
Laboratorio di metodi di acquisizione dati -...
39
Laboratorio di metodi di acquisizione dati Giorgio Maggi
Transcript of Laboratorio di metodi di acquisizione dati -...

Laboratorio di metodi diacquisizione dati
Giorgio Maggi

Argomenti
Sistemi complessi di acquisizione dati Apparato CMS
Concetto di trigger
L’event building
Sistemi complessi di elaborazione dati GRID
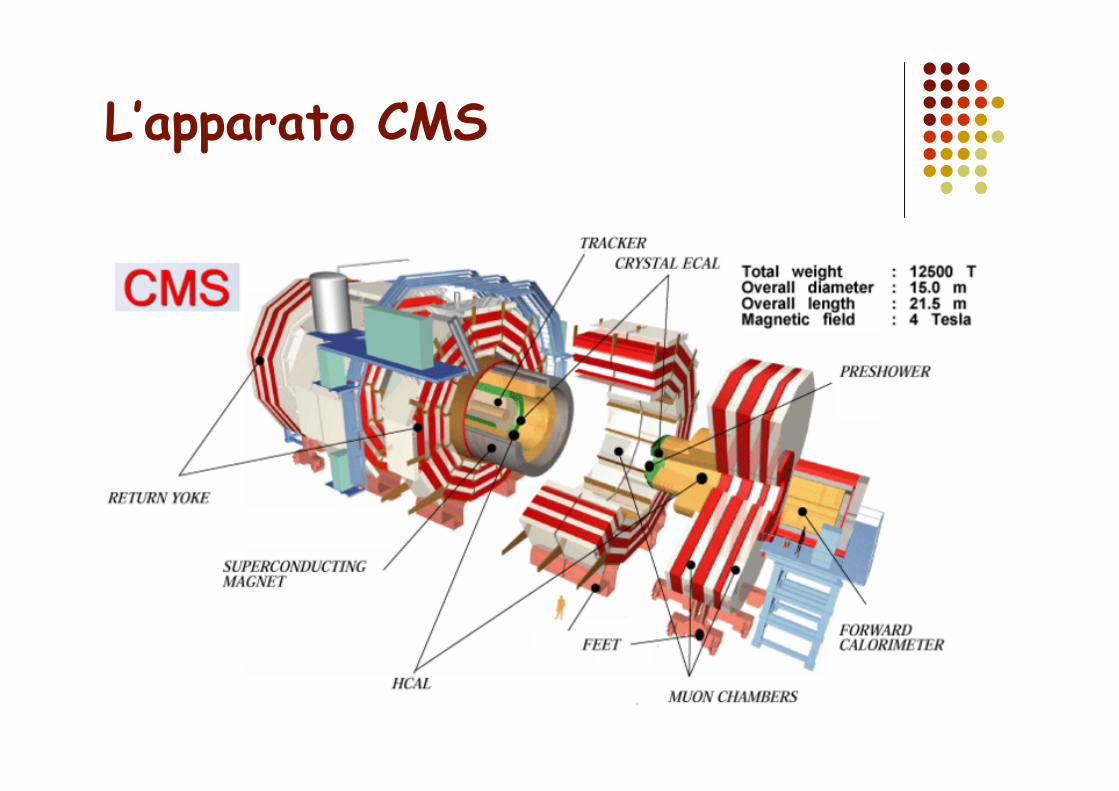
L’apparato CMS
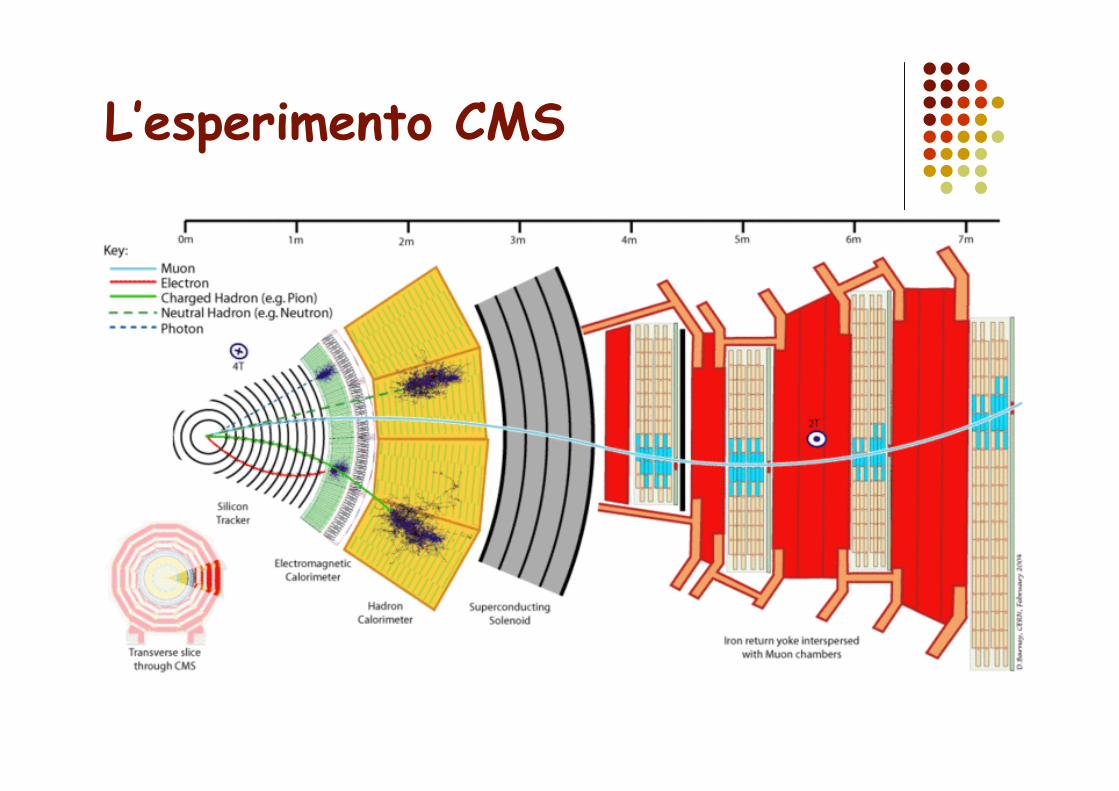
L’esperimento CMS

Il concetto di trigger
Ad LHC, i fasci di protoni si scontrano, al centro dell’apparatosperimentale, 40,000,000 di volte al secondo.
Alla più alta intensità, ci saranno circa 25 collisioni protone- protoneper ogni incrocio dei fasci
Memorizzare tutta l’informazione associata a tutte queste collisioni,corrisponde a 100TB/s, l’equivalente di 10000 Enciclopedie Britannicheal secondo.
Compito del Trigger e del Sistema di Acquisizione Dati (DAQ) è quello diselezionare, tra i molti milioni di eventi al secondo, i 100 più interessanti,in modo da immagazzinare le informazioni solo di questi eventi piùinteressanti per le successive analisi ed elaborazioni.
Un evento deve superare due insiemi indipendenti di test per essereselezionato
I test vanno da test semplici e di corta durata (Livello 1) a test piùsofisticati che richiedono un tempo maggiore per essere eseguiti (Livello2,3,….)

Il trigger di Primo Livello
Level 1 tregger. 40 MHz input, basato su: Processori specializzati in grado di prendere decisioni ogni 25 ns
Sistema a pipeline (l’informazione viene fatta sopravvivere fino a quando non vienepresa la decisione)
Le decisioni prese in base a un pattern recognition locale Informazione veloce da macroaree dei calorimetri e dei rivelatori di mu Indentificazioni di particele: elettrroni di altro pt (momento trasverso, fotoni, muoni,
jets, energia mancante, etc
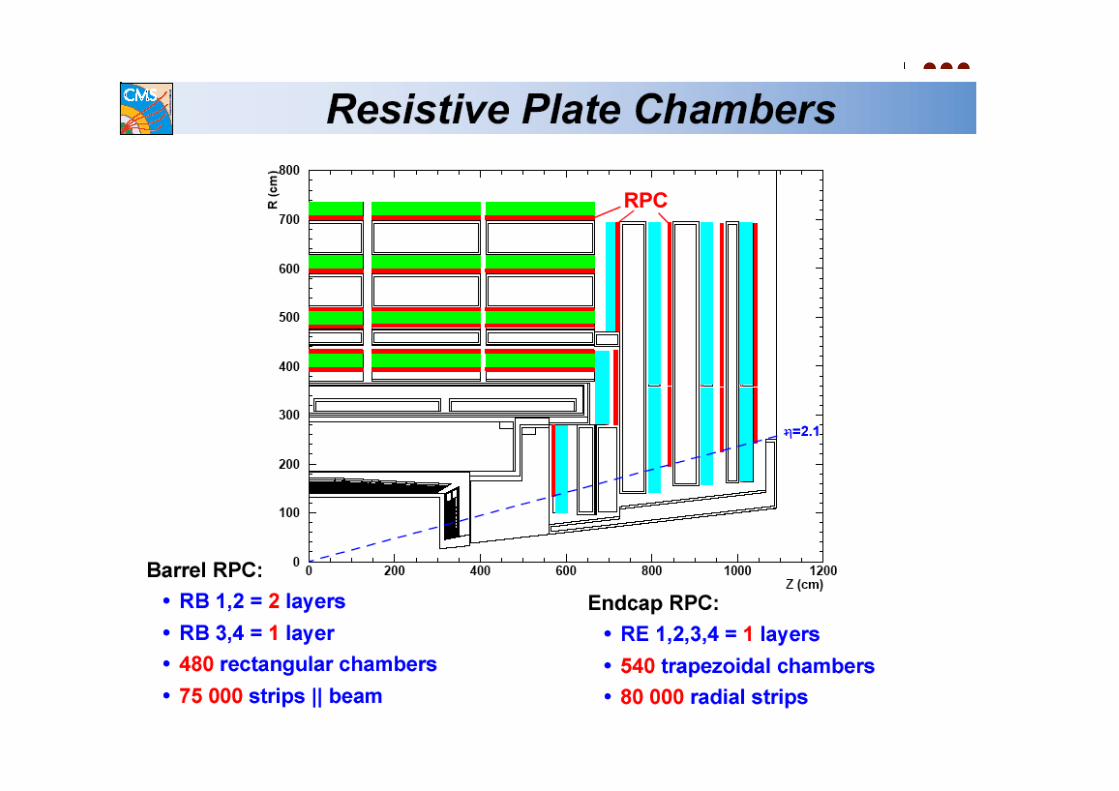

Trigger di livello 1 sui Muonicon gli RPC
Al sistema di trigger basato sugli RPC è richiesto l’identificazione e la localizzazione di muoni ad alto pT sia
nel barrel che negli end-caps.
La principale richiesta è che il sistema di trigger diprimo livello, nel suo insieme, rilasci al “Global MuonTrigger” fino a quattro tracce candidate di muoni conil più alto valore di momento traverso e questo sianel barrel che negli end-caps, ad ogni bunch-crossing.
La massima latenza consentita è di 81 periodi di“bunch crossing”.
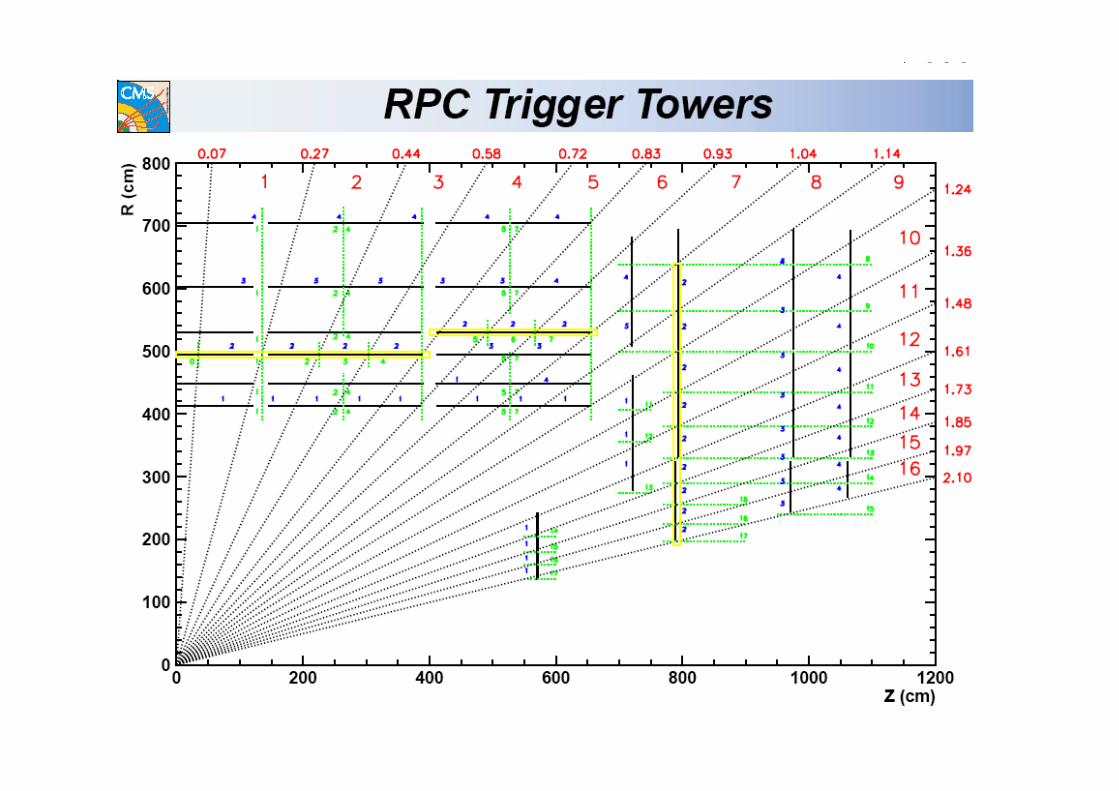
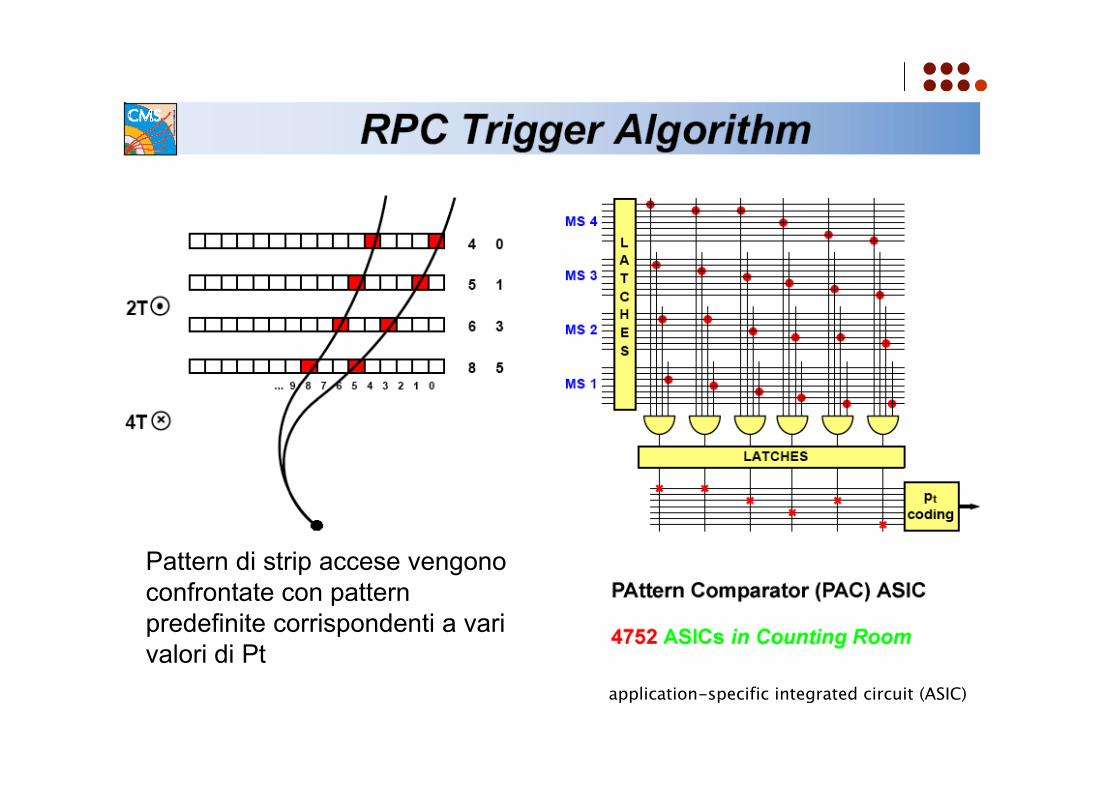
Pattern di strip accese vengonoconfrontate con patternpredefinite corrispondenti a varivalori di Pt
application-specific integrated circuit (ASIC)

RPC muon Trigger
Il cuore del sistema hardware di riconoscimento e convalida di un evento amuoni, nel caso degli RPC, è il PACT (Pattern Comparator Trigger). Alla base di tale sistema vi è un processore il PAC appunto, il cui compito è di
riconoscere il muone, all’interno di una regione angolare di 2,5° in ϕ e in unintervallo di pseudorapidità, pari a 0,1 (torre).
Un set di pattern di hit predefiniti, sono precaricati nel PACT, che liconfronta con i pattern osservati, assegnando un codice ad ogni valore di ptmisurato. Successivamente questi rilascia il codice di momento traverso più elevato,
all’interno della torre di trigger (regione ϕ, η), a lui assegnato. In totale nelrivelatore si avranno 144x33 muoni identificati con il valore di pt più elevato.
Ad ogni evento, vengono assegnati anche alcuni bit di qualità, per identificarne lapurezza, sulla base del numero di piani scattati, che hanno contribuito alla suaidentificazione.

RPC muon Trigger
Questa informazione, è ulteriormente processata dal secondo componentedi questa catena di identificazione, indicato con il nome di Sorter. [2]
Il compito del sistema di sorting degli RPC è quello di ridurre drasticamentela quantità di dati da inviare al sistema di Global Muon Trigger. Questa funzione, originariamente sviluppata con un prototipo denominato
appunto SORTER, costituisce il blocco di base funzionale del sistema.
Questo si sviluppa con una struttura ad albero, con il compito di ridurre le 144 x33 parole con i rispettivi indirizzi, rilasciate dai vari PAC, a sole 8 (4+4) parole,corrispondenti agli eventi con mu a più alto momento traverso, per ogni bunchcrossing.

I livelli di trigger superiore el’event building
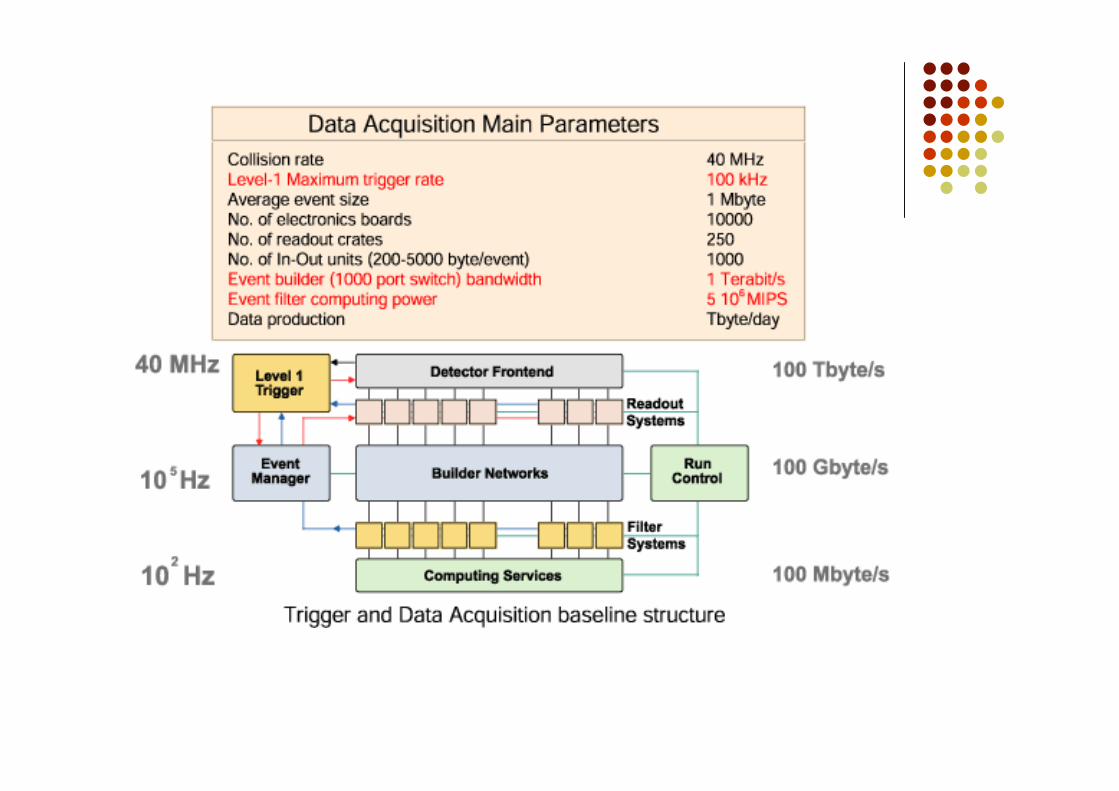
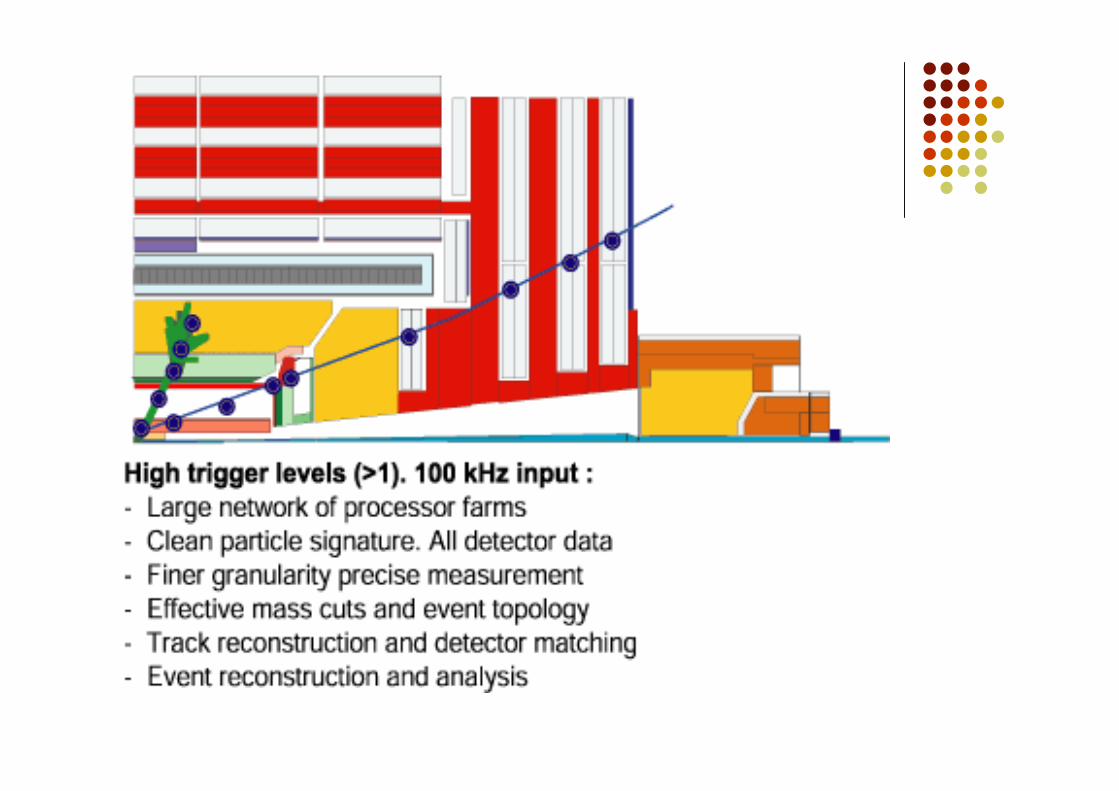
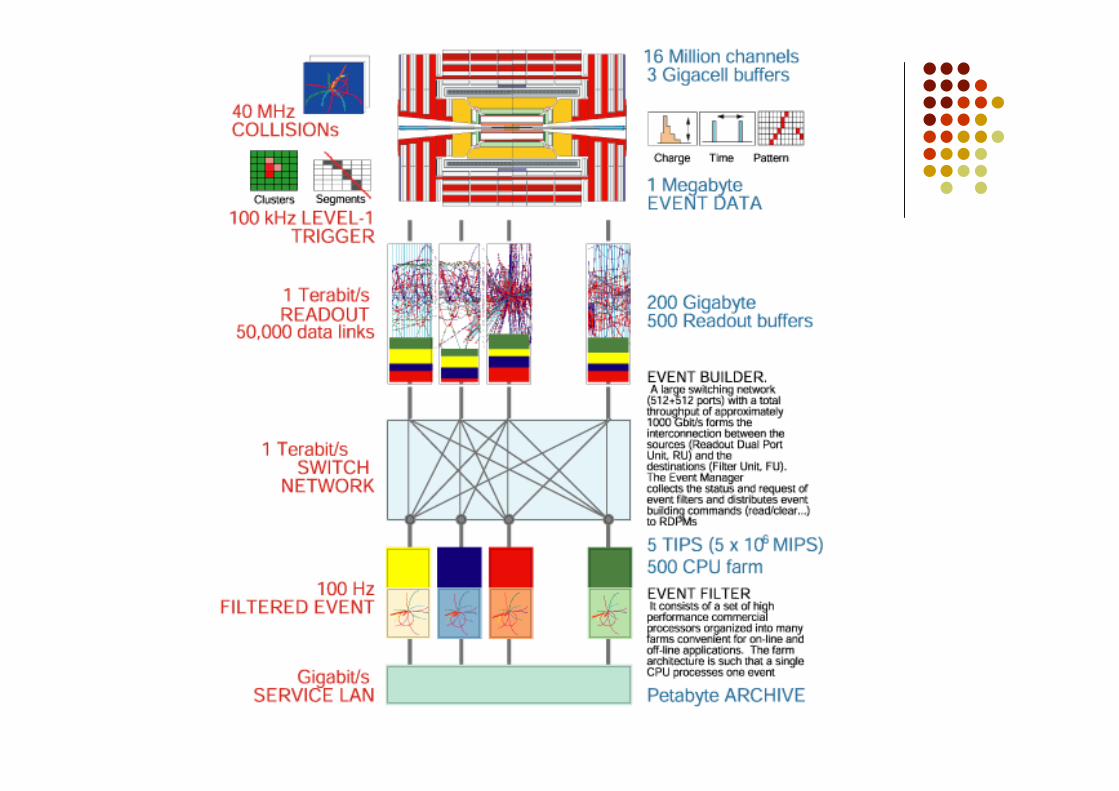
Al livello-1 (Lv1) la selezione de dati viene fatta da hardware speciale(Abbiamo visto i PAC per il trigger fornito dagli RPC) che vanno aguardare semplici segnali tipici di eventi interessanti Un grande deposito di energia in un piccolo gruppo di celle del calorimetro Le strip accese delle camere a muoni disposte secondo un preciso pattern
Il trigger di livello 1 deve esser molto veloce, impiegare meno di unmicrosecondo per prendere la decisione
Circa 100000 eventi al secondo sono selezionati dal trigger di 1° livello L’informazione relativa a questi 100000 eventi accettati dal trigger di
livello 1 viene immagazzinata in 500 memorie indipendenti, ciascunaconnessa ad una parte differente del rivelatore.
Il trigger di livello2 (Lv2) richiede l’informazione di più di un pezzo delrivelatore.
Prima di applicare il trigger di LV2 è necessario assemblare mettere inuna singolo posto tutte le informazioni che vengono fuori dalle varieparti dell’apparato.

L’event building
Prima di applicare il trigger di LV2 è necessario assemblare mettere in una singoloposto tutte le informazioni che vengono fuori dalle varie parti dell’apparato.
Questa operazione viene detta “event building”. In CMS c’è un grande Switch che connette le 500 memorie locali ad una farm di
computers in attesa di ricevere le informazione dell’evento per applicare i test deilivelli successivi (LV2, LV3, etc).
I test di livello successivo (2-3) vengono fatti girare su computer commerciali chefanno un’analisi più accurata dell’intero evento correlando tra loro le informazionipresenti nelle varie parti dell’apparato
Hanno bisogno di più tempo per poter girare e hanno bisogno di informazioni piùdettagliate dell’evento
Nel trigger di livello 3, quando l’intero evento è stato assemblato, uno può fargirare sofisticati algoritmi di fisica
Le tracce del tracciatore centrale vengono connesse con quelle rivelate dallecamere a muoni, i fotoni sono identificate come celle del calorimetroelettromagnetico con molta energia e in assenza di particelle cariche che puntanoin quella regione
L’intero processo viene anche usato oltre che per selezionare i 100 eventi alsecondo da memorizzare per l’analisi successiva off-line anche per monitorarel’apparato CMS per rivelare e correggere ogni segno di cattivo funzionamento.
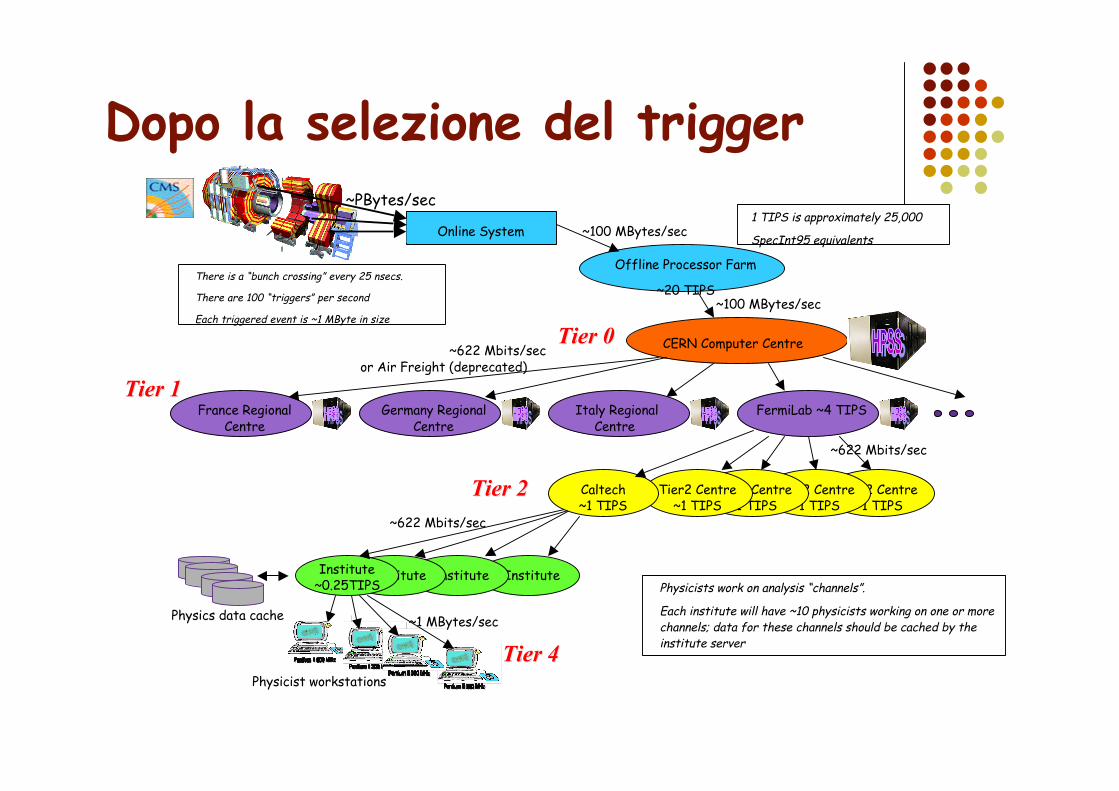
Dopo la selezione del trigger
Tier2 Centre~1 TIPS
Online System
Offline Processor Farm
~20 TIPS
CERN Computer Centre
FermiLab ~4 TIPSFrance RegionalCentre
Italy RegionalCentre
Germany RegionalCentre
InstituteInstituteInstituteInstitute~0.25TIPS
Physicist workstations
~100 MBytes/sec
~100 MBytes/sec
~622 Mbits/sec
~1 MBytes/sec
There is a “bunch crossing” every 25 nsecs.
There are 100 “triggers” per second
Each triggered event is ~1 MByte in size
Physicists work on analysis “channels”.
Each institute will have ~10 physicists working on one or morechannels; data for these channels should be cached by theinstitute server
Physics data cache
~PBytes/sec
~622 Mbits/secor Air Freight (deprecated)
Tier2 Centre~1 TIPS
Tier2 Centre~1 TIPS
Tier2 Centre~1 TIPS
Caltech~1 TIPS
~622 Mbits/sec
Tier 0Tier 0
Tier 1Tier 1
Tier 2Tier 2
Tier 4Tier 4
1 TIPS is approximately 25,000
SpecInt95 equivalents

Il computing distribuito di CMS• In CMS le CPU e lo spazio disco necessario viene fornito solo
attraverso un sistema distribuito che si basa sulle risorsecomputazionali, i servizi e gli strumenti forniti dalla Grid
• Il Worldwide LHC Computing Grid (WLCG) fornisce tutto ilcomputing richiesto dagli eesperimenti LHC
• CMS costruisce il suo strato di applicazioni in grado diinterfacciarsi con differenti implementazioni della Grid (EGEE inEuropa e OSG negli USA)
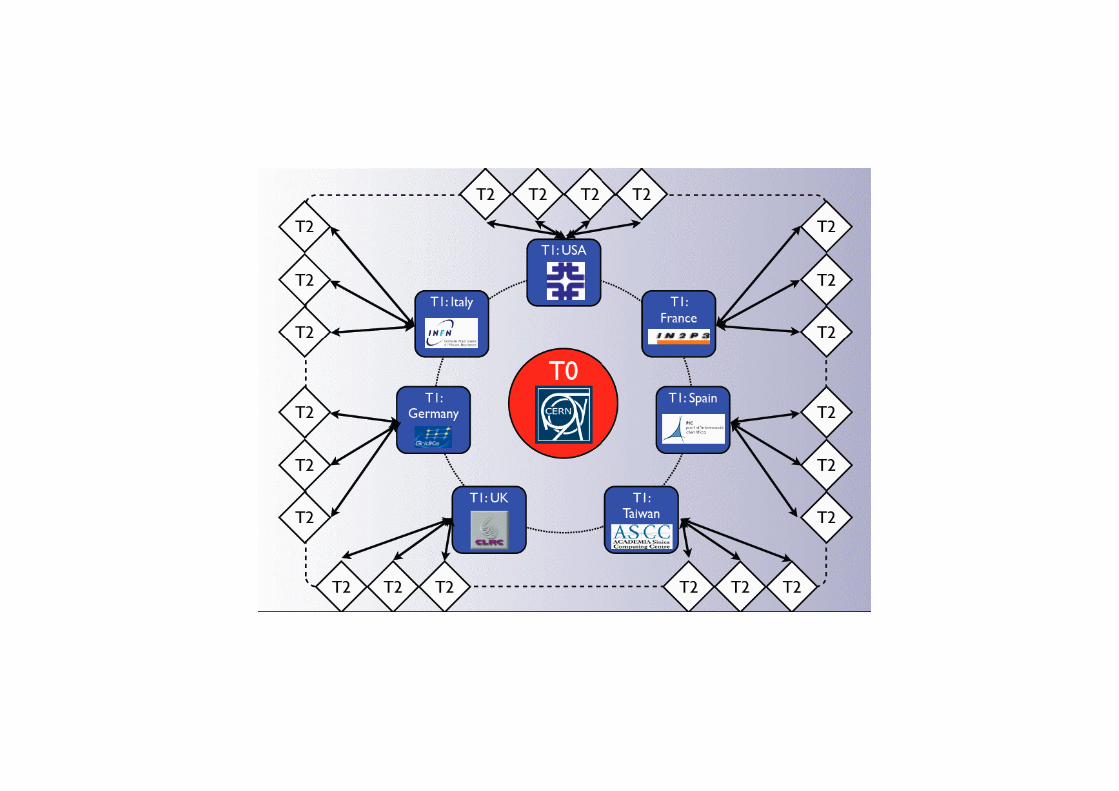
• Una struttura gerarchica di Tier fornisce:– Data storage– Re-reconstruzione– L’analisi degli utenti– La produzione MC
• Le risorse saranno ripartite all’incirca:20% al Tier0, 40% ai Tier1 and 40% ai Tier2
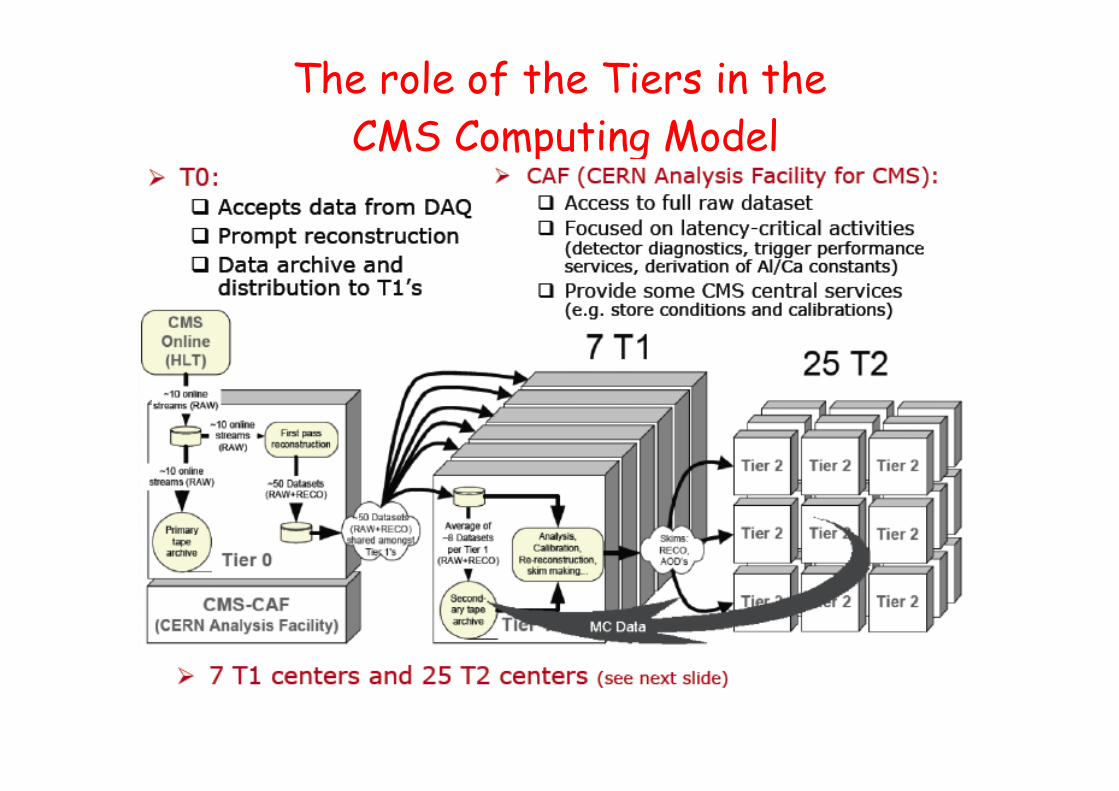
The role of the Tiers in the CMS Computing Model


The data types in CMS

The roles of Tier0,1,2 for CMS• Tier0 (CERN):
– safe keeping of RAW data (first copy);– first pass reconstruction;– distribution of RAW and RECO to Tier1;– reprocessing of data during LHC down-times.
• Tier1 (ASCC,CCIN2P3,FNAL,GridKA,INFN-CNAF,PIC,RAL):– safe keeping of a proportional share of RAW and RECO (2nd copy);– large scale reprocessing and safe keeping of the output;– distribution of data products to Tier2s and safe keeping of a share of
simulated data produced at these Tier2s.
• Tier2 (~40 centres):– handling analysis requirements;– proportional share of simulated event production and reconstruction.

Computing SoftwareAnalysis Challenge 2006
A 50 million event exercise to test the workflow and dataflow as defined inthe CMS computing model
A test at 25% of the capacity needed in 2008
Main components:• Preparation of large MC simulated datasets (some with HLT-tags)• Prompt reconstruction at Tier-0:
– Reconstruction at 40 Hz (over 150 Hz) using CMSSW– Application of calibration constants from offline DB– Generation of Reco, AOD, and AlCaReco datasets– Splitting of an HLT-tagged sample into 10 streams
• Distribution of all AOD & some FEVT to all participating Tier-1s• Calibration jobs on AlCaReco datasets at some Tier-1s and CAF• Re-reconstruction performed at Tier-1s• Skim jobs at some Tier-1s with data propagated to Tier-2s• Physics jobs at Tier-2s and Tier-1s on AOD and Reco
Italian
cont
ribu
tion
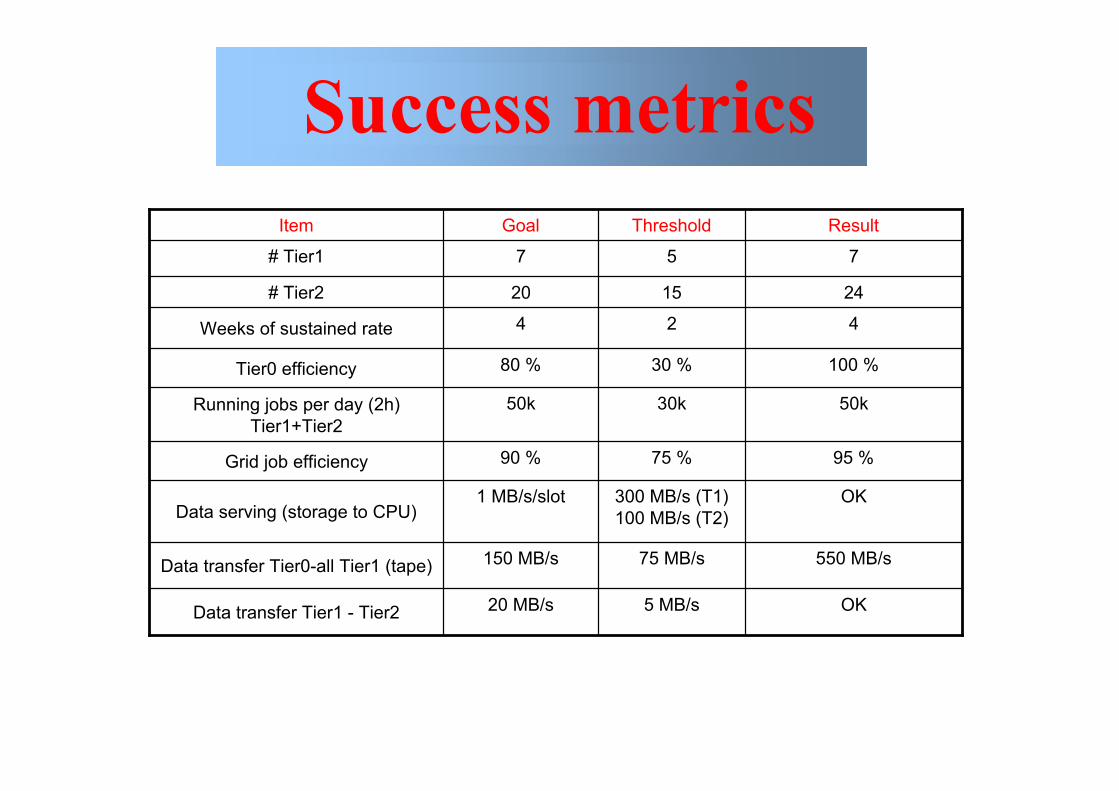
Success metrics
OK5 MB/s20 MB/sData transfer Tier1 - Tier2
550 MB/s75 MB/s150 MB/sData transfer Tier0-all Tier1 (tape)
OK300 MB/s (T1)100 MB/s (T2)
1 MB/s/slotData serving (storage to CPU)
95 %75 %90 %Grid job efficiency
50k30k50kRunning jobs per day (2h)Tier1+Tier2
100 %30 %80 %Tier0 efficiency
424Weeks of sustained rate
241520# Tier2
757# Tier1
ResultThresholdGoalItem
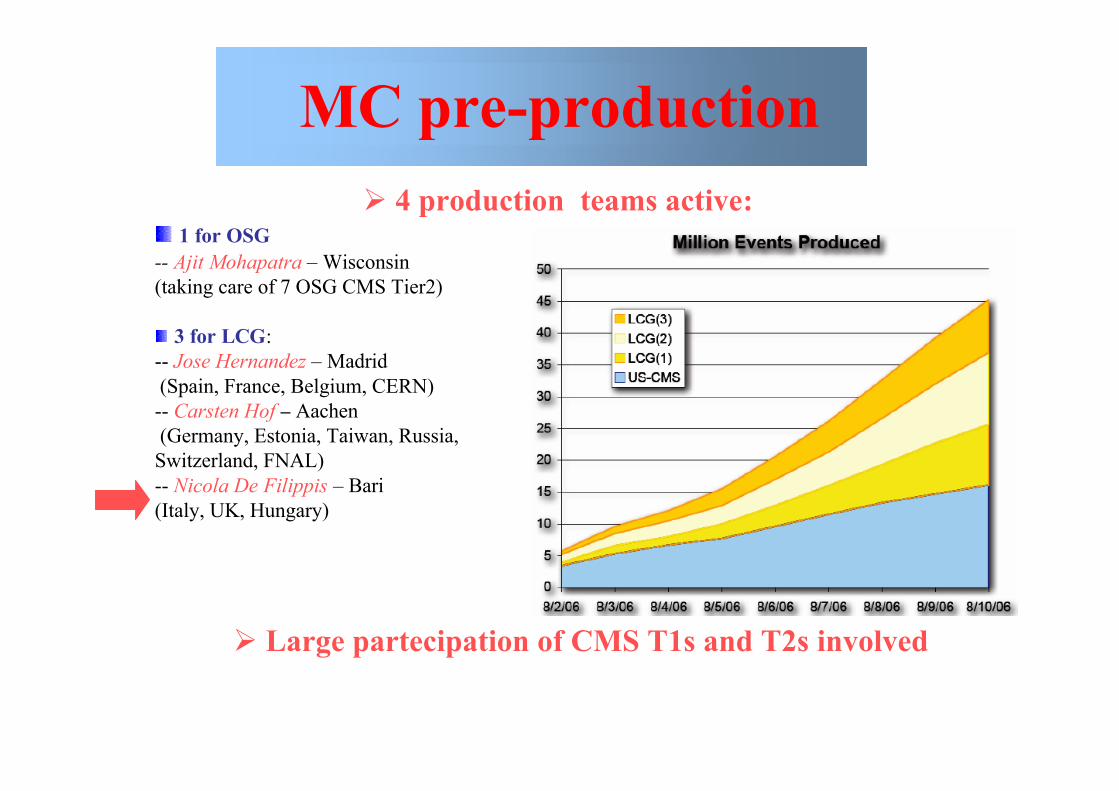
MC pre-production 4 production teams active:
1 for OSG-- Ajit Mohapatra – Wisconsin(taking care of 7 OSG CMS Tier2)
3 for LCG:-- Jose Hernandez – Madrid (Spain, France, Belgium, CERN)-- Carsten Hof – Aachen (Germany, Estonia, Taiwan, Russia,Switzerland, FNAL)-- Nicola De Filippis – Bari(Italy, UK, Hungary)
Large partecipation of CMS T1s and T2s involved

Monitoring of productionvia web interface (from Bari)
First prototype of monitoring was developed by Bari team:
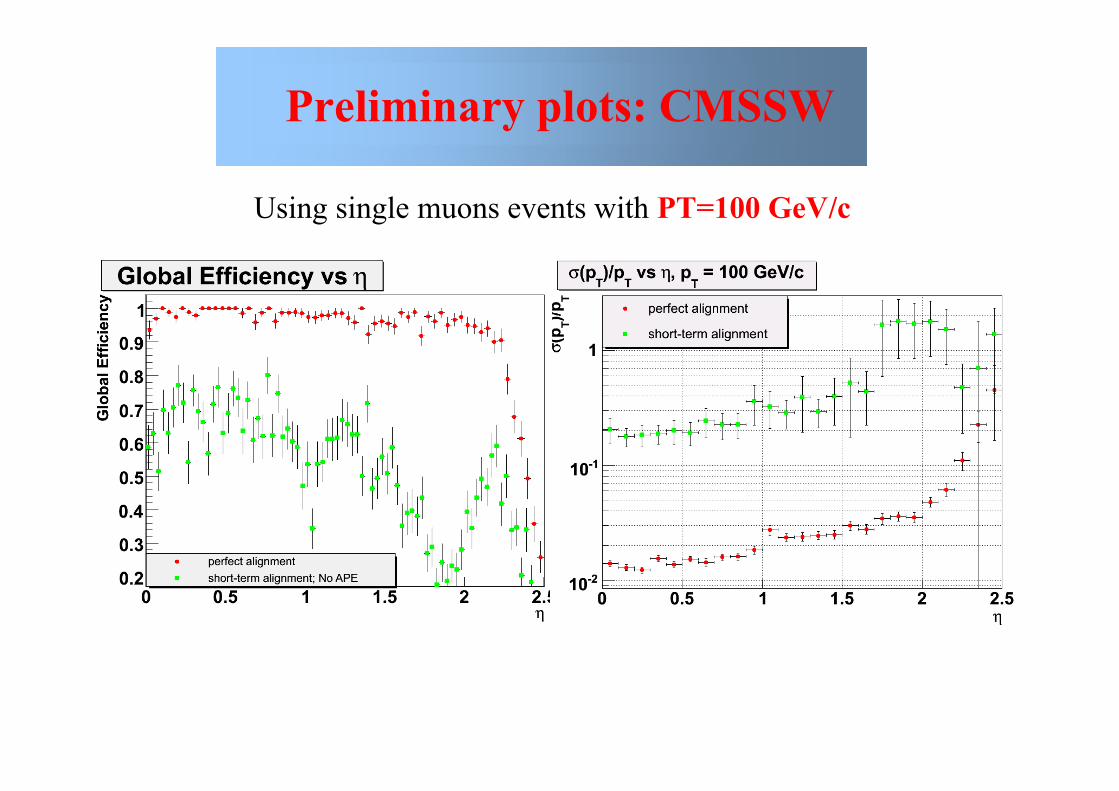
Preliminary plots: CMSSW
Using single muons events with PT=100 GeV/c

GRID(termine inglese per indicare la rete di distribuzione
dell’elettricità)
Obiettivo di GRID:
connettere il computer ad una presa nel muro ed avereimmediatamente accesso ad enormi risorse di calcolo
… esattamente come si fa quando si inserisce la spina dellalampada da tavolo alla presa elettrica per ottenereistantaneamente “l’illuminazione”
L’utente non si preoccupa di chi sta producendo l’energia elettrica chi la sta trasportando fino a lui
Deve solo essere abilitato ad effettuare la connessione disporre dell’opportuno hardware e pagare la bolletta

Perché GRID
La prossima generazionedell’esplorazione scientificarichiede potenze di calcolo e diimmagazzinamento dati chenessuna istituzione è capace diaffrontare da sola
E’ richiesto un accesso semplice ai“dati distribuiti” per migliorare lacondivisione dei risultati da partedi comunità scientifiche sparseper il mondo intero
La soluzione proposta è di abilitaredifferenti istituzioni, che lavoranonello stesso campo, a mettereinsieme i loro dati e le loro risorsedi calcolo e di immagazzinamentodati per raggiungere la scala e leprestazioni richiesti

I possibili utenti di GRID Utenti con applicazioni che fanno un uso intenso di dati (“Data
Intensive”) Accesso semplice a dati distribuiti (sorgenti, localizzazione, formato e
descrizione differenti) Accesso semplice a dati duplicati o replicati
Utenti con applicazioni che hanno bisogno di grandi risorse dicalcolo “Computer Intensive” sopratutto quando
I problemi possono essere parallelizzati (in una serie di tasks conlimitate interconnessioni tra le differenti tasks)
E che, quindi possono trarre benefici dal grande numero di CPU
Utenti disponibili a collaborare e a condividere Risorse Personale Conoscenze
Bonus: la soluzione è buona non solo per la scienza ma anche perl’industria
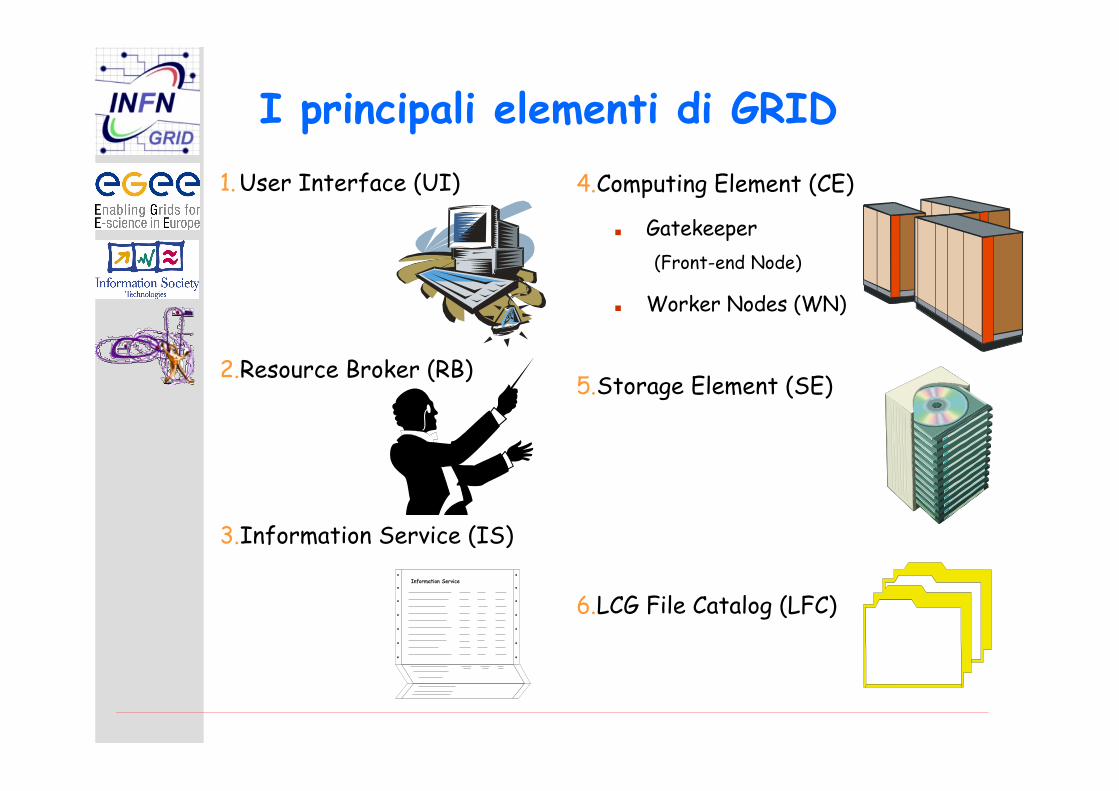
I principali elementi di GRID1.User Interface (UI)
2.Resource Broker (RB)
3.Information Service (IS)
4.Computing Element (CE)
Gatekeeper(Front-end Node)
Worker Nodes (WN)
5.Storage Element (SE)
6.LCG File Catalog (LFC)
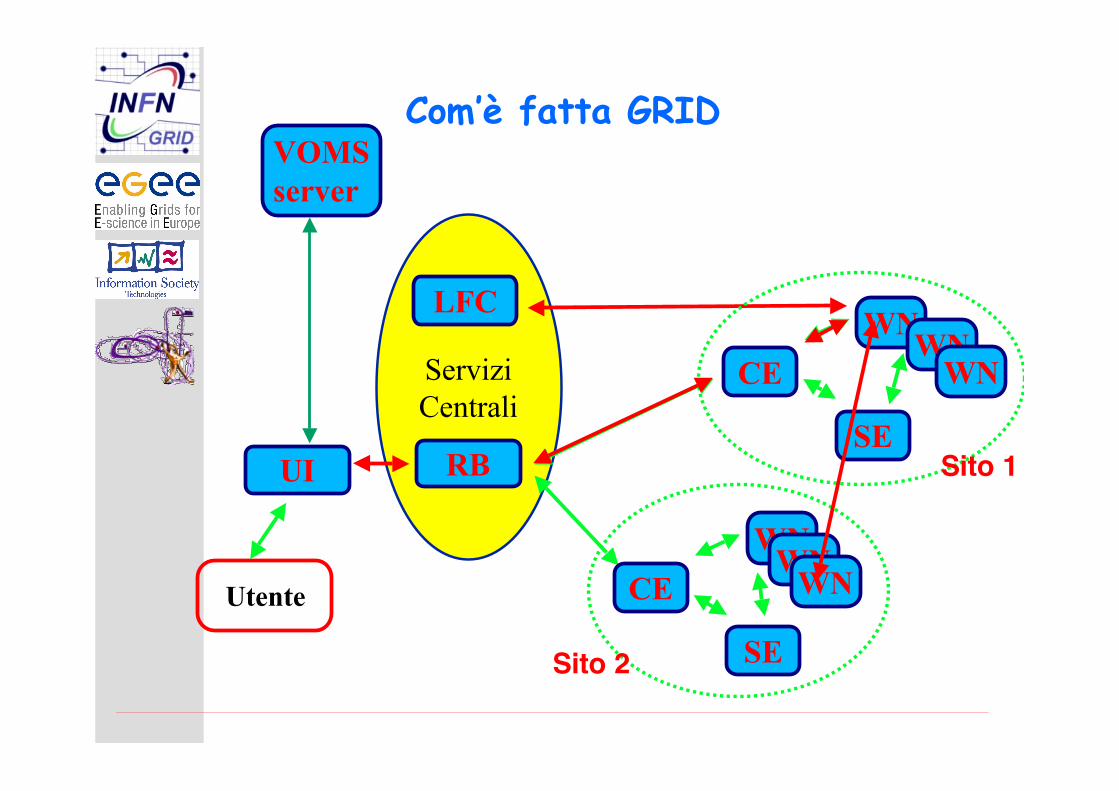
ServiziCentrali
RB
LFC
Com’è fatta GRID
UI
Utente
CE
WN
SESito 1
WNWN
CE
WN
SESito 2
WNWN
VOMSserver

I principali servizi di GRID
Autenticazione & autorizzazione (VOMS)
Servizio di sottomissione dei job
Workload Management System
Data management
Immagazzinamento di File : SRM, catalogo (LFC)
Movimentazione di file (grdiFTP, Phedex (tool di alto livello diCMS)
Logging & Bookkeeping
Conserva l’informazione di tutto quello che è successo
Monitoring
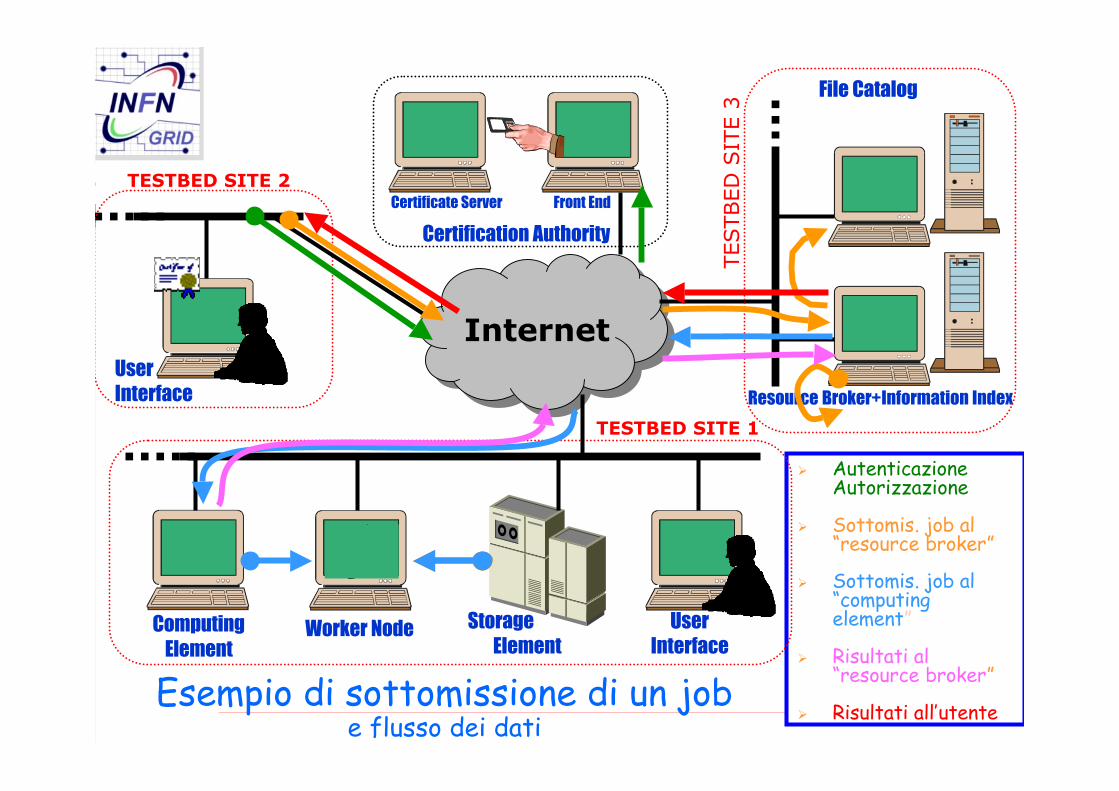
AutenticazioneAutorizzazione
Sottomis. job al“resource broker”
Sottomis. job al“computingelement”
Risultati al“resource broker”
Risultati all’utente
InternetInternet
Storage Element
ComputingElement
Worker Node UserInterface
File Catalog
Resource Broker+Information Index
Certification Authority
UserInterface
TESTBED SITE 1
TESTBED SITE 2Front EndCertificate Server
TESTBED
SIT
E 3
Esempio di sottomissione di un jobe flusso dei dati
0
5000
10000
15000
20000
25000
30000
35000
40000
Apr-04
Jun-04
Aug-04
Oct-04
Dec-04
Feb-05
Apr-05
Jun-05
Aug-05
Oct-05
Dec-05
Feb-06
Apr-06
Jun-06
Aug-06
Oct-06
Dec-06
No
. CP
U
0
50
100
150
200
250
Apr-04
Jun-04
Aug-04
Oct-04
Dec-04
Feb-05
Apr-05
Jun-05
Aug-05
Oct-05
Dec-05
Feb-06
Apr-06
Jun-06
Aug-06
Oct-06
Dec-06
No
. S
ites
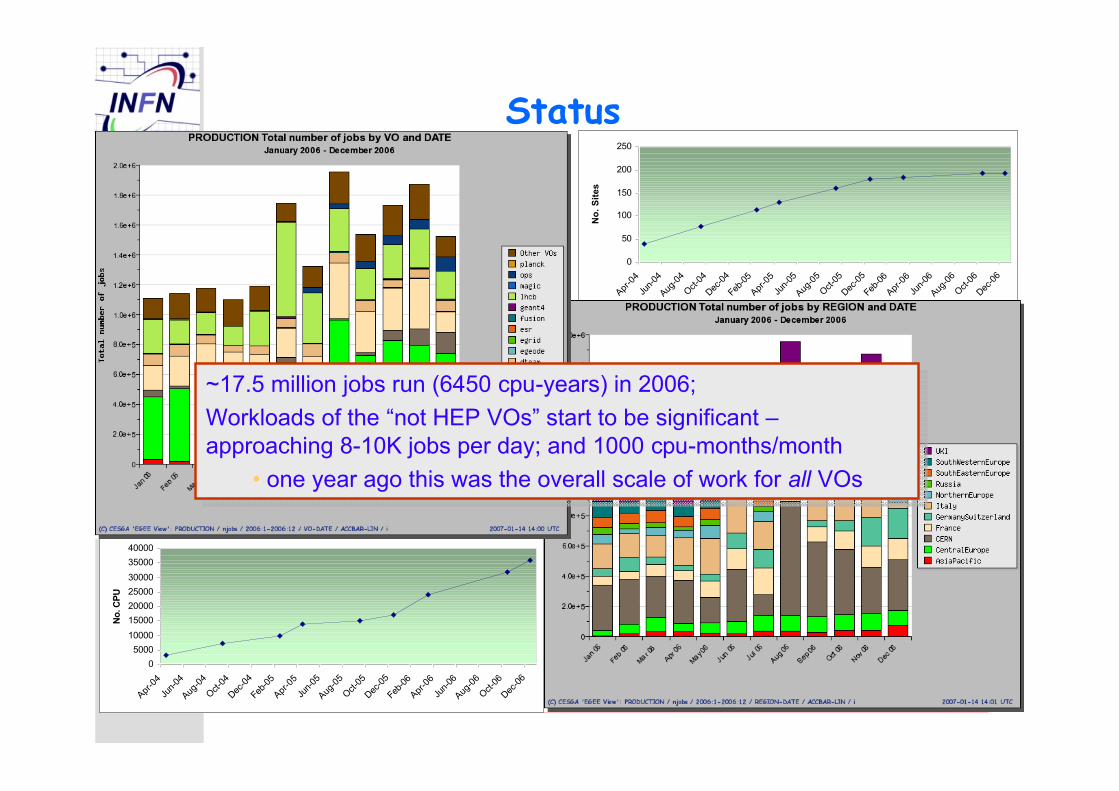
Status
~17.5 million jobs run (6450 cpu-years) in 2006;
Workloads of the “not HEP VOs” start to be significant –approaching 8-10K jobs per day; and 1000 cpu-months/month
• one year ago this was the overall scale of work for all VOs
~17.5 million jobs run (6450 cpu-years) in 2006;
Workloads of the “not HEP VOs” start to be significant –approaching 8-10K jobs per day; and 1000 cpu-months/month
• one year ago this was the overall scale of work for all VOs
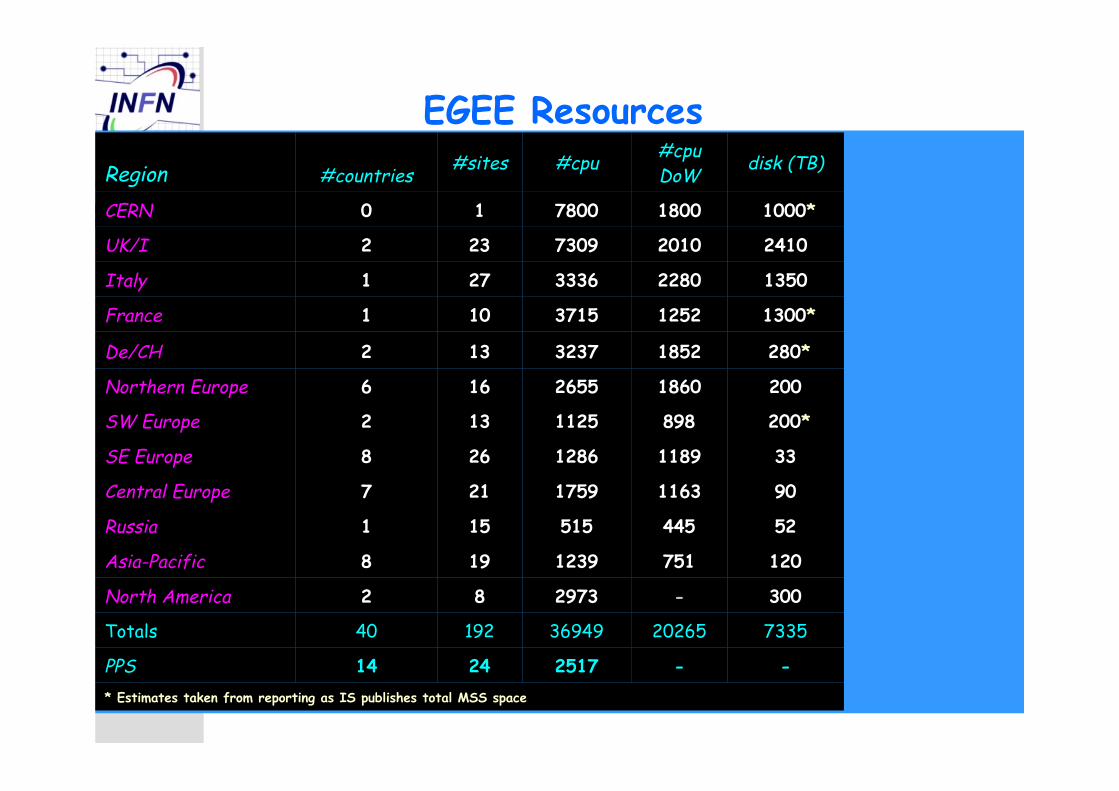
EGEE Resources
7335202653694919240Totals
* Estimates taken from reporting as IS publishes total MSS space
--25172414PPS
300-297382North America
1207511239198Asia-Pacific
52445515151Russia
9011631759217Central Europe
3311891286268SE Europe
200*8981125132SW Europe
20018602655166Northern Europe
280*18523237132De/CH
1300*12523715101France
135022803336271Italy
241020107309232UK/I
1000*1800780010CERN
disk (TB)#cpuDoW#cpu#sites#countriesRegion


















