
Information Retrieval Definizioni e metodi classici.
75
Information Retrieval Definizioni e metodi “classici”
-
Upload
elma-abbate -
Category
Documents
-
view
217 -
download
2
Transcript of Information Retrieval Definizioni e metodi classici.

Information Retrieval
Definizioni e metodi “classici”

Definizioni
• IR tratta problemi di rappresentazione, memorizzazione, organizzazione e accesso ad informazioni
• Obiettivo: facilitare l’accesso alle informazioni cui un utente è interessato
• Un testo libero non può direttamente essere usato per interrogare gli attuali motori di ricerca su Web.
• Una descrizione degli interessi dell’utente va trasformata in una query, una struttura di dati (usualmente un vettore) adatta all’elaborazione da parte di un motore di ricerca.

Caratterizzare l’interesse dell’utente
• Caratterizzare l’interesse di un utente non è facile: “trova tutte le pagine che contengono informazioni su squadre di tennis di Università Americane, e che partecipino alle gare NCAA. Mi interessano solo documenti che riportino anche la qualifica di queste squadre negli ultimi 3 anni e la email o telefono del loro allenatore”
• Rosso: irrilevante per la query
• Blu: necessitano una qualche forma di ragionamento induttivo, es:
MIT is_a Università_Americana
march_2002 january_2000 january_2003

..Tuttavia anche in casi più semplici cè il problema del silenzio-rumore
• Esempio: chi ha inventato il web?
• http://www.google.it

Dati e informazioni: che differenza?
• Data retrieval: trovare oggetti che soddisfino condizioni chiaramente specificate mediante una espressione regolare o di algebra relazionale. (FIND person WHERE age>40 AND…OR..). Un errore è segnale di totale fallimento del sistema (la risposta non esiste)
• Information retrieval: richiede una interpretazione della richiesta dell’utente. I documenti recuperati non possono essere classificati tout court come “buoni” o “cattivi”, ma vanno associati ad una misura di rilevanza rispetto alla richiesta dell’utente (o meglio: all’interpretazione della richiesta!)
• La nozione di rilevanza è centrale in IR

Perché IR è importante– IR aveva una ristretta nicchia di interesse
(bibliotecari ed esperti di informazioni, es. agenzie di stampa)
– L’avvento del Web ha cambiato radicalmente le cose
• Una sorgente di informazioni virtualmente illimitata • Accesso universale ed a basso costo• Non esiste un controllo editoriale centralizzato• Molti nuovi problemi si pongono: IR è vista come una
area chiave per identificare soluzioni appropriate
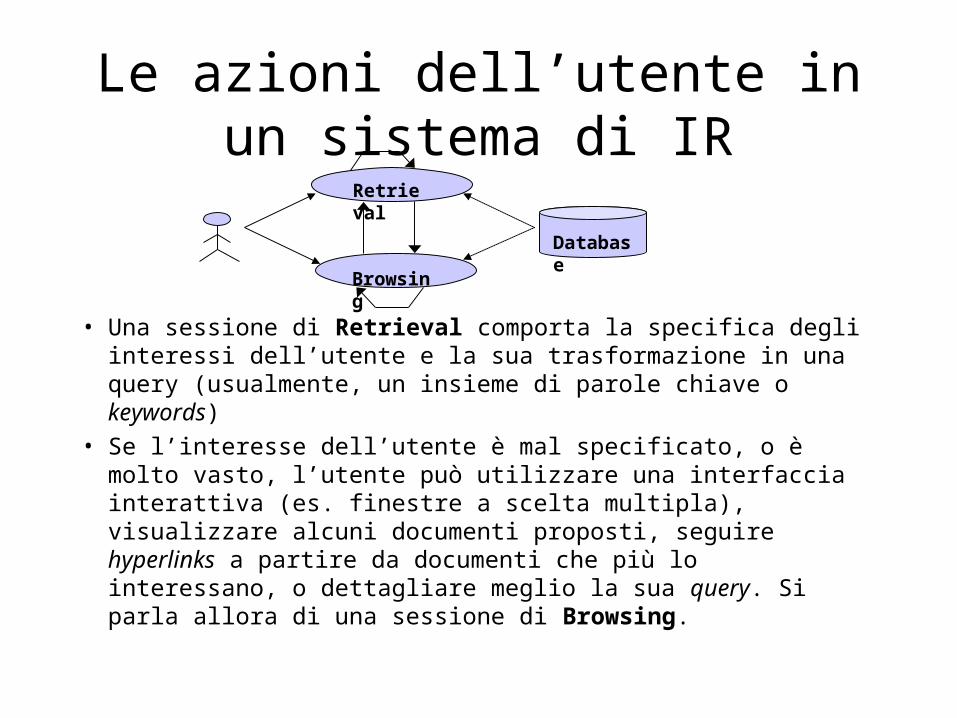
Le azioni dell’utente in un sistema di IR
• Una sessione di Retrieval comporta la specifica degli interessi dell’utente e la sua trasformazione in una query (usualmente, un insieme di parole chiave o keywords)
• Se l’interesse dell’utente è mal specificato, o è molto vasto, l’utente può utilizzare una interfaccia interattiva (es. finestre a scelta multipla), visualizzare alcuni documenti proposti, seguire hyperlinks a partire da documenti che più lo interessano, o dettagliare meglio la sua query. Si parla allora di una sessione di Browsing.
Retrieval
Browsing
Database

Pulling vrs pushing
• Retrieval e Browsing vengono classificate come azioni di pulling: l’utente “tira fuori” le informazioni richieste
• Alcuni sistemi sono in grado di prendere iniziative, cioè di sospingere (push) documenti verso l’utente. Ad esempio, filtrando notizie periodicamente sulla base di profili di utente (web assistant, information filtering and extraction).

Una caratterizzazione formale del task IR
• Def. Un modello di IR è una quadrupla [D,Q,F,R(qi,dj)] dove:
– D è un insieme di viste logiche, o rappresentazioni dei documenti nella collezione
– Q è un insieme di viste logiche, o rappresentazioni dei bisogni informativi dell’utente , dette query
– F è uno schema per modellare le rappresentazioni dei documenti, le query, e le inter-relazioni fra query e documenti
– R(qi,dj)] è una funzione di rilevanza, o ranking R : QD che definisce un ordine fra i documenti, in relazione alla query qi
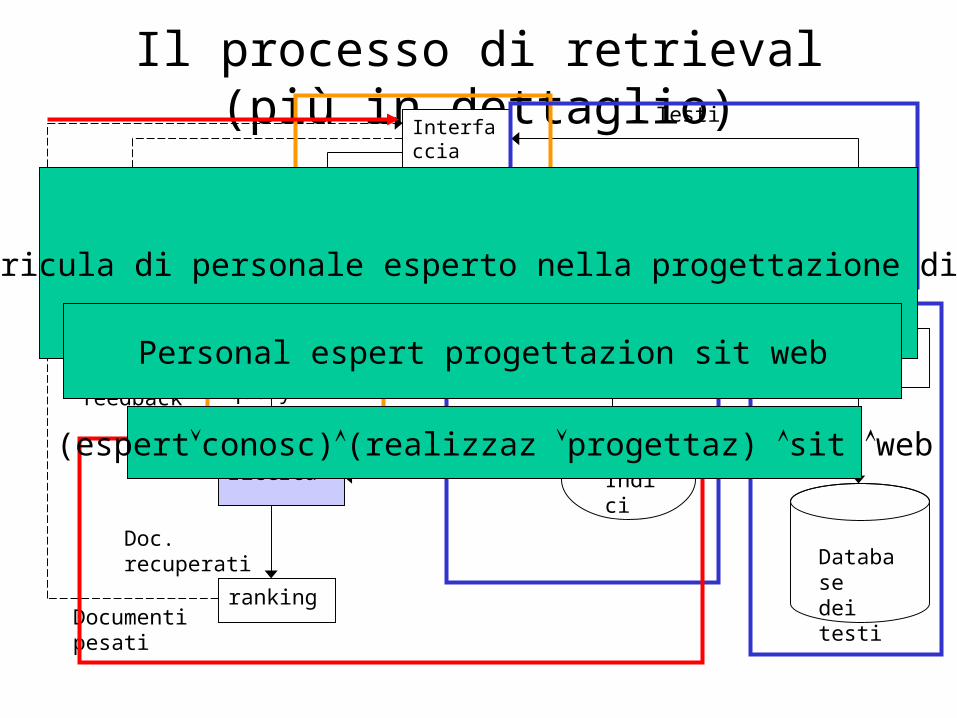
Il processo di retrieval (più in dettaglio)Interfaccia utente
Operazioni sui testi
Operazioni sulla query
Indicizzazione
ricerca
ranking
Indici
Testi
query
user need
user feedback
Documenti pesati
Doc. recuperati
Vista logicaVista logica
inverted file
DB Manager Module
Databasedei testi
Testi
Cerco curricula di personale esperto nella progettazione di siti web
Personal espert progettazion sit web
(espertconosc)(realizzaz progettaz) sit web
Query
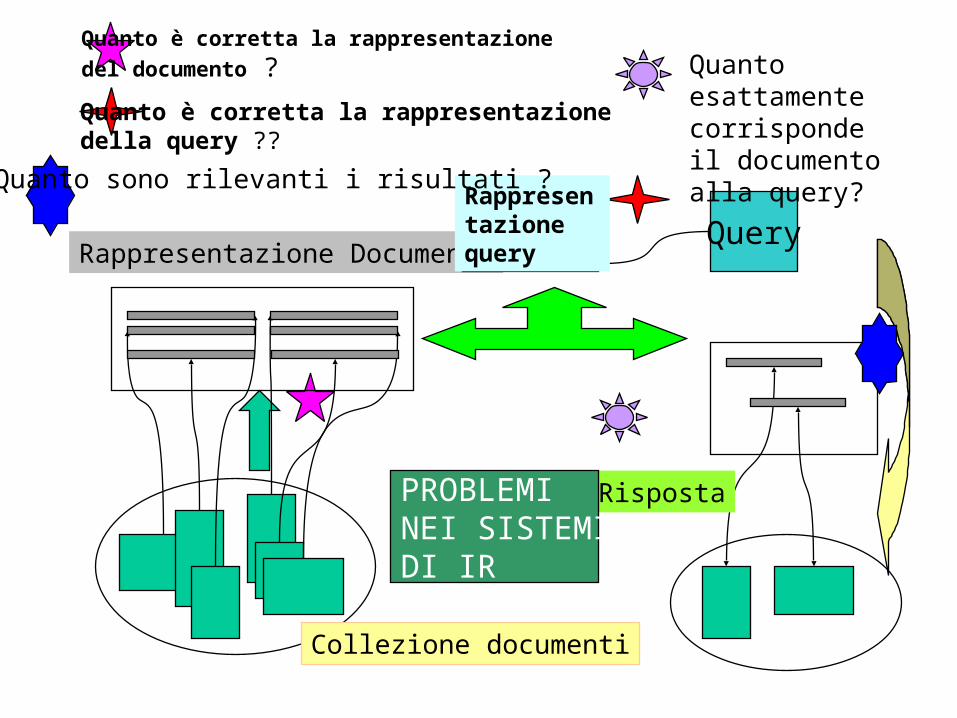
Quanto è corretta la rappresentazione
del documento ?
Quanto è corretta la rappresentazionedella query ??
Quanto esattamente corrisponde il documento alla query?
Collezione documenti
Rappresentazione Documenti
Rappresentazione query
RispostaPROBLEMINEI SISTEMIDI IR
Quanto sono rilevanti i risultati ?

3 fasi fondamentali
• Operazioni sui testi (query e documenti)
• Generazione di indici (strutture di puntamento)
• Ricerca e ranking

Operazioni sui testi• Un sistema di IR genera una rappresentazione più generale e
astratta dei documenti e delle richieste degli utenti (query) , detta logical view, o rappresentazione.
• Quando la rappresentazione di un documento comprende l’intero insieme delle parole che lo compongono, si parla di full text logical view.
• Tuttavia, anche nei moderni computers sono necessarie alcune operazioni di compressione dell’informazione
• Queste operazioni possono essere finalizzate non solo alla compressione (es. eliminazione di articoli, congiunzioni., lemmatizzazione...) ma anche alla generalizzazione (non rappresentare termini (ambigui) ma concetti )

Indicizzazione dei documenti• Ogni documento viene rappresentato mediante un insieme di
parole-chiave o termini indice
• Un termine-indice è una parola ritenuta utile per rappresentare il contenuto del documento
• In genere, nei sistemi di IR “classici”, gli indici sono nomi, perché maggiormente indicativi del contenuto
• Tuttavia, nei motori di ricerca vengono considerati tutti i termini (full text representation)
• Gli indici vengono utilizzati per generare strutture di puntamento ai documenti della collezione, facilitandone il recupero a fronte di una query.

Ranking (ordinamento)• Un ranking è un ordinamento dei documenti
recuperati che dovrebbe riflettere gli interessi dell’utente
• E’basato su :– Identificazione di gruppi di termini comuni
– Condivisione di termini pesati
– Probabilità di rilevanza
• La classificazione dei modelli di IR è basata si diversi criteri di ranking
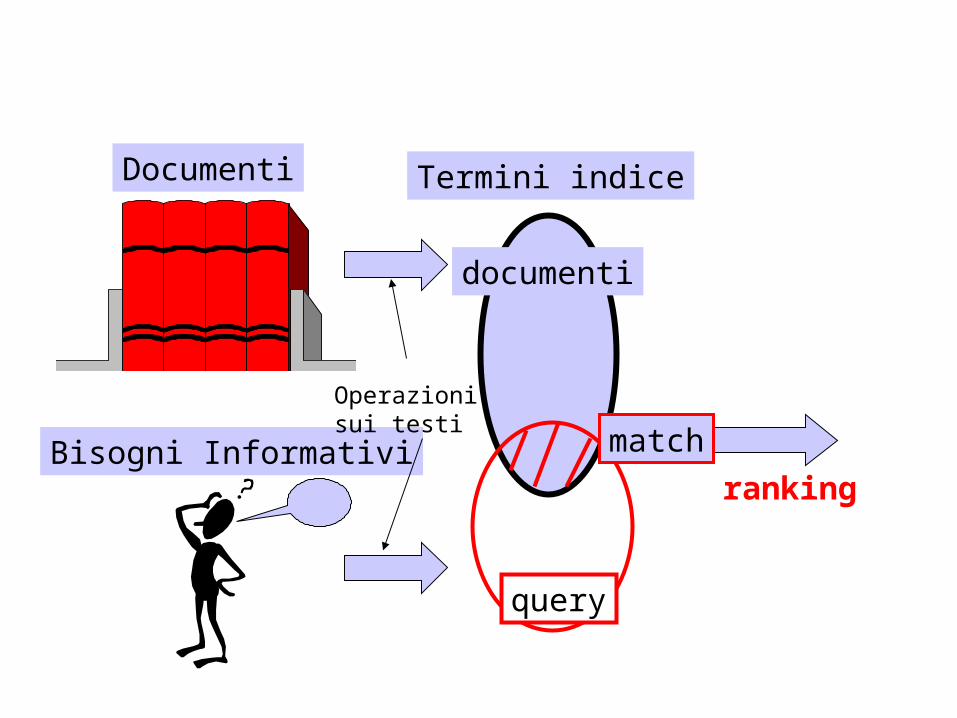
Documenti
Bisogni Informativi
Termini indice
documenti
query
match
ranking
Operazionisui testi

Trattamento dei testi, strutturazione
e metodi di Ricerca

1. Trattamento dei testi
• Come trasformare un documento in un vettore di keywords?
• Come organizzare i vettori dei documenti in modo da facilitarne il recupero a fronte di una query?
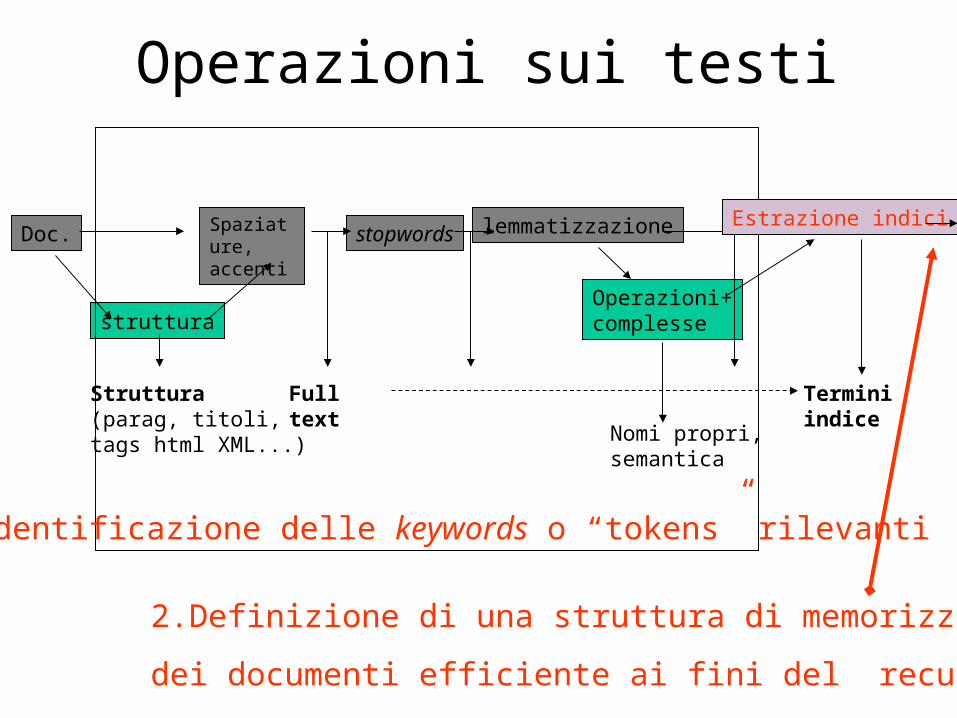
Operazioni sui testi
Struttura(parag, titoli,tags html XML...)
Full text Termini indice
struttura
Spaziature, accenti
stopwords lemmatizzazione
Operazioni+complesse
Doc.
Nomi propri,semantica
1.Identificazione delle keywords o “tokens” rilevanti
Estrazione indici
2.Definizione di una struttura di memorizzazione
dei documenti efficiente ai fini del recupero

Tokenizzazione• Un testo va trasformato in una lista di elementi
significativi detti token.• A volte, la punteggiatura, i numeri, e la differenza fra
maiuscole e minuscole possono essere elementi significativi. Anche le etichette html (o xml) possono o meno essere eliminate.
• Generalmente, più superficiale è l’analisi del testo, più dettagli vengono eliminati.
• L’approccio più semplice –quello usato dai motori di ricerca- consiste nell’ignorare numeri e punteggiatura e considerare solo stringhe contigue di caratteri alfabetici come tokens.

Tokenizzazione di simboli HTML
• Cosa fare del testo racchiuso nei comandi html che tipicamente non vengono visualizzati? Alcune di queste stringhe sono indicative del contenuto del testo:– Le parole contenute negli URLs (www.acquistionline.it)– Le parole contenute nei “meta testi” delle immagini.<meta name=“description” content=“gli sfondi di Vincent
Van Gogh per il vostro Desktop”>
• L’approccio più semplice esclude dalla tokenizzazione tutte le informazioni contenute fra tag HTML (fra “<“ e “>”).
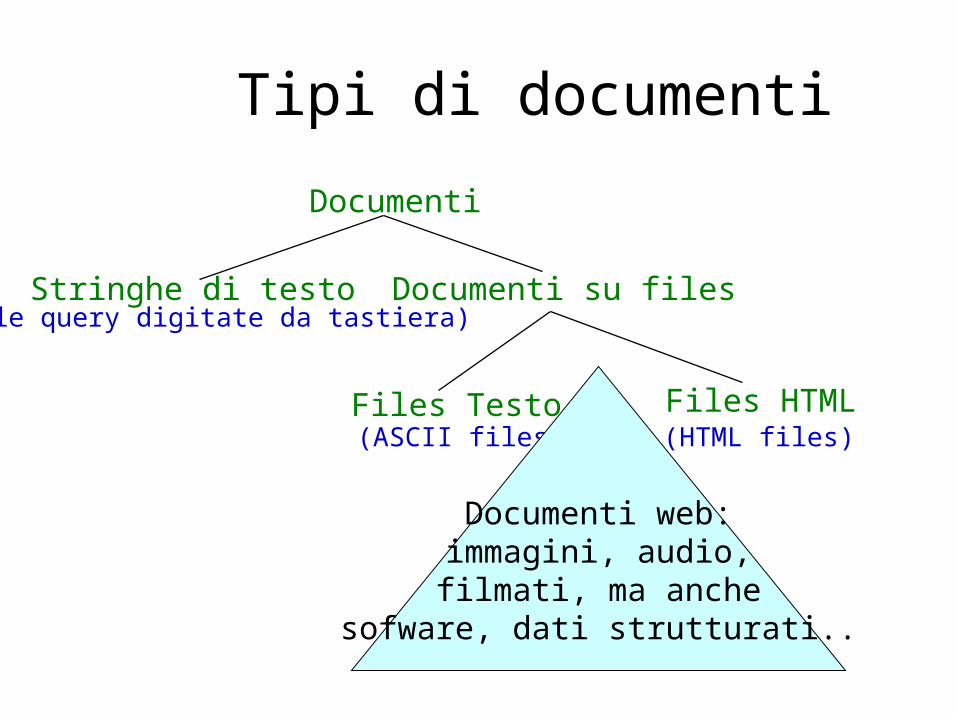
Tipi di documenti
Documenti
Stringhe di testo Documenti su files
Files Testo Files HTML
(per le query digitate da tastiera)
(ASCII files) (HTML files)
Documenti web:immagini, audio,filmati, ma anche
sofware, dati strutturati..

Stopwords• Tipicamente vengono eliminate parole ad elevata
frequenza in un linguaggio, dette stopwords (es. parole funzionali, in inglese: “a”, “the”, “in”, “to”; o pronomi: “I”, “he”, “she”, “it”, ecc.).
• Le Stopwords sono ovviamente dipendenti dalla lingua. Vector Space Retrieval (VSR) utilizza un set standard di circa 500 parole inglesi.
• http://bll.epnet.com/help/ehost/Stop_Words.htm
• Le stringhe di stopwords vengono memorizzate in una hashtable per essere riconosciute in tempo costante.

Stemming
• Si intende per stemming il processo di riduzione di un termine al lemma o alla radice, in modo da riconoscere variazioni morfologiche della stessa parola. – “comput-er”,“comput-ational”, “comput-ation”
“compute”
• L’analisi morfologica è specifica di ogni lingua, e può essere molto complessa (ad esempio in Italiano ben più che in Inglese)
• I sistemi di stemming più semplici si limitano ad identificare suffissi e prefissi e ad eliminarli.

Porter Stemmer• E’ una procedura semplice, che iterativamente riconosce ed
elimina suffissi e prefissi noti senza utilizzare un dizionario (lemmario).
• Può generare termini che non sono parole di una lingua:– “computer”, “computational”, “computation” diventano
tutti “comput”• Vengono unificate parole che in effetti sono diverse (matto e
mattone)• Non riconosce deviazioni morfologiche (vado e andiamo).• http://www.mozart-oz.org/mogul/doc/lager/porter-
stemmer/

Errori del Porter Stemmer
• Errori di “raggruppamento”:– organization, organ organ– police, policy polic– arm, army arm
• Errori di “omissione”:– cylinder, cylindrical– create, creation– Europe, European

Operazioni più complesse sui testi• Analisi morfosintattica
– I have been be• Analisi dei Nomi Propri, date, espressioni monetarie e numeriche, terminologia
– Medical Instrument inc– April 15th, 2003. 15-4-03…– 5 millions euros– Consiglio di amministrazione, week end, ..
• Analisi della struttura del testo– Es: I termini nel titolo o nei paragrafi hanno un peso maggiore, i termini in
grassetto o sottolineati..• Analisi semantica: associare a parole singole o a porzioni di testo dei concetti di una
ontologia– “L’albergo dispone di piscina..” swimming_pool hotel_facility– “L’albergo si trova a Corvara..” Val_Badia Dolomiti ..
is_a
is_in

Strumenti per l’analisi morfosintattica di testi
• Treetagger • On-line version su:
http://www.cele.nottingham.ac.uk/~cctz/treetagger.php
• Supporta diverse lingue (inglese tedesco italiano..)• Analisi delle parti del discorso e analisi dei gruppi
sintattici (gruppi nominali, verbali, preposizionali..)

2. Indicizzazione dei documenti
• Come recuperare le informazioni?
• Una semplice alternativa consiste nello scandire l’intero testo sequenzialmente
• Una opzione migliore è quella di costruire strutture di dati chiamate indici per velocizzare la ricerca

Indicizzazione: come memorizzare e recuperare i
documenti rappresentati mediante keywords
• Tecniche di indicizzazione:– Inverted files– Array di suffissi– Signature files

Notazione
• n: il numero di tokens nel testo
• m: lunghezza di un vettore
• v: taglia del vocabolario (quante parole diverse)
• M: memoria a disposizione

Inverted Files• Definizione: un inverted file è un meccanismo
orientato alla manipolazione di parole, per indicizzare una collezione di documenti in modo da velocizzare il processo di ricerca.
• Struttura di un inverted file:– Vocabolario: l’insieme di parole diverse nel testo
(NOTA: la taglia di V dipende dalle operazioni effettuate sui testi)
– Occorrenze: liste che contengono tutte le informazioni necessarie per ogni parola del vocabolario (posizione nel testo, frequenza, documenti nei quali appaiono, ecc.)
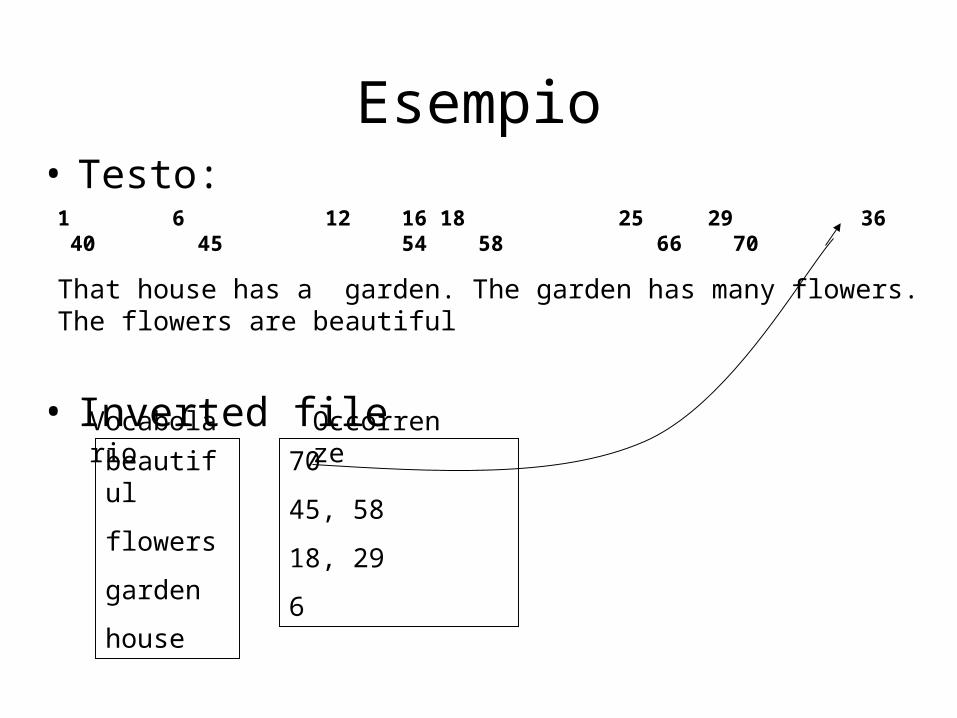
Esempio• Testo:
• Inverted file
1 6 12 16 18 25 29 36 40 45 54 58 66 70
That house has a garden. The garden has many flowers. The flowers are beautiful
beautiful
flowers
garden
house
70
45, 58
18, 29
6
Vocabolario Occorrenze

Spazio di memoria• Lo spazio necessario per memorizzare il vocabolario non
è eccessivo. Secondo la legge di Heap il vocabolario cresce come O(n), dove è una costante compresa fra 0.4 e 0.6 nei casi reali
• Viceversa, le occorrenze richiedono uno spazio molto maggiore. Poiché vi è un riferimento per ogni occorrenza della parola nel testo, lo spazio necessario è O(n) per ogni riga.
• Per ridurre lo spazio necessario, si può utilizzare una tecnica detta indirizzamento di blocco (block addressing)

Indirizzamento di blocco• Il testo viene suddiviso in blocchi
• Le occorrenze puntano ai blocchi in cui appare la parola
• Vantaggi:
– Il numero dei puntatori di blocco è minore del numero dei puntatori di posizione
– Tutte le occorenze di una parola all’interno di uno stesso blocco hanno un solo puntatore
• Svantaggi:
– Se è richiesta l’identificazione esatta del termine, è necessario scandire “online” i blocchi di interesse
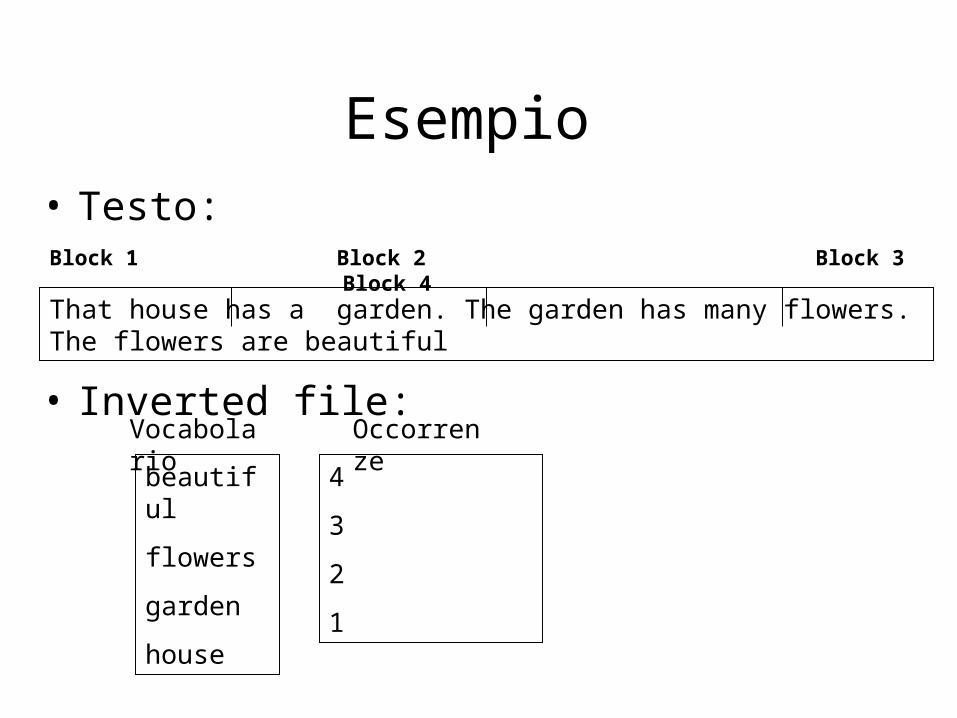
Esempio• Testo:
• Inverted file:
Block 1 Block 2 Block 3 Block 4
That house has a garden. The garden has many flowers. The flowers are beautiful
beautiful
flowers
garden
house
4
3
2
1
Vocabolario Occorrenze

In alcuni modelli IR vengono memorizzate solo le coppie Dk,tfik
system
computer
database
science D2, 4
D5, 2
D1, 3
D7, 4
Termini indice df
3
2
41
Dj, tfj
File Indice Lista delle Occorrenze
dfi = numero di documenti in cui compare il termine ti
tfik = frequenza del termine ti nel documento Dk

Ricerca su inverted indexes-files
• L’algoritmo di ricerca basato su indici inversi opera in tre fasi successsive: – Ricerca nel vocabolario: le parole presenti nella
query vengono ricercate nel vocabolario
– Recupero delle occorrenze: viene estratta la lista delle occorrenze di tutte le parole incluse nella query e presenti nel vocabolario
– Manipolazione delle occorrenze: la lista delle occorrenze viene elaborata, per generare una risposta alla query

Ricerca su inverted indexes(2)
• La ricerca parte sempre dal vocabolario, che dovrebbe essere memorizzato separatamente
• I vocabolari vengono memorizzati in strutture di tipo hashing, tries o B-trees
• Alternativamente, le parole possono essere memorizzate in ordine alfabetico (si risparmia in spazio, maggior tempo di ricerca)

Costruzione del vocabolario• Il vocabolario viene generato scandendo i testi del
repository
• Vengono effettuate operazioni preliminari sui testi, di cui abbiamo parlato, al fine di limitare la taglia del vocabolario (stemming e stop words)
• Ad ogni parola del vocabolario, quale che sia la struttura dati utilizzata, viene associata la lista delle occorrenze nei documenti
• Ogni parola incontrata in un testo viene prima cercata nel vocabolario: se non viene trovata, viene aggiunta al vocabolario, con una lista inizialmente vuota di
occorrenze.

Costruzione del vocabolario (2)
• Una volta che si siano esaminati tutti i testi, il vocabolario viene memorizzato con la lista delle occorrenze. Vengono generati due files:– Nel primo file, vengono memorizzate in locazioni
contigue le liste delle occorrenze – Nel secondo file, il vocabolario è memorizzato in
ordine lessicografico (alfabetico), e viene generato per ogni parola un puntatore alla sua lista di occorrenze nel primo file.
• L’intero processo ha un costo O(n) nel caso peggiore. La ricerca (binaria) ha un costo O(logn)
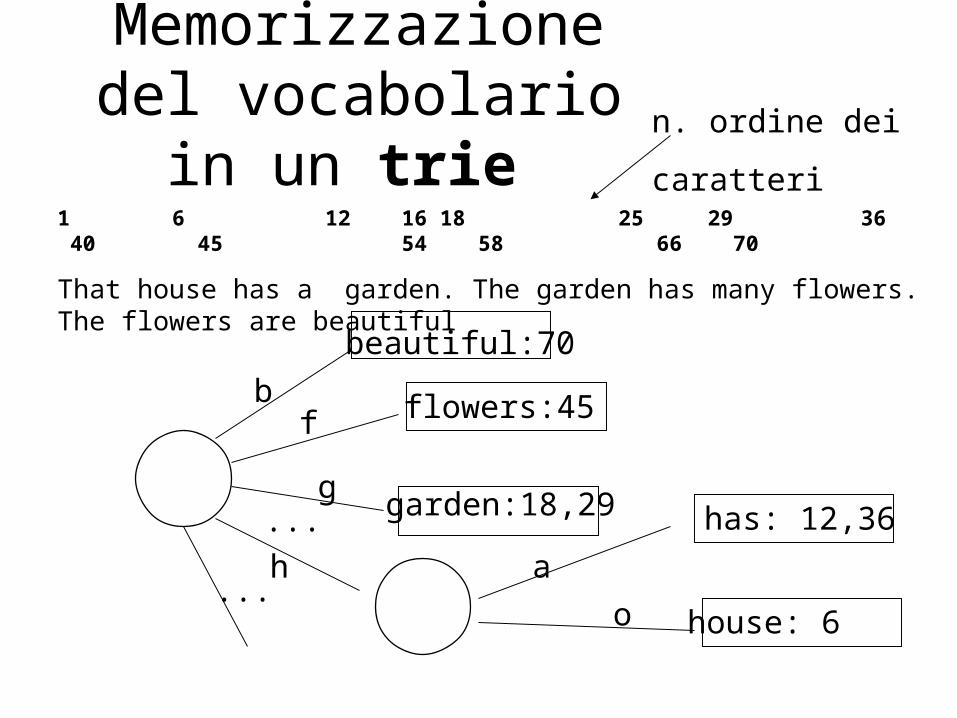
Memorizzazione del vocabolario in un trie
1 6 12 16 18 25 29 36 40 45 54 58 66 70
That house has a garden. The garden has many flowers. The flowers are beautiful
bf
g
h
...
...
beautiful:70
flowers:45
a
o
garden:18,29 has: 12,36
house: 6
n. ordine dei
caratteri

Modelli strutturati del testo
• La ricerca e indicizzazione per parole-chiave considera il documento come una struttura piatta
• Se cerco “consiglio di amministrazione” potrei trovare documenti in cui queste parole compaiono ma non sono correllate
• Inoltre, il peso di una parla è lo stesso sia che la parola compaia nel testo che, ad es. nel titolo

Modelli strutturati (2)
• Definizioni:– Match point: la posizione nel testo in cui
occorre una parola o sequenza di parole – Regione: una porzione contigua di testo
(frase, paragrafo..)– Nodo: un componente strutturale del testo, ad
esempio un capitolo, una sezione..

Esempio
Abstract—The so-called Semantic Web vision will certainly benefit from automatic semantic annotation of words in documents. We present a method, called structural semantic interconnections (SSI), that creates structural specifications of the possible senses for each word in a context, and selects the best hypothesis according to a grammar G, describing relations between sense specifications. The method has been applied to different semantic disambiguation problems, like automatic ontology construction, sense-based query expansion, disambiguation of words in glossary definitions. Evaluation experiments have been performed on each disambiguation task, as well as on standard publicly available word sense disambiguation test sets.
NODO
MATCH POINT
REGIONE

Proximal Nodes• Il testo viene rappresentato con una struttura
gerarchica
• Gli indci vengono definiti mediante gerarchie multiple
• Ogni struttura di indicizzazione è una gerarchia composta da: capitoli, sezioni, sottosezioni, paragrafi, linee
• Ognuno di questi componenti è un NODO
• Ad ogni nodo è associata una regione di testo
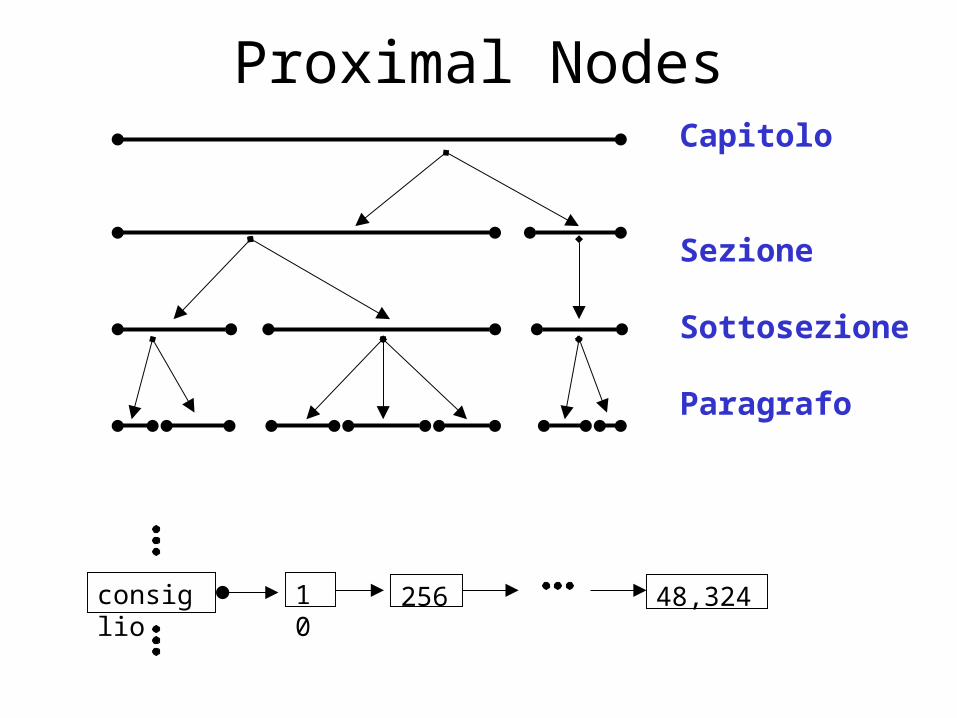
Proximal NodesCapitolo
Sezione
Sottosezione
Paragrafo
consiglio 10 256 48,324

Proximal Nodes
• Ogni nodo può essere contenuto in un altro nodo
• Due nodi sullo stesso livello non si possono sovrapporre
• L’informazione fornita dagli inverted indexes complementa quella degli indici gerarchici

Proximal Nodes
• E’ possibile fare query del tipo:
• Le query sono espressioni regolari, è possibile cercare stringhe e far riferimento a componenti strutturali
))()(()sec(* annotationandsemanticwithtion

Conclusioni sui metodi di archiviazione-indicizzazione
• Il meccanismo inverted file è il più adeguato nel caso di archivi testuali statici
• Altrimenti, se la collezione è volatile (ad esempio il web) la sola opzione è una ricerca online (Spiders, nel seguito di questo corso).
• In questo caso i metodi di trattamento dei testi devono essere semplici per garantire rapidità (li vedremo nella seconda parte: Web information retrieval)

3. Metodi di Ranking:Come ordinare i documenti per
“rilevanza” rispetto ad una query

Ranking• Supponiamo di avere a disposizione una visione logica, e
questa sia data da un insieme di parole-chiave o keywords.• Un banale matching di parole chiave fra documenti e query
spesso fornisce risultati modesti, gli utenti sono insoddisfatti.
• Inoltre, spesso gli utenti non sono in grado di esprimere i loro interessi mediante un elenco appropriato di keywords
• Il problema è resto più grave se siamo nell’ambito Web IR• Un ranking appropriato dei documenti ha un effetto
notevole sulle prestazioni (vedi i motori di ricerca)
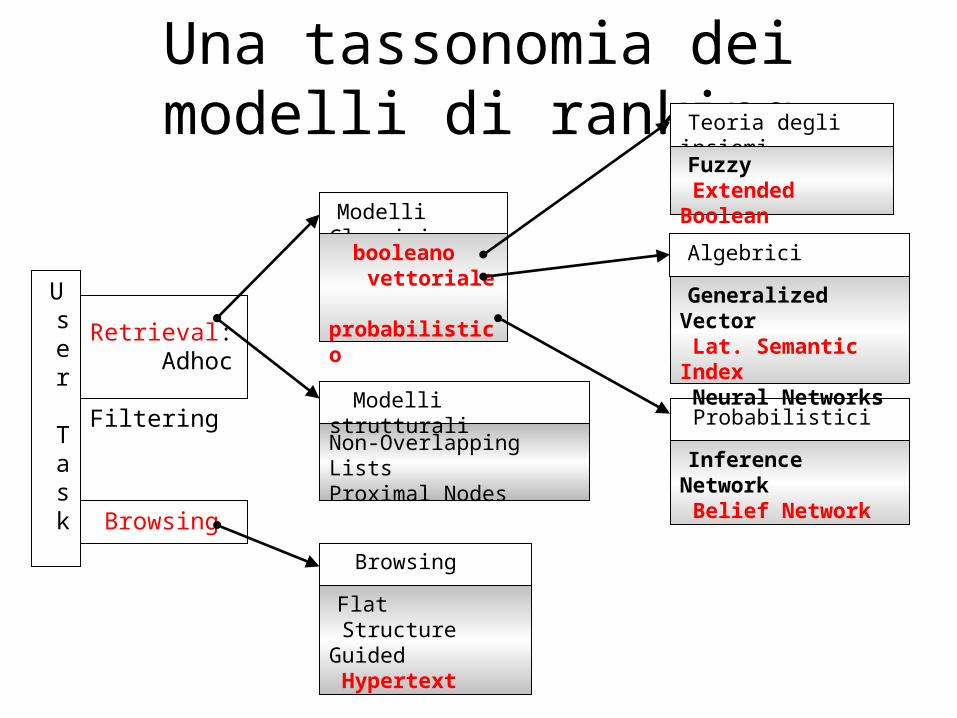
Una tassonomia dei modelli di ranking
Non-Overlapping ListsProximal Nodes
Modelli strutturali
Retrieval: Adhoc Filtering
Browsing
U s e r
T a s k
Modelli Classici
booleano vettoriale probabilistico
Teoria degli insiemi
Fuzzy Extended Boolean
Probabilistici
Inference Network Belief Network
Algebrici
Generalized Vector Lat. Semantic Index Neural Networks
Browsing
Flat Structure Guided Hypertext

Modelli “classici”: concetti base• Non tutti i termini sono ugualmente importanti per la
rappresentazione di un testo (o query). Nella selezione di termini indice è importante assegnare un peso di rilevanza alle varie parole.
• L’importanza di un termine indice è rappresentata da un valore che ad esso viene associato
• Sia – ki un termine indice– dj un documento della collezione – wij un peso associato a (ki,dj)
• Il peso wij quantifica l’importanza dell’indice ki per descrivere il contenuto del documento

Modelli “classici”: concetti base (2)
– ki è un termine indice– dj è un documento– N è il numero totale di documenti in D– K = (k1, k2, …, kt) è l’insieme dei termini indice– t è la taglia del vocabolario– wij >= 0 è un peso associato con (ki,dj)– wij = 0 indica che un termine non appartiene al documento– vec(dj) =dj=dj =(w1j, w2j, …, wtj) è un vettore pesato
associato a dj– gi(dj) = wij è una funzione che restituisce il peso associato
alla coppia (ki,dj)

Set theoretic models: Modello Booleano
• Un modello molto semplice basato sulla set theory• Le query vengono rappresentate mediante espressioni booleane
– La semantica è precisa– Il formalismo è elegante– q = ka (kb kc) Es: (automobili (vendita fabbricazione)
• I termini sono presenti o assenti. Dunque, wij {0,1}• Esempio
– q = ka (kb kc) DNF– = (1,1,1) (1,1,0) (1,0,0) (forma normale
disgiuntiva), = componente congiuntivo (vettore)q DNF
q cc
ka kb ka kc

Modello Booleano
• q = ka (kb kc)
)()(,()(1
0),( ccqigjdigikDNFqccqccqse
altrimentij qdsim
(1,1,1)(1,0,0)
(1,1,0)
ka kb
kc

Problemi del modello Booleano
• Il retrieval è basato su criteri di decisione binari, non esiste la nozione di corrispondenza parziale
• Non viene fornito un ordinamento parziale dei documenti (non c’è ranking!!)
• Gli utenti trovano difficile trasformare le loro richieste informative in una espressione booleana
• Gli utenti formulano spesso query booleane troppo semplicistiche (congiunzioni di termini)
• Di conseguenza, le query booleane restituiscono o troppo pochi (silenzio) o troppi (rumore) documenti

Modello vettoriale• Definisci:
– wij > 0 ogni volta che ki dj– wiq 0 associato alla coppia (ki,q)– = (w1j, w2j, ..., wtj) = (w1q,
w2q, ..., wtq)– Ad ogni termine ki è associato un vettore unitario – I vettori unitari si assumono essere ortonormali (Cioè si
assumono occorrere indipendentemente l’uno dall’altro nei documenti)
• I t vettori unitari formano una base ortonormale in uno spazio t-dimensionale
• In questo spazio, query e documenti sono rappresentati mediante vettori pesati
d j
q
i e
j
i 1
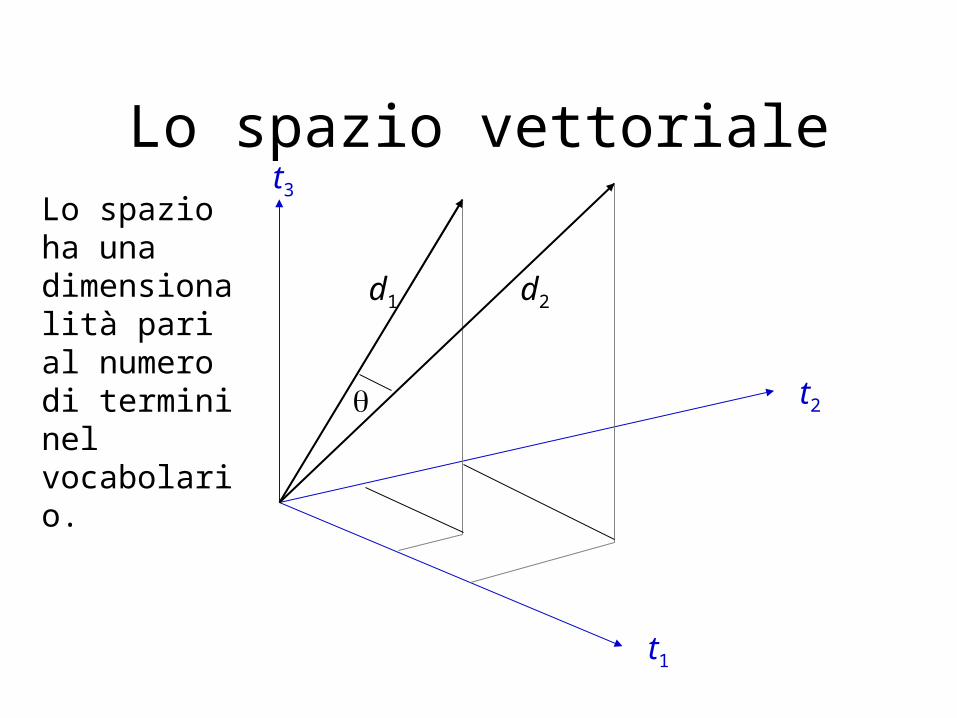
Lo spazio ha una dimensionalità pari al numero di termini nel vocabolario.
Lo spazio vettoriale
t1
t2
t3
d1 d2
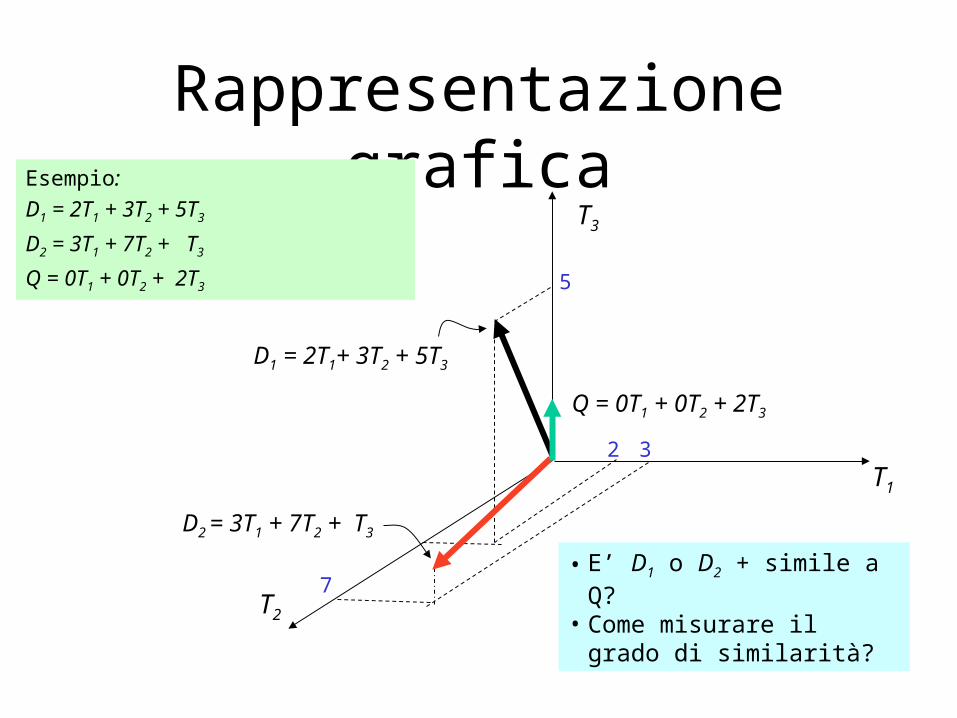
Rappresentazione graficaEsempio:
D1 = 2T1 + 3T2 + 5T3
D2 = 3T1 + 7T2 + T3
Q = 0T1 + 0T2 + 2T3
T3
T1
T2
D1 = 2T1+ 3T2 + 5T3
D2 = 3T1 + 7T2 + T3
Q = 0T1 + 0T2 + 2T3
7
32
5
• E’ D1 o D2 + simile a Q?• Come misurare il grado di
similarità?

Misura del coseno • Si misura il coseno dell’angolo fra due vettori.• Il prodotto scalare (al numeratore) è normalizzato con la lunghezza
dei vettori.
D1 = 2T1 + 3T2 + 5T3 CosSim(D1 , Q) = 10 / (4+9+25)(0+0+4) = 0.81D2 = 3T1 + 7T2 + 1T3 CosSim(D2 , Q) = 2 / (9+49+1)(0+0+4) = 0.13
Q = 0T1 + 0T2 + 2T3
t3
t1
t2
D1
D2
Q
D1 è 6 volte migliore di D2 usando la misura del coseno.
d j
q
d j q
( ijw iqw )
i1
t
2ijw 2
iqwi1
t
i1
t
CosSim(dj, q) =

Similarità nel modello vettoriale
i
j
dj
q
sim(dj,q) d j
q d j
q
wi, j wi,qi1
t
(wi, j )2 (wi,q )2
i1
t
i1
t
cos

Pesatura dei termini nel modello vettoriale
• Una misura del peso di un termine in un documento deve tenere conto di due fattori :– Quantificazione del peso che il termine ha nel documento:
• Fattore tf (term frequency) – Quanto il termine aiuta a discriminare il documento dj
dagli altri documenti in D• Fattore idf (inverse document frequency)
Dove: N numero di doc. nella collezione, ni numero dei documenti in cui il termine ki appare
– wij = tf(i,j) * idf(i)
tf (i, j) freqi, j
maxk
freqk, j
idfi logNni

Peso dei termini nella query
• Salton e Buckley suggeriscono:
wi,q 0,5 0,5 freqi,q
maxk
( freqk,q)
log
N
ni

Vantaggi e svantaggi del modello vettoriale
• Vantaggi:
– Il peso dei termini migliora la qualità delle risposte
– Poiché possono verificarsi matching parziali fra documenti e query, è possibile ottenere risposte che approssimino le richieste dell’utente
– La formula del coseno dell’angolo consente di ordinare i documenti rispetto al grado di similarità con la query
• Svantaggi:
– Si basa sull’assunzione che i termini siano fra loro indipendenti. Ma non è provato che questo sia un vero svantaggio..

Il modello vettoriale: Esempio I
k1 k2 k3 q djd1 1 0 1 2d2 1 0 0 1d3 0 1 1 2d4 1 0 0 1d5 1 1 1 3d6 1 1 0 2d7 0 1 0 1
q 1 1 1
d1
d2
d3d4 d5
d6d7
k1k2
k3
idf(k1)=log(7/5)=0,146 idf(k2)=log(7/4)=0,243idf(k3)=log(7/3)=0,367
tf
“coincidenze”

Esempio I (continua)
• Calcolo sim(d1,q):
• w1,1=10,145=0,145 w2,1=0 w3,1=0,367
• w1,q= (0,5+0,5 1) 0,145=0,145
w2,q=0,243 w3,q=0,367
sim(d1,q) 0,145 0,145 0,367 0,367
0,1452 0,3672 0,1452 0,2432 0,36720,85
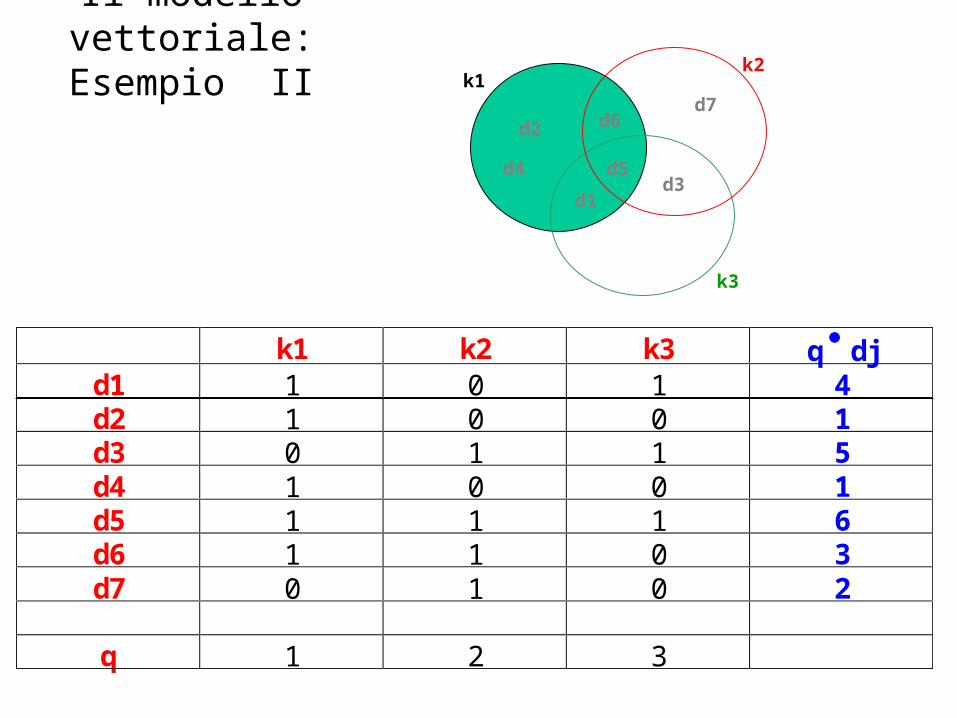
Il modello vettoriale: Esempio II
d1
d2
d3d4 d5
d6d7
k1k2
k3
k1 k2 k3 q djd1 1 0 1 4d2 1 0 0 1d3 0 1 1 5d4 1 0 0 1d5 1 1 1 6d6 1 1 0 3d7 0 1 0 2
q 1 2 3
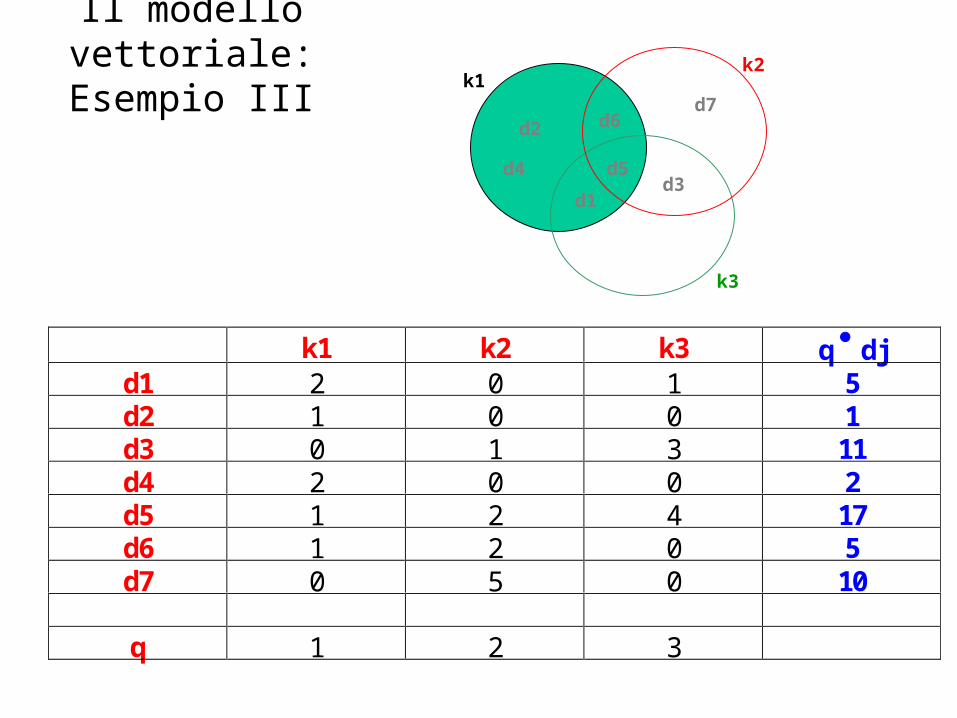
Il modello vettoriale: Esempio III
d1
d2
d3d4 d5
d6d7
k1k2
k3
k1 k2 k3 q djd1 2 0 1 5d2 1 0 0 1d3 0 1 3 11d4 2 0 0 2d5 1 2 4 17d6 1 2 0 5d7 0 5 0 10
q 1 2 3

Extended Boolean Model
• Il modello booleano è semplice ed elegante
• Ma non consente ranking
• Il modello booleano può essere esteso mediante la nozione di corrispondenza parziale e di pesatura dei termini
• Combina le caratteristiche del modello vettoriale con le proprietà dell’algebra booleana

Extended Boolean Model
• Il modello extended Boolean (introdotto da Salton, Fox, e Wu, 1983) si basa su una critica di una assunzione-base dell’algebra booleana
• Sia:
– q = kx ky o q = kx ky la query
– wxj = fxj * idf(x) peso associato a [kx,dj] max(idf(i))
– fxj è la frequenza normalizzata di kx in dj
0 wxj 1
– Inoltre, indichiamo wxj = x and wyj = y jdkxkjxfreq
ijxfreqijxf
))(max(
)()(
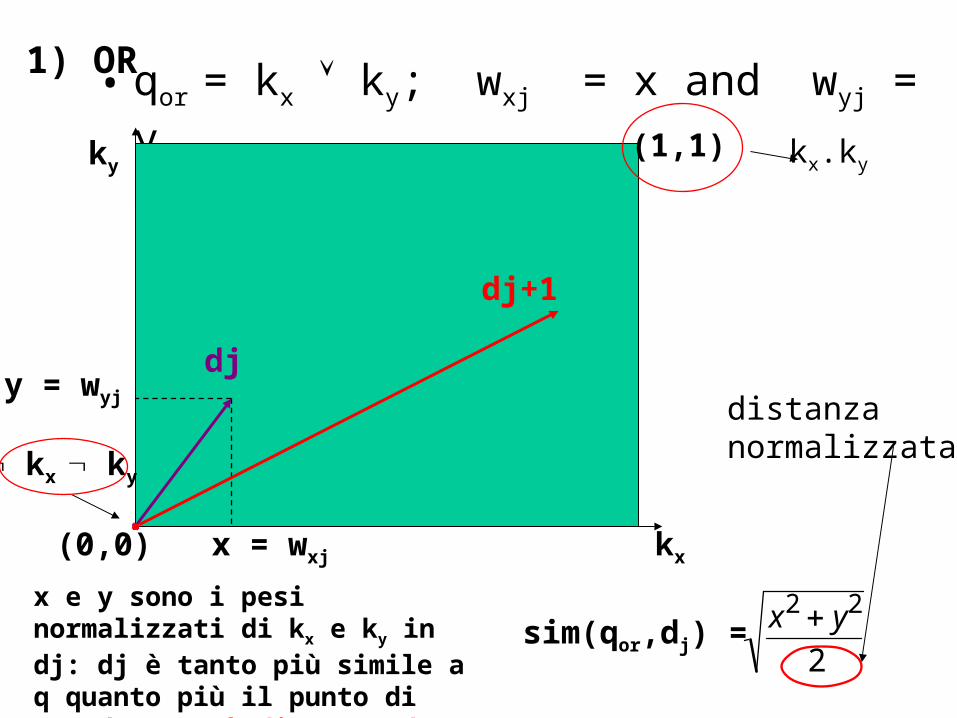
• qor = kx ky; wxj = x and wyj = y
dj
dj+1
y = wyj
x = wxj(0,0) kx
ky
sim(qor,dj) =x2 y2
2
x e y sono i pesi normalizzati di kx e ky in dj: dj è tanto più simile a q quanto più il punto di coord (x,y) è distante da (0,0)
kx ky
(1,1) kx.ky
distanza normalizzata
1) OR
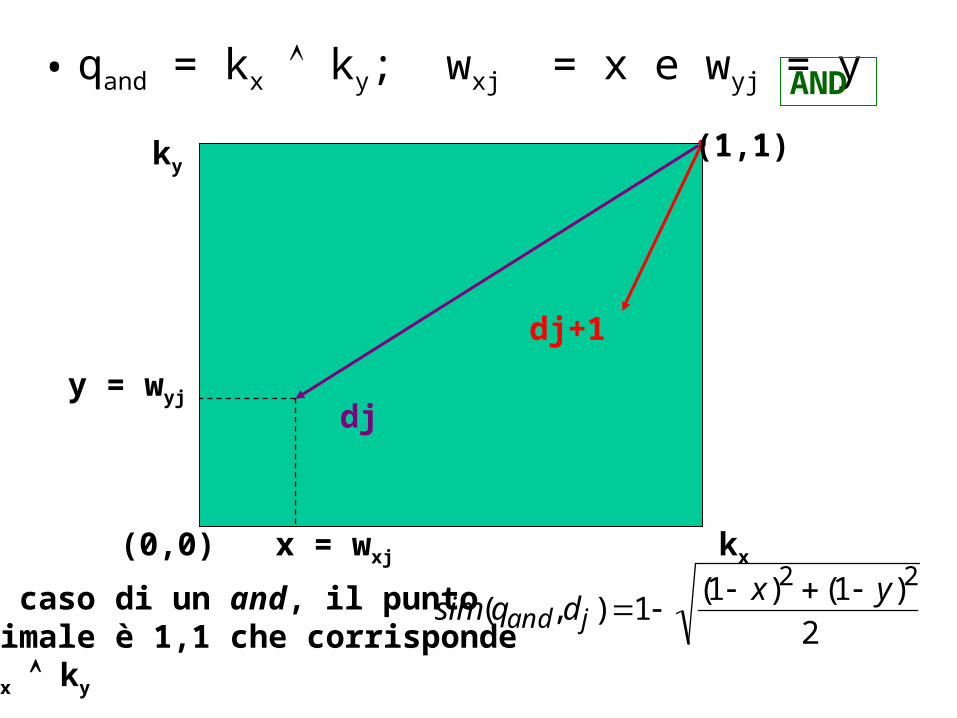
• qand = kx ky; wxj = x e wyj = y
dj
dj+1
y = wyj
x = wxj(0,0)
(1,1)
kx
ky
AND
sim(qand , d j ) 1(1 x)2 (1 y)2
2Nel caso di un and, il puntoottimale è 1,1 che corrisponde a kx ky

Extended Boolean Model
• Se esistono t termini indice, il modello può essere esteso ad uno spazio t-dimensionale
• Espressioni and-or es: (k1k2)k3
sim(q,d)
1(1 x1)2 (1 x2)2
2
2
( x3 )2
2


















