LOGICA SEQUENZIALEE COMBINATORIA - Il Sito Di …sevencombat.altervista.org/Elettronica...
96
INDICE 1. Segnali analogici e digitali 2. Rappresentazione dell’informazione Informazioni alfanumeriche Informazioni numeriche – notazione posizionale Il sistema di numerazione esadecimale Conversione esadecimale – binario e binario – esadecimale Complemento a due 3. Algebra booleana Funzione logica not Funzione logica and Funzione logica or Funzione logica xor Funzione logica nand Funzione logica nor 4. Implementazioni delle funzioni logiche Dalla funzione allo schema logico e viceversa Dallo schema alla funzione Dalla funzione alla tavola di verità Dalla tavola di verità alla funzione logica 5. Mappe di Karnaugh 6. Implementazione con porte nand 7. Logica sequenziale e combinatoria 8. Il FF-SR Il FF-D 9. Il FF-JK Il FF-T 10. Preset e clear 11. Il FF-JK master e slave 12. I registri a scorrimento Registro SIPO Registro SISO Registro PIPO Registro PISO 13. I contatori Contatore asincrono Contatore sincrono 14. Locazioni e celle 15. Schema base di un elaboratore: architettura di Von Noëmann I registri I bus Esecuzione di un’istruzione da parte della CPU 1
Transcript of LOGICA SEQUENZIALEE COMBINATORIA - Il Sito Di …sevencombat.altervista.org/Elettronica...

INDICE1. Segnali analogici e digitali 2. Rappresentazione dell’informazione
Informazioni alfanumericheInformazioni numeriche – notazione posizionaleIl sistema di numerazione esadecimaleConversione esadecimale – binario e binario – esadecimaleComplemento a due
3. Algebra booleana Funzione logica notFunzione logica andFunzione logica orFunzione logica xorFunzione logica nandFunzione logica nor
4. Implementazioni delle funzioni logiche Dalla funzione allo schema logico e viceversaDallo schema alla funzioneDalla funzione alla tavola di veritàDalla tavola di verità alla funzione logica
5. Mappe di Karnaugh 6. Implementazione con porte nand 7. Logica sequenziale e combinatoria 8. Il FF-SR
Il FF-D9. Il FF-JK
Il FF-T10. Preset e clear 11. Il FF-JK master e slave 12. I registri a scorrimento
Registro SIPORegistro SISORegistro PIPORegistro PISO
13. I contatori Contatore asincronoContatore sincrono
14. Locazioni e celle 15. Schema base di un elaboratore: architettura di Von Noëmann
I registriI busEsecuzione di un’istruzione da parte della CPUEsecuzione di un programma da parte della CPU
16. Classificazione delle memorie Memorie ad accesso sequenzialeMemorie ad accesso casualeTipi di memorie
APPENDICE: l’ALU 74LS382
1

SEGNALI ANALOGICI E DIGITALI
Un segnale si dice analogico qualora vari con continuità, ad es:
Mentre, si dice digitale quando assume solo dei valori discreti; ciò comporta una variazione discontinua del segnale:
Ed è proprio in base a questo tipo di segnali che viene fatta la distinzione tra elettronica analogica ed elettronica digitale. In particolare nella analogica si studiano i dispositivi più comuni e le loro risposte che ci vengono fornite sottoforma di segnali analogici; ma, facendo opportune osservazioni e sotto determinate condizioni tali segnali possono essere considerati digitali. Ad esempio, considerando la caratteristica del diodo:
I I
V V
2

RAPPRESENTAZIONE DELL’INFORMAZIONE
I calcolatori sono macchine elettroniche, quindi basate su dei circuiti in cui scorrono delle correnti
elettriche. Le informazioni che i calcolatori elaborano sono rappresentate mediante segnali elettrici.
Dal momento che la cosa più semplice da misurare in un circuito elettrico è controllare se la
corrente passa o non passa , segue che un dato circuito elettronico può rappresentare facilmente le
informazioni usando un alfabeto a due simboli (un simbolo, che convenzionalmente identifichiamo
con “0”, rappresenta fisicamente l’assenza di corrente nel circuito, e l’altro simbolo, che
convenzionalmente identifichiamo con “1”, rappresenta fisicamente il passaggio di corrente nel
circuito). In virtù di questa scelta, tutte le informazioni vengono rappresentate all’interno del
calcolatore con un alfabeto di due simboli detto alfabeto binario. Esiste solo un numero finito di
simboli (2) con i quali è possibile costruire delle parole binarie (sequenze finite di simboli binari) e
rappresentare le informazioni. I simboli “0” e “1” sono solo dei simboli convenzionali e non hanno
il significato di numeri. Ciascuno di questi due simboli si chiama BIT (che è un acronimo formato a
partire dalle parole BINARY DIGIT, cioè cifra binaria ). Avremo quindi un bit “0” e un bit “1”. Un
bit esprime nel calcolatore un’informazione elementare. E’ evidente che utilizzando un solo bit è
possibile rappresentare solo due informazioni. Se invece utilizziamo diversi bit ed associamo ad essi
un certo significato secondo una qualche convenzione, allora un insieme di bit può rappresentare un
numero di informazioni diverse. Ad esempio, utilizzando due bit possiamo rappresentare 4 (22)
informazioni diverse con le combinazioni (o parole binarie di 2 bit) “00”, “01”,”10”, “11”. In
generale con N bit (essendo N un numero intero positivo) potremo rappresentare 2N informazioni
diverse.
Informazioni alfanumeriche
Correntemente noi rappresentiamo le informazioni usando un alfabeto composto da alcune decine di
simboli: le lettere maiuscole dalla “A” alla “Z”, le lettere minuscole dalla “a” alla “z”, le cifre da
“0” a “9”, il carattere spazio “ ”, i segni di punteggiatura (“.”, “,”,”;”, “:”, “!”, “?”, etc.) e altri
simboli speciali (come “@”, “#”, etc.). Quindi, se vogliamo codificare informazioni costituite da
sequenze di tali simboli (informazioni alfanumeriche) è necessario avere una rappresentazione di
tutti i simboli utilizzati in termine di sequenze di bit.
Il codice oggi universalmente utilizzando è il codice ASCII (che è una sigla che sta per
AMERICAN STANDARD CODE FOR INFORMATION INTERCHANGE): si tratta di un codice
a 8 bit (8 bit costituiscono un byte). Con un 1 byte è possibile rappresentare 256 (28) informazioni
diverse, un numero sufficiente per i caratteri alfanumerici. Ad esempio, nel codice ASCII la
sequenza “01000001” rappresenta il carattere “A”.
3

Informazioni numeriche – Notazione posizionale
Oltre ai caratteri, un tipo importante di informazione con cui si ha a che fare è costituita dai numeri
(con o senza segno, con o senza parte frazionaria). Un modo di rappresentarli potrebbe essere quella
di convertire la sequenza dei caratteri che costituiscono un numero nella corrispondente sequenza di
byte in accordo con la codifica ASCII. Questo modo di procedere non è tuttavia molto efficiente
perché complicherebbe enormemente le operazioni aritmetiche. E’ possibile invece trovare un modo
di rappresentare i numeri usando l’alfabeto binario e preservando la facilità di effettuare le
operazioni aritmetiche. Per far questo è opportuno prima riflettere sul nostro modo di rappresentare
i numeri, che è detto sistema numerico decimale posizionale. Il sistema si dice decimale perché si
utilizzano 10 simboli diversi (le cifre 0, 1, 2, 3, 4, 5, 6, 7, 8, 9) e posizionale perché il valore (o
peso) di una cifra non è assoluto, ma dipende dalla posizione che essa occupa nel numero. Ad
esempio, nel numero 1471 la cifra 1 che sta a sinistra ha un peso maggiore della cifra 1 che sta a
destra. Più precisamente, si ha che in 1471 ci sono: 1 migliaio, 4 centinaia, 7 decine e 1 unità. Più
formalmente, andando da destra verso sinistra:
1471 = 1*100+ 7*101 + 4*102 + 1*103
Il sistema di numerazione decimale si dice anche in base 10, dal momento che ogni intero
decimale si esprime come somma dei prodotti delle singole cifre per il rispettivo peso (potenze del
10 crescenti da destra verso sinistra). Se vogliamo trasportare questo sistema ai calcolatori, è ovvio
che saremo costretti ad usare un sistema numerico binario posizionale, un sistema cioè in cui il peso
di ogni singola cifra (che può essere 0 o 1) all’interno del numero è una potenza del 2 (invece che
dal 10). Così, il numero binario (1011)2 può essere convertito nel suo equivalente decimale
(partendo da destra e andando verso sinistra) come segue:
1*20 + 1*21 + 0*22 + 1+23 = (11)10
e quindi rappresenta il numero decimale undici.
significativo). Dunque, data una sequenza di bit, se essa rappresenta la codifica di un nu
Nell’espressione di un numero binario, il bit più a sinistra, che ha il peso maggiore, si indica con
MSB (Most Significant Bit, bit più significativo), mentre il bit più a destra, che ha il peso minore, si
indica con LSB (Least Significant Bit, bit meno mero, è facile risalire al suo valore nel “nostro”
sistema decimale, semplicemente facendo la somma dei prodotti delle cifre che lo costituiscono (da
destra verso sinistra) per la corrispondente potenza del 2 (si parte dalla potenza 0 e si aumenta di 1
man mano che ci si sposta verso sinistra).
4

Per convertire invece un numero espresso nel sistema decimale in binario si usa il metodo detto
delle divisioni successive. Supponiamo ad esempio di voler trovare la rappresentazione binaria di
990: lo dividiamo per 2 ottenendo 495 e un resto che in questo caso sarà 0. Dividiamo ora il
risultato ottenuto per 2 e ripetiamo il procedimento fini ad ottenere come quoziente 0. I resti delle
successive divisioni, presi nell’ordine dall’ultimo al primo, forniscono le cifre della
rappresentazione binaria del numero, dalla più significativa alla meno significativa.
900 : 2 = 495 con resto 0
495 : 2 = 247 con resto 1
247 : 2 =123 con resto 1
123 :2 =61 con resto 1
61 : 2 =30 con resto 1
30 : 2 =15 con resto 0
15 : 2 =7 con resto 1
7 : 2 =3 con resto 1
3 . 2 =1 con resto 1
1 : 2 = 0 con resto 1
Dunque, la rappresentazione binaria di (990)10 è (1111011110)2. E’ chiaro a questo punto che si
può passare dal sistema di numerazione decimale a quello binario, e viceversa, per numeri interi;
queste operazioni di conversione, per quanto concettualmente semplici, sono in genere lunghe e
noiose. D’altra parte, la rappresentazione di un numero binario è molto più lunga e pesante della
rappresentazione decimale.
Per ovviare a questo inconveniente si usano due altri sistemi di numerazione, l’ottale e
l’esadecimale, che hanno il vantaggio di essere più compatti del sistema binario e, nello stesso
tempo, immediatamente convertibili in esso.
Il sistema ottale è in base 8 e usa i simboli da 0 a 7. La conversione di un numero da decimale ottale
si fa subito con le divisioni successive per 8 e prendendo al solito i resti.
Il sistema esadecimale è un sistema posizionale in base 16 (usa dunque 16 simboli per rappresentare
i numeri da 0 a 15). I simboli da “0” a “9” rappresentano i numeri da zero a nove, la lettera “A”
rappresenta il 10, la “B” l’undici, la “C” il dodici, la “D” il tredici, la “E” il quattordici, la “F” il
quindici.
5

Nella conversione da decimale a binario si utilizza normalmente la divisione ripetuta per 2, mentre
nella conversione da binario a decimale si fa la somma dei prodotti delle cifre binarie per le
corrispondenti potenze di 2. Dunque, utilizziamo due algoritmi diversi per fare essenzialmente la
stessa cosa (perché in entrambi i casi si tratta di conversione di base). L’uso di due algoritmi diversi
è dovuto alla nostra abilità a lavorare usando il sistema decimale.Dunque, la codifica (e la conversione) dei numeri interi nel sistema binario è risolta. Se utilizziamo ad esempio 2 byte
(16 bit) per rappresentare i numeri interi, è evidente che il più piccolo numero sarà 0 (codificato con 16 bit 0), mentre il
più grande sarà 65535 (codificato con 16 bit 1): infatti, con 16 bit possiamo rappresentare 65536 informazioni diverse.
Vediamo come si effettua la somma di due numeri binari. Analogamente a quanto succede nel sistema decimale,
sappiamo fare somma dei due numeri quando impariamo la tabellina della somma, che in binario è particolarmente
semplice, visto che si hanno solo due cifre diverse. Si ha la seguente tabellina della somma (N.B. si legge prima la riga
e poi la colonna):
+ 0 1
0 0 1
1 1 10cioè:
0 + 0 = 0, 0 + 1 = 1 + 0 = 1, 1 + 1= 0 con riporto di 1.
Quindi, se dobbiamo fare la somma dei numeri binari:
10110011 + 01000111
(in decimale 179+71) allineeremo i due numeri a destra e avremo:
10110011 +
01000111 =
11111010
che, espresso in decimale, rappresenta 250.
6

La moltiplicazione tra i due numeri binari di N bit si effettua anch’essa in maniera semplice. La
tabellina della moltiplicazione è la seguente:
* 0 1
0 0 0
1 0 1
Cioè 0 * 0= 0, 0 * 1= 0, 1 * 0= 0 e 1 * 1= 1
Facciamo un esempio:
1011 * 101=
1011 * ossia 11 *
101 = 5=
1011 55
0000
1011 .
110111
La tabellina della sottrazione è la seguente:
- 0 1
0 0 P
1 1 0
In questo caso sarà: 0 – 0= 0, 0 – 1= viene fatto un prestito, 1 – 0= 1, ed infine 1 – 1= 0
Facciamo un esempio:
1001001 – cioè 73 -
1110= 14=
7

111011 59
Ed infine vediamo la divisione,in binario si opera facendo una serie di sottrazioni finquando il resto
della sottrazione è nullo o un numero minore del divisore.
Facciamo un esempio:
1001001 1110
1110 101
10001-
1110
11
Cioè 73:14=5 con il resto di 3.
Anche per quanto riguarda la divisione si utilizzano le stesse tecniche di calcolo che abbiamo
appreso alle scuole elementari, ovvero si scrivono i numeri incolonnati come di consueto;
- si staccano tante cifre del divisore quante sono quelle del dividendo, o una in più se così
facendo il divisore è minore del dividendo;
- si scrive il quoziente parziale ottenuto, il primo è sempre 1;
- si sottrae al dividendo il prodotto del divisore per il quoziente parziale;
- si abbassa un'altra cifra scrivendola a destra del resto del primo resto parziale
- si ripete il procedimento dal punto3 fino ad esaurimento del dividendo.
In forma binaria è bene ricordare che:
- se il divisore è uno il quoziente è uguale al dividendo;
- se il divisore è zero, ed il dividendo è diverso da zero, la divisione produce il numero di
partenza;
Le proprietà formali della divisione, che abbiamo visto in precedenza, sono sempre valide,
naturalmente. Nel caso specifico dei numeri scritti è priva di significato.
8

SISTEMA DI NUMERAZIONE ESADECIMALE
Oltre al sistema binario un'altro sistema di numerazione usato da chi lavora con i computer è quello
esadecimale, cioè in base sedici. Per scrivere i numeri naturali abbiamo ora a disposizione sedici
simboli:
O, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F
Dalle definizioni date nel caso generale, per il sistema esadecimale risultano le seguenti:
Osservazioni:
Il numero uno si dice unità semplice o del primo ordine. Sono necessarie sedici unità di un
qualunque ordine per fare una unità dell'ordine superiore.
Abbiamo quindi le seguenti relazioni tra le unità esadecimali ed il loro valore nel sistema decimale:
unità esadecimale ordine decimale corrispondente:
1 l° 1 = 160
10 2° 16 = 161
100 3° 256 = 162
1000 4° 4096 = 163
10000 5° 65536= 164
Abbiamo quindi che a 16569 corrisponde 40B9.
Possiamo scrivere un qualunque numero nel sistema esadecimale seguendo la stessa regola che
abbiamo dato per il sistema binario.
9
Scriviamo ad esempio il decimale 16569 in base 16:. 16569 169 1035 16
B 64 16 0 4

In alcune occasioni può essere utile convertire un numero, scritto nel sistema esadecimale, nella sua
rappresentazione decimale. Come è facile immaginare da quanto visto nel sistema binario, è facile
fare la conversione in quello decimale, basta ricordarsi il significato delle convenzioni sulla
posizione.
Vogliamo ad esempio conoscere la rappresentazione decimale del numero che nel sistema
esadecimale si scrive A2C51. Secondo la regola che conosciamo risulta:
A2C51 = 1 * 16° + 5 * 161 + C * 162 + 2 * 163 + A* 164 = 1 * 16° + 5 * 161 + 12 * 162 + 2 * 163 + l0 * 164 = 666705
Abbiamo quindi che al numero A2C51 in rappresentazione esadecimale, corrisponde il numero
666705 in quella decimale.
CONVERSIONE ESADECIMALE- BINARIO
Si può fare una conversione immediata da esadecimale a binario e viceversa. Si procede come
segue:
Si legge la cifra esadecimale da sinistra verso destra
Il numero meno significativo si traduce in binario utilizzando 4 cifre (se il numero corrisponde a
meno di quattro cifre binarie si mettono gli 0 davanti secondo una corrispondenza 1 cifra
esadecimale – 4 binarie)
Facciamo un esempio:
Il numero di prima 40B9 viene tradotto come:
916 = 10012 (cifra meno significativa)
B16 = 10112 (perché B è 11 in decimale)
016 = 00002
416 = 01002 (cifra più significativa)
4 0 B 9
0100 0000 1011 1001
A questo punto si mettono le cifre binarie una di seguito all’altra partendo dalla più significativa:
10

40B916 = 01000000101110012
Se faceste la conversione di questo numero binario in decimale trovereste che è 16569.
CONVERSIONE BINARIO - ESADECIMALE
Si legge la cifra binaria da sinistra verso destra e la si spezzetta a gruppi di 4 bit. Ogni gruppo di 4
bit si converte in decimale, quindi in esadecimale.
Facciamo un esempio:
Il numero 100010010011010111010 si divide partendo dalle cifre meno significative come:
10102 = 1010 = A16
10112 = 1110 = B16
01102 = 610 = 616
00102 = 210 = 216
00012 = 110 = 116
00012 = 110 =116
0001 0001 0010 0110 1011 1010 1 1 2 6 B A
Quindi il corrispondente esadecimale è: 1126BA
11

COMPLEMENTO A DUE
In realtà il calcolatore non è in grado di eseguire tutte le operazioni binarie, è capace solo di
svolgere le addizioni, per cui:
- Le sottrazioni si opereranno attraverso la somma algebrica di un numero positivo ed un
numero negativo;
- Le moltiplicazioni si opereranno sommando tante volte il moltiplicando quanto vale il
moltiplicatore;
- Le divisioni, infine, si opereranno attraverso sottrazioni ripetute .
Per intenderci, si farà un esempio per ogni tipo di operazione:
Sottrazione
Si vuole fare l’operazione 7 – 5, dal calcolatore verrà tradotta in 7 + (- 5). Quindi si tratta ora di
trasformare il sottrattore in un numero da positivo a negativo. Ciò viene fatto per mezzo del
complemento a due, il quale a sua volta si ottiene in due passaggi:
1. facendo il complemento ad 1,cioè invertendole cifre del numero da sottrarre;
2. addizionando alla cifra complementata, al passo precedente, .
Nel caso dell’esempio precedente,si otterrebbe:
710= 1112 (sottraendo)
510= 1012 (sottrattore)
Complemento a 1: 010
Complemento a 2: 010 + 1= 0112 = - 510
Operando la somma si ottiene: 111 +
011=
1010
12

La cifra nel riquadro prende il nome di BIT di CARRY e non fa parte del risultato, cioè
l’operazione ci fornirà il risultato 0102 = 210
Quando si opera con il complemento a due bisogna avere l’accortezza di verificare che le cifre del
sottraendo e sottrattore siano uguali in numero,altrimenti il risultato ottenuto non sarà esatto.
In termini numerici, si fa l’esempio di 62-12=50
6210= 1111102
1210=11002
Si nota come l’equivalente binario del 62 sia composto da 6 cifre mentre il 12 da 4 cifre e poiché la
complementazione prevede lo stesso numero di cifre, il 12 diverrà 0011002.
Complemento a 1: 110011
Complemento a 2: 110011 + 1=110100
L’operazione produce: 111110 +
110100 =
1110010
1100102 = (2+16+32)10 =5010
Moltiplicazione
E’banale, poiché il modo di operare è praticamente uguale a quello del sistema di numerazione
decimale. Volendo fare l’operazione 12 * 3= 36, il calcolatore farà:
1210 = 11002
310 = 112
L’operazione produce: 1100+
1100+
1100=
100100
1001002 = (32 + 4)10 = 3610
13

Divisione
E’ l’operazione più complessa rispetto alle altre perché in più si ha un contatore. Il risultato della
divisione è pari al numero di sottrazioni conteggiate che vengono fatte tra divisore e dividendo, ad
esempio, volendo fare 21:5
Contatore Sottrazione Comparazione
1 21 –5 = 16 16 > 5 si continua
2 16 – 5 = 11 11 > 5 si continua
3 11 – 5 = 6 6 > 5 si continua
4 6 – 5 = 1 1< 5 STOP!!!
Il risultato sarà pari al numero di conteggi (4) con resto pari al risultato dell’ultima sottrazione (1).
In termini binari sarà pressappoco la stessa cosa:
2110 = 101012 e 510=1012
Dovendo fare la prima sottrazione operiamo con la complementazione facendo attenzione che il
numero delle cifre sia uguale:
Complemento a 1: 11010
Complemento a 2: 11010+ 1= 110112 = -510
Contatore Sottrazione Comparazione
10101 +
11011 = 10000 > 101 si continua
110000
10000 +
11011 = 1011 > 101 si continua
101011
1011 +
1011= 110 > 101 si continua
10110
14
1
2
NOTA:Poiché però il numero di cifre del numero ottenuto non è più uguale a quello dello cifra complementata, allora si deve operare una nuova complementazione del 5:Complemento a 1: 1010Complemento a 2: 10112= -510
3NOTA:Siamo ricaduti nella situazione precedente, in questo caso allora si avrà:Complemento a 1: 010Complemento a 2: 0112= -510

110 +
011 = 1 < 101 STOP!!!
1001
Come dimostrato prima, il risultato è 4 con resto 1.
ALGEBRA BOOLEANA
Nasce dall’idea che, a volte, per la descrizione completa di un evento ci si può riferire a due soli
stati possibili:
A B chiuso aperto vero falso off on si no alto basso 1 0
Addirittura, nel mondo dell’elettronica, l’algebra di Boole è utilizzata per la messa a punto di
metodi di calcolo, basati sull’aritmetica binaria e automatizzabili con l’ausilio di opportuni circuiti
elettronici che realizzano le funzioni, elementari e complesse, dell’algebradi Boole.Es:
I I L aperto (0) spenta (0) chiuso (1) accesa (1)
V L
I=variabile binaria L=soluzione dell’equazione binaria
Equazione binaria I=L
L’algebra booleana anche se tratta di equazioni e di espressioni, segue le regole della logica e non
quelle dell’aritmetica, per cui le sue operazioni risultano differenti da quelle dell’algebra
convenzionale. Inizieremo, quindi, a prendere manualità con quelle che vengono definite le
FUNZIONI BOOLEANE, consideriamo un esempio:
15
4resto

Supponiamo di considerare una scatola con alcuni oggetti colorati rossi e verdi. Ad ogni oggetto
della scatola possiamo associare il concetto di “rosso” con la relazione “..è di colore rosso..”.
Questa relazione è una funzione. Infatti considerando l’affermazione della relazione, prendendo un
oggetto rosso l’affermazione è vera, prendendone uno verde l’affermazione è falsa. Generalizzando
l’esempio, ed indicando la verità e la falsità di una proposizione rispettivamente con 1 e 0, si giunge
alla definizione di funzione booleana.
FUNZIONE LOGICA NOT
Simbolo: ¯
Tale funzione individua la negazione; quindi ha lo scopo di invertire il valore iniziale della variabile in ingresso:
X= la porta è aperta X = la porta non è aperta
La tabella di verità associata è: x y
0 1 1 0
dove, l’uscita y= x
Il simbolo elettrico che individua la porta not è:
x y
Ovviamente, una variabile booleana negata due volte origina un’affermazione:
x x y= x
0 1 0 1 0 1 x x x
16

FUNZIONE LOGICA AND
Simboli: * ,
Corrisponde alla congiunzione di due variabili:
a= possono votare i cittadini che godono dei diritti civili
b= possono votare i ragazzi maggiorenni
sarà: y= possono votare i cittadini che godono dei diritti civili e sono maggiorenni.
La tabella di verità associata è:a b y= ab
0 0 00 1 01 0 01 1 1
Notiamo che corrisponde esattamente al prodotto tra numeri binari, ma indipendentemente da ciò prende il nome anche di prodotto logico.
Il circuito elettrico che caratterizza tale funzione è:
A B
V L
Mentre, il simbolo circuitale che caratterizza l’operatore AND è:
17

Ay
B
Gode delle proprietà: A * 0 = 0A * 1 = AA * A = AA * A = 0
FUNZIONE LOGICA OR
Simboli: + ,
Corrisponde alla disgiunzione di due variabili:
A= persone in possesso di diploma commercialeB= persone che hanno frequentato il corso alla camera di commercio
risulterà:y= potranno aprire un’attività le persone in possesso di diploma commerciale o che hanno frequentato il corso alla camera di commercio.
La tabella di verità associata è: A B y= A+B 0 0 0 0 1 1 1 0 1 1 1 1
L’or prende il nome anche di somma logica (anche se non corrisponde perfettamente alla somma tra numeri binari).Il circuito equivalente è:
A
B V
L
Il simbolo circuitale che individua l’operatore or è:
A Y
B
18

Gode delle proprietà: A + 0 = AA + 1 = 1A + A = AA + A = 1
FUNZIONE LOGICA XOR
Ha il significato di or esclusivo, cioè non si possono verificare contemporaneamente due
condizioni:
a= respiro
b= muoio
sarà
y= o respiro o muoio
La tabella di verità associata è:
A B y= A B
0 0 0 0 1 1 1 0 1 1 1 0
Il simbolo circuitale
A
Y
B
19

FUNZIONE LOGICA NAND
Praticamente è una and negata, riferendoci all’esempio di prima:
a= possono votare i cittadini che godono dei diritti civilib= possono votare i ragazzi maggiorenni
sarà: y= non possono votare i cittadini che godono dei diritti civili e i ragazzi maggiorenni.
La tabella di verità associata è:a b y= ab
0 0 10 1 11 0 11 1 0
Volendo costruire i circuiti nei due casi:
A Y
B
FUNZIONE LOGICA NOR
E’ semplicemente una or negata:
A= persone in possesso di diploma commercialeB= persone che hanno frequentato il corso alla camera di commercio
risulterà:y= non potranno aprire un’attività le persone in possesso di diploma commerciale o che n hanno frequentato il corso alla camera di commercio.
La tabella di verità associata è: A B y= A+B 0 0 1 0 1 0 1 0 0 1 1 0
20

Il simbolo circuitale che individua l’operatore nor è: A
Y B
INTEGRATI
I circuiti elementari vengono integrati con opportune tecnologie e racchiusi in contenitori detti chip,
che a sua volta contengono più porte elementari dello stesso tipo.
Un integrato è costituito da un chip dotato di un certo numero di reofori, detti piedini, due dei quali
vengono utilizzati per l’alimentazione dei circuiti interni, mentre i rimanenti corrispondono ai
circuiti d’ingressi o d’uscita delle porte elementari contenute nel dispositivo. Es:
+5
TT
Ogni integrato ha un proprio nome o meglio una sigla, ad esempio il 7400 identifica un integrato di
porte NOT. In base alla sigla è possibile risalire alle sue caratteristiche che si trovano in dei tabulati
chiamati DATA SHEET.
21
1 2 3 4 5 6 7
8911111

Implementazioni delle funzioni logiche
L’algebra booleana consente di implementare circuiti, il cui comportamento è espresso da
specifiche funzioni logiche ed completamente definito dalle corrispondenti tavole di verità.
Dalla funzione allo schema logico e viceversa
Data una funzione logica, espressa in forma algebrica, risulta piuttosto semplice tracciare il
corrispondente schema logico utilizzando le porte. Si parte dalle variabili d’ingresso,che, se
espresse in forma negata, vanno complementate mediante il NOT(segnetto sopra la variabile); si
eseguono quindi le operazioni incluse nelle parentesi più interne. All’interno di una stessa parentesi
prima si eseguono i prodotti e poi le somme logiche.
Ad esempio, data la funzione logica:
Y=A(A+B) + BC + C
costruiamo il circuito:
A B C
Y
Come si può vedere ogni ingresso è collegato all’uscita Y del circuito attraverso un certo percorso
lungo il quale si incontra un numero più o meno elevato di porte.
Dallo schema alla funzione
22

Si procede da destra verso sinistra, leggendo via via le porte logiche incontrate e convertendo il
simbolo circuitale in simbolo logico.
Dalla funzione alla tavola di verità
Data una funzione logica, può essere necessario conoscere i valori assunti dalla variabile di uscita in
corrispondenza di tutte le combinazioni delle variabili d’ingresso,ovvero conoscere lasua tavola di
verità.
Occorre innanzitutto elencare ordinatamente tutte le possibili combinazioni di valori delle variabili
d’ingresso. Con N variabili d’ingresso,le combinazioni possibili sono 2N e quindi la tavola di verità
avrà 2N righe; per essere certi di non tralasciarne nessuna, conviene seguire la regola:
La variabile più a destra alternerà i propri valori continuamente (nell’es. è C)
La variabile a sinistra dell’ultima, cambierà i propri valori con passo due (nell’es. è B)
La variabile a sinistra di quella precedente cambierà i propri valori con passo quattro
(nell’es. è A)
Si procederà aumentando il passo,secondo la potenza del 2, man mano che ci si sposta verso
la variabile all’estrema sinistra.
I valori ricavati per la variabile d’uscita devono poi essere indicati in una colonna della tavola di
verità (in genere all’estrema destra) in corrispondenza della rispettiva combinazione delle variabili
d’ingresso.
Ad esempio, riferendoci alla variabile d’uscita vista precedentemente:
Y=A(A+B) + BC + C
A B C A+B A A(A+B) BC C Y
0 0 0 0 1 0 0 1 1
0 0 1 1 1 1 0 0 1
0 1 0 1 1 1 0 1 1
0 1 1 1 1 1 1 0 1 mintermine
1 0 0 1 0 0 0 1 1
1 0 1 1 0 0 0 0 0
1 1 0 1 0 0 0 1 1
1 1 1 1 0 0 1 0 1
23

Dalla tavola di verità alla funzione logica
A tale scopo si esprime la funzione d’uscita attraverso la forma canonica,cioè come somma dei
prodotti dei mintermini, quest’ultimi sono i valori delle variabili d’ingresso in corrispondenza del
valore ‘1’ della funzione d’uscita. Ogni mintermine è costituito dal prodotto logico delle variabili
d’ingresso,prese in forma diretta se valgono 1 o in forma negata se valgono 0.
Allora, se ci rifacciamo all’esempio precedente:
Y= ABC + ABC + ABC + ABC + ABC + ABC + ABC
La verifica della veridicità di questo metodo la facciamo ricavando nuovamente la tavola di verità con la funzione d’uscita ottenuta a partire dai mintermini:
A B C A B C ABC ABC ABC ABC ABC ABC ABC Y
0 0 0 1 1 1 1 0 0 0 0 0 0 1
0 0 1 1 1 0 0 1 0 0 0 0 0 1
0 1 0 1 0 1 0 0 1 0 0 0 0 1
0 1 1 1 0 0 0 0 0 1 0 0 0 1
1 0 0 0 1 1 0 0 0 0 1 0 0 1
1 0 1 0 1 0 0 0 0 0 0 0 0 0
1 1 0 0 0 1 0 0 0 0 0 1 0 1
1 1 1 0 0 0 0 0 0 0 0 0 1 1
Il corrispondente circuito è:
A B C
Y
24

MAPPE DI KARNAUGH
Guardando il circuito precedente è evidente l’abbondanza di porte logiche. Un metodo grafico che
consente di arrivare alla minimizzazione della funzione seguendo regole ben precise e di semplice
applicazione è quello delle mappe di Karnaugh o mappe K. Quest’ultime sono costituite da tante
caselle quante sono le combinazione dei valori delle variabili d’ingresso(ovvero quante sono le
righe della tavola di verità) opportunamente disposte una accanto all’altra. Si osservi ad esempio la
rappresentazione con due variabili:
La mappa corrispondente sarà caratterizzata dalle:
- casella 0, al quale corrisponde la riga 0 della tavola di verità, con A=0 e B=0;
- casella 1, al quale corrisponde la riga 1 della tavola di verità, con A=0 e B=1;
- casella 2, al quale corrisponde la riga 2 della tavola di verità, con A=1 e B=0;
- casella 3, al quale corrisponde la riga 3 della tavola di verità, con A=1 e B=1.
25
A
B 0 1
0Casella
0
Casella
2
1Casella
1
Casella
3

Si noti che la mappa K è costruita in modo che due caselle
adiacenti differiscano tra loro solo per il valore di una
variabile. Questa caratteristica risulta più evidente nelle
mappe a più variabili. Ad esempio
Y= CD + BD + BCD
Disegnata la mappa, si individuano sulla tavola di verità le righe che forniscono per la funzione Y il
valore 1 e per ogni ruga individuata si inserisce un 1 nella corrispondente casella della mappa K. Se
26
Riga n. A B C D Y
0 0 0 0 0 1
1 0 0 0 1 0
2 0 0 1 0 0
3 0 0 1 1 1
4 0 1 0 0 0
5 0 1 0 1 1
6 0 1 1 0 0
7 0 1 1 1 1
8 1 0 0 0 1
9 1 0 0 1 0
10 1 0 1 0 0
11 1 0 1 1 1
12 1 1 0 0 0
13 1 1 0 1 1
14 1 1 1 0 0
15 1 1 1 1 1
AB
CD 00 01 11 1000
11
011
1
111
1 1 1
10

la funzione, anziché mediante la tavola di verità, è espressa in forma algebrica come somma di
mintermini, si inserisce un 1 nelle caselle corrispondenti ai mintermini presenti nell’espressione.
Rimangono invece vuote le caselle corrispondenti ai mintermini non presenti nella funzione o a
righe della tavola di verità che forniscono per Y il valore 0.
Quanto detto è illustrato dall’esempio precedente. La cui espressione algebrica è:
Y=ABCD + ABCD + ABCD + ABCD + ABCD + ABCD + ABCD + ABCD
Una volta completata la mappa si raggruppano le caselle adiacenti contenenti 1 secondo le regole
seguenti:
1. I raggruppamenti possono essere costituiti da 2N= 1,2,4,8,16….caselle,tutte adiacenti l’una
all’altra, comprese quelle che si trovano ai bordi esterni della mappa (la forma della mappa è
quella che avrebbe un folio di carta quadrato ripiegato dagli vertici,che sono quindi
adiacenti, così come anche le zone laterali del quadrato della mappa sono contigue tra loro);
2. I raggruppamenti devono essere più ampi possibile e possono anche sovrapporsi
parzialmente (ciò è valido solo per permettere un raggruppamento più ampio);
3. Una casella già inclusa in un raggruppamento può essere associata ad un’altra casella solo se
ciò contribuisce a formare un nuovo gruppo; ovvero, se tutte le caselle della mappa sono
raggruppate non ha senso creare un ulteriore raggruppamento (sarebbe solo una ridondanza).
Effettuati i raggruppamenti, la funzione viene espressa in forma semplificata come somma di
prodotti, ciascuno corrispondente ad un raggruppamento. Ogni prodotto è costituito dalle sole
variabili che non cambiano di valore nel raggruppamento (VIVONO!!!!); le variabili sono prese in
forma diretta se valgono 1, in forma negata se valgono 0. Nei prodotti vengono pertanto eliminate le
variabili che cambiano all’interno del raggruppamento (MUOIONO!!!!).
La funzione minimizzata assume pertanto l’espressione:
Y= CD + BD + BCD
Allo stesso risultato, ma in maniera più faticosa e meno diretta,si poteva giungere applicando alla
funzione le proprietà delle funzioni booleane e le leggi di De Morgan.
27

IMPLEMENTAZIONE CON PORTE NAND
Si è visto nei paragrafi precedenti che una qualsiasi funzione logica può essere implementata
mediante porte NOT, AND, OR e XOR. Poiché però queste funzioni possono a loro volta essere
espresse con solo porte NAND (più raramente con sole porte NOR), si comprende come in linea di
principio, sia possibile implementare qualsiasi funzione con queste sole porte. Questo fatto si
rivela molto utile nelle realizzazioni pratiche, quando non sempre si hanno a disposizione tutti i
tipi di porte logiche necessarie o può risultare conveniente sfruttare le porte non utilizzate di
circuiti integrati già impegnati.
A tale scopo ricordiamo la tavola di verità di una NAND, considerando che non è altro che una
AND negata (prodotto logico negato):
Porta NOT:
Infatti si possono verificare solo le due condizioni :
28
A B NAND
0 0 1
0 1 1
1 0 1
1 1 0
A A NAND
0 0 1
1 1 0

Porta AND:
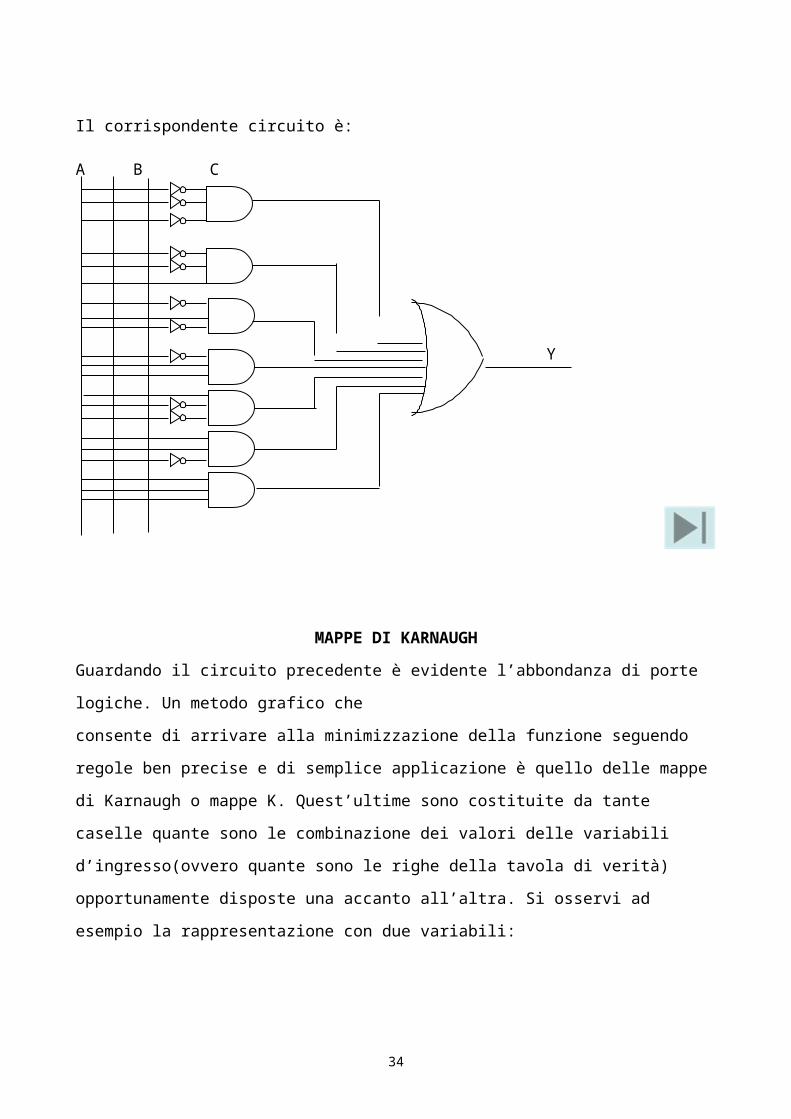
E’ semplicemente una NAND negata, ossia una doppia negazione di una AND cioè una AND.
Possiamo fare un riscontro attraverso la tavola di verità:
Porta OR
per ottenere questa funzione si può applicare la legge di De Morgan all’espressione della somma
logica come segue:
Y= A+B = A+B =A∙B
Questa procedura può essere estesa a funzioni di qualsiasi tipo.
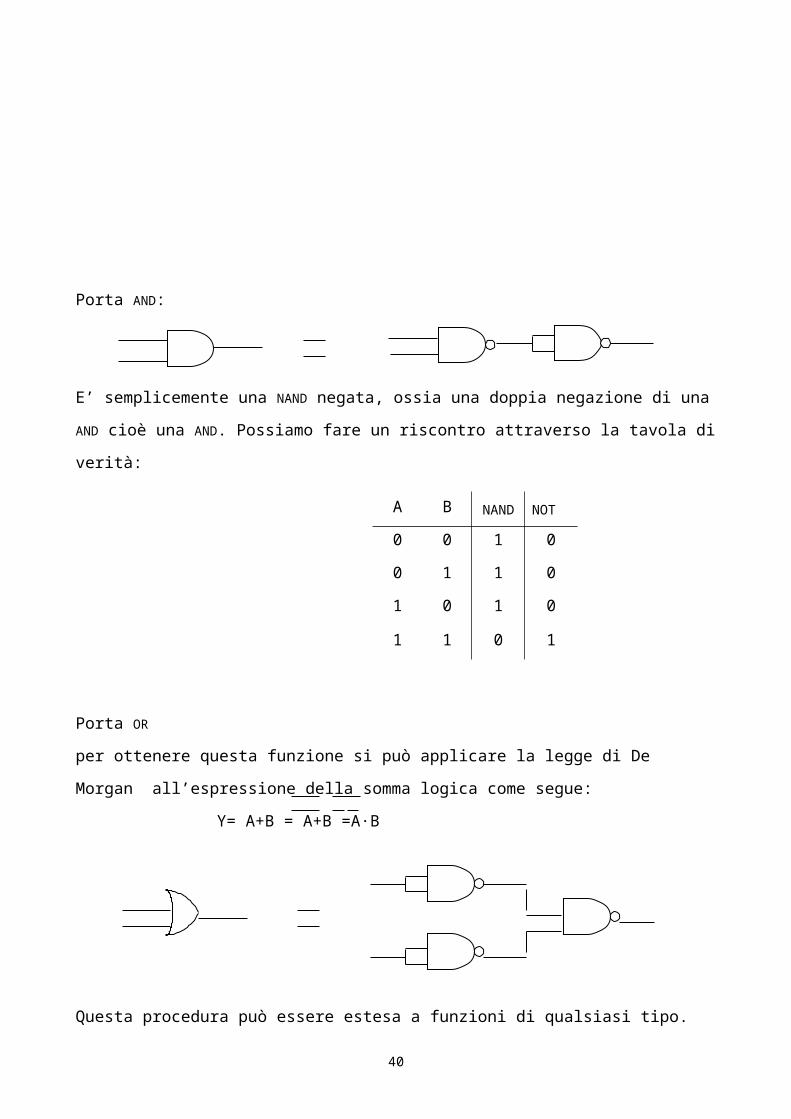
Come è noto,una funzione può essere sempre espressa come somma di prodotti; si abbia ad esempio
l’espressione
Y=ABC+AC+AB
Vedremo l’implementazione normale e con sole porte NAND:
A B C
29
A B NAND NOT
0 0 1 0
0 1 1 0
1 0 1 0
1 1 0 1

Il circuito trasformato sarà:
A B C
Salta all’occhio il numero di porte logiche, in realtà non sono tutte necessarie, in particolare ci sono
delle not seguite da altre not e poiché due negazioni equivalgono ad un’affermazione, non ha senso
inserirle nel circuito. Per cui, il circuito semplificato diventa:
A B C
30

31

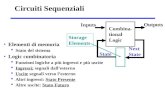
LOGICA SEQUENZIALE E COMBINATORIA
Tutti i circuiti caratterizzati dalla proprietà che lo stato logico delle uscite del sistema in un dato
istante di tempo è funzione solamente della configurazione logica presente agli ingressi nello stesso
istante vengono chiamati circuiti combinatori.
I1 U1
I2 U2
I3 U3
Im Un
Da quanto detto finora risulta evidente che le uscite di un circuito combinatorio sono prive di
memoria; infatti il loro stato in ogni istante dipende esclusivamente dallo stato degli ingressi al
medesimo istante.
E’ possibile però generalizzare questo principio di funzionamento ammettendo che le uscite di
qualunque circuito logico in un dato istante possano dipendere, oltre che dallo stato degli ingressi in
quello stesso istante, anche dal valore assunto dalle uscite stesse in istanti precedenti. In un circuito
siffatto lo stato attuale delle uscite dipende anche dalla loro storia precedente, cioè il circuito è
dotato di memoria . Inoltre, i sistemi in cui le uscite sono dotate di memoria vengono chiamati
circuiti sequenziali, in quanto lo stato attuale delle uscite è legato alla sequenza logica che ha
caratterizzato le stesse in istanti precedenti.
Un circuito sequenziale sarà quindi caratterizzato da una retroazione (reazione, feedback)
dell’uscita sull’ingresso.
I1 U1
I2 U2
I3 U3
Im Un
32

In genere nei circuiti sequenziali è presente anche un morsetto di temporizzazione, detto morsetto
di CLOCK (indicato con CK)che ha il compito di abilitare le eventuali variazioni di uscita. In
pratica la presenza attiva del segnale di clock, rivelata da un opportuno livello o da una transizione
logica al morsetto CK del circuito, dà l’abilitazione ad eventuali variazioni di uscita, mentre la sua
assenza nelle migliori ipotesi, porta le uscite a mantenere memorizzata l’ultima variazione
avvenuta; nel caso peggiore le uscite fluttuano in modo casuale. In entrambe le situazioni le uscite
sono insensibili nei riguardi di eventuali variazioni presenti ai morsetti d’ingresso.
Questo tipo di funzionamento consente tra l’altro ai circuiti sequenziali di poter lavorare su dei
segnali d’ingresso puliti, esenti cioè da variazioni transitorie al momento della loro lettura da parte
del circuito stesso. A tal fine è sufficiente che il segnale di clock si attivi quando tutti gli ingressi
sono in una configurazione stabile.
Tipicamente il clock si presenta come un treno di impulsi
ck
T
33
FLIP-FLOP SR
Il flip-flop è il più semplice dei circuiti sequenziali. In particolare, il FF RS è in grado di avere in
uscita due soli stati stabili. E’ chiamato anche latch per la sua capacità di memorizzare sulle uscite
gli stati logici presentati ai suoi ingressi.
SR. Y 00 01 11 10
0
1
E’ una rete sequenziale asincrona che ha due variabili di ingresso (s ed r) e due di uscita (y
ed y) che si evolvono secondo le specifiche (in logica positiva):
- s=1 ed r=0: il FF si setta, cioè porta l’uscita a livello alto, y =1 ed y =0;
- s=0 ed r=1: il FF si resetta, cioè porta l’uscita a livello basso, y =0 ed y =1;
- s=0 ed r=0: il FF si conserva, cioè resta inalterato il valore dell’uscita;
- s=1 ed r=1: il FF ha un comportamento che non è definito.
Il circuito che caratterizza il FF RS senza clock è del tipo:
S
Y
R Y
34
S Y
R Y
0 0 - 1
1 0 - 1

A causa dei collegamenti di reazione che riportano sull’ingresso di ciascuna porta lo stato logico
assunto dall’uscita dell’altra, si deduce che il dispositivo è dotato di memoria, e quindi ad ogni
variazione d’ingresso le uscite si adeguano alla nuova situazione tenendo conto anche dello stato
logico da esse posseduto dall’arrivo della variazione d’ingresso.
Vediamo la tabella di verità associata al FF RS:
S R YN+1 YN+1
0 1 0 11 0 1 01 1 - - (conf. eliminare)0 0 YN YN (conf. memoria)
La configurazione di memoria non fornisce un valore diretto per le uscite, ma ci rimanda al valore
assunto dalle stesse prima dello stabilirsi in ingresso della situazione s=r=0.
Se si suppone che i due ingressi non possano variare contemporaneamente si deduce che si può
giungere alla configurazione di memoria solo partendo dalle situazioni s=1 ed r=0 o
s=0 ed r=1.
In entrambi i casi si raggiunge la configurazione di memoria con una variazione da 0 a 1 su uno
solo dei due ingressi. Poiché la configurazione di memoria lascia le uscite inalterate si conclude che
le variazioni in ingresso dall’alto al basso lasciano inalterate le uscite, cioè sono INATTIVE.
Se adesso consideriamo eliminata da combinazione s=r=1, alle configurazioni s=1 ed r=0 o
s=0 ed r=1
si può giungere solo a partire dalla configurazione di memoria con una variazione da alto a basso su
un solo ingresso. Tali variazioni sono ATTIVE .
Se si hanno, invece, più variazioni consecutive attive sullo stesso ingresso, allora le uscite variano
solo in corrispondenza della prima variazione. Le successive variazioni vengono IGNORATE
essendo le uscite già predisposte al valore dettato dalle variazioni stesse.
35

FLIP-FLOP D
Discende direttamente dal flip flop RS, in questo caso si pone S = R, quindi possiede un solo
ingresso sincrono (D) attivo alto.
Il FF D viene usato per immagazzinare il dato presente sull’ingresso in corrispondenza del livello
oppure della transizione attiva del clock.
D ck D YN+1YN+1
0 - YN YN
1 0 0 11 1 1 0
ck
Questo tipo di flip-flop viene utilizzato come elemento di ritardo, infatti le uscite riproducono
fedelmente ciò che si presenta in ingresso.
36
S Y
R Y

FF JK
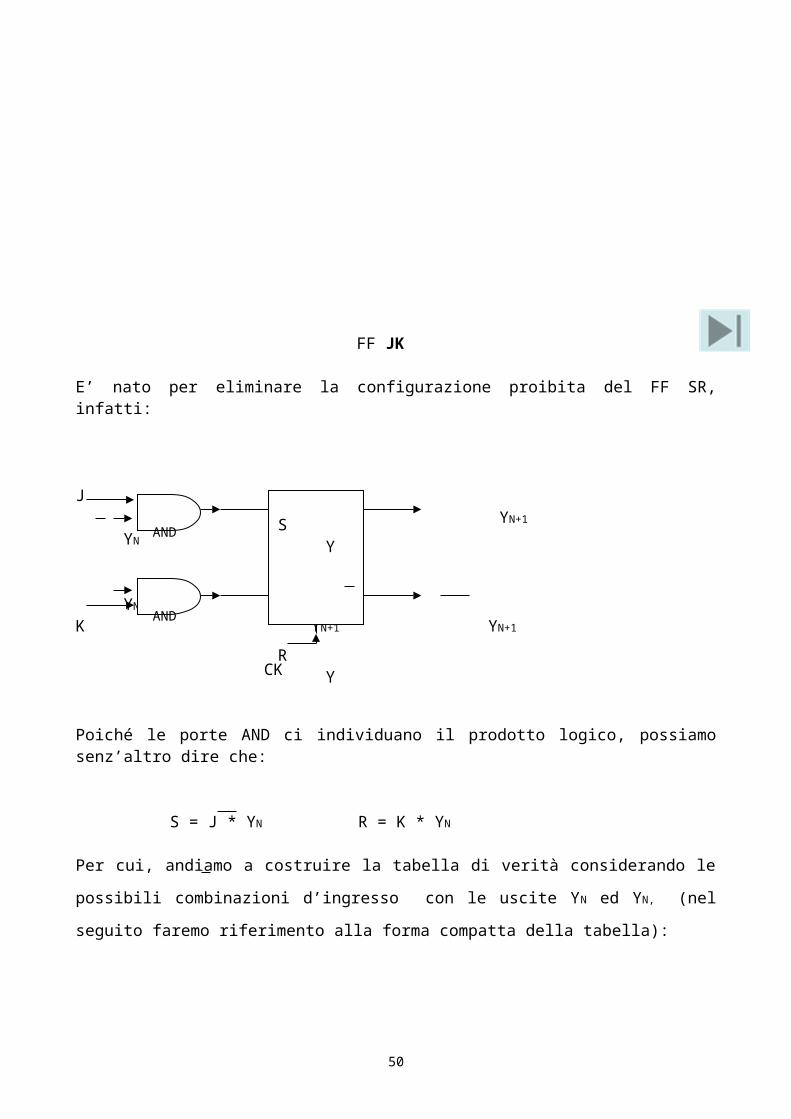
E’ nato per eliminare la configurazione proibita del FF SR, infatti:
J YN+1
YN
YN
K YN+1 YN+1
CK
Poiché le porte AND ci individuano il prodotto logico, possiamo senz’altro dire che:
S = J * YN R = K * YN
Per cui, andiamo a costruire la tabella di verità considerando le possibili combinazioni d’ingresso
con le uscite YN ed YN, (nel seguito faremo riferimento alla forma compatta della tabella):
J K YN YN S R YN+1 YN+1 J K YN+1
0 0 0 1 0 0 YN YN 0 0 YN
0 0 1 0 0 0 YN YN 1 0 11 0 0 1 1 0 1 0 0 1 01 0 1 0 0 0 YN YN 1 1 YN
0 1 0 1 0 0 YN YN
0 1 1 0 0 1 0 11 1 0 1 1 0 1 01 1 1 0 0 1 0 1
E’ facile verificarla dal suo circuito corrispondente:
Y J
CK
Y
K
37
S Y
R Y
AND
AND

FLIP-FLOP T
Discende direttamente dal flip flop JK, in questo caso si pongono J=K, quindi possiede un solo
ingresso sincrono (T) attivo alto.
Il FF T viene usato per immagazzinare il dato presente sull’ingresso in corrispondenza del livello
basso oppure della transizione attiva del clock.
T YN+1 T YN+1
0 YN
1 YN
Il fatto che gli ingressi vengano posti J=K=1 comporta che l’uscita avrà un valore inverso rispetto
all’uscita precedente.
38
J Y
K Y

PRESET E CLEAR (Precarica e azzeramento)
Il valore dell’uscita di un dispositivo, prima che sia applicato un impulso di clock, è arbitrario. Per
Stabilire lo stato iniziale del flip-flop sono previsti appunto i due morsetti di preset e clear.
L’operazione di azzeramento può essere eseguita programmando il terminale di clear a 0 ed il preset
ad 1, ad esempio:
PRY
J S
CK
YR
K
CL
Se CL=0 Y = 1Ck=0 S = 1 Y=0PR=1 R = 1
Mentre, se
CL=1 Y = 1Ck=0 S = 1 Y=0PR=0 R = 1
Le linee di preset e clear sono dirette e asincrone, cioè non sono in sincronismo con il clock ma
possono essere applicate in un istante qualsiasi tra due impulsi di clock.
La combinazione CL=0 e PR=0 non deve essere usata perché porta ad uno stato ambiguo; mentre,
la combinazione CL=1 e PR=1 si genera quando il clock è attivo, cioè quando il clock fa funzionare
normalmente il dispositivo: si dice in questo caso che il dispositivo è ABILITATO. In realtà la
configurazione CL=1 e PR=1 è utilizzata anche con CK=0 e comporta la permanenza dell’uscita nel
suo stato; è necessario però, per il corretto funzionamento del dispositivo, che questa
configurazione sia preceduta o da un clear o da un preset.
La tabella riassuntiva idica:
CK PR CL Y0 1 0 0 (clear)0 0 1 1 (preset)1 1 1 -- (enable)
39
NAND 2NAND 4
NAND 3 NAND 1
FF di tipo JK MASTER-SLAVE
E’ dato dalla serie di due flip-flop JK:
PR
CL
CK
Al master vengono applicati impulsi positivi del clock Ck=1 che vengono invertiti prima di essere
usati per pilotare lo slave Ck=0.
Quando CK=1 CL=1 il master è abilitato ed ha un funzionamento normale di un FF-JK PR=1
Però essendo CK=0 allo slave, quest’ultimo è inibito (cioè non può cambiare stato), per cui la sua
uscita non varia per tutta la durata dell’impulso.
Quando il master si trova nella condizione CK=0, è inibito mentre lo slave, avendo CK=1, è
abilitato quindi segue il comportamento normale di un FF-JK.
In questo modo, nell’intervallo tra impulsi successivi di clock, il valore dell’uscita del master è
trasferito all’uscita dello slave.
40
J Y
Master
K Y
J Y
slave
K Y

REGISTRI A SCORRIMENTO (SHIFT REGISTER)
Un registro è un’unità in grado di memorizzare singole informazioni, dove con il termine "singole
informazioni" si intende un dato oppure una istruzione. Ogni registro è, quindi, una piccola
memoria di tipo elettronico.
I registri sono costituiti da flip-flop; il circuito logico corrispondente è composto da n flip-flop,
dove n è pari al numero di bit memorizzabili nel registro.
Per permettere l’ingresso seriale dei dati della parola nel registro, l’uscita di un flip-flop è collegata
all’ingresso del successivo. Tale configurazione è detta registro a scorrimento.
Ogni flip-flop è del tipo SR o JK mater-slave. A questo punto vediamo i diversi tipi di registri a
scorrimento:
REGISTRI SIPO (serial in parallel output)
Y3 Y2 Y1 Y0
PR
D
CL
CK
Inizialmente vengono azzerati tutti i flip-flop ponendo CK=0 CL=0 così tutte le uscite sono PR=1 nulle: 0000
A questo punto supponiamo di voler registrare 1011, allora si abilitano i dispositivi: CK=1 PR=1 CL=1
Il bit meno significativo (LSB), cioè l’ultimo, entra nel master di FF3 per effetto del flip-flop D.
Dopo il primo impulso di clock il primo bit è trasferito allo slave di FF3, cosicchè Y3=1, mentre le
altre uscite sono ancora nulle.
41
J3 Y3
FF3
K3 Y3
J2 Y2
FF2
K2 Y2
J1 Y1
FF1
K1 Y1
J0 Y0
FF0
K0 Y0
Al secondo impulso di clock, Y3 è trasferita nel master FF2 e contemporaneamente il FF3
acquisisce il secondo dato (della parola 1011).
Dopo il secondo impulso di clock il bit di ciascun master di FF3 e FF2 è trasferito al relativo slave
cosicchè: Y3=1 e Y2=1, le altre uscite sono ancora nulle.
In pratica:
bit in ingresso D Y3 Y2 Y1 Y0 1 1 0 0 0 1 1 1 0 0 0 0 1 1 0 1 1 0 1 1
La parola in ingresso è quindi registrata dopo 4 impulsi di clock. Quando la parola è registrata, gli
impulsi di clock si interrompono.
Poiché ogni uscita è disponibile su una linea separata, possono essere lette tutte
contemporaneamente. Si parla in questo caso di codice temporale (un insieme di bit in istanti
diversi) è stato modificato in un codice spaziale (informazioni immagazzinate in una memoria
statica).
Sono necessari flip-flop master-slave per evitare il fatto che se tutti i flip-flop cambiassero stato
contemporaneamente ci sarebbe ambiguità riguardo a quale dato dovrebbe essere trasferito allo
stadio precedente. Per esempio al terzo impulso di clock Y3 cambia da 1 a 0 e sarebbe discutibile
quando Y2 cambia da 1 a 0, perciò è necessario che Y3 resti a 1 fino a che il bit non è entrato nel
master di FF2 e solo allora possa passare a 0.
42

REGISTRI SISO (serial in serial output)
Y0
PR
D
CL
CK
L’unica differenza sta nel fatto che c’è un’ unica uscita Y0. Il registro può essere letto applicando n
impulsi di clock per parole di n bit. Dopo l’n-simo impulso ciascun flip-flop legge 0.
Si noti che la frequenza del clock di lettura in uscita può essere diversa, maggiore o minore, di
quella del treno d’impulsi utilizzato per l’ingresso. Questo è un metodo per cambiare la spaziatura
temporale di un codice binario, il processo va sotto il nome di BUFFERING.
43
J3 Y3
FF3
K3 Y3
J2 Y2
FF2
K2 Y2
J1 Y1
FF1
K1 Y1
J0 Y0
FF0
K0 Y0

REGISTRI PISO (parallel in serial output)
Y0 W/E P3 P2 P1 P0
PR3 PR2 PR1 PR0
D
CL
CK
Il nuovo morsetto W/E (write enable) viene utilizzato per abilitare alla scrittura il dato. Mentre P3P2P1P0 rappresentano i pesi del dato che si vuole inserire.
Vediamo, ad esempio, le fasi di inserimento della parola 1001:
1° fase (azzeramento)CK=0CL=0 PRi =1 (i=0,1,2,3)W/E=0
W/E
0 0 0 0
CLCK
Semplicemente abbiamo resettato il dispositivo.
44
PR3=1
FF3
PR2=1
FF2
PR1=1
FF1
PR0=1
FF0
J3 Y3
FF3
K3 Y3
J2 Y2
FF2
K2 Y2
J1 Y1
FF1
K1 Y1
J0 Y0
FF0
K0 Y0

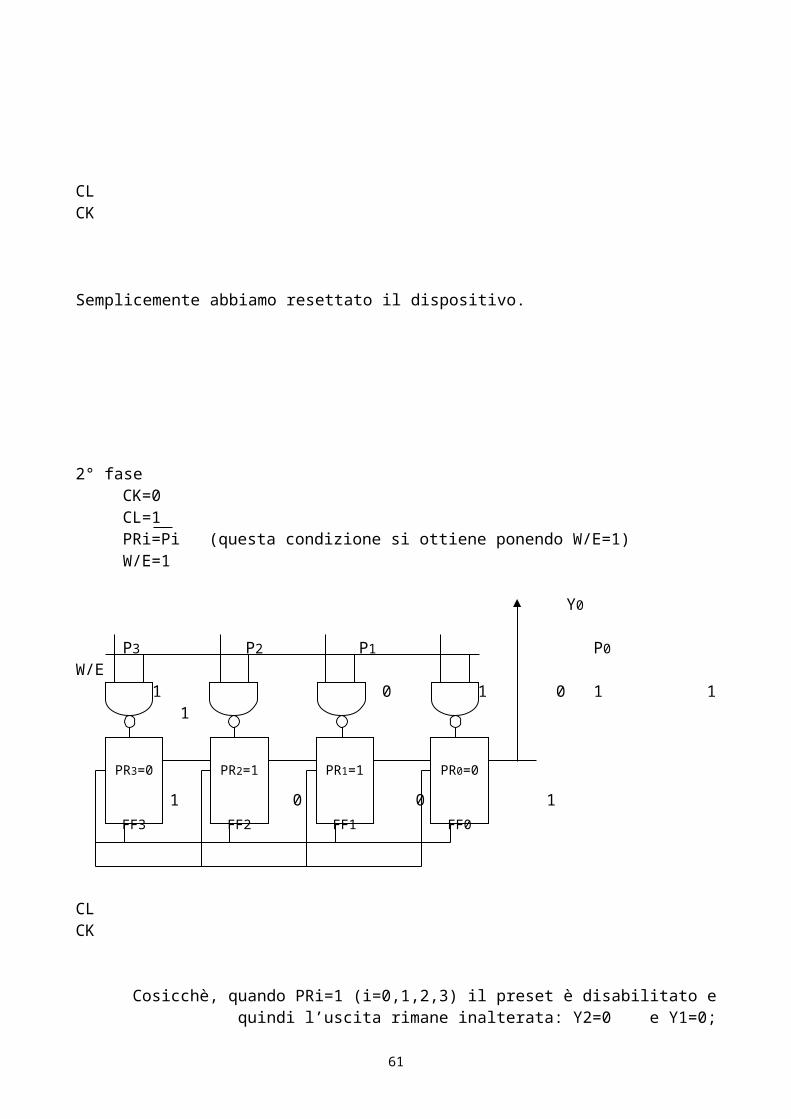
2° faseCK=0CL=1PRi=Pi (questa condizione si ottiene ponendo W/E=1)W/E=1
Y0
P3 P2 P1 P0W/E 1 1 0 1 0 1 1 1
1 0 0 1
CLCK
Cosicchè, quando PRi=1 (i=0,1,2,3) il preset è disabilitato e quindi l’uscita rimane inalterata: Y2=0 e Y1=0;
mentre, quando PRi=0 (i=0,1,2,3) il preset è attivo: Y3=1 e Y0=1.
A questo punto, la parola presente sugli ingressi paralleli è immagazzinata nel registro e pronta per
essere convertita. La conversione si realizza inviando 4 impulsi di clock. In corrispondenza di
ciascun impulso di cadenza il contenuto del registro si sposta verso destra di una posizione.
45
PR3=0
FF3
PR2=1
FF2
PR1=1
FF1
PR0=0
FF0

REGISTRI PIPO
Y3 Y2 Y1 Y0 P3 P2 P1 P0
W/E
PR3 PR2 PR1 PR0
D
CL
CK
Lo schema circuitale e il modo di ragionare è praticamente identico a quello del registro PISO, solo
che in questo caso oltre l’acquisizione dei dati paralleli anche la lettura finale avviene in modo
parallelo e quindi basta un solo impulso di clock per ritrovare i dati in uscita.
In quest’ultimo caso il sistema non funziona come un registro a scorrimento; infatti, ogni flip-flop è
semplicemente utilizzato come una memoria singola ad 1 bit di scrittura e lettura.
46
J3 Y3
FF3
K3 Y3
J2 Y2
FF2
K2 Y2
J1 Y1
FF1
K1 Y1
J0 Y0
FF0
K0 Y0

CONTATORI
E’ un dispositivo che consente di attuare il conteggio di un numero di volte in cui un dato evento si
ripete. Generalmente è costituito da una rete sequenziale formata da più flip-flop che ad ogni
impulso di clock producono un’uscita opportuna.
Bisogna quindi mettere subito in evidenza che il clock si comporta come un segnale periodico, cioè
si ripete esattamente dopo un certo tempo, ad es:
CK
t
Il contatore deve essere in grado di incrementare il suo contenuto all’arrivo di ogni impulso di
conteggio e di mantenere memorizzato il numero di impulsi complessivamente ricevuti fino
all’arrivo dell’impulso successivo.
Il limite massimo del numero di impulsi conteggiabili individua il MODULO del contatore, oltre il
quale il contatore si azzera ed inizia un nuovo ciclo di conteggio. E’ comunque possibile estendere
il campo di conteggio usando più moduli elementari in cascata.
47

CONTATORI ASINCRONI
E’ possibile creare un contatore asincrono con un registro SISO, associando ad ogni configurazione
di una stringa di bit (es: 1001) un corrispondente valore numerico. Se si tiene però conto che
l’uscita di ogni FF può essere vista come un variabile binaria e che l’insieme di n variabili binarie è
in grado di rappresentare n configurazioni diverse si comprende che un CONTATORE AD
ANELLO (ring counter) fatto con un registro SISO, sfrutti pochissimo le potenzialità numeriche,
infatti con n FF in cascata si possono generare n configurazioni contro le 2 –1 possibili.
Se ad esempio n=3 un contatore ad anello può dar luogo a:
y3 y2 y1
1 0 0 1 2 1 0 0 3 0 1 0
Mentre con un contatore asincrono avremo, con n=3, indicheremo :
y2 y1 y0
0 0 0 01 0 0 12 0 1 03 0 1 14 1 0 05 1 0 16 1 1 07 1 1 1
0 0 0
Si noti che raggiunto il numero massimo rappresentabile (7) le uscite dei FF si azzerano ed il ciclo
di conteggio ricomincia dall’inizio.
La regola di commutazione delle uscite consta di due step:
1. l’uscita di peso meno significativo (y0) deve commutare all’arrivo di ogni impulso di clock;
2. le altre uscite devono commutare solo se quella di peso meno significativo che la precede
subisce una transizione da alto a basso (da 1 a 0).
Poiché le commutazioni su ogni uscita (tranne la meno significativa) possono avvenire solo quando
all’uscita della cella precedente è avvenuta una transizione utile, ne consegue che le uscite del
contatore, a causa del ritardo introdotto da ogni FF, non commutano mai contemporaneamente;
48

quindi, sulle uscite dei contatore saranno presenti delle FALSE configurazioni di conteggio finché
l’uscita dell’ultimo FF interessato alla commutazione non raggiunge il valore che gli compete.
Questo inconveniente deve essere tenuto in considerazione per poter realizzare una corretta
decodifica del contenuto del contatore. Il problema si risolve dotando di un ingresso di abilitazione
la rete di decodifica, quest’ultima è abilitata da un impulso detto di STROBE che giunge dopo ogni
impulso di clock solo quando tutte le uscite del contatore hanno raggiunto la configurazione stabile.
Poiché l’uscita del FF deve commutare solo quando l’uscita del FF che lo precede ha una
transizione da alto a basso, il circuito risulta costituito da una serie di FF-T realizzati con FF-Jk di
tipo master-slave, nei quali si è posto J=K=1. Questo perché la peculiarità di del FF-T è il suo
funzionamento da invertitore.
Andando a studiare il circuito, si ricorda che il clock è scelto attivo basso e che il dispositivo è
inizialmente resettato.
Y0 Y1 Y2
CK
t Y0
t Y1
t Y2
t
49
J0 Y0
K0
J1 Y1
K1
J2 Y2
K2
CONTATORI SINCRONI
I contatori asincroni realizzano strutture circuitali semplici, da qui la loro facilità di progetto e
grande diffusione; per contro, la massima frequenza a cui può lavorare è limitata circa ad 1/n per
singolo FF della catena (n indica il numero di FF posti in cascata). E questa frequenza è
ulteriormente limitata per un numero crescente di FF, infatti la transizione attiva che giunge
all’ingresso del contatore deve attraversarne n-1 prima di raggiungere l’ultimo.
Così a discapito della semplicità circuitale ma a vantaggio di estendere il campo di frequenze
utilizzabili sono nati i contatori sincroni.
Per contatori sincroni si intende una cascata di FF, che ovviamente operano un conteggio, e tali da
essere comandati da un unico segnale di clock, facendo si che tutti i FF commutino
contemporaneamente e con il vantaggio di non creare false configurazioni di conteggio, quindi non
abbiamo bisogno del segnale di abilitazione di STROBE.
Attraverso l’introduzione di una opportuna funzione, detta “funzione di commutazione”, si può
riportare il progetto di un contatore sincrono a quello di un opportuno circuito combinatorio.
Prima di analizzare la tecnica di progetto basata sulla funzione di commutazione, illustriamo il
progetto di un contatore sincrono modulo 16.
50

CONTATORE SINCRONO MODULO 16
La regola di commutazione prevede:
1. l’uscita meno significativa y0 deve commutare all’arrivo di ogni impulso di clock;
2. le altre uscite commutano quando tutte le uscite precedenti di peso meno significativo sono a
livello logico 1:
3.
n. impulsi y3 y2 y1 y0
0 0 0 0 01 0 0 0 12 0 0 1 03 0 0 1 14 0 1 0 05 0 1 0 16 0 1 1 07 0 1 1 18 1 0 0 09 1 0 0 110 1 0 1 011 1 0 1 112 1 1 0 013 1 1 0 114 1 1 1 015 1 1 1 116 0 0 0 0
Secondo la regola descritta :
y0 commuta sempre
y1 commuta quando y0=1 T1=J1=k1=y0= 1
y2 commuta quando y0=y1=1 T2=1
y3 commuta quando y0=y1=y2= 1 T3=1
51

FUNZIONE DI COMMUTAZIONE
La funzione di commutazione di un FF è una funzione binaria che assume il valore:
- 1 quando l’uscita del FF commuta
- 0 quando l’uscita del FF non commuta
Ad esempio per un FF-JK ad ingressi attivi alti:
J K YN YN+1 XF
0 0 0 0 00 0 1 1 00 1 0 0 00 1 1 0 11 0 0 1 11 0 1 1 01 1 0 1 11 1 1 0 1
E cioè:
- se J=0 e K=0 siamo nella configurazione di memoria per cui YN+1 assume il valore della YN,
quindi non si verificano commutazione tra le due cosicchè XF =0;
- se J=0 e K=1 siamo nella configurazione di reset quindi l’uscita attuale YN+1 viene forzata a 0
indipendentemente dal valore assunto dall’uscita precedente. Andando ad analizzare come si
comportano le due uscite notiamo che se YN=0 e deve essere YN+1=0, XF=0 ; mentre, se YN=1
dovendo essere YN+1=0, vi è una commutazione per cui XF=1;
- se J=1 e K=0 siamo nella configurazione di set quindi l’uscita attuale YN+1 viene forzata a 1
indipendentemente dal valore assunto dall’uscita precedente. Andando ad analizzare come si
comportano le due uscite notiamo che se YN=0 e dovendo essere YN+1=1 vi è una commutazione
per cui XF=1 ; mentre, se YN=1 essendo YN+1=1 sarà XF=0;
- se J=1 e K=1 siamo nella configurazione di inversione, per la quale l’uscita attuale inverte
sempre il valore dell’uscita precedente, quindi in ogni caso vi è una commutazione per cui
XF=1.
52

A questo punto costruiamo la mappa di Karnaugh, rilevando sono le situazioni di ingresso e di YN
in cui XF=1:
jkyn 00 01 11 10 0
1
XF=J*YN + K*YN
CONTATORE SINCRONO MODULO 16
Per progettare un contatore sincrono di modulo qualunque è sufficiente ricavare per ogni FF la
relativa funzione di commutazione e da questa risalire alle condizioni a cui devono sottostare gli
ingressi JK del medesimo FF:
n. impulsi y3 y2 y1 y0 XF0 XF1 XF2 XF3
0 0 0 0 0 1 0 0 01 0 0 0 1 1 1 0 02 0 0 1 0 1 0 0 03 0 0 1 1 1 1 1 04 0 1 0 0 1 0 0 05 0 1 0 1 1 1 0 06 0 1 1 0 1 0 0 07 0 1 1 1 1 1 1 18 1 0 0 0 1 0 0 09 1 0 0 1 1 1 0 010 1 0 1 0 1 0 0 011 1 0 1 1 1 1 1 012 1 1 0 0 1 0 0 013 1 1 0 1 1 1 0 014 1 1 1 0 1 0 0 015 1 1 1 1 1 1 1 116 0 0 0 0 1 0 0 0
XF0 ha sempre valore 1 perché Y0 commuta continuamente, mentre le altre funzioni di
commutazione assumono valore unitario in corrispondenza delle frecce, secondo la regola di
commutazione.
Ricavare la funzione di commutazione è fondamentale perché ci rappresenta l’ingresso di ogni FF.
Così, tra l’altro, è facile costruire un contatore asincrono perché sarà dato da una cascata di FF-T,
tra loro connessi ad un unico segnale di clock, e i cui ingressi seguono la legge che troviamo per la
rispettiva XF.
53
1 1
1 1

Determiniamo quindi le XF tramite Karnaugh:
y3y2 y1y0 00 01 11 10
00
01XF0= 1
11
10
y3y2 y1y0 00 01 11 10
00
01XF1= Y0
11
10
y3y2 y1y0 00 01 11 10
00
01XF2=Y0*Y1
11
10
y3y2 y1y0 00 01 11 10
00
01XF3=Y0*Y1*Y2
11
10
54
1 1 1 11 1 1 1
1 1 1 1
0 0 0 0
1 1 1 1
1 1 1 10 0 0 0
0 0 0 0
0 0 0 0
1 1 1 1
0 0 0 0
0 0 0 0
0 0 0 0
0 1 1 0
0 0 0 0

A questo punto ci possiamo costruire il circuito equivalente al contatore sincrono in questione:
1
CK
Y0 Y1 Y2 Y3
55
J0 Y0
FF0
K0 Y0
J1 Y1
FF1
K1 Y1
J2 Y2
FF2
K2 Y2
J3 Y3
FF3
K3 Y3

LOCAZIONI E CELLE
Data la struttura:
CELLE
0EFF LOCAZIONE INDIRIZZI
0F00 0F01
0F02
0F03
Ogni byte costituisce una locazione, ed ogni locazione individua un indirizzo.
Se un indirizzo è formato da 4 cifre esadecimali cioè da 24 =16 bit, sarà possibile esprimere
216=65536 indirizzi.
Il numero totale di celle o di bit contenuti nella memoria definisce la sua CAPACITA’; cioè, se
N=2 è il numero di parole che possono essere contenute nel dispositivo ed ogni parola è composta
da B bit allora C= 2N * B ad esempio se N=10 e B=8 sarà:
C= 210 *8 = 8192 bit.
A questo punto facciamo un discorso generale partendo dalla struttura del microprocessore ( p ),
per capire quali sono le parti principali di un PC e come sono interconnesse tra loro, ed in
particolare ci soffermeremo sulle memorie.
Il p è un circuito integrato che realizza l’unità centrale di elaborazione di un elaboratore, su uno o
più chip. Il p contiene l’unità logico aritmetica (ALU è formata da una rete combinatoria e da due
ingressi ad una uscita) , l’unità di controllo, i tre bus (data, control e address) usati rispettivamente
per l’invio di dati, di segnali di controllo e per l’invio di indirizzi. Affinché queste parti possano
colloquiare tra loro vengono utilizzati dei registri (che vedremo nel dettaglio).
56
1 0 1 1 1 0 0 1

SCHEMA BASE DI UN ELABORATORE:ARCHITETTURA DI VON NOËMANN
Uno schema sintetico di quanto detto è:
DATA BUS
CONTROL BUS
Compito della CPU è permettere a tutte le parti del p di lavorare insieme nella corretta sequenza
temporale. La CPU è in grado di lavorare solo se supportata da alcuni registri che attuano le varie
funzione a seconda del tipo di parola contenuta e dai bus che permettono il dialogo tra le parti.
Lo schema di un processore basato sui registri è il seguente:
57
ADDRESS BUS
CPU(ALU+
CU) MEM I/O

I registri sono in numero diverso a seconda del p considerato, in ogni caso a livello minimo sono
presenti almeno 6 registri:
Il registro istruzioni (Instruction Register) IR contiene volta per volta l’istruzione che
l’elaboratore sta eseguendo, cioè, una copia dell’attuale istruzione del programma. Questo
registro è collegato ad un decodificatore di istruzione, che a sua volta è collegato ad
interruttori in vari punti del processore. In questo modo gli interruttori di controllo vengono
aperti o chiusi in conformità all’istruzione presente nel registro delle istruzioni.
Il registro dell’indirizzo delle istruzioni (Instruction Address Register) IAR, che contiene
l’indirizzo della cella di memoria dove si trova l’istruzione del programma successiva a quella
attualmente in esecuzione. Giusto per confondere ancora di più le idee……,questo registro è
anche chiamato Program Counter. Il contenuto del program counter viene incrementato
dall’unità di controllo non appena è stata letta l’istruzione da eseguire, in modo da contenere
l’indirizzo della locazione di memoria dove si trova memorizzata l’istruzione successiva.
Alcune istruzioni hanno la capacità di modificare il contenuto del program counter (istruzioni
di salto ad es. JUMP), in modo che l’istruzione seguente da eseguire non sia la successiva nella
sequenza ordinata delle istruzioni del programma. E’ proprio questa possibilità di alterare il
contenuto del program counter da parte dell’istruzione del programma che consente al
programmatore di saltare da un punto adun’altro dell’algoritmo, a seconda del verificarsi di
determinate condizioni.
Il registro indirizzi di memoria (Storage Address Register o Memory Address Register) SAR o
MAR interviene quando l’unità di controllo deve accedere ad un dato contenuto in una
determinata cella di memoria, l’indirizzo numerico che identifica la locazione di memoria
desiderata viene posta in tale registro che, quindi, è utilizzato per contenere un dato durante un
trasferimento da o verso una memoria principale.
Il registro dei dati di memoria (Storage Data Register) SDR viene utilizzato per memorizzare
ildato da trasferire in/da una locazione di memoria.
Registri di uso generale (General Purpose Register) GPR, chiamati anche spesso Accumulatori,
vengono utilizzati per la memorizzazione temporanea di dati o risultati intermedi. Il numero di
questo tipo di registri varia da elaboratore ad elaboratore, ovviamente, una macchina con un
numero più elevato di accumulatori offre una maggiore flessibilità di lavoro, cui si ccompagna,
in genere, una velocità di lavoro più elevata.
Il registro puntatore della pila SP (stack pointer) è utilizzato come registro di una memoria
stack.
58

La memoria stack ha la proprietà di poter essere “riempita” o memorizzata ordinatamente
dall’ultima locazione alla prima e riletta in senso inverso,dall’ultima locazione memorizzata (in
ordine di tempo) alla prima. Praticamente,come una pila di fogli che vengono accumulati uno
sull’altro man mano che vengono scritti,per cui il primo foglio scritto in ordine di tempo si trova
in fondo. Per questa metodologia di memorizzazione lo stack è definito una struttura di memoria
LIFO (Last In First Out).
L’indirizzo della cima dello stack viene indicato dal valore del registro Stack Pointer (SP).
INGRESSO USCITA
DATI
E’opportuno notare che lo stack pointer fornisce l’indirizzo della prima locazione vuota; nel
caso venga richiesta un’operazione di lettura,necessario decrementare il valore contenuto
nell’SP per avere l’indirizzo dell’ultimo dato memorizzato.
Il vantaggio della memoria stack è costituito dalla possibilità di memorizzare o accedere ai dati
da parte delle altre unità, senza che sia necessario fornire l’indirizzo della locazione di memoria
dove si trova il dato stesso.
Questo tipo di registro è fondamentale, viene utilizzato ad esempio per chiamate e ritorno da
sottoprogrammi, salvataggio e ripristino di contenuti di registri, nella gestione delle interruzioni,
eccetera.
Lo SP si muove insieme al top dello stack ogni volta che viene immesso o prelevato un dato,
possiamo suddividere in tre fasi:
inizializzazione:l’SP viene inizializzato con l’indirizzo successivo a quello della prima
locazione da cui comincia lo stack (indirizzo maggiore);
immissione:il contenuto dell’SP viene prima decrementato e poi utilizzato come indirizzo per
un’operazione di scrittura di un dato in memoria;
estrazione: il contenuto dell’SP viene prima utilizzato come indirizzo per un’operazione di
lettura di un dato dalla memoria e poi incrementato.
Il registro di controllo F (flag) è un registro ad 8 bit, dei quali 4 sono fondamentali: il carry
flag, lo zero flag, il sign flag e l’overflow flag:
59
STACK PONTER

- quando CF=1, indica che si è generato un riporto o si è richiesto un prestito, se l’istruzione
operava con i numeri naturali, questa situazione indica che il risultato dell’operazione
aritmetica realizzata dall’istruzione non è rappresentabile;
- quando ZF=1, indica che l’ultima istruzione eseguita ha prodotto un risultato con tutti i bit a
zero;
- quando SF=1, indica che l’ultima istruzione eseguita ha prodotto un risultato col bit più
significativo uguale ad 1 (per numeri interi ciò vuol dire che è un risultato negativo);
- quando OF=1, indica che durante l’esecuzione dell’ultima istruzione si è avuto un
traboccamento (con i numeri interi questa situazione non è rappresentabile);
Torniamo ai BUS, ognuno di essi costituito da un insieme di linee di trasmissione parallele
corrispondenti ai bit di informazione che sono trasferiti. Nel dettaglio, i bus si distinguono in:
Bus dati, vengono utilizzati per trasmettere da un’unità all’altra i dati.
Bus indirizzi, trasmettono i numeri binari corrispondenti agli indirizzi che servono ad individuare
una particolare locazione di memoria dove, per esempio,può essere memorizzato il risultato di
un’operazione (dato),o dove si trova il dato su cui effettuare una determinata operazione,o dove si
trova la prossima istruzione da eseguire.
Bus di controllo, composto da un certo numero di collegamenti che trasmettono segnali di
comando e di consenso tra le varie unità.
Classico esempio di utilizzo del suddetto bus, è il momento in cui due utenti hanno un’unica
stampante condivisa e mandano entrambi un foglio di stampa. Se le due richieste avvengono in
tempi differenti, viene esaudita quella che arriva prima; quindi, il registro destinatario, (in questo
della stampante), per poter accogliere la richiesta deve convertire il suo stato (ecco perché si opera
una sua scrittura). Qualora i due utenti avessero mandato contemporaneamente la richiesta di
stampa il control bus fa in modo che decadano entrambe.
60
Da quanto detto, si deduce che una delle caratteristiche fondamentali di un elaboratore sia il numero
di bit di cui sono dotati i bus dati ed indirizzi. Se un bus dispone di un numero piccolo di linee,
alcuni dati o istruzioni non potranno essere trasmessi interamente con una singola operazione di
trasferimento, ma saranno necessarie più operazioni di trasmissione; ciò richiede di conseguenza un
numero più elevato di passi, che singolarmente impiegheranno un tempo minore per essere svolte,
ma nel complesso, visto che numero cresce, il tempo sarà maggiore.
Uno dei parametri più importanti che caratterizzano un elaboratore numerico è quindi il grado di
“parallelismo” della macchina, intendendo con questa espressione il numero di bit che possono
essere trasmessi contemporaneamente dai bus che collegano le varie parti costituenti l’elaboratore.
In Sintesi, un elaboratore ( a logica programmata) è una macchina in grado di eseguire una
determinata elaborazione solo se è presente,memorizzato in esso,un apposito programma
(software)che contiene la descrizione completa delle singole operazioni elementari che devono
essere effettuate.
Ciascun programma è composto da un numero finito di istruzioni comprensibili dalla macchina, che
descrivono in sequenza tutti i passi dell’elaborazione.
Ciascuna istruzione corrisponde a sua volta ad un singolo passo dell’algoritmo di elaborazione,che
per essere eseguito necessita di una o più operazioni elementari di macchina.
E’opportuno notare che nello schema è necessaria la presenza della memoria in quanto la CPUèin
grado di elaborare i dati molto più velocemente di quanto possano essere forniti dalle unità d’I/O;
quindi se la CPU ricevesse i dati e le istruzioni direttamente dalle unità d’ingresso, dovrebbe
mantenere una velocità di elaborazione adeguata molto bassa. Poiché la memoria ha invece una
velocità di trasferimento dati di diversi ordini di grandezza superiore a qualunque unità d’I/O, anche
se non confrontabile con la velocità di elaborazione della CPU, i dati e le istruzioni del programma
vengono dapprima trasferiti a bassa velocità in memoria dalle unità d’ingresso; quindi la CPU
61

esegue l’elaborazione e fornisce i risultati colloquiando solamente con la memoria. Infine, i risultati
vengono inviati alle unità d’uscita,di nuovo a bassa velocità.
ESECUZIONE DI UN’ISTRUZIONE DA PARTE DELLA CPU
Un esempio di istruzione può essere:
Sommare al contenuto della locazione 200 di memoria il contenuto della locazione 350 e memorizzare il risultato nella locazione 400.
Tale istruzione deve essere codificata in linguaggio macchina, e cioè nella forma appropriata perché
possa essere interpretata dall’elaboratore. Nella forma binaria l’istruzione è rappresentata da un
insieme opportuno di bit che occupano uno o più byte a seconda non solo del tipo di istruzione Ma
anche del tipo di elaboratore.
Nella memorizzazione del programma nella memoria centrale del computer, ciascuna istruzione
viene identificata dall’indirizzo della prima locazione di memoria che essa occupa, cosicché, se
l’istruzione occupa 4 byte ed il primo byte si trova nella locazione di indirizzo 176,tutta l’istruzione
viene identificata come “istruzione di indirizzo 176”.
In generale, la CPU esegue ciascuna istruzione in due fasi dette fase di Fetch o Caricamento e fase
di Execute o di Esecuzione. Insieme formano il ciclo istruzione.
Durante la fase di fetch,viene individuato lì indirizzo dell’istruzione da eseguire e l’istruzione viene
caricata nel registro istruzione; vengono inoltre individuati gli indirizzi dei dati su cui operare,che
vengono caricati in appositi registri del tipo di uso generale.
La fase di execute consiste nell’esecuzione delle operazioni specificate dall’istruzione e nella
memorizzazione del risultato nel registro o nella locazione di memoria richiesta.
Lo schema di figura rappresenta il flusso dei dati durante l’esecuzione di una generica istruzione. In
dettaglio:
1. l’indirizzo di memoria, dove è contenuta l’istruzione da eseguire, viene caricato nel Program
Counter(PC) del Registro degli Indirizzi di Memoria(SAR);
62

2. l’unità di memoria preleva l’istruzione dall’indirizzo specifico e lo pone nel Registro dei
Dati di Memoria (SDR);
3. L’istruzione viene trasferita nel Registro delle Istruzioni (IR);
4. L’istruzione viene interpretata dal decodificatore e gli indirizzi di eventuali operandi
vengono passati nel SAR;
5. L’unità di memoria preleva ad uno ad uno i dati richiesti dalle locazioni specificate e li pone
nell’SDR;
6. I dati vengono inviati negli appositi Registri di Uso Generale (GPR);
7. L’ALU preleva i dati ed esegue su di essi l’operazione richiesta specificata dal
decodificatore;
8. L’ALU pone il risultato sempre in un GPR;
9. Il risultato viene trasferito nel SDR, mentre l’unità di controllo deposita nel SAR l’indirizzo
di memoria specificato dall’istruzione, che indica dove registrare il risultato;
10. La memoria preleva il dato dall’SDR e lo memorizza nella locazione specificata dal SAR.
Alla fine della fase di fetch, il PC viene incrementato,puntando così alla successiva istruzione in
sequenza del programma.
ESECUZIONE DI UN PROGRAMMA DA PARTE DELLA CPU
Di seguito viene riportata la descrizione dei passi seguiti dall’elaboratore per effettuare una
qualunque sequenza di istruzioni di un programma. Si suppone che il programma si trovi già
memorizzato nella memoria centrale del sistema.
1. L’indirizzo di memoria dove si trova la prima istruzione viene caricato nel program counter;
2. L’indirizzo di memoria viene trasferito dal program counter al SAR;
3. Il codice dell’istruzione viene trasferito dalla memoria all’SDR;
4. Il codice dell’istruzione viene trasferito nell’IR;
5. Nel program counter viene memorizzato l’indirizzo della cella di memoria dove si trova
l’istruzione successiva da eseguire;
6. L’istruzione contenuta nell’IR viene interpretata ed eseguita dalla CPU, utilizzando altri
registri eventualmente necessari per l’esecuzione, come per esempio i GPR;
7. Se l’istruzione appena eseguita non è uno STOP, lo svolgimento continua al passo 2
(esecuzione dell’istruzione successiva), altrimenti termina.
La sequenza di passi descritta viene eseguita con una velocità controllata dal clock di sistema, che
ha il compito di sincronizzare tutte le operazioni dell’elaboratore.
63

64

CLASSIFICAZIONE DELLE MEMORIE
Si parla di memorie volatili quando i bit di informazione possono essere letti o scritti e
vipermangono stabilmente memorizzati per tutto il tempo in cui il dispositivo è alimentato (cioè
per tutto il tempo in cui viene fornita l’alimentazione al dispositivo). Quando viene tolta
l’alimentazione le informazioni memorizzate vengono completamente definitivamente
cancellate.
Le memorie volatili sono utili durante la fase di lavoro dell’elaboratore in quanto è
estremamente flessibile alle operazioni di lettura e scrittura dei dati e istruzioni. A questa
categoria appartengono le RAM.
Le memorie non volatili invece mantengono permanentemente le informazioni in esse
depositate anche in assenza di alimentazione. Appartengono a questa categoria le ROM.
MEMORIE AD ACCESSO SEQUENZIALE
Sono formate da catene di registri disposti in cascata ed eventualmente chiusi ad anello con un
unico punto di accesso o uscita dei dati:
I/O DATA
Quindi per fare la lettura di un dato occorre farlo scorrere attraverso la struttura sino al punto
I/O.
L’inconveniente di questa memoria è il tempo di accesso ai dati che, oltre ad essere lungo è
anche diverso per ogni singola cella, dipendendo dalla posizione iniziale in cui si trovano i dati.
65
4 3 2
ST
876
R

MEMORIE AD ACCESSO CASUALE
Sono organizzate secondo una struttura reticolare a due o più dimensioni:
cella di memoria selezionata
indirizzo
di riga
indirizzo
di colonna
l’indirizzo di ogni casella è costituito dalle coordinate della riga e della colonna che la individuano;
quindi tutte le celle hanno uguale tempo di accesso qualunque sia la loro posizione nella memoria.
A questa categoria fanno parte le RAM.
TIPI DI MEMORIE
PROM (programmable ROM), memoria programmata una sola volta direttamente dall’utente.
Una volta programmata si comporta come le ROM e non può più essere corretta;
EPROM (erasable programmable ROM), cioè ROM programmabili e cancellabili per un
determinato numero di volte dall’utente. Per correggere anche un solo bit, si deve cancellarla
completamente e quindi riprogrammarla;
EAROM (electrically alterable ROM), cioè memoria alterabile elettricamente; è una memoria
cancellabile e programmabile ripetutamente dall’utente: la cancellazione può essere anche
parziale;
PLA (programmable logic array), è una rete combinatoria per applicazioni di tipo ROM;
66
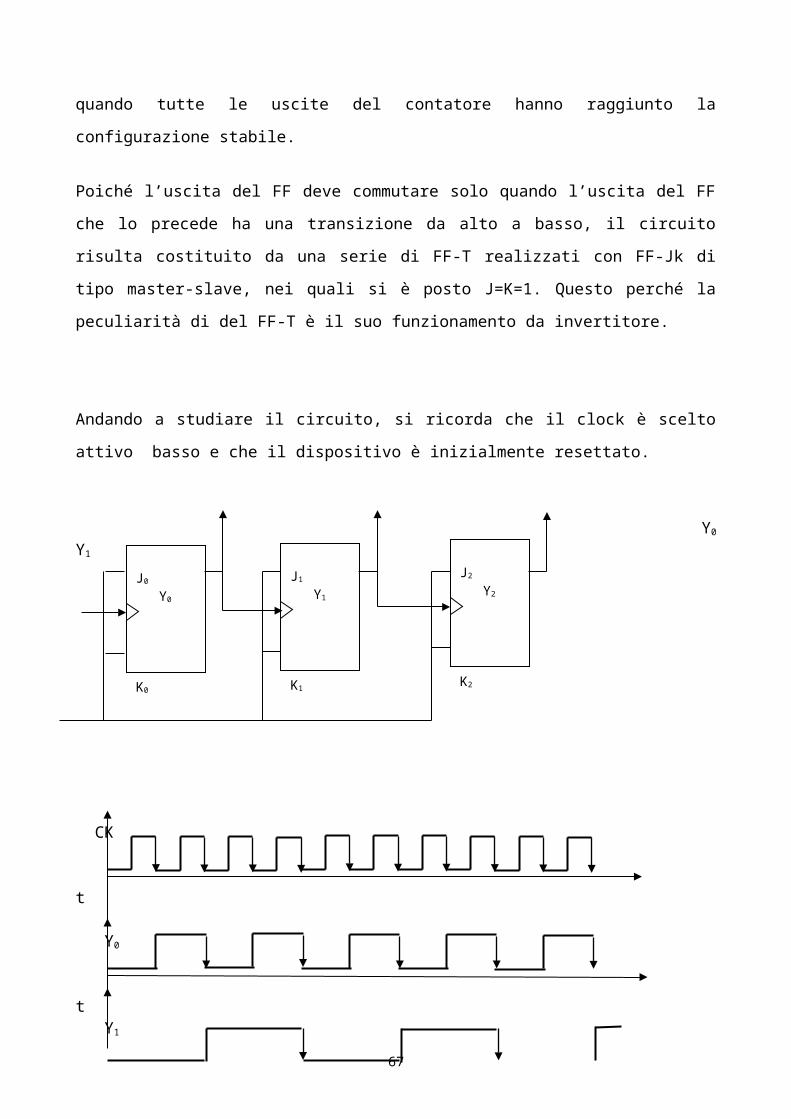
SRAM (static RAM) utilizzano come celle di memorizzazione un elemento attivo, tipicamente
un flip-flop.
Un gruppo di memoria di questo tipo di presenta come:
/RD
/WR
/SA15-A0
D7-D0
1Mx8
Potremmo potenziare la memoria mettendo più blocchi come segue:
/RD
/WRD7-D0
A16-A0 /SL
/S /SH
2Mx8
DRAM (dinamic RAM), utilizzano come celle di memorizzazione un elemento passivo: un
condensatore il cui livello di carica rappresenta uno dei possibili stati logici memorizzabili. E’
67
/RD/WR/SA15-A0
D3-D01Mx4
/RD/WR/SA15-A0
D3-D01Mx4
/RD/WRD7-D0A15-A0
/S1Mx8
/RD/WRD7-D0A15-A0
/S1Mx8
R

una memoria che per la sua peculiarità costitutiva deve essere continuamente rinfrescata, cioè in
esse, ad intervalli regolari, viene ripristinata, tramite opportuni processi, la carica delle singole
celle elementari; l’intervallo temporale che separa i successivi rinfreschi è detto tempo di
refresh.
Si presenta come:
Le celle sono organizzate a matrice per cui si ha bisogno di un indice di riga (RAS) ed uno di
colonna (CaS) per individuarle.
I bit di ingresso DI e quelli di uscita DO sono in genere supportati da due collegamenti distinti.
- Per fare una lettura: R/W=0, quindi viene attivato l’indice di riga /RAS e poi quello di
colonna /CAS: il piedino DO (generalmente ad alta resistenza) assume il valore della cella
indirizzata. Avviene infine una riscrittura della cella indirizzata (refresh).
- Per fare una scrittura: R/W=1, quindi sono specificati /RAS e /CAS; nella cella così
determinata viene scritto il dato presente su DI, mentre nelle altre celle della riga sezionata
viene riscritto il vecchio valore (refresh).
La memoria dinamica necessita di un opportuno controllore sia per le operazioni di lettura e
scrittura che per quelle di rinfresco. In particolare per quest’ultima, il controllore con una certa
frequenza (circa 10 ms) deve rinfrescare tutte le righe della DRAM, deve essere quindi previsto un
contatore, che genera in sequenza tutti gli indirizzi di riga.
68
A0 /RASA1 /CASA2A3 DOA4 DIA5A6 R/WA7
Vcc GND

APPENDICE: l’ALU 74LS382
Le unità logico aritmetiche (ALU) sono circuiti combinatori che accettano in ingresso due parole ad n bit A=An-1….A0 e B=Bn-1…….B0 e forniscono in uscita una funzione F=Fn-1…..F0 legata agli ingressi da una relazione logica o aritmetica. In genere una ALU è provvista di un ingresso di controllo che determina quale delle due tipologie è attiva, qual è il tipo di funzionamento e quali sono gli altri ingressi che Si che selezionano la funzione da realizzare.Nel modo di funzionamento logico le uscite Fi dipendono esclusivamente dai bit di ingresso Ai e Bi e dai bit di selezione Si. Così ad esempio la funzione selezionata è la AND, con A=1011 e B=1110,si avrà in uscita F=1010.Le ALU disponibili in commercio sono in grado di trattare dati a 4 bit; tuttavia esse possono essere collegate in cascata per elaborare dati digitali ad n bit.Per quanto riguarda le operazioni aritmetiche, ciò è possibile grazie alla presenza di un ingresso di riporto (Cin) da collegare ad un’eventuale ALU precedente e di un’uscita supplementare (Cout) da collegare ad un’ALU successiva (si noti che l’ingresso di controllo Cin condiziona l’esecuzione di tutte le operazioni aritmetiche e deve quindi essere sempre attentamente controllato e mantenuto al livello logico adeguato e prescritto per ciascuna operazione).
DATASHEET 74LS382
Le modalità operative vengono selezionate mediante i tre ingressi S2, S1 ed S0, secondo la tabella delle funzioni (vedi datasheet). Questa ALU è in grado di implementare 8 funzioni, di cui tre aritmetiche, tre logiche e due supplementari che consentono di resettare (portare a livello logico 0) o settare (portare a livello logico alto) tutte le uscite,indipendentemente dai dati A e B.Oltre alle linee di ingresso A3-A0 e B3-B0 e alle linee F3-F0 che forniscono i bit della funzione d’uscita, si notano l’ingresso Cn e l’uscita Cn+4, questi due collegamenti garantiscono la possibilità del collegamento in cascata di più unità per il trattamento di dati di lunghezza superiore a 4 bit.In un’operazione di somma aritmetica Cn rappresenta il riporto (C0) generato da un’eventuale ALU di ordine inferiore (a valle) mentre Cn+4 costituisce il riporto (C4) per un’altra ALU di ordine superiore; entrambe queste linee sono attive alte. Eseguendo una differenza Cn e Cn+4 rappresentano rispettivamente il bit di prestito fornito all’unità meno significativa e quello richiesto all’unità più significativa (entrambe queste linee sono attive basse).Il risultato delle operazioni aritmetiche si presenterà sulle uscite F3F2 F1F0 e su Cn+4. Si noti ancora che questo integrato presenta un’ulteriore uscita OVR prevista per rivelare e segnalare le condizioni di overflow che si verificano nella rappresentazione in complemento a 2 dei numeri.
69