
Introduzione ai Big Data e alla scienza dei dati - Exploratory Data Analysis
43
INTRODUZIONE AI BIG DATA E ALLA SCIENZA DEI DATI Vincenzo Manzoni vincenzomanzoni.com | [email protected] Lezione 2 Importare e esportare dati con MySQL; I formati markup-based; Analisi esplorativa dei dati con R e Tableau.
-
Upload
vincenzo-manzoni -
Category
Data & Analytics
-
view
649 -
download
1
Transcript of Introduzione ai Big Data e alla scienza dei dati - Exploratory Data Analysis

INTRODUZIONE AI BIG DATA E ALLA SCIENZA DEI DATI
Vincenzo Manzoni vincenzomanzoni.com | [email protected]
Lezione 2 Importare e esportare dati con MySQL; I formati markup-based;
Analisi esplorativa dei dati con R e Tableau.

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESERCIZI CONSEGNA
• Database • Restituire, per ogni azione, il valore minimo,
medio e massimo del maggio 2000. • Restituire le azioni il cui valore medio è stato
superiore a 200 $.
2

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESERCIZI SOLUZIONE
Restituire, per ogni azione, il valore minimo, medio e massimo del maggio 2000.
SELECT stock_symbol, MIN(stock_price_close) AS minimo, AVG(stock_price_close) AS media, MAX(stock_price_close) AS massimo
FROM nyse_stocks
WHERE date >= ‘2000-‐05-‐01’ AND date <= ‘2000-‐05-‐31’
GROUP BY stock_symbol
Restituire le azioni il cui valore medio è stato superiore a 200 $. SELECT stock_symbol, AVG(stock_price_close) AS media
FROM nyse_stocks
GROUP BY stock_symbol
HAVING media >= 200
3

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESERCIZI SOLUZIONI ALTERNATIVE
Restituire, per ogni azione, il valore minimo, medio e massimo del maggio 2000.
SELECT stock_symbol, MIN(stock_price_close) AS minimo, AVG(stock_price_close) AS media, MAX(stock_price_close) AS massimo
FROM nyse_stocks
WHERE date LIKE ‘2000-‐05-‐%’
GROUP BY stock_symbol
Restituire le azioni il cui valore medio è stato superiore a 200 $. SELECT stock_symbol, AVG((stock_price_close + stock_price_open) / 2) AS media
FROM nyse_stocks
GROUP BY stock_symbol
HAVING media >= 200
4
Dentro alla funzione di aggregazione ci può essere un calcolo basato sulle colonne
Si fissa anno e mese e si permette che il giorno valga qualunque valore.

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
IMPORTARE CSV IN MYSQL IL CSV: GLI STATI DEGLI USA
5
intestazione
Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
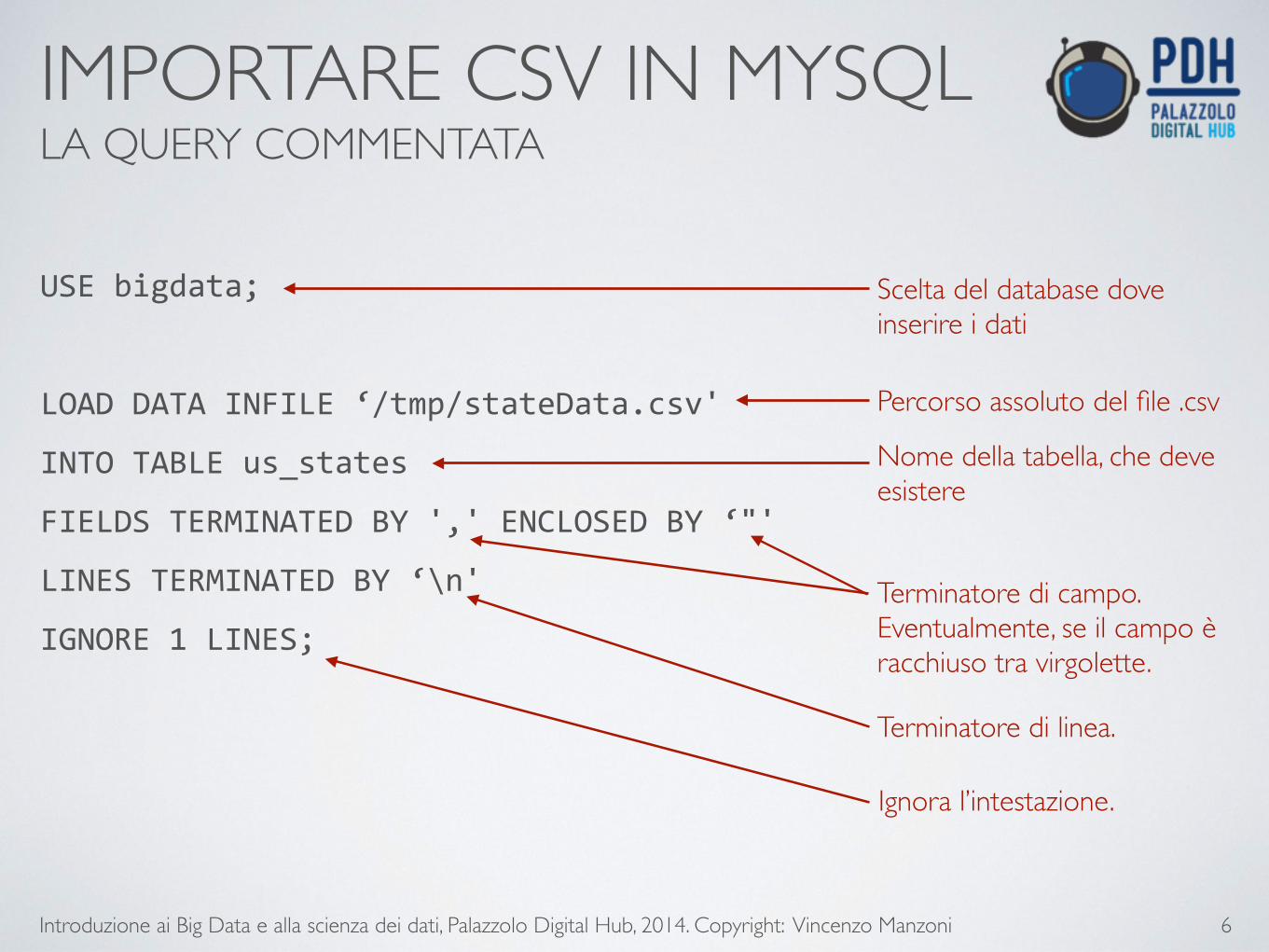
IMPORTARE CSV IN MYSQL LA QUERY COMMENTATA
USE bigdata;
!
LOAD DATA INFILE ‘/tmp/stateData.csv'
INTO TABLE us_states
FIELDS TERMINATED BY ',' ENCLOSED BY ‘"'
LINES TERMINATED BY ‘\n'
IGNORE 1 LINES;
6
Scelta del database dove inserire i dati
Percorso assoluto del file .csv
Nome della tabella, che deve esistere
Terminatore di campo. Eventualmente, se il campo è racchiuso tra virgolette.
Terminatore di linea.
Ignora l’intestazione.

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESPORTARE CSV DA MYSQL
USE bigdata;-‐-‐ Intestazione del fileSELECT 'state_fullname', 'life_exp'UNION ALL-‐-‐ DatiSELECT state_fullname, life_expFROM us_statesWHERE life_exp > 70ORDER BY life_exp DESCINTO OUTFILE '/tmp/output.csv'FIELDS TERMINATED BY ','LINES TERMINATED BY '\n'
7
Riga di intestazione con il nome delle colonne
Unione con le righe dei dati
Query che voglio esportare nel file .csv
Esportazione nel file output.csv

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
BACKUP E RESTORE MYSQL
8
Backup e restore fanno parte della amministrazione del server. Le funzioni per queste operazioni si trovano lì.
Demo!
Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
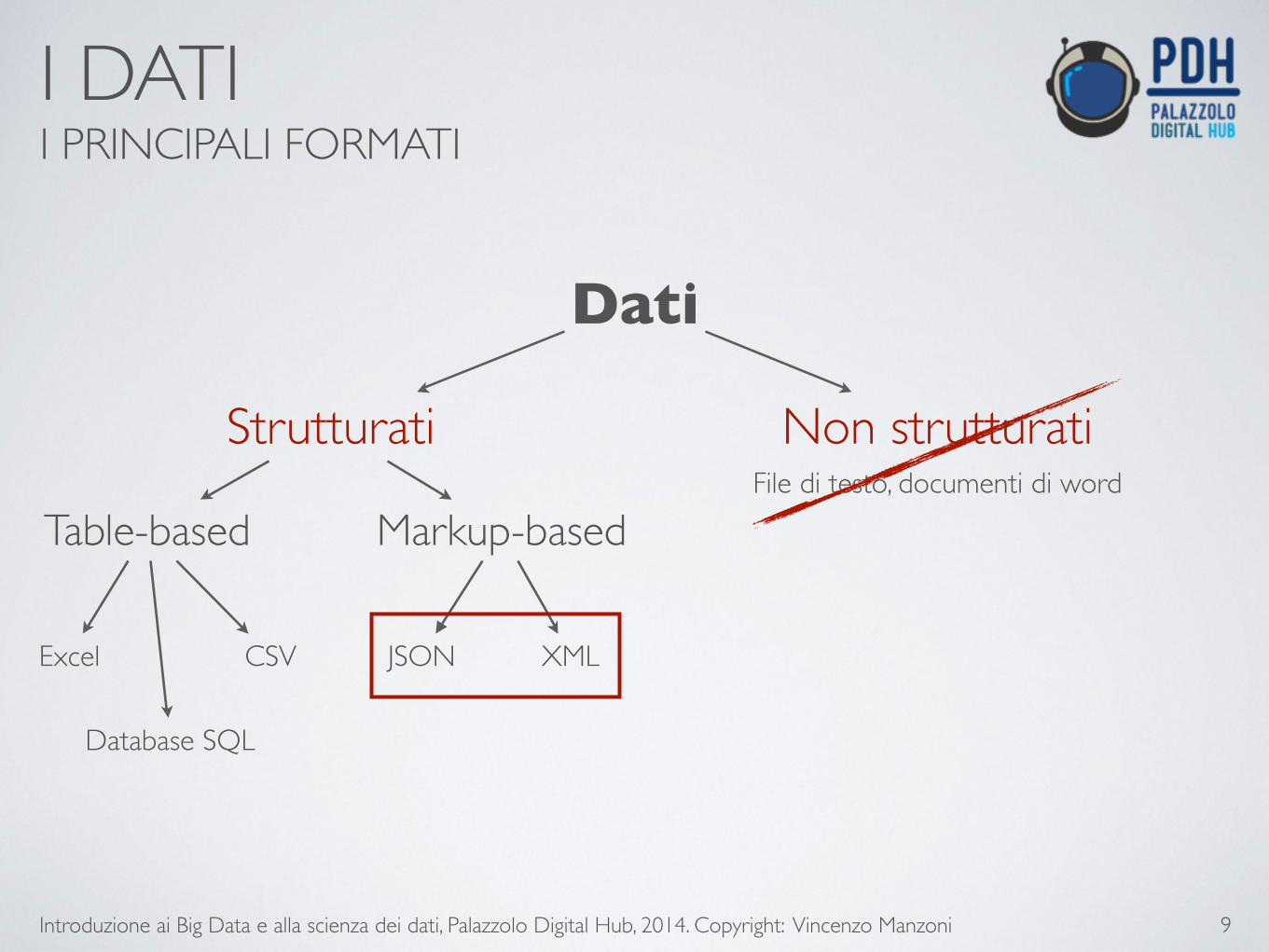
I DATI I PRINCIPALI FORMATI
9
Strutturati Non strutturati
Table-based Markup-based
Excel CSV JSON XML
Database SQL
File di testo, documenti di word
Dati

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
I FORMATI MARKUP-BASED JSON (1/3)
• File di testo • JSON significa JavaScript Object Notation • E’ basato sulla sintassi JavaScript • Viene usato principalmente per lo scambio dati in applicazioni
client-server. • Tipi supportati
• Booleani, interi, reali • Stringhe • Array, array associativi (coppia chiave-valore, o dizionari)
10

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
I FORMATI MARKUP-BASED JSON (2/3)
11
Riga 2
Riga
1
Campi

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
I FORMATI MARKUP-BASED JSON (3/3)
12
Pro ControSemplice rispetto ad altri linguaggi di markup (ad esempio, XML) I dati non sono tipizzati
E’ un file di testo, pertanto è sufficiente un editor di testo per visualizzarlo e modificarloEsistono librerie per leggerlo e scriverlo in tutti i linguaggi di programmazioneAdatto a rappresentare dati non tabellari (ovvero, in cui le righe hanno un numero variabile di colonne)

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
I FORMATI MARKUP-BASED XML
<?xml version="1.0" encoding="UTF-‐8" ?> <Passenger PassengerId=“1”> <Survived>0</Survived> <Pclass>3</Pclass> <Name>Braund, Mr. Owen Harris</Name> <Sex>male</Sex> <Age>22</Age> <SibSp>1</SibSp> <Parch>0</Parch> <Ticket>A/5 21171</Ticket> <Fare>7.25</Fare> <Cabin></Cabin> <Embarked>S</Embarked> </Passenger>
13

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
CONFRONTO JSON XML
14
XMLJSON

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ANALISI ESPLORATIVA DEI DATI CON R
15

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
• Linguaggio di programmazione specifico per l’analisi dei dati
• E’ gratuito, open source e disponibile per Windows, Mac OSX e Linux.
• E’ composto da un core e da moduli aggiuntivi che ne estendono le funzionalità.
• Web: www.r-project.org
16
R LINGUAGGIO PER L’ANALISI STATISTICA DEI DATI

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni 17
PERCHÉ HO SCELTO R? POPOLARITÀ
Post su StackOverflow
Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
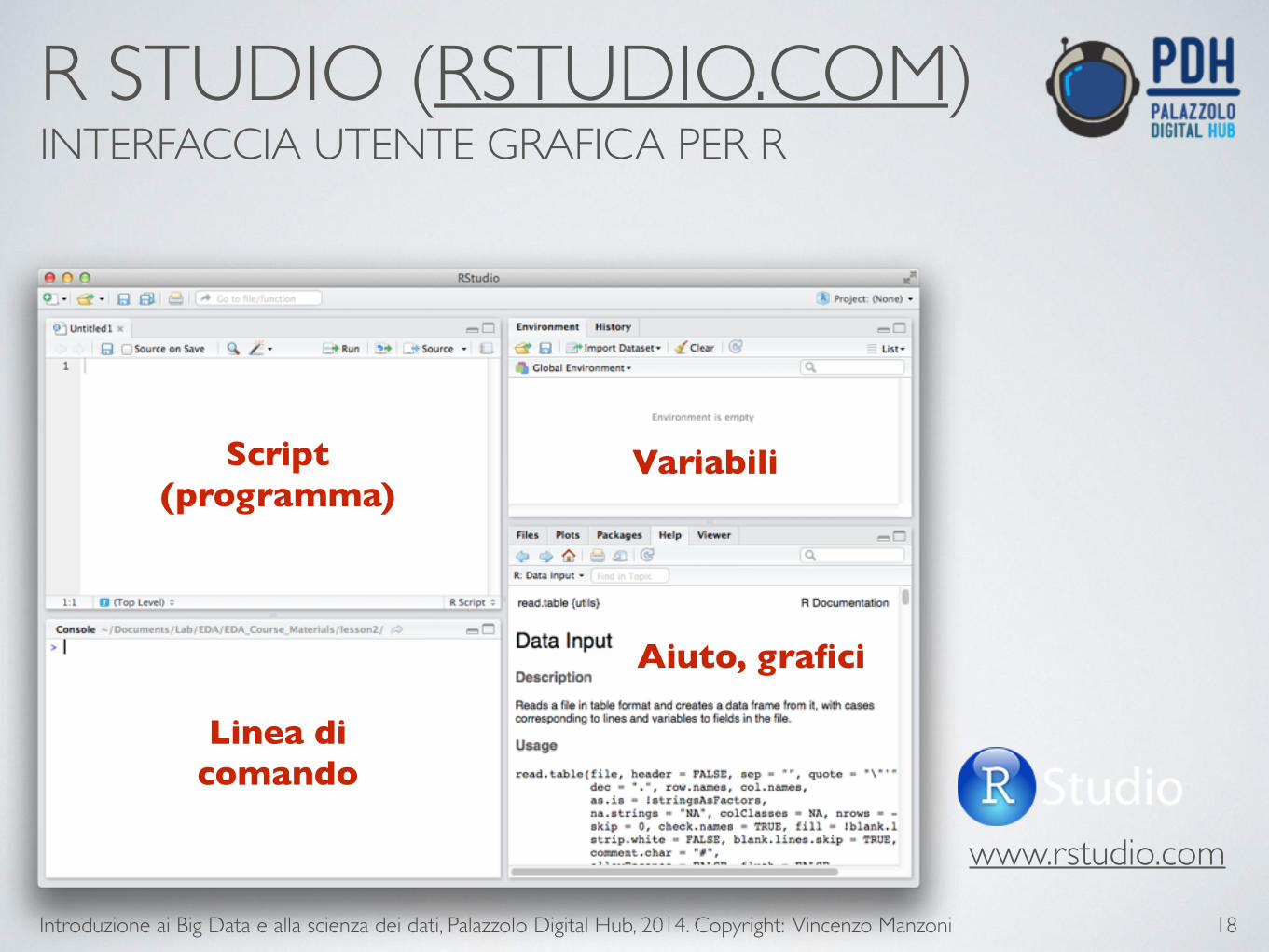
R STUDIO (RSTUDIO.COM) INTERFACCIA UTENTE GRAFICA PER R
18
Linea di comando
Script (programma)
Variabili
Aiuto, grafici
www.rstudio.com

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
RSTUDIOCliccare su RStudio per aprire l’applicazione e iniziare a
programmare in R19

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R CHIEDERE AIUTO
> ?nomecomando
20

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
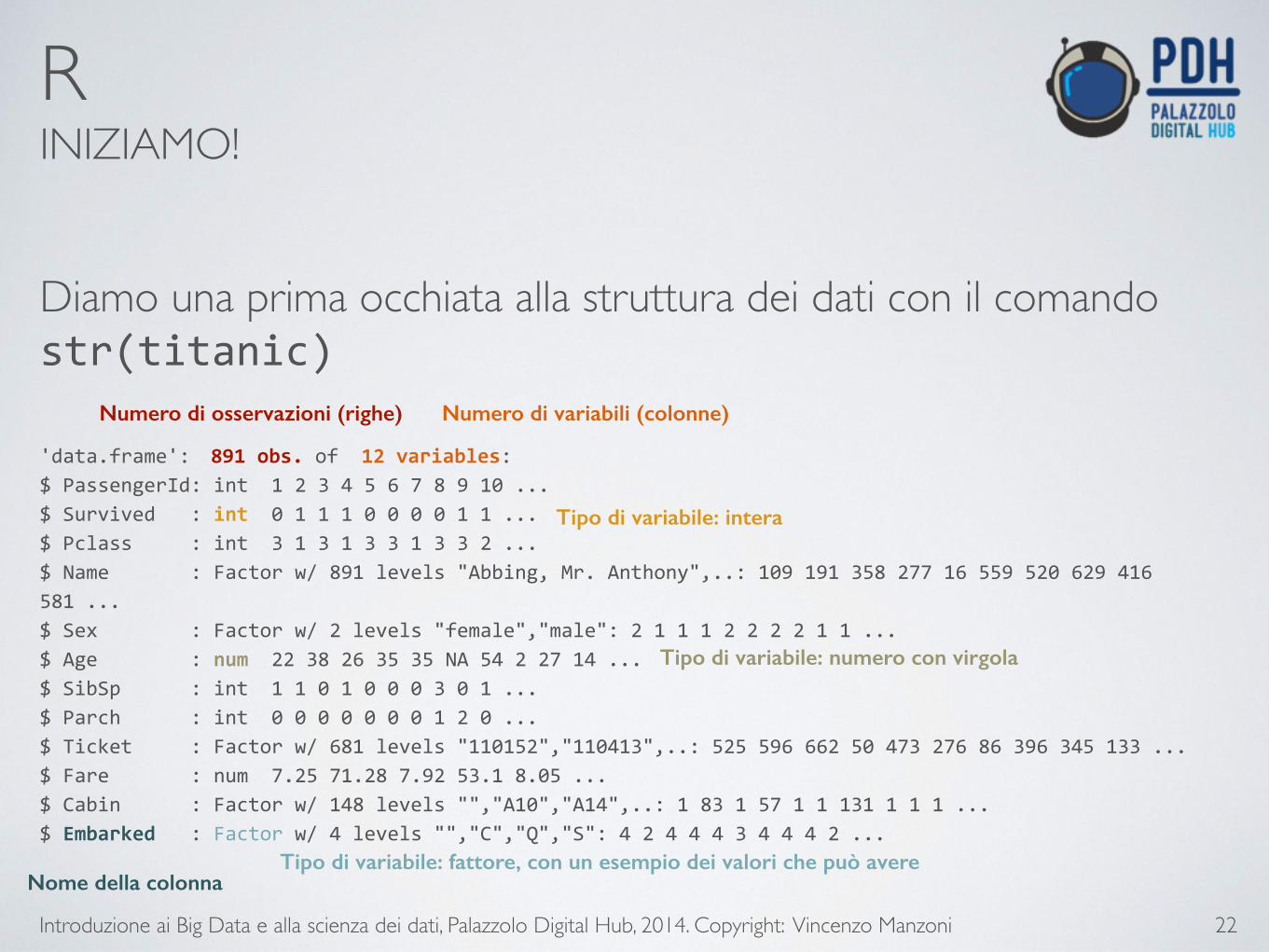
R INIZIAMO!
• Impostiamo la directory di lavoro con il comando setwd(‘/home/bigdata/Documenti/Lezione_1’);
• Carichiamo il file CSV con il comando titanic <-‐ read.csv(‘titanic.csv’, header=TRUE);
21
La freccina indica che quello che c’è a destra, finisce in quello che c’è a sinistra.
titanic è una variabile
Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R INIZIAMO!
Diamo una prima occhiata alla struttura dei dati con il comando str(titanic) !'data.frame': 891 obs. of 12 variables:$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ... $ Survived : int 0 1 1 1 0 0 0 0 1 1 ...$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ... $ Name : Factor w/ 891 levels "Abbing, Mr. Anthony",..: 109 191 358 277 16 559 520 629 416 581 ...$ Sex : Factor w/ 2 levels "female","male": 2 1 1 1 2 2 2 2 1 1 ... $ Age : num 22 38 26 35 35 NA 54 2 27 14 ...$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ... $ Parch : int 0 0 0 0 0 0 0 1 2 0 ... $ Ticket : Factor w/ 681 levels "110152","110413",..: 525 596 662 50 473 276 86 396 345 133 ... $ Fare : num 7.25 71.28 7.92 53.1 8.05 ... $ Cabin : Factor w/ 148 levels "","A10","A14",..: 1 83 1 57 1 1 131 1 1 1 ... $ Embarked : Factor w/ 4 levels "","C","Q","S": 4 2 4 4 4 3 4 4 4 2 ...
22
Numero di osservazioni (righe) Numero di variabili (colonne)
Nome della colonna
Tipo di variabile: intera
Tipo di variabile: numero con virgola
Tipo di variabile: fattore, con un esempio dei valori che può avere

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R INIZIAMO!
Per avere un’idea della distribuzione statistica dei valori di una colonna, usiamo il comando summary(titanic)
23
L’età è stata correttamente interpretata come una misura
Survived è stato interpretato come una misura, anziché come una dimensione (ovvero, variabile che può assumere solo un certo numero di valori discreti)

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R INIZIAMO!
24
Specifico che la colonna Survived è un factor (il modo con cui R chiama le dimensioni)
Per accedere alle colonne si usa il $.

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R INIZIAMO!
• Diamo un’occhiata ai primi elementi con il comando head(titanic)
• … e agli ultimi con il comando tail(titanic)
25

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESERCIZIO 2.1 R
1. Attraverso il comando str(), guardare il tipo dei campi riconosciuti da R.
2. Qual è la media del prezzo del biglietto?Suggerimento: il comando summary() può venirci in aiuto…
3. Convertire le dimensioni interpretate come misure. 4. Visualizzare i primi 3 e gli ultimi 3 passeggeri.
Suggerimento: la risposta si trova nella documentazione dei comandi head() e tail().
26
Durata esercizio: 15 minuti

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R: GRAFICI CON GGPLOT2
• ggplot2 è sistema per fare grafici in R, basato su una grammatica.
• Si occupa di gestire i dettagli in modo trasparente all’utente (e.g. le etichette degli assi, la legenda, …)
• Permette di produrre grafici a più livelli di alta qualità.
• Sito web: http://ggplot2.org
27

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R: GGPLOT2 INSTALLAZIONE DEL PACCHETTO E USO
• La prima volta che si usa, il pacchetto va installato con il comando install.packages(‘ggplot2’, dependencies=TRUE)
• Per usarlo in un proprio script, inserirlo con il comando library(‘ggplot2’)
28
Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R: GRAFICI DISTRIBUZIONI STATISTICHE
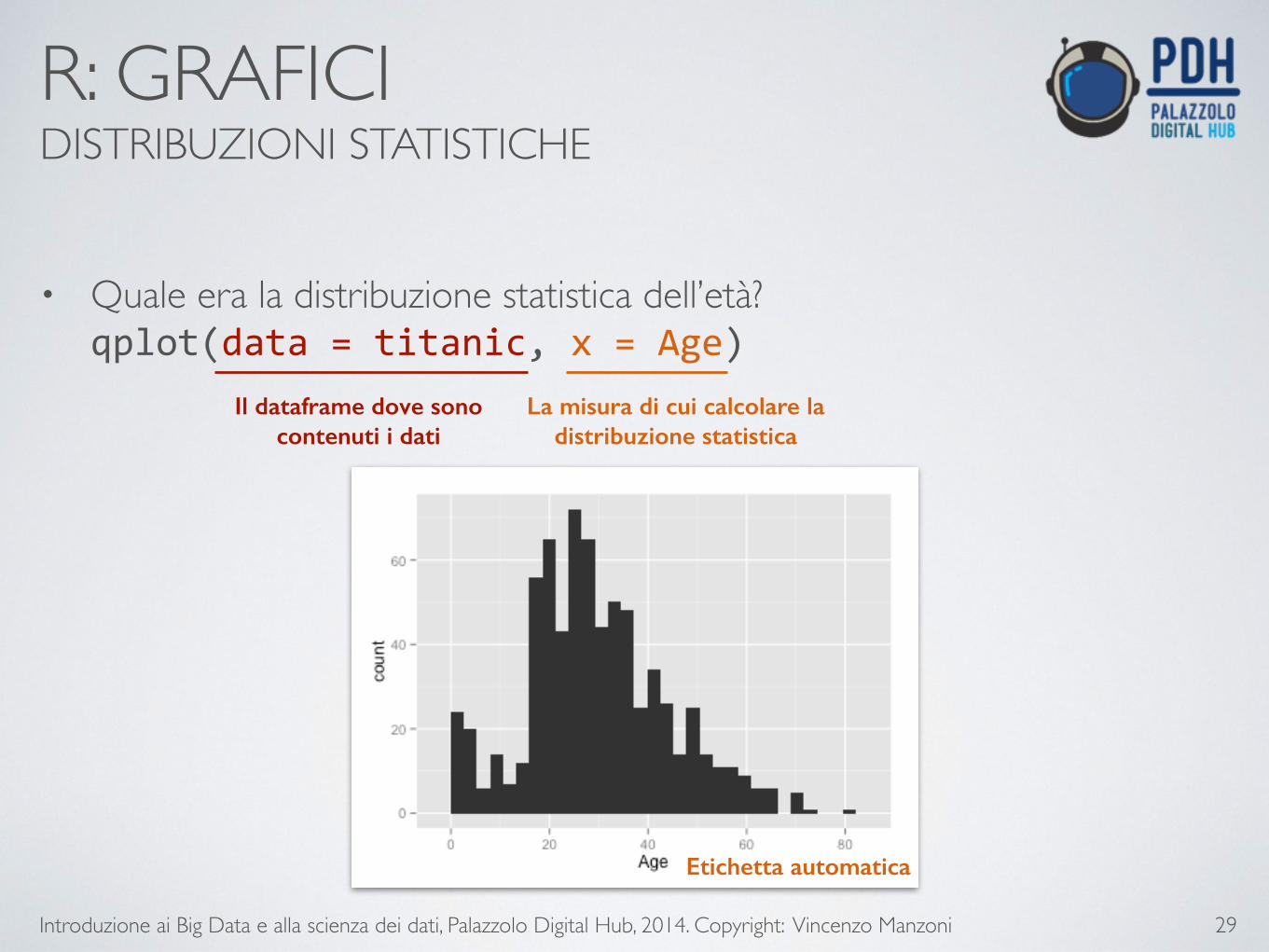
• Quale era la distribuzione statistica dell’età? qplot(data = titanic, x = Age)
29
Il dataframe dove sono contenuti i dati
La misura di cui calcolare la distribuzione statistica
Etichetta automatica
Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R: GRAFICI DISTRIBUZIONI STATISTICHE
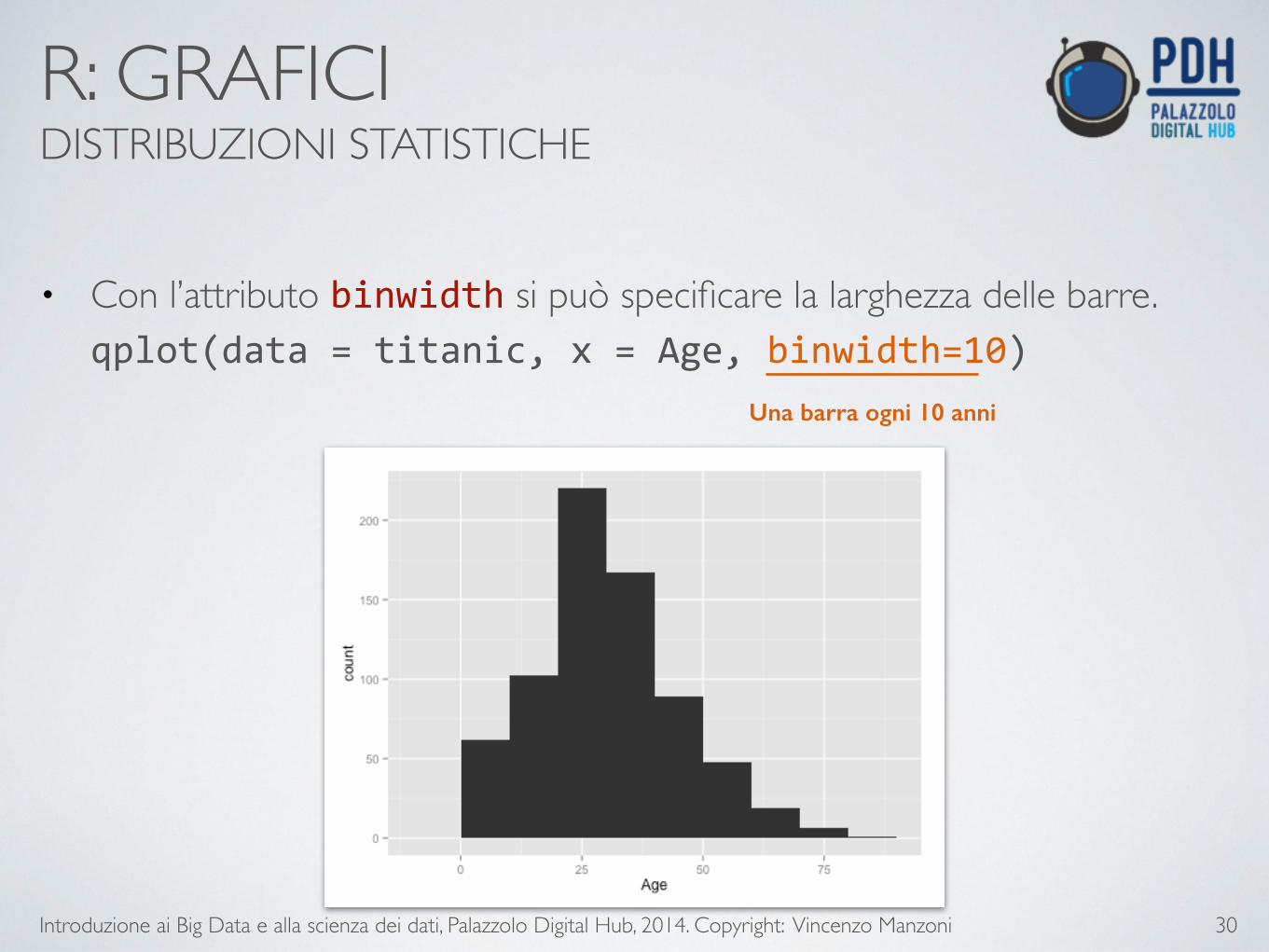
• Con l’attributo binwidth si può specificare la larghezza delle barre.qplot(data = titanic, x = Age, binwidth=10)
30
Una barra ogni 10 anni

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R: GRAFICI DISTRIBUZIONI STATISTICHE
• Con l’attributo xlab, si può specificare un’etichetta diversa qplot(data = titanic, x = Age, xlab=“Età”)
31
La misura di cui calcolare la distribuzione statistica

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R ESPLORIAMO GRAFICAMENTE I DATI
• Quanti sopravvissuti per sesso?table(titanic$Sex, titanic$Survived); 0 1 female 81 233 male 468 109
• Vediamolo in forma grafica.qplot(data=titanic, x=Sex, fill=Sex, facets=~Survived)
32
Coloro le barre in funzione del sesso
Categorie per sopravvissuti

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESERCIZIO 2.2 GRAFICI IN R
1. Jack Dawson aveva 20 anni quando si imbarcò sul Titanic in IIIa classe. Quale era la distribuzione statistica dell’età per classe? (Ovvero, graficare la distribuzione dell’età rispetto al sesso e alla classe di imbarco.)
2. Graficare quanti uomini e quante donne si sono imbarcati per ogni porto.
33
Durata esercizio: 15 minuti

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESERCIZIO 2.2 SOLUZIONE
34
qplot(data=subset(titanic, Embarked != ''), x=Embarked, fill=Sex, facets=~Pclass)
qplot(data=titanic, x=Age, fill=Sex, facets=Sex~Pclass, binwidth=5)

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
UN NUOVO DATASET
35
miglia per gallone
cilindri
potenza
peso tempo sul 1/4 di miglio
trasmissione (automatica / manuale)

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
SCATTER PLOT
cars <-‐ mtcarscars$am <-‐ as.factor(cars$am)cars$cyl <-‐ as.factor(cars$cyl)qplot(data=cars, x=mpg, y=hp, geom=c("point", "smooth"), method="lm") qplot(data=cars, x=hp, y=mpg, color=cyl, geom=c("point", "smooth"), method="lm")
36

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
R COMANDI UTILI
37
Comando Significato?comando Mostra la documentazione del comando (es. ?read.csv)# Commento Commento di riga.
setwd(‘directory’) Imposta la directory di lavoro.var <-‐ read.csv(‘nomefile’) Crea un dataset dal file ‘nomefile’ e lo salva in var. La presenza
di una intestazione e il separatore di campo si specificano head(variabile) Mostra i primi 6 elementi della variabile (vettore, matrice, dataframe).
tail(variabile) Mostra gli ultimi 6 elementi della variabile (vettore, matrice, dataframe).
str(variabile) Mostra la struttura della variabile.
summary(oggetto) Mostra il sommario dell’oggetto (compresi dataframe). Vedremo che oggetti diversi produco sommari diversi.as.factor(variabile) Converte una variabile da tipo int a tipo factor.
rm(variabile) Elimina la variabile (es. rm(foo)).
install.packages(‘pacchetto’, dependencies=TRUE)
Installa l’add-on pacchetto e le sue dipendenze.

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ESERCIZIO 2.3
• Il dataset Orange (per informazioni, ?Orange) contiene la misura della circonferenza di 5 alberi di arancia nel tempo. Verificare graficamente se esiste una relazione tra età in giorni e circonferenza.
• Il dataset movies (per informazioni, ?movies) contiene informazioni sui film. • Individuare in che anno è stato girato il primo film in catalogo. • Qual è la media di durata. • Visualizzare il numero di film per anno.
38

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
ANALISI ESPLORATIVA DEI DATI CON TABLEAU
39

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
TABLEAU
• Software per la visualizzazione interattiva dei dati. • Si collega a molte fonti di dati (Excel, file di testo, svariati tipi di
database). • Permette l’analisi dei dati in modo grafico. • Permette la creazione di dashboard. • Per il momento disponibile solo per Windows :( • Tableau: www.tableausoftware.com
40

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
TABLEAU DEMO
41

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
LINK UTILI
• Sito web del corso: www.vincenzomanzoni.com/corsi • Convertitore da CSV a JSON: http://www.convertcsv.com/csv-to-json.htm • Convertitore JSON-XML: http://www.utilities-online.info/xmltojson • R: www.r-project.org • RStudio: www.rstudio.com • Quick R (manuale di R): http://www.statmethods.net • Manuale per fare grafici in R: http://www.cookbook-r.com/Graphs/ • Documentazione ufficiale di ggplot2: http://docs.ggplot2.org/current/ • Tableau: www.tableausoftware.com
42

Introduzione ai Big Data e alla scienza dei dati, Palazzolo Digital Hub, 2014. Copyright: Vincenzo Manzoni
LA PROSSIMA LEZIONE AGENDA
1. Ottenere i dati attraverso le API 2. Fondamenti di Machine Learning… ovvero come
insegnare alle macchine.
43


















