la chiusura esistenziale di A. Si pone A1 = (∃A). Passo 1-4. Si applica ad A1 gli stessi passi 1-4 del teorema 5.2.10 Denotiamo il risultato con A2.

108
Passo 5. Si spostano i quantificatori a destra, sostituendo
Qx(B ⊗ C) con B ⊗ (QxC) se x non é libero in B o (QxB) ⊗ C se x non é libero in C
dove Q sta per (_),(∃_) e ⊗ sta per v,&. denotiamo il risultato con A3. Passo 6. Eliminazione dei quantificatori esistenziali. Ripetendo il se- guente processo fino a che tutti i quantificatori esistenziali sono eliminati:
Si prende ogni sottoformula della forma (∃x)B(y); supponendo che x1,...,xn (n≥0) siano tutte variabili distinte di (∃y)B(y) che sono quantificate universalmente a sinistra di (∃y)B(y); se n=0 allora sostituiamo (∃y)B(y) con B(a), dove a é una nuova costan- te individuale; se n > 0 allora sostituiamo (∃y)B(y) con B(f(x1,...,xn)) dove f é una nuova funzione n-ary costante. Denotiamo il risultato con A4. Il processo appena descritto é noto come Skolemizzazione. I simboli introdotti si chiamano funzioni di Skolem. Passo 7. Cancelliamo tutti i quantificatori da A4, otteniamo A5. Passo 8. Distribuzione di & sopra v, sostituendo (B & C) v D con (B v D) & (C v D) B v (C & D) con (B v C) & (B v D) denotiamo il risultato con A6. Passo 9. Eliminazione di "Vero" e "Falso". A6 é nella forma C1 & ... & Cn dove C1,...,Cn sono clausole.
Cancelliamo ogni Ci il cui letterale sia "Vero" o ¬"Falso". Dalle clausole rimanenti cancelliamo tutti i letterali della for-
ma "Falso" o ¬"Vero". Denotiamo la formula risultante con A7. Passo 10. Aggiungiamo quantificatori universali. A7 é nella forma C1 & ... & Cn dove C1,...,Cn sono clausole. Poniamo A8 = (C1) & ... & (Cn) che la desiderata forma in clau- sole per la A Esempio:
Sia A = P(a,w) -> (x)(∃y)(u)(∃z)[P(x,y) & Q(u,z)].
A1 = (∃w)P(a,w) -> (x)(∃y)(u)(∃z)[P(x,y) & Q(u,z)] A2 = (∃w)¬P(a,w) v (x)(∃y)(u)(∃z)[P(x,y) & Q(u,z)]

109
A3 = (∃w)¬P(a,w) v [(x)(∃y)P(x,y) & (u)(∃z)Q(u,z)] A4 = ¬P(a,b) v [(x)P(x,f(x)) & (u)Q(u,g(u))] (b, f e g sono le funzioni di Skolem)
A5 = ¬P(a,b) v [P(x,f(x)) & Q(u,g(u))] A6 = [¬P(a,b) v P(x,f(x))] & [¬P(a,b) v Q(u,g(u))] A7 = A6
A8 = [(x).¬P(a,b) v P(x,f(x))] & [(u).¬P(a,b) v Q(u,g(u))] Teorema 5.4.3 Se B é una forma in clausole di una formula A, allora B é sod- disfacibile sse A é soddisfacibile. Corollario 5.4.4 Ogni formula A può essere effettivamente trasformata in una for- mula in forma di clausole B tale che se A é soddisfacibile allo- ra lo é anche B e viceversa. Allora possiamo fare la seguente notevole osservazione: siccome solitamente siamo interessati solamente al problema di soddisfacibilità delle formule, possiamo assumere che le formule che prenderemo in considerazione siano sempre nella forma di clausole. Poiché ogni teoria può essere identificata con la teoria che contiene come affermazioni solo quelle relative agli assiomi, e che ogni teoria della forma A1 & ... & An é equivalente ad A1,...,An; ne consegue che ogni affermazione della forma (C1) & ... & (Cn) può essere identificata con la teoria (C1)&...&(Cn) e quindi possiamo utilizzare la notazione C1,...,Cn per le affermazioni in forma di clausole, dove le va- riabili ricorrenti in C1,...,Cn sono tutte implicitamente quanti- ficate universalmente. Se A é una formula, non necessariamente in forma di clausole, allora denotiamo con CLAUSOLE(A) l'insieme di clausole corrispon- denti ad una arbitraria forma in clausole di A. Una forma in clausole di una teoria T é una teoria ottenuta da T sostituendo tutti gli assiomi con gli assiomi corrispondenti in forma di clausole. Se T é definita sul linguaggio del primo or- dine L(AL) allora la teoria in forma di clausole T é una teoria sul linguaggio L(AL U F), dove F é l'insieme delle funzioni di Skolem introdotte. Teorema 5.4.5 Se T' é la forma in clausole di T, allora T' é soddisfacibile sse T é soddisfacibile. Sia T una teoria in forma di clausole. Con l'insieme di clausole corrispondenti a T intendiamo l'unione degli insiemi di clausole corrispondenti agli assiomi di T. Se T é una teoria non necessa- riamente in forma di clausole denotiamo con CLAUSOLE(T) l'insieme di clausole corrispondenti ad un arbitraria forma in clausole di T. Un insieme di clausole CL si dice soddisfacibile sse la teoria
(C): C ∈ CL é soddisfacibile altrimenti si dice non soddisfa- cibile.

110
Teorema 5.4.6 (i) A é soddisfacibile sse CLAUSOLE(A) é soddisfacibile; (ii) T é soddisfacibile sse CLAUSOLE(T) é soddisfacibile;
(iii) T ⇒ B sse CLAUSOLE(T) ∪ CLAUSOLE(¬(B)) non é soddisfacibi- le. 5.4.2 Regola di risoluzione Introdurremo ora una potente regola di inferenza, chiamata regola di risoluzione (Robinson 1965), che sta alla base del metodo di risoluzione. Per fissare le idee, cominciamo con lo specificare una versione ristretta della regola, chiamata regola di risolu- zione di base (ground resolution rule). Poiché una formula si dice di base sse non contiene variabili, la regola di risoluzione di base si può utilizzare per dimostrare la non soddisfacibili- tà di un insieme di clausole base (ground). La regola di risoluzione base consiste nella seguente regola di inferenza: per qualsiasi coppia di clausole di base C1, C2 e qualsiasi letterale di base l, C1 v C2 é una diretta conse-
guenza di C1 v l e C2 v ¬l, che simbolicamente si scrive:
C1 v l, C2 v ¬l ------------------- C1 v C2
Se C1 = C2 = Θ (insieme di clausole vuoto) allora
l,¬l --------
Θ É facile vedere che la regola di risoluzione di base é solida,
cioé C1 v C2 é vera in ogni struttura in cui C1 v l e C2 v ¬l sono vere. C1 v C2 si chiama risolvente di C1 v l e C2 v ¬l. Sia CL un insieme di clausole base; una confutazione da CL é una
sequenza C1,...,Cn di clausole base tali che Cn = Θ e, per cia- scun i (1≤i≤n), vale Ci ∈ CL oppure C1 é un risolvente base di Cj e Ck, dove j,k < i. Teorema 5.4.7 Un insieme CL di clausole base é non soddisfacibile sse esiste una confutazione base in CL. Esempio: Consideriamo una teoria T consistente in: (1) Uccello(Titti) (2) Uccello(Titti) -> Vola(Titti)
(3) ¬Ha-le-ali(Titti) -> ¬Vola(Titti) e l'affermazione (4) Ha-le ali(Titti)
ci proponiamo di mostrare che T ⇒ (4). Allora é sufficiente dimostrare che (1) & (2) & (3) -> (4) é
valida, che equivale a mostrare che ¬[(1) & (2) & (3) -> (4)] non é soddisfacibile.

111
Trasformiamo l'ultima affermazione in forma di clausole:
[Uccello(Titti)] & [¬Uccello(Titti) v Vola(Titti)] & & [Ha-le-ali(Titti) v ¬Vola(Titti)] & [¬Ha-le-ali(Titti)] L'insieme di clausole corrispondenti a questa affermazione consi- ste in: (5) Uccello(Titti)
(6) ¬Uccello(Titti) v Vola(Titti) (7) Ha-le-ali(Titti) v ¬Vola(Titti) (8) ¬Ha-le-ali(Titti) rimane da dimostrare che esiste una confutazione base dalle 5-8 e tale confutazione é data da: (9) Vola(Titti) dalle (5) e (6)
(10) ¬Vola(Titti) dalle (7) e (8) (11) Θ dalle (9) e (10) Per presentare la regola di risoluzione in forma generale, defi- niamo alcuni termini. Una sostituzione (di termini al posto di variabili) in un insieme
qualsiasi, anche vuoto, la denotiamo con x1 <- α1,...,xn <- αn, dove x1,...,xn sono n variabili distinte e ciascun αi é un ter- mine diverso da xi. Una espressione "xi <- αi" puo essere letta "αi sostituisce xi". La sostituzione corrispondente per un insie- me vuoto si dice sostituzione vuota, e la denotiamo con ∅. Una espressione semplice consiste in un letterale o un termine. Data una espressione semplice E e una sostituzione
θ = x1 <- α1,...,xn <- αn, denotiamo con Eθ l'espressione otte- nuta da E dalla sostituzione contemporanea in ciascuna ricorrenza
di xi (1≤i≤n) con αi. Per esempio, se E=P(x,f(y),z) e θ=x <- f(y), y <- g(b) allora Eθ = P(f(y),f(g(b)),z). Osserviamo che E∅ = E per ogni E.
Siano θ = x1 <- α1,...,xn <- αn e τ = y1 <- β1,...,ym <- βm due sostituzioni; la composizione di θτ di θ e τ é la sostitu- zione x1 <- α1τ,...,xn <- αnτ, y1 <- β1,..., ym <- βm cancellando ogni elemento xi <- αiτ, per cui xi = αiτ e cancel- lando ogni elemento yi <- βi tale che yi ∈ x1,...,xn.
Esempio: se θ = x <- g(y), y <- z e τ = x <- a, y <- b, z <-y allora θτ = x <- g(b), y <- y, x <- a, y <- b, z <- y - - y <- y, x <- a, y <- b = x <- g(b), z <- y. Dato un insieme non vuoto EX = E1,...,En di espressioni sempli- ci, diremo unificatore é di EX una sostituzione per cui
E1θ = E2θ = ... = Enθ. Se EX possiede un unificatore, allora pos- siamo dire che EX é unificabile. Esempio: se EX = P(a,y),P(x,f(b)), allora la sostituzione
θ = x <- a, y <- f(b) é un unificatore per EX. L'insieme P(a), P(b) non é unificabile.
Un unificatore θ di EX si dice l'unificatore più generale di EX sse per ciascun unificatore τ di EX esiste una sostituzione δ ta- le che τ = θδ. Si può mostrare che ogni insieme unificabile di espressioni semplici ha almeno unificatore più generale.

112
Esempio: consideriamo EX = P(x),P(y). Ciascuna delle seguenti sostituzioni é un unificatore per EX:
θ1 = x <- y θ2 = y <- x θ3 = x <- a, y <-a θ4 = x <- f(b), y <- f(b) θ1 e θ2 sono gli unificatori più generali per EX infatti θ3 = θ1y <- a = θ2x <- a θ4 = θ1y <- f(b) = θ2x <- f(b). Sia E una espressione semplice. E1 é una sottoespressione di E sse E1 é un'espressione semplice ricorrente in E. Esempio: le sottoespressioni di P(x,f(y,b)) sono P(x,f(y,b)), x, f(y,b), e b. Se EX = E1,...,En é un insieme di espressioni semplici, allora diremo insieme discordante per EX l'insieme E1',...,En' di sot- toespressioni di E1,...,En ricavato come segue. Consideriamo cia- scuna espressione E1,...,En come stringhe di simboli e troviamo la posizione più a sinistra in cui non tutte le espressioni di
EX mostrano lo stesso simbolo, poniamo per ciascun i (1≤i≤n) Ei’ uguale alla sottoespressione di Ei che inizia da tale posizione. Per esempio, l'insieme discordante di: P(x,f(a)),P(x,c),P(f(y),d) é x,x,f(y) = x,f(y) L'applicazione della regola di risoluzione richiede la capacità di risolvere il seguente problema di unificazione: dato un insieme finito EX di espressioni semplici, determinare se EX é unificabile oppure no, e se lo é fornire l'unificatore più generale per EX. Teorema 5.4.8 (Robinson 1965) Esiste un algoritmo. chiamato algoritmo di unificazione, che ri- solve il problema di unificazione. Sono stati proposti parecchi algoritmi di unificazione, il se- guente é forse quello dalle migliori prestazioni. Algoritmo di unificazione. Sia EX = E1,...,En un insieme di espressioni semplici. Per trovare un unificatore più generale di EX, se esiste, si procede nei seguenti passi:
passo 1. Poniamo k = 0, θ0 = ∅ ; Vai al passo 2.
passo 2. Se E1θk = ... = Enθk allora stop; θk é l'unificatore più generale per EX; altrimenti costruisci l'insieme discordante Dk
di E1θk,...,Enθk e vai al passo 3.
passo 3. Se Dk contiene una variabile x e un termine α, allora poni θ(k+1) = θkx <- α ; k = k + 1; e vai al passo 2 altrimenti dichiara che EX non é unificabile e stop. Si vede facilmente che l'algoritmo descritto termina sempre. Da notare anche che esso non é completamente determinato a causa

113
della libera scelta di x e di α. Esempio: Sia EX = Q(x,f(b)),Q(a,f(y)0.
(i) k=0; θ0 = ∅. (ii) D0 = x,a.
(iii) k=1; θ1 = x <- a. (iv) D1 = b,y.
(v) k=2; θ2 = x <-a;y <- b. (vi) θ2 é l'unificatore più generale per EX. Sia EX = Q(x,x),Q(a,b)
(i) k=0; θ0 = ∅. (ii) Do = x,a.
(iii) k=1; θ1 = x <- a. (iv) D1 = a,b. EX non é unificabile.
Se C = l1 v ... v ln e θ é una sostituzione, allora Cθ sta per l1θ v ... v lnθ. Notiamo che l1θ v ... v lnθ può a volte essere scritta in forma equivalente con un numero di letterali minore di
n; ciò succede quando θ possiede un unificatore di due o più letterali di C. Per esempio se C = P(x) v Q(b,y) v Q(z,y) e
θ = x <- a, z <- b, allora Cθ = P(a) v Q(b,y) v Q(b,y) che é equivalente a P(a) v Q(b,y). Sia C una clausola e supponiamo che V sia l'insieme di tutte le variabili ricorrenti in C. Una sostituzione di rinominazione per
C consiste in una sostituzione x1 <- y1,...,xn <- yn (n≥0) che soddisfi alle seguenti condizioni: (i) x1,...,xn contenuto in V; (ii) y1,...,yn sono variabili distinte;
(iii) (V - x1,...,xn) ∩ y1,...,yn = . Notiamo che ∅ é una sostituzione di rinominazione per qualsiasi clausola. Una clausola C1 si dice essere una variante di C sse
C1 = Cθ, dove θ é una sostituzione di rinominazione per C. Per esempio, C1 = P(x,y) v Q(z) é una variante di C = P(x,z) v Q(u), poiché C1 = Cz <- y,u <- z e z <- y,u <-z é una sostituzione di rinominazione per C.
Poiché ∅ é una sostituzione di rinominazione per ogni clausola, ogni clausola é un invariante di sé stessa. Se C1 é una va- riante di C e C1 diversa da C allora diremo che C1 si ottiene da C rinominando le variabili.
Scriviamo l1,...ln ∈ C per indicare che i letterali l1,...,ln ri- corrono in C; se l1,...,ln ∈ C allora scriviamo C - l1,...,ln per denotare la clausola che si ottiene da C cancellando l1,...,ln. Definizione 5.4.9 Siano C1 e C2 clausole tali che non abbiano variabili in comune.
Siano l1,...,ln ∈ C1 (n>0) e siano l1',...,lk' ∈ C2 (k>0). Assumiamo che l1,...,ln siano positivi e che l1',...,lk' siano
negativi, o viceversa. Se θ é l'unificatore più generale di |l1|,...,|ln|,|l1'|,...,|lk'| allora la clausola
[C1θ - l1θ,...,lnθ] v [C2θ - l1'θ,...,lk'θ] si chiama risolvente binaria di C1 e C2.

114
Esempio: Siano C1 = P(x) v P(y) v Q(b)
C2 = R(a) v ¬P(f(a))
Prendiamo l1 = P(x), l2 = P(y) e l1' = ¬P(f(a)). Poiché θ = x <- f(a), y <- f(a) é l'unificatore più genarale di |l1|,|l2|,|l1'|, la clausola Q(b) v R(a) é un risolvente binario di C1 e C2. Definizione 5.4.10 Un risolvente delle clausole C1 e C2, denotato con RIS(C1,C2), é un risolvente binario di una variante di C1 e una variante di C2. Diamo ora una definizione di regola di risoluzione. Definizione 5.4.11 La regola di risoluzione consiste nella regola di inferenza se- guente: Per ogni clausola C1 e C2, R(C1,C2) é una diretta conseguenza di C1 e C2. Sia CL un insieme di clausole. Una confutazione da CL consiste in
una sequenza di clausole C1,...,Cn tale che Cn = Θ e, per ogni 1≤n sia Ci ∈ CL oppure Ci é un risolvente di Cj e Ck dove j,k <i Definizione 5.4.12 Sia CL un insieme di clausole. Scriviamo EQ(CL) per denotare l'insieme di clausole di uguaglianza per CL, cioé l'insieme con- sistente nelle seguenti clausole: (EC1) x = x
(EC2) x ≠ y v y = x (EC3) x ≠ y v y ≠ z v x = z (EC4) x1 ≠ y1 v ... v xn ≠ yn v ¬P(x1,...,xn) v P(y1,...,yn) per ogni n-ary (n>0) predicato costante P presente in CL
(EC5) x1 ≠ y1 v ... v xn ≠ yn v f(x1,...,xn)=f(y1,...,yn) per ogni n-ary (n>0) funzione costante f presente in CL Notiamo che le clausole di uguaglianza CL corrispondono agli as- siomi di uguaglianza per il linguaggio su un alfabeto consistente di predicati e funzioni costanti presenti in CL. Adottiamo la seguente convenzione di notazione:
CL ∪ [EQ(CL)] = CL se "=" non compare in CL = CL ∪ EQ(CL) nel caso contrario. Teorema 5.4.13 Un insieme CL di clausole é non soddisfacibile sse esiste una
confutazione da CL ∪ [EQ(CL)]. Esempio: Sia CL consistente nelle seguenti clausole:
(1) ¬P(y,a) v ¬P(y,x) v ¬P(x,y) (2) P(y,f(y)) v P(y,a) (3) P(f(y),y) v P(y,a)

115
Si può dimostrare che CL non é soddisfacibile dimostrando che Θ può essere ricavato da CL applicando iterativamente la regola di risoluzione. Cerchiamo di risolvere (1) e (2). Per essere sicuri che queste clausole non hanno variabili in co- mune, sostituiamo (2) con una delle sue varianti: (2') P(y1,f(y1)) v P(y1,a)
prendiamo i letterali l1 = ¬P(y,a), l2 = ¬P(y,x), l3 = ¬P(x,y) dalla (1) e l1' = P(y1,a) dalla (2').
Poiché θ = x <- a, y <- a, y1 <- a é l'unificatore più gene- rale di |l1|,|l2|,|l3|,|l1'| la clausola (4) P(a,f(a)) é un risolvente binario di (1) e (2') e quindi un risolvente di (1) e (2). Ora, cerchiamo di risolvere (1) e (3). Sostituiamo la (3) con una sua variante (3') P(f(y2),y2) v P(y2,a) prendiamo l1,l2,l3 come prima e l1' = P(y2,a) dalla (3').
Poiché θ = x <- a, y <- a, y2 <- a é l'unificatore più gene- rale di |l1|,|l2|,|l3|,|l1'|, concludiamo che (5) P(f(a),a) é un risolvente binario della (1) e della (3') e quindi risol- vente di (1) e (3). Il passo successivo consiste nel risolvere
(1) e (4). Prendiamo l1 = ¬P(x,y) dalla (1) e l1' = P(a,f(a)) dalla (4). Poiché θ = x <- a, y <- a é l'unificatore più ge- nerale di |l1|,|l1'|, otteniamo:
¬P(f(a),a) v ¬P(f(a),a), cioé (6) ¬P(f(a),a) e finalmente dalla (5) e dalla (6) otteniamo, con la sostituzione vuota
(7) Θ (insieme di clausole vuoto). Riassumendo la sequenza (1),(2),(3),(4),(5),(6),(7) é una confu- tazione da CL, pertanto CL é non soddisfacibile. La confutazione sopra descritta può essere rappresentata in un albero di confutazione. In generale un albero di confutazione per un insieme di clausole CL é un albero binario D orientato verso l'alto che soddisfa al- le seguenti condizioni: (i) Tutti i nodi di D sono etichettati da clausole; (ii) Ciascun nodo foglia di D é etichettato da una clausola di CL;
(iii) Il nodo radice di D é etichettato da Θ; (iv) Se C etichetta un nodo n non-foglia, allora C é un risolvente delle clausole che etichettano i successori di n.
Ricordiamo che T ⇒ A sse CLAUSOLE(T) ∪ CLAUSOLE(¬(A)) é non sod- disfacibile (teorema 5.4.6) allora: Definizione 5.4.14 Una dimostrazione risolvente di una formula A da una teoria T é una confutazione da
CLAUSOLE(T) ∪ CLAUSOLE(¬(A) ∪ [EQ(CLAUSOLE(T) ∪ CLAUSOLE(¬(A))] Teorema 5.4.15
T ⇒ A sse esiste una dimostrazione risolvente di A in T.

116
5.4.3 Soluzione lineare Il ragionamento automatico tramite la regola di risoluzione ri- chiede una strategia per scegliere le clausole che devono essere risolte. L'approccio più efficace, chiamato metodo di risoluzio- ne base equivale alla generazione sistematica di tutti i possibi- li risolventi. Più specificatamente, per verificare la non sod- disfacibilità di un insieme finito di clausole CL, si parte cer- cando di costruire il risolvente di una coppia di clausole in CL, il procedimento si ripete fintanto che, o si trova la clausola vuota oppure non é più possibile generare nuovi risolventi. Nel primo caso, la procedura termina con la non soddisfacibilità di CL; nel secondo caso le clausole generate sono aggiunte a CL e il processo si ripete sull'insieme nuovo di clausole. A dispetto della sua semplicità, il metodo di risoluzione base é troppo inefficiente per essere di utilizzo pratico. Fortunata- mente può essere migliorato notevolmente imponendo alcune condi- zioni sulle clausole che devono essere risolte ad un determinato istante nel procedimento. Uno di questi accorgimenti, chiamato metodo di risoluzione lineare (Loveland 1970, Luckham 1970) si può schematizzare nel modo seguente.
(i) C0 ∈ CL ; (C0 si chiama clausola iniziale della confutazione)
(ii) per 0 ≤ i < n Bi ∈ CL oppure Bi coincide con Cj per qualche j < i;
(iii) per 1 ≤ i ≤ n Ci é un risolvente di Ci-1 e Bi-1;
(iv) Cn = Θ. In una confutazione lineare un nuovo risolvente viene sempre co- struito dal precedente. Teorema 5.4.16 Un insieme di clausole CL é non soddisfacibile sse esiste una
confutazione lineare da CL ∪ [EQ(CL)]. Uno dei problemi che si pongono nella costruzione di una confuta- zione lineare consiste nella scelta della clausole iniziale. Il teorema seguente fornisce una interessante indicazione in que- sto senso. Teorema 5.4.17 Sia CL un insieme di clausole non soddisfacibili e supponiamo che sia CL' contenuto in CL. Se l'insieme CL - CL' é soddisfacibile,
allora esiste una confutazione lineare da CL ∪ [EQ(CL)] con una clausola C ∈ CL' come clausola iniziale. Definizione 5.4.18 Una dimostrazione risolvente lineare di una formula A da una teo- ria T é una confutazione lineare da
CLAUSOLE(T) ∪ CLAUSOLE(¬(A)) ∪ [EQ(CLAUSOLE(T) ∪ CLAUSOLE(¬(A))]

117
con una clausola di CLAUSOLE(¬(A)) come clausola iniziale. Teorema 5.4.19
Se T é soddisfacibile, allora T ⇒ A sse esiste una dimostrazio- ne risolvente di A da T. Esempio: Sia T una teoria consistente dei seguenti assiomi (x).Uccello(x) -> Vola(x) Uccello(Titti) Titti = Canarino
mostriamo che T ⇒ A dove A = Vola(Canarino). Le clausole di T sono, CLAUSOLE(T):
(1) ¬Uccello(x) v Vola(x) (2) Uccello(Titti) (3) Titti = Canarino
le clausole relative ad A sono, CLAUSOLE(¬(A)) (4) ¬Vola(Canarino) le clausole di EQ[CLAUSOLE(T) ∪ CLAUSOLE(¬(A)) sono (5) x = x
(6) x ≠ y v y = x (7) x ≠ y v y ≠ z v x = z (8) x ≠ y v ¬Uccello(x) v Uccello(y) (9) x ≠ y v ¬Vola(x) v Vola(y) allora una risoluzione lineare é la seguente:
da ¬Vola(Canarino) e ¬Uccello(x) v Vola(x) si ha ¬Uccello(Canarino) da ¬Uccello(Canarino) e x ≠ y v ¬Uccello(x) v Uccello(y) si ha x ≠ Canarino v ¬Uccello(x) da x ≠ Canarino v ¬Uccello(x) e Uccello(Titti) si ha Titti ≠ Canarino da Titti ≠ Canarino e Titti = Canarino si ha Θ (clausola vuota) (Fig. 5.1)
¬Vola(Canarino) / (1) / / ¬Uccello(Canarino) / (8) / / x ≠ Canarino v ¬Uccello(x) / (2) / / Titti ≠ Canarino / (3) / / Θ

118
5.5 Logica classica del secondo ordine A differenza della logica del primo ordine, in cui tutte le va- riabili possono indicare solamente individui, nella logica del secondo ordine si ammette, in aggiunta, che le variabili possano indicare relazioni e funzioni specificate sopra agli individui. Vediamo una breve esposizione della logica classica del secondo ordine. 5.5.1 Il linguaggio logico del secondo ordine. Un alfabeto della logica del secondo ordine consiste di simboli primitivi appartenenti alle seguenti classi:
(i) Un insieme numerabile di (per ciascun n ≥ 0) variabili indi- canti funzioni n-ary ϕ(n,1),ϕ(n,2),...; variabili indicanti funzioni 0-ary vengono chiamate variabili individuali, e donotate con x1,x2,... (ii) Un insieme numerabile di variabili indicanti predicati n-
ary (per ciascun n ≥ 0) Φ(n,1),Φ(n,2),...; predicati 0-ary ven- gono chiamati variabili proposizionali. (iii) Una costante vera: "Vero"
(iv) Connettivi: "¬" e "->" (v) un quantificatore: "(_)" (vi) Separatori: "(" "," ")" (vii) Un insieme numerabile |P di predicati costanti; ciascun P
∈ |P ha assegnato un intero non negativo, chiamato arità di P. (viii) Un predicato costante distinto 2-ary: "="
(ix) Un insieme numerabile |F di funzioni costanti f ∈ |F; a ciascuna f é assegnato un numero intero non negativo chiamato arità della f. Le classi (i)-(vi) sono fisse, mentre le altre possono variare, e, in particolare, possono essere vuote. Gli insiemi |P e |F si assumono calcolabili. Predicati costanti 0-ary sono chiamati proposizioni costanti. Funzioni costanti denotano individui od oggetti costanti. Ogni alfabeto AL determina univocamente tre classi di espressio- ni: i termini TM(AL), le formule atomiche AFORM(AL) e le formule L(AL). Queste sono specificate come quelle nella logica classica del primo ordine con ugualianza, con in più le seguenti caratte- ristiche; per quanto riguarda i termini:
(iii) Se α1,...,αn ∈ TM(AL) (n≥1) e ϕ(n,i) é una funzione va- riable n-ary, allora ϕ(n,i)(α1,...,αn) ∈ AFORM(AL). La definizione di insieme di formule atomiche su AL si arricchi-

119
sce delle seguenti affermazione: (iv) Ogni proposizione variabile é una formula atomica su AL
(v) Se α1,...,αn ∈ TM(AL) (n≥1) e Φ(n,i) é un predicato va- riabile n-ary, allora Φ(n,i)(α1,...,αn) ∈ AFORM(AL). Inoltre la clausola (ii) nella definizione dell'insieme di formu- le su AL deve essere sostituita da
(iì) Se A,B ∈ L(AL) e X e una variabile, allora (¬A) ∈ L(AL), (A -> B) ∈ L(AL) e ((X)(A)) ∈ L(AL) [per ogni X(A) ∈ L(AL)]. L'insieme L(AL), come sopra specificato, si chiama linguaggio del secondo ordine su AL. Di solito si assume che AL sia fissato, e che L(AL) possa essere abbreviato in L. La condizione per cui gli alfabeti riguardano solo insiemi di predicati e funzioni costanti calcolabili assicuura la calcolabilità di ogni linguaggio del secondo ordine. I linguaggi logici del secondo ordine contengono il simbolo "=" ed allora non esiste più la distinzione in lin- guaggi con o senza l'uguaglianza. Impiegheremo le convenzioni di notazione introdotte per i lin- guaggi del primo ordine per denotare variabili individuali, co-
stanti individuali, predicati costanti n-ary (n≥1), funzioni co- stanti n-ary (n≥1) formule e termini. In più, assumeremo che le lettere ϕ e τ denotino variabili di funzioni n-ary (n≥1), mentre Φ e Ω si riferiscano a variabili predicato n-ary (n≥0). Il simbo- lo X per denotare una variabile arbitraria.
I connettivi logici &, v e ≡, il quantificatore esistenziale (∃_) e la costante Falso corrispondono alle solite definizioni. Le definizioni di "ricorrenza di una variabile universalmente (esistenzialmente) quantificata", "ricorrenza di una variabile vincolata", "ricorrenza di una variabile libera", "variabile libe- ra" e "campo di applicazione di una variabile" sono analoghe a quelle utilizzate nei linguaggi logici del primo ordine, ad ecce- zione del fatto che nel linguaggio logico del secondo ordine pos- sono essere applicate a tutti i tipi di variabili. Una formula chiusa o affermazione é una formula che non contiene variabili libere. Una formula non chiusa si dice aperta. Esempi.
Termini: x, f(a,y), ϕ(x,ϕ(b,z)) Formule atomiche: P(ϕ(a),a), Ω(b,x,ϕ(x)) Formule: (x)Ω(x), (x)(∃Φ).¬Φ(x) v Ω(x), (x)Φ.Φ(a) -> Φ'(x) & Ω(y)

120
5.5.2 Semantica della logica del secondo ordine Definizione 5.5.1 Una struttura per un linguaggio del secondo ordine L(AL) consiste in una coppia M = <D,m> dove D ed m sono specificati come nel ca- so del linguaggio del primo ordine. Cioé D é un insieme non vuoto che corrisponde al dominio di M (universo per M) ed m é
una funzione che assegna a ciascun predicato costante n-ary (n≥0) di AL, diverso da "=", una relazione n-ary su D, alla costante "=", la relazione identica su D, e a ciascuna funzione costante
n-ary (n≥0) di AL, una funzione n-ary da Dn a D. Di solito, data una struttura M =<D,m> per L(AL), si scrive |M| per indicare il dominio di M; M|K| per indicare m(K), dove K é un predicato o una funzione costante in AL. Diremo che M é una struttura del secondo ordine, o anche una struttura per la logica del secondo ordine sse M é una struttura per qualche linguaggio del secondo ordine L. Osserviamo a questo proposito che ogni struttura del secondo or- dine può essere interpretata come una struttura del primo ordine e viceversa, infatti la frase "struttura del primo ordine" e la frase "struttura del secondo ordine" non vengono utilizzate per distinguere tra oggetti differenti ma piuttosto tra logiche dif- ferenti. Sia M una struttura del secondo ordine; un assegnamento su M con- siste in una funzione che assegna ad ogni variabile di funzione
n-ary (n≥0) una funzione n-ary da |M|n in |M|, e a ciascuna va- riabile predicato n-ary (n≥0) una relazione n-ary su |M|. Osserviamo che le variabili individuali sono identificate da va- riabili funzione 0-ary. L'insieme di tutti gli assegnamenti su M viene denotato con As(M)
se a ∈ As(M) e X é una variabile qualsiasi allora scriviamo [a]x per denotare l'insieme di quegli assegnamenti su M che dif- feriscono da "a" al massimo per X. Definizione 5.5.2 Sia M una struttura del secondo ordine per L(AL).
Il valore Va(α) di un termine α ∈ TM(AL) in M dove a ∈ As(M) é un elemento di |M| definito come segue: (i) Va(x) = a(x), dove x é una variabile individuale; (ii) Va(a) = M|a|;
(iii) Va(f(α1,...,αn)) = M|f|(Va(α1),...,Va(αn)); (iv) Va(ϕ(α1,...,αn)) = a(ϕ)(Va(α1),...,Va(αn)).
Il valore di verità Va(A) di una formula A in M dove a ∈ As(M) é un elemento di 0,1 specificato nel modo seguente: (i) Va(Vero) = 1; (ii) Va(p) = M|p|;
(iii) Va(P(α1,...,αn)) = M|P|(Va(α1),...,Va(αn)); (iv) Va(α=β) = 1 sse Va(α) = Va(β); (v) Va(Φ) = a(Φ), dove Φ è qualsiasi variabile proposizione; (vi) Va(Φ(α1,...,αn)) = a(Φ)(Va(α1),...,Va(αn)) dove Φ é ogni variabile predicato n-ary (n≥0); (vii) Va(B -> C) = 1 sse Va(B) = 0 oppure Va(C) = 1;
(viii) Va(¬B) = 1 - Va(B);

121
(ix) Va((X)B) = 1 sse Va(B) = 1 per ogni a’ ∈ [a]x.
Le condizioni di verità per i simboli &, v, ≡, Falso, e (∃_) possono essere facilmente dedotte dalle loro definizioni. Una formula A si dice soddisfatta in una struttura M da un asse-
gnamento a ∈ As(M) sse Va(A) = 1. Una formula A é soddisfacibile sse Va(A) = 1 per qualche struttura M e qualche a ∈ AS(M); in ca- so contrario si dice non soddisfacibile. Una formula A é vera in
M sse Va(A) = 1, per ogni a ∈ As(M). Se A é vera in M, allora diremo che M é un modello per A. A é valida sse A é vera in ogni struttura M. Esempio:
Sia A = (Φ)(∃Ω)(x)(y)[Φ(x,y) ≡ Ω(y,x)]. Intuitivamente, A afferma che ogni relazione binaria possiede una inversa. Dimostriamo che A é valida. Assumiamo che A sia falsa,
cioé Va(A) = 0, per qualche struttura M e qualche a ∈ As(M). Allora esiste un a’ ∈ [a]Φ tale che
Va’((∃Ω)(x)(y)[Φ(x,y) ≡ Ω(y,x)]) = 0.
Supponiamo che a’(Φ) = R e sia a’’ l'assegnamento su M che é identico ad a’ eccetto che a’’(Φ) é l'inversa di R. Poiché, Va’’((x)(y)[Φ(x,y) ≡ Ω(y,x)]) = 1 quindi
Va’((∃Ω)(x)(y)[Φ(x,y) ≡ Ω(y,x)]) = 1 che contraddice l'ipotesi. Consideriamo lo schema
5.3.3 (α = β) ≡ ((Φ)[Φ(α) ≡ Φ(β)])
dove α e β sono termini qualsiasi. Questo schema rappresenta il principio di identità dell'indi- stinguibile di Leibnitz, in accordo col fatto che se due oggetti godono esattamente delle stesse proprietà allora sono identici. É facile vedere che ogni istanza della 5.3.3 é valida. Allora nella logica del secondo ordine la costante "=" non deve necessariamente essere un simbolo primitivo, ma può essere in- trodotta dalla seguente definizione:
α = β definita come ((Φ)[Φ(α) ≡ Φ(β)].
dove α e β sono termini qualsiasi. Il problema di validità della logica del secondo ordine consiste nel determinare se una data formula arbitraria del secondo ordine é valida oppure no. Poiché la classe delle formule valide del secondo ordine contiene le formule valide del primo ordine, e poiché il problema di validità per la logica del primo ordine é indecidibile, ne deduciamo immediatamente: Teorema 5.5.4 Il problema di validità per la logica del secondo ordine non é decidibile. Potremmo allora sperare di costruire un algoritmo per decidere se una data formula del secondo ordine é valida oppure no.

122
Sfortunatamente, a differenza della logica del primo ordine, é altrettanto impossibile fornire una procedura che possa essere utilizzata per confermare la validità di una arbitraria formula valida in un linguaggio logico del secondo ordine. Teorema 5.5.5 Sia L un linguaggio logico del secondo ordine. In generale, l'in- sieme di formule valide su L non é un sottoinsieme parzialmente calcolabile di L. Due formule A e B si dicono logicamente equivalenti, A <=> B, sse esse hanno gli stessi valori di verità per ogni struttura M ed
ogni a ∈ As(M). Formule equivalenti del linguaggio logico del se- condo ordine godono delle stesse proprietà delle formule equiva- lenti del linguaggio del primo ordine.

123
5.5.3 Teorie del secondo ordine Una teoria del secondo ordine consiste in una coppia T = <L,S>, dove L é il linguaggio del secondo ordine e S sono gli assiomi o premesse di T. Se S = , allora T si chiama calcolo dei predi- cati del secondo ordine su L. Tutte le notazioni per i termini e altre convenzioni introdotte precedentemente per le teorie del primo ordine possono essere u- tilizzate nelle teorie del secondo ordine. In particolare, le teorie del secondo ordine possono essere identificate con l'in- sieme dei loro assiomi, e questo ci consente di trattare ogni af- fermazione nel linguaggio logico del secondo ordine come ad una teoria del secondo ordine. Di solito una struttura in cui tutti gli assiomi di una data teo- ria T sono veri rappresenta un modello di T. Una teoria T é soddisfacibile sse ha un modello; altrimenti T non é soddisfacibile. Una formula A é conseguenza semantica di una teoria T ( A segue
da T, T implica A, A é implicata da T), T ⇒ A, sse A é vera in ogni modello di T. In particolare, A é una conseguenza semantica
del calcolo dei predicati del secondo ordine su L, ⇒ A, sse A é vera in ogni struttura per L.
Il simbolo ⇒ denota una relazione binaria, chiamata relazione di implicazione della logica classica del secondo ordine. La relazione di implicazione nella logica classica del secondo ordine gode delle stesse proprietà della relazione di implica- zione nella logica classica del primo ordine. Due teorie T e T' sono logicamente equivalenti, T <=> T', sse possiedono gli stessi modelli. Le proprietà di teorie equivalenti nella logica del primo ordine possono essere generalizzate alla logica del secondo ordine. Di solito, due formule A e B si dicono equivalenti in una teoria T sse esse hanno gli stessi valori di verità in ogni modello M
di T ed ogni assegnamento a ∈ As(M).

124
5.5.4 Sistemi di deduzione per la logica del secondo ordine Un sistema di deduzioni per la logica del secondo ordine viene definito analogamente ai sistemi di deduzione per la logica del primo ordine, ad eccezione del fatto che L é appunto un linguag- gio del secondo ordine. Di solito, dato un sistema di deduzioni DS = <L,S,R>, si dice che A é dimostrabile in DS sse esiste una sequenza A1,...,An di formule di L tali che An = A e, per ciascun
1≤i≤n, si ha che Ai ∈ S oppure Ai é una diretta conseguenza di qualche formula precedente nella sequenza in virtù di qualche regola di R. DS é solido sse ogni formula dimostrabile in DS é valida; é completo sse ogni formula valida di L é dimostrabile in DS. Il seguente teorema fondamentale afferma un importante risultato riguardante la logica del secondo ordine: Teorema 5.5.6 (Gödel) Non esiste un sistema di deduzione completo per la logica del se- condo ordine. Esiste una importante classe ristretta di formule valide del se- condo ordine, chiamata la classe delle formule secondariamente valide. É possibile costruire un sistema di deduzione per la lo- gica del secondo ordine, che sia solido e completo rispetto a ta- le classe ristretta di formule, cioé DS = <L,S,R> tale che A é dimostrabile in DS sse A é una formula secondariamente valida di L.

125
5.5.5 Espressioni con predicati e funzioni. Nella logica del primo ordine, é possibile sostituire termini al posto di variabili individuali. Nella logica del secondo ordine, possiamo, in aggiunta, sostituire espressioni di predicati al po- sto di variabili predicato ed espressioni di funzioni al posto di variabili funzione. Una espressione di predicati n-ary W é un'espressione della for- ma:
Γx1...xn A(x1,...,xn) (n≥0) dove x1,...,xn sono variabili individuali e A(x1,...,xn) é una formula nella logica del primo o del secondo ordine. Nel primo caso, W si chiama espressione di predicati del primo ordine, nel secondo espressione di predicati del secondo ordine. Un ricorrenza di una variabile X si dice essere libera in W
sse X ∉ x1,...,xn e la ricorrenza é libera in A(x1,...,xn). Ogni variabile individuale che ha ricorrenze libere in W si chia- ma parametro in W. Se non vi sono parametri in W, allora W si di- ce espressione di predicati senza parametri, altrimenti W é un'espressione di predicati con parametri. I seguenti sono espressioni di predicati:
W1 = ΓxP(x) W2 = Γxy[Φ(x) v Q(y)] W3 = ΓxQ(x,y). W1 e W2 sono espressioni di predicati senza parametri; W3 é un'espressione di predicati con y come parametro. Una espressione di predicati n-ary W ha lo scopo di rappresentare un predicato n-ary, cioé una relazione n-ary, che può essere considerata una estensione di W. Definizione 5.5.7 Sia W una espressione predicato della forma
Γx1,...,xn A(x1,...,xn). L'estensione Ea(W) di W in una struttura M dove a ∈ As(M) é la relazione n-ary R su |M| data da
<d1,...,dn> ∈ R sse Va(x1/d1,...,xn/dn)(A) = 1 dove a(x1/d1,...,xn/dn) é l'assegnamento su M che é identico ad eccezione di alcune tra le variabili x1,...,xn; a cui essa asse- gna d1,...,dn rispettivamente. Da notare che per ogni predicato costante n-ary P,
Ea(Γx1,...,xn P(x1,...,xn)) = M|P| così che P può essere inden- tificato da Γx1,...,xn P(x1,...,xn). In maniera analoga, per ogni variabile predicato n-ary é, Ea(Γx1,...,xn Φ(x1,...,xn)) = a(Φ). Allora Φ può essere identificata con Γx1,...,xn Φ(x1,...,xn). Una espressione di predicati Γx1...xn A(x1,...,xn) viene spesso _ _ _
scritta come Γx A(x), dove x rappresenta la n-tupla (x1,...,xn). _ _
Sia W una espressione predicato della forma ΓxA(x) e supponiamo che α = (α1,...,αn) sia una n-tupla di termini.
L'applicazione di W ad α, W(α), é la formula A(α). L'applicazione si dice corretta sse ogni αi, 1≤i≤n, é libero per

126
xi in A(x).
Per esempio, se W = Γxy P(x,y) e α = (z,f(b)), allora W(α) = P(z,f(b)). Se W = Γxy(∃z) P(x,y,z) e α = (z,f(a)), allora W(α) = (∃z) P(z,f(a),z). La prima applicazione é corretta, la seconda no. Una sostituzione di una espressione predicato al posto di varia-
bili predicato consiste in un insieme Φ1 <- W1,...,Φn <- Wn (n≥0), dove Φ1,...,Φn sono variabili predicato distinte, W1,...,Wn sono espressioni predicato e per ogni 1≤i≤n, Wi e Φi possiedono la stessa arità. Definizione 5.5.8
L'applicazione di una sostituzione τ = Φ1 <- W1,..., Φn <- Wn ad una formula A é la formula Aτ ottenuta da A eseguendo le se- guenti operazioni:
(i) Sostituzione di ciascuna ricorrenza di Φi (1≤i≤n) nella A con Wi; (ii) Nella espressione risultante, che in generale non é una
formula, sostituire ciascuna parte contenente la forma Wi(α) con l'applicazione di Wi ad α.
L'applicazione τ ad A si dice propria sse tutte le applicazioni, di espressioni predicato a termini, eseguite in (i) sono corret- te, e ogni ricorrenza libera di variabili in ogni W1,...,Wn di-
viene vincolata in Aτ, altrimenti, l'applicazione di τ ad A si dice impropria. Diremo che B si ottiene da A con la sostituzione di W1,...,Wn al
posto di Φ1,...,Φn sse B é l'applicazione di Φ1 <- W1,...,Φn <- Wn ad A. Esempio:
Sia A = (x)Φ(x) -> (x)Φ(b), τ = Φ <- Γy P(x,y) applicando τ ad A, otteniamo prima
(x)Γy P(x,y)(x) -> (x)Γy P(x,y)(b) e poi (x)P(x,x) -> (x) P(x,b).
Allora, Aτ = (x)P(x,x) -> (x)P(x,b). L'applicazione di τ ad A é impropria a causa del fatto che la ricorrenza libera di x in
Γy P(x,y) diviene vincolata in Aτ. Supponiamo ora che A’ = (x)Φ(x) -> Φ(y) e sia τ' = Φ <- Γx(∃y)Q(x,y); applicando τ' ad A’ otteniamo
(x)Γx(∃y)Q(x,y)(x) -> Γx(∃y)Q(x,y)(y) e
A’τ' = (x)(∃y)Q(x,y) -> (∃y)Q(y,y)
l'applicazione τ' ad A é impropria poiché l'applicazione di Γx(∃y)Q(x,y) ad y non é corretta essendo y vincolato alla x in (∃y)Q(x,y). Consideriamo A2 = (x)(y).Φ(x,y) v Ω(x,y) e τ2 = Φ <- Γxy P(x,y), Ω <- Γuz Q(u,z). Applicando τ2 ad A2 otteniamo:

127
(x)(y).Γxy P(x,y)(x,y) v Γuz Q(u,z)(x,y) e poi
A2τ2 = (x)(y).P(x,y) v Q(x,y).
L'applicazione di τ2 ad A2 é propria. Teorema 5.5.9
Per ogni sostituzione τ = Φ1 <- W1,...,Φn <- Wn ed ogni formula A la formula (Φ1) ... (Φn) A -> Aτ é valida, purché l'applica- zione di τ ad A sia propria. Il teorema precedente non é valido nel caso in cui l'applicazio-
ne di τ ad A non sia propria. Per vederlo consideriamo la formula A e la sostituzione τ dell'esempio precedente. É facile control- lare che la formula (Φ)A é valida mentre la formula Aτ non lo é. Il teorema precedente implica immediatamente il seguente risulta- to: Corollario 5.5.10
Per ogni sostituzione τ = Φ1 <- W1,...,Φn <- Wn ed ogni affer- mazione della forma (Φ1)...(Φn).A
(Φ1)...(Φn).A ⇒ Aτ
purché l'applicazione di τ ad A sia propria. Una espressione funzione n-ary F é una espressione nella forma
Γx1,...xn α(x1,...,xn) (n≥0)
dove x1,...,xn sono variabili individuali e α(x1,...,xn) é un termine, contenente alcune delle variabili inviduali xi.
Non si suppone comunque che tutte le x1,...,xn ricorrano in α e nemmeno che α non contenga altre variabili individuali. Una ricorrenza di una variabile individuale x si dice libera in F
sse x ∉ x1,...,xn e x ricorre in α. Esempio:
F1 = Γx f(x); F2 = Γxy f(g(x),y); F3 = Γx ϕ(x,y). Una espressione funzione F intende rappresentare una funzione n-ary che si può pensare come un'estensione di F. Definizione 5.5.11 Sia F una espressione funzione n-ary della forma
Γx1,...,xn α(x1,...,xn). L'estensione Ea(F) di F in una struttura M dove a ∈ As(M) é la funzione f da |M| alla n a |M| data da
f(d1,...,dn) = Va(x1/d1,...,xn/dn)(α)

128
dove a(x1/d1,...,xn/dn) é l'assegnamento su M che é identico ad ad eccezione di alcune tra le variabili x1,...,xn; a cui essa assegna d1,...,dn rispettivamente. Da notare che per ogni funzione costante n-ary f,
Ea(Γx1,...,xn f(x1,...,xn)) = M|f| così che f può essere inden- tificata da Γx1,...,xn f(x1,...,xn). In maniera analoga, per ogni variabile funzione n-ary ϕ, Ea(Γx1,...,xn ϕ(x1,...,xn)) = a(ϕ). Allora ϕ può essere identificata con Γx1,...,xn ϕ(x1,...,xn). Una espressione di funzioni Γx1...xn α(x1,...,xn) viene spesso _ _ _
scritta come Γx α(x), dove x rappresenta la n-tupla (x1,...,xn). _ _
Sia F una espressione funzione della forma Γxα(x) e supponiamo che β = (β1,...,βn) sia una n-tupla di termini. L'applicazione di F a β, F(β), é il termine α(β1,...,βn). Per esempio, se F = Γxy ϕ(f(x),g(y)) e β = (a,f(a)), allora F(β) = ϕ(f(a),g(f(a))). Una sostituzione di una espressione funzione al posto di variabi-
li funzione consiste in un insieme τ = ϕ1 <- F1,...,ϕn <- Fn (n≥0), dove ϕ1,...,ϕn sono variabili funzione distinte, F1,...,Fn sono espressioni funzione e per ogni 1≤i≤n, Fi e ϕi possiedono la stessa arità. Definizione 5.5.12
L'applicazione di una sostituzione τ = ϕ1 <- F1,..., ϕn <- Fn ad una formula A é la formula Aτ ottenuta da A eseguendo le se- guenti operazioni:
(i) Sostituzione di ciascuna ricorrenza di ϕi (1≤i≤n) nella A con Fi; (ii) Nella espressione risultante, che in generale non é una
formula, sostituire ciascuna parte contenente la forma Fi(β) con l'applicazione di Fi ad β.
L'applicazione τ ad A si dice propria sse nessuna ricorrenza di variabili individuali libere in ogni F1,...,Fn diventa vincolata
in Aτ; altrimenti l'applicazione di τ ad A si dice impropria. Diremo che B si ottiene da A con la sostituzione di F1,...,Fn al
posto di ϕ1,...,ϕn sse B é l'applicazione di ϕ1 <- F1,...,ϕn <- Fn ad A. Esempio:
Sia A = (y)[P(y) -> Q(ϕ(y))] -> (y)(z)[P(z) -> Q(ϕ(z))] e suppo- niamo che τ = ϕ <- Γx g(y,x) applicando τ ad A, otteniamo prima
(y)[P(y)->Q(Γx g(y,x)(y))]->(y)(z)[P(z)->Q(Γx g(y,x)(z))] e poi
Aτ = (y)[P(y) -> Q(g(y,y))] -> (y)(z)[P(z) -> Q(g(y,z))].
L'applicazione di τ ad A é impropria poiché la ricorrenza libe- ra di y in Γx g(y,x) diventa vincolata in Aτ.

129
Consideriamo ora A’ = (z).Φ(ϕ(z)) -> P(ϕ(z)) e sia τ' = ϕ <- Γx f(x,y); applicando τ' ad A’ otteniamo
(z).Φ(Γx f(x,y)(z)) -> P(Γx f(x,y)(z)) e
A’τ' = (z).Φ(f(z,y)) -> P(f(z,y)).
l'applicazione di τ' ad A é propria. Teorema 5.5.13
Per ogni sostituzione τ = ϕ1 <- F1,...,ϕn <- Fn ed ogni formula A la formula (ϕ1) ... (ϕn) A -> Aτ é valida, purché l'applica- zione di τ ad A sia propria. Il teorema precedente non é valido nel caso in cui l'applicazio-
ne di τ ad A non sia propria. Consideriamo per esempio la formula A e la sostituzione τ dell'esempio precedente. É facile control- lare che la formula (ϕ)A é valida mentre la formula Aτ non lo é. Il teorema precedente implica immediatamente il seguente risulta- to: Corollario 5.5.14
Per ogni sostituzione τ = ϕ1 <- F1,...,ϕn <- Fn ed ogni affer- mazione della forma (ϕ1)...(ϕn).A
(ϕ1)...(ϕn).A ⇒ Aτ
purché l'applicazione di τd ad A sia propria.

130
5.6 La logica modale La logica modale é stata sviluppata per formalizzare concetti che coinvolgono le nozioni di necessità e possibilità. Una pro- posizione necessaria é una proposizione vera che non può essere falsa. Una proposizione possibile é una proposizione che potreb- be essere vera. Questa distinzione si esprime spesso utilizzando il concetto di mondi possibili: le proposizioni necessarie sono quelle che sono vere in tutti i mondi possibili, mentre le propo- sizioni possibili sono quelle che sono vere in qualche possibile mondo. 5.6.1 Logica proposizionale modale Un alfabeto della logica proposizionale modale si ottiene da quello della logica proposizionale classica aggiungendo due ope- ratori modali: (i) M operatore delle possibilità (ii) L operatore della necessità Definizione 5.6.1 Sia AL un alfabeto della logica modale proposizionale. L'insieme L(AL) delle formule su AL é l'insieme più piccolo tale che: (i) "Vero" e tutte le proposizioni costanti di AL sono membri di L(AL);
(ii) Se A e B sono elementi di L(AL) allora anche (A -> B), (¬A), (LA) [necessariamente A] e (MA) [A é possibile] sono membri di L(AL). L'insieme L(AL) si chiama linguaggio proposizionale modale su AL. Di solito L(AL) viene abbreviato in L.
I simboli Falso, v, & e ≡ sono introdotti nel solito modo ed han- no il medesimo significato. Gli operatori M ed L sono definibili l'uno rispetto all'altro come segue:
(i) (MA) = ¬(L¬A); (ii) (LA) = ¬(M¬A). Gli operatori modali sono legati strettamente alla formula a cui sono applicati e si comportano come il segno di negazione. Definizione 5.6.2 Una struttura per un linguaggio modale proposizionale L(AL) con- siste in M = <W,R,m> dove: (i) W é un insieme non vuoto chiamato l'insieme dei mondi pos- sibili; (ii) R é una relazione binaria su W, chiamata relazione di ac- cessibilità; (iii) m é una funzione che a ciascuna coppia, costituita da una
proposizione costante di AL e un elemento w ∈ W, assegna un ele- mento di 0,1. I mondi possibili sono oggetti astratti e il loro preciso signi- ficato non é chiaramente definito. Intuitivamente, ogni mondo possibile possiamo pensarlo come uno stato accessibile a cose, situazioni,scenari,ecc.

131
Poiché una proposizione può avere valori di verità differenti a seconda dello stato effettivo in cui si trovano le cose, le si- tuazioni, gli scenari, ecc.; il valore di verità assegnato da m ad una proposizione costante dipende anche da quale mondo possi- bile si considera, in altri termini la funzione m assegna il va- lore di verità non solo alla proposizione costante ma anche ad un possibile mondo. Il valore m(p,w) può essere pensato come il valore di verità di p in w. La relazione di accessibilità ha il significato di e- sprimere l'intuizione che alcune cose possono essere possibili dal punto di vista di un certo mondo e impossibili, invece, in un mondo diverso. Se esiste la relazione w1Rw2 di accessibilità, allora possiamo dire che w2 é accessibile (concepibile, visibi- le,...) da w1. L'intenzione é quella di esprimere che i mondi accessibili da w1 sono quelli che sono considerati possibili dal punto di vista di w1. Definizione 5.6.3 Il valore di verità Vw(A) di una formula A in una struttura,
dove w ∈ W, é un elemento di 0,1 dato da: (i) Vw(p) = m(p,w);
(ii) Vw(¬B) = 1 - Vw(B); (iii) Vw(B -> C) = 1 sse Vw(B) = 0 oppure Vw(C) = 1;
(iv) Vw(LB) = 1 sse Vw(B) = 1 per ogni w' ∈ W tale che wRw'; (v) Vw(MB) = 1 sse Vw(B) = 1 per qualche w'∈ W tale che wRw'. Osserviamo che Vw(LA) e Vw(MA) non sono funzioni di Vw(A), ma di- pendono anche dai valori di verità di A nei mondi che sono ac- cessibili da w; allora, a differenza delle logica classica, la logica modale non ubbidisce al principio di funzionalità. Una formula A si dice vera in una struttura M = <W,R,m> sse
Vw(A)=1 per ogni w ∈ W. Se A é vera in M, allora M é un modello per A. Imponendo restrizioni diverse alla relazione di accessibi- lità si ottengono sistemi di logica proposizionale modale diffe- renti. Sia M = <W,R,m> una struttura. Diremo che M é una T-struttura sse R é riflessiva; diremo che M é S4-struttura sse R é ri- flessiva e transitiva; diremo che M é S5-struttura sse R é ri- flessiva, transitiva e simmetrica, cioé é una relazione di equivalenza.
Diremo che una formula A ∈ L é X-valida, X ∈ T,S4,S5, sse A é vera in ogni X-struttura per L. Ovviamente, ogni formula T-valida é anche S4-valida e S5-valida. L'inverso generalmente non é ve- ro; cioé esistono formule S5-valide che non sono T-valide o S4-valide. Esempio: Mostriamo che ogni istanza dello schema LA -> A é T-valido. Assumiamo il contrario; allora esiste una formula A, una
T-struttura M = <W,R,m> e w ∈ W tali che Vw(LA -> A) = 0. Ne consegue perciò che Vw(LA) = 1 e Vw(A) = 0; poiché M é una T-struttura, R é riflessiva, e pertanto Vw(LA) = 1 implica Vw(A) = 1 che contraddice l'ipotesi. Consideriamo lo schema LA -> LLA. Proviamo che ogni istanza di questo schema é S4-valida. Assumiamo il contrario; allora per qualche formula A, qualche
S4-struttura M = <W,R,m> e qualche w ∈ W si ha Vw(LA -> LLA) = 0;

132
allora Vw(LA) = 1 e Vw(LLA) = 0. Poiché Vw(LLA) = 0, deve esi-
stere un w' ∈ W tale che sia wRw' e Vw'(LA) = 0; ma Vw'(LA) = 0 implica l'esistenza di w2 ∈ W tale che w'Rw2 e Vw2(A) = 0. Sicco- me R é transitiva wRw' e wRw2 implica wRw2 e quindi se ne con- clude che Vw2(A) = 1, che contraddice l'ipotesi. In generale istanze dello schema LA -> LLA non sono T-valide. Consideriamo per esempio Lp -> LLp e prendiamo la T-struttura ta- le che: W = w1,w2,w3;
R = <w1,w2>,<w2,w3> ∪ <wi,wi>:1≤i≤3; m(p,w1) = 1; m(p,w2) = 1; m(p,w3) = 0. Si può verificare che Vw1(Lp -> LLp) = 0. Teorema 5.6.4
Per ogni X ∈ T,S4,S5, il problema di validità per la logica proposizionale X modale é decidibile. In virtù del teorema precedente é possibile costruire algoritmi per decidere se una data formula della logica modale é X-valida. Una teoria nella logica proposizionale modale consiste in T=<L,S> dove L é il linguaggio proposizionale modale ed S é il sistema di assiomi di T, ed é un sottoinsieme calcolabile di L. Di soli- to anche una teoria modale viene identificata con l'insieme dei suoi assiomi. Sia T una teoria; una struttura M si dice modello per T sse M é una struttura e tutti gli assiomi di T sono veri in M. Una teoria che possiede un modello si dice soddisfacibile, altrimenti si di- ce non soddisfacibile. Si dice che T X-implica una formula A,
T ⇒ A, sse A é vera in ogni modello di T. Un sistema di deduzione per la logica modale proposizionale é definito nel modo solito. Definizione 5.6.5 Sia L un linguaggio della logica proposizionale modale
e X ∈ T,S4,S5. Denotiamo con MPL(L,X) il sistema di deduzione <L,S(X),R> dato da (i) S(T) consiste nei seguenti assiomi: (A1) Vero (A2) A -> (B -> A) (A3) (A -> (B -> C)) -> ((A -> B) -> (A -> C))
(A4) (¬B -> ¬A) -> ((¬B -> A) -> B) (A5) LA -> A (A6) L(A -> B) -> (LA -> LB) S(S4) si ottiene da S(T) aggiungendo (A7) LA -> LLA S(S5) si ottiene da S(S4) aggiungendo (A8) MA -> LMA (ii) R consiste delle seguenti regole di inferenza: (MP) B é una diretta conseguenza A e A -> B

133
(NEC) LA é una diretta conseguenza di A (NEC) é la regola di necessità. Di solito normalmente si assume che il linguaggio in considera- zione sia fissato.
Se T → A, nel sistema di deduzione MPL(L,X), diremo che A é di- mostrabile da T nella logica proposizionale X modale, e A si dice teorema della logica proposizionale X modale. Denotiamo con Th(T) l'operatore di dimostrabilità nella logica
proposizionale X modale: Th(T) = A: T → A. Teorema 5.6.6
(i) Se T → A allora T ⇒ A (Solidità)
(ii) Se T ⇒ A allora T → A (Completezza) Corollario 5.6.7
⇒ A sse → A. Una teoria T su L si dice consistente sse esiste una formula
A ∈ L tale che T ¬→ A. Teorema 5.6.8 T é consistente sse T é soddisfacibile. Per concludere diremo che nella letteratura sulla logica, le no- zioni di implicazione modale e di dimostrabilità modale sono spesso interpretate cel seguente forte significato: diremo che
una teoria T implica fortemente una formula A, T s⇒ A, sse per
ogni struttura M = <W,R,m> e ogni w ∈ W, da Vw(B) = 1 per ogni B ∈ T ne consegue Vw(A) = 1. A si dice fortemente dimostrabile in T, T s→ A sse esistono delle formule B1,...,Bn ∈ T tali che → B1 & ... & Bn -> A. Si può vedere che T s⇒ A implica T ⇒ A e
che T s→ A implica T → A. Il contrario non é sempre vero.
Per esempio, p → Lp e p ⇒ Lp ma non vale p s→ Lp e nemmeno
p s⇒ Lp. É possibile dimostrare che la nozione di implicazione forte e di dimostrabilità forte sono correlate alla seguente af-
fermazione: T s⇒ A sse T s→ A.

134
5.6.2 Logica modale del primo ordine Un alfabeto della logica modale del primo ordine si ottiene dalla logica classica del primo ordine aggiungendo gli operatori "L" ed "M". Sia AL un alfabeto della logica modale del primo ordine. L'insie- me dei termini su AL e l'insieme delle formule atomiche su AL vengono definiti nella stessa maniera in cui sono definiti nella logica classica del primo ordine. L'insieme L(AL) delle formule su AL consiste nel più piccolo in- sieme tale che: (i) Tutte le formule atomiche su AL sono elementi di L(AL);
(ii) Se x é una variabile e A, B ∈ L(AL), allora (¬A), (A -> B) ((x)(A)), (LA), e (MA) sono membri di L(AL). La semantica della logica modale del primo ordine é definita co- me segue: (i) D é un insieme non vuoto chiamato dominio di M; (ii) W é un insieme non vuoto di "mondi possibili"; (iii) R é una relazione binaria di "accessibilità" su W; (iv) m é una funzione che assegna ad ogni coppia consistente in
un predicato costante n-ary (n≥0) diverso da "=", e un elemento w di W, una relazione n-ary su D, alla costante "=", se presente in AL, la relazione identità su D, e a ciascuna funzione n-ary
(n≥0) costante, una funzione da Dn a D. Data una struttura M = <D,W,R,m> scriviamo |M| per denotare il dominio di M. Se K é un predicato o una funzione costante, allo- ra M|K,w| o M|K| sta per m(K,w) o m(K) rispettivamente. Un assegnamento su una struttura M viene specificato nel modo so- lito e l'insieme di tutti gli assegnamenti su M viene denotato con As(M). Il simbolo [a]x indica l'insieme di tutti gli assegna- menti su M che sono identici ad "a", eccetto forse per l'assegna- mento sulla variabile x. Definizione 5.6.9 Sia M una struttura per L(AL).
Il valore di verità Va(α) di un termine in M dove a ∈ As(M), é specificato come nella logica classica del primo ordine, e il va-
lore di verità V[a,w](A) di una formula A ∈ L(AL) in M dove w ∈ W, é un elemento di 0,1 é definito da: (i) V[a,w](Vero) = 1; (ii) V[a,w](P0) = M|P0,w|;
(iii) V[a,w](Pn(α1,...,αn)) = M|Pn,w|(Va(α1),...,Va(αn)); (iv) V[a,w](α = β) = 1 sse Va(α) = Va(β); (v) V[a,w](B -> C) = 1 sse V[a,w](B) = 0 oppure V[a,w](C) = 1
(vi) V[a,w](¬B) = 1 - V[a,w](B); (vii) V[a,w]((x)B) = 1 sse V[a,w](B) = 1 per ogni a’ ∈ [a]x; (viii) V[a,w](LB) = 1 sse V[a,w](B) = 1 per ogni w' ∈ W tale che wRw';
(ix) V[a,w](MB) = 1 sse V[a,w](B) = 1 per qualche w' ∈ W tale che wRw'.
Le condizioni di verità dei simboli Falso, &, v, ≡ ed (∃_) si derivano dalle definizioni. Una formula A si dice vera in M sse V[a,w](A) = 1 per ogni

135
a ∈ As(M) ed ogni w ∈ W. Se A é vera in M allora diremo che M é un modello per A. Una struttura M = <Q,W,R,m> si dice T-struttura sse R é rifles- siva; S4-struttura se R é anche transitiva; S5-struttura se R é una relazione di equivalenza. Una formula A si dice valida sse A é vera in ogni X-struttura. Esempio: Mostriamo che ogni istanza dello schema (x)(LA) -> L((x)A) é T-valida. Assumiamo il contrario, esiste allora una formula A,
una struttura M = <D,W,R,m> a ∈ As(M) e w ∈ W tale che V[a,w]((x)(LA) -> L((x)A)) = 0, ne segue che V[a,w]((x)(LA)) = 1
e V[a,w](L((x)A)) = 0; poiché V[a,w](L((x)A)) = 0 esiste w' ∈ W e a’ ∈ [a]x tale che wRw' e V[a’,w'](A) = 0; d'altra parte, poi- ché V[a,w]((x)(LA)) = 1 otteniamo V[a’,w](LA) = 1 e quindi a causa della wRw' V[a’,w'](A) = 1, una contraddizione. Da notare che non é stato utilizzato il fatto che R é riflessi- va; perciò ne consegue che ogni istanza di (x))(LA) -> L((x)A) é vera in ogni struttura. Teorema 5.6.10 Il problema di validità della logica modale del primo ordine é indecidibile. Non esiste alcun algoritmo per decidere se una data formula arbi- traria nella logica modale del primo ordine é valida. Comunque, come nel caso della logica classica del primo ordine é
possibile costruire una procedura π tale che data una formula della logica modale del primo ordine A, ne determini la validi- tà, nel caso in cui é valida; nel caso contrario la procedura non termina mai. Una teoria della logica modale del primo ordine consiste in una coppia T = <L,S> dove L é un linguaggio modale del primo ordine e S l'insieme degli assiomi, insieme di affermazioni calcolabili di L, che costituiscono la teoria T. Se T possiede un modello allora T é soddisfacibile altrimenti é non soddisfacibile.
La nozione di implicazione "T implica A", T ⇒ A, é definita nel modo solito. Definizione 5.6.11
Sia L un linguaggio modale del primo ordine e X ∈ T,S4,S5. Denotiamo con MFOL(L,X) il sistema di deduzione <L,S,R> dato da: (i) S(T) consiste dei seguenti assiomi: (A1) Vero (A2) A -> (B -> A) (A3) (A -> (B -> C)) -> ((A -> B) -> (A -> C))
(A4) (¬B -> ¬A) -> ((¬a’B -> A) -> B) (A5) (x)A(x) -> A(α), dove α é qualsiasi termine libero che sostituisce x in A(x) (A6) (x)(A -> B) -> (A -> (x)B) dove A non contiene ricorrenze libere di x (A7) LA -> A (A8) L(A -> B) -> (LA -> LB) (A9) (x)(LA) -> L((x)A)

136
S(S4) si ottiene da S(T) aggiungendo (A10) LA -> LLA S(S5) si ottiene da S(S4) aggiungendo (A11) MA -> LMA Se L é un linguaggio con uguaglianza, allora S(X) contiene anche gli assiomi per l'uguaglianza di L. (ii) R consiste nelle seguenti regole di inferenza: (MP) B é una conseguenza diretta di A e A -> B (GEN) (x)A é una conseguenza diretta di A (NEC) LA é una conseguenza diretta di A Di solito si assume che il linguaggio in considerazione sia fis-
so, per cui si denota con T → A il fatto che A é dimostrabile da T nella logica modale del primo ordine, o anche che A é un teo-
rema nella logica modale del primo ordine sse → A. Denotiamo con Th(T) l'operatore di dimostrabilità:
Th(T) = A: a é una affermazione e T → A. Teorema 5.6.12
(i) Se T → A allora T ⇒ A (Solidità)
(ii) Se T ⇒ A allora T → A (Completezza) Corollario 5.6.13
→ A sse ⇒ A.
Una teoria T é consistente sse esiste una formula A ∈ L tale che non é dimostrabile in T, T ¬→ A. Teorema 5.6.14 T é consistente sse T é soddisfacibile.

137
6. PROGRAMMAZIONE LOGICA 6.1 Il ragionamento non-monotonico Le logiche deduttive tradizionali sono tutte monotoniche: aggiun- gendo nuovi assiomi o premesse, tutti i teoremi precedenti riman- gono validi, o in altri termini l'insieme delle conclusioni au- menta monotonicamente con l'aumentare delle premesse. Formalmente una logica é monotonica sse la sua relazione di di-
mostrabilità → gode della seguente proprietà per ogni insieme di premesse S ed S':
S contenuto in S' implica A:S→ A é contenuto in A: S'→ A. Recentemente, sistemi logici che non possiedono la proprietà di monotonicità sono stati oggetto di notevole interesse; tali lo- giche sono state studiate principalmente in relazione al tipo di ragionamento osservabile nelle situazioni quotidiane, ragionamen- to basato, come si dice di solito, sul senso comune. Un aspetto caratteristico del ragionamento umano é la capacità di districarsi in situazioni in cui le informazioni a disposizio- ne non sono complete. Nella vita di tutti i giorni siamo costan- temente immersi in situazioni in cui non tutte le evidenze deter- minanti per una particolare conclusione sono conosciute. Infatti, escludendo i casi più banali, esiste sempre una parte più o me- no importante che non fa parte della nostra conoscenza sugli ele- menti che vengono utilizzati dal nostro ragionamento. Tuttavia, non siamo paralizzati dalla nostra parziale ignoranza. Spinti dalla necessità di agire, traiamo conclusioni anche se le evi- denze a nostra disposizione non sono sufficienti a garantire la correttezza del ragionamento che le deduce. Ovviamente, tali con- clusioni sono rischiose e possono essere smentite alla luce di nuove, più appropriate, informazioni. Per illustrare questo fatto, supponiamo di avere il seguente pro- blema: contattare urgentemente Mario; e di avere a disposizione le seguenti informazioni: di solito Mario il sabato sera frequen- ta il suo club e oggi é proprio sabato sera. Sulla base di tale evidenza, ci sono buone possibilità, ma solo possibilità, che Mario sia al club. Infatti, possiamo immaginare molti posti dif- ferenti in cui egli può essere. Ma non si arriverebbe ad una a- zione se non si accettasse di essere guidati da conclusioni che sono solamente plausibili, ma non certe. Allora piuttosto che se- dersi e analizzare tutti i possibili scenari in cui può trovarsi Mario il comportamento più razionale é assumere che: Mario si trova al club e cercare di contattarlo. Supponiamo, prima di andare al club, di incontrare Giorgio, un a- mico di Mario che ci dice un fatto inaspettato: Mario ieri ha a- vuto un incidente in auto. Questo cambia radicalmente la situa- zione, se poco prima era plusibile che Mario potesse trovarsi al club, ora alla luce della nuova informazione, questa circostanza é divenuta altamente improbabile. Andare al club é ora solo una perdita di tempo, ora é più razionale cercare di contattare Ma- rio in ospedale. Questo esempio ci porta direttamente al tipo di ragionamento non monotonico originariamente proposto da Minsky (1975). Definizione 6.1.1

138
Con ragionamento non monotonico intendiamo il processo di trarre delle conclusioni che possono essere smentite alla luce di nuove informazioni. Un sistema logico si sice non monotonico sse le re- lazioni di dimostrabilità violano il principio di monotonicità. La definizione appena riportata é molto generale; essa considera la non monotonicità come una proprietà sintattica astratta ma non ci dice nulla sulla forma delle inferenze non monotoniche. Torniamo per un momento al ragionamento secondo il senso comune. A differenza del ragionamento logico formale, basato sul concetto di verità o falsità di una affermazione, il ragionamento secon- do il senso comune si fonda sul concetto di razionalità. Non possiamo aspettarci che le conclusioni di ogni giorno siano vere per sempre, questo é semplicemente impossibile; piuttosto non dobbiamo saltare a conclusioni completamente casuali. Per rendere minimo il rischio di risultati errati dobbiamo analizzare la co- noscenza a nostra disposizione e basandoci sulla nostra esperien- za valutare l'accettabilità o meno delle conclusioni che possia- mo trarre. Anche se molte delle inferenze che traiamo nella vita reale si dimostrano sbagliate, nondimeno ci sforziamo di ricavare delle conclusioni che siano razionali. La possibilità di avere una spiegazione razionale di una certa inferenza é una delle principali richieste che facciamo prima di accettare qualsiasi conclusione dedotta tramite un ragionamento basato sul senso co- mune. Ma la razionalità é un concetto vago e una definizione precisa di tale nozione che sia soddisfacente é difficile da ot- tenere. La nozione di verità in contrasto con la nozione di ra- zionalità gode di due specifiche proprietà: primo, essa é in- dipendente dall'agente: agenti diversi possono avere opinioni differenti su che cosa é razionale in una determinata situazio- ne. Secondo é indipendente dagli scopi che l'agente si prefigge: l'accettazione di una proposizione come conclusione razionale di- pende dal fine per cui viene utilizzata. Per esempio, una informazione superficiale può essere sufficien- te per uno scopo e non per un'altro: "Ho sufficienti informazioni su Antonio per ipotizzare che sia onesto e gli presto del denaro","Non ho sufficienti informazioni su Antonio per conside- rarlo mio socio in affari". Per sottolineare la natura soggettiva delle conclusioni basate sul senso comune, queste vengono chiamate credenze nella lettera- tura sulla intelligenza artificiale. Talvolta non si comprende bene in che senso conclusioni basate sul senso comune possano essere considerate credenze; in accordo con il significato di verità nella logica classica, il termine credenza sottintende che un fatto é "creduto" essere vero. Natu- ralmente, un tale fatto può in seguito dimostrarsi falso, ma ra- ramente, e comunque rimaniamo sempre molto sorpresi quando una nostra credenza si dimostra essere errata. Questo aspetto non viene solitamente evidenziato quando si parla di ragionamento se- condo il senso comune, in pratica, spesso accettiamo conclusioni la cui verità é a priori problematica. Un esempio tipico é il seguente: supponiamo che Roberto sia accusato di aver commesso un crimine, nel caso in cui non vi siano sufficienti prove contro di lui, l'unica posizione accettabile é quella di ritenerlo in- nocente, eppure i fatti sono generalmente contro di lui e il fat- to che egli sia colpevole é effettivamente probabile. Cerchiamo ora di impostare due problemi fondamentali: (1) Che cosa sono in pratica le conclusioni tratte col ragionamento basato sul senso comune (credenze) ? (2) Che tecnica possiamo utilizzare per ricavarle ? Il primo dei punti precedenti é analizzato in dettaglio da Per- lis (1987), in particolare egli fornisce la seguente definizione

139
che comprende una classe molto vasta di credenze. Definizione 6.1.2 Una proposizione p é creduta da un agente g, cioé g considera p come una conclusione razionale, se g é disposto ad usare p come se essa fosse vera. Vediamo un esempio: Supponiamo che io stia pensando di fare un viaggio in automobile. Per cominciare, devo decidere dove si trova la mia auto in questo momento. In assenza di evidenze migliori, é estremamente proba- bile che essa si trovi nel posto in cui l'ho parcheggiata l'ulti- ma volta. In accordo con la definizione di Perlis, questa affer- mazione diviene una credenza se sono disposto ad agire come se fosse vera. Cioé, se sono disposto ad ignorare tutte le circo- stanze in cui tale affermazione potrebbe essere falsa e basare la mia azione sull'assunzione che essa é certamente vera, questo anche se non posso essere sicuro che l'automobile sia effettiva- mente nel posto aspettato, in ogni caso "credo" che sia vera. D'altra parte, anche se sono quasi certo che l'affermazione é vera, potrebbe essere ragionevole, nello stesso tempo, cercare di aumentare le possibilità a disposizione; controllando per esem- pio se un autobus, che passa da quelle parti, può sostituire l'automobile al fine di effettuare il viaggio che mi proponevo di fare, in tal caso l'automobile non mi servirebbe più , pertanto l'affermazione precedente non la considerei una credenza, ma piuttosto a qualcosa di molto simile ad una contingenza. La definizione di Perlis non é l'unica possibile, e nemmeno com- prende tutti i tipi di inferenza del ragionamento secondo il sen- so comune, essa é comunque certamente degna di attenzione. Veniamo ora al problema di come possono essere ricavate le cre- denze; nel contesto presente, una osservazione fondamentale con- siste nel fatto che le conclusioni umane sono spesso basate sia sulla presenza che sulla assenza di informazione. Per illustrare come anche la mancanza di determinate informazioni si un aspetto determinante nel ragionamento secondo il senso comune riconside- riamo l'esempio precedente: (1) Oggi é sabato sera (2) Il sabato sera di solito Mario si trova al club chiaramente in virtù delle affermazioni precedenti (1) e (2) vi sono buone ragioni per trarre (A) Mario si trova al club. Sembrerebbe che la conclusione sia basata sulla regola (R) Dalla (1) si deduce (A) Questo, comunque non é vero in generale, potrei accettare la re- gola (R) e nello stesso tempo rifutarne la conclusione alla luce di una nuova informazione; per esempio che Mario ha avuto un in- cidente ieri. Il tipo di ragionamento coinvolto in questo caso é estremamente più complesso. Per crearne un modello che funzioni correttamente occorre restringere le possibilità di applicazione della (R). La regola deve essere bloccata in ogni situazione in cui il suo uso diviene inacettabile. In altri termini, dati (1) siamo preparati a concludere (A) a meno che non vi sia qualche evidenza che rende tale inferenza irrazionale. Ciò significa che un tale tipo di ragionamento non si basa solo su (R), ma piuttosto sulla seguente regola di dipendenza dall'i- gnoranza: (R') Dalla (1), in assenza di evidenze contrarie, si deduce (A). Esiste una stretta connessione tra la dipendenza dall'ignoranza e il ragionamento non monotonico basato sul senso comune. Da una parte, poiché nuove evidenze diminuiscono la nostra ignoranza, ogni credenza dipendente dall'ignoranza é soggetta ad essere

140
smentita da nuove informazioni. D'altra parte, poiché ogni con- clusione indipendente dall'ignoranza continua a valere quando la nostra conoscenza aumenta, ogni inferenza non monotonica deve es- sere necessariamente riferita all'assenza di qualche informazio- ne.

141
6.2 Le clausole di Horn La logica a clausole di Horn é un sottoinsieme della logica a clausole. Nel seguito si indicherà l'implicazione logica B -> A con: A <- B (B implica A).
Ricordando che ¬B v A equivale a A <- B la clausola: A1 v ... v An v ¬B1 v ... v Bm può essere scritta come: (A1 v ... v An) <- (B1 & ... & Bm) che per brevità di notazione scriveremo A1,...,An <- B1,...,Bm dove le "," che separano gli a- tomi Ai sono da interpretare come disgiunzioni mentre quelli che separano gli atomi Bj sono congiunzioni. Una clausola definita é una clausola che contiene un solo atomo positivo: A <- B1,...,Bm o anche A <- Una clausola negativa o clausola Goal é una clausola che contie- ne solo letterali negativi: <- B1,...,Bm. Gli atomi B1,...,Bm sono chiamati sottogoal. Una clausola di Horn é una clausola definita oppure una clausola goal. Esempi: A <- B1,...,Bm (regola) A <- (asserzione) <- B1,...,Bm (goal) <- (clausola vuota) In una regola, la parte sinistra e detta conseguente o testa del- la regola, la parte destra e detta antecedente o corpo della re- gola. Le clausole di Horn sono un sottinsieme della logica a clausole poiché non tutto quello che é esprimibile nella logica a clau- sole é ancora esprimibile in clausole di Horn.

142
6.3 Risoluzione SLD In programmazione logica un programma é un insieme di clausole definite sul quale si effettuano le interrogazioni che corrispon- dono a determinare se una formula é un teorema di quella teoria avente per assiomi le clausole utilizzate dal programma. Quello che si ottiene é la sostituzione di risposta per le va- riabili della formula da dimostrare, in altri termini si ottengo- no i legami delle variabili che rendono vera la formula. La computazione corrisponde alla dimostrazione di una formula da parte del programma logico, applicando il principio di risoluzio- ne. La strategia di risoluzione applicata solitamente é la stra- tegia SLD Risoluzione lineare per clausole Definite con funzione di Selezione ed é un caso particolare della risoluzione lineare. La strategia SLD é completa per le clausole di Horn. Solitamente un algoritmo di risoluzione opera per contraddizione e anche la strategia SLD procede negando la formula F da dimo- strare. Poiché solitamente una formula F é una congiunzione di formule atomiche quantificate esistenzialmente, la negazione pro- durrà una disgiunzione di formule atomiche negate quantificata universalmente, in altri termini una clausola di Horn goal. Dato un programma logico P ed una clausola goal G0, la risoluzio-
ne SLD cerca di derivare la contraddizione logica da P ∪ G0. Ad ogni passo di risoluzione si ricava il nuovo risolvente G(i+1) se esiste dalla clausola Gi, cioé dal risolvente ottenuto al passo precedente e da una variante Ci di una clausola dell'insie- me P. Una variante per una clausola C é la clausola C' ottenuta da C rinominando le sue variabili. La risoluzione SLD seleziona un atomo Am di Gi secondo un parti- colare criterio e lo unifica, se possibile, con la testa della clausola Ci attraverso la sostituzione più generale (mgu - most
general unification) Φi. In particolare se si ha: <- A1,...,Am,...,Ak (Gi)
A <- B1,...,Bq (Ci ∈ P)
tali che AmΦi = AΦi allora la risoluzione SLD deriva:
<- [A1,...,Am-1,B1,...,Bq,Am+1,...,Ak]Φi (Gi+1) Notiamo che questo é semplicemente un altro modo per descrivere il principio di risoluzione. L'unica differenza consiste nel fat- to che si é adottata la notazione "<-" (implicazione) al posto della notazione che utilizza solo i connettivi di disgiunzione v
e negazione ¬. La strategia applicata é quella di risoluzione lineare, in quan- to ogni nuovo risolvente, se esiste, si ottiene da quello prece- dente e da una variante della clausola del programma.

143
6.4 La semantica di un linguaggio di programmazione Con semantica si intende l'assegnazione di un significato alle frasi del linguaggio utilizzato, nel caso della logica corrispon- de a determinare una interpretazione. Esistono alcuni moalità di definizione della semantica per un linguaggio di programmazione. (i) Semantica operazionale: definisce le relazioni di ingresso e di uscita calcolate dal programma in termini delle operazioni e- lementari prodotte dall'esecuzione del programma su una partico- lare macchina astratta: una macchina che ha uno stato ed un'in- sieme di istruzioni (operazioni) elementari che specificano le trasformazioni di stato. La semantica operazionale di un linguaggio di programmazione si ottiene traslando ogni frase del linguaggio in istruzioni della macchina astratta. La semantica di un programma, una volta tra- slato nelle istruzioni elementari, consiste nella sequenza di configurazioni interne della macchina determinate dall'esecuzione del programma traslato. La caratteristica essenziale di tale ap- proccio é la dipendenza dalla macchina astratta adottata. (ii) semantica denotazionale: associa direttamente ad un program- ma il suo significato (detto denotazione). Tale significato é dato in termini di entità matematiche (ad esempio numeri, insie- mi, funzioni). Il significato del programma si ottiene attraverso una funzione di valutazione eventualmente ricorsiva, ottenuta at- tribuendo ad ogni costrutto sintattico una specifica denotazione. La semantica denotazionale é più astratta di quella operaziona- le in quanto é assolutamente indipendente da qualunque macchina che realizza il linguaggio. (iii) Semantica assiomatica: permette di definire le proprietà dei costrutti del linguaggio attrverso assiomi e regole di infe- renza della logica simbolica. Una proprietà del programma può essere dedotta utilizzando gli assiomi e le regole di inferenza e costruendo una dimostrazione per essa. La semantica assiomatica é più astratta delle precedenti, anche se le proprietà che es- sa é in grado di dimostrare per un programma possono non essere sufficienti per determinarne completamente il significato.

144
6.5 Base di conoscenza basata sulla logica dei predicati. La costruzione di una base di conoscenza ha inizio con l'indivi- duazione delle "informazioni" da codificare e memorizzare. Un si- stema di memorizzazione elabora l'insieme delle "informazioni" da memorizzare e produce un insieme di dati registrati che sono il risultato del processo di memorizzazione. Le informazioni vengono espresse in un linguaggio. Nel caso del linguaggio logico monadico del primo ordine in cui vi sono un certo numero di predicati a un posto: P1(x),P2(x),... ,Pk(x) nomi ed altri termini singolari liberi : a1,a2, ... , b1,b2, ... connettivi, quantificatori insieme alle variabili ad essi vincolate Esiste x, per ogni x ; enunciati atomici Pi(aj) sta per aj gode della proprietà Pi; é possibile rappre- sentare gli stati come Q-predicati del tipo: (+)P1(x)&(+)P2(x)&...&(+)Pk(x) ==> Sj(x) dove & sta per congiunzione e (+) sta per negazione o niente e Sj(x) é lo stato rappresentato. Supponendo di voler descrivere o rappresentare tramite un lin- guaggio (mondi possibili) un certo sottinsieme di "oggetti" (mon- do reale) ci troviamo a dover definire: 1. La correlazione tra oggetto e rappresentazione dell'oggetto nel linguaggio (semantica). 2. Il processo di "sperimentazione" dell'esistenza dell'oggetto corrispondente ad una frase del linguaggio. (attribuzione dei valori di verità). 3. La logica valida nel linguaggio (I paradigmi deduttivi o processi di elaborazione). I dati sono quanto rimane delle informazioni originarie rispetto al sistema di memorizzazione e ai messaggi in esso trasmessi. La rappresentazione di una realtà di interesse viene ricostruita sulla base delle registrazioni fisiche che tale realtà ha pro- dotto sul sistema di memorizzazione. Le rappresentazioni, le parole, i dati, denotano cose, oggetti, eventi ma da questi vanno accuratamente tenute distinte. L'organizzazione delle parole e la relativa sintassi non rispec- chia fedelmente, nel linguaggio, l'organizzazione delle cose e degli oggetti con le mutue relazioni, ma semplicemente le espri- me, le rappresenta. Gli oggetti possono essere organizzati in gruppi di natura empi- rica, categorica, logica. Gruppi empirici sono quelli che presentano contiguità spaziale o temporale. Gruppi categorici sono insiemi di oggetti elaborati sulla base di una classificazione. Questa é fondata su una o più proprietà comuni agli oggetti raggruppati. Gruppi logici sono insiemi di oggetti che hanno precise relazioni come ad esempio la relazione di inclusione spaziale: il magazzino é nell'edificio e l'edificio é nella città, allora il magazzi- no é nella città. Esistono corrispondenze e connessioni specifiche tra le parole e gli oggetti, tra gruppi di parole e gruppi di oggetti. Tali rela- zioni conducono a strutture che riconducono le parole agli ogget- ti e che sono la vera base del linguaggio.

145
Consideriamo la rappresentazione di un certo numero di oggetti con altrettanti vettori binari in cui ad ogni posizione corri- sponde una proprietà che può essere verificata oppure no. Allora ogni posizione, o se si vuole ogni proprietà, individua una classe dell'insieme di oggetti. Si realizza pertanto il processo di classificazione: una proprie- tà o una combinazione di proprietà individuano una classe di oggetti. Il processo di generalizzazione si realizza aggiungendo al vetto- re una proprietà che sia combinazione di altre proprietà: per esempio se abbiamo la classe impiegato e la classe operaio pos- siamo aggiungere la classe dipendente come quell'insieme di og- getti in cui sia presente o la proprietà impiegato o la proprie- tà operaio. Il processo di aggregazione si ottiene aggiungendo al vettore una proprietà che sia denotante l'aggregato e che si attivi rispet- tivamente agli oggetti aggregati. Il processo di associazione si ottiene aggiungendo al vettore le proprietà denotanti le nuove classi che corrispondono agli og- getti associati. Esiste quindi una possibilità notevolmente variabile nella mani- polazione degli insiemi di proprietà in dipendenza del signifi- cato interpretativo che ci interessa, anche se é possibile ri- condurre tutto ad uno stesso schema: identificazione o inserimen- to di proprietà. La soluzione del problema di rappresentare i dati in maniera del tutto generale é ancora lontano dall'essere trovata.

146
6.6 Un filtro prolog Il presente paragrafo intende prospettare una interfaccia tra la base di conoscenza in ambiente Data Base relazionale e il motore inferenziale in linguaggio PROLOG: un modulo filtro di ottimizza- zione ed assemblaggio dei programmi in PROLOG sulla base della specificità del goal. Per manipolare una base di conoscenza molto grande é necessario utilizzare tecniche di memorizzazione tipiche dei DBMS e ciò non si sposa facilmente con la struttura dei programmi PROLOG, inter- ponendo un filtro assemblatore del programma specifico tra un de- terminato goal e il motore inferenziale si ottiene verosimilmente un'ampliamento delle possibilità di soluzione e maggiori presta- zioni. Vediamo ora una breve introduzione al prolog. Il concetto di base della programmazione logica é di descrivere la conoscenza generale che si ha su un determinato problema, piuttosto che dettagliare uno specifico procedimento di soluzio- ne. Si tratta di trovare la rappresentazione più adeguata alla specifica area applicativa ed esprimerla in un linguaggio logico. Un problema o un'applicazione é caratterizzato dall'esistenza di oggetti discreti, o individui, da relazioni tra essi, e da propo- sizioni che esprimono proprietà logiche delle relazioni. Per rappresentare simbolicamente la conoscenza relativa ad un proble- ma, occorre fare uso di un linguaggio formale, assegnando innanzi tutto dei nomi sia agli oggetti che alle relazioni. Nel linguaggio naturale sembra che si possa fare a meno di questo passo di attribuzione del nome in moltissimi casi di conversazio- ne, nel linguaggio formale ciò non é possibile. Questo fatto é estremamente curioso e merita una approfondita riflessione, infatti di solito manipoliamo verbalmente gli ogget- ti tramite le classi a cui appartengono: nel linguaggio naturale non ci sono oggetti ma solo classi. Nel linguaggio formale tipo il prolog abbiamo a che fare con og- getti e relazioni. Un oggetto può essere concreto, ad esempio un minerale, un vege- tale, un animale, una persona, una cosa; oppure astratto, ad e- sempio il numero 2, il concetto di giustizia, la chimera, l'asce- tismo. Nell'assegnare un nome ad un oggetto, é indifferente che esso sia concreto o astratto. La scelta del nome é arbitraria, entro determinate convenzioni, ma naturalmente é opportuno che il nome sia espressivo, tale cioé da favorire l'associazione mnemonica all'oggetto da esso denotato. Nomi semplici di oggetti sono detti costanti. Essi denotano og- getti elementari definiti; volendo stabilire un'analogia con la lingua naturale, corrispondono a nomi comuni e nomi propri. In PROLOG, le costanti sono di due tipi: i numeri e gli atomi. Un oggetto può essere semplice oppure composto, ossia formato da altri oggetti componenti. oggetti composti sono denotati da nomi composti detti strutture. In PROLOG le strutture sono costituite da un primo nome, detto funtore, seguito tra parentesi da una se- quenza di uno o più altri nomi, detti componenti o argomenti. Esempio: quadro(tintoretto,olio(Titolo,1572)) É possibile dare un nome, oltre che ad oggetti particolari, an-

147
che ad oggetti specifici ma da determinare, cioé non ancora i- dentificati, in modo analogo all'uso del pronome nel linguaggio naturale. Oggetti non specificati sono rappresentati da nomi di variabili; anche questi ultimi sono arbitrari, ed in PROLOG sono caratterizzati dall'iniziare con una lettera maiuscola, o con "_". Mentre costanti distinte denotano sempre oggetti diversi, questo non vale per le variabili, in quanto variabili distinte potranno venire a rappresentare lo stesso oggetto. In generale i nomi degli oggetti sono detti termini. I termini non contenenti variabili sono detti termini chiusi. Riassumendo sono quindi termini: a. le costanti; b. le variabili; c. le strutture. Le strutture sono espressioni della forma f(t1,t2, ... ,tn) dove f é un funtore n-ario e t1,t2,...,tn sono termini. La definizione dei termini é ricorsiva, ossia ciò che si sta definendo, un termine, compare (ricorre) nella definizione stes- sa. Una definizione ricorsiva consente di costruire termini arbi- trariamente complessi. Il PROLOG mette a disposizione il termine, utilizzabile ricorsivamente, come unico strumento di rappresenta- zione di un oggetto, di applicabilità generale. Il tipo di og- getto, in base alle convenzioni di scrittura, é rappresentato dalla forma sintattica del termine che lo denota, ed é quindi riconosciuto senza necessità di specificarlo esplicitamente: non occorrono, in altre parole, dichiarazioni di tipo. L'insieme de- gli oggetti denotati da tutti i termini usati in una data rappre- sentazione é detto l'universo di discorso, ossia costituisce tutto ciò di cui si parla in quella rappresentazione. Una relazione é l'attribuzione di una qualità comune a più og- getti. Naturalmente una relazione può valere tra più di un gruppo di oggetti, viceversa un singolo gruppo di oggetti può soddisfare più di una relazione. In generale una relazione é un insieme di n-ple, e correla gli oggetti nominati in ogni n-pla. In PROLOG una relazione é deno- tata da un nome, detto predicato o simbolo predicativo seguito tra parentesi dalla n-pla dei nomi degli oggetti correlati sepa- rati da virgola. Riassumendo i predicati sono espressioni di forma p(t1,t2, ... ,tn) dove p é un simbolo predicativo e t1, t2, ... ,tn sono termini. Sussiste quindi una completa uguaglianza formale tra funtori e predicati; un predicato é semplicemente un funtore che compare come funtore principale in un particolare contesto. I termini denotano oggetti e i predicati denotano relazioni tra gli oggetti denotati da termini. Le proprietà logiche delle relazioni sono descritte da proposi- zioni (sentences). I predicati stessi singolarmente considerati possono costituire proposizioni atomiche. Proposizioni non atomiche sono costituite da più predicati con- nessi da operatori o connettivi logici, denotati con simboli spe- ciali. Il connettivo ":-" é detto condizionale o implicazione. Il connettivo "," denota una congiunzione.

148
Una proposizione del tipo: A :- B1, B2, ... , Bn. dove A, B1, B2, ... , Bn sono predicati, é detta una clausola di Horn: la conclusione A, che é costituita da un solo predicato é detta testa della clausola; la congiunzione delle condizioni B1, B2, ... , Bn é detta corpo o coda della clausola. Si può osservare che, strutturalmente, anche le clausole possono essere viste come termini. Infatti, una clausola unitaria ha già la forma di un termine, una clausola non unitaria può essere vi- sta come un termine che ha come funtore il connettivo ":-", come primo argomento la testa della clausola e come argomenti succes- sivi le n condizioni del corpo della clausola; come segue: :- (A, B1, B2, ... , Bn). Questa considerazione evidenzia l'uniformità del linguaggio, ed é alla base della possibilità di trattare clausole, e quindi più in generale programmi, come dati. Un programma PROLOG é un insieme finito di clausole, unitarie e non, scritte in sequenza. Tale insieme di clausole é detto anche la base di dati del programma. Essa rappresenta l'insieme delle conoscenze espresse (come fatti e come regole) sul problema. Riassumendo il linguaggio PROLOG con cui descrivere un problema é costituito da: a) il vocabolario, l'insieme di simboli, di costanti, variabili, funzioni e predicati; questi simboli, ed il significato ad essi associato, sono scelti dall'utente del linguaggio, in funzione del problema considerato; b) i connettivi logici ed i simboli ausiliari, le parentesi, il cui significato é prestabilito; c) le proposizioni costruite con i simboli precedenti, secondo le regole PROLOG considerate. Definizione della base di dati. Consideriamo ora il problema più generale costituito da una base di conoscenza relativamente vasta. Una tale base di conoscenza comprenderà fatti e regole in una forma articolata. Le possibili richieste espresse da un utente in relazione ad una tale base di conoscenza coprono una ampia casistica di combina- zioni. In particolare ogni GOAL coinvolgerà un certo numero di regole e un certo numero di fatti: un (piccolo) sottinsieme della base di conoscenza complessivamente considerata. Poniamoci nel caso in cui la base di conoscenza comprenda una grande quantità di dati e poniamoci il problema di organizzare tali dati in una struttura di base di dati con tecniche tipiche dei DBMS. I dati che dovremo memorizzare, in una rappresentazione stretta- mente formale per quanto detto più sopra, saranno della forma: :- (T1,T2, ... ,Tn). dove ciascun termine sarà nella forma: f(t1,t2, ... ,tk).

149
e ciascun termine avrà un'entrata corrispondente nel vocabolario dei termini: un nome. Supponiamo di frapporre fra l'utente e il motore inferenziale un modulo di interfaccia che richiesto in input il GOAL specifico acceda alla base di conoscenza, nel nostro caso una base di dati, e, sulla base di algoritmi di ricerca ottimizzati, estragga i fatti e le regole assemblandoli, seguendo alcuni criteri di se- quenzializzazione, in un programma PROLOG da sottoporre al motore inferenziale. In tal caso non sarebbe necessario avere in memoria tutta la base di conoscenza, ma solo quella parte necessaria al soddisfacimento del GOAL. Per progettare una interfaccia di tal genere occorre disegnare una base di dati che consenta la gestione e la memorizzazione in un formato efficiente dei fatti e delle regole della base di co- noscenza. Nel seguito viene descritto un prototipo di una tale base di da- ti. I fatti e le regole verrebbero mantenute aggiornate tramite pro- grammi specifici di aggiornamento della base di dati, in partico- lare un editor in grado di trattare ciascun fatto e ciascuna re- gola come una scatola nera a cui associare gli attributi signifi- cativi per una eventuale ricerca ed estrazione. Il criterio di estrazione dei fatti e delle regole pertinenti ad un determinato GOAL si basa sul concetto di propagazione dei le- gami. Ogni GOAL può essere espresso nella forma: :- (G1,G2, ... ,Gl). dove ogni termine é ancora nella forma: f(g1,g2, ... ,gm). Se escludiamo i termini che corrispondono alle variabili, consi- derando solo le costanti e le strutture, possiamo far corrispon- dere al GOAL un elenco di termini atomici, in altre parole, un elenco di nomi. Se estraiamo, ricorsivamente, dalla base di conoscenza tutti i fatti e tutte le regole che presentano una coincidenza con tali nomi otterremo tutti i fatti e tutte le regole che sono coinvolte dal possibile soddifacimento del GOAL. Assemblando questo risultato con criteri di sequenza basati sulla priorità di applicazione delle regole otteniamo il programma PROLOG che può essere sottoposto al motore inferenziale per la ricerca della risposta. Il problema é quindi come disegnare il data base per ottimizzare la ricerca dei fatti e delle regole che fanno riferimento (con- tengono) un determinato nome. Un possibile data base di questo tipo é il seguente. Tutti i nomi sono memorizzati in un vocabolario di termini. Sono memorizzati tutti i legami tra i termini a due a due. Le regole e i fatti sono memorizzati in BOX a cui é associato un nome (oggetti). I nomi sono raggruppati in classi. In particolare le tabelle del data base principale contengono le seguenti colonne: Tabella dei termini : Nome del termine,

150
Numero di legami, Classe di appartenenza, Descrizione del significato. Tabella dei legami : Primo termine, Termine di legame, Secondo termine. Tabella delle classi : Nome della classe, Priorità della classe, Numero termini nella classe. Tabella degli oggetti : Termine, Priorità dell'oggetto, Box. Per quanto riguarda gli oggetti nel Box vengono scritte le rego- le, i fatti e quanto é utile per l'assemblaggio del programma PROLOG. Le tipologie di dati, ciascuno dei quali richiede un criterio di ricerca ottimizzato diverso, sono: Le classi I domini I contesti Le regole I fatti Queste tipologie di dati consentono un raggruppamento che miglio- ra i tempi di accesso ai dati medesimi é utile tenere presente anche altre valenze semantiche attribuibili ai nomi: Oggetto Attributo Verbo Operatore Aggregato Gruppo Parte_di Composto_da Registrazione Nella tabella dei termini compare il numero dei legami attivi re- lativamente ad un certo termine, questo dato é estremamente uti- le per selezionare nelle ricerche congiuntive quale termine e- strarre per primo. La classe di appartenenza é utile per indirizzare la ricerca so- lo sui termini della classe nel caso in cui tale classe sia nota. La tabella dei legami é composta da tre elementi ed é accessi- bile sia dal primo condizionatamente al secondo sia dal terzo condizionatamente al secondo. Il primo termine é legato al terzo termine nella modalità spe- cificata dal secondo termine. Sulla base di tale tabella é possibile ricostruire dinamicamente tutto l'albero dei legami corrispondente ad un certo insieme di termini iniziali.

151
La tabella delle classi serve per accorciare i percorsi di ricer- ca quando sia specificata la classe nell'ambito in cui il GOAL deve essere soddisfatto. Per esempio nel caso in cui il contesto piloti l'ambito della ricerca delle soluzioni. La tabella degli oggetti contiene esplicitamente i fatti e le re- gole da assemblare nel programma PROLOG da passare al motore in- ferenziale. SCHEMA GENERALE DEL FILTRO PROLOG ---------------- ---------- | Utente | | EDITOR | | |-------- ---------- | GOAL | | | ---------------- ------------ | | | RISPOSTA | -------------- | ------------ | DATA BASE | ----------------- | | Regole |------------> | INTERFACCIA | | | Fatti | | FILTRO PROLOG | | | Termini | ----------------- | | BASE DI | | | | CONOSCENZA | ----------------- | -------------- | PROGRAMMA | | | PROLOG | | ----------------- | | | ----------------- | | MOTORE |------- | INFERENZIALE | ----------------- (fig 6.1) Esempio di applicazione ad un caso semplice. Consideriamo la seguente base di conoscenza composta da regole e fatti: nonno(X,Y) :- genitore(X,Z), genitore(Z,Y). genitore(X,Y) :- madre(X,Y). genitore(X,Y) :- padre(X,Y). padre(ugo,bruno). padre(bruno,valeria). padre(carlo,susanna). padre(dario,fulvio). padre(giorgio,andrea). padre(enea,marcella). madre(lucia,bruno). madre(anna,valeria). madre(valeria,susanna). madre(susanna,fulvio). madre(cristina,andrea). madre(rosa,marcella).

152
consideriamo il seguente goal ?- nonno(N,valeria). /* chi é nonno di valeria? */ La ricerca prende inizio dai nomi: nonno, valeria. Il nome nonno é legato a genitore che a sua volta é legato a madre e padre. L'elenco delle parole diviene pertanto: nonno, genitore, padre, madre, valeria. Il nome valeria é legata a padre, bruno, madre, anna, susanna. Bruno é legato a padre, ugo, madre, lucia, valeria. Anna é legata a madre, valeria. Susanna é legata a madre, valeria, padre, carlo, fulvio. Ugo é legato a padre, bruno. Lucia é legata a madre, bruno. Carlo é legato a padre, susanna. Fulvio é legato a padre dario. Riassumendo l'elenco di parole diviene: nonno, genitore, padre, madre, valeria, bruno, anna, susanna, u- go, lucia, carlo, fulvio. Di cui alcune sono congiunte, per esempio valeria, padre o vale- ria, madre. Ciò significa che per quanto riguarda i fatti, e cioé la relazione padre o la relazione madre, é possibile sele- zionare solo quei fatti che presentano congiuntamente almeno un nome tra quelli selezionati, per esempio la clausola: padre(bruno,valeria) viene selezionata, mentre la clausola padre(giorgio,andrea) non viene selezionata. Il programma selezionato potrebbe avere la forma: nonno(X,Y) :- genitore(X,Z), genitore(Z,Y). genitore(X,Y) :- madre(X,Y). genitore(X,Y) :- padre(X,Y). padre(ugo,bruno). padre(bruno,valeria). padre(carlo,susanna). padre(dario,fulvio). madre(lucia,bruno). madre(anna,valeria). madre(valeria,susanna). madre(susanna,fulvio). In questo esempio non sono state selezionate le clausole: padre(giorgio,andrea). padre(enea,marcella). madre(cristina,andrea). madre(rosa,marcella). Nel caso di una grande base di conoscenza il risparmio é certa- mente significativo poiché solitamente un goal in tale ambito coinvolge un numero relativamente ristretto di clausole. Ottimizzare gli algoritmi di ricerca dei fatti e delle regole me- morizzate nella base di dati non é certamente semplice, tuttavia lo schema abozzato può promettere un interessante sviluppo per ottenere filtri PROLOG che siano efficienti e che consentano di gestire una ampia base di conoscenza aggiornabile ed implementa- bile dinamicamente. Ottenere un software in grado di manipolare la base di conoscenza con tecniche tipiche dei DBMS é senza dub-

153
bio un aspetto estremamente interessante per lo sviluppo dei si- stemi di intelligenza artificiale.

154
7. TRASFORMAZIONE DELLE SIMIGLIANZE 7.1 Descrizione di oggetti come insieme di attributi 7.1.1 La funzione di appartenenza ad insiemi sfumati Nella teoria degli insiemi sfumati, la valutazione della funzione
caratteristica di appartenenza all'insieme ΦA(x) che ci dice quando un oggetto di un insieme X appartiene ad un sottoinsieme A di X stesso é un punto da considerare con molta attenzione. Un modo per farlo consiste nell'analizzare le proprietà che carat- terizzano sia x che A. In particolare, ogni oggetto x di un insieme X può essere carat- terizzato tramite delle proprietà, cioé delle l-tuple di valori logici che un finito numero l di dettagli hanno relativamente a x. Similmente, ogni sottoinsieme A di X é caratterizzato dagli oggetti che include. Tuttavia, non necessariamente tutti i detta- gli di cui sopra partecipano nella determinazione dell'inclusione di un x in A. Vale a dire, che alcuni di loro possono risultare irrilevanti ai fini dell'inclusione. Ne consegue che ciascun x di X contribuisce ad una particolare estensione per la formazione del sottoinsieme A, corrispondentemente alla quantità di detta- gli che sono rilevanti in esso rispetto allo stesso insieme.
Allora, il valore di ΦA(x) può essere espresso come una funzione di una misura di tale contributo. Sulla base di tale fondamentale ipotesi possiamo studiare un me-
todo di valutazione rigorosa di ΦA(x). Un primo passo consiste nel determinare come evitare di considerare i dettagli irrilevan- ti tra quelli che formano ciascun x incluso in A. É possibile costruire una struttura che da un insieme di pro- prietà con cui possono essere caratterizzati un certo numero di oggetti, determina l'introduzione nell'insieme stesso di un ordi- ne semantico. Quest'ultimo si basa sull'implicazione che sussiste tra due proprietà in conseguenza del loro significato. Vale a dire, quando i valori logici dei dettagli formanti una delle due proprietà sono gli stessi, eccetto quei dettagli che, nelle pro- prietà implicate, sono irrilevanti. La struttura ottenuta é quella con cui una misura li associerà in seguito. Il concetto di proposizione che implica semanticamente un'altra segue dalla distinzione fatta da R. Carnap, tra C-implicazione, che é l'implicazione formale, e la L-implicazione: che corri- sponde all'implicazione stretta di Lewis e Moore. Quest'ultima consiste in relazioni binarie che coinvolgono il significato che é sottinteso da entrambi gli elementi - proposizioni -: l'ante- cedente e il conseguente. In accordo con tale implicazione, date due proposizioni A e B, l'affermazione condizionale "A implica B" é vera quando la verità di A implica quella di B. Come esempio, consideriamo le seguenti proposizioni: (A) x é un intero negativo tale che x < n" (B) x é un intero tale che x < n" In accordo con B il segno di x é un dettaglio irrilevante, allo- ra per ogni x per cui A é o verificata o assunta per vera, così lo é anche B, senza doverlo accertare. Essendo la descritta relazione tra le proposizioni A e B relativa al loro significato, essa é chiamata implicazione semantica.

155
7.1.2 Rappresentazione tramite proprietà I dettagli menzionati, i cui valori caratterizzano gli oggetti x sono singolarmente denotati da D1,...,Dh,...Dl e possono avere valore logico o 0 o 1, che rispettivamente denotano o la presenza oppure no di ciascun Dh nell'oggetto x. Allora a ciascun x corri- sponde un l-tupla di valori che rappresenta una proprietà ele- mentare. Tutte le possibili proprietà elementari si ottengono dalle disposizioni con ripetizione di l valori logici. Denotando
con Pα le proprietà elementari e con A l'insieme che esse forma- no, la cardinalità |A| = 2 exp(l). Finalmente dato un sottoin-
sieme S di A, se le proprietà pα che lo formano sono equivalenti a quelle che caratterizzano un oggetto x, per uno specifico sco-
po, cioé il fatto che un oggetto x possiede tali pα é suffi- ciente a stabilire che x possiede una caratteristica specifica, allora S si dice proprietà composta e la denotiamo con C. Riassumendo: D = D1...Dh...Dl é l'insieme finito di dettagli
Pα = d1α...dhα...dlα é l'α-esima proprietà elementare dove dhα denota i valori logici che dettagli differenti assumono in essa e per ogni h,α dhα é un elemento di 0,1 A = pα:α=1,2,...,m;m=2 exp(l) é l'insieme delle proprietà elementari
C = pα:α=1,...,q é un sottoinsieme di A che include le pro- prietà elementari che sono equivalenti l'una all'altra, che é una proprietà composta.
Indichiamo con δ(α,β) l'insieme di tutti gli indici h per cui due proprietà elementari date pα e pβ differiscono. Se queste sono incluse nello stessa proprietà composta C e sono tali che
δ(α,β)=h, diremo che sono due proprietà adiacenti: denoteremo questo fatto con α|h|β. Più formalmente, data una coppia pα, pβ ∈ C tali che esiste un solo h per cui dhα é diverso da dhβ allora scriveremo α|h|β. Se due proprietà elementari sono tali che α|h|β assumeremo che l'h-esimo dettaglio é irrilevante in pα e pβ. Allora, possiamo concepire una terza proprietà ele- mentare pτ, isosignificante alle precedenti rispetto a C. Una tale pτ può essere composta da tutte i dk di pα e pβ che coincidono ad eccezione di dh che può essere denotato da "*" un
valore che non é né 1 né 0. La proprietà così concepita pτ rappresenta sinteticamente entrambe le proprietà pα e pβ. Il valore di ogni dettaglio dh appartiene pertanto all' insieme 0,1,* e l'insieme delle possibili proprietà elemetari diviene
P = pα:α=1,2,...,n;n=3 exp(l). Esempio: Per mostrare i concetti sopra esposti, supponiamo di avere un in- sieme di tre dettagli D = D1,D2,D3. Il numero delle l-tuple che possono essere generate da D sono: D1 D2 D3 ------------------------ p1 = 0 0 0 p2 = 0 0 1 p3 = 0 1 0 p4 = 0 1 1

156
p5 = 1 0 0 p6 = 1 0 1 p7 = 1 1 0 p8 = 1 1 1 Queste sono le proprietà elementari e costituiscono A. Consideriamo due possibili proprietà composte di A, una C1 con- sistente nel possedere o p1 o p3 o p6; C1 = p1,p3,p6, l'altra consistente in c2 = p3,p4,p8. Si vede immediatamente che in C1 vi sono un paio di proprietà adiacenti, p1 e p3; in C2 vi sono due paia di proprietà adiacenti, p3 e p4, p4 e p8. Allora, gli elementi delle coppie menzionate possono essere, a due a due, sinteticamente rappresentate dalle seguenti rispettive proprietà elementari: 0*0,01*,e *11. Queste possono essere denotate con p13, p34 e p48. In quest'ultimo caso, alcuni dettagli sono chia- ramente irrilevanti: D2 é irrilevante rispetto a C1; D3, D1 lo sono rispetto a C2.

157
7.1.3 L'implicazione semantica
Ogni proprietà pα di P si dice condizionata dal valore logico dei dettagli di pα che sono rilevanti in essa; in più, le condi- zioni attuate su due o più proprietà elementari pα,pβ,... dallo stesso Dh, quando questo assume in esse invariabilmente lo stesso valore, si chiama condizione di coerenza. Definizione 7.1.1
Date due proprietà elementari pα e pβ di P, nel caso in cui tut- ti i dettagli rilevanti i cui valori logici formano pβ condizio- nano coerentemente pα, diremo che la prima proprietà é implica- ta semanticamente dalla seconda.
L'implicazione semantica di una proprietà pβ con pα la denotiamo con pα → pβ. Osservazione 7.1.2
La proprietà pτ ottenuta dalle proprietà adiacenti pα e pβ come specificato precedentemente, é semanticamente implicata sia da
pα che da pβ: pα → pτ e pβ → pτ. Osservazione 7.1.3 L'insieme P é formato da (i) tutte le proprietà che formano A in cui nessun dettaglio é irrilevante; (ii) tutte le proprietà che sono semanticamente implicate da quelle di A.
Le proprietà elementari pα di A sono chiamate proprietà prima- rie.
Le proprietà pα che formano l'insieme P \ A sono chiamate pro- prietà secondarie; infatti le prime implicano le seconde.
Questo implica che ogni pα di A é implicato da se stessa e dall'insieme ∩ pα:pα ∈ A. Quest'ultimo, denotato con ∩A, α corrisponde all'insieme vuoto della teoria degli insiemi. Definizione 7.1.4 Dati due sottoinsiemi S ed R di P, con "S implica semanticamente
R" si intende che per ogni pβ di R esiste pα di S tale che pα → pβ. Definizione 7.1.5 Dato un S di P, il sottoinsieme di P che soddisfa alle due condi- zioni seguenti:
(i) per ogni pα ∈ S0 esiste pβ ∈ S tale che pα → pβ; (ii) S0 é implicato solo da sé stesso e da ∩A, cioé é formato esclusivamente da proprietà elementari pα di A. Le proprietà che formano S0 possono sinteticamente essere rap- presentate da un sottoinsieme (S0)m ottenuto come segue: vengono formate tutte le possibili coppie di proprietà adiacenti di S0: quindi, ciascuna coppia viene sostituita da una unica proprietà di P che rappresenta sinteticamente entrambi gli elementi, in questo modo si ottiene (S0)1.

158
Definizione 7.1.6 Il sottoinsieme (S0)1 di P appena descritto, si chiama prima rap- presentazione di S0, Per rappresentazione minimale di S0, e anche di S, si intende il sottoinsieme (S0)m che é uguale alla propria prima rappresentazione con più piccolo m. La rappresentazione minimale (S0)m di un sottoinsieme S di P si ottiene dall'iterazione esaustiva del processo di rappresentazio- ne di S0. Osservazione 7.1.7 Dati due sottoinsieme S e R di P tali che esistono i,j tali che (S0)i = (R0)j allora essi hanno la stessa rappresentazione mini- male, cioé (S0)m = (R0)m. Definizione 7.1.8 I due elementi R ed S considerati nella proposizione precedente si dicono semanticamente equivalenti l'uno rispetto all'altro. Osservazione 7.1.9 Ogni rappresentazione (S0)k dell'implicante primario di un sot- toinsieme S é semanticamente implicato da S0. In più, la rap- presentazione minimale (S0)m é implicata anche da S. Grazie all'osservazione precedente si può introdurre il concetto di famiglia di proprietà. Consideriamo la potenza dell'insieme P, denotata con |P, essa si chiama inseme delle proprietà e i sui elementi sono sottoinsiemi di P. Esempio: L'insieme P é lo stesso che si produce dalla combinazione dei dettagli D1,...,Dl. Prendiamo ad esempio D1,D2,D3. Le proprietà elemetari di P sono allora: p12= 00* p13= 0*0 p15= *00 p1= 000 p24= 0*1 p2= 001 p26= *01 p1234= p1324= 0** p3= 010 p34= 01* p1256= p1526= *0* p12345678 = p4= 011 p37= *01 p1357= p1537= **0 = p12563478 = p5= 100 p48= *11 p2468= p2648= **1 = p13572468 = p6= 101 p56= 10* p3478= p3748= *1* = p. = *** p7= 110 p57= 1*0 p5678= p5768= 1** p8= 111 p68= 1*1 p78= 11* Per semplificare il concetto di implicazione semantica e di im- plicante primario prendiamo in considerazione la proprietà p56. Essa implica p1526, p5768 e p12345678: i suoi implicanti primari
sono ∩A, p5 e p6. Consideriamo un elemento dell'insieme delle proprietà |P relati- vo a P. Questo sia S = p12,p3,p4,p5 allora

159
S S0 (S0)1 (S0)2 (S0)m ----------------------------------------- 00* 000 *00 *00 *00 001 00* 010 010 0*0 0** 0** 011 011 01* 100 100 0*1 Si può dimostrare che l'implicazione semantica tra elementi di
|P possiede le seguenti caratteristiche; per ogni R,S,T ∈ |P :
(i) R → R (riflessività)
(ii) Se R → S e S → R allora R = S (antisimmetria)
(iii) Se R → S e S → T allora R → T (transitività)
Ne consegue che la relazione → introduce un ordinamento tra gli elementi di |P. Tale ordine é parziale poiché vi sono elementi che anche implicandone altri ed essendo a loro volta implicati da altri, non possono essere confrontati fra loro. In tal modo, ogni relazione semantica tra tali elementi rimane indeterminata. Pos- siamo concludere che l'insieme delle proprietà |P é parzialmen-
te ordinato. In esso, l'elemento ∩ P costituisce l'elemento mas- simo: p*, l'elemento di P in cui tutti i dettagli sono irrilevan-
ti costituisce il minimo elemento. Allora in [|P,→], ∩A rappre- senta il limite universale superiore e il limite universale infe- riore é costituito da p*. Operazioni su |P utilizzando quanto é stato sviluppato, é possibile identificare le operazioni interne di tipo semantico che possono essere rea- lizzate su |P. Definizione 7.1.10 Con area semantica di un elemento S di |P si intende il sottoin-
sieme di |P stesso, Sa = ∩A,S0,(S0)1,...,(S0)m dove (S)i sono le rappresentazioni di S0. Definizione 7.1.11 L'elemento (S0)m dell'area semantica Sa, che corrisponde alla rappresentazione minimale di S e di S0, si chiama il più piccolo limite superiore (least upper bound) lub di S. Definizione 7.1.12 Il più grande limite inferiore (greatest lower bound) glb di un
elemento S di |P consiste nella rappresentazione minimale (∩α S0α)m, dove ∩α S0α denota l'intersezione degli implicanti primari relativi ad ogni proprietà elementare pα appartenente ad S. Osservazione 7.1.13
Se un elemento S é tale che ∩α S0α = 0, poiché ∩A = 0, allora il glb di tale S corrisponde al glb di ∩A. Definizione 7.1.14

160
Ogni elemento S di |P tale che ∩α S0α = ∩A si chiama elemento se- manticamente disgiunto. Osservazione 7.1.15 Dato un elemento disgiunto S, ogni altro elemento incluso in esso é disgiunto. Poiché entrambi lub e glb di un elemento di |P sono singolarmen- te elementi unici di |P stesso, questi due limiti costituiscono il risultato dello stesso numero di operazioni su |P; denoteremo
queste operazioni con "∧" e "∨" rispettivamente, e le chiame- remo unione semantica ed intersazione semantica, cioe:
∨S = lub(S) = unione semantica di S ∧S = glb(S) = intersezione semantica di S quest'ultima quando S = ∩A é uguale a glb(∩A) = ∧A In più, poiché ogni elemento S di |P può essere considerato come formato da uno o più elementi di |P, le operazioni appena
definite sono n-ary. Allora, se S ∈ |P é tale che S = (S1 ∪ S2) possiamo scrivere:
∨S = ∨(S1 ∪ S2) = S1 ∨ S2 = (S10 ∪ S20)m ∧S = ∧(S1 ∪ S2) = S1 ∧ S2 = [∩α(S1 ∪ S2)0α]m
quando S, e così S1 ∪ S2, sono elementi disgiunti ∧S = ∧A. Lemma 7.1.16
Dati due elementi R ed S di |P, se R → S allora
(i) R ∨ S = ∨R (ii) R ∧ S = ∧S
Dimostrazione: Nelle ipotesi assunte, dalla definizione di →,
entrambi R ed S sono implicati da R0, Pertanto (R0)m, cioé ∨R rappresenta i due elementi R e S, quindi, nel nostro caso
(R0 ∪ S0)m = (∪ R0)m = ∨R Dalla definizione di ∧ si ha (R0 ∩ S0)m = (S0)m = ∨S allora R ∧ S = ∧ S. Corollario 7.1.17 Il principio di compatibilità é soddisfatto In |P. Teorema 7.1.18
Le due operazione ∧ e ∨ su |P godono delle seguenti pro- prietà:
(i) R ∨ R = ∨ R (i’) R ∧ R = ∧ R
(ii) R ∨ S = S ∨ R (ii’) R ∧ S = S ∧ R
(iii) (R∨S)∨T = R∨(S∨T) (iii’) (R∧S)∧T = R∧(S∧R)
(iv) (R∧S)∨R = ∨R (iv') (R∨S)∧R = ∧R.

161
Dimostrazione:
(i) R∨R = (R0 ∪ R0)m; poiché R0 ∪ R0 = R0 allora R∨R = (R0)m = ∨R (ii) R∨S = (R0 ∪ S0)m; poiché R0 ∪ S0 = S0 ∪ R0, allora (R0 ∪ S0)m = (S0 ∪ R0)m = S ∨ R. (iii) (R ∨ S) ∨ T = [(R0 ∪ S0) ∪ T0]m; poiché (R0 ∪ S0) ∪ T0 = R0 ∪ (S0 ∪ T0) allora [(R0 ∪ S0) ∪ T0]m = [R0 ∪ (S0 ∪ T0)]m = R ∨ (S ∨ T). (iv) (R ∧ S) ∨ R = [(R ∧ S)0 ∪ R0]m =[[(R0 ∩ S0)m]0 ∪ R0]m = [(R0 ∩ S0) ∪ R0)]m = (R0)m = ∨ R. Per quanto riguarda (i’),(ii’),(iii’) possono essere dimostrati in maniera analoga.
Per quanto riguarda (iv') si usa R ∧ S = ∧ S al posto di R ∨ S = ∨ R. Corollario 7.1.19
Le operazioni ∧ e ∨ sono semanticamente idempotenti, commuta- tive ed associative, di più esse soddisfano alla legge dell'as- sorbimento semantico.
Le caratteristiche delle operazioni ∧ e ∨ ci permettono di affermare che <|P,∧,∨> possiede una struttura di tipo retico- lare. Se <|P,∧,∨> é un reticolo, nel senso della teoria dei reticoli, se ne deduce che per ogni elemento S di |P S ∨ S = S. Nel nostro caso, in cui gli aspetti semantici degli elementi con-
siderati sono preminenti, l'uguaglianza S ∨ S = ∨ S esprime la possibilità generale che S sia sinteticamente rappresentato da (S0)m. In particolare, anche se (S0)m é diverso da S esso é se-
manticamente equivalente ad S, in altri termini ∨S ed S hanno lo stesso significato. In più, é evidente che nel caso in cui S é disgiunto, e quindi non include alcuna proprietà elementare
adiacente, oppure é singolo, allora S ∨ S, come ∨S sono u- guali ad S. A causa della dipendenza dei risultati ottenuti da
∧ e ∨ sul significato sottinteso dagli elementi su cui tali operazioni sono attuate, la struttura <|P,∧,∨> la chiameremo reticolo semantico, e lo denoteremo con L(|P). Teorema 7.1.20 Dati tre elementi R, S, T di |P abbiamo:
(i) R ∧ (S ∨ T) = (R ∧ S) ∨ (R ∧ T);
(ii) R ∨ (S ∧ T) = (R ∨ S) ∧ (R ∨ T); Osservazione 7.1.21 Il reticolo L(|P) é distributivo. 7.1.4 Definizione di un'algebra sulle proprietà Dalla definizione di area semantica é possibile derivare l'area
semantica complementare: ¬S0 = A \ S0. Teorema 7.1.22

162
Il complementare ¬S di ogni elemento S di |P é unico e sta in ¬S0. Corollario 7.1.23
Nel reticolo L(|P) per ogni elemento S di |P vale ¬¬S = ∨ S. Vediamo ora come si generi una struttura algebrica sull'insieme delle proprietà |P. Teorema 7.1.24 Per ogni coppia di elementi R e S di un reticolo L(|P) esistono
in |P due elementi ¬(R∧S) e ¬(R∨S) tali che:
(i) ¬(R ∨ S) = ¬R ∧ ¬S
(ii) ¬(R ∧ S) = ¬R ∨ ¬S. Corollario 7.1.25 In L(|P) sono valide le leggi di De Morgan:
(i) R ∨ S = ¬(¬R ∧ ¬S)
(ii) R ∧ S = ¬(¬R ∨ ¬S) Poiché il reticolo L(|P) é fornito di limiti, elementi minimali
e massimali, rispettivamente ∧A e p* e poiché sono valide le leggi distributive e di complementazione, allora: Teorema 7.1.26 Il reticolo L(|P) é un'algebra booleana semantica
< |P, ∨, ∧, ¬, p*, ∧A>; la denoteremo con A(|P).

163
7.2 Ruolo delle irrilevanze nella formazione di concetti L'apprendimento di concetti (Concept learnig) CL é una forma di apprendimento dall'osservazione, e consiste nell'acquisizione di conoscenza da inferenze tratte da fatti appresi o ottenuti trami- te una diretta interazione con l'ambiente. CL rappresenta il primo passo verso la possibilità di categoriz- zazione autonoma, attività fondamentale e misteriosa, di grande interesse nell'ambito dell'intelligenza artificiale. Sono state sviluppate parecchie tecniche statistiche per imparare a risolvere problemi su base numerica: comunque un approccio pu- ramente statistico é soggetto ad alcuni limiti intrinseci: (i) incapacità di distinguere attributi rilevanti da attributi irrilevanti tra gli elementi che descrivono il problema; (ii) difficoltà a trattare efficacemente proprietà non numeri- che; (iii) impossibilità di fornire una descrizione delle classi create. Queste limitazioni sono di impatto centrale per l'efficacia delle applicazioni di CL nel raggruppamento concettuale (conceptual clustering) CC: l'attività di creazione di categorie. Naturalmente la possibilità di misurare le informazioni semanti- che proprie dei messaggi che descrivono gli elementi che devono essere classificati é determinante al fine di fornire un modello del processo di raggruppamento concettuale. Una tale informazione scaturisce dall'integrazione sia delle tipicità di ogni elemento ripetto ad ogni possibile concetto sia dalla ambiguità con cui questi sono rappresentati. Occorre considerare anche la rilevanza semiotica che attributi caratterizzanti gli elementi considerati possono avere al fine di definire un concetto e quindi calcolare la tipicità degli elementi rispetto al concetto definito. Gli elementi, che consistono di fatti, situazioni o oggetti, ven- gono nel seguito chiamati entità. Cerchiamo di definire ora il concetto di "attributi irrilevanti". Le entità vengono descritte da l-tuple di attributi booleani; queste derivano dall'interpretazione binaria data dai valori che sono in on nella l-tupla. Se dato un insieme base X di entità xà consideriamo i sottoinsiemi S, T,... di X, ciascuno di essi si dice coerente sulla base di un criterio specifico di funzionali- tà: in tal caso si può parlare di concetto. Ogni entità di un concetto S costituisce una estensione iso(S)-definente di di S.
Definiamo come irrilevante, in una entità xα di S, ogni caratte- ristica Xk che, qualsiasi sia l'attributo con cui compare in xα, questo rimanga ancora una entità S-definente.; cioé Xk non é
determinante per far sì che xα definisca S. Una tale irrilevanza deriva dalla esistenza in S di un'altra entità xβ che, quando é confrontata con xα differisce da xα esclusivamente per il k-esimo attributo.
Formalmente, date due entità xα = (x1α,...,xlα) e xβ = (x1β,...,xlβ) tali che esiste un solo k per cui xkα é di- verso da xkβ e per ogni h diverso da k si ha xhα = xhβ, allora gli attributi xkα e xkβ non hanno rilievo e la caratteristica corrispondente Xk con lo stesso indice k risulta irrilevante sia
in xα che in xβ. Una relazione binaria lega xα e xβ così che queste possono essere definite isosignificanti e la relazione é
possibile indicarla con xα - xβ. Gli attributi rilevanti Xh che caratterizzano ogni entità xα so- no indicati nella notazione binaria xhα ∈ 0,1; quelli irrile-

164
vanti sono indicati con *. Dopo aver accertato l'isosignificato
di due entità xα e xβ, entrambe queste entità possono essere sintetizzate in una terza xτ tale che xkτ = * e per ogni h diver- so da k xhτ = xhα = xhβ. Una tale sintesi implementa un operatore binario che indicheremo con Θ sull'insieme base X. Allora xτ sa- rà il risultato di xα Θ xβ: la struttura matematica che X riceve dalla nuova operazione deriva dalle relazioni semantiche tra i suoi elementi.
Applicando Θ su tutte le entità isosignificanti di S, si ottiene un sottoinsieme S1 di 0,1,*exp(l); in cui si aggiungeranno tut-
te le entità dello stesso tipo di xτ, una per ogni coppia di en- tità isosignificanti esistenti in S. Tramite l'applicazione ite-
rativa di Θ sugli elementi formati successivamente si ottiene una successione di Si e finalmente si ottiene Sm in cui non esistono ulteriori entità isosignificanti. Nelle entità incluse in Sm tutti gli attributi irrilevanti vengono evidenziati: questa rap- presentazione sintetica di S costituisce l'intensiva (essenziale) definizione del concetto S stesso. Esempio: Sia l'insieme base X generato dall'interpretazione dei valori di tre caratteristiche X1, X2, X3 sull'insieme primario X=000,001,010,011,100,101,110,111, tale che S = 010,011,100 sia il concetto definito. Le entità 010 e 011 sono isosignifi- canti, poiché esse differiscono solo per la caratteristica X3, a
cui corrispondono gli attributi x3α e x3β rispettivamente, allora la forma sintetica di S é Sm = 100,01* dove 01* é il risulta-
to di 010 Θ 011. Analizziamo il caso in cui vi sono differenze per più di un at- tributo. Vediamo la possibiltà di estendere gli stessi concetti di irri- levanza: sorgono dei problemi quando esistono differenza multiple tra le entità. Dopo aver ottenuto la definizione intensiva Sm di un concetto S, possono essere calcolate alcune proprietà simboliche e numeri- che, come il prototipo, la tipicità dell'entità, il concetto di coerenza, di ambiguità dell'indicazione, e altre ancora. Ma nel- lo sviluppo dell'argomento sorge una legittima domanda: che cosa succede quando due entità differiscono negli attributi relativi per più di una caratteristica? Questo succede per esempio tra le coppie 100 e 010 del concetto S considerato nell'esempio prece- dente: sono X1, X2 irrilevanti allo stesso modo in cui nell'esem- pio gli attributi differenti riguardavano una unica caratteristi- ca in X3 ? La risposta deve essere negativa. Vediamo l'assurdità che si ottiene quando assumiamo che anche con differenze per più di una caratteristica danno origine a en- tità isosignificanti. Consideriamo di nuovo l'esempio sopra riportato: la irrilevanza della caratteristica X1 sia in 100 che in 010 non consente di de- cidere se queste due entità debbano essere incluse in S oppure
nel suo complemento ¬S che include tutte le entità di X che non sono in S. Una conclusione analoga si ottiene anche considerando la possibile irrilevanza di X2 nella stessa entità. Infatti, nel caso di irrilevanza di una o più caratteristiche in tutte le entità di S, come nel caso considerato, queste dovreb-
bero essere irrilevanti anche in tutte le entità di ¬S. In tal caso, le entità **0 dovrebbero paradossalmente comparire sia in
Sm che in ¬Sm. Al fine di definire S coerentemente, dobbiamo quindi concludere che gli attributi connotati con queste caratte- ristiche non possono essere entrambi irrilevanti.
Inoltre possiamo dedurre che, se due entità xα e xβ sono entram-

165
be iso-definenti dello stesso concetto, potrebbe essere richiesta la loro multipla differenziazione. Questo succede quando la dif-
ferenziazione di due attributi omologhi xhα e xhβ di tali entità possono servire per estrarre due o più altre entità, nella de- finizione di un concetto. Comunque, il caso di differenziazione multipla tra due entità iso-definenti non esclude che più di una caratteristica risulti irrilevante per esse. Questo può accadere quando, nell'iterazio-
ne di Θ nei successivi Si, entità che sono sintetizzate con xα e xβ determinano in queste le irrilevanze di cui parliamo. L'esempio seguente può essere utile per illustrare il senso in- tuitivo del ragionamento precedente. Supponiamo che le tre carat- teristiche X1, X2, X3 riguardino il clima con le seguenti condi- zioni: X1 =1 freddo, =0 caldo; x2 =1 vento, 0= calmo X3 0= pioggia, 1= sole. Allora gli elementi del sottoinsieme S = 001,010,011 definiscono un concetto che esprime la necessità e la sufficienza per indossare un leggero impermeabile. Il relativo Sm é 0*1,01* da cui é evidente come l'impermeabile é utiliz- zabile per proteggersi dalla pioggia, dal vento o possibilmente da entrambi. D'altra parte, dalla doppia differenziazione tra 001 e 010, non sarebbe ragionevole concludere che le caratteristiche X2 e X3 sono entrambe irrilevanti. In tal caso, infatti, non sa- rebbe possibile decidere se queste due entità definiscono un
concetto S oppure il suo opposto ¬S; questo poiché la configura- zione 0** assumerebbe i seguenti significati: non solo caldo,calma,pioggia e caldo,vento,sole ma anche caldo,calma,sole, una situazione in cui l'impermeabile non sa- rebbe ragionevolmente richiesto.
Comunque analizzando la derivazione di ¬Sm = *00,1** da ¬S = 000,100,101,110,111 i cui elementi definiscono il concetto in accordo con il fatto che l'impermeabile é o non necessario o in- sufficiente, risulta che sia le coppie 100,111 che (101,110 derivano 1** anche se i loro elementi differiscono per due attri- buti, quelli relativi a X2 e X3. Questo risultato, ottenuto ope-
rando successivamente con nella derivazione di ¬Sm, differisce da quello precedentemente prospettato in cui si é ottenuto 0**, in questo caso però risulta intuitivamente corretto.

166
7.3 Simiglianze nel caso di corrispondenza biunivoca 7.3.1 Corrispondenze, trasformazioni, simiglianze Riportiamo brevemente alcuni richiami sui concetti di trasforma- zione su insiemi.
Si dice corrispondenza ƒ : A --> B un qualsiasi metodo, algorit- mo, operatore, meccanismo, trasformazione, ecc. in grado di far corrispondere ad ogni elemento dell'insieme A un elemento
dell'insieme B, e si denota con ƒ(x) = y dove x ∈ A e y ∈ B. Nota: può essere ƒ(x1) = y1 e ƒ(x1) = y2.
Si dice applicazione ƒ : A --> B una corrispondenza univoca, cioé tale che per ogni elemento xi ∈ A esiste un unico elemento yi ∈ B; ƒ(xi) = yi. Nota: può essere ƒ(x1) = y1 e ƒ(x2) = y1.
Si dice applicazione suriettiva ƒ : A --> B sse ƒ(A) = B; vale a dire che per ogni elemento yi ∈ B esiste un xi ∈ A tale che ƒ(xi) = yi.
Si dice applicazione iniettiva ƒ : A --> B se elementi distinti di A hanno corrispondenti distinti di B, vale a dire che per ogni
x1,x2 ∈ A e y1,y2 ∈ B tale che ƒ(x1) = y1 e ƒ(x2) = y2 x1 ≠ x2 si ha y1 ≠ y2. Se un'applicazione é suriettiva ed iniettiva allora é anche in-
vertibile e si dice che ƒ : A --> B é una corrispondenza biuni- voca ed esiste: -1
ƒ : B --> A. Sia A un insieme finito di m elementi. Sia B un insieme finito di n elementi. Allora il numero di applicazioni da A in B sono:
α(m,n) = n exp(m). Mentre il numero di applicazioni iniettive sono:
α'(m,n) = n (n-1) (n-2) ... (n-m+1) Ricordiamo che le combinazioni di n elementi presi a m alla volta sono: n n! ( ) = -------- m m!(n-m)!

167
(fig 7.1) Consideriamo due insiemi numerabili I1,I2.
Sia ƒ : I1 --> I2 una corrispondenza biunivoca da I1 a I2.
Indichiamola con ƒ(ik) = ek dove ik ∈ I1 ed ek ∈ I2. Denotiamo con |P(I1) la potenza di I1 e con |P(I2) la potenza di I2; costruiamo una trasformazione T : |P(I1) --> |P(I2)
definita come segue; per ogni xi ∈ |P(I1) xi = i1,i2,...,ik
T(xi) = T(i1,i2,...,ik) = ƒ(i1),ƒ(i2),...,ƒ(ik) =
= e1,e2,...,ek = yi ; yi ∈ |P(I2) Si vede facilmente che T é una corrispondenza biunivoca.
Sia µ1 : |P(I1) --> |R+ \ ∞ definita nel seguente modo:
per ogni xi ∈ |P(I1) numerabile e finito
µ1(xi) = numero di elementi distinti dell'insieme xi. Esempio:
xi = i1,i2,...ik si ha µ1(xi) = k.
Poniamo µ2 : |P(I2) --> |R+ \ ∞ tale che -1
µ2(yi) = µ1(T (yi)) = µ1(xi) allora
per ogni yi ∈ |P(I2) numerabile e finito

168
µ2(yi) = numero di elementi distinti dell'insieme yi -1 -1 infatti T (yi) = T (e1,e2,...,ek) = i1,i2,...,ik = xi (il numero di elementi é un invariante per la T !)
µ1(i1,i2,...,ik) = k
µ2(e1,e2,...,ek) = k Abbiamo introdotto una semplice misura su I1 e tale misura é possibile indurla, con lo stesso significato anche su I2.
(fig 7.2)
Possiamo ora costruire una metrica basata sulle misure µ1 e µ2 tale che induca spazi isometrici sulla potenza di I1 e di I2. Prendiamo pertanto le seguenti funzioni distanza: d1 : |P(I1) x |P(I1) --> [0,1]
µ1(xi ∆ xj) d1(xi,xj) = ------------------ per ogni xi,xj ∈ |P(I1) µ1(xi ∪ xj) d2 : |P(I2) x |P(I2) --> [0,1]
µ2(yi ∆ yj) d2(yi,yj) = ------------------ per ogni yi,yj ∈ |P(I2) µ2(yi ∪ yj) Prendiamo un arbitrario insieme, S1, di insiemi di |P(I1),

169
_ S1 contenuto in |P(I1), sia S1 l'immagine di S1 in |P(I2), _ S1 contenuto in |P(I2); allora: PROPOSIZIONE 7.3.1 _
Per ogni yi ∈ S1 la funzione distanza d2(yi,yj) fornisce
la simiglianza tra yi ed ogni yj ∈ S2. PROPOSIZIONE 7.3.2 _ _ Se d2(S1,S2) = 0 allora S1 coincide con S2. _ _ Se d2(S1,S2) = 1 allora S1 é disgiunto da S2 per cui _
per ogni ei ∈ S1 ej ∈ S2 d2(ei,ej) = 1 in altri termini non vi sono simiglianze. PROPOSIZIONE 7.3.3 Sia g : S1 x S2 --> [0,1] tale che
g(xi,yj) = d2(T(xi),yj) xi ∈ S1, yj ∈ S2 allora la g fornisce la simiglianza tra ogni elemento di S1 ed ogni elemento di S2. Definizione 7.3.4
Sia Bδ = yj; d(yi,yj) < δ δ ∈ [0,1] yi,yj ∈ |P(I1)
allora diremo che Bδ é un intorno di yi di raggio δ. PROPOSIZIONE 7.3.5 _
Per ogni yi ∈ S1, l'intersezione dell'intorno di raggio δ di yi
con S2, Bδ(yi) ∩ S2, fornisce un ordinamento parziale degli elementi di S2 in funzione delle simiglianze tra gli elementi _ stessi di S2 e l'elemento yi di S1. Esempio: Consideriamo un insieme di cinque elementi I1 = i1,i2,i3,i4,i5, I2 = e1,e2,e3,e4,e5 S1 = i1,i2,i2,i3,i4,i3,i4,i5,i1,i3,i5,i1,i4 S2 = e1,e2,e1,e2,e3,e1,e2,e3,e4,e1,e2,e3,e4,e5

170
g(xi,yj) | i1,i2 | i2,i3,i4 | i3,i4,i5 | i1,i3,i5 | i1,i4 --------------|------------------------------------------------ e1,e2 | 0 | 3/4 | 1 | 3/4 | 2/3 --------------|------------------------------------------------ e1,e2,e3 | 1/3 | 2/4 | 4/5 | 2/4 | 3/4 --------------|------------------------------------------------ e1,e2,e3,e4 | 2/4 | 1/4 | 3/5 | 3/5 | 2/4 --------------|------------------------------------------------ e1,e2,e3,e4,e5| 3/5 | 2/5 | 2/5 | 2/5 | 3/5 --------------------------------------------------------------- PROPOSIZIONE 7.3.6 _
Sia S1 ∩ S2 ≠ ∅.
Sia Tr : S1 --> S2 una corrispondenza tra xi ∈ S1 e yi ∈ S2
definita come: per ogni xi ∈ S1
Tr(xi) = yj: yi = T(xi), yj ∈ S2 tale che sia min(d2(yi,yj)) in altri termini Tr(xi) corisponde all'insieme degli yj che rendono minima la distanza d2(yi,yj) tra yj
e l'immagine yi ∈ S1 di xi.
O se vogliamo, Tr trasforma xi ∈ S1 nell'insieme yj ∈ S2 più simile in S2. Esempio: Consideriamo un insieme di cinque elementi I1 = i1,i2,i3,i4,i5, I2 = e1,e2,e3,e4,e5 S1 = i1,i2,i2,i3,i4,i3,i4,i5,i1,i3,i5,i1,i4 S2 = e1,e2,e1,e2,e3,e1,e2,e3,e4,e1,e2,e3,e4,e5 allora Tr(i2,i3,i4) = e1,e2,e3,e4 come si può verificare dalla tabella dell'esempio precedente.

171
(fig 7.3) Le definizioni e i concetti fin qui esposti ci consentono di de- finire delle trasformazioni delle simiglianze. Il presente lavoro propone un interessante approccio al problema della conservazione di simiglianze tra informazioni nel processo di comunicazione, trasmissione, invio, o ricezione delle stesse. Simiglianze presenti in un insieme di dati iniziali sembra venga- no perse, nella rappresentazione finale, a causa della trasforma- zione che essi stessi subiscono al fine della trasmissione ad al- tre rappresentazioni riceventi. Consideriamo ad esempio un pezzo musicale. Nello spartito l'informazione, la melodia, é rappresentata da note sul pentagramma, un esecutore trasforma le note, da una se- quenza spaziale, ad una sequenza temporale, pigiando i tasti di un pianoforte; a ciascuna nota corrisponde un tasto ed ad ogni battuta un intervallo di tempo. Il pianoforte produce un suono, un'onda sonora, con caratteristi- che ben precise di altezza e di composizione armonica, che pro- gressivamente nel tempo si propaga nello spazio. Se analizzassimo la forma d'onda prodotta, in linea di principio, potremmo ritrovare le onde corrispondenti a ciascuna nota sul pentagramma, ma dove é rintracciabile la melodia? Consideriamo il problema da un punto di vista astratto; per far ciò utilizziamo la matematica. Dal punto di vista matematico gli oggetti più generali con cui trattare l'informazione sono gli insiemi. Un insieme di messaggi, di oggetti, di configurazioni,... forni- scono il supporto per la trasmissione dell'informazione da un e- mittente ad un ricevente. Siccome desideriamo manipolare qualsiasi combinazione di oggetti del nostro insieme gli oggetti matematici più generali, che possono essere utili rappresentazioni, sono gli spazi topologici. Consideriamo pertanto due spazi topologici (X,T1) e (Y,T2), dove X é l'insieme di partenza, con topologia T1; Y é l'insieme di arrivo, con topologia T2. Sia OP: X --> Y un operatore, una trasformazione, che determini un'applicazione da X a Y tale che

172
yi = OP(xi), yj = OP(xj) se e solo se xi = xj. Per la definizione di topologia vale: 1) L'insieme vuoto appartiene alla topologia T L'insieme X appartiene alla topologia T. 2) L'unione di arbitrari elementi di T appartiene ancora a T. 3) L'intersezione di un numero finito di arbitrari elementi di T appartiene a T. Supponiamo che gli insiemi X,Y siano misurabili e in particolare esistano una misura m1 su X e una misura m2 su Y tali che:
1) m1: X --> R+ \ ∞ m2: Y --> R+ \ ∞ 2) Per ogni xi,yi, xi appartenente a X, yi appartenente a Y tali che yi=OP(xi) valga m1(xi) = m2(yi) In tali circostanze é possibile indurre una metrica su X e su Y utilizzando le funzioni distanza definite come:
m1(xi ∆ xj) a) dx (xi,xj) = kx ---------------
m1(xi ∪ xj)
m2(yi ∆ yj) b) dy (yi,yj) = ky ---------------
m2(yi ∪ yj) Infatti si vede che dx e dy sono distanze e inducono spazi metri- ci su X e Y : Mx = (X,dx) My = (Y,dy). Si verifica facilmente che per ogni xi,xj appartenenti ad X e yi,yj appartenenti a Y vale
c) dx(xi,xj) = β dy(yi,yj) allora Mx é isometrico ad My. Questo significa che se xi e xj sono simili nella rappresentazio- ne X allora anche yi e yj sono simili nella rappresentazione Y. Abbiamo ottenuto la corrispondenza di oggetti simili dalla rap- presentazione iniziale a quella finale. Ovviamente, rimane aperto il problema della costruzione delle funzioni misura; sotto quali condizioni é possibile costruire queste funzioni? Secondo, quale é il livello semantico a cui rimane valida la correlazione tra oggetti simili? In altri termini che cosa implica, al livello di significato, mo- dificare le funzioni misura? Cercheremo di rispondere nel seguito almeno ad alcune di queste domande. Comunque dalle definizioni delle trasformazioni che abbiamo in- trodotto se ne deduce che costruendo le funzioni misura sugli in- varianti delle trasformazioni medesime é possibile ottenere l'invarianza della metrica indotta sugli insiemi trasformati.

173
7.3.2 Costruzione di una metrica sull'insieme dei naturali Consideriamo una trasformazione Tr definita come:
Tr(xi) = yj: yj ∈ S2, yi = T(xi) tale che min(d(yi,yj)) Prendiamo come insieme S2 l'insieme dei naturali, vale a dire: S2 = 1,1,2,1,2,3,...,1,2,3,...,k,...
Se yj ∈ S2 e µ : S2 --> |N tale che µ(1,2,3...,k) = k allora possiamo classificare qualsiasi insieme arbitrario rapportandolo all'insieme dei numeri naturali. Consideriamo la g(xi,yj) = d(T(xi),yj) precedentemente introdotta considerato che se yk = T(xk), é l'insieme yk corrispondente, nell'insieme dei naturali, ad un arbitrario xk di S1 e Tr(xi) = yk, Tr(xj) = yk corrispondono a due elementi xi ed xj di S1 che sono simili ad yk, e pertanto ad xk
dove xi, xj, xk ∈ S1 e yk ∈ S2 (insieme dei naturali) allora vale d(xi,xj) ≤ g(xi,yk) + g(xj,yk) ovvero, in altri termini, yk rappresenta un buon prototipo per rappresentare, in maniera standard, sia xi che xj.
(fig 7.4) Esempio: Prendiamo S1 = 1,2,3,4,2,3,4,3,4,5

174
ed S2 = 1,1,2,1,2,3,1,2,3,4,1,2,3,4,5 1 1,2 1,2,3 1,2,3,4 1,2,3,4,5 ------------------------------------------------------------- 1,2 | 1/2 | 0 | 1/3 | 2/4 | 3/5 | | | | | 3,4 | 1 | 1 | 3/4 | 2/4 | 3/5 | | | | | 2,3,4 | 1 | 3/4 | 2/4 | 1/4 | 2/5 | | | | | 3,4,5 | 1 | 1 | 4/5 | 3/5 | 2/5 allora la trasformazione Tr(xi) assegna i seguenti valori agli insiemi di S1: Tr(1,2) = 1,2 corrispondente al numero 2 Tr(3,4) = 1,2,3,4 corrispondente al numero 4 Tr(2,3,4) = 1,2,3,4 corrispondente al numero 4 Tr(3,4,5) = 1,2,3,4,5 corrispondente al numero 5 Vediamo un'estensione di questa idea. Esempio di metrica su |N.
(fig 7.5) Consideriamo una corrispondenza tra un sottoinsieme di |N ed un insieme qualsiasi S numerabile.
ƒ : |N --> S Definiamo come misura di un arbitrario insieme di interi la cardinalità dell'insieme, formalmante:

175
µ : |P(|N) --> |R+
µ(n1,n2,...,nk) = k Prendiamo come metrica la funzione:
µ(xi ∆ xj) d(xi,xj) = -------------- xi,xj ∈ |P(|N) µ(xi ∪ xj) Analizziamo l'intorno di 1. Denotiamo con <1,2,...,n> l'insieme ordinato 1,2,...,n. Allora gli elementi di S2 sono: <1>, <1,2>, <1,2,3>, ..., <1,2,...,n>,... e la funzione distanza diviene: n - m
d(<1,2,...,m>,<1,2,...,n>) = ------- con n ≥ m n la matrice dei valori della distanza é: <1> <1,2> <1,2,3> ... <1,2,...,m> --------------------------------------------------------------- <1> | 0 1/2 2/3 ... (m-1)/m | <1,2> | 1/2 0 1/3 ... (m-2)/m | <1,2,3> | 2/3 1/3 0 ... (m-3)/m | | <1,2,...,n> | (n-1)/n (n-2)/n (n-3)/n ... (n-m)/n Da notare le serie numeriche nelle diagonali: 1 2 3 ---, ---, ---, ... n n n n - m Per visualizzare la funzione d(n,m) = ------- n
poniamo n => k costante ed m => x x ∈ [0,k[ k - x 1
allora la ƒ(x) = ------- = 1 - ------ x k k può essere rappresentata da una famiglia di rette del tipo:
176
(fig. 7.6)

177
7.4 Sistemi di deduzione basati su regole Siano x1,x2,...,xn variabili denotanti fatti atomici. Per esempio proposizioni costanti di un linguaggio logico L. Denoteremo con xi - xj una relazione binaria tra le variabili xi e xj a cui corrisponde una relazione inversa che chiameremo duale: xj - xi Consideriamo delle regole di deduzione espresse nella forma: xj implica xk
xj → xk (implicazione semantica)
xj ⇒ xk (implicazione logica)
xj → xk (deduzione logica sintattica) xj -> xk (implicazione materiale logica) xk <- xj (notazione per le clausole di horn) utilizzeremo nel seguito la notazione seguente per denotare la regola "Se xj allora xk": xk :- xj. Possiamo pensare a sistemi di questo tipo: OR) xk :- x1. xk :- x2. Se (x1 v x2) allora xk. AND) xk :- x1,x2. Se (x1 & x2) allora xk. In generale avremo sistemi di regole nella forma: xk1 :- x1,x2,...,xn. Se (x1 & x2 & ... & xn) allora xk. Esempio: 1) x3 :- x1,x2. 2) x3 :- x2,x4. 3) x4 :- x2,x3.

178
4) x5 :- x3,x4. 5) x6 :- x2,x3,x4,x5. dove xi sono fatti atomici appartenenti ad un insieme X. Prendiamo la potenza di X |P(X) allora le regole 1) - 5) possono essere interpretate come una trasformazione T : |P(X) --> |P(X) da x1,x2,x3,x4,x5 ---> x1,x2,x3,x4,x5,x6
(fig 7.8) ne consegue che un insieme di regole arbitrario del tipo di quel- le dell'esempio può essere interpretato come una trasformazione (corrispondenza) dalla potenza dell'insieme di definizione dei fatti su sé stesso. In particolare, l'insieme di regole, corrisponde ad una trasfor- mazione di evidenze iniziali in una serie di generazioni succes- sive di evidenze inferite. Sia E0 = e1,e2,...,et un insieme di evidenze iniziali appli- cando le regole all'insieme E0 una prima volta otteniamo un in- sieme di deduzioni x1,x2,...,xk = D1.
L'insieme E1 = E0 ∪ D1 corrisponde ai fatti che rappresentano (con una certa affidabilità) le nuove evidenze. Applicando di nuovo le regole otteniamo da E1 un ulteriore insie- me di deduzioni y1,y2,...,yh = D2.
Prendendo E2 = E1 ∪ D2 otteniamo le nuove evidenze; il processo si ripete fino a quando l'insieme di deduzioni ricavate dall'ap- plicazione delle regole risulta vuoto. In tal modo si producono generazioni successive di evidenze. Il processo é analogo alla generazione di nuove stringhe negli

179
algoritmi genetici: vedremo che l'analogia può essere spinta ad un livello di particolare interesse. Riassumendo si ha: E0 ==> E1 ==> E2 ==> ... ==> Er
(fig 7.9) Esempio: Considerando le regole 1) - 5) dell'esempio precedente e prendendo come E0 = x1,x2 si ottiene: E0 = x1,x2 E1 = x1,x2,x3 E3 = x1,x2,x3,x4 E4 = x1,x2,x3,x4,x5,x6 T T T T T E0 ==> E1 ==> E2 ==> E3 ==> E4 ==> E4

180
7.5 Logiche a più di due valori 7.5.1 Logica modale non monotonica intuizionista Gabbay (1982) ispirato dal primo formalismo non monotonico di de- bole interpretazione di McDermott e Doyle, ha suggerito di co- struire una logica basata sull'inferenza intuitiva. La logica intuizionista deriva da alcune considerazioni filosofi- che sui fondamenti della matematica, noti come intuizionismo. Il punto di vista intuizionista sulla natura della logica di base e sulla formazione teorica dei concetti differisce da quella classica sostenuta dalla maggioranza dei matematici. Una delle principali differenze riguarda l'interpretazione delle costanti logiche. Dal punto di vista classico, il significato di una co- stante logica consiste in una regola che specifica le condizioni di verità per una formula contenente la costante come connettivo primario. Per esempio, il significato della regola di implicazio- ne risiede nell'affermare che ogni formula della forma A -> B é vera sse A é falsa o B é vera. L'intuizionismo é stato fortemente influenzato dall'osservazione che una formula é vera sse possiede una dimostrazione. In accordo con questa osservazione, il significato intuizionista di una costante logica é meglio compreso quando é considerato come una specificazione di qualcosa di analogo ad una dimostra- zione di una formula contenente la costante come connettivo prin- cipale. Per esempio, il significato intuizionista dell'implica- zione é l'affermazione che la dimostrazione di una formula del- la forma A -> B consiste nel trovare un metodo per cui qualche dimostrazione intuizionista di A possa essere trasformata in una dimostrazione di B. In altre parole, gli intuizionisti accettano la formula A -> B sse é possibile costruire una dimostrazione di B a partire da A. La negazione é strettamente correlata all'implicazione; per pro-
vare una formula di negazione come ¬A, dal punto di vista intui- zionista, occorre provare che A -> Falso, cioé ¬A é accettata dagli intuizionisti se l'assunzione di A come vera conduce ad una contraddizione che possa essere costruttivamente derivata. Secon- do questa interpretazione dell'implicazione e della negazione,
risulta evidente che la formula A -> ¬(¬A) é intuizionisticamen- te accettabile, mentre la formula ¬(¬A) -> A non lo é. Per provare, dal punto di vista intuizionista, una disgiunzione occorre provare almeno un elmento della disgiunzione stessa. Pertanto, A v B viene accettata dagli intuizionisti sse almeno uno tra A, B é dimostrabile, nel senso che esiste un metodo co- struttivo che consente di determinarne la verità. Quest'ultima osservazione costringe gli intuizionisti a rifiutare la legge del
terzo escluso: A v ¬A. Infine, per provare una congiunzione, dal punto di vista intuizionista, occorre provare tutti i termini della congiunzione stessa. Il linguaggio della logica proposizionale intuizionista consiste
nel linguaggio proposizionale solito con i connettivi ¬, ->, v, & per le affermazioni. Come nella logica classica, la logica intui- zionista può essere definita come un sistema di deduzioni. Nella logica intuizionista la disgiunzione e la congiunzione non possono essere definite tramite l'implicazione e la negazione: entrambi i connettivi v e & devono essere introdotti come connet- tivi primitivi. Definizione 7.5.1 Sia L un linguaggio proposizionale. Con I(L) denotiamo il sistema deduttivo <L,S,R> dove:

181
(i) S consiste nei seguenti assiomi (1) A -> (A & A) (2) (A & B) -> (B & A) (3) (A -> B) -> ((A & C) -> (B & C)) (4) ((A -> B) & (B -> C)) -> (A -> C) (5) B -> (A -> B) (6) (A & (A -> B)) -> B (7) A -> (A v B) (8) (A v B) -> (B v A) (9) ((A -> C) & (B -> C)) -> ((A v B) -> C)
(10) ¬A -> (A -> B) (11) ((A -> B) & (A -> ¬B)) -> ¬B (ii) R contiene (MP) modus ponens come sua unica regola. Tutte le nozioni utilizzate nella logica classica si applicano anche alla logica intuizionista, così possiamo parlare di dimo- strazioni, teoremi, teorie, ecc. nell'ambito della logica intui- zionista e possiamo utilizzare le solite notazioni. Teorema 7.5.2 Per ogni teoria T, le affermazioni dimostrabili nella logica in- tuizionista sono un sottoinsieme di quelli dimostrabili nella lo- gica classica. Teorema 7.5.3
L'aggiunta dello schema A v ¬A (legge del terzo escluso) agli as- siomi (1)-(11) conduce alla logica proposizionale classica. Teorema 7.5.4 Per ogni teoria T e ogni formula A:
(1) A ∈ Th(T) sse ¬¬A ∈ Thi(T) (2) ¬A ∈ Th(T) sse ¬A ∈ Thi(T)
dove Th(T) = A: T → A é l'operatore di dimostrabilità della
logica classica e Thi(T) = A : T →i A é l'operatore di dimo- strabilità della logica intuizionista. In letteratura si trovano alcune semantiche per la logica intui- zionista, la più comune é forse quella di Kripke (1965). La semantica di Kripke può essere illustrata in termini di ac- quisizione della conoscenza; consideriamo un flusso temporale
(U,≤) dove U é un insieme di istanti nel tempo e ≤ é un pre- ordine su U, cioé una relazione transitiva e riflessiva su U, interpretata come relazione di prima-dopo. A ciascun istante
t ∈ U e per ciascuna proposizione costante p, viene assegnato un valore di verità m(t,p), dove m(t,p) non é interpretato nel senso di "p é vera al tempo t" ma invece come "p é divenuta no- ta (é stata verificata) al tempo t"; ed un'importante ipotesi é
che se t ≤ t' e m(t,p) = 1, allora anche m(t',p) = 1, quindi una volta che p é stata verificata questa conoscenza non viene per- duta. Le proposizioni costanti rappresentano fatti unitari che possono essere utilizzati per formare affermazioni complesse, in conse- guenza dell'ipotesi precedente la nozione di conoscenza acquisita si estende a tutto il linguaggio. Una formula della forma A v B é considerata conosciuta ad un certo istante t sse A é nota al

182
tempo t oppure é noto B. Una formula della forma A & B é cono- sciuta ad un certo istante t se sono noti sia A che B.
La formula A -> B é conosciuta al tempo t sse per ogni t' ∈ U, se t ≤ t' e A é conosciuta al tempo t', allora anche B é noto. Infine ¬A é conosciuta al tempo t sse non esiste un t' ∈ U tale che t ≤ t' e A é nota al tempo t'. Sulla base di queste regole e delle ipotesi su m delineate, é facile vedere che nessuna informazione acquisita viene perduta e la conoscenza segue un processo di continua crescita. Definizione 7.5.5 Una struttura intuizionista per un linguaggio L consiste in una
tripla M = <U,≤,m>, dove (i) U é un insieme non vuoto di istanti di tempo
(ii) ≤ é una relazione riflessiva e transitiva su U (iii) m é una funzione che a ciascun t ∈ U e a ciascuna propo- sizione costante di L assegna un elemento di 0,1;
se t ≤ t' e m(t,p) = 1 allora m(t',p) = 1.
Utilizziamo la notazione t M A per indicare che A é cono- sciuto al tempo t in M, ovvero:
(1) t M p sse m(t,p) = 1, dove p é una proposizione costante in L;
(2) t M A v B sse t M A o t M B;
(3) t M A & B sse t M A e t M B;
(4) t M A -> B sse t' M B ogni volta che t' M A
per ogni t' ≥ t;
(5) t M ¬A sse non esiste un t' ≥ t tale che t' M A.
Denotiamo con t ¬M A la negazione di t M A. Definizione 7.5.6
Diremo che A é vera in M = <U,≤,m> sse t M A , per ogni t ∈ U. Una teoria T si dice conosciuta al tempo t in M, t M T, sse t M
A, per ogni A ∈ T. T é soddisfacibile sse t M T, per qualche M,t. Due teorie T e T' si dicono intuizionisticamente equivalenti
sse per ogni struttura M = <U,≤,m> ed ogni t ∈ U, t M T sse
t M T'. Le formula A e A’ sono intuizionisticamente equivalenti sse le teorie A e A’ sono equivalenti. Una formula A é in-
tuizionisticamente implicata da una teoria T, T i A, sse per o-
gni struttura M = <U,≤,m> e ogni t ∈ U, t M A ogni volta che
t M T. Infine diremo che A é intuizionisticamente valida, i A, sse A é implicata da T = , o, in maniera equivalente, sse A é vera in ogni struttura intuizionista M. Teorema 7.5.7 (Kripke) Per ogni T ed ogni A:
(i) i→ A sse i A

183
(ii) T i→ A sse T i A. Esempio:
Consideriamo la struttura M = <U,≤,m>, dove U = a,b, a ≤ b, m(a,p)=0 e m(b,p)=1; poiché a ¬M ¬p e a ¬M p, a ¬M p v ¬p. Questo mostra come p v ¬p non sia intuizionisticamente valida. Esempio:
Definiamo A ≡ B come abbreviazione di (A -> B) & (B -> A) e con- sideriamo lo schema A v B ≡ ¬A -> B. Questo schema valido nella logica classica non é più valido nella logica intuizionista;
per vederlo poniamo A = p, B = ¬p e consideriamo la struttura dell'esempio precedente. Poiché a ¬M p v ¬p e a M ¬p -> ¬p otteniamo a ¬M (p v ¬p) ≡ (¬p -> ¬p). Vediamo ora la logica non monotonica di Gabbay. Partiamo estendendo la semantica di Kripke per la logica intui- zionista alla logica modale proposizionale utilizzando l'operato- re modale M: una formula MA può essere letta "é consistente as- sumere a questo istante che A sia vera". Allora, MA può essere considerato come accettare come vero ora ciò che può essere co- nosciuto in futuro.
Sia A ∈ L, la relazione t M A é definita come sopra.
(6) t M MA sse t' M A per qualche t' ≥ t. Gabbay ignora l'operatore L comunque si può vedere facilmente
che definendo LA come abbreviazione di ¬M¬A si ottiene
(7) t M LA sse per ogni t' ≥ t esiste t" ≥ t' tale che t" M A. Utilizzeremo le notazioni solite con il prefisso G per indicare la logica intuizionista di Gabbay. Esempio:
Mostriamo che per ogni A ∈ L la formula MA v ¬A é G-valida. Prendiamo una qualsiasi struttura M = <U,≤,m> e sia t ∈ U. Consideriamo i due casi:
(1) t' M A per qualche t' ≥ t; allora t M MA e quindi
t M MA v ¬A (2) t' ¬M A per ogni t' ≥ t; allora t M ¬A e quindi t MMA v ¬A. Poiché M e t sono scelti arbitrariamente se ne conclude che
MA v ¬A é G-valida. Si può vedere facilmente che i seguenti schemi sono G-validi:
(G1) ¬MA ≡ ¬A (G2) (MA -> B) ≡ ¬A v B (G3) (MA -> A) ≡ ¬A v A (G4) (MA -> ¬A) ≡ ¬A (G5) M(A & B) -> MA & MB.

184
Esempio:
Sia T = Mp, ¬p; T non é soddisfacibile nella G-logica. Esempio:
Sia T = ¬Mp; nella G-logica T é equivalente a ¬p. Esempio:
Sia T =M(p & q), ¬p; T non é soddisfacibile nella G-logica. Definizione 7.5.8 (Gabbay 1982) Diremo che una formula B segue non monotonicamente da una formula
A e scriveremo A > B sse esiste una sequenza finita di formule C0 = A, C1, ..., Cn = B e un insieme EA di formule MD11, ..., MD1k . . . . . . MDn1, ..., MDnk chiamate assunzioni extra tali che k
(1) Ci-1 & ∩ MDij G Ci per tutti 1≤i≤n, 1≤j≤k j=1
(2) Se A é G-soddisfacibile allora EA ∪ A é G- soddisfacibile. La sequenza C0, C1, ..., Cn si dice dimostrazione non monotonica di B da A. La condizione (2) omessa nella formulazione originaria di Gabbay restringe le assunzioni extra delle dimostrazioni non monotoniche solo a quelle G-soddisfacibili. Se si ignora questa restrizione, la nozione di dimostrazione non monotonica diviene estremamante problematica. Per esempio, ogni formula potrebbe essere ricavata
non monotonicamente da ogni formula della forma ¬A, infatti po- tremmo considerare MA come una assunzione extra e quindi, poiché
t ¬M ¬A & MA per tutti gli M,t , otteniamo ¬A & MA G B per qualsiasi formula B. Esempio:
Sia A = Mp -> p. Poiché (Mp -> p) & Mp G p e (Mp -> p) & Mp é G-soddisfacibile, la sequenza C0 = Mp -> p, C1 = p é una di- mostrazione non monotonica di p da A; l'insieme di assunzioni extra utilizzato in questa dimostrazione consiste di EA = Mp.
In maniera analoga, poiché (Mp -> p) & M¬P G ¬p e (Mp -> p) & M¬p é G-soddisfacibile, la sequenza C0 = Mp -> p C1 =¬p é una dimostrazione non monotonica di ¬p da A, e per tale dimostra- zione EA = M¬p. In conclusione A > p e A > ¬p. Dall'esempio appena visto appare evidente che il sistema di Gab-

185
bay risulta problematico nelle applicazioni formali del ragiona- mento basato sul senso comune. Che una formula e la sua negazione possano essere non monotonicamente derivabili da una affermazione particolare non é sorprendente e nemmeno porta a particolari difficoltà, comunque possiamo, come Gabbay suggerisce, scegliere una alternativa tra quelle possibili e da lì procedere, ma il
problema consiste nel fatto che se scegliamo di inferire ¬p da Mp ->p, le nostre scelte appaiono intuitivamente non fondate; infat- ti dal punto di vista del ragionamento basato sul senso comune il modo di intendere Mp -> p é "considerare p vera a meno di evi- denze che mostrano il contrario". Il concetto "B segue non monotonicamente da una formula A" può essere generalizzato ovviamente al concetto "B segue non monoto- nicamente da una teoria T": Definizione 7.5.8
Una formula B segue non monotonicamente da una teoria T, T G> B, sse A G> B, dove A = A1 & ... & An, e Ai ∈ T (1≤i≤n). Esempio: Sia T = Mp -> p, p & Mq -> q. Consideriamo A = Mp -> p & (p & Mq -> q).
Poiché A & Mp G A & p, A & p & Mq G q, a l'insieme A ∪ Mp,Mq é G-soddisfacibile, la sequenza C0 = A, C1 = A & p, e
l'insieme A ∪ Mp,Mq é G-soddisfacibile, la sequenza C0 = A1, C1 = A & p, C2 = q é una dimostrazione non monotonica di q in A.
(∃A) = Mp,Mq. Allora T G> q.

186
7.5.2 Logica modale non monotonica a tre valori Un differente approccio al problema di formalizzare la logica non monotonica é stato proposto da Turner (1984); il suo sistema a- nalogo a quello di Gabbay, si basa sulla logica a tre valori di Kleene. A differenza del punto di vista della logica classica, in cui o- gni formula può essere o vera o falsa, nella logica a tre valori si ammette l'esistenza di una terza possibilità. Questo terzo valore può essere interpretato in maniere diverse, ma general- mente esso rappresenta uno stato intermedio tra la verità dell'affermazione e la sua negazione. Nella logica a tre valori di Kleene (1952), una formula può es- sere vera (1), falsa (0) o indecidibile (u). Intuitivamente, una formula si trova nello stato (u) se la sua funzione di verità non é nota. Questa interpretazione porta alle seguenti tavole di verità per i connettivi tra le frasi:
¬A | A & B | 1 u 0 A v B | 1 u 0 ------- ------------------ ------------------ 1 | 0 1 | 1 u 0 1 | 1 1 1 u | u u | u u 0 u | 1 u u 0 | 1 0 | 0 0 0 0 | 1 u 0
A -> B | 1 u 0 A ≡ B | 1 u 0 -------------------- ------------------- 1 | 1 u 0 1 | 1 u 0 u | 1 u u u | u u u 0 | 1 1 1 0 | 0 u 1 la logica di Kleene (K-logica) é specificata su un linguaggio L analogamente alla logica classica. Definizione 7.5.9 Una interpretazione parziale per L consiste in una funzione m che assegna ad ogni proposizione costante di L un elemento 0,1,u. Il valore di una formula A in una interpretazione m, denotata con V(A), é un elemento di 0,1,u specificato come segue: (1) V(p) = m(p) per ogni proposizione costante p
(2) V(¬A) = ¬V(A) (3) V(A & B) = V(A) & V(B) (4) V(A v B) = V(A) v V(B) (5) V(A -> B) = V(A) -> V(B)
(6) V(A ≡ B) = V(A) ≡ V(B)
dove ¬, &, v, -> e ≡ sono calcolati in accordo con le tavole di verità sopra riportate. Diremo che A é K-valida sse V(A) = 1, per ogni interpretazione parziale m. É interessante notare che la legge del terzo escluso
non é valida nella K-logica, cioé lo schema A v ¬A non é K- valido. L'insieme dei valori di verità 1,u,0 possiede un ordine par-
ziale naturale, ≤, dato da 1≤1, u≤u, 0≤0, u≤0, u≤1:

187
1 0 \ / u
Intuitivamente i≤j sse i fornisce minore (o uguale) informazione di j. Definizione 7.5.10 siano m ed m' due interpretazioni parziali per L. Diremo che m'
estende m, m≤m', sse m(p) ≤ m'(p), per ogni proposizione costante p ∈ L. Teorema 7.5.11
Per ogni A ∈ L, se m ≤ m', allora V(A) in m é ≤ V(A) in m'. Accenniamo, brevemente, alla logica non monotonica di Turner. Il suo sistema é costruito su di un linguaggio logico modale del primo ordine, comprendente un operatore modale M : una formula della forma MA si interpreta "A é plausibile". Il sistema di Turner si basa concettualmente sulle seguenti as- sunzioni: (1) Le inferenze non monotoniche sono necessarie ed appropriate solo in quelle situazioni in cui la nostra conoscenza sul mondo é incompleta. (2) Ogni conclusione non monotonica derivata dalle nostre osser- vazioni deve essere plausibile rispetto alle informazioni parzia- li in nostro possesso. Nella logica di Turner, stati di informazione incompleta sono rappresentati da interpretazioni parziali della K-logica. Per descrivere l'idea di "conclusione palusibile" egli introduce
una relazione binaria ≈>, operante tra due interpretazioni: la relazione m1 ≈> m2 si legge "m2 plausibilmente estende m1". L'intenzione é quella di esprimere il fatto che A é plausibile relativamente ad un certo stato di conoscenza rappresentato da m sse A é vera in qualche interpretazione che plausibilmente e- stende m.
Occorre sottolineare che la relazione di plausibilità ≈> é un concetto primitivo; come la relazione di accessibilità implemen- tata nella logica modale, la relazione di plausibilità non può essere definita più precisamente. Il massimo che si può fare consiste nell'imporre alcune proprietà che tale relazione deve possedere, in maniera tale da riflettere la nostra idea di mondo plausibile. Definizione 7.5.12 (Turner 1984)
Sia ≈> una relazione binaria specificata su un insieme F di in- terpretazioni parziali della K-logica.
Diremo che ≈> é una relazione di plausibilità sse
(1) m ≈> m' implica m ≤ m'
(2) m ≈> m

188
(3) m ≈> m' e m' ≈> m" implica m ≈> m" per tutti m,m',m" in F. La logica non monotonica di Turner si basa sui seguenti concetti semantici: Definizione 7.5.13 (Turner 1984)
Una struttura modello per L consiste in un sistema M = <F,≈>>, dove F é l'insieme di tutte le interpretazioni parziali per L e
≈> é la relazione di plausibilità su F. É interessante osservare che la nozione di struttura modello re- stringe il concetto di struttura intuizionistica di Kripke; più
specificatamente, ogni struttura modello <F,≈>> può essere vista come una struttura intuizionista <F,≈>,m> dove per ogni m' ∈ F, m(m',p) = 1 sse m'(p) = 1. Si può vedere facilmente che <F,≈>,m> é una struttura intuizionista se <F,≈>> é una struttura model- lo. Definizione 7.5.14 (Turner 1984)
Sia M = <F,≈>> una struttura modello per un linguaggio L. Con Vm(A) denotiamo il valore di una formula A in M dove m ∈ F. Allora Vm(A) é un elemento di 1,u,0 definito dalle regole se- guenti:
(1) Vm(p) = m(p) per ogni proposizione costante p ∈ L (2) Vm(A v B) = Vm(A) v Vm(B) (3) Vm(A & B) = Vm(A) & Vm(B)
(4) Vm(¬A) = ¬Vm(A) (5) Vm(A -> B) = Vm(A) -> Vm(B)
(6) Vm(A ≡ B) = Vm(A) ≡ Vm(B)
(7) sia m ≈> m' m' ∈ F Vm(MA) = 1 se Vm'(A) = 1 per qualche m' Vm(MA) = 0 se Vm'(A) = 0 per ogni m' Vm(MA) = u negli altri casi
dove v, &, ¬, -> e ≡ sono i connettivi con lo stesso significato attribuito nella logica di Kleene. Le regole dalla (1) alla (6) sono esattamente le regole di valu- tazione per la K-logica. La regola (7) fornisce la semantica per l'operatore M; in accordo con tale regola, MA é vera rispetto ad una interpretazione parziale m sse A é vera in qualche interpre- tazione che plausibilmente estende m; MA é falsa rispetto ad una interpretazione parziale m sse A é falsa in tutte le interpreta- zioni parziali. Denoteremo la logica di Turner come T-logica. Corollario 7.5.15
Sia A ∈ L, cioé A non coinvolge l'operatore M, e supponiamo che M = <F,≈>> sia una struttura modello per L. Allora per tutti m,m' in F, m ≈> m' implica Vm(A) ≤ Vm'(A). Esempio:

189
Assumiamo che p sia l'unica proposizione costante di un linguag-
gio L e consideriamo la struttura modello m = <F,≈>> definita da: F = m1,m2,m3 dove m1(p)=u, m2(p)=0, m3(p)=1;
≈> = <m1,m2>,<m1,m3> ∪ <mi,mi>:i=1,2,3. Prendiamo A = Mp. Allora vale Vm1(A)=1 e Vm2(A)=0. Le nozioni semantiche per la K-logica possono essere riportate nella T-logica; in particolare diremo che una formula A é vera
in M = <F,≈>> sse Vm(A)=1 per ogni m ∈ F. Una teoria T si dice T-soddisfatta in M da m, m ⇒ T sse Vm(A)=1
per ogni A ∈ T. T si dice T-soddisfacibile sse m ⇒ T per qualche
M = <F,≈>> e qualche m ∈ F. Una formula A si dice T-implicata da T, T ⇒ A, sse m ⇒ A ogni volta che m ⇒ T , per ogni M = <F,≈>> ed ogni m ∈ F. Se T ⇒ A diremo anche che A T-segue da T. Esempio:
Sia L = ¬Mp. In accordo con la nostra intuizione, T ⇒ ¬p. Per mostrare questo risultato, prendiamo una struttura modello M
= <F,≈>> e assumiamo che Vm(¬Mp) = 1, per qualche m ∈ F. Allora Vm(Mp) = 0 e quindi Vm'(p)=0 per ogni m' tale che m ≈> m'. In particolare, Vm(p)=0 poiché m ≈> m. Allora Vm(¬p)=1. Esempio:
Sia T = Mp,¬p. In accordo con le nostre aspettative, T non é T-soddisfacibile e quindi qualsiasi formula T-segue da T. Per vedere questo, assumiamo il contrario, cioé che Vm(Mp)=1 e
Vm(¬p)=1, per qualche M = <F,≈>> e qualche m ∈ F. Vm(Mp)=1 implica Vm'(p)=1, per qualche m' tale che m ≈> m'. Vm(¬p)=1 implica che Vm(p)=0 per tutti m' tali che m ≈> m'. Questo porta ad una contraddizione. Allo stesso modo si può dimostrare la non soddisfacibilità di
una teoria MA,¬A, in cui A non presenti ricorrenze dell'opera- tore M. Nel caso in cui A includa l'operatore M, MA,¬A potrebbe essere soddisfacibile. Prendiamo per esempio A = ¬Mp e conside- riamo la struttura modello M = <F,≈>> definita come: F = m1,m2,m3 dove m1(p)=u, m2(p)=0, m3(p)=1;
≈> = <m1,m2>,<m1,m3> ∪ <mi,mi>:i=1,2,3.
é facile verificare che Vm1(MA)=1 e Vm1(¬A)=1. Turner considera questa situazione come intuitivamente corretta, se il lettore non fosse di questa opinione dovrebbe comunque no- tare un punto importante: ogni formula senza modalità rappresen- ta un fatto di un mondo reale, in tal caso non é razionale ac- cettare che tale fatto sia falso e simultaneamente considerarlo plausibile; comunque, se una formula include una modalità, essa rappresenta ciò che un agente ritiene plausibile o non plausibi- le intorno a fatti del mondo, e in tal caso un fatto può essere plausibile rispetto ad un determinato stato della conoscenza m e non plausibile in una qualche estensione di questa; le formule modalizzate possono cambiare i loro valori di verità quando la conoscenza degli agenti aumenta. Se A é una tale formula, forza-

190
re la non soddisfacibilità di MA,¬A é intuitivamente ingiu- stificato. Esempio:
Sia T = M(p & q), ¬p. Una tale teoria non é T-soddisfacibile. Più generalmente, la teoria M(A & B), ¬A é non T- soddisfacibile se A non include ricorrenze di M, nel caso contra- rio essa potrebbe essere soddisfacibile. Per costruire una versione non monotonica della T-logica Turner ha suggerito di implementare il meccanismo delle "extra assunzio- ni" di Gabbay. Esempio: Sia T = Mp -> p. Nella logica non monotonica di Turner, T si
comporta esattamente come nel sistema di Gabbay, cioé T p e
T ¬p. Mostriamo che T ¬p facendo vedere che (Mp -> p) & M¬p) ⇒ ¬p, infatti Mp -> p, M¬p é T-soddisfacibile. Prendiamo una struttura modello M = <F,≈>> tale che Vm((Mp -> p) & M¬p)=1 per qualche m ∈ F e assumiamo che Vm(¬p) ≠ 1. Consideriamo due casi:
(1) Vm(¬p)=0. Allora Vm(p)=1 e quindi Vm(p)=1 per ogni m' tale che m ≈> m'; d'altra parte Vm((Mp -> p) & M¬p)=1 implica Vm(M¬p)=1 e perciò Vm(p)=0 per qualche m' tale che m ≈> m'. Questo porta ad una contraddizione.
(2) Vm(¬p)=u. Allora Vm(p)=u, Vm((Mp -> p) & M¬p)=1 implica Vm(Mp -> p) = 1. Allora , poiché Vm(p)=u, Vm(Mp)=0 si ha
Vm'(p)=0 per ogni m' tale che m ≈> m'; inparticolare Vm(p)=0 poi- ché m ≈> m. Questo porta ad una contraddizione.
La possibilità di ricavare ¬p da Mp -> p mostra che la logica non monotonica di Turner soffre esattamente degli stessi problemi incontrati con il formalismo di Gabbay, quando venga considerato come uno strumento per rappresentare le inferenze basate sul sen- so comune.

191
7.5.3 Logica modale non monotonica a quattro valori Vediamo ora una ulteriore generalizzazione della logica a tre va- lori: un ulteriore approccio al problema di formalizzare la logi- ca non monotonica. A partire dalla logica a tre valori di Kleene in cui una formula può essere o vera (1), falsa (0) o indecidibile (u) aggiungiamo ora un ulteriore valore che chiameremo contraddizione elementare (c); per introdurre questo concetto consideriamo un linguaggio proposizionale L composto di n formule atomiche <p1,p2,...,pn> sia <m1,m2,...,mn> una interpretazione per L dove ciascun m1,m2,...,mn é descritto da una coppia di vettori <b1,b2,...,bn | d1,d2,...,dn> di 2n variabili binarie secondo la seguente regola tabellare di derivazione dei valori di verità : bi di | mi ----------------- 0 0 | u (Vm(Pi) = u mancanza di informazione) 1 0 | 1 (Vm(Pi) = 1 Pi é vera)
0 1 | 0 (Vm(pi) = 0 ¬Pi é vera) 1 1 | c (Vm(pi) = c contraddizione elementare) Questa interpretazione porta alle seguenti tavole di verità per i connettivi tra le frasi:
¬A | A & B | 1 u c 0 A v B | 1 u c 0 ------- ---------------------- --------------------- 1 | 0 1 | 1 u 0 0 1 | 1 1 1 1 u | u u | u u 0 0 u | 1 u u u c | c c | 0 0 0 0 c | 1 u 0 0 0 | 1 0 | 0 0 0 0 0 | 1 u 0 0
A -> B | 1 u c 0 A ≡ B | 1 u c 0 ----------------------- ---------------------- 1 | 1 u 0 0 1 | 1 u 0 0 u | 1 u 0 u u | u u u u c | 0 0 0 0 c | 0 u 1 0 0 | 1 1 0 1 0 | 0 u 0 1 la logica sopradescritta, che denoteremo con O-logica, é speci- ficata su un linguaggio L analogamente alla logica classica. Definizione 7.5.16 Una interpretazione parziale per L consiste in una funzione m che assegna ad ogni proposizione costante di L un elemento 0,1,u,c. Il valore di una formula A in una interpretazione m, denotata con V(A), é un elemento di 0,1,u,c specificato come segue: (1) V(p) = m(p) per ogni proposizione costante p
(2) V(¬A) = ¬V(A) (3) V(A & B) = V(A) & V(B) (4) V(A v B) = V(A) v V(B) (5) V(A -> B) = V(A) -> V(B)
(6) V(A ≡ B) = V(A) ≡ V(B)

192
dove ¬, &, v, -> e ≡ sono calcolati in accordo con le tavole di verità sopra riportate. Diremo che A é O-valida sse V(A) = 1, per ogni interpretazione parziale m. É interessante notare che la legge del terzo escluso
non é valida nella O-logica, cioé lo schema A v ¬A non é O- valido; comunque se Vm(A) = 1 allora Vm(¬A) = 0 e viceversa. L'insieme dei valori di verità u,1,0,c possiede un ordine par-
ziale naturale (n-ordine), ≤, dato da 1≤1, u≤u, 0≤0, c≤c, u≤0, u≤1, 1≤c, 0≤c: c / \ 1 0 \ / u
Intuitivamente i≤j sse i fornisce un minor numero di bit (o ugua- le) di informazione rispetto a j; da notare che l'informazione globale utile diviene zero quando due bit di informazione sono contradditori, in tal caso l'ordinamento per l'informazione uti- lizzabile diviene: (ordine parziale logico l-ordine)
1≤1, u≤u, 0≤0, c≤c, u≤0, u≤1, c≤1, c≤0: 1 0 \ / c - u Definizione 7.5.17 Siano m ed m' due interpretazioni parziali per L.
(i) Diremo che m' estende m relativamente ad un n-ordine, m≤m', sse m(p) ≤ m'(p), per ogni proposizione costante p ∈ L secondo la relazione d'ordine naturale (n-ordine).
(ii) Diremo che m' estende m relativamente ad un l-ordine, m≤m', sse m(p) ≤ m'(p), per ogni proposizione costante p ∈ L secondo la relazione d'ordine logica (l-ordine). Teorema 7.5.18
Per ogni A ∈ L, secondo un n-ordine, se m ≤ m', allora V(A) in m é ≤ V(A) in m' secondo un n-ordine.
Il significato dell'ordinamento naturale m ≤ m' descrive un in- cremento di informazione; quando due bit di informazione sono contradditori l'informazione aggiuntiva ottiene l'effetto di eli- dere una informazione precedentemente ritenuta valida: un'affer- mazione ritenuta vera si dimostra contradditoria e quindi falsa.
Il significato dell'ordinamento logico m ≤ m' descrive la possi- bilità di un decremento di informazione quando affermazioni vere o false divengono contradditorie. Accenniamo alla logica non monotonica che risulta dallo schema sopra proposto. Il sistema é costruito su di un linguaggio logico modale del primo ordine, comprendente un operatore modale M : una formula

193
della forma MA si interpreta "A é plausibile". Il sistema é basato concettualmente sulle seguenti assunzioni: (1) Le inferenze non monotoniche sono necessarie ed appropriate solo in quelle situazioni in cui la nostra conoscenza sul mondo é incompleta. (2) Ogni conclusione non monotonica derivata dalle nostre osser- vazioni deve essere plausibile rispetto alle informazioni parzia- li in nostro possesso. (3) Ogni conclusione non é mai definitiva, anche se derivata da precise osservazioni può essere contraddetta in qualsiasi momen- to da eventi futuri non ancora noti. Nella logica prospettata, stati di informazione incompleta sono rappresentati da interpretazioni parziali della O-logica. Per descrivere l'idea di "conclusione palusibile" si introduce
una relazione binaria ≈>, operante tra due interpretazioni: la relazione m1 ≈> m2 si legge "m2 plausibilmente estende m1". L'intenzione é quella di esprimere il fatto che A é plausibile relativamente ad un certo stato di conoscenza rappresentato da m sse A é vera in qualche interpretazione che plausibilmente e- stende m.
Occorre sottolineare che la relazione di plausibilità ≈> é un concetto primitivo; come la relazione di accessibilità implemen- tata nella logica modale, la relazione di plausibilità non può essere definita più precisamente. Il massimo che si può fare consiste nell'imporre alcune proprietà che tale relazione deve possedere, in maniera tale da riflettere la nostra idea di mondo plausibile. Definizione 7.5.19
Sia ≈> una relazione binaria specificata su un insieme F di in- terpretazioni parziali della O-logica. Introduciamo il concetto di generazione. Consideriamo generazioni successive di interpretazioni m0,m1,... ciascuna ricavabile dalla precedente sulla base di attribuzione di nuovi valori di verità a partire da una interpretazione ini- ziale m0, secondo le seguenti regole: (i) il valore di verità u può divenire 1,0,c; (ii) il valore di verità 1 può divenire c; (iii) il valore di verità 0 può divenire c; (iv) il valore di verità c non può cambiare.
Diremo che ≈> é una relazione di plausibilità sse
(1) m ≈> m' implica m ≤ m' alla prima generazione
(2) m ≈> m alla generazione zero
(3) m ≈> m' e m' ≈> m" implica m ≈> m" alla seconda ge- nerazione per tutti m,m',m" in F. Una tale logica non monotonica si basa sui seguenti concetti se- mantici:

194
Definizione 7.5.20
Una O-struttura modello per L consiste in un sistema M = <F,≈>>, dove F é l'insieme di tutte le interpretazioni parziali per L e
≈> é la relazione di plausibilità su F. É interessante osservare che ora la nozione di O-struttura mo- dello si differenzia dal concetto di struttura intuizionistica di
Kripke; più specificatamente, ogni struttura modello <F,≈>> non può essere vista come una struttura intuizionista <F,≈>,m>, come nel caso della struttura modello di Turner, infatti non é più
vero che per ogni m' ∈ F, m(m',p) = 1 sse m'(p) = 1; poiché nel momento in cui si creano contraddizioni anche se m(m',p) = 1 può essere che m'(p) = c. Definizione 7.5.21
Sia M = <F,≈>> una O-struttura modello per un linguaggio L. Con Vm(A) denotiamo il valore di una formula A in M dove m ∈ F. Allora Vm(A) é un elemento di 1,u,c,0 definito dalle regole seguenti:
(1) Vm(p) = m(p) per ogni proposizione costante p ∈ L (2) Vm(A v B) = Vm(A) v Vm(B) (3) Vm(A & B) = Vm(A) & Vm(B)
(4) Vm(¬A) = ¬Vm(A) (5) Vm(A -> B) = Vm(A) -> Vm(B)
(6) Vm(A ≡ B) = Vm(A) ≡ Vm(B)
(7) sia m ≈> m' m' ∈ F Vm(MA) = 1 se Vm'(A) = 1 per qualche m'
e Vm'(A) ≠ c per ogni m' Vm(MA) = 0 se Vm'(A) = 0 per ogni m'
e Vm'(A) ≠ c per ogni m' Vm(MA) = u negli altri casi
dove v, &, ¬, -> e ≡ sono i connettivi con lo stesso significato attribuito nella O-logica sopra esposta. Le regole dalla (1) alla (6) sono esattamente le regole di valu- tazione per la O-logica. La regola (7) fornisce la semantica per l'operatore M; in accordo con tale regola, MA é vera rispetto ad una interpretazione parziale m sse A é vera in qualche interpre- tazione che plausibilmente estende m, ma che non contenga con- traddizioni elementari; MA é falsa rispetto ad una interpreta- zione parziale m sse A é falsa in tutte le interpretazioni par- ziali, purché non siano presenti contraddizioni elementari. Denoteremo la logica così ricavata con B-logica. Corollario 7.5.22
Sia A ∈ L, cioé A non coinvolge l'operatore M, e supponiamo che M = <F,≈>> sia una O-struttura modello per L. Allora per tutti m,m' in F, m ≈> m' implica Vm(A) ≤ Vm'(A) secon- do l'ordine naturale. Esempio: Assumiamo che p sia l'unica proposizione costante di un linguag-
gio L e consideriamo la struttura modello m = <F,≈>> definita da:

195
F = <b1 | d1> = <0 | 0>,<0 | 1>,<1 | 0>,<1 | 1>; = m1,m2,m3,m4 dove m1(p)=u, m2(p)=0, m3(p)=1 m4(p)=c;
≈> = <m1,m2>,<m1,m3>,<m1,m4> ∪ <mi,mi>:i=1,2,3,4. Prendiamo A = Mp. Allora vale Vm1(A)=1 e Vm2(A)=0. Le nozioni semantiche per la O-logica possono essere riportate nella B-logica; in particolare diremo che una formula A é vera
in M = <F,≈>> sse Vm(A)=1 per ogni m ∈ F. Una teoria T si dice B-soddisfatta in M da m, m ⇒ T sse Vm(A)=1
per ogni A ∈ T. T si dice B-soddisfacibile sse m ⇒ T per qualche
M = <F,≈>> e qualche m ∈ F. Una formula A si dice B-implicata da T, T ⇒ A, sse m ⇒ A ogni volta che m ⇒ T , per ogni M = <F,≈>> ed ogni m ∈ F. Se T ⇒ A diremo anche che A B-segue da T.

196
7.6 Rappresentazione in uno spazio vettoriale binario Introduciamo alcune ulteriori convenzioni sulle notazioni. Definizione 7.6.1 Sia L un linguaggio logico proposizionale.
p1,p2,...,pn ∈ L. Siano x1,x2,...,xn fatti atomici corrispondenti a p1,p2,...,pn.
Siano b1,b2,...,bm variabili binarie, tali per cui bi ∈ 0,1 b1,b2,...,bm ∈ X. Poniamo che xi sia descrivibile con una combinazione di bj: xi = b1,b2,...,bj ovvero xi = b1 & b2 & ... & bj.
allora x1,x2,...,xn ∈ |P(X).
Siano x1,x2,x3,x4,x5 ∈ |P(X). Rappresentiamo le seguenti implicazioni con: 1) x1 -> x2 con x2 :- x1. 2) x1 & x2 & x3 -> x4 con x4 :- x1,x2,x3. o anche x4 :- x1,x2,x3. 3) x1 -> x2 v x3 con [x2,x3] :- x1. 4) x1 & x2 & x3 -> x4 v x5 con [x4,x5] :- x1,x2,x3. o anche [x4,x5] :- x1,x2,x3. 5) x1 v x2 v x3 -> x4 con x4 :- [x1,x2,x3]. o anche x4 :- x1. x4 :- x2. x4 :- x3. 6) x1 -> x2 & x3 con x2,x3 :- x1. o anche x2 :- x1. x3 :- x1. 7) x1 & x2 & x3 -> x4 & x5 con x4,x5 :- x1,x2,x3. o anche x4 :- x1,x2,x3. x5 :- x1,x2,x3. 8) x1 v x2 v x3 -> x4 & x5 con x4,x5 :- [x1,x2,x3]. o anche x4 :- [x1,x2,x3]. x5 :- [x1,x2,x3]. o anche x4 :- x1. x4 :- x2. x4 :- x3. x5 :- x1. x5 :- x2. x5 :- x3. In altri termini: x1,x2,x3 corrisponde a x1 & x2 & x3 [x1,x2,x3] corrisponde a x1 v x2 v x3. Definizione 7.6.2 Sia B un insieme numerabile finito di variabili binarie

197
B = b1,b2,...,bn consideriamo l'insieme potenza di B, X = |P(B), X contiene n n
Σ ( ) elementi distinti k=1 k
Siano xi,xj ∈ X; xi = bi1,bi2,...,bih, xj = bj1,bj2,...,bjl denotiamo con
xi,xj = xi ∪ xj = b1,b2,...,bk bk ∈ (xi v xj) xi,xj = xi & xj = (bi1 & ... & bih) & (bj1 & ... & bjl) [xi,xj] = xi v xj = (bi1 & ... & bih) v (bj1 & ... & bjl)
allora xi & xj é equivalente a xi ∪ xj mentre
[xi,xj] é equivalente a xi ∩ xj & [(xi \ xj) v (xj \ xi)]
se denotiamo con xi δ xj = [(xi \ xj) v (xj \ xi)] ne segue che
[xi,xj] é equivalente a (xi ∩ xj) ∪ (xi δ xj). in particolare é possibile trasformare la regola: [xi,xj] :- xk. nelle regole equivalenti:
(xi ∩ xk) :- xk. [(xi δ xk)] :- xk. o anche
(xi ∩ xk) :- xk. [(xi \ xj),(xj \ xi)] :- xk. Proposizione 7.6.3 É possibile eseguire una trasformazione da un sistema di regole dato ad un sistema di regole valido per le variabili binarie tra- mite sostituzione di variabili. Esempio: Sia xi,xj :- xk. un sistema di regole R1 dove: xi = bi1,....,bih, xj = bj1,...,bjl e xk = bk1,...,bkm allora R1 diviene, R2 : xi :- xk. xj :- xk. Sostituendo si ottiene R3: bi1,...,bih :- xk. bj1,...,bjl :- xk. da cui R4: bi1 :- xk. bi2 :- xk. ... bih :- xk.

198
bj1 :- xk. bj2 :- xk. ... bjh :- xk. eliminando le regole doppie, cioé le regole che si presentano identiche due volte nel sistema, si ottiene R5 (regola zero di riduzione dei sistemi) : br1 :- xk. br2 :- xk. ... brn :- xk.
dove brl ∈ (xi ∪ xj) (1≤l≤n)
ovvero (xi ∪ xj) :- xk. come si voleva mostrare. Esempio: Consideriamo il seguente sistema di regole R6: [xi,xj] :- xk.
allora per ogni brl ∈ (xi ∩ xj) si ha brl :- xk. mentre ogni combinazione di brm ∈ [(xi \ xj) v (xj \ xi)] sono, in alternativa, deducibili da xk; si ha pertanto R7:
(xi ∩ xj) :- xk. (xi δ xj) :- xk. come si voleva mostrare. Definizione 7.6.4 Data una regola nella forma xk :- x1,x2,x3,...,xn. diremo che xk é la testa della regola mentre x1,x2,...,xn co- stituisce il corpo della regola. Prendiamo in esame un sistema di rappresentazione di una "realtà di interesse" esterna. Come possiamo rappresentare internamente fatti, eventi, oggetti, attributi, ecc. di una realtà esterna? Definizione 7.6.5 Consideriamo n variabili binarie ordinate <b1,b2,...,bn>.
Sia B l'insieme di tali variabili bi ∈ B. Sia p : B --> [0,1] una funzione interpretabile come probabilità
definita per ogni bi ∈ B. Interpretiamo B come sistema di rappresentazione di una realtà esterna R, in particolare poniamo che ciascun valore binario bk sia in relazione con una variabile esterna al sistema a cui sono accessibili n stati. Consideriamo per esempio tre monete. Tre monete possono trovarsi nelle (2 exp(3) = 8 ) configurazioni: <TTT>,<TTC>,<TCT>,<TCC>,<CTT>,<CTC>,<CCT>,<CCC>. Supponiamo che bk rappresenti la configurazione <TTT>. Allora possiamo interpretare la funzione p nel seguente signifi- cato:

199
p(bk) = 1 la configurazione <TTT> é vera p(bk) = 0 la configurazione <TTT> é falsa 0 < p(bk) < 1 la configurazione é sconosciuta A priori si potrebbe dire che p(bk) = 1/8. Informazione ricavabile dalla conoscenza delle configurazioni possibili, ma tale conoscenza é sconosciuta al sistema all'ini- zio, per definizione. L'informazione apportata al sistema dall'osservazione delle mone- te é data da : Inf. = - ln(1/8) = 3 bit. L'informazione registrata nel sistema dopo l'osservazione della
configurazione, siccome può essere solo o <TTT> o ¬<TTT>, consi- ste in 1 bit di informazione. Supponiamo di utilizzare due vettori binari per rappresentare i fatti: <b1,b2,...,bn> e <d1,d2,...,dn> tali che ciascun valore binario bk sia accoppiato al rispettivo valore binario dk. In particolare scriveremo: <b1,b2,...,bn | d1,d2,...,dn>. La coppia <bk | dk> possiamo metterla in relazione con la confi- gurazione <TTT> ed interpretarla nel seguente significato: p(bk) = 1 <TTT> é vera
p(dk) = 1 ¬<TTT> é vera
Le relazioni logiche tra bk e dk sono bk :- ¬dk e dk :- ¬bk. Definizione 7.6.6 In particolare le combinazioni possibili per bk e dk divengono: p(bk) = 1 , p(dk) = 0 la configurazione <TTT> é vera
p(bk) = 0 , p(dk) = 1 la configurazione ¬<TTT> é vera p(bk) = 0 , p(dk) = 0 informazione mancante p(bk) = 1 , p(dk) = 1 contraddizione L'informazione registrata consiste di due bit. Nel caso in cui p(bk) e p(dk) possano assumere solo valori dell'insieme 0,1 allora é possibile considerare direttamente il valore binario di bk e dk nel seguente significato: <bk | dk> < 1 | 0 > fatto vero < 0 | 1 > fatto negato < 0 | 0 > informazione mancante < 1 | 1 > contraddizione Definizione 7.6.7 Vediamo il caso di deduzione logica da regole del tipo bi :- bj. Consideriamo un caso particolare di deduzione che utilizza varia- bili accoppiate e che ci fornisce una comoda modalità di propa- gazione della affidabilità.
Sia neg : X --> ¬X tale che per ogni bk ∈ X neg(bk) = dk dk ∈ ¬X -1
e neg (dk) = bk. In altri termini abbiamo bk :- ¬dk e dk :- ¬bk. Con questa convenzione abbiamo eliminato le affermazioni false dalle regole di deduzione, ed in particolare la regola:

200
¬bi :- bj diviene di :- bj.
Siano bi, bj ∈ X di,dj ∈ ¬X , rk ∈ R insieme delle regole, in particolare: rk) bj :- bi. otteniamo le seguenti combinazioni: <bi | di> | rk | <bj | dj> -------------------------------- 1 1 | 1 | 0 0 Contraddizione 1 0 | 1 | 1 0 bj :- bi. 0 1 | 1 | 0 1 dj :- di. 0 0 | 1 | 0 0 Manca informazione 1 1 | -1 | 0 0 Contraddizione 1 0 | -1 | 0 1 dj :- bi. 0 1 | -1 | 1 0 bj :- di. 0 0 | -1 | 0 0 Manca informazione Definizione 7.6.8 Vediamo come sia possibile definire una misura dell'informazione registrata che tenga conto delle contraddizioni elementari.
Sia B = <b1,b2,...,bn> e ¬B = <d1,d2,...,dn> due insiemi di va- riabili binarie ordinate; bi,di ∈ 0,1. Sia X = <b1,b2,...,bn | d1,d2,...,dn> un insieme di coppie di va- riabili con cui rappresentare dei fatti atomici.
Consideriamo xi ∈ |P(X); xi=<b1 | d1>,<b2 | d2>,...,<bk | dk>.
Definiamo come misura µ(<bi | di>) sulla coppia bi,di una funzio- ne tale che per ogni <bi | di> ∈ xi fornisca i seguenti valori:
<bi | di> | µ(<bi | di>) ---------------------------- 0 0 | 0 1 0 | 1 0 1 | 1 1 1 | 0
allora µ(xi) = Σ µ(<bk | dk>) = n bit di informazione k
µ(xi) é una misura su |P(X) e rappresenta la quantità di infor- mazione, in numero di bit, registrata.

201
7.7 Sistemi ipotetici in comunicazione reciproca Consideriamo due sistemi di elaborazione S1, S2 a stati finiti in comunicazione tra loro tramite un canale di trasmissione C. Denotiamo con R1 lo spazio di rappresentazioni possibili per S1 e con R2 lo spazio di rappresentazioni possibili per S2. In altri termini R1 ed R2 sono la memoria di S1 e di S2. Ipotizziamo che l'interazione tra S1 ed S2 consista nello scam- biarsi messaggi selezionati da un determinato repertorio.
(fig 7.10) Il processo di comunicazione tra S1 ed S2 potrebbe svolgersi nel modo seguente: 1) S1 manda un messaggio msg1 a S2, il messaggio msg1 é sele- zionato a caso tra n messaggi possibili. 2) S2 può riconoscere il messaggio oppure no. 3) S2 non riconosce il messaggio inviato da S1, in tal caso in- via ad S1 il messaggio corrispondente a "messaggio sconosciuto". 4) S2 riconosce il messaggio inviato da S1 e lo elabora (Elab2) trova in R2 la rappresentazione corrispondente decodificando il messaggio (Dec2) 5) L'elaborazione del messaggio da parte di S2 consiste essen- zialmente nel determinare le m risposte possibili relativamente al messaggio ricevuto: r1,r2,...,rm = Rp 6) S2 seleziona casualmente (Sel2) una risposta tra quelle pos-

202
sibili ri ∈ Rp. 7) S2 codifica (Cod2) la risposta selezionata ri in un messaggio msg2 e quindi lo invia ad S1. 8) S1 riceve il messaggio msg2 e si comporta analogamente. 9) Il processo si ripete. Analizziamo in maggior dettaglio la comunicazione che si istaura tra S1 ed S2; in particolare essa può essere schematizzata nella maniera seguente: Dec2 Elab2 Sel2 Cod2 1) msg1 ---> rk1 ----> r11,r12,...,r1r ----> ri1 ---> msg2 Dec1 Elab1 Sel1 Cod1 2) msg2 ---> rk2 ----> r21,r22,...,r2r ----> ri2 ---> msg3 Dec2 Elab2 Sel2 Cod2 3) msg3 ---> rk3 ----> r31,r32,...,r3r ----> ri3 ---> msg4 Supponiamo che Elab1, Elab2, le elaborazioni dei messaggi da par- te di S1 ed S2 siano descrivibili tramite un certo numero di re- gole del tipo: xk :- x1,x2,...,xn. Elab1 = xk1 :- x11, x12, ..., x1m1. xk2 :- x21, x22, ..., x2m2. ... xkn :- xn1, xn2, ..., xnmn. mentre la funzione di selezione Sel1 la consideriamo casuale: Sel1 x1,x2,...,xk -----> xi Supponiamo, per semplicità, che i messaggi corrispondano alle rappresentazioni; in altri termini, le funzioni di codifica e de- codifica coincidono con la trasformazione identica. Ipotizziamo inoltre che le rappresentazioni r1,...,rn siano dei vettori binari. Con le assunzioni descritte lo schema della comunicazione tra S1 ed S2 diventa: Elab2 Sel2 1) msg1 ----> r11,r12,...,r1r ----> msg2 Elab1 Sel1 2) msg2 ----> r21,r22,...,r2r ----> msg3 Elab1 Sel1 3) msg3 ----> r31,r32,...,r3r ----> msg4 Il processo di comunicazione descritto non é determinato; solo nel caso in cui, per un certo messaggio msg(k), l'elaborazione del messaggio stesso fornisce una unica possibile risposta si ot-

203
tiene una risposta determinata. Elab2 Sel2 k) msg(k) ----> rk -----> msg(k+1) Proposizione 7.7.1 Ogni volta che S1, dopo aver inviato il messaggio msg(i), riceve un messaggio msg(j), può dedurre che tra le regole di S2 é pre- sente la regola: msg(j) :- msg(i). In tal caso può inserirla nel proprio sistema di regole. Durante il processo di comunicazione si produce un allineamento di comportamento tra S1 ed S2: S1 assorbe la conoscenza sulla struttura di S2 e viceversa. Proposizione 7.7.2 Se tutte (un numero significativo) le volte che S1 invia ad S2 il _ _ messaggio msg(i) ottiene come risposta msg(j) allora il messaggio perde il proprio contenuto informativo. Infatti é divenuto prevedibile con alta probabilità.

204
7.8 Trasformazioni T da |P(X) a |P(X) Vediamo come costruire una rappresentazione in uno spazio di va- riabili binarie. Prendiamo n variabili binarie: <b1,b2,...,bn>.
Sia X l'insieme di tali variabili bi ∈ X. Prendiamo una trasformazione T : |P(X) ---> |P(X) dalla potenza di X su sé stessa tale che:
T(xi) = xj , xi contenuto in xj per ogni xi ∈ S1 dove S1 é un sottoinsieme di |P(X). _ Definiamo una trasformazione GEN : S1 ---> S1 tale che
GEN(xi) = T(xi) \ xi = xj \ xi = xk per ogni xi ∈ S1.
(fig. 7.11) Vediamo una interpretazione delle trasformazioni introdotte. Associando a ciascuna variabile un significato si ottiene una rappresentazione astratta di una realtà di interesse; per esem- pio possiamo associare alle variabili binarie i seguenti signifi- cati: b1 - insieme A b2 - insieme B b3 - proprietà P1 b4 - proprietà P2 b5 - oggetto o1 b6 - oggetto o2 b7 - oggetto o3 b8 - oggetto o4 b9 - oggetto o5

205
Allora ogni variabile può essere associata ad un arbitrario in- sieme di variabili. In particolare la trasformazione T applicata ad un sottoinsieme di S1, xi ci fornisce xj.
Inoltre GEN(xi) = xj può essere interpretata come xi ⇒ xj, xi
implica xj, oppure xi → xj, da xi si deduce xj. Di più, GEN(xi) = xk = xj \ xi, allora é possibile interpretare xk come l'insieme di variabili che la GEN collega direttamente all'insieme di variabili xi, in particolare possono essere consi- derate come proprietà associate all'insieme xi, ovvero proprie- tà descriventi xi. Alla luce di questa interpretazione, se xk = bk allora bk può essere interpretato come insieme, proprietà, oggetto, attributo, o altro ancora. Per esempio: Se GEN(xi) = b1, allora la GEN esprime una relazione di appar- tenenza, secondo la quale tutti gli elementi di xi appartengono all'insieme A. Se GEN(xj) = b3 allora la GEN esprime il fatto che tutti gli elementi di xj possiedono la proprietà P1. Se GEN(xk) = b5 allora la GEN esprime il fatto che gli elementi di xk sono attributi dell'oggetto o1. In particolare tenendo presente le associazioni sopra descritte Se GEN(o1,o2,o3) = A si può dire che l'insieme A é compo- sto dagli oggetti o1,o2,o3. Se GEN(A,P2) = o1 si può dire che l'oggetto o1 possiede le seguenti caratteristiche: appartiene all'insieme A ha la proprietà P2. Se GEN(o2,o3,o4) = P1 si può dire che gli oggetti o2,o3,o4 possiedono la proprietà P1. Da notare che GEN(o1,o2,o3) = A esprime la relazione "è composto da" GEN(A,P2) = o1 esprime la relazione "é parte di" "possiede la" GEN(o2,o3,o4) = P1 esprime la relazione "é posseduta da" _ La trasformazione GEN : S1 ---> S1 può essere descritta da n regole del tipo xk :- x1,x2,...,xn. Esempio: Sia GEN tale che o1,o2,o3 ---> A ; o3,o4,o5 ---> B o2,o3,o4 ---> P1 ; o1,o2,o5 ---> P2 Allora abbiamo il sistema di regole R1 che descrive gli insiemi definiti dagli elementi costituenti: 1) A :- o1,o2,o3. 2) B :- o3,o4,o5.

206
3) P1 :- o2,o3,o4. 4) P2 :- o1,o2,o5. Consideriamo anche le relazioni seguenti che chiameremo relazioni duali: A,P2 ---> o1 ; A,P1,P2 ---> o2 A,B,P1 ---> o3 ; B,P1 ---> o4 ; B,P2 ---> o5 Il sistema di regole corrispondente risulta essere R2 che descri- ve gli oggetti definiti dagli attributi posseduti: 1d) o1 :- A,P2. 2d) o2 :- A,P1,P2. 3d) o3 :- A,B,P1. 4d) o4 :- B,P1. 5d) o5 :- B,P2.
L'insieme delle regole R1 ∪ R2 descrivono la trasformazione GEN. L'insieme di regole R1 può essere interpretato come un certo nu- mero di relazioni binarie da considerarsi congiuntamente (inter- pretazione AND). Si possono prendere in considerazione anche le relazioni binarie che rappresentano R2, in tal caso esse sono le relazioni duali. Esempio: R1 Duali (A - o1) (o1 - A) (o2 - A) (A - o2) (o1 - P2) (o2 - P1) (A - o3) (o2 - P2)
(fig. 7.12)

207
Vediamo come sia possibile ricavare dai sistemi di regole de- scritti, dei sistemi di regole che esprimano le operazioni di u-
nione ∪ ed intersezione ∩ tra insiemi. In particolare cerchiamo di costruire il sistema di regole che
descriva A ∪ B. Poiché le relazioni binarie (nell'interpretazione AND) sono: (o1 - A) (o2 - A) (o3 - A) (o3 - B) (o4 - B) (o5 - B) (o2 - P1) (o3 - P1) (o4 - P1) (o1 - P2) (o2 - P2) (o5 - P2) che nell'interpretazione OR sono descritte dal sistema di regole R3: o1 :- A. o2 :- A. o3 :- A. o3 :- B. o4 :- B. o5 :- B. che corrisponde ad una GEN tale che A ---> o1,o2,o3 ; B ---> o3,o4,o5
A,B ---> o1,o2,o3,o4,o5 corrispondente all'unione A ∪ B. Dato A e B possiamo estrarre dalle relazioni binarie (interpreta- zione AND ristretta ad A e B) le regole R4:
o1 :- A,¬B (dove ¬B sta per non B) o2 :- A,¬B o3 :- A,B
o4 :- ¬A,B o5 :- ¬A,B che corrisponde ad una GEN tale che
A,¬B ---> o1,o2,o3 ; ¬A,B ---> o3,o4,o5 A,B ---> o3 corrispondente all'intersezione A ∩ B.
Vediamo un ulteriore esempio: P2 ∩ (A ∪ P1) Le relazioni sono: (o1 - A) (o2 - A) (o3 - A) (o4 - B) (o5 - B) (o1 - P2) (o2 - P1) (o3 - P1) (o4 - P1) (o5 - P2) (o2 - P2) (o3 - B) da cui dati P2, A, P1 possiamo ricavare (interpretazione AND ristretta ad A, P1, P2) le regole R5:
o1 :- A,¬P1,P2. o2 :- A,P1,P2.
o3 :- A,P1,¬P2. o4 :- ¬A,P1,¬P2. o5 :- ¬A,¬P1,P2.

208
ed anche (interpretazione OR) le regole R6: o1 :- A. o2 :- A. o3 :- A. o2 :- P1. o3 :- P1. o4 :- P1. o1 :- P2. o2 :- P2. o5 :- P2. Allora le regole R5 ed R6 consentono di costruire una GEN tale che: A ---> o1,o2,o3 ; P1 ---> o2,o3,o4 ; P2 ---> o1,o2,o5 ; dalla R5
A,P1,P2 ---> o2 corrispondente a P2 ∩ ( A ∩ P1). dalla R6
A,P1 ---> o1,o2,o3,o4 corrispondente ad A ∪ P1 possiamo quindi costruire un sistema di regole R7:
o1 :- (A ∪ P1),P2. o2 :- (A ∪ P1),P2. o3 :- (A ∪ P1),¬P2. o4 :- (A ∪ P1),¬P2. che corrisponde ad una GEN tale che
A,P1,P2 ---> o1,o2 corrispondente a P2 ∩ (A ∪ P1) Il procedimento mostrato presenta delle forti analogie con il processo di generazione (OR) e selezione (AND) di stringhe degli algoritmi genetici. Definizione 7.8.1 Interpretazione AND ed interpretazione OR delle relazioni. Siano (xk - x1), (xk - x2), ..., (xk - xn) n relazioni binarie elementari: i) diremo interpretazione OR le n regole ricavabili dalle rela- zioni binarie nella forma: xk :- x1. xk :- x2. ... xk :- xn. ii) diremo interpretazione AND la regola ricavabile dalle rela- zioni binarie nella forma: xk :- x1,x2,x3,...,xn. n iii) diremo interpretazione modulo m le ( ) regole ricavabili m dalle relazioni binarie nella forma:

209
xk :- x1,x2,...,xm. 1 ≤ m ≤ n Dalla definizione ne consegue che le interpretazioni OR ed AND sono: OR - modulo 1 - una variabile disgiuntamente AND - modulo n - tutte le variabili congiuntamente Se rm1, rm2 sono regole modulo m1, m2 con m1 > 1, m2 < n, m1 < m2 si ha:
µ(rm1 ∆ rm2) m2 - m1 m1 d(rm1,rm2) = ---------------- = --------- = 1 - ----
µ(rm1 ∪ rm2) m2 m2 quindi otteniamo che 1 d( r(OR), r(AND)) = 1 - ----- n Siano S1, S2 sottoinsiemi |P(X), S1 contenuto in S2 dove S1 é un sottoinsieme numerabile e finito di |P(X). Prendiamo una T : S1 --> S2 tale che:
T(xi) = xj , xi contenuto in xj per ogni xi ∈ S1
allora esiste una funzione π : S1 --> |N che associa ad ogni sottoinsieme xi di S1 un numero naturale.
Sia δ : |N --> S2 una corrispondenza tra i ∈ |N e xi ∈ S2 tale che se
T(xi) = xj , π(xi) = i allora
δ(i) = xj \ xi = xk in altri termini
T(xi) \ xi = δ(π(xi)) = δ(i) = xk In particolare se:
T π x1,x2 ---> x1,x2,x3 x1,x2 ---> 1 x2,x3 ---> x2,x3,x4 x2,x3 ---> 2 x2,x4 ---> x1,x2,x3,x4 x2,x4 ---> 3 si ottiene:
δ 1 ---> x3 2 ---> x4 3 ---> x1 3 ---> x4 Definizione 7.8.2
Diremo che la corrispondenza π ha interpretazione AND e che la corrispondenza δ ha interpretazione OR.
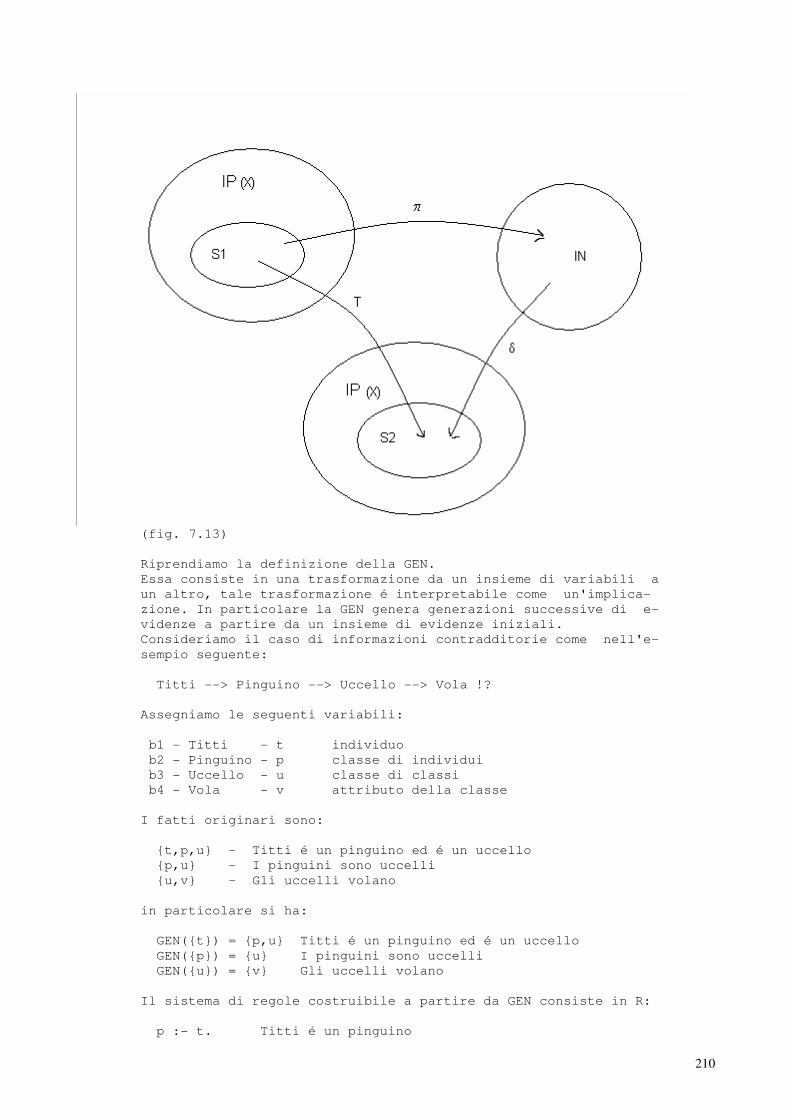
210
(fig. 7.13) Riprendiamo la definizione della GEN. Essa consiste in una trasformazione da un insieme di variabili a un altro, tale trasformazione é interpretabile come un'implica- zione. In particolare la GEN genera generazioni successive di e- videnze a partire da un insieme di evidenze iniziali. Consideriamo il caso di informazioni contradditorie come nell'e- sempio seguente: Titti --> Pinguino --> Uccello --> Vola !? Assegniamo le seguenti variabili: b1 - Titti - t individuo b2 - Pinguino - p classe di individui b3 - Uccello - u classe di classi b4 - Vola - v attributo della classe I fatti originari sono: t,p,u - Titti é un pinguino ed é un uccello p,u - I pinguini sono uccelli u,v - Gli uccelli volano in particolare si ha: GEN(t) = p,u Titti é un pinguino ed é un uccello GEN(p) = u I pinguini sono uccelli GEN(u) = v Gli uccelli volano Il sistema di regole costruibile a partire da GEN consiste in R: p :- t. Titti é un pinguino

211
u :- t. Titti é un uccello u :- p. I pinguini sono uccelli v :- u. Gli uccelli volano Allora applicando le regole si ottiene: t ---> p,u ---> v prima generazione seconda generazione fatti originari in questo caso questa deduzione é falsa !? In un certo senso le deduzioni della seconda generazione costi- tuiscono una generalizzazione universale che attribuisce a tutti gli individui della classe degli uccelli la proprietà di volare che nel caso del pinguino, il quale fa eccezione, risulta falsa. La suddivisione in generazioni successive delle affermazioni ri- cavate ci consente di attribuire una funzione di affidabilità che dipende dal livello della generazione considerata. Più ci allontaniamo dalle evidenze iniziali maggiore diviene l'incertezza sulla correttezza delle nostre deduzioni. Aggiungiamo al nostro sistema l'informazione aggiuntiva che i pinguini non volano: I fatti originari sono: t,p,u - Titti é un pinguino ed é un uccello
p,u,¬v - I pinguini sono uccelli che non volano u,v - Gli uccelli volano in particolare si ha: GEN(t) = p,u Titti é un pinguino ed é un uccello
GEN(p) = u,¬v I pinguini sono uccelli che non volano GEN(u) = v Gli uccelli volano Il sistema di regole costruibile a partire da GEN consiste in R: p :- t. Titti é un pinguino u :- t. Titti é un uccello u :- p. I pinguini sono uccelli
¬v :- p. I pinguini non volano v :- u. Gli uccelli volano Allora applicando le regole si ottiene:
t ---> p,u ---> v,¬v prima generazione seconda generazione fatti originari in questo caso questa deduzione mostra chiaramente una contraddizione e pertanto non apporta alcuna nuova informazione !! Anche se le nostre deduzioni possono essere errate nel caso di generalizzazioni successive, esiste sempre la possibilità di ri- condursi alle deduzioni corrette aggiungendo le informazioni man- canti ed eliminando le informazioni contradditorie.

212
7.9 Rappresentazioni di regole tramite corrispondenze Abbiamo visto come costruire una rappresentazione in uno spazio di variabili binarie. Vediamo ora come é possibile rappresentare un arbitrario sistema di regole con una corrispondenza opportuna. Prendiamo n variabili binarie: <b1,b2,...,bn>.
Sia X l'insieme di tali variabili bi ∈ X. Prendiamo una trasformazione T : |P(X) ---> |P(X) dalla potenza di X su sé stessa tale che:
T(xi) = xj , xi contenuto in xj per ogni xi ∈ S1 dove S1 é un sottoinsieme di |P(X). Sia Ri un insieme di regole arbitrario del tipo: xk1 :- x11, x12, ..., x1n. xk2 :- x21, x22, ..., x2n. ... xkm :- xm1, xm2, ..., xmn. Un simile sistema corrisponde ad una trasformazione che fa corri- spondere ad ogni insieme di variabili x1,x2,...,xl un insieme di variabili x(l+1),x(l+2),...,xh derivato dal sistema. Considerando l'unione delle variabili originarie con le variabili dedotte si ottiene la corrispondenza che a partire da un certo insieme di evidenze costruisce insiemi di generazione in genera- zione più ampi di evidenze. Definizione 7.9.1 Definizione di regole dominanti. Siano R1, Rk due insiemi di regole corrispondenti a due trasfor- mazioni: A) T(S1) = Si ==> Ri B) T(S2) = Sk ==> Rk tali che S1 contenuto in S2 e (Si \ S1) = (Sk \ S2) = Sj Allora diremo che Ri é dominante rispetto ad Rk. Infatti Sj si deduce da un insieme di premesse più ristretto, in
particolare µ(S1) ≤ µ(S2), pertanto si converrà di utilizzare le regole Ri al posto delle regole Rk. Proposizione 7.9.2 Sia T : |P(X) --> |P(X) una corrispondenza tale che
per ogni Si ∈ |P(X) T(Si) = Sj, Si contenuto in Sj allora é possibile descrivere T nella forma di un insieme di regole del tipo xk :- x1, x2, ..., xn. Infatti sia Sj = T(Si), Si contenuto in Sj Si = x1, x2, ..., xk Sj = x1, x2, ..., xk, x(k+1), ..., x(k+m)

213
é possibile trasformare Si --> Sj ( Si implica Si ∩ Sj) scrivendo m regole nella forma: x(k+1) :- x1, x2, ..., xk. x(k+2) :- x1, x2, ..., xk. ... x(k+m) :- x1, x2, ..., xk. Esempio: Prendiamo una T tale che: x1,x2,x3 ---> x1,x2,x3,x4,x5 allora otteniamo il sistema di regole seguente: 1) x4 :- x1, x2, x3. 2) x5 :- x1, x2, x3. 7.10 Sistemi di regole ricavabili da corrispondenze Prendiamo n variabili binarie: <b1,b2,...,bn>.
Sia X l'insieme di tali variabili bi ∈ X. Prendiamo una trasformazione T : |P(X) ---> |P(X) dalla potenza di X su sé stessa tale che:
T(xi) = xj , xi contenuto in xj per ogni xi ∈ S1 dove S1 é un sottoinsieme finito di |P(X).
Sia µ : S1 --> R+ \ ∞ definita come: per ogni Si contenuto in S1 numerabile e finito
µ(Si) = numero di elementi distinti dell'insieme Si
µ(x1,x2,...,xk) = k prendiamo la funzione distanza:
µ(Si ∆ Sj) d(Si,Sj) = -------------- per ogni Si, Sj ∈ S1 µ(Si ∪ Sj) essa induce una metrica su S1. Definizione 7.10.1 Ora se T : S1 --> S1 é una corrispondenza relativa ad un arbi- trario insieme di regole R e
Të : S1 --> S1 una corrispondenza tale che per ogni Si ∈ S1 vale: 1) T(Si) = Sj

214
2) Tδ(Si) = Sk , µ(Sk) ≥ µ(Si) , Si contenuto in Sk
3) d(Sj,Sk) < δ , δ ∈ [0,1]
allora diremo che Tδ é una corrispondenza che approssima T con differenza δ.
In altri termini Tδ rappresenta un sistema di deduzione simile a T, descrivibile con un insieme di regole Rδ simile ad R. Prendiamo n variabili binarie: <b1,b2,...,bn>.
Sia X l'insieme di tali variabili bi ∈ X. Definizione 7.10.2 Sia S un insieme di insiemi di |P(X); S = S1, S2, ..., Sn inoltre prendiamo una trasformazione T : |P(X) ---> |P(X) dalla potenza di X su sé stessa tale che:
i) T(Si) = Ski , per ogni Si ∈ S
ii) S(i+1) contenuto in Si e (Ski \ Si) = Sj per ogni Si ∈ S dove Sj rimane costante Allora per costruire le regole relative ad Sj (deduzione di Sj) utilizziamo Si tale che valga:
min(µ(Si)) Si ∈ S in particolare sceglieremo Sn l'insieme più piccolo di premesse da cui si deduce Sj. In altri termini selezioneremo le regole dominanti. Esempio: Sia T(Si) tale che Sj 1) x1,x2 --> x1,x2,x3 x3 2) x1,x2,x3 --> x1,x2,x3,x4 x4 3) x1,x2,x3,x4 --> x1,x2,x3,x4,x5 x5 4) x1,x2,x3,x4,x5 --> x1,x2,x3,x4,x5,x6 x6 5) x2,x3 --> x2,x3,x4 x4 6) x2,x3,x4 --> x1,x2,x3,x4,x5 x1,x5 7) x2,x4 --> x1,x2,x3,x4 x1,x3 8) x3,x4 --> x2,x3,x4,x5 x2,x5 9) x2,x3,x4,x5 --> x1,x2,x3,x4,x5,x6 x6 allora selezionando le regole dominanti otteniamo: a) x3 :- x1,x2. dalla 1) b) x4 :- x2,x3. dalla 5) c) x1 :- x2,x4. dalla 7) d) x3 :- x2,x4. dalla 7) e) x2 :- x3,x4. dalla 8) f) x5 :- x3,x4 dalla 8) g) x6 :- x2,x3,x4,x5. dalla 9)
Esercizio: verificare che questo insieme di regole Rδ é simile a quello riportato nell'esempio del paragrafo 7.4 con δ = 1/4.

215
7.11 Leggi di riduzione dei sistemi di regole Formalizziamo alcune leggi di riduzione dei sistemi di regole. Definizione 7.11.1
Siano b1,b2,...,bn ∈ B n variabili costituenti un sistema di regole del tipo: bi1 :- bj1, bj2, ..., bjl. bi2 :- bj1, bj2, ..., bjl. ... bih :- bj1, bj2, ..., bjl. (i) regola zero di riduzione: duplicazione Se una regola compare due volte nel sistema può essere elimina- ta. (ii) prima regola di riduzione: tautologia Se una regola contiene nel corpo della regola stessa la testa della regola allora l'intera regola può essere eliminata. Esempio b2 :- b1,b2,b3. b2 che é la testa compare nel corpo; é immediato verificare che b1 & b2 & b3 -> b2 é una tautologia. (iii) seconda regola di riduzione: irrilevanza Se una variabile compare in tutte le regole nel corpo di ciascuna (ricordando che il corpo di una regola rappresenta una congiun- zione di variabili) allora la variabile é determinante per il sistema complessivamente ma é irrilevante nelle singole regole del sistema e può essere eliminata. Esempio : b1 :- b2,b3,b4. b5 :- b3,b8. b6 :- b3,b8. é equivalente a: b1 :- b2,b4. b5 :- b8. b6 :- b8. (iv) terza regola di riduzione: dominanza Se due regole r1 ed r2 presentano la stessa testa e il corpo di r1 é un sottoinsieme del corpo di r2 allora diremo che r1 domina r2 ed in tal caso r2 può essere eliminata. Esempio: r1) b4 :- b2,b3. r2) b4 :- b1,b2,b3.

216
7.12 Equivalenza di sistemi di regole Vi sono sistemi di regole che possono essere considerati equiva- lenti, in relazione al comportamento che presentano relativamente a determinati insiemi di variabili in input. Teorema 7.12.1 Consideriamo una trasformazione di variabili del tipo: xi => b1 & b2 & ... & bk.
Dove xi ∈ |P(X) e bi ∈ |P(B). Prendiamo un insieme di regole Rc tale che per ogni xi ∈ |P(X) e per ogni bj ∈ |P(B) vale: i) Rc(bj) = xi -1 ii) Rc (xi) = bj sia Rx un insieme di regole per le variabili xi. allora Rx può essere trasformato in un insieme di regole per le variabili bj, Rb dove vale: -1 Rx( ) = Rc(Rb(Rc ( ))) Esempio: Prendiamo Rc definito da : x1 :- b1,b2. x2 :- b1,b3,b4. x3 :- b4,b5. x4 :- b6. x5 :- b4,b7. equivalente ai raggruppamenti: x1 = b1,b2 ; x2 = b1,b2,b3 ; x3 = b4,b5 ; x4 = b6 ; x5 = b4,b7. in particolare Rc(b1,b2,b3,b4) = x1,x2 -1 Il sistema di regole duale Rc é definito da: b1 :- x1. b1 :- x2. b2 :- x1. b3 :- x2. b4 :- x2. b4 :- x3. b4 :- x5.

217
b5 :- x3. b6 :- x4. b7 :- x5. Consideriamo come sistema Rx le regole: x1 :- x2. x3 :- x4,x5. x2 :- x3. sostituendo si ottiene il sistema Rb: b1 :- b1,b3,b4. * b2 :- b1,b3,b4. b4 :- b4,b6,b7. * b5 :- b4,b6,b7. b1 :- b4,b5. b3 :- b4,b5. b4 :- b4,b5. * riducendo il sistema secondo la prima regola di riduzione * eli- minazione delle regole ridondanti si ottiene: b1 :- b4,b5. b2 :- b1,b3,b4. b3 :- b4,b5. b5 :- b6,b4,b7. eliminando la variabile b4 in conformità con la seconda regola di riduzione si ottiene: b1 :- b5. b2 :- b1,b3. b3 :- b5. b5 :- b6,b7. Verifichiamo ora che il sistema così ottenuto Rb risulta effet- tivamente equivalente ad Rx. Rx(x1) = x1,x2 ; Rb(b1,b3,b4) = b1,b2,b3,b4 --> x1,x2 Rx(x3) = x2,x3 ; Rb(b4,b5) = b1,b3,b4,b5 --> x2,x3 Rx(x2,x3 = x1,x2,x3 ; Rb(b1,b3,b4,b5 = b1,b2,b3,b4,b5 --> x1,x2,x3 Rx(x4,x5) = x3,x4,x5 ; Rb(b4,b6,b7) = b4,b5,b6,b7 --> x3,x4,x5 il sistema risulta effettivamente equivalente come volevasi mo- strare.

218
7.13 Definizione di trasformazioni particolari Prendiamo n variabili binarie: <b1,b2,...,bn>.
Sia X l'insieme di tali variabili bi ∈ X. Prendiamo una trasformazione T : |P(X) ---> |P(X) dalla potenza di X su sé stessa tale che:
T(xi) = xj , xi contenuto in xj per ogni xi ∈ S1 dove S1 é un sottoinsieme finito di |P(X).
(fig. 7.14) Definizione 7.13.1 _ Prendiamo una trasformazione GEN : S1 ---> S1 definita come:
GEN(xi) = T(xi) \ xi = xj \ xi = xk per ogni xi ∈ S1 La trasformazione GEN ricava conseguenze deducibili da un certo insieme di premesse. Alla trasformazione GEN é possibile far corrispondere sistemi di regole con regole del tipo xk :- x1,x2,...,xn. La trasformazione GEN genera ulteriori fatti. Definizione 7.13.2 _ Prendiamo una trasformazione SEL : S1 x S1 ---> S1 definita come:
Sia GEN(xp) = xj , xp ∈ S1 , xi ∈ S1
consideriamo xk = xi ∩ xj allora
SEL(xi,xp) = GEN(xp) ∩ xi = xj ∩ xi = xk per ogni xi,xp ∈ S1.

219
La trasformazione SEL restringe gli elementi di xj al dominio di xi; restringe le conseguenze ricavabili, tramite la GEN, da xp all'insieme delle variabili di xi. La trasformazione SEL seleziona fatti in relazione ad un criterio dato. Esempio: GEN Siano xi = e1,e2,...,en n evidenze. GEN(xi) = xj = e(n+1),e(n+2),...,e(n+j) j fatti generati da xi può essere rappresentata da j x n regole (interpretazione OR): e(n+1) :- e1. e(n+1) :- e2. ... e(n+1) :- en. e(n+2) :- e1. e(n+2) :- e2. ... e(n+2) :- en. ... e(n+j) :- e1. e(n+j) :- e2. ... e(n+j) :- en. oppure, in maniera equivalente, da j regole (interpretazione AND) e(n+1) :- e1, e2, ..., en. e(n+2) :- e1, e2, ..., en. ... e(n+j) :- e1, e2, ..., en. Esempio: SEL A) Siano xi = o1,o2,...,oi i oggetti Sia xp = P una proprietà GEN(xp) = xj = o1,o2,...,op p oggetti di xj che possiedono la proprietà P
xi ∩ xj = xk = o1,o2,...,ok k oggetti di xi selezionati sulla base di possedere la proprietà P SEL(xi,xp) = xk B) Siano xi = a1,a2,...,ai i attributi Sia xp = op un oggetto GEN(xp) = xj = a1,a2,...,ap p attributi dell'oggetto op
xi ∩ xj = xk = a1,a2,...,ak k attributi di xi condivisi con gli attributi dell'oggetto xp = op SEL(xi,xp) = xk.

220
Vediamo ora alcune trasformazioni particolari ricavabili da GEN e da SEL relativamente a particolari caratteristiche dei sistemi di regole ricavabili. Definizione 7.13.3 _ UNO) Sia UNO : S1 ---> S1 una trasformazione che consenta di ri- cavare l'insieme di tutte le variabili collegate ad almento una variabile di xi. UNO(xi) = xk xk = tutti gli elementi collegati direttamnete ad almeno un ele- mento di xi. Nota: La UNO corrisponde all GEN nell'interpretazione OR. Definizione 7.13.4 _ UNO-SEL) Sia UNO-SEL : S1 ---> S1 una trasformazione che consenta di ricavare l'insieme di tutte le variabili collegate a tutti gli elementi di xi. UNO-SEL(xi) = xk xk = tutti gli elementi collegati direttamente a tutti gli ele- menti di xi. Definizione 7.13.5 _ TUTTI) Sia TUTTI : S1 ---> S1 una trasformazione che consenta di ricavare l'insieme di tutte le variabili a cui sono legati tutti gli attributi di xi. In particolare é possibile definire TUTTI nel modo seguente: posto xk = bk TUTTI(xi) = xj xj contenuto in GEN(xi) tale che
SEL(xi,xk) = GEN(xk) per ogni bk ∈ xj xj = tutti gli oggetti descritti da attributi, GEN(xk), che sono tutti compresi in xi. Definizione 7.13.6 _ SIMILI) Sia SIMILI : S1 x |R ---> S1 una classe di trasformazioni
dipendente da δ ∈ [0,1] definita come:
SIMILI(xi,δ) = xj , xj contenuto in GEN(xi) tale che
d(xi,GEN(xk)) < δ per ogni bk ∈ xj xj = tutti gli oggetti descritti da attributi GEN(xk) che sono
simili(δ) all'oggetto descritto da xi, cioé tale che GEN(oi) = xi

221
In altri termini se xi, xj sono premesse da cui si ricava che
d(GEN(xi),GEN(xj)) < δ cioé che la differenza tra le conseguenze é minore di una certa
soglia ë allora é verosimile che le premesse siano simili(δ). Esempio: Vediamo una applicazione delle definizioni sopra riportate. Sia E0 un insieme di evidenze iniziali e C1 un criterio di sele- zione; consideriamo i seguenti passi: 1) GEN(E0) = E1 evidenze della prima generazione SEL(E1,C1) = E2 selezione delle evidenze secondo C1 2) GEN(E2) = E3 evidenze della seconda generazione SEL(E3,C1) = E4 selezione secondo C1 GEN SEL GEN SEL GEN E0 ---> E1 ---> E2 ---> E3 ---> E4 ---> ... | | C1 - C1 - Otteniamo una successione di generazioni di fatti che cercano di sopravvivere ad un certo criterio C1 di selezione. É evidente l'analogia con gli algoritmi genetici. Di più, supponiamo che il primo criterio di selezione a cui sono sottoposte le evidenze man mano generate sia il criterio di non contraddizione, in altri termini che tutte le contraddizioni ele- mentari siano automaticamente eliminate ad ogni passo di selezio- ne: si ottiene un sistema deduttivo in grado di gestire informa- zioni mancanti o contradditorie. Definizione 7.13.7 Trasformazione delle simiglianze in presenza di invarianti. Consideriamo una trasformazione T : S1 ---> S2 essa può rappresentare per esempio un sistema che si evolve da uno stato S1 ad uno stato S2. Sia c(x) un invariante rispetto a T
Per ogni x ∈ S1 vale cioé la legge di conservazione:
i) c(x) = c(T(x)) = c(y) per ogni x ∈ S1, T(x) ∈ S2, y ∈ S2
allora sia µ(x) = µc(c(x)) = µc(c(T(x))) = µc(c(y)) = µ(y) una misura di c(x). La distanza:
µ(x1 ∆ x2) d(x1,x2) = -------------
µ(x1 ∪ x2) costituisce un invariante per T; in particolare vale:
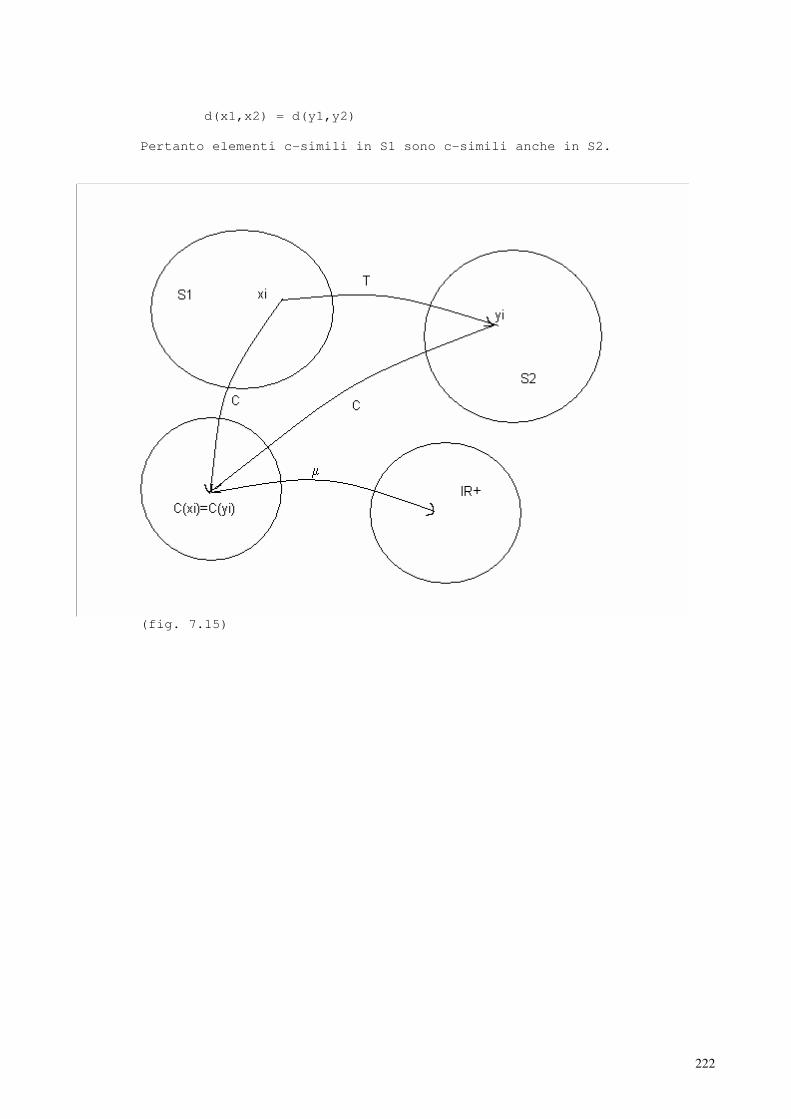
222
d(x1,x2) = d(y1,y2) Pertanto elementi c-simili in S1 sono c-simili anche in S2.
(fig. 7.15)

223
7.14 Misura dell'affidabilità delle deduzioni Definizione 7.14.1 Definizione dell'affidabilità sui fatti. Consideriamo n variabili binarie : <b1,b2,...,bn>.
Sia X l'insieme di tali variabili bi ∈ X. Sia Pe : X --->|R una funzione "peso" tale che
Pe(bk) ∈ [-1,1] per ogni bk ∈ X allora Pe(bk) può essere interpretata come affidabilità di un certo fatto bk (funzione di verità di bk) con: Pe(bk) = 1 bk vero Pe(bk) = -1 bk negato (falso) Pe(bk) = 0 bk indeterminato Pe(bk) = p |p| affidabilità (probabilità) di bk.
Sia µ: X ---> |R+ definita come µ(bk) = |Pe(bk)| valore assolu- to di Pe(bk).
Se xi = b1,b2,...,bi é un insieme di bi ∈ X
µ(xi) = Σ µ(bk) bk ∈ xi k
allora µ: |P(X) --> |R+ é una misura sulla potenza di X
La funzione µ può essere interpretata come funzione di ottimiz- zazione (objective function) dell'affidabilità di xi arbitrario insieme di fatti. Definizione 7.14.2 Definizione dell'affidabilità sulle regole. Consideriamo un insieme di regole R del tipo
rk) xk :- x1,x2,...,xn. rk ∈ R Sia Pr : R ---> [-1,1] una funzione "peso della regola" allora Pr(rk) può essere interpretata come affidabilità di una certa regola rk (verità della regola) con: Pr(rk) = 1 rk applicabile / vera Pr(rk) = -1 rk applicabile / contraria Pr(rk) = 0 rk indeterminata / falsa Pr(rk) = p |p| affidabilità della regola
Sia µr : R -->|R+ definita come µr(rk) = |Pr(rk)| valore assolu- to della funzione peso della regola.
Se wi = r1,r2,...,ri é un insieme di regole wi ∈ R
µr(wi) = Σ µr(rk) rk ∈ wi k definisce una misura sulla potenza di R. Definizione 7.14.3

224
Definizione di regole di deduzione a due valori. Consideriamo un caso particolare di deduzione che ci fornisce una comoda modalità di propagazione dell'affidabilità.
Supponiamo che per ogni bi,bj ∈ X e rk ∈ R le funzioni di affida- bilità forniscano solo due valori possibili -1,1, in partico- lare supponiamo valga: 1) Pe(bi) = 1 sse bi é vero
2) Pe(bj) = -1 sse bj é falso, (denotiamo con ¬bj) 3) Pe(rk) = 1 sse rk é vera 4) Pe(rk) = -1 sse rk é contraria Sia xj :- xi. la regola rk, xj = bj , xi = bi Costruiamo le seguenti regole per il calcolo di Pe(xj) sulla base dei valori di Pe(xi) e Pr(rk): Pe(xi) Pr(rk) | Pe(xj) ------------------------------------- 1 1 | 1 -1 1 | -1 1 -1 | -1 -1 -1 | 1
In particolare se Pr(rk) = -1 possiamo scrivere ¬bj :- bi. Ovvero bi implica che bj é falso. Definizione 7.14.4 Definizione di contraddizione elementare. Supponiamo di avere due regole r1 ed r2 tali che: r1) bj :- bi.
r2) ¬bj :- bi. allora diremo che le due regole considerate congiuntamente forma- no una contraddizione elementare: in altri termini (r1,r2) sono incompatibili. Proposizione 7.14.5 Sia E0 un insieme di evidenze iniziali. Sia Cd il criterio di non contraddizione, cioé: SEL(En,Cd) = E(n+1) dove E(n+1) é contenuto in En ed é tale che tutti i fatti in contraddizione sono eliminati.
Se vale bj e ¬bj allora bj e ¬bj vengono eliminati da En. Otteniamo allora i seguenti passi nella generazione di evidenze successive a partire da un insieme di evidenze iniziali: GEN SEL GEN SEL GEN E0 ---> E1 ---> E2 ---> E3 ---> E4 ---> ... | | Cd - Cd - Nota: Se ad un certo istante Pe(bj) = 1 e si applica r2 si ottie- ne Pe’(bj) = -1 allora sommando si ottiene Pe"(bj) = 0 In altri termini bj non é né vero né falso.

225
Definizione 7.14.6 Definizione di affidabilità sui fatti - seconda versione. Consideriamo n coppie di variabili binarie: <(b1,d1),(b2,d2),...,(bn,dn)> = <f1,f2,...,fn>
sia F l'insieme di tali variabili fi ∈ F
sia µ(fi) = µ(bi,di) definita come
µ(fi) = 1 sse (bi=1, di=0) oppure (bi=0,di=1) ; µ(fi) = 0 sse (bi=0, di=0) oppure (bi=1,di=1) ; sia P : F ---> [0,1] una funzione "peso" interpretabile come affidabilità di un certo fatto fk.
Se µa : F ---> |R+ é definita come
µa(fi) = P(fi) * µ(fi)
allora µa é una misura dell'affidabilità del fatto fi.
Se xi = f1,f2,...,fi é un insieme di fatti fi ∈ F
µx(xi) = Σ µa(fk) fk ∈ xi k é una misura di affidabilità sull'insieme di fatti xi. Di più, se P(fi) é interpretabile come probabilità e i k fatti sono tutti indipendenti allora
µp(xi) = Π µa(fk) fk ∈ xi k
il prodotto delle misure µa su fk può essere interpretato come una probabilità per xi. Proposizione 7.14.7 _
Siano xi,xj ∈ S1 xm,xn ∈ S1 Sia GEN(xi) = xm GEN(xj) = xn
µ1(xi) misura della affidabilità dei fatti in S1
posto che l'affidabilità dei fatti generati xm, µ2(xm) sia la stessa dei fatti di partenza: -1
µ2(xm) = µ1(GEN (xm)) = µ1(xi) e che
GEN(xi ∩ xj) = xm ∩ xn
allora se le premesse sono simili d1(xi,xj) < δ anche le conseguenze sono simili d2(xm,xn) < δ

226
µ1(xi ∆ xj) µ2(xm ∆ xn) dove d1(xi,xj) = ------------- e d2(xm,xn) = -------------
µ1(xi ∪ xj) µ2(xm ∪ xn) Le simiglianze delle conclusioni é valutata in base al peso dell'affidabilità delle affermazioni di fatti comuni nella pre- messe. In particolare, nel nostro caso, affidabilità di premesse comu- ni.

227
7.15 Interpretazione statistica dell'affidabilità Proposizione 7.15.1 Sull' affidabilità delle regole. Consideriamo una configurazione composta da m stati. Per esempio tre monete generano otto possibili stati. Poniamoci il problema di inserire nuove regole, nel nostro siste- ma di rappresentazione, sulla base del verificarsi di nuove espe- rienze. Sia r1 la seguente regola; basata su un'esperienza effettiva: r1) SE "osservo tre monete" (bk) ALLORA "vedo la configurazione TTT" (b1). che possiamo sinteticamente scrivere come: r1) b1 :- bk. Supponiamo di aver applicato la regola tre volte in casi in cui si é sempre dimostrata vera, possiamo assegnare alla regola un'affidabilità proporzionale al numero di successi che ha otte- nuto, nel caso specifico tre conferme. i) Attribuiremo alle regole un'affidabilità proporzionale al nu- mero n di conferme della regola stessa. Supponiamo, al quarto tentativo, di osservare una configurazione diversa, per esempio CCC (b2). Allora aggiungeremo una ulteriore regola e dovremo modificare l'affidabilità della regola precedentemente inserita; per esem- pio ponendo: r1) b1 :- bk. Ps(b1) = 3/4 = ne/n stima statistica r2) b2 :- bk. Ps(b2) = 1/4 = ne/n Proseguendo nelle esperienze un numero di volte sufficientemente grande si ottiene un allineamento statistico alla probabilità dovuta al numero di stati, supposti nel nostro caso equiprobabi- li, accessibili nella configurazione reale: ne ii) lim ---- = Pr(bi)
n -> ∞ n Nel caso di configurazioni equiprobabili si otterrà: 1 Pr(bi) = ---- dove nr = numero di stati accessibili nr nota: nr é anche uguale al numero di regole inserite, infatti ad ogni stato accessibile corrisponde una regola e quando per
n --> ∞ si esaurisce l'esplorazione degli stati possibili sono state inserite un numero corrispondente di regole. Esempio: Nel caso delle tre monete si ottiene: r1) b1 :- bk. r2) b2 :- bk.

228
r3) b3 :- bk. r4) b4 :- bk. r5) b5 :- bk. r6) b6 :- bk. r7) b7 :- bk. r8) b8 :- bk. dove nr = 8 e Pr(bi) = 1/8. Le regole sopra descritte possono essere riscritte in una nota- zione migliore nel modo seguente: rk) [b1,b2,b3,b4,b5,b5,b7,b8] :- bk. in cui l'affidabilità della regola rk) é sempre pari all'uni- tà. Da notare che 1/8 coincide con la probabilità che la regola r1) possa essere vera, perciò dato bk, cioé P(bk) = 1, 1/8 é anche la probabilità che b1 sia vero. Se P(bk) é diverso da 1, allora sembra sensato porre: P(b1) = P(r1) * P(bk). Proposizione 7.15.2 Secondo lo schema delineato semberebbe allora ragionevole porre, dato un fatto bk ed m regole ri ciascuna in alternativa all'altra del tipo: [b1,b2,...,bj] :- bk. m
iii) Σ Ps(ri) = 1 somma della probabilità statistica i=1 delle regole in alternativa = 1; in altri termini almeno una delle regole, in un determinato caso, é applicabile; in quanto ipotizziamo l'inserimento di una nuova regola tutte le volte in cui la iii) non si dimostra vera in relazione ad un determinato evento non prevedibile a priori. (Allineamento statistico a Pr(ri)). Allora se xi = b1,b2,...,bm e la probabilità di xi = P(xi) si ha:
iv) P(xi) = Σ P(bj) = Σ P(rj) * P(bk) = P(bk) Σ P(rj) = P(bk) j j j La affidabilità (probabilità) é un invariante per GEN. GEN(xk) = xi bk ---> b1,b2,...,bm
v) µp(xk) = µp(xi) ed é ragionevole ipotizzare che ciò sia _
vero per ogni xk ∈ S1 e per ogni GEN(xk) = xj ∈ S1 Alcune conseguenze della iii) P(xi) = P(xk) dove GEN(xk) = xi so- no le seguenti; poiché per la formula di Bayes: P(xi,xk) vi) P(xi\xk) = ----------- si ha

229
P(xk) P(xi,xk) vii) P(xi\xk) = ----------- = P(xk\xi) P(xi) In particolare se interpretiamo P(xi,xk) nel senso di probabili- tà che sia vero xi dato xk, ovvero probabilità che da xk conse- gua xi otteniamo le seguenti affermazioni: Proposizione 7.15.3 La probabilità che xk sia una conseguenza di xi é uguale alla probabilità che ha xi di essere una conseguenza di xk. Proposizione 7.15.4 La probabilità che da xk ne consegue xi é la stessa per cui da xi ne consegue xk. l'analisi approfondita di queste affermazioni ci porta a conside- razioni filosofiche ed epistemologiche che riguardano la relazio- ne di causa ed effetto. Ipotizziamo che esse siano vere, nell'ambito ristretto della rap- presentazione; sono conseguenze della iii) m
Σ Ps(ri) = 1. i=1 Le proposizioni 7.15.3 e 7.15.4 derivano dal meccanismo di crea- zione delle regole; tale meccanismo é basato sul concetto di coincidenza di eventi e sul raggruppamento di tutti gli eventi correlati, con tale meccanismo le probabilità relative della te- sta e della coda di una regola si mantengono sempre allineate e in particolare, non solo l'affidabilità delle conseguenze é u- guale all'affidabilità delle premesse, ma la funzione GEN é an- che invertibile. Definizione 7.15.5 Nell'ipotesi che le proposizioni 7.15.3 e 7.15.4 siano vere se GEN(xk) = yi sembra ragionevole estendere la trasformazione
GEN ad una REL tale che per ogni xk ∈ S1 e per ogni yi ∈ S1 a) REL(xk) = GEN(xk) = yi b) REL(yi) = xk (regole inverse) In altri termini se x1,...,xk ---> y1,...,yi può essere rappresentato dalle regole: y1 :- x1,x2,...,xk. y2 :- x1,x2,...,xk. ... yi :- x1,x2,...,xk. é possibile aggiungere le regole duali tali che y1,...,yi ---> x1,...,xk rappresentabili da: x1 :- y1,y2,...,yi. x2 :- y1,y2,...,yi. ... xk :- y1,y2,...,yi.

230
Esempio: Sia GEN tale che: x1,x2,x3 ---> y1,y2 e x1,x2 --> y2 y1 :- x1,x2,x3. y2 :- x1,x2. allora REL diventa: y1,y2 --> x1,x2,x3 e y2 --> x1,x2 x1 :- y1,y2. x2 :- y1,y2. x3 :- y1,y2. x1 :- y2. x2 :- y2. riducibile a: x1 :- y2. x2 :- y2. x3 :- y1,y2. Consideriamo il processo di comunicazione fra due sistemi a stati finiti S1 ed S2 che si scambiano messaggi selezionati da un de- terminato repertorio M. Sia M un insieme di messaggi utilizzabili nel colloquio tra S1 ed
S2, costituiti da n variabili binarie, xi ∈ M, xi = b1,...,bn. Il colloquio tra S1 ed S2 può essere descritto da una sequenza di messaggi x1 --> x2 --> x3 --> x4 ... tali che S1 --> x1 x1 --> S2 --> x2 x2 --> S1 --> x3 x3 --> S2 --> x4 ... S1 riceve, la successione di messaggi x2,x4,x6,... Poniamo per comodità di notazione: x1=O1, x2=I1, x3=O2, x4=I2, ..., x(2i) = Ii, x(2i+1) = O(i+1) Allora S1 invia i messaggi O1,O2,... e corrispondentemente riceve i messaggi I1,I2,...
Supponendo che per n --> ∞ vi sia un allineamento statistico tra la probabilità di ricevere il messaggio Ii e la frequenza stati- stica relativa al numero di volte che in media si é presentato il messaggio medesimo, é ragionevole supporre che sia: ne(Ii) numero di ricorrenze di Ii Ps(Ii) = lim ------ = lim -----------------------------
n -> ∞ n n -> ∞ numero di messaggi ricevuti Ora S1 può fare tre ipotesi (almeno) sul tipo di risposta che riceverà da S2 in relazione al messaggio che ha inviato Oi. 1) S2 risponde in maniera casuale, indipendentemente dal mes-

231
saggio inviato da S1 Oi. 2) S2 risponde in maniera determinata, strettamente dipendente dal messaggio inviato da S1 Oi; cioé ad ogni Oi corrisponde una unica risposta Ii. 3) S2 risponde in maniera pseudo-casuale, o anche pseudo- determinata, dipendente dal messaggio inviato, ma non strettamen- te determinata; cioé ad ogni Oi corrispondono più risposte pos- sibili che S2 può inviare. Analizziamo i singoli casi: nel caso 1) si ha: 1 P(Ii) = --- scelta casuale tra n messaggi n P(Ii\Oi) = P(Ii) il messaggio Ii é indipendente da Oi nel caso 2) si ha: P(Ii) = P(Oi) la frequenza relativa con cui compaiono Ii ed Oi nella serie dei messaggi é identica. P(Ii\Oi) = 1 il messaggio Ii dipende strettamente da Oi nel caso 3) si ha: Supponendo che ad Oi corrispondano k messaggi Ii1,...,Iik di- stinti e indipendenti si ottiene: 1 P(Ii1) = --- P(Oi) la frequenza statistica con cui compare Ii1 k é 1/k volte la frequenza statistica con cui compare Oi. 1 P(Ii1\Oi) = --- il messaggio Ii1 corrisponde ad Oi una k volta ogni k volte. Da notare che la frequenza statistica con cui compare Oi é la stessa di quella con cui compaiono le risposte ad Oi ==> Ii1,...,Iik considerate complessivamente; cioé se ne(Oi) e ne(Iij) sono le frequenze relative di Oi e di Iij si ha k
Σ ne(Iij) = ne(Oi) j=1 allora se GEN(Oi) = Ii1,...Iik = xk la frequenza statistica si conserva per la GEN !!! Proposizione 7.15.6 Per cui si può dire che Oi "implica" xk con affidabilità 1 Proposizione 7.15.7 Inoltre si può dire che xk "é implicato" da Oi con affidabili- tà 1.

232
Proposizione 7.15.8 Si vede facilmente che "implica" ed "é implicato" sono due a- spetti di una stessa relazione binaria. Proposizione 7.15.9 Consideriamo la frequenza statistica di una singola variabile bi- naria bk presente in k messaggi
bk ∈ x1 ∩ x2 ∩ ... ∩ xk in particolare bk ∈ Ii 1≤i≤k Supponiamo di aver ricevuto m messaggi; indicando con Ps(bk) una stima statistica delle aspettative su bk k
Σ ne(Ii) ne(bk) i=1 i) Ps(bk) = -------- = ----------- e poiché m m P(bk, Ii) ii) P(bk\Ii) = 1 = ----------- si ha P(bk,Ii) = P(Ii) P(Ii) P(bk,Ii) P(Ii) Ne(Ii) iii) P(Ii\bk) = ---------- = ------- = --------- P(bk) P(bk) k
Σ ne(Ij) j=1 Esempio: Prendiamo le seguenti variabili: xk1=bk1, xk2=bk2, xk3=bk3, xk4=bk4 ; x1=b1,b2, x2=b1,b3, x3=b2,b3, x4=b1, x5=b1,b2,b3 ; Supponiamo di aver costruito il seguente sistema di regole: r1) [xk1,xk4] :- x1. verificata 20 volte di cui xk1 :- x1. verificata 10 volte e xk4 :- x1. verificata 10 volte. r2) xk1 :- x2. verificata 15 volte. r3) xk1 :- x3. verificata 5 volte. r4) xk2 :- x4. verificata 35 volte. r5) xk3 :- x5. verificata 25 volte. Allora il numero di eventi complessivamente é 100. Il numero di evidenze di xk1, ne(xk1) = 30 ; ne(xk2) = 35 ; ne(xk3) = 25 ; ne(xk4) = 10 ; ne(x1) = 20; ne(x2) = 15; ne(x3) = 5; ne(x4) = 35; ne(x5) = 25; ne(b1) = 95; ne(b2) = 50; ne(b3) = 45; calcoliamo l'affidabilità statistica.

233
poiché: P(b1,x1) P(b1\x1) = 1 = ---------- ==> P(b1,x1) = P(x1) P(x1) P(xk1,x1) P(xk1\x1) = 1 = ---------- ==> P(xk1,x1) = P(x1) P(x1) quindi ne(x1) 20 ne(x1) 20 P(x1\b1) = -------- = ---- ; P(x1\b2) = --------- = ---- ne(b1) 95 ne(b2) 50 ne(x2) 15 ne(x2) 15 P(x2\b1) = -------- = ---- ; P(x2\b3) = --------- = ---- ne(b1) 95 ne(b3) 45 ne(x1) 20 ne(x4) 35 P(x1\xk1) = --------- = ---- ; P(x2\xk2) = -------- = ---- = 1 ne(xk1) 30 ne(xk2) 35

234
7.16 Generalizzazione operazioni OR AND XOR Le operazioni fondamentali su cui si basa la logica del computer sono l'operazione OR e l'operazione AND. Tipicamente queste operazioni si definiscono in termini di in- gressi ed uscite da un circuito elettronico; nel caso più sem- plice un circuito con due ingressi ed un'uscita si comporta come un OR se il segnale di uscita é in ON quando almeno un segnale in ingresso é in ON, mentre si comporta come un AND quando il segnale in uscita é in ON solo se entrambi i segnali in ingresso sono in ON. 1) OR ON ---| ON ---| |--- ON |--- ON OFF ---| OFF ---| 2) AND ON ---| |--- ON ON ---| Supponendo vi siano k ingressi ed un'uscita si può generalizzare dicendo che il circuito si comporta come un OR quando il segnale in uscita é in ON nel caso vi sia almeno un segnale in ingresso che sia in ON; si comporta come un AND quando il segnale in usci- ta é in ON solo nel caso in cui tutti i segnali in ingresso sono in ON. 3) OR ... ---| ON ---| ... ---|--- ON ... ---| 4) AND ON ---| ON ---| ON ---|--- ON ON ---| Un altro modo usuale per definire gli operatori OR ed AND é quello di utilizzare le tavole di verità: OR V V | V AND V V | V V F | V V F | F F V | V F V | F F F | F F F | F Vediamo ora le implicazioni di quanto esposto finora nel campo della programmazione logica. Denotiamo con x1,x2,...,xn enne fatti atomici. Denotiamo con xk :- x1,x2,...,xi. regole del tipo SE x1 AND x2 AND ... AND xi ALLORA xk. La regola: (AND) 5) x3 :- x1,x2 si può leggere anche come: x1 AND x2 implicano x3

235
Le regole: (OR) 6) x3 :- x1 x3 :- x2 si possono leggere anche: x1 OR x2 implicano x3. Introduciamo ora il concetto di relazione tra fatti atomici. Denotiamo con xi - xj una relazione tra xi e xj a cui corrisponde la relazione inversa che chiameremo relazione duale xj - xi. Per illustrare l'algoritmo di elaborazione che ci consente di in- terpretare in un senso allargato le operazioni di AND ed OR, fa- remo riferimento ad un esempio basato su di un ristretto numero di fatti e relazioni. Consideriamo le seguenti relazioni: Relazioni dirette Relazioni duali R1) x1 - x3 R11) x3 - x1 R2) x2 - x3 R12) x3 - x2 R3) x2 - x4 R13) x4 - x2 R4) x3 - x4 R14) x4 - x3 R5) x3 - x5 R15) x5 - x3 R6) x4 - x5 R16) x5 - x4 R7) x2 - x6 R17) x6 - x2 R8) x3 - x6 R18) x6 - x3 R9) x4 - x6 R19) x6 - x4 R10) x5 - x6 R20) x6 - x5 Possiamo interpretare le relazioni come regole di implicazione del tipo xi :- x1,x2,...,xk. (SE (x1,x2,...,xk) ALLORA xi. A) É possibile interpretare le relazioni nel senso di AND B) É possibile interpretare le relazioni nel senso di OR A) Interpretazione delle relazioni nel senso AND. Consideriamo le seguenti regole: R21) x3 :- x1,x2. R22) x4 :- x2,x3. R23) x5 :- x3,x4. R24) x6 :- x2,x3,x4,x5. Allora la regola R21) mette in relazione (x3,x1) e (x3,x2) ed é rappresentabile dalle relazioni R1) ed R2) oppure dalle R11) e R12), considerate congiuntamente (AND). x3 :- x1,x2. <=== (x1-x3),(x2-x3) oppure x3 :- x1,x2. <=== (x3-x1),(x3-x2) La stessa cosa si può fare per le regole R22), R23), R24). Conveniamo di utilizzare le relazioni duali; in altri termini dalle relazioni R11) e R12) considerate congiuntamente si può ricavare la regola R21): x3 - x1 x3 - x2 ===> x3 :- x1,x2. B) Interpretazione delle relazioni nel senso OR.

236
Consideriamo le seguenti regole: R25) x3 :- x1. R26) x3 :- x2. R27) x4 :- x2. R28) x4 :- x3. R29) x5 :- x3. R30) x5 :- x4. R31) x6 :- x2. R32) x6 :- x3. R33) x6 :- x4. R34) x6 :- x5. Allora la regola R25) é rappresentabile dalla relazione R1) op- pure dalla relazione R11), disgiuntamente (OR). x3 :- x1. <=== x1 - x3 oppure x3 :- x1. <=== x3 - x1 La stessa cosa si può fare per le regole da R25) a R34). Conveniamo di utilizzare le relazioni dirette: x3 :- x1. <=== x1 - x3 Nell'interpretazione OR esiste una corrispondenza diretta tra le regole e le relazioni. Definizione dell'algoritmo di espansione. Definiamo un algoritmo di espansione di fatti correlati ad un ar- bitrario insieme di fatti iniziali, che chiameremo per comodità di notazione "target". L'algoritmo funziona per generazioni successive: genera di volta in volta i fatti correlati direttamente all'in- sieme dei fatti del target, mantenuto, di volta in volta, costan- te, e incrementato ogni volta con i nuovi fatti (generalmente) veri implicati dal target. In altri termini, a partire da un insieme arbitrario di fatti i- niziale S0 = x1,x2,...,xk vengono generati gli insiemi di volta in volta direttamente correlati: S0 ==> S1 ==> S2 ==> ... ==> Sr ESEMPIO: Considerando le relazioni R1),...,R20), partendo dall'insieme S0=x1,x2 si ottiene ricorsivamente: S0 = x1,x2 S1 = x1,x2,x3,x4,x6 S2 = x1,x2,x3,x4,x5,x6 Per comodità di notazione scriviamo i risultati dell'elaborazio- ne nella forma: Target Prima generazione Seconda generazione x1 | | x2 | | | x3 |

237
| x4 | | x6 | | | x5 | | Vediamo ora come sia possibile utilizzare questo algoritmo di e- spansione ai fini della programmazione logica, in particolare per risolvere il problema del soddisfacimento di GOAL. Poniamoci la domanda: dato x1 e x2 se ne deduce x5 ? ? x5 :- x1,x2. (GOAL) Analizzeremo quattro casi distinti di elaborazione: C1) Procedimento Forward con interpretazione OR C2) Procedimento Forward con interpretazione AND C3) Procedimento Backward con interpretazione OR C4) Procedimento Backward con interpretazione AND Caso C1) (Forward,OR) Partiamo dai fatti x1,x2 del GOAL; S0 = x1,x2 ; a cui attribuiamo il valore di verità V vero. Consideriamo le relazioni da R1) a R20) e le regole OR da R25) a R34). Target x1 V | | x2 V | | | x3 V 25) | | x4 V 27) | | x6 V 31) | | | x5 V 29) ==> GOAL | | Dove, la notazione sta a significare, per esempio: x3 V 25) --> x3 é vero per la regola R25) x3 :- x1. ed in- fatti x1 é vero. In questo caso la corrispondenza tra le regole e le relazioni é immediata. Caso C2) (Forward,AND) Partiamo dai fatti x1,x2 del GOAL; S0 = x1,x2 ; a cui attribuiamo il valore di verità V vero. Consideriamo le relazioni da R1) a R20) e le regole AND da R21) a R24). Target x1 V | | | | x2 V | | | | | x3 V 21) | | | | x4 F | x4 V 22) | | | x6 F | x5 F | x5 V 23) |==> GOAL | | x6 F | x6 F | x6 V 24) Dove, per esempio, x4 nella prima generazione non risulta vero poiché il fatto x3 non risulta ancora vero.

238
Invece, x3 risulta vero sulla base della regola R21) x3 :- x1,x2 essendo x1 ed x2 entrambi veri. Ad ogni generazione i fatti non veri vengono eliminati dal tar- get. Caso C3) (Backward, OR) Partiamo dal fatto x5 del GOAL; S0 = x5 ; e ci chiediamo quali fatti debbono essere veri affinché sia vero x5. In altri termini, nel caso Backward, partiamo da x5 e ci chiediamo, tra i fatti che sono in relazione con x5, quali impli- cano x5. ? xj :- xi, xj = x5. Consideriamo le relazioni da R1) a R20) e le regole OR da R25) a R34). Target x5 F | | | | | x6 F | | | | x3 F | | | | x4 F | | | | | x1 V G | | | | x2 V G | | | | | x3 V 25) | | | | x4 V 27) | | | | x6 V 31) | | | | | x5 V 29) ==> GOAL In questo caso l'algoritmo non esclude i fatti falsi fino a che non siano istanziati tutti i fatti del GOAL. La notazione x1 V G sta per x1 é vero dal GOAL. Caso C4) (Backward, AND) Partiamo dal fatto x5 del GOAL; S0 = x5 ; e ci chiediamo quali fatti debbono essere veri affinché sia vero x5. In altri termini, nel caso Backward, partiamo da x5 e ci chiediamo, tra i fatti che sono in relazione con x5, quali impli- cano x5. ? xj :- xi, xj = x5. Consideriamo le relazioni da R1) a R20) e le regole AND da R21) a R24). Target x5 F | | | | | | x6 F | | | | | x3 F | | | | | x4 F | | | | | | x1 V G | | | | | x2 V G | | | | | | x3 V 25) | | | | | x4 F | x4 V 22) | | | | x6 F | x5 F | x5 V 23) ==>GOAL | | | | x6 F | x6 F | | | | |

239
La notazione x1 V G sta per x1 é vero dal GOAL. In questo caso l'algoritmo non esclude i fatti falsi fino a che non siano istanziati tutti i fatti del GOAL. Quando tutti i fatti del GOAL sono istanziati allora i fatti fal- si vengono eliminati. Consideriamo ora il significato che l'algoritmo di estrazione fornisce alle operazioni OR ed AND: P1) OR - Almeno un fatto presente nel target é corrispondente al fatto del corpo della regola. P2) AND - Tutti i fatti del corpo della regola sono presenti nel target. Esempio: E1) OR x1 V | x2 V | | x3 V x3 :- x1 | x4 V x4 :- x2 E2) AND x1 V | x2 V | | x3 V x3 :- x1,x2 | x4 F x4 :- x2,x3 (x3 é falso)
Generalizzando, possiamo immaginare un nuovo operatore: SIM(δ) di simiglianza, o di induzione probabilistica.
SIM(δ) - Se una percentuale di fatti del corpo della regola so- no presenti nel target in misura maggiore di δ, dove δ rappresen- ta una soglia arbitraria allora la testa della regola é da con- siderarsi una induzione con una certa probabilità dipendente
da δ. Esempio: Se dai fatti x1,x2,...,xk deduco xi allora dai fatti x1,x2,...,x(k-h) posso indurre xi con una probabilità dipendente da h. Riassumendo, nelle argomentazioni svolte abbiamo fatto riferimen- to esplicito ad operazioni di risoluzione dei problemi di pro- grammazione logica utilizzando gli operatori OR ed AND; alle note procedure di risoluzione abbiamo aggiunto un algoritmo di espan- sione delle relazioni che ci guida nella definizione dell'insieme ottimale di fatti e regole da considerare per migliorare le pre- stazioni nella risoluzione di un GOAL. L'impostazione e la forma che ha assunto il problema generale di risoluzione del GOAL ci ha suggerito un nuovo modo di interpretare le operazioni elementari di OR e di AND focalizzando come possa essere definita un'intera classe di operatori intermedi tra OR - Uno almeno e AND - Tutti. Tale famiglia di operatori potrebbe essere utilizzata per intro- durre un elemento di incertezza, da una parte, ed un elemento di aspettativa, dall'altra, in grado di pilotare il motore inferen- ziale verso le migliori strategie, o più probabilmente di suc- cesso, disponibili in un determinato punto nel procedimento di risoluzione.

240
7.17 Implicazione semantica di raggruppamento Riprendiamo alcuni concetti illustrati nei capitoli precedenti per sintetizzare un unico schema alcune idee precedentemente svi- luppate, in maniera più formale relativamente al problema dell'implicazione logica da una parte, e gli algoritmi di espan- zione di eventi veri dall'altra, costruibili a partire da tra- sformazioni del tipo della GEN precedentemente descritta. Prendiamo un linguaggio L definito per una B-logica. Consideriamo le interpretazioni m1,m2,...,mk come evoluzioni pro- gressive descritte da un certo numero di evidenze. Il passaggio da un'interpretazione nella B-logica alla logica proposizionale si può ottenere, per esempio, trasformando i va- lori di verità di ogni proposizione P, Vl(P), secondo le se- guenti regole:
i) Vl(P) = 1 e Vl(¬P) = 0 sse Vm(P) = 1
ii) Vl(P) = 0 e Vl(¬P) = 1 se Vm(P) = 0 oppure Vm(P) = u oppure Vm(P) = c Si suppone che per ogni proposizione costante P i valori di veri- tà procedano secondo lo schema, n-ordine, seguente: 1 / \ u c \ / 0 per cui una proposizione può essere sconosciuta (u), divenire vera (1) o falsa (0), quindi, eventualmente risultare contraddi- toria (c). Secondo tale schema il concetto di implicazione semantica può essere allargato. Il concetto di distinzione tra implicazione logica e implicazione semantica; per la quale, date due affermazioni A e B, la afferma-
zione "A implica B", A ⇒ B, é vera quando la verità di A im- plica che B é vera:
1 = m(A) → m(B) = 1. Per comprendere questa distinzione introduciamo il concetto di variabile irrilevante. Consideriamo la reguente regola: 1) b2,b3 :- b1,b2. equivalente a 2) (b1 & b2) -> (b2 & b3) possiamo dalla 1) trarre la seguente conclusione: 3) b3 :- b1. o anche

241
4) b1 -> b3. Vediamo la tavola della verità di b1 & b2 -> b2 & b3 e b1 -> b3. b1 b2 b3 | b1 & b2 | b2 & b3 | b1 & b2 -> b2 & b3 | b1 -> b3 --------------------------------------------------------------- 1 1 1 | 1 | 1 | 1 | 1 1 1 0 | 1 | 0 | 0 | 0 1 0 1 | 0 | 0 | 1 | 1 1 0 0 | 0 | 0 | 1 | 0 0 1 1 | 0 | 1 | 1 | 1 0 1 0 | 0 | 0 | 1 | 1 0 0 1 | 0 | 0 | 1 | 1 0 0 0 | 0 | 0 | 1 | 1 --------------------------------------------------------------- da cui si ricava che: i) (b1 -> b3) -> ((b1 & b2) -> (b2 & b3)) é una tautologia ii) ((b1 & b2) -> (b2 & b3)) -> (b1 -> b3) non é una tautologia eppure la ii) é semanticamente sempre vera se la variabile b2 é una variabile irrilevante. Definizione 7.17.1 Definiamo una implicazione semantica di raggruppamento. Consideriamo due variabili binarie b1 e b2, <b1 b2>. Definiamo le seguenti proprietà a partire da b1 e b2:
pα = <1 1> = b1 & b2 pβ = <1 0> = b1 & ¬b2 pτ = <1 *> = b1 & (b2 v ¬b2) => b1 allora
iii) pα ⇒ pτ e pβ ⇒ pτ ovviamente b1 & b2 -> b1 denotiamo per comodità di notazione con: A = b1 & b2
B = b1 & ¬b2 C = b1 & (b2 v ¬b2) D = ¬b1 & b2 E = ¬b1 & ¬b2 F = ¬b1 & (b2 v ¬b2) Costruiamo la tavola di verità per b1, b2, A, B, C, D, E, F, A->C, B->C, D->F, E->F : b1 b2 | A | B | C | D | E | F | A->C | B->C | D->F | E->F ----------------------------------------------------------- 1 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 1 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 0 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 0 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 -----------------------------------------------------------

242
dalla tavola si può verificare che la iii) é soddisfatta e inoltre se:
pα' = <0 1> = ¬b1 & b2 pβ' = <0 0> = ¬b1 & ¬b2 pτ' = <0 *> = ¬b1 & (b2 v ¬b2) => ¬b1 allora anche
iv) pα' ⇒ pτ' e pβ' ⇒ pτ' é soddisfatta. Utilizziamo quanto descritto nel capitolo 7.1 sulla rappresenta- zione tramite proprietà; in particolare riprendiamo le defini- zioni di lub e glb. Sia S = p1,p2 la rappresentazione minimale (lub) di due proprietà definite da: p1 = <1 1 0> e p2 = <1 0 1> allora lub(p1,p2) = <1 * *> mentre il più grande limite inferiore (glb) corrisponde a: glb = <1 0 0>
Rappresentiamo p1 e p2 con: pα = <b1 b2 b3 | d1 d2 d3> p1 = <1 1 0 | 0 0 1> p2 = <1 0 1 | 0 1 0>
lub = <1 0 0 | 0 0 0> = p1 ∩ p2 = p1 ∧ p2
glb = <1 1 1 | 0 1 1> = p1 ∪ p2 = p1 ∨ p2
δ = <0 1 1 | 0 1 1> = p1 ∆ p2 allora
p1 ≈ b1 & b2 & ¬b3
p2 ≈ b1 & ¬b2 & b3
lub ≈ b1
glb ≈ b1 & [(b2 v ¬b2) & (b3 v ¬b3)] Vediamo il comportamento di sistemi di regole rispetto ad una ta- le implicazione; in particolare prendiamo in considerazione l'o- perazione di allineamento delle variabili mancanti o irrilevanti e l'effetto che tale situazione produce sulla negazione. Prendiamo i seguenti sistemi di regole: R1 - b4 :- b1, b2. b5 :- b1, b3.

243
R2 - b4 :- b1,b2,¬b3. b5 :- b1,¬b2,b3.
R3 - b4 :- b1,b2,(b3 v ¬b3). b5 :- b1,(b2 v ¬b2),b3. Allora si ha: R1(b1,b2,b3) = b4,b5 R2(b1,b2,b3) = insieme vuoto !!! R3(b1,b2,b3) = b4,b5 D'altra parte b1 & b2 & b3 -> b1 & b2 -> b4 per R1 ma non per R2. Possiamo aggiungere alcune considerazioni sulle operazioni logi- che AND, OR e XOR in relazione alle leggi di implicazione. In particolare, prendiamo in esame il flusso informativo legato alla determinazione dei valori di verità nelle variabili logiche che descrivono le proprietà degli oggetti del sistema. Prendiamo due variabili binarie b1 e b2. Sia <b1,b2 | d1,d2> il vettore che le descrive. Le operazioni logiche che prendiamo in considerazione sono: AND) b1 & b2 OR) b1 v b2
XOR) b1 x b2 = b1 v b2 & ¬(b1 & b2) la tavola di verità relativa é la seguente: b1 b2 | b1 v b2 | b1 & b2 | b1 x b2 --------------------------------------------- 0 0 | 0 | 0 | 0 0 1 | 1 | 0 | 1 1 0 | 1 | 0 | 1 1 1 | 1 | 1 | 0 --------------------------------------------- poniamo x1 :- b1 v b2 x2 :- b1 & b2 x3 :- b1 x b2 ricaviamo i seguenti sistemi:
OR) - x1 :- b1,b2. (α1) x1 :- b2,d1. (α2) x1 :- b1,d2. (α3) AND) - x2 :- b1,b2. XOR) - x3 :- b1,d2. x3 :- b2,d1. É possibile ridurre il sistema OR nel modo seguente:
OR) - x1 :- b1,b2. (α1) ==> x1 :- b1. (b2 é irrilevante)

244
x1 :- b1,d2. (α3)
- x1 :- b2,b1. (α1) ==> x1 :- b2. (b1 é irrilevante) x1 :- b2,d1. (α2)
Da notare per inciso che α1 ∩ α2 ∩ α3 = 0 mentre α1 ∩ α3 = b1 e α1 ∩ α2 = b2. Ora consideriamo il numero di bit relativi alle informazioni do- vute alle evidenze b1 e b2 e confrontiamolo con il numero di bit relativi alle informazioni registrate: AND) - x2 :- b1,b2. sono due bit di informazione XOR) - x3 :- b1,d2. sono quattro bit di informazione x3 :- b2,d1. OR) - x1 :- b1. sono due bit di informazione x1 :- b2. In un certo senso l'operazione XOR cattura più bit di informa- zione rispetto alle operazioni AND ed OR che invece si dimostrano equivalenti, la XOR trasforma 2 bit di informazione in uno sol- tanto, esattamente come la AND e la OR, la differenza risiede nella configurazione più equilibrata della rappresentazione XOR rispetto alle rappresentazioni AND ed OR,come si può vedere dal- le tavole di verità. Per terminare questo capitolo accenneremo, brevemente, ad alcuni possibili sviluppi dei concetti esposti; in particolare alla pos- sibilità di costruire regole basate su relazioni binarie a cui viene attribuito un peso interpretabile come affidabilità delle deduzioni ricavabili dalle regole stesse. Ottenere un sistema deduttivo basato su relazioni binarie forni- rebbe immediatamente il seguente notevole risultato: Proposizione 7.17.1 Una equivalenza procedurale nell'algoritmo del motore inferenzia- le per il procedimento forward e backward nella ricerca delle ri- solventi per un determinato Goal. Vediamo un esempio a titolo esplicativo; consideriamo le seguenti regole binarie su fatti atomici x1,x2,x3,x4,x5,x6. 1) x1 --> x2 (w12) 2) x2 --> x1 (w21) 3) x1 --> x3 (w13) 4) x3 --> x1 (w31) 5) x2 --> x3 (w23) 6) x3 --> x2 (w32) 7) x4 --> x3 (w43) 8) x3 --> x4 (w34) 9) x3 --> x5 (w35) 10) x5 --> x3 (w53) 11) x6 --> x4 (w64) 12) x4 --> x6 (w46) corrispondente al seguente grafo:

245
(fig. 7.16) Come esempio di procedimento forward consideriamo la seguente do- manda: cosa implica il fatto x3 ? la risposta si può ottenere ricercando quali fatti sono in rela- zione con il fatto x3: x3 | | | x1 | | x2 | | x4 | | x5 | | | x6 e quindi selezionare tra tali fatti quelli che sono implicati dal fatto x3. nel nostro caso si ottiene: x3 | | x2 | x5 Come esempio di procedimento backward consideriamo la seguente domanda: cosa è implicato dal fatto x3 ? la risposta si può ottenere ricercando quali fatti sono in rela- zione con il fatto x3: x3 | | | x1 | | x2 | | x4 | | x5 | | | x6 e selezionare tra tali fatti quelli che implicano il fatto x3. nel nostro caso si ottiene:

246
x3 | | SEL | | | x1 | | x1 | | x2 | | x2 | | x4 | | x4 | | x5 | | | | x6 | | | x6 In particolare si otterrebbe un metodo unico e normalizzato per la propagazione della funzione di affidabilità sui fatti coin- volti dal procedimento di deduzione. Di più, in tal modo anche il metodo abduttivo potrebbe essere incluso tra le modalità di derivazione di conseguenze a partire da un determinato Goal.

247
7.18 Conclusioni Dal punto di vista computazionale le informazioni si dispongono, una volta codificate, in maniera naturale in termini di attributi e caratteristiche. E' possibile costruire una trattazione matematica a partire da uno spazio astratto di insieme di caratteristiche o più in generale da un insieme di informazioni. Operare su un simile spazio astratto costituisce un potente modello per la manipolazione delle informazioni, in particolare è possibile isolare alcune semplici trasformazioni e manipolazioni che consentono la realizzazione di processi di astrazione tipici della mente umana, per esempio la classificazione, la generalizzazione e l'aggregazione. Il fatto che sia possibile indurre una metrica potente e generale su uno spazio astratto di insiemi di informazioni ci consente di definire, tramite operazioni matematiche elementari, un potente metodo di manipolazione dell'informazione. Avere a disposizione una funzione distanza significa poter disporre di un criterio di simiglianza tra le informazioni, tale criterio (metrico) consente l'immediato confronto e classificazione di informazioni simili secondo un certo criterio arbitrario. Questo costituisce il primo passo verso la costruzione di una rete di correlazioni tra le informazioni che ne consente una successiva elaborazione. Il passo di codifica dell'informazione è cruciale, isolare caratteristiche dell'informazione che siano invarianti per alcune trasformazioni ci consente di estrarre proprietà che sono proprie dell'informazione stessa e che rappresentano generalizzazioni indipendenti dalla codifica dell'informazione stessa su un particolare supporto. Associare informazioni significa confrontarle secondo un certo criterio di simiglianza e questo consente il trattamento anche di informazioni nuove ovvero non precedentemente memorizzate. Passare da uno schema se A,B,... sono veri allora C e vera allo schema se A,B,... sono attivi allora C è attiva, consente una interessante generalizzazione della logica di deduzione utilizzata in programmazione logica e consente una potente analogia con lo schema utilizzato nello sviluppo delle reti neurali. In uno schema concettuale di insiemi di informazioni è possibile rappresentare qualsiasi cosa, qualsiasi dispositivo costruibile, pertanto disporre di una metrica su un simile spazio astratto consente un approccio molto generale al problema dell'elaborazione delle informazioni. Una metrica basata solo su semplici operazioni di intersezione ed unione di insiemi dispone di un vastissimo settore di applicazioni concrete. Ovviamente, praticamente occorre una opportuna codifica delle informazioni. D'altra parte un approccio teorico che affronti i problemi alla radice della rappresentazione è sempre preferibile ad un approccio che utilizzi euristiche di risoluzione basate sulle particolarità contingenti di codifica delle informazioni. Il presente lavoro costituisce un ponte di collegamento tra la programmazione logica e le reti neurali.

248
BIBLIOGRAFIA Adeli Hojjat, Knowledge engineering, McGraw-Hill, New York 1990. Arigoni Anio, Mathematical Developments Arising From 'Semantical Implication' And The Evaluation Of Membership Characteristic Fun- ctions, Fuzzy Sets and System 4, 1980. Arigoni Anio, Furlanello Cesare, Maniezzo Vittorio, Irrilevant Features In Concept Learning,IPMU Parigi 1990. Baldacci Maria Bruna, Rappresentazione e ricerca delle informazioni, NIS la Nuova Italia Scientifica, Roma, 1988. Baldissera C., Ceri S., Colorni A., Metodi di ottimizzazione, Clup editore, Milano 1981. Bencivenga Ermanno, Le logiche libere, Boringhieri editore, Tori- no 1976. Bettelli Oscar, Dati, Relazioni & Associazioni, Apogeo editore, Milano 1991. Bettelli Oscar, Macchine intelligenti, Arpa Publishing 1997. Bettelli Oscar, Sincronicità: un paradigma per la mente, Antitesi editoria, Roma. Bettelli Oscar, Processi cognitivi, CLUEB editore, Bologna 2000. Boden M., Artificial Intelligence and Natural Man, New York, Basic Books, 1977. De Bono Edward, Il meccanismo della mente, Garzanti editore 1972. Cannataro Mario, Spezzano Giandomenico, Talia Domenico, Programmazione logica e architetture parallele, Franco Angeli Carruccio Ettore, Mondi della logica, Zanichelli editore, Bologna 1971. Casadei Giorgio A., Teolis Antonio G.B., Prolog: dalla programma- zione all'intelligenza artificiale, Zanichelli, Bologna 1986. Ceri S., Gottlob G., Tanca L., Logic Programming and Databases, Springer Verlag, Germany 1990. Clocksin W.F., Mellish C.S., Programmare in prolog, Franco Angeli Churchland Paul M., Il motore della ragione, la sede dell'anima Il saggiatore editore. Console Luca, Lamma Evelina, Mello Paola, Programmazione Logica e Prolog, UTET, Torino 1991.

249
Feigenbaum E. e Feldman J., Computers and Thought, New York, McGraw-Hill, 1963. Furlan Franco Lanzarone A. Gaetano, Prolog, linguaggio e metodologia di programmazione, Franco Angeli Goldberg David E., Genetic Algorithms in Search, Optimization and Machine Learning, Addison-Wesley Pubblishing, Menlo Park Califor- nia 1989. Goldbeter A., Cell To Cell Signaling: from experiment to theore- tical models, Academic press, San Diego 1989. Hintikka Jaakko, Induzione, accettazione, informazione, Il Mulino editore, Bologna 1974. Jaspers Karl, Ragione e antiragione nel nostro tempo, Sansoni e- ditore, Firenze 1978. Jung Carl Gustav, Sulla sincronicita', Il mulino, Bologna Lashley Karl S., La fisica della mente, Boringhieri editore, To- rino 1969. Longo Giuseppe, Teoria dell'informazione, Boringhieri editore, Torino 1980. Lukaszewicz Witold, Non-Monotonic Reasoning, Ellis Horwood, New York 1990. Makinson David C., Temi fondamentali della logica moderna, Borin- ghieri editore, Torino 1979. Mendelson Elliott, Introduzione alla logica matematica, Borin- ghieri editore, Torino 1972. Nagao Makoto, Knowledge and Inference, Academic Press, United Kingdom, 1990. Nilsson Nils J., Metodi per la risoluzione dei problemi nella in- telligenza artificiale, Franco Angeli editore, Milano 1982. Pierce John R., La teoria dell'informazione, Edizioni Mondadori, Milano 1963. Prigogine Ilya, Stengers Isabelle, La nuova alleanza, Einaudi e- ditore, Torino 1981. Putnam Hilary, Rappresentazione e realtà, Garzanti editore. Rizzi Barbara, La gestione dell'incertezza nei sistemi esperti: La teoria di Hajek, Tesi di Laurea, Bologna 1990. Rumelhart David E., McCelland James L., Parallel Distribuited Processing, MIT Press, London 1989. Salton G., McGill M.J., Introduction to modern information re- trieval, McGraw-Hill, New York 1983. Saumya K. Debray, Raghu Ramakrishnan, Generalized Horn Clause Programs, 1991.

250
Schiavina Barbara, La gestione dell'incertezza nei sistemi esper- ti: Un'applicazione, Tesi di Laurea, Bologna 1990. Singh Jagjit, Linguaggio e cibernetica, Edizioni Mondadori, Mila- no 1969. Tsichritzis D.C., Lochovsky F.H., Data models, Prentice-Hall, Englewood Cliffs, N.Y., 1982.

















